Mirantis Container Cloud Documentation¶
The documentation is intended to help operators understand the core concepts of the product.
The information provided in this documentation set is being constantly improved and amended based on the feedback and kind requests from our software consumers. This documentation set outlines description of the features supported within three latest Container Cloud minor releases and their supported Cluster releases, with a corresponding note Available since <release-version>.
The following table lists the guides included in the documentation set you are reading:
Guide |
Purpose |
|---|---|
Learn the fundamentals of Container Cloud reference architecture to plan your deployment. |
|
Deploy Container Cloud of a preferred configuration using supported deployment profiles tailored to the demands of specific business cases. |
|
Deploy and operate the Container Cloud managed clusters. |
|
Deployment compatibility of the Container Cloud components versions for each product release. |
|
Learn about new features and bug fixes in the current Container Cloud version as well as in the Container Cloud minor releases. |
|
QuickStart Guides |
Easy and lightweight instructions to get started with Container Cloud. |
Intended audience¶
This documentation assumes that the reader is familiar with network and cloud concepts and is intended for the following users:
Infrastructure Operator
Is member of the IT operations team
Has working knowledge of Linux, virtualization, Kubernetes API and CLI, and OpenStack to support the application development team
Accesses Mirantis Container Cloud and Kubernetes through a local machine or web UI
Provides verified artifacts through a central repository to the Tenant DevOps engineers
Tenant DevOps engineer
Is member of the application development team and reports to line-of-business (LOB)
Has working knowledge of Linux, virtualization, Kubernetes API and CLI to support application owners
Accesses Container Cloud and Kubernetes through a local machine or web UI
Consumes artifacts from a central repository approved by the Infrastructure Operator
Conventions¶
This documentation set uses the following conventions in the HTML format:
Convention |
Description |
|---|---|
boldface font |
Inline CLI tools and commands, titles of the procedures and system response examples, table titles. |
|
Files names and paths, Helm charts parameters and their values, names of packages, nodes names and labels, and so on. |
italic font |
Information that distinguishes some concept or term. |
External links and cross-references, footnotes. |
|
Main menu > menu item |
GUI elements that include any part of interactive user interface and menu navigation. |
Superscript |
Some extra, brief information. For example, if a feature is available from a specific release or if a feature is in the Technology Preview development stage. |
Note The Note block |
Messages of a generic meaning that may be useful to the user. |
Caution The Caution block |
Information that prevents a user from mistakes and undesirable consequences when following the procedures. |
Warning The Warning block |
Messages that include details that can be easily missed, but should not be ignored by the user and are valuable before proceeding. |
See also The See also block |
List of references that may be helpful for understanding of some related tools, concepts, and so on. |
Learn more The Learn more block |
Used in the Release Notes to wrap a list of internal references to the reference architecture, deployment and operation procedures specific to a newly implemented product feature. |
Technology Preview features¶
A Technology Preview feature provides early access to upcoming product innovations, allowing customers to experiment with the functionality and provide feedback.
Technology Preview features may be privately or publicly available but neither are intended for production use. While Mirantis will provide assistance with such features through official channels, normal Service Level Agreements do not apply.
As Mirantis considers making future iterations of Technology Preview features generally available, we will do our best to resolve any issues that customers experience when using these features.
During the development of a Technology Preview feature, additional components may become available to the public for evaluation. Mirantis cannot guarantee the stability of such features. As a result, if you are using Technology Preview features, you may not be able to seamlessly update to subsequent product releases, as well as upgrade or migrate to the functionality that has not been announced as full support yet.
Mirantis makes no guarantees that Technology Preview features will graduate to generally available features.
Documentation history¶
The documentation set refers to Mirantis Container Cloud GA as to the latest released GA version of the product. For details about the Container Cloud GA minor releases dates, refer to Container Cloud releases.
Product Overview¶
Mirantis Container Cloud enables you to ship code faster by enabling speed with choice, simplicity, and security. Through a single pane of glass you can deploy, manage, and observe Kubernetes clusters on private clouds or bare metal infrastructure. Container Cloud provides the ability to leverage the following on premises cloud infrastructure: OpenStack, VMware, and bare metal.
The list of the most common use cases includes:
- Multi-cloud
Organizations are increasingly moving toward a multi-cloud strategy, with the goal of enabling the effective placement of workloads over multiple platform providers. Multi-cloud strategies can introduce a lot of complexity and management overhead. Mirantis Container Cloud enables you to effectively deploy and manage container clusters (Kubernetes and Swarm) across multiple cloud provider platforms.
- Hybrid cloud
The challenges of consistently deploying, tracking, and managing hybrid workloads across multiple cloud platforms is compounded by not having a single point that provides information on all available resources. Mirantis Container Cloud enables hybrid cloud workload by providing a central point of management and visibility of all your cloud resources.
- Kubernetes cluster lifecycle management
The consistent lifecycle management of a single Kubernetes cluster is a complex task on its own that is made infinitely more difficult when you have to manage multiple clusters across different platforms spread across the globe. Mirantis Container Cloud provides a single, centralized point from which you can perform full lifecycle management of your container clusters, including automated updates and upgrades. Container Cloud also supports attachment of existing Mirantis Kubernetes Engine clusters that are not originally deployed by Container Cloud.
- Highly regulated industries
Regulated industries need a fine level of access control granularity, high security standards and extensive reporting capabilities to ensure that they can meet and exceed the security standards and requirements. Mirantis Container Cloud provides for a fine-grained Role Based Access Control (RBAC) mechanism and easy integration and federation to existing identity management systems (IDM).
- Logging, monitoring, alerting
A complete operational visibility is required to identify and address issues in the shortest amount of time – before the problem becomes serious. Mirantis StackLight is the proactive monitoring, logging, and alerting solution designed for large-scale container and cloud observability with extensive collectors, dashboards, trend reporting and alerts.
- Storage
Cloud environments require a unified pool of storage that can be scaled up by simply adding storage server nodes. Ceph is a unified, distributed storage system designed for excellent performance, reliability, and scalability. Deploy Ceph utilizing Rook to provide and manage a robust persistent storage that can be used by Kubernetes workloads on the baremetal-based clusters.
- Security
Security is a core concern for all enterprises, especially with more of our systems being exposed to the Internet as a norm. Mirantis Container Cloud provides for a multi-layered security approach that includes effective identity management and role based authentication, secure out of the box defaults and extensive security scanning and monitoring during the development process.
- 5G and Edge
The introduction of 5G technologies and the support of Edge workloads requires an effective multi-tenant solution to manage the underlying container infrastructure. Mirantis Container Cloud provides for a full stack, secure, multi-cloud cluster management and Day-2 operations solution that supports both on premises bare metal and cloud.
Reference Architecture¶
Overview¶
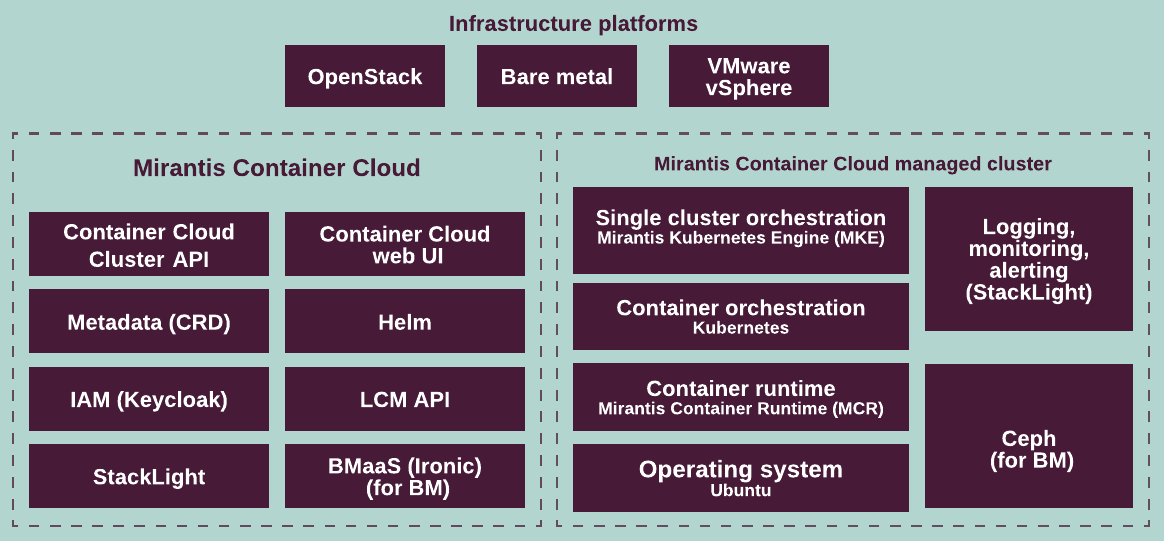
Mirantis Container Cloud is a set of microservices that are deployed using Helm charts and run in a Kubernetes cluster. Container Cloud is based on the Kubernetes Cluster API community initiative.
The following diagram illustrates an overview of Container Cloud and the clusters it manages:
All artifacts used by Kubernetes and workloads are stored on the Container Cloud content delivery network (CDN):
mirror.mirantis.com(Debian packages including the Ubuntu mirrors)binary.mirantis.com(Helm charts and binary artifacts)mirantis.azurecr.io(Docker image registry)
All Container Cloud components are deployed in the Kubernetes clusters. All Container Cloud APIs are implemented using the Kubernetes Custom Resource Definition (CRD) that represents custom objects stored in Kubernetes and allows you to expand Kubernetes API.
The Container Cloud logic is implemented using controllers.
A controller handles the changes in custom resources defined
in the controller CRD.
A custom resource consists of a spec that describes the desired state
of a resource provided by a user.
During every change, a controller reconciles the external state of a custom
resource with the user parameters and stores this external state in the
status subresource of its custom resource.
Container Cloud cluster types¶
The types of the Container Cloud clusters include:
- Bootstrap cluster
Contains the Bootstrap web UI for the OpenStack and vSphere providers. The Bootstrap web UI support for the bare metal provider will be added in one of the following Container Cloud releases.
Runs the bootstrap process on a seed node that can be reused after the management cluster deployment for other purposes. For the OpenStack or vSphere provider, it can be an operator desktop computer. For the bare metal provider, this is a data center node.
Requires access to one of the following provider backends: bare metal, OpenStack, or vSphere.
Initially, the bootstrap cluster is created with the following minimal set of components: Bootstrap Controller, public API charts, and the Bootstrap web UI.
The user can interact with the bootstrap cluster through the Bootstrap web UI or API to create the configuration for a management cluster and start its deployment. More specifically, the user performs the following operations:
Select the provider, add provider credentials.
Add proxy and SSH keys.
Configure the cluster and machines.
Deploy a management cluster.
The user can monitor the deployment progress of the cluster and machines.
After a successful deployment, the user can download the
kubeconfigartifact of the provisioned cluster.
- Management cluster
Comprises Container Cloud as product and provides the following functionality:
Runs all public APIs and services including the web UIs of Container Cloud.
Does not require access to any provider backend.
Runs the provider-specific services and internal API including LCMMachine and LCMCluster. Also, it runs an LCM controller for orchestrating managed clusters and other controllers for handling different resources.
Requires two-way access to a provider backend. The provider connects to a backend to spawn managed cluster nodes, and the agent running on the nodes accesses the regional cluster to obtain the deployment information.
For deployment details of a management cluster, see Deployment Guide.
- Managed cluster
A Mirantis Kubernetes Engine (MKE) cluster that an end user creates using the Container Cloud web UI.
Requires access to its management cluster. Each node of a managed cluster runs an LCM Agent that connects to the LCM machine of the management cluster to obtain the deployment details.
Since 2.25.2, an attached MKE cluster that is not created using Container Cloud for vSphere-based clusters. In such case, nodes of the attached cluster do not contain LCM Agent. For supported MKE versions that can be attached to Container Cloud, see Release Compatibility Matrix.
Baremetal-based managed clusters support the Mirantis OpenStack for Kubernetes (MOSK) product. For details, see MOSK documentation.
All types of the Container Cloud clusters except the bootstrap cluster are based on the MKE and Mirantis Container Runtime (MCR) architecture. For details, see MKE and MCR documentation.
The following diagram illustrates the distribution of services between each type of the Container Cloud clusters:
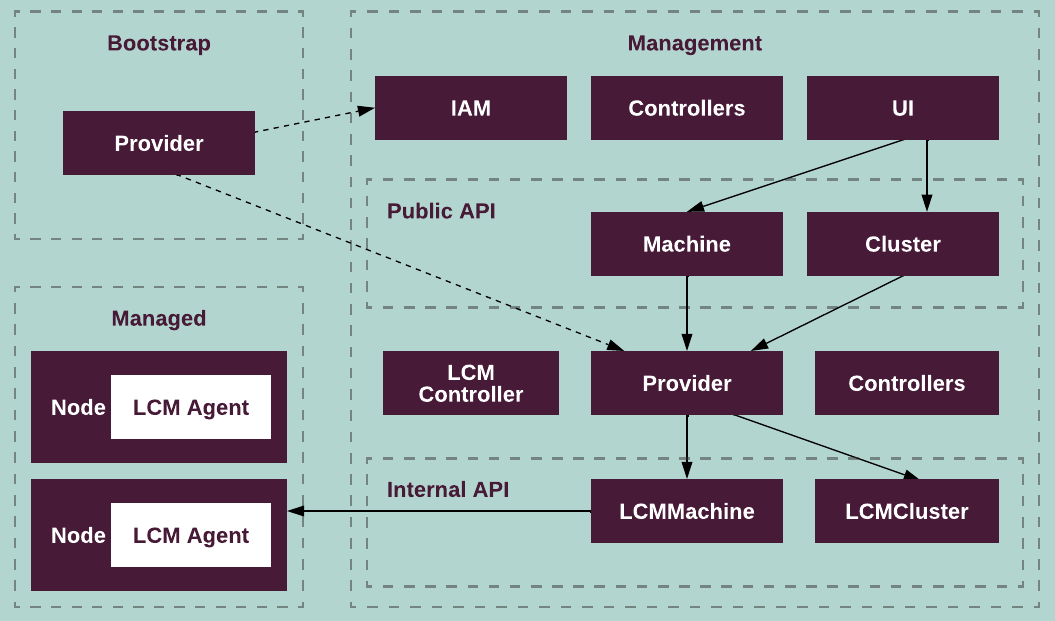
Cloud provider¶
The Mirantis Container Cloud provider is the central component of Container Cloud that provisions a node of a management, regional, or managed cluster and runs the LCM Agent on this node. It runs in a management and regional clusters and requires connection to a provider backend.
The Container Cloud provider interacts with the following types of public API objects:
Public API object name |
Description |
|---|---|
Container Cloud release object |
Contains the following information about clusters:
|
Cluster release object |
|
Cluster object |
|
Machine object |
|
Credentials object |
|
PublicKey object |
Is provided to every machine to obtain an SSH access. |
The following diagram illustrates the Container Cloud provider data flow:
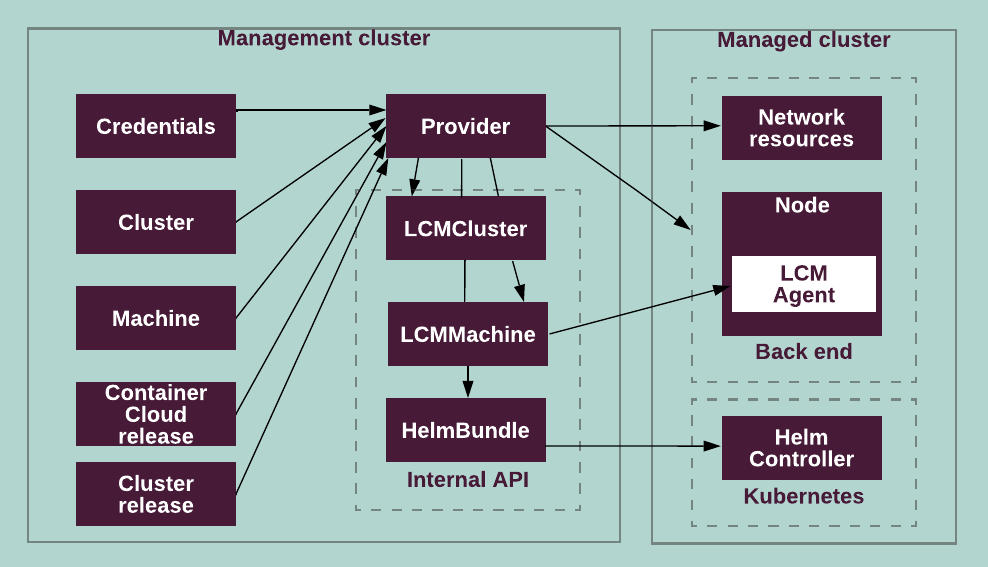
The Container Cloud provider performs the following operations in Container Cloud:
Consumes the below types of data from a management and regional cluster:
Credentials to connect to a provider backend
Deployment instructions from the
KaaSReleaseandClusterReleaseobjectsThe cluster-level parameters from the Cluster objects
The machine-level parameters from the Machine objects
Prepares data for all Container Cloud components:
Creates the
LCMClusterandLCMMachinecustom resources for LCM Controller and LCM Agent. TheLCMMachinecustom resources are created empty to be later handled by the LCM Controller.Creates the
HelmBundlecustom resources for the Helm Controller using data from theKaaSReleaseandClusterReleaseobjects.Creates service accounts for these custom resources.
Creates a scope in Identity and access management (IAM) for a user access to a managed cluster.
Provisions nodes for a managed cluster using the
cloud-initscript that downloads and runs the LCM Agent.Installs Helm Controller as a Helm v3 chart.
Release Controller¶
The Mirantis Container Cloud Release Controller is responsible for the following functionality:
Monitor and control the
KaaSReleaseandClusterReleaseobjects present in a management cluster. If any release object is used in a cluster, the Release Controller prevents the deletion of such an object.Sync the
KaaSReleaseandClusterReleaseobjects published at https://binary.mirantis.com/releases/ with an existing management cluster.Trigger the Container Cloud auto-upgrade procedure if a new
KaaSReleaseobject is found:Search for the managed clusters with old Cluster releases that are not supported by a new Container Cloud release. If any are detected, abort the auto-upgrade and display a corresponding note about an old Cluster release in the Container Cloud web UI for the managed clusters. In this case, a user must update all managed clusters using the Container Cloud web UI. Once all managed clusters are upgraded to the Cluster releases supported by a new Container Cloud release, the Container Cloud auto-upgrade is retriggered by the Release Controller.
Trigger the Container Cloud release upgrade of all Container Cloud components in a management cluster. The upgrade itself is processed by the Container Cloud provider.
Trigger the Cluster release upgrade of a management cluster to the Cluster release version that is indicated in the upgraded Container Cloud release version. The LCMCluster components, such as MKE, are upgraded before the HelmBundle components, such as StackLight or Ceph.
Once a management cluster is upgraded, an option to update a managed cluster becomes available in the Container Cloud web UI. During a managed cluster update, all cluster components including Kubernetes are automatically upgraded to newer versions if available. The LCMCluster components, such as MKE, are upgraded before the HelmBundle components, such as StackLight or Ceph.
The Operator can delay the Container Cloud automatic upgrade procedure for a limited amount of time or schedule upgrade to run at desired hours or weekdays. For details, see Schedule Mirantis Container Cloud upgrades.
Container Cloud remains operational during the management cluster upgrade. Managed clusters are not affected during this upgrade. For the list of components that are updated during the Container Cloud upgrade, see the Components versions section of the corresponding Container Cloud release in Release Notes.
When Mirantis announces support of the newest versions of Mirantis Container Runtime (MCR) and Mirantis Kubernetes Engine (MKE), Container Cloud automatically upgrades these components as well. For the maintenance window best practices before upgrade of these components, see MKE Documentation.
See also
Web UI¶
The Mirantis Container Cloud web UI is mainly designed to create and update the managed clusters as well as add or remove machines to or from an existing managed cluster.
You can use the Container Cloud web UI to obtain the management cluster details including endpoints, release version, and so on. The management cluster update occurs automatically with a new release change log available through the Container Cloud web UI.
The Container Cloud web UI is a JavaScript application that is based
on the React framework. The Container Cloud web UI is designed to work
on a client side only. Therefore, it does not require a special backend.
It interacts with the Kubernetes and Keycloak APIs directly.
The Container Cloud web UI uses a Keycloak token
to interact with Container Cloud API and download kubeconfig
for the management and managed clusters.
The Container Cloud web UI uses NGINX that runs on a management cluster and handles the Container Cloud web UI static files. NGINX proxies the Kubernetes and Keycloak APIs for the Container Cloud web UI.
Bare metal¶
The bare metal service provides for the discovery, deployment, and management of bare metal hosts.
The bare metal management in Mirantis Container Cloud is implemented as a set of modular microservices. Each microservice implements a certain requirement or function within the bare metal management system.
Bare metal components¶
The bare metal management solution for Mirantis Container Cloud includes the following components:
Component |
Description |
|---|---|
OpenStack Ironic |
The backend bare metal manager in a standalone mode with its auxiliary
services that include |
OpenStack Ironic Inspector |
Introspects and discovers the bare metal hosts inventory. Includes OpenStack Ironic Python Agent (IPA) that is used as a provision-time agent for managing bare metal hosts. |
Ironic Operator |
Monitors changes in the external IP addresses of |
Bare Metal Operator |
Manages bare metal hosts through the Ironic API. The Container Cloud bare-metal operator implementation is based on the Metal³ project. |
Bare metal resources manager |
Ensures that the bare metal provisioning artifacts such as the distribution image of the operating system is available and up to date. |
|
The plugin for the Kubernetes Cluster API integrated with Container Cloud.
Container Cloud uses the Metal³ implementation of
|
HAProxy |
Load balancer for external access to the Kubernetes API endpoint. |
LCM Agent |
Used for physical and logical storage, physical and logical network, and control over the life cycle of a bare metal machine resources. |
Ceph |
Distributed shared storage is required by the Container Cloud services to create persistent volumes to store their data. |
MetalLB |
Load balancer for Kubernetes services on bare metal. 1 |
Keepalived |
Monitoring service that ensures availability of the virtual IP for the external load balancer endpoint (HAProxy). 1 |
IPAM |
IP address management services provide consistent IP address space to the machines in bare metal clusters. See details in IP Address Management. |
- 1(1,2)
For details, see Built-in load balancing.
The diagram below summarizes the following components and resource kinds:
Metal³-based bare metal management in Container Cloud (white)
Internal APIs (yellow)
External dependency components (blue)
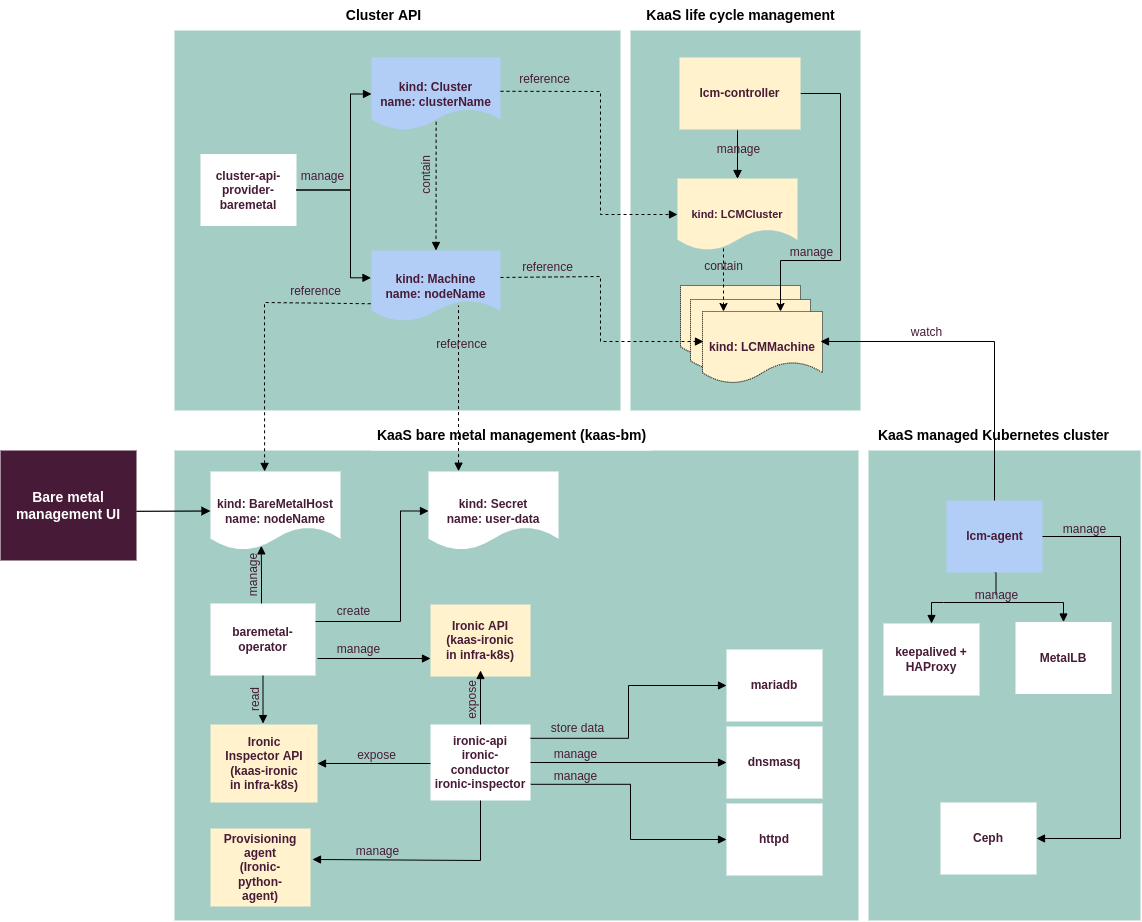
Bare metal networking¶
This section provides an overview of the networking configuration and the IP address management in the Mirantis Container Cloud on bare metal.
IP Address Management¶
Mirantis Container Cloud on bare metal uses IP Address Management (IPAM) to keep track of the network addresses allocated to bare metal hosts. This is necessary to avoid IP address conflicts and expiration of address leases to machines through DHCP.
Note
Only IPv4 address family is currently supported by Container Cloud and IPAM. IPv6 is not supported and not used in Container Cloud.
IPAM is provided by the kaas-ipam controller. Its functions
include:
Allocation of IP address ranges or subnets to newly created clusters using
SubnetPoolandSubnetresources.Allocation IP addresses to machines and cluster services at the request of
baremetal-providerusing theIpamHostandIPaddrresources.Creation and maintenance of host networking configuration on the bare metal hosts using the
IpamHostresources.
The IPAM service can support different networking topologies and network hardware configurations on the bare metal hosts.
In the most basic network configuration, IPAM uses a single L3 network to assign addresses to all bare metal hosts, as defined in Managed cluster networking.
You can apply complex networking configurations to a bare metal host using the L2 templates. The L2 templates imply multihomed host networking and enable you to create a managed cluster where nodes use separate host networks for different types of traffic. Multihoming is required to ensure the security and performance of a managed cluster.
Caution
Modification of L2 templates in use is allowed with a mandatory validation step from the Infrastructure Operator to prevent accidental cluster failures due to unsafe changes. The list of risks posed by modifying L2 templates includes:
Services running on hosts cannot reconfigure automatically to switch to the new IP addresses and/or interfaces.
Connections between services are interrupted unexpectedly, which can cause data loss.
Incorrect configurations on hosts can lead to irrevocable loss of connectivity between services and unexpected cluster partition or disassembly.
For details, see Modify network configuration on an existing machine.
See also
Management cluster networking¶
The main purpose of networking in a Container Cloud management cluster is to provide access to the Container Cloud Management API that consists of the Kubernetes API of the Container Cloud management cluster and the Container Cloud LCM API. This API allows end users to provision and configure managed clusters and machines. Also, this API is used by LCM agents in managed clusters to obtain configuration and report status.
The following types of networks are supported for the management clusters in Container Cloud:
- PXE network
Enables PXE boot of all bare metal machines in the Container Cloud region.
- PXE subnet
Provides IP addresses for DHCP and network boot of the bare metal hosts for initial inspection and operating system provisioning. This network may not have the default gateway or a router connected to it. The PXE subnet is defined by the Container Cloud Operator during bootstrap.
Provides IP addresses for the bare metal management services of Container Cloud, such as bare metal provisioning service (Ironic). These addresses are allocated and served by MetalLB.
- Management network
Connects LCM Agents running on the hosts to the Container Cloud LCM API. Serves the external connections to the Container Cloud Management API. The network is also used for communication between
kubeletand the Kubernetes API server inside a Kubernetes cluster. The MKE components use this network for communication inside a swarm cluster.- LCM subnet
Provides IP addresses for the Kubernetes nodes in the management cluster. This network also provides a Virtual IP (VIP) address for the load balancer that enables external access to the Kubernetes API of a management cluster. This VIP is also the endpoint to access the Container Cloud Management API in the management cluster.
Provides IP addresses for the externally accessible services of Container Cloud, such as Keycloak, web UI, StackLight. These addresses are allocated and served by MetalLB.
- Kubernetes workloads network
Technology Preview
Serves the internal traffic between workloads on the management cluster.
- Kubernetes workloads subnet
Provides IP addresses that are assigned to nodes and used by Calico.
- Out-of-Band (OOB) network
Connects to Baseboard Management Controllers of the servers that host the management cluster. The OOB subnet must be accessible from the management network through IP routing. The OOB network is not managed by Container Cloud and is not represented in the IPAM API.
Managed cluster networking¶
A Kubernetes cluster networking is typically focused on connecting pods on different nodes. On bare metal, however, the cluster networking is more complex as it needs to facilitate many different types of traffic.
Kubernetes clusters managed by Mirantis Container Cloud have the following types of traffic:
- PXE network
Enables the PXE boot of all bare metal machines in Container Cloud. This network is not configured on the hosts in a managed cluster. It is used by the bare metal provider to provision additional hosts in managed clusters and is disabled on the hosts after provisioning is done.
- Life-cycle management (LCM) network
Connects LCM Agents running on the hosts to the Container Cloud LCM API. The LCM API is provided by the management cluster. The LCM network is also used for communication between
kubeletand the Kubernetes API server inside a Kubernetes cluster. The MKE components use this network for communication inside a swarm cluster.When using the BGP announcement of the IP address for the cluster API load balancer, which is available as Technology Preview since Container Cloud 2.24.4, no segment stretching is required between Kubernetes master nodes. Also, in this scenario, the load balancer IP address is not required to match the LCM subnet CIDR address.
- LCM subnet(s)
Provides IP addresses that are statically allocated by the IPAM service to bare metal hosts. This network must be connected to the Kubernetes API endpoint of the management cluster through an IP router.
LCM Agents running on managed clusters will connect to the management cluster API through this router. LCM subnets may be different per managed cluster as long as this connection requirement is satisfied.
The Virtual IP (VIP) address for load balancer that enables access to the Kubernetes API of the managed cluster must be allocated from the LCM subnet.
- Cluster API subnet
Technology Preview
Provides a load balancer IP address for external access to the cluster API. Mirantis recommends that this subnet stays unique per managed cluster.
- Kubernetes workloads network
Serves as an underlay network for traffic between pods in the managed cluster. Do not share this network between clusters.
- Kubernetes workloads subnet(s)
Provides IP addresses that are statically allocated by the IPAM service to all nodes and that are used by Calico for cross-node communication inside a cluster. By default, VXLAN overlay is used for Calico cross-node communication.
- Kubernetes external network
Serves ingress traffic to the managed cluster from the outside world. You can share this network between clusters, but with dedicated subnets per cluster. Several or all cluster nodes must be connected to this network. Traffic from external users to the externally available Kubernetes load-balanced services comes through the nodes that are connected to this network.
- Services subnet(s)
Provides IP addresses for externally available Kubernetes load-balanced services. The address ranges for MetalLB are assigned from this subnet. There can be several subnets per managed cluster that define the address ranges or address pools for MetalLB.
- External subnet(s)
Provides IP addresses that are statically allocated by the IPAM service to nodes. The IP gateway in this network is used as the default route on all nodes that are connected to this network. This network allows external users to connect to the cluster services exposed as Kubernetes load-balanced services. MetalLB speakers must run on the same nodes. For details, see Configure node selector for MetalLB speaker.
- Storage network
Serves storage access and replication traffic from and to Ceph OSD services. The storage network does not need to be connected to any IP routers and does not require external access, unless you want to use Ceph from outside of a Kubernetes cluster. To use a dedicated storage network, define and configure both subnets listed below.
- Storage access subnet(s)
Provides IP addresses that are statically allocated by the IPAM service to Ceph nodes. The Ceph OSD services bind to these addresses on their respective nodes. Serves Ceph access traffic from and to storage clients. This is a public network in Ceph terms. 1
- Storage replication subnet(s)
Provides IP addresses that are statically allocated by the IPAM service to Ceph nodes. The Ceph OSD services bind to these addresses on their respective nodes. Serves Ceph internal replication traffic. This is a cluster network in Ceph terms. 1
- Out-of-Band (OOB) network
Connects baseboard management controllers (BMCs) of the bare metal hosts. This network must not be accessible from the managed clusters.
The following diagram illustrates the networking schema of the Container Cloud deployment on bare metal with a managed cluster:
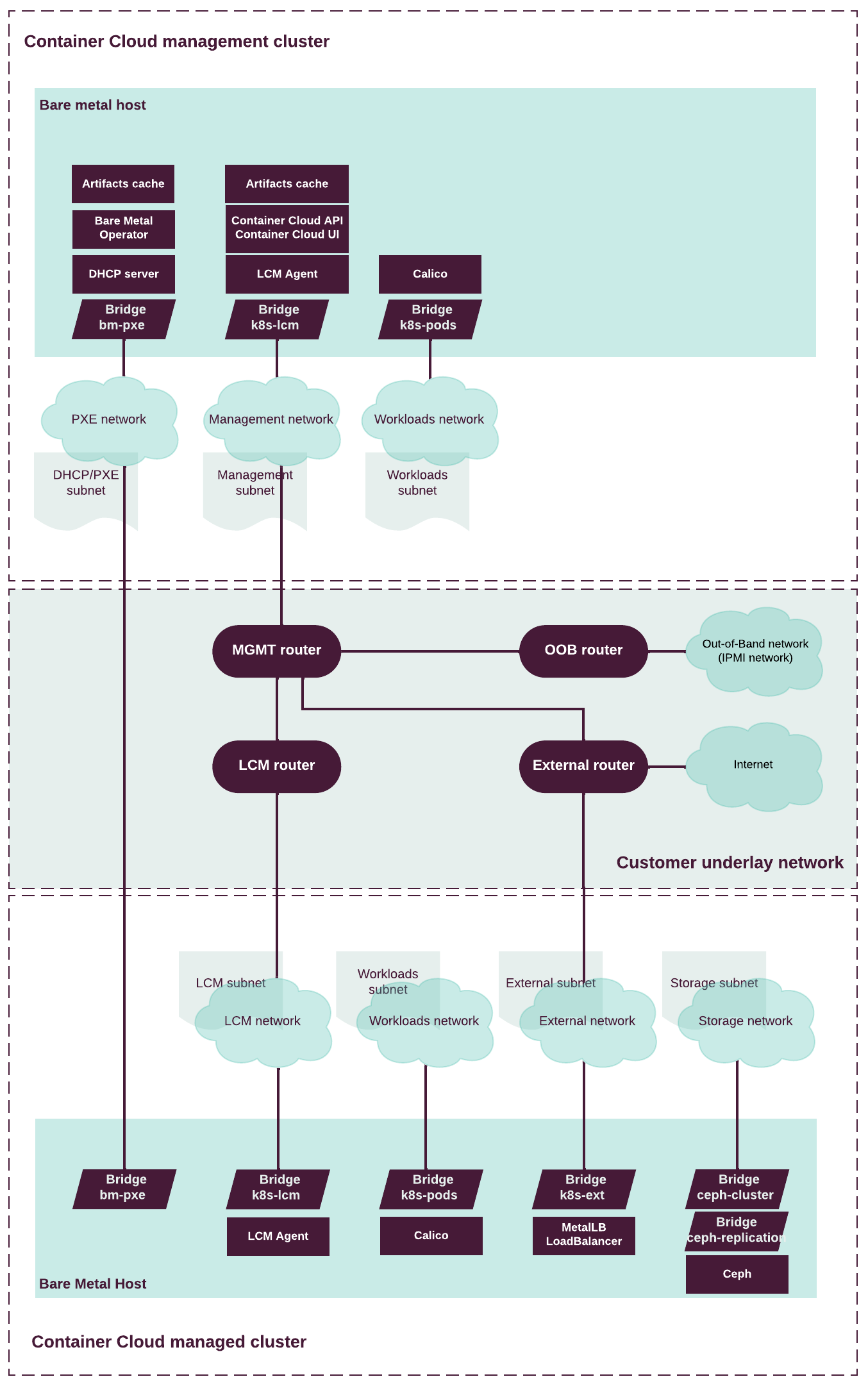
- 1(1,2)
For more details about Ceph networks, see Ceph Network Configuration Reference.
Host networking¶
The following network roles are defined for all Mirantis Container Cloud clusters nodes on bare metal including the bootstrap, management and managed cluster nodes:
- Out-of-band (OOB) network
Connects the Baseboard Management Controllers (BMCs) of the hosts in the network to Ironic. This network is out of band for the host operating system.
- PXE network
Enables remote booting of servers through the PXE protocol. In management clusters, DHCP server listens on this network for hosts discovery and inspection. In managed clusters, hosts use this network for the initial PXE boot and provisioning.
- LCM network
Connects LCM Agents running on the node to the LCM API of the management cluster. It is also used for communication between
kubeletand the Kubernetes API server inside a Kubernetes cluster. The MKE components use this network for communication inside a swarm cluster. In management clusters, it is replaced by the management network.
- Kubernetes workloads (pods) network
Technology Preview
Serves connections between Kubernetes pods. Each host has an address on this network, and this address is used by Calico as an endpoint to the underlay network.
- Kubernetes external network
Technology Preview
Serves external connection to the Kubernetes API and the user services exposed by the cluster. In management clusters, it is replaced by the management network.
- Management network
Serves external connections to the Container Cloud Management API and services of the management cluster. Not available in a managed cluster.
- Storage access network
Connects Ceph nodes to the storage clients. The Ceph OSD service is bound to the address on this network. This is a public network in Ceph terms. 0
- Storage replication network
Connects Ceph nodes to each other. Serves internal replication traffic. This is a cluster network in Ceph terms. 0
Each network is represented on the host by a virtual Linux bridge. Physical interfaces may be connected to one of the bridges directly, or through a logical VLAN subinterface, or combined into a bond interface that is in turn connected to a bridge.
The following table summarizes the default names used for the bridges connected to the networks listed above:
Network type |
Bridge name |
Assignment method TechPreview |
|---|---|---|
OOB network |
N/A |
N/A |
PXE network |
|
By a static interface name |
Management network |
|
By a subnet label |
Kubernetes workloads network |
|
By a static interface name |
Network type |
Bridge name |
Assignment method |
|---|---|---|
OOB network |
N/A |
N/A |
PXE network |
N/A |
N/A |
LCM network |
|
By a subnet label |
Kubernetes workloads network |
|
By a static interface name |
Kubernetes external network |
|
By a static interface name |
Storage access (public) network |
|
By the subnet label |
Storage replication (cluster) network |
|
By the subnet label |
Storage¶
The baremetal-based Mirantis Container Cloud uses Ceph as a distributed storage system for file, block, and object storage. This section provides an overview of a Ceph cluster deployed by Container Cloud.
Overview¶
Mirantis Container Cloud deploys Ceph on baremetal-based managed clusters using Helm charts with the following components:
- Rook Ceph Operator
A storage orchestrator that deploys Ceph on top of a Kubernetes cluster. Also known as
RookorRook Operator. Rook operations include:Deploying and managing a Ceph cluster based on provided Rook CRs such as
CephCluster,CephBlockPool,CephObjectStore, and so on.Orchestrating the state of the Ceph cluster and all its daemons.
KaaSCephClustercustom resource (CR)Represents the customization of a Kubernetes installation and allows you to define the required Ceph configuration through the Container Cloud web UI before deployment. For example, you can define the failure domain, Ceph pools, Ceph node roles, number of Ceph components such as Ceph OSDs, and so on. The
ceph-kcc-controllercontroller on the Container Cloud management cluster manages theKaaSCephClusterCR.- Ceph Controller
A Kubernetes controller that obtains the parameters from Container Cloud through a CR, creates CRs for Rook and updates its CR status based on the Ceph cluster deployment progress. It creates users, pools, and keys for OpenStack and Kubernetes and provides Ceph configurations and keys to access them. Also, Ceph Controller eventually obtains the data from the OpenStack Controller for the Keystone integration and updates the RADOS Gateway services configurations to use Kubernetes for user authentication. Ceph Controller operations include:
Transforming user parameters from the Container Cloud Ceph CR into Rook CRs and deploying a Ceph cluster using Rook.
Providing integration of the Ceph cluster with Kubernetes.
Providing data for OpenStack to integrate with the deployed Ceph cluster.
- Ceph Status Controller
A Kubernetes controller that collects all valuable parameters from the current Ceph cluster, its daemons, and entities and exposes them into the
KaaSCephClusterstatus. Ceph Status Controller operations include:Collecting all statuses from a Ceph cluster and corresponding Rook CRs.
Collecting additional information on the health of Ceph daemons.
Provides information to the
statussection of theKaaSCephClusterCR.
- Ceph Request Controller
A Kubernetes controller that obtains the parameters from Container Cloud through a CR and manages Ceph OSD lifecycle management (LCM) operations. It allows for a safe Ceph OSD removal from the Ceph cluster. Ceph Request Controller operations include:
Providing an ability to perform Ceph OSD LCM operations.
Obtaining specific CRs to remove Ceph OSDs and executing them.
Pausing the regular Ceph Controller reconcile until all requests are completed.
A typical Ceph cluster consists of the following components:
Ceph Monitors - three or, in rare cases, five Ceph Monitors.
Ceph Managers:
Before Container Cloud 2.22.0, one Ceph Manager.
Since Container Cloud 2.22.0, two Ceph Managers.
RADOS Gateway services - Mirantis recommends having three or more RADOS Gateway instances for HA.
Ceph OSDs - the number of Ceph OSDs may vary according to the deployment needs.
Warning
A Ceph cluster with 3 Ceph nodes does not provide hardware fault tolerance and is not eligible for recovery operations, such as a disk or an entire Ceph node replacement.
A Ceph cluster uses the replication factor that equals 3. If the number of Ceph OSDs is less than 3, a Ceph cluster moves to the degraded state with the write operations restriction until the number of alive Ceph OSDs equals the replication factor again.
The placement of Ceph Monitors and Ceph Managers is defined in the
KaaSCephCluster CR.
The following diagram illustrates the way a Ceph cluster is deployed in Container Cloud:
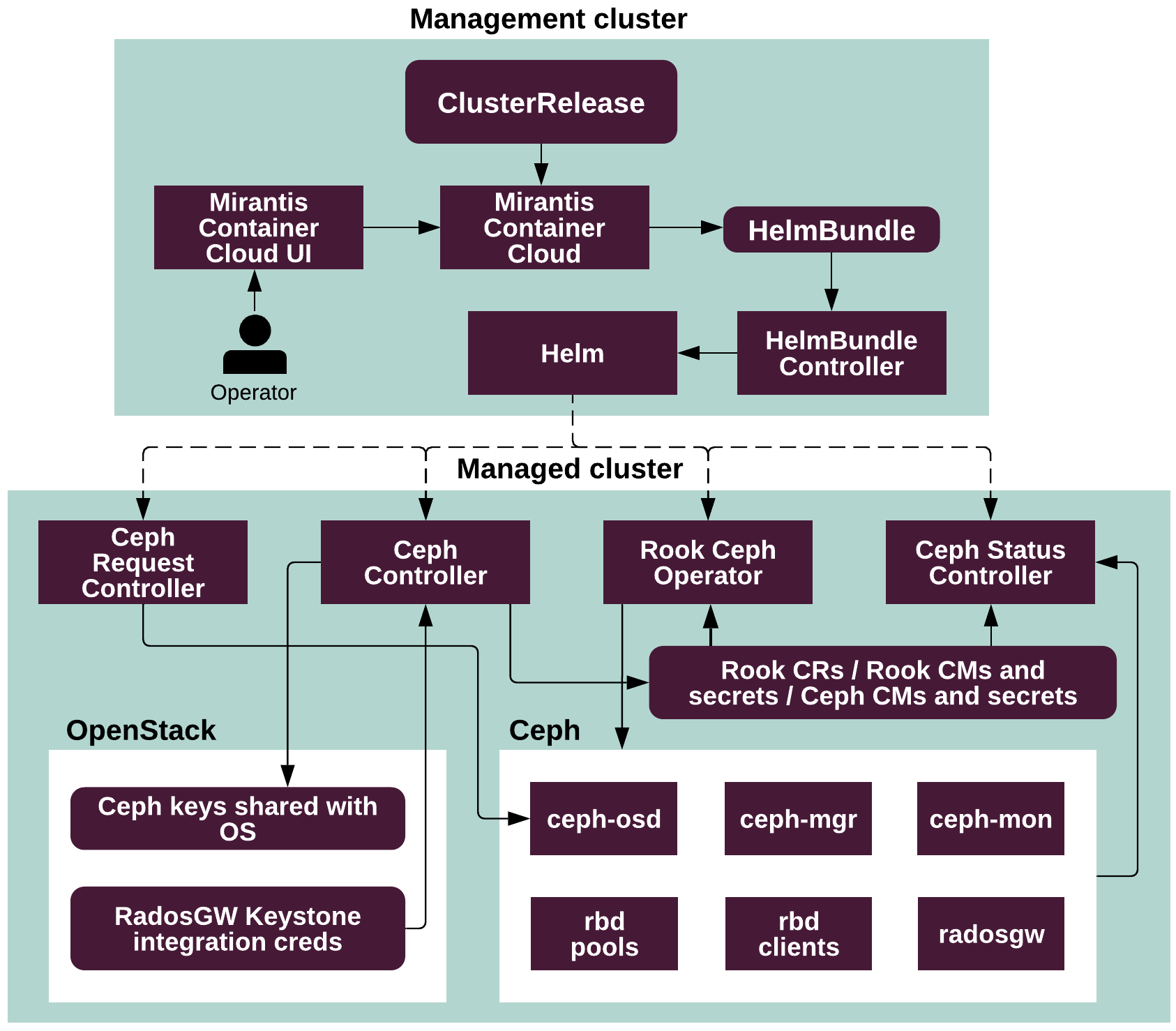
The following diagram illustrates the processes within a deployed Ceph cluster:
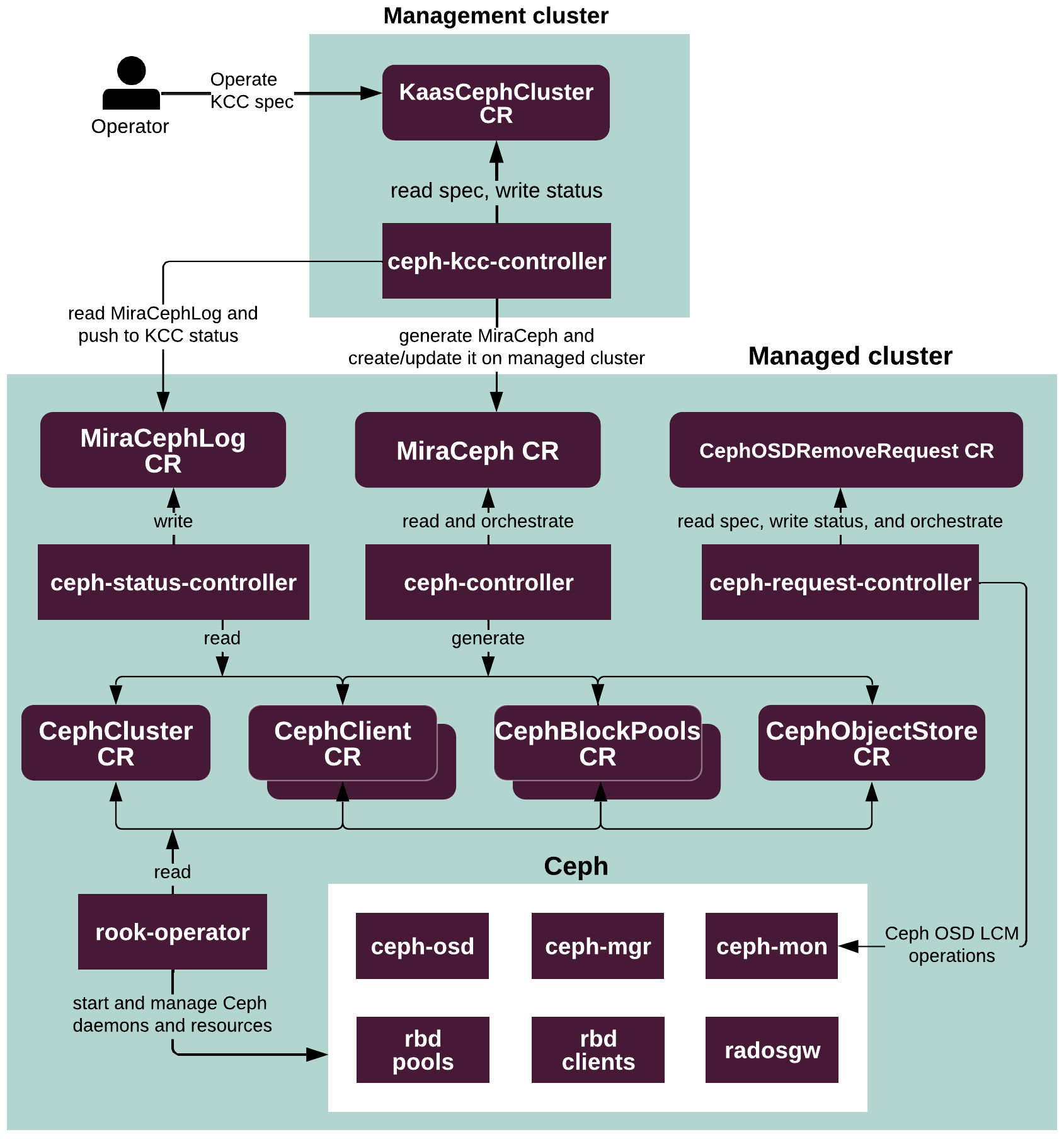
See also
Limitations¶
A Ceph cluster configuration in Mirantis Container Cloud includes but is not limited to the following limitations:
Only one Ceph Controller per a managed cluster and only one Ceph cluster per Ceph Controller are supported.
The replication size for any Ceph pool must be set to more than 1.
All CRUSH rules must have the same
failure_domain.Only one CRUSH tree per cluster. The separation of devices per Ceph pool is supported through device classes with only one pool of each type for a device class.
Only the following types of CRUSH buckets are supported:
topology.kubernetes.io/regiontopology.kubernetes.io/zonetopology.rook.io/datacentertopology.rook.io/roomtopology.rook.io/podtopology.rook.io/pdutopology.rook.io/rowtopology.rook.io/racktopology.rook.io/chassis
Only IPv4 is supported.
If two or more Ceph OSDs are located on the same device, there must be no dedicated WAL or DB for this class.
Only a full collocation or dedicated WAL and DB configurations are supported.
The minimum size of any defined Ceph OSD device is 5 GB.
Lifted since Container Cloud 2.24.2 (Cluster releases 14.0.1 and 15.0.1). Ceph cluster does not support removable devices (with hotplug enabled) for deploying Ceph OSDs.
Ceph OSDs support only raw disks as data devices meaning that no
dmorlvmdevices are allowed.When adding a Ceph node with the Ceph Monitor role, if any issues occur with the Ceph Monitor,
rook-cephremoves it and adds a new Ceph Monitor instead, named using the next alphabetic character in order. Therefore, the Ceph Monitor names may not follow the alphabetical order. For example,a,b,d, instead ofa,b,c.Reducing the number of Ceph Monitors is not supported and causes the Ceph Monitor daemons removal from random nodes.
Removal of the
mgrrole in thenodessection of theKaaSCephClusterCR does not remove Ceph Managers. To remove a Ceph Manager from a node, remove it from thenodesspec and manually delete themgrpod in the Rook namespace.Lifted since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.10). Ceph does not support allocation of Ceph RGW pods on nodes where the Federal Information Processing Standard (FIPS) mode is enabled.
Addressing storage devices¶
There are several formats to use when specifying and addressing storage devices
of a Ceph cluster. The default and recommended one is the /dev/disk/by-id
format. This format is reliable and unaffected by the disk controller actions,
such as device name shuffling or /dev/disk/by-path recalculating.
The storage device /dev/disk/by-id format in most of the cases bases on
a disk serial number, which is unique for each disk. A by-id symlink
is created by the udev rules in the following format, where <BusID>
is an ID of the bus to which the disk is attached and <DiskSerialNumber>
stands for a unique disk serial number:
/dev/disk/by-id/<BusID>-<DiskSerialNumber>
Typical by-id symlinks for storage devices look as follows:
/dev/disk/by-id/nvme-SAMSUNG_MZ1LB3T8HMLA-00007_S46FNY0R394543
/dev/disk/by-id/scsi-SATA_HGST_HUS724040AL_PN1334PEHN18ZS
/dev/disk/by-id/ata-WDC_WD4003FZEX-00Z4SA0_WD-WMC5D0D9DMEH
In the example above, symlinks contain the following IDs:
Bus IDs:
nvme,scsi-SATAandataDisk serial numbers:
SAMSUNG_MZ1LB3T8HMLA-00007_S46FNY0R394543,HGST_HUS724040AL_PN1334PEHN18ZSandWDC_WD4003FZEX-00Z4SA0_WD-WMC5D0D9DMEH.
An exception to this rule is the wwn by-id symlinks, which are
programmatically generated at boot. They are not solely based on disk
serial numbers but also include other node information. This can lead
to the wwn being recalculated when the node reboots. As a result,
this symlink type cannot guarantee a persistent disk identifier and should
not be used as a stable storage device symlink in a Ceph cluster.
The storage device name and by-path formats cannot be considered
persistent because the sequence in which block devices are added during boot
is semi-arbitrary. This means that block device names, for example, nvme0n1
and sdc, are assigned to physical disks during discovery, which may vary
inconsistently from the previous node state. The same inconsistency applies
to by-path symlinks, as they rely on the shortest physical path
to the device at boot and may differ from the previous node state.
Therefore, Mirantis highly recommends using storage device by-id symlinks
that contain disk serial numbers. This approach enables you to use a persistent
device identifier addressed in the Ceph cluster specification.
Below is an example KaaSCephCluster custom resource using the
/dev/disk/by-id format for storage devices specification:
Note
Container Cloud enables you to use fullPath for the by-id
symlinks since 2.25.0. For the earlier product versions, use the name
field instead.
apiVersion: kaas.mirantis.com/v1alpha1
kind: KaaSCephCluster
metadata:
name: ceph-cluster-managed-cluster
namespace: managed-ns
spec:
cephClusterSpec:
nodes:
# Add the exact ``nodes`` names.
# Obtain the name from the "get machine" list.
cz812-managed-cluster-storage-worker-noefi-58spl:
roles:
- mgr
- mon
# All disk configuration must be reflected in ``status.providerStatus.hardware.storage`` of the ``Machine`` object
storageDevices:
- config:
deviceClass: ssd
fullPath: /dev/disk/by-id/scsi-1ATA_WDC_WDS100T2B0A-00SM50_200231440912
cz813-managed-cluster-storage-worker-noefi-lr4k4:
roles:
- mgr
- mon
storageDevices:
- config:
deviceClass: nvme
fullPath: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB3T8HMLA-00007_S46FNY0R394543
cz814-managed-cluster-storage-worker-noefi-z2m67:
roles:
- mgr
- mon
storageDevices:
- config:
deviceClass: nvme
fullPath: /dev/disk/by-id/nvme-SAMSUNG_ML1EB3T8HMLA-00007_S46FNY1R130423
pools:
- default: true
deviceClass: ssd
name: kubernetes
replicated:
size: 3
role: kubernetes
k8sCluster:
name: managed-cluster
namespace: managed-ns
The majority of existing clusters uses device names as addressed storage
devices identifiers in the spec.cephClusterSpec.nodes section of
the KaaSCephCluster custom resource. Therefore, they are prone
to the issue of inconsistent storage device identifiers during cluster
update. Refer to Migrate Ceph cluster to address storage devices using by-id to mitigate possible
risks.
Extended hardware configuration¶
Mirantis Container Cloud provides APIs that enable you to define hardware configurations that extend the reference architecture:
Bare Metal Host Profile API
Enables for quick configuration of host boot and storage devices and assigning of custom configuration profiles to individual machines. See Create a custom bare metal host profile.
IP Address Management API
Enables for quick configuration of host network interfaces and IP addresses and setting up of IP addresses ranges for automatic allocation. See Create L2 templates.
Typically, operations with the extended hardware configurations are available through the API and CLI, but not the web UI.
Automatic upgrade of a host operating system¶
To keep operating system on a bare metal host up to date with the latest security updates, the operating system requires periodic software packages upgrade that may or may not require the host reboot.
Mirantis Container Cloud uses life cycle management tools to update the operating system packages on the bare metal hosts. Container Cloud may also trigger restart of bare metal hosts to apply the updates.
In the management cluster of Container Cloud, software package upgrade and host restart is applied automatically when a new Container Cloud version with available kernel or software packages upgrade is released.
In managed clusters, package upgrade and host restart is applied as part of usual cluster upgrade using the Update cluster option in the Container Cloud web UI.
Operating system upgrade and host restart are applied to cluster nodes one by one. If Ceph is installed in the cluster, the Container Cloud orchestration securely pauses the Ceph OSDs on the node before restart. This allows avoiding degradation of the storage service.
Caution
Depending on the cluster configuration, applying security updates and host restart can increase the update time for each node to up to 1 hour.
Cluster nodes are updated one by one. Therefore, for large clusters, the update may take several days to complete.
See also
Built-in load balancing¶
The Mirantis Container Cloud managed clusters that are based on vSphere or bare metal use MetalLB for load balancing of services and HAProxy with VIP managed by Virtual Router Redundancy Protocol (VRRP) with Keepalived for the Kubernetes API load balancer.
Kubernetes API load balancing¶
Every control plane node of each Kubernetes cluster runs the kube-api
service in a container. This service provides a Kubernetes API endpoint.
Every control plane node also runs the haproxy server that provides
load balancing with backend health checking for all kube-api endpoints as
backends.
The default load balancing method is least_conn. With this method,
a request is sent to the server with the least number of active
connections. The default load balancing method cannot be changed
using the Container Cloud API.
Only one of the control plane nodes at any given time serves as a front end for Kubernetes API. To ensure this, the Kubernetes clients use a virtual IP (VIP) address for accessing Kubernetes API. This VIP is assigned to one node at a time using VRRP. Keepalived running on each control plane node provides health checking and failover of the VIP.
Keepalived is configured in multicast mode.
Note
The use of VIP address for load balancing of Kubernetes API requires that all control plane nodes of a Kubernetes cluster are connected to a shared L2 segment. This limitation prevents from installing full L3 topologies where control plane nodes are split between different L2 segments and L3 networks.
Caution
External load balancers for services are not supported by the current version of the Container Cloud vSphere provider. The built-in load balancing described in this section is the only supported option and cannot be disabled.
Services load balancing¶
The services provided by the Kubernetes clusters, including
Container Cloud and user services, are balanced by MetalLB.
The metallb-speaker service runs on every worker node in
the cluster and handles connections to the service IP addresses.
MetalLB runs in the MAC-based (L2) mode. It means that all control plane nodes must be connected to a shared L2 segment. This is a limitation that does not allow installing full L3 cluster topologies.
Caution
External load balancers for services are not supported by the current version of the Container Cloud vSphere provider. The built-in load balancing described in this section is the only supported option and cannot be disabled.
VMware vSphere network objects and IPAM recommendations¶
The VMware vSphere provider of Mirantis Container Cloud supports the following types of vSphere network objects:
- Virtual network
A network of virtual machines running on a hypervisor(s) that are logically connected to each other so that they can exchange data. Virtual machines can be connected to virtual networks that you create when you add a network.
- Distributed port group
A port group associated with a vSphere distributed switch that specifies port configuration options for each member port. Distributed port groups define how connection is established through the vSphere distributed switch to the network.
A Container Cloud cluster can be deployed using one of these network objects with or without a DHCP server in the network:
- Non-DHCP
Container Cloud uses IPAM service to manage IP addresses assignment to machines. You must provide additional network parameters, such as CIDR, gateway, IP ranges, and nameservers. Container Cloud processes this data to the
cloud-initmetadata and passes the data to machines during their bootstrap.
- DHCP
Container Cloud relies on a DHCP server to assign IP addresses to virtual machines.
Mirantis recommends using IP address management (IPAM) for cluster machines provided by Container Cloud. IPAM must be enabled for deployment in the non-DHCP vSphere networks. But Mirantis recommends enabling IPAM in the DHCP-based networks as well. In this case, the dedicated IPAM range should not intersect with the IP range used in the DHCP server configuration for the provided vSphere network. Such configuration prevents issues with accidental IP address change for machines. For the issue details, see vSphere troubleshooting.
Note
To obtain IPAM parameters for the selected vSphere network, contact your vSphere administrator who provides you with IP ranges dedicated to your environment only.
The following parameters are required to enable IPAM:
Network CIDR.
Network gateway address.
Minimum 1 DNS server.
IP address include range to be allocated for cluster machines. Make sure that this range is not part of the DHCP range if the network has a DHCP server.
Minimal number of addresses in the range:
3 IPs for management cluster
3+N IPs for a managed cluster, where N is the number of worker nodes
Optional. IP address exclude range that is the list of IPs not to be assigned to machines from the include ranges.
A dedicated Container Cloud network must not contain any virtual machines
with the keepalived instance running inside them as this may lead to the
vrouter_id conflict. By default, the Container Cloud management cluster
is deployed with vrouter_id set to 1.
Managed clusters are deployed with the vrouter_id value starting from
2 and upper.
Kubernetes lifecycle management¶
The Kubernetes lifecycle management (LCM) engine in Mirantis Container Cloud consists of the following components:
- LCM Controller
Responsible for all LCM operations. Consumes the LCMCluster object and orchestrates actions through LCM Agent.
- LCM Agent
Runs on the target host. Executes Ansible playbooks in headless mode. Does not run on attached MKE clusters that are not originally deployed by Container Cloud.
- Helm Controller
Responsible for the Helm charts life cycle, is installed by a cloud provider as a Helm v3 chart.
The Kubernetes LCM components handle the following custom resources:
LCMCluster
LCMMachine
HelmBundle
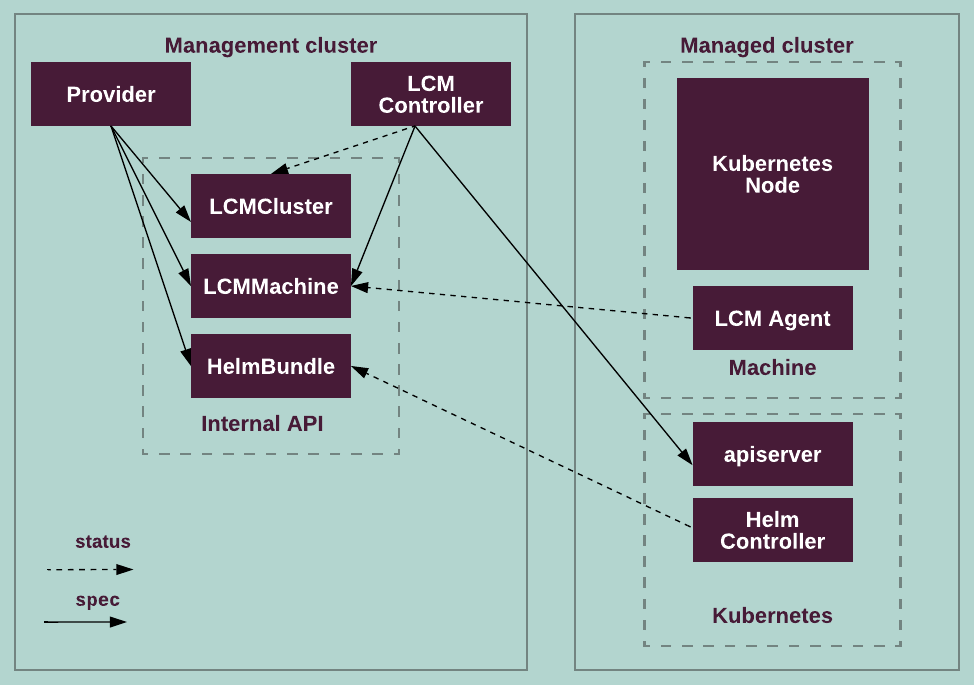
The following diagram illustrates handling of the LCM custom resources by
the Kubernetes LCM components. On a managed cluster,
apiserver handles multiple Kubernetes objects,
for example, deployments, nodes, RBAC, and so on.
LCM custom resources¶
The Kubernetes LCM components handle the following custom resources (CRs):
LCMMachine
LCMCluster
HelmBundle
- LCMMachine
Describes a machine that is located on a cluster. It contains the machine
type,controlorworker,StateItemsthat correspond to Ansible playbooks and miscellaneous actions, for example, downloading a file or executing a shell command. LCMMachine reflects the current state of the machine, for example, a node IP address, and eachStateItemthrough its status. Multiple LCMMachine CRs can correspond to a single cluster.- LCMCluster
Describes a managed cluster. In its
spec, LCMCluster contains a set ofStateItemsfor each type of LCMMachine, which describe the actions that must be performed to deploy the cluster. LCMCluster is created by the provider, usingmachineTypesof the Release object. Thestatusfield of LCMCluster reflects the status of the cluster, for example, the number of ready or requested nodes.- HelmBundle
Wrapper for Helm charts that is handled by Helm Controller. HelmBundle tracks what Helm charts must be installed on a managed cluster.
LCM Controller¶
LCM Controller runs on the management and regional cluster and orchestrates
the LCMMachine objects according to their type and their LCMCluster
object.
Once the LCMCluster and LCMMachine objects are created, LCM Controller
starts monitoring them to modify the spec fields and update
the status fields of the LCMMachine objects when required.
The status field of LCMMachine is updated by LCM Agent
running on a node of a management, regional, or managed cluster.
Each LCMMachine has the following lifecycle states:
Uninitialized - the machine is not yet assigned to an
LCMCluster.Pending - the agent reports a node IP address and host name.
Prepare - the machine executes
StateItemsthat correspond to thepreparephase. This phase usually involves downloading the necessary archives and packages.Deploy - the machine executes
StateItemsthat correspond to thedeployphase that is becoming a Mirantis Kubernetes Engine (MKE) node.Ready - the machine is being deployed.
Upgrade - the machine is being upgraded to the new MKE version.
Reconfigure - the machine executes
StateItemsthat correspond to thereconfigurephase. The machine configuration is being updated without affecting workloads running on the machine.
The templates for StateItems are stored in the machineTypes
field of an LCMCluster object, with separate lists
for the MKE manager and worker nodes.
Each StateItem has the execution phase field for a management,
regional, and managed cluster:
The
preparephase is executed for all machines for which it was not executed yet. This phase comprises downloading the files necessary for the cluster deployment, installing the required packages, and so on.During the
deployphase, a node is added to the cluster. LCM Controller applies thedeployphase to the nodes in the following order:First manager node is deployed.
The remaining manager nodes are deployed one by one and the worker nodes are deployed in batches (by default, up to 50 worker nodes at the same time).
LCM Controller deploys and upgrades a Mirantis Container Cloud cluster
by setting StateItems of LCMMachine objects following the corresponding
StateItems phases described above. The Container Cloud cluster upgrade
process follows the same logic that is used for a new deployment,
that is applying a new set of StateItems to the LCMMachines after
updating the LCMCluster object. But if the existing worker node is being
upgraded, LCM Controller performs draining and cordoning on this node honoring
the Pod Disruption Budgets.
This operation prevents unexpected disruptions of the workloads.
LCM Agent¶
LCM Agent handles a single machine that belongs to a management or managed
cluster. It runs on the machine operating system but communicates with
apiserver of the management cluster. LCM Agent is deployed as a systemd
unit using cloud-init. LCM Agent has a built-in self-upgrade mechanism.
LCM Agent monitors the spec of a particular LCMMachine object
to reconcile the machine state with the object StateItems and update
the LCMMachine status accordingly. The actions that LCM Agent performs
while handling the StateItems are as follows:
Download configuration files
Run shell commands
Run Ansible playbooks in headless mode
LCM Agent provides the IP address and host name of the machine for the
LCMMachine status parameter.
Helm Controller¶
Helm Controller is used by Mirantis Container Cloud to handle management and managed clusters core addons such as StackLight and the application addons such as the OpenStack components.
Helm Controller is installed as a separate Helm v3 chart by the Container
Cloud provider. Its Pods are created using Deployment.
The Helm release information is stored in the KaaSRelease object for
the management clusters and in the ClusterRelease object for all types of
the Container Cloud clusters.
These objects are used by the Container Cloud provider.
The Container Cloud provider uses the information from the
ClusterRelease object together with the Container Cloud API
Cluster spec. In Cluster spec, the operator can specify
the Helm release name and charts to use.
By combining the information from the Cluster providerSpec parameter
and its ClusterRelease object, the cluster actuator generates
the LCMCluster objects. These objects are further handled by LCM Controller
and the HelmBundle object handled by Helm Controller.
HelmBundle must have the same name as the LCMCluster object
for the cluster that HelmBundle applies to.
Although a cluster actuator can only create a single HelmBundle per cluster, Helm Controller can handle multiple HelmBundle objects per cluster.
Helm Controller handles the HelmBundle objects and reconciles them with the state of Helm in its cluster.
Helm Controller can also be used by the management cluster with corresponding HelmBundle objects created as part of the initial management cluster setup.
Identity and access management¶
Identity and access management (IAM) provides a central point of users and permissions management of the Mirantis Container Cloud cluster resources in a granular and unified manner. Also, IAM provides infrastructure for single sign-on user experience across all Container Cloud web portals.
IAM for Container Cloud consists of the following components:
- Keycloak
Provides the OpenID Connect endpoint
Integrates with an external identity provider (IdP), for example, existing LDAP or Google Open Authorization (OAuth)
Stores roles mapping for users
- IAM Controller
Provides IAM API with data about Container Cloud projects
Handles all role-based access control (RBAC) components in Kubernetes API
- IAM API
Provides an abstraction API for creating user scopes and roles
External identity provider integration¶
To be consistent and keep the integrity of a user database and user permissions, in Mirantis Container Cloud, IAM stores the user identity information internally. However in real deployments, the identity provider usually already exists.
Out of the box, in Container Cloud, IAM supports integration with LDAP and Google Open Authorization (OAuth). If LDAP is configured as an external identity provider, IAM performs one-way synchronization by mapping attributes according to configuration.
In the case of the Google Open Authorization (OAuth) integration, the user is automatically registered and their credentials are stored in the internal database according to the user template configuration. The Google OAuth registration workflow is as follows:
The user requests a Container Cloud web UI resource.
The user is redirected to the IAM login page and logs in using the Log in with Google account option.
IAM creates a new user with the default access rights that are defined in the user template configuration.
The user can access the Container Cloud web UI resource.
The following diagram illustrates the external IdP integration to IAM:
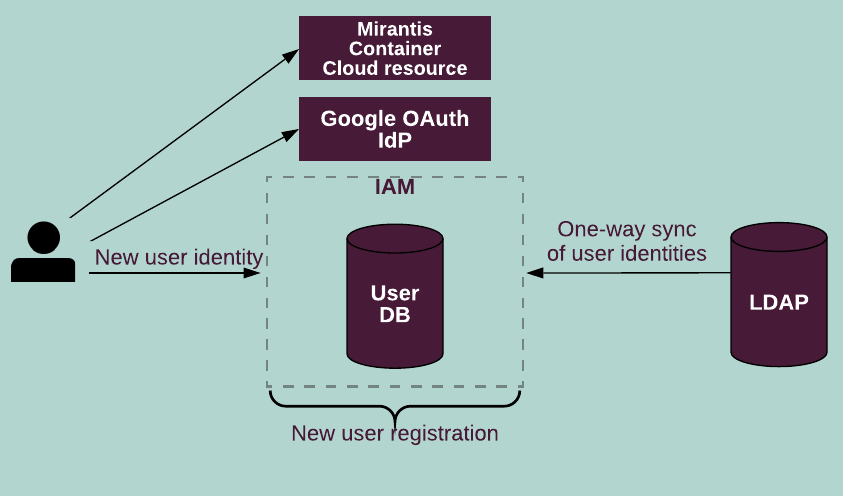
You can configure simultaneous integration with both external IdPs with the user identity matching feature enabled.
Authentication and authorization¶
Mirantis IAM uses the OpenID Connect (OIDC) protocol for handling authentication.
Implementation flow¶
Mirantis IAM performs as an OpenID Connect (OIDC) provider, it issues a token and exposes discovery endpoints.
The credentials can be handled by IAM itself or delegated to an external identity provider (IdP).
The issued JSON Web Token (JWT) is sufficient to perform operations across Mirantis Container Cloud according to the scope and role defined in it. Mirantis recommends using asymmetric cryptography for token signing (RS256) to minimize the dependency between IAM and managed components.
When Container Cloud calls Mirantis Kubernetes Engine (MKE), the user in Keycloak is created automatically with a JWT issued by Keycloak on behalf of the end user. MKE, in its turn, verifies whether the JWT is issued by Keycloak. If the user retrieved from the token does not exist in the MKE database, the user is automatically created in the MKE database based on the information from the token.
The authorization implementation is out of the scope of IAM in Container Cloud. This functionality is delegated to the component level. IAM interacts with a Container Cloud component using the OIDC token content that is processed by a component itself and required authorization is enforced. Such an approach enables you to have any underlying authorization that is not dependent on IAM and still to provide a unified user experience across all Container Cloud components.
Kubernetes CLI authentication flow¶
The following diagram illustrates the Kubernetes CLI authentication flow. The authentication flow for Helm and other Kubernetes-oriented CLI utilities is identical to the Kubernetes CLI flow, but JSON Web Tokens (JWT) must be pre-provisioned.
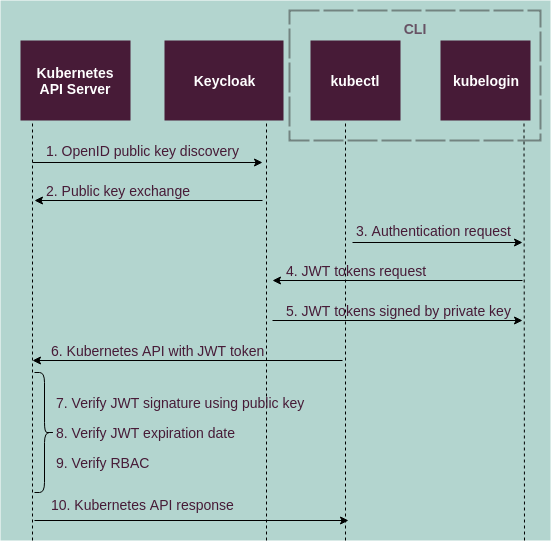
See also
Monitoring¶
Mirantis Container Cloud uses StackLight, the logging, monitoring, and alerting solution that provides a single pane of glass for cloud maintenance and day-to-day operations as well as offers critical insights into cloud health including operational information about the components deployed in management and managed clusters.
StackLight is based on Prometheus, an open-source monitoring solution and a time series database.
Deployment architecture¶
Mirantis Container Cloud deploys the StackLight stack
as a release of a Helm chart that contains the helm-controller
and helmbundles.lcm.mirantis.com (HelmBundle) custom resources.
The StackLight HelmBundle consists of a set of Helm charts
with the StackLight components that include:
StackLight component |
Description |
|---|---|
Alerta |
Receives, consolidates, and deduplicates the alerts sent by Alertmanager and visually represents them through a simple web UI. Using the Alerta web UI, you can view the most recent or watched alerts, group, and filter alerts. |
Alertmanager |
Handles the alerts sent by client applications such as Prometheus,
deduplicates, groups, and routes alerts to receiver integrations.
Using the Alertmanager web UI, you can view the most recent |
Elasticsearch Curator |
Maintains the data (indexes) in OpenSearch by performing such operations as creating, closing, or opening an index as well as deleting a snapshot. Also, manages the data retention policy in OpenSearch. |
Elasticsearch Exporter Compatible with OpenSearch |
The Prometheus exporter that gathers internal OpenSearch metrics. |
Grafana |
Builds and visually represents metric graphs based on time series databases. Grafana supports querying of Prometheus using the PromQL language. |
Database backends |
StackLight uses PostgreSQL for Alerta and Grafana. PostgreSQL reduces the data storage fragmentation while enabling high availability. High availability is achieved using Patroni, the PostgreSQL cluster manager that monitors for node failures and manages failover of the primary node. StackLight also uses Patroni to manage major version upgrades of PostgreSQL clusters, which allows leveraging the database engine functionality and improvements as they are introduced upstream in new releases, maintaining functional continuity without version lock-in. |
Logging stack |
Responsible for collecting, processing, and persisting logs and Kubernetes events. By default, when deploying through the Container Cloud web UI, only the metrics stack is enabled on managed clusters. To enable StackLight to gather managed cluster logs, enable the logging stack during deployment. On management clusters, the logging stack is enabled by default. The logging stack components include:
Note The logging mechanism performance depends on the cluster log load. In
case of a high load, you may need to increase the default resource requests
and limits for |
Metric collector |
Collects telemetry data (CPU or memory usage, number of active alerts, and so on) from Prometheus and sends the data to centralized cloud storage for further processing and analysis. Metric collector runs on the management cluster. Note This component is designated for internal StackLight use only. |
Prometheus |
Gathers metrics. Automatically discovers and monitors the endpoints. Using the Prometheus web UI, you can view simple visualizations and debug. By default, the Prometheus database stores metrics of the past 15 days or up to 15 GB of data depending on the limit that is reached first. |
Prometheus Blackbox Exporter |
Allows monitoring endpoints over HTTP, HTTPS, DNS, TCP, and ICMP. |
Prometheus-es-exporter |
Presents the OpenSearch data as Prometheus metrics by periodically sending configured queries to the OpenSearch cluster and exposing the results to a scrapable HTTP endpoint like other Prometheus targets. |
Prometheus Node Exporter |
Gathers hardware and operating system metrics exposed by kernel. |
Prometheus Relay |
Adds a proxy layer to Prometheus to merge the results from underlay Prometheus servers to prevent gaps in case some data is missing on some servers. Is available only in the HA StackLight mode. |
Reference Application Available since 2.21.0 |
Enables workload monitoring on non-MOSK managed clusters. Mimics a classical microservice application and provides metrics that describe the likely behavior of user workloads. Note For the feature support on MOSK deployments, refer to MOSK documentation: Deploy RefApp using automation tools. |
Salesforce notifier |
Enables sending Alertmanager notifications to Salesforce to allow creating Salesforce cases and closing them once the alerts are resolved. Disabled by default. |
Salesforce reporter |
Queries Prometheus for the data about the amount of vCPU, vRAM, and vStorage used and available, combines the data, and sends it to Salesforce daily. Mirantis uses the collected data for further analysis and reports to improve the quality of customer support. Disabled by default. |
Telegraf |
Collects metrics from the system. Telegraf is plugin-driven and has the concept of two distinct set of plugins: input plugins collect metrics from the system, services, or third-party APIs; output plugins write and expose metrics to various destinations. The Telegraf agents used in Container Cloud include:
|
Telemeter |
Enables a multi-cluster view through a Grafana dashboard of the management cluster. Telemeter includes a Prometheus federation push server and clients to enable isolated Prometheus instances, which cannot be scraped from a central Prometheus instance, to push metrics to the central location. The Telemeter services are distributed between the management cluster that hosts the Telemeter server and managed clusters that host the Telemeter client. The metrics from managed clusters are aggregated on management clusters. Note This component is designated for internal StackLight use only. |
Every Helm chart contains a default values.yml file. These default values
are partially overridden by custom values defined in the StackLight Helm chart.
Before deploying a managed cluster, you can select the HA or non-HA StackLight architecture type. The non-HA mode is set by default. On management clusters, StackLight is deployed in the HA mode only. The following table lists the differences between the HA and non-HA modes:
Non-HA StackLight mode default |
HA StackLight mode |
|---|---|
One persistent volume is provided for storing data. In case of a service or node failure, a new pod is redeployed and the volume is reattached to provide the existing data. Such setup has a reduced hardware footprint but provides less performance. |
Local Volume Provisioner is used to provide local host storage. In case
of a service or node failure, the traffic is automatically redirected to
any other running Prometheus or OpenSearch server. For better
performance, Mirantis recommends that you deploy StackLight in the HA
mode. Two |
Note
Before Container Cloud 2.24.0, Alertmanager has 2 replicas in the non-HA mode.
Depending on the Container Cloud cluster type and selected StackLight database mode, StackLight is deployed on the following number of nodes:
Cluster |
StackLight database mode |
Target nodes |
|---|---|---|
Management |
HA mode |
All Kubernetes master nodes |
Managed |
Non-HA mode |
|
HA mode |
All nodes with the |
Authentication flow¶
StackLight provides five web UIs including Prometheus, Alertmanager, Alerta, OpenSearch Dashboards, and Grafana. Access to StackLight web UIs is protected by Keycloak-based Identity and access management (IAM). All web UIs except Alerta are exposed to IAM through the IAM proxy middleware. The Alerta configuration provides direct integration with IAM.
The following diagram illustrates accessing the IAM-proxied StackLight web UIs, for example, Prometheus web UI:
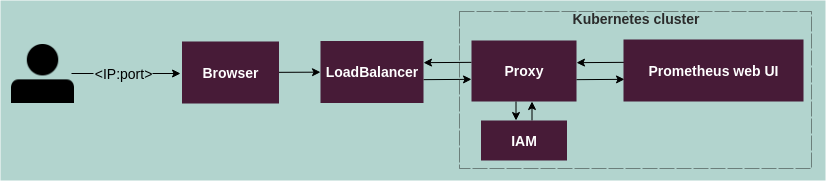
Authentication flow for the IAM-proxied StackLight web UIs:
A user enters the public IP of a StackLight web UI, for example, Prometheus web UI.
The public IP leads to IAM proxy, deployed as a Kubernetes LoadBalancer, which protects the Prometheus web UI.
LoadBalancer routes the HTTP request to Kubernetes internal IAM proxy service endpoints, specified in the X-Forwarded-Proto or X-Forwarded-Host headers.
The Keycloak login form opens (the
login_urlfield in the IAM proxy configuration, which points to Keycloak realm) and the user enters the user name and password.Keycloak validates the user name and password.
The user obtains access to the Prometheus web UI (the
upstreamsfield in the IAM proxy configuration).
Note
The discovery URL is the URL of the IAM service.
The upstream URL is the hidden endpoint of a web UI (Prometheus web UI in the example above).
The following diagram illustrates accessing the Alerta web UI:
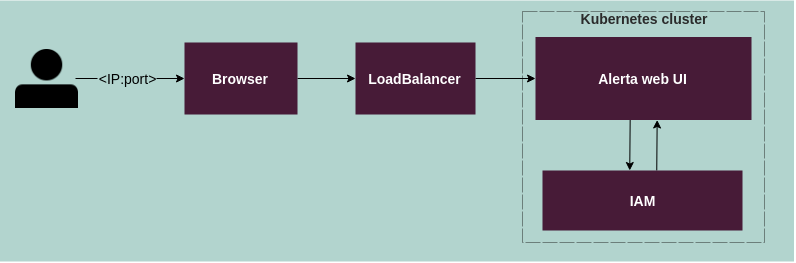
Authentication flow for the Alerta web UI:
A user enters the public IP of the Alerta web UI.
The public IP leads to Alerta deployed as a Kubernetes LoadBalancer type.
LoadBalancer routes the HTTP request to the Kubernetes internal Alerta service endpoint.
The Keycloak login form opens (Alerta refers to the IAM realm) and the user enters the user name and password.
Keycloak validates the user name and password.
The user obtains access to the Alerta web UI.
Supported features¶
Using the Mirantis Container Cloud web UI, on the pre-deployment stage of a managed cluster, you can view, enable or disable, or tune the following StackLight features available:
StackLight HA mode.
Database retention size and time for Prometheus.
Tunable index retention period for OpenSearch.
Tunable
PersistentVolumeClaim(PVC) size for Prometheus and OpenSearch set to 16 GB for Prometheus and 30 GB for OpenSearch by default. The PVC size must be logically aligned with the retention periods or sizes for these components.Email and Slack receivers for the Alertmanager notifications.
Predefined set of dashboards.
Predefined set of alerts and capability to add new custom alerts for Prometheus in the following exemplary format:
- alert: HighErrorRate expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5 for: 10m labels: severity: page annotations: summary: High request latency
Monitored components¶
StackLight measures, analyzes, and reports in a timely manner about failures that may occur in the following Mirantis Container Cloud components and their sub-components, if any:
Ceph
Ironic (Container Cloud bare-metal provider)
Kubernetes services:
Calico
etcd
Kubernetes cluster
Kubernetes containers
Kubernetes deployments
Kubernetes nodes
NGINX
Node hardware and operating system
PostgreSQL
StackLight:
Alertmanager
OpenSearch
Grafana
Prometheus
Prometheus Relay
Salesforce notifier
Telemeter
SSL certificates
Mirantis Kubernetes Engine (MKE)
Docker/Swarm metrics (through Telegraf)
Built-in MKE metrics
Storage-based log retention strategy¶
Available since 2.26.0 (17.1.0 and 16.1.0)
StackLight uses a storage-based log retention strategy that optimizes storage utilization and ensures effective data retention. A proportion of available disk space is defined as 80% of disk space allocated for the OpenSearch node with the following data types:
80% for system logs
10% for audit logs
5% for OpenStack notifications (applies only to MOSK clusters)
5% for Kubernetes events
This approach ensures that storage resources are efficiently allocated based on the importance and volume of different data types.
The logging index management implies the following advantages:
- Storage-based rollover mechanism
The rollover mechanism for system and audit indices enforces shard size based on available storage, ensuring optimal resource utilization.
- Consistent shard allocation
The number of primary shards per index is dynamically set based on cluster size, which boosts search and facilitates ingestion for large clusters.
- Minimal size of cluster state
The logging size of the cluster state is minimal and uses static mappings, which are based on Elastic Common Schema (ESC) with slight deviations from the standard. Dynamic mapping in index templates is avoided to reduce overhead.
- Storage compression
The system and audit indices utilize the
best_compressioncodec that minimizes the size of stored indices, resulting in significant storage savings of up to 50% on average.
- No filter by logging level
In light of non-even severity level over components in Container Cloud, logs of all severity levels are collected to prevent ignorance of important logs of low severity while debugging a cluster. Filtering by tags is still available.
See also
Outbound cluster metrics¶
The data collected and transmitted through an encrypted channel back to Mirantis provides our Customer Success Organization information to better understand the operational usage patterns our customers are experiencing as well as to provide feedback on product usage statistics to enable our product teams to enhance our products and services for our customers.
Mirantis collects the following statistics using configuration-collector:
Mirantis collects hardware information using the following metrics:
mcc_hw_machine_chassismcc_hw_machine_cpu_modelmcc_hw_machine_cpu_numbermcc_hw_machine_nicsmcc_hw_machine_rammcc_hw_machine_storage(storage devices and disk layout)mcc_hw_machine_vendor
Mirantis collects the summary of all deployed Container Cloud configurations using the following objects, if any:
Note
The data is anonymized from all sensitive information, such as IDs, IP addresses, passwords, private keys, and so on.
|
|
|
Note
In the Cluster releases 17.0.0, 16.0.0, and 14.1.0, Mirantis does
not collect any configuration summary in light of the
configuration-collector refactoring.
The node-level resource data are broken down into three broad categories: Cluster, Node, and Namespace. The telemetry data tracks Allocatable, Capacity, Limits, Requests, and actual Usage of node-level resources.
Term |
Definition |
|---|---|
Allocatable |
On a Kubernetes Node, the amount of compute resources that are available for pods |
Capacity |
The total number of available resources regardless of current consumption |
Limits |
Constraints imposed by Administrators |
Requests |
The resources that a given container application is requesting |
Usage |
The actual usage or consumption of a given resource |
The full list of the outbound data includes:
From all Container Cloud managed clusters
cluster_alerts_firingSince 2.23.0cluster_filesystem_size_bytescluster_filesystem_usage_bytescluster_filesystem_usage_ratiocluster_master_nodes_totalcluster_nodes_totalcluster_persistentvolumeclaim_requests_storage_bytescluster_total_alerts_triggeredcluster_capacity_cpu_corescluster_capacity_memory_bytescluster_usage_cpu_corescluster_usage_memory_bytescluster_usage_per_capacity_cpu_ratiocluster_usage_per_capacity_memory_ratiocluster_worker_nodes_totalcluster_workload_pods_totalSince 2.22.0cluster_workload_containers_totalSince 2.22.0kaas_infokaas_cluster_machines_ready_totalkaas_cluster_machines_requested_totalkaas_clusterskaas_cluster_updatingSince 2.21.0kaas_license_expirykaas_machines_readykaas_machines_requestedkubernetes_api_availabilitynode_labelsSince 2.24.0mke_api_availabilitymke_cluster_nodes_totalmke_cluster_containers_totalmke_cluster_vcpu_freemke_cluster_vcpu_usedmke_cluster_vram_freemke_cluster_vram_usedmke_cluster_vstorage_freemke_cluster_vstorage_used
From Mirantis OpenStack for Kubernetes (MOSK) clusters only
openstack_cinder_api_latency_90openstack_cinder_api_latency_99openstack_cinder_api_statusRemoved in MOSK 24.1openstack_cinder_availabilityopenstack_cinder_volumes_totalopenstack_glance_api_statusopenstack_glance_availabilityopenstack_glance_images_totalopenstack_glance_snapshots_totalRemoved in MOSK 24.1openstack_heat_availabilityopenstack_heat_stacks_totalopenstack_host_aggregate_instancesRemoved in MOSK 23.2openstack_host_aggregate_memory_used_ratioRemoved in MOSK 23.2openstack_host_aggregate_memory_utilisation_ratioRemoved in MOSK 23.2openstack_host_aggregate_cpu_utilisation_ratioRemoved in MOSK 23.2openstack_host_aggregate_vcpu_used_ratioRemoved in MOSK 23.2openstack_instance_availabilityopenstack_instance_create_endopenstack_instance_create_erroropenstack_instance_create_startopenstack_keystone_api_latency_90openstack_keystone_api_latency_99openstack_keystone_api_statusRemoved in MOSK 24.1openstack_keystone_availabilityopenstack_keystone_tenants_totalopenstack_keystone_users_totalopenstack_kpi_provisioningopenstack_lbaas_availabilityopenstack_mysql_flow_controlopenstack_neutron_api_latency_90openstack_neutron_api_latency_99openstack_neutron_api_statusRemoved in MOSK 24.1openstack_neutron_availabilityopenstack_neutron_lbaas_loadbalancers_totalopenstack_neutron_networks_totalopenstack_neutron_ports_totalopenstack_neutron_routers_totalopenstack_neutron_subnets_totalopenstack_nova_all_compute_cpu_utilisationopenstack_nova_all_compute_mem_utilisationopenstack_nova_all_computes_totalopenstack_nova_all_vcpus_totalopenstack_nova_all_used_vcpus_totalopenstack_nova_all_ram_total_gbopenstack_nova_all_used_ram_total_gbopenstack_nova_all_disk_total_gbopenstack_nova_all_used_disk_total_gbopenstack_nova_api_statusRemoved in MOSK 24.1openstack_nova_availabilityopenstack_nova_compute_cpu_utilisationopenstack_nova_compute_mem_utilisationopenstack_nova_computes_totalopenstack_nova_disk_total_gbopenstack_nova_instances_active_totalopenstack_nova_ram_total_gbopenstack_nova_used_disk_total_gbopenstack_nova_used_ram_total_gbopenstack_nova_used_vcpus_totalopenstack_nova_vcpus_totalopenstack_public_api_statusSince MOSK 22.5openstack_quota_instancesopenstack_quota_ram_gbopenstack_quota_vcpusopenstack_quota_volume_storage_gbopenstack_rmq_message_derivopenstack_usage_instancesopenstack_usage_ram_gbopenstack_usage_vcpusopenstack_usage_volume_storage_gbosdpl_aodh_alarmsSince MOSK 23.3osdpl_api_successSince MOSK 24.1osdpl_cinder_zone_volumesSince MOSK 23.3osdpl_manila_sharesSince MOSK 24.2osdpl_masakari_hostsSince MOSK 24.2osdpl_neutron_availability_zone_infoSince MOSK 23.3osdpl_neutron_zone_routersSince MOSK 23.3osdpl_nova_aggregate_hostsSince MOSK 23.3osdpl_nova_availability_zone_infoSince MOSK 23.3osdpl_nova_availability_zone_instancesSince MOSK 23.3osdpl_nova_availability_zone_hostsSince MOSK 23.3osdpl_version_infoSince MOSK 23.3tf_operator_infoSince MOSK 23.3 for Tungsten Fabric
StackLight proxy¶
StackLight components, which require external access, automatically use the same proxy that is configured for Mirantis Container Cloud clusters. Therefore, you only need to configure proxy during deployment of your management or managed clusters. No additional actions are required to set up proxy for StackLight. For more details about implementation of proxy support in Container Cloud, see Proxy and cache support.
Note
Proxy handles only the HTTP and HTTPS traffic. Therefore, for clusters with limited or no Internet access, it is not possible to set up Alertmanager email notifications, which use SMTP, when proxy is used.
Proxy is used for the following StackLight components:
Component |
Cluster type |
Usage |
|---|---|---|
Alertmanager |
Any |
As a default http_config
for all HTTP-based receivers except the predefined HTTP-alerta and
HTTP-salesforce. For these receivers, |
Metric Collector |
Management |
To send outbound cluster metrics to Mirantis. |
Salesforce notifier |
Any |
To send notifications to the Salesforce instance. |
Salesforce reporter |
Any |
To send metric reports to the Salesforce instance. |
Reference Application for workload monitoring¶
Available since 2.21.0 for non-MOSK managed clusters
Note
For the feature support on MOSK deployments, refer to MOSK documentation: Deploy RefApp using automation tools.
Reference Application is a small microservice application that enables workload monitoring on non-MOSK managed clusters. It mimics a classical microservice application and provides metrics that describe the likely behavior of user workloads.
The application consists of the following API and database services that allow putting simple records into the database through the API and retrieving them:
- Reference Application API
Runs on StackLight nodes and provides API access to the database. Runs three API instances for high availability.
- PostgreSQL Since Container Cloud 2.22.0
Runs on worker nodes and stores the data on an attached PersistentVolumeClaim (PVC). Runs three database instances for high availability.
Note
Before version 2.22.0, Container Cloud used MariaDB as the database management system instead of PostgreSQL.
StackLight queries the API measuring response times for each query. No caching is being done, so each API request must go to the database, allowing to verify the availability of a stateful workload on the cluster.
Reference Application requires the following resources on top of the main product requirements:
Up to 1 GiB of RAM per cluster
Up to 3 GiB of storage per cluster
The feature is disabled by default and can be enabled using the StackLight configuration manifest as described in StackLight configuration parameters: Reference Application.
Hardware and system requirements¶
Using Mirantis Container Cloud, you can deploy a Mirantis Kubernetes Engine (MKE) cluster on bare metal, OpenStack, or VMware vSphere cloud providers. Each cloud provider requires corresponding resources.
Requirements for a bootstrap node¶
A bootstrap node is necessary only to deploy the management cluster. When the bootstrap is complete, the bootstrap node can be redeployed and its resources can be reused for the managed cluster workloads.
The minimum reference system requirements of a baremetal-based bootstrap seed node are described in System requirements for the seed node. The minimum reference system requirements a bootstrap node for other supported Container Cloud providers are as follows:
Any local machine on Ubuntu 20.04 that requires access to the provider API with the following configuration:
2 vCPUs
4 GB of RAM
5 GB of available storage
Docker version currently available for Ubuntu 20.04
Internet access for downloading of all required artifacts
Note
For the vSphere cloud provider, you can also use RHEL 8.7 with the same system requirements as for Ubuntu.
Requirements for a baremetal-based cluster¶
If you use a firewall or proxy, make sure that the bootstrap and management clusters have access to the following IP ranges and domain names required for the Container Cloud content delivery network and alerting:
IP ranges:
Microsoft Azure (only IPs for
MicrosoftContainerRegistry)Amazon AWS (only IPs for
"service": "CLOUDFRONT")
Domain names:
mirror.mirantis.com and repos.mirantis.com for packages
binary.mirantis.com for binaries and Helm charts
mirantis.azurecr.io and *.blob.core.windows.net for Docker images
mcc-metrics-prod-ns.servicebus.windows.net:9093 for Telemetry (port 443 if proxy is enabled)
mirantis.my.salesforce.com and login.salesforce.com for Salesforce alerts
Note
Access to Salesforce is required from any Container Cloud cluster type.
If any additional Alertmanager notification receiver is enabled, for example, Slack, its endpoint must also be accessible from the cluster.
Caution
Regional clusters are unsupported since Container Cloud 2.25.0. Mirantis does not perform functional integration testing of the feature and the related code is removed in Container Cloud 2.26.0. If you still require this feature, contact Mirantis support for further information.
Reference hardware configuration¶
The following hardware configuration is used as a reference to deploy Mirantis Container Cloud with bare metal Container Cloud clusters with Mirantis Kubernetes Engine.
Server role |
Management cluster |
Managed cluster |
|---|---|---|
# of servers |
3 1 |
6 2 |
CPU cores |
Minimal: 16
Recommended: 32
|
Minimal: 16
Recommended: depends on workload
|
RAM, GB |
Minimal: 64
Recommended: 256
|
Minimal: 64
Recommended: 128
|
System disk, GB 3 |
Minimal: SSD 1x 120
Recommended: NVME 1 x 960
|
Minimal: SSD 1 x 120
Recommended: NVME 1 x 960
|
SSD/HDD storage, GB |
1 x 1900 4 |
2 x 1900 |
NICs 5 |
Minimal: 1 x 2-port
Recommended: 2 x 2-port
|
Minimal: 2 x 2-port
Recommended: depends on workload
|
- 1
Adding more than 3 nodes to a management cluster is not supported.
- 2
Three
managernodes for HA and threeworker storagenodes for a minimal Ceph cluster.- 3
A management cluster requires 2 volumes for Container Cloud (total 50 GB) and 5 volumes for StackLight (total 60 GB). A managed cluster requires 5 volumes for StackLight.
- 4
In total, at least 2 disks are required:
disk0- minimum 120 GB for systemdisk1- minimum 120 GB forLocalVolumeProvisioner
For the default storage schema, see Default configuration of the host system storage
- 5
Only one PXE port per node is allowed. The out-of-band management (IPMI) port is not included.
System requirements for the seed node¶
The seed node is necessary only to deploy the management cluster. When the bootstrap is complete, the bootstrap node can be redeployed and its resources can be reused for the managed cluster workloads.
The minimum reference system requirements for a baremetal-based bootstrap seed node are as follows:
Basic server on Ubuntu 20.04 with the following configuration:
Kernel version 4.15.0-76.86 or later
8 GB of RAM
4 CPU
10 GB of free disk space for the bootstrap cluster cache
No DHCP or TFTP servers on any NIC networks
Routable access IPMI network for the hardware servers. For more details, see Host networking.
Internet access for downloading of all required artifacts
Network fabric¶
The following diagram illustrates the physical and virtual L2 underlay networking schema for the final state of the Mirantis Container Cloud bare metal deployment.
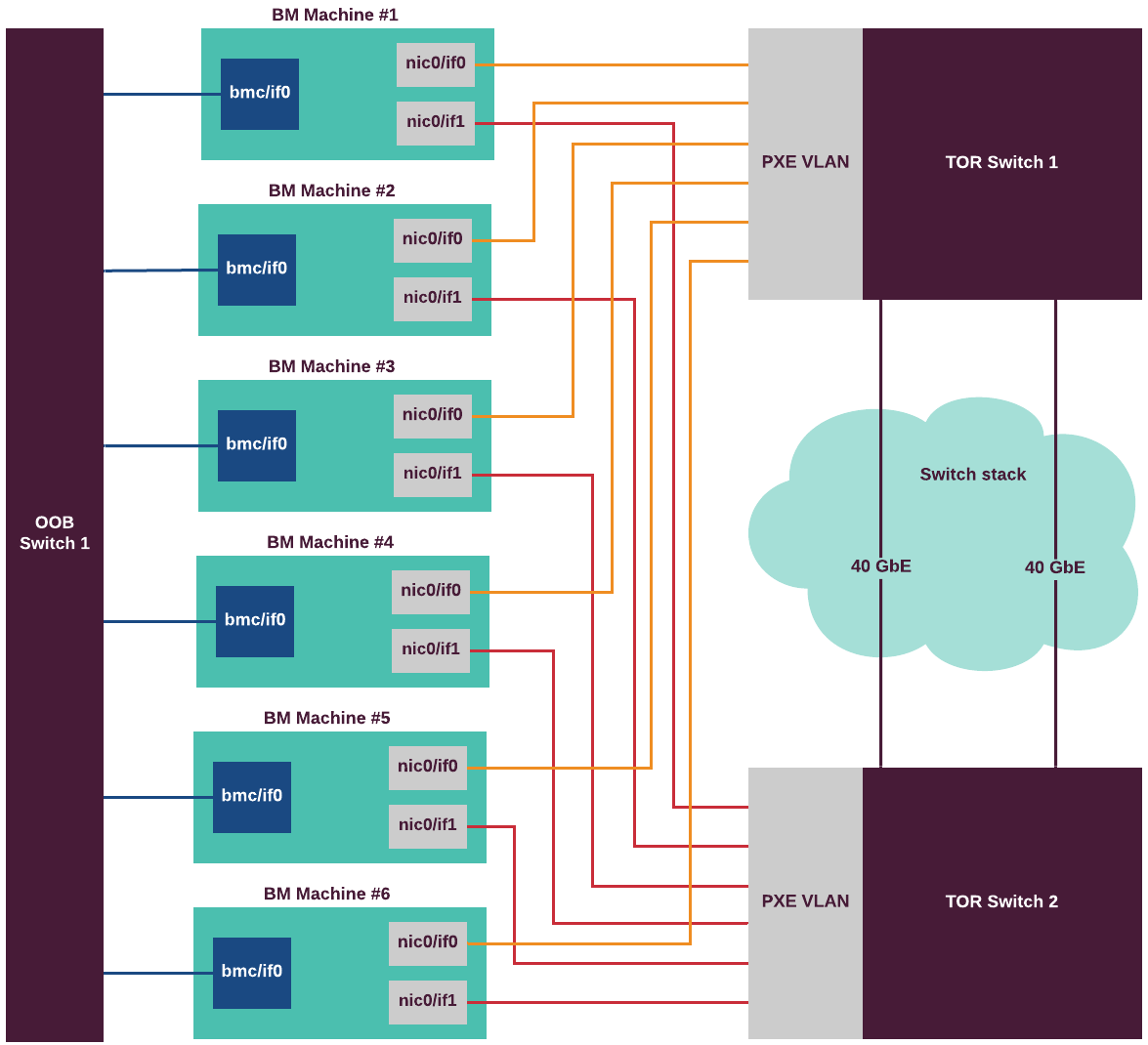
The network fabric reference configuration is a spine/leaf with 2 leaf ToR switches and one out-of-band (OOB) switch per rack.
Reference configuration uses the following switches for ToR and OOB:
Cisco WS-C3560E-24TD has 24 of 1 GbE ports. Used in OOB network segment.
Dell Force 10 S4810P has 48 of 1/10GbE ports. Used as ToR in Common/PXE network segment.
In the reference configuration, all odd interfaces from NIC0 are connected
to TOR Switch 1, and all even interfaces from NIC0 are connected
to TOR Switch 2. The Baseboard Management Controller (BMC) interfaces
of the servers are connected to OOB Switch 1.
The following recommendations apply to all types of nodes:
Use the Link Aggregation Control Protocol (LACP) bonding mode with MC-LAG domains configured on leaf switches. This corresponds to the
802.3adbond mode on hosts.Use ports from different multi-port NICs when creating bonds. This makes network connections redundant if failure of a single NIC occurs.
Configure the ports that connect servers to the PXE network with PXE VLAN as native or untagged. On these ports, configure LACP fallback to ensure that the servers can reach DHCP server and boot over network.
See also
DHCP range requirements for PXE¶
When setting up the network range for DHCP Preboot Execution Environment (PXE), keep in mind several considerations to ensure smooth server provisioning:
Determine the network size. For instance, if you target a concurrent provision of 50+ servers, a /24 network is recommended. This specific size is crucial as it provides sufficient scope for the DHCP server to provide unique IP addresses to each new Media Access Control (MAC) address, thereby minimizing the risk of collision.
The concept of collision refers to the likelihood of two or more devices being assigned the same IP address. With a /24 network, the collision probability using the SDBM hash function, which is used by the DHCP server, is low. If a collision occurs, the DHCP server provides a free address using a linear lookup strategy.
In the context of PXE provisioning, technically, the IP address does not need to be consistent for every new DHCP request associated with the same MAC address. However, maintaining the same IP address can enhance user experience, making the /24 network size more of a recommendation than an absolute requirement.
For a minimal network size, it is sufficient to cover the number of concurrently provisioned servers plus one additional address (50 + 1). This calculation applies after covering any exclusions that exist in the range. You can define excludes in the corresponding field of the
Subnetobject. For details, see API Reference: Subnet resource.When the available address space is less than the minimum described above, you will not be able to automatically provision all servers. However, you can manually provision them by combining manual IP assignment for each bare metal host with manual pauses. For these operations, use the
host.dnsmasqs.metal3.io/addressandbaremetalhost.metal3.io/detachedannotations in theBareMetalHostobject. For details, see Operations Guide: Manually allocate IP addresses for bare metal hosts.All addresses within the specified range must remain unused before provisioning. If an IP address in-use is issued by the DHCP server to a BOOTP client, that specific client cannot complete provisioning.
Management cluster storage¶
The management cluster requires minimum two storage devices per node. Each device is used for different type of storage.
The first device is always used for boot partitions and the root file system. SSD is recommended. RAID device is not supported.
One storage device per server is reserved for local persistent volumes. These volumes are served by the Local Storage Static Provisioner (
local-volume-provisioner) and used by many services of Container Cloud.
You can configure host storage devices using the BareMetalHostProfile
resources. For details, see Customize the default bare metal host profile.
Requirements for an OpenStack-based cluster¶
While planning the deployment of an OpenStack-based Mirantis Container Cloud cluster with Mirantis Kubernetes Engine (MKE), consider the following general requirements:
Kubernetes on OpenStack requires the Cinder API V3 and Octavia API availability.
Mirantis supports deployments based on OpenStack Victoria or Yoga with Open vSwitch (OVS) or Tungsten Fabric (TF) on top of Mirantis OpenStack for Kubernetes (MOSK) Victoria or Yoga with TF.
For system requirements for a bootstrap node, see Requirements for a bootstrap node.
If you use a firewall or proxy, make sure that the bootstrap and management clusters have access to the following IP ranges and domain names required for the Container Cloud content delivery network and alerting:
IP ranges:
Microsoft Azure (only IPs for
MicrosoftContainerRegistry)Amazon AWS (only IPs for
"service": "CLOUDFRONT")
Domain names:
mirror.mirantis.com and repos.mirantis.com for packages
binary.mirantis.com for binaries and Helm charts
mirantis.azurecr.io and *.blob.core.windows.net for Docker images
mcc-metrics-prod-ns.servicebus.windows.net:9093 for Telemetry (port 443 if proxy is enabled)
mirantis.my.salesforce.com and login.salesforce.com for Salesforce alerts
Note
Access to Salesforce is required from any Container Cloud cluster type.
If any additional Alertmanager notification receiver is enabled, for example, Slack, its endpoint must also be accessible from the cluster.
Caution
Regional clusters are unsupported since Container Cloud 2.25.0. Mirantis does not perform functional integration testing of the feature and the related code is removed in Container Cloud 2.26.0. If you still require this feature, contact Mirantis support for further information.
Note
The requirements in this section apply to the latest supported Container Cloud release.
Resource |
Management cluster |
Managed cluster |
Comments |
|---|---|---|---|
# of nodes |
3 (HA) + 1 (Bastion) |
5 (6 with StackLight HA) |
|
# of vCPUs per node |
8 |
8 |
|
RAM in GB per node |
24 |
16 |
To prevent issues with low RAM, Mirantis recommends the following types of instances for a managed cluster with 50-200 nodes:
The Bastion node requires 1 GB of RAM. |
Storage in GB per node |
120 |
120 |
|
Operating system |
Ubuntu 20.04
CentOS 7.9 0
|
Ubuntu 20.04
CentOS 7.9 0
|
For management and managed clusters, a base Ubuntu 20.04 or CentOS 7.9 image must be present in Glance. |
MCR |
23.0.9 Since 16.1.0
23.0.7 Since 16.0.0
20.10.17 Since 14.0.0
20.10.13 Before 14.0.0
|
23.0.9 Since 16.1.0
23.0.7 Since 16.0.0
20.10.17 Since 14.0.0
20.10.13 Before 14.0.0
|
Mirantis Container Runtime (MCR) is deployed by Container Cloud as a Container Runtime Interface (CRI) instead of Docker Engine. |
OpenStack version |
Queens, Victoria, Yoga |
Queens, Victoria, Yoga |
OpenStack Victoria and Yoga are supported on top of MOSK clusters. |
Obligatory OpenStack components |
Octavia, Cinder, OVS/TF |
Octavia, Cinder, OVS/TF |
|
# of Cinder volumes |
7 (total 110 GB) |
5 (total 60 GB) |
|
# of load balancers |
10 |
6 |
|
# of floating IPs |
11 |
11 |
|
Requirements for a VMware vSphere-based cluster¶
Note
Container Cloud is developed and tested on VMware vSphere 7.0 and 6.7.
For system requirements for a bootstrap node, see Requirements for a bootstrap node.
If you use a firewall or proxy, make sure that the bootstrap and management clusters have access to the following IP ranges and domain names required for the Container Cloud content delivery network and alerting:
IP ranges:
Microsoft Azure (only IPs for
MicrosoftContainerRegistry)Amazon AWS (only IPs for
"service": "CLOUDFRONT")
Domain names:
mirror.mirantis.com and repos.mirantis.com for packages
binary.mirantis.com for binaries and Helm charts
mirantis.azurecr.io and *.blob.core.windows.net for Docker images
mcc-metrics-prod-ns.servicebus.windows.net:9093 for Telemetry (port 443 if proxy is enabled)
mirantis.my.salesforce.com and login.salesforce.com for Salesforce alerts
Note
Access to Salesforce is required from any Container Cloud cluster type.
If any additional Alertmanager notification receiver is enabled, for example, Slack, its endpoint must also be accessible from the cluster.
Caution
Regional clusters are unsupported since Container Cloud 2.25.0. Mirantis does not perform functional integration testing of the feature and the related code is removed in Container Cloud 2.26.0. If you still require this feature, contact Mirantis support for further information.
Note
The requirements in this section apply to the latest supported Container Cloud release.
System requirements¶
Resource |
Management cluster |
Managed cluster |
Comments |
|---|---|---|---|
# of nodes |
3 (HA) |
5 (6 with StackLight HA) |
|
# of vCPUs per node |
8 |
8 |
Refer to the RAM recommendations described below to plan resources for different types of nodes. |
RAM in GB per node |
32 |
16 |
To prevent issues with low RAM, Mirantis recommends the following VM templates for a managed cluster with 50-200 nodes:
|
Storage in GB per node |
120 |
120 |
The listed amount of disk space must be available as a shared datastore of any type, for example, NFS or vSAN, mounted on all hosts of the vCenter cluster. |
Operating system |
RHEL 8.7 1
Ubuntu 20.04
|
RHEL 8.7 1
Ubuntu 20.04
|
For a management and managed cluster, a base OS VM template must be present in the VMware VM templates folder available to Container Cloud. For details, see VsphereVMTemplate. |
RHEL license
(for RHEL deployments only)
|
This license type allows running unlimited guests inside one hypervisor. The amount of licenses is equal to the amount of hypervisors in vCenter Server, which will be used to host RHEL-based machines. Container Cloud will schedule machines according to scheduling rules applied to vCenter Server. Therefore, make sure that your RedHat Customer portal account has enough licenses for allowed hypervisors. |
||
MCR |
23.0.9 Since 16.1.0
23.0.7 Since 16.0.1
20.10.17 Since 14.0.0
|
23.0.9 Since 16.1.0
23.0.7 Since 16.0.1
20.10.17 Since 14.0.0
|
Mirantis Container Runtime (MCR) is deployed by Container Cloud as a Container Runtime Interface (CRI) instead of Docker Engine. |
VMware vSphere version |
7.0, 6.7 |
7.0, 6.7 |
|
cloud-init version |
20.3 for RHEL |
20.3 for RHEL |
The minimal |
VMware Tools version |
11.0.5 |
11.0.5 |
The minimal |
Obligatory vSphere capabilities |
DRS,
Shared datastore
|
DRS,
Shared datastore
|
A shared datastore must be mounted on all hosts of the vCenter cluster. Combined with Distributed Resources Scheduler (DRS), it ensures that the VMs are dynamically scheduled to the cluster hosts. |
IP subnet size |
/24 |
/24 |
Consider the supported VMware vSphere network objects and IPAM recommendations. Minimal IP addresses distribution:
|
Deployment resources requirements¶
The VMware vSphere provider of Mirantis Container Cloud requires the following resources to successfully create virtual machines for Container Cloud clusters:
- Data center
All resources below must be related to one data center.
- Cluster
All virtual machines must run on the hosts of one cluster.
- Virtual Network or Distributed Port Group
Network for virtual machines. For details, see VMware vSphere network objects and IPAM recommendations.
- Datastore
Storage for virtual machines disks and Kubernetes volumes.
- Folder
Placement of virtual machines.
- Resource pool
Pool of CPU and memory resources for virtual machines.
You must provide the data center and cluster resources by name. You can provide other resources by:
- Name
Resource name must be unique in the data center and cluster. Otherwise, the vSphere provider detects multiple resources with same name and cannot determine which one to use.
- Full path (recommended)
Full path to a resource depends on its type. For example:
- Network
/<data_center>/network/<network_name>
- Resource pool
/<data_center>/host/<cluster>/Resources/<resource pool_name>
- Folder
/<data_center>/vm/<folder1>/<folder2>/.../<folder_name>or/<data_center>/vm/<folder_name>
- Datastore
/<data_center>/datastore/<datastore_name>
You can determine the proper resource name using the vSphere UI.
To obtain the full path to vSphere resources:
Download the latest version of GOVC utility depending on your operating system and unpack the
govcbinary intoPATHon your machine.Set the environment variables to access your vSphere cluster. For example:
export GOVC_USERNAME=user export GOVC_PASSWORD=password export GOVC_URL=https://vcenter.example.com
List the data center root using the govc ls command. Example output:
/<data_center>/vm /<data_center>/network /<data_center>/host /<data_center>/datastore
Obtain the full path to resources by name for:
Network or Distributed Port Group (Distributed Virtual Port Group):
govc find /<data_center> -type n -name <network_name>
Datastore:
govc find /<data_center> -type s -name <datastore_name>
Folder:
govc find /<data_center> -type f -name <folder_name>
Resource pool:
govc find /<data_center> -type p -name <resource_pool_name>
Verify the resource type by full path:
govc object.collect -json -o "<full_path_to_resource>" | jq .Self.Type
StackLight requirements for an MKE attached cluster¶
Available since 2.25.2
During attachment of a Mirantis Kubernetes Engine (MKE) cluster that is not deployed by Container Cloud to a vSphere-based management cluster, you can add StackLight as the logging, monitoring, and alerting solution. In this scenario, your cluster must satisfy several requirements that primarily involve alignment of cluster resources with specific StackLight settings.
General requirements¶
While planning the attachment of an existing MKE cluster that is not deployed by Container Cloud to a vSphere-based management cluster, consider the following general requirements for StackLight:
For StackLight in non-HA mode, make sure that you have the default storage class configured on the MKE cluster being attached. To select and configure a persistent storage for StackLight, refer to MKE documentation: Persistent Kubernetes storage.
Allow the StackLight monitoring agents (Node Exporter and Fluentd) to schedule on the MKE manager and MSR nodes as described in Allow services deployment on Kubernetes MKE manager or MSR nodes.
Make sure that StackLight can create
LoadBalancerServices in the cluster to externally expose StackLight web UIs.
Note
Attachment of MKE clusters is tested on Ubuntu 20.04.
Requirements for cluster size¶
While planning the attachment of an existing MKE cluster that is not deployed by Container Cloud to a vSphere-based management cluster, consider the cluster size requirements for StackLight. Depending on the following specific StackLight HA and logging settings, use the example size guidelines below:
The non-HA mode - StackLight services are installed on a minimum of one node with the StackLight label (StackLight nodes) with no redundancy using Persistent Volumes (PVs) from the default storage class to store data. Metric collection agents are installed on each node (Other nodes).
The HA mode - StackLight services are installed on a minimum of three nodes with the StackLight label (StackLight nodes) with redundancy using PVs provided by Local Volume Provisioner to store data. Metric collection agents are installed on each node (Other nodes).
Logging enabled - the Enable logging option is turned on, which enables the OpenSearch cluster to store infrastructure logs.
Logging disabled - the Enable logging option is turned off. In this case, StackLight will not install OpenSearch and will not collect infrastructure logs.
LoadBalancer (LB) Services support is required to provide external access
to StackLight web UIs.
StackLight nodes 1 |
Other nodes |
Storage (PVs) |
LBs |
|
Non-HA (1-node example) |
|
|
|
5 |
HA (3-nodes example) |
|
|
|
5 |
StackLight nodes 1 |
Other nodes |
Storage (PVs) |
LBs |
|
Non-HA (1-node example) |
|
|
|
4 |
HA (3-nodes example) |
|
|
|
4 |
- 1(1,2)
In the non-HA mode, StackLight components are bound to the nodes labeled with the StackLight label. If there are no nodes labeled, StackLight components will be scheduled to all schedulable worker nodes until the StackLight label(s) are added. The requirements presented in the table for the non-HA mode are summarized requirements for all StackLight nodes.
Proxy and cache support¶
Proxy support¶
If you require all Internet access to go through a proxy server for security and audit purposes, you can bootstrap management clusters using proxy. The proxy server settings consist of three standard environment variables that are set prior to the bootstrap process:
HTTP_PROXYHTTPS_PROXYNO_PROXY
These settings are not propagated to managed clusters. However, you can enable a separate proxy access on a managed cluster using the Container Cloud web UI. This proxy is intended for the end user needs and is not used for a managed cluster deployment or for access to the Mirantis resources.
Caution
Since Container Cloud uses the OpenID Connect (OIDC) protocol for IAM authentication, management clusters require a direct non-proxy access from managed clusters.
StackLight components, which require external access, automatically use the same proxy that is configured for Container Cloud clusters.
On the managed clusters with limited Internet access, a proxy is required for StackLight components that use HTTP and HTTPS and are disabled by default but need external access if enabled, for example, for the Salesforce integration and Alertmanager notifications external rules. For more details about proxy implementation in StackLight, see StackLight proxy.
For the list of Mirantis resources and IP addresses to be accessible from the Container Cloud clusters, see Hardware and system requirements.
After enabling proxy support on managed clusters, proxy is used for:
Docker traffic on managed clusters
StackLight
OpenStack on MOSK-based clusters
Warning
Any modification to the Proxy object used in any cluster, for
example, changing the proxy URL, NO_PROXY values, or
certificate, leads to cordon-drain and Docker
restart on the cluster machines.
Artifacts caching¶
The Container Cloud managed clusters are deployed without direct Internet access in order to consume less Internet traffic in your cloud. The Mirantis artifacts used during managed clusters deployment are downloaded through a cache running on a management cluster. The feature is enabled by default on new managed clusters and will be automatically enabled on existing clusters during upgrade to the latest version.
Caution
IAM operations require a direct non-proxy access of a managed cluster to a management cluster.
MKE API limitations¶
To ensure the Mirantis Container Cloud stability in managing the Container Cloud-based Mirantis Kubernetes Engine (MKE) clusters, the following MKE API functionality is not available for the Container Cloud-based MKE clusters as compared to the MKE clusters that are deployed not by Container Cloud. Use the Container Cloud web UI or CLI for this functionality instead.
API endpoint |
Limitation |
|---|---|
|
Swarm Join Tokens are filtered out for all users, including admins. |
|
All requests are forbidden. |
|
Requests for the following changes are forbidden:
|
|
All requests are forbidden. |
See also
MKE configuration management¶
This section describes configuration specifics of an MKE cluster deployed using Container Cloud.
MKE configuration managed by Container Cloud¶
Since 2.25.1 (Cluster releases 16.0.1 and 17.0.1), Container Cloud does not override changes in MKE configuration except the following list of parameters that are automatically managed by Container Cloud. These parameters are always overridden by the Container Cloud default values if modified direclty using the MKE API. For details on configuration using the MKE API, see MKE configuration managed directly by the MKE API.
However, you can manually configure a few options from this list using the
Cluster object of a Container Cloud cluster. They are labeled with the
superscript and contain references to the
respective configuration procedures in the Comments columns of the tables.
[audit_log_configuration]¶
MKE parameter name |
Default value in Container Cloud |
Comments |
|---|---|---|
|
You can configure this option either using MKE API with no Container Cloud
overrides or using the If configured using the |
|
|
|
For configuration procedure, see comments above. |
[auth]¶
MKE parameter name |
Default value in Container Cloud |
|---|---|
|
|
|
|
|
|
|
|
[auth.external_identity_provider]¶
MKE parameter name |
Default value in Container Cloud |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
[hardening_configuration]¶
MKE parameter name |
Default value in Container Cloud |
|---|---|
|
|
|
|
|
|
|
|
|
|
[scheduling_configuration]¶
MKE parameter name |
Default value in Container Cloud |
|---|---|
|
|
|
|
[tracking_configuration]¶
MKE parameter name |
Default value in Container Cloud |
|---|---|
|
|
[cluster_config]¶
MKE parameter name |
Default value in Container Cloud |
Comments |
|---|---|---|
|
|
|
|
|
For configuration steps, see Set the MTU size for Calico. |
|
|
|
|
|
|
|
|
|
|
|
Depends on the selected cloud provider. |
|
|
|
|
|
Applies only to MKE on the management cluster. |
|
|
|
|
|
|
|
|
|
|
|
For configuration steps, see Increase storage quota for etcd. |
|
|
|
|
|
|
|
For configuration steps, see Configure Kubernetes auditing and profiling. |
|
|
|
|
|
|
|
|
|
|
|
|
For configuration steps, see Configure Kubernetes auditing and profiling. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
You can override this value in |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
You can override this value in |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- 2(1,2)
The
CSIMigrationvSphereflag applies only to the vSphere provider since 2.25.1.- 3(1,2)
For
priv_attributesparameters, you can add custom options on top of existing parameters using the MKE API.- 4
For management clusters since 2.26.0 (Cluster release 16.1.0).
- 5
For management and managed clusters since 2.24.3 (Cluster releases 15.0.2 and 14.0.2).
- 6(1,2,3)
For management and managed clusters since 2.27.0 (Cluster releases 17.2.0 and 16.2.0). For configuration steps, see Configure Kubernetes auditing and profiling.
Note
All possible values for parameters labeled with the
superscript, which you can manually
configure using the Cluster object are described in
MKE Operations Guide: Configuration options.
MKE configuration managed directly by the MKE API¶
Since 2.25.1, aside from MKE parameters described in MKE configuration managed by Container Cloud, Container Cloud does not override changes in MKE configuration that are applied directly through the MKE API. For the configuration options and procedure, see MKE documentation:
Configure an existing MKE cluster
While using this procedure, replace the command to upload the newly edited MKE configuration file with the following one:
curl --silent --insecure -X PUT -H "X-UCP-Allow-Restricted-API: i-solemnly-swear-i-am-up-to-no-good" -H "accept: application/toml" -H "Authorization: Bearer $AUTHTOKEN" --upload-file 'mke-config.toml' https://$MKE_HOST/api/ucp/config-toml
Important
Mirantis cannot guarrantee the expected behavior of the functionality configured using the MKE API as long as customer-specific configuration does not undergo testing within Container Cloud. Therefore, Mirantis recommends that you test custom MKE settings configured through the MKE API on a staging environment before applying them to production.
Deployment Guide¶
Deploy a Container Cloud management cluster¶
Note
The deprecated bootstrap procedure using Bootstrap v1 was removed for the sake of Bootstrap v2 in Container Cloud 2.26.0.
Introduction¶
Available since 2.25.0
Mirantis Container Cloud Bootstrap v2 provides best user experience to set up Container Cloud. Using Bootstrap v2, you can provision and operate management clusters using required objects through the Container Cloud web UI.
Basic concepts and components of Bootstrap v2 include:
- Bootstrap cluster
Bootstrap cluster is any kind-based Kubernetes cluster that contains a minimal set of Container Cloud bootstrap components allowing the user to prepare the configuration for management cluster deployment and start the deployment. The list of these components includes:
- Bootstrap Controller
Controller that is responsible for:
Configuration of a bootstrap cluster with provider-specific charts through the bootstrap Helm bundle.
Configuration and deployment of a management cluster and its related objects.
- Helm Controller
Operator that manages Helm chart releases. It installs the Container Cloud bootstrap and provider-specific charts configured in the bootstrap Helm bundle.
- Public API charts
Helm charts that contain custom resource definitions for Container Cloud resources of supported providers.
- Admission Controller
Controller that performs mutations and validations for the Container Cloud resources including cluster and machines configuration.
- Bootstrap web UI
User-friendly web interface to prepare the configuration for a management cluster deployment.
Currently one bootstrap cluster can be used for deployment of only one management cluster. For example, to add a new management cluster with different settings, a new bootstrap cluster must be recreated from scratch.
- Bootstrap region
BootstrapRegionis the first object to create in the bootstrap cluster for the Bootstrap Controller to identify and install required provider components onto the bootstrap cluster. After, the user can prepare and deploy a management cluster with related resources.The bootstrap region is a starting point for the cluster deployment. The user needs to approve the
BootstrapRegionobject. Otherwise, the Bootstrap Controller will not be triggered for the cluster deployment.
- Bootstrap Helm bundle
Helm bundle that contains charts configuration for the bootstrap cluster. This object is managed by the Bootstrap Controller that updates the bundle depending on a provider selected by the user in the
BootstrapRegionobject. The Bootstrap Controller always configures provider-related charts listed in theregionalsection of the Container Cloud release for the selected provider. Depending on the provider and cluster configuration, the Bootstrap Controller may update or reconfigure this bundle even after the cluster deployment starts. For example, the Bootstrap Controller enables the provider in the bootstrap cluster only after the bootstrap region is approved for the deployment.
Overview of the deployment workflow¶
Management cluster deployment consists of several sequential stages. Each stage finishes when a specific condition is met or specific configuration applies to a cluster or its machines.
In case of issues at any deployment stage, you can identify the problem
and adjust it on the fly. The cluster deployment does not abort until all
stages complete by means of the infinite-timeout option enabled
by default in Bootstrap v2.
Infinite timeout prevents the bootstrap failure due to timeout. This option is useful in the following cases:
The network speed is slow for artifacts downloading
An infrastructure configuration does not allow booting fast
A bare-metal node inspecting presupposes more than two HDDSATA disks to attach to a machine
You can track the status of each stage in the bootstrapStatus section of
the Cluster object that is updated by the Bootstrap Controller.
The Bootstrap Controller starts deploying the cluster after you approve the
BootstrapRegion configuration.
The following table describes deployment states of a management cluster that apply in the strict order.
Step |
State |
Description |
|---|---|---|
1 |
|
Verifies proxy configuration in the |
2 |
|
Verifies SSH configuration for the cluster and machines. You can provide any number of SSH public keys, which are added to
cluster machines. But the Bootstrap Controller always adds the
The |
3 |
|
Synchronizes the provider and settings of its components between the
|
4 |
|
Enables the provider and its components if any were disabled by the Bootstrap Controller during preparation of the bootstrap region. A cluster and machines deployment starts after the provider enablement. |
5 |
Nodes readiness |
Waits for the provider to complete nodes deployment that comprises VMs creation and MKE installation. |
6 |
|
Creates required namespaces and IAM secrets. |
7 |
|
Verifies the provider configuration in the provisioned cluster. |
8 |
|
Verifies the Helm bundle readiness for the provisioned cluster. |
9 |
|
Collects the list of deployment controllers and disables them to prepare for pivot. |
10 |
|
Moves all cluster-related objects from the bootstrap cluster to the
provisioned cluster. The copies of |
11 |
|
Enables controllers in the provisioned cluster. |
12 |
|
Updates the |
13 |
|
Disables the Helm Controller before reconfiguration. |
14 |
|
Updates the Helm Controller configuration for the provisioned cluster. |
15 |
Cluster readiness |
Contains information about the global cluster status. The Bootstrap Controller verifies that OIDC, Helm releases, and all Deployments are ready. Once the cluster is ready, the Bootstrap Controller stops managing the cluster. |
Set up a bootstrap cluster¶
The setup of a bootstrap cluster comprises preparation of the seed node, configuration of environment variables, acquisition of the Container Cloud license file, and execution of the bootstrap script. The script eventually generates a link to the Bootstrap web UI for the management cluster deployment.
To set up a bootstrap cluster:
Prepare the seed node:
Bare metal
Verify that the hardware allocated for the installation meets the minimal requirements described in Requirements for a baremetal-based cluster.
Install basic Ubuntu 20.04 server using standard installation images of the operating system on the bare metal seed node.
Log in to the seed node that is running Ubuntu 20.04.
Prepare the system and network configuration:
Establish a virtual bridge using an IP address of the PXE network on the seed node. Use the following
netplan-based configuration file as an example:# cat /etc/netplan/config.yaml network: version: 2 renderer: networkd ethernets: ens3: dhcp4: false dhcp6: false bridges: br0: addresses: # Replace with IP address from PXE network to create a virtual bridge - 10.0.0.15/24 dhcp4: false dhcp6: false # Adjust for your environment gateway4: 10.0.0.1 interfaces: # Interface name may be different in your environment - ens3 nameservers: addresses: # Adjust for your environment - 8.8.8.8 parameters: forward-delay: 4 stp: false
Apply the new network configuration using
netplan:sudo netplan apply
Verify the new network configuration:
sudo apt update && sudo apt install -y bridge-utils sudo brctl show
Example of system response:
bridge name bridge id STP enabled interfaces br0 8000.fa163e72f146 no ens3
Verify that the interface connected to the PXE network belongs to the previously configured bridge.
Install the current Docker version available for Ubuntu 20.04:
sudo apt-get update sudo apt-get install docker.io
Verify that your logged
USERhas access to the Docker daemon:sudo usermod -aG docker $USER
Log out and log in again to the seed node to apply the changes.
Verify that Docker is configured correctly and has access to Container Cloud CDN. For example:
docker run --rm alpine sh -c "apk add --no-cache curl; \ curl https://binary.mirantis.com"
The system output must contain a
jsonfile with no error messages. In case of errors, follow the steps provided in Troubleshooting.Note
If you require all Internet access to go through a proxy server for security and audit purposes, configure Docker proxy settings as described in the official Docker documentation.
Verify that the seed node has direct access to the Baseboard Management Controller (BMC) of each bare metal host. All target hardware nodes must be in the
power offstate.For example, using the IPMI tool:
apt install ipmitool ipmitool -I lanplus -H 'IPMI IP' -U 'IPMI Login' -P 'IPMI password' \ chassis power status
Example of system response:
Chassis Power is off
OpenStack
Verify that the hardware allocated for installation meets minimal requirements described in Requirements for an OpenStack-based cluster.
Configure Docker:
Log in to any personal computer or VM running Ubuntu 20.04 that you will be using as the bootstrap node.
If you use a newly created VM, run:
sudo apt-get update
Install the current Docker version available for Ubuntu 20.04:
sudo apt install docker.io
Grant your
USERaccess to the Docker daemon:sudo usermod -aG docker $USER
Log off and log in again to the bootstrap node to apply the changes.
Verify that Docker is configured correctly and has access to Container Cloud CDN. For example:
docker run --rm alpine sh -c "apk add --no-cache curl; \ curl https://binary.mirantis.com"
The system output must contain no error records. In case of issues, follow the steps provided in Troubleshooting.
vSphere
Verify that the hardware allocated for installation meets minimal requirements described in Requirements for a VMware vSphere-based cluster.
Configure Ubuntu or RHEL on the bootstrap node:
Ubuntu:
Log in to any personal computer or VM running Ubuntu 20.04 that you will be using as the bootstrap node.
If you use a newly created VM, run:
sudo apt-get update
Install the current Docker version available for Ubuntu 20.04:
sudo apt install docker.io
Grant your
USERaccess to the Docker daemon:sudo usermod -aG docker $USER
Log off and log in again to the bootstrap node to apply the changes.
Verify that Docker is configured correctly and has access to Container Cloud CDN. For example:
docker run --rm alpine sh -c "apk add --no-cache curl; \ curl https://binary.mirantis.com"
The system output must contain no error records. In case of issues, follow the steps provided in Troubleshooting.
RHEL:
Note
RHEL 8.7 is generally available for a bootstrap node since Container Cloud 2.25.0. Before that, it is supported as Technology Preview.
Log in to a VM running RHEL 8.7 that you will be using as a bootstrap node.
Recommended. To avoid the potential Kubernetes upstream issue 3372 causing the cluster re-creation failure, apply the following workaround:
Update the
GRUB_CMDLINE_LINUXparameter in the/etc/default/grubfile with thesystemd.unified_cgroup_hierarchy=1option.Update the grub configuration:
grub2-mkconfig -o /boot/grub2/grub.cfg
Reboot the seed node.
If you do not use RedHat Satellite server locally in your infrastructure and require all Internet access to go through a proxy server, including access to RedHat customer portal, configure proxy parameters for
subscription-managerusing the example below:subscription-manager config \ --server.proxy_scheme=$SCHEME \ --server.proxy_hostname=$HOST \ --server.proxy_port=$PORT \ --server.proxy_user=$USER \ --server.proxy_password=$PASS \ --server.no_proxy=$NO_PROXY
Caution
In MITM proxy deployments, use the internal Red Hat Satellite server to register RHEL machines so that a VM can access this server directly without a MITM proxy.
Attach the RHEL subscription using
subscription-manager.Install the following packages:
sudo yum install yum-utils wget vim -y
Add the Docker mirror according to the operating system major version that is
8for RHEL 8.7. Provide the proxy URL, if required, or set to_none_.sudo cat <<EOF > /etc/yum.repos.d/docker-ee.repo [docker-ee] name=Docker EE gpgcheck=0 enabled=1 priority=1 baseurl=https://repos.mirantis.com/rhel/<RHEL_MAJOR_VERSION>/x86_64/stable-23.0/ module_hotfixes=1 proxy=PROXY EOF
Install and configure Docker:
sudo yum install docker-ee -y sudo systemctl start docker sudo chmod 666 /var/run/docker.sock
Verify that Docker is configured correctly and has access to Container Cloud CDN. For example:
docker run --rm alpine sh -c "apk add --no-cache curl; \ curl https://binary.mirantis.com"
The system output must contain no error records. In case of issues, follow the steps provided in Troubleshooting.
Note
If you require all Internet access to go through a proxy server for security and audit purposes, configure Docker proxy settings as described in the official Docker documentation.
Prepare the bootstrap script:
Download and run the Container Cloud bootstrap script:
sudo apt-get update sudo apt-get install wget wget https://binary.mirantis.com/releases/get_container_cloud.sh chmod 0755 get_container_cloud.sh ./get_container_cloud.sh
Change the directory to the
kaas-bootstrapfolder created by the script.
Obtain a Container Cloud license file required for the bootstrap:
Select from the following options:
Open the email from support@mirantis.com with the subject Mirantis Container Cloud License File or Mirantis OpenStack License File
In the Mirantis CloudCare Portal, open the Account or Cloud page
Download the License File and save it as
mirantis.licunder thekaas-bootstrapdirectory on the bootstrap node.Verify that
mirantis.liccontains the previously downloaded Container Cloud license by decoding the license JWT token, for example, using jwt.io.Example of a valid decoded Container Cloud license data with the mandatory
licensefield:{ "exp": 1652304773, "iat": 1636669973, "sub": "demo", "license": { "dev": false, "limits": { "clusters": 10, "workers_per_cluster": 10 }, "openstack": null } }
Warning
The MKE license does not apply to
mirantis.lic. For details about MKE license, see MKE documentation.
For the bare metal provider, export mandatory parameters.
Bare metal network mandatory parameters
Export the following mandatory parameters using the commands and table below:
export KAAS_BM_ENABLED="true" # export KAAS_BM_PXE_IP="172.16.59.5" export KAAS_BM_PXE_MASK="24" export KAAS_BM_PXE_BRIDGE="br0"
Bare metal prerequisites data¶ Parameter
Description
Example value
KAAS_BM_PXE_IPThe provisioning IP address in the PXE network. This address will be assigned on the seed node to the interface defined by the
KAAS_BM_PXE_BRIDGEparameter described below. The PXE service of the bootstrap cluster uses this address to network boot bare metal hosts.172.16.59.5KAAS_BM_PXE_MASKThe PXE network address prefix length to be used with the
KAAS_BM_PXE_IPaddress when assigning it to the seed node interface.24KAAS_BM_PXE_BRIDGEThe PXE network bridge name that must match the name of the bridge created on the seed node during the Set up a bootstrap cluster stage.
br0Optional. Add the following environment variables to bootstrap the cluster using proxy:
HTTP_PROXYHTTPS_PROXYNO_PROXYPROXY_CA_CERTIFICATE_PATH
Example snippet:
export HTTP_PROXY=http://proxy.example.com:3128 export HTTPS_PROXY=http://user:pass@proxy.example.com:3128 export NO_PROXY=172.18.10.0,registry.internal.lan export PROXY_CA_CERTIFICATE_PATH="/home/ubuntu/.mitmproxy/mitmproxy-ca-cert.cer"
The following formats of variables are accepted:
Proxy configuration data¶ Variable
Format
HTTP_PROXYHTTPS_PROXYhttp://proxy.example.com:port- for anonymous access.http://user:password@proxy.example.com:port- for restricted access.
NO_PROXYComma-separated list of IP addresses or domain names. For the vSphere provider, mandatory to add
host[:port]of the vCenter server.PROXY_CA_CERTIFICATE_PATHOptional. Absolute path to the proxy CA certificate for man-in-the-middle (MITM) proxies. Must be placed on the bootstrap node to be trusted. For details, see Install a CA certificate for a MITM proxy on a bootstrap node.
Warning
If you require Internet access to go through a MITM proxy, ensure that the proxy has streaming enabled as described in Enable streaming for MITM.
For proxy implementation details, see Proxy and cache support.
After the bootstrap cluster is set up, the
bootstrap-proxyobject is created with the provided proxy settings. You can use this object later for theClusterobject configuration.Deploy the bootstrap cluster:
./bootstrap.sh bootstrapv2When the bootstrap is complete, the system outputs a link to the Bootstrap web UI.
Make sure that port 80 is open for
localhostto prevent security requirements for the seed node:Note
Kind uses port mapping for the master node.
telnet localhost 80
Example of a positive system response:
Connected to localhost.
Example of a negative system response:
telnet: connect to address ::1: Connection refused telnet: Unable to connect to remote host
To open port 80:
iptables -A INPUT -p tcp --dport 80 -j ACCEPT
Access the Bootstrap web UI. It does not require any authorization.
The bootstrap cluster setup automatically creates the following objects that you can view in the Bootstrap web UI:
- Bootstrap SSH key
The SSH key pair is automatically generated by the bootstrap script and the private key is added to the
kaas-bootstrapfolder. The public key is automatically created in the bootstrap cluster as thebootstrap-keyobject. It will be used later for setting up the cluster machines.
- Bootstrap proxy
If a bootstrap cluster is configured with proxy settings, the
bootstrap-proxyobject is created. It will be automatically used in the cluster configuration unless a custom proxy is specified.
- Management
kubeconfig If a bootstrap cluster is provided with the management cluster
kubeconfig, it will be uploaded as a secret to the bootstrap cluster to thedefaultandkaasprojects asmanagement-kubeconfig.
- Management
Deploy a management cluster using the Container Cloud API¶
This section contains an overview of the cluster-related objects along with the configuration procedure of these objects during deployment of a management cluster using Bootstrap v2 through the Container Cloud API.
Deploy a management cluster using CLI¶
The following procedure describes how to prepare and deploy a management
cluster using Bootstrap v2 by operating YAML templates available in the
kaas-bootstrap/templates/ folder.
To deploy a management cluster using CLI:
Export
kubeconfigof the kind cluster:export KUBECONFIG=<pathToKindKubeconfig>
By default,
<pathToKindKubeconfig>is$HOME/.kube/kind-config-clusterapi.For the bare metal provider, configure BIOS on a bare metal host.
For the OpenStack provider, prepare the OpenStack configuration.
OpenStack configuration
Log in to the OpenStack Horizon.
In the Project section, select API Access.
In the right-side drop-down menu Download OpenStack RC File, select OpenStack clouds.yaml File.
Save the downloaded
clouds.yamlfile in thekaas-bootstrapfolder created by theget_container_cloud.shscript.In
clouds.yaml, add thepasswordfield with your OpenStack password under theclouds/openstack/authsection.Example:
clouds: openstack: auth: auth_url: https://auth.openstack.example.com/v3 username: your_username password: your_secret_password project_id: your_project_id user_domain_name: your_user_domain_name region_name: RegionOne interface: public identity_api_version: 3
If you deploy Container Cloud on top of MOSK Victoria with Tungsten Fabric and use the default security group for newly created load balancers, add the following rules for the Kubernetes API server endpoint, Container Cloud application endpoint, and for the MKE web UI and API using the OpenStack CLI:
direction='ingress'ethertype='IPv4'protocol='tcp'remote_ip_prefix='0.0.0.0/0'port_range_maxandport_range_min:'443'for Kubernetes API and Container Cloud application endpoints'6443'for MKE web UI and API
Verify access to the target cloud endpoint from Docker. For example:
docker run --rm alpine sh -c "apk add --no-cache curl; \ curl https://auth.openstack.example.com/v3"
The system output must contain no error records.
Depending on the selected provider, navigate to one of the following locations:
Bare metal:
kaas-bootstrap/templates/bmOpenStack:
kaas-bootstrap/templatesvSphere:
kaas-bootstrap/templates/vsphere
Warning
The kubectl apply command automatically saves the applied data as plain text into the
kubectl.kubernetes.io/last-applied-configurationannotation of the corresponding object. This may result in revealing sensitive data in this annotation when creating or modifying objects containing credentials. Such Container Cloud objects include:BareMetalHostCredentialByoCredentialClusterOIDCConfigurationLicense
OpenstackCredentialProxyRHELLicense
ServiceUserTLSConfigVsphereCredential
Therefore, do not use kubectl apply on these objects. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on these objects, you can remove the
kubectl.kubernetes.io/last-applied-configurationannotation from the objects using kubectl edit.Create the
BootstrapRegionobject by modifyingbootstrapregion.yaml.template.Configuration of
bootstrapregion.yaml.templateSelect from the following options:
Since Container Cloud 2.26.0 (Cluster releases 16.1.0 and 17.1.0), set the required
<providerName>and use the default<regionName>, which isregion-one.Before Container Cloud 2.26.0, set the required
<providerName>and<regionName>.
apiVersion: kaas.mirantis.com/v1alpha1 kind: BootstrapRegion metadata: name: <regionName> namespace: default spec: provider: <providerName>
Create the object:
./kaas-bootstrap/bin/kubectl create -f \ kaas-bootstrap/templates/<providerName>/bootstrapregion.yaml.template
Note
In the following steps, apply the changes to objects using the commands below with the required template name:
For bare metal:
./kaas-bootstrap/bin/kubectl create -f \ kaas-bootstrap/templates/bm/<templateName>.yaml.template
For OpenStack:
./kaas-bootstrap/bin/kubectl create -f \ kaas-bootstrap/templates/<templateName>.yaml.template
For vSphere:
./kaas-bootstrap/bin/kubectl create -f \ kaas-bootstrap/templates/vsphere/<templateName>.yaml.template
For the OpenStack and vSphere providers only. Create the
Credentialsobject by modifying<providerName>-config.yaml.template.Add the provider-specific parameters:
OpenStack
Parameter
Description
SET_OS_AUTH_URL
Identity endpoint URL.
SET_OS_USERNAME
OpenStack user name.
SET_OS_PASSWORD
Value of the OpenStack password. This field is available only when the user creates or changes password. Once the controller detects this field, it updates the password in the secret and removes the
valuefield from theOpenStackCredentialobject.SET_OS_PROJECT_ID
Unique ID of the OpenStack project.
vSphere
Note
Contact your vSphere administrator to provide you with the values for the below parameters.
Parameter
Description
SET_VSPHERE_SERVERIP address or FQDN of the vCenter Server.
SET_VSPHERE_SERVER_PORTPort of the vCenter Server. For example,
port: "8443". Leave empty to use"443"by default.SET_VSPHERE_DATACENTERvSphere data center name.
SET_VSPHERE_SERVER_INSECUREFlag that controls validation of the vSphere Server certificate. Must be
trueorfalse.SET_VSPHERE_CAPI_PROVIDER_USERNAMEvSphere Cluster API provider user name that you added when preparing the deployment user setup and permissions.
SET_VSPHERE_CAPI_PROVIDER_PASSWORDvSphere Cluster API provider user password.
SET_VSPHERE_CLOUD_PROVIDER_USERNAMEvSphere Cloud Provider deployment user name that you added when preparing the deployment user setup and permissions.
SET_VSPHERE_CLOUD_PROVIDER_PASSWORDvSphere Cloud Provider deployment user password.
Skip this step since Container Cloud 2.26.0. Before this release, set the
kaas.mirantis.com/region: <regionName>label that must match theBootstrapRegionobject name.Skip this step since Container Cloud 2.26.0. Before this release, set the
kaas.mirantis.com/regional-credentiallabel to"true"to use the credentials for the management cluster deployment. For example, for vSphere:cat vsphere-config.yaml.template --- apiVersion: kaas.mirantis.com/v1alpha1 kind: VsphereCredential metadata: name: cloud-config labels: kaas.mirantis.com/regional-credential: "true" spec: ...
Verify that the credentials for the management cluster deployment are valid. For example, for vSphere:
./kaas-bootstrap/bin/kubectl get vspherecredentials <credsName> \ -o yaml -o jsonpath='{.status.valid}'
The output of the command must be
"true". Otherwise, fix the issue with credentials before proceeding to the next step.
Create the
ServiceUserobject by modifyingserviceusers.yaml.template.Configuration of
serviceusers.yaml.templateService user is the initial user to create in Keycloak for access to a newly deployed management cluster. By default, it has the
global-admin,operator(namespaced), andbm-pool-operator(namespaced) roles.You can delete
serviceuserafter setting up other required users with specific roles or after any integration with an external identity provider, such as LDAP.apiVersion: kaas.mirantis.com/v1alpha1 kind: ServiceUserList items: - apiVersion: kaas.mirantis.com/v1alpha1 kind: ServiceUser metadata: name: SET_USERNAME spec: password: value: SET_PASSWORD
Optional. Prepare any number of additional SSH keys using the following example:
apiVersion: kaas.mirantis.com/v1alpha1 kind: PublicKey metadata: name: <SSHKeyName> namespace: default spec: publicKey: | <insert your public key here>
Optional. Add the
Proxyobject using the example below:apiVersion: kaas.mirantis.com/v1alpha1 kind: Proxy metadata: labels: kaas.mirantis.com/region: <regionName> name: <proxyName> namespace: default spec: ...
The
regionlabel must match theBootstrapRegionobject name.Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.Configure and apply the cluster configuration using cluster deployment templates:
In
cluster.yaml.template, set mandatory cluster labels:labels: kaas.mirantis.com/provider: <providerName> kaas.mirantis.com/region: <regionName>
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.Configure provider-specific settings as required.
Bare metal
Inspect the default bare metal host profile definition in
templates/bm/baremetalhostprofiles.yaml.templateand adjust it to fit your hardware configuration. For details, see Customize the default bare metal host profile.Warning
Any data stored on any device defined in the
fileSystemslist can be deleted or corrupted during cluster (re)deployment. It happens because each device from thefileSystemslist is a part of therootfsdirectory tree that is overwritten during (re)deployment.Examples of affected devices include:
A raw device partition with a file system on it
A device partition in a volume group with a logical volume that has a file system on it
An mdadm RAID device with a file system on it
An LVM RAID device with a file system on it
The
wipefield (deprecated) orwipeDevicestructure (recommended since Container Cloud 2.26.0) have no effect in this case and cannot protect data on these devices.Therefore, to prevent data loss, move the necessary data from these file systems to another server beforehand, if required.
In
templates/bm/baremetalhosts.yaml.template, update the bare metal host definitions according to your environment configuration. Use the reference table below to manually set all parameters that start withSET_.Note
Before Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0), also set the name of the
bootstrapRegionobject frombootstrapregion.yaml.templatefor thekaas.mirantis.com/regionlabel across all objects listed intemplates/bm/baremetalhosts.yaml.template.Bare metal hosts template mandatory parameters¶ Parameter
Description
Example value
SET_MACHINE_0_IPMI_USERNAMEThe IPMI user name to access the BMC. 0
userSET_MACHINE_0_IPMI_PASSWORDThe IPMI password to access the BMC. 0
passwordSET_MACHINE_0_MACThe MAC address of the first master node in the PXE network.
ac:1f:6b:02:84:71SET_MACHINE_0_BMC_ADDRESSThe IP address of the BMC endpoint for the first master node in the cluster. Must be an address from the OOB network that is accessible through the management network gateway.
192.168.100.11SET_MACHINE_1_IPMI_USERNAMEThe IPMI user name to access the BMC. 0
userSET_MACHINE_1_IPMI_PASSWORDThe IPMI password to access the BMC. 0
passwordSET_MACHINE_1_MACThe MAC address of the second master node in the PXE network.
ac:1f:6b:02:84:72SET_MACHINE_1_BMC_ADDRESSThe IP address of the BMC endpoint for the second master node in the cluster. Must be an address from the OOB network that is accessible through the management network gateway.
192.168.100.12SET_MACHINE_2_IPMI_USERNAMEThe IPMI user name to access the BMC. 0
userSET_MACHINE_2_IPMI_PASSWORDThe IPMI password to access the BMC. 0
passwordSET_MACHINE_2_MACThe MAC address of the third master node in the PXE network.
ac:1f:6b:02:84:73SET_MACHINE_2_BMC_ADDRESSThe IP address of the BMC endpoint for the third master node in the cluster. Must be an address from the OOB network that is accessible through the management network gateway.
192.168.100.13Configure cluster network:
Important
Bootstrap V2 supports only separated PXE and LCM networks.
To ensure successful bootstrap, enable asymmetric routing on the interfaces of the management cluster nodes. This is required because the seed node relies on one network by default, which can potentially cause traffic asymmetry.
In the
kernelParameterssection ofbm/baremetalhostprofiles.yaml.template, setrp_filterto2. This enables loose mode as defined in RFC3704.Example configuration of asymmetric routing
... kernelParameters: ... sysctl: # Enables the "Loose mode" for the "k8s-lcm" interface (management network) net.ipv4.conf.k8s-lcm.rp_filter: "2" # Enables the "Loose mode" for the "bond0" interface (PXE network) net.ipv4.conf.bond0.rp_filter: "2" ...
Note
More complicated solutions that are not described in this manual include getting rid of traffic asymmetry, for example:
Configure source routing on management cluster nodes.
Plug the seed node into the same networks as the management cluster nodes, which requires custom configuration of the seed node.
Update the network objects definition in
templates/bm/ipam-objects.yaml.templateaccording to the environment configuration. By default, this template implies the use of separate PXE and life-cycle management (LCM) networks.Manually set all parameters that start with
SET_.
For configuration details of bond network interface for the PXE and management network, see Configure NIC bonding.
Example of the default L2 template snippet for a management cluster:
bonds: bond0: interfaces: - {{ nic 0 }} - {{ nic 1 }} parameters: mode: active-backup primary: {{ nic 0 }} dhcp4: false dhcp6: false addresses: - {{ ip "bond0:mgmt-pxe" }} vlans: k8s-lcm: id: SET_VLAN_ID link: bond0 addresses: - {{ ip "k8s-lcm:kaas-mgmt" }} nameservers: addresses: {{ nameservers_from_subnet "kaas-mgmt" }} routes: - to: 0.0.0.0/0 via: {{ gateway_from_subnet "kaas-mgmt" }}
In this example, the following configuration applies:
A bond of two NIC interfaces
A static address in the PXE network set on the bond
An isolated L2 segment for the LCM network is configured using the
k8s-lcmVLAN with the static address in the LCM networkThe default gateway address is in the LCM network
For general concepts of configuring separate PXE and LCM networks for a management cluster, see Separate PXE and management networks. For the latest object templates and variable names to use, see the following tables.
Network parameters mapping overview¶ Deployment file name
Parameters list to update manually
ipam-objects.yaml.templateSET_LB_HOSTSET_MGMT_ADDR_RANGESET_MGMT_CIDRSET_MGMT_DNSSET_MGMT_NW_GWSET_MGMT_SVC_POOLSET_PXE_ADDR_POOLSET_PXE_ADDR_RANGESET_PXE_CIDRSET_PXE_SVC_POOLSET_VLAN_ID
bootstrap.envKAAS_BM_PXE_IPKAAS_BM_PXE_MASKKAAS_BM_PXE_BRIDGE
The below table contains examples of mandatory parameter values to set in
templates/bm/ipam-objects.yaml.templatefor the network scheme that has the following networks:172.16.59.0/24- PXE network172.16.61.0/25- LCM network
Mandatory network parameters of the IPAM objects template¶ Parameter
Description
Example value
SET_PXE_CIDRThe IP address of the PXE network in the CIDR notation. The minimum recommended network size is 256 addresses (
/24prefix length).172.16.59.0/24SET_PXE_SVC_POOLThe IP address range to use for endpoints of load balancers in the PXE network for the Container Cloud services: Ironic-API, DHCP server, HTTP server, and caching server. The minimum required range size is 5 addresses.
172.16.59.6-172.16.59.15SET_PXE_ADDR_POOLThe IP address range in the PXE network to use for dynamic address allocation for hosts during inspection and provisioning.
The minimum recommended range size is 30 addresses for management cluster nodes if it is located in a separate PXE network segment. Otherwise, it depends on the number of managed cluster nodes to deploy in the same PXE network segment as the management cluster nodes.
172.16.59.51-172.16.59.200SET_PXE_ADDR_RANGEThe IP address range in the PXE network to use for static address allocation on each management cluster node. The minimum recommended range size is 6 addresses.
172.16.59.41-172.16.59.50SET_MGMT_CIDRThe IP address of the LCM network for the management cluster in the CIDR notation. If managed clusters will have their separate LCM networks, those networks must be routable to the LCM network. The minimum recommended network size is 128 addresses (
/25prefix length).172.16.61.0/25SET_MGMT_NW_GWThe default gateway address in the LCM network. This gateway must provide access to the OOB network of the Container Cloud cluster and to the Internet to download the Mirantis artifacts.
172.16.61.1SET_LB_HOSTThe IP address of the externally accessible MKE API endpoint of the cluster in the CIDR notation. This address must be within the management
SET_MGMT_CIDRnetwork but must NOT overlap with any other addresses or address ranges within this network. External load balancers are not supported.172.16.61.5/32SET_MGMT_DNSAn external (non-Kubernetes) DNS server accessible from the LCM network.
8.8.8.8SET_MGMT_ADDR_RANGEThe IP address range that includes addresses to be allocated to bare metal hosts in the LCM network for the management cluster.
When this network is shared with managed clusters, the size of this range limits the number of hosts that can be deployed in all clusters sharing this network.
When this network is solely used by a management cluster, the range must include at least 6 addresses for bare metal hosts of the management cluster.
172.16.61.30-172.16.61.40SET_MGMT_SVC_POOLThe IP address range to use for the externally accessible endpoints of load balancers in the LCM network for the Container Cloud services, such as Keycloak, web UI, and so on. The minimum required range size is 19 addresses.
172.16.61.10-172.16.61.29SET_VLAN_IDThe VLAN ID used for isolation of LCM network. The bootstrap.sh process and the seed node must have routable access to the network in this VLAN.
3975When using separate PXE and LCM networks, the management cluster services are exposed in different networks using two separate MetalLB address pools:
Services exposed through the PXE network are as follows:
Ironic API as a bare metal provisioning server
HTTP server that provides images for network boot and server provisioning
Caching server for accessing the Container Cloud artifacts deployed on hosts
Services exposed through the LCM network are all other Container Cloud services, such as Keycloak, web UI, and so on.
The default MetalLB configuration described in the
MetalLBConfigTemplateobject template oftemplates/bm/ipam-objects.yaml.templateuses two separate MetalLB address pools. Also, it uses theinterfacesselector in itsl2Advertisementstemplate.Caution
When you change the
L2Templateobject template intemplates/bm/ipam-objects.yaml.template, ensure that interfaces listed in theinterfacesfield of theMetalLBConfigTemplate.spec.templates.l2Advertisementssection match those used in yourL2Template. For details about theinterfacesselector, see API Reference: MetalLBConfigTemplate spec.See Configure MetalLB for details on MetalLB configuration.
In
cluster.yaml.template, update the cluster-related settings to fit your deployment.Optional. Enable WireGuard for traffic encryption on the Kubernetes workloads network.
WireGuard configuration
Ensure that the Calico MTU size is at least 60 bytes smaller than the interface MTU size of the workload network. IPv4 WireGuard uses a 60-byte header. For details, see Set the MTU size for Calico.
In
templates/bm/cluster.yaml.template, enable WireGuard by adding thesecureOverlayparameter:spec: ... providerSpec: value: ... secureOverlay: true
Caution
Changing this parameter on a running cluster causes a downtime that can vary depending on the cluster size.
For more details about WireGuard, see Calico documentation: Encrypt in-cluster pod traffic.
OpenStack
Adjust the
templates/cluster.yaml.templateparameters to suit your deployment:In the
spec::providerSpec::valuesection, add the mandatoryExternalNetworkIDparameter that is the ID of an external OpenStack network. It is required to have public Internet access to virtual machines.In the
spec::clusterNetwork::servicessection, add the corresponding values forcidrBlocks.Configure other parameters as required.
vSphere
Configure MetalLB parameters:
Open the required configuration file for editing:
Open
templates/vsphere/metallbconfig.yaml.template. For a detailedMetalLBConfigobject description, see API Reference: MetalLBConfig resource.Open
templates/vsphere/cluster.yaml.template.Add
SET_VSPHERE_METALLB_RANGEthat is the MetalLB range of IP addresses to assign to load balancers for Kubernetes Services.Note
To obtain the
VSPHERE_METALLB_RANGEparameter for the selected vSphere network, contact your vSphere administrator who provides you with the IP ranges dedicated to your environment.
Modify
templates/vsphere/cluster.yaml.template:vSphere cluster network parameters
Modify the following required network parameters:
Required parameters¶ Parameter
Description
SET_LB_HOSTIP address from the provided vSphere network for Kubernetes API load balancer (Keepalived VIP).
SET_VSPHERE_DATASTOREName of the vSphere datastore. You can use different datastores for vSphere Cluster API and vSphere Cloud Provider.
SET_VSPHERE_MACHINES_FOLDERPath to a folder where the cluster machines metadata will be stored.
SET_VSPHERE_NETWORK_PATHPath to a network for cluster machines.
SET_VSPHERE_RESOURCE_POOL_PATHPath to a resource pool in which VMs will be created.
Note
To obtain the
LB_HOSTparameter for the selected vSphere network, contact your vSphere administrator who provides you with the IP ranges dedicated to your environment.Modify other parameters if required. For example, add the corresponding values for
cidrBlocksin thespec::clusterNetwork::servicessection.For either DHCP or non-DHCP vSphere network:
Determine the vSphere network parameters as described in VMware vSphere network objects and IPAM recommendations.
Provide the following additional parameters for a proper network setup on machines using embedded IP address management (IPAM) in
templates/vsphere/cluster.yaml.template:Note
To obtain IPAM parameters for the selected vSphere network, contact your vSphere administrator who provides you with IP ranges dedicated to your environment only.
vSphere configuration data¶ Parameter
Description
ipamEnabledEnables IPAM. Recommended value is
truefor either DHCP or non-DHCP networks.SET_VSPHERE_NETWORK_CIDRCIDR of the provided vSphere network. For example,
10.20.0.0/16.SET_VSPHERE_NETWORK_GATEWAYGateway of the provided vSphere network.
SET_VSPHERE_CIDR_INCLUDE_RANGESIP range for the cluster machines. Specify the range of the provided CIDR. For example,
10.20.0.100-10.20.0.200. If the DHCP network is used, this range must not intersect with the DHCP range of the network.SET_VSPHERE_CIDR_EXCLUDE_RANGESOptional. IP ranges to be excluded from being assigned to the cluster machines. The MetalLB range and
SET_LB_HOSTshould not intersect with the addresses for IPAM. For example,10.20.0.150-10.20.0.170.SET_VSPHERE_NETWORK_NAMESERVERSList of nameservers for the provided vSphere network.
For RHEL deployments, fill out
templates/vsphere/rhellicenses.yaml.template.RHEL license configuration
Use one of the following set of parameters for RHEL machines subscription:
The user name and password of your RedHat Customer Portal account associated with your RHEL license for Virtual Datacenters.
Optionally, provide the subscription allocation pools to use for the RHEL subscription activation. If not needed, remove the
poolIDsfield forsubscription-managerto automatically select the licenses for machines.For example:
spec: username: <username> password: value: <password> poolIDs: - <pool1> - <pool2>
The activation key and organization ID associated with your RedHat account with RHEL license for Virtual Datacenters. The activation key can be created by the organization administrator on the RedHat Customer Portal.
If you use the RedHat Satellite server for management of your RHEL infrastructure, you can provide a pre-generated activation key from that server. In this case:
Provide the URL to the RedHat Satellite RPM for installation of the CA certificate that belongs to that server.
Configure
squid-proxyon the management cluster to allow access to your Satellite server. For details, see Configure squid-proxy.
For example:
spec: activationKey: value: <activation key> orgID: "<organization ID>" rpmUrl: <rpm url>
Caution
For RHEL, verify mirrors configuration for your activation key. For more details, see RHEL 8 mirrors configuration.
Warning
Provide only one set of parameters. Mixing the parameters from different activation methods will cause deployment failure.
Warning
The kubectl apply command automatically saves the applied data as plain text into the
kubectl.kubernetes.io/last-applied-configurationannotation of the corresponding object. This may result in revealing sensitive data in this annotation when creating or modifying the object.Therefore, do not use kubectl apply on this object. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on this object, you can remove the
kubectl.kubernetes.io/last-applied-configurationannotation from the object using kubectl edit.Skip this step if you already have a custom image with a vSphere VM template to use for bootstrap.
In
templates/vsphere/vspherevmtemplate.yaml.template, set the following mandatory parameters:spec: packerImageOSName: SET_OS_NAME packerImageOSVersion: SET_OS_VERSION packerISOImage: SET_ISO_IMAGE vsphereCredentialsName: default/cloud-config vsphereClusterName: SET_VSPHERE_CLUSTER_NAME vsphereNetwork: SET_VSPHERE_NETWORK_PATH vsphereDatastore: SET_VSPHERE_DATASTORE_PATH vsphereFolder: SET_VSPHERE_FOLDER_PATH vsphereResourcePool: SET_VSPHERE_RESOURCE_POOL_PATH
For the parameters description, refer to VsphereVMTemplate configuration. You can also configure optional parameters if required.
Caution
For the
vsphereCredentialsNameandproxyNamefields, use names of the corresponding objects previously created using this procedure.For the
rhelLicenseNamefield, make sure to create the corresponding RHEL license before proceeding to the next step.
Configure StackLight. For parameters description, see StackLight configuration parameters.
Optional. Configure additional cluster settings as described in Configure optional cluster settings.
Apply configuration for machines using
machines.yaml.template.Configuration of
machines.yaml.templateAdd the following mandatory machine labels:
labels: kaas.mirantis.com/provider: <providerName> cluster.sigs.k8s.io/cluster-name: <clusterName> kaas.mirantis.com/region: <regionName> cluster.sigs.k8s.io/control-plane: "true"
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.Configure the provider-specific settings:
Bare metal
Inspect the
machines.yaml.templateand adjustspecandlabelsof each entry according to your deployment. Adjustspec.providerSpec.value.hostSelectorvalues to matchBareMetalHostcorresponding to each machine. For details, see API Reference: Bare metal Machine spec.OpenStack
In
templates/machines.yaml.template, modify thespec:providerSpec:valuesection for 3 control plane nodes marked with thecluster.sigs.k8s.io/control-planelabel by substituting theflavorandimageparameters with the corresponding values of the control plane nodes in the related OpenStack cluster. For example:spec: &cp_spec providerSpec: value: apiVersion: "openstackproviderconfig.k8s.io/v1alpha1" kind: "OpenstackMachineProviderSpec" flavor: kaas.minimal image: bionic-server-cloudimg-amd64-20190612
Note
The
flavorparameter value provided in the example above is cloud-specific and must meet the Container Cloud requirements.Optional. Available as TechPreview. To boot cluster machines from a block storage volume, define the following parameter in the
spec:providerSpecsection oftemplates/machines.yaml.template:bootFromVolume: enabled: true volumeSize: 120
Note
The minimal storage requirement is 120 GB per node. For details, see Requirements for an OpenStack-based cluster.
To boot the Bastion node from a volume, add the same parameter to
templates/cluster.yaml.templatein thespec:providerSpecsection for Bastion. The default amount of storage80is enough.
Also, modify other parameters as required.
vSphere
In
templates/vsphere/machines.yaml.template, define the following parameters:rhelLicenseRHEL license name defined in
rhellicenses.yaml.template, defaults tokaas-mgmt-rhel-license. Remove or comment out this parameter for Ubuntu deployments.
diskGiBDisk size in GiB for machines that must match the disk size of the VM template. You can leave this parameter commented to use the disk size of the VM template. The minimum requirement is 120 GiB.
templatePath to the VM template prepared in the previous step.
Sample template:
spec: providerSpec: value: apiVersion: vsphere.cluster.k8s.io/v1alpha1 kind: VsphereMachineProviderSpec rhelLicense: <rhelLicenseName> numCPUs: 8 memoryMiB: 32768 # diskGiB: 120 template: <vSphereVMTemplatePath>
Also, modify other parameters if required.
For the bare metal provider, monitor the inspecting process of the baremetal hosts and wait until all hosts are in the
availablestate:kubectl get bmh -o go-template='{{- range .items -}} {{.status.provisioning.state}}{{"\n"}} {{- end -}}'
Example of system response:
available available available
Monitor the
BootstrapRegionobject status and wait until it is ready.kubectl get bootstrapregions -o go-template='{{(index .items 0).status.ready}}{{"\n"}}'
To obtain more granular status details, monitor
status.conditions:kubectl get bootstrapregions -o go-template='{{(index .items 0).status.conditions}}{{"\n"}}'
For a more convenient system response, consider using dedicated tools such as jq or yq and adjust the
-oflag to output injsonoryamlformat accordingly.Note
For the bare metal provider, before Container Cloud 2.26.0, the
BareMetalObjectReferencescondition is not mandatory and may remain in thenot readystate with no effect on theBootstrapRegionobject. Since Container Cloud 2.26.0, this condition is mandatory.Change the directory to
/kaas-bootstrap/.Approve the
BootstrapRegionobject to start the cluster deployment:./container-cloud bootstrap approve all
./container-cloud bootstrap approve <bootstrapRegionName>
Caution
Once you approve the
BootstrapRegionobject, no cluster or machine modification is allowed.Warning
For the bare metal provider, do not manually restart or power off any of the bare metal hosts during the bootstrap process.
Monitor the deployment progress. For deployment stages description, see Overview of the deployment workflow.
Verify that network addresses used on your clusters do not overlap with the following default MKE network addresses for Swarm and MCR:
10.0.0.0/16is used for Swarm networks. IP addresses from this network are virtual.10.99.0.0/16is used for MCR networks. IP addresses from this network are allocated on hosts.
Verification of Swarm and MCR network addresses
To verify Swarm and MCR network addresses, run on any master node:
docker infoExample of system response:
Server: ... Swarm: ... Default Address Pool: 10.0.0.0/16 SubnetSize: 24 ... Default Address Pools: Base: 10.99.0.0/16, Size: 20 ...
Not all of Swarm and MCR addresses are usually in use. One Swarm Ingress network is created by default and occupies the
10.0.0.0/24address block. Also, three MCR networks are created by default and occupy three address blocks:10.99.0.0/20,10.99.16.0/20,10.99.32.0/20.To verify the actual networks state and addresses in use, run:
docker network ls docker network inspect <networkName>
Optional for the bare metal provider. If you plan to use multiple L2 segments for provisioning of managed cluster nodes, consider the requirements specified in Configure multiple DHCP ranges using Subnet resources.
Deploy a management cluster using the Container Cloud Bootstrap web UI¶
This section describes how to configure the cluster-related objects and deploy a management cluster with the selected cloud provider using Bootstrap v2 through the Container Cloud Bootstrap web UI.
Create a management cluster for the OpenStack provider¶
This section describes how to create an OpenStack-based management cluster using the Container Cloud Bootstrap web UI.
To create an OpenStack-based management cluster:
If you deploy Container Cloud on top of MOSK Victoria with Tungsten Fabric and use the default security group for newly created load balancers, add the following rules for the Kubernetes API server endpoint, Container Cloud application endpoint, and for the MKE web UI and API using the OpenStack CLI:
direction='ingress'ethertype='IPv4'protocol='tcp'remote_ip_prefix='0.0.0.0/0'port_range_maxandport_range_min:'443'for Kubernetes API and Container Cloud application endpoints'6443'for MKE web UI and API
Open the Container Cloud Bootstrap web UI.
Create a bootstrap object.
Bootstrap object configuration
In the Bootstrap tab, create a bootstrap object:
Set the bootstrap object name.
Select the required provider.
Optional. Recommended. Leave the Guided Bootstrap configuration check box selected. It enables the cluster creation helper in the next window with a series of guided steps for a complete setup of a functional management cluster.
The cluster creation helper contains the same configuration windows as in separate tabs of the left-side menu, but the helper enables the configuration of essential provider components one-by-one inside one modal window.
If you select this option, use the corresponding steps of this procedure described below for description of each tab in Guided Bootstrap configuration.
Click Save.
In the Status column of the Bootstrap page, monitor the bootstrap region readiness by hovering over the status icon of the bootstrap region.
Once the orange blinking status icon becomes green and Ready, the bootstrap region deployment is complete. If the cluster status is Error, refer to Troubleshooting.
You can monitor live deployment status of the following bootstrap region components:
Component
Status description
Helm
Installation status of bootstrap Helm releases
Provider
Status of provider configuration and installation for related charts and Deployments
Deployments
Readiness of all Deployments in the bootstrap cluster
Configure credentials for the new cluster.
Credentials configuration
In the Credentials tab:
Click Add Credential to add your OpenStack credentials. You can either upload your OpenStack
clouds.yamlconfiguration file or fill in the fields manually.Verify that the new credentials status is Ready. If the status is Error, hover over the status to determine the reason of the issue.
Optional. In the SSH Keys tab, click Add SSH Key to upload the public SSH key(s) for VMs creation.
Optional. Enable proxy access to the cluster.
Proxy configuration
In the Proxies tab, configure proxy:
Click Add Proxy.
In the Add New Proxy wizard, fill out the form with the following parameters:
Proxy configuration¶ Parameter
Description
Proxy Name
Name of the proxy server to use during cluster creation.
Region Removed in 2.26.0 (16.1.0 and 17.1.0)
From the drop-down list, select the required region.
HTTP Proxy
Add the HTTP proxy server domain name in the following format:
http://proxy.example.com:port- for anonymous accesshttp://user:password@proxy.example.com:port- for restricted access
HTTPS Proxy
Add the HTTPS proxy server domain name in the same format as for HTTP Proxy.
No Proxy
Comma-separated list of IP addresses or domain names.
For implementation details, see Proxy and cache support.
If your proxy requires a trusted CA certificate, select the CA Certificate check box and paste a CA certificate for a MITM proxy to the corresponding field or upload a certificate using Upload Certificate.
For the list of Mirantis resources and IP addresses to be accessible from the Container Cloud clusters, see Requirements for an OpenStack-based cluster.
In the Clusters tab, click Create Cluster and fill out the form with the following parameters:
Cluster configuration
Add Cluster name.
Set the provider Service User Name and Service User Password.
Service user is the initial user to create in Keycloak for access to a newly deployed management cluster. By default, it has the
global-admin,operator(namespaced), andbm-pool-operator(namespaced) roles.You can delete
serviceuserafter setting up other required users with specific roles or after any integration with an external identity provider, such as LDAP.Configure general provider settings and Kubernetes parameters:
Provider and Kubernetes configuration
Provider and Kubernetes configuration¶ Section
Parameter
Description
General Settings
Provider
Select OpenStack.
Provider Credential
From the drop-down list, select the OpenStack credentials name that you have previously created.
Release Version
The Container Cloud version.
Proxy
Optional. From the drop-down list, select the proxy server name that you have previously created.
SSH Keys
From the drop-down list, select the SSH key name(s) that you have previously added for SSH access to VMs.
Container Registry
From the drop-down list, select the Docker registry name that you have previously added using the Container Registries tab. For details, see Define a custom CA certificate for a private Docker registry.
Provider
External Network
Type of the external network in the OpenStack cloud provider.
DNS Name Servers
Comma-separated list of the DNS hosts IPs for the OpenStack VMs configuration.
Configure Bastion
Optional. Configuration parameters for the Bastion node:
Flavor
Image
Availability Zone
Server Metadata
For the parameters description, see Add a machine.
Technology Preview: select Boot From Volume to boot the Bastion node from a block storage volume and select the required amount of storage (80 GB is enough).
Kubernetes
Node CIDR
The Kubernetes nodes CIDR block. For example,
10.10.10.0/24.Services CIDR Blocks
The Kubernetes Services CIDR block. For example,
10.233.0.0/18.Pods CIDR Blocks
The Kubernetes Pods CIDR block. For example,
10.233.64.0/18.Note
The network subnet size of Kubernetes pods influences the number of nodes that can be deployed in the cluster. The default subnet size
/18is enough to create a cluster with up to 256 nodes. Each node uses the/26address blocks (64 addresses), at least one address block is allocated per node. These addresses are used by the Kubernetes pods withhostNetwork: false. The cluster size may be limited further when some nodes use more than one address block.Configure StackLight:
StackLight configuration
Click Create.
Add machines to the bootstrap cluster:
Machines configuration
In the Clusters tab, click the required cluster name. The cluster page with Machines list opens.
On the cluster page, click Create Machine.
Fill out the form with the following parameters:
Container Cloud machine configuration¶ Parameter
Description
Count
Specify the odd number of machines to create. Only Manager machines are allowed.
Caution
The required minimum number of manager machines is three for HA. A cluster can have more than three manager machines but only an odd number of machines.
In an even-sized cluster, an additional machine remains in the
Pendingstate until an extra manager machine is added. An even number of manager machines does not provide additional fault tolerance but increases the number of node required for etcd quorum.Flavor
From the drop-down list, select the required hardware configuration for the machine. The list of available flavors corresponds to the one in your OpenStack environment.
For the hardware requirements, see Requirements for an OpenStack-based cluster.
Image
From the drop-down list, select the required cloud image:
CentOS 7.9
Ubuntu 20.04
If you do not have the required image in the list, add it to your OpenStack environment using the Horizon web UI by downloading it from:
Warning
A Container Cloud cluster based on both Ubuntu and CentOS operating systems is not supported.
Availability Zone
From the drop-down list, select the availability zone from which the new machine will be launched.
Configure Server Metadata
Optional. Select Configure Server Metadata and add the required number of string key-value pairs for the machine
meta_dataconfiguration incloud-init.Prohibited keys are:
KaaS,cluster,clusterID,namespaceas they are used by Container Cloud.Boot From Volume
Optional. Technology Preview. Select to boot a machine from a block storage volume. Use the Up and Down arrows in the Volume Size (GiB) field to define the required volume size.
This option applies to clouds that do not have enough space on hypervisors. After enabling this option, the Cinder storage is used instead of the Nova storage.
Click Create.
Optional. Using the Container Cloud CLI, modify the provider-specific and other cluster settings as described in Configure optional cluster settings.
Select from the following options to start cluster deployment:
Click Deploy.
Approve the previously created bootstrap region using the Container Cloud CLI:
./kaas-bootstrap/container-cloud bootstrap approve all
./kaas-bootstrap/container-cloud bootstrap approve <bootstrapRegionName>
Caution
Once you approve the bootstrap region, no cluster or machine modification is allowed.
Monitor the deployment progress of the cluster and machines.
Monitoring of the cluster readiness
To monitor the cluster readiness, hover over the status icon of a specific cluster in the Status column of the Clusters page.
Once the orange blinking status icon becomes green and Ready, the cluster deployment or update is complete.
You can monitor live deployment status of the following cluster components:
Component
Description
Bastion
For the OpenStack-based management clusters, the Bastion node IP address status that confirms the Bastion node creation
Helm
Installation or upgrade status of all Helm releases
Kubelet
Readiness of the node in a Kubernetes cluster, as reported by kubelet
Kubernetes
Readiness of all requested Kubernetes objects
Nodes
Equality of the requested nodes number in the cluster to the number of nodes having the
ReadyLCM statusOIDC
Readiness of the cluster OIDC configuration
StackLight
Health of all StackLight-related objects in a Kubernetes cluster
Swarm
Readiness of all nodes in a Docker Swarm cluster
LoadBalancer
Readiness of the Kubernetes API load balancer
ProviderInstance
Readiness of all machines in the underlying infrastructure (virtual or bare metal, depending on the provider type)
Graceful Reboot
Readiness of a cluster during a scheduled graceful reboot, available since Cluster releases 15.0.1 and 14.0.0.
Infrastructure Status
Available since Container Cloud 2.25.0 for bare metal and OpenStack providers. Readiness of the following cluster components:
Bare metal: the
MetalLBConfigobject along with MetalLB and DHCP subnets.OpenStack: cluster network, routers, load balancers, and Bastion along with their ports and floating IPs.
LCM Operation
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Health of all LCM operations on the cluster and its machines.
LCM Agent
Available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Health of all LCM agents on cluster machines and the status of LCM agents update to the version from the current Cluster release.
For the history of a cluster deployment or update, refer to Inspect the history of a cluster and machine deployment or update.
Monitoring of machines readiness
To monitor machines readiness, use the status icon of a specific machine on the Clusters page.
- Quick status
On the Clusters page, in the Managers column. The green status icon indicates that the machine is Ready, the orange status icon indicates that the machine is Updating.
- Detailed status
In the Machines section of a particular cluster page, in the Status column. Hover over a particular machine status icon to verify the deploy or update status of a specific machine component.
You can monitor the status of the following machine components:
Component
Description
Kubelet
Readiness of a node in a Kubernetes cluster.
Swarm
Health and readiness of a node in a Docker Swarm cluster.
LCM
LCM readiness status of a node.
ProviderInstance
Readiness of a node in the underlying infrastructure (virtual or bare metal, depending on the provider type).
Graceful Reboot
Readiness of a machine during a scheduled graceful reboot of a cluster, available since Cluster releases 15.0.1 and 14.0.0.
Infrastructure Status
Available since Container Cloud 2.25.0 for the bare metal provider only. Readiness of the
IPAMHost,L2Template,BareMetalHost, andBareMetalHostProfileobjects associated with the machine.LCM Operation
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Health of all LCM operations on the machine.
LCM Agent
Available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Health of the LCM Agent on the machine and the status of the LCM Agent update to the version from the current Cluster release.
The machine creation starts with the Provision status. During provisioning, the machine is not expected to be accessible since its infrastructure (VM, network, and so on) is being created.
Other machine statuses are the same as the
LCMMachineobject states:Uninitialized - the machine is not yet assigned to an
LCMCluster.Pending - the agent reports a node IP address and host name.
Prepare - the machine executes
StateItemsthat correspond to thepreparephase. This phase usually involves downloading the necessary archives and packages.Deploy - the machine executes
StateItemsthat correspond to thedeployphase that is becoming a Mirantis Kubernetes Engine (MKE) node.Ready - the machine is being deployed.
Upgrade - the machine is being upgraded to the new MKE version.
Reconfigure - the machine executes
StateItemsthat correspond to thereconfigurephase. The machine configuration is being updated without affecting workloads running on the machine.
Once the status changes to Ready, the deployment of the cluster components on this machine is complete.
You can also monitor the live machine status using API:
kubectl get machines <machineName> -o wide
Example of system response since Container Cloud 2.23.0:
NAME READY LCMPHASE NODENAME UPGRADEINDEX REBOOTREQUIRED WARNINGS demo-0 true Ready kaas-node-c6aa8ad3 1 false
For the history of a machine deployment or update, refer to Inspect the history of a cluster and machine deployment or update.
Alternatively, verify machine statuses from the seed node on which the bootstrap cluster is deployed:
Log in to the seed node.
Export
KUBECONFIGto connect to the bootstrap cluster:export KUBECONFIG=~/.kube/kind-config-clusterapi
Verify the statuses of available
LCMMachineobjects:kubectl get lcmmachines -o wide
Verify the statuses of available cluster machines:
kubectl get machines -o wide
Verify that network addresses used on your clusters do not overlap with the following default MKE network addresses for Swarm and MCR:
10.0.0.0/16is used for Swarm networks. IP addresses from this network are virtual.10.99.0.0/16is used for MCR networks. IP addresses from this network are allocated on hosts.
Verification of Swarm and MCR network addresses
To verify Swarm and MCR network addresses, run on any master node:
docker infoExample of system response:
Server: ... Swarm: ... Default Address Pool: 10.0.0.0/16 SubnetSize: 24 ... Default Address Pools: Base: 10.99.0.0/16, Size: 20 ...
Not all of Swarm and MCR addresses are usually in use. One Swarm Ingress network is created by default and occupies the
10.0.0.0/24address block. Also, three MCR networks are created by default and occupy three address blocks:10.99.0.0/20,10.99.16.0/20,10.99.32.0/20.To verify the actual networks state and addresses in use, run:
docker network ls docker network inspect <networkName>
Create a management cluster for the vSphere provider¶
This section describes how to create a vSphere-based management cluster using the Container Cloud Bootstrap web UI.
To create a vSphere-based management cluster:
Open the Container Cloud Bootstrap web UI.
Create a bootstrap object.
Bootstrap object configuration
In the Bootstrap tab, create a bootstrap object:
Set the bootstrap object name.
Select the required provider.
Optional. Recommended. Leave the Guided Bootstrap configuration check box selected. It enables the cluster creation helper in the next window with a series of guided steps for a complete setup of a functional management cluster.
The cluster creation helper contains the same configuration windows as in separate tabs of the left-side menu, but the helper enables the configuration of essential provider components one-by-one inside one modal window.
If you select this option, use the corresponding steps of this procedure described below for description of each tab in Guided Bootstrap configuration.
Caution
If no VM templates are present in the vSphere Datacenter, deselect this check box, because VM template configuration is not currently supported by this helper and will be added in one of the following releases.
Click Save.
In the Status column of the Bootstrap page, monitor the bootstrap region readiness by hovering over the status icon of the bootstrap region.
Once the orange blinking status icon becomes green and Ready, the bootstrap region deployment is complete. If the cluster status is Error, refer to Troubleshooting.
You can monitor live deployment status of the following bootstrap region components:
Component
Status description
Helm
Installation status of bootstrap Helm releases
Provider
Status of provider configuration and installation for related charts and Deployments
Deployments
Readiness of all Deployments in the bootstrap cluster
Configure credentials for the new cluster.
Credentials configuration
In the Credentials tab:
Click Add Credential to add your vSphere credentials. You can either upload your
vsphere.yamlconfiguration file or fill in the fields manually:Credentials parameters¶ Parameter
Description
Name
Credentials name.
Provider
Provider name. Select
vsphere.Region
Region name. Select the bootstrap region name.
Insecure
Flag that controls validation of the vSphere Server certificate.
Server
IP address or FQDN of the vCenter Server.
Port
Port of the vCenter Server. For example,
port: "443".Datacenter
vSphere data center name.
Cloud provider username
Deployment user name of the vSphere Cloud Provider that you added when preparing the deployment user setup and permissions.
Cloud provider password
Deployment user password for the vSphere Cloud Provider.
ClusterAPI username
User name of the vSphere Cluster API provider that you added when preparing the deployment user setup and permissions.
ClusterAPI password
User password of the vSphere Cluster API provider.
Click Create.
Verify that the new credentials status is Ready. If the status is Error, hover over the status to determine the reason of the issue.
Optional. In the SSH Keys tab, click Add SSH Key to upload the public SSH key(s) for VMs creation.
Mandatory for RHEL-based deployments.
RHEL License configuration
In the RHEL Licenses tab, click Add RHEL License and fill out the form with the following parameters:
RHEL license parameters¶ Parameter
Description
RHEL License Name
RHEL license name
Username (User/Password Registration)
User name to access the RHEL license
Password (User/Password Registration)
Password to access the RHEL license
Organization ID (Activation Key)
Organization key to register a user by
Activation Key (Activation Key)
Activation key to use for user registration
RPM URL (Activation Key)
Optional. URL from which to download RPM packages using RPM Package Manager
Pool IDs
Optional. Specify the pool IDs for RHEL licenses for Virtual Datacenters. Otherwise, Subscription Manager will select a subscription from the list of available and appropriate for the machines.
Mandatory for offline environments with no direct access to the Internet. Otherwise, optional. Enable proxy access to the cluster. Such configuration usually contains proxy for the bootstrap cluster and already has the
bootstrap-proxyobject to use in the cluster configuration by default.Proxy configuration
In the Proxies tab, configure proxy:
Click Add Proxy.
In the Add New Proxy wizard, fill out the form with the following parameters:
Proxy configuration¶ Parameter
Description
Proxy Name
Name of the proxy server to use during cluster creation.
Region Removed in 2.26.0 (16.1.0 and 17.1.0)
From the drop-down list, select the required region.
HTTP Proxy
Add the HTTP proxy server domain name in the following format:
http://proxy.example.com:port- for anonymous accesshttp://user:password@proxy.example.com:port- for restricted access
HTTPS Proxy
Add the HTTPS proxy server domain name in the same format as for HTTP Proxy.
No Proxy
Comma-separated list of IP addresses or domain names. Mandatory to add
host[:port]of the vCenter server.For implementation details, see Proxy and cache support.
If your proxy requires a trusted CA certificate, select the CA Certificate check box and paste a CA certificate for a MITM proxy to the corresponding field or upload a certificate using Upload Certificate.
For the list of Mirantis resources and IP addresses to be accessible from the Container Cloud clusters, see Requirements for a VMware vSphere-based cluster.
In the Clusters tab, click Create Cluster and fill out the form with the following parameters:
Cluster configuration
Add Cluster name.
Set the provider Service User Name and Service User Password.
Service user is the initial user to create in Keycloak for access to a newly deployed management cluster. By default, it has the
global-admin,operator(namespaced), andbm-pool-operator(namespaced) roles.You can delete
serviceuserafter setting up other required users with specific roles or after any integration with an external identity provider, such as LDAP.Configure general provider settings and Kubernetes parameters:
Provider and Kubernetes configuration
Section
Parameter
Description
General Settings
Provider
Select vSphere.
Provider Credential
From the drop-down list, select the vSphere credentials name that you have previously created.
Release Version
The Container Cloud version.
Caution
Due to the known issue 40747, the Cluster release 16.0.0, which is not supported since Container Cloud 2.25.1 for greenfield deployments, is still available in the drop-down menu for managed clusters.
Do not select this Cluster release to prevent deployment failures. Select the latest supported version instead.
The issue 40747 is addressed in Container Cloud 2.26.1.
Proxy
Optional. From the drop-down list, select the proxy server name that you have previously created.
SSH Keys
From the drop-down list, select the SSH key name(s) that you have previously added for the SSH access to VMs.
Container Registry
From the drop-down list, select the Docker registry name that you have previously added using the Container Registries tab. For details, see Define a custom CA certificate for a private Docker registry.
Kubernetes
Node CIDR
Kubernetes nodes CIDR block. For example,
10.10.10.0/24.Services CIDR Blocks
Kubernetes Services CIDR block. For example,
10.233.0.0/18.Pods CIDR Blocks
Kubernetes pods CIDR block. For example,
10.233.64.0/18.Note
The network subnet size of Kubernetes pods influences the number of nodes that can be deployed in the cluster. The default subnet size
/18is enough to create a cluster with up to 256 nodes. Each node uses the/26address blocks (64 addresses), at least one address block is allocated per node. These addresses are used by the Kubernetes pods withhostNetwork: false. The cluster size may be limited further when some nodes use more than one address block.Provider
LB Host IP
IP address of the load balancer endpoint that will be used to access the Kubernetes API of the new cluster.
LB Address Range
MetalLB range of IP addresses that can be assigned to load balancers for Kubernetes Services.
vSphere
Machine Folder Path
Full path to the folder that will store the cluster machines metadata. Use the drop-down list to select the required item.
Note
Every drop-down list item of the vSphere section represents a short name of a particular vSphere resource, without the datacenter path. The Network Path drop-down list items also represent specific network types. Start typing the item name in the drop-down list field to filter the results and select the required item.
Network Path
Full path to a network for cluster machines. Use the drop-down list to select the required item.
Resource Pool Path
Full path to a resource pool where VMs will be created. Use the drop-down list to select the required item.
Datastore For Cluster
Full path to a storage for VMs disks. Use the drop-down list to select the required item.
Datastore For Cloud Provider
Full path to a storage for Kubernetes volumes. Use the drop-down list to select the required item.
SCSI Controller Type
SCSI controller type for VMs. Leave
pvscsias default.Enable IPAM
Enables IPAM. Set to
trueif a vSphere network has no DHCP server. Also, provide the following additional parameters for a proper network setup on machines using embedded IP address management (IPAM):Network CIDR
CIDR of the provided vSphere network. For example,
10.20.0.0/16.Network Gateway
Gateway of the provided vSphere network.
DNS Name Servers
List of nameservers for the provided vSphere network.
Include Ranges
IP range for the cluster machines. Specify the range of the provided CIDR. For example,
10.20.0.100-10.20.0.200.Exclude Ranges
Optional. IP ranges to be excluded from being assigned to the cluster machines. The MetalLB range and the load balancer IP address should not intersect with the addresses for IPAM. For example,
10.20.0.150-10.20.0.170.Optional General Settings
Enable Secure Overlay
Experimental, not recommended for production deployments. Removed in Cluster releases 16.0.0 and 14.1.0.
Enable WireGuard for traffic encryption on the Kubernetes workloads network.
WireGuard configuration
Ensure that the Calico MTU size is at least 60 bytes smaller than the interface MTU size of the workload network. IPv4 WireGuard uses a 60-byte header. For details, see Set the MTU size for Calico.
Enable WireGuard by selecting the Enable WireGuard check box.
Caution
Changing this parameter on a running cluster causes a downtime that can vary depending on the cluster size.
For more details about WireGuard, see Calico documentation: Encrypt in-cluster pod traffic.
Parallel Upgrade Of Worker Machines
Available since the Cluster release 14.1.0.
The maximum number of the worker nodes to update simultaneously. It serves as an upper limit on the number of machines that are drained at a given moment of time. Defaults to
1.You can configure this option after deployment before the cluster update.
Parallel Preparation For Upgrade Of Worker Machines
Available since the Cluster release 14.1.0.
The maximum number of worker nodes being prepared at a given moment of time, which includes downloading of new artifacts. It serves as a limit for the network load that can occur when downloading the files to the nodes. Defaults to
50.You can configure this option after deployment before the cluster update.
Configure StackLight:
StackLight configuration
Click Create.
Configure the VM template:
VM template configuration
In the Clusters tab, click the required cluster name. The cluster page with VM Templates list opens.
Click Create VM Template.
Configure the VM template:
Section
Parameter
Description
General Settings
Name
VM template name.
OS Name
Operating system name for the VM template: Ubuntu or RHEL.
Note
For RHEL, a RHEL license is required.
OS Version
Operating system version for the VM template. For the list of supported operating systems and their versions, refer to Requirements for a VMware vSphere-based cluster.
Region
Previously configured region name. For example, region-one.
Credentials
Name of previously configured credentials of the Container Cloud cluster.
Cluster
From the drop-down list, select the name of the related vSphere cluster in vCenter.
Caution
Do not confuse with the name of the vSphere cluster in Container Cloud.
Resource pool
Path to the vSphere resource pool.
Datastore
Datastore to use for the template.
ISO File Path
Path to the ISO file containing an installation image to clone within a datastore.
Network
Name of the vSphere network.
Folder
Path to store the VM template.
Hardware (optional)
CPUs
CPUs number of the template. Minimum number is 8.
Disk Size (GiB)
Disk size of the template. An integer value is considered as bytes. The minimum size is 120 Gi. You can use human-readable units. For details, see VsphereVMTemplate.
Memory (GiB)
RAM size of the template. An integer value is considered as bytes. The minimum size is 16 Gi. For details, see VsphereVMTemplate.
Network (optional)
IPv4 Settings
Select either DHCP or static protocol type.
Note
For a static protocol type, contact your vSphere administrator to provide you with the required network settings.
RHEL Licensing
RHEL License Name
Mandatory for RHEL-based deployments. Select the license added during the RHEL License configuration. For the
RHELLicenseobject description, see Overview of the cluster-related objects in the Container Cloud API/CLI.Virt-who
Optional. Select to define the user name and password of the
virt-whoservice.Additional Settings (optional)
Proxy
Name of the previously created
Proxyobject.Time Zone
Time zone of a machine in the IANA Timezone Database format. For example,
America/New_York.Click Create.
Add machines to the bootstrap cluster:
Machines configuration
In the Clusters tab, click the required cluster name. Click the Machines tab.
Click Create Machine.
Fill out the form with the following parameters:
Container Cloud machine configuration¶ Parameter
Description
Count
Specify the odd number of machines to create. Only Manager machines are allowed for a management cluster.
Caution
The required minimum number of manager machines is three for HA. A cluster can have more than three manager machines but only an odd number of machines.
In an even-sized cluster, an additional machine remains in the
Pendingstate until an extra manager machine is added. An even number of manager machines does not provide additional fault tolerance but increases the number of node required for etcd quorum.VM Source
Select Template Object and use the drop-down list to select the VM template name prepared in the previous step.
If you select vSphere Path, you may also use VM templates of your vSphere datacenter account that are displayed in the drop-down list. For the list of supported operating systems, refer to Requirements for a VMware vSphere-based cluster.
Note
Mirantis does not recommend using VM templates that contain the Unknown label in the drop-down list.
Caution
Container Cloud does not support mixed operating systems, RHEL combined with Ubuntu, in one cluster.
RHEL License
Applies to RHEL deployments only.
From the drop-down list, select the RHEL license that you previously added for the cluster being deployed.
VM Memory Size
VM memory size in GB, defaults to 24 GB.
VM CPU Size
VM CPUs number, defaults to 8.
Click Create.
Optional. Using the Container Cloud CLI, modify the provider-specific and other cluster settings as described in Configure optional cluster settings.
Select from the following options to start cluster deployment:
Click Deploy.
Approve the previously created bootstrap region using the Container Cloud CLI:
./kaas-bootstrap/container-cloud bootstrap approve all
./kaas-bootstrap/container-cloud bootstrap approve <bootstrapRegionName>
Caution
Once you approve the bootstrap region, no cluster or machine modification is allowed.
Monitor the deployment progress of the cluster and machines.
Monitoring of the cluster readiness
To monitor the cluster readiness, hover over the status icon of a specific cluster in the Status column of the Clusters page.
Once the orange blinking status icon becomes green and Ready, the cluster deployment or update is complete.
You can monitor live deployment status of the following cluster components:
Component
Description
Bastion
For the OpenStack-based management clusters, the Bastion node IP address status that confirms the Bastion node creation
Helm
Installation or upgrade status of all Helm releases
Kubelet
Readiness of the node in a Kubernetes cluster, as reported by kubelet
Kubernetes
Readiness of all requested Kubernetes objects
Nodes
Equality of the requested nodes number in the cluster to the number of nodes having the
ReadyLCM statusOIDC
Readiness of the cluster OIDC configuration
StackLight
Health of all StackLight-related objects in a Kubernetes cluster
Swarm
Readiness of all nodes in a Docker Swarm cluster
LoadBalancer
Readiness of the Kubernetes API load balancer
ProviderInstance
Readiness of all machines in the underlying infrastructure (virtual or bare metal, depending on the provider type)
Graceful Reboot
Readiness of a cluster during a scheduled graceful reboot, available since Cluster releases 15.0.1 and 14.0.0.
Infrastructure Status
Available since Container Cloud 2.25.0 for bare metal and OpenStack providers. Readiness of the following cluster components:
Bare metal: the
MetalLBConfigobject along with MetalLB and DHCP subnets.OpenStack: cluster network, routers, load balancers, and Bastion along with their ports and floating IPs.
LCM Operation
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Health of all LCM operations on the cluster and its machines.
LCM Agent
Available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Health of all LCM agents on cluster machines and the status of LCM agents update to the version from the current Cluster release.
For the history of a cluster deployment or update, refer to Inspect the history of a cluster and machine deployment or update.
Monitoring of machines readiness
To monitor machines readiness, use the status icon of a specific machine on the Clusters page.
- Quick status
On the Clusters page, in the Managers column. The green status icon indicates that the machine is Ready, the orange status icon indicates that the machine is Updating.
- Detailed status
In the Machines section of a particular cluster page, in the Status column. Hover over a particular machine status icon to verify the deploy or update status of a specific machine component.
You can monitor the status of the following machine components:
Component
Description
Kubelet
Readiness of a node in a Kubernetes cluster.
Swarm
Health and readiness of a node in a Docker Swarm cluster.
LCM
LCM readiness status of a node.
ProviderInstance
Readiness of a node in the underlying infrastructure (virtual or bare metal, depending on the provider type).
Graceful Reboot
Readiness of a machine during a scheduled graceful reboot of a cluster, available since Cluster releases 15.0.1 and 14.0.0.
Infrastructure Status
Available since Container Cloud 2.25.0 for the bare metal provider only. Readiness of the
IPAMHost,L2Template,BareMetalHost, andBareMetalHostProfileobjects associated with the machine.LCM Operation
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Health of all LCM operations on the machine.
LCM Agent
Available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Health of the LCM Agent on the machine and the status of the LCM Agent update to the version from the current Cluster release.
The machine creation starts with the Provision status. During provisioning, the machine is not expected to be accessible since its infrastructure (VM, network, and so on) is being created.
Other machine statuses are the same as the
LCMMachineobject states:Uninitialized - the machine is not yet assigned to an
LCMCluster.Pending - the agent reports a node IP address and host name.
Prepare - the machine executes
StateItemsthat correspond to thepreparephase. This phase usually involves downloading the necessary archives and packages.Deploy - the machine executes
StateItemsthat correspond to thedeployphase that is becoming a Mirantis Kubernetes Engine (MKE) node.Ready - the machine is being deployed.
Upgrade - the machine is being upgraded to the new MKE version.
Reconfigure - the machine executes
StateItemsthat correspond to thereconfigurephase. The machine configuration is being updated without affecting workloads running on the machine.
Once the status changes to Ready, the deployment of the cluster components on this machine is complete.
You can also monitor the live machine status using API:
kubectl get machines <machineName> -o wide
Example of system response since Container Cloud 2.23.0:
NAME READY LCMPHASE NODENAME UPGRADEINDEX REBOOTREQUIRED WARNINGS demo-0 true Ready kaas-node-c6aa8ad3 1 false
For the history of a machine deployment or update, refer to Inspect the history of a cluster and machine deployment or update.
Alternatively, verify machine statuses from the seed node on which the bootstrap cluster is deployed:
Log in to the seed node.
Export
KUBECONFIGto connect to the bootstrap cluster:export KUBECONFIG=~/.kube/kind-config-clusterapi
Verify the statuses of available
LCMMachineobjects:kubectl get lcmmachines -o wide
Verify the statuses of available cluster machines:
kubectl get machines -o wide
Verify that network addresses used on your clusters do not overlap with the following default MKE network addresses for Swarm and MCR:
10.0.0.0/16is used for Swarm networks. IP addresses from this network are virtual.10.99.0.0/16is used for MCR networks. IP addresses from this network are allocated on hosts.
Verification of Swarm and MCR network addresses
To verify Swarm and MCR network addresses, run on any master node:
docker infoExample of system response:
Server: ... Swarm: ... Default Address Pool: 10.0.0.0/16 SubnetSize: 24 ... Default Address Pools: Base: 10.99.0.0/16, Size: 20 ...
Not all of Swarm and MCR addresses are usually in use. One Swarm Ingress network is created by default and occupies the
10.0.0.0/24address block. Also, three MCR networks are created by default and occupy three address blocks:10.99.0.0/20,10.99.16.0/20,10.99.32.0/20.To verify the actual networks state and addresses in use, run:
docker network ls docker network inspect <networkName>
Note
The Bootstrap web UI support for the bare metal provider will be added in one of the following Container Cloud releases.
Configure a bare metal deployment¶
During creation of a bare metal management cluster using Bootstrap v2, configure several cluster settings to fit your deployment.
Configure BIOS on a bare metal host¶
Before adding new BareMetalHost objects, configure hardware hosts to
correctly load them over the PXE network.
Important
Consider the following common requirements for hardware hosts configuration:
Update firmware for BIOS and Baseboard Management Controller (BMC) to the latest available version, especially if you are going to apply the UEFI configuration.
Container Cloud uses the
ipxe.efibinary loader that might be not compatible with old firmware and have vendor-related issues with UEFI booting. For example, the Supermicro issue. In this case, we recommend using thelegacybooting format.Configure all or at least the
PXENIC on switches.If the hardware host has more than one PXE NIC to boot, we strongly recommend setting up only one in the boot order. It speeds up the provisioning phase significantly.
Some hardware vendors require a host to be rebooted during BIOS configuration changes from
legacytoUEFIor vice versa for the extra option with NIC settings to appear in the menu.Connect only one Ethernet port on a host to the PXE network at any given time. Collect the physical address (MAC) of this interface and use it to configure the
BareMetalHostobject describing the host.
To configure BIOS on a bare metal host:
Enable the global BIOS mode using BIOS > Boot > boot mode select > legacy. Reboot the host if required.
Enable the
LAN-PXE-OPROMsupport using the following menus:BIOS > Advanced > PCI/PCIe Configuration > LAB OPROM TYPE > legacy
BIOS > Advanced > PCI/PCIe Configuration > Network Stack > enabled
BIOS > Advanced > PCI/PCIe Configuration > IPv4 PXE Support > enabled
Set up the configured boot order:
BIOS > Boot > Legacy-Boot-Order#1 > Hard Disk
BIOS > Boot > Legacy-Boot-Order#2 > NIC
Save changes and power off the host.
Enable the global BIOS mode using BIOS > Boot > boot mode select > UEFI. Reboot the host if required.
Enable the
LAN-PXE-OPROMsupport using the following menus:BIOS > Advanced > PCI/PCIe Configuration > LAB OPROM TYPE > uefi
BIOS > Advanced > PCI/PCIe Configuration > Network Stack > enabled
BIOS > Advanced > PCI/PCIe Configuration > IPv4 PXE Support > enabled
Note
UEFI support might not apply to all NICs. But at least built-in network interfaces should support it.
Set up the configured boot order:
BIOS > Boot > UEFI-Boot-Order#1 > UEFI Hard Disk
BIOS > Boot > UEFI-Boot-Order#1 > UEFI Network
Save changes and power off the host.
Customize the default bare metal host profile¶
This section describes the bare metal host profile settings and instructs how to configure this profile before deploying Mirantis Container Cloud on physical servers.
The bare metal host profile is a Kubernetes custom resource. It allows the Infrastructure Operator to define how the storage devices and the operating system are provisioned and configured.
The bootstrap templates for a bare metal deployment include the template for
the default BareMetalHostProfile object in the following file
that defines the default bare metal host profile:
templates/bm/baremetalhostprofiles.yaml.template
Note
Using BareMetalHostProfile, you can configure LVM or mdadm-based
software RAID support during a management or managed cluster
creation. For details, see Configure RAID support.
This feature is available as Technology Preview. Use such configuration for testing and evaluation purposes only. For the Technology Preview feature definition, refer to Technology Preview features.
Warning
Any data stored on any device defined in the fileSystems
list can be deleted or corrupted during cluster (re)deployment. It happens
because each device from the fileSystems list is a part of the
rootfs directory tree that is overwritten during (re)deployment.
Examples of affected devices include:
A raw device partition with a file system on it
A device partition in a volume group with a logical volume that has a file system on it
An mdadm RAID device with a file system on it
An LVM RAID device with a file system on it
The wipe field (deprecated) or wipeDevice structure (recommended
since Container Cloud 2.26.0) have no effect in this case and cannot
protect data on these devices.
Therefore, to prevent data loss, move the necessary data from these file systems to another server beforehand, if required.
The customization procedure of BareMetalHostProfile is almost the same for
the management and managed clusters, with the following differences:
For a management cluster, the customization automatically applies to machines during bootstrap. And for a managed cluster, you apply the changes using
kubectlbefore creating a managed cluster.For a management cluster, you edit the default
baremetalhostprofiles.yaml.template. And for a managed cluster, you create a newBareMetalHostProfilewith the necessary configuration.
For the procedure details, see Create a custom bare metal host profile. Use this procedure for both types of clusters considering the differences described above.
Configure NIC bonding¶
You can configure L2 templates for the management cluster to set up a bond network interface for the PXE and management network.
This configuration must be applied to the bootstrap templates, before you run the bootstrap script to deploy the management cluster.
..admonition:: Configuration requirements for NIC bonding
Add at least two physical interfaces to each host in your management cluster.
Connect at least two interfaces per host to an Ethernet switch that supports Link Aggregation Control Protocol (LACP) port groups and LACP fallback.
Configure an LACP group on the ports connected to the NICs of a host.
Configure the LACP fallback on the port group to ensure that the host can boot over the PXE network before the bond interface is set up on the host operating system.
Configure server BIOS for both NICs of a bond to be PXE-enabled.
If the server does not support booting from multiple NICs, configure the port of the LACP group that is connected to the PXE-enabled NIC of a server to be the primary port. With this setting, the port becomes active in the fallback mode.
Configure the ports that connect servers to the PXE network with the PXE VLAN as native or untagged.
For reference configuration of network fabric in a baremetal-based cluster, see Network fabric.
To configure a bond interface that aggregates two interfaces for the PXE and management network:
In
kaas-bootstrap/templates/bm/ipam-objects.yaml.template:Verify that only the following parameters for the declaration of
{{nic 0}}and{{nic 1}}are set, as shown in the example below:dhcp4dhcp6
matchset-name
Remove other parameters.
Verify that the declaration of the bond interface
bond0has theinterfacesparameter listing both Ethernet interfaces.Verify that the node address in the PXE network (
ip "bond0:mgmt-pxe"in the below example) is bound to the bond interface or to the virtual bridge interface tied to that bond.Caution
No VLAN ID must be configured for the PXE network from the host side.
Configure bonding options using the
parametersfield. The only mandatory option ismode. See the example below for details.Note
You can set any mode supported by netplan and your hardware.
Important
Bond monitoring is disabled in Ubuntu by default. However, Mirantis highly recommends enabling it using Media Independent Interface (MII) monitoring by setting the
mii-monitor-intervalparameter to a non-zero value. For details, see Linux documentation: bond monitoring.
Verify your configuration using the following example:
kind: L2Template metadata: name: kaas-mgmt ... spec: ... l3Layout: - subnetName: kaas-mgmt scope: namespace npTemplate: | version: 2 ethernets: {{nic 0}}: dhcp4: false dhcp6: false match: macaddress: {{mac 0}} set-name: {{nic 0}} {{nic 1}}: dhcp4: false dhcp6: false match: macaddress: {{mac 1}} set-name: {{nic 1}} bonds: bond0: interfaces: - {{nic 0}} - {{nic 1}} parameters: mode: 802.3ad mii-monitor-interval: 100 dhcp4: false dhcp6: false addresses: - {{ ip "bond0:mgmt-pxe" }} vlans: k8s-lcm: id: SET_VLAN_ID link: bond0 addresses: - {{ ip "k8s-lcm:kaas-mgmt" }} nameservers: addresses: {{ nameservers_from_subnet "kaas-mgmt" }} routes: - to: 0.0.0.0/0 via: {{ gateway_from_subnet "kaas-mgmt" }} ...
Proceed to bootstrap your management cluster as described in Deploy a management cluster using CLI.
Separate PXE and management networks¶
This section describes how to configure a dedicated PXE network for a management bare metal cluster. A separate PXE network allows isolating sensitive bare metal provisioning process from the end users. The users still have access to Container Cloud services, such as Keycloak, to authenticate workloads in managed clusters, such as Horizon in a Mirantis OpenStack for Kubernetes cluster.
Note
This additional configuration procedure must be completed as part of the Deploy a management cluster using CLI steps. It substitutes or appends some configuration parameters and templates that are used in Deploy a management cluster using CLI for the management cluster to use two networks, PXE and management, instead of one PXE/management network. We recommend considering the Deploy a management cluster using CLI procedure first.
The following table describes the overall network mapping scheme with all
L2/L3 parameters, for example, for two networks, PXE (CIDR 10.0.0.0/24)
and management (CIDR 10.0.11.0/24):
Deployment file name |
Network |
Parameters and values |
|---|---|---|
|
Management |
|
|
PXE |
|
|
Management |
|
|
PXE |
|
When using separate PXE and management networks, the management cluster services are exposed in different networks using two separate MetalLB address pools:
Services exposed through the PXE network are as follows:
Ironic API as a bare metal provisioning server
HTTP server that provides images for network boot and server provisioning
Caching server for accessing the Container Cloud artifacts deployed on hosts
Services exposed through the management network are all other Container Cloud services, such as Keycloak, web UI, and so on.
To configure separate PXE and management networks:
Inspect guidelines to follow during configuration of the
Subnetobject as a MetalLB address pool as described MetalLB configuration guidelines for subnets.To ensure successful bootstrap, enable asymmetric routing on the interfaces of the management cluster nodes. This is required because the seed node relies on one network by default, which can potentially cause traffic asymmetry.
In the
kernelParameterssection ofbm/baremetalhostprofiles.yaml.template, setrp_filterto2. This enables loose mode as defined in RFC3704.Example configuration of asymmetric routing
... kernelParameters: ... sysctl: # Enables the "Loose mode" for the "k8s-lcm" interface (management network) net.ipv4.conf.k8s-lcm.rp_filter: "2" # Enables the "Loose mode" for the "bond0" interface (PXE network) net.ipv4.conf.bond0.rp_filter: "2" ...
Note
More complicated solutions that are not described in this manual include getting rid of traffic asymmetry, for example:
Configure source routing on management cluster nodes.
Plug the seed node into the same networks as the management cluster nodes, which requires custom configuration of the seed node.
In
kaas-bootstrap/templates/bm/ipam-objects.yaml.template:Substitute all the
Subnetobject templates with the new ones as described in the example template belowUpdate the L2 template
spec.l3Layoutandspec.npTemplatefields as described in the example template below
Example of the
Subnetobject templates# Subnet object that provides IP addresses for bare metal hosts of # management cluster in the PXE network. apiVersion: "ipam.mirantis.com/v1alpha1" kind: Subnet metadata: name: mgmt-pxe namespace: default labels: kaas.mirantis.com/provider: baremetal kaas-mgmt-pxe-subnet: "" spec: cidr: SET_IPAM_CIDR gateway: SET_PXE_NW_GW nameservers: - SET_PXE_NW_DNS includeRanges: - SET_IPAM_POOL_RANGE excludeRanges: - SET_METALLB_PXE_ADDR_POOL --- # Subnet object that provides IP addresses for bare metal hosts of # management cluster in the management network. apiVersion: "ipam.mirantis.com/v1alpha1" kind: Subnet metadata: name: mgmt-lcm namespace: default labels: kaas.mirantis.com/provider: baremetal kaas-mgmt-lcm-subnet: "" ipam/SVC-k8s-lcm: "1" ipam/SVC-ceph-cluster: "1" ipam/SVC-ceph-public: "1" cluster.sigs.k8s.io/cluster-name: CLUSTER_NAME spec: cidr: {{ SET_LCM_CIDR }} includeRanges: - {{ SET_LCM_RANGE }} excludeRanges: - SET_LB_HOST - SET_METALLB_ADDR_POOL --- # Deprecated since 2.27.0. Subnet object that provides configuration # for "services-pxe" MetalLB address pool that will be used to expose # services LB endpoints in the PXE network. apiVersion: "ipam.mirantis.com/v1alpha1" kind: Subnet metadata: name: mgmt-pxe-lb namespace: default labels: kaas.mirantis.com/provider: baremetal metallb/address-pool-name: services-pxe metallb/address-pool-protocol: layer2 metallb/address-pool-auto-assign: "false" cluster.sigs.k8s.io/cluster-name: CLUSTER_NAME spec: cidr: SET_IPAM_CIDR includeRanges: - SET_METALLB_PXE_ADDR_POOL
Example of the L2 template
speckind: L2Template ... spec: ... l3Layout: - scope: namespace subnetName: kaas-mgmt-pxe labelSelector: kaas.mirantis.com/provider: baremetal kaas-mgmt-pxe-subnet: "" - scope: namespace subnetName: kaas-mgmt-lcm labelSelector: kaas.mirantis.com/provider: baremetal kaas-mgmt-lcm-subnet: "" npTemplate: | version: 2 renderer: networkd ethernets: {{nic 0}}: dhcp4: false dhcp6: false match: macaddress: {{mac 0}} set-name: {{nic 0}} {{nic 1}}: dhcp4: false dhcp6: false match: macaddress: {{mac 1}} set-name: {{nic 1}} bridges: bm-pxe: interfaces: - {{ nic 0 }} dhcp4: false dhcp6: false addresses: - {{ ip "bm-pxe:kaas-mgmt-pxe" }} nameservers: addresses: {{ nameservers_from_subnet "kaas-mgmt-pxe" }} routes: - to: 0.0.0.0/0 via: {{ gateway_from_subnet "kaas-mgmt-pxe" }} k8s-lcm: interfaces: - {{ nic 1 }} dhcp4: false dhcp6: false addresses: - {{ ip "k8s-lcm:kaas-mgmt-lcm" }} nameservers: addresses: {{ nameservers_from_subnet "kaas-mgmt-lcm" }}
Deprecated since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0): the last
Subnettemplate namedmgmt-pxe-lbin the example above will be used to configure the MetalLB address pool in the PXE network. The bare metal provider will automatically configure MetalLB with address pools using theSubnetobjects identified by specific labels.Warning
The
bm-pxeaddress must have a separate interface with only one address on this interface.Verify the current MetalLB configuration that is stored in
MetalLBobjects:kubectl -n metallb-system get ipaddresspools,l2advertisements
For the example configuration described above, the system outputs a similar content:
NAME AGE ipaddresspool.metallb.io/default 129m ipaddresspool.metallb.io/services-pxe 129m NAME AGE l2advertisement.metallb.io/default 129m l2advertisement.metallb.io/services-pxe 129m
To verify the
MetalLBobjects:kubectl -n metallb-system get <object> -o json | jq '.spec'
For the example configuration described above, the system outputs a similar content for
ipaddresspoolobjects:{ "addresses": [ "10.0.11.61-10.0.11.80" ], "autoAssign": true, "avoidBuggyIPs": false } $ kubectl -n metallb-system get ipaddresspool.metallb.io/services-pxe -o json | jq '.spec' { "addresses": [ "10.0.0.61-10.0.0.70" ], "autoAssign": false, "avoidBuggyIPs": false }
The
auto-assignparameter will be set tofalsefor all address pools except thedefaultone. So, a particular service will get an address from such an address pool only if theServiceobject has a specialmetallb.universe.tf/address-poolannotation that points to the specific address pool name.Note
It is expected that every Container Cloud service on a management cluster will be assigned to one of the address pools. Current consideration is to have two MetalLB address pools:
services-pxeis a reserved address pool name to use for the Container Cloud services in the PXE network (Ironic API, HTTP server, caching server).The bootstrap cluster also uses the
services-pxeaddress pool for its provision services for management cluster nodes to be provisioned from the bootstrap cluster. After the management cluster is deployed, the bootstrap cluster is deleted and that address pool is solely used by the newly deployed cluster.defaultis an address pool to use for all other Container Cloud services in the management network. No annotation is required on theServiceobjects in this case.
Select from the following options for configuration of the
dedicatedMetallbPoolsflag:Skip this step because the flag is hardcoded to
true.Verify that the flag is set to the default
truevalue.The flag enables splitting of LB endpoints for the Container Cloud services. The
metallb.universe.tf/address-poolannotations on theServiceobjects are configured by the bare metal provider automatically when thededicatedMetallbPoolsflag is set totrue.Example
Serviceobject configured by thebaremetal-operatorHelm release:apiVersion: v1 kind: Service metadata: name: ironic-api annotations: metallb.universe.tf/address-pool: services-pxe spec: ports: - port: 443 targetPort: 443 type: LoadBalancer
The
metallb.universe.tf/address-poolannotation on theServiceobject is set toservices-pxeby the baremetal provider, so theironic-apiservice will be assigned an LB address from the corresponding MetalLB address pool.In addition to the network parameters defined in Deploy a management cluster using CLI, configure the following ones by replacing them in
templates/bm/ipam-objects.yaml.template:New subnet template parameters¶ Parameter
Description
Example value
SET_LCM_CIDRAddress of a management network for the management cluster in the CIDR notation. You can later share this network with managed clusters where it will act as the LCM network. If managed clusters have their separate LCM networks, those networks must be routable to the management network.
10.0.11.0/24SET_LCM_RANGEAddress range that includes addresses to be allocated to bare metal hosts in the management network for the management cluster. When this network is shared with managed clusters, the size of this range limits the number of hosts that can be deployed in all clusters that share this network. When this network is solely used by a management cluster, the range should include at least 3 IP addresses for bare metal hosts of the management cluster.
10.0.11.100-10.0.11.109SET_METALLB_PXE_ADDR_POOLAddress range to be used for LB endpoints of the Container Cloud services: Ironic-API, HTTP server, and caching server. This range must be within the PXE network. The minimum required range is 5 IP addresses.
10.0.0.61-10.0.0.70The following parameters will now be tied to the management network while their meaning remains the same as described in Deploy a management cluster using CLI:
Subnet template parameters migrated to management network¶ Parameter
Description
Example value
SET_LB_HOSTIP address of the externally accessible API endpoint of the management cluster. This address must NOT be within the
SET_METALLB_ADDR_POOLrange but within the management network. External load balancers are not supported.10.0.11.90SET_METALLB_ADDR_POOLThe address range to be used for the externally accessible LB endpoints of the Container Cloud services, such as Keycloak, web UI, and so on. This range must be within the management network. The minimum required range is 19 IP addresses.
10.0.11.61-10.0.11.80Proceed to further steps in Deploy a management cluster using CLI.
Configure multiple DHCP ranges using Subnet resources¶
To facilitate multi-rack and other types of distributed bare metal datacenter topologies, the dnsmasq DHCP server used for host provisioning in Container Cloud supports working with multiple L2 segments through network routers that support DHCP relay.
Container Cloud has its own DHCP relay running on one of the management cluster nodes. That DHCP relay serves for proxying DHCP requests in the same L2 domain where the management cluster nodes are located.
Caution
Networks used for hosts provisioning of a managed cluster must have routes to the PXE network (when a dedicated PXE network is configured) or to the combined PXE/management network of the management cluster. This configuration enables hosts to have access to the management cluster services that are used during host provisioning.
Management cluster nodes must have routes through the PXE network to PXE network segments used on a managed cluster. The following example contains L2 template fragments for a management cluster node:
l3Layout:
# PXE/static subnet for a management cluster
- scope: namespace
subnetName: kaas-mgmt-pxe
labelSelector:
kaas-mgmt-pxe-subnet: "1"
# management (LCM) subnet for a management cluster
- scope: namespace
subnetName: kaas-mgmt-lcm
labelSelector:
kaas-mgmt-lcm-subnet: "1"
# PXE/dhcp subnets for a managed cluster
- scope: namespace
subnetName: managed-dhcp-rack-1
- scope: namespace
subnetName: managed-dhcp-rack-2
- scope: namespace
subnetName: managed-dhcp-rack-3
...
npTemplate: |
...
bonds:
bond0:
interfaces:
- {{ nic 0 }}
- {{ nic 1 }}
parameters:
mode: active-backup
primary: {{ nic 0 }}
mii-monitor-interval: 100
dhcp4: false
dhcp6: false
addresses:
# static address on management node in the PXE network
- {{ ip "bond0:kaas-mgmt-pxe" }}
routes:
# routes to managed PXE network segments
- to: {{ cidr_from_subnet "managed-dhcp-rack-1" }}
via: {{ gateway_from_subnet "kaas-mgmt-pxe" }}
- to: {{ cidr_from_subnet "managed-dhcp-rack-2" }}
via: {{ gateway_from_subnet "kaas-mgmt-pxe" }}
- to: {{ cidr_from_subnet "managed-dhcp-rack-3" }}
via: {{ gateway_from_subnet "kaas-mgmt-pxe" }}
...
To configure DHCP ranges for dnsmasq, create the Subnet objects
tagged with the ipam/SVC-dhcp-range label while setting up subnets
for a managed cluster using CLI.
Caution
Support of multiple DHCP ranges has the following limitations:
Using of custom DNS server addresses for servers that boot over PXE is not supported.
The
Subnetobjects for DHCP ranges cannot be associated with any specific cluster, as DHCP server configuration is only applicable to the management cluster where DHCP server is running. Thecluster.sigs.k8s.io/cluster-namelabel will be ignored.Note
Before the Cluster release 16.1.0, the
Subnetobject contains thekaas.mirantis.com/regionlabel that specifies the region where the DHCP ranges will be applied.
Note
This section applies only to existing management clusters that are created before Container 2.24.0.
Caution
Since Container Cloud 2.24.0, you can only remove the deprecated
dnsmasq.dhcp_range, dnsmasq.dhcp_ranges, dnsmasq.dhcp_routers,
and dnsmasq.dhcp_dns_servers values from the cluster spec.
The Admission Controller does not accept any other changes in these values.
This configuration is completely superseded by the Subnet object.
The DHCP configuration automatically migrated from the cluster spec to
Subnet objects after cluster upgrade to 2.21.0.
To remove the deprecated dnsmasq parameters from the cluster spec:
Open the management cluster
specfor editing.In the
baremetal-operatorrelease values, remove thednsmasq.dhcp_range,dnsmasq.dhcp_ranges,dnsmasq.dhcp_routers, anddnsmasq.dhcp_dns_serversparameters. For example:regional: - helmReleases: - name: baremetal-operator values: dnsmasq: dhcp_range: 10.204.1.0,10.204.5.255,255.255.255.0
Caution
The
dnsmasq.dhcp_<name>parameters of thebaremetal-operatorHelm chart values in theClusterspecare deprecated since the Cluster release 11.5.0 and removed in the Cluster release 14.0.0.Ensure that the required DHCP ranges and options are set in the
Subnetobjects. For configuration details, see Configure DHCP ranges for dnsmasq.
The dnsmasq configuration options dhcp-option=3 and dhcp-option=6
are absent in the default configuration. So, by default, dnsmasq
will send the DNS server and default route to DHCP clients as defined in the
dnsmasq official documentation:
The netmask and broadcast address are the same as on the host running dnsmasq.
The DNS server and default route are set to the address of the host running dnsmasq.
If the domain name option is set, this name is sent to DHCP clients.
Create the
Subnetobjects tagged with theipam/SVC-dhcp-rangelabel.Caution
For cluster-specific subnets, create
Subnetobjects in the same namespace as the relatedClusterobject project. For shared subnets, createSubnetobjects in thedefaultnamespace.To create the
Subnetobjects, refer to Create subnets.Use the following
Subnetobject example to specify DHCP ranges and DHCP options to pass the default route address:apiVersion: "ipam.mirantis.com/v1alpha1" kind: Subnet metadata: name: mgmt-dhcp-range namespace: default labels: ipam/SVC-dhcp-range: "" kaas.mirantis.com/provider: baremetal spec: cidr: 10.11.0.0/24 gateway: 10.11.0.1 includeRanges: - 10.11.0.121-10.11.0.125 - 10.11.0.191-10.11.0.199
Note
Setting of custom nameservers in the DHCP subnet is not supported.
After creation of the above
Subnetobject, the provided data will be utilized to render theDnsmasqobject used for configuration of the dnsmasq deployment. You do not have to manually edit theDnsmasqobject.Verify that the changes are applied to the
Dnsmasqobject:kubectl --kubeconfig <pathToMgmtClusterKubeconfig> \ -n kaas get dnsmasq dnsmasq-dynamic-config -o json
See also
For servers to access the DHCP server across the L2 segment boundaries, for example, from another rack with a different VLAN for PXE network, you must configure DHCP relay (agent) service on the border switch of the segment. For example, on a top-of-rack (ToR) or leaf (distribution) switch, depending on the data center network topology.
Warning
To ensure predictable routing for the relay of DHCP packets, Mirantis strongly advises against the use of chained DHCP relay configurations. This precaution limits the number of hops for DHCP packets, with an optimal scenario being a single hop.
This approach is justified by the unpredictable nature of chained relay configurations and potential incompatibilities between software and hardware relay implementations.
The dnsmasq server listens on the PXE network of the management
cluster by using the dhcp-lb Kubernetes Service.
To configure the DHCP relay service, specify the external address of the
dhcp-lb Kubernetes Service as an upstream address for the relayed DHCP
requests, which is the IP helper address for DHCP. There is the dnsmasq
deployment behind this service that can only accept relayed DHCP requests.
Container Cloud has its own DHCP relay running on one of the management cluster nodes. That DHCP relay serves for proxying DHCP requests in the same L2 domain where the management cluster nodes are located.
To obtain the actual IP address issued to the dhcp-lb Kubernetes
Service:
kubectl -n kaas get service dhcp-lb
Enable dynamic IP allocation¶
Available since the Cluster release 16.1.0
This section instructs you on how to enable dynamic IP allocation feature to increase the amount of baremetal hosts to be provisioned in parallel on managed clusters.
Using this feature, you can effortlessly deploy a large managed cluster by provisioning up to 100 hosts simultaneously. In addition to dynamic IP allocation, this feature disables the ping check in the DHCP server. Therefore, if you plan to deploy large managed clusters, enable this feature during the management cluster bootstrap.
Caution
Before using this feature, familiarize yourself with DHCP range requirements for PXE.
To enable dynamic IP allocation for large managed clusters:
In the Cluster object of the management cluster, modify the configuration
of baremetal-provider by setting dynamic_bootp to true:
spec:
...
providerSpec:
value:
kaas:
...
regional:
- helmReleases:
- name: baremetal-provider
values:
dnsmasq:
dynamic_bootp: true
provider: baremetal
...
Configure a vSphere-based deployment¶
During creation of a vSphere-based management cluster using Bootstrap v2, configure several cluster settings to fit your deployment.
Prepare the VMware deployment user setup and permissions¶
To deploy Mirantis Container Cloud on the VMware vSphere-based environment, you need to prepare vSphere accounts for Container Cloud. Contact your vSphere administrator to set up the required users and permissions following the steps below:
Log in to the vCenter Server Web Console.
Create the
cluster-apiuser with the following privileges:Note
Container Cloud uses two separate vSphere accounts for:
Cluster API related operations, such as create or delete VMs, and for preparation of the VM template using Packer
Storage operations, such as dynamic PVC provisioning
You can also create one user that has all privileges sets mentioned above.
The cluster-api user privileges
Privilege
Permission
Content library
Download files
Read storage
Sync library item
Datastore
Allocate space
Browse datastore
Low-level file operations
Update virtual machine metadata
Distributed switch
Host operation
IPFIX operation
Modify
Network I/O control operation
Policy operation
Port configuration operation
Port setting operation
VSPAN operation
Folder
Create folder
Rename folder
Global
Cancel task
Host local operations
Create virtual machine
Delete virtual machine
Reconfigure virtual machine
Network
Assign network
Resource
Assign virtual machine to resource pool
Scheduled task
Create tasks
Modify task
Remove task
Run task
Sessions
Validate session
View and stop sessions
Storage views
View
Tasks
Create task
Update task
Virtual machine permissions¶ Privilege
Permission
Change configuration
Acquire disk lease
Add existing disk
Add new disk
Add or remove device
Advanced configuration
Change CPU count
Change Memory
Change Settings
Change Swapfile placement
Change resource
Configure Host USB device
Configure Raw device
Configure managedBy
Display connection settings
Extend virtual disk
Modify device settings
Query Fault Tolerance compatibility
Query unowned files
Reload from path
Remove disk
Rename
Reset guest information
Set annotation
Toggle disk change tracking
Toggle fork parent
Upgrade virtual machine compatibility
Interaction
Configure CD media
Configure floppy media
Console interaction
Device connection
Inject USB HID scan codes
Power off
Power on
Reset
Suspend
Inventory
Create from existing
Create new
Move
Register
Remove
Unregister
Provisioning
Allow disk access
Allow file access
Allow read-only disk access
Allow virtual machine download
Allow virtual machine files upload
Clone template
Clone virtual machine
Create template from virtual machine
Customize guest
Deploy template
Mark as template
Mark as virtual machine
Modify customization specification
Promote disks
Read customization specifications
Snapshot management
Create snapshot
Remove snapshot
Rename snapshot
Revert to snapshot
vSphere replication
Monitor replication
Create the
storageuser with the following privileges:Note
For more details about all required privileges for the
storageuser, see vSphere Cloud Provider documentation.The storage user privileges
Privilege
Permission
Cloud Native Storage
Searchable
Content library
View configuration settings
Datastore
Allocate space
Browse datastore
Low level file operations
Remove file
Folder
Create folder
Host configuration
Storage partition configuration
Host local operations
Create virtual machine
Delete virtual machine
Reconfigure virtual machine
Host profile
View
Profile-driven storage
Profile-driven storage view
Resource
Assign virtual machine to resource pool
Scheduled task
Create tasks
Modify task
Run task
Sessions
Validate session
View and stop sessions
Storage views
View
Virtual machine permissions¶ Privilege
Permission
Change configuration
Add existing disk
Add new disk
Add or remove device
Advanced configuration
Change CPU count
Change Memory
Change Settings
Configure managedBy
Extend virtual disk
Remove disk
Rename
Inventory
Create from existing
Create new
Remove
For RHEL deployments, if you do not have a RHEL machine with the
virt-whoservice configured to report the vSphere environment configuration and hypervisors information to RedHat Customer Portal or RedHat Satellite server, set up thevirt-whoservice inside the Container Cloud machines for a proper RHEL license activation.Create a
virt-whouser with at least read-only access to all objects in the vCenter Data Center.The
virt-whoservice on RHEL machines will be provided with thevirt-whouser credentials to properly manage RHEL subscriptions.For details on how to create the
virt-whouser, refer to the official RedHat Customer Portal documentation.
Now, proceed to bootstrapping the management cluster using the Container Cloud API or web UI.
RHEL 8 mirrors configuration¶
GA since 16.0.0 TechPreview before 16.0.0
By default, the RHEL subscription grants access to the AppStream
and BaseOS repositories that are not bound to a specific operating system
version and that are stream repositories, so they are frequently updated.
To deploy RHEL 8.7 and make sure that packages are installed
from the version 8.7 AppStream and BaseOS repositories, the
RHEL VM template has the releasever variable for .yum set to 8.7.
You can verify this variable in /etc/yum/vars/releasever on a VM.
If you are using the RedHat Satellite server, verify that your activation key
is configured with the release version set to 8.7 and includes only
the following repositories:
Red Hat Enterprise Linux 8 for x86_64 - BaseOS RPMs 8.7
Red Hat Enterprise Linux 8 for x86_64 - AppStream RPMs 8.7
Configure squid-proxy¶
By default squid-proxy allows an access only to the official RedHat
subscription.rhsm.redhat.com and .cdn.redhat.com URLs.
If you use RedHat Satellite server or if you want to access some specific
yum repositories of RedHat, allow those domains (or IPs addresses) in the
squid-proxy configuration on the management cluster.
Note
You can apply the procedure below before or after the management cluster deployment.
To configure squid-proxy for an access to specific domains:
Modify the allowed domains for
squid-proxyin the regional Helm releases configuration for thevsphereprovider using the example below.For new deployments, modify
templates/vsphere/cluster.yaml.templateFor existing deployments, modify the management cluster configuration:
kubectl edit cluster <mgmtClusterName> -n <projectName>
Example configuration:
spec: ... providerSpec: value: ... kaas: ... regional: - helmReleases: ... - name: squid-proxy values: config: domains: rhel: - .subscription.rhsm.redhat.com - .cdn.redhat.com - .satellite.server.org - 172.16.10.10 provider: vsphere
On a deployed cluster, verify that the configuration is applied properly by verifying
configmapforsquid-proxy:kubectl describe configmap squid-proxy -n kaas
The
squid.confdata should include the provided domains. For example:acl rhel dstdomain .subscription.rhsm.redhat.com .cdn.redhat.com .satellite.server.org 172.16.10.10
Configure optional cluster settings¶
During creation of a management cluster using Bootstrap v2, you can configure
optional cluster settings using the Container Cloud API by modifying the
Cluster object or cluster.yaml.template of the required provider.
To configure optional cluster settings:
Select from the following options:
If you create a management cluster using the Container Cloud API, proceed to the next step and configure
cluster.yaml.templateof the required provider instead of theClusterobject while following the below procedure.If you create a management cluster using the Container Cloud Bootstrap web UI:
Log in to the seed node where the bootstrap cluster is located.
Navigate to the
kaas-bootstrapfolder.Export
KUBECONFIGto connect to the bootstrap cluster:export KUBECONFIG=<pathToKindKubeconfig>
Obtain the cluster name and open its
Clusterobject for editing:kubectl get clusters kubectl edit cluster <clusterName>
Technology Preview. Enable custom host names for cluster machines. When enabled, any machine host name in a particular region matches the related
Machineobject name. For example, instead of the defaultkaas-node-<UID>, a machine host name will bemaster-0. The custom naming format is more convenient and easier to operate with.To enable the feature on the management and its future managed clusters:
In the
Clusterobject, find thespec.providerSpec.value.kaas.regional.helmReleases.name: <provider-name>section.Under
values.config, addcustomHostnamesEnabled: true.For example, for the bare metal provider:
regional: - helmReleases: - name: baremetal-provider values: config: allInOneAllowed: false customHostnamesEnabled: true internalLoadBalancers: false provider: baremetal-provider
In the
Clusterobject, find thespec.providerSpec.value.kaas.regionalsection of the required region.In this section, find the required provider
nameunderhelmReleases.Under
values.config, addcustomHostnamesEnabled: true.For example, for the bare metal provider in
region-one:regional: - helmReleases: - name: baremetal-provider values: config: allInOneAllowed: false customHostnamesEnabled: true internalLoadBalancers: false provider: baremetal-provider
Add the following environment variable:
export CUSTOM_HOSTNAMES=true
Technology Preview. Enable the Linux Audit daemon auditd to monitor activity of cluster processes and prevent potential malicious activity.
Configuration for auditd
In the
Clusterobject, add the auditd parameters:spec: providerSpec: value: audit: auditd: enabled: <bool> enabledAtBoot: <bool> backlogLimit: <int> maxLogFile: <int> maxLogFileAction: <string> maxLogFileKeep: <int> mayHaltSystem: <bool> presetRules: <string> customRules: <string> customRulesX32: <text> customRulesX64: <text>
Configuration parameters for auditd:
enabledBoolean, default -
false. Enables theauditdrole to install the auditd packages and configure rules. CIS rules: 4.1.1.1, 4.1.1.2.enabledAtBootBoolean, default -
false. Configures grub to audit processes that can be audited even if they start up prior to auditd startup. CIS rule: 4.1.1.3.backlogLimitInteger, default - none. Configures the backlog to hold records. If during boot
audit=1is configured, the backlog holds 64 records. If more than 64 records are created during boot, auditd records will be lost with a potential malicious activity being undetected. CIS rule: 4.1.1.4.maxLogFileInteger, default - none. Configures the maximum size of the audit log file. Once the log reaches the maximum size, it is rotated and a new log file is created. CIS rule: 4.1.2.1.
maxLogFileActionString, default - none. Defines handling of the audit log file reaching the maximum file size. Allowed values:
keep_logs- rotate logs but never delete themrotate- add a cron job to compress rotated log files and keep maximum 5 compressed files.compress- compress log files and keep them under the/var/log/auditd/directory. Requiresauditd_max_log_file_keepto be enabled.
CIS rule: 4.1.2.2.
maxLogFileKeepInteger, default -
5. Defines the number of compressed log files to keep under the/var/log/auditd/directory. Requiresauditd_max_log_file_action=compress. CIS rules - none.mayHaltSystemBoolean, default -
false. Halts the system when the audit logs are full. Applies the following configuration:space_left_action = emailaction_mail_acct = rootadmin_space_left_action = halt
CIS rule: 4.1.2.3.
customRulesString, default - none. Base64-encoded content of the
60-custom.rulesfile for any architecture. CIS rules - none.customRulesX32String, default - none. Base64-encoded content of the
60-custom.rulesfile for thei386architecture. CIS rules - none.customRulesX64String, default - none. Base64-encoded content of the
60-custom.rulesfile for thex86_64architecture. CIS rules - none.presetRulesString, default - none. Comma-separated list of the following built-in preset rules:
accessactionsdeletedocker
identityimmutableloginsmac-policy
modulesmountsperm-modprivileged
scopesessionsystem-localetime-change
You can use two keywords for these rules:
none- disables all built-in rules.all- enables all built-in rules. With this key, you can add the!prefix to a rule name to exclude some rules. You can use the!prefix for rules only if you add theallkeyword as the first rule. Place a rule with the!prefix only after theallkeyword.
Example configurations:
presetRules: none- disable all preset rulespresetRules: docker- enable only thedockerrulespresetRules: access,actions,logins- enable only theaccess,actions, andloginsrulespresetRules: all- enable all preset rulespresetRules: all,!immutable,!sessions- enable all preset rules exceptimmutableandsessions
CIS controls
4.1.3 (time-change)4.1.4 (identity)4.1.5 (system-locale)4.1.6 (mac-policy)4.1.7 (logins)4.1.8 (session)4.1.9 (perm-mod)4.1.10 (access)4.1.11 (privileged)4.1.12 (mounts)4.1.13 (delete)4.1.14 (scope)4.1.15 (actions)4.1.16 (modules)4.1.17 (immutable)Docker CIS controls
1.1.41.1.81.1.101.1.121.1.131.1.151.1.161.1.171.1.181.2.31.2.41.2.51.2.61.2.71.2.101.2.11
Configure OIDC integration:
LDAP configuration
Example configuration:
spec: providerSpec: value: kaas: management: helmReleases: - name: iam values: keycloak: userFederation: providers: - displayName: "<LDAP_NAME>" providerName: "ldap" priority: 1 fullSyncPeriod: -1 changedSyncPeriod: -1 config: pagination: "true" debug: "false" searchScope: "1" connectionPooling: "true" usersDn: "<DN>" # "ou=People, o=<ORGANIZATION>, dc=<DOMAIN_COMPONENT>" userObjectClasses: "inetOrgPerson,organizationalPerson" usernameLDAPAttribute: "uid" rdnLDAPAttribute: "uid" vendor: "ad" editMode: "READ_ONLY" uuidLDAPAttribute: "uid" connectionUrl: "ldap://<LDAP_DNS>" syncRegistrations: "false" authType: "simple" bindCredential: "" bindDn: "" mappers: - name: "username" federationMapperType: "user-attribute-ldap-mapper" federationProviderDisplayName: "<LDAP_NAME>" config: ldap.attribute: "uid" user.model.attribute: "username" is.mandatory.in.ldap: "true" read.only: "true" always.read.value.from.ldap: "false" - name: "full name" federationMapperType: "full-name-ldap-mapper" federationProviderDisplayName: "<LDAP_NAME>" config: ldap.full.name.attribute: "cn" read.only: "true" write.only: "false" - name: "last name" federationMapperType: "user-attribute-ldap-mapper" federationProviderDisplayName: "<LDAP_NAME>" config: ldap.attribute: "sn" user.model.attribute: "lastName" is.mandatory.in.ldap: "true" read.only: "true" always.read.value.from.ldap: "true" - name: "email" federationMapperType: "user-attribute-ldap-mapper" federationProviderDisplayName: "<LDAP_NAME>" config: ldap.attribute: "mail" user.model.attribute: "email" is.mandatory.in.ldap: "false" read.only: "true" always.read.value.from.ldap: "true"
Note
Verify that the
userFederationsection is located on the same level as theinitUserssection.Verify that all attributes set in the
mapperssection are defined for users in the specified LDAP system. Missing attributes may cause authorization issues.
For details, see Configure LDAP for IAM.
Google OAuth configuration
Example configuration:
keycloak: externalIdP: google: enabled: true config: clientId: <Google_OAuth_client_ID> clientSecret: <Google_OAuth_client_secret>
For details, see Configure Google OAuth IdP for IAM.
Disable NTP that is enabled by default. This option disables the management of
chronyconfiguration by Container Cloud to use your own system forchronymanagement. Otherwise, configure the regional NTP server parameters as described below.NTP configuration
Configure the regional NTP server parameters to be applied to all machines of managed clusters.
In the
Clusterobject, add thentp:serverssection with the list of required server names:spec: ... providerSpec: value: kaas: ... ntpEnabled: true regional: - helmReleases: - name: <providerName>-provider values: config: lcm: ... ntp: servers: - 0.pool.ntp.org ... provider: <providerName> ...
To disable NTP:
spec: ... providerSpec: value: ... ntpEnabled: false ...
Applies only to the bare metal provider since the Cluster release 16.1.0. If you plan to deploy large managed clusters, enable dynamic IP allocation to increase the amount of baremetal hosts to be provisioned in parallel. For details, see Enable dynamic IP allocation.
Applies to the OpenStack provider only:
Configure periodic backups of MariaDB. For more details, see Configure periodic backups of MariaDB.
Example configuration:
spec: providerSpec: value: kaas: management: helmReleases: ... - name: iam values: keycloak: mariadb: conf: phy_backup: enabled: true backup_timeout: 30000 allow_unsafe_backup: true backups_to_keep: 3 backup_pvc_name: mariadb-phy-backup-data full_backup_cycle: 70000 backup_required_space_ratio: 1.4 schedule_time: '30 2 * * *'
Technology Preview. Create all load balancers of the cluster with a specific Octavia flavor by defining the following parameter in the
spec:providerSpecsection oftemplates/cluster.yaml.template:serviceAnnotations: loadbalancer.openstack.org/flavor-id: <octaviaFlavorID>
For details, see OpenStack documentation: Octavia Flavors.
Note
This feature is not supported by OpenStack Queens.
Applies to the vSphere provider only. Configure
squid-proxyas described in Configure squid-proxy.Example configuration:
spec: ... providerSpec: value: ... kaas: ... regional: - helmReleases: ... - name: squid-proxy values: config: domains: rhel: - .subscription.rhsm.redhat.com - .cdn.redhat.com - .satellite.server.org - 172.16.10.10 provider: vsphere
Now, proceed with completing the bootstrap process using the Container Cloud Bootstrap web UI or API depending on the selected provider as described in Deploy a Container Cloud management cluster.
Post-deployment steps¶
After bootstrapping the management cluster, collect and save the following cluster details in a secure location:
Obtain the management cluster
kubeconfig:./container-cloud get cluster-kubeconfig \ --kubeconfig <pathToKindKubeconfig> \ --cluster-name <clusterName>
By default,
pathToKindKubeconfigis$HOME/.kube/kind-config-clusterapi.Obtain the Keycloak credentials as described in Access the Keycloak Admin Console.
Remove the kind cluster:
./bin/kind delete cluster -n <kindClusterName>
By default,
kindClusterNameisclusterapi.
Now, you can proceed with operating your management cluster through the Container Cloud web UI and deploying managed clusters as described in Operations Guide.
Troubleshooting¶
This section provides solutions to the issues that may occur while deploying a cluster with Container Cloud Bootstrap v2.
Troubleshoot the bootstrap region creation¶
If the BootstrapRegion object is in the Error state, find the error
type in the Status field of the object for the following components to
resolve the issue:
Field name |
Troubleshooting steps |
|---|---|
Helm |
If the bootstrap HelmBundle is not ready for a long time, for example, during 15 minutes in case of an average network bandwidth, verify statuses of non-ready releases and resolve the issue depending on the error message of a particular release: kubectl --kubeconfig <pathToKindKubeconfig> \
get helmbundle bootstrap -o json | \
jq '.status.releaseStatuses[] | select(.ready == false) | {name: .chart, message: .message}'
If fixing the issues with Helm releases does not help, collect the
Helm Controller logs and filter them by kubectl --kubeconfig <pathToKindKubeconfig> -n kube-sytem \
logs -lapp=helm-controller | grep "ERROR"
|
Deployments |
If some of deployments are not ready for a long time while the bootstrap HelmBundle is ready, restart the affected deployments: kubectl --kubeconfig <pathToKindKubeconfig> \
-n kaas rollout restart deploy <notReadyDeploymentName>
If restarting of the affected deployments does not help, collect and assess the logs of non-ready deployments: kubectl --kubeconfig <pathToKindKubeconfig> \
-n kaas logs -lapp.kubernetes.io/name=<notReadyDeploymentName>
|
Provider |
The status of this field becomes |
See also
Troubleshoot credentials creation¶
If the Credentials object is in the Error or Invalid state,
verify whether the provided credentials are valid and adjust them accordingly.
Warning
The kubectl apply command automatically saves the
applied data as plain text into the
kubectl.kubernetes.io/last-applied-configuration annotation of the
corresponding object. This may result in revealing sensitive data in this
annotation when creating or modifying the object.
Therefore, do not use kubectl apply on this object. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on this object, you
can remove the kubectl.kubernetes.io/last-applied-configuration
annotation from the object using kubectl edit.
To adjust the Credentials object:
Verify the
Credentialsobject status:kubectl --kubeconfig <pathToKindKubeconfig> \ get <providerName>credentials <credentialsObjectName> -o jsonpath='{.status.valid}{"\n"}'
Replace
<providerName>with the name of the selected provider. For example,openstackcredentialsorvspherecredentials.Open the
Credentialsobject for editing:kubectl --kubeconfig <pathToKindKubeconfig> \ edit <providerName>credentials <credentialsObjectName>
Adjust the credentials password:
In
password.secret.nameof theCredentialsobjectspecsection, obtain the relatedSecretobject.Replace the existing base64-encoded string of the related secret with a new one containing the adjusted password:
apiVersion: v1 kind: Secret data: value: Zm9vYmFyCg==
Troubleshoot machines creation¶
If a Machine object is stuck in the same status for a long time,
identify the status phase of the affected machine and proceed as described
below.
To verify the status of the created Machine objects:
kubectl --kubeconfig <pathToKindKubeconfig> \
get machines -o jsonpath='{.items[*].status.phase}'
The deployment statuses of a Machine object are the same as the
LCMMachine object states:
Uninitialized - the machine is not yet assigned to an
LCMCluster.Pending - the agent reports a node IP address and host name.
Prepare - the machine executes
StateItemsthat correspond to thepreparephase. This phase usually involves downloading the necessary archives and packages.Deploy - the machine executes
StateItemsthat correspond to thedeployphase that is becoming a Mirantis Kubernetes Engine (MKE) node.Ready - the machine is being deployed.
Upgrade - the machine is being upgraded to the new MKE version.
Reconfigure - the machine executes
StateItemsthat correspond to thereconfigurephase. The machine configuration is being updated without affecting workloads running on the machine.
If the system response is empty, approve the BootstrapRegion object:
Using the Container Cloud web UI, navigate to the Bootstrap tab and approve the related
BootstrapRegionobjectUsing the Container Cloud CLI:
./container-cloud bootstrap approve all
If the system response is not empty and the status remains the same for a
while, the issue may relate to machine misconfiguration. Therefore, verify
and adjust the parameters of the affected Machine object.
For provider-related issues, refer to the Troubleshooting section.
Troubleshoot deployment stages¶
If the cluster deployment is stuck on the same stage for a long time, it may
be related to configuration issues in the Machine or other deployment
objects.
To troubleshoot cluster deployment:
Identify the current deployment stage that got stuck:
kubectl --kubeconfig <pathToKindKubeconfig> \ get cluster <cluster-name> -o jsonpath='{.status.bootstrapStatus}{"\n"}'
For the deployment stages description, see Overview of the deployment workflow.
Collect the
bootstrap-providerlogs and identify a repetitive error that relates to the stuck deployment stage:kubectl --kubeconfig <pathToKindKubeconfig> \ -n kaas logs -lapp.kubernetes.io/name=bootstrap-provider
Examples of repetitive errors¶ Error name
Solution
Cluster nodes are not yet readyVerify the
Machineobjects configuration.Starting pivotContact Mirantis support for further issue assessment.
Some objects in cluster are not readywith the samedeploymentnamesVerify the related
deploymentconfiguration.
See also
Collect the bootstrap logs¶
If the bootstrap process is stuck or fails, collect and inspect the bootstrap and management cluster logs.
To collect the bootstrap logs:
If the Cluster object is not created yet
List all available deployments:
kubectl --kubeconfig <pathToKindKubeconfig> \ -n kaas get deploy
Collect the logs of the required deployment:
kubectl --kubeconfig <pathToKindKubeconfig> \ -n kaas logs -lapp.kubernetes.io/name=<deploymentName>
If the Cluster object is created
Select from the following options:
If a management cluster is not deployed yet:
CLUSTER_NAME=<clusterName> ./bootstrap.sh collect_logs
If a management cluster is deployed or pivoting is done:
Obtain the cluster
kubeconfig:./container-cloud get cluster-kubeconfig \ --kubeconfig <pathToKindKubeconfig> \ --cluster-name <clusterName> \ --kubeconfig-output <pathToMgmtClusterKubeconfig>
Collect the logs:
CLUSTER_NAME=<cluster-name> \ KUBECONFIG=<pathToMgmtClusterKubeconfig> \ ./bootstrap.sh collect_logs
Technology Preview. For bare metal clusters, assess the Ironic pod logs:
Extract the content of the
'message'fields from every log message:kubectl -n kaas logs <ironicPodName> -c syslog | jq -rRM 'fromjson? | .message'
Extract the content of the
'message'fields from theironic_conductorsource log messages:kubectl -n kaas logs <ironicPodName> -c syslog | jq -rRM 'fromjson? | select(.source == "ironic_conductor") | .message'
The syslog container collects logs generated by Ansible during the node deployment and cleanup and outputs them in the JSON format.
Note
Add COLLECT_EXTENDED_LOGS=true before the
collect_logs command to output the extended version of logs
that contains system and MKE logs, logs from LCM Ansible and LCM Agent
along with cluster events and Kubernetes resources description and logs.
Without the --extended flag, the basic version of logs is collected, which
is sufficient for most use cases. The basic version of logs contains all
events, Kubernetes custom resources, and logs from all Container Cloud
components. This version does not require passing --key-file.
The logs are collected in the directory where the bootstrap script is located.
The Container Cloud logs structure in <output_dir>/<cluster_name>/
is as follows:
/events.logHuman-readable table that contains information about the cluster events.
/systemSystem logs.
/system/mke(or/system/MachineName/mke)Mirantis Kuberntes Engine (MKE) logs.
/objects/clusterLogs of the non-namespaced Kubernetes objects.
/objects/namespacedLogs of the namespaced Kubernetes objects.
/objects/namespaced/<namespaceName>/core/podsLogs of the pods from a specific Kubernetes namespace. For example, logs of the pods from the
kaasnamespace contain logs of Container Cloud controllers, includingbootstrap-cluster-controllersince Container Cloud 2.25.0.
/objects/namespaced/<namespaceName>/core/pods/<containerName>.prev.logLogs of the pods from a specific Kubernetes namespace that were previously removed or failed.
/objects/namespaced/<namespaceName>/core/pods/<ironicPodName>/syslog.logTechnology Preview. Ironic pod logs of the bare metal clusters.Note
Logs collected by the syslog container during the bootstrap phase are not transferred to the management cluster during pivoting. These logs are located in
/volume/log/ironic/ansible_conductor.loginside the Ironic pod.
Each log entry of the management cluster logs contains a request ID that identifies chronology of actions performed on a cluster or machine. The format of the log entry is as follows:
<process ID>.[<subprocess ID>...<subprocess ID N>].req:<requestID>: <logMessage>
For example, os.machine.req:28 contains information about the task 28
applied to an OpenStack machine.
Since Container Cloud 2.22.0, the logging format has the following extended
structure for the admission-controller, storage-discovery, and all
supported <providerName>-provider services of a management cluster:
level:<debug,info,warn,error,panic>,
ts:<YYYY-MM-DDTHH:mm:ssZ>,
logger:<processID>.<subProcessID(s)>.req:<requestID>,
caller:<lineOfCode>,
msg:<message>,
error:<errorMessage>,
stacktrace:<codeInfo>
Since Container Cloud 2.23.0, this structure also applies to the
<name>-controller services of a management cluster.
Example of a log extract for openstack-provider since 2.22.0
{"level":"error","ts":"2022-11-14T21:37:18Z","logger":"os.cluster.req:318","caller":"lcm/machine.go:808","msg":"","error":"could not determine machine demo-46880-bastion host name”,”stacktrace”:”sigs.k8s.io/cluster-api-provider-openstack/pkg/lcm.GetMachineConditions\n\t/go/src/sigs.k8s.io/cluster-api-provider-openstack/pkg/lcm/machine.go:808\nsigs.k8s.io/cluster-api-provider-openstack/pkg...."}
{"level":"info","ts":"2022-11-14T21:37:23Z","logger":"os.machine.req:476","caller":"service/reconcile.go:128","msg":"request: default/demo-46880-2"}
{"level":"info","ts":"2022-11-14T21:37:23Z","logger":"os.machine.req:476","caller":"machine/machine_controller.go:201","msg":"Reconciling Machine \"default/demo-46880-2\""}
{"level":"info","ts":"2022-11-14T21:37:23Z","logger":"os.machine.req:476","caller":"machine/actuator.go:454","msg":"Checking if machine exists: \"default/demo-46880-2\" (cluster: \"default/demo-46880\")"}
{"level":"info","ts":"2022-11-14T21:37:23Z","logger":"os.machine.req:476","caller":"machine/machine_controller.go:327","msg":"Reconciling machine \"default/demo-46880-2\" triggers idempotent update"}
{"level":"info","ts":"2022-11-14T21:37:23Z","logger":"os.machine.req:476","caller":"machine/actuator.go:290","msg":"Updating machine: \"default/demo-46880-2\" (cluster: \"default/demo-46880\")"}
{"level":"info","ts":"2022-11-14T21:37:24Z","logger":"os.machine.req:476","caller":"lcm/machine.go:73","msg":"Machine in LCM cluster, reconciling LCM objects"}
{"level":"info","ts":"2022-11-14T21:37:26Z","logger":"os.machine.req:476","caller":"lcm/machine.go:902","msg":"Updating Machine default/demo-46880-2 conditions"}
levelInformational level. Possible values:
debug,info,warn,error,panic.
tsTime stamp in the
<YYYY-MM-DDTHH:mm:ssZ>format. For example:2022-11-14T21:37:23Z.
loggerDetails on the process ID being logged:
<processID>Primary process identifier. The list of possible values includes
bm,os,vsphere,iam,license, andbootstrap.Note
The
iamandlicensevalues are available since Container Cloud 2.23.0. Thebootstrapvalue is available since Container Cloud 2.25.0.
<subProcessID(s)>One or more secondary process identifiers. The list of possible values includes
cluster,machine,controller, andcluster-ctrl.Note
The
controllervalue is available since Container Cloud 2.23.0. Thecluster-ctrlvalue is available since Container Cloud 2.25.0 for thebootstrapprocess identifier.
reqRequest ID number that increases when a service performs the following actions:
Receives a request from Kubernetes about creating, updating, or deleting an object
Receives an HTTP request
Runs a background process
The request ID allows combining all operations performed with an object within one request. For example, the result of a
Machineobject creation, update of its statuses, and so on has the same request ID.
callerCode line used to apply the corresponding action to an object.
msgDescription of a deployment or update phase. If empty, it contains the
"error"key with a message followed by the"stacktrace"key with stack trace details. For example:"msg"="" "error"="Cluster nodes are not yet ready" "stacktrace": "<stack-trace-info>"
The log format of the following Container Cloud components does not contain the
"stacktrace"key for easier log handling:baremetal-provider, bootstrap-provider,host-os-modules-controller, andvsphere-vm-template-controller.
Note
Logs may also include a number of informational key-value pairs
containing additional cluster details. For example,
"name": "object-name", "foobar": "baz".
Depending on the type of issue found in logs, apply the corresponding fixes.
For example, if you detect the LoadBalancer ERROR state errors
during the bootstrap of an OpenStack-based management cluster,
contact your system administrator to fix the issue.
Requirements for a MITM proxy¶
Note
For MOSK, the feature is generally available since MOSK 23.1.
While bootstrapping a Container Cloud management cluster using proxy, you may require Internet access to go through a man-in-the-middle (MITM) proxy. Such configuration requires that you enable streaming and install a CA certificate on a bootstrap node.
Enable streaming for MITM¶
Ensure that the MITM proxy is configured with enabled streaming. For example, if you use mitmproxy, enable the stream_large_bodies=1 option:
./mitmdump --set stream_large_bodies=1
Install a CA certificate for a MITM proxy on a bootstrap node¶
Log in to the bootstrap node.
Install
ca-certificates:apt install ca-certificates
Copy your CA certificate to the
/usr/local/share/ca-certificates/directory. For example:sudo cp ~/.mitmproxy/mitmproxy-ca-cert.cer /usr/local/share/ca-certificates/mitmproxy-ca-cert.crt
Replace
~/.mitmproxy/mitmproxy-ca-cert.cerwith the path to your CA certificate.Caution
The target CA certificate file must be in the
PEMformat with the.crtextension.Apply the changes:
sudo update-ca-certificates
Now, proceed with bootstrapping your management cluster.
Create initial users after a management cluster bootstrap¶
Once you bootstrap your management cluster,create Keycloak users for access to the Container Cloud web UI. Use the created credentials to log in to the Container Cloud web UI.
Mirantis recommends creating at least two users, user and operator,
that are required for a typical Container Cloud deployment.
To create the user for access to the Container Cloud web UI, use:
./container-cloud bootstrap user add \
--username <userName> \
--roles <roleName> \
--kubeconfig <pathToMgmtKubeconfig>
Note
You will be asked for the user password interactively.
Flag |
Description |
|---|---|
|
Required. Name of the user to create. |
|
Required. Comma-separated list of roles to assign to the user.
|
|
Required. Path to the management cluster |
|
Optional. Name of the Container Cloud project where the user will be created. If not set, a global user will be created for all Container Cloud projects with the corresponding role access to view or manage all Container Cloud public objects. |
|
Optional. Flag to provide the user password through echo '$PASSWORD' | ./container-cloud bootstrap user add \
--username <userName> \
--roles <roleName> \
--kubeconfig <pathToMgmtKubeconfig> \
--password-stdin
|
To delete the user, run:
./container-cloud bootstrap user delete --username <userName> --kubeconfig <pathToMgmtKubeconfig>
Troubleshooting¶
This section provides solutions to the issues that may occur while deploying a management cluster.
Collect the bootstrap logs¶
If the bootstrap script fails during the deployment process, collect and inspect the bootstrap and management cluster logs.
Note
The below procedure applies to Bootstrap v1. For the Boostrap v2 procedure, refer to Collect the bootstrap logs.
Collect the bootstrap cluster logs¶
Log in to your local machine where the bootstrap script was executed.
If you bootstrapped the cluster a while ago, verify that the bootstrap directory is updated.
Select from the following options:
For clusters deployed using Container Cloud 2.11.0 or later:
./container-cloud bootstrap download --management-kubeconfig <pathToMgmtKubeconfig> \ --target-dir <pathToBootstrapDirectory>
For clusters deployed using the Container Cloud release earlier than 2.11.0 or if you deleted the
kaas-bootstrapfolder, download and run the Container Cloud bootstrap script:wget https://binary.mirantis.com/releases/get_container_cloud.sh chmod 0755 get_container_cloud.sh ./get_container_cloud.sh
Run the following command:
./bootstrap.sh collect_logsAdd
COLLECT_EXTENDED_LOGS=truebefore the command to output the extended version of logs that contains system and MKE logs, logs from LCM Ansible and LCM Agent along with cluster events and Kubernetes resources description and logs.Without the
--extendedflag, the basic version of logs is collected, which is sufficient for most use cases. The basic version of logs contains all events, Kubernetes custom resources, and logs from all Container Cloud components. This version does not require passing--key-file.The logs are collected in the directory where the bootstrap script is located.
Technology Preview. For bare metal clusters, assess the Ironic pod logs:
Extract the content of the
'message'fields from every log message:kubectl -n kaas logs <ironicPodName> -c syslog | jq -rRM 'fromjson? | .message'
Extract the content of the
'message'fields from theironic_conductorsource log messages:kubectl -n kaas logs <ironicPodName> -c syslog | jq -rRM 'fromjson? | select(.source == "ironic_conductor") | .message'
The syslog container collects logs generated by Ansible during the node deployment and cleanup and outputs them in the JSON format.
See also
Troubleshoot the bootstrap node configuration¶
This section provides solutions to the issues that may occur while configuring the bootstrap node.
DNS settings¶
If you have issues related to the DNS settings, the following error message may occur:
curl: (6) Could not resolve host
The issue may occur if a VPN is used to connect to the cloud or a local DNS forwarder is set up.
The workaround is to change the default DNS settings for Docker:
Log in to your local machine.
Identify your internal or corporate DNS server address:
systemd-resolve --statusCreate or edit
/etc/docker/daemon.jsonby specifying your DNS address:{ "dns": ["<YOUR_DNS_ADDRESS>"] }
Restart the Docker daemon:
sudo systemctl restart docker
Default network addresses¶
If you have issues related to the default network address configuration, curl either hangs or the following error occurs:
curl: (7) Failed to connect to xxx.xxx.xxx.xxx port xxxx: Host is unreachable
The issue may occur because the default Docker network address
172.17.0.0/16 and/or the kind Docker network, which is used by
kind, overlap with your cloud address or other addresses
of the network configuration.
Workaround:
Log in to your local machine.
Verify routing to the IP addresses of the target cloud endpoints:
Obtain the IP address of your target cloud. For example:
nslookup auth.openstack.example.comExample of system response:
Name: auth.openstack.example.com Address: 172.17.246.119
Verify that this IP address is not routed through
docker0but through any other interface, for example,ens3:ip r get 172.17.246.119
Example of the system response if the routing is configured correctly:
172.17.246.119 via 172.18.194.1 dev ens3 src 172.18.1.1 uid 1000 cache
Example of the system response if the routing is configured incorrectly:
172.17.246.119 via 172.18.194.1 dev docker0 src 172.18.1.1 uid 1000 cache
If the routing is incorrect, change the IP address of the default Docker bridge:
Create or edit
/etc/docker/daemon.jsonby adding the"bip"option:{ "bip": "192.168.91.1/24" }
Restart the Docker daemon:
sudo systemctl restart docker
If required, customize addresses for your
kindDocker network or any other additional Docker networks:Remove the
kindnetwork:docker network rm 'kind'
Choose from the following options:
Configure
/etc/docker/daemon.json:Note
The following steps are applied to to customize addresses for the
kindDocker network. Use these steps as an example for any other additional Docker networks.Add the following section to
/etc/docker/daemon.json:{ "default-address-pools": [ {"base":"192.169.0.0/16","size":24} ] }
Restart the Docker daemon:
sudo systemctl restart docker
After Docker restart, the newly created local or global scope networks, including
'kind', will be dynamically assigned a subnet from the defined pool.
Recreate the
'kind'Docker network manually with a subnet that is not in use in your network. For example:docker network create -o com.docker.network.bridge.enable_ip_masquerade=true -d bridge --subnet 192.168.0.0/24 'kind'
Caution
Docker pruning removes the user defined networks, including
'kind'. Therefore, every time after running the Docker pruning commands, re-create the'kind'network again using the command above.
Troubleshoot OpenStack-based deployments¶
This section provides solutions to the issues that may occur while deploying an OpenStack-based management cluster. To troubleshoot a managed cluster, see Operations Guide: Troubleshooting.
TLS handshake timeout¶
If you execute the bootstrap.sh script from an OpenStack VM
that is running on the OpenStack environment used for bootstrapping
the management cluster, the following error messages may occur
that can be related to the MTU settings discrepancy:
curl: (35) OpenSSL SSL_connect: SSL_ERROR_SYSCALL in connection to server:port
Failed to check if machine "<machine_name>" exists:
failed to create provider client ... TLS handshake timeout
To identify whether the issue is MTU-related:
Log in to the OpenStack VM in question.
Compare the MTU outputs for the
docker0andens3interfaces:ip addrExample of system response:
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500... ... 2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450...
If the MTU output values differ for
docker0andens3, proceed with the workaround below. Otherwise, inspect the logs further to identify the root cause of the error messages.
Workaround:
In your OpenStack environment used for Mirantis Container Cloud, log in to any machine with CLI access to OpenStack. For example, you can create a new Ubuntu VM (separate from the bootstrap VM) and install the
python-openstackclientpackage on it.Change the vXLAN MTU size for the VM to the required value depending on your network infrastructure and considering your physical network configuration, such as Jumbo frames, and so on.
openstack network set --mtu <YOUR_MTU_SIZE> <network-name>
Stop and start the VM in Nova.
Log in to the bootstrap VM dedicated for the management cluster.
Re-execute the
bootstrap.shscript.
Troubleshoot vSphere-based deployments¶
This section provides solutions to the issues that may occur while deploying a vSphere-based management cluster. To troubleshoot a managed cluster, see Operations Guide: Troubleshooting.
Virtual machine issues with obtaining an IP¶
Issues with virtual machines obtaining an IP may occur during the machines deployment of the vSphere-based Container Cloud management or managed cluster with IPAM enabled.
The issue symptoms are as follows:
On a cluster network with a DHCP server, the machine obtains a wrong IP address that is most likely provided by the DHCP server. The cluster deployment proceeds with unexpected IP addresses that are not in the IPAM range.
On a cluster network without a DHCP server, the machine does not obtain an IP address. The deployment freezes and fails by timeout.
To apply the issue resolution:
Verify that the
cloud-initpackage version in the VM template is19.4or later. Older versions are affected by the cloud-init bug.cloud-init --versionVerify that the
open-vm-toolspackage version is11.0.5or later.vmtoolsd --version vmware-toolbox-cmd --version
Verify that the
/etc/cloud/cloud.cfg.d/99-DataSourceVMwareGuestInfo.cfgfile is present on the cluster and it is not empty.Verify that the
DataSourceVMwareGuestInfo.pyfile is present in the cloud-init sources folder and is not empty. To obtain thecloud-initfolder:python -c 'import os; from cloudinit import sources; print(os.path.dirname(sources.__file__));'
If your deployment meets the requirements described in the verification steps above but the issue still persists, rebuild the VM template as described in Prepare the virtual machine template or contact Mirantis support.
Configure external identity provider for IAM¶
This section describes how to configure authentication for Mirantis Container Cloud depending on the external identity provider type integrated to your deployment.
Configure LDAP for IAM¶
If you integrate LDAP for IAM to Mirantis Container Cloud,
add the required LDAP configuration to cluster.yaml.template
during the bootstrap of the management cluster.
Note
The example below defines the recommended non-anonymous
authentication type. If you require anonymous authentication,
replace the following parameters with authType: "none":
authType: "simple"
bindCredential: ""
bindDn: ""
To configure LDAP for IAM:
Open
cluster.yaml.templatestored in the following locations depending on the cloud provider type:Bare metal:
templates/bm/cluster.yaml.templateOpenStack:
templates/cluster.yaml.templatevSphere:
templates/vsphere/cluster.yaml.template
Configure the
keycloak:userFederation:providers:andkeycloak:userFederation:mappers:sections as required:spec: providerSpec: value: kaas: management: helmReleases: - name: iam values: keycloak: userFederation: providers: - displayName: "<LDAP_NAME>" providerName: "ldap" priority: 1 fullSyncPeriod: -1 changedSyncPeriod: -1 config: pagination: "true" debug: "false" searchScope: "1" connectionPooling: "true" usersDn: "<DN>" # "ou=People, o=<ORGANIZATION>, dc=<DOMAIN_COMPONENT>" userObjectClasses: "inetOrgPerson,organizationalPerson" usernameLDAPAttribute: "uid" rdnLDAPAttribute: "uid" vendor: "ad" editMode: "READ_ONLY" uuidLDAPAttribute: "uid" connectionUrl: "ldap://<LDAP_DNS>" syncRegistrations: "false" authType: "simple" bindCredential: "" bindDn: "" mappers: - name: "username" federationMapperType: "user-attribute-ldap-mapper" federationProviderDisplayName: "<LDAP_NAME>" config: ldap.attribute: "uid" user.model.attribute: "username" is.mandatory.in.ldap: "true" read.only: "true" always.read.value.from.ldap: "false" - name: "full name" federationMapperType: "full-name-ldap-mapper" federationProviderDisplayName: "<LDAP_NAME>" config: ldap.full.name.attribute: "cn" read.only: "true" write.only: "false" - name: "last name" federationMapperType: "user-attribute-ldap-mapper" federationProviderDisplayName: "<LDAP_NAME>" config: ldap.attribute: "sn" user.model.attribute: "lastName" is.mandatory.in.ldap: "true" read.only: "true" always.read.value.from.ldap: "true" - name: "email" federationMapperType: "user-attribute-ldap-mapper" federationProviderDisplayName: "<LDAP_NAME>" config: ldap.attribute: "mail" user.model.attribute: "email" is.mandatory.in.ldap: "false" read.only: "true" always.read.value.from.ldap: "true"
Note
Verify that the
userFederationsection is located on the same level as theinitUserssection.Verify that all attributes set in the
mapperssection are defined for users in the specified LDAP system. Missing attributes may cause authorization issues.
Now, return to the bootstrap instruction depending on the provider type of your management cluster.
Configure Google OAuth IdP for IAM¶
Caution
The instruction below applies to the DNS-based management clusters. If you bootstrap a non-DNS-based management cluster, configure Google OAuth IdP for Keycloak after bootstrap using the official Keycloak documentation.
If you integrate Google OAuth external identity provider for IAM to
Mirantis Container Cloud, create the authorization credentials for IAM
in your Google OAuth account and configure cluster.yaml.template
during the bootstrap of the management cluster.
To configure Google OAuth IdP for IAM:
Create Google OAuth credentials for IAM:
Log in to your https://console.developers.google.com.
Navigate to Credentials.
In the APIs Credentials menu, select OAuth client ID.
In the window that opens:
In the Application type menu, select Web application.
In the Authorized redirect URIs field, type in
<keycloak-url>/auth/realms/iam/broker/google/endpoint, where<keycloak-url>is the corresponding DNS address.Press Enter to add the URI.
Click Create.
A page with your client ID and client secret opens. Save these credentials for further usage.
Log in to the bootstrap node.
Open
cluster.yaml.templatestored in the following locations depending on the cloud provider type:Bare metal:
templates/bm/cluster.yaml.templateOpenStack:
templates/cluster.yaml.templatevSphere:
templates/vsphere/cluster.yaml.template
In the
keycloak:externalIdP:section, add the following snippet with your credentials created in previous steps:keycloak: externalIdP: google: enabled: true config: clientId: <Google_OAuth_client_ID> clientSecret: <Google_OAuth_client_secret>
Now, return to the bootstrap instruction depending on the provider type of your management cluster.
Operations Guide¶
Mirantis Container Cloud CLI¶
The Mirantis Container Cloud APIs are implemented using the Kubernetes CustomResourceDefinitions (CRDs) that enable you to expand the Kubernetes API. For details, see API Reference.
You can operate Container Cloud using the kubectl command-line tool that is based on the Kubernetes API. For the kubectl reference, see the official Kubernetes documentation.
The Container Cloud Operations Guide mostly contains manuals that describe the Container Cloud web UI that is intuitive and easy to get started with. Some sections are divided into a web UI instruction and an analogous but more advanced CLI one. Certain Container Cloud operations can be performed only using CLI with the corresponding steps described in dedicated sections. For details, refer to the required component section of this guide.
Create and operate managed clusters¶
Note
This tutorial applies only to the Container Cloud web UI users
with the m:kaas:namespace@operator or m:kaas:namespace@writer
access role assigned by the Infrastructure Operator.
To add a bare metal host, the m:kaas@operator or
m:kaas:namespace@bm-pool-operator role is required.
After you deploy the Mirantis Container Cloud management cluster, you can start creating managed clusters that will be based on the same cloud provider type that you have for the management cluster: OpenStack, bare metal, or vSphere.
The deployment procedure is performed using the Container Cloud web UI and comprises the following steps:
Create a dedicated non-
defaultproject for managed clusters.For a baremetal-based managed cluster, create and configure bare metal hosts with corresponding labels for machines such as
worker,manager, orstorage.Create an initial cluster configuration depending on the provider type.
Add the required amount of machines with the corresponding configuration to the managed cluster.
For a baremetal-based managed cluster, add a Ceph cluster.
Note
The Container Cloud web UI communicates with Keycloak to authenticate users. Keycloak is exposed using HTTPS with self-signed TLS certificates that are not trusted by web browsers.
To use your own TLS certificates for Keycloak, refer to Configure TLS certificates for cluster applications.
Create a project for managed clusters¶
Note
The procedure below applies only to the Container Cloud web UI
users with the m:kaas@global-admin or m:kaas@writer access role
assigned by the infrastructure Operator.
The default project (Kubernetes namespace) in Container Cloud is dedicated
for management clusters only. Managed clusters require a separate project.
You can create as many projects as required by your company infrastructure.
To create a project for managed clusters using the Container Cloud web UI:
Log in to the Container Cloud web UI as
m:kaas@global-adminorm:kaas@writer.In the Projects tab, click Create.
Type the new project name.
Click Create.
Generate a kubeconfig for a managed cluster using API¶
This section describes how to generate a managed cluster kubeconfig using
the Container Cloud API. You can also download a managed cluster kubeconfig
using the Download Kubeconfig option in the Container Cloud web
UI. For details, see Connect to a Mirantis Container Cloud cluster.
To generate a managed cluster kubeconfig using API:
Obtain the following Container Cloud details:
Your
<username>with the corresponding password that were created after the management cluster bootstrap as described in Create initial users after a management cluster bootstrap.The
kubeconfigof your<username>that you can download through the Container Cloud web UI using Download Kubeconfig located under your<username>on the top-left of the page.
Obtain the
<cluster>object of the<cluster_name>managed cluster:kubectl get cluster <cluster_name> -n <project_name> -o yaml
Obtain the access token from Keycloak for the
<username>user:curl -d 'client_id=<cluster.status.providerStatus.oidc.clientId>' --data-urlencode 'username=<username>' --data-urlencode 'password=<password>' -d 'grant_type=password' -d 'response_type=id_token' -d 'scope=openid' <cluster.status.providerStatus.oidc.issuerURL>/protocol/openid-connect/token
Generate the managed cluster
kubeconfigusing the data from<cluster.status>and<token>obtained in the previous steps. Use the following template as an example:apiVersion: v1 clusters: - name: <cluster_name> cluster: certificate-authority-data: <cluster.status.providerStatus.apiServerCertificate> server: https://<cluster.status.providerStatus.loadBalancerHost>:443 contexts: - context: cluster: <cluster_name> user: <username> name: <username>@<cluster_name> current-context: <username>@<cluster_name> kind: Config preferences: {} users: - name: <username> user: auth-provider: config: client-id: <cluster.status.providerStatus.oidc.clientId> idp-certificate-authority-data: <cluster.status.providerStatus.oidc.certificate> idp-issuer-url: <cluster.status.providerStatus.oidc.issuerUrl> refresh-token: <token.refresh_token> id-token: <token.id_token> name: oidc
Create and operate a baremetal-based managed cluster¶
After bootstrapping your baremetal-based Mirantis Container Cloud management cluster as described in Deploy a Container Cloud management cluster, you can start creating the baremetal-based managed clusters.
Add a bare metal host¶
Before creating a bare metal managed cluster, add the required number of bare metal hosts either using the Container Cloud web UI for a default configuration or using CLI for an advanced configuration.
This section describes how to add bare metal hosts using the Container Cloud web UI during a managed cluster creation.
Before you proceed with adding a bare metal host:
Verify that the physical network on the server has been configured correctly. See Network fabric for details.
Prepare the host as described in Configure BIOS on a bare metal host.
Create a project for a managed cluster as described in Create a project for managed clusters.
To add a bare metal host to a baremetal-based managed cluster:
Optional. Create a custom bare metal host profile depending on your needs as described in Create a custom bare metal host profile.
Note
You can view the created profiles in the BM Host Profiles tab of the Container Cloud web UI.
Log in to the Container Cloud web UI with the
m:kaas@operatororm:kaas:namespace@bm-pool-operatorpermissions.Switch to the required non-
defaultproject using the Switch Project action icon located on top of the main left-side navigation panel.To create a project, refer to Create a project for managed clusters.
Optional. Available since Container Cloud 2.24.0. In the Credentials tab, click Add Credential and add the IPMI user name and password of the bare metal host to access the Baseboard Management Controller (BMC).
Select one of the following options:
In the Baremetal tab, click Create Host.
Fill out the Create baremetal host form as required:
- Name
Specify the name of the new bare metal host.
- Boot Mode
Specify the BIOS boot mode. Available options: Legacy, UEFI, or UEFISecureBoot.
- MAC Address
Specify the MAC address of the PXE network interface.
- Baseboard Management Controller (BMC)
Specify the following BMC details:
- IP Address
Specify the IP address to access the BMC.
- Credential Name
Specify the name of the previously added bare metal host credentials to associate with the current host.
- Cert Validation
Enable validation of the BMC API certificate. Applies only to the
redfish+httpBMC protocol. Disabled by default.
- Power off host after creation
Experimental. Select to power off the bare metal host after creation.
Caution
This option is experimental and intended only for testing and evaluation purposes. Do not use it for production deployments.
In the Baremetal tab, click Add BM host.
Fill out the Add new BM host form as required:
- Baremetal host name
Specify the name of the new bare metal host.
- Provider Credential
Optional. Available since Container Cloud 2.24.0. Specify the name of the previously added bare metal host credentials to associate with the current host.
