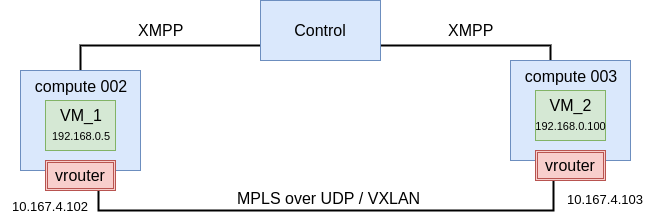
This section includes all OpenStack-related Day-2 operations such as
reprovisioning of OpenStack controller and compute nodes, preparing
the Ironic service to provision cloud workloads on bare metal nodes,
and others.
Manage Virtualized Control Plane
This section describes operations with the MCP Virtualized Control Plane (VCP).
Add a controller node
If you need to expand the size of VCP to handle a bigger data plane,
you can add more controller nodes to your cloud environment. This section
instructs on how to add a KVM node and an OpenStack controller VM to
an existing environment.
The same procedure can be applied for scaling the messaging, database, and
any other services.
Additional parameters will have to be added before the deployment.
To add a controller node:
Add a physical node using MAAS as described in the
MCP Deployment Guide: Provision physical nodes using MAAS.
Log in to the Salt Master node.
In the /classes/cluster/<cluster_name>/infra/init.yml file,
define the basic parameters for the new KVM node:
parameters:
_param:
infra_kvm_node04_address: <IP ADDRESS ON CONTROL NETWORK>
infra_kvm_node04_deploy_address: <IP ADDRESS ON DEPLOY NETWORK>
infra_kvm_node04_storage_address: ${_param:infra_kvm_node04_address}
infra_kvm_node04_public_address: ${_param:infra_kvm_node04_address}
infra_kvm_node04_hostname: kvm<NUM>
glusterfs_node04_address: ${_param:infra_kvm_node04_address}
linux:
network:
host:
kvm04:
address: ${_param:infra_kvm_node04_address}
names:
- ${_param:infra_kvm_node04_hostname}
- ${_param:infra_kvm_node04_hostname}.${_param:cluster_domain}
In the /classes/cluster/<cluster_name>/openstack/init.yml file,
define the basic parameters for the new OpenStack controller node.
openstack_control_node<NUM>_address: <IP_ADDRESS_ON_CONTROL_NETWORK>
openstack_control_node<NUM>_hostname: <HOSTNAME>
openstack_database_node<NUM>_address: <DB_IP_ADDRESS>
openstack_database_node<NUM>_hostname: <DB_HOSTNAME>
openstack_message_queue_node<NUM>_address: <IP_ADDRESS_OF_MESSAGE_QUEUE>
openstack_message_queue_node<NUM>_hostname: <HOSTNAME_OF_MESSAGE_QUEUE>
Example of configuration:
kvm04_control_ip: 10.167.4.244
kvm04_deploy_ip: 10.167.5.244
kvm04_name: kvm04
openstack_control_node04_address: 10.167.4.14
openstack_control_node04_hostname: ctl04
In the /classes/cluster/<cluster_name>/infra/config.yml file,
define the configuration parameters for the KVM and OpenStack controller
nodes. For example:
reclass:
storage:
node:
infra_kvm_node04:
name: ${_param:infra_kvm_node04_hostname}
domain: ${_param:cluster_domain}
classes:
- cluster.${_param:cluster_name}.infra.kvm
params:
keepalived_vip_priority: 103
salt_master_host: ${_param:reclass_config_master}
linux_system_codename: xenial
single_address: ${_param:infra_kvm_node04_address}
deploy_address: ${_param:infra_kvm_node04_deploy_address}
public_address: ${_param:infra_kvm_node04_public_address}
storage_address: ${_param:infra_kvm_node04_storage_address}
openstack_control_node04:
name: ${_param:openstack_control_node04_hostname}
domain: ${_param:cluster_domain}
classes:
- cluster.${_param:cluster_name}.openstack.control
params:
salt_master_host: ${_param:reclass_config_master}
linux_system_codename: xenial
single_address: ${_param:openstack_control_node04_address}
keepalived_vip_priority: 104
opencontrail_database_id: 4
rabbitmq_cluster_role: slave
In the /classes/cluster/<cluster_name>/infra/kvm.yml file,
define new brick for GlusterFS on all KVM nodes and salt:control
which later spawns the OpenStack controller node. For example:
_param:
cluster_node04_address: ${_param:infra_kvm_node04_address}
glusterfs:
server:
volumes:
glance:
replica: 4
bricks:
- ${_param:cluster_node04_address}:/srv/glusterfs/glance
keystone-keys:
replica: 4
bricks:
- ${_param:cluster_node04_address}:/srv/glusterfs/keystone-keys
keystone-credential-keys:
replica: 4
bricks:
- ${_param:cluster_node04_address}:/srv/glusterfs/keystone-credential-keys
salt:
control:
cluster:
internal:
domain: ${_param:cluster_domain}
engine: virt
node:
ctl04:
name: ${_param:openstack_control_node04_hostname}
provider: ${_param:infra_kvm_node04_hostname}.${_param:cluster_domain}
image: ${_param:salt_control_xenial_image}
size: openstack.control
In the /classes/cluster/<cluster_name>/openstack/control.yml file,
add the OpenStack controller node into existing services such as HAProxy,
and others, depending on your environment configuration.
Example of adding an HAProxy host for Glance:
_param:
cluster_node04_hostname: ${_param:openstack_control_node04_hostname}
cluster_node04_address: ${_param:openstack_control_node04_address}
haproxy:
proxy:
listen:
glance_api:
servers:
- name: ${_param:cluster_node04_hostname}
host: ${_param:cluster_node04_address}
port: 9292
params: check inter 10s fastinter 2s downinter 3s rise 3 fall 3
glance_registry_api:
servers:
- name: ${_param:cluster_node04_hostname}
host: ${_param:cluster_node04_address}
port: 9191
params: check
Refresh the deployed pillar data by applying the
reclass.storage state:
salt '*cfg*' state.sls reclass.storage
Verify that the target node has connectivity with the Salt Master node:
salt '*kvm<NUM>*' test.ping
Verify that the Salt Minion nodes are synchronized:
salt '*' saltutil.sync_all
On the Salt Master node, apply the Salt linux state for the
added node:
salt -C 'I@salt:control' state.sls linux
On the added node, verify that salt-common and salt-minion have
the 2017.7 version.
apt-cache policy salt-common
apt-cache policy salt-minion
Perform the initial Salt configuration:
salt -C 'I@salt:control' state.sls salt.minion
Set up the network interfaces and the SSH access:
salt -C 'I@salt:control' state.sls linux.system.user,openssh,linux.network,ntp
Reboot the KVM node:
salt '*kvm<NUM>*' cmd.run 'reboot'
On the Salt Master node, apply the libvirt state:
salt -C 'I@salt:control' state.sls libvirt
On the Salt Master node, create a controller VM for the added physical
node:
salt -C 'I@salt:control' state.sls salt.control
Note
Salt virt takes the name of a virtual machine and
registers the virtual machine on the Salt Master node.
Once created, the instance picks up an IP address from
the MAAS DHCP service and the key will be seen as accepted
on the Salt Master node.
Verify that the controller VM has connectivity with the Salt Master node:
salt 'ctl<NUM>*' test.ping
Verify that the Salt Minion nodes are synchronized:
salt '*' saltutil.sync_all
Apply the Salt highstate for the controller VM:
salt -C 'I@salt:control' state.highstate
Verify that the added controller node is registered on the Salt Master
node:
To reconfigure VCP VMs, run the openstack-deploy Jenkins pipeline
with all necessary install parmeters as described in
MCP Deployment guide: Deploy an OpenStack environment.
Replace a KVM node
If a KVM node hosting the Virtualized Control Plane has failed
and recovery is not possible, you can recreate the KVM node from scratch
with all VCP VMs that were hosted on the old KVM node.
The replaced KVM node will be assigned the same IP addresses
as the failed KVM node.
Replace a failed KVM node
This section describes how to recreate a failed KVM node with all VCP VMs
that were hosted on the old KVM node. The replaced KVM node will be assigned
the same IP addresses as the failed KVM node.
To replace a failed KVM node:
Log in to the Salt Master node.
Copy and keep the hostname and GlusterFS UUID of the old KVM node.
To obtain the UUIDs of all peers in the cluster:
salt '*kvm<NUM>*' cmd.run "gluster peer status"
Note
Run the command above from a different KVM node of the same cluster
since the command outputs other peers only.
Verify that the KVM node is not registered in salt-key.
If the node is present, remove it:
salt-key | grep kvm<NUM>
salt-key -d kvm<NUM>.domain_name
Remove the salt-key records for all VMs originally running on the failed
KVM node:
salt-key -d <kvm_node_name><NUM>.domain_name
Note
You can list all VMs running on the KVM node using the
salt '*kvm<NUM>*' cmd.run 'virsh list --all' command.
Alternatively, obtain the list of VMs from cluster/infra/kvm.yml.
Add or reprovision a physical node using MAAS as described in the
MCP Deployment Guide: Provision physical nodes using MAAS.
Verify that the new node has been registered on the Salt Master node
successfully:
Note
If the new node is not available in the list, wait some
time until the node becomes available or use the IPMI console to
troubleshoot the node.
Verify that the target node has connectivity with the Salt Master node:
salt '*kvm<NUM>*' test.ping
Verify that salt-common and salt-minion have the
same version for the new node as the rest of the cluster.
salt -t 10 'kvm*' cmd.run 'dpkg -l |grep "salt-minion\|salt-common"'
Verify that the Salt Minion nodes are synchronized:
salt '*' saltutil.refresh_pillar
Apply the linux state for the added node:
salt '*kvm<NUM>*' state.sls linux
Perform the initial Salt configuration:
Run the following commands:
salt '*kvm<NUM>*' cmd.run "touch /run/is_rebooted"
salt '*kvm<NUM>*' cmd.run 'reboot'
Wait some time before the node is rebooted.
Verify that the node is rebooted:
salt '*kvm<NUM>*' cmd.run 'if [ -f "/run/is_rebooted" ];then echo \
"Has not been rebooted!";else echo "Rebooted";fi'
Note
The node must be in the Rebooted state.
Set up the network interfaces and the SSH access:
salt -C 'I@salt:control' state.sls linux.system.user,openssh,linux.network,ntp
Apply the libvirt state for the added node:
salt '*kvm<NUM>*' state.sls libvirt
Recreate the original VCP VMs on the new node:
salt '*kvm<NUM>*' state.sls salt.control
Note
Salt virt takes the name of a VM and registers it
on the Salt Master node.
Once created, the instance picks up an IP address from
the MAAS DHCP service and the key will be seen as accepted
on the Salt Master node.
Verify that the added VCP VMs are registered on the Salt Master node:
Verify that the Salt Minion nodes are synchronized:
salt '*' saltutil.sync_all
Apply the highstate for the VCP VMs:
salt '*kvm<NUM>*' state.highstate
Verify whether the new node has correct IP address and proceed to
restore GlusterFS configuration as described in
Recover GlusterFS on a replaced KVM node.
Recover GlusterFS on a replaced KVM node
After you replace a KVM node as described in Replace a failed KVM node,
if your new KVM node has the same IP address, proceed with recovering
GlusterFS as described below.
To recover GlusterFS on a replaced KVM node:
Log in to the Salt Master node.
Define the IP address of the failed and any working KVM node
that is running the GlusterFS cluster services. For example:
FAILED_NODE_IP=<IP_of_failed_kvm_node>
WORKING_NODE_IP=<IP_of_working_kvm_node>
If the failed node has been recovered with the old disk and GlusterFS
installed:
Remove the /var/lib/glusterd directory:
salt -S $FAILED_NODE_IP file.remove '/var/lib/glusterd'
Restart glusterfs-server:
salt -S $FAILED_NODE_IP service.restart glusterfs-server
Configure glusterfs-server on the failed node:
salt -S $FAILED_NODE_IP state.apply glusterfs.server.service
Remove the failed node from the GlusterFS cluster:
salt -S $WORKING_NODE_IP cmd.run "gluster peer detach $FAILED_NODE_IP"
Re-add the failed node to the GlusterFS cluster with a new ID:
salt -S $WORKING_NODE_IP cmd.run "gluster peer probe $FAILED_NODE_IP"
Finalize the configuration of the failed node:
salt -S $FAILED_NODE_IP state.apply
Set the correct trusted.glusterfs.volume-id attribute in the GlusterFS
directories on the failed node:
for vol in $(salt --out=txt -S $WORKING_NODE_IP cmd.run 'for dir in /srv/glusterfs/*; \
do echo -n "${dir}@0x"; getfattr -n trusted.glusterfs.volume-id \
--only-values --absolute-names $dir | xxd -g0 -p;done' | awk -F: '{print $2}'); \
do VOL_PATH=$(echo $vol| cut -d@ -f1); TRUST_ID=$(echo $vol | cut -d@ -f2); \
salt -S $FAILED_NODE_IP cmd.run "setfattr -n trusted.glusterfs.volume-id -v $TRUST_ID $VOL_PATH"; \
done
Restart glusterfs-server:
salt -S $FAILED_NODE_IP service.restart glusterfs-server
Move a VCP node to another host
To ensure success during moving the VCP VMs running in the cloud environment
for specific services, take a single VM at a time, stop it, move the disk
to another host, and start the VM again on the new host machine.
The services running on the VM should remain running during the whole process
due to high availability ensured by Keepalived and HAProxy.
To move a VCP node to another host:
To synchronize your deployment model with the new setup, update
the /classes/cluster/<cluster_name>/infra/kvm.yml file:
salt:
control:
cluster:
internal:
node:
<nodename>:
name: <nodename>
provider: ${_param:infra_kvm_node03_hostname}.${_param:cluster_domain}
# replace 'infra_kvm_node03_hostname' param with the new kvm nodename provider
Apply the salt.control state on the new KVM node:
salt-call state.sls salt.control
Destroy the newly spawned VM on the new KVM node:
virsh list
virsh destroy <nodename><nodenum>.<domainname>
Log in to the KVM node originally hosting the VM.
Stop the VM:
virsh list
virsh destroy <nodename><nodenum>.<domainname>
Move the disk to the new KVM node using, for exmaple, the scp
utility, replacing the empty disk spawned by the salt.control
state with the correct one:
scp /var/lib/libvirt/images/<nodename><nodenum>.<domainname>/system.qcow2 \
<diff_kvm_nodename>:/var/lib/libvirt/images/<nodename><nodenum>.<domainname>/system.qcow2
Start the VM on the new KVM host:
virsh start <nodename><nodenum>.<domainname>
Verify that the services on the moved VM work correctly.
Log in to the KVM node that was hosting the VM originally
and undefine it:
virsh list --all
virsh undefine <nodename><nodenum>.<domainname>
Enable host passthrough for VCP
Note
This feature is available starting from the MCP 2019.2.16 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
This section describes how to enable the host-passthrough CPU mode that can
enhance performance of the MCP Virtualized Control Plane (VCP). For details,
see libvirt documentation: CPU model and topology.
Warning
Prior to enabling the host passthrough, run the following command
to verify that it is applicable to your deployment:
salt -C "I@salt:control" cmd.run "virsh list | tail -n +3 | awk '{print \$1}' | xargs -I{} virsh dumpxml {} | grep cpu_mode"
If the output is empty, proceed to enabling host passthrough. Otherwise,
first contact Mirantis support.
To enable host passthrough:
Log in to a KVM node.
Obtain the list of running VMs:
Example of system response:
Id Name State
------------------------------------------------
1 msg01.bm-cicd-queens-ovs-maas.local running
2 rgw01.bm-cicd-queens-ovs-maas.local running
3 dbs01.bm-cicd-queens-ovs-maas.local running
4 bmt01.bm-cicd-queens-ovs-maas.local running
5 kmn01.bm-cicd-queens-ovs-maas.local running
6 cid01.bm-cicd-queens-ovs-maas.local running
7 cmn01.bm-cicd-queens-ovs-maas.local running
8 ctl01.bm-cicd-queens-ovs-maas.local running
Edit the configuration of each VM using the virsh edit %VM_NAME%
command. Add the following lines to the XML configuration file:
<cpu mode='host-passthrough'>
<cache mode='passthrough'/>
</cpu>
For example:
<domain type='kvm'>
<name>msg01.bm-cicd-queens-ovs-maas.local</name>
<uuid>81e18795-cf2f-4ffc-ac90-9fa0a3596ffb</uuid>
<memory unit='KiB'>67108864</memory>
<currentMemory unit='KiB'>67108864</currentMemory>
<vcpu placement='static'>16</vcpu>
<cpu mode='host-passthrough'>
<cache mode='passthrough'/>
</cpu>
<os>
<type arch='x86_64' machine='pc-i440fx-bionic'>hvm</type>
<boot dev='hd'/>
</os>
.......
Perform the steps 1-3 on the remaning kvm nodes one by one.
Log in to the Salt Master node.
Reboot the VCP nodes as described in
Scheduled maintenance with a planned power outage using the
salt 'nodename01*' system.reboot command. Do not reboot the
kvm, apt, and cmp nodes.
Warning
Reboot nodes one by one instead of rebooting all nodes of the
same role at a time. Wait for 10 minutes between each reboot.
Manage compute nodes
This section provides instructions on how to manage the compute nodes in your
cloud environment.
Add a compute node
This section describes how to add a new compute node to an existing
OpenStack environment.
To add a compute node:
Add a physical node using MAAS as described in the
MCP Deployment Guide: Provision physical nodes using MAAS.
Verify that the compute node is defined in
/classes/cluster/<cluster_name>/infra/config.yml.
Note
Create as many hosts as you have compute nodes
in your environment within this file.
Note
Verify that the count parameter is increased by the number
of compute nodes being added.
Configuration example if the dynamic compute host generation is used:
reclass:
storage:
node:
openstack_compute_rack01:
name: ${_param:openstack_compute_rack01_hostname}<<count>>
domain: ${_param:cluster_domain}
classes:
- cluster.${_param:cluster_name}.openstack.compute
repeat:
count: 20
start: 1
digits: 3
params:
single_address:
value: 172.16.47.<<count>>
start: 101
tenant_address:
value: 172.16.47.<<count>>
start: 101
params:
salt_master_host: ${_param:reclass_config_master}
linux_system_codename: xenial
Configuration example if the static compute host generation is used:
reclass:
storage:
node:
openstack_compute_node01:
name: cmp01
domain: ${_param:cluster_domain}
classes:
- cluster.${_param:cluster_name}.openstack.compute
params:
salt_master_host: ${_param:reclass_config_master}:
linux_system_codename: xenial
single_address: 10.0.0.101
deploy_address: 10.0.1.101
tenant_address: 10.0.2.101
Define the cmp<NUM> control address and hostname in the
<cluster>/openstack/init.yml file:
_param:
openstack_compute_node<NUM>_address: <control_network_IP>
openstack_compute_node<NUM>_hostname: cmp<NUM>
linux:
network:
host:
cmp<NUM>:
address: ${_param:openstack_compute_node<NUM>_address}
names:
- ${_param:openstack_compute_node<NUM>_hostname}
- ${_param:openstack_compute_node<NUM>_hostname}.${_param:cluster_domain}
Apply the reclass.storage state on the Salt Master node to
generate node definitions:
salt '*cfg*' state.sls reclass.storage
Verify that the target nodes have connectivity with the Salt Master node:
salt '*cmp<NUM>*' test.ping
Apply the following states:
salt 'cfg*' state.sls salt.minion.ca
salt '*cmp<NUM>*' state.sls salt.minion.cert
Deploy a new compute node as described in
MCP Deployment Guide: Deploy physical servers.
Caution
Do not use compounds for this step, since it will
affect already running physical servers and reboot them.
Use the Salt minion IDs instead of compounds before running the pipelines
or deploying physical servers manually.
Incorrect:
salt -C 'I@salt:control or I@nova:compute or I@neutron:gateway' \
cmd.run "touch /run/is_rebooted"
salt --async -C 'I@nova:compute' cmd.run 'salt-call state.sls \
linux.system.user,openssh,linux.network;reboot'
Correct:
salt cmp<NUM> cmd.run "touch /run/is_rebooted"
salt --async cmp<NUM> cmd.run 'salt-call state.sls \
linux.system.user,openssh,linux.network;reboot'
Note
We recommend that you rerun the Jenkins
Deploy - OpenStack pipeline that runs on the Salt Master node
with the same parameters as you have set initially
during your environment deployment.
This guarantees that your compute node will be properly set up and added.
Reprovision a compute node
Provisioning of compute nodes is relatively straightforward as you
can run all states at once. Though, you need to run and reboot it multiple
times for network configuration changes to take effect.
Note
Multiple reboots are needed because the ordering of dependencies
is not yet orchestrated.
To reprovision a compute node:
Verify that the name of the cmp node is not registered in
salt-key on the Salt Master node:
If the node is shown in the above command output, remove it:
salt-key -d cmp<NUM>.domain_name
Add a physical node using MAAS as described in the
MCP Deployment Guide: Provision physical nodes using MAAS.
Verify that the required nodes are defined in
/classes/cluster/<cluster_name>/infra/config.yml.
Note
Create as many hosts as you have compute nodes
in your environment within this file.
Configuration example if the dynamic compute host generation is used:
reclass:
storage:
node:
openstack_compute_rack01:
name: ${_param:openstack_compute_rack01_hostname}<<count>>
domain: ${_param:cluster_domain}
classes:
- cluster.${_param:cluster_name}.openstack.compute
repeat:
count: 20
start: 1
digits: 3
params:
single_address:
value: 172.16.47.<<count>>
start: 101
tenant_address:
value: 172.16.47.<<count>>
start: 101
params:
salt_master_host: ${_param:reclass_config_master}
linux_system_codename: xenial
Configuration example if the static compute host generation is used:
reclass:
storage:
node:
openstack_compute_node01:
name: cmp01
domain: ${_param:cluster_domain}
classes:
- cluster.${_param:cluster_name}.openstack.compute
params:
salt_master_host: ${_param:reclass_config_master}
linux_system_codename: xenial
single_address: 10.0.0.101
deploy_address: 10.0.1.101
tenant_address: 10.0.2.101
Apply the reclass.storage state on the Salt Master node to
generate node definitions:
salt '*cfg*' state.sls reclass.storage
Verify that the target nodes have connectivity with the Salt Master node:
salt '*cmp<NUM>*' test.ping
Verify that the Salt Minion nodes are synchronized:
salt '*cmp<NUM>*' saltutil.sync_all
Apply the Salt highstate on the compute node(s):
salt '*cmp<NUM>*' state.highstate
Note
Failures may occur during the first run of highstate.
Rerun the state until it is successfully applied.
Reboot the compute node(s) to apply network configuration changes.
Reapply the Salt highstate on the node(s):
salt '*cmp<NUM>*' state.highstate
Provision the vRouter on the compute node using CLI
or the Contrail web UI.
Example of the CLI command:
salt '*cmp<NUM>*' cmd.run '/usr/share/contrail-utils/provision_vrouter.py \
--host_name <CMP_HOSTNAME> --host_ip <CMP_IP_ADDRESS> --api_server_ip <CONTRAIL_VIP> \
--oper add --admin_user admin --admin_password <PASSWORD> \
--admin_tenant_name admin --openstack_ip <OPENSTACK_VIP>'
Note
- To obtain
<CONTRAIL_VIP>, run
salt-call pillar.get _param:keepalived_vip_address
on any ntw node.
- To obtain
<OPENSTACK_VIP>, run
salt-call pillar.get _param:keepalived_vip_address
on any ctl node.
Remove a compute node
This section instructs you on how to safely remove a compute node from
your OpenStack environment.
To remove a compute node:
Stop and disable the salt-minion service on the compute node you want
to remove:
systemctl stop salt-minion
systemctl disable salt-minion
Verify that the name of the node is not registered in salt-key on
the Salt Master node. If the node is present, remove it:
salt-key | grep cmp<NUM>
salt-key -d cmp<NUM>.domain_name
Log in to an OpenStack controller node.
Source the OpenStack RC file to set the required environment variables for
the OpenStack command-line clients:
Disable the nova-compute service on the target compute node:
openstack compute service set --disable <cmp_host_name> nova-compute
Verify that Nova does not schedule new instances on the target compute
node by viewing the output of the following command:
openstack compute service list
The command output should display the disabled status for the
nova-compute service running on the target compute node.
Migrate your instances using the openstack server migrate
command. You can perform live or cold migration.
Log in to the target compute node.
Stop the nova-compute service:
systemctl disable nova-compute
systemctl stop nova-compute
Log in to the OpenStack controller node.
Obtain the ID of the compute service to delete:
openstack compute service list
Delete the compute service substituting service_id with the value
obtained in the previous step:
openstack compute service delete <service_id>
Select from the following options:
If you plan to replace the removed compute node with a new compute node
with the same hostname, you need to manually clean up the resource provider
record from the placement service using the curl tool:
Log in to an OpenStack controller node.
Obtain the token ID from the openstack token issue command
output. For example:
openstack token issue
+------------+-------------------------------------+
| Field | Value |
+------------+-------------------------------------+
| expires | 2018-06-22T10:30:17+0000 |
| id | gAAAAABbLMGpVq2Gjwtc5Qqmp... |
| project_id | 6395787cdff649cdbb67da7e692cc592 |
| user_id | 2288ac845d5a4e478ffdc7153e389310 |
+------------+-------------------------------------+
Obtain the resource provider UUID of the target compute node:
curl -i -X GET <placement-endpoint-address>/resource_providers?name=<target-compute-host-name> -H \
'content-type: application/json' -H 'X-Auth-Token: <token>'
Susbtitute the following parameters as required:
placement-endpoint-addressThe placement endpoint can be obtained from the
openstack catalog list command output.
A placement endpoint includes the scheme, endpoint address, and port,
for example, http://10.11.0.10:8778. Depending on the deployment,
you may need to specify the https scheme rather than http.
target-compute-host-nameThe hostname of the compute node you are removing. For the
correct hostname format to pass, see the Hypervisor Hostname
column in the openstack hypervisor list command output.
tokenThe token id value obtained in the previous step.
Example of system response:
{
"resource_providers": [
{
"generation": 1,
"uuid": "08090377-965f-4ad8-9a1b-87f8e8153896",
"links": [
{
"href": "/resource_providers/08090377-965f-4ad8-9a1b-87f8e8153896",
"rel": "self"
},
{
"href": "/resource_providers/08090377-965f-4ad8-9a1b-87f8e8153896/aggregates",
"rel": "aggregates"
},
{
"href": "/resource_providers/08090377-965f-4ad8-9a1b-87f8e8153896/inventories",
"rel": "inventories"
},
{
"href": "/resource_providers/08090377-965f-4ad8-9a1b-87f8e8153896/usages",
"rel": "usages"
}
],
"name": "<compute-host-name>"
}
]
}
Delete the resource provider record from the placement service
substituting placement-endpoint-address,
target-compute-node-uuid, and token with the values obtained in
the previous steps:
curl -i -X DELETE <placement-endpoint-address>/resource_providers/<target-compute-node-uuid> -H \
'content-type: application/json' -H 'X-Auth-Token: <token>'
Log in to the Salt Master node.
Remove the compute node definition from the model
in infra/config.yml under the reclass:storage:node pillar.
Remove the generated file for the removed compute node under
/srv/salt/reclass/nodes/_generated.
Remove the compute node from StackLight LMA:
Update and clear the Salt mine:
salt -C 'I@salt:minion' state.sls salt.minion.grains
salt -C 'I@salt:minion' saltutil.refresh_modules
salt -C 'I@salt:minion' mine.update clear=true
Refresh the targets and alerts:
salt -C 'I@docker:swarm and I@prometheus:server' state.sls prometheus -b 1
Reboot a compute node
This section instructs you on how to reboot an OpenStack compute node for a
planned maintenance.
To reboot an OpenStack compute node:
Log in to an OpenStack controller node.
Disable scheduling of new VMs to the node. Optionally provide a reason
comment:
openstack compute service set --disable --disable-reason \
maintenance <compute_node_hostname> nova-compute
Migrate workloads from the OpenStack compute node:
nova host-evacuate-live <compute_node_hostname>
Log in to an OpenStack compute node.
Stop the nova-compute service:
service nova-compute stop
Shut down the OpenStack compute node, perform the maintenance, and turn the
node back on.
Verify that the nova-compute service is up and running:
service nova-compute status
Perform the following steps from the OpenStack controller node:
Enable scheduling of VMs to the node:
openstack compute service set --enable <compute_node_hostname> nova-compute
Verify that the nova-compute service and neutron agents are
running on the node:
openstack network agent list --host <compute_node_hostname>
openstack compute service list --host <compute_node_hostname>
The OpeStack compute service state must be up. The Neutron agent
service state must be UP and the alive column must include
:-).
Examples of a positive system response:
+----+--------------+------+------+---------+-------+----------------------------+
| ID | Binary | Host | Zone | Status | State | Updated At |
+----+--------------+------+------+---------+-------+----------------------------+
| 70 | nova-compute | cmp1 | nova | enabled | up | 2020-09-17T08:51:07.000000 |
+----+--------------+------+------+---------+-------+----------------------------+
+----------+--------------------+------+-------------------+-------+-------+---------------------------+
| ID | Agent Type | Host | Availability Zone | Alive | State | Binary |
+----------+--------------------+------+-------------------+-------+-------+---------------------------+
| e4256d73 | Open vSwitch agent | cmp1 | None | :-) | UP | neutron-openvswitch-agent |
+----------+--------------------+------+-------------------+-------+-------+---------------------------+
Optional. Migrate the instances back to their original OpenStack compute
node.
Manage gateway nodes
This section describes how to manage tenant network gateway nodes that
provide access to an external network for the environments configured
with Neutron OVS as a networking solution.
Add a gateway node
The gateway nodes are hardware nodes that provide gateways and routers to the
OVS-based tenant networks using network virtualization functions. Standard
cloud configuration includes three gateway nodes. Though, you can scale the
networking thoughput by adding more gateway servers.
This section explains how to increase the number of the gateway nodes in your
cloud environment.
To add a gateway node:
Add a physical node using MAAS as described in the
MCP Deployment Guide: Provision physical nodes using MAAS.
Define the gateway node in
/classes/cluster/<cluster_name>/infra/config.yml.
For example:
parameters:
_param:
openstack_gateway_node03_hostname: gtw03
openstack_gateway_node03_tenant_address: <IP_of_gtw_node_tenant_address>
reclass:
storage:
node:
openstack_gateway_node03:
name: ${_param:openstack_gateway_node03_hostname}
domain: ${_param:cluster_domain}
classes:
- cluster.${_param:cluster_name}.openstack.gateway
params:
salt_master_host: ${_param:reclass_config_master}
linux_system_codename: ${_param:linux_system_codename}
single_address: ${_param:openstack_gateway_node03_address}
tenant_address: ${_param:openstack_gateway_node03_tenant_address}
On the Salt Master node, generate node definitions by applying the
reclass.storage state:
salt '*cfg*' state.sls reclass.storage
Verify that the target nodes have connectivity with the Salt Master node:
salt '*gtw<NUM>*' test.ping
Verify that the Salt Minion nodes are synchronized:
salt '*gtw<NUM>*' saltutil.sync_all
On the added node, verify that salt-common and salt-minion have the
2017.7 version.
apt-cache policy salt-common
apt-cache policy salt-minion
Perform the initial Salt configuration:
salt '*gtw<NUM>*' state.sls salt.minion
Set up the network interfaces and the SSH access:
salt '*gtw<NUM>*' state.sls linux.system.user,openssh,linux.network,ntp,neutron
Apply the highstate on the gateway node:
salt '*gtw<NUM>*' state.highstate
Reprovision a gateway node
If an tenant network gateway node is down, you may need to reprovision it.
To reprovision a gateway node:
Verify that the name of the gateway node is not registered in
salt-key on the Salt Master node. If the node is present, remove it:
salt-key | grep gtw<NUM>
salt-key -d gtw<NUM>.domain_name
Add a physical node using MAAS as described in the
MCP Deployment Guide: Provision physical nodes using MAAS.
Verify that the required gateway node is defined in
/classes/cluster/<cluster_name>/infra/config.yml.
Generate the node definition, by applying the reclass.storage
state on the Salt Master node:
salt '*cfg*' state.sls reclass.storage
Verify that the target node has connectivity with the Salt Master node:
salt '*gtw<NUM>*' test.ping
Verify that the Salt Minion nodes are synchronized:
salt '*gtw<NUM>*' saltutil.sync_all
On the added node, verify that salt-common and salt-minion have the
2017.7 version.
apt-cache policy salt-common
apt-cache policy salt-minion
Perform the initial Salt configuration:
salt '*gtw<NUM>*' state.sls salt.minion
Set up the network interfaces and the SSH access:
salt '*gtw<NUM>*' state.sls linux.system.user,openssh,linux.network,ntp,neutron
Apply the Salt highstate on the gateway node:
salt '*gtw<NUM>*' state.highstate
Manage RabbitMQ
A RabbitMQ cluster is sensitive to external factors like network throughput
and traffic spikes. When running under high load, it requires special start,
stop, and restart procedures.
