OpenStack large cloud
The Large Cloud is an OpenStack-based reference
architecture for MCP. It is designed to provide a generic public cloud user
experience to the cloud tenants in terms of available virtual infrastructure
capabilities and expectations.
The large reference architecture is designed to support up to 5000 virtual
servers or 500 hypervisor hosts. In addition to the desirable number of
hypervisors, 18 infrastructure physical servers are required for the control
plane. This number includes 9 servers that host OpenStack virtualized control
plane (VCP), 6 servers dedicated to the StackLight services, and 3 servers
for the OpenContrail control plane.
The following diagram describes the distribution of VCP
and other services throughout the infrastructure nodes.
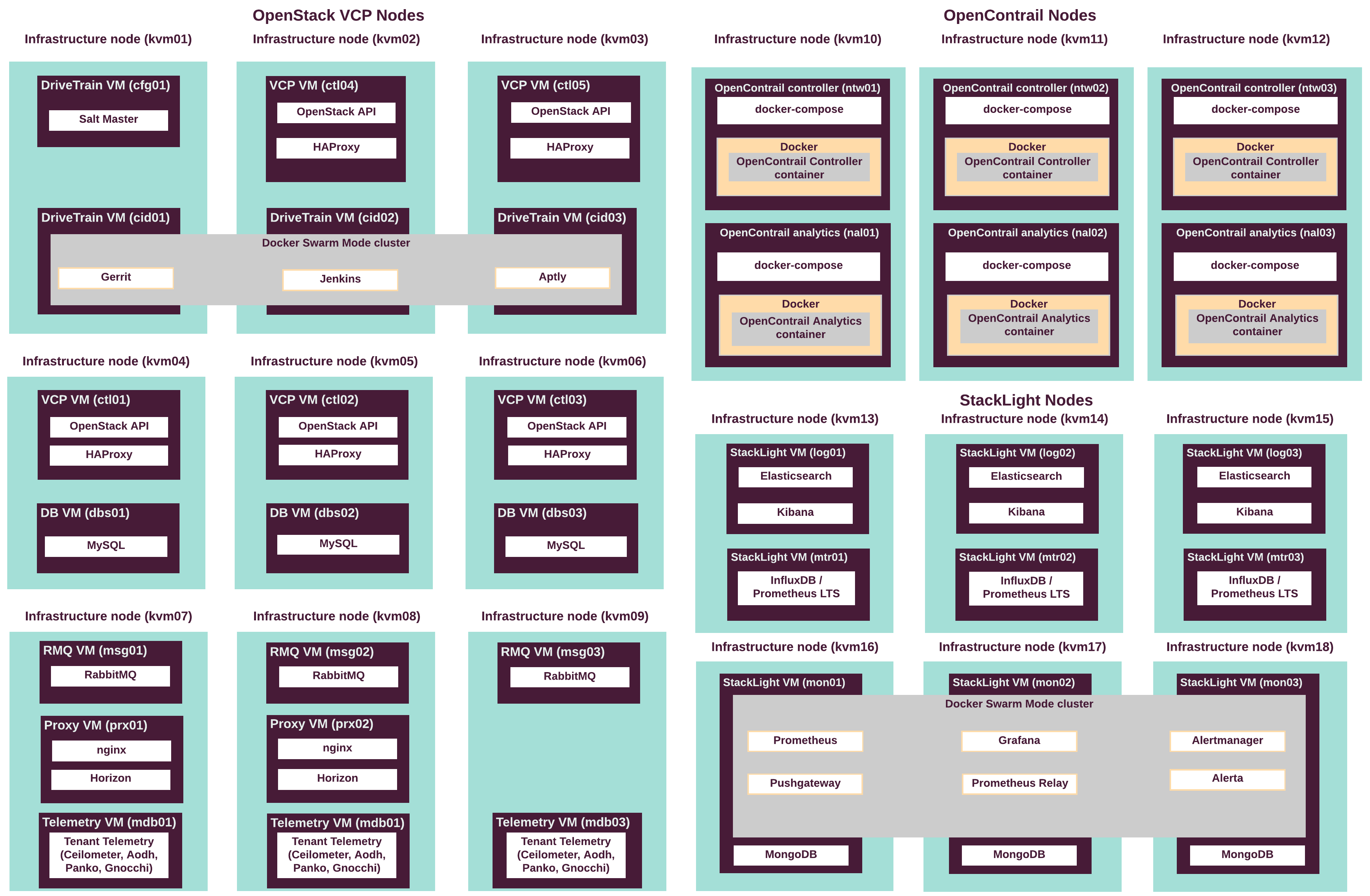
The following table describes the hardware nodes in the CPI reference
architecture, roles assigned to them, and the number of nodes of each type.