- Add New Credential
Optional. Available since Container Cloud 2.24.0. Applies if you did not add bare metal host credentials using the Credentials tab. Add the bare metal host credentials:
- Username
Specify the name of the IPMI user to access the BMC.
- Password
Specify the IPMI password of the user to access the BMC.
- Boot MAC address
Specify the MAC address of the PXE network interface.
- IP Address
Specify the IP address to access the BMC.
- Label
Assign the machine label to the new host that defines which type of machine may be deployed on this bare metal host. Only one label can be assigned to a host. The supported labels include:
- Manager
This label is selected and set by default. Assign this label to the bare metal hosts that can be used to deploy machines with the
managertype. These hosts must match the CPU and RAM requirements described in Reference hardware configuration.
- Worker
The host with this label may be used to deploy the
workermachine type. Assign this label to the bare metal hosts that have sufficient CPU and RAM resources, as described in Reference hardware configuration.
- Storage
Assign this label to the bare metal hosts that have sufficient storage devices to match Reference hardware configuration. Hosts with this label will be used to deploy machines with the storage type that run Ceph OSDs.
Click Create.
While adding the bare metal host, Container Cloud discovers and inspects the hardware of the bare metal host and adds it to
BareMetalHost.statusfor future references.During provisioning,
baremetal-operatorinspects the bare metal host and moves it to thePreparingstate. The host becomes ready to be linked to a bare metal machine.Verify the results of the hardware inspection to avoid unexpected errors during the host usage:
Select one of the following options:
In the left sidebar, click Baremetal. The Hosts page opens.
In the left sidebar, click BM Hosts.
Verify that the bare metal host is registered and switched to one of the following statuses:
Preparing for a newly added host
Ready for a previously used host or for a host that is already linked to a machine
Select one of the following options:
On the Hosts page, click the host kebab menu and select Host info.
On the BM Hosts page, click the name of the newly added bare metal host.
In the window with the host details, scroll down to the Hardware section.
Review the section and make sure that the number and models of disks, network interface cards, and CPUs match the hardware specification of the server.
If the hardware details are consistent with the physical server specifications for all your hosts, proceed to Add a managed baremetal cluster.
If you find any discrepancies in the hardware inspection results, it might indicate that the server has hardware issues or is not compatible with Container Cloud.
This section describes how to add bare metal hosts using the Container Cloud CLI during a managed cluster creation.
To add a bare metal host using API:
Create a project for a managed cluster as described in Create a project for managed clusters.
Verify that you configured each bare metal host as described in Configure BIOS on a bare metal host.
Optional. Create a custom bare metal host profile depending on your needs as described in Create a custom bare metal host profile.
Log in to the host where your management cluster
kubeconfigis located and where kubectl is installed.Select from the following options:
Create a YAML file that describes the unique credentials of the new bare metal host as a
BareMetalHostCredentialobject.Example of
BareMetalHostCredential:apiVersion: kaas.mirantis.com/v1alpha1 kind: BareMetalHostCredential metadata: labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: <bareMetalHostCredentialUniqueName> namespace: <managedClusterProjectName> spec: username: <ipmiUserName> password: value: <ipmiPassword>
In the
metadatasection, add a unique credentialsnameand the name of the non-defaultproject (namespace) dedicated for the managed cluster being created.In the
specsection, add the IPMI user name and password in plain text to access the Baseboard Management Controller (BMC). The password will not be stored in theBareMetalHostCredentialobject but will be erased and saved in an underlyingSecretobject.Caution
Each bare metal host must have a unique
BareMetalHostCredential.
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.Create a secret YAML file that describes the unique credentials of the new bare metal host.
Example of the bare metal host secret:
apiVersion: v1 data: password: <credentialsPassword> username: <credentialsUserName> kind: Secret metadata: labels: kaas.mirantis.com/credentials: "true" kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: <credentialsName> namespace: <managedClusterProjectName> type: Opaque
In the
datasection, add the IPMI user name and password in the base64 encoding to access the BMC. To obtain the base64-encoded credentials, you can use the following command in your Linux console:echo -n <username|password> | base64
Caution
Each bare metal host must have a unique
Secret.In the
metadatasection, add the uniquenameof credentials and the name of the non-defaultproject (namespace) dedicated for the managed cluster being created. To create a project, refer to Create a project for managed clusters.
Apply the created YAML file with credentials to your deployment:
Warning
The kubectl apply command automatically saves the applied data as plain text into the
kubectl.kubernetes.io/last-applied-configurationannotation of the corresponding object. This may result in revealing sensitive data in this annotation when creating or modifying the object.Therefore, do not use kubectl apply on this object. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on this object, you can remove the
kubectl.kubernetes.io/last-applied-configurationannotation from the object using kubectl edit.kubectl create -n <managedClusterProjectName> -f ${<BareMetalHostCredsFileName>}.yaml
Create a YAML file that contains a description of the new bare metal host.
Example of the bare metal host configuration file with the
workerrole:apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: annotations: kaas.mirantis.com/baremetalhost-credentials-name: <bareMetalHostCredentialUniqueName> labels: kaas.mirantis.com/baremetalhost-id: <uniqueBareMetalHostHardwareNodeId> hostlabel.bm.kaas.mirantis.com/worker: "true" kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: <BareMetalHostUniqueName> namespace: <managedClusterProjectName> spec: bmc: address: <ipAddressForIpmiAccess> credentialsName: '' bootMACAddress: <BareMetalHostBootMacAddress> online: true
Note
If you have a limited amount of free and unused IP addresses for server provisioning, you can add the
baremetalhost.metal3.io/detachedannotation that pauses automatic host management to manually allocate an IP address for the host. For details, see Manually allocate IP addresses for bare metal hosts.apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: kaas.mirantis.com/baremetalhost-id: <uniqueBareMetalHostHardwareNodeId> hostlabel.bm.kaas.mirantis.com/worker: "true" kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: <BareMetalHostUniqueName> namespace: <managedClusterProjectName> spec: bmc: address: <ipAddressForBmcAccess> credentialsName: <credentialsSecretName> bootMACAddress: <BareMetalHostBootMacAddress> online: true
For a detailed fields description, see BareMetalHost.
Apply this configuration YAML file to your deployment:
kubectl create -n <managedClusterProjectName> -f ${<BareMetalHostConfigFileName>}.yaml
During provisioning,
baremetal-operatorinspects the bare metal host and moves it to thePreparingstate. The host becomes ready to be linked to a bare metal machine.Verify the new
BareMetalHostobject status:kubectl -n <managedClusterProjectName> get bmh -o wide <BareMetalHostUniqueName>
Example of system response:
NAMESPACE NAME STATUS STATE CONSUMER BMC BOOTMODE ONLINE ERROR REGION my-project bmh1 OK preparing ip_address_for-bmc-access legacy true region-one
During provisioning, the status changes as follows:
registeringinspectingpreparing
After
BareMetalHostswitches to thepreparingstage, theinspectingphase finishes and you can verify hardware information available in the object status. For example:Verify the status of hardware NICs:
kubectl -n <managedClusterProjectName> get bmh -o yaml <BareMetalHostUniqueName> -o json | jq -r '[.status.hardware.nics]'
Example of system response:
[ [ { "ip": "172.18.171.32", "mac": "ac:1f:6b:02:81:1a", "model": "0x8086 0x1521", "name": "eno1", "pxe": true }, { "ip": "fe80::225:90ff:fe33:d5ac%ens1f0", "mac": "00:25:90:33:d5:ac", "model": "0x8086 0x10fb", "name": "ens1f0" }, ...
Verify the status of RAM:
kubectl -n <managedClusterProjectName> get bmh -o yaml <BareMetalHostUniqueName> -o json | jq -r '[.status.hardware.ramMebibytes]'
Example of system response:
[ 98304 ]
See also
Create a custom bare metal host profile¶
The bare metal host profile is a Kubernetes custom resource. It allows the operator to define how the storage devices and the operating system are provisioned and configured.
This section describes the bare metal host profile default settings and configuration of custom profiles for managed clusters using Mirantis Container Cloud API. This procedure also applies to a management cluster with a few differences described in Customize the default bare metal host profile.
Note
You can view the created profiles in the BM Host Profiles tab of the Container Cloud web UI.
Note
Using BareMetalHostProfile, you can configure LVM or mdadm-based
software RAID support during a management or managed cluster
creation. For details, see Configure RAID support.
This feature is available as Technology Preview. Use such configuration for testing and evaluation purposes only. For the Technology Preview feature definition, refer to Technology Preview features.
The default host profile requires three storage devices in the following strict order:
- Boot device and operating system storage
This device contains boot data and operating system data. It is partitioned using the GUID Partition Table (GPT) labels. The root file system is an
ext4file system created on top of an LVM logical volume. For a detailed layout, refer to the table below.
- Local volumes device
This device contains an
ext4file system with directories mounted as persistent volumes to Kubernetes. These volumes are used by the Mirantis Container Cloud services to store its data, including monitoring and identity databases.
- Ceph storage device
This device is used as a Ceph datastore or Ceph OSD on managed clusters. It is used as a Ceph datastore or Ceph OSD.
Warning
Any data stored on any device defined in the fileSystems
list can be deleted or corrupted during cluster (re)deployment. It happens
because each device from the fileSystems list is a part of the
rootfs directory tree that is overwritten during (re)deployment.
Examples of affected devices include:
A raw device partition with a file system on it
A device partition in a volume group with a logical volume that has a file system on it
An mdadm RAID device with a file system on it
An LVM RAID device with a file system on it
The wipe field (deprecated) or wipeDevice structure (recommended
since Container Cloud 2.26.0) have no effect in this case and cannot
protect data on these devices.
Therefore, to prevent data loss, move the necessary data from these file systems to another server beforehand, if required.
The following table summarizes the default configuration of the host system storage set up by the Container Cloud bare metal management.
Device/partition |
Name/Mount point |
Recommended size, GB |
Description |
|---|---|---|---|
|
|
4 MiB |
The mandatory GRUB boot partition required for non-UEFI systems. |
|
|
0.2 GiB |
The boot partition required for the UEFI boot mode. |
|
|
64 MiB |
The mandatory partition for the |
|
|
100% of the remaining free space in the LVM volume group |
The main LVM physical volume that is used to create the root file system. |
|
|
100% of the remaining free space in the LVM volume group |
The LVM physical volume that is used to create the file system
for |
|
|
100% of the remaining free space in the LVM volume group |
Clean raw disk that is used for the Ceph storage backend on managed clusters. |
If required, you can customize the default host storage configuration. For details, see Create a custom host profile.
Available since 2.26.0 (17.1.0 and 16.1.0)
Before deploying a cluster, you may need to erase existing data from hardware
devices to be used for deployment. You can either erase an existing partition
or remove all existing partitions from a physical device. For this purpose,
use the wipeDevice structure that configures cleanup behavior during
configuration of a custom bare metal host profile described in
Create a custom host profile.
The wipeDevice structure contains the following options:
eraseMetadataConfigures metadata cleanup of a device
eraseDeviceConfigures a complete cleanup of a device
When you enable the eraseMetadata option, which is disabled by default,
the Ansible provisioner attempts to clean up the existing metadata from
the target device. Examples of metadata include:
Existing file system
Logical Volume Manager (LVM) or Redundant Array of Independent Disks (RAID) configuration
The behavior of metadata erasure varies depending on the target device:
If a device is part of other logical devices, for example, a partition, logical volume, or MD RAID volume, such logical device is disassembled and its file system metadata is erased. On the final erasure step, the file system metadata of the target device is erased as well.
If a device is a physical disk, then all its nested partitions along with their nested logical devices, if any, are erased and disassembled. On the final erasure step, all partitions and metadata of the target device are removed.
Caution
None of the eraseMetadata actions include overwriting the
target device with data patterns. For this purpose, use the eraseDevice
option as described in Erase a device.
To enable the eraseMetadata option, use the wipeDevice field in the
spec:devices section of the BareMetalHostProfile object. For a
detailed description of the option, see API Reference:
BareMetalHostProfile.
If you require not only disassembling of existing logical volumes but also
removing of all data ever written to the target device, configure the
eraseDevice option, which is disabled by default. This option is not
applicable to paritions, LVM, or MD RAID logical volumes because such volumes
may use caching that prevents a physical device from being erased properly.
Important
The eraseDevice option does not replace the secure erase.
To configure the eraseDevice option, use the wipeDevice field in the
spec:devices section of the BareMetalHostProfile object. For a
detailed description of the option, see API Reference:
BareMetalHostProfile.
In addition to the default BareMetalHostProfile object installed
with Mirantis Container Cloud, you can create custom profiles
for managed clusters using Container Cloud API.
Note
The procedure below also applies to the Container Cloud management clusters.
Warning
Any data stored on any device defined in the fileSystems
list can be deleted or corrupted during cluster (re)deployment. It happens
because each device from the fileSystems list is a part of the
rootfs directory tree that is overwritten during (re)deployment.
Examples of affected devices include:
A raw device partition with a file system on it
A device partition in a volume group with a logical volume that has a file system on it
An mdadm RAID device with a file system on it
An LVM RAID device with a file system on it
The wipe field (deprecated) or wipeDevice structure (recommended
since Container Cloud 2.26.0) have no effect in this case and cannot
protect data on these devices.
Therefore, to prevent data loss, move the necessary data from these file systems to another server beforehand, if required.
To create a custom bare metal host profile:
Select from the following options:
For a management cluster, log in to the bare metal seed node that will be used to bootstrap the management cluster.
For a managed cluster, log in to the local machine where you management cluster
kubeconfigis located and wherekubectlis installed.Note
The management cluster
kubeconfigis created automatically during the last stage of the management cluster bootstrap.
Select from the following options:
For a management cluster, open
templates/bm/baremetalhostprofiles.yaml.templatefor editing.For a managed cluster, create a new bare metal host profile under the
templates/bm/directory.
Edit the host profile using the example template below to meet your hardware configuration requirements:
Example template of a bare metal host profile
apiVersion: metal3.io/v1alpha1 kind: BareMetalHostProfile metadata: name: <profileName> namespace: <ManagedClusterProjectName> # Add the name of the non-default project for the managed cluster # being created. spec: devices: # From the HW node, obtain the first device, which size is at least 120Gib. - device: minSize: 120Gi wipe: true partitions: - name: bios_grub partflags: - bios_grub size: 4Mi wipe: true - name: uefi partflags: - esp size: 200Mi wipe: true - name: config-2 size: 64Mi wipe: true - name: lvm_root_part size: 0 wipe: true # From the HW node, obtain the second device, which size is at least 120Gib. # If a device exists but does not fit the size, # the BareMetalHostProfile will not be applied to the node. - device: minSize: 120Gi wipe: true # From the HW node, obtain the disk device with the exact device path. - device: byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:1 minSize: 120Gi wipe: true partitions: - name: lvm_lvp_part size: 0 wipe: true # Example of wiping a device w\o partitioning it. # Mandatory for the case when a disk is supposed to be used for Ceph backend. # later - device: byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2 wipe: true fileSystems: - fileSystem: vfat partition: config-2 - fileSystem: vfat mountPoint: /boot/efi partition: uefi - fileSystem: ext4 logicalVolume: root mountPoint: / - fileSystem: ext4 logicalVolume: lvp mountPoint: /mnt/local-volumes/ logicalVolumes: - name: root size: 0 vg: lvm_root - name: lvp size: 0 vg: lvm_lvp postDeployScript: | #!/bin/bash -ex echo $(date) 'post_deploy_script done' >> /root/post_deploy_done preDeployScript: | #!/bin/bash -ex echo $(date) 'pre_deploy_script done' >> /root/pre_deploy_done volumeGroups: - devices: - partition: lvm_root_part name: lvm_root - devices: - partition: lvm_lvp_part name: lvm_lvp grubConfig: defaultGrubOptions: - GRUB_DISABLE_RECOVERY="true" - GRUB_PRELOAD_MODULES=lvm - GRUB_TIMEOUT=20 kernelParameters: sysctl: # For the list of options prohibited to change, refer to # https://docs.mirantis.com/mke/3.7/install/predeployment/set-up-kernel-default-protections.html kernel.dmesg_restrict: "1" kernel.core_uses_pid: "1" fs.file-max: "9223372036854775807" fs.aio-max-nr: "1048576" fs.inotify.max_user_instances: "4096" vm.max_map_count: "262144"
Optional. Configure wiping of the target device or partition to be used for cluster deployment as described in Wipe a device or partition.
Optional. Configure multiple devices for LVM volume using the example template extract below for reference.
Caution
The following template extract contains only sections relevant to LVM configuration with multiple PVs. Expand the main template described in the previous step with the configuration below if required.
spec: devices: ... - device: ... partitions: - name: lvm_lvp_part1 size: 0 wipe: true - device: ... partitions: - name: lvm_lvp_part2 size: 0 wipe: true volumeGroups: ... - devices: - partition: lvm_lvp_part1 - partition: lvm_lvp_part2 name: lvm_lvp logicalVolumes: ... - name: root size: 0 vg: lvm_lvp fileSystems: ... - fileSystem: ext4 logicalVolume: root mountPoint: /
For a managed cluster, configure required disks for the Ceph cluster as described in Configure Ceph disks in a host profile.
Optional. Technology Preview. Configure support of the Redundant Array of Independent Disks (RAID) that allows, for example, installing a cluster operating system on a RAID device, refer to Configure RAID support.
Optional. Configure the RX/TX buffer size for physical network interfaces and
txqueuelenfor any network interfaces.This configuration can greatly benefit high-load and high-performance network interfaces. You can configure these parameters using the
udevrules. For example:postDeployScript: | #!/bin/bash -ex ... echo 'ACTION=="add|change", SUBSYSTEM=="net", KERNEL=="eth*|en*", RUN+="/sbin/ethtool -G $name rx 4096 tx 4096"' > /etc/udev/rules.d/59-net.ring.rules echo 'ACTION=="add|change", SUBSYSTEM=="net", KERNEL=="eth*|en*|bond*|k8s-*|v*" ATTR{tx_queue_len}="10000"' > /etc/udev/rules.d/58-net.txqueue.rules
Add or edit the mandatory parameters in the new
BareMetalHostProfileobject. For the parameters description, see API: BareMetalHostProfile spec.Note
If asymmetric traffic is expected on some of the managed cluster nodes, enable the loose mode for the corresponding interfaces on those nodes by setting the
net.ipv4.conf.<interface-name>.rp_filterparameter to"2"in thekernelParameters.sysctlsection. For example:kernelParameters: sysctl: net.ipv4.conf.k8s-lcm.rp_filter: "2"
Select from the following options:
For a management cluster, proceed with the cluster bootstrap procedure as described in Deploy a management cluster using CLI.
For a managed cluster, select from the following options:
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0)
Log in to the Container Cloud web UI with the
operatorpermissions.Switch to the required non-
defaultproject using the Switch Project action icon located on top of the main left-side navigation panel.To create a project, refer to Create a project for managed clusters.
In the left sidebar, navigate to Baremetal and click the Host Profiles tab.
Click Create Host Profile.
Fill out the Create host profile form:
- Name
Name of the bare metal host profile.
- YAML file
BareMetalHostProfileobject in the YAML format that you have previously created. Click Upload to select the required file for uploading.
Add the bare metal host profile to your management cluster:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <managedClusterProjectName> apply -f <pathToBareMetalHostProfileFile>
If required, further modify the host profile:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <managedClusterProjectName> edit baremetalhostprofile <hostProfileName>
Proceed with Add a bare metal host either using web UI or CLI.
This section describes how to configure devices for the Ceph cluster in the
BareMetalHostProfile object of a managed cluster.
To configure disks for a Ceph cluster:
Open the
BareMetalHostProfileobject of a managed cluster for editing.In the
spec.devicessection, add each disk intended for use as a Ceph OSD data device withsize: 0andwipe: true.Example configuration for
sde-sdhdisks to use as Ceph OSDs:spec: devices: ... - device: byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:1 size: 0 wipe: true - device: byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2 size: 0 wipe: true - device: byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:3 size: 0 wipe: true - device: byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:4 size: 0 wipe: true
Since Container Cloud 2.24.0, if you plan to use a separate metadata device for Ceph OSD, configure the
spec.devicessection as described below.Important
Mirantis highly recommends configuring disk partitions for Ceph OSD metadata using
BareMetalHostProfile.Configuration of a separate metadata device for Ceph OSD
Add the device to
spec.deviceswith a single partition that will use the entire disk size.For example, if you plan to use four Ceph OSDs with a separate metadata device for each Ceph OSD, configure the
spec.devicessection as follows:spec: devices: ... - device: byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:5 wipe: true partitions: - name: ceph_meta size: 0 wipe: true
Create a volume group on top of the defined partition and create the required number of logical volumes (LVs) on top of the created volume group (VG). Add one logical volume per one Ceph OSD on the node.
Example snippet of an LVM configuration for a Ceph metadata disk:
spec: ... volumeGroups: ... - devices: - partition: ceph_meta name: bluedb logicalVolumes: ... - name: meta_1 size: 25%VG vg: bluedb - name: meta_2 size: 25%VG vg: bluedb - name: meta_3 size: 25%VG vg: bluedb - name: meta_4 size: 25%VG vg: bluedb
Important
Plan LVs of a separate metadata device thoroughly. Any logical volume misconfiguration causes redeployment of all Ceph OSDs that use this disk as metadata devices.
Note
General Ceph recommendation is to have a metadata device in between 1% to 4% of the Ceph OSD data size. Mirantis highly recommends having at least 4% of Ceph OSD data size.
If you plan using a disk as a separate metadata device for 10 Ceph OSDs, define the size of an LV for each Ceph OSD in between 1% to 4% of the corresponding Ceph OSD data size. If RADOS Gateway is enabled, the minimum data size must be 4%. For details, see Ceph documentation: Bluestore config reference.
For example, if the total data size of 10 Ceph OSDs equals
1Tbwith100Gbeach, assign a metadata disk less than10Gbwith1Gbper each LV. The recommended size is40Gbwith4Gbper each LV.After applying
BareMetalHostProfile, the bare metal provider creates an LVM partitioning for the metadata disk and places these volumes as/devpaths, for example,/dev/bluedb/meta_1or/dev/bluedb/meta_3.Example template of a host profile configuration for Ceph
spec: ... devices: ... - device: byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:1 wipe: true - device: byName: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2 wipe: true - device: byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:3 wipe: true - device: byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:4 wipe: true - device: byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:5 wipe: true partitions: - name: ceph_meta size: 0 wipe: true volumeGroups: ... - devices: - partition: ceph_meta name: bluedb logicalVolumes: ... - name: meta_1 size: 25%VG vg: bluedb - name: meta_2 size: 25%VG vg: bluedb - name: meta_3 size: 25%VG vg: bluedb - name: meta_4 size: 25%VG vg: bluedb
After applying such
BareMetalHostProfileto a node, thenodesspec of theKaaSCephClusterobject contains the followingstorageDevicessection:spec: cephClusterSpec: ... nodes: ... machine-1: ... storageDevices: - fullPath: /dev/disk/by-id/scsi-SATA_ST4000NM002A-2HZ_WS20NNKC config: metadataDevice: /dev/bluedb/meta_1 - fullPath: /dev/disk/by-id/ata-ST4000NM002A-2HZ101_WS20NEGE config: metadataDevice: /dev/bluedb/meta_2 - fullPath: /dev/disk/by-id/scsi-0ATA_ST4000NM002A-2HZ_WS20LEL3 config: metadataDevice: /dev/bluedb/meta_3 - fullPath: /dev/disk/by-id/ata-HGST_HUS724040ALA640_PN1334PEDN9SSU config: metadataDevice: /dev/bluedb/meta_4
spec: cephClusterSpec: ... nodes: ... machine-1: ... storageDevices: - name: sde config: metadataDevice: /dev/bluedb/meta_1 - name: sdf config: metadataDevice: /dev/bluedb/meta_2 - name: sdg config: metadataDevice: /dev/bluedb/meta_3 - name: sdh config: metadataDevice: /dev/bluedb/meta_4
The BareMetalHostProfile API allows configuring a host to use the
huge pages feature of the Linux kernel on managed clusters.
Note
Huge pages is a mode of operation of the Linux kernel. With huge pages enabled, the kernel allocates the RAM in bigger chunks, or pages. This allows a KVM (kernel-based virtual machine) and VMs running on it to use the host RAM more efficiently and improves the performance of VMs.
To enable huge pages in a custom bare metal host profile for a managed cluster:
Log in to the local machine where you management cluster
kubeconfigis located and wherekubectlis installed.Note
The management cluster
kubeconfigis created automatically during the last stage of the management cluster bootstrap.Open for editing or create a new bare metal host profile under the
templates/bm/directory.Edit the
grubConfigsection of the host profilespecusing the example below to configure the kernel boot parameters and enable huge pages:spec: grubConfig: defaultGrubOptions: - GRUB_DISABLE_RECOVERY="true" - GRUB_PRELOAD_MODULES=lvm - GRUB_TIMEOUT=20 - GRUB_CMDLINE_LINUX_DEFAULT="hugepagesz=1G hugepages=N"
The example configuration above will allocate
Nhuge pages of 1 GB each on the server boot. The lasthugepageszparameter value is default unlessdefault_hugepageszis defined. For details about possible values, see official Linux kernel documentation.Add the bare metal host profile to your management cluster:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <projectName> apply -f <pathToBareMetalHostProfileFile>
If required, further modify the host profile:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <projectName> edit baremetalhostprofile <hostProfileName>
Proceed with Add a bare metal host.
Caution
This feature is available as Technology Preview. Use such configuration for testing and evaluation purposes only. For the Technology Preview feature definition, refer to Technology Preview features.
You can configure support of the software-based Redundant Array of Independent
Disks (RAID) using BareMetalHosProfile to set up an LVM or mdadm-based RAID
level 1 (raid1). If required, you can further configure RAID in the same
profile, for example, to install a cluster operating system onto a RAID device.
Caution
RAID configuration on already provisioned bare metal machines or on an existing cluster is not supported.
To start using any kind of RAIDs, reprovisioning of machines with a new
BaremetalHostProfileis required.Mirantis supports the
raid1type of RAID devices both for LVM and mdadm.Mirantis supports the
raid0type for the mdadm RAID to be on par with the LVMlineartype.Mirantis recommends having at least two physical disks for the
raid0andraid1devices to prevent unnecessary complexity.Mirantis supports the
raid10type for mdadm RAID on MOSK clusters. At least four physical disks are required for this type of RAID.Only an even number of disks can be used for a
raid1orraid10device.
Caution
This feature is available as Technology Preview. Use such configuration for testing and evaluation purposes only. For the Technology Preview feature definition, refer to Technology Preview features.
Warning
The EFI system partition partflags: ['esp'] must be
a physical partition in the main partition table of the disk, not under
LVM or mdadm software RAID.
During configuration of your custom bare metal host profile,
you can create an LVM-based software RAID device raid1 by adding
type: raid1 to the logicalVolume spec in BaremetalHostProfile.
For the LVM RAID parameters description, refer to API: BareMetalHostProfile spec.
For a bare metal host profile configuration, refer to Create a custom bare metal host profile.
Caution
The logicalVolume spec of the raid1 type requires
at least two devices (partitions) in volumeGroup where you
build a logical volume. For an LVM of the linear type,
one device is enough.
Note
The LVM raid1 requires additional space to store the raid1
metadata on a volume group, roughly 4 MB for each partition.
Therefore, you cannot create a logical volume of exactly the same
size as the partitions it works on.
For example, if you have two partitions of 10 GiB, the corresponding
raid1 logical volume size will be less than 10 GiB. For that
reason, you can either set size: 0 to use all available space
on the volume group, or set a smaller size than the partition size.
For example, use size: 9.9Gi instead of size: 10Gi
for the logical volume.
The following example illustrates an extract of BaremetalHostProfile
with / on the LVM raid1.
...
devices:
- device:
byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:1
minSize: 200Gi
type: hdd
wipe: true
partitions:
- name: root_part1
size: 120Gi
- name: rest_sda
size: 0
- device:
byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2
minSize: 200Gi
type: hdd
wipe: true
partitions:
- name: root_part2
size: 120Gi
- name: rest_sdb
size: 0
volumeGroups:
- name: vg-root
devices:
- partition: root_part1
- partition: root_part2
- name: vg-data
devices:
- partition: rest_sda
- partition: rest_sdb
logicalVolumes:
- name: root
type: raid1 ## <-- LVM raid1
vg: vg-root
size: 119.9Gi
- name: data
type: linear
vg: vg-data
size: 0
fileSystems:
- fileSystem: ext4
logicalVolume: root
mountPoint: /
mountOpts: "noatime,nodiratime"
- fileSystem: ext4
logicalVolume: data
mountPoint: /mnt/data
Warning
Any data stored on any device defined in the fileSystems
list can be deleted or corrupted during cluster (re)deployment. It happens
because each device from the fileSystems list is a part of the
rootfs directory tree that is overwritten during (re)deployment.
Examples of affected devices include:
A raw device partition with a file system on it
A device partition in a volume group with a logical volume that has a file system on it
An mdadm RAID device with a file system on it
An LVM RAID device with a file system on it
The wipe field (deprecated) or wipeDevice structure (recommended
since Container Cloud 2.26.0) have no effect in this case and cannot
protect data on these devices.
Therefore, to prevent data loss, move the necessary data from these file systems to another server beforehand, if required.
Caution
This feature is available as Technology Preview. Use such configuration for testing and evaluation purposes only. For the Technology Preview feature definition, refer to Technology Preview features.
Warning
The EFI system partition partflags: ['esp'] must be
a physical partition in the main partition table of the disk, not under
LVM or mdadm software RAID.
During configuration of your custom bare metal host profile as described in
Create a custom bare metal host profile, you can create an mdadm-based software RAID
device raid1 by describing the mdadm devices under the softRaidDevices
field in BaremetalHostProfile. For example:
...
softRaidDevices:
- name: /dev/md0
devices:
- partition: sda1
- partition: sdb1
- name: raid-name
devices:
- partition: sda2
- partition: sdb2
...
The only two required fields to describe RAID devices are name
and devices. The devices field must describe at least two partitions
to build an mdadm RAID on it. For the mdadm RAID parameters, see
API: BareMetalHostProfile spec.
Caution
The mdadm RAID devices cannot be created on top of LVM devices, as well as LVM devices cannot be created on top of mdadm devices.
The following example illustrates an extract of BaremetalHostProfile
with / on the mdadm raid1 and some data storage on raid0:
...
devices:
- device:
byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:1
wipe: true
partitions:
- name: root_part1
sizeGiB: 120
- name: rest_sda
sizeGiB: 0
- device:
byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2
wipe: true
partitions:
- name: root_part2
sizeGiB: 120
- name: rest_sdb
sizeGiB: 0
softRaidDevices:
- name: root
level: raid1 ## <-- mdadm raid1
devices:
- partition: root_part1
- partition: root_part2
- name: raid-name
level: raid0 ## <-- mdadm raid0
devices:
- partition: rest_sda
- partition: rest_sdb
fileSystems:
- fileSystem: ext4
softRaidDevice: root
mountPoint: /
mountOpts: "noatime,nodiratime"
- fileSystem: ext4
softRaidDevice: data
mountPoint: /mnt/data
...
Warning
Any data stored on any device defined in the fileSystems
list can be deleted or corrupted during cluster (re)deployment. It happens
because each device from the fileSystems list is a part of the
rootfs directory tree that is overwritten during (re)deployment.
Examples of affected devices include:
A raw device partition with a file system on it
A device partition in a volume group with a logical volume that has a file system on it
An mdadm RAID device with a file system on it
An LVM RAID device with a file system on it
The wipe field (deprecated) or wipeDevice structure (recommended
since Container Cloud 2.26.0) have no effect in this case and cannot
protect data on these devices.
Therefore, to prevent data loss, move the necessary data from these file systems to another server beforehand, if required.
Technology Preview
Warning
The EFI system partition partflags: ['esp'] must be
a physical partition in the main partition table of the disk, not under
LVM or mdadm software RAID.
You can deploy Mirantis OpenStack for Kubernetes (MOSK) on local software-based Redundant Array of Independent Disks (RAID) devices to withstand failure of one device at a time.
Using a custom bare metal host profile, you can configure and create
an mdadm-based software RAID device of type raid10 if you have
an even number of devices available on your servers. At least four
storage devices are required for such RAID device.
During configuration of your custom bare metal host profile as described in
Create a custom bare metal host profile, create an mdadm-based software RAID device
raid10 by describing the mdadm devices under the softRaidDevices
field. For example:
...
softRaidDevices:
- name: /dev/md0
level: raid10
devices:
- partition: sda1
- partition: sdb1
- partition: sdc1
- partition: sdd1
...
The following fields in softRaidDevices describe RAID devices:
nameName of the RAID device to refer to throughout the
baremetalhostprofile.
devicesList of physical devices or partitions used to build a software RAID device. It must include at least four partitions or devices to build a
raid10device.
levelType or level of RAID used to create device. Set to
raid10orraid1to create a device of the corresponding type.
For the rest of the mdadm RAID parameters, see API Reference: BareMetalHostProfile spec.
Caution
The mdadm RAID devices cannot be created on top of an LVM device.
The following example illustrates an extract of baremetalhostprofile
with data storage on a raid10 device:
...
devices:
- device:
minSize: 60Gi
wipe: true
partitions:
- name: bios_grub1
partflags:
- bios_grub
size: 4Mi
wipe: true
- name: uefi
partflags:
- esp
size: 200Mi
wipe: true
- name: config-2
size: 64Mi
wipe: true
- name: lvm_root
size: 0
wipe: true
- device:
minSize: 60Gi
wipe: true
partitions:
- name: md_part1
partflags:
- raid
size: 40Gi
wipe: true
- device:
minSize: 60Gi
wipe: true
partitions:
- name: md_part2
partflags:
- raid
size: 40Gi
wipe: true
- device:
minSize: 60Gi
wipe: true
partitions:
- name: md_part3
partflags:
- raid
size: 40Gi
wipe: true
- device:
minSize: 60Gi
wipe: true
partitions:
- name: md_part4
partflags:
- raid
size: 40Gi
wipe: true
fileSystems:
- fileSystem: vfat
partition: config-2
- fileSystem: vfat
mountPoint: /boot/efi
partition: uefi
- fileSystem: ext4
mountOpts: rw,noatime,nodiratime,lazytime,nobarrier,commit=240,data=ordered
mountPoint: /
partition: root
- filesystem: ext4
mountPoint: /var
softRaidDevice: /dev/md0
softRaidDevices:
- devices:
- partition: md_root_part1
- partition: md_root_part2
- partition: md_root_part3
- partition: md_root_part4
level: raid10
metadata: "1.2"
name: /dev/md0
...
Warning
When building the raid10 array on top of device partitions,
make sure that only one partition per device is used for a given array.
Although having two partitions located on the same physical device as array members is technically possible, it may lead to data loss if mdadm selects both partitions of the same drive to be mirrored. In such case, redundancy against entire drive failure is lost.
Warning
Any data stored on any device defined in the fileSystems
list can be deleted or corrupted during cluster (re)deployment. It happens
because each device from the fileSystems list is a part of the
rootfs directory tree that is overwritten during (re)deployment.
Examples of affected devices include:
A raw device partition with a file system on it
A device partition in a volume group with a logical volume that has a file system on it
An mdadm RAID device with a file system on it
An LVM RAID device with a file system on it
The wipe field (deprecated) or wipeDevice structure (recommended
since Container Cloud 2.26.0) have no effect in this case and cannot
protect data on these devices.
Therefore, to prevent data loss, move the necessary data from these file systems to another server beforehand, if required.
Add a managed baremetal cluster¶
This section instructs you on how to configure and deploy a managed cluster that is based on the baremetal-based management cluster.
By default, Mirantis Container Cloud configures a single interface on the cluster nodes, leaving all other physical interfaces intact.
With L2 networking templates, you can create advanced host networking configurations for your clusters. For example, you can create bond interfaces on top of physical interfaces on the host or use multiple subnets to separate different types of network traffic.
You can use several host-specific L2 templates per one cluster to support different hardware configurations. For example, you can create L2 templates with different number and layout of NICs to be applied to the specific machines of one cluster.
When you create a baremetal-based project, the exemplary templates
with the ipam/PreInstalledL2Template label are copied to this project.
These templates are preinstalled during the management cluster bootstrap.
Using the L2 Templates section of the Clusters tab in the Container Cloud web UI, you can view a list of preinstalled templates and the ones that you manually create before a cluster deployment.
Note
Preinstalled L2 templates are removed in Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0).
Caution
Modification of L2 templates in use is allowed with a mandatory validation step from the Infrastructure Operator to prevent accidental cluster failures due to unsafe changes. The list of risks posed by modifying L2 templates includes:
Services running on hosts cannot reconfigure automatically to switch to the new IP addresses and/or interfaces.
Connections between services are interrupted unexpectedly, which can cause data loss.
Incorrect configurations on hosts can lead to irrevocable loss of connectivity between services and unexpected cluster partition or disassembly.
For details, see Modify network configuration on an existing machine.
Since Container Cloud 2.24.4, in the Technology Preview scope, you can create a managed cluster with a multi-rack topology, where cluster nodes including Kubernetes masters are distributed across multiple racks without L2 layer extension between them, and use BGP for announcement of the cluster API load balancer address and external addresses of Kubernetes load-balanced services.
Implementation of the multi-rack topology implies the use of Rack and
MultiRackCluster objects that support configuration of BGP announcement
of the cluster API load balancer address. For the configuration procedure,
refer to Configure BGP announcement for cluster API LB address. For configuring the BGP announcement of
external addresses of Kubernetes load-balanced services, refer to
Configure MetalLB.
Follow the procedures described in the below subsections to configure initial settings and advanced network objects for your managed clusters.
This section instructs you on how to create initial configuration of a managed cluster that is based on the baremetal-based management cluster through the Mirantis Container Cloud web UI.
To create a managed cluster on bare metal:
Available since the Cluster release 16.1.0 on the management cluster. If you plan to deploy a large managed cluster, enable dynamic IP allocation to increase the amount of baremetal hosts to be provisioned in parallel. For details, see Enable dynamic IP allocation.
Available since Container Cloud 2.24.0. Optional. Technology Preview. Enable custom host names for cluster machines. When enabled, any machine host name in a particular region matches the related
Machineobject name. For example, instead of the defaultkaas-node-<UID>, a machine host name will bemaster-0. The custom naming format is more convenient and easier to operate with.For details, see Configure host names for cluster machines.
If you enabled this feature during management cluster bootstrap, skip this step, as the feature applies to any cluster type.
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required non-
defaultproject using the Switch Project action icon located on top of the main left-side navigation panel.To create a project, refer to Create a project for managed clusters.
Optional. In the SSH Keys tab, click Add SSH Key to upload the public SSH key(s) for SSH access to VMs.
Optional. Enable proxy access to the cluster.
In the Proxies tab, configure proxy:
Click Add Proxy.
In the Add New Proxy wizard, fill out the form with the following parameters:
Proxy configuration¶ Parameter
Description
Proxy Name
Name of the proxy server to use during cluster creation.
Region Removed in 2.26.0 (16.1.0 and 17.1.0)
From the drop-down list, select the required region.
HTTP Proxy
Add the HTTP proxy server domain name in the following format:
http://proxy.example.com:port- for anonymous accesshttp://user:password@proxy.example.com:port- for restricted access
HTTPS Proxy
Add the HTTPS proxy server domain name in the same format as for HTTP Proxy.
No Proxy
Comma-separated list of IP addresses or domain names.
For implementation details, see Proxy and cache support.
If your proxy requires a trusted CA certificate, select the CA Certificate check box and paste a CA certificate for a MITM proxy to the corresponding field or upload a certificate using Upload Certificate.
For MOSK-based deployments, the possibility to use a MITM proxy with a CA certificate is available since MOSK 23.1.
For the list of Mirantis resources and IP addresses to be accessible from the Container Cloud clusters, see Requirements for a baremetal-based cluster.
In the Clusters tab, click Create Cluster.
Configure the new cluster in the Create New Cluster wizard that opens:
Define general and Kubernetes parameters:
Create new cluster: General, Provider, and Kubernetes¶ Section
Parameter name
Description
General settings
Cluster name
The cluster name.
Provider
Select Baremetal.
Region Removed in 2.26.0 (17.1.0 and 16.1.0)
From the drop-down list, select Baremetal.
Release version
The Container Cloud version.
Proxy
Optional. From the drop-down list, select the proxy server name that you have previously created.
SSH keys
From the drop-down list, select the SSH key name(s) that you have previously added for SSH access to the bare metal hosts.
Container Registry
From the drop-down list, select the Docker registry name that you have previously added using the Container Registries tab. For details, see Define a custom CA certificate for a private Docker registry.
Note
For MOSK-based deployments, the feature support is available since MOSK 22.5.
Enable WireGuard
Optional. Available as TechPreview since 2.24.0 and 2.24.2 for MOSK 23.2. Enable WireGuard for traffic encryption on the Kubernetes workloads network.
WireGuard configuration
Ensure that the Calico MTU size is at least 60 bytes smaller than the interface MTU size of the workload network. IPv4 WireGuard uses a 60-byte header. For details, see Set the MTU size for Calico.
Enable WireGuard by selecting the Enable WireGuard check box.
Caution
Changing this parameter on a running cluster causes a downtime that can vary depending on the cluster size.
For more details about WireGuard, see Calico documentation: Encrypt in-cluster pod traffic.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
Note
This parameter was renamed from Enable Secure Overlay to Enable WireGuard in Cluster releases 17.0.0 and 16.0.0.
Parallel Upgrade Of Worker Machines
Optional. Available since Cluster releases 17.0.0 and 16.0.0.
The maximum number of the worker nodes to update simultaneously. It serves as an upper limit on the number of machines that are drained at a given moment of time. Defaults to
1.You can also configure this option after deployment before the cluster update.
Parallel Preparation For Upgrade Of Worker Machines
Optional. Available since Cluster releases 17.0.0 and 16.0.0.
The maximum number of worker nodes being prepared at a given moment of time, which includes downloading of new artifacts. It serves as a limit for the network load that can occur when downloading the files to the nodes. Defaults to
50.You can also configure this option after deployment before the cluster update.
Provider
LB host IP
The IP address of the load balancer endpoint that will be used to access the Kubernetes API of the new cluster. This IP address must be in the LCM network if a separate LCM network is in use and if L2 (ARP) announcement of cluster API load balancer IP is in use.
LB address range
The range of IP addresses that can be assigned to load balancers for Kubernetes Services by MetalLB. For a more flexible MetalLB configuration, refer to Configure MetalLB.
Kubernetes
Services CIDR blocks
The Kubernetes Services CIDR blocks. For example,
10.233.0.0/18.Pods CIDR blocks
The Kubernetes pods CIDR blocks. For example,
10.233.64.0/18.Note
The network subnet size of Kubernetes pods influences the number of nodes that can be deployed in the cluster. The default subnet size
/18is enough to create a cluster with up to 256 nodes. Each node uses the/26address blocks (64 addresses), at least one address block is allocated per node. These addresses are used by the Kubernetes pods withhostNetwork: false. The cluster size may be limited further when some nodes use more than one address block.Configure StackLight:
Section
Parameter name
Description
StackLight
Enable Monitoring
Selected by default. Deselect to skip StackLight deployment. You can also enable, disable, or configure StackLight parameters after deploying a managed cluster. For details, see Change a cluster configuration or Configure StackLight.
Enable Logging
Select to deploy the StackLight logging stack.
For details about the logging components, see Deployment architecture.
Note
The logging mechanism performance depends on the cluster log load. In case of a high load, you may need to increase the default resource requests and limits for
fluentdLogs. For details, see StackLight configuration parameters: Resource limits.HA Mode
Select to enable StackLight monitoring in the HA mode. For the differences between HA and non-HA modes, see Deployment architecture.
StackLight Default Logs Severity Level
Log severity (verbosity) level for all StackLight components. The default value for this parameter is Default component log level that respects original defaults of each StackLight component. For details about severity levels, see Log verbosity.
StackLight Component Logs Severity Level
The severity level of logs for a specific StackLight component that overrides the value of the StackLight Default Logs Severity Level parameter. For details about severity levels, see Log verbosity.
Expand the drop-down menu for a specific component to display its list of available log levels.
OpenSearch
Logstash Retention Time
Skip this parameter since Container Cloud 2.26.0 (17.1.0, 16.1.0). It was removed from the code base and will be removed from the web UI in one of the following releases.
Available if you select Enable Logging. Specifies the
logstash-*index retention time.Events Retention Time
Available if you select Enable Logging. Specifies the
kubernetes_events-*index retention time.Notifications Retention
Available if you select Enable Logging. Specifies the
notification-*index retention time and is used for Mirantis OpenStack for Kubernetes.Persistent Volume Claim Size
Available if you select Enable Logging. The OpenSearch persistent volume claim size.
Collected Logs Severity Level
Available if you select Enable Logging. The minimum severity of all Container Cloud components logs collected in OpenSearch. For details about severity levels, see Logging.
Prometheus
Retention Time
The Prometheus database retention period.
Retention Size
The Prometheus database retention size.
Persistent Volume Claim Size
The Prometheus persistent volume claim size.
Enable Watchdog Alert
Select to enable the Watchdog alert that fires as long as the entire alerting pipeline is functional.
Custom Alerts
Specify alerting rules for new custom alerts or upload a YAML file in the following exemplary format:
- alert: HighErrorRate expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5 for: 10m labels: severity: page annotations: summary: High request latency
For details, see Official Prometheus documentation: Alerting rules. For the list of the predefined StackLight alerts, see Operations Guide: Available StackLight alerts.
StackLight Email Alerts
Enable Email Alerts
Select to enable the StackLight email alerts.
Send Resolved
Select to enable notifications about resolved StackLight alerts.
Require TLS
Select to enable transmitting emails through TLS.
Email alerts configuration for StackLight
Fill out the following email alerts parameters as required:
To - the email address to send notifications to.
From - the sender address.
SmartHost - the SMTP host through which the emails are sent.
Authentication username - the SMTP user name.
Authentication password - the SMTP password.
Authentication identity - the SMTP identity.
Authentication secret - the SMTP secret.
StackLight Slack Alerts
Enable Slack alerts
Select to enable the StackLight Slack alerts.
Send Resolved
Select to enable notifications about resolved StackLight alerts.
Slack alerts configuration for StackLight
Fill out the following Slack alerts parameters as required:
API URL - The Slack webhook URL.
Channel - The channel to send notifications to, for example, #channel-for-alerts.
StackLight optional settings
Enable Reference Application
Available since Container Cloud 2.22.0. Enables Reference Application that is a small microservice application that enables workload monitoring on non-MOSK managed clusters.
Note
For the feature support on MOSK deployments, refer to MOSK documentation: Deploy RefApp using automation tools.
Disabled by default. You can also enable this option after deployment from the Configure cluster menu.
Available since Container Cloud 2.24.0 and 2.24.2 for MOSK 23.2. Optional. Technology Preview. Enable the Linux Audit daemon auditd to monitor activity of cluster processes and prevent potential malicious activity.
Configuration for auditd
In the
Clusterobject, add the auditd parameters:spec: providerSpec: value: audit: auditd: enabled: <bool> enabledAtBoot: <bool> backlogLimit: <int> maxLogFile: <int> maxLogFileAction: <string> maxLogFileKeep: <int> mayHaltSystem: <bool> presetRules: <string> customRules: <string> customRulesX32: <text> customRulesX64: <text>
Configuration parameters for auditd:
enabledBoolean, default -
false. Enables theauditdrole to install the auditd packages and configure rules. CIS rules: 4.1.1.1, 4.1.1.2.enabledAtBootBoolean, default -
false. Configures grub to audit processes that can be audited even if they start up prior to auditd startup. CIS rule: 4.1.1.3.backlogLimitInteger, default - none. Configures the backlog to hold records. If during boot
audit=1is configured, the backlog holds 64 records. If more than 64 records are created during boot, auditd records will be lost with a potential malicious activity being undetected. CIS rule: 4.1.1.4.maxLogFileInteger, default - none. Configures the maximum size of the audit log file. Once the log reaches the maximum size, it is rotated and a new log file is created. CIS rule: 4.1.2.1.
maxLogFileActionString, default - none. Defines handling of the audit log file reaching the maximum file size. Allowed values:
keep_logs- rotate logs but never delete themrotate- add a cron job to compress rotated log files and keep maximum 5 compressed files.compress- compress log files and keep them under the/var/log/auditd/directory. Requiresauditd_max_log_file_keepto be enabled.
CIS rule: 4.1.2.2.
maxLogFileKeepInteger, default -
5. Defines the number of compressed log files to keep under the/var/log/auditd/directory. Requiresauditd_max_log_file_action=compress. CIS rules - none.mayHaltSystemBoolean, default -
false. Halts the system when the audit logs are full. Applies the following configuration:space_left_action = emailaction_mail_acct = rootadmin_space_left_action = halt
CIS rule: 4.1.2.3.
customRulesString, default - none. Base64-encoded content of the
60-custom.rulesfile for any architecture. CIS rules - none.customRulesX32String, default - none. Base64-encoded content of the
60-custom.rulesfile for thei386architecture. CIS rules - none.customRulesX64String, default - none. Base64-encoded content of the
60-custom.rulesfile for thex86_64architecture. CIS rules - none.presetRulesString, default - none. Comma-separated list of the following built-in preset rules:
accessactionsdeletedocker
identityimmutableloginsmac-policy
modulesmountsperm-modprivileged
scopesessionsystem-localetime-change
You can use two keywords for these rules:
none- disables all built-in rules.all- enables all built-in rules. With this key, you can add the!prefix to a rule name to exclude some rules. You can use the!prefix for rules only if you add theallkeyword as the first rule. Place a rule with the!prefix only after theallkeyword.
Example configurations:
presetRules: none- disable all preset rulespresetRules: docker- enable only thedockerrulespresetRules: access,actions,logins- enable only theaccess,actions, andloginsrulespresetRules: all- enable all preset rulespresetRules: all,!immutable,!sessions- enable all preset rules exceptimmutableandsessions
CIS controls
4.1.3 (time-change)4.1.4 (identity)4.1.5 (system-locale)4.1.6 (mac-policy)4.1.7 (logins)4.1.8 (session)4.1.9 (perm-mod)4.1.10 (access)4.1.11 (privileged)4.1.12 (mounts)4.1.13 (delete)4.1.14 (scope)4.1.15 (actions)4.1.16 (modules)4.1.17 (immutable)Docker CIS controls
1.1.41.1.81.1.101.1.121.1.131.1.151.1.161.1.171.1.181.2.31.2.41.2.51.2.61.2.71.2.101.2.11
Click Create.
To monitor the cluster readiness, hover over the status icon of a specific cluster in the Status column of the Clusters page.
Once the orange blinking status icon becomes green and Ready, the cluster deployment or update is complete.
You can monitor live deployment status of the following cluster components:
Component
Description
Bastion
For the OpenStack-based management clusters, the Bastion node IP address status that confirms the Bastion node creation
Helm
Installation or upgrade status of all Helm releases
Kubelet
Readiness of the node in a Kubernetes cluster, as reported by kubelet
Kubernetes
Readiness of all requested Kubernetes objects
Nodes
Equality of the requested nodes number in the cluster to the number of nodes having the
ReadyLCM statusOIDC
Readiness of the cluster OIDC configuration
StackLight
Health of all StackLight-related objects in a Kubernetes cluster
Swarm
Readiness of all nodes in a Docker Swarm cluster
LoadBalancer
Readiness of the Kubernetes API load balancer
ProviderInstance
Readiness of all machines in the underlying infrastructure (virtual or bare metal, depending on the provider type)
Graceful Reboot
Readiness of a cluster during a scheduled graceful reboot, available since Cluster releases 15.0.1 and 14.0.0.
Infrastructure Status
Available since Container Cloud 2.25.0 for bare metal and OpenStack providers. Readiness of the following cluster components:
Bare metal: the
MetalLBConfigobject along with MetalLB and DHCP subnets.OpenStack: cluster network, routers, load balancers, and Bastion along with their ports and floating IPs.
LCM Operation
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Health of all LCM operations on the cluster and its machines.
LCM Agent
Available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Health of all LCM agents on cluster machines and the status of LCM agents update to the version from the current Cluster release.
For the history of a cluster deployment or update, refer to Inspect the history of a cluster and machine deployment or update.
Configure an L2 template for a new cluster. For initial details, see Workflow of network interface naming.
To simplify operations with L2 templates, before you start creating them, inspect the general workflow of a network interface name gathering and processing.
Network interface naming workflow:
The Operator creates a
baremetalHostobject.The
baremetalHostobject executes theintrospectionstage and becomesready.The Operator collects information about NIC count, naming, and so on for further changes in the mapping logic.
At this stage, the NICs order in the object may randomly change during each introspection, but the NICs names are always the same. For more details, see Predictable Network Interface Names.
For example:
# Example commands: # kubectl -n managed-ns get bmh baremetalhost1 -o custom-columns='NAME:.metadata.name,STATUS:.status.provisioning.state' # NAME STATE # baremetalhost1 ready # kubectl -n managed-ns get bmh baremetalhost1 -o yaml # Example output: apiVersion: metal3.io/v1alpha1 kind: BareMetalHost ... status: ... nics: - ip: fe80::ec4:7aff:fe6a:fb1f%eno2 mac: 0c:c4:7a:6a:fb:1f model: 0x8086 0x1521 name: eno2 pxe: false - ip: fe80::ec4:7aff:fe1e:a2fc%ens1f0 mac: 0c:c4:7a:1e:a2:fc model: 0x8086 0x10fb name: ens1f0 pxe: false - ip: fe80::ec4:7aff:fe1e:a2fd%ens1f1 mac: 0c:c4:7a:1e:a2:fd model: 0x8086 0x10fb name: ens1f1 pxe: false - ip: 192.168.1.151 # Temp. PXE network adress mac: 0c:c4:7a:6a:fb:1e model: 0x8086 0x1521 name: eno1 pxe: true ...
The Operator selects from the following options:
Create an
l2templateobject with theifMappingconfiguration. For details, see Create L2 templates.Create a
Machineobject, with thel2TemplateIfMappingOverrideconfiguration. For details, see Override network interfaces naming and order.
The Operator creates a
MachineorSubnetobject.The
baremetal-providerservice links theMachineobject to thebaremetalHostobject.The
kaas-ipamandbaremetal-providerservices collect hardware information from thebaremetalHostobject and use it to configure host networking and services.The
kaas-ipamservice:Spawns the
IpamHostobject.Renders the
l2templateobject.Spawns the
ipaddrobject.Updates the
IpamHostobject status with all rendered and linked information.
The
baremetal-providerservice collects the rendered networking information from theIpamHostobjectThe
baremetal-providerservice proceeds with theIpamHostobject provisioning.
Before creating an L2 template, ensure that you have the required subnets
that can be used in the L2 template to allocate IP addresses for the
managed cluster nodes.
Where required, create a number of subnets for a particular project
using the Subnet CR. A subnet has three logical scopes:
global - CR uses the
defaultnamespace. A subnet can be used for any cluster located in any project.namespaced - CR uses the namespace that corresponds to a particular project where managed clusters are located. A subnet can be used for any cluster located in the same project.
cluster - CR uses the namespace where the referenced cluster is located. A subnet is only accessible to the cluster that
L2Template.metadata.labels:cluster.sigs.k8s.io/cluster-name(mandatory since 2.25.0) orL2Template.spec.clusterRef(deprecated since 2.25.0) refers to. TheSubnetobjects with theclusterscope will be created for every new cluster.
Note
The use of the ipam/SVC-MetalLB label in Subnet objects
is deprecated as part of the MetalLBConfigTemplate object deprecation
in Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). No
actions are required for existing objects. A Subnet object containing
this label will be ignored by baremetal-provider after cluster update
to the mentioned Cluster releases.
You can have subnets with the same name in different projects. In this case, the subnet that has the same project as the cluster will be used. One L2 template may often reference several subnets, those subnets may have different scopes in this case.
The IP address objects (IPaddr CR) that are allocated from subnets
always have the same project as their corresponding IpamHost objects,
regardless of the subnet scope.
You can create subnets using either the Container Cloud web UI or CLI.
Any Subnet object may contain ipam/SVC-<serviceName> labels.
All IP addresses allocated from the Subnet object that has service labels
defined, will inherit those labels.
When a particular IpamHost uses IP addresses allocated from such labeled
Subnet objects, the ServiceMap field in IpamHost.Status will
contain information about which IPs and interfaces correspond to which service
labels (that have been set in the Subnet objects). Using ServiceMap,
you can understand what IPs and interfaces of a particular host are used
for network traffic of a given service.
Currently, Container Cloud uses the following service labels that allow for the use of specific subnets for particular Container Cloud services:
ipam/SVC-k8s-lcmipam/SVC-ceph-clusteripam/SVC-ceph-publicipam/SVC-dhcp-rangeipam/SVC-MetalLBDeprecated since 2.27.0 (17.2.0 and 16.2.0)ipam/SVC-LBhost
Caution
The use of the ipam/SVC-k8s-lcm label is mandatory
for every cluster.
You can also add own service labels to the Subnet objects the same way you
add Container Cloud service labels. The mapping of IPs and interfaces to the
defined services is displayed in IpamHost.Status.ServiceMap.
You can assign multiple service labels to one network. You can also assign the
ceph-* and MetalLB services to multiple networks.
In the latter case, the system sorts the IP addresses in the ascending order:
serviceMap:
ipam/SVC-ceph-cluster:
- ifName: ceph-br2
ipAddress: 10.0.10.11
- ifName: ceph-br1
ipAddress: 10.0.12.22
ipam/SVC-ceph-public:
- ifName: ceph-public
ipAddress: 10.1.1.15
ipam/SVC-k8s-lcm:
- ifName: k8s-lcm
ipAddress: 10.0.1.52
You can add service labels during creation of subnets as described in Create subnets for a managed cluster using CLI.
Before creating an L2 template, create the required subnets to use in the L2 template to allocate IP addresses for the managed cluster nodes.
To create subnets for a managed cluster using web UI:
Log in to the Container Cloud web UI with the
operatorpermissions.Switch to the required non-
defaultproject using the Switch Project action icon located on top of the main left-side navigation panel.To create a project, refer to Create a project for managed clusters.
Select one of the following options:
In the left sidebar, navigate to Networks. The Subnets tab opens.
Click Create Subnet.
Fill out the Create subnet form as required:
- Name
Subnet name.
- Subnet Type
Subnet type:
- DHCP
DHCP subnet that configures DHCP address ranges used by the DHCP server on the management cluster. For details, see Configure multiple DHCP ranges using Subnet resources.
- LB
Cluster API subnet.
- LCM
LCM subnet(s).
- MetalLB
Services subnet(s).
- Custom
Custom subnet. For example, external, Kubernetes workloads, or storage subnets.
For description of subnet types in a managed cluster, see Managed cluster networking.
- Cluster
Cluster name that the subnet is being created for. Not required only for the DHCP subnet.
- CIDR
A valid IPv4 CIDR, for example, 10.11.0.0/24.
- Include Ranges Optional
A comma-separated list of IP address ranges within the given CIDR that should be used in the allocation of IPs for nodes. The gateway, network, broadcast, and DNSaddresses will be excluded (protected) automatically if they intersect with one of the range. The IPs outside the given ranges will not be used in the allocation. Each element of the list can be either an interval
10.11.0.5-10.11.0.70or a single address10.11.0.77. TheincludeRangesparameter is mutually exclusive withexcludeRanges.
- Exclude Ranges Optional
A comma-separated list of IP address ranges within the given CIDR that should not be used in the allocation of IPs for nodes. The IPs within the given CIDR but outside the given ranges will be used in the allocation. The gateway, network, broadcast, and DNS addresses will be excluded (protected) automatically if they are included in the CIDR. Each element of the list can be either an interval
10.11.0.5-10.11.0.70or a single address10.11.0.77. TheexcludeRangesparameter is mutually exclusive withincludeRanges.
- Gateway Optional
A valid IPv4 gateway address, for example, 10.11.0.9. Does not apply to the MetalLB subnet.
- Nameservers
IP addresses of nameservers separated by a comma. Does not apply to the DHCP and MetalLB subnet types.
- Use whole CIDR
Optional. Select to use the whole IPv4 CIDR range. Useful when defining single IP addressed (/32), for example, in the Cluster API load balancer (LB) subnet.
- Labels
Key-value pairs attached to the selected subnet:
MetalLB:
metallb/address-pool-nameName of the subnet address pool. Exemplary values:
services,default,external,services-pxe.The latter label is dedicated for management clusters only. For details about address pool names of a management cluster, see Separate PXE and management networks.
metallb/address-pool-auto-assignEnables automatic assignment of address pool. Boolean.
metallb/address-pool-protocolDefines the address pool protocol. Possible values:
layer2- announcement using the ARP protocol.bgp- announcement using the BGP protocol. Technology Preview.
For description of these protocols, refer to the MetalLB documentation.
For custom subnets, these are optional user-defined labels to distinguish different subnets of the same type. For an example of user-defined labels, see Expand IP addresses capacity in an existing cluster.
The following special values define the storage subnets:
ipam/SVC-ceph-clusteripam/SVC-ceph-public
For more examples of label usage, see Service labels and their life cycle and Create subnets for a managed cluster using CLI.
Click Add a label and assign the first custom label with the required name and value. To assign consecutive labels, use the + button located in the right side of the Labels section.
Click Create.
In the Networks tab, verify the status of the created subnet:
Ready - object is operational.
- Error - object is non-operational. Hover over the status
to obtain details of the issue.
Note
To verify subnet details, in the Networks tab, click the More action icon in the last column of the required subnet and select Subnet info.
In the Clusters tab, click the required cluster and scroll down to the Subnets section.
Click Add Subnet.
Fill out the Add new subnet form as required:
- Subnet Name
Subnet name.
- CIDR
A valid IPv4 CIDR, for example, 10.11.0.0/24.
- Include Ranges Optional
A comma-separated list of IP address ranges within the given CIDR that should be used in the allocation of IPs for nodes. The gateway, network, broadcast, and DNSaddresses will be excluded (protected) automatically if they intersect with one of the range. The IPs outside the given ranges will not be used in the allocation. Each element of the list can be either an interval
10.11.0.5-10.11.0.70or a single address10.11.0.77. TheincludeRangesparameter is mutually exclusive withexcludeRanges.
- Exclude Ranges Optional
A comma-separated list of IP address ranges within the given CIDR that should not be used in the allocation of IPs for nodes. The IPs within the given CIDR but outside the given ranges will be used in the allocation. The gateway, network, broadcast, and DNS addresses will be excluded (protected) automatically if they are included in the CIDR. Each element of the list can be either an interval
10.11.0.5-10.11.0.70or a single address10.11.0.77. TheexcludeRangesparameter is mutually exclusive withincludeRanges.
- Gateway Optional
A valid gateway address, for example, 10.11.0.9.
Click Create.
Proceed to creating L2 templates as described in Create L2 templates.
Before creating an L2 template, create the required subnets to use in the L2 template to allocate IP addresses for the managed cluster nodes.
To create subnets for a managed cluster using CLI:
Log in to a local machine where your management cluster
kubeconfigis located and wherekubectlis installed.Note
The management cluster
kubeconfigis created during the last stage of the management cluster bootstrap.Create the
subnet.yamlfile with a number of global or namespaced subnets depending on the configuration of your cluster:kubectl --kubeconfig <pathToManagementClusterKubeconfig> apply -f <SubnetFileName.yaml>
Note
In the command above and in the steps below, substitute the parameters enclosed in angle brackets with the corresponding values.
Example of a
subnet.yamlfile:apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: name: demo namespace: demo-namespace labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: cidr: 10.11.0.0/24 gateway: 10.11.0.9 includeRanges: - 10.11.0.5-10.11.0.70 nameservers: - 172.18.176.6
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.Specification fields of the Subnet object¶ Parameter
Description
cidr(singular)A valid IPv4 CIDR, for example, 10.11.0.0/24.
includeRanges(list)A comma-separated list of IP address ranges within the given CIDR that should be used in the allocation of IPs for nodes. The gateway, network, broadcast, and DNSaddresses will be excluded (protected) automatically if they intersect with one of the range. The IPs outside the given ranges will not be used in the allocation. Each element of the list can be either an interval
10.11.0.5-10.11.0.70or a single address10.11.0.77. TheincludeRangesparameter is mutually exclusive withexcludeRanges.excludeRanges(list)A comma-separated list of IP address ranges within the given CIDR that should not be used in the allocation of IPs for nodes. The IPs within the given CIDR but outside the given ranges will be used in the allocation. The gateway, network, broadcast, and DNS addresses will be excluded (protected) automatically if they are included in the CIDR. Each element of the list can be either an interval
10.11.0.5-10.11.0.70or a single address10.11.0.77. TheexcludeRangesparameter is mutually exclusive withincludeRanges.useWholeCidr(boolean)If set to
true, the subnet address (10.11.0.0 in the example above) and the broadcast address (10.11.0.255 in the example above) are included into the address allocation for nodes. Otherwise, (falseby default), the subnet address and broadcast address will be excluded from the address allocation.gateway(singular)A valid gateway address, for example, 10.11.0.9.
nameservers(list)A list of the IP addresses of name servers. Each element of the list is a single address, for example, 172.18.176.6.
Caution
The subnet for the PXE network of the management cluster is automatically created during deployment.
The subnet for the LCM network must contain the
ipam/SVC-k8s-lcm: "1"label. For details, see Service labels and their life cycle.Each cluster must use at least one subnet for its LCM network. Every node must have the address allocated in the LCM network using such subnet(s).
Each node of every cluster must have only one IP address in the LCM network that is allocated from one of the
Subnetobjects having theipam/SVC-k8s-lcmlabel defined. Therefore, allSubnetobjects used for LCM networks must have theipam/SVC-k8s-lcmlabel defined. For details, see Service labels and their life cycle.Note
You may use different subnets to allocate IP addresses to different Container Cloud components in your cluster. Add a label with the
ipam/SVC-prefix to each subnet that is used to configure a Container Cloud service. For details, see Service labels and their life cycle and the optional steps below.Caution
Use of a dedicated network for Kubernetes pods traffic, for external connection to the Kubernetes services exposed by the cluster, and for the Ceph cluster access and replication traffic is available as Technology Preview. Use such configurations for testing and evaluation purposes only. For the Technology Preview feature definition, refer to Technology Preview features.
Optional. Add subnets to configure address pools for the MetalLB service. Refer to Configure MetalLB for MetalLB configuration guidelines.
Optional. Technology Preview. Add a subnet for the externally accessible API endpoint of the managed cluster.
Make sure that
loadBalancerHostis set to""(empty string) in theClusterspec.spec: providerSpec: value: apiVersion: baremetal.k8s.io/v1alpha1 kind: BaremetalClusterProviderSpec ... loadBalancerHost: ""
Create a subnet with the
ipam/SVC-LBhostlabel having the"1"value to make thebaremetal-provideruse this subnet for allocation of cluster API endpoints addresses.
One IP address will be allocated for each cluster to serve its Kubernetes/MKE API endpoint.
Caution
Make sure that master nodes have host local-link addresses in the same subnet as the cluster API endpoint address. These host IP addresses will be used for VRRP traffic. The cluster API endpoint address will be assigned to the same interface on one of the master nodes where these host IPs are assigned.
Note
We highly recommend that you assign the cluster API endpoint address from the LCM network. For details on cluster networks types, refer to Managed cluster networking. See also the Single managed cluster use case example in the following table.
You can use several options of addresses allocation scope of API endpoints using subnets:
Use case
Example configuration
Several managed clusters in one management cluster
Create a subnet in the
defaultnamespace with no reference to any cluster.apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: name: lbhost-per-region namespace: default labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one ipam/SVC-LBhost: "1" spec: cidr: 191.11.0.0/24 includeRanges: - 191.11.0.6-191.11.0.20
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.Warning
Combining the
ipam/SVC-LBhostlabel with any other service labels on a single subnet is not supported. Use a dedicated subnet for addresses allocation for cluster API endpoints.Several managed clusters in a project
Create a subnet in a namespace corresponding to your project with no reference to any cluster. Such subnet has priority over the one described above.
apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: name: lbhost-per-namespace namespace: my-project labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one ipam/SVC-LBhost: "1" spec: cidr: 191.11.0.0/24 includeRanges: - 191.11.0.6-191.11.0.20
Warning
Combining the
ipam/SVC-LBhostlabel with any other service labels on a single subnet is not supported. Use a dedicated subnet for addresses allocation for cluster API endpoints.Single managed cluster
Create a subnet in a namespace corresponding to your project with a reference to the target cluster using the
cluster.sigs.k8s.io/cluster-namelabel. Such subnet has priority over the ones described above. In this case, it is not obligatory to use a dedicated subnet for addresses allocation of API endpoints. You can add theipam/SVC-LBhostlabel to the LCM subnet, and one of the addresses from this subnet will be allocated for an API endpoint:apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: name: lbhost-per-cluster namespace: my-project labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one ipam/SVC-LBhost: "1" ipam/SVC-k8s-lcm: "1" cluster.sigs.k8s.io/cluster-name: my-cluster spec: cidr: 10.11.0.0/24 includeRanges: - 10.11.0.6-10.11.0.50
Warning
You can combine the
ipam/SVC-LBhostlabel only with the following service labels on a single subnet:ipam/SVC-k8s-lcmipam/SVC-ceph-clusteripam/SVC-ceph-public
Otherwise, use a dedicated subnet for address allocation for the cluster API endpoint. Other combinations are not supported and can lead to unexpected results.
The above options can be used in conjunction. For example, you can define a subnet for a region, a number of subnets within this region defined for particular namespaces, and a number of subnets within the same region and namespaces defined for particular clusters.
Optional. Add a subnet(s) for the Storage access network.
Set the
ipam/SVC-ceph-publiclabel with the value"1"to create a subnet that will be used to configure the Ceph public network.Set the
cluster.sigs.k8s.io/cluster-namelabel to the name of the target cluster during the subnet creation.Use this subnet in the L2 template for storage nodes.
Assign this subnet to the interface connected to your Storage access network.
Ceph will automatically use this subnet for its external connections.
A Ceph OSD will look for and bind to an address from this subnet when it is started on a machine.
Optional. Add a subnet(s) for the Storage replication network.
Set the
ipam/SVC-ceph-clusterlabel with the value"1"to create a subnet that will be used to configure the Ceph cluster network.Set the
cluster.sigs.k8s.io/cluster-namelabel to the name of the target cluster during the subnet creation.Use this subnet in the L2 template for storage nodes.
Assign this subnet to the interface connected to your Storage replication network.
Ceph will automatically use this subnet for its internal replication traffic.
Optional. Add a subnet for Kubernetes pods traffic.
Use this subnet in the L2 template for all nodes in the cluster.
Assign this subnet to the interface connected to your Kubernetes workloads network.
Use the
npTemplate.bridges.k8s-podsbridge name in the L2 template. This bridge name is reserved for the Kubernetes workloads network. When thek8s-podsbridge is defined in an L2 template, Calico CNI uses that network for routing the pods traffic between nodes.
Optional. Add subnets for configuring multiple DHCP ranges. For details, see Configure multiple DHCP ranges using Subnet resources.
Verify that the subnet is successfully created:
kubectl get subnet kaas-mgmt -o yaml
In the system output, verify the
statusfields of thesubnet.yamlfile using the table below.Status fields of the Subnet object¶ Parameter
Description
stateSince 2.23.0Contains a short state description and a more detailed one if applicable. The short status values are as follows:
OK- object is operational.ERR- object is non-operational. This status has a detailed description in themessageslist.TERM- object was deleted and is terminating.
messagesSince 2.23.0Contains error or warning messages if the object state is
ERR. For example,ERR: Wrong includeRange for CIDR….statusMessageDeprecated since Container Cloud 2.23.0 and will be removed in one of the following releases in favor of
stateandmessages. Since Container Cloud 2.24.0, this field is not set for the objects of newly created clusters.cidrReflects the actual CIDR, has the same meaning as
spec.cidr.gatewayReflects the actual gateway, has the same meaning as
spec.gateway.nameserversReflects the actual name servers, has same meaning as
spec.nameservers.rangesSpecifies the address ranges that are calculated using the fields from
spec: cidr, includeRanges, excludeRanges, gateway, useWholeCidr. These ranges are directly used for nodes IP allocation.allocatableIncludes the number of currently available IP addresses that can be allocated for nodes from the subnet.
allocatedIPsSpecifies the list of IPv4 addresses with the corresponding
IPaddrobject IDs that were already allocated from the subnet.capacityContains the total number of IP addresses being held by ranges that equals to a sum of the
allocatableandallocatedIPsparameters values.objCreatedDate, time, and IPAM version of the
SubnetCR creation.objStatusUpdatedDate, time, and IPAM version of the last update of the
statusfield in theSubnetCR.objUpdatedDate, time, and IPAM version of the last
SubnetCR update bykaas-ipam.Example of a successfully created subnet:
apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: labels: ipam/UID: 6039758f-23ee-40ba-8c0f-61c01b0ac863 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one ipam/SVC-k8s-lcm: "1" name: kaas-mgmt namespace: default spec: cidr: 172.16.170.0/24 excludeRanges: - 172.16.170.100 - 172.16.170.101-172.16.170.139 gateway: 172.16.170.1 includeRanges: - 172.16.170.70-172.16.170.99 nameservers: - 172.18.176.6 - 172.18.224.6 status: allocatable: 27 allocatedIPs: - 172.16.170.70:ebabace8-7d9e-4913-a938-3d9e809f49fc - 172.16.170.71:c1109596-fba1-471b-950b-b1b60ef2c37c - 172.16.170.72:94c25734-c046-4a7e-a0fb-75582c5f20a9 capacity: 30 checksums: annotations: sha256:38e0b9de817f645c4bec37c0d4a3e58baecccb040f5718dc069a72c7385a0bed labels: sha256:5ed97704b05f15b204c1347603f9749ac015c29a4a16c6f599eed06babfb312e spec: sha256:60ead7c744564b3bfbbb3c4e846bce54e9128be49a279bf0c2bbebac2cfcebe6 cidr: 172.16.170.0/24 gateway: 172.16.170.1 labelSetChecksum: 5ed97704b05f15b204c1347603f9749ac015c29a4a16c6f599eed06babfb312e nameservers: - 172.18.176.6 - 172.18.224.6 objCreated: 2023-03-03T03:06:20.00000Z by v6.4.999-20230127-091906-c451398 objStatusUpdated: 2023-03-03T04:05:14.48469Z by v6.4.999-20230127-091906-c451398 objUpdated: 2023-03-03T04:05:14.48469Z by v6.4.999-20230127-091906-c451398 ranges: - 172.16.170.70-172.16.170.99 state: OK
Proceed to creating an L2 template for one or multiple managed clusters as described in Create L2 templates.
Note
Consider this section as deprecated since Container Cloud 2.27.0
(Cluster releases 17.2.0 and 16.2.0) due to the MetalLBConfigTemplate
object deprecation. For details, see Deprecation notes.
Caution
This section also applies to management cluster bootstrap
procedure with the following difference: instead of creating the Subnet
object, add its configuration to templates/bm/ipam-objects.yaml.template.
The Kubernetes Subnet object is created for a management cluster from
templates during bootstrap.
Each Subnet object can be used to define either a MetalLB address range or
MetalLB address pool. A MetalLB address pool may contain one or several
address ranges. The following rules apply to creation of address ranges or
pools:
To designate a subnet as a MetalLB address pool or range, use the
ipam/SVC-MetalLBlabel key. Set the label value to"1".The object must contain the
cluster.sigs.k8s.io/<cluster-name>label to reference the name of the target cluster where the MetalLB address pool is used.You may create multiple subnets with the
ipam/SVC-MetalLBlabel to define multiple IP address ranges or multiple address pools for MetalLB in the cluster.The IP addresses of the MetalLB address pool are not assigned to the interfaces on hosts. This subnet is virtual. Do not include such subnets to the L2 template definitions for your cluster.
If a
Subnetobject defines a MetalLB address range, no additional object properties are required.You can use any number of
Subnetobjects with each defining a single MetalLB address range. In this case, all address ranges are aggregated into a single MetalLB L2 address pool namedserviceshaving the auto-assign policy enabled.Intersection of IP address ranges within any single MetalLB address pool is not allowed.
The bare metal provider verifies intersection of IP address ranges. If it detects intersection, the MetalLB configuration is blocked and the provider logs contain corresponding error messages.
Use the following labels to identify the Subnet object as a MetalLB
address pool and configure the name and protocol for that address pool.
All labels below are mandatory for the Subnet object that configures
a MetalLB address pool.
Label |
Description |
|---|---|
Labels to link |
|
|
Defines that the |
|
Every address pool must have a distinct name. The |
|
Configures the auto-assign policy of an address pool. Boolean. Caution For the address pools defined using the MetalLB Helm chart
values in the For any service that does not have a specific MetalLB annotation
configured, MetalLB allocates external IPs from arbitrary address
pools that have the auto-assign policy set to Only for the service that has a specific MetalLB annotation with
the address pool name, MetalLB allocates external IPs from the address
pool having the auto-assign policy set to |
|
Sets the address pool protocol.
The only supported value is |
Caution
Do not set the same address pool name for two or more
Subnet objects. Otherwise, the corresponding MetalLB address pool
configuration fails with a warning message in the bare metal provider log.
Caution
For the auto-assign policy, the following configuration rules apply:
At least one MetalLB address pool must have the auto-assign policy enabled so that unannotated services can have load balancer IPs allocated for them. To satisfy this requirement, either configure one of address pools using the
Subnetobject withmetallb/address-pool-auto-assign: "true"or configure address range(s) using theSubnetobject(s) withoutmetallb/address-pool-*labels.When configuring multiple address pools with the auto-assign policy enabled, keep in mind that it is not determined in advance which pool of those multiple address pools is used to allocate an IP for a particular unannotated service.
This section describes how to set up and verify MetalLB parameters during configuration of subnets for a managed cluster creation.
Caution
This section also applies to the bootstrap procedure of a management cluster with the following differences:
Instead of the
Clusterobject, configuretemplates/bm/cluster.yaml.template.Instead of the
MetalLBConfigobject, configuretemplates/bm/metallbconfig.yaml.template.Instead of creating specific IPAM objects such as
Subnet, add their configuration totemplates/bm/ipam-objects.yaml.template.
The Kubernetes objects described below are created for a management cluster from template files during bootstrap.
Caution
The use of the MetalLBConfig object is mandatory for
management and managed clusters after a management cluster upgrade to the
Cluster release 17.0.0.
The following rules and requirements apply to configuration of the
MetalLBConfig and MetalLBConfigTemplate objects:
Define one
MetalLBConfigobject per cluster.Define the following mandatory labels:
cluster.sigs.k8s.io/cluster-nameSpecifies the cluster name where the MetalLB address pool is used.
kaas.mirantis.com/providerSpecifies the provider of the cluster where the MetalLB address pool is used.
kaas.mirantis.com/regionSpecifies the region name of the cluster where the MetalLB address pool is used.
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
Intersection of IP address ranges within any single MetalLB address pool is not allowed.
At least one MetalLB address pool must have the auto-assign policy enabled so that unannotated services can have load balancer IP addresses allocated to them.
When configuring multiple address pools with the auto-assign policy enabled, keep in mind that it is not determined in advance which pool of those multiple address pools is used to allocate an IP address for a particular unannotated service.
You can use the
MetalLBConfigobject to optimize address announcement for load-balanced services using theinterfacesselector for thel2Advertisementsobject. This selector allows for address announcement only on selected host interfaces. For details, see API Reference: MetalLB configuration examples.Note
Before Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0), use the deprecated
MetalLBConfigTemplateobject along withMetalLBConfigfor this purpose. For details, see API Reference: MetalLBConfigTemplate spec.Optional. Deprecated since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0) and will be removed in one of the following releases. Define one
MetalLBConfigTemplateobject per cluster. The use of this object withoutMetalLBConfigis not allowed.When using
MetalLBConfigTemplate:MetalLBConfigmust referenceMetalLBConfigTemplateby name:spec: templateName: <managed-metallb-template>
You can use
Subnetobjects for defining MetalLB address pools. Refer to MetalLB configuration guidelines for subnets for guidelines on configuring MetalLB address pools usingSubnetobjects.
Optional. Configure parameters related to MetalLB components life cycle such as deployment and update using the
metallbHelm chart values in theClusterspecsection. For example:Configure the MetalLB parameters related to IP address allocation and announcement for load-balanced cluster services. Select from the following options:
Recommended. Default. Mandatory after a management cluster upgrade to the Cluster release 17.2.0.
Create the
MetalLBConfigobject:For configuration rules and requirements, see Configuration rules for ‘MetalLBConfig’ and ‘MetalLBConfigTemplate’ objects.
For object description, see API documentation: MetalLBConfig.
For configuration examples, see the following sections:
Example of a complete L2 templates configuration for cluster creation (the MetalLB configuration objects step)
In the Technology Preview scope, you can use BGP for announcement of external addresses of Kubernetes load-balanced services for managed clusters. To configure the BGP announcement mode for MetalLB, use the
MetalLBConfigobject.The use of BGP is required to announce IP addresses for load-balanced services when using MetalLB on nodes that are distributed across multiple racks. In this case, setting of
rack-idlabels on nodes is required, they are used in node selectors forBGPPeer,BGPAdvertisement, or both MetalLB objects to properly configure BGP connections from each node.Configuration example of the
Machineobject for the BGP announcement modeapiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: name: test-cluster-compute-1 namespace: managed-ns labels: cluster.sigs.k8s.io/cluster-name: test-cluster ipam/RackRef: rack-1 # reference to the "rack-1" Rack kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: providerSpec: value: ... nodeLabels: - key: rack-id # node label can be used in "nodeSelectors" inside value: rack-1 # "BGPPeer" and/or "BGPAdvertisement" MetalLB objects ...
Configuration example of the
MetalLBConfigobject for the BGP announcement modeapiVersion: ipam.mirantis.com/v1alpha1 kind: MetalLBConfig metadata: name: test-cluster-metallb-config namespace: managed-ns labels: cluster.sigs.k8s.io/cluster-name: test-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: ... bgpPeers: - name: svc-peer-1 spec: holdTime: 0s keepaliveTime: 0s peerAddress: 10.77.42.1 peerASN: 65100 myASN: 65101 nodeSelectors: - matchLabels: rack-id: rack-1 # references the nodes having # the "rack-id=rack-1" label bgpAdvertisements: - name: services spec: aggregationLength: 32 aggregationLengthV6: 128 ipAddressPools: - services peers: - svc-peer-1 ...
Select from the following options:
Deprecated since the Cluster releases 17.2.0 and 16.2.0. Mandatory after a management cluster upgrade to the Cluster release 17.0.0.
Create
MetalLBConfigandMetalLBConfigTemplateobjects. This method allows using theSubnetobject to define MetalLB address pools.For configuration rules and requirements, see Configuration rules for ‘MetalLBConfig’ and ‘MetalLBConfigTemplate’ objects.
For objects description, see API documentation: MetalLBConfig and MetalLBConfigTemplate.
For configuration examples that use
MetalLBConfigandMetalLBConfigTemplate, see the following sections:Example of a complete L2 templates configuration for cluster creation (the MetalLB configuration objects step)
Note
For managed clusters, this configuration method is generally available since Cluster releases 17.0.0 and 16.0.0. And it is available as Technology Preview since Cluster releases 15.0.1, 14.0.1, and 14.0.0.
Since Cluster releases 15.0.3 and 14.0.3, in the Technology Preview scope, you can use BGP for announcement of external addresses of Kubernetes load-balanced services for managed clusters. To configure the BGP announcement mode for MetalLB, use
MetalLBConfigandMetalLBConfigTemplateobjects.The use of BGP is required to announce IP addresses for load-balanced services when using MetalLB on nodes that are distributed across multiple racks. In this case, setting of
rack-idlabels on nodes is required, they are used in node selectors forBGPPeer,BGPAdvertisement, or both MetalLB objects to properly configure BGP connections from each node.Configuration example of the
Machineobject for the BGP announcement modeapiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: name: test-cluster-compute-1 namespace: managed-ns labels: cluster.sigs.k8s.io/cluster-name: test-cluster ipam/RackRef: rack-1 # reference to the "rack-1" Rack kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: providerSpec: value: ... nodeLabels: - key: rack-id # node label can be used in "nodeSelectors" inside value: rack-1 # "BGPPeer" and/or "BGPAdvertisement" MetalLB objects ...
Configuration example of the
MetalLBConfigTemplateobject for the BGP announcement modeapiVersion: ipam.mirantis.com/v1alpha1 kind: MetalLBConfigTemplate metadata: name: test-cluster-metallb-config-template namespace: managed-ns labels: cluster.sigs.k8s.io/cluster-name: test-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: templates: ... bgpPeers: | - name: svc-peer-1 spec: peerAddress: 10.77.42.1 peerASN: 65100 myASN: 65101 nodeSelectors: - matchLabels: rack-id: rack-1 # references the nodes having # the "rack-id=rack-1" label bgpAdvertisements: | - name: services spec: ipAddressPools: - services peers: - svc-peer-1 ...
The
bgpPeersandbgpAdvertisementsfields are used to configure BGP announcement instead ofl2Advertisements.Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.The use of BGP for announcement also allows for better balancing of service traffic between cluster nodes as well as gives more configuration control and flexibility for infrastructure administrators. For configuration examples, refer to MetalLB configuration examples. For configuration procedure, refer to Configure BGP announcement for cluster API LB address.
Deprecated since Container Cloud 2.24.0. Configure the
configInlinevalue in the MetalLB chart of theClusterobject.Warning
This functionality is removed during the management cluster upgrade to the Cluster release 17.0.0. Therefore, this option becomes unavailable on managed clusters after the parent management cluster upgrade to 17.0.0.
Deprecated since Container Cloud 2.24.0. Configure the
Subnetobjects withoutMetalLBConfigTemplate.Warning
This functionality is removed during the management cluster upgrade to the Cluster release 17.0.0. Therefore, this option becomes unavailable on managed clusters after the parent management cluster upgrade to 17.0.0.
Caution
If the
MetalLBConfigobject is not used for MetalLB configuration related to address allocation and announcement for load-balanced services, then automated migration applies during creation of clusters of any type or cluster update to Cluster releases 15.0.x or 14.0.x.During automated migration, the
MetalLBConfigandMetalLBConfigTemplateobjects are created and contents of the MetalLB chartconfigInlinevalue is converted to the parameters of theMetalLBConfigTemplateobject.Any change to the
configInlinevalue made on a 15.0.x or 14.0.x cluster will be reflected in theMetalLBConfigTemplateobject.This automated migration is removed during your management cluster upgrade to the Cluster release 17.0.0, which is introduced in Container Cloud 2.25.0, together with the possibility to use the
configInlinevalue of the MetalLB chart. After that, any changes in MetalLB configuration related to address allocation and announcement for load-balanced services will be applied using theMetalLBConfigTemplateandSubnetobjects only.Select from the following options:
Configure
Subnetobjects. For details, see MetalLB configuration guidelines for subnets.Configure the
configInlinevalue for the MetalLB chart in theClusterobject.Configure both the
configInlinevalue for the MetalLB chart andSubnetobjects.The resulting MetalLB address pools configuration will contain address ranges from both cluster specification and
Subnetobjects. All address ranges for L2 address pools will be aggregated into a single L2 address pool and sorted as strings.
Changes to be applied since Container Cloud 2.25.0
The configuration options above are deprecated since Container Cloud 2.24.0, after your management cluster upgrade to the Cluster release 14.0.0 or 14.0.1. Automated migration of MetalLB parameters applies during cluster creation or update to Container Cloud 2.24.x.
During automated migration, the
MetalLBConfigandMetalLBConfigTemplateobjects are created and contents of the MetalLB chartconfigInlinevalue is converted to the parameters of theMetalLBConfigTemplateobject.Any change to the
configInlinevalue made on a Container Cloud 2.24.x cluster will be reflected in theMetalLBConfigTemplateobject.This automated migration is removed during your management cluster upgrade to the Cluster release 17.0.0, which is introduced in Container Cloud 2.25.0, together with the possibility to use the
configInlinevalue of the MetalLB chart. After that, any changes in MetalLB configuration related to address allocation and announcement for load-balanced services will be applied using theMetalLBConfigTemplateandSubnetobjects only.Verify the current MetalLB configuration:
Verify the MetalLB configuration that is stored in
MetalLBobjects:kubectl -n metallb-system get ipaddresspools,l2advertisements
The example system output:
NAME AGE ipaddresspool.metallb.io/default 129m ipaddresspool.metallb.io/services-pxe 129m NAME AGE l2advertisement.metallb.io/default 129m l2advertisement.metallb.io/services-pxe 129m
Verify one of the listed above
MetalLBobjects:kubectl -n metallb-system get <object> -o json | jq '.spec'
The example system output for
ipaddresspoolobjects:$ kubectl -n metallb-system get ipaddresspool.metallb.io/default -o json | jq '.spec' { "addresses": [ "10.0.11.61-10.0.11.80" ], "autoAssign": true, "avoidBuggyIPs": false } $ kubectl -n metallb-system get ipaddresspool.metallb.io/services-pxe -o json | jq '.spec' { "addresses": [ "10.0.0.61-10.0.0.70" ], "autoAssign": false, "avoidBuggyIPs": false }
Verify the MetalLB configuration that is stored in the
ConfigMapobject:kubectl -n metallb-system get cm metallb -o jsonpath={.data.config}
An example of a successful output:
address-pools: - name: default protocol: layer2 addresses: - 10.0.11.61-10.0.11.80 - name: services-pxe protocol: layer2 auto-assign: false addresses: - 10.0.0.61-10.0.0.70
The
auto-assignparameter will be set tofalsefor all address pools except thedefaultone. So, a particular service will get an address from such an address pool only if theServiceobject has a specialmetallb.universe.tf/address-poolannotation that points to the specific address pool name.Note
It is expected that every Container Cloud service on a management cluster will be assigned to one of the address pools. Current consideration is to have two MetalLB address pools:
services-pxeis a reserved address pool name to use for the Container Cloud services in the PXE network (Ironic API, HTTP server, caching server).defaultis an address pool to use for all other Container Cloud services in the management network. No annotation is required on theServiceobjects in this case.
By default, MetalLB speakers are deployed on all Kubernetes nodes. You can configure MetalLB to run its speakers on a particular set of nodes. This decreases the number of nodes that should be connected to external network. In this scenario, only a few nodes are exposed for ingress traffic from the outside world.
To customize the MetalLB speaker node selector:
Using
kubeconfigof the management cluster, open theClusterobject of the managed cluster for editing:kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <TargetClusterProjectName> edit cluster <TargetClusterName>
In the
spec:providerSpec:value:helmReleasessection, add thespeaker.nodeSelectorfield formetallb:spec: ... providerSpec: value: ... helmReleases: - name: metallb values: ... speaker: nodeSelector: metallbSpeakerEnabled: "true"
The
metallbSpeakerEnabled: "true"parameter in this example is the label on Kubernetes nodes where MetalLB speakers will be deployed. It can be an already existing node label or a new one.You can add user-defined labels to nodes using the
nodeLabelsfield.List of node labels to be attached to a node for the user to run certain components on separate cluster nodes. The list of allowed node labels is located in the
Clusterobject statusproviderStatus.releaseRef.current.allowedNodeLabelsfield.If the
valuefield is not defined inallowedNodeLabels, a label can have any value.Before or after a machine deployment, add the required label from the allowed node labels list with the corresponding value to
spec.providerSpec.value.nodeLabelsinmachine.yaml. For example:nodeLabels: - key: stacklight value: enabled
The addition of a node label that is not available in the list of allowed node labels is restricted.
Deprecated since 2.27.0 (17.2.0 and 16.2.0)
Warning
The SubnetPool object may not work as expected due to its
deprecation. If you still require this feature, contact Mirantis support
for further information.
Existing configurations that use the SubnetPool object in L2Template
will be automatically migrated during cluster update to the Cluster release
17.2.0 or 16.2.0. As a result of migration, existing Subnet objects will
be referenced in L2Template objects instead of SubnetPool.
Operators of Mirantis Container Cloud for on-demand self-service Kubernetes deployments will want their users to create networks without extensive knowledge about network topology or IP addresses. For that purpose, the Operator can prepare L2 network templates in advance for users to assign these templates to machines in their clusters.
The Operator can ensure that the users’ clusters have separate
IP address spaces using the SubnetPool resource.
SubnetPool allows for automatic creation of Subnet objects
that will consume blocks from the parent SubnetPool CIDR IP address
range. The SubnetPool blockSize setting defines the IP address
block size to allocate to each child Subnet. SubnetPool has a global
scope, so any SubnetPool can be used to create the Subnet objects
for any namespace and for any cluster.
You can use the SubnetPool resource in the L2Template resources to
automatically allocate IP addresses from an appropriate IP range that
corresponds to a specific cluster, or create a Subnet resource
if it does not exist yet. This way, every cluster will use subnets
that do not overlap with other clusters.
To automate multiple subnet creation using SubnetPool:
Log in to a local machine where your management cluster
kubeconfigis located and wherekubectlis installed.Note
The management cluster
kubeconfigis created during the last stage of the management cluster bootstrap.Create the
subnetpool.yamlfile with a number of subnet pools:Note
You can define either or both subnets and subnet pools, depending on the use case. A single L2 template can use either or both subnets and subnet pools.
kubectl --kubeconfig <pathToManagementClusterKubeconfig> apply -f <SubnetFileName.yaml>
Note
In the command above and in the steps below, substitute the parameters enclosed in angle brackets with the corresponding values.
Example of a
subnetpool.yamlfile:apiVersion: ipam.mirantis.com/v1alpha1 kind: SubnetPool metadata: name: kaas-mgmt namespace: default labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: cidr: 10.10.0.0/16 blockSize: /25 nameservers: - 172.18.176.6 gatewayPolicy: first
For the specification fields description of the
SubnetPoolobject, see SubnetPool spec.Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.Verify that the subnet pool is successfully created:
kubectl get subnetpool kaas-mgmt -oyaml
In the system output, verify the
statusfields of thesubnetpool.yamlfile. For the status fields description of theSunbetPoolobject, see SubnetPool status.Proceed to creating an L2 template for one or multiple managed clusters as described in Create L2 templates. In this procedure, select the exemplary L2 template for multiple subnets.
Caution
Using the
l3Layoutsection, define all subnets that are used in thenpTemplatesection. Defining only part of subnets is not allowed.If
labelSelectoris used inl3Layout, use any custom label name that differs from system names. This allows for easier cluster scaling in case of adding new subnets as described in Expand IP addresses capacity in an existing cluster.Mirantis recommends using a unique label prefix such as
user-defined/.
Caution
Since Container Cloud 2.9.0, L2 templates have a new format.
In the new L2 templates format, l2template:status:npTemplate
is used directly during provisioning. Therefore, a hardware node
obtains and applies a complete network configuration
during the first system boot.
Update any L2 template created before Container Cloud 2.9.0 as described in Release Notes: Switch L2 templates to the new format.
After you create subnets for one or more managed clusters or projects as described in Create subnets or Automate multiple subnet creation using SubnetPool, follow the procedure below to create L2 templates for a managed cluster. This procedure contains exemplary L2 templates for the following use cases:
This section contains an exemplary L2 template that demonstrates how to set up bonds and bridges on hosts for your managed clusters as described in Create L2 templates.
Caution
Use of a dedicated network for Kubernetes pods traffic, for external connection to the Kubernetes services exposed by the cluster, and for the Ceph cluster access and replication traffic is available as Technology Preview. Use such configurations for testing and evaluation purposes only. For the Technology Preview feature definition, refer to Technology Preview features.
Configure bonding options using the parameters field. The only
mandatory option is mode. See the example below for details.
Note
You can set any mode supported by netplan and your hardware.
Important
Bond monitoring is disabled in Ubuntu by default. However,
Mirantis highly recommends enabling it using Media Independent Interface
(MII) monitoring by setting the mii-monitor-interval parameter to a
non-zero value. For details, see Linux documentation: bond monitoring.
The Kubernetes LCM network connects LCM Agents running on nodes to the LCM API
of the management cluster. It is also used for communication between
kubelet and Kubernetes API server inside a Kubernetes cluster. The MKE
components use this network for communication inside a swarm cluster.
To configure each node with an IP address that will be used for LCM traffic,
use the npTemplate.bridges.k8s-lcm bridge in the L2 template, as
demonstrated in the example below.
Each node of every cluster must have only one IP address in the
LCM network that is allocated from one of the Subnet objects having the
ipam/SVC-k8s-lcm label defined. Therefore, all Subnet objects used for
LCM networks must have the ipam/SVC-k8s-lcm label defined. For details,
see Service labels and their life cycle.
As defined in Host networking, the LCM network can be collocated with the PXE network.
If you want to use a dedicated network for Kubernetes pods traffic,
configure each node with an IPv4
address that will be used to route the pods traffic between nodes.
To accomplish that, use the npTemplate.bridges.k8s-pods bridge
in the L2 template, as demonstrated in the example below.
As defined in Host networking, this bridge name is reserved for the
Kubernetes pods network. When the k8s-pods bridge is defined in an L2
template, Calico CNI uses that network for routing the pods traffic between
nodes.
You can use a dedicated network for external connection to the Kubernetes
services exposed by the cluster.
If enabled, MetalLB will listen and respond on the dedicated virtual bridge.
To accomplish that, configure each node where metallb-speaker is deployed
with an IPv4 address. For details on selecting nodes for metallb-speaker,
see Configure node selector for MetalLB speaker.
Both the MetalLB IP address ranges and the IP
addresses configured on those nodes must fit in the same CIDR.
Use the npTemplate.bridges.k8s-ext bridge in the L2 template,
as demonstrated in the example below.
This bridge name is reserved for the Kubernetes external network.
The Subnet object that corresponds to the k8s-ext bridge must have
explicitly excluded the IP address ranges that are in use by MetalLB.
You can configure dedicated networks for the Ceph cluster access and
replication traffic. Set labels on the Subnet CRs for the corresponding
networks, as described in Create subnets.
Container Cloud automatically configures Ceph to use the addresses from these
subnets. Ensure that the addresses are assigned to the storage nodes.
Use the npTemplate.bridges.ceph-cluster and
npTemplate.bridges.ceph-public bridges in the L2 template,
as demonstrated in the example below. These names are reserved for the Ceph
cluster access (public) and replication (cluster) networks.
The Subnet objects used to assign IP addresses to these bridges
must have corresponding labels ipam/SVC-ceph-public for the
ceph-public bridge and ipam/SVC-ceph-cluster for the
ceph-cluster bridge.
apiVersion: ipam.mirantis.com/v1alpha1
kind: L2Template
metadata:
name: test-managed
namespace: managed-ns
labels:
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
cluster.sigs.k8s.io/cluster-name: my-cluster
spec:
autoIfMappingPrio:
- provision
- eno
- ens
- enp
l3Layout:
- subnetName: demo-lcm
scope: namespace
- subnetName: demo-pods
scope: namespace
- subnetName: demo-ext
scope: namespace
- subnetName: demo-ceph-cluster
scope: namespace
- subnetName: demo-ceph-public
scope: namespace
npTemplate: |
version: 2
ethernets:
{{nic 2}}:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 2}}
set-name: {{nic 2}}
{{nic 3}}:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 3}}
set-name: {{nic 3}}
bonds:
bond0:
interfaces:
- {{nic 2}}
- {{nic 3}}
parameters:
mode: 802.3ad
mii-monitor-interval: 100
vlans:
k8s-ext-vlan:
id: 1001
link: bond0
k8s-pods-vlan:
id: 1002
link: bond0
stor-frontend:
id: 1003
link: bond0
stor-backend:
id: 1004
link: bond0
bridges:
k8s-lcm:
interfaces: [bond0]
addresses:
- {{ip "k8s-lcm:demo-lcm"}}
gateway4: {{gateway_from_subnet "demo-lcm"}}
nameservers:
addresses: {{nameservers_from_subnet "demo-lcm"}}
k8s-ext:
interfaces: [k8s-ext-vlan]
addresses:
- {{ip "k8s-ext:demo-ext"}}
k8s-pods:
interfaces: [k8s-pods-vlan]
addresses:
- {{ip "k8s-pods:demo-pods"}}
ceph-cluster:
interfaces: [stor-backend]
addresses:
- {{ip "ceph-cluster:demo-ceph-cluster"}}
ceph-public:
interfaces: [stor-frontend]
addresses:
- {{ip "ceph-public:demo-ceph-public"}}
Note
The kaas.mirantis.com/region label is removed from all
Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0).
Therefore, do not add the label starting these releases. On existing
clusters updated to these releases, or if manually added, this label will
be ignored by Container Cloud.
Deprecated since 2.27.0 (17.2.0 and 16.2.0)
Warning
The SubnetPool object may not work as expected due to its
deprecation. If you still require this feature, contact Mirantis support
for further information.
Existing configurations that use the SubnetPool object in L2Template
will be automatically migrated during cluster update to the Cluster release
17.2.0 or 16.2.0. As a result of migration, existing Subnet objects will
be referenced in L2Template objects instead of SubnetPool.
This section contains an exemplary L2 template for automatic multiple
subnet creation as described in Automate multiple subnet creation using SubnetPool. This template
also contains the L3Layout section that allows defining the Subnet
scopes and enables auto-creation of the Subnet objects from the
SubnetPool objects. For details about auto-creation of the Subnet
objects see Automate multiple subnet creation using SubnetPool.
For details on how to create L2 templates, see Create L2 templates.
Caution
Do not assign an IP address to the PXE nic 0 NIC explicitly
to prevent the IP duplication during updates.
The IP address is automatically assigned by the
bootstrapping engine.
Example of an L2 template for multiple subnets:
apiVersion: ipam.mirantis.com/v1alpha1
kind: L2Template
metadata:
name: test-managed
namespace: managed-ns
labels:
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
cluster.sigs.k8s.io/cluster-name: my-cluster
spec:
autoIfMappingPrio:
- provision
- eno
- ens
- enp
l3Layout:
- subnetName: lcm-subnet
scope: namespace
- subnetName: subnet-1
subnetPool: kaas-mgmt
scope: namespace
- subnetName: subnet-2
subnetPool: kaas-mgmt
scope: cluster
npTemplate: |
version: 2
ethernets:
onboard1gbe0:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 0}}
set-name: {{nic 0}}
# IMPORTANT: do not assign an IP address here explicitly
# to prevent IP duplication issues. The IP will be assigned
# automatically by the bootstrapping engine.
# addresses: []
onboard1gbe1:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 1}}
set-name: {{nic 1}}
ten10gbe0s0:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 2}}
set-name: {{nic 2}}
addresses:
- {{ip "2:subnet-1"}}
ten10gbe0s1:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 3}}
set-name: {{nic 3}}
addresses:
- {{ip "3:subnet-2"}}
bridges:
k8s-lcm:
interfaces: [onboard1gbe0]
addresses:
- {{ip "k8s-lcm:lcm-subnet"}}
gateway4: {{gateway_from_subnet "lcm-subnet"}}
nameservers:
addresses: {{nameservers_from_subnet "lcm-subnet"}}
Note
The kaas.mirantis.com/region label is removed from all
Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0).
Therefore, do not add the label starting these releases. On existing
clusters updated to these releases, or if manually added, this label will
be ignored by Container Cloud.
In the template above, the following networks are defined
in the l3Layout section:
lcm-subnet- the subnet name to use for the LCM network in thenpTemplate. This subnet is shared between the project clusters because it has thenamespacedscope.Since a subnet pool is not in use, create the corresponding
Subnetobject before machines are attached to cluster manually. For details, see Create subnets for a managed cluster using CLI.Mark this
Subnetwith theipam/SVC-k8s-lcmlabel. The L2 template must contain the definition of the virtual Linux bridge (k8s-lcmin the L2 template example) that is used to set up the LCM network interface. IP addresses for the defined bridge must be assigned from the LCM subnet, which is marked with theipam/SVC-k8s-lcmlabel.Each node of every cluster must have only one IP address in the LCM network that is allocated from one of the
Subnetobjects having theipam/SVC-k8s-lcmlabel defined. Therefore, allSubnetobjects used for LCM networks must have theipam/SVC-k8s-lcmlabel defined. For details, see Service labels and their life cycle.
subnet-1- unless already created, this subnet will be created from thekaas-mgmtsubnet pool. The subnet name must be unique within the project. This subnet is shared between the project clusters.subnet-2- will be created from thekaas-mgmtsubnet pool. This subnet has theclusterscope. Therefore, the real name of theSubnetCR object consists of the subnet name defined inl3Layoutand the cluster UID. But thenpTemplatesection of the L2 template must contain only the subnet name defined inl3Layout. The subnets of theclusterscope are not shared between clusters.
Caution
Using the l3Layout section, define all subnets that are used
in the npTemplate section.
Defining only part of subnets is not allowed.
If labelSelector is used in l3Layout, use any custom
label name that differs from system names. This allows for easier
cluster scaling in case of adding new subnets as described in
Expand IP addresses capacity in an existing cluster.
Mirantis recommends using a unique label prefix such as
user-defined/.
Caution
Modification of L2 templates in use is allowed with a mandatory validation step from the Infrastructure Operator to prevent accidental cluster failures due to unsafe changes. The list of risks posed by modifying L2 templates includes:
Services running on hosts cannot reconfigure automatically to switch to the new IP addresses and/or interfaces.
Connections between services are interrupted unexpectedly, which can cause data loss.
Incorrect configurations on hosts can lead to irrevocable loss of connectivity between services and unexpected cluster partition or disassembly.
For details, see Modify network configuration on an existing machine.
Caution
Make sure that you create L2 templates before adding any machines to your new managed cluster.
Log in to a local machine where your management cluster
kubeconfigis located and wherekubectlis installed.Note
The management cluster
kubeconfigis created during the last stage of the management cluster bootstrap.Inspect the existing L2 templates to select the one that fits your deployment:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> \ get l2template -n <ProjectNameForNewManagedCluster>
Create an L2 YAML template specific to your deployment using one of the exemplary templates:
Note
You can create several L2 templates with different configurations to be applied to different nodes of the same cluster. See Assign L2 templates to machines for details.
Add or edit the mandatory parameters in the new L2 template. The following tables provide the description of the mandatory parameters in the example templates mentioned in the previous step.
L2 template mandatory parameters¶ Parameter
Description
clusterRefCaution
Deprecated since Container Cloud 2.25.0 in favor of the mandatory
cluster.sigs.k8s.io/cluster-namelabel. Will be removed in one of the following releases.On existing clusters, this parameter is automatically migrated to the
cluster.sigs.k8s.io/cluster-namelabel since 2.25.0.If an existing cluster has
clusterRef: defaultset, the migration process involves removing this parameter. Subsequently, it is not substituted with thecluster.sigs.k8s.io/cluster-namelabel, ensuring the application of the L2 template across the entire Kubernetes namespace.The
Clusterobject name that this template is applied to. Thedefaultvalue is used to apply the given template to all clusters within a particular project, unless an L2 template that references a specific cluster name exists. TheclusterReffield has priority over thecluster.sigs.k8s.io/cluster-namelabel:When
clusterRefis set to a non-defaultvalue, thecluster.sigs.k8s.io/cluster-namelabel will be added or updated with that value.When
clusterRefis set todefault, thecluster.sigs.k8s.io/cluster-namelabel will be absent or removed.
L2 template requirements
An L2 template must have the same project (Kubernetes namespace) as the referenced cluster.
A cluster can be associated with many L2 templates. Only one of them can have the
ipam/DefaultForClusterlabel. Every L2 template that does not have theipam/DefaultForClusterlabel can be later assigned to a particular machine usingl2TemplateSelector.The following rules apply to the default L2 template of a namespace:
Since Container Cloud 2.25.0, creation of the default L2 template for a namespace is disabled. On existing clusters, the
Spec.clusterRef: defaultparameter of such an L2 template is automatically removed during the migration process. Subsequently, this parameter is not substituted with thecluster.sigs.k8s.io/cluster-namelabel, ensuring the application of the L2 template across the entire Kubernetes namespace. Therefore, you can continue using existing default namespaced L2 templates.Before Container Cloud 2.25.0, the default
L2Templateobject of a namespace must have theSpec.clusterRef: defaultparameter that is deprecated since 2.25.0.
ifMappingorautoIfMappingPrioifMappingList of interface names for the template. The interface mapping is defined globally for all bare metal hosts in the cluster but can be overridden at the host level, if required, by editing the
IpamHostobject for a particular host. TheifMappingparameter is mutually exclusive withautoIfMappingPrio.
autoIfMappingPrioautoIfMappingPriois a list of prefixes, such aseno,ens, and so on, to match the interfaces to automatically create a list for the template. If you are not aware of any specific ordering of interfaces on the nodes, use the default ordering from Predictable Network Interfaces Names specification for systemd. You can also override the default NIC list per host using theIfMappingOverrideparameter of the correspondingIpamHost. Theprovisionvalue corresponds to the network interface that was used to provision a node. Usually, it is the first NIC found on a particular node. It is defined explicitly to ensure that this interface will not be reconfigured accidentally.The
autoIfMappingPrioparameter is mutually exclusive withifMapping.
l3LayoutSubnets to be used in the
npTemplatesection. The field contains a list of subnet definitions with parameters used by template macros.subnetNameDefines the alias name of the subnet that can be used to reference this subnet from the template macros. This parameter is mandatory for every entry in the
l3Layoutlist.
subnetPoolDeprecated since 2.27.0 (17.2.0 and 16.2.0)Optional. Default: none. Defines a name of the parent
SubnetPoolobject that will be used to create aSubnetobject with a givensubnetNameandscope.If a corresponding
Subnetobject already exists, nothing will be created and the existing object will be used. If noSubnetPoolis provided, no newSubnetobject will be created.
scopeLogical scope of the
Subnetobject with a correspondingsubnetName. Possible values:global- theSubnetobject is accessible globally, for any Container Cloud project and cluster, for example, the PXE subnet.namespace- theSubnetobject is accessible within the same project where the L2 template is defined.cluster- theSubnetobject is only accessible to the cluster thatL2Template.spec.clusterRefrefers to. TheSubnetobjects with theclusterscope will be created for every new cluster.
labelSelectorContains a dictionary of labels and their respective values that will be used to find the matching
Subnetobject for the subnet. If thelabelSelectorfield is omitted, theSubnetobject will be selected by name, specified by thesubnetNameparameter.
Caution
The
l3Layoutsection is mandatory for eachL2Templatecustom resource.npTemplateA netplan-compatible configuration with special lookup functions that defines the networking settings for the cluster hosts, where physical NIC names and details are parameterized. This configuration will be processed using Go templates. Instead of specifying IP and MAC addresses, interface names, and other network details specific to a particular host, the template supports use of special lookup functions. These lookup functions, such as
nic,mac,ip, and so on, return host-specific network information when the template is rendered for a particular host.Caution
All rules and restrictions of the netplan configuration also apply to L2 templates. For details, see the official netplan documentation.
Caution
We strongly recommend following the below conventions on network interface naming:
A physical NIC name set by an L2 template must not exceed 15 symbols. Otherwise, an L2 template creation fails. This limit is set by the Linux kernel.
Names of virtual network interfaces such as VLANs, bridges, bonds, veth, and so on must not exceed 15 symbols.
We recommend setting interfaces names that do not exceed 13 symbols for both physical and virtual interfaces to avoid corner cases and issues in netplan rendering.
The following table describes the main lookup functions for an L2 template.
Lookup function
Description
{{nic N}}Name of a NIC number N. NIC numbers correspond to the interface mapping list. This macro can be used as a key for the elements of the
ethernetsmap, or as the value of thenameandset-nameparameters of a NIC. It is also used to reference the physical NIC from definitions of virtual interfaces (vlan,bridge).{{mac N}}MAC address of a NIC number N registered during a host hardware inspection.
{{ip “N:subnet-a”}}IP address and mask for a NIC number N. The address will be auto-allocated from the given subnet if the address does not exist yet.
{{ip “br0:subnet-x”}}IP address and mask for a virtual interface,
“br0”in this example. The address will be auto-allocated from the given subnet if the address does not exist yet.For virtual interfaces names, an IP address placeholder must contain a human-readable ID that is unique within the L2 template and must have the following format:
{{ip "<shortUniqueHumanReadableID>:<subnetNameFromL3Layout>"}}The
<shortUniqueHumanReadableID>is made equal to a virtual interface name throughout this document and Container Cloud bootstrap templates.{{cidr_from_subnet “subnet-a”}}IPv4 CIDR address from the given subnet.
{{gateway_from_subnet “subnet-a”}}IPv4 default gateway address from the given subnet.
{{nameservers_from_subnet “subnet-a”}}List of the IP addresses of name servers from the given subnet.
{{cluster_api_lb_ip}}Technology Preview since Container Cloud 2.24.4. IP address for a cluster API load balancer.
Note
Every subnet referenced in an L2 template can have either a global or namespaced scope. In the latter case, the subnet must exist in the same project where the corresponding cluster and L2 template are located.
Optional. To designate an L2 template as default, assign the
ipam/DefaultForClusterlabel to it. Only one L2 template in a cluster can have this label. It will be used for machines that do not have an L2 template explicitly assigned to them.To assign the default template to the cluster:
Since Container Cloud 2.25.0, use the mandatory
cluster.sigs.k8s.io/cluster-namelabel in the L2 templatemetadatasection.Before Container Cloud 2.25.0, use the
cluster.sigs.k8s.io/cluster-namelabel or theclusterRefparameter in the L2 templatespecsection. This parameter is deprecated and will be removed in one of the following releases. During cluster update to 2.25.0, this parameter is automatically migrated to thecluster.sigs.k8s.io/cluster-namelabel.
Optional. Add the
l2template-<NAME>: "exists"label to the L2 template. Replace<NAME>with the unique L2 template name or any other unique identifier. You can refer to this label to assign this L2 template when you create machines.Add the L2 template to your management cluster. Select one of the following options:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> apply -f <pathToL2TemplateYamlFile>
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0)
Log in to the Container Cloud web UI with the
operatorpermissions.Switch to the required non-
defaultproject using the Switch Project action icon located on top of the main left-side navigation panel.To create a project, refer to Create a project for managed clusters.
In the left sidebar, navigate to Networks and click the L2 Templates tab.
Click Create L2 Template.
Fill out the Create L2 Template form as required:
- Name
L2 template name.
- Cluster
Cluster name that the L2 template is being added for. To set the L2 template as default for all machines, also select Set default for the cluster.
- YAML file
L2 template file in the YAML format that you have previously created. Click Upload to select the required file for uploading.
Proceed with Add a machine. The resulting L2 template will be used to render the netplan configuration for the managed cluster machines.
The
kaas-ipamservice uses the data fromBareMetalHost, the L2 template, and subnets to generate the netplan configuration for every cluster machine.The generated netplan configuration is saved in the
status.netconfigFilessection of theIpamHostresource. If thestatus.netconfigFilesStatefield of theIpamHostresource isOK, the configuration was rendered in theIpamHostresource successfully. Otherwise, the status contains an error message.Caution
The following fields of the
ipamHoststatus are renamed since Container Cloud 2.22.0 in the scope of theL2TemplateandIpamHostobjects refactoring:netconfigV2tonetconfigCandidatenetconfigV2statetonetconfigCandidateStatenetconfigFilesStatetonetconfigFilesStates(per file)
No user actions are required after renaming.
The format of
netconfigFilesStatechanged after renaming. ThenetconfigFilesStatesfield contains a dictionary of statuses of network configuration files stored innetconfigFiles. The dictionary contains the keys that are file paths and values that have the same meaning for each file thatnetconfigFilesStatehad:For a successfully rendered configuration file:
OK: <timestamp> <sha256-hash-of-rendered-file>, where a timestamp is in the RFC 3339 format.For a failed rendering:
ERR: <error-message>.
The
baremetal-providerservice copies data from thestatus.netconfigFilesofIpamHostto theSpec.StateItemsOverwrites[‘deploy’][‘bm_ipam_netconfigv2’]parameter ofLCMMachine.The
lcm-agentservice on every host synchronizes theLCMMachinedata to its host. Thelcm-agentservice runs a playbook to update the netplan configuration on the host during thepre-downloadanddeployphases.
TechPreview Available since 2.24.4
When you create a bare metal managed cluster with the multi-rack topology, where Kubernetes masters are distributed across multiple racks without an L2 layer extension between them, you must configure BGP announcement of the cluster API load balancer address.
For clusters where Kubernetes masters are in the same rack or with an L2 layer extension between masters, you can configure either BGP or L2 (ARP) announcement of the cluster API load balancer address. The L2 (ARP) announcement is used by default and its configuration is covered in Create a cluster using web UI.
Caution
Create Rack and MultiRackCluster objects, which are
described in the below procedure, before initiating the provisioning
of master nodes to ensure that both BGP and netplan configurations
are applied simultaneously during the provisioning process.
To enable the use of BGP announcement for the cluster API LB address:
In the
Clusterobject, set theuseBGPAnnouncementparameter totrue:spec: providerSpec: value: useBGPAnnouncement: true
Create the
MultiRackClusterobject that is mandatory when configuring BGP announcement for the cluster API LB address. This object enables you to set cluster-wide parameters for configuration of BGP announcement.In this scenario, the
MultiRackClusterobject must be bound to the correspondingClusterobject using thecluster.sigs.k8s.io/cluster-namelabel.Container Cloud uses the
birdBGP daemon for announcement of the cluster API LB address. For this reason, set the correspondingbgpdConfigFileNameandbgpdConfigFilePathparameters in theMultiRackClusterobject, so thatbirdcan locate the configuration file. For details, see the configuration example below.The
bgpdConfigTemplateobject contains the default configuration file template for thebirdBGP daemon, which you can override inRackobjects.The
defaultPeerparameter contains default parameters of the BGP connection from master nodes to infrastructure BGP peers, which you can override inRackobjects.Configuration example for
MultiRackClusterapiVersion: ipam.mirantis.com/v1alpha1 kind: MultiRackCluster metadata: name: multirack-test-cluster namespace: managed-ns labels: cluster.sigs.k8s.io/cluster-name: test-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: bgpdConfigFileName: bird.conf bgpdConfigFilePath: /etc/bird bgpdConfigTemplate: | ... defaultPeer: localASN: 65101 neighborASN: 65100 neighborIP: "" password: deadbeef
For the object description, see API Reference: MultiRackCluster resource.
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.Create the
Rackobject(s). This object is mandatory when configuring BGP announcement for the cluster API LB address and it allows you to configure BGP announcement parameters for each rack.In this scenario,
Rackobjects must be bound toMachineobjects corresponding to master nodes of the cluster. EachRackobject describes the configuration for thebirdBGP daemon used to announce the cluster API LB address from a particular master node or from several master nodes in the same rack.The
Machineobject can optionally define therack-idnode label that is not used for BGP announcement of the cluster API LB IP but can be used for MetalLB. This label is required for MetalLB node selectors when MetalLB is used to announce LB IP addresses on nodes that are distributed across multiple racks. In this scenario, the L2 (ARP) announcement mode cannot be used for MetalLB because master nodes are in different L2 segments. So, the BGP announcement mode must be used for MetalLB, and node selectors are required to properly configure BGP connections from each node. See Configure MetalLB for details.The
L2Templateobject includes thelointerface configuration to set the IP address for thebirdBGP daemon that will be advertised as the cluster API LB address. The{{ cluster_api_lb_ip }}function is used innpTemplateto obtain the cluster API LB address value.Configuration example for
RackapiVersion: ipam.mirantis.com/v1alpha1 kind: Rack metadata: name: rack-master-1 namespace: managed-ns labels: cluster.sigs.k8s.io/cluster-name: test-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: bgpdConfigTemplate: | # optional ... peeringMap: lcm-rack-control-1: peers: - neighborIP: 10.77.31.2 # "localASN" & "neighborASN" are taken from - neighborIP: 10.77.31.3 # "MultiRackCluster.spec.defaultPeer" if # not set here
Configuration example for
MachineapiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: name: test-cluster-master-1 namespace: managed-ns annotations: metal3.io/BareMetalHost: managed-ns/test-cluster-master-1 labels: cluster.sigs.k8s.io/cluster-name: test-cluster cluster.sigs.k8s.io/control-plane: controlplane hostlabel.bm.kaas.mirantis.com/controlplane: controlplane ipam/RackRef: rack-master-1 # reference to the "rack-master-1" Rack kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: providerSpec: value: kind: BareMetalMachineProviderSpec apiVersion: baremetal.k8s.io/v1alpha1 hostSelector: matchLabels: kaas.mirantis.com/baremetalhost-id: test-cluster-master-1 l2TemplateSelector: name: test-cluster-master-1 nodeLabels: # optional. it is not used for BGP announcement - key: rack-id # of the cluster API LB IP but it can be used value: rack-master-1 # for MetalLB if "nodeSelectors" are required ...
Configuration example for
L2TemplateapiVersion: ipam.mirantis.com/v1alpha1 kind: L2Template metadata: labels: cluster.sigs.k8s.io/cluster-name: test-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: test-cluster-master-1 namespace: managed-ns spec: ... l3Layout: - subnetName: lcm-rack-control-1 # this network is referenced scope: namespace # in the "rack-master-1" Rack - subnetName: ext-rack-control-1 # optional. this network is used scope: namespace # for k8s services traffic and # MetalLB BGP connections ... npTemplate: | ... ethernets: lo: addresses: - {{ cluster_api_lb_ip }} # function for cluster API LB IP dhcp4: false dhcp6: false ...
The
Rackobject fields are described in API Reference: Rack resource.The configuration example for the scenario where Kubernetes masters are in the same rack or with an L2 layer extension between masters is described in Single rack configuration example.
The configuration example for the scenario where Kubernetes masters are distributed across multiple racks without L2 layer extension between them is described in Multiple rack configuration example.
Add a machine¶
This section describes how to add a machine to a newly created managed cluster using either the Mirantis Container Cloud web UI or CLI for an advanced configuration.
Warning
An operational managed cluster must contain a minimum of 3 Kubernetes manager machines to meet the etcd quorum and 2 Kubernetes worker machines.
The deployment of the cluster does not start until the minimum number of machines is created.
A machine with the manager role is automatically deleted during the cluster deletion. Manual deletion of manager machines is allowed only for the purpose of node replacement or recovery.
Support status of manager machine deletion
Since the Cluster releases 17.0.0, 16.0.0, and 14.1.0, the feature is generally available.
Before the Cluster releases 16.0.0 and 14.1.0, the feature is available within the Technology Preview features scope for non-MOSK-based clusters.
Before the Cluster release 17.0.0 the feature is not supported for MOSK.
After you add bare metal hosts and create a managed cluster as described in Add a managed baremetal cluster, proceed with associating Kubernetes machines of your cluster with the previously added bare metal hosts using the Mirantis Container Cloud web UI.
To add a Kubernetes machine to a baremetal-based managed cluster:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the required cluster name. The cluster page with the Machines list opens.
Click Create Machine button.
Fill out the Create New Machine form as required:
- Create Machines Pool
Select to create a set of machines with the same provider spec to manage them as a single unit. Enter the machine pool name in the Pool Name field.
- Count
Specify the number of machines to create. If you create a machine pool, specify the replicas count of the pool.
- Manager
Select Manager or Worker to create a Kubernetes manager or worker node.
Caution
The required minimum number of machines:
3 manager nodes for HA
3 worker storage nodes for a minimal Ceph cluster
- BareMetal Host Label
Assign the role to the new machine(s) to link the machine to a previously created bare metal host with the corresponding label. You can assign one role type per machine. The supported labels include:
- Manager
This node hosts the manager services of a managed cluster. For the reliability reasons, Container Cloud does not permit running end user workloads on the manager nodes or use them as storage nodes.
- Worker
The default role for any node in a managed cluster. Only the
kubeletservice is running on the machines of this type.
- Storage
This node is a worker node that also hosts Ceph OSDs and provides its disk resources to Ceph. Container Cloud permits end users to run workloads on storage nodes by default.
- Upgrade Index
Optional. A positive numeral value that defines the order of machine upgrade during a cluster update.
Note
You can change the upgrade order later on an existing cluster. For details, see Change the upgrade order of a machine or machine pool.
Consider the following upgrade index specifics:
The first machine to upgrade is always one of the control plane machines with the lowest
upgradeIndex. Other control plane machines are upgraded one by one according to their upgrade indexes.If the
ClusterspecdedicatedControlPlanefield isfalse, worker machines are upgraded only after the upgrade of all control plane machines finishes. Otherwise, they are upgraded after the first control plane machine, concurrently with other control plane machines.If several machines have the same upgrade index, they have the same priority during upgrade.
If the value is not set, the machine is automatically assigned a value of the upgrade index.
- Distribution
Operating system to provision the machine. From the drop-down list, select Ubuntu 20.04.
Caution
Do not use the outdated Ubuntu 18.04 distribution on greenfield deployments but only on existing clusters based on Ubuntu 18.04.
- L2 Template
From the drop-down list, select the previously created L2 template, if any. For details, see Create L2 templates. Otherwise, leave the default selection to use a preinstalled L2 template.
Note
Preinstalled L2 templates are removed in Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0).
- BM Host Profile
From the drop-down list, select the previously created custom bare metal host profile, if any. For details, see Create a custom bare metal host profile. Otherwise, leave the default selection.
- Node Labels
Add the required node labels for the worker machine to run certain components on a specific node. For example, for the StackLight nodes that run OpenSearch and require more resources than a standard node, add the StackLight label. The list of available node labels is obtained from
allowedNodeLabelsof your currentClusterrelease.If the
valuefield is not defined inallowedNodeLabels, from the drop-down list, select the required label and define an appropriate custom value for this label to be set to the node. For example, thenode-typelabel can have thestorage-ssdvalue to meet the service scheduling logic on a particular machine.Note
Due to the known issue 23002 fixed in Container Cloud 2.21.0, a custom value for a predefined node label cannot be set using the Container Cloud web UI. For a workaround, refer to the issue description.
Caution
If you deploy StackLight in the HA mode (recommended):
Add the StackLight label to minimum three worker nodes. Otherwise, StackLight will not be deployed until the required number of worker nodes is configured with the StackLight label.
Removal of the StackLight label from worker nodes along with removal of worker nodes with StackLight label can cause the StackLight components to become inaccessible. It is important to correctly maintain the worker nodes where the StackLight local volumes were provisioned. For details, see Delete a cluster machine.
To obtain the list of nodes where StackLight is deployed, refer to Upgrade managed clusters with StackLight deployed in HA mode.
If you move the StackLight label to a new worker machine on an existing cluster, manually deschedule all StackLight components from the old worker machine, which you remove the StackLight label from. For details, see Deschedule StackLight Pods from a worker machine.
Note
To add node labels after deploying a worker machine. navigate to the Machines page, click the More action icon in the last column of the required machine field, and select Configure machine.
Since Container Cloud 2.24.0, you can configure node labels for machine pools after deployment using the More > Configure Pool option.
Click Create.
At this point, Container Cloud adds the new machine object to the specified managed cluster. And the Bare Metal Operator Controller creates the relation to
BareMetalHostwith the labels matching the roles.Provisioning of the newly created machine starts when the machine object is created and includes the following stages:
Creation of partitions on the local disks as required by the operating system and the Container Cloud architecture.
Configuration of the network interfaces on the host as required by the operating system and the Container Cloud architecture.
Installation and configuration of the Container Cloud LCM Agent.
Repeat the steps above for the remaining machines.
Monitor the deploy or update live status of the machine:
- Quick status
On the Clusters page, in the Managers or Workers column. The green status icon indicates that the machine is Ready, the orange status icon indicates that the machine is Updating.
- Detailed status
In the Machines section of a particular cluster page, in the Status column. Hover over a particular machine status icon to verify the deploy or update status of a specific machine component.
You can monitor the status of the following machine components:
Component
Description
Kubelet
Readiness of a node in a Kubernetes cluster.
Swarm
Health and readiness of a node in a Docker Swarm cluster.
LCM
LCM readiness status of a node.
ProviderInstance
Readiness of a node in the underlying infrastructure (virtual or bare metal, depending on the provider type).
Graceful Reboot
Readiness of a machine during a scheduled graceful reboot of a cluster, available since Cluster releases 15.0.1 and 14.0.0.
Infrastructure Status
Available since Container Cloud 2.25.0 for the bare metal provider only. Readiness of the
IPAMHost,L2Template,BareMetalHost, andBareMetalHostProfileobjects associated with the machine.LCM Operation
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Health of all LCM operations on the machine.
LCM Agent
Available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Health of the LCM Agent on the machine and the status of the LCM Agent update to the version from the current Cluster release.
The machine creation starts with the Provision status. During provisioning, the machine is not expected to be accessible since its infrastructure (VM, network, and so on) is being created.
Other machine statuses are the same as the
LCMMachineobject states:Uninitialized - the machine is not yet assigned to an
LCMCluster.Pending - the agent reports a node IP address and host name.
Prepare - the machine executes
StateItemsthat correspond to thepreparephase. This phase usually involves downloading the necessary archives and packages.Deploy - the machine executes
StateItemsthat correspond to thedeployphase that is becoming a Mirantis Kubernetes Engine (MKE) node.Ready - the machine is being deployed.
Upgrade - the machine is being upgraded to the new MKE version.
Reconfigure - the machine executes
StateItemsthat correspond to thereconfigurephase. The machine configuration is being updated without affecting workloads running on the machine.
Once the status changes to Ready, the deployment of the cluster components on this machine is complete.
You can also monitor the live machine status using API:
kubectl get machines <machineName> -o wide
Example of system response since Container Cloud 2.23.0:
NAME READY LCMPHASE NODENAME UPGRADEINDEX REBOOTREQUIRED WARNINGS demo-0 true Ready kaas-node-c6aa8ad3 1 false
For the history of a machine deployment or update, refer to Inspect the history of a cluster and machine deployment or update.
Now, proceed to Add a Ceph cluster.
This section describes a bare metal host and machine configuration using Mirantis Container Cloud CLI.
A Kubernetes machine requires a dedicated bare metal host for deployment.
The bare metal hosts are represented by the BareMetalHost objects
in Kubernetes API. All BareMetalHost objects are labeled by the Operator
when created. A label reflects the hardware capabilities of a host.
As a result of labeling, all bare metal hosts are divided into three types:
Control Plane, Worker, and Storage.
In some cases, you may need to deploy a machine to a specific bare metal host. This is especially useful when some of your bare metal hosts have different hardware configuration than the rest.
To deploy a machine to a specific bare metal host:
Log in to the host where your management cluster
kubeconfigis located and where kubectl is installed.Identify the bare metal host that you want to associate with the specific machine. For example, host
host-1.kubectl get baremetalhost host-1 -o yaml
Add a label that will uniquely identify this host, for example, by the name of the host and machine that you want to deploy on it.
Caution
Do not remove any existing labels from the
BareMetalHostresource. For more details about labels, see BareMetalHost.kubectl edit baremetalhost host-1
Configuration example:
kind: BareMetalHost metadata: name: host-1 namespace: myProjectName labels: kaas.mirantis.com/baremetalhost-id: host-1-worker-HW11-cad5 ...
Create a new text file with the YAML definition of the
Machineobject, as defined in Machine.Note
Ubuntu 20.04 is used by default for greenfield deployments.
Add a label selector that matches the label you have added to the
BareMetalHostobject in the previous step.Example:
kind: Machine metadata: name: worker-HW11-cad5 namespace: myProjectName spec: ... providerSpec: value: apiVersion: baremetal.k8s.io/v1alpha1 kind: BareMetalMachineProviderSpec ... hostSelector: matchLabels: kaas.mirantis.com/baremetalhost-id: host-1-worker-HW11-cad5 ...
Specify the details of the machine configuration in the object created in the previous step. For example:
Add a reference to a custom
BareMetalHostProfileobject, as defined in Machine.Specify an override for the ordering and naming of the NICs for the machine. For details, see Override network interfaces naming and order.
If you use a specific L2 template for the machine, set the unique name or label of the corresponding L2 template in the
L2templateSelectorsection of theMachineobject.
Add the configured machine to the cluster:
kubectl create -f worker-HW11-cad5.yaml
Once done, this machine will be associated with the specified bare metal host.
Caution
The required minimum number of machines:
3 manager nodes for HA
3 worker storage nodes for a minimal Ceph cluster
You can create multiple L2 templates with different configurations and apply them to different machines in the same cluster. This section describes how to assign an L2 template to new cluster machines.
To change L2 template assignment on existing machines, refer to Modify network configuration on an existing machine.
To assign specific L2 templates to new machines in a cluster:
When you create a machine, set the l2TemplateSelector
field in the machine spec to the unique label of the L2 template
that you want to assign to the machine. Typically, you can use
l2template-<NAME>. For details, see Create an L2 template for a new managed cluster.
Alternatively, set the l2TemplateSelector field in the machine
spec to the name of the L2 template. This will work even if there is
no unique label on the L2 template that you want to use.
Consider the following examples of an L2 template assignment to a machine.
Example of an L2Template resource:
apiVersion: ipam.mirantis.com/v1alpha1
kind: L2Template
metadata:
name: ExampleNetConfig
namespace: MyProject
labels:
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
cluster.sigs.k8s.io/cluster-name: my-cluster
l2template-ExampleNetConfig: "true"
Note
The kaas.mirantis.com/region label is removed from all
Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0).
Therefore, do not add the label starting these releases. On existing
clusters updated to these releases, or if manually added, this label will
be ignored by Container Cloud.
Example of a Machine resource with the label-based L2 template selector:
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
name: Machine1
namespace: MyProject
...
spec:
providerSpec:
value:
l2TemplateSelector:
label: l2template-ExampleNetConfig
...
Example of a Machine resource with the name-based L2 template selector:
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
name: Machine1
namespace: MyProject
...
spec:
providerSpec:
value:
l2TemplateSelector:
name: ExampleNetConfig
...
An L2 template contains the ifMapping field that allows you to
identify Ethernet interfaces for the template. The Machine object
API enables the Operator to override the mapping from the L2 template
by enforcing a specific order of names of the interfaces when applied
to the template.
The field l2TemplateIfMappingOverride in the spec of the Machine
object contains a list of interfaces names. The order of the interfaces
names in the list is important because the L2Template object will
be rendered with NICs ordered as per this list.
Note
Changes in the l2TemplateIfMappingOverride field will apply
only once when the Machine and corresponding IpamHost objects
are created. Further changes to l2TemplateIfMappingOverride
will not reset the interfaces assignment and configuration.
Caution
The l2TemplateIfMappingOverride field must contain the names of
all interfaces of the bare metal host.
The following example illustrates how to include the override field to the
Machine object. In this example, we configure the interface eno1,
which is the second on-board interface of the server, to precede the first
on-board interface eno0.
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: kaas-mgmt
cluster.sigs.k8s.io/control-plane: "true"
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
spec:
providerSpec:
value:
apiVersion: baremetal.k8s.io/v1alpha1
hostSelector:
matchLabels:
kaas.mirantis.com/baremetalhost-id: hw-master-0
image: {}
kind: BareMetalMachineProviderSpec
l2TemplateIfMappingOverride:
- eno1
- eno0
- enp0s1
- enp0s2
Note
The kaas.mirantis.com/region label is removed from all
Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0).
Therefore, do not add the label starting these releases. On existing
clusters updated to these releases, or if manually added, this label will
be ignored by Container Cloud.
As a result of the configuration above, when used with the example
L2 template for bonds and bridges described in Create L2 templates,
the enp0s1 and enp0s2 interfaces will be in predictable
ordered state. This state will be used to create subinterfaces for
Kubernetes networks (k8s-pods) and for Kubernetes external
network (k8s-ext).
Also, you can use the non-case-sensitive list of NIC MAC addresses instead of the list of NIC names. For example:
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
...
spec:
providerSpec:
value:
...
kind: BareMetalMachineProviderSpec
l2TemplateIfMappingOverride:
- b4:96:91:6f:2e:10
- b4:96:91:6f:2e:11
- b5:a6:c1:6f:ee:02
- b5:a6:c1:6f:ee:02
Available since Cluster releases 16.0.0 and 17.0.0 as TechPreview and since 16.1.0 and 17.1.0 as GA
You can force the DHCP server to assign a particular IP address for a bare
metal host during PXE provisioning by adding the
host.dnsmasqs.metal3.io/address annotation with the desired IP address
value to the required bare metal host.
If you have a limited amount of free and unused IP addresses for a server provisioning, you can manually create bare metal hosts one by one and provision servers in small, manually managed batches.
For batching in small chunks, you can use the
host.dnsmasqs.metal3.io/address annotation to manually allocate IP
addresses along with the baremetalhost.metal3.io/detached annotation to
pause automatic host management by the bare metal Operator.
To pause bare metal hosts for a manual IP allocation during provisioning:
Set the
baremetalhost.metal3.io/detachedannotation for all bare metal hosts that pauses host management.Note
If the host provisioning has already started or completed, adding of this annotation deletes the information about the host from Ironic without triggering deprovisioning. The bare metal Operator recreates the host in Ironic once you remove the annotation. For details, see Metal3 documentation.
Add the
host.dnsmasqs.metal3.io/addressannotation with corresponding IP address values to a batch of bare metal hosts.Remove the
baremetalhost.metal3.io/detachedannotation from the batch used in the previous step.Repeat the steps 2 and 3 until all hosts are provisioned.
See also
Add a Ceph cluster¶
After you add machines to your new bare metal cluster as described in Add a machine to bare metal managed cluster, create a Ceph cluster on top of this managed cluster using the Mirantis Container Cloud web UI or CLI.
This section explains how to create a Ceph cluster on top of a managed cluster using the Mirantis Container Cloud web UI. As a result, you will deploy a Ceph cluster with minimum three Ceph nodes that provide persistent volumes to the Kubernetes workloads for your managed cluster.
Note
For the advanced configuration through the KaaSCephCluster custom
resource, see Ceph advanced configuration.
For the configuration of the Ceph Controller through Kubernetes templates to manage Ceph node resources, see Enable Ceph tolerations and resources management.
To create a Ceph cluster in the managed cluster:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the required cluster name. The Cluster page with the Machines and Ceph clusters lists opens.
In the Ceph Clusters block, click Create Cluster.
Configure the Ceph cluster in the Create New Ceph Cluster wizard that opens:
Create new Ceph cluster¶ Section
Parameter name
Description
General settings
Name
The Ceph cluster name.
Cluster Network
Replication network for Ceph OSDs. Must contain the CIDR definition and match the corresponding values of the cluster
Subnetobject or the environment network values. For configuration examples, see the descriptions ofmanaged-ns_Subnet_storageYAML files in :ref: e2example1.Public Network
Public network for Ceph data. Must contain the CIDR definition and match the corresponding values of the cluster
Subnetobject or the environment network values. For configuration examples, see the descriptions ofmanaged-ns_Subnet_storageYAML files in :ref: e2example1.Enable OSDs LCM
Select to enable LCM for Ceph OSDs.
Machines / Machine #1-3
Select machine
Select the name of the Kubernetes machine that will host the corresponding Ceph node in the Ceph cluster.
Manager, Monitor
Select the required Ceph services to install on the Ceph node.
Devices
Select the disk that Ceph will use.
Warning
Do not select the device for system services, for example,
sda.Warning
A Ceph cluster does not support removable devices that are hosts with hotplug functionality enabled. To use devices as Ceph OSD data devices, make them non-removable or disable the hotplug functionality in the BIOS settings for disks that are configured to be used as Ceph OSD data devices.
Enable Object Storage
Select to enable the single-instance RGW Object Storage.
To add more Ceph nodes to the new Ceph cluster, click + next to any Ceph Machine title in the Machines tab. Configure a Ceph node as required.
Warning
Do not add more than 3
Managerand/orMonitorservices to the Ceph cluster.After you add and configure all nodes in your Ceph cluster, click Create.
Verify your Ceph cluster as described in Verify Ceph.
Verify that network addresses used on your clusters do not overlap with the following default MKE network addresses for Swarm and MCR:
10.0.0.0/16is used for Swarm networks. IP addresses from this network are virtual.10.99.0.0/16is used for MCR networks. IP addresses from this network are allocated on hosts.
Verification of Swarm and MCR network addresses
To verify Swarm and MCR network addresses, run on any master node:
docker infoExample of system response:
Server: ... Swarm: ... Default Address Pool: 10.0.0.0/16 SubnetSize: 24 ... Default Address Pools: Base: 10.99.0.0/16, Size: 20 ...
Not all of Swarm and MCR addresses are usually in use. One Swarm Ingress network is created by default and occupies the
10.0.0.0/24address block. Also, three MCR networks are created by default and occupy three address blocks:10.99.0.0/20,10.99.16.0/20,10.99.32.0/20.To verify the actual networks state and addresses in use, run:
docker network ls docker network inspect <networkName>
This section explains how to create a Ceph cluster on top of a managed cluster using the Mirantis Container Cloud CLI. As a result, you will deploy a Ceph cluster with minimum three Ceph nodes that provide persistent volumes to the Kubernetes workloads for your managed cluster.
Note
For the advanced configuration through the KaaSCephCluster custom
resource, see Ceph advanced configuration.
For the configuration of the Ceph Controller through Kubernetes templates to manage Ceph node resources, see Enable Ceph tolerations and resources management.
To create a Ceph cluster in a managed cluster:
Verify that the managed cluster overall status is ready with all conditions in the
Readystate:kubectl -n <managedClusterProject> get cluster <clusterName> -o yaml
Substitute
<managedClusterProject>and<clusterName>with the corresponding managed cluster namespace and name accordingly.Example output:
status: providerStatus: ready: true conditions: - message: Helm charts are successfully installed(upgraded). ready: true type: Helm - message: Kubernetes objects are fully up. ready: true type: Kubernetes - message: All requested nodes are ready. ready: true type: Nodes - message: Maintenance state of the cluster is false ready: true type: Maintenance - message: TLS configuration settings are applied ready: true type: TLS - message: Kubelet is Ready on all nodes belonging to the cluster ready: true type: Kubelet - message: Swarm is Ready on all nodes belonging to the cluster ready: true type: Swarm - message: All provider instances of the cluster are Ready ready: true type: ProviderInstance - message: LCM agents have the latest version ready: true type: LCMAgent - message: StackLight is fully up. ready: true type: StackLight - message: OIDC configuration has been applied. ready: true type: OIDC - message: Load balancer 10.100.91.150 for kubernetes API has status HEALTHY ready: true type: LoadBalancer
Create a YAML file with the Ceph cluster specification:
apiVersion: kaas.mirantis.com/v1alpha1 kind: KaaSCephCluster metadata: name: <cephClusterName> namespace: <managedClusterProject> spec: k8sCluster: name: <clusterName> namespace: <managedClusterProject>
Substitute
<cephClusterName>with the desired name for the Ceph cluster. This name will be used in the Ceph LCM operations.Select from the following options:
Add explicit network configuration of the Ceph cluster using the
networksection:spec: cephClusterSpec: network: publicNet: <publicNet> clusterNet: <clusterNet>
Substitute the following values:
<publicNet>is a CIDR definition or comma-separated list of CIDR definitions (if the managed cluster uses multiple networks) of public network for the Ceph data. The values should match the corresponding values of the clusterSubnetobject.<clusterNet>is a CIDR definition or comma-separated list of CIDR definitions (if the managed cluster uses multiple networks) of replication network for the Ceph data. The values should match the corresponding values of the clusterSubnetobject.
Configure
Subnetobjects for the Storage access network by settingipam/SVC-ceph-public: "1"andipam/SVC-ceph-cluster: "1"labels to the correspondingSubnetobjects. For more details, refer to Create subnets for a managed cluster using CLI, Step 5.
Configure Ceph Manager and Ceph Monitor roles to select nodes that should place Ceph Monitor and Ceph Manager daemons:
Obtain the names of the machines to place Ceph Monitor and Ceph Manager daemons at:
kubectl -n <managedClusterProject> get machine
Add the
nodessection withmonandmgrroles defined:spec: cephClusterSpec: nodes: <mgr-node-1>: roles: - <role-1> - <role-2> ... <mgr-node-2>: roles: - <role-1> - <role-2> ...
Substitute
<mgr-node-X>with the correspondingMachineobject names and<role-X>with the corresponding roles of daemon placement, for example,monormgr.See also
Configure Ceph OSD daemons for Ceph cluster data storage:
Note
This step involves the deployment of Ceph Monitor and Ceph Manager daemons on nodes that are different from the ones hosting Ceph cluster OSDs. However, it is also possible to colocate Ceph OSDs, Ceph Monitor, and Ceph Manager daemons on the same nodes. You can achieve this by configuring the
rolesandstorageDevicessections accordingly. This kind of configuration flexibility is particularly useful in scenarios such as hyper-converged clusters.Warning
The minimal production cluster requires at least three nodes for Ceph Monitor daemons and three nodes for Ceph OSDs.
Obtain the names of the machines with disks intended for storing Ceph data:
kubectl -n <managedClusterProject> get machine
For each machine, use
status.providerStatus.hardware.storageto obtain information about node disks:kubectl -n <managedClusterProject> get machine <machineName> -o yaml
Output example of the machine hardware details:
status: providerStatus: hardware: storage: - byID: /dev/disk/by-id/wwn-0x05ad99618d66a21f byIDs: - /dev/disk/by-id/scsi-0QEMU_QEMU_HARDDISK_05ad99618d66a21f - /dev/disk/by-id/scsi-305ad99618d66a21f - /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_05ad99618d66a21f - /dev/disk/by-id/wwn-0x05ad99618d66a21f byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0 byPaths: - /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0 name: /dev/sda serialNumber: 05ad99618d66a21f size: 61 type: hdd - byID: /dev/disk/by-id/wwn-0x26d546263bd312b8 byIDs: - /dev/disk/by-id/scsi-0QEMU_QEMU_HARDDISK_26d546263bd312b8 - /dev/disk/by-id/scsi-326d546263bd312b8 - /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_26d546263bd312b8 - /dev/disk/by-id/wwn-0x26d546263bd312b8 byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2 byPaths: - /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2 name: /dev/sdb serialNumber: 26d546263bd312b8 size: 32 type: hdd - byID: /dev/disk/by-id/wwn-0x2e52abb48862dbdc byIDs: - /dev/disk/by-id/lvm-pv-uuid-MncrcO-6cel-0QsB-IKaY-e8UK-6gDy-k2hOtf - /dev/disk/by-id/scsi-0QEMU_QEMU_HARDDISK_2e52abb48862dbdc - /dev/disk/by-id/scsi-32e52abb48862dbdc - /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_2e52abb48862dbdc - /dev/disk/by-id/wwn-0x2e52abb48862dbdc byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:1 byPaths: - /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:1 name: /dev/sdc serialNumber: 2e52abb48862dbdc size: 61 type: hdd
Select
by-idsymlinks on the disks to be used in the Ceph cluster. The symlinks should meet the following requirements:A
by-idsymlink should containstatus.providerStatus.hardware.storage.serialNumberA
by-idsymlink should not containwwn
For the example above, if you are willing to use the
sdcdisk to store Ceph data on it, use the/dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_2e52abb48862dbdcsymlink. It will be persistent and will not be affected by node reboot.See also
Sepcify
by-idsymlinks:Specify selected
by-idsymlinks in thespec.cephClusterSpec.nodes.storageDevices.fullPathfield along with thespec.cephClusterSpec.nodes.storageDevices.config.deviceClassfield:spec: cephClusterSpec: nodes: <storage-node-1>: storageDevices: - fullPath: <byIDSymlink-1> config: deviceClass: <deviceClass-1> - fullPath: <byIDSymlink-2> config: deviceClass: <deviceClass-1> - fullPath: <byIDSymlink-3> config: deviceClass: <deviceClass-2> ... <storage-node-2>: storageDevices: - fullPath: <byIDSymlink-4> config: deviceClass: <deviceClass-1> - fullPath: <byIDSymlink-5> config: deviceClass: <deviceClass-1> - fullPath: <byIDSymlink-6> config: deviceClass: <deviceClass-2> <storage-node-3>: storageDevices: - fullPath: <byIDSymlink-7> config: deviceClass: <deviceClass-1> - fullPath: <byIDSymlink-8> config: deviceClass: <deviceClass-1> - fullPath: <byIDSymlink-9> config: deviceClass: <deviceClass-2>
Substitute the following values:
<storage-node-X>with the correspondingMachineobject names<byIDSymlink-X>with the obtainedby-idsymlinks fromstatus.providerStatus.hardware.storage.byIDs<deviceClass-X>with the obtained disk types fromstatus.providerStatus.hardware.storage.type
Specify selected
by-idsymlinks in thespec.cephClusterSpec.nodes.storageDevices.namefield along with thespec.cephClusterSpec.nodes.storageDevices.config.deviceClassfield:spec: cephClusterSpec: nodes: <storage-node-1>: storageDevices: - name: <byIDSymlink-1> config: deviceClass: <deviceClass-1> - name: <byIDSymlink-2> config: deviceClass: <deviceClass-1> - name: <byIDSymlink-3> config: deviceClass: <deviceClass-2> ... <storage-node-2>: storageDevices: - name: <byIDSymlink-4> config: deviceClass: <deviceClass-1> - name: <byIDSymlink-5> config: deviceClass: <deviceClass-1> - name: <byIDSymlink-6> config: deviceClass: <deviceClass-2> <storage-node-3>: storageDevices: - name: <byIDSymlink-7> config: deviceClass: <deviceClass-1> - name: <byIDSymlink-8> config: deviceClass: <deviceClass-1> - name: <byIDSymlink-9> config: deviceClass: <deviceClass-2>
Substitute the following values:
<storage-node-X>with the correspondingMachineobject names<byIDSymlink-X>with the obtainedby-idsymlinks fromstatus.providerStatus.hardware.storage.byIDs<deviceClass-X>with the obtained disk types fromstatus.providerStatus.hardware.storage.type
Optional. Configure Ceph Block Pools to use RBD. For the detailed configuration, refer to Pool parameters.
Example configuration:
spec: cephClusterSpec: pools: - name: kubernetes role: kubernetes deviceClass: hdd replicated: size: 3 targetSizeRatio: 10.0 default: true
Optional. Configure Ceph Object Storage to use RGW. For the detailed configuration, refer to RADOS Gateway parameters.
Example configuration:
spec: cephClusterSpec: objectStorage: rgw: dataPool: deviceClass: hdd erasureCoded: codingChunks: 1 dataChunks: 2 failureDomain: host gateway: instances: 3 port: 80 securePort: 8443 metadataPool: deviceClass: hdd failureDomain: host replicated: size: 3 name: object-store preservePoolsOnDelete: false
Optional. Configure Ceph Shared Filesystem to use CephFS. For the detailed configuration, refer to Enable Ceph Shared File System (CephFS).
Example configuration:
spec: cephClusterSpec: sharedFilesystem: cephFS: - name: cephfs-store dataPools: - name: cephfs-pool-1 deviceClass: hdd replicated: size: 3 failureDomain: host metadataPool: deviceClass: nvme replicated: size: 3 failureDomain: host metadataServer: activeCount: 1 activeStandby: false
When the Ceph cluster specification is complete, apply the built YAML file on the management cluster:
kubectl apply -f <kcc-template>.yaml
Substitue
<kcc-template>with the name of the file containing theKaaSCephClusterspecification.The resulting example of the
KaaSCephClustertemplateapiVersion: kaas.mirantis.com/v1alpha1 kind: KaaSCephCluster metadata: name: kaas-ceph namespace: child-namespace spec: k8sCluster: name: child-cluster namespace: child-namespace cephClusterSpec: network: publicNet: 10.10.0.0/24 clusterNet: 10.11.0.0/24 nodes: master-1: roles: - mon - mgr master-2: roles: - mon - mgr master-3: roles: - mon - mgr worker-1: storageDevices: - fullPath: dev/disk/by-id/scsi-1ATA_WDC_WDS100T2B0A-00SM50_200231443409 config: deviceClass: ssd worker-2: storageDevices: - fullPath: /dev/disk/by-id/scsi-1ATA_WDC_WDS100T2B0A-00SM50_200231440912 config: deviceClass: ssd worker-3: storageDevices: - fullPath: /dev/disk/by-id/scsi-1ATA_WDC_WDS100T2B0A-00SM50_200231434939 config: deviceClass: ssd pools: - name: kubernetes role: kubernetes deviceClass: ssd replicated: size: 3 targetSizeRatio: 10.0 default: true objectStorage: rgw: dataPool: deviceClass: ssd erasureCoded: codingChunks: 1 dataChunks: 2 failureDomain: host gateway: instances: 3 port: 80 securePort: 8443 metadataPool: deviceClass: ssd failureDomain: host replicated: size: 3 name: object-store preservePoolsOnDelete: false sharedFilesystem: cephFS: - name: cephfs-store dataPools: - name: cephfs-pool-1 deviceClass: ssd replicated: size: 3 failureDomain: host metadataPool: deviceClass: ssd replicated: size: 3 failureDomain: host metadataServer: activeCount: 1 activeStandby: false
Wait for the
KaaSCephClusterstatus and then forstatus.shortClusterInfo.stateto becomeReady:kubectl -n <managedClusterProject> get kcc -o yaml
Example of a complete L2 templates configuration for cluster creation¶
The following example contains all required objects of an advanced network and host configuration for a baremetal-based managed cluster.
The procedure below contains:
Various
.yamlobjects to be applied with a managed clusterkubeconfigUseful comments inside the
.yamlexample filesExample hardware and configuration data, such as
network,disk,auth, that must be updated accordingly to fit your cluster configurationExample templates, such as
l2templateandbaremetalhostprofline, that illustrate how to implement a specific configuration
Caution
The exemplary configuration described below is not production ready and is provided for illustration purposes only.
For illustration purposes, all files provided in this exemplary procedure are named by the Kubernetes object types:
managed-ns_BareMetalHost_cz7700-managed-cluster-control-noefi.yaml
managed-ns_BareMetalHost_cz7741-managed-cluster-control-noefi.yaml
managed-ns_BareMetalHost_cz7743-managed-cluster-control-noefi.yaml
managed-ns_BareMetalHost_cz812-managed-cluster-storage-worker-noefi.yaml
managed-ns_BareMetalHost_cz813-managed-cluster-storage-worker-noefi.yaml
managed-ns_BareMetalHost_cz814-managed-cluster-storage-worker-noefi.yaml
managed-ns_BareMetalHost_cz815-managed-cluster-worker-noefi.yaml
managed-ns_BareMetalHostProfile_bmhp-cluster-default.yaml
managed-ns_BareMetalHostProfile_worker-storage1.yaml
managed-ns_Cluster_managed-cluster.yaml
managed-ns_KaaSCephCluster_ceph-cluster-managed-cluster.yaml
managed-ns_L2Template_bm-1490-template-controls-netplan-cz7700-pxebond.yaml
managed-ns_L2Template_bm-1490-template-controls-netplan.yaml
managed-ns_L2Template_bm-1490-template-workers-netplan.yaml
managed-ns_Machine_cz7700-managed-cluster-control-noefi-.yaml
managed-ns_Machine_cz7741-managed-cluster-control-noefi-.yaml
managed-ns_Machine_cz7743-managed-cluster-control-noefi-.yaml
managed-ns_Machine_cz812-managed-cluster-storage-worker-noefi-.yaml
managed-ns_Machine_cz813-managed-cluster-storage-worker-noefi-.yaml
managed-ns_Machine_cz814-managed-cluster-storage-worker-noefi-.yaml
managed-ns_Machine_cz815-managed-cluster-worker-noefi-.yaml
managed-ns_PublicKey_managed-cluster-key.yaml
managed-ns_cz7700-cred.yaml
managed-ns_cz7741-cred.yaml
managed-ns_cz7743-cred.yaml
managed-ns_cz812-cred.yaml
managed-ns_cz813-cred.yaml
managed-ns_cz814-cred.yaml
managed-ns_cz815-cred.yaml
managed-ns_Subnet_lcm-nw.yaml
managed-ns_Subnet_metallb-public-for-managed.yaml
managed-ns_Subnet_metallb-public-for-extiface.yaml
managed-ns_MetalLBConfig-lb-managed.yaml
managed-ns_MetalLBConfigTemplate-lb-managed-template.yaml
managed-ns_Subnet_storage-backend.yaml
managed-ns_Subnet_storage-frontend.yaml
default_Namespace_managed-ns.yaml
Caution
The procedure below assumes that you apply each new .yaml
file using kubectl create -f <file_name.yaml>.
To create an example configuration for a managed cluster creation:
Verify that you have configured the following items:
All
bmhnodes for PXE boot as described in Add a bare metal host using CLIAll physical NICs of the
bmhnodesAll required physical subnets and routing
Create an empty
.yamlfile with thenamespaceobject:apiVersion: v1
Select from the following options:
Create the required number of
.yamlfiles with theBareMetalHostCredentialobjects for eachbmhnode with the uniquenameand authenticationdata. The following example contains oneBareMetalHostCredentialobject:Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.managed-ns_cz815-cred.yamlapiVersion: kaas.mirantis.com/v1alpha1 kind: BareMetalHostCredential metadata: name: cz815-cred namespace: managed-ns labels: kaas.mirantis.com/region: region-one spec: username: admin password: value: supersecret
Create the required number of
.yamlfiles with theSecretobjects for eachbmhnode with the uniquenameand authenticationdata. The following example contains oneSecretobject:managed-ns_cz815-cred.yamlapiVersion: v1 data: password: YWRtaW4= username: ZW5naW5lZXI= kind: Secret metadata: labels: kaas.mirantis.com/credentials: 'true' kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: cz815-cred namespace: managed-ns
Create a set of files with the
bmhnodes configuration:managed-ns_BareMetalHost_cz7700-managed-cluster-control-noefi.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/controlplane: controlplane # we will use those label, to link machine to exact bmh node kaas.mirantis.com/baremetalhost-id: cz7700 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one annotations: kaas.mirantis.com/baremetalhost-credentials-name: cz7700-cred name: cz7700-managed-cluster-control-noefi namespace: managed-ns spec: bmc: address: 192.168.1.12 # credentialsName is updated automatically during cluster deployment credentialsName: '' bootMACAddress: 0c:c4:7a:34:52:04 bootMode: legacy online: true
managed-ns_BareMetalHost_cz7741-managed-cluster-control-noefi.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/controlplane: controlplane kaas.mirantis.com/baremetalhost-id: cz7741 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one annotations: kaas.mirantis.com/baremetalhost-credentials-name: cz7741-cred name: cz7741-managed-cluster-control-noefi namespace: managed-ns spec: bmc: address: 192.168.1.76 credentialsName: '' bootMACAddress: 0c:c4:7a:34:92:f4 bootMode: legacy online: true
managed-ns_BareMetalHost_cz7743-managed-cluster-control-noefi.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/controlplane: controlplane kaas.mirantis.com/baremetalhost-id: cz7743 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one annotations: kaas.mirantis.com/baremetalhost-credentials-name: cz7743-cred name: cz7743-managed-cluster-control-noefi namespace: managed-ns spec: bmc: address: 192.168.1.78 credentialsName: '' bootMACAddress: 0c:c4:7a:34:66:fc bootMode: legacy online: true
managed-ns_BareMetalHost_cz812-managed-cluster-storage-worker-noefi.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/storage: storage hostlabel.bm.kaas.mirantis.com/worker: worker kaas.mirantis.com/baremetalhost-id: cz812 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one annotations: kaas.mirantis.com/baremetalhost-credentials-name: cz812-cred name: cz812-managed-cluster-storage-worker-noefi namespace: managed-ns spec: bmc: address: 192.168.1.182 credentialsName: '' bootMACAddress: 0c:c4:7a:bc:ff:2e bootMode: legacy online: true
managed-ns_BareMetalHost_cz813-managed-cluster-storage-worker-noefi.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/storage: storage hostlabel.bm.kaas.mirantis.com/worker: worker kaas.mirantis.com/baremetalhost-id: cz813 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one annotations: kaas.mirantis.com/baremetalhost-credentials-name: cz813-cred name: cz813-managed-cluster-storage-worker-noefi namespace: managed-ns spec: bmc: address: 192.168.1.183 credentialsName: '' bootMACAddress: 0c:c4:7a:bc:fe:36 bootMode: legacy online: true
managed-ns_BareMetalHost_cz814-managed-cluster-storage-worker-noefi.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/storage: storage hostlabel.bm.kaas.mirantis.com/worker: worker kaas.mirantis.com/baremetalhost-id: cz814 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one annotations: kaas.mirantis.com/baremetalhost-credentials-name: cz814-cred name: cz814-managed-cluster-storage-worker-noefi namespace: managed-ns spec: bmc: address: 192.168.1.184 credentialsName: '' bootMACAddress: 0c:c4:7a:bc:fb:20 bootMode: legacy online: true
managed-ns_BareMetalHost_cz815-managed-cluster-worker-noefi.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/worker: worker kaas.mirantis.com/baremetalhost-id: cz815 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one annotations: kaas.mirantis.com/baremetalhost-credentials-name: cz815-cred name: cz815-managed-cluster-worker-noefi namespace: managed-ns spec: bmc: address: 192.168.1.185 credentialsName: '' bootMACAddress: 0c:c4:7a:bc:fc:3e bootMode: legacy online: true
managed-ns_BareMetalHost_cz7700-managed-cluster-control-noefi.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/controlplane: controlplane # we will use those label, to link machine to exact bmh node kaas.mirantis.com/baremetalhost-id: cz7700 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: cz7700-managed-cluster-control-noefi namespace: managed-ns spec: bmc: address: 192.168.1.12 # The secret for credentials requires the username and password # keys in the Base64 encoding. credentialsName: cz7700-cred bootMACAddress: 0c:c4:7a:34:52:04 bootMode: legacy online: true
managed-ns_BareMetalHost_cz7741-managed-cluster-control-noefi.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/controlplane: controlplane kaas.mirantis.com/baremetalhost-id: cz7741 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: cz7741-managed-cluster-control-noefi namespace: managed-ns spec: bmc: address: 192.168.1.76 credentialsName: cz7741-cred bootMACAddress: 0c:c4:7a:34:92:f4 bootMode: legacy online: true
managed-ns_BareMetalHost_cz7743-managed-cluster-control-noefi.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/controlplane: controlplane kaas.mirantis.com/baremetalhost-id: cz7743 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: cz7743-managed-cluster-control-noefi namespace: managed-ns spec: bmc: address: 192.168.1.78 credentialsName: cz7743-cred bootMACAddress: 0c:c4:7a:34:66:fc bootMode: legacy online: true
managed-ns_BareMetalHost_cz812-managed-cluster-storage-worker-noefi.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/storage: storage hostlabel.bm.kaas.mirantis.com/worker: worker kaas.mirantis.com/baremetalhost-id: cz812 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: cz812-managed-cluster-storage-worker-noefi namespace: managed-ns spec: bmc: address: 192.168.1.182 credentialsName: cz812-cred bootMACAddress: 0c:c4:7a:bc:ff:2e bootMode: legacy online: true
managed-ns_BareMetalHost_cz813-managed-cluster-storage-worker-noefi.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/storage: storage hostlabel.bm.kaas.mirantis.com/worker: worker kaas.mirantis.com/baremetalhost-id: cz813 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: cz813-managed-cluster-storage-worker-noefi namespace: managed-ns spec: bmc: address: 192.168.1.183 credentialsName: cz813-cred bootMACAddress: 0c:c4:7a:bc:fe:36 bootMode: legacy online: true
managed-ns_BareMetalHost_cz814-managed-cluster-storage-worker-noefi.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/storage: storage hostlabel.bm.kaas.mirantis.com/worker: worker kaas.mirantis.com/baremetalhost-id: cz814 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: cz814-managed-cluster-storage-worker-noefi namespace: managed-ns spec: bmc: address: 192.168.1.184 credentialsName: cz814-cre bootMACAddress: 0c:c4:7a:bc:fb:20 bootMode: legacy online: true
managed-ns_BareMetalHost_cz815-managed-cluster-worker-noefi.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/worker: worker kaas.mirantis.com/baremetalhost-id: cz815 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: cz815-managed-cluster-worker-noefi namespace: managed-ns spec: bmc: address: 192.168.1.185 credentialsName: cz815-cred bootMACAddress: 0c:c4:7a:bc:fc:3e bootMode: legacy online: true
Verify that the
inspectingphase has started:KUBECONFIG=kubeconfig kubectl -n managed-ns get bmh -o wide
Example of system response:
NAME STATUS STATE CONSUMER BMC BOOTMODE ONLINE ERROR REGION cz7700-managed-cluster-control-noefi OK inspecting 192.168.1.12 legacy true region-one cz7741-managed-cluster-control-noefi OK inspecting 192.168.1.76 legacy true region-one cz7743-managed-cluster-control-noefi OK inspecting 192.168.1.78 legacy true region-one cz812-managed-cluster-storage-worker-noefi OK inspecting 192.168.1.182 legacy true region-one
Wait for inspection to complete. Usually, it takes up to 15 minutes.
Collect the
bmhhardware information to create thel2templateandbmhobjects:KUBECONFIG=kubeconfig kubectl -n managed-ns get bmh -o wide
Example of system response:
NAME STATUS STATE CONSUMER BMC BOOTMODE ONLINE ERROR REGION cz7700-managed-cluster-control-noefi OK ready 192.168.1.12 legacy true region-one cz7741-managed-cluster-control-noefi OK ready 192.168.1.76 legacy true region-one cz7743-managed-cluster-control-noefi OK ready 192.168.1.78 legacy true region-one cz812-managed-cluster-storage-worker-noefi OK ready 192.168.1.182 legacy true region-one
KUBECONFIG=kubeconfig kubectl -n managed-ns get bmh cz7700-managed-cluster-control-noefi -o yaml | less
Example of system response:
.. nics: - ip: "" mac: 0c:c4:7a:1d:f4:a6 model: 0x8086 0x10fb # discovered interfaces name: ens4f0 pxe: false # temporary PXE address discovered from baremetal-mgmt - ip: 172.16.170.30 mac: 0c:c4:7a:34:52:04 model: 0x8086 0x1521 name: enp9s0f0 pxe: true # duplicates temporary PXE address discovered from baremetal-mgmt # since we have fallback-bond configured on host - ip: 172.16.170.33 mac: 0c:c4:7a:34:52:05 model: 0x8086 0x1521 # discovered interfaces name: enp9s0f1 pxe: false ... storage: - by_path: /dev/disk/by-path/pci-0000:00:1f.2-ata-1 model: Samsung SSD 850 name: /dev/sda rotational: false sizeBytes: 500107862016 - by_path: /dev/disk/by-path/pci-0000:00:1f.2-ata-2 model: Samsung SSD 850 name: /dev/sdb rotational: false sizeBytes: 500107862016 ....
Create bare metal host profiles:
managed-ns_BareMetalHostProfile_bmhp-cluster-default.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHostProfile metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster # This label indicates that this profile will be default in # namespaces, so machines w\o exact profile selecting will use # this template kaas.mirantis.com/defaultBMHProfile: 'true' kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: bmhp-cluster-default namespace: managed-ns spec: devices: - device: byPath: /dev/disk/by-path/pci-0000:00:1f.2-ata-1 minSize: 120Gi wipe: true partitions: - name: bios_grub partflags: - bios_grub size: 4Mi wipe: true - name: uefi partflags: - esp size: 200Mi wipe: true - name: config-2 size: 64Mi wipe: true - name: lvm_dummy_part size: 1Gi wipe: true - name: lvm_root_part size: 0 wipe: true - device: byPath: /dev/disk/by-path/pci-0000:00:1f.2-ata-2 minSize: 30Gi wipe: true - device: byPath: /dev/disk/by-path/pci-0000:00:1f.2-ata-3 minSize: 30Gi wipe: true partitions: - name: lvm_lvp_part size: 0 wipe: true - device: byPath: /dev/disk/by-path/pci-0000:00:1f.2-ata-4 wipe: true fileSystems: - fileSystem: vfat partition: config-2 - fileSystem: vfat mountPoint: /boot/efi partition: uefi - fileSystem: ext4 logicalVolume: root mountPoint: / - fileSystem: ext4 logicalVolume: lvp mountPoint: /mnt/local-volumes/ grubConfig: defaultGrubOptions: - GRUB_DISABLE_RECOVERY="true" - GRUB_PRELOAD_MODULES=lvm - GRUB_TIMEOUT=30 kernelParameters: modules: - content: 'options kvm_intel nested=1' filename: kvm_intel.conf sysctl: # For the list of options prohibited to change, refer to # https://docs.mirantis.com/mke/3.7/install/predeployment/set-up-kernel-default-protections.html fs.aio-max-nr: '1048576' fs.file-max: '9223372036854775807' fs.inotify.max_user_instances: '4096' kernel.core_uses_pid: '1' kernel.dmesg_restrict: '1' net.ipv4.conf.all.rp_filter: '0' net.ipv4.conf.default.rp_filter: '0' net.ipv4.conf.k8s-ext.rp_filter: '0' net.ipv4.conf.k8s-ext.rp_filter: '0' net.ipv4.conf.m-pub.rp_filter: '0' vm.max_map_count: '262144' logicalVolumes: - name: root size: 0 vg: lvm_root - name: lvp size: 0 vg: lvm_lvp postDeployScript: | #!/bin/bash -ex # used for test-debug only! echo "root:r00tme" | sudo chpasswd echo 'ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="deadline"' > /etc/udev/rules.d/60-ssd-scheduler.rules echo $(date) 'post_deploy_script done' >> /root/post_deploy_done preDeployScript: | #!/bin/bash -ex echo "$(date) pre_deploy_script done" >> /root/pre_deploy_done volumeGroups: - devices: - partition: lvm_root_part name: lvm_root - devices: - partition: lvm_lvp_part name: lvm_lvp - devices: - partition: lvm_dummy_part # here we can create lvm, but do not mount or format it somewhere name: lvm_forawesomeapp
managed-ns_BareMetalHostProfile_worker-storage1.yamlapiVersion: metal3.io/v1alpha1 kind: BareMetalHostProfile metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: worker-storage1 namespace: managed-ns spec: devices: - device: minSize: 120Gi wipe: true partitions: - name: bios_grub partflags: - bios_grub size: 4Mi wipe: true - name: uefi partflags: - esp size: 200Mi wipe: true - name: config-2 size: 64Mi wipe: true # Create dummy partition w\o mounting - name: lvm_dummy_part size: 1Gi wipe: true - name: lvm_root_part size: 0 wipe: true - device: # Will be used for Ceph, so required to be wiped byPath: /dev/disk/by-path/pci-0000:00:1f.2-ata-1 minSize: 30Gi wipe: true - device: byPath: /dev/disk/by-path/pci-0000:00:1f.2-ata-2 minSize: 30Gi wipe: true partitions: - name: lvm_lvp_part size: 0 wipe: true - device: byPath: /dev/disk/by-path/pci-0000:00:1f.2-ata-3 wipe: true - device: byPath: /dev/disk/by-path/pci-0000:00:1f.2-ata-4 minSize: 30Gi wipe: true partitions: - name: lvm_lvp_part_sdf wipe: true size: 0 fileSystems: - fileSystem: vfat partition: config-2 - fileSystem: vfat mountPoint: /boot/efi partition: uefi - fileSystem: ext4 logicalVolume: root mountPoint: / - fileSystem: ext4 logicalVolume: lvp mountPoint: /mnt/local-volumes/ grubConfig: defaultGrubOptions: - GRUB_DISABLE_RECOVERY="true" - GRUB_PRELOAD_MODULES=lvm - GRUB_TIMEOUT=30 kernelParameters: modules: - content: 'options kvm_intel nested=1' filename: kvm_intel.conf sysctl: # For the list of options prohibited to change, refer to # https://docs.mirantis.com/mke/3.6/install/predeployment/set-up-kernel-default-protections.html fs.aio-max-nr: '1048576' fs.file-max: '9223372036854775807' fs.inotify.max_user_instances: '4096' kernel.core_uses_pid: '1' kernel.dmesg_restrict: '1' net.ipv4.conf.all.rp_filter: '0' net.ipv4.conf.default.rp_filter: '0' net.ipv4.conf.k8s-ext.rp_filter: '0' net.ipv4.conf.k8s-ext.rp_filter: '0' net.ipv4.conf.m-pub.rp_filter: '0' vm.max_map_count: '262144' logicalVolumes: - name: root size: 0 vg: lvm_root - name: lvp size: 0 vg: lvm_lvp postDeployScript: | #!/bin/bash -ex # used for test-debug only! That would allow operator to logic via TTY. echo "root:r00tme" | sudo chpasswd # Just an example for enforcing "ssd" disks to be switched to use "deadline" i\o scheduler. echo 'ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="deadline"' > /etc/udev/ rules.d/60-ssd-scheduler.rules echo $(date) 'post_deploy_script done' >> /root/post_deploy_done preDeployScript: | #!/bin/bash -ex echo "$(date) pre_deploy_script done" >> /root/pre_deploy_done volumeGroups: - devices: - partition: lvm_root_part name: lvm_root - devices: - partition: lvm_lvp_part - partition: lvm_lvp_part_sdf name: lvm_lvp - devices: - partition: lvm_dummy_part name: lvm_forawesomeapp
Create the
L2Templateobjects:managed-ns_L2Template_bm-1490-template-controls-netplan.yamlapiVersion: ipam.mirantis.com/v1alpha1 kind: L2Template metadata: labels: bm-1490-template-controls-netplan: anymagicstring cluster.sigs.k8s.io/cluster-name: managed-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: bm-1490-template-controls-netplan namespace: managed-ns spec: ifMapping: - enp9s0f0 - enp9s0f1 - eno1 - ens3f1 l3Layout: - scope: namespace subnetName: lcm-nw - scope: namespace subnetName: storage-frontend - scope: namespace subnetName: storage-backend - scope: namespace subnetName: metallb-public-for-extiface npTemplate: |- version: 2 ethernets: {{nic 0}}: dhcp4: false dhcp6: false match: macaddress: {{mac 0}} set-name: {{nic 0}} mtu: 1500 {{nic 1}}: dhcp4: false dhcp6: false match: macaddress: {{mac 1}} set-name: {{nic 1}} mtu: 1500 {{nic 2}}: dhcp4: false dhcp6: false match: macaddress: {{mac 2}} set-name: {{nic 2}} mtu: 1500 {{nic 3}}: dhcp4: false dhcp6: false match: macaddress: {{mac 3}} set-name: {{nic 3}} mtu: 1500 bonds: bond0: parameters: mode: 802.3ad #transmit-hash-policy: layer3+4 #mii-monitor-interval: 100 interfaces: - {{ nic 0 }} - {{ nic 1 }} bond1: parameters: mode: 802.3ad #transmit-hash-policy: layer3+4 #mii-monitor-interval: 100 interfaces: - {{ nic 2 }} - {{ nic 3 }} vlans: stor-f: id: 1494 link: bond1 addresses: - {{ip "stor-f:storage-frontend"}} stor-b: id: 1489 link: bond1 addresses: - {{ip "stor-b:storage-backend"}} m-pub: id: 1491 link: bond0 bridges: k8s-ext: interfaces: [m-pub] addresses: - {{ ip "k8s-ext:metallb-public-for-extiface" }} k8s-lcm: dhcp4: false dhcp6: false gateway4: {{ gateway_from_subnet "lcm-nw" }} addresses: - {{ ip "k8s-lcm:lcm-nw" }} nameservers: addresses: [ 172.18.176.6 ] interfaces: - bond0
managed-ns_L2Template_bm-1490-template-workers-netplan.yamlapiVersion: ipam.mirantis.com/v1alpha1 kind: L2Template metadata: labels: bm-1490-template-workers-netplan: anymagicstring cluster.sigs.k8s.io/cluster-name: managed-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: bm-1490-template-workers-netplan namespace: managed-ns spec: ifMapping: - eno1 - eno2 - ens7f0 - ens7f1 l3Layout: - scope: namespace subnetName: lcm-nw - scope: namespace subnetName: storage-frontend - scope: namespace subnetName: storage-backend - scope: namespace subnetName: metallb-public-for-extiface npTemplate: |- version: 2 ethernets: {{nic 0}}: match: macaddress: {{mac 0}} set-name: {{nic 0}} mtu: 1500 {{nic 1}}: dhcp4: false dhcp6: false match: macaddress: {{mac 1}} set-name: {{nic 1}} mtu: 1500 {{nic 2}}: dhcp4: false dhcp6: false match: macaddress: {{mac 2}} set-name: {{nic 2}} mtu: 1500 {{nic 3}}: dhcp4: false dhcp6: false match: macaddress: {{mac 3}} set-name: {{nic 3}} mtu: 1500 bonds: bond0: interfaces: - {{ nic 1 }} bond1: parameters: mode: 802.3ad #transmit-hash-policy: layer3+4 #mii-monitor-interval: 100 interfaces: - {{ nic 2 }} - {{ nic 3 }} vlans: stor-f: id: 1494 link: bond1 addresses: - {{ip "stor-f:storage-frontend"}} stor-b: id: 1489 link: bond1 addresses: - {{ip "stor-b:storage-backend"}} m-pub: id: 1491 link: {{ nic 1 }} bridges: k8s-lcm: interfaces: - {{ nic 0 }} gateway4: {{ gateway_from_subnet "lcm-nw" }} addresses: - {{ ip "k8s-lcm:lcm-nw" }} nameservers: addresses: [ 172.18.176.6 ] k8s-ext: interfaces: [m-pub]
managed-ns_L2Template_bm-1490-template-controls-netplan-cz7700-pxebond.yamlapiVersion: ipam.mirantis.com/v1alpha1 kind: L2Template metadata: labels: bm-1490-template-controls-netplan-cz7700-pxebond: anymagicstring cluster.sigs.k8s.io/cluster-name: managed-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: bm-1490-template-controls-netplan-cz7700-pxebond namespace: managed-ns spec: ifMapping: - enp9s0f0 - enp9s0f1 - eno1 - ens3f1 l3Layout: - scope: namespace subnetName: lcm-nw - scope: namespace subnetName: storage-frontend - scope: namespace subnetName: storage-backend - scope: namespace subnetName: metallb-public-for-extiface npTemplate: |- version: 2 ethernets: {{nic 0}}: dhcp4: false dhcp6: false match: macaddress: {{mac 0}} set-name: {{nic 0}} mtu: 1500 {{nic 1}}: dhcp4: false dhcp6: false match: macaddress: {{mac 1}} set-name: {{nic 1}} mtu: 1500 {{nic 2}}: dhcp4: false dhcp6: false match: macaddress: {{mac 2}} set-name: {{nic 2}} mtu: 1500 {{nic 3}}: dhcp4: false dhcp6: false match: macaddress: {{mac 3}} set-name: {{nic 3}} mtu: 1500 bonds: bond0: parameters: mode: 802.3ad #transmit-hash-policy: layer3+4 #mii-monitor-interval: 100 interfaces: - {{ nic 0 }} - {{ nic 1 }} bond1: parameters: mode: 802.3ad #transmit-hash-policy: layer3+4 #mii-monitor-interval: 100 interfaces: - {{ nic 2 }} - {{ nic 3 }} vlans: stor-f: id: 1494 link: bond1 addresses: - {{ip "stor-f:storage-frontend"}} stor-b: id: 1489 link: bond1 addresses: - {{ip "stor-b:storage-backend"}} m-pub: id: 1491 link: bond0 bridges: k8s-ext: interfaces: [m-pub] addresses: - {{ ip "k8s-ext:metallb-public-for-extiface" }} k8s-lcm: dhcp4: false dhcp6: false gateway4: {{ gateway_from_subnet "lcm-nw" }} addresses: - {{ ip "k8s-lcm:lcm-nw" }} nameservers: addresses: [ 172.18.176.6 ] interfaces: - bond0
Create the
Subnetobjects:managed-ns_Subnet_lcm-nw.yamlapiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster ipam/SVC-k8s-lcm: '1' kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: lcm-nw namespace: managed-ns spec: cidr: 172.16.170.0/24 excludeRanges: - 172.16.170.150 gateway: 172.16.170.1 includeRanges: - 172.16.170.150-172.16.170.250
managed-ns_Subnet_metallb-public-for-extiface.yamlapiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: metallb-public-for-extiface namespace: managed-ns spec: cidr: 172.16.168.0/24 gateway: 172.16.168.1 includeRanges: - 172.16.168.10-172.16.168.30
managed-ns_Subnet_storage-backend.yamlapiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster ipam/SVC-ceph-cluster: '1' kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: storage-backend namespace: managed-ns spec: cidr: 10.12.0.0/24
managed-ns_Subnet_storage-frontend.yamlapiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster ipam/SVC-ceph-public: '1' kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: storage-frontend namespace: managed-ns spec: cidr: 10.12.1.0/24
Create MetalLB configuration objects:
Since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0):
managed-ns_MetalLBConfig-lb-managed.yamlapiVersion: kaas.mirantis.com/v1alpha1 kind: MetalLBConfig metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: lb-managed namespace: managed-ns spec: ipAddressPools: - name: services spec: addresses: - 10.100.91.151-10.100.91.170 autoAssign: true avoidBuggyIPs: false l2Advertisements: - name: services spec: ipAddressPools: - services
Before Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0):
managed-ns_Subnet_metallb-public-for-managed.yamlapiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster ipam/SVC-MetalLB: '1' kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: metallb-public-for-managed namespace: managed-ns spec: cidr: 172.16.168.0/24 includeRanges: - 172.16.168.31-172.16.168.50
managed-ns_MetalLBConfig-lb-managed.yamlNote
Applies since Container Cloud 2.21.0 and 2.21.1 for MOSK as TechPreview and since 2.24.0 as GA for management clusters. For managed clusters, is generally available since Container Cloud 2.25.0.
apiVersion: kaas.mirantis.com/v1alpha1 kind: MetalLBConfig metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: lb-managed namespace: managed-ns spec: templateName: lb-managed-template
managed-ns_MetalLBConfigTemplate-lb-managed-template.yamlNote
The
MetalLBConfigTemplateobject is available as Technology Preview since Container Cloud 2.24.0 and is generally available since Container Cloud 2.25.0.apiVersion: ipam.mirantis.com/v1alpha1 kind: MetalLBConfigTemplate metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: lb-managed-template namespace: managed-ns spec: templates: l2Advertisements: | - name: services spec: ipAddressPools: - services
Before Container Cloud 2.24.0 (Cluster release 14.0.0):
managed-ns_Subnet_metallb-public-for-managed.yamlapiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: labels: cluster.sigs.k8s.io/cluster-name: managed-cluster ipam/SVC-MetalLB: '1' kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: metallb-public-for-managed namespace: managed-ns spec: cidr: 172.16.168.0/24 includeRanges: - 172.16.168.31-172.16.168.50
Create the
PublicKeyobject for a managed cluster connection. For details, see Public key resources.managed-ns_PublicKey_managed-cluster-key.yamlapiVersion: kaas.mirantis.com/v1alpha1 kind: PublicKey metadata: name: managed-cluster-key namespace: managed-ns spec: publicKey: ssh-rsa AAEXAMPLEXXX
Create the
Clusterobject. For details, see Cluster resources.managed-ns_Cluster_managed-cluster.yamlapiVersion: cluster.k8s.io/v1alpha1 kind: Cluster metadata: annotations: kaas.mirantis.com/lcm: 'true' labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: managed-cluster namespace: managed-ns spec: clusterNetwork: pods: cidrBlocks: - 192.169.0.0/16 serviceDomain: '' services: cidrBlocks: - 10.232.0.0/18 providerSpec: value: apiVersion: baremetal.k8s.io/v1alpha1 dedicatedControlPlane: false dnsNameservers: - 172.18.176.6 - 172.19.80.70 helmReleases: - name: ceph-controller - enabled: true name: stacklight values: alertmanagerSimpleConfig: email: enabled: false slack: enabled: false logging: persistentVolumeClaimSize: 30Gi highAvailabilityEnabled: false logging: enabled: false prometheusServer: customAlerts: [] persistentVolumeClaimSize: 16Gi retentionSize: 15GB retentionTime: 15d watchDogAlertEnabled: false - name: metallb values: {} kind: BaremetalClusterProviderSpec loadBalancerHost: 172.16.168.3 publicKeys: - name: managed-cluster-key region: region-one release: mke-5-16-0-3-3-6
Create the
Machineobjects linked to eachbmhnode. For details, see Machine resources.managed-ns_Machine_cz7700-managed-cluster-control-noefi-.yamlapiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: generateName: cz7700-managed-cluster-control-noefi- labels: cluster.sigs.k8s.io/cluster-name: managed-cluster cluster.sigs.k8s.io/control-plane: controlplane hostlabel.bm.kaas.mirantis.com/controlplane: controlplane kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one namespace: managed-ns spec: providerSpec: value: apiVersion: baremetal.k8s.io/v1alpha1 hostSelector: matchLabels: kaas.mirantis.com/baremetalhost-id: cz7700 kind: BareMetalMachineProviderSpec l2TemplateSelector: label: bm-1490-template-controls-netplan-cz7700-pxebond publicKeys: - name: managed-cluster-key
managed-ns_Machine_cz7741-managed-cluster-control-noefi-.yamlapiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: generateName: cz7741-managed-cluster-control-noefi- labels: cluster.sigs.k8s.io/cluster-name: managed-cluster cluster.sigs.k8s.io/control-plane: controlplane hostlabel.bm.kaas.mirantis.com/controlplane: controlplane kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one namespace: managed-ns spec: providerSpec: value: apiVersion: baremetal.k8s.io/v1alpha1 bareMetalHostProfile: name: bmhp-cluster-default namespace: managed-ns hostSelector: matchLabels: kaas.mirantis.com/baremetalhost-id: cz7741 kind: BareMetalMachineProviderSpec l2TemplateSelector: label: bm-1490-template-controls-netplan publicKeys: - name: managed-cluster-key
managed-ns_Machine_cz7743-managed-cluster-control-noefi-.yamlapiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: generateName: cz7743-managed-cluster-control-noefi- labels: cluster.sigs.k8s.io/cluster-name: managed-cluster cluster.sigs.k8s.io/control-plane: controlplane hostlabel.bm.kaas.mirantis.com/controlplane: controlplane kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one namespace: managed-ns spec: providerSpec: value: apiVersion: baremetal.k8s.io/v1alpha1 bareMetalHostProfile: name: bmhp-cluster-default namespace: managed-ns hostSelector: matchLabels: kaas.mirantis.com/baremetalhost-id: cz7743 kind: BareMetalMachineProviderSpec l2TemplateSelector: label: bm-1490-template-controls-netplan publicKeys: - name: managed-cluster-key
managed-ns_Machine_cz812-managed-cluster-storage-worker-noefi-.yamlapiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: generateName: cz812-managed-cluster-storage-worker-noefi- labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/storage: storage hostlabel.bm.kaas.mirantis.com/worker: worker kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one namespace: managed-ns spec: providerSpec: value: apiVersion: baremetal.k8s.io/v1alpha1 bareMetalHostProfile: name: worker-storage1 namespace: managed-ns hostSelector: matchLabels: kaas.mirantis.com/baremetalhost-id: cz812 kind: BareMetalMachineProviderSpec l2TemplateSelector: label: bm-1490-template-workers-netplan publicKeys: - name: managed-cluster-key
managed-ns_Machine_cz813-managed-cluster-storage-worker-noefi-.yamlapiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: generateName: cz813-managed-cluster-storage-worker-noefi- labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/storage: storage hostlabel.bm.kaas.mirantis.com/worker: worker kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one namespace: managed-ns spec: providerSpec: value: apiVersion: baremetal.k8s.io/v1alpha1 bareMetalHostProfile: name: worker-storage1 namespace: managed-ns hostSelector: matchLabels: kaas.mirantis.com/baremetalhost-id: cz813 kind: BareMetalMachineProviderSpec l2TemplateSelector: label: bm-1490-template-workers-netplan publicKeys: - name: managed-cluster-key
managed-ns_Machine_cz814-managed-cluster-storage-worker-noefi-.yamlapiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: generateName: cz814-managed-cluster-storage-worker-noefi- labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/storage: storage hostlabel.bm.kaas.mirantis.com/worker: worker kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one namespace: managed-ns spec: providerSpec: value: apiVersion: baremetal.k8s.io/v1alpha1 bareMetalHostProfile: name: worker-storage1 namespace: managed-ns hostSelector: matchLabels: kaas.mirantis.com/baremetalhost-id: cz814 kind: BareMetalMachineProviderSpec l2TemplateSelector: label: bm-1490-template-workers-netplan publicKeys: - name: managed-cluster-key
managed-ns_Machine_cz815-managed-cluster-worker-noefi-.yamlapiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: generateName: cz815-managed-cluster-worker-noefi- labels: cluster.sigs.k8s.io/cluster-name: managed-cluster hostlabel.bm.kaas.mirantis.com/worker: worker kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one si-role/node-for-delete: 'true' namespace: managed-ns spec: providerSpec: value: apiVersion: baremetal.k8s.io/v1alpha1 bareMetalHostProfile: name: worker-storage1 namespace: managed-ns hostSelector: matchLabels: kaas.mirantis.com/baremetalhost-id: cz815 kind: BareMetalMachineProviderSpec l2TemplateSelector: label: bm-1490-template-workers-netplan publicKeys: - name: managed-cluster-key
Verify that the
bmhnodes are in theprovisioningstate:KUBECONFIG=kubectl kubectl -n managed-ns get bmh -o wide
Example of system response:
NAME STATUS STATE CONSUMER BMC BOOTMODE ONLINE ERROR REGION cz7700-managed-cluster-control-noefi OK provisioning cz7700-managed-cluster-control-noefi-8bkqw 192.168.1.12 legacy true region-one cz7741-managed-cluster-control-noefi OK provisioning cz7741-managed-cluster-control-noefi-42tp2 192.168.1.76 legacy true region-one cz7743-managed-cluster-control-noefi OK provisioning cz7743-managed-cluster-control-noefi-8cwpw 192.168.1.78 legacy true region-one ...
Wait until all
bmhnodes are in theprovisionedstate.Verify that the
lcmmachinephase has started:KUBECONFIG=kubeconfig kubectl -n managed-ns get lcmmachines -o wide
Example of system response:
NAME CLUSTERNAME TYPE STATE INTERNALIP HOSTNAME AGENTVERSION cz7700-managed-cluster-control-noefi-8bkqw managed-cluster control Deploy 172.16.170.153 kaas-node-803721b4-227c-4675-acc5-15ff9d3cfde2 v0.2.0-349-g4870b7f5 cz7741-managed-cluster-control-noefi-42tp2 managed-cluster control Prepare 172.16.170.152 kaas-node-6b8f0d51-4c5e-43c5-ac53-a95988b1a526 v0.2.0-349-g4870b7f5 cz7743-managed-cluster-control-noefi-8cwpw managed-cluster control Prepare 172.16.170.151 kaas-node-e9b7447d-5010-439b-8c95-3598518f8e0a v0.2.0-349-g4870b7f5 ...
Verify that the
lcmmachinephase is complete and the Kubernetes cluster is created:KUBECONFIG=kubeconfig kubectl -n managed-ns get lcmmachines -o wide
Example of system response:
NAME CLUSTERNAME TYPE STATE INTERNALIP HOSTNAME AGENTVERSION cz7700-managed-cluster-control-noefi-8bkqw managed-cluster control Ready 172.16.170.153 kaas-node-803721b4-227c-4675-acc5-15ff9d3cfde2 v0.2.0-349-g4870b7f5 cz7741-managed-cluster-control-noefi-42tp2 managed-cluster control Ready 172.16.170.152 kaas-node-6b8f0d51-4c5e-43c5-ac53-a95988b1a526 v0.2.0-349-g4870b7f5 cz7743-managed-cluster-control-noefi-8cwpw managed-cluster control Ready 172.16.170.151 kaas-node-e9b7447d-5010-439b-8c95-3598518f8e0a v0.2.0-349-g4870b7f5 ...
Create the
KaaSCephClusterobject:managed-ns_KaaSCephCluster_ceph-cluster-managed-cluster.yamlapiVersion: kaas.mirantis.com/v1alpha1 kind: KaaSCephCluster metadata: name: ceph-cluster-managed-cluster namespace: managed-ns spec: cephClusterSpec: nodes: # Add the exact ``nodes`` names. # Obtain the name from "get bmh -o wide" ``consumer`` field. cz812-managed-cluster-storage-worker-noefi-58spl: roles: - mgr - mon # All disk configuration must be reflected in ``baremetalhostprofile`` storageDevices: - config: deviceClass: ssd fullPath: /dev/disk/by-id/scsi-1ATA_WDC_WDS100T2B0A-00SM50_200231434939 cz813-managed-cluster-storage-worker-noefi-lr4k4: roles: - mgr - mon storageDevices: - config: deviceClass: ssd fullPath: /dev/disk/by-id/scsi-1ATA_WDC_WDS100T2B0A-00SM50_200231440912 cz814-managed-cluster-storage-worker-noefi-z2m67: roles: - mgr - mon storageDevices: - config: deviceClass: ssd fullPath: /dev/disk/by-id/scsi-1ATA_WDC_WDS100T2B0A-00SM50_200231443409 pools: - default: true deviceClass: ssd name: kubernetes replicated: size: 3 role: kubernetes k8sCluster: name: managed-cluster namespace: managed-ns
Note
The
storageDevices[].fullPathfield is available since Container Cloud 2.25.0. For the clusters running earlier product versions, define the/dev/disk/by-idsymlinks usingstorageDevices[].nameinstead.Obtain
kubeconfigof the newly created managed cluster:KUBECONFIG=kubeconfig kubectl -n managed-ns get secrets managed-cluster-kubeconfig -o jsonpath='{.data.admin\.conf}' | base64 -d | tee managed.kubeconfig
Verify the status of the Ceph cluster in your managed cluster:
KUBECONFIG=managed.kubeconfig kubectl -n rook-ceph exec -it $(KUBECONFIG=managed.kubeconfig kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') -- ceph -s
Example of system response:
cluster: id: e75c6abd-c5d5-4ae8-af17-4711354ff8ef health: HEALTH_OK services: mon: 3 daemons, quorum a,b,c (age 55m) mgr: a(active, since 55m) osd: 3 osds: 3 up (since 54m), 3 in (since 54m) data: pools: 1 pools, 32 pgs objects: 273 objects, 555 MiB usage: 4.0 GiB used, 1.6 TiB / 1.6 TiB avail pgs: 32 active+clean io: client: 51 KiB/s wr, 0 op/s rd, 4 op/s wr
Manage an existing bare metal cluster¶
If the subnet capacity on your existing cluster is not enough to add new
machines, use the l2TemplateSelector feature to expand the IP addresses
capacity:
Create new
Subnetobject(s) to define additional address ranges for new machines.Set up routing between the existing and new subnets.
Create new L2 template(s) with the new subnet(s) being used in
l3Layout.Set up
l2TemplateSelectorin theMachineobjects for new machines.
To expand IP addresses capacity for an existing cluster:
Verify the capacity of the subnet(s) currently associated with the L2 template(s) used for cluster deployment:
If
labelSelectoris not used for the given subnet, use thenamespacevalue of the L2 template and thesubnetNamevalue from thel3Layoutsection:kubectl get subnet -n <namespace> <subnetName>
If
labelSelectoris used for the given subnet, use thenamespacevalue of the L2 template and comma-separated key-value pairs from thelabelSelectorsection for the given subnet in thel3Layoutsection:kubectl get subnet -n <namespace> -l <key1=value1>[<,key2=value2>...]
Example command:
kubectl get subnet -n test-ns -l cluster.sigs.k8s.io/cluster-name=managed123,user-defined/purpose=lcm-base
Example of system response:
NAME AGE CIDR GATEWAY CAPACITY ALLOCATABLE STATUS old-lcm-network 8d 192.168.1.0/24 192.168.1.1 253 0 OK
Existing Subnet example
apiVersion: "ipam.mirantis.com/v1alpha1" kind: Subnet metadata: name: old-lcm-network namespace: test-ns labels: cluster.sigs.k8s.io/cluster-name: managed123 ipam/SVC-k8s-lcm: "1" kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one user-defined/purpose: lcm-base spec: cidr: 192.168.1.0/24 gateway: 192.168.1.1 . . . status: allocatable: 0 allocatedIPs: . . . capacity: 253 cidr: 192.168.1.0/24 gateway: 192.168.1.1 ranges: - 192.168.1.2-192.168.1.254 state: OK
Existing L2 template example
apiVersion: ipam.mirantis.com/v1alpha1 kind: L2Template metadata: name: base-template namespace: test-ns labels: ipam/DefaultForCluster: "1" kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one cluster.sigs.k8s.io/cluster-name: managed123 spec: autoIfMappingPrio: - provision - eno - ens l3Layout: - scope: namespace subnetName: lcm-subnet1 labelSelector: cluster.sigs.k8s.io/cluster-name: managed123 user-defined/purpose: lcm-base npTemplate: | version: 2 renderer: networkd ethernets: {{nic 0}}: match: macaddress: {{mac 0}} set-name: {{nic 0}} bridges: k8s-lcm: interfaces: - {{nic 0}} addresses: - {{ip "k8s-lcm:lcm-subnet1"}} gateway4: {{gateway_from_subnet "lcm-subnet1"}} nameservers: addresses: {{nameservers_from_subnet "lcm-subnet1"}}
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.Create new objects:
Subnetwith theuser-defined/purpose: lcm-additionallabel.L2Templatewith thealternative-template: “1”label. The L2 template should reference the newSubnetobject using theuser-defined/purpose: lcm-additionallabel in thelabelSelectorfield.
Note
The label name
user-defined/purposeis used for illustration purposes. Use any custom label name that differs from system names. Use of a unique prefix such asuser-defined/is recommended.New subnet example
apiVersion: "ipam.mirantis.com/v1alpha1" kind: Subnet metadata: name: new-lcm-network namespace: test-ns labels: cluster.sigs.k8s.io/cluster-name: managed123 ipam/SVC-k8s-lcm: "1" kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one user-defined/purpose: lcm-additional spec: cidr: 192.168.200.0/24 gateway: 192.168.200.1 . . . status: allocatable: 253 allocatedIPs: . . . capacity: 253 cidr: 192.168.200.0/24 gateway: 192.168.200.1 ranges: - 192.168.200.2-192.168.200.254 state: OK
Alternative L2 template example
apiVersion: ipam.mirantis.com/v1alpha1 kind: L2Template metadata: name: alternative-template namespace: test-ns labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one cluster.sigs.k8s.io/cluster-name: managed123 alternative-template: “1” spec: autoIfMappingPrio: - provision - eno - ens l3Layout: - scope: namespace subnetName: lcm-subnet2 labelSelector: cluster.sigs.k8s.io/cluster-name: managed123 user-defined/purpose: lcm-additional npTemplate: | version: 2 renderer: networkd ethernets: {{nic 0}}: match: macaddress: {{mac 0}} set-name: {{nic 0}} bridges: k8s-lcm: interfaces: - {{nic 0}} addresses: - {{ip "k8s-lcm:lcm-subnet2"}} gateway4: {{gateway_from_subnet "lcm-subnet2"}} nameservers: addresses: {{nameservers_from_subnet "lcm-subnet2"}}
You can also reference the new
Subnetobject by using its name in thel3Layoutsection of thealternative-templateL2 template.Alternative L2 template example
... spec: ... l3Layout: - scope: namespace subnetName: new-lcm-network ... npTemplate: | ... bridges: k8s-lcm: interfaces: - {{nic 0}} addresses: - {{ip "k8s-lcm:new-lcm-network"}} gateway4: {{gateway_from_subnet "new-lcm-network"}} nameservers: addresses: {{nameservers_from_subnet "new-lcm-network"}}
Set up IP routing between the existing and new subnets using the tools of your cloud network infrastructure.
In the
providerSpecsection of the newMachineobject, define thealternative-templatelabel forl2TemplateSelector:Snippet example of the new Machine object
apiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: labels: cluster.sigs.k8s.io/cluster-name: managed123 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: additional-machine namespace: test-ns spec: ... providerSpec: value: ... l2TemplateSelector: label: alternative-template
After creation, the new machine will use the alternative L2 template that uses the
new-lcm-networksubnet linked byL3Layout.Optional. Configure an additional IP address pool for MetalLB:
Configure the additional
extensionIP address pool for themetallbload balancer service.Open the
MetalLBConfigobject of the management cluster for editing:kubectl edit metallbconfig <MetalLBConfigName>
In the
ipAddressPoolssection, add:... spec: ipAddressPools: - name: extension spec: addresses: - <pool_start_ip>-<pool_end_ip> autoAssign: false avoidBuggyIPs: false ...
In the snippet above, replace the following parameters:
<pool_start_ip>- first IP address in the required range<pool_end_ip>- last IP address in the range
Add the
extensionIP address pool name to theL2Advertisementsdefinition. You can add it to the same L2 advertisement as thedefaultIP address pool, or create a new L2 advertisement if required.... spec: l2Advertisements: - name: default spec: interfaces: - k8s-lcm ipAddressPools: - default - extension ...
Save and exit the object to apply changes.
Define additional address ranges for MetalLB. For details, see the optional step for the MetalLB service in Create subnets for a managed cluster using CLI.
You can create one or several
Subnetobjects to extend the MetalLB address pool with additional ranges. When the MetalLB traffic is routed through the default gateway, you can add the MetalLB address ranges that belong to different CIDR subnet addresses.For example:
MetalLB configuration example snippet
apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: labels: cluster.sigs.k8s.io/cluster-name: managed123 ipam/SVC-MetalLB: '1' kaas.mirantis.com/region: region-one kaas.mirantis.com/provider: baremetal user-defined/purpose: metallb-additional1 name: metallb-svc1-for-managed namespace: test-ns spec: cidr: 172.16.168.0/24 includeRanges: - 172.16.168.11-172.16.168.30 - 172.16.168.41-172.16.168.50 apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: labels: cluster.sigs.k8s.io/cluster-name: managed123 ipam/SVC-MetalLB: '1' kaas.mirantis.com/region: region-one kaas.mirantis.com/provider: baremetal user-defined/purpose: metallb-additional2 name: metallb-svc2-for-managed namespace: test-ns spec: cidr: 172.16.169.0/24 includeRanges: - 172.16.169.11-172.16.169.20
Verify the created objects for MetalLB. For reference, use the following objects in Example of a complete L2 templates configuration for cluster creation:
Since 2.27.0:
managed-ns_MetalLBConfig-lb-managed.yamlBefore 2.27.0:
managed-ns_Subnet_metallb-public-for-managed.yaml
Manage machines of a bare metal cluster¶
You can use the Container Cloud web UI and API to manage machines of your managed cluster.
Available since 14.0.1 and 15.0.1 for MOSK 23.2
Warning
During the course of the Container Cloud 2.24.x series, Mirantis highly recommends upgrading an operating system on your cluster machines to Ubuntu 20.04 before the next major Cluster release becomes available. It is not mandatory to upgrade all machines at once. You can upgrade them one by one or in small batches, for example, if the maintenance window is limited in time.
Otherwise, the Cluster release update of the 18.04 based clusters will become impossible as of the Cluster releases introduced in Container Cloud 2.25.0, in which only the 20.04 distribution will be supported.
Distribution upgrade of an operating system (OS) is implemented for management and managed bare metal clusters.
For management clusters, an OS distribution upgrade occurs automatically since Container Cloud 2.24.0 as part of cluster update and requires machines reboot. The upgrade workflow is as follows:
The distribution ID value is taken from the
idfield of the distribution from theallowedDistributionslist in the spec of theClusterReleaseobject.The distribution that has the
default: truevalue is used during update. This distribution ID is set in thespec:providerSpec:value:distributionfield of theMachineobject during cluster update.
For managed clusters, an in-place OS distribution upgrade should be performed between cluster updates. This scenario implies a machine cordoning, draining, and reboot.
To upgrade an OS distribution on managed cluster between releases:
Open the required
Machineobject for editing.In
spec:providerSpec:value:distribution, set the required ID of the new OS version. For example,ubuntu/focal.For description of the
Machineobject fields, see API Reference: Machine object.Monitor the upgrade progress using the
status:providerStatus:currentDistributionfield of the requiredMachineobject. Once the distribution upgrade completes, thecurrentDistributionwill match thedistributionvalue previously set in the objectspec. For the status fields description, see Machine status.Verify that
reboot.required.trueappears instatus:providerStatusof theMachineobject. This field indicates whether a manual host reboot is required to complete the Ubuntu operating system update.Repeat the procedure with the remaining machines.
Manually reboot the cluster as described in Perform a graceful reboot of a cluster.
See also
Available since 2.25.0
During a management or managed cluster update with Ubuntu package updates, Container Cloud automatically removes unnecessary kernel and system packages.
During cleanup, Container Cloud keeps two most recent kernel versions, which is the default behavior of the Ubuntu apt autoremove command. The number of kernel packages may be more than two if this command has never been used.
Mirantis recommends keeping two kernel versions with the previous kernel version for fallback in case the current kernel becomes unstable. However, if you absolutely require leaving only the latest version of kernel packages, you can use the script described below after considering all possible risks.
To remove all kernel packages of the previous version:
Verify that the cluster is successfully updated and is in the
Readystate.Log in as
rootto the required node using SSH.Run the following script that calls an Ansible module targeted at local host. The module outputs a list of packages to remove, if any, without actually removing them.
cleanup-kernel-packages
The script workflow includes the following tasks:
Task order
Task name
Description
1
Get kernels to cleanupCollect installed kernel packages and detect the candidates for removal.
2
Get kernels to cleanup (LOG)Print the log from the first task.
3
Kernel packages to removePrint the list of packages collected by the first task.
4
Remove kernel packagesRemove packages that are detected as candidates for removal if the following conditions are met:
The script detects at least one candidate for removal
You add the
--cleanupflag to the cleanup-kernel-packages command
If the system outputs any packages to remove, carefully assess the list from the output of the
Kernel packages to removetask.Caution
The script removes all detected packages. There is no possibility to modify the list of candidates for removal.
Example of system response with no found packages to remove
PLAY [localhost] TASK [Get kernels to cleanup] ok: [localhost] TASK [Get kernels to cleanup (LOG)] ok: [localhost] => { "cleanup_kernels.log": [ "2023-09-27 12:49:31,925 [INFO] Logging enabled", "2023-09-27 12:49:31,937 [DEBUG] Found kernel package linux-headers-5.15.0-83-generic, version 5.15.0.post83-generic", "2023-09-27 12:49:31,938 [DEBUG] Found kernel package linux-image-5.15.0-83-generic, version 5.15.0.post83-generic", "2023-09-27 12:49:31,938 [DEBUG] Found kernel package linux-modules-5.15.0-83-generic, version 5.15.0.post83-generic", "2023-09-27 12:49:31,938 [DEBUG] Found kernel package linux-modules-extra-5.15.0-83-generic, version 5.15.0.post83-generic", "2023-09-27 12:49:31,944 [DEBUG] Current kernel is 5.15.0.post83-generic", "2023-09-27 12:49:31,944 [INFO] No kernel packages prior version '5.15.0.post83' found, nothing to remove.", "2023-09-27 12:49:31,944 [INFO] Exiting successfully" ] } TASK [Kernel packages to remove] ok: [localhost] => { "cleanup_kernels.packages": [] } TASK [Remove kernel packages] skipping: [localhost]
Example of system response with several packages to remove
TASK [Get kernels to cleanup] ok: [localhost] TASK [Get kernels to cleanup (LOG)] ok: [localhost] => { "cleanup_kernels.log": [ "2023-09-28 10:08:42,849 [INFO] Logging enabled", "2023-09-28 10:08:42,865 [DEBUG] Found kernel package linux-headers-5.15.0-79-generic, version 5.15.0.post79-generic", "2023-09-28 10:08:42,865 [DEBUG] Found kernel package linux-headers-5.15.0-83-generic, version 5.15.0.post83-generic", "2023-09-28 10:08:42,865 [DEBUG] Found kernel package linux-hwe-5.15-headers-5.15.0-79, version 5.15.0.post79", "2023-09-28 10:08:42,865 [DEBUG] Found kernel package linux-hwe-5.15-headers-5.15.0-83, version 5.15.0.post83", "2023-09-28 10:08:42,866 [DEBUG] Found kernel package linux-image-5.15.0-79-generic, version 5.15.0.post79-generic", "2023-09-28 10:08:42,866 [DEBUG] Found kernel package linux-image-5.15.0-83-generic, version 5.15.0.post83-generic", "2023-09-28 10:08:42,866 [DEBUG] Found kernel package linux-modules-5.15.0-79-generic, version 5.15.0.post79-generic", "2023-09-28 10:08:42,866 [DEBUG] Found kernel package linux-modules-5.15.0-83-generic, version 5.15.0.post83-generic", "2023-09-28 10:08:42,866 [DEBUG] Found kernel package linux-modules-extra-5.15.0-79-generic, version 5.15.0.post79-generic", "2023-09-28 10:08:42,866 [DEBUG] Found kernel package linux-modules-extra-5.15.0-83-generic, version 5.15.0.post83-generic", "2023-09-28 10:08:42,871 [DEBUG] Current kernel is 5.15.0.post83-generic", "2023-09-28 10:08:42,871 [INFO] Kernel package version prior '5.15.0.post83': 5.15.0.post79", "2023-09-28 10:08:42,872 [INFO] No kernel packages after version '5.15.0.post83' found.", "2023-09-28 10:08:42,872 [INFO] Kernel package versions to remove: 5.15.0.post79", "2023-09-28 10:08:42,872 [DEBUG] The following packages are candidates for autoremoval: linux-headers-5.15.0-79-generic, linux-hwe-5.15-headers-5.15.0-79,linux-image-5.15.0-79-generic, linux-modules-5.15.0-79-generic, linux-modules-extra-5.15.0-79-generic", "2023-09-28 10:08:45,338 [DEBUG] The following packages are resolved reverse dependencies for autoremove candidates: linux-modules-5.15.0-79-generic, linux-modules-extra-5.15.0-79-generic, linux-hwe-5.15-headers-5.15.0-79, linux-headers-5.15.0-79-generic, linux-image-5.15.0-79-generic", "2023-09-28 10:08:45,338 [INFO] No protected packages found", "2023-09-28 10:08:45,339 [INFO] Exiting successfully" ] } TASK [Kernel packages to remove] ok: [localhost] => { "cleanup_kernels.packages": [ "linux-headers-5.15.0-79-generic", "linux-hwe-5.15-headers-5.15.0-79", "linux-image-5.15.0-79-generic", "linux-modules-5.15.0-79-generic", "linux-modules-extra-5.15.0-79-generic" ] } TASK [Remove kernel packages] **************** skipping: [localhost]
If you decide to proceed with removal of package candidates, rerun the script with the
--cleanupflag:cleanup-kernel-packages --cleanup
TechPreview
Caution
For MKE clusters that are part of MOSK infrastructure, the feature is not supported yet.
Modification of network configuration on an existing machine requires a separate approval step from the Infrastructure Operator. This validation is required to prevent accidental cluster failures due to misconfiguration.
While making approval decisions, the Operator verifies the result of network
configuration changes per host using the fields located in the IpamHost
object status. For details, see IpamHost status.
Warning
- When a new network configuration is being applied on nodes,
sequential draining of corresponding nodes and re-running of LCM on them occurs the same way as it is done during cluster update.
Therefore, before proceeding with modifying the network configuration, verify that the Container Cloud management cluster is up-to-date as described in Verify the Container Cloud status before managed cluster update.
To modify network configuration on existing machines:
Edit the
L2Templateor/andSubnetobjects as required.Caution
For the following
L2Templateconfigurations, Mirantis does not recommend changing the originalL2templateobject but creating a new one and change theL2Templateassignment exclusively for designated machines:If
L2Templateis used across a group of machines, and changes are required only to certain machines within the groupIf
L2Templateis used as the default one for the cluster and hence contains theipam/DefaultForClusterlabel
For these scenarios, select from the following options:
Create a new L2 template using the Create L2 templates procedure.
Duplicate the existing
L2Templateobject associated with the machine to be configured, ensuring that the duplicatedL2Template:Does not contain the
ipam/DefaultForClusterlabelRefers to the cluster using
Spec.clusterRef: <cluster-name>
Verify the statuses of the
IpamHostobjects that use the objects updated in the previous step:kubectl get IpamHost <ipamHostName> -o=jsonpath-as-json='{.status.netconfigCandidate}{"\n"}{.status.netconfigCandidateState}{"\n"}{.status.netconfigFilesStates}{"\n"}{.status.messages}'
Caution
The following fields of the
ipamHoststatus are renamed since Container Cloud 2.22.0 in the scope of theL2TemplateandIpamHostobjects refactoring:netconfigV2tonetconfigCandidatenetconfigV2statetonetconfigCandidateStatenetconfigFilesStatetonetconfigFilesStates(per file)
No user actions are required after renaming.
The format of
netconfigFilesStatechanged after renaming. ThenetconfigFilesStatesfield contains a dictionary of statuses of network configuration files stored innetconfigFiles. The dictionary contains the keys that are file paths and values that have the same meaning for each file thatnetconfigFilesStatehad:For a successfully rendered configuration file:
OK: <timestamp> <sha256-hash-of-rendered-file>, where a timestamp is in the RFC 3339 format.For a failed rendering:
ERR: <error-message>.
If the configuration is valid:
The
netconfigCandidatefield contains the Netplan configuration file candidate rendered using the modified objectsThe
netconfigCandidateStateandnetconfigFilesStatesfields have theOKstatusThe
netconfigFilesStatesfield contains the old date and checksum meaning that the effective Netplan configuration is still based on the previous versions of the modified objectsThe
messagesfield may contain some warnings but no errors
If the L2 template rendering fails, the candidate for Netplan configuration is empty and its
netconfigCandidateStatestatus contains an error message. A broken candidate for Netplan configuration cannot be approved and become the effective Netplan configuration.
Warning
Do not proceed to the next step until you make sure that the
netconfigCandidatefield contains the valid configuration and this configuration meets your expectations.Approve the new network configuration for the related
IpamHostobjects:kubectl patch IpamHost <ipamHostName> --type='merge' -p "{\"spec\":{\"netconfigUpdateAllow\":true}}"
Once applied, the new configuration is copied to the
netconfigFilesfield of the effective Netplan configuration, then copied to the correspondingLCMMachineobjects.Verify the statuses of the updated
IpamHostobjects:kubectl get IpamHost <ipamHostName> -o=jsonpath-as-json='{.status.netconfigCandidate}{"\n"}{.status.netconfigCandidateState}{"\n"}{.status.netconfigFilesStates}{"\n"}{.status.messages}'
Caution
The following fields of the
ipamHoststatus are renamed since Container Cloud 2.22.0 in the scope of theL2TemplateandIpamHostobjects refactoring:netconfigV2tonetconfigCandidatenetconfigV2statetonetconfigCandidateStatenetconfigFilesStatetonetconfigFilesStates(per file)
No user actions are required after renaming.
The format of
netconfigFilesStatechanged after renaming. ThenetconfigFilesStatesfield contains a dictionary of statuses of network configuration files stored innetconfigFiles. The dictionary contains the keys that are file paths and values that have the same meaning for each file thatnetconfigFilesStatehad:For a successfully rendered configuration file:
OK: <timestamp> <sha256-hash-of-rendered-file>, where a timestamp is in the RFC 3339 format.For a failed rendering:
ERR: <error-message>.
The new configuration is copied to the effective Netplan configuration and both configurations are valid when:
The
netconfigCandidateStateandnetconfigFilesStatesfields have theOKstatus and the same checksumThe messages list does not contain any errors
Verify the updated
LCMMachineobjects:kubectl get LCMMachine <LCMMachineName> -o=jsonpath-as-json='{.spec.stateItemsOverwrites}'
In the output of the above command, hash sums contained in the
bm_ipam_netconfig_filesvalues must match those in theIpamHost.status.netconfigFilesStatesoutput. If so, the new configuration is copied toLCMMachineobjects.Monitor the update operations that start on nodes. For details, see Update a managed cluster using the Container Cloud web UI.
This section describes how to change a user name and password of a bare metal
host using an existing BareMetalHostCredential object.
To change a user name and password for a bare metal host:
Open the
BareMetalHostCredentialobject of the required bare metal host for editing.In the
specsection:Update the
usernamefieldReplace
password.name: <secretName>withpassword.value: <hostPasswordInPlainText>
For example:
spec: username: admin password: value: superpassword
This action triggers creation of a new
Secretobject with updated credentials. After that, sensitivepassworddata is replaced with the newSecretobject name. For a detailed workflow description, see API Reference: BareMetalHostCredential.Caution
Adding a password value is mandatory for a user name change. You can either create a new password value or copy the existing one from the related
Secretobject.Caution
Changing a user name in the related
Secretobject does not automatically update theBareMetalHostCredentialobject. Therefore, Mirantis recommends updating credentials only using the theBareMetalHostCredentialobject.Warning
The kubectl apply command automatically saves the applied data as plain text into the
kubectl.kubernetes.io/last-applied-configurationannotation of the corresponding object. This may result in revealing sensitive data in this annotation when creating or modifying the object.Therefore, do not use kubectl apply on this object. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on this object, you can remove the
kubectl.kubernetes.io/last-applied-configurationannotation from the object using kubectl edit.
Manage Ceph¶
This section outlines Ceph LCM operations such as adding Ceph Monitor, Ceph nodes, and RADOS Gateway nodes to an existing Ceph cluster or removing them, as well as removing or replacing Ceph OSDs or updating your Ceph cluster.
The following documents describe Ceph cluster configuration options:
This section describes how to configure a Ceph cluster through the
KaaSCephCluster (kaascephclusters.kaas.mirantis.com) CR during or
after the deployment of a managed cluster.
The KaaSCephCluster CR spec has two sections, cephClusterSpec and
k8sCluster and specifies the nodes to deploy as Ceph components. Based on
the roles definitions in the KaaSCephCluster CR, Ceph Controller
automatically labels nodes for Ceph Monitors and Managers. Ceph OSDs are
deployed based on the storageDevices parameter defined for each Ceph node.
For a default KaaSCephCluster CR, see step 16 in Example of a complete L2 templates configuration for cluster creation.
To configure a Ceph cluster:
Select from the following options:
If you do not have a Container Cloud cluster yet, open
kaascephcluster.yaml.templatefor editing.If the Container Cloud cluster is already deployed, open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with a corresponding value.
Using the tables below, configure the Ceph cluster as required.
High-level parameters¶ Parameter
Description
cephClusterSpecDescribes a Ceph cluster in the Container Cloud cluster. For details on
cephClusterSpecparameters, see the tables below.k8sClusterDefines the cluster on which the
KaaSCephClusterdepends on. Use thek8sClusterparameter if the name or namespace of the corresponding Container Cloud cluster differs from default one:spec: k8sCluster: name: kaas-mgmt namespace: default
General parameters¶ Parameter
Description
networkSpecifies networks for the Ceph cluster:
clusterNet- specifies a Classless Inter-Domain Routing (CIDR) for the Ceph OSD replication network.Warning
To avoid ambiguous behavior of Ceph daemons, do not specify
0.0.0.0/0inclusterNet. Otherwise, Ceph daemons can select an incorrect public interface that can cause the Ceph cluster to become unavailable. The bare metal provider automatically translates the0.0.0.0/0network range to the default LCM IPAM subnet if it exists.Note
The
clusterNetandpublicNetparameters support multiple IP networks. For details, see Enable Ceph multinetwork.publicNet- specifies a CIDR for communication between the service and operator.Warning
To avoid ambiguous behavior of Ceph daemons, do not specify
0.0.0.0/0inpublicNet. Otherwise, Ceph daemons can select an incorrect public interface that can cause the Ceph cluster to become unavailable. The bare metal provider automatically translates the0.0.0.0/0network range to the default LCM IPAM subnet if it exists.Note
The
clusterNetandpublicNetparameters support multiple IP networks. For details, see Enable Ceph multinetwork.
nodesSpecifies the list of Ceph nodes. For details, see Node parameters. The
nodesparameter is a map with machine names as keys and Ceph node specifications as values, for example:nodes: master-0: <node spec> master-1: <node spec> ... worker-0: <node spec>
nodeGroupsSpecifies the list of Ceph nodes grouped by node lists or node labels. For details, see NodeGroups parameters. The
nodeGroupsparameter is a map with group names as keys and Ceph node specifications for defined nodes or node labels as values. For example:nodes: group-1: spec: <node spec> nodes: ["master-0", "master-1"] group-2: spec: <node spec> label: <nodeLabelExpression> ... group-3: spec: <node spec> nodes: ["worker-2", "worker-3"]
The
<nodeLabelExpression>must be a valid Kubernetes label selector expression.poolsSpecifies the list of Ceph pools. For details, see Pool parameters.
objectStorageSpecifies the parameters for Object Storage, such as RADOS Gateway, the Ceph Object Storage. Also specifies the RADOS Gateway Multisite configuration. For details, see RADOS Gateway parameters and Multisite parameters.
rookConfigOptional. String key-value parameter that allows overriding Ceph configuration options.
Since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0), use the
|delimiter to specify the section where a parameter must be placed. For example,monorosd. And, if required, use the.delimiter to specify the exact number of the Ceph OSD or Ceph Monitor to apply an option to a specificmonorosdand override the configuration of the corresponding section.The use of this option enables restart of only specific daemons related to the corresponding section. If you do not specify the section, a parameter is set in the
globalsection, which includes restart of all Ceph daemons except Ceph OSD.For example:
rookConfig: "osd_max_backfills": "64" "mon|mon_health_to_clog": "true" "osd|osd_journal_size": "8192" "osd.14|osd_journal_size": "6250"
extraOptsAvailable since Container Cloud 2.25.0. Enables specification of extra options for a setup, includes the
deviceLabelsparameter.Refer to ExtraOpts parameters for the details.
ingressEnables a custom ingress rule for public access on Ceph services, for example, Ceph RADOS Gateway. For details, see Enable TLS for Ceph public endpoints.
rbdMirrorEnables pools mirroring between two interconnected clusters. For details, see Enable Ceph RBD mirroring.
clientsList of Ceph clients. For details, see Clients parameters.
disableOsSharedKeysDisables autogeneration of shared Ceph values for OpenStack deployments. Set to
falseby default.mgrContains the
mgrModulesparameter that should list the following keys:name- Ceph Manager module nameenabled- flag that defines whether the Ceph Manager module is enabled
For example:
mgr: mgrModules: - name: balancer enabled: true - name: pg_autoscaler enabled: true
The
balancerandpg_autoscalerCeph Manager modules are enabled by default and cannot be disabled.Note
Most Ceph Manager modules require additional configuration that you can perform through the
ceph-toolspod on a managed cluster.healthCheckConfigures health checks and liveness probe settings for Ceph daemons. For details, see HealthCheck parameters.
Example configuration
spec: cephClusterSpec: network: clusterNet: 10.10.10.0/24 publicNet: 10.10.11.0/24 nodes: master-0: <node spec> ... pools: - <pool spec> ... rookConfig: "mon max pg per osd": "600" ...
Node parameters¶ Parameter
Description
rolesSpecifies the
mon,mgr, orrgwdaemon to be installed on a Ceph node. You can place the daemons on any nodes upon your decision. Consider the following recommendations:The recommended number of Ceph Monitors in a Ceph cluster is 3. Therefore, at least 3 Ceph nodes must contain the
monitem in therolesparameter.The number of Ceph Monitors must be odd.
Do not add more than 2 Ceph Monitors at a time and wait until the Ceph cluster is
Readybefore adding more daemons.For better HA and fault tolerance, the number of
mgrroles must equal the number ofmonroles. Therefore, we recommend labeling at least 3 Ceph nodes with themgrrole.If
rgwroles are not specified, allrgwdaemons will spawn on the same nodes withmondaemons.
If a Ceph node contains a
monrole, the Ceph Monitor Pod deploys on this node.If a Ceph node contains a
mgrrole, it informs the Ceph Controller that a Ceph Manager can be deployed on the node. Rook Operator selects the first available node to deploy the Ceph Manager on it:Before Container Cloud 2.22.0, only one Ceph Manager is deployed on a cluster.
Since Container Cloud 2.22.0, two Ceph Managers, active and stand-by, are deployed on a cluster.
If you assign the
mgrrole to three recommended Ceph nodes, one back-up Ceph node is available to redeploy a failed Ceph Manager in case of a server outage.
storageDevicesSpecifies the list of devices to use for Ceph OSD deployment. Includes the following parameters:
Note
Since Container Cloud 2.25.0, Mirantis recommends migrating all
storageDevicesitems toby-idsymlinks as persistent device identifiers.For details, refer to Addressing storage devices.
fullPath- a storage device symlink. Accepts the following values:Since Container Cloud 2.25.0, the device
by-idsymlink that contains the serial number of the physical device and does not containwwn. For example,/dev/disk/by-id/nvme-SAMSUNG_MZ1LB3T8HMLA-00007_S46FNY0R394543. Theby-idsymlink should be equal to the one ofMachinestatusstatus.providerStatus.hardware.storage.byIDslist. Mirantis recommends using this field for definingby-idsymlinks.The device
by-pathsymlink. For example,/dev/disk/by-path/pci-0000:00:11.4-ata-3. Since Container Cloud 2.25.0, Mirantis does not recommend specifying storage devices with deviceby-pathsymlinks because such identifiers are not persistent and can change at node boot.
This parameter is mutually exclusive with
name.name- a storage device name. Accepts the following values:The device name, for example,
sdc. Since Container Cloud 2.25.0, Mirantis does not recommend specifying storage devices with device names because such identifiers are not persistent and can change at node boot.The device
by-idsymlink that contains the serial number of the physical device and does not containwwn. For example,/dev/disk/by-id/nvme-SAMSUNG_MZ1LB3T8HMLA-00007_S46FNY0R394543.The
by-idsymlink should be equal to the one ofMachinestatusstatus.providerStatus.hardware.storage.byIDslist. Since Container Cloud 2.25.0, Mirantis recommends using thefullPathfield for definingby-idsymlinks instead.
This parameter is mutually exclusive with
fullPath.config- a map of device configurations that must contain a mandatorydeviceClassparameter set tohdd,ssd, ornvme. The device class must be defined in a pool and can optionally contain a metadata device, for example:storageDevices: - name: /dev/disk/by-id/scsi-SATA_HGST_HUS724040AL_PN1334PEHN18ZS config: deviceClass: hdd metadataDevice: nvme01 osdsPerDevice: "2"
The underlying storage format to use for Ceph OSDs is BlueStore.
The
metadataDeviceparameter accepts a device name or logical volume path for the BlueStore device. Mirantis recommends using logical volume paths created onnvmedevices. For devices partitioning on logical volumes, see Create a custom bare metal host profile.The
osdsPerDeviceparameter accepts the string-type natural numbers and allows splitting one device on several Ceph OSD daemons. Mirantis recommends using this parameter only forssdornvmedisks.
crushSpecifies the explicit key-value CRUSH topology for a node. For details, see Ceph official documentation: CRUSH maps. Includes the following parameters:
datacenter- a physical data center that consists of rooms and handles data.room- a room that accommodates one or more racks with hosts.pdu- a power distribution unit (PDU) device that has multiple outputs and distributes electric power to racks located within a data center.row- a row of computing racks insideroom.rack- a computing rack that accommodates one or more hosts.chassis- a bare metal structure that houses or physically assembles hosts.region- the geographic location of one or more Ceph Object instances within one or more zones.zone- a logical group that consists of one or more Ceph Object instances.
Example configuration:
crush: datacenter: dc1 room: room1 pdu: pdu1 row: row1 rack: rack1 chassis: ch1 region: region1 zone: zone1
NodeGroups parameters¶ Parameter
Description
specSpecifies a Ceph node specification. For the entire spec, see Node parameters.
nodesSpecifies a list of names of machines to which the Ceph node
specmust be applied. Mutually exclusive with thelabelparameter. For example:nodeGroups: group-1: spec: <node spec> nodes: - master-0 - master-1 - worker-0
labelSpecifies a string with a valid label selector expression to select machines to which the node spec must be applied. Mutually exclusive with
nodesparameter. For example:nodeGroup: group-2: spec: <node spec> label: "ceph-storage-node=true,!ceph-control-node"
Pool parameters¶ Parameter
Description
nameSpecifies the pool name as a prefix for each Ceph block pool. The resulting Ceph block pool name will be
<name>-<deviceClass>.useAsFullNameEnables Ceph block pool to use only the
namevalue as a name. The resulting Ceph block pool name will be<name>without thedeviceClasssuffix.roleSpecifies the pool role and is used mostly for Mirantis OpenStack for Kubernetes (MOSK) pools.
defaultDefines if the pool and dependent StorageClass should be set as default. Must be enabled only for one pool.
deviceClassSpecifies the device class for the defined pool. Possible values are HDD, SSD, and NVMe.
replicatedThe
replicatedparameter is mutually exclusive witherasureCodedand includes the following parameters:size- the number of pool replicas.targetSizeRatio- Optional. A float percentage from0.0to1.0, which specifies the expected consumption of the total Ceph cluster capacity. The default values are as follows:The default ratio of the Ceph Object Storage
dataPoolis 10.0%.For the pools ratio for MOSK, see MOSK Deployment Guide: Deploy a Ceph cluster.
erasureCodedEnables the erasure-coded pool. For details, see Rook documentation: Erasure coded and Ceph documentation: Erasure coded pool. The
erasureCodedparameter is mutually exclusive withreplicated.failureDomainThe failure domain across which the replicas or chunks of data will be spread. Set to
hostby default. The list of possible recommended values includes:host,rack,room, anddatacenter.Caution
Mirantis does not recommend using the following intermediate topology keys:
pdu,row,chassis. Consider theracktopology instead. Theosdfailure domain is prohibited.mirroringOptional. Enables the mirroring feature for the defined pool. Includes the
modeparameter that can be set topoolorimage. For details, see Enable Ceph RBD mirroring.allowVolumeExpansionOptional. Not updatable as it applies only once. Enables expansion of persistent volumes based on
StorageClassof a corresponding pool. For details, see Kubernetes documentation: Resizing persistent volumes using Kubernetes.Note
A Kubernetes cluster only supports increase of storage size.
rbdDeviceMapOptionsOptional. Not updatable as it applies only once. Specifies custom
rbd device mapoptions to use withStorageClassof a corresponding pool. Allows customizing the Kubernetes CSI driver interaction with Ceph RBD for the definedStorageClass. For the available options, see Ceph documentation: Kernel RBD (KRBD) options.parametersOptional. Available since Container Cloud 2.22.0. Specifies the key-value map for the parameters of the Ceph pool. For details, see Ceph documentation: Set Pool values.
reclaimPolicyOptional. Available since Container Cloud 2.25.0. Specifies reclaim policy for the underlying
StorageClassof the pool. AcceptsRetainandDeletevalues. Default isDeleteif not set.Example configuration:
pools: - name: kubernetes role: kubernetes deviceClass: hdd replicated: size: 3 targetSizeRatio: 10.0 default: true
To configure additional required pools for MOSK, see MOSK Deployment Guide: Deploy a Ceph cluster.
Caution
Since Ceph Pacific, Ceph CSI driver does not propagate the
777permission on the mount point of persistent volumes based on anyStorageClassof the Ceph pool.Clients parameters¶ Parameter
Description
nameCeph client name.
capsKey-value parameter with Ceph client capabilities. For details about
caps, refer to Ceph documentation: Authorization (capabilities).Example configuration:
clients: - name: glance caps: mon: allow r, allow command "osd blacklist" osd: profile rbd pool=images
RADOS Gateway parameters¶ Parameter
Description
nameCeph Object Storage instance name.
dataPoolMutually exclusive with the
zoneparameter. Object storage data pool spec that should only containreplicatedorerasureCodedandfailureDomainparameters. ThefailureDomainparameter may be set toosdorhost, defining the failure domain across which the data will be spread. FordataPool, Mirantis recommends using anerasureCodedpool. For details, see Rook documentation: Erasure coding. For example:cephClusterSpec: objectStorage: rgw: dataPool: erasureCoded: codingChunks: 1 dataChunks: 2
metadataPoolMutually exclusive with the
zoneparameter. Object storage metadata pool spec that should only containreplicatedandfailureDomainparameters. ThefailureDomainparameter may be set toosdorhost, defining the failure domain across which the data will be spread. Can use onlyreplicatedsettings. For example:cephClusterSpec: objectStorage: rgw: metadataPool: replicated: size: 3 failureDomain: host
where
replicated.sizeis the number of full copies of data on multiple nodes.Warning
When using the non-recommended Ceph pools
replicated.sizeof less than3, Ceph OSD removal cannot be performed. The minimal replica size equals a rounded up half of the specifiedreplicated.size.For example, if
replicated.sizeis2, the minimal replica size is1, and ifreplicated.sizeis3, then the minimal replica size is2. The replica size of1allows Ceph having PGs with only one Ceph OSD in theactingstate, which may cause aPG_TOO_DEGRADEDhealth warning that blocks Ceph OSD removal. Mirantis recommends settingreplicated.sizeto3for each Ceph pool.gatewayThe gateway settings corresponding to the
rgwdaemon settings. Includes the following parameters:port- the port on which the Ceph RGW service will be listening on HTTP.securePort- the port on which the Ceph RGW service will be listening on HTTPS.instances- the number of pods in the Ceph RGW ReplicaSet. IfallNodesis set totrue, a DaemonSet is created instead.Note
Mirantis recommends using 2 instances for Ceph Object Storage.
allNodes- defines whether to start the Ceph RGW pods as a DaemonSet on all nodes. Theinstancesparameter is ignored ifallNodesis set totrue.
For example:
cephClusterSpec: objectStorage: rgw: gateway: allNodes: false instances: 1 port: 80 securePort: 8443
preservePoolsOnDeleteDefines whether to delete the data and metadata pools in the
rgwsection if the object storage is deleted. Set this parameter totrueif you need to store data even if the object storage is deleted. However, Mirantis recommends setting this parameter tofalse.objectUsersandbucketsOptional. To create new Ceph RGW resources, such as buckets or users, specify the following keys. Ceph Controller will automatically create the specified object storage users and buckets in the Ceph cluster.
objectUsers- a list of user specifications to create for object storage. Contains the following fields:name- a user name to create.displayName- the Ceph user name to display.capabilities- user capabilities:user- admin capabilities to read/write Ceph Object Store users.bucket- admin capabilities to read/write Ceph Object Store buckets.metadata- admin capabilities to read/write Ceph Object Store metadata.usage- admin capabilities to read/write Ceph Object Store usage.zone- admin capabilities to read/write Ceph Object Store zones.
The available options are
*,read,write,read, write. For details, see Ceph documentation: Add/remove admin capabilities.quotas- user quotas:maxBuckets- the maximum bucket limit for the Ceph user. Integer, for example,10.maxSize- the maximum size limit of all objects across all the buckets of a user. String size, for example,10G.maxObjects- the maximum number of objects across all buckets of a user. Integer, for example,10.
For example:
objectUsers: - capabilities: bucket: '*' metadata: read user: read displayName: test-user name: test-user quotas: maxBuckets: 10 maxSize: 10G
users- a list of strings that contain user names to create for object storage.Note
This field is deprecated. Use
objectUsersinstead. Ifusersis specified, it will be automatically transformed to theobjectUserssection.buckets- a list of strings that contain bucket names to create for object storage.
zoneOptional. Mutually exclusive with
metadataPoolanddataPool. Defines the Ceph Multisite zone where the object storage must be placed. Includes thenameparameter that must be set to one of thezonesitems. For details, see Enable multisite for Ceph RGW Object Storage.For example:
cephClusterSpec: objectStorage: multisite: zones: - name: master-zone ... rgw: zone: name: master-zone
SSLCertOptional. Custom TLS certificate parameters used to access the Ceph RGW endpoint. If not specified, a self-signed certificate will be generated.
For example:
cephClusterSpec: objectStorage: rgw: SSLCert: cacert: | -----BEGIN CERTIFICATE----- ca-certificate here -----END CERTIFICATE----- tlsCert: | -----BEGIN CERTIFICATE----- private TLS certificate here -----END CERTIFICATE----- tlsKey: | -----BEGIN RSA PRIVATE KEY----- private TLS key here -----END RSA PRIVATE KEY-----
For configuration example, see Enable Ceph RGW Object Storage.
ExtraOpts parameters¶ Parameter
Description
deviceLabelsAvailable since Cluster releases 17.0.0 and 16.0.0. A key-value setting used to assign a specification label to any available device on a specific node. These labels can then be utilized within
nodeGroupsor node definitions to eliminate the need to specify different devices for each node individually. Additionally, it helps in avoiding the use of device names, facilitating the grouping of nodes with similar labels.Usage:
extraOpts: deviceLabels: <node-name>: <dev-label>: /dev/disk/by-id/<unique_ID> ... <node-name-n>: <dev-label-n>: /dev/disk/by-id/<unique_ID> nodesGroup: <group-name>: spec: storageDevices: - devLabel: <dev_label> - devLabel: <dev_label_n> nodes: - <node_name> - <node_name_n>
Before Cluster releases 17.0.0 and 16.0.0, you need to specify the device labels for each node separately:
nodes: <node-name>: - storageDevices: - fullPath: /dev/disk/by-id/<unique_ID> <node-name-n>: - storageDevices: - fullPath: /dev/disk/by-id/<unique_ID>
customDeviceClassesAvailable since Cluster releases 17.1.0 and 16.1.0 as TechPreview. A list of custom device class names to use in the specification. Enables you to specify the custom names different from the default ones, which include
ssd,hdd, andnvme, and use them in nodes and pools definitions.Usage:
extraOpts: customDeviceClasses: - <custom_class_name> nodes: kaas-node-5bgk6: storageDevices: - config: # existing item deviceClass: <custom_class_name> fullPath: /dev/disk/by-id/<unique_ID> pools: - default: false deviceClass: <custom_class_name> erasureCoded: codingChunks: 1 dataChunks: 2 failureDomain: host
Before Cluster releases 17.1.0 and 16.1.0, you cannot specify custom class names in the specification.
Multisite parameters¶ Parameter
Description
realmsTechnical PreviewList of realms to use, represents the realm namespaces. Includes the following parameters:
name- the realm name.pullEndpoint- optional, required only when the master zone is in a different storage cluster. The endpoint, access key, and system key of the system user from the realm to pull from. Includes the following parameters:endpoint- the endpoint of the master zone in the master zone group.accessKey- the access key of the system user from the realm to pull from.secretKey- the system key of the system user from the realm to pull from.
zoneGroupsTechnical PreviewThe list of zone groups for realms. Includes the following parameters:
name- the zone group name.realmName- the realm namespace name to which the zone group belongs to.
zonesTechnical PreviewThe list of zones used within one zone group. Includes the following parameters:
name- the zone name.metadataPool- the settings used to create the Object Storage metadata pools. Must use replication. For details, see Pool parameters.dataPool- the settings to create the Object Storage data pool. Can use replication or erasure coding. For details, see Pool parameters.zoneGroupName- the zone group name.endpointsForZone- available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). The list of all endpoints in the zone group. If you use ingress proxy for RGW, the list of endpoints must contain that FQDN/IP address to access RGW. By default, if no ingress proxy is used, the list of endpoints is set to the IP address of the RGW external service. Endpoints must follow the HTTP URL format.
For configuration example, see Enable multisite for Ceph RGW Object Storage.
HealthCheck parameters¶ Parameter
Description
daemonHealthSpecifies health check settings for Ceph daemons. Contains the following parameters:
status- configures health check settings for Ceph healthmon- configures health check settings for Ceph Monitorsosd- configures health check settings for Ceph OSDs
Each parameter allows defining the following settings:
disabled- a flag that disables the health check.interval- an interval in seconds or minutes for the health check to run. For example,60sfor 60 seconds.timeout- a timeout for the health check in seconds or minutes. For example,60sfor 60 seconds.
livenessProbeKey-value parameter with liveness probe settings for the defined daemon types. Can be one of the following:
mgr,mon,osd, ormds. Includes thedisabledflag and theprobeparameter. Theprobeparameter accepts the following options:initialDelaySeconds- the number of seconds after the container has started before the liveness probes are initiated. Integer.timeoutSeconds- the number of seconds after which the probe times out. Integer.periodSeconds- the frequency (in seconds) to perform the probe. Integer.successThreshold- the minimum consecutive successful probes for the probe to be considered successful after a failure. Integer.failureThreshold- the minimum consecutive failures for the probe to be considered failed after having succeeded. Integer.
Note
Ceph Controller specifies the following
livenessProbedefaults formon,mgr,osd, andmds(if CephFS is enabled):5fortimeoutSeconds5forfailureThreshold
startupProbeKey-value parameter with startup probe settings for the defined daemon types. Can be one of the following:
mgr,mon,osd, ormds. Includes thedisabledflag and theprobeparameter. Theprobeparameter accepts the following options:timeoutSeconds- the number of seconds after which the probe times out. Integer.periodSeconds- the frequency (in seconds) to perform the probe. Integer.successThreshold- the minimum consecutive successful probes for the probe to be considered successful after a failure. Integer.failureThreshold- the minimum consecutive failures for the probe to be considered failed after having succeeded. Integer.
Example configuration
healthCheck: daemonHealth: mon: disabled: false interval: 45s timeout: 600s osd: disabled: false interval: 60s status: disabled: true livenessProbe: mon: disabled: false probe: timeoutSeconds: 10 periodSeconds: 3 successThreshold: 3 mgr: disabled: false probe: timeoutSeconds: 5 failureThreshold: 5 osd: probe: initialDelaySeconds: 5 timeoutSeconds: 10 failureThreshold: 7 startupProbe: mon: disabled: true mgr: probe: successThreshold: 3
Select from the following options:
If you are creating a managed cluster, save the updated
KaaSCephClustertemplate to the corresponding file and proceed with the managed cluster creation.If you are configuring
KaaSCephClusterof an existing managed cluster, exit the text editor to apply the change.
Ceph Controller provides the capability to specify configuration options for
the Ceph cluster through the spec.cephClusterSpec.rookConfig key-value
parameter of the KaaSCephCluster resource as if they were set in a
usual ceph.conf file.
However, if rookConfig is empty, Ceph Controller still specifies the
following default configuration options for each Ceph cluster:
Required network parameters that you can change through the
spec.cephClusterSpec.networksection:cluster network = <spec.cephClusterSpec.network.clusterNet> public network = <spec.cephClusterSpec.network.publicNet>
General default configuration options that you can override using the
rookConfigparameter:mon target pg per osd = 200 mon max pg per osd = 600 # Workaround configuration option to avoid the # https://github.com/rook/rook/issues/7573 issue # when updating to Rook 1.6.x versions: rgw_data_log_backing = omap
See also
The following documents describe how to configure, manage, and verify specific aspects of a Ceph cluster:
This section describes the supported automated Ceph lifecycle management (LCM) operations.
The Ceph LCM automated operations such as Ceph OSD or Ceph node removal are
performed by creating a corresponding KaaSCephOperationRequest CR that
creates separate CephOsdRemoveRequest requests. It allows for automated
removal of healthy or non-healthy Ceph OSDs from a Ceph cluster and covers the
following scenarios:
Reducing hardware - all Ceph OSDs are up/in but you want to decrease the number of Ceph OSDs by reducing the number of disks or hosts.
Hardware issues. For example, if a host unexpectedly goes down and will not be restored, or if a disk on a host goes down and requires replacement.
This section describes the KaaSCephOperationRequest CR creation workflow,
specification, and request status.
For step-by-step procedures, refer to Automated Ceph LCM.
The workflow of creating a Ceph OSD removal request includes the following steps:
Removing obsolete nodes or disks from the
spec.nodessection of theKaaSCephClusterCR as described in Ceph advanced configuration.Note
Note the names of the removed nodes, devices or their paths exactly as they were specified in
KaaSCephClusterfor further usage.Creating a YAML template for the
KaaSCephOperationRequestCR. For details, see KaaSCephOperationRequest OSD removal specification.If
KaaSCephOperationRequestcontains information about Ceph OSDs to remove in a proper format, the information will be validated to eliminate human error and avoid a wrong Ceph OSD removal.If the
osdRemove.nodessection ofKaaSCephOperationRequestis empty, the Ceph Request Controller will automatically detect Ceph OSDs for removal, if any. Auto-detection is based not only on the information provided in theKaaSCephClusterbut also on the information from the Ceph cluster itself.
Once the validation or auto-detection completes, the entire information about the Ceph OSDs to remove appears in the
KaaSCephOperationRequestobject: hosts they belong to, OSD IDs, disks, partitions, and so on. The request then moves to theApproveWaitingphase until the Operator manually specifies theapproveflag in the spec.Manually adding an affirmative
approveflag in theKaaSCephOperationRequestspec. Once done, the Ceph Status Controller reconciliation pauses until the request is handled and executes the following:Stops regular Ceph Controller reconciliation
Removes Ceph OSDs
Runs batch jobs to clean up the device, if possible
Removes host information from the Ceph cluster if the entire Ceph node is removed
Marks the request with an appropriate result with a description of occurred issues
Note
If the request completes successfully, Ceph Controller reconciliation resumes. Otherwise, it remains paused until the issue is resolved.
Reviewing the Ceph OSD removal status. For details, see KaaSCephOperationRequest OSD removal status.
Manual removal of device cleanup jobs.
Note
Device cleanup jobs are not removed automatically and are kept in the
ceph-lcm-mirantisnamespace along with pods containing information about the executed actions. The jobs have the following labels:labels: app: miraceph-cleanup-disks host: <HOST-NAME> osd: <OSD-ID> rook-cluster: <ROOK-CLUSTER-NAME>
Additionally, jobs are labeled with disk names that will be cleaned up, such as
vdb=true. You can remove a single job or a group of jobs using any label described above, such as host, disk, and so on.
Example of KaaSCephOperationRequest resource
apiVersion: kaas.mirantis.com/v1alpha1
kind: KaaSCephOperationRequest
metadata:
name: remove-osd-3-4-request
namespace: managed-namespace
spec:
osdRemove:
approve: true
nodes:
worker-3:
cleanupByDevice:
- name: sdb
- path: /dev/disk/by-path/pci-0000:00:1t.9
kaasCephCluster:
name: ceph-cluster-managed-cluster
namespace: managed-namespace
Example of Ceph OSDs ready for removal
apiVersion: kaas.mirantis.com/v1alpha1
kind: KaaSCephOperationRequest
metadata:
generateName: remove-osds
namespace: managed-ns
spec:
osdRemove: {}
kaasCephCluster:
name: ceph-cluster-managed-cl
namespace: managed-ns
This section describes the KaaSCephOperationRequest CR specification used
to automatically create a CephOsdRemoveRequest request. For the procedure
workflow, see Creating a Ceph OSD removal request.
Parameter |
Description |
|---|---|
|
Describes the definition for the |
|
Defines spec:
kaasCephCluster:
name: kaas-mgmt
namespace: default
|
Parameter |
Description |
|---|---|
|
Map of Kubernetes nodes that specifies how to remove Ceph OSDs: by host-devices or OSD IDs. For details, see KaaSCephOperationRequest ‘nodes’ parameters spec. |
|
Flag that indicates whether a request is ready to execute removal. Can only be manually enabled by the Operator. For example: spec:
osdRemove:
approve: true
|
|
Flag used to keep requests in handling and not to proceed to the next
request if the If the For example: spec:
osdRemove:
keepOnFail: true
|
|
Optional. Flag that marks a finished request, even if it failed, to keep it in history. It allows resuming the Ceph Controller reconciliation without removing the failed request. The flag is used only by Ceph Controller and has no effect on request processing. Can only be manually specified. For example: spec:
osdRemove:
resolved: true
|
|
Optional. Flag used to resume a failed request and proceed with Ceph OSD
removal if the spec:
osdRemove:
resumeFailed: true
|
Parameter |
Description |
|---|---|
|
Flag used to clean up an entire node and drop it from the CRUSH map.
Mutually exclusive with |
|
List that describes devices to clean up by name or device path as they
were specified in
Warning Since Container Cloud 2.25.0, Mirantis does not recommend
setting device For details, see Addressing storage devices. |
|
List of Ceph OSD IDs to remove. Mutually exclusive with
|
Example of KaaSCephOperationRequest with
spec.osdRemove.nodes
apiVersion: kaas.mirantis.com/v1alpha1
kind: KaaSCephOperationRequest
metadata:
name: remove-osd-request
namespace: default
spec:
kaasCephCluster:
name: kaas-mgmt
namespace: default
osdRemove:
nodes:
"node-a":
completeCleanUp: true
"node-b":
cleanupByOsdId: [1, 15, 25]
"node-c":
cleanupByDevice:
- name: "sdb"
- path: "/dev/disk/by-path/pci-0000:00:1c.5"
- path: "/dev/disk/by-id/scsi-SATA_HGST_HUS724040AL_PN1334PEHN18ZS"
The example above includes the following actions:
For
node-a, full cleanup, including all OSDs on the node, node drop from the CRUSH map, and cleanup of all disks used for Ceph OSDs on this node.For
node-b, cleanup of Ceph OSDs with IDs1,15, and25along with the related disk information.For
node-c, cleanup of the device with namesdb, the device with path ID/dev/disk/by-path/pci-0000:00:1c.5, and the device withby-id/dev/disk/by-id/scsi-SATA_HGST_HUS724040AL_PN1334PEHN18ZS, dropping of OSDs running on these devices.
This section describes the status.osdRemoveStatus.removeInfo fields of the
KaaSCephOperationRequest CR that you can use to review a Ceph OSD or node
removal phases. The following diagram represents the phases flow:

Parameter |
Description |
|---|---|
|
Describes the status of the current |
|
The key-value mapping that reflects the management cluster machine names with their corresponding Kubernetes node names. |
Parameter |
Description |
|---|---|
|
Describes the current request phase that can be one of:
|
|
The overall information about the Ceph OSDs to remove: final removal
map, issues, and warnings. Once the The
|
|
Informational messages describing the reason for the request transition to the next phase. |
|
History of spec updates for the request. |
Example of status.osdRemoveStatus.removeInfo after
successful Validation
removeInfo:
cleanUpMap:
"node-a":
completeCleanUp: true
osdMapping:
"2":
deviceMapping:
"sdb":
path: "/dev/disk/by-path/pci-0000:00:0a.0"
partition: "/dev/ceph-a-vg_sdb/osd-block-b-lv_sdb"
type: "block"
class: "hdd"
zapDisk: true
"6":
deviceMapping:
"sdc":
path: "/dev/disk/by-path/pci-0000:00:0c.0"
partition: "/dev/ceph-a-vg_sdc/osd-block-b-lv_sdc-1"
type: "block"
class: "hdd"
zapDisk: true
"11":
deviceMapping:
"sdc":
path: "/dev/disk/by-path/pci-0000:00:0c.0"
partition: "/dev/ceph-a-vg_sdc/osd-block-b-lv_sdc-2"
type: "block"
class: "hdd"
zapDisk: true
"node-b":
osdMapping:
"1":
deviceMapping:
"sdb":
path: "/dev/disk/by-path/pci-0000:00:0a.0"
partition: "/dev/ceph-b-vg_sdb/osd-block-b-lv_sdb"
type: "block"
class: "ssd"
zapDisk: true
"15":
deviceMapping:
"sdc":
path: "/dev/disk/by-path/pci-0000:00:0b.1"
partition: "/dev/ceph-b-vg_sdc/osd-block-b-lv_sdc"
type: "block"
class: "ssd"
zapDisk: true
"25":
deviceMapping:
"sdd":
path: "/dev/disk/by-path/pci-0000:00:0c.2"
partition: "/dev/ceph-b-vg_sdd/osd-block-b-lv_sdd"
type: "block"
class: "ssd"
zapDisk: true
"node-c":
osdMapping:
"0":
deviceMapping:
"sdb":
path: "/dev/disk/by-path/pci-0000:00:1t.9"
partition: "/dev/ceph-c-vg_sdb/osd-block-c-lv_sdb"
type: "block"
class: "hdd"
zapDisk: true
"8":
deviceMapping:
"sde":
path: "/dev/disk/by-path/pci-0000:00:1c.5"
partition: "/dev/ceph-c-vg_sde/osd-block-c-lv_sde"
type: "block"
class: "hdd"
zapDisk: true
"sdf":
path: "/dev/disk/by-path/pci-0000:00:5a.5",
partition: "/dev/ceph-c-vg_sdf/osd-db-c-lv_sdf-1",
type: "db",
class: "ssd"
The example above is based on the example spec provided in
KaaSCephOperationRequest OSD removal specification.
During the Validation phase, the provided information was validated and
reflects the final map of the Ceph OSDs to remove:
For
node-a, Ceph OSDs with IDs2,6, and11will be removed with the related disk and its information: all block devices, names, paths, and disk class.For
node-b, the Ceph OSDs with IDs1,15, and25will be removed with the related disk information.For
node-c, the Ceph OSD with ID8will be removed, which is placed on the specifiedsdbdevice. The related partition on thesdfdisk, which is used as the BlueStore metadata device, will be cleaned up keeping the disk itself untouched. Other partitions on that device will not be touched.
Example of removeInfo with removeStatus succeeded
removeInfo:
cleanUpMap:
"node-a":
completeCleanUp: true
hostRemoveStatus:
status: Removed
osdMapping:
"2":
removeStatus:
osdRemoveStatus:
status: Removed
deploymentRemoveStatus:
status: Removed
name: "rook-ceph-osd-2"
deviceCleanUpJob:
status: Finished
name: "job-name-for-osd-2"
deviceMapping:
"sdb":
path: "/dev/disk/by-path/pci-0000:00:0a.0"
partition: "/dev/ceph-a-vg_sdb/osd-block-b-lv_sdb"
type: "block"
class: "hdd"
zapDisk: true
Example of removeInfo with removeStatus failed
removeInfo:
cleanUpMap:
"node-a":
completeCleanUp: true
osdMapping:
"2":
removeStatus:
osdRemoveStatus:
errorReason: "retries for cmd ‘ceph osd ok-to-stop 2’ exceeded"
status: Failed
deviceMapping:
"sdb":
path: "/dev/disk/by-path/pci-0000:00:0a.0"
partition: "/dev/ceph-a-vg_sdb/osd-block-b-lv_sdb"
type: "block"
class: "hdd"
zapDisk: true
Example of removeInfo with removeStatus failed by timeout
removeInfo:
cleanUpMap:
"node-a":
completeCleanUp: true
osdMapping:
"2":
removeStatus:
osdRemoveStatus:
errorReason: Timeout (30m0s) reached for waiting pg rebalance for osd 2
status: Failed
deviceMapping:
"sdb":
path: "/dev/disk/by-path/pci-0000:00:0a.0"
partition: "/dev/ceph-a-vg_sdb/osd-block-b-lv_sdb"
type: "block"
class: "hdd"
zapDisk: true
Note
In case of failures similar to the examples above, review the
ceph-request-controller logs and the Ceph cluster status. Such failures
may simply indicate timeout and retry issues. If no other issues were found,
re-create the request with a new name and skip adding successfully removed
Ceph OSDS or Ceph nodes.
Mirantis Ceph Controller simplifies a Ceph cluster management by automating LCM operations. This section describes how to add, remove, or reconfigure Ceph nodes.
Note
When adding a Ceph node with the Ceph Monitor role, if any issues occur with
the Ceph Monitor, rook-ceph removes it and adds a new Ceph Monitor instead,
named using the next alphabetic character in order. Therefore, the Ceph Monitor
names may not follow the alphabetical order. For example, a, b, d,
instead of a, b, c.
Prepare a new machine for the required managed cluster as described in Add a machine. During machine preparation, update the settings of the related bare metal host profile for the Ceph node being replaced with the required machine devices as described in Create a custom bare metal host profile.
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
nodessection, specify the parameters for a Ceph node as required. For the parameters description, see Node parameters.The example configuration of the
nodessection with the new node:nodes: kaas-node-5bgk6: roles: - mon - mgr storageDevices: - config: deviceClass: hdd fullPath: /dev/disk/by-id/scsi-SATA_HGST_HUS724040AL_PN1334PEHN18ZS
nodes: kaas-node-5bgk6: roles: - mon - mgr storageDevices: - config: deviceClass: hdd name: sdb
Warning
Since Container Cloud 2.25.0, Mirantis highly recommends using the non-wwn
by-idsymlinks to specify storage devices in thestorageDeviceslist.For details, see Addressing storage devices.
Note
To use a new Ceph node for a Ceph Monitor or Ceph Manager deployment, also specify the
rolesparameter.Reducing the number of Ceph Monitors is not supported and causes the Ceph Monitor daemons removal from random nodes.
Removal of the
mgrrole in thenodessection of theKaaSCephClusterCR does not remove Ceph Managers. To remove a Ceph Manager from a node, remove it from thenodesspec and manually delete themgrpod in the Rook namespace.
Verify that all new Ceph daemons for the specified node have been successfully deployed in the Ceph cluster. The
fullClusterInfosection should not contain any issues.kubectl -n <managedClusterProjectName> get kaascephcluster -o yaml
Example of system response
status: fullClusterInfo: daemonsStatus: mgr: running: a is active mgr status: Ok mon: running: '3/3 mons running: [a b c] in quorum' status: Ok osd: running: '3/3 running: 3 up, 3 in' status: Ok
Note
Ceph node removal presupposes usage of a KaaSCephOperationRequest
CR. For workflow overview, spec and phases description, see
High-level workflow of Ceph OSD or node removal.
Note
To remove a Ceph node with a mon role, first move the Ceph
Monitor to another node and remove the mon role from the Ceph node as
described in Move a Ceph Monitor daemon to another node.
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
spec.cephClusterSpec.nodessection, remove the required Ceph node specification.For example:
spec: cephClusterSpec: nodes: worker-5: # remove the entire entry for the required node storageDevices: {...} roles: [...]
Create a YAML template for the
KaaSCephOperationRequestCR. For example:apiVersion: kaas.mirantis.com/v1alpha1 kind: KaaSCephOperationRequest metadata: name: remove-osd-worker-5 namespace: <managedClusterProjectName> spec: osdRemove: nodes: worker-5: completeCleanUp: true kaasCephCluster: name: <kaasCephClusterName> namespace: <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding cluster namespace and<kaasCephClusterName>with the correspondingKaaSCephClustername.Apply the template on the management cluster in the corresponding namespace:
kubectl apply -f remove-osd-worker-5.yaml
Verify that the corresponding request has been created:
kubectl get kaascephoperationrequest remove-osd-worker-5 -n <managedClusterProjectName>
Verify that the
removeInfosection appeared in theKaaSCephOperationRequestCRstatus:kubectl -n <managedClusterProjectName> get kaascephoperationrequest remove-osd-worker-5 -o yaml
Example of system response
status: childNodesMapping: kaas-node-d4aac64d-1721-446c-b7df-e351c3025591: worker-5 osdRemoveStatus: removeInfo: cleanUpMap: kaas-node-d4aac64d-1721-446c-b7df-e351c3025591: osdMapping: "10": deviceMapping: sdb: path: "/dev/disk/by-path/pci-0000:00:1t.9" partition: "/dev/ceph-b-vg_sdb/osd-block-b-lv_sdb" type: "block" class: "hdd" zapDisk: true "16": deviceMapping: sdc: path: "/dev/disk/by-path/pci-0000:00:1t.10" partition: "/dev/ceph-b-vg_sdb/osd-block-b-lv_sdc" type: "block" class: "hdd" zapDisk: true
Verify that the
cleanUpMapsection matches the required removal and wait for theApproveWaitingphase to appear instatus:kubectl -n <managedClusterProjectName> get kaascephoperationrequest remove-osd-worker-5 -o yaml
Example of system response:
status: phase: ApproveWaiting
Edit the
KaaSCephOperationRequestCR and set theapproveflag totrue:kubectl -n <managedClusterProjectName> edit kaascephoperationrequest remove-osd-worker-5
For example:
spec: osdRemove: approve: true
Review the status of the
KaaSCephOperationRequestresource request processing. The valuable parameters are as follows:status.phase- the current state of request processingstatus.messages- the description of the current phasestatus.conditions- full history of request processing before the current phasestatus.removeInfo.issuesandstatus.removeInfo.warnings- contain error and warning messages occurred during request processing
Verify that the
KaaSCephOperationRequesthas been completed. For example:status: phase: Completed # or CompletedWithWarnings if there are non-critical issues
Remove the device cleanup jobs:
kubectl delete jobs -n ceph-lcm-mirantis -l app=miraceph-cleanup-disks
There is no hot reconfiguration procedure for existing Ceph OSDs and Ceph Monitors. To reconfigure an existing Ceph node, follow the steps below:
Remove the Ceph node from the Ceph cluster as described in Remove a Ceph node from a managed cluster.
Add the same Ceph node but with a modified configuration as described in Add Ceph nodes on a managed cluster.
Mirantis Ceph Controller simplifies Ceph cluster management by automating LCM operations. This section describes how to add, remove, or reconfigure Ceph OSDs.
Manually prepare the required machine devices with LVM2 on the existing node because
BareMetalHostProfiledoes not support in-place changes.To add a Ceph OSD to an existing or hot-plugged raw device
If you want to add a Ceph OSD on top of a raw device that already exists on a node or is hot-plugged, add the required device using the following guidelines:
You can add a raw device to a node during node deployment.
If a node supports adding devices without node reboot, you can hot plug a raw device to a node.
If a node does not support adding devices without node reboot, you can hot plug a raw device during node shutdown. In this case, complete the following steps:
Enable maintenance mode on the managed cluster.
Turn off the required node.
Attach the required raw device to the node.
Turn on the required node.
Disable maintenance mode on the managed cluster.
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
nodes.<machineName>.storageDevicessection, specify the parameters for a Ceph OSD as required. For the parameters description, see Node parameters.The example configuration of the
nodessection with the new node:nodes: kaas-node-5bgk6: roles: - mon - mgr storageDevices: - config: # existing item deviceClass: hdd fullPath: /dev/disk/by-id/scsi-SATA_HGST_HUS724040AL_PN1334PEHN18ZS - config: # new item deviceClass: hdd fullPath: /dev/disk/by-id/scsi-0ATA_HGST_HUS724040AL_PN1334PEHN1VBC
nodes: kaas-node-5bgk6: roles: - mon - mgr storageDevices: - config: # existing item deviceClass: hdd name: sdb - config: # new item deviceClass: hdd name: sdc
Warning
Since Container Cloud 2.25.0, Mirantis highly recommends using the non-wwn
by-idsymlinks to specify storage devices in thestorageDeviceslist.For details, see Addressing storage devices.
Verify that the Ceph OSD on the specified node is successfully deployed. The
fullClusterInfosection should not contain any issues.kubectl -n <managedClusterProjectName> get kaascephcluster -o yaml
For example:
status: fullClusterInfo: daemonsStatus: ... osd: running: '3/3 running: 3 up, 3 in' status: Ok
Note
Since Container Cloud 2.24.0,
cephDeviceMappingis removed because its large size can potentially exceed the Kubernetes 1.5 MB quota.Verify the Ceph OSD on the managed cluster:
kubectl -n rook-ceph get pod -l app=rook-ceph-osd -o wide | grep <machineName>
Note
Ceph OSD removal presupposes usage of a KaaSCephOperationRequest
CR. For workflow overview, spec and phases description, see
High-level workflow of Ceph OSD or node removal.
Warning
When using the non-recommended Ceph pools replicated.size of
less than 3, Ceph OSD removal cannot be performed. The minimal replica
size equals a rounded up half of the specified replicated.size.
For example, if replicated.size is 2, the minimal replica size is
1, and if replicated.size is 3, then the minimal replica size
is 2. The replica size of 1 allows Ceph having PGs with only one
Ceph OSD in the acting state, which may cause a PG_TOO_DEGRADED
health warning that blocks Ceph OSD removal. Mirantis recommends setting
replicated.size to 3 for each Ceph pool.
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.Remove the required Ceph OSD specification from the
spec.cephClusterSpec.nodes.<machineName>.storageDeviceslist:The example configuration of the
nodessection with the new node:nodes: kaas-node-5bgk6: roles: - mon - mgr storageDevices: - config: deviceClass: hdd fullPath: /dev/disk/by-id/scsi-SATA_HGST_HUS724040AL_PN1334PEHN18ZS - config: # remove the entire item entry from storageDevices list deviceClass: hdd fullPath: /dev/disk/by-id/scsi-0ATA_HGST_HUS724040AL_PN1334PEHN1VBC
nodes: kaas-node-5bgk6: roles: - mon - mgr storageDevices: - config: deviceClass: hdd name: sdb - config: # remove the entire item entry from storageDevices list deviceClass: hdd name: sdc
Create a YAML template for the
KaaSCephOperationRequestCR. Select from the following options:Remove Ceph OSD by device name,
by-pathsymlink, orby-idsymlink:apiVersion: kaas.mirantis.com/v1alpha1 kind: KaaSCephOperationRequest metadata: name: remove-osd-<machineName>-sdb namespace: <managedClusterProjectName> spec: osdRemove: nodes: <machineName>: cleanupByDevice: - name: sdb kaasCephCluster: name: <kaasCephClusterName> namespace: <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding cluster namespace and<kaasCephClusterName>with the correspondingKaaSCephClustername.Warning
Since Container Cloud 2.25.0, Mirantis does not recommend setting device
nameor deviceby-pathsymlink in thecleanupByDevicefield as these identifiers are not persistent and can change at node boot. Remove Ceph OSDs withby-idsymlinks specified in thepathfield or usecleanupByOsdIdinstead.For details, see Addressing storage devices.
Note
Since Container Cloud 2.23.0 and 2.23.1 for MOSK 23.1,
cleanupByDeviceis not supported if a device was physically removed from a node. Therefore, usecleanupByOsdIdinstead. For details, see Remove a failed Ceph OSD by Ceph OSD ID.Before Container Cloud 2.23.0 and 2.23.1 for MOSK 23.1, if the
storageDeviceitem was specified withby-id, specify thepathparameter in thecleanupByDevicesection instead ofname.If the
storageDeviceitem was specified with aby-pathdevice path, specify thepathparameter in thecleanupByDevicesection instead ofname.
Remove Ceph OSD by OSD ID:
apiVersion: kaas.mirantis.com/v1alpha1 kind: KaaSCephOperationRequest metadata: name: remove-osd-<machineName>-sdb namespace: <managedClusterProjectName> spec: osdRemove: nodes: <machineName>: cleanupByOsdId: - 2 kaasCephCluster: name: <kaasCephClusterName> namespace: <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding cluster namespace and<kaasCephClusterName>with the correspondingKaaSCephClustername.
Apply the template on the management cluster in the corresponding namespace:
kubectl apply -f remove-osd-<machineName>-sdb.yaml
Verify that the corresponding request has been created:
kubectl get kaascephoperationrequest remove-osd-<machineName>-sdb -n <managedClusterProjectName>
Verify that the
removeInfosection appeared in theKaaSCephOperationRequestCRstatus:kubectl -n <managedClusterProjectName> get kaascephoperationrequest remove-osd-<machineName>-sdb -o yaml
Example of system response:
status: childNodesMapping: kaas-node-d4aac64d-1721-446c-b7df-e351c3025591: <machineName> osdRemoveStatus: removeInfo: cleanUpMap: kaas-node-d4aac64d-1721-446c-b7df-e351c3025591: osdMapping: "10": deviceMapping: sdb: path: "/dev/disk/by-path/pci-0000:00:1t.9" partition: "/dev/ceph-b-vg_sdb/osd-block-b-lv_sdb" type: "block" class: "hdd" zapDisk: true
Verify that the
cleanUpMapsection matches the required removal and wait for theApproveWaitingphase to appear instatus:kubectl -n <managedClusterProjectName> get kaascephoperationrequest remove-osd-<machineName>-sdb -o yaml
Example of system response:
status: phase: ApproveWaiting
Edit the
KaaSCephOperationRequestCR and set theapproveflag totrue:kubectl -n <managedClusterProjectName> edit kaascephoperationrequest remove-osd-<machineName>-sdb
For example:
spec: osdRemove: approve: true
Review the status of the
KaaSCephOperationRequestresource request processing. The valuable parameters are as follows:status.phase- the current state of request processingstatus.messages- the description of the current phasestatus.conditions- full history of request processing before the current phasestatus.removeInfo.issuesandstatus.removeInfo.warnings- contain error and warning messages occurred during request processing
Verify that the
KaaSCephOperationRequesthas been completed. For example:status: phase: Completed # or CompletedWithWarnings if there are non-critical issues
Remove the device cleanup jobs:
kubectl delete jobs -n ceph-lcm-mirantis -l app=miraceph-cleanup-disks
There is no hot reconfiguration procedure for existing Ceph OSDs. To reconfigure an existing Ceph node, follow the steps below:
Remove a Ceph OSD from the Ceph cluster as described in Remove a Ceph OSD from a managed cluster.
Add the same Ceph OSD but with a modified configuration as described in Add a Ceph OSD on a managed cluster.
Mirantis Ceph Controller simplifies Ceph cluster management by automating LCM operations. This section describes how to add, remove, or reconfigure Ceph OSDs with a separate metadata device.
From the Ceph disks defined in the
BareMetalHostProfileobject that was configured using the Configure Ceph disks in a host profile procedure, select one disk for data and one logical volume for metadata of a Ceph OSD to be added to the Ceph cluster.Note
If you add a new disk after machine provisioning, manually prepare the required machine devices using Logical Volume Manager (LVM) 2 on the existing node because
BareMetalHostProfiledoes not support in-place changes.To add a Ceph OSD to an existing or hot-plugged raw device
If you want to add a Ceph OSD on top of a raw device that already exists on a node or is hot-plugged, add the required device using the following guidelines:
You can add a raw device to a node during node deployment.
If a node supports adding devices without node reboot, you can hot plug a raw device to a node.
If a node does not support adding devices without node reboot, you can hot plug a raw device during node shutdown. In this case, complete the following steps:
Enable maintenance mode on the managed cluster.
Turn off the required node.
Attach the required raw device to the node.
Turn on the required node.
Disable maintenance mode on the managed cluster.
Open the
KaasCephClusterobject for editing:kubectl -n <managedClusterProjectName> edit kaascephcluster
Substitute
<managedClusterProjectName>with the corresponding value.In the
nodes.<machineName>.storageDevicessection, specify the parameters for a Ceph OSD as required. For the parameters description, see Node parameters.The example configuration of the
nodessection with the new node:nodes: kaas-node-5bgk6: roles: - mon - mgr storageDevices: - config: # existing item deviceClass: hdd fullPath: /dev/disk/by-id/scsi-SATA_HGST_HUS724040AL_PN1334PEHN18ZS - config: # new item deviceClass: hdd metadataDevice: /dev/bluedb/meta_1 fullPath: /dev/disk/by-id/scsi-0ATA_HGST_HUS724040AL_PN1334PEHN1VBC
nodes: kaas-node-5bgk6: roles: - mon - mgr storageDevices: - config: # existing item deviceClass: hdd name: sdb - config: # new item deviceClass: hdd metadataDevice: /dev/bluedb/meta_1 name: sdc
Warning
Since Container Cloud 2.25.0, Mirantis highly recommends using the non-wwn
by-idsymlinks to specify storage devices in thestorageDeviceslist.For details, see Addressing storage devices.
Verify that the Ceph OSD is successfully deployed on the specified node:
kubectl -n <managedClusterProjectName> get kaascephcluster -o yaml
In the system response, the
fullClusterInfosection should not contain any issues.Example of a successful system response:
status: fullClusterInfo: daemonsStatus: ... osd: running: '4/4 running: 4 up, 4 in' status: Ok
Obtain the name of the node on which the machine with the Ceph OSD is running:
kubectl -n <managedClusterProjectName> get machine <machineName> -o jsonpath='{.status.nodeRef.name}'
Substitute
<managedClusterProjectName>and<machineName>with corresponding values.Verify the Ceph OSD status:
kubectl -n rook-ceph get pod -l app=rook-ceph-osd -o wide | grep <nodeName>
Substitute
<nodeName>with the value obtained on the previous step.Example of system response:
rook-ceph-osd-0-7b8d4d58db-f6czn 1/1 Running 0 42h 10.100.91.6 kaas-node-6c5e76f9-c2d2-4b1a-b047-3c299913a4bf <none> <none> rook-ceph-osd-1-78fbc47dc5-px9n2 1/1 Running 0 21h 10.100.91.6 kaas-node-6c5e76f9-c2d2-4b1a-b047-3c299913a4bf <none> <none> rook-ceph-osd-3-647f8d6c69-87gxt 1/1 Running 0 21h 10.100.91.6 kaas-node-6c5e76f9-c2d2-4b1a-b047-3c299913a4bf <none> <none>
Note
Ceph OSD removal implies the usage of the
KaaSCephOperationRequest custom resource (CR). For workflow overview,
spec and phases description, see High-level workflow of Ceph OSD or node removal.
Warning
When using the non-recommended Ceph pools replicated.size of
less than 3, Ceph OSD removal cannot be performed. The minimal replica
size equals a rounded up half of the specified replicated.size.
For example, if replicated.size is 2, the minimal replica size is
1, and if replicated.size is 3, then the minimal replica size
is 2. The replica size of 1 allows Ceph having PGs with only one
Ceph OSD in the acting state, which may cause a PG_TOO_DEGRADED
health warning that blocks Ceph OSD removal. Mirantis recommends setting
replicated.size to 3 for each Ceph pool.
Open the
KaasCephClusterobject of the managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.Remove the required Ceph OSD specification from the
spec.cephClusterSpec.nodes.<machineName>.storageDeviceslist:The example configuration of the
nodessection with the new node:nodes: kaas-node-5bgk6: roles: - mon - mgr storageDevices: - config: deviceClass: hdd fullPath: /dev/disk/by-id/scsi-SATA_HGST_HUS724040AL_PN1334PEHN18ZS - config: # remove the entire item entry from storageDevices list deviceClass: hdd metadataDevice: /dev/bluedb/meta_1 fullPath: /dev/disk/by-id/scsi-0ATA_HGST_HUS724040AL_PN1334PEHN1VBC
nodes: kaas-node-5bgk6: roles: - mon - mgr storageDevices: - config: deviceClass: hdd name: sdb - config: # remove the entire item entry from storageDevices list deviceClass: hdd metadataDevice: /dev/bluedb/meta_1 name: sdc
Create a YAML template for the
KaaSCephOperationRequestCR. For example:apiVersion: kaas.mirantis.com/v1alpha1 kind: KaaSCephOperationRequest metadata: name: remove-osd-<machineName>-sdb namespace: <managedClusterProjectName> spec: osdRemove: nodes: <machineName>: cleanupByDevice: - name: sdb kaasCephCluster: name: <kaasCephClusterName> namespace: <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding cluster namespace and<kaasCephClusterName>with the correspondingKaaSCephClustername.Warning
Since Container Cloud 2.25.0, Mirantis does not recommend setting device
nameor deviceby-pathsymlink in thecleanupByDevicefield as these identifiers are not persistent and can change at node boot. Remove Ceph OSDs withby-idsymlinks specified in thepathfield or usecleanupByOsdIdinstead.For details, see Addressing storage devices.
Note
Since Container Cloud 2.23.0 and 2.23.1 for MOSK 23.1,
cleanupByDeviceis not supported if a device was physically removed from a node. Therefore, usecleanupByOsdIdinstead. For details, see Remove a failed Ceph OSD by Ceph OSD ID.Before Container Cloud 2.23.0 and 2.23.1 for MOSK 23.1, if the
storageDeviceitem was specified withby-id, specify thepathparameter in thecleanupByDevicesection instead ofname.If the
storageDeviceitem was specified with aby-pathdevice path, specify thepathparameter in thecleanupByDevicesection instead ofname.
Apply the template on the management cluster in the corresponding namespace:
kubectl apply -f remove-osd-<machineName>-sdb.yaml
Verify that the corresponding request has been created:
kubectl get kaascephoperationrequest remove-osd-<machineName>-sdb -n <managedClusterProjectName>
Verify that the
removeInfosection appeared in theKaaSCephOperationRequestCRstatus:kubectl -n <managedClusterProjectName> get kaascephoperationrequest remove-osd-<machineName>-sdb -o yaml
Example of system response:
status: childNodesMapping: kaas-node-d4aac64d-1721-446c-b7df-e351c3025591: <machineName> osdRemoveStatus: removeInfo: cleanUpMap: kaas-node-d4aac64d-1721-446c-b7df-e351c3025591: osdMapping: "10": deviceMapping: sdb: path: "/dev/disk/by-path/pci-0000:00:1t.9" partition: "/dev/ceph-b-vg_sdb/osd-block-b-lv_sdb" type: "block" class: "hdd" zapDisk: true "5": deviceMapping: /dev/sdc: deviceClass: hdd devicePath: /dev/disk/by-path/pci-0000:00:0f.0 devicePurpose: block usedPartition: /dev/ceph-2d11bf90-e5be-4655-820c-fb4bdf7dda63/osd-block-e41ce9a8-4925-4d52-aae4-e45167cfcf5c zapDisk: true /dev/sdf: deviceClass: hdd devicePath: /dev/disk/by-path/pci-0000:00:12.0 devicePurpose: db usedPartition: /dev/bluedb/meta_1
Verify that the
cleanUpMapsection matches the required removal and wait for theApproveWaitingphase to appear instatus:kubectl -n <managedClusterProjectName> get kaascephoperationrequest remove-osd-<machineName>-sdb -o yaml
Example of system response:
status: phase: ApproveWaiting
In the
KaaSCephOperationRequestCR, set theapproveflag totrue:kubectl -n <managedClusterProjectName> edit kaascephoperationrequest remove-osd-<machineName>-sdb
Configuration snippet:
spec: osdRemove: approve: true
Review the following
statusfields of theKaaSCephOperationRequestCR request processing:status.phase- current state of request processingstatus.messages- description of the current phasestatus.conditions- full history of request processing before the current phasestatus.removeInfo.issuesandstatus.removeInfo.warnings- error and warning messages occurred during request processing, if any
Verify that the
KaaSCephOperationRequesthas been completed.Example of the positive
status.phasefield:status: phase: Completed # or CompletedWithWarnings if there are non-critical issues
Remove the device cleanup jobs:
kubectl delete jobs -n ceph-lcm-mirantis -l app=miraceph-cleanup-disks
There is no hot reconfiguration procedure for existing Ceph OSDs. To reconfigure an existing Ceph node, remove and re-add a Ceph OSD with a metadata device using the following options:
Since Container Cloud 2.24.0, if metadata device partitions are specified in the
BareMetalHostProfileobject as described in Configure Ceph disks in a host profile, the metadata device definition is an LVM path inmetadataDeviceof theKaaSCephClusterobject.Therefore, automated LCM will clean up the logical volume without removal and it can be reused. For this reason, to reconfigure a partition of a Ceph OSD metadata device:
Remove a Ceph OSD from the Ceph cluster as described in Remove a Ceph OSD with a metadata device.
Add the same Ceph OSD but with a modified configuration as described in Add a Ceph OSD with a metadata device.
Before Container Cloud 2.24.0 or if metadata device partitions are not specified in the
BareMetalHostProfileobject as described in Configure Ceph disks in a host profile, the most common definition of a metadata device is a full device name (by-pathorby-id) inmetadataDeviceof theKaaSCephClusterobject for Ceph OSD. For example,metadataDevice: /dev/nvme0n1. In this case, to reconfigure a partition of a Ceph OSD metadata device:Remove a Ceph OSD from the Ceph cluster as described in Remove a Ceph OSD with a metadata device. Automated LCM will clean up the data device and will remove the metadata device partition for the required Ceph OSD.
Reconfigure the metadata device partition manually to use it during addition of a new Ceph OSD.
Manual reconfiguration of a metadata device partition
Log in to the Ceph node running a Ceph OSD to reconfigure.