Restart a RabbitMQ node
Caution
We recommend that you do not restart a RabbitMQ node on a production
environment by executing systemctl restart rabbitmq-server
since a cluster can become inoperative.
To restart a single RabbitMQ node:
Gracefully stop rabbitmq-server on the target node:
systemctl stop rabbitmq-server
Verify that the node is removed from the cluster and RabbitMQ is stopped
on this node:
rabbitmqctl cluster_status
Example of system response:
Cluster status of node rabbit@msg01
[{nodes,[{disc,[rabbit@msg01,rabbit@msg02,rabbit@msg03]}]},
{running_nodes,[rabbit@msg03,rabbit@msg01]}, # <<< rabbit stopped on msg02
{cluster_name,<<"openstack">>},
{partitions,[]},
{alarms,[{rabbit@msg03,[]},{rabbit@msg01,[]}]}]
Start rabbitmq-server:
systemctl start rabbitmq-server
Restart a RabbitMQ cluster
To restart the whole RabbitMQ cluster:
Stop RabbitMQ on nodes one by one:
salt msg01* cmd.run 'systemctl stop rabbitmq-server'
salt msg02* cmd.run 'systemctl stop rabbitmq-server'
salt msg03* cmd.run 'systemctl stop rabbitmq-server'
Restart RabbitMQ in the reverse order:
salt msg03* cmd.run 'systemctl start rabbitmq-server'
salt msg02* cmd.run 'systemctl start rabbitmq-server'
salt msg01* cmd.run 'systemctl start rabbitmq-server'
Restart RabbitMQ with clearing the Mnesia database
To restart RabbitMQ with clearing the Mnesia database:
Stop RabbitMQ on nodes one by one:
salt msg01* cmd.run 'systemctl stop rabbitmq-server'
salt msg02* cmd.run 'systemctl stop rabbitmq-server'
salt msg03* cmd.run 'systemctl stop rabbitmq-server'
Remove the Mnesia database on all nodes:
salt msg0* cmd.run 'rm -rf /var/lib/rabbitmq/mnesia/'
Apply the rabbitmq state on the first RabbitMQ node:
salt msg01* state.apply rabbitmq
Apply the rabbitmq state on the remaining RabbitMQ nodes:
salt -C "msg02* or msg03*" state.apply rabbitmq
Switch to nonclustered RabbitMQ
Note
This feature is available starting from the MCP 2019.2.13 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
Note
This feature is available for OpenStack Queens and from the RabbitMQ
version 3.8.2.
You can switch clustered RabbitMQ to a nonclustered configuration. Mirantis
recommends using such approach only to improve the stability and performance on
large deployments in case the clustered configuration causes issues.
Switch to nonclustered RabbitMQ
This section instructs you on how to switch clustered RabbitMQ to a
nonclustered configuration.
Note
This feature is available starting from the MCP 2019.2.13 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
Caution
- This feature is available for OpenStack Queens and from the RabbitMQ
version 3.8.2.
- The procedure below applies only to environments without manual changes in
the configuration files of OpenStack services. The procedure applies all
OpenStack states to all OpenStack nodes and implies that any state can
apply without any errors before starting the maintenance.
To switch RabbitMQ to a nonclustered configuration:
Perform the following prerequisite steps:
Log in to the Salt Master node.
Verify that the salt-formula-nova version is
2016.12.1+202101271624.d392d41~xenial1 or newer:
dpkg -l |grep salt-formula-nova
Verify that the salt-formula-oslo-templates version is
2018.1+202101191343.e24fd64~xenial1 or newer.
dpkg -l |grep salt-formula-oslo-templates
Create /root/non-clustered-rabbit-helpers.sh with the following
content:
#!/bin/bash
# Apply all known openstack states on given target
# example: run_openstack_states ctl*
function run_openstack_states {
local target="$1"
all_formulas=$(salt-call config.get orchestration:upgrade:applications --out=json | jq '.[] | . as $in | keys_unsorted | map ({"key": ., "priority": $in[.].priority}) | sort_by(.priority) | map(.key | [(.)]) | add' | sed -e 's/"//g' -e 's/,//g' -e 's/\[//g' -e 's/\]//g')
#List of nodes in cloud
list_nodes=`salt -C "$target" test.ping --out=text | cut -d: -f1 | tr '\n' ' '`
for node in $list_nodes; do
#List of applications on the given node
node_applications=$(salt $node pillar.items __reclass__:applications --out=json | jq 'values |.[] | values |.[] | .[]' | tr -d '"' | tr '\n' ' ')
for component in $all_formulas ; do
if [[ " ${node_applications[*]} " == *"$component"* ]]; then
echo "Applying state: $component on the $node"
salt $node state.apply $component
fi
done
done
}
# Apply specified update state for all OpenStack applications on given target
# example: run_openstack_update_states ctl0* upgrade.verify
# will run {nova|glance|cinder|keystone}.upgrade.verify on ctl01
function run_openstack_update_states {
local target="$1"
local state="$2"
all_formulas=$(salt-call config.get orchestration:upgrade:applications --out=json | jq '.[] | . as $in | keys_unsorted | map ({"key": ., "priority": $in[.].priority}) | sort_by(.priority) | map(.key | [(.)]) | add' | sed -e 's/"//g' -e 's/,//g' -e 's/\[//g' -e 's/\]//g')
#List of nodes in cloud
list_nodes=`salt -C "$target" test.ping --out=text | cut -d: -f1 | tr '\n' ' '`
for node in $list_nodes; do
#List of applications on the given node
node_applications=$(salt $node pillar.items __reclass__:applications --out=json | jq 'values |.[] | values |.[] | .[]' | tr -d '"' | tr '\n' ' ')
for component in $all_formulas ; do
if [[ " ${node_applications[*]} " == *"$component"* ]]; then
echo "Applying state: $component.${state} on the $node"
salt $node state.apply $component.${state}
fi
done
done
}
Run simple API checks for ctl01*. The output should not include
errors.
. /root/non-clustered-rabbit-helpers.sh
run_openstack_update_states ctl01* upgrade.verify
Open your project Git repository with the Reclass model on the cluster
level.
Prepare the Neutron server for the RabbitMQ reconfiguration:
In openstack/control.yml, specify the
allow_automatic_dhcp_failover parameter as required.
Caution
If set to true, the server reschedules the nets from
the failed DHCP agents so that the alive agents catch up the net
and serve DHCP. Once the agent reconnects to RabbitMQ, it detects
that its net has been rescheduled and removes the DHCP port,
namespace, and flows. This parameter is useful if the entire
gateway node goes down. In case of an unstable RabbitMQ, agents do
not go down and the data plane is not affected. Therefore, we
recommend that you set the allow_automatic_dhcp_failover
parameter to false. However, consider the risks of a gateway
node going down before setting the
allow_automatic_dhcp_failover parameter.
neutron:
server:
allow_automatic_dhcp_failover: false
Apply the changes:
salt -C 'I@neutron:server' state.apply neutron.server
Verify the changes:
salt -C 'I@neutron:server' cmd.run "grep allow_automatic_dhcp_failover /etc/neutron/neutron.conf"
Perform the following changes in the Reclass model on the cluster level:
In infra/init.yml, add the following variable:
parameters:
_param:
openstack_rabbitmq_standalone_mode: true
In openstack/message_queue.yml, comment the following class:
classes:
#- system.rabbitmq.server.cluster
In openstack/message_queue.yml, add the following classes:
classes:
- system.keepalived.cluster.instance.rabbitmq_vip
- system.rabbitmq.server.single
If your deployment has OpenContrail, add the following variables:
In opencontrail/analytics.yml, add:
parameters:
opencontrail:
collector:
message_queue:
~members:
- host: ${_param:openstack_message_queue_address}
In opencontrail/control.yml, add:
parameters:
opencontrail:
config:
message_queue:
~members:
- host: ${_param:openstack_message_queue_address}
control:
message_queue:
~members:
- host: ${_param:openstack_message_queue_address}
To update the cells database when running Nova states, add the following
variable to openstack/control.yml:
parameters:
nova:
controller:
update_cells: true
Refresh pillars on all nodes:
salt '*' saltutil.sync_all; salt '*' saltutil.refresh_pillar
Verify that the messaging variables are set correctly:
Note
The following validation highlights the output for core OpenStack
services only. Validate any additional deployed services appropriately.
For Keystone:
salt -C 'I@keystone:server' pillar.items keystone:server:message_queue:use_vip_address keystone:server:message_queue:host
For Heat:
salt -C 'I@heat:server' pillar.items heat:server:message_queue:use_vip_address heat:server:message_queue:host
For Cinder:
salt -C 'I@cinder:controller' pillar.items cinder:controller:message_queue:use_vip_address cinder:controller:message_queue:host
For Glance:
salt -C 'I@glance:server' pillar.items glance:server:message_queue:use_vip_address glance:server:message_queue:host
For Nova:
salt -C 'I@nova:controller' pillar.items nova:controller:message_queue:use_vip_address nova:controller:message_queue:host
For the OpenStack compute nodes:
salt -C 'I@nova:compute' pillar.items nova:compute:message_queue:use_vip_address nova:compute:message_queue:host
For Neutron:
salt -C 'I@neutron:server' pillar.items neutron:server:message_queue:use_vip_address neutron:server:message_queue:host
salt -C 'I@neutron:gateway' pillar.items neutron:gateway:message_queue:use_vip_address neutron:gateway:message_queue:host
If your deployment has OpenContrail:
salt 'ntw01*' pillar.items opencontrail:config:message_queue:members opencontrail:control:message_queue:members
salt 'nal01*' pillar.items opencontrail:collector:message_queue:members
Apply the changes:
Stop the OpenStack control plane services on the ctl nodes:
. /root/non-clustered-rabbit-helpers.sh
run_openstack_update_states ctl* upgrade.service_stopped
Stop the OpenStack services on the gtw nodes. Skip this step if your
deployment has OpenContrail or does not have gtw nodes.
. /root/non-clustered-rabbit-helpers.sh
run_openstack_update_states gtw* upgrade.service_stopped
Reconfigure the Keepalived and RabbitMQ clusters on the msg nodes:
Verify that the rabbitmq:cluster pillars are not present:
salt -C 'I@rabbitmq:server' pillar.items rabbitmq:cluster
Verify that the haproxy pillars are not present:
salt -C 'I@rabbitmq:server' pillar.item haproxy
Remove HAProxy, HAProxy monitoring, and reconfigure Keepalived:
salt -C 'I@rabbitmq:server' cmd.run "export DEBIAN_FRONTEND=noninteractive; apt purge haproxy -y"
salt -C 'I@rabbitmq:server' state.apply telegraf
salt -C 'I@rabbitmq:server' state.apply keepalived
Verify that a VIP address is present on one of the msg nodes:
OPENSTCK_MSG_Q_ADDRESS=$(salt msg01* pillar.items _param:openstack_message_queue_address --out json|jq '.[][]')
salt -C 'I@rabbitmq:server' cmd.run "ip addr |grep $OPENSTCK_MSG_Q_ADDRESS"
Stop the RabbitMQ server, clear mnesia, and reconfigure
rabbitmq-server:
salt -C 'I@rabbitmq:server' cmd.run 'systemctl stop rabbitmq-server'
salt -C 'I@rabbitmq:server' cmd.run 'rm -rf /var/lib/rabbitmq/mnesia/'
salt -C 'I@rabbitmq:server' state.apply rabbitmq
Verify that the RabbitMQ server is running in a nonclustered
configuration:
salt -C 'I@rabbitmq:server' cmd.run "rabbitmqctl --formatter=erlang cluster_status |grep running_nodes"
Example of system response:
msg01.heat-cicd-queens-dvr-sl.local:
{running_nodes,[rabbit@msg01]},
msg03.heat-cicd-queens-dvr-sl.local:
{running_nodes,[rabbit@msg03]},
msg02.heat-cicd-queens-dvr-sl.local:
{running_nodes,[rabbit@msg02]},
Reconfigure OpenStack services on the ctl nodes:
Apply all OpenStack states on ctl nodes:
. /root/non-clustered-rabbit-helpers.sh
run_openstack_states ctl*
Verify transport_url for the OpenStack services on the ctl
nodes:
salt 'ctl*' cmd.run "for s in nova glance cinder keystone heat neutron; do if [[ -d "/etc/\$s" ]]; then grep ^transport_url /etc/\$s/*.conf; fi; done" shell=/bin/bash
Verify that the cells database is updated and transport_url has a
VIP address:
salt -C 'I@nova:controller and *01*' cmd.run ". /root/keystonercv3; nova-manage cell_v2 list_cells"
Reconfigure RabbitMQ on the gtw nodes. Skip this step if your
deployment has OpenContrail or does not have gtw nodes.
Apply all OpenStack states on the gtw nodes:
. /root/non-clustered-rabbit-helpers.sh
run_openstack_states gtw*
Verify transport_url for the OpenStack services on the gtw
nodes:
salt 'gtw*' cmd.run "for s in nova glance cinder keystone heat neutron; do if [[ -d "/etc/\$s" ]]; then grep ^transport_url /etc/\$s/*.conf; fi; done" shell=/bin/bash
Verify that the agents are up:
salt -C 'I@nova:controller and *01*' cmd.run ". /root/keystonercv3; openstack orchestration service list"
If your deployment has OpenContrail, reconfigure RabbitMQ on the ntw
and nal nodes:
Apply the following state on the ntw and nal nodes:
salt -C 'ntw* or nal*' state.apply opencontrail
Verify transport_url for the OpenStack services on the ntw
and nal nodes:
salt -C 'ntw* or nal*' cmd.run "for s in contrail; do if [[ -d "/etc/\$s" ]]; then grep ^rabbitmq_server_list /etc/\$s/*.conf; fi; done" shell=/bin/bash
salt 'ntw*' cmd.run "for s in contrail; do if [[ -d "/etc/\$s" ]]; then grep ^rabbit_server /etc/\$s/*.conf; fi; done" shell=/bin/bash
Verify the OpenContrail status:
salt -C 'ntw* or nal*' cmd.run 'doctrail all contrail-status'
Reconfigure OpenStack services on the cmp nodes:
Apply all OpenStack states on the cmp nodes:
. /root/non-clustered-rabbit-helpers.sh
run_openstack_states cmp*
Verify transport_url for the OpenStack services on the cmp
nodes:
salt 'cmp*' cmd.run "for s in nova glance cinder keystone heat neutron; do if [[ -d "/etc/\$s" ]]; then grep ^transport_url /etc/\$s/*.conf; fi; done" shell=/bin/bash
Caution
If your deployment has other nodes with OpenStack services,
apply the changes on such nodes as well using the required states.
Verify the services:
Verify that the Neutron services are up. Skip this step if your
deployment has OpenContrail.
salt -C 'I@nova:controller and *01*' cmd.run ". /root/keystonercv3; openstack network agent list"
Verify that the Nova services are up:
salt -C 'I@nova:controller and *01*' cmd.run ". /root/keystonercv3; openstack compute service list"
Verify that Heat services are up:
salt -C 'I@nova:controller and *01*' cmd.run ". /root/keystonercv3; openstack orchestration service list"
Verify that the Cinder services are up:
salt -C 'I@nova:controller and *01*' cmd.run ". /root/keystonercv3; openstack volume service list"
From the ctl01* node, apply the <app>.upgrade.verify
state. The output should not include errors.
. /root/non-clustered-rabbit-helpers.sh
run_openstack_update_states ctl01* upgrade.verify
Perform post-configuration steps:
Disable the RabbitMQUnequalQueueCritical Prometheus alert:
In stacklight/server.yml, add the following variable:
parameters:
prometheus:
server:
alert:
RabbitMQUnequalQueueCritical:
enabled: false
Apply the Prometheus state to the mon nodes:
salt -C 'I@docker:swarm and I@prometheus:server' state.sls prometheus.server -b1
Revert the changes in the Reclass model on the cluster level:
- In
openstack/control.yaml, set allow_automatic_dhcp_failover
back to true or leave as is if you did not change the value.
- In
openstack/control.yaml, remove
nova:controller:update_cells:true.
Apply the Neutron state:
salt -C 'I@neutron:server' state.apply neutron.server
Verify the changes:
salt -C 'I@neutron:server' cmd.run "grep allow_automatic_dhcp_failover /etc/neutron/neutron.conf"
Remove the script:
rm -f /root/non-clustered-rabbit-helpers.sh
Roll back to clustered RabbitMQ
This section instructs you on how to roll back RabbitMQ to a clustered
configuration after switching it to a nonclustered configuration as described
in Switch to nonclustered RabbitMQ.
Note
After performing the rollback procedure, you may notice a number of
down heat-engine instances of a previous version among the
heat-engine running instances. Such behavior is abnormal but expected.
Verify the Updated At field of the running instances of heat-engine.
Ignore the stopped(down) instances of heat-engine.
To roll back RabbitMQ to a clustered configuration:
If you have removed the non-clustered-rabbit-helpers.sh script, create
it again as described in Switch to nonclustered RabbitMQ.
Revert the changes performed in the cluster model in the step 2 during
Switch to nonclustered RabbitMQ. Use git stash, for example, if
you did not commit the changes.
From the Salt Master node, refresh pillars on all nodes:
salt '*' saltutil.sync_all; salt '*' saltutil.refresh_pillar
Roll back the changes on the RabbitMQ nodes:
salt -C 'I@rabbitmq:server' cmd.run 'systemctl stop rabbitmq-server'
salt -C 'I@rabbitmq:server' cmd.run 'rm -rf /var/lib/rabbitmq/mnesia/'
salt -C 'I@rabbitmq:server' state.apply keepalived
salt -C 'I@rabbitmq:server' state.apply haproxy
salt -C 'I@rabbitmq:server' state.apply telegraf
salt -C 'I@rabbitmq:server' state.apply rabbitmq
Verify that the RabbitMQ server is running in a clustered configuration:
salt -C 'I@rabbitmq:server' cmd.run "rabbitmqctl --formatter=erlang cluster_status |grep running_nodes"
Example of system response:
msg01.heat-cicd-queens-dvr-sl.local:
{running_nodes,[rabbit@msg02,rabbit@msg03,rabbit@msg01]},
msg02.heat-cicd-queens-dvr-sl.local:
{running_nodes,[rabbit@msg01,rabbit@msg03,rabbit@msg02]},
msg03.heat-cicd-queens-dvr-sl.local:
{running_nodes,[rabbit@msg02,rabbit@msg01,rabbit@msg03]},
Roll back the changes on other nodes:
Roll back the changes on the ctl nodes:
. /root/non-clustered-rabbit-helpers.sh
run_openstack_states ctl*
Roll back changes on the gtw nodes. Skip this step if your deployment
has OpenContrail or does not have gtw nodes.
. /root/non-clustered-rabbit-helpers.sh
run_openstack_states gtw*
If your environment has OpenContrail, roll back the changes on the ntw
and nal nodes:
salt -C 'ntw* or nal*' state.apply opencontrail
Roll back the changes on the cmp nodes:
. /root/non-clustered-rabbit-helpers.sh
run_openstack_states cmp*
Enable queue mirroring
Note
This feature is available starting from the MCP 2019.2.15 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
Mirroring policy enables RabbitMQ to mirror the queues content to an additional
RabbitMQ node in the RabbitMQ cluster. Such approach reduces failures during
the RabbitMQ cluster recovery.
Warning
- This feature is of use only for clustered RabbitMQ configurations.
- Enabling mirroring for queues and exchanges in RabbitMQ may increase the
message passing latency and prolong the RabbitMQ cluster recovery after a
network partition. Therefore, we recommend accomplishing the procedure on
a staging environment before applying it to production.
To enable queue mirroring:
Open your project Git repository with the Reclass model on the cluster
level.
In <cluster_name>/openstack/message_queue.yml, specify
ha_exactly_ttl_120 in classes:
classes:
...
- system.rabbitmq.server.vhost.openstack
- system.rabbitmq.server.vhost.openstack.without_rpc_ha
- system.rabbitmq.server.vhost.openstack.ha_exactly_ttl_120
...
Log in to the Salt Master node.
Apply the rabbitmq.server state:
salt -C 'I@rabbitmq:server and *01*' state.sls rabbitmq.server
Randomize RabbitMQ reconnection intervals
Note
This feature is available starting from the MCP 2019.2.15 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
You can randomize RabbitMQ reconnection intervals (or timeouts) for the
required OpenStack services. It is helpful for large OpenStack environments
where a simultaneous reconnection of all OpenStack services after a RabbitMQ
cluster partitioning can significantly prolong the RabbitMQ cluster recovery or
cause the cluster to enter the split-brain mode.
Using this feature, the following OpenStack configuration options will be
randomized:
kombu_reconnect_delay - from 30 to 60 secondsrabbit_retry_interval - from 10 to 60 secondsrabbit_retry_backoff - from 30 to 60 secondsrabbit_interval_max - from 60 to 180 seconds
To randomize RabbitMQ reconnection intervals :
Open your project Git repository with the Reclass model on the cluster
level.
Open the configuration file of the required OpenStack service. For example,
for the OpenStack Compute service (Nova), open
<cluster_name>/openstack/compute/init.yml.
Under message_queue, specify rabbit_timeouts_random: True:
parameters:
nova:
compute:
message_queue:
rabbit_timeouts_random: True
Log in to the Salt Master node.
Apply the corresponding OpenStack service state(s). For example, for the
OpenStack Compute service (Nova), apply the following state:
salt -C 'I@nova:compute' state.sls nova.compute
Note
Each service configured with this feature on every node will
receive new unique timeouts on every run of the corresponding OpenStack
service Salt state.
Perform the steps 2-5 for other OpenStack services as required.
Remove a node
Removal of a node from a Salt-managed environment is a matter of disabling
the salt-minion service running on the node, removing its key from
the Salt Master node, and updating the services so that they know that the
node is not available anymore.
To remove a node:
Stop and disable the salt-minion service on the node you want to
remove:
systemctl stop salt-minion
systemctl disable salt-minion
Verify that the name of the node is not registered in salt-key on
the Salt Master node. If the node is present, remove it:
salt-key | grep <nodename><NUM>
salt-key -d <nodename><NUM>.domain_name
Update your Reclass metadata model to remove the node from services.
Apply the necessary Salt states. This step is generic as different
services can be involved depending on the node being removed.
Manage certificates
After you deploy an MCP cluster, you can renew your expired certificates or
replace them by the endpoint certificates provided by a customer as required.
When you renew a certificate, its key remains the same. When you replace
a certificate, a new certificate key is added accordingly.
You can either push certificates from pillars or regenerate them
as follows:
- Generate and update by
salt-minion (signed by salt-master)
- Generate and update by external certificate authorities, for example, by
Let’s Encrypt
Certificates generated by salt-minion can be renewed by the salt-minion
state. The renewal operation becomes available within 30 days before the
expiration date. This is controlled by the days_remaining parameter of the
x509.certificate_managed Salt state.
Refer to
Salt.states.x509
for details.
You can force renewal of certificates by removing old certificates
and running salt.minion.cert state on each target node.
Publish CA certificates
If you use certificates issued by Certificate Authorities that are not
recognized by an operating system, you must publish them.
To publish CA certificates:
Open your project Git repository with the Reclass model
on the cluster level.
Create the /infra/ssl/init.yml file with the following configuration
as an example:
parameters:
linux:
system:
ca_certificates:
ca-salt_master_ca: |
-----BEGIN CERTIFICATE-----
MIIGXzCCBEegAwIBAgIDEUB0MA0GCSqGSIb3DQEBCwUAMFkxEzARBgoJkiaJk/Is
...
YqQO
-----END CERTIFICATE-----
ca-salt_master_ca_old: |
-----BEGIN CERTIFICATE-----
MIIFgDCCA2igAwIBAgIDET0sMA0GCSqGSIb3DQEBCwUAMFkxEzARBgoJkiaJk/Is
...
WzUuf8H9dBW2DPtk5Jq/+QWtYMs=
-----END CERTIFICATE-----
To publish the certificates on all nodes managed by Salt,
update /infra/init.yml by adding the newly created class:
classes:
- cluster.<cluster_name>.infra.ssl
To publish the certificates on a specific node, update
/infra/config.yml. For example:
parameters:
reclass:
storage:
node:
openstack_control_node01:
classes:
- cluster.${_param:cluster_name}.openstack.ssl
Log in to the Salt Master node.
Update the Reclass storage:
salt-call state.sls reclass.storage -l debug
Apply the linux.system state on all nodes:
salt \* state.sls linux.system.certificate -l debug
NGINX certificates
This section describes how to renew or replace the NGINX certificates
managed by either salt-minion or self-managed certificates using pillars.
For both cases, you must verify the GlusterFS share salt_pki
before renewal.
Verify the GlusterFS share salt_pki
Before you proceed with the NGINX certificates renewal or replacement,
verify the GlusterFS share salt_pki.
To verify the GlusterFS share salt_pki:
Log in to any infrastructure node that hosts the salt_pki GlusterFS
volume.
Obtain the list of the GlusterFS minions IDs:
salt -C 'I@glusterfs:server' test.ping --output yaml | cut -d':' -f1
Example of system response:
kvm01.multinode-ha.int
kvm03.multinode-ha.int
kvm02.multinode-ha.int
Verify that the volume is replicated and is online for any of the minion IDs
from the list obtained in the previous step.
salt <minion_id> cmd.run 'gluster volume status salt_pki'
Example of system response:
Status of volume: salt_pki
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick 192.168.2.241:/srv/glusterfs/salt_pki 49154 0 Y 9211
Brick 192.168.2.242:/srv/glusterfs/salt_pki 49154 0 Y 8499
Brick 192.168.2.243:/srv/glusterfs/salt_pki 49154 0 Y 8332
Self-heal Daemon on localhost N/A N/A Y 6313
Self-heal Daemon on 192.168.2.242 N/A N/A Y 10203
Self-heal Daemon on 192.168.2.243 N/A N/A Y 2068
Task Status of Volume salt_pki
------------------------------------------------------------------------------
There are no active volume tasks
Log in to the Salt Master node.
Verify that the salt_pki volume is mounted on each proxy node and the
Salt Master node:
salt -C 'I@nginx:server:site:*:host:protocol:https or I@salt:master' \
cmd.run 'mount | grep salt_pki'
Example of system response:
prx01.multinode-ha.int:
192.168.2.240:/salt_pki on /srv/salt/pki type fuse.glusterfs \
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
prx02.multinode-ha.int:
192.168.2.240:/salt_pki on /srv/salt/pki type fuse.glusterfs \
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
cfg01.multinode-ha.int:
192.168.2.240:/salt_pki on /srv/salt/pki type fuse.glusterfs \
(rw,relatime,user_id=0,group_id=0,default_permissions,allow_other,max_read=131072)
Proceed with the renewal or replacement of the NGINX certificates
as required.
Renew or replace the NGINX certificates managed by salt-minion
This section describes how to renew or replace the NGINX certificates
managed by salt-minion.
To renew or replace the NGINX certificates managed by salt-minion:
Complete the steps described in Verify the GlusterFS share salt_pki.
Log in to the Salt Master node.
Verify the certificate validity date:
openssl x509 -in /srv/salt/pki/*/proxy.crt -text -noout | grep -Ei 'after|before'
Example of system response:
Not Before: May 30 17:21:10 2018 GMT
Not After : May 30 17:21:10 2019 GMT
Remove your current certificates from the Salt Master node.
Note
The following command also removes certificates from all proxy
nodes as they use the same GlusterFS share.
rm -f /srv/salt/pki/*/*.[pemcrt]*
If you replace the certificates, remove the private key:
rm -f /srv/salt/pki/*/proxy.key
Renew or replace your certificates by applying the salt.minion state
on all proxy nodes one by one:
salt -C 'I@nginx:server:site:*:host:protocol:https' state.sls salt.minion.cert -b 1
Apply the nginx state on all proxy nodes one by one:
salt -C 'I@nginx:server:site:*:host:protocol:https' state.sls nginx -b 1
Verify the new certificate validity date:
openssl x509 -in /srv/salt/pki/*/proxy.crt -text -noout | grep -Ei 'after|before'
Example of system response:
Not Before: May 30 17:21:10 2018 GMT
Not After : May 30 17:21:10 2019 GMT
Renew the self-managed NGINX certificates
This section describes how to renew the self-managed NGINX certificates.
To renew the self-managed NGINX certificates:
Complete the steps described in Verify the GlusterFS share salt_pki.
Open your project Git repository with the Reclass model on the cluster
level.
Update the /openstack/proxy.yml file with the following configuration
as an example:
parameters:
_params:
nginx_proxy_ssl:
enabled: true
mode: secure
key_file: /srv/salt/pki/${_param:cluster_name}/FQDN_PROXY_CERT.key
cert_file: /srv/salt/pki/${_param:cluster_name}/FQDN_PROXY_CERT.crt
chain_file: /srv/salt/pki/${_param:cluster_name}/FQDN_PROXY_CERT_CHAIN.crt
key: |
-----BEGIN PRIVATE KEY-----
MIIJRAIBADANBgkqhkiG9w0BAQEFAASCCS4wggkqAgEAAoICAQC3qXiZiugf6HlR
...
aXK0Fg1hJKu60Oh+E5H1d+ZVbP30xpdQ
-----END PRIVATE KEY-----
cert: |
-----BEGIN CERTIFICATE-----
MIIHDzCCBPegAwIBAgIDLYclMA0GCSqGSIb3DQEBCwUAMFkxEzARBgoJkiaJk/Is
...
lHfjP1c6iWAL0YEp1IMCeM01l4WWj0ymb7f4wgOzcULfwzU=
-----END CERTIFICATE-----
chain: |
-----BEGIN CERTIFICATE-----
MIIFgDCCA2igAwIBAgIDET0sMA0GCSqGSIb3DQEBCwUAMFkxEzARBgoJkiaJk/Is
...
UPwFzYIVkwy4ny+UJm9js8iynKro643mXty9vj5TdN1iK3ZA4f4/7kenuHtGBNur
WzUuf8H9dBW2DPtk5Jq/+QWtYMs=
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
MIIGXzCCBEegAwIBAgIDEUB0MA0GCSqGSIb3DQEBCwUAMFkxEzARBgoJkiaJk/Is
...
/inxvBr89TvbCP2hweGMD6w1mKJU2SWEQwMs7P72dU7VuVqyyoutMWakJZ+xoGE9
YqQO
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
MIIHDzCCBPegAwIBAgIDLYclMA0GCSqGSIb3DQEBCwUAMFkxEzARBgoJkiaJk/Is
...
lHfjP1c6iWAL0YEp1IMCeM01l4WWj0ymb7f4wgOzcULfwzU=
-----END CERTIFICATE-----
Note
Modify the example above by adding your certificates and key:
- If you renew the certificates, leave your existing
key and
update the cert and chain sections.
- If you replace the certificates, modify all three sections.
Note
The key, cert, and chain sections are optional.
You can select from the following options:
- Store certificates in the file system in
/srv/salt/pki/**/
and add the key_file, cert_file, and chain_file
lines to /openstack/proxy.yml.
- Add only the
key, cert, and chain sections
without the key_file, cert_file, and chain_file
lines to /openstack/proxy.yml. The certificates are stored
under the /etc directory as default paths in the Salt
formula.
- Use all three sections, as in the example above.
All content is available in pillar and is stored
in
/srv/salt/pki/** as well.
This option requires manual upload of the certificates and key
files content to the .yml files.
Log in to the Salt Master node.
Verify the new certificate validity date:
openssl x509 -in /srv/salt/pki/*/proxy.crt -text -noout | grep -Ei 'after|before'
Example of system response:
Not Before: May 30 17:21:10 2018 GMT
Not After : May 30 17:21:10 2019 GMT
Remove the current certificates.
Note
The following command also removes certificates from all proxy
nodes as they use the same GlusterFS share.
rm -f /srv/salt/pki/*/*.[pemcrt]*
If you replace the certificates, remove the private key:
/srv/salt/pki/*/proxy.key
Apply the nginx state on all proxy nodes one by one:
salt -C 'I@nginx:server' state.sls nginx -b 1
Verify the new certificate validity date:
openssl x509 -in /srv/salt/pki/*/proxy.crt -text -noout | grep -Ei 'after|before'
Example of system response:
Not Before: May 30 17:21:10 2018 GMT
Not After : May 30 17:21:10 2019 GMT
Restart the NGINX services and remove the VIP before restart:
salt -C 'I@nginx:server' cmd.run 'service keepalived stop; sleep 5; \
service nginx restart; service keepalived start' -b 1
HAProxy certificates
This section describes how to renew or replace the HAProxy certificates managed
by either salt-minion or self-managed certificates using pillars.
Renew or replace the HAProxy certificates managed by salt-minion
This section describes how to renew or replace the HAProxy certificates
managed by salt-minion.
To renew or replace the HAProxy certificates managed by salt-minion:
Log in to the Salt Master node.