Physical server roles and quantities
| Node type |
Role name |
Number of servers |
|---|
| Infrastructure nodes (VCP) |
kvm |
9 |
| Infrastructure nodes (OpenContrail) |
kvm |
3 |
| Monitoring nodes (StackLight LMA) |
mon |
3 |
| Infrastructure nodes (StackLight LMA) |
kvm |
3 |
| OpenStack compute nodes |
cmp |
200 - 500 |
| Staging infrastructure nodes |
kvm |
18 |
| Staging OpenStack compute nodes |
cmp |
2 - 5 |
The following table summarizes the VCP virtual machines mapped to
physical servers.
Resource requirements per VCP role
| Virtual server roles |
Physical servers |
# of instances |
CPU vCores per instance |
Memory (GB) per instance |
Disk space (GB) per instance |
|---|
ctl |
kvm02 kvm03 kvm04 kvm05 kvm06 |
5 |
24 |
128 |
100 |
dbs |
kvm04 kvm05 kvm06 |
3 |
24 |
64 |
1000 |
msg |
kvm07 kvm08 kvm09 |
3 |
32 |
196 |
100 |
prx |
kvm07 kvm08 |
2 |
8 |
32 |
100 |
mdb |
kvm07 kvm08 kvm09 |
3 |
8 |
32 |
150 |
| TOTAL |
|
16 |
328 |
1580 |
4450 |
Resource requirements per DriveTrain role
| Virtual server roles |
Physical servers |
# of instances |
CPU vCores per instance |
Memory (GB) per instance |
Disk space (GB) per instance |
|---|
cfg |
kvm01 |
1 |
8 |
32 |
50 |
cid |
kvm01 kvm02 kvm03 |
3 |
4 |
32 |
500 |
| TOTAL |
|
4 |
20 |
128 |
1550 |
Resource requirements per OpenContrail role
| Virtual server roles |
Physical servers |
# of instances |
CPU vCores per instance |
Memory (GB) per instance |
Disk space (GB) per instance |
|---|
ntw |
kvm10 kvm11 kvm12 |
3 |
16 |
64 |
100 |
nal |
kvm10 kvm11 kvm12 |
3 |
24 |
128 |
2000 |
| TOTAL |
|
6 |
120 |
576 |
6300 |
Resource requirements per Ceph role
| Virtual server roles |
Physical servers |
# of instances |
CPU vCores per instance |
Memory (GB) per instance |
Disk space (GB) per instance |
|---|
cmn |
kvm01 kvm02 kvm03 |
3 |
16 |
32 |
100 |
rgw |
kvm01 kvm02 kvm03 |
3 |
16 |
32 |
50 |
| TOTAL |
|
6 |
96 |
192 |
450 |
Resource requirements per StackLight role
| Virtual server roles |
Physical servers |
# of instances |
CPU vCores per instance |
Memory (GB) per instance |
Disk space (GB) per instance |
|---|
mon |
kvm16 kvm17 kvm18 |
3 |
24 |
256 |
1000 |
mtr |
kvm13 kvm14 kvm15 |
3 |
16 |
196 |
3000 |
log |
kvm13 kvm14 kvm15 |
3 |
16 |
64 |
5000 |
| TOTAL |
|
9 |
192 |
1548 |
27000 |
Note
- The
prx VM should have an additional NIC for the Proxy network.
- All other nodes should have two NICs for DHCP and Primary networks.