Find the required metadata device used for Ceph OSDs that should have LVM partitions with the
osd--dbsubstring:lsblk
Example of system response:
... vdf 252:80 0 32G 0 disk ├─ceph--7831901d--398e--415d--8941--e78486f3b019-osd--db--4bdbb0a0--e613--416e--ab97--272f237b7eab │ 253:3 0 16G 0 lvm └─ceph--7831901d--398e--415d--8941--e78486f3b019-osd--db--8f439d5c--1a19--49d5--b71f--3c25ae343303 253:5 0 16G 0 lvm
Capture the volume group UUID and logical volume sizes. In the example above, the volume group UUID is
ceph--7831901d--398e--415d--8941--e78486f3b019and the size is16G.Find the volume group of the metadata device:
vgs
Example of system response:
VG #PV #LV #SN Attr VSize VFree ceph-508c7a6d-db01-4873-98c3-52ab204b5ca8 1 1 0 wz--n- <32.00g 0 ceph-62d84b29-8de5-440c-a6e9-658e8e246af7 1 1 0 wz--n- <32.00g 0 ceph-754e0772-6d0f-4629-bf1d-24cb79f3ee82 1 1 0 wz--n- <32.00g 0 ceph-7831901d-398e-415d-8941-e78486f3b019 1 2 0 wz--n- <48.00g <17.00g lvm_root 1 1 0 wz--n- <61.03g 0
Capture the volume group with the name that matches the prefix of LVM partitions of the metadata device. In the example above, the required volume group is
ceph-7831901d-398e-415d-8941-e78486f3b019.Make a manual LVM partitioning for the new Ceph OSD. Create a new logical volume in the obtained volume group:
lvcreate -L <lvSize> -n <lvName> <vgName>
Substitute the following parameters:
<lvSize>with the previously obtained logical volume size. In the example above, it is16G.<lvName>with a new logical volume name. For example,meta_1.<vgName>with the previously obtained volume group name. In the example above, it isceph-7831901d-398e-415d-8941-e78486f3b019.
Note
Manually created partitions can be removed only manually, or during a complete metadata disk removal, or during the
Machineobject removal or re-provisioning.
Add the same Ceph OSD but with a modified configuration and manually created logical volume of the metadata device as described in Add a Ceph OSD with a metadata device.
For example, instead of
metadataDevice: /dev/bluedb/meta_1definemetadataDevice: /dev/ceph-7831901d-398e-415d-8941-e78486f3b019/meta_1that was manually created in the previous step.
After a physical disk replacement, you can use Ceph LCM API to redeploy a failed Ceph OSD. The common flow of replacing a failed Ceph OSD is as follows:
Remove the obsolete Ceph OSD from the Ceph cluster by device name, by Ceph OSD ID, or by path.
Add a new Ceph OSD on the new disk to the Ceph cluster.
Note
Ceph OSD replacement presupposes usage of a
KaaSCephOperationRequest CR. For workflow overview, spec and phases
description, see High-level workflow of Ceph OSD or node removal.
Warning
The procedure below presuppose that the Operator knows the exact
device name, by-path, or by-id of the replaced device, as well as on
which node the replacement occurred.
Warning
Since Container Cloud 2.23.0 and 2.23.1 for MOSK
23.1, a Ceph OSD removal using by-path, by-id, or device name is
not supported if a device was physically removed from a node. Therefore, use
cleanupByOsdId instead. For details, see
Remove a failed Ceph OSD by Ceph OSD ID.
Warning
Since Container Cloud 2.25.0, Mirantis does not recommend
setting device name or device by-path symlink in the
cleanupByDevice field as these identifiers are not persistent and
can change at node boot. Remove Ceph OSDs with by-id symlinks
specified in the path field or use cleanupByOsdId instead.
For details, see Addressing storage devices.
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
nodessection, remove the required device:spec: cephClusterSpec: nodes: <machineName>: storageDevices: - name: <deviceName> # remove the entire item from storageDevices list # fullPath: <deviceByPath> if device is specified with symlink instead of name config: deviceClass: hdd
Substitute
<machineName>with the machine name of the node where the device<deviceName>or<deviceByPath>is going to be replaced.Save
KaaSCephClusterand close the editor.Create a
KaaSCephOperationRequestCR template and save it asreplace-failed-osd-<machineName>-<deviceName>-request.yaml:apiVersion: kaas.mirantis.com/v1alpha1 kind: KaaSCephOperationRequest metadata: name: replace-failed-osd-<machineName>-<deviceName> namespace: <managedClusterProjectName> spec: osdRemove: nodes: <machineName>: cleanupByDevice: - name: <deviceName> # If a device is specified with by-path or by-id instead of # name, path: <deviceByPath> or <deviceById>. kaasCephCluster: name: <kaasCephClusterName> namespace: <managedClusterProjectName>
Substitute
<kaasCephClusterName>with the correspondingKaaSCephClusterresource from the<managedClusterProjectName>namespace.Apply the template to the cluster:
kubectl apply -f replace-failed-osd-<machineName>-<deviceName>-request.yaml
Verify that the corresponding request has been created:
kubectl get kaascephoperationrequest -n <managedClusterProjectName>
Verify that the
removeInfosection appeared in theKaaSCephOperationRequestCRstatus:kubectl -n <managedClusterProjectName> get kaascephoperationrequest replace-failed-osd-<machineName>-<deviceName> -o yaml
Example of system response:
status: childNodesMapping: <nodeName>: <machineName> osdRemoveStatus: removeInfo: cleanUpMap: <nodeName>: osdMapping: <osdId>: deviceMapping: <dataDevice>: deviceClass: hdd devicePath: <dataDeviceByPath> devicePurpose: block usedPartition: /dev/ceph-d2d3a759-2c22-4304-b890-a2d87e056bd4/osd-block-ef516477-d2da-492f-8169-a3ebfc3417e2 zapDisk: true
Definition of values in angle brackets:
<machineName>- name of the machine on which the device is being replaced, for example,worker-1<nodeName>- underlying node name of the machine, for example,kaas-node-5a74b669-7e53-4535-aabd-5b509ec844af<osdId>- Ceph OSD ID for the device being replaced, for example,1<dataDevice>- name of the device placed on the node, for example,/dev/sdb<dataDeviceByPath>-by-pathof the device placed on the node, for example,/dev/disk/by-path/pci-0000:00:1t.9
Verify that the
cleanUpMapsection matches the required removal and wait for theApproveWaitingphase to appear instatus:kubectl -n <managedClusterProjectName> get kaascephoperationrequest replace-failed-osd-<machineName>-<deviceName> -o yaml
Example of system response:
status: phase: ApproveWaiting
Edit the
KaaSCephOperationRequestCR and set theapproveflag totrue:kubectl -n <managedClusterProjectName> edit kaascephoperationrequest replace-failed-osd-<machineName>-<deviceName>
For example:
spec: osdRemove: approve: true
Review the status of the
KaaSCephOperationRequestresource request processing. The valuable parameters are as follows:status.phase- the current state of request processingstatus.messages- the description of the current phasestatus.conditions- full history of request processing before the current phasestatus.removeInfo.issuesandstatus.removeInfo.warnings- contain error and warning messages occurred during request processing
Verify that the
KaaSCephOperationRequesthas been completed. For example:status: phase: Completed # or CompletedWithWarnings if there are non-critical issues
Remove the device cleanup jobs:
kubectl delete jobs -n ceph-lcm-mirantis -l app=miraceph-cleanup-disks
Caution
The procedure below presupposes that the Operator knows only the failed Ceph OSD ID.
Identify the node and device names used by the affected Ceph OSD:
Using the Ceph CLI in the
rook-ceph-toolsPod, run:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph osd metadata <osdId>
Substitute
<osdId>with the affected OSD ID.Example output:
{ "id": 1, ... "bluefs_db_devices": "vdc", ... "bluestore_bdev_devices": "vde", ... "devices": "vdc,vde", ... "hostname": "kaas-node-6c5e76f9-c2d2-4b1a-b047-3c299913a4bf", ... },
In the example above,
hostnameis the node name anddevicesare all devices used by the affected Ceph OSD.In the
statussection of theKaaSCephClusterCR, obtain theosd-devicemapping:kubectl get kaascephcluster -n <managedClusterProjectName> -o yaml
Substitute
<managedClusterProjectName>with the corresponding value.For example:
status: fullClusterInfo: cephDetails: cephDeviceMapping: <nodeName>: <osdId>: <deviceName>
In the system response, capture the following parameters:
<nodeName>- the corresponding node name that hosts the Ceph OSD<osdId>- the ID of the Ceph OSD to replace<deviceName>- an actual device name to replace
Obtain
<machineName>for<nodeName>where the Ceph OSD is placed:kubectl -n rook-ceph get node -o jsonpath='{range .items[*]}{@.metadata.name}{" "}{@.metadata.labels.kaas\.mirantis\.com\/machine-name}{"\n"}{end}'
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
nodessection, remove the required device:spec: cephClusterSpec: nodes: <machineName>: storageDevices: - name: <deviceName> # remove the entire item from storageDevices list config: deviceClass: hdd
Substitute
<machineName>with the machine name of the node where the device<deviceName>is going to be replaced.Save
KaaSCephClusterand close the editor.Create a
KaaSCephOperationRequestCR template and save it asreplace-failed-<machineName>-osd-<osdId>-request.yaml:apiVersion: kaas.mirantis.com/v1alpha1 kind: KaaSCephOperationRequest metadata: name: replace-failed-<machineName>-osd-<osdId> namespace: <managedClusterProjectName> spec: osdRemove: nodes: <machineName>: cleanupByOsdId: - <osdId> kaasCephCluster: name: <kaasCephClusterName> namespace: <managedClusterProjectName>
Substitute
<kaasCephClusterName>with the correspondingKaaSCephClusterresource from the<managedClusterProjectName>namespace.Apply the template to the cluster:
kubectl apply -f replace-failed-<machineName>-osd-<osdId>-request.yaml
Verify that the corresponding request has been created:
kubectl get kaascephoperationrequest -n <managedClusterProjectName>
Verify that the
removeInfosection appeared in theKaaSCephOperationRequestCRstatus:kubectl -n <managedClusterProjectName> get kaascephoperationrequest replace-failed-<machineName>-osd-<osdId>-request -o yaml
Example of system response
status: childNodesMapping: <nodeName>: <machineName> osdRemoveStatus: removeInfo: cleanUpMap: <nodeName>: osdMapping: <osdId>: deviceMapping: <dataDevice>: deviceClass: hdd devicePath: <dataDeviceByPath> devicePurpose: block usedPartition: /dev/ceph-d2d3a759-2c22-4304-b890-a2d87e056bd4/osd-block-ef516477-d2da-492f-8169-a3ebfc3417e2 zapDisk: true
Definition of values in angle brackets:
<machineName>- name of the machine on which the device is being replaced, for example,worker-1<nodeName>- underlying node name of the machine, for example,kaas-node-5a74b669-7e53-4535-aabd-5b509ec844af<osdId>- Ceph OSD ID for the device being replaced, for example,1<dataDevice>- name of the device placed on the node, for example,/dev/sdb<dataDeviceByPath>-by-pathof the device placed on the node, for example,/dev/disk/by-path/pci-0000:00:1t.9
Verify that the
cleanUpMapsection matches the required removal and wait for theApproveWaitingphase to appear instatus:kubectl -n <managedClusterProjectName> get kaascephoperationrequest replace-failed-<machineName>-osd-<osdId>-request -o yaml
Example of system response:
status: phase: ApproveWaiting
Edit the
KaaSCephOperationRequestCR and set theapproveflag totrue:kubectl -n <managedClusterProjectName> edit kaascephoperationrequest replace-failed-<machineName>-osd-<osdId>-request
For example:
spec: osdRemove: approve: true
Review the status of the
KaaSCephOperationRequestresource request processing. The valuable parameters are as follows:status.phase- the current state of request processingstatus.messages- the description of the current phasestatus.conditions- full history of request processing before the current phasestatus.removeInfo.issuesandstatus.removeInfo.warnings- contain error and warning messages occurred during request processing
Verify that the
KaaSCephOperationRequesthas been completed. For example:status: phase: Completed # or CompletedWithWarnings if there are non-critical issues
Remove the device cleanup jobs:
kubectl delete jobs -n ceph-lcm-mirantis -l app=miraceph-cleanup-disks
Note
You can spawn Ceph OSD on a raw device, but it must be clean and without any data or partitions. If you want to add a device that was in use, also ensure it is raw and clean. To clean up all data and partitions from a device, refer to official Rook documentation.
If you want to add a Ceph OSD on top of a raw device that already exists on a node or is hot-plugged, add the required device using the following guidelines:
You can add a raw device to a node during node deployment.
If a node supports adding devices without node reboot, you can hot plug a raw device to a node.
If a node does not support adding devices without node reboot, you can hot plug a raw device during node shutdown. In this case, complete the following steps:
Enable maintenance mode on the managed cluster.
Turn off the required node.
Attach the required raw device to the node.
Turn on the required node.
Disable maintenance mode on the managed cluster.
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
nodessection, add a new device:spec: cephClusterSpec: nodes: <machineName>: storageDevices: - fullPath: <deviceByID> # Since Container Cloud 2.25.0 if device is supposed to be added with by-id # name: <deviceByID> # Prior Container Cloud 2.25.0 if device is supposed to be added with by-id # fullPath: <deviceByPath> # if device is supposed to be added with by-path config: deviceClass: hdd
Substitute
<machineName>with the machine name of the node where device<deviceName>or<deviceByPath>is going to be added as a Ceph OSD.Verify that the new Ceph OSD has appeared in the Ceph cluster and is
inandup. ThefullClusterInfosection should not contain any issues.kubectl -n <managedClusterProjectName> get kaascephcluster -o yaml
For example:
status: fullClusterInfo: daemonStatus: osd: running: '3/3 running: 3 up, 3 in' status: Ok
The document describes various scenarios of a Ceph OSD outage and recovery or replacement. More specifically, this section describes how to replace a failed Ceph OSD with a metadata device:
If the metadata device is specified as a logical volume in the
BareMetalHostProfileobject and defined in theKaaSCephClusterobject as a logical volume pathIf the metadata device is specified in the
KaaSCephClusterobject as a device name
Note
Ceph OSD replacement implies the usage of the
KaaSCephOperationRequest custom resource (CR). For workflow overview,
spec and phases description, see High-level workflow of Ceph OSD or node removal.
You can apply the below procedure in the following cases:
A Ceph OSD failed without data or metadata device outage. In this case, first remove a failed Ceph OSD and clean up all corresponding disks and partitions. Then add a new Ceph OSD to the same data and metadata paths.
A Ceph OSD failed with data or metadata device outage. In this case, you also first remove a failed Ceph OSD and clean up all corresponding disks and partitions. Then add a new Ceph OSD to a newly replaced data device with the same metadata path.
Note
The below procedure also applies to manually created metadata partitions.
Identify the ID of Ceph OSD related to a failed device. For example, use the Ceph CLI in the
rook-ceph-toolsPod:ceph osd metadata
Example of system response:
{ "id": 0, ... "bluestore_bdev_devices": "vdc", ... "devices": "vdc", ... "hostname": "kaas-node-6c5e76f9-c2d2-4b1a-b047-3c299913a4bf", ... "pod_name": "rook-ceph-osd-0-7b8d4d58db-f6czn", ... }, { "id": 1, ... "bluefs_db_devices": "vdf", ... "bluestore_bdev_devices": "vde", ... "devices": "vde,vdf", ... "hostname": "kaas-node-6c5e76f9-c2d2-4b1a-b047-3c299913a4bf", ... "pod_name": "rook-ceph-osd-1-78fbc47dc5-px9n2", ... }, ...
Open the
KaasCephClustercustom resource (CR) for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
nodessection:Find and capture the
metadataDevicepath to reuse it during re-creation of the Ceph OSD.Remove the required device:
Example configuration snippet:
spec: cephClusterSpec: nodes: <machineName>: storageDevices: - name: <deviceName> # remove the entire item from the storageDevices list # fullPath: <deviceByPath> if device is specified using by-path instead of name config: deviceClass: hdd metadataDevice: /dev/bluedb/meta_1
In the example above,
<machineName>is the name of machine that relates to the node on which the device<deviceName>or<deviceByPath>must be replaced.Create a
KaaSCephOperationRequestCR template and save it asreplace-failed-osd-<machineName>-<osdID>-request.yaml:apiVersion: kaas.mirantis.com/v1alpha1 kind: KaaSCephOperationRequest metadata: name: replace-failed-osd-<machineName>-<deviceName> namespace: <managedClusterProjectName> spec: osdRemove: nodes: <machineName>: cleanupByOsdId: - <osdID> kaasCephCluster: name: <kaasCephClusterName> namespace: <managedClusterProjectName>
Substitute the following parameters:
<machineName>and<deviceName>with the machine and device names from the previous step<managedClusterProjectName>with the cluster project name<osdID>with the ID of the affected Ceph OSD<kaasCephClusterName>with theKaaSCephClusterresource name<managedClusterProjectName>with the project name of the related managed cluster
Apply the template to the cluster:
kubectl apply -f replace-failed-osd-<machineName>-<osdID>-request.yaml
Verify that the corresponding request has been created:
kubectl get kaascephoperationrequest -n <managedClusterProjectName>
Verify that the
statussection ofKaaSCephOperationRequestcontains theremoveInfosection:kubectl -n <managedClusterProjectName> get kaascephoperationrequest replace-failed-osd-<machineName>-<osdID> -o yaml
Example of system response:
childNodesMapping: <nodeName>: <machineName> removeInfo: cleanUpMap: <nodeName>: osdMapping: "<osdID>": deviceMapping: <dataDevice>: deviceClass: hdd devicePath: <dataDeviceByPath> devicePurpose: block usedPartition: /dev/ceph-d2d3a759-2c22-4304-b890-a2d87e056bd4/osd-block-ef516477-d2da-492f-8169-a3ebfc3417e2 zapDisk: true <metadataDevice>: deviceClass: hdd devicePath: <metadataDeviceByPath> devicePurpose: db usedPartition: /dev/bluedb/meta_1 uuid: ef516477-d2da-492f-8169-a3ebfc3417e2
Definition of values in angle brackets:
<machineName>- name of the machine on which the device is being replaced, for example,worker-1<nodeName>- underlying node name of the machine, for example,kaas-node-5a74b669-7e53-4535-aabd-5b509ec844af<osdId>- Ceph OSD ID for the device being replaced, for example,1<dataDevice>- name of the device placed on the node, for example,/dev/vde<dataDeviceByPath>-by-pathof the device placed on the node, for example,/dev/disk/by-path/pci-0000:00:1t.9<metadataDevice>- metadata name of the device placed on the node, for example,/dev/vdf<metadataDeviceByPath>- metadataby-pathof the device placed on the node, for example,/dev/disk/by-path/pci-0000:00:12.0
Note
The partitions that are manually created or configured using the
BareMetalHostProfileobject can be removed only manually, or during a complete metadata disk removal, or during theMachineobject removal or re-provisioning.Verify that the
cleanUpMapsection matches the required removal and wait for theApproveWaitingphase to appear instatus:kubectl -n <managedClusterProjectName> get kaascephoperationrequest replace-failed-osd-<machineName>-<osdID> -o yaml
Example of system response:
status: phase: ApproveWaiting
In the
KaaSCephOperationRequestCR, set theapproveflag totrue:kubectl -n <managedClusterProjectName> edit kaascephoperationrequest replace-failed-osd-<machineName>-<osdID>
Configuration snippet:
spec: osdRemove: approve: true
Review the following
statusfields of theKaaSCephOperationRequestCR request processing:status.phase- current state of request processingstatus.messages- description of the current phasestatus.conditions- full history of request processing before the current phasestatus.removeInfo.issuesandstatus.removeInfo.warnings- error and warning messages occurred during request processing, if any
Verify that the
KaaSCephOperationRequesthas been completed. For example:status: phase: Completed # or CompletedWithWarnings if there are non-critical issues
Note
You can spawn Ceph OSD on a raw device, but it must be clean and without any data or partitions. If you want to add a device that was in use, also ensure it is raw and clean. To clean up all data and partitions from a device, refer to official Rook documentation.
If you want to add a Ceph OSD on top of a raw device that already exists on a node or is hot-plugged, add the required device using the following guidelines:
You can add a raw device to a node during node deployment.
If a node supports adding devices without node reboot, you can hot plug a raw device to a node.
If a node does not support adding devices without node reboot, you can hot plug a raw device during node shutdown. In this case, complete the following steps:
Enable maintenance mode on the managed cluster.
Turn off the required node.
Attach the required raw device to the node.
Turn on the required node.
Disable maintenance mode on the managed cluster.
Open the
KaasCephClusterCR for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
nodessection, add the replaced device with the samemetadataDevicepath as on the removed Ceph OSD. For example:spec: cephClusterSpec: nodes: <machineName>: storageDevices: - name: <deviceByID> # Recommended. Add a new device by ID, for example, /dev/disk/by-id/... #fullPath: <deviceByPath> # Add a new device by path, for example, /dev/disk/by-path/... config: deviceClass: hdd metadataDevice: /dev/bluedb/meta_1 # Must match the value of the previously removed OSD
Substitute
<machineName>with the machine name of the node where the new device<deviceByID>or<deviceByPath>must be added.Wait for the replaced disk to apply to the Ceph cluster as a new Ceph OSD.
You can monitor the application state using either the
statussection of theKaaSCephClusterCR or in therook-ceph-toolsPod:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph -s
You can apply the below procedure if a Ceph OSD failed with data disk outage
and the metadata partition is not specified in the BareMetalHostProfile
custom resource (CR). This scenario implies that the Ceph cluster
automatically creates a required metadata logical volume on a desired device.
To remove the affected Ceph OSD with a metadata device as a device name, follow the Remove a failed Ceph OSD by ID with a defined metadata device procedure and capture the following details:
While editing
KaasCephClusterin thenodessection, capture themetadataDevicepath to reuse it during re-creation of the Ceph OSD.Example of the
spec.nodessection:spec: cephClusterSpec: nodes: <machineName>: storageDevices: - name: <deviceName> # remove the entire item from the storageDevices list # fullPath: <deviceByPath> if device is specified using by-path instead of name config: deviceClass: hdd metadataDevice: /dev/nvme0n1
In the example above, save the
metadataDevicedevice name/dev/nvme0n1.During verification of
removeInfo, capture theusedPartitionvalue of the metadata device located in thedeviceMapping.<metadataDevice>section.Example of the
removeInfosection:removeInfo: cleanUpMap: <nodeName>: osdMapping: "<osdID>": deviceMapping: <dataDevice>: deviceClass: hdd devicePath: <dataDeviceByPath> devicePurpose: block usedPartition: /dev/ceph-d2d3a759-2c22-4304-b890-a2d87e056bd4/osd-block-ef516477-d2da-492f-8169-a3ebfc3417e2 zapDisk: true <metadataDevice>: deviceClass: hdd devicePath: <metadataDeviceByPath> devicePurpose: db usedPartition: /dev/ceph-b0c70c72-8570-4c9d-93e9-51c3ab4dd9f9/osd-db-ecf64b20-1e07-42ac-a8ee-32ba3c0b7e2f uuid: ef516477-d2da-492f-8169-a3ebfc3417e2
In the example above, capture the following values from the
<metadataDevice>section:ceph-b0c70c72-8570-4c9d-93e9-51c3ab4dd9f9- name of the volume group that contains all metadata partitions on the<metadataDevice>diskosd-db-ecf64b20-1e07-42ac-a8ee-32ba3c0b7e2f- name of the logical volume that relates to a failed Ceph OSD
After you remove the Ceph OSD disk, manually create a separate logical volume for the metadata partition in an existing volume group on the metadata device:
lvcreate -l 100%FREE -n meta_1 <vgName>
Subtitute <vgName> with the name of a volume group captured in the
usedPartiton parameter.
Note
If you removed more than one OSD, replace 100%FREE with the
corresponding partition size. For example:
lvcreate -l <partitionSize> -n meta_1 <vgName>
Substitute <partitionSize> with the corresponding value that matches the
size of other partitions placed on the affected metadata drive. To obtain
<partitionSize>, use the output of the lvs command. For example:
16G.
During execution of the lvcreate command, the system asks you to wipe the found bluestore label on a metadata device. For example:
WARNING: ceph_bluestore signature detected on /dev/ceph-b0c70c72-8570-4c9d-93e9-51c3ab4dd9f9/meta_1 at offset 0. Wipe it? [y/n]:
Using the interactive shell, answer n to keep all metadata partitions
alive. After answering n, the system outputs the following:
Aborted wiping of ceph_bluestore.
1 existing signature left on the device.
Logical volume "meta_1" created.
Note
You can spawn Ceph OSD on a raw device, but it must be clean and without any data or partitions. If you want to add a device that was in use, also ensure it is raw and clean. To clean up all data and partitions from a device, refer to official Rook documentation.
If you want to add a Ceph OSD on top of a raw device that already exists on a node or is hot-plugged, add the required device using the following guidelines:
You can add a raw device to a node during node deployment.
If a node supports adding devices without node reboot, you can hot plug a raw device to a node.
If a node does not support adding devices without node reboot, you can hot plug a raw device during node shutdown. In this case, complete the following steps:
Enable maintenance mode on the managed cluster.
Turn off the required node.
Attach the required raw device to the node.
Turn on the required node.
Disable maintenance mode on the managed cluster.
Open the
KaasCephClusterCR for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
nodessection, add the replaced device with the samemetadataDevicepath as in the previous Ceph OSD:spec: cephClusterSpec: nodes: <machineName>: storageDevices: - fullPath: <deviceByID> # Recommended since Container Cloud 2.25.0. # Add a new device by-id symlink, for example, /dev/disk/by-id/... #name: <deviceByID> # Add a new device by ID, for example, /dev/disk/by-id/... #fullPath: <deviceByPath> # Add a new device by path, for example, /dev/disk/by-path/... config: deviceClass: hdd metadataDevice: /dev/<vgName>/meta_1
Substitute
<machineName>with the machine name of the node where the new device<deviceByID>or<deviceByPath>must be added. Also specifymetadataDevicewith the path to the logical volume created during the Re-create the metadata partition on the existing metadata disk procedure.Wait for the replaced disk to apply to the Ceph cluster as a new Ceph OSD.
You can monitor the application state using either the
statussection of theKaaSCephClusterCR or in therook-ceph-toolsPod:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph -s
This section describes the scenario when an underlying metadata device fails with all related Ceph OSDs. In this case, the only solution is to remove all Ceph OSDs related to the failed metadata device, then attach a device that will be used as a new metadata device, and re-create all affected Ceph OSDs.
Caution
If you used BareMetalHostProfile to automatically partition
the failed device, you must create a manual partition of the new device
because BareMetalHostProfile does not support hot-load changes and
creates an automatic device partition only during node provisioning.
Save the
KaaSCephClusterspecification of all Ceph OSDs affected by the failed metadata device to re-use this specification during re-creation of Ceph OSDs after disk replacement.Identify Ceph OSD IDs related to the failed metadata device, for example, using Ceph CLI in the
rook-ceph-toolsPod:ceph osd metadata
Example of system response:
{ "id": 11, ... "bluefs_db_devices": "vdc", ... "bluestore_bdev_devices": "vde", ... "devices": "vdc,vde", ... "hostname": "kaas-node-6c5e76f9-c2d2-4b1a-b047-3c299913a4bf", ... }, { "id": 12, ... "bluefs_db_devices": "vdd", ... "bluestore_bdev_devices": "vde", ... "devices": "vdd,vde", ... "hostname": "kaas-node-6c5e76f9-c2d2-4b1a-b047-3c299913a4bf", ... }, { "id": 13, ... "bluefs_db_devices": "vdf", ... "bluestore_bdev_devices": "vde", ... "devices": "vde,vdf", ... "hostname": "kaas-node-6c5e76f9-c2d2-4b1a-b047-3c299913a4bf", ... }, ...
Open the
KaasCephClustercustom resource (CR) for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
nodessection, remove allstorageDevicesitems that relate to the failed metadata device. For example:spec: cephClusterSpec: nodes: <machineName>: storageDevices: - name: <deviceName1> # remove the entire item from the storageDevices list # fullPath: <deviceByPath> if device is specified using symlink instead of name config: deviceClass: hdd metadataDevice: <metadataDevice> - name: <deviceName2> # remove the entire item from the storageDevices list config: deviceClass: hdd metadataDevice: <metadataDevice> - name: <deviceName3> # remove the entire item from the storageDevices list config: deviceClass: hdd metadataDevice: <metadataDevice> ...
In the example above,
<machineName>is the machine name of the node where the metadata device<metadataDevice>must be replaced.Create a
KaaSCephOperationRequestCR template and save it asreplace-failed-meta-<machineName>-<metadataDevice>-request.yaml:apiVersion: kaas.mirantis.com/v1alpha1 kind: KaaSCephOperationRequest metadata: name: replace-failed-meta-<machineName>-<metadataDevice> namespace: <managedClusterProjectName> spec: osdRemove: nodes: <machineName>: cleanupByOsdId: - <osdID-1> - <osdID-2> ... kaasCephCluster: name: <kaasCephClusterName> namespace: <managedClusterProjectName>
Substitute the following parameters:
<machineName>and<metadataDevice>with the machine and device names from the previous step<managedClusterProjectName>with the cluster project name<osdID-*>with IDs of the affected Ceph OSDs<kaasCephClusterName>with theKaaSCephClusterCR name<managedClusterProjectName>with the project name of the related managed cluster
Apply the template to the cluster:
kubectl apply -f replace-failed-meta-<machineName>-<metadataDevice>-request.yaml
Verify that the corresponding request has been created:
kubectl get kaascephoperationrequest -n <managedClusterProjectName>
Verify that the
removeInfosection is present in theKaaSCephOperationRequestCRstatusand that thecleanUpMapsection matches the required removal:kubectl -n <managedClusterProjectName> get kaascephoperationrequest replace-failed-meta-<machineName>-<metadataDevice> -o yaml
Example of system response:
childNodesMapping: <nodeName>: <machineName> removeInfo: cleanUpMap: <nodeName>: osdMapping: "<osdID-1>": deviceMapping: <dataDevice-1>: deviceClass: hdd devicePath: <dataDeviceByPath-1> devicePurpose: block usedPartition: <dataLvPartition-1> zapDisk: true <metadataDevice>: deviceClass: hdd devicePath: <metadataDeviceByPath> devicePurpose: db usedPartition: /dev/ceph-b0c70c72-8570-4c9d-93e9-51c3ab4dd9f9/osd-db-ecf64b20-1e07-42ac-a8ee-32ba3c0b7e2f uuid: ef516477-d2da-492f-8169-a3ebfc3417e2 "<osdID-2>": deviceMapping: <dataDevice-2>: deviceClass: hdd devicePath: <dataDeviceByPath-2> devicePurpose: block usedPartition: <dataLvPartition-2> zapDisk: true <metadataDevice>: deviceClass: hdd devicePath: <metadataDeviceByPath> devicePurpose: db usedPartition: /dev/ceph-b0c70c72-8570-4c9d-93e9-51c3ab4dd9f9/osd-db-ecf64b20-1e07-42ac-a8ee-32ba3c0b7e2f uuid: ef516477-d2da-492f-8169-a3ebfc3417e2 ...
Definition of values in angle brackets:
<machineName>- name of the machine on which the device is being replaced, for example,worker-1<nodeName>- underlying node name of the machine, for example,kaas-node-5a74b669-7e53-4535-aabd-5b509ec844af<osdId>- Ceph OSD ID for the device being replaced, for example,1<dataDevice>- name of the device placed on the node, for example,/dev/vdc<dataDeviceByPath>-by-pathof the device placed on the node, for example,/dev/disk/by-path/pci-0000:00:1t.9<metadataDevice>- metadata name of the device placed on the node, for example,/dev/vde<metadataDeviceByPath>- metadataby-pathof the device placed on the node, for example,/dev/disk/by-path/pci-0000:00:12.0
<dataLvPartition>logical volume partition of the data device
Wait for the
ApproveWaitingphase to appear instatus:kubectl -n <managedClusterProjectName> get kaascephoperationrequest replace-failed-meta-<machineName>-<metadataDevice> -o yaml
Example of system response:
status: phase: ApproveWaiting
In the
KaaSCephOperationRequestCR, set theapproveflag totrue:kubectl -n <managedClusterProjectName> edit kaascephoperationrequest replace-failed-meta-<machineName>-<metadataDevice>
Configuration snippet:
spec: osdRemove: approve: true
Review the following
statusfields of theKaaSCephOperationRequestCR request processing:status.phase- current state of request processingstatus.messages- description of the current phasestatus.conditions- full history of request processing before the current phasestatus.removeInfo.issuesandstatus.removeInfo.warnings- error and warning messages occurred during request processing, if any
Verify that the
KaaSCephOperationRequesthas been completed. For example:status: phase: Completed # or CompletedWithWarnings if there are non-critical issues
Note
This section describes how to create a metadata disk partition on N logical volumes. To create one partition on a metadata disk, refer to Reconfigure a partition of a Ceph OSD metadata device.
Partition the replaced metadata device by N logical volumes (LVs), where N is the number of Ceph OSDs previously located on a failed metadata device.
Calculate the new metadata LV percentage of used volume group capacity using the
100 / Nformula.Log in to the node with the replaced metadata disk.
Create an LVM physical volume atop the replaced metadata device:
pvcreate <metadataDisk>Substitute
<metadataDisk>with the replaced metadata device.Create an LVM volume group atop of the physical volume:
vgcreate bluedb <metadataDisk>
Substitute
<metadataDisk>with the replaced metadata device.Create N LVM logical volumes with the calculated capacity per each volume:
lvcreate -l <X>%VG -n meta_<i> bluedb
Substitute
<X>with the result of the100 / Nformula and<i>with the current number of metadata partitions.
As a result, the replaced metadata device will have N LVM paths, for example,
/dev/bluedb/meta_1.
Note
You can spawn Ceph OSD on a raw device, but it must be clean and without any data or partitions. If you want to add a device that was in use, also ensure it is raw and clean. To clean up all data and partitions from a device, refer to official Rook documentation.
Open the
KaasCephClusterCR for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
nodessection, add the cleaned Ceph OSD device with the replaced LVM paths of the metadata device from previous steps. For example:spec: cephClusterSpec: nodes: <machineName>: storageDevices: - name: <deviceByID-1> # Recommended. Add the new device by ID /dev/disk/by-id/... #fullPath: <deviceByPath-1> # Add a new device by path /dev/disk/by-path/... config: deviceClass: hdd metadataDevice: /dev/<vgName>/<lvName-1> - name: <deviceByID-2> # Recommended. Add the new device by ID /dev/disk/by-id/... #fullPath: <deviceByPath-2> # Add a new device by path /dev/disk/by-path/... config: deviceClass: hdd metadataDevice: /dev/<vgName>/<lvName-2> - name: <deviceByID-3> # Recommended. Add the new device by ID /dev/disk/by-id/... #fullPath: <deviceByPath-3> # Add a new device by path /dev/disk/by-path/... config: deviceClass: hdd metadataDevice: /dev/<vgName>/<lvName-3>
Substitute
<machineName>with the machine name of the node where the metadata device has been replaced.Add all data devices for re-created Ceph OSDs and specify
metadataDevicethat is the path to the previously created logical volume. Substitute<vgName>with a volume group name that contains N logical volumes<lvName-i>.
Wait for the re-created Ceph OSDs to apply to the Ceph cluster.
You can monitor the application state using either the
statussection of theKaaSCephClusterCR or in therook-ceph-toolsPod:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph -s
After a physical node replacement, you can use the Ceph LCM API to redeploy failed Ceph nodes. The common flow of replacing a failed Ceph node is as follows:
Remove the obsolete Ceph node from the Ceph cluster.
Add a new Ceph node with the same configuration to the Ceph cluster.
Note
Ceph OSD node replacement presupposes usage of a
KaaSCephOperationRequest CR. For workflow overview, spec and phases
description, see High-level workflow of Ceph OSD or node removal.
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
nodessection, remove the required device:spec: cephClusterSpec: nodes: <machineName>: # remove the entire entry for the node to replace storageDevices: {...} role: [...]
Substitute
<machineName>with the machine name to replace.Save
KaaSCephClusterand close the editor.Create a
KaaSCephOperationRequestCR template and save it asreplace-failed-<machineName>-request.yaml:apiVersion: kaas.mirantis.com/v1alpha1 kind: KaaSCephOperationRequest metadata: name: replace-failed-<machineName>-request namespace: <managedClusterProjectName> spec: osdRemove: nodes: <machineName>: completeCleanUp: true kaasCephCluster: name: <kaasCephClusterName> namespace: <managedClusterProjectName>
Substitute
<kaasCephClusterName>with the correspondingKaaSCephClusterresource from the<managedClusterProjectName>namespace.Apply the template to the cluster:
kubectl apply -f replace-failed-<machineName>-request.yaml
Verify that the corresponding request has been created:
kubectl get kaascephoperationrequest -n <managedClusterProjectName>
Verify that the
removeInfosection appeared in theKaaSCephOperationRequestCRstatus:kubectl -n <managedClusterProjectName> get kaascephoperationrequest replace-failed-<machineName>-request -o yaml
Example of system response:
status: childNodesMapping: <nodeName>: <machineName> osdRemoveStatus: removeInfo: cleanUpMap: <nodeName>: osdMapping: ... <osdId>: deviceMapping: ... <deviceName>: path: <deviceByPath> partition: "/dev/ceph-b-vg_sdb/osd-block-b-lv_sdb" type: "block" class: "hdd" zapDisk: true
If needed, change the following values:
<machineName>- machine name where the replacement occurs, for example,worker-1.<nodeName>- underlying machine node name, for example,kaas-node-5a74b669-7e53-4535-aabd-5b509ec844af.<osdId>- actual Ceph OSD ID for the device being replaced, for example,1.<deviceName>- actual device name placed on the node, for example,sdb.<deviceByPath>- actual deviceby-pathplaced on the node, for example,/dev/disk/by-path/pci-0000:00:1t.9.
Verify that the
cleanUpMapsection matches the required removal and wait for theApproveWaitingphase to appear instatus:kubectl -n <managedClusterProjectName> get kaascephoperationrequest replace-failed-<machineName>-request -o yaml
Example of system response:
status: phase: ApproveWaiting
Edit the
KaaSCephOperationRequestCR and set theapproveflag totrue:kubectl -n <managedClusterProjectName> edit kaascephoperationrequest replace-failed-<machineName>-request
For example:
spec: osdRemove: approve: true
Review the status of the
KaaSCephOperationRequestresource request processing. The valuable parameters are as follows:status.phase- the current state of request processingstatus.messages- the description of the current phasestatus.conditions- full history of request processing before the current phasestatus.removeInfo.issuesandstatus.removeInfo.warnings- contain error and warning messages occurred during request processing
Verify that the
KaaSCephOperationRequesthas been completed. For example:status: phase: Completed # or CompletedWithWarnings if there are non-critical issues
Remove the device cleanup jobs:
kubectl delete jobs -n ceph-lcm-mirantis -l app=miraceph-cleanup-disks
Note
You can spawn Ceph OSD on a raw device, but it must be clean and without any data or partitions. If you want to add a device that was in use, also ensure it is raw and clean. To clean up all data and partitions from a device, refer to official Rook documentation.
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
nodessection, add a new device:spec: cephClusterSpec: nodes: <machineName>: # add new configuration for replaced Ceph node storageDevices: - fullPath: <deviceByID> # Recommended since Container Cloud 2.25.0, non-wwn by-id symlink # name: <deviceByID> # Prior Container Cloud 2.25.0, non-wwn by-id symlink # fullPath: <deviceByPath> # if device is supposed to be added with by-path config: deviceClass: hdd ...
Substitute
<machineName>with the machine name of the replaced node and configure it as required.Warning
Since Container Cloud 2.25.0, Mirantis highly recommends using non-wwn
by-idsymlinks only to specify storage devices in thestorageDeviceslist.For details, see Addressing storage devices.
Verify that all Ceph daemons from the replaced node have appeared on the Ceph cluster and are
inandup. ThefullClusterInfosection should not contain any issues.kubectl -n <managedClusterProjectName> get kaascephcluster -o yaml
Example of system response:
status: fullClusterInfo: clusterStatus: ceph: health: HEALTH_OK ... daemonStatus: mgr: running: a is active mgr status: Ok mon: running: '3/3 mons running: [a b c] in quorum' status: Ok osd: running: '3/3 running: 3 up, 3 in' status: Ok
Verify the Ceph node on the managed cluster:
kubectl -n rook-ceph get pod -o wide | grep <machineName>
The by-id identifier is the only persistent device identifier for a Ceph
cluster that remains stable after the cluster upgrade or any other maintenance.
Therefore, Mirantis recommends using device by-id symlinks rather than
device names or by-path symlinks.
Container Cloud uses the device by-id identifier as the default method
of addressing the underlying devices of Ceph OSDs. Thus, you should migrate
all existing Ceph clusters, which are still utilizing the device names or
device by-path symlinks, to the by-id format.
This section explains how to configure the KaaSCephCluster specification
to use the by-id symlinks instead of disk names and by-path
identifiers as the default method of addressing storage devices.
Note
Mirantis recommends avoiding the use of wwn symlinks as
by-id identifiers due to their lack of persistence expressed in
inconsistent discovery during node boot.
Besides migrating to by-id, consider using the fullPath field for the
by-id symlinks configuration, instead of the name field in the
spec.cephClusterSpec.nodes.storageDevices section. This approach allows for
clear understanding of field namings and their use cases.
Note
Container Cloud enables you to use fullPath for the by-id
symlinks since 2.25.0. For the earlier product versions, use the name
field instead.
Available since 2.25.0
Make sure that your managed cluster is not currently running an upgrade or any other maintenance process.
Obtain the list of all
KaasCephClusterstorage devices that use disk names or diskby-pathas identifiers of Ceph node storage devices:kubectl -n <managedClusterProject> get kcc -o yaml
Substitute
<managedClusterProject>with the corresponding managed cluster namespace.Output example:
spec: cephClusterSpec: nodes: ... managed-worker-1: storageDevices: - config: deviceClass: hdd name: sdc - config: deviceClass: hdd fullPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2 managed-worker-2: storageDevices: - config: deviceClass: hdd name: /dev/disk/by-id/wwn-0x26d546263bd312b8 - config: deviceClass: hdd name: /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_2e52abb48862dsdc managed-worker-3: storageDevices: - config: deviceClass: nvme name: nvme3n1 - config: deviceClass: hdd fullPath: /dev/disk/by-id/scsi-SATA_HGST_HUS724040AL_PN1334PEHN18ZS
Verify the items from the
storageDevicessections to be moved to theby-idsymlinks. The list of the items to migrate includes:A disk name in the
namefield. For example,sdc,nvme3n1, and so on.A disk
/dev/disk/by-pathsymlink in thefullPathfield. For example,/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2.A disk
/dev/disk/by-idsymlink in thenamefield.Note
This condition applies since Container Cloud 2.25.0.
A disk
/dev/disk/by-id/wwnsymlink, which is programmatically calculated at boot. For example,/dev/disk/by-id/wwn-0x26d546263bd312b8.
For the example above, we have to migrate both items of
managed-worker-1, both items ofmanaged-worker-2, and the first item ofmanaged-worker-3. The second item ofmanaged-worker-3has already been configured in the required format, therefore, we are leaving it as is.To migrate all affected
storageDevicesitems toby-idsymlinks, open theKaaSCephClustercustom resource for editing:kubectl -n <managedClusterProject> edit kccFor each affected node from the
spec.cephClusterSpec.nodessection, obtain a correspondingstatus.providerStatus.hardware.storagesection from theMachinecustom resource:kubectl -n <managedClusterProject> get machine <machineName> -o yaml
Substitute
<managedClusterProject>with the corresponding cluster namespace and<machineName>with the machine name.Output example for
managed-worker-1:status: providerStatus: hardware: storage: - byID: /dev/disk/by-id/wwn-0x05ad99618d66a21f byIDs: - /dev/disk/by-id/scsi-0QEMU_QEMU_HARDDISK_05ad99618d66a21f - /dev/disk/by-id/scsi-305ad99618d66a21f - /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_05ad99618d66a21f - /dev/disk/by-id/wwn-0x05ad99618d66a21f byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0 byPaths: - /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0 name: /dev/sda serialNumber: 05ad99618d66a21f size: 61 type: hdd - byID: /dev/disk/by-id/wwn-0x26d546263bd312b8 byIDs: - /dev/disk/by-id/scsi-0QEMU_QEMU_HARDDISK_26d546263bd312b8 - /dev/disk/by-id/scsi-326d546263bd312b8 - /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_26d546263bd312b8 - /dev/disk/by-id/wwn-0x26d546263bd312b8 byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2 byPaths: - /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2 name: /dev/sdb serialNumber: 26d546263bd312b8 size: 32 type: hdd - byID: /dev/disk/by-id/wwn-0x2e52abb48862dbdc byIDs: - /dev/disk/by-id/lvm-pv-uuid-MncrcO-6cel-0QsB-IKaY-e8UK-6gDy-k2hOtf - /dev/disk/by-id/scsi-0QEMU_QEMU_HARDDISK_2e52abb48862dbdc - /dev/disk/by-id/scsi-32e52abb48862dbdc - /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_2e52abb48862dbdc - /dev/disk/by-id/wwn-0x2e52abb48862dbdc byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:1 byPaths: - /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:1 name: /dev/sdc serialNumber: 2e52abb48862dbdc size: 61 type: hdd
For each affected
storageDevicesitem from the consideredMachine, obtain a correctby-idsymlink fromstatus.providerStatus.hardware.storage.byIDs. Suchby-idsymlink must containstatus.providerStatus.hardware.storage.serialNumberand must not containwwn.For
managed-worker-1, according to the example output above, we can use the followingby-idsymlinks:Replace the first item of
storageDevicesthat containsname: sdcwithfullPath: /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_2e52abb48862dbdc;Replace the second item of
storageDevicesthat containsfullPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2withfullPath: /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_26d546263bd312b8.
Replace all affected
storageDevicesitems inKaaSCephClusterwith the obtained ones.Note
Prior to Container Cloud 2.25.0, place the
by-idsymlinks in thenamefield instead of thefullPathfield.The resulting example of the storage device identifier migration:
spec: cephClusterSpec: nodes: ... managed-worker-1: storageDevices: - config: deviceClass: hdd fullPath: /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_2e52abb48862dbdc - config: deviceClass: hdd fullPath: /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_26d546263bd312b8 managed-worker-2: storageDevices: - config: deviceClass: hdd fullPath: /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_031d9054c9b48f79 - config: deviceClass: hdd fullPath: /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_2e52abb48862dsdc managed-worker-3: storageDevices: - config: deviceClass: nvme fullPath: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB3T8HMLA-00007_S46FNY0R394543 - config: deviceClass: hdd fullPath: /dev/disk/by-id/scsi-SATA_HGST_HUS724040AL_PN1334PEHN18ZS
Save and quit editing the
KaaSCephClustercustom resource.
After migration, the re-orchestration occurs. The whole procedure should not result in any real changes to the Ceph cluster state in Ceph OSDs.
Available since 2.25.0
Besides the nodes section, your cluster may contain the nodeGroups
section specified with disk names instead of by-id symlinks. Despite
of inplace replacement of the nodes storage device identifiers,
nodeGroups requires another approach because of the repeatable spec
section for different nodes.
In the case of migrating nodeGroups storage devices, the deviceLabels
section should be used to label different disks with the same labels and use
these labels in node groups after. For the deviceLabels section
specification, refer to Ceph advanced configuration: extraOpts.
The following procedure describes how to keep the nodeGroups section
but use unique by-id identifiers instead of disk names.
To migrate the Ceph nodeGroups section to by-id identifiers:
Make sure that your managed cluster is not currently running an upgrade or any other maintenance process.
Obtain the list of all
KaasCephClusterstorage devices that use disk names or diskby-pathas identifiers of Ceph node group storage devices:kubectl -n <managedClusterProject> get kcc -o yaml
Substitute
<managedClusterProject>with the corresponding managed cluster namespace.Output example of the
KaaSCephClusternodeGroupssection with disk names used as identifiers:spec: cephClusterSpec: nodeGroups: ... rack-1: nodes: - node-1 - node-2 spec: crush: rack: "rack-1" storageDevices: - name: nvme0n1 config: deviceClass: nvme - name: nvme1n1 config: deviceClass: nvme - name: nvme2n1 config: deviceClass: nvme rack-2: nodes: - node-3 - node-4 spec: crush: rack: "rack-2" storageDevices: - name: nvme0n1 config: deviceClass: nvme - name: nvme1n1 config: deviceClass: nvme - name: nvme2n1 config: deviceClass: nvme rack-3: nodes: - node-5 - node-6 spec: crush: rack: "rack-3" storageDevices: - name: nvme0n1 config: deviceClass: nvme - name: nvme1n1 config: deviceClass: nvme - name: nvme2n1 config: deviceClass: nvme
Verify the items from the
storageDevicessections to be moved toby-idsymlinks. The list of the items to migrate includes:A disk name in the
namefield. For example,sdc,nvme3n1, and so on.A disk
/dev/disk/by-pathsymlink in thefullPathfield. For example,/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2.A disk
/dev/disk/by-idsymlink in thenamefield.Note
This condition applies since Container Cloud 2.25.0.
A disk
/dev/disk/by-id/wwnsymlink, which is programmatically calculated at boot. For example,/dev/disk/by-id/wwn-0x26d546263bd312b8.
All
storageDevicesections in the example above contain disk names in thenamefield. Therefore, you need to replace them withby-idsymlinks.Open the
KaaSCephClustercustom resource for editing to start migration of all affectedstorageDevicesitems toby-idsymlinks:kubectl -n <managedClusterProject> edit kccWithin each impacted Ceph node group in the
nodeGroupssection, add disk labels to thedeviceLabelssections for every affected storage device linked with the nodes listed innodesof that specific node group. Verify that these disk labels are equal toby-idsymlinks of corresponding disks.For example, if the node group
rack-1contains two nodesnode-1andnode-2andspeccontains three items withname, you need to obtain properby-idsymlinks for disk names from both nodes and write it down with the same disk labels. The following example contains the labels forby-idsymlinks ofnvme0n1,nvme1n1, andnvme2n1disks fromnode-1andnode-2correspondingly:spec: cephClusterSpec: extraOpts: deviceLabels: node-1: nvme-1: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB3T8HMLA-00007_S46FNY0R394543 nvme-2: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB3T8HMLA-00007_S46FNY0R372150 nvme-3: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB3T8HMLA-00007_S46FNY0R183266 node-2: nvme-1: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB4040ALR-00007_S46FNY0R900128 nvme-2: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB4040ALR-00007_S46FNY0R805840 nvme-3: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB4040ALR-00007_S46FNY0R848469
Note
Keep device labels repeatable for all nodes from the node group. This allows for specifying unified
specfor differentby-idsymlinks of different nodes.Example of the full
deviceLabelssection for thenodeGroupssection:spec: cephClusterSpec: extraOpts: deviceLabels: node-1: nvme-1: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB3T8HMLA-00007_S46FNY0R394543 nvme-2: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB3T8HMLA-00007_S46FNY0R372150 nvme-3: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB3T8HMLA-00007_S46FNY0R183266 node-2: nvme-1: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB4040ALR-00007_S46FNY0R900128 nvme-2: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB4040ALR-00007_S46FNY0R805840 nvme-3: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB4040ALR-00007_S46FNY0R848469 node-3: nvme-1: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB00T2B0A-00007_S46FNY0R900128 nvme-2: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB00T2B0A-00007_S46FNY0R805840 nvme-3: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB00T2B0A-00007_S46FNY0R848469 node-4: nvme-1: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB00Z4SA0-00007_S46FNY0R286212 nvme-2: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB00Z4SA0-00007_S46FNY0R350024 nvme-3: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB00Z4SA0-00007_S46FNY0R300756 node-5: nvme-1: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB8UK0QBD-00007_S46FNY0R577024 nvme-2: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB8UK0QBD-00007_S46FNY0R718411 nvme-3: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB8UK0QBD-00007_S46FNY0R831424 node-6: nvme-1: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB01DAU34-00007_S46FNY0R908440 nvme-2: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB01DAU34-00007_S46FNY0R945405 nvme-3: /dev/disk/by-id/nvme-SAMSUNG_MZ1LB01DAU34-00007_S46FNY0R224911
For each affected node group in the
nodeGroupssection, replace the field with the insufficient disk identifier to thedevLabelfield with the disk label from thedeviceLabelssection.For the example above, the updated
nodeGroupssection looks as follows:spec: cephClusterSpec: nodeGroups: ... rack-1: nodes: - node-1 - node-2 spec: crush: rack: "rack-1" storageDevices: - devLabel: nvme-1 config: deviceClass: nvme - devLabel: nvme-2 config: deviceClass: nvme - devLabel: nvme-3 config: deviceClass: nvme rack-2: nodes: - node-3 - node-4 spec: crush: rack: "rack-2" storageDevices: - devLabel: nvme-1 config: deviceClass: nvme - devLabel: nvme-2 config: deviceClass: nvme - devLabel: nvme-3 config: deviceClass: nvme rack-3: nodes: - node-5 - node-6 spec: crush: rack: "rack-3" storageDevices: - devLabel: nvme-1 config: deviceClass: nvme - devLabel: nvme-2 config: deviceClass: nvme - devLabel: nvme-3 config: deviceClass: nvme
Save and quit editing the
KaaSCephClustercustom resource.
After migration, the re-orchestration occurs. The whole procedure should not result in any real changes to the Ceph cluster state in Ceph OSDs.
You can start using a storage device only after a corresponding Machine
becomes ready and accessible. Thus, KaaSCephCluster can be created only
after all machines receive the status.providerStatus.hardware.storage
configuration containing all required device by-id symlinks.
To obtain a device by-id symlink:
Verify that the
MachineisReady:kubectl -n <managedClusterProject> get machine <machineName> -o jsonpath='{.status.phase}{"\n"}'
Substitute
<managedClusterProject>with the cluster namespace and<machineName>with the machine name.Obtain storage details for the
Machine:kubectl -n <managedClusterProject> get machine <machineName> -o yaml
Output example:
status: providerStatus: hardware: storage: - byID: /dev/disk/by-id/wwn-0x05ad99618d66a21f byIDs: - /dev/disk/by-id/scsi-0QEMU_QEMU_HARDDISK_05ad99618d66a21f - /dev/disk/by-id/scsi-305ad99618d66a21f - /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_05ad99618d66a21f - /dev/disk/by-id/wwn-0x05ad99618d66a21f byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0 byPaths: - /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0 name: /dev/sda serialNumber: 05ad99618d66a21f size: 61 type: hdd - byID: /dev/disk/by-id/wwn-0x26d546263bd312b8 byIDs: - /dev/disk/by-id/scsi-0QEMU_QEMU_HARDDISK_26d546263bd312b8 - /dev/disk/by-id/scsi-326d546263bd312b8 - /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_26d546263bd312b8 - /dev/disk/by-id/wwn-0x26d546263bd312b8 byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2 byPaths: - /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:2 name: /dev/sdb serialNumber: 26d546263bd312b8 size: 32 type: hdd - byID: /dev/disk/by-id/wwn-0x2e52abb48862dbdc byIDs: - /dev/disk/by-id/lvm-pv-uuid-MncrcO-6cel-0QsB-IKaY-e8UK-6gDy-k2hOtf - /dev/disk/by-id/scsi-0QEMU_QEMU_HARDDISK_2e52abb48862dbdc - /dev/disk/by-id/scsi-32e52abb48862dbdc - /dev/disk/by-id/scsi-SQEMU_QEMU_HARDDISK_2e52abb48862dbdc - /dev/disk/by-id/wwn-0x2e52abb48862dbdc byPath: /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:1 byPaths: - /dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:1 name: /dev/sdc serialNumber: 2e52abb48862dbdc size: 61 type: hdd
Obtain the item from the
byIDslist from thestatus.providerStatus.hardware.storagesection that containsserialNumberand does not containwwnas a bus ID.In the example above, for the disk with the
/dev/sdcname, you can use the/dev/disk/by-id/scsi-0QEMU_QEMU_HARDDISK_2e52abb48862dbdcsymlink as a persistent identifier of the storage device because it contains the2e52abb48862dbdcserial number and does not containwwn.Note
Do not rely on the
byIDfield only. This field may contain a/dev/disk/by-id/wwnsymlink that cannot be considered a persistent identifier of a storage device.
This section describes how to increase the overall storage size for all Ceph
pools of the same device class: hdd, ssd, or nvme.
The procedure presupposes adding a new Ceph OSD. The overall storage size for
the required device class automatically increases once the Ceph OSD becomes
available in the Ceph cluster.
To increase the overall storage size for a device class:
Identify the current storage size for the required device class:
kubectl --kubeconfig <managedClusterKubeconfig> -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph df
Substitute
<managedClusterKubeconfig>with a managed clusterkubeconfig.Example of system response:
--- RAW STORAGE --- CLASS SIZE AVAIL USED RAW USED %RAW USED hdd 128 GiB 101 GiB 23 GiB 27 GiB 21.40 TOTAL 128 GiB 101 GiB 23 GiB 27 GiB 21.40 --- POOLS --- POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL device_health_metrics 1 1 0 B 0 0 B 0 30 GiB kubernetes-hdd 2 32 12 GiB 3.13k 23 GiB 20.57 45 GiB
Identify the number of Ceph OSDs with the required device class:
kubectl --kubeconfig <managedClusterKubeconfig> -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph osd df <deviceClass>
Substitute the following parameters:
<managedClusterKubeconfig>with a managed clusterkubeconfig<deviceClass>with the required device class:hdd,ssd, ornvme
Example of system response for the
hdddevice class:ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS 1 hdd 0.03119 1.00000 32 GiB 5.8 GiB 4.8 GiB 1.5 MiB 1023 MiB 26 GiB 18.22 0.85 14 up 3 hdd 0.03119 1.00000 32 GiB 6.9 GiB 5.9 GiB 1.1 MiB 1023 MiB 25 GiB 21.64 1.01 17 up 0 hdd 0.03119 0.84999 32 GiB 6.8 GiB 5.8 GiB 1013 KiB 1023 MiB 25 GiB 21.24 0.99 16 up 2 hdd 0.03119 1.00000 32 GiB 7.9 GiB 6.9 GiB 1.2 MiB 1023 MiB 24 GiB 24.55 1.15 20 up TOTAL 128 GiB 27 GiB 23 GiB 4.8 MiB 4.0 GiB 101 GiB 21.41 MIN/MAX VAR: 0.85/1.15 STDDEV: 2.29
Follow Add a Ceph OSD on a managed cluster to add a new device with a supported device class:
hdd,ssd, ornvme.Wait for the new Ceph OSD pod to start
Running:kubectl --kubeconfig <managedClusterKubeconfig> -n rook-ceph get pod -l app=rook-ceph-osd
Substitute
<managedClusterKubeconfig>with a managed clusterkubeconfig.Verify that the new Ceph OSD has rebalanced and Ceph health is
HEALTH_OK:kubectl --kubeconfig <managedClusterKubeconfig> -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph -s
Substitute
<managedClusterKubeconfig>with a managed cluster kubeconfig.Verify that the new Ceph has been OSD added to the list of device class OSDs:
kubectl --kubeconfig <managedClusterKubeconfig> -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph osd df <deviceClass>
Substitute the following parameters:
<managedClusterKubeconfig>with a managed clusterkubeconfig<deviceClass>with the required device class:hdd,ssd, ornvme
Example of system response for the
hdddevice class after adding a new Ceph OSD:ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS 1 hdd 0.03119 1.00000 32 GiB 4.5 GiB 3.5 GiB 1.5 MiB 1023 MiB 28 GiB 13.93 0.78 10 up 3 hdd 0.03119 1.00000 32 GiB 5.5 GiB 4.5 GiB 1.1 MiB 1023 MiB 26 GiB 17.22 0.96 13 up 0 hdd 0.03119 0.84999 32 GiB 6.5 GiB 5.5 GiB 1013 KiB 1023 MiB 25 GiB 20.32 1.14 15 up 2 hdd 0.03119 1.00000 32 GiB 7.5 GiB 6.5 GiB 1.2 MiB 1023 MiB 24 GiB 23.43 1.31 19 up 4 hdd 0.03119 1.00000 32 GiB 4.6 GiB 3.6 GiB 0 B 1 GiB 27 GiB 14.45 0.81 10 up TOTAL 160 GiB 29 GiB 24 GiB 4.8 MiB 5.0 GiB 131 GiB 17.87 MIN/MAX VAR: 0.78/1.31 STDDEV: 3.62
Verify the total storage capacity increased for the entire device class:
kubectl --kubeconfig <managedClusterKubeconfig> -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph df
Substitute
<managedClusterKubeconfig>with a managed clusterkubeconfig.Example of system response:
--- RAW STORAGE --- CLASS SIZE AVAIL USED RAW USED %RAW USED hdd 160 GiB 131 GiB 24 GiB 29 GiB 17.97 TOTAL 160 GiB 131 GiB 24 GiB 29 GiB 17.97 --- POOLS --- POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL device_health_metrics 1 1 0 B 0 0 B 0 38 GiB kubernetes-hdd 2 32 12 GiB 3.18k 24 GiB 17.17 57 GiB
This document describes how to migrate a Ceph Monitor daemon from one node to another without changing the general number of Ceph Monitors in the cluster. In the Ceph Controller concept, migration of a Ceph Monitor means manually removing it from one node and adding it to another.
Consider the following exemplary placement scheme of Ceph Monitors in the
nodes spec of the KaaSCephCluster CR:
nodes:
node-1:
roles:
- mon
- mgr
node-2:
roles:
- mgr
Using the example above, if you want to move the Ceph Monitor from node-1
to node-2 without changing the number of Ceph Monitors, the roles table
of the nodes spec must result as follows:
nodes:
node-1:
roles:
- mgr
node-2:
roles:
- mgr
- mon
However, due to the Rook limitation related to Kubernetes architecture, once
you move the Ceph Monitor through the KaaSCephCluster CR, changes will not
apply automatically. This is caused by the following Rook behavior:
Rook creates Ceph Monitor resources as deployments with
nodeSelector, which binds Ceph Monitor pods to a requested node.Rook does not recreate new Ceph Monitors with the new node placement if the current
monquorum works.
Therefore, to move a Ceph Monitor to another node, you must also manually apply the new Ceph Monitors placement to the Ceph cluster as described below.
To move a Ceph Monitor to another node:
Open the
KaasCephClusterCR of a managed cluster:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
nodesspec of theKaaSCephClusterCR, change themonroles placement without changing the total number ofmonroles. For details, see the example above. Note the nodes on which themonroles have been removed.Wait until the corresponding
MiraCephresource is updated with the newnodesspec:kubectl --kubeconfig <kubeconfig> -n ceph-lcm-mirantis get miraceph -o yaml
Substitute
<kubeconfig>with the Container Cloud clusterkubeconfigthat hosts the required Ceph cluster.In the
MiraCephresource, determine which node has been changed in thenodesspec. Save thenamevalue of the node where themonrole has been removed for further usage.kubectl -n <managedClusterProjectName> get machine -o jsonpath='{range .items[*]}{.metadata.name .status.nodeRef.name}{"\n"}{end}'
Substitute
<managedClusterProjectName>with the corresponding value.If you perform a managed cluster update, follow additional steps:
Verify that the following conditions are met before proceeding to the next step:
There are at least 2 running and available Ceph Monitors so that the Ceph cluster is accessible during the Ceph Monitor migration:
kubectl -n rook-ceph get pod -l app=rook-ceph-mon kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph -s
The
MiraCephobject on the managed cluster has the required node with themonrole added in thenodessection ofspec:kubectl -n ceph-lcm-mirantis get miraceph -o yaml
The Ceph
NodeWorkloadLockfor the required node is created:kubectl --kubeconfig child-kubeconfig get nodeworkloadlock -o jsonpath='{range .items[?(@.spec.nodeName == "<desiredNodeName>")]}{@.metadata.name}{"\n"}{end}' | grep ceph
Scale the
ceph-maintenance-controllerdeployment to0replicas:kubectl -n ceph-lcm-mirantis scale deploy ceph-maintenance-controller --replicas 0
Manually edit the managed cluster node labels: remove the
ceph_role_monlabel from the obsolete node and add this label to the new node:kubectl label node <obsoleteNodeName> ceph_role_mon- kubectl label node <newNodeName> ceph_role_mon=true
Verify that the
rook-ceph-operatordeployment is scaled to0replica:kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 0
Obtain the
rook-ceph-mondeployment name placed on the obsolete node using the previously obtained node name:kubectl -n rook-ceph get deploy -l app=rook-ceph-mon -o jsonpath="{.items[?(@.spec.template.spec.nodeSelector['kubernetes\.io/hostname'] == '<nodeName>')].metadata.name}"
Substitute
<nodeName>with the name of the node where you removed themonrole.Back up the
rook-ceph-mondeployment placed on the obsolete node:kubectl -n rook-ceph get deploy <rook-ceph-mon-name> -o yaml > <rook-ceph-mon-name>-backup.yaml
Remove the
rook-ceph-mondeployment placed on the obsolete node:kubectl -n rook-ceph delete deploy <rook-ceph-mon-name>
If you perform a managed cluster update, follow additional steps:
Enter the
ceph-toolspod:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
Remove the Ceph Monitor from the Ceph monmap by letter:
ceph mon rm <monLetter>
Substitute
<monLetter>with the old Ceph Monitor letter. For example,mon-bhas the letterb.Verify that the Ceph cluster does not have any information about the the removed Ceph Monitor:
ceph mon dump ceph -s
Exit the
ceph-toolspod.Scale up the
rook-ceph-operatordeployment to1replica:kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 1
Wait for the missing Ceph Monitor failover process to start:
kubectl -n rook-ceph logs -l app=rook-ceph-operator -f
Example of log extract:
2024-03-01 12:33:08.741215 W | op-mon: mon b NOT found in ceph mon map, failover 2024-03-01 12:33:08.741244 I | op-mon: marking mon "b" out of quorum ... 2024-03-01 12:33:08.766822 I | op-mon: Failing over monitor "b" 2024-03-01 12:33:08.766881 I | op-mon: starting new mon...
Select one of the following options:
Wait approximately 10 minutes until
rook-ceph-operatorperforms a failover of thePendingmonpod. Inspect the logs during the failover process:kubectl -n rook-ceph logs -l app=rook-ceph-operator -f
Example of log extract:
2021-03-15 17:48:23.471978 W | op-mon: mon "a" not found in quorum, waiting for timeout (554 seconds left) before failover
Note
If the failover process fails:
Scale down the
rook-ceph-operatordeployment to0replicas.Apply the backed-up
rook-ceph-mondeployment.Scale back the
rook-ceph-operatordeployment to1replica.
Scale the
rook-ceph-operatordeployment to0replicas:kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 0
Scale the
ceph-maintenance-controllerdeployment to3replicas:kubectl -n ceph-lcm-mirantis scale deploy ceph-maintenance-controller --replicas 3
Once done, Rook removes the obsolete Ceph Monitor from the node and creates
a new one on the specified node with a new letter. For example, if the a,
b, and c Ceph Monitors were in quorum and mon-c was obsolete, Rook
removes mon-c and creates mon-d. In this case, the new quorum includes
the a, b, and d Ceph Monitors.
Note
The feature is available as Technology Preview for non-MOSK-based clusters.
This document describes how to migrate a Ceph Monitor to another machine on baremetal-based clusters before node replacement as described in Delete a cluster machine using web UI.
Warning
Remove the Ceph Monitor role before the machine removal.
Make sure that the Ceph cluster always has an odd number of Ceph Monitors.
The procedure of a Ceph Monitor migration assumes that you temporarily move the Ceph Manager/Monitor to a worker machine. After a node replacement, we recommend migrating the Ceph Manager/Monitor to the new manager machine.
To migrate a Ceph Monitor to another machine:
Move the Ceph Manager/Monitor daemon from the affected machine to one of the worker machines as described in Move a Ceph Monitor daemon to another node.
Delete the affected machine as described in Delete a cluster machine.
Add a new manager machine without the Monitor and Manager role as described in Add a machine.
Warning
The addition of a new machine with the Monitor and Manager role breaks the odd number quorum of Ceph Monitors.
Move the previously migrated Ceph Manager/Monitor daemon to the new manager machine as described in Move a Ceph Monitor daemon to another node.
Ceph Controller enables you to deploy RADOS Gateway (RGW) Object Storage instances and automatically manage its resources such as users and buckets. Ceph Object Storage has an integration with OpenStack Object Storage (Swift) in Mirantis OpenStack for Kubernetes (MOSK).
To enable the RGW Object Storage:
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with a corresponding value.Using the following table, update the
cephClusterSpec.objectStorage.rgwsection specification as required:Caution
Since Container Cloud 2.23.0, explicitly specify the
deviceClassparameter fordataPoolandmetadataPool.Warning
Since Container Cloud 2.6.0, the
spec.rgwsection is deprecated and its parameters are moved underobjectStorage.rgw. If you continue usingspec.rgw, it is automatically translated intoobjectStorage.rgwduring the Container Cloud update to 2.6.0.We strongly recommend changing
spec.rgwtoobjectStorage.rgwin allKaaSCephClusterCRs beforespec.rgwbecomes unsupported and is deleted.RADOS Gateway parameters¶ Parameter
Description
nameCeph Object Storage instance name.
dataPoolMutually exclusive with the
zoneparameter. Object storage data pool spec that should only containreplicatedorerasureCodedandfailureDomainparameters. ThefailureDomainparameter may be set toosdorhost, defining the failure domain across which the data will be spread. FordataPool, Mirantis recommends using anerasureCodedpool. For details, see Rook documentation: Erasure coding. For example:cephClusterSpec: objectStorage: rgw: dataPool: erasureCoded: codingChunks: 1 dataChunks: 2
metadataPoolMutually exclusive with the
zoneparameter. Object storage metadata pool spec that should only containreplicatedandfailureDomainparameters. ThefailureDomainparameter may be set toosdorhost, defining the failure domain across which the data will be spread. Can use onlyreplicatedsettings. For example:cephClusterSpec: objectStorage: rgw: metadataPool: replicated: size: 3 failureDomain: host
where
replicated.sizeis the number of full copies of data on multiple nodes.Warning
When using the non-recommended Ceph pools
replicated.sizeof less than3, Ceph OSD removal cannot be performed. The minimal replica size equals a rounded up half of the specifiedreplicated.size.For example, if
replicated.sizeis2, the minimal replica size is1, and ifreplicated.sizeis3, then the minimal replica size is2. The replica size of1allows Ceph having PGs with only one Ceph OSD in theactingstate, which may cause aPG_TOO_DEGRADEDhealth warning that blocks Ceph OSD removal. Mirantis recommends settingreplicated.sizeto3for each Ceph pool.gatewayThe gateway settings corresponding to the
rgwdaemon settings. Includes the following parameters:port- the port on which the Ceph RGW service will be listening on HTTP.securePort- the port on which the Ceph RGW service will be listening on HTTPS.instances- the number of pods in the Ceph RGW ReplicaSet. IfallNodesis set totrue, a DaemonSet is created instead.Note
Mirantis recommends using 2 instances for Ceph Object Storage.
allNodes- defines whether to start the Ceph RGW pods as a DaemonSet on all nodes. Theinstancesparameter is ignored ifallNodesis set totrue.
For example:
cephClusterSpec: objectStorage: rgw: gateway: allNodes: false instances: 1 port: 80 securePort: 8443
preservePoolsOnDeleteDefines whether to delete the data and metadata pools in the
rgwsection if the object storage is deleted. Set this parameter totrueif you need to store data even if the object storage is deleted. However, Mirantis recommends setting this parameter tofalse.objectUsersandbucketsOptional. To create new Ceph RGW resources, such as buckets or users, specify the following keys. Ceph Controller will automatically create the specified object storage users and buckets in the Ceph cluster.
objectUsers- a list of user specifications to create for object storage. Contains the following fields:name- a user name to create.displayName- the Ceph user name to display.capabilities- user capabilities:user- admin capabilities to read/write Ceph Object Store users.bucket- admin capabilities to read/write Ceph Object Store buckets.metadata- admin capabilities to read/write Ceph Object Store metadata.usage- admin capabilities to read/write Ceph Object Store usage.zone- admin capabilities to read/write Ceph Object Store zones.
The available options are
*,read,write,read, write. For details, see Ceph documentation: Add/remove admin capabilities.quotas- user quotas:maxBuckets- the maximum bucket limit for the Ceph user. Integer, for example,10.maxSize- the maximum size limit of all objects across all the buckets of a user. String size, for example,10G.maxObjects- the maximum number of objects across all buckets of a user. Integer, for example,10.
For example:
objectUsers: - capabilities: bucket: '*' metadata: read user: read displayName: test-user name: test-user quotas: maxBuckets: 10 maxSize: 10G
users- a list of strings that contain user names to create for object storage.Note
This field is deprecated. Use
objectUsersinstead. Ifusersis specified, it will be automatically transformed to theobjectUserssection.buckets- a list of strings that contain bucket names to create for object storage.
zoneOptional. Mutually exclusive with
metadataPoolanddataPool. Defines the Ceph Multisite zone where the object storage must be placed. Includes thenameparameter that must be set to one of thezonesitems. For details, see Enable multisite for Ceph RGW Object Storage.For example:
cephClusterSpec: objectStorage: multisite: zones: - name: master-zone ... rgw: zone: name: master-zone
SSLCertOptional. Custom TLS certificate parameters used to access the Ceph RGW endpoint. If not specified, a self-signed certificate will be generated.
For example:
cephClusterSpec: objectStorage: rgw: SSLCert: cacert: | -----BEGIN CERTIFICATE----- ca-certificate here -----END CERTIFICATE----- tlsCert: | -----BEGIN CERTIFICATE----- private TLS certificate here -----END CERTIFICATE----- tlsKey: | -----BEGIN RSA PRIVATE KEY----- private TLS key here -----END RSA PRIVATE KEY-----
For example:
cephClusterSpec: objectStorage: rgw: name: rgw-store dataPool: deviceClass: hdd erasureCoded: codingChunks: 1 dataChunks: 2 failureDomain: host metadataPool: deviceClass: hdd failureDomain: host replicated: size: 3 gateway: allNodes: false instances: 1 port: 80 securePort: 8443 preservePoolsOnDelete: false
Caution
This feature is available as Technology Preview. Use such configuration for testing and evaluation purposes only. For the Technology Preview feature definition, refer to Technology Preview features.
The Ceph multisite feature allows object storage to replicate its data over multiple Ceph clusters. Using multisite, such object storage is independent and isolated from another object storage in the cluster. Only the multi-zone multisite setup is currently supported. For more details, see Ceph documentation: Multisite.
Select from the following options:
If you do not have a Container cloud cluster yet, open
kaascephcluster.yaml.templatefor editing.If the Container cloud cluster is already deployed, open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with a corresponding value.
Using the following table, update the
cephClusterSpec.objectStorage.multisitesection specification as required:Multisite parameters¶ Parameter
Description
realmsTechnical PreviewList of realms to use, represents the realm namespaces. Includes the following parameters:
name- the realm name.pullEndpoint- optional, required only when the master zone is in a different storage cluster. The endpoint, access key, and system key of the system user from the realm to pull from. Includes the following parameters:endpoint- the endpoint of the master zone in the master zone group.accessKey- the access key of the system user from the realm to pull from.secretKey- the system key of the system user from the realm to pull from.
zoneGroupsTechnical PreviewThe list of zone groups for realms. Includes the following parameters:
name- the zone group name.realmName- the realm namespace name to which the zone group belongs to.
zonesTechnical PreviewThe list of zones used within one zone group. Includes the following parameters:
name- the zone name.metadataPool- the settings used to create the Object Storage metadata pools. Must use replication. For details, see Pool parameters.dataPool- the settings to create the Object Storage data pool. Can use replication or erasure coding. For details, see Pool parameters.zoneGroupName- the zone group name.endpointsForZone- available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). The list of all endpoints in the zone group. If you use ingress proxy for RGW, the list of endpoints must contain that FQDN/IP address to access RGW. By default, if no ingress proxy is used, the list of endpoints is set to the IP address of the RGW external service. Endpoints must follow the HTTP URL format.
Caution
The multisite configuration requires master and secondary zones to be reachable from each other.
Select from the following options:
If you do not need to replicate data from a different storage cluster, and the current cluster represents the master zone, modify the current
objectStoragesection to use the multisite mode:Configure the
zoneRADOS Gateway (RGW) parameter by setting it to the RGW Object Storage name.Note
Leave
dataPoolandmetadataPoolempty. These parameters are ignored because thezoneblock in the multisite configuration specifies the pools parameters. Other RGW parameters do not require changes.For example:
objectStorage: rgw: dataPool: {} gateway: allNodes: false instances: 2 port: 80 securePort: 8443 healthCheck: {} metadataPool: {} name: openstack-store preservePoolsOnDelete: false zone: name: openstack-store
Create the
multiSitesection where the names of realm, zone group, and zone must match the current RGW name.Since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0), specify the
endpointsForZoneparameter according to your configuration:If you use ingress proxy, which is defined in the
spec.cephClusterSpec.ingresssection, add the FQDN endpoint.If you do not use any ingress proxy and access the RGW API using the default RGW external service, add the IP address of the external service or leave this parameter empty.
The following example illustrates a complete
objectStoragesection:objectStorage: multiSite: realms: - name: openstack-store zoneGroups: - name: openstack-store realmName: openstack-store zones: - name: openstack-store zoneGroupName: openstack-store endpointsForZone: http://10.11.0.75:8080 metadataPool: failureDomain: host replicated: size: 3 dataPool: erasureCoded: codingChunks: 1 dataChunks: 2 failureDomain: host rgw: dataPool: {} gateway: allNodes: false instances: 2 port: 80 securePort: 8443 healthCheck: {} metadataPool: {} name: openstack-store preservePoolsOnDelete: false zone: name: openstack-store
If you use a different storage cluster, and its object storage data must be replicated, specify the realm and zone group names along with the
pullEndpointparameter. Additionally, specify the endpoint, access key, and system keys of the system user of the realm from which you need to replicate data. For details, see the step 2 of this procedure.To obtain the endpoint of the cluster zone that must be replicated, run the following command by specifying the zone group name of the required master zone on the master zone side:
radosgw-admin zonegroup get --rgw-zonegroup=<ZONE_GROUP_NAME> | jq -r '.endpoints'
The endpoint is located in the
endpointsfield.To obtain the access key and the secret key of the system user, run the following command on the required Ceph cluster:
radosgw-admin user list
To obtain the system user name, which has your RGW
ObjectStoragename as prefix:radosgw-admin user info --uid="<USER_NAME>" | jq -r '.keys'
For example:
objectStorage: multiSite: realms: - name: openstack-store pullEndpoint: endpoint: http://10.11.0.75:8080 accessKey: DRND5J2SVC9O6FQGEJJF secretKey: qpjIjY4lRFOWh5IAnbrgL5O6RTA1rigvmsqRGSJk zoneGroups: - name: openstack-store realmName: openstack-store zones: - name: openstack-store-backup zoneGroupName: openstack-store metadataPool: failureDomain: host replicated: size: 3 dataPool: erasureCoded: codingChunks: 1 dataChunks: 2 failureDomain: host
Note
Mirantis recommends using the same
metadataPoolanddataPoolsettings as you use in the master zone.
Configure the
zoneRGW parameter and leavedataPoolandmetadataPoolempty. These parameters are ignored because thezonesection in the multisite configuration specifies the pools parameters.Also, you can split the RGW daemon on daemons serving clients and daemons running synchronization. To enable this option, specify
splitDaemonForMultisiteTrafficSyncin thegatewaysection.For example:
objectStorage: multiSite: realms: - name: openstack-store pullEndpoint: endpoint: http://10.11.0.75:8080 accessKey: DRND5J2SVC9O6FQGEJJF secretKey: qpjIjY4lRFOWh5IAnbrgL5O6RTA1rigvmsqRGSJk zoneGroups: - name: openstack-store realmName: openstack-store zones: - name: openstack-store-backup zoneGroupName: openstack-store metadataPool: failureDomain: host replicated: size: 3 dataPool: erasureCoded: codingChunks: 1 dataChunks: 2 failureDomain: host rgw: dataPool: {} gateway: allNodes: false instances: 2 splitDaemonForMultisiteTrafficSync: true port: 80 securePort: 8443 healthCheck: {} metadataPool: {} name: openstack-store-backup preservePoolsOnDelete: false zone: name: openstack-store-backup
On the
ceph-toolspod, verify the multisite status:radosgw-admin sync status
Once done, ceph-operator will create the required resources and Rook will
handle the multisite configuration. For details, see: Rook documentation:
Object Multisite.
Warning
Rook does not handle multisite configuration changes and cleanup.
Therefore, once you enable multisite for Ceph RGW Object Storage, perform
these operations manually in the ceph-tools pod. For details, see
Rook documentation: Multisite cleanup.
If automatic update of zone group hostnames is disabled, manually specify all
required hostnames and update the zone group. In the ceph-tools pod, run
the following script:
/usr/local/bin/zonegroup_hostnames_update.sh --rgw-zonegroup <ZONEGROUP_NAME> --hostnames fqdn1[,fqdn2]
If the multisite setup is completely cleaned up, manually execute the following
steps on the ceph-tools pod:
Remove the
.rgw.rootpool:ceph osd pool rm .rgw.root .rgw.root --yes-i-really-really-mean-it
Some other RGW pools may also require a removal after cleanup.
Remove the related RGW crush rules:
ceph osd crush rule ls | grep rgw | xargs -I% ceph osd crush rule rm %
Available since 2.21.0 for non-MOSK clusters
The section describes how to create, access, and remove Ceph RADOS Block Device (RBD) or Ceph File System (CephFS) clients and RADOS Gateway (RGW) users.
The KaaSCephCluster resource allows managing custom Ceph RADOS Block
Device (RBD) or Ceph File System (CephFS) clients. This section describes
how to create, access, and remove Ceph RBD or CephFS clients.
For all supported parameters of Ceph clients, refer to Clients parameters.
Warning
CephFS is available as Technology Preview. Therefore, use it at your own risk.
Edit the
KaaSCephClusterresource by adding a new Ceph client to thespecsection:kubectl -n <managedClusterProjectName> edit kaascephcluster
Substitute
<managedClusterProject>with the corresponding Container Cloud project where the managed cluster was created.Example of adding an RBD client to the
kubernetes-ssdpool:spec: cephClusterSpec: clients: - name: rbd-client caps: mon: allow r, allow command "osd blacklist" osd: profile rbd pool=kubernetes-ssd
Example of adding a CephFS client to the
cephfs-1Ceph File System :spec: cephClusterSpec: clients: - name: cephfs-1-client caps: mds: allow rwp mon: allow r, allow command "osd blacklist" osd: allow rw tag cephfs data=cephfs-1 metadata=*
For details about
caps, refer to Ceph documentation: Authorization (capabilities).Note
Ceph supports only providing of client access to the whole Ceph File System with all data pools in it.
Wait for created clients to become ready in the
KaaSCephClusterstatus:kubectl -n <managedClusterProject> get kaascephcluster -o yaml
Example output:
status: fullClusterInfo: blockStorageStatus: clientsStatus: rbd-client: present: true status: Ready cephfs-1-client: present: true status: Ready
Available since 2.21.0 for non-MOSK clusters
Using the
KaaSCephClusterstatus, obtainsecretInfowith the Ceph client credentials :kubectl -n <managedClusterProject> get kaascephcluster -o yaml
Example output:
status: miraCephSecretsInfo: secretInfo: clientSecrets: - name: rbd-client secretName: rook-ceph-client-rbd-client secretNamespace: rook-ceph - name: cephfs-1-client secretName: rook-ceph-client-cephfs-1-client secretNamespace: rook-ceph
Use
secretNameandsecretNamespaceto access the Ceph client credentials from a managed cluster:kubectl --kubeconfig <managedClusterKubeconfig> -n <secretNamespace> get secret <secretName> -o jsonpath='{.data.<clientName>}' | base64 -d; echo
Substitute the following parameters:
<managedClusterKubeconfig>with a managed clusterkubeconfig<secretNamespace>withsecretNamespacefrom the previous step<secretName>withsecretNamefrom the previous step<clientName>with the Ceph RBD or CephFS client name set inspec.cephClusterSpec.clientstheKaaSCephClusterresource, for example,rbd-client
Example output:
AQAGHDNjxWYXJhAAjafCn3EtC6KgzgI1x4XDlg==
Using the obtained credentials, create two configuration files on the required workloads to connect them with Ceph pools or file systems:
/etc/ceph/ceph.conf:[default] mon_host = <mon1IP>:6789,<mon2IP>:6789,...,<monNIP>:6789
where
mon_hostare the comma-separated IP addresses with6789ports of the current Ceph Monitors. For example,10.10.0.145:6789,10.10.0.153:6789,10.10.0.235:6789./etc/ceph/ceph.client.<clientName>.keyring:[client.<clientName>] key = <cephClientCredentials>
<clientName>is a client name set inspec.cephClusterSpec.clientstheKaaSCephClusterresource, for example,rbd-client<cephClientCredentials>are the client credentials obtained in the previous steps. For example,AQAGHDNjxWYXJhAAjafCn3EtC6KgzgI1x4XDlg==
If the client
capsparameters containmon: allow r, verify the client access using the following command:ceph -n client.<clientName> -s
Edit the
KaaSCephClusterresource by removing the Ceph client fromspec.cephClusterSpec.clients:kubectl -n <managedClusterProject> edit kaascephcluster
Wait for the client to be removed from the
KaaSCephClusterstatus instatus.fullClusterInfo.blockStorageStatus.clientsStatus:kubectl -n <managedClusterProject> get kaascephcluster -o yaml
Available since 2.21.0 for non-MOSK clusters
The KaaSCephCluster resource allows managing custom Ceph Object Storage
users. This section describes how to create, access, and remove Ceph Object
Storage users.
For all supported parameters of Ceph Object Storage users, refer to RADOS Gateway parameters.
Edit the
KaaSCephClusterresource by adding a new Ceph Object Storage user to thespecsection:kubectl -n <managedClusterProject> edit kaascephcluster
Substitute
<managedClusterProject>with the corresponding Container Cloud project where the managed cluster was created.Example of adding the Ceph Object Storage user
user-a:Caution
For user
name, apply the UUID format with no capital letters.spec: cephClusterSpec: objectStorage: rgw: objectUsers: - capabilities: bucket: '*' metadata: read user: read displayName: user-a name: userA quotas: maxBuckets: 10 maxSize: 10G
Wait for the created user to become ready in the
KaaSCephClusterstatus:kubectl -n <managedClusterProject> get kaascephcluster -o yaml
Example output:
status: fullClusterInfo: objectStorageStatus: objectStoreUsers: user-a: present: true phase: Ready
Using the
KaaSCephClusterstatus, obtainsecretInfowith the Ceph user credentials :kubectl -n <managedClusterProject> get kaascephcluster -o yaml
Example output:
status: miraCephSecretsInfo: secretInfo: rgwUserSecrets: - name: user-a secretName: rook-ceph-object-user-<objstoreName>-<username> secretNamespace: rook-ceph
Substitute
<objstoreName>with a Ceph Object Storage name and<username>with a Ceph Object Storage user name.Use
secretNameandsecretNamespaceto access the Ceph Object Storage user credentials from a managed cluster. The secret contains Amazon S3 access and secret keys.To obtain the user S3 access key:
kubectl --kubeconfig <managedClusterKubeconfig> -n <secretNamespace> get secret <secretName> -o jsonpath='{.data.AccessKey}' | base64 -d; echo
Substitute the following parameters in the commands above and below:
<managedClusterKubeconfig>with a managed clusterkubeconfig<secretNamespace>withsecretNamespacefrom the previous step<secretName>withsecretNamefrom the previous step
Example output:
D49G060HQ86U5COBTJ13To obtain the user S3 secret key:
kubectl --kubeconfig <managedClusterKubeconfig> -n <secretNamespace> get secret <secretName> -o jsonpath='{.data.SecretKey}' | base64 -d; echo
Example output:
bpuYqIieKvzxl6nzN0sd7L06H40kZGXNStD4UNda
Configure the S3 client with the access and secret keys of the created user. You can access the S3 client using various tools such as s3cmd or awscli.
Edit the
KaaSCephClusterresource by removing the required Ceph Object Storage user fromspec.cephClusterSpec.objectStorage.rgw.objectUsers:kubectl -n <managedClusterProject> edit kaascephcluster
Wait for the removed user to be removed from the
KaaSCephClusterstatus instatus.fullClusterInfo.objectStorageStatus.objectStoreUsers:kubectl -n <managedClusterProject> get kaascephcluster -o yaml
This section explains how to create an Amazon Simple Storage Service (Amazon S3 or S3) bucket and set an S3 bucket policy between two Ceph Object Storage users.
Ceph Object Storage users can create Amazon S3 buckets and bucket policies that grant access to other users.
This section describes how to create two Ceph Object Storage users and configure their S3 credentials.
To create and configure Ceph Object Storage users:
Open the
KaaSCephClusterCR:kubectl --kubeconfig <managementKubeconfig> -n <managedClusterProject> edit kaascephcluster
Substitute
<managementKubeconfig>with a management clusterkubeconfigfile and<managedClusterProject>with a managed cluster project name.In the
cephClusterSpecsection, add new Ceph Object Storage users.Caution
For user
name, apply the UUID format with no capital letters.For example:
spec: cephClusterSpec: objectStorage: rgw: objectUsers: - name: user-b displayName: user-a capabilities: bucket: "*" user: read - name: user-t displayName: user-t capabilities: bucket: "*" user: read
Verify that
rgwUserSecretsare created for both users:kubectl --kubeconfig <managementKubeconfig> -n <managedClusterProject> get kaascephcluster -o yaml
Substitute
<managementKubeconfig>with a management clusterkubeconfigfile and<managedClusterProject>with a managed cluster project name.Example of a positive system response:
status: miraCephSecretsInfo: secretInfo: rgwUserSecrets: - name: user-a secretName: <user-aCredSecretName> secretNamespace: <user-aCredSecretNamespace> - name: user-t secretName: <user-tCredSecretName> secretNamespace: <user-tCredSecretNamespace>
Obtain S3 user credentials from the cluster secrets. Specify an access key and a secret key for both users:
kubectl --kubeconfig <managedKubeconfig> -n <user-aCredSecretNamespace> get secret <user-aCredSecretName> -o jsonpath='{.data.AccessKey}' | base64 -d kubectl --kubeconfig <managedKubeconfig> -n <user-aCredSecretNamespace> get secret <user-aCredSecretName> -o jsonpath='{.data.SecretKey}' | base64 -d kubectl --kubeconfig <managedKubeconfig> -n <user-tCredSecretNamespace> get secret <user-tCredSecretName> -o jsonpath='{.data.AccessKey}' | base64 -d kubectl --kubeconfig <managedKubeconfig> -n <user-tCredSecretNamespace> get secret <user-tCredSecretName> -o jsonpath='{.data.SecretKey}' | base64 -d
Substitute
<managementKubeconfig>with a management clusterkubeconfigand specify the correspondingsecretNamespaceandsecretNamefor both users.Obtain Ceph Object Storage public endpoint from the
KaaSCephClusterstatus:kubectl --kubeconfig <managementKubeconfig> -n <managedClusterProject> get kaascephcluster -o yaml | grep PublicEndpoint
Substitute
<managementKubeconfig>with a management clusterkubeconfigfile and<managedClusterProject>with a managed cluster project name.Example of a positive system response:
objectStorePublicEndpoint: https://object-storage.mirantis.example.comObtain the CA certificate to use an HTTPS endpoint:
kubectl --kubeconfig <managedKubeconfig> -n rook-ceph get secret $(kubectl -n rook-ceph get ingress -o jsonpath='{.items[0].spec.tls[0].secretName}{"\n"}') -o jsonpath='{.data.ca\.crt}' | base64 -d; echo
Save the output to
ca.crt.
Available since 2.21.0 for non-MOSK clusters
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
Amazon S3 is an object storage service with different access policies. A bucket policy is a resource-based policy that grants permissions to a bucket and objects in it. For more details, see Amazon S3 documentation: Using bucket policies .
The following procedure illustrates the process of setting a bucket policy for
a bucket (test01) stored in a Ceph Object Storage. The bucket policy
requires at least two users: a bucket owner (user-a) and a bucket user
(user-t). The bucket owner creates the bucket and sets the policy that
regulates access for the bucket user.
Caution
For user name, apply the UUID format with no capital letters.
To configure an Amazon S3 bucket policy:
Note
The s3cmd is a free command-line tool and client for uploading, retrieving, and managing data in Amazon S3 and other cloud storage service providers that use the S3 protocol. You can download the s3cmd CLI tool from Amazon S3 tools: Download s3cmd.
Configure the s3cmd client with the
user-acredentials:s3cmd --configure --ca-certs=ca.crt
Specify the bucket access parameters as required:
Bucket access parameters¶ Parameter
Description
Comment
Access KeyPublic part of access credentials.
Specify a user access key.
Secret KeySecret part of access credentials.
Specify a user secret key.
Default RegionRegion of AWS servers where requests are sent by default.
Use the default value.
S3 EndpointConnection point to the Ceph Object Storage.
Specify the Ceph Object Storage public endpoint.
DNS-style bucket+hostname:port template for accessing a bucketBucket location.
Specify the Ceph Object Storage public endpoint.
Path to GPG programPath to the GNU Privacy Guard encryption suite.
Use the default value.
Use HTTPS protocolHTTPS protocol switch.
Specify
Yes.HTTP Proxy server nameHTTP Proxy server name.
Skip this parameter.
When configured correctly, the s3cmd tool connects to the Ceph Object Storage. Save new settings when prompted by the system.
As
user-a, create a new buckettest01:s3cmd mb s3://test01
Example of a positive system response:
Bucket 's3://test01/' created
Upload an object to the bucket:
touch test.txt s3cmd put test.txt s3://test01
Example of a positive system response:
upload: 'test.txt' -> 's3://test01/test.txt' [1 of 1] 0 of 0 0% in 0s 0.00 B/s done
Verify that the object is in the
test01bucket:s3cmd ls s3://test01
Example of a positive system response:
2022-09-02 13:06 0 s3://test01/test.txt
Create the bucket policy file and add bucket CRUD permissions for
user-t:{ "Version": "2012-10-17", "Id": "S3Policy1", "Statement": [ { "Sid": "BucketAllow", "Effect": "Allow", "Principal": { "AWS": ["arn:aws:iam:::user/user-t"] }, "Action": [ "s3:ListBucket", "s3:PutObject", "s3:GetObject" ], "Resource": [ "arn:aws:s3:::test01", "arn:aws:s3:::test01/*" ] } ] }
Set the bucket policy for the
test01bucket:s3cmd setpolicy policy.json s3://test01
Example of a positive system response:
s3://test01/: Policy updated
Verify that the
user-thas access for thetest01bucket by reconfiguring the s3cmd client with theuser-tcredentials:s3cmd --ca-certs=ca.crt --configure
Specify the bucket access parameters in a similar to the step 1 manner.
When configured correctly, the s3cmd tool connects to the Ceph Object Storage. Save new settings when prompted by the system.
Verify that the
user-tcan read the buckettest01content:s3cmd ls s3://test01
Example of a positive system response:
2022-09-02 13:06 0 s3://test01/test.txt
Download the object from the
test01bucket:s3cmd get s3://test01/test.txt check.txt
Example of a positive system response:
download: 's3://test01/test.txt' -> 'check.txt' [1 of 1] 0 of 0 0% in 0s 0.00 B/s done
Upload a new object to the
test01bucket:s3cmd put check.txt s3://test01
Example of a positive system response:
upload: 'check.txt' -> 's3://test01/check.txt' [1 of 1] 0 of 0 0% in 0s 0.00 B/s done
Verify that the object is in the
test01bucket:s3cmd ls s3://test01
Example of a positive system response:
2022-09-02 14:41 0 s3://test01/check.txt 2022-09-02 13:06 0 s3://test01/test.txt
Verify the new object by reconfiguring the s3cmd client with the
user-acredentials:s3cmd --configure --ca-certs=ca.crt
List
test01bucket objects:s3cmd ls s3://test01
Example of a positive system response:
2022-09-02 14:41 0 s3://test01/check.txt 2022-09-02 13:06 0 s3://test01/test.txt
This section describes how to verify the components of a Ceph cluster after deployment. For troubleshooting, verify Ceph Controller and Rook logs as described in Verify Ceph Controller and Rook.
To confirm that all Ceph components including mon, mgr, osd, and
rgw have joined your cluster properly, analyze the logs for each pod and
verify the Ceph status:
kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
ceph -s
Example of a positive system response:
cluster:
id: 4336ab3b-2025-4c7b-b9a9-3999944853c8
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 20m)
mgr: a(active, since 19m)
osd: 6 osds: 6 up (since 16m), 6 in (since 16m)
rgw: 1 daemon active (miraobjstore.a)
data:
pools: 12 pools, 216 pgs
objects: 201 objects, 3.9 KiB
usage: 6.1 GiB used, 174 GiB / 180 GiB avail
pgs: 216 active+clean
To ensure that rook-discover is running properly, verify if the
local-device configmap has been created for each Ceph node specified
in the cluster configuration:
Obtain the list of local devices:
kubectl get configmap -n rook-ceph | grep local-device
Example of a system response:
local-device-01 1 30m local-device-02 1 29m local-device-03 1 30m
Verify that each device from the list contains information about available devices for the Ceph node deployment:
kubectl describe configmap local-device-01 -n rook-ceph
Example of a positive system response:
Name: local-device-01 Namespace: rook-ceph Labels: app=rook-discover rook.io/node=01 Annotations: <none> Data ==== devices: ---- [{"name":"vdd","parent":"","hasChildren":false,"devLinks":"/dev/disk/by-id/virtio-41d72dac-c0ff-4f24-b /dev/disk/by-path/virtio-pci-0000:00:09.0","size":32212254720,"uuid":"27e9cf64-85f4-48e7-8862-faa7270202ed","serial":"41d72dac-c0ff-4f24-b","type":"disk","rotational":true,"readOnly":false,"Partitions":null,"filesystem":"","vendor":"","model":"","wwn":"","wwnVendorExtension":"","empty":true,"cephVolumeData":"{\"path\":\"/dev/vdd\",\"available\":true,\"rejected_reasons\":[],\"sys_api\":{\"size\":32212254720.0,\"scheduler_mode\":\"none\",\"rotational\":\"1\",\"vendor\":\"0x1af4\",\"human_readable_size\":\"30.00 GB\",\"sectors\":0,\"sas_device_handle\":\"\",\"rev\":\"\",\"sas_address\":\"\",\"locked\":0,\"sectorsize\":\"512\",\"removable\":\"0\",\"path\":\"/dev/vdd\",\"support_discard\":\"0\",\"model\":\"\",\"ro\":\"0\",\"nr_requests\":\"128\",\"partitions\":{}},\"lvs\":[]}","label":""},{"name":"vdb","parent":"","hasChildren":false,"devLinks":"/dev/disk/by-path/virtio-pci-0000:00:07.0","size":67108864,"uuid":"988692e5-94ac-4c9a-bc48-7b057dd94fa4","serial":"","type":"disk","rotational":true,"readOnly":false,"Partitions":null,"filesystem":"","vendor":"","model":"","wwn":"","wwnVendorExtension":"","empty":true,"cephVolumeData":"{\"path\":\"/dev/vdb\",\"available\":false,\"rejected_reasons\":[\"Insufficient space (\\u003c5GB)\"],\"sys_api\":{\"size\":67108864.0,\"scheduler_mode\":\"none\",\"rotational\":\"1\",\"vendor\":\"0x1af4\",\"human_readable_size\":\"64.00 MB\",\"sectors\":0,\"sas_device_handle\":\"\",\"rev\":\"\",\"sas_address\":\"\",\"locked\":0,\"sectorsize\":\"512\",\"removable\":\"0\",\"path\":\"/dev/vdb\",\"support_discard\":\"0\",\"model\":\"\",\"ro\":\"0\",\"nr_requests\":\"128\",\"partitions\":{}},\"lvs\":[]}","label":""},{"name":"vdc","parent":"","hasChildren":false,"devLinks":"/dev/disk/by-id/virtio-e8fdba13-e24b-41f0-9 /dev/disk/by-path/virtio-pci-0000:00:08.0","size":32212254720,"uuid":"190a50e7-bc79-43a9-a6e6-81b173cd2e0c","serial":"e8fdba13-e24b-41f0-9","type":"disk","rotational":true,"readOnly":false,"Partitions":null,"filesystem":"","vendor":"","model":"","wwn":"","wwnVendorExtension":"","empty":true,"cephVolumeData":"{\"path\":\"/dev/vdc\",\"available\":true,\"rejected_reasons\":[],\"sys_api\":{\"size\":32212254720.0,\"scheduler_mode\":\"none\",\"rotational\":\"1\",\"vendor\":\"0x1af4\",\"human_readable_size\":\"30.00 GB\",\"sectors\":0,\"sas_device_handle\":\"\",\"rev\":\"\",\"sas_address\":\"\",\"locked\":0,\"sectorsize\":\"512\",\"removable\":\"0\",\"path\":\"/dev/vdc\",\"support_discard\":\"0\",\"model\":\"\",\"ro\":\"0\",\"nr_requests\":\"128\",\"partitions\":{}},\"lvs\":[]}","label":""}]
Verifying Ceph cluster state is an entry point for issues investigation.
This section describes how to verify Ceph state using the KaaSCephCluster,
MiraCeph, and MiraCephLog resources.
To verify the state of a Ceph cluster, Ceph Controller provides special
sections in KaaSCephCluster.status. The resource contains information about
the state of the Ceph cluster components, their health, and potentially
problematic components.
To verify the Ceph cluster state from a managed cluster:
Obtain
kubeconfigof a managed cluster and provide it as an environment variable:export KUBECONFIG=<pathToManagedKubeconfig>
Obtain the
MiraCephresource in YAML format:kubectl -n ceph-lcm-mirantis get miraceph -o yaml
Information from
MiraCeph.statusis passed to themiraCephInfosection of theKaaSCephClusterCR. For details, see KaaSCephCluster.status miraCephInfo specification.Obtain the
MiraCephLogresource in YAML format:kubectl -n ceph-lcm-mirantis get miracephlog -o yaml
Information from
MiraCephLogis passed to thefullClusterInfoandshortClusterInfosections of theKaaSCephClusterCR. For details, see KaaSCephCluster.status shortClusterInfo specification and KaaSCephCluster.status fullClusterInfo specification.
To verify the Ceph cluster state from a management cluster:
Obtain the
KaaSCephClusterresource in the YAML format:kubectl -n <projectName> get kaascephcluster -o yaml
Substitute
<projectName>with the project name of the managed cluster.Verify the state of the required component using KaaSCephCluster.status description.
KaaSCephCluster.status allows you to learn the current health of a Ceph
cluster and identify potentially problematic components. This section describes
KaaSCephCluster.status and its fields. To view KaaSCephCluster.status,
perform the steps described in Verify Ceph cluster state through CLI.
KaaSCephCluster.status miraCephSecretsInfo specification Available since 2.21.0 for non-MOSK clusters
Field |
Description |
|---|---|
|
Available since 2.25.0.
Describes the current state of |
|
Describes the current phase of Ceph spec reconciliation and spec
validation result. The |
|
Reresents a short version of |
|
Contains a complete Ceph cluster information including cluster, Ceph
resources, and daemons health. It helps to reveal the potentially
problematic components. For |
|
Available since 2.21.0 for non-MOSK clusters. Contains information
about secrets of the managed cluster that are used in the Ceph cluster,
such as keyrings, Ceph clients, RADOS Gateway user credentials, and so
on. For |
The following tables describe all sections of KaaSCephCluster.status.
Field |
Description |
|---|---|
|
Contains the current phase of handling of the applied Ceph cluster spec.
Can equal to |
|
Contains a detailed description of the current phase or an error message
if the phase is |
|
Contains the validation:
result: Succeed or Failed
messages: ["error", "messages", "list"]
|
Field |
Description |
|---|---|
|
Current Ceph cluster collector status:
|
|
|
|
|
|
List of error or warning messages found when gathering the facts about the Ceph cluster. |
Field |
Description |
|---|---|
|
General information from Rook about the Ceph cluster health and current
state. The clusterStatus:
state: <rook ceph cluster common status>
phase: <rook ceph cluster spec reconcile phase>
message: <rook ceph cluster phase details>
conditions: <history of rook ceph cluster
reconcile steps>
ceph: <ceph cluster health>
storage:
deviceClasses: <list of used device classes
in ceph cluster>
version:
image: <ceph image used in ceph cluster>
version: <ceph version of ceph cluster>
|
|
Status of the Rook Ceph Operator pod that is |
|
Map of statuses for each Ceph cluster daemon type. Indicates the
expected and actual number of Ceph daemons on the cluster. Available
daemon types are: daemonsStatus:
<daemonType>:
status: <daemons status>
running: <number of running daemons with
details>
For example: daemonsStatus:
mgr:
running: a is active mgr ([] standBy)
status: Ok
mon:
running: '3/3 mons running: [a c d] in quorum'
status: Ok
osd:
running: '4/4 running: 4 up, 4 in'
status: Ok
rgw:
running: 2/2 running
([openstack.store.a openstack.store.b])
status: Ok
|
|
State of the Ceph cluster block storage resources. Includes the following fields:
|
|
State of the Ceph cluster object storage resources. Includes the following fields:
|
|
Verbose details of the Ceph cluster state.
|
|
Contains information, similar to the cephCSIPluginDaemonsStatus:
<csiPlugin>:
running: <number of running daemons with details>
status: <csi plugin status>
For example: cephCSIPluginDaemonsStatus:
csi-rbdplugin:
running: 1/3 running
status: Some csi-rbdplugin daemons are not ready
csi-cephfsplugin:
running: 3/3 running
status: Ok
|
Field |
Description |
|---|---|
|
Current state of the secret collector on the Ceph cluster:
|
|
|
|
|
|
List of secrets for Ceph clients and RADOS Gateway users:
For example: lastSecretCheck: "2022-09-05T07:05:35Z"
lastSecretUpdate: "2022-09-05T06:02:00Z"
secretInfo:
clientSecrets:
- name: client.admin
secretName: rook-ceph-admin-keyring
secretNamespace: rook-ceph
state: Ready
|
|
List of error or warning messages, if any, found when collecting information about the Ceph cluster. |
Verifying Ceph cluster state is an entry point for issues investigation. Through the Ceph Clusters page of the Container Cloud web UI, you can view a detailed summary on all Ceph clusters deployed, including the cluster name and ID, health status, number of Ceph OSDs, and so on.
To view Ceph cluster summary:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the required cluster name. The page with cluster details opens.
In the Ceph Clusters tab, verify the overall cluster health and rebalancing statuses.
Available since Cluster releases 17.0.0 and 16.0.0. Click Cluster Details:
The Machines tab contains the list of deployed Ceph machines with the following details:
Status - deployment status
Role - role assigned to a machine, manager or monitor
Storage devices - number of storage devices assigned to a machine
UP OSDs and IN OSDs - number of
upandinCeph OSDs belonging to a machine
Note
To obtain details about a specific machine used for Ceph deployment, in the Clusters > <clusterName> > Machines tab, click the required machine name containing the storage label.
The OSDs tab contains the list of Ceph OSDs comprising the Ceph cluster with the following details:
OSD - Ceph OSD ID
Storage Device ID - storage device ID assigned to a Ceph OSD
Type - type of storage device assigned to a Ceph OSD
Partition - partition name where Ceph OSD is located
Machine - machine name where Ceph OSD is located
UP/DOWN - status of a Ceph OSD in a cluster
IN/OUT - service state of a Ceph OSD in a cluster
The starting point for Ceph troubleshooting is the ceph-controller and
rook-operator logs. Once you locate the component that causes issues,
verify the logs of the related pod. This section describes how to verify the
Ceph Controller and Rook objects of a Ceph cluster.
To verify Ceph Controller and Rook:
Verify the Ceph cluster status:
Verify that the status of each pod in the
ceph-lcm-mirantisandrook-cephname spaces isRunning:For
ceph-lcm-mirantis:kubectl get pod -n ceph-lcm-mirantis
For
rook-ceph:kubectl get pod -n rook-ceph
Verify Ceph Controller. Ceph Controller prepares the configuration that Rook uses to deploy the Ceph cluster, managed using the
KaasCephClusterresource. If Rook cannot finish the deployment, verify the Rook Operator logs as described in the step 4.List the pods:
kubectl -n ceph-lcm-mirantis get pods
Verify the logs of the required pod:
kubectl -n ceph-lcm-mirantis logs <ceph-controller-pod-name>
Verify the configuration:
kubectl get kaascephcluster -n <managedClusterProjectName> -o yaml
On the managed cluster, verify the
MiraCephsubresource:kubectl get miraceph -n ceph-lcm-mirantis -o yaml
Verify the Rook Operator logs. Rook deploys a Ceph cluster based on custom resources created by the Ceph Controller, such as pools, clients,
cephcluster, and so on. Rook logs contain details about components orchestration. For details about the Ceph cluster status and to get access to CLI tools, connect to theceph-toolspod as described in the step 5.Verify the Rook Operator logs:
kubectl -n rook-ceph logs -l app=rook-ceph-operator
Verify the
CephClusterconfiguration:Note
The Ceph Controller manages the
CephClusterCR . Open theCephClusterCR only for verification and do not modify it manually.kubectl get cephcluster -n rook-ceph -o yaml
Verify the
ceph-toolspod:Execute the
ceph-toolspod:kubectl --kubeconfig <pathToManagedClusterKubeconfig> -n rook-ceph exec -it $(kubectl --kubeconfig <pathToManagedClusterKubeconfig> -n rook-ceph get pod -l app=rook-ceph-tools -o jsonpath='{.items[0].metadata.name}') bash
Verify that CLI commands can run on the
ceph-toolspod:ceph -s
Verify hardware:
Through the
ceph-toolspod, obtain the required device in your cluster:ceph osd tree
Enter all Ceph OSD pods in the
rook-cephnamespace one by one:kubectl exec -it -n rook-ceph <osd-pod-name> bash
Verify that the
ceph-volumetool is available on all pods running on the target node:ceph-volume lvm list
Verify data access. Ceph volumes can be consumed directly by Kubernetes workloads and internally, for example, by OpenStack services. To verify the Kubernetes storage:
Verify the available storage classes. The storage classes that are automatically managed by Ceph Controller use the
rook-ceph.rbd.csi.ceph.comprovisioner.kubectl get storageclass
Example of system response:
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE kubernetes-ssd (default) rook-ceph.rbd.csi.ceph.com Delete Immediate false 55m stacklight-alertmanager-data kubernetes.io/no-provisioner Delete WaitForFirstConsumer false 55m stacklight-elasticsearch-data kubernetes.io/no-provisioner Delete WaitForFirstConsumer false 55m stacklight-postgresql-db kubernetes.io/no-provisioner Delete WaitForFirstConsumer false 55m stacklight-prometheus-data kubernetes.io/no-provisioner Delete WaitForFirstConsumer false 55m
Verify that volumes are properly connected to the Pod:
Obtain the list of volumes in all namespaces or use a particular one:
kubectl get persistentvolumeclaims -A
Example of system response:
NAMESPACE NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE rook-ceph app-test Bound pv-test 1Gi RWO kubernetes-ssd 11m
For each volume, verify the connection. For example:
kubectl describe pvc app-test -n rook-ceph
Example of a positive system response:
Name: app-test Namespace: kaas StorageClass: rook-ceph Status: Bound Volume: pv-test Labels: <none> Annotations: pv.kubernetes.io/bind-completed: yes pv.kubernetes.io/bound-by-controller: yes volume.beta.kubernetes.io/storage-provisioner: rook-ceph.rbd.csi.ceph.com Finalizers: [kubernetes.io/pvc-protection] Capacity: 1Gi Access Modes: RWO VolumeMode: Filesystem Events: <none>
In case of connection issues, inspect the Pod description for the volume information:
kubectl describe pod <crashloopbackoff-pod-name>
Example of system response:
... Events: FirstSeen LastSeen Count From SubObjectPath Type Reason Message --------- -------- ----- ---- ------------- -------- ------ ------- 1h 1h 3 default-scheduler Warning FailedScheduling PersistentVolumeClaim is not bound: "app-test" (repeated 2 times) 1h 35s 36 kubelet, 172.17.8.101 Warning FailedMount Unable to mount volumes for pod "wordpress-mysql-918363043-50pjr_default(08d14e75-bd99-11e7-bc4c-001c428b9fc8)": timeout expired waiting for volumes to attach/mount for pod "default"/"wordpress-mysql-918363043-50pjr". list of unattached/unmounted volumes=[mysql-persistent-storage] 1h 35s 36 kubelet, 172.17.8.101 Warning FailedSync Error syncing pod
Verify that the CSI provisioner plugins started properly and are in the
Runningstatus:Obtain the list of CSI provisioner plugins:
kubectl -n rook-ceph get pod -l app=csi-rbdplugin-provisioner
Verify the logs of the required CSI provisioner:
kubectl logs -n rook-ceph <csi-provisioner-plugin-name> csi-provisioner
This section describes how to configure Ceph Controller to manage Ceph nodes resources.
Warning
This document does not provide any specific recommendations on requests and limits for Ceph resources. The document stands for a native Ceph resources configuration for any cluster with Mirantis Container Cloud or Mirantis OpenStack for Kubernetes (MOSK).
You can configure Ceph Controller to manage Ceph resources by specifying their requirements and constraints. To configure the resources consumption for the Ceph nodes, consider the following options that are based on different Helm release configuration values:
Configuring tolerations for taint nodes for the Ceph Monitor, Ceph Manager, and Ceph OSD daemons. For details, see Taints and Tolerations.
Configuring nodes resources requests or limits for the Ceph daemons and for each Ceph OSD device class such as HDD, SSD, or NVMe. For details, see Managing Resources for Containers.
To enable Ceph tolerations and resources management:
To avoid Ceph cluster health issues during daemons configuration changing, set Ceph
noout,nobackfill,norebalance, andnorecoverflags through theceph-toolspod before editing Ceph tolerations and resources:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l \ "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash ceph osd set noout ceph osd set nobackfill ceph osd set norebalance ceph osd set norecover exit
Note
Skip this step if you are only configuring the PG rebalance timeout and replicas count parameters.
Edit the
KaaSCephClusterresource of a managed cluster:kubectl -n <managedClusterProjectName> edit kaascephcluster
Substitute
<managedClusterProjectName>with the project name of the required managed cluster.Specify the parameters in the
hyperconvergesection as required. Thehyperconvergesection includes the following parameters:Ceph tolerations and resources parameters¶ Parameter
Description
Example values
tolerationsSpecifies tolerations for taint nodes for the defined daemon type. Each daemon type key contains the following parameters:
cephClusterSpec: hyperconverge: tolerations: <daemonType>: rules: - key: "" operator: "" value: "" effect: "" tolerationSeconds: 0
Possible values for
<daemonType>areosd,mon,mgr, andrgw. The following values are also supported:all- specifies general toleration rules for all daemons if no separate daemon rule is specified.mds- specifies the CephFS Metadata Server daemons.
hyperconverge: tolerations: mon: rules: - effect: NoSchedule key: node-role.kubernetes.io/controlplane operator: Exists mgr: rules: - effect: NoSchedule key: node-role.kubernetes.io/controlplane operator: Exists osd: rules: - effect: NoSchedule key: node-role.kubernetes.io/controlplane operator: Exists rgw: rules: - effect: NoSchedule key: node-role.kubernetes.io/controlplane operator: Exists
resourcesSpecifies resources requests or limits. The parameter is a map with the daemon type as a key and the following structure as a value:
hyperconverge: resources: <daemonType>: requests: <kubernetes valid spec of daemon resource requests> limits: <kubernetes valid spec of daemon resource limits>
Possible values for
<daemonType>aremon,mgr,osd,osd-hdd,osd-ssd,osd-nvme,prepareosd,rgw, andmds. Theosd-hdd,osd-ssd, andosd-nvmeresource requirements handle only the Ceph OSDs with a corresponding device class.hyperconverge: resources: mon: requests: memory: 1Gi cpu: 2 limits: memory: 2Gi cpu: 3 mgr: requests: memory: 1Gi cpu: 2 limits: memory: 2Gi cpu: 3 osd: requests: memory: 1Gi cpu: 2 limits: memory: 2Gi cpu: 3 osd-hdd: requests: memory: 1Gi cpu: 2 limits: memory: 2Gi cpu: 3 osd-ssd: requests: memory: 1Gi cpu: 2 limits: memory: 2Gi cpu: 3 osd-nvme: requests: memory: 1Gi cpu: 2 limits: memory: 2Gi cpu: 3
For the Ceph node specific resources settings, specify the
resourcessection in the correspondingnodesspec ofKaaSCephCluster:spec: cephClusterSpec: nodes: <nodeName>: resources: requests: <kubernetes valid spec of daemon resource requests> limits: <kubernetes valid spec of daemon resource limits>
Substitute
<nodeName>with the node requested for specific resources. For example:spec: cephClusterSpec: nodes: <nodeName>: resources: requests: memory: 1Gi cpu: 2 limits: memory: 2Gi cpu: 3
For the RADOS Gateway instances specific resources settings, specify the
resourcessection in thergwspec ofKaaSCephCluster:spec: cephClusterSpec: objectStorage: rgw: gateway: resources: requests: <kubernetes valid spec of daemon resource requests> limits: <kubernetes valid spec of daemon resource limits>
For example:
spec: cephClusterSpec: objectStorage: rgw: gateway: resources: requests: memory: 1Gi cpu: 2 limits: memory: 2Gi cpu: 3
Save the reconfigured
KaaSCephClusterresource and wait forceph-controllerto apply the updated Ceph configuration. It will recreate Ceph Monitors, Ceph Managers, or Ceph OSDs according to the specifiedhyperconvergeconfiguration.If you have specified any
osdtolerations, additionally specify tolerations for therookinstances:Open the
Clusterresource of the required Ceph cluster on a management cluster:kubectl -n <ClusterProjectName> edit cluster
Substitute
<ClusterProjectName>with the project name of the required cluster.Specify the parameters in the
ceph-controllersection ofspec.providerSpec.value.helmReleases:Specify the
hyperconverge.tolerations.rookparameter as required:hyperconverge: tolerations: rook: | <yamlFormattedKubernetesTolerations>
In
<yamlFormattedKubernetesTolerations>, specify YAML-formatted tolerations fromcephClusterSpec.hyperconverge.tolerations.osd.rulesof theKaaSCephClusterspec. For example:hyperconverge: tolerations: rook: | - effect: NoSchedule key: node-role.kubernetes.io/controlplane operator: Exists
In
controllers.cephRequest.parameters.pgRebalanceTimeoutMin, specify the PG rebalance timeout for requests. The default is30minutes. For example:controllers: cephRequest: parameters: pgRebalanceTimeoutMin: 35
In
controllers.cephController.replicas,controllers.cephRequest.replicas, andcontrollers.cephStatus.replicas, specify the replicas count. The default is3replicas. For example:controllers: cephController: replicas: 1 cephRequest: replicas: 1 cephStatus: replicas: 1
Save the reconfigured
Clusterresource and wait for theceph-controllerHelm release update. It will recreate Ceph CSI and discover pods according to the specifiedhyperconverge.tolerations.rookconfiguration.
Specify tolerations for different Rook resources using the following chart-based options:
hyperconverge.tolerations.rook- general toleration rules for each Rook service if no exact rules specifiedhyperconverge.tolerations.csiplugin- for tolerations of theceph-csiplugins DaemonSetshyperconverge.tolerations.csiprovisioner- for theceph-csiprovisioner deployment tolerationshyperconverge.nodeAffinity.csiprovisioner- provides theceph-csiprovisioner node affinity with avaluesection
After a successful Ceph reconfiguration, unset the flags set in step 1 through the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l \ "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash ceph osd unset ceph osd unset noout ceph osd unset nobackfill ceph osd unset norebalance ceph osd unset norecover exit
Note
Skip this step if you have only configured the PG rebalance timeout and replicas count parameters.
Once done, proceed to Verify Ceph tolerations and resources management.
After you enable Ceph resources management as described in Enable Ceph tolerations and resources management, perform the steps below to verify that the configured tolerations, requests, or limits have been successfully specified in the Ceph cluster.
To verify Ceph tolerations and resources management:
To verify that the required tolerations are specified in the Ceph cluster, inspect the output of the following commands:
kubectl -n rook-ceph get $(kubectl -n rook-ceph get cephcluster -o name) -o jsonpath='{.spec.placement.mon.tolerations}' kubectl -n rook-ceph get $(kubectl -n rook-ceph get cephcluster -o name) -o jsonpath='{.spec.placement.mgr.tolerations}' kubectl -n rook-ceph get $(kubectl -n rook-ceph get cephcluster -o name) -o jsonpath='{.spec.placement.osd.tolerations}'
To verify RADOS Gateway tolerations:
kubectl -n rook-ceph get $(kubectl -n rook-ceph get cephobjectstore -o name) -o jsonpath='{.spec.gateway.placement.tolerations}'
To verify that the required resources requests or limits are specified for the Ceph
mon,mgr, orosddaemons, inspect the output of the following command:kubectl -n rook-ceph get $(kubectl -n rook-ceph get cephcluster -o name) -o jsonpath='{.spec.resources}'
To verify that the required resources requests and limits are specified for the RADOS Gateway daemons, inspect the output of the following command:
kubectl -n rook-ceph get $(kubectl -n rook-ceph get cephobjectstore -o name) -o jsonpath='{.spec.gateway.resources}'
To verify that the required resources requests or limits are specified for the Ceph OSDs
hdd,ssd, ornvmedevice classes, perform the following steps:Identify which Ceph OSDs belong to the
<deviceClass>device class in question:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l app=rook-ceph-tools -o name) -- ceph osd crush class ls-osd <deviceClass>
For each
<osdID>obtained in the previous step, run the following command. Compare the output with the desired result.kubectl -n rook-ceph get deploy rook-ceph-osd-<osdID> -o jsonpath='{.spec.template.spec.containers[].resources}'
Ceph allows establishing multiple IP networks and subnet masks for clusters
with configured L3 network rules. In Container Cloud, you can configure
multinetwork through the network section of the KaaSCephCluster CR.
Ceph Controller uses this section to specify the Ceph networks for external
access and internal daemon communication. The parameters in the network
section use the CIDR notation, for example, 10.0.0.0/24.
Before enabling multiple networks for a Ceph cluster, consider the following requirements:
Do not confuse the IP addresses you define with the public-facing IP addresses the network clients may use to access the services.
If you define more than one IP address and subnet mask for the public or cluster network, ensure that the subnets within the network can route to each other.
Include each IP address or subnet in the
networksection to IP tables and open ports for them as necessary.The pods of the Ceph OSD and RadosGW daemons use cross-pods health checkers to verify that the entire Ceph cluster is healthy. Therefore, each CIDR must be accessible inside Ceph pods.
Avoid using the
0.0.0.0/0CIDR in thenetworksection. With a zero range inpublicNetand/orclusterNet, the Ceph daemons behavior is unpredictable.
To enable multinetwork for Ceph:
Select from the following options:
If the Ceph cluster is not deployed on a managed cluster yet, edit the deployment
KaaSCephClusterYAML template.If the Ceph cluster is already deployed on a managed cluster, open
KaaSCephClusterfor editing:kubectl -n <managedClusterProjectName> edit kaascephcluster
Substitute
<managedClusterProjectName>with a corresponding value.
In the
clusterNetand/orpublicNetparameters of thecephClusterSpec.networksection, define a comma-separated array of CIDRs. For example:network: publicNet: 10.12.0.0/24,10.13.0.0/24 clusterNet: 10.10.0.0/24,10.11.0.0/24
Select from the following options:
If you are creating a managed cluster, save the updated
KaaSCephClustertemplate to the corresponding file and proceed with the managed cluster creation.If you are configuring
KaaSCephClusterof an existing managed cluster, exiting the text editor will apply the changes.
Once done, the specified network CIDRs will be passed to the Ceph daemons pods
through the rook-config-override ConfigMap.
Ceph Controller allows configuring a TLS-secured public access to Ceph entities. This section describes how to configure the TLS protocol for a Ceph cluster on Container Cloud through a custom ingress rule for Ceph public endpoints.
Note
For deployments with Mirantis OpenStack for Kubernetes (MOSK), the
ingress rule is automatically configured by Ceph Controller. However, an
external RGW will not be created if Ceph Controller detects OpenStack
pools or a configured customIngress section. For details, see
MOSK Operations Guide: Configure Ceph RGW TLS
and NGINX Ingress Controller: Annotations.
To enable TLS for Ceph public endpoints:
Select from the following options:
If you do not have a Container cloud cluster yet, open
kaascephcluster.yaml.templatefor editing.If the Container cloud cluster is already deployed, open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with a corresponding value.
Specify the
cephClusterSpec.ingresssection in theKaaSCephClusterCR:spec: cephClusterSpec: ingress: publicDomain: public.domain.name cacert: | -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE----- tlsCert: | -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE----- tlsKey: | -----BEGIN RSA PRIVATE KEY----- ... -----END RSA PRIVATE KEY----- customIngress: className: <ingress-controller-class-name> annotations: key: value # sensible for chosen ingress controller annotations
The
cephClusterSpec.ingresssection contains the following parameters:Parameter
Description
publicDomainThe Domain name to use for public endpoints.
cacertThe Certificate Authority (CA) certificate, used for the ingress rule TLS support.
tlsCertThe TLS certificate, used for the ingress rule TLS support.
tlsKeyThe TLS private key, used for the ingress rule TLS support.
customIngressSpecifies the following custom Ingress Controller parameters:
className- the custom Ingress Controller class name.annotations- extra annotations for the ingress proxy.
Note
For Container Cloud clusters, no default
customIngressvalues are specified. Therefore, if you do not specifycustomIngress, the ingress rule creation will be omitted.For deployments with Mirantis OpenStack for Kubernetes, the
openstack-ingress-nginxclass name is specified and Ceph uses the OpenStack component Ingress Controller based on NGINX. For details, see MOSK Operations Guide: Configure Ceph RGW TLS.
Select from the following options:
If you are creating a managed cluster, save the updated
KaaSCephClustertemplate to the corresponding file and proceed with the managed cluster creation.If you are configuring
KaaSCephClusterof an existing managed cluster, run the following command:kubectl edit -n <managedClusterProjectName> kaascephcluster <cephClusterName>
Substitute
<managedClusterProjectName>and<cephClusterName>with the corresponding values.
This section describes how to configure and use RADOS Block Device (RBD)
mirroring for Ceph pools using the rbdMirror section in the
KaaSCephCluster CR. The feature may be useful if, for example, you have
two interconnected managed clusters. Once you enable RBD mirroring, the
images in the specified pools will be replicated and if a cluster becomes
unreachable, the second one will provide users with instant access to all
images. For details, see Ceph Documentation: RBD Mirroring.
Note
Ceph Controller only supports bidirectional mirroring.
To enable Ceph RBD monitoring, follow the procedure below and use the following
rbdMirror parameters description:
Parameter |
Description |
|---|---|
|
Count of |
|
Optional. List of mirroring peers of an external cluster to connect to.
Only a single peer is supported. The
|
To enable Ceph RBD mirroring:
In
KaaSCephClusterCRs of both Ceph clusters where you want to enable mirroring, specify positivedaemonsCountin thespec.cephClusterSpec.rbdMirrorsection:spec: cephClusterSpec: rbdMirror: daemonsCount: 1
On both Ceph clusters where you want to enable mirroring, wait for the Ceph RBD Mirror daemons to start running:
kubectl -n rook-ceph get pod -l app=rook-ceph-rbd-mirror
In
KaaSCephClusterof both Ceph clusters where you want to enable mirroring, specify thespec.cephClusterSpec.pools.mirroring.modeparameter for allpoolsthat must be mirrored.Note
Mirantis recommends using the
poolmode for mirroring. For thepoolmode, explicitly enable journaling for each image.To use the
imagemirroring mode, explicitly enable mirroring as described in the step 8.
spec: cephClusterSpec: pools: - name: image-hdd ... mirroring: mode: pool - name: volumes-hdd ... mirroring: mode: pool
Obtain the name of an external site to mirror with. On pools with mirroring enabled, the name is typically
ceph fsid:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l \ "app=rook-ceph-tools" -o name rbd mirror pool info <mirroringPoolName> # or ceph fsid
Substitute
<mirroringPoolName>with the name of a pool to be mirrored.On an external site to mirror with, create a new bootstrap peer token. Execute the following command within the
ceph-toolspod CLI:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l \ "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash rbd mirror pool peer bootstrap create <mirroringPoolName> --site-name <siteName>
Substitute
<mirroringPoolName>with the name of a pool to be mirrored. In<siteName>, assign a label for the external Ceph cluster that will be used along with mirroring.For details, see Ceph documentation: Bootstrap peers.
In
KaaSCephClusteron the cluster that should mirror pools, specifyspec.cephClusterSpec.rbdMirror.peerswith the obtained peer and pools to mirror:spec: cephClusterSpec: rbdMirror: ... peers: - site: <siteName> token: <bootstrapPeer> pools: [<mirroringPoolName1>, <mirroringPoolName2>, ...]
Substitute
<siteName>with the label assigned to the external Ceph cluster,<bootstrapPeer>with the token obtained in the previous step, and<mirroringPoolName>with names of pools that have themirroring.modeparameter defined.For example:
spec: cephClusterSpec: rbdMirror: ... peers: - site: cluster-b token: <base64-string> pools: - images-hdd - volumes-hdd - special-pool-ssd
Verify that mirroring is enabled and each pool with
spec.cephClusterSpec.pools.mirroring.modedefined has an external peer site:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l \ "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash rbd mirror pool info <mirroringPoolName>
Substitute
<mirroringPoolName>with the name of a pool with mirroring enabled.If you have set the
imagemirroring mode in thepoolssection, explicitly enable mirroring for each image withrbdwithin the pool:Note
Execute the following command within the
ceph-toolspod withcephandrbdCLI.rbd mirror image enable <poolName>/<imageName> <imageMirroringMode>
Substitute
<poolName>with the name of a pool with theimagemirroring mode,<imageName>with the name of an image stored in the specified pool. Substitute<imageMirroringMode>with one of:journal- for mirroring to use the RBD journaling image feature to replicate the image contents. If the RBD journaling image feature is not yet enabled on the image, it will be enabled automatically.snapshot- for mirroring to use RBD image mirror-snapshots to replicate the image contents. Once enabled, an initial mirror-snapshot will automatically be created. To create additional RBD image mirror-snapshots, use the rbd command.
For details, see Ceph Documentation: Enable image mirroring.
Ceph pool target ratio defines for the Placement Group (PG) autoscaler the amount of data the pools are expected to acquire over time in relation to each other. You can set initial PG values for each Ceph pool. Otherwise, the autoscaler starts with the minimum value and scales up, causing a lot of data to move in the background.
You can allocate several pools to use the same device class, which is a solid
block of available capacity in Ceph. For example, if three pools
(kubernetes-hdd, images-hdd, and volumes-hdd) are set to use the
same device class hdd, you can set the target ratio for Ceph pools to
provide 80% of capacity to the volumes-hdd pool and distribute the
remaining capacity evenly between the two other pools. This way, Ceph pool
target ratio instructs Ceph on when to warn that a pool is running out of free
space and, at the same time, instructs Ceph on how many placement groups Ceph
should allocate/autoscale for a pool for better data distribution.
Ceph pool target ratio is not a constant value and you can change it according to new capacity plans. Once you specify target ratio, if the PG number of a pool scales, other pools with specified target ratio will automatically scale accordingly.
For details, see Ceph Documentation: Autoscaling Placement Groups.
To calculate target ratio for each Ceph pool:
Define raw capacity of the entire storage by device class:
kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o name) -- ceph df
For illustration purposes, the procedure below uses raw capacity of 185 TB or 189440 GB.
Design Ceph pools with the considered device class upper bounds of the possible capacity. For example, consider the
hdddevice class that contains the following pools:The
kubernetes-hddpool will contain not more than 2048 GB.The
stacklight-hddpool will contain not more than 100000 GB.
Note
If
dataPoolis replicated and Ceph Object Store is planned for intensive use, also calculate upper bounds fordataPool.Calculate target ratio for each considered pool. For example:
Example bounds and capacity¶ Pools upper bounds
Pools capacity
kubernetes-hdd= 2048 GBstacklight-hdd= 100000 GB
Summary capacity = 102048 GB
Total raw capacity = 189440 GB
Calculate pools fit factor using the (total raw capacity) / (pools summary capacity) formula. For example:
pools fit factor = 189440 / 102048 = 1.8563
Calculate pools upper bounds size using the (pool upper bounds) * (pools fit factor) formula. For example:
kubernetes-hdd = 2048 GB * 1.8563 = 3801.7024 GB stacklight-hdd = 100000 GB * 1.8563 = 185630 GB
Calculate pool target ratio using the (pool upper bounds) * 100 / (total raw capacity) formula. For example:
kubernetes-hdd = 3801.7024 GB * 100 / 189440 GB = 2.007 stacklight-hdd = 185630 GB * 100 / 189440 GB = 97.989
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
spec.cephClusterSpec.poolssection, specify the calculated relatives astargetSizeRatiofor each considered pool:spec: cephClusterSpec: pools: - name: kubernetes deviceClass: hdd ... replicated: size: 3 targetSizeRatio: 2.007 - name: stacklight deviceClass: hdd ... replicated: size: 3 targetSizeRatio: 97.989
If Ceph Object Store
dataPoolisreplicatedand a proper value is calculated, also specify it:spec: cephClusterSpec: objectStorage: rgw: name: rgw-store ... dataPool: ... replicated: deviceClass: hdd size: 3 targetSizeRatio: <relative>
Verify that all target ratio has been successfully applied to the Ceph cluster:
kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o name) -- ceph osd pool autoscale-status
Example of system response:
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE device_health_metrics 0 2.0 149.9G 0.0000 1.0 1 on kubernetes-hdd 2068 2.0 149.9G 0.0000 2.007 2.0076 1.0 32 on stacklight-hdd 2068 2.0 149.9G 0.0000 97.989 97.9894 1.0 256 on
Optional. Repeat the steps above for other device classes.
If you need to configure the placement of Rook daemons on nodes, you can add
extra values in the Cluster providerSpec section of the
ceph-controller Helm release.
The procedures in this section describe how to specify the placement of
rook-ceph-operator, rook-discover, and csi-rbdplugin.
To specify rook-ceph-operator placement:
On a management cluster, edit the desired
Clusterresource:kubectl -n <managedClusterProjectName> edit cluster
Add the following parameters to the
ceph-controllerHelm release values:spec: providerSpec: value: helmReleases: - name: ceph-controller values: rookOperatorPlacement: affinity: <rookOperatorAffinity> nodeSelector: <rookOperatorNodeSelector> tolerations: <rookOperatorTolerations>
<rookOperatorAffinity>is a key-value mapping that contains a valid Kubernetesaffinityspecification<rookOperatorNodeSelector>is a key-value mapping that contains a valid KubernetesnodeSelectorspecification<rookOperatorTolerations>is a list that contains valid Kubernetestolerationitems
Wait for some time and verify on a managed cluster that the changes have applied:
kubectl -n rook-ceph get deploy rook-ceph-operator -o yaml
To specify rook-discover and csi-rbdplugin placement simultaneously:
On a management cluster, edit the desired
Clusterresource:kubectl -n <managedClusterProjectName> edit cluster
Add the following parameters to the
ceph-controllerHelm release values:spec: providerSpec: value: helmReleases: - name: ceph-controller values: rookExtraConfig: extraDaemonsetLabels: <labelSelector>
Substitute
<labelSelector>with a valid Kubernetes label selector expression to place therook-discoverandcsi-rbdpluginDaemonSet pods.Wait for some time and verify on a managed cluster that the changes have applied:
kubectl -n rook-ceph get ds rook-discover -o yaml kubectl -n rook-ceph get ds csi-rbdplugin -o yaml
To specify rook-discover and csi-rbdplugin placement separately:
On a management cluster, edit the desired
Clusterresource:kubectl -n <managedClusterProjectName> edit cluster
If required, add the following parameters to the
ceph-controllerHelm release values:spec: providerSpec: value: helmReleases: - name: ceph-controller values: hyperconverge: nodeAffinity: csiplugin: <labelSelector1> rookDiscover: <labelSelector2>
Substitute
<labelSelectorX>with a valid Kubernetes label selector expression to place therook-discoverandcsi-rbdpluginDaemonSet pods. For example,"role=storage-node; discover=true".Wait for some time and verify on a managed cluster that the changes have applied:
kubectl -n rook-ceph get ds rook-discover -o yaml kubectl -n rook-ceph get ds csi-rbdplugin -o yaml
The document describes how to change the failure domain of an already deployed Ceph cluster.
Note
This document focuses on changing the failure domain from a smaller
to wider one, for example, from host to rack. Using the same
instruction, you can move the failure domain from a wider to smaller scale.
Caution
Data movement implies the Ceph cluster rebalancing that may impact cluster performance, depending on the cluster size.
High-level overview of the procedure includes the following steps:
Set correct labels on the nodes.
Create the new bucket hierarchy.
Move nodes to new buckets.
Modify the CRUSH rules.
Add the manual changes to the
KaaSCephClusterspec.Scale the Ceph controllers.
Verify that the Ceph cluster has enough space for multiple copies of data to migrate. Mirantis highly recommends that the Ceph cluster has a minimum of 25% of free space for the procedure to succeed.
Note
The migration procedure implies data movement and optional modification of CRUSH rules that cause a large amount of data (depending on the cluster size) to be first copied to a new location in the Ceph cluster before data removal.
Create a backup of the current
KaaSCephClusterobject from the managed namespace of the management cluster:kubectl -n <managedClusterProject> get kaascephcluster -o yaml > kcc-backup.yaml
Substitute
<managedClusterProject>with the corresponding managed cluster namespace of the management cluster.In the
rook-ceph-toolspod on a managed cluster, obtain a backup of the CRUSH map:ceph osd getcrushmap -o /tmp/crush-map-orig crushtool -d /tmp/crush-map-orig -o /tmp/crush-map-orig.txt
This procedure contains an example of moving failure domains of all
pools from host to rack. Using the same instruction, you can
migrate pools from other other types of failure domains, migrate pools
separately, and so on.
To migrate Ceph pools from one failure domain to another:
Set the required CRUSH topology in the
KaaSCephClusterobject for each defined node. For details on thecrushparameter, see Node parameters.Setting the CRUSH topology to each node causes the Ceph Controller to set proper Kubernetes labels on the nodes.
Example of adding the
rackCRUSH topology key for each node in thenodessectionspec: cephClusterSpec: nodes: machine1: crush: rack: rack-1 machine2: crush: rack: rack-1 machine3: crush: rack: rack-2 machine4: crush: rack: rack-2 machine5: crush: rack: rack-3 machine6: crush: rack: rack-3
On a managed cluster, verify that the required buckets and bucket types are present in the Ceph hierarchy:
Enter the
ceph-toolspod:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
Verify that the required bucket type is present by default:
ceph osd getcrushmap -o /tmp/crush-map crushtool -d /tmp/crush-map -o /tmp/crush-map.txt cat /tmp/crush-map.txt # Look for the section named → “# types”
Example output:
# types type 0 osd type 1 host type 2 chassis type 3 rack type 4 row type 5 pdu type 6 pod type 7 room type 8 datacenter type 9 zone type 10 region type 11 root
Verify that the buckets with the required bucket type are present:
cat /tmp/crush-map.txt # Look for the section named → “# buckets”
Example output of an existing
rackbucket# buckets rack rack-1 { id -15 id -16 class hdd # weight 0.00000 alg straw2 hash 0 }
If the required buckets are not created, create new ones with the required bucket type:
ceph osd crush add-bucket <bucketName> <bucketType> root=default
For example:
ceph osd crush add-bucket rack-1 rack root=default ceph osd crush add-bucket rack-2 rack root=default ceph osd crush add-bucket rack-3 rack root=default
Exit the
ceph-toolspod.
Optional. Order buckets as required:
On the managed cluster, add the first Ceph CRUSH smaller bucket to its respective wider bucket:
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash ceph osd crush move <smallerBucketName> <bucketType>=<widerBucketName>
Substitute the following parameters:
<smallerBucketName>with the name of the smaller bucket, for example host name<bucketType>with the required bucket type, for examplerack<widerBucketName>with the name of the wider bucket, for example rack name
For example:
ceph osd crush move kaas-node-1 rack=rack-1 root=default
Warning
Mirantis highly recommends moving one bucket at a time.
For more details, refer to official Ceph documentation: CRUHS Maps: Moving a bucket.
After the bucket is moved to the new location in the CRUSH hierarchy, verify that no data rebalancing occurs:
ceph -sCaution
Wait for rebalancing to complete before proceeding to the next step.
Add the remaining Ceph CRUSH smaller buckets to their respective wider buckets one by one.
Scale the Ceph Controller and Rook Operator deployments to
0replicas:kubectl -n ceph-lcm-mirantis scale deploy --all --replicas 0 kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 0
On the managed cluster, manually modify the CRUSH rules for Ceph pools to enable data placement on a new failure domain:
Enter the
ceph-toolspod:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
List the CRUSH rules and erasure code profiles for the pools:
ceph osd pool ls detail
Example output
pool 1 'mirablock-k8s-block-hdd' replicated size 2 min_size 1 crush_rule 9 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 1193 lfor 0/0/85 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd read_balance_score 1.31 pool 2 '.mgr' replicated size 2 min_size 1 crush_rule 1 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 70 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 6.06 pool 3 'openstack-store.rgw.otp' replicated size 2 min_size 1 crush_rule 11 object_hash rjenkins pg_num 8 pgp_num 8 autoscale_mode on last_change 1197 flags hashpspool stripe_width 0 pg_num_min 8 application rook-ceph-rgw read_balance_score 2.27 pool 4 'openstack-store.rgw.meta' replicated size 2 min_size 1 crush_rule 12 object_hash rjenkins pg_num 8 pgp_num 8 autoscale_mode on last_change 1197 flags hashpspool stripe_width 0 pg_num_min 8 application rook-ceph-rgw read_balance_score 1.50 pool 5 'openstack-store.rgw.log' replicated size 2 min_size 1 crush_rule 10 object_hash rjenkins pg_num 8 pgp_num 8 autoscale_mode on last_change 1197 flags hashpspool stripe_width 0 pg_num_min 8 application rook-ceph-rgw read_balance_score 3.00 pool 6 'openstack-store.rgw.buckets.non-ec' replicated size 2 min_size 1 crush_rule 13 object_hash rjenkins pg_num 8 pgp_num 8 autoscale_mode on last_change 1197 flags hashpspool stripe_width 0 pg_num_min 8 application rook-ceph-rgw read_balance_score 1.50 pool 7 'openstack-store.rgw.buckets.index' replicated size 2 min_size 1 crush_rule 15 object_hash rjenkins pg_num 8 pgp_num 8 autoscale_mode on last_change 1197 flags hashpspool stripe_width 0 pg_num_min 8 application rook-ceph-rgw read_balance_score 2.25 pool 8 '.rgw.root' replicated size 2 min_size 1 crush_rule 14 object_hash rjenkins pg_num 8 pgp_num 8 autoscale_mode on last_change 1197 flags hashpspool stripe_width 0 pg_num_min 8 application rook-ceph-rgw read_balance_score 3.75 pool 9 'openstack-store.rgw.control' replicated size 2 min_size 1 crush_rule 16 object_hash rjenkins pg_num 8 pgp_num 8 autoscale_mode on last_change 1197 flags hashpspool stripe_width 0 pg_num_min 8 application rook-ceph-rgw read_balance_score 3.00 pool 10 'other-hdd' replicated size 2 min_size 1 crush_rule 19 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 1179 lfor 0/0/85 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd read_balance_score 1.69 pool 11 'openstack-store.rgw.buckets.data' erasure profile openstack-store.rgw.buckets.data_ecprofile size 3 min_size 2 crush_rule 18 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 1198 lfor 0/0/86 flags hashpspool,ec_overwrites stripe_width 8192 application rook-ceph-rgw pool 12 'vms-hdd' replicated size 2 min_size 1 crush_rule 21 object_hash rjenkins pg_num 256 pgp_num 256 autoscale_mode on last_change 1182 lfor 0/0/95 flags hashpspool,selfmanaged_snaps stripe_width 0 target_size_ratio 0.4 application rbd read_balance_score 1.24 pool 13 'volumes-hdd' replicated size 2 min_size 1 crush_rule 23 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode on last_change 1185 lfor 0/0/89 flags hashpspool,selfmanaged_snaps stripe_width 0 target_size_ratio 0.2 application rbd read_balance_score 1.31 pool 14 'backup-hdd' replicated size 2 min_size 1 crush_rule 25 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 1188 lfor 0/0/90 flags hashpspool,selfmanaged_snaps stripe_width 0 target_size_ratio 0.1 application rbd read_balance_score 2.06 pool 15 'images-hdd' replicated size 2 min_size 1 crush_rule 27 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 1191 lfor 0/0/90 flags hashpspool,selfmanaged_snaps stripe_width 0 target_size_ratio 0.1 application rbd read_balance_score 1.50
For each replicated Ceph pool:
Obtain the current CRUSH rule name:
ceph osd crush rule dump <oldCrushRuleName>
Create a new CRUSH rule with the required bucket type using the same root, device class, and new bucket type:
ceph osd crush rule create-replicated <newCrushRuleName> <root> <bucketType> <deviceClass>
For example:
ceph osd crush rule create-replicated images-hdd-rack default rack hdd
For more details, refer to official Ceph documentation: CRUSH Maps: Creating a rule for a replicated pool.
Apply a new crush rule to the Ceph pool:
ceph osd pool set <poolName> crush_rule <newCrushRuleName>
For example:
ceph osd pool set images-hdd crush_rule images-hdd-rack
Wait for data to be rebalanced after moving the Ceph pool under the new failure domain (bucket type) by monitoring Ceph health:
ceph -sCaution
Update the following Ceph pool only after data rebalancing completes for the current Ceph pool.
Verify that the old CRUSH rule is not used anymore:
ceph osd pool ls detail
The rule ID is located in the CRUSH map and must match the rule ID in the output of ceph osd dump.
Remove the old unused CRUSH rule and rename the new one to the original name:
ceph osd crush rule rm <oldCrushRuleName> ceph osd crush rule rename <newCrushRuleName> <oldCrushRuleName>
For each erasure-coded Ceph pool:
Note
Erasure-coded pools require different number of buckets to store data. Instead of the number of replicas in replicated pools, erasure-coded pools require the
coding chunks + data chunksnumber of buckets existing in the Ceph cluster. For example, if an erasure-coded pool has 2 coding chunks and 2 data chunks configured, then the pool requires 4 different buckets, for example, 4 racks, to store data.Obtain the current parameters of the erasure-coded profile:
ceph osd erasure-code-profile get <ecProfile>
In the profile, add the new bucket type as the failure domain using the
crush-failure-domainparameter:ceph osd erasure-code-profile set <ecProfile> k=<int> m=<int> crush-failure-domain=<bucketType> crush-device-class=<deviceClass>
Create a new CRUSH rule in the profile:
ceph osd crush rule create-erasure <newEcCrushRuleName> <ecProfile>
Apply the new CRUSH rule to the pool:
ceph osd pool set <poolName> crush_rule <newEcCrushRuleName>
Wait for data to be rebalanced after moving the Ceph pool under the new failure domain (bucket type) by monitoring Ceph health:
ceph -sCaution
Update the following Ceph pool only after data rebalancing completes for the current Ceph pool.
Verify that the old CRUSH rule is not used anymore:
ceph osd pool ls detail
The rule ID is located in the CRUSH map and must match the rule ID in the output of ceph osd dump.
Remove the old unused CRUSH rule and rename the new one to the original name:
ceph osd crush rule rm <oldCrushRuleName> ceph osd crush rule rename <newCrushRuleName> <oldCrushRuleName>
Note
New erasure-coded profiles cannot be renamed, so they will not be removed automatically during pools cleanup. Remove them manually, if needed.
Exit the
ceph-toolspod.
In the management cluster, update the
KaaSCephClusterobject by setting thefailureDomain: rackparameter for each pool. The configuration from the Rook perspective must match the manually created configuration. For example:spec: cephClusterSpec: pools: - name: images ... failureDomain: rack - name: volumes ... failureDomain: rack ... objectStorage: rgw: dataPool: failureDomain: rack ... metadataPool: failureDomain: rack ...
Monitor the Ceph cluster health and wait until rebalancing is completed:
ceph -sExample of a successful system response:
HEALTH_OK
Scale back the Ceph Controller and Rook Operator deployments:
kubectl -n ceph-lcm-mirantis scale deploy --all --replicas 3 kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 1
See also
Delete a managed cluster¶
Due to a development limitation in baremetal operator,
deletion of a managed cluster requires preliminary deletion
of the worker machines running on the cluster.
Warning
We recommend deleting cluster machines using the Container Cloud web UI or API instead of using the cloud provider tools directly. Otherwise, the cluster deletion or detachment may hang and additional manual steps will be required to clean up machine resources.
Using the Container Cloud web UI, first delete worker machines one by one until you hit the minimum of 2 workers for an operational cluster. After that, you can delete the cluster with the remaining workers and managers.
To delete a baremetal-based managed cluster:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the required cluster name to open the list of machines running on it.
Click the More action icon in the last column of the worker machine you want to delete and select Delete. Confirm the deletion.
Repeat the step above until you have 2 workers left.
In the Clusters tab, click the More action icon in the last column of the required cluster and select Delete.
Verify the list of machines to be removed. Confirm the deletion.
If the cluster deletion hangs and the Deleting status message does not disappear after a while, refer to Cluster deletion or detachment freezes to fix the issue.
Optional. If you do not plan to reuse the credentials of the deleted cluster, delete them:
In the Credentials tab, click the Delete credential action icon next to the name of the credentials to be deleted.
Confirm the deletion.
Warning
You can delete credentials only after deleting the managed cluster they relate to.
Deleting a cluster automatically frees up the resources allocated for this cluster, for example, instances, load balancers, networks, floating IPs, and so on.
Day-2 operations¶
TechPreview since 2.26.0 (17.1.0 and 16.1.0)
Important
The cloud operator takes all risks and responsibility for module execution on cluster machines. For any questions, contact Mirantis support.
The day-2 operations API extends configuration management of baremetal-based clusters and machines after initial deployment. The feature allows managing the operating system of a bare metal host granularly using modules without rebuilding the node from scratch. Such approach prevents workload evacuation and significantly reduces configuration time.
The day-2 operations API does not limit the cloud operator’s ability to configure machines in any way, making the operator responsible for day-2 adjustments.
This section provides guidelines for Container Cloud or custom modules that
are used by the HostOSConfiguration and HostOSConfigurationModules
custom resources designed for baremetal-based management and managed clusters.
TechPreview since 2.26.0 (17.1.0 and 16.1.0)
The workflow of the day-2 operations API that use Container Cloud or custom modules is as follows:
Select one of the following options:
If you do not intend to use custom modules, skip to step 2.
If you intend to use custom modules:
Contact the module creator to obtain the link to the module and its SHA256.
Add the module to an existing
HostOSConfigurationModules(hocm) object or create a newhocmobject. For details, see HostOSConfigurationModules and Add a custom module to a Container Cloud deployment.
Add the configuration of the Container Cloud or custom module to an existing
HostOSConfiguration(hoc) object or create a newhocobject with the following details:Add the required configuration details of the module.
Set the selector for machines to apply the configuration.
For details, see HostOSConfiguration along with HostOSConfiguration and HostOSConfigurationModules concepts.
Optional. Retrigger the same successfully applied module configuration. For details, see Retrigger a module configuration.
Create a custom configuration module as required. For reference, see Format and structure of a module package and Modules provided by Container Cloud.
Publish the module in a repository from which the cloud operator can fetch the module.
Share the module details with the cloud operator.
The following diagram illustrates the high-level overview of the day-2 operations API:

The following global recommendations are intended to help creators of modules and cloud operators to work with the day-2 operations API for module implementation and execution, in order to keep the cluster and machines healthy and ensure safe and reliable cluster operability.
Module functionality is limited only by the Ansible itself along with playbook rules for a particular Ansible version. But Mirantis highly recommends paying a special attention to critical components of Container Cloud, some of which are mentioned below, and not managing them by the means of day-2 modules.
Important
The cloud operator takes all risks and responsibility for module execution on cluster machines. For any questions, contact Mirantis support.
Do not restart Docker, containerd, and Kubernetes-related services.
Do not configure Docker and Kubernetes node labels.
Do not reconfigure or upgrade MKE.
Do not change the MKE bundle.
Do not reboot nodes using a day-2 module.
Do not change network configuration, especially on critical LCM and external networks, so that they remain consistent with
kaas-ipamobjects.Do not change iptables, especially for Docker, Kubernetes, and Calico rules.
Do not change partitions on the fly, especially the
/and/var/lib/dockerones.
Since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0), the following Ansible versions are supported for Ubuntu 20.04 and 22.04: Ansible 2.12.10 and Ansible 5.10.0-collection. Therefore, your custom modules must be compatible with the corresponding Ansible versions provided for a specific Cluster release, on which your cluster is based.
To verify the Ansible version in a specific Cluster release, refer to the Cluster releases section in Release Notes. Use the Artifacts > System and MCR artifacts section of the corresponding Cluster release. For example, for 17.2.0.
Treat a day-2 module as an Ansible module to control a limited set of system resources related to one component, for example, a service or driver, so that a module contains a very limited amount of tasks to set up that component.
For example, if you need to configure a service on a host, the module must manage only package installation, related configuration files, and service enablement. Do not implement the module in a way so that it manages all tasks required for the day-2 configuration of a host. Split such functionality on tasks (modules) responsible for management of a single component. This helps to re-apply (re-run) every module separately in case of any changes.
Mirantis highly recommends using the following key principles during module implementation:
- Idempotency
Any module re-run with the same configuration values must lead to the same result.
- Granularity
The module must manage only one specific component on a host.
- Reset action
The module must be able to revert changes introduced by the module, or at least the module must be able to disable the component controller. The Container Cloud LCM does not provide a way to revert a day-2 change due to unpredictability of potential functionality of any module. Therefore, the reset action must be implemented on the module level. For example, the package or file state can be
presentorabsent, a service can beenabledordisabled. And these states must be controlled by the configuration values.
Mirantis highly recommends verifying any Container Cloud or custom module on one machine before applying it to all target machines. For the testing procedure, see Test a custom or Container Cloud module after creation.
A custom module may require node reboot after execution.
Implement a custom module using the following options, so that it can notify
lcm-agent and Container Cloud controllers about the required reboot:
If a module installs a package that requires a host reboot, then the
/run/reboot-requiredand/var/run/reboot-required.pkgsfiles are created automatically by the package manager. LCM Agent detects these files and places information about the reboot reason in theLCMMachinestatus.A module can create the
/run/reboot-requiredfile on the node. You can add the reason for reboot in the/run/lcm/reboot-requiredfile as plain text. This text is passed to the reboot reason in theLCMMachinestatus.
Once done, you can handle a machine reboot using GracefulRebootRequest.
TechPreview since 2.26.0 (17.1.0 and 16.1.0)
A module package for day-2 operations is an archive that contains Ansible playbooks, metadata, and optionally a JSON-validation schema.
Archive the file with the module package in the GZIP format.
Implement all playbooks for Ansible version used by a specific Cluster release of your Container Cloud cluster. For example, in Cluster releases 16.2.0 and 17.2.0, Ansible collection 5.10.0 and Ansible core 2.12.10 are used.
To verify the Ansible version in a specific Cluster release, refer to the Cluster releases section in Release Notes. Use the Artifacts > System and MCR artifacts section of the corresponding Cluster release. For example, for 17.2.0.
Note
Mirantis recommends implementing each module in modular approach avoiding a single module for everything. This ensures maintainability and readability, as well as improves testing and debugging. For details, refer to Global recommendations for implementation of custom modules.
The common structure within a module archive is as follows:
main.yamlFile name of the primary playbook that defines tasks to be executed.
metadata.yamlMetadata of the module such as name, version, and relevant documentation URLs.
schema.jsonOptional. JSON schema for validating module-specific configurations that are restricted values.
The common structure of metadata.yaml is as follows:
nameRequired. Name of the module.
versionRequired. Version of the module.
docURLOptional. URL to the module documentation.
descriptionOptional. Brief summary of the module, useful if the complete documentation is too detailed.
playbookRequired. Path to the module playbook. Path must be related to the archive root that is
directory/playbook.yamlifdirectoryis a directory in the root of the archive.
valuesJsonSchemaOptional. Path to the JSON-validation schema of the module. Path must be related to the archive root that is
directory/schema.jsonifdirectoryis a directory in the root of the archive.
Example of metadata.yaml:
name: module-sample
version: 1.0.0
docURL: https://docs.mirantis.com
description: 'Module for sample purposes'
playbook: main.yaml
valuesJsonSchema: schema.json
For description of JSON schema and its format, refer to JSON Schema official documentation.
Example of schema.json:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"kernel.panic": {"type": "string", "const": "1"}
}
}
A playbook for a module must follow the rules of a particular Ansible
version as mentioned in Requirements.
The only specific requirement for playbook format is to use the values
variable that consists of values described in the
inventory file.
Note
As hosts are selected in a HostOSConfiguration object, Mirantis
recommends using hosts: all in module playbooks.
For example:
- name: <variable-name>
hosts: all
become: true
tasks:
- name: <value-name>
module:
name: "{{ item.key }}"
value: "{{ item.value }}"
state: present
reload: yes
with_dict: "{{ values }}"
An archive of a module does not require an inventory because the inventory
is generated by lcm-controller while processing configurations.
The format of the generated inventory is as follows:
all:
hosts:
localhost:
ansible_connection: local
vars:
values:
{{- range $key, $value := .Values }}
{{ $key }}: {{ $value }}
{{- end }}
The .Values parameter contains the values from the provided module
configuration of the HostOSConfiguration object.
TechPreview since 2.27.0 (17.2.0 and 16.2.0)
This section outlines configuration modules implemented by Container Cloud.
These modules use the designated hocm object named mcc-modules.
All other hocm objects contain custom modules.
Warning
Do not modify the mcc-modules object, any changes will be
overwritten with data from an external source.
TechPreview since 2.27.0 (17.2.0 and 16.2.0)
The irqbalance module is designed to allow the cloud operator to install
and configure the irqbalance service on cluster machines using the day-2
operations API.
Note
This module is implemented and validated against the following Ansible versions provided by Container Cloud for Ubuntu 20.04 and 22.04 in the Cluster releases 16.2.0 and 17.2.0: Ansible core 2.12.10 and Ansible collection 5.10.0.
To verify the Ansible version in a specific Cluster release, refer to the Cluster releases section in Release Notes. Use the Artifacts > System and MCR artifacts section of the corresponding Cluster release. For example, for 17.2.0.
For information on the irqbalance service, refer to the official
irqbalance documentation for Ubuntu 22.04
and the
Upstream GitHub project.
The default configuration file /etc/default/irqbalance can contain the
following settings, as defined in the irqbalance documentation:
# irqbalance is a daemon process that distributes interrupts across
# CPUs on SMP systems. The default is to rebalance once every 10
# seconds. This is the environment file that is specified to systemd via the
# EnvironmentFile key in the service unit file (or via whatever method the init
# system you're using has).
#
# IRQBALANCE_ONESHOT
# After starting, wait for a minute, then look at the interrupt
# load and balance it once; after balancing exit and do not change
# it again.
#
#IRQBALANCE_ONESHOT=
#
# IRQBALANCE_BANNED_CPUS
# 64 bit bitmask which allows you to indicate which CPUs should
# be skipped when reblancing IRQs. CPU numbers which have their
# corresponding bits set to one in this mask will not have any
# IRQs assigned to them on rebalance.
#
#IRQBALANCE_BANNED_CPUS=
#
# IRQBALANCE_BANNED_CPULIST
# The CPUs list which allows you to indicate which CPUs should
# be skipped when reblancing IRQs. CPU numbers in CPUs list will
# not have any IRQs assigned to them on rebalance.
#
# The format of CPUs list is:
# <cpu number>,...,<cpu number>
# or a range:
# <cpu number>-<cpu number>
# or a mixture:
# <cpu number>,...,<cpu number>-<cpu number>
#
#IRQBALANCE_BANNED_CPULIST=
#
# IRQBALANCE_ARGS
# Append any args here to the irqbalance daemon as documented in the man
# page.
#
#IRQBALANCE_ARGS=
When the cloud operator defines values for the irqbalance module in the
HOC object, those values overwrite particular parameters in the
/etc/default/irqbalance file. If the operator does not define a value or
sets it to an empty string "", the corresponding parameter in the
/etc/default/irqbalance configuration file keeps its current value.
For example, if you define values.args in the HOC object, this value
overwrites the IRQBALANCE_ARGS parameter in /etc/default/irqbalance.
Otherwise, the IRQBALANCE_ARGS value remains the same in the
configuration file.
If you need to provide an empty IRQBALANCE_ARGS value, you can define
values.args: " " (double quotes separated by a space) in the HOC
object. Other parameters defined in /etc/default/irqbalance follow
the same logic.
The module allows installing, configuring, and enabling or disabling the
irqbalance service on cluster machines.
The module accepts the following parameters, all of them are optional:
Parameter |
Description |
|---|---|
|
Enable the |
|
The |
|
The |
|
The |
|
The irqbalance policy script, which is bash-compatible. |
|
The full file path name to store the irqbalance policy script that can be used
with the |
|
Enables the update of |
Note
IRQBALANCE_BANNED_CPUS is deprecated in irqbalance v1.8.0, which
is used in Ubuntu 22.04, and is being replaced with
IRQBALANCE_BANNED_CPULIST. For details, see Release notes for
irqbalance v1.8.0.
Caution
When you configure the policy script, at least three parameters must
be set: args, policy_script, and policy_script_filepath.
Otherwise, the corresponding error message will be displayed in the status
of the HostOSConfiguration object.
Note
If an error message in the status of the HostOSConfiguration
object contains schema validation failed, verify the following:
Whether the types of used parameters are correct
Whether the used combination of parameters is allowed
Note
If you enable the service without setting banned_cpulist,
banned_cpus, or args, the corresponding values in
/etc/default/irqbalance will remain as they were before applying the
current HostOSConfiguration.
spec:
...
configs:
...
- description: Example irqbalance configuration
module: irqbalance
moduleVersion: 1.0.0
order: 1
phase: "reconfigure"
values: {}
As a result of this configuration, no parameters will be set or overridden
in the irqbalance configuration file.
spec:
...
configs:
...
- description: Example irqbalance configuration
module: irqbalance
moduleVersion: 1.0.0
order: 1
phase: "reconfigure"
values:
banned_cpulist: "0-15,31"
args: "--journal"
As a result of this configuration, IRQBALANCE_BANNED_CPULIST and
IRQBALANCE_ARGS will be set or overridden, and IRQBALANCE_BANNED_CPUS
will be removed from the irqbalance configuration file.
spec:
...
configs:
...
- description: Example irqbalance configuration
module: irqbalance
moduleVersion: 1.0.0
order: 1
phase: "reconfigure"
values:
args: "--policyscript=/etc/default/irqbalance-numa.sh"
policy_script: |
#!/bin/bash
# specifying a -1 here forces irqbalance to consider an interrupt from a
# device to be equidistant from all NUMA nodes.
echo 'numa_node=-1'
policy_script_filepath: "/etc/default/irqbalance-numa.sh"
As a result of this configuration:
The
IRQBALANCE_ARGSparameter will be set or overridden in theirqbalanceconfiguration fileThe contents of
policy_scriptwill be written to/etc/default/irqbalance-numa.shThe
irqbalanceservice will use the provided policy script
For the policy script description, refer to the irqbalance documentation.
In particular, refer to the numa_node variable used in the example.
Action |
Command |
|---|---|
Verify the service status |
sudo systemctl status irqbalance
|
Verify the configuration |
less /etc/default/irqbalance
|
Verify the |
less /etc/init.d/irqbalance
|
Verify logs |
journalctl -u irqbalance*
|
Verify statistics of interrupts |
less -S /proc/interrupts
|
Verify connections of NICs to NUMA nodes |
cat /sys/class/net/<nic_name>/device/numa_node
Note The |
TechPreview since 2.27.0 (17.2.0 and 16.2.0)
The package module allows the operator to configure additional Ubuntu
mirrors and install required packages from these mirrors on cluster machines
using the mechanism implemented in the day-2 operations API.
Under the hood, this module is based on
apt and
apt_repository
Ansible modules.
Note
This module is implemented and validated against the following Ansible versions provided by Container Cloud for Ubuntu 20.04 and 22.04 in the Cluster releases 16.2.0 and 17.2.0: Ansible core 2.12.10 and Ansible collection 5.10.0.
To verify the Ansible version in a specific Cluster release, refer to the Cluster releases section in Release Notes. Use the Artifacts > System and MCR artifacts section of the corresponding Cluster release. For example, for 17.2.0.
Using the package module 1.1.0, you can configure additional Ubuntu mirrors
and install packages from these mirrors on cluster machines.
Parameter |
Description |
|---|---|
|
Optional. Comma-separated list of |
|
Optional. Version of the Ubuntu operating system. Possible values are
|
|
Optional. Map with packages to be installed using the |
|
Required. Package name. |
|
Optional. Parameter that enables management of packages from
unauthenticated sources. Defaults to |
|
Optional. Parameter that enables removal of unused dependency packages. Defaults to |
|
Optional. Parameter that enables purging of configuration files if a package state
is |
|
Optional. Module state. Possible values: |
|
Optional. Configuration map of repositories to be managed on machines
using the the |
|
Optional. Code name of the repository. |
|
Required. Name of the file that stores the repository configuration. |
|
Optional. URL of the repository GPG key. |
|
Required. URL of the repository. |
|
Optional. Module state. Possible values are |
|
Optional. Validator of the repository SSL certificate. Default is |
Example of HostOSConfiguration with the package module 1.1.0 for
installation of a repository and package:
apiVersion: kaas.mirantis.com/v1alpha1
kind: HostOSConfiguration
metadata:
name: package-200
namespace: default
spec:
configs:
- module: package
moduleVersion: 1.1.0
values:
dpkg_options: "force-confold,force-confdef"
packages:
- name: packageName
state: present
repositories:
- filename: fileName
key: https://example.org/packages/key.gpg
repo: deb https://example.org/packages/ apt/stable/
state: present
machineSelector:
matchLabels:
day2-custom-label: "true"
Example of HostOSConfiguration with the package module 1.1.0 for
removal of the previously configured repository and package:
apiVersion: kaas.mirantis.com/v1alpha1
kind: HostOSConfiguration
metadata:
name: package-200
namespace: default
spec:
configs:
- module: package
moduleVersion: 1.1.0
values:
packages:
- name: packageName
state: absent
repositories:
- filename: examplefile
repo: deb https://example.org/packages/ apt/stable/
state: absent
machineSelector:
matchLabels:
day2-custom-label: "true"
Deprecated in 2.27.0 (17.2.0 and 16.2.0)
Note
The sysctl module 1.0.0 is obsolete and not recommended for usage
in production environments.
Using the package module version 1.0.0, you can install packages from
already configured mirrors only. It cannot configure additional mirrors.
The module input values are a map of key-value pairs, where the key is a
package name and the value is a package state (present or absent).
Example of HostOSConfiguration with the package module 1.0.0:
apiVersion: kaas.mirantis.com/v1alpha1
kind: HostOSConfiguration
metadata:
name: package-100
namespace: default
spec:
configs:
- module: package
moduleVersion: 1.0.0
values:
package1: present
package2: absent
machineSelector:
matchLabels:
day2-custom-label: "true"
TechPreview since 2.27.0 (17.2.0 and 16.2.0)
The sysctl module allows the operator to manage kernel parameters at
runtime on cluster machines using the mechanism implemented in the day-2
operations API. Under the hood, this module is based on the
sysctl
Ansible module.
Note
This module is implemented and validated against the following Ansible versions provided by Container Cloud for Ubuntu 20.04 and 22.04 in the Cluster releases 16.2.0 and 17.2.0: Ansible core 2.12.10 and Ansible collection 5.10.0.
To verify the Ansible version in a specific Cluster release, refer to the Cluster releases section in Release Notes. Use the Artifacts > System and MCR artifacts section of the corresponding Cluster release. For example, for 17.2.0.
Using the sysctl module 1.1.0, you can configure kernel parameters using
the common /etc/sysctl.conf file or using a standalone file with ability
to clean up changes.
Parameter |
Description |
|---|---|
|
Optional. Name of the file that stores the provided kernel parameters. |
|
Optional. Enables cleanup of the dedicated file name before setting new parameters. |
|
Optional. Module state. Possible values are |
|
List of key-value kernel parameters to be applied on the machine. Caution For integer or float values, the system accepts only strings.
For example, |
Example of HostOSConfiguration with the sysctl module 1.1.0 for
configuration of kernel parameters:
apiVersion: kaas.mirantis.com/v1alpha1
kind: HostOSConfiguration
metadata:
name: sysctl-200
namespace: default
spec:
configs:
- module: sysctl
moduleVersion: 1.1.0
values:
filename: custom
cleanup_before: true
options:
net.ipv4.ip_forward: "1"
state: present
machineSelector:
matchLabels:
day2-custom-label: "true"
Example of HostOSConfiguration with the sysctl module 1.1.0 for
dropping previously configured kernel parameters:
apiVersion: kaas.mirantis.com/v1alpha1
kind: HostOSConfiguration
metadata:
name: sysctl-200
namespace: default
spec:
configs:
- module: sysctl
moduleVersion: 1.1.0
values:
filename: custom
cleanup_before: true
machineSelector:
matchLabels:
day2-custom-label: "true"
Deprecated in 2.27.0 (17.2.0 and 16.2.0)
Note
The sysctl module 1.0.0 is obsolete and not recommended for usage
in production environments.
Using the sysctl module version 1.0.0, you can configure kernel parameters
using the common /etc/sysctl.conf file without the ability to roll back
changes.
Caution
For integer or float values, the system accepts only strings.
For example, 1 -> "1", 1.01 -> "1.01".
Example of HostOSConfiguration with the sysctl module 1.0.0:
apiVersion: kaas.mirantis.com/v1alpha1
kind: HostOSConfiguration
metadata:
name: sysctl-100
namespace: default
spec:
configs:
- module: sysctl
moduleVersion: 1.0.0
values:
net.ipv4.ip_forward: "1"
machineSelector:
matchLabels:
day2-custom-label: "true"
TechPreview since 2.26.0 (17.1.0 and 16.1.0)
This section outlines fundamental concepts of the HostOSConfiguration, aka
hoc, and HostOSConfigurationModules, aka hocm, custom resources
as well as provides usage guidelines for these resources. For detailed
descriptions of these resources, see
API Reference: Bare metal resources.
Container Cloud provides modules, which are described in
Modules provided by Container Cloud, using the designated hocm object named
mcc-modules. All other hocm objects contain custom modules.
Warning
Do not modify the mcc-modules object, any changes will be
overwritten with data from an external source.
When the value of the machineSelector field in a hoc object is empty
(by default), no machines are selected. Therefore, no actions are triggered
until you provide a non-empty machineSelector.
This approach differs from the default behavior of Kubernetes selectors to ensure that none of configurations are applied to all machines in a cluster accidentally.
It is crucial to ensure that the namespace of a hoc object is the same as
the namespace of the associated Machine objects defined in the
machineSelector field.
For example, the following machines are located in two separate namespaces,
default and other-ns, and the hoc object is located in
other-ns:
NAMESPACE NAME LABELS
default machine.cluster.k8s.io/master-0 example-label="1"
default machine.cluster.k8s.io/master-1 example-label="1"
default machine.cluster.k8s.io/master-2 example-label="1"
other-ns machine.cluster.k8s.io/worker-0 example-label="1"
other-ns machine.cluster.k8s.io/worker-1 example-label="1"
other-ns machine.cluster.k8s.io/worker-2 example-label="1"
NAMESPACE NAME LABELS
other-ns hostosconfigurations.kaas.mirantis.com/example <none>
And although machineSelector in the hoc object contains
example-label="1", which is set for machines in both namespaces, but only
worker-0, worker-1, worker-2 will be selected because the hoc
object is located in the other-ns namespace.
machineSelector:
matchLabels:
example-label: "1"
You may use arbitrary types for primitive (non-nested) values. But for optimal
compatibility and clarity, Mirantis recommends using string values for
primitives in the values section of a hoc object. This practice helps
maintain consistency and simplifies the interpretation of configurations.
Under the hood, all primitive values are converted to strings.
For example:
values:
# instead of
# primitive-float-value: 1.05
primitive-float-value: "1.05"
# instead of
# primitive-boolean-value: true
primitive-boolean-value: "true"
object-value:
object-key: "string-data"
You can pass the values of any day-2 module to the HostOSConfiguration
object using both the values and secretValues fields simultaneously.
But if a key is present in both fields, the value from secretValues
is applied.
The values field supports the YAML format for values with any nesting
level. The HostOSConfiguration controller and provider use the YAML parser
underneath to manage the values. The following examples illustrate simple and
nested configuration formats:
Simple key-value map:
apiVersion: kaas.mirantis.com/v1alpha1 kind: HostOSConfiguration ... spec: configs: - module: somemodule moduleVersion: 1.0.0 values: key1: value1 key2: value2
Nested YAML:
apiVersion: kaas.mirantis.com/v1alpha1 kind: HostOSConfiguration ... spec: configs: - module: somemodule moduleVersion: 1.0.0 values: nestedkey1: nestedkey2: - value1 - value2 key2: value3
The secretValues field is a reference (namespace and name) to the
Secret object.
Warning
The referenced Secret object must contain only
primitive non-nested values. Otherwise, the values will not be applied
correctly. Therefore, implement your custom modules in a way that secret
parameters are on the top level and not used within nested module
parameters.
You can create a Secret object in the YAML format. For example:
apiVersion: v1
data:
key1: <base64-encoded-string-value1>
key2: <base64-encoded-string-value2>
kind: Secret
metadata:
name: top-secret
namespace: default
type: Opaque
Caution
Manually encode secret values using the base64 format and ensure
that the value does not contain trailing whitespaces or line translation
such as the \n symbol. For example:
echo -n "secret" | base64
You can also create the Secret object using the kubectl command.
This way, the secret values are automatically base64-encoded:
kubectl create secret generic top-secret --from-literal=key1=value1 --from-literal=key2=value2
The following example illustrates the use of a secret in
HostOSConfiguration:
apiVersion: kaas.mirantis.com/v1alpha1
kind: HostOSConfiguration
...
spec:
configs:
- module: somemodule
moduleVersion: 1.0.0
secretValues:
name: top-secret
namespace: default
values:
key3: value3
key4: value4
For details about execution order of configurations, see API Reference: HostOSConfiguration - spec.configs.order.
TechPreview since 2.26.0 (17.1.0 and 16.1.0)
This section describes integrations between the HostOSConfiguration
custom resouce, aka hoc, HostOSConfigurationModules custom resouce,
aka hocm, LCMCluster, and LCMMachine.
The implementation of the internal API used by day-2 operations utilizes
the current approach of StateItems, including the way how they are
processed and passed to lcm-agent.
The workflow of the internal API implementation is as follows:
Create a set of
StateItementries inLCMClustertaking into account allhocobjects in the namespace ofLCMCluster.Fill out
StateItemsfor eachLCMMachinethat was selected by themachineSelectorfield value of ahocobject.Pass
StateItemstolcm-agentthat is responsible for their execution on nodes.
The machineSelector field selects Machine objects, but they map to
LCMMachine objects in 1-1 relation. This way, each selected Machine
exactly maps to a relevant LCMMachine object.
LCMCluster utilizes empty StateItem to establish
a baseline connection between the hoc, LCMMachine objects
and lcm-agent on nodes. These empty items have no parameters and
serve as placeholders, providing a template for further processing.
To identify items added from hoc objects, these StateItems along with
other state items of an LCMCluster object are located in the
.spec.machinesTypes.control and .spec.machinesTypes.worker blocks
with the following fields in an LCMCluster object:
paramsis absentphaseisreconfigureas the only supported valueversionisv1as the only supported valuerunnercan be eitherdownloaderoransible:downloaderdownloads the package of a module of the provided version into machine.ansibleexecutes the module on the machine with provided values.
namehas the following patterns:host-os-<hocObjectName>-<moduleName>-<moduleVersion>-<modulePhase>if therunnerfield has theansiblevalue sethost-os-download-<hocObjectName>-<moduleName>-<moduleVersion> -<modulePhase>if therunnerfield has thedownloadervalue set.
The following example of an LCMCluster object illustrates empty
StateItems for the following configuration:
Machine type -
workerhocobject name -testwith a single entry in theconfigsfieldModule name -
sample-moduleModule version -
1.0.0
spec:
machineTypes:
worker:
- name: host-os-download-test-sample-module-1.0.0-reconfigure
runner: downloader
version: "v1"
phase: reconfigure
- name: host-os-test-sample-module-1.0.0-reconfigure
runner: ansible
version: "v1"
phase: reconfigure
To properly execute the StateItem list according to given configurations
from a hoc object, the implementation utilizes the
.spec.stateItemsOverwrites field in an LCMMachine object.
For each state item that corresponds to a hoc object selected for current
machine, each entry of the stateItemsOverwrites field dictionary is filled
in with key-value pairs:
Key is a
StateItemnameValue is a set of parameters from the module configuration values that will be passed as parameters to
StateItem.
After the stateItemsOverwrites field is updated, the corresponding
StateItem entries are filled out with values from the
stateItemsOverwrites.
Once the StateItem list is updated, it is passed to lcm-agent to be
finally applied on nodes.
The following example of an LCMMachine object illustrates the
stateItemsOverwrites field having a hoc object with a single entry
in the configs field, configuring a module named sample-module with
version 1.0.0:
spec:
stateItemsOverwrites:
host-os-download-test-sample-module-1.0.0-reconfigure:
playbook: directory/playbook-name.yaml
ansible: /usr/bin/ansible-playbook
host-os-test-sample-module-1.0.0-reconfigure:
path: "/root/host-os-modules/sample-module-1.0.0"
sha256: <sha256sum>
url: https://example.mirantis.com/path/to/sample-module.tgz
While processing the hoc object, baremetal-provider verifies the
hoc resource for both controlled LCMCluster and LCMMachine
resources.
Each change to a hoc object immediately triggers its resources if
host-os-modules-controller has successfully validated changes.
This behavior enables updates to existing LCMCluster and LCMMachine
objects described in the sections above. Thus, all empty StateItems,
overwrites, and filled out StateItems appear almost instantly.
This behavior also applies when removing a hoc object, thereby cleaning
everything related to the object. The object deletion is suspended until the
corresponding StateItems of a particular LCMMachine object is cleaned
up from the object status field.
Warning
A configuration that is already applied using the deleted hoc
object will not be reverted from nodes, because the feature does not provide
rollback mechanism. For module implementation details, refer to
Global recommendations for implementation of custom modules.
TechPreview since 2.26.0 (17.1.0 and 16.1.0)
Important
The cloud operator takes all risks and responsibility for module execution on cluster machines. For any questions, contact Mirantis support.
You can create a new hocm object or add a new entry with a custom-made
module to the .spec.modules list in the existing hocm object. For the
object specification, see API Reference: HostOSConfigurationModules
resource.
To add a custom module to a Container Cloud deployment:
If you use a proxy on the management and/or managed cluster, ensure that the custom module can be downloaded through that proxy, or domain address of the module URL is added to the
NO_PROXYvalue of the relatedProxyobjects.This way, the HostOSConfiguration Controller can download and verify the module and its input parameters on the management cluster. After that, the LCM Agent can download the module to any cluster machines for execution.
Caution
A management and managed cluster can use different
Proxyobjects. In this case, both proxies must satisfy the requirement above. For theProxyobject details, see Proxy and cache support.In the
hocmobject, set thenameandversionfields with the same values from the corresponding fields inmetadata.yamlof the module archive. For details, see Metadata file format.Set the
urlfield with the URL to the archive file of the module. For details, see Format and structure of a module package.Set the
sha256sumfield with the calculated SHA256 hash sum of the archive file.To obtain the SHA256 hash sum, you can use the following example command:
curl -sSL https://fully.qualified.domain.name/to/module/archive/name-1.0.0.tgz | shasum -a 256 | tr -d ' -' bc5fafd15666cb73379d2e63571a0de96fff96ac28e5bce603498cc1f34de299
After applying the changes, monitor the hocm object status to ensure that
the new module has been successfully validated and is ready to use. For the
hocm status description, see HostOSConfigurationModules status.
After you add a custom module to a Container Cloud deployment, the process of fetching a module archive involves the following automatic steps:
Retrieve the
.tgzarchive of the module and unpack it into a temporary directory.Retrieve the metadata.yaml file and validate its contents. Once done, the status of the module in the
hocmobject reflects whether the archive fetching and validating succeeded or failed.
The validation process includes the following verifications:
Validate that the SHA256 hash sum of the archive equals the value defined in the
sha256sumfield.Validate that the
playbookkey is present.Validate that the file defined in the
playbookkey value exists in the archive and has a non-zero length.Validate that the
nameandversionvalues frommetadata.yamlequal the corresponding fields in thehocmobject.If the
valuesJsonSchemakey is defined, validate that the file from the key value exists in the archive and has a non-zero length.
TechPreview since 2.26.0 (17.1.0 and 16.1.0)
Important
The cloud operator takes all risks and responsibility for module execution on cluster machines. For any questions, contact Mirantis support.
After you create a custom or configure a Container Cloud module, verify it on one machine before applying it to all target machines. This approach ensures safe and reliable cluster operability.
To test a module:
Add a custom label to one
Machineobject:kubectl edit machine master-0
apiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: ... labels: ... day2-module-testing-example: "true" name: master-0 namespace: default ...
Create the
HostOSConfigurationobject withmachineSelectorfor that custom label. For example:apiVersion: kaas.mirantis.com/v1alpha1 kind: HostOSConfiguration metadata: name: day2-test namespace: default spec: ... machineSelector: matchLabels: day2-module-testing-example: "true"
Verify that the
statusfield of modules execution is healthy, validate logs, and verify that the machine is in thereadystate.If the execution result meets your expectations, continue applying
HostOSConfigurationon other machines using one of the following options:Use the same
HostOSConfigurationobject:Change the
matchLabelsvalue in themachineSelectorfield to match all target machines.Assign the labels from the
matchLabelsvalue to other target machines.
Create a new
HostOSConfigurationobject.
Note
Mirantis highly recommends using specific custom labels on machines
and in the HostOSConfiguration selector, so that HostOSConfiguration
is applied only to the machines with the specific custom label.
Important
The cloud operator takes all risks and responsibility for module execution on cluster machines. For any questions, contact Mirantis support.
There is no API to reexecute the same successfully applied module configuration
upon user request. Once executed, the same configuration will never be executed
prior to either of the following actions is taken on the hoc object:
Change the module-related
valuesof theconfigsfield listChange the data of the
Secretobject referenced by the module-relatedsecretValuesof theconfigsfield list
To retrigger exactly the same configuration for a module, select one of the following options:
Reapply
machineSelector:Save the current selector value.
Update the selector to match no machines (empty value) or those machines where configuration should not be reapplied.
Update the selector to the previously saved value.
Re-create the
hocobject:Dump the whole
hocobject.Remove the
hocobject.Reapply the
hocobject from the dump.
Caution
The above steps retrigger all configuration from the configs
field of the hoc object. To avoid such behavior, Mirantis recommends
the following procedure:
Copy a particular module configuration to a new
hocobject and remove the previousmachineSelectorfield.Remove this configuration from the original
hocobject.Add the required values to the
machineSelectorfield in the new object.
This section describes possible issues you may encounter while working with day-2 operations as well as approaches on how to address these issues.
In .status.modules, verify whether all modules have been loaded and
verified successfully. Each module must have the available value in the
state field. If not, the error field contains the reason of the issue.
Example of different erroneous states in a hocm object:
status:
modules:
# error state: hashes mismatched
- error: 'hashes are not the same: got ''d78352e51792bbe64e573b841d12f54af089923c73bc185bac2dc5d0e6be84cd''
want ''c726ab9dfbfae1d1ed651bdedd0f8b99af589e35cb6c07167ce0ac6c970129ac'''
name: sysctl
sha256sum: d78352e51792bbe64e573b841d12f54af089923c73bc185bac2dc5d0e6be84cd
state: error
url: <url-to-package>
version: 1.0.0
# error state: an archive is not available because of misconfigured proxy
- error: 'failed to perform request to fetch the module archive: Get "<url-to-package>": Forbidden'
name: custom-module
state: error
url: <url-to-package>
version: 0.0.1
# successfully loaded and verified module
- description: Module for package installation
docURL: https://docs.mirantis.com
name: package
playbookName: main.yaml
sha256sum: 2c7c91206ce7a81a90e0068cd4ce7ca05eab36c4da1893555824b5ab82c7cc0e
state: available
url: <url-to-package>
valuesValidationSchema: <gzip+base64 encoded data>
version: 1.0.0
If a module is in the error state, it might affect the corresponding
hoc object that contains the module configuration.
Example of erroneous status in a hoc object:
status:
configs:
- moduleName: sysctl
moduleVersion: 1.0.0
modulesReference: mcc-modules
error: module is not found or not verified in any HostOSConfigurationModules object
To resolve an issue described in the error field:
Address the root cause. For example, ensure that a package has the correct hash sum, or adjust the proxy configuration to fetch the package, and so on.
Recreate the
hocmobject with correct settings.
Setting syncPeriod for debug sessions
During test or debug sessions where errors are inevitable, you can set a
reasonable sync period for host-os-modules-controller to avoid manual
recreation of hocm objects.
To enable the option, set the syncPeriod parameter in the
spec:providerSpec:value:kaas:regional:helmReleases: section of the
management Cluster object:
spec:
providerSpec:
value:
kaas:
regional:
- provider: baremetal
helmReleases:
- name: host-os-modules-controller
values:
syncPeriod: 2m
Normally, syncPeriod is not required in the cluster settings. Therefore,
you can remove this option after completing a debug session.
After creation of a hoc object with various configurations,
perform the following steps with reference to HostOSConfiguration status:
Verify that the
.status.isValidfield has thetruevalue.Verify that the
.status.configs[*].errorfields are absent.Verify that all
.status.machinesStates.<machineName>.configStateItemsStatuseshave noFailedstatus.
Also, verify the LCM-related objects:
Verify that the corresponding
LCMClusterobject has all related StateItems.Verify that all selected
LCMMachineshave the .spec.stateItemsOverwrites field, in which allStateItemsfrom the previous step are present.Verify that all
StateItemsfrom the previous step have been successfully processed bylcm-agent. Otherwise, a manual intervention is required.
To address an issue with a specific StateItem for which the lcm-agent
is reporting an error, log in to the corresponding node and
inspect Ansible execution logs:
ssh -i <path-to-ssh-key> mcc-user@<ip-addr-of-the-node>
sudo -i
cd /var/log/lcm/runners/
# from 2 directories, select the one
# with subdirectories having 'host-os-' prefix
cd <selected-dir>/<name-of-the-erroneous-state-item>
less <logs-file>
After the inspection, either resolve the issue manually or escalate the issue to Mirantis support.
The day-2 operations API allows enabling logs of debug level, which is
integrated into the baremetal-provider controller and
host-os-modules-controller. Both may be helpful during debug sessions.
To enable log debugging in host-os-modules-controller, add the following
snippet to the Cluster object:
providerSpec:
# ...
value:
# ...
kaas:
regional:
- helmReleases:
- name: host-os-modules-controller
values:
logLevel: 2
To enable log debugging in baremetal-provider, add the following snippet
to the Cluster object:
providerSpec:
# ...
value:
# ...
kaas:
regional:
- helmReleases:
- name: baremetal-provider
values:
cluster_api_provider_baremetal:
log:
verbosity: 3
To obtain the logs related to day-2 operations in baremetal-provider,
filter them by the .host-os. key:
kubectl logs -n kaas <baremetal-provider-pod> | grep ".host-os."
See also
API Reference:
Create and operate an OpenStack-based managed cluster¶
After bootstrapping your OpenStack-based Mirantis Container Cloud management cluster as described in Deploy a Container Cloud management cluster, you can create the OpenStack-based managed clusters using the Container Cloud web UI or API.
Create a managed cluster¶
This section describes how to create an OpenStack-based managed cluster using the Mirantis Container Cloud web UI of the OpenStack-based management cluster.
To create an OpenStack-based managed cluster:
Available since Container Cloud 2.24.0. Optional. Technology Preview. Enable custom host names for cluster machines. When enabled, any machine host name in a particular region matches the related
Machineobject name. For example, instead of the defaultkaas-node-<UID>, a machine host name will bemaster-0. The custom naming format is more convenient and easier to operate with.For details, see Configure host names for cluster machines.
If you enabled this feature during management cluster bootstrap, skip this step, as the feature applies to any cluster type.
If you deploy Container Cloud on top of MOSK Victoria with Tungsten Fabric and use the default security group for newly created load balancers, add the following rules for the Kubernetes API server endpoint, Container Cloud application endpoint, and for the MKE web UI and API using the OpenStack CLI:
direction='ingress'ethertype='IPv4'protocol='tcp'remote_ip_prefix='0.0.0.0/0'port_range_maxandport_range_min:'443'for Kubernetes API and Container Cloud application endpoints'6443'for MKE web UI and API
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required non-
defaultproject using the Switch Project action icon located on top of the main left-side navigation panel.To create a project, refer to Create a project for managed clusters.
Optional. In the SSH Keys tab, click Add SSH Key to upload the public SSH key(s) for VMs creation.
In the Credentials tab:
Click Add Credential to add your OpenStack credentials. You can either upload your OpenStack
clouds.yamlconfiguration file or fill in the fields manually.Verify that the new credentials status is Ready. If the status is Error, hover over the status to determine the reason of the issue.
Optional. Enable proxy access to the cluster.
In the Proxies tab, configure proxy:
Click Add Proxy.
In the Add New Proxy wizard, fill out the form with the following parameters:
Proxy configuration¶ Parameter
Description
Proxy Name
Name of the proxy server to use during cluster creation.
Region Removed in 2.26.0 (16.1.0 and 17.1.0)
From the drop-down list, select the required region.
HTTP Proxy
Add the HTTP proxy server domain name in the following format:
http://proxy.example.com:port- for anonymous accesshttp://user:password@proxy.example.com:port- for restricted access
HTTPS Proxy
Add the HTTPS proxy server domain name in the same format as for HTTP Proxy.
No Proxy
Comma-separated list of IP addresses or domain names.
For implementation details, see Proxy and cache support.
If your proxy requires a trusted CA certificate, select the CA Certificate check box and paste a CA certificate for a MITM proxy to the corresponding field or upload a certificate using Upload Certificate.
For the list of Mirantis resources and IP addresses to be accessible from the Container Cloud clusters, see Requirements for an OpenStack-based cluster.
In the Clusters tab, click Create Cluster and fill out the form with the following parameters as required:
Add Cluster name.
Configure general provider settings and the Kubernetes parameters:
Provider and Kubernetes configuration¶ Section
Parameter
Description
General Settings
Provider
Select OpenStack.
Provider Credential
From the drop-down list, select the OpenStack credentials name that you have previously created.
Release Version
The Container Cloud version.
Proxy
Optional. From the drop-down list, select the proxy server name that you have previously created.
SSH Keys
From the drop-down list, select the SSH key name(s) that you have previously added for SSH access to VMs.
Container Registry
From the drop-down list, select the Docker registry name that you have previously added using the Container Registries tab. For details, see Define a custom CA certificate for a private Docker registry.
Provider
External Network
Type of the external network in the OpenStack cloud provider.
DNS Name Servers
Comma-separated list of the DNS hosts IPs for the OpenStack VMs configuration.
Configure Bastion
Optional. Configuration parameters for the Bastion node:
Flavor
Image
Availability Zone
Server Metadata
For the parameters description, see Add a machine.
Technology Preview: select Boot From Volume to boot the Bastion node from a block storage volume and select the required amount of storage (80 GB is enough).
Kubernetes
Node CIDR
The Kubernetes nodes CIDR block. For example,
10.10.10.0/24.Services CIDR Blocks
The Kubernetes Services CIDR block. For example,
10.233.0.0/18.Pods CIDR Blocks
The Kubernetes Pods CIDR block. For example,
10.233.64.0/18.Note
The network subnet size of Kubernetes pods influences the number of nodes that can be deployed in the cluster. The default subnet size
/18is enough to create a cluster with up to 256 nodes. Each node uses the/26address blocks (64 addresses), at least one address block is allocated per node. These addresses are used by the Kubernetes pods withhostNetwork: false. The cluster size may be limited further when some nodes use more than one address block.Optional General Settings
Enable Secure Overlay
Experimental, not recommended for production deployments. Removed in Cluster release 16.0.0.
Enable WireGuard for traffic encryption on the Kubernetes workloads network.
WireGuard configuration
Ensure that the Calico MTU size is at least 60 bytes smaller than the interface MTU size of the workload network. IPv4 WireGuard uses a 60-byte header. For details, see Set the MTU size for Calico.
Enable WireGuard by selecting the Enable WireGuard check box.
Caution
Changing this parameter on a running cluster causes a downtime that can vary depending on the cluster size.
For more details about WireGuard, see Calico documentation: Encrypt in-cluster pod traffic.
Parallel Upgrade Of Worker Machines
Available since the Cluster release 16.0.0.
The maximum number of the worker nodes to update simultaneously. It serves as an upper limit on the number of machines that are drained at a given moment of time. Defaults to
1.You can configure this option after deployment before the cluster update.
Parallel Preparation For Upgrade Of Worker Machines
Available since the Cluster release 16.0.0.
The maximum number of worker nodes being prepared at a given moment of time, which includes downloading of new artifacts. It serves as a limit for the network load that can occur when downloading the files to the nodes. Defaults to
50.You can configure this option after deployment before the cluster update.
Configure StackLight:
Section
Parameter name
Description
StackLight
Enable Monitoring
Selected by default. Deselect to skip StackLight deployment. You can also enable, disable, or configure StackLight parameters after deploying a managed cluster. For details, see Change a cluster configuration or Configure StackLight.
Enable Logging
Select to deploy the StackLight logging stack.
For details about the logging components, see Deployment architecture.
Note
The logging mechanism performance depends on the cluster log load. In case of a high load, you may need to increase the default resource requests and limits for
fluentdLogs. For details, see StackLight configuration parameters: Resource limits.HA Mode
Select to enable StackLight monitoring in the HA mode. For the differences between HA and non-HA modes, see Deployment architecture.
StackLight Default Logs Severity Level
Log severity (verbosity) level for all StackLight components. The default value for this parameter is Default component log level that respects original defaults of each StackLight component. For details about severity levels, see Log verbosity.
StackLight Component Logs Severity Level
The severity level of logs for a specific StackLight component that overrides the value of the StackLight Default Logs Severity Level parameter. For details about severity levels, see Log verbosity.
Expand the drop-down menu for a specific component to display its list of available log levels.
OpenSearch
Logstash Retention Time
Skip this parameter since Container Cloud 2.26.0 (17.1.0, 16.1.0). It was removed from the code base and will be removed from the web UI in one of the following releases.
Available if you select Enable Logging. Specifies the
logstash-*index retention time.Events Retention Time
Available if you select Enable Logging. Specifies the
kubernetes_events-*index retention time.Notifications Retention
Available if you select Enable Logging. Specifies the
notification-*index retention time and is used for Mirantis OpenStack for Kubernetes.Persistent Volume Claim Size
Available if you select Enable Logging. The OpenSearch persistent volume claim size.
Collected Logs Severity Level
Available if you select Enable Logging. The minimum severity of all Container Cloud components logs collected in OpenSearch. For details about severity levels, see Logging.
Prometheus
Retention Time
The Prometheus database retention period.
Retention Size
The Prometheus database retention size.
Persistent Volume Claim Size
The Prometheus persistent volume claim size.
Enable Watchdog Alert
Select to enable the Watchdog alert that fires as long as the entire alerting pipeline is functional.
Custom Alerts
Specify alerting rules for new custom alerts or upload a YAML file in the following exemplary format:
- alert: HighErrorRate expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5 for: 10m labels: severity: page annotations: summary: High request latency
For details, see Official Prometheus documentation: Alerting rules. For the list of the predefined StackLight alerts, see Operations Guide: Available StackLight alerts.
StackLight Email Alerts
Enable Email Alerts
Select to enable the StackLight email alerts.
Send Resolved
Select to enable notifications about resolved StackLight alerts.
Require TLS
Select to enable transmitting emails through TLS.
Email alerts configuration for StackLight
Fill out the following email alerts parameters as required:
To - the email address to send notifications to.
From - the sender address.
SmartHost - the SMTP host through which the emails are sent.
Authentication username - the SMTP user name.
Authentication password - the SMTP password.
Authentication identity - the SMTP identity.
Authentication secret - the SMTP secret.
StackLight Slack Alerts
Enable Slack alerts
Select to enable the StackLight Slack alerts.
Send Resolved
Select to enable notifications about resolved StackLight alerts.
Slack alerts configuration for StackLight
Fill out the following Slack alerts parameters as required:
API URL - The Slack webhook URL.
Channel - The channel to send notifications to, for example, #channel-for-alerts.
StackLight optional settings
Enable Reference Application
Available since Container Cloud 2.22.0. Enables Reference Application that is a small microservice application that enables workload monitoring on non-MOSK managed clusters.
Note
For the feature support on MOSK deployments, refer to MOSK documentation: Deploy RefApp using automation tools.
Disabled by default. You can also enable this option after deployment from the Configure cluster menu.
Available since Container Cloud 2.24.0 and 2.24.2 for MOSK 23.2. Optional. Technology Preview. Enable the Linux Audit daemon auditd to monitor activity of cluster processes and prevent potential malicious activity.
Configuration for auditd
In the
Clusterobject, add the auditd parameters:spec: providerSpec: value: audit: auditd: enabled: <bool> enabledAtBoot: <bool> backlogLimit: <int> maxLogFile: <int> maxLogFileAction: <string> maxLogFileKeep: <int> mayHaltSystem: <bool> presetRules: <string> customRules: <string> customRulesX32: <text> customRulesX64: <text>
Configuration parameters for auditd:
enabledBoolean, default -
false. Enables theauditdrole to install the auditd packages and configure rules. CIS rules: 4.1.1.1, 4.1.1.2.enabledAtBootBoolean, default -
false. Configures grub to audit processes that can be audited even if they start up prior to auditd startup. CIS rule: 4.1.1.3.backlogLimitInteger, default - none. Configures the backlog to hold records. If during boot
audit=1is configured, the backlog holds 64 records. If more than 64 records are created during boot, auditd records will be lost with a potential malicious activity being undetected. CIS rule: 4.1.1.4.maxLogFileInteger, default - none. Configures the maximum size of the audit log file. Once the log reaches the maximum size, it is rotated and a new log file is created. CIS rule: 4.1.2.1.
maxLogFileActionString, default - none. Defines handling of the audit log file reaching the maximum file size. Allowed values:
keep_logs- rotate logs but never delete themrotate- add a cron job to compress rotated log files and keep maximum 5 compressed files.compress- compress log files and keep them under the/var/log/auditd/directory. Requiresauditd_max_log_file_keepto be enabled.
CIS rule: 4.1.2.2.
maxLogFileKeepInteger, default -
5. Defines the number of compressed log files to keep under the/var/log/auditd/directory. Requiresauditd_max_log_file_action=compress. CIS rules - none.mayHaltSystemBoolean, default -
false. Halts the system when the audit logs are full. Applies the following configuration:space_left_action = emailaction_mail_acct = rootadmin_space_left_action = halt
CIS rule: 4.1.2.3.
customRulesString, default - none. Base64-encoded content of the
60-custom.rulesfile for any architecture. CIS rules - none.customRulesX32String, default - none. Base64-encoded content of the
60-custom.rulesfile for thei386architecture. CIS rules - none.customRulesX64String, default - none. Base64-encoded content of the
60-custom.rulesfile for thex86_64architecture. CIS rules - none.presetRulesString, default - none. Comma-separated list of the following built-in preset rules:
accessactionsdeletedocker
identityimmutableloginsmac-policy
modulesmountsperm-modprivileged
scopesessionsystem-localetime-change
You can use two keywords for these rules:
none- disables all built-in rules.all- enables all built-in rules. With this key, you can add the!prefix to a rule name to exclude some rules. You can use the!prefix for rules only if you add theallkeyword as the first rule. Place a rule with the!prefix only after theallkeyword.
Example configurations:
presetRules: none- disable all preset rulespresetRules: docker- enable only thedockerrulespresetRules: access,actions,logins- enable only theaccess,actions, andloginsrulespresetRules: all- enable all preset rulespresetRules: all,!immutable,!sessions- enable all preset rules exceptimmutableandsessions
CIS controls
4.1.3 (time-change)4.1.4 (identity)4.1.5 (system-locale)4.1.6 (mac-policy)4.1.7 (logins)4.1.8 (session)4.1.9 (perm-mod)4.1.10 (access)4.1.11 (privileged)4.1.12 (mounts)4.1.13 (delete)4.1.14 (scope)4.1.15 (actions)4.1.16 (modules)4.1.17 (immutable)Docker CIS controls
1.1.41.1.81.1.101.1.121.1.131.1.151.1.161.1.171.1.181.2.31.2.41.2.51.2.61.2.71.2.101.2.11
Click Create.
To monitor the cluster readiness, hover over the status icon of a specific cluster in the Status column of the Clusters page.
Once the orange blinking status icon becomes green and Ready, the cluster deployment or update is complete.
You can monitor live deployment status of the following cluster components:
Component
Description
Bastion
For the OpenStack-based management clusters, the Bastion node IP address status that confirms the Bastion node creation
Helm
Installation or upgrade status of all Helm releases
Kubelet
Readiness of the node in a Kubernetes cluster, as reported by kubelet
Kubernetes
Readiness of all requested Kubernetes objects
Nodes
Equality of the requested nodes number in the cluster to the number of nodes having the
ReadyLCM statusOIDC
Readiness of the cluster OIDC configuration
StackLight
Health of all StackLight-related objects in a Kubernetes cluster
Swarm
Readiness of all nodes in a Docker Swarm cluster
LoadBalancer
Readiness of the Kubernetes API load balancer
ProviderInstance
Readiness of all machines in the underlying infrastructure (virtual or bare metal, depending on the provider type)
Graceful Reboot
Readiness of a cluster during a scheduled graceful reboot, available since Cluster releases 15.0.1 and 14.0.0.
Infrastructure Status
Available since Container Cloud 2.25.0 for bare metal and OpenStack providers. Readiness of the following cluster components:
Bare metal: the
MetalLBConfigobject along with MetalLB and DHCP subnets.OpenStack: cluster network, routers, load balancers, and Bastion along with their ports and floating IPs.
LCM Operation
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Health of all LCM operations on the cluster and its machines.
LCM Agent
Available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Health of all LCM agents on cluster machines and the status of LCM agents update to the version from the current Cluster release.
For the history of a cluster deployment or update, refer to Inspect the history of a cluster and machine deployment or update.
Available since Container Cloud 2.24.0 and 2.24.2 for MOSK 23.2. Optional. Technology Preview. Enable the Linux Audit daemon auditd to monitor activity of cluster processes and prevent potential malicious activity.
Configuration for auditd
In the
Clusterobject, add the auditd parameters:spec: providerSpec: value: audit: auditd: enabled: <bool> enabledAtBoot: <bool> backlogLimit: <int> maxLogFile: <int> maxLogFileAction: <string> maxLogFileKeep: <int> mayHaltSystem: <bool> presetRules: <string> customRules: <string> customRulesX32: <text> customRulesX64: <text>
Configuration parameters for auditd:
enabledBoolean, default -
false. Enables theauditdrole to install the auditd packages and configure rules. CIS rules: 4.1.1.1, 4.1.1.2.enabledAtBootBoolean, default -
false. Configures grub to audit processes that can be audited even if they start up prior to auditd startup. CIS rule: 4.1.1.3.backlogLimitInteger, default - none. Configures the backlog to hold records. If during boot
audit=1is configured, the backlog holds 64 records. If more than 64 records are created during boot, auditd records will be lost with a potential malicious activity being undetected. CIS rule: 4.1.1.4.maxLogFileInteger, default - none. Configures the maximum size of the audit log file. Once the log reaches the maximum size, it is rotated and a new log file is created. CIS rule: 4.1.2.1.
maxLogFileActionString, default - none. Defines handling of the audit log file reaching the maximum file size. Allowed values:
keep_logs- rotate logs but never delete themrotate- add a cron job to compress rotated log files and keep maximum 5 compressed files.compress- compress log files and keep them under the/var/log/auditd/directory. Requiresauditd_max_log_file_keepto be enabled.
CIS rule: 4.1.2.2.
maxLogFileKeepInteger, default -
5. Defines the number of compressed log files to keep under the/var/log/auditd/directory. Requiresauditd_max_log_file_action=compress. CIS rules - none.mayHaltSystemBoolean, default -
false. Halts the system when the audit logs are full. Applies the following configuration:space_left_action = emailaction_mail_acct = rootadmin_space_left_action = halt
CIS rule: 4.1.2.3.
customRulesString, default - none. Base64-encoded content of the
60-custom.rulesfile for any architecture. CIS rules - none.customRulesX32String, default - none. Base64-encoded content of the
60-custom.rulesfile for thei386architecture. CIS rules - none.customRulesX64String, default - none. Base64-encoded content of the
60-custom.rulesfile for thex86_64architecture. CIS rules - none.presetRulesString, default - none. Comma-separated list of the following built-in preset rules:
accessactionsdeletedocker
identityimmutableloginsmac-policy
modulesmountsperm-modprivileged
scopesessionsystem-localetime-change
You can use two keywords for these rules:
none- disables all built-in rules.all- enables all built-in rules. With this key, you can add the!prefix to a rule name to exclude some rules. You can use the!prefix for rules only if you add theallkeyword as the first rule. Place a rule with the!prefix only after theallkeyword.
Example configurations:
presetRules: none- disable all preset rulespresetRules: docker- enable only thedockerrulespresetRules: access,actions,logins- enable only theaccess,actions, andloginsrulespresetRules: all- enable all preset rulespresetRules: all,!immutable,!sessions- enable all preset rules exceptimmutableandsessions
CIS controls
4.1.3 (time-change)4.1.4 (identity)4.1.5 (system-locale)4.1.6 (mac-policy)4.1.7 (logins)4.1.8 (session)4.1.9 (perm-mod)4.1.10 (access)4.1.11 (privileged)4.1.12 (mounts)4.1.13 (delete)4.1.14 (scope)4.1.15 (actions)4.1.16 (modules)4.1.17 (immutable)Docker CIS controls
1.1.41.1.81.1.101.1.121.1.131.1.151.1.161.1.171.1.181.2.31.2.41.2.51.2.61.2.71.2.101.2.11
Proceed with Add a machine.
See also
Add a machine¶
After you create a new OpenStack-based Mirantis Container Cloud managed cluster as described in Create a managed cluster, proceed with adding machines to this cluster using the Container Cloud web UI.
You can also use the instruction below to scale up an existing managed cluster.
To add a machine to an OpenStack-based managed cluster:
Optional. Available as TechPreview. If you need to boot a machine from a block storage volume, complete steps described in Boot a machine from a block storage volume.
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the required cluster name. The cluster page with Machines list opens.
On the cluster page, click Create Machine.
Fill out the form with the following parameters as required:
Container Cloud machine configuration¶ Parameter
Description
Create Machines Pool
Select to create a set of machines with the same provider spec to manage them as a single unit. Enter the machine pool name in the Pool Name field.
Count
Specify the number of machines to create. If you create a machine pool, specify the replicas count of the pool.
Select Manager or Worker to create a Kubernetes manager or worker node.
Caution
The required minimum number of manager machines is three for HA. A cluster can have more than three manager machines but only an odd number of machines.
In an even-sized cluster, an additional machine remains in the
Pendingstate until an extra manager machine is added. An even number of manager machines does not provide additional fault tolerance but increases the number of node required for etcd quorum.The required minimum number of worker machines for the Container Cloud workloads is two. If the multiserver mode is enabled for StackLight, add three worker nodes.
Flavor
From the drop-down list, select the required hardware configuration for the machine. The list of available flavors corresponds to the one in your OpenStack environment.
For the hardware requirements, see Requirements for an OpenStack-based cluster.
Image
From the drop-down list, select the required cloud image:
CentOS 7.9
Ubuntu 20.04
If you do not have the required image in the list, add it to your OpenStack environment using the Horizon web UI by downloading it from:
Warning
A Container Cloud cluster based on both Ubuntu and CentOS operating systems is not supported.
Availability Zone
From the drop-down list, select the availability zone from which the new machine will be launched.
Configure Server Metadata
Optional. Select Configure Server Metadata and add the required number of string key-value pairs for the machine
meta_dataconfiguration incloud-init.Prohibited keys are:
KaaS,cluster,clusterID,namespaceas they are used by Container Cloud.Boot From Volume
Optional. Technology Preview. Select to boot a machine from a block storage volume. Use the Up and Down arrows in the Volume Size (GiB) field to define the required volume size.
This option applies to clouds that do not have enough space on hypervisors. After enabling this option, the Cinder storage is used instead of the Nova storage.
Upgrade Index
Optional. A positive numeral value that defines the order of machine upgrade during a cluster update.
Note
You can change the upgrade order later on an existing cluster. For details, see Change the upgrade order of a machine or machine pool.
Consider the following upgrade index specifics:
The first machine to upgrade is always one of the control plane machines with the lowest
upgradeIndex. Other control plane machines are upgraded one by one according to their upgrade indexes.If the
ClusterspecdedicatedControlPlanefield isfalse, worker machines are upgraded only after the upgrade of all control plane machines finishes. Otherwise, they are upgraded after the first control plane machine, concurrently with other control plane machines.If several machines have the same upgrade index, they have the same priority during upgrade.
If the value is not set, the machine is automatically assigned a value of the upgrade index.
Node Labels
Add the required node labels for the worker machine to run certain components on a specific node. For example, for the StackLight nodes that run OpenSearch and require more resources than a standard node, add the StackLight label. The list of available node labels is obtained from
allowedNodeLabelsof your currentClusterrelease.If the
valuefield is not defined inallowedNodeLabels, from the drop-down list, select the required label and define an appropriate custom value for this label to be set to the node. For example, thenode-typelabel can have thestorage-ssdvalue to meet the service scheduling logic on a particular machine.Note
Due to the known issue 23002 fixed in Container Cloud 2.21.0, a custom value for a predefined node label cannot be set using the Container Cloud web UI. For a workaround, refer to the issue description.
Caution
If you deploy StackLight in the HA mode (recommended):
Add the StackLight label to minimum three worker nodes. Otherwise, StackLight will not be deployed until the required number of worker nodes is configured with the StackLight label.
Removal of the StackLight label from worker nodes along with removal of worker nodes with StackLight label can cause the StackLight components to become inaccessible. It is important to correctly maintain the worker nodes where the StackLight local volumes were provisioned. For details, see Delete a cluster machine.
To obtain the list of nodes where StackLight is deployed, refer to Upgrade managed clusters with StackLight deployed in HA mode.
If you move the StackLight label to a new worker machine on an existing cluster, manually deschedule all StackLight components from the old worker machine, which you remove the StackLight label from. For details, see Deschedule StackLight Pods from a worker machine.
Note
To add node labels after deploying a worker machine. navigate to the Machines page, click the More action icon in the last column of the required machine field, and select Configure machine.
Since Container Cloud 2.24.0, you can configure node labels for machine pools after deployment using the More > Configure Pool option.
Click Create.
Repeat the steps above for the remaining machines.
Monitor the deploy or update live status of the machine:
- Quick status
On the Clusters page, in the Managers or Workers column. The green status icon indicates that the machine is Ready, the orange status icon indicates that the machine is Updating.
- Detailed status
In the Machines section of a particular cluster page, in the Status column. Hover over a particular machine status icon to verify the deploy or update status of a specific machine component.
You can monitor the status of the following machine components:
Component
Description
Kubelet
Readiness of a node in a Kubernetes cluster.
Swarm
Health and readiness of a node in a Docker Swarm cluster.
LCM
LCM readiness status of a node.
ProviderInstance
Readiness of a node in the underlying infrastructure (virtual or bare metal, depending on the provider type).
Graceful Reboot
Readiness of a machine during a scheduled graceful reboot of a cluster, available since Cluster releases 15.0.1 and 14.0.0.
Infrastructure Status
Available since Container Cloud 2.25.0 for the bare metal provider only. Readiness of the
IPAMHost,L2Template,BareMetalHost, andBareMetalHostProfileobjects associated with the machine.LCM Operation
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Health of all LCM operations on the machine.
LCM Agent
Available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Health of the LCM Agent on the machine and the status of the LCM Agent update to the version from the current Cluster release.
The machine creation starts with the Provision status. During provisioning, the machine is not expected to be accessible since its infrastructure (VM, network, and so on) is being created.
Other machine statuses are the same as the
LCMMachineobject states:Uninitialized - the machine is not yet assigned to an
LCMCluster.Pending - the agent reports a node IP address and host name.
Prepare - the machine executes
StateItemsthat correspond to thepreparephase. This phase usually involves downloading the necessary archives and packages.Deploy - the machine executes
StateItemsthat correspond to thedeployphase that is becoming a Mirantis Kubernetes Engine (MKE) node.Ready - the machine is being deployed.
Upgrade - the machine is being upgraded to the new MKE version.
Reconfigure - the machine executes
StateItemsthat correspond to thereconfigurephase. The machine configuration is being updated without affecting workloads running on the machine.
Once the status changes to Ready, the deployment of the cluster components on this machine is complete.
You can also monitor the live machine status using API:
kubectl get machines <machineName> -o wide
Example of system response since Container Cloud 2.23.0:
NAME READY LCMPHASE NODENAME UPGRADEINDEX REBOOTREQUIRED WARNINGS demo-0 true Ready kaas-node-c6aa8ad3 1 false
For the history of a machine deployment or update, refer to Inspect the history of a cluster and machine deployment or update.
Verify the status of the cluster nodes as described in Connect to a Mirantis Container Cloud cluster.
Warning
An operational managed cluster must contain a minimum of 3 Kubernetes manager machines to meet the etcd quorum and 2 Kubernetes worker machines.
The deployment of the cluster does not start until the minimum number of machines is created.
A machine with the manager role is automatically deleted during the cluster deletion. Manual deletion of manager machines is allowed only for the purpose of node replacement or recovery.
Support status of manager machine deletion
Since the Cluster releases 17.0.0, 16.0.0, and 14.1.0, the feature is generally available.
Before the Cluster releases 16.0.0 and 14.1.0, the feature is available within the Technology Preview features scope for non-MOSK-based clusters.
Before the Cluster release 17.0.0 the feature is not supported for MOSK.
Verify that network addresses used on your clusters do not overlap with the following default MKE network addresses for Swarm and MCR:
10.0.0.0/16is used for Swarm networks. IP addresses from this network are virtual.10.99.0.0/16is used for MCR networks. IP addresses from this network are allocated on hosts.
Verification of Swarm and MCR network addresses
To verify Swarm and MCR network addresses, run on any master node:
docker infoExample of system response:
Server: ... Swarm: ... Default Address Pool: 10.0.0.0/16 SubnetSize: 24 ... Default Address Pools: Base: 10.99.0.0/16, Size: 20 ...
Not all of Swarm and MCR addresses are usually in use. One Swarm Ingress network is created by default and occupies the
10.0.0.0/24address block. Also, three MCR networks are created by default and occupy three address blocks:10.99.0.0/20,10.99.16.0/20,10.99.32.0/20.To verify the actual networks state and addresses in use, run:
docker network ls docker network inspect <networkName>
See also
Boot a machine from a block storage volume¶
Technology Preview
Clouds that do not have enough space on hypervisors may require booting of cluster machines from a block storage volume. After enabling this option, the Cinder storage is used instead of the Nova storage.
Requirements:
The minimal storage requirement is 120 GB per node. For details, see Requirements for an OpenStack-based cluster.
Disks performance must match etcd requirements. For details, see etcd documentation.
The following procedure describes how to boot an OpenStack-based machine from a volume using CLI. You can also boot a machine from volume using the Container Cloud web UI by selecting the Boot From Volume option in the machine creation wizard. For details, see Add a machine.
To boot an OpenStack-based machine from a volume using CLI:
Download your management cluster
kubeconfig:Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
Expand the menu of the tab with your user name.
Click Download kubeconfig to download
kubeconfigof your management cluster.Log in to any local machine with
kubectlinstalled.Copy the downloaded
kubeconfigto this machine.
Scale down the OpenStack provider on the required management cluster:
kubectl --kubeconfig <pathToMgmtClusterKubeconfig> -n kaas scale deploy openstack-provider --replicas 0
Create a machine using the Container Cloud web UI as described in Add a machine.
Open the required
Machineobject for editing:kubectl --kubeconfig <pathToMgmtClusterKubeconfig> -n <projectName> edit machine <machineName>
In the
spec:providerSpecsection, define the following parameter to boot a server from a block storage volume based on the given image:bootFromVolume: enabled: true volumeSize: 120
Note
The minimal storage requirement is 120 GB per node. For details, see Requirements for an OpenStack-based cluster.
Scale up the OpenStack provider:
kubectl -n kaas scale deploy openstack-provider --replicas 3
Delete a managed cluster¶
Deleting a managed cluster does not require a preliminary deletion of VMs that run on this cluster.
Warning
We recommend deleting cluster machines using the Container Cloud web UI or API instead of using the cloud provider tools directly. Otherwise, the cluster deletion or detachment may hang and additional manual steps will be required to clean up machine resources.
To delete an OpenStack-based managed cluster:
Optional. Applies to clusters with volumes created using Persistent Volume Claims (PVCs). Select from the following options:
Since Container Cloud 2.24.0, skip this step as the system performs it automatically if you select the Delete all volumes in the cluster check box in the web UI as described below.
Since Container Cloud 2.23.0, schedule the volumes created using PVCs to be deleted during cluster deletion using the API:
Caution
The feature applies only to volumes created on clusters that are based on or updated to the Cluster release 11.7.0 or later.
If you added volumes to an existing cluster before it was updated to the Cluster release 11.7.0, delete such volumes manually after the cluster deletion.
Log in to the host where your management cluster
kubeconfigis located and where kubectl is installed.In the
valuesection ofproviderSpecof theClusterobject, setvolumesCleanupEnabledtotrue:kubectl patch clusters.cluster.k8s.io -n <managedClusterProjectName> <managedclusterName> --type=merge -p '{"spec":{"providerSpec":{"value":{"volumesCleanupEnabled":true}}}}'
Replace the parameters enclosed in angle brackets with the corresponding values.
Caution
This feature is available as Technology Preview. Use such configuration for testing and evaluation purposes only. For the Technology Preview feature definition, refer to Technology Preview features.
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the More action icon in the last column of the required cluster and select Delete.
Verify and confirm the list of machines to be removed.
Since the Container Cloud 2.24.0, if you do not plan to reuse volumes created using PVCs, select the Delete all volumes in the cluster .
Caution
The feature applies only to volumes created on clusters that are based on or updated to the Cluster release 11.7.0 or later.
If you added volumes to an existing cluster before it was updated to the Cluster release 11.7.0, delete such volumes manually after the cluster deletion.
Deleting a cluster automatically frees up the resources allocated for this cluster, for example, instances, load balancers, networks, floating IPs.
If the cluster deletion hangs and the Deleting status message does not disappear after a while, refer to Cluster deletion or detachment freezes to fix the issue.
If you do not plan to reuse the credentials of the deleted cluster, delete them:
In the Credentials tab, verify that the required credentials are not in the In Use status.
Click the Delete credential action icon next to the name of the credentials to be deleted.
Confirm the deletion.
Warning
You can delete credentials only after deleting the managed cluster they relate to.
Create and operate a VMware vSphere-based managed cluster¶
After bootstrapping your VMware vSphere-based Mirantis Container Cloud management cluster as described in Deploy a Container Cloud management cluster, you can create vSphere-based managed clusters using the Container Cloud web UI.
Create a managed cluster¶
This section describes how to create a VMware vSphere-based managed cluster using the Mirantis Container Cloud web UI of the vSphere-based management cluster.
To create a vSphere-based managed cluster:
Available since Container Cloud 2.24.0. Optional. Technology Preview. Enable custom host names for cluster machines. When enabled, any machine host name in a particular region matches the related
Machineobject name. For example, instead of the defaultkaas-node-<UID>, a machine host name will bemaster-0. The custom naming format is more convenient and easier to operate with.For details, see Configure host names for cluster machines.
If you enabled this feature during management cluster bootstrap, skip this step, as the feature applies to any cluster type.
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required non-
defaultproject using the Switch Project action icon located on top of the main left-side navigation panel.To create a project, refer to Create a project for managed clusters.
Optional. In the SSH Keys tab, click Add SSH Key to upload the public SSH key(s) for VMs creation.
In the Credentials tab:
Click Add Credential to add your vSphere credentials. You can either upload your vSphere
vsphere.yamlconfiguration file or fill in the fields manually.Verify that the new credentials status is Ready. If the status is Error, hover over the status to determine the reason of the issue.
Optional. Enable proxy access to the cluster.
In the Proxies tab, configure proxy:
Click Add Proxy.
In the Add New Proxy wizard, fill out the form with the following parameters:
Proxy configuration¶ Parameter
Description
Proxy Name
Name of the proxy server to use during cluster creation.
Region Removed in 2.26.0 (16.1.0 and 17.1.0)
From the drop-down list, select the required region.
HTTP Proxy
Add the HTTP proxy server domain name in the following format:
http://proxy.example.com:port- for anonymous accesshttp://user:password@proxy.example.com:port- for restricted access
HTTPS Proxy
Add the HTTPS proxy server domain name in the same format as for HTTP Proxy.
No Proxy
Comma-separated list of IP addresses or domain names. Mandatory to add
host[:port]of the vCenter server.For implementation details, see Proxy and cache support.
If your proxy requires a trusted CA certificate, select the CA Certificate check box and paste a CA certificate for a MITM proxy to the corresponding field or upload a certificate using Upload Certificate.
For the list of Mirantis resources and IP addresses to be accessible from the Container Cloud clusters, see Requirements for a VMware vSphere-based cluster.
In the RHEL Licenses tab, click Add RHEL License and fill out the form with the following parameters:
RHEL license parameters¶ Parameter
Description
RHEL License Name
RHEL license name
Username (User/Password Registration)
User name to access the RHEL license
Password (User/Password Registration)
Password to access the RHEL license
Organization ID (Activation Key)
Organization key to register a user by
Activation Key (Activation Key)
Activation key to use for user registration
RPM URL (Activation Key)
Optional. URL from which to download RPM packages using RPM Package Manager
Pool IDs
Optional. Specify the pool IDs for RHEL licenses for Virtual Datacenters. Otherwise, Subscription Manager will select a subscription from the list of available and appropriate for the machines.
In the Clusters tab, click Create Cluster and fill out the form with the following parameters as required:
Configure general provider settings and the Kubernetes parameters:
Section
Parameter
Description
General Settings
Provider
Select vSphere.
Provider Credential
From the drop-down list, select the vSphere credentials name that you have previously created.
Release Version
The Container Cloud version.
Caution
Due to the known issue 40747, the Cluster release 16.0.0, which is not supported since Container Cloud 2.25.1 for greenfield deployments, is still available in the drop-down menu for managed clusters.
Do not select this Cluster release to prevent deployment failures. Select the latest supported version instead.
The issue 40747 is addressed in Container Cloud 2.26.1.
Proxy
Optional. From the drop-down list, select the proxy server name that you have previously created.
SSH Keys
From the drop-down list, select the SSH key name(s) that you have previously added for the SSH access to VMs.
Container Registry
From the drop-down list, select the Docker registry name that you have previously added using the Container Registries tab. For details, see Define a custom CA certificate for a private Docker registry.
Kubernetes
Node CIDR
Kubernetes nodes CIDR block. For example,
10.10.10.0/24.Services CIDR Blocks
Kubernetes Services CIDR block. For example,
10.233.0.0/18.Pods CIDR Blocks
Kubernetes pods CIDR block. For example,
10.233.64.0/18.Note
The network subnet size of Kubernetes pods influences the number of nodes that can be deployed in the cluster. The default subnet size
/18is enough to create a cluster with up to 256 nodes. Each node uses the/26address blocks (64 addresses), at least one address block is allocated per node. These addresses are used by the Kubernetes pods withhostNetwork: false. The cluster size may be limited further when some nodes use more than one address block.Provider
LB Host IP
IP address of the load balancer endpoint that will be used to access the Kubernetes API of the new cluster.
LB Address Range
MetalLB range of IP addresses that can be assigned to load balancers for Kubernetes Services.
vSphere
Machine Folder Path
Full path to the folder that will store the cluster machines metadata. Use the drop-down list to select the required item.
Note
Every drop-down list item of the vSphere section represents a short name of a particular vSphere resource, without the datacenter path. The Network Path drop-down list items also represent specific network types. Start typing the item name in the drop-down list field to filter the results and select the required item.
Network Path
Full path to a network for cluster machines. Use the drop-down list to select the required item.
Resource Pool Path
Full path to a resource pool where VMs will be created. Use the drop-down list to select the required item.
Datastore For Cluster
Full path to a storage for VMs disks. Use the drop-down list to select the required item.
Datastore For Cloud Provider
Full path to a storage for Kubernetes volumes. Use the drop-down list to select the required item.
SCSI Controller Type
SCSI controller type for VMs. Leave
pvscsias default.Enable IPAM
Enables IPAM. Set to
trueif a vSphere network has no DHCP server. Also, provide the following additional parameters for a proper network setup on machines using embedded IP address management (IPAM):Network CIDR
CIDR of the provided vSphere network. For example,
10.20.0.0/16.Network Gateway
Gateway of the provided vSphere network.
DNS Name Servers
List of nameservers for the provided vSphere network.
Include Ranges
IP range for the cluster machines. Specify the range of the provided CIDR. For example,
10.20.0.100-10.20.0.200.Exclude Ranges
Optional. IP ranges to be excluded from being assigned to the cluster machines. The MetalLB range and the load balancer IP address should not intersect with the addresses for IPAM. For example,
10.20.0.150-10.20.0.170.Optional General Settings
Enable Secure Overlay
Experimental, not recommended for production deployments. Removed in Cluster releases 16.0.0 and 14.1.0.
Enable WireGuard for traffic encryption on the Kubernetes workloads network.
WireGuard configuration
Ensure that the Calico MTU size is at least 60 bytes smaller than the interface MTU size of the workload network. IPv4 WireGuard uses a 60-byte header. For details, see Set the MTU size for Calico.
Enable WireGuard by selecting the Enable WireGuard check box.
Caution
Changing this parameter on a running cluster causes a downtime that can vary depending on the cluster size.
For more details about WireGuard, see Calico documentation: Encrypt in-cluster pod traffic.
Parallel Upgrade Of Worker Machines
Available since the Cluster release 14.1.0.
The maximum number of the worker nodes to update simultaneously. It serves as an upper limit on the number of machines that are drained at a given moment of time. Defaults to
1.You can configure this option after deployment before the cluster update.
Parallel Preparation For Upgrade Of Worker Machines
Available since the Cluster release 14.1.0.
The maximum number of worker nodes being prepared at a given moment of time, which includes downloading of new artifacts. It serves as a limit for the network load that can occur when downloading the files to the nodes. Defaults to
50.You can configure this option after deployment before the cluster update.
Configure StackLight:
Section
Parameter name
Description
StackLight
Enable Monitoring
Selected by default. Deselect to skip StackLight deployment. You can also enable, disable, or configure StackLight parameters after deploying a managed cluster. For details, see Change a cluster configuration or Configure StackLight.
Enable Logging
Select to deploy the StackLight logging stack.
For details about the logging components, see Deployment architecture.
Note
The logging mechanism performance depends on the cluster log load. In case of a high load, you may need to increase the default resource requests and limits for
fluentdLogs. For details, see StackLight configuration parameters: Resource limits.HA Mode
Select to enable StackLight monitoring in the HA mode. For the differences between HA and non-HA modes, see Deployment architecture.
StackLight Default Logs Severity Level
Log severity (verbosity) level for all StackLight components. The default value for this parameter is Default component log level that respects original defaults of each StackLight component. For details about severity levels, see Log verbosity.
StackLight Component Logs Severity Level
The severity level of logs for a specific StackLight component that overrides the value of the StackLight Default Logs Severity Level parameter. For details about severity levels, see Log verbosity.
Expand the drop-down menu for a specific component to display its list of available log levels.
OpenSearch
Logstash Retention Time
Skip this parameter since Container Cloud 2.26.0 (17.1.0, 16.1.0). It was removed from the code base and will be removed from the web UI in one of the following releases.
Available if you select Enable Logging. Specifies the
logstash-*index retention time.Events Retention Time
Available if you select Enable Logging. Specifies the
kubernetes_events-*index retention time.Notifications Retention
Available if you select Enable Logging. Specifies the
notification-*index retention time and is used for Mirantis OpenStack for Kubernetes.Persistent Volume Claim Size
Available if you select Enable Logging. The OpenSearch persistent volume claim size.
Collected Logs Severity Level
Available if you select Enable Logging. The minimum severity of all Container Cloud components logs collected in OpenSearch. For details about severity levels, see Logging.
Prometheus
Retention Time
The Prometheus database retention period.
Retention Size
The Prometheus database retention size.
Persistent Volume Claim Size
The Prometheus persistent volume claim size.
Enable Watchdog Alert
Select to enable the Watchdog alert that fires as long as the entire alerting pipeline is functional.
Custom Alerts
Specify alerting rules for new custom alerts or upload a YAML file in the following exemplary format:
- alert: HighErrorRate expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5 for: 10m labels: severity: page annotations: summary: High request latency
For details, see Official Prometheus documentation: Alerting rules. For the list of the predefined StackLight alerts, see Operations Guide: Available StackLight alerts.
StackLight Email Alerts
Enable Email Alerts
Select to enable the StackLight email alerts.
Send Resolved
Select to enable notifications about resolved StackLight alerts.
Require TLS
Select to enable transmitting emails through TLS.
Email alerts configuration for StackLight
Fill out the following email alerts parameters as required:
To - the email address to send notifications to.
From - the sender address.
SmartHost - the SMTP host through which the emails are sent.
Authentication username - the SMTP user name.
Authentication password - the SMTP password.
Authentication identity - the SMTP identity.
Authentication secret - the SMTP secret.
StackLight Slack Alerts
Enable Slack alerts
Select to enable the StackLight Slack alerts.
Send Resolved
Select to enable notifications about resolved StackLight alerts.
Slack alerts configuration for StackLight
Fill out the following Slack alerts parameters as required:
API URL - The Slack webhook URL.
Channel - The channel to send notifications to, for example, #channel-for-alerts.
StackLight optional settings
Enable Reference Application
Available since Container Cloud 2.22.0. Enables Reference Application that is a small microservice application that enables workload monitoring on non-MOSK managed clusters.
Note
For the feature support on MOSK deployments, refer to MOSK documentation: Deploy RefApp using automation tools.
Disabled by default. You can also enable this option after deployment from the Configure cluster menu.
Available since Container Cloud 2.24.0 and 2.24.2 for MOSK 23.2. Optional. Technology Preview. Enable the Linux Audit daemon auditd to monitor activity of cluster processes and prevent potential malicious activity.
Configuration for auditd
In the
Clusterobject, add the auditd parameters:spec: providerSpec: value: audit: auditd: enabled: <bool> enabledAtBoot: <bool> backlogLimit: <int> maxLogFile: <int> maxLogFileAction: <string> maxLogFileKeep: <int> mayHaltSystem: <bool> presetRules: <string> customRules: <string> customRulesX32: <text> customRulesX64: <text>
Configuration parameters for auditd:
enabledBoolean, default -
false. Enables theauditdrole to install the auditd packages and configure rules. CIS rules: 4.1.1.1, 4.1.1.2.enabledAtBootBoolean, default -
false. Configures grub to audit processes that can be audited even if they start up prior to auditd startup. CIS rule: 4.1.1.3.backlogLimitInteger, default - none. Configures the backlog to hold records. If during boot
audit=1is configured, the backlog holds 64 records. If more than 64 records are created during boot, auditd records will be lost with a potential malicious activity being undetected. CIS rule: 4.1.1.4.maxLogFileInteger, default - none. Configures the maximum size of the audit log file. Once the log reaches the maximum size, it is rotated and a new log file is created. CIS rule: 4.1.2.1.
maxLogFileActionString, default - none. Defines handling of the audit log file reaching the maximum file size. Allowed values:
keep_logs- rotate logs but never delete themrotate- add a cron job to compress rotated log files and keep maximum 5 compressed files.compress- compress log files and keep them under the/var/log/auditd/directory. Requiresauditd_max_log_file_keepto be enabled.
CIS rule: 4.1.2.2.
maxLogFileKeepInteger, default -
5. Defines the number of compressed log files to keep under the/var/log/auditd/directory. Requiresauditd_max_log_file_action=compress. CIS rules - none.mayHaltSystemBoolean, default -
false. Halts the system when the audit logs are full. Applies the following configuration:space_left_action = emailaction_mail_acct = rootadmin_space_left_action = halt
CIS rule: 4.1.2.3.
customRulesString, default - none. Base64-encoded content of the
60-custom.rulesfile for any architecture. CIS rules - none.customRulesX32String, default - none. Base64-encoded content of the
60-custom.rulesfile for thei386architecture. CIS rules - none.customRulesX64String, default - none. Base64-encoded content of the
60-custom.rulesfile for thex86_64architecture. CIS rules - none.presetRulesString, default - none. Comma-separated list of the following built-in preset rules:
accessactionsdeletedocker
identityimmutableloginsmac-policy
modulesmountsperm-modprivileged
scopesessionsystem-localetime-change
You can use two keywords for these rules:
none- disables all built-in rules.all- enables all built-in rules. With this key, you can add the!prefix to a rule name to exclude some rules. You can use the!prefix for rules only if you add theallkeyword as the first rule. Place a rule with the!prefix only after theallkeyword.
Example configurations:
presetRules: none- disable all preset rulespresetRules: docker- enable only thedockerrulespresetRules: access,actions,logins- enable only theaccess,actions, andloginsrulespresetRules: all- enable all preset rulespresetRules: all,!immutable,!sessions- enable all preset rules exceptimmutableandsessions
CIS controls
4.1.3 (time-change)4.1.4 (identity)4.1.5 (system-locale)4.1.6 (mac-policy)4.1.7 (logins)4.1.8 (session)4.1.9 (perm-mod)4.1.10 (access)4.1.11 (privileged)4.1.12 (mounts)4.1.13 (delete)4.1.14 (scope)4.1.15 (actions)4.1.16 (modules)4.1.17 (immutable)Docker CIS controls
1.1.41.1.81.1.101.1.121.1.131.1.151.1.161.1.171.1.181.2.31.2.41.2.51.2.61.2.71.2.101.2.11
Click Create.
To monitor the cluster readiness, hover over the status icon of a specific cluster in the Status column of the Clusters page.
Once the orange blinking status icon becomes green and Ready, the cluster deployment or update is complete.
You can monitor live deployment status of the following cluster components:
Component
Description
Bastion
For the OpenStack-based management clusters, the Bastion node IP address status that confirms the Bastion node creation
Helm
Installation or upgrade status of all Helm releases
Kubelet
Readiness of the node in a Kubernetes cluster, as reported by kubelet
Kubernetes
Readiness of all requested Kubernetes objects
Nodes
Equality of the requested nodes number in the cluster to the number of nodes having the
ReadyLCM statusOIDC
Readiness of the cluster OIDC configuration
StackLight
Health of all StackLight-related objects in a Kubernetes cluster
Swarm
Readiness of all nodes in a Docker Swarm cluster
LoadBalancer
Readiness of the Kubernetes API load balancer
ProviderInstance
Readiness of all machines in the underlying infrastructure (virtual or bare metal, depending on the provider type)
Graceful Reboot
Readiness of a cluster during a scheduled graceful reboot, available since Cluster releases 15.0.1 and 14.0.0.
Infrastructure Status
Available since Container Cloud 2.25.0 for bare metal and OpenStack providers. Readiness of the following cluster components:
Bare metal: the
MetalLBConfigobject along with MetalLB and DHCP subnets.OpenStack: cluster network, routers, load balancers, and Bastion along with their ports and floating IPs.
LCM Operation
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Health of all LCM operations on the cluster and its machines.
LCM Agent
Available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Health of all LCM agents on cluster machines and the status of LCM agents update to the version from the current Cluster release.
For the history of a cluster deployment or update, refer to Inspect the history of a cluster and machine deployment or update.
Available since Container Cloud 2.24.0 and 2.24.2 for MOSK 23.2. Optional. Technology Preview. Enable the Linux Audit daemon auditd to monitor activity of cluster processes and prevent potential malicious activity.
Configuration for auditd
In the
Clusterobject, add the auditd parameters:spec: providerSpec: value: audit: auditd: enabled: <bool> enabledAtBoot: <bool> backlogLimit: <int> maxLogFile: <int> maxLogFileAction: <string> maxLogFileKeep: <int> mayHaltSystem: <bool> presetRules: <string> customRules: <string> customRulesX32: <text> customRulesX64: <text>
Configuration parameters for auditd:
enabledBoolean, default -
false. Enables theauditdrole to install the auditd packages and configure rules. CIS rules: 4.1.1.1, 4.1.1.2.enabledAtBootBoolean, default -
false. Configures grub to audit processes that can be audited even if they start up prior to auditd startup. CIS rule: 4.1.1.3.backlogLimitInteger, default - none. Configures the backlog to hold records. If during boot
audit=1is configured, the backlog holds 64 records. If more than 64 records are created during boot, auditd records will be lost with a potential malicious activity being undetected. CIS rule: 4.1.1.4.maxLogFileInteger, default - none. Configures the maximum size of the audit log file. Once the log reaches the maximum size, it is rotated and a new log file is created. CIS rule: 4.1.2.1.
maxLogFileActionString, default - none. Defines handling of the audit log file reaching the maximum file size. Allowed values:
keep_logs- rotate logs but never delete themrotate- add a cron job to compress rotated log files and keep maximum 5 compressed files.compress- compress log files and keep them under the/var/log/auditd/directory. Requiresauditd_max_log_file_keepto be enabled.
CIS rule: 4.1.2.2.
maxLogFileKeepInteger, default -
5. Defines the number of compressed log files to keep under the/var/log/auditd/directory. Requiresauditd_max_log_file_action=compress. CIS rules - none.mayHaltSystemBoolean, default -
false. Halts the system when the audit logs are full. Applies the following configuration:space_left_action = emailaction_mail_acct = rootadmin_space_left_action = halt
CIS rule: 4.1.2.3.
customRulesString, default - none. Base64-encoded content of the
60-custom.rulesfile for any architecture. CIS rules - none.customRulesX32String, default - none. Base64-encoded content of the
60-custom.rulesfile for thei386architecture. CIS rules - none.customRulesX64String, default - none. Base64-encoded content of the
60-custom.rulesfile for thex86_64architecture. CIS rules - none.presetRulesString, default - none. Comma-separated list of the following built-in preset rules:
accessactionsdeletedocker
identityimmutableloginsmac-policy
modulesmountsperm-modprivileged
scopesessionsystem-localetime-change
You can use two keywords for these rules:
none- disables all built-in rules.all- enables all built-in rules. With this key, you can add the!prefix to a rule name to exclude some rules. You can use the!prefix for rules only if you add theallkeyword as the first rule. Place a rule with the!prefix only after theallkeyword.
Example configurations:
presetRules: none- disable all preset rulespresetRules: docker- enable only thedockerrulespresetRules: access,actions,logins- enable only theaccess,actions, andloginsrulespresetRules: all- enable all preset rulespresetRules: all,!immutable,!sessions- enable all preset rules exceptimmutableandsessions
CIS controls
4.1.3 (time-change)4.1.4 (identity)4.1.5 (system-locale)4.1.6 (mac-policy)4.1.7 (logins)4.1.8 (session)4.1.9 (perm-mod)4.1.10 (access)4.1.11 (privileged)4.1.12 (mounts)4.1.13 (delete)4.1.14 (scope)4.1.15 (actions)4.1.16 (modules)4.1.17 (immutable)Docker CIS controls
1.1.41.1.81.1.101.1.121.1.131.1.151.1.161.1.171.1.181.2.31.2.41.2.51.2.61.2.71.2.101.2.11
Proceed with Add a machine.
See also
Add a machine¶
After you create a new VMware vSphere-based Mirantis Container Cloud managed cluster as described in Create a managed cluster, proceed with adding machines to this cluster using the Container Cloud web UI.
You can also use the instruction below to scale up an existing managed cluster.
To add a machine to a vSphere-based managed cluster:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the required cluster name. The cluster page with Machines list opens.
On the cluster page, click Create Machine.
Fill out the form with the following parameters as required:
Container Cloud machine configuration¶ Parameter
Description
Create Machines Pool
Select to create a set of machines with the same provider spec to manage them as a single unit. Enter the machine pool name in the Pool Name field.
Count
Specify the number of machines to create. If you create a machine pool, specify the replicas count of the pool.
Select Manager or Worker to create a Kubernetes manager or worker node.
Caution
The required minimum number of manager machines is three for HA. A cluster can have more than three manager machines but only an odd number of machines.
In an even-sized cluster, an additional machine remains in the
Pendingstate until an extra manager machine is added. An even number of manager machines does not provide additional fault tolerance but increases the number of node required for etcd quorum.The required minimum number of worker machines for the Container Cloud workloads is two. If the multiserver mode is enabled for StackLight, add three worker nodes.
Template Path
Path to the VM template prepared during the management cluster bootstrap. Use the drop-down list to select the required item.
You may select VM templates of your vSphere datacenter account that are also displayed in the drop-down list. For the list of supported operating systems, refer to Requirements for a VMware vSphere-based cluster.
Note
Mirantis does not recommend using VM templates that contain the Unknown label in the drop-down list.
Caution
Container Cloud does not support mixed operating systems, RHEL combined with Ubuntu, in one cluster.
RHEL License
Applies to RHEL deployments only.
From the drop-down list, select the RHEL license that you previously added for the cluster being deployed.
VM Memory Size
VM memory size in GB, defaults to 16 GB.
To prevent issues with low RAM, Mirantis recommends the following VM templates for a managed cluster with 50-200 nodes:
16 vCPUs and 40 GB of RAM - manager node
16 vCPUs and 128 GB of RAM - nodes where the StackLight server components run
VM CPU Size
VM CPUs number, defaults to 8.
Upgrade Index
Optional. A positive numeral value that defines the order of machine upgrade during a cluster update.
Note
You can change the upgrade order later on an existing cluster. For details, see Change the upgrade order of a machine or machine pool.
Consider the following upgrade index specifics:
The first machine to upgrade is always one of the control plane machines with the lowest
upgradeIndex. Other control plane machines are upgraded one by one according to their upgrade indexes.If the
ClusterspecdedicatedControlPlanefield isfalse, worker machines are upgraded only after the upgrade of all control plane machines finishes. Otherwise, they are upgraded after the first control plane machine, concurrently with other control plane machines.If several machines have the same upgrade index, they have the same priority during upgrade.
If the value is not set, the machine is automatically assigned a value of the upgrade index.
Node Labels
Add the required node labels for the worker machine to run certain components on a specific node. For example, for the StackLight nodes that run OpenSearch and require more resources than a standard node, add the StackLight label. The list of available node labels is obtained from
allowedNodeLabelsof your currentClusterrelease.If the
valuefield is not defined inallowedNodeLabels, from the drop-down list, select the required label and define an appropriate custom value for this label to be set to the node. For example, thenode-typelabel can have thestorage-ssdvalue to meet the service scheduling logic on a particular machine.Note
Due to the known issue 23002 fixed in Container Cloud 2.21.0, a custom value for a predefined node label cannot be set using the Container Cloud web UI. For a workaround, refer to the issue description.
Caution
If you deploy StackLight in the HA mode (recommended):
Add the StackLight label to minimum three worker nodes. Otherwise, StackLight will not be deployed until the required number of worker nodes is configured with the StackLight label.
Removal of the StackLight label from worker nodes along with removal of worker nodes with StackLight label can cause the StackLight components to become inaccessible. It is important to correctly maintain the worker nodes where the StackLight local volumes were provisioned. For details, see Delete a cluster machine.
To obtain the list of nodes where StackLight is deployed, refer to Upgrade managed clusters with StackLight deployed in HA mode.
If you move the StackLight label to a new worker machine on an existing cluster, manually deschedule all StackLight components from the old worker machine, which you remove the StackLight label from. For details, see Deschedule StackLight Pods from a worker machine.
Note
To add node labels after deploying a worker machine. navigate to the Machines page, click the More action icon in the last column of the required machine field, and select Configure machine.
Since Container Cloud 2.24.0, you can configure node labels for machine pools after deployment using the More > Configure Pool option.
Click Create.
Repeat the steps above for the remaining machines.
Monitor the deploy or update live status of the machine:
- Quick status
On the Clusters page, in the Managers or Workers column. The green status icon indicates that the machine is Ready, the orange status icon indicates that the machine is Updating.
- Detailed status
In the Machines section of a particular cluster page, in the Status column. Hover over a particular machine status icon to verify the deploy or update status of a specific machine component.
You can monitor the status of the following machine components:
Component
Description
Kubelet
Readiness of a node in a Kubernetes cluster.
Swarm
Health and readiness of a node in a Docker Swarm cluster.
LCM
LCM readiness status of a node.
ProviderInstance
Readiness of a node in the underlying infrastructure (virtual or bare metal, depending on the provider type).
Graceful Reboot
Readiness of a machine during a scheduled graceful reboot of a cluster, available since Cluster releases 15.0.1 and 14.0.0.
Infrastructure Status
Available since Container Cloud 2.25.0 for the bare metal provider only. Readiness of the
IPAMHost,L2Template,BareMetalHost, andBareMetalHostProfileobjects associated with the machine.LCM Operation
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Health of all LCM operations on the machine.
LCM Agent
Available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Health of the LCM Agent on the machine and the status of the LCM Agent update to the version from the current Cluster release.
The machine creation starts with the Provision status. During provisioning, the machine is not expected to be accessible since its infrastructure (VM, network, and so on) is being created.
Other machine statuses are the same as the
LCMMachineobject states:Uninitialized - the machine is not yet assigned to an
LCMCluster.Pending - the agent reports a node IP address and host name.
Prepare - the machine executes
StateItemsthat correspond to thepreparephase. This phase usually involves downloading the necessary archives and packages.Deploy - the machine executes
StateItemsthat correspond to thedeployphase that is becoming a Mirantis Kubernetes Engine (MKE) node.Ready - the machine is being deployed.
Upgrade - the machine is being upgraded to the new MKE version.
Reconfigure - the machine executes
StateItemsthat correspond to thereconfigurephase. The machine configuration is being updated without affecting workloads running on the machine.
Once the status changes to Ready, the deployment of the cluster components on this machine is complete.
You can also monitor the live machine status using API:
kubectl get machines <machineName> -o wide
Example of system response since Container Cloud 2.23.0:
NAME READY LCMPHASE NODENAME UPGRADEINDEX REBOOTREQUIRED WARNINGS demo-0 true Ready kaas-node-c6aa8ad3 1 false
For the history of a machine deployment or update, refer to Inspect the history of a cluster and machine deployment or update.
Verify the status of the cluster nodes as described in Connect to a Mirantis Container Cloud cluster.
Warning
An operational managed cluster must contain a minimum of 3 Kubernetes manager machines to meet the etcd quorum and 2 Kubernetes worker machines.
The deployment of the cluster does not start until the minimum number of machines is created.
A machine with the manager role is automatically deleted during the cluster deletion. Manual deletion of manager machines is allowed only for the purpose of node replacement or recovery.
Support status of manager machine deletion
Since the Cluster releases 17.0.0, 16.0.0, and 14.1.0, the feature is generally available.
Before the Cluster releases 16.0.0 and 14.1.0, the feature is available within the Technology Preview features scope for non-MOSK-based clusters.
Before the Cluster release 17.0.0 the feature is not supported for MOSK.
Verify that network addresses used on your clusters do not overlap with the following default MKE network addresses for Swarm and MCR:
10.0.0.0/16is used for Swarm networks. IP addresses from this network are virtual.10.99.0.0/16is used for MCR networks. IP addresses from this network are allocated on hosts.
Verification of Swarm and MCR network addresses
To verify Swarm and MCR network addresses, run on any master node:
docker infoExample of system response:
Server: ... Swarm: ... Default Address Pool: 10.0.0.0/16 SubnetSize: 24 ... Default Address Pools: Base: 10.99.0.0/16, Size: 20 ...
Not all of Swarm and MCR addresses are usually in use. One Swarm Ingress network is created by default and occupies the
10.0.0.0/24address block. Also, three MCR networks are created by default and occupy three address blocks:10.99.0.0/20,10.99.16.0/20,10.99.32.0/20.To verify the actual networks state and addresses in use, run:
docker network ls docker network inspect <networkName>
See also
Delete a managed cluster¶
Deleting a managed cluster does not require a preliminary deletion of VMs that run on this cluster.
Warning
We recommend deleting cluster machines using the Container Cloud web UI or API instead of using the cloud provider tools directly. Otherwise, the cluster deletion or detachment may hang and additional manual steps will be required to clean up machine resources.
To delete a VMware vSphere-based managed cluster:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the More action icon in the last column of the required cluster and select Delete.
Verify the list of machines to be removed. Confirm the deletion.
Deleting a cluster automatically turns the machines off. Therefore, clean up the hosts manually in the vSphere web UI. The machines will be automatically released from the RHEL subscription.
If the cluster deletion hangs and the Deleting status message does not disappear after a while, refer to Cluster deletion or detachment freezes to fix the issue.
If you do not plan to reuse the credentials of the deleted cluster, delete them:
In the Credentials tab, verify that the required credentials are not in the In Use status.
Click the Delete credential action icon next to the name of the credentials to be deleted.
Confirm the deletion.
Warning
You can delete credentials only after deleting the managed cluster they relate to.
Add or update a CA certificate for a MITM proxy using API¶
Note
For MOSK, the feature is generally available since MOSK 23.1.
When you enable a man-in-the-middle (MITM) proxy access to a managed cluster,
your proxy requires a trusted CA certificate. This section describes how to
manually add the caCertificate field to the spec section
of the Proxy object. You can also use this instruction to update an
expired certificate on an existing cluster.
You can also add a CA certificate for a MITM proxy using the Container Cloud web UI through the Proxies tab. For details, refer to the cluster creation procedure for the required cloud provider as described in Create and operate managed clusters.
Warning
Any modification to the Proxy object, for example, changing
the proxy URL, NO_PROXY values, or certificate, leads to cordon-drain
and Docker restart on the cluster machines.
To add or update a CA certificate for a MITM proxy using API:
Encode your proxy CA certificate. For example:
cat ~/.mitmproxy/mitmproxy-ca-cert.cer | base64 -w0
Replace
~/.mitmproxy/mitmproxy-ca-cert.cerwith the path to your CA certificate file.Open the existing
Proxyobject for editing:Warning
The kubectl apply command automatically saves the applied data as plain text into the
kubectl.kubernetes.io/last-applied-configurationannotation of the corresponding object. This may result in revealing sensitive data in this annotation when creating or modifying the object.Therefore, do not use kubectl apply on this object. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on this object, you can remove the
kubectl.kubernetes.io/last-applied-configurationannotation from the object using kubectl edit.kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <projectName> edit proxy <proxyName>
In the system response, find the
specsection with the current proxy configuration. For example:spec: httpProxy: http://172.19.123.57:8080 httpsProxy: http://172.19.123.57:8080
In the
specsection, add or update thespec.caCertificatefield with the base64-encoded proxy CA certificate data. For example:spec: caCertificate: <BASE64_ENCODED_CA_CERTIFICATE> httpProxy: http://172.19.123.57:8080 httpsProxy: http://172.19.123.57:8080
Save the
Proxyobject and proceed with the managed cluster creation. If you update an expired certificate on an existing managed cluster, wait until the machines switch from theReconfiguretoReadystate to apply changes.
Add a custom OIDC provider for MKE¶
Available since 17.0.0, 16.0.0, and 14.1.0
By default, MKE uses Keycloak as the OIDC provider. Using the
ClusterOIDCConfiguration custom resource, you can add your own OpenID
Connect (OIDC) provider for MKE on managed clusters to authenticate user
requests to Kubernetes. For OIDC provider requirements, see OIDC official
specification.
Note
For OpenStack and StackLight, Container Cloud supports only Keycloak, which is configured on the management cluster, as the OIDC provider.
To add a custom OIDC provider for MKE:
Configure the OIDC provider:
Log in to the OIDC provider dashboard.
Create an OIDC client. If you are going to use an existing one, skip this step.
Add the MKE
redirectURLof the managed cluster to the OIDC client. By default, the URL format ishttps://<MKE IP>:6443/login.Add the
<Container Cloud web UI IP>/tokento the OIDC client for generation ofkubeconfigfiles of the target managed cluster through the Container Cloud web UI.Ensure that the
audclaim of the issuedid_tokenfor audience will be equal to the created client ID.Optional. Allow MKE to refresh authentication when
id_tokenexpires by allowing theoffline_accessclaim for the OIDC client.
Create the
ClusterOIDCConfigurationobject in the YAML format containing the OIDC client settings. For details, see API Reference: ClusterOIDCConfiguration resource for MKE.Warning
The kubectl apply command automatically saves the applied data as plain text into the
kubectl.kubernetes.io/last-applied-configurationannotation of the corresponding object. This may result in revealing sensitive data in this annotation when creating or modifying the object.Therefore, do not use kubectl apply on this object. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on this object, you can remove the
kubectl.kubernetes.io/last-applied-configurationannotation from the object using kubectl edit.The
ClusterOIDCConfigurationobject is created in the management cluster. Users with them:kaas:ns@operator/writer/memberroles have access to this object.Once done, the following dependent objects are created automatically in the target managed cluster: the
rbac.authorization.k8s.io/v1/ClusterRoleBindingobject that binds the admin group defined inspec:adminRoleCriteria:valueto thecluster-adminrbac.authorization.k8s.io/v1/ClusterRoleobject.In the
Clusterobject of the managed cluster, add the name of theClusterOIDCConfigurationobject to thespec.providerSpec.value.oidcfield.Wait until the cluster machines switch from the
ReconfiguretoReadystate for the changes to apply.
Operate machine pools¶
A machine pool is a template that allows managing a set of machines with the same provider spec as a single unit. You can create machine pools during machines creation on a new or existing cluster. You can assign or unassign machines from a pool, if required. You can also increase or decrease replicas count. In case of replicas count increasing, new machines will be added automatically.
This section describes how to operate machine pools for clusters of any provider type using the Container Cloud web UI.
Assign or unassign a machine to or from a machine pool¶
If a machine was originally created outside a machine pool, you can assign it later on an existing cluster. You may also need to unassign a machine from a machine pool, for example, to delete a machine.
To assign or unassign a machine to or from a machine pool:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the required cluster name to open the list of machines and machine pools running on it.
Select from the following options:
To assign a machine to a machine pool:
In the Unassigned Machines section, click the More action icon in the last column of the machine you want to assign and select Assign machine to pool.
Note
A machine spec must match the spec of the assigned machine pool.
You can assign only unassigned machines to a pool.
From the list of available machine pools, select the required machine pool with a spec that matches the machine spec and click Update.
To unassign a machine from the machine pool:
In the corresponding machine pools section, click the More action icon in the last column of the machine you want to unassign and select Unassign from pool.
Confirm your action.
Note
The replicas count automatically decreases by one when you unassign a machine from a pool with a positive replicas count.
Caution
If a machine is assigned to a machine pool, the providerSpec
section of the specific Machine object automatically updates during pool
configuration. The only providerSpec field that is not overwritten
automatically is maintenance. Do not edit other fields of this section
manually.
Change replicas count of a machine pool¶
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the required cluster name to open the list of machines and machine pools running on it.
Next to the name of the required machine pool, click the More action icon and select Change replicas count.
Set the desired replicas count and click Update.
If you increase the replicas count, additional machines are created automatically.
If you decrease the replicas count, extra machines are not deleted automatically. Therefore, manually delete extra machines from the pool to match the decreased replicas count.
Deleting a machine assigned to a pool without decreasing replicas count causes automatic machine recreation.
Delete a machine pool¶
We recommend deleting cluster machines using the Container Cloud web UI or API instead of using the cloud provider tools directly. Otherwise, the cluster deletion or detachment may hang and additional manual steps will be required to clean up machine resources.
An operational managed cluster must contain a minimum of 3 Kubernetes manager machines to meet the etcd quorum and 2 Kubernetes worker machines.
The deployment of the cluster does not start until the minimum number of machines is created.
A machine with the manager role is automatically deleted during the cluster deletion. Manual deletion of manager machines is allowed only for the purpose of node replacement or recovery.
Support status of manager machine deletion
Since the Cluster releases 17.0.0, 16.0.0, and 14.1.0, the feature is generally available.
Before the Cluster releases 16.0.0 and 14.1.0, the feature is available within the Technology Preview features scope for non-MOSK-based clusters.
Before the Cluster release 17.0.0 the feature is not supported for MOSK.
To delete a machine pool from a managed cluster:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the required cluster name to open the list of machines and machine pools running on it.
Click the More action icon in the required machine pool section and select Delete. Confirm the deletion by selecting Delete All Machines In The Pool and clicking Delete.
Deleting a machine pool automatically deletes all machines assigned to the pool and frees up the resources allocated to them.
See also
See also
Change a cluster configuration¶
After deploying a managed cluster, you can configure a few cluster settings using the Container Cloud web UI as described below.
To change a cluster configuration:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Select the required project.
On the Clusters page, click the More action icon in the last column of the required cluster and select Configure cluster.
In the Configure cluster window:
In the General Settings tab, you can:
Add or update proxy for a cluster by selecting the name of previously created proxy settings from the Proxy drop-down menu. To add or update proxy parameters:
In the Proxies tab, configure proxy:
Click Add Proxy.
In the Add New Proxy wizard, fill out the form with the following parameters:
Proxy configuration¶ Parameter
Description
Proxy Name
Name of the proxy server to use during cluster creation.
Region Removed in 2.26.0 (16.1.0 and 17.1.0)
From the drop-down list, select the required region.
HTTP Proxy
Add the HTTP proxy server domain name in the following format:
http://proxy.example.com:port- for anonymous accesshttp://user:password@proxy.example.com:port- for restricted access
HTTPS Proxy
Add the HTTPS proxy server domain name in the same format as for HTTP Proxy.
No Proxy
Comma-separated list of IP addresses or domain names. For vSphere-based clusters, mandatory to add
host[:port]of the vCenter server.For implementation details, see Proxy and cache support.
If your proxy requires a trusted CA certificate, select the CA Certificate check box and paste a CA certificate for a MITM proxy to the corresponding field or upload a certificate using Upload Certificate.
Using the SSH Keys drop-down menu, select the required previously created SSH key to add it to the running cluster. If required, you can add several keys or remove unused ones, if any.
Note
To delete an SSH key, use the SSH Keys tab of the main menu.
Applies since Cluster releases 12.5.0 and 11.5.0. Using the Container Registry drop-down menu, select the previously created Docker container registry name to add it to the running cluster.
Applies since Cluster releases 17.0.0, 16.0.0, and 14.1.0. Using the following options, define the maximum number of worker machines to be upgraded in parallel during cluster update:
- Parallel Upgrade Of Worker Machines
The maximum number of the worker nodes to update simultaneously. It serves as an upper limit on the number of machines that are drained at a given moment of time. Defaults to
1.- Parallel Preparation For Upgrade Of Worker Machines
The maximum number of worker nodes being prepared at a given moment of time, which includes downloading of new artifacts. It serves as a limit for the network load that can occur when downloading the files to the nodes. Defaults to
50.
In the Stacklight tab, select or deselect StackLight and configure its parameters if enabled.
You can also update the default log level severity for all StackLight components as well as set a custom log level severity for specific StackLight components. For details about severity levels, see Log verbosity.
Click Update to apply the changes.
Disable a machine¶
TechPreview since 2.25.0 (17.0.0 and 16.0.0) for workers on managed clusters
You can use the machine disabling API to seamlessly remove a worker machine from the LCM control of a managed cluster. This action isolates the affected node without impacting other machines in the cluster, effectively eliminating it from the Kubernetes cluster. This functionality proves invaluable in scenarios where a malfunctioning machine impedes cluster updates.
Note
The Technology Preview support of the machine disabling feature also applies during cluster update to the Cluster release 17.1.0 or 16.1.0.
Precautions for machine disablement¶
Before disabling a cluster machine, carefully read the following essential information for a successful machine disablement:
Container Cloud supports machine disablement of worker machines only.
If an issue occurs on the control plane, which is updated before worker machines, fix the issue or replace the affected control machine as soon as possible to prevent issues with workloads. For reference, see Troubleshooting and Delete a cluster machine.
Disabling a machine can break high availability (HA) of components such as StackLight. Therefore, Mirantis recommends adding a new machine as soon as possible to provide sufficient node number for components HA.
Note
It is expected that the cluster status contains degraded replicas of some components during or after cluster update with a disabled machine. These replicas become available as soon as you replace the disabled machine.
When a machine is
disabled, some services may switch to theNodeReadystate and may require additional actions to unblock LCM tasks.A disabled machine is removed from the overall cluster status and is labeled as Disabled. The requested node number for the cluster remains the same, but an additional
disabledfield is displayed with the number of disabled nodes.A disabled machine is not taken into account for any calculations, for example, when the number of StackLight nodes is required for some restriction check.
Container Cloud removes the node running the disabled machine from the Kubernetes cluster.
Deletion of the disabled machine with the
gracefuldeletion policy is not allowed. Use theunsafedeletion policy instead. For details, see Delete a cluster machine.For a major cluster update, the Cluster release of a disabled machine must match the Cluster release of other cluster machines.
If a machine is disabled during the major Cluster release update, then the upgrade should be completed if all other requirements are met. However, cluster update to the next available major Cluster release will be blocked until you re-enable or replace the disabled machine.
Patch updates do not have such limitation on different patch Cluster releases. You can update a cluster with a disabled machine to several patch Cluster releases in the scope of one major Cluster release.
After enabling the machine, it will be updated to match the Cluster release of the corresponding cluster, including all related components.
For Ceph machines, you need to perform additional disablement steps.
Disable a machine using the Container Cloud web UI¶
Carefully read the precautions for machine disablement.
Power off the underlying host of a machine to be disabled.
Warning
If the underlying host of a machine is not powered off, the cluster may still contain the disabled machine in the list of available nodes with
kubeletattempting to start the corresponding containers on the disabled machine.Therefore, Mirantis strongly recommends powering off the underlying host to prevent manual removal of the related Kubernetes node from the Docker Swarm cluster using the MKE web UI.
In the Clusters tab, click the required cluster name to open the list of machines running on it.
Click the More action icon in the last column of the required machine and click Disable.
Wait until the machine Status switches to Disabled.
If the disabled machine contains StackLight or Ceph, migrate these services to a healthy machine:
Verify that the required disabled and healthy machines are not currently added to
GracefulRebootRequest:Note
Machine configuration changes, such as reassigning Ceph and StackLight labels from a disabled machine to a healthy one, which are described in the following steps, are not allowed during graceful reboot. For details, see Perform a graceful reboot of a cluster.
Verify that the More > Reboot machines option is not disabled. If the option is active, skip the following sub-step and proceed to the next step. If the option is disabled, proceed to the following sub-step.
Using the Container Cloud CLI, verify that the new machine, which you are going to use for StackLight or Ceph services migration, is not included in the list of the
GracefulRebootRequestresource. Otherwise, removeGracefulRebootRequestbefore proceeding. For details, see Disable a machine using the Container Cloud CLI.
Note
Since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0), reboot of the disabled machine is automatically skipped in
GracefulRebootRequest.If StackLight is deployed on the machine, unblock LCM tasks by moving the
stacklight=enabledlabel to another healthy machine with a sufficient amount of resources and manually remove StackLight Pods along with related local persistent volumes from the disabled machine. For details, see Deschedule StackLight Pods from a worker machine.If Ceph is deployed on the machine:
Disable a Ceph machine
Select one of the following options to open the Ceph cluster
spec:In the CephClusters tab, click the required Ceph cluster name to open its
spec.Open the
KaaSCephClusterobject for editing:kubectl edit kaascephcluster -n <managedClusterProjectName> <KaaSCephClusterName>
In
spec.node, find the machine to be disabled.Back up the machine configuration.
Verify the machine role:
For
mgr,rgw, ormds, move such role to another node located in thenodesection. Such node must meet resource requirements to run the corresponding daemon type and must not have the respective node assigned yet.For
mon, refer to Move a Ceph Monitor daemon to another node for further instructions. Mirantis recommends considering nodes with sufficient resources to run the moved monitor daemon.For
osd, proceed to the next step.
Remove the machine from
spec.
Enable machine using the Container Cloud web UI¶
In the Clusters tab, click the required cluster name to open the list of machines running on it.
Click the More action icon in the last column of the required machine and click Enable.
Wait until the machine Status switches to Ready.
If Ceph is deployed on the machine:
Enable a Ceph machine
Select one of the following options to open the Ceph cluster
spec:In the CephClusters tab, click the required Ceph cluster name to open its
spec.Open the
KaaSCephClusterobject for editing:kubectl edit kaascephcluster -n <managedClusterProjectName> <KaaSCephClusterName>
In
spec.node, add a new or backed-up configuration of the machine to be enabled.If the machine must have any role besides
osd, consider the following options to return a role back to the node:For
mgr,rgw, ormds, add the role to the enabled node in thenodesection.For
mon, refer to Move a Ceph Monitor daemon to another node for further instructions.
Disable a machine using the Container Cloud CLI¶
Carefully read the precautions for machine disablement.
Power off the underlying host of a machine to be disabled.
Warning
If the underlying host of a machine is not powered off, the cluster may still contain the disabled machine in the list of available nodes with
kubeletattempting to start the corresponding containers on the disabled machine.Therefore, Mirantis strongly recommends powering off the underlying host to prevent manual removal of the related Kubernetes node from the Docker Swarm cluster using the MKE web UI.
Open the required
Machineobject for editing.In the
providerSpec:valuesection, setdisabletotrue:kubectl patch machines.cluster.k8s.io -n <projectName> <machineName> --type=merge -p '{"spec":{"providerSpec":{"value":{"disable":true}}}}'
Wait until the machine status switches to
Disabled:kubectl get machines.cluster.k8s.io -n <projectName> <machineName> -o jsonpath='{.status.providerStatus.status}'
If the disabled machine contains StackLight or Ceph, migrate these services to a healthy machine:
Verify that the required disabled and healthy machines are not currently added to
GracefulRebootRequest:Note
Machine configuration changes, such as reassigning Ceph and StackLight labels from a disabled machine to a healthy one, which are described in the following steps, are not allowed during graceful reboot. For details, see Perform a graceful reboot of a cluster.
kubectl get gracefulrebootrequest -A kubectl -n <projectName> get gracefulrebootrequest <gracefulRebootRequestName> -o yaml
If the machine is listed in the object
specsection, remove theGracefulRebootRequestobject:kubectl -n <projectName> delete gracefulrebootrequest <gracefulRebootRequestName>
Note
Since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0), reboot of the disabled machine is automatically skipped in
GracefulRebootRequest.If StackLight is deployed on the machine, unblock LCM tasks by moving the
stacklight=enabledlabel to another healthy machine with a sufficient amount of resources and manually remove StackLight Pods along with related local persistent volumes from the disabled machine. For details, see Deschedule StackLight Pods from a worker machine.If Ceph is deployed on the machine:
Disable a Ceph machine
Select one of the following options to open the Ceph cluster
spec:In the CephClusters tab, click the required Ceph cluster name to open its
spec.Open the
KaaSCephClusterobject for editing:kubectl edit kaascephcluster -n <managedClusterProjectName> <KaaSCephClusterName>
In
spec.node, find the machine to be disabled.Back up the machine configuration.
Verify the machine role:
For
mgr,rgw, ormds, move such role to another node located in thenodesection. Such node must meet resource requirements to run the corresponding daemon type and must not have the respective node assigned yet.For
mon, refer to Move a Ceph Monitor daemon to another node for further instructions. Mirantis recommends considering nodes with sufficient resources to run the moved monitor daemon.For
osd, proceed to the next step.
Remove the machine from
spec.
Enable a machine using the Container Cloud CLI¶
Open the required
Machineobject for editing.In the
providerSpec:valuesection, setdisabletofalse:kubectl patch machines.cluster.k8s.io -n <projectName> <machineName> --type=merge -p '{"spec":{"providerSpec":{"value":{"disable":false}}}}'
Wait until the machine status switches to
Ready:kubectl get machines.cluster.k8s.io -n <projectName> <machineName> -o jsonpath='{.status.providerStatus.status}'
If Ceph is deployed on the machine:
Enable a Ceph machine
Select one of the following options to open the Ceph cluster
spec:In the CephClusters tab, click the required Ceph cluster name to open its
spec.Open the
KaaSCephClusterobject for editing:kubectl edit kaascephcluster -n <managedClusterProjectName> <KaaSCephClusterName>
In
spec.node, add a new or backed-up configuration of the machine to be enabled.If the machine must have any role besides
osd, consider the following options to return a role back to the node:For
mgr,rgw, ormds, add the role to the enabled node in thenodesection.For
mon, refer to Move a Ceph Monitor daemon to another node for further instructions.
See also
Release Notes: Known issue 40036 (fixed in 2.26.1, Cluster releases 17.1.1 and 16.1.1)
Configure the parallel update of worker nodes¶
Available since 17.0.0, 16.0.0, and 14.1.0 as GA Available since 14.0.1(0) and 15.0.1 as TechPreview
Note
For MOSK clusters, you can start using the below procedure during cluster update from 23.1 to 23.2. For details, see MOSK documentation: Parallelizing node update operations.
By default, worker machines are upgraded sequentially, which includes node draining, software upgrade, services restart, and so on. Though, Container Cloud enables you to parallelize node upgrade operations, significantly improving the efficiency of your deployment, especially on large clusters.
For upgrade workflow of the control plane, see Change the upgrade order of a machine or machine pool.
Configure the parallel update of worker nodes using web UI¶
Available since 17.0.0, 16.0.0, and 14.1.0
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the required cluster name. The cluster page with the Machines list opens.
On the Clusters page, click the More action icon in the last column of the required cluster and select Configure cluster.
In General Settings of the Configure cluster window, define the following parameters:
- Parallel Upgrade Of Worker Machines
The maximum number of the worker nodes to update simultaneously. It serves as an upper limit on the number of machines that are drained at a given moment of time. Defaults to
1.You can configure this option after deployment before the cluster update.
- Parallel Preparation For Upgrade Of Worker Machines
The maximum number of worker nodes being prepared at a given moment of time, which includes downloading of new artifacts. It serves as a limit for the network load that can occur when downloading the files to the nodes. Defaults to
50.
Configure the parallel update of worker nodes using CLI¶
Available since 15.0.1 and 14.0.1(0)
Open the
Clusterobject for editing.Adjust the following parameters as required:
Configuration of the parallel node update¶ Parameter
Default
Description
spec.providerSpec.maxWorkerUpgradeCount1The maximum number of the worker nodes to update simultaneously. It serves as an upper limit on the number of machines that are drained at a given moment of time.
Caution
Since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0),
maxWorkerUpgradeCountis deprecated and will be removed in one of the following releases. Use theconcurrentUpdatesparameter in theUpdateGroupobject instead. For details, see Create update groups for worker machines.spec.providerSpec.maxWorkerPrepareCount50The maximum number of workers being prepared at a given moment of time, which includes downloading of new artifacts. It serves as a limit for the network load that can occur when downloading the files to the nodes.
Save the
Clusterobject to apply the change.
See also
Create update groups for worker machines¶
Available since 2.27.0 (17.2.0 and 16.2.0)
The use of update groups provides enhanced control over update of worker
machines by allowing granular concurrency settings for specific machine groups.
This feature uses the UpdateGroup object to decouple the concurrency
settings from the global cluster level, providing flexibility based on the
workload characteristics of different machine sets.
The UpdateGroup objects are processed sequentially based on their indexes.
Update groups with the same indexes are processed concurrently.
Note
The update order of a machine within the same group is determined by the upgrade index of a specific machine. For details, see Change the upgrade order of a machine or machine pool.
The maxWorkerUpgradeCount parameter of the Cluster object is inherited
by the default update group. Changing maxWorkerUpgradeCount leads to
changing the concurrentUpdates parameter of the default update group.
Note
The maxWorkerUpgradeCount parameter of the Cluster object is
deprecated and will be removed in one of the following Container Cloud
releases. You can still use this parameter to change the
concurrentUpdates value of the default update group. However, Mirantis
recommends changing this value directly in the UpdateGroup object.
Default update group¶
The default update group is automatically created during initial cluster creation with the following settings:
Name:
<cluster-name>-defaultIndex: 1
Concurrent updates: inherited from the
maxWorkerUpgradeCountparameter set in theClusterobject.
Note
On existing clusters created before 2.27.0, the default update group is created after upgrade of the Container Cloud release to 2.27.0 (Cluster release 16.2.0) on the management cluster.
Example of the default update group:
apiVersion: kaas.mirantis.com/v1alpha1
kind: UpdateGroup
metadata:
name: example-cluster-default
namespace: example-ns
spec:
index: 1
concurrentUpdates: 1
If you require custom update settings for worker machines, create one or
several custom UpdateGroup objects as described below.
Assign a machine to an update group using CLI¶
Note
All worker machines that are not assigned to any update group are automatically assigned to the default update group.
Create an
UpdateGroupobject with the required specification. For description of the object fields, see UpdateGroup resource.Label the machines to associate them with the newly created
UpdateGroupobject:kubectl label machine <machineName> kaas.mirantis.com/update-group=<UpdateGroupObjectName>
To change the update group of a machine, update the
kaas.mirantis.com/update-grouplabel of the machine with the new update group name. Removing this label from a machine automatically assigns such machine to the default update group.
Note
After creation of a custom UpdateGroup object, if you plan to
add a new machine that requires a non-default update group, manually add
the corresponding label to the machine as described above. Otherwise, the
default update group is applied to such machine.
Note
Before removing the UpdateGroup object, reassign all machines to
another update group.
Change the upgrade order of a machine or machine pool¶
You can define the upgrade sequence for existing machines or machine pools to allow prioritized machines to be upgraded first during a cluster update.
Consider the following upgrade index specifics:
The first machine to upgrade is always one of the control plane machines with the lowest
upgradeIndex. Other control plane machines are upgraded one by one according to their upgrade indexes.If the
ClusterspecdedicatedControlPlanefield isfalse, worker machines are upgraded only after the upgrade of all control plane machines finishes. Otherwise, they are upgraded after the first control plane machine, concurrently with other control plane machines.If several machines have the same upgrade index, they have the same priority during upgrade.
If the value is not set, the machine is automatically assigned a value of the upgrade index.
To define the upgrade order of an existing machine or machine pool:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the required cluster name. The cluster page with the Machines list opens.
In the Machine pool or one of Unassigned machines settings menu, select Change upgrade index.
In the Configure Upgrade Priority window that opens, use the Up and Down arrows in the Upgrade Index field to configure the upgrade sequence of a machine or machine pool. Click Update to apply changes.
Using the Pool info or Machine info options in the machine pool or machine settings menu, verify that the Upgrade Priority Index contains the updated value.
Update a managed cluster¶
A Mirantis Container Cloud management cluster automatically upgrades to a new available Container Cloud release version that supports new Cluster releases. Once done, a newer version of a Cluster release becomes available for managed clusters that you update using the Container Cloud web UI.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
Note
To silence StackLight alerts before performing the update, see Silence alerts.
This section describes how to update a managed cluster of any provider type using the Container Cloud web UI.
Verify the Container Cloud status before managed cluster update¶
Before you start updating your managed clusters, Mirantis recommends verifying that the associated management cluster is upgraded successfully.
To verify that the management cluster is upgraded successfully:
Using
kubeconfigof the management cluster, verify the Cluster release version of the management cluster machines:for i in $(kubectl get lcmmachines | awk '{print $1}' | sed '1d'); do echo $i; kubectl get lcmmachines $i -o yaml | grep release | tail -1; doneExample of system response:
master-0 release: 14.0.0+3.6.5 master-1 release: 14.0.0+3.6.5 master-2 release: 14.0.0+3.6.5
Obtain the name of the latest available Container Cloud release object:
kubectl get kaasrelease
Example of system response:
NAME AGE kaas-2-15-0 63m kaas-2-14-0 40d
Using the name of the latest Container Cloud release object, obtain the latest available Cluster release version:
kubectl get -o yaml clusterrelease $(kubectl get kaasrelease kaas-2-15-0 -o yaml | egrep "^ +clusterRelease:" | cut -d: -f2 | tr -d ' ') | egrep "^ version:"
Example of system response:
version: 14.0.0+3.6.4
Compare the outputs obtained in the first and previous steps.
If the Cluster releases match, proceed to Update a managed cluster using the Container Cloud web UI.
If the Cluster releases do not match, contact Mirantis support for further details.
Update a managed cluster using the Container Cloud web UI¶
After you verify that the Mirantis Container Cloud management cluster is upgraded successfully as described in Verify the Container Cloud status before managed cluster update, proceed to update your managed clusters using the Container Cloud web UI.
Caution
During a baremetal-based cluster update, hosts can be restarted to apply the latest supported Ubuntu 18.04 or 20.04 packages. In this case:
Depending on the cluster configuration, applying security updates and host restart can increase the update time for each node to up to 1 hour.
Cluster nodes are updated one by one. Therefore, for large clusters, the update may take several days to complete.
Note
For a MOSK-based cluster update procedure, refer to MOSK documentation: Update a MOSK cluster.
Caution
During a baremetal-based cluster update, the false positive
CalicoDataplaneFailuresHigh alert may be firing. Disregard this alert,
which will disappear once cluster update succeeds.
The observed behavior is typical for calico-node during upgrades,
as workload changes occur frequently. Consequently, there is a possibility
of temporary desynchronization in the Calico dataplane. This can occasionally
result in throttling when applying workload changes to the Calico dataplane.
To update a managed cluster:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
Optional. Configure the update sequence of cluster machines:
In the Clusters tab, select from the following options:
Available since Container Cloud 2.23.0. Click Upgrade next to the More action icon located in the last column for each cluster where available.
Note
If Upgrade is greyed out, the cluster is in maintenance mode that must be disabled before you can proceed with cluster update. For details, see Disable maintenance mode on a cluster and machine.
If Upgrade does not display, your cluster is up-to-date.
Click the More action icon in the last column for each cluster and select Upgrade cluster where available.
In the Release update window, select the required Cluster release to update your managed cluster to.
The Description section contains the list of components versions to be installed with a new Cluster release. The release notes for each Container Cloud and Cluster release are available at Container Cloud releases and Cluster releases (managed).
Click Update.
Before the cluster update starts, Container Cloud performs a backup of MKE and Docker Swarm. The backup directory is located under:
/srv/backup/swarmon every Container Cloud node for Docker Swarm/srv/backup/ucpon one of the controller nodes for MKE
To monitor the cluster readiness, hover over the status icon of a specific cluster in the Status column of the Clusters page.