Obtain the list of the HAProxy minions IDs where the certificate
should be replaced:
salt -C 'I@haproxy:proxy:listen:*:binds:ssl:enabled:true' \
pillar.get _nonexistent | cut -d':' -f1
Example of system response:
cid02.multinode-ha.int
cid03.multinode-ha.int
cid01.multinode-ha.int
Verify the certificate validity date for each HAProxy minion listed in the
output of the above command:
for m in $(salt -C 'I@haproxy:proxy:listen:*:binds:ssl:enabled:true' \
pillar.get _nonexistent | cut -d':' -f1); do for c in $(salt -C ${m} \
pillar.get 'haproxy:proxy:listen' --out=txt | egrep -o "'pem_file': '\S+'" | \
cut -d"'" -f4 | sort | uniq | tr '\n' ' '); do salt -C ${m} \
cmd.run "openssl x509 -in ${c} -text | egrep -i 'after|before'"; done; done;
Example of system response:
cid02.multinode-ha.int:
Not Before: May 29 12:58:21 2018 GMT
Not After : May 29 12:58:21 2019 GMT
Remove your current certificates from each HAProxy minion:
for m in $(salt -C 'I@haproxy:proxy:listen:*:binds:ssl:enabled:true' \
pillar.get _nonexistent | cut -d':' -f1); do for c in $(salt -C ${m} \
pillar.get 'haproxy:proxy:listen' --out=txt | egrep -o "'pem_file': '\S+'" | cut -d"'" \
-f4 | sort | uniq | sed s/-all.pem/.crt/ | tr '\n' ' '); \
do salt -C ${m} cmd.run "rm -f ${c}"; done; done; \
for m in $(salt -C 'I@haproxy:proxy:listen:*:binds:ssl:enabled:true' \
pillar.get _nonexistent | cut -d':' -f1); do for c in $(salt -C ${m} \
pillar.get 'haproxy:proxy:listen' --out=txt | egrep -o "'pem_file': '\S+'" | cut -d"'" \
-f4 | sort | uniq | tr '\n' ' '); do salt -C ${m} cmd.run "rm -f ${c}"; done; done; \
salt -C 'I@haproxy:proxy:listen:*:binds:ssl:enabled:true' \
cmd.run 'rm -f /etc/haproxy/ssl/salt_master_ca-ca.crt'
If you replace the certificates, remove the private key:
for m in $(salt -C 'I@haproxy:proxy:listen:*:binds:ssl:enabled:true' \
pillar.get _nonexistent | cut -d':' -f1); do for c in $(salt -C ${m} \
pillar.get 'haproxy:proxy:listen' --out=txt | egrep -o "'pem_file': '\S+'" | cut -d"'" \
-f4 | sort | uniq | sed s/-all.pem/.key/ | tr '\n' ' '); \
do salt -C ${m} cmd.run "rm -f ${c}"; done; done;
Apply the salt.minion.grains state for all HAProxy nodes
to retrieve the CA certificate from Salt Master:
salt -C 'I@haproxy:proxy:listen:*:binds:ssl:enabled:true' state.sls salt.minion.grains
Apply the salt.minion.cert state for all HAProxy nodes:
salt -C 'I@haproxy:proxy:listen:*:binds:ssl:enabled:true' state.sls salt.minion.cert
Verify the new certificate validity date:
for m in $(salt -C 'I@haproxy:proxy:listen:*:binds:ssl:enabled:true' \
pillar.get _nonexistent | cut -d':' -f1); do for c in $(salt -C ${m} \
pillar.get 'haproxy:proxy:listen' --out=txt | egrep -o "'pem_file': '\S+'" | cut -d"'" \
-f4 | sort | uniq | tr '\n' ' '); do salt -C ${m} \
cmd.run "openssl x509 -in ${c} -text | egrep -i 'after|before'"; done; done;
Example of system response:
cid02.multinode-ha.int:
Not Before: Jun 6 17:24:09 2018 GMT
Not After : Jun 6 17:24:09 2019 GMT
Restart the HAProxy services on each HAProxy minion
and remove the VIP before restart:
salt -C 'I@haproxy:proxy:listen:*:binds:ssl:enabled:true' \
cmd.run 'service keepalived stop; sleep 5; \
service haproxy stop; service haproxy start; service keepalived start' -b 1
Renew or replace the self-managed HAProxy certificates
This section describes how to renew or replace the self-managed
HAProxy certificates.
To renew or replace the self-managed HAProxy certificates:
Log in to the Salt Master node.
Verify the certificate validity date:
for node in $(salt -C 'I@haproxy:proxy' test.ping --output yaml | cut -d':' -f1); do
for name in $(salt ${node} pillar.get haproxy:proxy --output=json | jq '.. \
| .listen? | .. | .ssl? | .pem_file?' | grep -v null | sort | uniq); do
salt ${node} cmd.run "openssl x509 -in ${name} -text -noout | grep -Ei 'after|before'";
done;
done;
Note
In the command above, the pem_file value is used
to specify the explicit certificate path.
Example of system response:
cid02.multinode-ha.int:
Not Before: May 25 15:32:17 2018 GMT
Not After : May 25 15:32:17 2019 GMT
cid01.multinode-ha.int:
Not Before: May 25 15:29:17 2018 GMT
Not After : May 25 15:29:17 2019 GMT
cid03.multinode-ha.int:
Not Before: May 25 15:21:17 2018 GMT
Not After : May 25 15:21:17 2019 GMT
Open your project Git repository with Reclass model on the cluster level.
For each class file with the HAProxy class enabled, update its pillar values
with the following configuration as an example:
parameters:
_params:
haproxy_proxy_ssl:
enabled: true
mode: secure
key: |
-----BEGIN RSA PRIVATE KEY-----
MIIJKAIBAAKCAgEAxSXLtYhzptxcAdnsNy2r8NkgskPm3J/l54hmhuSoL61LpEIi
...
0z/c5yAddRpU/i6/TH2RlBaSGfmoNw/IuFfLsZI2O6dQo4e+QKX+V3JTeNY=
-----END RSA PRIVATE KEY-----
cert: |
-----BEGIN CERTIFICATE-----
MIIGEzCCA/ugAwIBAgIILX5kuGcAhw8wDQYJKoZIhvcNAQELBQAwSjELMAkGA1UE
...
/in+Y5Wrl1uGHYeFe0yOdb1uxH+PLxc=
-----END CERTIFICATE-----
chain: |
-----BEGIN RSA PRIVATE KEY-----
MIIJKAIBAAKCAgEAxSXLtYhzptxcAdnsNy2r8NkgskPm3J/l54hmhuSoL61LpEIi
...
0z/c5yAddRpU/i6/TH2RlBaSGfmoNw/IuFfLsZI2O6dQo4e+QKX+V3JTeNY=
-----END RSA PRIVATE KEY-----
-----BEGIN CERTIFICATE-----
MIIGEzCCA/ugAwIBAgIILX5kuGcAhw8wDQYJKoZIhvcNAQELBQAwSjELMAkGA1UE
...
/in+Y5Wrl1uGHYeFe0yOdb1uxH+PLxc=
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
MIIF0TCCA7mgAwIBAgIJAOkTQnjLz6rEMA0GCSqGSIb3DQEBCwUAMEoxCzAJBgNV
...
M8IfJ5I=
-----END CERTIFICATE-----
Note
Modify the example above by adding your certificates and key:
- If you renew the certificates, leave your existing
key and
update the cert and chain sections.
- If you replace the certificates, modify all three sections.
Remove your current certificates from the HAProxy nodes:
for node in $(salt -C 'I@haproxy:proxy' test.ping --output yaml | cut -d':' -f1); do
for name in $(salt ${node} pillar.get haproxy:proxy --output=json | jq '.. \
| .listen? | .. | .ssl? | .pem_file?' | grep -v null | sort | uniq); do
salt ${node} cmd.run "rm -f ${name}";
done;
done;
Apply the haproxy.proxy state on all HAProxy nodes one by one:
salt -C 'I@haproxy:proxy' state.sls haproxy.proxy -b 1
Verify the new certificate validity date:
for node in $(salt -C 'I@haproxy:proxy' test.ping --output yaml | cut -d':' -f1); do
for name in $(salt ${node} pillar.get haproxy:proxy --output=json | jq '.. \
| .listen? | .. | .ssl? | .pem_file?' | grep -v null | sort | uniq); do
salt ${node} cmd.run "openssl x509 -in ${name} -text -noout | grep -Ei 'after|before'";
done;
done;
Example of system response:
cid02.multinode-ha.int:
Not Before: May 25 15:29:17 2018 GMT
Not After : May 25 15:29:17 2019 GMT
cid03.multinode-ha.int:
Not Before: May 25 15:29:17 2018 GMT
Not After : May 25 15:29:17 2019 GMT
cid01.multinode-ha.int:
Not Before: May 25 15:29:17 2018 GMT
Not After : May 25 15:29:17 2019 GMT
Restart the HAProxy services one by one and remove the VIP before restart:
salt -C 'I@haproxy:proxy' cmd.run 'service keepalived stop; sleep 5; \
service haproxy stop; service haproxy start; service keepalived start' -b 1
Apache certificates
This section describes how to renew or replace the Apache certificates
managed by either salt-minion or self-managed certificates using pillars.
Renew or replace the Apache certificates managed by salt-minion
This section describes how to renew or replace the Apache certificates
managed by salt-minion.
Warning
If you replace or renew the Apache certificates after the Salt
Master CA certificate has been replaced, make sure that both
new and old CA certificates are published as described in
Publish CA certificates.
To renew or replace the Apache certificates managed by salt-minion:
Log in to the Salt Master node.
Verify your current certificate validity date:
salt -C 'I@apache:server' cmd.run 'openssl x509 \
-in /etc/ssl/certs/internal_proxy.crt -text -noout | grep -Ei "after|before"'
Example of system response:
ctl02.multinode-ha.int:
Not Before: May 29 12:58:21 2018 GMT
Not After : May 29 12:58:21 2019 GMT
ctl03.multinode-ha.int:
Not Before: May 29 12:58:25 2018 GMT
Not After : May 29 12:58:25 2019 GMT
ctl01.multinode-ha.int:
Not Before: Apr 27 12:37:28 2018 GMT
Not After : Apr 27 12:37:28 2019 GMT
Remove your current certificates from the Apache nodes:
salt -C 'I@apache:server' cmd.run 'rm -f /etc/ssl/certs/internal_proxy.crt'
If you replace the certificates, remove the private key:
salt -C 'I@apache:server' cmd.run 'rm -f /etc/ssl/private/internal_proxy.key'
Renew or replace your certificates by applying the salt.minion.cert
state on all Apache nodes one by one:
salt -C 'I@apache:server' state.sls salt.minion.cert
Refresh the CA chain:
salt -C 'I@apache:server' cmd.run 'cat /etc/ssl/certs/internal_proxy.crt \
/usr/local/share/ca-certificates/ca-salt_master_ca.crt > \
/etc/ssl/certs/internal_proxy-with-chain.crt; \
chmod 0644 /etc/ssl/certs/internal_proxy-with-chain.crt; \
chown root:root /etc/ssl/certs/internal_proxy-with-chain.crt'
Verify the new certificate validity date:
salt -C 'I@apache:server' cmd.run 'openssl x509 \
-in /etc/ssl/certs/internal_proxy.crt -text -noout | grep -Ei "after|before"'
Example of system response:
ctl02.multinode-ha.int:
Not Before: Jun 6 17:24:09 2018 GMT
Not After : Jun 6 17:24:09 2019 GMT
ctl03.multinode-ha.int:
Not Before: Jun 6 17:24:42 2018 GMT
Not After : Jun 6 17:24:42 2019 GMT
ctl01.multinode-ha.int:
Not Before: Jun 6 17:23:38 2018 GMT
Not After : Jun 6 17:23:38 2019 GMT
Restart the Apache services one by one:
salt -C 'I@apache:server' cmd.run 'service apache2 stop; service apache2 start; sleep 60' -b1
Replace the self-managed Apache certificates
This section describes how to replace the self-managed Apache certificates.
Warning
If you replace or renew the Apache certificates after the Salt
Master CA certificate has been replaced, make sure that both
new and old CA certificates are published as described in
Publish CA certificates.
To replace the self-managed Apache certificates:
Log in to the Salt Master node.
Verify your current certificate validity date:
for node in $(salt -C 'I@apache:server' test.ping --output yaml | cut -d':' -f1); do
for name in $(salt ${node} pillar.get apache:server:site --output=json | \
jq '.. | .host? | .name?' | grep -v null | sort | uniq); do
salt ${node} cmd.run "openssl x509 -in /etc/ssl/certs/${name}.crt -text \
-noout | grep -Ei 'after|before'";
done;
done;
Example of system response:
ctl02.multinode-ha.int:
Not Before: May 29 12:58:21 2018 GMT
Not After : May 29 12:58:21 2019 GMT
ctl03.multinode-ha.int:
Not Before: May 29 12:58:25 2018 GMT
Not After : May 29 12:58:25 2019 GMT
ctl01.multinode-ha.int:
Not Before: Apr 27 12:37:28 2018 GMT
Not After : Apr 27 12:37:28 2019 GMT
Open your project Git repository with Reclass model on the cluster level.
For each class file with the Apache server class enabled,
update the _param:apache_proxy_ssl value
with the following configuration as an example:
parameters:
_params:
apache_proxy_ssl:
enabled: true
mode: secure
key: |
-----BEGIN RSA PRIVATE KEY-----
MIIJKAIBAAKCAgEAxSXLtYhzptxcAdnsNy2r8NkgskPm3J/l54hmhuSoL61LpEIi
...
0z/c5yAddRpU/i6/TH2RlBaSGfmoNw/IuFfLsZI2O6dQo4e+QKX+V3JTeNY=
-----END RSA PRIVATE KEY-----
cert: |
-----BEGIN CERTIFICATE-----
MIIGEzCCA/ugAwIBAgIILX5kuGcAhw8wDQYJKoZIhvcNAQELBQAwSjELMAkGA1UE
...
/in+Y5Wrl1uGHYeFe0yOdb1uxH+PLxc=
-----END CERTIFICATE-----
chain: |
-----BEGIN RSA PRIVATE KEY-----
MIIJKAIBAAKCAgEAxSXLtYhzptxcAdnsNy2r8NkgskPm3J/l54hmhuSoL61LpEIi
...
0z/c5yAddRpU/i6/TH2RlBaSGfmoNw/IuFfLsZI2O6dQo4e+QKX+V3JTeNY=
-----END RSA PRIVATE KEY-----
-----BEGIN CERTIFICATE-----
MIIGEzCCA/ugAwIBAgIILX5kuGcAhw8wDQYJKoZIhvcNAQELBQAwSjELMAkGA1UE
...
/in+Y5Wrl1uGHYeFe0yOdb1uxH+PLxc=
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
MIIF0TCCA7mgAwIBAgIJAOkTQnjLz6rEMA0GCSqGSIb3DQEBCwUAMEoxCzAJBgNV
...
M8IfJ5I=
-----END CERTIFICATE-----
Note
Modify the example above by adding your certificates and key:
- If you renew the certificates, leave your existing
key and
update the cert and chain sections.
- If you replace the certificates, modify all three sections.
Remove your current certificates from the Apache nodes:
for node in $(salt -C 'I@apache:server' test.ping --output yaml | cut -d':' -f1); do
for name in $(salt ${node} pillar.get apache:server:site --output=json | \
jq '.. | .host? | .name?' | grep -v null | sort | uniq); do
salt ${node} cmd.run "rm -f /etc/ssl/certs/${name}.crt";
done;
done;
Apply the apache.server state on all Apache nodes one by one:
salt -C 'I@apache:server' state.sls apache.server
Verify the new certificate validity date:
for node in $(salt -C 'I@apache:server' test.ping --output yaml | cut -d':' -f1); do
for name in $(salt ${node} pillar.get apache:server:site --output=json | \
jq '.. | .host? | .name?' | grep -v null | sort | uniq); do
salt ${node} cmd.run "openssl x509 -in /etc/ssl/certs/${name}.crt -text \
-noout | grep -Ei 'after|before'";
done;
done;
Example of system response:
ctl02.multinode-ha.int:
Not Before: Jun 6 17:24:09 2018 GMT
Not After : Jun 6 17:24:09 2019 GMT
ctl03.multinode-ha.int:
Not Before: Jun 6 17:24:42 2018 GMT
Not After : Jun 6 17:24:42 2019 GMT
ctl01.multinode-ha.int:
Not Before: Jun 6 17:23:38 2018 GMT
Not After : Jun 6 17:23:38 2019 GMT
Restart the Apache services one by one:
salt -C 'I@apache:server' cmd.run 'service apache2 stop; service apache2 start' -b 1
RabbitMQ certificates
This section describes how to renew or replace the RabbitMQ cluster
certificates managed by either salt-minion or self-managed certificates
using pillars.
Verify that the RabbitMQ cluster uses certificates
This section describes how to determine whether your RabbitMQ cluster
uses certificates and identify their location on the system.
To verify that the RabbitMQ cluster uses certificates:
Log in to the Salt Master node.
Run the following command:
salt -C 'I@rabbitmq:server' cmd.run "rabbitmqctl environment | \
grep -E '/ssl/|ssl_listener|protocol_version'"
Example of system response:
msg02.multinode-ha.int:
{ssl_listeners,[{"0.0.0.0",5671}]},
[{cacertfile,"/etc/rabbitmq/ssl/ca.pem"},
{certfile,"/etc/rabbitmq/ssl/cert.pem"},
{keyfile,"/etc/rabbitmq/ssl/key.pem"},
{ssl,[{protocol_version,['tlsv1.2','tlsv1.1',tlsv1]}]},
msg01.multinode-ha.int:
{ssl_listeners,[{"0.0.0.0",5671}]},
[{cacertfile,"/etc/rabbitmq/ssl/ca.pem"},
{certfile,"/etc/rabbitmq/ssl/cert.pem"},
{keyfile,"/etc/rabbitmq/ssl/key.pem"},
{ssl,[{protocol_version,['tlsv1.2','tlsv1.1',tlsv1]}]},
msg03.multinode-ha.int:
{ssl_listeners,[{"0.0.0.0",5671}]},
[{cacertfile,"/etc/rabbitmq/ssl/ca.pem"},
{certfile,"/etc/rabbitmq/ssl/cert.pem"},
{keyfile,"/etc/rabbitmq/ssl/key.pem"},
{ssl,[{protocol_version,['tlsv1.2','tlsv1.1',tlsv1]}]},
Proceed to renewal or replacement of your certificates as required.
Renew or replace the RabbitMQ certificates managed by salt-minion
This section describes how to renew or replace the RabbitMQ certificates
managed by salt-minion.
To renew or replace the RabbitMQ certificates managed by salt-minion:
Log in to the Salt Master node.
Verify the certificates validity dates:
salt -C 'I@rabbitmq:server' cmd.run 'openssl x509 \
-in /etc/rabbitmq/ssl/cert.pem -text -noout' | grep -Ei 'after|before'
Example of system response:
Not Before: Apr 27 12:37:14 2018 GMT
Not After : Apr 27 12:37:14 2019 GMT
Not Before: Apr 27 12:37:08 2018 GMT
Not After : Apr 27 12:37:08 2019 GMT
Not Before: Apr 27 12:37:13 2018 GMT
Not After : Apr 27 12:37:13 2019 GMT
Remove the certificates from the RabbitMQ nodes:
salt -C 'I@rabbitmq:server' cmd.run 'rm -f /etc/rabbitmq/ssl/cert.pem'
If you replace the certificates, remove the private key:
salt -C 'I@rabbitmq:server' cmd.run 'rm -f /etc/rabbitmq/ssl/key.pem'
Regenerate the certificates on the RabbitMQ nodes:
salt -C 'I@rabbitmq:server' state.sls salt.minion.cert
Verify that the certificates validity dates have changed:
salt -C 'I@rabbitmq:server' cmd.run 'openssl x509 \
-in /etc/rabbitmq/ssl/cert.pem -text -noout' | grep -Ei 'after|before'
Example of system response:
Not Before: Jun 4 23:52:40 2018 GMT
Not After : Jun 4 23:52:40 2019 GMT
Not Before: Jun 4 23:52:41 2018 GMT
Not After : Jun 4 23:52:41 2019 GMT
Not Before: Jun 4 23:52:41 2018 GMT
Not After : Jun 4 23:52:41 2019 GMT
Restart the RabbitMQ services one by one:
salt -C 'I@rabbitmq:server' cmd.run 'service rabbitmq-server stop; \
service rabbitmq-server start' -b1
Verify the RabbitMQ cluster status:
salt -C 'I@rabbitmq:server' cmd.run 'rabbitmqctl cluster_status'
Example of system response:
msg03.multinode-ha.int:
Cluster status of node rabbit@msg03
[{nodes,[{disc,[rabbit@msg01,rabbit@msg02,rabbit@msg03]}]},
{running_nodes,[rabbit@msg01,rabbit@msg02,rabbit@msg03]},
{cluster_name,<<"openstack">>},
{partitions,[]},
{alarms,[{rabbit@msg01,[]},{rabbit@msg02,[]},{rabbit@msg03,[]}]}]
msg01.multinode-ha.int:
Cluster status of node rabbit@msg01
[{nodes,[{disc,[rabbit@msg01,rabbit@msg02,rabbit@msg03]}]},
{running_nodes,[rabbit@msg03,rabbit@msg02,rabbit@msg01]},
{cluster_name,<<"openstack">>},
{partitions,[]},
{alarms,[{rabbit@msg03,[]},{rabbit@msg02,[]},{rabbit@msg01,[]}]}]
msg02.multinode-ha.int:
Cluster status of node rabbit@msg02
[{nodes,[{disc,[rabbit@msg01,rabbit@msg02,rabbit@msg03]}]},
{running_nodes,[rabbit@msg03,rabbit@msg01,rabbit@msg02]},
{cluster_name,<<"openstack">>},
{partitions,[]},
{alarms,[{rabbit@msg03,[]},{rabbit@msg01,[]},{rabbit@msg02,[]}]}]
Renew or replace the self-managed RabbitMQ certificates
This section describes how to renew or replace the self-managed
RabbitMQ certificates.
To renew or replace the self-managed RabbitMQ certificates:
Open your project Git repository with Reclass model on the cluster level.
Create the /openstack/ssl/rabbitmq.yml file with the following
configuration as an example:
classes:
- cluster.<cluster_name>.openstack.ssl
parameters:
rabbitmq:
server:
enabled: true
...
ssl:
enabled: True
key: ${_param:rabbitmq_ssl_key}
cacert_chain: ${_param:rabbitmq_ssl_cacert_chain}
cert: ${_param:rabbitmq_ssl_cert}
Note
Substitute <cluster_name> with the appropriate value.
Create the /openstack/ssl/init.yml file with the following configuration
as an example:
parameters:
_param:
rabbitmq_ssl_cacert_chain: |
-----BEGIN CERTIFICATE-----
MIIF0TCCA7mgAwIBAgIJAOkTQnjLz6rEMA0GCSqGSIb3DQEBCwUAMEoxCzAJBgNV
...
RHXc4FoWv9/n8ZcfsqjQCjF3vUUZBB3zdlfLCLJRruB4xxYukc3gFpFLm21+0ih+
M8IfJ5I=
-----END CERTIFICATE-----
rabbitmq_ssl_key: |
-----BEGIN RSA PRIVATE KEY-----
MIIJKQIBAAKCAgEArVSJ16ePjCik+6bZBzhiu3enXw8R9Ms1k4x57633IX1sEZTJ
...
0VgM2bDSNyUuiwCbOMK0Kyn+wGeHF/jGSbVsxYI4OeLFz8gdVUqm7olJj4j3xemY
BlWVHRa/dEG1qfSoqFU9+IQTd+U42mtvvH3oJHEXK7WXzborIXTQ/08Ztdvy
-----END RSA PRIVATE KEY-----
rabbitmq_ssl_cert: |
-----BEGIN CERTIFICATE-----
MIIGIDCCBAigAwIBAgIJAJznLlNteaZFMA0GCSqGSIb3DQEBCwUAMEoxCzAJBgNV
...
MfXPTUI+7+5WQLx10yavJ2gOhdyVuDVagfUM4epcriJbACuphDxHj45GINOGhaCd
UVVCxqnB9qU16ea/kB3Yzsrus7egr9OienpDCFV2Q/kgUSc7
-----END CERTIFICATE-----
Note
Modify the example above by adding your certificates and key:
- If you renew the certificates, leave your existing
key and
update the cert and chain sections.
- If you replace the certificates, modify all three sections.
Update the /openstack/message_queue.yml file by adding the newly created
class to the RabbitMQ nodes:
classes:
- service.rabbitmq.server.ssl
- cluster.<cluster_name>.openstack.ssl.rabbitmq
Log in to the Salt Master node.
Refresh pillars:
salt -C 'I@rabbitmq:server' saltutil.refresh_pillar
Publish new certificates
salt -C 'I@rabbitmq:server' state.sls rabbitmq -l debug
Verify the new certificates validity dates:
salt -C 'I@rabbitmq:server' cmd.run 'openssl x509 \
-in /etc/rabbitmq/ssl/cert.pem -text -noout' | grep -Ei 'after|before'
Example of system response:
Not Before: Apr 27 12:37:14 2018 GMT
Not After : Apr 27 12:37:14 2019 GMT
Not Before: Apr 27 12:37:08 2018 GMT
Not After : Apr 27 12:37:08 2019 GMT
Not Before: Apr 27 12:37:13 2018 GMT
Not After : Apr 27 12:37:13 2019 GMT
Restart the RabbitMQ services one by one:
salt -C 'I@rabbitmq:server' cmd.run 'service rabbitmq-server stop; \
service rabbitmq-server start' -b1
Verify the RabbitMQ cluster status:
salt -C 'I@rabbitmq:server' cmd.run 'rabbitmqctl cluster_status'
Example of system response:
msg03.multinode-ha.int:
Cluster status of node rabbit@msg03
[{nodes,[{disc,[rabbit@msg01,rabbit@msg02,rabbit@msg03]}]},
{running_nodes,[rabbit@msg01,rabbit@msg02,rabbit@msg03]},
{cluster_name,<<"openstack">>},
{partitions,[]},
{alarms,[{rabbit@msg01,[]},{rabbit@msg02,[]},{rabbit@msg03,[]}]}]
msg01.multinode-ha.int:
Cluster status of node rabbit@msg01
[{nodes,[{disc,[rabbit@msg01,rabbit@msg02,rabbit@msg03]}]},
{running_nodes,[rabbit@msg03,rabbit@msg02,rabbit@msg01]},
{cluster_name,<<"openstack">>},
{partitions,[]},
{alarms,[{rabbit@msg03,[]},{rabbit@msg02,[]},{rabbit@msg01,[]}]}]
msg02.multinode-ha.int:
Cluster status of node rabbit@msg02
[{nodes,[{disc,[rabbit@msg01,rabbit@msg02,rabbit@msg03]}]},
{running_nodes,[rabbit@msg03,rabbit@msg01,rabbit@msg02]},
{cluster_name,<<"openstack">>},
{partitions,[]},
{alarms,[{rabbit@msg03,[]},{rabbit@msg01,[]},{rabbit@msg02,[]}]}]
Restart all OpenStack API services and agents.
MySQL/Galera certificates
This section describes how to renew or replace the MySQL/Galera certificates
managed by either salt-minion or self-managed certificates using pillars.
Verify that the MySQL/Galera cluster uses certificates
This section describes how to determine whether your MySQL/Galera cluster
uses certificates and identify their location on the system.
To verify that the MySQL/Galera cluster uses certificates:
Log in to the Salt Master node.
Run the following command:
salt -C 'I@galera:master' mysql.showglobal | grep -EB3 '(have_ssl|ssl_(key|ca|cert))$'
Example of system response:
Value:
YES
Variable_name:
have_ssl
Value:
/etc/mysql/ssl/ca.pem
Variable_name:
ssl_ca
Value:
/etc/mysql/ssl/cert.pem
Variable_name:
ssl_cert
Value:
/etc/mysql/ssl/key.pem
Variable_name:
ssl_key
Proceed to renewal or replacement of your certificates as required.
Renew or replace the MySQL/Galera certificates managed by salt-minion
This section describes how to renew or replace the MySQL/Galera certificates
managed by salt-minion.
Prerequisites:
Log in to the Salt Master node.
Verify that the MySQL/Galera cluster is up and synced:
salt -C 'I@galera:master' mysql.status | grep -EA1 'wsrep_(local_state_c|incoming_a|cluster_size)'
Example of system response:
wsrep_cluster_size:
3
wsrep_incoming_addresses:
192.168.2.52:3306,192.168.2.53:3306,192.168.2.51:3306
wsrep_local_state_comment:
Synced
Verify that the log files have no errors:
salt -C 'I@galera:master or I@galera:slave' cmd.run 'cat /var/log/mysql/error.log |grep ERROR|wc -l'
Example of system response:
dbs01.multinode-ha.int
0
dbs02.multinode-ha.int
0
dbs03.multinode-ha.int
0
Any value except 0 in the output indicates that the log files include
errors. Review them before proceeding to operations with MySQL/Galera.
Verify that the ca-salt_master_ca certificate is available on all nodes
with MySQL/Galera:
salt -C 'I@galera:master or I@galera:slave' cmd.run 'ls /usr/local/share/ca-certificates/ca-salt_master_ca.crt'
Example of system response:
dbs01.multinode-ha.int
/usr/local/share/ca-certificates/ca-salt_master_ca.crt
dbs02.multinode-ha.int
/usr/local/share/ca-certificates/ca-salt_master_ca.crt
dbs03.multinode-ha.int
/usr/local/share/ca-certificates/ca-salt_master_ca.crt
To renew or replace the MySQL/Galera certificates managed by salt-minion:
Log in to the Salt Master node.
Obtain the list of the Galera cluster minions:
salt -C 'I@galera:master or I@galera:slave' pillar.get _nonexistent | cut -d':' -f1
Example of system response:
dbs02.multinode-ha.int
dbs03.multinode-ha.int
dbs01.multinode-ha.int
Verify the certificates validity dates:
salt -C 'I@galera:master' cmd.run 'openssl x509 -in /etc/mysql/ssl/cert.pem -text -noout' | grep -Ei 'after|before'
salt -C 'I@galera:slave' cmd.run 'openssl x509 -in /etc/mysql/ssl/cert.pem -text -noout' | grep -Ei 'after|before'
Example of system response:
Not Before: May 30 17:21:10 2018 GMT
Not After : May 30 17:21:10 2019 GMT
Not Before: May 30 17:25:24 2018 GMT
Not After : May 30 17:25:24 2019 GMT
Not Before: May 30 17:26:52 2018 GMT
Not After : May 30 17:26:52 2019 GMT
Prepare the Galera nodes to work with old one and new
Salt Master CA certificates:
salt -C 'I@galera:master or I@galera:slave' cmd.run 'cat /usr/local/share/ca-certificates/ca-salt_master_ca.crt /usr/local/share/ca-certificates/ca-salt_master_ca_old.crt > /etc/mysql/ssl/ca.pem'
Verify that the necessary files are present in the ssl directory:
salt -C 'I@galera:master or I@galera:slave' cmd.run 'ls /etc/mysql/ssl'
Example of system response:
dbs01.multinode-ha.int
ca.pem
cert.pem
key.pem
dbs02.multinode-ha.int
ca.pem
cert.pem
key.pem
dbs03.multinode-ha.int
ca.pem
cert.pem
key.pem
Identify the Galera nodes minions IDs:
For the Galera master node:
salt -C 'I@galera:master' test.ping --output yaml | cut -d':' -f1
Example of system response:
For the Galera slave nodes:
salt -C 'I@galera:slave' test.ping --output yaml | cut -d':' -f1
Example of system response:
dbs02.multinode-ha.int
dbs03.multinode-ha.int
Restart the MySQL service for every Galera minion ID one by one.
After each Galera minion restart, verify the Galera cluster
size and status. Proceed to the next Galera minion restart only if
the Galera cluster is synced.
To restart the MySQL service for a Galera minion:
salt <minion_ID> service.stop mysql
salt <minion_ID> service.start mysql
To verify the Galera cluster size and status:
salt -C 'I@galera:master' mysql.status | grep -EA1 'wsrep_(local_state_c|incoming_a|cluster_size)'
Example of system response:
wsrep_cluster_size:
3
wsrep_incoming_addresses:
192.168.2.52:3306,192.168.2.53:3306,192.168.2.51:3306
wsrep_local_state_comment:
Synced
If you replace the certificates, remove the private key:
salt -C 'I@galera:master' cmd.run 'mv /etc/mysql/ssl/key.pem /root'
Force the certificates regeneration for the Galera master node:
salt -C 'I@galera:master' cmd.run 'mv /etc/mysql/ssl/cert.pem /root; mv /etc/mysql/ssl/ca.pem /root'
salt -C 'I@galera:master' state.sls salt.minion.cert -l debug
salt -C 'I@galera:master' cmd.run 'cat /usr/local/share/ca-certificates/ca-salt_master_ca.crt /usr/local/share/ca-certificates/ca-salt_master_ca_old.crt > /etc/mysql/ssl/ca.pem'
Verify that the certificates validity dates have changed:
salt -C 'I@galera:master' cmd.run 'openssl x509 -in /etc/mysql/ssl/cert.pem -text -noout' | grep -Ei 'after|before'
Example of system response:
Not Before: Jun 4 16:14:24 2018 GMT
Not After : Jun 4 16:14:24 2019 GMT
Verify that the necessary files are present in the ssl directory on the
Galera master node:
salt -C 'I@galera:master' cmd.run 'ls /etc/mysql/ssl'
Example of system response:
dbs01.multinode-ha.int
ca.pem
cert.pem
key.pem
Restart the MySQL service on the Galera master node:
salt -C 'I@galera:master' service.stop mysql
salt -C 'I@galera:master' service.start mysql
Verify that the Galera cluster status is up. For details, see the step 7.
If you replace the certificates, remove the private key:
salt -C 'I@galera:slave' cmd.run 'mv /etc/mysql/ssl/key.pem /root'
Force the certificates regeneration for the Galera slave nodes:
salt -C 'I@galera:slave' cmd.run 'mv /etc/mysql/ssl/cert.pem /root; mv /etc/mysql/ssl/ca.pem /root'
salt -C 'I@galera:slave' state.sls salt.minion.cert -l debug
salt -C 'I@galera:slave' cmd.run 'cat /usr/local/share/ca-certificates/ca-salt_master_ca.crt /usr/local/share/ca-certificates/ca-salt_master_ca_old.crt > /etc/mysql/ssl/ca.pem'
Verify that the necessary files are present in the ssl directory on the
Galera slave nodes:
salt -C 'I@galera:slave' cmd.run 'ls /etc/mysql/ssl'
Example of system response:
dbs02.multinode-ha.int
ca.pem
cert.pem
key.pem
dbs03.multinode-ha.int
ca.pem
cert.pem
key.pem
Verify that the certificates validity dates have changed:
salt -C 'I@galera:slave' cmd.run 'openssl x509 -in /etc/mysql/ssl/cert.pem -text -noout' | grep -Ei 'after|before'
Example of system response:
Not Before: Jun 4 16:14:24 2018 GMT
Not After : Jun 4 16:14:24 2019 GMT
Not Before: Jun 4 16:14:31 2018 GMT
Not After : Jun 4 16:14:31 2019 GMT
Restart the MySQL service for every Galera slave minion ID one by one.
After each Galera slave minion restart, verify the Galera cluster
size and status. Proceed to the next Galera slave minion restart only if
the Galera cluster is synced. For details, see the step 7.
Renew or replace the self-managed MySQL/Galera certificates
This section describes how to renew or replace the self-managed
MySQL/Galera certificates.
To renew or replace the self-managed MySQL/Galera certificates:
Log in to the Salt Master node.
Create the
classes/cluster/<cluster_name>/openstack/ssl/galera_master.yml
file with the following configuration as an example:
classes:
- cluster.<cluster_name>.openstack.ssl
parameters:
galera:
master:
ssl:
enabled: True
cacert_chain: ${_param:galera_ssl_cacert_chain}
key: ${_param:galera_ssl_key}
cert: ${_param:galera_ssl_cert}
ca_file: ${_param:mysql_ssl_ca_file}
key_file: ${_param:mysql_ssl_key_file}
cert_file: ${_param:mysql_ssl_cert_file}
Note
Substitute <cluster_name> with the appropriate value.
Create the
classes/cluster/<cluster_name>/openstack/ssl/galera_slave.yml
file with the following configuration as an example:
classes:
- cluster.<cluster_name>.openstack.ssl
parameters:
galera:
slave:
ssl:
enabled: True
cacert_chain: ${_param:galera_ssl_key}
key: ${_param:galera_ssl_key}
cert: ${_param:galera_ssl_key}
ca_file: ${_param:mysql_ssl_ca_file}
key_file: ${_param:mysql_ssl_key_file}
cert_file: ${_param:mysql_ssl_cert_file}
Note
Substitute <cluster_name> with the appropriate value.
Create the classes/cluster/<cluster_name>/openstack/ssl/init.yml file
with the following configuration as an example:
parameters:
_param:
mysql_ssl_key_file: /etc/mysql/ssl/key.pem
mysql_ssl_cert_file: /etc/mysql/ssl/cert.pem
mysql_ssl_ca_file: /etc/mysql/ssl/ca.pem
galera_ssl_cacert_chain: |
-----BEGIN CERTIFICATE-----
MIIF0TCCA7mgAwIBAgIJAOkTQnjLz6rEMA0GCSqGSIb3DQEBCwUAMEoxCzAJBgNV
...
RHXc4FoWv9/n8ZcfsqjQCjF3vUUZBB3zdlfLCLJRruB4xxYukc3gFpFLm21+0ih+
M8IfJ5I=
-----END CERTIFICATE-----
galera_ssl_key: |
-----BEGIN RSA PRIVATE KEY-----
MIIJKQIBAAKCAgEArVSJ16ePjCik+6bZBzhiu3enXw8R9Ms1k4x57633IX1sEZTJ
...
0VgM2bDSNyUuiwCbOMK0Kyn+wGeHF/jGSbVsxYI4OeLFz8gdVUqm7olJj4j3xemY
BlWVHRa/dEG1qfSoqFU9+IQTd+U42mtvvH3oJHEXK7WXzborIXTQ/08Ztdvy
-----END RSA PRIVATE KEY-----
galera_ssl_cert: |
-----BEGIN CERTIFICATE-----
MIIGIDCCBAigAwIBAgIJAJznLlNteaZFMA0GCSqGSIb3DQEBCwUAMEoxCzAJBgNV
...
MfXPTUI+7+5WQLx10yavJ2gOhdyVuDVagfUM4epcriJbACuphDxHj45GINOGhaCd
UVVCxqnB9qU16ea/kB3Yzsrus7egr9OienpDCFV2Q/kgUSc7
-----END CERTIFICATE-----
Note
Modify the example above by adding your certificates and key:
- If you renew the certificates, leave your existing
key and
update the cert and chain sections.
- If you replace the certificates, modify all three sections.
Update the classes/cluster/<cluster_name>/infra/config.yml file by
adding the newly created classes to the database nodes:
openstack_database_node01:
params:
linux_system_codename: xenial
deploy_address: ${_param:openstack_database_node01_deploy_address}
classes:
- cluster.${_param:cluster_name}.openstack.database_init
- cluster.${_param:cluster_name}.openstack.ssl.galera_master
openstack_database_node02:
params:
linux_system_codename: xenial
deploy_address: ${_param:openstack_database_node02_deploy_address}
classes:
- cluster.${_param:cluster_name}.openstack.ssl.galera_slave
openstack_database_node03:
params:
linux_system_codename: xenial
deploy_address: ${_param:openstack_database_node03_deploy_address}
classes:
- cluster.${_param:cluster_name}.openstack.ssl.galera_slave
Regenerate the Reclass storage:
salt-call state.sls reclass.storage -l debug
Refresh pillars:
salt -C 'I@galera:master or I@galera:slave' saltutil.refresh_pillar
Verify the certificates validity dates:
salt -C 'I@galera:master' cmd.run 'openssl x509 \
-in /etc/mysql/ssl/cert.pem -text -noout' | grep -Ei 'after|before'
salt -C 'I@galera:slave' cmd.run 'openssl x509 \
-in /etc/mysql/ssl/cert.pem -text -noout' | grep -Ei 'after|before'
Example of system response:
Not Before: May 30 17:21:10 2018 GMT
Not After : May 30 17:21:10 2019 GMT
Not Before: May 30 17:25:24 2018 GMT
Not After : May 30 17:25:24 2019 GMT
Not Before: May 30 17:26:52 2018 GMT
Not After : May 30 17:26:52 2019 GMT
Force the certificate regeneration on the Galera master node:
salt -C 'I@galera:master' state.sls galera -l debug
Verify the new certificates validity dates on the Galera master node:
salt -C 'I@galera:master' cmd.run 'openssl x509 \
-in /etc/mysql/ssl/cert.pem -text -noout' | grep -Ei 'after|before'
Restart the MySQL service on the Galera master node:
salt -C 'I@galera:master' service.stop mysql
salt -C 'I@galera:master' service.start mysql
Verify that the Galera cluster status is up:
salt -C 'I@galera:master' mysql.status | \
grep -EA1 'wsrep_(local_state_c|incoming_a|cluster_size)'
Example of system response:
wsrep_cluster_size:
3
wsrep_incoming_addresses:
192.168.2.52:3306,192.168.2.53:3306,192.168.2.51:3306
wsrep_local_state_comment:
Synced
Force the certificate regeneration on the Galera slave nodes:
salt -C 'I@galera:slave' state.sls galera -l debug
Verify that the certificates validity dates have changed:
salt -C 'I@galera:slave' cmd.run 'openssl x509 \
-in /etc/mysql/ssl/cert.pem -text -noout' | grep -Ei 'after|before'
Example of system response:
Not Before: Jun 4 16:14:24 2018 GMT
Not After : Jun 4 16:14:24 2019 GMT
Not Before: Jun 4 16:14:31 2018 GMT
Not After : Jun 4 16:14:31 2019 GMT
Obtain the Galera slave nodes minions IDs:
salt -C 'I@galera:slave' test.ping --output yaml | cut -d':' -f1
Example of system response:
dbs02.multinode-ha.int
dbs03.multinode-ha.int
Restart the MySQL service for every Galera slave minion ID one by one.
After each Galera slave minion restart, verify the Galera cluster
size and status. Proceed to the next Galera slave minion restart only if
the Galera cluster is synced.
To restart the MySQL service for a Galera slave minion:
salt <minion_ID> service.stop mysql
salt <minion_ID> service.start mysql
To verify the Galera cluster size and status:
salt -C 'I@galera:master' mysql.status | \
grep -EA1 'wsrep_(local_state_c|incoming_a|cluster_size)'
Example of system response:
wsrep_cluster_size:
3
wsrep_incoming_addresses:
192.168.2.52:3306,192.168.2.53:3306,192.168.2.51:3306
wsrep_local_state_comment:
Synced
Barbican certificates
This section describes how to renew certificates in the Barbican service with
a configured Dogtag plugin.
Renew Barbican administrator certificates
This section describes how to renew administrator certificates in the Barbican
service with a configured Dogtag plugin.
Prerequisites:
Log in to the OpenStack secrets storage node (kmn).
Obtain the list of certificates:
certutil -L -d /root/.dogtag/pki-tomcat/ca/alias/
Example of system response:
Certificate Nickname Trust Attributes
SSL,S/MIME,JAR/XPI
caadmin u,u,u
Note the nickname and attributes of the administrator certificate to renew:
Review the certificate validity date and note its serial number:
certutil -L -d /root/.dogtag/pki-tomcat/ca/alias/ -n "caadmin" | egrep "Serial|Before|After"
Example of system response:
Serial Number: 6 (0x6)
Not Before: Tue Apr 26 12:42:31 2022
Not After : Mon Apr 15 12:42:31 2024
To renew the Barbican administrator certificate:
Log in to the OpenStack secrets storage node (kmn).
Obtain the profile template:
pki ca-cert-request-profile-show caManualRenewal --output caManualRenewal.xml
Edit the profile template and add the serial number of the certificate to
renew to the highlighted lines of the below template:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<CertEnrollmentRequest>
<Attributes/>
<ProfileID>caManualRenewal</ProfileID>
<Renewal>true</Renewal>
<SerialNumber>6</SerialNumber> <!--Insert SerialNumber here-->
<RemoteHost></RemoteHost>
<RemoteAddress></RemoteAddress>
<Input id="i1">
<ClassID>serialNumRenewInputImpl</ClassID>
<Name>Serial Number of Certificate to Renew</Name>
<Attribute name="serial_num">
<Value>6</Value> <!--Insert SerialNumber here-->
<Descriptor>
<Syntax>string</Syntax>
<Description>Serial Number of Certificate to Renew</Description>
</Descriptor>
</Attribute>
</Input>
</CertEnrollmentRequest>
Submit the request and note the request ID:
pki ca-cert-request-submit caManualRenewal.xml
Example of system response:
-----------------------------
Submitted certificate request
-----------------------------
Request ID: 9
Type: renewal
Request Status: pending
Operation Result: success
Using the password from /root/.dogtag/pki-tomcat/ca/password.conf,
approve the request and note the ID of the new certificate:
Note
During the first run of a system with self-signed certificates
you may get a warning informing of an untrusted issuer. In this
case, proceed with importing the CA certificate and accept the
default CA server URI.
pki -d /root/.dogtag/pki-tomcat/ca/alias/ -c rCWuvkszR4tbiDmMHfpLqJDtVQbHP1da -n caadmin ca-cert-request-review 9 --action approve
Example of system response:
-------------------------------
Approved certificate request 10
-------------------------------
Request ID: 9
Type: renewal
Request Status: complete
Operation Result: success
Certificate ID: 0x10
Download the renewed certificate:
pki ca-cert-show 0x10 --output ca_admin_new.crt
Example of system response:
------------------
Certificate "0x10"
------------------
Serial Number: 0x10
Issuer: CN=CA Signing Certificate,O=EXAMPLE
Subject: CN=PKI Administrator,E=caadmin@example.com,O=EXAMPLE
Status: VALID
Not Before: Tue Jun 14 12:24:14 UTC 2022
Not After: Wed Jun 14 12:24:14 UTC 2023
Add the renewed certificate to the caadmin and kraadmin users in the
LADP database:
pki -d /root/.dogtag/pki-tomcat/ca/alias/ -c rCWuvkszR4tbiDmMHfpLqJDtVQbHP1da -n caadmin ca-user-cert-add --serial 0x10 caadmin
pki -d /root/.dogtag/pki-tomcat/ca/alias/ -c rCWuvkszR4tbiDmMHfpLqJDtVQbHP1da -n caadmin kra-user-cert-add --serial 0x10 kraadmin
Example of system response:
-----------------------------------------------------------------------------------------------------------------
Added certificate "2;16;CN=CA Signing Certificate,O=EXAMPLE;CN=PKI Administrator,E=caadmin@example.com,O=EXAMPLE"
-----------------------------------------------------------------------------------------------------------------
Cert ID: 2;16;CN=CA Signing Certificate,O=EXAMPLE;CN=PKI Administrator,E=caadmin@example.com,O=EXAMPLE
Version: 2
Serial Number: 0x10
Issuer: CN=CA Signing Certificate,O=EXAMPLE
Subject: CN=PKI Administrator,E=caadmin@example.com,O=EXAMPLE
Verify that the new certificate is present in the system:
ldapsearch -D "cn=Directory Manager" -b "dc=example,dc=com" -w rCWuvkszR4tbiDmMHfpLqJDtVQbHP1da "uid=caadmin"
ldapsearch -D "cn=Directory Manager" -b "o=pki-tomcat-KRA" -w rCWuvkszR4tbiDmMHfpLqJDtVQbHP1da "uid=kraadmin"
Example of system response:
# extended LDIF
#
# LDAPv3
# base <dc=example,dc=com> with scope subtree
# filter: uid=caadmin
# requesting: ALL
#
# caadmin, people, example.com
dn: uid=caadmin,ou=people,dc=example,dc=com
objectClass: top
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: cmsuser
uid: caadmin
sn: caadmin
cn: caadmin
mail: caadmin@example.com
usertype: adminType
userstate: 1
userPassword:: e1NTSEF9QWY5Mys3a2ZHRUh0cHVyMnhVbDNPcVB2TGZoZHREd2Y3ejRhYnc9PQ=
=
description: 2;6;CN=CA Signing Certificate,O=EXAMPLE;CN=PKI Administrator,E=ca
admin@example.com,O=EXAMPLE
description: 2;16;CN=CA Signing Certificate,O=EXAMPLE;CN=PKI Administrator,E=c
aadmin@example.com,O=EXAMPLE
userCertificate:: MIIDnTCCAoWgAwIBAgIBBjANBgkqhkiG9w0BAQsFADAzMRAwDgYDVQQKDAdF
...
userCertificate:: MIIDnTCCAoWgAwIBAgIBEDANBgkqhkiG9w0BAQsFADAzMRAwDgYDVQQKDAdF
...
Stop the pki-tomcatd service:
systemctl stop pki-tomcatd
Delete the old certificate using the nickname noted in the prerequisite
steps:
certutil -D -n "caadmin" -d /root/.dogtag/pki-tomcat/ca/alias/
Import the renewed certificate using the attributes noted in the
prerequisite steps:
certutil -A -n "caadmin" -t u,u,u -d /root/.dogtag/pki-tomcat/ca/alias/ -a -i ca_admin_new.crt
Start the pki-tomcatd service:
systemctl start pki-tomcatd
Verify the new certificate:
certutil -L -d /root/.dogtag/pki-tomcat/ca/alias/ -n "caadmin" | egrep "Serial|Before|After"
Example of system response:
Serial Number: 16 (0x10)
Not Before: Tue Jun 14 12:24:14 2022
Not After : Wed Jun 14 12:24:14 2023
Create new ca_admin_cert.p12 and kra_admin_cert.pem files:
openssl pkcs12 -in /root/.dogtag/pki-tomcat/ca_admin_cert.p12 -passin pass:rCWuvkszR4tbiDmMHfpLqJDtVQbHP1da -passout pass:1234567 -nocerts -out passPrivateKey.pem
openssl rsa -in passPrivateKey.pem -out "privateKey.pem" -passin pass:1234567
openssl pkcs12 -export -in ca_admin_new.crt -inkey privateKey.pem -out ca_admin_new.p12 -clcerts -passout pass:rCWuvkszR4tbiDmMHfpLqJDtVQbHP1da
openssl pkcs12 -in ca_admin_new.p12 -passin pass:rCWuvkszR4tbiDmMHfpLqJDtVQbHP1da -out kra_admin_cert_new.pem -nodes
You can change the passout and passin parameters for a stronger password pair.
Update kra_admin_cert.pem in the barbican and dogtag folders:
cp /etc/barbican/kra_admin_cert.pem ./kra_admin_cert_old.pem
cp kra_admin_cert_new.pem /etc/barbican/kra_admin_cert.pem
cp kra_admin_cert_new.pem /etc/dogtag/kra_admin_cert.pem
systemctl restart barbican-worker.service
systemctl restart apache2
Warning
Once you update the cerificate on the master node, replicate the
changes to other nodes. To do so, transfer
kra_admin_cert_new.pem from the master node to
/etc/barbican/kra_admin_cert.pem on other nodes.
Renew Barbican system certificates
This section describes how to renew system certificates in the Barbican service
with a configured Dogtag plugin.
Prerequisites:
Log in to the OpenStack secrets storage node (kmn).
Back up the pki-tomcat configuration files:
/etc/pki/pki-tomcat/ca/CS.cfg/etc/pki/pki-tomcat/kra/CS.cfg
Obtain the list of used certificates:
certutil -L -d /etc/pki/pki-tomcat/alias
Example of system response:
Certificate Nickname Trust Attributes
SSL,S/MIME,JAR/XPI
ocspSigningCert cert-pki-tomcat CA u,u,u
subsystemCert cert-pki-tomcat u,u,u
storageCert cert-pki-tomcat KRA u,u,u
Server-Cert cert-pki-tomcat u,u,u
caSigningCert cert-pki-tomcat CA CTu,Cu,Cu
auditSigningCert cert-pki-tomcat CA u,u,Pu
transportCert cert-pki-tomcat KRA u,u,u
auditSigningCert cert-pki-tomcat KRA u,u,Pu
Note
Server-Cert cert-pki-tomcat certificates are unique for
each kmn node.
To obtain the serial numbers of these certificates, run the following
command on the Salt master node:
salt 'kmn*' cmd.run "certutil -L -d /etc/pki/pki-tomcat/alias -n 'Server-Cert cert-pki-tomcat' | egrep 'Serial|Before|After'"
Example of system response:
kmn01.dogtag.local:
Serial Number: 3 (0x3)
Not Before: Mon Dec 19 16:57:18 2022
Not After : Sun Dec 08 16:57:18 2024
kmn02.dogtag.local:
Serial Number: 11 (0xb)
Not Before: Mon Dec 19 17:02:39 2022
Not After : Sun Dec 08 17:02:39 2024
kmn03.dogtag.local:
Serial Number: 10 (0xa)
Not Before: Mon Dec 19 17:00:40 2022
Not After : Sun Dec 08 17:00:40 2024
Other certificates are the same for all servers:
ocspSigningCert cert-pki-tomcat CA
subsystemCert cert-pki-tomcat
storageCert cert-pki-tomcat KRA
caSigningCert cert-pki-tomcat CA
auditSigningCert cert-pki-tomcat CA
transportCert cert-pki-tomcat KRA
auditSigningCert cert-pki-tomcat KRA
Note the nickname and attributes of the certificate to renew:
transportCert cert-pki-tomcat KRA u,u,u
Review the certificate validity date and note its serial number:
certutil -L -d /etc/pki/pki-tomcat/alias -n "transportCert cert-pki-tomcat KRA" | egrep "Serial|Before|After"
Example of system response:
Serial Number: 7 (0x7)
Not Before: Tue Apr 26 12:42:31 2022
Not After : Mon Apr 15 12:42:31 2024
To renew the Barbican system certificate:
Log in to the OpenStack secrets storage node (kmn).
Obtain the profile template:
pki ca-cert-request-profile-show caManualRenewal --output caManualRenewal.xml
Edit the profile template and add the serial number of the certificate to
renew to the highlighted lines of the below template:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<CertEnrollmentRequest>
<Attributes/>
<ProfileID>caManualRenewal</ProfileID>
<Renewal>true</Renewal>
<SerialNumber>6</SerialNumber> <!--Insert SerialNumber here-->
<RemoteHost></RemoteHost>
<RemoteAddress></RemoteAddress>
<Input id="i1">
<ClassID>serialNumRenewInputImpl</ClassID>
<Name>Serial Number of Certificate to Renew</Name>
<Attribute name="serial_num">
<Value>6</Value> <!--Insert SerialNumber here-->
<Descriptor>
<Syntax>string</Syntax>
<Description>Serial Number of Certificate to Renew</Description>
</Descriptor>
</Attribute>
</Input>
</CertEnrollmentRequest>
Submit the request and note the request ID:
pki ca-cert-request-submit caManualRenewal.xml
Example of system response:
-----------------------------
Submitted certificate request
-----------------------------
Request ID: 16
Type: renewal
Request Status: pending
Operation Result: success
Using the password from /root/.dogtag/pki-tomcat/ca/password.conf,
approve the request and note the new cerificate ID:
pki -d /root/.dogtag/pki-tomcat/ca/alias/ -c rCWuvkszR4tbiDmMHfpLqJDtVQbHP1da -n caadmin ca-cert-request-review 16 --action approve
Example of system response:
-------------------------------
Approved certificate request 16
-------------------------------
Request ID: 16
Type: renewal
Request Status: complete
Operation Result: success
Certificate ID: 0xf
Download the renewed certificate:
pki ca-cert-show 0xf --output kra_transport.crt
Example of system response:
-----------------
Certificate "0xf"
-----------------
Serial Number: 0xf
Issuer: CN=CA Signing Certificate,O=EXAMPLE
Subject: CN=DRM Transport Certificate,O=EXAMPLE
Status: VALID
Not Before: Fri Jun 10 13:11:50 UTC 2022
Not After: Thu May 30 13:11:50 UTC 2024
Note
You can also download an old certificate as a backup measure to
revert the changes:
pki ca-cert-show 0x7 --output kra_old_transport.crt
Stop the pki-tomcatd service:
systemctl stop pki-tomcatd
Delete the old certificate using nickname noted in the prerequisite steps:
certutil -D -d /etc/pki/pki-tomcat/alias -n 'transportCert cert-pki-tomcat KRA'
Import the renewed certificate using the attributes noted in the
prerequisite steps:
certutil -A -d /etc/pki/pki-tomcat/alias -n 'transportCert cert-pki-tomcat KRA' -i kra_transport.crt -t "u,u,u"
Update the certificate information in /etc/pki/pki-tomcat/kra/CS.cfg
with the base64-encoded data of the new certificate (without the header and
footer):
kra.transport.cert=MIIDdzCCAl+gAwIBAgIBDzANBgkqhkiG9w0BAQsFADAzMRAwDgYDVQQKDAdFWEFNUExFMR8wHQYDVQQDDBZDQSBTaWduaW5nIENlcnRpZmljYXRlMB4XDTIyMDYxMDEzMTE1MFoXDTI0MDUzMDEzMTE1MFowNjEQMA4GA1UECgwHRVhBTVBMRTEiMCAGA1UEAwwZRFJNIFRyYW5zcG9ydCBDZXJ0aWZpY2F0ZTCCASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEBAKkh/JkTJpr+4uaz7fNgC7gD9vJCl670nYFqxCdwQWPzmXxg5lpJcM6L15C1cOH9ad8D2h8Dv4H8YknenK0GXrEoRrqAnG9nMHPEV1HTap9exOgZ4gk6aIanzEqqbun54mkAKF0LLmytcY5oyJLVoDpPVnkawLXdWyi7lUFEMnsILGH0kS0o8/9TPlP8HPXegHTAPMZWRHAVyDDJVmw/Qv8NB/oOFuWCZSDOItZQB44i7WgRIj6lPwCQoCZqdjRtq+bW9ITqZnXrFZmfFPfeh1NGiTnoE3aebm2FTCA5R9+9nsoQtAE6cdsmalua8+P0le2oGXbWED8meViYkAwLxYcCAwEAAaOBkjCBjzAfBgNVHSMEGDAWgBRBpHkrpV9RctaTblmz/H96WRecxDBHBggrBgEFBQcBAQQ7MDkwNwYIKwYBBQUHMAGGK2h0dHA6Ly9rbW4wMS5ybC1kb2d0YWctMi5sb2NhbDo4MDgwL2NhL29jc3AwDgYDVR0PAQH/BAQDAgTwMBMGA1UdJQQMMAoGCCsGAQUFBwMCMA0GCSqGSIb3DQEBCwUAA4IBAQCbzfQob6XsJYv3fDEytLH6mn7xBe1Z+U9qUE9V1GWNAeR8Q8cTSdroNS1VARiZwdOfJMnmryZ/WQJuafJTzwtlw1Ge7DaLa2xULGeHmUCfbV+GFSyiF8d90yBHYN6vGWqRVyEDQKegit0OG092bsxIHawPBGh2LabUPuoKmKuz2EzWRLmtOWgE8irHdG8kqsjXHlFpJWq/NNeqK5mohMJeDVzFevkJnj7lizY2F+UCfOs/JG1PZZEdgFoE4Un9VsOoUdWFsNwfRLUiAWzSQrHEm2FzqltTlEutI66PovwZMnqh9AGw67m8YLXDrIQqiAzvzF3YGsxeJvXi0VL8j64B
Note
When updating all certificates, update both the
/etc/pki/pki-tomcat/kra/CS.cfg and
/etc/pki/pki-tomcat/ca/CS.cfg files.
Examples of files containing data about the certificates:
/etc/pki/pki-tomcat/ca/CS.cfg
ca.subsystem.cert <- subsystemCert cert-pki-tomcat
ca.ocsp_signing.cert <- ocspSigningCert cert-pki-tomcat CA
ca.sslserver.cert <- Server-Cert cert-pki-tomcat (unique for each kmn server)
ca.signing.cert <- caSigningCert cert-pki-tomcat CA
ca.audit_signing.cert <- auditSigningCert cert-pki-tomcat CA
/etc/pki/pki-tomcat/kra/CS.cfg
kra.subsystem.cert <- subsystemCert cert-pki-tomcat
kra.storage.cert <- storageCert cert-pki-tomcat KRA
kra.sslserver.cert <- Server-Cert cert-pki-tomcat (unique for each kmn server)
kra.transport.cert <- transportCert cert-pki-tomcat KRA
kra.audit_signing.cert <- auditSigningCert cert-pki-tomcat KRA
If you are updating a transportCert cert-pki-tomcat KRA certificate,
also update Barbican Network Security Services database (NSSDB):
certutil -L -d /etc/barbican/alias
certutil -L -d /etc/barbican/alias -n "KRA transport cert" | egrep "Serial|Before|After"
certutil -D -d /etc/barbican/alias -n 'KRA transport cert'
certutil -A -d /etc/barbican/alias -n 'KRA transport cert' -i kra_transport.crt -t ,,
Start the pki-tomcatd service:
systemctl start pki-tomcatd
Verify that the new certificate is used:
certutil -L -d /etc/pki/pki-tomcat/alias -n "transportCert cert-pki-tomcat KRA" | egrep "Serial|Before|After"
certutil -L -d /etc/barbican/alias -n "KRA transport cert" | egrep "Serial|Before|After"
Replicate newly generated certificates to other nodes. If you have updated
the Server-Cert cert-pki-tomcat certificates, verify that each
kmn node has a unique updated certificate.
Upload the renewed certificates to the remaining kmn nodes by repeating
steps 7-13.
Add a new LDAP user certificate
You may need to add a new certificate for an LDAP user. For example, if the
certificate is outdated and you cannot access the subsystem. In this case, you
may see the following error message when trying to reach the Key Recovery
Authority (KRA) subsystem:
pki -d /root/.dogtag/pki-tomcat/ca/alias/ -c rCWuvkszR4tbiDmMHfpLqJDtVQbHP1da -n caadmin kra
PKIException: Unauthorized
To add a new LDAP user certificate:
Log in to the OpenStack secrets storage node (kmn).
Obtain information about the new certificate:
pki cert-show 16 --encode
------------------
Certificate "0x10"
------------------
Serial Number: 0x10
Issuer: CN=CA Signing Certificate,O=EXAMPLE
Subject: CN=PKI Administrator,E=caadmin@example.com,O=EXAMPLE
Status: VALID
Not Before: Tue Jun 14 12:24:14 UTC 2022
Not After: Wed Jun 14 12:24:14 UTC 2023
-----BEGIN CERTIFICATE-----
MIIDnTCCAoWgAwIBAgIBEDANBgkqhkiG9w0BAQsFADAzMRAwDgYDVQQKDAdFWEFN
UExFMR8wHQYDVQQDDBZDQSBTaWduaW5nIENlcnRpZmljYXRlMB4XDTIyMDYxNDEy
MjQxNFoXDTIzMDYxNDEyMjQxNFowUjEQMA4GA1UECgwHRVhBTVBMRTEiMCAGCSqG
SIb3DQEJARYTY2FhZG1pbkBleGFtcGxlLmNvbTEaMBgGA1UEAwwRUEtJIEFkbWlu
aXN0cmF0b3IwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCv28DjVwwQ
LIGkmHgL+ySLY/ja8rKAmL+e7wE1sub6fMFBnSNIi3FbX6850/Nx3GgU+IrwS9lw
vVXArs7Z7Kw/rm29CDrWlC8fWNYzTmQwhgIlccOiOuaa0QktWUuCUyjhDLyU6VGR
UIUMz4EG7TU7zg71nYrVjR8elKBDS/ol1jq5qymG0IbKCfL6mNhjTVOy5awbW3ja
bRp6QgAeRvABzF2R9xVee25/E42351lX76fhnoMvyaMeRfu+l3KVaSHNzupljr0G
No+l4Wfi2LkxxdX435uv8id0o52KzbofjJMaWdoL70rkL/xng/gaWQ4mW0u0cJyo
+vVdgIWxUcDBAgMBAAGjgZwwgZkwHwYDVR0jBBgwFoAUQaR5K6VfUXLWk25Zs/x/
elkXnMQwRwYIKwYBBQUHAQEEOzA5MDcGCCsGAQUFBzABhitodHRwOi8va21uMDEu
cmwtZG9ndGFnLTIubG9jYWw6ODA4MC9jYS9vY3NwMA4GA1UdDwEB/wQEAwIE8DAd
BgNVHSUEFjAUBggrBgEFBQcDAgYIKwYBBQUHAwQwDQYJKoZIhvcNAQELBQADggEB
ALmwU2uL1tBl2n2kEUaxyrA+GMmFIZg58hS0Wo2c92lhF1pYypRVy44Bf+iOcdix
CCy1rV0tpf7qng5VjnFq9aEkbQ14Zg+u6oNopZCKBKFD5lLeEu5wlvuQEsTiTay5
dzaqdZ1nQ5yobyuTuOOepKTbGzVKh1qPCYLGGX6TUzZB8y8ORqgrm9yo1i9BStUS
zDhisATkGBoltK8zFeNdXfjd91VsaeiLQz4p38kqv05tCHshJNE7SLwkcGOC3bOQ
O2EEQJ0U+2QTMX2bg+u41TiPYkFeXvyqXHcmnyGnxhGT18TWH48rxGNh53x5qVFr
T8AoLwQvSnmT7CpSeF9ebWw=
-----END CERTIFICATE-----
Note the certificate data and serial number in decimal
(serial number: 0x10 = 16).