Once the orange blinking status icon becomes green and Ready, the cluster deployment or update is complete.
You can monitor live deployment status of the following cluster components:
Component
Description
Bastion
For the OpenStack-based management clusters, the Bastion node IP address status that confirms the Bastion node creation
Helm
Installation or upgrade status of all Helm releases
Kubelet
Readiness of the node in a Kubernetes cluster, as reported by kubelet
Kubernetes
Readiness of all requested Kubernetes objects
Nodes
Equality of the requested nodes number in the cluster to the number of nodes having the
ReadyLCM statusOIDC
Readiness of the cluster OIDC configuration
StackLight
Health of all StackLight-related objects in a Kubernetes cluster
Swarm
Readiness of all nodes in a Docker Swarm cluster
LoadBalancer
Readiness of the Kubernetes API load balancer
ProviderInstance
Readiness of all machines in the underlying infrastructure (virtual or bare metal, depending on the provider type)
Graceful Reboot
Readiness of a cluster during a scheduled graceful reboot, available since Cluster releases 15.0.1 and 14.0.0.
Infrastructure Status
Available since Container Cloud 2.25.0 for bare metal and OpenStack providers. Readiness of the following cluster components:
Bare metal: the
MetalLBConfigobject along with MetalLB and DHCP subnets.OpenStack: cluster network, routers, load balancers, and Bastion along with their ports and floating IPs.
LCM Operation
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Health of all LCM operations on the cluster and its machines.
LCM Agent
Available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Health of all LCM agents on cluster machines and the status of LCM agents update to the version from the current Cluster release.
For the history of a cluster deployment or update, refer to Inspect the history of a cluster and machine deployment or update.
Available since Container Cloud 2.22.0 for baremetal-based clusters and since 2.24.2 for MOSK 23.2. In the Clusters tab, verify whether the required cluster has the One or more machines require a reboot warning icon. If so, reboot the corresponding hosts manually to apply the Ubuntu operating system updates.
To identify the hosts to reboot:
In the Clusters tab, click the required cluster name. The page with Machines opens.
Hover over the status of every machine. A machine to reboot contains the Reboot > The machine requires a reboot notification in the Status tooltip.
Caution
During cluster update to the Cluster release 11.6.0 or 12.7.0 with StackLight logging enabled, a short outage of OpenSearch and its dependent components may occur with the following alerts firing on the cluster. This behavior is expected. Therefore, disregard these alerts.
StackLight alerts list firing during cluster update
Cluster size and outage probability level |
Alert name |
Label name and component |
|---|---|---|
Any cluster with high probability |
|
|
|
|
|
Large cluster with average probability |
|
|
|
n/a |
|
|
n/a |
|
|
n/a |
|
|
n/a |
|
Any cluster with low probability |
|
|
|
|
Note
MKE and Kubernetes API may return short-term 50x errors during the upgrade process. Ignore these errors.
Caution
If the cluster update includes MKE upgrade from 3.4 to 3.5
and you need to access the cluster while the update is in progress,
use the admin kubeconfig instead of the existing one while OIDC
settings are being reconfigured.
To obtain the admin kubeconfig:
kubectl --kubeconfig <pathToMgmtKubeconfig> get secret -n <affectedClusterNamespace> \
-o yaml <affectedClusterName>-kubeconfig | awk '/admin.conf/ {print $2}' | \
head -1 | base64 -d > clusterKubeconfig.yaml
Granularly update a managed cluster using the ClusterUpdatePlan object¶
TechPreview since 2.27.0 (17.2.0 and 16.2.0)
You can control the process of a managed cluster update by manually launching
update stages using the ClusterUpdatePlan custom resource. Between the
update stages, a cluster remains functional from the perspective of cloud
users and workloads.
A ClusterUpdatePlan object contains the following funtionality:
The object is automatically created by the respective Container Cloud provider when a new Cluster release becomes available for your cluster.
The object is created in the management cluster for the same namespace that the corresponding managed cluster refers to.
The object contains a list of predefined self-descriptive update steps that are cluster-specific. These steps are defined in the
specsection of the object with information about their impact on the cluster.The object starts cluster update when the operator manually changes the
commencefield of the first update step totrue. All steps have thecommenceflag initially set tofalseso that the operator can decide when to pause or resume the update process.The object has the following naming convention:
<managedClusterName>-<targetClusterReleaseVersion>.
To update a managed cluster granularly:
Verify that the management cluster is upgraded successfully as described in Verify the Container Cloud status before managed cluster update.
Open the
ClusterUpdatePlanobject for editing.Start cluster update by changing the
spec:steps:commencefield of the first update step totrue.Once done, the following actions are applied to the cluster:
The Cluster release in the corresponding
Clusterspecis changed to the target Cluster version defined in theClusterUpdatePlanspec.The cluster update starts and pauses before the next update step with
commence: falseset in theClusterUpdatePlanspec.
Caution
Cancelling an already started update
stepis not supported.The following example illustrates the
ClusterUpdatePlanobject of a MOSK cluster update that has completed:Example of a completed
ClusterUpdatePlanobjectObject: apiVersion: kaas.mirantis.com/v1alpha1 kind: ClusterUpdatePlan metadata: creationTimestamp: "2024-05-20T14:03:47Z" generation: 3 name: demo-child-67835-17.2.0 namespace: child-namespace resourceVersion: "534402" uid: 2eab536b-55aa-4870-b732-67ebf0a8a5bb spec: cluster: demo-child-67835 steps: - commence: true constraints: - until the step is complete, it wont be possible to perform normal LCM operations on the cluster description: - install new version of life cycle management modules - restart OpenStack control plane components in parallel duration: eta: 2h0m0s info: - 15 minutes to update one OpenStack controller node - 5 minutes to update one compute node granularity: cluster impact: info: - 'up to 8% unavailability of APIs: OpenStack' users: minor workloads: none name: Update OpenStack control plane on a MOSK cluster - commence: true description: - major Ceph version upgrade - update monitors, managers, RGW/MDS - OSDs are restarted sequentially, or by rack - takes into account the failure domain config in cluster (rack updated in parallel) duration: eta: 40m0s info: - up to 40 minutes to update Ceph cluster (30 nodes) granularity: cluster impact: info: - 'up to 8% unavailability of APIs: S3/Swift' users: none workloads: none name: Update Ceph cluster on a MOSK cluster - commence: true description: - new host OS kernel and packages get installed - host OS configuration re-applied - new versions of Kubernetes components installed duration: eta: 45m0s info: - 15 minutes per Kubernetes master node, nodes updated sequentially granularity: cluster impact: users: none workloads: none name: Update host OS and Kubernetes components on master nodes - commence: true description: - new host OS kernel and packages get installed - host OS configuration re-applied - new versions of Kubernetes components installed - containerd and MCR get bumped - Open vSwitch and Neutron L3 agents gets restarted on gateway and compute nodes duration: eta: 12h0m0s info: - 'depends on the type of the nodes: controller, compute, OSD' granularity: machine impact: info: - some OpenStack running operations might not complete due to restart of docker/containerd on controller nodes (up to 30%, assuming seq. controller update) - OpenStack LCM will prevent OpenStack controllers and gateways from parallel cordon / drain, despite node-group config - Ceph LCM will prevent parallel restart of OSDs, monitors and managers, despite node-group config - minor loss of the East-West connectivity with the Open vSwitch networking back end that causes approximately 5 min of downtime per compute node - 'minor loss of the North-South connectivity with the Open vSwitch networking back end: a non-distributed HA virtual router needs up to 1 minute to fail over; a non-distributed and non-HA virtual router failover time depends on many factors and may take up to 10 minutes' users: minor workloads: major name: Update host OS and Kubernetes components on worker nodes - commence: true description: - restart of StackLight, MetalLB services - restart of auxilary controllers and charts duration: eta: 30m0s info: - 30 minutes minimum granularity: cluster impact: info: - minor cloud API downtime due restart of MetalLB components users: minor workloads: none name: Auxilary components update target: mosk-17-2-0-24-2 status: startedAt: "2024-05-20T14:05:23Z" status: Completed steps: - duration: 29m16.887573286s message: Ready name: Update OpenStack control plane startedAt: "2024-05-20T14:05:23Z" status: Completed - duration: 8m1.808804491s message: Ready name: Update Ceph cluster startedAt: "2024-05-20T14:34:39Z" status: Completed - duration: 33m5.100480887s message: Ready name: Update host OS and Kubernetes components on master nodes startedAt: "2024-05-20T14:42:40Z" status: Completed - duration: 1h39m9.896875724s message: Ready name: Update host OS and Kubernetes components on worker nodes startedAt: "2024-05-20T15:34:46Z" status: Completed - duration: 2m1.426000849s message: Ready name: Auxilary components update startedAt: "2024-05-20T17:13:55Z" status: Completed
Monitor the
messageandstatusfields of the first step. Themessagefield contains information about the progress of the current step. Thestatusfield can have the following values:NotStartedInProgressStuckCompleted
The
Stuckstatus indicates an issue and that the step can not fit into the ETA defined in thedurationfield for this step. The ETA for each step is defined statically and does not change depending on the cluster.Caution
The status is not populated for the
ClusterUpdatePlanobjects that have not been started by adding thecommence: trueflag to the first object step. Therefore, always start updating the object from the first step.Proceed with changing the
commenceflag of the following update steps granularly depending on the cluster update requirements.Caution
Launch the update steps sequentially. A consecutive step is not started until the previous step is completed.
Update a patch Cluster release of a managed cluster¶
Available since 2.23.2
A Container Cloud management cluster automatically upgrades to a new Container Cloud patch release, when available. Once done, a newer version of a patch Cluster release becomes available for managed clusters that you update using the Container Cloud web UI.
As compared to a major Cluster release update, a patch release update does not involve any public API or LCM changes, MKE or other major component version bumps, workloads evacuation. A patch cluster update only requires restart of containers running the Container Cloud controllers, Ceph, and StackLight services to update base images with related libraries and apply CVE fixes to images. The data plane is not affected. For details, see Patch releases.
Caution
If you delay the Container Cloud upgrade and schedule it at a later time as described in Schedule Mirantis Container Cloud upgrades, make sure to schedule a longer maintenance window as the upgrade queue can include several patch releases along with the major release upgrade.
For patch update rules and differences between the update scheme before and since Container Cloud 2.26.5, see Release Notes: Patch update schemes before and since 2.26.5.
To update a patch Cluster release of a managed cluster:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click Upgrade next to the More action icon located in the last column for each cluster where available.
Note
If Upgrade is greyed out, the cluster is in maintenance mode that must be disabled before you can proceed with cluster update. For details, see Disable maintenance mode on a cluster and machine.
If Upgrade does not display, your cluster is up-to-date.
In the Release update window, select the required patch Cluster release to update your managed cluster to.
The release notes for patch Cluster releases are available at Patch releases.
Click Update.
To monitor the cluster readiness, hover over the status icon of a specific cluster in the Status column of the Clusters page.
Once the orange blinking status icon becomes green and Ready, the cluster deployment or update is complete.
You can monitor live deployment status of the following cluster components:
Component
Description
Bastion
For the OpenStack-based management clusters, the Bastion node IP address status that confirms the Bastion node creation
Helm
Installation or upgrade status of all Helm releases
Kubelet
Readiness of the node in a Kubernetes cluster, as reported by kubelet
Kubernetes
Readiness of all requested Kubernetes objects
Nodes
Equality of the requested nodes number in the cluster to the number of nodes having the
ReadyLCM statusOIDC
Readiness of the cluster OIDC configuration
StackLight
Health of all StackLight-related objects in a Kubernetes cluster
Swarm
Readiness of all nodes in a Docker Swarm cluster
LoadBalancer
Readiness of the Kubernetes API load balancer
ProviderInstance
Readiness of all machines in the underlying infrastructure (virtual or bare metal, depending on the provider type)
Graceful Reboot
Readiness of a cluster during a scheduled graceful reboot, available since Cluster releases 15.0.1 and 14.0.0.
Infrastructure Status
Available since Container Cloud 2.25.0 for bare metal and OpenStack providers. Readiness of the following cluster components:
Bare metal: the
MetalLBConfigobject along with MetalLB and DHCP subnets.OpenStack: cluster network, routers, load balancers, and Bastion along with their ports and floating IPs.
LCM Operation
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Health of all LCM operations on the cluster and its machines.
LCM Agent
Available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Health of all LCM agents on cluster machines and the status of LCM agents update to the version from the current Cluster release.
For the history of a cluster deployment or update, refer to Inspect the history of a cluster and machine deployment or update.
Note
Since patch Cluster releases 17.1.1 and 16.1.1, on bare metal clusters, the update of Ubuntu packages with kernel minor version update may apply in certain Container Cloud releases.
In this case, cordon-drain and reboot of machines does not apply
automatically, and all machines have the reboot is required notification
after the cluster update. You can manually handle the reboot of machines
during a convenient maintenance window as described in
Perform a graceful reboot of a cluster.
See also
Add a Container Cloud cluster to Lens¶
For quick and easy inspection and monitoring, you can add any type of Container Cloud clusters to Lens using the Container Cloud web UI. The following options are available in the More action icon menu of each cluster:
Add cluster to Lens
Open cluster in Lens
Before you can start monitoring your Container Cloud clusters in Lens, install the Container Cloud Lens extension as described below.
To install the Container Cloud Lens extension:
Start Lens.
Verify that your Lens version is 4.2.4 or later.
Select Lens > Extensions.
Copy and paste the following text into the Install Extension field:
@mirantis/lens-extension-cc
Click Install.
Verify that the Container Cloud Lens extension appears in the Installed Extensions section.
To add a cluster to Lens:
Enable your browser to open pop-ups for the Container Cloud web UI.
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Open the Clusters tab.
Verify that the target cluster is successfully deployed and is in the Ready status.
In the last column of the target cluster area, click the More action icon and select Add cluster to Lens.
In the Add Cluster To Lens window, click Add.
The system redirects you to Lens that now contains the previously added Container Cloud cluster.
Caution
If prompted, allow your browser to open Lens.
To open a cluster in Lens:
Add the target Container Cloud cluster to Lens as described above.
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Open the Clusters tab.
In the last column of the target cluster area, click the More action icon and select Open cluster in Lens.
Attach an existing MKE cluster to a vSphere-based management cluster¶
Available since 2.25.2
Using the Container Cloud web UI, you can attach an existing Mirantis Kubernetes Engine (MKE) cluster that is not deployed by Container Cloud to a vSphere-based management cluster. This feature allows for a detailed visualization of all your MKE clusters in one place including cluster health, capacity, and usage.
Supported MKE versions for attachment¶
Mirantis supports two MKE minor release series for MKE cluster attachment: 3.5.x and 3.6.x with two MKE patch releases in each series. Each MKE patch release is linked to a dedicated Cluster release in Container Cloud. The supported MKE versions for a cluster attachment are defined in Compatibility matrix of component versions.
Note
Attachment of MKE clusters is tested on Ubuntu 20.04.
Features and limitations¶
The following table describes the main features and limitations of an existing MKE cluster attached to Container Cloud:
Features |
Limitations |
|---|---|
|
|
Caution
An MKE cluster can be attached to only one management cluster. Attachment of a Container Cloud-based MKE cluster to another management cluster is not supported.
Attach an existing MKE cluster¶
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, expand the Create Cluster menu and click Attach Existing MKE Cluster.
In the wizard that opens, fill out the form with the following parameters as required:
Configure general settings:
Cluster Name - specify the cluster name
Region - select vSphere
Note
The Region parameter was removed in Container Cloud 2.26.0.
Upload the MKE client bundle using upload MKE client bundle or fill in the fields manually.
To download the MKE client bundle, refer to MKE user access: Download client certificates.
For StackLight, make sure that your deployment meets the requirements described in StackLight requirements for an MKE attached cluster.
Configure StackLight:
Section
Parameter name
Description
StackLight
Enable Monitoring
Selected by default. Deselect to skip StackLight deployment. You can also enable, disable, or configure StackLight parameters after deploying a managed cluster. For details, see Change a cluster configuration or Configure StackLight.
Enable Logging
Select to deploy the StackLight logging stack.
For details about the logging components, see Deployment architecture.
Note
The logging mechanism performance depends on the cluster log load. In case of a high load, you may need to increase the default resource requests and limits for
fluentdLogs. For details, see StackLight configuration parameters: Resource limits.HA Mode
Select to enable StackLight monitoring in the HA mode. For the differences between HA and non-HA modes, see Deployment architecture.
StackLight Default Logs Severity Level
Log severity (verbosity) level for all StackLight components. The default value for this parameter is Default component log level that respects original defaults of each StackLight component. For details about severity levels, see Log verbosity.
StackLight Component Logs Severity Level
The severity level of logs for a specific StackLight component that overrides the value of the StackLight Default Logs Severity Level parameter. For details about severity levels, see Log verbosity.
Expand the drop-down menu for a specific component to display its list of available log levels.
OpenSearch
Logstash Retention Time
Skip this parameter since Container Cloud 2.26.0 (17.1.0, 16.1.0). It was removed from the code base and will be removed from the web UI in one of the following releases.
Available if you select Enable Logging. Specifies the
logstash-*index retention time.Events Retention Time
Available if you select Enable Logging. Specifies the
kubernetes_events-*index retention time.Notifications Retention
Available if you select Enable Logging. Specifies the
notification-*index retention time and is used for Mirantis OpenStack for Kubernetes.Persistent Volume Claim Size
Available if you select Enable Logging. The OpenSearch persistent volume claim size.
Collected Logs Severity Level
Available if you select Enable Logging. The minimum severity of all Container Cloud components logs collected in OpenSearch. For details about severity levels, see Logging.
Prometheus
Retention Time
The Prometheus database retention period.
Retention Size
The Prometheus database retention size.
Persistent Volume Claim Size
The Prometheus persistent volume claim size.
Enable Watchdog Alert
Select to enable the Watchdog alert that fires as long as the entire alerting pipeline is functional.
Custom Alerts
Specify alerting rules for new custom alerts or upload a YAML file in the following exemplary format:
- alert: HighErrorRate expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5 for: 10m labels: severity: page annotations: summary: High request latency
For details, see Official Prometheus documentation: Alerting rules. For the list of the predefined StackLight alerts, see Operations Guide: Available StackLight alerts.
StackLight Email Alerts
Enable Email Alerts
Select to enable the StackLight email alerts.
Send Resolved
Select to enable notifications about resolved StackLight alerts.
Require TLS
Select to enable transmitting emails through TLS.
Email alerts configuration for StackLight
Fill out the following email alerts parameters as required:
To - the email address to send notifications to.
From - the sender address.
SmartHost - the SMTP host through which the emails are sent.
Authentication username - the SMTP user name.
Authentication password - the SMTP password.
Authentication identity - the SMTP identity.
Authentication secret - the SMTP secret.
StackLight Slack Alerts
Enable Slack alerts
Select to enable the StackLight Slack alerts.
Send Resolved
Select to enable notifications about resolved StackLight alerts.
Slack alerts configuration for StackLight
Fill out the following Slack alerts parameters as required:
API URL - The Slack webhook URL.
Channel - The channel to send notifications to, for example, #channel-for-alerts.
StackLight optional settings
Enable Reference Application
Available since Container Cloud 2.22.0. Enables Reference Application that is a small microservice application that enables workload monitoring on non-MOSK managed clusters.
Note
For the feature support on MOSK deployments, refer to MOSK documentation: Deploy RefApp using automation tools.
Disabled by default. You can also enable this option after deployment from the Configure cluster menu.
Click Create.
To monitor the cluster readiness, hover over the status icon of a specific cluster in the Status column of the Clusters page.
Once the orange blinking status icon becomes green and Ready, the cluster deployment or update is complete.
You can monitor live deployment status of the following cluster components:
Component
Description
Bastion
For the OpenStack-based management clusters, the Bastion node IP address status that confirms the Bastion node creation
Helm
Installation or upgrade status of all Helm releases
Kubelet
Readiness of the node in a Kubernetes cluster, as reported by kubelet
Kubernetes
Readiness of all requested Kubernetes objects
Nodes
Equality of the requested nodes number in the cluster to the number of nodes having the
ReadyLCM statusOIDC
Readiness of the cluster OIDC configuration
StackLight
Health of all StackLight-related objects in a Kubernetes cluster
Swarm
Readiness of all nodes in a Docker Swarm cluster
LoadBalancer
Readiness of the Kubernetes API load balancer
ProviderInstance
Readiness of all machines in the underlying infrastructure (virtual or bare metal, depending on the provider type)
Graceful Reboot
Readiness of a cluster during a scheduled graceful reboot, available since Cluster releases 15.0.1 and 14.0.0.
Infrastructure Status
Available since Container Cloud 2.25.0 for bare metal and OpenStack providers. Readiness of the following cluster components:
Bare metal: the
MetalLBConfigobject along with MetalLB and DHCP subnets.OpenStack: cluster network, routers, load balancers, and Bastion along with their ports and floating IPs.
LCM Operation
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Health of all LCM operations on the cluster and its machines.
LCM Agent
Available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Health of all LCM agents on cluster machines and the status of LCM agents update to the version from the current Cluster release.
For the history of a cluster deployment or update, refer to Inspect the history of a cluster and machine deployment or update.
For StackLight, add the StackLight label to worker nodes. For details, see Node Labels in Create a machine using web UI.
On the Machines page, click the More action icon in the last column of the required machine field and select Configure machine.
In Node Labels, select StackLight.
Caution
To detach an MKE cluster, use the Detach button in the cluster menu of the Container Cloud web UI. Do not delete the cluster machines using the cloud provider tools directly to prevent issues with cluster detachment or cleaning of machines resources manually.
Note
Before Container Cloud 2.26.0, to detach an MKE cluster, use the Delete button in the cluster menu.
Connect to the Mirantis Kubernetes Engine web UI¶
After you deploy a new or attach an existing Mirantis Kubernetes Engine (MKE) cluster to a management cluster, start managing your cluster using the MKE web UI.
To connect to the MKE web UI:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operator,cluster-admin, orm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the More action icon in the last column of the required MKE cluster and select Cluster info.
In the dialog box with the cluster information, copy the MKE UI endpoint and paste it to a web browser.
On the MKE sign-in page, click Sign in with External Provider.
The system uses the same credentials as for access to the Container Cloud web UI.
Warning
To ensure the Container Cloud stability in managing the Container Cloud-based MKE clusters, a number of MKE API functions is not available for the Container Cloud-based MKE clusters as compared to the MKE clusters that are deployed not by Container Cloud. Use the Container Cloud web UI or CLI for this functionality instead.
See MKE API limitations for details.
Caution
The MKE web UI contains help links that lead to the MKE, MSR, and MCR documentation suite. Besides MKE and Mirantis Container Runtime (MCR), which are integrated with Container Cloud, that documentation suite covers other MKE, MSR, and MCR components and cannot be fully applied to the Container Cloud-based MKE clusters. Therefore, to avoid any sort of misconceptions, before you proceed with MKE web UI documentation, read MKE API limitations and make sure you are using the documentation of the supported MKE version as per Release Compatibility Matrix.
Connect to a Mirantis Container Cloud cluster¶
Note
The Container Cloud web UI communicates with Keycloak to authenticate users. Keycloak is exposed using HTTPS with self-signed TLS certificates that are not trusted by web browsers.
To use your own TLS certificates for Keycloak, refer to Configure TLS certificates for cluster applications.
After you deploy a Mirantis Container Cloud management or managed cluster, connect to the cluster to verify the availability and status of the nodes as described below.
This section also describes how to SSH to a node of an OpenStack-based management cluster where a Bastion host is used for SSH access.
To connect to a managed cluster:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the required cluster name. The cluster page with the Machines list opens.
Verify the status of the manager nodes. Once the first manager node is deployed and has the Ready status, the Download Kubeconfig option for the cluster being deployed becomes active.
Open the Clusters tab.
Click the More action icon in the last column of the required cluster and select Download Kubeconfig:
Enter your user password.
Not recommended. Select Offline Token to generate an offline IAM token. Otherwise, for security reasons, the
kubeconfigtoken expires every 30 minutes of the Container Cloud API idle time and you have to downloadkubeconfigagain with a newly generated token.Click Download.
Verify the availability of the managed cluster machines:
Export the
kubeconfigparameters to your local machine with access to kubectl. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Obtain the list of available Container Cloud machines:
kubectl get nodes -o wide
The system response must contain the details of the nodes in the
READYstatus.
To connect to a management cluster:
Log in to a local machine where your management cluster
kubeconfigis located and wherekubectlis installed.Note
The management cluster
kubeconfigis created during the last stage of the management cluster bootstrap.Obtain the list of available management cluster machines:
kubectl get nodes -o wide
The system response must contain the details of the nodes in the
READYstatus.
To SSH to an OpenStack-based management cluster node if Bastion is used:
Obtain
kubeconfigof the management cluster as described in the procedures above.Obtain the internal IP address of a node you require access to:
kubectl get nodes -o wide
Obtain the Bastion public IP:
kubectl get cluster -o jsonpath='{.status.providerStatus.bastion.publicIP}' \ -n <project_name> <cluster_name>
Run the following command substituting the parameters enclosed in angle brackets with the corresponding values of your cluster obtained in previous steps:
ssh -i <private_key> mcc-user@<node_internal_ip> -o "proxycommand ssh -W %h:%p \ -i <private_key> mcc-user@<bastion_public_ip>"
The
<private_key>isssh_keycreated during bootstrap in the same directory as the bootstrap script.Note
If the initial version of your Container Cloud management cluster was earlier than 2.6.0,
ssh_keyis namedopenstack_tmpand is located at~/.ssh/.
Inspect the history of a cluster and machine deployment or update¶
Available since 2.22.0
Using the ClusterDeploymentStatus, ClusterUpgradeStatus,
MachineDeploymentStatus, and MachineUpgradeStatus objects, you
can inspect historical data of cluster and machine deployment or update
stages, their time stamps, statuses, and failure messages, if any.
Caution
The order of cluster and machine update stages may not always be sorted by a time stamp but have an approximate logical order due to several components running simultaneously.
View the history using the web UI¶
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon on top of the main left-side navigation panel.
In the Clusters tab, click the More action icon in the last column of the required cluster area and select History to display details of the
ClusterDeploymentStatusorClusterUpgradeStatusobject, if any.In the window that opens, click the required object to display the object stages, their time stamps, and statuses.
Object names match the initial and/or target Cluster release versions and MKE versions of the cluster at a specific date and time. For example, 11.6.0+3.5.5 (initial version) or 11.5.0+3.5.5 -> 11.6.0+3.5.5.
If any stage fails, hover over the Failure status field to display the failure message.
Optional. Inspect the deployment and update status of the cluster machines:
In the Clusters tab, click the required cluster name. The cluster page with Machines list opens.
Click More action icon in the last column of the required machine area and select History.
View the history using the CLI¶
Log in to a local machine where your management cluster
kubeconfigis located and where kubectl is installed.Select from the following options:
Inspect the cluster or machine deployment history using the
ClusterDeploymentStatusorMachineDeploymentStatusobject:./bin/kubectl --kubeconfig <pathToClusterKubeconfig> get clusterdeploymentstatus ./bin/kubectl --kubeconfig <pathToClusterKubeconfig> get machinedeploymentstatus
Example extract from a ClusterDeploymentStatus objectkind: ClusterDeploymentStatus metadata: annotations: lcm.mirantis.com/new-history: "true" creationTimestamp: "2022-12-13T15:25:49Z" name: test-managed namespace: default ownerReferences: - apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster name: test-managed release: 11.6.0+3.5.5 stages: - message: "" name: Network prepared status: Success success: true timestamp: "2022-12-13T15:27:19Z" - message: "" name: Load balancers created status: Success success: true timestamp: "2022-12-13T15:27:56Z" - message: "" name: IAM objects created status: Success success: true timestamp: "2022-12-13T15:27:21Z" - message: "" name: Kubernetes API started status: Success success: true timestamp: "2022-12-13T15:57:05Z" - message: "" name: Helm-controller deployed status: Success success: true timestamp: "2022-12-13T15:57:13Z" - message: "" name: HelmBundle created status: Success success: true timestamp: "2022-12-13T15:57:15Z" - message: "" name: Certificates configured status: Success success: true timestamp: "2022-12-13T15:58:29Z" - message: "" name: All machines of the cluster are ready status: Success success: true timestamp: "2022-12-13T16:04:49Z" - message: "" name: OIDC configured status: Success success: true timestamp: "2022-12-13T16:04:07Z" - message: "" name: Cluster is ready status: Success success: true timestamp: "2022-12-13T16:14:04Z"
Example extract from a MachineDeploymentStatus objectapiVersion: kaas.mirantis.com/v1alpha1 kind: MachineDeploymentStatus metadata: creationTimestamp: "2022-12-16T09:57:07Z" name: test-managed-2-master-cwtf8 namespace: default ownerReferences: - apiVersion: cluster.k8s.io/v1alpha1 kind: Machine name: test-managed-2-master-cwtf8 release: 11.6.0+3.5.5 stages: - message: "" name: Provider instance ready status: Success success: true timestamp: "2022-12-16T09:59:28Z" - message: "" name: Prepare phase done status: Success success: true timestamp: "2022-12-16T10:12:05Z" - message: "" name: Deploy phase done status: Success success: true timestamp: "2022-12-16T10:16:36Z" - message: "" name: Reconfigure phase done status: Success success: true timestamp: "2022-12-16T10:16:40Z"
Inspect the cluster or machine update history using the
ClusterUpgradeStatusandMachineUpgradeStatusobjects:./bin/kubectl --kubeconfig <pathToClusterKubeconfig> get clusterupgradestatus ./bin/kubectl --kubeconfig <pathToClusterKubeconfig> get machineupgradestatus
Example extract from a ClusterUpgradeStatus objectapiVersion: kaas.mirantis.com/v1alpha1 fromRelease: 11.5.0+3.5.5 kind: ClusterUpgradeStatus metadata: annotations: lcm.mirantis.com/new-history: "true" creationTimestamp: "2022-12-16T09:02:20Z" name: test-managed-11.6.0+3.5.5 namespace: default ownerReferences: - apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster name: test-managed stages: - message: "" name: Requested cluster maintenance status: Success success: true timestamp: "2022-12-16T09:02:02Z" - message: "" name: Cluster workload locks are inactive status: Success success: true timestamp: "2022-12-16T09:02:02Z" - message: "" name: Worker nodes MKE upgraded status: Success success: true timestamp: "2022-12-16T09:47:48Z" - message: "" name: Control plane nodes MKE upgraded status: Success success: true timestamp: "2022-12-16T09:37:33Z" - message: "" name: Cluster maintenance request removed status: Success success: true timestamp: "2022-12-16T09:48:16Z" toRelease: 11.6.0+3.5.5
Example extract from a MachineUpgradeStatus object for a control plane machineapiVersion: kaas.mirantis.com/v1alpha1 fromRelease: 11.5.0+3.5.5 kind: MachineUpgradeStatus metadata: annotations: lcm.mirantis.com/new-history: "true" creationTimestamp: "2022-12-16T09:02:24Z" name: test-managed-master-j2vmj-11.6.0+3.5.5 namespace: default ownerReferences: - apiVersion: cluster.k8s.io/v1alpha1 kind: Machine name: test-managed-master-j2vmj stages: - message: "" name: Agent upgraded status: Success success: true timestamp: "2022-12-16T09:02:22Z" - message: "" name: Machine Upgraded status: Success success: true timestamp: "2022-12-16T09:37:14Z" toRelease: 11.6.0+3.5.5
Example extract from a MachineUpgradeStatus object for a worker machineapiVersion: kaas.mirantis.com/v1alpha1 fromRelease: 11.5.0+3.5.5 kind: MachineUpgradeStatus metadata: annotations: lcm.mirantis.com/new-history: "true" creationTimestamp: "2022-12-16T09:02:58Z" name: test-managed-node-ggzn2-11.6.0+3.5.5 namespace: default ownerReferences: - apiVersion: cluster.k8s.io/v1alpha1 kind: Machine name: test-managed-node-ggzn2 stages: - message: "" name: Agent upgraded status: Success success: true timestamp: "2022-12-16T09:02:56Z" - message: "" name: Previous machines are deployed status: Success success: true timestamp: "2022-12-16T09:42:20Z" - message: "" name: Node maintenance requested status: Success success: true timestamp: "2022-12-16T09:42:13Z" - message: "" name: Node workload locks inactive status: Success success: true timestamp: "2022-12-16T09:42:14Z" - message: "" name: Kubernetes drained status: Success success: true timestamp: "2022-12-16T09:42:14Z" - message: "" name: Deploy phase done status: Success success: true timestamp: "2022-12-16T09:43:33Z" - message: "" name: Reconfigure phase done status: Success success: true timestamp: "2022-12-16T09:43:36Z" - message: "" name: Machine Upgraded status: Success success: true timestamp: "2022-12-16T09:48:15Z" - message: "" name: Kubernetes uncordoned status: Success success: true timestamp: "2022-12-16T09:47:47Z" - message: "" name: Node maintenance request removed status: Success success: true timestamp: "2022-12-16T09:47:48Z" toRelease: 11.6.0+3.5.5
Object names match the initial and/or target Cluster release versions and MKE versions of the cluster. For example, 11.5.0+3.5.5 (initial version) or 11.5.0+3.5.5 -> 11.6.0+3.5.5. Each object displays the update stages, their time stamps, and statuses. If any stage fails, the
successfield contains a failure message.
Operate management clusters¶
Note
The Container Cloud web UI communicates with Keycloak to authenticate users. Keycloak is exposed using HTTPS with self-signed TLS certificates that are not trusted by web browsers.
To use your own TLS certificates for Keycloak, refer to Configure TLS certificates for cluster applications.
Caution
Regional clusters are unsupported since Container Cloud 2.25.0. Mirantis does not perform functional integration testing of the feature and the related code is removed in Container Cloud 2.26.0. If you still require this feature, contact Mirantis support for further information.
The Mirantis Container Cloud web UI enables you to perform the following operations with the Container Cloud management clusters:
View the cluster details (such as cluster ID, creation date, nodes count, and so on) as well as obtain a list of the cluster endpoints including the StackLight components, depending on your deployment configuration.
To view generic cluster details, in the Clusters tab, click the More action icon in the last column of the required cluster and select Cluster info.
Note
Adding more than 3 nodes from a management cluster is not supported.
Removing a management cluster using the Container Cloud web UI is not supported. Use the dedicated cleanup script instead. For details, see Remove a management cluster.
Verify the current release version of the cluster including the list of installed components with their versions and the cluster release change log.
To view a cluster release version details, in the Clusters tab, click the version in the Release column next to the name of the required cluster.
This section outlines the operations that you can perform with a management cluster.
Automatic upgrade workflow¶
A management cluster upgrade to a newer version is performed automatically once a new Container Cloud version is released. For more details about the Container Cloud release upgrade mechanism, see: Release Controller.
The Operator can delay the Container Cloud automatic upgrade procedure for a limited amount of time or schedule upgrade to run at desired hours or weekdays. For details, see Schedule Mirantis Container Cloud upgrades.
Container Cloud remains operational during the management cluster upgrade. Managed clusters are not affected during this upgrade. For the list of components that are updated during the Container Cloud upgrade, see the Components versions section of the corresponding Container Cloud release in Release Notes.
When Mirantis announces support of the newest versions of Mirantis Container Runtime (MCR) and Mirantis Kubernetes Engine (MKE), Container Cloud automatically upgrades these components as well. For the maintenance window best practices before upgrade of these components, see MKE Documentation.
Since Container Cloud 2.23.2, the release update train includes patch release updates being delivered between major releases. For details on the currently available patch releases, see Patch releases.
Note
MKE and Kubernetes API may return short-term 50x errors during the upgrade process. Ignore these errors.
Caution
If the cluster update includes MKE upgrade from 3.4 to 3.5
and you need to access the cluster while the update is in progress,
use the admin kubeconfig instead of the existing one while OIDC
settings are being reconfigured.
To obtain the admin kubeconfig:
kubectl --kubeconfig <pathToMgmtKubeconfig> get secret -n <affectedClusterNamespace> \
-o yaml <affectedClusterName>-kubeconfig | awk '/admin.conf/ {print $2}' | \
head -1 | base64 -d > clusterKubeconfig.yaml
Caution
During cluster upgrade from the release 2.21.1 to 2.22.0 with StackLight logging enabled, a short outage of OpenSearch and its dependent components may occur with the following alerts firing on the cluster. This behavior is expected. Therefore, disregard these alerts.
StackLight alerts list firing during cluster update
Cluster size and outage probability level |
Alert name |
Label name and component |
|---|---|---|
Any cluster with high probability |
|
|
|
|
|
Large cluster with average probability |
|
|
|
n/a |
|
|
n/a |
|
|
n/a |
|
|
n/a |
|
Any cluster with low probability |
|
|
|
|
To inspect the cluster upgrade progress or history, refer to Inspect the history of a cluster and machine deployment or update.
Once the management cluster is upgraded to the latest version, update the original bootstrap tarball for successful cluster management, such as collecting logs and so on.
To update the bootstrap tarball after an automatic cluster upgrade:
Select from the following options:
For clusters deployed using Container Cloud 2.11.0 or later:
./container-cloud bootstrap download --management-kubeconfig <pathToMgmtKubeconfig> \ --target-dir <pathToBootstrapDirectory>
For clusters deployed using the Container Cloud release earlier than 2.11.0 or if you deleted the
kaas-bootstrapfolder, download and run the Container Cloud bootstrap script:wget https://binary.mirantis.com/releases/get_container_cloud.sh chmod 0755 get_container_cloud.sh ./get_container_cloud.sh
Schedule Mirantis Container Cloud upgrades¶
By default, Container Cloud automatically upgrades to the latest version, once available. An Operator can delay or reschedule Container Cloud automatic upgrade process using CLI or web UI. The scheduling feature allows:
Blocking Container Cloud upgrade process for up to 7 days from the current date and up to 30 days from the latest Container Cloud release
Limiting hours and weekdays when Container Cloud upgrade can run
Caution
Since Container Cloud 2.23.2, the release update train includes patch release updates being delivered between major releases. The new approach increases the frequency of the release updates. Therefore, schedule a longer maintenance window for the Container Cloud upgrade as there can be more than one scheduled update in the queue.
For details on the currently available patch releases, see Patch releases.
Schedule upgrade using CLI¶
You can delay or reschedule Container Cloud automatic
upgrade by editing the MCCUpgrade object named mcc-upgrade
in Kubernetes API.
Caution
Only the management cluster admin and users with the operator
(or writer in old-style Keycloak roles) permissions can edit the
MCCUpgrade object. For object editing, use kubeconfig generated
during the management cluster bootstrap or kubeconfig generated with the
operator (or writer) permissions.
To edit the current configuration, run the following command in the command line:
kubectl edit mccupgrade mcc-upgrade
In the system response, the editor displays the current state of the
MCCUpgrade object in the YAML format. The spec section contains
the current upgrade schedule configuration, for example:
spec:
blockUntil: 2021-12-31T00:00:00
timeZone: CET
schedule:
- hours:
from: 10
to: 17
weekdays:
monday: true
tuesday: true
- hours:
from: 7
to: 10
weekdays:
monday: true
friday: true
In this example:
Upgrades are blocked until December 31, 2021
All schedule calculations are done in the CET timezone
Upgrades are allowed only:
From 7:00 to 17:00 on Mondays
From 10:00 to 17:00 on Tuesdays
From 7:00 to 10:00 on Fridays
For details about the MCCUpgrade object, see MCCUpgrade resource.
On every upgrade step, the Release Controller verifies if the current time is allowed by the schedule and does not start or proceed with the upgrade if it is not.
Schedule upgrade using web UI¶
TechPreview
The Container Cloud web UI provides an upgrade scheduling tool.
To schedule upgrades using the Container Cloud web UI:
Log in to the Container Cloud web UI as
m:kaas@global-adminorm:kaas@writer.In the left-side navigation panel, click Upgrade Schedule in the Admin section.
Click Configure Schedule.
Select the time zone from the Time Zone list. You can also type the necessary location to find it in the list.
Optional. In Delay Upgrade, configure the upgrade delay. You can set no delay or select the exact day, hour, and minute. You can delay the upgrade up to 7 days, but not more than 30 days from the latest release date. For example, the current time is 10:00 March 28, and the latest release was on March 1. In this case, the maximum delay you can set is 10:00 March 31. Regardless of your time zone, configure time in accordance with the previously selected time zone.
Optional. In Allowed Time for Upgrade, set the time intervals when to allow upgrade. Select the upgrade hours in the From and To time input fields. Select days of the week in the corresponding check boxes. Click + to set additional upgrade hours.
Renew the Container Cloud and MKE licenses¶
When your Mirantis Container Cloud expires, contact you account manager to
request a new license by submitting a ticket through the
Mirantis CloudCare Portal.
If your trial license has expired, contact
Mirantis support for further
information.
Once you obtain a new mirantis.lic file, update Container Cloud along
with MKE clusters using the instructions below.
Important
Once your Container Cloud license expires, all API operations with new and existing clusters are blocked until license renewal. Existing workloads are not affected.
Additionally, since Cluster releases 17.0.0, 16.0.0, and 14.1.0, you cannot perform the following operations on your cluster with an expired license:
Create new clusters and machines
Automatically upgrade the management cluster
Update managed clusters
To update the Container Cloud and MKE licenses:
Log in to the Container Cloud web UI with the
m:kaas@global-adminrole.Navigate to Admin > License.
Click Update License and upload your new license.
Click Update.
Caution
Machines are not cordoned and drained, user workloads are not interrupted, and the MKE license is updated automatically for all clusters starting from Cluster releases 7.6.0, 8.6.0, and 11.0.0.
See also
Configure NTP server¶
If you did not add the NTP server parameters during the management cluster bootstrap, configure them on the existing management cluster as required. These parameters are applied to all machines of managed clusters deployed within the configured management cluster.
Caution
The procedure below applies only if ntpEnabled=true (default)
was set during a management cluster bootstrap. Enabling or disabling NTP
after bootstrap is not supported.
Warning
The procedure below triggers an upgrade of all clusters in a specific management cluster, which may lead to workload disruption during nodes cordoning and draining.
To configure an NTP server for managed clusters:
Download your management cluster
kubeconfig:Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
Expand the menu of the tab with your user name.
Click Download kubeconfig to download
kubeconfigof your management cluster.Log in to any local machine with
kubectlinstalled.Copy the downloaded
kubeconfigto this machine.
Use the downloaded
kubeconfigto edit the management cluster:kubectl --kubeconfig <kubeconfigPath> edit -n <projectName> cluster <managementClusterName>
In the command above and the step below, replace the parameters enclosed in angle brackets with the corresponding values of your cluster.
In the
regionalsection, add thentp:serverssection with the list of required server names:spec: ... providerSpec: value: kaas: ... ntpEnabled: true ... regional: - helmReleases: - name: <providerName> values: config: lcm: ... ntp: servers: - 0.pool.ntp.org ...
Automatically propagate Salesforce configuration to all clusters¶
You can enable automatic propagation of the Salesforce configuration of your
management cluster to the related managed clusters using the
autoSyncSalesForceConfig=true flag added to the Cluster object of the
management cluster. This option allows for automatic update and sync of the
Salesforce settings on all your clusters after you update your management
cluster configuration.
You can also set custom settings for managed clusters that always override automatically propagated Salesforce values.
Enable propagation of Salesforce configuration using web UI¶
Log in to the Container Cloud web UI as
m:kaas@global-adminorm:kaas@writer.In the Clusters tab, click the More action icon in the last column of the required management cluster and select Configure.
In the Configure cluster window, navigate to StackLight > Salesforce and select Salesforce Configuration Propagation To Managed Clusters.
Click Update.
Once the automatic propagation applies, the Events section of the corresponding managed cluster displays the following message: Propagated Cluster Salesforce Config From Management <clusterName> Cluster uses SalesForce configuration from management cluster.
Note
To set custom Salesforce settings for your managed clusters that will override the related management cluster settings, refer to the optional step in Enable propagation of Salesforce configuration using CLI.
Enable propagation of Salesforce configuration using CLI¶
Download your management cluster
kubeconfig:Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
Expand the menu of the tab with your user name.
Click Download kubeconfig to download
kubeconfigof your management cluster.Log in to any local machine with
kubectlinstalled.Copy the downloaded
kubeconfigto this machine.
In the
Clusterobjects of the required managed cluster, remove all Salesforce settings that you want to automatically sync with the same settings of the management cluster:kubectl --kubeconfig <mgmtClusterKubeconfigPath> edit -n <managedClusterProjectName> cluster <managedClusterName>
From the StackLight
valuessection, remove the following Salesforce parameters:spec: ... providerSpec: value: helmReleases: - name: stacklight values: ...
alertmanagerSimpleConfig.salesForce.enabled alertmanagerSimpleConfig.salesForce.auth sfReporter.salesForceAuth sfReporter.enabled sfReporter.cronjob
For details about these parameters, refer to StackLight configuration parameters for Salesforce.
In the
managementsection of the management clusterClusterobject, add theautoSyncSalesForceConfig: trueflag:kubectl --kubeconfig <kubeconfigPath> edit -n <projectName> cluster <managementClusterName>
spec: ... providerSpec: value: kaas: ... management: ... autoSyncSalesForceConfig: true
Note
If the
autoSyncSalesForceConfigis not set to any value, automatic propagation is disabled.Once enabled, the following Salesforce parameters are copied to all managed clusters where these settings were not configured yet:
alertmanagerSimpleConfig.salesForce.enabled alertmanagerSimpleConfig.salesForce.auth sfReporter.salesForceAuth sfReporter.enabled sfReporter.cronjob
The existing Salesforce settings of managed clusters will not be overridden after you enable automatic propagation.
To verify the automatic propagation status:
kubectl edit helmbundles <managedClusterName> -n <managedClusterProjectName>
Optional. Set custom Salesforce settings for your managed cluster to override the related management cluster settings. Add the required custom settings to the StackLight
valuessection of the correspondingClusterobject of your managed cluster:spec: ... providerSpec: value: helmReleases: - name: stacklight values: ...
For details, refer to StackLight configuration procedure and StackLight configuration parameters for Salesforce.
Note
Custom settings are not overridden if you update the management cluster settings for Salesforce.
Update the Keycloak IP address on bare metal clusters¶
The following instruction describes how to update the IP address of the Keycloak service on baremetal-based management clusters.
Note
The commands below contain the default kaas-mgmt name of the
management cluster. If you changed the default name,
replace it accordingly. To verify the cluster name, run
kubectl get clusters.
To update the Keycloak IP address on a bare metal management cluster:
Log in to a node that contains
kubeconfigof the required management cluster.Make sure that the configuration file is in your
.kubedirectory. Otherwise, set theKUBECONFIGenvironment variable with a full path to the configuration file.Configure the additional
externalIP address pool for themetallbload balancer service.The Keycloak service requires one IP address. Therefore, the
externalIP address pool must contain at least one IP address.Open the
MetalLBConfigobject of the management cluster for editing:kubectl edit metallbconfig <MetalLBConfigName>
In the
ipAddressPoolssection, add:... spec: ipAddressPools: - name: external spec: addresses: - <pool_start_ip>-<pool_end_ip> autoAssign: false avoidBuggyIPs: false ...
In the snippet above, replace the following parameters:
<pool_start_ip>- first IP address in the required range<pool_end_ip>- last IP address in the range
Add the
externalIP address pool name to theL2Advertisementsdefinition. You can add it to the same L2 advertisement as thedefaultIP address pool, or create a new L2 advertisement if required.... spec: l2Advertisements: - name: default spec: interfaces: - k8s-lcm ipAddressPools: - default - external ...
Save and exit the object to apply changes.
Create the
Subnetobject template with the following content:apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: labels: cluster.sigs.k8s.io/cluster-name: kaas-mgmt kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one metallb/address-pool-auto-assign: "false" metallb/address-pool-name: external metallb/address-pool-protocol: layer2 name: master-lb-external namespace: default spec: cidr: <pool_cidr> includeRanges: - <pool_start_ip>-<pool_end_ip>
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.In the template above, replace the following parameters:
<pool_start_ip>- first IP address in the desired range.<pool_end_ip>- last IP address in the range.<pool_cidr>- corresponding CIDR address. The only requirement for this CIDR address is that the address range mentioned above must fit into this CIDR. The CIDR address is not used by MetalLB, it is just formally required forSubnetobjects.
Note
If required, use a different IP address pool name.
Apply the
Subnettemplate created in the previous step:kubectl create -f <subnetTemplateName>
Open the
MetalLBConfigTemplateobject of the management cluster for editing:kubectl edit <MetalLBConfigTemplateName>
Add the
externalIP address pool name to theL2Advertisementsdefinition. You can add it to the same L2 advertisement as thedefaultIP address pool, or create a new L2 advertisement if required.... spec: templates: l2Advertisements: | - name: management-lcm spec: ipAddressPools: - default - external interfaces: - k8s-lcm - name: provision-pxe spec: ipAddressPools: - services-pxe interfaces: - k8s-pxe ...
Save and exit the object to apply changes.
Open the
Clusterobject for editing:kubectl edit cluster <clusterName>
Add the following highlighted lines by replacing
<pool_start_ip>with the first IP address in the desired range and<pool_end_ip>with the last IP address in the range:spec: providerSpec: value: helmReleases: - name: metallb values: configInline: address-pools: - name: default protocol: layer2 addresses: - 10.0.0.100-10.0.0.120 // example values - name: external protocol: layer2 auto-assign: false addresses: - <pool_start_ip>-<pool_end_ip>
Note
If required, use a different IP address pool name.
Save and exit the object to apply changes.
Obtain the current Keycloak IP address for reference:
kubectl -n kaas get service iam-keycloak-http -o jsonpath='{.status.loadBalancer.ingress[0].ip}{"\n"}'
Configure the
iam-keycloak-httpservice to listen on one of the IP addresses from theexternalpool:kubectl -n kaas edit service iam-keycloak-http
Add the following annotation to the service:
kind: Service metadata: annotations: metallb.universe.tf/address-pool: external
Save and exit to apply changes.
Verify that the Keycloak service IP address has changed:
kubectl -n kaas get service iam-keycloak-http -o jsonpath='{.status.loadBalancer.ingress[0].ip}{"\n"}'
Monitor the cluster status to verify that the changes are applied:
kubectl get cluster kaas-mgmt -o yaml
In the output, monitor the
urlparameter value in thekeycloakfield:... status: providerStatus: helm: ready: true ... releases: ... iam: keycloak: url: https://<pool_start_ip>
The value of the parameter is typically the first address of the
externalpool rage.Once the parameter has updated, delete the old certificate for the former address:
kubectl delete secret keycloak-tls-certs -n kaas
Note
The new certificate secret with the same name
keycloak-tls-certswill be generated automatically.Verify the new certificate, once available:
kubectl get secret keycloak-tls-certs -n kaas -o yaml
Restart the
iam-keycloak-httppod to ensure that the new certificate is used:Change the number of the
iam-keycloakStatefulSetreplicas to0:kubectl -n kaas scale statefulsets iam-keycloak --replicas=0
Wait until the
READYcolumn has0/0pods:kubectl -n kaas get statefulsets iam-keycloak
Change the number of the
iam-keycloakStatefulSetreplicas back to 3:kubectl -n kaas scale statefulsets iam-keycloak --replicas=3
Wait until the
READYcolumn has at least1/3pods:kubectl -n kaas get statefulsets iam-keycloak
Verify that the IP address in the
status.providerStatus.oidc.issuerUrlfield of theClusterobject has changed:kubectl get cluster kaas-mgmt -o jsonpath='{.status.providerStatus.oidc.issuerUrl}{"\n"}'
If it still contains the old IP address, update it manually:
kubectl edit cluster kaas-mgmt
Under
spec.providerSpec.value.kaas.management.helmReleases, update thevalues.api.keycloak.urlfield inside theiamHelm object definition:spec: providerSpec: value: kaas: management: helmReleases: - name: iam values: api: keycloak: url: https://<newKeycloakServiceIpAddress>
Save and exit to apply changes.
Wait a few minutes until
issuerUrlis changed and OIDC is ready.To verify
issuerUrl:kubectl get cluster kaas-mgmt -o jsonpath='{.status.providerStatus.oidc.issuerUrl}{"\n"}'
To verify OIDC readiness:
kubectl get cluster kaas-mgmt -o jsonpath='{.status.providerStatus.oidc.ready}{"\n"}'
Verify that the Container Cloud and MKE web UIs are accessible with the new Keycloak IP address and certificate.
Configure host names for cluster machines¶
TechPreview Available since 2.24.0
You can enable custom host names for cluster machines so that any machine host
name in a particular management cluster and its managed clusters matches
the related Machine object name.
For example, instead of the default kaas-node-<UID>, a machine host name
will be master-0. The custom naming format is more convenient and easier
to operate with.
Note
After you enable custom host names on an existing management cluster, names of all newly deployed machines in this cluster and its managed clusters will match machine host names. Existing host names will remain the same.
If you are going to clean up a management cluster with this feature enabled after cluster deployment, make sure to manually delete machines with existing non-custom host names before cluster cleanup to prevent cleanup failure. For details, see Remove a management cluster.
You can enable custom host names during management cluster bootstrap during initial cluster configuration. For details, see Deployment Guide. To enable the feature on an existing cluster, see the procedure below.
To enable custom host names on an existing management cluster:
Open the
Clusterobject of the management cluster for editing:kubectl edit cluster <mgmtClusterName>
In the
spec.providerSpec.value.kaas.regionalsection of the required region, find the required providernameunderhelmReleasesand addcustomHostnamesEnabled: trueundervalues.config.For example, for the bare metal provider:
regional: - helmReleases: - name: baremetal-provider values: config: allInOneAllowed: false customHostnamesEnabled: true internalLoadBalancers: false
The configuration applies in several minutes after the
<providerName>-provider-*Pods restart automatically.Verify that
customHostnamesis present in the provider ConfigMap:kubectl -n kaas get configmap provider-config-<providerName> -o=yaml | grep customHostnames
kubectl -n kaas get configmap provider-config-<providerName>-<regionName> -o=yaml | grep customHostnames
Back up MariaDB on a management cluster¶
Container Cloud uses a MariaDB database to store data generated by the Container Cloud components. Mirantis recommends backing up your databases to ensure the integrity of your data. Also, you should create an instant backup before upgrading your database to restore it if required.
After the management cluster deployment, the cluster configuration includes the MariaDB backup functionality for the OpenStack provider.
The Kubernetes cron job responsible for the MariaDB backup is enabled by default to create daily backups. You can modify the default configuration before or after the management cluster deployment.
Warning
For bare metal and vSphere providers, a local volume of only one node of a management cluster is selected when the backup is created for the first time. This volume is used for all subsequent backups.
If the node containing backup data must be redeployed, first move the MySQL backup to another node and update the PVC binding along with the MariaDB backup job to use another node as described in Change the storage node for MariaDB on bare metal and vSphere clusters.
For the OpenStack provider, a backup job is configured to work with
the default csi-sc-cinderplugin storage class. With this class, a PV
is created as a Cinder volume. This way, it is independent from any of the
management cluster nodes.
Configure periodic backups of MariaDB¶
Note
For bare metal and vSphere providers, the MariaDB backup functionality is enabled since Container Cloud 2.27.0 (Cluster release 16.2.0).
After the management cluster deployment, the cluster configuration includes the MariaDB backup functionality. The Kubernetes cron job responsible for the MariaDB backup is enabled by default. For the MariaDB backup workflow, see Mirantis OpenStack for Kubernetes Operations Guide: MariaDB backup workflow.
Warning
For bare metal and vSphere providers, a local volume of only one node of a management cluster is selected when the backup is created for the first time. This volume is used for all subsequent backups.
If the node containing backup data must be redeployed, first move the MySQL backup to another node and update the PVC binding along with the MariaDB backup job to use another node as described in Change the storage node for MariaDB on bare metal and vSphere clusters.
For the OpenStack provider, a backup job is configured to work with
the default csi-sc-cinderplugin storage class. With this class, a PV
is created as a Cinder volume. This way, it is independent from any of the
management cluster nodes.
To manually create a MariaDB database backup, run:
kubectl -n kaas create job --from=cronjob/mariadb-phy-backup mariadb-phy-backup-manual-001
To modify the default backup configuration for MariaDB:
Select from the following options:
If the management cluster is not bootstrapped yet, proceed to the next step.
If the management cluster is already deployed, verify that the
mariadb-phy-backupCronJobobject is present:kubectl -n kaas get cronjob mariadb-phy-backup
Example of a positive system response:
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE mariadb-phy-backup 0 0 * * * False 0 6h3m 10d
If the object is missing, make sure that your management cluster is successfully upgraded to the latest version.
Select from the following options:
If the management cluster is not bootstrapped yet, modify
cluster.yaml.templateusing the steps below.If the management cluster is already deployed, modify the configuration kubectl edit <mgmtClusterName> using the steps below. By default, the management cluster name is
kaas-mgmt.
Enable the MariaDB backup in the
Clusterobject:spec: providerSpec: value: kaas: management: helmReleases: ... - name: iam values: keycloak: mariadb: conf: phy_backup: enabled: true
Modify the configuration as required. By default, the backup is set up as follows:
Runs on a daily basis at 00:00 AM
Creates full backups daily
Keeps 5 latest full backups
Saves backups to the
mariadb-phy-backup-dataPVCThe backup timeout is
21600secondsThe backup type is
full
The
mariadb-phy-backupcron job launches backups of the MariaDB Galera cluster. The job accepts settings through parameters and environment variables.Modify the following backup parameters that you can pass to the cron job and override from the
Clusterobject:MariaDB backup: Configuration parameters¶ Parameter
Default
Description
--backup-type(string)fullBackup type. The list of possible values include:
incrementalIf the newest full backup is older than the value of the
full_backup_cycleparameter, the system performs a full backup. Otherwise, the system performs an incremental backup of the newest full backup.
fullAlways performs only a full backup.
Usage example:
spec: providerSpec: value: kaas: management: helmReleases: - name: iam values: keycloak: mariadb: conf: phy_backup: backup_type: incremental
--backup-timeout(integer)21600Timeout in seconds for the system to wait for the backup operation to succeed.
Usage example:
spec: providerSpec: value: kaas: management: helmReleases: - name: iam values: keycloak: mariadb: conf: phy_backup: backup_timeout: 30000
--allow-unsafe-backup(boolean)falseIf set to
true, enables the MariaDB cluster backup on a not fully operational cluster where:The current number of ready pods is not equal to
MARIADB_REPLICASSome replicas do not have healthy wsrep statuses
Usage example:
spec: providerSpec: value: kaas: management: helmReleases: - name: iam values: keycloak: mariadb: conf: phy_backup: allow_unsafe_backup: true
Modify the following environment variables that you can pass to the cron job and override from the
Clusterobject:MariaDB backup: Environment variables¶ Variable
Default
Description
MARIADB_BACKUPS_TO_KEEP(integer)10Number of full backups to keep.
Usage example:
spec: providerSpec: value: kaas: management: helmReleases: - name: iam values: keycloak: mariadb: conf: phy_backup: backups_to_keep: 3
MARIADB_BACKUP_PVC_NAME(string)mariadb-phy-backup-dataPersistent volume claim used to store backups.
Usage example:
spec: providerSpec: value: kaas: management: helmReleases: - name: iam values: keycloak: mariadb: conf: phy_backup: backup_pvc_name: mariadb-phy-backup-data
MARIADB_FULL_BACKUP_CYCLE(integer)604800Number of seconds that defines a period between 2 full backups. During this period, incremental backups are performed. The parameter is taken into account only if
backup_typeis set toincremental. Otherwise, it is ignored. For example, withfull_backup_cycleset to604800seconds, a full backup is performed weekly and, if cron is set to0 0 * * *, an incremental backup is performed daily.Usage example:
spec: providerSpec: value: kaas: management: helmReleases: - name: iam values: keycloak: mariadb: conf: phy_backup: full_backup_cycle: 70000
MARIADB_BACKUP_REQUIRED_SPACE_RATIO(floating)1.2Multiplier for the database size to predict the space required to create a backup, either full or incremental, and perform a restoration keeping the uncompressed backup files on the same file system as the compressed ones.
To estimate the size of
MARIADB_BACKUP_REQUIRED_SPACE_RATIO, use the following formula: size of (1 uncompressed full backup + all related incremental uncompressed backups + 1 full compressed backup) in KB =< (DB_SIZE*MARIADB_BACKUP_REQUIRED_SPACE_RATIO) in KB.The
DB_SIZEis the disk space allocated in the MySQL data directory, which is/var/lib/mysql, for databases data excludinggalera.cacheandib_logfile*files. This parameter prevents the backup PVC from being full in the middle of the restoration and backup procedures. If the current available space is lower thanDB_SIZE*MARIADB_BACKUP_REQUIRED_SPACE_RATIO, the backup script fails before the system starts the actual backup and the overall status of the backup job is failed.Usage example:
spec: providerSpec: value: kaas: management: helmReleases: - name: iam values: keycloak: mariadb: conf: phy_backup: backup_required_space_ratio: 1.4
Configuration example:
To perform full backups monthly and incremental backups
daily at 02:30 AM and keep the backups for the last six months,
configure the database backup in your Cluster object
as follows:
spec:
providerSpec:
value:
kaas:
management:
helmReleases:
- name: iam
values:
keycloak:
mariadb:
conf:
phy_backup:
enabled: true
backups_to_keep: 6
schedule_time: '30 2 * * *'
full_backup_cycle: 2628000
Verify operability of the MariaDB backup jobs¶
After you configure the MariaDB periodic jobs, verify that backup jobs are operational by creating a helper pod to view the backup volume content.
To verify operability of the MariaDB backup jobs:
Verify pods in the
kaasproject. After the backup jobs have succeeded, the pods remain in theCompletedstate:kubectl -n kaas get pods -l application=mariadb-phy-backup
Example of a positive system response:
NAME READY STATUS RESTARTS AGE mariadb-phy-backup-1599613200-n7jqv 0/1 Completed 0 43h mariadb-phy-backup-1599699600-d79nc 0/1 Completed 0 30h mariadb-phy-backup-1599786000-d5kc7 0/1 Completed 0 6h17m
Note
By default, the system keeps five latest successful and one latest failed pods.
Obtain an image of the MariaDB container:
kubectl -n kaas get pods mariadb-server-0 -o jsonpath='{.spec.containers[0].image}'
Create the
check_pod.yamlfile to create the helper pod required to view the backup volume content.Configuration example:
apiVersion: v1 kind: ServiceAccount metadata: name: check-backup-helper namespace: kaas --- apiVersion: v1 kind: Pod metadata: name: check-backup-helper namespace: kaas labels: application: check-backup-helper spec: containers: - name: helper securityContext: allowPrivilegeEscalation: false runAsUser: 0 readOnlyRootFilesystem: true command: - sleep - infinity # using image from mariadb sts image: <<insert_image_of_mariadb_container_here>> imagePullPolicy: IfNotPresent volumeMounts: - name: pod-tmp mountPath: /tmp - mountPath: /var/backup name: mysql-backup restartPolicy: Never serviceAccount: check-backup-helper serviceAccountName: check-backup-helper volumes: - name: pod-tmp emptyDir: {} - name: mariadb-secrets secret: secretName: mariadb-secrets defaultMode: 0444 - name: mariadb-bin configMap: name: mariadb-bin defaultMode: 0555 - name: mysql-backup persistentVolumeClaim: claimName: mariadb-phy-backup-data
Apply the helper service account and pod resources:
kubectl -n kaas apply -f check_pod.yaml kubectl -n kaas get pods -l application=check-backup-helper
Example of a positive system response:
NAME READY STATUS RESTARTS AGE check-backup-helper 1/1 Running 0 27s
Verify the directories structure within the
/var/backupdirectory of the spawned pod:kubectl -n kaas exec -t check-backup-helper -- tree /var/backup
Example of a system response:
/var/backup |-- base | `-- 2021-09-09_11-35-48 | |-- backup.stream.gz | |-- backup.successful | |-- grastate.dat | |-- xtrabackup_checkpoints | `-- xtrabackup_info |-- incr | `-- 2021-09-09_11-35-48 | |-- 2021-09-10_01-02-36 | | |-- backup.stream.gz | | |-- backup.successful | | |-- grastate.dat | | |-- xtrabackup_checkpoints | | `-- xtrabackup_info | `-- 2021-09-11_01-02-02 | |-- backup.stream.gz | |-- backup.successful | |-- grastate.dat | |-- xtrabackup_checkpoints | `-- xtrabackup_info
The
basedirectory contains full backups. Each directory in theincrfolder contains incremental backups related to a certain full backup in thebasefolder. All incremental backups always have the base backup name as the parent folder.Delete the helper pod:
kubectl delete -f check_pod.yaml
Restore MariaDB databases¶
During the restore procedure, the MariaDB service will be unavailable because the MariaDB StatefulSet scales down to 0 replicas. Therefore, plan the maintenance window according to the database size. The restore speed depends on the following:
Network throughput
Storage performance where backups are kept
Local disks performance of nodes with MariaDB local volumes
To restore MariaDB databases:
Obtain an image of the MariaDB container:
kubectl -n kaas get pods mariadb-server-0 -o jsonpath='{.spec.containers[0].image}'
Create the
check_pod.yamlfile to create the helper pod required to view the backup volume content. For example:--- apiVersion: v1 kind: ServiceAccount metadata: name: check-backup-helper namespace: kaas --- apiVersion: v1 kind: Pod metadata: name: check-backup-helper namespace: kaas labels: application: check-backup-helper spec: containers: - name: helper securityContext: allowPrivilegeEscalation: false runAsUser: 0 readOnlyRootFilesystem: true command: - sleep - infinity image: <<insert_image_of_mariadb_container_here>> imagePullPolicy: IfNotPresent volumeMounts: - name: pod-tmp mountPath: /tmp - mountPath: /var/backup name: mysql-backup restartPolicy: Never serviceAccount: check-backup-helper serviceAccountName: check-backup-helper volumes: - name: pod-tmp emptyDir: {} - name: mariadb-secrets secret: secretName: mariadb-secrets defaultMode: 0444 - name: mariadb-bin configMap: name: mariadb-bin defaultMode: 0555 - name: mysql-backup persistentVolumeClaim: claimName: mariadb-phy-backup-data
Create the helper pod:
kubectl -n kaas apply -f check_pod.yaml
Obtain the name of the backup to restore:
kubectl -n kaas exec -t check-backup-helper -- tree /var/backup
Example of system response:
/var/backup |-- base | `-- 2021-09-09_11-35-48 | |-- backup.stream.gz | |-- backup.successful | |-- grastate.dat | |-- xtrabackup_checkpoints | `-- xtrabackup_info |-- incr | `-- 2021-09-09_11-35-48 | |-- 2021-09-10_01-02-36 | |-- 2021-09-11_01-02-02 | |-- 2021-09-12_01-01-54 | |-- 2021-09-13_01-01-55 | `-- 2021-09-14_01-01-55 `-- lost+found 10 directories, 5 files
If you want to restore the full backup, the name from the example above is
2021-09-09_11-35-48. To restore a specific incremental backup, the name from the example above is2021-09-09_11-35-48/2021-09-12_01-01-54.In the example above, the backups will be restored in the following strict order:
2021-09-09_11-35-48- full backup, path/var/backup/base/2021-09-09_11-35-482021-09-10_01-02-36- incremental backup, path/var/backup/incr/2021-09-09_11-35-48/2021-09-10_01-02-362021-09-11_01-02-02- incremental backup, path/var/backup/incr/2021-09-09_11-35-48/2021-09-11_01-02-022021-09-12_01-01-54- incremental backup, path/var/backup/incr/2021-09-09_11-35-48/2021-09-12_01-01-54
Delete the helper pod to prevent PVC multi-attach issues:
kubectl -n kaas delete -f check_pod.yaml
Verify that no other restore job exists on the cluster:
cd kaas-bootstrap kubectl -n kaas get jobs | grep restore kubectl -n kaas get po | grep check-backup-helper
Edit the
Clusterobject by configuring the MariaDB parameters. For example:spec: providerSpec: kaas: management: helmReleases: - name: iam values: keycloak: mariadb: manifests: job_mariadb_phy_restore: true conf: phy_restore: backup_name: "2021-09-09_11-35-48/2021-09-12_01-01-54" replica_restore_timeout: 7200
Parameter
Type
Default
Description
backup-nameString
-
Name of a folder with backup in
<baseBackup>or<baseBackup>/<incrementalBackup>.replica-restore-timeoutInteger
3600Timeout in seconds for 1 replica data to be restored to the
mysqldata directory. Also, includes time for spawning a rescue runner pod in Kubernetes and extracting data from a backup archive.Wait until the
mariadb-phy-restorejob succeeds:kubectl -n kaas get jobs mariadb-phy-restore -o jsonpath='{.status}'The
mariadb-phy-restorejob is an immutable object. Therefore, remove the job after each execution. To correctly remove the job, clean up all settings from theClusterobject that you have configured during step 7 of this procedure. This will remove all related pods as well.
Note
If you create a new user after creating the MariaDB backup file, such user obviously will not exist in the database after restoring MariaDB. But Keycloak may still contain cache about such user. Therefore, during an attempt of this user to log in, the Container Cloud web UI may start the authentication procedure that fails with the following error: Data loading failed: Failed to log in: Failed to get token. Reason: “User not found”. To clear cache in Keycloak, refer to the official Keycloak documentation.
Change the storage node for MariaDB on bare metal and vSphere clusters¶
The default storage class cannot be used on a bare metal or vSphere management
cluster, so a specially created one is used for this purpose. For storage, this
class uses local volumes, which are managed by local-volume-provisioner.
Each node of a management cluster contains a local volume, and the volume bound with a PVC is selected when the backup gets created for the first time. This volume is used for all subsequent backups. Therefore, to ensure reliable backup storage, consider creating a regular backup copy of this volume in a separate location.
If the node that contains backup data must be redeployed, first move the MySQL backup data to another node and update the PVC binding along with the MariaDB backup job to use another node as described below.
Download and save the following script on the node where kubectl is installed and configured to use the Kubernetes API:
Make the script executable and execute it:
vim get_lv_info.sh chmod +x get_lv_info.sh ./get_lv_info.sh
The script outputs the following information:
Primary local volumeCurrent active local volume, which is bound to the PVC using the
backup_pvc_namefield and which is used to store backup data.Secondary local volumeUnused volumes of two remaining nodes of the management cluster.
Example of system response:
Primary local volume ==================== Volume: local-pv-a1c9425b Volume path: /mnt/local-volumes/iam/kaas-iam-backup/vol00 Data PVC: mysql-data-mariadb-server-1 Backup PVC: mariadb-phy-backup-data Node: kaas-node-788dba0a-f931-45ff-a66d-1b583851c3ba Machine: master-1 Internal IP: 10.100.91.50 Secondary local volume ---------------------- Volume: local-pv-8519d270 Volume path: /mnt/local-volumes/iam/kaas-iam-backup/vol00 Data PVC: mysql-data-mariadb-server-0 Node: kaas-node-2b83025a-d4d1-4ccc-a263-11b07150f302 Machine: master-0 Internal IP: 10.100.91.51 Secondary local volume ---------------------- Volume: local-pv-1bfef721 Volume path: /mnt/local-volumes/iam/kaas-iam-backup/vol00 Data PVC: mysql-data-mariadb-server-2 Node: kaas-node-f4742907-5fb0-41fb-ba6c-3ce467779754 Machine: master-2 Internal IP: 10.100.91.52
Note
The order of nodes that contain
Secondary local volumeis random.Capture details of the node containing the primary local volume for further usage. For example, you can use the
Internal IPvalue to SSH to the required node and copy the backup data located underVolume pathto a separate location.
Capture details of the local volume and node containing backups as described in Identify a node where backup data is stored. Also, capture details of
Secondary local volumethat you select to move backup data to.Using
Internal IPofPrimary local volume, SSH to the corresponding node and create a backup tarball:Note
In the command below, replace
<newVolumePath>with the value of theVolume pathfield of the selectedSecondary local volume.sudo tar -czPvf ~/mariadb-backup.tar.gz -C <newVolumePath>
Using
Internal IPofSecondary local volume, SSH to the corresponding node and copy the created backupmariadb-backup.tar.gzusing a dedicated utility such as scp, rsync, or other.Restore
mariadb-backup.tar.gzunder the selectedVolume path:sudo tar -xzPvf ~/mariadb-backup.tar.gz -C <newVolumePath>
Update the
CronJobobject to associate it with the new backup node:Download and save the following helper script on a node where kubectl is installed and configured to use Kubernetes API:
Make the script executable:
vim fix_cronjob_pvc.sh chmod +x fix_cronjob_pvc.sh
Using the
Data PVCvalue of the selectedSecondary local volume, run the script:./fix_cronjob_pvc.sh <secondaryDataPVCName>
Back up and restore a management cluster¶
This section contains a backup and restore procedure for the OpenStack-based clusters. A management cluster backup consists of backing up MKE and MariaDB.
Note
The backup and restore procedure for other supported cloud providers is on the testing stage and will be published in one of the following Container Cloud releases.
Caution
The procedures below imply backup and restore of a management cluster to the same hardware nodes.
The restore procedure below implies that the MCR swarm is healthy. If the MCR swarm is not operational, first recover it as described in MKE documentation: Swarm disaster recovery.
The restore procedure below implies usage of the same MKE Docker version of the image that was used during backup. Restoring of an MKE cluster to an MKE version later than the one used during backup is not supported.
To back up an OpenStack-based management cluster:
Back up MKE as described in MKE Operations Guide: Back up MKE.
Update the root permissions of the backup archive created in the previous step for
mcc-user:sudo chown mcc-user:mcc-user <backup-archive-name>.tar
Verify that the MKE cluster backup has been created as described in MKE Operations Guide: Back up MKE: Verify an MKE backup.
Back up MariaDB as described in Configure periodic backups of MariaDB.
Verify that the backup has been created as described in Verify operability of the MariaDB backup jobs.
To restore an OpenStack-based management cluster:
If MKE is still installed on the swarm, uninstall MKE as described in MKE documentation: Recover an MKE cluster from an existing backup.
Restore MKE as described in MKE documentation: Restore MKE.
Restore MariaDB as described in Restore MariaDB databases.
Remove a management cluster¶
This section describes how to remove a management cluster.
To remove a management cluster:
Verify that you have successfully removed all managed clusters that run on top of the management cluster to be removed. For details, see the corresponding Delete a managed cluster section depending on your cloud provider in Create and operate managed clusters.
If you enabled custom host names on an existing management cluster as described in Configure host names for cluster machines, and the cluster contains hosts with non-custom names, manually delete such hosts to prevent cleanup failure.
Log in to a local machine where your management cluster
kubeconfigis located and wherekubectlis installed.Note
The management cluster
kubeconfigis created during the last stage of the management cluster bootstrap.Verify that the bootstrap directory is updated.
Select from the following options:
For clusters deployed using Container Cloud 2.11.0 or later:
./container-cloud bootstrap download --management-kubeconfig <pathToMgmtKubeconfig> \ --target-dir <pathToBootstrapDirectory>
For clusters deployed using the Container Cloud release earlier than 2.11.0 or if you deleted the
kaas-bootstrapfolder, download and run the Container Cloud bootstrap script:wget https://binary.mirantis.com/releases/get_container_cloud.sh chmod 0755 get_container_cloud.sh ./get_container_cloud.sh
Run the following script:
bootstrap.sh cleanup
Note
Removing a management cluster using the Container Cloud web UI is not supported.
Warm up the Container Cloud cache¶
TechPreview Available since 2.24.0 and 23.2 for MOSK clusters
This section describes how to speed up deployment and update process of
managed clusters, which usually do not have access to the Internet and
consume artifacts from a management cluster using the mcc-cache service.
By default, after auto-upgrade of a management cluster,
before each managed cluster deployment or update, mcc-cache downloads the
required list of images, thus slowing down the process.
Using the CacheWarmupRequest resource, you can predownload (warm up)
a list of images included in a given set of Cluster releases into the
mcc-cache service only once per release for further usage on all managed
clusters.
After a successful cache warm-up, the object of the CacheWarmupRequest
resource is automatically deleted from the cluster and cache remains for
managed clusters deployment or update until next Container Cloud auto-upgrade
of the management cluster.
Caution
If the disk space for cache runs out, the cache for the oldest object is evicted. To avoid running out of space in the cache, verify and adjust its size before each cache warm-up.
Requirements¶
Cache warm-up requires a lot of disk storage, it may take up to 100% of disk
space. Therefore, make sure to have enough space for storing cached objects
on each node of the management cluster before creating the
CacheWarmupRequest resource. The following example contains minimal
required values for the cache size for the management cluster:
Cluster release |
Minimal value in GiB |
|---|---|
Non-MOSK Cluster release |
20 |
MOSK Cluster release with one OpenStack version |
50 |
MOSK Cluster release with an OpenStack version upgrade
from |
120 |
Increase cache size for ‘mcc-cache’¶
After you calculate the disk size for warming up cache depending on your
cluster settings and minimal cache warm-up requirements, configure the size of
cache in the Cluster object of your cluster.
In the spec:providerSpec:value:kaas:regionalHelmReleases: section of the
management Cluster object, add the following snippet to the
mcc-cache entry with the required size value in GiB:
nginx:
cacheSize: 100
kubectl --kubeconfig <pathToManagementClusterKubeconfig> edit cluster <clusterName>
Configuration example:
spec:
providerSpec:
value:
kaas:
regionalHelmReleases:
- name: mcc-cache
values:
nginx:
cacheSize: 100
Note
The cacheSize parameter is set in GiB.
Warm up cache using CLI¶
After you increase the size of cache on the cluster as described in
Increase cache size for ‘mcc-cache’, create the CacheWarmupRequest object in the
Kubernetes API.
Caution
For any cluster type, create CacheWarmupRequest objects only
on the management cluster.
To warm up cache using CLI:
Identify the latest available Cluster releases to use for deployment of new clusters and update of existing clusters:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> get kaasreleases -l=kaas.mirantis.com/active="true" -o=json | jq -r '.items[].spec.supportedClusterReleases[] | select(.availableUpgrades | length == 0) | .name'
Example of system response:
mke-14-0-1-3-6-5 mosk-15-0-1
On the management cluster, create a
.yamlfile for theCacheWarmupRequestobject using the following example:apiVersion: kaas.mirantis.com/v1alpha1 kind: CacheWarmupRequest metadata: name: example-cluster-name namespace: default spec: clusterReleases: - mke-14-0-1 - mosk-15-0-1 openstackReleases: - yoga fetchRequestTimeout: 30m clientsPerEndpoint: 2 openstackOnly: false
In this example:
The
CacheWarmupRequestobject is created for a management cluster namedexample-cluster-name.The
CacheWarmupRequestobject is created in the only alloweddefaultContainer Cloud project.Two Cluster releases
mosk-15-0-1andmke-14-0-1will be predownloaded.For
mosk-15-0-1, only images related to the OpenStack versionYogawill be predownloaded.Maximum time-out for a single request to download a single artifact is 30 minutes.
Two parallel workers will fetch artifacts per each
mcc-cacheservice endpoint.All artifacts will be fetched, not only those related to OpenStack.
For details about the
CacheWarmupRequestobject, see CacheWarmupRequest resource.Apply the object to the cluster:
kubectl --kubeconfig <pathToManagementKubeconfig> apply -f <pathToFile>
Once done, during deployment and update of managed clusters, Container Cloud uses cached artifacts from the
mcc-cacheservice to facilitate and speed up the procedure.
When a new Container Cloud release becomes available and the management cluster auto-upgrades to a new Container Cloud release, repeat the above steps to predownload a new set of artifacts for managed clusters.
Note
For day-2 operations on a baremetal-based management cluster, refer to Day-2 operations.
Increase memory limits for cluster components¶
When any Container Cloud component reaches the limit of memory resources usage, the affected pod may be killed by OOM killer to prevent memory leaks and further destabilization of resource distribution.
A periodic recreation of a pod killed by OOM killer is normal once a
day or week. But if the alerts frequency increases or pods cannot start and
move to the CrashLoopBack state, adjust the default memory limits to fit
your cluster needs and prevent critical workloads interruption.
When any Container Cloud component reaches the limit of CPU resources usage,
StackLight raises the CPUThrottlingHigh alerts. CPU limits for Container
Cloud components (except the StackLight ones) were removed in the Cluster
release 14.0.0. For earlier Cluster releases, use the resources:limits:cpu
parameter located in the same section as the resources:limits:memory
parameter of the corresponding component.
Note
For StackLight resources limits, refer to Resource limits.
To increase memory limits on a Container Cloud cluster:
In the spec:providerSpec:value: section of cluster.yaml,
add the resources:limits parameters with the required values for necessary
Container Cloud components:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <projectName> edit cluster <clusterName>
The limits key location in the Cluster object can differ depending on
component. Different cluster types have different set of components that
you can adjust limits for.
The following sections describe components that relate to a specific cluster
type with corresponding limits key location provided in configuration
examples. Limit values in the examples correspond to default values used since
Container Cloud 2.24.0 (Cluster releases 15.0.1, 14.0.1, and 14.0.0).
Note
For StackLight resources limits, refer to Resource limits.
Limits for common components of any cluster type¶
No limits are set for the following components:
storage-discovery
The memory limits for the following components can be increased on the management and managed clusters:
client-certificate-controllermetrics-servermetallb
Note
For
helm-controller, limits configuration is not supported.For
metallbapplicable to bare metal and vSphere providers, the limits key incluster.yamldiffers from other common components.
Component name |
Configuration example |
|---|---|
|
spec:
providerSpec:
value:
helmReleases:
- name: client-certificate-controller
values:
resources:
limits:
memory: 500Mi
|
|
spec:
providerSpec:
value:
helmReleases:
- name: metallb
values:
controller:
resources:
limits:
memory: 200Mi
# no CPU limit and 200Mi of memory limit since Container Cloud 2.24.0
# 200m CPU and 200Mi of memory limit since Container Cloud 2.23.0
speaker:
resources:
limits:
memory: 500Mi
# no CPU limit and 500Mi of memory limit since Container Cloud 2.24.0
# 500m CPU and 500Mi of memory limit since Container Cloud 2.23.0
|
Limits for management cluster components¶
No limits are set for the following components:
baremetal-operatorbaremetal-providercert-manager
The memory limits for the following components can be increased on a
management cluster in the
spec:providerSpec:value:kaas:management:helmReleases: section:
|
- 0(1,2)
The
proxy-controllerandrhellicense-controllerare replaced withsecret-controllerin Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0).
The memory limits for the following components can be increased on a management cluster in the following sections:
spec:providerSpec:value:kaas:regional:[(provider:<provider-name>): helmReleases]:spec:providerSpec:value:kaas:regionalHelmReleases:
|
|
- 1
The
byo-credentials-controlleris replaced withsecret-controllerin Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0).- 2
The memory limits for
vsphere-vm-template-controllercan be increased for the controller itself and for the Packer job.
Component name |
Configuration example |
|---|---|
|
spec:
providerSpec:
value:
kaas:
management:
helmReleases:
- name: release-controller
values:
resources:
limits:
memory: 200Mi
|
|
spec:
providerSpec:
value:
kaas:
regional:
- provider: openstack
helmReleases:
- name: openstack-provider
values:
resources:
openstackMachineController:
limits:
memory: 1Gi
|
|
spec:
providerSpec:
value:
kaas:
regional:
- provider: openstack
helmReleases:
- name: os-credentials-controller
values:
resources:
limits:
memory: 1Gi
|
|
spec:
providerSpec:
value:
kaas:
regional:
- provider: vsphere # <provider-name>
helmReleases:
- name: vsphere-provider # <provider-name>
values:
vsphereController: # <provider-name>Controller:
resources:
limits:
memory: 1Gi
|
|
spec:
providerSpec:
value:
kaas:
regional:
- provider: vsphere # <provider-name>
helmReleases:
- name: vsphere-credentials-controller
# <provider-credentials-controller-name>
values:
resources:
limits:
memory: 1Gi
|
|
spec:
providerSpec:
value:
kaas:
regional:
- provider: vsphere
helmReleases:
- name: vsphere-vm-template-controller
values:
resources:
limits:
memory: 150Mi
packer:
packer_job:
resources:
limits:
memory: 500Mi
|
|
spec:
providerSpec:
value:
kaas:
regionalHelmReleases:
- name: lcm-controller
values:
resources:
limits:
memory: 1Gi
|
|
spec:
providerSpec:
value:
kaas:
regionalHelmReleases:
- name: mcc-cache
values:
nginx:
resources:
limits:
memory: 500Mi
registry:
resources:
limits:
memory: 500Mi
kproxy:
resources:
limits:
memory: 300Mi
|
|
spec:
providerSpec:
value:
kaas:
regional:
- provider: vsphere
helmReleases:
- name: squid-proxy
values:
resources:
limits:
memory: 1Gi
|
Set the MTU size for Calico¶
TechPreview Available since 2.24.0 and 2.24.2 for MOSK 23.2
You can set the maximum transmission unit (MTU) size for Calico in the
Cluster object using the calico.mtu parameter. By default, the MTU
size for Calico is 1450 bytes. You can change it for any supported Container
Cloud provider regardless of the host operating system.
For details on how to calculate the MTU size, see Calico documentation: Configure MTU to maximize network performance.
The following configuration example of the Cluster object covers a use
case where the interface MTU size of the workload network, which is the
smallest value across cluster nodes, is set to 9000 and the use of
WireGuard is expected:
spec:
...
providerSpec:
value:
...
calico:
mtu: 8940
Caution
If you do not expect to use WireGuard encryption, ensure that the MTU size for Calico is at least 50 bytes smaller than the interface MTU size of the workload network. IPv4 VXLAN uses a 50-byte header.
Caution
Mirantis does not recommend changing this parameter on a running cluster. It leads to sequential draining of nodes and re-installation of packets, as during cluster upgrade.
Increase storage quota for etcd¶
Available since Cluster releases 15.0.3 and 14.0.3
You may need to increase the default etcd storage quota that is 2 GB if etcd runs out of space and there is no other way to clean up the storage on your management or managed cluster.
To increase storage quota for etcd:
In the
spec:providerSpec:value:section ofcluster.yaml, edit theetcd:storageQuotavalue:kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <projectName> edit cluster <clusterName>
Configuration example:
apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster metadata: name: mycluster labels: kaas.mirantis.com/provider: openstack kaas.mirantis.com/region: region-one spec: providerSpec: value: apiVersion: openstackproviderconfig.k8s.io/v1alpha1 kind: OpenstackClusterProviderSpec etcd: storageQuota: 4GB
Caution
You cannot decrease the
storageQuotaonce set.Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.Applies only to the following Cluster releases:
15.0.3 or 14.0.3
15.0.4 or 14.0.4 if you scheduled a delayed management cluster upgrade
Before upgrading your management cluster to 2.25.0, configure
LCMMachineresources of the cluster controller nodes as described in Configure managed clusters with the etcd storage quota set.
Configure Kubernetes auditing and profiling¶
Available since 2.24.3 (Cluster releases 15.0.2 and 14.0.2)
This section instructs you on how to enable and configure Kubernetes auditing
and profiling options for MKE using the Cluster object of your
Container Cloud managed or management cluster. These options enable auditing
and profiling of MKE performance with specialized debugging endpoints.
Note
You can also enable audit_log_configuration using the MKE API
with no Container Cloud overrides.
However, if you enable the option using the Cluster object, use the same
object to disable the option. Otherwise, if you disable the option using the
MKE API, it will be overridden by Container Cloud and enabled again.
References:
For Container Cloud overrides, see Reference Architecture: MKE options managed by Container Cloud
For configuration using the MKE API, see MKE documentation: Enable MKE audit logging
To enable Kubernetes auditing and profiling for MKE:
Open the
Clusterobject of your Container Cloud cluster for editing.In
spec:providerSpec:value:section:Add or configure the
auditconfiguration. For example:spec: ... providerSpec: value: ... audit: kubernetes: level: request includeInSupportDump: true apiServer: enabled: true maxAge: <uint> maxBackup: <uint> maxSize: <uint>
You can configure the following parameters that are also defined in the MKE configuration file:
Note
The names of the corresponding MKE options are marked with
[]in the below definitions.levelDefines the value of
[audit_log_configuration]level. Valid values arerequestandmetadata.Note
For management clusters, the
metadatavalue is set by default since the Cluster release 16.1.0.
includeInSupportDumpDefines the value of
[audit_log_configuration]support_dump_include_audit_logs. Boolean.
apiServer:enabledDefines the value of
[cluster_config]kube_api_server_auditing. Boolean. If set totruebut with nolevelset, the[audit_log_configuration]levelMKE option is set tometadata.Note
For management clusters, this option is enabled by default since the Cluster release 16.1.0.
maxAgeAvailable since Cluster releases 17.2.0 and 16.2.0 (Container Cloud 2.27.0). Defines the value of
kube_api_server_audit_log_maxage. Integer. If not set, defaults to30.
maxBackupAvailable since Cluster releases 17.2.0 and 16.2.0 (Container Cloud 2.27.0). Defines the value of
kube_api_server_audit_log_maxbackup. Integer. If not set, defaults to10.
maxSizeAvailable since Cluster releases 17.2.0 and 16.2.0 (Container Cloud 2.27.0). Defines the value of
kube_api_server_audit_log_maxsize. Integer. If not set, defaults to10.
Enable profiling:
spec: ... providerSpec: value: ... profiling: enabled: true
Enabling profiling automatically enables the following MKE configuration options:
[cluster_config]kube_api_server_profiling_enabled [cluster_config]kube_controller_manager_profiling_enabled [cluster_config]kube_scheduler_profiling_enabled
Since Cluster releases 17.1.4 and 16.1.4 (Container Cloud 2.26.4), manually enable audit log rotation in the MKE configuration file:
Note
Since Cluster releases 17.2.0 and 16.2.0 (Container Cloud 2.27.0), the below parameters are automatically enabled with default values along with the auditing feature. Therefore, skip this step.
[cluster_config] kube_api_server_audit_log_maxage=30 kube_api_server_audit_log_maxbackup=10 kube_api_server_audit_log_maxsize=10
For the configuration procedure, see MKE documentation: Configure an existing MKE cluster.
While using this procedure, replace the command to upload the newly edited MKE configuration file with the following one:
curl --silent --insecure -X PUT -H "X-UCP-Allow-Restricted-API: i-solemnly-swear-i-am-up-to-no-good" -H "accept: application/toml" -H "Authorization: Bearer $AUTHTOKEN" --upload-file 'mke-config.toml' https://$MKE_HOST/api/ucp/config-toml
The value for the
MKE_HOSTvariable has the<loadBalancerHost>:6443format, whereloadBalancerHostis the corresponding field in the cluster status.The value for
MKE_PASSWORDis taken from theucp-admin-password-<clusterName>secret in the cluster namespace of the management cluster.The value for
MKE_USERNAMEis alwaysadmin.
See also
Configure TLS certificates for cluster applications¶
Technology Preview
The Container Cloud web UI and StackLight endpoints are available through Transport Layer Security (TLS) with self-signed certificates generated by the Container Cloud provider.
Caution
The Container Cloud endpoints are available only through HTTPS.
Application name |
Cluster Type |
Comment |
|---|---|---|
Container Cloud web UI |
Management |
|
|
Management and managed |
Available since Container Cloud 2.22.0. |
Keycloak |
Management |
|
|
Management |
|
MKE |
Management and managed |
Available for clusters deployed or updated by Container Cloud using the latest Cluster release in its series. For management clusters, available since Container Cloud 2.24.0. Note For attached MKE clusters that were not originally deployed by Container Cloud, the feature is not tested on the system integration level. Therefore, Mirantis does not recommend using the feature on production deployments. Caution For MKE clusters that are part of MOSK infrastructure, the feature is not supported yet. |
Caution
The organization administrator must ensure that the application host name is resolvable within and outside the cluster.
Custom TLS certificates for Keycloak are supported for new and existing clusters originally deployed using Container Cloud 2.9.0 or later.
Workflow of custom MKE certificates configuration¶
Available since 2.24.0 Applies to management clusters only
When you add custom MKE certificates on a management cluster, the following workflow applies:
LCM agents are notified to connect to the management cluster using a different certificate.
After all agents confirm that they are ready to support both current and custom authentication, new MKE certificates apply.
LCM agents switch to the new configuration as soon as it gets valid.
The next cluster reconciliation reconfigures
helm-controllerfor each managed cluster created within the configured management cluster.If MKE certificates apply to the management cluster, the Container Cloud web UI reconfigures.
Caution
If MKE certificates apply to the management cluster, the Container Cloud web UI requires up to 10 minutes to update the configuration for communication with the management cluster. During this time, requests to the management cluster fail with the following example error:
Data loading failed
Failed to get projects list. Server response code: 502
This error is expected and disappears once new certificates apply.
Warning
During certificates application, LCM agents from every node must confirm that they have a new configuration prepared. If managed clusters contain a big number of nodes and some are stuck or orphaned, then the whole process gets stuck. Therefore, before applying new certificates, make sure that all nodes are ready.
Warning
If you apply MKE certificates to the management cluster with proxy enabled, all nodes and pods of this cluster and its managed clusters are triggered for reconfiguration and restart, which may cause the API and workload outage.
Prepare TLS certificates¶
Obtain your DNS server name. For example,
container-cloud-auth.example.com.Buy or generate a certificate from a certification authority (CA) that contains the following items:
A full CA bundle including the root and all intermediate CA certificates.
Your server certificate issued for the
container-cloud-auth.example.comDNS name.Your secret key that was used to sign the certificate signing request. For example,
cert.key.
Select the root CA certificate from your CA bundle and add it to
root_ca.crt.Combine all certificates including the root CA, intermediate CA from the CA bundle, and your server certificate into one file. For example,
full_chain_cert.crt.
Configure TLS certificates using the Container Cloud web UI¶
Available since 2.24.0
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the More action icon in the last column of the required cluster and select Configure cluster.
In the Security > TLS Certificates section, click Add certificate.
In the wizard that opens, fill out and save the form:
Parameter
Description
Server name
Host name of the application.
Applications
Drop-down list of available applications for TLS certificates configuration.
Server certificate
Certificate to authenticate the identity of the server to a client. You can also add a valid certificate bundle. The server certificate must be on the top of the chain.
Private key
Private key for the server that must correspond to the public key used in the server certificate.
CA Certificate
CA certificate that issued the server certificate. Required when configuring Keycloak,
mcc-cache, or MKE. Use the top-most intermediate certificate if the CA certificate is unavailable.The Security section displays the expiration date and the readiness status for every application with user-defined certificates.
Optional. Edit the certificate using the Edit action icon located to the right of the application status and edit the form filled out in the previous step.
Note
To revoke a certificate, use the Delete action icon located to the right of the application status.
Configure TLS certificates using the Container Cloud API¶
For clusters deployed using the Container Cloud release earlier than 2.9.0, download the latest version of the bootstrap script on the management cluster:
wget https://binary.mirantis.com/releases/get_container_cloud.sh chmod 0755 get_container_cloud.sh ./get_container_cloud.sh
Change the directory to
kaas-boostrap.If you deleted this directory, restore it using the step 1 of the Collect cluster logs procedure.
Select from the following options:
Set a TLS certificate for the Container Cloud web UI:
./container-cloud set certificate \ --cert-file <fullPathToCertForUI> \ --key-file <pathToPrivateKeyForUI> \ --for ui \ --hostname <applicationHostName> \ --kubeconfig <mgmtClusterKubeconfig>
Since Container Cloud 2.22.0, set a TLS certificate for
iam-proxy:./container-cloud set certificate \ --cert-file <fullPathToCertForIAMProxyEndpoint> \ --key-file <pathToPrivateKeyForIAMProxyEndpoint> \ --for <IAMProxyEndpoint> --hostname <IAMProxyEndpointHostName> \ --kubeconfig <mgmtClusterKubeconfig> \ --cluster-name <targetClusterName> \ --cluster-namespace <targetClusterNamespace>
Possible values for
IAMProxyEndpointare as follows:iam-proxy-alertaiam-proxy-alertmanageriam-proxy-grafanaiam-proxy-kibanaiam-proxy-prometheus
Set a TLS certificate for Keycloak:
./container-cloud set certificate \ --cacert-file <fullRootpathToCACertForKeycloak> \ --cert-file <fullPathToCertForKeycloak> \ --key-file <pathToPrivateKeyForKeycloak> \ --for keycloak --hostname <applicationHostName> \ --kubeconfig <mgmtClusterKubeconfig>
Set a TLS certificate for
mcc-cache:./container-cloud set certificate \ --cacert-file <fullRootpathToCACertForCache> \ --cert-file <fullPathToCertForCache> \ --key-file <pathToPrivateKeyForCache> \ --for cache --hostname <applicationHostName> \ --kubeconfig <mgmtClusterKubeconfig> \ --cluster-name <targetClusterName> \ --cluster-namespace <targetClusterProjectName>
Caution
All managed clusters must be updated to the latest available Cluster release.
The organization administrator must ensure that the
mcc-cachehost name is resolvable for all managed clusters.
Set a TLS certificate for MKE:
./container-cloud set certificate \ --cacert-file <fullRootpathToCACertForMKE> \ --cert-file <fullPathToCertForMKE> \ --key-file <pathToPrivateKeyForMKE> \ --for mke --hostname <applicationHostName> \ --kubeconfig <mgmtClusterKubeconfig> \ --cluster-name <targetClusterName> \ --cluster-namespace <targetClusterNamespace>
Caution
For MKE clusters that are part of MOSK infrastructure, the feature is not supported yet.
In the commands above, replace the parameters enclosed in angle brackets with the corresponding values of your cluster.
Flag
Description
--cacert-fileMust contain only one PEM-encoded root CA certificate in the certificate chain of trust.
--cert-fileMust contain all certificates in the server certificate chain of trust including the PEM-encoded server certificate.
--key-filePrivate key used to generate the provided certificate.
--for<applicationName>or<IAMProxyEndpoint>Configures a certificate for a supported application. The list of possible values for application names includes:
cache,keycloak,mke,ui.--hostnameDNS server host name.
--kubeconfigManagement cluster
kubeconfigthat is by default located in thekaas-bootstrapdirectory.--cluster-nameTarget cluster name.
--cluster-namespaceTarget cluster project name in Container Cloud.
Example command:
./container-cloud set certificate \ --cacert-file root_ca.crt \ --cert-file full_chain_cert.crt \ --key-file cert.key \ --for keycloak \ --hostname container-cloud-auth.example.com \ --kubeconfig kubeconfig
The self-signed certificates generated and managed by the Container Cloud
provider are stored in *-tls-certs secrets in the kaas and
stacklight namespaces.
Renew expired TLS certificates¶
Container Cloud provides automatic renewal of certificates for internal Container Cloud services and for MKE on managed clusters deployed by Container Cloud. Custom certificates require manual renewal.
If you have permissions to view the default project in the Container Cloud
web UI, you may see the Certificate Is Expiring Soon warning for
custom certificates. The warning appears on top of the Container Cloud web UI.
It displays the certificate with the least number of days before expiration.
Click See Details and get more information about other expiring
certificates. You can also find the details about the expiring certificates in
the Status column’s Certificate Issues tooltip on the
Clusters page.
The Certificate Issues status may include the following messages:
- Some certificates require manual renewal
A custom certificate is expiring in less than seven days. Renew the certificate manually using the same container-cloud binary as for the certificate configuration. For details, see Configure TLS certificates using the Container Cloud API.
- Some certificates were not renewed automatically
An automatic certificate renewal issue. Unexpected error, contact Mirantis support.
Define a custom CA certificate for a private Docker registry¶
This section instructs you on how to define a custom CA certificate for Docker registry connections on your management or managed cluster using the Container Cloud web UI or CLI.
Caution
A Docker registry that is being used by a cluster cannot be deleted.
Define a custom CA certificate for a Docker registry using CLI¶
Create a
ContainerRegistryresource(s) with the required registry domain and CA certificate. For details, see API Reference: ContainerRegistry resource.In the
providerSpecsection of theClusterobject, set thecontainerRegistriesfield with the names list of createdContainerRegistryresource objects:kubectl patch cluster -n <clusterProjectName> <clusterName> --type merge -p '{"spec":{"providerSpec":{"value":{"containerRegistries":["<containerRegistryName>"]}}}}'
Define a custom CA certificate for a Docker registry using web UI¶
Available since 2.21.0 and 2.21.1 for MOSK 22.5
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.In the Container Registries tab, click Add Container Registry.
In the Add new Container Registry window, define the following parameters:
- Container Registry Name
Name of the Docker registry to select during cluster creation or post-deployment configuration.
- Domain
Host name and optional port of the registry. For example,
demohost:5000.
- CA Certificate
SSL CA certificate of the registry to upload or insert in plain text.
Click Create.
You can add the created Docker registry configuration to a new or existing managed cluster as well as to an existing management cluster:
For a new managed cluster, in the Create new cluster wizard, select the required registry name from the drop-down menu of the Container Registry option. For details on a new cluster creation, see Create and operate managed clusters.
For an existing cluster of any type, in the More menu of the cluster, select the required registry name from the drop-down menu of the Configure cluster > General Settings > Container Registry option. For details on an existing managed cluster configuration, see Change a cluster configuration.
Enable cluster and machine maintenance mode¶
Before performing node maintenance operations that are not managed by Container Cloud, such as operating system configuration or node reboot, enable maintenance mode on the cluster and required machines using the Container Cloud web UI or CLI to prepare workloads for maintenance.
Enable maintenance mode on a cluster and machine using web UI¶
You can use the instructions below for any type of Container Cloud clusters. To enable maintenance mode using the Container Cloud CLI, refer to Enable maintenance mode on a cluster and machine using CLI.
Caution
To enable maintenance mode on a machine, first enable maintenance mode on the related cluster.
To disable maintenance mode on a cluster, first disable maintenance mode on all machines of the cluster.
Warning
During cluster and machine maintenance:
Cluster upgrades and configuration changes (except of the SSH keys setting) are unavailable. Make sure you disable maintenance mode on the cluster after maintenance is complete.
Data load balancing is disabled while Ceph is in maintenance mode.
Workloads are not affected.
Enable maintenance mode on a cluster and machine¶
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Enable maintenance mode on the cluster:
In the Clusters tab, click the More action icon in the last column of the cluster you want to put into maintenance mode and select Enter maintenance. Confirm your selection.
Wait until the Status of the cluster switches to Maintenance.
Now, you can switch cluster machines to maintenance mode.
In the Clusters tab, click the required cluster name to open the list of machines running on it.
In the Maintenance column of the machine you want to put into maintenance mode, enable the toggle switch.
Wait until the machine Status switches to Maintenance.
Once done, the node of the selected machine is cordoned, drained, and prepared for maintenance operations.
Important
Proceed with the node maintenance only after the machine Status switches to Maintenance.
Disable maintenance mode on a cluster and machine¶
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.In the Clusters tab, click the required cluster name to open its machines list.
In the Maintenance column of the machine you want to disable maintenance mode, disable the toggle switch.
Wait until the machine Status does not display Maintenance, Pending maintenance, or the progress indicator.
Repeat the above steps for all machines that are in maintenance mode.
Disable maintenance mode on the related cluster:
In the Clusters tab, click the More action icon in the last column of the cluster where you want to disable maintenance mode and select Exit maintenance.
Wait until the cluster Status does not display Maintenance, Pending maintenance, or the progress indicator.
Enable maintenance mode on a cluster and machine using CLI¶
You can use the instructions below for any type of Container Cloud clusters. To enable maintenance mode using the Container Cloud web UI, refer to Enable maintenance mode on a cluster and machine using web UI.
Caution
To enable maintenance mode on a machine, first enable maintenance mode on the related cluster.
To disable maintenance mode on a cluster, first disable maintenance mode on all machines of the cluster.
Warning
During cluster and machine maintenance:
Cluster upgrades and configuration changes (except of the SSH keys setting) are unavailable. Make sure you disable maintenance mode on the cluster after maintenance is complete.
Data load balancing is disabled while Ceph is in maintenance mode.
Workloads are not affected.
Enable maintenance mode on a cluster and machine¶
Log in to the host where your management cluster
kubeconfigis located and where kubectl is installed.Enable maintenance mode on the cluster:
In the
valuesection ofproviderSpecof theClusterobject, setmaintenancetotrue:kubectl patch clusters.cluster.k8s.io -n <projectName> <clusterName> --type=merge -p '{"spec":{"providerSpec":{"value":{"maintenance":true}}}}'
Replace the parameters enclosed in angle brackets with the corresponding values.
Wait until the
maintenancestatus istrue:kubectl get clusters.cluster.k8s.io -n <projectName> <clusterName> -o jsonpath='{.status.providerStatus.maintenance}'
Enable maintenance mode on the required machine:
In the
valuesection ofproviderSpecof theMachineobject, setmaintenancetotrue:kubectl patch machines.cluster.k8s.io -n <projectName> <machineName> --type=merge -p '{"spec":{"providerSpec":{"value":{"maintenance":true}}}}'
Wait until the
maintenancestatus istrue:kubectl get machines.cluster.k8s.io -n <projectName> <machineName> -o jsonpath='{.status.providerStatus.maintenance}'
Once done, the node of the selected machine is cordoned, drained, and prepared for maintenance operations.
Disable maintenance mode on a cluster and machine¶
Log in to the host where your management cluster
kubeconfigis located and where kubectl is installed.Disable maintenance mode on the machine:
In the
valuesection ofproviderSpecof theClusterobject, setmaintenancetofalse:kubectl patch machines.cluster.k8s.io -n <projectName> <machineName> --type=merge -p '{"spec":{"providerSpec":{"value":{"maintenance":false}}}}'
Wait until the machine maintenance mode disables:
kubectl get machines.cluster.k8s.io -n <projectName> <machineName> -o jsonpath='{.status.providerStatus.maintenance}'
Verify that the system output is
falseor empty.
Repeat the above steps for all machines that are in maintenance mode.
Disable maintenance mode on the cluster:
In the
valuesection ofproviderSpecof theClusterobject, setmaintenancetofalse:kubectl patch clusters.cluster.k8s.io -n <projectName> <clusterName> --type=merge -p '{"spec":{"providerSpec":{"value":{"maintenance":false}}}}'
Wait until the cluster maintenance mode disables:
kubectl get clusters.cluster.k8s.io -n <projectName> <clusterName> -o jsonpath='{.status.providerStatus.maintenance}'
Verify that the system output is
falseor empty.
Perform a graceful reboot of a cluster¶
Available since 2.23.0
You can perform a graceful reboot on a management or managed cluster. Use the below procedure to cordon, drain, and reboot the required cluster machines using a rolling reboot without workloads interruption. The procedure is also useful for a bulk reboot of machines, for example, on large clusters.
The reboot occurs in the order of cluster upgrade policy that you can change for managed clusters as described in Change the upgrade order of a machine or machine pool.
Caution
The cluster and machines must have the Ready status to
perform a graceful reboot.
Perform a rolling reboot of a cluster using web UI¶
Available since 2.24.0 and 2.24.2 for MOSK 23.2
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
On the Clusters page, verify that the status of the required cluster is Ready. Otherwise, the Reboot machines option is disabled.
Click the More action icon in the last column of the required cluster and select Reboot machines. Confirm the selection.
Note
While a graceful reboot is in progress, the Reboot machines option is disabled.
To monitor the cluster readiness, hover over the status icon of a specific cluster in the Status column of the Clusters page.
Once the orange blinking status icon becomes green and Ready, the cluster deployment or update is complete.
You can monitor live deployment status of the following cluster components:
Component
Description
Bastion
For the OpenStack-based management clusters, the Bastion node IP address status that confirms the Bastion node creation
Helm
Installation or upgrade status of all Helm releases
Kubelet
Readiness of the node in a Kubernetes cluster, as reported by kubelet
Kubernetes
Readiness of all requested Kubernetes objects
Nodes
Equality of the requested nodes number in the cluster to the number of nodes having the
ReadyLCM statusOIDC
Readiness of the cluster OIDC configuration
StackLight
Health of all StackLight-related objects in a Kubernetes cluster
Swarm
Readiness of all nodes in a Docker Swarm cluster
LoadBalancer
Readiness of the Kubernetes API load balancer
ProviderInstance
Readiness of all machines in the underlying infrastructure (virtual or bare metal, depending on the provider type)
Graceful Reboot
Readiness of a cluster during a scheduled graceful reboot, available since Cluster releases 15.0.1 and 14.0.0.
Infrastructure Status
Available since Container Cloud 2.25.0 for bare metal and OpenStack providers. Readiness of the following cluster components:
Bare metal: the
MetalLBConfigobject along with MetalLB and DHCP subnets.OpenStack: cluster network, routers, load balancers, and Bastion along with their ports and floating IPs.
LCM Operation
Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Health of all LCM operations on the cluster and its machines.
LCM Agent
Available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Health of all LCM agents on cluster machines and the status of LCM agents update to the version from the current Cluster release.
For the history of a cluster deployment or update, refer to Inspect the history of a cluster and machine deployment or update.
Caution
Machine configuration changes are forbidden during graceful reboot. Therefore, either wait until reboot is completed or cancel it using CLI, as described in the following section.
Perform a rolling reboot of a cluster using CLI¶
Available since 2.23.0
Create a
GracefulRebootRequestresource with a name that matches the name of the required cluster. For the resource fields description, see GracefulRebootRequest resource.In
spec:machines, add the machine list or leave it empty to reboot all cluster machines.Wait until all specified machines are rebooted. You can monitor the reboot status of the cluster and machines using the
Conditions:GracefulRebootfields of the correspondingClusterandMachineobjects.The
GracefulRebootRequestobject is automatically deleted once the reboot on all target machines completes.To monitor the live machine status:
kubectl get machines <machineName> -o wide
Example of system response:
NAME READY LCMPHASE NODENAME UPGRADEINDEX REBOOTREQUIRED WARNINGS demo-0 true Ready kaas-node-c6aa8ad3 1 true
Caution
Machine configuration changes are forbidden during graceful reboot.
In emergency cases, for example, to migrate StackLight or Ceph services
from a disabled machine that fails during graceful reboot and blocks the
process, cancel the reboot by deleting the GracefulRebootRequest object:
kubectl -n <projectName> delete gracefulrebootrequest <gracefulRebootRequestName>
Once you migrate StackLight or Ceph services to another machine and disable it,
re-create the GracefulRebootRequest object for the remaining machines
that require reboot.
Note
To reboot a single node, for example, for maintenance purposes, refer to Enable cluster and machine maintenance mode.
See also
Delete a cluster machine¶
This section instructs you on how to scale down an existing management or managed cluster through the Mirantis Container Cloud web UI or CLI.
Precautions for a cluster machine deletion¶
Before deleting a cluster machine, carefully read the following essential information for a successful machine deletion:
We recommend deleting cluster machines using the Container Cloud web UI or API instead of using the cloud provider tools directly. Otherwise, the cluster deletion or detachment may hang and additional manual steps will be required to clean up machine resources.
An operational managed cluster must contain a minimum of 3 Kubernetes manager machines to meet the etcd quorum and 2 Kubernetes worker machines.
The deployment of the cluster does not start until the minimum number of machines is created.
A machine with the manager role is automatically deleted during the cluster deletion. Manual deletion of manager machines is allowed only for the purpose of node replacement or recovery.
Support status of manager machine deletion
Since the Cluster releases 17.0.0, 16.0.0, and 14.1.0, the feature is generally available.
Before the Cluster releases 16.0.0 and 14.1.0, the feature is available within the Technology Preview features scope for non-MOSK-based clusters.
Before the Cluster release 17.0.0 the feature is not supported for MOSK.
Consider the following precautions before deleting manager machines:
Create a new manager machine to replace the deleted one as soon as possible. This is necessary since after machine removal, the cluster has limited capabilities to tolerate faults. Deletion of manager machines is intended only for replacement or recovery of failed nodes.
You can delete a manager machine only if your cluster has at least two manager machines in the
Readystate.Do not delete more than one manager machine at once to prevent cluster failure and data loss.
For MOSK-based clusters, after deletion of a manager machine, proceed with additional manual steps described in Mirantis OpenStack for Kubernetes Operations Guide: Replace a failed controller node.
Before replacing a failed manager machine, make sure that all
Deploymentswith replicas configured to1are ready.For the bare metal provider, ensure that the machine to delete is not a Ceph Monitor. Otherwise, migrate the Ceph Monitor to keep the odd number quorum of Ceph Monitors after the machine deletion. For details, see Migrate a Ceph Monitor before machine replacement.
On managed clusters, deletion of a machine assigned to a machine pool without decreasing replicas count of a pool automatically recreates the machine in the pool. Therefore, to delete a machine from a machine pool, first decrease the pool replicas count.
If StackLight in HA mode is enabled and you are going to delete a machine with the StackLight label:
Make sure that at least 3 machines with the StackLight label remain after the deletion. Otherwise, add an additional machine with such label before the deletion. After the deletion, perform the additional steps described in the deletion procedure, if required.
Do not delete more than 1 machine with the StackLight label. Since StackLight in HA mode uses local volumes bound to machines, the data from these volumes on the deleted machine will be purged but its replicas remain on other machines. Removal of more than 1 machine can cause data loss.
If you move the StackLight label to a new worker machine on an existing cluster, manually deschedule all StackLight components from the old worker machine, which you remove the StackLight label from. For details, see Deschedule StackLight Pods from a worker machine.
If the machine being deleted has a prioritized upgrade index and you want to preserve the same upgrade order, manually set the required index to the new node that replaces the deleted one. Otherwise, the new node is automatically set the greatest upgrade index that is prioritized the last. To set the upgrade index, refer to Change the upgrade order of a machine or machine pool.
Delete a cluster machine using web UI¶
This section instructs you on how to scale down an existing management or managed cluster through the Mirantis Container Cloud web UI.
To delete a machine from a cluster using web UI:
Carefully read the machine deletion precautions.
For the bare metal provider, ensure that the machine being deleted is not a Ceph Monitor. If it is, migrate the Ceph Monitor to keep the odd number quorum of Ceph Monitors after the machine deletion. For details, see Migrate a Ceph Monitor before machine replacement.
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.If the machine is assigned to a machine pool, decrease replicas count of the pool as described in Change replicas count of a machine pool.
Click the More action icon in the last column of the machine you want to delete and select Delete.
Select from the following options:
Select the machine deletion method:
- Graceful
Recommended. The machine will be prepared for deletion with all workloads safely evacuated. Using this option, you can cancel the deletion before the corresponding node is removed from Docker Swarm.
- Unsafe
Not recommended. The machine will be deleted without any preparation.
- Forced
Not recommended. The machine will be deleted with no guarantee of resources cleanup. Therefore, Mirantis recommends trying Graceful or Unsafe option first.
For deletion workflow of each method, see Overview of machine deletion policies.
Confirm the deletion.
If machine deletion fails, you can reduce the deletion policy restrictions and try another method but in the following order only: Graceful > Unsafe > Forced.
Confirm the deletion.
Deleting a machine automatically frees up the resources allocated to this machine.
See also
Delete a cluster machine using CLI¶
Available since 17.0.0, 16.0.0, 14.1.0 as GA Available since 11.5.0 and 7.11.0 for non-MOSK clusters as TechPreview
This section instructs you on how to scale down an existing management or managed cluster through the Container Cloud API. To delete a machine using the Container Cloud web UI, see Delete a cluster machine using web UI.
Using the Container Cloud API, you can delete a cluster machine using the following methods:
Recommended. Enable the
deletefield in theproviderSpecsection of the requiredMachineobject. It allows aborting graceful machine deletion before the node is removed from Docker Swarm.Not recommended. Apply the
deleterequest to theMachineobject.
You can control machine deletion steps by following a specific machine deletion policy.
Overview of machine deletion policies¶
The deletion policy of the Machine resource used in the Container Cloud
API defines specific steps occurring before a machine deletion.
The Container Cloud API contains the following types of deletion policies: graceful, unsafe, forced.
By default, the graceful deletion policy is used since the Cluster releases 17.0.0, 16.0.0, and 14.1.0. In previous releases, the unsafe deletion policy was used by default.
You can change the deletion policy before the machine deletion. If the deletion process has already started, you can reduce the deletion policy restrictions in the following order only: graceful > unsafe > forced.
Recommended and default since 17.0.0, 16.0.0, 14.1.0
During a graceful machine deletion, the cloud provider and LCM controllers perform the following steps:
Cordon and drain the node being deleted.
Remove the node from Docker Swarm.
Send the
deleterequest to the correspondingMachineresource.Remove the provider resources such as the VM instance, network, volume, and so on. Remove the related Kubernetes resources.
Remove the finalizer from the
Machineresource. This step completes the machine deletion from Kubernetes resources.
Caution
You can abort a graceful machine deletion only before the corresponding node is removed from Docker Swarm.
During a graceful machine deletion, the Machine object status displays
prepareDeletionPhase with the following possible values:
startedCloud provider controller prepares a machine for deletion by cordoning, draining the machine, and so on.
completedLCM Controller starts removing the machine resources since the preparation for deletion is complete.
abortingCloud provider controller attempts to uncordon the node. If the attempt fails, the status changes to
failed.
failedError in the deletion workflow.
During an unsafe machine deletion, the cloud provider and LCM controllers perform the following steps:
Send the
deleterequest to the correspondingMachineresource.Remove the provider resources such as the VM instance, network, volume, and so on. Remove the related Kubernetes resources.
Remove the finalizer from the
Machineresource. This step completes the machine deletion from Kubernetes resources.
During a forced machine deletion, the cloud provider and LCM controllers perform the following steps:
Send the
deleterequest to the correspondingMachineresource.Remove the provider resources such as the VM instance, network, volume, and so on. Remove the related Kubernetes resources.
Remove the finalizer from the
Machineresource. This step completes the machine deletion from Kubernetes resources.
This policy type allows deleting a Machine resource even if the cloud
provider or LCM controller gets stuck at some step. But this policy may
require a manual cleanup of machine resources in case of a controller
failure. For details, see Delete a machine from a cluster using CLI.
Caution
Consider the following precautions applied to the forced machine deletion policy:
Use the forced machine deletion only if either graceful or unsafe machine deletion fails.
If the forced machine deletion fails at any step, the LCM Controller removes the finalizer anyway.
Before starting the forced machine deletion, back up the related
Machineresource:kubectl get machine -n <projectName> <machineName> -o json > deleted_machine.json
Delete a machine from a cluster using CLI¶
Carefully read the machine deletion precautions.
Log in to the host where your management cluster
kubeconfigis located and where kubectl is installed.For the bare metal provider, ensure that the machine being deleted is not a Ceph Monitor. If it is, migrate the Ceph Monitor to keep the odd number quorum of Ceph Monitors after the machine deletion. For details, see Migrate a Ceph Monitor before machine replacement.
If the machine is assigned to a machine pool, decrease replicas count of the pool as described in Change replicas count of a machine pool.
Select from the following options:
Recommended. In the
providerSpec.valuesection of theMachineobject, setdeletetotrue:kubectl patch machines.cluster.k8s.io -n <projectName> <machineName> --type=merge -p '{"spec":{"providerSpec":{"value":{"delete":true}}}}'
Replace the parameters enclosed in angle brackets with the corresponding values.
Delete the
Machineobject.kubectl delete machines.cluster.k8s.io -n <projectName> <machineName>
After a successful
unsafeorgracefulmachine deletion, the resources allocated to the machine are automatically freed up.If you applied the
forcedmachine deletion, verify that all machine resources are freed up. Otherwise, manually clean up resources:Delete the Kubernetes
Nodeobject related to the deletedMachineobject:Note
Since Container Cloud 2.23.0, skip this step as the system performs it automatically.
Log in to the host where your managed cluster
kubeconfigis located.Verify whether the
Nodeobject for the deletedMachineobject still exists:kubectl get node $(jq -r '.status.nodeRef.name' deleted_machine.json)
If the system response is positive:
Log in to the host where your management cluster
kubeconfigis located.Delete the
LcmMachineobject with same name and project name as the deletedMachineobject.kubectl delete lcmmachines.lcm.mirantis.com -n <projectName> <machineName>
Clean up the provider-specific resources. Select from the following options:
Bare metal
Log in to the host that contains the following configuration:
Management cluster
kubeconfigvSphere credentials configured
jq installed
If the deleted machine was located on a managed cluster, delete the Ceph node as described in High-level workflow of Ceph OSD or node removal.
Obtain the
BareMetalHostobject that relates to the deleted machine:BMH=$(jq -r '.metadata.annotations."metal3.io/BareMetalHost"| split("/") | .[1]' deleted_machine.json)
Delete the
BareMetalHostcredentials:kubectl delete secret -n <projectName> <machineName>-user-data
Deprovision the related
BareMetalHostobject:kubectl patch baremetalhost -n <projectName> ${BMH} --type merge --patch '{"spec": {"image": null, "userData": null, "online":false}}' kubectl patch baremetalhost -n <projectName> ${BMH} --type merge --patch '{"spec": {"consumerRef": null}}'
OpenStack
Log in to the host that contains the following configuration:
Management cluster
kubeconfigOpenStack credentials configured
Required tools: kubectl, jq, openstack-cli
Obtain the instance ID of the deleted machine:
SERVER_ID=$(jq -r ".status.providerStatus.providerInstanceState.id" deleted_machine.json)
Verify whether the OpenStack server still exists:
openstack server show ${SERVER_ID}
If the system response is positive, delete the OpenStack server:
openstack server delete ${SERVER_ID}
Delete the floating IP on the related managed cluster:
PORT=$(openstack port list --device-id <serverID> -c ID -f value) FLOATING=$(openstack floating ip list --port ${PORT} -c ID -f value) openstack floating ip delete ${FLOATING}
vSphere
Log in to the host that contains the following configuration:
Management cluster
kubeconfigvSphere credentials configured
Required tools: kubectl, jq, govc
Obtain the VM UUID that relates to the deleted machine:
VM_UUID=$(jq -r ".status.providerStatus.providerInstanceState.id" deleted_machine.json)
Verify whether the VM still exists:
govc vm.info -vm.uuid ${VM_UUID}
If the system response is positive, delete the VM:
govc vm.destroy -vm.uuid ${VM_UUID}
See also
Manage IAM¶
Note
The Container Cloud web UI communicates with Keycloak to authenticate users. Keycloak is exposed using HTTPS with self-signed TLS certificates that are not trusted by web browsers.
To use your own TLS certificates for Keycloak, refer to Configure TLS certificates for cluster applications.
Manage user roles through Container Cloud API¶
You can manage IAM user role bindings through Container Cloud API. For the API reference of the IAM custom resources, see IAM resources. You can also manage user roles using the Container Cloud web UI.
Note
User management for the Mirantis OpenStack for Kubernetes m:os roles is not
yet available through API or web UI. Therefore, continue managing these
roles using Keycloak.
You can use the following objects depending on the way you want the role to be assigned to the user:
IAMGlobalRoleBindingfor global role bindingsAny IAM role can be used in
IAMGlobalRoleBindingand will be applied globally, not limited to a specific project or cluster. For example, theglobal-adminrole.
IAMRoleBindingfor project role bindingsAny role except the
global-adminone apply. For example, using theoperatoranduserIAM roles inIAMRoleBindingof theexampleproject corresponds to assigning ofm:kaas:example@operator/userin Keycloak. You can also use these IAM roles inIAMGlobalRoleBinding. In this case, the roles corresponding to every project will be assigned to a user in Keycloak.
IAMClusterRoleBindingfor cluster role bindingsOnly the
cluster-adminandstacklight-adminroles apply toIAMClusterRoleBinding. Creation of such objects corresponds to the assignment ofm:k8s:namespace:cluster@cluster-admin/stacklight-adminin Keycloak. You can also bind these roles to eitherIAMGlobalRoleBindingorIAMRoleBinding. In this case, the roles corresponding to all clusters and in all projects or one particular project will be assigned to a user.
This section describes available IAM roles with use cases and the Container
Cloud API IAM*RoleBinding mapping with Keycloak.
Available IAM roles and use cases¶
This section describes IAM roles and access rights they provide with possible use cases.
The following table illustrates the IAM roles available in Container Cloud and read/write or read-only permissions for specific project and cluster operations:
Roles |
global-admin |
management-admin |
bm-pool-operator |
operator |
user |
member |
cluster-admin |
stacklight-admin |
|---|---|---|---|---|---|---|---|---|
Scope |
Global |
Global |
Namespace |
Namespace |
Namespace |
Namespace |
Cluster |
Cluster |
User Role
Management API
|
r/w |
r/w |
- |
r/w |
r/o |
- |
- |
- |
Create BM hosts |
- |
r/w |
r/w |
- |
- |
- |
- |
- |
Ceph objects |
- |
r/w |
- |
r/w |
- |
r/w |
- |
- |
Projects (Kubernetes namespaces) |
r/w |
r/w |
r/o |
r/o |
r/o |
r/o |
- |
- |
Container Cloud API |
- |
r/w |
- |
r/w |
r/o |
r/w |
- |
- |
Kubernetes API (managed cluster) |
- |
- |
- |
r/w |
- |
r/w |
r/w |
- |
StackLight UI/API (managed cluster) |
- |
- |
- |
r/w |
- |
r/w |
r/w |
r/w |
The following table illustrates possible role use cases for a better understanding on which roles should be assigned to users who perform particular operations in a Container Cloud cluster:
Role |
Use case |
|---|---|
kind: IAMGlobalRoleBinding
metadata:
name: mybinding-ga
role:
name: global-admin
user:
name: myuser-1943c384
|
Infrastructure Operator with the
|
kind: IAMGlobalRoleBinding
metadata:
name: mybinding-ma
role:
name: management-admin
user:
name: myuser-1943c384
|
Available since Container Cloud 2.25.0 (17.0.0, 16.0.0, 14.1.0).
Infrastructure Operator with the |
kind: IAMRoleBinding
metadata:
name: mybinding-bm
namespace: mynamespace
role:
name: bm-pool-operator
user:
name: myuser-1943c384
|
Infrastructure Operator with the |
kind: IAMRoleBinding
metadata:
name: mybinding-op
namespace: mynamespace
role:
name: operator
user:
name: myuser-1943c384
|
Infrastructure Operator with the
|
kind: IAMRoleBinding
metadata:
name: mybinding-us
namespace: mynamespace
role:
name: user
user:
name: myuser-1943c384
|
Infrastructure support Operator with the
|
kind: IAMRoleBinding
metadata:
name: mybinding-me
namespace: mynamespace
role:
name: member
user:
name: myuser-1943c384
|
Infrastructure support Operator with the |
kind: IAMClusterRoleBinding
metadata:
name: mybinding-ca
namespace: mynamespace
role:
name: cluster-admin
user:
name: myuser-1943c384
cluster:
name: mycluster
|
User with the
|
kind: IAMClusterRoleBinding
metadata:
name: mybinding-sa
namespace: mynamespace
role:
name: stacklight-admin
user:
name: myuser-1943c384
cluster:
name: mycluster
|
User with the
|
Mapping of Keycloak roles to IAM*RoleBinding objects¶
Starting from Container Cloud 2.14.0, the Container Cloud role naming has changed. The old role names logic has been reworked and new role names are introduced.
Old-style role mappings are reflected in the Container Cloud API with the new
roles and the legacy: true and legacyRole: “<oldRoleName>” fields set.
If you remove the legacy flag, user-controller automatically performs
the following update in Keycloak:
Grants the new-style role
Removes the old-style role mapping
Note
You can assign the old-style roles using Keycloak only. These roles will be synced into the Container Cloud API as the corresponding
IAM*RoleBindingobjects with theexternal: true,legacy: true, andlegacyRole: “<oldRoleName>”fields set.If you assign new-style roles using Keycloak, they will be synced into the Container Cloud API with the
external: truefield set.
The following table describes how the IAM*RoleBinding objects in the
Container Cloud API map to roles in Keycloak.
Container Cloud new role names |
global-admin |
bm-pool-operator |
operator |
user |
cluster-admin |
stacklight-admin |
|---|---|---|---|---|---|---|
m:kaas@global-admin |
||||||
m:kaas@management-admin Since 2.25.0 (17.0.0, 16.0.0, 14.1.0) |
||||||
m:kaas:{ns}@bm-pool-operator |
||||||
m:kaas:{ns}@operator |
||||||
m:kaas:{ns}@user |
||||||
m:k8s:{ns}:{cluster}@cluster-admin |
||||||
m:sl:{ns}:{cluster}@stacklight-admin |
The following table describes how the role names available before the
Container Cloud 2.14.0 map with the current IAM*RoleBinding objects in the
Container Cloud API map:
Container Cloud new role names |
global-admin |
bm-pool-operator |
operator |
user |
cluster-admin |
stacklight-admin |
|---|---|---|---|---|---|---|
m:kaas@writer |
||||||
m:kaas@reader |
||||||
m:kaas@operator |
||||||
m:kaas:{ns}@writer |
||||||
m:kaas:{ns}@reader |
||||||
m:k8s:{ns}:{cluster}@cluster-admin |
||||||
m:sl:{ns}:{cluster}@admin |
The following tables contain several examples of role assignment either through Keycloak or the Container Cloud IAM objects with the corresponding role mappings for each use case.
Use case |
Namespace operator role binding |
IAM*RoleBinding example |
apiVersion: iam.mirantis.com/v1alpha1
kind: IAMRoleBinding
metadata:
namespace: ns1
name: user1-operator
role:
name: operator
user:
name: user1-f150d839
|
Mapped role in Keycloak |
The role |
Use case |
Cluster-admin role assigned globally |
IAM*RoleBinding example |
apiVersion: iam.mirantis.com/v1alpha1
kind: IAMGlobalRoleBinding
metadata:
name: user1-global-cluster-admin
role:
name: cluster-admin
user:
name: user1-f150d839
|
Mapped role in Keycloak |
For example, if you have two namespaces (
If you create a new |
The following table provides the new-style and old-style examples on how a role assigned to a user through Keycloak will be translated into IAM objects.
Role type |
New-style role |
Role example in Keycloak |
The role The |
Mapped IAM*RoleBinding example |
apiVersion: iam.mirantis.com/v1alpha1
kind: IAMRoleBinding
metadata:
namespace: ns1
name: user1-f150d839-operator
external: true
role:
name: operator
user:
name: user1-f150d839
|
Role type |
Old-style role |
Role example in Keycloak |
The role Creation of this role through Keycloak triggers creation of two
To migrate the old-style For example, if you have two namespaces (
If you create a new If you do not remove the |
Mapped IAM*RoleBinding example |
apiVersion: iam.mirantis.com/v1alpha1
kind: IAMGlobalRoleBinding
metadata:
name: user1-f150d839-global-admin
external: true
legacy: true
legacyRole: m:kaas@writer
role:
name: global-admin
user:
name: user1-f150d839
apiVersion: iam.mirantis.com/v1alpha1
kind: IAMGlobalRoleBinding
metadata:
name: user1-f150d839-operator
external: true
legacy: true
legacyRole: m:kaas@writer
role:
name: operator
user:
name: user1-f150d839
|
Manage user roles through the Container Cloud web UI¶
If you are assigned the global-admin role, you can manage the
IAM*RoleBinding objects through the Container Cloud web UI. The possibility
to manage project role bindings using the operator role will become
available in one of the following Container Cloud releases.
To add or remove a role binding using the Container Cloud web UI:
Log in to the Container Cloud web UI as
global-admin.In the left-side navigation panel, click Users to open the active users list and view the number and types of bindings for each user. Click on a user name to open the details page with the user Role Bindings.
Select from the following options:
To add a new binding:
Click Create Role Binding.
In the window that opens, configure the following fields:
Parameter
Description
Role
global-adminManage all types of role bindings for all users
management-adminSince 2.25.0 (17.0.0, 16.0.0, 14.1.0)Have full access to the management cluster
bm-pool-operatorManage bare metal hosts of a particular namespace
operatorManage Container Cloud API and Ceph-related objects in a particular project, create clusters and machines, have full access to Kubernetes clusters and StackLight APIs deployed by anyone in this project
Manage role bindings in the current namespace for users who require the
bm-pool-operator,operator, oruserrole
userManage infrastructure of a particular project with access to live statuses of the project cluster machines to monitor cluster health
cluster-adminHave admin access to Kubernetes clusters and StackLight components of a particular cluster and project
stacklight-adminHave admin access to the StackLight components of a particular Kubernetes cluster deployed in a particular project to monitor the cluster health.
Binding type
- Global
Bind a role globally, not limited to a specific project or cluster. By default,
global-adminhas the global binding type.You can bind any role globally. For example, you can change the default project binding of the
operatorrole to apply this role globally, to all existing and new projects.
- Project
Bind a role to a specific project. If selected, also define the Project name that the binding is assigned to.
By default, the following IAM roles have the project binding type:
bm-pool-operator,operator, anduser. You can bind any role to a project except theglobal-adminone.
- Cluster
Bind a role to a specific cluster. If selected, also define the Project and Cluster name that the binding is assigned to. You can bind only the
cluster-adminandstacklight-adminroles to a cluster.
To remove a binding, click the Delete action icon located in the last column of the required role binding.
Bindings that have the
externalflag set totruewill be synced back from Keycloak during the nextuser-controllerreconciliation. Therefore, manage such bindings through Keycloak.
Manage user roles through Keycloak¶
Note
Starting from Container Cloud 2.14.0:
User roles management is available through the Container Cloud API and web UI.
User management for the
m:osroles is not yet available through API or web UI. Therefore, continue managing these roles using Keycloak.Role names have been updated. For details, see Mapping of Keycloak roles to IAM*RoleBinding objects.
Mirantis Container Cloud creates the IAM roles in scopes.
For each application type, such as kaas, k8s, or sl,
Container Cloud creates a set of roles such as @admin, @cluster-admin,
@reader, @writer, @operator.
Depending on the role, you can perform specific operations in a Container Cloud cluster. For example:
With the
m:kaas@writerrole, you can create a project using the Container Cloud web UI. The corresponding project-specific roles will be automatically created in Keycloak byiam-controller.With the
m:kaas*roles, you can download thekubeconfigof the management cluster.
The semantic structure of role naming in Container Cloud is as follows:
m:<appType>:<namespaceName>:<clusterName>@<roleName>
Element |
Description |
|---|---|
|
Prefix for all IAM roles in Container Cloud |
|
Application type:
|
|
Namespace name, is optional depending on the application type |
|
Managed cluster name, is optional depending on the application type |
|
Delimiter between a scope and role |
|
Short name of a role within a scope |
This section outlines the IAM roles and scopes structure in Container Cloud and role assignment to users using the Keycloak Admin Console.
Container Cloud roles and scopes¶
The Container Cloud roles can have three types of scopes:
Scope |
Application type |
Components |
Example |
|---|---|---|---|
Global |
|
|
This scope applies to all managed clusters and namespaces. |
Namespace |
|
|
|
Cluster |
|
|
|
Not recommended
Users with the m:kaas@writer role are considered global Container Cloud
administrators. They can create the Container Cloud projects that are
Kubernetes namespaces in the management cluster. After a project is created,
the m:kaas:<namespaceName>@writer and m:kaas:<namespaceName>@reader
roles are created in Keycloak by iam-controller.
These roles are automatically included into the corresponding global roles,
such as m:kaas@writer, so that users with the global-scoped role also
obtain the rights provided by the namespace-scoped roles. The global role
m:kaas@operator provides full access to bare metal objects.
When a managed cluster is created, roles for the sl and k8s
applications are created:
m:k8s:<namespaceName>:<clusterName>@cluster-admin(also applies to new-style roles, recommended)m:sl:<namespaceName>:<clusterName>@admin
These roles provide access to the corresponding resources in a managed cluster
and are included into the corresponding m:kaas:<namespaceName>@writer role.
Recommended
Since Container Cloud 2.14.0, new-style roles were introduced. They can be assigned to users through Keycloak directly as well as by using IAM API objects. Mirantis recommends using IAM API for roles assignment.
Users with the m:kaas@global-admin role can create Container Cloud
projects, which are Kubernetes namespaces in a management cluster, and all
IAM API objects that manage users access to Container Cloud.
Users with the m:kaas@management-admin role have full access to the
Container Cloud management cluster. This role is available since Container
Cloud 2.25.0 (Cluster releases 17.0.0, 16.0.0, 14.1.0).
After project creation, iam-controller creates the following roles in
Keycloak:
m:kaas:<namespaceName>@operatorProvides the same permissions as
m:kaas:<namespaceName>@writer
m:kaas:<namespaceName>@bm-pool-operatorProvides the same permissions as
m:kaas@operatorbut restricted to a single namespace
m:kaas:<namespaceName>@userProvides the same permissions as
m:kaas:<namespaceName>@reader
m:kaas:<namespaceName>@memberProvides the same permissions as
m:kaas:<namespaceName>@operatorexcept for IAM API access
The old-style m:k8s:<namespaceName>:<clusterName>@cluster-admin role is
unchanged in the new-style format and is recommended for usage.
When a managed cluster is created, a new role
m:sl:<namespaceName>:<clusterName>@stacklight-admin for the sl
application is created. This role provides the same access to the StackLight
resources in the managed cluster as
m:sl:<namespaceName>:<clusterName>@admin and is included into the
corresponding m:k8s:<namespaceName>:<clusterName>@cluster-admin
role.
The following tables include the Container Cloud scopes and their roles descriptions by three application types:
Scope identifier |
Short role name |
Full role name |
Role description |
|---|---|---|---|
|
|
|
List the API resources within the Container Cloud scope. |
|
|
Create, update, or delete the API resources within the Container Cloud scope. Create projects. |
|
|
|
Add or delete a bare metal host within the Container Cloud scope. |
|
|
|
Create, update, or delete the IAM API resources within the Container Cloud scope. Create projects. |
|
|
|
Have full access to the management cluster. Available since Container Cloud 2.25.0 (Cluster releases 17.0.0, 16.0.0, 14.1.0). |
|
|
|
|
List the API resources within the specified Container Cloud project. |
|
|
Create, update, or delete the API resources within the specified Container Cloud project. |
|
|
|
List the API resources within the specified Container Cloud project. |
|
|
|
Create, update, or delete the API resources within the specified Container Cloud project. |
|
|
|
Add or delete a bare metal host within the specified Container Cloud project. |
- 0(1,2,3,4,5)
Role is available by default. Other roles will be added during a managed cluster deployment or project creation.
Scope identifier |
Short role name |
Full role name |
Role description |
|---|---|---|---|
|
|
|
Allow the superuser to perform any action on any resource in the specified cluster. |
Scope identifier |
Short role name |
Full role name |
Role description |
|---|---|---|---|
|
|
|
Access the following web UIs within the scope:
|
|
|
Access the following web UIs within the scope:
|
Use cases¶
This section illustrates possible use cases for a better understanding on which roles should be assigned to users who perform particular operations in a Container Cloud cluster:
Role |
Use case |
|---|---|
|
Member of a dedicated infrastructure team who only manages bare metal hosts in Container Cloud |
|
Infrastructure Operator who performs the following operations:
|
|
Member of a dedicated infrastructure support team responsible for the Container Cloud infrastructure who performs the following operations:
|
|
User who administers a particular project:
|
|
Member of a dedicated infrastructure support team in a particular project.
For use cases, see the |
|
User who has admin access to a Kubernetes cluster deployed in a particular project. |
|
User who has full access to the StackLight components of a particular Kubernetes cluster deployed in a particular project to monitor the cluster health status. |
Access the Keycloak Admin Console¶
Using the Keycloak Admin Console you can create or delete a user as well as grant or revoke roles to or from a user. The Keycloak administrator is responsible for assigning roles to users depending on the level of access they need in Container Cloud.
Available since 2.22.0
./container-cloud get keycloak-creds --mgmt-kubeconfig <pathToManagementClusterKubeconfig>
Optionally, use the --output key to save credentials in a YAML file.
Example of system response:
Keycloak admin credentials:
Address: https://<keycloak-ip-adress>/auth
Login: keycloak
Password: foobar
kubectl get cluster <mgmtClusterName> -o=jsonpath='{.status.providerStatus.helm.releases.iam.keycloak.url}'
The system response contains the URL to access the Keycloak Admin Console.
The user name is keycloak by default. The password is located in
passwords.yaml generated during bootstrap.
You can also obtain the password from the iam-api-secrets secret
in the kaas namespace of the management cluster and
decode the content of the keycloak_password key:
kubectl get secret iam-api-secrets -n kaas -o=jsonpath='{.data.keycloak_password}' | base64 -d
Change passwords for IAM users¶
This section describes how to change passwords for IAM users on publicly accessible Mirantis Container Cloud deployments using the Keycloak web UI.
To change the IAM passwords:
Obtain the Keycloak admin password:
kubectl get secret -n kaas iam-api-secrets -o jsonpath='{.data.keycloak_password}' | base64 -d ; echo
Obtain the Keycloak load balancer IP:
kubectl get svc -n kaas iam-keycloak-http
Log in to the Keycloak web UI using the following link form with the default
keycloakadmin user and the Keycloak credentials obtained in the previous steps:https://<Keycloak-LB-IP>/auth/admin/master/console/#/iam/usersNavigate to Users > User list that contains all users in the IAM realm.
Click the required user name. The page with user settings opens.
Open Credentials tab.
Using the Reset password form, update the password as required.
Note
To change the password permanently, toggle the Temporary switch to the OFF position. Otherwise, the user will be prompted to change the password after the next login.
See also
Obtain MariaDB credentials for IAM¶
Available since Container Cloud 2.22.0
To obtain the MariaDB credentials for IAM, use the Container Cloud binary:
./container-cloud get iam-creds --mgmt-kubeconfig <pathToManagementClusterKubeconfig>
Example of system response:
IAM DB credentials:
MYSQL_DBADMIN_PASSWORD: foobar
MYSQL_DBSST_PASSWORD: barbaz
Caution
Credentials provided in the system response allow operating
MariaDB with the root user inside a container. Therefore, use them with
caution.
Manage Keycloak truststore using the Container Cloud web UI¶
Available since 2.26.0 (17.1.0 and 16.1.0)
While communicating with external services, Keycloak must validate the certificate of the remote server to ensure secured connection.
By default, the standard Java Truststore configuration is used for validating outgoing requests. In order to properly validate client self-signed certificates, the truststore configuration must be added. The truststore is used to ensure secured connection to identity brokers, LDAP identity providers, and so on.
If a custom truststore is set, only certificates from that truststore are used. If trusted public CA certificates are also required, they must be included in the custom truststore.
To add a custom truststore for Keycloak using the Container Cloud web UI:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the default project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the More action icon in the last column of the management cluster and select Configure cluster.
In the window that opens, click Keycloak and select Configure trusted certificates.
Note
The Configure trusted certificates check box is available since Container Cloud 2.26.4 (Cluster releases 17.1.4 and 16.1.4).
In the Truststore section that opens, fill out and save the form with the following parameters:
Parameter
Description
Data
Content of the truststore file. Click Upload to select the required file.
Password
Password of the truststore. Mandatory.
Type
Supported truststore types: jks, pkcs12, or bcfks.
Hostname verification policy
Optional verification of the host name of the server certificate:
The default WILDCARD value allows wildcards in subdomain names.
The STRICT value requires the Common Name (CN) to match the host name.
Click Update.
Once a custom truststore for Keycloak is applied, the following configuration
is added to the Cluster object:
spec:
providerSpec:
value:
kaas:
management:
keycloak:
truststore:
data:
value: # base64 encoded truststore file content
password:
value: # string
type: # string
hostnameVerificationPolicy: # string
Note
Use the same web UI menu to customize an existing truststore or reset it to default settings, which is available since Container Cloud 2.26.4 (Cluster releases 17.1.4 and 16.1.4).
Manage StackLight¶
Using StackLight, you can monitor the components deployed in Mirantis Container Cloud and be quickly notified of critical conditions that may occur in the system to prevent service downtimes.
Access StackLight web UIs¶
By default, StackLight provides five web UIs including Prometheus, Alertmanager, Alerta, OpenSearch Dashboards, and Grafana. This section describes how to access any of these web UIs.
To access a StackLight web UI:
Log in to the Mirantis Container Cloud web UI.
Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the More action icon in the last column of the required cluster and select Cluster info.
In the dialog box with the cluster information, copy the required endpoint IP from the StackLight Endpoints section.
Paste the copied IP to a web browser and use the default credentials to log in to the web UI. Once done, you are automatically authenticated to all StackLight web UIs.
Note
The Alertmanager web UI displays alerts received by all configured receivers, which can be mistaken for duplicates. To only display the alerts received by a particular receiver, use the Receivers filter.
StackLight logging indices¶
Available since 2.26.0 (17.1.0 and 16.1.0)
StackLight logging indices are managed by OpenSearch data streams, which are introduced in OpenSearch 2.6. It is a convenient way to manage insert-only pipelines such as log message collection. The solution consists of the following elements:
Data stream objects that can be referred to as alias:
Audit - dedicated for Container Cloud, MKE, and host audit logs, ensuring data integrity and security.
System - replaces Logstash for system logs, provides a streamlined approach to log management.
Write index - current index where ingestion can be performed without removing a data stream.
Read indices - indices created after the rollover mechanism is applied.
Rollover policy - creating new write index for data stream based on the size of shards
Example of an initial index list:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .ds-audit-000001 30q4HLGmR0KmpRR8Kvy5jw 1 1 2961719 0 496.3mb 248mb
green open .ds-system-000001 5_eFtMAFQa6aFB7nttHjkA 1 1 2476 0 6.1mb 3mb
Example of the index after the rollover is applied to the audit index:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .ds-audit-000001 30q4HLGmR0KmpRR8Kvy5jw 1 1 9819913 0 1.5gb 784.8mb
green open .ds-audit-000002 U1fbs0i9TJmOsAOoR7cERg 1 1 2961719 0 496.3mb 248mb
green open .ds-system-000001 5_eFtMAFQa6aFB7nttHjkA 1 1 2476 0 6.1mb 3mb
Audit and system index templates¶
The following table contains a simplified template of the audit and system indices. The user can perform aggregation queries over keyword fields.
Field |
Type |
Description |
|---|---|---|
|
date |
Time when a log event was produced, if available in the parsed message. Otherwise time when the event was ingested. |
|
keyword |
Identifier of the Docker container that the application generating the event was running in. |
|
text |
Name of the Docker image defined as |
|
keyword |
Name of the Docker container that the application generating the event was running in. |
|
keyword |
Source of the event: |
|
keyword |
Name of the application that produced the message. |
|
keyword |
Name of the host that the message was collected from. |
|
keyword |
Path on the host to the source file for the message if the message was not produced by the application running in the container or system unit. |
|
keyword |
Severity level of the event taken from the parsed message content. |
|
text |
Unparsed content of the event message. |
|
flat_object |
Kubernetes metadata labels of the pod that runs the Docker container of the application. |
|
keyword |
Kubernetes namespace where the application pod was running. |
|
keyword |
Kubernetes pod name of the pod running the application Docker container. |
|
keyword |
Type of orchestrator: |
The following table contains a simplified template of extra fields for the system index that are not present in the audit template.
Field |
Type |
Description |
|---|---|---|
|
keyword |
IP address of the HTTP request destination. |
|
keyword |
Name of the OpenStack service that the HTTP request was sent to. Applies to MOSK clusters only. |
|
long |
Request duration in nanoseconds. |
|
keyword |
Request ID generated by OpenStack. Applies to MOSK clusters only. |
|
keyword |
HTTP request method. |
|
keyword |
Path of the HTTP URL request. |
|
long |
HTTP status code of the response. |
|
keyword |
IP address of the HTTP request source. |
System index mapping to the Logstash index¶
The following table lists mapping of the system index fields to the Logstash ones:
System |
Logstash Removed in 2.26.0 |
|---|---|
|
|
|
|
|
|
|
|
|
n/a |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n/a |
|
|
|
|
|
|
|
|
|
|
|
n/a |
OpenSearch Dashboards¶
This section describes OpenSearch Dashboards that enable you to observe visual representation of logs and Kubernetes events of your cluster.
View OpenSearch Dashboards¶
Using the OpenSearch Dashboards web UI, you can view the visual representation of logs, Kubernetes events, and other cluster notifications related to your deployment.
To view OpenSearch Dashboards:
Log in to the OpenSearch Dashboards web UI as described in Access StackLight web UIs.
Click the required dashboard to inspect the visualizations or perform a search:
Dashboard
Description
K8s events
Provides visualizations on the number of Kubernetes events per type, and top event-producing resources and namespaces by reason and event type. Includes search.
System Logs
Available for clusters created since Container Cloud 2.26.0 (Cluster releases 17.1.x, 16.1.x, or later).
Provides visualizations on the number of log messages per severity, source, and top log-producing host, namespaces, containers, and applications. Includes search.
Caution
Due to a known issue, this dashboard does not exist in Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). The issue is addressed in Container Cloud 2.26.1 (Cluster releases 17.1.1 and 16.1.1). To work around the issue in 2.26.0, you can map the fields of the
logstashindex to thesystemone and view logs in the deprecated Logs dashboard. For mapping details, see System index fields mapped to Logstash index fields.Logs Deprecated in 2.26.0
Available only for clusters created before Container Cloud 2.26.0 (Cluster releases 17.0.x, 16.0.x, or earlier).
Analogous to System Logs but contains logs generated only for the mentioned Cluster releases.
Search in OpenSearch Dashboards¶
OpenSearch Dashboards provide the following search tools:
Filters
Queries
Full-text search
Filters enable you to organize the output information using the interface tools. You can search for information by a set of indexed fields using a variety of logical operators.
Queries enable you to construct search commands using OpenSearch query domain-specific language (DSL) expressions. These expressions allow you to search by the fields not included in the index.
In addition to filters and queries, you can use the Search input field for full-text search.
From the dashboard view, click Add filter.
In the dialog that opens, select the field of search in the Field drop-down menu.
Select the logical operator in the Operator drop-down menu.
Type or select the filter value from the Value drop-down menu.
Available since 2.23.0 (12.7.0 and 11.7.0)
For the orchestrator.labels field of the system and audit log indices,
you can use the flat_object field type to apply the filtering using
value or valueAndPath. For example:
Using
value: to obtain all logs produced byiam-proxy, add the following filters:orchestrator.typethat matcheskubernetesorchestrator.labels._valuethat matchesiam-proxy
Using
valueAndPath: to obtain all logs produced by the OpenSearch cluster, add the following filters:orchestrator.typethat matcheskubernetesorchestrator.labels._valueAndPaththat matchesorchestrator.labels.app=opensearch-master
From the dashboard view, click Add filter.
In the dialog that opens, click Edit as Query DSL and type in the search request.
Export logs from OpenSearch Dashboards to CSV¶
Available since 2.23.0 (12.7.0 and 11.7.0)
This section describes how to export logs from the OpenSearch Dashboards navigation panel to the CSV format.
Caution
The log limit is set 10 000 rows, and it does not take into account the resulted file size.
Note
The following instruction describes how to export all logs from the
opensearch-master-0 node of an OpenSearch cluster.
To export logs from the OpenSearch Dashboards navigation panel to CSV:
Log in to the OpenSearch Dashboards web UI as described in Access StackLight web UIs.
Navigate to the Discover page.
In the left navigation panel, select the required log index pattern from the top drop-down menu. For example, system* for system logs and audit* for audit logs.
In the middle top menu, click Add filter and add the required filters. For example:
event.provider matches the
opensearch-masterloggerorchestrator.pod matches the
opensearch-master-0node name
In Search field names, search for required fields to be present in the resulting CSV file. For example:
orchestrator.pod for
opensearch-master-0message for the log message
In the right top menu:
Click Save to save the filter after naming it.
Click Reporting > Generate CSV.
When the report generation completes, download the file depending on your browser settings.
Tune OpenSearch performance for the bare metal provider¶
The following hardware recommendations and software settings apply for better OpenSearch performance in a baremetal-based Container Cloud cluster.
To tune OpenSearch performance:
Depending on your cluster size, set the required disk and CPU size along with memory limit and heap size.
Heap size is calculated in StackLight as ⅘ of the specified memory limit. If the calculated heap size exceeds 32 GB, slightly crossing this threshold causes significant waste of memory due to loss of Ordinary Object Pointers (OOPS) compression, which allows storing 64-bit pointers in 32-bits.
Since Cluster releases 17.0.0, 16.0.0, and 14.1.0, to prevent this behavior, for the memory limit in the 31-50 GB range, the heap size is set to fixed 31 GB using the
enforceOopsCompressionparameter, which is enabled by default. For details, see Enforce OOPS compression. Exceeding the range causes loss of benefit of OOPS compression, so the ⅘ formula applies again.OpenSearch is write-heavy, so SSD is preferable as a disk type.
Hardware recommendations for OpenSearch¶ Cluster size
Memory limit (GB)
Heap size (GB)
CPU (# of cores)
Small
16
12.8
2
Medium
32
25.6
4
Large
64
51.2
8
To configure hardware settings for OpenSearch, refer to Resource limits in the Configure StackLight section.
Configure the maximum count of
mmapfiles. OpenSearch uses mmapfs to map shards stored on disk, which is set to65530by default.To verify
max_map_count:sysctl -n vm.max_map_count
To increase
max_map_count, follow the Create a custom host profile procedure.Example configuration:
kernelParameters: sysctl: vm.max_map_count: "<value>"
Extended retention periods, which depend on open shards, require increasing this value significantly. For example, to
262144.Configure swap as it significantly degrades performance. Lower
swappinessto1or0(to disable swap). For details, use the Create a custom host profile procedure.Example configuration:
kernelParameters: sysctl: vm.swappiness: "<value>"
Configure the kernel I/O scheduler to improve timing of disk writing operations. Change it to one of the following options:
none- applies the FIFO queue.mq-deadline- applies three queues: FIFO read, FIFO write, and sorted.
Changing I/O scheduling is also possible through
BareMetalHostProfile. However, the specific implementation highly depends on the disk type used:cat /sys/block/sda/queue/scheduler mq-deadline kyber bfq [none]
View Grafana dashboards¶
Using the Grafana web UI, you can view the visual representation of the metric graphs based on the time series databases.
Most Grafana dashboards include a View logs in OpenSearch Dashboards link to immediately view relevant logs in the OpenSearch Dashboards web UI. The OpenSearch Dashboards web UI displays logs filtered using the Grafana dashboard variables, such as the drop-downs. Once you amend the variables, wait for Grafana to generate a new URL.
Note
Due to the known issue, the View logs in OpenSearch Dashboards link does not work in Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). The issue is addressed in Container Cloud 2.26.1 (Cluster releases 17.1.1 and 16.1.1).
Caution
The Grafana dashboards that contain drop-down lists are limited to 1000 lines. Therefore, if you require data on a specific item, use the filter by name instead.
Note
Grafana dashboards that present node data have an additional Node identifier drop-down menu. By default, it is set to machine to display short names for Kubernetes nodes. To display Kubernetes node name labels, change this option to node.
To view the Grafana dashboards:
Log in to the Grafana web UI as described in Access StackLight web UIs.
From the drop-down list, select the required dashboard to inspect the status and statistics of the corresponding service in your management or managed cluster:
Component
Dashboard
Description
Ceph cluster
Ceph Cluster
Provides the overall health status of the Ceph cluster, capacity, latency, and recovery metrics.
Ceph Nodes
Provides an overview of the host-related metrics, such as the number of Ceph Monitors, Ceph OSD hosts, average usage of resources across the cluster, network and hosts load.
This dashboard is deprecated since Container Cloud 2.25.0 (Cluster releases 17.0.0, 16.0.0, 14.1.0) and is removed in Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0).
Therefore, Mirantis recommends switching to the following dashboards in the current release:
For Ceph stats, use the Ceph Cluster dashboard.
For resource utilization, use the System dashboard, which includes filtering by Ceph node labels, such as
ceph_role_osd,ceph_role_mon, andceph_role_mgr.
Ceph OSDs
Provides metrics for Ceph OSDs, including the Ceph OSD read and write latencies, distribution of PGs per Ceph OSD, Ceph OSDs and physical device performance.
Ceph Pools
Provides metrics for Ceph pools, including the client IOPS and throughput by pool and pools capacity usage.
Ironic bare metal
Ironic BM
Provides graphs on Ironic health, HTTP API availability, provisioned nodes by state and installed
ironic-conductorbackend drivers.Container Cloud
Clusters Overview
Represents the main cluster capacity statistics for all clusters of a Mirantis Container Cloud deployment where StackLight is installed.
Note
Due to the known issue, the Prometheus Targets Unavailable panel of the Clusters Overview dashboard does not display data for managed clusters of the 11.7.0, 11.7.4, 12.5.0, and 12.7.x series Cluster releases after update to Container Cloud 2.24.0.
Etcd
Available since Container Cloud 2.21.0 and 2.21.1 for MOSK 22.5. Provides graphs on database size, leader elections, requests duration, incoming and outgoing traffic.
MCC Applications Performance
Available since Container Cloud 2.23.0 and 2.23.1 for MOSK 23.1. Provides information on the Container Cloud internals work based on Golang, controller runtime, and custom metrics. You can use it to verify performance of applications and for troubleshooting purposes.
Kubernetes resources
Kubernetes Calico
Provides metrics of the entire Calico cluster usage, including the cluster status, host status, and Felix resources.
Kubernetes Cluster
Provides metrics for the entire Kubernetes cluster, including the cluster status, host status, and resources consumption.
Kubernetes Containers
Provides charts showing resource consumption per deployed Pod containers running on Kubernetes nodes.
Kubernetes Deployments
Provides information on the desired and current state of all service replicas deployed on a Container Cloud cluster.
Kubernetes Namespaces
Provides the Pods state summary and the CPU, MEM, network, and IOPS resources consumption per name space.
Kubernetes Nodes
Provides charts showing resources consumption per Container Cloud cluster node.
Kubernetes Pods
Provides charts showing resources consumption per deployed Pod.
NGINX
NGINX
Provides the overall status of the NGINX cluster and information about NGINX requests and connections.
StackLight
Alertmanager
Provides performance metrics on the overall health status of the Prometheus Alertmanager service, the number of firing and resolved alerts received for various periods, the rate of successful and failed notifications, and the resources consumption.
OpenSearch
Provides information about the overall health status of the OpenSearch cluster, including the resources consumption, number of operations and their performance.
OpenSearch Indices
Provides detailed information about the state of indices, including their size, the number and the size of segments.
Grafana
Provides performance metrics for the Grafana service, including the total number of Grafana entities, CPU and memory consumption.
PostgreSQL
Provides PostgreSQL statistics, including read (DQL) and write (DML) row operations, transaction and lock, replication lag and conflict, and checkpoint statistics, as well as PostgreSQL performance metrics.
Prometheus
Provides the availability and performance behavior of the Prometheus servers, the sample ingestion rate, and system usage statistics per server. Also, provides statistics about the overall status and uptime of the Prometheus service, the chunks number of the local storage memory, target scrapes, and queries duration.
Prometheus Relay
Provides service status and resources consumption metrics.
Reference Application
Available since Container Cloud 2.21.0 for non-MOSK clusters. Provides check statuses of Reference Application and statistics such as response time and content length.
Note
For the feature support on MOSK deployments, refer to MOSK documentation: Deploy RefApp using automation tools.
Telemeter Server
Provides statistics and the overall health status of the Telemeter service.
Note
Due to the known issue, the Telemeter Client Status panel of the Telemeter Server dashboard does not display data for managed clusters of the 11.7.0, 11.7.4, 12.5.0, and 12.7.x series Cluster releases after update to Container Cloud 2.24.0.
System
System
Provides a detailed resource consumption and operating system information per Container Cloud cluster node.
Mirantis Kubernetes Engine (MKE)
MKE Cluster
Provides a global overview of an MKE cluster: statistics about the number of the worker and manager nodes, containers, images, Swarm services.
MKE Containers
Provides per container resources consumption metrics for the MKE containers such as CPU, RAM, network.
Export data from Table panels of Grafana dashboards to CSV¶
This section describes how to export data from Table panels of
Grafana dashboards to .csv files.
Note
Grafana performs data exports for individual panels on a dashboard, not the entire dashboard.
To export data from Table panels of Grafana dashboards to CSV:
Log in to the Grafana web UI as described in Access StackLight web UIs.
In the right top corner of the required Table panel, click the kebab menu icon and select Inspect > Data.
In Data options of the Data tab, configure export options:
Enable Apply panel transformation
Leave Formatted data enabled
Enable Download for Excel, if required
Click Download CSV.
Available StackLight alerts¶
This section provides an overview of the available predefined StackLight alerts. To view the alerts, use the Prometheus web UI. To view the firing alerts, use Alertmanager or Alerta web UI.
For alert troubleshooting guidelines, see Troubleshoot alerts.
Alert dependencies¶
Note
The alert dependencies in this section apply to the latest supported Cluster releases.
Using alert inhibition rules, Alertmanager decreases alert noise by suppressing dependent alerts notifications to provide a clearer view on the cloud status and simplify troubleshooting. Alert inhibition rules are enabled by default.
The following table describes the dependency between alerts. Once an alert from the Alert column raises, the alert from the Inhibits and rules column will be suppressed with the Inhibited status in the Alertmanager web UI.
The Inhibits and rules column lists the labels and conditions, if any, for the inhibition to apply.
Alert |
Inhibits and rules |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
With the same
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
With the same
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
OpenSearchStorageUsageCriticalSince 2.26.0 (17.1.0 and 16.1.0)
|
|
OpenSearchStorageUsageMajorSince 2.26.0 (17.1.0 and 16.1.0)
|
|
|
With the same
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Alertmanager¶
This section describes the alerts for the Alertmanager service.
Available since 17.0.0, 16.0.0, and 14.1.0
Severity |
Major |
|---|---|
Summary |
Prometheus Alertmanager target down. |
Description |
Prometheus fails to scrape metrics from the {{ $labels.pod }} Pod on the {{ $labels.node }} node. |
Replaced with AlertmanagerTargetDown in 17.0.0, 16.0.0, and 14.1.0
Severity |
Major |
|---|---|
Summary |
Prometheus Alertmanager targets outage. |
Description |
Prometheus fails to scrape metrics from all Alertmanager endpoints (more than 1/10 failed scrapes). |
Severity |
Warning |
|---|---|
Summary |
Failure to reload Alertmanager configuration. |
Description |
Reloading the Alertmanager configuration has failed. |
Severity |
Major |
|---|---|
Summary |
Alertmanager cluster members cannot be found. |
Description |
Alertmanager has not found all other members of the cluster. |
Severity |
Warning |
|---|---|
Summary |
Alertmanager notifications fail. |
Description |
An average of |
Severity |
Warning |
|---|---|
Summary |
Alertmanager alerts are invalid. |
Description |
An average of |
Bond interface¶
Available since 2.24.0 and 2.24.2 for MOSK 23.2
This section describes the alerts for bond interface issues that may occur on clusters based on bare metal.
Severity |
Critical |
|---|---|
Summary |
|
Description |
The |
Severity |
Warning |
|---|---|
Summary |
|
Description |
The |
Severity |
Critical |
|---|---|
Summary |
|
Description |
The |
Severity |
Major |
|---|---|
Summary |
|
Description |
The |
Calico¶
This section describes the alerts for Calico.
Severity |
Warning |
|---|---|
Summary |
Data plane updates fail. |
Description |
The Felix daemon on the |
Severity |
Warning |
|---|---|
Summary |
Interface address messages in a batch exceed 5. |
Description |
The Felix daemon on the |
Severity |
Warning |
|---|---|
Summary |
Interface state messages in a batch exceed 5. |
Description |
The Felix daemon on the |
Severity |
Warning |
|---|---|
Summary |
ipset commands fail. |
Description |
The Felix daemon on the |
Severity |
Warning |
|---|---|
Summary |
iptables-save fails. |
Description |
The Felix daemon on the |
Severity |
Warning |
|---|---|
Summary |
iptables-restore fails. |
Description |
The Felix daemon on the |
Severity |
Major |
|---|---|
Summary |
Calico Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the Calico pod on the
|
Severity |
Critical |
|---|---|
Summary |
Calico Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from all Calico pods. |
Ceph¶
This section describes the alerts for the Ceph cluster.
Severity |
Warning |
|---|---|
Summary |
Ceph cluster health is |
Description |
The Ceph cluster is in the |
Severity |
Critical |
|---|---|
Summary |
Ceph cluster health is |
Description |
The Ceph cluster is in the |
Severity |
Critical |
|---|---|
Summary |
Ceph cluster Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the
|
Available since 15.0.0 and 14.0.0
Severity |
Warning |
|---|---|
Summary |
|
Description |
|
Available since 15.0.0 and 14.0.0
Severity |
Warning |
|---|---|
Summary |
Ceph Monitor clock skew detected. |
Description |
Ceph Monitor clock drift exceeds configured threshold on the Ceph cluster. |
Severity |
Major |
|---|---|
Summary |
Ceph cluster quorum at risk. |
Description |
The Ceph Monitors quorum on the Ceph cluster is low. |
Removed in 17.0.0, 16.0.0, and 14.1.0
Severity |
Critical |
|---|---|
Summary |
Ceph OSDs are down. |
Description |
|
Available since 15.0.0 and 14.0.0
Severity |
Warning |
|---|---|
Summary |
Ceph OSDs flap due to network issues. |
Description |
The Ceph OSD |
Severity |
Critical |
|---|---|
Summary |
Disk not responding. |
Description |
The |
Available since 15.0.0 and 14.0.0
Severity |
Warning |
|---|---|
Summary |
Cluster network slows down Ceph OSD heartbeats. |
Description |
Ceph OSD heartbeats on the cluster network (backend) of the cluster are slow. |
Available since 15.0.0 and 14.0.0
Severity |
Warning |
|---|---|
Summary |
Public network slows down Ceph OSD heartbeats. |
Description |
Ceph OSD heartbeats on the public network (front end) are running slow. |
Severity |
Warning |
|---|---|
Summary |
Ceph cluster is nearly full. |
Description |
The Ceph cluster utilization has crossed 85%. Expansion is required. |
Severity |
Critical |
|---|---|
Summary |
Ceph cluster is full. |
Description |
The Ceph cluster utilization has crossed 95% and needs immediate expansion. |
Severity |
Warning |
|---|---|
Summary |
Ceph OSDs have more than 200 PGs. |
Description |
Some Ceph OSDs contain more than 200 Placement Groups. This may have a negative impact on the cluster performance. For details, run ceph pg dump. |
Severity |
Critical |
|---|---|
Summary |
Ceph OSDs have more than 300 PGs. |
Description |
Some Ceph OSDs contain more than 300 Placement Groups. This may have a negative impact on the cluster performance. For details, run ceph pg dump. |
Severity |
Major |
|---|---|
Summary |
Ceph cluster has too many leader changes. |
Description |
The Ceph Monitor |
Since 17.0.0, 16.0.0, and 14.1.0 to replace CephNodeDown
Severity |
Critical |
|---|---|
Summary |
Ceph node |
Description |
The Ceph OSD node |
Renamed to CephOSDNodeDown in 17.0.0, 16.0.0, and 14.1.0
Severity |
Critical |
|---|---|
Summary |
Ceph node |
Description |
The Ceph node |
Severity |
Warning |
|---|---|
Summary |
Multiple versions of Ceph OSDs running. |
Description |
|
Severity |
Warning |
|---|---|
Summary |
Multiple versions of Ceph Monitors running. |
Description |
|
Severity |
Warning |
|---|---|
Summary |
Too many inconsistent Ceph PGs. |
Description |
The Ceph cluster detects inconsistencies in one or more replicas of an
object in |
Severity |
Warning |
|---|---|
Summary |
Too many undersized Ceph PGs. |
Description |
The Ceph cluster reports |
Docker Swarm¶
This section describes the alerts for the Docker Swarm service.
Severity |
Warning |
|---|---|
Summary |
Docker Swarm network unhealthy. |
Description |
The Note For the |
Severity |
Major |
|---|---|
Summary |
Docker Swarm node is flapping. |
Description |
The |
Severity |
Major |
|---|---|
Summary |
Docker Swarm replica is down. |
Description |
The |
Severity |
Major |
|---|---|
Summary |
Docker Swarm service is flapping. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Docker Swarm service outage. |
Description |
All |
Elasticsearch Exporter¶
This section describes the alerts for the Elasticsearch Exporter service.
Severity |
Critical |
|---|---|
Summary |
Elasticsearch Exporter Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the Elasticsearch Exporter service. |
Severity |
Major |
|---|---|
Summary |
Prometheus Elasticsearch Exporter Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the Prometheus Elasticsearch Exporter service. |
Etcd¶
This section describes the alerts for the etcd service.
Available since 12.5.0, 11.5.0, and 7.11.0
Severity |
Critical |
|---|---|
Summary |
Etcd database passed 95% of quota. |
Description |
The |
Available since 12.5.0, 11.5.0, and 7.11.0
Severity |
Major |
|---|---|
Summary |
Etcd database passed 85% of quota. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Etcd cluster has insufficient members. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Etcd cluster has no leader. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Etcd cluster has detected more than 3 leader changes within the last hour. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Etcd cluster has more than 5 proposal failures. |
Description |
The |
Since 17.0.0, 16.0.0, and 14.1.0 to replace etcdTargetsOutage
Severity |
Critical |
|---|---|
Summary |
Etcd cluster Prometheus target down. |
Description |
Prometheus fails to scrape metrics from the etcd
|
Replaced with etcdTargetDown in 17.0.0, 16.0.0, and 14.1.0
Severity |
Critical |
|---|---|
Summary |
Etcd cluster Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from 2/3 of etcd nodes (more than 1/10 failed scrapes). |
External endpoint¶
This section describes the alerts for external endpoints.
Severity |
Critical |
|---|---|
Summary |
External endpoint is down. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Failure to establish a TCP or TLS connection. |
Description |
The system cannot establish a TCP or TLS connection to
|
Severity |
Critical |
|---|---|
Summary |
|
Description |
Prometheus fails to probe the |
Fluentd¶
This section describes the alerts for Fluentd-logs.
Severity |
Major |
|---|---|
Summary |
Fluentd Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the Fluentd pod on the
|
Severity |
Critical |
|---|---|
Summary |
Fluentd Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from all Fluentd pods. |
General alerts¶
This section lists the general available alerts.
Severity |
Critical |
|---|---|
Summary |
|
Description |
The |
Severity |
None |
|---|---|
Summary |
Watchdog alert that is always firing. |
Description |
This alert ensures that the entire alerting pipeline is functional.
This alert should always be firing in Alertmanager against a receiver.
Some integrations with various notification mechanisms can send a
notification when this alert is not firing. For example, the
|
Severity |
Major |
|---|---|
Summary |
|
Description |
Prometheus fails to scrape metrics from all
|
General node alerts¶
This section lists the general alerts for Kubernetes nodes.
Severity |
Major |
|---|---|
Summary |
Node uses 90% of file descriptors. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Node uses 80% of file descriptors. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Node Exporter Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the Node Exporter endpoint on
the |
Severity |
Critical |
|---|---|
Summary |
Node Exporter Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from all Node Exporter endpoints. |
Severity |
Warning |
|---|---|
Summary |
High CPU consumption. |
Description |
The average CPU consumption on the |
Severity |
Warning |
|---|---|
Summary |
System load is more than 1 per CPU. |
Description |
The system load per CPU on the |
Severity |
Critical |
|---|---|
Summary |
System load is more than 2 per CPU. |
Description |
The system load per CPU on the |
Severity |
Warning |
|---|---|
Summary |
Disk partition |
Description |
The |
Severity |
Major |
|---|---|
Summary |
Disk partition |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
|
Description |
The |
Severity |
Major |
|---|---|
Summary |
|
Description |
The |
Severity |
Warning |
|---|---|
Summary |
The |
Description |
The |
Severity |
Major |
|---|---|
Summary |
The |
Description |
The |
Grafana¶
This section describes the alerts for Grafana.
Severity |
Major |
|---|---|
Summary |
Grafana Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the
|
Helm Controller¶
This section lists the alerts for the Helm Controller service
and the HelmBundle custom resources.
For troubleshooting guidelines, see Troubleshoot Helm Controller alerts.
Severity |
Critical |
|---|---|
Summary |
HelmBundle release is not deployed. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Helm Controller reconciliation is down. |
Description |
Reconciliation fails in the |
Severity |
Critical |
|---|---|
Summary |
Helm Controller Prometheus target is down |
Description |
Prometheus fails to scrape metrics from the
|
Ironic¶
This section describes the alerts for Ironic bare metal. The alerted events include Ironic API availability and Ironic processes availability.
Removed since 2.24.0 in favor of IronicBmApiOutage
Severity |
Major |
|---|---|
Summary |
Ironic metrics missing. |
Description |
Metrics retrieved from the Ironic Exporter are not available for 2 minutes. |
Severity |
Critical |
|---|---|
Summary |
Ironic API outage. |
Description |
The Ironic API is not accessible. |
Severity |
Critical |
|---|---|
Summary |
Ironic Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the Ironic service. |
Kernel¶
This section describes the alerts for Ubuntu kernel.
Available since 2.27.0 (Cluster releases 17.2.0 and 16.2.0)
Severity |
Critical |
|---|---|
Summary |
The |
Description |
The |
Kubernetes applications¶
This section lists the alerts for Kubernetes applications.
For troubleshooting guidelines, see Troubleshoot Kubernetes applications alerts.
Severity |
Warning |
|---|---|
Summary |
Pod of |
Description |
At least one Pod container of
|
Removed in 17.0.0, 16.0.0, and 14.1.0
Severity |
Warning |
|---|---|
Summary |
Pods of |
Description |
|
Severity |
Warning |
|---|---|
Summary |
|
Description |
The Pod of |
Severity |
Major |
|---|---|
Summary |
Deployment |
Description |
The |
Severity |
Major |
|---|---|
Summary |
Deployment |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Deployment |
Description |
The |
Severity |
Major |
|---|---|
Summary |
StatefulSet |
Description |
The |
Severity |
Major |
|---|---|
Summary |
StatefulSet |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
StatefulSet |
Description |
The |
Severity |
Major |
|---|---|
Summary |
StatefulSet |
Description |
The |
Severity |
Major |
|---|---|
Summary |
DaemonSet |
Description |
|
Severity |
Warning |
|---|---|
Summary |
DaemonSet |
Description |
|
Removed in 2.27.0 (17.2.0 and 16.2.0)
Severity |
Warning |
|---|---|
Summary |
DaemonSet |
Description |
|
Severity |
Critical |
|---|---|
Summary |
DaemonSet |
Description |
All Pods of the |
Severity |
Warning |
|---|---|
Summary |
CronJob |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Job |
Description |
|
Kubernetes resources¶
This section lists the alerts for Kubernetes resources.
For troubleshooting guidelines, see Troubleshoot Kubernetes resources alerts.
Severity |
Warning |
|---|---|
Summary |
Kubernetes has overcommitted CPU requests. |
Description |
The Kubernetes cluster has overcommitted CPU resource requests for Pods and cannot tolerate node failure. |
Severity |
Warning |
|---|---|
Summary |
Kubernetes has overcommitted memory requests. |
Description |
The Kubernetes cluster has overcommitted memory resource requests for Pods and cannot tolerate node failure. |
Severity |
Warning |
|---|---|
Summary |
Containers CPU throttling. |
Description |
|
Kubernetes storage¶
This section lists the alerts for Kubernetes storage.
For troubleshooting guidelines, see Troubleshoot Kubernetes storage alerts.
Caution
Due to the upstream bug in Kubernetes,
metrics for the KubePersistentVolumeUsageCritical and
KubePersistentVolumeFullInFourDays alerts that are collected
for persistent volumes provisioned by cinder-csi-plugin
are not available.
Severity |
Critical |
|---|---|
Summary |
PersistentVolume |
Description |
The PersistentVolume claimed by |
Severity |
Warning |
|---|---|
Summary |
PersistentVolume |
Description |
The PersistentVolume claimed by |
Severity |
Critical |
|---|---|
Summary |
PersistentVolume |
Description |
The PersistentVolume |
Kubernetes system¶
This section lists the alerts for the Kubernetes system.
Severity |
Warning |
|---|---|
Summary |
Node |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
|
Description |
Prometheus fails to scrape metrics from the |
Severity |
Warning |
|---|---|
Summary |
Kubernetes components version mismatch. |
Description |
There are |
Severity |
Critical |
|---|---|
Summary |
Kubelet Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from kubelet on the
|
Severity |
Critical |
|---|---|
Summary |
Kubelet Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from kubelet on all nodes (more than 1/10 failed scrapes). |
Severity |
Warning |
|---|---|
Summary |
Kubernetes API client has more than 1% of error requests. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Failure to get Kubernetes container metrics. |
Description |
cAdvisor was not able to scrape metrics from some containers on the
|
Removed in 17.0.0, 16.0.0, and 14.1.0
Severity |
Critical |
|---|---|
Summary |
CoreDNS Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from all CoreDNS endpoints (more than 1/10 failed scrapes). |
Severity |
Warning |
|---|---|
Summary |
kubelet reached 90% of Pods limit. |
Description |
The kubelet container on the |
Severity |
Major |
|---|---|
Summary |
cAdvisor Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the cAdvisor endpoint on the
|
Severity |
Critical |
|---|---|
Summary |
cAdvisor Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from all cAdvisor endpoints. |
Severity |
Critical |
|---|---|
Summary |
A Kubernetes API endpoint is down. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Kubernetes API is down. |
Description |
The Kubernetes API is not accessible for the last 30 seconds. |
Severity |
Major |
|---|---|
Summary |
API server is returning errors for more than 3% of requests. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
API server is returning errors for more than 1% of requests. |
Description |
The API server is returning errors for |
Severity |
Major |
|---|---|
Summary |
API server is returning errors for 10% of requests. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
API server is returning errors for 5% of requests. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Client certificate expires in 7 days. |
Description |
The client certificate used to authenticate to the API server expires in less than 7 days. |
Severity |
Critical |
|---|---|
Summary |
Client certificate expires in 24 hours. |
Description |
The client certificate used to authenticate to the API server expires in less than 24 hours. |
Severity |
Major |
|---|---|
Summary |
Kubernetes API certificate expires in less than 10 days. |
Description |
The SSL certificate for Kubernetes API expires in less than 10 days. |
Severity |
Warning |
|---|---|
Summary |
Kubernetes API certificate expires in less than 30 days. |
Description |
The SSL certificate for Kubernetes API expires in less than 30 days. |
Severity |
Critical |
|---|---|
Summary |
Kubernetes API server Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from 2/3 of Kubernetes API server endpoints. |
Severity |
Critical |
|---|---|
Summary |
Kubernetes master API Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from 2/3 of Kubernetes master API nodes. |
Mirantis Container Cloud¶
This section describes the alerts for Mirantis Container Cloud. These alerts are based on metrics from the Mirantis Container Cloud Metric Exporter (MCC Exporter) service.
For troubleshooting guidelines, see Troubleshoot Mirantis Container Cloud Exporter alerts.
Severity |
Informational |
|---|---|
Summary |
Mirantis Container Cloud cluster is updating. |
Description |
The Mirantis Container Cloud
|
Severity |
Critical |
|---|---|
Summary |
MCC Exporter Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the MCC Exporter service. |
Severity |
Critical |
|---|---|
Summary |
Mirantis Container Cloud license expires in less than 10 days. |
Description |
The Mirantis Container Cloud license expires in
|
Severity |
Warning |
|---|---|
Summary |
Mirantis Container Cloud license expires in less than 30 days. |
Description |
The Mirantis Container Cloud license expires in
|
Mirantis Container Cloud cache¶
This section describes the alerts for mcc-cache.
Severity |
Major |
|---|---|
Summary |
|
Description |
Prometheus fails to scrape metrics from the
|
Mirantis Container Cloud controllers¶
Available since Cluster releases 12.7.0 and 11.7.0
This section describes the alerts for the mcc-controllers service.
Severity |
Critical |
|---|---|
Summary |
|
Description |
Prometheus fails to scrape metrics from the
|
Mirantis Container Cloud providers¶
Available since Cluster releases 12.7.0 and 11.7.0
This section describes the alerts for the mcc-providers service.
Severity |
Critical |
|---|---|
Summary |
|
Description |
Prometheus fails to scrape metrics from the
|
Mirantis Kubernetes Engine¶
This section describes the alerts for the Mirantis Kubernetes Engine (MKE) cluster.
For troubleshooting guidelines, see Troubleshoot Mirantis Kubernetes Engine alerts.
Severity |
Major |
|---|---|
Summary |
MKE API certificate expires in less than 10 days. |
Description |
The SSL certificate for MKE API expires in less than 10 days. |
Severity |
Warning |
|---|---|
Summary |
MKE API certificate expires in less than 30 days. |
Description |
The SSL certificate for MKE API expires in less than 30 days. |
Severity |
Critical |
|---|---|
Summary |
MKE API endpoint is down. |
Description |
The MKE API endpoint on the |
Severity |
Critical |
|---|---|
Summary |
MKE API is down. |
Description |
The MKE API (port 443) is not accessible for the last 1 minute. |
Severity |
Major |
|---|---|
Summary |
MKE containers are |
Description |
|
Severity |
Critical |
|---|---|
Summary |
MKE manager API cluster Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from 2/3 of MKE manager API nodes. |
Severity |
Critical |
|---|---|
Summary |
MKE metrics controller Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from all MKE metrics controller endpoints. |
Severity |
Major |
|---|---|
Summary |
MKE metrics engine Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the MKE metrics engine on the
|
Severity |
Critical |
|---|---|
Summary |
MKE metrics engine Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from the MKE metrics engine on all nodes. |
Severity |
Critical |
|---|---|
Summary |
MKE node disk is 95% full. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
MKE node disk is 85% full. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
MKE node is down. |
Description |
The |
NGINX¶
This section lists the alerts for the NGINX service.
Severity |
Critical |
|---|---|
Summary |
The NGINX service is down. |
Description |
The NGINX service on the |
Severity |
Warning |
|---|---|
Summary |
NGINX drops incoming connections. |
Description |
The NGINX service on the |
Severity |
Critical |
|---|---|
Summary |
NGINX Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the NGINX endpoint(s) (more than 1/10 failed scrapes). |
Node network¶
This section lists the alerts for a Kubernetes node network.
Severity |
Critical |
|---|---|
Summary |
|
Description |
The |
Severity |
Critical |
|---|---|
Summary |
|
Description |
The |
Severity |
Major |
|---|---|
Summary |
60 received packets were dropped. |
Description |
|
Severity |
Major |
|---|---|
Summary |
100 transmitted packets were dropped. |
Description |
|
Severity |
Warning |
|---|---|
Summary |
|
Description |
The |
Node time¶
This section lists the alerts for a Kubernetes node time.
Severity |
Warning |
|---|---|
Summary |
NTP offset reached the limit of 0.03 seconds. |
Description |
Clock skew was detected on the |
OpenSearch¶
This section describes the alerts for the OpenSearch service.
See also
Severity |
Critical |
|---|---|
Summary |
OpenSearch heap usage is too high (>90%). |
Description |
The heap usage of the OpenSearch |
Severity |
Warning |
|---|---|
Summary |
OpenSearch heap usage is high (>80%). |
Description |
The heap usage of the OpenSearch |
Severity |
Critical |
|---|---|
Summary |
OpenSearch critical status. |
Description |
The OpenSearch |
Severity |
Warning |
|---|---|
Summary |
OpenSearch warning status. |
Description |
The OpenSearch |
Available since 2.22.0
Severity |
Warning |
|---|---|
Summary |
OpenSearch PVC size mismatch |
Description |
The PVC size requested by OpenSearch StatefulSet does not match the configured PVC size. To troubleshoot the issue, refer to OpenSearchPVCMismatch alert raises due to the OpenSearch PVC size mismatch. |
Severity |
Warning |
|---|---|
Summary |
Shards relocation takes more than 20 minutes. |
Description |
The number of relocating shards in the OpenSearch cluster
|
Severity |
Warning |
|---|---|
Summary |
Shards initialization takes more than 10 minutes. |
Description |
The number of initializing shards in the OpenSearch cluster
|
Removed in 2.27.0 (17.2.0 and 16.2.0)
Severity |
Major |
|---|---|
Summary |
Shards have unassigned status for 10 minutes. |
Description |
The number of unassigned shards in the OpenSearch cluster
|
Severity |
Warning |
|---|---|
Summary |
Tasks have pending state for 10 minutes. |
Description |
The number of pending tasks in the OpenSearch cluster
|
Available since 2.26.0 (17.1.0 and 16.1.0)
Severity |
Critical |
|---|---|
Summary |
OpenSearch node reached 95% of storage usage |
Description |
Storage usage of |
Available since 2.26.0 (17.1.0 and 16.1.0)
Severity |
Major |
|---|---|
Summary |
OpenSearch node reached 90% of storage usage |
Description |
Storage usage of |
PostgreSQL¶
This section lists the alerts for the PoststgreSQL and Patroni services.
Severity |
Critical |
|---|---|
Summary |
Patroni cluster member is experiencing data page corruption. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
PostgreSQL transactions deadlocks. |
Description |
The transactions submitted to the |
Severity |
Warning |
|---|---|
Summary |
Insufficient memory for PostgreSQL queries. |
Description |
The query data does not fit into working memory of the
|
Severity |
Critical |
|---|---|
Summary |
Patroni cluster split-brain detected. |
Description |
The |
Severity |
Major |
|---|---|
Summary |
Patroni cluster primary node is missing. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Patroni cluster has replicas with inoperable PostgreSQL. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Patroni cluster has non-streaming replicas. |
Description |
The |
Severity |
Major |
|---|---|
Summary |
Replication has stopped. |
Description |
Replication has stopped on the
|
Severity |
Warning |
|---|---|
Summary |
WAL segment application is slow. |
Description |
Slow replication while applying WAL segments on the
|
Severity |
Warning |
|---|---|
Summary |
Streaming replication is slow. |
Description |
Slow replication while downloading WAL segments for the
|
See also
Severity |
Major |
|---|---|
Summary |
Patroni cluster WAL segment writes are failing. |
Description |
The |
Replaced with PostgresqlTargetDown in 17.0.0, 16.0.0, and 14.1.0
Severity |
Critical |
|---|---|
Summary |
Patroni cluster Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from 2/3 of Patroni
|
Since 17.0.0, 16.0.0, and 14.1.0 to replace PostgresqlTargetsOutage
Severity |
Critical |
|---|---|
Summary |
Patroni cluster Prometheus target down. |
Description |
Prometheus fails to scrape metrics from the
|
Prometheus¶
This section describes the alerts for the Prometheus service.
Severity |
Warning |
|---|---|
Summary |
Failure to reload the Prometheus configuration. |
Description |
Reloading of the Prometheus configuration has failed. |
Severity |
Warning |
|---|---|
Summary |
Prometheus alert notification queue is running full. |
Description |
The Prometheus alert notification queue is running full for the
|
Severity |
Warning |
|---|---|
Summary |
Errors while sending alerts from Prometheus. |
Description |
Errors while sending alerts from the
|
Severity |
Major |
|---|---|
Summary |
Errors while sending alerts from Prometheus. |
Description |
Errors while sending alerts from the
|
Severity |
Warning |
|---|---|
Summary |
Prometheus is not connected to any Alertmanager. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Prometheus has issues reloading data blocks from disk. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Prometheus has issues compacting sample blocks. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Prometheus encountered WAL corruptions. |
Description |
The |
Severity |
Major |
|---|---|
Summary |
Prometheus does not ingest samples. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Prometheus has many samples rejected. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Prometheus failed to evaluate recording rules. |
Description |
The |
Since 17.0.0, 16.0.0, 14.1.0 to replace PrometheusServerTargetsOutage
Severity |
Critical |
|---|---|
Summary |
Prometheus server target down. |
Description |
Prometheus fails to scrape metrics from the
|
Replaced with PrometheusServerTargetDown in 17.0.0, 16.0.0, 14.1.0
Severity |
Critical |
|---|---|
Summary |
Prometheus server targets outage. |
Description |
Prometheus fails to scrape metrics from all of its endpoints (more than 1/10 failed scrapes). |
Prometheus MS Teams¶
This section lists the alerts for the Prometheus MS Teams service.
Severity |
Major |
|---|---|
Summary |
Prometheus MS Teams Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the
|
Prometheus Relay¶
This section describes the alerts for the Prometheus Relay service.
Severity |
Major |
|---|---|
Summary |
Prometheus Relay Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the
|
Reference Application¶
Available since 2.21.0 for non-MOSK managed clusters
Note
For the feature support on MOSK deployments, refer to MOSK documentation: Deploy RefApp using automation tools.
This section describes the alerts for the Reference Application service.
Severity |
Critical |
|---|---|
Summary |
Reference Application DNS lookup takes too long. |
Description |
The DNS lookup of the Reference Application probe takes on average more than 20 milliseconds for the last 2 minutes (based on at least 12 probes). |
Severity |
Warning |
|---|---|
Summary |
Reference Application service is down. |
Description |
The Reference Application service is not accessible for more than 5% of probes for the last 2 minutes (based on at least 12 probes). |
Severity |
Critical |
|---|---|
Summary |
Reference Application probe takes too long. |
Description |
The Reference Application probe takes on average more than 100 milliseconds for the last 2 minutes (based on at least 12 probes). |
Severity |
Warning |
|---|---|
Summary |
Reference Application target is down. |
Description |
Prometheus fails to probe the Reference Application service for more than 5% of attempts for the last 2 minutes (based on at least 12 attempts). |
Release Controller¶
This section describes the alerts for the Mirantis Container Cloud Release Controller service.
For troubleshooting guidelines, see Troubleshoot Release Controller alerts.
Severity |
Critical |
|---|---|
Summary |
Release Controller deployment is missing or has 0 replicas. |
Description |
The Release Controller deployment is not present or scaled down to 0 replicas. |
ServiceNow¶
This section lists the alerts for the ServiceNow receiver service.
Severity |
Major |
|---|---|
Summary |
|
Description |
The |
Severity |
Major |
|---|---|
Summary |
|
Description |
Prometheus fails to scrape metrics from the
|
Salesforce notifier¶
This section lists the alerts for the Salesforce notifier service.
Severity |
Critical |
|---|---|
Summary |
Failure to authenticate to Salesforce. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Salesforce notifier Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the
|
SSL certificates¶
This section lists the alerts for SSL certificates.
Severity |
Warning |
|---|---|
Summary |
SSL certificate expires in less than 30 days. |
Description |
The SSL certificate for |
Severity |
Major |
|---|---|
Summary |
SSL certificate expires in less than 10 days. |
Description |
The SSL certificate for |
Severity |
Critical |
|---|---|
Summary |
SSL certificate probes are failing. |
Description |
The SSL certificate probes for |
Severity |
Critical |
|---|---|
Summary |
|
Description |
Prometheus fails to probe the |
Severity |
Major |
|---|---|
Summary |
SSL certificate for a Mirantis Container Cloud service expires in less than 10 days. |
Description |
The SSL certificate for the Mirantis Container Cloud
|
Severity |
Warning |
|---|---|
Summary |
SSL certificate for a Mirantis Container Cloud service expires in less than 30 days. |
Description |
The SSL certificate for the Mirantis Container Cloud
|
Severity |
Major |
|---|---|
Summary |
Mirantis Container Cloud |
Description |
Prometheus fails to probe 2/3 of the Mirantis Container Cloud
|
Severity |
Critical |
|---|---|
Summary |
SSL certificate probes for a Mirantis Container Cloud service are failing. |
Description |
SSL certificate probes for the Mirantis Container Cloud
|
Severity |
Critical |
|---|---|
Summary |
Mirantis Container Cloud |
Description |
Prometheus fails to probe the Mirantis Container Cloud
|
Telegraf¶
This section lists the alerts for the Telegraf service.
Severity |
Major |
|---|---|
Summary |
|
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Telegraf Docker Swarm Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the |
Removed in MOSK 24.1
Severity |
Critical |
|---|---|
Summary |
Telegraf OpenStack Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the Telegraf OpenStack service. |
Severity |
Major |
|---|---|
Summary |
Telegraf SMART Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the Telegraf SMART endpoint on
the |
Severity |
Critical |
|---|---|
Summary |
Telegraf SMART Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from all Telegraf SMART endpoints. |
Telemeter¶
This section describes the alerts for the Telemeter service.
Severity |
Warning |
|---|---|
Summary |
Telemeter client failed to federate or send data. |
Description |
Telemeter client has failed to federate data from the Prometheus or send data to the Telemeter server more than four times for the last 10 minutes. |
Severity |
Warning |
|---|---|
Summary |
Telemeter client failed to federate or send data. |
Description |
Telemeter client has failed to federate data from the Prometheus or send data to the Telemeter server more than once for the last 10 minutes. |
Severity |
Major |
|---|---|
Summary |
Telemeter client Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the
|
Severity |
Major |
|---|---|
Summary |
Telemeter server Prometheus federation target is down. |
Description |
Prometheus fails to federate metrics from the
|
Severity |
Major |
|---|---|
Summary |
Telemeter server Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the
|
Troubleshoot alerts¶
This section describes the root causes, investigation, and mitigation steps for the available predefined StackLight alerts.
Note
The list of alerts in this section is not full and will be expanded.
Troubleshoot cAdvisor alerts¶
This section describes the investigation and troubleshooting steps for the cAdvisor service.
Root cause |
The alert is based on the metric |
|---|---|
Investigation |
The alert usually fires when a Pod starts, often during brief intervals. It may solve automatically once the Pod CPU usage stabilizes. If the issue persists:
|
Mitigation |
As a possible solution, increase Pod limits. |
Troubleshoot Helm Controller alerts¶
This section describes the investigation and troubleshooting steps for the Helm Controller service and the HelmBundle custom resources.
Root cause |
Helm Controller release status differs from |
|---|---|
Investigation |
|
Mitigation |
If the chart artifact is not accessible from your cluster, investigate the network-related alerts, if any, and verify that the file is available in the repository. |
See also
Root cause |
Helm Controller failed to reconcile the HelmBundle spec. |
|---|---|
Investigation and mitigation |
Refer to HelmBundleReleaseNotDeployed. |
Root cause |
Prometheus fails in at least 10% of Helm Controller metrics scrapes. The following two components can cause the alert to fire:
|
|---|---|
Investigation and mitigation |
|
Troubleshoot Ubuntu kernel alerts¶
This section describes the investigation and troubleshooting steps for the Ubuntu kernel alerts.
Available since 2.27.0 (Cluster releases 17.2.0 and 16.2.0)
Root cause |
Kernel logs generated IO error logs, potentially indicating disk issues. IO errors may occur due to various reasons and are often unpredictable. |
|---|---|
Investigation |
Inspect kernel logs on affected nodes for If the issue is not related to a faulty disk, further inspect errors in logs to identify the root cause. |
Mitigation |
Mitigation steps depend on the identified issue. If the issue is caused by a faulty disk, replace the affected disk. Additionally, consider the following measures to prevent such issues in the future:
|
Troubleshoot Kubernetes applications alerts¶
This section describes the investigation and troubleshooting steps for the Kubernetes applications alerts.
Related inhibited alert: KubePodsRegularLongTermRestarts.
Root cause |
Termination of containers in Pods having |
|---|---|
Investigation |
Note Verify if there are more alerts firing in the Container Cloud cluster to obtain more information on the cluster state and simplify issue investigation and mitigation. Also examine the relation of the affected application with other applications (dependencies) and Kubernetes resources it relies on. During investigation, the affected Pod will likely be in the
|
Mitigation |
Fixes typically fall into one of the following categories:
|
Removed in 17.0.0, 16.0.0, and 14.1.0
Root cause |
The Pod could not start successfully for the last 15 minutes, meaning that its status phase is one of the following:
|
|---|---|
Investigation |
Note Verify if there are more alerts firing in the Container Cloud cluster to obtain more information on the cluster state and simplify issue investigation and mitigation. Also examine the relation of the affected application with other applications (dependencies) and Kubernetes resources it relies on.
|
Mitigation |
|
See also
Related inhibiting alert: KubePodsCrashLooping.
Root cause |
It is a long-term version of the |
|---|---|
Investigation |
While investigating, the affected Pod will likely be in the
|
Mitigation |
Refer to the KubePodsCrashLooping Mitigation section. Fixing this issue may require more effort than simple application tuning. You may need to upgrade the application, upgrade its dependency libraries, or apply a fix in the application code. |
Root cause |
Deployment generation, or
When the Deployment controller fails to observe a new Deployment version, these 2 fields differ. The mismatch lasting for more than 15 minutes triggers the alert. |
|---|---|
Investigation and mitigation |
The alert indicates failure of a Kubernetes built-in Deployment controller and requires debugging on the control plane level. See Troubleshooting for details on collecting cluster state and mitigating known issues. |
Root cause |
The number of available Deployment replicas did not match the desired
state set in the |
|---|---|
Investigation and mitigation |
Refer to KubePodsCrashLooping. |
Related inhibited alert: KubeDeploymentReplicasMismatch.
Root cause |
All Deployment replicas are unavailable for the last 10 minutes, meaning that the application is likely down. |
|---|---|
Investigation |
|
Mitigation |
Refer to KubePodsCrashLooping. |
Root cause |
The number of running StatefulSet replicas did not match the desired
state set in the |
|---|---|
Investigation and mitigation |
Refer to KubePodsCrashLooping. |
Root cause |
StatefulSet generation, or
When the StatefulSet controller fails to observe a new StatefulSet version, these 2 fields differ. The mismatch lasting for more than 15 minutes triggers the alert. |
|---|---|
Investigation and mitigation |
The alert indicates failure of a Kubernetes built-in StatefulSet controller and requires debugging on the control plane level. See Troubleshooting for details on collecting cluster state and mitigating known issues. |
Related inhibited alerts: KubeStatefulSetReplicasMismatch and
KubeStatefulSetUpdateNotRolledOut.
Root cause |
StatefulSet workloads are typically distributed across Kubernetes nodes. Therefore, losing more than one replica indicates either a serious application failure or issues on the Kubernetes cluster level. The application likely experiences severe performance degradation and availability issues. |
|---|---|
Investigation |
|
Mitigation |
Refer to KubePodsCrashLooping. If after fixing the root cause
on the Pod level the affected Pods are still non- |
Root cause |
The StatefulSet update did not finish in 30 minutes, which was
detected in the mismatch of the |
|---|---|
Investigation |
|
Mitigation |
Refer to KubePodsCrashLooping. If after fixing the root cause on the Pod level the affected Pods are still non-Running, contact Mirantis support. Treat StatefulSets with special caution as they store data and their internal state. Improper handling may result in a broken application cluster state and data loss. |
Related inhibiting alert: KubeDaemonSetOutage.
Root cause |
For the last 30 minutes, DaemonSet has at least one Pod (not necessarily the same one), which is not ready after being correctly scheduled. It may be caused by missing Pod requirements on the node or unexpected Pod termination. |
|---|---|
Investigation |
|
Mitigation |
See KubePodsCrashLooping. |
See also
Can relate to: KubeCPUOvercommitPods, KubeMemOvercommitPods.
Root cause |
At least one Pod of the DaemonSet was not scheduled to a target node. This may happen if resource requests for the Pod cannot be satisfied by the node or if the node lacks other resources that the Pod requires, such as PV of a specific storage class. |
|---|---|
Investigation |
|
Mitigation |
Removed in 2.27.0 (17.2.0 and 16.2.0)
Root cause |
At least one node where the DaemonSet Pods were deployed got a
|
|---|---|
Investigation |
|
Mitigation |
|
Related inhibiting alert: KubeDaemonSetRolloutStuck.
Root cause |
Although the DaemonSet was not scaled down to zero, there are zero healthy Pods. As each DaemonSet Pod is deployed to a separate Kubernetes node, such situation is rare and typically caused by a broken configuration (ConfigMaps or Secrets) or wrongly tuned resource limits. |
|---|---|
Investigation |
|
Mitigation |
See KubePodsCrashLooping. |
See also
Related alert: ClockSkewDetected.
Root cause |
A CronJob Pod fails to start in 15 minutes from the configured schedule due to the following possible root causes:
|
|---|---|
Investigation |
|
Mitigation |
|
Related inhibited alert: KubePodsNotReady.
Root cause |
At least one container of a Pod started by the Job exited with a non-zero status or was terminated by the Kubernetes or Linux system. |
|---|---|
Investigation |
See KubePodsCrashLooping. |
Mitigation |
|
See also
Troubleshoot Kubernetes resources alerts¶
This section describes the investigation and troubleshooting steps for the Kubernetes resources alerts.
Root cause |
The sum of Kubernetes Pods CPU requests is higher than the average capacity of the cluster without one node or 80% of total nodes CPU capacity, depending on what is higher. It is a common issue of a cluster with too many resources deployed. |
|---|---|
Investigation |
Select one of the following options to verify nodes CPU requests:
|
Mitigation |
Increase the node(s) CPU capacity or add a worker node(s). |
Root cause |
The sum of Kubernetes Pods RAM requests is higher than the average capacity of the cluster without one node or 80% of total nodes RAM capacity, depending on what is higher. It is a common issue of a cluster with too many resources deployed. |
|---|---|
Investigation |
Select one of the following options to verify nodes RAM requests:
|
Mitigation |
Increase the node(s) CPU capacity or add a worker node(s). |
Troubleshoot Kubernetes storage alerts¶
This section describes the investigation and troubleshooting steps for the Kubernetes storage alerts.
Related inhibited alert: KubePersistentVolumeFullInFourDays.
Root cause |
Persistent volume (PV) has less than 3% of free space. Applications that rely on writing to the disk will crash without space available. |
|---|---|
Investigation and mitigation |
Refer to KubePersistentVolumeFullInFourDays. |
Root cause |
The PV has less than 15% of total space available. Based on the
|
|---|---|
Investigation |
|
Mitigation |
Select from the following options:
|
Root cause |
Some PVs are in the |
|---|---|
Investigation |
|
Mitigation |
|
Troubleshoot Kubernetes system alerts¶
This section describes the investigation and troubleshooting steps for the Kubernetes system alerts.
Root cause |
A node has entered the
|
|---|---|
Investigation |
|
Mitigation |
Contact Mirantis support for a detailed procedure on dealing with each of the root causes. |
Root cause |
The number of Pods reached 90% of Kubernetes node capacity. |
|---|---|
Investigation |
|
Mitigation |
|
Root cause |
Prometheus scraping of the Related alert: |
|---|---|
Investigation |
In the Prometheus web UI, search for firing alerts that relate to networking issues in the Container Cloud cluster and fix them. If the cluster network is healthy, refer to the
Investigation section of the
|
Mitigation |
Based on the investigation results, select from the following options:
If the issue still persists, collect the investigation output and contact Mirantis support for further information. |
Root cause |
The Prometheus Blackbox Exporter target probing Related alert: |
|---|---|
Investigation |
In the Prometheus web UI, search for firing alerts that relate to networking issues in the Container Cloud cluster and fix them. If the cluster network is healthy, refer to the
Investigation section of the
|
Mitigation |
Based on the investigation results, select from the following options:
If the issue still persists, collect the investigation output and contact Mirantis support for further information. |
Troubleshoot Mirantis Container Cloud Exporter alerts¶
This section describes the investigation and troubleshooting steps for the Mirantis Container Cloud Exporter (MCC Exporter) service alerts.
Root cause |
Prometheus failed to scrape MCC Exporter metrics because of the
|
|---|---|
Investigation |
For further steps, see the Investigation section of the KubePodsCrashLooping alert. |
Mitigation |
Refer to KubePodsCrashLooping. |
Troubleshoot Mirantis Kubernetes Engine alerts¶
This section describes the investigation and troubleshooting steps for the Mirantis Kubernetes Engine (MKE) cluster alerts.
Root cause |
MKE cluster root certificate authority (CA) expires in less than 10 days. |
|---|---|
Investigation |
|
Mitigation |
Contact Mirantis support for a detailed procedure on certificate rotation. |
Root cause |
MKE cluster root CA expires in less than 30 days. |
|---|---|
Investigation and mitigation |
Refer to MKEAPICertExpirationHigh. |
Troubleshoot OpenSearch alerts¶
Available since 2.26.0 (17.1.0 and 16.1.0)
This section describes the investigation and troubleshooting steps for the OpenSearch alerts.
Root cause |
The OpenSearch volume has reached the default |
|---|---|
Investigation and mitigation |
|
Root cause |
The OpenSearch volume has reached the default value for the high disk allocation watermark of 90% disk usage. At this point, OpenSearch attempts to reassign shards to other nodes if these nodes are still under 90% of used disk space. |
|---|---|
Investigation and mitigation |
|
Troubleshoot Release Controller alerts¶
This section describes the investigation and troubleshooting steps for the Mirantis Container Cloud Release Controller service.
Root cause |
There are no Release Controller replicas scheduled in the Mirantis Container Cloud cluster. By default, 3 replicas should be scheduled. The controller was either deleted or downscaled to 0. |
|---|---|
Investigation |
|
Mitigation |
If the Release Controller deployment has been downscaled to 0, set the
replicas back to 3 in the kubectl edit deployment -n kaas release-controller-release-controller
|
Troubleshoot Telemeter client alerts¶
This section describes the investigation and troubleshooting steps for the Mirantis Container Cloud Telemeter client service.
Root cause |
The Telemeter client fails to federate data from Prometheus or to send
data to the Telemeter server due to a very long incoming data sample.
The |
|---|---|
Investigation |
|
Mitigation |
|
Silence alerts¶
Due to the Alertmanager issue, silences with
regexp matchers do not mute all notifications for all alerts matched by the
specified regular expression.
If you need to mute multiple alerts, for example, for maintenance or before
cluster update, Mirantis recommends using a set of fixed-matcher silences
instead. As an example, this section describes how to silence all alerts for a
specified period through the Alertmanager web UI or CLI without using the
regexp matchers. You can also manually force silence expiration before the
specified period ends.
To silence all alerts:
Silence alerts through the Alertmanager web UI:
Log in to the Alertmanager web UI as described in Access StackLight web UIs.
Click New Silence.
Create four Prometheus Alertmanager silences. In Matchers, set Name to severity and Value to warning, minor, major, and critical, one for each silence.
Note
To silence the
Watchdogalert, create an additional silence with severity set in Name and informational set in Value.
Silence alerts through CLI:
Log in to the host where your management cluster
kubeconfigis located and wherekubectlis installed.Run the following command setting the required
duration:kubectl exec -it -n stacklight prometheus-alertmanager-1 prometheus-alertmanager -- sh -c 'rm -f /tmp/all_silences; \ touch /tmp/all_silences; \ for severity in warning minor major critical; do \ echo $severity; \ amtool silence add severity=${severity} \ --alertmanager.url=<http://prometheus-alertmanager> \ --comment="silence them all" \ --duration="2h" | tee /tmp/all_silences; \ done'
Note
To silence the
Watchdogalert, addinformationalto the list of severities.
To exprire alert silences:
To expire alert silences through the Alertmanager web UI, click Expire next to each silence.
To expire alert silences through CLI, run the following command:
kubectl exec -it -n stacklight prometheus-alertmanager-1 prometheus-alertmanager -- sh -c 'for silence in $(cat /tmp/all_silences); do \ echo $severity; \ amtool silence expire $silence \ --alertmanager.url=<http://prometheus-alertmanager;> \ done'
StackLight rules for Kubernetes network policies¶
Available since Cluster releases 17.0.1 and 16.0.1
The Kubernetes NetworkPolicy resource allows controlling network connections to and from Pods within a cluster. This enhances security by restricting communication from compromised Pod applications and provides transparency into how applications communicate with each other.
Network Policies are enabled by default in StackLight using the
networkPolicies parameter. For configuration details, see
Kubernetes network policies.
The following table contains general network policy rules applied to StackLight components:
Network policy rule |
Component |
|---|---|
Deny all ingress for Pods not expecting incoming traffic (including Prometheus scrape) |
|
Deny all egress for Pods not expecting outgoing traffic |
|
Allow all ingress for Pods that can be exposed through load balancers |
|
Allow all egress for Pods connecting to outside world or external APIs (Kubernetes, Docker, Keycloak, OpenStack) |
|
Allow DNS traffic from all Pods specifying communication endpoints of other StackLight workloads. |
|
The following exceptions apply to the StackLight network policy rules:
Because Prometheus Node Exporter uses the host network, the allow-all rule applies to both ingress and egress that is the no-op placeholder.
Due to dynamically created scrape configurations, the allow-all rule applies to egress for Prometheus Server.
Configure StackLight¶
This section describes how to configure StackLight in your Mirantis Container Cloud deployment and includes the description of StackLight parameters and their verification.
StackLight configuration procedure¶
This section describes the initial steps required for StackLight configuration. For a detailed description of StackLight configuration options, see StackLight configuration parameters.
Download your management cluster
kubeconfig:Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
Expand the menu of the tab with your user name.
Click Download kubeconfig to download
kubeconfigof your management cluster.Log in to any local machine with
kubectlinstalled.Copy the downloaded
kubeconfigto this machine.
Run one of the following commands:
For a management cluster:
kubectl --kubeconfig <mgmtClusterKubeconfigPath> edit -n default cluster <mgmtClusterName>
For a managed cluster:
kubectl --kubeconfig <mgmtClusterKubeconfigPath> edit -n <managedClusterProjectName> cluster <managedClusterName>
In the following section of the opened manifest, configure the required StackLight parameters as described in StackLight configuration parameters.
spec: providerSpec: value: helmReleases: - name: stacklight values:
StackLight configuration parameters¶
This section describes the StackLight configuration keys that you can specify
in the values section to change StackLight settings as required. Prior to
making any changes to StackLight configuration, perform the steps described in
StackLight configuration procedure.
After changing StackLight configuration, verify the changes as described in
Verify StackLight after configuration.
Important
Some parameters are marked as mandatory. Failure to specify values for such parameters causes the Admission Controller to reject cluster creation.
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables Alerta. Set to |
|
Key |
Description |
Example values |
|---|---|---|
|
Disables Grafana Image Renderer. For example, for resource-limited environments. Enabled by default. |
|
|
Defines the home dashboard. Set to |
|
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables the StackLight logging stack. For details about the
logging components, see Deployment architecture. Set to |
|
|
Removed in Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0).
Sets the least important level of log messages to send to OpenSearch.
Requires The default logging level is Note The |
|
|
Allows configuring OpenSearch queries for the data present in OpenSearch. Prometheus Elasticsearch Exporter then queries the OpenSearch database and exposes such metrics in the Prometheus format. For details, see Create logs-based metrics. Includes the following parameters:
|
For usage example, see Create logs-based metrics. |
|
Removed in Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Specifies the retention time per index. Includes the following parameters:
The allowed values include integers (days) and numbers with suffixes: y, m, w, d, h, including capital letters. |
logging:
retentionTime:
logstash: 3
events: "2w"
notifications: "1M"
|
Key |
Description |
Example values |
|---|---|---|
|
Defines the log verbosity level for all StackLight components if not
defined using |
|
|
Defines (overrides the |
component:
kubeStateMetrics: ""
prometheusAlertManager: ""
prometheusBlackboxExporter: ""
prometheusNodeExporter: ""
prometheusServer: ""
alerta: ""
alertmanagerWebhookServicenow: ""
elasticsearchCurator: ""
postgresql: ""
prometheusEsExporter: ""
sfNotifier: ""
sfReporter: ""
fluentd: ""
# fluentdElasticsearch ""
fluentdLogs: ""
telemeterClient: ""
telemeterServer: ""
tfControllerExporter: ""
tfVrouterExporter: ""
telegrafDs: ""
telegrafS: ""
# elasticsearch: ""
opensearch: ""
# kibana: ""
grafana: ""
opensearchDashboards: ""
metricbeat: ""
prometheusMsTeams: ""
|
Available since 2.23.0 and 2.23.1 for MOSK 23.1
Key |
Description |
Example values |
|---|---|---|
|
Specifies external Elasticsearch, OpenSearch, and syslog destinations
as |
logging:
externalOutputs:
elasticsearch:
# disabled: false
type: elasticsearch
level: info
plugin_log_level: info
tag_exclude: '{fluentd-logs,systemd}'
host: elasticsearch-host
port: 9200
logstash_date_format: '%Y.%m.%d'
logstash_format: true
logstash_prefix: logstash
...
buffer:
# disabled: false
chunk_limit_size: 16m
flush_interval: 15s
flush_mode: interval
overflow_action: block
...
opensearch:
disabled: true
type: opensearch
...
|
Available since 2.23.0 and 2.23.1 for MOSK 23.1
Key |
Description |
Example values |
|---|---|---|
|
Specifies authentication secret mounts for external log destinations.
Requires
|
Secret mount configuration: logging:
externalOutputSecretMounts:
- secretName: elasticsearch-certs
mountPath: /tmp/elasticsearch-certs
defaultMode: 420
- secretName: opensearch-certs
mountPath: /tmp/opensearch-certs
Elasticsearch configuration for the above secret mount: logging:
externalOutputs:
elasticsearch:
...
ca_file: /tmp/elasticsearch-certs/ca.pem
client_cert: /tmp/elasticsearch-certs/client.pem
client_key: /tmp/elasticsearch-certs/client.key
client_key_pass: password
|
Deprecated since 2.23.0
Note
Since Container Cloud 2.23.0, logging.syslog is deprecated for
the sake of logging.externalOutputs. For details, see
Logging to external outputs.
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables remote logging to syslog. Disabled by default.
Requires |
|
|
Specifies the remote syslog host. |
|
|
Removed in Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Specifies logging level for the syslog output. |
|
|
Specifies the remote syslog port. |
|
|
Defines the packet size in bytes for the syslog logging output. Set to
|
|
|
Specifies the remote syslog protocol. Set to |
|
|
Optional. Disabled by default. Enables or disables TLS. Use TLS only for the TCP protocol. TLS will not be enabled if you set a protocol other than TCP. |
|
|
Optional. Configures TLS verification. |
|
|
Defines how to pass the certificate.
|
certificate:
secret: ""
hostPath: "/etc/ssl/certs/ca-bundle.pem"
|
|
Optional. Overrides
How to obtain tags for logsSelect from the following options:
The values for |
|
|
Optional. Is overridden by |
|
Available since Cluster releases 17.0.0, 16.0.0, 14.1.0
Key |
Description |
Example values |
|---|---|---|
|
Limits the number of namespaces for Pods log collection. Enabled by default with the following list of monitored Kubernetes namespaces:
Kubernetes namespaces monitored by default
|
|
|
Adds extra namespaces to collect Kubernetes Pod logs from. Requires
|
logging:
namespaceFiltering:
logs:
enabled: true
extraNamespaces:
- custom-ns-1
|
|
Limits the number of namespaces for Kubernetes events collection.
Disabled by default due to sysdig scanner present on some
MOSK clusters and due to cluster-scoped objects
producing events by default to the |
|
|
Adds extra namespaces to collect Kubernetes events from. Requires
|
logging:
namespaceFiltering:
events:
enabled: true
extraNamespaces:
- custom-ns-1
|
Available since Cluster releases 17.0.0, 16.0.0, 14.1.0
Key |
Description |
Example values |
|---|---|---|
|
Enforces 32 GB of heap size, unless the defined memory limit allows using
50 GB of heap. Requires |
logging:
enforceOopsCompression: true
|
Key |
Description |
Example values |
|---|---|---|
|
Removed in Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Specifies the retention time per index. Includes the following parameters:
The allowed values include integers (days) and numbers with suffixes: y, m, w, d, h, including capital letters. By default, values set in |
elasticsearch:
retentionTime:
logstash: 3
events: "2w"
notifications: "1M"
|
|
Removed in Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Defines the OpenSearch (Elasticsearch) Note Due to the known issue 27732-2, a custom
setting for this parameter is dismissed during cluster deployment and
changes to one day (default). Refer to the known issue description
for the affected |
|
|
Specifies the OpenSearch (Elasticsearch) PVC(s) size. The number of PVCs depends on the StackLight database mode. For HA, three PVCs will be created, each of the size specified in this parameter. For non-HA, one PVC of the specified size. Important You cannot modify this parameter after cluster creation. Note Due to the known issue 27732-1 that is
fixed in Container Cloud 2.22.0 (Cluster releases 11.6.0 and 12.7.0),
the OpenSearch PVC size configuration is dismissed during a cluster
deployment. Refer to the known issue description for affected
|
elasticsearch:
persistentVolumeClaimSize: 30Gi
|
|
Optional. Specifies the number of gigabytes that is exclusively available
for the OpenSearch data. Defines ceiling for storage-based retention
where 80% of the defined value is assumed as available disk space
for normal OpenSearch node functioning. If not set (by default),
the number of gigabytes from This parameter is useful in the following cases:
|
elasticsearch:
persistentVolumeUsableStorageSizeGB: 160
|
Key |
Description |
Example values |
|---|---|---|
|
Additional configuration for |
logging:
extraConfig:
cluster.max_shards_per_node: 5000
|
Key |
Description |
Example values |
|---|---|---|
|
Additional configuration for |
logging:
dashboardsExtraConfig:
opensearch.requestTimeout: 60000
|
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables StackLight multiserver mode. For details, see
StackLight database modes in Deployment architecture.
On managed clusters, set to |
|
Key |
Description |
Example values |
|---|---|---|
|
Defines the minimum amount of time for Prometheus to wait before
resending an alert to Alertmanager. Passed to the
|
|
|
Defines the list of labels to be injected to firing alerts while they are sent to Alertmanager. Empty by default. The following labels are reserved for internal purposes and cannot
be overridden: Caution When new labels are injected, Prometheus sends alert updates with a new set of labels, which can potentially cause Alertmanager to have duplicated alerts for a short period of time if the cluster currently has firing alerts. |
alertsCommonLabels:
region: west
environment: prod
|
|
Specifies the Prometheus PVC(s) size. The number of PVCs depends on the StackLight database mode. For HA, three PVCs will be created, each of the size specified in this parameter. For non-HA, one PVC of the specified size. Important You cannot modify this parameter after cluster creation. |
prometheusServer:
persistentVolumeClaimSize: 16Gi
|
|
Defines the number of concurrent queries limit. Passed to the
|
|
|
Defines the Prometheus database retention size. Passed to the
|
|
|
Defines the Prometheus database retention period. Passed to the
|
|
Allows sending of metrics from Prometheus to a custom monitoring endpoint. For details, see Prometheus Documentation: remote_write.
Key |
Description |
Example values |
|---|---|---|
|
Skip this step if your remote server does not have authorization.
Defines additional mounts for Note To create more than one file for the same remote write
endpoint, for example, to configure TLS connections,
use a single secret object with multiple keys in the ...
data:
cert_file: aWx1dnRlc3Rz
key_file: dGVzdHVzZXI=
...
|
remoteWriteSecretMounts:
- secretName: prom-secret-files
mountPath: /etc/config/remote_write
|
|
Defines the configuration of a custom remote_write endpoint for sending Prometheus samples. Note If the remote server uses authorization, first create
secret(s) in the |
remoteWrites:
- url: http://remote_url/push
authorization:
credentials_file: /etc/config/remote_write/key_file
|
Note
Prometheus Relay is set up as an endpoint in the Prometheus datasource in Grafana. Therefore, all requests from Grafana are sent to Prometheus through Prometheus Relay. If Prometheus Relay reports request timeouts or exceeds the response size limits, you can configure the parameters below. In this case, Prometheus Relay resource limits may also require tuning.
Key |
Description |
Example values |
|---|---|---|
|
Specifies the client timeout in seconds. If empty, defaults to a value
determined by the cluster size: Note The cluster size parameters are available since Container Cloud 2.24.0. |
|
|
Specifies the response size limit in bytes. If empty, defaults to a
value determined by the cluster size: Note The cluster size parameters are available since Container Cloud 2.24.0. |
|
Key |
Description |
Example values |
|---|---|---|
|
Defines custom Prometheus recording rules. Overriding of existing recording rules is not supported. |
customRecordingRules:
- name: ExampleRule.http_requests_total
rules:
- expr: sum by(job) (rate(http_requests_total[5m]))
record: job:http_requests:rate5m
- expr: avg_over_time(job:http_requests:rate5m[1w])
record: job:http_requests:rate5m:avg_over_time_1w
|
Key |
Description |
Example values |
|---|---|---|
|
Defines custom Prometheus scrape configurations. For details, see Prometheus documentation: scrape_config. The names of default StackLight scrape configurations, which you can view in the Status -> Targets tab of the Prometheus web UI, are reserved for internal usage and any overrides will be discarded. Therefore, provide unique names to avoid overrides. |
customScrapeConfigs:
custom-grafana:
scrape_interval: 10s
scrape_timeout: 5s
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels:
- __meta_kubernetes_service_label_app
- __meta_kubernetes_endpoint_port_name
regex: grafana;service
action: keep
- source_labels:
- __meta_kubernetes_pod_name
target_label: pod
|
Key |
Description |
Example values |
|---|---|---|
|
Specifies the approximate expected cluster size. Set to
|
|
Key |
Description |
Example values |
|---|---|---|
|
Provides the capability to override the default resource requests or limits for any StackLight component for the predefined cluster sizes.
StackLight components for resource limits customizationNote The below list has the
alerta: alerta/alerta
alertmanager: prometheus-alertmanager/prometheus-alertmanager
alertmanagerWebhookServicenow: alertmanager-webhook-servicenow/alertmanager-webhook-servicenow
blackboxExporter: prometheus-blackbox-exporter/blackbox-exporter
elasticsearch: opensearch-master/opensearch # Deprecated
elasticsearchCurator: elasticsearch-curator/elasticsearch-curator
elasticsearchExporter: elasticsearch-exporter/elasticsearch-exporter
fluentdElasticsearch: fluentd-logs/fluentd-logs # Deprecated
fluentdLogs: fluentd-logs/fluentd-logs
fluentdNotifications: fluentd-notifications/fluentd # for MOSK
grafana: grafana/grafana
grafanaRenderer: grafana/grafana-renderer # Removed in 2.27.0 (Cluster releases 17.2.0 and 16.2.0)
iamProxy: iam-proxy/iam-proxy # Deprecated
iamProxyAlerta: iam-proxy-alerta/iam-proxy
iamProxyAlertmanager: iam-proxy-alertmanager/iam-proxy
iamProxyGrafana: iam-proxy-grafana/iam-proxy
iamProxyKibana: iam-proxy-kibana/iam-proxy # Deprecated
iamProxyOpenSearchDashboards: iam-proxy-kibana/iam-proxy
iamProxyPrometheus: iam-proxy-prometheus/iam-proxy
kibana: opensearch-dashboards/opensearch-dashboards # Deprecated
kubeStateMetrics: prometheus-kube-state-metrics/prometheus-kube-state-metrics
libvirtExporter: prometheus-libvirt-exporter/prometheus-libvirt-exporter # for MOSK
metricCollector: metric-collector/metric-collector
metricbeat: metricbeat/metricbeat
nodeExporter: prometheus-node-exporter/prometheus-node-exporter
opensearch: opensearch-master/opensearch
opensearchDashboards: opensearch-dashboards/opensearch-dashboards
patroniExporter: patroni/patroni-patroni-exporter
pgsqlExporter: patroni/patroni-pgsql-exporter
postgresql: patroni/patroni
prometheusEsExporter: prometheus-es-exporter/prometheus-es-exporter
prometheusMsTeams: prometheus-msteams/prometheus-msteams
prometheusRelay: prometheus-relay/prometheus-relay
prometheusServer: prometheus-server/prometheus-server
refapp: refapp/refapp
refappCleanup: refapp-cleanup/refapp-cleanup
refappInit: db-init/db-init
sfNotifier: sf-notifier/sf-notifier
sfReporter: sf-reporter/sf-reporter
stacklightHelmControllerController: stacklight-helm-controller/controller
telegrafDockerSwarm: telegraf-docker-swarm/telegraf-docker-swarm
telegrafDs: telegraf-ds-smart/telegraf-ds-smart # Deprecated
telegrafDsSmart: telegraf-ds-smart/telegraf-ds-smart
telegrafOpenstack: telegraf-openstack/telegraf-openstack # for MOSK, replaced with osdpl-exporter in 24.1
telegrafS: telegraf-docker-swarm/telegraf-docker-swarm # deprecated
telemeterClient: telemeter-client/telemeter-client
telemeterServer: telemeter-server/telemeter-server
telemeterServerAuthServer: telemeter-server/telemeter-server-authorization-server
tfControllerExporter: prometheus-tf-controller-exporter/prometheus-tungstenfabric-exporter # for MOSK
tfVrouterExporter: prometheus-tf-vrouter-exporter/prometheus-tungstenfabric-exporter # for MOSK
|
resourcesPerClusterSize:
# elasticsearch:
opensearch:
small:
limits:
cpu: "1000m"
memory: "4Gi"
medium:
limits:
cpu: "2000m"
memory: "8Gi"
requests:
cpu: "1000m"
memory: "4Gi"
large:
limits:
cpu: "4000m"
memory: "16Gi"
|
|
Provides the capability to override the containers resource requests or limits for any StackLight component.
StackLight components for resource limits customizationNote The below list has the
alerta: alerta/alerta
alertmanager: prometheus-alertmanager/prometheus-alertmanager
alertmanagerWebhookServicenow: alertmanager-webhook-servicenow/alertmanager-webhook-servicenow
blackboxExporter: prometheus-blackbox-exporter/blackbox-exporter
elasticsearch: opensearch-master/opensearch # Deprecated
elasticsearchCurator: elasticsearch-curator/elasticsearch-curator
elasticsearchExporter: elasticsearch-exporter/elasticsearch-exporter
fluentdElasticsearch: fluentd-logs/fluentd-logs # Deprecated
fluentdLogs: fluentd-logs/fluentd-logs
fluentdNotifications: fluentd-notifications/fluentd # for MOSK
grafana: grafana/grafana
grafanaRenderer: grafana/grafana-renderer # Removed in 2.27.0 (Cluster releases 17.2.0 and 16.2.0)
iamProxy: iam-proxy/iam-proxy # Deprecated
iamProxyAlerta: iam-proxy-alerta/iam-proxy
iamProxyAlertmanager: iam-proxy-alertmanager/iam-proxy
iamProxyGrafana: iam-proxy-grafana/iam-proxy
iamProxyKibana: iam-proxy-kibana/iam-proxy # Deprecated
iamProxyOpenSearchDashboards: iam-proxy-kibana/iam-proxy
iamProxyPrometheus: iam-proxy-prometheus/iam-proxy
kibana: opensearch-dashboards/opensearch-dashboards # Deprecated
kubeStateMetrics: prometheus-kube-state-metrics/prometheus-kube-state-metrics
libvirtExporter: prometheus-libvirt-exporter/prometheus-libvirt-exporter # for MOSK
metricCollector: metric-collector/metric-collector
metricbeat: metricbeat/metricbeat
nodeExporter: prometheus-node-exporter/prometheus-node-exporter
opensearch: opensearch-master/opensearch
opensearchDashboards: opensearch-dashboards/opensearch-dashboards
patroniExporter: patroni/patroni-patroni-exporter
pgsqlExporter: patroni/patroni-pgsql-exporter
postgresql: patroni/patroni
prometheusEsExporter: prometheus-es-exporter/prometheus-es-exporter
prometheusMsTeams: prometheus-msteams/prometheus-msteams
prometheusRelay: prometheus-relay/prometheus-relay
prometheusServer: prometheus-server/prometheus-server
refapp: refapp/refapp
refappCleanup: refapp-cleanup/refapp-cleanup
refappInit: db-init/db-init
sfNotifier: sf-notifier/sf-notifier
sfReporter: sf-reporter/sf-reporter
stacklightHelmControllerController: stacklight-helm-controller/controller
telegrafDockerSwarm: telegraf-docker-swarm/telegraf-docker-swarm
telegrafDs: telegraf-ds-smart/telegraf-ds-smart # Deprecated
telegrafDsSmart: telegraf-ds-smart/telegraf-ds-smart
telegrafOpenstack: telegraf-openstack/telegraf-openstack # for MOSK, replaced with osdpl-exporter in 24.1
telegrafS: telegraf-docker-swarm/telegraf-docker-swarm # deprecated
telemeterClient: telemeter-client/telemeter-client
telemeterServer: telemeter-server/telemeter-server
telemeterServerAuthServer: telemeter-server/telemeter-server-authorization-server
tfControllerExporter: prometheus-tf-controller-exporter/prometheus-tungstenfabric-exporter # for MOSK
tfVrouterExporter: prometheus-tf-vrouter-exporter/prometheus-tungstenfabric-exporter # for MOSK
|
resources:
alerta:
requests:
cpu: "50m"
memory: "200Mi"
limits:
memory: "500Mi"
Using the example above, each pod in the Note The logging mechanism performance depends on the cluster log
load. If the cluster components send an excessive amount of logs, the
default resource requests and limits for resources:
# fluentdElasticsearch:
fluentdLogs:
requests:
memory: "500Mi"
limits:
memory: "1500Mi"
|
For internal StackLight use only
Key |
Description |
Example values |
|---|---|---|
|
Specifies the size limit of the incoming data length in bytes for the
Telemeter client. Defaults to |
|
Available since Cluster releases 17.0.1 and 16.0.1
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables the Kubernetes Network Policy resource that allows
controlling network connections to and from Pods deployed in the
For the list of network policy rules, refer to StackLight rules for Kubernetes network policies. Customization of network policies is not supported. |
|
Key |
Description |
Example values |
|---|---|---|
|
Kubernetes tolerations to add to all StackLight components. |
default:
- key: "com.docker.ucp.manager"
operator: "Exists"
effect: "NoSchedule"
|
|
Defines Kubernetes tolerations (overrides the default ones) for any StackLight component. |
component:
# elasticsearch:
opensearch:
- key: "com.docker.ucp.manager"
operator: "Exists"
effect: "NoSchedule"
postgresql:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
|
In an HA StackLight setup, when highAvailabilityEnabled is set to true,
all StackLight Persistent Volumes (PVs) use the Local Volume Provisioner (LVP)
storage class not to rely on dynamic provisioners such as Ceph, which are not
available in every Container Cloud deployment. In a non-HA StackLight setup,
when no storage class is specified, PVs use the default storage class of a
cluster.
Key |
Description |
Example values |
|---|---|---|
|
Defines the |
|
|
Defines (overrides the |
componentStorageClasses:
elasticsearch: ""
opensearch: ""
fluentd: ""
postgresql: ""
prometheusAlertManager: ""
prometheusServer: ""
|
Key |
Description |
Example values |
|---|---|---|
|
Defines the |
default:
role: stacklight
|
|
Defines the |
component:
alerta:
role: stacklight
component: alerta
# kibana:
# role: stacklight
# component: kibana
opensearchDashboards:
role: stacklight
component: opensearchdashboards
|
Key |
Description |
Example values |
|---|---|---|
|
Excludes monitoring of RegExp-specified network devices. The number of network interface-related metrics is significant and may cause extended Prometheus RAM usage in big clusters. Therefore, Prometheus Node Exporter only collects information of a basic set of interfaces (both host and container) and excludes the following monitoring interfaces:
To enable information collecting for the interfaces above, edit the list of blacklisted devices as needed. |
nodeExporter:
netDeviceExclude: "^(veth.+|cali.+|o-hm0|tap.+|qg-.+|qr-.+|ha-.+|br-.+|ovs-system|docker0)$"
|
|
Enables Node Exporter collectors. For a list of available collectors, see Node Exporter Collectors. The following collectors are enabled by default in StackLight:
|
extraCollectorsEnabled:
- bcache
- bonding
- softnet
|
Key |
Description |
Example values |
|---|---|---|
|
Specifies a set of custom Blackbox Exporter modules. For details, see
Blackbox Exporter configuration: module.
The |
customModules:
http_post_2xx:
prober: http
timeout: 5s
http:
method: POST
headers:
Content-Type: application/json
body: '{}'
|
|
Specifies the offset to subtract from timeout in seconds
( |
|
Available since 2.21.0 for non-MOSK managed clusters
Note
For the feature support on MOSK deployments, refer to MOSK documentation: Deploy RefApp using automation tools.
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables Reference Application that is a small microservice application that enables workload monitoring on non-MOSK managed clusters. Disabled by default. |
|
|
Available since Container Cloud 2.23.0.
Enables or disables persistent volumes for Reference Application.
Enabled by default. Disabling is not recommended for production clusters.
Once set, the value cannot be changed.
|
|
|
Defines |
refapp:
workload:
storageClassName: kubernetes-ssd
|
|
Available since Container Cloud 2.23.0.
Defines the size of persistent volumes for the Reference Application.
Default is
1Gi. Applies only if persistent volumes are enabled. |
refapp:
workload:
persistentVolumeSize: 1Gi
|
On the managed clusters with limited Internet access, proxy is required for StackLight components that use HTTP and HTTPS and are disabled by default but need external access if enabled. The Salesforce reporter depends on the Internet access through HTTPS.
Key |
Description |
Example values |
|---|---|---|
|
Unique cluster identifier
The |
Do not modify |
|
Enables or disables reporting of Prometheus metrics to Salesforce. For details, see Deployment architecture. Disabled by default. |
|
|
Salesforce parameters and credentials for the metrics reporting integration. |
Note Modify this parameter if salesForceAuth:
url: "<SF instance URL>"
username: "<SF account email address>"
password: "<SF password>"
environment_id: "<Cloud identifier>"
organization_id: "<Organization identifier>"
sandbox_enabled: "<Set to true or false>"
|
|
Defines the Kubernetes cron job for sending metrics to Salesforce. By default, reports are sent at midnight server time. |
cronjob:
schedule: "0 0 * * *"
concurrencyPolicy: "Allow"
failedJobsHistoryLimit: ""
successfulJobsHistoryLimit: ""
startingDeadlineSeconds: 200
|
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables Ceph monitoring on baremetal-based managed clusters.
Set to |
|
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables HTTP endpoints monitoring. If enabled, the
monitoring tool performs the probes against the defined endpoints every
15 seconds. Set to |
|
|
Defines the directory path with external endpoints certificates on host. |
|
|
Defines the list of HTTP endpoints to monitor. The endpoints must successfully respond to a liveness probe. For success, a request to a specific endpoint must result in a 2xx HTTP response code. |
domains:
- https://prometheus.io/health
- http://example.com:8080/status
- http://example.net:8080/pulse
|
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables monitoring of bare metal Ironic on baremetal-based clusters. To enable, specify the Ironic API URL. |
|
|
Defines whether to skip the chain and host verification. Set to
|
|
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables StackLight to monitor and alert on the expiration
date of the TLS certificate of an HTTPS endpoint. If enabled, the
monitoring tool performs the probes against the defined endpoints every
hour. Set to |
|
|
Defines the list of HTTPS endpoints to monitor the certificates from. |
domains:
- https://prometheus.io
- https://example.com:8080
|
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables Mirantis Kubernetes Engine (MKE) monitoring.
Set to |
|
|
Defines the dockerd data root directory of persistent Docker state. For details, see Docker documentation: Daemon CLI (dockerd). |
|
Key |
Description |
Example values |
|---|---|---|
|
On the clusters that run large-scale workloads, workload monitoring generates a big amount of resource-consuming metrics. To prevent generation of excessive metrics, you can disable workload monitoring in the StackLight metrics and monitor only the infrastructure. The |
metricFilter:
enabled: true
action: keep
namespaces:
- kaas
- kube-system
- stacklight
|
Available since 2.24.0 and 2.24.2 for MOSK 23.2
Key |
Description |
Example values |
|---|---|---|
|
Configuration for managing Prometheus metrics filtering. When enabled (default), only actively used and explicitly white-listed metrics get scraped by Prometheus. |
prometheusServer:
metricsFiltering:
enabled: true
|
|
List of extra metrics to whitelist, which are dropped by default. Contains the following parameters:
|
prometheusServer:
metricsFiltering:
enabled: true
extraMetricsInclude:
cadvisor:
- container_memory_failcnt
- container_network_transmit_errors_total
calico:
- felix_route_table_per_iface_sync_seconds_sum
- felix_bpf_dataplane_endpoints
_group-go-collector-metrics:
- go_gc_heap_goal_bytes
- go_gc_heap_objects_objects
|
Key |
Description |
Example values |
|---|---|---|
|
Defines custom alerts. Also, modifies or disables existing alert configurations. For the list of predefined alerts, see Available StackLight alerts. While adding or modifying alerts, follow the Alerting rules. |
customAlerts:
# To add a new alert:
- alert: ExampleAlert
annotations:
description: Alert description
summary: Alert summary
expr: example_metric > 0
for: 5m
labels:
severity: warning
# To modify an existing alert expression:
- alert: AlertmanagerFailedReload
expr: alertmanager_config_last_reload_successful == 5
# To disable an existing alert:
- alert: TargetDown
enabled: false
An optional field |
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables the |
|
On the managed clusters with limited Internet access, proxy is required for StackLight components that use HTTP and HTTPS and are disabled by default but need external access if enabled, for example, for the Salesforce integration and Alertmanager notifications external rules.
Key |
Description |
Example values |
|---|---|---|
|
Provides a generic template for notifications receiver configurations. For a list of supported receivers, see Prometheus Alertmanager documentation: Receiver. |
For example, to enable notifications to OpsGenie: alertmanagerSimpleConfig:
genericReceivers:
- name: HTTP-opsgenie
enabled: true # optional
opsgenie_configs:
- api_url: "https://example.app.eu.opsgenie.com/"
api_key: "secret-key"
send_resolved: true
|
|
Provides a template for notifications route configuration. For details, see Prometheus Alertmanager documentation: Route. |
genericRoutes:
- receiver: HTTP-opsgenie
enabled: true # optional
matchers:
severity=~"major|critical"
continue: true
|
|
Disables or enables alert inhibition rules. If enabled, Alertmanager decreases alert noise by suppressing dependent alerts notifications to provide a clearer view on the cloud status and simplify troubleshooting. Enabled by default. For details, see Alert dependencies. For details on inhibition rules, see Prometheus documentation. |
|
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables Alertmanager integration with email. Set to
|
|
|
Defines the notification parameters for Alertmanager integration with email. For details, see Prometheus Alertmanager documentation: Email configuration. |
email:
enabled: false
send_resolved: true
to: "to@test.com"
from: "from@test.com"
smarthost: smtp.gmail.com:587
auth_username: "from@test.com"
auth_password: password
auth_identity: "from@test.com"
require_tls: true
|
|
Defines the route for Alertmanager integration with email. For details, see Prometheus Alertmanager documentation: Route. |
route:
matchers: []
routes: []
|
On the managed clusters with limited Internet access, proxy is required for StackLight components that use HTTP and HTTPS and are disabled by default but need external access if enabled. The Salesforce integration depends on the Internet access through HTTPS.
Key |
Description |
Example values |
|---|---|---|
|
Unique cluster identifier
The |
Do not modify |
|
Enables or disables Alertmanager integration with Salesforce using the
|
|
|
Defines the Salesforce parameters and credentials for integration with Alertmanager. |
auth:
url: "<SF instance URL>"
username: "<SF account email address>"
password: "<SF password>"
environment_id: "<Cloud identifier>"
organization_id: "<Organization identifier>"
sandbox_enabled: "<Set to true or false>"
|
|
Defines the notifications route for Alertmanager integration with Salesforce. For details, see Prometheus Alertmanager documentation: Route. |
route:
matchers:
- severity="critical"
routes: []
Note By default, only |
|
Enables or disables feed update in Salesforce. To save API calls, this
parameter is set to |
|
|
Enables or disables links to the Prometheus web UI in alerts sent to
Salesforce. To simplify troubleshooting, set to |
|
On the managed clusters with limited Internet access, proxy is required for StackLight components that use HTTP and HTTPS and are disabled by default but need external access if enabled. The Slack integration depends on the Internet access through HTTPS.
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables Alertmanager integration with Slack. For
details, see Prometheus Alertmanager documentation: Slack configuration.
Set to |
|
|
Defines the Slack webhook URL. |
|
|
Defines the Slack channel or user to send notifications to. |
|
|
Defines the notifications route for Alertmanager integration with Slack. For details, see Prometheus Alertmanager documentation: Route. |
route:
matchers: []
routes: []
|
On the managed clusters with limited Internet access, proxy is required for StackLight components that use HTTP and HTTPS and are disabled by default but need external access if enabled. The Microsoft Teams integration depends on the Internet access through HTTPS.
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables Alertmanager integration with Microsoft Teams.
Requires a set up Microsoft Teams channel and a channel connector. Set
to |
|
|
Defines the URL of an Incoming Webhook connector of a Microsoft Teams channel. For details about channel connectors, see Microsoft documentation. |
|
|
Defines the notifications route for Alertmanager integration with MS Teams. For details, see Prometheus Alertmanager documentation: Route. |
route:
matchers: []
routes: []
|
Caution
Prior to configuring the integration with ServiceNow, perform the following prerequisite steps using the ServiceNow documentation of the required version.
In a new or existing Incident table, add the Alert ID field as described in Add fields to a table. To avoid alerts duplication, select Unique.
Create an Access Control List (ACL) with read/write permissions for the Incident table as described in Securing table records.
Key |
Description |
Example values |
|---|---|---|
|
Enables or disables Alertmanager integration with ServiceNow. Set to
|
|
|
Defines the ServiceNow parameters and credentials for integration with Alertmanager:
|
serviceNow:
enabled: true
incident_table: "incident"
api_version: "v1"
alert_id_field: "u_alert_id"
auth:
instance: "https://dev00001.service-now.com"
username: "testuser"
password: "testpassword"
|
Verify StackLight after configuration¶
This section describes how to verify StackLight after configuring its parameters as described in Configure StackLight and StackLight configuration parameters. Perform the verification procedure described for a particular modified StackLight key.
To verify StackLight after configuration:
Key |
Verification procedure |
|---|---|
|
Verify that Alerta is present in the list of StackLight resources. An empty output indicates that Alerta is disabled. kubectl get all -n stacklight -l app=alerta
|
|
|
elasticsearch.logstashRetentionTimeRemoved in 2.26.0 (17.1.0, 16.1.0)
|
Verify that the kubectl get cm elasticsearch-curator-config -n \
stacklight -o=jsonpath='{.data.action_file\.yml}'
|
|
Verify that the PVC(s) capacity equals or is higher (in case of statically provisioned volumes) than specified: kubectl get pvc -n stacklight -l "app=opensearch-master"
|
grafana.renderer.enabledRemoved in 2.27.0 (17.2.0, 16.2.0)
|
Verify the Grafana Image Renderer. If set to kubectl logs -f -n stacklight -l app=grafana \
--container grafana-renderer
|
|
In the Grafana web UI, verify that the desired dashboard is set as a home dashboard. |
|
Verify that OpenSearch, Fluentd, and OpenSearch Dashboards are present in the list of StackLight resources. An empty output indicates that the StackLight logging stack is disabled. kubectl get all -n stacklight -l 'app in
(opensearch-master,opensearchDashboards,fluentd-logs)'
|
logging.levelRemoved in 2.26.0 (17.1.0, 16.1.0)
|
|
|
To troubleshoot issues with Splunk, refer to No logs are forwarded to Splunk. |
|
Verify that files were created for the specified path in the Fluentd container: kubectl get pods -n stacklight -o name | grep fluentd-logs | \
xargs -I{} kubectl exec -i {} -c fluentd-logs -n stacklight -- \
ls <logging.externalOutputSecretMounts.mountPath>
|
|
|
|
Verify that the kubectl get cm -n stacklight fluentd-logs -o \
yaml | grep packet_size
|
|
For details, see steps 4.2 and 4.3 in Create logs-based metrics. |
|
Verify that the customization has applied: kubectl -n stacklight get cm opensearch-master-config -o=jsonpath='{.data}'
Example of system response: {"opensearch.yml":"cluster.name: opensearch\
\nnetwork.host: 0.0.0.0\
\nplugins.security.disabled: true\
\nplugins.index_state_management.enabled: false\
\npath.data: /usr/share/opensearch/data\
\ncompatibility.override_main_response_version: true\
\ncluster.max_shards_per_node: 5000\n"}
|
|
Verify that the customization has applied: kubectl -n stacklight get cm opensearch-dashboards -o=jsonpath='{.data}'
Example of system response: {"opensearch_dashboards.yml":"opensearch.hosts: http://opensearch-master:9200\
\nopensearch.requestTimeout: 60000\
\nopensearchDashboards.defaultAppId: dashboard/2d53aa40-ad1f-11e9-9839-052bda0fdf49\
\nserver:\
\n host: 0.0.0.0\
\n name: opensearch-dashboards\n"}
|
|
Verify the number of service replicas for the HA or non-HA StackLight mode. For details, see Deployment architecture. kubectl get sts -n stacklight
|
|
|
|
|
|
Verify that the PVC(s) capacity equals or is higher (in case of statically provisioned volumes) than specified: kubectl get pvc -n stacklight -l "app=prometheus,component=server"
|
|
|
|
It may take up to 10 minutes for the change to apply. |
|
Verify that files were created for the specified path in the Prometheus container: kubectl exec -it prometheus-server-0 -c prometheus-server -n \
stacklight -- ls <remoteWriteSecretMounts.mountPath>
|
|
|
|
|
|
|
|
Verify that the appropriate components pods are located on the intended nodes: kubectl get pod -o=custom-columns=NAME:.metadata.name,\
STATUS:.status.phase,NODE:.spec.nodeName -n stacklight
|
|
|
|
In the Prometheus web UI, run the following PromQL queries. The result should not be empty. node_scrape_collector_duration_seconds{collector="<COLLECTOR_NAME>"}
node_scrape_collector_success{collector="<COLLECTOR_NAME>"}
|
|
|
|
Verify that the kubectl get deployment.apps/prometheus-blackbox-exporter -n stacklight \
-o=jsonpath='{.spec.template.spec.containers[?(@.name=="blackbox-exporter")].args}'
For example, for |
|
Verify that the appropriate components PVCs have been created according
to the configured kubectl get pvc -n stacklight
|
|
|
|
|
|
|
|
|
|
In the Grafana web UI, verify that the Ironic BM dashboard displays valuable data (no false-positive or empty panels). |
|
|
|
|
|
|
|
In the Prometheus web UI, navigate to Alerts and verify that
the |
|
In the Prometheus web UI, navigate to Alerts and verify that the list of alerts has changed according to your customization. |
|
In the Prometheus web UI, navigate to Alerts and verify that
the list of alerts contains the |
|
In the Alertmanager web UI, navigate to Status and verify that the Config section contains the intended receiver(s). |
|
In the Alertmanager web UI, navigate to Status and verify that the Config section contains the intended route(s). |
|
Run the following command. An empty output indicates either a failure or that the feature is disabled. kubectl get cm -n stacklight prometheus-alertmanager -o \
yaml | grep -A 6 inhibit_rules
|
|
In the Alertmanager web UI, navigate to Status and verify
that the Config section contains the |
|
|
|
|
|
Verify that kubectl get deployment sf-notifier \
-o=jsonpath='{.spec.template.spec.containers[0].env}' | jq .
|
|
In the Alertmanager web UI, navigate to Status and verify
that the Config section contains the |
|
|
|
In case of any failure:
|
Tune StackLight for long-term log retention¶
Available since 2.24.0 and 2.24.2 for MOSK 23.2
If you plan to switch to a long log retention period (months), tune StackLight
by increasing the cluster.max_shards_per_node limit. This configuration
enables OpenSearch to successfully accept new logs and prevents the
maximum open shards error.
To tune StackLight for long-term log retention:
Increase the
cluster.max_shards_per_nodelimit:logging: extraConfig: cluster.max_shards_per_node: 10000
If you increase the limit to more than double the default value, increase the memory and CPU limit for
opensearchto preventMaxHeapUsagewarnings.For example, if you set
cluster.max_shards_per_node: 20000, configure theresources:opensearch:limitssection as follows:resources: opensearch: limits: cpu: "8" memory: "45Gi"
Enable log forwarding to external destinations¶
Available since 2.23.0 and 2.23.1 for MOSK 23.1
By default, StackLight sends logs to OpenSearch. However, you can
configure StackLight to add external Elasticsearch, OpenSearch, and syslog
destinations as the fluentd-logs output. In this case, StackLight will
send logs both to an external server(s) and OpenSearch.
Since Cluster releases 17.0.0, 16.0.0, and 14.1.0, you can also enable sending of Container Cloud service logs to Splunk using the syslog external output configuration. The feature is available in the Technology Preview scope.
Warning
Sending logs to Splunk implies that the target Splunk instance is available from the Container Cloud cluster. If proxy is enabled, the feature is not supported.
Prior to enabling the functionality, complete the following prerequisites:
Enable StackLight logging
Deploy an external server outside Container Cloud
Make sure that Container Cloud proxy is not enabled since it only supports the HTTP(S) traffic
For Splunk, configure the server to accept logs:
Create an index and set its type to
EventConfigure data input:
Open the required port
Configure the required protocol (TCP/UDP)
Configure connection to the created index
To enable log forwarding to external destinations:
Perform the steps 1-2 described in Configure StackLight.
In the
stacklight.valuessection of the opened manifest, configure thelogging.externalOutputsparameters using the following table.Key
Description
Example values
disabled(bool)Optional. Disables the output destination using
disabled: true. If not set, defaults todisabled: false.trueorfalsetype(string)Required. Specifies the type of log destination. The following values are accepted:
elasticsearch,opensearch,remote_syslog, andopensearch_data_stream(since Container Cloud 2.26.0, Cluster releases 17.1.0 and 16.1.0).remote_sysloglevel(string)Removed in 2.26.0 (17.1.0, 16.1.0)Optional. Sets the least important level of log messages to send. For example, values that are defined using the
severity_labelfield, see thelogging.leveldescription in Logging.warningplugin_log_level(string)Optional. Defaults to
info. Sets the value of@log_levelof the output plugin for a particular backend. For other available values, refer to thelogging.leveldescription in Logging.noticetag_exclude(string)Optional. Overrides
tag_include. Sets logs by tags to exclude from the destination output. For example, to exclude all logs with thetesttag, settag_exclude: '/.*test.*/'.How to obtain tags for logs
Select from the following options:
In the main OpenSearch output, use the
loggerfield that equals the tag.Use logs of a particular Pod or container by following the below order, with the first match winning:
The value of the
appPod label. For example, forapp=opensearch-master, useopensearch-masteras the log tag.The value of the
k8s-appPod label.The value of the
app.kubernetes.io/namePod label.If a
release_groupPod label exists and the component Pod label starts withapp, use the value of the component label as the tag. Otherwise, the tag is the application label joined to the component label with a-.The name of the container from which the log is taken.
The values for
tag_excludeandtag_includeare placed into<match>directives of Fluentd and only accept regex types that are supported by the<match>directive of Fluentd. For details, refer to the Fluentd official documentation.'{fluentd-logs,systemd}'tag_include(string)Optional. Is overridden by
tag_exclude. Sets logs by tags to include to the destination output. For example, to include all logs with theauthtag, settag_include: '/.*auth.*/'.'/.*auth.*/'<pluginConfigOptions>(map)Configures plugin settings. Has a hierarchical structure. The first-level configuration parameters are dynamic except
type,id, andlog_levelthat are reserved by StackLight. For available options, refer to the required plugin documentation. Mirantis does not set any default values for plugin configuration settings except the reserved ones.The second-level configuration options are predefined and limited to
buffer(for any type of log destination) andformat(forremote_syslogonly). Inside the second-level configuration, the parameters are dynamic.For available configuration options, refer to the following documentation:
First-level configuration options:
elasticsearch: ... tag_exclude: '{fluentd-logs,systemd}' host: elasticsearch-host port: 9200 logstash_date_format: '%Y.%m.%d' logstash_format: true logstash_prefix: logstash ...
Second-level configuration options:
syslog: format: "@type": single_value message_key: message
buffer(map)Configures buffering of events using the second-level configuration options. Applies to any type of log destinations. Parameters are dynamic except the following mandatory ones that should not be modified:
type: filethat sets the default buffer typepath: <pathToBufferFile>that sets the path to the buffer destination fileoverflow_action: blockthat prevents Fluentd from crashing if the output destination is down
For details about other mandatory and optional
bufferparameters, see the Fluentd: Output Plugins documentation.Note
To disable
bufferwithout deleting it, usebuffer.disabled: true.buffer: # disabled: false chunk_limit_size: 16m flush_interval: 15s flush_mode: interval overflow_action: block
output_kind(string)Since 2.26.0 (17.1.0, 16.1.0)Configures the type of logs to forward. If set to
audit, only audit logs are forwarded. If unset, only system logs are forwarded.opensearch: output_kind: audit
Example configuration for logging.externalOutputs
logging: externalOutputs: elasticsearch: # disabled: false type: elasticsearch level: info # Removed in 2.26.0 (17.1.0, 16.1.0) plugin_log_level: info tag_exclude: '{fluentd-logs,systemd}' host: elasticsearch-host port: 9200 logstash_date_format: '%Y.%m.%d' logstash_format: true logstash_prefix: logstash ... buffer: # disabled: false chunk_limit_size: 16m flush_interval: 15s flush_mode: interval overflow_action: block ... opensearch: disabled: true type: opensearch level: info # Removed in 2.26.0 (17.1.0, 16.1.0) plugin_log_level: info tag_include: '/.*auth.*/' host: opensearch-host port: 9200 logstash_date_format: '%Y.%m.%d' logstash_format: true logstash_prefix: logstash output_kind: audit # Since 2.26.0 (17.1.0, 16.1.0) ... buffer: chunk_limit_size: 16m flush_interval: 15s flush_mode: interval overflow_action: block ... syslog: type: remote_syslog plugin_log_level: info level: info # Removed in 2.26.0 (17.1.0, 16.1.0) tag_include: '{iam-proxy,systemd}' host: remote-syslog.svc port: 514 hostname: example-hostname packetSize: 1024 protocol: udp tls: false buffer: disabled: true format: "@type": single_value message_key: message ... splunk_syslog_output: type: remote_syslog host: remote-splunk-syslog.svc port: 514 protocol: tcp tls: true ca_file: /etc/ssl/certs/splunk-syslog.pem verify_mode: 0 buffer: chunk_limit: 16MB total_limit: 128MB externalOutputSecretMounts: - secretName: syslog-pem mountPath: /etc/ssl/certs/splunk-syslog.pem
Note
Mirantis recommends that you tune the
packetSizeparameter value to allow sending full log lines.The
hostnamefield in the remote syslog database will be set based onclusterIdspecified in the StackLight chart values. For example, ifclusterIdisns/cluster/example-uid, thehostnamewill transform tons_cluster_example-uid. For details, seeclusterIdin StackLight configuration parameters.
Optional. Mount authentication secrets for the required external destination to Fluentd using
logging.externalOutputSecretMounts. For the parameter options, see Secrets for external log outputs.Example command to create a secret:
kubectl -n stacklight create secret generic elasticsearch-certs \ --from-file=./ca.pem \ --from-file=./client.pem \ --from-file=./client.key
Recommended. Increase the CPU limit for the
fluentd-logsDaemonSet by 50% of the original value per each external output.The following table describes default and recommended limits for the
fluentd-logsDaemonSet per external destination on clusters of different sizes:CPU limits for fluentd-logs per external output¶ Cluster size
Default CPU limit
Recommended CPU limit
Small
1000m1500mMedium
1500m2250mLarge
2000m3000mTo increase the CPU limit for
fluentd-logs, configure theresourcesPerClusterSizeStackLight parameter. For details, see Configure StackLight and Resource limits.Verify remote logging to syslog as described in Verify StackLight after configuration.
Note
If Fluentd cannot flush logs and the buffer of the external output
starts to fill depending on resources and configuration of the external
Elasticsearch or OpenSearch server, the
Data too large, circuit_breaking_exception error may occur even after
you resolve the external output issues.
This error indicates that the output destination cannot accept logs data sent in bulk because of their size. To mitigate the issue, select from the following options:
Set
bulk_message_request_thresholdto10MBor lower. It is unlimited by default. For details, see the Fluentd plugin documentation for Elasticsearch.Adjust output destinations to accept a large amount of data at once. For details, refer to the official documentation of the required external system.
Enable remote logging to syslog¶
Deprecated since 2.23.0
Caution
Since Container Cloud 2.23.0, this procedure and the
logging.syslog parameter are deprecated. For a new configuration of
remote logging to syslog, follow the Enable log forwarding to external destinations procedure
instead.
By default, StackLight sends logs to OpenSearch. However, you can configure StackLight to forward all logs to an external syslog server. In this case, StackLight will send logs both to the syslog server and to OpenSearch. Prior to enabling the functionality, consider the following requirements:
StackLight logging must be enabled
A remote syslog server must be deployed outside Container Cloud
Container Cloud proxy must not be enabled since it only supports the HTTP(S) traffic
To enable sending of logs to syslog:
Perform the steps 1-2 described in Configure StackLight.
In the
stacklight.valuessection of the opened manifest, configure thelogging.syslogparameters as described in StackLight configuration parameters.For example:
logging: enabled: true syslog: enabled: true host: remote-syslog.svc port: 514 packetSize: 1024 protocol: tcp tls: enabled: true certificate: secret: "" hostPath: "/etc/ssl/certs/ca-bundle.pem" verify_mode: 1
Note
Mirantis recommends that you tune the
packetSizeparameter value to allow sending full log lines.The
hostnamefield in the remote syslog database will be set based onclusterIdspecified in the StackLight chart values. For example, ifclusterIdisns/cluster/example-uid, thehostnamewill transform tons_cluster_example-uid. For details, seeclusterIdin StackLight configuration parameters.
Verify remote logging to syslog as described in Verify StackLight after configuration.
Create logs-based metrics¶
StackLight provides a vast variety of metrics for Container Cloud components. However, you may need to create a custom log-based metric to use it for alert notifications, for example, in the following cases:
If a component producing logs does not expose scraping targets. In this case, component-specific metrics may be missing.
If a scraping target lacks information that can be collected by aggregating the log messages.
If alerting reasons are more explicitly presented in log messages.
For example, you want to receive alert notifications when more than 10 cases
are created in Salesforce within an hour. The sf-notifier scraping
endpoint does not expose such information. However, sf-notifier logs are
stored in OpenSearch and using prometheus-es-exporter you can perform the
following:
Configure a query using Query DSL (Domain Specific Language) and test it in Dev Tools in in OpenSearch Dashboards.
Configure Prometheus Elasticsearch Exporter to expose the result as a Prometheus metric showing the total amount of Salesforce cases created daily, for example,
salesforce_cases_daily_total_value.Configure StackLight to send a notification once the value of this metric increases by 10 or more within an hour.
Caution
StackLight logging must be enabled and functional.
Prometheus-es-exporteruses OpenSearch Search API. Therefore, configured queries must be tuned for this specific API and must include:The query part to filter documents
The aggregation part to combine filtered documents into a metric-oriented result
For details, see Supported Aggregations.
The following procedure is based on the salesforce_cases_daily_total_value
metric described in the example above.
To create a custom logs-based metric:
Perform steps 1-2 as described in StackLight configuration procedure.
In the manifest that opens, verify that StackLight logging is enabled:
logging: enabled: true
Create a query using Query DSL:
Select one of the following options:
In the OpenSearch Dashboards web UI, select an index to query. StackLight stores logs in hourly OpenSearch indices.
Note
Optimize the query time by limiting the number of results. For example, we will use the OpenSearch
event.providerfield set tosf-notifierto limit the number of logs to search.For example:
GET system/_search { "query": { "bool": { "filter": [ { "term": { "event.provider": { "value": "sf-notifier" } } }, { "range": { "@timestamp": { "gte": "now/d" } } } ] } } }
In the OpenSearch Dashboards web UI, select an index to query. StackLight stores logs in hourly OpenSearch indices. To select all indices for a day, use the
<logstash-{now/d}*>index pattern, which stands for%3Clogstash-%7Bnow%2Fd%7D*%3Ewhen URL-encoded.Note
Optimize the query time by limiting the number of results. For example, we will use the OpenSearch
loggerfield set tosf-notifierto limit the number of logs to search.For example:
GET /%3Clogstash-%7Bnow%2Fd%7D*%3E/_search { "query": { "bool": { "must": { "term": { "logger": { "value": "sf-notifier" } } } } } }
Test the query in Dev Tools in OpenSearch Dashboards.
Select the log lines that include information about Salesforce cases creation. For the
infologging level, to indicate case creation,sf-notifierproduces log messages similar to the following one:[2021-07-02 12:35:28,596] INFO in client: Created case: OrderedDict([('id', '5007h000007iqmKAAQ'), ('success', True), ('errors', [])]).
Such log messages include the Created case phrase. Use it in the query to filter log messages for created cases:
"filter": { "match_phrase_prefix" : { "message" : "Created case" } }
Combine the query result to a single value that
prometheus-es-exporterwill expose as a metric. Use thevalue_countaggregation:GET system/_search { "query": { "bool": { "filter": [ { "term": { "event.provider": { "value": "sf-notifier" } } }, { "range": { "@timestamp": { "gte": "now/d" } } }, { "match_phrase_prefix" : { "message" : "Created case" } } ] } }, "aggs" : { "daily_total": { "value_count": { "field" : "event.provider" } } } }
GET /%3Clogstash-%7Bnow%2Fd%7D*%3E/_search { "query": { "bool": { "must": { "term": { "logger": { "value": "sf-notifier" } } }, "filter": { "match_phrase_prefix" : { "message" : "Created case" } } } }, "aggs" : { "daily_total": { "value_count": { "field" : "logger" } } } }
The aggregation result in Dev Tools should look as follows:
"aggregations" : { "daily_total" : { "value" : 19 } }
Note
The metric name is suffixed with the aggregation name and the result field name:
salesforce_cases_daily_total_value.
Configure Prometheus Elasticsearch Exporter:
In StackLight values of the cluster resource, specify the new metric using the
logging.metricQueriesparameter and configure the query parameters as described in StackLight configuration parameters: logging.metricQueries.In the example below,
salesforce_casesis the query name. The final metric name can be generalized using the<query_name>_<aggregation_name>_<aggregation_result_field_name>template.logging: metricQueries: salesforce_cases: indices: system interval: 600 timeout: 60 onError: preserve onMissing: zero body: "{\"query\":{\"bool\":{\"filter\":[{\"term\":{\"event.provider\":{\"value\":\"sf-notifier\"}}},{\"range\":{\"@timestamp\":{\"gte\":\"now/d\"}}},{\"match_phrase_prefix\":{\"message\":\"Created case\"}}]}},\"aggs\":{\"daily_total\":{\"value_count\":{\"field\":\"event.provider\"}}}}"
logging: metricQueries: salesforce_cases: indices: '<logstash-{now/d}*>' interval: 600 timeout: 60 onError: preserve onMissing: zero body: "{\"query\":{\"bool\":{\"must\":{\"term\":{\"logger\":{\"value\":\"sf-notifier\"}}},\"filter\":{\"match_bool_prefix\":{\"message\":\"Created case\"}}}},\"aggs\":{\"daily_total\":{\"value_count\":{\"field\":\"logger\"}}}}"
Verify that the
prometheus-es-exporterConfigMap has been updated:kubectl describe cm -n stacklight prometheus-es-exporter
Example of system response:
QueryOnError = preserve QueryOnMissing = zero QueryJson = "{\"aggs\":{\"component\":{\"terms\":{\"field\":\"event.provider\"}}},\"query\":{\"match_all\":{}},\"size\":0}" [query_salesforce_cases] QueryIntervalSecs = 600 QueryTimeoutSecs = 60 QueryIndices = system QueryOnError = preserve QueryOnMissing = zero QueryJson = "{\"query\":{\"bool\":{\"filter\":[{\"term\":{\"event.provider\":{\"value\":\"sf-notifier\"}}},{\"range\":{\"@timestamp\":{\"gte\":\"now/d\"}}},{\"match_phrase_prefix\":{\"message\":\"Created case\"}}]}},\"aggs\":{\"daily_total\":{\"value_count\":{\"field\":\"event.provider\"}}}}" Events: <none>
QueryOnError = preserve QueryOnMissing = zero QueryJson = "{\"aggs\":{\"component\":{\"terms\":{\"field\":\"logger\"}}},\"query\":{\"match_all\":{}},\"size\":0}" [query_salesforce_cases] QueryIntervalSecs = 600 QueryTimeoutSecs = 60 QueryIndices = <logstash-{now/d}*> QueryOnError = preserve QueryOnMissing = zero QueryJson = "{\"query\":{\"bool\":{\"must\":{\"term\":{\"logger\":{\"value\":\"sf-notifier\"}}},\"filter\":{\"match_phrase_prefix\":{\"message\":\"Created case\"}}}},\"aggs\":{\"daily_total\":{\"value_count\":{\"field\":\"logger\"}}}}" Events: <none>
ConfigMap update triggers the
prometheus-es-exporterpod restart.Verify that the newly configured query has been executed.
kubectl logs -f -n stacklight <prometheus-es-exporter-pod-id>
Example of system response:
[...] [2021-08-04 12:08:51,989] opensearch.info MainThread POST http://opensearch-master:9200/%3Cnotification-%7Bnow%2Fd%7D%3E/_search [status:200 request:0.040s] [2021-08-04 12:08:52,089] opensearch.info MainThread POST http://opensearch-master:9200/%3Cnotification-%7Bnow%2Fd%7D%3E/_search [status:200 request:0.100s] [2021-08-04 12:08:54,469] opensearch.info MainThread POST http://opensearch-master:9200/%3Csystem-%7Bnow%2Fd%7D*%3E/_search [status:200 request:2.278s]
Once done,
prometheus-es-exporterwill expose metrics from Prometheus in its scraping endpoint. You can view the new metric in the Prometheus web UI.
(Optional) Configure StackLight notifications:
Add a new alert as described in Alerts configuration. For example:
prometheusServer: customAlerts: - alert: SalesforceCasesDailyWarning annotations: description: The number of cases created today in Salesforce increased by 10 within the last hour. summary: Too many cases in Salesforce expr: increase(salesforce_cases_daily_total_value[1h]) >= 10 labels: severity: warning service: custom
Configure receivers as described in StackLight configuration parameters. For example, to send alert notifications to Slack only:
alertmanagerSimpleConfig: slack: enabled: true api_url: https://hooks.slack.com/services/i45f3k3/w3bh00kU9L/06vi0u5ly channel: Slackbot route: match: alertname: SalesforceCasesDailyWarning salesForce: enabled: true route: routes: - receiver: HTTP-slack match: - alertname: SalesforceCasesDailyWarning
Enable generic metric scraping¶
StackLight can scrape metrics from any service that exposes Prometheus metrics
and is running on the Kubernetes cluster. Such metrics appear in Prometheus
under the
{job="stacklight-generic",service="<service_name>",namespace="<service_namespace>"}
set of labels. If the Kubernetes service is backed by Kubernetes pods, the set
of labels also includes {pod="<pod_name>"}.
To enable the functionality, define at least one of the following annotations in the service metadata:
"generic.stacklight.mirantis.com/scrape-port"- the HTTP endpoint port. By default, the port number found through Kubernetes service discovery, usually __meta_kubernetes_pod_container_port_number. If none discovered, use the default port for the chosen scheme."generic.stacklight.mirantis.com/scrape-path"- the HTTP endpoint path, related to the Prometheusscrape_config.metrics_pathoption. By default,/metrics."generic.stacklight.mirantis.com/scrape-scheme"- the HTTP endpoint scheme between HTTP and HTTPS, related to the Prometheusscrape_config.schemeoption. By default,http.
For example:
metadata:
annotations:
"generic.stacklight.mirantis.com/scrape-path": "/metrics"
metadata:
annotations:
"generic.stacklight.mirantis.com/scrape-port": "8080"
Manage metrics filtering¶
Available since 2.24.0 and 2.24.2 for MOSK 23.2
By default, StackLight drops unused metrics to increase Prometheus performance providing better resource utilization and faster query response. The following list contains white-listed scrape jobs grouped by the job name. Prometheus collects metrics from this list by default.