Verify that the LDAP user does not have a new certificate:
ldapsearch -D "cn=Directory Manager" -b "o=pki-tomcat-KRA" -w rCWuvkszR4tbiDmMHfpLqJDtVQbHP1da -h kmn01.rl-dogtag-2.local "uid=kraadmin"
# extended LDIF
#
# LDAPv3
# base <o=pki-tomcat-KRA> with scope subtree
# filter: uid=kraadmin
# requesting: ALL
#
# kraadmin, people, pki-tomcat-KRA
dn: uid=kraadmin,ou=people,o=pki-tomcat-KRA
objectClass: top
objectClass: person
# extended LDIF
objectClass: organizationalPerson
objectClass: inetOrgPerson
# extended LDIF
objectClass: cmsuser
uid: kraadmin
sn: kraadmin
# extended LDIF
cn: kraadmin
mail: kraadmin@example.com
usertype: adminType
userstate: 1
userPassword:: e1NTSEF9a2N4aUEvS1BzMWtDZ3VYK1hnaGxNa1QwdDk1emhoZk4yL2xvR2c9PQ=
=
description: 2;6;CN=CA Signing Certificate,O=EXAMPLE;CN=PKI Administrator,E=ca
admin@example.com,O=EXAMPLE
userCertificate:: MIIDnTCCAoWgAwIBAgIBBjANBgkqhkiG9w0BAQsFADAzMRAwDgYDVQQKDAdF
WEFNUExFMR8wHQYDVQQDDBZDQSBTaWduaW5nIENlcnRpZmljYXRlMB4XDTIyMDQyNjEyNDEzN1oXD
TI0MDQxNTEyNDEzN1owUjEQMA4GA1UECgwHRVhBTVBMRTEiMCAGCSqGSIb3DQEJARYTY2FhZG1pbk
BleGFtcGxlLmNvbTEaMBgGA1UEAwwRUEtJIEFkbWluaXN0cmF0b3IwggEiMA0GCSqGSIb3DQEBAQU
AA4IBDwAwggEKAoIBAQCv28DjVwwQLIGkmHgL+ySLY/ja8rKAmL+e7wE1sub6fMFBnSNIi3FbX685
0/Nx3GgU+IrwS9lwvVXArs7Z7Kw/rm29CDrWlC8fWNYzTmQwhgIlccOiOuaa0QktWUuCUyjhDLyU6
VGRUIUMz4EG7TU7zg71nYrVjR8elKBDS/ol1jq5qymG0IbKCfL6mNhjTVOy5awbW3jabRp6QgAeRv
ABzF2R9xVee25/E42351lX76fhnoMvyaMeRfu+l3KVaSHNzupljr0GNo+l4Wfi2LkxxdX435uv8id
0o52KzbofjJMaWdoL70rkL/xng/gaWQ4mW0u0cJyo+vVdgIWxUcDBAgMBAAGjgZwwgZkwHwYDVR0j
BBgwFoAUQaR5K6VfUXLWk25Zs/x/elkXnMQwRwYIKwYBBQUHAQEEOzA5MDcGCCsGAQUFBzABhitod
HRwOi8va21uMDEucmwtZG9ndGFnLTIubG9jYWw6ODA4MC9jYS9vY3NwMA4GA1UdDwEB/wQEAwIE8D
AdBgNVHSUEFjAUBggrBgEFBQcDAgYIKwYBBQUHAwQwDQYJKoZIhvcNAQELBQADggEBAAvXysrUFQT
gQqQudT7jzxj/X++gNytno0kWOQeIoJSgp0qiz4RFVF/RIF7zn0jMl6a3hipRBU2nU1Fr4De/xcx4
gPD/MWJquD6bSNywlYCkhxCwf3Z8xwLlyV1pYQ8YQAkVK0S9qLHLgjZdPRuzW3SGpyOevcY9JaLpX
qaYJ5Tr9fiAcoD8jvf2w0cRmYVw2RELP3ATTrF1V00WnyVwDyda8eNacBxOd831mQOrA9JJm5c/fQ
cZr0MovXjyU3ddp3MXS4zmTz4skR3qjvHBSRuUuOAvXhnXtP1OzPeLNSGsXozcL/0mqSEQFrV+TiF
7hVeYF0IGhvkWQOvKdDgZMF8=
# search result
search: 2
result: 0 Success
Create a modify_kra_admin.ldif file with information about the new
certificate. In userCertificate, insert the certificate data and in
description insert the certificate ID with a correct serial number in
decimal (serial number: 0x10 = 16).
root@kmn01:~/1# cat modify_kra_admin.ldif
# extended LDIF
#
# LDAPv3
# base <o=pki-tomcat-KRA> with scope subtree
# filter: uid=kraadmin
# requesting: ALL
#
# kraadmin, people, pki-tomcat-KRA
dn: uid=kraadmin,ou=people,o=pki-tomcat-KRA
changetype: modify
add: userCertificate
userCertificate:: MIIDnTCCAoWgAwIBAgIBEDANBgkqhkiG9w0BAQsFADAzMRAwDgYDVQQKDAdF
WEFNUExFMR8wHQYDVQQDDBZDQSBTaWduaW5nIENlcnRpZmljYXRlMB4XDTIyMDYxNDEyMjQxNFoXD
TIzMDYxNDEyMjQxNFowUjEQMA4GA1UECgwHRVhBTVBMRTEiMCAGCSqGSIb3DQEJARYTY2FhZG1pbk
BleGFtcGxlLmNvbTEaMBgGA1UEAwwRUEtJIEFkbWluaXN0cmF0b3IwggEiMA0GCSqGSIb3DQEBAQU
AA4IBDwAwggEKAoIBAQCv28DjVwwQLIGkmHgL+ySLY/ja8rKAmL+e7wE1sub6fMFBnSNIi3FbX685
0/Nx3GgU+IrwS9lwvVXArs7Z7Kw/rm29CDrWlC8fWNYzTmQwhgIlccOiOuaa0QktWUuCUyjhDLyU6
VGRUIUMz4EG7TU7zg71nYrVjR8elKBDS/ol1jq5qymG0IbKCfL6mNhjTVOy5awbW3jabRp6QgAeRv
ABzF2R9xVee25/E42351lX76fhnoMvyaMeRfu+l3KVaSHNzupljr0GNo+l4Wfi2LkxxdX435uv8id
0o52KzbofjJMaWdoL70rkL/xng/gaWQ4mW0u0cJyo+vVdgIWxUcDBAgMBAAGjgZwwgZkwHwYDVR0j
BBgwFoAUQaR5K6VfUXLWk25Zs/x/elkXnMQwRwYIKwYBBQUHAQEEOzA5MDcGCCsGAQUFBzABhitod
HRwOi8va21uMDEucmwtZG9ndGFnLTIubG9jYWw6ODA4MC9jYS9vY3NwMA4GA1UdDwEB/wQEAwIE8D
AdBgNVHSUEFjAUBggrBgEFBQcDAgYIKwYBBQUHAwQwDQYJKoZIhvcNAQELBQADggEBALmwU2uL1tB
l2n2kEUaxyrA+GMmFIZg58hS0Wo2c92lhF1pYypRVy44Bf+iOcdixCCy1rV0tpf7qng5VjnFq9aEk
bQ14Zg+u6oNopZCKBKFD5lLeEu5wlvuQEsTiTay5dzaqdZ1nQ5yobyuTuOOepKTbGzVKh1qPCYLGG
X6TUzZB8y8ORqgrm9yo1i9BStUSzDhisATkGBoltK8zFeNdXfjd91VsaeiLQz4p38kqv05tCHshJN
E7SLwkcGOC3bOQO2EEQJ0U+2QTMX2bg+u41TiPYkFeXvyqXHcmnyGnxhGT18TWH48rxGNh53x5qVF
rT8AoLwQvSnmT7CpSeF9ebWw=
dn: uid=kraadmin,ou=people,o=pki-tomcat-KRA
changetype: modify
add: description
description: 2;16;CN=CA Signing Certificate,O=EXAMPLE;CN=PKI Administrator,E=c
aadmin@example.com,O=EXAMPLE
Apply the changes:
ldapmodify -D "cn=Directory Manager" -w rCWuvkszR4tbiDmMHfpLqJDtVQbHP1da -h kmn01.rl-dogtag-2.local -f ./modify_kra_admin.ldif
Verify that the LDAP user has a new certificate:
ldapsearch -D "cn=Directory Manager" -b "o=pki-tomcat-KRA" -w rCWuvkszR4tbiDmMHfpLqJDtVQbHP1da -h kmn01.rl-dogtag-2.local "uid=kraadmin"
# extended LDIF
#
# LDAPv3
# base <o=pki-tomcat-KRA> with scope subtree
# filter: uid=kraadmin
# requesting: ALL
#
# kraadmin, people, pki-tomcat-KRA
dn: uid=kraadmin,ou=people,o=pki-tomcat-KRA
objectClass: top
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: cmsuser
uid: kraadmin
sn: kraadmin
cn: kraadmin
mail: kraadmin@example.com
usertype: adminType
userstate: 1
userPassword:: e1NTSEF9a2N4aUEvS1BzMWtDZ3VYK1hnaGxNa1QwdDk1emhoZk4yL2xvR2c9PQ=
=
description: 2;6;CN=CA Signing Certificate,O=EXAMPLE;CN=PKI Administrator,E=ca
admin@example.com,O=EXAMPLE
description: 2;16;CN=CA Signing Certificate,O=EXAMPLE;CN=PKI Administrator,E=c
aadmin@example.com,O=EXAMPLE
userCertificate:: MIIDnTCCAoWgAwIBAgIBBjANBgkqhkiG9w0BAQsFADAzMRAwDgYDVQQKDAdF
WEFNUExFMR8wHQYDVQQDDBZDQSBTaWduaW5nIENlcnRpZmljYXRlMB4XDTIyMDQyNjEyNDEzN1oXD
TI0MDQxNTEyNDEzN1owUjEQMA4GA1UECgwHRVhBTVBMRTEiMCAGCSqGSIb3DQEJARYTY2FhZG1pbk
BleGFtcGxlLmNvbTEaMBgGA1UEAwwRUEtJIEFkbWluaXN0cmF0b3IwggEiMA0GCSqGSIb3DQEBAQU
AA4IBDwAwggEKAoIBAQCv28DjVwwQLIGkmHgL+ySLY/ja8rKAmL+e7wE1sub6fMFBnSNIi3FbX685
0/Nx3GgU+IrwS9lwvVXArs7Z7Kw/rm29CDrWlC8fWNYzTmQwhgIlccOiOuaa0QktWUuCUyjhDLyU6
VGRUIUMz4EG7TU7zg71nYrVjR8elKBDS/ol1jq5qymG0IbKCfL6mNhjTVOy5awbW3jabRp6QgAeRv
ABzF2R9xVee25/E42351lX76fhnoMvyaMeRfu+l3KVaSHNzupljr0GNo+l4Wfi2LkxxdX435uv8id
0o52KzbofjJMaWdoL70rkL/xng/gaWQ4mW0u0cJyo+vVdgIWxUcDBAgMBAAGjgZwwgZkwHwYDVR0j
BBgwFoAUQaR5K6VfUXLWk25Zs/x/elkXnMQwRwYIKwYBBQUHAQEEOzA5MDcGCCsGAQUFBzABhitod
HRwOi8va21uMDEucmwtZG9ndGFnLTIubG9jYWw6ODA4MC9jYS9vY3NwMA4GA1UdDwEB/wQEAwIE8D
AdBgNVHSUEFjAUBggrBgEFBQcDAgYIKwYBBQUHAwQwDQYJKoZIhvcNAQELBQADggEBAAvXysrUFQT
gQqQudT7jzxj/X++gNytno0kWOQeIoJSgp0qiz4RFVF/RIF7zn0jMl6a3hipRBU2nU1Fr4De/xcx4
gPD/MWJquD6bSNywlYCkhxCwf3Z8xwLlyV1pYQ8YQAkVK0S9qLHLgjZdPRuzW3SGpyOevcY9JaLpX
qaYJ5Tr9fiAcoD8jvf2w0cRmYVw2RELP3ATTrF1V00WnyVwDyda8eNacBxOd831mQOrA9JJm5c/fQ
cZr0MovXjyU3ddp3MXS4zmTz4skR3qjvHBSRuUuOAvXhnXtP1OzPeLNSGsXozcL/0mqSEQFrV+TiF
7hVeYF0IGhvkWQOvKdDgZMF8=
userCertificate:: MIIDnTCCAoWgAwIBAgIBEDANBgkqhkiG9w0BAQsFADAzMRAwDgYDVQQKDAdF
WEFNUExFMR8wHQYDVQQDDBZDQSBTaWduaW5nIENlcnRpZmljYXRlMB4XDTIyMDYxNDEyMjQxNFoXD
TIzMDYxNDEyMjQxNFowUjEQMA4GA1UECgwHRVhBTVBMRTEiMCAGCSqGSIb3DQEJARYTY2FhZG1pbk
BleGFtcGxlLmNvbTEaMBgGA1UEAwwRUEtJIEFkbWluaXN0cmF0b3IwggEiMA0GCSqGSIb3DQEBAQU
AA4IBDwAwggEKAoIBAQCv28DjVwwQLIGkmHgL+ySLY/ja8rKAmL+e7wE1sub6fMFBnSNIi3FbX685
0/Nx3GgU+IrwS9lwvVXArs7Z7Kw/rm29CDrWlC8fWNYzTmQwhgIlccOiOuaa0QktWUuCUyjhDLyU6
VGRUIUMz4EG7TU7zg71nYrVjR8elKBDS/ol1jq5qymG0IbKCfL6mNhjTVOy5awbW3jabRp6QgAeRv
ABzF2R9xVee25/E42351lX76fhnoMvyaMeRfu+l3KVaSHNzupljr0GNo+l4Wfi2LkxxdX435uv8id
0o52KzbofjJMaWdoL70rkL/xng/gaWQ4mW0u0cJyo+vVdgIWxUcDBAgMBAAGjgZwwgZkwHwYDVR0j
BBgwFoAUQaR5K6VfUXLWk25Zs/x/elkXnMQwRwYIKwYBBQUHAQEEOzA5MDcGCCsGAQUFBzABhitod
HRwOi8va21uMDEucmwtZG9ndGFnLTIubG9jYWw6ODA4MC9jYS9vY3NwMA4GA1UdDwEB/wQEAwIE8D
AdBgNVHSUEFjAUBggrBgEFBQcDAgYIKwYBBQUHAwQwDQYJKoZIhvcNAQELBQADggEBALmwU2uL1tB
l2n2kEUaxyrA+GMmFIZg58hS0Wo2c92lhF1pYypRVy44Bf+iOcdixCCy1rV0tpf7qng5VjnFq9aEk
bQ14Zg+u6oNopZCKBKFD5lLeEu5wlvuQEsTiTay5dzaqdZ1nQ5yobyuTuOOepKTbGzVKh1qPCYLGG
X6TUzZB8y8ORqgrm9yo1i9BStUSzDhisATkGBoltK8zFeNdXfjd91VsaeiLQz4p38kqv05tCHshJN
E7SLwkcGOC3bOQO2EEQJ0U+2QTMX2bg+u41TiPYkFeXvyqXHcmnyGnxhGT18TWH48rxGNh53x5qVF
rT8AoLwQvSnmT7CpSeF9ebWw=
# search result
search: 2
result: 0 Success
# numResponses: 2
# numEntries: 1
Verify that the subsystem is accessible:
pki -d /root/.dogtag/pki-tomcat/ca/alias/ -c rCWuvkszR4tbiDmMHfpLqJDtVQbHP1da -n caadmin kra
Example of system response:
Commands:
kra-group Group management commands
kra-key Key management commands
kra-selftest Selftest management commands
kra-user User management commands
Certificates for Nova compute services
This section describes how to update certificates required for Nova compute
services managed by salt-minion.
Update libvirt certificates
This section describes how to update the libvirt certificates
managed by salt-minion.
To update the libvirt certificates managed by salt-minion:
Log in to the Salt Master node.
Create certificate backups for all compute nodes:
salt -C 'I@nova:compute' cmd.run 'cp -pr /etc/pki/libvirt-vnc/server-cert.pem /etc/pki/libvirt-vnc/server-cert.pem_$(date +"%Y_%m_%d").bak'
Remove your current certificates from each compute node:
salt -C 'I@nova:compute' cmd.run 'rm -rf /etc/pki/libvirt-vnc/server-cert.pem'
Apply the salt.minion.grains state for all compute nodes to
retrieve the CA certificate from Salt Master:
salt -C 'I@nova:compute' state.sls salt.minion.grains test=true -b 1
salt -C 'I@nova:compute' state.sls salt.minion.grains -b 1
Apply the salt.minion.cert state for all compute nodes:
salt -C 'I@nova:compute' state.sls salt.minion.cert test=true -b 2
salt -C 'I@nova:compute' state.sls salt.minion.cert -b 2
Restart the libvrit service on one of the compute nodes:
salt '*cmp*' cmd.run 'service libvirtd restart'
Verify that the service has restarted successfully:
salt '*cmp*' cmd.run 'service libvirtd status'
Restart the libvirt service and apply the nova state on the remaining
nova compute nodes:
salt -C 'I@nova:compute' cmd.run 'service libvirtd restart' -b 1
salt -C 'I@nova:compute' state.sls nova test=true -b 2
salt -C 'I@nova:compute' state.sls nova -b 2
Update nova certificates
This section describes how to update the Nova NoVNCProxy certificates
managed by salt-minion.
To update the Nova NoVNCProxy certificates managed by salt-minion:
Log in to the Salt Master node.
Create certificate backups for all compute nodes:
salt '*ctl*' cmd.run 'cp -pr /etc/pki/nova-novncproxy/client-cert.pem /etc/pki/nova-novncproxy/client-cert.pem_$(date +"%Y_%m_%d").bak'
salt '*ctl*' cmd.run 'cp -pr /etc/pki/nova-novncproxy/server-cert.pem /etc/pki/nova-novncproxy/server-cert.pem_$(date +"%Y_%m_%d").bak'
Remove your current certificates from each compute node:
salt '*ctl*' cmd.run 'rm -rf /etc/pki/nova-novncproxy/client-cert.pem /etc/pki/nova-novncproxy/server-cert.pem'
Apply the salt.minion.grains state for all compute nodes to
retrieve the CA certificate from Salt Master:
salt '*ctl*' state.sls salt.minion.grains test=true -b 1
salt '*ctl*' state.sls salt.minion.grains -b 1
Apply the salt.minion.cert state on all compute nodes:
salt '*ctl*' state.sls salt.minion.cert test=true -b 2
salt '*ctl*' state.sls salt.minion.cert -b 2
Restart the nova-novncproxy service:
salt '*ctl*' cmd.run 'service nova-novncproxy restart' -b 1
Change the certificate validity period
You can change a certificate validity period by managing the validity period
of the signing policy, which is used for certificates generation and is set to
365 days by default.
Note
The procedure does not update the CA certificates and does not change
the signing policy itself.
To change the certificate validity period:
Log in to the Salt Master node.
In classes/cluster/<cluster_name>/infra/config/init.yml, specify the
following pillar:
parameters:
_param:
salt_minion_ca_days_valid_certificate: <required_value>
qemu_vnc_ca_days_valid_certificate: <required_value>
Apply the changes:
salt '*' saltutil.sync_all
salt -C 'I@salt:master' state.sls salt.minion.ca
salt -C 'I@salt:master' state.sls salt.minion
Remove the certificate you need to update.
Apply the following state:
salt -C '<target_node>' state.sls salt.minion.cert
Verify the end date of the updated certificate:
salt -C <taget_node> cmd.run 'openssl x509 -enddate -noout -in <path_to_cert>'
Enable FQDN on internal endpoints in the Keystone catalog
In the new MCP 2019.2.3 deployments, the OpenStack environments use FQDN on
the internal endpoints in the Keystone catalog by default.
In the existing MCP deployments, the IP addresses are used on the internal
Keystone endpoints. This section instructs you on how to enable FQDN on
the internal endpoints for the existing MCP deployments updated to the MCP
2019.2.3 or newer version.
To enable FQDN on the Keystone internal endpoints:
Verify that you have updated MCP DriveTrain to the 2019.2.3 or newer
version as described in Update DriveTrain.
Log in to the Salt Master node.
On the system Reclass level:
Verify that there are classes present under the
/srv/salt/reclass/classes/system/linux/network/hosts/openstack
directory.
Verify that the following parameters are set in
defaults/openstack/init.yml as follows:
parameters:
_param:
openstack_service_hostname: os-ctl-vip
openstack_service_host: ${_param:openstack_service_hostname}.${linux:system:domain}
If you have the extra OpenStack services installed, define the additional
parameters in defaults/openstack/init.yml as required:
For Manila:
parameters:
_param:
openstack_share_service_hostname: os-share-vip
openstack_share_service_host: ${_param:openstack_share_service_hostname}.${linux:system:domain}
For Barbican:
parameters:
_param:
openstack_kmn_service_hostname: os-kmn-vip
openstack_kmn_service_host: ${_param:openstack_kmn_service_hostname}.${linux:system:domain}
For Tenant Telemetry:
parameters:
_param:
openstack_telemetry_service_hostname: os-telemetry-vip
openstack_telemetry_service_host: ${_param:openstack_telemetry_service_hostname}.${linux:system:domain}
On the cluster Reclass level, configure the FQDN on internal endpoints
by editing infra/init.yml:
Add the following class for the core OpenStack services:
classes:
- system.linux.network.hosts.openstack
If you have the extra OpenStack services installed, define the
additional classes as required:
For Manila:
classes:
- system.linux.network.hosts.openstack.share
For Barbican:
classes:
- system.linux.network.hosts.openstack.kmn
For Tenant Telemetry:
classes:
- system.linux.network.hosts.openstack.telemetry
On the cluster Reclass level, define the following parameters in the
openstack/init.yml file:
Define the following parameters for the core OpenStack services:
parameters:
_param:
glance_service_host: ${_param:openstack_service_host}
keystone_service_host: ${_param:openstack_service_host}
heat_service_host: ${_param:openstack_service_host}
cinder_service_host: ${_param:openstack_service_host}
nova_service_host: ${_param:openstack_service_host}
placement_service_host: ${_param:openstack_service_host}
neutron_service_host: ${_param:openstack_service_host}
If you have the extra services installed, define the following
parameters as required:
For Tenant Telemetry:
parameters:
_param:
aodh_service_host: ${_param:openstack_telemetry_service_host}
ceilometer_service_host: ${_param:openstack_telemetry_service_host}
panko_service_host: ${_param:openstack_telemetry_service_host}
gnocchi_service_host: ${_param:openstack_telemetry_service_host}
For Manila:
parameters:
_param:
manila_service_host: ${_param:openstack_share_service_host}
For Designate:
parameters:
_param:
designate_service_host: ${_param:openstack_service_host}
For Barbican:
parameters:
_param:
barbican_service_host: ${_param:openstack_kmn_service_host}
Apply the keystone state:
salt -C 'I@keystone:server' state.apply keystone
Log in to one of the OpenStack controller nodes.
Verify that the changes have been applied successfully:
If SSL is used on the Keystone internal endpoints:
If Manila or Telemetry is installed:
Log in to the Salt Master node.
Open the Reclass cluster level of your deployment.
For Manila, edit /openstack/share.yml. For example:
parameters:
_param:
openstack_api_cert_alternative_names: IP:127.0.0.1,IP:${_param:cluster_local_address},IP:${_param:cluster_vip_address},DNS:${linux:system:name},DNS:${linux:network:fqdn},DNS:${_param:cluster_vip_address},DNS:${_param:openstack_share_service_host}
For Tenant Telemetry, edit /openstack/telemetry.yml. For example:
parameters:
_param:
openstack_api_cert_alternative_names: IP:128.0.0.1,IP:${_param:cluster_local_address},IP:${_param:cluster_vip_address},DNS:${linux:system:name},DNS:${linux:network:fqdn},DNS:${_param:cluster_vip_address},DNS:${_param:openstack_telemetry_service_host}
Renew the OpenStack API certificates to include FQDN in CommonName (CN)
as described in Manage certificates.
Enable Keystone security compliance policies
In the MCP OpenStack deployments, you can enable additional Keystone security
compliance features independently of each other based on your corporate
security policy. All available features apply only to the SQL back end for the
Identity driver. By default, all security compliance features are disabled.
Note
This feature is available starting from the MCP 2019.2.4 maintenance
update. Before enabling the feature, follow the steps
described in Apply maintenance updates.
This section instructs you on how to enable the Keystone security compliance
features on an existing MCP OpenStack deployment. For the new deployments, you
can configure the compliance features during the Reclass deployment model
creation through Model Designer.
Keystone security compliance parameters
| Operation |
Enable in Keystone for all SQL back-end users |
Override settings for specific users |
|---|
| Force the user to change the password upon the first use |
change_password_upon_first_use: True- Forces the user to change their password upon the first use
|
ignore_change_password_upon_first_use: True |
| Configure password expiration |
password_expires_days: <NUM>- Sets the number of days after which the password would expire
|
ignore_password_expiry: True |
| Set an account lockout threshold |
lockout_failure_attempts: <NUM>- Sets the maximum number of failed authentication attempts
lockout_duration: <NUM>- Sets the number of minutes (in seconds) after which a user would be
locked out
|
ignore_lockout_failure_attempts: True |
| Restrict the user from changing their password |
N/A |
lock_password: True |
| Configure password strength requirements |
password_regex: <STRING> - Sets the strength requirements for the passwords
password_regex_description: <STRING>- Provides the text that describes the password strength requirements.
Required if the
password_regex is set.
|
N/A |
| Disable inactive users |
disable_user_account_days_inactive: <NUM> - Sets the number of days after which the user would be disabled
|
N/A |
| Configure a unique password history |
unique_last_password_count: <NUM>- Sets the number of passwords for a user that must be unique before an
old password can be reused
minimum_password_age: <NUM>- Sets the number of days for the password to be used before the user
can change it
|
N/A |
To enable the security compliance policies:
Log in to the Salt Master node.
Open your Git project repository with the Reclass model on the cluster
level.
Open the openstack/control/init.yml file for editing.
Configure the security compliance policies for the OpenStack service users
as required.
For all OpenStack service users. For example:
parameters:
_param:
openstack_service_user_options:
ignore_change_password_upon_first_use: True
ignore_password_expiry: True
ignore_lockout_failure_attempts: False
lock_password: False
For specific OpenStack Queens and newer OpenStack releases service
users. For example:
keystone:
client:
resources:
v3:
users:
cinder:
options:
ignore_change_password_upon_first_use: True
ignore_password_expiry: False
ignore_lockout_failure_attempts: False
lock_password: True
For specific OpenStack Pike and older OpenStack releases service users.
For example:
keystone:
client:
server:
identity:
project:
service:
user:
cinder:
options:
ignore_change_password_upon_first_use: True
ignore_password_expiry: False
ignore_lockout_failure_attempts: False
lock_password: True
Enable the security compliance features on the Keystone server side by
defining the related Keystone sever parameters as required.
Example configuration:
keystone:
server:
security_compliance:
disable_user_account_days_inactive: 90
lockout_failure_attempts: 5
lockout_duration: 600
password_expires_days: 90
unique_last_password_count: 10
minimum_password_age: 0
password_regex: '^(?=.*\d)(?=.*[a-zA-Z]).{7,}$$'
password_regex_description: 'Your password must contains at least 1 letter, 1 digit, and have a minimum length of 7 characters'
change_password_upon_first_use: true
Apply the changes:
salt -C 'I@keystone:client' state.sls keystone.client
salt -C 'I@keystone:server' state.sls keystone.server
Restrict the VM image policy
This section instructs you on how to restrict Glance, Nova, and Cinder
snapshot policy to only allow Administrators to manage images and snapshots in
your OpenStack environment.
To configure Administrator only policy:
In the /etc/nova directory, create and edit the policy.json for Nova
as follows:
{
"os_compute_api:servers:create_image": "rule:admin_api",
"os_compute_api:servers:create_image:allow_volume_backed": "rule:admin_api",
}
In the openstack/control.yml file, restrict managing operations
by setting the role:admin value for the following parameters for Glance
and Cinder:
parameters:
glance:
server:
policy:
add_image: "role:admin"
delete_image: "role:admin"
modify_image: "role:admin"
publicize_image: "role:admin"
copy_from: "role:admin"
upload_image: "role:admin"
delete_image_location: "role:admin"
set_image_location: "role:admin"
deactivate: "role:admin"
reactivate: "role:admin"
cinder:
server:
policy:
'volume_extension:volume_actions:upload_image': "role:admin"
Apply the following states:
salt 'ctl*' state.sls glance.server,cinder.controller
Verify that the rules have changed in the states output.
If the Comment: State 'keystone_policy.rule_present' was not found
in SLS 'glance.server' error occurs, synchronize Salt modules and
re-apply the glance.server state:
salt 'ctl*' saltutil.sync_all
salt 'ctl*' state.sls glance.server
To apply the changes, restart the glance-api service:
salt 'ctl*' service.restart glance-api
Ironic operations
Ironic is an Administrators only service allowing access to all API requests
only to the OpenStack users with the admin or baremetal_admin roles.
However, some read-only operations are also available to the users with
the baremetal_observer role.
In MCP, Ironic has not been integrated with the OpenStack Dashboard service
yet. To manage and use Ironic, perform any required actions either
through the Bare Metal service command-line client using the
ironic or openstack baremetal commands,
from scripts using the ironicclient Python API, or through direct
REST API interactions.
Managing and using Ironic include creating suitable images, enrolling bare
metal nodes into Ironic and configuring them appropriately, and adding compute
flavors that correspond to the available bare metal nodes.
Prepare images for Ironic
To provision bare metal servers using Ironic, you need to create special
images and upload them to Glance.
The configuration of images much depends on an actual hardware. Therefore,
they cannot be provided as pre-built images, and you must prepare them
after you deploy Ironic.
These images include:
- Deploy image that runs the
ironic-python-agent required for the
deployment and control of bare metal nodes
- User image based on the hardware used in your non-virtualized
environment
Note
This section explains how to create the required images using the
diskimage-builder tool.
Prepare deploy images
A deploy image is the image that the bare metal node is PXE-booted into
during the image provisioning or node cleaning.
It resides in the node’s RAM and has a special agent running that
the ironic-conductor service communicates with to orchestrate
the image provisioning and node cleaning.
Such images must contain drivers for all network interfaces and disks
of the bare metal server.
Note
This section provides example instructions on how to prepare the required
images using the diskimage-builder tool. The steps may differ
depending on your specific needs and the builder tool. For more information,
see Building or downloading a deploy ramdisk image.
To prepare deploy images:
Create the required image by typing:
diskimage-create <BASE-OS> ironic-agent
Upload the resulting *.kernel and *.initramfs images to Glance
as aki and ari images:
To upload an aki image, type:
glance image-create --name <IMAGE_NAME> \
--disk-format aki \
--container-format aki \
--file <PATH_TO_IMAGE_KERNEL>
To upload an ari image, type:
glance image-create --name <IMAGE_NAME> \
--disk-format ari \
--container-format ari \
--file <PATH_TO_IMAGE_INITRAMFS>
Prepare user images
Ironic understands two types of user images that include:
- Whole disk image
Image of complete operating system with the partition table and
partitions
- Partition image
Image of root partition only, without the partition table.
Such images must have appropriate kernel and initramfs images
associated with them.
The partition images can be deployed using one of the following methods:
- netboot (default)
The node is PXE-booted over network to kernel and ramdisk over TFTP.
- local boot
During a deployment, the image is modified on a disk to boot from a local
disk.
See Ironic Advanced features
for details.
User images are deployed in a non-virtualized environment on real hardware
servers. Therefore, they require all necessary drivers for a given bare metal
server hardware to be included, that are disks, NICs, and so on.
Note
This section provides example instructions on how to prepare the required
images using the diskimage-builder tool. The steps may differ
depending on your specific needs and the builder tool. For more information,
see the Create and add images to the Image service.
To prepare whole disk images:
Use standard cloud images as whole disk images if they contain all necessary
drivers. Otherwise, rebuild a cloud image by typing:
diskimage-create <base system> -p <EXTRA_PACKAGE_TO_INSTALL> [-p ..]
To prepare partition images for netboot:
Use the images from UEC cloud images that have kernel and initramfs
as separate images if they contain all the required drivers.
If additional drivers are required, rebuild the standard whole disk cloud
image adding the packages as follows:
diskimage-create <BASE_SYSTEM>> baremetal -p <EXTRA_PACKAGE_TO_INSTALL> [-p ..]
Upload images to Glance in the following formats:
For an aki image for kernel, type:
glance image-create --name <IMAGE_NAME> \
--disk-format aki \
--container-format aki \
--file <PATH_TO_IMAGE_KERNEL>
For an ari image for initramfs, type:
glance image-create --name <IMAGE_NAME> \
--disk-format ari \
--container-format ari \
--file <PATH_TO_IMAGE_INITRAMFS>
For a rootfs or whole disk image in the output format (qcow2 by
default) specified during rebuild, type:
glance image-create --name <IMAGE_NAME> \
--disk-format <'QCOW2'_FROM_THE_ABOVE_COMMAND> \
--container-format <'BARE'_FROM_THE_ABOVE_COMMAND> \
--kernel-id <UUID_OF_UPLOADED_AKI_IMAGE> \
--ramdisk-id <UUID_OF_UPLOADED_ARI_IMAGE> \
--file <PATH_TO_IMAGE_KERNEL>
Note
For rootfs images, set the kernel_id and ramdisk_id
image properties to UUIDs of the uploaded aki and ari
images respectively.
To prepare partition images for local boot:
Use the images from UEC cloud images that have kernel and initramfs
as separate images if they contain all the required drivers.
If additional drivers are required, rebuild the standard whole disk cloud
image adding the packages as follows:
Caution
Verify that the base operating system has the grub2
package available for installation. And enable it during
the rebuild as illustrated in the command below.
diskimage-create <BASE_SYSTEM> baremetal grub2 -p <EXTRA_PACKAGE_TO_INSTALL> [-p ..]
Create compute flavors
The appropriately created compute flavors allows for proper compute service
scheduling of workloads to bare metal nodes.
To create nova flavors:
Create a flavor using the nova flavor-create command:
nova flavor-create <FLAVOR_NAME> <UUID_OR_'auto'> <RAM> <DISK> <CPUS>
Where RAM, DISK, and CPUS equal to the corresponding properties
set on the bare metal nodes.
Use the above command to create flavors for each type of bare metal nodes
you need to differentiate.
Provision instances
After Ironic nodes, ports, and flavors have been successfully configured,
deploy the nova-compute instances to the bare metal nodes using the
nova boot command:
nova boot <server name> \
--image <IMAGE_NAME_OR_ID> \
--flavor <BAREMETAL_FLAVOR_NAME_OR_ID> \
--nic net-id=<ID_OF_SHARED_BAREMETAL_NETWORK>
Enable SSL on Ironic internal API
Note
This feature is available starting from the MCP 2019.2.6 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
You can enable SSL for all OpenStack components while generating a
deployment metadata model using the
Model Designer UI
before deploying a new OpenStack environment.
You can also enable SSL on Ironic internal API
on an existing OpenStack environment.
The example instruction below describes the following Ironic configuration:
- The OpenStack Ironic API service runs on the OpenStack
ctl nodes.
- The OpenStack Ironic deploy API and conductor services run
on the
bmt nodes.
You may need to modify this example configuration
depending on the needs of your deployment.
To enable SSL on Ironic internal API on an existing MCP cluster:
Open your Git project repository with the Reclass model
on the cluster level.
Modify ./openstack/baremetal.yml as follows:
classes:
- system.salt.minion.cert.openstack_api
- system.apache.server.proxy
- system.apache.server.proxy.openstack.ironic
parameters:
_param:
apache_proxy_openstack_api_address: ${_param:cluster_baremetal_local_address}
apache_proxy_openstack_api_host: ${_param:cluster_baremetal_local_address}
ironic_conductor_api_url_protocol: https
openstack_api_cert_alternative_names: IP:127.0.0.1,IP:${_param:cluster_baremetal_local_address},IP:${_param:cluster_baremetal_vip_address},DNS:${linux:system:name},DNS:${linux:network:fqdn},DNS:$ {_param:cluster_baremetal_local_address},DNS:${_param:cluster_baremetal_vip_address}
apache_ssl:
enabled: true
authority: "${_param:salt_minion_ca_authority}"
key_file: ${_param:openstack_api_cert_key_file}
cert_file: ${_param:openstack_api_cert_cert_file}
chain_file: ${_param:openstack_api_cert_all_file}
apache_proxy_openstack_ironic_host: 127.0.0.1
haproxy_https_check_options:
- httpchk GET /
- httpclose
- tcplog
haproxy_ironic_deploy_check_params: check inter 10s fastinter 2s downinter 3s rise 3 fall 3 check-ssl verify none
haproxy:
proxy:
listen:
ironic_deploy:
type: None
mode: tcp
options: ${_param:haproxy_https_check_options}
ironic:
api:
bind:
address: 127.0.0.1
Modify ./openstack/control.yml as follows:
classes:
- system.apache.server.proxy.openstack.ironic
parameters:
_param:
apache_proxy_openstack_ironic_host: 127.0.0.1
haproxy_ironic_check_params: check inter 10s fastinter 2s downinter 3s rise 3 fall 3 check-ssl verify none
haproxy:
proxy:
listen:
ironic:
type: None
mode: tcp
options: ${_param:haproxy_https_check_options}
ironic:
api:
bind:
address: 127.0.0.1
Modify ./openstack/control/init.yml as follows:
parameters:
_param:
ironic_service_protocol: ${_param:cluster_internal_protocol}
Modify ./openstack/init.yml as follows:
parameters:
_param:
ironic_service_host: ${_param:openstack_service_host}
ironic_service_protocol: ${_param:cluster_internal_protocol}
Modify ./openstack/proxy.yml as follows:
parameters:
_param:
nginx_proxy_openstack_ironic_protocol: https
Refresh pillars:
salt '*' saltutil.refresh_pillar
Apply the following Salt states:
salt 'bmt*' state.apply salt
salt -C 'I@ironic:api' state.apply apache
salt 'prx*' state.apply nginx
salt -C 'I@ironic:api' state.apply haproxy
salt -C 'I@ironic:api' state.apply ironic
Enable the networking-generic-switch driver
Note
This feature is available starting from the MCP 2019.2.6 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
Note
This feature is available as technical preview. Use such
configuration for testing and evaluation purposes only.
The networking-generic-switch ML2 mechanism driver in Neutron
implements the features required for multitenancy support
on the Ironic bare metal nodes. This driver requires the corresponding
configuration of the Neutron server service.
To enable the networking-generic-switch driver:
Log in to the Salt Master node.
Open the cluster level of your deployment model.
In openstack/control.yml, add pillars for networking-generic-switch
using the example below:
parameters:
...
neutron:
server:
backend:
mechanism:
ngs:
driver: genericswitch
n_g_s:
enabled: true
coordination: # optional
enabled: true
backend_url: "etcd3+http://1.2.3.4:2379"
devices:
s1brbm:
options:
device_type:
value: netmiko_ovs_linux
ip:
value: 1.2.3.4
username:
value: ngs_ovs_manager
password:
value: password
Apply the new configuration for the Neutron server:
salt -C 'I@neutron:server' saltutil.refresh_pillar
salt -C 'I@neutron:server' state.apply neutron.server
Troubleshoot Ironic
The most possible and typical failures of Ironic are caused by the following
peculiarities of the service design:
Ironic is sensitive to possible time difference between the nodes that host
the ironic-api and ironic-conductor services.
One of the symptoms of time being out of sync is inability to enroll a
bare metal node into Ironic with the error message
No conductor service registered which supports driver <DRIVER_NAME>
Although, the DRIVER_NAME driver is known to be enabled and is shown
in the output of the ironic driver-list command.
To fix the issue, verify that the time is properly synced between the nodes.
Ironic requires IPMI access credentials for the nodes to have the admin
privilege level. Any lower privilege level, for example, engineer
precludes Ironic from functioning properly.
Designate operations
After you deploy an MCP cluster that includes Designate, you can start
creating DNS zones and zone records as well as configure auto-generation
of records in DNS zones.
Create a DNS zone and record
This section describes how to create a DNS zone and a record in the created
DNS zone on the MCP cluster where Designate is deployed.
To create a DNS zone and record:
Log in to the Salt Master node.
Create a test DNS zone called testdomain.tld. by running
the following command against one of the controller nodes
where Designate is deployed. For example, ctl01.
salt 'ctl01*' cmd.run ". /root/keystonercv3; openstack zone create \
--email dnsmaster@testdomain.tld testdomain.tld."
Once the change is applied to one controller node, the updated
distributed database replicates this change between
all controller nodes.
Example of system response:
ctl01.virtual-mcp-ocata-ovs.local:
+----------------+--------------------------------------+
| Field | Value |
+----------------+--------------------------------------+
| action | CREATE |
| attributes | |
| created_at | 2017-08-01T12:25:33.000000 |
| description | None |
| email | dnsmaster@testdomain.tld |
| id | ce9836a9-ba78-4960-9c89-6a4989a9e095 |
| masters | |
| name | testdomain.tld. |
| pool_id | 794ccc2c-d751-44fe-b57f-8894c9f5c842 |
| project_id | 49c11a3aa9534d8b897cf06890871840 |
| serial | 1501590333 |
| status | PENDING |
| transferred_at | None |
| ttl | 3600 |
| type | PRIMARY |
| updated_at | None |
| version | 1 |
+----------------+--------------------------------------+
Verify that a DNS zone is successfully created and is in the ACTIVE
status:
salt 'ctl01*' cmd.run ". /root/keystonercv3; openstack zone list"
Example of system response:
ctl01.virtual-mcp-ocata-ovs.local:
+------------------------------------+---------------+-------+-----------+------+------+
|id |name |type |serial |status|action|
+------------------------------------+---------------+-------+-----------+------+------+
|571243e5-17dd-49bd-af09-de6b0c175d8c|example.tld. |PRIMARY| 1497877051|ACTIVE|NONE |
|7043de84-3a40-4b44-ad4c-94dd1e802370|domain.tld. |PRIMARY| 1498209223|ACTIVE|NONE |
|ce9836a9-ba78-4960-9c89-6a4989a9e095|testdomain.tld.|PRIMARY| 1501590333|ACTIVE|NONE |
+------------------------------------+---------------+-------+-----------+------+------+
Create a record in the new DNS zone by running the command below.
Use any IPv4 address to test that it works.
For example, 192.168.0.1.
salt 'ctl01*' cmd.run ". /root/keystonercv3; openstack recordset create \
--records '192.168.0.1' --type A testdomain.tld. tstserver01"
Example of system response:
ctl01.virtual-mcp-ocata-ovs.local:
+-------------+--------------------------------------+
| Field | Value |
+-------------+--------------------------------------+
| action | CREATE |
| created_at | 2017-08-01T12:28:37.000000 |
| description | None |
| id | d099f013-460b-41ee-8cf1-3cf0e3c49bc7 |
| name | tstserver01.testdomain.tld. |
| project_id | 49c11a3aa9534d8b897cf06890871840 |
| records | 192.168.0.1 |
| status | PENDING |
| ttl | None |
| type | A |
| updated_at | None |
| version | 1 |
| zone_id | ce9836a9-ba78-4960-9c89-6a4989a9e095 |
| zone_name | testdomain.tld. |
+-------------+--------------------------------------+
Verify that the record is successfully created and is in the ACTIVE
status by running the openstack recordset list [zone_id]
command. The zone_id parameter can be found in the output
of the command described in the previous step.
Example:
salt 'ctl01*' cmd.run ". /root/keystonercv3; openstack recordset list \
ce9836a9-ba78-4960-9c89-6a4989a9e095"
ctl01.virtual-mcp-ocata-ovs.local:
+---+---------------------------+----+----------------------------------------------------------+------+------+
| id| name |type|records |status|action|
+---+---------------------------+----+----------------------------------------------------------+------+------+
|...|testdomain.tld. |SOA |ns1.example.org. dnsmaster.testdomain.tld. 1501590517 3598|ACTIVE|NONE |
|...|testdomain.tld. |NS |ns1.example.org. |ACTIVE|NONE |
|...|tstserver01.testdomain.tld.|A |192.168.0.1 |ACTIVE|NONE |
+---+---------------------------+----+----------------------------------------------------------+------+------+
Verify that the DNS record can be resolved by running the
nslookup tstserver01.domain.tld [dns server address]
command. In the example below, the DNS server address of the
Designate back end is 10.0.0.1.
Example:
nslookup tstserver01.testdomain.tld 10.0.0.1
Server: 10.0.0.1
Address: 10.0.0.1#53
Name: tstserver01.testdomain.tld
Address: 192.168.0.1
Ceph operations
Ceph is a storage back end for cloud environments. After you successfully
deploy a Ceph cluster, you can manage its nodes and object storage daemons
(Ceph OSDs). This section describes how to add Ceph Monitor, Ceph OSD, and
RADOS Gateway nodes to an existing Ceph cluster or remove them, as well as how
to remove or replace Ceph OSDs.
Prerequisites
Before you proceed to manage Ceph nodes and OSDs, or upgrade Ceph, perform the
steps below.
Verify that your Ceph cluster is up and running.
Log in to the Salt Master node.
Add Ceph pipelines to DriveTrain.
Add the following class to the cluster/cicd/control/leader.yml file:
classes:
- system.jenkins.client.job.ceph
Apply the salt -C 'I@jenkins:client' state.sls jenkins.client
state.
Manage Ceph nodes
This section describes how to add Ceph Monitor, Ceph OSD, and RADOS Gateway
nodes to an existing Ceph cluster or remove them.
Add a Ceph Monitor node
This section describes how to add a Ceph Monitor node to an existing
Ceph cluster.
Warning
Prior to the 2019.2.10 maintenance update, this feature is
available as technical preview only.
Note
The Ceph Monitor service is quorum-based. Therefore, keep an odd number of
Ceph Monitor nodes to establish a
quorum.
To add a Ceph Monitor node:
In your project repository, add the following lines to the
cluster/ceph/init.yml file and modify them according to your
environment:
_param:
ceph_mon_node04_hostname: cmn04
ceph_mon_node04_address: 172.16.47.145
ceph_mon_node04_ceph_public_address: 10.13.0.4
ceph_mon_node04_deploy_address: 192.168.0.145
linux:
network:
host:
cmn04:
address: ${_param:ceph_mon_node04_address}
names:
- ${_param:ceph_mon_node04_hostname}
- ${_param:ceph_mon_node04_hostname}.${_param:cluster_domain}
Note
Skip the ceph_mon_node04_deploy_address parameter if you have
DHCP enabled on a PXE network.
Define the backup configuration for the new node in
cluster/ceph/init.yml. For example:
parameters:
_param:
ceph_mon_node04_ceph_backup_hour: 4
ceph_mon_node04_ceph_backup_minute: 0
Add the following lines to the cluster/ceph/common.yml file and modify
them according to your environment:
parameters:
ceph:
common:
members:
- name: ${_param:ceph_mon_node04_hostname}
host: ${_param:ceph_mon_node04_address}
Add the following lines to the cluster/infra/config/nodes.yml file:
parameters:
reclass:
storage:
node:
ceph_mon_node04:
name: ${_param:ceph_mon_node04_hostname}
domain: ${_param:cluster_domain}
classes:
- cluster.${_param:cluster_name}.ceph.mon
params:
ceph_public_address: ${_param:ceph_mon_node04_ceph_public_address}
ceph_backup_time_hour: ${_param:ceph_mon_node04_ceph_backup_hour}
ceph_backup_time_minute: ${_param:ceph_mon_node04_ceph_backup_minute}
salt_master_host: ${_param:reclass_config_master}
linux_system_codename: ${_param:ceph_mon_system_codename}
single_address: ${_param:ceph_mon_node04_address}
deploy_address: ${_param:ceph_mon_node04_deploy_address}
ceph_public_address: ${_param:ceph_mon_node04_public_address}
keepalived_vip_priority: 104
Note
Skip the deploy_address parameter if you have DHCP enabled on
a PXE network.
Add the following lines to the cluster/infra/kvm.yml file and modify
infra_kvm_node03_hostname depending on which KVM node the Ceph Monitor
node should run on:
parameters:
salt:
control:
size:
ceph.mon:
cpu: 8
ram: 16384
disk_profile: small
net_profile: default
cluster:
internal:
node:
cmn04:
name: ${_param:ceph_mon_node04_hostname}
provider: ${_param:infra_kvm_node03_hostname}.${_param:cluster_domain}
image: ${_param:salt_control_xenial_image}
size: ceph.mon
Refresh pillars:
salt '*' saltutil.refresh_pillar
Log in to the Jenkins web UI.
Open the Ceph - add node pipeline.
Specify the following parameters:
| Parameter |
Description and values |
|---|
| SALT_MASTER_CREDENTIALS |
The Salt Master credentials to use for connection, defaults to
salt. |
| SALT_MASTER_URL |
The Salt Master node host URL with the salt-api port, defaults to
the jenkins_salt_api_url parameter. For example,
http://172.18.170.27:6969. |
| HOST |
Add the Salt target name of the new Ceph Monitor node. For example,
cmn04*. |
| HOST_TYPE Removed since 2019.2.13 update |
Add mon as the type of Ceph node that is going to be added. |
Click Deploy.
The Ceph - add node pipeline workflow:
- Launch the Ceph Monitor VMs.
- Run the
reclass state.
- Run the
linux, openssh, salt, ntp, rsyslog,
ceph.mon states.
- Update
ceph.conf files on all Ceph nodes.
- Run the
ceph.mgr state if the pillar is present.
Add a Ceph OSD node
This section describes how to add a Ceph OSD node to an existing Ceph cluster.
Warning
Prior to the 2019.2.10 maintenance update, this feature is
available as technical preview only.
To add a Ceph OSD node:
Connect the Ceph OSD salt-minion node to salt-master.
In your project repository, if the nodes are not generated dynamically, add
the following lines to cluster/ceph/init.yml and modify according to
your environment:
_param:
ceph_osd_node05_hostname: osd005
ceph_osd_node05_address: 172.16.47.72
ceph_osd_node05_backend_address: 10.12.100.72
ceph_osd_node05_public_address: 10.13.100.72
ceph_osd_node05_deploy_address: 192.168.0.72
ceph_osd_system_codename: xenial
linux:
network:
host:
osd005:
address: ${_param:ceph_osd_node05_address}
names:
- ${_param:ceph_osd_node05_hostname}
- ${_param:ceph_osd_node05_hostname}.${_param:cluster_domain}
Note
Skip the ceph_osd_node05_deploy_address parameter if you have
DHCP enabled on a PXE network.
If the nodes are not generated dynamically, add the following lines to the
cluster/infra/config/nodes.yml and modify according to your environment.
Otherwise, increase the number of generated OSDs.
parameters:
reclass:
storage:
node:
ceph_osd_node05:
name: ${_param:ceph_osd_node05_hostname}
domain: ${_param:cluster_domain}
classes:
- cluster.${_param:cluster_name}.ceph.osd
params:
salt_master_host: ${_param:reclass_config_master}
linux_system_codename: ${_param:ceph_osd_system_codename}
single_address: ${_param:ceph_osd_node05_address}
deploy_address: ${_param:ceph_osd_node05_deploy_address}
backend_address: ${_param:ceph_osd_node05_backend_address}
ceph_public_address: ${_param:ceph_osd_node05_public_address}
ceph_crush_parent: rack02
Note
Skip the deploy_address parameter if you have DHCP enabled on
a PXE network.
Since 2019.2.3, skip this step
Verify that the cluster/ceph/osd.yml file and the pillar of the new
Ceph OSD do not contain the following lines:
parameters:
ceph:
osd:
crush_update: false
Log in to the Jenkins web UI.
Select from the following options:
- For MCP versions starting from the 2019.2.10 maintenance update, open the
Ceph - add osd (upmap) pipeline.
- For MCP versions prior to the 2019.2.10 maintenance update, open the
Ceph - add node pipeline.
Note
Prior to the 2019.2.10 maintenance update, the
Ceph - add node and Ceph - add osd (upmap)
Jenkins pipeline jobs are available as technical preview only.
Caution
A large change in the crush weights distribution after the
addition of Ceph OSDs can cause massive unexpected rebalancing, affect
performance, and in some cases can cause data corruption. Therefore, if
you are using Ceph - add node, Mirantis recommends that you
add all disks with zero weight and reweight them gradually.
Specify the following parameters:
| Parameter |
Description and values |
|---|
| SALT_MASTER_CREDENTIALS |
The Salt Master credentials to use for connection, defaults to
salt. |
| SALT_MASTER_URL |
The Salt Master node host URL with the salt-api port, defaults to
the jenkins_salt_api_url parameter. For example,
http://172.18.170.27:6969. |
| HOST |
Add the Salt target name of the new Ceph OSD. For example,
osd005*. |
| HOST_TYPE Removed since 2019.2.3 update |
Add osd as the type of Ceph node that is going to be added. |
| CLUSTER_FLAGS Added since 2019.2.7 update |
Add a comma-separated list of flags to check after the
pipeline execution. |
| USE_UPMAP Added since 2019.2.13 update |
Use to facilitate the upmap module during rebalancing to minimize
impact on cluster performance. |
Click Deploy.
The Ceph - add node pipeline workflow prior to the 2019.2.3
maintenance update:
- Apply the
reclass state.
- Apply the
linux, openssh, salt, ntp, rsyslog,
ceph.osd states.
The Ceph - add node pipeline workflow starting from 2019.2.3
maintenance update:
- Apply the
reclass state.
- Verify that all installed Ceph clients have the Luminous version.
- Apply the
linux, openssh, salt, ntp, rsyslog,
states.
- Set the Ceph cluster compatibility to Luminous.
- Switch the balancer module to the
upmap mode.
- Set the
norebalance flag before adding a Ceph OSD.
- Apply the
ceph.osd state on the selected Ceph OSD node.
- Update the mappings for the remapped placement group (PG) using
upmap back to the old Ceph OSDs.
- Unset the
norebalance flag and verify that the cluster is healthy.
If you use a custom CRUSH map, update the CRUSH map:
Verify the updated /etc/ceph/crushmap file on cmn01. If correct,
apply the CRUSH map using the following commands:
crushtool -c /etc/ceph/crushmap -o /etc/ceph/crushmap.compiled
ceph osd setcrushmap -i /etc/ceph/crushmap.compiled
Add the following lines to the cluster/ceph/osd.yml file:
parameters:
ceph:
osd:
crush_update: false
Apply the ceph.osd state to persist the CRUSH map:
salt -C 'I@ceph:osd' state.sls ceph.osd
Integrate the Ceph OSD nodes with StackLight:
Update the Salt mine:
salt -C 'I@ceph:osd or I@telegraf:remote_agent' state.sls salt.minion.grains
salt -C 'I@ceph:osd or I@telegraf:remote_agent' saltutil.refresh_modules
salt -C 'I@ceph:osd or I@telegraf:remote_agent' mine.update
Wait for one minute.
Apply the following states:
salt -C 'I@ceph:osd or I@telegraf:remote_agent' state.sls telegraf
salt -C 'I@ceph:osd' state.sls fluentd
salt 'mon*' state.sls prometheus
Add a RADOS Gateway node
This section describes how to add a RADOS Gateway (rgw) node to an existing
Ceph cluster.
To add a RADOS Gateway node:
In your project repository, add the following lines to the
cluster/ceph/init.yml and modify them according to your environment:
_param:
ceph_rgw_node04_hostname: rgw04
ceph_rgw_node04_address: 172.16.47.162
ceph_rgw_node04_ceph_public_address: 10.13.0.162
ceph_rgw_node04_deploy_address: 192.168.0.162
linux:
network:
host:
rgw04:
address: ${_param:ceph_rgw_node04_address}
names:
- ${_param:ceph_rgw_node04_hostname}
- ${_param:ceph_rgw_node04_hostname}.${_param:cluster_domain}
Note
Skip the ceph_rgw_node04_deploy_address parameter if you have
DHCP enabled on a PXE network.
Add the following lines to the cluster/ceph/rgw.yml file:
parameters:
_param:
cluster_node04_hostname: ${_param:ceph_rgw_node04_hostname}
cluster_node04_address: ${_param:ceph_rgw_node04_address}
ceph:
common:
keyring:
rgw.rgw04:
caps:
mon: "allow rw"
osd: "allow rwx"
haproxy:
proxy:
listen:
radosgw:
servers:
- name: ${_param:cluster_node04_hostname}
host: ${_param:cluster_node04_address}
port: ${_param:haproxy_radosgw_source_port}
params: check
Note
Starting from the MCP 2019.2.10 maintenance update, the
capabilities for RADOS Gateway have been restricted. To update the
existing capabilities, perform the steps described in
Restrict the RADOS Gateway capabilities.
Add the following lines to the cluster/infra/config/init.yml file:
parameters:
reclass:
storage:
node:
ceph_rgw_node04:
name: ${_param:ceph_rgw_node04_hostname}
domain: ${_param:cluster_domain}
classes:
- cluster.${_param:cluster_name}.ceph.rgw
params:
salt_master_host: ${_param:reclass_config_master}
linux_system_codename: ${_param:ceph_rgw_system_codename}
single_address: ${_param:ceph_rgw_node04_address}
deploy_address: ${_param:ceph_rgw_node04_deploy_address}
ceph_public_address: ${_param:ceph_rgw_node04_ceph_public_address}
keepalived_vip_priority: 104
Note
Skip the deploy_address parameter if you have DHCP enabled on
a PXE network.
Add the following lines to the cluster/infra/kvm.yml file and modify
infra_kvm_node03_hostname depending on which KVM node the rgw must
be running on:
parameters:
salt:
control:
size:
ceph.rgw:
cpu: 8
ram: 16384
disk_profile: small
net_profile: default
cluster:
internal:
node:
rgw04:
name: ${_param:ceph_rgw_node04_hostname}
provider: ${_param:infra_kvm_node03_hostname}.${_param:cluster_domain}
image: ${_param:salt_control_xenial_image}
size: ceph.rgw
Log in to the Jenkins web UI.
Open the Ceph - add node pipeline.
Specify the following parameters:
| Parameter |
Description and values |
|---|
| SALT_MASTER_CREDENTIALS |
The Salt Master credentials to use for connection, defaults to
salt. |
| SALT_MASTER_URL |
The Salt Master node host URL with the salt-api port, defaults to
the jenkins_salt_api_url parameter. For example,
http://172.18.170.27:6969. |
| HOST |
Add the Salt target name of the new RADOS Gateway node. For example,
rgw04*. |
| HOST_TYPE Removed since 2019.2.13 update |
Add rgw as the type of Ceph node that is going to be added. |
Click Deploy.
The Ceph - add node pipeline workflow:
- Launch RADOS Gateway VMs.
- Run the
reclass state.
- Run the
linux, openssh, salt, ntp, rsyslog,
keepalived, haproxy, ceph.radosgw states.
Add a Ceph OSD daemon
This section describes how to add new or re-add the existing Ceph OSD daemons
on an existing Ceph OSD node.
Note
This feature is available starting from the MCP 2019.2.13 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
Note
The pipeline used in this section is a wrapper for
Ceph - add node, which simplifies common operations.
To add a new or re-add the existing Ceph OSD daemon:
If you are adding a new Ceph OSD daemon, perform the following prerequisite
steps. Otherwise, proceed to the next step.
- Open your Git project repository with the Reclass model on the cluster
level.
- In
cluster/ceph/osd.yml, add the new Ceph OSD daemon definition. Use
the existing definition as a template.
Log in to the Jenkins web UI.
Select from the following options:
- For MCP version 2019.2.13, open the
Ceph - add osd (upmap) Jenkins pipeline job.
- For MCP versions starting from 2019.2.14, open the
Ceph - add osd Jenkins pipeline job.
Specify the following parameters:
| Parameter |
Description and values |
|---|
| SALT_MASTER_CREDENTIALS |
The Salt Master credentials to use for connection, defaults to
salt. |
| SALT_MASTER_URL |
The Salt Master node host URL with the salt-api port, defaults to
the jenkins_salt_api_url parameter. For example,
http://172.18.170.27:6969. |
| HOST |
The Salt target name of the host to which the Ceph OSD daemons are
going to be added. For example, osd005*. |
| CLUSTER_FLAGS |
A comma-separated list of flags to check after the pipeline
execution. |
Click Deploy.
The Ceph - add osd pipeline runs Ceph - add node
with the following predefined values:
OSD_ONLY is set to True to omit enforcing the node configuration
because a working node is already configured in the cluster.USE_UPMAP is set to True to gradually add Ceph OSD daemons to the
cluster and prevent consuming excessive I/O for rebalancing.
Remove a Ceph Monitor node
This section describes how to remove a Ceph Monitor node from a Ceph
cluster.
Note
The Ceph Monitor service is quorum-based. Therefore, keep an odd number of
Ceph Monitor nodes to establish a
quorum.
To remove a Ceph Monitor node:
In your project repository, remove the following lines from the
cluster/infra/config/init.yml file or from the pillar based on your
environment:
parameters:
reclass:
storage:
node:
ceph_mon_node04:
name: ${_param:ceph_mon_node04_hostname}
domain: ${_param:cluster_domain}
classes:
- cluster.${_param:cluster_name}.ceph.mon
params:
salt_master_host: ${_param:reclass_config_master}
linux_system_codename: ${_param:ceph_mon_system_codename}
single_address: ${_param:ceph_mon_node04_address}
keepalived_vip_priority: 104
Remove the following lines from the cluster/ceph/common.yml file or
from the pillar based on your environment:
parameters:
ceph:
common:
members:
- name: ${_param:ceph_mon_node04_hostname}
host: ${_param:ceph_mon_node04_address}
Log in to the Jenkins web UI.
Open the Ceph - remove node pipeline.
Specify the following parameters:
| Parameter |
Description and values |
|---|
| SALT_MASTER_CREDENTIALS |
The Salt Master credentials to use for connection, defaults to
salt. |
| SALT_MASTER_URL |
The Salt Master node host URL with the salt-api port, defaults to
the jenkins_salt_api_url parameter. For example,
http://172.18.170.27:6969. |
| HOST |
Add the Salt target name of the Ceph Monitor node to remove. For
example, cmn04*. |
| HOST_TYPE Removed since 2019.2.13 update |
Add mon as the type of Ceph node that is going to be removed. |
Click Deploy.
The Ceph - remove node pipeline workflow:
- Reconfigure the configuration file on all
ceph:common minions.
- Destroy the VM.
- Remove the Salt Minion node ID from salt-key on the Salt Master node.
Remove the following lines from the cluster/infra/kvm.yml file or from
the pillar based on your environment:
parameters:
salt:
control:
cluster:
internal:
node:
cmn04:
name: ${_param:ceph_mon_node04_hostname}
provider: ${_param:infra_kvm_node03_hostname}.${_param:cluster_domain}
image: ${_param:salt_control_xenial_image}
size: ceph.mon
Remove the following lines from the cluster/ceph/init.yml file or from
the pillar based on your environment:
_param:
ceph_mon_node04_hostname: cmn04
ceph_mon_node04_address: 172.16.47.145
linux:
network:
host:
cmn04:
address: ${_param:ceph_mon_node04_address}
names:
- ${_param:ceph_mon_node04_hostname}
- ${_param:ceph_mon_node04_hostname}.${_param:cluster_domain}
Remove a Ceph OSD node
This section describes how to remove a Ceph OSD node from a Ceph cluster.
To remove a Ceph OSD node:
If the host is explicitly defined in the model, perform the following steps.
Otherwise, proceed to step 2.
In your project repository, remove the following lines from the
cluster/ceph/init.yml file or from the pillar based on your
environment:
_param:
ceph_osd_node05_hostname: osd005
ceph_osd_node05_address: 172.16.47.72
ceph_osd_system_codename: xenial
linux:
network:
host:
osd005:
address: ${_param:ceph_osd_node05_address}
names:
- ${_param:ceph_osd_node05_hostname}
- ${_param:ceph_osd_node05_hostname}.${_param:cluster_domain}
Remove the following lines from the cluster/infra/config/init.yml
file or from the pillar based on your environment:
parameters:
reclass:
storage:
node:
ceph_osd_node05:
name: ${_param:ceph_osd_node05_hostname}
domain: ${_param:cluster_domain}
classes:
- cluster.${_param:cluster_name}.ceph.osd
params:
salt_master_host: ${_param:reclass_config_master}
linux_system_codename: ${_param:ceph_osd_system_codename}
single_address: ${_param:ceph_osd_node05_address}
ceph_crush_parent: rack02
Log in to the Jenkins web UI.
Open the Ceph - remove node pipeline.
Specify the following parameters:
| Parameter |
Description and values |
|---|
| SALT_MASTER_CREDENTIALS |
The Salt Master credentials to use for connection, defaults to
salt. |
| SALT_MASTER_URL |
The Salt Master node host URL with the salt-api port, defaults to
the jenkins_salt_api_url parameter. For example,
http://172.18.170.27:6969. |
| HOST |
Add the Salt target name of the Ceph OSD node to remove. For
example, osd005*. |
| HOST_TYPE Removed since 2019.2.13 update |
Add osd as the type of Ceph node that is going to be removed. |
| OSD Added since 2019.2.13 update |
Specify the list of Ceph OSDs to remove while keeping the rest and
the entire node as part of the cluster. To remove all, leave empty or
set to *. |
| GENERATE_CRUSHMAP |
Select if the CRUSH map file should be updated. Enforce has to
happen manually unless it is specifically set to be enforced in
pillar. |
| ADMIN_HOST Removed since 2019.2.13 update |
Add cmn01* as the Ceph cluster node with the admin keyring. |
| WAIT_FOR_HEALTHY |
Mandatory since the 2019.2.13 maintenance update. Verify that this
parameter is selected as it enables the Ceph health check within the
pipeline. |
| CLEANDISK Added since 2019.2.10 update |
Mandatory since the 2019.2.13 maintenance update. Select to clean the
data or block partitions. |
| CLEAN_ORPHANS Added since 2019.2.13 update |
Select to clean orphaned disks of Ceph OSDs that are no longer part
of the cluster. |
| FAST_WIPE Added since 2019.2.13 update |
Deselect if the entire disk needs zero filling. |
Click Deploy.