White list of Prometheus scrape jobs
{
"_group-blackbox-metrics": [
"probe_dns_lookup_time_seconds",
"probe_duration_seconds",
"probe_http_content_length",
"probe_http_duration_seconds",
"probe_http_ssl",
"probe_http_uncompressed_body_length",
"probe_ssl_earliest_cert_expiry",
"probe_success"
],
"_group-controller-runtime-metrics": [
"workqueue_adds_total",
"workqueue_depth",
"workqueue_queue_duration_seconds_count",
"workqueue_queue_duration_seconds_sum",
"workqueue_retries_total",
"workqueue_work_duration_seconds_count",
"workqueue_work_duration_seconds_sum"
],
"_group-etcd-metrics": [
"etcd_cluster_version",
"etcd_debugging_snap_save_total_duration_seconds_sum",
"etcd_disk_backend_commit_duration_seconds_bucket",
"etcd_disk_backend_commit_duration_seconds_count",
"etcd_disk_backend_commit_duration_seconds_sum",
"etcd_disk_backend_snapshot_duration_seconds_count",
"etcd_disk_backend_snapshot_duration_seconds_sum",
"etcd_disk_wal_fsync_duration_seconds_bucket",
"etcd_disk_wal_fsync_duration_seconds_count",
"etcd_disk_wal_fsync_duration_seconds_sum",
"etcd_mvcc_db_total_size_in_bytes",
"etcd_network_client_grpc_received_bytes_total",
"etcd_network_client_grpc_sent_bytes_total",
"etcd_network_peer_received_bytes_total",
"etcd_network_peer_sent_bytes_total",
"etcd_server_go_version",
"etcd_server_has_leader",
"etcd_server_leader_changes_seen_total",
"etcd_server_proposals_applied_total",
"etcd_server_proposals_committed_total",
"etcd_server_proposals_failed_total",
"etcd_server_proposals_pending",
"etcd_server_quota_backend_bytes",
"etcd_server_version",
"grpc_server_handled_total",
"grpc_server_started_total"
],
"_group-go-collector-metrics": [
"go_gc_duration_seconds",
"go_gc_duration_seconds_count",
"go_gc_duration_seconds_sum",
"go_goroutines",
"go_info",
"go_memstats_alloc_bytes",
"go_memstats_alloc_bytes_total",
"go_memstats_buck_hash_sys_bytes",
"go_memstats_frees_total",
"go_memstats_gc_sys_bytes",
"go_memstats_heap_alloc_bytes",
"go_memstats_heap_idle_bytes",
"go_memstats_heap_inuse_bytes",
"go_memstats_heap_released_bytes",
"go_memstats_heap_sys_bytes",
"go_memstats_lookups_total",
"go_memstats_mallocs_total",
"go_memstats_mcache_inuse_bytes",
"go_memstats_mcache_sys_bytes",
"go_memstats_mspan_inuse_bytes",
"go_memstats_mspan_sys_bytes",
"go_memstats_next_gc_bytes",
"go_memstats_other_sys_bytes",
"go_memstats_stack_inuse_bytes",
"go_memstats_stack_sys_bytes",
"go_memstats_sys_bytes",
"go_threads"
],
"_group-process-collector-metrics": [
"process_cpu_seconds_total",
"process_max_fds",
"process_open_fds",
"process_resident_memory_bytes",
"process_start_time_seconds",
"process_virtual_memory_bytes"
],
"_group-rest-client-metrics": [
"rest_client_request_latency_seconds_count",
"rest_client_request_latency_seconds_sum"
],
"_group-service-handler-metrics": [
"service_handler_count",
"service_handler_sum"
],
"_group-service-http-metrics": [
"service_http_count",
"service_http_sum"
],
"_group-service-reconciler-metrics": [
"service_reconciler_count",
"service_reconciler_sum"
],
"alertmanager-webhook-servicenow": [
"servicenow_auth_ok"
],
"blackbox": [],
"blackbox-external-endpoint": [],
"cadvisor": [
"cadvisor_version_info",
"container_cpu_cfs_periods_total",
"container_cpu_cfs_throttled_periods_total",
"container_cpu_usage_seconds_total",
"container_fs_reads_bytes_total",
"container_fs_reads_total",
"container_fs_writes_bytes_total",
"container_fs_writes_total",
"container_memory_usage_bytes",
"container_memory_working_set_bytes",
"container_network_receive_bytes_total",
"container_network_transmit_bytes_total",
"container_scrape_error",
"machine_cpu_cores"
],
"calico": [
"felix_active_local_endpoints",
"felix_active_local_policies",
"felix_active_local_selectors",
"felix_active_local_tags",
"felix_cluster_num_host_endpoints",
"felix_cluster_num_hosts",
"felix_cluster_num_workload_endpoints",
"felix_host",
"felix_int_dataplane_addr_msg_batch_size_count",
"felix_int_dataplane_addr_msg_batch_size_sum",
"felix_int_dataplane_failures",
"felix_int_dataplane_iface_msg_batch_size_count",
"felix_int_dataplane_iface_msg_batch_size_sum",
"felix_ipset_errors",
"felix_ipsets_calico",
"felix_iptables_chains",
"felix_iptables_restore_errors",
"felix_iptables_save_errors",
"felix_resyncs_started"
],
"etcd-server": [],
"fluentd": [
"apache_http_request_duration_seconds_bucket",
"apache_http_request_duration_seconds_count",
"docker_networkdb_stats_netmsg",
"docker_networkdb_stats_qlen",
"kernel_io_errors_total"
],
"helm-controller": [
"helmbundle_reconcile_up",
"helmbundle_release_ready",
"helmbundle_release_status",
"helmbundle_release_success",
"rest_client_requests_total"
],
"ironic": [
"ironic_driver_metadata",
"ironic_drivers_total",
"ironic_nodes",
"ironic_up"
],
"kaas-exporter": [
"kaas_cluster_info",
"kaas_cluster_updating",
"kaas_clusters",
"kaas_info",
"kaas_license_expiry",
"kaas_machine_ready",
"kaas_machines_ready",
"kaas_machines_requested",
"rest_client_requests_total"
],
"kubelet": [
"kubelet_running_containers",
"kubelet_running_pods",
"kubelet_volume_stats_available_bytes",
"kubelet_volume_stats_capacity_bytes",
"kubelet_volume_stats_used_bytes",
"kubernetes_build_info",
"rest_client_requests_total"
],
"kubernetes-apiservers": [
"apiserver_client_certificate_expiration_seconds_bucket",
"apiserver_client_certificate_expiration_seconds_count",
"apiserver_request_total",
"kubernetes_build_info",
"rest_client_requests_total"
],
"kubernetes-master-api": [],
"mcc-blackbox": [],
"mcc-cache": [],
"mcc-controllers": [
"rest_client_requests_total"
],
"mcc-providers": [
"rest_client_requests_total"
],
"mke-manager-api": [],
"mke-metrics-controller": [
"ucp_controller_services",
"ucp_engine_node_health"
],
"mke-metrics-engine": [
"ucp_engine_container_cpu_percent",
"ucp_engine_container_cpu_total_time_nanoseconds",
"ucp_engine_container_health",
"ucp_engine_container_memory_usage_bytes",
"ucp_engine_container_network_rx_bytes_total",
"ucp_engine_container_network_tx_bytes_total",
"ucp_engine_container_unhealth",
"ucp_engine_containers",
"ucp_engine_disk_free_bytes",
"ucp_engine_disk_total_bytes",
"ucp_engine_images",
"ucp_engine_memory_total_bytes",
"ucp_engine_num_cpu_cores"
],
"msr-api": [],
"openstack-blackbox-ext": [],
"openstack-cloudprober": [
"cloudprober_success",
"cloudprober_total"
],
"openstack-ingress-controller": [
"nginx_ingress_controller_build_info",
"nginx_ingress_controller_config_hash",
"nginx_ingress_controller_config_last_reload_successful",
"nginx_ingress_controller_nginx_process_connections",
"nginx_ingress_controller_nginx_process_cpu_seconds_total",
"nginx_ingress_controller_nginx_process_resident_memory_bytes",
"nginx_ingress_controller_request_duration_seconds_bucket",
"nginx_ingress_controller_request_size_sum",
"nginx_ingress_controller_requests",
"nginx_ingress_controller_response_size_sum",
"nginx_ingress_controller_ssl_expire_time_seconds",
"nginx_ingress_controller_success"
],
"osdpl-exporter": [
"osdpl_aodh_alarms",
"osdpl_certificate_expiry",
"osdpl_cinder_zone_volumes",
"osdpl_neutron_availability_zone_info",
"osdpl_neutron_zone_routers",
"osdpl_nova_aggregate_hosts",
"osdpl_nova_availability_zone_info",
"osdpl_nova_availability_zone_instances",
"osdpl_nova_availability_zone_hosts",
"osdpl_version_info"
],
"patroni": [
"patroni_patroni_cluster_unlocked",
"patroni_patroni_info",
"patroni_postgresql_info",
"patroni_replication_info",
"patroni_xlog_location",
"patroni_xlog_paused",
"patroni_xlog_received_location",
"patroni_xlog_replayed_location",
"python_info"
],
"postgresql": [
"pg_database_size",
"pg_locks_count",
"pg_stat_activity_count",
"pg_stat_activity_max_tx_duration",
"pg_stat_archiver_failed_count",
"pg_stat_bgwriter_buffers_alloc",
"pg_stat_bgwriter_buffers_alloc_total",
"pg_stat_bgwriter_buffers_backend",
"pg_stat_bgwriter_buffers_backend_fsync",
"pg_stat_bgwriter_buffers_backend_fsync_total",
"pg_stat_bgwriter_buffers_backend_total",
"pg_stat_bgwriter_buffers_checkpoint",
"pg_stat_bgwriter_buffers_checkpoint_total",
"pg_stat_bgwriter_buffers_clean",
"pg_stat_bgwriter_buffers_clean_total",
"pg_stat_bgwriter_checkpoint_sync_time",
"pg_stat_bgwriter_checkpoint_sync_time_total",
"pg_stat_bgwriter_checkpoint_write_time",
"pg_stat_bgwriter_checkpoint_write_time_total",
"pg_stat_database_blks_hit",
"pg_stat_database_blks_read",
"pg_stat_database_checksum_failures",
"pg_stat_database_conflicts",
"pg_stat_database_conflicts_confl_bufferpin",
"pg_stat_database_conflicts_confl_deadlock",
"pg_stat_database_conflicts_confl_lock",
"pg_stat_database_conflicts_confl_snapshot",
"pg_stat_database_conflicts_confl_tablespace",
"pg_stat_database_deadlocks",
"pg_stat_database_temp_bytes",
"pg_stat_database_tup_deleted",
"pg_stat_database_tup_fetched",
"pg_stat_database_tup_inserted",
"pg_stat_database_tup_returned",
"pg_stat_database_tup_updated",
"pg_stat_database_xact_commit",
"pg_stat_database_xact_rollback",
"postgres_exporter_build_info"
],
"prometheus-alertmanager": [
"alertmanager_active_alerts",
"alertmanager_active_silences",
"alertmanager_alerts",
"alertmanager_alerts_invalid_total",
"alertmanager_alerts_received_total",
"alertmanager_build_info",
"alertmanager_cluster_failed_peers",
"alertmanager_cluster_health_score",
"alertmanager_cluster_members",
"alertmanager_cluster_messages_pruned_total",
"alertmanager_cluster_messages_queued",
"alertmanager_cluster_messages_received_size_total",
"alertmanager_cluster_messages_received_total",
"alertmanager_cluster_messages_sent_size_total",
"alertmanager_cluster_messages_sent_total",
"alertmanager_cluster_peer_info",
"alertmanager_cluster_peers_joined_total",
"alertmanager_cluster_peers_left_total",
"alertmanager_cluster_reconnections_failed_total",
"alertmanager_cluster_reconnections_total",
"alertmanager_config_last_reload_success_timestamp_seconds",
"alertmanager_config_last_reload_successful",
"alertmanager_nflog_gc_duration_seconds_count",
"alertmanager_nflog_gc_duration_seconds_sum",
"alertmanager_nflog_gossip_messages_propagated_total",
"alertmanager_nflog_queries_total",
"alertmanager_nflog_query_duration_seconds_bucket",
"alertmanager_nflog_query_errors_total",
"alertmanager_nflog_snapshot_duration_seconds_count",
"alertmanager_nflog_snapshot_duration_seconds_sum",
"alertmanager_nflog_snapshot_size_bytes",
"alertmanager_notification_latency_seconds_bucket",
"alertmanager_notifications_failed_total",
"alertmanager_notifications_total",
"alertmanager_oversize_gossip_message_duration_seconds_bucket",
"alertmanager_oversized_gossip_message_dropped_total",
"alertmanager_oversized_gossip_message_failure_total",
"alertmanager_oversized_gossip_message_sent_total",
"alertmanager_partial_state_merges_failed_total",
"alertmanager_partial_state_merges_total",
"alertmanager_silences",
"alertmanager_silences_gc_duration_seconds_count",
"alertmanager_silences_gc_duration_seconds_sum",
"alertmanager_silences_gossip_messages_propagated_total",
"alertmanager_silences_queries_total",
"alertmanager_silences_query_duration_seconds_bucket",
"alertmanager_silences_query_errors_total",
"alertmanager_silences_snapshot_duration_seconds_count",
"alertmanager_silences_snapshot_duration_seconds_sum",
"alertmanager_silences_snapshot_size_bytes",
"alertmanager_state_replication_failed_total",
"alertmanager_state_replication_total"
],
"prometheus-elasticsearch-exporter": [
"elasticsearch_breakers_estimated_size_bytes",
"elasticsearch_breakers_limit_size_bytes",
"elasticsearch_breakers_tripped",
"elasticsearch_cluster_health_active_primary_shards",
"elasticsearch_cluster_health_active_shards",
"elasticsearch_cluster_health_delayed_unassigned_shards",
"elasticsearch_cluster_health_initializing_shards",
"elasticsearch_cluster_health_number_of_data_nodes",
"elasticsearch_cluster_health_number_of_nodes",
"elasticsearch_cluster_health_number_of_pending_tasks",
"elasticsearch_cluster_health_relocating_shards",
"elasticsearch_cluster_health_status",
"elasticsearch_cluster_health_unassigned_shards",
"elasticsearch_exporter_build_info",
"elasticsearch_indices_docs",
"elasticsearch_indices_docs_deleted",
"elasticsearch_indices_docs_primary",
"elasticsearch_indices_fielddata_evictions",
"elasticsearch_indices_fielddata_memory_size_bytes",
"elasticsearch_indices_filter_cache_evictions",
"elasticsearch_indices_flush_time_seconds",
"elasticsearch_indices_flush_total",
"elasticsearch_indices_get_exists_time_seconds",
"elasticsearch_indices_get_exists_total",
"elasticsearch_indices_get_missing_time_seconds",
"elasticsearch_indices_get_missing_total",
"elasticsearch_indices_get_time_seconds",
"elasticsearch_indices_get_total",
"elasticsearch_indices_indexing_delete_time_seconds_total",
"elasticsearch_indices_indexing_delete_total",
"elasticsearch_indices_indexing_index_time_seconds_total",
"elasticsearch_indices_indexing_index_total",
"elasticsearch_indices_merges_docs_total",
"elasticsearch_indices_merges_total",
"elasticsearch_indices_merges_total_size_bytes_total",
"elasticsearch_indices_merges_total_time_seconds_total",
"elasticsearch_indices_query_cache_evictions",
"elasticsearch_indices_query_cache_memory_size_bytes",
"elasticsearch_indices_refresh_time_seconds_total",
"elasticsearch_indices_refresh_total",
"elasticsearch_indices_search_fetch_time_seconds",
"elasticsearch_indices_search_fetch_total",
"elasticsearch_indices_search_query_time_seconds",
"elasticsearch_indices_search_query_total",
"elasticsearch_indices_segment_count_primary",
"elasticsearch_indices_segment_count_total",
"elasticsearch_indices_segment_doc_values_memory_bytes_primary",
"elasticsearch_indices_segment_doc_values_memory_bytes_total",
"elasticsearch_indices_segment_fields_memory_bytes_primary",
"elasticsearch_indices_segment_fields_memory_bytes_total",
"elasticsearch_indices_segment_fixed_bit_set_memory_bytes_primary",
"elasticsearch_indices_segment_fixed_bit_set_memory_bytes_total",
"elasticsearch_indices_segment_index_writer_memory_bytes_primary",
"elasticsearch_indices_segment_index_writer_memory_bytes_total",
"elasticsearch_indices_segment_memory_bytes_primary",
"elasticsearch_indices_segment_memory_bytes_total",
"elasticsearch_indices_segment_norms_memory_bytes_primary",
"elasticsearch_indices_segment_norms_memory_bytes_total",
"elasticsearch_indices_segment_points_memory_bytes_primary",
"elasticsearch_indices_segment_points_memory_bytes_total",
"elasticsearch_indices_segment_terms_memory_primary",
"elasticsearch_indices_segment_terms_memory_total",
"elasticsearch_indices_segment_version_map_memory_bytes_primary",
"elasticsearch_indices_segment_version_map_memory_bytes_total",
"elasticsearch_indices_segments_count",
"elasticsearch_indices_segments_memory_bytes",
"elasticsearch_indices_store_size_bytes",
"elasticsearch_indices_store_size_bytes_primary",
"elasticsearch_indices_store_size_bytes_total",
"elasticsearch_indices_store_throttle_time_seconds_total",
"elasticsearch_indices_translog_operations",
"elasticsearch_indices_translog_size_in_bytes",
"elasticsearch_jvm_gc_collection_seconds_count",
"elasticsearch_jvm_gc_collection_seconds_sum",
"elasticsearch_jvm_memory_committed_bytes",
"elasticsearch_jvm_memory_max_bytes",
"elasticsearch_jvm_memory_pool_peak_used_bytes",
"elasticsearch_jvm_memory_used_bytes",
"elasticsearch_os_load1",
"elasticsearch_os_load15",
"elasticsearch_os_load5",
"elasticsearch_process_cpu_percent",
"elasticsearch_process_cpu_seconds_total",
"elasticsearch_process_cpu_time_seconds_sum",
"elasticsearch_process_open_files_count",
"elasticsearch_thread_pool_active_count",
"elasticsearch_thread_pool_completed_count",
"elasticsearch_thread_pool_queue_count",
"elasticsearch_thread_pool_rejected_count",
"elasticsearch_transport_rx_size_bytes_total",
"elasticsearch_transport_tx_size_bytes_total"
],
"prometheus-grafana": [
"grafana_api_dashboard_get_milliseconds",
"grafana_api_dashboard_get_milliseconds_count",
"grafana_api_dashboard_get_milliseconds_sum",
"grafana_api_dashboard_save_milliseconds",
"grafana_api_dashboard_save_milliseconds_count",
"grafana_api_dashboard_save_milliseconds_sum",
"grafana_api_dashboard_search_milliseconds",
"grafana_api_dashboard_search_milliseconds_count",
"grafana_api_dashboard_search_milliseconds_sum",
"grafana_api_dataproxy_request_all_milliseconds",
"grafana_api_dataproxy_request_all_milliseconds_count",
"grafana_api_dataproxy_request_all_milliseconds_sum",
"grafana_api_login_oauth_total",
"grafana_api_login_post_total",
"grafana_api_response_status_total",
"grafana_build_info",
"grafana_feature_toggles_info",
"grafana_http_request_duration_seconds_count",
"grafana_page_response_status_total",
"grafana_plugin_build_info",
"grafana_proxy_response_status_total",
"grafana_stat_total_orgs",
"grafana_stat_total_users",
"grafana_stat_totals_dashboard"
],
"prometheus-kube-state-metrics": [
"kube_cronjob_next_schedule_time",
"kube_daemonset_created",
"kube_daemonset_status_current_number_scheduled",
"kube_daemonset_status_desired_number_scheduled",
"kube_daemonset_status_number_available",
"kube_daemonset_status_number_misscheduled",
"kube_daemonset_status_number_ready",
"kube_daemonset_status_number_unavailable",
"kube_daemonset_status_observed_generation",
"kube_daemonset_status_updated_number_scheduled",
"kube_deployment_created",
"kube_deployment_metadata_generation",
"kube_deployment_spec_replicas",
"kube_deployment_status_observed_generation",
"kube_deployment_status_replicas",
"kube_deployment_status_replicas_available",
"kube_deployment_status_replicas_unavailable",
"kube_deployment_status_replicas_updated",
"kube_endpoint_address_available",
"kube_job_status_active",
"kube_job_status_failed",
"kube_job_status_succeeded",
"kube_namespace_created",
"kube_namespace_status_phase",
"kube_node_info",
"kube_node_labels",
"kube_node_role",
"kube_node_spec_taint",
"kube_node_spec_unschedulable",
"kube_node_status_allocatable",
"kube_node_status_capacity",
"kube_node_status_condition",
"kube_persistentvolume_capacity_bytes",
"kube_persistentvolume_status_phase",
"kube_persistentvolumeclaim_resource_requests_storage_bytes",
"kube_pod_container_info",
"kube_pod_container_resource_limits",
"kube_pod_container_resource_requests",
"kube_pod_container_status_restarts_total",
"kube_pod_container_status_running",
"kube_pod_container_status_terminated",
"kube_pod_container_status_waiting",
"kube_pod_info",
"kube_pod_init_container_status_running",
"kube_pod_status_phase",
"kube_service_status_load_balancer_ingress",
"kube_statefulset_created",
"kube_statefulset_metadata_generation",
"kube_statefulset_replicas",
"kube_statefulset_status_current_revision",
"kube_statefulset_status_observed_generation",
"kube_statefulset_status_replicas",
"kube_statefulset_status_replicas_available",
"kube_statefulset_status_replicas_current",
"kube_statefulset_status_replicas_ready",
"kube_statefulset_status_replicas_updated",
"kube_statefulset_status_update_revision"
],
"prometheus-libvirt-exporter": [
"libvirt_domain_block_stats_allocation",
"libvirt_domain_block_stats_capacity",
"libvirt_domain_block_stats_physical",
"libvirt_domain_block_stats_read_bytes_total",
"libvirt_domain_block_stats_read_requests_total",
"libvirt_domain_block_stats_write_bytes_total",
"libvirt_domain_block_stats_write_requests_total",
"libvirt_domain_info_cpu_time_seconds_total",
"libvirt_domain_info_maximum_memory_bytes",
"libvirt_domain_info_memory_usage_bytes",
"libvirt_domain_info_state",
"libvirt_domain_info_virtual_cpus",
"libvirt_domain_interface_stats_receive_bytes_total",
"libvirt_domain_interface_stats_receive_drops_total",
"libvirt_domain_interface_stats_receive_errors_total",
"libvirt_domain_interface_stats_receive_packets_total",
"libvirt_domain_interface_stats_transmit_bytes_total",
"libvirt_domain_interface_stats_transmit_drops_total",
"libvirt_domain_interface_stats_transmit_errors_total",
"libvirt_domain_interface_stats_transmit_packets_total",
"libvirt_domain_memory_actual_balloon_bytes",
"libvirt_domain_memory_available_bytes",
"libvirt_domain_memory_rss_bytes",
"libvirt_domain_memory_unused_bytes",
"libvirt_domain_memory_usable_bytes",
"libvirt_up"
],
"prometheus-memcached-exporter": [
"memcached_commands_total",
"memcached_current_bytes",
"memcached_current_connections",
"memcached_current_items",
"memcached_exporter_build_info",
"memcached_items_evicted_total",
"memcached_items_reclaimed_total",
"memcached_limit_bytes",
"memcached_read_bytes_total",
"memcached_up",
"memcached_version",
"memcached_written_bytes_total"
],
"prometheus-msteams": [],
"prometheus-mysql-exporter": [
"mysql_global_status_aborted_clients",
"mysql_global_status_aborted_connects",
"mysql_global_status_buffer_pool_pages",
"mysql_global_status_bytes_received",
"mysql_global_status_bytes_sent",
"mysql_global_status_commands_total",
"mysql_global_status_created_tmp_disk_tables",
"mysql_global_status_created_tmp_files",
"mysql_global_status_created_tmp_tables",
"mysql_global_status_handlers_total",
"mysql_global_status_innodb_log_waits",
"mysql_global_status_innodb_num_open_files",
"mysql_global_status_innodb_page_size",
"mysql_global_status_max_used_connections",
"mysql_global_status_open_files",
"mysql_global_status_open_table_definitions",
"mysql_global_status_open_tables",
"mysql_global_status_opened_files",
"mysql_global_status_opened_table_definitions",
"mysql_global_status_opened_tables",
"mysql_global_status_qcache_free_memory",
"mysql_global_status_qcache_hits",
"mysql_global_status_qcache_inserts",
"mysql_global_status_qcache_lowmem_prunes",
"mysql_global_status_qcache_not_cached",
"mysql_global_status_qcache_queries_in_cache",
"mysql_global_status_queries",
"mysql_global_status_questions",
"mysql_global_status_select_full_join",
"mysql_global_status_select_full_range_join",
"mysql_global_status_select_range",
"mysql_global_status_select_range_check",
"mysql_global_status_select_scan",
"mysql_global_status_slow_queries",
"mysql_global_status_sort_merge_passes",
"mysql_global_status_sort_range",
"mysql_global_status_sort_rows",
"mysql_global_status_sort_scan",
"mysql_global_status_table_locks_immediate",
"mysql_global_status_table_locks_waited",
"mysql_global_status_threads_cached",
"mysql_global_status_threads_connected",
"mysql_global_status_threads_created",
"mysql_global_status_threads_running",
"mysql_global_status_wsrep_flow_control_paused",
"mysql_global_status_wsrep_local_recv_queue",
"mysql_global_status_wsrep_local_state",
"mysql_global_status_wsrep_ready",
"mysql_global_variables_innodb_buffer_pool_size",
"mysql_global_variables_innodb_log_buffer_size",
"mysql_global_variables_key_buffer_size",
"mysql_global_variables_max_connections",
"mysql_global_variables_open_files_limit",
"mysql_global_variables_query_cache_size",
"mysql_global_variables_table_definition_cache",
"mysql_global_variables_table_open_cache",
"mysql_global_variables_thread_cache_size",
"mysql_global_variables_wsrep_desync",
"mysql_up",
"mysql_version_info",
"mysqld_exporter_build_info"
],
"prometheus-node-exporter": [
"node_arp_entries",
"node_bonding_active",
"node_bonding_slaves",
"node_boot_time_seconds",
"node_context_switches_total",
"node_cpu_seconds_total",
"node_disk_io_now",
"node_disk_io_time_seconds_total",
"node_disk_io_time_weighted_seconds_total",
"node_disk_read_bytes_total",
"node_disk_read_time_seconds_total",
"node_disk_reads_completed_total",
"node_disk_reads_merged_total",
"node_disk_write_time_seconds_total",
"node_disk_writes_completed_total",
"node_disk_writes_merged_total",
"node_disk_written_bytes_total",
"node_entropy_available_bits",
"node_exporter_build_info",
"node_filefd_allocated",
"node_filefd_maximum",
"node_filesystem_avail_bytes",
"node_filesystem_files",
"node_filesystem_files_free",
"node_filesystem_free_bytes",
"node_filesystem_readonly",
"node_filesystem_size_bytes",
"node_forks_total",
"node_hwmon_temp_celsius",
"node_hwmon_temp_crit_alarm_celsius",
"node_hwmon_temp_crit_celsius",
"node_hwmon_temp_crit_hyst_celsius",
"node_hwmon_temp_max_celsius",
"node_intr_total",
"node_load1",
"node_load15",
"node_load5",
"node_memory_Active_anon_bytes",
"node_memory_Active_bytes",
"node_memory_Active_file_bytes",
"node_memory_AnonHugePages_bytes",
"node_memory_AnonPages_bytes",
"node_memory_Bounce_bytes",
"node_memory_Buffers_bytes",
"node_memory_Cached_bytes",
"node_memory_CommitLimit_bytes",
"node_memory_Committed_AS_bytes",
"node_memory_DirectMap1G",
"node_memory_DirectMap2M_bytes",
"node_memory_DirectMap4k_bytes",
"node_memory_Dirty_bytes",
"node_memory_HardwareCorrupted_bytes",
"node_memory_HugePages_Free",
"node_memory_HugePages_Rsvd",
"node_memory_HugePages_Surp",
"node_memory_HugePages_Total",
"node_memory_Hugepagesize_bytes",
"node_memory_Inactive_anon_bytes",
"node_memory_Inactive_bytes",
"node_memory_Inactive_file_bytes",
"node_memory_KernelStack_bytes",
"node_memory_Mapped_bytes",
"node_memory_MemAvailable_bytes",
"node_memory_MemFree_bytes",
"node_memory_MemTotal_bytes",
"node_memory_Mlocked_bytes",
"node_memory_NFS_Unstable_bytes",
"node_memory_PageTables_bytes",
"node_memory_SReclaimable_bytes",
"node_memory_SUnreclaim_bytes",
"node_memory_Shmem_bytes",
"node_memory_Slab_bytes",
"node_memory_SwapCached_bytes",
"node_memory_SwapFree_bytes",
"node_memory_SwapTotal_bytes",
"node_memory_Unevictable_bytes",
"node_memory_VmallocChunk_bytes",
"node_memory_VmallocTotal_bytes",
"node_memory_VmallocUsed_bytes",
"node_memory_WritebackTmp_bytes",
"node_memory_Writeback_bytes",
"node_netstat_TcpExt_TCPSynRetrans",
"node_netstat_Tcp_ActiveOpens",
"node_netstat_Tcp_AttemptFails",
"node_netstat_Tcp_CurrEstab",
"node_netstat_Tcp_EstabResets",
"node_netstat_Tcp_InCsumErrors",
"node_netstat_Tcp_InErrs",
"node_netstat_Tcp_InSegs",
"node_netstat_Tcp_MaxConn",
"node_netstat_Tcp_OutRsts",
"node_netstat_Tcp_OutSegs",
"node_netstat_Tcp_PassiveOpens",
"node_netstat_Tcp_RetransSegs",
"node_netstat_Udp_InCsumErrors",
"node_netstat_Udp_InDatagrams",
"node_netstat_Udp_InErrors",
"node_netstat_Udp_NoPorts",
"node_netstat_Udp_OutDatagrams",
"node_netstat_Udp_RcvbufErrors",
"node_netstat_Udp_SndbufErrors",
"node_network_mtu_bytes",
"node_network_receive_bytes_total",
"node_network_receive_compressed_total",
"node_network_receive_drop_total",
"node_network_receive_errs_total",
"node_network_receive_fifo_total",
"node_network_receive_frame_total",
"node_network_receive_multicast_total",
"node_network_receive_packets_total",
"node_network_transmit_bytes_total",
"node_network_transmit_carrier_total",
"node_network_transmit_colls_total",
"node_network_transmit_compressed_total",
"node_network_transmit_drop_total",
"node_network_transmit_errs_total",
"node_network_transmit_fifo_total",
"node_network_transmit_packets_total",
"node_network_up",
"node_nf_conntrack_entries",
"node_nf_conntrack_entries_limit",
"node_procs_blocked",
"node_procs_running",
"node_scrape_collector_duration_seconds",
"node_scrape_collector_success",
"node_sockstat_FRAG_inuse",
"node_sockstat_FRAG_memory",
"node_sockstat_RAW_inuse",
"node_sockstat_TCP_alloc",
"node_sockstat_TCP_inuse",
"node_sockstat_TCP_mem",
"node_sockstat_TCP_mem_bytes",
"node_sockstat_TCP_orphan",
"node_sockstat_TCP_tw",
"node_sockstat_UDPLITE_inuse",
"node_sockstat_UDP_inuse",
"node_sockstat_UDP_mem",
"node_sockstat_UDP_mem_bytes",
"node_sockstat_sockets_used",
"node_textfile_scrape_error",
"node_time_seconds",
"node_timex_estimated_error_seconds",
"node_timex_frequency_adjustment_ratio",
"node_timex_maxerror_seconds",
"node_timex_offset_seconds",
"node_timex_sync_status",
"node_uname_info"
],
"prometheus-rabbitmq-exporter": [
"rabbitmq_channels",
"rabbitmq_connections",
"rabbitmq_consumers",
"rabbitmq_exchanges",
"rabbitmq_exporter_build_info",
"rabbitmq_fd_available",
"rabbitmq_fd_used",
"rabbitmq_node_disk_free",
"rabbitmq_node_disk_free_alarm",
"rabbitmq_node_mem_alarm",
"rabbitmq_node_mem_used",
"rabbitmq_partitions",
"rabbitmq_queue_messages_global",
"rabbitmq_queue_messages_ready_global",
"rabbitmq_queue_messages_unacknowledged_global",
"rabbitmq_queues",
"rabbitmq_sockets_available",
"rabbitmq_sockets_used",
"rabbitmq_up",
"rabbitmq_uptime",
"rabbitmq_version_info"
],
"prometheus-relay": [],
"prometheus-server": [
"prometheus_build_info",
"prometheus_config_last_reload_success_timestamp_seconds",
"prometheus_config_last_reload_successful",
"prometheus_engine_query_duration_seconds",
"prometheus_engine_query_duration_seconds_sum",
"prometheus_http_request_duration_seconds_count",
"prometheus_notifications_alertmanagers_discovered",
"prometheus_notifications_errors_total",
"prometheus_notifications_queue_capacity",
"prometheus_notifications_queue_length",
"prometheus_notifications_sent_total",
"prometheus_rule_evaluation_failures_total",
"prometheus_target_interval_length_seconds",
"prometheus_target_interval_length_seconds_count",
"prometheus_target_scrapes_sample_duplicate_timestamp_total",
"prometheus_tsdb_blocks_loaded",
"prometheus_tsdb_compaction_chunk_range_seconds_count",
"prometheus_tsdb_compaction_chunk_range_seconds_sum",
"prometheus_tsdb_compaction_chunk_samples_count",
"prometheus_tsdb_compaction_chunk_samples_sum",
"prometheus_tsdb_compaction_chunk_size_bytes_sum",
"prometheus_tsdb_compaction_duration_seconds_bucket",
"prometheus_tsdb_compaction_duration_seconds_count",
"prometheus_tsdb_compaction_duration_seconds_sum",
"prometheus_tsdb_compactions_failed_total",
"prometheus_tsdb_compactions_total",
"prometheus_tsdb_compactions_triggered_total",
"prometheus_tsdb_head_active_appenders",
"prometheus_tsdb_head_chunks",
"prometheus_tsdb_head_chunks_created_total",
"prometheus_tsdb_head_chunks_removed_total",
"prometheus_tsdb_head_gc_duration_seconds_sum",
"prometheus_tsdb_head_samples_appended_total",
"prometheus_tsdb_head_series",
"prometheus_tsdb_head_series_created_total",
"prometheus_tsdb_head_series_removed_total",
"prometheus_tsdb_reloads_failures_total",
"prometheus_tsdb_reloads_total",
"prometheus_tsdb_storage_blocks_bytes",
"prometheus_tsdb_wal_corruptions_total",
"prometheus_tsdb_wal_fsync_duration_seconds_count",
"prometheus_tsdb_wal_fsync_duration_seconds_sum",
"prometheus_tsdb_wal_truncations_failed_total",
"prometheus_tsdb_wal_truncations_total"
],
"rabbitmq-operator-metrics": [
"rest_client_requests_total"
],
"refapp": [],
"sf-notifier": [
"sf_auth_ok",
"sf_error_count_created",
"sf_error_count_total",
"sf_request_count_created",
"sf_request_count_total"
],
"telegraf-docker-swarm": [
"docker_n_containers",
"docker_n_containers_paused",
"docker_n_containers_running",
"docker_n_containers_stopped",
"docker_swarm_node_ready",
"docker_swarm_tasks_desired",
"docker_swarm_tasks_running",
"internal_agent_gather_errors"
],
"telemeter-client": [
"federate_errors",
"federate_filtered_samples",
"federate_samples"
],
"telemeter-server": [
"telemeter_cleanups_total",
"telemeter_partitions",
"telemeter_samples_total"
],
"tf-cassandra-jmx-exporter": [
"cassandra_cache_entries",
"cassandra_cache_estimated_size_bytes",
"cassandra_cache_hits_total",
"cassandra_cache_requests_total",
"cassandra_client_authentication_failures_total",
"cassandra_client_native_connections",
"cassandra_client_request_failures_total",
"cassandra_client_request_latency_seconds_count",
"cassandra_client_request_latency_seconds_sum",
"cassandra_client_request_timeouts_total",
"cassandra_client_request_unavailable_exceptions_total",
"cassandra_client_request_view_write_latency_seconds",
"cassandra_commit_log_pending_tasks",
"cassandra_compaction_bytes_compacted_total",
"cassandra_compaction_completed_total",
"cassandra_dropped_messages_total",
"cassandra_endpoint_connection_timeouts_total",
"cassandra_storage_exceptions_total",
"cassandra_storage_hints_total",
"cassandra_storage_load_bytes",
"cassandra_table_estimated_pending_compactions",
"cassandra_table_repaired_ratio",
"cassandra_table_sstables_per_read_count",
"cassandra_table_tombstones_scanned",
"cassandra_thread_pool_active_tasks",
"cassandra_thread_pool_blocked_tasks"
],
"tf-control": [
"tf_controller_sessions",
"tf_controller_up"
],
"tf-kafka-jmx": [
"jmx_exporter_build_info",
"kafka_controller_controllerstats_count",
"kafka_controller_controllerstats_oneminuterate",
"kafka_controller_kafkacontroller_value",
"kafka_log_log_value",
"kafka_network_processor_value",
"kafka_network_requestmetrics_99thpercentile",
"kafka_network_requestmetrics_mean",
"kafka_network_requestmetrics_oneminuterate",
"kafka_network_socketserver_value",
"kafka_server_brokertopicmetrics_count",
"kafka_server_brokertopicmetrics_oneminuterate",
"kafka_server_delayedoperationpurgatory_value",
"kafka_server_kafkarequesthandlerpool_oneminuterate",
"kafka_server_replicamanager_oneminuterate",
"kafka_server_replicamanager_value"
],
"tf-operator": [
"tf_operator_info"
],
"tf-redis": [
"redis_commands_duration_seconds_total",
"redis_commands_processed_total",
"redis_commands_total",
"redis_connected_clients",
"redis_connected_slaves",
"redis_db_keys",
"redis_db_keys_expiring",
"redis_evicted_keys_total",
"redis_expired_keys_total",
"redis_exporter_build_info",
"redis_instance_info",
"redis_keyspace_hits_total",
"redis_keyspace_misses_total",
"redis_memory_max_bytes",
"redis_memory_used_bytes",
"redis_net_input_bytes_total",
"redis_net_output_bytes_total",
"redis_rejected_connections_total",
"redis_slave_info",
"redis_up",
"redis_uptime_in_seconds"
],
"tf-vrouter": [
"tf_vrouter_ds_discard",
"tf_vrouter_ds_flow_action_drop",
"tf_vrouter_ds_flow_queue_limit_exceeded",
"tf_vrouter_ds_flow_table_full",
"tf_vrouter_ds_frag_err",
"tf_vrouter_ds_invalid_if",
"tf_vrouter_ds_invalid_label",
"tf_vrouter_ds_invalid_nh",
"tf_vrouter_flow_active",
"tf_vrouter_flow_aged",
"tf_vrouter_flow_created",
"tf_vrouter_lls_session_info",
"tf_vrouter_up",
"tf_vrouter_xmpp_connection_state"
],
"tf-zookeeper": [
"approximate_data_size",
"bytes_received_count",
"commit_count",
"connection_drop_count",
"connection_rejected",
"connection_request_count",
"dead_watchers_cleaner_latency_sum",
"dead_watchers_cleared",
"dead_watchers_queued",
"digest_mismatches_count",
"election_time_sum",
"ephemerals_count",
"follower_sync_time_count",
"follower_sync_time_sum",
"fsynctime_sum",
"global_sessions",
"jvm_classes_loaded",
"jvm_gc_collection_seconds_sum",
"jvm_info",
"jvm_memory_pool_bytes_used",
"jvm_threads_current",
"jvm_threads_deadlocked",
"jvm_threads_state",
"leader_uptime",
"learner_commit_received_count",
"learner_proposal_received_count",
"learners",
"local_sessions",
"max_file_descriptor_count",
"node_changed_watch_count_sum",
"node_children_watch_count_sum",
"node_created_watch_count_sum",
"node_deleted_watch_count_sum",
"num_alive_connections",
"om_commit_process_time_ms_sum",
"om_proposal_process_time_ms_sum",
"open_file_descriptor_count",
"outstanding_requests",
"packets_received",
"packets_sent",
"pending_syncs",
"proposal_count",
"quorum_size",
"response_packet_cache_hits",
"response_packet_cache_misses",
"response_packet_get_children_cache_hits",
"response_packet_get_children_cache_misses",
"revalidate_count",
"snapshottime_sum",
"stale_sessions_expired",
"synced_followers",
"synced_non_voting_followers",
"synced_observers",
"unrecoverable_error_count",
"uptime",
"watch_count",
"znode_count"
],
"ucp-kv": []
}
Note
The kernel_io_errors_total metric from the above list
is available since Container Cloud 2.27.0 (Cluster releases 17.2.0 and
16.2.0).
Note
The following MOSK-related metrics from the above list of white-listed scrape jobs are available since 23.3:
The
tf-operatorgroup:tf_operator_infofor Tungsten Fabric deployments.Removed in 24.1. The
osdpl-exportergroup:osdpl_aodh_alarmsosdpl_cinder_zone_volumesosdpl_neutron_availability_zone_infoosdpl_neutron_zone_routersosdpl_nova_aggregate_hostsosdpl_nova_availability_zone_infoosdpl_nova_availability_zone_instancesosdpl_nova_availability_zone_hostsosdpl_version_info
Note
The kubelet_volume_stats_used_bytes metric from the above list
is available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and
16.1.0).
Note
The following Prometheus metrics are removed from the above list of white-listed scrape jobs in Container Cloud 2.25.0 (Cluster releases 17.0.0, 16.0.0, 14.1.0):
The
prometheus-kube-state-metricsgroup:kube_deployment_spec_pausedkube_deployment_spec_strategy_rollingupdate_max_unavailablekube_deployment_status_conditionkube_deployment_status_replicas_ready
The
prometheus-corednsjob from thego-collector-metricsandprocess-collector-metricsgroups
You can add necessary metrics that are dropped to this white list as described below. It is also possible to disable the filtering feature. However, Mirantis does not recommend disabling the feature to prevent direct impact on the Prometheus index size, which affects query speed. For clusters with extended retention period, performance degradation will be the most noticeable.
Add dropped metrics to the white list¶
You can expand the default white list of Prometheus
metrics using the prometheusServer.metricsFiltering.extraMetricsInclude
parameter to enable metrics that are dropped by default. For the
parameter description, see Prometheus metrics filtering. For configuration
steps, see StackLight configuration procedure.
Example configuration:
prometheusServer:
metricsFiltering:
enabled: true
extraMetricsInclude:
cadvisor:
- container_memory_failcnt
- container_network_transmit_errors_total
calico:
- felix_route_table_per_iface_sync_seconds_sum
- felix_bpf_dataplane_endpoints
_group-go-collector-metrics:
- go_gc_heap_goal_bytes
- go_gc_heap_objects_objects
Disable metrics filtering¶
Mirantis does not recommend disabling metrics filtering to prevent direct impact on the Prometheus index size, which affects query speed. In clusters with an extended retention period, performance degradation will be the most noticeable. Therefore, the best option is to keep the feature enabled and add the required dropped metrics to the white list as described in Add dropped metrics to the white list.
If disabling of metrics filtering is absolutely necessary, set the
prometheusServer.metricsFiltering.enabled parameter to false:
prometheusServer:
metricsFiltering:
enabled: false
For configuration steps, see StackLight configuration procedure.
Use S.M.A.R.T. metrics for creating alert rules on bare metal clusters¶
Available since 2.27.0 (Cluster releases 17.2.0 and 16.2.0)
The StackLight telegraf-ds-smart exporter uses the
S.M.A.R.T. plugin to
obtain detailed disk information and export it as metrics on bare metal
clusters. S.M.A.R.T. is a commonly used system across vendors with performance
data provided as attributes, whereas attribute names can be different across
vendors. Each attribute contains the following different values:
- Raw value
Actual value of the attribute for the time being. Units may not be the same across vendors.
- Current value
Health valuation where values can range from
1to253(1represents the worst case and253represents the best one). Depending on the manufacturer, a value of100or200will often be selected as the normal value.
- Worst value
The worst value ever observed as a current one for a particular device.
- Threshold value
Lower threshold for the current value. If the current value drops below the lower threshold, it requires attention.
The following table provides examples for alert rules based on S.M.A.R.T. metrics. These examples may not work for all clusters depending on vendor or disk types.
Caution
Before creating alert rules, manually test these expressions to verify whether they are valid for the cluster. You can also implement any other alerts based on S.M.A.R.T. metrics.
To create custom alert rules in StackLight, use the customAlerts
parameter described in Alerts configuration.
Expression |
Description |
|
Alerts when a device |
|
Indicates disk health failure. |
|
Targets any S.M.A.R.T. attribute reaching its predefined threshold, indicating a potential risk or imminent failure of the disk. Utilizing this alert might eliminate the need for more specific attribute alerts by relying on the vendor’s established thresholds, streamlining the monitoring process. Implementing inhibition rules may be necessary to manage overlaps with other alerts effectively. |
|
Is triggered when disk temperature exceeds 60°C, indicating potential overheating issues. |
|
Identifies an increase in UDMA CRC errors, indicating data transmission issues between the disk and controller. |
|
Is triggered during a noticeable increase in the rate of read errors on the disk. This is a strong indicator of issues with the disk surface or read/write heads that can affect data integrity and accessibility. |
|
Is triggered when the disk experiences an increase in attempts to spin up to its operational speed, indicating potential issues with the disk motor, bearings, or power supply, which can lead to drive failure. |
|
Is triggered during an increase in the number of disk sectors that cannot be corrected by the error correction algorithms of the drive, pointing towards serious disk surface or read/write head issues. |
|
Is triggered on a rise in sectors that are marked as pending for remapping due to read errors. Persistent increases can indicate deteriorating disk health and impending failure. |
|
Detects an upsurge in errors during the process of data transmission from the host to the disk and vice versa, highlighting potential issues in data integrity during transfer operations. |
|
Is triggered during an increase in sectors that have been reallocated due to being deemed defective. A rising count is a critical sign of ongoing wear and tear, or damage to the disk surface. |
The following table describes S.M.A.R.T. metrics provided by Stacklight that you can use for creating alert rules depending on your cluster requirements:
Metric |
Description |
|
Reports current S.M.A.R.T. attribute values with labels for detailed context. |
|
Indicates the fetching status of individual attributes. A non-zero code indicates monitoring issues. |
|
Reports raw S.M.A.R.T. attribute values with labels for detailed context. |
|
Reports S.M.A.R.T. attribute threshold values with labels for detailed context. |
|
Reports the worst recorded values of S.M.A.R.T. attributes with labels for detailed context. |
|
Counts timeouts when a drive fails to respond to a command, indicating responsiveness issues. |
|
Reflects the overall device status post-checks, where values other than
|
|
Indicates overall device health, where values other than |
The following table describes metrics from various S.M.A.R.T. attributes that
are part of the above smart_attribute* metrics. But their value
representation can be different, such as unified units or counter information.
Also, vendors may have different attribute namings. The following metrics are
standardized across different vendors. Depending on the disk or vendor type,
a cluster may miss some of the following metrics or have extra ones.
Metric |
Description |
|
Monitors data transmission errors, where an increase suggests potential transfer issues. |
|
Counts sectors awaiting remapping due to unrecoverable errors, with decreases over time indicating successful remapping. |
|
Tracks errors occurring during disk data reads. |
|
Counts defective sectors that have been remapped, with increases indicating drive degradation. |
|
Measures the error frequency of the drive positioning mechanism, with high values indicating mechanical issues. |
|
Tracks the drive attempts to spin up to operational speed, with increases indicating mechanical issues. |
|
Reports the drive temperature in Celsius. |
|
Counts errors in data communication between the drive and host. |
|
Records total uncorrectable read/write errors. |
|
Counts sectors that cannot be corrected indicating potentially damaged sectors. |
Deschedule StackLight Pods from a worker machine¶
On an existing managed cluster, addition of a worker machine that replaces the one containing the StackLight node label requires the label migration to the new machine and a manual removal of StackLight Pods from the old machine, which you remove the label from.
Caution
In this procedure, replace <machine-name> with the name of
the machine from which you remove the StackLight node label.
To deschedule StackLight Pods from a worker machine:
Remove the
stacklight=enablednode label from thespecsection of the targetMachineobject.Connect to the required cluster using its
kubeconfig.Verify that the
stacklight=enabledlabel was removed successfully:kubectl get node -l "kaas.mirantis.com/machine-name=<machine name>" --show-labels | grep "stacklight=enabled"
A positive system response must be empty.
Verify the list of StackLight Pods to be deleted that run on the target machine:
kubectl get pods -n stacklight -o wide --field-selector spec.nodeName=$(kubectl get node -l "kaas.mirantis.com/machine-name=<machine name>" -o jsonpath='{.items[0].metadata.name}')
Example of system response extract:
NAME READY STATUS AGE IP NODE alerta-fc45c8f6-6qlfx 1/1 Running 63m 10.233.76.3 node-3a0de232-c1b4-43b0-8f21-44cd1 grafana-9bc56cdff-sl5w6 3/3 Running 63m 10.233.76.4 node-3a0de232-c1b4-43b0-8f21-44cd1 iam-proxy-alerta-57585798d7-kqwd7 1/1 Running 58m 10.233.76.17 node-3a0de232-c1b4-43b0-8f21-44cd1 iam-proxy-alertmanager-6b4c4c8867-pdwcs 1/1 Running 56m 10.233.76.18 node-3a0de232-c1b4-43b0-8f21-44cd1 iam-proxy-grafana-87b984c45-2qwvb 1/1 Running 55m 10.233.76.19 node-3a0de232-c1b4-43b0-8f21-44cd1 iam-proxy-prometheus-545789585-9mll8 1/1 Running 54m 10.233.76.21 node-3a0de232-c1b4-43b0-8f21-44cd1 patroni-13-0 3/3 Running 61m 10.233.76.11 node-3a0de232-c1b4-43b0-8f21-44cd1 prometheus-alertmanager-0 1/1 Running 55m 10.233.76.20 node-3a0de232-c1b4-43b0-8f21-44cd1 prometheus-blackbox-exporter-9f6bdfd75-8zn4w 2/2 Running 61m 10.233.76.8 node-3a0de232-c1b4-43b0-8f21-44cd1 prometheus-kube-state-metrics-67ff88649f-tslxc 1/1 Running 61m 10.233.76.7 node-3a0de232-c1b4-43b0-8f21-44cd1 prometheus-node-exporter-zl8pj 1/1 Running 61m 10.10.10.143 node-3a0de232-c1b4-43b0-8f21-44cd1 telegraf-docker-swarm-69567fcf7f-jvbgn 1/1 Running 61m 10.233.76.10 node-3a0de232-c1b4-43b0-8f21-44cd1 telemeter-client-55d465dcc5-9thds 1/1 Running 61m 10.233.76.9 node-3a0de232-c1b4-43b0-8f21-44cd1
Delete all StackLight Pods from the target machine:
kubectl -n stacklight delete $(kubectl get pods -n stacklight -o wide --field-selector spec.nodeName=$(kubectl get node -l "kaas.mirantis.com/machine-name=<machine name>" -o jsonpath='{.items[0].metadata.name}') -o name)
Example of system response:
pod "alerta-fc45c8f6-6qlfx" deleted pod "grafana-9bc56cdff-sl5w6" deleted pod "iam-proxy-alerta-57585798d7-kqwd7" deleted pod "iam-proxy-alertmanager-6b4c4c8867-pdwcs" deleted pod "iam-proxy-grafana-87b984c45-2qwvb" deleted pod "iam-proxy-prometheus-545789585-9mll8" deleted pod "patroni-13-0" deleted pod "prometheus-alertmanager-0" deleted pod "prometheus-blackbox-exporter-9f6bdfd75-8zn4w" deleted pod "prometheus-kube-state-metrics-67ff88649f-tslxc" deleted pod "prometheus-node-exporter-zl8pj" deleted pod "telegraf-docker-swarm-69567fcf7f-jvbgn" deleted pod "telemeter-client-55d465dcc5-9thds" deleted
Wait about three minutes for Pods to be rescheduled.
Verify that you do not have
PendingPods in thestacklightnamespace:kubectl -n stacklight get pods --field-selector status.phase=Pending
If the system response is
No resources found in stacklight namespace, all Pods are rescheduled successfully.If the system response still contains some Pods, remove local persistent volumes (LVP) bound to the target machine.
Remove LVP from a machine
Connect to the managed cluster as described in the steps 5-7 in Connect to a Mirantis Container Cloud cluster.
Define the pods in the
Pendingstate:kubectl get po -n stacklight | grep Pending
Example of system response:
opensearch-master-2 0/1 Pending 0 49s patroni-12-0 0/3 Pending 0 51s patroni-13-0 0/3 Pending 0 48s prometheus-alertmanager-1 0/1 Pending 0 47s prometheus-server-0 0/2 Pending 0 47s
Verify that the reason for the pod
Pendingstate isvolume node affinity conflict:kubectl describe pod <POD_NAME> -n stacklight
Example of system response:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 6m53s default-scheduler 0/6 nodes are available: 3 node(s) didn't match node selector, 3 node(s) had volume node affinity conflict. Warning FailedScheduling 6m53s default-scheduler 0/6 nodes are available: 3 node(s) didn't match node selector, 3 node(s) had volume node affinity conflict.
Obtain the PVC of one of the pods:
kubectl get pod <POD_NAME> -n stacklight -o=jsonpath='{range .spec.volumes[*]}{.persistentVolumeClaim}{"\n"}{end}'
Example of system response:
{"claimName":"opensearch-master-opensearch-master-2"}
Remove the PVC using the obtained name. For example, for
opensearch-master-opensearch-master-2:kubectl delete pvc opensearch-master-opensearch-master-2 -n stacklight
Delete the pod:
kubectl delete po <POD_NAME> -n stacklight
Verify that a new pod is created and scheduled to the spare node. This may take some time. For example:
kubectl get po opensearch-master-2 -n stacklight NAME READY STATUS RESTARTS AGE opensearch-master-2 1/1 Running 0 7m1s
Repeat the steps above for the remaining pods in the
Pendingstate.
Calculate the storage retention time¶
Obsolete since 2.26.0 (17.1.0, 16.1.0) for OpenSearch Available since 2.22.0 and 2.23.1 (12.7.0, 11.6.0)
Caution
In Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0), the storage-based log retention together with the updated proportion of available disk space replaces the estimated storage retention management in OpenSearch. For details, see Storage-based log retention strategy.
The logging.retentionTime parameter is removed from the StackLight
configuration. While the Estimated Retention panel of the
OpenSearch dashboard in Grafana can provide some information,
it does not provide any guarantees. The panel is removed in Container Cloud
2.26.1 (Cluster releases 17.1.1 and 16.1.1). Therefore, consider this section
as obsolete for OpenSearch.
Using the following panels in the OpenSearch and Prometheus dashboards, you can view details about the storage usage on managed clusters. These details allow you to calculate the possible retention time based on provisioned storage and its average usage:
OpenSearch dashboard:
Shards > Estimated Retention
Resources > Disk
Resources > File System Used Space by Percentage
Resources > Stored Indices Disk Usage
Resources > Age of Logs
Prometheus dashboard:
General > Estimated Retention
Resources > Storage
Resources > Storage by Percentage
To calculate the storage retention time:
Log in to the Grafana web UI. For details, see Access StackLight web UIs.
Assess the OpenSearch and Prometheus dashboards. For details on Grafana dashboards, see View Grafana dashboards.
On each dashboard, select the required period for calculation.
Tip
Mirantis recommends analyzing at least one day of data collected in the respective component to benefit from results presented on the Estimated Retention panels.
Assess the Cluster > Estimated Retention panel of each dashboard.
The panel displays maximum possible retention days while other panels provide details on utilized and available storage.
If persistent volumes of some StackLight components share storage, partition the storage logically to separate components before estimating the retention threshold. This is required since the Estimated Retention panel uses the entire provisioned storage as the calculation base.
For example, if StackLight is deployed in the default HA mode, then it uses Local Volume Provisioner that provides shared storage unless two separate partitions are configured for each cluster node for exclusive use of Prometheus and OpenSearch.
Two main storage provisioners are OpenSearch and Prometheus. The level of storage usage by other StackLight components is relatively low. For example, you can share storage logically as follows:
35% for Prometheus
35% for OpenSearch
30% for other components
In this case, take 35% of the calculated maximum retention value and set it as threshold.
In the Prometheus dashboard, navigate to Resources (Row) > Storage (Panel) > total provisioned disk per pod (Metric) to verify the retention size for the Prometheus storage.
If both retention time and size are set, Prometheus applies retention to the first reached threshold.
Caution
Mirantis does not recommend setting the retention size to
0and replying on the retention time only.
You can change the retention settings through either the web UI or API:
Using the Container Cloud web UI, navigate to the Configure cluster menu and use the StackLight tab
Using the Container Cloud API:
For OpenSearch, use the
logging.retentionTimeparameterFor Prometheus, use the
prometheusServer.retentionTimeandprometheusServer.retentionSizeparameters
For details, see Change a cluster configuration and Configure StackLight.
Troubleshooting¶
This section provides solutions to the issues that can occur while operating a Mirantis Container Cloud management or managed cluster.
For the list of known issues that you may encounter in the two latest Container Cloud releases, refer to 2.27.0 known issues and 2.26.0 known issues.
Collect cluster logs¶
While operating your management or managed cluster, you may require collecting and inspecting the cluster logs to analyze cluster events or troubleshoot issues.
To collect cluster logs:
Verify that the bootstrap directory is updated.
Select from the following options:
For clusters deployed using Container Cloud 2.11.0 or later:
./container-cloud bootstrap download --management-kubeconfig <pathToMgmtKubeconfig> \ --target-dir <pathToBootstrapDirectory>
For clusters deployed using the Container Cloud release earlier than 2.11.0 or if you deleted the
kaas-bootstrapfolder, download and run the Container Cloud bootstrap script:wget https://binary.mirantis.com/releases/get_container_cloud.sh chmod 0755 get_container_cloud.sh ./get_container_cloud.sh
Obtain
kubeconfigof the required cluster. The management clusterkubeconfigfile is created during the last stage of the management cluster bootstrap. To obtain a managed clusterkubeconfig, see Connect to a Mirantis Container Cloud cluster.Obtain the private SSH key of the required cluster:
For a managed cluster, this is an SSH key added in the Container Cloud web UI before the managed cluster creation.
For a management cluster,
ssh_keyis created in the same directory as the bootstrap script during cluster bootstrap.Note
If the initial version of your Container Cloud management cluster was earlier than 2.6.0,
ssh_keyis namedopenstack_tmpand is located at~/.ssh/.
Depending on the cluster type that you require logs from, run the corresponding command:
For a management cluster:
./container-cloud collect logs --management-kubeconfig <pathToMgmtClusterKubeconfig> \ --key-file <pathToMgmtClusterPrivateSshKey> \ --cluster-name <clusterName> --cluster-namespace <clusterProject>
For a managed cluster:
./container-cloud collect logs --management-kubeconfig <pathToMgmtClusterKubeconfig> \ --key-file <pathToManagedClusterSshKey> --kubeconfig <pathToManagedClusterKubeconfig> \ --cluster-name <clusterName> --cluster-namespace <clusterProject>
Substitute the parameters enclosed in angle brackets with the corresponding values of your cluster.
Optional flags:
--output-dirDirectory path to save logs. The default value is
logs/. For example,logs/<clusterName>/events.log.
--extendedOutput the extended version of logs that contains system and MKE logs, logs from LCM Ansible and LCM Agent along with cluster events and Kubernetes resources description and logs.
Without the
--extendedflag, the basic version of logs is collected, which is sufficient for most use cases. The basic version of logs contains all events, Kubernetes custom resources, and logs from all Container Cloud components. This version does not require passing--key-file.
For the logs structure, see Collect the bootstrap logs.
If you require logs of a cluster update, inspect the following folders on the control plane nodes:
/objects/namespaced/<namespaceName>/core/pods/lcm-lcm-controller- <controllerID>/for thelcm-controllerlogs./objects/namespaced/<namespaceName>/core/pods/<cloudProviderName-ID>/for logs of the cloud provider controller. For example,vsphere-provider-5b96fb4fd6-bhl7g./system/mke/<controllerMachineName>/(or/system/<controllerMachineName>/mke/) for the MKE support dump. Thedsinfo/dsinfo.txtfile contains Docker and system information of the MKE configuration set before and after update.events.logfor cluster events logs.
Technology Preview. For bare metal clusters, assess the Ironic pod logs:
Extract the content of the
'message'fields from every log message:kubectl -n kaas logs <ironicPodName> -c syslog | jq -rRM 'fromjson? | .message'
Extract the content of the
'message'fields from theironic_conductorsource log messages:kubectl -n kaas logs <ironicPodName> -c syslog | jq -rRM 'fromjson? | select(.source == "ironic_conductor") | .message'
The syslog container collects logs generated by Ansible during the node deployment and cleanup and outputs them in the JSON format.
Compress the collected log files and send the archive to the Mirantis support team.
Cluster deletion or detachment freezes¶
If you delete managed cluster nodes not using the Container Cloud web UI or API, the cluster deletion or detachment may hang with the Deleting message remaining in the cluster status.
To apply the issue resolution:
Expand the menu of the tab with your username.
Click
Download kubeconfigto downloadkubeconfigof your management cluster.Log in to any local machine with
kubectlinstalled.Copy the downloaded
kubeconfigto this machine.Run the following command:
kubectl --kubeconfig <mgmtClusterKubeconfigPath> edit -n <projectName> cluster <managedClusterName>
Edit the opened
kubeconfigby removing the following lines:finalizers: - cluster.cluster.k8s.ioManually clean up the resources of the nodes that you have previously deleted not using the Container Cloud web UI.
Keycloak admin console becomes inaccessible after changing the theme¶
Due to the upstream Keycloack issue, the Keycloak admin console becomes inaccessible after changing the theme to base using the Themes tab.
To apply the issue resolution:
Obtain the MySQL admin password:
kubectl get secret -n kaas mariadb-dbadmin-password -o yaml | awk '/MYSQL_DBADMIN_PASSWORD/ {print $2}' | base64 -d
Connect to the MariaDB server:
kubectl exec -it -n kaas mariadb-server-0 -- mysql -h localhost -u root -p
Update the Keycloak database for the following themes:
ADMIN_THEMEACCOUNT_THEMEEMAIL_THEMELOGIN_THEME
For example:
use keycloak; update REALM set ADMIN_THEME = REPLACE(ADMIN_THEME, 'base','keycloak');
Restart Keycloak:
kubectl scale sts -n kaas --replicas=0 iam-keycloak kubectl scale sts -n kaas --replicas=3 iam-keycloak
Stuck kubelet on the Cluster release 5.x.x series¶
Occasionally, kubelet may get stuck on the Cluster release 5.x.x series
with different errors in the ucp-kubelet containers leading to the nodes
failures. The following error occurs every time when accessing
the Kubernetes API server:
an error on the server ("") has prevented the request from succeeding
To apply the issue resolution, restart ucp-kubelet on the failed node:
ctr -n com.docker.ucp snapshot rm ucp-kubelet
docker rm -f ucp-kubelet
MOSK clusters update fails with stuck kubelet¶
Managed clusters running MOSK may fail to update to the latest Cluster release with kubelet being stuck and reporting authorization errors.
The cluster is affected by the issue if you see the Failed to make webhook authorizer request: context canceled error in the kubelet logs:
docker logs ucp-kubelet --since 5m 2>&1 | grep 'Failed to make webhook authorizer request: context canceled'
To apply the issue resolution, restart the ucp-kubelet container
on the affected node(s):
ctr -n com.docker.ucp snapshot rm ucp-kubelet
docker rm -f ucp-kubelet
Note
Ignore failures in the output of the first command, if any.
The ‘database space exceeded’ error on large clusters¶
Occasionally, cluster upgrade may get stuck on large clusters running 500+ nodes along with 15k+ pods due to the etcd database overflow. The following error occurs every time when accessing the Kubernetes API server:
etcdserver: mvcc: database space exceeded
Normally, kube-apiserver actively compacts the etcd database. In rare cases, it is required to manually compact the etcd database as described below, for example, during rapid creation of numerous Kubernetes objects. Once done, Mirantis recommends that you identify the root cause of the issue and clean up unnecessary resources to prevent manual etcd compacting and defragmentation in future.
To apply the issue resolution:
Open an SSH connection to any controller node.
Execute the following script to compact and defragment the etcd database:
sudo -i compact_etcd.sh defrag_etcd.sh
Defragment the etcd database as described in MKE documentation: Apply etcd defragmentation.
The auditd events cause ‘backlog limit exceeded’ messages¶
If auditd generates a lot of events, some of them may be lost with the following numerous messages in dmesg or kernel logs:
auditd: backlog limit exceeded
You may also observe high or growing values of the lost counter in the
auditctl output. For example:
auditctl -s
...
lost 1351280
...
To resolve the issue, you may need to update the rules loaded to auditd and adjust the size of the backlog buffer.
Update the rules loaded to auditd¶
If auditd contains a lot of rules, it may generate a lot of events and overrun
the buffer. Therefore, verify and update your preset and custom rules. Preset
rules are defined as presetRules, custom rules are defined as follows:
customRulescustomRulesX32customRulesX64
To verify and update the rules:
In the
Clusterobject of the affected cluster, verify that thepresetRulesstring does not start with the!symbol.Verify all audit rules:
Log in through SSH or directly using the console to the node having the buffer overrun symptoms.
Run the following command:
auditctl -lIn the system response, identify the rules to exclude.
In
/etc/audit/rules.d, find the files containing the rules to exclude.If the file is named
60-custom.rules, remove the rules from any of the following parameters located in theClusterobject:customRulescustomRulesX32customRulesX64
If the file is named
50-<NAME>.rules, and you want to exclude all rules from that file, exclude the preset named<NAME>from the list of allowed presets defined underpresetRulesin theClusterobject.If the file is named
50-<NAME>.rules, and you want to exclude only several rules from that file:Copy the rules you want to keep to one of the following parameters located in the
Clusterobject:customRulescustomRulesX32customRulesX64
Exclude the preset named
<NAME>from the list of allowed presets.
Adjust the size of the backlog buffer¶
By default, the backlog buffer size is set to 8192, which is enough for most use cases. To prevent buffer overrun, you can adjust the default value to fit your needs. But keep in mind that increasing this value leads to higher memory requirements because the buffer uses RAM.
To estimate RAM requirements for the buffer, you can use the following calculation:
A buffer of 8192 audit records uses ~70 MiB of RAM
A buffer of 15000 audit records uses ~128 MiB of RAM
To change the backlog buffer size, adjust the backlogLimit value in the
Cluster object of the affected cluster.
You may also want to change the size directly on the system and verify
the result at once. But to change the size permanently, use the Cluster
object.
To adjust the size of the backlog buffer on a node:
Log in to the affected node through SSH or directly through the console.
If
enabledAtBootis enabled, adjust theaudit_backlog_limitvalue in kernel options:List grub configuration files where
GRUB_CMDLINE_LINUXis defined:grep -rn 'GRUB_CMDLINE_LINUX' /etc/default/grub /etc/default/grub.d/* \ | cut -d: -f1 | sort -u
In each file obtained in the previous step, edit the
GRUB_CMDLINE_LINUXstring by changing the integer value afteraudit_backlog_limit=to the desired value.
In
/etc/audit/rules.d/audit.rules, adjust the buffer size by editing the integer value after-b.Select from the following options:
If the auditd configuration is not immutable, restart the
auditdservice:systemctl restart auditd.service
If the auditd configuration is immutable, reboot the node. The auditd configuration is immutable if any of the following conditions are met:
In the auditctl -s output, the
enabledparameter is set to2The
-e 2flag is defined explicitly in parameters of any custom ruleThe
immutablepreset is defined explicitlyThe virtual preset
allis enabled and theimmutablepreset is not excluded explicitly
Caution
Arrange the time to reboot the node according to your maintenance schedule. For the exact reboot procedure, use your maintenance policies.
If the
backlog limit exceededmessage disappears, adjust the size permanently using thebacklogLimitvalue in theClusterobject.
Troubleshoot baremetal-based clusters¶
This section provides solutions to the issues that may occur while managing the baremetal-based clusters.
Log in to the IPA virtual console for hardware troubleshooting¶
Container Cloud uses kernel and initramfs files with the pre-installed Ironic Python Agent (IPA) for inspection of server hardware. The IPA image initramfs is based on Ubuntu Server.
If you need to troubleshoot hardware during inspection, you can use the IPA virtual console to assess hardware logs and image configuration.
To log in to the IPA virtual console of a bare metal host:
Create the
BareMetalHostobject for the required bare metal host as described in Add a bare metal host using CLI and wait for inspection to complete.Caution
Meantime, do not create the
Machineobject for the bare metal host being inspected to prevent automatic provisioning.Using the pwgen utility, recover the dynamically calculated password of the IPA image:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> \ -n kaas get secret ironic-ssh-key \ -o jsonpath="{.data.public}" | base64 -d > /tmp/ironic-ssh-key.pub pwgen -H /tmp/ironic-ssh-key.pub -1 -s 16 rm /tmp/ironic-ssh-key.pub
Remotely log in to the IPA console of the bare metal host using the
devuseruser name and the password obtained in the previous step. For example, use IPMItool, Integrated Lights-Out, or the iDRAC web UI.
Note
To assess the IPA logs, use the journalctl -u ironic-python-agent.service command.
Bare metal hosts in ‘provisioned registration error’ state after update¶
After update of a management or managed cluster created using the Container
Cloud release earlier than 2.6.0, a bare metal host state is
Provisioned in the Container Cloud web UI while having the error state
in logs with the following message:
status:
errorCount: 1
errorMessage: 'Host adoption failed: Error while attempting to adopt node 7a8d8aa7-e39d-48ec-98c1-ed05eacc354f:
Validation of image href http://10.10.10.10/images/stub_image.qcow2 failed,
reason: Got HTTP code 404 instead of 200 in response to HEAD request..'
errorType: provisioned registration error
The issue is caused by the image URL pointing to an unavailable resource due to the URI IP change during update. To apply the issue resolution, update URLs for the bare metal host status and spec with the correct values that use a stable DNS record as a host.
To apply the issue resolution:
Note
In the commands below, we update master-2 as an example.
Replace it with the corresponding value to fit your deployment.
Exit Lens.
In a new terminal, configure access to the affected cluster.
Start
kube-proxy:kubectl proxy &
Pause the reconcile:
kubectl patch bmh master-2 --type=merge --patch '{"metadata":{"annotations":{"baremetalhost.metal3.io/paused": "true"}}}'
Create the payload data with the following content:
For
status_payload.json:{ "status": { "errorCount": 0, "errorMessage": "", "provisioning": { "image": { "checksum": "http://httpd-http/images/stub_image.qcow2.md5sum", "url": "http://httpd-http/images/stub_image.qcow2" }, "state": "provisioned" } } }
For
status_payload.json:{ "spec": { "image": { "checksum": "http://httpd-http/images/stub_image.qcow2.md5sum", "url": "http://httpd-http/images/stub_image.qcow2" } } }
Verify that the payload data is valid:
cat status_payload.json | jq cat spec_payload.json | jq
The system response must contain the data added in the previous step.
Patch the bare metal host status with payload:
curl -k -v -XPATCH -H "Accept: application/json" -H "Content-Type: application/merge-patch+json" --data-binary "@status_payload.json" 127.0.0.1:8001/apis/metal3.io/v1alpha1/namespaces/default/baremetalhosts/master-2/status
Patch the bare metal host spec with payload:
kubectl patch bmh master-2 --type=merge --patch "$(cat spec_payload.json)"
Resume the reconcile:
kubectl patch bmh master-2 --type=merge --patch '{"metadata":{"annotations":{"baremetalhost.metal3.io/paused":null}}}'
Close the terminal to quit
kube-proxyand resume Lens.
Troubleshoot an operating system upgrade with host restart¶
Mandatory host restart for the operating system (OS) upgrade is designed to be safe and takes certain precautions to protect the user data and the cluster integrity. However, sometimes it may result in a host-level failure and block the cluster upgrade. Use this section to troubleshoot such issues.
Warning
The OS upgrade cannot be rolled back on a host or cluster level. If the OS upgrade fails, recover or remove the faulty host before you can complete the cluster upgrade.
Caution
Depending on the cluster configuration, applying security updates and host restart can increase the update time for each node to up to 1 hour.
Cluster nodes are updated one by one. Therefore, for large clusters, the update may take several days to complete.
If the cluster upgrade does not start, verify whether the
ceph-clusterworkloadlock object is present in the Container Cloud
Management API:
kubectl get clusterworkloadlocks
Example of system response:
NAME AGE
ceph-clusterworkloadlock 7h37m
This object indicates that LCM operations that require hosts restart cannot
start on the cluster. The Ceph Controller verifies that Ceph services are
prepared for restart. Once the Ceph Controller completes verification, it
removes the ceph-clusterworkloadlock object and the cluster upgrade starts.
If this object is still present after the upgrade is initiated, assess the
logs of the ceph-controller pod to identify and fix errors:
kubectl -n ceph-lcm-mirantis logs deployments/ceph-controller
If a node upgrade does not start, verify whether the NodeWorkloadLock
object is present in the Container Cloud Management API:
kubectl get nodeworkloadlocks
If the object is present, assess the affected node logs to identify and fix errors.
If the host cannot boot after upgrade, verify the following possible issues:
- Invalid boot order configuration in the host BIOS settings
Inspect the host settings using the IPMI console. If you see a message about an invalid boot device, verify and correct the boot order in the host BIOS settings. Set the first boot device to a network card and the second device to a local disk (legacy or UEFI).
- The host is stuck in the GRUB rescue mode
If you see the following message, you are likely affected by the Ubuntu known issue in the Ubuntu
grub-installer:Entering rescue mode... grub rescue>
In this case, redeploy the host with a correctly defined
BareMetalHostProfile. You will have to delete the correspondingMachineresource and create a newMachinewith the correspondingBareMetalHostProfile. For details, see Create a custom host profile.
Troubleshoot iPXE boot issues¶
Container Cloud relies on iPXE to remotely bootstrap bare metal machines before provisioning them to Kubernetes clusters. The remote bootstrap with iPXE depends on the state of the underlay network. Incorrect or suboptimal configuration of the underlay network can cause the process to fail.
The following error may mean that network configuration is incorrect:
iPXE 1.21.1+ (g74c5) - Open Source Network Boot Firmware - http://ipxe.org
Features: DNS HTTP iSCSI TFTP SRP AoE EFI Menu
net2: 3c:ec:ef:70:39:fe using 14e4-16D8 on 0000:ca:00.0 (Ethernet) [open]
[Link:up, TX:0 TXE:1 RX:0 RXE:0]
[TXE: 1 x "Network unreachable (http://ipxe.org/28086090)"]
Configuring (net2 3c:ec:ef:70:39:fe)...... No configuration methods
succeeded (http://ipxe.org/040ee186)
No more network devices
Network switch not forwarding packets for a prolonged period after the server brings up a link to a switch port may be the reason for this error. It may happen because the switch waits for the Spanning Tree Protocol (STP) configuration on the port.
To avoid this issue, configure the ports connecting the servers in STP portfast mode. See details in the vendor documentation for your particular network switch, for example:
Provisioning failure due to device naming issues in a bare metal host profile¶
During a bare metal host provisioning, transition to each stage implies the
host reboot. This may cause device name issues if a device is configured
using the by_name device identifier.
In Linux, assignment of device names, for example, /dev/sda,
to physical disks can change, especially in systems with multiple
disks or when hardware configuration changes. For example:
If you add or remove a hard drive or change the boot order, the device names can shift.
If the system uses hardware with additional disk array controllers, such as
RaidControllersin theJBODmode, device names can shift during reboot. This can lead to unintended consequences and potential data loss if your file systems are not mounted correctly.The
/dev/sdapartition on the first boot may become/dev/sdbon the second boot. Consequently, your file system may not be provisioned as expected, leading to errors during disk formatting and assembling.
Linux recommends using unique identifiers (UUIDs) or labels for device
identification in /etc/fstab. These identifiers are more stable and ensure
that the defined devices are mounted regardless of the naming changes.
Therefore, to prevent device naming issues during a bare metal host
provisioning, instead of the by_name identifier, Mirantis recommends using
the workBy parameter along with device labels or filters such as
minSize and maxSize. These device settings ensure a successful
bare metal host provisioning with /dev/disk/by-uuid/<UUID> or
/dev/disk/by-label/<label> in /etc/fstab. For details on workBy,
see BareMetalHostProfile spec.
To manage physical devices, the bare metal provider uses the following entities:
- The
BareMetalHostProfileobject Object created by an operator with description of the required file-system schema on a node. For details, see Create a custom bare metal host profile.
- The
- The
status.hardware.storagefields of theBareMetalHostobject Initial description of physical disks that is discovered only once during a bare metal host inspection.
- The
- The
status.hostInfo.storagefields of theLCMMachineobject Current state of physical disks during life cycle of
MachineandLCMMachineobjects.
- The
The default device naming workflow during management of BareMetalHost and
BareMetalHostProfile objects is as follows:
An operator creates the
BareMetalHostandBareMetalHostCredentialobjects.The
baremetal-operatorservice inspects the objects.The operator creates or reviews an existing
BareMetalHostProfileobject using thestatus.hardware.storagefields of theBareMetalHostobject. For details, see Create a custom bare metal host profile.The operator creates a
Machineobject and maps it to the relatedBareMetalHostandBareMetalHostProfileobjects. For details, see Deploy a machine to a specific bare metal host.The
baremeral-providerservice starts processingBareMetalHostProfileand searching for suitable hardware disks to build the internalAnsibleExtraobject configuration. During the building process:The
bmh:hardware:storagelist is sorted using thehardwaredetails-storage-sort-termrule. For details, see Add a bare metal host using CLI and BareMetalHost metadata.The first suitable disk for an item in the
bmhp.spec.deviceslist is selected.
The cleanup and provisioning stage of
BareMetalHoststarts:During provisioning, the selection order described in
bmhp.workByapplies. For details, see Create a custom host profile.This logic ensures that an exact
by_idname is taken from the discovery stage, as opposed toby_namethat can be changed during transition from the inspection to provisioning stage.After provisioning finishes, the target system
/etc/fstabis generated usingUUIDs.
Note
For the /dev/disk/by-id mapping in Ceph, see
Addressing storage devices.
Troubleshoot vSphere-based clusters¶
This section provides solutions to the issues that may occur while managing the vSphere-based clusters.
Node leaves the cluster after IP address change¶
A vSphere-based management cluster bootstrap fails due to a node leaving the cluster after an accidental IP address change.
The issue affects a vSphere-based cluster only when IPAM is not enabled and IP addresses assignment to the vSphere virtual machines is done by a DHCP server present in the vSphere network.
By default, a DHCP server keeps lease of the IP address for 30 minutes.
Usually, a VM dhclient prolongs such lease by frequent DHCP requests
to the server before the lease period ends.
The DHCP prolongation request period is always less than the default lease time
on the DHCP server, so prolongation usually works.
But in case of network issues, for example, when dhclient from the
VM cannot reach the DHCP server, or the VM is being slowly powered on
for more than the lease time, such VM may lose its assigned IP address.
As a result, it obtains a new IP address.
Container Cloud does not support network reconfiguration after the IP of the VM has been changed. Therefore, such issue may lead to a VM leaving the cluster.
One of the nodes is in the
NodeNotReadyordownstate:kubectl get nodes -o wide docker node ls
The UCP Swarm manager logs on the healthy manager node contain the following example error:
docker logs -f ucp-swarm-manager level=debug msg="Engine refresh failed" id="<docker node ID>|<node IP>: 12376"
If the affected node is manager:
The output of the docker info command contains the following example error:
Error: rpc error: code = Unknown desc = The swarm does not have a leader. \ It's possible that too few managers are online. \ Make sure more than half of the managers are online.
The UCP controller logs contain the following example error:
docker logs -f ucp-controller "warning","msg":"Node State Active check error: \ Swarm Mode Manager health check error: \ info: Cannot connect to the Docker daemon at tcp://<node IP>:12376. \ Is the docker daemon running?
On the affected node, the IP address on the first interface
eth0does not match the IP address configured in Docker. Verify theNode Addressfield in the output of the docker info command.The following lines are present in
/var/log/messages:dhclient[<pid>]: bound to <node IP> -- renewal in 1530 seconds
If there are several lines where the IP is different, the node is affected.
Select from the following options:
Bind IP addresses for all machines to their MAC addresses on the DHCP server for the dedicated vSphere network. In this case, VMs receive only specified IP addresses that never change.
Remove the Container Cloud node IPs from the IP range on the DHCP server for the dedicated vSphere network and configure the first interface
eth0on VMs with a static IP address.If a managed cluster is affected, redeploy it with IPAM enabled for new machines to be created and IPs to be assigned properly.
Troubleshoot Ceph¶
This section provides solutions to the issues that may occur during Ceph usage.
Ceph disaster recovery¶
This section describes how to recover a failed or accidentally removed Ceph cluster in the following cases:
If Ceph Controller underlying a running Rook Ceph cluster has failed and you want to install a new Ceph Controller Helm release and recover the failed Ceph cluster onto the new Ceph Controller.
To migrate the data of an existing Ceph cluster to a new Container Cloud or Mirantis OpenStack for Kubernetes (MOSK) deployment in case downtime can be tolerated.
Consider the common state of a failed or removed Ceph cluster:
The
rook-cephnamespace does not contain pods or they are in theTerminatingstate.The
rook-cephor/andceph-lcm-mirantisnamespaces are in theTerminatingstate.The
ceph-operatoris in theFAILEDstate:For Container Cloud: the state of the
ceph-operatorHelm release in the management HelmBundle, such asdefault/kaas-mgmt, has switched fromDEPLOYEDtoFAILED.For MOSK: the state of the
osh-system/ceph-operatorHelmBundle, or a related namespace, has switched fromDEPLOYEDtoFAILED.
The Rook
CephCluster,CephBlockPool,CephObjectStoreCRs in therook-cephnamespace cannot be found or have thedeletionTimestampparameter in themetadatasection.
Note
Prior to recovering the Ceph cluster, verify that your deployment meets the following prerequisites:
The Ceph cluster
fsidexists.The Ceph cluster Monitor keyrings exist.
The Ceph cluster devices exist and include the data previously handled by Ceph OSDs.
Overview of the recovery procedure workflow:
Create a backup of the remaining data and resources.
Clean up the failed or removed
ceph-operatorHelm release.Deploy a new
ceph-operatorHelm release with the previously usedKaaSCephClusterand one Ceph Monitor.Replace the
ceph-mondata with the old cluster data.Replace
fsidinsecrets/rook-ceph-monwith the old one.Fix the Monitor map in the
ceph-mondatabase.Fix the Ceph Monitor authentication key and disable authentication.
Start the restored cluster and inspect the recovery.
Fix the admin authentication key and enable authentication.
Restart the cluster.
To recover a failed or removed Ceph cluster:
Back up the remaining resources. Skip the commands for the resources that have already been removed:
kubectl -n rook-ceph get cephcluster <clusterName> -o yaml > backup/cephcluster.yaml # perform this for each cephblockpool kubectl -n rook-ceph get cephblockpool <cephBlockPool-i> -o yaml > backup/<cephBlockPool-i>.yaml # perform this for each client kubectl -n rook-ceph get cephclient <cephclient-i> -o yaml > backup/<cephclient-i>.yaml kubectl -n rook-ceph get cephobjectstore <cephObjectStoreName> -o yaml > backup/<cephObjectStoreName>.yaml # perform this for each secret kubectl -n rook-ceph get secret <secret-i> -o yaml > backup/<secret-i>.yaml # perform this for each configMap kubectl -n rook-ceph get cm <cm-i> -o yaml > backup/<cm-i>.yaml
SSH to each node where the Ceph Monitors or Ceph OSDs were placed before the failure and back up the valuable data:
mv /var/lib/rook /var/lib/rook.backup mv /etc/ceph /etc/ceph.backup mv /etc/rook /etc/rook.backup
Once done, close the SSH connection.
Clean up the previous installation of
ceph-operator. For details, see Rook documentation: Cleaning up a cluster.Delete the
ceph-lcm-mirantis/ceph-controllerdeployment:kubectl -n ceph-lcm-mirantis delete deployment ceph-controller
Delete all deployments, DaemonSets, and jobs from the
rook-cephnamespace, if any:kubectl -n rook-ceph delete deployment --all kubectl -n rook-ceph delete daemonset --all kubectl -n rook-ceph delete job --all
Edit the
MiraCephandMiraCephLogCRs of theceph-lcm-mirantisnamespace and remove thefinalizerparameter from themetadatasection:kubectl -n ceph-lcm-mirantis edit miraceph kubectl -n ceph-lcm-mirantis edit miracephlog
Edit the
CephCluster,CephBlockPool,CephClient, andCephObjectStoreCRs of therook-cephnamespace and remove thefinalizerparameter from themetadatasection:kubectl -n rook-ceph edit cephclusters kubectl -n rook-ceph edit cephblockpools kubectl -n rook-ceph edit cephclients kubectl -n rook-ceph edit cephobjectstores kubectl -n rook-ceph edit cephobjectusers
Once you clean up every single resource related to the Ceph release, open the
ClusterCR for editing:kubectl -n <projectName> edit cluster <clusterName>
Substitute
<projectName>withdefaultfor the management cluster or with a related project name for the managed cluster.Remove the
ceph-controllerHelm release item from thespec.providerSpec.value.helmReleasesarray and save theClusterCR:- name: ceph-controller values: {}
Verify that
ceph-controllerhas disappeared from the corresponding HelmBundle:kubectl -n <projectName> get helmbundle -o yaml
Open the
KaaSCephClusterCR of the related management or managed cluster for editing:kubectl -n <projectName> edit kaascephcluster
Substitute
<projectName>withdefaultfor the management cluster or with a related project name for the managed cluster.Edit the roles of nodes. The entire
nodesspec must contain only onemonrole. SaveKaaSCephClusterafter editing.Open the
ClusterCR for editing:kubectl -n <projectName> edit cluster <clusterName>
Substitute
<projectName>withdefaultfor the management cluster or with a related project name for the managed cluster.Add
ceph-controllertospec.providerSpec.value.helmReleasesto restore theceph-controllerHelm release. SaveClusterafter editing.- name: ceph-controller values: {}
Verify that the
ceph-controllerHelm release is deployed:Inspect the Rook Operator logs and wait until the orchestration has settled:
kubectl -n rook-ceph logs -l app=rook-ceph-operator
Verify that the pods in the
rook-cephnamespace haverook-ceph-mon-a,rook-ceph-mgr-a, and all the auxiliary pods ar up and running, and norook-ceph-osd-ID-xxxxxxare running:kubectl -n rook-ceph get pod
Verify the Ceph state. The output must indicate that one
monand onemgrare running, all Ceph OSDs are down, and all PGs are in theUnknownstate.kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l app=rook-ceph-tools -o jsonpath='{.items[0].metadata.name}') -- ceph -s
Note
Rook should not start any Ceph OSD daemon because all devices belong to the old cluster that has a different
fsid. To verify the Ceph OSD daemons, inspect theosd-preparepods logs:kubectl -n rook-ceph logs -l app=rook-ceph-osd-prepare
Connect to the terminal of the
rook-ceph-mon-apod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod \ -l app=rook-ceph-mon -o jsonpath='{.items[0].metadata.name}') bash
Output the
keyringfile and save it for further usage:cat /etc/ceph/keyring-store/keyring exit
Obtain and save the
nodeNameofmon-afor further usage:kubectl -n rook-ceph get pod $(kubectl -n rook-ceph get pod \ -l app=rook-ceph-mon -o jsonpath='{.items[0].metadata.name}') -o jsonpath='{.spec.nodeName}'
Obtain and save the
cephImageused in the Ceph cluster for further usage:kubectl -n ceph-lcm-mirantis get cm ccsettings -o jsonpath='{.data.cephImage}'
Stop Rook Operator and scale the deployment replicas to
0:kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 0
Remove the Rook deployments generated with Rook Operator:
kubectl -n rook-ceph delete deploy -l app=rook-ceph-mon kubectl -n rook-ceph delete deploy -l app=rook-ceph-mgr kubectl -n rook-ceph delete deploy -l app=rook-ceph-osd kubectl -n rook-ceph delete deploy -l app=rook-ceph-crashcollector
Using the saved
nodeName, SSH to the host whererook-ceph-mon-ain the new Kubernetes cluster is placed and perform the following steps:Remove
/var/lib/rook/mon-aor copy it to another folder:mv /var/lib/rook/mon-a /var/lib/rook/mon-a.new
Pick a healthy
rook-ceph-mon-IDdirectory (/var/lib/rook.backup/mon-ID) in the previous backup, copy to/var/lib/rook/mon-a:cp -rp /var/lib/rook.backup/mon-<ID> /var/lib/rook/mon-a
Substitute
IDwith any healthymonnode ID of the old cluster.Replace
/var/lib/rook/mon-a/keyringwith the previously saved keyring, preserving only the[mon.]section. Remove the[client.admin]section.Run the
cephImageDocker container using the previously savedcephImageimage:docker run -it --rm -v /var/lib/rook:/var/lib/rook <cephImage> bash
Inside the container, create
/etc/ceph/ceph.conffor a stable operation ofceph-mon:touch /etc/ceph/ceph.confChange the directory to
/var/lib/rookand editmonmapby replacing the existingmonhosts with the newmon-aendpoints:cd /var/lib/rook rm /var/lib/rook/mon-a/data/store.db/LOCK # make sure the quorum lock file does not exist ceph-mon --extract-monmap monmap --mon-data ./mon-a/data # Extract monmap from old ceph-mon db and save as monmap monmaptool --print monmap # Print the monmap content, which reflects the old cluster ceph-mon configuration. monmaptool --rm a monmap # Delete `a` from monmap. monmaptool --rm b monmap # Repeat, and delete `b` from monmap. monmaptool --rm c monmap # Repeat this pattern until all the old ceph-mons are removed and monmap won't be empty monmaptool --addv a [v2:<nodeIP>:3300,v1:<nodeIP>:6789] monmap # Replace it with the rook-ceph-mon-a address you got from previous command. ceph-mon --inject-monmap monmap --mon-data ./mon-a/data # Replace monmap in ceph-mon db with our modified version. rm monmap exit
Substitute
<nodeIP>with the IP address of the current<nodeName>node.Close the SSH connection.
Change
fsidto the original one to run Rook as an old cluster:kubectl -n rook-ceph edit secret/rook-ceph-mon
Note
The
fsidisbase64encoded and must not contain a trailing carriage return. For example:echo -n a811f99a-d865-46b7-8f2c-f94c064e4356 | base64 # Replace with the fsid from the old cluster.
Scale the
ceph-lcm-mirantis/ceph-controllerdeployment replicas to0:kubectl -n ceph-lcm-mirantis scale deployment ceph-controller --replicas 0
Disable authentication:
Open the
cm/rook-config-overrideConfigMap for editing:kubectl -n rook-ceph edit cm/rook-config-override
Add the following content:
data: config: | [global] ... auth cluster required = none auth service required = none auth client required = none auth supported = none
Start Rook Operator by scaling its deployment replicas to
1:kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 1
Inspect the Rook Operator logs and wait until the orchestration has settled:
kubectl -n rook-ceph logs -l app=rook-ceph-operator
Verify that the pods in the
rook-cephnamespace have therook-ceph-mon-a,rook-ceph-mgr-a, and all the auxiliary pods are up and running, and allrook-ceph-osd-ID-xxxxxxgreater than zero are running:kubectl -n rook-ceph get pod
Verify the Ceph state. The output must indicate that one
mon, onemgr, and all Ceph OSDs are up and running and all PGs are either in theActiveorDegradedstate:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod \ -l app=rook-ceph-tools -o jsonpath='{.items[0].metadata.name}') -- ceph -s
Enter the
ceph-toolspod and import the authentication key:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod \ -l app=rook-ceph-tools -o jsonpath='{.items[0].metadata.name}') bash vi key [paste keyring content saved before, preserving only `[client admin]` section] ceph auth import -i key rm key exit
Stop Rook Operator by scaling the deployment to
0replicas:kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 0
Re-enable authentication:
Open the
cm/rook-config-overrideConfigMap for editing:kubectl -n rook-ceph edit cm/rook-config-override
Remove the following content:
data: config: | [global] ... auth cluster required = none auth service required = none auth client required = none auth supported = none
Remove all Rook deployments generated with Rook Operator:
kubectl -n rook-ceph delete deploy -l app=rook-ceph-mon kubectl -n rook-ceph delete deploy -l app=rook-ceph-mgr kubectl -n rook-ceph delete deploy -l app=rook-ceph-osd kubectl -n rook-ceph delete deploy -l app=rook-ceph-crashcollector
Start Ceph Controller by scaling its deployment replicas to
1:kubectl -n ceph-lcm-mirantis scale deployment ceph-controller --replicas 1
Start Rook Operator by scaling its deployment replicas to
1:kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 1
Inspect the Rook Operator logs and wait until the orchestration has settled:
kubectl -n rook-ceph logs -l app=rook-ceph-operator
Verify that the pods in the
rook-cephnamespace have therook-ceph-mon-a,rook-ceph-mgr-a, and all the auxiliary pods are up and running, and allrook-ceph-osd-ID-xxxxxxgreater than zero are running:kubectl -n rook-ceph get pod
Verify the Ceph state. The output must indicate that one
mon, onemgr, and all Ceph OSDs are up and running and the overall stored data size equals to the old cluster data size.kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l app=rook-ceph-tools -o jsonpath='{.items[0].metadata.name}') -- ceph -s
Edit the
MiraCephCR and add two moremonandmgrroles to the corresponding nodes:kubectl -n ceph-lcm-mirantis edit miraceph
Inspect the Rook namespace and wait until all Ceph Monitors are in the
Runningstate:kubectl -n rook-ceph get pod -l app=rook-ceph-mon
Verify the Ceph state. The output must indicate that three
mon(three in quorum), onemgr, and all Ceph OSDs are up and running and the overall stored data size equals to the old cluster data size.kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l app=rook-ceph-tools -o jsonpath='{.items[0].metadata.name}') -- ceph -s
Once done, the data from the failed or removed Ceph cluster is restored and ready to use.
Ceph Monitors recovery¶
This section describes how to recover failed Ceph Monitors of an existing Ceph cluster in the following state:
The Ceph cluster contains failed Ceph Monitors that cannot start and hang in the
ErrororCrashLoopBackOffstate.The logs of the failed Ceph Monitor pods contain the following lines:
mon.g does not exist in monmap, will attempt to join an existing cluster ... mon.g@-1(???) e11 not in monmap and have been in a quorum before; must have been removed mon.g@-1(???) e11 commit suicide!
The Ceph cluster contains at least one
RunningCeph Monitor and theceph -scommand outputs one healthymonand one healthymgrinstance.
Perform the following steps for all failed Ceph Monitors at a time if not stated otherwise.
To recover failed Ceph Monitors:
Obtain and export the
kubeconfigof the affected cluster.Scale the
rook-ceph/rook-ceph-operatordeployment down to0replicas:kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 0
Delete all failed Ceph Monitor deployments:
Identify the Ceph Monitor pods in the
ErrororCrashLookBackOffstate:kubectl -n rook-ceph get pod -l 'app in (rook-ceph-mon,rook-ceph-mon-canary)'
Verify that the affected pods contain the failure logs described above:
kubectl -n rook-ceph logs <failedMonPodName>
Substitute
<failedMonPodName>with the Ceph Monitor pod name. For example,rook-ceph-mon-g-845d44b9c6-fjc5d.Save the identifying letters of failed Ceph Monitors for further usage. For example,
f,e, and so on.Delete all corresponding deployments of these pods:
Identify the affected Ceph Monitor pod deployments:
kubectl -n rook-ceph get deploy -l 'app in (rook-ceph-mon,rook-ceph-mon-canary)'
Delete the affected Ceph Monitor pod deployments. For example, if the Ceph cluster has the
rook-ceph-mon-c-845d44b9c6-fjc5dpod in theCrashLoopBackOffstate, remove the correspondingrook-ceph-mon-c:kubectl -n rook-ceph delete deploy rook-ceph-mon-c
Canary
mondeployments have the suffix-canary.
Remove all corresponding entries of Ceph Monitors from the MON map:
Enter the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l \ app=rook-ceph-tools -o jsonpath='{.items[0].metadata.name}') bash
Inspect the current MON map and save the IP addresses of the failed Ceph monitors for further usage:
ceph mon dump
Remove all entries of failed Ceph Monitors using the previously saved letters:
ceph mon rm <monLetter>
Substitute
<monLetter>with the corresponding letter of a failed Ceph Monitor.Exit the
ceph-toolspod.
Remove all failed Ceph Monitors entries from the Rook
monendpoints ConfigMap:Open the
rook-ceph/rook-ceph-mon-endpointsConfigMap for editing:kubectl -n rook-ceph edit cm rook-ceph-mon-endpoints
Remove all entries of failed Ceph Monitors from the ConfigMap data and update the
maxMonIdvalue with the current number ofRunningCeph Monitors. For example,rook-ceph-mon-endpointshas the followingdata:data: csi-cluster-config-json: '[{"clusterID":"rook-ceph","monitors":["172.0.0.222:6789","172.0.0.223:6789","172.0.0.224:6789","172.16.52.217:6789","172.16.52.216:6789"]}]' data: a=172.0.0.222:6789,b=172.0.0.223:6789,c=172.0.0.224:6789,f=172.0.0.217:6789,e=172.0.0.216:6789 mapping: '{"node":{ "a":{"Name":"kaas-node-21465871-42d0-4d56-911f-7b5b95cb4d34","Hostname":"kaas-node-21465871-42d0-4d56-911f-7b5b95cb4d34","Address":"172.16.52.222"}, "b":{"Name":"kaas-node-43991b09-6dad-40cd-93e7-1f02ed821b9f","Hostname":"kaas-node-43991b09-6dad-40cd-93e7-1f02ed821b9f","Address":"172.16.52.223"}, "c":{"Name":"kaas-node-15225c81-3f7a-4eba-b3e4-a23fd86331bd","Hostname":"kaas-node-15225c81-3f7a-4eba-b3e4-a23fd86331bd","Address":"172.16.52.224"}, "e":{"Name":"kaas-node-ba3bfa17-77d2-467c-91eb-6291fb219a80","Hostname":"kaas-node-ba3bfa17-77d2-467c-91eb-6291fb219a80","Address":"172.16.52.216"}, "f":{"Name":"kaas-node-6f669490-f0c7-4d19-bf73-e51fbd6c7672","Hostname":"kaas-node-6f669490-f0c7-4d19-bf73-e51fbd6c7672","Address":"172.16.52.217"}} }' maxMonId: "5"
If
eandfare the letters of failed Ceph Monitors, the resulting ConfigMap data must be as follows:data: csi-cluster-config-json: '[{"clusterID":"rook-ceph","monitors":["172.0.0.222:6789","172.0.0.223:6789","172.0.0.224:6789"]}]' data: a=172.0.0.222:6789,b=172.0.0.223:6789,c=172.0.0.224:6789 mapping: '{"node":{ "a":{"Name":"kaas-node-21465871-42d0-4d56-911f-7b5b95cb4d34","Hostname":"kaas-node-21465871-42d0-4d56-911f-7b5b95cb4d34","Address":"172.16.52.222"}, "b":{"Name":"kaas-node-43991b09-6dad-40cd-93e7-1f02ed821b9f","Hostname":"kaas-node-43991b09-6dad-40cd-93e7-1f02ed821b9f","Address":"172.16.52.223"}, "c":{"Name":"kaas-node-15225c81-3f7a-4eba-b3e4-a23fd86331bd","Hostname":"kaas-node-15225c81-3f7a-4eba-b3e4-a23fd86331bd","Address":"172.16.52.224"}} }' maxMonId: "3"
Back up the data of the failed Ceph Monitors one by one:
SSH to the node of a failed Ceph Monitor using the previously saved IP address.
Move the Ceph Monitor data directory to another place:
mv /var/lib/rook/mon-<letter> /var/lib/rook/mon-<letter>.backup
Close the SSH connection.
Scale the
rook-ceph/rook-ceph-operatordeployment up to1replica:kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 1
Wait until all Ceph Monitors are in the
Runningstate:kubectl -n rook-ceph get pod -l app=rook-ceph-mon -w
Restore the data from the backup for each recovered Ceph Monitor one by one:
Enter a recovered Ceph Monitor pod:
kubectl -n rook-ceph exec -it <monPodName> bash
Substitute
<monPodName>with the recovered Ceph Monitor pod name. For example,rook-ceph-mon-g-845d44b9c6-fjc5d.Recover the
mondata backup for the current Ceph Monitor:ceph-monstore-tool /var/lib/rook/mon-<letter>.backup/data store-copy /var/lib/rook/mon-<letter>/data/
Substitute
<letter>with the current Ceph Monitor pod letter, for example,e.
Verify the Ceph state. The output must indicate the desired number of Ceph Monitors and all of them must be in quorum.
kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l app=rook-ceph-tools -o jsonpath='{.items[0].metadata.name}') -- ceph -s
Remove Ceph OSD manually¶
You may need to manually remove a Ceph OSD, for example, in the following cases:
If you have removed a device or node from the
KaaSCephClusterspec.cephClusterSpec.nodesorspec.cephClusterSpec.nodeGroupssection withmanageOsdsset tofalse.If you do not want to rely on Ceph LCM operations and want to manage the Ceph OSDs life cycle manually.
To safely remove one or multiple Ceph OSDs from a Ceph cluster, perform the following procedure for each Ceph OSD one by one.
Warning
The procedure presupposes the Ceph OSD disk or logical volumes partition cleanup.
To remove a Ceph OSD manually:
Edit the
KaaSCephClusterresource on a management cluster:kubectl --kubeconfig <mgmtKubeconfig> -n <managedClusterProjectName> edit kaascephcluster
Substitute
<mgmtKubeconfig>with the management clusterkubeconfigand<managedClusterProjectName>with the project name of the managed cluster.In the
spec.cephClusterSpec.nodessection, remove the requiredstorageDevicesitem of the corresponding node spec. If after removalstorageDevicesbecomes empty and the node spec has no roles specified, also remove the node spec.Obtain
kubeconfigof the managed cluster and provide it as an environment variable:export KUBECONFIG=<pathToManagedKubeconfig>
Verify that all Ceph OSDs are
upandin, the Ceph cluster is healthy, and no rebalance or recovery is in progress:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l \ app=rook-ceph-tools -o jsonpath='{.items[0].metadata.name}') -- ceph -s
Example of system response:
cluster: id: 8cff5307-e15e-4f3d-96d5-39d3b90423e4 health: HEALTH_OK ... osd: 4 osds: 4 up (since 10h), 4 in (since 10h)
Stop the
rook-ceph/rook-ceph-operatordeployment to avoid premature reorchestration of the Ceph cluster:kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 0
Enter the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l \ app=rook-ceph-tools -o jsonpath='{.items[0].metadata.name}') bash
Mark the required Ceph OSD as
out:ceph osd out osd.<ID>
Note
In the command above and in the steps below, substitute
<ID>with the number of the Ceph OSD to remove.Wait until data backfilling to other OSDs is complete:
ceph -sOnce all of the PGs are
active+clean, backfilling is complete and it is safe to remove the disk.Note
For additional information on PGs backfilling, run ceph pg dump_stuck.
Exit from the
ceph-toolspod:exitScale the
rook-ceph/rook-ceph-osd-<ID>deployment to0replicas:kubectl -n rook-ceph scale deploy rook-ceph-osd-<ID> --replicas 0
Enter the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l \ app=rook-ceph-tools -o jsonpath='{.items[0].metadata.name}') bash
Verify that the number of Ceph OSDs that are
upandinhas decreased by one daemon:ceph -sExample of system response:
osd: 4 osds: 3 up (since 1h), 3 in (since 5s)
Remove the Ceph OSD from the Ceph cluster:
ceph osd purge <ID> --yes-i-really-mean-it
Delete the Ceph OSD
authentry, if present. Otherwise, skip this step.ceph auth del osd.<ID>
If you have removed the last Ceph OSD on the node and want to remove this node from the Ceph cluster, remove the CRUSH map entry:
ceph osd crush remove <nodeName>
Substitute
<nodeName>with the name of the node where the removed Ceph OSD was placed.Verify that the failure domain within Ceph OSDs has been removed from the CRUSH map:
ceph osd tree
If you have removed the node, it will be removed from the CRUSH map.
Exit from the
ceph-toolspod:exitClean up the disk used by the removed Ceph OSD. For details, see official Rook documentation.
Warning
If you are using multiple Ceph OSDs per device or metadata device, make sure that you can clean up the entire disk. Otherwise, instead clean up only the logical volume partitions for the volume group by running lvremove <lvpartion_uuid> any Ceph OSD pod that belongs to the same host as the removed Ceph OSD.
Delete the
rook-ceph/rook-ceph-osd-<ID>deployment previously scaled to0replicas:kubectl -n rook-ceph delete deploy rook-ceph-osd-<ID>
Substitute
<ID>with the number of the removed Ceph OSD.Scale the
rook-ceph/rook-ceph-operatordeployment to1replica and wait for the orchestration to complete:kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 1 kubectl -n rook-ceph get pod -w
Once done, Ceph OSD removal is complete.
KaaSCephOperationRequest failure with a timeout during rebalance¶
Ceph OSD removal procedure includes the Ceph OSD out action that starts
the Ceph PGs rebalancing process. The total time for rebalancing depends on a
cluster hardware configuration: network bandwidth, Ceph PGs placement, number
of Ceph OSDs, and so on. The default rebalance timeout is limited by 30
minutes, which applies to standard cluster configurations.
If the rebalance takes more than 30 minutes, the KaaSCephOperationRequest
resources created for removing Ceph OSDs or nodes fail with the following
example message:
status:
removeStatus:
osdRemoveStatus:
errorReason: Timeout (30m0s) reached for waiting pg rebalance for osd 2
status: Failed
To apply the issue resolution, increase the timeout for all future
KaaSCephOperationRequest resources:
On the management cluster, open the
Clusterresource of the affected managed cluster for editing:kubectl -n <managedClusterProjectName> edit cluster <managedClusterName>
Replace
<managedClusterProjectName>and<managedClusterName>with the corresponding values of the affected managed cluster.Add
pgRebalanceTimeoutMinto theceph-controllerHelm release values section in theClusterspec:spec: providerSpec: value: helmReleases: - name: ceph-controller values: controllers: cephRequest: parameters: pgRebalanceTimeoutMin: <rebalanceTimeout>
The
<rebalanceTimeout>value is a required rebalance timeout in minutes. Must be an integer greater than zero. For example,60.Save the edits and exit from the
Clusterresource.
If you have an existing KaaSCephOperationRequest resource with
errorReason to process:
Copy the
specsection in the failedKaaSCephOperationRequestresource.Create a new
KaaSCephOperationRequestwith a different name. For details, see Creating a Ceph OSD removal request.Paste the previously copied
specsection of the failedKaaSCephOperationRequestresource to the new one.Remove the failed
KaaSCephOperationRequestresource.
Ceph Monitors store.db size rapidly growing¶
The MON_DISK_LOW Ceph Cluster health message indicates that the
store.db size of the Ceph Monitor is rapidly growing and the compaction
procedure is not working. In most cases, store.db starts storing a
number of logm keys that are buffered due to Ceph OSD shadow errors.
To verify if store.db size is rapidly growing:
Identify the Ceph Monitors
store.dbsize:for pod in $(kubectl get pods -n rook-ceph | grep mon | awk '{print $1}'); \ do printf "$pod:\n"; kubectl exec -n rook-ceph "$pod" -it -c mon -- \ du -cms /var/lib/ceph/mon/ ; done
Repeat the previous step two or three times within the interval of 5-15 seconds.
If between the command runs the total size increases by more than 10 MB, perform the steps described below to resolve the issue.
To apply the issue resolution:
Verify the original state of placement groups (PGs):
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph -s
Apply
clog_to_monitorswith thefalsevalue for all Ceph OSDs at runtime:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash ceph tell osd.* config set clog_to_monitors false
Restart Ceph OSDs one by one:
Restart one of the Ceph OSDs:
for pod in $(kubectl get pods -n rook-ceph -l app=rook-ceph-osd | \ awk 'FNR>1{print $1}'); do printf "$pod:\n"; kubectl -n rook-ceph \ delete pod "$pod"; echo "Continue?"; read; done
Once prompted
Continue?, first verify that rebalancing has finished for the Ceph cluster, the Ceph OSD isupandin, and all PGs have returned to their original state:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph -s kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph osd tree
Once you are confident that the Ceph OSD restart and recovery is over, press
ENTER.Restart the remaining Ceph OSDs.
Note
Periodically verify the Ceph Monitors
store.dbsize:for pod in $(kubectl get pods -n rook-ceph | grep mon | awk \ '{print $1}'); do printf "$pod:\n"; kubectl exec -n rook-ceph \ "$pod" -it -c mon -- du -cms /var/lib/ceph/mon/ ; done
After some of the affected Ceph OSDs restart, Ceph Monitors will start
decreasing the store.db size to the original 100-300 MB. However,
complete the restart of all Ceph OSDs.
Troubleshoot StackLight¶
This section provides solutions to the issues that may occur during StackLight usage. To troubleshoot StackLight alerts, refer to Troubleshoot alerts.
Patroni replication lag¶
PostgreSQL replication in a Patroni cluster is based on the Write-Ahead Log (WAL) syncing between the cluster leader and replica. Occasionally, this mechanism may lag due to networking issues, missing WAL segments (on rotation or recycle), increased Patroni Pods CPU usage, or due to a hardware failure.
In StackLight, the PostgresqlReplicationSlowWalDownload alert indicates
that the Patroni cluster Replica is out of sync. This alert has the
Warning severity because under such conditions Patroni cluster is still
operational and the issue may disappear without intervention. However, a
persisting replication lag may impact the cluster availability if another Pod
in the cluster fails, leaving the leader alone to serve requests. In this case,
the Patroni leader will become read-only and unable to serve write requests,
which can cause outage of Alerta backed by Patroni. Grafana, which also uses
Patroni, will still be operational but any dashboard changes will not be saved.
Therefore, if PostgresqlReplicationSlowWalDownload fires, observe the
cluster and fix it if the issue persists or if the lag grows.
To apply the issue resolution:
Enter the Patroni cluster Pod:
kubectl exec -it -n stacklight patroni-13-2 patroni -- bash
Verify the current cluster state:
patronictl -c postgres.yml list
In the
Lag in MBcolumn of the output table, the replica Pod will indicate a non-zero value.Enter the leader Pod if it is not the current one.
From the leader Pod, resync the replica Pod:
patronictl -c postgres.yml reinit patroni-13 <REPLICA-MEMBER-NAME>
In the Alertmanager or Alerta web UI, verify that no new alerts are firing for Patroni. The
PostgresqlInsufficientWorkingMemoryalert may become pending during the operation but should not fire.Verify that the replication is in sync:
patronictl -c postgres.yml list
Example of a positive system response:
+ Cluster: patroni-13 (6974829572195451235)---+---------+-----+-----------+ | Member | Host | Role | State | TL | Lag in MB | +--------------+---------------+--------------+---------+-----+-----------+ | patroni-13-0 | 10.233.96.11 | Replica | running | 875 | 0 | | patroni-13-1 | 10.233.108.39 | Leader | running | 875 | | | patroni-13-2 | 10.233.64.113 | Sync Standby | running | 875 | 0 | +--------------+---------------+--------------+---------+-----+-----------+
Alertmanager does not send resolve notifications for custom alerts¶
Due to the Alertmanager issue, Alertmanager loses the in-memory alerts during restart. As a result, StackLight does not send notifications for custom alerts in the following case:
Adding a custom alert.
Then removing the custom alert and at the same time changing the Alertmanager configuration such as adding or removing a receiver.
For a removed custom alert, Alertmanager does not send a resolve notification
to any of the configured receivers. Therefore, until after the time set in
repeat_interval (3 hours by default), the alert will be visible in all
receivers but not in the Prometheus and Alertmanager web UIs.
When the alert is re-added, Alertmanager does not send a firing notification
for it until after the time set in repeat_interval, but the alert will be
visible in the Prometheus and Alertmanager web UIs.
OpenSearchPVCMismatch alert raises due to the OpenSearch PVC size mismatch¶
Caution
The below issue resolution applies since Container Cloud 2.22.0 to existing clusters with insufficient resources. Before Container Cloud 2.22.0, use the workaround described in the StackLight known issue 27732-1. New clusters deployed on top of Container Cloud 2.22.0 are not affected.
The OpenSearch elasticsearch.persistentVolumeClaimSize custom setting can
be overwritten by logging.persistentVolumeClaimSize during deployment of a
Container Cloud cluster of any type and is set to the default 30Gi. This
issue raises the OpenSearchPVCMismatch alert. Since
elasticsearch.persistentVolumeClaim is immutable, you cannot update
the value by editing of the Cluster object.
Note
This issue does not affect cluster operability if the current volume capacity is enough for the cluster needs.
To apply the issue resolution, select from the following use cases:
StackLight with an expandable StorageClass for OpenSearch PVCs
Verify that the StorageClass provisioner has enough space to satisfy the new size:
kubectl get helmbundle stacklight-bundle -n stacklight -o json | jq '.spec.releases[] | select(.name == "opensearch") | .values.volumeClaimTemplate.resources.requests.storage'
The system response contains the value of the
elasticsearch.persistentVolumeClaimSizeparameter.Scale down the
opensearch-masterStatefulSet with dependent resources to 0 and disable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards \ && kubectl -n stacklight get pods -l app=opensearch-dashboards | awk '{if (NR!=1) {print $1}}' | \ xargs -r kubectl -n stacklight wait --for=delete --timeout=10m pod kubectl -n stacklight scale --replicas 0 deployment metricbeat \ && kubectl -n stacklight get pods -l app=metricbeat | awk '{if (NR!=1) {print $1}}' | \ xargs -r kubectl -n stacklight wait --for=delete --timeout=10m pod kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec": {"suspend": true}}' kubectl -n stacklight scale --replicas 0 statefulset opensearch-master \ && kubectl -n stacklight get pods -l app=opensearch-master | awk '{if (NR!=1) {print $1}}' | \ xargs -r kubectl -n stacklight wait --for=delete --timeout=30m pod
Patch the PVC with the correct value for
elasticsearch.persistentVolumeClaimSize:pvc_size=$(kubectl -n stacklight get statefulset -l 'app=opensearch-master' \ -o json | jq -r '.items[] | select(.spec.volumeClaimTemplates[].metadata.name // "" | startswith("opensearch-master")).spec.volumeClaimTemplates[].spec.resources.requests.storage') kubectl -n stacklight patch pvc opensearch-master-opensearch-master-0 \ -p '{ "spec": { "resources": { "requests": { "storage": "'"${pvc_size}"'" }}}}'
Scale up the
opensearch-masterStatefulSet with dependent resources to1and enable theelasticsearch-curatorCronJob:replicas=$(kubectl get helmbundle stacklight-bundle -n stacklight \ -o json | jq '.spec.releases[] | select(.name == "opensearch") | .values.replicas') kubectl -n stacklight scale --replicas ${replicas} statefulset opensearch-master \ && kubectl -n stacklight wait --for=condition=Ready --timeout=30m pod -l app=opensearch-master kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards \ && kubectl -n stacklight wait --for=condition=Ready --timeout=10m pod -l app=opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat \ && kubectl -n stacklight wait --for=condition=Ready --timeout=10m pod -l app=metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec": {"suspend": false}}'
StackLight with a non-expandable StorageClass for OpenSearch PVCs
If StackLight is operating in HA mode, the local volume provisioner (LVP) has a non-expandable StorageClass used for OpenSearch PVCs provisioning. Thus, the affected PV nodes have insufficient disk space.
If StackLight is operating in non-HA mode, the default non-expandable storage provisioner is used.
Warning
After applying this issue resolution, the existing OpenSearch data will be lost. If data loss is acceptable, proceed with the steps below.
Move the existing log data to a new PV if required.
Verify that the provisioner has enough space to satisfy the new size:
kubectl get helmbundle stacklight-bundle -n stacklight -o json | jq '.spec.releases[] | select(.name == "opensearch") | .values.volumeClaimTemplate.resources.requests.storage'
The system response contains the value of the
elasticsearch.persistentVolumeClaimSizeparameter.To satisfy the required size:
For LVP, increase the disk size
For non-LVP, make sure that the default StorageClass provisioner has enough space
Scale down the
opensearch-masterStatefulSet with dependent resources to0and disable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards \ && kubectl -n stacklight get pods -l app=opensearch-dashboards | awk '{if (NR!=1) {print $1}}' | \ xargs -r kubectl -n stacklight wait --for=delete --timeout=10m pod kubectl -n stacklight scale --replicas 0 deployment metricbeat \ && kubectl -n stacklight get pods -l app=metricbeat | awk '{if (NR!=1) {print $1}}' | \ xargs -r kubectl -n stacklight wait --for=delete --timeout=10m pod kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec": {"suspend": true}}' kubectl -n stacklight scale --replicas 0 statefulset opensearch-master \ && kubectl -n stacklight get pods -l app=opensearch-master | awk '{if (NR!=1) {print $1}}' | \ xargs -r kubectl -n stacklight wait --for=delete --timeout=30m pod
Delete existing PVCs:
kubectl delete pvc -l 'app=opensearch-master' -n stacklight
Warning
This command removes all existing logs data from PVCs.
Scale up the
opensearch-masterStatefulSet with dependent resources and enable theelasticsearch-curatorCronJob:replicas=$(kubectl get helmbundle stacklight-bundle -n stacklight \ -o json | jq '.spec.releases[] | select(.name == "opensearch") | .values.replicas') kubectl -n stacklight scale --replicas ${replicas} statefulset opensearch-master \ && kubectl -n stacklight wait --for=condition=Ready --timeout=30m pod -l app=opensearch-master kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards \ && kubectl -n stacklight wait --for=condition=Ready --timeout=10m pod -l app=opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat \ && kubectl -n stacklight wait --for=condition=Ready --timeout=10m pod -l app=metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec": {"suspend": false}}'
Tip
To verify whether a StorageClass is expandable:
kubectl get pvc -l 'app=opensearch-master' -n stacklight \
-Ao jsonpath='{range .items[*]}{.spec.storageClassName}{"\n"}{end}' | \
xargs -I{} bash -c "echo -n 'StorageClass: {}, expandable: ' \
&& kubectl get storageclass {} -Ao jsonpath='{.allowVolumeExpansion}' && echo ''"
Example of a system response for an expandable StorageClass:
StorageClass: csi-sc-cinderplugin, expandable: true
Example of a system response for a non-expandable StorageClass:
StorageClass: stacklight-elasticsearch-data, expandable:
StorageClass: stacklight-elasticsearch-data, expandable:
StorageClass: stacklight-elasticsearch-data, expandable:
OpenSearch cluster deadlock due to the corrupted index¶
Due to instability issues in a cluster, for example, after disaster recovery,
networking issues, or low resources, some OpenSearch master pods may remain
in the PostStartHookError due to the corrupted .opendistro-ism-config
index.
To verify that the cluster is affected:
The cluster is affected only when both conditions are met:
One or two
opensearch-masterpods are stuck in thePostStartHookErrorstate.The following example contains two failed pods:
kubectl get pod -n stacklight | grep opensearch-master opensearch-master-0 1/1 Running 0 41d opensearch-master-1 0/1 PostStartHookError 1659 (2m12s ago) 41d opensearch-master-2 0/1 PostStartHookError 1660 (6m6s ago) 41d
In the logs of the
opensearchcontainer of the affected pods, the followingWARNmessage is present:kubectl logs opensearch-master-1 -n stacklight -c opensearch ... [2024-06-05T08:30:26,241][WARN ][r.suppressed ] [opensearch-master-1] path: /_plugins/_ism/policies/audit_rollover_policy, params: {policyID=audit_rollover_policy, if_seq_no=30554, if_primary_term=3} org.opensearch.action.support.replication.ReplicationOperation$RetryOnPrimaryException: shard is not in primary mode ...
The message itself can differ, but the following two parts of this message indicate that the cluster is affected:
The
/_plugins/_ismprefix in the pathThe
shard is not in primary modeexception
To apply the issue resolution:
Decrease the number of replica shards from
1to0for the.opendistro-ism-configinternal index:Log in to the pod that is not affected by this issue, for example,
opensearch-master-0:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
Verify that the
.opendistro-ism-configindex number of replicas is"1":curl "http://localhost:9200/.opendistro-ism-config/_settings" | jq '.".opendistro-ism-config".settings.index.number_of_replicas'
Example of system response:
"1"Decrease replicas from
1to0:curl -X PUT -H 'Content-Type: application/json' "http://localhost:9200/.opendistro-ism-config/_settings" -d '{"index.number_of_replicas": 0 }'
Verify that the
.opendistro-ism-configindex number of replicas is"0".Wait around 30 minutes and verify whether the affected pods started normally or are still failing in the
PostStartHookErrorloop.If the pods started, increase the number of replicas for the
.opendistro-ism-configindex back to1again.If the pods did not start, proceed to the following step.
Remove the internal
.opendistro-ism-configindex to recreate it again:Remove the index:
curl -X DELETE "http://localhost:9200/.opendistro-ism-config"
Wait until all shards of this index are removed, which usually takes up to 10-15 seconds:
curl localhost:9200/_cat/shards | grep opendistro-ism-config
The system response must be empty.
This internal index will be recreated on the next
PostStartHookexecution of any affected replica.Wait up to 30 minutes, assuming that during this time at least one attempt of
PostStartHookexecution occurs, and verify that the internal index was recreated:curl localhost:9200/_cat/shards | grep opendistro-ism-config
The system response must contain two shards in the output, for example:
.opendistro-ism-config 0 p STARTED 10.233.118.238 opensearch-master-2 .opendistro-ism-config 0 r STARTED 10.233.113.58 opensearch-master-1
Wait up to 30 minutes and verify whether the affected pods started normally.
Before 2.27.0 (Cluster releases 17.2.0 and 16.2.0), verify that the cluster is not affected by the issue 40020. If it is affected, proceed to the corresponding workaround.
Failure of shard relocation in the OpenSearch cluster¶
On large managed clusters, shard relocation may fail in the OpenSearch cluster
with the yellow or red status of the OpenSearch cluster.
The characteristic symptom of the issue is that in the stacklight
namespace, the statefulset.apps/opensearch-master containers are
experiencing throttling with the KubeContainersCPUThrottlingHigh alert
firing for the following set of labels:
{created_by_kind="StatefulSet",created_by_name="opensearch-master",namespace="stacklight"}
Caution
The throttling that OpenSearch is experiencing may be a temporary situation, which may be related, for example, to a peaky load and the ongoing shards initialization as part of disaster recovery or after node restart. In this case, Mirantis recommends waiting until initialization of all shards is finished. After that, verify the cluster state and whether throttling still exists. And only if throttling does not disappear, apply the workaround below.
To verify that the initialization of shards is ongoing:
kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
curl "http://localhost:9200/_cat/shards" | grep INITIALIZING
Example of system response:
.ds-system-000072 2 r INITIALIZING 10.232.182.135 opensearch-master-1
.ds-system-000073 1 r INITIALIZING 10.232.7.145 opensearch-master-2
.ds-system-000073 2 r INITIALIZING 10.232.182.135 opensearch-master-1
.ds-audit-000001 2 r INITIALIZING 10.232.7.145 opensearch-master-2
The system response above indicates that shards from the
.ds-system-000072, .ds-system-000073, and .ds-audit-000001
indicies are in the INITIALIZING state. In this case, Mirantis
recommends waiting until this process is finished, and only then consider
changing the limit.
You can additionally analyze the exact level of throttling and the current CPU usage on the Kubernetes Containers dashboard in Grafana.
To apply the issue resolution:
Verify the currently configured CPU requests and limits for the
opensearchcontainers:kubectl -n stacklight get statefulset.apps/opensearch-master -o jsonpath="{.spec.template.spec.containers[?(@.name=='opensearch')].resources}"
Example of system response:
{"limits":{"cpu":"600m","memory":"8Gi"},"requests":{"cpu":"500m","memory":"6Gi"}}
In the example above, the CPU request is
500mand the CPU limit is600m.Increase the CPU limit to a reasonably high number.
For example, the default CPU limit for the clusters with the
clusterSize:largeparameter set was increased from8000mto12000mfor StackLight in Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0).Note
For details, on the
clusterSizeparameter, see Operations Guide: StackLight configuration parameters - Cluster size.If the defaults are already overridden on the affected cluster using the
resourcesPerClusterSizeorresourcesparameters as described in Operations Guide: StackLight configuration parameters - Resource limits, then the exact recommended number depends on the currently set limit.Mirantis recommends increasing the limit by 50%. If it does not resolve the issue, another increase iteration will be required.
When you select the required CPU limit, increase it as described in Operations Guide: StackLight configuration parameters - Resource limits.
If the CPU limit for the
opensearchcomponent is already set, increase it in theClusterobject for theopensearchparameter. Otherwise, the default StackLight limit is used. In this case, increase the CPU limit for theopensearchcomponent using theresourcesparameter.Wait until all
opensearch-masterpods are recreated with the new CPU limits and becomerunningandready.To verify the current CPU limit for every
opensearchcontainer in everyopensearch-masterpod separately:kubectl -n stacklight get pod/opensearch-master-<podSuffixNumber> -o jsonpath="{.spec.containers[?(@.name=='opensearch')].resources}"
In the command above, replace
<podSuffixNumber>with the name of the pod suffix. For example,pod/opensearch-master-0orpod/opensearch-master-2.Example of system response:
{"limits":{"cpu":"900m","memory":"8Gi"},"requests":{"cpu":"500m","memory":"6Gi"}}
The waiting time may take up to 20 minutes depending on the cluster size.
If the issue is fixed, the KubeContainersCPUThrottlingHigh alert stops
firing immediately, while OpenSearchClusterStatusWarning or
OpenSearchClusterStatusCritical can still be firing for some time during
shard relocation.
If the KubeContainersCPUThrottlingHigh alert is still firing, proceed with
another iteration of the CPU limit increase.
StackLight pods get stuck with the ‘NodeAffinity failed’ error¶
On a managed cluster, the StackLight Pods may get stuck with the
Pod predicate NodeAffinity failed error in the Pod status. The issue may
occur if the StackLight node label was added to one machine and
then removed from another one.
The issue does not affect the StackLight services, all required StackLight Pods migrate successfully except extra Pods that are created and stuck during Pod migration.
To apply the issue resolution, remove the stuck Pods:
kubectl --kubeconfig <managedClusterKubeconfig> -n stacklight delete pod <stuckPodName>
No logs are forwarded to Splunk¶
After enabling log forwarding to Splunk as described in Enable log forwarding to external destinations, you may see no specific errors but logs are not being sent to Splunk. In this case, debug the issue using the procedure below.
To debug the issue:
Temporary set the
debuglogging level for the syslog output plugin:logging: externalOutputs: splunk_syslog_output: plugin_log_level: debug type: remote_syslog host: remote-splunk-syslog.svc port: 514 protocol: tcp tls: true ca_file: /etc/ssl/certs/splunk-syslog.pem verify_mode: 0 buffer: chunk_limit: 16MB total_limit: 128MB externalOutputSecretMounts: - secretName: syslog-pem mountPath: /etc/ssl/certs/splunk-syslog.pem
When the
fluentd-logspods are updated, grep any pod bysplunk_syslog_output:kubectl logs -n stacklight -f <fluentd-logs-pod-name>| grep 'splunk_syslog_output'
In the following example output, the error indicates that the specified Splunk host name cannot be resolved. Therefore, verify and update the host name accordingly.
Example output
2023-07-25 09:57:29 +0000 [info]: adding match in @splunk_syslog_output-external pattern="**" type="remote_syslog" @label @splunk_syslog_output-external <label @splunk_syslog_output-external> @id splunk_syslog_output-external path "/var/log/fluentd-buffers/splunk_syslog_output-external.system.buffer" path "/var/log/fluentd-buffers/splunk_syslog_output-external.system.buffer" path "/var/log/fluentd-buffers/splunk_syslog_output-external.system.buffer" 2023-07-25 09:57:30 +0000 [debug]: [splunk_syslog_output-external] restoring buffer file: path = /var/log/fluentd-buffers/splunk_syslog_output-external.system.buffer/buffer.q6014c3643b68e68c03c6217052e1af55.log 2023-07-25 09:57:30 +0000 [debug]: [splunk_syslog_output-external] restoring buffer file: path = /var/log/fluentd-buffers/splunk_syslog_output-external.system.buffer/buffer.q6014c36877047570ab3b892f6bd5afe8.log 2023-07-25 09:57:30 +0000 [debug]: [splunk_syslog_output-external] restoring buffer file: path = /var/log/fluentd-buffers/splunk_syslog_output-external.system.buffer/buffer.b6014c36d40fcc16ea630fa86c9315638.log 2023-07-25 09:57:30 +0000 [debug]: [splunk_syslog_output-external] buffer started instance=61140 stage_size=17628134 queue_size=5026605 2023-07-25 09:57:30 +0000 [debug]: [splunk_syslog_output-external] flush_thread actually running 2023-07-25 09:57:30 +0000 [debug]: [splunk_syslog_output-external] enqueue_thread actually running 2023-07-25 09:57:33 +0000 [debug]: [splunk_syslog_output-external] taking back chunk for errors. chunk="6014c3643b68e68c03c6217052e1af55" 2023-07-25 09:57:33 +0000 [warn]: [splunk_syslog_output-external] failed to flush the buffer. retry_times=0 next_retry_time=2023-07-25 09:57:35 +0000 chunk="6014c3643b68e68c03c6217052e1af55" error_class=SocketError error="getaddrinfo: Name or service not known"
Security Guide¶
This guide provides recommendations on how to effectively use product capabilities to harden the security of a Container Cloud deployment.
Note
The guide is being under development and will be updated with new sections in future releases of the product documentation.
Firewall configuration¶
This section includes the details about ports and protocols used in a Container Cloud deployment.
Container Cloud¶
Component |
Network |
Protocol |
Port |
Consumers |
|---|---|---|---|---|
Web UI, cache, Kubernetes API, and others |
LCM API/Mgmt |
TCP |
443, 6443 |
External clients |
Squid Proxy |
LCM API/Mgmt |
TCP |
3128 |
Applicable to the vSphere provider only. All nodes in management and managed clusters. |
SSH |
LCM API/Mgmt |
TCP |
22 |
External clients |
Chrony |
LCM_API/Mgmt |
TCP |
323 |
All nodes in management and managed clusters. |
NTP |
LCM_API/Mgmt |
UDP |
123 |
All nodes in management and managed clusters. |
LDAP |
LCM API/Mgmt |
UDP |
389 |
|
LDAPs |
LCM API/Mgmt |
TCP/UDP |
686 |
Component |
Network |
Protocol |
Port |
|---|---|---|---|
Ironic |
LCM 0 |
TCP/UDP |
|
Ironic syslog |
PXE |
TCP/UDP |
|
Ironic image repo |
PXE |
TCP |
80 |
MKE/Kubernetes API |
LCM 0 |
TCP/UDP |
|
BOOTP |
PXE |
UDP |
68 |
DHCP server |
PXE |
UDP |
67 |
IPMI |
PXE/LCM 0 |
TCP/UDP |
|
SSH |
PXE/LCM |
TCP |
22 |
DNS |
LCM 0 |
TCP/UDP |
53 |
NTP |
LCM 0 |
TCP/UDP |
123 |
TFTP |
PXE |
UDP |
69 |
Squid Proxy |
LCM 0 |
TCP |
3128 |
LDAP |
LCM 0 |
TCP |
636 |
HTTPS |
LCM 0 |
TCP |
443 |
StackLight |
LCM 0 |
TCP |
|
Mirantis Kubernetes Engine¶
For available Mirantis Kubernetes Engine (MKE) ports, refer to MKE Documentation: Open ports to incoming traffic.
StackLight¶
The tables below contain the details about ports and protocols used by different StackLight components.
Warning
This section does not describe communications within the cluster network.
User interfaces¶
Component |
Network |
Direction |
Port/Protocol |
Consumer |
Comments |
|---|---|---|---|---|---|
Alerta UI |
External network (LB service) |
Inbound |
443/TCP/HTTPS |
Cluster users |
Add the assigned external IP to the |
Alertmanager UI |
External network (LB service) |
Inbound |
443/TCP/HTTPS |
Cluster users |
Add the assigned external IP to the |
Grafana UI |
External network (LB service) |
Inbound |
443/TCP/HTTPS |
Cluster users |
Add the assigned external IP to the |
OpenSearch Dashboards UI |
External network (LB service) |
Inbound |
443/TCP/HTTPS |
Cluster users |
Only when the StackLight logging stack
is enabled. Add the assigned external IP to the |
Prometheus UI |
External network (LB service) |
Inbound |
443/TCP/HTTPS |
Cluster users |
Add the assigned external IP to the |
Alertmanager notifications receivers¶
Component |
Network |
Direction |
Port/Protocol |
Destination |
Comments |
|---|---|---|---|---|---|
Alertmanager Email notifications integration |
Cluster network |
Outbound |
TCP/SMTP |
Depends on the configuration, see the comment. |
Only when email notifications
are enabled. Add an SMTP host URL to the |
Alertmanager Microsoft Teams notifications integration |
Cluster network |
Outbound |
TCP/HTTPS |
Depends on the configuration, see the comment. |
Only when Microsoft Teams notifications
are enabled. Add a webhook URL to the |
Alertmanager Salesforce notifications integration |
Cluster network |
Outbound |
TCP/HTTPS |
For Mirantis support mirantis.my.salesforce.com and login.salesforce.com. Depends on the configuration, see the comment. |
Only when Salesforce notifications
are enabled. Add an SF instance URL and an SF login URL to the |
Alertmanager ServiceNow notifications integration |
Cluster network |
Outbound |
TCP/HTTPS |
Depends on the configuration, see the comment. |
Only when notifications to ServiceNow
are enabled. Add a configured ServiceNow URL to the |
Alertmanager Slack notifications integration |
Cluster network |
Outbound |
TCP/HTTPS |
Depends on the configuration, see the comment. |
Only when notifications to Slack
are enabled. Add a configured Slack URL to the |
Notification integration of Alertmanager generic receivers |
Cluster network |
Outbound |
Customizable, see the comment |
Depends on the configuration, see the comment. |
Only when any custom Alertmanager integration
is enabled. Depending on the integration type, add the corresponding URL to the |
External integrations¶
Component |
Network |
Direction |
Port/Protocol |
Destination |
Comments |
|---|---|---|---|---|---|
Salesforce reporter |
Cluster network |
Outbound |
TCP/HTTPS |
For Mirantis support mirantis.my.salesforce.com and login.salesforce.com. Depends on the configuration, see the comment. |
Only when the
Salesforce reporter
is enabled. Add a SF instance URL and SF login URL to the |
Prometheus Remote Write |
Cluster network |
Outbound |
TCP |
Depends on the configuration, see the comment. |
Only when the
Prometheus Remote Write
feature is enabled. Add a configured remote write destination URL to the |
Prometheus custom scrapes |
Cluster network |
Outbound |
TCP |
Depends on the configuration, see the comment. |
Only when the
Custom Prometheus scrapes
feature is enabled. Add configured scrape targets to the |
Fluentd remote syslog output |
Cluster network |
Outbound |
TCP or UDP (protocol and port are configurable) |
Depends on the configuration, see the comment. |
Only when the
Logging to remote Syslog
feature is enabled. Add a configured remote syslog URL to the |
Metric Collector |
Cluster network |
Outbound |
9093/443/TCP |
Applicable to management clusters only. Add a specific URL from Microsoft Azure to the |
|
External Endpoint monitoring |
Cluster network |
Outbound |
TCP/HTTP(S) |
Depends on the configuration, see the comment. |
Only when the
External endpoint monitoring
feature is enabled. Add configured monitored URLs to the |
SSL certificate monitoring |
Cluster network |
Outbound |
TCP/HTTP(S) |
Depends on the configuration, see the comment. |
Only when SSL certificates monitoring feature is enabled. Add configured monitored URLs to the allowlist. |
Metrics exporters¶
Component |
Network |
Direction |
Port/Protocol |
Consumer |
Comments |
|---|---|---|---|---|---|
Prometheus Node Exporter |
Host network |
Inbound (from cluster network) |
19100/TCP Since 17.0.0, 16.0.0, 14.1.0, 9100/TCP Before 17.0.0, 16.0.0, 14.1.0 |
Prometheus from the |
Prometheus from Cluster network scrape metrics from all nodes. |
Fluentd (Prometheus metrics endpoint) |
Host network |
Inbound (from cluster network) |
24231/TCP |
Prometheus from the |
Only when the StackLight logging stack is enabled. Prometheus from the cluster network scrapes metrics from all nodes. |
Calico node |
Host network |
Inbound (from cluster network) |
9091/TCP |
Prometheus from the |
Prometheus from cluster network scrape metrics from all nodes. |
Telegraf SMART plugin |
Host network |
Inbound (from cluster network) |
9126/TCP |
Prometheus from the |
Applicable to the bare metal provider obly. Prometheus from scrapes metrics of the cluster network from all nodes. |
MKE Manager API |
Host network |
Inbound (from cluster network) |
4443/TCP, 6443/TCP |
Blackbox exporter from the |
Applicable to the master node only. Blackbox exporter from cluster network probes all master nodes.
On attached MKE clusters, the port and protocol depend on the MKE cluster configuration. |
MKE Metrics Engine |
Host network |
Inbound (from cluster network) |
12376/TCP |
Prometheus from the |
Prometheus from cluster network scrape metrics from all nodes. |
Kubernetes Master API |
Host network |
Inbound (from cluster network) |
443/TCP, 5443/TCP |
Blackbox exporter from the |
Applicable to the master node only. Blackbox exporter from cluster network probes all master nodes.
|
Container Cloud telemetry¶
Component |
Network |
Direction |
Port/Protocol |
Consumer |
Destination |
Comments |
|---|---|---|---|---|---|---|
Telemeter client |
Cluster network (managed cluster) |
Outbound (to management cluster external LB) |
443/TCP |
n/a |
Telemeter server on a management cluster (Telemeter server external
IP from the |
Applicable to managed clusters only. The Telemeter client on a managed cluster pushes metrics to the Telemeter server on a management cluster. |
Telemeter server |
External network (LB service) |
Inbound (from managed cluster network) |
443/TCP |
Telemeter client on managed clusters |
n/a |
Applicable to management clusters only. The Telemeter client on the managed cluster pushes metrics to the Telemeter server on the management cluster. |
Ceph¶
Ceph monitors use their node host networks to interact with Ceph daemons. Ceph daemons communicate with each other over a specified cluster network and provide endpoints over the public network.
The messenger V2 (msgr2) or earlier V1 (msgr) protocols are used for
communication between Ceph daemons.
Ceph daemon |
Network |
Protocol |
Port |
Description |
Consumers |
|---|---|---|---|---|---|
Manager ( |
Cluster network |
msgr/msgr2 |
6800 |
Listens on the first available port of the 6800-7300 range |
csi-rbdplugin,csi-rbdprovisioner,rook-ceph-mon |
Metadata server ( |
Cluster network |
msgr/msgr2 |
6800 |
Listens on the first available port of the 6800-7300 range |
csi-cephfsplugin,csi-cephfsprovisioner |
Monitor ( |
LCM host network |
msgr/msgr2 |
msgr:3300,
msgr2:6789
|
Monitor has separate ports for |
Ceph clients
rook-ceph-osd,rook-ceph-rgw |
Ceph OSD ( |
Cluster network |
msgr/msgr2 |
6800-7300 |
Binds to the first available port from the 6800-7300 range |
rook-ceph-mon,rook-ceph-mgr,rook-ceph-mds |
Ceph network policies¶
Available since 2.26.0 (17.1.0 and 16.1.0)
Ceph Controller uses the NetworkPolicy objects for each Ceph daemon.
Each NetworkPolicy is applied to a pod with defined labels in the
rook-ceph namespace. It only allows the use of the ports specified in the
NetworkPolicy spec. Any other port is prohibited.
Ceph daemon |
Pod label |
Allowed ports |
|---|---|---|
Manager ( |
|
6800-7300,
9283
|
Monitor ( |
|
3300,
6789
|
Ceph OSD ( |
|
6800-7300 |
Metadata server ( |
|
6800-7300 |
Ceph Object Storage ( |
|
Value from
spec.cephClusterSpec.objectStorage.rgw.gateway.port,Value from
spec.cephClusterSpec.objectStorage.rgw.gateway.securePort |
Container images signing and validation¶
Available since 2.26.0 (17.1.0 and 16.1.0) Technology Preview
Container Cloud uses policy-controller for signature validation of
pod images. It verifies that images used by the Container Cloud and
Mirantis OpenStack for Kubernetes (MOSK) controllers are signed by a trusted
authority. The policy-controller inspects defined image policies that
list image registries and authorities for signature validation.
The policy-controller validates only pods with image references from
the Container Cloud content delivery network (CDN). Other registries are
ignored by the controller.
The policy-controller supports two modes of image policy validation for
Container Cloud and MOSK images:
warnDefault. Allows controllers to use untrusted images, but a warning message is logged in the
policy-controllerlogs and sent as an admission response.
enforceExperimental. Blocks pod creating and updating operations if a pod image does not have a valid Mirantis signature. If a pod creation or update is blocked in the
enforcemode, send the untrusted artifact to Mirantis support for further inspection. To unblock pod operations, switch to thewarnmode.Warning
The
enforcemode is still under development and is available as an experimental option. Mirantis does not recommend enabling this option for production deployments. The full support for this option will be announced separately in one of the following Container Cloud releases.
In case of unstable connections from the policy-controller to Container
Cloud CDN that disrupt pod creation and update operations, you can disable
the controller by setting enabled: false in the configuration.
The policy-controller configuration is located in the Cluster object:
spec:
...
providerSpec:
value:
...
helmReleases:
...
- name: policy-controller
enabled: [true|false]
values:
policy:
mode: [enforce|warn]
See also
API Reference¶
Warning
This section is intended only for advanced Infrastructure Operators who are familiar with Kubernetes Cluster API.
Mirantis currently supports only those Mirantis Container Cloud API features that are implemented in the Container Cloud web UI. Use other Container Cloud API features for testing and evaluation purposes only.
The Container Cloud APIs are implemented using the Kubernetes
CustomResourceDefinitions (CRDs) that enable you to expand
the Kubernetes API. Different types of resources are grouped in the dedicated
files, such as cluster.yaml or machines.yaml.
For testing and evaluation purposes, you may also use the experimental public Container Cloud API that allows for implementation of custom clients for creating and operating of managed clusters. This repository contains branches that correspond to the Container Cloud releases. For an example usage, refer to the README file of the repository.
Public key resources¶
This section describes the PublicKey resource used in Mirantis
Container Cloud API for all supported providers. This resource is used to
provide SSH access to every machine of a Container Cloud cluster.
The Container Cloud PublicKey CR contains the following fields:
apiVersionAPI version of the object that is
kaas.mirantis.com/v1alpha1
kindObject type that is
PublicKey
metadataThe
metadataobject field of thePublicKeyresource contains the following fields:nameName of the public key
namespaceProject where the public key is created
specThe
specobject field of thePublicKeyresource contains thepublicKeyfield that is an SSH public key value.
The PublicKey resource example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: PublicKey
metadata:
name: demokey
namespace: test
spec:
publicKey: |
ssh-rsa AAAAB3NzaC1yc2EAAAA…
License resource¶
This section describes the License custom resource (CR) used in Mirantis
Container Cloud API to maintain the Mirantis Container Cloud license data.
Warning
The kubectl apply command automatically saves the
applied data as plain text into the
kubectl.kubernetes.io/last-applied-configuration annotation of the
corresponding object. This may result in revealing sensitive data in this
annotation when creating or modifying the object.
Therefore, do not use kubectl apply on this object. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on this object, you
can remove the kubectl.kubernetes.io/last-applied-configuration
annotation from the object using kubectl edit.
The Container Cloud License CR contains the following fields:
apiVersionThe API version of the object that is
kaas.mirantis.com/v1alpha1.
kindThe object type that is
License.
metadataThe
metadataobject field of theLicenseresource contains the following fields:nameThe name of the
Licenseobject, must belicense.
specThe
specobject field of theLicenseresource contains the Secret reference where license data is stored.licensesecretThe Secret reference where the license data is stored.
keyThe name of a key in the license Secret
datafield under which the license data is stored.
nameThe name of the Secret where the license data is stored.
valueThe value of the updated license. If you need to update the license, place it under this field. The new license data will be placed to the Secret and
valuewill be cleaned.
statuscustomerIDThe unique ID of a customer generated during the license issuance.
instanceThe unique ID of the current Mirantis Container Cloud instance.
devThe license is for development.
limitsThe license limits for all supported cloud providers clusters except Mirantis OpenStack for Kubernetes (MOSK):
clustersThe maximum number of managed clusters to be deployed. If the field is absent, the number of deployments is unlimited.
workersPerClusterThe maximum number of workers per cluster to be created. If the field is absent, the number of workers is unlimited.
openstackThe license limits for MOSK clusters:
clustersThe maximum number of MOSK clusters to be deployed. If the field is absent, the number of deployments is unlimited.
workersPerClusterThe maximum number of workers per MOSK cluster to be created. If the field is absent, the number of workers is unlimited.
expirationTimeThe license expiration time in the ISO 8601 format.
expiredThe license expiration state. If the value is
true, the license has expired. If the field is absent, the license is valid.
Configuration example of the status fields:
status:
customerID: "auth0|5dd501e54138450d337bc356"
instance: 7589b5c3-57c5-4e64-96a0-30467189ae2b
dev: true
limits:
clusters: 3
workersPerCluster: 5
expirationTime: 2028-11-28T23:00:00Z
IAM resources¶
This section contains descriptions and examples of the IAM resources for Mirantis Container Cloud. For management details, see Manage user roles through Container Cloud API.
IAMUser¶
IAMUser is the Cluster (non-namespaced) object. Its objects are synced
from Keycloak that is they are created upon user creation in Keycloak and
deleted user upon deletion in Keycloak. The IAMUser is exposed as read-only
to all users. It contains the following fields:
apiVersionAPI version of the object that is
iam.mirantis.com/v1alpha1
kindObject type that is
IAMUser
metadataObject metadata that contains the following field:
nameSanitized user name without special characters with first 8 symbols of the user UUID appended to the end
displayNameName of the user as defined in the Keycloak database
externalIDID of the user as defined in the Keycloak database
Configuration example:
apiVersion: iam.mirantis.com/v1alpha1
kind: IAMUser
metadata:
name: userone-f150d839
displayName: userone
externalID: f150d839-d03a-47c4-8a15-4886b7349791
IAMRole¶
IAMRole is the read-only cluster-level object that can have global,
namespace, or cluster scope. It contains the following fields:
apiVersionAPI version of the object that is
iam.mirantis.com/v1alpha1.
kindObject type that is
IAMRole.
metadataObject metadata that contains the following field:
nameRole name. Possible values are:
global-admin,cluster-admin,operator,bm-pool-operator,user,member,stacklight-admin,management-admin.For details on user role assignment, see Manage user roles through Container Cloud API.
Note
The
management-adminrole is available since Container Cloud 2.25.0 (Cluster releases 17.0.0, 16.0.0, 14.1.0).
descriptionRole description.
scopeRole scope.
Configuration example:
apiVersion: iam.mirantis.com/v1alpha1
kind: IAMRole
metadata:
name: global-admin
description: Gives permission to manage IAM role bindings in the Container Cloud deployment.
scope: global
IAMGlobalRoleBinding¶
IAMGlobalRoleBinding is the Cluster (non-namespaced) object that
should be used for global role bindings in all namespaces. This object is
accessible to users with the global-admin IAMRole assigned through the
IAMGlobalRoleBinding object. The object contains the following fields:
apiVersionAPI version of the object that is
iam.mirantis.com/v1alpha1.
kindObject type that is
IAMGlobalRoleBinding.
metadataObject metadata that contains the following field:
nameRole binding name. If the role binding is user-created, user can set any unique name. If a name relates to a binding that is synced by
user-controllerfrom Keycloak, the naming convention is<username>-<rolename>.
roleObject role that contains the following field:
nameRole name.
userObject name that contains the following field:
nameName of the
iamuserobject that the defined role is provided to. Not equal to the user name in Keycloak.
legacyDefines whether the role binding is legacy. Possible values are
trueorfalse.
legacyRoleApplicable when the
legacyfield value istrue. Defines the legacy role name in Keycloak.
externalDefines whether the role is assigned through Keycloak and is synced by
user-controllerwith the Container Cloud API as theIAMGlobalRoleBindingobject. Possible values aretrueorfalse.
Caution
If you create the IAM*RoleBinding, do not set or modify
the legacy, legacyRole, and external fields unless absolutely
necessary and you understand all implications.
Configuration example:
apiVersion: iam.mirantis.com/v1alpha1
kind: IAMGlobalRoleBinding
metadata:
name: userone-global-admin
role:
name: global-admin
user:
name: userone-f150d839
external: false
legacy: false
legacyRole: “”
IAMRoleBinding¶
IAMRoleBinding is the namespaced object that represents a grant of one
role to one user in all clusters of the namespace. It is accessible to users
that have either of the following bindings assigned to them:
IAMGlobalRoleBindingthat binds them with theglobal-admin,operator, oruseriamRole. Foruser, the bindings are read-only.IAMRoleBindingthat binds them with theoperatororuseriamRolein a particular namespace. Foruser, the bindings are read-only.apiVersionAPI version of the object that is
iam.mirantis.com/v1alpha1.
kindObject type that is
IAMRoleBinding.
metadataObject metadata that contains the following fields:
namespaceNamespace that the defined binding belongs to.
nameRole binding name. If the role is user-created, user can set any unique name. If a name relates to a binding that is synced from Keycloak, the naming convention is
<userName>-<roleName>.
legacyDefines whether the role binding is legacy. Possible values are
trueorfalse.
legacyRoleApplicable when the
legacyfield value istrue. Defines the legacy role name in Keycloak.
externalDefines whether the role is assigned through Keycloak and is synced by
user-controllerwith the Container Cloud API as theIAMGlobalRoleBindingobject. Possible values aretrueorfalse.
Caution
If you create the IAM*RoleBinding, do not set or modify
the legacy, legacyRole, and external fields unless absolutely
necessary and you understand all implications.
roleObject role that contains the following field:
nameRole name.
userObject user that contains the following field:
nameName of the
iamuserobject that the defined role is granted to. Not equal to the user name in Keycloak.
Configuration example:
apiVersion: iam.mirantis.com/v1alpha1
kind: IAMRoleBinding
metadata:
namespace: nsone
name: userone-operator
external: false
legacy: false
legacyRole: “”
role:
name: operator
user:
name: userone-f150d839
IAMClusterRoleBinding¶
IAMClusterRoleBinding is the namespaced object that represents a grant
of one role to one user on one cluster in the namespace.This object is
accessible to users that have either of the following bindings
assigned to them:
IAMGlobalRoleBindingthat binds them with theglobal-admin,operator, oruseriamRole. Foruser, the bindings are read-only.IAMRoleBindingthat binds them with theoperatororuseriamRolein a particular namespace. Foruser, the bindings are read-only.
The IAMClusterRoleBinding object contains the following fields:
apiVersionAPI version of the object that is
iam.mirantis.com/v1alpha1.
kindObject type that is
IAMClusterRoleBinding.
metadataObject metadata that contains the following fields:
namespaceNamespace of the cluster that the defined binding belongs to.
nameRole binding name. If the role is user-created, user can set any unique name. If a name relates to a binding that is synced from Keycloak, the naming convention is
<userName>-<roleName>-<clusterName>.
roleObject role that contains the following field:
nameRole name.
userObject user that contains the following field:
nameName of the
iamuserobject that the defined role is granted to. Not equal to the user name in Keycloak.
clusterObject cluster that contains the following field:
nameName of the cluster on which the defined role is granted.
legacyDefines whether the role binding is legacy. Possible values are
trueorfalse.
legacyRoleApplicable when the
legacyfield value istrue. Defines the legacy role name in Keycloak.
externalDefines whether the role is assigned through Keycloak and is synced by
user-controllerwith the Container Cloud API as theIAMGlobalRoleBindingobject. Possible values aretrueorfalse.
Caution
If you create the IAM*RoleBinding, do not set or modify
the legacy, legacyRole, and external fields unless absolutely
necessary and you understand all implications.
Configuration example:
apiVersion: iam.mirantis.com/v1alpha1
kind: IAMClusterRoleBinding
metadata:
namespace: nsone
name: userone-clusterone-admin
role:
name: cluster-admin
user:
name: userone-f150d839
cluster:
name: clusterone
legacy: false
legacyRole: “”
external: false
ClusterOIDCConfiguration resource for MKE¶
Available since 17.0.0, 16.0.0, and 14.1.0
This section contains description of the OpenID Connect (OIDC) custom resource for Mirantis Container Cloud that you can use to customize OIDC for Mirantis Kubernetes Engine (MKE) on managed clusters. Using this resource, add your own OIDC provider to authenticate user requests to Kubernetes. For OIDC provider requirements, see OIDC official specification.
The creation procedure of the ClusterOIDCConfiguration for a managed
cluster is described in Add a custom OIDC provider for MKE.
The Container Cloud ClusterOIDCConfiguration custom resource contains
the following fields:
apiVersionThe API version of the object that is
kaas.mirantis.com/v1alpha1.
kindThe object type that is
ClusterOIDCConfiguration.
metadataThe
metadataobject field of theClusterOIDCConfigurationresource contains the following fields:nameThe object name.
namespaceThe project name (Kubernetes namespace) of the related managed cluster.
specThe
specobject field of theClusterOIDCConfigurationresource contains the following fields:adminRoleCriteriaDefinition of the
id_tokenclaim with the admin role and the role value.matchTypeMatching type of the claim with the requested role. Possible values that MKE uses to match the claim with the requested value:
mustRequires a plain string in the
id_tokenclaim, for example,"iam_role": "mke-admin".
containsRequires an array of strings in the
id_tokenclaim, for example,"iam_role": ["mke-admin", "pod-reader"].
nameName of the admin
id_tokenclaim containing a role or array of roles.
valueRole value that matches the
"iam_role"value in the adminid_tokenclaim.
caBundleBase64-encoded certificate authority bundle of the OIDC provider endpoint.
clientIDID of the OIDC client to be used by Kubernetes.
clientSecretSecret
valueof theclientIDparameter. After theClusterOIDCConfigurationobject creation, this field is updated automatically with a reference to the corresponding Secret. For example:clientSecret: secret: key: value name: CLUSTER_NAME-wqbkj
issuerOIDC endpoint.
Configuration example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: ClusterOIDCConfiguration
metadata:
name: CLUSTER_NAME
namespace: CLUSTER_NAMESPACE
spec:
adminRoleCriteria:
matchType: contains
name: iam_roles
value: mke-admin
caBundle: BASE64_ENCODED_CA
clientID: MY_CLIENT
clientSecret:
value: MY_SECRET
issuer: https://auth.example.com/
MachinePool resource¶
This section describes the MachinePool resource used in the Container
Cloud API for all types of supported cloud providers.
The MachinePool resource describes the parameters of a machine pool
and machines assigned to it.
For demonstration purposes, the Container Cloud MachinePool
custom resource (CR) can be split into the following major sections:
metadata¶
The Container Cloud MachinePool custom resource (CR) contains the following
fields:
apiVersionObject API version that is
kaas.mirantis.com/v1alpha1.
kindObject type that is
MachinePool.
The metadata object field of the MachinePool resource contains
the following fields:
nameName of the
MachinePoolobject.
namespaceContainer Cloud project in which the
MachinePoolobject has been created. Any machine assigned to this machine pool will be created in the same project.
labelsKey-value pairs attached to the object:
kaas.mirantis.com/providerProvider type that matches the provider type in the
Clusterobject.
kaas.mirantis.com/regionRegion name that matches the region name in the
Clusterobject.Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
cluster.sigs.k8s.io/cluster-nameCluster name that this machine pool is linked to.
cluster.sigs.k8s.io/control-planeFor the control plane role of machines assigned to the machine pool, this label contains any value, for example,
"true".For the worker role, this label is absent.
Machines assigned to a machine pool have the same
labelsas their machine pool.
Configuration example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: MachinePool
metadata:
name: example-control-plane
namespace: example-ns
labels:
kaas.mirantis.com/provider: openstack
cluster.sigs.k8s.io/cluster-name: example-cluster
cluster.sigs.k8s.io/control-plane: "true" # remove for pool of workers
MachinePool spec¶
The spec field of the MachinePool object contains the following fields:
deletePolicyPolicy used to identify nodes for deletion when downscaling. Defaults to
never, which is currently the only supported value.
replicasRequired number of machines assigned to the machine pool.
Caution
Manually decrease replicas count when you unassign a machine from a pool with positive replicas count using the Container Cloud API.
If you decrease the replicas count, extra machines are not deleted automatically. Therefore, manually delete extra machines from the pool to match the decreased replicas count.
Deleting a machine assigned to a pool without decreasing replicas count causes automatic machine recreation.
If you increase the replicas count, additional machines are created automatically.
machineSpecValue used to fill the
specfield of machines created for the machine pool. The field is provider-specific, for details see theMachineobject API documentation of a particular provider.Caution
Changing
machineSpecof theMachinePoolobject causes the corresponding change in the spec of every machine assigned to the pool. Therefore, edit it with caution.
Configuration example (OpenStack):
spec:
deletePolicy: never
replicas: 3
machineSpec: #here goes example spec for an OpenStack machine
providerSpec:
value:
apiVersion: openstackproviderconfig.k8s.io/v1alpha1
kind: OpenstackMachineProviderSpec
availabilityZone: nova
flavor: kaas.small
image: focal-server-cloudimg-amd64-20210810
securityGroups:
- kaas-sg-ctrl-abcdefgh-0123-4567-890a-0a1b2c3d4e5f
- kaas-sg-glob-abcdefgh-0123-4567-890a-0a1b2c3d4e5f
nodeLabels:
- displayName: Stacklight
key: stacklight
value: enabled
MachinePool status¶
The status field of the MachinePool object contains the following
fields:
replicasMost recent observed number of machines assigned to the machine pool.
readyReplicasNumber of ready machines assigned to the machine pool.
Configuration example:
status:
readyReplicas: 3
replicas: 3
UpdateGroup resource¶
Available since 2.27.0 (17.2.0 and 16.2.0)
This section describes the UpdateGroup custom resource (CR) used in the
Container Cloud API for all supported providers. Use this resource to configure
update concurrency for specific sets of machines or machine pools within a
cluster. This resource enhances the update process by allowing a more granular
control over the concurrency of machine updates.
The Container Cloud UpdateGroup CR contains the following fields:
apiVersionAPI version of the object that is
kaas.mirantis.com/v1alpha1.
kindObject type that is
UpdateGroup.
metadataMetadata of the
UpdateGroupCR that contains the following fields:nameName of the
UpdateGroupobject.
namespaceProject where the
UpdateGroupis created.
labelsLabel to associate the
UpdateGroupwith a specific cluster in thecluster.sigs.k8s.io/cluster-name: <cluster-name>format.
specSpecification of the
UpdateGroupCR that contains the following fields:indexIndex to determine the processing order of the
UpdateGroupobject. Groups with the same index are processed concurrently.The update order of a machine within the same group is determined by the upgrade index of a specific machine. For details, see Change the upgrade order of a machine or machine pool.
concurrentUpdatesNumber of machines to update concurrently within
UpdateGroup.
Configuration example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: UpdateGroup
metadata:
name: update-group-example
namespace: managed-ns
labels:
cluster.sigs.k8s.io/cluster-name: managed-cluster
spec:
index: 10
concurrentUpdates: 2
MCCUpgrade resource¶
This section describes the MCCUpgrade resource used in Mirantis
Container Cloud API to configure a schedule for the Container Cloud upgrade.
The Container Cloud MCCUpgrade CR contains the following fields:
apiVersionAPI version of the object that is
kaas.mirantis.com/v1alpha1.
kindObject type that is
MCCUpgrade.
metadataThe
metadataobject field of theMCCUpgraderesource contains the following fields:nameThe name of
MCCUpgradeobject, must bemcc-upgrade.
specThe
specobject field of theMCCUpgraderesource contains the schedule when Container Cloud upgrade is allowed or blocked. This field contains the following fields:blockUntilTime stamp in the ISO 8601 format, for example,
2021-12-31T12:30:00-05:00. Upgrades will be disabled until this time. You cannot set this field to more than 7 days in the future and more than 30 days after the latest Container Cloud release.
timeZoneName of a time zone in the IANA Time Zone Database. This time zone will be used for all schedule calculations. For example:
Europe/Samara,CET,America/Los_Angeles.
scheduleList of schedule items that allow an upgrade at specific hours or weekdays. The upgrade process can proceed if at least one of these items allows it. Schedule items allow upgrade when both
hoursandweekdaysconditions are met. When this list is empty or absent, upgrade is allowed at any hour of any day. Every schedule item contains the following fields:hoursObject with 2 fields:
fromandto. Both must be non-negative integers not greater than 24. Thetofield must be greater than thefromone. Upgrade is allowed if the current hour in the time zone specified bytimeZoneis greater or equals tofromand is less thanto. Ifhoursis absent, upgrade is allowed at any hour.
weekdaysObject with boolean fields with these names:
mondaytuesdaywednesdaythursdayfridaysaturdaysunday
Upgrade is allowed only on weekdays that have the corresponding field set to
true. If all fields arefalseor absent, orweekdaysis empty or absent, upgrade is allowed on all weekdays.
Full
specexample:spec: blockUntil: 2021-12-31T00:00:00 timeZone: CET schedule: - hours: from: 10 to: 17 weekdays: monday: true tuesday: true - hours: from: 7 to: 10 weekdays: monday: true friday: true
In this example:
Upgrades are blocked until December 31, 2021
All schedule calculations are done in the CET timezone
Upgrades are allowed only:
From 7:00 to 17:00 on Mondays
From 10:00 to 17:00 on Tuesdays
From 7:00 to 10:00 on Fridays
statusThe
statusobject field of theMCCUpgraderesource contains information about the next planned Container Cloud upgrade, if available. This field contains the following fields:nextAttemptTime stamp in the ISO 8601 format indicating the time when the Release Controller will attempt to discover and install a new Container Cloud release. Set to the next allowed time according to the schedule configured in
specor one minute in the future if the schedule currently allows upgrade.
messageMessage from the last upgrade step or attempt.
nextReleaseObject describing the next release that Container Cloud will be upgraded to. Absent if no new releases have been discovered. Contains the following fields:
versionSemver-compatible version of the next Container Cloud release, for example,
2.22.0.
dateTime stamp in the ISO 8601 format indicating the time when the Container Cloud release defined in
versionhas been first discovered.
lastUpgradeTime stamps of the latest Container Cloud upgrade:
startedAtTime stamp in the ISO 8601 format indicating the time when the last Container Cloud upgrade started.
finishedAtTime stamp in the ISO 8601 format indicating the time when the last Container Cloud upgrade finished.
CacheWarmupRequest resource¶
TechPreview Available since 2.24.0 and 23.2 for MOSK clusters
This section describes the CacheWarmupRequest custom resource (CR) used in
the Container Cloud API to predownload images and store them in the
mcc-cache service.
The Container Cloud CacheWarmupRequest CR contains the following fields:
apiVersionAPI version of the object that is
kaas.mirantis.com/v1alpha1.
kindObject type that is
CacheWarmupRequest.
metadataThe
metadataobject field of theCacheWarmupRequestresource contains the following fields:nameName of the
CacheWarmupRequestobject that must match the existing management cluster name to which the warm-up operation applies.
namespaceContainer Cloud project in which the cluster is created. Always set to
defaultas the only available project for management clusters creation.
specThe
specobject field of theCacheWarmupRequestresource contains the settings for artifacts fetching and artifacts filtering through Cluster releases. This field contains the following fields:clusterReleasesArray of strings. Defines a set of Cluster release names to warm up in the
mcc-cacheservice.
openstackReleasesOptional. Array of strings. Defines a set of OpenStack releases to warm up in
mcc-cache. Applicable only ifClusterReleasesfield containsmoskreleases.If you plan to upgrade an OpenStack version, define the current and the target versions including the intermediate versions, if any. For example, to upgrade OpenStack from Victoria to Yoga:
openstackReleases: - victoria - wallaby - xena - yoga
fetchRequestTimeoutOptional. String. Time for a single request to download a single artifact. Defaults to
30m. For example,1h2m3s.
clientsPerEndpointOptional. Integer. Number of clients to use for fetching artifacts per each
mcc-cacheservice endpoint. Defaults to2.
openstackOnlyOptional. Boolean. Enables fetching of the OpenStack-related artifacts for MOSK. Defaults to
false. Applicable only if theClusterReleasesfield containsmoskreleases. Useful when you need to upgrade only an OpenStack version on MOSK-based clusters.
Example configuration:
apiVersion: kaas.mirantis.com/v1alpha1
kind: CacheWarmupRequest
metadata:
name: example-cluster-name
namespace: default
spec:
clusterReleases:
- mke-14-0-1
- mosk-15-0-1
openstackReleases:
- yoga
fetchRequestTimeout: 30m
clientsPerEndpoint: 2
openstackOnly: false
In this example:
The
CacheWarmupRequestobject is created for a management cluster namedexample-cluster-name.The
CacheWarmupRequestobject is created in the only alloweddefaultContainer Cloud project.Two Cluster releases
mosk-15-0-1andmke-14-0-1will be predownloaded.For
mosk-15-0-1, only images related to the OpenStack versionYogawill be predownloaded.Maximum time-out for a single request to download a single artifact is 30 minutes.
Two parallel workers will fetch artifacts per each
mcc-cacheservice endpoint.All artifacts will be fetched, not only those related to OpenStack.
GracefulRebootRequest resource¶
Available since 2.23.0 and 2.23.1 for MOSK 23.1
This section describes the GracefulRebootRequest custom resource (CR)
used in the Container Cloud API for all supported providers. Use this resource
for a rolling reboot of several or all cluster machines without workloads
interruption. The resource is also useful for a bulk reboot of machines,
for example, on large clusters.
The Container Cloud GracefulRebootRequest CR contains the following fields:
apiVersionAPI version of the object that is
kaas.mirantis.com/v1alpha1.
kindObject type that is
GracefulRebootRequest.
metadataMetadata of the
GracefulRebootRequestCR that contains the following fields:nameName of the
GracefulRebootRequestobject. The object name must match the name of the cluster on which you want to reboot machines.
namespaceProject where the
GracefulRebootRequestis created.
specSpecification of the
GracefulRebootRequestCR that contains the following fields:machinesList of machines for a rolling reboot. Each machine of the list is cordoned, drained, rebooted, and uncordoned in the order of cluster upgrade policy. For details about the upgrade order, see Change the upgrade order of a machine or machine pool.
Leave this field empty to reboot all cluster machines.
Caution
The cluster and machines must have the
Readystatus to perform a graceful reboot.
Configuration example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: GracefulRebootRequest
metadata:
name: demo-cluster
namespace: demo-project
spec:
machines:
- demo-worker-machine-1
- demo-worker-machine-3
ContainerRegistry resource¶
This section describes the ContainerRegistry custom resource (CR) used in
Mirantis Container Cloud API for all supported providers. This resource is
used to configure CA certificates on machines to access private Docker
registries.
The Container Cloud ContainerRegistry CR contains the following fields:
apiVersionAPI version of the object that is
kaas.mirantis.com/v1alpha1
kindObject type that is
ContainerRegistry
metadataThe
metadataobject field of theContainerRegistryCR contains the following fields:nameName of the container registry
namespaceProject where the container registry is created
specThe
specobject field of theContainerRegistryCR contains the following fields:domainHost name and optional port of the registry
CACertCA certificate of the registry in the base64-encoded format
Caution
Only one ContainerRegistry resource can exist per domain.
To configure multiple CA certificates for the same domain, combine them into
one certificate.
The ContainerRegistry resource example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: ContainerRegistry
metadata:
name: demoregistry
namespace: test
spec:
domain: demohost:5000
CACert: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0...
TLSConfig resource¶
This section describes the TLSConfig resource used in Mirantis
Container Cloud API for all supported providers. This resource is used to
configure TLS certificates for cluster applications.
Warning
The kubectl apply command automatically saves the
applied data as plain text into the
kubectl.kubernetes.io/last-applied-configuration annotation of the
corresponding object. This may result in revealing sensitive data in this
annotation when creating or modifying the object.
Therefore, do not use kubectl apply on this object. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on this object, you
can remove the kubectl.kubernetes.io/last-applied-configuration
annotation from the object using kubectl edit.
The Container Cloud TLSConfig CR contains the following fields:
apiVersionAPI version of the object that is
kaas.mirantis.com/v1alpha1.
kindObject type that is
TLSConfig.
metadataThe
metadataobject field of theTLSConfigresource contains the following fields:nameName of the public key.
namespaceProject where the TLS certificate is created.
specThe
specobject field contains the configuration to apply for an application. It contains the following fields:serverNameHost name of a server.
serverCertificateCertificate to authenticate server’s identity to a client. A valid certificate bundle can be passed. The server certificate must be on the top of the chain.
privateKeyReference to the
Secretobject that contains a private key. A private key is a key for the server. It must correspond to the public key used in the server certificate.keyKey name in the secret.
nameSecret name.
caCertificateCertificate that issued the server certificate. The top-most intermediate certificate should be used if a CA certificate is unavailable.
Configuration example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: TLSConfig
metadata:
namespace: default
name: keycloak
spec:
caCertificate: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0...
privateKey:
secret:
key: value
name: keycloak-s7mcj
serverCertificate: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0...
serverName: keycloak.mirantis.com
Bare metal resources¶
This section contains descriptions and examples of the baremetal-based Kubernetes resources for Mirantis Container Cloud.
BareMetalHost¶
This section describes the BareMetalHost resource used in the
Mirantis Container Cloud API. BareMetalHost object
is being created for each Machine and contains all information about
machine hardware configuration. It is needed for further selecting which
machine to choose for the deploy. When machine is created
the provider assigns a BareMetalHost to that machine based on
labels and BareMetalHostProfile configuration.
For demonstration purposes, the Container Cloud BareMetalHost
custom resource (CR) can be split into the following major sections:
BareMetalHost metadata¶
The Container Cloud BareMetalHost CR contains the following fields:
apiVersionAPI version of the object that is
metal3.io/v1alpha1.
kindObject type that is
BareMetalHost.
metadataThe metadata field contains the following subfields:
nameName of the
BareMetalHostobject.
namespaceProject in which the
BareMetalHostobject was created.
annotationsAvailable since Cluster releases 12.5.0, 11.5.0, and 7.11.0. Key-value pairs to attach additional metadata to the object:
kaas.mirantis.com/baremetalhost-credentials-nameKey that connects the
BareMetalHostobject with a previously createdBareMetalHostCredentialobject. The value of this key must match theBareMetalHostCredentialobject name.
host.dnsmasqs.metal3.io/addressAvailable since Cluster releases 17.0.0 and 16.0.0. Key that assigns a particular IP address to a bare metal host during PXE provisioning.
baremetalhost.metal3.io/detachedAvailable since Cluster releases 17.0.0 and 16.0.0. Key that pauses host management by the bare metal Operator for a manual IP address assignment.
Note
If the host provisioning has already started or completed, adding of this annotation deletes the information about the host from Ironic without triggering deprovisioning. The bare metal Operator recreates the host in Ironic once you remove the annotation. For details, see Metal3 documentation.
inspect.metal3.io/hardwaredetails-storage-sort-termAvailable since Cluster releases 17.0.0 and 16.0.0. Optional. Key that defines sorting of the
bmh:status:storage[]list during inspection of a bare metal host. Accepts multiple tags separated by a comma or semi-column with theASC/DESCsuffix for sorting direction. Example terms:sizeBytes DESC,hctl ASC,type ASC,name DESC.Since Cluster releases 17.1.0 and 16.1.0, the following default value applies:
hctl ASC, wwn ASC, by_id ASC, name ASC.
labelsLabels used by the bare metal provider to find a matching
BareMetalHostobject to deploy a machine:hostlabel.bm.kaas.mirantis.com/controlplanehostlabel.bm.kaas.mirantis.com/workerhostlabel.bm.kaas.mirantis.com/storage
Each
BareMetalHostobject added using the Container Cloud web UI will be assigned one of these labels. If theBareMetalHostandMachineobjects are created using API, any label may be used to match these objects for a bare metal host to deploy a machine.
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Configuration example:
apiVersion: metal3.io/v1alpha1
kind: BareMetalHost
metadata:
name: master-0
namespace: default
labels:
kaas.mirantis.com/baremetalhost-id: hw-master-0
kaas.mirantis.com/baremetalhost-id: <bareMetalHostHardwareNodeUniqueId>
annotations: # Since 2.21.0 (7.11.0, 12.5.0, 11.5.0)
kaas.mirantis.com/baremetalhost-credentials-name: hw-master-0-credentials
BareMetalHost configuration¶
The spec section for the BareMetalHost object defines the desired state
of BareMetalHost. It contains the following fields:
bmcDetails for communication with the Baseboard Management Controller (
bmc) module on a host. Contains the following subfields:addressURL for communicating with the BMC. URLs vary depending on the communication protocol and the BMC type, for example:
- IPMI
Default BMC type in the
ipmi://<host>:<port>format. You can also use a plain<host>:<port>format. A port is optional if using the default port 623.You can change the IPMI privilege level from the default
ADMINISTRATORtoOPERATORwith an optional URL parameterprivilegelevel:ipmi://<host>:<port>?privilegelevel=OPERATOR.
- Redfish
BMC type in the
redfish://format. To disable TLS, you can use theredfish+http://format. A host name or IP address and a path to the system ID are required for both formats. For example,redfish://myhost.example/redfish/v1/Systems/System.Embedded.1orredfish://myhost.example/redfish/v1/Systems/1.
credentialsNameName of the secret containing the
BareMetalHostobject credentials.Since Container Cloud 2.21.0 and 2.21.1 for MOSK 22.5, this field is updated automatically during cluster deployment. For details, see BareMetalHostCredential.
Before Container Cloud 2.21.0 or MOSK 22.5, the secret requires the
usernameandpasswordkeys in the Base64 encoding.
disableCertificateVerificationBoolean to skip certificate validation when
true.
bootMACAddressMAC address for booting.
bootModeBoot mode:
UEFIif UEFI is enabled andlegacyif disabled.
onlineDefines whether the server must be online after provisioning is done.
Warning
Setting
online: falseto more than one bare metal host in a management cluster at a time can make the cluster non-operational.
Configuration example for Container Cloud 2.21.0 or later:
metadata:
name: node-1-name
annotations:
kaas.mirantis.com/baremetalhost-credentials-name: node-1-credentials # Since Container Cloud 2.21.0
spec:
bmc:
address: 192.168.33.106:623
credentialsName: ''
bootMACAddress: 0c:c4:7a:a8:d3:44
bootMode: legacy
online: true
Configuration example for Container Cloud 2.20.1 or earlier:
metadata:
name: node-1-name
spec:
bmc:
address: 192.168.33.106:623
credentialsName: node-1-credentials-secret-f9g7d9f8h79
bootMACAddress: 0c:c4:7a:a8:d3:44
bootMode: legacy
online: true
BareMetalHost status¶
The status field of the BareMetalHost object defines the current
state of BareMetalHost. It contains the following fields:
errorMessageLast error message reported by the provisioning subsystem.
goodCredentialsLast credentials that were validated.
hardwareHardware discovered on the host. Contains information about the storage, CPU, host name, firmware, and so on.
operationalStatusStatus of the host:
OKHost is configured correctly and is manageable.
discoveredHost is only partially configured. For example, the
bmcaddress is discovered but not the login credentials.
errorHost has any sort of error.
poweredOnHost availability status: powered on (
true) or powered off (false).
provisioningState information tracked by the provisioner:
stateCurrent action being done with the host by the provisioner.
idUUID of a machine.
triedCredentialsDetails of the last credentials sent to the provisioning backend.
Configuration example:
status:
errorMessage: ""
goodCredentials:
credentials:
name: master-0-bmc-secret
namespace: default
credentialsVersion: "13404"
hardware:
cpu:
arch: x86_64
clockMegahertz: 3000
count: 32
flags:
- 3dnowprefetch
- abm
...
model: Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz
firmware:
bios:
date: ""
vendor: ""
version: ""
hostname: ipa-fcab7472-892f-473c-85a4-35d64e96c78f
nics:
- ip: ""
mac: 0c:c4:7a:a8:d3:45
model: 0x8086 0x1521
name: enp8s0f1
pxe: false
speedGbps: 0
vlanId: 0
...
ramMebibytes: 262144
storage:
- by_path: /dev/disk/by-path/pci-0000:00:1f.2-ata-1
hctl: "4:0:0:0"
model: Micron_5200_MTFD
name: /dev/sda
rotational: false
serialNumber: 18381E8DC148
sizeBytes: 1920383410176
vendor: ATA
wwn: "0x500a07511e8dc148"
wwnWithExtension: "0x500a07511e8dc148"
...
systemVendor:
manufacturer: Supermicro
productName: SYS-6018R-TDW (To be filled by O.E.M.)
serialNumber: E16865116300188
operationalStatus: OK
poweredOn: true
provisioning:
state: provisioned
triedCredentials:
credentials:
name: master-0-bmc-secret
namespace: default
credentialsVersion: "13404"
BareMetalHostCredential¶
Available since 2.21.0 and 2.21.1 for MOSK 22.5
This section describes the BareMetalHostCredential custom resource (CR)
used in the Mirantis Container Cloud API. The BareMetalHostCredential
object is created for each BareMetalHost and contains all information
about the Baseboard Management Controller (bmc) credentials.
Warning
The kubectl apply command automatically saves the
applied data as plain text into the
kubectl.kubernetes.io/last-applied-configuration annotation of the
corresponding object. This may result in revealing sensitive data in this
annotation when creating or modifying the object.
Therefore, do not use kubectl apply on this object. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on this object, you
can remove the kubectl.kubernetes.io/last-applied-configuration
annotation from the object using kubectl edit.
For demonstration purposes, the BareMetalHostCredential CR can be split
into the following sections:
BareMetalHostCredential metadata¶
The BareMetalHostCredential metadata contains the following fields:
apiVersionAPI version of the object that is
kaas.mirantis.com/v1alpha1
kindObject type that is
BareMetalHostCredential
metadataThe metadata field contains the following subfields:
nameName of the
BareMetalHostCredentialobject
namespaceContainer Cloud project in which the related
BareMetalHostobject was created
labelsLabels used by the bare metal provider:
kaas.mirantis.com/regionRegion name
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
BareMetalHostCredential configuration¶
The spec section for the BareMetalHostCredential object contains
sensitive information that is moved to a separate
Secret object during cluster deployment:
usernameUser name of the
bmcaccount with administrator privileges to control the power state and boot source of the bare metal host
passwordDetails on the user password of the
bmcaccount with administrator privileges:valuePassword that will be automatically removed once saved in a separate
Secretobject
nameName of the
Secretobject where credentials are saved
The BareMetalHostCredential object creation triggers the following
automatic actions:
Create an underlying
Secretobject containing data aboutusernameandpasswordof thebmcaccount of the relatedBareMetalHostCredentialobject.Erase sensitive
passworddata of thebmcaccount from theBareMetalHostCredentialobject.Add the created
Secretobject name to thespec.password.namesection of the relatedBareMetalHostCredentialobject.Update
BareMetalHost.spec.bmc.credentialsNamewith theBareMetalHostCredentialobject name.
Note
When you delete a BareMetalHost object, the related
BareMetalHostCredential object is deleted automatically.
Note
On existing clusters, a BareMetalHostCredential object is
automatically created for each BareMetalHost object during a cluster
update.
Example of BareMetalHostCredential before the cluster deployment starts:
apiVersion: kaas.mirantis.com/v1alpha1
kind: BareMetalHostCredential
metadata:
name: hw-master-0-credetnials
namespace: default
spec:
username: admin
password:
value: superpassword
Example of BareMetalHostCredential created during cluster deployment:
apiVersion: kaas.mirantis.com/v1alpha1
kind: BareMetalHostCredential
metadata:
name: hw-master-0-credetnials
namespace: default
spec:
username: admin
password:
name: secret-cv98n7c0vb9
BareMetalHostProfile¶
This section describes the BareMetalHostProfile resource used
in Mirantis Container Cloud API
to define how the storage devices and operating system
are provisioned and configured.
For demonstration purposes, the Container Cloud BareMetalHostProfile
custom resource (CR) is split into the following major sections:
metadata¶
The Container Cloud BareMetalHostProfile CR contains
the following fields:
apiVersionAPI version of the object that is
metal3.io/v1alpha1.
kindObject type that is
BareMetalHostProfile.
metadataThe
metadatafield contains the following subfields:nameName of the bare metal host profile.
namespaceProject in which the bare metal host profile was created.
Configuration example:
apiVersion: metal3.io/v1alpha1
kind: BareMetalHostProfile
metadata:
name: default
namespace: default
spec¶
The spec field of BareMetalHostProfile object contains
the fields to customize your hardware configuration:
Warning
Any data stored on any device defined in the fileSystems
list can be deleted or corrupted during cluster (re)deployment. It happens
because each device from the fileSystems list is a part of the
rootfs directory tree that is overwritten during (re)deployment.
Examples of affected devices include:
A raw device partition with a file system on it
A device partition in a volume group with a logical volume that has a file system on it
An mdadm RAID device with a file system on it
An LVM RAID device with a file system on it
The wipe field (deprecated) or wipeDevice structure (recommended
since Container Cloud 2.26.0) have no effect in this case and cannot
protect data on these devices.
Therefore, to prevent data loss, move the necessary data from these file systems to another server beforehand, if required.
devicesList of definitions of the physical storage devices. To configure more than three storage devices per host, add additional devices to this list. Each
devicein the list can have one or morepartitionsdefined by the list in thepartitionsfield.Each
devicein the list must have the following fields in thepropertiessection for device handling:workBy(recommended, string)Defines how the device should be identified. Accepts a comma-separated string with the following recommended value (in order of priority):
by_id,by_path,by_wwn,by_name. Since 2.25.1, this value is set by default.
wipeDevice(recommended, object)Available since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Enables and configures cleanup of a device or its metadata before cluster deployment. Contains the following fields:
eraseMetadata(dictionary)Enables metadata cleanup of a device. Contains the following field:
enable(boolean)Enables the
eraseMetadataoption.Falseby default.
eraseDevice(dictionary)Configures a complete cleanup of a device. Contains the following fields:
blkdiscard(object)Executes the blkdiscard command on the target device to discard all data blocks. Contains the following fields:
enable(boolean)Enables the
blkdiscardoption.Falseby default.
zeroout(string)Configures writing of zeroes to each block during device erasure. Contains the following options:
fallback- default, blkdiscard attempts to write zeroes only if the device does not support the block discard feature. In this case, the blkdiscard command is re-executed with an additional--zerooutflag.always- always write zeroes.never- never write zeroes.
userDefined(object)Enables execution of a custom command or shell script to erase the target device. Contains the following fields:
enabled(boolean)Enables the
userDefinedoption.Falseby default.
command(string)Defines a command to erase the target device. Empty by default. Mutually exclusive with
script. For the command execution, theansible.builtin.commandmodule is called.
script(string)Defines a plain-text script allowing pipelines (
|) to erase the target device. Empty by default. Mutually exclusive withcommand. For the script execution, theansible.builtin.shellmodule is called.
When executing a command or a script, you can use the following environment variables:
DEVICE_KNAME(always defined by Ansible)Device kernel path, for example,
/dev/sda
DEVICE_BY_NAME(optional)Link from
/dev/disk/by-name/if it was added by udev
DEVICE_BY_ID(optional)Link from
/dev/disk/by-id/if it was added by udev
DEVICE_BY_PATH(optional)Link from
/dev/disk/by-path/if it was added by udev
DEVICE_BY_WWN(optional)Link from
/dev/disk/by-wwn/if it was added by udev
For configuration details, see Wipe a device or partition.
wipe(boolean, deprecated)Defines whether the device must be wiped of the data before being used.
Note
This field is deprecated since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0) for the sake of
wipeDeviceand will be removed in one of the following releases.For backward compatibility, any existing
wipe: trueoption is automatically converted to the following structure:wipeDevice: eraseMetadata: enabled: True
Before Container Cloud 2.26.0, the
wipefield is mandatory.
Each
devicein the list can have the following fields in its properties section that affect the selection of the specific device when the profile is applied to a host:type(optional, string)The device type. Possible values:
hdd,ssd,nvme. This property is used to filter selected devices by type.
partflags(optional, string)Extra partition flags to be applied on a partition. For example,
bios_grub.
minSizeGiB,maxSizeGiB(deprecated, optional, string)The lower and upper limit of the selected device size. Only the devices matching these criteria are considered for allocation. Omitted parameter means no upper or lower limit.
The
minSizeandmaxSizeparameter names are also available for the same purpose.Caution
Mirantis recommends using only one parameter name type and units throughout the configuration files. If both
sizeGiBandsizeare used,sizeGiBis ignored during deployment and the suffix is adjusted accordingly. For example,1.5Giwill be serialized as1536Mi. The size without units is counted in bytes. For example,size: 120means 120 bytes.Since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0),
minSizeGiBandmaxSizeGiBare deprecated. Instead of floats that define sizes in GiB for*GiBfields, use the<sizeNumber>Gitext notation (Ki,Mi, and so on). All newly created profiles are automatically migrated to theGisyntax. In existing profiles, migrate the syntax manually.
byName(forbidden in new profiles since 2.27.0, optional, string)The specific device name to be selected during provisioning, such as
dev/sda.Warning
With NVME devices and certain hardware disk controllers, you cannot reliably select such device by the system name. Therefore, use a more specific
byPath,serialNumber, orwwnselector.Caution
Since Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0),
byNameis deprecated. Since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0),byNameis blocked byadmission-controllerin newBareMetalHostProfileobjects. As a replacement, use a more specific selector, such asbyPath,serialNumber, orwwn.
byPath(optional, string) Since 2.26.0 (17.1.0, 16.1.0)The specific device name with its path to be selected during provisioning, such as
/dev/disk/by-path/pci-0000:00:07.0.
serialNumber(optional, string) Since 2.26.0 (17.1.0, 16.1.0)The specific serial number of a physical disk to be selected during provisioning, such as
S2RBNXAH116186E.
wwn(optional, string) Since 2.26.0 (17.1.0, 16.1.0)The specific World Wide Name number of a physical disk to be selected during provisioning, such as
0x5002538d409aeeb4.Warning
When using strict filters, such as
byPath,serialNumber, orwwn, Mirantis strongly recommends not combining them with a soft filter, such asminSize/maxSize. Use only one approach.
softRaidDevicesTech PreviewList of definitions of a software-based Redundant Array of Independent Disks (RAID) created by mdadm. Use the following fields to describe an mdadm RAID device:
name(mandatory, string)Name of a RAID device. Supports the following formats:
devpath, for example,/dev/md0.simple name, for example,
raid-namethat will be created as/dev/md/raid-nameon the target OS.
devices(mandatory, list)List of partitions from the
deviceslist. Expand the resulting list of devices into at least two partitions.
level(optional, string)Level of a RAID device, defaults to
raid1. Possible values:raid1,raid0,raid10.
metadata(optional, string)Metadata version of RAID, defaults to
1.0. Possible values:1.0,1.1,1.2. For details about the differences in metadata, see man 8 mdadm.Warning
The EFI system partition
partflags: ['esp']must be a physical partition in the main partition table of the disk, not under LVM or mdadm software RAID.
fileSystemsList of file systems. Each file system can be created on top of either device, partition, or logical volume. If more file systems are required for additional devices, define them in this field. Each
fileSystemsin the list has the following fields:fileSystem(mandatory, string)Type of a file system to create on a partition. For example,
ext4,vfat.
mountOpts(optional, string)Comma-separated string of mount options. For example,
rw,noatime,nodiratime,lazytime,nobarrier,commit=240,data=ordered.
mountPoint(optional, string)Target mount point for a file system. For example,
/mnt/local-volumes/.
partition(optional, string)Partition name to be selected for creation from the list in the
devicessection. For example,uefi.
logicalVolume(optional, string)LVM logical volume name if the file system is supposed to be created on an LVM volume defined in the
logicalVolumessection. For example,lvp.
logicalVolumesList of LVM logical volumes. Every logical volume belongs to a volume group from the
volumeGroupslist and has thesizeattribute for a size in the corresponding units.You can also add a software-based RAID
raid1created by LVM using the following fields:name(mandatory, string)Name of a logical volume.
vg(mandatory, string)Name of a volume group that must be a name from the
volumeGroupslist.
sizeGiBorsize(mandatory, string)Size of a logical volume in gigabytes. When set to
0, all available space on the corresponding volume group will be used. The0value equals-l 100%FREEin the lvcreate command.
type(optional, string)Type of a logical volume. If you require a usual logical volume, you can omit this field.
Possible values:
linearDefault. A usual logical volume. This value is implied for bare metal host profiles created using the Container Cloud release earlier than 2.12.0 where the
typefield is unavailable.
raid1Tech PreviewServes to build the
raid1type of LVM. Equals to the lvcreate --type raid1... command. For details, see man 8 lvcreate and man 7 lvmraid.
Caution
Mirantis recommends using only one parameter name type and units throughout the configuration files. If both
sizeGiBandsizeare used,sizeGiBis ignored during deployment and the suffix is adjusted accordingly. For example,1.5Giwill be serialized as1536Mi. The size without units is counted in bytes. For example,size: 120means 120 bytes.
volumeGroupsList of definitions of LVM volume groups. Each volume group contains one or more devices or partitions from the
deviceslist. Contains the following field:devices(mandatory, list)List of partitions to be used in a volume group. For example:
- partition: lvm_root_part1 - partition: lvm_root_part2
Must contain the following field:
name(mandatory, string)Name of a volume group to be created. For example:
lvm_root.
preDeployScript(optional, string)Shell script that executes on a host before provisioning the target operating system inside the
ramfssystem.
postDeployScript(optional, string)Shell script that executes on a host after deploying the operating system inside the
ramfssystem that is chrooted to the target operating system. To use a specific default gateway (for example, to have Internet access) on this stage, refer to Migration of DHCP configuration for existing management clusters.
grubConfig(optional, object)Set of options for the Linux GRUB bootloader on the target operating system. Contains the following field:
defaultGrubOptions(optional, array)Set of options passed to the Linux GRUB bootloader. Each string in the list defines one parameter. For example:
defaultGrubOptions: - GRUB_DISABLE_RECOVERY="true" - GRUB_PRELOAD_MODULES=lvm - GRUB_TIMEOUT=20
kernelParameters:sysctl(optional, object)List of kernel sysctl options passed to
/etc/sysctl.d/999-baremetal.confduring abmhprovisioning. For example:kernelParameters: sysctl: fs.aio-max-nr: "1048576" fs.file-max: "9223372036854775807"
For the list of options prohibited to change, refer to MKE documentation: Set up kernel default protections.
Note
If asymmetric traffic is expected on some of the managed cluster nodes, enable the loose mode for the corresponding interfaces on those nodes by setting the
net.ipv4.conf.<interface-name>.rp_filterparameter to"2"in thekernelParameters.sysctlsection. For example:kernelParameters: sysctl: net.ipv4.conf.k8s-lcm.rp_filter: "2"
kernelParameters:modules(optional, object)List of options for kernel modules to be passed to
/etc/modprobe.d/{filename}during a bare metal host provisioning. For example:kernelParameters: modules: - content: | options kvm_intel nested=1 filename: kvm_intel.conf
Configuration example with strict filtering for device -
applies since 2.26.0 (17.1.0 and 16.1.0)
spec:
devices:
- device:
wipe: true
workBy: by_wwn,by_path,by_id,by_name
wwn: "0x5002538d409aeeb4"
partitions:
- name: bios_grub
partflags:
- bios_grub
size: 4Mi
wipe: true
- name: uefi
partflags:
- esp
size: 200Mi
wipe: true
- name: config-2
size: 64Mi
wipe: true
- name: lvm_root_part
size: 0
wipe: true
- device:
byPath: /dev/disk/by-path/pci-0000:00:1f.2-ata-1
minSize: 30Gi
wipe: true
workBy: by_id,by_path,by_wwn,by_name
partitions:
- name: lvm_lvp_part1
size: 0
wipe: true
- device:
byPath: /dev/disk/by-path/pci-0000:00:1f.2-ata-3
minSize: 30Gi
wipe: true
workBy: by_id,by_path,by_wwn,by_name
partitions:
- name: lvm_lvp_part2
size: 0
wipe: true
- device:
serialNumber: 'Z1X69DG6'
wipe: true
workBy: by_id,by_path,by_wwn,by_name
fileSystems:
- fileSystem: vfat
partition: config-2
- fileSystem: vfat
mountPoint: /boot/efi
partition: uefi
- fileSystem: ext4
logicalVolume: root
mountPoint: /
- fileSystem: ext4
logicalVolume: lvp
mountPoint: /mnt/local-volumes/
grubConfig:
defaultGrubOptions:
- GRUB_DISABLE_RECOVERY="true"
- GRUB_PRELOAD_MODULES=lvm
- GRUB_TIMEOUT=5
...
logicalVolumes:
- name: root
size: 0
type: linear
vg: lvm_root
- name: lvp
size: 0
type: linear
vg: lvm_lvp
...
volumeGroups:
- devices:
- partition: lvm_root_part
name: lvm_root
- devices:
- partition: lvm_lvp_part1
- partition: lvm_lvp_part2
name: lvm_lvp
General configuration example with the wipeDevice option
for devices - applies since 2.26.0 (17.1.0 and 16.1.0)
spec:
devices:
- device:
wipeDevice:
eraseMetadata:
enabled: true
workBy: by_wwn,by_path,by_id,by_name
partitions:
- name: bios_grub
partflags:
- bios_grub
size: 4Mi
- name: uefi
partflags:
- esp
size: 200Mi
- name: config-2
size: 64Mi
- name: lvm_root_part
size: 0
- device:
minSize: 30Gi
wipeDevice:
eraseMetadata:
enabled: true
workBy: by_id,by_path,by_wwn,by_name
partitions:
- name: lvm_lvp_part1
size: 0
wipe: true
- device:
minSize: 30Gi
wipeDevice:
eraseMetadata:
enabled: true
workBy: by_id,by_path,by_wwn,by_name
partitions:
- name: lvm_lvp_part2
size: 0
- device:
wipeDevice:
eraseMetadata:
enabled: true
workBy: by_id,by_path,by_wwn,by_name
fileSystems:
- fileSystem: vfat
partition: config-2
- fileSystem: vfat
mountPoint: /boot/efi
partition: uefi
- fileSystem: ext4
logicalVolume: root
mountPoint: /
- fileSystem: ext4
logicalVolume: lvp
mountPoint: /mnt/local-volumes/
grubConfig:
defaultGrubOptions:
- GRUB_DISABLE_RECOVERY="true"
- GRUB_PRELOAD_MODULES=lvm
- GRUB_TIMEOUT=5
...
logicalVolumes:
- name: root
size: 0
type: linear
vg: lvm_root
- name: lvp
size: 0
type: linear
vg: lvm_lvp
...
volumeGroups:
- devices:
- partition: lvm_root_part
name: lvm_root
- devices:
- partition: lvm_lvp_part1
- partition: lvm_lvp_part2
name: lvm_lvp
General configuration example with the deprecated wipe
option for devices - applies before 2.26.0 (17.1.0 and 16.1.0)
spec:
devices:
- device:
#byName: /dev/sda
minSize: 61GiB
wipe: true
workBy: by_wwn,by_path,by_id,by_name
partitions:
- name: bios_grub
partflags:
- bios_grub
size: 4Mi
wipe: true
- name: uefi
partflags: ['esp']
size: 200Mi
wipe: true
- name: config-2
# limited to 64Mb
size: 64Mi
wipe: true
- name: md_root_part1
wipe: true
partflags: ['raid']
size: 60Gi
- name: lvm_lvp_part1
wipe: true
partflags: ['raid']
# 0 Means, all left space
size: 0
- device:
#byName: /dev/sdb
minSize: 61GiB
wipe: true
workBy: by_wwn,by_path,by_id,by_name
partitions:
- name: md_root_part2
wipe: true
partflags: ['raid']
size: 60Gi
- name: lvm_lvp_part2
wipe: true
# 0 Means, all left space
size: 0
- device:
#byName: /dev/sdc
minSize: 30Gib
wipe: true
workBy: by_wwn,by_path,by_id,by_name
softRaidDevices:
- name: md_root
metadata: "1.2"
devices:
- partition: md_root_part1
- partition: md_root_part2
volumeGroups:
- name: lvm_lvp
devices:
- partition: lvm_lvp_part1
- partition: lvm_lvp_part2
logicalVolumes:
- name: lvp
vg: lvm_lvp
# Means, all left space
sizeGiB: 0
postDeployScript: |
#!/bin/bash -ex
echo $(date) 'post_deploy_script done' >> /root/post_deploy_done
preDeployScript: |
#!/bin/bash -ex
echo 'ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="deadline"' > /etc/udev/rules.d/60-ssd-scheduler.rules
echo $(date) 'pre_deploy_script done' >> /root/pre_deploy_done
fileSystems:
- fileSystem: vfat
partition: config-2
- fileSystem: vfat
partition: uefi
mountPoint: /boot/efi/
- fileSystem: ext4
softRaidDevice: md_root
mountPoint: /
- fileSystem: ext4
logicalVolume: lvp
mountPoint: /mnt/local-volumes/
grubConfig:
defaultGrubOptions:
- GRUB_DISABLE_RECOVERY="true"
- GRUB_PRELOAD_MODULES=lvm
- GRUB_TIMEOUT=20
kernelParameters:
sysctl:
# For the list of options prohibited to change, refer to
# https://docs.mirantis.com/mke/3.7/install/predeployment/set-up-kernel-default-protections.html
kernel.dmesg_restrict: "1"
kernel.core_uses_pid: "1"
fs.file-max: "9223372036854775807"
fs.aio-max-nr: "1048576"
fs.inotify.max_user_instances: "4096"
vm.max_map_count: "262144"
modules:
- filename: kvm_intel.conf
content: |
options kvm_intel nested=1
Cluster¶
This section describes the Cluster resource used the in Mirantis
Container Cloud API that describes the cluster-level parameters.
For demonstration purposes, the Container Cloud Cluster
custom resource (CR) is split into the following major sections:
Warning
The fields of the Cluster resource that are located
under the status section including providerStatus
are available for viewing only.
They are automatically generated by the bare metal cloud provider
and must not be modified using Container Cloud API.
metadata¶
The Container Cloud Cluster CR contains the following fields:
apiVersionAPI version of the object that is
cluster.k8s.io/v1alpha1.
kindObject type that is
Cluster.
The metadata object field of the Cluster resource
contains the following fields:
nameName of a cluster. A managed cluster name is specified under the
Cluster Namefield in the Create Cluster wizard of the Container Cloud web UI. A management cluster name is configurable in the bootstrap script.
namespaceProject in which the cluster object was created. The management cluster is always created in the
defaultproject. The managed cluster project equals to the selected project name.
labelsKey-value pairs attached to the object:
kaas.mirantis.com/providerProvider type that is
baremetalfor the baremetal-based clusters.
kaas.mirantis.com/regionRegion name. The default region name for the management cluster is
region-one.Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Configuration example:
apiVersion: cluster.k8s.io/v1alpha1
kind: Cluster
metadata:
name: demo
namespace: test
labels:
kaas.mirantis.com/provider: baremetal
spec:providerSpec¶
The spec object field of the Cluster object
represents the BaremetalClusterProviderSpec subresource that
contains a complete description of the desired bare metal cluster
state and all details to create the cluster-level
resources. It also contains the fields required for LCM deployment
and integration of the Container Cloud components.
The providerSpec object field is custom for each cloud provider and
contains the following generic fields for the bare metal provider:
apiVersionAPI version of the object that is
baremetal.k8s.io/v1alpha1
kindObject type that is
BaremetalClusterProviderSpec
Configuration example:
spec:
...
providerSpec:
value:
apiVersion: baremetal.k8s.io/v1alpha1
kind: BaremetalClusterProviderSpec
spec:providerSpec common¶
The common providerSpec object field of the Cluster resource
contains the following fields:
credentialsField reserved for other cloud providers, has an empty value. Disregard this field.
dedicatedControlPlaneCluster control plane nodes to be tainted, defaults to
true
publicKeysList of the
PublicKeyresource referencesnamePublic key name
releaseName of the
ClusterReleaseobject to install on a cluster
helmReleasesList of enabled Helm releases from the
Releaseobject that run on a cluster
proxyName of the
Proxyobject
tlsTLS configuration for endpoints of a cluster
keycloakKeyCloak endpoint
tlsConfigRefReference to the
TLSConfigobject
uiWeb UI endpoint
tlsConfigRefReference to the
TLSConfigobject
For more details, see TLSConfig resource.
maintenanceMaintenance mode of a cluster. Prepares a cluster for maintenance and enables the possibility to switch machines into maintenance mode.
containerRegistriesList of the
ContainerRegistriesresources names.
ntpEnabledNTP server mode. Boolean, enabled by default.
Since Container Cloud 2.23.0, you can optionally disable NTP to disable the management of
chronyconfiguration by Container Cloud and use your own system forchronymanagement. Otherwise, configure the regional NTP server parameters to be applied to all machines of managed clusters.Before Container Cloud 2.23.0, you can optionally configure NTP parameters if servers from the Ubuntu NTP pool (
*.ubuntu.pool.ntp.org) are accessible from the node where a management cluster is being provisioned. Otherwise, this configuration is mandatory.NTP configuration
Configure the regional NTP server parameters to be applied to all machines of managed clusters.
In the
Clusterobject, add thentp:serverssection with the list of required server names:spec: ... providerSpec: value: kaas: ... ntpEnabled: true regional: - helmReleases: - name: <providerName>-provider values: config: lcm: ... ntp: servers: - 0.pool.ntp.org ... provider: <providerName> ...
To disable NTP:
spec: ... providerSpec: value: ... ntpEnabled: false ...
auditSince 2.24.0 as TechPreviewOptional. Auditing tools enabled on the cluster. Contains the
auditdfield that enables the Linux Audit daemon auditd to monitor activity of cluster processes and prevent potential malicious activity.Configuration for auditd
In the
Clusterobject, add the auditd parameters:spec: providerSpec: value: audit: auditd: enabled: <bool> enabledAtBoot: <bool> backlogLimit: <int> maxLogFile: <int> maxLogFileAction: <string> maxLogFileKeep: <int> mayHaltSystem: <bool> presetRules: <string> customRules: <string> customRulesX32: <text> customRulesX64: <text>
Configuration parameters for auditd:
enabledBoolean, default -
false. Enables theauditdrole to install the auditd packages and configure rules. CIS rules: 4.1.1.1, 4.1.1.2.enabledAtBootBoolean, default -
false. Configures grub to audit processes that can be audited even if they start up prior to auditd startup. CIS rule: 4.1.1.3.backlogLimitInteger, default - none. Configures the backlog to hold records. If during boot
audit=1is configured, the backlog holds 64 records. If more than 64 records are created during boot, auditd records will be lost with a potential malicious activity being undetected. CIS rule: 4.1.1.4.maxLogFileInteger, default - none. Configures the maximum size of the audit log file. Once the log reaches the maximum size, it is rotated and a new log file is created. CIS rule: 4.1.2.1.
maxLogFileActionString, default - none. Defines handling of the audit log file reaching the maximum file size. Allowed values:
keep_logs- rotate logs but never delete themrotate- add a cron job to compress rotated log files and keep maximum 5 compressed files.compress- compress log files and keep them under the/var/log/auditd/directory. Requiresauditd_max_log_file_keepto be enabled.
CIS rule: 4.1.2.2.
maxLogFileKeepInteger, default -
5. Defines the number of compressed log files to keep under the/var/log/auditd/directory. Requiresauditd_max_log_file_action=compress. CIS rules - none.mayHaltSystemBoolean, default -
false. Halts the system when the audit logs are full. Applies the following configuration:space_left_action = emailaction_mail_acct = rootadmin_space_left_action = halt
CIS rule: 4.1.2.3.
customRulesString, default - none. Base64-encoded content of the
60-custom.rulesfile for any architecture. CIS rules - none.customRulesX32String, default - none. Base64-encoded content of the
60-custom.rulesfile for thei386architecture. CIS rules - none.customRulesX64String, default - none. Base64-encoded content of the
60-custom.rulesfile for thex86_64architecture. CIS rules - none.presetRulesString, default - none. Comma-separated list of the following built-in preset rules:
accessactionsdeletedocker
identityimmutableloginsmac-policy
modulesmountsperm-modprivileged
scopesessionsystem-localetime-change
You can use two keywords for these rules:
none- disables all built-in rules.all- enables all built-in rules. With this key, you can add the!prefix to a rule name to exclude some rules. You can use the!prefix for rules only if you add theallkeyword as the first rule. Place a rule with the!prefix only after theallkeyword.
Example configurations:
presetRules: none- disable all preset rulespresetRules: docker- enable only thedockerrulespresetRules: access,actions,logins- enable only theaccess,actions, andloginsrulespresetRules: all- enable all preset rulespresetRules: all,!immutable,!sessions- enable all preset rules exceptimmutableandsessions
CIS controls
4.1.3 (time-change)4.1.4 (identity)4.1.5 (system-locale)4.1.6 (mac-policy)4.1.7 (logins)4.1.8 (session)4.1.9 (perm-mod)4.1.10 (access)4.1.11 (privileged)4.1.12 (mounts)4.1.13 (delete)4.1.14 (scope)4.1.15 (actions)4.1.16 (modules)4.1.17 (immutable)Docker CIS controls
1.1.41.1.81.1.101.1.121.1.131.1.151.1.161.1.171.1.181.2.31.2.41.2.51.2.61.2.71.2.101.2.11
secureOverlayTechPreview since 2.24.0 and 2.24.2 for MOSK 23.2Optional. Enables WireGuard for traffic encryption on the Kubernetes workloads network. Boolean. Disabled by default.
Caution
Before enabling WireGuard, ensure that the Calico MTU size is at least 60 bytes smaller than the interface MTU size of the workload network. IPv4 WireGuard uses a 60-byte header. For details, see Set the MTU size for Calico.
Caution
Changing this parameter on a running cluster causes a downtime that can vary depending on the cluster size.
For more details about WireGuard, see Calico documentation: Encrypt in-cluster pod traffic.
useBGPAnnouncementSince 2.24.4 as TechPreviewOptional. To enable the use of BGP announcement for the cluster API LB address, set to
true. See Configure BGP announcement for cluster API LB address for details.
Configuration example:
spec:
...
providerSpec:
value:
credentials: ""
publicKeys:
- name: bootstrap-key
release: ucp-5-7-0-3-3-3-tp11
helmReleases:
- name: metallb
values:
configInline:
address-pools:
- addresses:
- 10.0.0.101-10.0.0.120
name: default
protocol: layer2
...
- name: stacklight
...
tls:
keycloak:
certificate:
name: keycloak
hostname: container-cloud-auth.example.com
ui:
certificate:
name: ui
hostname: container-cloud-ui.example.com
containerRegistries:
- demoregistry
ntpEnabled: false
...
spec:providerSpec configuration¶
This section represents the Container Cloud components that are enabled on a cluster. It contains the following fields:
managementConfiguration for the management cluster components:
enabledManagement cluster enabled (
true) or disabled (false).
helmReleasesList of the management cluster Helm releases that will be installed on the cluster. A Helm release includes the
nameandvaluesfields. The specified values will be merged with relevant Helm release values of the management cluster in theReleaseobject.
regionalList of regional cluster components for the provider:
providerProvider type that is
baremetal.
helmReleasesList of the regional Helm releases that will be installed on the cluster. A Helm release includes the
nameandvaluesfields. The specified values will be merged with relevant regional Helm release values in theReleaseobject.
releaseName of the Container Cloud
Releaseobject.
Configuration example:
spec:
...
providerSpec:
value:
kaas:
management:
enabled: true
helmReleases:
- name: kaas-ui
values:
serviceConfig:
server: https://10.0.0.117
regional:
- helmReleases:
- name: baremetal-provider
values: {}
provider: baremetal
...
release: kaas-2-0-0
status:providerStatus common¶
Must not be modified using API
The common providerStatus object field of the Cluster resource
contains the following fields:
apiVersionAPI version of the object that is
baremetal.k8s.io/v1alpha1
kindObject type that is
BaremetalClusterProviderStatus
loadBalancerHostLoad balancer IP or host name of the Container Cloud cluster
apiServerCertificateServer certificate of Kubernetes API
ucpDashboardURL of the Mirantis Kubernetes Engine (MKE) Dashboard
maintenanceMaintenance mode of a cluster. Prepares a cluster for maintenance and enables the possibility to switch machines into maintenance mode.
Configuration example:
status:
providerStatus:
apiVersion: baremetal.k8s.io/v1alpha1
kind: BaremetalClusterProviderStatus
loadBalancerHost: 10.0.0.100
apiServerCertificate: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS…
ucpDashboard: https://10.0.0.100:6443
status:providerStatus for cluster readiness¶
Must not be modified using API
The providerStatus object field of the Cluster resource that reflects
the cluster readiness contains the following fields:
persistentVolumesProviderProvisionedStatus of the persistent volumes provisioning. Prevents the Helm releases that require persistent volumes from being installed until some default
StorageClassis added to theClusterobject.
helmDetails about the deployed Helm releases:
readyStatus of the deployed Helm releases. The
truevalue indicates that all Helm releases are deployed successfully.
releasesList of the enabled Helm releases that run on the Container Cloud cluster:
releaseStatusesList of the deployed Helm releases. The
success: truefield indicates that the release is deployed successfully.
stacklightStatus of the StackLight deployment. Contains URLs of all StackLight components. The
success: truefield indicates that StackLight is deployed successfully.
nodesDetails about the cluster nodes:
readyNumber of nodes that completed the deployment or update.
requestedTotal number of nodes. If the number of
readynodes does not match the number ofrequestednodes, it means that a cluster is being currently deployed or updated.
notReadyObjectsThe list of the
services,deployments, andstatefulsetsKubernetes objects that are not in theReadystate yet. Aserviceis not ready if its external address has not been provisioned yet. Adeploymentorstatefulsetis not ready if the number of ready replicas is not equal to the number of desired replicas. Both objects contain the name and namespace of the object and the number of ready and desired replicas (for controllers). If all objects are ready, thenotReadyObjectslist is empty.
Configuration example:
status:
providerStatus:
persistentVolumesProviderProvisioned: true
helm:
ready: true
releases:
releaseStatuses:
iam:
success: true
...
stacklight:
alerta:
url: http://10.0.0.106
alertmanager:
url: http://10.0.0.107
grafana:
url: http://10.0.0.108
kibana:
url: http://10.0.0.109
prometheus:
url: http://10.0.0.110
success: true
nodes:
ready: 3
requested: 3
notReadyObjects:
services:
- name: testservice
namespace: default
deployments:
- name: baremetal-provider
namespace: kaas
replicas: 3
readyReplicas: 2
statefulsets: {}
status:providerStatus for Open ID Connect¶
Must not be modified using API
The oidc section of the providerStatus object field
in the Cluster resource reflects the Open ID Connect configuration details.
It contains the required details to obtain a token for
a Container Cloud cluster and consists of the following fields:
certificateBase64-encoded OIDC certificate.
clientIdClient ID for OIDC requests.
groupsClaimName of an OIDC groups claim.
issuerUrlIssuer URL to obtain the representation of the realm.
readyOIDC status relevance. If
true, the status corresponds to theLCMClusterOIDC configuration.
Configuration example:
status:
providerStatus:
oidc:
certificate: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUREekNDQWZ...
clientId: kaas
groupsClaim: iam_roles
issuerUrl: https://10.0.0.117/auth/realms/iam
ready: true
status:providerStatus for cluster releases¶
Must not be modified using API
The releaseRefs section of the providerStatus object field
in the Cluster resource provides the current Cluster release version
as well as the one available for upgrade. It contains the following fields:
currentDetails of the currently installed Cluster release:
lcmTypeType of the Cluster release (
ucp).
nameName of the Cluster release resource.
versionVersion of the Cluster release.
unsupportedSinceKaaSVersionIndicates that a Container Cloud release newer than the current one exists and that it does not support the current Cluster release.
availableList of the releases available for upgrade. Contains the
nameandversionfields.
Configuration example:
status:
providerStatus:
releaseRefs:
available:
- name: ucp-5-5-0-3-4-0-dev
version: 5.5.0+3.4.0-dev
current:
lcmType: ucp
name: ucp-5-4-0-3-3-0-beta1
version: 5.4.0+3.3.0-beta1
HostOSConfiguration¶
TechPreview since 2.26.0 (17.1.0 and 16.1.0)
Warning
For security reasons and to ensure safe and reliable cluster operability, test this configuration on a staging environment before applying it to production. For any questions, contact Mirantis support.
Caution
As long as the feature is still on the development stage,
Mirantis highly recommends deleting all HostOSConfiguration objects,
if any, before automatic upgrade of the management cluster to Container Cloud
2.27.0 (Cluster release 16.2.0). After the upgrade, you can recreate the
required objects using the updated parameters.
This precautionary step prevents re-processing and re-applying of existing
configuration, which is defined in HostOSConfiguration objects, during
management cluster upgrade to 2.27.0. Such behavior is caused by changes in
the HostOSConfiguration API introduced in 2.27.0.
This section describes the HostOSConfiguration custom resource (CR)
used in the Container Cloud API. It contains all necessary information to
introduce and load modules for further configuration of the host operating
system of the related Machine object.
Note
This object must be created and managed on the management cluster.
For demonstration purposes, we split the Container Cloud
HostOSConfiguration CR into the following sections:
HostOSConfiguration metadata¶
metadata¶
The Container Cloud HostOSConfiguration custom resource (CR) contains the following
fields:
apiVersionObject API version that is
kaas.mirantis.com/v1alpha1.
kindObject type that is
HostOSConfiguration.
The metadata object field of the HostOSConfiguration resource contains
the following fields:
nameObject name.
namespaceProject in which the
HostOSConfigurationobject is created.
Configuration example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: HostOSConfiguration
metadata:
name: host-os-configuration-sample
namespace: default
HostOSConfiguration configuration¶
The spec object field contains configuration for a
HostOSConfiguration object and has the following fields:
machineSelectorRequired for production deployments. A set of
Machineobjects to apply theHostOSConfigurationobject to. Has the format of the Kubernetes label selector.
configsRequired. List of configurations to apply to
Machineobjects defined inmachineSelector. Each entry has the following fields:moduleRequired. Name of the module that refers to an existing module in one of the HostOSConfigurationModules objects.
moduleVersionRequired. Version of the module in use in the SemVer format.
descriptionOptional. Description and purpose of the configuration.
orderOptional. Positive integer between
1and1024that indicates the order of applying the module configuration. A configuration with the lowest order value is applied first. If theorderfield is not set:The configuration is applied in the order of appearance in the list after all configurations with the value are applied.
The following rules apply to the ordering when comparing each pair of entries:
Ordering by alphabet based on the
modulevalues unless they are equal.Ordering by version based on the
moduleVersionvalues, with preference given to the lesser value.
valuesOptional if
secretValuesis set. Module configuration in the format of key-value pairs.
secretValuesOptional if
valuesis set. Reference to aSecretobject that contains the configuration values for the module:namespaceProject name of the
Secretobject.
nameName of the
Secretobject.
Note
You can use both
valuesandsecretValuestogether. But if the values are duplicated, thesecretValuesdata rewrites duplicated keys of thevaluesdata.Warning
The referenced
Secretobject must contain only primitive non-nested values. Otherwise, the values will not be applied correctly.
phaseOptional. LCM phase, in which a module configuration must be executed. The only supported and default value is
reconfigure. Hence, you may omit this field.
orderRemoved in 2.27.0 (17.2.0 and 16.2.0)Optional. Positive integer between
1and1024that indicates the order of applyingHostOSConfigurationobjects on newly added or newly assigned machines. An object with the lowest order value is applied first. If the value is not set, the object is applied last in the order.If no
orderfield is set for allHostOSConfigurationobjects, the objects are sorted by name.Note
If a user changes the
HostOSConfigurationobject that was already applied on some machines, then only the changed items from thespec.configssection of theHostOSConfigurationobject are applied to those machines, and the execution order applies only to the changed items.The configuration changes are applied on corresponding
LCMMachineobjects almost immediately afterhost-os-modules-controllerverifies the changes.
Configuration example:
spec:
machineSelector:
matchLabels:
label-name: "label-value"
configs:
- description: Brief description of the configuration
module: container-cloud-provided-module-name
moduleVersion: 1.0.0
order: 1
# the 'phase' field is provided for illustration purposes. it is redundant
# because the only supported value is "reconfigure".
phase: "reconfigure"
values:
foo: 1
bar: "baz"
secretValues:
name: values-from-secret
namespace: default
HostOSConfiguration status¶
The status field of the HostOSConfiguration object contains the
current state of the object:
controllerUpdateSince 2.27.0 (17.2.0 and 16.2.0)Reserved. Indicates whether the status updates are initiated by
host-os-modules-controller.
isValidSince 2.27.0 (17.2.0 and 16.2.0)Indicates whether all given configurations have been validated successfully and are ready to be applied on machines. An invalid object is discarded from processing.
specUpdatedAtSince 2.27.0 (17.2.0 and 16.2.0)Defines the time of the last change in the object
specobserved byhost-os-modules-controller.
machinesStatesSince 2.27.0 (17.2.0 and 16.2.0)Specifies the per-machine state observed by
baremetal-provider. The keys are machines names, and each entry has the following fields:observedGenerationRead-only. Specifies the sequence number representing the quantity of changes in the object since its creation. For example, during object creation, the value is
1.
selectedIndicates whether the machine satisfied the selector of the object. Non-selected machines are not defined in
machinesStates. Boolean.
secretValuesChangedIndicates whether the secret values have been changed and the corresponding
stateItemshave to be updated. Boolean.The value is set to
truebyhost-os-modules-controllerif changes in the secret data are detected. The value is set tofalsebybaremetal-providerafter processing.
configStateItemsStatusesSpecifies key-value pairs with statuses of
StateItemsthat are applied to the machine. Each key contains thenameandversionof the configuration module. Each key value has the following format:Key: name of a configuration
StateItemValue: simplified status of the configuration
StateItemthat has the following fields:hashValue of the hash sum from the status of the corresponding
StateItemin theLCMMachineobject. Appears when the status switches toSuccess.
stateActual state of the corresponding
StateItemfrom theLCMMachineobject. Possible values:Not Started,Running,Success,Failed.
configsList of configurations statuses, indicating results of application of each configuration. Every entry has the following fields:
moduleNameExisting module name from the list defined in the
spec:modulessection of the related HostOSConfigurationModules object.
moduleVersionExisting module version defined in the
spec:modulessection of the relatedHostOSConfigurationModulesobject.
modulesReferenceName of the
HostOSConfigurationModulesobject that contains the related module configuration.
modulePlaybookName of the Ansible playbook of the module. The value is taken from the related
HostOSConfigurationModulesobject where this module is defined.
moduleURLURL to the module package in the FQDN format. The value is taken from the related
HostOSConfigurationModulesobject where this module is defined.
moduleHashsumHash sum of the module. The value is taken from the related
HostOSConfigurationModulesobject where this module is defined.
lastDesignatedConfigurationRemoved in Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Key-value pairs representing the latest designated configuration data for modules. Each key corresponds to a machine name, while the associated value contains the configuration data encoded in the
gzip+base64format.
lastValidatedSpecRemoved in Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Last validated module configuration encoded in the
gzip+base64format.
valuesValidRemoved in Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Validation state of the configuration and secret values defined in the object
specagainst the modulevaluesValidationSchema. AlwaystruewhenvaluesValidationSchemais empty.
errorDetails of an error, if any, that occurs during the object processing by
host-os-modules-controller.
secretObjectVersionAvailable since Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0). Resource version of the corresponding
Secretobject observed byhost-os-modules-controller. Is present only ifsecretValuesis set.
HostOSConfiguration status example:
status:
configs:
- moduleHashsum: bc5fafd15666cb73379d2e63571a0de96fff96ac28e5bce603498cc1f34de299
moduleName: module-name
modulePlaybook: main.yaml
moduleURL: <url-to-module-archive.tgz>
moduleVersion: 1.1.0
modulesReference: mcc-modules
- moduleHashsum: 53ec71760dd6c00c6ca668f961b94d4c162eef520a1f6cb7346a3289ac5d24cd
moduleName: another-module-name
modulePlaybook: main.yaml
moduleURL: <url-to-another-module-archive.tgz>
moduleVersion: 1.1.0
modulesReference: mcc-modules
secretObjectVersion: "14234794"
isValid: true
machinesStates:
default/master-0:
configStateItemsStatuses:
# moduleName-moduleVersion
module-name-1.1.0:
# corresponding state item
host-os-download-<object-name>-module-name-1.1.0-reconfigure:
hash: 0e5c4a849153d3278846a8ed681f4822fb721f6d005021c4509e7126164f428d
state: Success
host-os-<object-name>-module-name-1.1.0-reconfigure:
state: Not Started
another-module-name-1.1.0:
host-os-download-<object-name>-another-module-name-1.1.0-reconfigure:
state: Not Started
host-os-<object-name>-another-module-name-1.1.0-reconfigure:
state: Not Started
observedGeneration: 1
selected: true
updatedAt: "2024-04-23T14:10:28Z"
HostOSConfigurationModules¶
TechPreview since 2.26.0 (17.1.0 and 16.1.0)
Warning
For security reasons and to ensure safe and reliable cluster operability, test this configuration on a staging environment before applying it to production. For any questions, contact Mirantis support.
This section describes the HostOSConfigurationModules custom resource (CR)
used in the Container Cloud API. It contains all necessary information to
introduce and load modules for further configuration of the host operating
system of the related Machine object. For description of module format,
schemas, and rules, see Format and structure of a module package.
Note
This object must be created and managed on the management cluster.
For demonstration purposes, we split the Container Cloud
HostOSConfigurationModules CR into the following sections:
HostOSConfigurationModules metadata¶
metadata¶
The Container Cloud HostOSConfigurationModules custom resource (CR) contains the following
fields:
apiVersionObject API version that is
kaas.mirantis.com/v1alpha1.
kindObject type that is
HostOSConfigurationModules.
The metadata object field of the HostOSConfigurationModules resource contains
the following fields:
nameObject name.
Configuration example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: HostOSConfigurationModules
metadata:
name: host-os-configuration-modules-sample
HostOSConfigurationModules configuration¶
The spec object field contains configuration for a
HostOSConfigurationModules object and has the following fields:
modulesList of available modules to use as a configuration. Each entry has the following fields:
nameRequired. Module name that must equal the corresponding custom module name defined in the
metadatasection of the corresponding module. For reference, see Metadata file format.
urlRequired for custom modules. URL to the archive containing the module package in the FQDN format. If omitted, the module is considered as the one provided and validated by Container Cloud.
versionRequired. Module version in SemVer format that must equal the corresponding custom module version defined in the
metadatasection of the corresponding module. For reference, see Metadata file format.
sha256sumRequired. Hash sum computed using the SHA-256 algorithm. The hash sum is automatically validated upon fetching the module package, the module does not load if the hash sum is invalid.
Configuration example:
spec:
modules:
- name: mirantis-provided-module-name
sha256sum: ff3c426d5a2663b544acea74e583d91cc2e292913fc8ac464c7d52a3182ec146
version: 1.0.0
- name: custom-module-name
url: https://fully.qualified.domain.name/to/module/archive/module-name-1.0.0.tgz
sha256sum: 258ccafac1570de7b7829bde108fa9ee71b469358dbbdd0215a081f8acbb63ba
version: 1.0.0
HostOSConfigurationModules status¶
The status field of the HostOSConfigurationModules object contains the
current state of the object:
modulesList of module statuses, indicating the loading results of each module. Each entry has the following fields:
nameName of the loaded module.
versionVersion of the loaded module.
urlURL to the archive containing the loaded module package in the FQDN format.
docURLURL to the loaded module documentation if it was initially present in the module package.
descriptionDescription of the loaded module if it was initially present in the module package.
sha256sumActual SHA-256 hash sum of the loaded module.
valuesValidationSchemaJSON schema used against the module configuration values if it was initially present in the module package. The value is encoded in the
gzip+base64format.
stateActual availability state of the module. Possible values are:
availableorerror.
errorError, if any, that occurred during the module fetching and verification.
playbookNameName of the module package playbook.
HostOSConfigurationModules status example:
status:
modules:
- description: Brief description of the module
docURL: https://docs.mirantis.com
name: mirantis-provided-module-name
playbookName: directory/main.yaml
sha256sum: ff3c426d5a2663b544acea74e583d91cc2e292913fc8ac464c7d52a3182ec146
state: available
url: https://example.mirantis.com/path/to/module-name-1.0.0.tgz
valuesValidationSchema: <gzip+base64 encoded data>
version: 1.0.0
- description: Brief description of the module
docURL: https://example.documentation.page/module-name
name: custom-module-name
playbookName: directory/main.yaml
sha256sum: 258ccafac1570de7b7829bde108fa9ee71b469358dbbdd0215a081f8acbb63ba
state: available
url: https://fully.qualified.domain.name/to/module/archive/module-name-1.0.0.tgz
version: 1.0.0
IPaddr¶
This section describes the IPaddr resource used in Mirantis
Container Cloud API. The IPAddr object describes an IP address
and contains all information about the associated MAC address.
For demonstration purposes, the Container Cloud IPaddr
custom resource (CR) is split into the following major sections:
IPaddr metadata¶
The Container Cloud IPaddr CR contains the following fields:
apiVersionAPI version of the object that is
ipam.mirantis.com/v1alpha1
kindObject type that is
IPaddr
metadataThe
metadatafield contains the following subfields:nameName of the
IPaddrobject in theauto-XX-XX-XX-XX-XX-XXformat where XX-XX-XX-XX-XX-XX is the associated MAC address
namespaceProject in which the
IPaddrobject was created
labelsKey-value pairs that are attached to the object:
ipam/IPIPv4 address
ipam/IpamHostIDUnique ID of the associated
IpamHostobject
ipam/MACMAC address
ipam/SubnetIDUnique ID of the
Subnetobject
ipam/UIDUnique ID of the
IPAddrobject
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Configuration example:
apiVersion: ipam.mirantis.com/v1alpha1
kind: IPaddr
metadata:
name: auto-0c-c4-7a-a8-b8-18
namespace: default
labels:
ipam/IP: 172.16.48.201
ipam/IpamHostID: 848b59cf-f804-11ea-88c8-0242c0a85b02
ipam/MAC: 0C-C4-7A-A8-B8-18
ipam/SubnetID: 572b38de-f803-11ea-88c8-0242c0a85b02
ipam/UID: 84925cac-f804-11ea-88c8-0242c0a85b02
IPAddr spec¶
The spec object field of the IPAddr resource contains the associated
MAC address and the reference to the Subnet object:
macMAC address in the
XX:XX:XX:XX:XX:XXformat
subnetRefReference to the
Subnetresource in the<subnetProjectName>/<subnetName>format
Configuration example:
spec:
mac: 0C:C4:7A:A8:B8:18
subnetRef: default/kaas-mgmt
IPAddr status¶
The status object field of the IPAddr resource reflects the actual
state of the IPAddr object. In contains the following fields:
addressIP address.
cidrIPv4 CIDR for the
Subnet.
gatewayGateway address for the
Subnet.
macMAC address in the
XX:XX:XX:XX:XX:XXformat.
nameserversList of the IP addresses of name servers of the
Subnet. Each element of the list is a single address, for example, 172.18.176.6.
stateSince 2.23.0Message that reflects the current status of the resource. The list of possible values includes the following:
OK- object is operational.ERR- object is non-operational. This status has a detailed description in themessageslist.TERM- object was deleted and is terminating.
messagesSince 2.23.0List of error or warning messages if the object state is
ERR.
objCreatedDate, time, and IPAM version of the resource creation.
objStatusUpdatedDate, time, and IPAM version of the last update of the
statusfield in the resource.
objUpdatedDate, time, and IPAM version of the last resource update.
phaseDeprecated since Container Cloud 2.23.0 and will be removed in one of the following releases in favor of
state. Possible values:Active,Failed, orTerminating.
Configuration example:
status:
address: 172.16.48.201
cidr: 172.16.48.201/24
gateway: 172.16.48.1
objCreated: 2021-10-21T19:09:32Z by v5.1.0-20210930-121522-f5b2af8
objStatusUpdated: 2021-10-21T19:14:18.748114886Z by v5.1.0-20210930-121522-f5b2af8
objUpdated: 2021-10-21T19:09:32.606968024Z by v5.1.0-20210930-121522-f5b2af8
mac: 0C:C4:7A:A8:B8:18
nameservers:
- 172.18.176.6
state: OK
phase: Active
IpamHost¶
This section describes the IpamHost resource used in Mirantis
Container Cloud API. The kaas-ipam controller monitors
the current state of the bare metal Machine, verifies if BareMetalHost
is successfully created and inspection is completed.
Then the kaas-ipam controller fetches the information about the network
card, creates the IpamHost object, and requests the IP address.
The IpamHost object is created for each Machine and contains
all configuration of the host network interfaces and IP address.
It also contains the information about associated BareMetalHost,
Machine, and MAC addresses.
For demonstration purposes, the Container Cloud IpamHost
custom resource (CR) is split into the following major sections:
IpamHost metadata¶
The Container Cloud IpamHost CR contains the following fields:
apiVersionAPI version of the object that is
ipam.mirantis.com/v1alpha1
kindObject type that is
IpamHost
metadataThe
metadatafield contains the following subfields:nameName of the
IpamHostobject
namespaceProject in which the
IpamHostobject has been created
labelsKey-value pairs that are attached to the object:
cluster.sigs.k8s.io/cluster-nameReferences the
Clusterobject name thatIpamHostis assigned to
ipam/BMHostIDUnique ID of the associated
BareMetalHostobject
ipam/MAC-XX-XX-XX-XX-XX-XX: "1"Number of NICs of the host that the corresponding MAC address is assigned to
ipam/MachineIDUnique ID of the associated
Machineobject
ipam/UIDUnique ID of the
IpamHostobject
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Configuration example:
apiVersion: ipam.mirantis.com/v1alpha1
kind: IpamHost
metadata:
name: master-0
namespace: default
labels:
cluster.sigs.k8s.io/cluster-name: kaas-mgmt
ipam/BMHostID: 57250885-f803-11ea-88c8-0242c0a85b02
ipam/MAC-0C-C4-7A-1E-A9-5C: "1"
ipam/MAC-0C-C4-7A-1E-A9-5D: "1"
ipam/MachineID: 573386ab-f803-11ea-88c8-0242c0a85b02
ipam/UID: 834a2fc0-f804-11ea-88c8-0242c0a85b02
IpamHost configuration¶
The spec field of the IpamHost resource describes the desired
state of the object. It contains the following fields:
nicMACmapRepresents an unordered list of all NICs of the host obtained during the bare metal host inspection. Each NIC entry contains such fields as
name,mac,ip, and so on. Theprimaryfield defines which NIC was used for PXE booting. Only one NIC can be primary. The IP address is not configurable and is provided only for debug purposes.
l2TemplateSelectorIf specified, contains the
name(first priority) orlabelof the L2 template that will be applied during a machine creation. Thel2TemplateSelectorfield is copied from theMachineproviderSpecobject to theIpamHostobject only once, during a machine creation. To modifyl2TemplateSelectorafter creation of aMachineCR, edit theIpamHostobject.
netconfigUpdateModeTechPreviewUpdate mode of network configuration. Possible values:
MANUALDefault, recommended. An operator manually applies new network configuration.
AUTO-UNSAFEUnsafe, not recommended. If new network configuration is rendered by
kaas-ipamsuccessfully, it is applied automatically with no manual approval.
MANUAL-GRACEPERIODInitial value set during the
IpamHostobject creation. If new network configuration is rendered bykaas-ipamsuccessfully, it is applied automatically with no manual approval. This value is implemented for automatic changes in theIpamHostobject during the host provisioning and deployment. The value is changed automatically toMANUALin three hours after theIpamHostobject creation.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
netconfigUpdateAllowTechPreviewManual approval of network changes. Possible values:
trueorfalse. Set totrueto approve the Netplan configuration file candidate (stored innetconfigCandidate) and copy its contents to the effective Netplan configuration file list (stored innetconfigFiles). After that, its value is automatically switched back tofalse.Note
This value has effect only if
netconfigUpdateModeis set toMANUAL.Set to
trueonly ifstatus.netconfigCandidateStateof network configuration candidate isOK.Caution
The following fields of the
ipamHoststatus are renamed since Container Cloud 2.22.0 in the scope of theL2TemplateandIpamHostobjects refactoring:netconfigV2tonetconfigCandidatenetconfigV2statetonetconfigCandidateStatenetconfigFilesStatetonetconfigFilesStates(per file)
No user actions are required after renaming.
The format of
netconfigFilesStatechanged after renaming. ThenetconfigFilesStatesfield contains a dictionary of statuses of network configuration files stored innetconfigFiles. The dictionary contains the keys that are file paths and values that have the same meaning for each file thatnetconfigFilesStatehad:For a successfully rendered configuration file:
OK: <timestamp> <sha256-hash-of-rendered-file>, where a timestamp is in the RFC 3339 format.For a failed rendering:
ERR: <error-message>.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
Configuration example:
spec:
nicMACmap:
- mac: 0c:c4:7a:1e:a9:5c
name: ens11f0
- ip: 172.16.48.157
mac: 0c:c4:7a:1e:a9:5d
name: ens11f1
primary: true
l2TemplateSelector:
label:xxx
netconfigUpdateMode: manual
netconfigUpdateAllow: false
IpamHost status¶
Caution
The following fields of the ipamHost status are renamed since
Container Cloud 2.22.0 in the scope of the L2Template and IpamHost
objects refactoring:
netconfigV2tonetconfigCandidatenetconfigV2statetonetconfigCandidateStatenetconfigFilesStatetonetconfigFilesStates(per file)
No user actions are required after renaming.
The format of netconfigFilesState changed after renaming. The
netconfigFilesStates field contains a dictionary of statuses of network
configuration files stored in netconfigFiles. The dictionary contains
the keys that are file paths and values that have the same meaning for each
file that netconfigFilesState had:
For a successfully rendered configuration file:
OK: <timestamp> <sha256-hash-of-rendered-file>, where a timestamp is in the RFC 3339 format.For a failed rendering:
ERR: <error-message>.
The status field of the IpamHost resource describes the observed
state of the object. It contains the following fields:
netconfigCandidateCandidate of the Netplan configuration file in human readable format that is rendered using the corresponding
L2Template. This field contains valid data ifl2RenderResultandnetconfigCandidateStateretain theOKresult.
l2RenderResultDeprecatedStatus of a rendered Netplan configuration candidate stored in
netconfigCandidate. Possible values:For a successful L2 template rendering:
OK: timestamp sha256-hash-of-rendered-netplan, where timestamp is in the RFC 3339 formatFor a failed rendering:
ERR: <error-message>
This field is deprecated and will be removed in one of the following releases. Use
netconfigCandidateStateinstead.
netconfigCandidateStateTechPreviewStatus of a rendered Netplan configuration candidate stored in
netconfigCandidate. Possible values:For a successful L2 template rendering:
OK: timestamp sha256-hash-of-rendered-netplan, where timestamp is in the RFC 3339 formatFor a failed rendering:
ERR: <error-message>
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
netconfigFilesList of Netplan configuration files rendered using the corresponding
L2Template. It is used to configure host networking during bare metal host provisioning (BaremetalHostretains a copy of this configuration) and during Kubernetes node deployment (refer to Workflow of the netplan configuration using an L2 template for details).Its contents are changed only if rendering of Netplan configuration was successful. So, it always retains the last successfully rendered Netplan configuration. To apply changes in contents, the Infrastructure Operator approval is required. For details, see Modify network configuration on an existing machine.
Every item in this list contains:
contentThe
base64-encoded Netplan configuration file that was rendered using the correspondingL2Template.
pathThe file path for the Netplan configuration file on the target host.
netconfigFilesStatesStatus of Netplan configuration files stored in
netconfigFiles. Possible values are:For a successful L2 template rendering:
OK: timestamp sha256-hash-of-rendered-netplan, where timestamp is in the RFC 3339 formatFor a failed rendering:
ERR: <error-message>
serviceMapDictionary of services and their endpoints (IP address and optional interface name) that have the
ipam/SVC-<serviceName>label. These addresses are added to theServiceMapdictionary during rendering of an L2 template for a givenIpamHost. For details, see Service labels and their life cycle.
stateSince 2.23.0Message that reflects the current status of the resource. The list of possible values includes the following:
OK- object is operational.ERR- object is non-operational. This status has a detailed description in themessageslist.TERM- object was deleted and is terminating.
messagesSince 2.23.0List of error or warning messages if the object state is
ERR.
objCreatedDate, time, and IPAM version of the resource creation.
objStatusUpdatedDate, time, and IPAM version of the last update of the
statusfield in the resource.
objUpdatedDate, time, and IPAM version of the last resource update.
Configuration example:
status:
l2RenderResult: OK
l2TemplateRef: namespace_name/l2-template-name/1/2589/88865f94-04f0-4226-886b-2640af95a8ab
netconfigFiles:
- content: ...<base64-encoded Netplan configuration file>...
path: /etc/netplan/60-kaas-lcm-netplan.yaml
netconfigFilesStates: /etc/netplan/60-kaas-lcm-netplan.yaml: 'OK: 2023-01-23T09:27:22.71802Z ece7b73808999b540e32ca1720c6b7a6e54c544cc82fa40d7f6b2beadeca0f53'
netconfigCandidate:
...
<Netplan configuration file in plain text, rendered from L2Template>
...
netconfigCandidateState: OK: 2022-06-08T03:18:08.49590Z a4a128bc6069638a37e604f05a5f8345cf6b40e62bce8a96350b5a29bc8bccde\
serviceMap:
ipam/SVC-ceph-cluster:
- ifName: ceph-br2
ipAddress: 10.0.10.11
- ifName: ceph-br1
ipAddress: 10.0.12.22
ipam/SVC-ceph-public:
- ifName: ceph-public
ipAddress: 10.1.1.15
ipam/SVC-k8s-lcm:
- ifName: k8s-lcm
ipAddress: 10.0.1.52
phase: Active
state: OK
objCreated: 2021-10-21T19:09:32Z by v5.1.0-20210930-121522-f5b2af8
objStatusUpdated: 2021-10-21T19:14:18.748114886Z by v5.1.0-20210930-121522-f5b2af8
objUpdated: 2021-10-21T19:09:32.606968024Z by v5.1.0-20210930-121522-f5b2af8
L2Template¶
This section describes the L2Template resource used in Mirantis
Container Cloud API.
By default, Container Cloud configures a single interface on cluster nodes,
leaving all other physical interfaces intact.
With L2Template, you can create advanced host networking configurations
for your clusters. For example, you can create bond interfaces on top of
physical interfaces on the host.
For demonstration purposes, the Container Cloud L2Template
custom resource (CR) is split into the following major sections:
L2Template metadata¶
The Container Cloud L2Template CR contains the following fields:
apiVersionAPI version of the object that is
ipam.mirantis.com/v1alpha1.
kindObject type that is
L2Template.
metadataThe
metadatafield contains the following subfields:nameName of the
L2Templateobject.
namespaceProject in which the
L2Templateobject was created.
labelsKey-value pairs that are attached to the object:
Caution
All
ipam/*labels, exceptipam/DefaultForCluster, are set automatically and must not be configured manually.cluster.sigs.k8s.io/cluster-nameReferences the
Clusterobject name that this template is applied to. Mandatory for newly createdL2Templatesince Container Cloud 2.25.0.The process of selecting the
L2Templateobject for a specific cluster is as follows:The
kaas-ipamcontroller monitors theL2Templateobjects with thecluster.sigs.k8s.io/cluster-name: <clusterName>label.The
L2Templateobject with thecluster.sigs.k8s.io/cluster-name: <clusterName>label is assigned to a cluster withName: <clusterName>, if available.
ipam/PreInstalledL2Template: "1"Is automatically added during a management cluster deployment. Indicates that the current
L2Templateobject was preinstalled. Represents L2 templates that are automatically copied to a project once it is created. Once the L2 templates are copied, theipam/PreInstalledL2Templatelabel is removed.Note
Preinstalled L2 templates are removed in Container Cloud 2.26.0 (Cluster releases 17.1.0 and 16.1.0) along with the
ipam/PreInstalledL2Templatelabel. During cluster update to the mentioned releases, existing preinstalled templates are automatically removed.
ipam/DefaultForClusterThis label is unique per cluster. When you use several L2 templates per cluster, only the first template is automatically labeled as the default one. All consequent templates must be referenced in the machines configuration files using
L2templateSelector. You can manually configure this label if required.
ipam/UIDUnique ID of an object.
kaas.mirantis.com/providerProvider type.
kaas.mirantis.com/regionRegion name.
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Configuration example:
apiVersion: ipam.mirantis.com/v1alpha1
kind: L2Template
metadata:
name: l2template-test
namespace: default
labels:
ipam/DefaultForCluster: "1"
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
L2Template configuration¶
The spec field of the L2Template resource describes the desired
state of the object. It contains the following fields:
clusterRefCaution
Deprecated since Container Cloud 2.25.0 in favor of the mandatory
cluster.sigs.k8s.io/cluster-namelabel. Will be removed in one of the following releases.On existing clusters, this parameter is automatically migrated to the
cluster.sigs.k8s.io/cluster-namelabel since 2.25.0.If an existing cluster has
clusterRef: defaultset, the migration process involves removing this parameter. Subsequently, it is not substituted with thecluster.sigs.k8s.io/cluster-namelabel, ensuring the application of the L2 template across the entire Kubernetes namespace.The
Clusterobject name that this template is applied to. Thedefaultvalue is used to apply the given template to all clusters within a particular project, unless an L2 template that references a specific cluster name exists. TheclusterReffield has priority over thecluster.sigs.k8s.io/cluster-namelabel:When
clusterRefis set to a non-defaultvalue, thecluster.sigs.k8s.io/cluster-namelabel will be added or updated with that value.When
clusterRefis set todefault, thecluster.sigs.k8s.io/cluster-namelabel will be absent or removed.
L2 template requirements
An L2 template must have the same project (Kubernetes namespace) as the referenced cluster.
A cluster can be associated with many L2 templates. Only one of them can have the
ipam/DefaultForClusterlabel. Every L2 template that does not have theipam/DefaultForClusterlabel can be later assigned to a particular machine usingl2TemplateSelector.The following rules apply to the default L2 template of a namespace:
Since Container Cloud 2.25.0, creation of the default L2 template for a namespace is disabled. On existing clusters, the
Spec.clusterRef: defaultparameter of such an L2 template is automatically removed during the migration process. Subsequently, this parameter is not substituted with thecluster.sigs.k8s.io/cluster-namelabel, ensuring the application of the L2 template across the entire Kubernetes namespace. Therefore, you can continue using existing default namespaced L2 templates.Before Container Cloud 2.25.0, the default
L2Templateobject of a namespace must have theSpec.clusterRef: defaultparameter that is deprecated since 2.25.0.
ifMappingList of interface names for the template. The interface mapping is defined globally for all bare metal hosts in the cluster but can be overridden at the host level, if required, by editing the
IpamHostobject for a particular host. TheifMappingparameter is mutually exclusive withautoIfMappingPrio.
autoIfMappingPrioautoIfMappingPriois a list of prefixes, such aseno,ens, and so on, to match the interfaces to automatically create a list for the template. If you are not aware of any specific ordering of interfaces on the nodes, use the default ordering from Predictable Network Interfaces Names specification for systemd. You can also override the default NIC list per host using theIfMappingOverrideparameter of the correspondingIpamHost. Theprovisionvalue corresponds to the network interface that was used to provision a node. Usually, it is the first NIC found on a particular node. It is defined explicitly to ensure that this interface will not be reconfigured accidentally.The
autoIfMappingPrioparameter is mutually exclusive withifMapping.
l3LayoutSubnets to be used in the
npTemplatesection. The field contains a list of subnet definitions with parameters used by template macros.subnetNameDefines the alias name of the subnet that can be used to reference this subnet from the template macros. This parameter is mandatory for every entry in the
l3Layoutlist.
subnetPoolDeprecated since 2.27.0 (17.2.0 and 16.2.0)Optional. Default: none. Defines a name of the parent
SubnetPoolobject that will be used to create aSubnetobject with a givensubnetNameandscope.If a corresponding
Subnetobject already exists, nothing will be created and the existing object will be used. If noSubnetPoolis provided, no newSubnetobject will be created.
scopeLogical scope of the
Subnetobject with a correspondingsubnetName. Possible values:global- theSubnetobject is accessible globally, for any Container Cloud project and cluster, for example, the PXE subnet.namespace- theSubnetobject is accessible within the same project where the L2 template is defined.cluster- theSubnetobject is only accessible to the cluster thatL2Template.spec.clusterRefrefers to. TheSubnetobjects with theclusterscope will be created for every new cluster.
labelSelectorContains a dictionary of labels and their respective values that will be used to find the matching
Subnetobject for the subnet. If thelabelSelectorfield is omitted, theSubnetobject will be selected by name, specified by thesubnetNameparameter.
Caution
The
l3Layoutsection is mandatory for eachL2Templatecustom resource.
npTemplateA netplan-compatible configuration with special lookup functions that defines the networking settings for the cluster hosts, where physical NIC names and details are parameterized. This configuration will be processed using Go templates. Instead of specifying IP and MAC addresses, interface names, and other network details specific to a particular host, the template supports use of special lookup functions. These lookup functions, such as
nic,mac,ip, and so on, return host-specific network information when the template is rendered for a particular host.Caution
All rules and restrictions of the netplan configuration also apply to L2 templates. For details, see the official netplan documentation.
Caution
We strongly recommend following the below conventions on network interface naming:
A physical NIC name set by an L2 template must not exceed 15 symbols. Otherwise, an L2 template creation fails. This limit is set by the Linux kernel.
Names of virtual network interfaces such as VLANs, bridges, bonds, veth, and so on must not exceed 15 symbols.
We recommend setting interfaces names that do not exceed 13 symbols for both physical and virtual interfaces to avoid corner cases and issues in netplan rendering.
Configuration example:
spec:
autoIfMappingPrio:
- provision
- eno
- ens
- enp
l3Layout:
- subnetName: kaas-mgmt
scope: global
labelSelector:
kaas-mgmt-subnet: ""
- subnetName: demo-pods
scope: namespace
- subnetName: demo-ext
scope: namespace
- subnetName: demo-ceph-cluster
scope: namespace
- subnetName: demo-ceph-replication
scope: namespace
npTemplate: |
version: 2
ethernets:
{{nic 1}}:
dhcp4: false
dhcp6: false
addresses:
- {{ip "1:kaas-mgmt"}}
gateway4: {{gateway_from_subnet "kaas-mgmt"}}
nameservers:
addresses: {{nameservers_from_subnet "kaas-mgmt"}}
match:
macaddress: {{mac 1}}
set-name: {{nic 1}}
L2Template status¶
The status field of the L2Template resource reflects the actual state
of the L2Template object and contains the following fields:
stateSince 2.23.0Message that reflects the current status of the resource. The list of possible values includes the following:
OK- object is operational.ERR- object is non-operational. This status has a detailed description in themessageslist.TERM- object was deleted and is terminating.
messagesSince 2.23.0List of error or warning messages if the object state is
ERR.
objCreatedDate, time, and IPAM version of the resource creation.
objStatusUpdatedDate, time, and IPAM version of the last update of the
statusfield in the resource.
objUpdatedDate, time, and IPAM version of the last resource update.
phaseDeprecated since Container Cloud 2.23.0 and will be removed in one of the following releases in favor of
state. Possible values:Active,Failed, orTerminating.
reasonDeprecated since Container Cloud 2.23.0 and will be removed in one of the following releases in favor of
messages. For the field description, seemessages.
Configuration example:
status:
phase: Failed
state: ERR
messages:
- "ERR: The kaas-mgmt subnet in the terminating state."
objCreated: 2021-10-21T19:09:32Z by v5.1.0-20210930-121522-f5b2af8
objStatusUpdated: 2021-10-21T19:14:18.748114886Z by v5.1.0-20210930-121522-f5b2af8
objUpdated: 2021-10-21T19:09:32.606968024Z by v5.1.0-20210930-121522-f5b2af8
Machine¶
This section describes the Machine resource used in Mirantis
Container Cloud API for bare metal provider.
The Machine resource describes the machine-level parameters.
For demonstration purposes, the Container Cloud Machine
custom resource (CR) is split into the following major sections:
metadata¶
The Container Cloud Machine CR contains the following fields:
apiVersionAPI version of the object that is
cluster.k8s.io/v1alpha1.
kindObject type that is
Machine.
The metadata object field of the Machine resource contains
the following fields:
nameName of the
Machineobject.
namespaceProject in which the
Machineobject is created.
annotationsKey-value pair to attach arbitrary metadata to the object:
metal3.io/BareMetalHostAnnotation attached to the
Machineobject to reference the correspondingBareMetalHostobject in the<BareMetalHostProjectName/BareMetalHostName>format.
labelsKey-value pairs that are attached to the object:
kaas.mirantis.com/providerProvider type that matches the provider type in the
Clusterobject and must bebaremetal.
kaas.mirantis.com/regionRegion name that matches the region name in the
Clusterobject.Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
cluster.sigs.k8s.io/cluster-nameCluster name that the
Machineobject is linked to.
cluster.sigs.k8s.io/control-planeFor the control plane role of a machine, this label contains any value, for example,
"true". For the worker role, this label is absent.
kaas.mirantis.com/machinepool-name(optional)Name of the
MachinePoolobject to which this machine is assigned to. If the machine is not assigned to any machine pool, this label is absent.
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Configuration example:
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
name: example-control-plane
namespace: example-ns
annotations:
metal3.io/BareMetalHost: default/master-0
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: example-cluster
cluster.sigs.k8s.io/control-plane: "true" # remove for worker
spec:providerSpec for instance configuration¶
Caution
If a machine is assigned to a machine pool, the providerSpec
section of the specific Machine object automatically updates during pool
configuration. The only providerSpec field that is not overwritten
automatically is maintenance. Do not edit other fields of this section
manually.
The spec object field of the Machine object represents
the BareMetalMachineProviderSpec subresource with all required
details to create a bare metal instance. It contains the following fields:
apiVersionAPI version of the object that is
baremetal.k8s.io/v1alpha1.
kindObject type that is
BareMetalMachineProviderSpec.
bareMetalHostProfileConfiguration profile of a bare metal host:
nameName of a bare metal host profile
namespaceProject in which the bare metal host profile is created.
l2TemplateIfMappingOverrideIf specified, overrides the interface mapping value for the corresponding
L2Templateobject.
l2TemplateSelectorIf specified, contains the
name(first priority) orlabelof the L2 template that will be applied during a machine creation. Thel2TemplateSelectorfield is copied from theMachineproviderSpecobject to theIpamHostobject only once, during a machine creation. To modifyl2TemplateSelectorafter creation of aMachineCR, edit theIpamHostobject.
hostSelectorSpecifies the matching criteria for labels on the bare metal hosts. Limits the set of the
BareMetalHostobjects considered for claiming for theMachineobject. The following selector labels can be added when creating a machine using the Container Cloud web UI:hostlabel.bm.kaas.mirantis.com/controlplanehostlabel.bm.kaas.mirantis.com/workerhostlabel.bm.kaas.mirantis.com/storage
Any custom label that is assigned to one or more bare metal hosts using API can be used as a host selector. If the
BareMetalHostobjects with the specified label are missing, theMachineobject will not be deployed until at least one bare metal host with the specified label is available.
nodeLabelsList of node labels to be attached to a node for the user to run certain components on separate cluster nodes. The list of allowed node labels is located in the
Clusterobject statusproviderStatus.releaseRef.current.allowedNodeLabelsfield.If the
valuefield is not defined inallowedNodeLabels, a label can have any value.Before or after a machine deployment, add the required label from the allowed node labels list with the corresponding value to
spec.providerSpec.value.nodeLabelsinmachine.yaml. For example:nodeLabels: - key: stacklight value: enabled
The addition of a node label that is not available in the list of allowed node labels is restricted.
distributionMandatorySpecifies an operating system (OS) distribution ID that is present in the current
ClusterReleaseobject under theAllowedDistributionslist. When specified, theBareMetalHostobject linked to thisMachineobject will be provisioned using the selected OS distribution instead of the default one.By default,
ubuntu/focalis installed on greenfield managed clusters. The default distribution is marked with the boolean flagdefaultinside one of the elements under theAllowedDistributionslist.Caution
The outdated
ubuntu/bionicdistribution, which is removed in Cluster releases 17.0.0 and 16.0.0, is only supported for existing clusters based on Ubuntu 18.04. For greenfield deployments of managed clusters, onlyubuntu/focalis supported.Warning
During the course of the Container Cloud 2.24.x series, Mirantis highly recommends upgrading an operating system on your cluster machines to Ubuntu 20.04 before the next major Cluster release becomes available. It is not mandatory to upgrade all machines at once. You can upgrade them one by one or in small batches, for example, if the maintenance window is limited in time.
Otherwise, the Cluster release update of the 18.04 based clusters will become impossible as of the Cluster releases introduced in Container Cloud 2.25.0, in which only the 20.04 distribution will be supported.
maintenanceMaintenance mode of a machine. If enabled, the node of the selected machine is drained, cordoned, and prepared for maintenance operations.
upgradeIndex(optional)Positive numeral value that determines the order of machines upgrade. The first machine to upgrade is always one of the control plane machines with the lowest
upgradeIndex. Other control plane machines are upgraded one by one according to their upgrade indexes.If the
ClusterspecdedicatedControlPlanefield isfalse, worker machines are upgraded only after the upgrade of all control plane machines finishes. Otherwise, they are upgraded after the first control plane machine, concurrently with other control plane machines.If two or more machines have the same value of
upgradeIndex, these machines are equally prioritized during upgrade.
deletionPolicyTechnology Preview since 2.21.0 for non-MOSK clusters. Policy used to identify steps required during a
Machineobject deletion. Supported policies are as follows:gracefulPrepares a machine for deletion by cordoning, draining, and removing from Docker Swarm of the related node. Then deletes Kubernetes objects and associated resources. Can be aborted only before a node is removed from Docker Swarm.
unsafeDefault. Deletes Kubernetes objects and associated resources without any preparations.
forcedDeletes Kubernetes objects and associated resources without any preparations. Removes the
Machineobject even if the cloud provider or LCM Controller gets stuck at some step. May require a manual cleanup of machine resources in case of the controller failure.
For more details on the workflow of machine deletion policies, see Overview of machine deletion policies.
deleteTechnology Preview since 2.21.0 for non-MOSK clusters. Boolean trigger for a machine deletion. Set to
falseto abort a machine deletion.
Configuration example:
spec:
...
providerSpec:
value:
apiVersion: baremetal.k8s.io/v1alpha1
kind: BareMetalMachineProviderSpec
bareMetalHostProfile:
name: default
namespace: default
l2TemplateIfMappingOverride:
- eno1
- enp0s0
l2TemplateSelector:
label: l2-template1-label-1
hostSelector:
matchLabels:
kaas.mirantis.com/baremetalhost-id: hw-master-0
kind: BareMetalMachineProviderSpec
nodeLabels:
- key: stacklight
value: enabled
distribution: ubuntu/focal
delete: false
deletionPolicy: graceful
Machine status¶
The status object field of the Machine object represents the
BareMetalMachineProviderStatus subresource that describes the current
bare metal instance state and contains the following fields:
apiVersionAPI version of the object that is
cluster.k8s.io/v1alpha1.
kindObject type that is
BareMetalMachineProviderStatus.
hardwareProvides a machine hardware information:
cpuNumber of CPUs.
ramRAM capacity in GB.
storageList of hard drives mounted on the machine. Contains the disk name and size in GB.
statusRepresents the current status of a machine:
ProvisionA machine is yet to obtain a status
UninitializedA machine is yet to obtain the node IP address and host name
PendingA machine is yet to receive the deployment instructions and it is either not booted yet or waits for the LCM controller to be deployed
PrepareA machine is running the
Preparephase during which Docker images and packages are being predownloaded
DeployA machine is processing the LCM Controller instructions
ReconfigureA machine is being updated with a configuration without affecting workloads running on the machine
ReadyA machine is deployed and the supported Mirantis Kubernetes Engine (MKE) version is set
MaintenanceA machine host is cordoned, drained, and prepared for maintenance operations
currentDistributionSince 2.24.0 as TechPreview and 2.24.2 as GADistribution ID of the current operating system installed on the machine. For example,
ubuntu/focal.
maintenanceMaintenance mode of a machine. If enabled, the node of the selected machine is drained, cordoned, and prepared for maintenance operations.
rebootAvailable since 2.22.0Indicator of a host reboot to complete the Ubuntu operating system updates, if any.
requiredSpecifies whether a host reboot is required. Boolean. If
true, a manual host reboot is required.
reasonSpecifies the package name(s) to apply during a host reboot.
upgradeIndexPositive numeral value that determines the order of machines upgrade. The first machine to upgrade is always one of the control plane machines with the lowest
upgradeIndex. Other control plane machines are upgraded one by one according to their upgrade indexes.If the
ClusterspecdedicatedControlPlanefield isfalse, worker machines are upgraded only after the upgrade of all control plane machines finishes. Otherwise, they are upgraded after the first control plane machine, concurrently with other control plane machines.If two or more machines have the same value of
upgradeIndex, these machines are equally prioritized during upgrade.If
upgradeIndexin theMachineobject spec is set, this status value equals the one in the spec. Otherwise, this value displays the automatically generated order of upgrade.
deleteTechnology Preview since 2.21.0 for non-MOSK clusters. Start of a machine deletion or a successful abortion. Boolean.
prepareDeletionPhaseTechnology Preview since 2.21.0 for non-MOSK clusters. Preparation phase for a graceful machine deletion. Possible values are as follows:
startedCloud provider controller prepares a machine for deletion by cordoning, draining the machine, and so on.
completedLCM Controller starts removing the machine resources since the preparation for deletion is complete.
abortingCloud provider controller attempts to uncordon the node. If the attempt fails, the status changes to
failed.
failedError in the deletion workflow.
For the workflow description of a graceful deletion, see Overview of machine deletion policies.
Configuration example:
status:
providerStatus:
apiVersion: baremetal.k8s.io/v1alpha1
kind: BareMetalMachineProviderStatus
hardware:
cpu: 11
ram: 16
storage:
- name: /dev/vda
size: 61
- name: /dev/vdb
size: 32
- name: /dev/vdc
size: 32
reboot:
required: true
reason: |
linux-image-5.13.0-51-generic
linux-base
status: Ready
upgradeIndex: 1
MetalLBConfig¶
TechPreview since 2.21.0 and 2.21.1 for MOSK 22.5 GA since 2.24.0 for management and regional clusters GA since 2.25.0 for managed clusters
This section describes the MetalLBConfig custom resource used in the
Container Cloud API that contains the MetalLB configuration objects for a
particular cluster.
Note
The MetalLBConfig custom resource described below applies to
bare metal deployments only. For the vSphere provider, refer to
MetalLBConfig for vSphere.
For demonstration purposes, the Container Cloud MetalLBConfig
custom resource description is split into the following major sections:
The Container Cloud API also uses the third-party open source MetalLB API. For details, see MetalLB objects.
MetalLBConfig metadata¶
The Container Cloud MetalLBConfig CR contains the following fields:
apiVersionAPI version of the object that is
kaas.mirantis.com/v1alpha1.
kindObject type that is
MetalLBConfig.
The metadata object field of the MetalLBConfig resource
contains the following fields:
nameName of the
MetalLBConfigobject.
namespaceProject in which the object was created. Must match the project name of the target cluster.
labelsKey-value pairs attached to the object. Mandatory labels:
kaas.mirantis.com/providerProvider type that is
baremetal.
kaas.mirantis.com/regionRegion name that matches the region name of the target cluster.
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
cluster.sigs.k8s.io/cluster-nameName of the cluster that the MetalLB configuration must apply to.
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Configuration example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: MetalLBConfig
metadata:
name: metallb-demo
namespace: test-ns
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: test-cluster
MetalLBConfig spec¶
The spec field of the MetalLBConfig object represents the
MetalLBConfigSpec subresource that contains the description of MetalLB
configuration objects.
These objects are created in the target cluster during its deployment.
The spec field contains the following optional fields:
addressPoolsList of
MetalLBAddressPoolobjects to create MetalLBAddressPoolobjects.
bfdProfilesList of
MetalLBBFDProfileobjects to create MetalLBBFDProfileobjects.
bgpAdvertisementsList of
MetalLBBGPAdvertisementobjects to create MetalLBBGPAdvertisementobjects.
bgpPeersList of
MetalLBBGPPeerobjects to create MetalLBBGPPeerobjects.
communitiesList of
MetalLBCommunityobjects to create MetalLBCommunityobjects.
ipAddressPoolsList of
MetalLBIPAddressPoolobjects to create MetalLBIPAddressPoolobjects.
l2AdvertisementsList of
MetalLBL2Advertisementobjects to create MetalLBL2Advertisementobjects.The
l2Advertisementsobject allows defining interfaces to optimize the announcement. When you use theinterfacesselector, LB addresses are announced only on selected host interfaces. Mirantis recommends this configuration if nodes use separate host networks for different types of traffic. The pros of such configuration are as follows: less spam on other interfaces and networks and limited chances to reach IP addresses of load-balanced services from irrelevant interfaces and networks.Caution
Interface names in the
interfaceslist must match those on the corresponding nodes.
templateNameDeprecated since 2.27.0 (17.2.0 and 16.2.0). Available since 2.24.0 (14.0.0).
Name of the
MetalLBConfigTemplateobject used as a source of MetalLB configuration objects. Mutually exclusive with the fields listed below that will be part of theMetalLBConfigTemplateobject. For details, see MetalLBConfigTemplate.Before Cluster releases 17.2.0 and 16.2.0,
MetalLBConfigTemplateis the default configuration method for MetalLB on bare metal deployments. Since Cluster releases 17.2.0 and 16.2.0, use theMetalLBConfigobject instead.Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
Caution
For managed clusters, this field is available as Technology Preview since Container Cloud 2.24.0, is generally available since 2.25.0, and is deprecated since 2.27.0.
The objects listed in the spec field of the MetalLBConfig object,
such as MetalLBIPAddressPool, MetalLBL2Advertisement, and so on,
are used as templates for the MetalLB objects that will be created in the
target cluster. Each of these objects has the following structure:
labelsOptional. Key-value pairs attached to the
metallb.io/<objectName>object asmetadata.labels.
nameName of the
metallb.io/<objectName>object.
specContents of the
specsection of themetallb.io/<objectName>object. Thespecfield has themetallb.io/<objectName>Spectype. For details, see MetalLB objects.
For example, MetalLBIPAddressPool is a template for the
metallb.io/IPAddressPool object and has the following structure:
labelsOptional. Key-value pairs attached to the
metallb.io/IPAddressPoolobject asmetadata.labels.
nameName of the
metallb.io/IPAddressPoolobject.
specContents of
specsection of themetallb.io/IPAddressPoolobject. Thespechas themetallb.io/IPAddressPoolSpectype.
MetalLB objects¶
Container Cloud supports the following MetalLB object types of the
metallb.io API group:
|
|
As of v1beta1 and v1beta2 API versions, metadata of MetalLB objects
has a standard format with no specific fields or labels defined for any
particular object:
apiVersionAPI version of the object that can be
metallb.io/v1beta1ormetallb.io/v1beta2.
kindObject type that is one of the
metallb.iotypes listed above. For example,AddressPool.
metadataObject metadata that contains the following subfields:
nameName of the object.
namespaceNamespace where the MetalLB components are located. It matches
metallb-systemin Container Cloud.
labelsOptional. Key-value pairs that are attached to the object. It can be an arbitrary set of labels. No special labels are defined as of
v1beta1andv1beta2API versions.
The MetalLBConfig object contains spec sections of the
metallb.io/<objectName> objects that have the
metallb.io/<objectName>Spec type. For metallb.io/<objectName> and
metallb.io/<objectName>Spec types definitions, refer to the official
MetalLB documentation:
MetalLBConfig status¶
Available since 2.24.0 for management clusters
Caution
For managed clusters, this field is available as Technology Preview and is generally available since Container Cloud 2.25.0.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
The status field describes the actual state of the object.
It contains the following fields:
bootstrapModeOnly in 2.24.0Field that appears only during a management cluster bootstrap as
trueand is used internally for bootstrap. Once deployment completes, the value is moved tofalseand is excluded from thestatusoutput.
objectsDescription of MetalLB objects that is used to create MetalLB native objects in the target cluster.
The format of underlying objects is the same as for those in the
specfield, excepttemplateNamethat is not present in this field. Theobjectscontents are rendered from the following locations, with possible modifications for the bootstrap cluster:MetalLBConfigTemplate.statusof the corresponding template ifMetalLBConfig.spec.templateNameis definedMetalLBConfig.specifMetalLBConfig.spec.templateNameis not defined
propagateResultResult of objects propagation. During objects propagation, native MetalLB objects of the target cluster are created and updated according to the description of the objects present in the
status.objectsfield.This field contains the following information:
messageText message that describes the result of the last attempt of objects propagation. Contains an error message if the last attempt was unsuccessful.
successResult of the last attempt of objects propagation. Boolean.
timeTimestamp of the last attempt of objects propagation. For example,
2023-07-04T00:30:36Z.
If the objects propagation was successful, the MetalLB objects of the target cluster match the ones present in the
status.objectsfield.
updateResultStatus of the MetalLB objects update. Has the same format of subfields that in
propagateResultdescribed above.During objects update, the
status.objectscontents are rendered as described in theobjectsfield definition above.If the objects update was successful, the MetalLB objects description present in
status.objectsis rendered successfully and up to date. This description is used to update MetalLB objects in the target cluster. If the objects update was not successful, MetalLB objects will not be propagated to the target cluster.
MetalLB configuration examples¶
Example of configuration template for using L2 announcements:
apiVersion: kaas.mirantis.com/v1alpha1
kind: MetalLBConfig
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: managed-cluster
kaas.mirantis.com/provider: baremetal
name: managed-l2
namespace: managed-ns
spec:
ipAddressPools:
- name: services
spec:
addresses:
- 10.100.91.151-10.100.91.170
autoAssign: true
avoidBuggyIPs: false
l2Advertisements:
- name: services
spec:
ipAddressPools:
- services
Example of configuration extract for using the interfaces selector, which
enables announcement of LB addresses only on selected host interfaces:
l2Advertisements:
- name: services
spec:
ipAddressPools:
- default
interfaces:
- k8s-lcm
Caution
Interface names in the interfaces list must match the ones
on the corresponding nodes.
After the object is created and processed by the MetalLB Controller, the
status field is added. For example:
status:
objects:
ipAddressPools:
- name: services
spec:
addresses:
- 10.100.100.151-10.100.100.170
autoAssign: true
avoidBuggyIPs: false
l2Advertisements:
- name: services
spec:
ipAddressPools:
- services
propagateResult:
message: Objects were successfully updated
success: true
time: "2023-07-04T14:31:40Z"
updateResult:
message: Objects were successfully read from MetalLB configuration specification
success: true
time: "2023-07-04T14:31:39Z"
Example of native MetalLB objects to be created in the
managed-ns/managed-cluster cluster during deployment:
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: services
namespace: metallb-system
spec:
addresses:
- 10.100.91.151-10.100.91.170
autoAssign: true
avoidBuggyIPs: false
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: services
namespace: metallb-system
spec:
ipAddressPools:
- services
Example of configuration template for using BGP announcements:
apiVersion: kaas.mirantis.com/v1alpha1
kind: MetalLBConfig
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: managed-cluster
kaas.mirantis.com/provider: baremetal
name: managed-bgp
namespace: managed-ns
spec:
bgpPeers:
- name: bgp-peer-rack1
spec:
peerAddress: 10.0.41.1
peerASN: 65013
myASN: 65099
nodeSelectors:
- matchLabels:
rack-id: rack1
- name: bgp-peer-rack2
spec:
peerAddress: 10.0.42.1
peerASN: 65023
myASN: 65099
nodeSelectors:
- matchLabels:
rack-id: rack2
- name: bgp-peer-rack3
spec:
peerAddress: 10.0.43.1
peerASN: 65033
myASN: 65099
nodeSelectors:
- matchLabels:
rack-id: rack3
ipAddressPools:
- name: services
spec:
addresses:
- 10.100.191.151-10.100.191.170
autoAssign: true
avoidBuggyIPs: false
bgpAdvertisements:
- name: services
spec:
ipAddressPools:
- services
MetalLBConfigTemplate¶
Deprecated in 2.27.0 (17.2.0 and 16.2.0)
Warning
The MetalLBConfigTemplate object may not work as expected
due to its deprecation. Existing MetalLBConfigTemplate objects and
related Subnet objects will be automatically migrated to
MetallbConfig during cluster update to the Cluster release 17.2.0 or
16.2.0.
Support status of MetalLBConfigTemplate
Container Cloud release |
Cluster release |
Support status |
|---|---|---|
2.27.0 |
17.2.0 and 16.2.0 |
Deprecated for any cluster type and will be removed in one of the following releases |
2.25.0 |
17.0.0 and 16.0.0 |
Generally available for managed clusters |
2.24.2 |
15.0.1, 14.0.1, 14.0.0 |
Technology Preview for managed clusters |
2.24.0 |
14.0.0 |
Generally available for management clusters |
This section describes the MetalLBConfigTemplate custom resource used in
the Container Cloud API that contains the template for MetalLB configuration
for a particular cluster.
Note
The MetalLBConfigTemplate object applies to bare metal
deployments only.
Before Cluster releases 17.2.0 and 16.2.0, MetalLBConfigTemplate is the
default configuration method for MetalLB on bare metal deployments. This method
allows the use of Subnet objects to define MetalLB IP address pools
the same way as they were used before introducing the MetalLBConfig and
MetalLBConfigTemplate objects. Since Cluster releases 17.2.0 and 16.2.0,
use the MetalLBConfig object for this purpose instead.
For demonstration purposes, the Container Cloud MetalLBConfigTemplate
custom resource description is split into the following major sections:
MetalLBConfigTemplate metadata¶
The Container Cloud MetalLBConfigTemplate CR contains the following fields:
apiVersionAPI version of the object that is
ipam.mirantis.com/v1alpha1.
kindObject type that is
MetalLBConfigTemplate.
The metadata object field of the MetalLBConfigTemplate resource
contains the following fields:
nameName of the
MetalLBConfigTemplateobject.
namespaceProject in which the object was created. Must match the project name of the target cluster.
labelsKey-value pairs attached to the object. Mandatory labels:
kaas.mirantis.com/providerProvider type that is
baremetal.
kaas.mirantis.com/regionRegion name that matches the region name of the target cluster.
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
cluster.sigs.k8s.io/cluster-nameName of the cluster that the MetalLB configuration applies to.
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Configuration example:
apiVersion: ipam.mirantis.com/v1alpha1
kind: MetalLBConfigTemplate
metadata:
name: metallb-demo
namespace: test-ns
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: test-cluster
MetalLBConfigTemplate spec¶
The spec field of the MetalLBConfigTemplate object contains the
templates of MetalLB configuration objects and optional auxiliary variables.
Container Cloud uses these templates to create MetalLB configuration objects
during the cluster deployment.
The spec field contains the following optional fields:
machinesKey-value dictionary to select
IpamHostobjects corresponding to nodes of the target cluster. Keys contain machine aliases used inspec.templates. Values contain theNameLabelsSelectoritems that selectIpamHostby name or by labels. For example:machines: control1: name: mosk-control-uefi-0 worker1: labels: uid: kaas-node-4003a5f6-2667-40e3-aa64-ebe713a8a7ba
This field is required if some IP addresses of nodes are used in
spec.templates.
varsKey-value dictionary of arbitrary user-defined variables that are used in
spec.templates. For example:vars: localPort: 4561
templatesList of templates for MetalLB configuration objects that are used to render MetalLB configuration definitions and create MetalLB objects in the target cluster. Contains the following optional fields:
bfdProfilesTemplate for the
MetalLBBFDProfileobject list to create MetalLBBFDProfileobjects.
bgpAdvertisementsTemplate for the
MetalLBBGPAdvertisementobject list to create MetalLBBGPAdvertisementobjects.
bgpPeersTemplate for the
MetalLBBGPPeerobject list to create MetalLBBGPPeerobjects.
communitiesTemplate for the
MetalLBCommunityobject list to create MetalLBCommunityobjects.
ipAddressPoolsTemplate for the
MetalLBIPAddressPoolobject list to create MetalLBIPAddressPoolobjects.
l2AdvertisementsTemplate for the
MetalLBL2Advertisementobject list to create MetalLBL2Advertisementobjects.
Each template is a string and has the same structure as the list of the corresponding objects described in MetalLBConfig spec such as
MetalLBIPAddressPoolandMetalLBL2Advertisement, but you can use additional functions and variables inside these templates.Note
When using the
MetalLBConfigTemplateobject, you can define MetalLB IP address pools using bothSubnetobjects andspec.ipAddressPoolstemplates. IP address pools rendered from these sources will be concatenated and then written tostatus.renderedObjects.ipAddressPools.You can use the following functions in templates:
ipAddressPoolNamesSelects all IP address pools of the given announcement type found for the target cluster. Possible types:
layer2,bgp,any.The
anytype includes all IP address pools found for the target cluster. The announcement types of IP address pools are verified using themetallb/address-pool-protocollabels of the correspondingSubnetobject.The
ipAddressPoolstemplates have no types as native MetalLBIPAddressPoolobjects have no announcement type.The
l2Advertisementstemplate can refer to IP address pools of thelayer2oranytype.The
bgpAdvertisementstemplate can refer to IP address pools of thebgporanytype.IP address pools are searched in the
templates.ipAddressPoolsfield and in theSubnetobjects of the target cluster. For example:l2Advertisements: | - name: l2services spec: ipAddressPools: {{ipAddressPoolNames "layer2"}} bgpAdvertisements: | - name: l3services spec: ipAddressPools: {{ipAddressPoolNames "bgp"}} l2Advertisements: | - name: any spec: ipAddressPools: {{ipAddressPoolNames "any"}} bgpAdvertisements: | - name: any spec: ipAddressPools: {{ipAddressPoolNames "any"}}
The
l2Advertisementsobject allows defining interfaces to optimize the announcement. When you use theinterfacesselector, LB addresses are announced only on selected host interfaces. Mirantis recommends this configuration if nodes use separate host networks for different types of traffic. The pros of such configuration are as follows: less spam on other interfaces and networks, limited chances to reach services LB addresses from irrelevant interfaces and networks.Configuration example:
l2Advertisements: | - name: management-lcm spec: ipAddressPools: - default interfaces: # LB addresses from the "default" address pool will be announced # on the "k8s-lcm" interface - k8s-lcm
Caution
Interface names in the
interfaceslist must match those on the corresponding nodes.
MetalLBConfigTemplate status¶
The status field describes the actual state of the object.
It contains the following fields:
renderedObjectsMetalLB objects description rendered from
spec.templatesin the same format as they are defined in the MetalLBConfig spec field.All underlying objects are optional. The following objects can be present:
bfdProfiles,bgpAdvertisements,bgpPeers,communities,ipAddressPools,l2Advertisements.
stateSince 2.23.0Message that reflects the current status of the resource. The list of possible values includes the following:
OK- object is operational.ERR- object is non-operational. This status has a detailed description in themessageslist.TERM- object was deleted and is terminating.
messagesSince 2.23.0List of error or warning messages if the object state is
ERR.
objCreatedDate, time, and IPAM version of the resource creation.
objStatusUpdatedDate, time, and IPAM version of the last update of the
statusfield in the resource.
objUpdatedDate, time, and IPAM version of the last resource update.
MetalLB configuration examples¶
The following examples contain configuration templates that include
MetalLBConfigTemplate.
Configuration example for MetalLBConfig
apiVersion: kaas.mirantis.com/v1alpha1
kind: MetalLBConfig
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: kaas-mgmt
kaas.mirantis.com/provider: baremetal
name: mgmt-l2
namespace: default
spec:
templateName: mgmt-metallb-template
Configuration example for MetalLBConfigTemplate
apiVersion: ipam.mirantis.com/v1alpha1
kind: MetalLBConfigTemplate
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: kaas-mgmt
kaas.mirantis.com/provider: baremetal
name: mgmt-metallb-template
namespace: default
spec:
templates:
l2Advertisements: |
- name: management-lcm
spec:
ipAddressPools:
- default
interfaces:
# IPs from the "default" address pool will be announced on the "k8s-lcm" interface
- k8s-lcm
- name: provision-pxe
spec:
ipAddressPools:
- services-pxe
interfaces:
# IPs from the "services-pxe" address pool will be announced on the "k8s-pxe" interface
- k8s-pxe
Configuration example for Subnet of the default pool
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: kaas-mgmt
ipam/SVC-MetalLB: ""
kaas.mirantis.com/provider: baremetal
metallb/address-pool-auto-assign: "true"
metallb/address-pool-name: default
metallb/address-pool-protocol: layer2
name: master-lb-default
namespace: default
spec:
cidr: 10.0.34.0/24
includeRanges:
- 10.0.34.101-10.0.34.120
Configuration example for Subnet of the services-pxe
pool
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: kaas-mgmt
ipam/SVC-MetalLB: ""
kaas.mirantis.com/provider: baremetal
metallb/address-pool-auto-assign: "false"
metallb/address-pool-name: services-pxe
metallb/address-pool-protocol: layer2
name: master-lb-pxe
namespace: default
spec:
cidr: 10.0.24.0/24
includeRanges:
- 10.0.24.221-10.0.24.230
After the objects are created and processed by the kaas-ipam Controller,
the status field displays for MetalLBConfigTemplate:
Configuration example of the status field for
MetalLBConfigTemplate
status:
checksums:
annotations: sha256:38e0b9de817f645c4bec37c0d4a3e58baecccb040f5718dc069a72c7385a0bed
labels: sha256:380337902278e8985e816978c349910a4f7ed98169c361eb8777411ac427e6ba
spec: sha256:0860790fc94217598e0775ab2961a02acc4fba820ae17c737b94bb5d55390dbe
messages:
- Template for BFDProfiles is undefined
- Template for BGPAdvertisements is undefined
- Template for BGPPeers is undefined
- Template for Communities is undefined
objCreated: 2023-06-30T21:22:56.00000Z by v6.5.999-20230627-072014-ba8d918
objStatusUpdated: 2023-07-04T00:30:35.82023Z by v6.5.999-20230627-072014-ba8d918
objUpdated: 2023-06-30T22:10:51.73822Z by v6.5.999-20230627-072014-ba8d918
renderedObjects:
ipAddressPools:
- name: default
spec:
addresses:
- 10.0.34.101-10.0.34.120
autoAssign: true
- name: services-pxe
spec:
addresses:
- 10.0.24.221-10.0.24.230
autoAssign: false
l2Advertisements:
- name: management-lcm
spec:
interfaces:
- k8s-lcm
ipAddressPools:
- default
- name: provision-pxe
spec:
interfaces:
- k8s-pxe
ipAddressPools:
- services-pxe
state: OK
The following example illustrates contents of the status field that
displays for MetalLBConfig after the objects are processed
by the MetalLB Controller.
Configuration example of the status field for
MetalLBConfig
status:
objects:
ipAddressPools:
- name: default
spec:
addresses:
- 10.0.34.101-10.0.34.120
autoAssign: true
avoidBuggyIPs: false
- name: services-pxe
spec:
addresses:
- 10.0.24.221-10.0.24.230
autoAssign: false
avoidBuggyIPs: false
l2Advertisements:
- name: management-lcm
spec:
interfaces:
- k8s-lcm
ipAddressPools:
- default
- name: provision-pxe
spec:
interfaces:
- k8s-pxe
ipAddressPools:
- services-pxe
propagateResult:
message: Objects were successfully updated
success: true
time: "2023-07-05T03:10:23Z"
updateResult:
message: Objects were successfully read from MetalLB configuration specification
success: true
time: "2023-07-05T03:10:23Z"
Using the objects described above, several native MetalLB objects are created
in the kaas-mgmt cluster during deployment.
Configuration example of MetalLB objects created during cluster
deployment
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: management-lcm
namespace: metallb-system
spec:
interfaces:
- k8s-lcm
ipAddressPools:
- default
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: provision-pxe
namespace: metallb-system
spec:
interfaces:
- k8s-pxe
ipAddressPools:
- services-pxe
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: default
namespace: metallb-system
spec:
addresses:
- 10.0.34.101-10.0.34.120
autoAssign: true
avoidBuggyIPs: false
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: services-pxe
namespace: metallb-system
spec:
addresses:
- 10.0.24.221-10.0.24.230
autoAssign: false
avoidBuggyIPs: false
In the following configuration example, MetalLB is configured to use BGP for announcement of external addresses of Kubernetes load-balanced services for the managed cluster from master nodes. Each master node is located in its own rack without the L2 layer extension between racks.
This section contains only examples of the objects required to illustrate
the MetalLB configuration. For Rack, MultiRackCluster, L2Template
and other objects required to configure BGP announcement of the cluster API
load balancer address for this scenario, refer to Multiple rack configuration example.
Configuration example for MetalLBConfig
apiVersion: kaas.mirantis.com/v1alpha1
kind: MetalLBConfig
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
name: test-cluster-metallb-bgp
namespace: managed-ns
spec:
templateName: test-cluster-metallb-bgp-template
Configuration example for MetalLBConfigTemplate
apiVersion: ipam.mirantis.com/v1alpha1
kind: MetalLBConfigTemplate
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
name: test-cluster-metallb-bgp-template
namespace: managed-ns
spec:
templates:
bgpAdvertisements: |
- name: services
spec:
ipAddressPools:
- services
peers: # "peers" can be omitted if all defined peers
- svc-peer-rack1 # are used in a particular "bgpAdvertisement"
- svc-peer-rack2
- svc-peer-rack3
bgpPeers: |
- name: svc-peer-rack1
spec:
peerAddress: 10.77.41.1 # peer address is in the external subnet #1
peerASN: 65100
myASN: 65101
nodeSelectors:
- matchLabels:
rack-id: rack-master-1 # references the node corresponding
# to the "test-cluster-master-1" Machine
- name: svc-peer-rack2
spec:
peerAddress: 10.77.42.1 # peer address is in the external subnet #2
peerASN: 65100
myASN: 65101
nodeSelectors:
- matchLabels:
rack-id: rack-master-2 # references the node corresponding
# to the "test-cluster-master-2" Machine
- name: svc-peer-rack3
spec:
peerAddress: 10.77.43.1 # peer address is in the external subnet #3
peerASN: 65100
myASN: 65101
nodeSelectors:
- matchLabels:
rack-id: rack-master-3 # references the node corresponding
# to the "test-cluster-master-3" Machine
Configuration example for Subnet
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
ipam/SVC-MetalLB: ""
kaas.mirantis.com/provider: baremetal
metallb/address-pool-auto-assign: "true"
metallb/address-pool-name: services
metallb/address-pool-protocol: bgp
name: test-cluster-lb
namespace: managed-ns
spec:
cidr: 134.33.24.0/24
includeRanges:
- 134.33.24.221-134.33.24.240
The following objects illustrate configuration for three subnets that are used to configure external network in three racks. Each master node uses its own external L2/L3 network segment.
Configuration example for the Subnet ext-rack-control-1
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
name: ext-rack-control-1
namespace: managed-ns
spec:
cidr: 10.77.41.0/28
gateway: 10.77.41.1
includeRanges:
- 10.77.41.3-10.77.41.13
nameservers:
- 1.2.3.4
Configuration example for the Subnet ext-rack-control-2
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
name: ext-rack-control-2
namespace: managed-ns
spec:
cidr: 10.77.42.0/28
gateway: 10.77.42.1
includeRanges:
- 10.77.42.3-10.77.42.13
nameservers:
- 1.2.3.4
Configuration example for the Subnet ext-rack-control-3
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
name: ext-rack-control-3
namespace: managed-ns
spec:
cidr: 10.77.43.0/28
gateway: 10.77.43.1
includeRanges:
- 10.77.43.3-10.77.43.13
nameservers:
- 1.2.3.4
Rack objects and ipam/RackRef labels in Machine objects are not
required for MetalLB configuration. But in this example, rack objects
are implied to be used for configuration of BGP announcement of the cluster
API load balancer address. Rack objects are not present in this example.
Machine objects select different L2 templates because each master node uses
different L2/L3 network segments for LCM, external, and other networks.
Configuration example for the Machine
test-cluster-master-1
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
name: test-cluster-master-1
namespace: managed-ns
annotations:
metal3.io/BareMetalHost: managed-ns/test-cluster-master-1
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
cluster.sigs.k8s.io/control-plane: controlplane
hostlabel.bm.kaas.mirantis.com/controlplane: controlplane
ipam/RackRef: rack-master-1
kaas.mirantis.com/provider: baremetal
spec:
providerSpec:
value:
kind: BareMetalMachineProviderSpec
apiVersion: baremetal.k8s.io/v1alpha1
hostSelector:
matchLabels:
kaas.mirantis.com/baremetalhost-id: test-cluster-master-1
l2TemplateSelector:
name: test-cluster-master-1
nodeLabels:
- key: rack-id # it is used in "nodeSelectors"
value: rack-master-1 # of "bgpPeer" MetalLB objects
Configuration example for the Machine
test-cluster-master-2
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
name: test-cluster-master-2
namespace: managed-ns
annotations:
metal3.io/BareMetalHost: managed-ns/test-cluster-master-2
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
cluster.sigs.k8s.io/control-plane: controlplane
hostlabel.bm.kaas.mirantis.com/controlplane: controlplane
ipam/RackRef: rack-master-2
kaas.mirantis.com/provider: baremetal
spec:
providerSpec:
value:
kind: BareMetalMachineProviderSpec
apiVersion: baremetal.k8s.io/v1alpha1
hostSelector:
matchLabels:
kaas.mirantis.com/baremetalhost-id: test-cluster-master-2
l2TemplateSelector:
name: test-cluster-master-2
nodeLabels:
- key: rack-id # it is used in "nodeSelectors"
value: rack-master-1 # of "bgpPeer" MetalLB objects
Configuration example for the Machine
test-cluster-master-2
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
name: test-cluster-master-3
namespace: managed-ns
annotations:
metal3.io/BareMetalHost: managed-ns/test-cluster-master-3
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
cluster.sigs.k8s.io/control-plane: controlplane
hostlabel.bm.kaas.mirantis.com/controlplane: controlplane
ipam/RackRef: rack-master-3
kaas.mirantis.com/provider: baremetal
spec:
providerSpec:
value:
kind: BareMetalMachineProviderSpec
apiVersion: baremetal.k8s.io/v1alpha1
hostSelector:
matchLabels:
kaas.mirantis.com/baremetalhost-id: test-cluster-master-3
l2TemplateSelector:
name: test-cluster-master-3
nodeLabels:
- key: rack-id # it is used in "nodeSelectors"
value: rack-master-3 # of "bgpPeer" MetalLB objects
MultiRackCluster¶
TechPreview Available since 2.24.4
This section describes the MultiRackCluster resource used in the
Container Cloud API.
When you create a bare metal managed cluster with a multi-rack topology,
where Kubernetes masters are distributed across multiple racks
without L2 layer extension between them, the MultiRackCluster resource
allows you to set cluster-wide parameters for configuration of the
BGP announcement of the cluster API load balancer address.
In this scenario, the MultiRackCluster object must be bound to the
Cluster object.
The MultiRackCluster object is generally used for a particular cluster
in conjunction with Rack objects described in Rack.
For demonstration purposes, the Container Cloud MultiRackCluster
custom resource (CR) description is split into the following major sections:
MultiRackCluster metadata¶
The Container Cloud MultiRackCluster CR metadata contains the following
fields:
apiVersionAPI version of the object that is
ipam.mirantis.com/v1alpha1.
kindObject type that is
MultiRackCluster.
metadataThe
metadatafield contains the following subfields:nameName of the
MultiRackClusterobject.
namespaceContainer Cloud project (Kubernetes namespace) in which the object was created.
labelsKey-value pairs that are attached to the object:
cluster.sigs.k8s.io/cluster-nameClusterobject name that thisMultiRackClusterobject is applied to. To enable the use of BGP announcement for the cluster API LB address, set theuseBGPAnnouncementparameter in theClusterobject totrue:spec: providerSpec: value: useBGPAnnouncement: true
kaas.mirantis.com/providerProvider name that is
baremetal.
kaas.mirantis.com/regionRegion name.
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
The MultiRackCluster metadata configuration example:
apiVersion: ipam.mirantis.com/v1alpha1
kind: MultiRackCluster
metadata:
name: multirack-test-cluster
namespace: managed-ns
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
MultiRackCluster spec¶
The spec field of the MultiRackCluster resource describes the desired
state of the object. It contains the following fields:
bgpdConfigFileNameName of the configuration file for the BGP daemon (bird). Recommended value is
bird.conf.
bgpdConfigFilePathPath to the directory where the configuration file for the BGP daemon (bird) is added. The recommended value is
/etc/bird.
bgpdConfigTemplateOptional. Configuration text file template for the BGP daemon (bird) configuration file where you can use
gotemplate constructs and the following variables:RouterID,LocalIPLocal IP on the given network, which is a key in the
Rack.spec.peeringMapdictionary, for a given node. You can use it, for example, in therouter id {{$.RouterID}};instruction.
LocalASNLocal AS number.
NeighborASNNeighbor AS number.
NeighborIPNeighbor IP address. Its values are taken from
Rack.spec.peeringMap, it can be used only inside therangeiteration through theNeighborslist.
NeighborsList of peers in the given network and node. It can be iterated through the
rangestatement in thegotemplate.
Values for
LocalASNandNeighborASNare taken from:MultiRackCluster.defaultPeer- if not used as a field inside therangeiteration through theNeighborslist.Corresponding values of
Rack.spec.peeringMap- if used as a field inside therangeiteration through theNeighborslist.
This template can be overridden using the
Rackobjects. For details, see Rack spec.
defaultPeerConfiguration parameters for the default BGP peer. These parameters will be used in rendering of the configuration file for BGP daemon from the template if they are not overridden for a particular rack or network using
Rackobjects. For details, see Rack spec.localASNMandatory. Local AS number.
neighborASNMandatory. Neighbor AS number.
neighborIPReserved. Neighbor IP address. Leave it as an empty string.
passwordOptional. Neighbor password. If not set, you can hardcode it in
bgpdConfigTemplate. It is required for MD5 authentication between BGP peers.