The Ceph - remove node pipeline workflow:
- Mark all Ceph OSDs running on the specified
HOST as out. If you
selected the WAIT_FOR_HEALTHY parameter, Jenkins pauses the
execution of the pipeline until the data migrates to a different Ceph
OSD.
- Stop all Ceph OSDs services running on the specified HOST.
- Remove all Ceph OSDs running on the specified
HOST from the CRUSH
map.
- Remove all Ceph OSD authentication keys running on the specified HOST.
- Remove all Ceph OSDs running on the specified
HOST from Ceph cluster.
- Purge CEPH packages from the specified
HOST.
- Stop the Salt Minion node on the specified
HOST.
- Remove all Ceph OSDs running on the specified
HOST from Ceph cluster.
- Remove the Salt Minion node ID from salt-key on the Salt Master node.
- Update the CRUSHMAP file on the I@ceph:setup:crush node if
GENERATE_CRUSHMAP was selected. You must manually apply the
update unless it is specified otherwise in the pillar.
If you selected GENERATE_CRUSHMAP, check the updated
/etc/ceph/crushmap file on cmn01. If it is correct, apply the CRUSH
map:
crushtool -c /etc/ceph/crushmap -o /etc/ceph/crushmap.compiled
ceph osd setcrushmap -i /etc/ceph/crushmap.compiled
Remove a RADOS Gateway node
This section describes how to remove a RADOS Gateway (rgw) node from a
Ceph cluster.
To remove a RADOS Gateway node:
In your project repository, remove the following lines from the
cluster/ceph/rgw.yml file or from the pillar based on your environment:
parameters:
_param:
cluster_node04_hostname: ${_param:ceph_rgw_node04_hostname}
cluster_node04_address: ${_param:ceph_rgw_node04_address}
ceph:
common:
keyring:
rgw.rgw04:
caps:
mon: "allow rw"
osd: "allow rwx"
haproxy:
proxy:
listen:
radosgw:
servers:
- name: ${_param:cluster_node04_hostname}
host: ${_param:cluster_node04_address}
port: ${_param:haproxy_radosgw_source_port}
params: check
Remove the following lines from the cluster/infra/config/init.yml file
or from the pillar based on your environment:
parameters:
reclass:
storage:
node:
ceph_rgw_node04:
name: ${_param:ceph_rgw_node04_hostname}
domain: ${_param:cluster_domain}
classes:
- cluster.${_param:cluster_name}.ceph.rgw
params:
salt_master_host: ${_param:reclass_config_master}
linux_system_codename: ${_param:ceph_rgw_system_codename}
single_address: ${_param:ceph_rgw_node04_address}
keepalived_vip_priority: 104
Log in to the Jenkins web UI.
Open the Ceph - remove node pipeline.
Specify the following parameters:
| Parameter |
Description and values |
|---|
| SALT_MASTER_CREDENTIALS |
The Salt Master credentials to use for connection, defaults to
salt. |
| SALT_MASTER_URL |
The Salt Master node host URL with the salt-api port, defaults to
the jenkins_salt_api_url parameter. For example,
http://172.18.170.27:6969. |
| HOST |
Add the Salt target name of the RADOS Gateway node to remove. For
example, rgw04*. |
| HOST_TYPE Removed since 2019.2.13 update |
Add rgw as the type of Ceph node that is going to be removed. |
| CLEANDISK Added since 2019.2.10 update |
Mandatory since the 2019.2.13 maintenance update. Select to clean the
data or block partitions. |
Click Deploy.
The Ceph - remove node pipeline workflow:
- Reconfigure HAProxy on the rest of RADOS Gateway nodes.
- Destroy the VM.
- Remove the Salt Minion node ID from salt-key on the Salt Master node.
Remove the following lines from the cluster/infra/kvm.yml file or from
the pillar based on your environment:
parameters:
salt:
control:
cluster:
internal:
node:
rgw04:
name: ${_param:ceph_rgw_node04_hostname}
provider: ${_param:infra_kvm_node03_hostname}.${_param:cluster_domain}
image: ${_param:salt_control_xenial_image}
size: ceph.rgw
Remove the following lines from the cluster/ceph/init.yml file or from
the pillar based on your environment:
_param:
ceph_rgw_node04_hostname: rgw04
ceph_rgw_node04_address: 172.16.47.162
linux:
network:
host:
rgw04:
address: ${_param:ceph_rgw_node04_address}
names:
- ${_param:ceph_rgw_node04_hostname}
- ${_param:ceph_rgw_node04_hostname}.${_param:cluster_domain}
Remove a Ceph OSD daemon
Note
This feature is available starting from the MCP 2019.2.13 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
Note
The pipeline used in this section is a wrapper for
Ceph - remove node, which simplifies common operations.
This section describes how to remove a Ceph OSD daemon from the cluster without
removing the entire Ceph OSD node.
To remove a Ceph OSD daemon:
Log in to the Jenkins web UI.
Open the Ceph - remove osd pipeline.
Specify the following parameters:
| Parameter |
Description and values |
|---|
| SALT_MASTER_CREDENTIALS |
The Salt Master credentials to use for connection, defaults to
salt. |
| SALT_MASTER_URL |
The Salt Master node host URL with the salt-api port, defaults to
the jenkins_salt_api_url parameter. For example,
http://172.18.170.27:6969. |
| HOST |
The Salt target name of the host from which the Ceph OSD daemons are
going to be removed. For example, osd005*. |
| OSD |
A comma-separated list of Ceph OSD daemons to remove while keeping
the rest and the entire node as part of the cluster. Do not leave
this parameter empty. |
| WAIT_FOR_HEALTHY |
Verify that this parameter is selected as it enables the Ceph health
check within the pipeline. |
| CLEAN_ORPHANS |
Select to clean orphaned disks of Ceph OSDs that are no longer part
of the cluster. |
| FAST_WIPE |
Deselect if the entire disk needs zero filling. |
Click Deploy.
Replace a failed Ceph OSD
This section instructs you on how to replace a failed physical node with a Ceph
OSD or multiple OSD nodes running on it using the
Ceph - replace failed OSD Jenkins pipeline.
To replace a failed physical node with a Ceph OSD or multiple OSD nodes:
Log in to the Jenkins web UI.
Open the Ceph - replace failed OSD pipeline.
Specify the following parameters:
| Parameter |
Description and values |
|---|
| SALT_MASTER_CREDENTIALS |
The Salt Master credentials to use for connection, defaults to
salt. |
| SALT_MASTER_URL |
The Salt Master node host URL with the salt-api port, defaults to
the jenkins_salt_api_url parameter. For example,
http://172.18.170.27:6969. |
| HOST |
Add the Salt target name of the Ceph OSD node. For example,
osd005*. |
| OSD |
Add a comma-separated list of Ceph OSDs on the specified HOST
node. For example 1,2. |
| DEVICE |
Add a comma-separated list of failed devices to replace at HOST.
For example, /dev/sdb,/dev/sdc. |
| DATA_PARTITION: |
(Optional) Add a comma-separated list of mounted partitions of
the failed device. These partitions will be unmounted. We recommend
that multiple OSD nodes per device are used. For example,
/dev/sdb1,/dev/sdb3. |
| JOURNAL_BLOCKDB_BLOCKWAL_PARTITION: |
Add a comma-separated list of partitions that store journal,
block_db, or block_wal of the failed devices on the
specified HOST. For example, /dev/sdh2,/dev/sdh3. |
| ADMIN_HOST |
Add cmn01* as the Ceph cluster node with the admin keyring. |
| CLUSTER_FLAGS |
Add a comma-separated list of flags to apply before and after the
pipeline. |
| WAIT_FOR_HEALTHY |
Select to perform the Ceph health check within the pipeline. |
| DMCRYPT |
Select if you are replacing an encrypted OSD. In such case, also
specify noout,norebalance as CLUSTER_FLAGS. |
Click Deploy.
The Ceph - replace failed OSD pipeline workflow:
- Mark the Ceph OSD as
out.
- Wait until the Ceph cluster is in a healthy state if
WAIT_FOR_HEALTHY was selected. In this case. Jenkins pauses
the execution of the pipeline until the data migrates to a different
Ceph OSD.
- Stop the Ceph OSD service.
- Remove the Ceph OSD from the CRUSH map.
- Remove the Ceph OSD authentication key.
- Remove the Ceph OSD from the Ceph cluster.
- Unmount data partition(s) of the failed disk.
- Delete the partition table of the failed disk.
- Remove the partition from the
block_db, block_wal, or journal.
- Perform one of the following depending on the MCP release version:
- For deployments prior to the MCP 2019.2.3 update, redeploy the failed Ceph
OSD.
- For deployments starting from the MCP 2019.2.3 update:
- Wait for the hardware replacement and confirmation to proceed.
- Redeploy the failed Ceph OSD on the replaced hardware.
Note
If any of the steps 1 - 9 has already been performed manually, Jenkins
proceeds to the next step.
Restrict the RADOS Gateway capabilities
Note
This feature is available starting from the MCP 2019.2.10 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
To avoid a potential security vulnerability, Mirantis recommends that you
restrict the RADOS Gateway capabilities of your existing MCP deployment to
a bare minimum.
To restrict the RADOS Gateway capabilities of an existing MCP
deployment:
Open your project Git repository with the Reclass model on the cluster
level.
In cluster/ceph/rgw.yml, modify the RADOS Gateway capabilities as
follows:
ceph:
common:
keyring:
rgw.rgw01:
caps:
mon: "allow rw"
osd: "allow rwx"
rgw.rgw02:
caps:
mon: "allow rw"
osd: "allow rwx"
rgw.rgw03:
caps:
mon: "allow rw"
osd: "allow rwx"
Log in to the Salt Master node.
Apply the changes:
salt -I ceph:radosgw state.apply ceph.common,ceph.setup.keyring
Enable the Ceph Prometheus plugin
If you have deployed StackLight LMA, you can enhance Ceph monitoring by
enabling the Ceph Prometheus plugin that is based on the native Prometheus
exporter introduced in Ceph Luminous. In this case, the Ceph Prometheus plugin,
instead of Telegraf, collects Ceph metrics providing a wider set of graphs in
the Grafana web UI, such as an overview of the Ceph cluster, hosts, OSDs,
pools, RADOS gateway nodes, as well as detailed graphs on the Ceph OSD and
RADOS Gateway nodes.
You can enable the Ceph Prometheus plugin manually on an existing MCP cluster
as described below or during the upgrade of StackLight LMA as described in
Upgrade StackLight LMA using the Jenkins job.
To enable the Ceph Prometheus plugin manually:
Update the Ceph formula package.
Open your project Git repository with Reclass model on the cluster level.
In classes/cluster/cluster_name/ceph/mon.yml, remove the
service.ceph.monitoring.cluster_stats class.
In classes/cluster/cluster_name/ceph/osd.yml, remove the
service.ceph.monitoring.node_stats class.
Log in to the Salt Master node.
Refresh grains to set the new alerts and graphs:
salt '*' state.sls salt.minion.grains
Enable the Prometheus plugin:
salt -C I@ceph:mon state.sls ceph.mgr
Update the targets and alerts in Prometheus:
salt -C 'I@docker:swarm and I@prometheus:server' state.sls prometheus
Update the new Grafana dashboards:
salt -C 'I@grafana:client' state.sls grafana
(Optional) Enable the StackLight LMA prediction alerts for Ceph.
Note
This feature is available as technical preview. Use such
configuration for testing and evaluation purposes only.
Warning
This feature is available starting from the MCP 2019.2.3
maintenance update. Before enabling the feature, follow the steps
described in Apply maintenance updates.
Open your project Git repository with Reclass model on the cluster level.
In classes/cluster/cluster_name/ceph/common.yml, set
enable_prediction to True:
parameters:
ceph:
common:
enable_prediction: True
Log in to the Salt Master node.
Refresh grains to set the new alerts and graphs:
salt '*' state.sls salt.minion.grains
Verify and update the alerts thresholds based on the cluster hardware.
Note
For details about tuning the thresholds, contact Mirantis
support.
Update the targets and alerts in Prometheus:
salt -C 'I@docker:swarm and I@prometheus:server' state.sls prometheus
Customize Ceph prediction alerts as described in Ceph.
Enable Ceph compression
Note
This feature is available starting from the MCP 2019.2.5 maintenance
update. Before enabling the feature, follow the steps
described in Apply maintenance updates.
RADOS Gateway supports server-side compression of uploaded objects using the
Ceph compression plugins. You can manually enable Ceph compression to
rationalize the capacity usage on the MCP cluster.
To enable Ceph compression:
Log in to any rgw node.
Run the radosgw-admin zone placement modify command with the
--compression=<type> option specifying the compression plugin type and
other options as required. The available compression plugins to use when
writing a new object data are zlib, snappy, or zstd.
For example:
radosgw-admin zone placement modify \
--rgw-zone default \
--placement-id default-placement \
--storage-class STANDARD \
--compression zlib
Note
If you have not previously performed any Multi-site configuration, you can use the
default values for the options except compression. To disable
compression, set the compression type to an empty string or none.
Shut down a Ceph cluster for maintenance
This section describes how to properly shut down an entire Ceph cluster for
maintenance and bring it up afterward.
To shut down a Ceph cluster for maintenance:
Log in to the Salt Master node.
Stop the OpenStack workloads.
Stop the services that are using the Ceph cluster. For example:
- Manila workloads (if you have shares on top of Ceph mount points)
heat-engine (if it has the autoscaling option enabled)glance-api (if it uses Ceph to store images)cinder-scheduler (if it uses Ceph to store images)
Identify the first Ceph Monitor for operations:
CEPH_MON=$(salt -C 'I@ceph:mon' --out=txt test.ping | sort | head -1 | \
cut -d: -f1)
Verify that the Ceph cluster is in healthy state:
salt "${CEPH_MON}" cmd.run 'ceph -s'
Example of system response:
cmn01.domain.com:
cluster e0b75d1b-544c-4e5d-98ac-cfbaf29387ca
health HEALTH_OK
monmap e3: 3 mons at {cmn01=192.168.16.14:6789/0,cmn02=192.168.16.15:6789/0,cmn03=192.168.16.16:6789/0}
election epoch 42, quorum 0,1,2 cmn01,cmn02,cmn03
osdmap e102: 6 osds: 6 up, 6 in
flags sortbitwise,require_jewel_osds
pgmap v41138: 384 pgs, 6 pools, 45056 kB data, 19 objects
798 MB used, 60575 MB / 61373 MB avail
384 active+clean
Set the following flags to disable rebalancing and restructuring and to
pause the Ceph cluster:
salt "${CEPH_MON}" cmd.run 'ceph osd set noout'
salt "${CEPH_MON}" cmd.run 'ceph osd set nobackfill'
salt "${CEPH_MON}" cmd.run 'ceph osd set norecover'
salt "${CEPH_MON}" cmd.run 'ceph osd set norebalance'
salt "${CEPH_MON}" cmd.run 'ceph osd set nodown'
salt "${CEPH_MON}" cmd.run 'ceph osd set pause'
Verify that the flags are set:
salt "${CEPH_MON}" cmd.run 'ceph -s'
Example of system response:
cmn01.domain.com:
cluster e0b75d1b-544c-4e5d-98ac-cfbaf29387ca
health **HEALTH_WARN**
**pauserd**,**pausewr**,**nodown**,**noout**,**nobackfill**,**norebalance**,**norecover** flag(s) set
monmap e3: 3 mons at {cmn01=192.168.16.14:6789/0,cmn02=192.168.16.15:6789/0,cmn03=192.168.16.16:6789/0}
election epoch 42, quorum 0,1,2 cmn01,cmn02,cmn03
osdmap e108: 6 osds: 6 up, 6 in
flags **pauserd**,**pausewr**,**nodown**,**noout**,**nobackfill**,**norebalance**,**norecover**,sortbitwise,require_jewel_osds
pgmap v41152: 384 pgs, 6 pools, 45056 kB data, 19 objects
799 MB used, 60574 MB / 61373 MB avail
384 active+clean
Shut down the Ceph cluster.
Warning
Shut down the nodes one by one in the following order:
- Service nodes (for example, RADOS Gateway nodes)
- Ceph OSD nodes
- Ceph Monitor nodes
Once done, perform the maintenance as required.
To start a Ceph cluster after maintenance:
Log in to the Salt Master node.
Start the Ceph cluster nodes.
Warning
Start the Ceph nodes one by one in the following order:
- Ceph Monitor nodes
- Ceph OSD nodes
- Service nodes (for example, RADOS Gateway nodes)
Verify that the Salt minions are up:
salt -C "I@ceph:common" test.ping
Verify that the date is the same for all Ceph clients:
salt -C "I@ceph:common" cmd.run date
Identify the first Ceph Monitor for operations:
CEPH_MON=$(salt -C 'I@ceph:mon' --out=txt test.ping | sort | head -1 | \
cut -d: -f1)
Unset the following flags to resume the Ceph cluster:
salt "${CEPH_MON}" cmd.run 'ceph osd unset pause'
salt "${CEPH_MON}" cmd.run 'ceph osd unset nodown'
salt "${CEPH_MON}" cmd.run 'ceph osd unset norebalance'
salt "${CEPH_MON}" cmd.run 'ceph osd unset norecover'
salt "${CEPH_MON}" cmd.run 'ceph osd unset nobackfill'
salt "${CEPH_MON}" cmd.run 'ceph osd unset noout'
Verify that the Ceph cluster is in healthy state:
salt "${CEPH_MON}" cmd.run 'ceph -s'
Example of system response:
cmn01.domain.com:
cluster e0b75d1b-544c-4e5d-98ac-cfbaf29387ca
health HEALTH_OK
monmap e3: 3 mons at {cmn01=192.168.16.14:6789/0,cmn02=192.168.16.15:6789/0,cmn03=192.168.16.16:6789/0}
election epoch 42, quorum 0,1,2 cmn01,cmn02,cmn03
osdmap e102: 6 osds: 6 up, 6 in
flags sortbitwise,require_jewel_osds
pgmap v41138: 384 pgs, 6 pools, 45056 kB data, 19 objects
798 MB used, 60575 MB / 61373 MB avail
384 active+clean
Back up and restore Ceph
This section describes how to back up and restore Ceph OSD nodes metadata and
Ceph Monitor nodes.
Note
This documentation does not provide instructions on how to back up
the data stored in Ceph.
Create a backup schedule for Ceph nodes
This section describes how to manually create a backup schedule for Ceph OSD
nodes metadata and for Ceph Monitor nodes.
By default, the backing up functionality enables automatically for the new MCP
OpenStack with Ceph deployments in the cluster models generated using Model
Designer. Use this procedure in case of manual deployment only or if you want
to change the default backup configuration.
Note
The procedure below does not cover the backup of the Ceph OSD node
data.
To create a backup schedule for Ceph nodes:
Log in to the Salt Master node.
Decide on which node you want to store the backups.
Get <STORAGE_ADDRESS> of the node from point 2.
cfg01:~\# salt NODE_NAME grains.get fqdn_ip4
Configure the ceph backup server role by adding the
cluster.deployment_name.infra.backup.server class to the definition
of the target storage node from step 2:
classes:
- cluster.deployment_name.infra.backup.server
parameters:
_param:
ceph_backup_public_key: <generate_your_keypair>
By default, adding this include statement results in Ceph keeping five
complete backups. To change the default setting, add the following pillar
to the cluster/infra/backup/server.yml file:
parameters:
ceph:
backup:
server:
enabled: true
hours_before_full: 24
full_backups_to_keep: 5
To back up the Ceph Monitor nodes, configure the ceph backup client
role by adding the following lines to the cluster/ceph/mon.yml file:
Note
Change <STORAGE_ADDRESS> to the address of the target storage
node from step 2
classes:
- system.ceph.backup.client.single
parameters:
_param:
ceph_remote_backup_server: <STORAGE_ADDRESS>
root_private_key: |
<generate_your_keypair>
To back up the Ceph OSD nodes metadata, configure the ceph backup
client role by adding the following lines to the cluster/ceph/osd.yml
file:
Note
Change <STORAGE_ADDRESS> to the address of the target storage
node from step 2
classes:
- system.ceph.backup.client.single
parameters:
_param:
ceph_remote_backup_server: <STORAGE_ADDRESS>
root_private_key: |
<generate_your_keypair>
By default, adding the above include statement results in Ceph keeping
three complete backups on the client node. To change the default setting,
add the following pillar to the cluster/ceph/mon.yml or
cluster/ceph/osd.yml files:
Note
Change <STORAGE_ADDRESS> to the address of the target storage
node from step 2
parameters:
ceph:
backup:
client:
enabled: true
full_backups_to_keep: 3
hours_before_full: 24
target:
host: <STORAGE_ADDRESS>
Refresh Salt pillars:
salt -C '*' saltutil.refresh_pillar
Apply the salt.minion state:
salt -C 'I@ceph:backup:client or I@ceph:backup:server' state.sls salt.minion
Refresh grains for the ceph client node:
salt -C 'I@ceph:backup:client' saltutil.sync_grains
Update the mine for the ceph client node:
salt -C 'I@ceph:backup:client' mine.flush
salt -C 'I@ceph:backup:client' mine.update
Apply the following state on the ceph client node:
salt -C 'I@ceph:backup:client' state.sls openssh.client,ceph.backup
Apply the linux.system.cron state on the ceph server node:
salt -C 'I@ceph:backup:server' state.sls linux.system.cron
Apply the ceph.backup state on the ceph server node:
salt -C 'I@ceph:backup:server' state.sls ceph.backup
Restore a Ceph Monitor node
You may need to restore a Ceph Monitor node after a failure. For example, if
the data in the Ceph-related directories disappeared.
To restore a Ceph Monitor node:
Verify that the Ceph Monitor instance is up and running and connected to
the Salt Master node.
Log in to the Ceph Monitor node.
Synchronize Salt modules and refresh Salt pillars:
salt-call saltutil.sync_all
salt-call saltutil.refresh_pillar
Run the following Salt states:
salt-call state.sls linux,openssh,salt,ntp,rsyslog
Manually install Ceph packages:
Remove the following files from Ceph:
rm -rf /etc/ceph/* /var/lib/ceph/*
From the Ceph backup, copy the files from /etc/ceph/ and
/var/lib/ceph to their original directories:
cp -r /<etc_ceph_backup_path>/* /etc/ceph/
cp -r /<var_lib_ceph_backup_path>/* /var/lib/ceph/
Change the files ownership:
chown -R ceph:ceph /var/lib/ceph/*
Run the following Salt state:
If the output contains an error, rerun the state.
Migrate the Ceph back end
Ceph uses FileStore or BlueStore as a storage back end. You can migrate the
Ceph storage back end from FileStore to BlueStore and vice versa using the
Ceph - backend migration pipeline.
Note
Starting from the 2019.2.10 maintenance update, this procedure is
deprecated and all Ceph OSDs should use LVM with BlueStore. Back-end
migration is described in Enable the ceph-volume tool.
For earlier versions, if you are going to upgrade Ceph to Nautilus, also
skip this procedure to avoid a double migration of the back end. In this
case, first apply the 2019.2.10 maintenance update and then enable
ceph-volume as well.
To migrate the Ceph back end:
In your project repository, open the cluster/ceph/osd.yml file for
editing:
- Change the back end type and
block_db or journal for every OSD
disk device.
- Specify the size of the
journal or block_db device if it resides
on another device than the storage device. The device storage will be
divided equally by the number of OSDs using it.
Example:
parameters:
ceph:
osd:
bluestore_block_db_size: 10073741824
# journal_size: 10000
backend:
# filestore:
bluestore:
disks:
- dev: /dev/sdh
block_db: /dev/sdj
# journal: /dev/sdj
Where the commented lines are the example lines that must be replaced and
removed if migrating from FileStore to BlueStore.
Log in to the Jenkins web UI.
Open the Ceph - backend migration pipeline.
Specify the following parameters:
| Parameter |
Description and values |
|---|
| SALT_MASTER_CREDENTIALS |
The Salt Master credentials to use for connection, defaults to
salt. |
| SALT_MASTER_URL |
The Salt Master node host URL with the salt-api port, defaults to
the jenkins_salt_api_url parameter. For example,
http://172.18.170.27:6969. |
| ADMIN_HOST |
Add cmn01* as the Ceph cluster node with the admin keyring. |
| TARGET |
Add the Salt target name of the Ceph OSD node(s). For example,
osd005* to migrate on one OSD HOST or osd* to migrate on all
OSD hosts. |
| OSD |
Add * to target all OSD disks on all TARGET OSD hosts or
comma-separated list of Ceph OSDs if targeting just one OSD host by
TARGET For example 1,2. |
| WAIT_FOR_HEALTHY |
Verify that this parameter is selected as it enables the Ceph health
check within the pipeline. |
| PER_OSD_CONTROL |
Select to verify the Ceph status after migration of each OSD disk. |
| PER_OSD_HOST_CONTROL |
Select to verify the Ceph status after the whole OSD host migration. |
| CLUSTER_FLAGS |
Add a comma-separated list of flags to apply for the migration
procedure. Tested with blank. |
| ORIGIN_BACKEND |
Specify the Ceph back end before migration. |
Note
The PER_OSD_CONTROL and PER_OSD_HOST_CONTROL options provide
granular control during the migration to verify each OSD disk after its
migration. You can decide to continue or abort.
Click Deploy.
The Ceph - upgrade pipeline workflow:
- Set back-end migration flags.
- Perform the following for each targeted OSD disk:
- Mark the Ceph OSD as
out.
- Stop the Ceph OSD service.
- Remove the Ceph OSD authentication key.
- Remove the Ceph OSD from the Ceph cluster
- Remove
block_db, block_wal, or journal of the OSD.
- Run the
ceph.osd state to deploy the OSD with a desired back end.
- Unset the back-end migration flags.
Note
During the pipeline execution, a check is performed to verify whether
the back end type for an OSD disk differs from the one specified in
ORIGIN_BACKEND. If the back end differs, Jenkins does not apply any
changes to that OSD disk.
Migrate the management of a Ceph cluster
You can migrate the management of an existing Ceph cluster deployed by Decapod
to a cluster managed by the Ceph Salt formula.
To migrate the management of a Ceph cluster:
Log in to the Decapod web UI.
Navigate to the CONFIGURATIONS tab.
Select the required configuration and click VIEW.
Generate a new cluster model with Ceph as described in
MCP Deployment Guide: Create a deployment metadata model using
the Model Designer.
Verify that you fill in the correct values from the Decapod configuration
file displayed in the VIEW tab of the Decapod web UI.
In the <cluster_name>/ceph/setup.yml file, specify the right pools and
parameters for the existing pools.
Note
Verify that the keyring names and their caps match the ones that
already exist in the Ceph cluster deployed by Decapod.
In the <cluster_name>/infra/config.yml file, add the following pillar
and modify the parameters according to your environment:
ceph:
decapod:
ip: 192.168.1.10
user: user
pass: psswd
deploy_config_name: ceph
On the node defined in the previous step, apply the following state:
salt-call state.sls ceph.migration
Note
The output of this state must contain defined configurations, Ceph OSD
disks, Ceph File System ID (FSID), and so on.
Using the output of the previous command, add the following pillars to your
cluster model:
- Add the
ceph:common pillar to <cluster_name>/ceph/common.yml.
- Add the
ceph:osd pillar to <cluster_name>/ceph/osd.yml.
Examine the newly generated cluster model for any occurrence of the
ceph keyword and verify that it exists in your current cluster model.
Examine each Ceph cluster file to verify that the parameters match the
configuration specified in Decapod.
Copy the Ceph cluster directory to the existing cluster model.
Verify that the ceph subdirectory is included in your cluster model in
<cluster_name>/infra/init.yml or <cluster_name>/init.yml for older
cluster model versions:
classes:
- cluster.<cluster_name>.ceph
Add the Reclass storage nodes to <cluster_name>/infra/config.yml and
change the count variable to the number of OSDs you have. For example:
classes:
- system.reclass.storage.system.ceph_mon_cluster
- system.reclass.storage.system.ceph_rgw_cluster # Add this line only if
# RadosGW services run on separate nodes than the Ceph Monitor services.
parameters:
reclass:
storage:
node:
ceph_osd_rack01:
name: ${_param:ceph_osd_rack01_hostname}<<count>>
domain: ${_param:cluster_domain}
classes:
- cluster.${_param:cluster_name}.ceph.osd
repeat:
count: 3
start: 1
digits: 3
params:
single_address:
value: ${_param:ceph_osd_rack01_single_subnet}.<<count>>
start: 201
backend_address:
value: ${_param:ceph_osd_rack01_backend_subnet}.<<count>>
start: 201
If the Ceph RADOS Gateway service is running on the same nodes as the Ceph
monitor services:
Add the following snippet to <cluster_name>/infra/config.yml:
reclass:
storage:
node:
ceph_mon_node01:
classes:
- cluster.${_param:cluster_name}.ceph.rgw
ceph_mon_node02:
classes:
- cluster.${_param:cluster_name}.ceph.rgw
ceph_mon_node03:
classes:
- cluster.${_param:cluster_name}.ceph.rgw
Verify that the parameters in <cluster_name>/ceph/rgw.yml are
defined correctly according to the existing Ceph cluster.
From the Salt Master node, generate the Ceph nodes:
salt-call state.sls reclass
Run the commands below.
Warning
If the outputs of the commands below contain any changes that can
potentially break the cluster, change the cluster model as needed and
optionally run the salt-call pillar.data ceph command to
verify that the Salt pillar contains the correct value. Proceed to the
next step only once you are sure that your model is correct.
From the Ceph monitor nodes:
salt-call state.sls ceph test=True
From the Ceph OSD nodes:
salt-call state.sls ceph test=True
From the Ceph RADOS Gateway nodes:
salt-call state.sls ceph test=True
From the Salt Master node:
salt -C 'I@ceph:common' state.sls ceph test=True
Once you have verified that no changes by the Salt Formula can break the
running Ceph cluster, run the following commands.
From the Salt Master node:
salt -C 'I@ceph:common:keyring:admin' state.sls ceph.mon
salt -C 'I@ceph:mon' saltutil.sync_grains
salt -C 'I@ceph:mon' mine.update
salt -C 'I@ceph:mon' state.sls ceph.mon
From one of the OSD nodes:
salt-call state.sls ceph.osd
Note
Before you proceed, verify that the OSDs on this node are
working fine.
From the Salt Master node:
salt -C 'I@ceph:osd' state.sls ceph.osd
From the Salt Master node:
salt -C 'I@ceph:radosgw' state.sls ceph.radosgw
Enable RBD monitoring
Warning
This feature is available as technical preview starting from the
MCP 2019.2.10 maintenance update and requires Ceph Nautilus. Use such
configuration for testing and evaluation purposes only. Before using the
feature, follow the steps described in Apply maintenance
updates.
If required, you can enable RADOS Block Device (RBD) images monitoring
introduced with Ceph Nautilus. Once done, you can view RBD metrics using the
Ceph RBD Overview Grafana dashboard. For details, see
Ceph dashboards.
To enable RBD monitoring:
Open your Git project repository with the Reclass model on the cluster
level.
In classes/cluster/<cluster_name>/ceph/setup.yml add the rbd_stats
flag for pools serving RBD images to enable serving RBD metrics:
parameters:
ceph:
setup:
pool:
<pool_name>:
pg_num: 8
pgp_num: 8
type: replicated
application: rbd
rbd_stats: True
In classes/cluster/<cluster_name>/ceph/common.yml, set the
rbd_monitoring_enabled parameter to True to enable the
Ceph RBD Overview Grafana dashboard:
ceph:
common:
public_network: 10.13.0.0/16
cluster_network: 10.12.0.0/16
rbd_monitoring_enabled: True
Log in to the Salt Master node.
Apply the changes:
salt "*" saltutil.refresh_pillar
salt "*" state.apply salt.minion.grains
salt "*" saltutil.refresh_grains
salt -C "I@ceph:mgr" state.apply 'ceph.mgr'
salt -C 'I@grafana:client' state.apply 'grafana.client'
Enable granular distribution of Ceph keys
Note
This feature is available starting from the MCP 2019.2.14 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
This section describes how to enable granular distribution of Ceph keys on an
existing deployment to avoid keeping the Ceph keys for the services that do not
belong to a particular node.
To enable granular distribution of Ceph keys:
Open your Git project repository with the Reclass model on the cluster
level.
Create a new ceph/keyrings folder.
Open the ceph/common.yml file for editing.