Configuration examples:
Since Cluster releases 17.1.0 and 16.1.0 for bird v2.x
spec:
bgpdConfigFileName: bird.conf
bgpdConfigFilePath: /etc/bird
bgpdConfigTemplate: |
protocol device {
}
#
protocol direct {
interface "lo";
ipv4;
}
#
protocol kernel {
ipv4 {
export all;
};
}
#
{{range $i, $peer := .Neighbors}}
protocol bgp 'bgp_peer_{{$i}}' {
local port 1179 as {{.LocalASN}};
neighbor {{.NeighborIP}} as {{.NeighborASN}};
ipv4 {
import none;
export filter {
if dest = RTD_UNREACHABLE then {
reject;
}
accept;
};
};
}
{{end}}
defaultPeer:
localASN: 65101
neighborASN: 65100
neighborIP: ""
Before Cluster releases 17.1.0 and 16.1.0 for bird v1.x
spec:
bgpdConfigFileName: bird.conf
bgpdConfigFilePath: /etc/bird
bgpdConfigTemplate: |
listen bgp port 1179;
protocol device {
}
#
protocol direct {
interface "lo";
}
#
protocol kernel {
export all;
}
#
{{range $i, $peer := .Neighbors}}
protocol bgp 'bgp_peer_{{$i}}' {
local as {{.LocalASN}};
neighbor {{.NeighborIP}} as {{.NeighborASN}};
import all;
export filter {
if dest = RTD_UNREACHABLE then {
reject;
}
accept;
};
}
{{end}}
defaultPeer:
localASN: 65101
neighborASN: 65100
neighborIP: ""
MultiRackCluster status¶
The status field of the MultiRackCluster resource reflects the actual
state of the MultiRackCluster object and contains the following fields:
stateSince 2.23.0Message that reflects the current status of the resource. The list of possible values includes the following:
OK- object is operational.ERR- object is non-operational. This status has a detailed description in themessageslist.TERM- object was deleted and is terminating.
messagesSince 2.23.0List of error or warning messages if the object state is
ERR.
objCreatedDate, time, and IPAM version of the resource creation.
objStatusUpdatedDate, time, and IPAM version of the last update of the
statusfield in the resource.
objUpdatedDate, time, and IPAM version of the last resource update.
Configuration example:
status:
checksums:
annotations: sha256:38e0b9de817f645c4bec37c0d4a3e58baecccb040f5718dc069a72c7385a0bed
labels: sha256:d8f8eacf487d57c22ca0ace29bd156c66941a373b5e707d671dc151959a64ce7
spec: sha256:66b5d28215bdd36723fe6230359977fbede828906c6ae96b5129a972f1fa51e9
objCreated: 2023-08-11T12:25:21.00000Z by v6.5.999-20230810-155553-2497818
objStatusUpdated: 2023-08-11T12:32:58.11966Z by v6.5.999-20230810-155553-2497818
objUpdated: 2023-08-11T12:32:57.32036Z by v6.5.999-20230810-155553-2497818
state: OK
MultiRackCluster and Rack usage examples¶
The following configuration examples of several bare metal objects illustrate how to configure BGP announcement of the load balancer address used to expose the cluster API.
In the following example, all master nodes are in a single rack. One Rack
object is required in this case for master nodes. Some worker nodes can
coexist in the same rack with master nodes or occupy separate racks. It is
implied that the useBGPAnnouncement parameter is set to true in the
corresponding Cluster object.
Configuration example for MultiRackCluster
Since Cluster releases 17.1.0 and 16.1.0 for bird v2.x:
apiVersion: ipam.mirantis.com/v1alpha1
kind: MultiRackCluster
metadata:
name: multirack-test-cluster
namespace: managed-ns
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
spec:
bgpdConfigFileName: bird.conf
bgpdConfigFilePath: /etc/bird
bgpdConfigTemplate: |
protocol device {
}
#
protocol direct {
interface "lo";
ipv4;
}
#
protocol kernel {
ipv4 {
export all;
};
}
#
{{range $i, $peer := .Neighbors}}
protocol bgp 'bgp_peer_{{$i}}' {
local port 1179 as {{.LocalASN}};
neighbor {{.NeighborIP}} as {{.NeighborASN}};
ipv4 {
import none;
export filter {
if dest = RTD_UNREACHABLE then {
reject;
}
accept;
};
};
}
{{end}}
defaultPeer:
localASN: 65101
neighborASN: 65100
neighborIP: ""
Before Cluster releases 17.1.0 and 16.1.0 for bird v1.x:
apiVersion: ipam.mirantis.com/v1alpha1
kind: MultiRackCluster
metadata:
name: multirack-test-cluster
namespace: managed-ns
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
spec:
bgpdConfigFileName: bird.conf
bgpdConfigFilePath: /etc/bird
bgpdConfigTemplate: |
listen bgp port 1179;
protocol device {
}
#
protocol direct {
interface "lo";
}
#
protocol kernel {
export all;
}
#
{{range $i, $peer := .Neighbors}}
protocol bgp 'bgp_peer_{{$i}}' {
local as {{.LocalASN}};
neighbor {{.NeighborIP}} as {{.NeighborASN}};
import all;
export filter {
if dest = RTD_UNREACHABLE then {
reject;
}
accept;
};
}
{{end}}
defaultPeer:
localASN: 65101
neighborASN: 65100
neighborIP: ""
Configuration example for Rack
apiVersion: ipam.mirantis.com/v1alpha1
kind: Rack
metadata:
name: rack-master
namespace: managed-ns
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
spec:
peeringMap:
lcm-rack-control:
peers:
- neighborIP: 10.77.31.1 # "localASN" and "neighborASN" are taken from
- neighborIP: 10.77.37.1 # "MultiRackCluster.spec.defaultPeer"
# if not set here
Configuration example for Machine
# "Machine" templates for "test-cluster-master-2" and "test-cluster-master-3"
# differ only in BMH selectors in this example.
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
name: test-cluster-master-1
namespace: managed-ns
annotations:
metal3.io/BareMetalHost: managed-ns/test-cluster-master-1
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
cluster.sigs.k8s.io/control-plane: controlplane
hostlabel.bm.kaas.mirantis.com/controlplane: controlplane
ipam/RackRef: rack-master # used to connect "IpamHost" to "Rack" objects, so that
# BGP parameters can be obtained from "Rack" to
# render BGP configuration for the given "IpamHost" object
kaas.mirantis.com/provider: baremetal
spec:
providerSpec:
value:
kind: BareMetalMachineProviderSpec
apiVersion: baremetal.k8s.io/v1alpha1
hostSelector:
matchLabels:
kaas.mirantis.com/baremetalhost-id: test-cluster-master-1
l2TemplateSelector:
name: test-cluster-master
Configuration example for L2Template
apiVersion: ipam.mirantis.com/v1alpha1
kind: L2Template
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
name: test-cluster-master
namespace: managed-ns
spec:
...
l3Layout:
- subnetName: lcm-rack-control # this network is referenced in "rack-master" Rack
scope: namespace
...
npTemplate: |
...
ethernets:
lo:
addresses:
- {{ cluster_api_lb_ip }} # function for cluster API LB IP
dhcp4: false
dhcp6: false
...
After the objects are created and nodes are provisioned, the IpamHost
objects will have BGP daemon configuration files in their status fields.
For example:
Configuration example for IpamHost
apiVersion: ipam.mirantis.com/v1alpha1
kind: IpamHost
...
status:
...
netconfigFiles:
- content: bGlzdGVuIGJncCBwb3J0IDExNzk7CnByb3RvY29sIGRldmljZSB7Cn0KIwpwcm90b2NvbCBkaXJlY3QgewogIGludGVyZmFjZSAibG8iOwp9CiMKcHJvdG9jb2wga2VybmVsIHsKICBleHBvcnQgYWxsOwp9CiMKCnByb3RvY29sIGJncCAnYmdwX3BlZXJfMCcgewogIGxvY2FsIGFzIDY1MTAxOwogIG5laWdoYm9yIDEwLjc3LjMxLjEgYXMgNjUxMDA7CiAgaW1wb3J0IGFsbDsKICBleHBvcnQgZmlsdGVyIHsKICAgIGlmIGRlc3QgPSBSVERfVU5SRUFDSEFCTEUgdGhlbiB7CiAgICAgIHJlamVjdDsKICAgIH0KICAgIGFjY2VwdDsKICB9Owp9Cgpwcm90b2NvbCBiZ3AgJ2JncF9wZWVyXzEnIHsKICBsb2NhbCBhcyA2NTEwMTsKICBuZWlnaGJvciAxMC43Ny4zNy4xIGFzIDY1MTAwOwogIGltcG9ydCBhbGw7CiAgZXhwb3J0IGZpbHRlciB7CiAgICBpZiBkZXN0ID0gUlREX1VOUkVBQ0hBQkxFIHRoZW4gewogICAgICByZWplY3Q7CiAgICB9CiAgICBhY2NlcHQ7CiAgfTsKfQoK
path: /etc/bird/bird.conf
- content: ...
path: /etc/netplan/60-kaas-lcm-netplan.yaml
netconfigFilesStates:
/etc/bird/bird.conf: 'OK: 2023-08-17T08:00:58.96140Z 25cde040e898fd5bf5b28aacb12f046b4adb510570ecf7d7fa5a8467fa4724ec'
/etc/netplan/60-kaas-lcm-netplan.yaml: 'OK: 2023-08-11T12:33:24.54439Z 37ac6e9fe13e5969f35c20c615d96b4ed156341c25e410e95831794128601e01'
...
You can decode /etc/bird/bird.conf contents and verify the configuration:
echo "<<base64-string>>" | base64 -d
The following system output applies to the above configuration examples:
Configuration example for the decoded bird.conf
Since Cluster releases 17.1.0 and 16.1.0 for bird v2.x:
protocol device {
}
#
protocol direct {
interface "lo";
ipv4;
}
#
protocol kernel {
ipv4 {
export all;
};
}
#
protocol bgp 'bgp_peer_0' {
local port 1179 as 65101;
neighbor 10.77.31.1 as 65100;
ipv4 {
import none;
export filter {
if dest = RTD_UNREACHABLE then {
reject;
}
accept;
};
};
}
protocol bgp 'bgp_peer_1' {
local port 1179 as 65101;
neighbor 10.77.37.1 as 65100;
ipv4 {
import none;
export filter {
if dest = RTD_UNREACHABLE then {
reject;
}
accept;
};
};
}
Before Cluster releases 17.1.0 and 16.1.0 for bird v1.x:
listen bgp port 1179;
protocol device {
}
#
protocol direct {
interface "lo";
}
#
protocol kernel {
export all;
}
#
protocol bgp 'bgp_peer_0' {
local as 65101;
neighbor 10.77.31.1 as 65100;
import all;
export filter {
if dest = RTD_UNREACHABLE then {
reject;
}
accept;
};
}
protocol bgp 'bgp_peer_1' {
local as 65101;
neighbor 10.77.37.1 as 65100;
import all;
export filter {
if dest = RTD_UNREACHABLE then {
reject;
}
accept;
};
}
BGP daemon configuration files are copied from IpamHost.status
to the corresponding LCMMachine object the same way as it is done for
netplan configuration files. Then, the configuration files are written to the
corresponding node by the LCM-Agent.
In the following configuration example, each master node is located in its own
rack. Three Rack objects are required in this case for master nodes.
Some worker nodes can coexist in the same racks with master nodes or occupy
separate racks.
Only objects that are required to show configuration for BGP announcement
of the cluster API load balancer address are provided here.
For the description of Rack, MetalLBConfig,
and other objects that are required for MetalLB configuration in this scenario,
refer to Configuration example for using BGP announcement.
It is implied that the useBGPAnnouncement parameter is set to true
in the corresponding Cluster object.
Configuration example for MultiRackCluster
Since Cluster releases 17.1.0 and 16.1.0 for bird v2.x:
# It is the same object as in the single rack example.
apiVersion: ipam.mirantis.com/v1alpha1
kind: MultiRackCluster
metadata:
name: multirack-test-cluster
namespace: managed-ns
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
spec:
bgpdConfigFileName: bird.conf
bgpdConfigFilePath: /etc/bird
bgpdConfigTemplate: |
protocol device {
}
#
protocol direct {
interface "lo";
ipv4;
}
#
protocol kernel {
ipv4 {
export all;
};
}
#
{{range $i, $peer := .Neighbors}}
protocol bgp 'bgp_peer_{{$i}}' {
local port 1179 as {{.LocalASN}};
neighbor {{.NeighborIP}} as {{.NeighborASN}};
ipv4 {
import none;
export filter {
if dest = RTD_UNREACHABLE then {
reject;
}
accept;
};
};
}
{{end}}
defaultPeer:
localASN: 65101
neighborASN: 65100
neighborIP: ""
Before Cluster releases 17.1.0 and 16.1.0 for bird v1.x:
# It is the same object as in the single rack example.
apiVersion: ipam.mirantis.com/v1alpha1
kind: MultiRackCluster
metadata:
name: multirack-test-cluster
namespace: managed-ns
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
spec:
bgpdConfigFileName: bird.conf
bgpdConfigFilePath: /etc/bird
bgpdConfigTemplate: |
listen bgp port 1179;
protocol device {
}
#
protocol direct {
interface "lo";
}
#
protocol kernel {
export all;
}
#
{{range $i, $peer := .Neighbors}}
protocol bgp 'bgp_peer_{{$i}}' {
local as {{.LocalASN}};
neighbor {{.NeighborIP}} as {{.NeighborASN}};
import all;
export filter {
if dest = RTD_UNREACHABLE then {
reject;
}
accept;
};
}
{{end}}
defaultPeer:
localASN: 65101
neighborASN: 65100
neighborIP: ""
The following Rack objects differ in neighbor IP addresses and in the
network (L3 subnet) used for BGP connection to announce the cluster API LB IP
and for cluster API traffic.
Configuration example for Rack 1
apiVersion: ipam.mirantis.com/v1alpha1
kind: Rack
metadata:
name: rack-master-1
namespace: managed-ns
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
spec:
peeringMap:
lcm-rack-control-1:
peers:
- neighborIP: 10.77.31.2 # "localASN" and "neighborASN" are taken from
- neighborIP: 10.77.31.3 # "MultiRackCluster.spec.defaultPeer" if
# not set here
Configuration example for Rack 2
apiVersion: ipam.mirantis.com/v1alpha1
kind: Rack
metadata:
name: rack-master-2
namespace: managed-ns
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
spec:
peeringMap:
lcm-rack-control-2:
peers:
- neighborIP: 10.77.32.2 # "localASN" and "neighborASN" are taken from
- neighborIP: 10.77.32.3 # "MultiRackCluster.spec.defaultPeer" if
# not set here
Configuration example for Rack 3
apiVersion: ipam.mirantis.com/v1alpha1
kind: Rack
metadata:
name: rack-master-3
namespace: managed-ns
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
spec:
peeringMap:
lcm-rack-control-3:
peers:
- neighborIP: 10.77.33.2 # "localASN" and "neighborASN" are taken from
- neighborIP: 10.77.33.3 # "MultiRackCluster.spec.defaultPeer" if
# not set here
As compared to single rack examples, the following Machine objects differ
in:
BMH selectors
L2Template selectors
Rack selectors (the
ipam/RackReflabel)The
rack-idnode labelsThe labels on master nodes are required for MetalLB node selectors if MetalLB is used to announce LB IP addresses on master nodes. In this scenario, the L2 (ARP) announcement mode cannot be used for MetalLB because master nodes are in different L2 segments. So, the BGP announcement mode must be used for MetalLB. Node selectors are required to properly configure BGP connections from each master node.
Configuration example for Machine 1
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
name: test-cluster-master-1
namespace: managed-ns
annotations:
metal3.io/BareMetalHost: managed-ns/test-cluster-master-1
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
cluster.sigs.k8s.io/control-plane: controlplane
hostlabel.bm.kaas.mirantis.com/controlplane: controlplane
ipam/RackRef: rack-master-1
kaas.mirantis.com/provider: baremetal
spec:
providerSpec:
value:
kind: BareMetalMachineProviderSpec
apiVersion: baremetal.k8s.io/v1alpha1
hostSelector:
matchLabels:
kaas.mirantis.com/baremetalhost-id: test-cluster-master-1
l2TemplateSelector:
name: test-cluster-master-1
nodeLabels: # not used for BGP announcement of the
- key: rack-id # cluster API LB IP but can be used for
value: rack-master-1 # MetalLB if "nodeSelectors" are required
Configuration example for Machine 2
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
name: test-cluster-master-2
namespace: managed-ns
annotations:
metal3.io/BareMetalHost: managed-ns/test-cluster-master-2
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
cluster.sigs.k8s.io/control-plane: controlplane
hostlabel.bm.kaas.mirantis.com/controlplane: controlplane
ipam/RackRef: rack-master-2
kaas.mirantis.com/provider: baremetal
spec:
providerSpec:
value:
kind: BareMetalMachineProviderSpec
apiVersion: baremetal.k8s.io/v1alpha1
hostSelector:
matchLabels:
kaas.mirantis.com/baremetalhost-id: test-cluster-master-2
l2TemplateSelector:
name: test-cluster-master-2
nodeLabels: # not used for BGP announcement of the
- key: rack-id # cluster API LB IP but can be used for
value: rack-master-2 # MetalLB if "nodeSelectors" are required
Configuration example for Machine 3
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
name: test-cluster-master-3
namespace: managed-ns
annotations:
metal3.io/BareMetalHost: managed-ns/test-cluster-master-3
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
cluster.sigs.k8s.io/control-plane: controlplane
hostlabel.bm.kaas.mirantis.com/controlplane: controlplane
ipam/RackRef: rack-master-3
kaas.mirantis.com/provider: baremetal
spec:
providerSpec:
value:
kind: BareMetalMachineProviderSpec
apiVersion: baremetal.k8s.io/v1alpha1
hostSelector:
matchLabels:
kaas.mirantis.com/baremetalhost-id: test-cluster-master-3
l2TemplateSelector:
name: test-cluster-master-3
nodeLabels: # optional. not used for BGP announcement of
- key: rack-id # the cluster API LB IP but can be used for
value: rack-master-3 # MetalLB if "nodeSelectors" are required
Configuration example for Subnet defining the cluster API
LB IP address
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: test-cluster-api-lb
namespace: managed-ns
labels:
kaas.mirantis.com/provider: baremetal
ipam/SVC-LBhost: "1"
cluster.sigs.k8s.io/cluster-name: test-cluster
spec:
cidr: 134.33.24.201/32
useWholeCidr: true
Configuration example for Subnet of the LCM network in the
rack-master-1 rack
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
name: lcm-rack-control-1
namespace: managed-ns
spec:
cidr: 10.77.31.0/28
gateway: 10.77.31.1
includeRanges:
- 10.77.31.4-10.77.31.13
nameservers:
- 1.2.3.4
Configuration example for Subnet of the LCM network in the
rack-master-2 rack
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
name: lcm-rack-control-2
namespace: managed-ns
spec:
cidr: 10.77.32.0/28
gateway: 10.77.32.1
includeRanges:
- 10.77.32.4-10.77.32.13
nameservers:
- 1.2.3.4
Configuration example for Subnet of the LCM network in the
rack-master-3 rack
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
name: lcm-rack-control-3
namespace: managed-ns
spec:
cidr: 10.77.33.0/28
gateway: 10.77.33.1
includeRanges:
- 10.77.33.4-10.77.33.13
nameservers:
- 1.2.3.4
The following L2Template objects differ in LCM and external subnets that
each master node uses.
Configuration example for L2Template 1
apiVersion: ipam.mirantis.com/v1alpha1
kind: L2Template
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
name: test-cluster-master-1
namespace: managed-ns
spec:
...
l3Layout:
- subnetName: lcm-rack-control-1 # this network is referenced
scope: namespace # in the "rack-master-1" Rack
- subnetName: ext-rack-control-1 # this optional network is used for
scope: namespace # Kubernetes services traffic and
# MetalLB BGP connections
...
npTemplate: |
...
ethernets:
lo:
addresses:
- {{ cluster_api_lb_ip }} # function for cluster API LB IP
dhcp4: false
dhcp6: false
...
Configuration example for L2Template 2
apiVersion: ipam.mirantis.com/v1alpha1
kind: L2Template
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
name: test-cluster-master-2
namespace: managed-ns
spec:
...
l3Layout:
- subnetName: lcm-rack-control-2 # this network is referenced
scope: namespace # in "rack-master-2" Rack
- subnetName: ext-rack-control-2 # this network is used for Kubernetes services
scope: namespace # traffic and MetalLB BGP connections
...
npTemplate: |
...
ethernets:
lo:
addresses:
- {{ cluster_api_lb_ip }} # function for cluster API LB IP
dhcp4: false
dhcp6: false
...
Configuration example for L2Template 3
apiVersion: ipam.mirantis.com/v1alpha1
kind: L2Template
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
name: test-cluster-master-3
namespace: managed-ns
spec:
...
l3Layout:
- subnetName: lcm-rack-control-3 # this network is referenced
scope: namespace # in "rack-master-3" Rack
- subnetName: ext-rack-control-3 # this network is used for Kubernetes services
scope: namespace # traffic and MetalLB BGP connections
...
npTemplate: |
...
ethernets:
lo:
addresses:
- {{ cluster_api_lb_ip }} # function for cluster API LB IP
dhcp4: false
dhcp6: false
...
The following MetalLBConfig example illustrates how node labels
are used in nodeSelectors of bgpPeers. Each of bgpPeers
corresponds to one of master nodes.
Configuration example for MetalLBConfig
apiVersion: ipam.mirantis.com/v1alpha1
kind: MetalLBConfig
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
name: test-cluster-metallb-config
namespace: managed-ns
spec:
...
bgpPeers:
- name: svc-peer-rack1
spec:
holdTime: 0s
keepaliveTime: 0s
peerAddress: 10.77.41.1 # peer address is in external subnet
# instead of LCM subnet used for BGP
# connection to announce cluster API LB IP
peerASN: 65100 # the same as for BGP connection used to announce
# cluster API LB IP
myASN: 65101 # the same as for BGP connection used to announce
# cluster API LB IP
nodeSelectors:
- matchLabels:
rack-id: rack-master-1 # references the node corresponding
# to "test-cluster-master-1" Machine
- name: svc-peer-rack2
spec:
holdTime: 0s
keepaliveTime: 0s
peerAddress: 10.77.42.1
peerASN: 65100
myASN: 65101
nodeSelectors:
- matchLabels:
rack-id: rack-master-1
- name: svc-peer-rack3
spec:
holdTime: 0s
keepaliveTime: 0s
peerAddress: 10.77.43.1
peerASN: 65100
myASN: 65101
nodeSelectors:
- matchLabels:
rack-id: rack-master-1
...
After the objects are created and nodes are provisioned, the IpamHost
objects will have BGP daemon configuration files in their status fields.
Refer to Single rack configuration example on how to verify the BGP configuration
files.
Rack¶
TechPreview Available since 2.24.4
This section describes the Rack resource used in the Container Cloud API.
When you create a bare metal managed cluster with a multi-rack topology,
where Kubernetes masters are distributed across multiple racks
without L2 layer extension between them, the Rack resource allows you
to configure BGP announcement of the cluster API load balancer address from
each rack.
In this scenario, Rack objects must be bound to Machine objects
corresponding to master nodes of the cluster. Each Rack object describes
the configuration of the BGP daemon (bird) used to announce the cluster API LB
address from a particular master node (or from several nodes in the same rack).
Rack objects are used for a particular cluster only in conjunction with
the MultiRackCluster object described in MultiRackCluster.
For demonstration purposes, the Container Cloud Rack custom resource (CR)
description is split into the following major sections:
For configuration examples, see MultiRackCluster and Rack usage examples.
Rack metadata¶
The Container Cloud Rack CR metadata contains the following fields:
apiVersionAPI version of the object that is
ipam.mirantis.com/v1alpha1.
kindObject type that is
Rack.
metadataThe
metadatafield contains the following subfields:nameName of the
Rackobject. CorrespondingMachineobjects must have theiripam/RackReflabel value set to the name of theRackobject. This label is required only forMachineobjects of the master nodes that announce the cluster API LB address.
namespaceContainer Cloud project (Kubernetes namespace) where the object was created.
labelsKey-value pairs that are attached to the object:
cluster.sigs.k8s.io/cluster-nameClusterobject name that thisRackobject is applied to.
kaas.mirantis.com/providerProvider name that is
baremetal.
kaas.mirantis.com/regionRegion name.
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Rack metadata example:
apiVersion: ipam.mirantis.com/v1alpha1
kind: Rack
metadata:
name: rack-1
namespace: managed-ns
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
kaas.mirantis.com/provider: baremetal
Corresponding Machine metadata example:
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: test-cluster
cluster.sigs.k8s.io/control-plane: controlplane
hostlabel.bm.kaas.mirantis.com/controlplane: controlplane
ipam/RackRef: rack-1
kaas.mirantis.com/provider: baremetal
name: managed-master-1-control-efi-6tg52
namespace: managed-ns
Rack spec¶
The spec field of the Rack resource describes the desired
state of the object. It contains the following fields:
bgpdConfigTemplateOptional. Configuration file template that will be used to create configuration file for a BGP daemon on nodes in this rack. If not set, the configuration file template from the corresponding
MultiRackClusterobject is used.
peeringMapStructure that describes general parameters of BGP peers to be used in the configuration file for a BGP daemon for each network where BGP announcement is used. Also, you can define a separate configuration file template for the BGP daemon for each of those networks. The
peeringMapstructure is as follows:peeringMap: <network-name-a>: peers: - localASN: <localASN-1> neighborASN: <neighborASN-1> neighborIP: <neighborIP-1> password: <password-1> - localASN: <localASN-2> neighborASN: <neighborASN-2> neighborIP: <neighborIP-2> password: <password-2> bgpdConfigTemplate: | <configuration file template for a BGP daemon> ...
<network-name-a>Name of the network where a BGP daemon should connect to the neighbor BGP peers. By default, it is implied that the same network is used on the node to make connection to the neighbor BGP peers as well as to receive and respond to the traffic directed to the IP address being advertised. In our scenario, the advertised IP address is the cluster API LB IP address.
This network name must be the same as the subnet name used in the L2 template (
l3Layoutsection) for the corresponding master node(s).
peersOptional. List of dictionaries where each dictionary defines configuration parameters for a particular BGP peer. Peer parameters are as follows:
localASNOptional. Local AS number. If not set, it can be taken from
MultiRackCluster.spec.defaultPeeror can be hardcoded inbgpdConfigTemplate.
neighborASNOptional. Neighbor AS number. If not set, it can be taken from
MultiRackCluster.spec.defaultPeeror can be hardcoded inbgpdConfigTemplate.
neighborIPMandatory. Neighbor IP address.
passwordOptional. Neighbor password. If not set, it can be taken from
MultiRackCluster.spec.defaultPeeror can be hardcoded inbgpdConfigTemplate. It is required when MD5 authentication between BGP peers is used.
bgpdConfigTemplateOptional. Configuration file template that will be used to create the configuration file for the BGP daemon of the
network-name-anetwork on a particular node. If not set,Rack.spec.bgpdConfigTemplateis used.
Configuration example:
Since Cluster releases 17.1.0 and 16.1.0 for bird v2.x
spec:
bgpdConfigTemplate: |
protocol device {
}
#
protocol direct {
interface "lo";
ipv4;
}
#
protocol kernel {
ipv4 {
export all;
};
}
#
protocol bgp bgp_lcm {
local port 1179 as {{.LocalASN}};
neighbor {{.NeighborIP}} as {{.NeighborASN}};
ipv4 {
import none;
export filter {
if dest = RTD_UNREACHABLE then {
reject;
}
accept;
};
};
}
peeringMap:
lcm-rack1:
peers:
- localASN: 65050
neighborASN: 65011
neighborIP: 10.77.31.1
Before Cluster releases 17.1.0 and 16.1.0 for bird v1.x
spec:
bgpdConfigTemplate: |
listen bgp port 1179;
protocol device {
}
#
protocol direct {
interface "lo";
}
#
protocol kernel {
export all;
}
#
protocol bgp bgp_lcm {
local as {{.LocalASN}};
neighbor {{.NeighborIP}} as {{.NeighborASN}};
import all;
export filter {
if dest = RTD_UNREACHABLE then {
reject;
}
accept;
};
}
peeringMap:
lcm-rack1:
peers:
- localASN: 65050
neighborASN: 65011
neighborIP: 10.77.31.1
Rack status¶
The status field of the Rack resource reflects the actual state
of the Rack object and contains the following fields:
stateSince 2.23.0Message that reflects the current status of the resource. The list of possible values includes the following:
OK- object is operational.ERR- object is non-operational. This status has a detailed description in themessageslist.TERM- object was deleted and is terminating.
messagesSince 2.23.0List of error or warning messages if the object state is
ERR.
objCreatedDate, time, and IPAM version of the resource creation.
objStatusUpdatedDate, time, and IPAM version of the last update of the
statusfield in the resource.
objUpdatedDate, time, and IPAM version of the last resource update.
Configuration example:
status:
checksums:
annotations: sha256:cd4b751d9773eacbfd5493712db0cbebd6df0762156aefa502d65a9d5e8af31d
labels: sha256:fc2612d12253443955e1bf929f437245d304b483974ff02a165bc5c78363f739
spec: sha256:8f0223b1eefb6a9cd583905a25822fd83ac544e62e1dfef26ee798834ef4c0c1
objCreated: 2023-08-11T12:25:21.00000Z by v6.5.999-20230810-155553-2497818
objStatusUpdated: 2023-08-11T12:33:00.92163Z by v6.5.999-20230810-155553-2497818
objUpdated: 2023-08-11T12:32:59.11951Z by v6.5.999-20230810-155553-2497818
state: OK
Subnet¶
This section describes the Subnet resource used in Mirantis
Container Cloud API to allocate IP addresses for the cluster nodes.
For demonstration purposes, the Container Cloud Subnet
custom resource (CR) can be split into the following major sections:
Subnet metadata¶
The Container Cloud Subnet CR contains the following fields:
apiVersionAPI version of the object that is
ipam.mirantis.com/v1alpha1.
kindObject type that is
Subnet
metadataThis field contains the following subfields:
nameName of the
Subnetobject.
namespaceProject in which the
Subnetobject was created.
labelsKey-value pairs that are attached to the object:
ipam/DefaultSubnet: "1"Deprecated since 2.14.0Indicates that this subnet was automatically created for the PXE network.
ipam/UIDUnique ID of a subnet.
kaas.mirantis.com/providerProvider type.
kaas.mirantis.com/regionRegion name.
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Configuration example:
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: kaas-mgmt
namespace: default
labels:
ipam/UID: 1bae269c-c507-4404-b534-2c135edaebf5
kaas.mirantis.com/provider: baremetal
Subnet spec¶
The spec field of the Subnet resource describes the desired state of
a subnet. It contains the following fields:
cidrA valid IPv4 CIDR, for example,
10.11.0.0/24.
gatewayA valid gateway address, for example,
10.11.0.9.
includeRangesA comma-separated list of IP address ranges within the given CIDR that should be used in the allocation of IPs for nodes. The gateway, network, broadcast, and DNSaddresses will be excluded (protected) automatically if they intersect with one of the range. The IPs outside the given ranges will not be used in the allocation. Each element of the list can be either an interval
10.11.0.5-10.11.0.70or a single address10.11.0.77. TheincludeRangesparameter is mutually exclusive withexcludeRanges.
excludeRangesA comma-separated list of IP address ranges within the given CIDR that should not be used in the allocation of IPs for nodes. The IPs within the given CIDR but outside the given ranges will be used in the allocation. The gateway, network, broadcast, and DNS addresses will be excluded (protected) automatically if they are included in the CIDR. Each element of the list can be either an interval
10.11.0.5-10.11.0.70or a single address10.11.0.77. TheexcludeRangesparameter is mutually exclusive withincludeRanges.
useWholeCidrIf set to
false(by default), the subnet address and broadcast address will be excluded from the address allocation. If set totrue, the subnet address and the broadcast address are included into the address allocation for nodes.
nameserversThe list of IP addresses of name servers. Each element of the list is a single address, for example,
172.18.176.6.
Configuration example:
spec:
cidr: 172.16.48.0/24
excludeRanges:
- 172.16.48.99
- 172.16.48.101-172.16.48.145
gateway: 172.16.48.1
nameservers:
- 172.18.176.6
Subnet status¶
The status field of the Subnet resource describes the actual state of
a subnet. It contains the following fields:
allocatableThe number of IP addresses that are available for allocation.
allocatedIPsThe list of allocated IP addresses in the
IP:<IPAddr object UID>format.
capacityThe total number of IP addresses to be allocated, including the sum of allocatable and already allocated IP addresses.
cidrThe IPv4 CIDR for a subnet.
gatewayThe gateway address for a subnet.
nameserversThe list of IP addresses of name servers.
rangesThe list of IP address ranges within the given CIDR that are used in the allocation of IPs for nodes.
statusMessageDeprecated since Container Cloud 2.23.0 and will be removed in one of the following releases in favor of
stateandmessages. Since Container Cloud 2.24.0, this field is not set for the subnets of newly created clusters. For the field description, seestate.
stateSince 2.23.0Message that reflects the current status of the resource. The list of possible values includes the following:
OK- object is operational.ERR- object is non-operational. This status has a detailed description in themessageslist.TERM- object was deleted and is terminating.
messagesSince 2.23.0List of error or warning messages if the object state is
ERR.
objCreatedDate, time, and IPAM version of the resource creation.
objStatusUpdatedDate, time, and IPAM version of the last update of the
statusfield in the resource.
objUpdatedDate, time, and IPAM version of the last resource update.
Configuration example:
status:
allocatable: 51
allocatedIPs:
- 172.16.48.200:24e94698-f726-11ea-a717-0242c0a85b02
- 172.16.48.201:2bb62373-f726-11ea-a717-0242c0a85b02
- 172.16.48.202:37806659-f726-11ea-a717-0242c0a85b02
capacity: 54
cidr: 172.16.48.0/24
gateway: 172.16.48.1
nameservers:
- 172.18.176.6
ranges:
- 172.16.48.200-172.16.48.253
objCreated: 2021-10-21T19:09:32Z by v5.1.0-20210930-121522-f5b2af8
objStatusUpdated: 2021-10-21T19:14:18.748114886Z by v5.1.0-20210930-121522-f5b2af8
objUpdated: 2021-10-21T19:09:32.606968024Z by v5.1.0-20210930-121522-f5b2af8
state: OK
SubnetPool¶
Deprecated since 2.27.0 (17.2.0 and 16.2.0)
Warning
The SubnetPool object may not work as expected due to its
deprecation. If you still require this feature, contact Mirantis support
for further information.
Existing configurations that use the SubnetPool object in L2Template
will be automatically migrated during cluster update to the Cluster release
17.2.0 or 16.2.0. As a result of migration, existing Subnet objects will
be referenced in L2Template objects instead of SubnetPool.
This section describes the SubnetPool resource used in
Mirantis Container Cloud API to manage a pool of addresses
from which subnets can be allocated.
For demonstration purposes, the Container Cloud SubnetPool
custom resource (CR) is split into the following major sections:
SubnetPool metadata¶
The Container Cloud SubnetPool CR contains the following fields:
apiVersionAPI version of the object that is
ipam.mirantis.com/v1alpha1.
kindObject type that is
SubnetPool.
metadataThe
metadatafield contains the following subfields:nameName of the
SubnetPoolobject.
namespaceProject in which the
SubnetPoolobject was created.
labelsKey-value pairs that are attached to the object:
kaas.mirantis.com/providerProvider type that is
baremetal.
kaas.mirantis.com/regionRegion name.
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Configuration example:
apiVersion: ipam.mirantis.com/v1alpha1
kind: SubnetPool
metadata:
name: kaas-mgmt
namespace: default
labels:
kaas.mirantis.com/provider: baremetal
SubnetPool spec¶
The spec field of the SubnetPool resource describes the desired state
of a subnet pool. It contains the following fields:
cidrValid IPv4 CIDR. For example, 10.10.0.0/16.
blockSizeIP address block size to use when assigning an IP address block to every new child
Subnetobject. For example, if you set/25, every new childSubnetwill have 128 IPs to allocate. Possible values are from/29to thecidrsize. Immutable.
nameserversOptional. List of IP addresses of name servers to use for every new child
Subnetobject. Each element of the list is a single address, for example, 172.18.176.6. Default: empty.
gatewayPolicyOptional. Method of assigning a gateway address to new child
Subnetobjects. Default:none. Possible values are:first- first IP of the IP address block assigned to a childSubnet, for example, 10.11.10.1.last- last IP of the IP address block assigned to a childSubnet, for example, 10.11.10.254.none- no gateway address.
Configuration example:
spec:
cidr: 10.10.0.0/16
blockSize: /25
nameservers:
- 172.18.176.6
gatewayPolicy: first
SubnetPool status¶
The status field of the SubnetPool resource describes the actual state
of a subnet pool. It contains the following fields:
allocatedSubnetsList of allocated subnets. Each subnet has the
<CIDR>:<SUBNET_UID>format.
blockSizeBlock size to use for IP address assignments from the defined pool.
capacityTotal number of IP addresses to be allocated. Includes the number of allocatable and already allocated IP addresses.
allocatableNumber of subnets with the
blockSizesize that are available for allocation.
stateSince 2.23.0Message that reflects the current status of the resource. The list of possible values includes the following:
OK- object is operational.ERR- object is non-operational. This status has a detailed description in themessageslist.TERM- object was deleted and is terminating.
messagesSince 2.23.0List of error or warning messages if the object state is
ERR.
objCreatedDate, time, and IPAM version of the resource creation.
objStatusUpdatedDate, time, and IPAM version of the last update of the
statusfield in the resource.
objUpdatedDate, time, and IPAM version of the last resource update.
Example:
status:
allocatedSubnets:
- 10.10.0.0/24:0272bfa9-19de-11eb-b591-0242ac110002
blockSize: /24
capacity: 54
allocatable: 51
objCreated: 2021-10-21T19:09:32Z by v5.1.0-20210930-121522-f5b2af8
objStatusUpdated: 2021-10-21T19:14:18.748114886Z by v5.1.0-20210930-121522-f5b2af8
objUpdated: 2021-10-21T19:09:32.606968024Z by v5.1.0-20210930-121522-f5b2af8
state: OK
vSphere resources¶
This section contains descriptions and examples of the VMware vSphere-based Kubernetes resources for Mirantis Container Cloud.
VsphereCredential¶
This section describes the VsphereCredential custom resource (CR)
used in Mirantis Container Cloud API. It contains all information
necessary to connect to a provider backend.
Warning
The kubectl apply command automatically saves the
applied data as plain text into the
kubectl.kubernetes.io/last-applied-configuration annotation of the
corresponding object. This may result in revealing sensitive data in this
annotation when creating or modifying the object.
Therefore, do not use kubectl apply on this object. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on this object, you
can remove the kubectl.kubernetes.io/last-applied-configuration
annotation from the object using kubectl edit.
For demonstration purposes, the Container Cloud VsphereCredential
custom resource (CR) can be split into the following sections:
Warning
The fields in this resource are available for viewing only. They are automatically generated by the vSphere cloud provider and must not be modified using the Container Cloud API.
metadata¶
The Container Cloud VsphereCredential custom resource (CR) contains the following
fields:
apiVersionObject API version that is
kaas.mirantis.com/v1alpha1.
kindObject type that is
VsphereCredential.
The metadata object field of the VsphereCredential resource contains
the following fields:
nameName of the
VsphereCredentialobject
namespaceContainer Cloud project in which the
VsphereCredentialobject has been created
labelskaas.mirantis.com/regional-credentialMust be
trueto useVsphereCredentialfor the management clusterNote
The
kaas.mirantis.com/regional-credentiallabel is removed from in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
kaas.mirantis.com/regionRegion name
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
Configuration example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: VsphereCredential
metadata:
name: demo
namespace: test
labels:
kaas.mirantis.com/regional-credential: "true"
VsphereCredential configuration¶
The spec object field of the VsphereCredential resource contains
configuration and authentication details for the vSphere server.
It contains the following fields:
vspherevSphere server information:
serverIP or host name of the vSphere server.
portvSphere server port.
insecureSSL certificate verification for connection. Possible values are
falseto enable andtrueto disable verification.
datacentervSphere Data center name.
clusterApiCredentials of the user that manages vSphere virtual machines:
usernameKey name in the secret.
passwordReference to the secret that contains the user password.
valueUser password.
cloudProviderCredentials of the user that manages storage and volumes for Kubernetes.
usernameKey name in the secret.
passwordReference to the secret that contains the user password.
valueUser password.
Configuration example:
...
spec:
vsphere:
server: vcenter.server.example.org
port: "443"
insecure: true
datacenter: example
clusterApi:
username: vm-user
password: vm-user-password
cloudProvider:
username: storage-user
password: storage-user-password
Cluster¶
This section describes the vSphere Cluster resource used in Mirantis
Container Cloud API. The Cluster resource describes the cluster-level
parameters.
For demonstration purposes, the vSphere Cluster custom resource (CR) can
be split into the following major sections:
Warning
The fields in this resource are available for viewing only. They are automatically generated by the vSphere cloud provider and must not be modified using the Container Cloud API.
metadata¶
The Container Cloud Cluster custom resource (CR) contains the following
fields:
apiVersionObject API version that is
cluster.k8s.io/v1alpha1.
kindObject type that is
Cluster.
The metadata object field of the Cluster resource contains
the following fields:
nameCluster name that is set using the Cluster Name field of the Create Cluster wizard in the Container Cloud web UI. For a management cluster, the cluster name can be also set using
cluster.yaml.template.
namespaceNamespace in which the
Clusterobject is created. Management clusters are created in thedefaultnamespace. The namespace of a managed cluster matches the selected Project name in the Container Cloud web UI.
labelsKey-value pairs attached to the object:
kaas.mirantis.com/providerProvider type that is
vspherefor the vSphere-based clusters.
kaas.mirantis.com/regionRegion name. The default region name for a management cluster is
region-one.Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
Configuration example:
apiVersion: cluster.k8s.io/v1alpha1
kind: Cluster
metadata:
name: demo
namespace: test
labels:
kaas.mirantis.com/provider: vsphere
spec:providerSpec¶
The providerSpec object field of the Cluster resource
contains all required details to create the cluster-level resources.
It also contains fields required for LCM deployment and
the Container Cloud components integration.
The providerSpec object field is custom for each cloud provider and
contains the following generic fields:
apiVersionvsphere.cluster.k8s.io/v1alpha1
kindObject type that is
VsphereClusterProviderSpec
Configuration example:
spec:
...
providerSpec:
value:
apiVersion: vsphere.cluster.k8s.io/v1alpha1
kind: VsphereClusterProviderSpec
spec:providerSpec common¶
The common providerSpec object field of the Cluster resource
contains the following fields:
credentialsName of the
VsphereCredentialobject used by the cluster to connect to the provider backend
dedicatedControlPlaneCluster control plane nodes to be tainted, defaults to
true
publicKeysList of the
PublicKeyresource referencesnamePublic key name
releaseName of the
ClusterReleaseobject to install on a cluster
helmReleasesList of enabled Helm releases from the
Releaseobject that run on a cluster
proxyName of the
Proxyobject
tlsTLS configuration for endpoints of a cluster
keycloakKeyCloak endpoint
tlsConfigRefReference to the
TLSConfigobject
uiWeb UI endpoint
tlsConfigRefReference to the
TLSConfigobject
For more details, see TLSConfig resource.
maintenanceMaintenance mode of a cluster. Prepares a cluster for maintenance and enables the possibility to switch machines into maintenance mode.
containerRegistriesList of the
ContainerRegistriesresources names.
ntpEnabledNTP server mode. Boolean, enabled by default.
Since Container Cloud 2.23.0, you can optionally disable NTP to disable the management of
chronyconfiguration by Container Cloud and use your own system forchronymanagement. Otherwise, configure the regional NTP server parameters to be applied to all machines of managed clusters.Before Container Cloud 2.23.0, you can optionally configure NTP parameters if servers from the Ubuntu NTP pool (
*.ubuntu.pool.ntp.org) are accessible from the node where a management cluster is being provisioned. Otherwise, this configuration is mandatory.NTP configuration
Configure the regional NTP server parameters to be applied to all machines of managed clusters.
In the
Clusterobject, add thentp:serverssection with the list of required server names:spec: ... providerSpec: value: kaas: ... ntpEnabled: true regional: - helmReleases: - name: <providerName>-provider values: config: lcm: ... ntp: servers: - 0.pool.ntp.org ... provider: <providerName> ...
To disable NTP:
spec: ... providerSpec: value: ... ntpEnabled: false ...
auditSince 2.24.0 as TechPreviewOptional. Auditing tools enabled on the cluster. Contains the
auditdfield that enables the Linux Audit daemon auditd to monitor activity of cluster processes and prevent potential malicious activity.Configuration for auditd
In the
Clusterobject, add the auditd parameters:spec: providerSpec: value: audit: auditd: enabled: <bool> enabledAtBoot: <bool> backlogLimit: <int> maxLogFile: <int> maxLogFileAction: <string> maxLogFileKeep: <int> mayHaltSystem: <bool> presetRules: <string> customRules: <string> customRulesX32: <text> customRulesX64: <text>
Configuration parameters for auditd:
enabledBoolean, default -
false. Enables theauditdrole to install the auditd packages and configure rules. CIS rules: 4.1.1.1, 4.1.1.2.enabledAtBootBoolean, default -
false. Configures grub to audit processes that can be audited even if they start up prior to auditd startup. CIS rule: 4.1.1.3.backlogLimitInteger, default - none. Configures the backlog to hold records. If during boot
audit=1is configured, the backlog holds 64 records. If more than 64 records are created during boot, auditd records will be lost with a potential malicious activity being undetected. CIS rule: 4.1.1.4.maxLogFileInteger, default - none. Configures the maximum size of the audit log file. Once the log reaches the maximum size, it is rotated and a new log file is created. CIS rule: 4.1.2.1.
maxLogFileActionString, default - none. Defines handling of the audit log file reaching the maximum file size. Allowed values:
keep_logs- rotate logs but never delete themrotate- add a cron job to compress rotated log files and keep maximum 5 compressed files.compress- compress log files and keep them under the/var/log/auditd/directory. Requiresauditd_max_log_file_keepto be enabled.
CIS rule: 4.1.2.2.
maxLogFileKeepInteger, default -
5. Defines the number of compressed log files to keep under the/var/log/auditd/directory. Requiresauditd_max_log_file_action=compress. CIS rules - none.mayHaltSystemBoolean, default -
false. Halts the system when the audit logs are full. Applies the following configuration:space_left_action = emailaction_mail_acct = rootadmin_space_left_action = halt
CIS rule: 4.1.2.3.
customRulesString, default - none. Base64-encoded content of the
60-custom.rulesfile for any architecture. CIS rules - none.customRulesX32String, default - none. Base64-encoded content of the
60-custom.rulesfile for thei386architecture. CIS rules - none.customRulesX64String, default - none. Base64-encoded content of the
60-custom.rulesfile for thex86_64architecture. CIS rules - none.presetRulesString, default - none. Comma-separated list of the following built-in preset rules:
accessactionsdeletedocker
identityimmutableloginsmac-policy
modulesmountsperm-modprivileged
scopesessionsystem-localetime-change
You can use two keywords for these rules:
none- disables all built-in rules.all- enables all built-in rules. With this key, you can add the!prefix to a rule name to exclude some rules. You can use the!prefix for rules only if you add theallkeyword as the first rule. Place a rule with the!prefix only after theallkeyword.
Example configurations:
presetRules: none- disable all preset rulespresetRules: docker- enable only thedockerrulespresetRules: access,actions,logins- enable only theaccess,actions, andloginsrulespresetRules: all- enable all preset rulespresetRules: all,!immutable,!sessions- enable all preset rules exceptimmutableandsessions
CIS controls
4.1.3 (time-change)4.1.4 (identity)4.1.5 (system-locale)4.1.6 (mac-policy)4.1.7 (logins)4.1.8 (session)4.1.9 (perm-mod)4.1.10 (access)4.1.11 (privileged)4.1.12 (mounts)4.1.13 (delete)4.1.14 (scope)4.1.15 (actions)4.1.16 (modules)4.1.17 (immutable)Docker CIS controls
1.1.41.1.81.1.101.1.121.1.131.1.151.1.161.1.171.1.181.2.31.2.41.2.51.2.61.2.71.2.101.2.11
loadBalancerHostIP of the built-in load balancer for the cluster API.
Configuration example:
spec:
...
providerSpec:
value:
credentials: cloud-config
publicKeys:
- name: demo-key
release: release: mke-5-16-0-3-3-6
helmReleases:
- name: stacklight
values:
...
proxy: proxy-object-name-example
tls:
keycloak:
certificate:
name: keycloak
hostname: container-cloud-auth.example.com
ui:
certificate:
name: ui
hostname: container-cloud-ui.example.com
containerRegistries:
- demoregistry
ntpEnabled: false
...
loadBalancerHost: 172.16.1.21
spec:providerSpec for vSphere resources¶
The vsphere section in spec:providerSpec contains the vSphere
resources configuration. For more details about vSphere resources, see
Deployment resources requirements.
The vsphere section contains the following fields:
vspherevSphere resources configuration:
cloudProviderDatastoreDatastore for Kubernetes volumes.
clusterApiDatastoreDatastore for cluster machines disks.
machineFolderPathFolder to store cluster machines on vSphere.
networkPathPath to the vSphere network.
resourcePoolPathPath to the vSphere resource pool.
scsiControllerTypeSmall Computer System Interface (SCSI) controller type that is
pvscsi. Other types are not supported.
Configuration example:
spec:
...
providerSpec:
value:
apiVersion: vsphere.cluster.k8s.io/v1alpha1
...
vsphere:
cloudProviderDatastore: /DATACENTER/datastore/storage-example
clusterApiDatastore: /DATACENTER/datastore/storage-example
machineFolderPath: /DATACENTER/vm/vm-folder
networkPath: /DATACENTER/network/VMWare_Network
resourcePoolPath: /DATACENTER/host/ClusterName/Resources/ResPoolName
scsiControllerType: pvscsi
spec:providerSpec for clusterNetwork¶
The spec:providerSpec section for clusterNetwork configuration
contains the following fields:
clusterNetworkCluster network configuration:
ipamEnabledOption to enable static IP address management. Set to
truefor networks without DHCP.
Caution
The following fields are mandatory only if IPAM is enabled. Otherwise, they do not apply.
Note
To obtain IPAM parameters for the selected vSphere network, contact your vSphere administrator who provides you with IP ranges dedicated to your environment only.
cidrCIDR of the provided vSphere network.
gatewayGateway of the provided vSphere network.
nameserversList of nameservers for the network.
includeRangesIP range for cluster machines. Specify the range of the provided CIDR. For example,
10.20.0.100-10.20.0.200.
excludeRangesOptional. IP ranges to be excluded from being assigned to the cluster machines. The MetalLB range and
loadBalancerHostshould not intersect with the addresses for IPAM. For example,10.20.0.150-10.20.0.170.
Configuration example:
spec:
...
providerSpec:
value:
apiVersion: vsphere.cluster.k8s.io/v1alpha1
...
clusterNetwork:
cidr: 172.16.1.0/24
gateway: 172.16.1.1
includeRanges:
- 172.16.1.10-172.16.1.20
ipamEnabled: true
nameservers:
- 172.16.1.100
- 172.16.1.200
...
spec:providerSpec for Container Cloud configuration¶
This section represents the Container Cloud components that are enabled
on the cluster. It contains the kaas section with the following fields:
managementConfiguration for the management cluster components:
enabledCluster type:
true- management clusterfalse- managed cluster
helmReleasesList of management cluster Helm releases that will be installed on a cluster. A Helm release includes the
nameandvaluesfields. Specified values will be merged with relevant management cluster Helm release values in theReleaseobject.
regionalList of regional cluster components of the Container Cloud cluster for the configured provider:
providerProvider type
vsphere
helmReleasesList of regional Helm releases to be installed. A Helm release includes such fields as
nameandvalues. Specified values will be merged with relevant regional Helm release values in theReleaseobject.
releaseName of the Container Cloud
Releaseobject.
Configuration example:
spec:
...
providerSpec:
value:
kaas:
management:
enabled: true
helmReleases:
- name: kaas-ui
values:
serviceConfig:
server: <service_config>
regional:
- helmReleases:
- name: <provider_name>-provider
values: {}
provider: <provider_name>
release: kaas-2-0-0
status:providerStatus common¶
The common providerStatus object field of the Cluster resource
contains the following fields:
loadBalancerHostLoad balancer IP or host name of the cluster
loadBalancerStatusLoad balancer status
idID of the load balancer
readyReadiness flag
statusStatus details
apiServerCertificateServer certificate of Kubernetes API
ucpDashboardMKE Dashboard URL
maintenanceMaintenance mode of a cluster. Prepares a cluster for maintenance and enables the possibility to switch machines into maintenance mode.
Configuration example:
status:
...
providerStatus:
loadBalancerHost: 172.16.123.456
apiServerCertificate: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS…
ucpDashboard: https://172.16.123.456:6443
loadBalancerStatus:
id: 7851a962-1deb-11eb-8bec-0242ac11
ready: true
status: active
status:providerStatus for Cluster readiness¶
Warning
Do not modify this section using API.
The providerStatus object field of the Cluster resource that reflects
cluster readiness contains the following fields:
persistentVolumesProviderProvisionedProvision status of the provider persistent volumes (PVs). Used to prevent Helm releases that require PVs from being installed until some default
StorageClassis present in the cluster.
helmStatus of deployed Helm releases:
readyIf all Helm releases have been deployed successfully, the value switches to
true.
releasesList of enabled Helm Releases that run on a cluster:
releaseStatusesList of Helm releases being deployed. Each release has the
successfield that switches totrueonce a release is deployed.
stacklightStatus of the StackLight deployment. Contains URLs of all StackLight components.
iamStatus of the IAM deployment. Contains URLs of the
keycloakandapicomponents.
deccStatus of the remaining
container cloudcomponents. Contains URLs of theui,cache, andproxycomponents.
nodesreadyNumber of nodes that completed deployment or update.
requestedTotal number of nodes. If the number of
readynodes does not match the number ofrequestednodes, it means that a cluster is being updated.
cephreadyCeph readiness flag.
messageCeph status details.
readyCluster readiness flag. If
true, the cluster is deployed successfully and all components are up and running.
conditionsList of objects status condition:
typeObject type
readyReadiness flag
messageStatus details
notReadyObjectsList of Kubernetes objects (
Service,Deployment, andStatefulSet) that are not in theReadystate yet:Serviceis not ready if its external address has not been provisioned yet.DeploymentorStatefulSetis not ready if the number of ready replicas is not equal to the number of required replicas.
Contains the name and namespace of the object and the number of ready and required replicas for controllers. If all objects are ready, the
notReadyObjectslist is empty.
Configuration example:
status:
providerStatus:
persistentVolumesProviderProvisioned: true
helm:
ready: true
releases:
decc:
cache:
url: >-
https://a618e3d36d7f44f2e8d56bbcc53ffbf7-1765661812.us-east-2.elb.amazonaws.com
proxy:
url: >-
http://a0d8d8966e0d24f50aead0942da92456-2114585625.us-east-2.elb.amazonaws.com:3128
ui:
url: >-
https://a43fe72c644de41ae9db3cc77dd992d5-566275388.us-east-2.elb.amazonaws.com
iam:
api:
url: >-
https://a08d8bdd8553b49a88ab8e663d384001-1745154108.us-east-2.elb.amazonaws.com
keycloak:
url: >-
https://a2b58b6a3ee3c4884b034fd791ebff6d-1687192379.us-east-2.elb.amazonaws.com
releaseStatuses:
admission-controller:
success: true
iam:
success: true
iam-controller:
success: true
kaas-exporter:
success: true
kaas-public-api:
success: true
kaas-ui:
success: true
lcm-controller:
...
stacklight:
alerta:
url: http://172.16.248.170
alertmanager:
url: http://172.16.247.217
grafana:
url: http://172.16.248.49
kibana:
url: http://172.16.245.164
prometheus:
url: http://172.16.249.211
success: true
nodes:
ready: 3
requested: 3
notReadyObjects:
services:
- name: testservice
namespace: default
deployments:
- name: <provider_name>-provider
namespace: kaas
replicas: 3
readyReplicas: 2
statefulsets: {}
ready: false
ceph:
- message: Ceph cluster has been configured successfully
ready: true
conditions:
- message: Helm charts are successfully installed(upgraded).
ready: true
type: Helm
- message: Kubernetes objects are fully up.
ready: true
type: Kubernetes
- message: All requested nodes are ready.
ready: true
type: Nodes
status:providerStatus for Open ID Connect¶
Warning
Do not modify this section using API.
The oidc section of the providerStatus object field
of the Cluster resource reflects the Open ID Connect (OIDC) configuration
details. It contains the required details to obtain a cluster token
and contains the following fields:
certificateBase64-encoded OIDC certificate.
clientIdClient ID for OIDC requests.
groupsClaimName of an OIDC groups claim.
issuerUrlIsuer URL to get the representation of the realm.
readyOIDC status relevance. Is
trueif the status fits the configuration of the LCMCluster OIDC.
Configuration example:
status:
providerStatus:
oidc:
certificate: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUREekNDQWZ...
clientId: kaas
groupsClaim: iam_roles
issuerUrl: https://172.16.243.211/auth/realms/iam
ready: true
status:providerStatus for Cluster releases¶
Warning
Do not modify this section using API.
The releaseRefs section of the providerStatus object field
of the Cluster resource provides the current Cluster release version
as well as the one available for upgrade. It contains the following fields:
currentDetails of the currently installed Cluster release:
lcmTypeType of the Cluster release (
mke)
nameName of the Cluster release resource
versionRelease version
unsupportedSinceKaaSVersionIndicates that a newer Container Cloud release exists and it does not support the current Cluster release
availableList of releases available for upgrade that contains the
nameandversionfields
Configuration example:
status:
providerStatus:
releaseRefs:
available:
- name: mke-5-15-0-3-4-0-dev
version: 5.15.0+3.4.0-dev
current:
lcmType: mke
name: mke-5-14-0-3-3-0-beta1
version: 5.14.0+3.3.0-beta1
Machine¶
This section describes the Machine resource used in Mirantis Container
Cloud API. The Machine resource describes the machine-level parameters.
For demonstration purposes, the Container Cloud the Machine
custom resource (CR) can be split into the following major sections:
Warning
The fields in this resource are available for viewing only. They are automatically generated by the vSphere cloud provider and must not be modified using the Container Cloud API.
metadata¶
The Container Cloud Machine custom resource (CR) contains the following
fields:
apiVersionObject API version that is
cluster.k8s.io/v1alpha1.
kindObject type that is
Machine.
The metadata object field of the Machine resource contains
the following fields:
nameName of the
Machineobject
namespaceContainer Cloud project in which the machine has been created
labelskaas.mirantis.com/providerProvider type that is
vspherefor vSphere machines and matches the provider type in theClusterobject
kaas.mirantis.com/regionRegion name that matches the region name in the
ClusterobjectNote
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
cluster.sigs.k8s.io/cluster-nameCluster name that the machine is assigned to
cluster.sigs.k8s.io/control-planeFor the control plane role of a machine, this label contains any value, for example,
"true"For the worker role, this label is absent or does not contain any value
Configuration example:
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
name: example-control-plane
namespace: example-ns
labels:
kaas.mirantis.com/provider: vsphere
cluster.sigs.k8s.io/cluster-name: example-cluster
cluster.sigs.k8s.io/control-plane: "true" # remove for worker
spec:providerSpec for instance configuration¶
The spec object field of the Machine object represents the
VsphereMachineProviderSpec subresource with all required details to create
a vSphere virtual machine. It contains the following fields:
apiVersionvsphere.cluster.k8s.io/v1alpha1.
kindVsphereMachineProviderSpec.
machineRefField used to look up a vSphere VM. The field value is set automatically at runtime by the vSphere provider and must not be set or modified manually.
networkNetwork configuration of a vSphere VM:
devicesList of network devices connected to a vSphere virtual machine (VM). This list is managed by the vSphere provider depending on static or dynamic network configuration. For details on network objects, see VMware vSphere network objects and IPAM recommendations.
diskGiBDisk size of a VM.
memoryMiBRAM size of a VM.
numCPUsCPU number of a VM.
rhelLicenseFor RHEL-based deployments, a RHEL license name to be applied to a vSphere VM.
templateFull path to a VM template used to create a VM. Mutually exclusive with
vsphereVMTemplate.
vsphereVMTemplateGA since 2.25.0 and TechPreview since 2.24.0Name of the existing
VsphereVMTemplateobject to use for VM creation. For details, see VsphereVMTemplate. Mutually exclusive withtemplate.Caution
Before using the
vsphereVMTemplatefield, make sure that thetemplateStatusfield in theVsphereVMTemplateobject is set toPresent.After the
Machineconfiguration applies, thevsphereVMTemplatefield is automatically removed and thetemplatefield is automatically set to the corresponding template path from the referenced object.
nodeLabelsList of node labels to be attached to a node for the user to run certain components on separate cluster nodes. The list of allowed node labels is located in the
Clusterobject statusproviderStatus.releaseRef.current.allowedNodeLabelsfield.If the
valuefield is not defined inallowedNodeLabels, a label can have any value.Before or after a machine deployment, add the required label from the allowed node labels list with the corresponding value to
spec.providerSpec.value.nodeLabelsinmachine.yaml. For example:nodeLabels: - key: stacklight value: enabled
The addition of a node label that is not available in the list of allowed node labels is restricted.
maintenanceMaintenance mode of a machine. If enabled, the node of the selected machine is drained, cordoned, and prepared for maintenance operations.
deletionPolicyTechnology Preview since 2.21.0 for non-MOSK clusters. Policy used to identify steps required during a
Machineobject deletion. Supported policies are as follows:gracefulPrepares a machine for deletion by cordoning, draining, and removing from Docker Swarm of the related node. Then deletes Kubernetes objects and associated resources. Can be aborted only before a node is removed from Docker Swarm.
unsafeDefault. Deletes Kubernetes objects and associated resources without any preparations.
forcedDeletes Kubernetes objects and associated resources without any preparations. Removes the
Machineobject even if the cloud provider or LCM Controller gets stuck at some step. May require a manual cleanup of machine resources in case of the controller failure.
For more details on the workflow of machine deletion policies, see Overview of machine deletion policies.
deleteTechnology Preview since 2.21.0 for non-MOSK clusters. Boolean trigger for a machine deletion. Set to
falseto abort a machine deletion.
Configuration example:
providerSpec:
value:
apiVersion: vsphere.cluster.k8s.io/v1alpha1
diskGiB: 120
kind: VsphereMachineProviderSpec
memoryMiB: 32768
metadata:
creationTimestamp: null
network:
devices:
- dhcp4: true
numCPUs: 8
rhelLicense: rhel-license
template: /DATACENTER/vm/vm-folder/templates/rhel-8.7-template
delete: false
deletionPolicy: graceful
status:providerStatus¶
The status object field of the vSphere Machine object represents
the VsphereMachineProviderStatus subresource that describes the current
state of a vSphere virtual machine. It contains the following fields:
apiVersionvsphere.cluster.k8s.io/v1alpha1
kindVsphereMachineProviderStatus
conditionsList of a machine status conditions:
typeObject type, for example,
Kubelet
readyReadiness flag
messageStatus details
providerInstanceStateCurrent state of a vSphere VM:
idID of a VM
readyReadiness flag
stateState of a VM
networkStatusNetwork status of a vSphere VM:
networkNamevSphere network name that a VM is assigned to
connectedFlag indicating whether the network is currently connected to the VM
ipAddrsOne or more IP addresses reported by
vm-tools
macAddrMAC addresses of the VM network interface
privateIpPrivate IPv4 address assigned to a VM
maintenanceMaintenance mode of a machine. If enabled, the node of the selected machine is drained, cordoned, and prepared for maintenance operations.
statusCurrent status of a machine:
ProvisionA machine is yet to obtain a status
UninitializedA machine is yet to obtain the node IP address and host name
PendingA machine is yet to receive the deployment instructions and it is either not booted yet or waits for the LCM controller to be deployed
PrepareA machine is running the
Preparephase during which Docker images and packages are being predownloaded
DeployA machine is processing the LCM Controller instructions
ReconfigureA machine is being updated with a configuration without affecting workloads running on the machine
ReadyA machine is deployed and the supported Mirantis Kubernetes Engine (MKE) version is set
MaintenanceA machine host is cordoned, drained, and prepared for maintenance operations
deleteTechnology Preview since 2.21.0 for non-MOSK clusters. Start of a machine deletion or a successful abortion. Boolean.
prepareDeletionPhaseTechnology Preview since 2.21.0 for non-MOSK clusters. Preparation phase for a graceful machine deletion. Possible values are as follows:
startedCloud provider controller prepares a machine for deletion by cordoning, draining the machine, and so on.
completedLCM Controller starts removing the machine resources since the preparation for deletion is complete.
abortingCloud provider controller attempts to uncordon the node. If the attempt fails, the status changes to
failed.
failedError in the deletion workflow.
For the workflow description of a graceful deletion, see Overview of machine deletion policies.
Configuration example:
status:
providerStatus:
apiVersion: vsphere.cluster.k8s.io/v1alpha1
conditions:
- message: Kubelet's NodeReady condition is True
ready: true
type: Kubelet
- message: Swarm state of the machine is ready
ready: true
type: Swarm
- message: Maintenance state of the machine is false
ready: true
type: Maintenance
- message: LCM Status of the machine is Ready
ready: true
type: LCM
- message: Provider instance 4215081f-7460-be62-0274-e437f6a1fe9b has status green
ready: true
type: ProviderInstance
hardware: {}
kind: VsphereMachineProviderStatus
metadata:
creationTimestamp: null
networkStatus:
- connected: true
ipAddrs:
- 172.16.39.203
macAddr: 00:50:56:95:54:a0
networkName: VMWare_Network
privateIp: 10.0.0.3
providerInstanceState:
id: 4215081f-7460-be62-0274-e437f6a1fe9b
ready: true
state: green
ready: true
status: Ready
upgradeIndex: 3
delete: true
prepareDeletionPhase: started
VsphereResources¶
This section describes the VsphereResources custom resource (CR)
used in the Container Cloud API. The VsphereResources object contains the
list of available vSphere resources such as resource pool,
networks, folders, datastores and virtual machine templates.
For demonstration purposes, the Container Cloud VsphereResources
CR can be split into the following sections:
Warning
The fields in this resource are available for viewing only. They are automatically generated by the vSphere cloud provider and must not be modified using the Container Cloud API.
metadata¶
The Container Cloud VsphereResources custom resource (CR) contains the following
fields:
apiVersionObject API version that is
kaas.mirantis.com/v1alpha1.
kindObject type that is
VsphereResources.
The metadata object field of the VsphereResources resource contains
the following fields:
nameName of the
VsphereResourcesobject
namespaceProject in which the
VsphereResourcesobject is created
Configuration example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: VsphereResources
metadata:
name: cloud-config
namespace: test
VsphereResources status¶
The status field of the VsphereResources object contains the list of
available vSphere resources:
cloudProviderUserResources available for the cloud provider (
storage) user, for example,datastores
clusterApiUserResources available for the virtual machine (
cluster-api) user, for example:datastoresisoFilePathsAvailable since 2.22.0
machineFoldersmachineTemplatesnetworksresourcePools
Note
For details on vSphere resources, see Deployment resources requirements.
For details on vSphere users and their privileges, see Prepare the VMware deployment user setup and permissions.
Example configuration extract:
apiVersion: kaas.mirantis.com/v1alpha1
kind: VsphereResources
metadata:
name: cloud-config
namespace: default
status:
<cloudProviderUser>:
datastores:
- name: <ds1>
path: /DATACENTER/datastore/<ds1>
...
<clusterApiUser>:
datastoreFolders:
- name: <dsFolder1>
path: /DATACENTER/datastore/<dsFolder1>
...
datastores:
- name: <ds1>
path: /DATACENTER/datastore/<ds1>
isoFilePaths:
- <folderName>/<isoFileName.iso>
...
machineFolders:
- name: <folder1>
path: /DATACENTER/vm/<folder1>
...
machineTemplates:
- mccTemplate: <version>
name: <template1>
path: /DATACENTER/vm/<template1>
...
networks:
- name: <network1>
path: /DATACENTER/network/<network1>
type: DistributedVirtualPortgroup
...
resourcePools:
- name: <cluster-name>/Resources/<res-pool-name>
path: /DATACENTER/host/<cluster-name>/Resources/<res-pool-name>
...
VsphereVMTemplate¶
Available since 2.25.0 as GA Available since 2.24.0 as TechPreview
This section describes the VsphereVMTemplate custom resource (CR)
used in the Container Cloud API. It contains all necessary information to
build your own VM templates for the vSphere-based clusters.
For demonstration purposes, we split the Container Cloud VsphereVMTemplate
CR into the following sections:
Warning
The fields in this resource are available for viewing only. They are automatically generated by the vSphere cloud provider and must not be modified using the Container Cloud API.
metadata¶
The Container Cloud VsphereVMTemplate custom resource (CR) contains the following
fields:
apiVersionObject API version that is
kaas.mirantis.com/v1alpha1.
kindObject type that is
VsphereVMTemplate.
The metadata object field of the VsphereVMTemplate resource contains
the following fields:
nameString. Name of the
VsphereVMTemplateobject.
labelskaas.mirantis.com/regionRegion name that matches the region name in the
Clusterobject.Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
Configuration example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: VsphereVMTemplate
metadata:
name: kaas-mgmt-vsphere-template
VsphereVMTemplate configuration¶
The spec object field contains configuration for a VM template and
references for other objects, if any. It contains the following fields:
packerImageOSNameString. Name of an operating system to be used for the template. Only one of the following values is allowed:
ubuntuorrhel(case sensitive).
packerImageOSVersionString. Version of the selected operating system to use for the template:
20.04forubuntuor8.7forrhel.
packerISOImageString. Path to the ISO file containing an installation image or the virtual hard drive (VHD or VHDX) file to clone within a datastore. For example,
[<datastoreName>] /<path/to>/ubuntu-20.04.iso.Note
The support of the URL format for
packerISOImageis experimental. For example,https://example.com/direct-download-file.iso.The matching checksum applies only to
ubuntu. TherhelISO files have no capability of using cache.
vsphereCredentialsNameString. Reference to the existing VsphereCredential object in the format
<namespaceName>/<vSphereCredsName>. Ifnamespaceis omitted, thedefaultnamespace applies. Configuration and authentication details for the vSphere server are sourced from this object.
vsphereClusterNameString. Name of the vSphere cluster in vCenter. Do not confuse with the name of the vSphere cluster in Container Cloud.
vsphereNetworkString. Path to the vSphere network.
vsphereDatastoreString. Datastore to use for the template.
vsphereFolderString. Folder to store the template.
vsphereResourcePoolString. Path to the vSphere resource pool.
scsiControllerTypeString. Small Computer System Interface (SCSI) controller type that is
pvscsi. Other types are not supported.
numCPUsInteger. CPUs number of the template. Minimum number is
8.
ramInteger or string. RAM size of the template. An integer value is considered as bytes. The minimum size is
16Gi. You can use the following human-readable units:Possible unit values for RAM size
Unit
Description
kKilobytes
KiKibibytes
MMegabytes
MiMebibytes
GGigabytes
GiGibibytes
TTerabytes
TiTebibytes
PPetabytes
PiPebibytes
EExabytes
EiExbibytes
diskSizeInteger or string. Disk size of the template. An integer value is considered as bytes. You can use human-readable units. For details, see the above table. The minimum size is
120Gi.
networkBootProtocolString. Boot protocol type:
dhcp(default) orstatic.
machineNetworkParamsMap. Mandatory and applies only for the
staticnetwork protocol. Network boot parameters of a machine:netMaskString. IPv4 network mask in the decimal format. For example,
255.255.255.0.
gatewayString. IPv4 address of a gateway.
ipString. IPv4 address of a network device.
dnsServerString. IPv4 address of a DNS server.
rhelLicenseNameString. Mandatory for RHEL-based templates. Reference name of an existing
RHELLicenseobject.
virtWhoUsernameOptional. String. For RHEL-based templates, a user name of the
virt-whoservice.
virtWhoPasswordOptional. Map. For RHEL-based templates, the password of the
virt-whoservice user.valueString. User password. For example:
virtWhoPassword: value: "foobar"
proxyNameOptional. String. Reference name of an existing
Proxyobject.
timezoneOptional. String. Time zone of a machine in the IANA Timezone Database format.
sshTimeoutOptional. String. Time to wait for SSH to become available. For example,
1h2m3s.
actionOnErrorOptional. String. Action to apply to a VM if build failed. Possible values:
cleanup- removes the VM and creates a new one on the next retryabort- preserves the VM and prevents retries
packerJobBackoffLimitOptional. Integer. Number of retries to apply in case of failure before considering the
VsphereVMTemplatebuild asFailed. Equals0if you setactionOnErrortoabort.
Configuration example:
...
spec:
packerImageOSName: "ubuntu"
packerImageOSVersion: "20.04"
packerISOImage: "[<datastoreName>] /iso/ubuntu-20.04.iso"
vsphereCredentialsName: "default/cloud-config"
vsphereClusterName: "/DATACENTER/host/<ClusterName>"
vsphereNetwork: "/DATACENTER/network/<VMwareNetworkName>"
vsphereDatastore: "/DATACENTER/<datastoreName>/<storageExample>"
vsphereFolder: "/DATACENTER/templates/<templateFolderName>"
vsphereResourcePool: "/DATACENTER/host/<ClusterName>/Resources/<ResPoolName>"
numCPUs: 8
ram: "24Gi"
diskSize: "120Gi"
VsphereVMTemplate status¶
The status field of the VsphereVMTemplate object contains the
build status of the VM template and the VM template status itself:
templatePathFull path to the template.
templateStatusStatus of the template on the vSphere server. Possible values are
PresentorNot Present.
buildStatusBuild status of the template:
statusProgress of building the template. Possible values are:
Failed,In Progress, orSuccess.
messageHuman-readable error message. Available only if the build fails.
templatePath: /MIRANTIS/vm/BareMetal/ubuntu-url-ubuntu-20.04-template-1.34.14-106-657181dd
templateStatus: Present
buildStatus:
status: Success
MetalLBConfig¶
Available since 2.24.0 (14.0.1 and 14.0.0) for management clusters
Caution
For managed clusters, this object is available as Technology Preview since Container Cloud 2.24.0 and is generally available since 2.25.0.
This section describes the MetalLBConfig custom resource used in the
Container Cloud API that contains the MetalLB configuration objects for a
particular cluster.
Note
The MetalLBConfig custom resource described below applies to
vSphere-based deployments only. For the bare metal provider, refer to
MetalLBConfig for bare metal.
For demonstration purposes, the Container Cloud MetalLBConfig
custom resource description is split into the following major sections:
The Container Cloud API also uses the third-party open source MetalLB API. For details, see MetalLB objects.
MetalLBConfig metadata¶
The Container Cloud MetalLBConfig CR contains the following fields:
apiVersionAPI version of the object that is
kaas.mirantis.com/v1alpha1.
kindObject type that is
MetalLBConfig.
The metadata object field of the MetalLBConfig resource
contains the following fields:
nameName of the
MetalLBConfigobject.
namespaceProject in which the object was created. Must match the project name of the target cluster.
labelsKey-value pairs attached to the object. Mandatory labels are:
kaas.mirantis.com/providerProvider type:
vsphere.
kaas.mirantis.com/regionRegion name that matches the region name of the target cluster.
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
cluster.sigs.k8s.io/cluster-nameName of the cluster that the MetalLB configuration must apply to.
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Configuration example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: MetalLBConfig
metadata:
name: metallb-demo
namespace: test-ns
labels:
kaas.mirantis.com/provider: vsphere
cluster.sigs.k8s.io/cluster-name: test-cluster
MetalLBConfig spec¶
The spec field of the MetalLBConfig object represents the
MetalLBConfigSpec subresource that contains the description of MetalLB
configuration objects. These objects are created in the target cluster
during its deployment.
The spec field contains the following optional fields:
addressPoolsList of
MetalLBAddressPoolobjects to create MetalLBAddressPoolobjects.
ipAddressPoolsList of
MetalLBIPAddressPoolobjects to create MetalLBIPAddressPoolobjects.
l2AdvertisementsList of
MetalLBL2Advertisementobjects to create MetalLBL2Advertisementobjects.
The objects listed in the spec field of the MetalLBConfig object,
such as MetalLBIPAddressPool, MetalLBL2Advertisement, and so on,
are used as templates for the MetalLB objects that will be created in the
target cluster. Each of these objects has the following structure:
labelsOptional. Key-value pairs attached to the
metallb.io/<objectName>object asmetadata.labels.
nameName of the
metallb.io/<objectName>object.
specContents of the
specsection of themetallb.io/<objectName>object. Thespecfield has themetallb.io/<objectName>Spectype. For details, see MetalLB objects.
For example, MetalLBIPAddressPool is a template for the
metallb.io/IPAddressPool object and has the following structure:
labelsOptional. Key-value pairs attached to the
metallb.io/IPAddressPoolobject asmetadata.labels.
nameName of the
metallb.io/IPAddressPoolobject.
specContents of
specsection of themetallb.io/IPAddressPoolobject. Thespechas themetallb.io/IPAddressPoolSpectype.
MetalLB objects¶
Container Cloud supports the following MetalLB object types of the
metallb.io API group:
AddressPoolIPAddressPoolL2Advertisement
As of v1beta1 and v1beta2 API versions, metadata of MetalLB objects
has a standard format with no specific fields or labels defined for any
particular object:
apiVersionAPI version of the object that can be
metallb.io/v1beta1ormetallb.io/v1beta2.
kindObject type that is one of the
metallb.iotypes listed above. For example,AddressPool.
metadataObject metadata that contains the following subfields:
nameName of the object.
namespaceNamespace where the MetalLB components are located. It matches
metallb-systemin Container Cloud.
labelsOptional. Key-value pairs that are attached to the object. It can be an arbitrary set of labels. No special labels are defined as of
v1beta1andv1beta2API versions.
The MetalLBConfig object contains spec sections of the
metallb.io/<objectName> objects that have the
metallb.io/<objectName>Spec type. For metallb.io/<objectName> and
metallb.io/<objectName>Spec types definitions, refer to the official
MetalLB documentation:
MetalLBConfig status¶
The status field describes the actual state of the object.
It contains the following fields:
bootstrapModeOnly in 2.24.0 (14.0.1 and 14.0.0)Field that appears only during a management cluster bootstrap as
trueand is used internally for bootstrap. Once deployment completes, the value is moved tofalseand is excluded from thestatusoutput.
objectsDescription of MetalLB objects taken from
specfield and used to create MetalLB native objects in the target cluster.The format of the underlying objects is the same as for those in the
specfield. These objects have to match thespeccontents. Otherwise, an error appears in thestatus.updateResultfield.
propagateResultResult of objects propagation. During objects propagation, native MetalLB objects of the target cluster are created and updated according to the description of the objects present in the
status.objectsfield.This field contains the following information:
messageText message that describes the result of the last attempt of objects propagation. Contains an error message if the last attempt was unsuccessful.
successResult of the last attempt of objects propagation. Boolean.
timeTimestamp of the last attempt of objects propagation. For example,
2023-07-04T00:30:36Z.
If the objects propagation was successful, the MetalLB objects of the target cluster match the ones present in the
status.objectsfield.
updateResultStatus of the MetalLB objects update. Has the same format of subfields that in
propagateResultdescribed above.During objects update, the
status.objectscontents are rendered fromMetalLBConfig.spec.If the objects update was successful, the MetalLB objects description present in
status.objectsis rendered successfully and up to date. This description is used to update MetalLB objects in the target cluster. If the objects update was not successful, MetalLB objects will not be propagated to the target cluster.
MetalLB configuration examples¶
Example of configuration template for a managed cluster:
apiVersion: kaas.mirantis.com/v1alpha1
kind: MetalLBConfig
metadata:
labels:
cluster.sigs.k8s.io/cluster-name: managed-cluster
kaas.mirantis.com/provider: vsphere
name: managed-l2
namespace: managed-ns
spec:
ipAddressPools:
- name: services
spec:
addresses:
- 10.100.91.151-10.100.91.170
autoAssign: true
avoidBuggyIPs: false
l2Advertisements:
- name: services
spec:
ipAddressPools:
- services
After the object is created and processed by the MetalLB Controller, the
status field is added. For example:
status:
objects:
ipAddressPools:
- name: services
spec:
addresses:
- 10.100.100.151-10.100.100.170
autoAssign: true
avoidBuggyIPs: false
l2Advertisements:
- name: services
spec:
ipAddressPools:
- services
propagateResult:
message: Objects were successfully updated
success: true
time: "2023-07-04T14:31:40Z"
updateResult:
message: Objects were successfully read from MetalLB configuration specification
success: true
time: "2023-07-04T14:31:39Z"
Example of native MetalLB objects to be created in the
managed-ns/managed-cluster cluster during deployment:
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: services
namespace: metallb-system
spec:
addresses:
- 10.100.91.151-10.100.91.170
autoAssign: true
avoidBuggyIPs: false
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: services
namespace: metallb-system
spec:
ipAddressPools:
- services
OpenStack resources¶
This section contains descriptions and examples of the OpenStack-based Kubernetes resources for Mirantis Container Cloud.
Cluster¶
This section describes the Cluster resource used in Mirantis Container
Cloud API for the OpenStack-based clusters.
The Cluster resource describes the cluster-level parameters.
For demonstration purposes, the Container Cloud Cluster
custom resource (CR) can be split into the following major sections:
Warning
The fields of the Cluster resource that are located
under the status section including providerStatus
are available for viewing only.
They are automatically generated by the OpenStack cloud provider
and must not be modified using Container Cloud API.
metadata¶
The Container Cloud Cluster custom resource (CR) contains the following
fields:
apiVersionObject API version that is
cluster.k8s.io/v1alpha1.
kindObject type that is
Cluster.
The metadata object field of the Cluster resource contains
the following fields:
nameCluster name that is set using the Cluster Name field of the Create Cluster wizard in the Container Cloud web UI. For a management cluster, the cluster name can be also set using
cluster.yaml.template.
namespaceNamespace in which the
Clusterobject is created. Management clusters are created in thedefaultnamespace. The namespace of a managed cluster matches the selected Project name in the Container Cloud web UI.
labelsKey-value pairs attached to the object:
kaas.mirantis.com/providerProvider type that is
openstackfor the OpenStack-based clusters.
kaas.mirantis.com/regionRegion name. The default region name for a management cluster is
region-one.Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Configuration example:
apiVersion: cluster.k8s.io/v1alpha1
kind: Cluster
metadata:
name: demo
namespace: test
labels:
kaas.mirantis.com/provider: openstack
spec:providerSpec¶
The providerSpec object field of the Cluster resource
contains all required details to create the cluster-level resources.
It also contains fields required for LCM deployment and
the Container Cloud components integration.
The providerSpec object field is custom for each cloud provider and
contains the following generic fields:
apiVersionopenstackproviderconfig.k8s.io/v1alpha1
kindObject type that is
OpenstackClusterProviderSpec
Configuration example:
spec:
...
providerSpec:
value:
apiVersion: openstackproviderconfig.k8s.io/v1alpha1
kind: OpenstackClusterProviderSpec
spec:providerSpec common¶
The common providerSpec object field of the Cluster resource
contains the following fields:
credentialsName of the
OpenStackCredentialobject used by the cluster to connect to the provider backend
dedicatedControlPlaneCluster control plane nodes to be tainted, defaults to
true
publicKeysList of the
PublicKeyresource referencesnamePublic key name
releaseName of the
ClusterReleaseobject to install on a cluster
helmReleasesList of enabled Helm releases from the
Releaseobject that run on a cluster
proxyName of the
Proxyobject
tlsTLS configuration for endpoints of a cluster
keycloakKeyCloak endpoint
tlsConfigRefReference to the
TLSConfigobject
uiWeb UI endpoint
tlsConfigRefReference to the
TLSConfigobject
For more details, see TLSConfig resource.
maintenanceMaintenance mode of a cluster. Prepares a cluster for maintenance and enables the possibility to switch machines into maintenance mode.
containerRegistriesList of the
ContainerRegistriesresources names.
ntpEnabledNTP server mode. Boolean, enabled by default.
Since Container Cloud 2.23.0, you can optionally disable NTP to disable the management of
chronyconfiguration by Container Cloud and use your own system forchronymanagement. Otherwise, configure the regional NTP server parameters to be applied to all machines of managed clusters.Before Container Cloud 2.23.0, you can optionally configure NTP parameters if servers from the Ubuntu NTP pool (
*.ubuntu.pool.ntp.org) are accessible from the node where a management cluster is being provisioned. Otherwise, this configuration is mandatory.NTP configuration
Configure the regional NTP server parameters to be applied to all machines of managed clusters.
In the
Clusterobject, add thentp:serverssection with the list of required server names:spec: ... providerSpec: value: kaas: ... ntpEnabled: true regional: - helmReleases: - name: <providerName>-provider values: config: lcm: ... ntp: servers: - 0.pool.ntp.org ... provider: <providerName> ...
To disable NTP:
spec: ... providerSpec: value: ... ntpEnabled: false ...
auditSince 2.24.0 as TechPreviewOptional. Auditing tools enabled on the cluster. Contains the
auditdfield that enables the Linux Audit daemon auditd to monitor activity of cluster processes and prevent potential malicious activity.Configuration for auditd
In the
Clusterobject, add the auditd parameters:spec: providerSpec: value: audit: auditd: enabled: <bool> enabledAtBoot: <bool> backlogLimit: <int> maxLogFile: <int> maxLogFileAction: <string> maxLogFileKeep: <int> mayHaltSystem: <bool> presetRules: <string> customRules: <string> customRulesX32: <text> customRulesX64: <text>
Configuration parameters for auditd:
enabledBoolean, default -
false. Enables theauditdrole to install the auditd packages and configure rules. CIS rules: 4.1.1.1, 4.1.1.2.enabledAtBootBoolean, default -
false. Configures grub to audit processes that can be audited even if they start up prior to auditd startup. CIS rule: 4.1.1.3.backlogLimitInteger, default - none. Configures the backlog to hold records. If during boot
audit=1is configured, the backlog holds 64 records. If more than 64 records are created during boot, auditd records will be lost with a potential malicious activity being undetected. CIS rule: 4.1.1.4.maxLogFileInteger, default - none. Configures the maximum size of the audit log file. Once the log reaches the maximum size, it is rotated and a new log file is created. CIS rule: 4.1.2.1.
maxLogFileActionString, default - none. Defines handling of the audit log file reaching the maximum file size. Allowed values:
keep_logs- rotate logs but never delete themrotate- add a cron job to compress rotated log files and keep maximum 5 compressed files.compress- compress log files and keep them under the/var/log/auditd/directory. Requiresauditd_max_log_file_keepto be enabled.
CIS rule: 4.1.2.2.
maxLogFileKeepInteger, default -
5. Defines the number of compressed log files to keep under the/var/log/auditd/directory. Requiresauditd_max_log_file_action=compress. CIS rules - none.mayHaltSystemBoolean, default -
false. Halts the system when the audit logs are full. Applies the following configuration:space_left_action = emailaction_mail_acct = rootadmin_space_left_action = halt
CIS rule: 4.1.2.3.
customRulesString, default - none. Base64-encoded content of the
60-custom.rulesfile for any architecture. CIS rules - none.customRulesX32String, default - none. Base64-encoded content of the
60-custom.rulesfile for thei386architecture. CIS rules - none.customRulesX64String, default - none. Base64-encoded content of the
60-custom.rulesfile for thex86_64architecture. CIS rules - none.presetRulesString, default - none. Comma-separated list of the following built-in preset rules:
accessactionsdeletedocker
identityimmutableloginsmac-policy
modulesmountsperm-modprivileged
scopesessionsystem-localetime-change
You can use two keywords for these rules:
none- disables all built-in rules.all- enables all built-in rules. With this key, you can add the!prefix to a rule name to exclude some rules. You can use the!prefix for rules only if you add theallkeyword as the first rule. Place a rule with the!prefix only after theallkeyword.
Example configurations:
presetRules: none- disable all preset rulespresetRules: docker- enable only thedockerrulespresetRules: access,actions,logins- enable only theaccess,actions, andloginsrulespresetRules: all- enable all preset rulespresetRules: all,!immutable,!sessions- enable all preset rules exceptimmutableandsessions
CIS controls
4.1.3 (time-change)4.1.4 (identity)4.1.5 (system-locale)4.1.6 (mac-policy)4.1.7 (logins)4.1.8 (session)4.1.9 (perm-mod)4.1.10 (access)4.1.11 (privileged)4.1.12 (mounts)4.1.13 (delete)4.1.14 (scope)4.1.15 (actions)4.1.16 (modules)4.1.17 (immutable)Docker CIS controls
1.1.41.1.81.1.101.1.121.1.131.1.151.1.161.1.171.1.181.2.31.2.41.2.51.2.61.2.71.2.101.2.11
volumesCleanupEnabledAvailable since Container Cloud 2.23.0 as Technology Preview. Schedules the volumes created using Persistent Volume Claims to be deleted during cluster deletion. Boolean,
falseby default.Caution
The feature applies only to volumes created on clusters that are based on or updated to the Cluster release 11.7.0 or later.
If you added volumes to an existing cluster before it was updated to the Cluster release 11.7.0, delete such volumes manually after the cluster deletion.
serviceAnnotationsSince 2.24.0 as TechPreviewEnables passing of any custom settings to load balancers created by Container Cloud. These annotations are set on service objects created by Container Cloud and are propagated to the OpenStack cloud provider that applies new settings to a load balancer during initial cluster deployment and creation of a new load balancer.
Caution
Mirantis does not recommend enabling this feature after the cluster deployment because it will apply to newly created load balancers only.
The
loadbalancer.openstack.org/flavor-id: <octaviaFlavorID>field enables creation of load balancers with defined Octavia flavors.For details, see OpenStack documentation: Octavia Flavors.
Note
This feature is not supported by OpenStack Queens.
Configuration example:
spec:
...
providerSpec:
value:
credentials: cloud-config
publicKeys:
- name: demo-key
release: release: mke-11-7-0-3-5-7
helmReleases:
- name: stacklight
values:
...
proxy: proxy-object-name
tls:
keycloak:
tlsConfigRef: keycloak
ui:
tlsConfigRef: ui
containerRegistries:
- demoregistry
volumesCleanupEnabled: false
spec:providerSpec for OpenStack network¶
The providerSpec object field of a Cluster resource contains
the following fields to configure the OpenStack network:
dnsNameserversList of nameservers for the OpenStack subnet to be created
externalNetworkIdID of an external OpenStack network
nodeCidrCIDR of the OpenStack subnet to be created
Configuration example:
spec:
...
providerSpec:
value:
dnsNameservers:
- 172.18.224.4
externalNetworkId: c3799996-dc8e-4477-a309-09ea6dd71946
nodeCidr: 10.10.10.0/24
spec:providerSpec for Container Cloud configuration¶
This section represents the Container Cloud components that are enabled
on the cluster. It contains the kaas section with the following fields:
managementConfiguration for the management cluster components:
enabledCluster type:
true- management clusterfalse- managed cluster
helmReleasesList of management cluster Helm releases that will be installed on a cluster. A Helm release includes the
nameandvaluesfields. Specified values will be merged with relevant management cluster Helm release values in theReleaseobject.
regionalList of regional cluster components of the Container Cloud cluster for the configured provider:
providerProvider type
openstack
helmReleasesList of regional Helm releases to be installed. A Helm release includes such fields as
nameandvalues. Specified values will be merged with relevant regional Helm release values in theReleaseobject.
releaseName of the Container Cloud
Releaseobject.
Configuration example:
spec:
...
providerSpec:
value:
kaas:
management:
enabled: true
helmReleases:
- name: kaas-ui
values:
serviceConfig:
server: <service_config>
regional:
- helmReleases:
- name: <provider_name>-provider
values: {}
provider: <provider_name>
release: kaas-2-0-0
spec:providerSpec for Bastion¶
The providerSpec object field of the Cluster resource
for the Bastion instance contains the following fields:
imageImage name to use for the Bastion instance.
redeployAllowedFlag that allows redeploying the Bastion host to update the SSH keys. Defaults to
false.
flavorName of the flavor to use for building the Bastion host.
availabilityZoneName of the availability zone to place the Bastion host in.
bootFromVolumeTechPreviewConfiguration to boot the Bastion node from a block storage volume based on a given image. Required parameters:
enabledSet to
trueto boot from a volume.
volumeSizeSize of the volume to create in GB. The default amount of storage
80is enough for the Bastion node.
Configuration example:
spec:
...
providerSpec:
value:
bastion:
redeployAllowed: false
image: bionic-server-cloudimg-amd64-20200724
availabilityZone: nova
flavor: kaas.small
bootFromVolume:
enabled: true
volumeSize: 80
status:providerStatus¶
Warning
Do not modify this section using API.
The common providerStatus object field of the Cluster resource
contains the following fields:
apiVersionopenstackproviderconfig.k8s.io/v1alpha1
kindObject type that is
OpenstackClusterProviderStatus
Configuration example:
spec:
...
providerStatus:
value:
apiVersion: openstackproviderconfig.k8s.io/v1alpha1
kind: OpenstackClusterProviderStatus
status:providerStatus common¶
The common providerStatus object field of the Cluster resource
contains the following fields:
loadBalancerHostLoad balancer IP or host name of the cluster
loadBalancerStatusLoad balancer status
idID of the load balancer
readyReadiness flag
statusStatus details
apiServerCertificateServer certificate of Kubernetes API
ucpDashboardMKE Dashboard URL
maintenanceMaintenance mode of a cluster. Prepares a cluster for maintenance and enables the possibility to switch machines into maintenance mode.
Configuration example:
status:
...
providerStatus:
loadBalancerHost: 172.16.123.456
apiServerCertificate: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS…
ucpDashboard: https://172.16.123.456:6443
loadBalancerStatus:
id: 7851a962-1deb-11eb-8bec-0242ac11
ready: true
status: active
status:providerStatus for OpenStack network¶
Warning
Do not modify this section using API.
The network section of the providerStatus object field of the
Cluster resource represents basic information about the associated
OpenStack network of the OpenStack cloud provider.
It contains the following fields:
idNetwork ID
nameNetwork name
loadbalancerLoad balancer information:
floatingIP- floating IP of a load balancerid- ID of a load balancerlisteners- listeners configuration of a load balancername- load balancer namepools- load balancer pools IDs
routerNetwork router information:
id- ID of a routername- name of a router
subnetNetwork subnet details:
cidr- CIDR block of a subnetid- ID of a subnetname- name of a subnet
Configuration example:
status:
providerStatus:
network:
id: 01234456-7890-abcd-efgh-876543219876
name: kaas-net-abcdefgh-0123-4567-890a-0a1b2c3d4e5f
loadbalancer:
floatingIP: 172.19.116.5
id: 43bc4b9d-cb44-42ed-908d-3a08dc494f5a
listeners:
kube-api:
id: 8ec3dc99-ab73-401f-8036-1d3635833f0e
port: 443
ucp-api:
id: f67ec325-933c-417c-af72-bfc2d7e084d6
port: 6443
name: kaas-lb-fc0278f0-ce30-11e9-b326-fa163e1b05fd
pools:
kube-api:
id: e948ae06-3017-4345-8d63-010c5c0f57b4
ucp-api:
id: 4a893e8a-e915-441a-a74e-db44b1f8f8d4
router:
id: 7d892f20-5f6a-44ce-badc-8b040b1bfb51
name: kaas-router-fc0278f0-ce30-11e9-b326-fa163e1b05fd
subnet:
cidr: 10.10.10.0/24
id: 9515ee68-5039-476a-b35a-1c690c58a050
name: kaas-subnet-fc0278f0-ce30-11e9-b326-fa163e1b05fd
status:providerStatus for OpenStack security groups¶
Warning
Do not modify this section using API.
The providerStatus object field of the Cluster resource
for the OpenStack security groups contains the following fields:
controlPlaneSecurityGroupContains the following information about the OpenStack security group rules for the control plane nodes of a Container Cloud cluster:
id- ID of a security groupname- name of a security grouprules- list of the security group rules
globalSecurityGroupContains the following information about the OpenStack security group rules for all nodes of a Container Cloud cluster:
id- ID of a security groupname- name of a security grouprules- list of the security group rules
Configuration example:
status:
providerStatus:
controlPlaneSecurityGroup:
id: 01234456-7890-abcd-efgh-876543219876
name: kaas-sg-ctrl-abcdefgh-0123-4567-890a-0a1b2c3d4e5
rules:
...
globalSecurityGroup:
id: 01234456-7890-abcd-efgh-876543219876
name: kaas-sg-glob-abcdefgh-0123-4567-890a-0a1b2c3d4e5
rules:
...
status:providerStatus for Bastion¶
The providerStatus object field of the Cluster resource
for the Bastion instance contains the following fields:
bastionpublicIP- public IP of the Bastion instancelcmManaged- flag indicating that Bastion is managed by LCM
bastionSecurityGroupContains the following information about the OpenStack security group rules for the Bastion instance of a Container Cloud cluster:
id- ID of a security groupname- name of a security grouprules- list of the security group rules
Configuration example:
status:
providerStatus:
bastion:
publicIP: 172.16.247.162
bastionSecurityGroup:
id: 01234456-7890-abcd-efgh-876543219876
name: kaas-sg-bastion-abcdefgh-0123-4567-890a-0a1b2c3d4e5
rules:
...
status:providerStatus for Cluster readiness¶
Warning
Do not modify this section using API.
The providerStatus object field of the Cluster resource that reflects
cluster readiness contains the following fields:
persistentVolumesProviderProvisionedProvision status of the provider persistent volumes (PVs). Used to prevent Helm releases that require PVs from being installed until some default
StorageClassis present in the cluster.
helmStatus of deployed Helm releases:
readyIf all Helm releases have been deployed successfully, the value switches to
true.
releasesList of enabled Helm Releases that run on a cluster:
releaseStatusesList of Helm releases being deployed. Each release has the
successfield that switches totrueonce a release is deployed.
stacklightStatus of the StackLight deployment. Contains URLs of all StackLight components.
iamStatus of the IAM deployment. Contains URLs of the
keycloakandapicomponents.
deccStatus of the remaining
container cloudcomponents. Contains URLs of theui,cache, andproxycomponents.
nodesreadyNumber of nodes that completed deployment or update.
requestedTotal number of nodes. If the number of
readynodes does not match the number ofrequestednodes, it means that a cluster is being updated.
cephreadyCeph readiness flag.
messageCeph status details.
readyCluster readiness flag. If
true, the cluster is deployed successfully and all components are up and running.
conditionsList of objects status condition:
typeObject type
readyReadiness flag
messageStatus details
notReadyObjectsList of Kubernetes objects (
Service,Deployment, andStatefulSet) that are not in theReadystate yet:Serviceis not ready if its external address has not been provisioned yet.DeploymentorStatefulSetis not ready if the number of ready replicas is not equal to the number of required replicas.
Contains the name and namespace of the object and the number of ready and required replicas for controllers. If all objects are ready, the
notReadyObjectslist is empty.
Configuration example:
status:
providerStatus:
persistentVolumesProviderProvisioned: true
helm:
ready: true
releases:
decc:
cache:
url: >-
https://a618e3d36d7f44f2e8d56bbcc53ffbf7-1765661812.us-east-2.elb.amazonaws.com
proxy:
url: >-
http://a0d8d8966e0d24f50aead0942da92456-2114585625.us-east-2.elb.amazonaws.com:3128
ui:
url: >-
https://a43fe72c644de41ae9db3cc77dd992d5-566275388.us-east-2.elb.amazonaws.com
iam:
api:
url: >-
https://a08d8bdd8553b49a88ab8e663d384001-1745154108.us-east-2.elb.amazonaws.com
keycloak:
url: >-
https://a2b58b6a3ee3c4884b034fd791ebff6d-1687192379.us-east-2.elb.amazonaws.com
releaseStatuses:
admission-controller:
success: true
iam:
success: true
iam-controller:
success: true
kaas-exporter:
success: true
kaas-public-api:
success: true
kaas-ui:
success: true
lcm-controller:
...
stacklight:
alerta:
url: http://172.16.248.170
alertmanager:
url: http://172.16.247.217
grafana:
url: http://172.16.248.49
kibana:
url: http://172.16.245.164
prometheus:
url: http://172.16.249.211
success: true
nodes:
ready: 3
requested: 3
notReadyObjects:
services:
- name: testservice
namespace: default
deployments:
- name: <provider_name>-provider
namespace: kaas
replicas: 3
readyReplicas: 2
statefulsets: {}
ready: false
ceph:
- message: Ceph cluster has been configured successfully
ready: true
conditions:
- message: Helm charts are successfully installed(upgraded).
ready: true
type: Helm
- message: Kubernetes objects are fully up.
ready: true
type: Kubernetes
- message: All requested nodes are ready.
ready: true
type: Nodes
status:providerStatus for Open ID Connect¶
Warning
Do not modify this section using API.
The oidc section of the providerStatus object field
of the Cluster resource reflects the Open ID Connect (OIDC) configuration
details. It contains the required details to obtain a cluster token
and contains the following fields:
certificateBase64-encoded OIDC certificate.
clientIdClient ID for OIDC requests.
groupsClaimName of an OIDC groups claim.
issuerUrlIsuer URL to get the representation of the realm.
readyOIDC status relevance. Is
trueif the status fits the configuration of the LCMCluster OIDC.
Configuration example:
status:
providerStatus:
oidc:
certificate: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUREekNDQWZ...
clientId: kaas
groupsClaim: iam_roles
issuerUrl: https://172.16.243.211/auth/realms/iam
ready: true
status:providerStatus for Cluster releases¶
Warning
Do not modify this section using API.
The releaseRefs section of the providerStatus object field
of the Cluster resource provides the current Cluster release version
as well as the one available for upgrade. It contains the following fields:
currentDetails of the currently installed Cluster release:
lcmTypeType of the Cluster release (
mke)
nameName of the Cluster release resource
versionRelease version
unsupportedSinceKaaSVersionIndicates that a newer Container Cloud release exists and it does not support the current Cluster release
availableList of releases available for upgrade that contains the
nameandversionfields
Configuration example:
status:
providerStatus:
releaseRefs:
available:
- name: mke-5-15-0-3-4-0-dev
version: 5.15.0+3.4.0-dev
current:
lcmType: mke
name: mke-5-14-0-3-3-0-beta1
version: 5.14.0+3.3.0-beta1
Machine¶
This section describes the Machine resource used in Mirantis Container
Cloud API for the OpenStack-based clusters.
The Machine resource describes the machine-level parameters.
For demonstration purposes, the Container Cloud Machine
custom resource (CR) can be split into the following major sections:
metadata¶
The Container Cloud Machine custom resource (CR) contains the following
fields:
apiVersionObject API version that is
cluster.k8s.io/v1alpha1.
kindObject type that is
Machine.
The metadata object field of the Machine resource contains
the following fields:
nameName of the
Machineobject.
namespaceContainer Cloud project in which the
Machineobject has been created.
annotationsopenstack-floating-ip-addressAutomatically generated floating IP which will be associated with an OpenStack instance.
labelskaas.mirantis.com/providerProvider type that matches the provider type in the
Clusterobject and should beopenstackfor OpenStack machines.
kaas.mirantis.com/regionRegion name that matches the region name in the
Clusterobject.Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
cluster.sigs.k8s.io/cluster-nameCluster name that this machine is linked to.
cluster.sigs.k8s.io/control-planeFor the control plane role of a machine, this label contains any value, for example,
"true".For the worker role, this label is absent.
kaas.mirantis.com/machinepool-name(optional)Name of the
MachinePoolobject to which this machine is assigned to. If the machine is not assigned to any machine pool, this label is absent.
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Configuration example:
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
name: example-control-plane
namespace: example-ns
annotations:
openstack-floating-ip-address: 172.16.246.182
labels:
kaas.mirantis.com/provider: openstack
cluster.sigs.k8s.io/cluster-name: example-cluster
cluster.sigs.k8s.io/control-plane: "true" # remove for worker
spec:providerSpec for instance configuration¶
Caution
If a machine is assigned to a machine pool, the providerSpec
section of the specific Machine object automatically updates during pool
configuration. The only providerSpec field that is not overwritten
automatically is maintenance. Do not edit other fields of this section
manually.
The spec object field of the Machine object represents
the OpenstackMachineProviderSpec subresource with all required
details to create an OpenStack instance. It contains the following fields:
apiVersionopenstackproviderconfig.k8s.io/v1alpha.
kindOpenstackMachineProviderSpec.
availabilityZoneAvailability zone to launch the OpenStack instance from.
flavorFlavor reference to the OpenStack instance flavor.
imageName of the image to use for the OpenStack instance.
securityGroupsList of the security groups IDs assigned to the OpenStack instance.
nodeLabelsList of node labels to be attached to a node for the user to run certain components on separate cluster nodes. The list of allowed node labels is located in the
Clusterobject statusproviderStatus.releaseRef.current.allowedNodeLabelsfield.If the
valuefield is not defined inallowedNodeLabels, a label can have any value.Before or after a machine deployment, add the required label from the allowed node labels list with the corresponding value to
spec.providerSpec.value.nodeLabelsinmachine.yaml. For example:nodeLabels: - key: stacklight value: enabled
The addition of a node label that is not available in the list of allowed node labels is restricted.
maintenanceMaintenance mode of a machine. If enabled, the node of the selected machine is drained, cordoned, and prepared for maintenance operations.
upgradeIndex(optional)Positive numeral value that determines the order of machines upgrade. The first machine to upgrade is always one of the control plane machines with the lowest
upgradeIndex. Other control plane machines are upgraded one by one according to their upgrade indexes.If the
ClusterspecdedicatedControlPlanefield isfalse, worker machines are upgraded only after the upgrade of all control plane machines finishes. Otherwise, they are upgraded after the first control plane machine, concurrently with other control plane machines.If two or more machines have the same value of
upgradeIndex, these machines are equally prioritized during upgrade.
bootFromVolumeTechPreviewConfiguration to boot a server from a block storage volume based on a given image. Required parameters:
enabledSet to
trueto boot from a volume.
volumeSizeSize of the volume to create in GB. The minimal storage requirement is 120 GB per node. For details, see Requirements for an OpenStack-based cluster.
deletionPolicyTechnology Preview since 2.21.0 for non-MOSK clusters. Policy used to identify steps required during a
Machineobject deletion. Supported policies are as follows:gracefulPrepares a machine for deletion by cordoning, draining, and removing from Docker Swarm of the related node. Then deletes Kubernetes objects and associated resources. Can be aborted only before a node is removed from Docker Swarm.
unsafeDefault. Deletes Kubernetes objects and associated resources without any preparations.
forcedDeletes Kubernetes objects and associated resources without any preparations. Removes the
Machineobject even if the cloud provider or LCM Controller gets stuck at some step. May require a manual cleanup of machine resources in case of the controller failure.
For more details on the workflow of machine deletion policies, see Overview of machine deletion policies.
deleteTechnology Preview since 2.21.0 for non-MOSK clusters. Boolean trigger for a machine deletion. Set to
falseto abort a machine deletion.
Configuration example:
providerSpec:
value:
apiVersion: openstackproviderconfig.k8s.io/v1alpha1
kind: OpenstackMachineProviderSpec
availabilityZone: nova
flavor: kaas.small
image: bionic-server-cloudimg-amd64-20200724
securityGroups:
- kaas-sg-ctrl-abcdefgh-0123-4567-890a-0a1b2c3d4e5f
- kaas-sg-glob-abcdefgh-0123-4567-890a-0a1b2c3d4e5f
nodeLabels:
- key: openstack-control-plane
value: enabled
bootFromVolume:
enabled: true
volumeSize: 120
delete: false
deletionPolicy: graceful
status:providerStatus¶
The status object field of the Machine object represents
the OpenstackMachineProviderStatus subresource that describes current
state of an OpenStack instance and contains the following fields:
apiVersionopenstackproviderconfig.k8s.io/v1alpha1
kindOpenstackMachineProviderStatus
conditionsList of the
Machinestatus condition:typeObject type
readyReadiness flag
messageStatus details
providerInstanceStateCurrent state of an OpenStack instance:
idID of an OpenStack instance
readyReadiness flag
stateState of an OpenStack instance
hardwareMachine hardware information:
cpuCPUs number
ramRAM capacity (in GB)
privateIpPrivate IPv4 address assigned to the instance
maintenanceMaintenance mode of a machine. If enabled, the node of the selected machine is drained, cordoned, and prepared for maintenance operations.
upgradeIndexPositive numeral value that determines the order of machines upgrade. The first machine to upgrade is always one of the control plane machines with the lowest
upgradeIndex. Other control plane machines are upgraded one by one according to their upgrade indexes.If the
ClusterspecdedicatedControlPlanefield isfalse, worker machines are upgraded only after the upgrade of all control plane machines finishes. Otherwise, they are upgraded after the first control plane machine, concurrently with other control plane machines.If two or more machines have the same value of
upgradeIndex, these machines are equally prioritized during upgrade.If
upgradeIndexin theMachineobject spec is set, this status value equals the one in the spec. Otherwise, this value displays the automatically generated order of upgrade.
statusCurrent state of a machine:
ProvisionA machine is yet to obtain a status
UninitializedA machine is yet to obtain the node IP address and host name
PendingA machine is yet to receive the deployment instructions and it is either not booted yet or waits for the LCM controller to be deployed
PrepareA machine is running the
Preparephase during which Docker images and packages are being predownloaded
DeployA machine is processing the LCM Controller instructions
ReconfigureA machine is being updated with a configuration without affecting workloads running on the machine
ReadyA machine is deployed and the supported Mirantis Kubernetes Engine (MKE) version is set
MaintenanceA machine host is cordoned, drained, and prepared for maintenance operations
deleteTechnology Preview since 2.21.0 for non-MOSK clusters. Start of a machine deletion or a successful abortion. Boolean.
prepareDeletionPhaseTechnology Preview since 2.21.0 for non-MOSK clusters. Preparation phase for a graceful machine deletion. Possible values are as follows:
startedCloud provider controller prepares a machine for deletion by cordoning, draining the machine, and so on.
completedLCM Controller starts removing the machine resources since the preparation for deletion is complete.
abortingCloud provider controller attempts to uncordon the node. If the attempt fails, the status changes to
failed.
failedError in the deletion workflow.
For the workflow description of a graceful deletion, see Overview of machine deletion policies.
Configuration example:
status:
providerStatus:
apiVersion: openstackproviderconfig.k8s.io/v1alpha1
kind: OpenstackMachineProviderStatus
conditions:
- message: Kubelet's NodeReady condition is True
ready: true
type: Kubelet
- message: Swarm state of the machine is ready
ready: true
type: Swarm
- message: LCM Status of the machine is Ready
ready: true
type: LCM
...
providerInstanceState:
id: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
ready: true
state: ACTIVE
hardware:
cpu: 8
ram: 24
privateIp: 10.10.10.169
status: Ready
delete: true
prepareDeletionPhase: started
OpenStackCredential¶
This section describes the OpenStackCredential custom resource (CR)
used in Mirantis Container Cloud API. It contains all required details
to connect to a provider backend.
Warning
The kubectl apply command automatically saves the
applied data as plain text into the
kubectl.kubernetes.io/last-applied-configuration annotation of the
corresponding object. This may result in revealing sensitive data in this
annotation when creating or modifying the object.
Therefore, do not use kubectl apply on this object. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on this object, you
can remove the kubectl.kubernetes.io/last-applied-configuration
annotation from the object using kubectl edit.
For demonstration purposes, the Container Cloud OpenStackCredential
custom resource (CR) can be split into the following sections:
metadata¶
The Container Cloud OpenStackCredential custom resource (CR) contains the following
fields:
apiVersionObject API version that is kaas.mirantis.com/v1alpha1.
kindObject type that is
OpenStackCredential.
The metadata object field of the OpenStackCredential resource contains
the following fields:
nameName of the
OpenStackCredentialobject
namespaceNamespace in which the
OpenStackCredentialobject has been created
labelskaas.mirantis.com/providerProvider type that matches the provider type in the Cluster object and must be
openstack
kaas.mirantis.com/regional-credentialMust be
trueto useOpenStackCredentialfor the management cluster objectsNote
The
kaas.mirantis.com/regional-credentiallabel is removed from in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
kaas.mirantis.com/regionRegion name
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud objects in 2.26.0 (Cluster releases 17.1.0 and 16.1.0). Therefore, do not add the label starting these releases. On existing clusters updated to these releases, or if manually added, this label will be ignored by Container Cloud.
Warning
Labels and annotations that are not documented in this API Reference are generated automatically by Container Cloud. Do not modify them using the Container Cloud API.
Configuration example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: OpenStackCredential
metadata:
name: demo
namespace: test
labels:
kaas.mirantis.com/regional-credential: "true"
OpenStackCredential configuration¶
The spec object field of the OpenStackCredential resource
contains a cloud configuration to use for OpenStack authentication.
It contains the following fields:
authauthURLIdentity endpoint URL.
passwordvalueValue of the password. This field is available only when the user creates or changes password. Once the controller detects this field, it updates the password in the secret and removes the
valuefield from theOpenStackCredentialobject.
secretReference to the
Secretobject that contains the password:keySecret key name
nameSecret name
projectIDUnique ID of a project.
userDomainNameName of a domain where the user resides.
userNameUser name
regionNameName of an OpenStack region.
CACertBase64 encoded CA certificate bundle for verification of SSL API requests.
Configuration example:
...
spec:
auth:
authURL: https://container-cloud.ssl.example.com/v3
password:
secret:
key: value
name: cloud-config
projectDomainName: k8s-team
projectID: d67a2680ded144af8bcc91314e560616
projectName: k8s-team
userDomainName: default
userName: k8s-team
regionName: RegionOne
OpenStackResources¶
This section describes the OpenStackResources custom resource (CR)
used in Container Cloud API. The OpenStackResources object contains the
list of available OpenStack resources, such as flavors, images,
external networks, and compute availability zones.
For demonstration purposes, the Container Cloud OpenStackResources
custom resource (CR) can be split into the following sections:
metadata¶
The Container Cloud OpenStackResources custom resource (CR) contains the following
fields:
apiVersionObject API version that is
kaas.mirantis.com/v1alpha1.
kindObject type that is
OpenStackResources.
The metadata object field of the OpenStackResources resource contains
the following fields:
nameName of the
OpenStackResourcesobject
namespaceProject in which the
OpenStackResourcesobject has been created
Configuration example:
apiVersion: kaas.mirantis.com/v1alpha1
kind: OpenStackResources
metadata:
name: cloud-config
namespace: test
OpenStackResources status¶
The status field of OpenStackResources object contains the list of
available OpenStack resources:
computeAZList of available availability zones
externalNetworksList of available external networks with each entry containing network
IDandname
flavorsList of available flavors with description:
DiskAmount of disk space (in GB)
EphemeralAmount of disk space (in GB) to use for the ephemeral partition
IDUnique ID of a flavor
NameName of a flavor
RAMAmount of RAM to use (in MB)
VCPUsNumber of virtual CPUs to use
imagesList of available images with
IDandName
Configuration example:
status:
computeAZ:
- Name: nova
- Name: DMZ
externalNetworks:
- ID: c3799996-dc8e-4477-a309-09ea6dd71946
Name: public
flavors:
- Disk: 500 GB
Ephemeral: 0 GB
ID: 06508206-c027-4596-954e-89b1f6490a43
Name: re.jenkins.slave.big
RAM: 65536 MB
VCPUs: "24"
- Disk: 160 GB
Ephemeral: 0 GB
ID: 0840136f-9e61-488d-a8d6-8425d0e2378e
Name: kaas-bm.worker.160
RAM: 12288 MB
VCPUs: "8"
...
images:
- ID: 4779aa8e-cb59-41bb-b2ac-49bd692d8e1f
Name: bionic-server-cloudimg-amd64-20200724
...
Release Compatibility Matrix¶
The Mirantis Container Cloud Release Compatibility Matrix outlines the specific operating environments that are validated and supported.
The document provides the deployment compatibility for each product release and determines the upgrade paths between major components versions when upgrading. The document also provides the Container Cloud browser compatibility.
A Container Cloud management cluster upgrades automatically when a new product release becomes available. Once the management cluster has been updated, the user may trigger the managed clusters upgrade through the Container Cloud web UI or API.
To view the full components list with their respective versions for each Container Cloud release, refer to the Container Cloud Release Notes related to the release version of your deployment or use the Releases section in the web UI or API.
Caution
The document applies to the Container Cloud regular deployments. For supported configurations of existing Mirantis Kubernetes Engine (MKE) clusters that are not deployed by Container Cloud, refer to MKE Compatibility Matrix.
Compatibility matrix of component versions¶
The following tables outline the compatibility matrices of the most recent major Container Cloud and Cluster releases along with patch releases and their component versions. For details about unsupported releases, see Releases summary.
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on your deployment needs, you can either update only between major Cluster releases or apply patch updates between major releases. Choosing the latter option ensures you receive security fixes as soon as they become available. Though, be prepared to update your cluster frequently, approximately once every three weeks. Otherwise, you can update only between major Cluster releases as each subsequent major Cluster release includes patch Cluster release updates of the previous major Cluster release.
Legend
Symbol |
Definition |
|---|---|
Cluster release is not included in the Container Cloud release yet. |
|
Latest supported Cluster release to use for cluster deployment or update. |
|
Deprecated Cluster release that you must update to the latest supported Cluster release. The deprecated Cluster release will become unsupported in one of the following Container Cloud releases. Greenfield deployments based on a deprecated Cluster release are not supported. Use the latest supported Cluster release instead. |
|
Unsupported Cluster release that blocks automatic upgrade of a management cluster. Update the Cluster release to the latest supported one to unblock management cluster upgrade and obtain newest product features and enhancements. |
|
Component is included in the Container Cloud release. |
|
Component is available in the Technology Preview scope. Use it only for testing purposes on staging environments. |
Release |
Container Cloud |
2.27.1 (current) |
2.27.0 |
2.26.5 |
2.26.4 |
2.26.3 |
2.26.2 |
2.26.1 |
2.26.0 |
|---|---|---|---|---|---|---|---|---|---|
Release history |
Release date |
July 16, 2024 |
July 02, 2024 |
June 18, 2024 |
May 20, 2024 |
Apr 29, 2024 |
Apr 08, 2024 |
Mar 20, 2024 |
Mar 04, 2024 |
Major Cluster releases (managed) |
17.2.0 +
MOSK 24.2
MKE 3.7.8
|
||||||||
17.1.0 +
MOSK 24.1
MKE 3.7.5
|
|||||||||
17.0.0 +
MOSK 23.3
MKE 3.7.1
|
|||||||||
16.2.0
MKE 3.7.8
|
|||||||||
16.1.0
MKE 3.7.5
|
|||||||||
16.0.0
MKE 3.7.1
|
|||||||||
Patch Cluster releases (managed) |
17.1.x + MOSK 24.1.x |
17.1.6+24.1.6
17.1.5+24.1.5
|
17.1.5+24.1.5
|
17.1.5+24.1.5
17.1.4+24.1.4
17.1.3+24.1.3
17.1.2+24.1.2
17.1.1+24.1.1
|
17.1.4+24.1.4
17.1.3+24.1.3
17.1.2+24.1.2
17.1.1+24.1.1
|
17.1.3+24.1.3
17.1.2+24.1.2
17.1.1+24.1.1
|
17.1.2+24.1.2
17.1.1+24.1.1
|
17.1.1+24.1.1
|
|
17.0.x + MOSK 23.3.x |
17.0.4+23.3.4
|
17.0.4+23.3.4
|
17.0.4+23.3.4
|
17.0.4+23.3.4
|
17.0.4+23.3.4
|
17.0.4+23.3.4
|
17.0.4+23.3.4
|
17.0.4+23.3.4
17.0.3+23.3.3
17.0.2+23.3.2
17.0.1+23.3.1
|
|
16.2.x |
16.2.1 |
||||||||
16.1.x |
16.1.6
16.1.5
|
16.1.5
|
16.1.5
16.1.4
16.1.3
16.1.2
16.1.1
|
16.1.4
16.1.3
16.1.2
16.1.1
|
16.1.3
16.1.2
16.1.1
|
16.1.2
16.1.1
|
16.1.1
|
||
16.0.x |
16.0.4
|
16.0.4
|
16.0.4
|
16.0.4
|
16.0.4
|
16.0.4
|
16.0.4
|
16.0.4
16.0.3
16.0.2
16.0.1
|
|
Fully managed cluster |
Mirantis Kubernetes Engine (MKE) |
3.7.10
17.1.6, 16.2.1, 16.1.6
|
3.7.8
17.2.0, 16.2.0
|
3.7.8
17.1.5, 16.1.5
|
3.7.8
17.1.4, 16.1.4
|
3.7.7
17.1.3, 16.1.3
|
3.7.6
17.1.2, 16.1.2
|
3.7.5
17.1.1, 16.1.1
|
3.7.5
17.1.0, 16.1.0
|
Attached managed cluster |
MKE 7 |
3.6.8
19.1.0
3.6.1
19.0.0
3.5.5
18.1.0
3.5.3
18.0.0
|
3.6.8
19.1.0
3.6.1
19.0.0
3.5.5
18.1.0
3.5.3
18.0.0
|
3.6.8
19.1.0
3.6.1
19.0.0
3.5.5
18.1.0
3.5.3
18.0.0
|
3.6.8
19.1.0
3.6.1
19.0.0
3.5.5
18.1.0
3.5.3
18.0.0
|
3.6.8
19.1.0
3.6.1
19.0.0
3.5.5
18.1.0
3.5.3
18.0.0
|
3.6.8
19.1.0
3.6.1
19.0.0
3.5.5
18.1.0
3.5.3
18.0.0
|
3.6.8
19.1.0
3.6.1
19.0.0
3.5.5
18.1.0
3.5.3
18.0.0
|
3.6.8
19.1.0
3.6.1
19.0.0
3.5.5
18.1.0
3.5.3
18.0.0
|
Container orchestration |
Kubernetes |
1.27 17.x, 16.x |
1.27 17.x, 16.x |
1.27 17.1.x, 16.1.x |
1.27 17.1.x, 16.1.x |
1.27 17.1.x, 16.1.x |
1.27 17.1.x, 16.1.x |
1.27 17.1.x, 16.1.x |
1.27 17.1.x, 16.1.x |
Container runtime |
Mirantis Container Runtime (MCR) |
23.0.11 17.2.x, 16.2.x |
23.0.9 17.1.x, 16.1.x 2 |
23.0.9 17.1.x, 16.1.x 2 |
23.0.9 17.1.x, 16.1.x 2 |
23.0.9 17.1.x, 16.1.x 2 |
23.0.9 17.1.x, 16.1.x |
23.0.9 17.1.x, 16.1.x |
|
OS distributions |
Ubuntu |
22.04 9
20.04
|
22.04 9
20.04
|
20.04
|
20.04
|
20.04
|
20.04
|
20.04
|
20.04
|
Infrastructure platform |
Bare metal 8 |
kernel 5.15.0-113-generic
|
kernel 5.15.0-107-generic
|
kernel 5.15.0-107-generic
|
kernel 5.15.0-105-generic
|
kernel 5.15.0-102-generic
|
kernel 5.15.0-101-generic
|
kernel 5.15.0-97-generic
|
kernel 5.15.0-92-generic
|
MOSK Yoga or Antelope with OVS 3 |
|||||||||
Queens
Yoga
Antelope
|
Queens
Yoga
Antelope
|
Queens
Yoga
Antelope
|
Queens
Yoga
Antelope
|
Queens
Yoga
Antelope
|
Queens
Yoga
Antelope
|
Queens
Yoga
Antelope
|
Queens
Yoga
Antelope
|
||
VMware vSphere 5 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
|
Software defined storage |
Ceph |
18.2.3-2.cve
16.2.1
17.2.7-15.cve
17.1.6, 16.1.6
|
18.2.3-1.release
17.2.0, 16.2.0
|
17.2.7-13.cve
17.1.5, 16.1.5
|
17.2.7-12.cve
17.1.4, 16.1.4
|
17.2.7-11.cve
17.1.3, 16.1.3
|
17.2.7-10.release
17.1.2, 16.1.2
|
17.2.7-9.release
17.1.1, 16.1.1
|
17.2.7-8.release
17.1.0, 16.1.0
|
Rook |
1.13.5-16
16.2.1
1.12.10-21
17.1.6, 16.1.6
|
1.13.5-15
17.2.0, 16.2.0
|
1.12.10-19
17.1.5, 16.1.5
|
1.12.10-18
17.1.4, 16.1.4
|
1.12.10-17
17.1.3, 16.1.3
|
1.12.10-16
17.1.2, 16.1.2
|
1.12.10-14
17.1.1, 16.1.1
|
1.12.10-13
17.1.0, 16.1.0
|
|
Logging, monitoring, and alerting |
StackLight |
The following table outlines the compatibility matrix for the Container Cloud release series 2.25.x.
Container Cloud compatibility matrix 2.25.x
Release |
Container Cloud |
2.25.4 |
2.25.3 |
2.25.2 |
2.25.1 |
2.25.0 |
|---|---|---|---|---|---|---|
Release history |
Release date |
Jan 10, 2024 |
Dec 18, 2023 |
Dec 05, 2023 |
Nov 27, 2023 |
Nov 06, 2023 |
17.0.0 +
MOSK 23.3
MKE 3.7.1
|
||||||
16.0.0
MKE 3.7.1
|
||||||
15.0.1 +
MOSK 23.2
MKE 3.6.5
|
||||||
14.1.0 1
MKE 3.6.6
|
||||||
14.0.1
MKE 3.6.5
|
||||||
12.7.0 +
MOSK 23.1
MKE 3.5.7
|
||||||
11.7.0
MKE 3.5.7
|
||||||
Patch Cluster releases (managed) |
17.0.x + MOSK 23.3.x |
17.0.4+23.3.4
17.0.3+23.3.3
17.0.2+23.3.2
17.0.1+23.3.1
|
17.0.3+23.3.3
17.0.2+23.3.2
17.0.1+23.3.1
|
17.0.2+23.3.2
17.0.1+23.3.1
|
17.0.1+23.3.1
|
|
16.0.x |
16.0.4
16.0.3
16.0.2
16.0.1
|
16.0.3
16.0.2
16.0.1
|
16.0.2
16.0.1
|
16.0.1
|
||
15.0.x + MOSK 23.2.x |
15.0.4+23.2.3 |
15.0.4+23.2.3 |
15.0.4+23.2.3 |
15.0.4+23.2.3 |
15.0.4+23.2.3 |
|
14.0.x |
14.0.4 |
14.0.4 |
14.0.4 |
14.0.4 |
14.0.4 |
|
Fully managed cluster |
Mirantis Kubernetes Engine (MKE) |
3.7.3
Since 17.0.3, 16.0.3
3.7.2
Since 17.0.1, 16.0.1
3.7.1
17.0.0, 16.0.0
|
3.7.3
Since 17.0.3, 16.0.3
3.7.2
Since 17.0.1, 16.0.1
3.7.1
17.0.0, 16.0.0
|
3.7.2
Since 17.0.1, 16.0.1
3.7.1
17.0.0, 16.0.0
|
3.7.2
Since 17.0.1, 16.0.1
3.7.1
17.0.0, 16.0.0
|
3.7.1
17.0.0, 16.0.0
|
Attached managed cluster |
MKE 7 |
3.6.8
19.1.0
3.6.1
19.0.0
3.5.5
18.1.0
3.5.3
18.0.0
|
3.6.8
19.1.0
3.6.1
19.0.0
3.5.5
18.1.0
3.5.3
18.0.0
|
3.6.8
19.1.0
3.6.1
19.0.0
3.5.5
18.1.0
3.5.3
18.0.0
|
||
Container orchestration |
Kubernetes |
1.27 17.0.x, 16.0.x |
1.27 17.0.x, 16.0.x |
1.27 17.0.x, 16.0.x |
1.27 17.0.x, 16.0.x |
1.27 17.0.0, 16.0.0 |
Container runtime |
Mirantis Container Runtime (MCR) |
23.0.7 17.0.x, 16.0.x |
23.0.7 17.0.x, 16.0.x |
23.0.7 17.0.x, 16.0.x |
23.0.7 17.0.x, 16.0.x |
23.0.7 17.0.0, 16.0.0 |
OS distributions |
Ubuntu |
20.04 |
20.04 |
20.04 |
20.04 |
20.04 |
Infrastructure platform |
Bare metal 8 |
kernel 5.15.0-86-generic |
kernel 5.15.0-86-generic |
kernel 5.15.0-86-generic |
kernel 5.15.0-86-generic |
kernel 5.15.0-86-generic |
MOSK Yoga or Antelope with Tungsten Fabric 3 |
||||||
MOSK Yoga or Antelope with OVS 3 |
||||||
Queens
Yoga
Antelope
|
Queens
Yoga
Antelope
|
Queens
Yoga
Antelope
|
Queens
Yoga
Antelope
|
Queens
Yoga
Antelope
|
||
VMware vSphere 5 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
|
Software defined storage |
Ceph |
17.2.6-8.cve
Since 17.0.3, 16.0.3
17.2.6-5.cve
17.0.2, 16.0.2
17.2.6-2.cve
17.0.1, 16.0.1
17.2.6-cve-1
17.0.0, 16.0.0, 14.1.0
|
17.2.6-8.cve
17.0.3, 16.0.3
17.2.6-5.cve
17.0.2, 16.0.2
17.2.6-2.cve
17.0.1, 16.0.1
17.2.6-cve-1
17.0.0, 16.0.0, 14.1.0
|
17.2.6-5.cve
17.0.2, 16.0.2
17.2.6-2.cve
17.0.1, 16.0.1
17.2.6-cve-1
17.0.0, 16.0.0, 14.1.0
|
17.2.6-2.cve
17.0.1, 16.0.1
17.2.6-cve-1
17.0.0, 16.0.0, 14.1.0
|
17.2.6-cve-1
17.0.0, 16.0.0, 14.1.0
|
Rook |
1.11.11-22
17.0.4, 16.0.4
1.11.11-21
17.0.3, 16.0.3
1.11.11-17
17.0.2, 16.0.2
1.11.11-15
17.0.1, 16.0.1
1.11.11-13
17.0.0, 16.0.0, 14.1.0
|
1.11.11-21
17.0.3, 16.0.3
1.11.11-17
17.0.2, 16.0.2
1.11.11-15
17.0.1, 16.0.1
1.11.11-13
17.0.0, 16.0.0, 14.1.0
|
1.11.11-17
17.0.2, 16.0.2
1.11.11-15
S17.0.1, 16.0.1
1.11.11-13
17.0.0, 16.0.0, 14.1.0
|
1.11.11-15
17.0.1, 16.0.1
1.11.11-13
17.0.0, 16.0.0, 14.1.0
|
1.11.11-13
17.0.0, 16.0.0, 14.1.0
|
|
Logging, monitoring, and alerting |
StackLight |
The following table outlines the compatibility matrix for the Container Cloud release series 2.24.x.
Container Cloud compatibility matrix 2.24.x
Release |
Container Cloud |
2.24.5 |
2.24.4 |
2.24.3 |
2.24.2 |
2.24.0
2.24.1 0
|
|---|---|---|---|---|---|---|
Release history |
Release date |
Sep 26, 2023 |
Sep 14, 2023 |
Aug 29, 2023 |
Aug 21, 2023 |
Jul 20, 2023
Jul 27, 2023
|
Major Cluster releases (managed) |
15.0.1 +
MOSK 23.2
MKE 3.6.5
|
|||||
14.0.1
MKE 3.6.5
|
||||||
14.0.0
MKE 3.6.5
|
||||||
12.7.0 +
MOSK 23.1
MKE 3.5.7
|
||||||
11.7.0
MKE 3.5.7
|
||||||
Patch Cluster releases (managed) |
15.0.x + MOSK 23.2.x |
15.0.4+23.2.3
15.0.3+23.2.2
15.0.2+23.2.1
|
15.0.3+23.2.2
15.0.2+23.2.1
|
15.0.2+23.2.1
|
||
14.0.x |
14.0.4
14.0.3
14.0.2
|
14.0.3
14.0.2
|
14.0.2
|
|||
Managed cluster |
Mirantis Kubernetes Engine (MKE) |
3.6.6
Since 15.0.2, 14.0.2
3.6.5
15.0.1, 14.0.1
|
3.6.6
Since 15.0.2, 14.0.2
3.6.5
15.0.1, 14.0.1
|
3.6.6
15.0.2, 14.0.2
3.6.5
15.0.1, 14.0.1
|
3.6.5
15.0.1, 14.0.1
|
3.6.5
14.0.0
|
Container orchestration |
Kubernetes |
1.24
15.0.x, 14.0.x
|
1.24
15.0.x, 14.0.x
|
1.24
15.0.x, 14.0.x
|
1.24
15.0.1, 14.0.1
|
1.24
14.0.0
|
Container runtime |
Mirantis Container Runtime (MCR) |
20.10.17
15.0.x, 14.0.x
|
20.10.17
15.0.x, 14.0.x
|
20.10.17 2
15.0.x, 14.0.x
|
20.10.17
15.0.1, 14.0.1
|
20.10.17
14.0.0
|
OS distributions |
Ubuntu |
20.04 |
20.04 |
20.04 |
20.04 |
20.04 |
Infrastructure platform |
Bare metal |
kernel 5.4.0-150-generic |
kernel 5.4.0-150-generic |
kernel 5.4.0-150-generic |
kernel 5.4.0-150-generic |
kernel 5.4.0-150-generic |
MOSK Yoga or Antelope with Tungsten Fabric 3 |
||||||
MOSK Yoga or Antelope with OVS 3 |
||||||
Queens
Yoga
|
Queens
Yoga
|
Queens
Yoga
|
Queens
Yoga
|
Queens
Yoga
|
||
VMware vSphere 5 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
|
Software defined storage |
Ceph 6 |
17.2.6-cve-1 Since 15.0.2, 14.0.2
17.2.6-rel-5 15.0.1, 14.0.1
|
17.2.6-cve-1
Since 15.0.2, 14.0.2
17.2.6-rel-5
15.0.1, 14.0.1
|
17.2.6-cve-1
15.0.2, 14.0.2
17.2.6-rel-5
15.0.1, 14.0.1
|
17.2.6-rel-5
|
17.2.6-rel-5
16.2.11-cve-4
16.2.11
|
Rook 6 |
1.11.4-12
Since 15.0.3, 14.0.3
1.11.4-11
15.0.2, 14.0.2
1.11.4-10
15.0.1, 14.0.1
|
1.11.4-12
15.0.3, 14.0.3
1.11.4-11
15.0.2, 14.0.2
1.11.4-10
15.0.1, 14.0.1
|
1.11.4-11
15.0.2, 14.0.2
1.11.4-10
15.0.1, 14.0.1
|
1.11.4-10
|
1.11.4-10
1.10.10-10
1.0.0-20230120144247
|
|
Logging, monitoring, and alerting |
StackLight |
The following table outlines the compatibility matrix for the Container Cloud release series 2.23.x.
Container Cloud compatibility matrix 2.23.x
Release |
Container Cloud |
2.23.5 |
2.23.4 |
2.23.3 |
2.23.2 |
2.23.1 |
2.23.0 |
|---|---|---|---|---|---|---|---|
Release history |
Release date |
Jun 05, 2023 |
May 22, 2023 |
May 04, 2023 |
Apr 20, 2023 |
Apr 04, 2023 |
Mar 07, 2023 |
Major Cluster releases (managed) |
12.7.0 +
MOSK 23.1 MKE 3.5.7
|
||||||
12.5.0 +
MOSK 22.5 MKE 3.5.5
|
|||||||
11.7.0
MKE 3.5.7
|
|||||||
11.6.0
MKE 3.5.5
|
|||||||
Patch Cluster releases (managed) |
12.7.x + MOSK 23.1.x |
12.7.4 + 23.1.4
12.7.3 + 23.1.3
12.7.2 + 23.1.2
12.7.1 + 23.1.1
|
12.7.3 + 23.1.3
12.7.2 + 23.1.2
12.7.1 + 23.1.1
|
12.7.2 + 23.1.2
12.7.1 + 23.1.1
|
12.7.1 + 23.1.1
|
||
11.7.x |
11.7.4
11.7.3
11.7.2
11.7.1
|
11.7.3
11.7.2
11.7.1
|
11.7.2
11.7.1
|
11.7.1
|
|||
Managed cluster |
Mirantis Kubernetes Engine (MKE) |
3.5.7 12.7.x, 11.7.x |
3.5.7 12.7.x, 11.7.x |
3.5.7 12.7.x, 11.7.x |
3.5.7 12.7.x, 11.7.x |
3.5.7 12.7.0, 11.7.0 |
3.5.7 11.7.0 |
Container orchestration |
Kubernetes |
1.21 12.7.x, 11.7.x |
1.21 12.7.x, 11.7.x |
1.21 12.7.x, 11.7.x |
1.21 12.7.x, 11.7.x |
1.21 12.7.0, 11.7.0 |
1.21 12.5.0, 11.7.0 |
Container runtime |
Mirantis Container Runtime (MCR) 2 |
20.10.13 |
20.10.13 |
20.10.13 |
20.10.13 |
20.10.13 |
20.10.13 |
OS distributions |
Ubuntu |
20.04 |
20.04 |
20.04 |
20.04 |
20.04 |
20.04 |
Infrastructure platform |
Bare metal |
kernel 5.4.0-137-generic |
kernel 5.4.0-137-generic |
kernel 5.4.0-137-generic |
kernel 5.4.0-137-generic |
kernel 5.4.0-137-generic |
kernel 5.4.0-137-generic |
MOSK Victoria or Yoga with Tungsten Fabric 3 |
|||||||
MOSK Victoria or Yoga with OVS 3 |
|||||||
Queens
Victoria
Yoga
|
Queens
Victoria
Yoga
|
Queens
Victoria
Yoga
|
Queens
Victoria
Yoga
|
Queens
Victoria
Yoga
|
Queens
Victoria
Yoga
|
||
VMware vSphere 5 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
7.0, 6.7 |
|
Software defined storage |
Ceph 6 |
16.2.11-cve-4
16.2.11-cve-2
16.2.11
|
16.2.11-cve-4
16.2.11-cve-2
16.2.11
|
16.2.11-cve-4
16.2.11-cve-2
16.2.11
|
16.2.11-cve-2
16.2.11
|
16.2.11
|
16.2.11
|
Rook 6 |
1.10.10-10
1.10.10-9
1.0.0-20230120144247
|
1.10.10-10
1.10.10-9
1.0.0-20230120144247
|
1.10.10-10
1.10.10-9
1.0.0-20230120144247
|
1.10.10-9
1.0.0-20230120144247
|
1.0.0-20230120144247
|
1.0.0-20230120144247
|
|
Logging, monitoring, and alerting |
StackLight |
- 0
Container Cloud 2.23.5 or 2.24.0 automatically upgrades to the 2.24.1 patch release containing several hot fixes.
- 1
The major Cluster release 14.1.0 is dedicated for the vSphere provider only. This is the last Cluster release for the vSphere provider based on MCR 20.10 and MKE 3.6.6 with Kubernetes 1.24.
Container Cloud 2.25.1 introduces the patch Cluster release 16.0.1 that supports the vSphere provider on MCR 23.0.7 and MKE 3.7.2 with Kubernetes 1.27. For details, see External vSphere CCM with CSI supporting vSphere 6.7 on Kubernetes 1.27.
- 2(1,2,3,4,5,6)
In Container Cloud 2.26.2,
docker-ee-cliis updated to 23.0.10 for MCR 23.0.9 to fix several CVEs.In Container Cloud 2.24.3,
docker-ee-cliis updated to 20.10.18 for MCR 20.10.17 to fix the following CVEs: CVE-2023-28840, CVE-2023-28642, CVE-2022-41723.
- 3(1,2,3,4,5,6,7,8,9,10,11)
OpenStack Antelope is supported as TechPreview since MOSK 23.3.
A Container Cloud cluster based on MOSK Yoga or Antelope with Tungsten Fabric is supported as TechPreview since Container Cloud 2.25.1. Since Container Cloud 2.26.0, support for this configuration is suspended. If you still require this configuration, contact Mirantis support for further information.
OpenStack Victoria is supported until September, 2023. MOSK 23.2 is the last release version where OpenStack Victoria packages are updated.
If you have not already upgraded your OpenStack version to Yoga, Mirantis highly recommends doing this during the course of the MOSK 23.2 series. For details, see MOSK documentation: Upgrade OpenStack.
- 4(1,2,3,4)
Only Cinder API V3 is supported.
- 5(1,2,3,4)
VMware vSphere is supported on RHEL 8.7 or Ubuntu 20.04.
RHEL 8.7 is generally available since Cluster releases 16.0.0 and 14.1.0. Before these Cluster releases, it is supported within the Technology Preview features scope.
For Ubuntu deployments, Packer builds a vSphere virtual machine template that is based on Ubuntu 20.04 with kernel 5.15.0-113-generic. If you build a VM template manually, we recommend installing the same kernel version 5.15.0-113-generic.
- 6(1,2,3,4)
Ceph Pacific supported in 2.23.0 is automatically updated to Quincy during cluster update to 2.24.0.
Ceph Pacific 16.2.11 and Rook 1.0.0-20230120144247 apply to major Cluster releases 12.7.0 and 11.7.0 only.
- 7(1,2)
Attachment of non Container Cloud based MKE clusters is supported only for vSphere-based management clusters on Ubuntu 20.04.
- 8(1,2)
The kernel version of the host operating system is validated by Mirantis and confirmed to be working for the supported use cases. Usage of custom kernel versions or third-party vendor-provided kernels, such as FIPS-enabled, assume full responsibility for validating the compatibility of components in such environments.
- 9(1,2)
On non-MOSK clusters, Ubuntu 22.04 is installed by default on management and managed clusters. Ubuntu 20.04 is not supported.
On MOSK clusters, Ubuntu 22.04 is installed by default on management clusters only. And Ubuntu 20.04 is the only supported distribution for managed clusters.
- 10(1,2)
In Container Cloud 2.27.1,
docker-ee-cliis updated to 23.0.13 for MCR 23.0.11 and 23.0.9 to fix several CVEs.
See also
Container Cloud web UI browser compatibility¶
The Container Cloud web UI runs in the browser, separate from any backend software. As such, Mirantis aims to support browsers separately from the backend software in use, although each Container Cloud release is tested with specific browser versions.
Mirantis currently supports the following web browsers for the Container Cloud web UI:
Browser |
Supported version |
Release date |
Supported operating system |
|---|---|---|---|
Firefox |
94.0 or newer |
November 2, 2021 |
Windows, macOS |
Google Chrome |
96.0.4664 or newer |
November 15, 2021 |
Windows, macOS |
Microsoft Edge |
95.0.1020 or newer |
October 21, 2021 |
Windows |
Caution
This table does not apply to third-party web UIs such as the StackLight or Keycloak endpoints that are available through the Container Cloud web UI. Refer to the official documentation of the corresponding third-party component for details about its supported browsers versions.
To ensure the best user experience, Mirantis recommends that you use the latest version of any of the supported browsers. The use of other browsers or older versions of the browsers we support can result in rendering issues, and can even lead to glitches and crashes in the event that the Container Cloud web UI does not support some JavaScript language features or browser web APIs.
Important
Mirantis does not tie browser support to any particular Container Cloud release.
Mirantis strives to leverage the latest in browser technology to build more performant client software, as well as ensuring that our customers benefit from the latest browser security updates. To this end, our strategy is to regularly move our supported browser versions forward, while also lagging behind the latest releases by approximately one year to give our customers a sufficient upgrade buffer.
See also
Release Notes¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on your deployment needs, you can either update only between major Cluster releases or apply patch updates between major releases. Choosing the latter option ensures you receive security fixes as soon as they become available. Though, be prepared to update your cluster frequently, approximately once every three weeks. Otherwise, you can update only between major Cluster releases as each subsequent major Cluster release includes patch Cluster release updates of the previous major Cluster release.
Container Cloud release
|
Release date
|
Supported Cluster releases |
Summary
|
|---|---|---|---|
Jul 16, 2024 |
Container Cloud 2.27.1 is the first patch release of the 2.27.x release series that introduces the following updates:
|
||
Jul 02, 2024 |
|
||
June 18, 2024 |
Container Cloud 2.26.5 is the fifth patch release of the 2.26.x and MOSK 24.1.x release series that introduces the following updates:
|
||
May 20, 2024 |
Container Cloud 2.26.4 is the fourth patch release of the 2.26.x and MOSK 24.1.x release series that introduces the following updates:
|
||
Apr 29, 2024 |
Container Cloud 2.26.3 is the third patch release of the 2.26.x and MOSK 24.1.x release series that introduces the following updates:
|
||
Apr 08, 2024 |
Container Cloud 2.26.2 is the second patch release of the 2.26.x and MOSK 24.1.x release series that introduces the following updates:
|
||
Mar 20, 2024 |
Container Cloud 2.26.1 is the first patch release of the 2.26.x and MOSK 24.1.x release series that introduces the following updates:
|
||
Mar 04, 2024 |
|
||
Jan 10, 2024 |
Container Cloud 2.25.4 is the fourth patch release of the 2.25.x and MOSK 23.3.x release series that introduces the following updates:
|
||
Dec 18, 2023 |
Container Cloud 2.25.3 is the third patch release of the 2.25.x and MOSK 23.3.x release series that introduces the following updates:
|
||
Dec 05, 2023 |
Container Cloud 2.25.2 is the second patch release of the 2.25.x and MOSK 23.3.x release series that introduces the following updates:
|
||
Nov 27, 2023 |
Container Cloud 2.25.1 is the first patch release of the 2.25.x and MOSK 23.3.x release series that introduces the following updates:
|
||
Nov 06, 2023 |
|
- Cluster release is deprecated and will become unsupported in one of the following Container Cloud releases.
Container Cloud releases¶
This section outlines the release notes for the Mirantis Container Cloud GA release. Within the scope of the Container Cloud GA release, major releases are being published continuously with new features, improvements, and critical issues resolutions to enhance the Container Cloud GA version. Between major releases, patch releases that incorporate fixes for CVEs of high and critical severity are being delivered. For details, see Container Cloud releases, Cluster releases (managed), and Patch releases.
Once a new Container Cloud release is available, a management cluster automatically upgrades to a newer consecutive release unless this cluster contains managed clusters with a Cluster release unsupported by the newer Container Cloud release. For more details about the Container Cloud release mechanism, see Reference Architecture: Release Controller.
2.27.1 (current)¶
Important
For MOSK clusters, Container Cloud 2.27.1 is the continuation for MOSK 24.1.x series using the patch Cluster release 17.1.6. There is no ability to update to the 24.2.x (17.2.x) series from 2.27.1. However, the management cluster is automatically updated to the latest patch Cluster release 16.2.1.
The Container Cloud patch release 2.27.1, which is based on the 2.27.0 major release, provides the following updates:
Support for the patch Cluster release 16.2.1.
Support for the patch Cluster releases 16.1.6 and 17.1.6 that represents Mirantis OpenStack for Kubernetes (MOSK) patch release 24.1.6.
Support for MKE 3.7.10.
Support for
docker-ee-cli23.0.13 in MCR 23.0.11 to fix several CVEs.Bare metal: update of Ubuntu mirror from ubuntu-2024-05-17-013445 to ubuntu-2024-06-27-095142 along with update of minor kernel version from 5.15.0-107-generic to 5.15.0-113-generic.
Security fixes for CVEs in images.
Bug fixes.
This patch release also supports the latest major Cluster releases 17.2.0 and 16.2.0. And it does not support greenfield deployments based on deprecated Cluster releases. Use the latest available Cluster release instead.
For main deliverables of the parent Container Cloud release of 2.27.1, refer to 2.27.0.
Security notes¶
In total, since Container Cloud 2.27.0, 270 Common Vulnerabilities and Exposures (CVE) of high severity have been fixed in 2.27.1.
The table below includes the total numbers of addressed unique and common CVEs in images by product component since Container Cloud 2.27.0. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
Ceph |
Unique |
0 |
6 |
6 |
Common |
0 |
29 |
29 |
|
Kaas core |
Unique |
0 |
10 |
10 |
Common |
0 |
178 |
178 |
|
StackLight |
Unique |
0 |
14 |
14 |
Common |
0 |
63 |
63 |
Mirantis Security Portal
For the detailed list of fixed and existing CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
MOSK CVEs
For the number of fixed CVEs in the MOSK-related components including OpenStack and Tungsten Fabric, refer to MOSK 24.1.6: Security notes.
Addressed issues¶
The following issues have been addressed in the Container Cloud patch release 2.27.1 along with the patch Cluster releases 16.2.1, 16.1.6, and 17.1.6.
[42304] [StackLight] [Cluster releases 17.1.6, 16.1.6] Fixed the issue with failure of shard relocation in the OpenSearch cluster on large Container Cloud managed clusters.
[40020] [StackLight] [Cluster releases 17.1.6, 16.1.6] Fixed the issue with
rollover_policynot being applied to the current indices while updating the policy for the currentsystem*andaudit*data streams.
Known issues¶
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.27.1 including the Cluster releases 16.2.1, 16.1.6, and 17.1.6.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
After node maintenance of a management cluster, the newly added nodes may fail to undergo provisioning successfully. The issue relates to new nodes that are in the same L2 domain as the management cluster.
The issue was observed on environments having management cluster nodes configured with a single L2 segment used for all network traffic (PXE and LCM/management networks).
To verify whether the cluster is affected:
Verify whether the dnsmasq and dhcp-relay pods run on the same node
in the management cluster:
kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of system response:
dhcp-relay-7d85f75f76-5vdw2 2/2 Running 2 (36h ago) 36h 10.10.0.122 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (36h ago) 36h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
If this is the case, proceed to the workaround below.
Workaround:
Log in to a node that contains
kubeconfigof the affected management cluster.Make sure that at least two management cluster nodes are schedulable:
kubectl get node
Example of a positive system response:
NAME STATUS ROLES AGE VERSION kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 Ready master 37h v1.27.10-mirantis-1 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad Ready master 37h v1.27.10-mirantis-1 kaas-node-ad5a6f51-b98f-43c3-91d5-55fed3d0ff21 Ready master 37h v1.27.10-mirantis-1
Delete the
dhcp-relaypod:kubectl -n kaas delete pod <dhcp-relay-xxxxx>
Verify that the
dnsmasqanddhcp-relaypods are scheduled into different nodes:kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of a positive system response:
dhcp-relay-7d85f75f76-rkv03 2/2 Running 0 49s 10.10.0.121 kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 <none> <none> dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (37h ago) 37h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
During the replacement of a master node on a cluster of any type, the process
may get stuck with Kubelet's NodeReady condition is Unknown in the
machine status on the remaining master nodes.
As a workaround, log in on the affected node and run the following command:
docker restart ucp-kubelet
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
During replacement of a master node on a cluster of any type, the
calico-node Pod fails to start on a new node that has the same IP address
as the node being replaced.
Workaround:
Log in to any
masternode.From a CLI with an MKE client bundle, create a shell alias to start calicoctl using the
mirantis/ucp-dsinfoimage:alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/key.pem \ -e ETCD_CA_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/ca.pem \ -e ETCD_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/cert.pem \ -v /var/run/calico:/var/run/calico \ -v /var/lib/docker/volumes/ucp-kv-certs/_data:/var/lib/docker/volumes/ucp-kv-certs/_data:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl \ "
alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/ucp-node-certs/key.pem \ -e ETCD_CA_CERT_FILE=/ucp-node-certs/ca.pem \ -e ETCD_CERT_FILE=/ucp-node-certs/cert.pem \ -v /var/run/calico:/var/run/calico \ -v ucp-node-certs:/ucp-node-certs:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl --allow-version-mismatch \ "
In the above command, replace the following values with the corresponding settings of the affected cluster:
<etcdEndpoint>is the etcd endpoint defined in the Calico configuration file. For example,ETCD_ENDPOINTS=127.0.0.1:12378<mkeVersion>is the MKE version installed on your cluster. For example,mirantis/ucp-dsinfo:3.5.7.
Verify the node list on the cluster:
kubectl get node
Compare this list with the node list in Calico to identify the old node:
calicoctl get node -o wide
Remove the old node from Calico:
calicoctl delete node kaas-node-<nodeID>
During replacement of a manager machine, the following problems may occur:
The system adds the node to Docker swarm but not to Kubernetes
The node
Deploymentgets stuck with failed RethinkDB health checks
Workaround:
Delete the failed node.
Wait for the MKE cluster to become healthy. To monitor the cluster status:
Log in to the MKE web UI as described in Connect to the Mirantis Kubernetes Engine web UI.
Monitor the cluster status as described in MKE Operations Guide: Monitor an MKE cluster with the MKE web UI.
Deploy a new node.
During the unsafe or forced deletion of a manager machine running the
calico-kube-controllers Pod in the kube-system namespace,
the following issues occur:
The
calico-kube-controllersPod fails to clean up resources associated with the deleted nodeThe
calico-nodePod may fail to start up on a newly created node if the machine is provisioned with the same IP address as the deleted machine had
As a workaround, before deletion of the node running the
calico-kube-controllers Pod, cordon and drain the node:
kubectl cordon <nodeName>
kubectl drain <nodeName>
Update of a managed cluster based on bare metal and Ceph enabled fails with
PersistentVolumeClaim getting stuck in the Pending state for the
prometheus-server StatefulSet and the
MountVolume.MountDevice failed for volume warning in the StackLight event
logs.
Workaround:
Verify that the description of the Pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name where the Pods failed to run<affectedPodName>is a Pod name that failed to run in the specified project
In the Pod description, identify the node name where the Pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain therbd volume mount failed: <csi-vol-uuid> is being usederror. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the Pod that fails to0replicas.On every
csi-rbdpluginPod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected Pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state becomesRunning.
During a cluster update, a Kubernetes helm-controller Deployment may
get stuck in a restarting Pod loop with Terminating and Running states
flapping. Other Deployment types may also be affected.
As a workaround, restart the Deployment that got stuck:
kubectl -n <affectedProjectName> get deploy <affectedDeployName> -o yaml
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas 0
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas <replicasNumber>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name containing the cluster with stuck Pods<affectedDeployName>is theDeploymentname that failed to run Pods in the specified project<replicasNumber>is the original number of replicas for theDeploymentthat you can obtain using the get deploy command
Update notes¶
This section describes the specific actions you as a cloud operator need to complete before or after your Container Cloud cluster update to the Cluster releases 17.1.6, 16.2.1, or 16.1.6.
Consider this information as a supplement to the generic update procedures published in Operations Guide: Automatic upgrade of a management cluster and Update a patch Cluster release of a managed cluster.
Note
If you do not use Ceph metrics in any customizations, for example, custom alerts, Grafana dashboards, or queries in custom workloads, skip this section.
After deprecating the performance metric exporter that is integrated into the Ceph Manager daemon for the sake of the dedicated Ceph Exporter daemon in Container Cloud 2.27.0, you may need to prepare for updating values of several labels in Ceph metrics if you use them in any customizations such as custom alerts, Grafana dashboards, or queries in custom tools. These labels will be changed in Container Cloud 2.28.0 (Cluster releases 16.3.0 and 17.3.0).
Note
Names of metrics will not be changed, no metrics will be removed.
All Ceph metrics to be collected by the Ceph Exporter daemon will change their
labels job and instance due to scraping metrics from new Ceph Exporter
daemon instead of the performance metric exporter of Ceph Manager:
Values of the
joblabels will be changed fromrook-ceph-mgrtoprometheus-rook-exporterfor all Ceph metrics moved to Ceph Exporter. The full list of moved metrics is presented below.Values of the
instancelabels will be changed from the metric endpoint of Ceph Manager with port9283to the metric endpoint of Ceph Exporter with port9926for all Ceph metrics moved to Ceph Exporter. The full list of moved metrics is presented below.Values of the
instance_idlabels of Ceph metrics from the RADOS Gateway (RGW) daemons will be changed from the daemon GID to the daemon subname. For example, instead ofinstance_id="<RGW_PROCESS_GID>", theinstance_id="a"(ceph_rgw_qlen{instance_id="a"}) will be used. The list of moved Ceph RGW metrics is presented below.
List of affected Ceph RGW metrics
ceph_rgw_cache_.*ceph_rgw_failed_reqceph_rgw_gc_retire_objectceph_rgw_get.*ceph_rgw_keystone_.*ceph_rgw_lc_.*ceph_rgw_lua_.*ceph_rgw_pubsub_.*ceph_rgw_put.*ceph_rgw_qactiveceph_rgw_qlenceph_rgw_req
List of all metrics to be collected by Ceph Exporter instead of
Ceph Manager
ceph_bluefs_.*ceph_bluestore_.*ceph_mds_cache_.*ceph_mds_capsceph_mds_ceph_.*ceph_mds_dir_.*ceph_mds_exported_inodesceph_mds_forwardceph_mds_handle_.*ceph_mds_imported_inodesceph_mds_inodes.*ceph_mds_load_centceph_mds_log_.*ceph_mds_mem_.*ceph_mds_openino_dir_fetchceph_mds_process_request_cap_releaseceph_mds_reply_.*ceph_mds_requestceph_mds_root_.*ceph_mds_server_.*ceph_mds_sessions_.*ceph_mds_slow_replyceph_mds_subtreesceph_mon_election_.*ceph_mon_num_.*ceph_mon_session_.*ceph_objecter_.*ceph_osd_numpg.*ceph_osd_op.*ceph_osd_recovery_.*ceph_osd_stat_.*ceph_paxos.*ceph_prioritycache.*ceph_purge.*ceph_rgw_cache_.*ceph_rgw_failed_reqceph_rgw_gc_retire_objectceph_rgw_get.*ceph_rgw_keystone_.*ceph_rgw_lc_.*ceph_rgw_lua_.*ceph_rgw_pubsub_.*ceph_rgw_put.*ceph_rgw_qactiveceph_rgw_qlenceph_rgw_reqceph_rocksdb_.*
Artifacts¶
This section lists the artifacts of components included in the Container Cloud patch release 2.27.1. For artifacts of the Cluster releases introduced in 2.27.1, see patch Cluster releases 16.2.1, 16.1.6, and 17.1.6.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20240627104414 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20240627104414 |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.40.15.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.40.15.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.40.15.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.40.15.tgz |
|
kaas-ipam |
||
metallb |
||
Docker images |
ambasador Updated |
mirantis.azurecr.io/core/external/nginx:1.40.15 |
baremetal-dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-2-27-alpine-20240701130209 |
|
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-2-27-alpine-20240701130001 |
|
bm-collective Updated |
mirantis.azurecr.io/bm/bm-collective:base-2-27-alpine-20240701130719 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.40.15 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:antelope-jammy-20240522120643 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:antelope-jammy-20240522120643 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20240117102150 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-2-27-alpine-20240701133222 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-ba8ada4-20240405150338 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.17-focal-20240523075821 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.25.0-40-g890ffca |
|
metallb-controller |
mirantis.azurecr.io/bm/metallb/controller:v0.14.5-e86184d9-amd64 |
|
metallb-speaker |
mirantis.azurecr.io/bm/metallb/speaker:v0.14.5-e86184d9-amd64 |
|
syslog-ng Updated |
mirantis.azurecr.io/bm/syslog-ng:base-alpine-20240701125905 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.40.15.tgz |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.40.15.tgz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.40.15.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.40.15.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.40.15.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.40.15.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.40.15.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.40.15.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.40.15.tgz |
|
host-os-modules-controller |
https://binary.mirantis.com/core/helm/host-os-modules-controller-1.40.15.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.40.15.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.40.15.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.40.15.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.40.15.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.40.15.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.40.15.tgz |
|
mcc-cache |
||
mcc-cache-warmup |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.40.15.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.40.15.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.40.15.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.40.15.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.40.15.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.40.15.tgz |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.40.15.tgz |
|
secret-controller |
https://binary.mirantis.com/core/helm/secret-controller-1.40.15.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.40.15.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.40.15.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.40.15.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.40.15.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.40.15.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.40.15.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.40.15 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.40.15 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.40.15 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.40.15 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-6 |
|
configuration-collector Updated |
mirantis.azurecr.io/core/configuration-collector:1.40.15 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.40.15 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.40.15 |
|
host-os-modules-controller Updated |
mirantis.azurecr.io/core/host-os-modules-controller:1.40.15 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.40.15 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.40.15 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.40.15 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.40.15 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.40.15 |
|
livenessprobe |
mirantis.azurecr.io/lcm/k8scsi/livenessprobe:v2.9.0-5 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.40.15 |
|
mcc-haproxy Updated |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.25.0-40-g890ffca |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.25.0-40-g890ffca |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.40.15 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.40.15 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.40.15 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.40.15 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.40.15 |
|
registry Updated |
mirantis.azurecr.io/lcm/registry:v2.8.1-10 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.40.15 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.40.15 |
|
secret-controller Updated |
mirantis.azurecr.io/core/secret-controller:1.40.15 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.40.15 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.40.15 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.40.15 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.40.15 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.40.15 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts Updated |
iam |
|
Docker images |
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240501023013 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-ba8ada4-20240405150338 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.17-focal-20240523075821 |
|
mcc-keycloak Updated |
mirantis.azurecr.io/iam/mcc-keycloak:24.0.5-20240621131831 |
Unsupported releases¶
Version |
Release date |
Summary |
|---|---|---|
Jul 02, 2024 |
|
|
June 18, 2024 |
Container Cloud 2.26.5 is the fifth patch release of the 2.26.x and MOSK 24.1.x release series that introduces the following updates:
|
|
May 20, 2024 |
Container Cloud 2.26.4 is the fourth patch release of the 2.26.x and MOSK 24.1.x release series that introduces the following updates:
|
|
Apr 29, 2024 |
Container Cloud 2.26.3 is the third patch release of the 2.26.x and MOSK 24.1.x release series that introduces the following updates:
|
|
Apr 08, 2024 |
Container Cloud 2.26.2 is the second patch release of the 2.26.x and MOSK 24.1.x release series that introduces the following updates:
|
|
Mar 20, 2024 |
Container Cloud 2.26.1 is the first patch release of the 2.26.x and MOSK 24.1.x release series that introduces the following updates:
|
|
Mar 04, 2024 |
|
|
Jan 10, 2024 |
Container Cloud 2.25.4 is the fourth patch release of the 2.25.x and MOSK 23.3.x release series that introduces the following updates:
|
2.27.0¶
The Mirantis Container Cloud major release 2.27.0:
Introduces support for the Cluster release 17.2.0 that is based on the Cluster release 16.2.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 24.2.
Introduces support for the Cluster release 16.2.0 that is based on Mirantis Container Runtime (MCR) 23.0.11 and Mirantis Kubernetes Engine (MKE) 3.7.8 with Kubernetes 1.27.
Does not support greenfield deployments on deprecated Cluster releases of the 17.1.x and 16.1.x series. Use the latest available Cluster releases of the series instead.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.27.0.
This section outlines new features and enhancements introduced in the Container Cloud release 2.27.0. For the list of enhancements delivered with the Cluster releases introduced by Container Cloud 2.27.0, see 17.2.0 and 16.2.0.
Implemented full support for Ubuntu 22.04 LTS (Jellyfish) as the default host operating system that now installs on non-MOSK bare metal management and managed clusters.
For MOSK:
Existing management clusters are automatically updated to Ubuntu 22.04 during cluster upgrade to Container Cloud 2.27.0 (Cluster release 16.2.0).
Greenfield deployments of management clusters are based on Ubuntu 22.04.
Existing and greenfield deployments of managed clusters are still based on Ubuntu 20.04. The support for Ubuntu 22.04 on this cluster type will be announced in one of the following releases.
Caution
Upgrading from Ubuntu 20.04 to 22.04 on existing deployments of Container Cloud managed clusters is not supported.
TechPreview
Enhanced the day-2 management API the bare metal provider with several key improvements:
Implemented the
sysctl,package, andirqbalanceconfiguration modules, which become available for usage after your management cluster upgrade to the Cluster release 16.2.0. These Container Cloud modules use the designatedHostOSConfigurationobject namedmcc-modulesto distingish them from custom modules.Configuration modules allow managing the operating system of a bare metal host granularly without rebuilding the node from scratch. Such approach prevents workload evacuation and significantly reduces configuration time.
Optimized performance for faster, more efficient operations.
Enhanced user experience for easier and more intuitive interactions.
Resolved various internal issues to ensure smoother functionality.
Added comprehensive documentation, including concepts, guidelines, and recommendations for effective use of day-2 operations.
Optimized the BareMetalHostProfile custom resource, which uses
the strict byID filtering to target system disks using the byPath,
serialNumber, and wwn reliable device options instead of the
unpredictable byName naming format.
The optimization includes changes in admission-controller that now blocks
the use of bmhp:spec:devices:by_name in new BareMetalHostProfile
objects.
As part of refactoring of the bare metal provider, deprecated the
SubnetPool and MetalLBConfigTemplate objects. The objects will be
completely removed from the product in one of the following releases.
Both objects are automatically migrated to the MetallbConfig object during
cluster update to the Cluster release 17.2.0 or 16.2.0.
Learn more
TechPreview
Implemented the ClusterUpdatePlan custom resource to enable a granular
step-by-step update of a managed cluster. The operator can control the update
process by manually launching update stages using the commence flag.
Between the update stages, a cluster remains functional from the perspective
of cloud users and workloads.
A ClusterUpdatePlan object is automatically created by the respective
Container Cloud provider when a new Cluster release becomes available for your
cluster. This object contains a list of predefined self-descriptive update
steps that are cluster-specific. These steps are defined in the spec
section of the object with information about their impact on the cluster.
Implemented the UpdateGroup custom resource for creation of update groups
for worker machines on managed clusters. The use of update groups provides
enhanced control over update of worker machines. This feature decouples the
concurrency settings from the global cluster level, providing update
flexibility based on the workload characteristics of different worker machine
sets.
Implemented the same heartbeat model for the LCM Agent as Kubernetes uses for Nodes. This model allows reflecting the actual status of the LCM Agent when it fails. For visual representation, added the corresponding LCM Agent status to the Container Cloud web UI for clusters and machines, which reflects health status of the LCM agent along with its status of update to the version from the current Cluster release.
Implemented secret-controller that runs on a management cluster and cleans
up secret leftovers of credentials that are not cleaned up automatically after
creation of new secrets. This controller replaces rhellicense-controller,
proxy-controller, and byo-credentials-controller as well as partially
replaces the functionality of license-controller and other credential
controllers.
Note
You can change memory limits for secret-controller on a
management cluster using the resources:limits parameter in the
spec:providerSpec:value:kaas:management:helmReleases: section of the
Cluster object.
Implemented the capability to back up and restore MariaDB databases on management clusters for bare metal and vSphere providers. Also, added documentation on how to change the storage node for backups on clusters of these provider types.
The following issues have been addressed in the Mirantis Container Cloud release 2.27.0 along with the Cluster releases 17.2.0 and 16.2.0.
Note
This section provides descriptions of issues addressed since the last Container Cloud patch release 2.26.5.
For details on addressed issues in earlier patch releases since 2.26.0, which are also included into the major release 2.27.0, refer to 2.26.x patch releases.
[42304] [StackLight] Fixed the issue with failure of shard relocation in the OpenSearch cluster on large Container Cloud managed clusters.
[41890] [StackLight] Fixed the issue with Patroni failing to start because of the short default timeout.
[40020] [StackLight] Fixed the issue with
rollover_policynot being applied to the current indices while updating the policy for the currentsystem*andaudit*data streams.[41819] [Ceph] Fixed the issue with the graceful cluster reboot being blocked by active Ceph
ClusterWorkloadLockobjects.[28865] [LCM] Fixed the issue with validation of the NTP configuration before cluster deployment. Now, deployment does not start until the NTP configuration is validated.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.27.0 including the Cluster releases 17.2.0 and 16.2.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
After node maintenance of a management cluster, the newly added nodes may fail to undergo provisioning successfully. The issue relates to new nodes that are in the same L2 domain as the management cluster.
The issue was observed on environments having management cluster nodes configured with a single L2 segment used for all network traffic (PXE and LCM/management networks).
To verify whether the cluster is affected:
Verify whether the dnsmasq and dhcp-relay pods run on the same node
in the management cluster:
kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of system response:
dhcp-relay-7d85f75f76-5vdw2 2/2 Running 2 (36h ago) 36h 10.10.0.122 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (36h ago) 36h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
If this is the case, proceed to the workaround below.
Workaround:
Log in to a node that contains
kubeconfigof the affected management cluster.Make sure that at least two management cluster nodes are schedulable:
kubectl get node
Example of a positive system response:
NAME STATUS ROLES AGE VERSION kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 Ready master 37h v1.27.10-mirantis-1 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad Ready master 37h v1.27.10-mirantis-1 kaas-node-ad5a6f51-b98f-43c3-91d5-55fed3d0ff21 Ready master 37h v1.27.10-mirantis-1
Delete the
dhcp-relaypod:kubectl -n kaas delete pod <dhcp-relay-xxxxx>
Verify that the
dnsmasqanddhcp-relaypods are scheduled into different nodes:kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of a positive system response:
dhcp-relay-7d85f75f76-rkv03 2/2 Running 0 49s 10.10.0.121 kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 <none> <none> dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (37h ago) 37h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
During the replacement of a master node on a cluster of any type, the process
may get stuck with Kubelet's NodeReady condition is Unknown in the
machine status on the remaining master nodes.
As a workaround, log in on the affected node and run the following command:
docker restart ucp-kubelet
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
During replacement of a master node on a cluster of any type, the
calico-node Pod fails to start on a new node that has the same IP address
as the node being replaced.
Workaround:
Log in to any
masternode.From a CLI with an MKE client bundle, create a shell alias to start calicoctl using the
mirantis/ucp-dsinfoimage:alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/key.pem \ -e ETCD_CA_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/ca.pem \ -e ETCD_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/cert.pem \ -v /var/run/calico:/var/run/calico \ -v /var/lib/docker/volumes/ucp-kv-certs/_data:/var/lib/docker/volumes/ucp-kv-certs/_data:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl \ "
alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/ucp-node-certs/key.pem \ -e ETCD_CA_CERT_FILE=/ucp-node-certs/ca.pem \ -e ETCD_CERT_FILE=/ucp-node-certs/cert.pem \ -v /var/run/calico:/var/run/calico \ -v ucp-node-certs:/ucp-node-certs:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl --allow-version-mismatch \ "
In the above command, replace the following values with the corresponding settings of the affected cluster:
<etcdEndpoint>is the etcd endpoint defined in the Calico configuration file. For example,ETCD_ENDPOINTS=127.0.0.1:12378<mkeVersion>is the MKE version installed on your cluster. For example,mirantis/ucp-dsinfo:3.5.7.
Verify the node list on the cluster:
kubectl get node
Compare this list with the node list in Calico to identify the old node:
calicoctl get node -o wide
Remove the old node from Calico:
calicoctl delete node kaas-node-<nodeID>
During replacement of a manager machine, the following problems may occur:
The system adds the node to Docker swarm but not to Kubernetes
The node
Deploymentgets stuck with failed RethinkDB health checks
Workaround:
Delete the failed node.
Wait for the MKE cluster to become healthy. To monitor the cluster status:
Log in to the MKE web UI as described in Connect to the Mirantis Kubernetes Engine web UI.
Monitor the cluster status as described in MKE Operations Guide: Monitor an MKE cluster with the MKE web UI.
Deploy a new node.
During the unsafe or forced deletion of a manager machine running the
calico-kube-controllers Pod in the kube-system namespace,
the following issues occur:
The
calico-kube-controllersPod fails to clean up resources associated with the deleted nodeThe
calico-nodePod may fail to start up on a newly created node if the machine is provisioned with the same IP address as the deleted machine had
As a workaround, before deletion of the node running the
calico-kube-controllers Pod, cordon and drain the node:
kubectl cordon <nodeName>
kubectl drain <nodeName>
After a managed cluster update, the ceph-exporter pods are present in the
ceph crash list while rook-ceph-exporter attempts to obtain the
port that is still in use. The issue does not block the managed cluster update.
Once the port becomes available, rook-ceph-exporter obtains the port and
the issue disappears.
As a workaround, run ceph crash archive-all to remove
ceph-exporter pods from the Ceph crash list.
Update of a managed cluster based on bare metal and Ceph enabled fails with
PersistentVolumeClaim getting stuck in the Pending state for the
prometheus-server StatefulSet and the
MountVolume.MountDevice failed for volume warning in the StackLight event
logs.
Workaround:
Verify that the description of the Pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name where the Pods failed to run<affectedPodName>is a Pod name that failed to run in the specified project
In the Pod description, identify the node name where the Pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain therbd volume mount failed: <csi-vol-uuid> is being usederror. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the Pod that fails to0replicas.On every
csi-rbdpluginPod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected Pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state becomesRunning.
The initial index for the system* and audit* data streams can be
created without any policy attached due to race condition.
One of indicators that the cluster is most likely affected is the
KubeJobFailed alert firing for the elasticsearch-curator job and one or
both of the following errors being present in elasticsearch-curator pods
that remain in the Error status:
2024-05-31 13:16:04,459 ERROR Failed to complete action: delete_indices. \
<class 'curator.exceptions.FailedExecution'>: Exception encountered. \
Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. \
Exception: RequestError(400, 'illegal_argument_exception', 'index [.ds-system-000001] \
is the write index for data stream [system] and cannot be deleted')
or
2024-05-31 13:16:04,459 ERROR Failed to complete action: delete_indices. \
<class 'curator.exceptions.FailedExecution'>: Exception encountered. \
Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. \
Exception: RequestError(400, 'illegal_argument_exception', 'index [.ds-audit-000001] \
is the write index for data stream [audit] and cannot be deleted')
If the above mentioned alert and errors are present, an immediate action is required, because it indicates that the corresponding index size has already exceeded the space allocated for the index.
To verify that the cluster is affected:
Caution
Verify and apply the workaround to both index patterns, system and audit, separately.
If one of indices is affected, the second one is most likely affected as well. Although in rare cases, only one index may be affected.
Log in to the
opensearch-master-0Pod:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
Verify whether the rollover policy is attached to the index with the
000001number:system:curl localhost:9200/_plugins/_ism/explain/.ds-system-000001audit:curl localhost:9200/_plugins/_ism/explain/.ds-audit-000001
If the rollover policy is not attached, the cluster is affected. Examples of system responses in an affected cluster:
{ ".ds-system-000001": { "index.plugins.index_state_management.policy_id": null, "index.opendistro.index_state_management.policy_id": null, "enabled": null }, "total_managed_indices": 0 }
{ ".ds-audit-000001": { "index.plugins.index_state_management.policy_id": null, "index.opendistro.index_state_management.policy_id": null, "enabled": null }, "total_managed_indices": 0 }
Workaround:
Log in to the
opensearch-master-0Pod:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
Add the policy:
system:curl -XPOST -H "Content-type: application/json" localhost:9200/_plugins/_ism/add/system* -d'{"policy_id":"system_rollover_policy"}'
audit:curl -XPOST -H "Content-type: application/json" localhost:9200/_plugins/_ism/add/audit* -d'{"policy_id":"audit_rollover_policy"}'
Perform again the last step of the cluster verification procedure provided above and make sure that the policy is attached to the index.
During a cluster update, a Kubernetes helm-controller Deployment may
get stuck in a restarting Pod loop with Terminating and Running states
flapping. Other Deployment types may also be affected.
As a workaround, restart the Deployment that got stuck:
kubectl -n <affectedProjectName> get deploy <affectedDeployName> -o yaml
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas 0
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas <replicasNumber>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name containing the cluster with stuck Pods<affectedDeployName>is theDeploymentname that failed to run Pods in the specified project<replicasNumber>is the original number of replicas for theDeploymentthat you can obtain using the get deploy command
The following table lists the major components and their versions delivered in Container Cloud 2.27.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Bare metal |
baremetal-dnsmasq Updated |
base-2-27-alpine-20240523143049 |
baremetal-operator Updated |
base-2-27-alpine-20240523142757 |
|
baremetal-provider Updated |
1.40.11 |
|
bm-collective Updated |
base-2-27-alpine-20240523143803 |
|
cluster-api-provider-baremetal Updated |
1.40.11 |
|
ironic Updated |
antelope-jammy-20240522120643 |
|
ironic-inspector Updated |
antelope-jammy-20240522120643 |
|
ironic-prometheus-exporter |
0.1-20240117102150 |
|
kaas-ipam Updated |
base-2-27-alpine-20240531082457 |
|
kubernetes-entrypoint |
v1.0.1-ba8ada4-20240405150338 |
|
mariadb |
10.6.17-focal-20240523075821 |
|
metallb-controller Updated |
v0.14.5-e86184d9-amd64 |
|
metallb-speaker Updated |
v0.14.5-e86184d9-amd64 |
|
syslog-ng |
base-alpine-20240129163811 |
|
Container Cloud |
admission-controller Updated |
1.40.11 |
agent-controller Updated |
1.40.11 |
|
byo-cluster-api-controller Updated |
1.40.11 |
|
byo-credentials-controller Removed |
n/a |
|
ceph-kcc-controller Updated |
1.40.11 |
|
cert-manager-controller |
1.11.0-6 |
|
cinder-csi-plugin |
1.27.2-16 |
|
client-certificate-controller Updated |
1.40.11 |
|
configuration-collector Updated |
1.40.11 |
|
csi-attacher |
4.2.0-5 |
|
csi-node-driver-registrar |
2.7.0-5 |
|
csi-provisioner |
3.4.1-5 |
|
csi-resizer |
1.7.0-5 |
|
csi-snapshotter |
6.2.1-mcc-4 |
|
event-controller Updated |
1.40.11 |
|
frontend Updated |
1.40.12 |
|
golang |
1.21.7-alpine3.18 |
|
iam-controller Updated |
1.40.11 |
|
kaas-exporter Updated |
1.40.11 |
|
kproxy Updated |
1.40.11 |
|
lcm-controller Updated |
1.40.11 |
|
license-controller Updated |
1.40.11 |
|
livenessprobe Updated |
2.9.0-5 |
|
machinepool-controller Updated |
1.40.11 |
|
mcc-haproxy Updated |
0.25.0-37-gc15c97d |
|
metrics-server |
0.6.3-7 |
|
nginx Updated |
1.40.11 |
|
policy-controller New |
1.40.11 |
|
portforward-controller Updated |
1.40.11 |
|
proxy-controller Updated |
1.40.11 |
|
rbac-controller Updated |
1.40.11 |
|
registry |
2.8.1-9 |
|
release-controller Updated |
1.40.11 |
|
rhellicense-controller Removed |
n/a |
|
scope-controller Updated |
1.40.11 |
|
secret-controller New |
1.40.11 |
|
storage-discovery Updated |
1.40.11 |
|
user-controller Updated |
1.40.11 |
|
IAM |
iam Updated |
1.40.11 |
mariadb |
10.6.17-focal-20240523075821 |
|
mcc-keycloak Updated |
24.0.3-20240527150505 |
|
OpenStack Updated |
host-os-modules-controller Updated |
1.40.11 |
openstack-cloud-controller-manager |
v1.27.2-16 |
|
openstack-cluster-api-controller |
1.40.11 |
|
openstack-provider |
1.40.11 |
|
os-credentials-controller |
1.40.11 |
|
VMware vSphere |
mcc-keepalived Updated |
0.25.0-37-gc15c97d |
squid-proxy |
0.0.1-10-g24a0d69 |
|
vsphere-cloud-controller-manager |
v1.27.0-6 |
|
vsphere-cluster-api-controller Updated |
1.40.11 |
|
vsphere-credentials-controller Updated |
1.40.11 |
|
vsphere-csi-driver |
v3.0.2-1 |
|
vsphere-csi-syncer |
v3.0.2-1 |
|
vsphere-provider Updated |
1.40.11 |
|
vsphere-vm-template-controller Updated |
1.40.11 |
This section lists the artifacts of components included in the Container Cloud release 2.27.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20240517093708 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20240517093708 |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.40.11.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.40.11.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.40.11.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.40.11.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.40.11.tgz |
|
metallb |
||
Docker images |
ambasador Updated |
mirantis.azurecr.io/core/external/nginx:1.40.11 |
baremetal-dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-2-27-alpine-20240523143049 |
|
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-2-27-alpine-20240523142757 |
|
bm-collective Updated |
mirantis.azurecr.io/bm/bm-collective:base-2-27-alpine-20240523143803 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.40.11 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:antelope-jammy-20240522120643 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:antelope-jammy-20240522120643 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20240117102150 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-2-27-alpine-20240531082457 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-ba8ada4-20240405150338 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.17-focal-20240523075821 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.25.0-37-gc15c97d |
|
metallb-controller Updated |
mirantis.azurecr.io/bm/metallb/controller:v0.14.5-e86184d9-amd64 |
|
metallb-speaker Updated |
mirantis.azurecr.io/bm/metallb/speaker:v0.14.5-e86184d9-amd64 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-alpine-20240129163811 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.40.11.tgz |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.40.11.tgz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.40.11.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.40.11.tgz |
|
byo-credentials-controller Removed |
n/a |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.40.11.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.40.11.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.40.11.tgz |
|
cinder-csi-plugin |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.40.11.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.40.11.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.40.11.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.40.11.tgz |
|
host-os-modules-controller |
https://binary.mirantis.com/core/helm/host-os-modules-controller-1.40.11.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.40.11.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.40.11.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.40.11.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.40.11.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.40.11.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.40.11.tgz |
|
mcc-cache |
||
mcc-cache-warmup |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.40.11.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.40.11.tgz |
|
openstack-cloud-controller-manager |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.40.11.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.40.11.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.40.11.tgz |
|
policy-controller |
https://binary.mirantis.com/core/helm/policy-controller-1.40.11.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.40.11.tgz |
|
proxy-controller Removed |
n/a |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.40.11.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.40.11.tgz |
|
rhellicense-controller Removed |
n/a |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.40.11.tgz |
|
secret-controller New |
https://binary.mirantis.com/core/helm/secret-controller-1.40.11.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.40.11.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.40.11.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.40.11.tgz |
|
vsphere-cloud-controller-manager |
https://binary.mirantis.com/core/helm/vsphere-cloud-controller-manager-1.40.11.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.40.11.tgz |
|
vsphere-csi-plugin |
https://binary.mirantis.com/core/helm/vsphere-csi-plugin-1.40.11.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.40.11.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.40.11.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.40.11 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.40.11 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.40.11 |
|
byo-credentials-controller Removed |
n/a |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.40.11 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-6 |
|
cinder-csi-plugin |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-16 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.40.11 |
|
configuration-collector Updated |
mirantis.azurecr.io/core/configuration-collector:1.40.11 |
|
csi-attacher |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-5 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-5 |
|
csi-provisioner |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-5 |
|
csi-resizer |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-5 |
|
csi-snapshotter |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-4 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.40.11 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.40.12 |
|
host-os-modules-controller Updated |
mirantis.azurecr.io/core/host-os-modules-controller:1.40.11 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.40.11 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.40.11 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.40.11 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.40.11 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.40.11 |
|
livenessprobe |
mirantis.azurecr.io/lcm/k8scsi/livenessprobe:v2.9.0-5 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.40.11 |
|
mcc-haproxy Updated |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.25.0-37-gc15c97d |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.25.0-37-gc15c97d |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-7 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.40.11 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-16 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.40.11 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.40.11 |
|
policy-controller Updated |
mirantis.azurecr.io/core/policy-controller:1.40.11 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.40.11 |
|
proxy-controller Removed |
n/a |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.40.11 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-9 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.40.11 |
|
rhellicense-controller Removed |
n/a |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.40.11 |
|
secret-controller New |
mirantis.azurecr.io/core/secret-controller:1.40.11 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.40.11 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.40.11 |
|
vsphere-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/vsphere-cloud-controller-manager:v1.27.0-6 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.40.11 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.40.11 |
|
vsphere-csi-driver |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-driver:v3.0.2-1 |
|
vsphere-csi-syncer |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-syncer:v3.0.2-1 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.40.11 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts Updated |
iam |
|
Docker images |
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240501023013 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-ba8ada4-20240405150338 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.17-focal-20240523075821 |
|
mcc-keycloak Updated |
mirantis.azurecr.io/iam/mcc-keycloak:24.0.3-20240527150505 |
In total, since Container Cloud 2.26.0, in 2.27.0, 408 Common Vulnerabilities and Exposures (CVE) have been fixed: 26 of critical and 382 of high severity.
The table below includes the total numbers of addressed unique and common vulnerabilities and exposures (CVE) by product component since the 2.26.5 patch release. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
Kaas core |
Unique |
0 |
7 |
7 |
Common |
0 |
13 |
13 |
|
StackLight |
Unique |
4 |
14 |
18 |
Common |
4 |
25 |
29 |
Mirantis Security Portal
For the detailed list of fixed and existing CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
MOSK CVEs
For the number of fixed CVEs in the MOSK-related components including OpenStack and Tungsten Fabric, refer to MOSK 24.2: Security notes.
This section describes the specific actions you as a cloud operator need to complete before or after your Container Cloud cluster update to the Cluster releases 17.2.0 or 16.2.0.
Consider this information as a supplement to the generic update procedures published in Operations Guide: Automatic upgrade of a management cluster and Update a managed cluster.
Starting from Container Cloud 2.26.5, Mirantis introduces a new update scheme allowing for the update path flexibility. For details, see Patch update schemes before and since 2.26.5. For details on MOSK update scheme, refer to MOSK documentation: Update notes.
For those clusters that update between only major versions, the update scheme remains unchaged.
Caution
In Container Cloud patch releases 2.27.1 and 2.27.2, only the 16.2.x patch Cluster releases will be delivered with an automatic update of management clusters and the possibility to update non-MOSK managed clusters.
In parallel, 2.27.1 and 2.27.2 will include new 16.1.x and 17.1.x patches for MOSK 24.1.x. And the first 17.2.x patch Cluster release for MOSK 24.2.x will be delivered in 2.27.3. For details, see MOSK documentation: Update path for 24.1 and 24.2 series.
Note
If you have already completed the below procedure after updating your clusters to Container Cloud 2.26.0 (Cluster releases 17.1.0 or 16.1.0), skip this subsection.
Container Cloud 2.26.0 introduced the bird daemon update from v1.6.8
to v2.0.7 on master nodes if BGP is used for BGP announcement of the cluster
API load balancer address.
Configuration files for bird v1.x are not fully compatible with those for
bird v2.x. Therefore, if you used BGP announcement of cluster API LB address
on a deployment based on Cluster releases 17.0.0 or 16.0.0, update bird
configuration files to fit bird v2.x using configuration examples provided in
the API Reference: MultirRackCluster section.
Note
If you have already completed the below procedure after updating your clusters to Container Cloud 2.26.0 (Cluster releases 17.1.0 or 16.1.0), skip this subsection.
To prevent underused or overused storage space, review your storage space parameters for OpenSearch on the StackLight cluster:
Review the value of
elasticsearch.persistentVolumeClaimSizeand the real storage available on volumes.Decide whether you have to additionally set
elasticsearch.persistentVolumeUsableStorageSizeGB.
For description of both parameters, see StackLight configuration parameters: OpenSearch.
Note
If you do not use Ceph metrics in any customizations, for example, custom alerts, Grafana dashboards, or queries in custom workloads, skip this section.
After deprecating the performance metric exporter that is integrated into the Ceph Manager daemon for the sake of the dedicated Ceph Exporter daemon in Container Cloud 2.27.0, you may need to prepare for updating values of several labels in Ceph metrics if you use them in any customizations such as custom alerts, Grafana dashboards, or queries in custom tools. These labels will be changed in Container Cloud 2.28.0 (Cluster releases 16.3.0 and 17.3.0).
Note
Names of metrics will not be changed, no metrics will be removed.
All Ceph metrics to be collected by the Ceph Exporter daemon will change their
labels job and instance due to scraping metrics from new Ceph Exporter
daemon instead of the performance metric exporter of Ceph Manager:
Values of the
joblabels will be changed fromrook-ceph-mgrtoprometheus-rook-exporterfor all Ceph metrics moved to Ceph Exporter. The full list of moved metrics is presented below.Values of the
instancelabels will be changed from the metric endpoint of Ceph Manager with port9283to the metric endpoint of Ceph Exporter with port9926for all Ceph metrics moved to Ceph Exporter. The full list of moved metrics is presented below.Values of the
instance_idlabels of Ceph metrics from the RADOS Gateway (RGW) daemons will be changed from the daemon GID to the daemon subname. For example, instead ofinstance_id="<RGW_PROCESS_GID>", theinstance_id="a"(ceph_rgw_qlen{instance_id="a"}) will be used. The list of moved Ceph RGW metrics is presented below.
List of affected Ceph RGW metrics
ceph_rgw_cache_.*ceph_rgw_failed_reqceph_rgw_gc_retire_objectceph_rgw_get.*ceph_rgw_keystone_.*ceph_rgw_lc_.*ceph_rgw_lua_.*ceph_rgw_pubsub_.*ceph_rgw_put.*ceph_rgw_qactiveceph_rgw_qlenceph_rgw_req
List of all metrics to be collected by Ceph Exporter instead of
Ceph Manager
ceph_bluefs_.*ceph_bluestore_.*ceph_mds_cache_.*ceph_mds_capsceph_mds_ceph_.*ceph_mds_dir_.*ceph_mds_exported_inodesceph_mds_forwardceph_mds_handle_.*ceph_mds_imported_inodesceph_mds_inodes.*ceph_mds_load_centceph_mds_log_.*ceph_mds_mem_.*ceph_mds_openino_dir_fetchceph_mds_process_request_cap_releaseceph_mds_reply_.*ceph_mds_requestceph_mds_root_.*ceph_mds_server_.*ceph_mds_sessions_.*ceph_mds_slow_replyceph_mds_subtreesceph_mon_election_.*ceph_mon_num_.*ceph_mon_session_.*ceph_objecter_.*ceph_osd_numpg.*ceph_osd_op.*ceph_osd_recovery_.*ceph_osd_stat_.*ceph_paxos.*ceph_prioritycache.*ceph_purge.*ceph_rgw_cache_.*ceph_rgw_failed_reqceph_rgw_gc_retire_objectceph_rgw_get.*ceph_rgw_keystone_.*ceph_rgw_lc_.*ceph_rgw_lua_.*ceph_rgw_pubsub_.*ceph_rgw_put.*ceph_rgw_qactiveceph_rgw_qlenceph_rgw_reqceph_rocksdb_.*
2.26.5¶
The Container Cloud patch release 2.26.5, which is based on the 2.26.0 major release, provides the following updates:
Support for the patch Cluster releases 16.1.5 and 17.1.5 that represents Mirantis OpenStack for Kubernetes (MOSK) patch release 24.1.5.
Bare metal: update of Ubuntu mirror from 20.04~20240502102020 to 20.04~20240517090228 along with update of minor kernel version from 5.15.0-105-generic to 5.15.0-107-generic.
Security fixes for CVEs in images.
Bug fixes.
This patch release also supports the latest major Cluster releases 17.1.0 and 16.1.0. And it does not support greenfield deployments based on deprecated Cluster releases. Use the latest available Cluster release instead.
For main deliverables of the parent Container Cloud release of 2.26.5, refer to 2.26.0.
The table below includes the total numbers of addressed unique and common CVEs in images by product component since the Container Cloud 2.26.4 patch release. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
Ceph |
Unique |
0 |
1 |
1 |
Common |
0 |
3 |
3 |
|
Kaas core |
Unique |
0 |
5 |
5 |
Common |
0 |
12 |
12 |
|
StackLight |
Unique |
1 |
3 |
4 |
Common |
2 |
6 |
8 |
Mirantis Security Portal
For the detailed list of fixed and existing CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
MOSK CVEs
For the number of fixed CVEs in the MOSK-related components including OpenStack and Tungsten Fabric, refer to MOSK 24.1.5: Security notes.
The following issues have been addressed in the Container Cloud patch release 2.26.5 along with the patch Cluster releases 17.1.5 and 16.1.5.
[42408] [bare metal] Fixed the issue with old versions of system packages, including kernel, remaining on the manager nodes after cluster update.
[41540] [LCM] Fixed the issue with
lcm-agentfailing to grab storage information on a host and leavinglcmmachine.status.hostinfo.hardwareempty due to issues with managing physical NVME devices.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.26.4 including the Cluster releases 17.1.5 and 16.1.5.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
After node maintenance of a management cluster, the newly added nodes may fail to undergo provisioning successfully. The issue relates to new nodes that are in the same L2 domain as the management cluster.
The issue was observed on environments having management cluster nodes configured with a single L2 segment used for all network traffic (PXE and LCM/management networks).
To verify whether the cluster is affected:
Verify whether the dnsmasq and dhcp-relay pods run on the same node
in the management cluster:
kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of system response:
dhcp-relay-7d85f75f76-5vdw2 2/2 Running 2 (36h ago) 36h 10.10.0.122 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (36h ago) 36h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
If this is the case, proceed to the workaround below.
Workaround:
Log in to a node that contains
kubeconfigof the affected management cluster.Make sure that at least two management cluster nodes are schedulable:
kubectl get node
Example of a positive system response:
NAME STATUS ROLES AGE VERSION kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 Ready master 37h v1.27.10-mirantis-1 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad Ready master 37h v1.27.10-mirantis-1 kaas-node-ad5a6f51-b98f-43c3-91d5-55fed3d0ff21 Ready master 37h v1.27.10-mirantis-1
Delete the
dhcp-relaypod:kubectl -n kaas delete pod <dhcp-relay-xxxxx>
Verify that the
dnsmasqanddhcp-relaypods are scheduled into different nodes:kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of a positive system response:
dhcp-relay-7d85f75f76-rkv03 2/2 Running 0 49s 10.10.0.121 kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 <none> <none> dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (37h ago) 37h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
During the replacement of a master node on a cluster of any type, the process
may get stuck with Kubelet's NodeReady condition is Unknown in the
machine status on the remaining master nodes.
As a workaround, log in on the affected node and run the following command:
docker restart ucp-kubelet
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
During replacement of a master node on a cluster of any type, the
calico-node Pod fails to start on a new node that has the same IP address
as the node being replaced.
Workaround:
Log in to any
masternode.From a CLI with an MKE client bundle, create a shell alias to start calicoctl using the
mirantis/ucp-dsinfoimage:alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/key.pem \ -e ETCD_CA_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/ca.pem \ -e ETCD_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/cert.pem \ -v /var/run/calico:/var/run/calico \ -v /var/lib/docker/volumes/ucp-kv-certs/_data:/var/lib/docker/volumes/ucp-kv-certs/_data:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl \ "
alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/ucp-node-certs/key.pem \ -e ETCD_CA_CERT_FILE=/ucp-node-certs/ca.pem \ -e ETCD_CERT_FILE=/ucp-node-certs/cert.pem \ -v /var/run/calico:/var/run/calico \ -v ucp-node-certs:/ucp-node-certs:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl --allow-version-mismatch \ "
In the above command, replace the following values with the corresponding settings of the affected cluster:
<etcdEndpoint>is the etcd endpoint defined in the Calico configuration file. For example,ETCD_ENDPOINTS=127.0.0.1:12378<mkeVersion>is the MKE version installed on your cluster. For example,mirantis/ucp-dsinfo:3.5.7.
Verify the node list on the cluster:
kubectl get node
Compare this list with the node list in Calico to identify the old node:
calicoctl get node -o wide
Remove the old node from Calico:
calicoctl delete node kaas-node-<nodeID>
During replacement of a manager machine, the following problems may occur:
The system adds the node to Docker swarm but not to Kubernetes
The node
Deploymentgets stuck with failed RethinkDB health checks
Workaround:
Delete the failed node.
Wait for the MKE cluster to become healthy. To monitor the cluster status:
Log in to the MKE web UI as described in Connect to the Mirantis Kubernetes Engine web UI.
Monitor the cluster status as described in MKE Operations Guide: Monitor an MKE cluster with the MKE web UI.
Deploy a new node.
During the unsafe or forced deletion of a manager machine running the
calico-kube-controllers Pod in the kube-system namespace,
the following issues occur:
The
calico-kube-controllersPod fails to clean up resources associated with the deleted nodeThe
calico-nodePod may fail to start up on a newly created node if the machine is provisioned with the same IP address as the deleted machine had
As a workaround, before deletion of the node running the
calico-kube-controllers Pod, cordon and drain the node:
kubectl cordon <nodeName>
kubectl drain <nodeName>
Fixed in 2.27.0 (17.2.0 and 16.2.0)
During graceful reboot of a cluster with Ceph enabled, the reboot is blocked
with the following message in the MiraCephMaintenance object status:
message: ClusterMaintenanceRequest found, Ceph Cluster is not ready to upgrade,
delaying cluster maintenance
As a workaround, add the following snippet to the cephFS section under
metadataServer in the spec section of <kcc-name>.yaml in the Ceph
cluster:
cephClusterSpec:
sharedFilesystem:
cephFS:
- name: cephfs-store
metadataServer:
activeCount: 1
healthCheck:
livenessProbe:
probe:
failureThreshold: 5
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 5
Update of a managed cluster based on bare metal and Ceph enabled fails with
PersistentVolumeClaim getting stuck in the Pending state for the
prometheus-server StatefulSet and the
MountVolume.MountDevice failed for volume warning in the StackLight event
logs.
Workaround:
Verify that the description of the Pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name where the Pods failed to run<affectedPodName>is a Pod name that failed to run in the specified project
In the Pod description, identify the node name where the Pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain therbd volume mount failed: <csi-vol-uuid> is being usederror. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the Pod that fails to0replicas.On every
csi-rbdpluginPod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected Pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state becomesRunning.
Fixed in 17.2.0, 16.2.0, 17.1.6, 16.1.6
On large managed clusters, shard relocation may fail in the OpenSearch cluster
with the yellow or red status of the OpenSearch cluster.
The characteristic symptom of the issue is that in the stacklight
namespace, the statefulset.apps/opensearch-master containers are
experiencing throttling with the KubeContainersCPUThrottlingHigh alert
firing for the following set of labels:
{created_by_kind="StatefulSet",created_by_name="opensearch-master",namespace="stacklight"}
Caution
The throttling that OpenSearch is experiencing may be a temporary situation, which may be related, for example, to a peaky load and the ongoing shards initialization as part of disaster recovery or after node restart. In this case, Mirantis recommends waiting until initialization of all shards is finished. After that, verify the cluster state and whether throttling still exists. And only if throttling does not disappear, apply the workaround below.
To verify that the initialization of shards is ongoing:
kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
curl "http://localhost:9200/_cat/shards" | grep INITIALIZING
Example of system response:
.ds-system-000072 2 r INITIALIZING 10.232.182.135 opensearch-master-1
.ds-system-000073 1 r INITIALIZING 10.232.7.145 opensearch-master-2
.ds-system-000073 2 r INITIALIZING 10.232.182.135 opensearch-master-1
.ds-audit-000001 2 r INITIALIZING 10.232.7.145 opensearch-master-2
The system response above indicates that shards from the
.ds-system-000072, .ds-system-000073, and .ds-audit-000001
indicies are in the INITIALIZING state. In this case, Mirantis
recommends waiting until this process is finished, and only then consider
changing the limit.
You can additionally analyze the exact level of throttling and the current CPU usage on the Kubernetes Containers dashboard in Grafana.
Workaround:
Verify the currently configured CPU requests and limits for the
opensearchcontainers:kubectl -n stacklight get statefulset.apps/opensearch-master -o jsonpath="{.spec.template.spec.containers[?(@.name=='opensearch')].resources}"
Example of system response:
{"limits":{"cpu":"600m","memory":"8Gi"},"requests":{"cpu":"500m","memory":"6Gi"}}
In the example above, the CPU request is
500mand the CPU limit is600m.Increase the CPU limit to a reasonably high number.
For example, the default CPU limit for the clusters with the
clusterSize:largeparameter set was increased from8000mto12000mfor StackLight in Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0).Note
For details, on the
clusterSizeparameter, see Operations Guide: StackLight configuration parameters - Cluster size.If the defaults are already overridden on the affected cluster using the
resourcesPerClusterSizeorresourcesparameters as described in Operations Guide: StackLight configuration parameters - Resource limits, then the exact recommended number depends on the currently set limit.Mirantis recommends increasing the limit by 50%. If it does not resolve the issue, another increase iteration will be required.
When you select the required CPU limit, increase it as described in Operations Guide: StackLight configuration parameters - Resource limits.
If the CPU limit for the
opensearchcomponent is already set, increase it in theClusterobject for theopensearchparameter. Otherwise, the default StackLight limit is used. In this case, increase the CPU limit for theopensearchcomponent using theresourcesparameter.Wait until all
opensearch-masterpods are recreated with the new CPU limits and becomerunningandready.To verify the current CPU limit for every
opensearchcontainer in everyopensearch-masterpod separately:kubectl -n stacklight get pod/opensearch-master-<podSuffixNumber> -o jsonpath="{.spec.containers[?(@.name=='opensearch')].resources}"
In the command above, replace
<podSuffixNumber>with the name of the pod suffix. For example,pod/opensearch-master-0orpod/opensearch-master-2.Example of system response:
{"limits":{"cpu":"900m","memory":"8Gi"},"requests":{"cpu":"500m","memory":"6Gi"}}
The waiting time may take up to 20 minutes depending on the cluster size.
If the issue is fixed, the KubeContainersCPUThrottlingHigh alert stops
firing immediately, while OpenSearchClusterStatusWarning or
OpenSearchClusterStatusCritical can still be firing for some time during
shard relocation.
If the KubeContainersCPUThrottlingHigh alert is still firing, proceed with
another iteration of the CPU limit increase.
Fixed in 17.2.0, 16.2.0, 17.1.6, 16.1.6
While updating rollover_policy for the current system* and audit*
data streams, the update is not applied to indices.
One of indicators that the cluster is most likely affected is the
KubeJobFailed alert firing for the elasticsearch-curator job and one or
both of the following errors being present in elasticsearch-curator pods
that remain in the Error status:
2024-05-31 13:16:04,459 ERROR Failed to complete action: delete_indices. <class 'curator.exceptions.FailedExecution'>: Exception encountered. Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. Exception: RequestError(400, 'illegal_argument_exception', 'index [.ds-audit-000001] is the write index for data stream [audit] and cannot be deleted')
or
2024-05-31 13:16:04,459 ERROR Failed to complete action: delete_indices. <class 'curator.exceptions.FailedExecution'>: Exception encountered. Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. Exception: RequestError(400, 'illegal_argument_exception', 'index [.ds-system-000001] is the write index for data stream [system] and cannot be deleted')
Note
Instead of .ds-audit-000001 or .ds-system-000001 index names,
similar names can be present with the same prefix but different suffix
numbers.
If the above mentioned alert and errors are present, an immediate action is required, because it indicates that the corresponding index size has already exceeded the space allocated for the index.
To verify that the cluster is affected:
Caution
Verify and apply the workaround to both index patterns, system and audit, separately.
If one of indices is affected, the second one is most likely affected as well. Although in rare cases, only one index may be affected.
Log in to the
opensearch-master-0Pod:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
Verify that the rollover policy is present:
system:curl localhost:9200/_plugins/_ism/policies/system_rollover_policyaudit:curl localhost:9200/_plugins/_ism/policies/audit_rollover_policy
The cluster is affected if the rollover policy is missing. Otherwise, proceed to the following step.
Verify the system response from the previous step. For example:
{"_id":"system_rollover_policy","_version":7229,"_seq_no":42362,"_primary_term":28,"policy":{"policy_id":"system_rollover_policy","description":"system index rollover policy.","last_updated_time":1708505222430,"schema_version":19,"error_notification":null,"default_state":"rollover","states":[{"name":"rollover","actions":[{"retry":{"count":3,"backoff":"exponential","delay":"1m"},"rollover":{"min_size":"14746mb","copy_alias":false}}],"transitions":[]}],"ism_template":[{"index_patterns":["system*"],"priority":200,"last_updated_time":1708505222430}]}}
Verify and capture the following items separately for every policy:
The
_seq_noand_primary_termvaluesThe rollover policy threshold, which is defined in
policy.states[0].actions[0].rollover.min_size
List indices:
system:curl localhost:9200/_cat/indices | grep system
Example of system response:
[...] green open .ds-system-000001 FjglnZlcTKKfKNbosaE9Aw 2 1 1998295 0 1gb 507.9mb
audit:curl localhost:9200/_cat/indices | grep audit
Example of system response:
[...] green open .ds-audit-000001 FjglnZlcTKKfKNbosaE9Aw 2 1 1998295 0 1gb 507.9mb
Select the index with the highest number and verify the rollover policy attached to the index:
system:curl localhost:9200/_plugins/_ism/explain/.ds-system-000001audit:curl localhost:9200/_plugins/_ism/explain/.ds-audit-000001If the rollover policy is not attached, the cluster is affected.
If the rollover policy is attached but
_seq_noand_primary_termnumbers do not match the previously captured ones, the cluster is affected.If the index size drastically exceeds the defined threshold of the rollover policy (which is the previously captured
min_size), the cluster is most probably affected.
Workaround:
Log in to the
opensearch-master-0Pod:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
If the policy is attached to the index but has different
_seq_noand_primary_term, remove the policy from the index:Note
Use the index with the highest number in the name, which was captured during verification procedure.
system:curl -XPOST localhost:9200/_plugins/_ism/remove/.ds-system-000001
audit:curl -XPOST localhost:9200/_plugins/_ism/remove/.ds-audit-000001
Re-add the policy:
system:curl -XPOST -H "Content-type: application/json" localhost:9200/_plugins/_ism/add/system* -d'{"policy_id":"system_rollover_policy"}'
audit:curl -XPOST -H "Content-type: application/json" localhost:9200/_plugins/_ism/add/audit* -d'{"policy_id":"audit_rollover_policy"}'
Perform again the last step of the cluster verification procedure provided above and make sure that the policy is attached to the index and has the same
_seq_noand_primary_term.If the index size drastically exceeds the defined threshold of the rollover policy (which is the previously captured
min_size), wait up to 15 minutes and verify that the additional index is created with the consecutive number in the index name. For example:system: if you applied changes to.ds-system-000001, wait until.ds-system-000002is created.audit: if you applied changes to.ds-audit-000001, wait until.ds-audit-000002is created.
If such index is not created, escalate the issue to Mirantis support.
During a cluster update, a Kubernetes helm-controller Deployment may
get stuck in a restarting Pod loop with Terminating and Running states
flapping. Other Deployment types may also be affected.
As a workaround, restart the Deployment that got stuck:
kubectl -n <affectedProjectName> get deploy <affectedDeployName> -o yaml
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas 0
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas <replicasNumber>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name containing the cluster with stuck Pods<affectedDeployName>is theDeploymentname that failed to run Pods in the specified project<replicasNumber>is the original number of replicas for theDeploymentthat you can obtain using the get deploy command
This section describes the specific actions you as a cloud operator need to complete before or after your Container Cloud cluster update to the Cluster releases 17.1.5 or 16.1.5.
Consider this information as a supplement to the generic update procedures published in Operations Guide: Automatic upgrade of a management cluster and Update a managed cluster.
To improve user update experience and make the update path more flexible, Container Cloud is introducing a new scheme of updating between patch Cluster releases. More specifically, Container Cloud intends to ultimately provide a possibility to update to any newer patch version within single series at any point of time. The patch version downgrade is not supported.
Though, in some cases, Mirantis may request to update to some specific patch version in the series to be able to update to the next major series. This may be necessary due to the specifics of technical content already released or planned for the release. For possible update paths in MOSK in 24.1 and 24.2 series, see MOSK documentation: Cluster update scheme.
The exact number of patch releases for the 16.1.x and 17.1.x series is yet to be confirmed, but the current target is 7 releases.
Note
The management cluster update scheme remains the same. A management cluster obtains the new product version automatically after release.
See also
MOSK documentation:
If you use the HostOSConfiguration and HostOSConfigurationModules
custom resources for the bare metal provider, which are available in the
Technology Preview scope in Container Cloud 2.26.x, delete all
HostOSConfiguration objects right after update of your managed cluster to
the Cluster release 17.1.5 or 16.1.5, before automatic upgrade of the
management cluster to Container Cloud 2.27.0 (Cluster release 16.2.0).
After the upgrade, you can recreate the required objects using the updated
parameters.
This precautionary step prevents re-processing and re-applying of existing
configuration, which is defined in HostOSConfiguration objects, during
management cluster upgrade to 2.27.0. Such behavior is caused by changes in
the HostOSConfiguration API introduced in 2.27.0.
Note
Skip this procedure if you have already completed it after updating your managed cluster to Container Cloud 2.26.4 (Cluster release 17.1.4 or 16.1.4).
After the MKE update to 3.7.8, if you are going to enable or already enabled Kubernetes auditing and profiling on your managed or management cluster, keep in mind that enabling audit log rotation requires an additional step. Set the following options in the MKE configuration file after enabling auditing and profiling:
[cluster_config]
kube_api_server_audit_log_maxage=30
kube_api_server_audit_log_maxbackup=10
kube_api_server_audit_log_maxsize=10
For the configuration procedure, see MKE documentation: Configure an existing MKE cluster.
While using this procedure, replace the command to upload the newly edited MKE configuration file with the following one:
curl --silent --insecure -X PUT -H "X-UCP-Allow-Restricted-API: i-solemnly-swear-i-am-up-to-no-good" -H "accept: application/toml" -H "Authorization: Bearer $AUTHTOKEN" --upload-file 'mke-config.toml' https://$MKE_HOST/api/ucp/config-toml
The value for
MKE_HOSThas the<loadBalancerHost>:6443format, whereloadBalancerHostis the corresponding field in the cluster status.The value for
MKE_PASSWORDis taken from theucp-admin-password-<clusterName>secret in the cluster namespace of the management cluster.The value for
MKE_USERNAMEis alwaysadmin.
This section lists the artifacts of components included in the Container Cloud patch release 2.26.5. For artifacts of the Cluster releases introduced in 2.26.5, see patch Cluster releases 17.1.5 and 16.1.5.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20240517093708 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20240517093708 |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.39.28.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.39.28.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.39.28.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.39.28.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.39.28.tgz |
|
metallb |
||
Docker images |
ambasador Updated |
mirantis.azurecr.io/core/external/nginx:1.39.28 |
baremetal-dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-2-26-alpine-20240523095922 |
|
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-2-26-alpine-20240523095601 |
|
bm-collective |
mirantis.azurecr.io/bm/bm-collective:base-2-26-alpine-20240408142218 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.39.28 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20240522120640 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20240522120640 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20240117102150 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-2-26-alpine-20240408150853 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-ba8ada4-20240405150338 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.17-focal-20240523075821 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.24.0-47-gf77368e |
|
metallb-controller |
mirantis.azurecr.io/bm/metallb/controller:v0.13.12-ef4c9453-amd64 |
|
metallb-speaker |
mirantis.azurecr.io/bm/metallb/speaker:v0.13.12-ef4c9453-amd64 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-alpine-20240129163811 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.39.28.tgz |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.39.28.tgz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.39.28.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.39.28.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.39.28.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.39.28.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.39.28.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.39.28.tgz |
|
cinder-csi-plugin |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.39.28.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.39.28.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.39.28.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.39.28.tgz |
|
host-os-modules-controller |
https://binary.mirantis.com/core/helm/host-os-modules-controller-1.39.28.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.39.28.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.39.28.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.39.28.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.39.28.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.39.28.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.39.28.tgz |
|
mcc-cache |
||
mcc-cache-warmup |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.39.28.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.39.28.tgz |
|
openstack-cloud-controller-manager |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.39.28.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.39.28.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.39.28.tgz |
|
policy-controller |
https://binary.mirantis.com/core/helm/policy-controller-1.39.28.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.39.28.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.39.28.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.39.28.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.39.28.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.39.28.tgz |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.39.28.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.39.28.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.39.28.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.39.28.tgz |
|
vsphere-cloud-controller-manager |
https://binary.mirantis.com/core/helm/vsphere-cloud-controller-manager-1.39.28.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.39.28.tgz |
|
vsphere-csi-plugin |
https://binary.mirantis.com/core/helm/vsphere-csi-plugin-1.39.28.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.39.28.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.39.28.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.39.28 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.39.28 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.39.28 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.39.28 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.39.28 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-6 |
|
cinder-csi-plugin |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-16 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.39.28 |
|
configuration-collector Updated |
mirantis.azurecr.io/core/configuration-collector:1.39.28 |
|
csi-attacher |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-5 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-5 |
|
csi-provisioner |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-5 |
|
csi-resizer |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-5 |
|
csi-snapshotter |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-4 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.39.28 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.39.28 |
|
host-os-modules-controller Updated |
mirantis.azurecr.io/core/host-os-modules-controller:1.39.28 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.39.28 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.39.28 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.39.28 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.39.28 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.39.28 |
|
livenessprobe |
mirantis.azurecr.io/lcm/k8scsi/livenessprobe:v2.9.0-5 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.39.28 |
|
mcc-haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.24.0-47-gf77368e |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.24.0-47-gf77368e |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-7 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.39.28 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-16 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.39.28 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.39.28 |
|
policy-controller Updated |
mirantis.azurecr.io/core/policy-controller:1.39.28 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.39.28 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.39.28 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.39.28 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-9 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.39.28 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.39.28 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.39.28 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.39.28 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.39.28 |
|
vsphere-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/vsphere-cloud-controller-manager:v1.27.0-6 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.39.28 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.39.28 |
|
vsphere-csi-driver |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-driver:v3.0.2-1 |
|
vsphere-csi-syncer |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-syncer:v3.0.2-1 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.39.28 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts |
iam Updated |
|
Docker images |
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240501023013 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-ba8ada4-20240405150338 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.17-focal-20240523075821 |
|
mcc-keycloak |
mirantis.azurecr.io/iam/mcc-keycloak:23.0.6-20240216125244 |
See also
2.26.4¶
The Container Cloud patch release 2.26.4, which is based on the 2.26.0 major release, provides the following updates:
Support for the patch Cluster releases 16.1.4 and 17.1.4 that represents Mirantis OpenStack for Kubernetes (MOSK) patch release 24.1.4.
Support for MKE 3.7.8.
Bare metal: update of Ubuntu mirror from 20.04~20240411171541 to 20.04~20240502102020 along with update of minor kernel version from 5.15.0-102-generic to 5.15.0-105-generic.
Security fixes for CVEs in images.
Bug fixes.
This patch release also supports the latest major Cluster releases 17.1.0 and 16.1.0. And it does not support greenfield deployments based on deprecated Cluster releases. Use the latest available Cluster release instead.
For main deliverables of the parent Container Cloud release of 2.26.4, refer to 2.26.0.
The table below includes the total numbers of addressed unique and common CVEs in images by product component since the Container Cloud 2.26.3 patch release. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
Ceph |
Unique |
0 |
1 |
1 |
Common |
0 |
3 |
3 |
|
StackLight |
Unique |
2 |
8 |
10 |
Common |
6 |
9 |
15 |
Mirantis Security Portal
For the detailed list of fixed and existing CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
MOSK CVEs
For the number of fixed CVEs in the MOSK-related components including OpenStack and Tungsten Fabric, refer to MOSK 24.1.4: Security notes.
The following issues have been addressed in the Container Cloud patch release 2.26.4 along with the patch Cluster releases 17.1.4 and 16.1.4.
[41806] [Container Cloud web UI] Fixed the issue with failure to configure management cluster using the Configure cluster web UI menu without updating the Keycloak Truststore settings.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.26.4 including the Cluster releases 17.1.4 and 16.1.4.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
After managed cluster update, old versions of system packages, including kernel, may remain on the manager nodes. This issue occurs because the task responsible for updating packages fails to run after updating Ubuntu mirrors.
As a workaround, manually run apt-get upgrade on every manager node after the cluster update but before rebooting the node.
After node maintenance of a management cluster, the newly added nodes may fail to undergo provisioning successfully. The issue relates to new nodes that are in the same L2 domain as the management cluster.
The issue was observed on environments having management cluster nodes configured with a single L2 segment used for all network traffic (PXE and LCM/management networks).
To verify whether the cluster is affected:
Verify whether the dnsmasq and dhcp-relay pods run on the same node
in the management cluster:
kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of system response:
dhcp-relay-7d85f75f76-5vdw2 2/2 Running 2 (36h ago) 36h 10.10.0.122 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (36h ago) 36h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
If this is the case, proceed to the workaround below.
Workaround:
Log in to a node that contains
kubeconfigof the affected management cluster.Make sure that at least two management cluster nodes are schedulable:
kubectl get node
Example of a positive system response:
NAME STATUS ROLES AGE VERSION kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 Ready master 37h v1.27.10-mirantis-1 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad Ready master 37h v1.27.10-mirantis-1 kaas-node-ad5a6f51-b98f-43c3-91d5-55fed3d0ff21 Ready master 37h v1.27.10-mirantis-1
Delete the
dhcp-relaypod:kubectl -n kaas delete pod <dhcp-relay-xxxxx>
Verify that the
dnsmasqanddhcp-relaypods are scheduled into different nodes:kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of a positive system response:
dhcp-relay-7d85f75f76-rkv03 2/2 Running 0 49s 10.10.0.121 kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 <none> <none> dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (37h ago) 37h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
Due to issues with managing physical NVME devices, lcm-agent cannot grab
storage information on a host. As a result,
lcmmachine.status.hostinfo.hardware is empty and the following example
error is present in logs:
{"level":"error","ts":"2024-05-02T12:26:10Z","logger":"agent", \
"msg":"get hardware details", \
"host":"kaas-node-548b2861-aed0-41c9-8ff2-10c5476b000b", \
"error":"new storage info: get disk info \"nvme0c0n1\": \
invoke command: exit status 1","errorVerbose":"exit status 1
As a workaround, on the affected node, create a symlink for any device
indicated in lcm-agent logs. For example:
ln -sfn /dev/nvme0n1 /dev/nvme0c0n1
During the replacement of a master node on a cluster of any type, the process
may get stuck with Kubelet's NodeReady condition is Unknown in the
machine status on the remaining master nodes.
As a workaround, log in on the affected node and run the following command:
docker restart ucp-kubelet
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
During replacement of a master node on a cluster of any type, the
calico-node Pod fails to start on a new node that has the same IP address
as the node being replaced.
Workaround:
Log in to any
masternode.From a CLI with an MKE client bundle, create a shell alias to start calicoctl using the
mirantis/ucp-dsinfoimage:alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/key.pem \ -e ETCD_CA_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/ca.pem \ -e ETCD_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/cert.pem \ -v /var/run/calico:/var/run/calico \ -v /var/lib/docker/volumes/ucp-kv-certs/_data:/var/lib/docker/volumes/ucp-kv-certs/_data:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl \ "
alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/ucp-node-certs/key.pem \ -e ETCD_CA_CERT_FILE=/ucp-node-certs/ca.pem \ -e ETCD_CERT_FILE=/ucp-node-certs/cert.pem \ -v /var/run/calico:/var/run/calico \ -v ucp-node-certs:/ucp-node-certs:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl --allow-version-mismatch \ "
In the above command, replace the following values with the corresponding settings of the affected cluster:
<etcdEndpoint>is the etcd endpoint defined in the Calico configuration file. For example,ETCD_ENDPOINTS=127.0.0.1:12378<mkeVersion>is the MKE version installed on your cluster. For example,mirantis/ucp-dsinfo:3.5.7.
Verify the node list on the cluster:
kubectl get node
Compare this list with the node list in Calico to identify the old node:
calicoctl get node -o wide
Remove the old node from Calico:
calicoctl delete node kaas-node-<nodeID>
During replacement of a manager machine, the following problems may occur:
The system adds the node to Docker swarm but not to Kubernetes
The node
Deploymentgets stuck with failed RethinkDB health checks
Workaround:
Delete the failed node.
Wait for the MKE cluster to become healthy. To monitor the cluster status:
Log in to the MKE web UI as described in Connect to the Mirantis Kubernetes Engine web UI.
Monitor the cluster status as described in MKE Operations Guide: Monitor an MKE cluster with the MKE web UI.
Deploy a new node.
During the unsafe or forced deletion of a manager machine running the
calico-kube-controllers Pod in the kube-system namespace,
the following issues occur:
The
calico-kube-controllersPod fails to clean up resources associated with the deleted nodeThe
calico-nodePod may fail to start up on a newly created node if the machine is provisioned with the same IP address as the deleted machine had
As a workaround, before deletion of the node running the
calico-kube-controllers Pod, cordon and drain the node:
kubectl cordon <nodeName>
kubectl drain <nodeName>
Fixed in 2.27.0 (17.2.0 and 16.2.0)
During graceful reboot of a cluster with Ceph enabled, the reboot is blocked
with the following message in the MiraCephMaintenance object status:
message: ClusterMaintenanceRequest found, Ceph Cluster is not ready to upgrade,
delaying cluster maintenance
As a workaround, add the following snippet to the cephFS section under
metadataServer in the spec section of <kcc-name>.yaml in the Ceph
cluster:
cephClusterSpec:
sharedFilesystem:
cephFS:
- name: cephfs-store
metadataServer:
activeCount: 1
healthCheck:
livenessProbe:
probe:
failureThreshold: 5
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 5
Update of a managed cluster based on bare metal and Ceph enabled fails with
PersistentVolumeClaim getting stuck in the Pending state for the
prometheus-server StatefulSet and the
MountVolume.MountDevice failed for volume warning in the StackLight event
logs.
Workaround:
Verify that the description of the Pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name where the Pods failed to run<affectedPodName>is a Pod name that failed to run in the specified project
In the Pod description, identify the node name where the Pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain therbd volume mount failed: <csi-vol-uuid> is being usederror. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the Pod that fails to0replicas.On every
csi-rbdpluginPod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected Pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state becomesRunning.
Fixed in 17.2.0, 16.2.0, 17.1.6, 16.1.6
On large managed clusters, shard relocation may fail in the OpenSearch cluster
with the yellow or red status of the OpenSearch cluster.
The characteristic symptom of the issue is that in the stacklight
namespace, the statefulset.apps/opensearch-master containers are
experiencing throttling with the KubeContainersCPUThrottlingHigh alert
firing for the following set of labels:
{created_by_kind="StatefulSet",created_by_name="opensearch-master",namespace="stacklight"}
Caution
The throttling that OpenSearch is experiencing may be a temporary situation, which may be related, for example, to a peaky load and the ongoing shards initialization as part of disaster recovery or after node restart. In this case, Mirantis recommends waiting until initialization of all shards is finished. After that, verify the cluster state and whether throttling still exists. And only if throttling does not disappear, apply the workaround below.
To verify that the initialization of shards is ongoing:
kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
curl "http://localhost:9200/_cat/shards" | grep INITIALIZING
Example of system response:
.ds-system-000072 2 r INITIALIZING 10.232.182.135 opensearch-master-1
.ds-system-000073 1 r INITIALIZING 10.232.7.145 opensearch-master-2
.ds-system-000073 2 r INITIALIZING 10.232.182.135 opensearch-master-1
.ds-audit-000001 2 r INITIALIZING 10.232.7.145 opensearch-master-2
The system response above indicates that shards from the
.ds-system-000072, .ds-system-000073, and .ds-audit-000001
indicies are in the INITIALIZING state. In this case, Mirantis
recommends waiting until this process is finished, and only then consider
changing the limit.
You can additionally analyze the exact level of throttling and the current CPU usage on the Kubernetes Containers dashboard in Grafana.
Workaround:
Verify the currently configured CPU requests and limits for the
opensearchcontainers:kubectl -n stacklight get statefulset.apps/opensearch-master -o jsonpath="{.spec.template.spec.containers[?(@.name=='opensearch')].resources}"
Example of system response:
{"limits":{"cpu":"600m","memory":"8Gi"},"requests":{"cpu":"500m","memory":"6Gi"}}
In the example above, the CPU request is
500mand the CPU limit is600m.Increase the CPU limit to a reasonably high number.
For example, the default CPU limit for the clusters with the
clusterSize:largeparameter set was increased from8000mto12000mfor StackLight in Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0).Note
For details, on the
clusterSizeparameter, see Operations Guide: StackLight configuration parameters - Cluster size.If the defaults are already overridden on the affected cluster using the
resourcesPerClusterSizeorresourcesparameters as described in Operations Guide: StackLight configuration parameters - Resource limits, then the exact recommended number depends on the currently set limit.Mirantis recommends increasing the limit by 50%. If it does not resolve the issue, another increase iteration will be required.
When you select the required CPU limit, increase it as described in Operations Guide: StackLight configuration parameters - Resource limits.
If the CPU limit for the
opensearchcomponent is already set, increase it in theClusterobject for theopensearchparameter. Otherwise, the default StackLight limit is used. In this case, increase the CPU limit for theopensearchcomponent using theresourcesparameter.Wait until all
opensearch-masterpods are recreated with the new CPU limits and becomerunningandready.To verify the current CPU limit for every
opensearchcontainer in everyopensearch-masterpod separately:kubectl -n stacklight get pod/opensearch-master-<podSuffixNumber> -o jsonpath="{.spec.containers[?(@.name=='opensearch')].resources}"
In the command above, replace
<podSuffixNumber>with the name of the pod suffix. For example,pod/opensearch-master-0orpod/opensearch-master-2.Example of system response:
{"limits":{"cpu":"900m","memory":"8Gi"},"requests":{"cpu":"500m","memory":"6Gi"}}
The waiting time may take up to 20 minutes depending on the cluster size.
If the issue is fixed, the KubeContainersCPUThrottlingHigh alert stops
firing immediately, while OpenSearchClusterStatusWarning or
OpenSearchClusterStatusCritical can still be firing for some time during
shard relocation.
If the KubeContainersCPUThrottlingHigh alert is still firing, proceed with
another iteration of the CPU limit increase.
Fixed in 17.2.0, 16.2.0, 17.1.6, 16.1.6
While updating rollover_policy for the current system* and audit*
data streams, the update is not applied to indices.
One of indicators that the cluster is most likely affected is the
KubeJobFailed alert firing for the elasticsearch-curator job and one or
both of the following errors being present in elasticsearch-curator pods
that remain in the Error status:
2024-05-31 13:16:04,459 ERROR Failed to complete action: delete_indices. <class 'curator.exceptions.FailedExecution'>: Exception encountered. Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. Exception: RequestError(400, 'illegal_argument_exception', 'index [.ds-audit-000001] is the write index for data stream [audit] and cannot be deleted')
or
2024-05-31 13:16:04,459 ERROR Failed to complete action: delete_indices. <class 'curator.exceptions.FailedExecution'>: Exception encountered. Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. Exception: RequestError(400, 'illegal_argument_exception', 'index [.ds-system-000001] is the write index for data stream [system] and cannot be deleted')
Note
Instead of .ds-audit-000001 or .ds-system-000001 index names,
similar names can be present with the same prefix but different suffix
numbers.
If the above mentioned alert and errors are present, an immediate action is required, because it indicates that the corresponding index size has already exceeded the space allocated for the index.
To verify that the cluster is affected:
Caution
Verify and apply the workaround to both index patterns, system and audit, separately.
If one of indices is affected, the second one is most likely affected as well. Although in rare cases, only one index may be affected.
Log in to the
opensearch-master-0Pod:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
Verify that the rollover policy is present:
system:curl localhost:9200/_plugins/_ism/policies/system_rollover_policyaudit:curl localhost:9200/_plugins/_ism/policies/audit_rollover_policy
The cluster is affected if the rollover policy is missing. Otherwise, proceed to the following step.
Verify the system response from the previous step. For example:
{"_id":"system_rollover_policy","_version":7229,"_seq_no":42362,"_primary_term":28,"policy":{"policy_id":"system_rollover_policy","description":"system index rollover policy.","last_updated_time":1708505222430,"schema_version":19,"error_notification":null,"default_state":"rollover","states":[{"name":"rollover","actions":[{"retry":{"count":3,"backoff":"exponential","delay":"1m"},"rollover":{"min_size":"14746mb","copy_alias":false}}],"transitions":[]}],"ism_template":[{"index_patterns":["system*"],"priority":200,"last_updated_time":1708505222430}]}}
Verify and capture the following items separately for every policy:
The
_seq_noand_primary_termvaluesThe rollover policy threshold, which is defined in
policy.states[0].actions[0].rollover.min_size
List indices:
system:curl localhost:9200/_cat/indices | grep system
Example of system response:
[...] green open .ds-system-000001 FjglnZlcTKKfKNbosaE9Aw 2 1 1998295 0 1gb 507.9mb
audit:curl localhost:9200/_cat/indices | grep audit
Example of system response:
[...] green open .ds-audit-000001 FjglnZlcTKKfKNbosaE9Aw 2 1 1998295 0 1gb 507.9mb
Select the index with the highest number and verify the rollover policy attached to the index:
system:curl localhost:9200/_plugins/_ism/explain/.ds-system-000001audit:curl localhost:9200/_plugins/_ism/explain/.ds-audit-000001If the rollover policy is not attached, the cluster is affected.
If the rollover policy is attached but
_seq_noand_primary_termnumbers do not match the previously captured ones, the cluster is affected.If the index size drastically exceeds the defined threshold of the rollover policy (which is the previously captured
min_size), the cluster is most probably affected.
Workaround:
Log in to the
opensearch-master-0Pod:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
If the policy is attached to the index but has different
_seq_noand_primary_term, remove the policy from the index:Note
Use the index with the highest number in the name, which was captured during verification procedure.
system:curl -XPOST localhost:9200/_plugins/_ism/remove/.ds-system-000001
audit:curl -XPOST localhost:9200/_plugins/_ism/remove/.ds-audit-000001
Re-add the policy:
system:curl -XPOST -H "Content-type: application/json" localhost:9200/_plugins/_ism/add/system* -d'{"policy_id":"system_rollover_policy"}'
audit:curl -XPOST -H "Content-type: application/json" localhost:9200/_plugins/_ism/add/audit* -d'{"policy_id":"audit_rollover_policy"}'
Perform again the last step of the cluster verification procedure provided above and make sure that the policy is attached to the index and has the same
_seq_noand_primary_term.If the index size drastically exceeds the defined threshold of the rollover policy (which is the previously captured
min_size), wait up to 15 minutes and verify that the additional index is created with the consecutive number in the index name. For example:system: if you applied changes to.ds-system-000001, wait until.ds-system-000002is created.audit: if you applied changes to.ds-audit-000001, wait until.ds-audit-000002is created.
If such index is not created, escalate the issue to Mirantis support.
During a cluster update, a Kubernetes helm-controller Deployment may
get stuck in a restarting Pod loop with Terminating and Running states
flapping. Other Deployment types may also be affected.
As a workaround, restart the Deployment that got stuck:
kubectl -n <affectedProjectName> get deploy <affectedDeployName> -o yaml
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas 0
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas <replicasNumber>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name containing the cluster with stuck Pods<affectedDeployName>is theDeploymentname that failed to run Pods in the specified project<replicasNumber>is the original number of replicas for theDeploymentthat you can obtain using the get deploy command
This section describes the specific actions you as a cloud operator need to complete before or after your Container Cloud cluster update to the Cluster releases 17.1.4 or 16.1.4.
Consider this information as a supplement to the generic update procedures published in Operations Guide: Automatic upgrade of a management cluster and Update a patch Cluster release of a managed cluster.
After the MKE update to 3.7.8, if you are going to enable or already enabled Kubernetes auditing and profiling on your managed or management cluster, keep in mind that enabling audit log rotation requires an additional step. Set the following options in the MKE configuration file after enabling auditing and profiling:
[cluster_config]
kube_api_server_audit_log_maxage=30
kube_api_server_audit_log_maxbackup=10
kube_api_server_audit_log_maxsize=10
For the configuration procedure, see MKE documentation: Configure an existing MKE cluster.
While using this procedure, replace the command to upload the newly edited MKE configuration file with the following one:
curl --silent --insecure -X PUT -H "X-UCP-Allow-Restricted-API: i-solemnly-swear-i-am-up-to-no-good" -H "accept: application/toml" -H "Authorization: Bearer $AUTHTOKEN" --upload-file 'mke-config.toml' https://$MKE_HOST/api/ucp/config-toml
The value for
MKE_HOSThas the<loadBalancerHost>:6443format, whereloadBalancerHostis the corresponding field in the cluster status.The value for
MKE_PASSWORDis taken from theucp-admin-password-<clusterName>secret in the cluster namespace of the management cluster.The value for
MKE_USERNAMEis alwaysadmin.
This section lists the artifacts of components included in the Container Cloud patch release 2.26.4. For artifacts of the Cluster releases introduced in 2.26.4, see patch Cluster releases 17.1.4 and 16.1.4.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20240502103738 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20240502103738 |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.39.26.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.39.26.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.39.26.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.39.26.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.39.26.tgz |
|
metallb |
||
Docker images |
ambasador Updated |
mirantis.azurecr.io/core/external/nginx:1.39.26 |
baremetal-dnsmasq |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-2-26-alpine-20240408141922 |
|
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-2-26-alpine-20240415095355 |
|
bm-collective |
mirantis.azurecr.io/bm/bm-collective:base-2-26-alpine-20240408142218 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.39.26 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20240510100941 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20240510100941 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20240117102150 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-2-26-alpine-20240408150853 |
|
kubernetes-entrypoint Updated |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-ba8ada4-20240405150338 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20240311120505 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.24.0-47-gf77368e |
|
metallb-controller |
mirantis.azurecr.io/bm/metallb/controller:v0.13.12-ef4c9453-amd64 |
|
metallb-speaker |
mirantis.azurecr.io/bm/metallb/speaker:v0.13.12-ef4c9453-amd64 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-alpine-20240129163811 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.39.26.tgz |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.39.26.tgz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.39.26.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.39.26.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.39.26.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.39.26.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.39.26.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.39.26.tgz |
|
cinder-csi-plugin |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.39.26.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.39.26.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.39.26.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.39.26.tgz |
|
host-os-modules-controller |
https://binary.mirantis.com/core/helm/host-os-modules-controller-1.39.26.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.39.26.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.39.26.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.39.26.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.39.26.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.39.26.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.39.26.tgz |
|
mcc-cache |
||
mcc-cache-warmup |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.39.26.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.39.26.tgz |
|
openstack-cloud-controller-manager |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.39.26.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.39.26.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.39.26.tgz |
|
policy-controller |
https://binary.mirantis.com/core/helm/policy-controller-1.39.26.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.39.26.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.39.26.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.39.26.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.39.26.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.39.26.tgz |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.39.26.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.39.26.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.39.26.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.39.26.tgz |
|
vsphere-cloud-controller-manager |
https://binary.mirantis.com/core/helm/vsphere-cloud-controller-manager-1.39.26.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.39.26.tgz |
|
vsphere-csi-plugin |
https://binary.mirantis.com/core/helm/vsphere-csi-plugin-1.39.26.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.39.26.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.39.26.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.39.26 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.39.26 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.39.26 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.39.26 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.39.26 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-6 |
|
cinder-csi-plugin Updated |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-16 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.39.26 |
|
configuration-collector Updated |
mirantis.azurecr.io/core/configuration-collector:1.39.26 |
|
csi-attacher |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-5 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-5 |
|
csi-provisioner |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-5 |
|
csi-resizer |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-5 |
|
csi-snapshotter |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-4 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.39.26 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.39.26 |
|
host-os-modules-controller Updated |
mirantis.azurecr.io/core/host-os-modules-controller:1.39.26 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.39.26 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.39.26 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.39.26 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.39.26 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.39.26 |
|
livenessprobe |
mirantis.azurecr.io/lcm/k8scsi/livenessprobe:v2.9.0-5 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.39.26 |
|
mcc-haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.24.0-47-gf77368e |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.24.0-47-gf77368e |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-7 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.39.26 |
|
openstack-cloud-controller-manager Updated |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-16 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.39.26 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.39.26 |
|
policy-controller Updated |
mirantis.azurecr.io/core/policy-controller:1.39.26 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.39.26 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.39.26 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.39.26 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-9 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.39.26 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.39.26 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.39.26 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.39.26 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.39.26 |
|
vsphere-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/vsphere-cloud-controller-manager:v1.27.0-6 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.39.26 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.39.26 |
|
vsphere-csi-driver |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-driver:v3.0.2-1 |
|
vsphere-csi-syncer |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-syncer:v3.0.2-1 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.39.26 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts |
iam Updated |
|
Docker images |
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240501023013 |
kubernetes-entrypoint Updated |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-ba8ada4-20240405150338 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.17-focal-20240327104027 |
|
mcc-keycloak |
mirantis.azurecr.io/iam/mcc-keycloak:23.0.6-20240216125244 |
See also
2.26.3¶
The Container Cloud patch release 2.26.3, which is based on the 2.26.0 major release, provides the following updates:
Support for the patch Cluster releases 16.1.3 and 17.1.3 that represents Mirantis OpenStack for Kubernetes (MOSK) patch release 24.1.3.
Support for MKE 3.7.7.
Bare metal: update of Ubuntu mirror from 20.04~20240324172903 to 20.04~20240411171541 along with update of minor kernel version from 5.15.0-101-generic to 5.15.0-102-generic.
Security fixes for CVEs in images.
Bug fixes.
This patch release also supports the latest major Cluster releases 17.1.0 and 16.1.0. And it does not support greenfield deployments based on deprecated Cluster releases. Use the latest available Cluster release instead.
For main deliverables of the parent Container Cloud release of 2.26.3, refer to 2.26.0.
The table below includes the total numbers of addressed unique and common CVEs in images by product component since the Container Cloud 2.26.2 patch release. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
Ceph |
Unique |
0 |
1 |
1 |
Common |
0 |
10 |
10 |
|
Core |
Unique |
0 |
4 |
4 |
Common |
0 |
105 |
105 |
|
StackLight |
Unique |
1 |
4 |
5 |
Common |
1 |
24 |
25 |
Mirantis Security Portal
For the detailed list of fixed and existing CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
MOSK CVEs
For the number of fixed CVEs in the MOSK-related components including OpenStack and Tungsten Fabric, refer to MOSK 24.1.3: Security notes.
The following issues have been addressed in the Container Cloud patch release 2.26.3 along with the patch Cluster releases 17.1.3 and 16.1.3.
[40811] [LCM] Fixed the issue with the DaemonSet Pod remaining on the deleted node in the
Terminatingstate during machine deletion.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.26.3 including the Cluster releases 17.1.3 and 16.1.3.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
After node maintenance of a management cluster, the newly added nodes may fail to undergo provisioning successfully. The issue relates to new nodes that are in the same L2 domain as the management cluster.
The issue was observed on environments having management cluster nodes configured with a single L2 segment used for all network traffic (PXE and LCM/management networks).
To verify whether the cluster is affected:
Verify whether the dnsmasq and dhcp-relay pods run on the same node
in the management cluster:
kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of system response:
dhcp-relay-7d85f75f76-5vdw2 2/2 Running 2 (36h ago) 36h 10.10.0.122 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (36h ago) 36h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
If this is the case, proceed to the workaround below.
Workaround:
Log in to a node that contains
kubeconfigof the affected management cluster.Make sure that at least two management cluster nodes are schedulable:
kubectl get node
Example of a positive system response:
NAME STATUS ROLES AGE VERSION kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 Ready master 37h v1.27.10-mirantis-1 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad Ready master 37h v1.27.10-mirantis-1 kaas-node-ad5a6f51-b98f-43c3-91d5-55fed3d0ff21 Ready master 37h v1.27.10-mirantis-1
Delete the
dhcp-relaypod:kubectl -n kaas delete pod <dhcp-relay-xxxxx>
Verify that the
dnsmasqanddhcp-relaypods are scheduled into different nodes:kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of a positive system response:
dhcp-relay-7d85f75f76-rkv03 2/2 Running 0 49s 10.10.0.121 kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 <none> <none> dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (37h ago) 37h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
Due to issues with managing physical NVME devices, lcm-agent cannot grab
storage information on a host. As a result,
lcmmachine.status.hostinfo.hardware is empty and the following example
error is present in logs:
{"level":"error","ts":"2024-05-02T12:26:10Z","logger":"agent", \
"msg":"get hardware details", \
"host":"kaas-node-548b2861-aed0-41c9-8ff2-10c5476b000b", \
"error":"new storage info: get disk info \"nvme0c0n1\": \
invoke command: exit status 1","errorVerbose":"exit status 1
As a workaround, on the affected node, create a symlink for any device
indicated in lcm-agent logs. For example:
ln -sfn /dev/nvme0n1 /dev/nvme0c0n1
During the replacement of a master node on a cluster of any type, the process
may get stuck with Kubelet's NodeReady condition is Unknown in the
machine status on the remaining master nodes.
As a workaround, log in on the affected node and run the following command:
docker restart ucp-kubelet
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
During replacement of a master node on a cluster of any type, the
calico-node Pod fails to start on a new node that has the same IP address
as the node being replaced.
Workaround:
Log in to any
masternode.From a CLI with an MKE client bundle, create a shell alias to start calicoctl using the
mirantis/ucp-dsinfoimage:alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/key.pem \ -e ETCD_CA_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/ca.pem \ -e ETCD_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/cert.pem \ -v /var/run/calico:/var/run/calico \ -v /var/lib/docker/volumes/ucp-kv-certs/_data:/var/lib/docker/volumes/ucp-kv-certs/_data:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl \ "
alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/ucp-node-certs/key.pem \ -e ETCD_CA_CERT_FILE=/ucp-node-certs/ca.pem \ -e ETCD_CERT_FILE=/ucp-node-certs/cert.pem \ -v /var/run/calico:/var/run/calico \ -v ucp-node-certs:/ucp-node-certs:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl --allow-version-mismatch \ "
In the above command, replace the following values with the corresponding settings of the affected cluster:
<etcdEndpoint>is the etcd endpoint defined in the Calico configuration file. For example,ETCD_ENDPOINTS=127.0.0.1:12378<mkeVersion>is the MKE version installed on your cluster. For example,mirantis/ucp-dsinfo:3.5.7.
Verify the node list on the cluster:
kubectl get node
Compare this list with the node list in Calico to identify the old node:
calicoctl get node -o wide
Remove the old node from Calico:
calicoctl delete node kaas-node-<nodeID>
During replacement of a manager machine, the following problems may occur:
The system adds the node to Docker swarm but not to Kubernetes
The node
Deploymentgets stuck with failed RethinkDB health checks
Workaround:
Delete the failed node.
Wait for the MKE cluster to become healthy. To monitor the cluster status:
Log in to the MKE web UI as described in Connect to the Mirantis Kubernetes Engine web UI.
Monitor the cluster status as described in MKE Operations Guide: Monitor an MKE cluster with the MKE web UI.
Deploy a new node.
During the unsafe or forced deletion of a manager machine running the
calico-kube-controllers Pod in the kube-system namespace,
the following issues occur:
The
calico-kube-controllersPod fails to clean up resources associated with the deleted nodeThe
calico-nodePod may fail to start up on a newly created node if the machine is provisioned with the same IP address as the deleted machine had
As a workaround, before deletion of the node running the
calico-kube-controllers Pod, cordon and drain the node:
kubectl cordon <nodeName>
kubectl drain <nodeName>
Fixed in 2.27.0 (17.2.0 and 16.2.0)
During graceful reboot of a cluster with Ceph enabled, the reboot is blocked
with the following message in the MiraCephMaintenance object status:
message: ClusterMaintenanceRequest found, Ceph Cluster is not ready to upgrade,
delaying cluster maintenance
As a workaround, add the following snippet to the cephFS section under
metadataServer in the spec section of <kcc-name>.yaml in the Ceph
cluster:
cephClusterSpec:
sharedFilesystem:
cephFS:
- name: cephfs-store
metadataServer:
activeCount: 1
healthCheck:
livenessProbe:
probe:
failureThreshold: 5
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 5
Update of a managed cluster based on bare metal and Ceph enabled fails with
PersistentVolumeClaim getting stuck in the Pending state for the
prometheus-server StatefulSet and the
MountVolume.MountDevice failed for volume warning in the StackLight event
logs.
Workaround:
Verify that the description of the Pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name where the Pods failed to run<affectedPodName>is a Pod name that failed to run in the specified project
In the Pod description, identify the node name where the Pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain therbd volume mount failed: <csi-vol-uuid> is being usederror. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the Pod that fails to0replicas.On every
csi-rbdpluginPod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected Pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state becomesRunning.
Fixed in 17.2.0, 16.2.0, 17.1.6, 16.1.6
On large managed clusters, shard relocation may fail in the OpenSearch cluster
with the yellow or red status of the OpenSearch cluster.
The characteristic symptom of the issue is that in the stacklight
namespace, the statefulset.apps/opensearch-master containers are
experiencing throttling with the KubeContainersCPUThrottlingHigh alert
firing for the following set of labels:
{created_by_kind="StatefulSet",created_by_name="opensearch-master",namespace="stacklight"}
Caution
The throttling that OpenSearch is experiencing may be a temporary situation, which may be related, for example, to a peaky load and the ongoing shards initialization as part of disaster recovery or after node restart. In this case, Mirantis recommends waiting until initialization of all shards is finished. After that, verify the cluster state and whether throttling still exists. And only if throttling does not disappear, apply the workaround below.
To verify that the initialization of shards is ongoing:
kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
curl "http://localhost:9200/_cat/shards" | grep INITIALIZING
Example of system response:
.ds-system-000072 2 r INITIALIZING 10.232.182.135 opensearch-master-1
.ds-system-000073 1 r INITIALIZING 10.232.7.145 opensearch-master-2
.ds-system-000073 2 r INITIALIZING 10.232.182.135 opensearch-master-1
.ds-audit-000001 2 r INITIALIZING 10.232.7.145 opensearch-master-2
The system response above indicates that shards from the
.ds-system-000072, .ds-system-000073, and .ds-audit-000001
indicies are in the INITIALIZING state. In this case, Mirantis
recommends waiting until this process is finished, and only then consider
changing the limit.
You can additionally analyze the exact level of throttling and the current CPU usage on the Kubernetes Containers dashboard in Grafana.
Workaround:
Verify the currently configured CPU requests and limits for the
opensearchcontainers:kubectl -n stacklight get statefulset.apps/opensearch-master -o jsonpath="{.spec.template.spec.containers[?(@.name=='opensearch')].resources}"
Example of system response:
{"limits":{"cpu":"600m","memory":"8Gi"},"requests":{"cpu":"500m","memory":"6Gi"}}
In the example above, the CPU request is
500mand the CPU limit is600m.Increase the CPU limit to a reasonably high number.
For example, the default CPU limit for the clusters with the
clusterSize:largeparameter set was increased from8000mto12000mfor StackLight in Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0).Note
For details, on the
clusterSizeparameter, see Operations Guide: StackLight configuration parameters - Cluster size.If the defaults are already overridden on the affected cluster using the
resourcesPerClusterSizeorresourcesparameters as described in Operations Guide: StackLight configuration parameters - Resource limits, then the exact recommended number depends on the currently set limit.Mirantis recommends increasing the limit by 50%. If it does not resolve the issue, another increase iteration will be required.
When you select the required CPU limit, increase it as described in Operations Guide: StackLight configuration parameters - Resource limits.
If the CPU limit for the
opensearchcomponent is already set, increase it in theClusterobject for theopensearchparameter. Otherwise, the default StackLight limit is used. In this case, increase the CPU limit for theopensearchcomponent using theresourcesparameter.Wait until all
opensearch-masterpods are recreated with the new CPU limits and becomerunningandready.To verify the current CPU limit for every
opensearchcontainer in everyopensearch-masterpod separately:kubectl -n stacklight get pod/opensearch-master-<podSuffixNumber> -o jsonpath="{.spec.containers[?(@.name=='opensearch')].resources}"
In the command above, replace
<podSuffixNumber>with the name of the pod suffix. For example,pod/opensearch-master-0orpod/opensearch-master-2.Example of system response:
{"limits":{"cpu":"900m","memory":"8Gi"},"requests":{"cpu":"500m","memory":"6Gi"}}
The waiting time may take up to 20 minutes depending on the cluster size.
If the issue is fixed, the KubeContainersCPUThrottlingHigh alert stops
firing immediately, while OpenSearchClusterStatusWarning or
OpenSearchClusterStatusCritical can still be firing for some time during
shard relocation.
If the KubeContainersCPUThrottlingHigh alert is still firing, proceed with
another iteration of the CPU limit increase.
Fixed in 17.2.0, 16.2.0, 17.1.6, 16.1.6
While updating rollover_policy for the current system* and audit*
data streams, the update is not applied to indices.
One of indicators that the cluster is most likely affected is the
KubeJobFailed alert firing for the elasticsearch-curator job and one or
both of the following errors being present in elasticsearch-curator pods
that remain in the Error status:
2024-05-31 13:16:04,459 ERROR Failed to complete action: delete_indices. <class 'curator.exceptions.FailedExecution'>: Exception encountered. Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. Exception: RequestError(400, 'illegal_argument_exception', 'index [.ds-audit-000001] is the write index for data stream [audit] and cannot be deleted')
or
2024-05-31 13:16:04,459 ERROR Failed to complete action: delete_indices. <class 'curator.exceptions.FailedExecution'>: Exception encountered. Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. Exception: RequestError(400, 'illegal_argument_exception', 'index [.ds-system-000001] is the write index for data stream [system] and cannot be deleted')
Note
Instead of .ds-audit-000001 or .ds-system-000001 index names,
similar names can be present with the same prefix but different suffix
numbers.
If the above mentioned alert and errors are present, an immediate action is required, because it indicates that the corresponding index size has already exceeded the space allocated for the index.
To verify that the cluster is affected:
Caution
Verify and apply the workaround to both index patterns, system and audit, separately.
If one of indices is affected, the second one is most likely affected as well. Although in rare cases, only one index may be affected.
Log in to the
opensearch-master-0Pod:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
Verify that the rollover policy is present:
system:curl localhost:9200/_plugins/_ism/policies/system_rollover_policyaudit:curl localhost:9200/_plugins/_ism/policies/audit_rollover_policy
The cluster is affected if the rollover policy is missing. Otherwise, proceed to the following step.
Verify the system response from the previous step. For example:
{"_id":"system_rollover_policy","_version":7229,"_seq_no":42362,"_primary_term":28,"policy":{"policy_id":"system_rollover_policy","description":"system index rollover policy.","last_updated_time":1708505222430,"schema_version":19,"error_notification":null,"default_state":"rollover","states":[{"name":"rollover","actions":[{"retry":{"count":3,"backoff":"exponential","delay":"1m"},"rollover":{"min_size":"14746mb","copy_alias":false}}],"transitions":[]}],"ism_template":[{"index_patterns":["system*"],"priority":200,"last_updated_time":1708505222430}]}}
Verify and capture the following items separately for every policy:
The
_seq_noand_primary_termvaluesThe rollover policy threshold, which is defined in
policy.states[0].actions[0].rollover.min_size
List indices:
system:curl localhost:9200/_cat/indices | grep system
Example of system response:
[...] green open .ds-system-000001 FjglnZlcTKKfKNbosaE9Aw 2 1 1998295 0 1gb 507.9mb
audit:curl localhost:9200/_cat/indices | grep audit
Example of system response:
[...] green open .ds-audit-000001 FjglnZlcTKKfKNbosaE9Aw 2 1 1998295 0 1gb 507.9mb
Select the index with the highest number and verify the rollover policy attached to the index:
system:curl localhost:9200/_plugins/_ism/explain/.ds-system-000001audit:curl localhost:9200/_plugins/_ism/explain/.ds-audit-000001If the rollover policy is not attached, the cluster is affected.
If the rollover policy is attached but
_seq_noand_primary_termnumbers do not match the previously captured ones, the cluster is affected.If the index size drastically exceeds the defined threshold of the rollover policy (which is the previously captured
min_size), the cluster is most probably affected.
Workaround:
Log in to the
opensearch-master-0Pod:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
If the policy is attached to the index but has different
_seq_noand_primary_term, remove the policy from the index:Note
Use the index with the highest number in the name, which was captured during verification procedure.
system:curl -XPOST localhost:9200/_plugins/_ism/remove/.ds-system-000001
audit:curl -XPOST localhost:9200/_plugins/_ism/remove/.ds-audit-000001
Re-add the policy:
system:curl -XPOST -H "Content-type: application/json" localhost:9200/_plugins/_ism/add/system* -d'{"policy_id":"system_rollover_policy"}'
audit:curl -XPOST -H "Content-type: application/json" localhost:9200/_plugins/_ism/add/audit* -d'{"policy_id":"audit_rollover_policy"}'
Perform again the last step of the cluster verification procedure provided above and make sure that the policy is attached to the index and has the same
_seq_noand_primary_term.If the index size drastically exceeds the defined threshold of the rollover policy (which is the previously captured
min_size), wait up to 15 minutes and verify that the additional index is created with the consecutive number in the index name. For example:system: if you applied changes to.ds-system-000001, wait until.ds-system-000002is created.audit: if you applied changes to.ds-audit-000001, wait until.ds-audit-000002is created.
If such index is not created, escalate the issue to Mirantis support.
During a cluster update, a Kubernetes helm-controller Deployment may
get stuck in a restarting Pod loop with Terminating and Running states
flapping. Other Deployment types may also be affected.
As a workaround, restart the Deployment that got stuck:
kubectl -n <affectedProjectName> get deploy <affectedDeployName> -o yaml
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas 0
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas <replicasNumber>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name containing the cluster with stuck Pods<affectedDeployName>is theDeploymentname that failed to run Pods in the specified project<replicasNumber>is the original number of replicas for theDeploymentthat you can obtain using the get deploy command
During configuration of a management cluster settings using the Configure cluster web UI menu, updating the Keycloak Truststore settings is mandatory, despite being optional.
As a workaround, update the management cluster using the API or CLI.
This section lists the artifacts of components included in the Container Cloud patch release 2.26.3. For artifacts of the Cluster releases introduced in 2.26.3, see patch Cluster releases 17.1.3 and 16.1.3.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20240411174919 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20240411174919 |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.39.23.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.39.23.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.39.23.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.39.23.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.39.23.tgz |
|
metallb |
||
Docker images |
ambasador Updated |
mirantis.azurecr.io/core/external/nginx:1.39.23 |
baremetal-dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-2-26-alpine-20240408141922 |
|
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-2-26-alpine-20240408141703 |
|
bm-collective Updated |
mirantis.azurecr.io/bm/bm-collective:base-2-26-alpine-20240408142218 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.39.23 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20240226060024 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20240226060024 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20240117102150 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-2-26-alpine-20240408150853 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20240311120505 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.24.0-47-gf77368e |
|
metallb-controller Updated |
mirantis.azurecr.io/bm/metallb/controller:v0.13.12-ef4c9453-amd64 |
|
metallb-speaker Updated |
mirantis.azurecr.io/bm/metallb/speaker:v0.13.12-ef4c9453-amd64 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-alpine-20240129163811 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.39.23.tgz |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.39.23.tgz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.39.23.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.39.23.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.39.23.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.39.23.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.39.23.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.39.23.tgz |
|
cinder-csi-plugin |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.39.23.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.39.23.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.39.23.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.39.23.tgz |
|
host-os-modules-controller |
https://binary.mirantis.com/core/helm/host-os-modules-controller-1.39.23.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.39.23.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.39.23.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.39.23.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.39.23.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.39.23.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.39.23.tgz |
|
mcc-cache |
||
mcc-cache-warmup |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.39.23.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.39.23.tgz |
|
openstack-cloud-controller-manager |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.39.23.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.39.23.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.39.23.tgz |
|
policy-controller |
https://binary.mirantis.com/core/helm/policy-controller-1.39.23.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.39.23.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.39.23.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.39.23.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.39.23.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.39.23.tgz |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.39.23.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.39.23.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.39.23.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.39.23.tgz |
|
vsphere-cloud-controller-manager |
https://binary.mirantis.com/core/helm/vsphere-cloud-controller-manager-1.39.23.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.39.23.tgz |
|
vsphere-csi-plugin |
https://binary.mirantis.com/core/helm/vsphere-csi-plugin-1.39.23.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.39.23.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.39.23.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.39.23 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.39.23 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.39.23 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.39.23 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.39.23 |
|
cert-manager-controller Updated |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-6 |
|
cinder-csi-plugin Updated |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-14 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.39.23 |
|
configuration-collector Updated |
mirantis.azurecr.io/core/configuration-collector:1.39.23 |
|
csi-attacher Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-5 |
|
csi-node-driver-registrar Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-5 |
|
csi-provisioner Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-5 |
|
csi-resizer Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-5 |
|
csi-snapshotter Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-4 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.39.23 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.39.23 |
|
host-os-modules-controller Updated |
mirantis.azurecr.io/core/host-os-modules-controller:1.39.23 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.39.23 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.39.23 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.39.23 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.39.23 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.39.23 |
|
livenessprobe Updated |
mirantis.azurecr.io/lcm/k8scsi/livenessprobe:v2.9.0-5 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.39.23 |
|
mcc-haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.24.0-47-gf77368e |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.24.0-47-gf77368e |
|
metrics-server Updated |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-7 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.39.23 |
|
openstack-cloud-controller-manager Updated |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-14 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.39.23 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.39.23 |
|
policy-controller Updated |
mirantis.azurecr.io/core/policy-controller:1.39.23 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.39.23 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.39.23 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.39.23 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-9 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.39.23 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.39.23 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.39.23 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.39.23 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.39.23 |
|
vsphere-cloud-controller-manager Updated |
mirantis.azurecr.io/lcm/kubernetes/vsphere-cloud-controller-manager:v1.27.0-6 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.39.23 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.39.23 |
|
vsphere-csi-driver |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-driver:v3.0.2-1 |
|
vsphere-csi-syncer |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-syncer:v3.0.2-1 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.39.23 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts |
iam Updated |
|
Docker images |
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240221023016 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20240311120505 |
|
mcc-keycloak |
mirantis.azurecr.io/iam/mcc-keycloak:23.0.6-20240216125244 |
See also
2.26.2¶
The Container Cloud patch release 2.26.2, which is based on the 2.26.0 major release, provides the following updates:
Support for the patch Cluster releases 16.1.2 and 17.1.2 that represents Mirantis OpenStack for Kubernetes (MOSK) patch release 24.1.2.
Support for MKE 3.7.6.
Support for
docker-ee-cli23.0.10 in MCR 23.0.9 to fix several CVEs.Bare metal: update of Ubuntu mirror from 20.04~20240302175618 to 20.04~20240324172903 along with update of minor kernel version from 5.15.0-97-generic to 5.15.0-101-generic.
Security fixes for CVEs in images.
This patch release also supports the latest major Cluster releases 17.1.0 and 16.1.0. And it does not support greenfield deployments based on deprecated Cluster releases. Use the latest available Cluster release instead.
For main deliverables of the parent Container Cloud release of 2.26.2, refer to 2.26.0.
The table below includes the total numbers of addressed unique and common CVEs in images by product component since the Container Cloud 2.26.1 patch release. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
Ceph |
Unique |
0 |
3 |
3 |
Common |
0 |
12 |
12 |
|
Kaas core |
Unique |
1 |
6 |
7 |
Common |
1 |
11 |
12 |
|
StackLight |
Unique |
0 |
1 |
1 |
Common |
0 |
10 |
10 |
Mirantis Security Portal
For the detailed list of fixed and existing CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
MOSK CVEs
For the number of fixed CVEs in the MOSK-related components including OpenStack and Tungsten Fabric, refer to MOSK 24.1.2: Security notes.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.26.2 including the Cluster releases 17.1.2 and 16.1.2.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
After node maintenance of a management cluster, the newly added nodes may fail to undergo provisioning successfully. The issue relates to new nodes that are in the same L2 domain as the management cluster.
The issue was observed on environments having management cluster nodes configured with a single L2 segment used for all network traffic (PXE and LCM/management networks).
To verify whether the cluster is affected:
Verify whether the dnsmasq and dhcp-relay pods run on the same node
in the management cluster:
kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of system response:
dhcp-relay-7d85f75f76-5vdw2 2/2 Running 2 (36h ago) 36h 10.10.0.122 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (36h ago) 36h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
If this is the case, proceed to the workaround below.
Workaround:
Log in to a node that contains
kubeconfigof the affected management cluster.Make sure that at least two management cluster nodes are schedulable:
kubectl get node
Example of a positive system response:
NAME STATUS ROLES AGE VERSION kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 Ready master 37h v1.27.10-mirantis-1 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad Ready master 37h v1.27.10-mirantis-1 kaas-node-ad5a6f51-b98f-43c3-91d5-55fed3d0ff21 Ready master 37h v1.27.10-mirantis-1
Delete the
dhcp-relaypod:kubectl -n kaas delete pod <dhcp-relay-xxxxx>
Verify that the
dnsmasqanddhcp-relaypods are scheduled into different nodes:kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of a positive system response:
dhcp-relay-7d85f75f76-rkv03 2/2 Running 0 49s 10.10.0.121 kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 <none> <none> dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (37h ago) 37h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
Due to issues with managing physical NVME devices, lcm-agent cannot grab
storage information on a host. As a result,
lcmmachine.status.hostinfo.hardware is empty and the following example
error is present in logs:
{"level":"error","ts":"2024-05-02T12:26:10Z","logger":"agent", \
"msg":"get hardware details", \
"host":"kaas-node-548b2861-aed0-41c9-8ff2-10c5476b000b", \
"error":"new storage info: get disk info \"nvme0c0n1\": \
invoke command: exit status 1","errorVerbose":"exit status 1
As a workaround, on the affected node, create a symlink for any device
indicated in lcm-agent logs. For example:
ln -sfn /dev/nvme0n1 /dev/nvme0c0n1
During deletion of a machine, the related DaemonSet Pod can remain on the
deleted node in the Terminating state. As a workaround, manually
delete the Pod:
kubectl delete pod -n <podNamespace> <podName>
During the replacement of a master node on a cluster of any type, the process
may get stuck with Kubelet's NodeReady condition is Unknown in the
machine status on the remaining master nodes.
As a workaround, log in on the affected node and run the following command:
docker restart ucp-kubelet
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
During replacement of a master node on a cluster of any type, the
calico-node Pod fails to start on a new node that has the same IP address
as the node being replaced.
Workaround:
Log in to any
masternode.From a CLI with an MKE client bundle, create a shell alias to start calicoctl using the
mirantis/ucp-dsinfoimage:alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/key.pem \ -e ETCD_CA_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/ca.pem \ -e ETCD_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/cert.pem \ -v /var/run/calico:/var/run/calico \ -v /var/lib/docker/volumes/ucp-kv-certs/_data:/var/lib/docker/volumes/ucp-kv-certs/_data:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl \ "
alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/ucp-node-certs/key.pem \ -e ETCD_CA_CERT_FILE=/ucp-node-certs/ca.pem \ -e ETCD_CERT_FILE=/ucp-node-certs/cert.pem \ -v /var/run/calico:/var/run/calico \ -v ucp-node-certs:/ucp-node-certs:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl --allow-version-mismatch \ "
In the above command, replace the following values with the corresponding settings of the affected cluster:
<etcdEndpoint>is the etcd endpoint defined in the Calico configuration file. For example,ETCD_ENDPOINTS=127.0.0.1:12378<mkeVersion>is the MKE version installed on your cluster. For example,mirantis/ucp-dsinfo:3.5.7.
Verify the node list on the cluster:
kubectl get node
Compare this list with the node list in Calico to identify the old node:
calicoctl get node -o wide
Remove the old node from Calico:
calicoctl delete node kaas-node-<nodeID>
During replacement of a manager machine, the following problems may occur:
The system adds the node to Docker swarm but not to Kubernetes
The node
Deploymentgets stuck with failed RethinkDB health checks
Workaround:
Delete the failed node.
Wait for the MKE cluster to become healthy. To monitor the cluster status:
Log in to the MKE web UI as described in Connect to the Mirantis Kubernetes Engine web UI.
Monitor the cluster status as described in MKE Operations Guide: Monitor an MKE cluster with the MKE web UI.
Deploy a new node.
During the unsafe or forced deletion of a manager machine running the
calico-kube-controllers Pod in the kube-system namespace,
the following issues occur:
The
calico-kube-controllersPod fails to clean up resources associated with the deleted nodeThe
calico-nodePod may fail to start up on a newly created node if the machine is provisioned with the same IP address as the deleted machine had
As a workaround, before deletion of the node running the
calico-kube-controllers Pod, cordon and drain the node:
kubectl cordon <nodeName>
kubectl drain <nodeName>
Fixed in 2.27.0 (17.2.0 and 16.2.0)
During graceful reboot of a cluster with Ceph enabled, the reboot is blocked
with the following message in the MiraCephMaintenance object status:
message: ClusterMaintenanceRequest found, Ceph Cluster is not ready to upgrade,
delaying cluster maintenance
As a workaround, add the following snippet to the cephFS section under
metadataServer in the spec section of <kcc-name>.yaml in the Ceph
cluster:
cephClusterSpec:
sharedFilesystem:
cephFS:
- name: cephfs-store
metadataServer:
activeCount: 1
healthCheck:
livenessProbe:
probe:
failureThreshold: 5
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 5
Update of a managed cluster based on bare metal and Ceph enabled fails with
PersistentVolumeClaim getting stuck in the Pending state for the
prometheus-server StatefulSet and the
MountVolume.MountDevice failed for volume warning in the StackLight event
logs.
Workaround:
Verify that the description of the Pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name where the Pods failed to run<affectedPodName>is a Pod name that failed to run in the specified project
In the Pod description, identify the node name where the Pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain therbd volume mount failed: <csi-vol-uuid> is being usederror. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the Pod that fails to0replicas.On every
csi-rbdpluginPod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected Pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state becomesRunning.
Fixed in 17.2.0, 16.2.0, 17.1.6, 16.1.6
On large managed clusters, shard relocation may fail in the OpenSearch cluster
with the yellow or red status of the OpenSearch cluster.
The characteristic symptom of the issue is that in the stacklight
namespace, the statefulset.apps/opensearch-master containers are
experiencing throttling with the KubeContainersCPUThrottlingHigh alert
firing for the following set of labels:
{created_by_kind="StatefulSet",created_by_name="opensearch-master",namespace="stacklight"}
Caution
The throttling that OpenSearch is experiencing may be a temporary situation, which may be related, for example, to a peaky load and the ongoing shards initialization as part of disaster recovery or after node restart. In this case, Mirantis recommends waiting until initialization of all shards is finished. After that, verify the cluster state and whether throttling still exists. And only if throttling does not disappear, apply the workaround below.
To verify that the initialization of shards is ongoing:
kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
curl "http://localhost:9200/_cat/shards" | grep INITIALIZING
Example of system response:
.ds-system-000072 2 r INITIALIZING 10.232.182.135 opensearch-master-1
.ds-system-000073 1 r INITIALIZING 10.232.7.145 opensearch-master-2
.ds-system-000073 2 r INITIALIZING 10.232.182.135 opensearch-master-1
.ds-audit-000001 2 r INITIALIZING 10.232.7.145 opensearch-master-2
The system response above indicates that shards from the
.ds-system-000072, .ds-system-000073, and .ds-audit-000001
indicies are in the INITIALIZING state. In this case, Mirantis
recommends waiting until this process is finished, and only then consider
changing the limit.
You can additionally analyze the exact level of throttling and the current CPU usage on the Kubernetes Containers dashboard in Grafana.
Workaround:
Verify the currently configured CPU requests and limits for the
opensearchcontainers:kubectl -n stacklight get statefulset.apps/opensearch-master -o jsonpath="{.spec.template.spec.containers[?(@.name=='opensearch')].resources}"
Example of system response:
{"limits":{"cpu":"600m","memory":"8Gi"},"requests":{"cpu":"500m","memory":"6Gi"}}
In the example above, the CPU request is
500mand the CPU limit is600m.Increase the CPU limit to a reasonably high number.
For example, the default CPU limit for the clusters with the
clusterSize:largeparameter set was increased from8000mto12000mfor StackLight in Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0).Note
For details, on the
clusterSizeparameter, see Operations Guide: StackLight configuration parameters - Cluster size.If the defaults are already overridden on the affected cluster using the
resourcesPerClusterSizeorresourcesparameters as described in Operations Guide: StackLight configuration parameters - Resource limits, then the exact recommended number depends on the currently set limit.Mirantis recommends increasing the limit by 50%. If it does not resolve the issue, another increase iteration will be required.
When you select the required CPU limit, increase it as described in Operations Guide: StackLight configuration parameters - Resource limits.
If the CPU limit for the
opensearchcomponent is already set, increase it in theClusterobject for theopensearchparameter. Otherwise, the default StackLight limit is used. In this case, increase the CPU limit for theopensearchcomponent using theresourcesparameter.Wait until all
opensearch-masterpods are recreated with the new CPU limits and becomerunningandready.To verify the current CPU limit for every
opensearchcontainer in everyopensearch-masterpod separately:kubectl -n stacklight get pod/opensearch-master-<podSuffixNumber> -o jsonpath="{.spec.containers[?(@.name=='opensearch')].resources}"
In the command above, replace
<podSuffixNumber>with the name of the pod suffix. For example,pod/opensearch-master-0orpod/opensearch-master-2.Example of system response:
{"limits":{"cpu":"900m","memory":"8Gi"},"requests":{"cpu":"500m","memory":"6Gi"}}
The waiting time may take up to 20 minutes depending on the cluster size.
If the issue is fixed, the KubeContainersCPUThrottlingHigh alert stops
firing immediately, while OpenSearchClusterStatusWarning or
OpenSearchClusterStatusCritical can still be firing for some time during
shard relocation.
If the KubeContainersCPUThrottlingHigh alert is still firing, proceed with
another iteration of the CPU limit increase.
Fixed in 17.2.0, 16.2.0, 17.1.6, 16.1.6
While updating rollover_policy for the current system* and audit*
data streams, the update is not applied to indices.
One of indicators that the cluster is most likely affected is the
KubeJobFailed alert firing for the elasticsearch-curator job and one or
both of the following errors being present in elasticsearch-curator pods
that remain in the Error status:
2024-05-31 13:16:04,459 ERROR Failed to complete action: delete_indices. <class 'curator.exceptions.FailedExecution'>: Exception encountered. Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. Exception: RequestError(400, 'illegal_argument_exception', 'index [.ds-audit-000001] is the write index for data stream [audit] and cannot be deleted')
or
2024-05-31 13:16:04,459 ERROR Failed to complete action: delete_indices. <class 'curator.exceptions.FailedExecution'>: Exception encountered. Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. Exception: RequestError(400, 'illegal_argument_exception', 'index [.ds-system-000001] is the write index for data stream [system] and cannot be deleted')
Note
Instead of .ds-audit-000001 or .ds-system-000001 index names,
similar names can be present with the same prefix but different suffix
numbers.
If the above mentioned alert and errors are present, an immediate action is required, because it indicates that the corresponding index size has already exceeded the space allocated for the index.
To verify that the cluster is affected:
Caution
Verify and apply the workaround to both index patterns, system and audit, separately.
If one of indices is affected, the second one is most likely affected as well. Although in rare cases, only one index may be affected.
Log in to the
opensearch-master-0Pod:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
Verify that the rollover policy is present:
system:curl localhost:9200/_plugins/_ism/policies/system_rollover_policyaudit:curl localhost:9200/_plugins/_ism/policies/audit_rollover_policy
The cluster is affected if the rollover policy is missing. Otherwise, proceed to the following step.
Verify the system response from the previous step. For example:
{"_id":"system_rollover_policy","_version":7229,"_seq_no":42362,"_primary_term":28,"policy":{"policy_id":"system_rollover_policy","description":"system index rollover policy.","last_updated_time":1708505222430,"schema_version":19,"error_notification":null,"default_state":"rollover","states":[{"name":"rollover","actions":[{"retry":{"count":3,"backoff":"exponential","delay":"1m"},"rollover":{"min_size":"14746mb","copy_alias":false}}],"transitions":[]}],"ism_template":[{"index_patterns":["system*"],"priority":200,"last_updated_time":1708505222430}]}}
Verify and capture the following items separately for every policy:
The
_seq_noand_primary_termvaluesThe rollover policy threshold, which is defined in
policy.states[0].actions[0].rollover.min_size
List indices:
system:curl localhost:9200/_cat/indices | grep system
Example of system response:
[...] green open .ds-system-000001 FjglnZlcTKKfKNbosaE9Aw 2 1 1998295 0 1gb 507.9mb
audit:curl localhost:9200/_cat/indices | grep audit
Example of system response:
[...] green open .ds-audit-000001 FjglnZlcTKKfKNbosaE9Aw 2 1 1998295 0 1gb 507.9mb
Select the index with the highest number and verify the rollover policy attached to the index:
system:curl localhost:9200/_plugins/_ism/explain/.ds-system-000001audit:curl localhost:9200/_plugins/_ism/explain/.ds-audit-000001If the rollover policy is not attached, the cluster is affected.
If the rollover policy is attached but
_seq_noand_primary_termnumbers do not match the previously captured ones, the cluster is affected.If the index size drastically exceeds the defined threshold of the rollover policy (which is the previously captured
min_size), the cluster is most probably affected.
Workaround:
Log in to the
opensearch-master-0Pod:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
If the policy is attached to the index but has different
_seq_noand_primary_term, remove the policy from the index:Note
Use the index with the highest number in the name, which was captured during verification procedure.
system:curl -XPOST localhost:9200/_plugins/_ism/remove/.ds-system-000001
audit:curl -XPOST localhost:9200/_plugins/_ism/remove/.ds-audit-000001
Re-add the policy:
system:curl -XPOST -H "Content-type: application/json" localhost:9200/_plugins/_ism/add/system* -d'{"policy_id":"system_rollover_policy"}'
audit:curl -XPOST -H "Content-type: application/json" localhost:9200/_plugins/_ism/add/audit* -d'{"policy_id":"audit_rollover_policy"}'
Perform again the last step of the cluster verification procedure provided above and make sure that the policy is attached to the index and has the same
_seq_noand_primary_term.If the index size drastically exceeds the defined threshold of the rollover policy (which is the previously captured
min_size), wait up to 15 minutes and verify that the additional index is created with the consecutive number in the index name. For example:system: if you applied changes to.ds-system-000001, wait until.ds-system-000002is created.audit: if you applied changes to.ds-audit-000001, wait until.ds-audit-000002is created.
If such index is not created, escalate the issue to Mirantis support.
During a cluster update, a Kubernetes helm-controller Deployment may
get stuck in a restarting Pod loop with Terminating and Running states
flapping. Other Deployment types may also be affected.
As a workaround, restart the Deployment that got stuck:
kubectl -n <affectedProjectName> get deploy <affectedDeployName> -o yaml
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas 0
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas <replicasNumber>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name containing the cluster with stuck Pods<affectedDeployName>is theDeploymentname that failed to run Pods in the specified project<replicasNumber>is the original number of replicas for theDeploymentthat you can obtain using the get deploy command
During configuration of a management cluster settings using the Configure cluster web UI menu, updating the Keycloak Truststore settings is mandatory, despite being optional.
As a workaround, update the management cluster using the API or CLI.
This section lists the artifacts of components included in the Container Cloud patch release 2.26.2. For artifacts of the Cluster releases introduced in 2.26.2, see patch Cluster releases 17.1.2 and 16.1.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20240324195604 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20240324195604 |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.39.19.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.39.19.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.39.19.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.39.19.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.39.19.tgz |
|
metallb |
||
Docker images |
ambasador Updated |
mirantis.azurecr.io/core/external/nginx:1.39.19 |
baremetal-dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-2-26-alpine-20240325100252 |
|
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-2-26-alpine-20240325093002 |
|
bm-collective |
mirantis.azurecr.io/bm/bm-collective:base-2-26-alpine-20240129155244 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.39.19 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20240226060024 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20240226060024 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20240117102150 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-2-26-alpine-20240129213142 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20240311120505 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.24.0-47-gf77368e |
|
metallb-controller |
mirantis.azurecr.io/bm/metallb/controller:v0.13.12-31212f9e-amd64 |
|
metallb-speaker |
mirantis.azurecr.io/bm/metallb/speaker:v0.13.12-31212f9e-amd64 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-alpine-20240129163811 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.39.19.tgz |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.39.19.tgz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.39.19.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.39.19.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.39.19.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.39.19.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.39.19.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.39.19.tgz |
|
cinder-csi-plugin |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.39.19.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.39.19.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.39.19.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.39.19.tgz |
|
host-os-modules-controller |
https://binary.mirantis.com/core/helm/host-os-modules-controller-1.39.19.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.39.19.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.39.19.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.39.19.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.39.19.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.39.19.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.39.19.tgz |
|
mcc-cache |
||
mcc-cache-warmup |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.39.19.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.39.19.tgz |
|
openstack-cloud-controller-manager |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.39.19.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.39.19.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.39.19.tgz |
|
policy-controller |
https://binary.mirantis.com/core/helm/policy-controller-1.39.19.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.39.19.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.39.19.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.39.19.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.39.19.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.39.19.tgz |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.39.19.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.39.19.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.39.19.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.39.19.tgz |
|
vsphere-cloud-controller-manager |
https://binary.mirantis.com/core/helm/vsphere-cloud-controller-manager-1.39.19.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.39.19.tgz |
|
vsphere-csi-plugin |
https://binary.mirantis.com/core/helm/vsphere-csi-plugin-1.39.19.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.39.19.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.39.19.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.39.19 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.39.19 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.39.19 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.39.19 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.39.19 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-5 |
|
cinder-csi-plugin |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-13 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.39.19 |
|
configuration-collector Updated |
mirantis.azurecr.io/core/configuration-collector:1.39.19 |
|
csi-attacher |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-4 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-4 |
|
csi-provisioner |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-4 |
|
csi-resizer |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-4 |
|
csi-snapshotter |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-3 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.39.19 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.39.19 |
|
host-os-modules-controller Updated |
mirantis.azurecr.io/core/host-os-modules-controller:1.39.19 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.39.19 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.39.19 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.39.19 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.39.19 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.39.19 |
|
livenessprobe |
mirantis.azurecr.io/lcm/k8scsi/livenessprobe:v2.9.0-4 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.39.19 |
|
mcc-haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.24.0-47-gf77368e |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.24.0-47-gf77368e |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-6 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.39.19 |
|
openstack-cloud-controller-manager Updated |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-13 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.39.19 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.39.19 |
|
policy-controller Updated |
mirantis.azurecr.io/core/policy-controller:1.39.19 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.39.19 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.39.19 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.39.19 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-9 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.39.19 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.39.19 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.39.19 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.39.19 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.39.19 |
|
vsphere-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/vsphere-cloud-controller-manager:v1.27.0-5 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.39.19 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.39.19 |
|
vsphere-csi-driver |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-driver:v3.0.2-1 |
|
vsphere-csi-syncer |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-syncer:v3.0.2-1 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.39.19 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts Updated |
iam |
|
Docker images |
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240221023016 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
|
mcc-keycloak Updated |
mirantis.azurecr.io/iam/mcc-keycloak:23.0.6-20240216125244 |
See also
2.26.1¶
The Container Cloud patch release 2.26.1, which is based on the 2.26.0 major release, provides the following updates:
Support for the patch Cluster releases 16.1.1 and 17.1.1 that represents Mirantis OpenStack for Kubernetes (MOSK) patch release 24.1.1.
Delivery mechanism for CVE fixes on Ubuntu in bare metal clusters that includes update of Ubuntu kernel minor version. For details, see Enhancements.
Security fixes for CVEs in images.
This patch release also supports the latest major Cluster releases 17.1.0 and 16.1.0. And it does not support greenfield deployments based on deprecated Cluster releases. Use the latest available Cluster release instead.
For main deliverables of the parent Container Cloud release of 2.26.1, refer to 2.26.0.
This section outlines new features and enhancements introduced in the Container Cloud patch release 2.26.1 along with Cluster releases 17.1.1 and 16.1.1.
Introduced the ability to update Ubuntu packages including kernel minor version update, when available in a Cluster release, for both management and managed bare metal clusters to address CVE issues on a host operating system.
On management clusters, the update of Ubuntu mirror along with the update of minor kernel version occurs automatically with cordon-drain and reboot of machines.
On managed clusters, the update of Ubuntu mirror along with the update of minor kernel version applies during a manual cluster update without automatic cordon-drain and reboot of machines. After a managed cluster update, all cluster machines have the
reboot is requirednotification. You can manually handle the reboot of machines during a convenient maintenance window using GracefulRebootRequest.
This section lists the artifacts of components included in the Container Cloud patch release 2.26.1. For artifacts of the Cluster releases introduced in 2.26.1, see patch Cluster releases 17.1.1 and 16.1.1.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20240302181430 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20240302181430 |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-155-1882779.tgz |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.39.15.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.39.15.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.39.15.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.39.15.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.39.15.tgz |
|
metallb |
||
Docker images |
ambasador Updated |
mirantis.azurecr.io/core/external/nginx:1.39.15 |
baremetal-dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-2-26-alpine-20240226130438 |
|
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-2-26-alpine-20240226130310 |
|
bm-collective |
mirantis.azurecr.io/bm/bm-collective:base-2-26-alpine-20240129155244 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.39.15 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20240226060024 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20240226060024 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20240117102150 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-2-26-alpine-20240129213142 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.24.0-47-gf77368e |
|
metallb-controller |
mirantis.azurecr.io/bm/metallb/controller:v0.13.12-31212f9e-amd64 |
|
metallb-speaker |
mirantis.azurecr.io/bm/metallb/speaker:v0.13.12-31212f9e-amd64 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-alpine-20240129163811 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.39.15.tgz |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.39.15.tgz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.39.15.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.39.15.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.39.15.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.39.15.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.39.15.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.39.15.tgz |
|
cinder-csi-plugin |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.39.15.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.39.15.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.39.15.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.39.15.tgz |
|
host-os-modules-controller |
https://binary.mirantis.com/core/helm/host-os-modules-controller-1.39.15.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.39.15.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.39.15.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.39.15.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.39.15.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.39.15.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.39.15.tgz |
|
mcc-cache |
||
mcc-cache-warmup |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.39.15.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.39.15.tgz |
|
openstack-cloud-controller-manager |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.39.15.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.39.15.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.39.15.tgz |
|
policy-controller |
https://binary.mirantis.com/core/helm/policy-controller-1.39.15.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.39.15.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.39.15.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.39.15.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.39.15.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.39.15.tgz |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.39.15.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.39.15.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.39.15.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.39.15.tgz |
|
vsphere-cloud-controller-manager |
https://binary.mirantis.com/core/helm/vsphere-cloud-controller-manager-1.39.15.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.39.15.tgz |
|
vsphere-csi-plugin |
https://binary.mirantis.com/core/helm/vsphere-csi-plugin-1.39.15.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.39.15.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.39.15.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.39.15 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.39.15 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.39.15 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.39.15 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.39.15 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-5 |
|
cinder-csi-plugin Updated |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-13 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.39.15 |
|
configuration-collector Updated |
mirantis.azurecr.io/core/configuration-collector:1.39.15 |
|
csi-attacher |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-4 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-4 |
|
csi-provisioner |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-4 |
|
csi-resizer |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-4 |
|
csi-snapshotter |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-3 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.39.15 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.39.15 |
|
host-os-modules-controller Updated |
mirantis.azurecr.io/core/host-os-modules-controller:1.39.15 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.39.15 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.39.15 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.39.15 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.39.15 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.39.15 |
|
livenessprobe |
mirantis.azurecr.io/lcm/k8scsi/livenessprobe:v2.9.0-4 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.39.15 |
|
mcc-haproxy Updated |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.24.0-47-gf77368e |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.24.0-47-gf77368e |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-6 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.39.15 |
|
openstack-cloud-controller-manager Updated |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-13 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.39.15 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.39.15 |
|
policy-controller Updated |
mirantis.azurecr.io/core/policy-controller:1.39.15 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.39.15 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.39.15 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.39.15 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-9 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.39.15 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.39.15 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.39.15 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.39.15 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.39.15 |
|
vsphere-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/vsphere-cloud-controller-manager:v1.27.0-5 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.39.15 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.39.15 |
|
vsphere-csi-driver |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-driver:v3.0.2-1 |
|
vsphere-csi-syncer |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-syncer:v3.0.2-1 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.39.15 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts |
iam |
|
Docker images |
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240105023016 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
|
mcc-keycloak |
mirantis.azurecr.io/iam/mcc-keycloak:23.0.3-1 |
The table below includes the total numbers of addressed unique and common CVEs in images by product component since the Container Cloud 2.26.0 major release. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
Ceph |
Unique |
0 |
1 |
1 |
Common |
0 |
3 |
3 |
|
Kaas core |
Unique |
0 |
6 |
6 |
Common |
0 |
27 |
27 |
|
StackLight |
Unique |
0 |
15 |
15 |
Common |
0 |
51 |
51 |
Mirantis Security Portal
For the detailed list of fixed and existing CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
MOSK CVEs
For the number of fixed CVEs in the MOSK-related components including OpenStack and Tungsten Fabric, refer to MOSK 24.1.1: Security notes.
The following issues have been addressed in the Container Cloud patch release 2.26.1 along with the patch Cluster releases 17.1.1 and 16.1.1.
[39330] [StackLight] Fixed the issue with the OpenSearch cluster being stuck due to initializing replica shards.
[39220] [StackLight] Fixed the issue with Patroni failure due to no limit configuration for the
max_timelines_historyparameter.[39080] [StackLight] Fixed the issue with the
OpenSearchClusterStatusWarningalert firing during cluster upgrade if StackLight is deployed in the HA mode.[38970] [StackLight] Fixed the issue with the Logs dashboard in the OpenSearch Dashboards web UI not working for the
systemindex.[38937] [StackLight] Fixed the issue with the View logs in OpenSearch Dashboards link not working in the Grafana web UI.
[40747] [vSphere] Fixed the issue with the unsupported Cluster release being available for greenfield vSphere-based managed cluster deployments in the drop-down menu of the cluster creation window in the Container Cloud web UI.
[40036] [LCM] Fixed the issue causing nodes to remain in the Kubernetes cluster when the corresponding
Machineobject isdisabledduring cluster update.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.26.1 including the Cluster releases 17.1.1 and 16.1.1.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
After node maintenance of a management cluster, the newly added nodes may fail to undergo provisioning successfully. The issue relates to new nodes that are in the same L2 domain as the management cluster.
The issue was observed on environments having management cluster nodes configured with a single L2 segment used for all network traffic (PXE and LCM/management networks).
To verify whether the cluster is affected:
Verify whether the dnsmasq and dhcp-relay pods run on the same node
in the management cluster:
kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of system response:
dhcp-relay-7d85f75f76-5vdw2 2/2 Running 2 (36h ago) 36h 10.10.0.122 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (36h ago) 36h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
If this is the case, proceed to the workaround below.
Workaround:
Log in to a node that contains
kubeconfigof the affected management cluster.Make sure that at least two management cluster nodes are schedulable:
kubectl get node
Example of a positive system response:
NAME STATUS ROLES AGE VERSION kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 Ready master 37h v1.27.10-mirantis-1 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad Ready master 37h v1.27.10-mirantis-1 kaas-node-ad5a6f51-b98f-43c3-91d5-55fed3d0ff21 Ready master 37h v1.27.10-mirantis-1
Delete the
dhcp-relaypod:kubectl -n kaas delete pod <dhcp-relay-xxxxx>
Verify that the
dnsmasqanddhcp-relaypods are scheduled into different nodes:kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of a positive system response:
dhcp-relay-7d85f75f76-rkv03 2/2 Running 0 49s 10.10.0.121 kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 <none> <none> dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (37h ago) 37h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
Due to issues with managing physical NVME devices, lcm-agent cannot grab
storage information on a host. As a result,
lcmmachine.status.hostinfo.hardware is empty and the following example
error is present in logs:
{"level":"error","ts":"2024-05-02T12:26:10Z","logger":"agent", \
"msg":"get hardware details", \
"host":"kaas-node-548b2861-aed0-41c9-8ff2-10c5476b000b", \
"error":"new storage info: get disk info \"nvme0c0n1\": \
invoke command: exit status 1","errorVerbose":"exit status 1
As a workaround, on the affected node, create a symlink for any device
indicated in lcm-agent logs. For example:
ln -sfn /dev/nvme0n1 /dev/nvme0c0n1
During deletion of a machine, the related DaemonSet Pod can remain on the
deleted node in the Terminating state. As a workaround, manually
delete the Pod:
kubectl delete pod -n <podNamespace> <podName>
During the replacement of a master node on a cluster of any type, the process
may get stuck with Kubelet's NodeReady condition is Unknown in the
machine status on the remaining master nodes.
As a workaround, log in on the affected node and run the following command:
docker restart ucp-kubelet
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
During replacement of a master node on a cluster of any type, the
calico-node Pod fails to start on a new node that has the same IP address
as the node being replaced.
Workaround:
Log in to any
masternode.From a CLI with an MKE client bundle, create a shell alias to start calicoctl using the
mirantis/ucp-dsinfoimage:alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/key.pem \ -e ETCD_CA_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/ca.pem \ -e ETCD_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/cert.pem \ -v /var/run/calico:/var/run/calico \ -v /var/lib/docker/volumes/ucp-kv-certs/_data:/var/lib/docker/volumes/ucp-kv-certs/_data:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl \ "
alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/ucp-node-certs/key.pem \ -e ETCD_CA_CERT_FILE=/ucp-node-certs/ca.pem \ -e ETCD_CERT_FILE=/ucp-node-certs/cert.pem \ -v /var/run/calico:/var/run/calico \ -v ucp-node-certs:/ucp-node-certs:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl --allow-version-mismatch \ "
In the above command, replace the following values with the corresponding settings of the affected cluster:
<etcdEndpoint>is the etcd endpoint defined in the Calico configuration file. For example,ETCD_ENDPOINTS=127.0.0.1:12378<mkeVersion>is the MKE version installed on your cluster. For example,mirantis/ucp-dsinfo:3.5.7.
Verify the node list on the cluster:
kubectl get node
Compare this list with the node list in Calico to identify the old node:
calicoctl get node -o wide
Remove the old node from Calico:
calicoctl delete node kaas-node-<nodeID>
During replacement of a manager machine, the following problems may occur:
The system adds the node to Docker swarm but not to Kubernetes
The node
Deploymentgets stuck with failed RethinkDB health checks
Workaround:
Delete the failed node.
Wait for the MKE cluster to become healthy. To monitor the cluster status:
Log in to the MKE web UI as described in Connect to the Mirantis Kubernetes Engine web UI.
Monitor the cluster status as described in MKE Operations Guide: Monitor an MKE cluster with the MKE web UI.
Deploy a new node.
During the unsafe or forced deletion of a manager machine running the
calico-kube-controllers Pod in the kube-system namespace,
the following issues occur:
The
calico-kube-controllersPod fails to clean up resources associated with the deleted nodeThe
calico-nodePod may fail to start up on a newly created node if the machine is provisioned with the same IP address as the deleted machine had
As a workaround, before deletion of the node running the
calico-kube-controllers Pod, cordon and drain the node:
kubectl cordon <nodeName>
kubectl drain <nodeName>
Fixed in 2.27.0 (17.2.0 and 16.2.0)
During graceful reboot of a cluster with Ceph enabled, the reboot is blocked
with the following message in the MiraCephMaintenance object status:
message: ClusterMaintenanceRequest found, Ceph Cluster is not ready to upgrade,
delaying cluster maintenance
As a workaround, add the following snippet to the cephFS section under
metadataServer in the spec section of <kcc-name>.yaml in the Ceph
cluster:
cephClusterSpec:
sharedFilesystem:
cephFS:
- name: cephfs-store
metadataServer:
activeCount: 1
healthCheck:
livenessProbe:
probe:
failureThreshold: 5
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 5
Update of a managed cluster based on bare metal and Ceph enabled fails with
PersistentVolumeClaim getting stuck in the Pending state for the
prometheus-server StatefulSet and the
MountVolume.MountDevice failed for volume warning in the StackLight event
logs.
Workaround:
Verify that the description of the Pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name where the Pods failed to run<affectedPodName>is a Pod name that failed to run in the specified project
In the Pod description, identify the node name where the Pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain therbd volume mount failed: <csi-vol-uuid> is being usederror. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the Pod that fails to0replicas.On every
csi-rbdpluginPod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected Pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state becomesRunning.
Fixed in 17.2.0, 16.2.0, 17.1.6, 16.1.6
On large managed clusters, shard relocation may fail in the OpenSearch cluster
with the yellow or red status of the OpenSearch cluster.
The characteristic symptom of the issue is that in the stacklight
namespace, the statefulset.apps/opensearch-master containers are
experiencing throttling with the KubeContainersCPUThrottlingHigh alert
firing for the following set of labels:
{created_by_kind="StatefulSet",created_by_name="opensearch-master",namespace="stacklight"}
Caution
The throttling that OpenSearch is experiencing may be a temporary situation, which may be related, for example, to a peaky load and the ongoing shards initialization as part of disaster recovery or after node restart. In this case, Mirantis recommends waiting until initialization of all shards is finished. After that, verify the cluster state and whether throttling still exists. And only if throttling does not disappear, apply the workaround below.
To verify that the initialization of shards is ongoing:
kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
curl "http://localhost:9200/_cat/shards" | grep INITIALIZING
Example of system response:
.ds-system-000072 2 r INITIALIZING 10.232.182.135 opensearch-master-1
.ds-system-000073 1 r INITIALIZING 10.232.7.145 opensearch-master-2
.ds-system-000073 2 r INITIALIZING 10.232.182.135 opensearch-master-1
.ds-audit-000001 2 r INITIALIZING 10.232.7.145 opensearch-master-2
The system response above indicates that shards from the
.ds-system-000072, .ds-system-000073, and .ds-audit-000001
indicies are in the INITIALIZING state. In this case, Mirantis
recommends waiting until this process is finished, and only then consider
changing the limit.
You can additionally analyze the exact level of throttling and the current CPU usage on the Kubernetes Containers dashboard in Grafana.
Workaround:
Verify the currently configured CPU requests and limits for the
opensearchcontainers:kubectl -n stacklight get statefulset.apps/opensearch-master -o jsonpath="{.spec.template.spec.containers[?(@.name=='opensearch')].resources}"
Example of system response:
{"limits":{"cpu":"600m","memory":"8Gi"},"requests":{"cpu":"500m","memory":"6Gi"}}
In the example above, the CPU request is
500mand the CPU limit is600m.Increase the CPU limit to a reasonably high number.
For example, the default CPU limit for the clusters with the
clusterSize:largeparameter set was increased from8000mto12000mfor StackLight in Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0).Note
For details, on the
clusterSizeparameter, see Operations Guide: StackLight configuration parameters - Cluster size.If the defaults are already overridden on the affected cluster using the
resourcesPerClusterSizeorresourcesparameters as described in Operations Guide: StackLight configuration parameters - Resource limits, then the exact recommended number depends on the currently set limit.Mirantis recommends increasing the limit by 50%. If it does not resolve the issue, another increase iteration will be required.
When you select the required CPU limit, increase it as described in Operations Guide: StackLight configuration parameters - Resource limits.
If the CPU limit for the
opensearchcomponent is already set, increase it in theClusterobject for theopensearchparameter. Otherwise, the default StackLight limit is used. In this case, increase the CPU limit for theopensearchcomponent using theresourcesparameter.Wait until all
opensearch-masterpods are recreated with the new CPU limits and becomerunningandready.To verify the current CPU limit for every
opensearchcontainer in everyopensearch-masterpod separately:kubectl -n stacklight get pod/opensearch-master-<podSuffixNumber> -o jsonpath="{.spec.containers[?(@.name=='opensearch')].resources}"
In the command above, replace
<podSuffixNumber>with the name of the pod suffix. For example,pod/opensearch-master-0orpod/opensearch-master-2.Example of system response:
{"limits":{"cpu":"900m","memory":"8Gi"},"requests":{"cpu":"500m","memory":"6Gi"}}
The waiting time may take up to 20 minutes depending on the cluster size.
If the issue is fixed, the KubeContainersCPUThrottlingHigh alert stops
firing immediately, while OpenSearchClusterStatusWarning or
OpenSearchClusterStatusCritical can still be firing for some time during
shard relocation.
If the KubeContainersCPUThrottlingHigh alert is still firing, proceed with
another iteration of the CPU limit increase.
Fixed in 17.2.0, 16.2.0, 17.1.6, 16.1.6
While updating rollover_policy for the current system* and audit*
data streams, the update is not applied to indices.
One of indicators that the cluster is most likely affected is the
KubeJobFailed alert firing for the elasticsearch-curator job and one or
both of the following errors being present in elasticsearch-curator pods
that remain in the Error status:
2024-05-31 13:16:04,459 ERROR Failed to complete action: delete_indices. <class 'curator.exceptions.FailedExecution'>: Exception encountered. Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. Exception: RequestError(400, 'illegal_argument_exception', 'index [.ds-audit-000001] is the write index for data stream [audit] and cannot be deleted')
or
2024-05-31 13:16:04,459 ERROR Failed to complete action: delete_indices. <class 'curator.exceptions.FailedExecution'>: Exception encountered. Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. Exception: RequestError(400, 'illegal_argument_exception', 'index [.ds-system-000001] is the write index for data stream [system] and cannot be deleted')
Note
Instead of .ds-audit-000001 or .ds-system-000001 index names,
similar names can be present with the same prefix but different suffix
numbers.
If the above mentioned alert and errors are present, an immediate action is required, because it indicates that the corresponding index size has already exceeded the space allocated for the index.
To verify that the cluster is affected:
Caution
Verify and apply the workaround to both index patterns, system and audit, separately.
If one of indices is affected, the second one is most likely affected as well. Although in rare cases, only one index may be affected.
Log in to the
opensearch-master-0Pod:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
Verify that the rollover policy is present:
system:curl localhost:9200/_plugins/_ism/policies/system_rollover_policyaudit:curl localhost:9200/_plugins/_ism/policies/audit_rollover_policy
The cluster is affected if the rollover policy is missing. Otherwise, proceed to the following step.
Verify the system response from the previous step. For example:
{"_id":"system_rollover_policy","_version":7229,"_seq_no":42362,"_primary_term":28,"policy":{"policy_id":"system_rollover_policy","description":"system index rollover policy.","last_updated_time":1708505222430,"schema_version":19,"error_notification":null,"default_state":"rollover","states":[{"name":"rollover","actions":[{"retry":{"count":3,"backoff":"exponential","delay":"1m"},"rollover":{"min_size":"14746mb","copy_alias":false}}],"transitions":[]}],"ism_template":[{"index_patterns":["system*"],"priority":200,"last_updated_time":1708505222430}]}}
Verify and capture the following items separately for every policy:
The
_seq_noand_primary_termvaluesThe rollover policy threshold, which is defined in
policy.states[0].actions[0].rollover.min_size
List indices:
system:curl localhost:9200/_cat/indices | grep system
Example of system response:
[...] green open .ds-system-000001 FjglnZlcTKKfKNbosaE9Aw 2 1 1998295 0 1gb 507.9mb
audit:curl localhost:9200/_cat/indices | grep audit
Example of system response:
[...] green open .ds-audit-000001 FjglnZlcTKKfKNbosaE9Aw 2 1 1998295 0 1gb 507.9mb
Select the index with the highest number and verify the rollover policy attached to the index:
system:curl localhost:9200/_plugins/_ism/explain/.ds-system-000001audit:curl localhost:9200/_plugins/_ism/explain/.ds-audit-000001If the rollover policy is not attached, the cluster is affected.
If the rollover policy is attached but
_seq_noand_primary_termnumbers do not match the previously captured ones, the cluster is affected.If the index size drastically exceeds the defined threshold of the rollover policy (which is the previously captured
min_size), the cluster is most probably affected.
Workaround:
Log in to the
opensearch-master-0Pod:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
If the policy is attached to the index but has different
_seq_noand_primary_term, remove the policy from the index:Note
Use the index with the highest number in the name, which was captured during verification procedure.
system:curl -XPOST localhost:9200/_plugins/_ism/remove/.ds-system-000001
audit:curl -XPOST localhost:9200/_plugins/_ism/remove/.ds-audit-000001
Re-add the policy:
system:curl -XPOST -H "Content-type: application/json" localhost:9200/_plugins/_ism/add/system* -d'{"policy_id":"system_rollover_policy"}'
audit:curl -XPOST -H "Content-type: application/json" localhost:9200/_plugins/_ism/add/audit* -d'{"policy_id":"audit_rollover_policy"}'
Perform again the last step of the cluster verification procedure provided above and make sure that the policy is attached to the index and has the same
_seq_noand_primary_term.If the index size drastically exceeds the defined threshold of the rollover policy (which is the previously captured
min_size), wait up to 15 minutes and verify that the additional index is created with the consecutive number in the index name. For example:system: if you applied changes to.ds-system-000001, wait until.ds-system-000002is created.audit: if you applied changes to.ds-audit-000001, wait until.ds-audit-000002is created.
If such index is not created, escalate the issue to Mirantis support.
During a cluster update, a Kubernetes helm-controller Deployment may
get stuck in a restarting Pod loop with Terminating and Running states
flapping. Other Deployment types may also be affected.
As a workaround, restart the Deployment that got stuck:
kubectl -n <affectedProjectName> get deploy <affectedDeployName> -o yaml
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas 0
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas <replicasNumber>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name containing the cluster with stuck Pods<affectedDeployName>is theDeploymentname that failed to run Pods in the specified project<replicasNumber>is the original number of replicas for theDeploymentthat you can obtain using the get deploy command
During configuration of a management cluster settings using the Configure cluster web UI menu, updating the Keycloak Truststore settings is mandatory, despite being optional.
As a workaround, update the management cluster using the API or CLI.
See also
2.26.0¶
The Mirantis Container Cloud major release 2.26.0:
Introduces support for the Cluster release 17.1.0 that is based on the Cluster release 16.1.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 24.1.
Introduces support for the Cluster release 16.1.0 that is based on Mirantis Container Runtime (MCR) 23.0.9 and Mirantis Kubernetes Engine (MKE) 3.7.5 with Kubernetes 1.27.
Does not support greenfield deployments on deprecated Cluster releases of the 17.0.x and 16.0.x series. Use the latest available Cluster releases of the series instead.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.26.0.
This section outlines new features and enhancements introduced in the Container Cloud release 2.26.0. For the list of enhancements delivered with the Cluster releases introduced by Container Cloud 2.26.0, see 17.1.0 and 16.1.0.
To ensure that Container Cloud clusters remain consistently updated with the
latest security fixes and product improvements, the Admission Controller
has been enhanced. Now, it actively prevents the utilization of pinned
custom artifacts for Container Cloud components. Specifically, it blocks
a management or managed cluster release update, or any cluster configuration
update, for example, adding public keys or proxy, if a Cluster object
contains any custom Container Cloud artifacts with global or image-related
values overwritten in the helm-releases section, until these values are
removed.
Normally, the Container Cloud clusters do not contain pinned artifacts,
which eliminates the need for any pre-update actions in most deployments.
However, if the update of your cluster is blocked with the
invalid HelmReleases configuration error, refer to
Update notes: Pre-update actions for details.
Note
In rare cases, if the image-related or global values should be
changed, you can use the ClusterRelease or KaaSRelease objects
instead. But make sure to update these values manually after every major
and patch update.
Note
The pre-update inspection applies only to images delivered by Container Cloud that are overwritten. Any custom images unrelated to the product components are not verified and do not block cluster update.
Learn more
TechPreview
Implemented the machine disabling API that allows you to seamlessly remove a worker machine from the LCM control of a managed cluster. This action isolates the affected node without impacting other machines in the cluster, effectively eliminating it from the Kubernetes cluster. This functionality proves invaluable in scenarios where a malfunctioning machine impedes cluster updates.
Learn more
TechPreview
Added initial Technology Preview support for the HostOSConfiguration and
HostOSConfigurationModules custom resources in the bare metal provider.
These resources introduce configuration modules that allow managing the
operating system of a bare metal host granularly without rebuilding the node
from scratch. Such approach prevents workload evacuation and significantly
reduces configuration time.
Configuration modules manage various settings of the operating system using Ansible playbooks, adhering to specific schemas and metadata requirements. For description of module format, schemas, and rules, contact Mirantis support.
Warning
For security reasons and to ensure safe and reliable cluster operability, contact Mirantis support to start using these custom resources.
Caution
As long as the feature is still on the development stage,
Mirantis highly recommends deleting all HostOSConfiguration objects,
if any, before automatic upgrade of the management cluster to Container Cloud
2.27.0 (Cluster release 16.2.0). After the upgrade, you can recreate the
required objects using the updated parameters.
This precautionary step prevents re-processing and re-applying of existing
configuration, which is defined in HostOSConfiguration objects, during
management cluster upgrade to 2.27.0. Such behavior is caused by changes in
the HostOSConfiguration API introduced in 2.27.0.
Implemented the strict byID filtering for targeting system disks using
specific device options: byPath, serialNumber, and wwn.
These options offer a more reliable alternative to the unpredictable
byName naming format.
Mirantis recommends adopting these new device naming options when adding new nodes and redeploying existing ones to ensure a predictable and stable device naming schema.
Learn more
Introduced a mechanism in the Container Cloud dnsmasq server to dynamically allocate IP addresses for baremetal hosts during provisioning. This new mechanism replaces sequential IP allocation that includes the ping check with dynamic IP allocation without the ping check. Such behavior significantly increases the amount of baremetal servers that you can provision in parallel, which allows you to streamline the process of setting up a large managed cluster.
Added support for the Kubernetes auditing and profiling enablement and
configuration on management clusters. The auditing option is enabled by
default. You can configure both options using Cluster object of the
management cluster.
Note
For managed clusters, you can also configure Kubernetes auditing
along with profiling using the Cluster object of a managed cluster.
Implemented automatic cleanup of LVM thin pool volumes during the provisioning stage to prevent issues with logical volume detection before removal, which could cause node cleanup failure during cluster redeployment.
Implemented the capability to erase existing data from hardware devices to be
used for a bare metal management or managed cluster deployment. Using the
new wipeDevice structure, you can either erase an existing partition or
remove all existing partitions from a physical device. For these purposes,
use the eraseMetadata or eraseDevice option that configures cleanup
behavior during configuration of a custom bare metal host profile.
Note
The wipeDevice option replaces the deprecated wipe option
that will be removed in one of the following releases. For backward
compatibility, any existing wipe: true option is automatically converted
to the following structure:
wipeDevice:
eraseMetadata:
enabled: True
Technology Preview
Introduced initial Technology Preview support for the Policy Controller that validates signatures of pod images. The Policy Controller verifies that images used by the Container Cloud and Mirantis OpenStack for Kubernetes controllers are signed by a trusted authority. The Policy Controller inspects defined image policies that list Docker registries and authorities for signature validation.
Added support for configuring Keycloak truststore using the Container Cloud web UI to allow for a proper validation of client self-signed certificates. The truststore is used to ensure secured connection to identity brokers, LDAP identity providers, and others.
Added the LCM Operation condition to monitor health of all LCM operations on a cluster and its machines that is useful during cluster update. You can monitor the status of LCM operations using the the Container Cloud web UI in the status hover menus of a cluster and machine.
Learn more
Reorganized the Container Cloud web UI to optimize the baremetal-based managed cluster deployment and management:
Moved the L2 Templates and Subnets tabs from the Clusters menu to the separate Networks tab on the left sidebar.
Improved the Create Subnet menu by adding configuration for different subnet types.
Reorganized the Baremetal tab in the left sidebar that now contains Hosts, Hosts Profiles, and Credentials tabs.
Implemented the ability to add bare metal host profiles using the web UI.
Moved description of a baremetal host to Host info located in a baremetal host kebab menu on the Hosts page of the Baremetal tab.
Moved description of baremetal host credentials to Credential info located in a credential kebab menu on the Credentials page of the Baremetal tab.
On top of continuous improvements delivered to the existing Container Cloud guides, added the documentation on how to export logs from OpenSearch dashboards to CSV.
The following issues have been addressed in the Mirantis Container Cloud release 2.26.0 along with the Cluster releases 17.1.0 and 16.1.0.
Note
This section provides descriptions of issues addressed since the last Container Cloud patch release 2.25.4.
For details on addressed issues in earlier patch releases since 2.25.0, which are also included into the major release 2.26.0, refer to 2.25.x patch releases.
[32761] [LCM] Fixed the issue with node cleanup failing on MOSK clusters due to the Ansible provisioner hanging in a loop while trying to remove LVM thin pool logical volumes, which occurred due to issues with volume detection before removal during cluster redeployment. The issue resolution comprises implementation of automatic cleanup of LVM thin pool volumes during the provisioning stage.
[36924] [LCM] Fixed the issue with Ansible starting to run on nodes of a managed cluster after the
mcc-cachecertificate is applied on a management cluster.[37268] [LCM] Fixed the issue with Container Cloud cluster being blocked by a node stuck in the
PrepareorDeploystate witherror processing package openssh-server. The issue was caused by customizations in/etc/ssh/sshd_config, such as additionalMatchstatements.[34820] [Ceph] Fixed the issue with the Ceph
rook-operatorfailing to connect to Ceph RADOS Gateway pods on clusters with the Federal Information Processing Standard mode enabled.[38340] [StackLight] Fixed the issue with Telegraf Docker Swarm timing out while collecting data by increasing its timeout from 10 to 25 seconds.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.26.0 including the Cluster releases 17.1.0 and 16.1.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
After node maintenance of a management cluster, the newly added nodes may fail to undergo provisioning successfully. The issue relates to new nodes that are in the same L2 domain as the management cluster.
The issue was observed on environments having management cluster nodes configured with a single L2 segment used for all network traffic (PXE and LCM/management networks).
To verify whether the cluster is affected:
Verify whether the dnsmasq and dhcp-relay pods run on the same node
in the management cluster:
kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of system response:
dhcp-relay-7d85f75f76-5vdw2 2/2 Running 2 (36h ago) 36h 10.10.0.122 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (36h ago) 36h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
If this is the case, proceed to the workaround below.
Workaround:
Log in to a node that contains
kubeconfigof the affected management cluster.Make sure that at least two management cluster nodes are schedulable:
kubectl get node
Example of a positive system response:
NAME STATUS ROLES AGE VERSION kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 Ready master 37h v1.27.10-mirantis-1 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad Ready master 37h v1.27.10-mirantis-1 kaas-node-ad5a6f51-b98f-43c3-91d5-55fed3d0ff21 Ready master 37h v1.27.10-mirantis-1
Delete the
dhcp-relaypod:kubectl -n kaas delete pod <dhcp-relay-xxxxx>
Verify that the
dnsmasqanddhcp-relaypods are scheduled into different nodes:kubectl -n kaas get pods -o wide| grep -e "dhcp\|dnsmasq"
Example of a positive system response:
dhcp-relay-7d85f75f76-rkv03 2/2 Running 0 49s 10.10.0.121 kaas-node-bcedb87b-b3ce-46a4-a4ca-ea3068689e40 <none> <none> dnsmasq-8f4b484b4-slhbd 5/5 Running 1 (37h ago) 37h 10.233.123.75 kaas-node-8a24b81c-76d0-4d4c-8421-962bd39df5ad <none> <none>
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
The Cluster release 16.0.0, which is not supported for greenfield vSphere-based deployments, is still available in the drop-down menu of the cluster creation window in the Container Cloud web UI.
Do not select this Cluster release to prevent deployment failures. Use the latest supported version instead.
Due to issues with managing physical NVME devices, lcm-agent cannot grab
storage information on a host. As a result,
lcmmachine.status.hostinfo.hardware is empty and the following example
error is present in logs:
{"level":"error","ts":"2024-05-02T12:26:10Z","logger":"agent", \
"msg":"get hardware details", \
"host":"kaas-node-548b2861-aed0-41c9-8ff2-10c5476b000b", \
"error":"new storage info: get disk info \"nvme0c0n1\": \
invoke command: exit status 1","errorVerbose":"exit status 1
As a workaround, on the affected node, create a symlink for any device
indicated in lcm-agent logs. For example:
ln -sfn /dev/nvme0n1 /dev/nvme0c0n1
Fixed in 2.26.1 (17.1.1 and 16.1.1)
During the ClusterRelease update of a MOSK cluster, a
node cannot be removed from the Kubernetes cluster if the related
Machine object is disabled.
As a workaround, remove the finalizer from the affected Node
object.
During the replacement of a master node on a cluster of any type, the process
may get stuck with Kubelet's NodeReady condition is Unknown in the
machine status on the remaining master nodes.
As a workaround, log in on the affected node and run the following command:
docker restart ucp-kubelet
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
During replacement of a master node on a cluster of any type, the
calico-node Pod fails to start on a new node that has the same IP address
as the node being replaced.
Workaround:
Log in to any
masternode.From a CLI with an MKE client bundle, create a shell alias to start calicoctl using the
mirantis/ucp-dsinfoimage:alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/key.pem \ -e ETCD_CA_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/ca.pem \ -e ETCD_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/cert.pem \ -v /var/run/calico:/var/run/calico \ -v /var/lib/docker/volumes/ucp-kv-certs/_data:/var/lib/docker/volumes/ucp-kv-certs/_data:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl \ "
alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/ucp-node-certs/key.pem \ -e ETCD_CA_CERT_FILE=/ucp-node-certs/ca.pem \ -e ETCD_CERT_FILE=/ucp-node-certs/cert.pem \ -v /var/run/calico:/var/run/calico \ -v ucp-node-certs:/ucp-node-certs:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl --allow-version-mismatch \ "
In the above command, replace the following values with the corresponding settings of the affected cluster:
<etcdEndpoint>is the etcd endpoint defined in the Calico configuration file. For example,ETCD_ENDPOINTS=127.0.0.1:12378<mkeVersion>is the MKE version installed on your cluster. For example,mirantis/ucp-dsinfo:3.5.7.
Verify the node list on the cluster:
kubectl get node
Compare this list with the node list in Calico to identify the old node:
calicoctl get node -o wide
Remove the old node from Calico:
calicoctl delete node kaas-node-<nodeID>
During replacement of a manager machine, the following problems may occur:
The system adds the node to Docker swarm but not to Kubernetes
The node
Deploymentgets stuck with failed RethinkDB health checks
Workaround:
Delete the failed node.
Wait for the MKE cluster to become healthy. To monitor the cluster status:
Log in to the MKE web UI as described in Connect to the Mirantis Kubernetes Engine web UI.
Monitor the cluster status as described in MKE Operations Guide: Monitor an MKE cluster with the MKE web UI.
Deploy a new node.
During the unsafe or forced deletion of a manager machine running the
calico-kube-controllers Pod in the kube-system namespace,
the following issues occur:
The
calico-kube-controllersPod fails to clean up resources associated with the deleted nodeThe
calico-nodePod may fail to start up on a newly created node if the machine is provisioned with the same IP address as the deleted machine had
As a workaround, before deletion of the node running the
calico-kube-controllers Pod, cordon and drain the node:
kubectl cordon <nodeName>
kubectl drain <nodeName>
Fixed in 2.27.0 (17.2.0 and 16.2.0)
During graceful reboot of a cluster with Ceph enabled, the reboot is blocked
with the following message in the MiraCephMaintenance object status:
message: ClusterMaintenanceRequest found, Ceph Cluster is not ready to upgrade,
delaying cluster maintenance
As a workaround, add the following snippet to the cephFS section under
metadataServer in the spec section of <kcc-name>.yaml in the Ceph
cluster:
cephClusterSpec:
sharedFilesystem:
cephFS:
- name: cephfs-store
metadataServer:
activeCount: 1
healthCheck:
livenessProbe:
probe:
failureThreshold: 5
initialDelaySeconds: 30
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 5
Update of a managed cluster based on bare metal and Ceph enabled fails with
PersistentVolumeClaim getting stuck in the Pending state for the
prometheus-server StatefulSet and the
MountVolume.MountDevice failed for volume warning in the StackLight event
logs.
Workaround:
Verify that the description of the Pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name where the Pods failed to run<affectedPodName>is a Pod name that failed to run in the specified project
In the Pod description, identify the node name where the Pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain therbd volume mount failed: <csi-vol-uuid> is being usederror. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the Pod that fails to0replicas.On every
csi-rbdpluginPod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected Pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state becomesRunning.
Fixed in 17.2.0, 16.2.0, 17.1.6, 16.1.6
On large managed clusters, shard relocation may fail in the OpenSearch cluster
with the yellow or red status of the OpenSearch cluster.
The characteristic symptom of the issue is that in the stacklight
namespace, the statefulset.apps/opensearch-master containers are
experiencing throttling with the KubeContainersCPUThrottlingHigh alert
firing for the following set of labels:
{created_by_kind="StatefulSet",created_by_name="opensearch-master",namespace="stacklight"}
Caution
The throttling that OpenSearch is experiencing may be a temporary situation, which may be related, for example, to a peaky load and the ongoing shards initialization as part of disaster recovery or after node restart. In this case, Mirantis recommends waiting until initialization of all shards is finished. After that, verify the cluster state and whether throttling still exists. And only if throttling does not disappear, apply the workaround below.
To verify that the initialization of shards is ongoing:
kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
curl "http://localhost:9200/_cat/shards" | grep INITIALIZING
Example of system response:
.ds-system-000072 2 r INITIALIZING 10.232.182.135 opensearch-master-1
.ds-system-000073 1 r INITIALIZING 10.232.7.145 opensearch-master-2
.ds-system-000073 2 r INITIALIZING 10.232.182.135 opensearch-master-1
.ds-audit-000001 2 r INITIALIZING 10.232.7.145 opensearch-master-2
The system response above indicates that shards from the
.ds-system-000072, .ds-system-000073, and .ds-audit-000001
indicies are in the INITIALIZING state. In this case, Mirantis
recommends waiting until this process is finished, and only then consider
changing the limit.
You can additionally analyze the exact level of throttling and the current CPU usage on the Kubernetes Containers dashboard in Grafana.
Workaround:
Verify the currently configured CPU requests and limits for the
opensearchcontainers:kubectl -n stacklight get statefulset.apps/opensearch-master -o jsonpath="{.spec.template.spec.containers[?(@.name=='opensearch')].resources}"
Example of system response:
{"limits":{"cpu":"600m","memory":"8Gi"},"requests":{"cpu":"500m","memory":"6Gi"}}
In the example above, the CPU request is
500mand the CPU limit is600m.Increase the CPU limit to a reasonably high number.
For example, the default CPU limit for the clusters with the
clusterSize:largeparameter set was increased from8000mto12000mfor StackLight in Container Cloud 2.27.0 (Cluster releases 17.2.0 and 16.2.0).Note
For details, on the
clusterSizeparameter, see Operations Guide: StackLight configuration parameters - Cluster size.If the defaults are already overridden on the affected cluster using the
resourcesPerClusterSizeorresourcesparameters as described in Operations Guide: StackLight configuration parameters - Resource limits, then the exact recommended number depends on the currently set limit.Mirantis recommends increasing the limit by 50%. If it does not resolve the issue, another increase iteration will be required.
When you select the required CPU limit, increase it as described in Operations Guide: StackLight configuration parameters - Resource limits.
If the CPU limit for the
opensearchcomponent is already set, increase it in theClusterobject for theopensearchparameter. Otherwise, the default StackLight limit is used. In this case, increase the CPU limit for theopensearchcomponent using theresourcesparameter.Wait until all
opensearch-masterpods are recreated with the new CPU limits and becomerunningandready.To verify the current CPU limit for every
opensearchcontainer in everyopensearch-masterpod separately:kubectl -n stacklight get pod/opensearch-master-<podSuffixNumber> -o jsonpath="{.spec.containers[?(@.name=='opensearch')].resources}"
In the command above, replace
<podSuffixNumber>with the name of the pod suffix. For example,pod/opensearch-master-0orpod/opensearch-master-2.Example of system response:
{"limits":{"cpu":"900m","memory":"8Gi"},"requests":{"cpu":"500m","memory":"6Gi"}}
The waiting time may take up to 20 minutes depending on the cluster size.
If the issue is fixed, the KubeContainersCPUThrottlingHigh alert stops
firing immediately, while OpenSearchClusterStatusWarning or
OpenSearchClusterStatusCritical can still be firing for some time during
shard relocation.
If the KubeContainersCPUThrottlingHigh alert is still firing, proceed with
another iteration of the CPU limit increase.
Fixed in 17.2.0, 16.2.0, 17.1.6, 16.1.6
While updating rollover_policy for the current system* and audit*
data streams, the update is not applied to indices.
One of indicators that the cluster is most likely affected is the
KubeJobFailed alert firing for the elasticsearch-curator job and one or
both of the following errors being present in elasticsearch-curator pods
that remain in the Error status:
2024-05-31 13:16:04,459 ERROR Failed to complete action: delete_indices. <class 'curator.exceptions.FailedExecution'>: Exception encountered. Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. Exception: RequestError(400, 'illegal_argument_exception', 'index [.ds-audit-000001] is the write index for data stream [audit] and cannot be deleted')
or
2024-05-31 13:16:04,459 ERROR Failed to complete action: delete_indices. <class 'curator.exceptions.FailedExecution'>: Exception encountered. Rerun with loglevel DEBUG and/or check Elasticsearch logs for more information. Exception: RequestError(400, 'illegal_argument_exception', 'index [.ds-system-000001] is the write index for data stream [system] and cannot be deleted')
Note
Instead of .ds-audit-000001 or .ds-system-000001 index names,
similar names can be present with the same prefix but different suffix
numbers.
If the above mentioned alert and errors are present, an immediate action is required, because it indicates that the corresponding index size has already exceeded the space allocated for the index.
To verify that the cluster is affected:
Caution
Verify and apply the workaround to both index patterns, system and audit, separately.
If one of indices is affected, the second one is most likely affected as well. Although in rare cases, only one index may be affected.
Log in to the
opensearch-master-0Pod:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
Verify that the rollover policy is present:
system:curl localhost:9200/_plugins/_ism/policies/system_rollover_policyaudit:curl localhost:9200/_plugins/_ism/policies/audit_rollover_policy
The cluster is affected if the rollover policy is missing. Otherwise, proceed to the following step.
Verify the system response from the previous step. For example:
{"_id":"system_rollover_policy","_version":7229,"_seq_no":42362,"_primary_term":28,"policy":{"policy_id":"system_rollover_policy","description":"system index rollover policy.","last_updated_time":1708505222430,"schema_version":19,"error_notification":null,"default_state":"rollover","states":[{"name":"rollover","actions":[{"retry":{"count":3,"backoff":"exponential","delay":"1m"},"rollover":{"min_size":"14746mb","copy_alias":false}}],"transitions":[]}],"ism_template":[{"index_patterns":["system*"],"priority":200,"last_updated_time":1708505222430}]}}
Verify and capture the following items separately for every policy:
The
_seq_noand_primary_termvaluesThe rollover policy threshold, which is defined in
policy.states[0].actions[0].rollover.min_size
List indices:
system:curl localhost:9200/_cat/indices | grep system
Example of system response:
[...] green open .ds-system-000001 FjglnZlcTKKfKNbosaE9Aw 2 1 1998295 0 1gb 507.9mb
audit:curl localhost:9200/_cat/indices | grep audit
Example of system response:
[...] green open .ds-audit-000001 FjglnZlcTKKfKNbosaE9Aw 2 1 1998295 0 1gb 507.9mb
Select the index with the highest number and verify the rollover policy attached to the index:
system:curl localhost:9200/_plugins/_ism/explain/.ds-system-000001audit:curl localhost:9200/_plugins/_ism/explain/.ds-audit-000001If the rollover policy is not attached, the cluster is affected.
If the rollover policy is attached but
_seq_noand_primary_termnumbers do not match the previously captured ones, the cluster is affected.If the index size drastically exceeds the defined threshold of the rollover policy (which is the previously captured
min_size), the cluster is most probably affected.
Workaround:
Log in to the
opensearch-master-0Pod:kubectl exec -it pod/opensearch-master-0 -n stacklight -c opensearch -- bash
If the policy is attached to the index but has different
_seq_noand_primary_term, remove the policy from the index:Note
Use the index with the highest number in the name, which was captured during verification procedure.
system:curl -XPOST localhost:9200/_plugins/_ism/remove/.ds-system-000001
audit:curl -XPOST localhost:9200/_plugins/_ism/remove/.ds-audit-000001
Re-add the policy:
system:curl -XPOST -H "Content-type: application/json" localhost:9200/_plugins/_ism/add/system* -d'{"policy_id":"system_rollover_policy"}'
audit:curl -XPOST -H "Content-type: application/json" localhost:9200/_plugins/_ism/add/audit* -d'{"policy_id":"audit_rollover_policy"}'
Perform again the last step of the cluster verification procedure provided above and make sure that the policy is attached to the index and has the same
_seq_noand_primary_term.If the index size drastically exceeds the defined threshold of the rollover policy (which is the previously captured
min_size), wait up to 15 minutes and verify that the additional index is created with the consecutive number in the index name. For example:system: if you applied changes to.ds-system-000001, wait until.ds-system-000002is created.audit: if you applied changes to.ds-audit-000001, wait until.ds-audit-000002is created.
If such index is not created, escalate the issue to Mirantis support.
During a cluster update, a Kubernetes helm-controller Deployment may
get stuck in a restarting Pod loop with Terminating and Running states
flapping. Other Deployment types may also be affected.
As a workaround, restart the Deployment that got stuck:
kubectl -n <affectedProjectName> get deploy <affectedDeployName> -o yaml
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas 0
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas <replicasNumber>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name containing the cluster with stuck Pods<affectedDeployName>is theDeploymentname that failed to run Pods in the specified project<replicasNumber>is the original number of replicas for theDeploymentthat you can obtain using the get deploy command
During configuration of a management cluster settings using the Configure cluster web UI menu, updating the Keycloak Truststore settings is mandatory, despite being optional.
As a workaround, update the management cluster using the API or CLI.
The following table lists the major components and their versions delivered in the Container Cloud 2.26.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Bare metal Updated |
ambasador |
1.39.13 |
baremetal-dnsmasq |
base-2-26-alpine-20240129134230 |
|
baremetal-operator |
base-2-26-alpine-20240129135007 |
|
baremetal-provider |
1.39.13 |
|
bm-collective |
base-2-26-alpine-20240129155244 |
|
cluster-api-provider-baremetal |
1.39.13 |
|
ironic |
yoga-jammy-20240108060019 |
|
ironic-inspector |
yoga-jammy-20240108060019 |
|
ironic-prometheus-exporter |
0.1-20240117102150 |
|
kaas-ipam |
base-2-26-alpine-20240129213142 |
|
kubernetes-entrypoint |
1.0.1-55b02f7-20231019172556 |
|
mariadb |
10.6.14-focal-20231127070342 |
|
metallb-controller |
0.13.12-31212f9e-amd64 |
|
metallb-speaker |
0.13.12-31212f9e-amd64 |
|
syslog-ng |
base-alpine-20240129163811 |
|
Container Cloud |
admission-controller Updated |
1.39.13 |
agent-controller Updated |
1.39.13 |
|
byo-cluster-api-controller New |
1.39.13 |
|
byo-credentials-controller New |
1.39.13 |
|
ceph-kcc-controller Updated |
1.39.13 |
|
cert-manager-controller |
1.11.0-5 |
|
cinder-csi-plugin Updated |
1.27.2-11 |
|
client-certificate-controller Updated |
1.39.13 |
|
configuration-collector Updated |
1.39.13 |
|
csi-attacher Updated |
4.2.0-4 |
|
csi-node-driver-registrar Updated |
2.7.0-4 |
|
csi-provisioner Updated |
3.4.1-4 |
|
csi-resizer Updated |
1.7.0-4 |
|
csi-snapshotter Updated |
6.2.1-mcc-3 |
|
event-controller Updated |
1.39.13 |
|
frontend Updated |
1.39.13 |
|
golang |
1.20.4-alpine3.17 |
|
iam-controller Updated |
1.39.13 |
|
kaas-exporter Updated |
1.39.13 |
|
kproxy Updated |
1.39.13 |
|
lcm-controller Updated |
1.39.13 |
|
license-controller Updated |
1.39.13 |
|
livenessprobe Updated |
2.9.0-4 |
|
machinepool-controller Updated |
1.38.17 |
|
mcc-haproxy Updated |
0.24.0-46-gdaf7dbc |
|
metrics-server Updated |
0.6.3-6 |
|
nginx Updated |
1.39.13 |
|
policy-controller New |
1.39.13 |
|
portforward-controller Updated |
1.39.13 |
|
proxy-controller Updated |
1.39.13 |
|
rbac-controller Updated |
1.39.13 |
|
registry Updated |
2.8.1-9 |
|
release-controller Updated |
1.39.13 |
|
rhellicense-controller Updated |
1.39.13 |
|
scope-controller Updated |
1.39.13 |
|
storage-discovery Updated |
1.39.13 |
|
user-controller Updated |
1.39.13 |
|
IAM |
iam Updated |
1.39.13 |
iam-controller Updated |
1.39.13 |
|
keycloak Removed |
n/a |
|
mcc-keycloak New |
23.0.3-1 |
|
OpenStack Updated |
host-os-modules-controller New |
1.39.13 |
openstack-cloud-controller-manager |
v1.27.2-12 |
|
openstack-cluster-api-controller |
1.39.13 |
|
openstack-provider |
1.39.13 |
|
os-credentials-controller |
1.39.13 |
|
VMware vSphere |
mcc-keepalived Updated |
0.24.0-46-gdaf7dbc |
squid-proxy |
0.0.1-10-g24a0d69 |
|
vsphere-cloud-controller-manager New |
v1.27.0-5 |
|
vsphere-cluster-api-controller Updated |
1.39.13 |
|
vsphere-credentials-controller Updated |
1.39.13 |
|
vsphere-csi-driver New |
v3.0.2-1 |
|
vsphere-csi-syncer New |
v3.0.2-1 |
|
vsphere-provider Updated |
1.39.13 |
|
vsphere-vm-template-controller Updated |
1.39.13 |
This section lists the artifacts of components included in the Container Cloud release 2.26.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20240201183421 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20240201183421 |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-146-1bd8e71.tgz |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.39.13.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.39.13.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.39.13.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.39.13.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.39.13.tgz |
|
metallb |
||
Docker images Updated |
ambasador |
mirantis.azurecr.io/core/external/nginx:1.39.13 |
baremetal-dnsmasq |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-2-26-alpine-20240129134230 |
|
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-2-26-alpine-20240129135007 |
|
bm-collective |
mirantis.azurecr.io/bm/bm-collective:base-2-26-alpine-20240129155244 |
|
cluster-api-provider-baremetal |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.39.13 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20240108060019 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20240108060019 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20240117102150 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-2-26-alpine-20240129213142 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.24.0-46-gdaf7dbc |
|
metallb-controller |
mirantis.azurecr.io/bm/metallb/controller:v0.13.12-31212f9e-amd64 |
|
metallb-speaker |
mirantis.azurecr.io/bm/metallb/speaker:v0.13.12-31212f9e-amd64 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-alpine-20240129163811 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.39.13.tgz |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.39.13.tgz |
|
Helm charts |
admission-controller Updated |
https://binary.mirantis.com/core/helm/admission-controller-1.39.13.tgz |
agent-controller Updated |
https://binary.mirantis.com/core/helm/agent-controller-1.39.13.tgz |
|
byo-credentials-controller New |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.39.13.tgz |
|
byo-provider New |
https://binary.mirantis.com/core/helm/byo-provider-1.39.13.tgz |
|
ceph-kcc-controller Updated |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.39.13.tgz |
|
cert-manager Updated |
https://binary.mirantis.com/core/helm/cert-manager-1.39.13.tgz |
|
cinder-csi-plugin Updated |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.39.13.tgz |
|
client-certificate-controller Updated |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.39.13.tgz |
|
configuration-collector Updated |
https://binary.mirantis.com/core/helm/configuration-collector-1.39.13.tgz |
|
event-controller Updated |
https://binary.mirantis.com/core/helm/event-controller-1.39.13.tgz |
|
host-os-modules-controller New |
https://binary.mirantis.com/core/helm/host-os-modules-controller-1.39.13.tgz |
|
iam-controller Updated |
https://binary.mirantis.com/core/helm/iam-controller-1.39.13.tgz |
|
kaas-exporter Updated |
https://binary.mirantis.com/core/helm/kaas-exporter-1.39.13.tgz |
|
kaas-public-api Updated |
https://binary.mirantis.com/core/helm/kaas-public-api-1.39.13.tgz |
|
kaas-ui Updated |
||
lcm-controller Updated |
https://binary.mirantis.com/core/helm/lcm-controller-1.39.13.tgz |
|
license-controller Updated |
https://binary.mirantis.com/core/helm/license-controller-1.39.13.tgz |
|
machinepool-controller Updated |
https://binary.mirantis.com/core/helm/machinepool-controller-1.39.13.tgz |
|
mcc-cache Updated |
||
mcc-cache-warmup Updated |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.39.13.tgz |
|
metrics-server Updated |
https://binary.mirantis.com/core/helm/metrics-server-1.39.13.tgz |
|
openstack-cloud-controller-manager Updated |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.39.13.tgz |
|
openstack-provider Updated |
https://binary.mirantis.com/core/helm/openstack-provider-1.39.13.tgz |
|
os-credentials-controller Updated |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.39.13.tgz |
|
policy-controller New |
https://binary.mirantis.com/core/helm/policy-controller-1.39.13.tgz |
|
portforward-controller Updated |
https://binary.mirantis.com/core/helm/portforward-controller-1.39.13.tgz |
|
proxy-controller Updated |
https://binary.mirantis.com/core/helm/proxy-controller-1.39.13.tgz |
|
rbac-controller Updated |
https://binary.mirantis.com/core/helm/rbac-controller-1.39.13.tgz |
|
release-controller Updated |
https://binary.mirantis.com/core/helm/release-controller-1.39.13.tgz |
|
rhellicense-controller Updated |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.39.13.tgz |
|
scope-controller Updated |
https://binary.mirantis.com/core/helm/scope-controller-1.39.13.tgz |
|
squid-proxy Updated |
https://binary.mirantis.com/core/helm/squid-proxy-1.39.13.tgz |
|
storage-discovery Updated |
https://binary.mirantis.com/core/helm/storage-discovery-1.39.13.tgz |
|
user-controller Updated |
https://binary.mirantis.com/core/helm/user-controller-1.39.13.tgz |
|
vsphere-cloud-controller-manager New |
https://binary.mirantis.com/core/helm/vsphere-cloud-controller-manager-1.39.13.tgz |
|
vsphere-credentials-controller Updated |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.39.13.tgz |
|
vsphere-csi-plugin New |
https://binary.mirantis.com/core/helm/vsphere-csi-plugin-1.39.13.tgz |
|
vsphere-provider Updated |
https://binary.mirantis.com/core/helm/vsphere-provider-1.39.13.tgz |
|
vsphere-vm-template-controller Updated |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.39.13.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.39.13 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.39.13 |
|
byo-cluster-api-controller New |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.39.13 |
|
byo-credentials-controller New |
mirantis.azurecr.io/core/byo-credentials-controller:1.39.13 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.39.13 |
|
cert-manager-controller Updated |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-5 |
|
cinder-csi-plugin Updated |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-11 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.39.13 |
|
configuration-collector Updated |
mirantis.azurecr.io/core/configuration-collector:1.39.13 |
|
csi-attacher Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-4 |
|
csi-node-driver-registrar Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-4 |
|
csi-provisioner Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-4 |
|
csi-resizer Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-4 |
|
csi-snapshotter Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-3 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.39.13 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.39.13 |
|
host-os-modules-controller New |
mirantis.azurecr.io/core/host-os-modules-controller:1.39.13 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.39.13 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.39.13 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.39.13 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.39.13 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.39.13 |
|
livenessprobe Updated |
mirantis.azurecr.io/lcm/k8scsi/livenessprobe:v2.9.0-4 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.39.13 |
|
mcc-haproxy Updated |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.24.0-46-gdaf7dbc |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.24.0-46-gdaf7dbc |
|
metrics-server Updated |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-6 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.39.13 |
|
openstack-cloud-controller-manager Updated |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-12 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.39.13 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.39.13 |
|
policy-controller New |
mirantis.azurecr.io/core/policy-controller:1.39.13 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.39.13 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.39.13 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.39.13 |
|
registry Updated |
mirantis.azurecr.io/lcm/registry:v2.8.1-9 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.39.13 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.39.13 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.39.13 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.39.13 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.39.13 |
|
vsphere-cloud-controller-manager New |
mirantis.azurecr.io/lcm/kubernetes/vsphere-cloud-controller-manager:v1.27.0-5 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.39.13 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.39.13 |
|
vsphere-csi-driver New |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-driver:v3.0.2-1 |
|
vsphere-csi-syncer New |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-syncer:v3.0.2-1 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.39.13 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts Updated |
iam |
|
Docker images |
keycloak Removed |
n/a |
kubectl New |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240105023016 |
|
kubernetes-entrypoint Updated |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
|
mcc-keycloak New |
mirantis.azurecr.io/iam/mcc-keycloak:23.0.3-1 |
The table below includes the total numbers of addressed unique and common vulnerabilities and exposures (CVE) by product component since the 2.25.4 patch release. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
Ceph |
Unique |
0 |
2 |
2 |
Common |
0 |
6 |
6 |
|
Kaas core |
Unique |
0 |
7 |
7 |
Common |
0 |
8 |
8 |
|
StackLight |
Unique |
3 |
7 |
10 |
Common |
5 |
19 |
24 |
Mirantis Security Portal
For the detailed list of fixed and existing CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
MOSK CVEs
For the number of fixed CVEs in the MOSK-related components including OpenStack and Tungsten Fabric, refer to MOSK 24.1: Security notes.
This section describes the specific actions you as a cloud operator need to complete before or after your Container Cloud cluster update to the Cluster releases 17.1.0 or 16.1.0.
Consider this information as a supplement to the generic update procedures published in Operations Guide: Automatic upgrade of a management cluster and Update a managed cluster.
If any pinned product artifacts are present in the Cluster object of a
management or managed cluster, the update will be blocked by the Admission
Controller with the invalid HelmReleases configuration error until such
artifacts are removed. The update process does not start and any changes in
the Cluster object are blocked by the Admission Controller except the
removal of fields with pinned product artifacts.
Therefore, verify that the following sections of the Cluster objects
do not contain any image-related (tag, name, pullPolicy,
repository) and global values inside Helm releases:
.spec.providerSpec.value.helmReleases.spec.providerSpec.value.kaas.management.helmReleases.spec.providerSpec.value.regionalHelmReleases.spec.providerSpec.value.regional
For example, a cluster configuration that contains the following highlighted lines will be blocked until you remove them:
- name: kaas-ipam
values:
kaas_ipam:
image:
tag: base-focal-20230127092754
exampleKey: exampleValue
- name: kaas-ipam
values:
global:
anyKey: anyValue
kaas_ipam:
image:
tag: base-focal-20230127092754
exampleKey: exampleValue
The custom pinned product artifacts are inspected and blocked by the Admission Controller to ensure that Container Cloud clusters remain consistently updated with the latest security fixes and product improvements
Note
The pre-update inspection applies only to images delivered by Container Cloud that are overwritten. Any custom images unrelated to the product components are not verified and do not block cluster update.
Container Cloud 2.26.0 introduces reorganized and significantly improved
StackLight logging pipeline. It involves changes in queries implemented
in the scope of the logging.metricQueries feature designed for creation
of custom log-based metrics. For the procedure, see StackLight
operations: Create logs-based metrics.
If you already have some custom log-based metrics:
Before the cluster update, save existing queries.
After the cluster update, update the queries according to the changes implemented in the scope of the
logging.metricQueriesfeature.
These steps prevent failures of queries containing fields that are renamed or removed in Container Cloud 2.26.0.
Container Cloud 2.26.0 introduces the bird daemon update from v1.6.8
to v2.0.7 on master nodes if BGP is used for BGP announcement of the cluster
API load balancer address.
Configuration files for bird v1.x are not fully compatible with those for
bird v2.x. Therefore, if you used BGP announcement of cluster API LB address
on a deployment based on Cluster releases 17.0.0 or 16.0.0, update bird
configuration files to fit bird v2.x using configuration examples provided in
the API Reference: MultirRackCluster section.
To prevent underused or overused storage space, review your storage space parameters for OpenSearch on the StackLight cluster:
Review the value of
elasticsearch.persistentVolumeClaimSizeand the real storage available on volumes.Decide whether you have to additionally set
elasticsearch.persistentVolumeUsableStorageSizeGB.
For both parameters description, see StackLight configuration parameters: OpenSearch.
2.25.4¶
The Container Cloud patch release 2.25.4, which is based on the 2.25.0 major release, provides the following updates:
Support for the patch Cluster releases 16.0.4 and 17.0.4 that represents Mirantis OpenStack for Kubernetes (MOSK) patch release 23.3.4.
Security fixes for CVEs in images.
This patch release also supports the latest major Cluster releases 17.0.0 and 16.0.0. And it does not support greenfield deployments based on deprecated Cluster releases. Use the latest available Cluster release instead.
For main deliverables of the parent Container Cloud release of 2.25.4, refer to 2.25.0.
This section lists the artifacts of components included in the Container Cloud patch release 2.25.4. For artifacts of the Cluster releases introduced in 2.25.4, see patch Cluster releases 17.0.4 and 16.0.4.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20231012141354 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20231012141354 |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-113-4f8b843.tgz |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.38.33.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.38.33.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.38.33.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.38.33.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.38.33.tgz |
|
metallb |
||
Docker images |
ambasador Updated |
mirantis.azurecr.io/core/external/nginx:1.38.33 |
baremetal-dnsmasq |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-2-25-alpine-20231128145936 |
|
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-2-25-alpine-20231204121500 |
|
bm-collective |
mirantis.azurecr.io/bm/bm-collective:base-2-25-alpine-20231121115652 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.38.33 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20231204153029 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20231204153029 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20231204142028 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-2-25-alpine-20231121164200 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.23.0-88-g35be0fc |
|
metallb-controller |
mirantis.azurecr.io/bm/metallb/controller:v0.13.9-ef4faae9-amd64 |
|
metallb-speaker |
mirantis.azurecr.io/bm/metallb/speaker:v0.13.9-ef4faae9-amd64 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-alpine-20231121121917 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.38.33.tgz |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.38.33.tgz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.38.33.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.38.33.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.38.33.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.38.33.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.38.33.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.38.33.tgz |
|
cinder-csi-plugin |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.38.33.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.38.33.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.38.33.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.38.33.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.38.33.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.38.33.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.38.33.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.38.33.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.38.33.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.38.33.tgz |
|
mcc-cache |
||
mcc-cache-warmup |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.38.33.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.38.33.tgz |
|
openstack-cloud-controller-manager |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.38.33.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.38.33.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.38.33.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.38.33.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.38.33.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.38.33.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.38.33.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.38.33.tgz |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.38.33.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.38.33.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.38.33.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.38.33.tgz |
|
vsphere-cloud-controller-manager |
https://binary.mirantis.com/core/helm/vsphere-cloud-controller-manager-1.38.33.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.38.33.tgz |
|
vsphere-csi-plugin |
https://binary.mirantis.com/core/helm/vsphere-csi-plugin-1.38.33.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.38.33.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.38.33.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.38.33 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.38.33 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.38.33 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.38.33 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.38.33 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-5 |
|
cinder-csi-plugin |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-11 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.38.33 |
|
configuration-collector Updated |
mirantis.azurecr.io/core/configuration-collector:1.38.33 |
|
csi-attacher |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-4 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-4 |
|
csi-provisioner |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-4 |
|
csi-resizer |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-4 |
|
csi-snapshotter |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-3 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.38.33 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.38.33 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.38.33 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.38.33 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.38.33 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.38.33 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.38.33 |
|
livenessprobe |
mirantis.azurecr.io/lcm/k8scsi/livenessprobe:v2.9.0-4 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.38.33 |
|
mcc-haproxy Updated |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.23.0-88-g35be0fc |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.23.0-88-g35be0fc |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-6 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.38.33 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-12 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.38.33 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.38.33 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.38.33 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.38.33 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.38.33 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-7 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.38.33 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.38.33 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.38.33 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.38.33 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.38.33 |
|
vsphere-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/vsphere-cloud-controller-manager:v1.27.0-5 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.38.33 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.38.33 |
|
vsphere-csi-driver |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-driver:v3.0.2-1 |
|
vsphere-csi-syncer |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-syncer:v3.0.2-1 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.38.33 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts Updated |
iam |
|
Docker images |
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20231208023019 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
|
mcc-keycloak |
mirantis.azurecr.io/iam/mcc-keycloak:22.0.5-1 |
The table below includes the total numbers of addressed unique and common CVEs in images by product component since the Container Cloud 2.25.3 patch release. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
Ceph |
Unique |
0 |
1 |
1 |
Common |
0 |
5 |
5 |
|
Kaas core |
Unique |
0 |
1 |
1 |
Common |
0 |
1 |
1 |
|
StackLight |
Unique |
0 |
3 |
3 |
Common |
0 |
9 |
9 |
Mirantis Security Portal
For the detailed list of fixed and existing CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
MOSK CVEs
For the number of fixed CVEs in the MOSK-related components including OpenStack and Tungsten Fabric, refer to MOSK 23.3.4: Security notes.
The following issues have been addressed in the Container Cloud patch release 2.25.4 along with the patch Cluster releases 17.0.4 and 16.0.4.
[38259] Fixed the issue causing the failure to attach an existing MKE cluster to a Container Cloud management cluster. The issue was related to
byo-providerand prevented the attachment of MKE clusters having less than three manager nodes and two worker nodes.[38399] Fixed the issue causing the failure to deploy a management cluster in the offline mode due to the issue in the setup script.
See also
Releases delivered in 2023¶
This section contains historical information on the unsupported Container Cloud releases delivered in 2023. For the latest supported Container Cloud release, see Container Cloud releases.
Version |
Release date |
Summary |
|---|---|---|
Dec 18, 2023 |
Container Cloud 2.25.3 is the third patch release of the 2.25.x and MOSK 23.3.x release series that introduces the following updates:
|
|
Dec 05, 2023 |
Container Cloud 2.25.2 is the second patch release of the 2.25.x and MOSK 23.3.x release series that introduces the following updates:
|
|
Nov 27, 2023 |
Container Cloud 2.25.1 is the first patch release of the 2.25.x and MOSK 23.3.x release series that introduces the following updates:
|
|
Nov 06, 2023 |
|
|
Sep 26, 2023 |
Container Cloud 2.24.4 is the third patch release of the 2.24.x and MOSK 23.2.x release series that introduces the following updates:
|
|
Sep 14, 2023 |
Container Cloud 2.24.4 is the second patch release of the 2.24.x and MOSK 23.2.x release series that introduces the following updates:
|
|
Aug 29, 2023 |
Container Cloud 2.24.3 is the first patch release of the 2.24.x and MOSK 23.2.x release series that introduces the following updates:
For details, see Patch releases. |
|
Aug 21, 2023 |
Based on 2.24.1, Container Cloud 2.24.2:
|
|
Jul 27, 2023 |
Patch release containing hot fixes for the major Container Cloud release 2.24.0. |
|
Jul 20, 2023 |
|
|
June 05, 2023 |
Container Cloud 2.23.5 is the fourth patch release of the 2.23.0 and 2.23.1 major releases that:
For details, see Patch releases. |
|
May 22, 2023 |
Container Cloud 2.23.4 is the third patch release of the 2.23.0 and 2.23.1 major releases that:
For details, see Patch releases. |
|
May 04, 2023 |
Container Cloud 2.23.3 is the second patch release of the 2.23.0 and 2.23.1 major releases that:
For details, see Patch releases. |
|
Apr 20, 2023 |
Container Cloud 2.23.2 is the first patch release of the 2.23.0 and 2.23.1 major releases that:
For details, see Patch releases. |
|
Apr 04, 2023 |
Based on 2.23.0, Container Cloud 2.23.1:
|
|
Mar 07, 2023 |
|
|
Jan 31, 2023 |
|
The Container Cloud patch release 2.25.3, which is based on the 2.25.0 major release, provides the following updates:
Support for MKE 3.7.3. For details, see MKE documentation: Release Notes.
Support for the patch Cluster releases 16.0.3 and 17.0.3 that represents Mirantis OpenStack for Kubernetes (MOSK) patch release 23.3.3.
Security fixes for CVEs in images.
This patch release also supports the latest major Cluster releases 17.0.0 and 16.0.0. And it does not support greenfield deployments based on deprecated Cluster releases. Use the latest available Cluster release instead.
For main deliverables of the parent Container Cloud release of 2.25.3, refer to 2.25.0.
This section lists the artifacts of components included in the Container Cloud patch release 2.25.3. For artifacts of the Cluster releases introduced in 2.25.3, see patch Cluster releases 17.0.3 and 16.0.3.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20231012141354 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20231012141354 |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-113-4f8b843.tgz |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.38.31.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.38.31.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.38.31.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.38.31.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.38.31.tgz |
|
metallb |
||
Docker images |
ambasador Updated |
mirantis.azurecr.io/core/external/nginx:1.38.31 |
baremetal-dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-2-25-alpine-20231128145936 |
|
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-2-25-alpine-20231204121500 |
|
bm-collective |
mirantis.azurecr.io/bm/bm-collective:base-2-25-alpine-20231121115652 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.38.31 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20231204153029 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20231204153029 |
|
ironic-prometheus-exporter Updated |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20231204142028 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-2-25-alpine-20231121164200 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.23.0-87-gc9d7d3b |
|
metallb-controller Updated |
mirantis.azurecr.io/bm/metallb/controller:v0.13.9-ef4faae9-amd64 |
|
metallb-speaker Updated |
mirantis.azurecr.io/bm/metallb/speaker:v0.13.9-ef4faae9-amd64 |
|
syslog-ng Updated |
mirantis.azurecr.io/bm/syslog-ng:base-alpine-20231121121917 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.38.31.tgz |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.38.31.tgz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.38.31.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.38.31.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.38.31.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.38.31.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.38.31.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.38.31.tgz |
|
cinder-csi-plugin |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.38.31.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.38.31.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.38.31.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.38.31.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.38.31.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.38.31.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.38.31.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.38.31.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.38.31.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.38.31.tgz |
|
mcc-cache |
||
mcc-cache-warmup |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.38.31.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.38.31.tgz |
|
openstack-cloud-controller-manager |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.38.31.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.38.31.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.38.31.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.38.31.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.38.31.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.38.31.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.38.31.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.38.31.tgz |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.38.31.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.38.31.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.38.31.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.38.31.tgz |
|
vsphere-cloud-controller-manager |
https://binary.mirantis.com/core/helm/vsphere-cloud-controller-manager-1.38.31.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.38.31.tgz |
|
vsphere-csi-plugin |
https://binary.mirantis.com/core/helm/vsphere-csi-plugin-1.38.31.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.38.31.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.38.31.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.38.31 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.38.31 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.38.31 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.38.31 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.38.31 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-5 |
|
cinder-csi-plugin |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-11 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.38.31 |
|
configuration-collector Updated |
mirantis.azurecr.io/core/configuration-collector:1.38.31 |
|
csi-attacher |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-4 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-4 |
|
csi-provisioner |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-4 |
|
csi-resizer |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-4 |
|
csi-snapshotter |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-3 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.38.31 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.38.31 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.38.31 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.38.31 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.38.31 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.38.31 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.38.31 |
|
livenessprobe |
mirantis.azurecr.io/lcm/k8scsi/livenessprobe:v2.9.0-4 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.38.31 |
|
mcc-haproxy Updated |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.23.0-87-gc9d7d3b |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.23.0-87-gc9d7d3b |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-6 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.38.31 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-12 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.38.31 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.38.31 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.38.31 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.38.31 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.38.31 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-7 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.38.31 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.38.31 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.38.31 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.38.31 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.38.31 |
|
vsphere-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/vsphere-cloud-controller-manager:v1.27.0-5 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.38.31 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.38.31 |
|
vsphere-csi-driver |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-driver:v3.0.2-1 |
|
vsphere-csi-syncer |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-syncer:v3.0.2-1 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.38.31 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts Updated |
iam |
|
Docker images |
keycloak |
n/a (replaced with |
kubectl New |
mirantis.azurecr.io/stacklight/kubectl:1.22-20231201023019 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
|
mcc-keycloak New |
mirantis.azurecr.io/iam/mcc-keycloak:22.0.5-1 |
The table below includes the total numbers of addressed unique and common CVEs in images by product component since the Container Cloud 2.25.2 patch release. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
Ceph |
Unique |
0 |
1 |
1 |
Common |
0 |
3 |
3 |
|
KaaS core |
Unique |
2 |
9 |
11 |
Common |
3 |
18 |
21 |
|
StackLight |
Unique |
1 |
18 |
19 |
Common |
1 |
52 |
53 |
Mirantis Security Portal
For the detailed list of fixed and existing CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
MOSK CVEs
For the number of fixed CVEs in the MOSK-related components including OpenStack and Tungsten Fabric, refer to MOSK 23.3.3: Security notes.
The following issues have been addressed in the Container Cloud patch release 2.25.3 along with the patch Cluster releases 17.0.3 and 16.0.3.
[37634][OpenStack] Fixed the issue with a management or managed cluster deployment or upgrade being blocked by all pods being stuck in the
Pendingstate due to incorrect secrets being used to initialize the OpenStack external Cloud Provider Interface.[37766][IAM] Fixed the issue with sign-in to the MKE web UI of the management cluster using the Sign in with External Provider option, which failed with the invalid parameter: redirect_uri error.
See also
The Container Cloud patch release 2.25.2, which is based on the 2.25.0 major release, provides the following updates:
Renewed support for attachment of MKE clusters that are not originally deployed by Container Cloud for vSphere-based management clusters. For details, see Attach an existing MKE cluster to a vSphere-based management cluster.
Support for the patch Cluster releases 16.0.2 and 17.0.2 that represents Mirantis OpenStack for Kubernetes (MOSK) patch release 23.3.2.
Security fixes for CVEs in images.
This patch release also supports the latest major Cluster releases 17.0.0 and 16.0.0. And it does not support greenfield deployments based on deprecated Cluster releases 14.0.1, 15.0.1, 16.0.1, and 17.0.1. Use the latest available Cluster releases instead.
For main deliverables of the parent Container Cloud release of 2.25.2, refer to 2.25.0.
This section lists the artifacts of components included in the Container Cloud patch release 2.25.2. For artifacts of the Cluster releases introduced in 2.25.2, see patch Cluster releases 17.0.2 and 16.0.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20231012141354 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20231012141354 |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-113-4f8b843.tgz |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.38.29.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.38.29.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.38.29.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.38.29.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.38.29.tgz |
|
metallb |
||
Docker images |
ambasador Updated |
mirantis.azurecr.io/core/external/nginx:1.38.29 |
baremetal-dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-2-25-alpine-20231121112823 |
|
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-2-25-alpine-20231121112816 |
|
bm-collective Updated |
mirantis.azurecr.io/bm/bm-collective:base-2-25-alpine-20231121115652 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.38.29 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20231120060019 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20231030060018 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20230912104602 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-2-25-alpine-20231121164200 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231024091216 |
|
mcc-keepalived |
mirantis.azurecr.io/docker.mirantis.net/lcm/mcc-keepalived:v0.23.0-84-g8d74d7c |
|
metallb-controller Updated |
mirantis.azurecr.io/bm/metallb/controller:v0.13.9-ef4faae9-amd64 |
|
metallb-speaker Updated |
mirantis.azurecr.io/bm/metallb/speaker:v0.13.9-ef4faae9-amd64 |
|
syslog-ng Updated |
mirantis.azurecr.io/bm/syslog-ng:base-alpine-20231121121917 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.38.29.tgz |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.38.29.tgz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.38.29.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.38.29.tgz |
|
byo-credentials-controller New |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.38.29.tgz |
|
byo-provider New |
https://binary.mirantis.com/core/helm/byo-provider-1.38.29.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.38.29.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.38.29.tgz |
|
cinder-csi-plugin |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.38.29.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.38.29.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.38.29.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.38.29.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.38.29.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.38.29.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.38.29.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.38.29.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.38.29.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.38.29.tgz |
|
mcc-cache |
||
mcc-cache-warmup |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.38.29.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.38.29.tgz |
|
openstack-cloud-controller-manager |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.38.29.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.38.29.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.38.29.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.38.29.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.38.29.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.38.29.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.38.29.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.38.29.tgz |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.38.29.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.38.29.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.38.29.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.38.29.tgz |
|
vsphere-cloud-controller-manager |
https://binary.mirantis.com/core/helm/vsphere-cloud-controller-manager-1.38.29.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.38.29.tgz |
|
vsphere-csi-plugin |
https://binary.mirantis.com/core/helm/vsphere-csi-plugin-1.38.29.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.38.29.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.38.29.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.38.29 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.38.29 |
|
byo-credentials-controller New |
mirantis.azurecr.io/core/byo-credentials-controller:1.38.29 |
|
byo-provider New |
mirantis.azurecr.io/core/byo-provider:1.38.29 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.38.29 |
|
cert-manager-controller Updated |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-5 |
|
cinder-csi-plugin |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-11 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.38.29 |
|
configuration-collector Updated |
mirantis.azurecr.io/core/configuration-collector:1.38.29 |
|
csi-attacher |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-4 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-4 |
|
csi-provisioner |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-4 |
|
csi-resizer |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-4 |
|
csi-snapshotter |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-3 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.38.29 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.38.29 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.38.29 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.38.29 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.38.29 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.38.29 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.38.29 |
|
livenessprobe |
mirantis.azurecr.io/lcm/k8scsi/livenessprobe:v2.9.0-4 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.38.29 |
|
mcc-haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.23.0-84-g8d74d7c |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.23.0-84-g8d74d7c |
|
metrics-server Updated |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-6 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.38.29 |
|
openstack-cloud-controller-manager Updated |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-12 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.38.29 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.38.29 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.38.29 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.38.29 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.38.29 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-7 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.38.29 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.38.29 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.38.29 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.38.29 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.38.29 |
|
vsphere-cloud-controller-manager Updated |
mirantis.azurecr.io/lcm/kubernetes/vsphere-cloud-controller-manager:v1.27.0-5 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.38.29 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.38.29 |
|
vsphere-csi-driver Updated |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-driver:v3.0.2-1 |
|
vsphere-csi-syncer Updated |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-syncer:v3.0.2-1 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.38.29 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts |
iam |
|
Docker images |
keycloak |
mirantis.azurecr.io/iam/keycloak:0.6.0-1 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231024091216 |
The table below includes the total numbers of addressed unique and common CVEs in images by product component since the Container Cloud 2.25.1 patch release. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
Kaas core |
Unique |
0 |
6 |
6 |
Common |
0 |
20 |
20 |
|
Ceph |
Unique |
0 |
2 |
2 |
Common |
0 |
6 |
6 |
|
StackLight |
Unique |
0 |
16 |
16 |
Common |
0 |
70 |
70 |
Mirantis Security Portal
For the detailed list of fixed and existing CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
MOSK CVEs
For the number of fixed CVEs in the MOSK-related components including OpenStack and Tungsten Fabric, refer to MOSK 23.3.2: Security notes.
See also
The Container Cloud patch release 2.25.1, which is based on the 2.25.0 major release, provides the following updates:
Support for the patch Cluster releases 16.0.1 and 17.0.1 that represents Mirantis OpenStack for Kubernetes (MOSK) patch release 23.3.1.
Several product improvements. For details, see Enhancements.
Security fixes for CVEs in images.
This patch release also supports the latest major Cluster releases 17.0.0 and 16.0.0. And it does not support greenfield deployments based on deprecated Cluster releases 14.1.0, 14.0.1, and 15.0.1. Use the latest available Cluster releases instead.
For main deliverables of the parent Container Cloud release of 2.25.1, refer to 2.25.0.
This section outlines new features and enhancements introduced in the Container Cloud patch release 2.25.1 along with Cluster releases 17.0.1 and 16.0.1.
Introduced support for Mirantis Kubernetes Engine (MKE) 3.7.2 on Container Cloud management and managed clusters. On existing managed clusters, MKE is updated to the latest supported version when you update your cluster to the patch Cluster release 17.0.1 or 16.0.1.
Learn more
To simplify MKE configuration through API, moved management of MKE parameters
controlled by Container Cloud from lcm-ansible to lcm-controller.
Now, Container Cloud overrides only a set of MKE configuration parameters that
are automatically managed by Container Cloud.
Analyzed and fixed the majority of failed compliance checks in the MKE benchmark compliance for StackLight. The following controls were analyzed:
Control ID |
Control description |
Analyzed item |
|---|---|---|
5.2.7 |
Minimize the admission of containers with the |
Containers with |
5.2.6 |
Minimize the admission of root containers |
|
Introduced Kubernetes network policies for all StackLight components. The
feature is implemented using the networkPolicies parameter that is enabled
by default.
The Kubernetes NetworkPolicy resource allows controlling network connections to and from Pods within a cluster. This enhances security by restricting communication from compromised Pod applications and provides transparency into how applications communicate with each other.
Switched to the external vSphere cloud controller manager (CCM) that uses vSphere Container Storage Plug-in 3.0 for volume attachment. The feature implementation implies an automatic migration of PersistentVolume and PersistentVolumeClaim.
The external vSphere CCM supports vSphere 6.7 on Kubernetes 1.27 as compared to the in-tree vSphere CCM that does not support vSphere 6.7 since Kubernetes 1.25.
Important
The major Cluster release 14.1.0 is the last Cluster release for the vSphere provider based on MCR 20.10 and MKE 3.6.6 with Kubernetes 1.24. Therefore, Mirantis highly recommends updating your existing vSphere-based managed clusters to the Cluster release 16.0.1 that contains newer versions on MCR and MKE with Kubernetes. Otherwise, your management cluster upgrade to Container Cloud 2.25.2 will blocked.
For the update procedure, refer to Operations Guide: Update a patch Cluster release of a managed cluster.
Since Container Cloud 2.25.1, the major Cluster release 14.1.0 is deprecated. Greenfield vSphere-based deployments on this Cluster release are not supported. Use the patch Cluster release 16.0.1 for new deployments instead.
This section lists the artifacts of components included in the Container Cloud patch release 2.25.1. For artifacts of the Cluster releases introduced in 2.25.1, see patch Cluster releases 17.0.1 and 16.0.1.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20231012141354 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20231012141354 |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-113-4f8b843.tgz |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.38.22.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.38.22.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.38.22.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.38.22.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.38.22.tgz |
|
metallb |
||
Docker images Updated |
ambasador |
mirantis.azurecr.io/core/external/nginx:1.38.22 |
baremetal-dnsmasq |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-alpine-20231030180650 |
|
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-alpine-20231101201729 |
|
bm-collective |
mirantis.azurecr.io/bm/bm-collective:base-alpine-20231027135748 |
|
cluster-api-provider-baremetal |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.38.22 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20231030060018 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20231030060018 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20230912104602 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-alpine-20231027151726 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231024091216 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.23.0-84-g8d74d7c |
|
metallb-controller |
mirantis.azurecr.io/bm/metallb/controller:v0.13.9-fd3b03b0-amd64 |
|
metallb-speaker |
mirantis.azurecr.io/bm/metallb/speaker:v0.13.9-fd3b03b0-amd64 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-apline-20231030181839 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com//core/binbootstrap-darwin-1.38.22.tgz |
bootstrap-linux |
https://binary.mirantis.com//core/binbootstrap-linux-1.38.22.tgz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.38.22.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.38.22.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.38.22.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.38.22.tgz |
|
cinder-csi-plugin |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.38.22.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.38.22.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.38.22.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.38.22.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.38.22.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.38.22.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.38.22.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.38.22.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.38.22.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.38.22.tgz |
|
mcc-cache |
||
mcc-cache-warmup |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.38.22.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.38.22.tgz |
|
openstack-cloud-controller-manager |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.38.22.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.38.22.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.38.22.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.38.22.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.38.22.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.38.22.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.38.22.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.38.22.tgz |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.38.22.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.38.22.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.38.22.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.38.22.tgz |
|
vsphere-cloud-controller-manager New |
https://binary.mirantis.com/core/helm/vsphere-cloud-controller-manager-1.38.22.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.38.22.tgz |
|
vsphere-csi-plugin New |
https://binary.mirantis.com/core/helm/vsphere-csi-plugin-1.38.22.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.38.22.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.38.22.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.38.22 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.38.22 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.38.22 |
|
cert-manager-controller Updated |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-4 |
|
cinder-csi-plugin Updated |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-11 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.38.22 |
|
configuration-collector Updated |
mirantis.azurecr.io/core/configuration-collector:1.38.22 |
|
csi-attacher Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-4 |
|
csi-node-driver-registrar Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-4 |
|
csi-provisioner Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-4 |
|
csi-resizer Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-4 |
|
csi-snapshotter Updated |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-3 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.38.22 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.38.22 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.38.22 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.38.22 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.38.22 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.38.22 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.38.22 |
|
livenessprobe Updated |
mirantis.azurecr.io/lcm/k8scsi/livenessprobe:v2.9.0-4 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.38.22 |
|
mcc-haproxy Updated |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.23.0-84-g8d74d7c |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.23.0-84-g8d74d7c |
|
metrics-server Updated |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-4 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.38.22 |
|
openstack-cloud-controller-manager Updated |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-11 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.38.22 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.38.22 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.38.22 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.38.22 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.38.22 |
|
registry Updated |
mirantis.azurecr.io/lcm/registry:v2.8.1-7 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.38.22 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.38.22 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.38.22 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.38.22 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.38.22 |
|
vsphere-cloud-controller-manager New |
mirantis.azurecr.io/lcm/kubernetes/vsphere-cloud-controller-manager:v1.27.0-4 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.38.22 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.38.22 |
|
vsphere-csi-driver New |
mirantis.azurecr.io/core/external/vsphere-csi-driver:v3.0.2 |
|
vsphere-csi-syncer New |
mirantis.azurecr.io/core/external/vsphere-csi-syncer:v3.0.2 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.38.22 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts Updated |
iam |
|
Docker images Updated |
keycloak |
mirantis.azurecr.io/iam/keycloak:0.6.0-1 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231024091216 |
The table below includes the total numbers of addressed unique and common CVEs in images by product component since the Container Cloud 2.25.0 major release. The common CVEs are issues addressed across several images.
Container Cloud component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
Kaas core |
Unique |
0 |
12 |
12 |
Common |
0 |
280 |
280 |
|
Ceph |
Unique |
0 |
8 |
8 |
Common |
0 |
41 |
41 |
|
StackLight |
Unique |
4 |
33 |
37 |
Common |
18 |
130 |
148 |
Mirantis Security Portal
For the detailed list of fixed and existing CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
MOSK CVEs
For the number of fixed CVEs in the MOSK-related components including OpenStack and Tungsten Fabric, refer to MOSK 23.3.1: Security notes.
The following issues have been addressed in the Container Cloud patch release 2.25.1 along with the patch Cluster releases 17.0.1 and 16.0.1.
[35426] [StackLight] Fixed the issue with the
prometheus-libvirt-exporterPod failing to reconnect to libvirt after thelibvirtPod recovery from a failure.[35339] [LCM] Fixed the issue with the LCM Ansible task of copying
kubectlfrom theucp-hyperkubeimage failing if kubectl exec is in use, for example, during a management cluster upgrade.[35089] [bare metal, Calico] Fixed the issue with arbitrary Kubernetes pods getting stuck in an error loop due to a failed Calico networking setup for that pod.
[33936] [bare metal, Calico] Fixed the issue with deletion failure of a controller node during machine replacement due to the upstream Calico issue.
See also
The Mirantis Container Cloud major release 2.25.0:
Introduces support for the Cluster release 17.0.0 that is based on the Cluster release 16.0.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 23.3.
Introduces support for the Cluster release 16.0.0 that is based on Mirantis Container Runtime (MCR) 23.0.7 and Mirantis Kubernetes Engine (MKE) 3.7.1 with Kubernetes 1.27.
Introduces support for the Cluster release 14.1.0 that is dedicated for the vSphere provider only. This is the last Cluster release for the vSphere provider based on MKE 3.6.6 with Kubernetes 1.24.
Does not support greenfield deployments on deprecated Cluster releases of the 15.x and 14.x series. Use the latest available Cluster releases of the series instead.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.25.0.
This section outlines new features and enhancements introduced in the Container Cloud release 2.25.0. For the list of enhancements delivered with the Cluster releases introduced by Container Cloud 2.25.0, see 17.0.0, 16.0.0, and 14.1.0.
Implemented Container Cloud Bootstrap v2 that provides an exceptional user experience to set up Container Cloud. With Bootstrap v2, you also gain access to a comprehensive and user-friendly web UI for the OpenStack and vSphere providers.
Bootstrap v2 empowers you to effortlessly provision management clusters before deployment, while benefiting from a streamlined process that isolates each step. This approach not only simplifies the bootstrap process but also enhances troubleshooting capabilities for addressing any potential intermediate failures.
Note
The Bootstrap web UI support for the bare metal provider will be added in one of the following Container Cloud releases.
Completed development of the MetalLB configuration related to address
allocation and announcement for load-balanced services using the
MetalLBConfigTemplate object for bare metal and the MetalLBConfig
object for vSphere. Container Cloud uses these objects in default templates as
recommended during creation of a management or managed cluster.
At the same time, removed the possibility to use the deprecated options, such
as configInline value of the MetalLB chart and the use of Subnet
objects without new MetalLBConfigTemplate and MetalLBConfig objects.
Automated migration, which applied to these deprecated options during creation
of clusters of any type or cluster update to Container Cloud 2.24.x, is
removed automatically during your management cluster upgrade to Container
Cloud 2.25.0. After that, any changes in MetalLB configuration related to
address allocation and announcement for load-balanced services will be applied
using the MetalLBConfig, MetalLBConfigTemplate, and Subnet objects
only.
Technology Preview
Implemented the following annotations for bare metal hosts that enable manual allocation of IP addresses during PXE provisioning on managed clusters:
host.dnsmasqs.metal3.io/address- assigns a specific IP address to a hostbaremetalhost.metal3.io/detached- pauses automatic host management
These annotations are helpful if you have a limited amount of free and unused IP addresses for server provisioning. Using these annotations, you can manually create bare metal hosts one by one and provision servers in small, manually managed chunks.
Implemented the Infrastructure Status condition to monitor infrastructure readiness in the Container Cloud web UI during cluster deployment for bare metal and OpenStack providers. Readiness of the following components is monitored:
Bare metal: the
MetalLBConfigobject along with MetalLB and DHCP subnetsOpenStack: cluster network, routers, load balancers, and Bastion along with their ports and floating IPs
For the bare metal provider, also implemented the
Infrastructure Status condition for machines to monitor readiness
of the IPAMHost, L2Template, BareMetalHost, and
BareMetalHostProfile objects associated with the machine.
Introduced general availability support for RHEL 8.7 on VMware vSphere-based clusters. You can install this operating system on any type of a Container Cloud cluster including the bootstrap node.
Note
RHEL 7.9 is not supported as the operating system for the bootstrap node.
Caution
A Container Cloud cluster based on mixed RHEL versions, such as RHEL 7.9 and 8.7, is not supported.
Implemented automatic cleanup of old Ubuntu kernel and other unnecessary system packages. During cleanup, Container Cloud keeps two most recent kernel versions, which is the default behavior of the Ubuntu apt autoremove command.
Mirantis recommends keeping two kernel versions with the previous kernel version as a fallback option in the event that the current kernel may become unstable at any time. However, if you absolutely require leaving only the latest version of kernel packages, you can use the cleanup-kernel-packages script after considering all possible risks.
Implemented the ability to configure a custom OpenID Connect (OIDC) provider
for MKE on managed clusters using the ClusterOIDCConfiguration custom
resource. Using this resource, you can add your own OIDC provider
configuration to authenticate user requests to Kubernetes.
Note
For OpenStack and StackLight, Container Cloud supports only Keycloak, which is configured on the management cluster, as the OIDC provider.
Implemented the management-admin OIDC role to grant full admin access
specifically to a management cluster. This role enables the user to manage
Pods and all other resources of the cluster, for example, for debugging
purposes.
Introduced general availability support for graceful machine deletion with a safe cleanup of node resources:
Changed the default deletion policy from
unsafetogracefulfor machine deletion using the Container Cloud API.Using the
deletionPolicy: gracefulparameter in theproviderSpec.valuesection of theMachineobject, the cloud provider controller prepares a machine for deletion by cordoning, draining, and removing the related node from Docker Swarm. If required, you can abort a machine deletion when usingdeletionPolicy: graceful, but only before the related node is removed from Docker Swarm.Implemented the following machine deletion methods in the Container Cloud web UI: Graceful, Unsafe, Forced.
Added support for deletion of manager machines, which is intended only for replacement or recovery of failed nodes, for MOSK-based clusters using either of deletion policies mentioned above.
Completed development of the parallel update of worker nodes during cluster update by implementing the ability to configure the required options using the Container Cloud web UI. Parallelizing of node update operations significantly optimizes the update efficiency of large clusters.
The following options are added to the Create Cluster window:
Parallel Upgrade Of Worker Machines that sets the maximum number of worker nodes to update simultaneously
Parallel Preparation For Upgrade Of Worker Machines that sets the maximum number of worker nodes for which new artifacts are downloaded at a given moment of time
The following issues have been addressed in the Mirantis Container Cloud release 2.25.0 along with the Cluster releases 17.0.0, 16.0.0, and 14.1.0.
Note
This section provides descriptions of issues addressed since the last Container Cloud patch release 2.24.5.
For details on addressed issues in earlier patch releases since 2.24.0, which are also included into the major release 2.25.0, refer to 2.24.x patch releases.
[34462] [BM] Fixed the issue with incorrect handling of the DHCP egress traffic by reconfiguring the external traffic policy for the
dhcp-lbKubernetes Service. For details about the issue, refer to the Kubernetes upstream bug.On existing clusters with multiple L2 segments using DHCP relays on the border switches, in order to successfully provision new nodes or reprovision existing ones, manually point the DHCP relays on your network infrastructure to the new IP address of the
dhcp-lbService of the Container Cloud cluster.To obtain the new IP address:
kubectl -n kaas get service dhcp-lb
[35429] [BM] Fixed the issue with the WireGuard interface not having the IPv4 address assigned. The fix implies automatic restart of the
calico-nodePod to allocate the IPv4 address on the WireGuard interface.[36131] [BM] Fixed the issue with
IpamHostobject changes not being propagated toLCMMachineduring netplan configuration after cluster deployment.[34657] [LCM] Fixed the issue with
iam-keycloakPods not starting after powering up master nodes and starting the Container Cloud upgrade right after.[34750] [LCM] Fixed the issue with
journaldgenerating a lot of log messages that already exist in the auditd log due to enabledsystemd-journald-audit.socket.[35738] [StackLight] Fixed the issue with
ucp-node-exporterbeing unable to bind the port 9100 with theucp-node-exporterfailing to start due to a conflict with the StackLightnode-exporterbinding the same port.The resolution of the issue involves an automatic change of the port for the StackLight
node-exporterfrom 9100 to 19100. No manual port update is required.If your cluster uses a firewall, add an additional firewall rule that grants the same permissions to port 19100 as those currently assigned to port 9100 on all cluster nodes.
[34296] [StackLight] Fixed the issue with the CPU over-consumption by
helm-controllerleading to theKubeContainersCPUThrottlingHighalert firing.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.25.0 including the Cluster releases 17.0.0, 16.0.0, and 14.1.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Fixed in 17.0.1 and 16.0.1 for MKE 3.7.2
An arbitrary Kubernetes pod may get stuck in an error loop due to a failed Calico networking setup for that pod. The pod cannot access any network resources. The issue occurs more often during cluster upgrade or node replacement, but this can sometimes happen during the new deployment as well.
You may find the following log for the failed pod IP (for example,
10.233.121.132) in calico-node logs:
felix/route_table.go 898: Syncing routes: found unexpected route; ignoring due to grace period. dest=10.233.121.132/32 ifaceName="cali9731b965838" ifaceRegex="^cali." ipVersion=0x4 tableIndex=254
felix/route_table.go 898: Syncing routes: found unexpected route; ignoring due to grace period. dest=10.233.121.132/32 ifaceName="cali9731b965838" ifaceRegex="^cali." ipVersion=0x4 tableIndex=254
...
felix/route_table.go 902: Remove old route dest=10.233.121.132/32 ifaceName="cali9731b965838" ifaceRegex="^cali.*" ipVersion=0x4 routeProblems=[]string{"unexpected route"} tableIndex=254
felix/conntrack.go 90: Removing conntrack flows ip=10.233.121.132
The workaround is to manually restart the affected pod:
kubectl delete pod <failedPodID>
Fixed in 17.0.1 and 16.0.1 for MKE 3.7.2
Due to the upstream Calico issue, a controller node
cannot be deleted if the calico-node Pod is stuck blocking node deletion.
One of the symptoms is the following warning in the baremetal-operator
logs:
Resolving dependency Service dhcp-lb in namespace kaas failed: \
the server was unable to return a response in the time allotted,\
but may still be processing the request (get endpoints dhcp-lb).
As a workaround, delete the Pod that is stuck to retrigger the node deletion.
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
When using OpenStackCredential with a custom CACert, a management or
managed cluster deployment or upgrade is blocked by all pods being stuck in
the Pending state. The issue is caused by incorrect secrets being used to
initialize the OpenStack external Cloud Provider Interface.
As a workaround, copy CACert from the OpenStackCredential object
to openstack-ca-secret:
kubectl --kubeconfig <pathToFailedClusterKubeconfig> patch secret -n kube-system openstack-ca-secret -p '{"data":{"ca.pem":"'$(kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <affectedProjectName> get openstackcredentials <credentialsName> -o go-template="{{.spec.CACert}}")'"}}'
If the CACert from the OpenStackCredential is not base64-encoded:
kubectl --kubeconfig <pathToFailedClusterKubeconfig> patch secret -n kube-system openstack-ca-secret -p '{"data":{"ca.pem":"'$(kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <affectedProjectName> get openstackcredentials <credentialsName> -o go-template="{{.spec.CACert}}" | base64)'"}}'
In either command above, replace the following values:
<pathToFailedClusterKubeconfig>is the file path to the affected managed or management clusterkubeconfig.<pathToManagementClusterKubeconfig>is the file path to the Container Cloud management clusterkubeconfig.<affectedProjectName>is the Container Cloud project name containing the cluster with stuck pods. For a management cluster, the value isdefault.<credentialsName>is theOpenStackCredentialname used for the deployment.
A sign-in to the MKE web UI of the management cluster using the Sign in with External Provider option can fail with the invalid parameter: redirect_uri error.
Workaround:
Log in to the Keycloak admin console.
In the sidebar menu, switch to the IAM realm.
Navigate to Clients > kaas.
On the page, navigate to Seetings > Access settings > Valid redirect URIs.
Add
https://<mgmt mke ip>:6443/*to the list of valid redirect URIs and click Save.Refresh the browser window with the sign-in URI.
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
On MOSK clusters, the Ansible provisioner may hang in a loop while trying to remove LVM thin pool logical volumes (LVs) due to issues with volume detection before removal. The Ansible provisioner cannot remove LVM thin pool LVs correctly, so it consistently detects the same volumes whenever it scans disks, leading to a repetitive cleanup process.
The following symptoms mean that a cluster can be affected:
A node was configured to use thin pool LVs. For example, it had the OpenStack Cinder role in the past.
A bare metal node deployment flaps between
provisioniniganddeprovisioningstates.In the Ansible provisioner logs, the following example warnings are growing:
88621.log:7389:2023-06-22 16:30:45.109 88621 ERROR ansible.plugins.callback.ironic_log [-] Ansible task clean : fail failed on node 14eb0dbc-c73a-4298-8912-4bb12340ff49: {'msg': 'There are more devices to clean', '_ansible_no_log': None, 'changed': False}
Important
There are more devices to cleanis a regular warning indicating some in-progress tasks. But if the number of such warnings is growing along with the node flapping betweenprovisioniniganddeprovisioningstates, the cluster is highly likely affected by the issue.
As a workaround, erase disks manually using any preferred tool.
During replacement of a master node on a cluster of any type, the
calico-node Pod fails to start on a new node that has the same IP address
as the node being replaced.
Workaround:
Log in to any
masternode.From a CLI with an MKE client bundle, create a shell alias to start calicoctl using the
mirantis/ucp-dsinfoimage:alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/key.pem \ -e ETCD_CA_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/ca.pem \ -e ETCD_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/cert.pem \ -v /var/run/calico:/var/run/calico \ -v /var/lib/docker/volumes/ucp-kv-certs/_data:/var/lib/docker/volumes/ucp-kv-certs/_data:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl \ "
alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/ucp-node-certs/key.pem \ -e ETCD_CA_CERT_FILE=/ucp-node-certs/ca.pem \ -e ETCD_CERT_FILE=/ucp-node-certs/cert.pem \ -v /var/run/calico:/var/run/calico \ -v ucp-node-certs:/ucp-node-certs:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl --allow-version-mismatch \ "
In the above command, replace the following values with the corresponding settings of the affected cluster:
<etcdEndpoint>is the etcd endpoint defined in the Calico configuration file. For example,ETCD_ENDPOINTS=127.0.0.1:12378<mkeVersion>is the MKE version installed on your cluster. For example,mirantis/ucp-dsinfo:3.5.7.
Verify the node list on the cluster:
kubectl get node
Compare this list with the node list in Calico to identify the old node:
calicoctl get node -o wide
Remove the old node from Calico:
calicoctl delete node kaas-node-<nodeID>
During replacement of a manager machine, the following problems may occur:
The system adds the node to Docker swarm but not to Kubernetes
The node
Deploymentgets stuck with failed RethinkDB health checks
Workaround:
Delete the failed node.
Wait for the MKE cluster to become healthy. To monitor the cluster status:
Log in to the MKE web UI as described in Connect to the Mirantis Kubernetes Engine web UI.
Monitor the cluster status as described in MKE Operations Guide: Monitor an MKE cluster with the MKE web UI.
Deploy a new node.
During the unsafe or forced deletion of a manager machine running the
calico-kube-controllers Pod in the kube-system namespace,
the following issues occur:
The
calico-kube-controllersPod fails to clean up resources associated with the deleted nodeThe
calico-nodePod may fail to start up on a newly created node if the machine is provisioned with the same IP address as the deleted machine had
As a workaround, before deletion of the node running the
calico-kube-controllers Pod, cordon and drain the node:
kubectl cordon <nodeName>
kubectl drain <nodeName>
Due to the upstream Ceph issue,
on clusters with the Federal Information Processing Standard (FIPS) mode
enabled, the Ceph rook-operator fails to connect to Ceph RADOS Gateway
(RGW) pods.
As a workaround, do not place Ceph RGW pods on nodes where FIPS mode is enabled.
Update of a managed cluster based on bare metal and Ceph enabled fails with
PersistentVolumeClaim getting stuck in the Pending state for the
prometheus-server StatefulSet and the
MountVolume.MountDevice failed for volume warning in the StackLight event
logs.
Workaround:
Verify that the description of the Pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name where the Pods failed to run<affectedPodName>is a Pod name that failed to run in the specified project
In the Pod description, identify the node name where the Pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain therbd volume mount failed: <csi-vol-uuid> is being usederror. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the Pod that fails to0replicas.On every
csi-rbdpluginPod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected Pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state becomesRunning.
Container Cloud upgrade may be blocked by a node being stuck in the Prepare
or Deploy state with error processing package openssh-server.
The issue is caused by customizations in /etc/ssh/sshd_config, such as
additional Match statements. This file is managed by Container Cloud and
must not be altered manually.
As a workaround, move customizations from sshd_config to a new file
in the /etc/ssh/sshd_config.d/ directory.
During a cluster update, a Kubernetes helm-controller Deployment may
get stuck in a restarting Pod loop with Terminating and Running states
flapping. Other Deployment types may also be affected.
As a workaround, restart the Deployment that got stuck:
kubectl -n <affectedProjectName> get deploy <affectedDeployName> -o yaml
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas 0
kubectl -n <affectedProjectName> scale deploy <affectedDeployName> --replicas <replicasNumber>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name containing the cluster with stuck Pods<affectedDeployName>is theDeploymentname that failed to run Pods in the specified project<replicasNumber>is the original number of replicas for theDeploymentthat you can obtain using the get deploy command
During cluster update of a managed bare metal cluster, the false positive
CalicoDataplaneFailuresHigh alert may be firing. Disregard this alert,
which will disappear once cluster update succeeds.
The observed behavior is typical for calico-node during upgrades,
as workload changes occur frequently. Consequently, there is a possibility
of temporary desynchronization in the Calico dataplane. This can occasionally
result in throttling when applying workload changes to the Calico dataplane.
The following table lists the major components and their versions delivered in the Container Cloud 2.25.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Bare metal Updated |
ambasador |
1.38.17 |
baremetal-dnsmasq |
base-alpine-20231013162346 |
|
baremetal-operator |
base-alpine-20231101201729 |
|
baremetal-provider |
1.38.17 |
|
bm-collective |
base-alpine-20230929115341 |
|
cluster-api-provider-baremetal |
1.38.17 |
|
ironic |
yoga-jammy-20230914091512 |
|
ironic-inspector |
yoga-jammy-20230914091512 |
|
ironic-prometheus-exporter |
0.1-20230912104602 |
|
kaas-ipam |
base-alpine-20230911165405 |
|
kubernetes-entrypoint |
1.0.1-27d64fb-20230421151539 |
|
mariadb |
10.6.14-focal-20230912121635 |
|
metallb-controller |
0.13.9-0d8e8043-amd64 |
|
metallb-speaker |
0.13.9-0d8e8043-amd64 |
|
syslog-ng |
base-apline-20230914091214 |
|
IAM |
iam Updated |
2.5.8 |
iam-controller Updated |
1.38.17 |
|
keycloak |
21.1.1 |
|
Container Cloud |
admission-controller Updated |
1.38.17 |
agent-controller Updated |
1.38.17 |
|
ceph-kcc-controller Updated |
1.38.17 |
|
cert-manager-controller |
1.11.0-2 |
|
cinder-csi-plugin New |
1.27.2-8 |
|
client-certificate-controller Updated |
1.38.17 |
|
configuration-collector New |
1.38.17 |
|
csi-attacher New |
4.2.0-2 |
|
csi-node-driver-registrar New |
2.7.0-2 |
|
csi-provisioner New |
3.4.1-2 |
|
csi-resizer New |
1.7.0-2 |
|
csi-snapshotter New |
6.2.1-mcc-1 |
|
event-controller Updated |
1.38.17 |
|
frontend Updated |
1.38.17 |
|
golang |
1.20.4-alpine3.17 |
|
iam-controller Updated |
1.38.17 |
|
kaas-exporter Updated |
1.38.17 |
|
kproxy Updated |
1.38.17 |
|
lcm-controller Updated |
1.38.17 |
|
license-controller Updated |
1.38.17 |
|
livenessprobe New |
2.9.0-2 |
|
machinepool-controller Updated |
1.38.17 |
|
mcc-haproxy |
0.23.0-73-g01aa9b3 |
|
metrics-server |
0.6.3-2 |
|
nginx Updated |
1.38.17 |
|
portforward-controller Updated |
1.38.17 |
|
proxy-controller Updated |
1.38.17 |
|
rbac-controller Updated |
1.38.17 |
|
registry |
2.8.1-5 |
|
release-controller Updated |
1.38.17 |
|
rhellicense-controller Updated |
1.38.17 |
|
scope-controller Updated |
1.38.17 |
|
storage-discovery Updated |
1.38.17 |
|
user-controller Updated |
1.38.17 |
|
OpenStack Updated |
openstack-cloud-controller-manager |
1.27.2-8 |
openstack-cluster-api-controller |
1.38.17 |
|
openstack-provider |
1.38.17 |
|
os-credentials-controller |
1.38.17 |
|
VMware vSphere |
mcc-keepalived Updated |
0.23.0-73-g01aa9b3 |
squid-proxy |
0.0.1-10-g24a0d69 |
|
vsphere-cluster-api-controller Updated |
1.38.17 |
|
vsphere-credentials-controller Updated |
1.38.17 |
|
vsphere-provider Updated |
1.38.17 |
|
vsphere-vm-template-controller Updated |
1.38.17 |
This section lists the artifacts of components included in the Container Cloud release 2.25.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20231012141354 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20231012141354 |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-113-4f8b843.tgz |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.38.17.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.38.17.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.38.17.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.38.17.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.38.17.tgz |
|
metallb |
||
Docker images Updated |
ambasador |
mirantis.azurecr.io/core/external/nginx:1.38.17 |
baremetal-dnsmasq |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-alpine-20231013162346 |
|
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-alpine-20231101201729 |
|
bm-collective |
mirantis.azurecr.io/bm/bm-collective:base-alpine-20230929115341 |
|
cluster-api-provider-baremetal |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.38.17 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20230914091512 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20230914091512 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20230912104602 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-alpine-20230911165405 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230912121635 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.23.0-73-g01aa9b3 |
|
metallb-controller |
mirantis.azurecr.io/bm/metallb/controller:v0.13.9-0d8e8043-amd64 |
|
metallb-speaker |
mirantis.azurecr.io/bm/metallb/speaker:v0.13.9-0d8e8043-amd64 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-apline-20230914091214 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.38.17.tgz |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.38.17.tgz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.38.17.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.38.17.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.38.17.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.38.17.tgz |
|
cinder-csi-plugin New |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.38.17.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.38.17.tgz |
|
configuration-collector New |
https://binary.mirantis.com/core/helm/configuration-collector-1.38.17.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.38.17.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.38.17.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.38.17.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.38.17.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.38.17.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.38.17.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.38.17.tgz |
|
mcc-cache |
||
mcc-cache-warmup |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.38.17.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.38.17.tgz |
|
openstack-cloud-controller-manager New |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.38.17.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.38.17.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.38.17.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.38.17.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.38.17.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.38.17.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.38.17.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.38.17.tgz |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.38.17.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.38.17.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.38.17.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.38.17.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.38.17.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.38.17.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.38.17.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.38.17 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.38.17 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.38.17 |
|
cert-manager-controller Updated |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-2 |
|
cinder-csi-plugin New |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-8 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.38.17 |
|
configuration-collector New |
mirantis.azurecr.io/core/configuration-collector:1.38.17 |
|
csi-attacher New |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-2 |
|
csi-node-driver-registrar New |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-2 |
|
csi-provisioner New |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-2 |
|
csi-resizer New |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-2 |
|
csi-snapshotter New |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-1 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.38.17 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.38.17 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.38.17 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.38.17 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.38.17 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.38.17 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.38.17 |
|
livenessprobe New |
mirantis.azurecr.io/lcm/k8scsi/livenessprobe:v2.9.0-2 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.38.17 |
|
mcc-haproxy Updated |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.23.0-73-g01aa9b3 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.23.0-73-g01aa9b3 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-2 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.38.17 |
|
openstack-cloud-controller-manager Updated |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-8 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.38.17 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.38.17 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.38.17 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.38.17 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.38.17 |
|
registry Updated |
mirantis.azurecr.io/lcm/registry:v2.8.1-6 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.38.17 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.38.17 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.38.17 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.38.17 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.38.17 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.38.17 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.38.17 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.38.17 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts Updated |
iam |
|
Docker images |
keycloak |
mirantis.azurecr.io/iam/keycloak:0.6.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230730124341 |
The table below includes the total numbers of addressed unique and common CVEs by product component since the 2.24.5 patch release. The common CVEs are issues addressed across several images.
Container Cloud component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
Kaas core |
Unique |
7 |
39 |
46 |
Common |
54 |
305 |
359 |
|
Ceph |
Unique |
0 |
1 |
1 |
Common |
0 |
1 |
1 |
|
StackLight |
Unique |
0 |
5 |
5 |
Common |
0 |
13 |
13 |
Mirantis Security Portal
For the detailed list of fixed and existing CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
MOSK CVEs
For the number of fixed CVEs in the MOSK-related components including OpenStack and Tungsten Fabric, refer to MOSK 23.3: Security notes.
This section describes the specific actions you as a cloud operator need to complete before or after your Container Cloud cluster update to the Cluster releases 17.0.0, 16.0.0, or 14.1.0.
Consider this information as a supplement to the generic update procedures published in Operations Guide: Automatic upgrade of a management cluster and Update a managed cluster.
The Cluster release series 14.x and 15.x are the last ones where Ubuntu 18.04 is supported on existing clusters. A Cluster release update to 17.0.0 or 16.0.0 is impossible for a cluster running on Ubuntu 18.04.
Therefore, if your cluster update is blocked, make sure that the operating system on all cluster nodes is upgraded to Ubuntu 20.04 as described in Operations Guide: Upgrade an operating system distribution.
If your cluster has custom etcd storage quota set as described in
Increase storage quota for etcd, before the management cluster upgrade to 2.25.0,
configure LCMMachine resources:
Manually set the
ucp_etcd_storage_quotaparameter inLCMMachineresources of the cluster controller nodes:spec: stateItemsOverwrites: deploy: ucp_etcd_storage_quota: "<custom_etcd_storage_quota_value>"
If the
stateItemsOverwrites.deploysection is already set, appenducp_etcd_storage_quotato the existing parameters.To obtain the list of the cluster
LCMMachineresources:kubectl -n <cluster_namespace> get lcmmachine
To patch the cluster
LCMMachineresources of theTypecontrol:kubectl -n <cluster_namespace> edit lcmmachine <control_lcmmachine_name>
After the management cluster is upgraded to 2.25.0, update your managed cluster to the Cluster release 17.0.0 or 16.0.0.
Manually remove the
ucp_etcd_storage_quotaparameter from thestateItemsOverwrites.deploysection.
The Cluster release 16.x and 17.x series are shipped with MKE 3.7.x. To ensure cluster operability after the update, verify that the TCP port 12392 is allowed in your network for the Container Cloud management cluster nodes.
For the full list of the required ports for MKE, refer to MKE Documentation: Open ports to incoming traffic.
Container Cloud uses the device by-id identifier as the default method
of addressing the underlying devices of Ceph OSDs. This is the only persistent
device identifier for a Ceph cluster that remains stable after cluster
upgrade or any other cluster maintenance.
Therefore, if your existing Ceph clusters are still utilizing the device names
or device by-path symlinks, migrate them to the by-id format as
described in Migrate Ceph cluster to address storage devices using by-id.
If your managed cluster has multiple L2 segments using DHCP relays on the
border switches, after the related management cluster automatically upgrades
to Container Cloud 2.25.0, manually point the DHCP relays on your network
infrastructure to the new IP address of the dhcp-lb service of the
Container Cloud managed cluster in order to successfully provision new nodes
or reprovision existing ones.
To obtain the new IP address:
kubectl -n kaas get service dhcp-lb
This change is required after the product has included the resolution of
the issue related to the incorrect handling of DHCP egress traffic. The fix
involves reconfiguring the external traffic policy for the dhcp-lb
Kubernetes Service. For details about the issue, refer to the
Kubernetes upstream bug.
The Container Cloud patch release 2.24.5, which is based on the 2.24.2 major release, provides the following updates:
Support for the patch Cluster releases 14.0.4 and 15.0.4 that represents Mirantis OpenStack for Kubernetes (MOSK) patch release 23.2.3.
Security fixes for CVEs of Critical and High severity
This patch release also supports the latest major Cluster releases 14.0.1 and 15.0.1. And it does not support greenfield deployments based on deprecated Cluster releases 15.0.3, 15.0.2, 14.0.3, 14.0.2 along with 12.7.x and 11.7.x series. Use the latest available Cluster releases for new deployments instead.
For main deliverables of the parent Container Cloud releases of 2.24.5, refer to 2.24.0 and 2.24.1.
This section lists the components artifacts of the Container Cloud patch release 2.24.5. For artifacts of the Cluster releases introduced in 2.24.5, see patch Cluster releases 15.0.4 and 14.0.4.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20230606121129 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20230606121129 |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.37.25.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.37.25.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.37.25.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.37.25.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.37.25.tgz |
|
metallb |
||
Docker images |
ambasador Updated |
mirantis.azurecr.io/core/external/nginx:1.37.25 |
baremetal-dnsmasq |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-alpine-20230810152159 |
|
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-alpine-20230803175048 |
|
bm-collective |
mirantis.azurecr.io/bm/bm-collective:base-alpine-20230829084517 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.37.25 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230810113432 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230810113432 |
|
ironic-prometheus-exporter Updated |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20230912104602 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-alpine-20230810155639 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230730124341 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.22.0-75-g08569a8 |
|
metallb-controller |
mirantis.azurecr.io/bm/metallb/controller:v0.13.9-53df4a9c-amd64 |
|
metallb-speaker |
mirantis.azurecr.io/bm/metallb/speaker:v0.13.9-53df4a9c-amd64 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-apline-20230814110635 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.37.25.tgz |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.37.25.tgz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.37.25.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.37.25.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.37.25.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.37.25.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.37.25.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.37.25.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.37.25.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.37.25.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.37.25.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.37.25.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.37.25.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.37.25.tgz |
|
mcc-cache |
||
mcc-cache-warmup |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.37.25.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.37.25.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.37.25.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.37.25.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.37.25.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.37.25.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.37.25.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.37.25.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.37.25.tgz |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.37.25.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.37.25.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.37.25.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.37.25.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.37.25.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.37.25.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.37.25.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.37.25 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.37.25 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.37.25 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-2 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.37.25 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.37.25 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.37.25 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.37.25 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.37.25 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.37.25 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.37.25 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.37.25 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.37.25 |
|
mcc-haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.22.0-75-g08569a8 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.22.0-75-g08569a8 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-2 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.37.25 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager-amd64:v1.24.5-13 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.37.25 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.37.25 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.37.25 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.37.25 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.37.25 |
|
registry Updated |
mirantis.azurecr.io/lcm/registry:v2.8.1-5 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.37.25 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.37.25 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.37.25 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.37.25 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.37.25 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.37.25 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.37.25 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.37.25 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts |
iam |
|
Docker images |
keycloak |
mirantis.azurecr.io/iam/keycloak:0.6.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230423170220 |
In total, since Container Cloud 2.24.4, in 2.24.5, 21 Common Vulnerabilities and Exposures (CVE) have been fixed: 18 of critical and 3 of high severity.
The summary table contains the total number of unique CVEs along with the total number of issues fixed across the images.
The full list of the CVEs present in the current Container Cloud release is available at the Mirantis Security Portal.
Severity |
Critical |
High |
Total |
|---|---|---|---|
Unique CVEs |
1 |
1 |
2 |
Total issues across images |
18 |
3 |
21 |
Image |
Component name |
CVE |
|---|---|---|
core/external/nginx |
libwebp |
CVE-2023-4863 (High) |
core/frontend |
libwebp |
CVE-2023-4863 (High) |
lcm/kubernetes/openstack-cloud-controller-manager-amd64 |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
lcm/registry |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
scale/curl-jq |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
stacklight/alertmanager-webhook-servicenow |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
stacklight/grafana-image-renderer |
libwebp |
CVE-2023-4863 (High) |
stacklight/ironic-prometheus-exporter |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
stacklight/sf-reporter |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
The Container Cloud patch release 2.24.4, which is based on the 2.24.2 major release, provides the following updates:
Support for the patch Cluster releases 14.0.3 and 15.0.3 that represents Mirantis OpenStack for Kubernetes (MOSK) patch release 23.2.2.
Support for the multi-rack topology on bare metal managed clusters
Support for configuration of the etcd storage quota
Security fixes for CVEs of Critical and High severity
This patch release also supports the latest major Cluster releases 14.0.1 and 15.0.1. And it does not support greenfield deployments based on deprecated Cluster releases 15.0.2, 14.0.2, along with 12.7.x and 11.7.x series. Use the latest available Cluster releases for new deployments instead.
For main deliverables of the parent Container Cloud releases of 2.24.4, refer to 2.24.0 and 2.24.1.
This section outlines new features and enhancements introduced in the Container Cloud patch release 2.24.4.
Added the capability to configure storage quota, which is 2 GB by default. You may need to increase the default etcd storage quota if etcd runs out of space and there is no other way to clean up the storage on your management or managed cluster.
TechPreview
Added support for the multi-rack topology on bare metal managed clusters.
Implementation of the multi-rack topology implies the use of Rack and
MultiRackCluster objects that support configuration of BGP announcement
of the cluster API load balancer address.
You can now create a managed cluster where cluster nodes including Kubernetes masters are distributed across multiple racks without L2 layer extension between them, and use BGP for announcement of the cluster API load balancer address and external addresses of Kubernetes load-balanced services.
Learn more
This section lists the components artifacts of the Container Cloud patch release 2.24.4. For artifacts of the Cluster releases introduced in 2.24.4, see patch Cluster releases 15.0.3 and 14.0.3.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20230606121129 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20230606121129 |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.37.24.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.37.24.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.37.24.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.37.24.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.37.24.tgz |
|
metallb |
||
Docker images |
ambasador Updated |
mirantis.azurecr.io/core/external/nginx:1.37.24 |
baremetal-dnsmasq |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-alpine-20230810152159 |
|
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-alpine-20230803175048 |
|
bm-collective Updated |
mirantis.azurecr.io/bm/bm-collective:base-alpine-20230829084517 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.37.24 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230810113432 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230810113432 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20230531081117 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-alpine-20230810155639 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230730124341 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.22.0-66-ga855169 |
|
metallb-controller |
mirantis.azurecr.io/bm/metallb/controller:v0.13.9-53df4a9c-amd64 |
|
metallb-speaker |
mirantis.azurecr.io/bm/metallb/speaker:v0.13.9-53df4a9c-amd64 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-apline-20230814110635 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com//core/binbootstrap-darwin-1.37.24.tgz |
bootstrap-linux |
https://binary.mirantis.com//core/binbootstrap-linux-1.37.24.tgz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.37.24.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.37.24.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.37.24.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.37.24.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.37.24.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.37.24.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.37.24.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.37.24.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.37.24.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.37.24.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.37.24.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.37.24.tgz |
|
mcc-cache |
||
mcc-cache-warmup |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.37.24.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.37.24.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.37.24.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.37.24.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.37.24.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.37.24.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.37.24.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.37.24.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.37.24.tgz |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.37.24.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.37.24.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.37.24.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.37.24.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.37.24.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.37.24.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.37.24.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.37.24 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.37.24 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.37.24 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-2 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.37.24 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.37.24 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.37.24 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.37.24 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.37.24 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.37.24 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.37.24 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.37.24 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.37.24 |
|
mcc-haproxy Updated |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.22.0-66-ga855169 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.22.0-66-ga855169 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-2 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.37.24 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager-amd64:v1.24.5-10-g93314b86 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.37.24 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.37.24 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.37.24 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.37.24 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.37.24 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-4 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.37.24 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.37.24 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.37.24 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.37.24 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.37.24 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.37.24 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.37.24 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.37.24 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts |
iam |
|
Docker images |
keycloak |
mirantis.azurecr.io/iam/keycloak:0.6.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230423170220 |
In total, since Container Cloud 2.24.3, in 2.24.4, 18 Common Vulnerabilities and Exposures (CVE) have been fixed: 3 of critical and 15 of high severity.
The summary table contains the total number of unique CVEs along with the total number of issues fixed across the images.
The full list of the CVEs present in the current Container Cloud release is available at the Mirantis Security Portal.
Severity |
Critical |
High |
Total |
|---|---|---|---|
Unique CVEs |
1 |
10 |
11 |
Total issues across images |
3 |
15 |
18 |
Image |
Component name |
CVE |
|---|---|---|
iam/keycloak-gatekeeper |
golang.org/x/crypto |
CVE-2021-43565 (High) |
CVE-2022-27191 (High) |
||
CVE-2020-29652 (High) |
||
golang.org/x/net |
CVE-2022-27664 (High) |
|
CVE-2021-33194 (High) |
||
golang.org/x/text |
CVE-2021-38561 (High) |
|
CVE-2022-32149 (High) |
||
github.com/prometheus/client_golang |
CVE-2022-21698 (High) |
|
scale/psql-client |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
libpq |
CVE-2023-39417 (High) |
|
postgresql13-client |
CVE-2023-39417 (High) |
|
stacklight/alerta-web |
grpcio |
CVE-2023-33953 (High) |
libpq |
CVE-2023-39417 (High) |
|
postgresql15-client |
CVE-2023-39417 (High) |
|
stacklight/pgbouncer |
libpq |
CVE-2023-39417 (High) |
postgresql-client |
CVE-2023-39417 (High) |
The following issues have been addressed in the Container Cloud patch release 2.24.4 along with the patch Cluster releases 14.0.3 and 15.0.3.
[34200][Ceph] Fixed the watch command missing in the
rook-ceph-toolsPod.[34836][Ceph] Fixed
ceph-disk-daemonspawning a lot of zombie processes.
The Container Cloud patch release 2.24.3, which is based on the 2.24.2 major release, provides the following updates:
Support for MKE 3.6.6. For details, see MKE documentation: MKE release notes.
Support for enablement of Kubernetes auditing and profiling options using the Container Cloud
Clusterobject on managed clusters. For details, see Configure Kubernetes auditing and profiling.Updated
docker-ee-clito 20.10.18 for MCR 20.10.17 to fix the following CVEs: CVE-2023-28840, CVE-2023-28642, CVE-2022-41723.Security fixes for CVEs of High severity.
Support for the patch Cluster releases 14.0.2 and 15.0.2 that represents Mirantis OpenStack for Kubernetes (MOSK) patch release. 23.2.1.
This patch release also supports the latest major Cluster releases 14.0.1 and 15.0.1. And it does not support greenfield deployments based on deprecated Cluster release 14.0.0 along with 12.7.x and 11.7.x series. Use the latest available Cluster releases instead.
For main deliverables of the parent Container Cloud releases of 2.24.3, refer to 2.24.0 and 2.24.1.
This section lists the components artifacts of the Container Cloud patch release 2.24.3. For artifacts of the Cluster releases introduced in 2.24.3, see Cluster releases 15.0.2 and 14.0.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20230606121129 |
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20230606121129 |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.37.23.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.37.23.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.37.23.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.37.23.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.37.23.tgz |
|
metallb |
||
Docker images |
ambasador Updated |
mirantis.azurecr.io/core/external/nginx:1.37.23 |
baremetal-dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-alpine-20230810152159 |
|
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-alpine-20230803175048 |
|
bm-collective Updated |
mirantis.azurecr.io/bm/bm-collective:base-alpine-20230810134945 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.37.23 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230810113432 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230810113432 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20230531081117 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-alpine-20230810155639 |
|
kubernetes-entrypoint Updated |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230730124341 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.22.0-63-g8f4f248 |
|
metallb-controller Updated |
mirantis.azurecr.io/bm/metallb/controller:v0.13.9-53df4a9c-amd64 |
|
metallb-speaker Updated |
mirantis.azurecr.io/bm/metallb/speaker:v0.13.9-53df4a9c-amd64 |
|
syslog-ng Updated |
mirantis.azurecr.io/bm/syslog-ng:base-apline-20230814110635 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com//core/binbootstrap-darwin-1.37.23.tgz |
bootstrap-linux |
https://binary.mirantis.com//core/binbootstrap-linux-1.37.23.tgz |
|
Helm charts |
admission-controller Updated |
https://binary.mirantis.com/core/helm/admission-controller-1.37.23.tgz |
agent-controller Updated |
https://binary.mirantis.com/core/helm/agent-controller-1.37.23.tgz |
|
ceph-kcc-controller Updated |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.37.23.tgz |
|
cert-manager Updated |
https://binary.mirantis.com/core/helm/cert-manager-1.37.23.tgz |
|
client-certificate-controller Updated |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.37.23.tgz |
|
event-controller Updated |
https://binary.mirantis.com/core/helm/event-controller-1.37.23.tgz |
|
iam-controller Updated |
https://binary.mirantis.com/core/helm/iam-controller-1.37.23.tgz |
|
kaas-exporter Updated |
https://binary.mirantis.com/core/helm/kaas-exporter-1.37.23.tgz |
|
kaas-public-api Updated |
https://binary.mirantis.com/core/helm/kaas-public-api-1.37.23.tgz |
|
kaas-ui Updated |
||
lcm-controller Updated |
https://binary.mirantis.com/core/helm/lcm-controller-1.37.23.tgz |
|
license-controller Updated |
https://binary.mirantis.com/core/helm/license-controller-1.37.23.tgz |
|
machinepool-controller Updated |
https://binary.mirantis.com/core/helm/machinepool-controller-1.37.23.tgz |
|
mcc-cache Updated |
||
mcc-cache-warmup Updated |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.37.23.tgz |
|
metrics-server Updated |
https://binary.mirantis.com/core/helm/metrics-server-1.37.23.tgz |
|
openstack-provider Updated |
https://binary.mirantis.com/core/helm/openstack-provider-1.37.23.tgz |
|
os-credentials-controller Updated |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.37.23.tgz |
|
portforward-controller Updated |
https://binary.mirantis.com/core/helm/portforward-controller-1.37.23.tgz |
|
proxy-controller Updated |
https://binary.mirantis.com/core/helm/proxy-controller-1.37.23.tgz |
|
rbac-controller Updated |
https://binary.mirantis.com/core/helm/rbac-controller-1.37.23.tgz |
|
release-controller Updated |
https://binary.mirantis.com/core/helm/release-controller-1.37.23.tgz |
|
rhellicense-controller Updated |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.37.23.tgz |
|
scope-controller Updated |
https://binary.mirantis.com/core/helm/scope-controller-1.37.23.tgz |
|
squid-proxy Updated |
https://binary.mirantis.com/core/helm/squid-proxy-1.37.23.tgz |
|
storage-discovery Updated |
https://binary.mirantis.com/core/helm/storage-discovery-1.37.23.tgz |
|
user-controller Updated |
https://binary.mirantis.com/core/helm/user-controller-1.37.23.tgz |
|
vsphere-credentials-controller Updated |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.37.23.tgz |
|
vsphere-provider Updated |
https://binary.mirantis.com/core/helm/vsphere-provider-1.37.23.tgz |
|
vsphere-vm-template-controller Updated |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.37.23.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.37.23 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.37.23 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.37.23 |
|
cert-manager-controller Updated |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0-2 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.37.23 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.37.23 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.37.23 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.37.23 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.37.23 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.37.23 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.37.23 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.37.23 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.37.23 |
|
mcc-haproxy Updated |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.22.0-63-g8f4f248 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.22.0-63-g8f4f248 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-2 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.37.23 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager-amd64:v1.24.5-10-g93314b86 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.37.23 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.37.23 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.37.23 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.37.23 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.37.23 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-4 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.37.23 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.37.23 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.37.23 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.37.23 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.37.23 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.37.23 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.37.23 |
|
vsphere-vm-template-controller Updated |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.37.23 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts |
iam Updated |
|
Docker images |
keycloak |
mirantis.azurecr.io/iam/keycloak:0.6.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230423170220 |
In total, since Container Cloud 2.24.1, in 2.24.3, 63 Common Vulnerabilities and Exposures (CVE) with high severity have been fixed.
The summary table contains the total number of unique CVEs along with the total number of issues fixed across the images.
The full list of the CVEs present in the current Container Cloud release is available at the Mirantis Security Portal.
Severity |
Critical |
High |
Total |
|---|---|---|---|
Unique CVEs |
0 |
15 |
15 |
Total issues across images |
0 |
63 |
63 |
Image |
Component name |
CVE |
|---|---|---|
bm/external/metallb/controller |
libcrypto3 |
CVE-2023-0464 (High) |
CVE-2023-2650 (High) |
||
libssl3 |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
golang.org/x/net |
CVE-2022-41723 (High) |
|
bm/external/metallb/speaker |
libcrypto3 |
CVE-2023-2650 (High) |
CVE-2023-0464 (High) |
||
libssl3 |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
golang.org/x/net |
CVE-2022-41723 (High) |
|
core/external/cert-manager-cainjector |
golang.org/x/net |
CVE-2022-41723 (High) |
core/external/cert-manager-controller |
golang.org/x/net |
CVE-2022-41723 (High) |
core/external/cert-manager-webhook |
golang.org/x/net |
CVE-2022-41723 (High) |
core/external/nginx |
nghttp2-libs |
CVE-2023-35945 (High) |
core/frontend |
nghttp2-libs |
CVE-2023-35945 (High) |
lcm/external/csi-attacher |
github.com/prometheus/client_golang |
CVE-2022-21698 (High) |
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
gopkg.in/yaml.v3 |
CVE-2022-28948 (High) |
|
lcm/external/csi-node-driver-registrar |
github.com/prometheus/client_golang |
CVE-2022-21698 (High) |
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/external/csi-provisioner |
golang.org/x/crypto |
CVE-2021-43565 (High) |
CVE-2022-27191 (High) |
||
github.com/prometheus/client_golang |
CVE-2022-21698 (High) |
|
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
gopkg.in/yaml.v3 |
CVE-2022-28948 (High) |
|
lcm/external/csi-resizer |
github.com/prometheus/client_golang |
CVE-2022-21698 (High) |
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
gopkg.in/yaml.v3 |
CVE-2022-28948 (High) |
|
lcm/external/csi-snapshotter |
github.com/prometheus/client_golang |
CVE-2022-21698 (High) |
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
gopkg.in/yaml.v3 |
CVE-2022-28948 (High) |
|
lcm/external/livenessprobe |
golang.org/x/text |
CVE-2021-38561 (High) |
CVE-2022-32149 (High) |
||
github.com/prometheus/client_golang |
CVE-2022-21698 (High) |
|
golang.org/x/net |
CVE-2022-27664 (High) |
|
lcm/kubernetes/cinder-csi-plugin-amd64 |
libpython3.7-minimal |
CVE-2021-3737 (High) |
CVE-2020-10735 (High) |
||
CVE-2022-45061 (High) |
||
CVE-2015-20107 (High) |
||
libpython3.7-stdlib |
CVE-2021-3737 (High) |
|
CVE-2020-10735 (High) |
||
CVE-2022-45061 (High) |
||
CVE-2015-20107 (High) |
||
python3.7 |
CVE-2021-3737 (High) |
|
CVE-2020-10735 (High) |
||
CVE-2022-45061 (High) |
||
CVE-2015-20107 (High) |
||
python3.7-minimal |
CVE-2021-3737 (High) |
|
CVE-2020-10735 (High) |
||
CVE-2022-45061 (High) |
||
CVE-2015-20107 (High) |
||
libssl1.1 |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
openssl |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
lcm/mcc-haproxy |
nghttp2-libs |
CVE-2023-35945 (High) |
openstack/ironic |
cryptography |
CVE-2023-2650 (High) |
openstack/ironic-inspector |
cryptography |
CVE-2023-2650 (High) |
The following issues have been addressed in the Container Cloud patch release 2.24.3 along with the patch Cluster releases 14.0.2 and 15.0.2.
[34638][BM] Fixed the issue with failure to delete a management cluster due to the issue with secrets during machine deletion.
[34220][BM] Fixed the issue with
ownerReferencesbeing lost forHardwareDataafter pivoting during a management cluster bootstrap.[34280][LCM] Fixed the issue with no cluster reconciles generated if a cluster is stuck on waiting for agents upgrade.
[33439][TLS] Fixed the issue with
client-certificate-controllersilently replacing user-provided key if PEM header and key format do not match.[33686][audit] Fixed the issue with rules provided by the
dockerauditd preset not covering the Sysdig Docker CIS benchmark.[34080][StackLight] Fixed the issue with missing events in OpenSearch that have
lastTimestampset tonullandeventTimeset to a non-nullvalue.
The Container Cloud major release 2.24.2 based on 2.24.0 and 2.24.1 provides the following:
Introduces support for the major Cluster release 15.0.1 that is based on the Cluster release 14.0.1 and represents Mirantis OpenStack for Kubernetes (MOSK) 23.2. This Cluster release is based on the updated version of Mirantis Kubernetes Engine 3.6.5 with Kubernetes 1.24 and Mirantis Container Runtime 20.10.17.
Supports the latest Cluster release 14.0.1.
Does not support greenfield deployments based on deprecated Cluster release 14.0.0 along with 12.7.x and 11.7.x series. Use the latest available Cluster releases of the series instead.
For main deliverables of the Container Cloud release 2.24.2, refer to its parent release 2.24.0:
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
The Container Cloud patch release 2.24.1 based on 2.24.0
includes updated baremetal-operator, admission-controller, and iam
artifacts and provides hot fixes for the following issues:
[34218] Fixed the issue with the
iam-keycloakPod being stuck in thePendingstate during Keycloak upgrade to version 21.1.1.[34247] Fixed the issue with MKE backup failing during cluster update due to wrong permissions in the etcd backup directory. If the issue still persists, which may occur on clusters that were originally deployed using early Container Cloud releases delivered in 2020-2021, follow the workaround steps described in Known issues: LCM.
Note
Container Cloud patch release 2.24.1 does not introduce new Cluster releases.
For main deliverables of the Container Cloud release 2.24.1, refer to its parent release 2.24.0:
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
Important
Container Cloud 2.24.0 has been successfully applied to a certain number of clusters. The 2.24.0 related documentation content fully applies to these clusters.
If your cluster started to update but was reverted to the previous product version or the update is stuck, you automatically receive the 2.24.1 patch release with the bug fixes to unblock the update to the 2.24 series.
There is no impact on the cluster workloads. For details on the patch release, see 2.24.1.
The Mirantis Container Cloud GA release 2.24.0:
Introduces support for the Cluster release 14.0.0 that is based on Mirantis Container Runtime 20.10.17 and Mirantis Kubernetes Engine 3.6.5 with Kubernetes 1.24.
Supports the latest major and patch Cluster releases of the 12.7.x series that supports Mirantis OpenStack for Kubernetes (MOSK) 23.1 series.
Does not support greenfield deployments on deprecated Cluster releases 12.7.3, 11.7.4, or earlier patch releases, 12.5.0, or 11.7.0. Use the latest available Cluster releases of the series instead.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.24.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.24.0. For the list of enhancements in the Cluster release 14.0.0 that is introduced by the Container Cloud release 2.24.0, see the 14.0.0.
Automated upgrade of operating system on bare metal clusters
Deletion of persistent volumes during an OpenStack-based cluster deletion
Creation and deletion of bare metal host credentials using web UI
Support status of the feature
Since MOSK 23.2, the feature is generally available for MOSK clusters.
Since Container Cloud 2.24.2, the feature is generally available for any type of bare metal clusters.
Since Container Cloud 2.24.0, the feature is available as Technology Preview for management and regional clusters only.
Implemented automatic in-place upgrade of an operating system (OS) distribution on bare metal clusters. The OS upgrade occurs as part of cluster update that requires machines reboot. The OS upgrade workflow is as follows:
The distribution ID value is taken from the
idfield of the distribution from theallowedDistributionslist in the spec of theClusterReleaseobject.The distribution that has the
default: truevalue is used during update. This distribution ID is set in thespec:providerSpec:value:distributionfield of theMachineobject during cluster update.
On management and regional clusters, the operating system upgrades automatically during cluster update. For managed clusters, an in-place OS distribution upgrade should be performed between cluster updates. This scenario implies a machine cordoning, draining, and reboot.
Warning
During the course of the Container Cloud 2.24.x series, Mirantis highly recommends upgrading an operating system on your cluster machines to Ubuntu 20.04 before the next major Cluster release becomes available. It is not mandatory to upgrade all machines at once. You can upgrade them one by one or in small batches, for example, if the maintenance window is limited in time.
Otherwise, the Cluster release update of the 18.04 based clusters will become impossible as of the Cluster releases introduced in Container Cloud 2.25.0, in which only the 20.04 distribution will be supported.
TechPreview
Added initial Technology Preview support for WireGuard that enables traffic
encryption on the Kubernetes workloads network. Set secureOverlay: true
in the Cluster object during deployment of management, regional, or
managed bare metal clusters to enable WireGuard encryption.
Also, added the possibility to configure the maximum transmission unit (MTU) size for Calico that is required for the WireGuard functionality and allows maximizing network performance.
Note
For MOSK-based deployments, the feature support is available since MOSK 23.2.
For management and regional clusters
Caution
For managed clusters, this object is available as Technology Preview and will become generally available in one of the following Container Cloud releases.
Introduced the following MetalLB configuration changes and objects related to address allocation and announcement of services LB for bare metal and vSphere providers:
Introduced the
MetalLBConfigTemplateobject for bare metal and theMetalLBConfigobject for vSphere to be used as default and recommended.For vSphere, during creation of clusters of any type, now a separate
MetalLBConfigobject is created instead of corresponding settings in theClusterobject.The use of either
Subnetobjects without the new MetalLB objects or theconfigInlineMetalLB value of theClusterobject is deprecated and will be removed in one of the following releases.If the
MetalLBConfigobject is not used for MetalLB configuration related to address allocation and announcement of services LB, then automated migration applies during creation of clusters of any type or cluster update to Container Cloud 2.24.0.During automated migration, the
MetalLBConfigandMetalLBConfigTemplateobjects for bare metal or theMetalLBConfigfor vSphere are created and contents of the MetalLB chartconfigInlinevalue is converted to the parameters of theMetalLBConfigTemplateobject for bare metal or of theMetalLBConfigobject for vSphere.
The following changes apply to the bare metal bootstrap procedure:
Moved the following environment variables from
cluster.yaml.templateto the dedicatedipam-objects.yaml.template:BOOTSTRAP_METALLB_ADDRESS_POOLKAAS_BM_BM_DHCP_RANGESET_METALLB_ADDR_POOLSET_LB_HOST
Modified the default network configuration. Now it includes a bond interface and separated PXE and management networks. Mirantis recommends using separate PXE and management networks for management and regional clusters.
TechPreview
Added support for RHEL 8.7 on the vSphere-based management, regional, and managed clusters.
Caution
Container Cloud does not support mixed operating systems, RHEL combined with Ubuntu, in one cluster.
Implemented the possibility to use custom Octavia Amphora flavors that you can
enable in spec:providerSpec section of the Cluster object using
serviceAnnotations:loadbalancer.openstack.org/flavor-id during
management or regional cluster deployment.
Note
For managed clusters, you can enable the feature through the Container Cloud API. The web UI functionality will be added in one of the following Container Cloud releases.
Completed the development of persistent volumes deletion during an OpenStack-based managed cluster deletion by implementing the Delete all volumes in the cluster check box in the cluster deletion menu of the Container Cloud web UI.
Caution
The feature applies only to volumes created on clusters that are based on or updated to the Cluster release 11.7.0 or later.
If you added volumes to an existing cluster before it was updated to the Cluster release 11.7.0, delete such volumes manually after the cluster deletion.
Upgraded the Keycloak major version from 18.0.0 to 21.1.1. For the list of new features and enhancements, see Keycloak Release Notes.
The upgrade path is fully automated. No data migration or custom LCM changes are required.
Important
After the Keycloak upgrade, access the Keycloak Admin Console
using the new URL format: https://<keycloak.ip>/auth instead of
https://<keycloak.ip>. Otherwise, the Resource not found
error displays in a browser.
TechPreview
Added initial Technology Preview support for custom host names of machines on
any supported provider and any cluster type. When enabled, any machine host
name in a particular region matches the related Machine object name. For
example, instead of the default kaas-node-<UID>, a machine host name will
be master-0. The custom naming format is more convenient and easier to
operate with.
You can enable the feature before or after management or regional cluster deployment. If enabled after deployment, custom host names will apply to all newly deployed machines in the region. Existing host names will remain the same.
TechPreview
Added initial Technology Preview support for parallelizing of node update
operations that significantly improves the efficiency of your cluster. To
configure the parallel node update, use the following parameters located under
spec.providerSpec of the Cluster object:
maxWorkerUpgradeCount- maximum number of worker nodes for simultaneous update to limit machine draining during updatemaxWorkerPrepareCount- maximum number of workers for artifacts downloading to limit network load during update
Note
For MOSK clusters, you can start using this feature during cluster update from 23.1 to 23.2. For details, see MOSK documentation: Parallelizing node update operations.
Implemented the CacheWarmupRequest resource to predownload, aka warm up,
a list of artifacts included in a given set of Cluster releases into the
mcc-cache service only once per release. The feature facilitates and
speeds up deployment and update of managed clusters.
After a successful cache warm-up, the object of the CacheWarmupRequest
resource is automatically deleted from the cluster and cache remains for
managed clusters deployment or update until next Container Cloud auto-upgrade
of the management or regional cluster.
Caution
If the disk space for cache runs out, the cache for the oldest object is evicted. To avoid running out of space in the cache, verify and adjust its size before each cache warm-up.
Note
For MOSK-based deployments, the feature support is available since MOSK 23.2.
TechPreview
Added initial Technology Preview support for the Linux Audit daemon auditd to monitor activity of cluster processes on any type of Container Cloud cluster. The feature is an essential requirement for many security guides that enables auditing of any cluster process to detect potential malicious activity.
You can enable and configure auditd either during or after cluster deployment
using the Cluster object.
Note
For MOSK-based deployments, the feature support is available since MOSK 23.2.
TechPreview
Enhanced TLS certificates configuration for cluster applications:
Added support for configuration of TLS certificates for MKE on management or regional clusters to the existing support on managed clusters.
Implemented the ability to configure TLS certificates using the Container Cloud web UI through the Security section located in the More > Configure cluster menu.
Expanded the capability to perform a graceful reboot on a management, regional, or managed cluster for all supported providers by adding the Reboot machines option to the cluster menu in the Container Cloud web UI. The feature allows for a rolling reboot of all cluster machines without workloads interruption. The reboot occurs in the order of cluster upgrade policy.
Note
For MOSK-based deployments, the feature support is available since MOSK 23.2.
Improved management of bare metal host credentials using the Container Cloud web UI:
Added the Add Credential menu to the Credentials tab. The feature facilitates association of credentials with bare metal hosts created using the BM Hosts tab.
Implemented automatic deletion of credentials during deletion of bare metal hosts after deletion of managed cluster.
Improved the Node Labels menu in the Container Cloud web UI by making it more intuitive. Replaced the greyed out (disabled) label names with the No labels have been assigned to this machine. message and the Add a node label button link.
Also, added the possibility to configure node labels for machine pools after deployment using the More > Configure Pool option.
On top of continuous improvements delivered to the existing Container Cloud guides, added the documentation on managing Ceph OSDs with a separate metadata device.
The following issues have been addressed in the Mirantis Container Cloud release 2.24.0 along with the Cluster release 14.0.0. For the list of hot fixes delivered in the 2.24.1 patch release, see 2.24.1.
[5981] Fixed the issue with upgrade of a cluster containing more than 120 nodes getting stuck on one node with errors about IP addresses exhaustion in the
dockerlogs. On existing clusters, after updating to the Cluster release 14.0.0 or later, you can optionally remove the abandonedmke-overlaynetwork using docker network rm mke-overlay.[29604] Fixed the issue with the false positive
failed to get kubeconfigerror occurring on theWaiting for TLS settings to be appliedstage during TLS configuration.[29762] Fixed the issue with a wrong IP address being assigned after the MetalLB controller restart.
[30635] Fixed the issue with the
pg_autoscalermodule of Ceph Manager failing with the pool <poolNumber> has overlapping roots error if a Ceph cluster contains a mix of pools withdeviceClasseither explicitly specified or not specified.[30857] Fixed the issue with irrelevant error message displaying in the
osd-preparePod during the deployment of Ceph OSDs on removable devices on AMD nodes. Now, the error message clearly states that removable devices (with hotplug enabled) are not supported for deploying Ceph OSDs. This issue has been addressed since the Cluster release 14.0.0.[30781] Fixed the issue with cAdvisor failing to collect metrics on CentOS-based deployments. Missing metrics affected the
KubeContainersCPUThrottlingHighalert and the following Grafana dashboards: Kubernetes Containers, Kubernetes Pods, and Kubernetes Namespaces.[31288] Fixed the issue with Fluentd agent failing and the
fluentd-logsPods reporting themaximum open shardslimit error, thus preventing OpenSearch to accept new logs. The fix enables the possibility to increase the limit for maximum open shards usingcluster.max_shards_per_node. For details, see Tune StackLight for long-term log retention.[31485] Fixed the issue with Elasticsearch Curator not deleting indices according to the configured retention period on any type of Container Cloud clusters.
This section lists known issues with workarounds for the Mirantis Container Cloud releases 2.24.0 and 2.24.1 including the Cluster release 14.0.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
During netplan configuration after cluster deployment, changes in the
IpamHost object are not propagated to LCMMachine.
The workaround is to manually add any new label to the labels section
of the Machine object for the target host, which triggers machine
reconciliation and propagates network changes.
Due to the upstream Calico issue, on clusters with WireGuard enabled, the WireGuard interface on a node may not have the IPv4 address assigned. This leads to broken inter-Pod communication between the affected node and other cluster nodes.
The node is affected if the IP address is missing on the WireGuard interface:
ip a show wireguard.cali
Example of system response:
40: wireguard.cali: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000 link/none
The workaround is to manually restart the calico-node Pod to allocate
the IPv4 address on the WireGuard interface:
docker restart $(docker ps -f "label=name=Calico node" -q)
The cluster update is stuck on waiting for agents to upgrade with the following message in the cluster status:
Helm charts are not installed(upgraded) yet. Not ready releases: managed-lcm-api
The workaround is to retrigger the cluster update, for example, by adding an annotation to the cluster object:
Log in to a local machine where your management cluster
kubeconfigis located and where kubectl is installed.Open the management
Clusterobject for editing:kubectl edit cluster <mgmtClusterName>
Set the annotation
force-reconcile: true.
The cluster update is blocked with the following message in the cluster status:
Helm charts are not installed(upgraded) yet.
Not ready releases: iam, managed-lcm-api, admission-controller, baremetal-operator.
Workaround:
Log in to a local machine where your management cluster
kubeconfigis located and wherekubectlis installed.Open the
baremetal-operatordeployment object for editing:kubectl edit deploy -n kaas baremetal-operator
Modify the image that the
initcontainer and the container are using tomirantis.azurecr.io/bm/baremetal-operator:base-alpine-20230721153358.
The baremetal-operator pods will be re-created, and the cluster update
will get unblocked.
Fixed in 17.0.1 and 16.0.1 for MKE 3.7.2
Due to the upstream Calico issue, a controller node
cannot be deleted if the calico-node Pod is stuck blocking node deletion.
One of the symptoms is the following warning in the baremetal-operator
logs:
Resolving dependency Service dhcp-lb in namespace kaas failed: \
the server was unable to return a response in the time allotted,\
but may still be processing the request (get endpoints dhcp-lb).
As a workaround, delete the Pod that is stuck to retrigger the node deletion.
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
If a baremetal-based regional cluster deployment fails before pivoting is done, the corresponding region deletion fails.
Workaround:
Using the command below, manually delete all possible traces of the failed
regional cluster deployment, including but not limited to the following
objects that contain the kaas.mirantis.com/region label of the affected
region:
clustermachinebaremetalhostbaremetalhostprofilel2templatesubnetipamhostipaddr
kubectl delete <objectName> -l kaas.mirantis.com/region=<regionName>
Warning
Do not use the same region name again after the regional cluster deployment failure since some objects that reference the region name may still exist.
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
On MOSK clusters, the Ansible provisioner may hang in a loop while trying to remove LVM thin pool logical volumes (LVs) due to issues with volume detection before removal. The Ansible provisioner cannot remove LVM thin pool LVs correctly, so it consistently detects the same volumes whenever it scans disks, leading to a repetitive cleanup process.
The following symptoms mean that a cluster can be affected:
A node was configured to use thin pool LVs. For example, it had the OpenStack Cinder role in the past.
A bare metal node deployment flaps between
provisioniniganddeprovisioningstates.In the Ansible provisioner logs, the following example warnings are growing:
88621.log:7389:2023-06-22 16:30:45.109 88621 ERROR ansible.plugins.callback.ironic_log [-] Ansible task clean : fail failed on node 14eb0dbc-c73a-4298-8912-4bb12340ff49: {'msg': 'There are more devices to clean', '_ansible_no_log': None, 'changed': False}
Important
There are more devices to cleanis a regular warning indicating some in-progress tasks. But if the number of such warnings is growing along with the node flapping betweenprovisioniniganddeprovisioningstates, the cluster is highly likely affected by the issue.
As a workaround, erase disks manually using any preferred tool.
MKE backup may fail during update of a management, regional, or managed
cluster due to wrong permissions in the etcd backup
/var/lib/docker/volumes/ucp-backup/_data directory.
The issue affects only clusters that were originally deployed using early Container Cloud releases delivered in 2020-2021.
Workaround:
Fix permissions on all affected nodes:
chown -R nobody:nogroup /var/lib/docker/volumes/ucp-backup/_data
Using the admin
kubeconfig, increase themkeUpgradeAttemptsvalue:Open the
LCMClusterobject of the management cluster for editing:kubectl edit lcmcluster <mgmtClusterName>
In the
mkeUpgradeAttemptsfield, increase the value to6. Once done, MKE backup retriggers automatically.
During replacement of a master node on a cluster of any type, the
calico-node Pod fails to start on a new node that has the same IP address
as the node being replaced.
Workaround:
Log in to any
masternode.From a CLI with an MKE client bundle, create a shell alias to start calicoctl using the
mirantis/ucp-dsinfoimage:alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/key.pem \ -e ETCD_CA_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/ca.pem \ -e ETCD_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/cert.pem \ -v /var/run/calico:/var/run/calico \ -v /var/lib/docker/volumes/ucp-kv-certs/_data:/var/lib/docker/volumes/ucp-kv-certs/_data:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl \ "
alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/ucp-node-certs/key.pem \ -e ETCD_CA_CERT_FILE=/ucp-node-certs/ca.pem \ -e ETCD_CERT_FILE=/ucp-node-certs/cert.pem \ -v /var/run/calico:/var/run/calico \ -v ucp-node-certs:/ucp-node-certs:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl --allow-version-mismatch \ "
In the above command, replace the following values with the corresponding settings of the affected cluster:
<etcdEndpoint>is the etcd endpoint defined in the Calico configuration file. For example,ETCD_ENDPOINTS=127.0.0.1:12378<mkeVersion>is the MKE version installed on your cluster. For example,mirantis/ucp-dsinfo:3.5.7.
Verify the node list on the cluster:
kubectl get node
Compare this list with the node list in Calico to identify the old node:
calicoctl get node -o wide
Remove the old node from Calico:
calicoctl delete node kaas-node-<nodeID>
During replacement of a manager machine, the following problems may occur:
The system adds the node to Docker swarm but not to Kubernetes
The node
Deploymentgets stuck with failed RethinkDB health checks
Workaround:
Delete the failed node.
Wait for the MKE cluster to become healthy. To monitor the cluster status:
Log in to the MKE web UI as described in Connect to the Mirantis Kubernetes Engine web UI.
Monitor the cluster status as described in MKE Operations Guide: Monitor an MKE cluster with the MKE web UI.
Deploy a new node.
During the unsafe or forced deletion of a manager machine running the
calico-kube-controllers Pod in the kube-system namespace,
the following issues occur:
The
calico-kube-controllersPod fails to clean up resources associated with the deleted nodeThe
calico-nodePod may fail to start up on a newly created node if the machine is provisioned with the same IP address as the deleted machine had
As a workaround, before deletion of the node running the
calico-kube-controllers Pod, cordon and drain the node:
kubectl cordon <nodeName>
kubectl drain <nodeName>
Due to the upstream Ceph issue,
on clusters with the Federal Information Processing Standard (FIPS) mode
enabled, the Ceph rook-operator fails to connect to Ceph RADOS Gateway
(RGW) pods.
As a workaround, do not place Ceph RGW pods on nodes where FIPS mode is enabled.
On management clusters based on Ubuntu 18.04, after the cluster starts upgrading from 2.23.5 to 2.24.1, all controller machines are stuck in the In Progress state with the Distribution update in progress hover message displaying in the Container Cloud web UI.
The issue is caused by clusterworkloadlock containing the outdated
release name in the status.release field, which blocks LCM Controller
to proceed with machine upgrade. This behavior is caused by a complete removal
of the ceph-controller chart from management clusters and a failed
ceph-clusterworkloadlock removal.
The workaround is to manually remove ceph-clusterworkloadlock from the
management cluster to unblock upgrade:
kubectl delete clusterworkloadlock ceph-clusterworkloadlock
Update of a managed cluster based on bare metal and Ceph enabled fails with
PersistentVolumeClaim getting stuck in the Pending state for the
prometheus-server StatefulSet and the
MountVolume.MountDevice failed for volume warning in the StackLight event
logs.
Workaround:
Verify that the description of the Pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name where the Pods failed to run<affectedPodName>is a Pod name that failed to run in the specified project
In the Pod description, identify the node name where the Pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain therbd volume mount failed: <csi-vol-uuid> is being usederror. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the Pod that fails to0replicas.On every
csi-rbdpluginPod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected Pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state becomesRunning.
During cluster update of a managed bare metal cluster, the false positive
CalicoDataplaneFailuresHigh alert may be firing. Disregard this alert,
which will disappear once cluster update succeeds.
The observed behavior is typical for calico-node during upgrades,
as workload changes occur frequently. Consequently, there is a possibility
of temporary desynchronization in the Calico dataplane. This can occasionally
result in throttling when applying workload changes to the Calico dataplane.
The following table lists the major components and their versions delivered in the Container Cloud releases 2.24.0 - 2.24.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Bare metal Updated |
ambassador |
1.37.15 |
baremetal-operator |
base-alpine-20230607164516 2.24.0 |
|
base-alpine-20230721153358 2.24.1(2) |
||
baremetal-public-api |
1.37.15 |
|
baremetal-provider |
1.37.15 |
|
ironic |
yoga-focal-20230605060019 |
|
kaas-ipam |
base-alpine-20230614192933 |
|
keepalived |
0.22.0-49-g9618f2a |
|
local-volume-provisioner |
2.5.0-4 |
|
mariadb |
10.6.12-focal-20230606052917 |
|
IAM Updated |
iam |
2.5.1 2.24.0 |
2.5.3 2.24.1(2) |
||
iam-controller |
1.37.15 |
|
keycloak |
21.1.1 |
|
Container Cloud Updated |
admission-controller |
1.37.15 2.24.0 |
1.37.16 2.24.1 |
||
1.37.19 2.24.2 |
||
agent-controller |
1.37.15 |
|
byo-credentials-controller Removed |
n/a |
|
byo-provider Removed |
n/a |
|
ceph-kcc-controller |
1.37.15 |
|
cert-manager |
1.37.15 |
|
client-certificate-controller |
1.37.15 |
|
event-controller |
1.37.15 |
|
golang |
1.20.4-alpine3.17 |
|
kaas-public-api |
1.37.15 |
|
kaas-exporter |
1.37.15 |
|
kaas-ui |
1.37.15 |
|
license-controller |
1.37.15 |
|
lcm-controller |
1.37.15 |
|
machinepool-controller |
1.37.15 |
|
mcc-cache |
1.37.15 |
|
portforward-controller |
1.37.15 |
|
proxy-controller |
1.37.15 |
|
rbac-controller |
1.37.15 |
|
release-controller |
1.37.15 |
|
rhellicense-controller |
1.37.15 |
|
scope-controller |
1.37.15 |
|
user-controller |
1.37.15 |
|
OpenStack Updated |
openstack-provider |
1.37.15 |
os-credentials-controller |
1.37.15 |
|
VMware vSphere Updated |
vsphere-provider |
1.37.15 |
vsphere-credentials-controller |
1.37.15 |
|
keepalived |
0.22.0-49-g9618f2a |
|
squid-proxy |
0.0.1-10-g24a0d69 |
This section lists the component artifacts of the Container Cloud releases 2.24.0 - 2.24.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
ironic-python-agent.initramfs Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20230606121129 |
ironic-python-agent.kernel Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20230606121129 |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
Helm charts Updated |
baremetal-api |
https://binary.mirantis.com/core/helm/baremetal-api-1.37.15.tgz |
baremetal-operator |
https://binary.mirantis.com/core/helm/baremetal-operator-1.37.15.tgz 2.24.0 |
|
https://binary.mirantis.com/core/helm/baremetal-operator-1.37.16.tgz 2.24.1(2) |
||
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.37.15.tgz |
|
baremetal-public-api |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.37.15.tgz |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.37.15.tgz |
|
metallb |
||
Docker images |
ambasador Updated |
mirantis.azurecr.io/core/external/nginx:1.37.15 |
baremetal-dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-alpine-20230607171021 |
|
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-alpine-20230607164516 2.24.0 |
|
mirantis.azurecr.io/bm/baremetal-operator:base-alpine-20230721153358 2.24.1(2) |
||
bm-collective Updated |
mirantis.azurecr.io/bm/bm-collective:base-alpine-20230607154546 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.37.15 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230605060019 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230605060019 |
|
ironic-prometheus-exporter Updated |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20230531081117 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-alpine-20230614192933 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230606052917 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.22.0-49-g9618f2a |
|
metallb-controller Updated |
mirantis.azurecr.io/bm/external/metallb/controller:v0.13.9 |
|
metallb-speaker Updated |
mirantis.azurecr.io/bm/external/metallb/speaker:v0.13.9 |
|
syslog-ng Updated |
mirantis.azurecr.io/bm/syslog-ng:base-apline-20230607165607 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.37.15.tgz 2.24.0(1) |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.37.19.tgz 2.24.2 |
||
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.37.15.tgz 2.24.0(1) |
|
https://binary.mirantis.com/core/bin/bootstrap-linux-1.37.19.tgz 2.24.2 |
||
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.37.15.tgz 2.24.0 |
https://binary.mirantis.com/core/helm/admission-controller-1.37.16.tgz 2.24.1(2) |
||
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.37.15.tgz |
|
byo-credentials-controller Removed |
n/a |
|
byo-provider Removed |
n/a |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.37.15.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.37.15.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.37.15.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.37.15.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.37.15.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.37.15.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.37.15.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.37.15.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.37.15.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.37.15.tgz |
|
mcc-cache |
||
mcc-cache-warmup New |
https://binary.mirantis.com/core/helm/mcc-cache-warmup-1.37.15.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.37.15.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.37.15.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.37.15.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.37.15.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.37.15.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.37.15.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.37.15.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.37.15.tgz |
|
scope-controller |
https://binary.mirantis.com/core/helm/scope-controller-1.37.15.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.37.15.tgz |
|
storage-discovery |
https://binary.mirantis.com/core/helm/storage-discovery-1.37.15.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.37.15.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.37.15.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.37.15.tgz |
|
vsphere-vm-template-controller |
https://binary.mirantis.com/core/helm/vsphere-vm-template-controller-1.37.15.tgz |
|
Docker images Updated |
admission-controller |
mirantis.azurecr.io/core/admission-controller:1.37.15 2.24.0 |
mirantis.azurecr.io/core/admission-controller:1.37.16 2.24.1(2) |
||
agent-controller |
mirantis.azurecr.io/core/agent-controller:1.37.15 |
|
byo-cluster-api-controller Removed |
n/a |
|
byo-credentials-controller Removed |
n/a |
|
ceph-kcc-controller |
mirantis.azurecr.io/core/ceph-kcc-controller:1.37.15 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.11.0 |
|
client-certificate-controller |
mirantis.azurecr.io/core/client-certificate-controller:1.37.15 |
|
event-controller |
mirantis.azurecr.io/core/event-controller:1.37.15 |
|
frontend |
mirantis.azurecr.io/core/frontend:1.37.15 |
|
iam-controller |
mirantis.azurecr.io/core/iam-controller:1.37.15 |
|
kaas-exporter |
mirantis.azurecr.io/core/kaas-exporter:1.37.15 |
|
kproxy |
mirantis.azurecr.io/core/kproxy:1.37.15 |
|
lcm-controller |
mirantis.azurecr.io/core/lcm-controller:1.37.15 |
|
license-controller |
mirantis.azurecr.io/core/license-controller:1.37.15 |
|
machinepool-controller |
mirantis.azurecr.io/core/machinepool-controller:1.37.15 |
|
mcc-haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.22.0-49-g9618f2a |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.22.0-49-g9618f2a |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-2 |
|
nginx |
mirantis.azurecr.io/core/external/nginx:1.37.15 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager-amd64:v1.24.5-10-g93314b86 |
|
openstack-cluster-api-controller |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.37.15 |
|
os-credentials-controller |
mirantis.azurecr.io/core/os-credentials-controller:1.37.15 |
|
portforward-controller |
mirantis.azurecr.io/core/portforward-controller:1.37.15 |
|
proxy-controller |
mirantis.azurecr.io/core/proxy-controller:1.37.15 |
|
rbac-controller |
mirantis.azurecr.io/core/rbac-controller:1.37.15 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-4 |
|
release-controller |
mirantis.azurecr.io/core/release-controller:1.37.15 |
|
rhellicense-controller |
mirantis.azurecr.io/core/rhellicense-controller:1.37.15 |
|
scope-controller |
mirantis.azurecr.io/core/scope-controller:1.37.15 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery |
mirantis.azurecr.io/core/storage-discovery:1.37.15 |
|
user-controller |
mirantis.azurecr.io/core/user-controller:1.37.15 |
|
vsphere-cluster-api-controller |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.37.15 |
|
vsphere-credentials-controller |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.37.15 |
|
vsphere-vm-template-controller |
mirantis.azurecr.io/core/vsphere-vm-template-controller:1.37.15 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
|
Helm charts |
iam Updated |
|
https://binary.mirantis.com/iam/helm/iam-2.5.3.tgz 2.24.1(2) |
||
Docker images Updated |
keycloak |
mirantis.azurecr.io/iam/keycloak:0.6.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230423170220 |
In total, since Container Cloud 2.23.0 major release, in 2.24.0, 2130 Common Vulnerabilities and Exposures (CVE) have been fixed: 98 of critical and 2032 of high severity.
Among them, 984 CVEs that are listed in Addressed CVEs - detailed Addressed CVEs - detailed have been fixed since the 2.23.5 patch release: 62 of critical and 922 of high severity. The remaining CVEs were addressed since Container Cloud 2.23.0 and the fixes released with the patch releases of the 2.23.x series.
The summary table contains the total number of unique CVEs along with the total number of issues fixed across the images.
The full list of the CVEs present in the current Container Cloud release is available at the Mirantis Security Portal.
Severity |
Critical |
High |
Total |
|---|---|---|---|
Unique CVEs |
18 |
88 |
106 |
Total issues across images |
62 |
922 |
984 |
Image |
Component name |
CVE |
|---|---|---|
bm/baremetal-dnsmasq |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
bm/baremetal-operator |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
cryptography |
CVE-2023-2650 (High) |
|
bm/bm-collective |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
bm/kaas-ipam |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
bm/syslog-ng |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
ceph/mcp/ceph-controller |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
ceph/rook |
openssl |
CVE-2022-3786 (High) |
CVE-2023-0286 (High) |
||
CVE-2022-3602 (High) |
||
openssl-libs |
CVE-2022-3602 (High) |
|
CVE-2022-3786 (High) |
||
CVE-2023-0286 (High) |
||
cryptography |
CVE-2023-2650 (High) |
|
core/admission-controller |
helm.sh/helm/v3 |
CVE-2021-32690 (High) |
CVE-2022-23525 (High) |
||
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/agent-controller |
helm.sh/helm/v3 |
CVE-2021-32690 (High) |
CVE-2022-23525 (High) |
||
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/aws-cluster-api-controller |
helm.sh/helm/v3 |
CVE-2021-32690 (High) |
CVE-2022-23525 (High) |
||
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/aws-credentials-controller |
github.com/containerd/containerd |
CVE-2023-25173 (High) |
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/azure-cluster-api-controller |
helm.sh/helm/v3 |
CVE-2022-23525 (High) |
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
CVE-2021-32690 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/azure-credentials-controller |
helm.sh/helm/v3 |
CVE-2021-32690 (High) |
CVE-2022-23525 (High) |
||
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/bootstrap-controller |
helm.sh/helm/v3 |
CVE-2022-23525 (High) |
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
CVE-2021-32690 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/byo-cluster-api-controller |
helm.sh/helm/v3 |
CVE-2021-32690 (High) |
CVE-2022-23525 (High) |
||
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/byo-credentials-controller |
github.com/containerd/containerd |
CVE-2023-25173 (High) |
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/ceph-kcc-controller |
helm.sh/helm/v3 |
CVE-2022-23525 (High) |
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
CVE-2021-32690 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/cluster-api-provider-baremetal |
helm.sh/helm/v3 |
CVE-2022-23525 (High) |
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
CVE-2021-32690 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/configuration-collector |
helm.sh/helm/v3 |
CVE-2021-32690 (High) |
CVE-2022-23525 (High) |
||
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/equinix-cluster-api-controller |
helm.sh/helm/v3 |
CVE-2021-32690 (High) |
CVE-2022-23525 (High) |
||
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/equinix-credentials-controller |
helm.sh/helm/v3 |
CVE-2021-32690 (High) |
CVE-2022-23525 (High) |
||
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/event-controller |
github.com/containerd/containerd |
CVE-2023-25173 (High) |
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/external/nginx |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
libx11 |
CVE-2023-3138 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
core/frontend |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
libx11 |
CVE-2023-3138 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
core/iam-controller |
github.com/containerd/containerd |
CVE-2023-25173 (High) |
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/kaas-exporter |
helm.sh/helm/v3 |
CVE-2021-32690 (High) |
CVE-2022-23525 (High) |
||
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/kproxy |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
core/lcm-controller |
github.com/containerd/containerd |
CVE-2023-25173 (High) |
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/license-controller |
github.com/containerd/containerd |
CVE-2023-25173 (High) |
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/machinepool-controller |
github.com/containerd/containerd |
CVE-2023-25173 (High) |
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/openstack-cluster-api-controller |
helm.sh/helm/v3 |
CVE-2022-23525 (High) |
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
CVE-2021-32690 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/os-credentials-controller |
github.com/containerd/containerd |
CVE-2023-25173 (High) |
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/portforward-controller |
helm.sh/helm/v3 |
CVE-2022-23525 (High) |
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
CVE-2021-32690 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/proxy-controller |
github.com/containerd/containerd |
CVE-2023-25173 (High) |
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/rbac-controller |
github.com/containerd/containerd |
CVE-2023-25173 (High) |
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/release-controller |
helm.sh/helm/v3 |
CVE-2021-32690 (High) |
CVE-2022-23525 (High) |
||
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/rhellicense-controller |
github.com/containerd/containerd |
CVE-2023-25173 (High) |
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/scope-controller |
github.com/containerd/containerd |
CVE-2023-25173 (High) |
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/user-controller |
github.com/containerd/containerd |
CVE-2023-25173 (High) |
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/vsphere-cluster-api-controller |
helm.sh/helm/v3 |
CVE-2022-23525 (High) |
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
CVE-2021-32690 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/vsphere-credentials-controller |
helm.sh/helm/v3 |
CVE-2022-23525 (High) |
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
CVE-2021-32690 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
core/vsphere-vm-template-controller |
helm.sh/helm/v3 |
CVE-2021-32690 (High) |
CVE-2022-23525 (High) |
||
CVE-2022-23526 (High) |
||
CVE-2022-23524 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
libcrypto3 |
CVE-2023-2650 (High) |
|
libssl3 |
CVE-2023-2650 (High) |
|
iam/keycloak |
io.vertx:vertx-core |
CVE-2021-4125 (High) |
CVE-2021-44228 (Critical) |
||
CVE-2021-44530 (Critical) |
||
CVE-2021-45046 (Critical) |
||
org.apache.cxf:cxf-core |
CVE-2022-46364 (Critical) |
|
CVE-2022-46363 (High) |
||
org.apache.cxf:cxf-rt-transports-http |
CVE-2022-46363 (High) |
|
CVE-2022-46364 (Critical) |
||
org.apache.santuario:xmlsec |
CVE-2022-21476 (High) |
|
CVE-2022-47966 (Critical) |
||
org.apache.kafka:kafka-clients |
CVE-2023-25194 (High) |
|
CVE-2021-46877 (High) |
||
CVE-2020-36518 (High) |
||
com.fasterxml.jackson.core:jackson-databind |
CVE-2023-35116 (High) |
|
CVE-2022-42003 (High) |
||
CVE-2022-42004 (High) |
||
CVE-2023-35116 (High) |
||
CVE-2022-42003 (High) |
||
CVE-2022-42004 (High) |
||
CVE-2023-35116 (High) |
||
CVE-2022-42003 (High) |
||
CVE-2022-42004 (High) |
||
com.google.protobuf:protobuf-java |
CVE-2022-3509 (High) |
|
CVE-2022-3510 (High) |
||
com.google.protobuf:protobuf-java-util |
CVE-2022-3509 (High) |
|
CVE-2022-3510 (High) |
||
org.yaml:snakeyaml |
CVE-2022-25857 (High) |
|
java-11-openjdk-headless |
CVE-2023-21930 (High) |
|
platform-python |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
lcm/docker/ucp |
curl |
CVE-2023-27533 (High) |
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-23914 (Critical) |
||
CVE-2023-28319 (High) |
||
libcurl |
CVE-2023-28319 (High) |
|
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-23914 (Critical) |
||
github.com/crewjam/saml |
CVE-2022-41912 (Critical) |
|
CVE-2023-28119 (High) |
||
libcrypto1.1 |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
libssl1.1 |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
github.com/opencontainers/runc |
CVE-2023-28642 (High) |
|
github.com/docker/cli |
CVE-2021-41092 (High) |
|
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
lcm/docker/ucp-agent |
curl |
CVE-2023-27533 (High) |
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
CVE-2023-23914 (Critical) |
||
libcurl |
CVE-2023-23914 (Critical) |
|
CVE-2023-28319 (High) |
||
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
github.com/crewjam/saml |
CVE-2022-41912 (Critical) |
|
CVE-2023-28119 (High) |
||
libcrypto1.1 |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
libssl1.1 |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
github.com/opencontainers/runc |
CVE-2023-28642 (High) |
|
github.com/docker/cli |
CVE-2021-41092 (High) |
|
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/docker/ucp-auth |
curl |
CVE-2023-23914 (Critical) |
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
libcurl |
CVE-2023-27533 (High) |
|
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
CVE-2023-23914 (Critical) |
||
github.com/crewjam/saml |
CVE-2022-41912 (Critical) |
|
CVE-2023-28119 (High) |
||
libcrypto1.1 |
CVE-2023-0464 (High) |
|
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-2650 (High) |
||
libssl1.1 |
CVE-2023-2650 (High) |
|
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-0464 (High) |
||
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/docker/ucp-auth-store |
github.com/crewjam/saml |
CVE-2023-28119 (High) |
CVE-2022-41912 (Critical) |
||
curl |
CVE-2023-28319 (High) |
|
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
libcurl |
CVE-2023-28319 (High) |
|
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
libcrypto1.1 |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
libssl1.1 |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
lcm/docker/ucp-azure-ip-allocator |
curl |
CVE-2023-27533 (High) |
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
libcurl |
CVE-2023-27533 (High) |
|
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
libcrypto1.1 |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
libssl1.1 |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
lcm/docker/ucp-calico-cni |
github.com/emicklei/go-restful |
CVE-2022-1996 (Critical) |
golang.org/x/crypto |
CVE-2022-27191 (High) |
|
CVE-2020-29652 (High) |
||
CVE-2021-43565 (High) |
||
golang.org/x/text |
CVE-2022-32149 (High) |
|
CVE-2020-14040 (High) |
||
CVE-2021-38561 (High) |
||
CVE-2022-32149 (High) |
||
golang.org/x/net |
CVE-2022-27664 (High) |
|
CVE-2021-33194 (High) |
||
CVE-2022-27664 (High) |
||
github.com/containernetworking/cni |
CVE-2021-20206 (High) |
|
github.com/gogo/protobuf |
CVE-2021-3121 (High) |
|
lcm/docker/ucp-calico-kube-controllers |
github.com/emicklei/go-restful |
CVE-2022-1996 (Critical) |
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/docker/ucp-calico-node |
github.com/emicklei/go-restful |
CVE-2022-1996 (Critical) |
openssl-libs |
CVE-2023-0286 (High) |
|
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/docker/ucp-cfssl |
curl |
CVE-2023-28319 (High) |
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-23914 (Critical) |
||
libcurl |
CVE-2023-23914 (Critical) |
|
CVE-2023-28319 (High) |
||
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
libcrypto1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-0464 (High) |
||
CVE-2023-2650 (High) |
||
libssl1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-0464 (High) |
||
CVE-2023-2650 (High) |
||
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/docker/ucp-compose |
github.com/emicklei/go-restful |
CVE-2022-1996 (Critical) |
golang.org/x/crypto |
CVE-2021-43565 (High) |
|
CVE-2022-27191 (High) |
||
CVE-2021-43565 (High) |
||
CVE-2022-27191 (High) |
||
golang.org/x/net |
CVE-2021-33194 (High) |
|
CVE-2022-27664 (High) |
||
CVE-2021-33194 (High) |
||
CVE-2022-27664 (High) |
||
golang.org/x/text |
CVE-2022-32149 (High) |
|
CVE-2021-38561 (High) |
||
CVE-2022-32149 (High) |
||
CVE-2021-38561 (High) |
||
CVE-2022-32149 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
github.com/prometheus/client_golang |
CVE-2022-21698 (High) |
|
lcm/docker/ucp-containerd-shim-process |
golang.org/x/net |
CVE-2021-33194 (High) |
CVE-2022-27664 (High) |
||
CVE-2021-33194 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
lcm/docker/ucp-controller |
curl |
CVE-2023-27533 (High) |
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
CVE-2023-23914 (Critical) |
||
libcurl |
CVE-2023-23914 (Critical) |
|
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
github.com/crewjam/saml |
CVE-2022-41912 (Critical) |
|
CVE-2023-28119 (High) |
||
libcrypto1.1 |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
libssl1.1 |
CVE-2023-2650 (High) |
|
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-0464 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
github.com/opencontainers/runc |
CVE-2023-28642 (High) |
|
github.com/docker/cli |
CVE-2021-41092 (High) |
|
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/docker/ucp-coredns |
golang.org/x/net |
CVE-2022-27664 (High) |
CVE-2022-41721 (High) |
||
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/docker/ucp-dsinfo |
github.com/emicklei/go-restful |
CVE-2022-1996 (Critical) |
golang.org/x/crypto |
CVE-2021-43565 (High) |
|
CVE-2022-27191 (High) |
||
CVE-2021-43565 (High) |
||
golang.org/x/net |
CVE-2022-27664 (High) |
|
CVE-2021-33194 (High) |
||
CVE-2022-27664 (High) |
||
golang.org/x/text |
CVE-2022-32149 (High) |
|
CVE-2021-38561 (High) |
||
CVE-2022-32149 (High) |
||
CVE-2021-38561 (High) |
||
CVE-2022-32149 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
github.com/prometheus/client_golang |
CVE-2022-21698 (High) |
|
lcm/docker/ucp-etcd |
curl |
CVE-2023-28319 (High) |
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-23914 (Critical) |
||
libcurl |
CVE-2023-28319 (High) |
|
CVE-2023-23914 (Critical) |
||
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
libcrypto1.1 |
CVE-2023-2650 (High) |
|
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-0464 (High) |
||
libssl1.1 |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
golang.org/x/text |
CVE-2022-32149 (High) |
|
CVE-2021-38561 (High) |
||
CVE-2022-32149 (High) |
||
CVE-2021-38561 (High) |
||
CVE-2022-32149 (High) |
||
golang.org/x/net |
CVE-2022-27664 (High) |
|
lcm/docker/ucp-hardware-info |
curl |
CVE-2023-28319 (High) |
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-23914 (Critical) |
||
libcurl |
CVE-2023-27533 (High) |
|
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-23914 (Critical) |
||
CVE-2023-28319 (High) |
||
libcrypto1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-2650 (High) |
||
CVE-2023-0464 (High) |
||
libssl1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-2650 (High) |
||
CVE-2023-0464 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
github.com/docker/docker |
CVE-2023-28840 (High) |
|
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/docker/ucp-interlock |
curl |
CVE-2023-27533 (High) |
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
CVE-2023-23914 (Critical) |
||
libcurl |
CVE-2023-28319 (High) |
|
CVE-2023-23914 (Critical) |
||
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
libcrypto1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-2650 (High) |
||
CVE-2023-0464 (High) |
||
libssl1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-2650 (High) |
||
CVE-2023-0464 (High) |
||
golang.org/x/net |
CVE-2022-41721 (High) |
|
CVE-2022-27664 (High) |
||
github.com/containerd/containerd |
CVE-2023-25173 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/docker/ucp-interlock-config |
curl |
CVE-2023-27533 (High) |
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
libcurl |
CVE-2023-27533 (High) |
|
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
libcrypto1.1 |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
libssl1.1 |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
libwebp |
CVE-2023-1999 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
lcm/docker/ucp-interlock-extension |
curl |
CVE-2023-27533 (High) |
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
CVE-2023-23914 (Critical) |
||
libcurl |
CVE-2023-27533 (High) |
|
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-23914 (Critical) |
||
CVE-2023-28319 (High) |
||
libcrypto1.1 |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
libssl1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-0464 (High) |
||
CVE-2023-2650 (High) |
||
golang.org/x/net |
CVE-2022-41721 (High) |
|
CVE-2022-27664 (High) |
||
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/docker/ucp-interlock-proxy |
curl |
CVE-2023-27533 (High) |
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
libcurl |
CVE-2023-27533 (High) |
|
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
libcrypto1.1 |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
libssl1.1 |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
libwebp |
CVE-2023-1999 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
lcm/docker/ucp-kube-ingress-controller |
curl |
CVE-2022-43551 (High) |
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-23914 (Critical) |
||
CVE-2022-32221 (Critical) |
||
CVE-2022-42915 (High) |
||
CVE-2022-42916 (High) |
||
CVE-2023-28319 (High) |
||
libcurl |
CVE-2022-32221 (Critical) |
|
CVE-2022-42915 (High) |
||
CVE-2022-42916 (High) |
||
CVE-2023-23914 (Critical) |
||
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
CVE-2022-43551 (High) |
||
libcrypto1.1 |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
libssl1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-0464 (High) |
||
CVE-2023-2650 (High) |
||
openssl |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-2650 (High) |
||
CVE-2023-0464 (High) |
||
golang.org/x/net |
CVE-2022-41721 (High) |
|
CVE-2022-27664 (High) |
||
libxml2 |
CVE-2022-40303 (High) |
|
CVE-2022-40304 (High) |
||
github.com/opencontainers/runc |
CVE-2023-28642 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
lcm/docker/ucp-metrics |
curl |
CVE-2023-27533 (High) |
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
libcurl |
CVE-2023-27533 (High) |
|
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
libcrypto1.1 |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
libssl1.1 |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
github.com/docker/docker |
CVE-2023-28840 (High) |
|
golang.org/x/net |
CVE-2022-41723 (High) |
|
lcm/docker/ucp-node-feature-discovery |
libssl3 |
CVE-2023-0286 (High) |
openssl |
CVE-2023-0286 (High) |
|
github.com/prometheus/client_golang |
CVE-2022-21698 (High) |
|
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
gopkg.in/yaml.v3 |
CVE-2022-28948 (High) |
|
lcm/docker/ucp-nvidia-device-plugin |
golang.org/x/net |
CVE-2022-27664 (High) |
CVE-2021-33194 (High) |
||
golang.org/x/text |
CVE-2022-32149 (High) |
|
CVE-2021-38561 (High) |
||
libssl3 |
CVE-2023-0286 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
github.com/prometheus/client_golang |
CVE-2022-21698 (High) |
|
lcm/docker/ucp-nvidia-gpu-feature-discovery |
golang.org/x/net |
CVE-2022-41721 (High) |
CVE-2022-27664 (High) |
||
libssl3 |
CVE-2023-0286 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/docker/ucp-secureoverlay-agent |
curl |
CVE-2023-28319 (High) |
CVE-2023-23914 (Critical) |
||
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
libcurl |
CVE-2023-28319 (High) |
|
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-23914 (Critical) |
||
libcrypto1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-0464 (High) |
||
CVE-2023-2650 (High) |
||
libssl1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-0464 (High) |
||
CVE-2023-2650 (High) |
||
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/docker/ucp-secureoverlay-mgr |
curl |
CVE-2023-27533 (High) |
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-23914 (Critical) |
||
CVE-2023-28319 (High) |
||
libcurl |
CVE-2023-23914 (Critical) |
|
CVE-2023-28319 (High) |
||
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
libcrypto1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-0464 (High) |
||
CVE-2023-2650 (High) |
||
libssl1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-0464 (High) |
||
CVE-2023-2650 (High) |
||
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/docker/ucp-sf-notifier |
Werkzeug |
CVE-2022-29361 (Critical) |
CVE-2023-25577 (High) |
||
libcrypto1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-0464 (High) |
||
CVE-2023-2650 (High) |
||
libssl1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-2650 (High) |
||
CVE-2023-0464 (High) |
||
openssl-dev |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
cryptography |
CVE-2023-2650 (High) |
|
Flask |
CVE-2023-30861 (High) |
|
krb5-libs |
CVE-2022-42898 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
lcm/docker/ucp-swarm |
curl |
CVE-2023-23914 (Critical) |
CVE-2023-27533 (High) |
||
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
libcurl |
CVE-2023-27533 (High) |
|
CVE-2023-27534 (High) |
||
CVE-2023-27536 (High) |
||
CVE-2023-28319 (High) |
||
CVE-2023-23914 (Critical) |
||
libcrypto1.1 |
CVE-2023-0464 (High) |
|
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-2650 (High) |
||
libssl1.1 |
CVE-2023-0464 (High) |
|
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-2650 (High) |
||
github.com/hashicorp/consul |
CVE-2022-29153 (High) |
|
CVE-2022-38149 (High) |
||
CVE-2020-7219 (High) |
||
CVE-2021-37219 (High) |
||
golang.org/x/crypto |
CVE-2022-27191 (High) |
|
CVE-2020-29652 (High) |
||
CVE-2021-43565 (High) |
||
golang.org/x/net |
CVE-2021-33194 (High) |
|
CVE-2022-27664 (High) |
||
github.com/docker/docker |
CVE-2023-28840 (High) |
|
github.com/docker/distribution |
CVE-2017-11468 (High) |
|
lcm/external/aws-cloud-controller-manager |
github.com/emicklei/go-restful |
CVE-2022-1996 (Critical) |
golang.org/x/crypto |
CVE-2021-43565 (High) |
|
CVE-2022-27191 (High) |
||
github.com/prometheus/client_golang |
CVE-2022-21698 (High) |
|
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
gopkg.in/yaml.v3 |
CVE-2022-28948 (High) |
|
lcm/external/aws-ebs-csi-driver |
ncurses-libs |
CVE-2023-29491 (High) |
systemd-libs |
CVE-2023-26604 (High) |
|
golang.org/x/net |
CVE-2022-41721 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
lcm/external/csi-attacher |
golang.org/x/crypto |
CVE-2021-43565 (High) |
CVE-2022-27191 (High) |
||
CVE-2020-29652 (High) |
||
CVE-2021-43565 (High) |
||
CVE-2022-27191 (High) |
||
CVE-2020-29652 (High) |
||
CVE-2021-43565 (High) |
||
CVE-2022-27191 (High) |
||
CVE-2020-29652 (High) |
||
golang.org/x/net |
CVE-2021-33194 (High) |
|
golang.org/x/text |
CVE-2021-38561 (High) |
|
github.com/gogo/protobuf |
CVE-2021-3121 (High) |
|
github.com/emicklei/go-restful |
CVE-2022-1996 (Critical) |
|
lcm/external/csi-provisioner |
github.com/emicklei/go-restful |
CVE-2022-1996 (Critical) |
lcm/external/csi-resizer |
github.com/emicklei/go-restful |
CVE-2022-1996 (Critical) |
lcm/helm/tiller |
libcrypto1.1 |
CVE-2021-23840 (High) |
CVE-2020-1967 (High) |
||
CVE-2021-3450 (High) |
||
CVE-2021-3711 (Critical) |
||
CVE-2021-3712 (High) |
||
libssl1.1 |
CVE-2020-1967 (High) |
|
CVE-2021-3450 (High) |
||
CVE-2021-3711 (Critical) |
||
CVE-2021-3712 (High) |
||
CVE-2021-23840 (High) |
||
apk-tools |
CVE-2021-36159 (Critical) |
|
CVE-2021-30139 (High) |
||
zlib |
CVE-2022-37434 (Critical) |
|
busybox |
CVE-2021-42378 (High) |
|
CVE-2021-42379 (High) |
||
CVE-2021-42380 (High) |
||
CVE-2021-42381 (High) |
||
CVE-2021-42382 (High) |
||
CVE-2021-42383 (High) |
||
CVE-2021-42384 (High) |
||
CVE-2021-42385 (High) |
||
CVE-2021-42386 (High) |
||
CVE-2021-28831 (High) |
||
ssl_client |
CVE-2021-28831 (High) |
|
CVE-2021-42378 (High) |
||
CVE-2021-42379 (High) |
||
CVE-2021-42380 (High) |
||
CVE-2021-42381 (High) |
||
CVE-2021-42382 (High) |
||
CVE-2021-42383 (High) |
||
CVE-2021-42384 (High) |
||
CVE-2021-42385 (High) |
||
CVE-2021-42386 (High) |
||
lcm/kubernetes/cinder-csi-plugin-amd64 |
libtasn1-6 |
CVE-2021-46848 (Critical) |
github.com/emicklei/go-restful |
CVE-2022-1996 (Critical) |
|
libssl1.1 |
CVE-2023-0286 (High) |
|
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
openssl |
CVE-2023-0286 (High) |
|
CVE-2022-4450 (High) |
||
CVE-2023-0215 (High) |
||
libsystemd0 |
CVE-2023-26604 (High) |
|
libudev1 |
CVE-2023-26604 (High) |
|
udev |
CVE-2023-26604 (High) |
|
libgnutls30 |
CVE-2023-0361 (High) |
|
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
gopkg.in/yaml.v3 |
CVE-2022-28948 (High) |
|
lcm/kubernetes/openstack-cloud-controller-manager-amd64 |
github.com/emicklei/go-restful |
CVE-2022-1996 (Critical) |
zlib |
CVE-2022-37434 (Critical) |
|
golang.org/x/crypto |
CVE-2022-27191 (High) |
|
CVE-2021-43565 (High) |
||
golang.org/x/text |
CVE-2021-38561 (High) |
|
CVE-2022-32149 (High) |
||
github.com/prometheus/client_golang |
CVE-2022-21698 (High) |
|
golang.org/x/net |
CVE-2022-27664 (High) |
|
gopkg.in/yaml.v3 |
CVE-2022-28948 (High) |
|
k8s.io/kubernetes |
CVE-2021-25741 (High) |
|
lcm/mcc-haproxy |
pcre2 |
CVE-2022-1586 (Critical) |
CVE-2022-1587 (Critical) |
||
zlib |
CVE-2022-37434 (Critical) |
|
libcrypto1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-2650 (High) |
||
CVE-2023-0464 (High) |
||
libssl1.1 |
CVE-2022-4450 (High) |
|
CVE-2023-0215 (High) |
||
CVE-2023-0286 (High) |
||
CVE-2023-2650 (High) |
||
CVE-2023-0464 (High) |
||
busybox |
CVE-2022-30065 (High) |
|
ssl_client |
CVE-2022-30065 (High) |
|
lcm/registry |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
mirantis/ceph |
openssl |
CVE-2022-3786 (High) |
CVE-2023-0286 (High) |
||
CVE-2022-3602 (High) |
||
openssl-libs |
CVE-2022-3602 (High) |
|
CVE-2022-3786 (High) |
||
CVE-2023-0286 (High) |
||
python3 |
CVE-2023-24329 (High) |
|
python3-devel |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
mirantis/cephcsi |
openssl |
CVE-2022-3786 (High) |
CVE-2023-0286 (High) |
||
CVE-2022-3602 (High) |
||
openssl-libs |
CVE-2022-3602 (High) |
|
CVE-2022-3786 (High) |
||
CVE-2023-0286 (High) |
||
cryptography |
CVE-2023-2650 (High) |
|
mirantis/fio |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/alerta-web |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/alertmanager-webhook-servicenow |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
openssl-dev |
CVE-2023-2650 (High) |
|
Flask |
CVE-2023-30861 (High) |
|
stacklight/alpine-utils |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/blackbox-exporter |
golang.org/x/net |
CVE-2022-41723 (High) |
stacklight/cadvisor |
libcrypto1.1 |
CVE-2023-2650 (High) |
libssl1.1 |
CVE-2023-2650 (High) |
|
stacklight/cerebro |
org.xerial:sqlite-jdbc |
CVE-2023-32697 (Critical) |
com.fasterxml.jackson.core:jackson-databind |
CVE-2023-35116 (High) |
|
CVE-2022-42003 (High) |
||
CVE-2022-42004 (High) |
||
CVE-2020-36518 (High) |
||
CVE-2021-46877 (High) |
||
libssl1.1 |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
openssl |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
stacklight/ironic-prometheus-exporter |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/k8s-sidecar |
libcrypto1.1 |
CVE-2023-2650 (High) |
libssl1.1 |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/kubectl |
libssl1.1 |
CVE-2023-2650 (High) |
CVE-2023-0464 (High) |
||
openssl |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
stacklight/metric-collector |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/node-exporter |
golang.org/x/net |
CVE-2022-41723 (High) |
stacklight/opensearch |
org.codelibs.elasticsearch.module:ingest-common |
CVE-2019-7611 (High) |
CVE-2015-5377 (Critical) |
||
org.springframework:spring-core |
CVE-2023-20860 (High) |
|
stacklight/opensearch-dashboards |
decode-uri-component |
CVE-2022-38900 (High) |
glob-parent |
CVE-2021-35065 (High) |
|
stacklight/prometheus |
github.com/docker/docker |
CVE-2023-28840 (High) |
golang.org/x/net |
CVE-2022-41723 (High) |
|
stacklight/prometheus-es-exporter |
libcrypto1.1 |
CVE-2023-2650 (High) |
libssl1.1 |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/prometheus-libvirt-exporter |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/prometheus-patroni-exporter |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/prometheus-relay |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/sf-notifier |
libcrypto1.1 |
CVE-2023-2650 (High) |
libssl1.1 |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
openssl-dev |
CVE-2023-2650 (High) |
|
stacklight/sf-reporter |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/stacklight-toolkit |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/telegraf |
libssl1.1 |
CVE-2023-2650 (High) |
CVE-2023-0464 (High) |
||
CVE-2023-2650 (High) |
||
CVE-2023-0464 (High) |
||
openssl |
CVE-2023-2650 (High) |
|
CVE-2023-0464 (High) |
||
CVE-2023-2650 (High) |
||
CVE-2023-0464 (High) |
||
stacklight/telemeter |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/tungstenfabric-prometheus-exporter |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/yq |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
This section describes the specific actions you as a cloud operator need to complete before or after your Container Cloud cluster update to the Cluster release 14.0.0.
Consider this information as a supplement to the generic update procedures published in Operations Guide: Automatic upgrade of a management cluster and Update a managed cluster.
Since Container Cloud 2.24.0, the use of the l3Layout section in L2
templates is mandatory. Therefore, if your L2 templates do not contain this
section, manually add it for all existing clusters by defining all
subnets that are used in the npTemplate section of the L2 template.
Example L2 template with the l3Layout section
apiVersion: ipam.mirantis.com/v1alpha1
kind: L2Template
metadata:
labels:
bm-1490-template-controls-netplan: anymagicstring
cluster.sigs.k8s.io/cluster-name: managed-cluster
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
name: bm-1490-template-controls-netplan
namespace: managed-ns
spec:
ifMapping:
- enp9s0f0
- enp9s0f1
- eno1
- ens3f1
l3Layout:
- scope: namespace
subnetName: lcm-nw
- scope: namespace
subnetName: storage-frontend
- scope: namespace
subnetName: storage-backend
- scope: namespace
subnetName: metallb-public-for-extiface
npTemplate: |-
version: 2
ethernets:
{{nic 0}}:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 0}}
set-name: {{nic 0}}
mtu: 1500
{{nic 1}}:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 1}}
set-name: {{nic 1}}
mtu: 1500
{{nic 2}}:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 2}}
set-name: {{nic 2}}
mtu: 1500
{{nic 3}}:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 3}}
set-name: {{nic 3}}
mtu: 1500
bonds:
bond0:
parameters:
mode: 802.3ad
#transmit-hash-policy: layer3+4
#mii-monitor-interval: 100
interfaces:
- {{ nic 0 }}
- {{ nic 1 }}
bond1:
parameters:
mode: 802.3ad
#transmit-hash-policy: layer3+4
#mii-monitor-interval: 100
interfaces:
- {{ nic 2 }}
- {{ nic 3 }}
vlans:
stor-f:
id: 1494
link: bond1
addresses:
- {{ip "stor-f:storage-frontend"}}
stor-b:
id: 1489
link: bond1
addresses:
- {{ip "stor-b:storage-backend"}}
m-pub:
id: 1491
link: bond0
bridges:
k8s-ext:
interfaces: [m-pub]
addresses:
- {{ ip "k8s-ext:metallb-public-for-extiface" }}
k8s-lcm:
dhcp4: false
dhcp6: false
gateway4: {{ gateway_from_subnet "lcm-nw" }}
addresses:
- {{ ip "k8s-lcm:lcm-nw" }}
nameservers:
addresses: [ 172.18.176.6 ]
interfaces:
- bond0
For details on L2 template configuration, see Create L2 templates.
Caution
Partial definition of subnets is prohibited.
Container Cloud 2.23.5 is the fourth patch release of the 2.23.x release series that incorporates security fixes for CVEs of Critical and High severity. This patch release:
Introduces the patch Cluster release 12.7.4 for MOSK 23.1.4.
Introduces the patch Cluster release 11.7.4
Does not support greenfield deployments based on deprecated Cluster releases 12.7.3, 11.7.3, 12.7.2, 11.7.2, 12.7.1, 11.7.1, 12.5.0, and 11.6.0. Use the latest available Cluster releases of the series instead.
This section describes known issues and contains the lists of updated artifacts and CVE fixes for the Container Cloud release 2.23.5. For CVE fixes delivered with the previous patch release, see security notes for 2.23.4, 2.23.3, and 2.23.2.
For enhancements, addressed and known issues of the parent Container Cloud release 2.23.0, refer to 2.23.0.
This section lists the components artifacts of the Container Cloud patch release 2.23.5. For artifacts of the Cluster releases introduced in 2.23.5, see Cluster release 12.7.4 and Cluster release 11.7.4.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-api Updated |
https://binary.mirantis.com/core/helm/baremetal-api-1.36.27.tgz |
baremetal-operator Updated |
https://binary.mirantis.com/core/helm/baremetal-operator-1.36.27.tgz |
|
baremetal-public-api Updated |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.36.27.tgz |
|
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20230126190304 |
|
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20230126190304 |
|
kaas-ipam Updated |
||
local-volume-provisioner Updated |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.36.27.tgz |
|
metallb Updated |
||
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
Docker images |
ambassador Updated |
mirantis.azurecr.io/core/external/nginx:1.36.27 |
baremetal-dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-alpine-20230522161215 |
|
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-focal-20230522160916 |
|
bm-collective Updated |
mirantis.azurecr.io/bm/bm-collective:base-alpine-20230522161437 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230523063451 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230523063451 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20230330140456 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-focal-20230522161025 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230423170220 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.19.0-5-g6a7e17d |
|
metallb-controller Updated |
mirantis.azurecr.io/bm/external/metallb/controller:v0.13.7-3 |
|
metallb-speaker Updated |
mirantis.azurecr.io/bm/external/metallb/speaker:v0.13.7-3 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-alpine-20230424092635 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.36.28.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.36.28.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.36.27.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.36.27.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.36.27.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.36.27.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.36.27.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.36.27.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.36.27.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.36.27.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.36.27.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.36.27.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.36.27.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.36.27.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.36.27.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.36.27.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.36.27.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.36.27.tgz |
|
mcc-cache |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.36.27.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.36.27.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.36.27.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.36.27.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.36.27.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.36.27.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.36.27.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.36.27.tgz |
|
scope-controller |
http://binary.mirantis.com/core/helm/scope-controller-1.36.27.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.36.27.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.36.27.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.36.27.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.36.27.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.36.27 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.36.27 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.36.27 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.36.27 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.36.27 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.6.1 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.36.27 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.36.27 |
|
configuration-collector Updated |
mirantis.azurecr.io/core/configuration-collector:1.36.27 |
|
event-controller Updated |
mirantis.azurecr.io/core/event-controller:1.36.27 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.36.27 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.36.27 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.36.27 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.36.27 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.36.27 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.36.27 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.36.27 |
|
mcc-haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.17.0-8-g6ca89d5 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.19.0-5-g6a7e17d |
|
metrics-server |
mirantis.azurecr.io/core/external/metrics-server:v0.6.3-2 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.36.27 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager-amd64:v1.22.1-7-gc11024f8 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.36.27 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.36.27 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.36.27 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.36.27 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.36.27 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-3 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.36.27 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.36.27 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.36.27 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.36.27 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.36.27 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.36.27 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.36.27 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
Helm charts |
iam |
|
iam-proxy |
||
Docker images |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230331112513 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.5.16 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-4 |
In the Container Cloud patch release 2.23.5, 70 vendor-specific Common Vulnerabilities and Exposures (CVE) have been addressed: 7 of critical and 63 of high severity.
The full list of the CVEs present in the current Container Cloud release is available at the Mirantis Security Portal.
Image |
Component name |
CVE |
|---|---|---|
bm/baremetal-dnsmasq |
curl |
CVE-2023-28319 (High) |
CVE-2023-28321 (High) |
||
CVE-2023-28322 (High) |
||
libcurl |
CVE-2023-28319 (High) |
|
CVE-2023-28321 (High) |
||
CVE-2023-28322 (High) |
||
libcap2 |
CVE-2023-2603 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
bm/baremetal-operator |
openssh-client-common |
CVE-2023-28531 (Critical) |
openssh-client-default |
CVE-2023-28531 (Critical) |
|
openssh-keygen |
CVE-2023-28531 (Critical) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
core/external/nginx |
libwebp |
CVE-2023-1999 (Critical) |
curl |
CVE-2023-28319 (High) |
|
CVE-2023-28321 (High) |
||
CVE-2023-28322 (High) |
||
libcurl |
CVE-2023-28319 (High) |
|
CVE-2023-28321 (High) |
||
CVE-2023-28322 (High) |
||
core/frontend |
libwebp |
CVE-2023-1999 (Critical) |
curl |
CVE-2023-28319 (High) |
|
CVE-2023-28321 (High) |
||
CVE-2023-28322 (High) |
||
libcurl |
CVE-2023-28319 (High) |
|
CVE-2023-28321 (High) |
||
CVE-2023-28322 (High) |
||
openstack/ironic |
sqlparse |
CVE-2023-30608 (High) |
openstack/ironic-inspector |
Flask |
CVE-2023-30861 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
stacklight/alerta-web |
libcurl |
CVE-2023-28319 (High) |
CVE-2023-28321 (High) |
||
CVE-2023-28322 (High) |
||
libpq |
CVE-2023-2454 (High) |
|
postgresql15-client |
CVE-2023-2454 (High) |
|
Flask |
CVE-2023-30861 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/alertmanager-webhook-servicenow |
ncurses-libs |
CVE-2023-29491 (High) |
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/alpine-utils |
curl |
CVE-2023-28319 (High) |
CVE-2023-28321 (High) |
||
CVE-2023-28322 (High) |
||
libcurl |
CVE-2023-28319 (High) |
|
CVE-2023-28321 (High) |
||
CVE-2023-28322 (High) |
||
stacklight/opensearch |
org.apache.santuario:xmlsec |
CVE-2022-47966 (Critical) |
CVE-2022-21476 (High) |
||
org.slf4j:slf4j-api |
CVE-2018-8088 (Critical) |
|
glib2 |
CVE-2018-16428 (High) |
|
CVE-2018-16429 (High) |
||
stacklight/opensearch-dashboards |
glib2 |
CVE-2018-16428 (High) |
CVE-2018-16429 (High) |
||
stacklight/pgbouncer |
libpq |
CVE-2023-2454 (High) |
postgresql-client |
CVE-2023-2454 (High) |
|
stacklight/prometheus-libvirt-exporter |
libcurl |
CVE-2023-28319 (High) |
CVE-2023-28321 (High) |
||
CVE-2023-28322 (High) |
||
stacklight/prometheus-patroni-exporter |
ncurses-libs |
CVE-2023-29491 (High) |
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/sf-notifier |
flask |
CVE-2023-30861 (High) |
stacklight/stacklight-toolkit |
curl |
CVE-2023-28319 (High) |
CVE-2023-28321 (High) |
||
CVE-2023-28322 (High) |
||
libcurl |
CVE-2023-28319 (High) |
|
CVE-2023-28321 (High) |
||
CVE-2023-28322 (High) |
||
stacklight/telegraf |
github.com/docker/docker |
CVE-2023-28840 (High) |
CVE-2023-28840 (High) |
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.23.5 including the Cluster releases 12.7.4 and 11.7.4.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
During the initial deployment of Container Cloud, some nodes may get stuck in the cleaning state. As a workaround, wipe disks manually before initializing the Container Cloud bootstrap.
Container Cloud 2.23.4 is the third patch release of the 2.23.x release series that includes several addressed issues and incorporates security fixes for CVEs of Critical and High severity. This patch release:
Introduces the patch Cluster release 12.7.3 for MOSK 23.1.3.
Introduces the patch Cluster release 11.7.3
Does not support greenfield deployments based on deprecated Cluster releases 12.7.2, 11.7.2, 12.7.1, 11.7.1, 12.5.0, and 11.6.0. Use the latest available Cluster releases of the series instead.
This section describes addressed issues and contains the lists of updated artifacts and CVE fixes for the Container Cloud release 2.23.4. For CVE fixes delivered with the previous patch release, see security notes for 2.23.3 and 2.23.2.
For enhancements, addressed and known issues of the parent Container Cloud release 2.23.0, refer to 2.23.0.
This section lists the components artifacts of the Container Cloud patch release 2.23.4. For artifacts of the Cluster releases introduced in 2.23.4, see Cluster release 12.7.3 and Cluster release 11.7.3.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-api Updated |
https://binary.mirantis.com/core/helm/baremetal-api-1.36.26.tgz |
baremetal-operator Updated |
https://binary.mirantis.com/core/helm/baremetal-operator-1.36.26.tgz |
|
baremetal-public-api Updated |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.36.26.tgz |
|
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20230126190304 |
|
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20230126190304 |
|
kaas-ipam Updated |
||
local-volume-provisioner Updated |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.36.26.tgz |
|
metallb Updated |
||
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
Docker images |
ambassador Updated |
mirantis.azurecr.io/core/external/nginx:1.36.26 |
baremetal-dnsmasq |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-alpine-20230421100738 |
|
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-focal-20230421100444 |
|
bm-collective |
mirantis.azurecr.io/bm/bm-collective:base-alpine-20230421101033 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230417060018 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230417060018 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20230330140456 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-focal-20230421100530 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230423170220 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.19.0-5-g6a7e17d |
|
metallb-controller |
mirantis.azurecr.io/bm/external/metallb/controller:v0.13.7-20221130155702-refresh-2023033102 |
|
metallb-speaker |
mirantis.azurecr.io/bm/external/metallb/speaker:v0.13.7-20221130155702-refresh-2023033102 |
|
syslog-ng Updated |
mirantis.azurecr.io/bm/syslog-ng:base-alpine-20230424092635 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.36.26.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.36.26.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.36.26.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.36.26.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.36.26.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.36.26.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.36.26.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.36.26.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.36.26.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.36.26.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.36.26.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.36.26.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.36.26.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.36.26.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.36.26.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.36.26.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.36.26.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.36.26.tgz |
|
mcc-cache |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.36.26.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.36.26.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.36.26.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.36.26.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.36.26.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.36.26.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.36.26.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.36.26.tgz |
|
scope-controller |
http://binary.mirantis.com/core/helm/scope-controller-1.36.26.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.36.26.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.36.26.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.36.26.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.36.26.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.36.26 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.36.26 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.36.26 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.36.26 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.36.26 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.6.1 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.36.26 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.36.26 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.36.26 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.36.26 |
|
kaas-exporter Updated |
mirantis.azurecr.io/core/kaas-exporter:1.36.26 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.36.26 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.36.26 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.36.26 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.36.26 |
|
mcc-haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.17.0-8-g6ca89d5 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.19.0-5-g6a7e17d |
|
metrics-server |
mirantis.azurecr.io/core/external/metrics-server:v0.6.3-2 |
|
nginx Updated |
mirantis.azurecr.io/core/external/nginx:1.36.26 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager-amd64:v1.22.1-7-gc11024f8 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.36.26 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.36.26 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.36.26 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.36.26 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.36.26 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-3 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.36.26 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.36.26 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.36.26 |
|
storage-discovery Updated |
mirantis.azurecr.io/core/storage-discovery:1.36.26 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.36.26 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.36.26 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.36.26 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
Helm charts |
iam |
|
iam-proxy |
||
Docker images |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230331112513 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.5.16 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-4 |
In the Container Cloud patch release 2.23.4, 35 vendor-specific CVEs have been addressed, 1 of critical and 34 of high severity.
The full list of the CVEs present in the current Container Cloud release is available at the Mirantis Security Portal.
The following issues have been addressed in the Container Cloud patch release 2.23.4 along with the Cluster releases 12.7.3 and 11.7.3:
[31869] Fixed the issue with
agent-controllerfailing to obtain secrets due to the incorrect indexer initialization.[31810,30970] Fixed the issue with
hardware.storageflapping in the machinestatusand causing constant reconciles.[30474,28654] Fixed the issue with the
agent-controllersecrets leaking.[5771] Fixed the issue with unnecessary reconciles during compute node deployment by optimizing the
baremetal-provideroperation.
Container Cloud 2.23.3 is the second patch release of the 2.23.x release series that incorporates security fixes for CVEs of Critical and High severity. This patch release:
Introduces the patch Cluster release 12.7.2 for MOSK 23.1.2.
Introduces the patch Cluster release 11.7.2.
Does not support greenfield deployments based on deprecated Cluster releases 12.7.1, 11.7.1, 12.5.0, and 11.6.0. Use the latest available Cluster releases of the series instead.
This section contains the lists of updated artifacts and CVE fixes for the Container Cloud release 2.23.3. For CVE fixes delivered with the previous patch release, see security notes for 2.23.2. For enhancements, addressed and known issues of the parent Container Cloud release 2.23.0, refer to 2.23.0.
This section lists the components artifacts of the Container Cloud patch release 2.23.3. For artifacts of the Cluster releases introduced in 2.23.3, see Cluster release 12.7.2 and Cluster release 11.7.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-api Updated |
https://binary.mirantis.com/core/helm/baremetal-api-1.36.23.tgz |
baremetal-operator Updated |
https://binary.mirantis.com/core/helm/baremetal-operator-1.36.23.tgz |
|
baremetal-public-api Updated |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.36.23.tgz |
|
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20230126190304 |
|
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20230126190304 |
|
kaas-ipam Updated |
||
local-volume-provisioner Updated |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.36.23.tgz |
|
metallb Updated |
||
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
Docker images |
ambassador |
mirantis.azurecr.io/core/external/nginx:1.36.23 |
baremetal-dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-alpine-20230421100738 |
|
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-focal-20230421100444 |
|
bm-collective Updated |
mirantis.azurecr.io/bm/bm-collective:base-alpine-20230421101033 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230417060018 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230417060018 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20230330140456 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-focal-20230421100530 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230328123811 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.19.0-5-g6a7e17d |
|
metallb-controller |
mirantis.azurecr.io/bm/external/metallb/controller:v0.13.7-20221130155702-refresh-2023033102 |
|
metallb-speaker |
mirantis.azurecr.io/bm/external/metallb/speaker:v0.13.7-20221130155702-refresh-2023033102 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-focal-20230316094816 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.36.23.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.36.23.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.36.23.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.36.23.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.36.23.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.36.23.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.36.23.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.36.23.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.36.23.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.36.23.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.36.23.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.36.23.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.36.23.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.36.23.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.36.23.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.36.23.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.36.23.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.36.23.tgz |
|
mcc-cache |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.36.23.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.36.23.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.36.23.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.36.23.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.36.23.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.36.23.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.36.23.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.36.23.tgz |
|
scope-controller |
http://binary.mirantis.com/core/helm/scope-controller-1.36.23.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.36.23.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.36.23.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.36.23.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.36.23.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.36.23 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.36.23 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.36.23 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.36.23 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.36.23 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.6.1 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.36.23 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.36.23 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.36.23 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.36.23 |
|
kaas-exporter |
mirantis.azurecr.io/core/kaas-exporter:1.36.23 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.36.23 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.36.23 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.36.23 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.36.23 |
|
mcc-haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.17.0-8-g6ca89d5 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.19.0-5-g6a7e17d |
|
metrics-server |
mirantis.azurecr.io/core/external/metrics-server:v0.6.3-2 |
|
nginx |
mirantis.azurecr.io/core/external/nginx:1.36.23 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager-amd64:v1.22.1-7-gc11024f8 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.36.23 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.36.23 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.36.23 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.36.23 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.36.23 |
|
registry |
mirantis.azurecr.io/lcm/registry:v2.8.1-3 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.36.23 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.36.23 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.36.23 |
|
storage-discovery |
mirantis.azurecr.io/core/storage-discovery:1.36.23 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.36.23 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.36.23 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.36.23 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
Helm charts Updated |
iam |
|
iam-proxy |
||
Docker images |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230331112513 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.5.16 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-4 |
In the Container Cloud patch release 2.23.3, 28 vendor-specific CVEs have been addressed, 2 of critical and 26 of high severity.
The full list of the CVEs present in the current Container Cloud release is available at the Mirantis Security Portal.
Container Cloud 2.23.2 is the first patch release of the 2.23.x release series that incorporates security updates for CVEs with Critical and High severity. This patch release:
Introduces support for patch Cluster releases 12.7.1 and 11.7.1.
Supports the latest major Cluster releases 12.7.0 and 11.7.0.
Does not support greenfield deployments based on deprecated Cluster releases 12.5.0 and 11.6.0. Use the latest available Cluster releases of the series instead.
This section contains the lists of updated artifacts and CVE fixes for the Container Cloud release 2.23.2. For enhancements, addressed and known issues of the parent Container Cloud release 2.23.0, refer to 2.23.0.
This section lists the components artifacts of the Mirantis Container Cloud release 2.23.2. For artifacts of the Cluster releases introduced in 2.23.2, see Cluster release 12.7.1 and Cluster release 11.7.1.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-api Updated |
https://binary.mirantis.com/core/helm/baremetal-api-1.36.14.tgz |
baremetal-operator Updated |
https://binary.mirantis.com/core/helm/baremetal-operator-1.36.15.tgz |
|
baremetal-public-api Updated |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.36.14.tgz |
|
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20230126190304 |
|
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20230126190304 |
|
kaas-ipam Updated |
||
local-volume-provisioner Updated |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.36.14.tgz |
|
metallb |
||
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
Docker images |
ambassador |
mirantis.azurecr.io/core/external/nginx:1.36.14 |
baremetal-dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-alpine-20230406194234 |
|
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-focal-20230405200004 |
|
baremetal-resource-controller |
n/a (merged to bm-collective) |
|
bm-collective New |
mirantis.azurecr.io/bm/bm-collective:base-alpine-20230405184901 |
|
dynamic_ipxe |
n/a (merged to bm-collective) |
|
dnsmasq-controller |
n/a (merged to bm-collective) |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230403060017 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230403060017 |
|
ironic-prometheus-exporter Updated |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20230330140456 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-focal-20230405184421 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230328123811 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.19.0-5-g6a7e17d |
|
metallb-controller |
mirantis.azurecr.io/bm/external/metallb/controller:v0.13.7-20221130155702-refresh-2023033102 |
|
metallb-speaker |
mirantis.azurecr.io/bm/external/metallb/speaker:v0.13.7-20221130155702-refresh-2023033102 |
|
syslog-ng Updated |
mirantis.azurecr.io/bm/syslog-ng:base-focal-20230316094816 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.36.14.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.36.14.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.36.14.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.36.14.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.36.14.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.36.14.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.36.14.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.36.14.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.36.14.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.36.14.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.36.14.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.36.14.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.36.14.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.36.14.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.36.14.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.36.14.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.36.14.tgz |
|
machinepool-controller |
https://binary.mirantis.com/core/helm/machinepool-controller-1.36.14.tgz |
|
mcc-cache |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.36.14.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.36.14.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.36.14.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.36.14.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.36.14.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.36.14.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.36.14.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.36.14.tgz |
|
scope-controller |
http://binary.mirantis.com/core/helm/scope-controller-1.36.14.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.36.14.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.36.14.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.36.14.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.36.14.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.36.14 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.36.14 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.36.14 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.36.14 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.36.14 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.6.1 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.36.14 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.36.14 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.36.14 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.36.14 |
|
kaas-exporter |
mirantis.azurecr.io/core/kaas-exporter:1.36.14 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.36.14 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.36.14 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.36.14 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.36.14 |
|
mcc-haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.17.0-8-g6ca89d5 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.19.0-5-g6a7e17d |
|
metrics-server |
mirantis.azurecr.io/core/external/metrics-server:v0.6.3-2 |
|
nginx |
mirantis.azurecr.io/core/external/nginx:1.36.14 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager-amd64:v1.22.1-7-gc11024f8 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.36.14 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.36.14 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.36.14 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.36.14 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.36.14 |
|
registry Updated |
mirantis.azurecr.io/lcm/registry:v2.8.1-1-g7bde01d2 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.36.14 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.36.14 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.36.14 |
|
squid-proxy Updated |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-10-g24a0d69 |
|
storage-discovery |
mirantis.azurecr.io/core/storage-discovery:1.36.14 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.36.14 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.36.14 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.36.14 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
Helm charts Updated |
iam |
|
iam-proxy |
||
Docker images |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230227122722 |
|
keycloak Updated |
mirantis.azurecr.io/iam/keycloak:0.5.16 |
|
keycloak-gatekeeper Updated |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-4 |
In Container Cloud 2.23.2, 1087 vendor-specific CVEs have been addressed, 53 with critical and 1034 with high severity.
The full list of the CVEs present in the current Container Cloud release is available at the Mirantis Security Portal.
The Mirantis Container Cloud GA release 2.23.1 is based on 2.23.0 and:
Introduces support for the Cluster release 12.7.0 that is based on the Cluster release 11.7.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 23.1.
This Cluster release is based on the updated version of Mirantis Kubernetes Engine 3.5.7 with Kubernetes 1.21 and Mirantis Container Runtime 20.10.13.
Supports the latest Cluster release 11.7.0
Does not support greenfield deployments based on deprecated Cluster releases 12.5.0 and 11.6.0. Use the latest available Cluster releases of the series instead.
For details about the Container Cloud release 2.23.1, refer to its parent releases 2.23.0 and 2.22.0:
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
The Mirantis Container Cloud GA release 2.23.0:
Introduces support for the Cluster release 11.7.0 that is based on Mirantis Container Runtime 20.10.13 and Mirantis Kubernetes Engine 3.5.7 with Kubernetes 1.21.
Supports the Cluster release 12.5.0 that is based on the Cluster release 11.5.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 22.5.
Does not support greenfield deployments on deprecated Cluster releases 11.6.0, 8.10.0, and 7.11.0. Use the latest available Cluster releases of the series instead.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.23.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.23.0. For the list of enhancements in the Cluster release 11.7.0 that is introduced by the Container Cloud release 2.23.0, see the Cluster releases (managed).
Deletion of persistent volumes during an OpenStack-based cluster deletion
The ‘Upgrade’ button for easy cluster update through the web UI
Implemented the capability to perform a graceful reboot on a management,
regional, or managed cluster for all supported providers using the
GracefulRebootRequest custom resource. Use this resource for a rolling
reboot of several or all cluster machines without workloads interruption.
The reboot occurs in the order of cluster upgrade policy.
The resource is also useful for a bulk reboot of machines, for example, on large clusters.
To verify the reboot status of a machine:
kubectl get machines <machineName> -o wide
Example of system response:
NAME READY LCMPHASE NODENAME UPGRADEINDEX REBOOTREQUIRED WARNINGS
demo-0 true Ready kaas-node-c6aa8ad3 1 true
Note
For MOSK-based deployments, the feature support is available since MOSK 23.1.
Enhanced Machine and Cluster objects by adding the following output
columns to the kubectl get machines -o wide and
kubectl get cluster -o wide commands to simplify
monitoring of machine and cluster states. More specifically, you can now
obtain the following machine and cluster details:
Machineobject:READYUPGRADEINDEXREBOOTREQUIREDWARNINGSLCMPHASE(renamed fromPHASE)
Clusterobject:READYRELEASEWARNINGS
Example system response of the kubectl get machines <machineName> -o wide command:
NAME READY LCMPHASE NODENAME UPGRADEINDEX REBOOTREQUIRED WARNINGS
demo-0 true Ready kaas-node-c6aa8ad3 1 true
TechPreview
Implemented the initial Technology Preview API support for deletion of
persistent volumes during an OpenStack-based managed cluster deletion.
To enable the feature, set the boolean volumesCleanupEnabled option in the
spec.providerSpec.value section of the Cluster object before a managed
cluster deletion.
Caution
The feature applies only to volumes created on clusters that are based on or updated to the Cluster release 11.7.0 or later.
If you added volumes to an existing cluster before it was updated to the Cluster release 11.7.0, delete such volumes manually after the cluster deletion.
Implemented the capability to disable time sync management during a management
or regional cluster bootstrap using the ntpEnabled=false option.
The default setting remains ntpEnabled=true. The feature disables
the management of chrony configuration by Container Cloud and enables you
to use your own system for chrony management.
Note
For MOSK-based deployments, the feature support is available since MOSK 23.1.
The following issues have been addressed in the Mirantis Container Cloud release 2.23.0 along with the Cluster release 11.7.0:
[29647] Fixed the issue with the
Network preparedstage getting stuck in theNotStartedstatus during deployment of a vSphere-based management or regional cluster with IPAM disabled.[26896] Fixed the issue with the MetalLB liveness and readiness timeouts in a slow network.
[28313] Fixed the issue with the
iam-keycloakPod starting slowly because of DB errors causing timeouts while waiting for the OIDC configuration readiness.[28675] Fixed the issue with the Ceph OSD-related parameters configured using
rookConfiginKaaSCephclusterbeing not applied until OSDs are restarted. Now, parameters for Ceph OSD daemons apply during runtime instead of setting them directly inceph.conf. Therefore, no restart is required.[30040] Fixed the issue with the
HelmBundleReleaseNotDeployedalert that has therelease_name=opensearchlabel firing during the Container Cloud or Cluster release update due to issues with the claim request size in theelasticsearch.persistentVolumeClaimSizeconfiguration.[29329] Fixed the issue with recreation of the Patroni container replica being stuck in the degraded state due to the liveness probe killing the container that runs the
pg_rewindprocedure during cluster update.[28822] Fixed the issue with Reference Application triggering false-positive alerts related to Reference Application during its upgrade.
[28479] Fixed the issue with the restarts count of the
metric-collectorPod being increased in time withreason: OOMKilledincontainerStatusesof themetric-collectorPod on baremetal-based management clusters with HTTP proxy enabled.[28417] Fixed the issue with the Reports Dashboards plugin not being enabled by default preventing the use of the reporting option. For details about this plugin, see the GitHub OpenSearch documentation: OpenSearch Dashboards Reports.
[28373] Fixed the issue with Alerta getting stuck after a failed initialization during cluster creation with StackLight enabled.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.23.0 including the Cluster release 11.7.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Due to the upstream MetalLB issue,
a race condition occurs when assigning an IP address after the MetalLB
controller restart. If a new service of the LoadBalancer type is created
during the MetalLB Controller restart, then this service can be assigned an IP
address that was already assigned to another service before the MetalLB
Controller restart.
To verify that the cluster is affected:
Verify whether IP addresses of the LoadBalancer (LB) type are duplicated
where they are not supposed to:
kubectl get svc -A|grep LoadBalancer
Note
Some services use shared IP addresses on purpose. In the example system response below, these are services using the IP address 10.0.1.141.
Example system response:
kaas dhcp-lb LoadBalancer 10.233.4.192 10.0.1.141 53:32594/UDP,67:30048/UDP,68:30464/UDP,69:31898/UDP,123:32450/UDP 13h
kaas dhcp-lb-tcp LoadBalancer 10.233.6.79 10.0.1.141 8080:31796/TCP,53:32012/TCP 11h
kaas httpd-http LoadBalancer 10.233.0.92 10.0.1.141 80:30115/TCP 13h
kaas iam-keycloak-http LoadBalancer 10.233.55.2 10.100.91.101 443:30858/TCP,9990:32301/TCP 2h
kaas ironic-kaas-bm LoadBalancer 10.233.26.176 10.0.1.141 6385:31748/TCP,8089:30604/TCP,5050:32200/TCP,9797:31988/TCP,601:31888/TCP 13h
kaas ironic-syslog LoadBalancer 10.233.59.199 10.0.1.141 514:32098/UDP 13h
kaas kaas-kaas-ui LoadBalancer 10.233.51.167 10.100.91.101 443:30976/TCP 13h
kaas mcc-cache LoadBalancer 10.233.40.68 10.100.91.102 80:32278/TCP,443:32462/TCP 12h
kaas mcc-cache-pxe LoadBalancer 10.233.10.75 10.0.1.142 80:30112/TCP,443:31559/TCP 12h
stacklight iam-proxy-alerta LoadBalancer 10.233.4.102 10.100.91.104 443:30101/TCP 12h
stacklight iam-proxy-alertmanager LoadBalancer 10.233.46.45 10.100.91.105 443:30944/TCP 12h
stacklight iam-proxy-grafana LoadBalancer 10.233.39.24 10.100.91.106 443:30953/TCP 12h
stacklight iam-proxy-prometheus LoadBalancer 10.233.12.174 10.100.91.107 443:31300/TCP 12h
stacklight telemeter-server-external LoadBalancer 10.233.56.63 10.100.91.103 443:30582/TCP 12h
In the above example, the iam-keycloak-http and kaas-kaas-ui
services erroneously use the same IP address 10.100.91.101. They both use the
same port 443 producing a collision when an application tries to access the
10.100.91.101:443 endpoint.
Workaround:
Unassign the current LB IP address for the selected service, as no LB IP address can be used for the
NodePortservice:kubectl -n kaas patch svc <serviceName> -p '{"spec":{"type":"NodePort"}}'
Assign a new LB IP address for the selected service:
kubectl -n kaas patch svc <serviceName> -p '{"spec":{"type":"LoadBalancer"}}'
The second affected service will continue using its current LB IP address.
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
If a baremetal-based regional cluster deployment fails before pivoting is done, the corresponding region deletion fails.
Workaround:
Using the command below, manually delete all possible traces of the failed
regional cluster deployment, including but not limited to the following
objects that contain the kaas.mirantis.com/region label of the affected
region:
clustermachinebaremetalhostbaremetalhostprofilel2templatesubnetipamhostipaddr
kubectl delete <objectName> -l kaas.mirantis.com/region=<regionName>
Warning
Do not use the same region name again after the regional cluster deployment failure since some objects that reference the region name may still exist.
Upgrade of a cluster with more than 120 nodes gets stuck with errors about
IP addresses exhaustion in the docker logs.
Note
If you plan to scale your cluster to more than 120 nodes, the cluster will be affected by the issue. Therefore, you will have to perform the workaround below.
Workaround:
Caution
If you have not run the cluster upgrade yet, simply recreate the
mke-overlay network as described in the step 6 and skip all other steps.
Note
If you successfully upgraded the cluster with less than 120 nodes but plan to scale it to more that 120 node, proceed with steps 2-9.
Verify that MKE nodes are upgraded:
On any master node, run the following command to identify
ucp-worker-agentthat has a newer version:docker service ls
Example of system response:
ID NAME MODE REPLICAS IMAGE PORTS 7jdl9m0giuso ucp-3-5-7 global 0/0 mirantis/ucp:3.5.7 uloi2ixrd0br ucp-auth-api global 3/3 mirantis/ucp-auth:3.5.7 pfub4xa17nkb ucp-auth-worker global 3/3 mirantis/ucp-auth:3.5.7 00w1kqn0x69w ucp-cluster-agent replicated 1/1 mirantis/ucp-agent:3.5.7 xjhwv1vrw9k5 ucp-kube-proxy-win global 0/0 mirantis/ucp-agent-win:3.5.7 oz28q8a7swmo ucp-kubelet-win global 0/0 mirantis/ucp-agent-win:3.5.7 ssjwonmnvk3s ucp-manager-agent global 3/3 mirantis/ucp-agent:3.5.7 ks0ttzydkxmh ucp-pod-cleaner-win global 0/0 mirantis/ucp-agent-win:3.5.7 w5d25qgneibv ucp-tigera-felix-win global 0/0 mirantis/ucp-agent-win:3.5.7 ni86z33o10n3 ucp-tigera-node-win global 0/0 mirantis/ucp-agent-win:3.5.7 iyyh1f0z6ejc ucp-worker-agent-win-x global 0/0 mirantis/ucp-agent-win:3.5.5 5z6ew4fmf2mm ucp-worker-agent-win-y global 0/0 mirantis/ucp-agent-win:3.5.7 gr52h05hcwwn ucp-worker-agent-x global 56/56 mirantis/ucp-agent:3.5.5 e8coi9bx2j7j ucp-worker-agent-y global 121/121 mirantis/ucp-agent:3.5.7
In the above example, it is
ucp-worker-agent-y.Obtain the node list:
docker service ps ucp-worker-agent-y | awk -F ' ' ‘$4 ~ /^kaas/ {print $4}’ > upgraded_nodes.txt
Identify the cluster ID. For example, run the following command on the management cluster:
kubectl -n <clusterNamespace> get cluster <clusterName> -o json | jq '.status.providerStatus.mke.clusterID'
Create a backup of MKE as described in the MKE documentation: Backup procedure.
Remove MKE services:
docker service rm ucp-cluster-agent ucp-manager-agent ucp-worker-agent-win-y ucp-worker-agent-y ucp-worker-agent-win-x ucp-worker-agent-x
Remove the
mke-overlaynetwork:docker network rm mke-overlay
Recreate the
mke-overlaynetwork with a correct CIDR that must be at least/20and have no interventions with other subnets in the cluster network. For example:docker network create -d overlay --subnet 10.1.0.0/20 mke-overlay
Create placeholder worker services:
docker service create --name ucp-worker-agent-x --mode global --constraint node.labels.foo==bar --detach busybox sleep 3d docker service create --name ucp-worker-agent-win-x --mode global --constraint node.labels.foo==bar --detach busybox sleep 3d
Recreate all MKE services using the previously obtained cluster ID. Use the target version for your cluster, for example,
3.5.7:docker container run --rm -it --name ucp -v /var/run/docker.sock:/var/run/docker.sock mirantis/ucp:3.5.7 upgrade --debug --manual-worker-upgrade --force-minimums --id <cluster ID> --interactive --force-port-check
Note
Because of interactive mode, you may need to use
Ctrl+Cwhen the command execution completes.Verify that all services are recreated:
docker service ls
The exemplary
ucp-worker-agent-yservice must have 1 replica running with a node that was previously stuck.Using the node list obtained in the first step, remove the
upgrade-holdlabels from the nodes that were previously upgraded:for i in $(cat upgraded_nodes.txt); do docker node update --label-rm com.docker.ucp.upgrade-hold $i; done
Verify that all nodes from the list obtained in the first step are present in the
ucp-worker-agent-yservice. For example:docker service ps ucp-worker-agent-y
During replacement of a manager machine, the following problems may occur:
The system adds the node to Docker swarm but not to Kubernetes
The node
Deploymentgets stuck with failed RethinkDB health checks
Workaround:
Delete the failed node.
Wait for the MKE cluster to become healthy. To monitor the cluster status:
Log in to the MKE web UI as described in Connect to the Mirantis Kubernetes Engine web UI.
Monitor the cluster status as described in MKE Operations Guide: Monitor an MKE cluster with the MKE web UI.
Deploy a new node.
During the unsafe or forced deletion of a manager machine running the
calico-kube-controllers Pod in the kube-system namespace,
the following issues occur:
The
calico-kube-controllersPod fails to clean up resources associated with the deleted nodeThe
calico-nodePod may fail to start up on a newly created node if the machine is provisioned with the same IP address as the deleted machine had
As a workaround, before deletion of the node running the
calico-kube-controllers Pod, cordon and drain the node:
kubectl cordon <nodeName>
kubectl drain <nodeName>
During replacement of a master node on a cluster of any type, the
calico-node Pod fails to start on a new node that has the same IP address
as the node being replaced.
Workaround:
Log in to any
masternode.From a CLI with an MKE client bundle, create a shell alias to start calicoctl using the
mirantis/ucp-dsinfoimage:alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/key.pem \ -e ETCD_CA_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/ca.pem \ -e ETCD_CERT_FILE=/var/lib/docker/volumes/ucp-kv-certs/_data/cert.pem \ -v /var/run/calico:/var/run/calico \ -v /var/lib/docker/volumes/ucp-kv-certs/_data:/var/lib/docker/volumes/ucp-kv-certs/_data:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl \ "
alias calicoctl="\ docker run -i --rm \ --pid host \ --net host \ -e constraint:ostype==linux \ -e ETCD_ENDPOINTS=<etcdEndpoint> \ -e ETCD_KEY_FILE=/ucp-node-certs/key.pem \ -e ETCD_CA_CERT_FILE=/ucp-node-certs/ca.pem \ -e ETCD_CERT_FILE=/ucp-node-certs/cert.pem \ -v /var/run/calico:/var/run/calico \ -v ucp-node-certs:/ucp-node-certs:ro \ mirantis/ucp-dsinfo:<mkeVersion> \ calicoctl --allow-version-mismatch \ "
In the above command, replace the following values with the corresponding settings of the affected cluster:
<etcdEndpoint>is the etcd endpoint defined in the Calico configuration file. For example,ETCD_ENDPOINTS=127.0.0.1:12378<mkeVersion>is the MKE version installed on your cluster. For example,mirantis/ucp-dsinfo:3.5.7.
Verify the node list on the cluster:
kubectl get node
Compare this list with the node list in Calico to identify the old node:
calicoctl get node -o wide
Remove the old node from Calico:
calicoctl delete node kaas-node-<nodeID>
During update of a Container Cloud cluster of any type, if the MKE minor
version is updated from 3.4.x to 3.5.x, access to the cluster using the
existing kubeconfig fails with the You must be logged in to the server
(Unauthorized) error due to OIDC settings being reconfigured.
As a workaround, during the cluster update process, use the admin
kubeconfig instead of the existing one. Once the update completes, you can
use the existing cluster kubeconfig again.
To obtain the admin kubeconfig:
kubectl --kubeconfig <pathToMgmtKubeconfig> get secret -n <affectedClusterNamespace> \
-o yaml <affectedClusterName>-kubeconfig | awk '/admin.conf/ {print $2}' | \
head -1 | base64 -d > clusterKubeconfig.yaml
If the related cluster is regional, replace <pathToMgmtKubeconfig> with
<pathToRegionalKubeconfig>.
When setting a new Transport Layer Security (TLS) certificate for a cluster,
the false positive failed to get kubeconfig error may occur on the
Waiting for TLS settings to be applied stage. No actions are required.
Therefore, disregard the error.
To verify the status of the TLS configuration being applied:
kubectl get cluster <ClusterName> -n <ClusterProjectName> -o jsonpath-as-json="{.status.providerStatus.tls.<Application>}"
Possible values for the <Application> parameter are as follows:
keycloakuicachemkeiamProxyAlertaiamProxyAlertManageriamProxyGrafanaiamProxyKibanaiamProxyPrometheus
Example of system response:
[
{
"expirationTime": "2024-01-06T09:37:04Z",
"hostname": "domain.com",
}
]
In this example, expirationTime equals the NotAfter field of the
server certificate. And the value of hostname contains the configured
application name.
The deployment of Ceph OSDs fails with the following messages in the status
section of the KaaSCephCluster custom resource:
shortClusterInfo:
messages:
- Not all osds are deployed
- Not all osds are in
- Not all osds are up
To find out if your cluster is affected, verify if the devices on
the AMD hosts you use for the Ceph OSDs deployment are removable.
For example, if the sdb device name is specified in
spec.cephClusterSpec.nodes.storageDevices of the KaaSCephCluster
custom resource for the affected host, run:
# cat /sys/block/sdb/removable
1
The system output shows that the reason of the above messages in status
is the enabled hotplug functionality on the AMD nodes, which marks all drives
as removable. And the hotplug functionality is not supported by Ceph in
Container Cloud.
As a workaround, disable the hotplug functionality in the BIOS settings for disks that are configured to be used as Ceph OSD data devices.
Due to the upstream Ceph issue
occurring since Ceph Pacific, the pg_autoscaler module of Ceph Manager
fails with the pool <poolNumber> has overlapping roots error if a Ceph
cluster contains a mix of pools with deviceClass either explicitly
specified or not specified.
The deviceClass parameter is required for a pool definition in the
spec section of the KaaSCephCluster object, but not required for Ceph
RADOS Gateway (RGW) and Ceph File System (CephFS).
Therefore, if sections for Ceph RGW or CephFS data or metadata pools are
defined without deviceClass, then autoscaling of placement groups is
disabled on a cluster due to overlapping roots. Overlapping roots imply that
Ceph RGW and/or CephFS pools obtained the default crush rule and have no
demarcation on a specific class to store data.
Note
If pools for Ceph RGW and CephFS already have deviceClass
specified, skip the corresponding steps of the below procedure.
Note
Perform the below procedure on the affected managed cluster using
its kubeconfig.
Workaround:
Obtain
failureDomainand required replicas for Ceph RGW and/or CephFS pools:Note
If the
KaasCephClusterspecsection does not containfailureDomain,failureDomainequalshostby default to store one replica per node.Note
The types of pools crush rules include:
An
erasureCodedpool requires thecodingChunks + dataChunksnumber of available units offailureDomain.A
replicatedpool requires thereplicated.sizenumber of available units offailureDomain.
To obtain Ceph RGW pools, use the
spec.cephClusterSpec.objectStorage.rgwsection of theKaaSCephClusterobject. For example:objectStorage: rgw: dataPool: failureDomain: host erasureCoded: codingChunks: 1 dataChunks: 2 metadataPool: failureDomain: host replicated: size: 3 gateway: allNodes: false instances: 3 port: 80 securePort: 8443 name: openstack-store preservePoolsOnDelete: false
The
dataPoolpool requires the sum ofcodingChunksanddataChunksvalues representing the number of available units offailureDomain. In the example above, forfailureDomain: host,dataPoolrequires3available nodes to store its objects.The
metadataPoolpool requires thereplicated.sizenumber of available units offailureDomain. ForfailureDomain: host,metadataPoolrequires3available nodes to store its objects.To obtain CephFS pools, use the
spec.cephClusterSpec.sharedFilesystem.cephFSsection of theKaaSCephClusterobject. For example:sharedFilesystem: cephFS: - name: cephfs-store dataPools: - name: default-pool replicated: size: 3 failureDomain: host - name: second-pool erasureCoded: dataChunks: 2 codingChunks: 1 metadataPool: replicated: size: 3 failureDomain: host ...
The
default-poolandmetadataPoolpools require thereplicated.sizenumber of available units offailureDomain. ForfailureDomain: host,default-poolrequires3available nodes to store its objects.The
second-poolpool requires the sum ofcodingChunksanddataChunksrepresenting the number of available units offailureDomain. ForfailureDomain: host,second-poolrequires3available nodes to store its objects.
Obtain the device class that meets the desired number of required replicas for the defined
failureDomain.Obtaining of the device class
Get a shell of the
ceph-toolsPod:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
Obtain the Ceph crush tree with all available crush rules of the device class:
ceph osd tree
Example output:
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.18713 root default -3 0.06238 host kaas-node-a29ecf2d-a2cc-493e-bd83-00e9639a7db8 0 hdd 0.03119 osd.0 up 1.00000 1.00000 3 ssd 0.03119 osd.3 up 1.00000 1.00000 -5 0.06238 host kaas-node-dd6826b0-fe3f-407c-ae29-6b0e4a40019d 1 hdd 0.03119 osd.1 up 1.00000 1.00000 4 ssd 0.03119 osd.4 up 1.00000 1.00000 -7 0.06238 host kaas-node-df65fa30-d657-477e-bad2-16f69596d37a 2 hdd 0.03119 osd.2 up 1.00000 1.00000 5 ssd 0.03119 osd.5 up 1.00000 1.00000
Calculate the number of the
failureDomainunits with each device class.For
failureDomain: host,hddandssddevice classes from the example output above have3units each.Select the device classes that meet the replicas requirement. In the example output above, both
hddandssdare applicable to store the pool data.Exit the
ceph-toolsPod.
Calculate potential data size for Ceph RGW and CephFS pools.
Calculation of data size
Obtain Ceph data stored by classes and pools:
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph df
Example output:
--- RAW STORAGE --- CLASS SIZE AVAIL USED RAW USED %RAW USED hdd 96 GiB 90 GiB 6.0 GiB 6.0 GiB 6.26 ssd 96 GiB 96 GiB 211 MiB 211 MiB 0.21 TOTAL 192 GiB 186 GiB 6.2 GiB 6.2 GiB 3.24 --- POOLS --- POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL device_health_metrics 1 1 0 B 0 0 B 0 42 GiB kubernetes-hdd 2 32 2.3 GiB 707 4.6 GiB 5.15 42 GiB kubernetes-2-ssd 11 32 19 B 1 8 KiB 0 45 GiB openstack-store.rgw.meta 12 32 2.5 KiB 10 64 KiB 0 45 GiB openstack-store.rgw.log 13 32 23 KiB 309 1.3 MiB 0 45 GiB .rgw.root 14 32 4.8 KiB 16 120 KiB 0 45 GiB openstack-store.rgw.otp 15 32 0 B 0 0 B 0 45 GiB openstack-store.rgw.control 16 32 0 B 8 0 B 0 45 GiB openstack-store.rgw.buckets.index 17 32 2.7 KiB 22 5.3 KiB 0 45 GiB openstack-store.rgw.buckets.non-ec 18 32 0 B 0 0 B 0 45 GiB openstack-store.rgw.buckets.data 19 32 103 MiB 26 155 MiB 0.17 61 GiB
Summarize the
USEDsize of all<rgwName>.rgw.*pools and compare it with theAVAILsize of each applicable device class selected in the previous step.Note
As Ceph RGW pools lack explicit specification of
deviceClass, they may store objects on all device classes. The resulted device size can be smaller than the calculatedUSEDsize because part of data can already be stored in the desired class. Therefore, limiting pools to a single device class may result in a smaller occupied data size than the totalUSEDsize. Nonetheless, calculating theUSEDsize of all pools remains valid because the pool data may not be stored on the selected device class.For CephFS data or metadata pools, use the previous step to calculate the
USEDsize of pools and compare it with theAVAILsize.Decide which device class from applicable by required replicas and available size is more preferable to store Ceph RGW and CephFS data. In the example output above,
hddandssdare both applicable. Therefore, select any of them.Note
You can select different device classes for Ceph RGW and CephFS. For example,
hddfor Ceph RGW andssdfor CephFS. Select a device class based on performance expectations, if any.
Create the
rule-helperscript to switch Ceph RGW or CephFS pools to a device usage.Creation of the
rule-helperscriptCreate the
rule-helperscript file:Get a shell of the
ceph-toolsPod:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
Create the
/tmp/rule-helper.pyfile with the following content:cat > /tmp/rule-helper.py << EOF import argparse import json import subprocess from sys import argv, exit def get_cmd(cmd_args): output_args = ['--format', 'json'] _cmd = subprocess.Popen(cmd_args + output_args, stdout=subprocess.PIPE, stderr=subprocess.PIPE) stdout, stderr = _cmd.communicate() if stderr: error = stderr print("[ERROR] Failed to get '{0}': {1}".format(cmd_args.join(' '), stderr)) return return stdout def format_step(action, cmd_args): return "{0}:\n\t{1}".format(action, ' '.join(cmd_args)) def process_rule(rule): steps = [] new_rule_name = rule['rule_name'] + '_v2' if rule['type'] == "replicated": rule_create_args = ['ceph', 'osd', 'crush', 'create-replicated', new_rule_name, rule['root'], rule['failure_domain'], rule['device_class']] steps.append(format_step("create a new replicated rule for pool", rule_create_args)) else: new_profile_name = rule['profile_name'] + '_' + rule['device_class'] profile_create_args = ['ceph', 'osd', 'erasure-code-profile', 'set', new_profile_name] for k,v in rule['profile'].items(): profile_create_args.append("{0}={1}".format(k,v)) rule_create_args = ['ceph', 'osd', 'crush', 'create-erasure', new_rule_name, new_profile_name] steps.append(format_step("create a new erasure-coded profile", profile_create_args)) steps.append(format_step("create a new erasure-coded rule for pool", rule_create_args)) set_rule_args = ['ceph', 'osd', 'pool', 'set', 'crush_rule', rule['pool_name'], new_rule_name] revert_rule_args = ['ceph', 'osd', 'pool', 'set', 'crush_rule', new_rule_name, rule['pool_name']] rm_old_rule_args = ['ceph', 'osd', 'crush', 'rule', 'rm', rule['rule_name']] rename_rule_args = ['ceph', 'osd', 'crush', 'rule', 'rename', new_rule_name, rule['rule_name']] steps.append(format_step("set pool crush rule to new one", set_rule_args)) steps.append("check that replication is finished and status healthy: ceph -s") steps.append(format_step("in case of any problems revert step 2 and stop procedure", revert_rule_args)) steps.append(format_step("remove standard (old) pool crush rule", rm_old_rule_args)) steps.append(format_step("rename new pool crush rule to standard name", rename_rule_args)) if rule['type'] != "replicated": rm_old_profile_args = ['ceph', 'osd', 'erasure-code-profile', 'rm', rule['profile_name']] steps.append(format_step("remove standard (old) erasure-coded profile", rm_old_profile_args)) for idx, step in enumerate(steps): print(" {0}) {1}".format(idx+1, step)) def check_rules(args): extra_pools_lookup = [] if args.type == "rgw": extra_pools_lookup.append(".rgw.root") pools_str = get_cmd(['ceph', 'osd', 'pool', 'ls', 'detail']) if pools_str == '': return rules_str = get_cmd(['ceph', 'osd', 'crush', 'rule', 'dump']) if rules_str == '': return try: pools_dump = json.loads(pools_str) rules_dump = json.loads(rules_str) if len(pools_dump) == 0: print("[ERROR] No pools found") return if len(rules_dump) == 0: print("[ERROR] No crush rules found") return crush_rules_recreate = [] for pool in pools_dump: if pool['pool_name'].startswith(args.prefix) or pool['pool_name'] in extra_pools_lookup: rule_id = pool['crush_rule'] for rule in rules_dump: if rule['rule_id'] == rule_id: recreate = False new_rule = {'rule_name': rule['rule_name'], 'pool_name': pool['pool_name']} for step in rule.get('steps',[]): root = step.get('item_name', '').split('~') if root[0] != '' and len(root) == 1: new_rule['root'] = root[0] continue failure_domain = step.get('type', '') if failure_domain != '': new_rule['failure_domain'] = failure_domain if new_rule.get('root', '') == '': continue new_rule['device_class'] = args.device_class if pool['erasure_code_profile'] == "": new_rule['type'] = "replicated" else: new_rule['type'] = "erasure" profile_str = get_cmd(['ceph', 'osd', 'erasure-code-profile', 'get', pool['erasure_code_profile']]) if profile_str == '': return profile_dump = json.loads(profile_str) profile_dump['crush-device-class'] = args.device_class new_rule['profile_name'] = pool['erasure_code_profile'] new_rule['profile'] = profile_dump crush_rules_recreate.append(new_rule) break print("Found {0} pools with crush rules require device class set".format(len(crush_rules_recreate))) for new_rule in crush_rules_recreate: print("- Pool {0} requires crush rule update, device class is not set".format(new_rule['pool_name'])) process_rule(new_rule) except Exception as err: print("[ERROR] Failed to get info from Ceph: {0}".format(err)) return if __name__ == '__main__': parser = argparse.ArgumentParser( description='Ceph crush rules checker. Specify device class and service name.', prog=argv[0], usage='%(prog)s [options]') parser.add_argument('--type', type=str, help='Type of pool: rgw, cephfs', default='', required=True) parser.add_argument('--prefix', type=str, help='Pool prefix. If objectstore - use objectstore name, if CephFS - CephFS name.', default='', required=True) parser.add_argument('--device-class', type=str, help='Device class to switch on.', required=True) args = parser.parse_args() if len(argv) < 3: parser.print_help() exit(0) check_rules(args) EOF
Exit the
ceph-toolsPod.
For Ceph RGW, execute the
rule-helperscript to output the step-by-step instruction and run each step provided in the output manually.Note
The following steps include creation of crush rules with the same parameters as before but with the device class specification and switching of pools to new crush rules.
Execution of the
rule-helperscript steps for Ceph RGWGet a shell of the
ceph-toolsPod:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
Run the
/tmp/rule-helper.pyscript with the following parameters:python3 /tmp/rule-helper.py --prefix <rgwName> --type rgw --device-class <deviceClass>
Substitute the following parameters:
<rgwName>with the Ceph RGW name fromspec.cephClusterSpec.objectStorage.rgw.namein theKaaSCephClusterobject. In the example above, the name isopenstack-store.<deviceClass>with the device class selected in the previous steps.
Using the output of the command from the previous step, run manual commands step-by-step.
Example output for the
hdddevice class:Found 7 pools with crush rules require device class set - Pool openstack-store.rgw.control requires crush rule update, device class is not set 1) create a new replicated rule for pool: ceph osd crush create-replicated openstack-store.rgw.control_v2 default host hdd 2) set pool crush rule to new one: ceph osd pool set crush_rule openstack-store.rgw.control openstack-store.rgw.control_v2 3) check that replication is finished and status healthy: ceph -s 4) in case of any problems revert step 2 and stop procedure: ceph osd pool set crush_rule openstack-store.rgw.control_v2 openstack-store.rgw.control 5) remove standard (old) pool crush rule: ceph osd crush rule rm openstack-store.rgw.control 6) rename new pool crush rule to standard name: ceph osd crush rule rename openstack-store.rgw.control_v2 openstack-store.rgw.control - Pool openstack-store.rgw.log requires crush rule update, device class is not set 1) create a new replicated rule for pool: ceph osd crush create-replicated openstack-store.rgw.log_v2 default host hdd 2) set pool crush rule to new one: ceph osd pool set crush_rule openstack-store.rgw.log openstack-store.rgw.log_v2 3) check that replication is finished and status healthy: ceph -s 4) in case of any problems revert step 2 and stop procedure: ceph osd pool set crush_rule openstack-store.rgw.log_v2 openstack-store.rgw.log 5) remove standard (old) pool crush rule: ceph osd crush rule rm openstack-store.rgw.log 6) rename new pool crush rule to standard name: ceph osd crush rule rename openstack-store.rgw.log_v2 openstack-store.rgw.log - Pool openstack-store.rgw.buckets.non-ec requires crush rule update, device class is not set 1) create a new replicated rule for pool: ceph osd crush create-replicated openstack-store.rgw.buckets.non-ec_v2 default host hdd 2) set pool crush rule to new one: ceph osd pool set crush_rule openstack-store.rgw.buckets.non-ec openstack-store.rgw.buckets.non-ec_v2 3) check that replication is finished and status healthy: ceph -s 4) in case of any problems revert step 2 and stop procedure: ceph osd pool set crush_rule openstack-store.rgw.buckets.non-ec_v2 openstack-store.rgw.buckets.non-ec 5) remove standard (old) pool crush rule: ceph osd crush rule rm openstack-store.rgw.buckets.non-ec 6) rename new pool crush rule to standard name: ceph osd crush rule rename openstack-store.rgw.buckets.non-ec_v2 openstack-store.rgw.buckets.non-ec - Pool .rgw.root requires crush rule update, device class is not set 1) create a new replicated rule for pool: ceph osd crush create-replicated .rgw.root_v2 default host hdd 2) set pool crush rule to new one: ceph osd pool set crush_rule .rgw.root .rgw.root_v2 3) check that replication is finished and status healthy: ceph -s 4) in case of any problems revert step 2 and stop procedure: ceph osd pool set crush_rule .rgw.root_v2 .rgw.root 5) remove standard (old) pool crush rule: ceph osd crush rule rm .rgw.root 6) rename new pool crush rule to standard name: ceph osd crush rule rename .rgw.root_v2 .rgw.root - Pool openstack-store.rgw.meta requires crush rule update, device class is not set 1) create a new replicated rule for pool: ceph osd crush create-replicated openstack-store.rgw.meta_v2 default host hdd 2) set pool crush rule to new one: ceph osd pool set crush_rule openstack-store.rgw.meta openstack-store.rgw.meta_v2 3) check that replication is finished and status healthy: ceph -s 4) in case of any problems revert step 2 and stop procedure: ceph osd pool set crush_rule openstack-store.rgw.meta_v2 openstack-store.rgw.meta 5) remove standard (old) pool crush rule: ceph osd crush rule rm openstack-store.rgw.meta 6) rename new pool crush rule to standard name: ceph osd crush rule rename openstack-store.rgw.meta_v2 openstack-store.rgw.meta - Pool openstack-store.rgw.buckets.index requires crush rule update, device class is not set 1) create a new replicated rule for pool: ceph osd crush create-replicated openstack-store.rgw.buckets.index_v2 default host hdd 2) set pool crush rule to new one: ceph osd pool set crush_rule openstack-store.rgw.buckets.index openstack-store.rgw.buckets.index_v2 3) check that replication is finished and status healthy: ceph -s 4) in case of any problems revert step 2 and stop procedure: ceph osd pool set crush_rule openstack-store.rgw.buckets.index_v2 openstack-store.rgw.buckets.index 5) remove standard (old) pool crush rule: ceph osd crush rule rm openstack-store.rgw.buckets.index 6) rename new pool crush rule to standard name: ceph osd crush rule rename openstack-store.rgw.buckets.index_v2 openstack-store.rgw.buckets.index - Pool openstack-store.rgw.buckets.data requires crush rule update, device class is not set 1) create a new erasure-coded profile: ceph osd erasure-code-profile set openstack-store_ecprofile_hdd crush-device-class=hdd crush-failure-domain=host crush-root=default jerasure-per-chunk-alignment=false k=2 m=1 plugin=jerasure technique=reed_sol_van w=8 2) create a new erasure-coded rule for pool: ceph osd crush create-erasure openstack-store.rgw.buckets.data_v2 openstack-store_ecprofile_hdd 3) set pool crush rule to new one: ceph osd pool set crush_rule openstack-store.rgw.buckets.data openstack-store.rgw.buckets.data_v2 4) check that replication is finished and status healthy: ceph -s 5) in case of any problems revert step 2 and stop procedure: ceph osd pool set crush_rule openstack-store.rgw.buckets.data_v2 openstack-store.rgw.buckets.data 6) remove standard (old) pool crush rule: ceph osd crush rule rm openstack-store.rgw.buckets.data 7) rename new pool crush rule to standard name: ceph osd crush rule rename openstack-store.rgw.buckets.data_v2 openstack-store.rgw.buckets.data 8) remove standard (old) erasure-coded profile: ceph osd erasure-code-profile rm openstack-store_ecprofile
Verify that the Ceph cluster has rebalanced and has the
HEALTH_OKstatus:ceph -sExit the
ceph-toolsPod.
For CephFS, execute the
rule-helperscript to output the step-by-step instruction and run each step provided in the output manually.Execution of the
rule-helperscript steps for CephFSGet a shell of the
ceph-toolsPod:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
Run the
/tmp/rule-helper.pyscript with the following parameters:python3 /tmp/rule-helper.py --prefix <cephfsName> --type cephfs --device-class <deviceClass>
Substitute the following parameters:
<cephfsName>with CephFS name fromspec.cephClusterSpec.sharedFilesystem.cephFS[0].namein theKaaSCephClusterobject. In the example above, the name iscephfs-store.<deviceClass>with the device class selected in the previous steps.
Using the output of the command from the previous step, run manual commands step-by-step.
Example output for the
hdddevice class:Found 3 rules require device class set - Pool cephfs-store-metadata requires crush rule update, device class is not set 1) create a new replicated rule for pool: ceph osd crush create-replicated cephfs-store-metadata_v2 default host ssd 2) set pool crush rule to new one: ceph osd pool set crush_rule cephfs-store-metadata cephfs-store-metadata_v2 3) check that replication is finished and status healthy: ceph -s 4) in case of any problems revert step 2 and stop procedure: ceph osd pool set crush_rule cephfs-store-metadata_v2 cephfs-store-metadata 5) remove standard (old) pool crush rule: ceph osd crush rule rm cephfs-store-metadata 6) rename new pool crush rule to standard name: ceph osd crush rule rename cephfs-store-metadata_v2 cephfs-store-metadata - Pool cephfs-store-default-pool requires crush rule update, device class is not set 1) create a new replicated rule for pool: ceph osd crush create-replicated cephfs-store-default-pool_v2 default host ssd 2) set pool crush rule to new one: ceph osd pool set crush_rule cephfs-store-default-pool cephfs-store-default-pool_v2 3) check that replication is finished and status healthy: ceph -s 4) in case of any problems revert step 2 and stop procedure: ceph osd pool set crush_rule cephfs-store-default-pool_v2 cephfs-store-default-pool 5) remove standard (old) pool crush rule: ceph osd crush rule rm cephfs-store-default-pool 6) rename new pool crush rule to standard name: ceph osd crush rule rename cephfs-store-default-pool_v2 cephfs-store-default-pool - Pool cephfs-store-second-pool requires crush rule update, device class is not set 1) create a new erasure-coded profile: ceph osd erasure-code-profile set cephfs-store-second-pool_ecprofile_ssd crush-device-class=ssd crush-failure-domain=host crush-root=default jerasure-per-chunk-alignment=false k=2 m=1 plugin=jerasure technique=reed_sol_van w=8 2) create a new erasure-coded rule for pool: ceph osd crush create-erasure cephfs-store-second-pool_v2 cephfs-store-second-pool_ecprofile_ssd 3) set pool crush rule to new one: ceph osd pool set crush_rule cephfs-store-second-pool cephfs-store-second-pool_v2 4) check that replication is finished and status healthy: ceph -s 5) in case of any problems revert step 2 and stop procedure: ceph osd pool set crush_rule cephfs-store-second-pool_v2 cephfs-store-second-pool 6) remove standard (old) pool crush rule: ceph osd crush rule rm cephfs-store-second-pool 7) rename new pool crush rule to standard name: ceph osd crush rule rename cephfs-store-second-pool_v2 cephfs-store-second-pool 8) remove standard (old) erasure-coded profile: ceph osd erasure-code-profile rm cephfs-store-second-pool_ecprofile
Verify that the Ceph cluster has rebalanced and has the
HEALTH_OKstatus:ceph -sExit the
ceph-toolsPod.
Verify the
pg_autoscalermodule after switchingdeviceClassfor all required pools:ceph osd pool autoscale-status
The system response must contain all Ceph RGW and CephFS pools.
On the management cluster, edit the
KaaSCephClusterobject of the corresponding managed cluster by adding the selected device class to thedeviceClassparameter of the updated Ceph RGW and CephFS pools:kubectl -n <managedClusterProjectName> edit kaascephcluster
Example configuration
spec: cephClusterSpec: objectStorage: rgw: dataPool: failureDomain: host deviceClass: <rgwDeviceClass> erasureCoded: codingChunks: 1 dataChunks: 2 metadataPool: failureDomain: host deviceClass: <rgwDeviceClass> replicated: size: 3 gateway: allNodes: false instances: 3 port: 80 securePort: 8443 name: openstack-store preservePoolsOnDelete: false ... sharedFilesystem: cephFS: - name: cephfs-store dataPools: - name: default-pool deviceClass: <cephfsDeviceClass> replicated: size: 3 failureDomain: host - name: second-pool deviceClass: <cephfsDeviceClass> erasureCoded: dataChunks: 2 codingChunks: 1 metadataPool: deviceClass: <cephfsDeviceClass> replicated: size: 3 failureDomain: host ...
Substitute
<rgwDeviceClass>with the device class applied to Ceph RGW pools and<cephfsDeviceClass>with the device class applied to CephFS pools.You can use this configuration step for further management of Ceph RGW and/or CephFS. It does not impact the existing Ceph cluster configuration.
Update of a managed cluster based on bare metal and Ceph enabled fails with
PersistentVolumeClaim getting stuck in the Pending state for the
prometheus-server StatefulSet and the
MountVolume.MountDevice failed for volume warning in the StackLight event
logs.
Workaround:
Verify that the description of the Pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name where the Pods failed to run<affectedPodName>is a Pod name that failed to run in the specified project
In the Pod description, identify the node name where the Pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain therbd volume mount failed: <csi-vol-uuid> is being usederror. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the Pod that fails to0replicas.On every
csi-rbdpluginPod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected Pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state becomesRunning.
Note
If you obtain patch releases, the issue is addressed in 2.23.2 for management and regional clusters and in 11.7.1 and 12.7.1 for managed clusters.
Elasticsearch Curator does not delete any indices according to the configured retention period on any type of Container Cloud clusters.
To verify whether your cluster is affected:
Identify versions of Cluster releases installed on your clusters:
kubectl get cluster --all-namespaces \
-o custom-columns=CLUSTER:.metadata.name,NAMESPACE:.metadata.namespace,VERSION:.spec.providerSpec.value.release
The following list contains all affected Cluster releases:
mke-11-7-0-3-5-7
mke-13-4-4
mke-13-5-3
mke-13-6-0
mke-13-7-0
mosk-12-7-0-23-1
As a workaround, on the affected clusters, create a temporary CronJob for
elasticsearch-curator to clean the required indices:
kubectl get cronjob elasticsearch-curator -n stacklight -o json \
| sed 's/5.7.6-[0-9]*/5.7.6-20230404082402/g' \
| jq '.spec.schedule = "30 * * * *"' \
| jq '.metadata.name = "temporary-elasticsearch-curator"' \
| jq 'del(.metadata.resourceVersion,.metadata.uid,.metadata.selfLink,.metadata.creationTimestamp,.metadata.annotations,.metadata.generation,.metadata.ownerReferences,.metadata.labels,.spec.jobTemplate.metadata.labels,.spec.jobTemplate.spec.template.metadata.creationTimestamp,.spec.jobTemplate.spec.template.metadata.labels)' \
| jq '.metadata.labels.app = "temporary-elasticsearch-curator"' \
| jq '.spec.jobTemplate.metadata.labels.app = "temporary-elasticsearch-curator"' \
| jq '.spec.jobTemplate.spec.template.metadata.labels.app = "temporary-elasticsearch-curator"' \
| kubectl create -f -
Note
This CronJob is removed automatically during upgrade to the major Container Cloud release 2.24.0 or to the patch Container Cloud release 2.23.3 if you obtain patch releases.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.23.0. For major components and versions of the Cluster release introduced in 2.23.0, see Cluster release 11.7.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Bare metal |
ambassador Updated |
1.23.3-alpine |
baremetal-operator Updated |
base-focal-20230126095055 |
|
baremetal-public-api Updated |
1.36.3 |
|
baremetal-provider Updated |
1.36.5 |
|
baremetal-resource-controller Updated |
base-focal-20230130170757 |
|
ironic Updated |
yoga-focal-20230130125656 |
|
kaas-ipam Updated |
base-focal-20230127092754 |
|
keepalived |
0.19.0-5-g6a7e17d |
|
local-volume-provisioner Updated |
2.5.0-1 |
|
mariadb |
10.6.7-focal-20221028120155 |
|
metallb-controller |
0.13.7 |
|
IAM |
iam Updated |
2.4.38 |
iam-controller Updated |
1.36.3 |
|
keycloak |
18.0.0 |
|
Container Cloud Updated |
admission-controller |
1.36.3 |
agent-controller |
1.36.3 |
|
byo-credentials-controller |
1.36.3 |
|
byo-provider |
1.36.3 |
|
ceph-kcc-controller |
1.36.3 |
|
cert-manager |
1.36.3 |
|
client-certificate-controller |
1.36.3 |
|
event-controller |
1.36.3 |
|
golang |
1.18.10 |
|
kaas-public-api |
1.36.3 |
|
kaas-exporter |
1.36.3 |
|
kaas-ui |
1.36.3 |
|
license-controller |
1.36.3 |
|
lcm-controller |
1.36.3 |
|
machinepool-controller |
1.36.3 |
|
metrics-server |
0.5.2 |
|
mcc-cache |
1.36.3 |
|
portforward-controller |
1.36.3 |
|
proxy-controller |
1.36.3 |
|
rbac-controller |
1.36.3 |
|
release-controller |
1.36.3 |
|
rhellicense-controller |
1.36.3 |
|
scope-controller |
1.36.3 |
|
user-controller |
1.36.3 |
|
OpenStack Updated |
openstack-provider |
1.36.3 |
os-credentials-controller |
1.36.3 |
|
VMware vSphere |
metallb-controller |
0.13.7 |
vsphere-provider Updated |
1.36.3 |
|
vsphere-credentials-controller Updated |
1.36.3 |
|
keepalived |
0.19.0-5-g6a7e17d |
|
squid-proxy Updated |
0.0.1-8 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.23.0. For artifacts of the Cluster release introduced in 2.23.0, see Cluster release 11.7.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-api Updated |
https://binary.mirantis.com/core/helm/baremetal-api-1.36.3.tgz |
baremetal-operator Updated |
https://binary.mirantis.com/core/helm/baremetal-operator-1.36.3.tgz |
|
baremetal-public-api Updated |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.36.3.tgz |
|
ironic-python-agent.initramfs Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20230126190304 |
|
ironic-python-agent.kernel Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20230126190304 |
|
kaas-ipam Updated |
||
local-volume-provisioner Updated |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.36.3.tgz |
|
metallb |
||
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
Docker images |
ambassador Updated |
mirantis.azurecr.io/general/external/docker.io/library/nginx:1.23.3-alpine |
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-focal-20230126095055 |
|
baremetal-resource-controller Updated |
mirantis.azurecr.io/bm/baremetal-resource-controller:base-focal-20230130170757 |
|
dynamic_ipxe Updated |
mirantis.azurecr.io/bm/dynamic-ipxe:base-focal-20230126202529 |
|
dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-alpine-20230118150429 |
|
dnsmasq-controller Updated |
mirantis.azurecr.io/bm/dnsmasq-controller:base-focal-20230213185438 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230130125656 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230130125656 |
|
ironic-prometheus-exporter Updated |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20221227163037 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-focal-20230127092754 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.7-focal-20221028120155 |
|
metallb-controller |
mirantis.azurecr.io/bm/external/metallb/controller:v0.13.7-20221130155702 |
|
metallb-speaker |
mirantis.azurecr.io/bm/external/metallb/speaker:v0.13.7-20221130155702 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.19.0-5-g6a7e17d |
|
syslog-ng Updated |
mirantis.azurecr.io/bm/syslog-ng:base-focal-20230126094812 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.36.4.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.36.4.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.36.3.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.36.3.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.36.5.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.36.3.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.36.3.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.36.3.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.36.3.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.36.3.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.36.3.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.36.3.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.36.3.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.36.3.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.36.3.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.36.3.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.36.3.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.36.3.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.36.3.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.36.3.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.36.3.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.36.3.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.36.3.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.36.3.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.36.3.tgz |
|
scope-controller |
http://binary.mirantis.com/core/helm/scope-controller-1.36.3.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.36.3.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.36.3.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.36.3.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.36.3.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.36.3 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.36.3 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.36.3 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.36.3 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.36.3 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.6.1 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.36.3 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.36.3 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.36.3 |
|
haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.17.0-8-g6ca89d5 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.36.3 |
|
kaas-exporter |
mirantis.azurecr.io/core/kaas-exporter:1.36.3 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.36.3 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.36.3 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.36.3 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.36.3 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.19.0-5-g6a7e17d |
|
metrics-server |
mirantis.azurecr.io/core/external/metrics-server:v0.5.2 |
|
nginx |
mirantis.azurecr.io/core/external/nginx:1.36.3 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.36.3 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.36.3 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.36.3 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.36.3 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.36.3 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.8.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.36.3 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.36.3 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.36.3 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-8 |
|
storage-discovery |
mirantis.azurecr.io/core/storage-discovery:1.36.3 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.36.3 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.36.3 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.36.3 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
Helm charts |
iam Updated |
|
iam-proxy Updated |
||
keycloak_proxy Removed |
n/a |
|
Docker images |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.7-focal-20220811085105 |
|
keycloak Updated |
mirantis.azurecr.io/iam/keycloak:0.5.14 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-3 |
The table below contains the number of vendor-specific addressed CVEs with Critical or High severity.
In total, in the current Container Cloud release, 212 CVEs have been fixed and 16 artifacts (images) updated.
Fixed CVE ID |
# of updated artifacts |
|---|---|
RHSA-2022:6206 |
20 |
RHSA-2022:4991 |
11 |
RHSA-2023:0838 |
8 |
RHSA-2022:7089 |
8 |
RHSA-2022:1065 |
8 |
RHSA-2022:0332 |
8 |
RHSA-2021:5082 |
8 |
RHSA-2021:2717 |
8 |
RHSA-2022:8638 |
7 |
RHSA-2022:6878 |
7 |
RHSA-2022:1642 |
7 |
RHSA-2022:0951 |
7 |
RHSA-2022:0658 |
7 |
RHSA-2022:1537 |
6 |
RHSA-2021:4903 |
5 |
RHSA-2020:3014 |
5 |
RHSA-2019:4114 |
5 |
RHSA-2022:6778 |
4 |
RHSA-2020:0575 |
4 |
RHSA-2022:5095 |
3 |
RHSA-2021:2359 |
3 |
RHSA-2023:0284 |
2 |
RHSA-2022:5056 |
2 |
RHSA-2022:4799 |
2 |
RHSA-2021:1206 |
2 |
RHSA-2019:0997 |
2 |
RHSA-2022:7192 |
1 |
RHSA-2021:2170 |
1 |
RHSA-2021:1989 |
1 |
RHSA-2021:1024 |
1 |
RHSA-2021:0670 |
1 |
RHSA-2020:5476 |
1 |
RHSA-2020:3658 |
1 |
RHSA-2020:2755 |
1 |
RHSA-2020:2637 |
1 |
RHSA-2020:2338 |
1 |
RHSA-2020:0902 |
1 |
RHSA-2020:0273 |
1 |
RHSA-2020:0271 |
1 |
RHSA-2019:2692 |
1 |
RHSA-2019:1714 |
1 |
RHSA-2019:1619 |
1 |
RHSA-2019:1145 |
1 |
CVE-2021-33574 |
18 |
CVE-2022-2068 |
7 |
CVE-2022-1664 |
7 |
CVE-2022-1292 |
7 |
CVE-2022-29155 |
6 |
CVE-2019-25013 |
6 |
CVE-2022-0778 |
5 |
CVE-2022-23219 |
4 |
CVE-2022-23218 |
4 |
CVE-2019-20916 |
4 |
CVE-2022-24407 |
3 |
CVE-2022-32207 |
2 |
CVE-2022-27404 |
2 |
CVE-2022-40023 |
1 |
CVE-2022-1941 |
1 |
CVE-2021-32839 |
1 |
CVE-2021-3711 |
1 |
CVE-2021-3517 |
1 |
ALAS2-2023-1915 |
1 |
ALAS2-2023-1911 |
1 |
ALAS2-2023-1908 |
1 |
ALAS2-2022-1902 |
2 |
ALAS2-2022-1885 |
1 |
The full list of the CVEs present in the current Container Cloud release is available at the Mirantis Security Portal.
The Mirantis Container Cloud GA release 2.22.0:
Introduces support for the Cluster release 11.6.0 that is based on Mirantis Container Runtime 20.10.13 and Mirantis Kubernetes Engine 3.5.5 with Kubernetes 1.21.
Supports the Cluster release 12.5.0 that is based on the Cluster release 11.5.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 22.5.
Does not support greenfield deployments on deprecated Cluster releases 11.5.0 and 8.10.0. Use the latest available Cluster releases of the series instead.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.22.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.22.0. For the list of enhancements in the Cluster release 11.6.0 that is introduced by the Container Cloud release 2.22.0, see the Cluster releases (managed).
The ‘rebootRequired’ notification in the baremetal-based machine status
Custom network configuration for managed clusters based on Equinix Metal with private networking
Custom TLS certificates for the StackLight ‘iam-proxy’ endpoints
Extended logging format for essential management cluster components
Added the rebootRequired field to the status of a Machine object for
the bare metal provider. This field indicates whether a manual host reboot
is required to complete the Ubuntu operating system updates, if any.
You can view this notification either using the Container Cloud API or web UI:
API:
reboot.required.trueinstatus:providerStatusof aMachineobjectWeb UI: the One or more machines require a reboot notification on the Clusters and Machines pages
Note
For MOSK-based deployments, the feature support is available since MOSK 23.1.
TechPreview
Implemented the ability to configure advanced network settings on managed
clusters that are based on Equinix Metal with private networking. Using the custom parameter in the
Cluster object, you can customize network configuration for the cluster
machines. The feature comprises usage of dedicated Subnet and
L2Template objects that contain necessary configuration for cluster
machines.
Implemented the ability to set up custom TLS certificates for the following
StackLight iam-proxy endpoints on any type of Container Cloud clusters:
iam-proxy-alertaiam-proxy-alertmanageriam-proxy-grafanaiam-proxy-kibanaiam-proxy-prometheus
Implemented the following Container Cloud objects describing the history of a cluster and machine deployment and update:
ClusterDeploymentStatusClusterUpgradeStatusMachineDeploymentStatusMachineUpgradeStatus
Using these objects, you can inspect cluster and machine deployment and update stages, their time stamps, statuses, and failure messages, if any. In the Container Cloud web UI, use the History option located under the More action icon of a cluster and machine.
For existing clusters, these objects become available after the management cluster upgrade to Container Cloud 2.22.0.
Extended the logging format for the admission-controller,
storage-discovery, and all supported <providerName>-provider services
of a management cluster. Now, log records for these services contain
the following entries:
level:<debug,info,warn,error,panic>,
ts:<YYYY-MM-DDTHH:mm:ssZ>,
logger:<providerType>.<objectName>.req:<requestID>,
caller:<lineOfCode>,
msg:<message>,
error:<errorMessage>,
stacktrace:<codeInfo>
Learn more
The following issues have been addressed in the Mirantis Container Cloud release 2.22.0 along with the Cluster release 11.6.0:
[27192] Fixed the issue that prevented
portforward-controllerfrom accepting new connections correctly.[26659] Fixed the issue that caused the deployment of a regional cluster based on bare metal or Equinix Metal with private networking to fail with
mcc-cachePods being stuck in theCrashLoopBackOffstatus of restarts.[28783] Fixed the issue with Ceph condition getting stuck in absence of the Ceph cluster secrets information on the MOSK 22.3 clusters.
Caution
Starting from MOSK 22.4, the Ceph cluster version updates to 15.2.17. Therefore, if you applied the workaround for MOSK 22.3 described in Ceph known issue 28783, remove the
versionparameter definition fromKaaSCephClusterafter the managed cluster update to MOSK 22.4.[26820] Fixed the issue with the
statussection in theKaaSCephCluster.statusCR not reflecting issues during a Ceph cluster deletion.[25624] Fixed the issue with inability to specify the Ceph pool API parameters by adding the
parametersoption that specifies the key-value map for the parameters of the Ceph pool.Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
[28526] Fixed the issue with a low CPU limit
100mforkaas-exporterblocking metric collection.[28134] Fixed the issue with failure to update a cluster with nodes being stuck in the
Preparestate due toerror when evicting podsfor Patroni.[27732-1] Fixed the issue with the OpenSearch
elasticsearch.persistentVolumeClaimSizecustom setting being overwritten bylogging.persistentVolumeClaimSizeduring deployment of a Container Cloud cluster of any type and be set to the default30Gi.Depending on available resources on existing clusters that were affected by the issue, additional actions may be required after an update to Container Cloud 2.22.0. For details, see OpenSearchPVCMismatch alert raises due to the OpenSearch PVC size mismatch. New clusters deployed on top of Container Cloud 2.22.0 are not affected.
[27732-2] Fixed the issue with custom settings for the deprecated
elasticsearch.logstashRetentionTimeparameter being overwritten by the default setting set to 1 day.[20876] Fixed the issue with StackLight Pods getting stuck with the
Pod predicate NodeAffinity failederror due to the StackLight node label added to one machine and then removed from another one.[28651] Updated Telemeter for StackLight to fix the discovered vulnerabilities.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.22.0 including the Cluster release 11.6.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
If a baremetal-based regional cluster deployment fails before pivoting is done, the corresponding region deletion fails.
Workaround:
Using the command below, manually delete all possible traces of the failed
regional cluster deployment, including but not limited to the following
objects that contain the kaas.mirantis.com/region label of the affected
region:
clustermachinebaremetalhostbaremetalhostprofilel2templatesubnetipamhostipaddr
kubectl delete <objectName> -l kaas.mirantis.com/region=<regionName>
Warning
Do not use the same region name again after the regional cluster deployment failure since some objects that reference the region name may still exist.
Deployment of a managed cluster based on Equinix Metal with private networking fails during provisioning with the following error:
InspectionError: Failed to obtain hardware details.
Ensure DHCP relay is up and running
Workaround:
In
deployment/dnsmasq, udate the image tag version for thedhcpdcontainer tobase-alpine-20230118150429:kubectl -n kaas edit deployment/dnsmasq
In
dnsmasq.conf, override the defaultundionly.kpxewith theipxe.pxeone:kubectl -n kaas edit cm dnsmasq-config
Example of existing configuration:
dhcp-boot=/undionly.kpxe,httpd-http.ipxe.boot.local,dhcp-lb.ipxe.boot.localExample of new configuration:
dhcp-boot=/ipxe.pxe,httpd-http.ipxe.boot.local,dhcp-lb.ipxe.boot.local
During deployment of a vSphere-based management or regional cluster with IPAM
disabled, the Network prepared stage gets stuck in the NotStarted
status. The issue does not affect cluster deployment. Therefore, disregard
the error message.
During replacement of a manager machine, the following problems may occur:
The system adds the node to Docker swarm but not to Kubernetes
The node
Deploymentgets stuck with failed RethinkDB health checks
Workaround:
Delete the failed node.
Wait for the MKE cluster to become healthy. To monitor the cluster status:
Log in to the MKE web UI as described in Connect to the Mirantis Kubernetes Engine web UI.
Monitor the cluster status as described in MKE Operations Guide: Monitor an MKE cluster with the MKE web UI.
Deploy a new node.
During the unsafe or forced deletion of a manager machine running the
calico-kube-controllers Pod in the kube-system namespace,
the following issues occur:
The
calico-kube-controllersPod fails to clean up resources associated with the deleted nodeThe
calico-nodePod may fail to start up on a newly created node if the machine is provisioned with the same IP address as the deleted machine had
As a workaround, before deletion of the node running the
calico-kube-controllers Pod, cordon and drain the node:
kubectl cordon <nodeName>
kubectl drain <nodeName>
During update of a Container Cloud cluster of any type, if the MKE minor
version is updated from 3.4.x to 3.5.x, access to the cluster using the
existing kubeconfig fails with the You must be logged in to the server
(Unauthorized) error due to OIDC settings being reconfigured.