Move the configuration for each component from the
parameters:ceph:common:keyrings section to a corresponding file in the
newly created folder. For example, the following configuration must be split
to four different files.
ceph:
common:
keyring:
glance:
name: ${_param:glance_storage_user}
caps:
mon: 'allow r, allow command "osd blacklist"'
osd: "profile rbd pool=images"
cinder:
name: ${_param:cinder_storage_user}
caps:
mon: 'allow r, allow command "osd blacklist"'
osd: "profile rbd pool=volumes, profile rbd-read-only pool=images, profile rbd pool=${_param:cinder_ceph_backup_pool}"
nova:
name: ${_param:nova_storage_user}
caps:
mon: 'allow r, allow command "osd blacklist"'
osd: "profile rbd pool=vms, profile rbd-read-only pool=images"
gnocchi:
name: ${_param:gnocchi_storage_user}
caps:
mon: 'allow r, allow command "osd blacklist"'
osd: "profile rbd pool=${_param:gnocchi_storage_pool}"
In this case, each file must have its own component keyring. For example:
In ceph/keyrings/nova.yml, add:
parameters:
ceph:
common:
keyring:
nova:
name: ${_param:nova_storage_user}
caps:
mon: 'allow r, allow command "osd blacklist"'
osd: "profile rbd pool=vms, profile rbd-read-only pool=images"
In ceph/keyrings/cinder.yml, add:
parameters:
ceph:
common:
keyring:
cinder:
name: ${_param:cinder_storage_user}
caps:
mon: 'allow r, allow command "osd blacklist"'
osd: "profile rbd pool=volumes, profile rbd-read-only pool=images, profile rbd pool=${_param:cinder_ceph_backup_pool}"
In ceph/keyrings/glance.yml, add:
parameters:
ceph:
common:
keyring:
glance:
name: ${_param:glance_storage_user}
caps:
mon: 'allow r, allow command "osd blacklist"'
osd: "profile rbd pool=images"
In ceph/keyrings/gnocchi.yml, add:
parameters:
ceph:
common:
keyring:
gnocchi:
name: ${_param:gnocchi_storage_user}
caps:
mon: 'allow r, allow command "osd blacklist"'
osd: "profile rbd pool=${_param:gnocchi_storage_pool}"
In the same ceph/keyrings folder, create an init.yml file and add
the newly created keyrings:
classes:
- cluster.<cluster_name>.ceph.keyrings.glance
- cluster.<cluster_name>.ceph.keyrings.cinder
- cluster.<cluster_name>.ceph.keyrings.nova
- cluster.<cluster_name>.ceph.keyrings.gnocchi
Note
If Telemetry is disabled, Gnocchi may not be present in your
deployment.
In openstack/compute/init.yml, add the Cinder and Nova keyrings
after class cluster.<cluster_name>.ceph.common:
- cluster.<cluster_name>.ceph.keyrings.cinder
- cluster.<cluster_name>.ceph.keyrings.nova
In openstack/control.yml, add the following line after
cluster.<cluster_name>.ceph.common:
- cluster.<cluster_name>.ceph.keyrings
In openstack/telemetry.yml add the Gnocchi keyring after
class cluster.<cluster_name>.ceph.common:
- cluster.<cluster_name>.ceph.keyrings.gnocchi
Log in to the Salt Master node.
Synchronize the Salt modules and update mines:
salt "*" saltutil.sync_all
salt "*" mine.update
Drop the redundant keyrings from the corresponding nodes and verify that the
keyrings will not change with the new Salt run:
Note
If ceph:common:manage_keyring is enabled, modify the last
state for each component using the following template:
salt "<target>" state.sls ceph.common,ceph.setup.keyring,ceph.setup.managed_keyring test=true
For the OpenStack compute nodes, run:
salt "cmp*" cmd.run "rm /etc/ceph/ceph.client.glance.keyring"
salt "cmp*" cmd.run "rm /etc/ceph/ceph.client.gnocchi.keyring"
salt "cmp*" state.sls ceph.common,ceph.setup.keyring test=true
For the Ceph Monitor nodes, run:
salt "cmn*" cmd.run "rm /etc/ceph/ceph.client.glance.keyring"
salt "cmn*" cmd.run "rm /etc/ceph/ceph.client.gnocchi.keyring"
salt "cmn*" cmd.run "rm /etc/ceph/ceph.client.nova.keyring"
salt "cmn*" cmd.run "rm /etc/ceph/ceph.client.cinder.keyring"
salt "cmn*" state.sls ceph.common,ceph.setup.keyring test=true
For the RADOS Gateway nodes, run:
salt "rgw*" cmd.run "rm /etc/ceph/ceph.client.glance.keyring"
salt "rgw*" cmd.run "rm /etc/ceph/ceph.client.gnocchi.keyring"
salt "rgw*" cmd.run "rm /etc/ceph/ceph.client.nova.keyring"
salt "rgw*" cmd.run "rm /etc/ceph/ceph.client.cinder.keyring"
salt "rgw*" state.sls ceph.common,ceph.setup.keyring test=true
For the Telemetry nodes, run:
salt "mdb*" cmd.run "rm /etc/ceph/ceph.client.glance.keyring"
salt "mdb*" cmd.run "rm /etc/ceph/ceph.client.nova.keyring"
salt "mdb*" cmd.run "rm /etc/ceph/ceph.client.cinder.keyring"
salt "mdb*" state.sls ceph.common,ceph.setup.keyring test=true
Apply the changes for all components one by one:
Glance operations
This section describes the OpenStack Image service (Glance) operations you may
need to perform after the deployment of an MCP cluster.
Enable uploading of an image through Horizon with self-managed SSL certificates
By default, the OpenStack Dashboard (Horizon) supports direct uploading of
images to Glance. However, if an MCP cluster is deployed using self-signed
certificates for public API endpoints and Horizon, uploading of images to
Glance through the Horizon web UI may fail. While accessing the Horizon web UI
of such MCP deployment for the first time, a warning informs that the site is
insecure and you must force trust the certificate of this site. However, when
trying to upload an image directly from the web browser, the certificate of
the Glance API is still not considered by the web browser as a trusted one
since host:port of the site is different. In this case, you must explicitly
trust the certificate of the Glance API.
To enable uploading of an image through Horizon with self-managed SSL
certificates:
Navigate to the Horizon web UI.
On the page that opens, configure your web browser to trust the Horizon
certificate if you have not done so yet:
- In Google Chrome or Chromium, click
Advanced > Proceed to <URL> (unsafe).
- In Mozilla Firefox, navigate to Advanced > Add Exception,
enter the URL in the Location field, and click
Confirm Security Exception.
Note
For other web browsers, the steps may vary slightly.
Navigate to Project > API Access.
Copy the Service Endpoint URL of the Image service.
Open this URL in a new window or tab of the same web browser.
Configure your web browser to trust the certificate of this site as
described in the step 2.
As a result, the version discovery document should appear with contents
depending on the OpenStack version. For example, for OpenStack Ocata:
{"versions": [{"status": "CURRENT", "id": "v2.5", "links": \
[{"href": "http://cloud-cz.bud.mirantis.net:9292/v2/", "rel": "self"}]}, \
{"status": "SUPPORTED", "id": "v2.4", "links": \
[{"href": "http://cloud-cz.bud.mirantis.net:9292/v2/", "rel": "self"}]}, \
{"status": "SUPPORTED", "id": "v2.3", "links": \
[{"href": "http://cloud-cz.bud.mirantis.net:9292/v2/", "rel": "self"}]}, \
{"status": "SUPPORTED", "id": "v2.2", "links": \
[{"href": "http://cloud-cz.bud.mirantis.net:9292/v2/", "rel": "self"}]}, \
{"status": "SUPPORTED", "id": "v2.1", "links": \
[{"href": "http://cloud-cz.bud.mirantis.net:9292/v2/", "rel": "self"}]}, \
{"status": "SUPPORTED", "id": "v2.0", "links": \
[{"href": "http://cloud-cz.bud.mirantis.net:9292/v2/", "rel": "self"}]}]}
Once done, you should be able to upload an image through Horizon with
self-managed SSL certificates.
Telemetry operations
This section describes the Tenant Telemetry service (Ceilometer) operations you
may need to perform after the deployment of an MCP cluster.
Enable the Gnocchi archive policies in Tenant Telemetry
The Gnocchi archive policies allow you to define the aggregation and storage
policies for metrics received from Ceilometer.
Each archive policy definition is set as the number of points over a timespan.
The default archive policy contains two definitions and one rule.
It allows you to store metrics for seven days with granularity of one minute
and for 365 days with granularity of one hour. It is applied to any metrics
sent to Gnocchi with the metric pattern *. You can customize all
parameters on the cluster level of your Reclass model.
To enable the Gnocchi archive policies:
Open your Git project repository with the Reclass model
on the cluster level.
In /openstack/telemetry.yml, verify that the following class is present:
classes:
...
- system.ceilometer.server.backend.gnocchi
In /openstack/control/init.yml, add the following classes:
classes:
...
- system.gnocchi.client
- system.gnocchi.client.v1.archive_policy.default
The parameters of system.gnocchi.client.v1.archive_policy.default are
as follows:
parameters:
_param:
gnocchi_default_policy_granularity_1: '0:01:00'
gnocchi_default_policy_points_1: 10080
gnocchi_default_policy_timespan_1: '7 days'
gnocchi_default_policy_granularity_2: '1:00:00'
gnocchi_default_policy_points_2: 8760
gnocchi_default_policy_timespan_2: '365 days'
gnocchi_default_policy_rule_metric_pattern: '"*"'
gnocchi:
client:
resources:
v1:
enabled: true
cloud_name: 'admin_identity'
archive_policies:
default:
definition:
- granularity: "${_param:gnocchi_default_policy_granularity_1}"
points: "${_param:gnocchi_default_policy_points_1}"
timespan: "${_param:gnocchi_default_policy_timespan_1}"
- granularity: "${_param:gnocchi_default_policy_granularity_2}"
points: "${_param:gnocchi_default_policy_points_2}"
timespan: "${_param:gnocchi_default_policy_timespan_2}"
rules:
default:
metric_pattern: "${_param:gnocchi_default_policy_rule_metric_pattern}"
Optional. Specify additional archive policies as required.
For example, to aggregate the CPU and disk-related metrics
with the timespan of 30 days and granularity 1, add the following parameters
to /openstack/control/init.yml under the default Gnocchi
archive policy parameters:
parameters:
_param:
...
gnocchi:
client:
resources:
v1:
enabled: true
cloud_name: 'admin_identity'
archive_policies:
default:
...
cpu_disk_policy:
definition:
- granularity: '0:00:01'
points: 2592000
timespan: '30 days'
rules:
cpu_rule:
metric_pattern: 'cpu*'
disk_rule:
metric_pattern: 'disk*'
Caution
Rule names defined across archive policies must be unique.
Log in to the Salt Master node.
Apply the following states:
salt -C 'I@gnocchi:client and *01*' saltutil.pillar_refresh
salt -C 'I@gnocchi:client and *01*' state.sls gnocchi.client
salt -C 'I@gnocchi:client' state.sls gnocchi.client
Verify that the archive policies are set successfully:
Log in to any OpenStack controller node.
Boot a test VM:
source keystonercv3
openstack server create --flavor <flavor_id> \
--nic net-id=<net_id> --image <image_id> test_vm1
Run the following command:
openstack metric list | grep <vm_id>
Use the vm_id parameter value from the output of the command
that you run in the previous step.
Example of system response extract:
+---------+-------------------+-------------------------------+------+-----------+
| id |archive_policy/name| name | unit |resource_id|
+---------+-------------------+-------------------------------+------+-----------+
| 0ace... | cpu_disk_policy | disk.allocation | B | d9011... |
| 0ca6... | default | perf.instructions | None | d9011... |
| 0fcb... | default | compute.instance.booting.time | sec | d9011... |
| 10f0... | cpu_disk_policy | cpu_l3_cache | None | d9011... |
| 2392... | default | memory | MB | d9011... |
| 2395... | cpu_disk_policy | cpu_util | % | d9011... |
| 26a0... | default | perf.cache.references | None | d9011... |
| 367e... | cpu_disk_policy | disk.read.bytes.rate | B/s | d9011... |
| 3857... | default | memory.bandwidth.total | None | d9011... |
| 3bb2... | default | memory.usage | None | d9011... |
| 4288... | cpu_disk_policy | cpu | ns | d9011... |
+---------+-------------------+-------------------------------+------+-----------+
In the example output above, all metrics are aggregated using
the default archive policy except for the CPU and disk metrics aggregated by
cpu_disk_policy. The cpu_disk_policy parameters were previously
customized in the Reclass model.
Add availability zone to Gnocchi instance resource
Note
This feature is available starting from the MCP 2019.2.7 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
This section describes how to add availability zones to a Gnocchi instance
and consume the consuming instance.create.end events.
Add an availability zone to a Gnocchi instance resource:
Open your Git project repository with the Reclass model
on the cluster level.
In /openstack/telemetry.yml, set the create_resources parameter to
True:
ceilometer:
server:
publisher:
gnocchi:
enabled: True
create_resources: True
From the Salt Master node, apply the following state:
salt -C 'I@ceilometer:server' saltutil.refresh_pillar
salt -C 'I@ceilometer:server' state.apply ceilometer.server
Migrate from GlusterFS to rsync for fernet and credential keys rotation
By default, the latest MCP deployments use rsync for fernet and
credential keys rotation. Though, if your MCP version is 2018.8.0 or earlier,
GlusterFS is used as a default rotation driver and credential keys rotation
driver. This section provides an instruction on how to configure your MCP
OpenStack deployment to use rsync with SSH instead of GlusterFS.
To migrate from GlusterFS to rsync:
Log in to the Salt Master node.
On the system level, verify that the following class is included in
keystone/server/cluster.yml:
- system.keystone.server.fernet_rotation.cluster
Note
The default configuration for the
system.keystone.server.fernet_rotation.cluster class is defined in
keystone/server/fernet_rotation/cluster.yml. It includes the default
list of nodes to synchronize fernet and credential keys that are
sync_node01 and sync_node02. If there are more nodes to
synchronize fernet and credential keys, expand this list as required.
Verify that the crontab job is disabled in the keystone/client/core.yml
and keystone/client/single.yml system-level files:
linux:
system:
job:
keystone_job_rotate:
command: '/usr/bin/keystone-manage fernet_rotate --keystone-user keystone --keystone-group keystone >> /var/log/key_rotation_log 2>> /var/log/key_rotation_log'
enabled: false
user: root
minute: 0
Apply the Salt orchestration state to configure all required prerequisites
like creating an SSH public key, uploading it to mine and secondary control
nodes:
salt-run state.orchestrate keystone.orchestrate.deploy
Apply the keystone.server state to put the Keystone rotation
script and run it in the sync mode hence fernet and credential keys
will be synchronized with the Keystone secondary nodes:
salt -C 'I@keystone:server:role:primary' state.apply keystone.server
salt -C 'I@keystone:server' state.apply keystone.server
Apply the linux.system state to add crontab jobs for the Keystone
user:
salt -C 'I@keystone:server' state.apply linux.system
On all OpenStack Controller nodes:
Copy the current credential and fernet keys to temporary directories:
mkdir /tmp/keystone_credential /tmp/keystone_fernet
cp /var/lib/keystone/credential-keys/* /tmp/keystone_credential
cp /var/lib/keystone/fernet-keys/* /tmp/keystone_fernet
Unmount the related GlusterFS mount points:
umount /var/lib/keystone/credential-keys
umount /var/lib/keystone/fernet-keys
Copy the keys from the temporary directories to
var/lib/keystone/credential-keys/ and
/var/lib/keystone/fernet-keys/:
mkdir -p /var/lib/keystone/credential-keys/ /var/lib/keystone/fernet-keys/
cp /tmp/keystone_credential/* /var/lib/keystone/credential-keys/
cp /tmp/keystone_fernet/* /var/lib/keystone/fernet-keys/
chown -R keystone:keystone /var/lib/keystone/credential-keys/*
chown -R keystone:keystone /var/lib/keystone/fernet-keys/*
On a KVM node, stop and delete the keystone-credential-keys and
keystone-keys volumes:
Stop the volumes:
gluster volume stop keystone-credential-keys
gluster volume stop keystone-keys
Delete the GlusterFS volumes:
gluster volume delete keystone-credential-keys
gluster volume delete keystone-keys
On the cluster level model, remove the following GlusterFS classes
included in the openstack/control.yml file by default:
- system.glusterfs.server.volume.keystone
- system.glusterfs.client.volume.keystone
Disable the Memcached listener on the UDP port
Starting from the Q4‘18 MCP release, to reduce the attack surface and increase
the product security, Memcached on the controller nodes listens on TCP only.
The UDP port for Memcached is disabled by default. This section explains how
to disable the UDP listeners for the existing OpenStack environments deployed
on top of the earlier MCP versions.
To disable the Memcached listener on the UDP port:
Log in to the Salt Master node.
Update your Reclass metadata model.
Verify the memcached:server pillar:
salt ctl01* pillar.get memcached:server
The memcached:server:bind:proto pillar should be available after
update of the Reclass metadata model and set to False for
proto:udp:enabled for all Memcached server instances.
Example of system response:
-- start output --
----------
bind:
----------
address:
0.0.0.0
port:
11211
proto:
----------
tcp:
----------
enabled:
True
udp:
----------
enabled:
False
protocol:
tcp
enabled:
True
maxconn:
8192
-- end output --
Run the memcached.server state to apply the changes to all
memcached instances:
salt -C 'I@memcached:server' state.sls memcached.server
Configuring rate limiting with NGINX
MCP enables you to limit the number of HTTP requests that a user can make in a
given period of time for your OpenStack deployments. The rate limiting with
NGINX can be used to protect an OpenStack environment against DDoS attacks as
well as to protect the community application servers from being overwhelmed by
too many user requests at the same time.
For rate limiting configuration, MCP supports the following NGINX modules:
ngx_http_geo_modulengx_http_map_modulengx_http_limit_req_modulengx_http_limit_conn_module
This section provides the related NGINX directives description with the
configuration samples which you can use to enable rate limiting in your MCP
OpenStack deployment.
Starting from the MCP 2019.2.20 maintenance update, you can also configure
request limiting for custom locations.
NGINX rate limiting configuration sample
This section includes the configuration sample of NGINX rate limiting feature
that enables you to limit the number of HTTP requests a user can make in a
given period of time.
In the sample, all clients except for 10.12.100.1 are limited to 1
request per second. More specifically, the sample illustrates how to:
- Create a geo instance that will match the IP address and set the
limit_action variable where 0 stands for unlimited and 1 stands
for limited.
- Create
global_geo_limiting_map that will map ip_limit_key to
ip_limit_action.
- Create a global
limit_req_zone zone called global_limit_zone that
limits the number of requests to 1 request per second.
- Apply
global_limit_zone globally to all requests with 5 requests
burst and nodelay.
Configuration sample:
nginx:
server:
enabled: true
geo:
enabled: true
items:
global_geo_limiting:
enabled: true
variable: ip_limit_key
body:
default:
value: '1'
unlimited_client1:
name: '10.12.100.1/32'
value: '0'
map:
enabled: true
items:
global_geo_limiting_map:
enabled: true
string: ip_limit_key
variable: ip_limit_action
body:
limited:
name: 1
value: '$binary_remote_addr'
unlimited:
name: 0
value: '""'
limit_req_module:
limit_req_zone:
global_limit_zone:
key: ip_limit_action
size: 10m
rate: '1r/s'
limit_req_status: 503
limit_req:
global_limit_zone:
burst: 5
enabled: true
To apply the request limiting to a particular site, define the limit_req
on a site level. For example:
nginx:
server:
site:
nginx_proxy_openstack_api_keystone:
limit_req_module:
limit_req:
global_limit_zone:
burst: 5
nodelay: true
enabled: true
Configuring the geo module
The ngx_http_geo_module module creates variables with values depending on
the client IP address.
| Syntax |
geo [$address] $variable { ... } |
|---|
| Default |
— |
|---|
| Context |
HTTP |
|---|
| NGINX configuration sample |
geo $my_geo_map {
default 0;
127.0.0.1 0;
10.12.100.1/32 1;
10.13.0.0/16 2;
2001:0db8::/32 1;
}
|
|---|
Example of a Salt pillar for the geo module:
nginx:
server:
geo:
enabled: true
items:
my_geo_map:
enabled: true
variable: my_geo_map_variable
body:
default:
value: '0'
localhost:
name: 127.0.0.1
value: '0'
client:
name: 10.12.100.1/32
value: '1'
network:
name: 10.13.0.0/16
value: '2'
ipv6_client:
name: 2001:0db8::/32
value: '1'
All geo variables specified in the pillars, after applying the
nginx.server state, will be reflected in the
/etc/nginx/conf.d/geo.conf file.
Configuring the mapping
The ngx_http_map_module module creates variables which values depend on
values of other source variables specified in the first parameter.
| Syntax |
map string $variable { ... } |
|---|
| Default |
— |
|---|
| Context |
HTTP |
|---|
| NGINX configuration sample |
map $my_geo_map_variable $ip_limit_action {
default "";
1 $binary_remote_addr;
0 "";
}
|
|---|
Example of a Salt pillar for the map module:
nginx:
server:
map:
enabled: true
items:
global_geo_limiting_map:
enabled: true
string: my_geo_map_variable
variable: ip_limit_action
body:
default:
value: '""'
limited:
name: '1'
value: '$binary_remote_addr'
unlimited:
name: '0'
value: '""'
All map variables specified in the pillars, after applying
the nginx.server state, will be reflected in the
/etc/nginx/conf.d/map.conf file.
Configuring the request limiting
The ngx_http_limit_req_module module limits the request processing rate
per a defined key. The module directives include the mandatory
limit_req_zone and limit_req directives and an optional
limit_req_status directive.
The limit_req_zone directive defines the parameters for the rate limiting.
| Syntax |
limit_req_zone key zone=name:size rate=rate [sync]; |
|---|
| Default |
— |
|---|
| Context |
HTTP |
|---|
| NGINX configuration sample |
limit_req_zone $binary_remote_addr zone=global_limit_zone1:10m rate=1r/s ;
limit_req_zone $ip_limit_action zone=global_limit_zone2:10m rate=2r/s ;
|
|---|
The limit_req directive enables rate limiting within the context where it
appears.
| Syntax |
limit_req zone=name [burst=number] [nodelay | delay=number]; |
|---|
| Default |
— |
|---|
| Context |
HTTP, server, location |
|---|
| NGINX configuration sample |
limit_req zone=global_limit_zone1 burst=2 ;
limit_req zone=global_limit_zone2 burst=4 nodelay ;
|
|---|
The limit_req_status directive sets the status code to return in
response to rejected requests.
| Syntax |
limit_req_status code; |
|---|
| Default |
limit_req_status 503; |
|---|
| Context |
http, server, location that corresponds to the
nginx:server and nginx:server:site definitions of a pillar. |
|---|
| NGINX configuration sample |
|
|---|
Example of a Salt pillar for limit_req_zone and limit_req:
nginx:
server:
limit_req_module:
limit_req_zone:
global_limit_zone1:
key: binary_remote_addr
size: 10m
rate: '1r/s'
global_limit_zone2:
key: ip_limit_action
size: 10m
rate: '2r/s'
limit_req_status: 429
limit_req:
global_limit_zone1:
burst: 2
enabled: true
global_limit_zone2:
burst: 4
enabled: true
nodelay: true
In the configuration example above, the states are kept in a 10 megabyte
global_limit_zone1 and global_limit_zone2 zones. An average request
processing rate cannot exceed 1 request per second for
global_limit_zone1 and 2 requests per second for
global_limit_zone2.
The $binary_remote_addr, a client’s IP address, serves as a key for the
global_limit_zone1 zone. And the mapped $ip_limit_action variable is
a key for the global_limit_zone2 zone.
To apply the request limiting to a particular site, define the limit_req
on a site level. For example:
nginx:
server:
site:
nginx_proxy_openstack_api_keystone:
limit_req_module:
limit_req:
global_limit_zone:
burst: 5
nodelay: true
enabled: true
Configuring the connection limiting
The ngx_http_limit_conn_module module limits the number of connections per
defined key. The main directives include limit_conn_zone and
limit_conn.
The limit_conn_zone directive sets parameters for a shared memory zone
that keeps states for various keys. A state is the current number of
connections. The key value can contain text, variables, and their combination.
The requests with an empty key value are not accounted.
| Syntax |
limit_conn_zone key zone=name:size; |
|---|
| Default |
— |
|---|
| Context |
HTTP |
|---|
| NGINX configuration sample |
limit_conn_zone $binary_remote_addr zone=global_limit_conn_zone:20m;
limit_conn_zone $binary_remote_addr zone=openstack_web_conn_zone:10m;
|
|---|
The limit_conn directive sets the shared memory zone and the maximum
allowed number of connections for a given key value. When this limit is
exceeded, the server returns the error in reply to a request.
| Syntax |
limit_conn zone number; |
|---|
| Default |
— |
|---|
| Context |
HTTP, server, location |
|---|
| NGINX configuration sample |
limit_conn global_limit_conn_zone 100;
limit_conn_status 429;
|
|---|
Example of a Salt pillar with limit_conn_zone and limit_conn:
nginx:
server:
limit_conn_module:
limit_conn_zone:
global_limit_conn_zone:
key: 'binary_remote_addr'
size: 20m
enabled: true
api_keystone_conn_zone:
key: 'binary_remote_addr'
size: 10m
enabled: true
limit_conn:
global_limit_conn_zone:
connections: 100
enabled: true
limit_conn_status: 429
To apply the connection limiting to a particular site, define limit_conn
on a site level. For example:
nginx:
server:
site:
nginx_proxy_openstack_api_keystone:
limit_conn_module:
limit_conn_status: 429
limit_conn:
api_keystone_conn_zone:
connections: 50
enabled: true
Expose a hardware RNG device to Nova instances
Warning
This feature is available starting from the MCP 2019.2.3
maintenance update. Before enabling the feature, follow the steps
described in Apply maintenance updates.
MCP enables you to define the path to an Random Number Generator (RNG) device
that will be used as the source of entropy on the host. The default source of
entropy is /dev/urandom. Other available options include /dev/random
and /dev/hwrng.
The example structure of the RNG definition in the Nova pillar:
nova:
controller:
libvirt:
rng_dev_path: /dev/random
compute:
libvirt:
rng_dev_path: /dev/random
The procedure included in this section can be used for both existing and
new MCP deployments.
To define the path to an RNG device:
Log in to the Salt Master node.
In classes/cluster/<cluster_name>/openstack/control.yml, define the
rng_dev_path parameter for nova:contoroller:
nova:
controller:
libvirt:
rng_dev_path: /dev/random
In classes/cluster/<cluster_name>/openstack/compute/init.yml, define
the rng_dev_path parameter for nova:compute:
nova:
compute:
libvirt:
rng_dev_path: /dev/random
Apply the changes:
salt -C 'I@nova:controller' state.sls nova.controller
salt -C 'I@nova:compute' state.sls nova.compute
Set the directory for lock files
Note
This feature is available starting from the MCP 2019.2.7 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
You can set the directory for lock files for the Ceilometer, Cinder, Designate,
Glance, Ironic, Neutron, and Nova OpenStack services by specifying the
lock_path parameter in the Reclass model. This section provides
the example of the lock path configuration for Nova.
To set the lock path for Nova:
Open your Git project repository with the Reclass model on the cluster
level.
Define the lock_path parameter:
In openstack/control.yml, specify:
parameters:
nova:
controller:
concurrency:
lock_path: '/var/lib/nova/tmp'
In openstack/compute.yml, specify:
parameters:
nova:
compute:
concurrency:
lock_path: '/var/lib/nova/tmp'
Apply the changes from the Salt Master node:
salt -C 'I@nova:controller or I@nova:compute' saltutil.refresh_pillar
salt -C 'I@nova:controller' state.apply nova.controller
salt -C 'I@nova:compute' state.apply nova.compute
Add the Nova CpuFlagsFilter custom filter
Note
This feature is available starting from the MCP 2019.2.10 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
CpuFlagsFilter is a custom Nova scheduler filter for live migrations. The
filter ensures that the CPU features of a live migration source host match the
target host. Use the CpuFlagsFilter filter only if your deployment meets
the following criteria:
- The CPU mode is set to
host-passthrough or host-model. For details,
see MCP Deployment Guide: Configure a CPU model.
- The OpenStack compute nodes have heterogeneous CPUs.
- The OpenStack compute nodes are not organized in aggregates with the same CPU
in each aggregate.
To add the Nova CpuFlagsFilter custom filter:
Open your project Git repository with the Reclass model on the cluster
level.
Open the classes/cluster/<cluster_name>/openstack/control.yml file for
editing.
Verify that the cpu_mode parameter is set to host-passthrough or
host-model.
Add CpuFlagsFilter to the scheduler_default_filters parameter for
nova:contoroller:
nova:
controller:
scheduler_default_filters: “DifferentHostFilter,SameHostFilter,RetryFilter,AvailabilityZoneFilter,RamFilter,CoreFilter,DiskFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,ServerGroupAntiAffinityFilter,ServerGroupAffinityFilter,PciPassthroughFilter,NUMATopologyFilter,AggregateInstanceExtraSpecsFilter,CpuFlagsFilter”
Log in to the Salt Master node.
Apply the changes:
salt -C 'I@nova:controller' state.sls nova.controller
Disable Nova cell mapping
Note
This feature is available starting from the MCP 2019.2.16 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
You may need to disable cell mapping and database migrations for the OpenStack
Compute service (Nova), for example, to faster redeploy the nova state.
Note
Enable Nova cell mapping before performing any update or upgrade.
To disable Nova cell mapping:
In defaults/openstack/init.yml on the system Reclass level, set the
nova_control_update_cells parameter to False:
_param:
nova_control_update_cells: False
Log in to the Salt Master node.
Refresh cache, synchronize Salt pillars and resources:
salt '*' saltutil.clear_cache && \
salt '*' saltutil.refresh_pillar && \
salt '*' saltutil.sync_all
Clean up an OpenStack database
Note
This feature is available starting from the MCP 2019.2.12 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
Using the Deploy - Openstack Database Cleanup Jenkins pipeline job,
you can automatically clean up stale records from the Nova, Cinder, Heat, or
Glance database to make it smaller. This is helpful before any update or
upgrade activity. You can execute the
Deploy - Openstack Database Cleanup Jenkins pipeline job without a
maintenance window, just as for an online dbsync.
To clean up an OpenStack database:
Open your Git project repository with the Reclass model on the cluster
level.
In <cluster_name>/openstack/control.yml, specify the pillars below with
the following parameters:
- Set
db_purge to True.
- Set
days as required. If you skip setting the days parameter:
- For Nova and Heat, all stale records will be archived or purged.
- For Cinder on OpenStack Pike, records older than 1 day will be deleted.
For Cinder on OpenStack Queens, all entries will be deleted.
- For Glance, all entries will be deleted.
- For Nova, set
max_rows to limit the rows for deletion. It is safe to
specify 500-1000 rows. Unlimited cleanup may cause the database being
inaccessible and, as a result, OpenStack being inoperable.
For example:
Log in to the Jenkins web UI.
Open the Deploy - Openstack Database Cleanup Jenkins pipeline
job.
Specify the following parameters:
| Parameter |
Description and values |
|---|
| SALT_MASTER_CREDENTIALS |
The Salt Master credentials to use for connection, defaults to
salt. |
| SALT_MASTER_URL |
The Salt Master node host URL with the salt-api port,
defaults to the jenkins_salt_api_url parameter.
For example, http://172.18.170.27:6969. |
Click Deploy.
The Jenkins pipeline job workflow:
- For Nova, move the deleted rows from the production tables to shadow tables.
Data from shadow tables is purged to save disk space.
- For Cinder, purge the database entries that are marked as deleted.
- For Heat, purge the database entries that are marked as deleted.
- For Glance, purge the database entries that are marked as deleted.
Galera operations
This section describes the Galera service operations you may need to perform
after the deployment of an MCP cluster.
Enable Cinder coordination
Note
This feature is available starting from the MCP 2019.2.16 maintenance
update. Before using the feature, follow the steps
described in Apply maintenance updates.
To avoid race conditions in the OpenStack Block Storage service (Cinder) with
an active/active configuration, you can use a coordination manager system with
MySQL as a back end. For example, to prevent deletion of a volume that is being
used to create another volume or prevent from attaching a volume that is
already being attached.
To enable Cinder coordination:
From the Salt Master node, verify that the salt-formula-cinder package
version is 2016.12.1+202108101137.19b6edd~xenial1_all or later.
From an OpenStack controller node, verify that the python-tooz package
version is 1.60.2-1.0~u16.04+mcp4 or later.
Open the cluster level of your deployment model.
In <cluster_name>/openstack/control.yml, specify the following
configuration:
cinder:
controller:
coordination:
enabled: true
backend: mysql
Log in to the Salt Master node.
Apply the changes:
salt -C 'I@cinder:controller' state.sls cinder