As a workaround, during the cluster update process, use the admin
kubeconfig instead of the existing one. Once the update completes, you can
use the existing cluster kubeconfig again.
To obtain the admin kubeconfig:
kubectl --kubeconfig <pathToMgmtKubeconfig> get secret -n <affectedClusterNamespace> \
-o yaml <affectedClusterName>-kubeconfig | awk '/admin.conf/ {print $2}' | \
head -1 | base64 -d > clusterKubeconfig.yaml
If the related cluster is regional, replace <pathToMgmtKubeconfig> with
<pathToRegionalKubeconfig>.
When setting a new Transport Layer Security (TLS) certificate for a cluster,
the false positive failed to get kubeconfig error may occur on the
Waiting for TLS settings to be applied stage. No actions are required.
Therefore, disregard the error.
To verify the status of the TLS configuration being applied:
kubectl get cluster <ClusterName> -n <ClusterProjectName> -o jsonpath-as-json="{.status.providerStatus.tls.<Application>}"
Possible values for the <Application> parameter are as follows:
keycloakuicachemkeiamProxyAlertaiamProxyAlertManageriamProxyGrafanaiamProxyKibanaiamProxyPrometheus
Example of system response:
[
{
"expirationTime": "2024-01-06T09:37:04Z",
"hostname": "domain.com",
}
]
In this example, expirationTime equals the NotAfter field of the
server certificate. And the value of hostname contains the configured
application name.
Note
The issue may affect the Container Cloud or Cluster release update to the following versions:
2.22.0 for management and regional clusters
11.6.0 for management, regional, and managed clusters
13.2.5, 13.3.5, 13.4.3, and 13.5.2 for attached MKE clusters
The issue does not affect clusters originally deployed since the following Cluster releases: 11.0.0, 8.6.0, 7.6.0.
During cluster update to versions mentioned in the note above, the following OpenSearch-related error may occur on clusters that were originally deployed or attached using Container Cloud 2.15.0 or earlier, before the transition from Elasticsearch to OpenSearch:
The stacklight/opensearch release of the stacklight/stacklight-bundle HelmBundle
reconciled by the stacklight/stacklight-helm-controller Controller
is not in the "deployed" status for the last 15 minutes.
The issue affects clusters with elasticsearch.persistentVolumeClaimSize
configured for values other than 30Gi.
To verify that the cluster is affected:
Verify whether the
HelmBundleReleaseNotDeployedalert for theopensearchrelease is firing. If so, the cluster is most probably affected. Otherwise, the cluster is not affected.Verify the reason of the
HelmBundleReleaseNotDeployedalert for theopensearchrelease:kubectl get helmbundle stacklight-bundle -n stacklight -o json | jq '.status.releaseStatuses[] | select(.chart == "opensearch") | .message'
Example system response from the affected cluster:
Upgrade "opensearch" failed: cannot patch "opensearch-master" with kind StatefulSet: \ StatefulSet.apps "opensearch-master" is invalid: spec: Forbidden: \ updates to statefulset spec for fields other than 'replicas', 'template', and 'updateStrategy' are forbidden
Workaround:
Scale down the
opensearch-dashboardsandmetricbeatresources to0:kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards && \ kubectl -n stacklight get pods -l app=opensearch-dashboards | awk '{if (NR!=1) {print $1}}' | xargs -r \ kubectl -n stacklight wait --for=delete --timeout=10m pod kubectl -n stacklight scale --replicas 0 deployment metricbeat && \ kubectl -n stacklight get pods -l app=metricbeat | awk '{if (NR!=1) {print $1}}' | xargs -r \ kubectl -n stacklight wait --for=delete --timeout=10m pod
Wait for the commands in this and next step to complete. The completion time depends on the cluster size.
Disable the
elasticsearch-curatorCronJob:kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec": {"suspend": true}}'
Scale down the
opensearch-masterStatefulSet:kubectl -n stacklight scale --replicas 0 statefulset opensearch-master && \ kubectl -n stacklight get pods -l app=opensearch-master | awk '{if (NR!=1) {print $1}}' | xargs -r \ kubectl -n stacklight wait --for=delete --timeout=30m pod
Delete the OpenSearch Helm release:
helm uninstall --no-hooks opensearch -n stacklight
Wait up to 5 minutes for Helm Controller to retry the upgrade and properly create the
opensearch-masterStatefulSet.To verify readiness of the
opensearch-masterPods:kubectl -n stacklight wait --for=condition=Ready --timeout=30m pod -l app=opensearch-master
Example of a successful system response in an HA setup:
pod/opensearch-master-0 condition met pod/opensearch-master-1 condition met pod/opensearch-master-2 condition met
Example of a successful system response in an non-HA setup:
pod/opensearch-master-0 condition met
Scale up the
opensearch-dashboardsandmetricbeatresources:kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards && \ kubectl -n stacklight wait --for=condition=Ready --timeout=10m pod -l app=opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat && \ kubectl -n stacklight wait --for=condition=Ready --timeout=10m pod -l app=metricbeat
Enable the
elasticsearch-curatorCronJob:kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec": {"suspend": false}}'
During an update of a Container Cloud cluster of any type, recreation of the
Patroni container replica is stuck in the degraded state due to the liveness
probe killing the container that runs the pg_rewind procedure. The issue
affects clusters on which the pg_rewind procedure takes more time than the
full cycle of the liveness probe.
The sample logs of the affected cluster:
INFO: doing crash recovery in a single user mode
ERROR: Crash recovery finished with code=-6
INFO: stdout=
INFO: stderr=2023-01-11 10:20:34 GMT [64]: [1-1] 63be8d72.40 0 LOG: database system was interrupted; last known up at 2023-01-10 17:00:59 GMT
[64]: [2-1] 63be8d72.40 0 LOG: could not read from log segment 00000002000000000000000F, offset 0: read 0 of 8192
[64]: [3-1] 63be8d72.40 0 LOG: invalid primary checkpoint record
[64]: [4-1] 63be8d72.40 0 PANIC: could not locate a valid checkpoint record
Workaround:
For the affected replica and PVC, run:
kubectl delete persistentvolumeclaim/storage-volume-patroni-<replica-id> -n stacklight
kubectl delete pod/patroni-<replica-id> -n stacklight
On managed clusters with enabled Reference Application, the following alerts are triggered during a managed cluster update from the Cluster release 11.5.0 to 11.6.0 or 7.11.0 to 11.5.0:
KubeDeploymentOutagefor therefappDeploymentRefAppDownRefAppProbeTooLongRefAppTargetDown
This behavior is expected, no actions are required. Therefore, disregard these alerts.
On the baremetal-based management clusters, the restarts count of the
metric-collector Pod is increased in time with reason: OOMKilled in
the containerStatuses of the metric-collector Pod. Only clusters with
HTTP proxy enabled are affected.
Such behavior is expected. Therefore, disregard these restarts.
During creation of a Container Cloud cluster of any type with StackLight
enabled, Alerta can get stuck after a failed initialization with only 1 Pod
in the READY state. For example:
kubectl get po -n stacklight -l app=alerta
NAME READY STATUS RESTARTS AGE
pod/alerta-5f96b775db-45qsz 1/1 Running 0 20h
pod/alerta-5f96b775db-xj4rl 0/1 Running 0 20h
Workaround:
Recreate the affected Alerta Pod:
kubectl --kubeconfig <affectedClusterKubeconfig> -n stacklight delete pod <stuckAlertaPodName>
Verify that both Alerta Pods are in the
READYstate:kubectl get po -n stacklight -l app=alerta
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshoot StackLight.
On a managed cluster, the StackLight pods may get stuck with the
Pod predicate NodeAffinity failed error in the pod status. The issue may
occur if the StackLight node label was added to one machine and
then removed from another one.
The issue does not affect the StackLight services, all required StackLight pods migrate successfully except extra pods that are created and stuck during pod migration.
As a workaround, remove the stuck pods:
kubectl --kubeconfig <managedClusterKubeconfig> -n stacklight delete pod <stuckPodName>
Update of a managed cluster based on bare metal and Ceph enabled fails with
PersistentVolumeClaim getting stuck in the Pending state for the
prometheus-server StatefulSet and the
MountVolume.MountDevice failed for volume warning in the StackLight event
logs.
Workaround:
Verify that the description of the Pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name where the Pods failed to run<affectedPodName>is a Pod name that failed to run in the specified project
In the Pod description, identify the node name where the Pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain therbd volume mount failed: <csi-vol-uuid> is being usederror. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the Pod that fails to0replicas.On every
csi-rbdpluginPod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected Pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state becomesRunning.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.22.0. For major components and versions of the Cluster release introduced in 2.22.0, see Cluster release 11.6.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.35.11 |
aws-credentials-controller |
1.35.11 |
|
Azure Updated |
azure-provider |
1.35.11 |
azure-credentials-controller |
1.35.11 |
|
Bare metal |
ambassador |
1.20.1-alpine |
baremetal-operator Updated |
base-focal-20221130142939 |
|
baremetal-public-api Updated |
1.35.11 |
|
baremetal-provider Updated |
1.35.11 |
|
baremetal-resource-controller |
base-focal-20221219124546 |
|
ironic Updated |
yoga-focal-20221118093824 |
|
kaas-ipam |
base-focal-20221202191902 |
|
keepalived |
0.19.0-5-g6a7e17d |
|
local-volume-provisioner Updated |
2.5.0-1 |
|
mariadb Updated |
10.6.7-focal-20221028120155 |
|
metallb-controller Updated |
0.13.7 |
|
IAM |
iam Updated |
2.4.36 |
iam-controller Updated |
1.35.11 |
|
keycloak |
18.0.0 |
|
Container Cloud Updated |
admission-controller |
1.35.12 |
agent-controller |
1.35.11 |
|
byo-credentials-controller |
1.35.11 |
|
byo-provider |
1.35.11 |
|
ceph-kcc-controller |
1.35.11 |
|
cert-manager |
1.35.11 |
|
client-certificate-controller |
1.35.11 |
|
event-controller |
1.35.11 |
|
golang Updated |
1.18.8 |
|
kaas-public-api |
1.35.11 |
|
kaas-exporter |
1.35.11 |
|
kaas-ui |
1.35.11 |
|
license-controller |
1.35.11 |
|
lcm-controller |
0.3.0-352-gf55d6378 |
|
machinepool-controller |
1.35.11 |
|
mcc-cache |
1.35.11 |
|
metrics-server |
0.5.2 |
|
portforward-controller |
1.35.11 |
|
proxy-controller |
1.35.11 |
|
rbac-controller |
1.35.11 |
|
release-controller |
1.35.11 |
|
rhellicense-controller |
1.35.11 |
|
scope-controller |
1.35.11 |
|
user-controller |
1.35.11 |
|
Equinix Metal |
equinix-provider Updated |
1.35.11 |
equinix-credentials-controller Updated |
1.35.11 |
|
keepalived |
0.19.0-5-g6a7e17d |
|
OpenStack Updated |
openstack-provider |
1.35.11 |
os-credentials-controller |
1.35.11 |
|
VMware vSphere |
metallb-controller |
0.13.7 |
vsphere-provider Updated |
1.35.11 |
|
vsphere-credentials-controller Updated |
1.35.11 |
|
keepalived |
0.19.0-5-g6a7e17d |
|
squid-proxy Updated |
0.0.1-8 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.22.0. For artifacts of the Cluster release introduced in 2.22.0, see Cluster release 11.6.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-api Updated |
https://binary.mirantis.com/core/helm/baremetal-api-1.35.11.tgz |
baremetal-operator Updated |
https://binary.mirantis.com/core/helm/baremetal-operator-1.35.11.tgz |
|
baremetal-public-api Updated |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.35.11.tgz |
|
ironic-python-agent.initramfs Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20221228205257 |
|
ironic-python-agent.kernel Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20221228205257 |
|
kaas-ipam Updated |
||
local-volume-provisioner Updated |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.35.11.tgz |
|
metallb |
||
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
Docker images |
ambassador |
mirantis.azurecr.io/general/external/docker.io/library/nginx:1.20.1-alpine |
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-focal-20221130142939 |
|
baremetal-resource-controller Updated |
mirantis.azurecr.io/bm/baremetal-resource-controller:base-focal-20221219124546 |
|
dynamic_ipxe Updated |
mirantis.azurecr.io/bm/dynamic-ipxe:base-focal-20221219135753 |
|
dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-alpine-20221121215534 |
|
dnsmasq-controller Updated |
mirantis.azurecr.io/bm/dnsmasq-controller:base-focal-20221219112845 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20221118093824 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20221118093824 |
|
ironic-prometheus-exporter Updated |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20221117115942 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-focal-20221202191902 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.7-focal-20221028120155 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.19.0-5-g6a7e17d |
|
metallb-controller Updated |
mirantis.azurecr.io/bm/external/metallb/controller:v0.13.7-20221130155702 |
|
metallb-speaker Updated |
mirantis.azurecr.io/bm/external/metallb/speaker:v0.13.7-20221130155702 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-focal-20220128103433 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.35.11.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.35.11.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.35.11.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.35.11.tgz |
|
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.35.11.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.35.11.tgz |
|
azure-credentials-controller |
https://binary.mirantis.com/core/helm/azure-credentials-controller-1.35.11.tgz |
|
azure-provider |
https://binary.mirantis.com/core/helm/azure-provider-1.35.11.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.35.11.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.35.11.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.35.11.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.35.11.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.35.11.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.35.11.tgz |
|
configuration-collector |
https://binary.mirantis.com/core/helm/configuration-collector-1.35.11.tgz |
|
equinix-credentials-controller |
https://binary.mirantis.com/core/helm/equinix-credentials-controller-1.35.11.tgz |
|
equinix-provider |
https://binary.mirantis.com/core/helm/equinix-provider-1.35.11.tgz |
|
equinixmetalv2-provider |
https://binary.mirantis.com/core/helm/equinixmetalv2-provider-1.35.11.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.35.11.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.35.11.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.35.11.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.35.11.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.35.11.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.35.11.tgz |
|
mcc-cache |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.35.11.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.35.11.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.35.11.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.35.11.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.35.11.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.35.11.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.35.11.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.35.11.tgz |
|
scope-controller |
http://binary.mirantis.com/core/helm/scope-controller-1.35.11.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.35.11.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.35.11.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.35.11.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.35.11.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.35.11 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.35.11 |
|
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.35.11 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.35.11 |
|
azure-cloud-controller-manager New |
mirantis.azurecr.io/lcm/external/azure-cloud-controller-manager:v1.23.11 |
|
azure-cloud-node-manager New |
mirantis.azurecr.io/lcm/external/azure-cloud-node-manager:v1.23.11 |
|
azure-cluster-api-controller Updated |
mirantis.azurecr.io/core/azure-cluster-api-controller:1.35.11 |
|
azure-credentials-controller Updated |
mirantis.azurecr.io/core/azure-credentials-controller:1.35.11 |
|
azuredisk-csi New |
mirantis.azurecr.io/lcm/azuredisk-csi-driver:v0.20.0-25-gfaef237 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.35.11 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.35.11 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.35.11 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.6.1 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.35.11 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.35.11 |
|
cluster-api-provider-equinix Updated |
mirantis.azurecr.io/core/equinix-cluster-api-controller:1.35.11 |
|
equinix-credentials-controller Updated |
mirantis.azurecr.io/core/equinix-credentials-controller:1.35.11 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.35.11 |
|
haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.17.0-8-g6ca89d5 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.35.11 |
|
kaas-exporter |
mirantis.azurecr.io/core/kaas-exporter:1.35.11 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.35.11 |
|
lcm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-352-gf55d6378 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.35.11 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.35.11 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.19.0-5-g6a7e17d |
|
metrics-server |
mirantis.azurecr.io/core/external/metrics-server:v0.5.2 |
|
nginx |
mirantis.azurecr.io/core/external/nginx:1.35.11 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.35.11 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.35.11 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.35.11 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.35.11 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.35.11 |
|
registry Updated |
mirantis.azurecr.io/lcm/registry:2.8.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.35.11 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.35.11 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.35.11 |
|
squid-proxy Updated |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-8 |
|
storage-discovery |
mirantis.azurecr.io/core/storage-discovery:1.35.11 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.35.11 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.35.11 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.35.11 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
Helm charts |
iam Updated |
|
iam-proxy |
||
keycloak_proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.35.11.tgz |
|
Docker images |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.7-focal-20220811085105 |
|
keycloak Updated |
mirantis.azurecr.io/iam/keycloak:0.5.13 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-3 |
The table below contains the number of vendor-specific addressed CVEs with Critical or High severity.
In total, in the current Container Cloud release, 6 CVEs have been fixed and 4 artifacts (images) updated.
Fixed CVE ID |
# of updated artifacts |
|---|---|
CVE-2022-40023 |
2 |
CVE-2022-25236 |
1 |
CVE-2022-25235 |
1 |
RHSA-2022:8638 |
1 |
RHSA-2022:7089 |
1 |
RHSA-2022:6878 |
1 |
The full list of the CVEs present in the current Container Cloud release is available at the Mirantis Security Portal.
Releases delivered in 2022¶
This section contains historical information on the unsupported Container Cloud releases delivered in 2022. For the latest supported Container Cloud release, see Container Cloud releases.
Version |
Release date |
Summary |
|---|---|---|
Dec 19, 2022 |
Based on 2.21.0, Container Cloud 2.21.1:
|
|
Nov 22, 2022 |
|
|
Sep 29, 2022 |
Based on 2.20.0, Container Cloud 2.20.1:
|
|
Sep 5, 2022 |
|
|
July 27, 2022 |
|
|
June 30, 2022 |
Based on 2.18.0, Container Cloud 2.18.1:
|
|
June 13, 2022 |
|
|
May 11, 2022 |
|
|
Apr 14, 2022 |
Based on 2.16.0, Container Cloud 2.16.1:
|
|
Mar 31, 2022 |
|
|
Feb 23, 2022 |
Based on 2.15.0, this release introduces the Cluster release 8.5.0 that is based on 5.22.0 and supports Mirantis OpenStack for Kubernetes (MOSK) 22.1. For the list of Cluster releases 7.x and 5.x that are supported by 2.15.1 as well as for its features with addressed and known issues, refer to the parent release 2.15.0. |
|
Jan 31, 2022 |
|
The Mirantis Container Cloud GA release 2.21.1 is based on 2.21.0 and:
Introduces support for the Cluster release 12.5.0 that is based on the Cluster release 11.5.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 22.5.
Introduces support for Mirantis Kubernetes Engine 3.5.5 with Kubernetes 1.21 and Mirantis Container Runtime 20.10.13 in the 12.x Cluster release series.
Does not support greenfield deployments based on deprecated Cluster releases 11.4.0, 8.10.0, and 7.10.0. Use the latest available Cluster releases of the series instead.
For details about the Container Cloud release 2.21.1, refer to its parent release 2.21.0:
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
The Mirantis Container Cloud GA release 2.21.0:
Introduces support for the Cluster release 11.5.0 that is based on Mirantis Container Runtime 20.10.13 and Mirantis Kubernetes Engine 3.5.5 with Kubernetes 1.21.
Introduces support for the Cluster release 7.11.0 that is based on Mirantis Container Runtime 20.10.13 and Mirantis Kubernetes Engine 3.4.11 with Kubernetes 1.20.
Supports the Cluster release 8.10.0 that is based on the Cluster release 7.10.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 22.4.
Does not support greenfield deployments on deprecated Cluster releases 11.4.0, 8.8.0, and 7.10.0. Use the latest available Cluster releases of the series instead.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.21.0.
Caution
Container Cloud 2.21.0 requires manual post-upgrade steps. For details, see Post-upgrade actions.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.21.0. For the list of enhancements in the Cluster releases 11.5.0 and 7.11.0 that are introduced by the Container Cloud release 2.21.0, see the Cluster releases (managed).
‘BareMetalHostCredential’ custom resource for bare metal hosts
Combining router and seed node settings on one Equinix Metal server
Add custom Docker registries using the Container Cloud web UI
Implemented the BareMetalHostCredential custom resource to simplify
permissions and roles management on a bare metal management, regional, and
managed cluster.
Note
For MOSK-based deployments, the feature support is available since MOSK 22.5.
The BareMetalHostCredential object creation triggers the following
automatic actions:
Create an underlying
Secretobject containing data aboutusernameandpasswordof thebmcaccount of the relatedBareMetalHostCredentialobject.Erase sensitive
passworddata of thebmcaccount from theBareMetalHostCredentialobject.Add the created
Secretobject name to thespec.password.namesection of the relatedBareMetalHostCredentialobject.Update
BareMetalHost.spec.bmc.credentialsNamewith theBareMetalHostCredentialobject name.
Note
When you delete a BareMetalHost object, the related
BareMetalHostCredential object is deleted automatically.
Note
On existing clusters, a BareMetalHostCredential object is
automatically created for each BareMetalHost object during a cluster
update.
Enhanced the logic of the dnsmasq server to listen on the PXE network of
the management cluster by using the dhcp-lb Kubernetes Service instead of
listening on the PXE interface of one management cluster node.
To configure the DHCP relay service, specify the external address of the
dhcp-lb Kubernetes Service as an upstream address for the relayed DHCP
requests, which is the IP helper address for DHCP. There is the dnsmasq
Deployment behind this service that can only accept relayed DHCP requests.
Container Cloud has its own DHCP relay running on one of the management cluster nodes. That DHCP relay serves for proxying DHCP requests in the same L2 domain where the management cluster nodes are located.
The enhancement comprises deprecation of the dnsmasq.dhcp_range parameter.
Use the Subnet object configuration for this purpose instead.
Note
If you configured multiple DHCP ranges before Container Cloud 2.21.0
during the management cluster bootstrap, the DHCP configuration will
automatically migrate to Subnet objects after cluster upgrade to 2.21.0.
Caution
Using of custom DNS server addresses for servers that boot over PXE is not supported.
Implemented the ability to combine configuration of a router and seed node on
the same server when preparing infrastructure for an Equinix Metal based
Container Cloud with private networking using Terraform templates.
Set router_as_seed to true in the required Metro configuration while
preparing terraform.tfvars to combine both the router and seed node roles.
Learn more
TechPreview
Implemented the possibility to safely clean up a node resources using the
Container Cloud API before deleting it from a cluster. Using the
deletionPolicy: graceful parameter in the providerSpec.value section
of the Machine object, the cloud provider controller now prepares a
machine for deletion by cordoning, draining, and removing the related node
from Docker Swarm. If required, you can abort a machine deletion when using
deletionPolicy: graceful, but only before the related node is removed
from Docker Swarm.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
Learn more
Enhanced support for custom Docker registries configuration in management, regional, and managed clusters by adding the Container Registries tab to the Container Cloud web UI. Using this tab, you can configure CA certificates on machines to access private Docker registries.
Note
For MOSK-based deployments, the feature support is available since MOSK 22.5.
On top of continuous improvements delivered to the existing Container Cloud guides, added the documentation on firewall configuration that includes the details about ports and protocols used in a Container Cloud deployment.
Learn more
The following issues have been addressed in the Mirantis Container Cloud release 2.21.0 along with the Cluster releases 11.5.0 and 7.11.0:
[23002] Fixed the issue with inability to set a custom value for a predefined node label using the Container Cloud web UI.
[26416] Fixed the issue with inability to automatically upload an MKE client bundle during cluster attachment using the Container Cloud web UI.
[26740] Fixed the issue with failure to upgrade a management cluster with a Keycloak or web UI TLS custom certificate.
[27193] Fixed the issue with missing permissions for the
m:kaas:<namespaceName>@memberrole that are required for the Container Cloud web UI to work properly. The issue relates to reading permissions for resources objects of all providers as well asclusterRelease,unsupportedClusterobjects, and so on.[26379] Fixed the issue with missing logs for MOSK-related namespaces when using the container-cloud collect logs command without the
--extendedflag.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.21.0 including the Cluster releases 11.5.0 and 7.11.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
A managed cluster deployment, attachment, or update to a Cluster release with
MKE versions 3.3.13, 3.4.6, 3.5.1, or earlier may fail with the
compose pods flapping (ready > terminating > pending) and with the
following error message appearing in logs:
'not ready: deployments: kube-system/compose got 0/0 replicas, kube-system/compose-api
got 0/0 replicas'
ready: false
type: Kubernetes
Workaround:
Disable Docker Content Trust (DCT):
Access the MKE web UI as admin.
Navigate to Admin > Admin Settings.
In the left navigation pane, click Docker Content Trust and disable it.
Restart the affected deployments such as
calico-kube-controllers,compose,compose-api,coredns, and so on:kubectl -n kube-system delete deployment <deploymentName>
Once done, the cluster deployment or update resumes.
Re-enable DCT.
Deployment of a regional cluster based on bare metal or Equinix Metal with
private networking fails with mcc-cache Pods being stuck in the
CrashLoopBackOff status of restarts.
As a workaround, remove failed mcc-cache Pods to restart them
automatically. For example:
kubectl -n kaas delete pod mcc-cache-0
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
If a baremetal-based regional cluster deployment fails before pivoting is done, the corresponding region deletion fails.
Workaround:
Using the command below, manually delete all possible traces of the failed
regional cluster deployment, including but not limited to the following
objects that contain the kaas.mirantis.com/region label of the affected
region:
clustermachinebaremetalhostbaremetalhostprofilel2templatesubnetipamhostipaddr
kubectl delete <objectName> -l kaas.mirantis.com/region=<regionName>
Warning
Do not use the same region name again after the regional cluster deployment failure since some objects that reference the region name may still exist.
Deployment of a regional cluster based on bare metal or Equinix Metal with
private networking fails with mcc-cache Pods being stuck in the
CrashLoopBackOff status of restarts.
As a workaround, remove failed mcc-cache Pods to restart them
automatically. For example:
kubectl -n kaas delete pod mcc-cache-0
Deployment of RHEL machines using the Red Hat portal registration, which requires user and password credentials, over MITM proxy fails while building the virtual machines template with the following error:
Unable to verify server's identity: [SSL: CERTIFICATE_VERIFY_FAILED]
certificate verify failed (_ssl.c:618)
The Container Cloud deployment gets stuck while applying the RHEL license
to machines with the same error in the lcm-agent logs.
As a workaround, use the internal Red Hat Satellite server that a VM can access directly without a MITM proxy.
During replacement of a manager machine, the following problems may occur:
The system adds the node to Docker swarm but not to Kubernetes
The node
Deploymentgets stuck with failed RethinkDB health checks
Workaround:
Delete the failed node.
Wait for the MKE cluster to become healthy. To monitor the cluster status:
Log in to the MKE web UI as described in Connect to the Mirantis Kubernetes Engine web UI.
Monitor the cluster status as described in MKE Operations Guide: Monitor an MKE cluster with the MKE web UI.
Deploy a new node.
During the unsafe or forced deletion of a manager machine running the
calico-kube-controllers Pod in the kube-system namespace,
the following issues occur:
The
calico-kube-controllersPod fails to clean up resources associated with the deleted nodeThe
calico-nodePod may fail to start up on a newly created node if the machine is provisioned with the same IP address as the deleted machine had
As a workaround, before deletion of the node running the
calico-kube-controllers Pod, cordon and drain the node:
kubectl cordon <nodeName>
kubectl drain <nodeName>
During update of a Container Cloud cluster of any type, if the MKE minor
version is updated from 3.4.x to 3.5.x, access to the cluster using the
existing kubeconfig fails with the You must be logged in to the server
(Unauthorized) error due to OIDC settings being reconfigured.
As a workaround, during the cluster update process, use the admin
kubeconfig instead of the existing one. Once the update completes, you can
use the existing cluster kubeconfig again.
To obtain the admin kubeconfig:
kubectl --kubeconfig <pathToMgmtKubeconfig> get secret -n <affectedClusterNamespace> \
-o yaml <affectedClusterName>-kubeconfig | awk '/admin.conf/ {print $2}' | \
head -1 | base64 -d > clusterKubeconfig.yaml
If the related cluster is regional, replace <pathToMgmtKubeconfig> with
<pathToRegionalKubeconfig>.
During bootstrap of a management or regional cluster of any type,
portforward-controller ends accepting new connections after receiving the
Accept error: “EOF” error. Hence, nothing is copied between clients.
The workaround below applies only if machines are stuck in the Provision
state. Otherwise, contact Mirantis support to further assess the issue.
Workaround:
Verify that machines are stuck in the
Provisionstate for up to 20 minutes or more. For example:kubectl --kubeconfig <kindKubeconfigPath> get machines -o wide
Verify whether the
portforward-controllerPod logs contain{{Accept error: “EOF”}}and{{Stopped forwarding}}:kubectl --kubeconfig <kindKubeconfigPath> -n kaas logs -lapp.kubernetes.io/name=portforward-controller | grep 'Accept error: "EOF"' kubectl --kubeconfig <kindKubeconfigPath> -n kaas logs -lapp.kubernetes.io/name=portforward-controller | grep 'Stopped forwarding'
Select from the following options:
If the errors mentioned in the previous step are present:
Restart the
portforward-controllerDeployment:kubectl --kubeconfig <kindKubeconfigPath> -n kaas rollout restart deploy portforward-controller
Monitor the states of machines and the
portforward-controllerPod logs. If the errors recur, restart theportforward-controllerDeployment again.
If the errors mentioned in the previous step are not present, contact Mirantis support to further assess the issue.
During an update of a Container Cloud cluster of any type, recreation of the
Patroni container replica is stuck in the degraded state due to the liveness
probe killing the container that runs the pg_rewind procedure. The issue
affects clusters on which the pg_rewind procedure takes more time than the
full cycle of the liveness probe.
The sample logs of the affected cluster:
INFO: doing crash recovery in a single user mode
ERROR: Crash recovery finished with code=-6
INFO: stdout=
INFO: stderr=2023-01-11 10:20:34 GMT [64]: [1-1] 63be8d72.40 0 LOG: database system was interrupted; last known up at 2023-01-10 17:00:59 GMT
[64]: [2-1] 63be8d72.40 0 LOG: could not read from log segment 00000002000000000000000F, offset 0: read 0 of 8192
[64]: [3-1] 63be8d72.40 0 LOG: invalid primary checkpoint record
[64]: [4-1] 63be8d72.40 0 PANIC: could not locate a valid checkpoint record
Workaround:
For the affected replica and PVC, run:
kubectl delete persistentvolumeclaim/storage-volume-patroni-<replica-id> -n stacklight
kubectl delete pod/patroni-<replica-id> -n stacklight
A low CPU limit 100m for kaas-exporter blocks metric collection.
As a workaround, increase the CPU limit for kaas-exporter to 500m
on the management cluster in the
spec:providerSpec:value:kaas:management:helmReleases: section as
described in Limits for management cluster components.
On the baremetal-based management clusters, the restarts count of the
metric-collector Pod is increased in time with reason: OOMKilled in
the containerStatuses of the metric-collector Pod. Only clusters with
HTTP proxy enabled are affected.
Such behavior is expected. Therefore, disregard these restarts.
A Container Cloud cluster of any type fails to update with nodes being
stuck in the Prepare state and the following example error in
Conditions of the affected machine:
Error: error when evicting pods/"patroni-13-2" -n "stacklight": global timeout reached: 10m0s
Other symptoms of the issue are as follows:
One of the Patroni Pods has 2/3 of containers ready. For example:
kubectl get po -n stacklight -l app=patroni NAME READY STATUS RESTARTS AGE patroni-13-0 3/3 Running 0 32h patroni-13-1 3/3 Running 0 38h patroni-13-2 2/3 Running 0 38h
The
patroni-patroni-exportercontainer from the affected Pod is not ready. For example:kubectl get pod/patroni-13-2 -n stacklight -o jsonpath='{.status.containerStatuses[?(@.name=="patroni-patroni-exporter")].ready}' false
As a workaround, restart the patroni-patroni-exporter container of
the affected Patroni Pod:
kubectl exec <affectedPatroniPodName> -n stacklight -c patroni-patroni-exporter -- kill 1
For example:
kubectl exec patroni-13-2 -n stacklight -c patroni-patroni-exporter -- kill 1
The OpenSearch elasticsearch.persistentVolumeClaimSize custom setting is
overwritten by logging.persistentVolumeClaimSize during deployment of a
Container Cloud cluster of any type and is set to the default 30Gi.
Note
This issue does not block the OpenSearch cluster operations if the default retention time is set. The default setting is usually enough for the capacity size of this cluster.
The issue may affect the following Cluster releases:
11.2.0 - 11.5.0
7.8.0 - 7.11.0
8.8.0 - 8.10.0, 12.5.0 (MOSK clusters)
10.2.4 - 10.8.1 (attached MKE 3.4.x clusters)
13.0.2 - 13.5.1 (attached MKE 3.5.x clusters)
To verify that the cluster is affected:
Note
In the commands below, substitute parameters enclosed in angle brackets to match the affected cluster values.
kubectl --kubeconfig=<managementClusterKubeconfigPath> \
-n <affectedClusterProjectName> \
get cluster <affectedClusterName> \
-o=jsonpath='{.spec.providerSpec.value.helmReleases[*].values.elasticsearch.persistentVolumeClaimSize}' | xargs echo config size:
kubectl --kubeconfig=<affectedClusterKubeconfigPath> \
-n stacklight get pvc -l 'app=opensearch-master' \
-o=jsonpath="{.items[*].status.capacity.storage}" | xargs echo capacity sizes:
The cluster is not affected if the configuration size value matches or is less than any capacity size. For example:
config size: 30Gi capacity sizes: 30Gi 30Gi 30Gi config size: 50Gi capacity sizes: 100Gi 100Gi 100Gi
The cluster is affected if the configuration size is larger than any capacity size. For example:
config size: 200Gi capacity sizes: 100Gi 100Gi 100Gi
Workaround for a new cluster creation:
Select from the following options:
For a management or regional cluster, during the bootstrap procedure, open
cluster.yaml.templatefor editing.For a managed cluster, open the
Clusterobject for editing.Caution
For a managed cluster, use the Container Cloud API instead of the web UI for cluster creation.
In the opened
.yamlfile, addlogging.persistentVolumeClaimSizealong withelasticsearch.persistentVolumeClaimSize. For example:apiVersion: cluster.k8s.io/v1alpha1 spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Continue the cluster deployment. The system will use the custom value set in
logging.persistentVolumeClaimSize.Caution
If
elasticsearch.persistentVolumeClaimSizeis absent in the.yamlfile, the Admission Controller blocks the configuration update.
Workaround for an existing cluster:
Caution
During the application of the below workarounds, a short outage of OpenSearch and its dependent components may occur with the following alerts firing on the cluster. This behavior is expected. Therefore, disregard these alerts.
StackLight alerts list firing during cluster update
Cluster size and outage probability level |
Alert name |
Label name and component |
|---|---|---|
Any cluster with high probability |
|
|
|
|
|
Large cluster with average probability |
|
|
|
n/a |
|
|
n/a |
|
|
n/a |
|
|
n/a |
|
Any cluster with low probability |
|
|
|
|
StackLight in HA mode with LVP provisioner for OpenSearch PVCs
Warning
After applying this workaround, the existing log data will be lost. Therefore, if required, migrate log data to a new persistent volume (PV).
Move the existing log data to a new PV, if required.
Increase the disk size for local volume provisioner (LVP).
Scale down the
opensearch-masterStatefulSet with dependent resources to 0 and disable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 0 statefulset opensearch-master kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 0 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : true }}'
Recreate the
opensearch-masterStatefulSet with the updated disk size.kubectl get statefulset opensearch-master -o yaml -n stacklight | sed 's/storage: 30Gi/storage: <pvcSize>/g' > opensearch-master.yaml kubectl -n stacklight delete statefulset opensearch-master kubectl create -f opensearch-master.yaml
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.Delete existing PVCs:
kubectl delete pvc -l 'app=opensearch-master' -n stacklight
Warning
This command removes all existing logs data from PVCs.
In the
Clusterconfiguration, set the samelogging.persistentVolumeClaimSizeas the size ofelasticsearch.persistentVolumeClaimSize. For example:apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Scale up the
opensearch-masterStatefulSet with dependent resources and enable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 3 statefulset opensearch-master sleep 100 kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : false }}'
StackLight in non-HA mode with an expandable StorageClass for
OpenSearch PVCs
Note
To verify whether a StorageClass is expandable:
kubectl -n stacklight get pvc | grep opensearch-master | awk '{print $6}' | xargs -I{} kubectl get storageclass {} -o yaml | grep 'allowVolumeExpansion: true'
A positive system response is allowVolumeExpansion: true. A negative
system response is blank or false.
Scale down the
opensearch-masterStatefulSet with dependent resources to 0 and disable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 0 statefulset opensearch-master kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 0 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : true }}'
Recreate the
opensearch-masterStatefulSet with the updated disk size.kubectl -n stacklight get statefulset opensearch-master -o yaml | sed 's/storage: 30Gi/storage: <pvc_size>/g' > opensearch-master.yaml kubectl -n stacklight delete statefulset opensearch-master kubectl create -f opensearch-master.yaml
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.Patch the PVCs with the new
elasticsearch.persistentVolumeClaimSizevalue:kubectl -n stacklight patch pvc opensearch-master-opensearch-master-0 -p '{ "spec": { "resources": { "requests": { "storage": "<pvc_size>" }}}}'
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.In the
Clusterconfiguration, setlogging.persistentVolumeClaimSizethe same as the size ofelasticsearch.persistentVolumeClaimSize. For example:apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Scale up the
opensearch-masterStatefulSet with dependent resources to1and enable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 1 statefulset opensearch-master sleep 100 kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : false }}'
StackLight in non-HA mode with a non-expandable StorageClass
and no LVP for OpenSearch PVCs
Warning
After applying this workaround, the existing log data will be lost. Depending on your custom provisioner, you may find a third-party tool, such as pv-migrate, that provides a possibility to copy all data from one PV to another.
If data loss is acceptable, proceed with the workaround below.
Note
To verify whether a StorageClass is expandable:
kubectl -n stacklight get pvc | grep opensearch-master | awk '{print $6}' | xargs -I{} kubectl get storageclass {} -o yaml | grep 'allowVolumeExpansion: true'
A positive system response is allowVolumeExpansion: true. A negative
system response is blank or false.
Scale down the
opensearch-masterStatefulSet with dependent resources to 0 and disable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 0 statefulset opensearch-master kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 0 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : true }}'
Recreate the
opensearch-masterStatefulSet with the updated disk size:kubectl get statefulset opensearch-master -o yaml -n stacklight | sed 's/storage: 30Gi/storage: <<pvc_size>>/g' > opensearch-master.yaml kubectl -n stacklight delete statefulset opensearch-master kubectl create -f opensearch-master.yaml
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.Delete existing PVCs:
kubectl delete pvc -l 'app=opensearch-master' -n stacklight
Warning
This command removes all existing logs data from PVCs.
In the
Clusterconfiguration, setlogging.persistentVolumeClaimSizeto the same value as the size of theelasticsearch.persistentVolumeClaimSizeparameter. For example:apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Scale up the
opensearch-masterStatefulSet with dependent resources to1and enable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 1 statefulset opensearch-master sleep 100 kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : false }}'
Custom settings for the deprecated elasticsearch.logstashRetentionTime
parameter are overwritten by the default setting set to 1 day.
The issue may affect the following Cluster releases with enabled
elasticsearch.logstashRetentionTime:
11.2.0 - 11.5.0
7.8.0 - 7.11.0
8.8.0 - 8.10.0, 12.5.0 (MOSK clusters)
10.2.4 - 10.8.1 (attached MKE 3.4.x clusters)
13.0.2 - 13.5.1 (attached MKE 3.5.x clusters)
As a workaround, in the Cluster object, replace
elasticsearch.logstashRetentionTime with elasticsearch.retentionTime
that was implemented to replace the deprecated parameter. For example:
apiVersion: cluster.k8s.io/v1alpha1
kind: Cluster
spec:
...
providerSpec:
value:
...
helmReleases:
- name: stacklight
values:
elasticsearch:
retentionTime:
logstash: 10
events: 10
notifications: 10
logging:
enabled: true
For the StackLight configuration procedure and parameters description, refer to Configure StackLight.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshoot StackLight.
On a managed cluster, the StackLight pods may get stuck with the
Pod predicate NodeAffinity failed error in the pod status. The issue may
occur if the StackLight node label was added to one machine and
then removed from another one.
The issue does not affect the StackLight services, all required StackLight pods migrate successfully except extra pods that are created and stuck during pod migration.
As a workaround, remove the stuck pods:
kubectl --kubeconfig <managedClusterKubeconfig> -n stacklight delete pod <stuckPodName>
Ceph conditon gets stuck in absence of the Ceph cluster secrets information. The observed behaviour can be found on the MOSK 22.3 clusters running on top of Container Cloud 2.21.
The list of the symptoms includes:
The
Clusterobject contains the following condition:Failed to configure Ceph cluster: ceph cluster status info is not \ updated at least for 5 minutes, ceph cluster secrets info is not available yet
The
ceph-kcc-controllerlogs from thekaasnamespace contain the following loglines:2022-11-30 19:39:17.393595 E | ceph-spec: failed to update cluster condition to \ {Type:Ready Status:True Reason:ClusterCreated Message:Cluster created successfully \ LastHeartbeatTime:2022-11-30 19:39:17.378401993 +0000 UTC m=+2617.717554955 \ LastTransitionTime:2022-05-16 16:14:37 +0000 UTC}. failed to update object \ "rook-ceph/rook-ceph" status: Operation cannot be fulfilled on \ cephclusters.ceph.rook.io "rook-ceph": the object has been modified; please \ apply your changes to the latest version and try again
Workaround:
Edit
KaaSCephClusterof the affected managed cluster:kubectl -n <managedClusterProject> edit kaascephcluster
Substitute
<managedClusterProject>with the corresponding managed cluster namespace.Define the
versionparameter in theKaaSCephClusterspec:spec: cephClusterSpec: version: 15.2.13
Note
Starting from MOSK 22.4, the Ceph cluster version updates to 15.2.17. Therefore, remove the
versionparameter definition fromKaaSCephClusterafter the managed cluster update.Save the updated
KaaSCephClusterspec.Find the
MiraCephCustom Resource on a managed cluster and copy all annotations starting withmeta.helm.sh:kubectl --kubeconfig <managedClusterKubeconfig> get crd miracephs.lcm.mirantis.com -o yaml
Substitute
<managedClusterKubeconfig>with a corresponding managed clusterkubeconfig.Example of a system output:
apiVersion: apiextensions.k8s.io/v1 kind: CustomResourceDefinition metadata: annotations: controller-gen.kubebuilder.io/version: v0.6.0 # save all annotations with "meta.helm.sh" somewhere meta.helm.sh/release-name: ceph-controller meta.helm.sh/release-namespace: ceph ...
Create the
miracephsecretscrd.yamlfile and fill it with the following template:apiVersion: apiextensions.k8s.io/v1 kind: CustomResourceDefinition metadata: annotations: controller-gen.kubebuilder.io/version: v0.6.0 <insert all "meta.helm.sh" annotations here> labels: app.kubernetes.io/managed-by: Helm name: miracephsecrets.lcm.mirantis.com spec: conversion: strategy: None group: lcm.mirantis.com names: kind: MiraCephSecret listKind: MiraCephSecretList plural: miracephsecrets singular: miracephsecret scope: Namespaced versions: - name: v1alpha1 schema: openAPIV3Schema: description: MiraCephSecret aggregates secrets created by Ceph properties: apiVersion: type: string kind: type: string metadata: type: object status: properties: lastSecretCheck: type: string lastSecretUpdate: type: string messages: items: type: string type: array state: type: string type: object type: object served: true storage: true
Insert the copied
meta.helm.shannotations to themetadata.annotationssection of the template.Apply
miracephsecretscrd.yamlon the managed cluster:kubectl --kubeconfig <managedClusterKubeconfig> apply -f miracephsecretscrd.yaml
Substitute
<managedClusterKubeconfig>with a corresponding managed clusterkubeconfig.Obtain the
MiraCephname from the managed cluster:kubectl --kubeconfig <managedClusterKubeconfig> -n ceph-lcm-mirantis get miraceph -o name
Substitute
<managedClusterKubeconfig>with the corresponding managed clusterkubeconfig.Example of a system output:
miraceph.lcm.mirantis.com/rook-ceph
Copy the
MiraCephname after slash, therook-cephpart from the example above.Create the
mcs.yamlfile and fill it with the following template:apiVersion: lcm.mirantis.com/v1alpha1 kind: MiraCephSecret metadata: name: <miracephName> namespace: ceph-lcm-mirantis status: {}
Substitute
<miracephName>with theMiraCephname from the previous step.Apply
mcs.yamlon the managed cluster:kubectl --kubeconfig <managedClusterKubeconfig> apply -f mcs.yaml
Substitute
<managedClusterKubeconfig>with a corresponding managed clusterkubeconfig.
After some delay, the cluster condition will be updated to the health
state.
Update of a managed cluster based on bare metal and Ceph enabled fails with
PersistentVolumeClaim getting stuck in the Pending state for the
prometheus-server StatefulSet and the
MountVolume.MountDevice failed for volume warning in the StackLight event
logs.
Workaround:
Verify that the description of the Pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name where the Pods failed to run<affectedPodName>is a Pod name that failed to run in the specified project
In the Pod description, identify the node name where the Pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain therbd volume mount failed: <csi-vol-uuid> is being usederror. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the Pod that fails to0replicas.On every
csi-rbdpluginPod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected Pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state becomesRunning.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.21.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.34.16 |
aws-credentials-controller |
1.34.16 |
|
Azure Updated |
azure-provider |
1.34.16 |
azure-credentials-controller |
1.34.16 |
|
Bare metal |
ambassador |
1.20.1-alpine |
baremetal-operator Updated |
base-focal-20220611131433 |
|
baremetal-public-api Updated |
1.34.16 |
|
baremetal-provider Updated |
1.34.16 |
|
baremetal-resource-controller |
base-focal-20220627134752 |
|
ironic |
yoga-focal-20220719132049 |
|
kaas-ipam |
base-focal-20220503165133 |
|
keepalived Updated |
0.19.0-5-g6a7e17d |
|
local-volume-provisioner Updated |
2.4.0 |
|
mariadb |
10.4.17-bionic-20220113085105 |
|
metallb-controller Updated |
0.13.4 0 |
|
IAM |
iam Updated |
2.4.35 |
iam-controller Updated |
1.34.16 |
|
keycloak |
18.0.0 |
|
Container Cloud Updated |
admission-controller |
1.34.16 |
agent-controller |
1.34.16 |
|
byo-credentials-controller |
1.34.16 |
|
byo-provider |
1.34.16 |
|
ceph-kcc-controller |
1.34.16 |
|
cert-manager |
1.34.16 |
|
client-certificate-controller |
1.34.16 |
|
event-controller |
1.34.16 |
|
golang |
1.18.5 |
|
kaas-public-api |
1.34.16 |
|
kaas-exporter |
1.34.16 |
|
kaas-ui |
1.34.16 |
|
license-controller |
1.34.16 |
|
lcm-controller |
0.3.0-327-gbc30b11b |
|
machinepool-controller |
1.34.16 |
|
mcc-cache |
1.34.16 |
|
metrics-server |
0.5.2 |
|
portforward-controller |
1.34.16 |
|
proxy-controller |
1.34.16 |
|
rbac-controller |
1.34.16 |
|
release-controller |
1.34.16 |
|
rhellicense-controller |
1.34.16 |
|
scope-controller |
1.34.16 |
|
user-controller |
1.34.16 |
|
Equinix Metal Updated |
equinix-provider |
1.34.16 |
equinix-credentials-controller |
1.34.16 |
|
keepalived |
0.19.0-5-g6a7e17d |
|
OpenStack Updated |
openstack-provider |
1.34.16 |
os-credentials-controller |
1.34.16 |
|
VMware vSphere Updated |
metallb-controller Updated |
0.13.4 |
vsphere-provider |
1.34.16 |
|
vsphere-credentials-controller |
1.34.16 |
|
keepalived |
0.19.0-5-g6a7e17d |
|
squid-proxy |
0.0.1-7 |
- 0
For MOSK-based deployments, the
metallb-controllerversion is updated from 0.12.1 to 0.13.4 in MOSK 22.5.
This section lists the components artifacts of the Mirantis Container Cloud release 2.21.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-api Updated |
https://binary.mirantis.com/core/helm/baremetal-api-1.34.16.tgz |
baremetal-operator Updated |
https://binary.mirantis.com/core/helm/baremetal-operator-1.34.17.tgz |
|
baremetal-public-api Updated |
https://binary.mirantis.com/core/helm/baremetal-public-api-1.34.16.tgz |
|
ironic-python-agent.initramfs Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20220915111547 |
|
ironic-python-agent.kernel Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20220915111547 |
|
kaas-ipam Updated |
||
metallb |
||
local-volume-provisioner Updated |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.34.16.tgz |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
Docker images |
ambassador |
mirantis.azurecr.io/general/external/docker.io/library/nginx:1.20.1-alpine |
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-focal-20220611131433 |
|
baremetal-resource-controller |
mirantis.azurecr.io/bm/baremetal-resource-controller:base-focal-20220627134752 |
|
dynamic_ipxe Updated |
mirantis.azurecr.io/bm/dynamic-ipxe:base-focal-20221018205745 |
|
dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-alpine-20221025105458 |
|
dnsmasq-controller Updated |
mirantis.azurecr.io/bm/dnsmasq-controller:base-focal-20220811133223 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20220719132049 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20220719132049 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20220602121226 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-focal-20220503165133 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20220113085105 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.19.0-5-g6a7e17d |
|
metallb-controller Updated 0 |
mirantis.azurecr.io/bm/external/metallb/controller:v0.13.4 |
|
metallb-speaker Updated 0 |
mirantis.azurecr.io/bm/external/metallb/speaker:v0.13.4 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-focal-20220128103433 |
- 0(1,2)
For MOSK-based deployments, the
metallbversion is updated from 0.12.1 to 0.13.4 in MOSK 22.5.
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.34.16.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.34.16.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.34.16.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.34.16.tgz |
|
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.34.16.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.34.16.tgz |
|
azure-credentials-controller |
https://binary.mirantis.com/core/helm/azure-credentials-controller-1.34.16.tgz |
|
azure-provider |
https://binary.mirantis.com/core/helm/azure-provider-1.34.16.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.34.16.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.34.16.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.34.16.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.34.16.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.34.16.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.34.16.tgz |
|
configuration-collector New |
https://binary.mirantis.com/core/helm/configuration-collector-1.34.16.tgz |
|
equinix-credentials-controller |
https://binary.mirantis.com/core/helm/equinix-credentials-controller-1.34.16.tgz |
|
equinix-provider |
https://binary.mirantis.com/core/helm/equinix-provider-1.34.16.tgz |
|
equinixmetalv2-provider |
https://binary.mirantis.com/core/helm/equinixmetalv2-provider-1.34.16.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.34.16.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.34.16.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.34.16.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.34.16.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.34.16.tgz |
|
license-controller |
https://binary.mirantis.com/core/helm/license-controller-1.34.16.tgz |
|
mcc-cache |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.34.16.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.34.16.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.34.16.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.34.16.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.34.16.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.34.16.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.34.16.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.34.16.tgz |
|
scope-controller |
http://binary.mirantis.com/core/helm/scope-controller-1.34.16.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.34.16.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.34.16.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.34.16.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.34.16.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.34.16 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.34.16 |
|
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.34.16 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.34.16 |
|
azure-cluster-api-controller Updated |
mirantis.azurecr.io/core/azure-cluster-api-controller:1.34.16 |
|
azure-credentials-controller Updated |
mirantis.azurecr.io/core/azure-credentials-controller:1.34.16 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.34.16 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.34.16 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.34.16 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.6.1 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.34.16 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.34.16 |
|
cluster-api-provider-equinix Updated |
mirantis.azurecr.io/core/equinix-cluster-api-controller:1.34.16 |
|
equinix-credentials-controller Updated |
mirantis.azurecr.io/core/equinix-credentials-controller:1.34.16 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.34.16 |
|
haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.17.0-8-g6ca89d5 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.34.16 |
|
kaas-exporter |
mirantis.azurecr.io/core/kaas-exporter:1.34.16 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.34.16 |
|
lcm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-327-gbc30b11b |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.34.16 |
|
machinepool-controller Updated |
mirantis.azurecr.io/core/machinepool-controller:1.34.16 |
|
mcc-keepalived Updated |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.19.0-5-g6a7e17d |
|
metrics-server |
mirantis.azurecr.io/core/external/metrics-server:v0.5.2 |
|
nginx |
mirantis.azurecr.io/core/external/nginx:1.34.16 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.34.16 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.34.16 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.34.16 |
|
proxy-controller Updated |
mirantis.azurecr.io/core/proxy-controller:1.34.16 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.34.16 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.34.16 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.34.16 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.34.16 |
|
squid-proxy Updated |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-7 |
|
storage-discovery |
mirantis.azurecr.io/core/storage-discovery:1.34.16 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.34.16 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.34.16 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.34.16 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
Helm charts Updated |
iam |
|
iam-proxy |
||
keycloak_proxy |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.34.16.tgz |
|
Docker images |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.6.7-focal-20220811085105 |
|
keycloak Updated |
mirantis.azurecr.io/iam/keycloak:0.5.12 |
|
keycloak-gatekeeper Updated |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-3 |
Since Kubernetes policy does not allow updating images in existing IAM jobs, after Container Cloud automatically upgrades to 2.21.0, update the MariaDB image manually using the following steps:
Delete the existing job:
kubectl delete job -n kaas iam-cluster-wait
In the management
Clusterobject, and add following snippet:kaas: management: enabled: true helmReleases: - name: iam values: keycloak: mariadb: images: tags: mariadb_scripted_test: general/mariadb:10.6.7-focal-20220811085105
Wait until
helm-controllerapplies changes.Verify that the job was recreated and the new image was added:
kubectl describe job -n kaas iam-cluster-wait | grep -i image
The Mirantis Container Cloud GA release 2.20.1 is based on 2.20.0 and:
Introduces support for the Cluster release 8.10.0 that is based on the Cluster release 7.10.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 22.4.
This Cluster release is based on the updated version of Mirantis Kubernetes Engine 3.4.10 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.12.
Does not support greenfield deployments based on deprecated Cluster releases 11.3.0, 8.8.0, and 7.9.0. Use the latest available Cluster releases of the series instead.
For details about the Container Cloud release 2.20.1, refer to its parent release 2.20.0:
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
The Mirantis Container Cloud GA release 2.20.0:
Introduces support for the Cluster release 11.4.0 that is based on Mirantis Container Runtime 20.10.12 and Mirantis Kubernetes Engine 3.5.4 with Kubernetes 1.21.
Introduces support for the Cluster release 7.10.0 that is based on Mirantis Container Runtime 20.10.12 and Mirantis Kubernetes Engine 3.4.10 with Kubernetes 1.20.
Supports the Cluster release 8.8.0 that is based on the Cluster release 7.8.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 22.3.
Does not support greenfield deployments on deprecated Cluster releases 11.3.0, 8.6.0, and 7.9.0. Use the latest available Cluster releases of the series instead.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.20.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.20.0. For the list of enhancements in the Cluster releases 11.4.0 and 7.10.0 that are introduced by the Container Cloud release 2.20.0, see the Cluster releases (managed).
Added the IAM member role to the existing IAM roles list. The
Infrastructure Operator with the member role has the read and write
access to Container Cloud API allowing cluster operations and does not have
access to IAM objects.
Implemented the capability to configure the Bastion node on greenfield deployments of the OpenStack-based and AWS-based managed clusters using the Container Cloud web UI. Using the Create Cluster wizard, you can now configure the following parameters for the Bastion node:
OpenStack-based: flavor, image, availability zone, server metadata, booting from a volume
AWS-based: instance type, AMI ID
Note
Reconfiguration of the Bastion node on an existing cluster is not supported.
Made the ipam/SVC-k8s-lcm label mandatory for the LCM subnet on new
deployments of management and managed bare metal clusters. It allows the
LCM Agent to correctly identify IP addresses to use on multi-homed bare metal
hosts. Therefore, you must add this label explicitly on new clusters.
Each node of every cluster must now have only one IP address in the LCM
network that is allocated from one of the Subnet objects having the
ipam/SVC-k8s-lcm label defined. Therefore, all Subnet objects used
for LCM networks must have the ipam/SVC-k8s-lcm label defined.
Note
For MOSK-based deployments, the feature support is available since MOSK 22.4.
Implemented the possibility to use flexible size units throughout bare
metal host profiles for management, regional, and managed clusters. For
example, you can now use either sizeGiB: 0.1 or size: 100Mi when
specifying a device size. The size without units is counted in bytes. For
example, size: 120 means 120 bytes.
Caution
Mirantis recommends using only one parameter name type and units
throughout the configuration files. If both sizeGiB and size are
used, sizeGiB is ignored during deployment and the suffix is adjusted
accordingly. For example, 1.5Gi will be serialized as 1536Mi.
The size without units is counted in bytes. For example, size: 120 means
120 bytes.
Note
For MOSK-based deployments, the feature support is available since MOSK 22.4.
Completed integration of the man-in-the-middle (MITM) proxies support for offline deployments by adding AWS, vSphere, and Equinix Metal with private networking to the list of existing supported providers: OpenStack and bare metal.
With trusted proxy CA certificates that you can now add using the CA Certificate check box in the Add new Proxy window during a managed cluster creation, the feature allows monitoring all cluster traffic for security and audit purposes.
Note
For Azure and Equinix Metal with public networking, the feature is not supported
For MOSK-based deployments, the feature support will become available in one of the following Container Cloud releases.
Implemented the ability to configure TLS certificates for mcc-cache on
management or regional clusters and for MKE on managed clusters deployed or
updated by Container Cloud using the latest Cluster release.
Note
TLS certificates configuration for MKE is not supported:
For MOSK-based clusters
For attached MKE clusters that were not originally deployed by Container Cloud
On top of continuous improvements delivered to the existing Container Cloud
guides, added a document on how to increase the overall storage size for all
Ceph pools of the same device class: hdd, ssd, or nvme. For
details, see Increase Ceph cluster storage size.
The following issues have been addressed in the Mirantis Container Cloud release 2.20.0 along with the Cluster releases 11.4.0 and 7.10.0:
[25476] Fixed the timeout behavior to avoid Keepalived and HAProxy check failures.
[25076] Fixed the
remote_syslogconfiguration. Now, you can optionally define SSL verification modes. For details, see StackLight configuration parameters: Logging to syslog.[24927] Fixed the issue wherein a failure to create
lcmclusterstatedid not trigger a retry.[24852] Fixed the issue wherein the Upgrade Schedule tab in the Container Cloud web UI was displaying the NOT ALLOWED label instead of ALLOWED if the upgrade was enabled.
[24837] Fixed the issue wherein some Keycloak
iam-keycloak-*pods were in theCrashLoopBackOffstate during an update of a baremetal-based management or managed cluster with enabled FIPs.[24813] Fixed the issue wherein the
IPaddrobjects were not reconciled after theipam/SVC-*labels changed on the parent subnet. This prevented theipam/SVC-*labels from propagating toIPaddrobjects and caused theserviceMapupdate to fail in the correspondingIpamHost.[23125] Fixed the issue wherein an OpenStack-based regional cluster creation in an offline mode was failing. Adding the Kubernetes load balancer address to the
NO_PROXYenvironment variable is no longer required.[22576] Fixed the issue wherein
provisioning-ansibledid not use thewipeflags during the deployment phase.[5238] Improved the Bastion readiness checks to avoid issues with some clusters having several Bastion nodes.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.20.0 including the Cluster releases 11.4.0 and 7.10.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
A managed cluster deployment, attachment, or update to a Cluster release with
MKE versions 3.3.13, 3.4.6, 3.5.1, or earlier may fail with the
compose pods flapping (ready > terminating > pending) and with the
following error message appearing in logs:
'not ready: deployments: kube-system/compose got 0/0 replicas, kube-system/compose-api
got 0/0 replicas'
ready: false
type: Kubernetes
Workaround:
Disable Docker Content Trust (DCT):
Access the MKE web UI as admin.
Navigate to Admin > Admin Settings.
In the left navigation pane, click Docker Content Trust and disable it.
Restart the affected deployments such as
calico-kube-controllers,compose,compose-api,coredns, and so on:kubectl -n kube-system delete deployment <deploymentName>
Once done, the cluster deployment or update resumes.
Re-enable DCT.
Deployment of a regional cluster based on bare metal or Equinix Metal with
private networking fails with mcc-cache Pods being stuck in the
CrashLoopBackOff status of restarts.
As a workaround, remove failed mcc-cache Pods to restart them
automatically. For example:
kubectl -n kaas delete pod mcc-cache-0
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
If a baremetal-based regional cluster deployment fails before pivoting is done, the corresponding region deletion fails.
Workaround:
Using the command below, manually delete all possible traces of the failed
regional cluster deployment, including but not limited to the following
objects that contain the kaas.mirantis.com/region label of the affected
region:
clustermachinebaremetalhostbaremetalhostprofilel2templatesubnetipamhostipaddr
kubectl delete <objectName> -l kaas.mirantis.com/region=<regionName>
Warning
Do not use the same region name again after the regional cluster deployment failure since some objects that reference the region name may still exist.
Deployment of a regional cluster based on bare metal or Equinix Metal with
private networking fails with mcc-cache Pods being stuck in the
CrashLoopBackOff status of restarts.
As a workaround, remove failed mcc-cache Pods to restart them
automatically. For example:
kubectl -n kaas delete pod mcc-cache-0
Deployment of RHEL machines using the Red Hat portal registration, which requires user and password credentials, over MITM proxy fails while building the virtual machines template with the following error:
Unable to verify server's identity: [SSL: CERTIFICATE_VERIFY_FAILED]
certificate verify failed (_ssl.c:618)
The Container Cloud deployment gets stuck while applying the RHEL license
to machines with the same error in the lcm-agent logs.
As a workaround, use the internal Red Hat Satellite server that a VM can access directly without a MITM proxy.
A low CPU limit 100m for kaas-exporter blocks metric collection.
As a workaround, increase the CPU limit for kaas-exporter to 500m
on the management cluster in the
spec:providerSpec:value:kaas:management:helmReleases: section as
described in Limits for management cluster components.
The OpenSearch elasticsearch.persistentVolumeClaimSize custom setting is
overwritten by logging.persistentVolumeClaimSize during deployment of a
Container Cloud cluster of any type and is set to the default 30Gi.
Note
This issue does not block the OpenSearch cluster operations if the default retention time is set. The default setting is usually enough for the capacity size of this cluster.
The issue may affect the following Cluster releases:
11.2.0 - 11.5.0
7.8.0 - 7.11.0
8.8.0 - 8.10.0, 12.5.0 (MOSK clusters)
10.2.4 - 10.8.1 (attached MKE 3.4.x clusters)
13.0.2 - 13.5.1 (attached MKE 3.5.x clusters)
To verify that the cluster is affected:
Note
In the commands below, substitute parameters enclosed in angle brackets to match the affected cluster values.
kubectl --kubeconfig=<managementClusterKubeconfigPath> \
-n <affectedClusterProjectName> \
get cluster <affectedClusterName> \
-o=jsonpath='{.spec.providerSpec.value.helmReleases[*].values.elasticsearch.persistentVolumeClaimSize}' | xargs echo config size:
kubectl --kubeconfig=<affectedClusterKubeconfigPath> \
-n stacklight get pvc -l 'app=opensearch-master' \
-o=jsonpath="{.items[*].status.capacity.storage}" | xargs echo capacity sizes:
The cluster is not affected if the configuration size value matches or is less than any capacity size. For example:
config size: 30Gi capacity sizes: 30Gi 30Gi 30Gi config size: 50Gi capacity sizes: 100Gi 100Gi 100Gi
The cluster is affected if the configuration size is larger than any capacity size. For example:
config size: 200Gi capacity sizes: 100Gi 100Gi 100Gi
Workaround for a new cluster creation:
Select from the following options:
For a management or regional cluster, during the bootstrap procedure, open
cluster.yaml.templatefor editing.For a managed cluster, open the
Clusterobject for editing.Caution
For a managed cluster, use the Container Cloud API instead of the web UI for cluster creation.
In the opened
.yamlfile, addlogging.persistentVolumeClaimSizealong withelasticsearch.persistentVolumeClaimSize. For example:apiVersion: cluster.k8s.io/v1alpha1 spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Continue the cluster deployment. The system will use the custom value set in
logging.persistentVolumeClaimSize.Caution
If
elasticsearch.persistentVolumeClaimSizeis absent in the.yamlfile, the Admission Controller blocks the configuration update.
Workaround for an existing cluster:
Caution
During the application of the below workarounds, a short outage of OpenSearch and its dependent components may occur with the following alerts firing on the cluster. This behavior is expected. Therefore, disregard these alerts.
StackLight alerts list firing during cluster update
Cluster size and outage probability level |
Alert name |
Label name and component |
|---|---|---|
Any cluster with high probability |
|
|
|
|
|
Large cluster with average probability |
|
|
|
n/a |
|
|
n/a |
|
|
n/a |
|
|
n/a |
|
Any cluster with low probability |
|
|
|
|
StackLight in HA mode with LVP provisioner for OpenSearch PVCs
Warning
After applying this workaround, the existing log data will be lost. Therefore, if required, migrate log data to a new persistent volume (PV).
Move the existing log data to a new PV, if required.
Increase the disk size for local volume provisioner (LVP).
Scale down the
opensearch-masterStatefulSet with dependent resources to 0 and disable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 0 statefulset opensearch-master kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 0 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : true }}'
Recreate the
opensearch-masterStatefulSet with the updated disk size.kubectl get statefulset opensearch-master -o yaml -n stacklight | sed 's/storage: 30Gi/storage: <pvcSize>/g' > opensearch-master.yaml kubectl -n stacklight delete statefulset opensearch-master kubectl create -f opensearch-master.yaml
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.Delete existing PVCs:
kubectl delete pvc -l 'app=opensearch-master' -n stacklight
Warning
This command removes all existing logs data from PVCs.
In the
Clusterconfiguration, set the samelogging.persistentVolumeClaimSizeas the size ofelasticsearch.persistentVolumeClaimSize. For example:apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Scale up the
opensearch-masterStatefulSet with dependent resources and enable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 3 statefulset opensearch-master sleep 100 kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : false }}'
StackLight in non-HA mode with an expandable StorageClass for
OpenSearch PVCs
Note
To verify whether a StorageClass is expandable:
kubectl -n stacklight get pvc | grep opensearch-master | awk '{print $6}' | xargs -I{} kubectl get storageclass {} -o yaml | grep 'allowVolumeExpansion: true'
A positive system response is allowVolumeExpansion: true. A negative
system response is blank or false.
Scale down the
opensearch-masterStatefulSet with dependent resources to 0 and disable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 0 statefulset opensearch-master kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 0 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : true }}'
Recreate the
opensearch-masterStatefulSet with the updated disk size.kubectl -n stacklight get statefulset opensearch-master -o yaml | sed 's/storage: 30Gi/storage: <pvc_size>/g' > opensearch-master.yaml kubectl -n stacklight delete statefulset opensearch-master kubectl create -f opensearch-master.yaml
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.Patch the PVCs with the new
elasticsearch.persistentVolumeClaimSizevalue:kubectl -n stacklight patch pvc opensearch-master-opensearch-master-0 -p '{ "spec": { "resources": { "requests": { "storage": "<pvc_size>" }}}}'
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.In the
Clusterconfiguration, setlogging.persistentVolumeClaimSizethe same as the size ofelasticsearch.persistentVolumeClaimSize. For example:apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Scale up the
opensearch-masterStatefulSet with dependent resources to1and enable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 1 statefulset opensearch-master sleep 100 kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : false }}'
StackLight in non-HA mode with a non-expandable StorageClass
and no LVP for OpenSearch PVCs
Warning
After applying this workaround, the existing log data will be lost. Depending on your custom provisioner, you may find a third-party tool, such as pv-migrate, that provides a possibility to copy all data from one PV to another.
If data loss is acceptable, proceed with the workaround below.
Note
To verify whether a StorageClass is expandable:
kubectl -n stacklight get pvc | grep opensearch-master | awk '{print $6}' | xargs -I{} kubectl get storageclass {} -o yaml | grep 'allowVolumeExpansion: true'
A positive system response is allowVolumeExpansion: true. A negative
system response is blank or false.
Scale down the
opensearch-masterStatefulSet with dependent resources to 0 and disable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 0 statefulset opensearch-master kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 0 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : true }}'
Recreate the
opensearch-masterStatefulSet with the updated disk size:kubectl get statefulset opensearch-master -o yaml -n stacklight | sed 's/storage: 30Gi/storage: <<pvc_size>>/g' > opensearch-master.yaml kubectl -n stacklight delete statefulset opensearch-master kubectl create -f opensearch-master.yaml
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.Delete existing PVCs:
kubectl delete pvc -l 'app=opensearch-master' -n stacklight
Warning
This command removes all existing logs data from PVCs.
In the
Clusterconfiguration, setlogging.persistentVolumeClaimSizeto the same value as the size of theelasticsearch.persistentVolumeClaimSizeparameter. For example:apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Scale up the
opensearch-masterStatefulSet with dependent resources to1and enable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 1 statefulset opensearch-master sleep 100 kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : false }}'
Custom settings for the deprecated elasticsearch.logstashRetentionTime
parameter are overwritten by the default setting set to 1 day.
The issue may affect the following Cluster releases with enabled
elasticsearch.logstashRetentionTime:
11.2.0 - 11.5.0
7.8.0 - 7.11.0
8.8.0 - 8.10.0, 12.5.0 (MOSK clusters)
10.2.4 - 10.8.1 (attached MKE 3.4.x clusters)
13.0.2 - 13.5.1 (attached MKE 3.5.x clusters)
As a workaround, in the Cluster object, replace
elasticsearch.logstashRetentionTime with elasticsearch.retentionTime
that was implemented to replace the deprecated parameter. For example:
apiVersion: cluster.k8s.io/v1alpha1
kind: Cluster
spec:
...
providerSpec:
value:
...
helmReleases:
- name: stacklight
values:
elasticsearch:
retentionTime:
logstash: 10
events: 10
notifications: 10
logging:
enabled: true
For the StackLight configuration procedure and parameters description, refer to Configure StackLight.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshoot StackLight.
On a managed cluster, the StackLight pods may get stuck with the
Pod predicate NodeAffinity failed error in the pod status. The issue may
occur if the StackLight node label was added to one machine and
then removed from another one.
The issue does not affect the StackLight services, all required StackLight pods migrate successfully except extra pods that are created and stuck during pod migration.
As a workaround, remove the stuck pods:
kubectl --kubeconfig <managedClusterKubeconfig> -n stacklight delete pod <stuckPodName>
The status section in the KaaSCephCluster.status CR does not reflect
issues during the process of a Ceph cluster deletion.
As a workaround, inspect Ceph Controller logs on the managed cluster:
kubectl --kubeconfig <managedClusterKubeconfig> -n ceph-lcm-mirantis logs <ceph-controller-pod-name>
Update of a managed cluster based on bare metal and Ceph enabled fails with
PersistentVolumeClaim getting stuck in the Pending state for the
prometheus-server StatefulSet and the
MountVolume.MountDevice failed for volume warning in the StackLight event
logs.
Workaround:
Verify that the description of the Pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
In the command above, replace the following values:
<affectedProjectName>is the Container Cloud project name where the Pods failed to run<affectedPodName>is a Pod name that failed to run in the specified project
In the Pod description, identify the node name where the Pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain therbd volume mount failed: <csi-vol-uuid> is being usederror. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the Pod that fails to0replicas.On every
csi-rbdpluginPod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected Pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state becomesRunning.
An upgrade of a Container Cloud management cluster with a custom Keycloak or web UI TLS certificate fails with the following example error:
failed to update management cluster: \
admission webhook "validations.kaas.mirantis.com" denied the request: \
failed to validate TLS spec for Cluster 'default/kaas-mgmt': \
desired hostname is not set for 'ui'
Workaround:
Verify that the tls section of the management cluster contains the
hostname and certificate fields for configured applications:
Open the management
Clusterobject for editing:kubectl edit cluster <mgmtClusterName>
Verify that the
tlssection contains the following fields:tls: keycloak: certificate: name: keycloak hostname: <keycloakHostName> tlsConfigRef: “” or “keycloak” ui: certificate: name: ui hostname: <webUIHostName> tlsConfigRef: “” or “ui”
Fixed in 7.11.0, 11.5.0 and 12.5.0
During attachment of an existing MKE cluster using the Container Cloud web UI, uploading of an MKE client bundle fails with a false-positive message about a successful uploading.
Workaround:
Select from the following options:
Fill in the required fields for the MKE client bundle manually.
In the Attach Existing MKE Cluster window, use upload MKE client bundle twice to upload
ucp.bundle-admin.zipanducp-docker-bundle.ziplocated in the first archive.
Fixed in 7.11.0, 11.5.0 and 12.5.0
During machine creation using the Container Cloud web UI, a custom value for a node label cannot be set.
As a workaround, manually add the value to
spec.providerSpec.value.nodeLabels in machine.yaml.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.20.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.33.5 |
aws-credentials-controller |
1.33.5 |
|
Azure Updated |
azure-provider |
1.33.5 |
azure-credentials-controller |
1.33.5 |
|
Bare metal |
ambassador |
1.20.1-alpine |
baremetal-operator Updated |
6.3.3 |
|
baremetal-public-api Updated |
6.3.3 |
|
baremetal-provider Updated |
1.33.5 |
|
baremetal-resource-controller Updated |
base-focal-20220627134752 |
|
ironic Updated |
yoga-focal-20220719132049 |
|
ironic-operator Removed |
n/a |
|
kaas-ipam |
base-focal-20220503165133 |
|
keepalived |
2.1.5 |
|
local-volume-provisioner |
2.5.0-mcp |
|
mariadb |
10.4.17-bionic-20220113085105 |
|
IAM Updated |
iam |
2.4.31 |
iam-controller |
1.33.5 |
|
keycloak |
18.0.0 |
|
Container Cloud |
admission-controller Updated |
1.33.5 |
agent-controller Updated |
1.33.5 |
|
byo-credentials-controller Updated |
1.33.5 |
|
byo-provider Updated |
1.33.5 |
|
ceph-kcc-controller Updated |
1.33.5 |
|
cert-manager Updated |
1.33.5 |
|
client-certificate-controller Updated |
1.33.5 |
|
golang |
1.17.6 |
|
event-controller Updated |
1.33.5 |
|
kaas-public-api Updated |
1.33.5 |
|
kaas-exporter Updated |
1.33.5 |
|
kaas-ui Updated |
1.33.6 |
|
lcm-controller Updated |
0.3.0-285-g8498abe0 |
|
license-controller Updated |
1.33.5 |
|
machinepool-controller Updated |
1.33.5 |
|
mcc-cache Updated |
1.33.5 |
|
portforward-controller Updated |
1.33.5 |
|
proxy-controller Updated |
1.33.5 |
|
rbac-controller Updated |
1.33.5 |
|
release-controller Updated |
1.33.5 |
|
rhellicense-controller Updated |
1.33.5 |
|
scope-controller Updated |
1.33.5 |
|
user-controller Updated |
1.33.5 |
|
Equinix Metal |
equinix-provider Updated |
1.33.5 |
equinix-credentials-controller Updated |
1.33.5 |
|
keepalived |
2.1.5 |
|
OpenStack Updated |
openstack-provider |
1.33.5 |
os-credentials-controller |
1.33.5 |
|
VMware vSphere |
vsphere-provider Updated |
1.33.7 |
vsphere-credentials-controller Updated |
1.33.5 |
|
keepalived |
2.1.5 |
|
squid-proxy |
0.0.1-6 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.20.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-6.3.3.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-6.3.3.tgz |
|
ironic-python-agent.initramfs Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-yoga-focal-debug-20220801150933 |
|
ironic-python-agent.kernel Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-yoga-focal-debug-20220801150933 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-2.5.0-mcp.tgz |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
target ubuntu system |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-20210622161844 |
|
Docker images |
ambassador |
mirantis.azurecr.io/general/external/docker.io/library/nginx:1.20.1-alpine |
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-focal-20220611131433 |
|
baremetal-resource-controller Updated |
mirantis.azurecr.io/bm/baremetal-resource-controller:base-focal-20220627134752 |
|
dynamic_ipxe Updated |
mirantis.azurecr.io/bm/dynamic-ipxe:base-focal-20220805114906 |
|
dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-focal-20220705175454 |
|
dnsmasq-controller Updated |
mirantis.azurecr.io/bm/dnsmasq-controller:base-focal-20220704102028 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20220719132049 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20220719132049 |
|
ironic-operator Removed |
n/a |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20220602121226 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-focal-20220503165133 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20220113085105 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.14.0-1-g8725814 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-focal-20220128103433 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.33.5.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.33.5.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.33.5.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.33.5.tgz |
|
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.33.5.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.33.5.tgz |
|
azure-credentials-controller |
https://binary.mirantis.com/core/helm/azure-credentials-controller-1.33.5.tgz |
|
azure-provider |
https://binary.mirantis.com/core/helm/azure-provider-1.33.5.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.33.5.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.33.5.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.33.5.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.33.5.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.33.5.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.33.5.tgz |
|
equinix-credentials-controller |
https://binary.mirantis.com/core/helm/equinix-credentials-controller-1.33.5.tgz |
|
equinix-provider |
https://binary.mirantis.com/core/helm/equinix-provider-1.33.5.tgz |
|
equinixmetalv2-provider |
https://binary.mirantis.com/core/helm/equinixmetalv2-provider-1.33.5.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.33.5.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.33.5.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.33.5.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.33.5.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.33.5.tgz |
|
license-controller Updated |
https://binary.mirantis.com/core/helm/license-controller-1.33.5.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.33.5.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.33.5.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.33.5.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.33.5.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.33.5.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.33.5.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.33.5.tgz |
|
scope-controller |
http://binary.mirantis.com/core/helm/scope-controller-1.33.5.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.33.5.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.33.5.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.33.7.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.33.5.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.33.5 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.33.5 |
|
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.33.5 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.33.5 |
|
azure-cluster-api-controller Updated |
mirantis.azurecr.io/core/azure-cluster-api-controller:1.33.5 |
|
azure-credentials-controller Updated |
mirantis.azurecr.io/core/azure-credentials-controller:1.33.5 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.33.5 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.33.5 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.33.5 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.6.1 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.33.5 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.33.5 |
|
cluster-api-provider-equinix Updated |
mirantis.azurecr.io/core/equinix-cluster-api-controller:1.33.5 |
|
equinix-credentials-controller Updated |
mirantis.azurecr.io/core/equinix-credentials-controller:1.33.5 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.33.5 |
|
haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.17.0-8-g6ca89d5 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.33.5 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.33.5 |
|
lcm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-285-g8498abe0 |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.33.5 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.14.0-1-g8725814 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.33.5 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.33.5 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.33.5 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.33.5 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.33.5 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.33.5 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.33.5 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-6 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.33.5 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.33.5 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.33.5 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
Helm charts Updated |
iam |
|
iam-proxy |
||
keycloak_proxy |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.33.5.tgz |
|
Docker images |
kubernetes-entrypoint |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak Updated |
mirantis.azurecr.io/iam/keycloak:0.5.10 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-2 |
The Mirantis Container Cloud GA release 2.19.0:
Introduces support for the Cluster release 11.3.0 that is based on Mirantis Container Runtime 20.10.11 and Mirantis Kubernetes Engine 3.5.3 with Kubernetes 1.21.
Introduces support for the Cluster release 7.9.0 that is based on Mirantis Container Runtime 20.10.11 and Mirantis Kubernetes Engine 3.4.9 with Kubernetes 1.20.
Supports the Cluster release 8.8.0 that is based on the Cluster release 7.8.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 22.3.
Does not support greenfield deployments on deprecated Cluster releases 11.2.0, 8.6.0, and 7.8.0. Use the latest Cluster releases of the series instead.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.19.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.19.0. For the list of enhancements in the Cluster releases 11.3.0 and 7.9.0 that are introduced by the Container Cloud release 2.19.0, see the Cluster releases (managed).
Implemented full support for the upgrade sequence of machines that allows prioritized machines to be upgraded first. You can now set the upgrade index on an existing machine or machine pool using the Container Cloud web UI.
Consider the following upgrade index specifics:
The first machine to upgrade is always one of the control plane machines with the lowest
upgradeIndex. Other control plane machines are upgraded one by one according to their upgrade indexes.If the
ClusterspecdedicatedControlPlanefield isfalse, worker machines are upgraded only after the upgrade of all control plane machines finishes. Otherwise, they are upgraded after the first control plane machine, concurrently with other control plane machines.If several machines have the same upgrade index, they have the same priority during upgrade.
If the value is not set, the machine is automatically assigned a value of the upgrade index.
TechPreview
Implemented the Boot From Volume option for the OpenStack machine creation wizard in the Container Cloud web UI. The feature allows booting OpenStack-based machines from a block storage volume.
The feature is beneficial for clouds that do not have enough space on hypervisors. After enabling this option, the Cinder storage is used instead of the Nova storage.
TechPreview
Enabled the ability to modify existing network configuration on running bare metal clusters with a mandatory approval of new settings by an Infrastructure Operator. This validation is required to prevent accidental cluster failures due to misconfiguration.
After you make necessary network configuration changes in the required L2
template, you now need to approve the changes by setting the
spec.netconfigUpdateAllow:true flag in each affected IpamHost object.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
Implemented a new format of log entries for cluster and machine logs of a management cluster. Each log entry now contains a request ID that identifies chronology of actions performed on a cluster or machine. The feature applies to all supported cloud providers.
The new format is <providerType>.<objectName>.req:<requestID>.
For example, bm.machine.req:374, bm.cluster.req:172.
<providerType>- provider name, possible values:aws,azure,os,bm,vsphere,equinix.<objectName>- name of an object being processed by provider, possible values:cluster,machine.<requestID>- request ID number that increases when a provider receives a request from Kubernetes about creating, updating, deleting an object. The request ID allows combining all operations performed with an object within one request. For example, the result of a machine creation, update of its statuses, and so on.
Implemented the --extended flag for collecting the extended version of
logs that contains system and MKE logs, logs from LCM Ansible and LCM Agent
along with cluster events and Kubernetes resources description and logs.
You can use this flag to collect logs on any cluster type.
Without the --extended flag, the basic version of logs is collected, which
is sufficient for most use cases. The basic version of logs contains all
events, Kubernetes custom resources, and logs from all Container Cloud
components. This version does not require passing --key-file.
Added the Distribution field to the bare metal machine creation wizard in the Container Cloud web UI. The default operating system in the distribution list is Ubuntu 20.04.
Caution
Do not use the outdated Ubuntu 18.04 distribution on greenfield deployments but only on existing clusters based on Ubuntu 18.04.
After switching all remaining OpenStack Helm releases from v2 to v3, dropped support for Helm v2 in Helm Controller and removed the Tiller image for all related components.
The following issues have been addressed in the Mirantis Container Cloud release 2.19.0 along with the Cluster releases 11.3.0 and 7.9.0:
[16379, 23865] Fixed the issue that caused an Equinix-based management or managed cluster update to fail with the FailedAttachVolume and FailedMount warnings.
[24286] Fixed the issue wherein creation of a new Equinix-based managed cluster failed due to failure to release a new vRouter ID.
[24722] Fixed the issue that caused Ceph clusters to be broken on Equinix-based managed clusters deployed on a Container Cloud instance with a non-default (different from
region-one) region configured.[24806] Fixed the issue wherein the
dhcp-option=tagparameters were not applied todnsmasq.confduring the bootstrap of a bare metal management cluster with a multi-rack topology.[17778] Fixed the issue wherein the Container Cloud web UI displayed the new release version while update for some nodes was still in progress.
[24676] Fixed the issue wherein the deployment of an Equinix-based management cluster failed with the following error message:
Failed waiting for OIDC configuration readiness: timed out waiting for the condition
[25050] For security reasons, disabled the deprecated TLS v1.0 and v1.1 for the
mcc-cacheandkaas-uiContainer Cloud services.[25256] Optimized the number of simultaneous connections to etcd to be open during configuration of Calico policies.
[24914] Fixed the issue wherein Helm Controller was getting stuck during readiness checks due to the timeout for
helmclientbeing not set.[24317] Fixed a number of security vulnerabilities in the Container Cloud Docker images:
Updated the following Docker images to fix CVE-2022-24407 and CVE-2022-0778:
admission-controller
agent-controller
aws-cluster-api-controller
aws-credentials-controller
azure-cluster-api-controller
azure-credentials-controller
bootstrap-controller
byo-cluster-api-controller
byo-credentials-controller
ceph-kcc-controller
cluster-api-provider-baremetal
equinix-cluster-api-controller
equinix-credentials-controller
event-controller
iam-controller
imc-sync
kaas-exporter
kproxy
license-controller
machinepool-controller
openstack-cluster-api-controller
os-credentials-controller
portforward-controller
proxy-controller
rbac-controller
release-controller
rhellicense-controller
scope-controller
storage-discovery
user-controller
vsphere-cluster-api-controller
vsphere-credentials-controller
Updated
aws-ebs-csi-driverto fix the following Amazon Linux Security Advisories:Updated
keycloakto fix the following security vulnerabilities:Updated
busybox,iam/api,iam/helm, andnginxto fix CVE-2022-28391Updated
frontendto fix CVE-2022-27404Updated
kube-proxyto fix CVE-2022-1292
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.19.0 including the Cluster releases 11.3.0 and 7.9.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
A managed cluster deployment, attachment, or update to a Cluster release with
MKE versions 3.3.13, 3.4.6, 3.5.1, or earlier may fail with the
compose pods flapping (ready > terminating > pending) and with the
following error message appearing in logs:
'not ready: deployments: kube-system/compose got 0/0 replicas, kube-system/compose-api
got 0/0 replicas'
ready: false
type: Kubernetes
Workaround:
Disable Docker Content Trust (DCT):
Access the MKE web UI as admin.
Navigate to Admin > Admin Settings.
In the left navigation pane, click Docker Content Trust and disable it.
Restart the affected deployments such as
calico-kube-controllers,compose,compose-api,coredns, and so on:kubectl -n kube-system delete deployment <deploymentName>
Once done, the cluster deployment or update resumes.
Re-enable DCT.
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
If a baremetal-based regional cluster deployment fails before pivoting is done, the corresponding region deletion fails.
Workaround:
Using the command below, manually delete all possible traces of the failed
regional cluster deployment, including but not limited to the following
objects that contain the kaas.mirantis.com/region label of the affected
region:
clustermachinebaremetalhostbaremetalhostprofilel2templatesubnetipamhostipaddr
kubectl delete <objectName> -l kaas.mirantis.com/region=<regionName>
Warning
Do not use the same region name again after the regional cluster deployment failure since some objects that reference the region name may still exist.
The OpenSearch elasticsearch.persistentVolumeClaimSize custom setting is
overwritten by logging.persistentVolumeClaimSize during deployment of a
Container Cloud cluster of any type and is set to the default 30Gi.
Note
This issue does not block the OpenSearch cluster operations if the default retention time is set. The default setting is usually enough for the capacity size of this cluster.
The issue may affect the following Cluster releases:
11.2.0 - 11.5.0
7.8.0 - 7.11.0
8.8.0 - 8.10.0, 12.5.0 (MOSK clusters)
10.2.4 - 10.8.1 (attached MKE 3.4.x clusters)
13.0.2 - 13.5.1 (attached MKE 3.5.x clusters)
To verify that the cluster is affected:
Note
In the commands below, substitute parameters enclosed in angle brackets to match the affected cluster values.
kubectl --kubeconfig=<managementClusterKubeconfigPath> \
-n <affectedClusterProjectName> \
get cluster <affectedClusterName> \
-o=jsonpath='{.spec.providerSpec.value.helmReleases[*].values.elasticsearch.persistentVolumeClaimSize}' | xargs echo config size:
kubectl --kubeconfig=<affectedClusterKubeconfigPath> \
-n stacklight get pvc -l 'app=opensearch-master' \
-o=jsonpath="{.items[*].status.capacity.storage}" | xargs echo capacity sizes:
The cluster is not affected if the configuration size value matches or is less than any capacity size. For example:
config size: 30Gi capacity sizes: 30Gi 30Gi 30Gi config size: 50Gi capacity sizes: 100Gi 100Gi 100Gi
The cluster is affected if the configuration size is larger than any capacity size. For example:
config size: 200Gi capacity sizes: 100Gi 100Gi 100Gi
Workaround for a new cluster creation:
Select from the following options:
For a management or regional cluster, during the bootstrap procedure, open
cluster.yaml.templatefor editing.For a managed cluster, open the
Clusterobject for editing.Caution
For a managed cluster, use the Container Cloud API instead of the web UI for cluster creation.
In the opened
.yamlfile, addlogging.persistentVolumeClaimSizealong withelasticsearch.persistentVolumeClaimSize. For example:apiVersion: cluster.k8s.io/v1alpha1 spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Continue the cluster deployment. The system will use the custom value set in
logging.persistentVolumeClaimSize.Caution
If
elasticsearch.persistentVolumeClaimSizeis absent in the.yamlfile, the Admission Controller blocks the configuration update.
Workaround for an existing cluster:
Caution
During the application of the below workarounds, a short outage of OpenSearch and its dependent components may occur with the following alerts firing on the cluster. This behavior is expected. Therefore, disregard these alerts.
StackLight alerts list firing during cluster update
Cluster size and outage probability level |
Alert name |
Label name and component |
|---|---|---|
Any cluster with high probability |
|
|
|
|
|
Large cluster with average probability |
|
|
|
n/a |
|
|
n/a |
|
|
n/a |
|
|
n/a |
|
Any cluster with low probability |
|
|
|
|
StackLight in HA mode with LVP provisioner for OpenSearch PVCs
Warning
After applying this workaround, the existing log data will be lost. Therefore, if required, migrate log data to a new persistent volume (PV).
Move the existing log data to a new PV, if required.
Increase the disk size for local volume provisioner (LVP).
Scale down the
opensearch-masterStatefulSet with dependent resources to 0 and disable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 0 statefulset opensearch-master kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 0 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : true }}'
Recreate the
opensearch-masterStatefulSet with the updated disk size.kubectl get statefulset opensearch-master -o yaml -n stacklight | sed 's/storage: 30Gi/storage: <pvcSize>/g' > opensearch-master.yaml kubectl -n stacklight delete statefulset opensearch-master kubectl create -f opensearch-master.yaml
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.Delete existing PVCs:
kubectl delete pvc -l 'app=opensearch-master' -n stacklight
Warning
This command removes all existing logs data from PVCs.
In the
Clusterconfiguration, set the samelogging.persistentVolumeClaimSizeas the size ofelasticsearch.persistentVolumeClaimSize. For example:apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Scale up the
opensearch-masterStatefulSet with dependent resources and enable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 3 statefulset opensearch-master sleep 100 kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : false }}'
StackLight in non-HA mode with an expandable StorageClass for
OpenSearch PVCs
Note
To verify whether a StorageClass is expandable:
kubectl -n stacklight get pvc | grep opensearch-master | awk '{print $6}' | xargs -I{} kubectl get storageclass {} -o yaml | grep 'allowVolumeExpansion: true'
A positive system response is allowVolumeExpansion: true. A negative
system response is blank or false.
Scale down the
opensearch-masterStatefulSet with dependent resources to 0 and disable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 0 statefulset opensearch-master kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 0 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : true }}'
Recreate the
opensearch-masterStatefulSet with the updated disk size.kubectl -n stacklight get statefulset opensearch-master -o yaml | sed 's/storage: 30Gi/storage: <pvc_size>/g' > opensearch-master.yaml kubectl -n stacklight delete statefulset opensearch-master kubectl create -f opensearch-master.yaml
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.Patch the PVCs with the new
elasticsearch.persistentVolumeClaimSizevalue:kubectl -n stacklight patch pvc opensearch-master-opensearch-master-0 -p '{ "spec": { "resources": { "requests": { "storage": "<pvc_size>" }}}}'
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.In the
Clusterconfiguration, setlogging.persistentVolumeClaimSizethe same as the size ofelasticsearch.persistentVolumeClaimSize. For example:apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Scale up the
opensearch-masterStatefulSet with dependent resources to1and enable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 1 statefulset opensearch-master sleep 100 kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : false }}'
StackLight in non-HA mode with a non-expandable StorageClass
and no LVP for OpenSearch PVCs
Warning
After applying this workaround, the existing log data will be lost. Depending on your custom provisioner, you may find a third-party tool, such as pv-migrate, that provides a possibility to copy all data from one PV to another.
If data loss is acceptable, proceed with the workaround below.
Note
To verify whether a StorageClass is expandable:
kubectl -n stacklight get pvc | grep opensearch-master | awk '{print $6}' | xargs -I{} kubectl get storageclass {} -o yaml | grep 'allowVolumeExpansion: true'
A positive system response is allowVolumeExpansion: true. A negative
system response is blank or false.
Scale down the
opensearch-masterStatefulSet with dependent resources to 0 and disable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 0 statefulset opensearch-master kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 0 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : true }}'
Recreate the
opensearch-masterStatefulSet with the updated disk size:kubectl get statefulset opensearch-master -o yaml -n stacklight | sed 's/storage: 30Gi/storage: <<pvc_size>>/g' > opensearch-master.yaml kubectl -n stacklight delete statefulset opensearch-master kubectl create -f opensearch-master.yaml
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.Delete existing PVCs:
kubectl delete pvc -l 'app=opensearch-master' -n stacklight
Warning
This command removes all existing logs data from PVCs.
In the
Clusterconfiguration, setlogging.persistentVolumeClaimSizeto the same value as the size of theelasticsearch.persistentVolumeClaimSizeparameter. For example:apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Scale up the
opensearch-masterStatefulSet with dependent resources to1and enable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 1 statefulset opensearch-master sleep 100 kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : false }}'
Custom settings for the deprecated elasticsearch.logstashRetentionTime
parameter are overwritten by the default setting set to 1 day.
The issue may affect the following Cluster releases with enabled
elasticsearch.logstashRetentionTime:
11.2.0 - 11.5.0
7.8.0 - 7.11.0
8.8.0 - 8.10.0, 12.5.0 (MOSK clusters)
10.2.4 - 10.8.1 (attached MKE 3.4.x clusters)
13.0.2 - 13.5.1 (attached MKE 3.5.x clusters)
As a workaround, in the Cluster object, replace
elasticsearch.logstashRetentionTime with elasticsearch.retentionTime
that was implemented to replace the deprecated parameter. For example:
apiVersion: cluster.k8s.io/v1alpha1
kind: Cluster
spec:
...
providerSpec:
value:
...
helmReleases:
- name: stacklight
values:
elasticsearch:
retentionTime:
logstash: 10
events: 10
notifications: 10
logging:
enabled: true
For the StackLight configuration procedure and parameters description, refer to Configure StackLight.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshoot StackLight.
On a managed cluster, the StackLight pods may get stuck with the
Pod predicate NodeAffinity failed error in the pod status. The issue may
occur if the StackLight node label was added to one machine and
then removed from another one.
The issue does not affect the StackLight services, all required StackLight pods migrate successfully except extra pods that are created and stuck during pod migration.
As a workaround, remove the stuck pods:
kubectl --kubeconfig <managedClusterKubeconfig> -n stacklight delete pod <stuckPodName>
Fixed in 7.11.0, 11.5.0 and 12.5.0
During attachment of an existing MKE cluster using the Container Cloud web UI, uploading of an MKE client bundle fails with a false-positive message about a successful uploading.
Workaround:
Select from the following options:
Fill in the required fields for the MKE client bundle manually.
In the Attach Existing MKE Cluster window, use upload MKE client bundle twice to upload
ucp.bundle-admin.zipanducp-docker-bundle.ziplocated in the first archive.
Fixed in 7.11.0, 11.5.0 and 12.5.0
During machine creation using the Container Cloud web UI, a custom value for a node label cannot be set.
As a workaround, manually add the value to
spec.providerSpec.value.nodeLabels in machine.yaml.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.19.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.32.4 |
aws-credentials-controller |
1.32.4 |
|
Azure Updated |
azure-provider |
1.32.4 |
azure-credentials-controller |
1.32.4 |
|
Bare metal |
ambassador |
1.20.1-alpine |
baremetal-operator Updated |
6.2.8 |
|
baremetal-public-api Updated |
6.2.8 |
|
baremetal-provider Updated |
1.32.4 |
|
baremetal-resource-controller Updated |
base-focal-20220530195224 |
|
ironic Updated |
xena-focal-20220603085546 |
|
ironic-operator Updated |
base-focal-20220605090941 |
|
kaas-ipam Updated |
base-focal-20220503165133 |
|
keepalived |
2.1.5 |
|
local-volume-provisioner |
2.5.0-mcp |
|
mariadb |
10.4.17-bionic-20220113085105 |
|
IAM |
iam Updated |
2.4.29 |
iam-controller Updated |
1.32.4 |
|
keycloak |
16.1.1 |
|
Container Cloud |
admission-controller Updated |
1.32.10 |
agent-controller Updated |
1.32.4 |
|
byo-credentials-controller Updated |
1.32.4 |
|
byo-provider Updated |
1.32.4 |
|
ceph-kcc-controller Updated |
1.32.8 |
|
cert-manager Updated |
1.32.4 |
|
client-certificate-controller Updated |
1.32.4 |
|
event-controller Updated |
1.32.4 |
|
golang |
1.17.6 |
|
kaas-public-api Updated |
1.32.4 |
|
kaas-exporter Updated |
1.32.4 |
|
kaas-ui Updated |
1.32.10 |
|
lcm-controller Updated |
0.3.0-257-ga93244da |
|
license-controller Updated |
1.32.4 |
|
machinepool-controller Updated |
1.32.4 |
|
mcc-cache Updated |
1.32.4 |
|
portforward-controller Updated |
1.32.4 |
|
proxy-controller Updated |
1.32.4 |
|
rbac-controller Updated |
1.32.4 |
|
release-controller Updated |
1.32.4 |
|
rhellicense-controller Updated |
1.32.4 |
|
scope-controller Updated |
1.32.4 |
|
user-controller Updated |
1.32.4 |
|
Equinix Metal |
equinix-provider Updated |
1.32.4 |
equinix-credentials-controller Updated |
1.32.4 |
|
keepalived |
2.1.5 |
|
OpenStack Updated |
openstack-provider |
1.32.4 |
os-credentials-controller |
1.32.4 |
|
VMware vSphere |
vsphere-provider Updated |
1.32.4 |
vsphere-credentials-controller Updated |
1.32.4 |
|
keepalived |
2.1.5 |
|
squid-proxy |
0.0.1-6 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.19.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-6.2.8.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-6.2.8.tgz |
|
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-xena-focal-debug-20220512084815 |
|
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-xena-focal-debug-20220512084815 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-2.5.0-mcp.tgz |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
target ubuntu system |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-20210622161844 |
|
Docker images |
ambassador |
mirantis.azurecr.io/general/external/docker.io/library/nginx:1.20.1-alpine |
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-focal-20220611131433 |
|
baremetal-resource-controller Updated |
mirantis.azurecr.io/bm/baremetal-resource-controller:base-focal-20220530195224 |
|
dynamic_ipxe |
mirantis.azurecr.io/bm/dynamic-ipxe:base-focal-20220429170829 |
|
dnsmasq Updated |
mirantis.azurecr.io/bm/baremetal-dnsmasq:base-focal-20220518104155 |
|
dnsmasq-controller Updated |
mirantis.azurecr.io/bm/dnsmasq-controller:base-focal-20220620190158 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:xena-focal-20220603085546 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:xena-focal-20220603085546 |
|
ironic-operator Updated |
mirantis.azurecr.io/bm/ironic-operator:base-focal-20220605090941 |
|
ironic-prometheus-exporter Updated |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20220602121226 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-focal-20220503165133 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20220113085105 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.14.0-1-g8725814 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-focal-20220128103433 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.32.4.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.32.4.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.32.10.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.32.4.tgz |
|
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.32.4.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.32.4.tgz |
|
azure-credentials-controller |
https://binary.mirantis.com/core/helm/azure-credentials-controller-1.32.4.tgz |
|
azure-provider |
https://binary.mirantis.com/core/helm/azure-provider-1.32.4.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.32.4.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.32.4.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.32.4.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.32.4.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.32.4.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.32.4.tgz |
|
equinix-credentials-controller |
https://binary.mirantis.com/core/helm/equinix-credentials-controller-1.32.4.tgz |
|
equinix-provider |
https://binary.mirantis.com/core/helm/equinix-provider-1.32.4.tgz |
|
equinixmetalv2-provider |
https://binary.mirantis.com/core/helm/equinixmetalv2-provider-1.32.4.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.32.4.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.32.4.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.32.4.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.32.4.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.32.4.tgz |
|
license-controller Updated |
https://binary.mirantis.com/core/helm/license-controller-1.32.4.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.32.4.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.32.4.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.32.4.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.32.4.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.32.4.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.32.4.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.32.4.tgz |
|
scope-controller |
http://binary.mirantis.com/core/helm/scope-controller-1.32.4.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.32.4.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.32.4.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.32.4.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.32.4.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.32.10 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.32.4 |
|
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.32.4 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.32.4 |
|
azure-cluster-api-controller Updated |
mirantis.azurecr.io/core/azure-cluster-api-controller:1.32.4 |
|
azure-credentials-controller Updated |
mirantis.azurecr.io/core/azure-credentials-controller:1.32.4 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.32.4 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.32.4 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:1.32.8 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.6.1 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.32.4 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.32.4 |
|
cluster-api-provider-equinix Updated |
mirantis.azurecr.io/core/equinix-cluster-api-controller:1.32.4 |
|
equinix-credentials-controller Updated |
mirantis.azurecr.io/core/equinix-credentials-controller:1.32.4 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.32.10 |
|
haproxy Updated |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.17.0-8-g6ca89d5 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.32.4 |
|
kproxy Updated |
mirantis.azurecr.io/core/kproxy:1.32.4 |
|
lcm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-257-ga93244da |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.32.4 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.14.0-1-g8725814 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.32.4 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.32.4 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.32.4 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.32.4 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.32.4 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.32.4 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.32.4 |
|
squid-proxy |
mirantis.azurecr.io/lcm/squid-proxy:0.0.1-6 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-cluster-api-controller:1.32.4 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.32.4 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.32.4 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
Helm charts |
iam Updated |
|
iam-proxy |
||
keycloak_proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.32.4.tgz |
|
Docker images |
kubernetes-entrypoint |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak Updated |
mirantis.azurecr.io/iam/keycloak:0.5.8 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-2 |
The Mirantis Container Cloud GA release 2.18.1 is based on 2.18.0 and:
Introduces support for the Cluster release 8.8.0 that is based on the Cluster release 7.8.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 22.3. This Cluster release is based on the updated version of Mirantis Kubernetes Engine 3.4.8 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.11.
Does not support new deployments based on the deprecated Cluster releases 11.1.0, 8.6.0, and 7.7.0.
For details about the Container Cloud release 2.18.1, refer to its parent release 2.18.0:
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
The Mirantis Container Cloud GA release 2.18.0:
Introduces support for the Cluster release 11.2.0 that is based on Mirantis Container Runtime 20.10.8 and Mirantis Kubernetes Engine 3.5.1 with Kubernetes 1.21.
Introduces support for the Cluster release 7.8.0 that is based on Mirantis Container Runtime 20.10.8 and Mirantis Kubernetes Engine 3.4.7 with Kubernetes 1.20.
Supports the Cluster release 8.6.0 that is based on the Cluster release 7.6.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 22.2.
Does not support greenfield deployments on deprecated Cluster releases 11.1.0, 8.5.0, and 7.7.0. Use the latest Cluster releases of the series instead.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.18.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.18.0. For the list of enhancements in the Cluster releases 11.2.0 and 7.8.0 that are introduced by the Container Cloud release 2.18.0, see the Cluster releases (managed).
Booting a machine from a block storage volume for OpenStack provider
Enablement of Salesforce propagation to all clusters using web UI
Updated the Ubuntu kernel version to 5.4.0-109-generic for bare metal non-MOSK-based management, regional, and managed clusters to apply Ubuntu 18.04 or 20.04 security and system updates.
Caution
During a baremetal-based cluster update to Container Cloud 2.18 and to the latest Cluster releases 11.2.0 and 7.8.0, hosts will be restarted to apply the latest supported Ubuntu 18.04 or 20.04 packages. Therefore:
Depending on the cluster configuration, applying security updates and host restart can increase the update time for each node to up to 1 hour.
Cluster nodes are updated one by one. Therefore, for large clusters, the update may take several days to complete.
Implemented full support for Ubuntu 20.04 LTS (Focal Fossa) as the default host operating system that now installs on management, regional, and managed clusters for the vSphere cloud provider.
Caution
Upgrading from Ubuntu 18.04 to 20.04 on existing deployments is not supported.
TechPreview
Implemented initial Technology Preview support for booting of the OpenStack-based machines from a block storage volume. The feature is beneficial for clouds that do not have enough space on hypervisors. After enabling this option, the Cinder storage is used instead of the Nova storage.
Using the Container Cloud API, you can boot the Bastion node, or the required management, regional, or managed cluster nodes from a volume.
Note
The ability to enable the boot from volume option using the Container Cloud web UI for managed clusters will be implemented in one of the following Container Cloud releases.
TechPreview Experimental since 2.19.0
Implemented initial Technology Preview support for enabling IPSec encryption for the Kubernetes workloads network. The feature allows for secure communication between servers.
You can enable encryption for the Kubernetes workloads network on greenfield
deployments during initial creation of a management, regional, and managed
cluster through the Cluster object using the secureOverlay parameter.
Caution
For the Azure cloud provider, the feature is not supported. For details, see MKE documentation: Kubernetes network encryption.
For the bare metal cloud provider and MOSK-based deployments, the feature support will become available in one of the following Container Cloud releases.
For existing deployments, the feature support will become available in one of the following Container Cloud releases.
TechPreview
Implemented the initial Technology Preview support for man-in-the-middle (MITM) proxies on offline OpenStack and non-MOSK-based bare metal deployments. Using trusted proxy CA certificates, the feature allows monitoring all cluster traffic for security and audit purposes.
Implemented support for custom Docker registries configuration in the
Container Cloud management, regional, and managed clusters. Using the
ContainerRegistry custom resource, you can configure CA certificates on
machines to access private Docker registries.
Note
For MOSK-based deployments, the feature support is available since Container Cloud 2.18.1.
TechPreview
Implemented initial Technology Preview support for machines upgrade index that allows prioritized machines to be upgraded first. During a machine or a machine pool creation, you can use the Container Cloud web UI Upgrade Index option to set a positive numeral value that defines the order of machine upgrade during cluster update.
To set the upgrade order on an existing cluster, use the Container Cloud API:
For a machine that is not assigned to a machine pool, add the
upgradeIndexfield with the required value to thespec:providerSpec:valuesection in theMachineobject.For a machine pool, add the
upgradeIndexfield with the required value to thespec:machineSpec:providerSpec:valuesection of theMachinePoolobject to apply the upgrade order to all machines in the pool.
Note
The first machine to upgrade is always one of the control plane machines with the lowest
upgradeIndex. Other control plane machines are upgraded one by one according to their upgrade indexes. If theClusterspecdedicatedControlPlanefield isfalse, worker machines are upgraded only after the upgrade of all control plane machines finishes. Otherwise, they are upgraded after the first control plane machine, concurrently with other control plane machines.If two or more machines have the same value of
upgradeIndex, these machines are equally prioritized during upgrade.Changing of the machine upgrade index during an already running cluster update or maintenance is not supported.
Simplified the ability to enable automatic update and sync of the Salesforce configuration on all your clusters by adding the corresponding check box to the Salesforce settings in the Container Cloud web UI.
On top of continuous improvements delivered to the existing Container Cloud guides, added the following documentation:
The following issues have been addressed in the Mirantis Container Cloud release 2.18.0 along with the Cluster releases 11.2.0 and 7.8.0:
[24075] Fixed the issue with the Ubuntu 20.04 option not displaying in the operating systems drop-down list during machine creation for the AWS and Equinix Metal with public networking providers.
Warning
After Container Cloud is upgraded to 2.18.0, remove the values added during the workaround application from the
Clusterobject.[9339] Fixed the issue with incorrect health monitoring for Kubernetes and MKE endpoints on OpenStack-based clusters.
[21710] Fixed the issue with a too high threshold being set for the
KubeContainersCPUThrottlingHighStackLight alert.[22872] Removed the inefficient
ElasticNoNewDataClusterandElasticNoNewDataNodeStackLight alerts.[23853] Fixed the issue wherein the
KaaSCephOperationRequestresource created to remove the failed node from the Ceph cluster was stuck with theFailedstatus and an error message inerrorReason. TheFailedstatus blocked the replacement of the failed master node on regional clusters of the bare metal and Equinix Metal providers.[23841] Improved error logging for load balancers deletion:
The reason for the inability to delete an LB is now displayed in the provider logs.
If the search of an FIP associated with the LB deletion returns more than one FIP, the provider returns an error instead of deleting all found FIPs.
[18331] Fixed the issue with the Keycloak admin console menu disappearing on the Add identity provider page during configuration of an identity provider SAML.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.18.0 including the Cluster releases 11.2.0 and 7.8.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
A managed cluster deployment, attachment, or update to a Cluster release with
MKE versions 3.3.13, 3.4.6, 3.5.1, or earlier may fail with the
compose pods flapping (ready > terminating > pending) and with the
following error message appearing in logs:
'not ready: deployments: kube-system/compose got 0/0 replicas, kube-system/compose-api
got 0/0 replicas'
ready: false
type: Kubernetes
Workaround:
Disable Docker Content Trust (DCT):
Access the MKE web UI as admin.
Navigate to Admin > Admin Settings.
In the left navigation pane, click Docker Content Trust and disable it.
Restart the affected deployments such as
calico-kube-controllers,compose,compose-api,coredns, and so on:kubectl -n kube-system delete deployment <deploymentName>
Once done, the cluster deployment or update resumes.
Re-enable DCT.
During bootstrap of a bare metal management cluster with a multi-rack topology,
the dhcp-option=tag parameters are not applied to dnsmasq.conf.
Symptoms:
The dnasmq-controller service contains the following exemplary error
message:
KUBECONFIG=kaas-mgmt-kubeconfig kubectl -n kaas logs --tail 50 deployment/dnsmasq -c dnsmasq-controller
...
I0622 09:05:26.898898 8 handler.go:19] Failed to watch Object, kind:'dnsmasq': failed to list *unstructured.Unstructured: the server could not find the requested resource
E0622 09:05:26.899108 8 reflector.go:138] pkg/mod/k8s.io/client-go@v0.22.8/tools/cache/reflector.go:167: Failed to watch *unstructured.Unstructured: failed to list *unstructured.Unstructured: the server could not find the requested resource
...
Workaround:
Manually update deployment/dnsmasq with the updated image:
KUBECONFIG=kaas-mgmt-kubeconfig kubectl -n kaas set image deployment/dnsmasq dnsmasq-controller=mirantis.azurecr.io/bm/dnsmasq-controller:base-focal-2-18-issue24806-20220618085127
During deletion of a manager machine running the ironic Pod from a bare
metal management cluster, the following problems occur:
All Pods are stuck in the
TerminatingstateA new
ironicPod fails to startThe related bare metal host is stuck in the
deprovisioningstate
As a workaround, before deletion of the node running the ironic Pod,
cordon and drain the node using the kubectl cordon <nodeName> and
kubectl drain <nodeName> commands.
If a baremetal-based regional cluster deployment fails before pivoting is done, the corresponding region deletion fails.
Workaround:
Using the command below, manually delete all possible traces of the failed
regional cluster deployment, including but not limited to the following
objects that contain the kaas.mirantis.com/region label of the affected
region:
clustermachinebaremetalhostbaremetalhostprofilel2templatesubnetipamhostipaddr
kubectl delete <objectName> -l kaas.mirantis.com/region=<regionName>
Warning
Do not use the same region name again after the regional cluster deployment failure since some objects that reference the region name may still exist.
An Equinix-based management or managed cluster fails to update with the
FailedAttachVolume and FailedMount warnings.
Workaround:
Verify that the description of the pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
<affectedProjectName>is the Container Cloud project name where the pods failed to run<affectedPodName>is a pod name that failed to run in this project
In the pod description, identify the node name where the pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain the rbd volume mount failed: <csi-vol-uuid> is being used error. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the pod that fails to init to0replicas.On every
csi-rbdpluginpod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state isRunning.
The OpenSearch elasticsearch.persistentVolumeClaimSize custom setting is
overwritten by logging.persistentVolumeClaimSize during deployment of a
Container Cloud cluster of any type and is set to the default 30Gi.
Note
This issue does not block the OpenSearch cluster operations if the default retention time is set. The default setting is usually enough for the capacity size of this cluster.
The issue may affect the following Cluster releases:
11.2.0 - 11.5.0
7.8.0 - 7.11.0
8.8.0 - 8.10.0, 12.5.0 (MOSK clusters)
10.2.4 - 10.8.1 (attached MKE 3.4.x clusters)
13.0.2 - 13.5.1 (attached MKE 3.5.x clusters)
To verify that the cluster is affected:
Note
In the commands below, substitute parameters enclosed in angle brackets to match the affected cluster values.
kubectl --kubeconfig=<managementClusterKubeconfigPath> \
-n <affectedClusterProjectName> \
get cluster <affectedClusterName> \
-o=jsonpath='{.spec.providerSpec.value.helmReleases[*].values.elasticsearch.persistentVolumeClaimSize}' | xargs echo config size:
kubectl --kubeconfig=<affectedClusterKubeconfigPath> \
-n stacklight get pvc -l 'app=opensearch-master' \
-o=jsonpath="{.items[*].status.capacity.storage}" | xargs echo capacity sizes:
The cluster is not affected if the configuration size value matches or is less than any capacity size. For example:
config size: 30Gi capacity sizes: 30Gi 30Gi 30Gi config size: 50Gi capacity sizes: 100Gi 100Gi 100Gi
The cluster is affected if the configuration size is larger than any capacity size. For example:
config size: 200Gi capacity sizes: 100Gi 100Gi 100Gi
Workaround for a new cluster creation:
Select from the following options:
For a management or regional cluster, during the bootstrap procedure, open
cluster.yaml.templatefor editing.For a managed cluster, open the
Clusterobject for editing.Caution
For a managed cluster, use the Container Cloud API instead of the web UI for cluster creation.
In the opened
.yamlfile, addlogging.persistentVolumeClaimSizealong withelasticsearch.persistentVolumeClaimSize. For example:apiVersion: cluster.k8s.io/v1alpha1 spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Continue the cluster deployment. The system will use the custom value set in
logging.persistentVolumeClaimSize.Caution
If
elasticsearch.persistentVolumeClaimSizeis absent in the.yamlfile, the Admission Controller blocks the configuration update.
Workaround for an existing cluster:
Caution
During the application of the below workarounds, a short outage of OpenSearch and its dependent components may occur with the following alerts firing on the cluster. This behavior is expected. Therefore, disregard these alerts.
StackLight alerts list firing during cluster update
Cluster size and outage probability level |
Alert name |
Label name and component |
|---|---|---|
Any cluster with high probability |
|
|
|
|
|
Large cluster with average probability |
|
|
|
n/a |
|
|
n/a |
|
|
n/a |
|
|
n/a |
|
Any cluster with low probability |
|
|
|
|
StackLight in HA mode with LVP provisioner for OpenSearch PVCs
Warning
After applying this workaround, the existing log data will be lost. Therefore, if required, migrate log data to a new persistent volume (PV).
Move the existing log data to a new PV, if required.
Increase the disk size for local volume provisioner (LVP).
Scale down the
opensearch-masterStatefulSet with dependent resources to 0 and disable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 0 statefulset opensearch-master kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 0 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : true }}'
Recreate the
opensearch-masterStatefulSet with the updated disk size.kubectl get statefulset opensearch-master -o yaml -n stacklight | sed 's/storage: 30Gi/storage: <pvcSize>/g' > opensearch-master.yaml kubectl -n stacklight delete statefulset opensearch-master kubectl create -f opensearch-master.yaml
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.Delete existing PVCs:
kubectl delete pvc -l 'app=opensearch-master' -n stacklight
Warning
This command removes all existing logs data from PVCs.
In the
Clusterconfiguration, set the samelogging.persistentVolumeClaimSizeas the size ofelasticsearch.persistentVolumeClaimSize. For example:apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Scale up the
opensearch-masterStatefulSet with dependent resources and enable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 3 statefulset opensearch-master sleep 100 kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : false }}'
StackLight in non-HA mode with an expandable StorageClass for
OpenSearch PVCs
Note
To verify whether a StorageClass is expandable:
kubectl -n stacklight get pvc | grep opensearch-master | awk '{print $6}' | xargs -I{} kubectl get storageclass {} -o yaml | grep 'allowVolumeExpansion: true'
A positive system response is allowVolumeExpansion: true. A negative
system response is blank or false.
Scale down the
opensearch-masterStatefulSet with dependent resources to 0 and disable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 0 statefulset opensearch-master kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 0 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : true }}'
Recreate the
opensearch-masterStatefulSet with the updated disk size.kubectl -n stacklight get statefulset opensearch-master -o yaml | sed 's/storage: 30Gi/storage: <pvc_size>/g' > opensearch-master.yaml kubectl -n stacklight delete statefulset opensearch-master kubectl create -f opensearch-master.yaml
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.Patch the PVCs with the new
elasticsearch.persistentVolumeClaimSizevalue:kubectl -n stacklight patch pvc opensearch-master-opensearch-master-0 -p '{ "spec": { "resources": { "requests": { "storage": "<pvc_size>" }}}}'
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.In the
Clusterconfiguration, setlogging.persistentVolumeClaimSizethe same as the size ofelasticsearch.persistentVolumeClaimSize. For example:apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Scale up the
opensearch-masterStatefulSet with dependent resources to1and enable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 1 statefulset opensearch-master sleep 100 kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : false }}'
StackLight in non-HA mode with a non-expandable StorageClass
and no LVP for OpenSearch PVCs
Warning
After applying this workaround, the existing log data will be lost. Depending on your custom provisioner, you may find a third-party tool, such as pv-migrate, that provides a possibility to copy all data from one PV to another.
If data loss is acceptable, proceed with the workaround below.
Note
To verify whether a StorageClass is expandable:
kubectl -n stacklight get pvc | grep opensearch-master | awk '{print $6}' | xargs -I{} kubectl get storageclass {} -o yaml | grep 'allowVolumeExpansion: true'
A positive system response is allowVolumeExpansion: true. A negative
system response is blank or false.
Scale down the
opensearch-masterStatefulSet with dependent resources to 0 and disable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 0 statefulset opensearch-master kubectl -n stacklight scale --replicas 0 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 0 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : true }}'
Recreate the
opensearch-masterStatefulSet with the updated disk size:kubectl get statefulset opensearch-master -o yaml -n stacklight | sed 's/storage: 30Gi/storage: <<pvc_size>>/g' > opensearch-master.yaml kubectl -n stacklight delete statefulset opensearch-master kubectl create -f opensearch-master.yaml
Replace
<pvcSize>with theelasticsearch.persistentVolumeClaimSizevalue.Delete existing PVCs:
kubectl delete pvc -l 'app=opensearch-master' -n stacklight
Warning
This command removes all existing logs data from PVCs.
In the
Clusterconfiguration, setlogging.persistentVolumeClaimSizeto the same value as the size of theelasticsearch.persistentVolumeClaimSizeparameter. For example:apiVersion: cluster.k8s.io/v1alpha1 kind: Cluster spec: ... providerSpec: value: ... helmReleases: - name: stacklight values: elasticsearch: persistentVolumeClaimSize: 100Gi logging: enabled: true persistentVolumeClaimSize: 100Gi
Scale up the
opensearch-masterStatefulSet with dependent resources to1and enable theelasticsearch-curatorCronJob:kubectl -n stacklight scale --replicas 1 statefulset opensearch-master sleep 100 kubectl -n stacklight scale --replicas 1 deployment opensearch-dashboards kubectl -n stacklight scale --replicas 1 deployment metricbeat kubectl -n stacklight patch cronjobs elasticsearch-curator -p '{"spec" : {"suspend" : false }}'
Custom settings for the deprecated elasticsearch.logstashRetentionTime
parameter are overwritten by the default setting set to 1 day.
The issue may affect the following Cluster releases with enabled
elasticsearch.logstashRetentionTime:
11.2.0 - 11.5.0
7.8.0 - 7.11.0
8.8.0 - 8.10.0, 12.5.0 (MOSK clusters)
10.2.4 - 10.8.1 (attached MKE 3.4.x clusters)
13.0.2 - 13.5.1 (attached MKE 3.5.x clusters)
As a workaround, in the Cluster object, replace
elasticsearch.logstashRetentionTime with elasticsearch.retentionTime
that was implemented to replace the deprecated parameter. For example:
apiVersion: cluster.k8s.io/v1alpha1
kind: Cluster
spec:
...
providerSpec:
value:
...
helmReleases:
- name: stacklight
values:
elasticsearch:
retentionTime:
logstash: 10
events: 10
notifications: 10
logging:
enabled: true
For the StackLight configuration procedure and parameters description, refer to Configure StackLight.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshoot StackLight.
On a managed cluster, the StackLight pods may get stuck with the
Pod predicate NodeAffinity failed error in the pod status. The issue may
occur if the StackLight node label was added to one machine and
then removed from another one.
The issue does not affect the StackLight services, all required StackLight pods migrate successfully except extra pods that are created and stuck during pod migration.
As a workaround, remove the stuck pods:
kubectl --kubeconfig <managedClusterKubeconfig> -n stacklight delete pod <stuckPodName>
Affects only Container Cloud 2.18.0
On clusters with enabled proxy and the NO_PROXY settings containing
localhost/127.0.0.1 or matching the automatically added Container Cloud
internal endpoints, the Container Cloud release upgrade from 2.17.0 to 2.18.0
triggers automatic update of managed clusters to the latest available Cluster
releases in their respective series.
For the issue workaround, contact Mirantis support.
Affects Ubuntu-based clusters deployed after Feb 10, 2022
If you deploy an Ubuntu-based cluster using the deprecated Cluster release
7.4.0 (and earlier) or 5.21.0 (and earlier) starting from February 10, 2022,
the cluster update to the Cluster releases 7.5.0 and 5.22.0 may get stuck
while applying the Deploy state to the cluster machines. The issue
affects all cluster types: management, regional, and managed.
To verify that the cluster is affected:
Log in to the Container Cloud web UI.
In the Clusters tab, capture the RELEASE and AGE values of the required Ubuntu-based cluster. If the values match the ones from the issue description, the cluster may be affected.
Using SSH, log in to the manager or worker node that got stuck while applying the
Deploystate and identify the containerd package version:containerd --versionIf the version is 1.5.9, the cluster is affected.
In
/var/log/lcm/runners/<nodeName>/deploy/, verify whether the Ansible deployment logs contain the following errors that indicate that the cluster is affected:The following packages will be upgraded: docker-ee docker-ee-cli The following packages will be DOWNGRADED: containerd.io STDERR: E: Packages were downgraded and -y was used without --allow-downgrades.
Workaround:
Warning
Apply the steps below to the affected nodes one-by-one and
only after each consecutive node gets stuck on the Deploy phase with the
Ansible log errors. Such sequence ensures that each node is cordon-drained
and Docker is properly stopped. Therefore, no workloads are affected.
Using SSH, log in to the first affected node and install containerd 1.5.8:
apt-get install containerd.io=1.5.8-1 -y --allow-downgrades --allow-change-held-packages
Wait for Ansible to reconcile. The node should become
Readyin several minutes.Wait for the next node of the cluster to get stuck on the
Deployphase with the Ansible log errors. Only after that, apply the steps above on the next node.Patch the remaining nodes one-by-one using the steps above.
Fixed in 7.11.0, 11.5.0 and 12.5.0
During machine creation using the Container Cloud web UI, a custom value for a node label cannot be set.
As a workaround, manually add the value to
spec.providerSpec.value.nodeLabels in machine.yaml.
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.18.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.31.9 |
aws-credentials-controller |
1.31.9 |
|
Azure Updated |
azure-provider |
1.31.9 |
azure-credentials-controller |
1.31.9 |
|
Bare metal |
ambassador |
1.20.1-alpine |
baremetal-operator Updated |
6.1.9 |
|
baremetal-public-api Updated |
6.1.9 |
|
baremetal-provider Updated |
1.31.9 |
|
baremetal-resource-controller |
base-focal-20220429170738 |
|
ironic Updated |
xena-focal-20220513073431 |
|
ironic-operator Updated |
base-focal-20220501190529 |
|
kaas-ipam |
base-focal-20220310095439 |
|
keepalived |
2.1.5 |
|
local-volume-provisioner |
2.5.0-mcp |
|
mariadb |
10.4.17-bionic-20220113085105 |
|
IAM |
iam Updated |
2.4.25 |
iam-controller Updated |
1.31.9 |
|
keycloak Updated |
16.1.1 |
|
Container Cloud |
admission-controller Updated |
1.31.11 |
agent-controller Updated |
1.31.9 |
|
byo-credentials-controller Updated |
1.31.9 |
|
byo-provider Updated |
1.31.9 |
|
ceph-kcc-controller Updated |
1.31.9 |
|
cert-manager Updated |
1.31.9 |
|
client-certificate-controller Updated |
1.31.9 |
|
event-controller Updated |
1.31.9 |
|
golang |
1.17.6 |
|
kaas-public-api Updated |
1.31.9 |
|
kaas-exporter Updated |
1.31.9 |
|
kaas-ui Updated |
1.31.12 |
|
lcm-controller Updated |
0.3.0-239-gae7218ea |
|
license-controller Updated |
1.31.9 |
|
machinepool-controller Updated |
1.31.9 |
|
mcc-cache Updated |
1.31.9 |
|
portforward-controller Updated |
1.31.9 |
|
proxy-controller Updated |
1.31.9 |
|
rbac-controller Updated |
1.31.9 |
|
release-controller Updated |
1.31.9 |
|
rhellicense-controller Updated |
1.31.9 |
|
scope-controller Updated |
1.31.9 |
|
squid-proxy |
0.0.1-6 |
|
user-controller Updated |
1.31.9 |
|
Equinix Metal |
equinix-provider Updated |
1.31.9 |
equinix-credentials-controller Updated |
1.31.9 |
|
keepalived |
2.1.5 |
|
OpenStack Updated |
openstack-provider |
1.31.9 |
os-credentials-controller |
1.31.9 |
|
VMware vSphere |
vsphere-provider Updated |
1.31.9 |
vsphere-credentials-controller Updated |
1.31.9 |
|
keepalived |
2.1.5 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.18.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-6.1.9.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-6.1.9.tgz |
|
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-xena-focal-debug-20220512084815 |
|
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-xena-focal-debug-20220512084815 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-2.5.0-mcp.tgz |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
target ubuntu system |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-20210622161844 |
|
Docker images |
ambassador |
mirantis.azurecr.io/general/external/docker.io/library/nginx:1.20.1-alpine |
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-focal-20220208045851 |
|
baremetal-resource-controller Updated |
mirantis.azurecr.io/bm/baremetal-resource-controller:base-focal-20220429170738 |
|
dynamic_ipxe Updated |
mirantis.azurecr.io/bm/dnsmasq/dynamic-ipxe:base-focal-20220429170829 |
|
dnsmasq Updated |
mirantis.azurecr.io/general/dnsmasq:focal-20220429170747 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:xena-focal-20220513073431 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:xena-focal-20220513073431 |
|
ironic-operator Updated |
mirantis.azurecr.io/bm/ironic-operator:base-focal-20220501190529 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20210608113804 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-focal-20220310095439 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20220113085105 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.14.0-1-g8725814 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-focal-20220128103433 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.31.9.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.31.9.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.31.11.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.31.9.tgz |
|
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.31.9.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.31.9.tgz |
|
azure-credentials-controller |
https://binary.mirantis.com/core/helm/azure-credentials-controller-1.31.9.tgz |
|
azure-provider |
https://binary.mirantis.com/core/helm/azure-provider-1.31.9.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.31.9.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.31.9.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.31.9.tgz |
|
ceph-kcc-controller |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.31.9.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.31.9.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.31.9.tgz |
|
equinix-credentials-controller |
https://binary.mirantis.com/core/helm/equinix-credentials-controller-1.31.9.tgz |
|
equinix-provider |
https://binary.mirantis.com/core/helm/equinix-provider-1.31.9.tgz |
|
equinixmetalv2-provider |
https://binary.mirantis.com/core/helm/equinixmetalv2-provider-1.31.9.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.31.9.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.31.9.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.31.9.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.31.9.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.31.9.tgz |
|
license-controller Updated |
https://binary.mirantis.com/core/helm/license-controller-1.31.9.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.31.9.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.31.9.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.31.9.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.31.9.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.31.9.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.31.9.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.31.9.tgz |
|
scope-controller |
http://binary.mirantis.com/core/helm/scope-controller-1.31.9.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.31.9.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.31.9.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.31.9.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.31.9.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.31.11 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.31.9 |
|
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.31.9 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.31.9 |
|
azure-cluster-api-controller Updated |
mirantis.azurecr.io/core/azure-cluster-api-controller:1.31.9 |
|
azure-credentials-controller Updated |
mirantis.azurecr.io/core/azure-credentials-controller:1.31.9 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.31.9 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.31.9 |
|
ceph-kcc-controller Updated |
mirantis.azurecr.io/core/ceph-kcc-controller:v1.31.9 |
|
cert-manager-controller |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.6.1 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.31.9 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.31.9 |
|
cluster-api-provider-equinix Updated |
mirantis.azurecr.io/core/cluster-api-provider-equinix:1.31.9 |
|
equinix-credentials-controller Updated |
mirantis.azurecr.io/core/equinix-credentials-controller:1.31.9 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.31.12 |
|
haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.12.0-8-g6fabf1c |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.31.9 |
|
kproxy Updated |
mirantis.azurecr.io/lcm/kproxy:1.31.9 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:v0.3.0-239-gae7218ea |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.31.9 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.14.0-1-g8725814 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.31.9 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.31.9 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.31.9 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.31.9 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.31.9 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.31.9 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.31.9 |
|
squid-proxy |
mirantis.azurecr.io/core/squid-proxy:0.0.1-6 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-api-controller:1.31.9 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.31.9 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.31.9 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux Removed |
n/a |
|
iamctl-darwin Removed |
n/a |
|
iamctl-windows Removed |
n/a |
|
Helm charts |
iam Updated |
|
iam-proxy |
||
keycloak_proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.31.9.tgz |
|
Docker images |
api Removed |
n/a |
auxiliary Removed |
n/a |
|
kubernetes-entrypoint |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak Updated |
mirantis.azurecr.io/iam/keycloak:0.5.7 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-2 |
The Mirantis Container Cloud GA release 2.17.0:
Introduces support for the Cluster release 11.1.0 that is based on Mirantis Container Runtime 20.10.8 and Mirantis Kubernetes Engine 3.5.1 with Kubernetes 1.21.
Introduces support for the Cluster release 7.7.0 that is based on Mirantis Container Runtime 20.10.8 and Mirantis Kubernetes Engine 3.4.7 with Kubernetes 1.20.
Supports the Cluster release 8.6.0 that is based on the Cluster release 7.6.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 22.2.
Does not support greenfield deployments on deprecated Cluster releases 11.0.0, 8.5.0, and 7.6.0. Use the latest Cluster releases of the series instead.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.17.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.17.0. For the list of enhancements in the Cluster releases 11.1.0 and 7.7.0 that are introduced by the Container Cloud release 2.17.0, see the Cluster releases (managed).
General availability for Ubuntu 20.04 on greenfield deployments
Container Cloud on top of MOSK Victoria with Tungsten Fabric
EBS instead of NVMe as persistent storage for AWS-based nodes
Automatic propagation of Salesforce configuration to all clusters
Implemented full support for Ubuntu 20.04 LTS (Focal Fossa) as the default host operating system that now installs on management, regional, and managed clusters for the following cloud providers: AWS, Azure, OpenStack, Equinix Metal with public or private networking, and non-MOSK-based bare metal.
For the vSphere and MOSK-based (managed) deployments, support for Ubuntu 20.04 will be announced in one of the following Container Cloud releases.
Note
The management or regional bare metal cluster dedicated for managed clusters running MOSK is based on Ubuntu 20.04.
Caution
Upgrading from Ubuntu 18.04 to 20.04 on existing deployments is not supported.
Implemented the capability to deploy Container Cloud management, regional, and managed clusters based on OpenStack Victoria with Tungsten Fabric networking on top of Mirantis OpenStack for Kubernetes (MOSK) Victoria with Tungsten Fabric.
Note
On the MOSK Victoria with Tungsten Fabric clusters of Container Cloud deployed before MOSK 22.3, Octavia enables a default security group for newly created load balancers. To change this configuration, refer to MOSK Operations Guide: Configure load balancing. To use the default security group, configure ingress rules as described in Create a managed cluster.
Replaced the Non-Volatile Memory Express (NVMe) drive type with the Amazon Elastic Block Store (EBS) one as the persistent storage requirement for AWS-based nodes. This change prevents cluster nodes from becoming unusable after instances are stopped and NVMe drives are erased.
Previously, the /var/lib/docker Docker data was located on local NVMe SSDs
by default. Now, this data is located on the same EBS volume drive as the
operating system.
TechPreview
Implemented the capability to delete manager nodes with the purpose of replacement or recovery. Consider the following precautions:
Create a new manager machine to replace the deleted one as soon as possible. This is necessary since after a machine removal, the cluster has limited capabilities to tolerate faults. Deletion of manager machines is intended only for replacement or recovery of failed nodes.
You can delete a manager machine only if your cluster has at least two manager machines in the
Readystate.Do not delete more than one manager machine at once to prevent cluster failure and data loss.
For MOSK-based clusters, after a manager machine deletion, proceed with additional manual steps described in Mirantis OpenStack for Kubernetes Operations Guide: Replace a failed controller node.
For the Equinix Metal and bare metal providers:
Ensure that the machine to delete is not a Ceph Monitor. If it is, migrate the Ceph Monitor to keep the odd number quorum of Ceph Monitors after the machine deletion. For details, see Migrate a Ceph Monitor before machine replacement.
If you delete a machine on the regional cluster, refer to the known issue 23853 to complete the deletion.
For the sake of HA, limited a managed cluster size to have only an odd number
of manager machines. In an even-sized cluster, an additional machine remains
in the Pending state until an extra manager machine is added.
Learn more
Extended the use of node labels for all supported cloud providers with the
ability to set custom values. Especially from the MOSK
standpoint, this feature makes it easy to schedule overrides for OpenStack
services using API. For example, now you can set the node-type label to
define the node purpose such as hpc-compute, compute-lvm, or
storage-ssd in its value.
The list of allowed node labels is located in the Cluster object status
providerStatus.releaseRef.current.allowedNodeLabels field. Before or after
a machine deployment, add the required label from the allowed node labels list
with the corresponding value to spec.providerSpec.value.nodeLabels in
machine.yaml.
Note
Due to the known issue 23002, it is not possible to set a custom value for a predefined node label using the Container Cloud web UI. For a workaround, refer to the issue description.
Introduced the MachinePool custom resource. A machine pool is a template
that allows managing a set of machines with the same provider spec as a
single unit. You can create different sets of machine pools with required
specs during machines creation on a new or existing cluster using the
Create machine wizard in the Container Cloud web UI. You can
assign or unassign machines from a pool, if required. You can also increase
or decrease replicas count. In case of replicas count increasing, new
machines will be added automatically.
Implemented the capability to enable automatic propagation of the Salesforce
configuration of your management cluster to the related regional and managed
clusters using the autoSyncSalesForceConfig=true flag added to the
Cluster object of the management cluster. This option allows for
automatic update and sync of the Salesforce settings on all your clusters
after you update your management cluster configuration.
You can also set custom settings for regional and managed clusters that always override automatically propagated Salesforce values.
Note
The capability to enable this option using the Container Cloud web UI will be announced in one of the following releases.
The following issues have been addressed in the Mirantis Container Cloud release 2.17.0 along with the Cluster releases 11.1.0 and 7.7.0:
Bare metal:
[22563] Fixed the issue wherein a deployment of a bare metal node with an LVM volume on top of a mdadm-based
raid10failed during provisioning due to insufficient cleanup of RAID devices.
Equinix Metal:
[22264] Fixed the issue wherein the
KubeContainersCPUThrottlingHighalerts for Equinix Metal and AWS deployments raised due to low default deployment limits set for Equinix Metal and AWS controller containers.
StackLight:
[23006] Fixed the issue that caused StackLight endpoints to crash on start with the private key does not match public key error message.
[22626] Fixed the issue that caused constant restarts of the
kaas-exporterpod. Increased the memory forkaas-exporterrequests and limits.[22337] Improved the certificate expiration alerts by enhancing the alert severities.
[20856] Fixed the issue wherein variables values in the PostgreSQL Grafana dashboard were not calculated.
[20855] Fixed the issue wherein the Cluster > Health panel showed N/A in the Elasticsearch Grafana dashboard.
Ceph:
[19014] Updated the Rook Docker image and fixed the following security vulnerabilities:
LCM:
[22341] Fixed the issue wherein the cordon-drain states were not removed after unsetting the maintenance mode for a machine.
Cluster health:
[21494] Fixed the issue wherein controller pods were killed by OOM after a successful deployment of a management or regional cluster.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.17.0 including the Cluster releases 11.1.0 and 7.7.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
A managed cluster deployment, attachment, or update to a Cluster release with
MKE versions 3.3.13, 3.4.6, 3.5.1, or earlier may fail with the
compose pods flapping (ready > terminating > pending) and with the
following error message appearing in logs:
'not ready: deployments: kube-system/compose got 0/0 replicas, kube-system/compose-api
got 0/0 replicas'
ready: false
type: Kubernetes
Workaround:
Disable Docker Content Trust (DCT):
Access the MKE web UI as admin.
Navigate to Admin > Admin Settings.
In the left navigation pane, click Docker Content Trust and disable it.
Restart the affected deployments such as
calico-kube-controllers,compose,compose-api,coredns, and so on:kubectl -n kube-system delete deployment <deploymentName>
Once done, the cluster deployment or update resumes.
Re-enable DCT.
If a baremetal-based regional cluster deployment fails before pivoting is done, the corresponding region deletion fails.
Workaround:
Using the command below, manually delete all possible traces of the failed
regional cluster deployment, including but not limited to the following
objects that contain the kaas.mirantis.com/region label of the affected
region:
clustermachinebaremetalhostbaremetalhostprofilel2templatesubnetipamhostipaddr
kubectl delete <objectName> -l kaas.mirantis.com/region=<regionName>
Warning
Do not use the same region name again after the regional cluster deployment failure since some objects that reference the region name may still exist.
An Equinix-based management or managed cluster fails to update with the
FailedAttachVolume and FailedMount warnings.
Workaround:
Verify that the description of the pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
<affectedProjectName>is the Container Cloud project name where the pods failed to run<affectedPodName>is a pod name that failed to run in this project
In the pod description, identify the node name where the pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain the rbd volume mount failed: <csi-vol-uuid> is being used error. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the pod that fails to init to0replicas.On every
csi-rbdpluginpod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state isRunning.
During replacement of a failed master node on regional clusters of the
bare metal and Equinix Metal providers, the KaaSCephOperationRequest
resource created to remove the failed node from the Ceph cluster is stuck with
the Failed status and an error message in errorReason. For example:
status:
removeStatus:
osdRemoveStatus:
errorReason: Timeout (30m0s) reached for waiting pg rebalance for osd 2
status: Failed
The Failed status blocks the replacement of the failed master node.
Workaround:
On the management cluster, obtain
metadata.name,metadata.namespace, and thespecsection ofKaaSCephOperationRequestbeing stuck:kubectl get kaascephoperationrequest <kcorName> -o yaml
Replace
<kcorName>with the name ofKaaSCephOperationRequestthat has theFailedstatus.Create a new
KaaSCephOperationRequesttemplate and save it as.yaml. For example,kcor-stuck-regional.yaml.apiVersion: kaas.mirantis.com/v1alpha1 kind: KaaSCephOperationRequest metadata: name: <newKcorName> namespace: <kcorNamespace> spec: <kcorSpec>
<newKcorName>Name of new
KaaSCephOperationRequestthat differs from the failed one. Usually a failedKaaSCephOperationRequestresource is calleddelete-request-for-<masterMachineName>. Therefore, you can name the new resource asdelete-request-for-<masterMachineName>-new.
<kcorNamespace>Namespace of the failed
KaaSCephOperationRequestresource.
<kcorSpec>Spec of the failed
KaaSCephOperationRequestresource.
Apply the created template to the management cluster. For example:
kubectl apply -f kcor-stuck-regional.yaml
Remove the failed
KaaSCephOperationRequestresource from the management cluster:kubectl delete kaascephoperationrequest <kcorName>
Replace
<kcorName>with the name ofKaaSCephOperationRequestthat has theFailedstatus.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshoot StackLight.
On a managed cluster, the StackLight pods may get stuck with the
Pod predicate NodeAffinity failed error in the pod status. The issue may
occur if the StackLight node label was added to one machine and
then removed from another one.
The issue does not affect the StackLight services, all required StackLight pods migrate successfully except extra pods that are created and stuck during pod migration.
As a workaround, remove the stuck pods:
kubectl --kubeconfig <managedClusterKubeconfig> -n stacklight delete pod <stuckPodName>
Affects Ubuntu-based clusters deployed after Feb 10, 2022
If you deploy an Ubuntu-based cluster using the deprecated Cluster release
7.4.0 (and earlier) or 5.21.0 (and earlier) starting from February 10, 2022,
the cluster update to the Cluster releases 7.5.0 and 5.22.0 may get stuck
while applying the Deploy state to the cluster machines. The issue
affects all cluster types: management, regional, and managed.
To verify that the cluster is affected:
Log in to the Container Cloud web UI.
In the Clusters tab, capture the RELEASE and AGE values of the required Ubuntu-based cluster. If the values match the ones from the issue description, the cluster may be affected.
Using SSH, log in to the manager or worker node that got stuck while applying the
Deploystate and identify the containerd package version:containerd --versionIf the version is 1.5.9, the cluster is affected.
In
/var/log/lcm/runners/<nodeName>/deploy/, verify whether the Ansible deployment logs contain the following errors that indicate that the cluster is affected:The following packages will be upgraded: docker-ee docker-ee-cli The following packages will be DOWNGRADED: containerd.io STDERR: E: Packages were downgraded and -y was used without --allow-downgrades.
Workaround:
Warning
Apply the steps below to the affected nodes one-by-one and
only after each consecutive node gets stuck on the Deploy phase with the
Ansible log errors. Such sequence ensures that each node is cordon-drained
and Docker is properly stopped. Therefore, no workloads are affected.
Using SSH, log in to the first affected node and install containerd 1.5.8:
apt-get install containerd.io=1.5.8-1 -y --allow-downgrades --allow-change-held-packages
Wait for Ansible to reconcile. The node should become
Readyin several minutes.Wait for the next node of the cluster to get stuck on the
Deployphase with the Ansible log errors. Only after that, apply the steps above on the next node.Patch the remaining nodes one-by-one using the steps above.
During creation of a machine for AWS or Equinix Metal provider with public networking, the Ubuntu 20.04 option does not display in the drop-down list of operating systems in the Container Cloud UI. Only Ubuntu 18.04 displays in the list.
Workaround:
Identify the parent management or regional cluster of the affected managed cluster located in the same region.
For example, if the affected managed cluster was deployed in
region-one, identify its parent cluster by running:kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n default get cluster -l kaas.mirantis.com/region=region-one
Replace
region-onewith the corresponding value.Example of system response:
NAME AGE test-cluster 19d
Modify the related management or regional
Clusterobject with the correct values for thecredentials-controllerHelm releases:kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n default edit cluster <managementOrRegionalClusterName>
In the system response, the editor displays the current state of the cluster. Find the
spec.providerSpec.value.kaas.regionalsection.Example of the
regionalsection in theClusterobject:spec: providerSpec: value: kaas: regional: - provider: aws helmReleases: - name: aws-credentials-controller values: region: region-one ... - provider: equinixmetal ...
For the
awsandequinixmetalproviders (if available), modify thecredentials-controllervalues as follows:Warning
Do not overwrite existing values. For example, if one of Helm releases already has
region: region-one, do not modify or remove it.For
aws-credentials-controller:values: config: allowedAMIs: - - name: name values: - "ubuntu/images/hvm-ssd/ubuntu-focal-20.04-amd64-server-20211129" - name: owner-id values: - "099720109477"
For
equinixmetal-credentials-controller:values: config: allowedOperatingSystems: - distro: ubuntu version: 20.04
If the
aws-credentials-controllerorequinixmetal-credentials-controllerHelm releases are missing in thespec.providerSpec.value.kaas.regionalsection or thehelmReleasesarray is missing for the corresponding provider, add the releases with the overwritten values.Example of the
helmReleasesarray for AWS:- provider: aws helmReleases: - name: aws-credentials-controller values: config: allowedAMIs: - - name: name values: - "ubuntu/images/hvm-ssd/ubuntu-focal-20.04-amd64-server-20211129" - name: owner-id values: - "099720109477" ...
Example of the
helmReleasesarray for Equinix Metal:- provider: equinixmetal helmReleases: - name: equinixmetal-credentials-controller values: config: allowedOperatingSystems: - distro: ubuntu version: 20.04
Wait for approximately 2 minutes for the AWS and/or Equinix
credentials-controllerto be restarted.Log out and log in again to the Container Cloud web UI.
Restart the machine addition procedure.
Warning
After Container Cloud is upgraded to 2.18.0, remove the values
added during the workaround application from the Cluster object.
Fixed in 7.11.0, 11.5.0 and 12.5.0
During machine creation using the Container Cloud web UI, a custom value for a node label cannot be set.
As a workaround, manually add the value to
spec.providerSpec.value.nodeLabels in machine.yaml.
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.17.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.30.6 |
aws-credentials-controller |
1.30.6 |
|
Azure Updated |
azure-provider |
1.30.6 |
azure-credentials-controller |
1.30.6 |
|
Bare metal |
ambassador |
1.20.1-alpine |
baremetal-operator Updated |
6.1.4 |
|
baremetal-public-api Updated |
6.1.4 |
|
baremetal-provider Updated |
1.30.6 |
|
baremetal-resource-controller |
base-focal-20220128182941 |
|
ironic Updated |
victoria-bionic-20220328060019 |
|
ironic-operator Updated |
base-focal-20220310095139 |
|
kaas-ipam Updated |
base-focal-20220310095439 |
|
keepalived |
2.1.5 |
|
local-volume-provisioner |
2.5.0-mcp |
|
mariadb |
10.4.17-bionic-20220113085105 |
|
IAM |
iam |
2.4.14 |
iam-controller Updated |
1.30.6 |
|
keycloak |
15.0.2 |
|
Container Cloud |
admission-controller Updated |
1.30.6 |
agent-controller Updated |
1.30.6 |
|
byo-credentials-controller Updated |
1.30.6 |
|
byo-provider Updated |
1.30.6 |
|
ceph-kcc-controller New |
1.30.6 |
|
cert-manager Updated |
1.30.6 |
|
client-certificate-controller Updated |
1.30.6 |
|
event-controller Updated |
1.30.6 |
|
golang |
1.17.6 |
|
kaas-public-api Updated |
1.30.6 |
|
kaas-exporter Updated |
1.30.6 |
|
kaas-ui Updated |
1.30.9 |
|
lcm-controller Updated |
0.3.0-230-gdc7efe1c |
|
license-controller Updated |
1.30.6 |
|
machinepool-controller New |
1.30.6 |
|
mcc-cache Updated |
1.30.6 |
|
portforward-controller Updated |
1.30.6 |
|
proxy-controller Updated |
1.30.6 |
|
rbac-controller Updated |
1.30.6 |
|
release-controller Updated |
1.30.8 |
|
rhellicense-controller Updated |
1.30.6 |
|
scope-controller Updated |
1.30.6 |
|
squid-proxy |
0.0.1-6 |
|
user-controller Updated |
1.30.6 |
|
Equinix Metal |
equinix-provider Updated |
1.30.6 |
equinix-credentials-controller Updated |
1.30.6 |
|
keepalived |
2.1.5 |
|
OpenStack Updated |
openstack-provider |
1.30.6 |
os-credentials-controller |
1.30.6 |
|
VMware vSphere |
vsphere-provider Updated |
1.30.6 |
vsphere-credentials-controller Updated |
1.30.6 |
|
keepalived |
2.1.5 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.17.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-6.1.4.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-6.1.4.tgz |
|
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-victoria-focal-debug-20220208120746 |
|
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-victoria-focal-debug-20220208120746 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-2.5.0-mcp.tgz |
|
provisioning_ansible Updated |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-104-6e2e82c.tgz |
|
target ubuntu system |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-20210622161844 |
|
Docker images |
ambassador |
mirantis.azurecr.io/general/external/docker.io/library/nginx:1.20.1-alpine |
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-focal-20220208045851 |
|
baremetal-resource-controller |
mirantis.azurecr.io/bm/baremetal-resource-controller:base-focal-20220128182941 |
|
dynamic_ipxe Updated |
mirantis.azurecr.io/bm/dnsmasq/dynamic-ipxe:base-focal-20220310100410 |
|
dnsmasq |
mirantis.azurecr.io/general/dnsmasq:focal-20210617094827 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20220328060019 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20220328060019 |
|
ironic-operator Updated |
mirantis.azurecr.io/bm/ironic-operator:base-focal-20220310095139 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20210608113804 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-focal-20220310095439 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20220113085105 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.14.0-1-g8725814 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-focal-20220128103433 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.30.6.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.30.6.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.30.6.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.30.6.tgz |
|
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.30.6.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.30.6.tgz |
|
azure-credentials-controller |
https://binary.mirantis.com/core/helm/azure-credentials-controller-1.30.6.tgz |
|
azure-provider |
https://binary.mirantis.com/core/helm/azure-provider-1.30.6.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.30.6.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.30.6.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.30.6.tgz |
|
ceph-kcc-controller New |
https://binary.mirantis.com/core/helm/ceph-kcc-controller-1.30.6.tgz |
|
cert-manager |
https://binary.mirantis.com/core/helm/cert-manager-1.30.6.tgz |
|
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.30.6.tgz |
|
equinix-credentials-controller |
https://binary.mirantis.com/core/helm/equinix-credentials-controller-1.30.6.tgz |
|
equinix-provider |
https://binary.mirantis.com/core/helm/equinix-provider-1.30.6.tgz |
|
equinixmetalv2-provider |
https://binary.mirantis.com/core/helm/equinixmetalv2-provider-1.30.6.tgz |
|
event-controller |
https://binary.mirantis.com/core/helm/event-controller-1.30.6.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.30.6.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.30.6.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.30.6.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.30.6.tgz |
|
license-controller Updated |
https://binary.mirantis.com/core/helm/license-controller-1.30.6.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.30.6.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.30.6.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.30.6.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.30.6.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.30.6.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.30.8.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.30.6.tgz |
|
scope-controller |
http://binary.mirantis.com/core/helm/scope-controller-1.30.6.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.30.6.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.30.6.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.30.6.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.30.6.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.30.6 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.30.6 |
|
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.30.6 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.30.6 |
|
azure-cluster-api-controller Updated |
mirantis.azurecr.io/core/azure-cluster-api-controller:1.30.6 |
|
azure-credentials-controller Updated |
mirantis.azurecr.io/core/azure-credentials-controller:1.30.6 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.30.6 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.30.6 |
|
ceph-kcc-controller New |
mirantis.azurecr.io/core/ceph-kcc-controller:v1.30.6 |
|
cert-manager-controller Updated |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.6.1 |
|
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.30.6 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.30.6 |
|
cluster-api-provider-equinix Updated |
mirantis.azurecr.io/core/cluster-api-provider-equinix:1.30.6 |
|
equinix-credentials-controller Updated |
mirantis.azurecr.io/core/equinix-credentials-controller:1.30.6 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.30.6 |
|
haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.12.0-8-g6fabf1c |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.30.6 |
|
kproxy Updated |
mirantis.azurecr.io/lcm/kproxy:1.30.6 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:v0.3.0-230-gdc7efe1c |
|
license-controller Updated |
mirantis.azurecr.io/core/license-controller:1.30.6 |
|
mcc-keepalived |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.14.0-1-g8725814 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.30.6 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.30.6 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.30.6 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.30.6 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.30.8 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.30.6 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.30.6 |
|
squid-proxy |
mirantis.azurecr.io/core/squid-proxy:0.0.1-6 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-api-controller:1.30.6 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.30.6 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.30.6 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux Updated |
||
iamctl-darwin Updated |
||
iamctl-windows Updated |
||
Helm charts |
iam |
|
iam-proxy |
||
keycloak_proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.30.9.tgz |
|
Docker images |
api Deprecated |
mirantis.azurecr.io/iam/api:0.5.5 |
auxiliary |
mirantis.azurecr.io/iam/auxiliary:0.5.5 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.5.4 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-2 |
The Mirantis Container Cloud GA release 2.16.1 is based on 2.16.0 and:
Introduces support for the Cluster release 8.6.0 that is based on the Cluster release 7.6.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 22.2. This Cluster release is based on the updated version of Mirantis Kubernetes Engine 3.4.7 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.8.
Does not support new deployments based on the deprecated Cluster releases 8.5.0, 7.5.0, 6.20.0, and 5.22.0 that were deprecated in 2.16.0.
For details about the Container Cloud release 2.16.1, refer to its parent release 2.16.0:
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
The Mirantis Container Cloud GA release 2.16.0:
Introduces support for the Cluster release 11.0.0 for managed clusters that is based on Mirantis Container Runtime 20.10.8 and the updated version of Mirantis Kubernetes Engine 3.5.1 with Kubernetes 1.21.
Introduces support for the Cluster release 7.6.0 for all types of clusters that is based on Mirantis Container Runtime 20.10.8 and the updated version of Mirantis Kubernetes Engine 3.4.7 with Kubernetes 1.20.
Supports the Cluster release 8.5.0 that is based on the Cluster release 7.5.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 22.1.
Does not support greenfield deployments on deprecated Cluster releases 7.5.0, 6.20.0, and 5.22.0. Use the latest Cluster releases of the series instead.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.16.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.16.0. For the list of enhancements in the Cluster releases 11.0.0 and 7.6.0 that are introduced by the Container Cloud release 2.16.0, see the Cluster releases (managed).
Implemented a mechanism for the Container Cloud and MKE license update using the Container Cloud web UI. During the automatic license update, machines are not cordoned and drained and user workloads are not interrupted for all clusters starting from Cluster releases 7.6.0, 8.6.0, and 11.0.0. Therefore, after your management cluster upgrades to Container Cloud 2.16.0, make sure to update your managed clusters to the latest available Cluster releases.
Caution
Only the Container Cloud web UI users with the
m:kaas@global-admin role can update the Container Cloud license.
TechPreview
Implemented initial Technology Preview support for management cluster upgrade scheduling through the Container Cloud web UI. Also, added full support for management cluster upgrade scheduling through CLI.
Learn more
Implemented automatic renewal of self-signed TLS certificates for internal Container Cloud services that are generated and managed by the Container Cloud provider.
Note
Custom certificates still require manual renewal. If applicable, the information about expiring custom certificates is available in the Container Cloud web UI.
TechPreview
Implemented initial Technology Preview support for Ubuntu 20.04 (Focal Fossa) on bare metal non-MOSK-based greenfield deployments of managed clusters. Now, you can optionally deploy Kubernetes machines with Ubuntu 20.04 on bare metal hosts. By default, Ubuntu 18.04 is used.
Caution
Upgrading to Ubuntu 20.04 on existing deployments initially created before Container Cloud 2.16.0 is not supported.
Note
Support for Ubuntu 20.04 on MOSK-based Cluster releases will be added in one of the following Container Cloud releases.
Learn more
Extended the regional clusters support by implementing the ability to deploy an additional regional cluster on bare metal. This provides an ability to create baremetal-based managed clusters in bare metal regions in parallel with managed clusters of other private-based regional clusters within a single Container Cloud deployment.
TechPreview
Implemented the initial Technology Preview support for Mirantis OpenStack for Kubernetes (MOSK) deployment on local software-based Redundant Array of Independent Disks (RAID) devices to withstand failure of one device at a time. The feature is available in the Cluster release 8.5.0 after the Container Cloud upgrade to 2.16.0.
Using a custom bare metal host profile, you can configure and create
an mdadm-based software RAID device of type raid10 if you have
an even number of devices available on your servers. At least four
storage devices are required for such RAID device.
Implemented the ability to use any interface name instead of the k8s-lcm
bridge for the LCM network traffic on a bare metal cluster. The Subnet
objects for the LCM network must have the ipam/SVC-k8s-lcm label.
For details, see Service labels and their life cycle.
For the Container Cloud managed clusters that are based on vSphere, Equinix Metal, or bare metal, moved Keepalived for the built-in load balancer to run in standalone Docker containers managed by systemd as a service. This change ensures version consistency of crucial infrastructure services and reduces dependency on a host operating system version and configuration.
Learn more
Reworked the Reconfigure phase applicable to LCMMachine that now can
apply to all nodes. This phase runs after the Deploy phase to apply
stateItems that relate to this phase without affecting workloads
running on the machine.
Learn more
The following issues have been addressed in the Mirantis Container Cloud release 2.16.0 along with the Cluster releases 11.0.0 and 7.6.0:
Bare metal:
[15989] Fixed the issue wherein removal of a bare metal-based management cluster failed with a timeout.
[20189] Fixed the issue with the Container Cloud web UI reporting a successful upgrade of a baremetal-based management cluster while running the previous release.
OpenStack:
[20992] Fixed the issue that caused inability to deploy an OpenStack-based managed cluster if DVR was enabled.
[20549] Fixed the CVE-2021-3520 security vulnerability in the
cinder-csi-plugin imageDocker image.
Equinix Metal:
[20467] Fixed the issue that caused deployment of an Equinix Metal based management cluster with private networking to fail with the following error message during the Ironic deployment:
0/3 nodes are available: 3 pod has unbound immediate PersistentVolumeClaims.
[21324] Fixed the issue wherein the bare metal host was trying to configure an Equinix node as UEFI even for nodes with UEFI disabled.
[21326] Fixed the issue wherein the Ironic agent could not properly determine which disk will be the first disk on the node. As a result, some Equinix servers failed to boot from the proper disk.
[21338] Fixed the issue wherein some Equinix servers were configured in BIOS to always boot from PXE, which caused the operation system to fail to start from disk after provisioning.
StackLight:
[21646] Adjusted the
kaas-exporterresource requests and limits to avoid issues with thekaas-exportercontainer being occassionally throttled and OOMKilled, preventing the Container Cloud metrics gathering.[20591] Adjusted the RAM usage limit and disabled indices monitoring for
prometheus-es-exporterto avoidprometheus-es-exporterpod crash looping due to low memory issues.[17493] Fixed the following security vulnerabilities in the
fluentdandspiloDocker images:
Ceph:
[20745] Fixed the issue wherein namespace deletion failed after removal of a managed cluster.
[7073] Fixed the issue with inability to automatically remove a Ceph node when removing a worker node.
IAM:
[20157] Fixed the CVE-2019-20916 security vulnerability in IAM.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.16.0 including the Cluster releases 11.0.0 and 7.6.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
A managed cluster deployment, attachment, or update to a Cluster release with
MKE versions 3.3.13, 3.4.6, 3.5.1, or earlier may fail with the
compose pods flapping (ready > terminating > pending) and with the
following error message appearing in logs:
'not ready: deployments: kube-system/compose got 0/0 replicas, kube-system/compose-api
got 0/0 replicas'
ready: false
type: Kubernetes
Workaround:
Disable Docker Content Trust (DCT):
Access the MKE web UI as admin.
Navigate to Admin > Admin Settings.
In the left navigation pane, click Docker Content Trust and disable it.
Restart the affected deployments such as
calico-kube-controllers,compose,compose-api,coredns, and so on:kubectl -n kube-system delete deployment <deploymentName>
Once done, the cluster deployment or update resumes.
Re-enable DCT.
The default deployment limits for Equinix and AWS controller containers
set to 400m may be lower than the consumed amount of resources leading
to KubeContainersCPUThrottlingHigh alerts in StackLight.
As a workaround, increase the default resource limits for the affected
equinix-controllers or aws-controllers to 700m. For example:
kubectl edit deployment -n kaas aws-controllers
spec:
...
resources:
limits:
cpu: 700m
...
An Equinix-based management or managed cluster fails to update with the
FailedAttachVolume and FailedMount warnings.
Workaround:
Verify that the description of the pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
<affectedProjectName>is the Container Cloud project name where the pods failed to run<affectedPodName>is a pod name that failed to run in this project
In the pod description, identify the node name where the pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain the rbd volume mount failed: <csi-vol-uuid> is being used error. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the pod that fails to init to0replicas.On every
csi-rbdpluginpod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state isRunning.
If a baremetal-based regional cluster deployment fails before pivoting is done, the corresponding region deletion fails.
Workaround:
Using the command below, manually delete all possible traces of the failed
regional cluster deployment, including but not limited to the following
objects that contain the kaas.mirantis.com/region label of the affected
region:
clustermachinebaremetalhostbaremetalhostprofilel2templatesubnetipamhostipaddr
kubectl delete <objectName> -l kaas.mirantis.com/region=<regionName>
Warning
Do not use the same region name again after the regional cluster deployment failure since some objects that reference the region name may still exist.
Deployment of a bare metal node with an mdadm-based raid10 with LVM
enabled fails during provisioning due to insufficient cleanup of RAID devices.
Workaround:
Boot the affected node from any LiveCD, preferably Ubuntu.
Obtain details about the mdadm RAID devices:
sudo mdadm --detail --scan --verbose
Stop all mdadm RAID devices listed in the output of the above command. For example:
sudo mdadm --stop /dev/md0
Clean up the metadata on partitions with the mdadm RAID device(s) enabled. For example:
sudo mdadm --zero-superblock /dev/sda1
In the above example, replace
/dev/sda1with partitions listed in the output of the command provided in the step 2.
If you run bootstrap.sh preflight with
KAAS_BM_FULL_PREFLIGHT=true, the script fails with the following message:
preflight check failed: preflight full check failed: \
error waiting for BareMetalHosts to power on: \
timed out waiting for the condition
Workaround:
Unset full preflight using the
unset KAAS_BM_FULL_PREFLIGHTenvironment variable.Rerun bootstrap.sh preflight that executes fast preflight instead.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshoot StackLight.
On a managed cluster, the StackLight pods may get stuck with the
Pod predicate NodeAffinity failed error in the pod status. The issue may
occur if the StackLight node label was added to one machine and
then removed from another one.
The issue does not affect the StackLight services, all required StackLight pods migrate successfully except extra pods that are created and stuck during pod migration.
As a workaround, remove the stuck pods:
kubectl --kubeconfig <managedClusterKubeconfig> -n stacklight delete pod <stuckPodName>
In rare cases, StackLight applications may receive the wrong TLS certificates, which prevents them to start correctly.
As a workaround, delete the old secret for the affected StackLight
component. For example, for iam-proxy-alerta:
kubectl -n stacklight delete secret iam-proxy-alerta-tls-certs
The cordon-drain states are not removed after the maintenance mode is unset
for a machine. This issue may occur due to the maintenance transition
being stuck on the NodeWorkloadLock object.
Workaround:
Select from the following options:
Disable the maintenance mode on the affected cluster as described in Enable cluster and machine maintenance mode.
Edit
LCMClusterStatein thespecsection by settingvalueto"false":kubectl edit lcmclusterstates -n <projectName> <LCMCLusterStateName>
apiVersion: lcm.mirantis.com/v1alpha1 kind: LCMClusterState metadata: ... spec: ... value: "false"
Affects Ubuntu-based clusters deployed after Feb 10, 2022
If you deploy an Ubuntu-based cluster using the deprecated Cluster release
7.4.0 (and earlier) or 5.21.0 (and earlier) starting from February 10, 2022,
the cluster update to the Cluster releases 7.5.0 and 5.22.0 may get stuck
while applying the Deploy state to the cluster machines. The issue
affects all cluster types: management, regional, and managed.
To verify that the cluster is affected:
Log in to the Container Cloud web UI.
In the Clusters tab, capture the RELEASE and AGE values of the required Ubuntu-based cluster. If the values match the ones from the issue description, the cluster may be affected.
Using SSH, log in to the manager or worker node that got stuck while applying the
Deploystate and identify the containerd package version:containerd --versionIf the version is 1.5.9, the cluster is affected.
In
/var/log/lcm/runners/<nodeName>/deploy/, verify whether the Ansible deployment logs contain the following errors that indicate that the cluster is affected:The following packages will be upgraded: docker-ee docker-ee-cli The following packages will be DOWNGRADED: containerd.io STDERR: E: Packages were downgraded and -y was used without --allow-downgrades.
Workaround:
Warning
Apply the steps below to the affected nodes one-by-one and
only after each consecutive node gets stuck on the Deploy phase with the
Ansible log errors. Such sequence ensures that each node is cordon-drained
and Docker is properly stopped. Therefore, no workloads are affected.
Using SSH, log in to the first affected node and install containerd 1.5.8:
apt-get install containerd.io=1.5.8-1 -y --allow-downgrades --allow-change-held-packages
Wait for Ansible to reconcile. The node should become
Readyin several minutes.Wait for the next node of the cluster to get stuck on the
Deployphase with the Ansible log errors. Only after that, apply the steps above on the next node.Patch the remaining nodes one-by-one using the steps above.
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
After a successful deployment of a management or regional cluster, controller
pods may be OOMkilled and get stuck in CrashLoopBackOff state due to
incorrect memory limits.
Workaround:
Increase memory resources limits on the affected Deployment:
Open the affected
Deploymentconfiguration for editing:kubectl --kubeconfig <mgmtOrRegionalKubeconfig> -n kaas edit deployment <deploymentName>
Update the value of
spec.template.spec.containers.resources.limitsby 100-200 Mi. For example:spec: template: spec: containers: - ... resources: limits: cpu: "3" memory: 500Mi requests: cpu: "1" memory: 300Mi
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.16.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.29.6 |
aws-credentials-controller |
1.29.6 |
|
Azure Updated |
azure-provider |
1.29.6 |
azure-credentials-controller |
1.29.6 |
|
Bare metal |
ambassador |
1.20.1-alpine |
baremetal-operator Updated |
6.1.2 |
|
baremetal-public-api Updated |
6.1.3 |
|
baremetal-provider Updated |
1.29.9 |
|
baremetal-resource-controller Updated |
base-focal-20220128182941 |
|
ironic Updated |
victoria-bionic-20220208100053 |
|
ironic-operator Updated |
base-focal-20220217095047 |
|
kaas-ipam Updated |
base-focal-20220131093130 |
|
keepalived Updated |
2.1.5 |
|
local-volume-provisioner |
2.5.0-mcp |
|
mariadb Updated |
10.4.17-bionic-20220113085105 |
|
IAM |
iam Updated |
2.4.14 |
iam-controller Updated |
1.29.6 |
|
keycloak |
15.0.2 |
|
Container Cloud |
admission-controller Updated |
1.29.7 |
agent-controller Updated |
1.29.6 |
|
byo-credentials-controller Updated |
1.29.6 |
|
byo-provider Updated |
1.29.6 |
|
cert-manager New |
1.29.6 |
|
client-certificate-controller New |
1.29.6 |
|
event-controller New |
1.29.6 |
|
golang Updated |
1.17.6 |
|
kaas-public-api Updated |
1.29.6 |
|
kaas-exporter Updated |
1.29.6 |
|
kaas-ui Updated |
1.29.6 |
|
lcm-controller Updated |
0.3.0-187-gba894556 |
|
license-controller New |
1.29.6 |
|
mcc-cache Updated |
1.29.6 |
|
portforward-controller Updated |
1.29.6 |
|
proxy-controller Updated |
1.29.6 |
|
rbac-controller Updated |
1.29.6 |
|
release-controller Updated |
1.29.7 |
|
rhellicense-controller Updated |
1.29.6 |
|
scope-controller Updated |
1.29.6 |
|
squid-proxy |
0.0.1-6 |
|
user-controller Updated |
1.29.6 |
|
Equinix Metal Updated |
equinix-provider |
1.29.6 |
equinix-credentials-controller |
1.29.6 |
|
keepalived |
2.1.5 |
|
OpenStack Updated |
openstack-provider |
1.29.6 |
os-credentials-controller |
1.29.6 |
|
VMware vSphere Updated |
vsphere-provider |
1.29.6 |
vsphere-credentials-controller |
1.29.6 |
|
keepalived |
2.1.5 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.16.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-6.1.2.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-6.1.3.tgz |
|
ironic-python-agent-bionic.kernel Removed |
Replaced with |
|
ironic-python-agent-bionic.initramfs Removed |
Replaced with |
|
ironic-python-agent.initramfs New |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-victoria-focal-debug-20220208120746 |
|
ironic-python-agent.kernel New |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-victoria-focal-debug-20220208120746 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-2.5.0-mcp.tgz |
|
provisioning_ansible Updated |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-102-08af94e.tgz |
|
target ubuntu system |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-20210622161844 |
|
Docker images |
ambassador |
mirantis.azurecr.io/general/external/docker.io/library/nginx:1.20.1-alpine |
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-focal-20220208045851 |
|
baremetal-resource-controller Updated |
mirantis.azurecr.io/bm/baremetal-resource-controller:base-focal-20220128182941 |
|
dynamic_ipxe New |
mirantis.azurecr.io/bm/dnsmasq/dynamic-ipxe:base-focal-20220126144549 |
|
dnsmasq Updated |
mirantis.azurecr.io/general/dnsmasq:focal-20210617094827 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20220208100053 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20220208100053 |
|
ironic-operator Updated |
mirantis.azurecr.io/bm/ironic-operator:base-focal-20220217095047 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20210608113804 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-focal-20220131093130 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20220113085105 |
|
mcc-keepalived New |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.14.0-1-g8725814 |
|
syslog-ng Updated |
mirantis.azurecr.io/bm/syslog-ng:base-focal-20220128103433 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.29.6.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.29.6.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.29.7.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.29.6.tgz |
|
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.29.6.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.29.6.tgz |
|
azure-credentials-controller |
https://binary.mirantis.com/core/helm/azure-credentials-controller-1.29.6.tgz |
|
azure-provider |
https://binary.mirantis.com/core/helm/azure-provider-1.29.6.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.29.9.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.29.6.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.29.6.tgz |
|
cert-manager New |
https://binary.mirantis.com/core/helm/cert-manager-1.29.6.tgz |
|
client-certificate-controller New |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.29.6.tgz |
|
equinix-credentials-controller |
https://binary.mirantis.com/core/helm/equinix-credentials-controller-1.29.6.tgz |
|
equinix-provider |
https://binary.mirantis.com/core/helm/equinix-provider-1.29.6.tgz |
|
equinixmetalv2-provider |
https://binary.mirantis.com/core/helm/equinixmetalv2-provider-1.29.6.tgz |
|
event-controller New |
https://binary.mirantis.com/core/helm/event-controller-1.29.6.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.29.6.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.29.6.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.29.6.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.29.6.tgz |
|
license-controller New |
https://binary.mirantis.com/core/helm/license-controller-1.29.6.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.29.6.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.29.6.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.29.6.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.29.6.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.29.6.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.29.7.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.29.6.tgz |
|
scope-controller |
http://binary.mirantis.com/core/helm/scope-controller-1.29.6.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.29.6.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.29.6.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.29.6.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.29.6.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.29.7 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.29.6 |
|
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.29.6 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.29.6 |
|
azure-cluster-api-controller Updated |
mirantis.azurecr.io/core/azure-cluster-api-controller:1.29.6 |
|
azure-credentials-controller Updated |
mirantis.azurecr.io/core/azure-credentials-controller:1.29.6 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.29.6 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.29.6 |
|
cert-manager-controller New |
mirantis.azurecr.io/core/external/cert-manager-controller:v1.6.1 |
|
client-certificate-controller New |
mirantis.azurecr.io/core/client-certificate-controller:1.29.6 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.29.6 |
|
cluster-api-provider-equinix Updated |
mirantis.azurecr.io/core/cluster-api-provider-equinix:1.29.6 |
|
equinix-credentials-controller Updated |
mirantis.azurecr.io/core/equinix-credentials-controller:1.29.6 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.29.6 |
|
haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.12.0-8-g6fabf1c |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.29.6 |
|
kproxy Updated |
mirantis.azurecr.io/lcm/kproxy:1.29.6 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:v0.3.0-187-gba894556 |
|
license-controller New |
mirantis.azurecr.io/core/license-controller:1.29.6 |
|
mcc-keepalived New |
mirantis.azurecr.io/lcm/mcc-keepalived:v0.14.0-1-g8725814 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.29.6 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.29.6 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.29.6 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.29.6 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.29.7 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.29.6 |
|
scope-controller Updated |
mirantis.azurecr.io/core/scope-controller:1.29.6 |
|
squid-proxy |
mirantis.azurecr.io/core/squid-proxy:0.0.1-6 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-api-controller:1.29.6 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.29.6 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.29.6 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux Updated |
||
iamctl-darwin Updated |
||
iamctl-windows Updated |
||
Helm charts |
iam Updated |
|
iam-proxy Updated |
||
keycloak_proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.29.8.tgz |
|
Docker images |
api Deprecated |
mirantis.azurecr.io/iam/api:0.5.5 |
auxiliary Updated |
mirantis.azurecr.io/iam/auxiliary:0.5.5 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.5.4 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-2 |
The Mirantis Container Cloud GA release 2.15.1 is based on 2.15.0 and:
Introduces support for the Cluster release 8.5.0 that is based on the Cluster release 7.5.0 and represents Mirantis OpenStack for Kubernetes (MOSK) 22.1. This Cluster release is based on Mirantis Kubernetes Engine 3.4.6 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.8.
Does not support new deployments based on the Cluster releases 7.4.0 and 5.21.0 that were deprecated in 2.15.0.
For details about the Container Cloud release 2.15.1, refer to its parent release 2.15.0:
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
The Mirantis Container Cloud GA release 2.15.0:
Introduces support for the Cluster release 7.5.0 that is based on Mirantis Container Runtime 20.10.8 and the updated version of Mirantis Kubernetes Engine 3.4.6 with Kubernetes 1.20.
Introduces support for the Cluster release 5.22.0 that is based on the updated version of Mirantis Kubernetes Engine 3.3.13 with Kubernetes 1.18 and Mirantis Container Runtime 20.10.8.
Supports the Cluster release 6.20.0 that is based on the Cluster release 5.20.0 and represents Mirantis OpenStack for Kubernetes (MOS) 21.6.
Does not support greenfield deployments on deprecated Cluster releases 7.4.0, 6.19.0, and 5.21.0. Use the latest Cluster releases of the series instead.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.15.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.15.0. For the list of enhancements in the Cluster releases 7.5.0 and 5.22.0 that are supported by the Container Cloud release 2.15.0, see the Cluster releases (managed).
Automatic upgrade of bare metal host operating system during cluster update
Dedicated subnet for externally accessible Kubernetes API endpoint
HAProxy instead of NGINX for vSphere, Equinix Metal, and bare metal providers
Additional regional cluster on Equinix Metal with private networking
Improvements for monitoring of machine deployment live status
Introduced automatic upgrade of Ubuntu 18.04 packages on the bare metal hosts during a management or managed cluster update.
Mirantis Container Cloud uses life cycle management tools to update the operating system packages on the bare metal hosts. Container Cloud may also trigger restart of the bare metal hosts to apply the updates, when applicable.
Warning
During managed cluster update to the latest Cluster releases available in Container Cloud 2.15.0, hosts are restarted to apply the latest supported Ubuntu 18.04 packages and update kernel to version 5.4.0-90.101.
If Ceph is installed in the cluster, the Container Cloud orchestration securely pauses the Ceph OSDs on the node before restart. This allows avoiding degradation of the storage service.
TechPreview
Implemented a capability to add a dedicated subnet for the externally accessible Kubernetes API endpoint of a baremetal-based managed cluster.
Implemented a health check mechanism to verify target server availability by reworking the high availability setup for the Container Cloud manager nodes of the vSphere, Equinix Metal, and bare metal providers to use HAProxy instead of NGINX. This change affects only the Ansible part. HAproxy deploys as a container managed directly by containerd.
Learn more
Extended the regional clusters support by implementing the capability to deploy an additional regional cluster on Equinix Metal with private networking. This provides the capability to create managed clusters in the Equinix Metal regions with private networking in parallel with managed clusters of other supported providers within a single Container Cloud deployment.
TechPreview
Introduced the initial Technology Preview support for a scheduled Container
Cloud auto-upgrade using the MCCUpgrade object named mcc-upgrade
in Kubernetes API.
An Operator can delay or reschedule Container Cloud auto-upgrade that allows:
Blocking Container Cloud upgrade process for up to 7 days from the current date and up to 30 days from the latest Container Cloud release
Limiting hours and weekdays when Container Cloud upgrade can run
Caution
Only the management cluster admin has access to the MCCUpgrade object.
You must use kubeconfig generated during the management cluster
bootstrap to access this object.
Note
Scheduling of the Container Cloud auto-upgrade using the Container Cloud web UI will be implemented in one of the following releases.
Implemented the maintenance mode for management and managed clusters and machines to prepare workloads for maintenance operations.
To enable maintenance mode on a machine, first enable maintenance mode on a related cluster.
To disable maintenance mode on a cluster, first disable maintenance mode on all machines of the cluster.
Warning
Cluster upgrades and configuration changes (except of the SSH keys setting) are unavailable while a cluster is under maintenance. Make sure you disable maintenance mode on the cluster after maintenance is complete.
Implemented the following improvements to the live status of a machine deployment that you can monitor using the Container Cloud web UI:
Increased the events coverage
Added information about cordon and drain (if a node is being cordoned, drained, or uncordoned) to the Kubelet and Swarm machine components statuses.
These improvements are implemented for all supported Container Cloud providers.
Deprecated the iam-api service and IAM CLI (the iamctl command).
The logic of the iam-api service required for Container Cloud is moved
to scope-controller.
The iam-api service is used by IAM CLI only to manage users and
permissions. Instead of IAM CLI, Mirantis recommends using the Keycloak web UI
to perform necessary IAM operations.
The iam-api service and IAM CLI will be removed in one of the following
Container Cloud releases.
Upgraded the Ceph Helm releases in the ClusterRelease object from v2 to v3.
Switching of the remaining OpenStack Helm releases for Mirantis OpenStack for
Kubernetes to v3 will be implemented in one of the following Container Cloud
releases.
On top of continuous improvements delivered to the existing Container Cloud guides, added the following procedures:
Expand IP addresses capacity in an existing cluster for the bare metal provider
The following issues have been addressed in the Mirantis Container Cloud release 2.15.0 along with the Cluster releases 7.5.0 and 5.22.0:
vSphere:
[19737] Fixed the issue with the vSphere VM template build hanging with an empty kickstart file on the vSphere deployments with the RHEL 8.4 seed node.
[19468] Fixed the issue with the ‘Failed to remove finalizer from machine’ error during cluster deletion if a RHEL license is removed before the related managed cluster was deleted.
IAM:
[5025] Updated the Keycloak version from 12.0.0 to 15.0.2 to fix the CVE-2020-2757.
[21024][Custom certificates] Fixed the issue with the readiness check failure during addition of a custom certificate for Keycloak that hung with the failed to wait for OIDC certificate to be updated timeout warning.
StackLight:
[20193] Updated the Grafana Docker image from 8.2.2 to 8.2.7 to fix the high-severity CVE-2021-43798.
[18933] Fixed the issue with the Alerta pods failing to pass the readiness check even if Patroni, the Alerta backend, operated correctly.
[19682] Fixed the issue with the Prometheus web UI URLs in notifications sent to Salesforce using the HTTP protocol instead of HTTPS on deployments with TLS enabled for IAM.
Ceph:
[19645] Fixed the issue with the Ceph OSD removal request failure during the
Processingstage.[19574] Fixed the issue with the Ceph OSD removal not cleaning up the device used for multiple OSDs.
[20298] Fixed the issue with spec validation failing during creation of
KaaSCephOperationRequest.[20355] Fixed the issue with
KaaSCephOperationRequestbeing cached after recreation with the same name, specified inmetadata.name, as the previousKaaSCephOperationRequestCR. The issue caused no removal to be performed upon applying the newKaaSCephOperationRequestCR.
Bare metal:
[19786] Fixed the issue with managed cluster deployment failing on long-running management clusters with
BareMetalHostbeing stuck in thePreparingstate and theironic-conductorandironic-apipods reporting the not enough disk space error due to thednsmasq-dhcpdlogs overflow.
Upgrade:
[20459] Fixed the issue with failure to upgrade a management or regional cluster originally deployed using the Container Cloud release earlier than 2.8.0. The failure occurred during Ansible update if a machine contained
/usr/local/share/ca-certificates/mcc.crt, which was either empty or invalid.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.15.0 including the Cluster releases 7.5.0 and 5.22.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
A managed cluster deployment, attachment, or update to a Cluster release with
MKE versions 3.3.13, 3.4.6, 3.5.1, or earlier may fail with the
compose pods flapping (ready > terminating > pending) and with the
following error message appearing in logs:
'not ready: deployments: kube-system/compose got 0/0 replicas, kube-system/compose-api
got 0/0 replicas'
ready: false
type: Kubernetes
Workaround:
Disable Docker Content Trust (DCT):
Access the MKE web UI as admin.
Navigate to Admin > Admin Settings.
In the left navigation pane, click Docker Content Trust and disable it.
Restart the affected deployments such as
calico-kube-controllers,compose,compose-api,coredns, and so on:kubectl -n kube-system delete deployment <deploymentName>
Once done, the cluster deployment or update resumes.
Re-enable DCT.
Deployment of an Equinix Metal based management cluster with private networking
may fail with the following error message during the Ironic deployment. The
issue is caused by csi-rbdplugin provisioner pods that got stuck.
0/3 nodes are available: 3 pod has unbound immediate PersistentVolumeClaims.
The workaround is to restart the csi-rbdplugin provisioner pods:
kubectl -n rook-ceph delete pod -l app=csi-rbdplugin-provisioner
After removal of a managed cluster, the namespace is not deleted due to
KaaSCephOperationRequest CRs blocking the deletion. The workaround is to
manually remove finalizers and delete the KaaSCephOperationRequest CRs.
Workaround:
Remove finalizers from all
KaaSCephOperationRequestresources:kubectl -n <managed-ns> get kaascephoperationrequest -o name | xargs -I % kubectl -n <managed-ns> patch % -p '{"metadata":{"finalizers":{}}}' --type=merge
Delete all
KaaSCephOperationRequestresources:kubectl -n <managed-ns> delete kaascephoperationrequest --all
If you run bootstrap.sh preflight with
KAAS_BM_FULL_PREFLIGHT=true, the script fails with the following message:
preflight check failed: preflight full check failed: \
error waiting for BareMetalHosts to power on: \
timed out waiting for the condition
Workaround:
Unset full preflight using the
unset KAAS_BM_FULL_PREFLIGHTenvironment variable.Rerun bootstrap.sh preflight that executes fast preflight instead.
The cordon-drain states are not removed after the maintenance mode is unset
for a machine. This issue may occur due to the maintenance transition
being stuck on the NodeWorkloadLock object.
Workaround:
Select from the following options:
Disable the maintenance mode on the affected cluster as described in Enable cluster and machine maintenance mode.
Edit
LCMClusterStatein thespecsection by settingvalueto"false":kubectl edit lcmclusterstates -n <projectName> <LCMCLusterStateName>
apiVersion: lcm.mirantis.com/v1alpha1 kind: LCMClusterState metadata: ... spec: ... value: "false"
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshoot StackLight.
On a managed cluster, the StackLight pods may get stuck with the
Pod predicate NodeAffinity failed error in the pod status. The issue may
occur if the StackLight node label was added to one machine and
then removed from another one.
The issue does not affect the StackLight services, all required StackLight pods migrate successfully except extra pods that are created and stuck during pod migration.
As a workaround, remove the stuck pods:
kubectl --kubeconfig <managedClusterKubeconfig> -n stacklight delete pod <stuckPodName>
On the highly loaded clusters, the kaas-exporter resource limits for CPU
and RAM are lower than the consumed amount of resources. As a result, the
kaas-exporter container is periodically throttled and OOMKilled preventing
the Container Cloud metrics gathering.
As a workaround, increase the default resource limits for kaas-exporter
in the Cluster object of the management cluster. For example:
spec:
...
providerSpec:
...
value:
...
kaas:
management:
helmReleases:
...
- name: kaas-exporter
values:
resources:
limits:
cpu: 100m
memory: 200Mi
Affects Ubuntu-based clusters deployed after Feb 10, 2022
If you deploy an Ubuntu-based cluster using the deprecated Cluster release
7.4.0 (and earlier) or 5.21.0 (and earlier) starting from February 10, 2022,
the cluster update to the Cluster releases 7.5.0 and 5.22.0 may get stuck
while applying the Deploy state to the cluster machines. The issue
affects all cluster types: management, regional, and managed.
To verify that the cluster is affected:
Log in to the Container Cloud web UI.
In the Clusters tab, capture the RELEASE and AGE values of the required Ubuntu-based cluster. If the values match the ones from the issue description, the cluster may be affected.
Using SSH, log in to the manager or worker node that got stuck while applying the
Deploystate and identify the containerd package version:containerd --versionIf the version is 1.5.9, the cluster is affected.
In
/var/log/lcm/runners/<nodeName>/deploy/, verify whether the Ansible deployment logs contain the following errors that indicate that the cluster is affected:The following packages will be upgraded: docker-ee docker-ee-cli The following packages will be DOWNGRADED: containerd.io STDERR: E: Packages were downgraded and -y was used without --allow-downgrades.
Workaround:
Warning
Apply the steps below to the affected nodes one-by-one and
only after each consecutive node gets stuck on the Deploy phase with the
Ansible log errors. Such sequence ensures that each node is cordon-drained
and Docker is properly stopped. Therefore, no workloads are affected.
Using SSH, log in to the first affected node and install containerd 1.5.8:
apt-get install containerd.io=1.5.8-1 -y --allow-downgrades --allow-change-held-packages
Wait for Ansible to reconcile. The node should become
Readyin several minutes.Wait for the next node of the cluster to get stuck on the
Deployphase with the Ansible log errors. Only after that, apply the steps above on the next node.Patch the remaining nodes one-by-one using the steps above.
Under certain conditions, the upgrade of the baremetal-based management
cluster may get stuck even though the Container Cloud web UI reports a
successful upgrade. The issue is caused by inconsistent metadata in IPAM that
prevents automatic allocation of the Ceph network. It happens when IPAddr
objects associated with the management cluster nodes refer to a non-existent
Subnet object by the resource UID.
To verify whether the cluster is affected:
Inspect the
baremetal-providerlogs:kubectl -n kaas logs deployments/baremetal-provider
If the logs contain the following entries, the cluster may be affected:
Ceph public network address validation failed for cluster default/kaas-mgmt: invalid address '0.0.0.0/0' \ Ceph cluster network address validation failed for cluster default/kaas-mgmt: invalid address '0.0.0.0/0' \ 'default/kaas-mgmt' cluster nodes internal (LCM) IP addresses: 10.64.96.171,10.64.96.172,10.64.96.173 \ failed to configure ceph network for cluster default/kaas-mgmt: \ Ceph network addresses auto-assignment error: validation failed for Ceph network addresses: \ error parsing address '': invalid CIDR address:
Empty values of the network parameters in the last entry indicate that the provider cannot locate the
Subnetobject based on the data from theIPAddrobject.Note
In the logs, capture the
internal (LCM) IP addressesof the cluster nodes to use them later in this procedure.Validate the network address used for Ceph by inspecting the
MiraCephobject:kubectl -n ceph-lcm-mirantis get miraceph -o yaml | egrep "^ +clusterNet:" kubectl -n ceph-lcm-mirantis get miraceph -o yaml | egrep "^ +publicNet:"
In the system response, verify that the
clusterNetandpublicNetvalues do not contain the0.0.0.0/0range.Example of the system response on the affected cluster:
clusterNet: 0.0.0.0/0 publicNet: 0.0.0.0/0
Workaround:
Add a label to the
Subnetobject:Note
To obtain the correct name of the label, use one of the cluster nodes internal (LCM) IP addresses from the
baremetal-providerlogs.Add
SUBNETIDas an environment variable to theIPAddrobject. For example:SUBNETID=$(kubectl get ipaddr -n default --selector=ipam/IP=10.64.96.171 -o custom-columns=":metadata.labels.ipam/SubnetID" | tr -d '\n')
Use the
SUBNETIDvariable to restore the required label in theSubnetobject:kubectl -n default label subnet master-region-one ipam/UID-${SUBNETID}="1"
Verify that the
cluster.sigs.k8s.io/cluster-namelabel exists forIPaddrobjects:kubectl -n default get ipaddr --show-labels|grep "cluster.sigs.k8s.io/cluster-name"
Skip the next step if all
IPaddrobjects corresponding to the management cluster nodes have this label.Add the
cluster.sigs.k8s.io/cluster-namelabel toIPaddrobjects:IPADDRNAMES=$(kubectl -n default get ipaddr -o custom-columns=":metadata.name") for IP in $IPADDRNAMES; do kubectl -n default label ipaddr $IP cluster.sigs.k8s.io/cluster-name=<managementClusterName>; done
In the command above, substitute
<managementClusterName>with the corresponding value.
An Equinix-based management or managed cluster fails to update with the
FailedAttachVolume and FailedMount warnings.
Workaround:
Verify that the description of the pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
<affectedProjectName>is the Container Cloud project name where the pods failed to run<affectedPodName>is a pod name that failed to run in this project
In the pod description, identify the node name where the pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain the rbd volume mount failed: <csi-vol-uuid> is being used error. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the pod that fails to init to0replicas.On every
csi-rbdpluginpod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state isRunning.
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.15.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.28.7 |
aws-credentials-controller |
1.28.7 |
|
Azure Updated |
azure-provider |
1.28.7 |
azure-credentials-controller |
1.28.7 |
|
Bare metal |
ambassador |
1.20.1-alpine |
baremetal-operator Updated |
6.0.4 |
|
baremetal-public-api Updated |
6.0.4 |
|
baremetal-provider Updated |
1.28.7 |
|
baremetal-resource-controller Updated |
base-bionic-20211224163705 |
|
ironic Updated |
victoria-bionic-20211213142623 |
|
ironic-operator |
base-bionic-20210930105000 |
|
kaas-ipam Updated |
base-bionic-20211213150212 |
|
local-volume-provisioner |
2.5.0-mcp |
|
mariadb |
10.4.17-bionic-20210617085111 |
|
IAM |
iam |
2.4.10 |
iam-controller Updated |
1.28.7 |
|
keycloak Updated |
15.0.2 |
|
Container Cloud Updated |
admission-controller |
1.28.7 (1.28.18 for 2.15.1) |
agent-controller |
1.28.7 |
|
byo-credentials-controller |
1.28.7 |
|
byo-provider |
1.28.7 |
|
kaas-public-api |
1.28.7 |
|
kaas-exporter |
1.28.7 |
|
kaas-ui |
1.28.8 |
|
lcm-controller |
0.3.0-132-g83a348fa |
|
mcc-cache |
1.28.7 |
|
portforward-controller |
1.28.12 |
|
proxy-controller |
1.28.7 |
|
rbac-controller |
1.28.7 |
|
release-controller |
1.28.7 |
|
rhellicense-controller |
1.28.7 |
|
scope-controller New |
1.28.7 |
|
squid-proxy |
0.0.1-6 |
|
user-controller |
1.28.7 |
|
Equinix Metal Updated |
equinix-provider |
1.28.11 |
equinix-credentials-controller |
1.28.7 |
|
OpenStack Updated |
openstack-provider |
1.28.7 |
os-credentials-controller |
1.28.7 |
|
VMware vSphere Updated |
vsphere-provider |
1.28.7 |
vsphere-credentials-controller |
1.28.7 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.15.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-6.0.4.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-6.0.4.tgz |
|
ironic-python-agent-bionic.kernel Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-victoria-bionic-5.4-debug-20211126120723 |
|
ironic-python-agent-bionic.initramfs Updated |
||
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-2.5.0-mcp.tgz |
|
provisioning_ansible Updated |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-88-02063c4.tgz |
|
target ubuntu system |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-20210622161844 |
|
Docker images |
ambassador |
mirantis.azurecr.io/general/external/docker.io/library/nginx:1.20.1-alpine |
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20211005112459 |
|
baremetal-resource-controller Updated |
mirantis.azurecr.io/bm/baremetal-resource-controller:base-bionic-20211224163705 |
|
dnsmasq |
mirantis.azurecr.io/general/dnsmasq:focal-20210617094827 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20211213142623 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20211213142623 |
|
ironic-operator |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20210930105000 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20210608113804 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20211213150212 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210617085111 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-bionic-20210617094817 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.28.7.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.28.7.tar.gz |
|
Helm charts Updated |
admission-controller 0 |
https://binary.mirantis.com/core/helm/admission-controller-1.28.7.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.28.7.tgz |
|
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.28.7.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.28.7.tgz |
|
azure-credentials-controller |
https://binary.mirantis.com/core/helm/azure-credentials-controller-1.28.7.tgz |
|
azure-provider |
https://binary.mirantis.com/core/helm/azure-provider-1.28.7.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.28.7.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.28.7.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.28.7.tgz |
|
equinix-credentials-controller |
https://binary.mirantis.com/core/helm/equinix-credentials-controller-1.28.7.tgz |
|
equinix-provider |
https://binary.mirantis.com/core/helm/equinix-provider-1.28.11.tgz |
|
equinixmetalv2-provider |
https://binary.mirantis.com/core/helm/equinixmetalv2-provider-1.28.7.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.28.7.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.28.7.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.28.7.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.28.7.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.28.7.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.28.7.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.28.7.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.28.7.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.28.7.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.28.7.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.28.7.tgz |
|
scope-controller New |
http://binary.mirantis.com/core/helm/scope-controller-1.28.7.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.28.7.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.28.7.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.28.7.tgz |
|
user-controller |
https://binary.mirantis.com/core/helm/user-controller-1.28.7.tgz |
|
Docker images |
admission-controller 0 Updated |
mirantis.azurecr.io/core/admission-controller:1.28.7 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.28.7 |
|
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.28.7 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.28.7 |
|
azure-cluster-api-controller Updated |
mirantis.azurecr.io/core/azure-cluster-api-controller:1.28.7 |
|
azure-credentials-controller Updated |
mirantis.azurecr.io/core/azure-credentials-controller:1.28.7 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.28.7 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.28.7 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.28.7 |
|
cluster-api-provider-equinix Updated |
mirantis.azurecr.io/core/cluster-api-provider-equinix:1.28.7 |
|
equinix-credentials-controller Updated |
mirantis.azurecr.io/core/equinix-credentials-controller:1.28.7 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.28.8 |
|
haproxy |
mirantis.azurecr.io/lcm/mcc-haproxy:v0.12.0-8-g6fabf1c |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.28.7 |
|
kproxy Updated |
mirantis.azurecr.io/lcm/kproxy:1.28.7 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:v0.3.0-132-g83a348fa |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.28.7 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.28.7 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.28.12 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.28.7 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.28.7 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.28.7 |
|
scope-controller New |
mirantis.azurecr.io/core/scope-controller:1.28.7 |
|
squid-proxy Updated |
mirantis.azurecr.io/core/squid-proxy:0.0.1-6 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-api-controller:1.28.7 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.28.7 |
|
user-controller Updated |
mirantis.azurecr.io/core/user-controller:1.28.7 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux |
||
iamctl-darwin |
||
iamctl-windows |
||
Helm charts |
iam |
|
iam-proxy Updated |
||
keycloak_proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.28.9.tgz |
|
Docker images |
api Deprecated |
mirantis.azurecr.io/iam/api:0.5.4 |
auxiliary |
mirantis.azurecr.io/iam/auxiliary:0.5.4 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.5.4 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-2 |
Releases delivered in 2020-2021¶
This section contains historical information on the unsupported Container Cloud releases delivered in 2020-2021. For the latest supported Container Cloud release, see Container Cloud releases.
Version |
Release date |
Supported Cluster releases |
Summary |
|---|---|---|---|
Dec 07, 2021 |
|
||
Nov 11, 2021 |
Based on 2.13.0, this release introduces the Cluster release 6.20.0 that is based on 5.20.0 and supports Mirantis OpenStack for Kubernetes (MOS) 21.6. For the list of Cluster releases 7.x and 5.x that are supported by 2.13.1 as well as for its features with addressed and known issues, refer to the parent release 2.13.0. |
||
Oct 28, 2021 |
|
||
Oct 5, 2021 |
|
||
August 31, 2021 |
|
||
July 21, 2021 |
|
||
June 15, 2021 |
|
||
May 18, 2021 |
|
||
April 22, 2021 |
|
||
March 24, 2021 |
|
||
March 1, 2021 |
|
||
February 2, 2021 |
|
||
December 23, 2020 |
|
||
November 5, 2020 |
|
||
October 19, 2020 |
|
||
September 16, 2020 |
First GA release of Container Cloud with the following key features:
|
** - the Cluster release supports only attachment of existing MKE 3.3.4 clusters. For the deployment of new or attachment of existing clusters based on other supported MKE versions, the latest available Cluster releases are used.
The Mirantis Container Cloud GA release 2.14.0:
Introduces support for the Cluster release 7.4.0 that is based on Mirantis Container Runtime 20.10.6 and the updated version of Mirantis Kubernetes Engine 3.4.6 with Kubernetes 1.20.
Introduces support for the Cluster release 5.21.0 that is based on the updated version of Mirantis Kubernetes Engine 3.3.13 with Kubernetes 1.18 and Mirantis Container Runtime 20.10.6.
Supports the Cluster release 6.20.0 that is based on the Cluster release 5.20.0 and represents Mirantis OpenStack for Kubernetes (MOS) 21.6.
Supports deprecated Cluster releases 5.20.0, 6.19.0, and 7.3.0 that will become unsupported in the following Container Cloud releases.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.14.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.14.0. For the list of enhancements in the Cluster releases 7.4.0 and 5.21.0 that are supported by the Container Cloud release 2.14.0, see the Cluster releases (managed).
Support of the Equinix Metal provider with private networking
Support of the community CentOS 7.9 version for the OpenStack provider
Configuration of server metadata for OpenStack machines in web UI
Visualization of service mapping in the bare metal IpamHost object
Separation of PXE and management networks for bare metal clusters
User access management through the Container Cloud API or web UI
The ‘Interface Guided Tour’ button in the Container Cloud web UI
Switch of bare metal and StackLight Helm releases from v2 to v3
TechPreview
Introduced the Technology Preview support of Container Cloud deployments that are based on the Equinix Metal infrastructure with private networking.
Private networks are required for the following use cases:
Connect the Container Cloud to the on-premises corporate networks without exposing it to the Internet. This can be required by corporate security policies.
Reduce ingress and egress bandwidth costs and the number of public IP addresses utilized by the deployment. Public IP addresses are a scarce and valuable resource, and Container Cloud should only expose the necessary services in that address space.
Testing and staging environments typically do not require accepting connections from the outside of the cluster. Such Container Cloud clusters should be isolated in private VLANs.
Caution
The feature is supported starting from the Cluster releases 7.4.0 and 5.21.0.
Note
Support of the regional clusters that are based on Equinix Metal with private networking will be announced in one of the following Container Cloud releases.
Introduced support of the community version of the CentOS 7.9 operating system for the management, regional, and managed clusters machines deployed with the OpenStack provider. The following CentOS resources are used:
Latest upstream CentOS 7.9 image: CentOS-7-x86_64-GenericCloud-2009.qcow2
Latest CentOS 7.9
.yumrepositories: mirror.centos.org
Learn more
Implemented the possibility to specify the cloud-init metadata
during the OpenStack machines creation through the Container Cloud web UI.
Server metadata is a set of string key-value pairs that you can configure
in the meta_data field of cloud-init.
Learn more
TechPreview
Introduced the initial Technology Preview support of the RHEL 8.4 operating system for the vSphere-based management, regional, and managed clusters.
Caution
Deployment of a Container Cloud cluster based on both RHEL and CentOS operating systems or on mixed RHEL versions is not supported.
Implemented the possibility to configure the following settings during a vSphere machine creation using the Container Cloud web UI:
VM memory size that defaults to 16 GB
VM CPUs number that defaults to 8
Learn more
Implemented the following amendments to the ipam/SVC-* labels to simplify
visualization of service mapping in the bare metal IpamHost object:
All IP addresses allocated from the Subnet` object that has the
ipam/SVC-*service labels defined will inherit those labelsThe new
ServiceMapfield inIpamHost.Statuscontains information about which IPs and interfaces correspond to which Container Cloud services.
Added the capability to configure a dedicated PXE network that is separated from the management network on management or regional bare metal clusters. A separate PXE network allows isolating sensitive bare metal provisioning process from the end users. The users still have access to Container Cloud services, such as Keycloak, to authenticate workloads in managed clusters, such as Horizon in a Mirantis OpenStack for Kubernetes cluster.
Learn more
Implemented the capability to manage user access through the Container Cloud API or web UI by introducing the following objects to manage user role bindings:
IAMUserIAMRoleIAMGlobalRoleBindingIAMRoleBindingIAMClusterRoleBinding
Also, updated the role naming used in Keycloak by introducing the following IAM roles with the possibility to upgrade the old-style role names with the new-style ones:
global-adminbm-pool-operatoroperatoruserstacklight-admin
Caution
User management for the MOSK
m:osroles through API or web UI is on the final development stage and will be announced in one of the following Container Cloud releases. Meanwhile, continue managing these roles using Keycloak.The possibility to manage the
IAM*RoleBindingobjects through the Container Cloud web UI is available for theglobal-adminrole only. The possibility to manage project role bindings using theoperatorrole will become available in one of the following Container Cloud releases.
Updated the matrix of supported MKE versions for cluster attachment to improve the upgrade and testing procedures:
Implemented separate Cluster release series to support 2 series of MKE versions for cluster attachment:
Cluster release series 9.x for the 3.3.x version series
Cluster release series 10.x for the 3.4.x version series
Added a requirement to update an existing MKE cluster to the latest available supported MKE version in a series to trigger the Container Cloud upgrade that allows updating its components, such as StackLight, to the latest versions.
When a new MKE version for cluster attachment is released in a series, the oldest supported version of the previous Container Cloud release is dropped.
Upgraded the bare metal and StackLight Helm releases in the ClusterRelease
and KaasRelease objects from v2 to v3. Switching of the remaining Ceph and
OpenStack Helm releases to v3 will be implemented in one of the following
Container Cloud releases.
The following issues have been addressed in the Mirantis Container Cloud release 2.14.0 along with the Cluster releases 7.4.0 and 5.21.0.
[18429][StackLight] Increased the default resource requirements for Prometheus Elasticsearch Exporter to prevent the
KubeContainersCPUThrottlingHighfiring too often.[18879][Ceph] Fixed the issue with the RADOS Gateway (RGW) pod overriding the global CA bundle located at
/etc/pki/tls/certswith an incorrect self-signed CA bundle during deployment of a Ceph cluster.[9899][Upgrade] Fixed the issue with Helm releases getting stuck in the
PENDING_UPGRADEstate during a management or managed cluster upgrade.[18708][LCM] Fixed the issue with the
Pendingstate of machines during deployment of any Container Cloud cluster or attachment of an existing MKE cluster due to some project being stuck in theTerminatingstate.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.14.0 including the Cluster releases 7.4.0, 6.20.0, and 5.21.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
After removal of a managed cluster, the namespace is not deleted due to
KaaSCephOperationRequest CRs blocking the deletion. The workaround is to
manually remove finalizers and delete the KaaSCephOperationRequest CRs.
Workaround:
Remove finalizers from all
KaaSCephOperationRequestresources:kubectl -n <managed-ns> get kaascephoperationrequest -o name | xargs -I % kubectl -n <managed-ns> patch % -p '{"metadata":{"finalizers":{}}}' --type=merge
Delete all
KaaSCephOperationRequestresources:kubectl -n <managed-ns> delete kaascephoperationrequest --all
A managed cluster deployment fails on long-running management clusters with
BareMetalHost being stuck in the Preparing state and the
ironic-conductor and ironic-api pods reporting the
not enough disk space error due to the dnsmasq-dhcpd logs overflow.
Workaround:
Log in to the
ironic-conductorpod.Verify the free space in
/volume/log/dnsmasq.If the free space on a volume is less than 10%:
Manually delete log files in
/volume/log/dnsmasq/.Scale down the
dnsmasqpod to 0 replicas:kubectl -n kaas scale deployment dnsmasq --replicas=0
Scale up the
dnsmasqpod to 1 replica:kubectl -n kaas scale deployment dnsmasq --replicas=1
If the volume has enough space, assess the Ironic logs to identify the root cause of the issue.
If you run bootstrap.sh preflight with
KAAS_BM_FULL_PREFLIGHT=true, the script fails with the following message:
preflight check failed: preflight full check failed: \
error waiting for BareMetalHosts to power on: \
timed out waiting for the condition
Workaround:
Unset full preflight using the
unset KAAS_BM_FULL_PREFLIGHTenvironment variable.Rerun bootstrap.sh preflight that executes fast preflight instead.
On the vSphere deployments with the RHEL 8.4 seed node, the VM template build for deployment hangs because of an empty kickstart file provided to the VM. In this case, the VMware web console displays the following error for the affected VM:
Kickstart file /run/install/ks.cfg is missing
The fix for the issue is implemented in the latest version of the Packer image for the VM template build.
Workaround:
Open
bootstrap.shin thekaas-bootstrapfolder for editing.Update the Docker image tag for the
VSPHERE_PACKER_DOCKER_IMAGEvariable tov1.0-39.Save edits and restart the VM template build:
./bootstrap.sh vsphere_template
If a RHEL license is removed before the related managed cluster is deleted,
the cluster deletion hangs with the following Machine object error:
Failed to remove finalizer from machine ...
failed to get RHELLicense object
As a workaround, recreate the removed RHEL license object with the same name using the Container Cloud web UI or API.
Warning
The kubectl apply command automatically saves the
applied data as plain text into the
kubectl.kubernetes.io/last-applied-configuration annotation of the
corresponding object. This may result in revealing sensitive data in this
annotation when creating or modifying the object.
Therefore, do not use kubectl apply on this object. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on this object, you
can remove the kubectl.kubernetes.io/last-applied-configuration
annotation from the object using kubectl edit.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
A vSphere-based management cluster bootstrap fails due to a node leaving the cluster after an accidental IP address change.
The issue may affect a vSphere-based cluster only when IPAM is not enabled and IP addresses assignment to the vSphere virtual machines is done by a DHCP server present in the vSphere network.
By default, a DHCP server keeps lease of the IP address for 30 minutes.
Usually, a VM dhclient prolongs such lease by frequent DHCP requests
to the server before the lease period ends.
The DHCP prolongation request period is always less than the default lease time
on the DHCP server, so prolongation usually works.
But in case of network issues, for example, when dhclient from the
VM cannot reach the DHCP server, or the VM is being slowly powered on
for more than the lease time, such VM may lose its assigned IP address.
As a result, it obtains a new IP address.
Container Cloud does not support network reconfiguration after the IP of the VM has been changed. Therefore, such issue may lead to a VM leaving the cluster.
Symptoms:
One of the nodes is in the
NodeNotReadyordownstate:kubectl get nodes -o wide docker node ls
The UCP Swarm manager logs on the healthy manager node contain the following example error:
docker logs -f ucp-swarm-manager level=debug msg="Engine refresh failed" id="<docker node ID>|<node IP>: 12376"
If the affected node is manager:
The output of the docker info command contains the following example error:
Error: rpc error: code = Unknown desc = The swarm does not have a leader. \ It's possible that too few managers are online. \ Make sure more than half of the managers are online.
The UCP controller logs contain the following example error:
docker logs -f ucp-controller "warning","msg":"Node State Active check error: \ Swarm Mode Manager health check error: \ info: Cannot connect to the Docker daemon at tcp://<node IP>:12376. \ Is the docker daemon running?
On the affected node, the IP address on the first interface
eth0does not match the IP address configured in Docker. Verify theNode Addressfield in the output of the docker info command.The following lines are present in
/var/log/messages:dhclient[<pid>]: bound to <node IP> -- renewal in 1530 seconds
If there are several lines where the IP is different, the node is affected.
Workaround:
Select from the following options:
Bind IP addresses for all machines to their MAC addresses on the DHCP server for the dedicated vSphere network. In this case, VMs receive only specified IP addresses that never change.
Remove the Container Cloud node IPs from the IP range on the DHCP server for the dedicated vSphere network and configure the first interface
eth0on VMs with a static IP address.If a managed cluster is affected, redeploy it with IPAM enabled for new machines to be created and IPs to be assigned properly.
Note
The issue affects only Helm v2 releases and is addressed for Helm v3. Starting from Container Cloud 2.19.0, all Helm releases are switched to v3.
During a management, regional, or managed cluster deployment,
Helm releases may get stuck in the FAILED or UNKNOWN state
although the corresponding machines statuses are Ready
in the Container Cloud web UI. For example, if the StackLight Helm release
fails, the links to its endpoints are grayed out in the web UI.
In the cluster status, providerStatus.helm.ready and
providerStatus.helm.releaseStatuses.<releaseName>.success are false.
HelmBundle cannot recover from such states and requires manual actions.
The workaround below describes the recovery steps for the stacklight
release that got stuck during a cluster deployment.
Use this procedure as an example for other Helm releases as required.
Workaround:
Verify the failed release has the
UNKNOWNorFAILEDstatus in the HelmBundle object:kubectl --kubeconfig <regionalClusterKubeconfigPath> get helmbundle <clusterName> -n <clusterProjectName> -o=jsonpath={.status.releaseStatuses.stacklight} In the command above and in the steps below, replace the parameters enclosed in angle brackets with the corresponding values of your cluster.
Example of system response:
stacklight: attempt: 2 chart: "" finishedAt: "2021-02-05T09:41:05Z" hash: e314df5061bd238ac5f060effdb55e5b47948a99460c02c2211ba7cb9aadd623 message: '[{"occurrence":1,"lastOccurrenceDate":"2021-02-05 09:41:05","content":"error updating the release: rpc error: code = Unknown desc = customresourcedefinitions.apiextensions.k8s.io \"helmbundles.lcm.mirantis.com\" already exists"}]' notes: "" status: UNKNOWN success: false version: 0.1.2-mcp-398
Log in to the
helm-controllerpod console:kubectl --kubeconfig <affectedClusterKubeconfigPath> exec -n kube-system -it helm-controller-0 sh -c tiller
Download the Helm v3 binary. For details, see official Helm documentation.
Remove the failed release:
helm delete <failed-release-name>
For example:
helm delete stacklight
Once done, the release triggers for redeployment.
Adding a custom certificate for Keycloak using the container-cloud binary hangs with the failed to wait for OIDC certificate to be updated timeout warning. The readiness check fails due to a wrong condition.
Ignore the timeout warning. If you can log in to the Container Cloud web UI, the certificate has been applied successfully.
Occasionally, an Alerta pod may be not Ready even if Patroni, the Alerta
backend, operates correctly. In this case, some of the following errors may
appear in the Alerta logs:
2021-10-25 13:10:55,865 DEBG 'nginx' stdout output:
2021/10/25 13:10:55 [crit] 25#25: *17408 connect() to unix:/tmp/uwsgi.sock failed (2: No such file or directory) while connecting to upstream, client: 127.0.0.1, server: , request: "GET /api/config HTTP/1.1", upstream: "uwsgi://unix:/tmp/uwsgi.sock:", host: "127.0.0.1:8080"
ip=\- [\25/Oct/2021:13:10:55 +0000] "\GET /api/config HTTP/1.1" \502 \157 "\-" "\python-requests/2.24.0"
/web | /api/config | > GET /api/config HTTP/1.1
2021-11-11 00:02:23,969 DEBG 'nginx' stdout output:
2021/11/11 00:02:23 [error] 23#23: *2014 connect() to unix:/tmp/uwsgi.sock failed (11: Resource temporarily unavailable) while connecting to upstream, client: 172.16.37.243, server: , request: "GET /api/services HTTP/1.1", upstream: "uwsgi://unix:/tmp/uwsgi.sock:", host: "10.233.113.143:8080"
ip=\- [\11/Nov/2021:00:02:23 +0000] "\GET /api/services HTTP/1.1" \502 \157 "\-" "\kube-probe/1.20+"
/web | /api/services | > GET /api/services HTTP/1.1
As a workaround, manually restart the affected Alerta pods:
kubectl delete pod -n stacklight <POD_NAME>
Prometheus web UI URLs in StackLight notifications sent to Salesforce use a wrong protocol: HTTP instead of HTTPS. The issue affects deployments with TLS enabled for IAM.
The workaround is to manually change the URL protocol in the web browser.
The csi-rbdplugin-provisioner pod (csi-provisioner container) may show
constant retries attempting to create a PV if the csi-rbdplugin-provisioner
pod was scheduled and started on a node with no connectivity to the Ceph
storage. As a result, creation of a Ceph-based persistent volume (PV) may get
stuck in the Pending state.
As a workaround manually specify the affinity or toleration rules for the
csi-rbdplugin-provisioner pod.
Workaround:
On the managed cluster, open the
rook-ceph-operator-configmap for editing:kubectl edit configmap -n rook-ceph rook-ceph-operator-config
To avoid spawning pods on the nodes where this is not needed, set the provisioner node affinity specifying the required node labels. For example:
CSI_PROVISIONER_NODE_AFFINITY: "role=storage-node; storage=rook, ceph"
Note
If needed, you can also specify CSI_PROVISIONER_TOLERATIONS
tolerations. For example:
CSI_PROVISIONER_TOLERATIONS: |
- effect: NoSchedule
key: node-role.kubernetes.io/controlplane
operator: Exists
- effect: NoExecute
key: node-role.kubernetes.io/etcd
operator: Exists
When creating a new KaaSCephOperationRequest CR with the same name
specified in metadata.name as in the previous KaaSCephOperationRequest
CR, even if the previous request was deleted manually, the new request includes
information about the previous actions and is in the Completed phase. In
this case, no removal is performed.
Workaround:
On the management cluster, manually delete the old
KaasCephOperationRequestCR with the samemetadata.name:kubectl -n ceph-lcm-mirantis delete KaasCephOperationRequest <name>
On the managed cluster, manually delete the old
CephOsdRemoveRequestwith the samemetadata.name:kubectl -n ceph-lcm-mirantis delete CephOsdRemoveRequest <name>
Spec validation may fail with the following error when creating a
KaaSCephOperationRequest CR:
The KaaSCephOperationRequest "test-remove-osd" is invalid: spec: Invalid value: 1:
spec in body should have at most 1 properties
Workaround:
On the management cluster, open the
kaascephoperationrequests.kaas.mirantis.comCRD for editing:kubectl edit crd kaascephoperationrequests.kaas.mirantis.com
Remove
maxProperties: 1andminProperties: 1fromspec.versions[0].schema.openAPIV3Schema.properties.spec:spec: maxProperties: 1 minProperties: 1
Ocassionally, when Processing a Ceph OSD removal request,
KaaSCephOperationRequest retries the osd stop command without an
interval, which leads to removal request failure.
As a workaround create a new request to proceed with the Ceph OSD removal.
When executing a Ceph OSD removal request to remove Ceph OSDs placed on one disk, the request completes without errors but the device itself still keeps the old LVM partitions. As a result, Rook cannot use such device.
The workaround is to manually clean up the affected device as described in Rook documentation: Zapping Devices.
An upgrade of a management or regional cluster originally deployed using
the Container Cloud release earlier than 2.8.0 fails with
error setting certificate verify locations during Ansible update if a
machine contains /usr/local/share/ca-certificates/mcc.crt, which is
either empty or invalid. Managed clusters are not affected.
Workaround:
On every machine of the affected management or regional cluster:
Delete
/usr/local/share/ca-certificates/mcc.crt.In
/etc/lcm/environment, remove the following line:export SSL_CERT_FILE="/usr/local/share/ca-certificates/mcc.crt"
Restart
lcm-agent:systemctl restart lcm-agent-v0.3.0-104-gb7f5e8d8
An upgrade of a management or regional cluster originally deployed using the Container Cloud release earlier than 2.8.0 fails with:
The LCM Agent version not updating from v0.3.0-67-g25ab9f1a to v0.3.0-105-g6fb89599
The following error message appearing in the events of the related
LCMMachine:kubectl describe lcmmachine <machineName> Failed to upgrade agent: failed to update agent upgrade status: \ LCMMachine.lcm.mirantis.com "master-0" is invalid: \ status.lcmAgentUpgradeStatus.finishedAt: Invalid value: "null": \ status.lcmAgentUpgradeStatus.finishedAt in body must be of type string: "null"
As a workaround, change the preserveUnknownFields value for the
LCMMachine CRD to false:
kubectl patch crd lcmmachines.lcm.mirantis.com -p '{"spec":{"preserveUnknownFields":false}}'
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
The Equinix Metal and MOS-based managed clusters may fail to update to the latest Cluster release with kubelet being stuck and reporting authorization errors.
The cluster is affected by the issue if you see the Failed to make webhook authorizer request: context canceled error in the kubelet logs:
docker logs ucp-kubelet --since 5m 2>&1 | grep 'Failed to make webhook authorizer request: context canceled'
As a workaround, restart the ucp-kubelet container on the affected
node(s):
ctr -n com.docker.ucp snapshot rm ucp-kubelet
docker rm -f ucp-kubelet
Note
Ignore failures in the output of the first command, if any.
An Equinix-based management or managed cluster fails to update with the
FailedAttachVolume and FailedMount warnings.
Workaround:
Verify that the description of the pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
<affectedProjectName>is the Container Cloud project name where the pods failed to run<affectedPodName>is a pod name that failed to run in this project
In the pod description, identify the node name where the pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain the rbd volume mount failed: <csi-vol-uuid> is being used error. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the pod that fails to init to0replicas.On every
csi-rbdpluginpod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state isRunning.
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.14.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.27.6 |
aws-credentials-controller |
1.27.6 |
|
Azure Updated |
azure-provider |
1.27.6 |
azure-credentials-controller |
1.27.6 |
|
Bare metal |
ambassador Updated |
1.20.1-alpine |
baremetal-operator Updated |
5.2.7 |
|
baremetal-public-api Updated |
5.2.7 |
|
baremetal-provider Updated |
1.27.6 |
|
ironic Updated |
victoria-bionic-20211103083724 |
|
ironic-operator |
base-bionic-20210930105000 |
|
kaas-ipam Updated |
base-bionic-20211028140230 |
|
local-volume-provisioner Updated |
2.5.0-mcp |
|
mariadb |
10.4.17-bionic-20210617085111 |
|
IAM |
iam Updated |
2.4.10 |
iam-controller Updated |
1.27.6 |
|
keycloak |
12.0.0 |
|
Container Cloud |
admission-controller Updated |
1.27.6 |
agent-controller Updated |
1.27.6 |
|
byo-credentials-controller Updated |
1.27.6 |
|
byo-provider Updated |
1.27.6 |
|
kaas-public-api Updated |
1.27.6 |
|
kaas-exporter Updated |
1.27.6 |
|
kaas-ui Updated |
1.27.8 |
|
lcm-controller Updated |
0.3.0-105-g6fb89599 |
|
mcc-cache Updated |
1.27.6 |
|
portforward-controller Updated |
1.27.6 |
|
proxy-controller Updated |
1.27.6 |
|
rbac-controller Updated |
1.27.6 |
|
release-controller Updated |
1.27.6 |
|
rhellicense-controller Updated |
1.27.6 |
|
squid-proxy |
0.0.1-5 |
|
user-controller New |
1.27.9 |
|
Equinix Metal Updated |
equinix-provider |
1.27.6 |
equinix-credentials-controller |
1.27.6 |
|
OpenStack Updated |
openstack-provider |
1.27.6 |
os-credentials-controller |
1.27.6 |
|
VMware vSphere Updated |
vsphere-provider |
1.27.6 |
vsphere-credentials-controller |
1.27.6 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.14.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-5.2.7.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-5.2.7.tgz |
|
ironic-python-agent-bionic.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-victoria-bionic-debug-20210817124316 |
|
ironic-python-agent-bionic.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-victoria-bionic-debug-20210817124316 |
|
kaas-ipam Updated |
||
local-volume-provisioner Updated |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-2.5.0-mcp.tgz |
|
provisioning_ansible |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-82-342bd22.tgz |
|
target ubuntu system |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-20210622161844 |
|
Docker images |
ambassador Updated |
mirantis.azurecr.io/lcm/nginx:1.20.1-alpine |
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20211005112459 |
|
dnsmasq |
mirantis.azurecr.io/general/dnsmasq:focal-20210617094827 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20211103083724 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20211103083724 |
|
ironic-operator |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20210930105000 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20210608113804 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20211028140230 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210617085111 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-bionic-20210617094817 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.27.6.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.27.6.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.27.6.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.27.6.tgz |
|
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.27.6.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.27.6.tgz |
|
azure-credentials-controller |
https://binary.mirantis.com/core/helm/azure-credentials-controller-1.27.6.tgz |
|
azure-provider |
https://binary.mirantis.com/core/helm/azure-provider-1.27.6.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.27.6.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.27.6.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.27.6.tgz |
|
equinix-credentials-controller |
https://binary.mirantis.com/core/helm/equinix-credentials-controller-1.27.6.tgz |
|
equinix-provider |
https://binary.mirantis.com/core/helm/equinix-provider-1.27.6.tgz |
|
equinixmetalv2-provider New |
https://binary.mirantis.com/core/helm/equinixmetalv2-provider-1.27.6.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.27.6.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.27.6.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.27.6.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.27.6.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.27.6.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.27.6.tgz |
|
portforward-controller |
https://binary.mirantis.com/core/helm/portforward-controller-1.27.6.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.27.6.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.27.6.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.27.6.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.27.6.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.27.6.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.27.6.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.27.6.tgz |
|
user-controller New |
https://binary.mirantis.com/core/helm/user-controller-1.27.9.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.27.6 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.27.6 |
|
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.27.6 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.27.6 |
|
azure-cluster-api-controller Updated |
mirantis.azurecr.io/core/azure-cluster-api-controller:1.27.6 |
|
azure-credentials-controller Updated |
mirantis.azurecr.io/core/azure-credentials-controller:1.27.6 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.27.6 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.27.6 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.27.6 |
|
cluster-api-provider-equinix Updated |
mirantis.azurecr.io/core/cluster-api-provider-equinix:1.27.6 |
|
equinix-credentials-controller Updated |
mirantis.azurecr.io/core/equinix-credentials-controller:1.27.6 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.27.8 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.27.6 |
|
kproxy Updated |
mirantis.azurecr.io/lcm/kproxy:1.27.6 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:v0.3.0-105-g6fb89599 |
|
nginx |
mirantis.azurecr.io/lcm/nginx:1.20.1-alpine |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.27.6 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.27.6 |
|
portforward-controller Updated |
mirantis.azurecr.io/core/portforward-controller:1.27.6 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.27.6 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.27.6 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.27.6 |
|
squid-proxy |
mirantis.azurecr.io/core/squid-proxy:0.0.1-5 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-api-controller:1.27.6 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.27.6 |
|
user-controller New |
mirantis.azurecr.io/core/user-controller:1.27.9 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux Updated |
||
iamctl-darwin Updated |
||
iamctl-windows Updated |
||
Helm charts |
iam Updated |
|
iam-proxy |
||
keycloak_proxy |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.26.6.tgz |
|
Docker images |
api Updated |
mirantis.azurecr.io/iam/api:0.5.4 |
auxiliary Updated |
mirantis.azurecr.io/iam/auxiliary:0.5.4 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak Updated |
mirantis.azurecr.io/iam/keycloak:0.5.4 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-2 |
The Mirantis Container Cloud GA release 2.13.1 is based on 2.13.0 and:
Introduces support for the Cluster release 6.20.0 that is based on the Cluster release 5.20.0 and represents Mirantis OpenStack for Kubernetes (MOS) 21.6. This Cluster release is based on Mirantis Kubernetes Engine 3.3.12 with Kubernetes 1.18 and Mirantis Container Runtime 20.10.6.
Supports deprecated Cluster releases 7.2.0, 6.19.0, and 5.19.0 that will become unsupported in the following Container Cloud releases.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
For details about the Container Cloud release 2.13.1, refer to its parent release 2.13.0.
The Mirantis Container Cloud GA release 2.13.0:
Introduces support for the Cluster release 7.3.0 that is based on Mirantis Container Runtime 20.10.6 and Mirantis Kubernetes Engine 3.4.5 with Kubernetes 1.20.
Introduces support for the Cluster release 5.20.0 that is based on Mirantis Kubernetes Engine 3.3.12 with Kubernetes 1.18 and Mirantis Container Runtime 20.10.6.
Supports the Cluster release 6.19.0 that is based on the Cluster release 5.19.0 and represents Mirantis OpenStack for Kubernetes (MOS) 21.5.
Supports deprecated Cluster releases 5.19.0, 6.18.0, and 7.2.0 that will become unsupported in the following Container Cloud releases.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.13.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.13.0. For the list of enhancements in the Cluster releases 7.3.0 and 5.20.0 that are supported by the Container Cloud release 2.13.0, see the Cluster releases (managed).
Configuration of multiple DHCP ranges for bare metal clusters
Updated RAM requirements for management and regional clusters
Implemented the possibility to configure multiple DHCP ranges using the
bare metal Subnet resources to facilitate multi-rack and other
types of distributed bare metal datacenter topologies.
The dnsmasq DHCP server used for host provisioning in Container Cloud now
supports working with multiple L2 segments through DHCP relay capable
network routers.
To configure DHCP ranges for dnsmasq, create the Subnet objects
tagged with the ipam/SVC-dhcp-range label while setting up subnets
for a managed cluster using Container Cloud CLI.
To improve the Container Cloud performance and stability, increased RAM requirements for management and regional clusters from 16 to 24 GB for all supported cloud providers except bare metal, with the corresponding flavor changes for the AWS and Azure providers:
AWS: updated the instance type from
c5d.2xlargetoc5d.4xlargeAzure: updated the VM size from
Standard_F8s_v2toStandard_F16s_v2
For the Container Cloud managed clusters, requirements remain the same.
Learn more
The following issues have been addressed in the Mirantis Container Cloud release 2.13.0 along with the Cluster releases 7.3.0 and 5.20.0.
[17705][Azure] Fixed the issue with the failure to deploy more than 62 Azure worker nodes.
[17938][bare metal] Fixed the issue with the bare metal host profile being stuck in the
match profilestate during bootstrap.[17960][bare metal] Fixed the issue with overflow of the Ironic storage volume causing a StackLight alert being triggered for the
ironic-aio-pvcvolume filling up.[17981][bare metal] Fixed the issue with failure to redeploy a bare metal node with an mdadm-based
raid1enabled due to insufficient cleanup of RAID devices.[17359][regional cluster] Fixed the issue with failure to delete an AWS-based regional cluster due to the issue with the cluster credential deletion.
[18193][upgrade] Fixed the issue with failure to upgrade an Equinix Metal or baremetal-based management cluster with Ceph cluster being not ready.
[18076][upgrade] Fixed the issue with StackLight update failure on managed cluster with logging disabled after changing NodeSelector.
[17771][StackLight] Fixed the issue with the Watchdog alert not routing to Salesforce by default.
If you have applied the workaround as described in StackLight known issues: 17771, revert it after updating the Cluster releases to 5.20.0, 6.20.0, or 7.3.0:
Open the StackLight configuration manifest as described in StackLight configuration procedure.
In
alertmanagerSimpleConfig.salesForce:remove the
matchandmarch_reparameters since they are deprecatedremove the
matchersparameter since it changes the default settings
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.13.0 including the Cluster releases 7.3.0, 6.19.0, and 5.20.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
After update of a management or managed cluster created using the Container
Cloud release earlier than 2.6.0, a bare metal host state is
Provisioned in the Container Cloud web UI while having the error state
in logs with the following message:
status:
errorCount: 1
errorMessage: 'Host adoption failed: Error while attempting to adopt node 7a8d8aa7-e39d-48ec-98c1-ed05eacc354f:
Validation of image href http://10.10.10.10/images/stub_image.qcow2 failed,
reason: Got HTTP code 404 instead of 200 in response to HEAD request..'
errorType: provisioned registration error
The issue is caused by the image URL pointing to an unavailable resource due to the URI IP change during update. As a workaround, update URLs for the bare metal host status and spec with the correct values that use a stable DNS record as a host.
Workaround:
Note
In the commands below, we update master-2 as an example.
Replace it with the corresponding value to fit your deployment.
Exit Lens.
In a new terminal, configure access to the affected cluster.
Start
kube-proxy:kubectl proxy &
Pause the reconcile:
kubectl patch bmh master-2 --type=merge --patch '{"metadata":{"annotations":{"baremetalhost.metal3.io/paused": "true"}}}'
Create the payload data with the following content:
For
status_payload.json:{ "status": { "errorCount": 0, "errorMessage": "", "provisioning": { "image": { "checksum": "http://httpd-http/images/stub_image.qcow2.md5sum", "url": "http://httpd-http/images/stub_image.qcow2" }, "state": "provisioned" } } }
For
status_payload.json:{ "spec": { "image": { "checksum": "http://httpd-http/images/stub_image.qcow2.md5sum", "url": "http://httpd-http/images/stub_image.qcow2" } } }
Verify that the payload data is valid:
cat status_payload.json | jq cat spec_payload.json | jq
The system response must contain the data added in the previous step.
Patch the bare metal host status with payload:
curl -k -v -XPATCH -H "Accept: application/json" -H "Content-Type: application/merge-patch+json" --data-binary "@status_payload.json" 127.0.0.1:8001/apis/metal3.io/v1alpha1/namespaces/default/baremetalhosts/master-2/status
Patch the bare metal host spec with payload:
kubectl patch bmh master-2 --type=merge --patch "$(cat spec_payload.json)"
Resume the reconcile:
kubectl patch bmh master-2 --type=merge --patch '{"metadata":{"annotations":{"baremetalhost.metal3.io/paused":null}}}'
Close the terminal to quit
kube-proxyand resume Lens.
If you run bootstrap.sh preflight with
KAAS_BM_FULL_PREFLIGHT=true, the script fails with the following message:
preflight check failed: preflight full check failed: \
error waiting for BareMetalHosts to power on: \
timed out waiting for the condition
Workaround:
Unset full preflight using the
unset KAAS_BM_FULL_PREFLIGHTenvironment variable.Rerun bootstrap.sh preflight that executes fast preflight instead.
An OpenStack-based regional cluster cleanup fails with the timeout error.
Workaround:
Wait for the
Clusterobject to be deleted in the bootstrap cluster:kubectl --kubeconfig <(./bin/kind get kubeconfig --name clusterapi) get cluster
The system output must be empty.
Remove the bootstrap cluster manually:
./bin/kind delete cluster --name clusterapi
If a RHEL license is removed before the related managed cluster is deleted,
the cluster deletion hangs with the following Machine object error:
Failed to remove finalizer from machine ...
failed to get RHELLicense object
As a workaround, recreate the removed RHEL license object with the same name using the Container Cloud web UI or API.
Warning
The kubectl apply command automatically saves the
applied data as plain text into the
kubectl.kubernetes.io/last-applied-configuration annotation of the
corresponding object. This may result in revealing sensitive data in this
annotation when creating or modifying the object.
Therefore, do not use kubectl apply on this object. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on this object, you
can remove the kubectl.kubernetes.io/last-applied-configuration
annotation from the object using kubectl edit.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
A vSphere-based management cluster bootstrap fails due to a node leaving the cluster after an accidental IP address change.
The issue may affect a vSphere-based cluster only when IPAM is not enabled and IP addresses assignment to the vSphere virtual machines is done by a DHCP server present in the vSphere network.
By default, a DHCP server keeps lease of the IP address for 30 minutes.
Usually, a VM dhclient prolongs such lease by frequent DHCP requests
to the server before the lease period ends.
The DHCP prolongation request period is always less than the default lease time
on the DHCP server, so prolongation usually works.
But in case of network issues, for example, when dhclient from the
VM cannot reach the DHCP server, or the VM is being slowly powered on
for more than the lease time, such VM may lose its assigned IP address.
As a result, it obtains a new IP address.
Container Cloud does not support network reconfiguration after the IP of the VM has been changed. Therefore, such issue may lead to a VM leaving the cluster.
Symptoms:
One of the nodes is in the
NodeNotReadyordownstate:kubectl get nodes -o wide docker node ls
The UCP Swarm manager logs on the healthy manager node contain the following example error:
docker logs -f ucp-swarm-manager level=debug msg="Engine refresh failed" id="<docker node ID>|<node IP>: 12376"
If the affected node is manager:
The output of the docker info command contains the following example error:
Error: rpc error: code = Unknown desc = The swarm does not have a leader. \ It's possible that too few managers are online. \ Make sure more than half of the managers are online.
The UCP controller logs contain the following example error:
docker logs -f ucp-controller "warning","msg":"Node State Active check error: \ Swarm Mode Manager health check error: \ info: Cannot connect to the Docker daemon at tcp://<node IP>:12376. \ Is the docker daemon running?
On the affected node, the IP address on the first interface
eth0does not match the IP address configured in Docker. Verify theNode Addressfield in the output of the docker info command.The following lines are present in
/var/log/messages:dhclient[<pid>]: bound to <node IP> -- renewal in 1530 seconds
If there are several lines where the IP is different, the node is affected.
Workaround:
Select from the following options:
Bind IP addresses for all machines to their MAC addresses on the DHCP server for the dedicated vSphere network. In this case, VMs receive only specified IP addresses that never change.
Remove the Container Cloud node IPs from the IP range on the DHCP server for the dedicated vSphere network and configure the first interface
eth0on VMs with a static IP address.If a managed cluster is affected, redeploy it with IPAM enabled for new machines to be created and IPs to be assigned properly.
During deployment of any Container Cloud cluster or attachment of an existing
MKE cluster that is not deployed by Container Cloud, the machines are stuck
in the Pending state with no lcmcluster-controller entries from the
lcm-controller logs except the following ones:
kubectl --kubeconfig <pathToMgmtOrRegionalClusterKubeconfig> logs lcm-lcm-controller-<controllerID> -n kaas | grep lcmcluster-controller
{"level":"info","ts":1634808016.777575,"logger":"controller-runtime.manager.controller.lcmcluster-controller","msg":"Starting EventSource","source":"kind source: /, Kind="}
{"level":"info","ts":1634808016.8779392,"logger":"controller-runtime.manager.controller.lcmcluster-controller","msg":"Starting EventSource","source":"kind source: /, Kind="}
The issue affects only clusters with the Container Cloud projects (Kubernetes
namespaces) in the Terminating state.
Workaround:
Verify the state of the Container Cloud projects:
kubectl --kubeconfig <pathToMgmtOrRegionalClusterKubeconfig> get ns
If any project is in the
Terminatingstate, proceed to the next step. Otherwise, further assess the cluster logs to identify the root cause of the issue.Clean up the project that is stuck in the
Terminatingstate:Identify the objects that are stuck in the project:
kubectl --kubeconfig <pathToMgmtOrRegionalClusterKubeconfig> get ns <projectName> -o yaml
Example of system response:
... status: conditions: ... - lastTransitionTime: "2021-10-19T17:05:23Z" message: 'Some resources are remaining: pods. has 1 resource instances' reason: SomeResourcesRemain status: "True" type: NamespaceContentRemaining
Remove the
metadata.finalizersfield from the affected objects:kubectl --kubeconfig <pathToMgmtOrRegionalClusterKubeconfig> edit <objectType>/<objecName> -n <objectProjectName>
Restart
lcm-controlleron the affected management or regional cluster:kubectl --kubeconfig <pathToMgmtOrRegionalClusterKubeconfig> get pod -n kaas | awk '/lcm-controller/ {print $1}' | xargs kubectl --kubeconfig <pathToMgmtOrRegionalClusterKubeconfig> delete pod -n kaas
Note
The issue affects only Helm v2 releases and is addressed for Helm v3. Starting from Container Cloud 2.19.0, all Helm releases are switched to v3.
During a management, regional, or managed cluster deployment,
Helm releases may get stuck in the FAILED or UNKNOWN state
although the corresponding machines statuses are Ready
in the Container Cloud web UI. For example, if the StackLight Helm release
fails, the links to its endpoints are grayed out in the web UI.
In the cluster status, providerStatus.helm.ready and
providerStatus.helm.releaseStatuses.<releaseName>.success are false.
HelmBundle cannot recover from such states and requires manual actions.
The workaround below describes the recovery steps for the stacklight
release that got stuck during a cluster deployment.
Use this procedure as an example for other Helm releases as required.
Workaround:
Verify the failed release has the
UNKNOWNorFAILEDstatus in the HelmBundle object:kubectl --kubeconfig <regionalClusterKubeconfigPath> get helmbundle <clusterName> -n <clusterProjectName> -o=jsonpath={.status.releaseStatuses.stacklight} In the command above and in the steps below, replace the parameters enclosed in angle brackets with the corresponding values of your cluster.
Example of system response:
stacklight: attempt: 2 chart: "" finishedAt: "2021-02-05T09:41:05Z" hash: e314df5061bd238ac5f060effdb55e5b47948a99460c02c2211ba7cb9aadd623 message: '[{"occurrence":1,"lastOccurrenceDate":"2021-02-05 09:41:05","content":"error updating the release: rpc error: code = Unknown desc = customresourcedefinitions.apiextensions.k8s.io \"helmbundles.lcm.mirantis.com\" already exists"}]' notes: "" status: UNKNOWN success: false version: 0.1.2-mcp-398
Log in to the
helm-controllerpod console:kubectl --kubeconfig <affectedClusterKubeconfigPath> exec -n kube-system -it helm-controller-0 sh -c tiller
Download the Helm v3 binary. For details, see official Helm documentation.
Remove the failed release:
helm delete <failed-release-name>
For example:
helm delete stacklight
Once done, the release triggers for redeployment.
Prometheus web UI URLs in StackLight notifications sent to Salesforce use a wrong protocol: HTTP instead of HTTPS. The issue affects deployments with TLS enabled for IAM.
The workaround is to manually change the URL protocol in the web browser.
The csi-rbdplugin-provisioner pod (csi-provisioner container) may show
constant retries attempting to create a PV if the csi-rbdplugin-provisioner
pod was scheduled and started on a node with no connectivity to the Ceph
storage. As a result, creation of a Ceph-based persistent volume (PV) may get
stuck in the Pending state.
As a workaround manually specify the affinity or toleration rules for the
csi-rbdplugin-provisioner pod.
Workaround:
On the managed cluster, open the
rook-ceph-operator-configmap for editing:kubectl edit configmap -n rook-ceph rook-ceph-operator-config
To avoid spawning pods on the nodes where this is not needed, set the provisioner node affinity specifying the required node labels. For example:
CSI_PROVISIONER_NODE_AFFINITY: "role=storage-node; storage=rook, ceph"
Note
If needed, you can also specify CSI_PROVISIONER_TOLERATIONS
tolerations. For example:
CSI_PROVISIONER_TOLERATIONS: |
- effect: NoSchedule
key: node-role.kubernetes.io/controlplane
operator: Exists
- effect: NoExecute
key: node-role.kubernetes.io/etcd
operator: Exists
During deployment of a Ceph cluster, the RADOS Gateway (RGW) pod overrides
the global CA bundle located at /etc/pki/tls/certs with an incorrect
self-signed CA bundle. The issue affects only clusters with public
certificates.
Workaround:
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with a corresponding value.Select from the following options:
If you are using the GoDaddy certificates, in the
cephClusterSpec.objectStorage.rgwsection, replace thecacertparameters with your public CA certificate that already contains both the root CA certificate and intermediate CA certificate:cephClusterSpec: objectStorage: rgw: SSLCert: cacert: | -----BEGIN CERTIFICATE----- ca-certificate here -----END CERTIFICATE----- tlsCert: | -----BEGIN CERTIFICATE----- private TLS certificate here -----END CERTIFICATE----- tlsKey: | -----BEGIN RSA PRIVATE KEY----- private TLS key here -----END RSA PRIVATE KEY-----
If you are using the DigiCert certificates:
Download the
<root_CA>from DigiCert.In the
cephClusterSpec.objectStorage.rgwsection, replace thecacertparameters with your public intermediate CA certificate along with the root one:cephClusterSpec: objectStorage: rgw: SSLCert: cacert: | -----BEGIN CERTIFICATE----- <root CA here> <intermediate CA here> -----END CERTIFICATE----- tlsCert: | -----BEGIN CERTIFICATE----- private TLS certificate here -----END CERTIFICATE----- tlsKey: | -----BEGIN RSA PRIVATE KEY----- private TLS key here -----END RSA PRIVATE KEY-----
Affects only Container Cloud 2.11,0, 2.12,0, 2.13.0, and 2.13.1
Ceph LCM automatic operations such as Ceph OSD or Ceph node removal are
unstable for the new Rook 1.6.8 and Ceph 15.2.13 (Ceph Octopus) versions and
may cause data corruption. Therefore, manageOsds is disabled until further
notice.
As a workaround, to safely remove a Ceph OSD or node from a Ceph cluster, perform the steps described in Remove Ceph OSD manually.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
The Equinix Metal and MOS-based managed clusters may fail to update to the latest Cluster release with kubelet being stuck and reporting authorization errors.
The cluster is affected by the issue if you see the Failed to make webhook authorizer request: context canceled error in the kubelet logs:
docker logs ucp-kubelet --since 5m 2>&1 | grep 'Failed to make webhook authorizer request: context canceled'
As a workaround, restart the ucp-kubelet container on the affected
node(s):
ctr -n com.docker.ucp snapshot rm ucp-kubelet
docker rm -f ucp-kubelet
Note
Ignore failures in the output of the first command, if any.
An Equinix-based management or managed cluster fails to update with the
FailedAttachVolume and FailedMount warnings.
Workaround:
Verify that the description of the pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
<affectedProjectName>is the Container Cloud project name where the pods failed to run<affectedPodName>is a pod name that failed to run in this project
In the pod description, identify the node name where the pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain the rbd volume mount failed: <csi-vol-uuid> is being used error. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the pod that fails to init to0replicas.On every
csi-rbdpluginpod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state isRunning.
Helm releases may get stuck in the PENDING_UPGRADE status
during a management or managed cluster upgrade. The HelmBundle Controller
cannot recover from this state and requires manual actions. The workaround
below describes the recovery process for the openstack-operator release
that stuck during a managed cluster update. Use it as an example for other
Helm releases as required.
Workaround:
Log in to the
helm-controllerpod console:kubectl exec -n kube-system -it helm-controller-0 sh -c tiller
Identify the release that stuck in the
PENDING_UPGRADEstatus. For example:./helm --host=localhost:44134 history openstack-operator
Example of system response:
REVISION UPDATED STATUS CHART DESCRIPTION 1 Tue Dec 15 12:30:41 2020 SUPERSEDED openstack-operator-0.3.9 Install complete 2 Tue Dec 15 12:32:05 2020 SUPERSEDED openstack-operator-0.3.9 Upgrade complete 3 Tue Dec 15 16:24:47 2020 PENDING_UPGRADE openstack-operator-0.3.18 Preparing upgrade
Roll back the failed release to the previous revision:
Download the Helm v3 binary. For details, see official Helm documentation.
Roll back the failed release:
helm rollback <failed-release-name>
For example:
helm rollback openstack-operator 2
Once done, the release will be reconciled.
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.13.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.26.6 |
aws-credentials-controller |
1.26.6 |
|
Azure Updated |
azure-provider |
1.26.6 |
azure-credentials-controller |
1.26.6 |
|
Bare metal |
ambassador New |
1.18.0 |
Bare metal |
baremetal-operator Updated |
5.2.3 |
baremetal-public-api Updated |
5.2.3 |
|
baremetal-provider Updated |
1.26.6 |
|
httpd Replaced with ambassador |
n/a |
|
ironic Updated |
victoria-bionic-20211006090712 |
|
ironic-operator Updated |
base-bionic-20210930105000 |
|
kaas-ipam Updated |
base-bionic-20210930121606 |
|
local-volume-provisioner |
1.0.6-mcp |
|
mariadb |
10.4.17-bionic-20210617085111 |
|
IAM |
iam |
2.4.8 |
iam-controller Updated |
1.26.6 |
|
keycloak |
12.0.0 |
|
Container Cloud |
admission-controller Updated |
1.26.6 |
agent-controller Updated |
1.26.6 |
|
byo-credentials-controller Updated |
1.26.6 |
|
byo-provider Updated |
1.26.6 |
|
kaas-public-api Updated |
1.26.6 |
|
kaas-exporter Updated |
1.26.6 |
|
kaas-ui Updated |
1.26.6 |
|
lcm-controller Updated |
0.3.0-76-g3a45ff9e |
|
mcc-cache Updated |
1.26.6 |
|
portforward-controller New |
1.26.6 |
|
proxy-controller Updated |
1.26.6 |
|
rbac-controller Updated |
1.26.6 |
|
release-controller Updated |
1.26.6 |
|
rhellicense-controller Updated |
1.26.6 |
|
squid-proxy |
0.0.1-5 |
|
Equinix Metal Updated |
equinix-provider |
1.26.6 |
equinix-credentials-controller |
1.26.6 |
|
OpenStack Updated |
openstack-provider |
1.26.6 |
os-credentials-controller |
1.26.6 |
|
VMware vSphere Updated |
vsphere-provider |
1.26.6 |
vsphere-credentials-controller |
1.26.6 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.13.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-5.2.3.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-5.2.3.tgz |
|
ironic-python-agent-bionic.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-victoria-bionic-debug-20210817124316 |
|
ironic-python-agent-bionic.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-victoria-bionic-debug-20210817124316 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-1.0.6-mcp.tgz |
|
provisioning_ansible Updated |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-82-342bd22.tgz |
|
target ubuntu system |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-20210622161844 |
|
Docker images |
ambassador New |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20211005112459 |
|
dnsmasq |
mirantis.azurecr.io/general/dnsmasq:focal-20210617094827 |
|
httpd |
n/a (replaced with ambassador) |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20211006090712 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20211006090712 |
|
ironic-operator Updated |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20210930105000 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20210608113804 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20210930121606 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210617085111 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-bionic-20210617094817 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.26.6.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.26.6.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.26.6.tgz |
agent-controller |
https://binary.mirantis.com/core/helm/agent-controller-1.26.6.tgz |
|
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.26.6.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.26.6.tgz |
|
azure-credentials-controller |
https://binary.mirantis.com/core/helm/azure-credentials-controller-1.26.6.tgz |
|
azure-provider |
https://binary.mirantis.com/core/helm/azure-provider-1.26.6.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.26.6.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.26.6.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.26.6.tgz |
|
equinix-credentials-controller |
https://binary.mirantis.com/core/helm/equinix-credentials-controller-1.26.6.tgz |
|
equinix-provider |
https://binary.mirantis.com/core/helm/equinix-provider-1.26.6.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.26.6.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.26.6.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.26.6.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.26.6.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.26.6.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.26.6.tgz |
|
portforward-controller New |
https://binary.mirantis.com/core/helm/portforward-controller-1.26.6.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.26.6.tgz |
|
rbac-controller |
https://binary.mirantis.com/core/helm/rbac-controller-1.26.6.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.26.6.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.26.6.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.26.6.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.26.6.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.26.6.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.26.6 |
agent-controller Updated |
mirantis.azurecr.io/core/agent-controller:1.26.6 |
|
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.26.6 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.26.6 |
|
azure-cluster-api-controller Updated |
mirantis.azurecr.io/core/azure-cluster-api-controller:1.26.6 |
|
azure-credentials-controller Updated |
mirantis.azurecr.io/core/azure-credentials-controller:1.26.6 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.26.6 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.26.6 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.26.6 |
|
cluster-api-provider-equinix Updated |
mirantis.azurecr.io/core/cluster-api-provider-equinix:1.26.6 |
|
equinix-credentials-controller Updated |
mirantis.azurecr.io/core/equinix-credentials-controller:1.26.6 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.26.6 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.26.6 |
|
kproxy Updated |
mirantis.azurecr.io/lcm/kproxy:1.26.6 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:v0.3.0-76-g3a45ff9e |
|
nginx Updated |
mirantis.azurecr.io/lcm/nginx:1.20.1-alpine |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.26.6 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.26.6 |
|
portforward-controller New |
mirantis.azurecr.io/core/portforward-controller:1.26.6 |
|
rbac-controller Updated |
mirantis.azurecr.io/core/rbac-controller:1.26.6 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.26.6 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.26.6 |
|
squid-proxy |
mirantis.azurecr.io/core/squid-proxy:0.0.1-5 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-api-controller:1.26.6 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.26.6 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux |
||
iamctl-darwin |
||
iamctl-windows |
||
Helm charts |
iam |
|
iam-proxy Updated |
||
keycloak_proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.26.6.tgz |
|
Docker images |
api |
mirantis.azurecr.io/iam/api:0.5.3 |
auxiliary |
mirantis.azurecr.io/iam/auxiliary:0.5.3 |
|
kubernetes-entrypoint Updated |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.5.3 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-2 |
The Mirantis Container Cloud GA release 2.12.0:
Introduces support for the Cluster release 7.2.0 that is based on Mirantis Container Runtime 20.10.6 and Mirantis Kubernetes Engine 3.4.5 with Kubernetes 1.20.
Introduces support for the Cluster release 5.19.0 that is based on Mirantis Kubernetes Engine 3.3.12 with Kubernetes 1.18 and Mirantis Container Runtime 20.10.6.
Introduces support for the Cluster release 6.19.0 that is based on the Cluster release 5.19.0 and represents Mirantis OpenStack for Kubernetes (MOS) 21.5.
Supports deprecated Cluster releases 5.18.0, 6.18.0, and 7.1.0 that will become unsupported in the following Container Cloud releases.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.12.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.12.0. For the list of enhancements in the Cluster releases 7.2.0, 6.19.0, and 5.19.0 that are supported by the Container Cloud release 2.12.0, see the Cluster releases (managed).
Introduced official support for the Microsoft Azure cloud provider, including support for creating and operating of management, regional, and managed clusters.
Implemented the possibility to deploy Container Cloud management, regional, and managed clusters on top of Mirantis OpenStack for Kubernetes (MOS) Victoria that is based on the Open vSwitch networking.
TECHNOLOGY PREVIEW
Added the Technology Preview support for configuration of software-based
Redundant Array of Independent Disks (RAID) using BareMetalHosProfile
to set up LVM or mdadm-based RAID level 1 (raid1).
If required, you can further configure RAID in the same profile,
for example, to install a cluster operating system onto a RAID device.
You can configure RAID during a baremetal-based management or managed cluster creation. RAID configuration on already provisioned bare metal machines or on an existing cluster is not supported.
Caution
This feature is available as Technology Preview. Use such configuration for testing and evaluation purposes only. For the Technology Preview feature definition, refer to Technology Preview features.
Learn more
Added the Preparing state to the provisioning workflow of bare metal hosts.
Bare Metal Operator inspects a bare metal host and moves it to the
Preparing state. In this state, the host becomes ready to be linked
to a bare metal machine.
Learn more
Added the Transport Layer Security (TLS) configuration to all Container Cloud endpoints for all supported cloud providers. The Container Cloud web UI and StackLight endpoints are now available through TLS with self-signed certificates generated by the Container Cloud provider. If required, you can also add your own TLS certificates to the Container Cloud web UI and Keycloak.
Caution
After the Container Cloud upgrade from 2.11.0 to 2.12.0, all Container Cloud endpoints are available only through HTTPS.
Migrated iam-proxy from the deprecated Louketo Proxy, formerly known as
keycloak-proxy to OAuth2 Proxy.
To apply the migration, all iam-proxy services in the StackLight namespace
are restarted during a management cluster upgrade or managed cluster update.
This causes a short downtime for the web UI access to StackLight services,
although all services themselves, such as Kibana or Grafana, continue working.
Implemented the possibility to customize the default backup configuration for a MariaDB database on a management cluster. You can customize the default configuration either during a management cluster bootstrap or on an existing management cluster. The Kubernetes cron job responsible for the MariaDB backup is enabled by default for the OpenStack and AWS cloud providers and is disabled for other supported providers.
In the scope of continuous improvement of the product,
renamed the Container Cloud binary from kaas to container-cloud.
On top of continuous improvements delivered to the existing Container Cloud guides, added a procedure on how to back up and restore an OpenStack or AWS-based management cluster. The procedure consists of the MariaDB and MKE backup and restore steps.
Learn more
The following issues have been addressed in the Mirantis Container Cloud release 2.12.0 along with the Cluster releases 7.2.0, 6.19.0, and 5.19.0.
[16718][Equinix Metal] Fixed the issue with the Equinix Metal provider failing to create machines with an SSH key error if an Equinix Metal based cluster was being deployed in an Equinix Metal project with no SSH keys.
[17118][bare metal] Fixed the issue with failure to add a new machine to a baremetal-based managed cluster after the management cluster upgrade.
[16959][OpenStack] Fixed the issue with failure to create a proxy-based OpenStack regional cluster due to the issue with the proxy secret creation.
[13385][IAM] Fixed the issue with MariaDB pods failing to start after MariaDB blocked itself during the State Snapshot Transfers sync.
[8367][LCM] Fixed the issue with joining etcd from a new node to an existing etcd cluster. The issue caused the new managed node to hang in the
Deploystate when adding it to a managed cluster.[16873][bootstrap] Fixed the issue with a management cluster bootstrap failing with failed to establish connection with tiller error due to kind 0.9.0 delivered with the bootstrap script being not compatible with the latest Ubuntu 18.04 image that requires kind 0.11.1.
[16964][Ceph] Fixed the issue with a bare metal or Equinix Metal management cluster upgrade getting stuck and then failing with some Ceph daemons being stuck on upgrade to Octopus and with the
insecure global_id reclaimhealth warning in Ceph logs.[16843][StackLight] Fixed the issue causing inability to override default route matchers for Salesforce notifier.
If you have applied the workaround as described in StackLight known issues: 16843 after updating the cluster releases to 5.19.0, 7.2.0, or 6.19.0 and if you need to define custom matchers, replace the deprecated
matchandmatch_reparameters withmatchersas required. For details, see Deprecation notes and StackLight configuration parameters.[17477][Update][StackLight] Fixed the issue with StackLight in HA mode placed on controller nodes being not deployed or cluster update being blocked. Once you update your Mirantis OpenStack for Kubernetes cluster from the Cluster release 6.18.0 to 6.19.0, roll back the workaround applied as described in Upgrade known issues: 17477:
Remove
stacklightlabels from worker nodes. Wait for the labels to be removed.Remove the custom
nodeSelectorsection from the cluster spec.
[16777][Update][StackLight] Fixed the issue causing the Cluster release update from 7.0.0 to 7.1.0 to fail due to failed Patroni pod. The issue affected the Container Cloud management, regional, or managed cluster of any cloud provider.
[17069][Update][Ceph] Fixed the issue with upgrade of a bare metal or Equinix Metal based management or managed cluster failing with the Failed to configure Ceph cluster error due to different versions of the
rook-ceph-osddeployments.[17007][Update] Fixed the issue with the false-positive release: “squid-proxy” not found error during a management cluster upgrade of any supported cloud provider except vSphere.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.12.0 including the Cluster releases 7.2.0, 6.19.0, and 5.19.0.
For other issues that can occur while deploying and operating a Container Cloud cluster, see Deployment Guide: Troubleshooting and Operations Guide: Troubleshooting.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Fixed in the Cluster release 7.0.0
Note
The issue below affects only the Kubernetes 1.18 deployments. Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
On a management cluster with multiple AWS-based managed
clusters, some clusters fail to complete the deployments that require
persistent volumes (PVs), for example, Elasticsearch.
Some of the affected pods get stuck in the Pending state
with the pod has unbound immediate PersistentVolumeClaims and
node(s) had volume node affinity conflict errors.
Warning
The workaround below applies to HA deployments where data can be rebuilt from replicas. If you have a non-HA deployment, back up any existing data before proceeding, since all data will be lost while applying the workaround.
Workaround:
Obtain the persistent volume claims related to the storage mounts of the affected pods:
kubectl get pod/<pod_name1> pod/<pod_name2> \ -o jsonpath='{.spec.volumes[?(@.persistentVolumeClaim)].persistentVolumeClaim.claimName}'
Note
In the command above and in the subsequent steps, substitute the parameters enclosed in angle brackets with the corresponding values.
Delete the affected
PodsandPersistentVolumeClaimsto reschedule them: For example, for StackLight:kubectl -n stacklight delete \ pod/<pod_name1> pod/<pod_name2> ... pvc/<pvc_name2> pvc/<pvc_name2> ...
Fixed in 2.13.0
The default value of the Ports per instance load balancer
outbound NAT setting that is 1024 prevents from deploying
more than 62 Azure worker nodes on a managed cluster. To workaround the issue,
set the Ports per instance parameter to 256.
Workaround:
Log in to the Azure portal.
Navigate to Home > Load Balancing.
Find and click the load balancer called mcc-<uniqueClusterID>. You can obtain
<uniqueClusterID>in the Cluster info field in the Container Cloud web UI.In the load balancer Settings left-side menu, click Outbound rules > OutboundNATAllProtocols.
In the Outbound ports > Choose by menu, select Ports per instance.
In the Ports per instance field, replace the default 1024 value with 256.
Click Save to apply the new setting.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
After update of a management or managed cluster created using the Container
Cloud release earlier than 2.6.0, a bare metal host state is
Provisioned in the Container Cloud web UI while having the error state
in logs with the following message:
status:
errorCount: 1
errorMessage: 'Host adoption failed: Error while attempting to adopt node 7a8d8aa7-e39d-48ec-98c1-ed05eacc354f:
Validation of image href http://10.10.10.10/images/stub_image.qcow2 failed,
reason: Got HTTP code 404 instead of 200 in response to HEAD request..'
errorType: provisioned registration error
The issue is caused by the image URL pointing to an unavailable resource due to the URI IP change during update. As a workaround, update URLs for the bare metal host status and spec with the correct values that use a stable DNS record as a host.
Workaround:
Note
In the commands below, we update master-2 as an example.
Replace it with the corresponding value to fit your deployment.
Exit Lens.
In a new terminal, configure access to the affected cluster.
Start
kube-proxy:kubectl proxy &
Pause the reconcile:
kubectl patch bmh master-2 --type=merge --patch '{"metadata":{"annotations":{"baremetalhost.metal3.io/paused": "true"}}}'
Create the payload data with the following content:
For
status_payload.json:{ "status": { "errorCount": 0, "errorMessage": "", "provisioning": { "image": { "checksum": "http://httpd-http/images/stub_image.qcow2.md5sum", "url": "http://httpd-http/images/stub_image.qcow2" }, "state": "provisioned" } } }
For
status_payload.json:{ "spec": { "image": { "checksum": "http://httpd-http/images/stub_image.qcow2.md5sum", "url": "http://httpd-http/images/stub_image.qcow2" } } }
Verify that the payload data is valid:
cat status_payload.json | jq cat spec_payload.json | jq
The system response must contain the data added in the previous step.
Patch the bare metal host status with payload:
curl -k -v -XPATCH -H "Accept: application/json" -H "Content-Type: application/merge-patch+json" --data-binary "@status_payload.json" 127.0.0.1:8001/apis/metal3.io/v1alpha1/namespaces/default/baremetalhosts/master-2/status
Patch the bare metal host spec with payload:
kubectl patch bmh master-2 --type=merge --patch "$(cat spec_payload.json)"
Resume the reconcile:
kubectl patch bmh master-2 --type=merge --patch '{"metadata":{"annotations":{"baremetalhost.metal3.io/paused":null}}}'
Close the terminal to quit
kube-proxyand resume Lens.
Fixed in 2.13.0
Redeployment of a bare metal node with an mdadm-based raid1 enabled
fails due to insufficient cleanup of RAID devices.
Workaround:
Boot the affected node from any LiveCD, preferably Ubuntu.
Obtain details about the mdadm RAID devices:
sudo mdadm --detail --scan --verbose
Stop all mdadm RAID devices listed in the output of the above command. For example:
sudo mdadm --stop /dev/md0
Clean up the metadata on partitions with the mdadm RAID device(s) enabled. For example:
sudo mdadm --zero-superblock /dev/sda1
In the above example, replace
/dev/sda1with partitions listed in the output of the command provided in the step 2.
Fixed in 2.13.0
On the baremetal-based management clusters with the Container Cloud version
2.12.0 or earlier, the storage volume used by Ironic can run out of free space.
As a result, a StackLight alert is triggered for the ironic-aio-pvc volume
filling up.
Symptoms
One or more of the following symptoms are observed:
The StackLight KubePersistentVolumeUsageCritical alert is firing for the volume
ironic-aio-pvc.The
ironicanddnsmasqDeploymentsare not in theOKstatus:kubectl -n kaas get deployments
One or multiple
ironicanddnsmasqpods fail to start:For
dnsmasq:kubectl get pods -n kaas -o wide | grep dnsmasq
If the number of ready containers for the pod is not 2/2, the management cluster can be affected by the issue.
For
ironic:kubectl get pods -n kaas -o wide | grep ironic
If the number of ready containers for the pod is not 6/6, the management cluster can be affected by the issue.
The free space on a volume is less than 10%. To verify space usage on a volume:
kubectl -n kaas exec -ti deployment/ironic -c ironic-api -- /bin/bash -c 'df -h |grep -i "volume\|size"'
Example of system response where
14%is the used space of a volume:Filesystem Size Used Avail Use% Mounted on /dev/rbd0 4.9G 686M 4.2G 14% /volume
As a workaround, truncate the log files on the storage volume:
kubectl -n kaas exec -ti deployment/dnsmasq -- /bin/bash -c 'truncate -s 0 /volume/log/ironic/ironic-api.log'
kubectl -n kaas exec -ti deployment/dnsmasq -- /bin/bash -c 'truncate -s 0 /volume/log/ironic/ironic-conductor.log'
kubectl -n kaas exec -ti deployment/dnsmasq -- /bin/bash -c 'truncate -s 0 /volume/log/ironic/ansible-playbook.log'
kubectl -n kaas exec -ti deployment/dnsmasq -- /bin/bash -c 'truncate -s 0 /volume/log/ironic-inspector/ironic-inspector.log'
kubectl -n kaas exec -ti deployment/dnsmasq -- /bin/bash -c 'truncate -s 0 /volume/log/dnsmasq/dnsmasq-dhcpd.log'
kubectl -n kaas exec -ti deployment/dnsmasq -- /bin/bash -c 'truncate -s 0 /volume/log/ambassador/access.log
kubectl -n kaas exec -ti deployment/dnsmasq -- /bin/bash -c 'truncate -s 0 /volume/log/ambassador/error.log
If you run bootstrap.sh preflight with
KAAS_BM_FULL_PREFLIGHT=true, the script fails with the following message:
preflight check failed: preflight full check failed: \
error waiting for BareMetalHosts to power on: \
timed out waiting for the condition
Workaround:
Unset full preflight using the
unset KAAS_BM_FULL_PREFLIGHTenvironment variable.Rerun bootstrap.sh preflight that executes fast preflight instead.
An OpenStack-based regional cluster cleanup fails with the timeout error.
Workaround:
Wait for the
Clusterobject to be deleted in the bootstrap cluster:kubectl --kubeconfig <(./bin/kind get kubeconfig --name clusterapi) get cluster
The system output must be empty.
Remove the bootstrap cluster manually:
./bin/kind delete cluster --name clusterapi
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
A vSphere-based management cluster bootstrap fails due to a node leaving the cluster after an accidental IP address change.
The issue may affect a vSphere-based cluster only when IPAM is not enabled and IP addresses assignment to the vSphere virtual machines is done by a DHCP server present in the vSphere network.
By default, a DHCP server keeps lease of the IP address for 30 minutes.
Usually, a VM dhclient prolongs such lease by frequent DHCP requests
to the server before the lease period ends.
The DHCP prolongation request period is always less than the default lease time
on the DHCP server, so prolongation usually works.
But in case of network issues, for example, when dhclient from the
VM cannot reach the DHCP server, or the VM is being slowly powered on
for more than the lease time, such VM may lose its assigned IP address.
As a result, it obtains a new IP address.
Container Cloud does not support network reconfiguration after the IP of the VM has been changed. Therefore, such issue may lead to a VM leaving the cluster.
Symptoms:
One of the nodes is in the
NodeNotReadyordownstate:kubectl get nodes -o wide docker node ls
The UCP Swarm manager logs on the healthy manager node contain the following example error:
docker logs -f ucp-swarm-manager level=debug msg="Engine refresh failed" id="<docker node ID>|<node IP>: 12376"
If the affected node is manager:
The output of the docker info command contains the following example error:
Error: rpc error: code = Unknown desc = The swarm does not have a leader. \ It's possible that too few managers are online. \ Make sure more than half of the managers are online.
The UCP controller logs contain the following example error:
docker logs -f ucp-controller "warning","msg":"Node State Active check error: \ Swarm Mode Manager health check error: \ info: Cannot connect to the Docker daemon at tcp://<node IP>:12376. \ Is the docker daemon running?
On the affected node, the IP address on the first interface
eth0does not match the IP address configured in Docker. Verify theNode Addressfield in the output of the docker info command.The following lines are present in
/var/log/messages:dhclient[<pid>]: bound to <node IP> -- renewal in 1530 seconds
If there are several lines where the IP is different, the node is affected.
Workaround:
Select from the following options:
Bind IP addresses for all machines to their MAC addresses on the DHCP server for the dedicated vSphere network. In this case, VMs receive only specified IP addresses that never change.
Remove the Container Cloud node IPs from the IP range on the DHCP server for the dedicated vSphere network and configure the first interface
eth0on VMs with a static IP address.If a managed cluster is affected, redeploy it with IPAM enabled for new machines to be created and IPs to be assigned properly.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
Occasionally, kubelet may get stuck on the Cluster release 5.x.x series
with different errors in the ucp-kubelet containers leading to the nodes
failures. The following error occurs every time when accessing
the Kubernetes API server:
an error on the server ("") has prevented the request from succeeding
As a workaround, restart ucp-kubelet on the failed node:
ctr -n com.docker.ucp snapshot rm ucp-kubelet
docker rm -f ucp-kubelet
Note
The issue affects only Helm v2 releases and is addressed for Helm v3. Starting from Container Cloud 2.19.0, all Helm releases are switched to v3.
During a management, regional, or managed cluster deployment,
Helm releases may get stuck in the FAILED or UNKNOWN state
although the corresponding machines statuses are Ready
in the Container Cloud web UI. For example, if the StackLight Helm release
fails, the links to its endpoints are grayed out in the web UI.
In the cluster status, providerStatus.helm.ready and
providerStatus.helm.releaseStatuses.<releaseName>.success are false.
HelmBundle cannot recover from such states and requires manual actions.
The workaround below describes the recovery steps for the stacklight
release that got stuck during a cluster deployment.
Use this procedure as an example for other Helm releases as required.
Workaround:
Verify the failed release has the
UNKNOWNorFAILEDstatus in the HelmBundle object:kubectl --kubeconfig <regionalClusterKubeconfigPath> get helmbundle <clusterName> -n <clusterProjectName> -o=jsonpath={.status.releaseStatuses.stacklight} In the command above and in the steps below, replace the parameters enclosed in angle brackets with the corresponding values of your cluster.
Example of system response:
stacklight: attempt: 2 chart: "" finishedAt: "2021-02-05T09:41:05Z" hash: e314df5061bd238ac5f060effdb55e5b47948a99460c02c2211ba7cb9aadd623 message: '[{"occurrence":1,"lastOccurrenceDate":"2021-02-05 09:41:05","content":"error updating the release: rpc error: code = Unknown desc = customresourcedefinitions.apiextensions.k8s.io \"helmbundles.lcm.mirantis.com\" already exists"}]' notes: "" status: UNKNOWN success: false version: 0.1.2-mcp-398
Log in to the
helm-controllerpod console:kubectl --kubeconfig <affectedClusterKubeconfigPath> exec -n kube-system -it helm-controller-0 sh -c tiller
Download the Helm v3 binary. For details, see official Helm documentation.
Remove the failed release:
helm delete <failed-release-name>
For example:
helm delete stacklight
Once done, the release triggers for redeployment.
Fixed in 2.13.0
The Watchdog alert is not routed to Salesforce by default.
Note
After applying the workaround, you may notice the following warning message. It is expected and does not affect configuration rendering:
Warning: Merging destination map for chart 'stacklight'. Overwriting table
item 'match', with non table value: []
Workaround:
Open the StackLight configuration manifest as described in StackLight configuration procedure.
In
alertmanagerSimpleConfig.salesForce, specify the following configuration:alertmanagerSimpleConfig: salesForce: route: match: [] match_re: severity: "informational|critical" matchers: - severity=~"informational|critical"
Prometheus web UI URLs in StackLight notifications sent to Salesforce use a wrong protocol: HTTP instead of HTTPS. The issue affects deployments with TLS enabled for IAM.
The workaround is to manually change the URL protocol in the web browser.
The csi-rbdplugin-provisioner pod (csi-provisioner container) may show
constant retries attempting to create a PV if the csi-rbdplugin-provisioner
pod was scheduled and started on a node with no connectivity to the Ceph
storage. As a result, creation of a Ceph-based persistent volume (PV) may get
stuck in the Pending state.
As a workaround manually specify the affinity or toleration rules for the
csi-rbdplugin-provisioner pod.
Workaround:
On the managed cluster, open the
rook-ceph-operator-configmap for editing:kubectl edit configmap -n rook-ceph rook-ceph-operator-config
To avoid spawning pods on the nodes where this is not needed, set the provisioner node affinity specifying the required node labels. For example:
CSI_PROVISIONER_NODE_AFFINITY: "role=storage-node; storage=rook, ceph"
Note
If needed, you can also specify CSI_PROVISIONER_TOLERATIONS
tolerations. For example:
CSI_PROVISIONER_TOLERATIONS: |
- effect: NoSchedule
key: node-role.kubernetes.io/controlplane
operator: Exists
- effect: NoExecute
key: node-role.kubernetes.io/etcd
operator: Exists
During deployment of a Ceph cluster, the RADOS Gateway (RGW) pod overrides
the global CA bundle located at /etc/pki/tls/certs with an incorrect
self-signed CA bundle. The issue affects only clusters with public
certificates.
Workaround:
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with a corresponding value.Select from the following options:
If you are using the GoDaddy certificates, in the
cephClusterSpec.objectStorage.rgwsection, replace thecacertparameters with your public CA certificate that already contains both the root CA certificate and intermediate CA certificate:cephClusterSpec: objectStorage: rgw: SSLCert: cacert: | -----BEGIN CERTIFICATE----- ca-certificate here -----END CERTIFICATE----- tlsCert: | -----BEGIN CERTIFICATE----- private TLS certificate here -----END CERTIFICATE----- tlsKey: | -----BEGIN RSA PRIVATE KEY----- private TLS key here -----END RSA PRIVATE KEY-----
If you are using the DigiCert certificates:
Download the
<root_CA>from DigiCert.In the
cephClusterSpec.objectStorage.rgwsection, replace thecacertparameters with your public intermediate CA certificate along with the root one:cephClusterSpec: objectStorage: rgw: SSLCert: cacert: | -----BEGIN CERTIFICATE----- <root CA here> <intermediate CA here> -----END CERTIFICATE----- tlsCert: | -----BEGIN CERTIFICATE----- private TLS certificate here -----END CERTIFICATE----- tlsKey: | -----BEGIN RSA PRIVATE KEY----- private TLS key here -----END RSA PRIVATE KEY-----
Affects only Container Cloud 2.11,0, 2.12,0, 2.13.0, and 2.13.1
Ceph LCM automatic operations such as Ceph OSD or Ceph node removal are
unstable for the new Rook 1.6.8 and Ceph 15.2.13 (Ceph Octopus) versions and
may cause data corruption. Therefore, manageOsds is disabled until further
notice.
As a workaround, to safely remove a Ceph OSD or node from a Ceph cluster, perform the steps described in Remove Ceph OSD manually.
Fixed in 2.13.0
During deletion of an AWS-based regional cluster, deletion of the cluster credential fails with error deleting regional credential: error waiting for credential deletion: timed out waiting for the condition.
Workaround:
Change the directory to
kaas-bootstrap.Scale up the
aws-credentials-controller-aws-credentials-controllerdeployment:./bin/kind get kubeconfig --name clusterapi > kubeconfig-bootstrap kubectl --kubeconfig kubeconfig-bootstrap scale deployment \ aws-credentials-controller-aws-credentials-controller \ --namespace kaas --replicas=1
Wait until the affected credential is deleted:
kubectl --kubeconfig <pathToMgmtClusterKubeconfig> \ get awscredentials.kaas.mirantis.com -A -l kaas.mirantis.com/region=<regionName>
In the above command, replace:
<regionName>with the name of the region where the regional cluster is located.<pathToMgmtClusterKubeconfig>with the path to the correspondingmanagement cluster
kubeconfig.
Example of a positive system response:
No resources found
Delete the bootstrap cluster:
./bin/kind delete cluster --name clusterapi
Fixed in 2.13.0
An Equinix Metal or baremetal-based management cluster upgrade may fail with the following error message:
Reconcile MiraCeph 'ceph-lcm-mirantis/rook-ceph' failed with error:
failed to ensure cephcluster: failed to ensure cephcluster rook-ceph/rook-ceph:
ceph cluster rook-ceph/rook-ceph is not ready to be updated
Your cluster is affected if:
The
rook-ceph/rook-ceph-operatorlogs contain the following errors:Failed to update lock: Internal error occurred: unable to unmarshal response in forceLegacy: json: cannot unmarshal number into Go value of type bool Failed to update lock: Internal error occurred: unable to perform request for determining if legacy behavior should be forced
The kubectl -n rook-ceph get cephcluster command returns the
cephclusterresource with theProgressingstate.
As a workaround, restart the rook-ceph-operator pod:
kubectl -n rook-ceph delete pod -l app=rook-ceph-operator
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
The Equinix Metal and MOS-based managed clusters may fail to update to the latest Cluster release with kubelet being stuck and reporting authorization errors.
The cluster is affected by the issue if you see the Failed to make webhook authorizer request: context canceled error in the kubelet logs:
docker logs ucp-kubelet --since 5m 2>&1 | grep 'Failed to make webhook authorizer request: context canceled'
As a workaround, restart the ucp-kubelet container on the affected
node(s):
ctr -n com.docker.ucp snapshot rm ucp-kubelet
docker rm -f ucp-kubelet
Note
Ignore failures in the output of the first command, if any.
An Equinix-based management or managed cluster fails to update with the
FailedAttachVolume and FailedMount warnings.
Workaround:
Verify that the description of the pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
<affectedProjectName>is the Container Cloud project name where the pods failed to run<affectedPodName>is a pod name that failed to run in this project
In the pod description, identify the node name where the pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain the rbd volume mount failed: <csi-vol-uuid> is being used error. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the pod that fails to init to0replicas.On every
csi-rbdpluginpod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state isRunning.
Helm releases may get stuck in the PENDING_UPGRADE status
during a management or managed cluster upgrade. The HelmBundle Controller
cannot recover from this state and requires manual actions. The workaround
below describes the recovery process for the openstack-operator release
that stuck during a managed cluster update. Use it as an example for other
Helm releases as required.
Workaround:
Log in to the
helm-controllerpod console:kubectl exec -n kube-system -it helm-controller-0 sh -c tiller
Identify the release that stuck in the
PENDING_UPGRADEstatus. For example:./helm --host=localhost:44134 history openstack-operator
Example of system response:
REVISION UPDATED STATUS CHART DESCRIPTION 1 Tue Dec 15 12:30:41 2020 SUPERSEDED openstack-operator-0.3.9 Install complete 2 Tue Dec 15 12:32:05 2020 SUPERSEDED openstack-operator-0.3.9 Upgrade complete 3 Tue Dec 15 16:24:47 2020 PENDING_UPGRADE openstack-operator-0.3.18 Preparing upgrade
Roll back the failed release to the previous revision:
Download the Helm v3 binary. For details, see official Helm documentation.
Roll back the failed release:
helm rollback <failed-release-name>
For example:
helm rollback openstack-operator 2
Once done, the release will be reconciled.
Fixed in 2.13.0
On a managed cluster with logging disabled, changing NodeSelector can cause StackLight update failure with the following message in the StackLight Helm Controller logs:
Upgrade "stacklight" failed: Job.batch "stacklight-delete-logging-pvcs-*" is invalid: spec.template: Invalid value: ...
As a workaround, disable the stacklight-delete-logging-pvcs-* job.
Workaround:
Open the affected
Clusterobject for editing:kubectl edit cluster <affectedManagedClusterName> -n <affectedManagedClusterProjectName>
Set
deleteVolumestofalse:spec: ... providerSpec: ... value: ... helmReleases: ... - name: stacklight values: ... logging: deleteVolumes: false ...
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.12.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.25.6 |
aws-credentials-controller |
1.25.6 |
|
Azure Updated |
azure-provider |
1.25.6 |
azure-credentials-controller |
1.25.6 |
|
Bare metal |
baremetal-operator Updated |
5.2.1 |
baremetal-public-api Updated |
5.2.1 |
|
baremetal-provider Updated |
1.25.6 |
|
httpd |
1.18.0 |
|
ironic |
victoria-bionic-20210719060025 |
|
ironic-operator Updated |
base-bionic-20210908110402 |
|
kaas-ipam Updated |
base-bionic-20210819150000 |
|
local-volume-provisioner |
1.0.6-mcp |
|
mariadb |
10.4.17-bionic-20210617085111 |
|
IAM |
iam Updated |
2.4.8 |
iam-controller Updated |
1.25.6 |
|
keycloak |
12.0.0 |
|
Container Cloud |
admission-controller Updated |
1.25.6 |
agent-controller New |
1.25.6 |
|
byo-credentials-controller Updated |
1.25.6 |
|
byo-provider Updated |
1.25.6 |
|
kaas-public-api Updated |
1.25.6 |
|
kaas-exporter Updated |
1.25.6 |
|
kaas-ui Updated |
1.25.8 |
|
lcm-controller Updated |
0.3.0-41-g6ecc1974 |
|
mcc-cache Updated |
1.25.6 |
|
proxy-controller Updated |
1.25.6 |
|
rbac-controller New |
1.25.7 |
|
release-controller Updated |
1.25.6 |
|
rhellicense-controller Updated |
1.25.6 |
|
squid-proxy |
0.0.1-5 |
|
Equinix Metal Updated |
equinix-provider |
1.25.6 |
equinix-credentials-controller |
1.25.6 |
|
OpenStack Updated |
openstack-provider |
1.25.6 |
os-credentials-controller |
1.25.6 |
|
VMware vSphere Updated |
vsphere-provider |
1.25.6 |
vsphere-credentials-controller |
1.25.6 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.12.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-5.2.1.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-5.2.1.tgz |
|
ironic-python-agent-bionic.kernel Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-victoria-bionic-debug-20210817124316 |
|
ironic-python-agent-bionic.initramfs Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-victoria-bionic-debug-20210817124316 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-1.0.6-mcp.tgz |
|
provisioning_ansible Updated |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-79-41e503a.tgz |
|
target ubuntu system |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-20210622161844 |
|
Docker images |
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20210908111623 |
dnsmasq |
mirantis.azurecr.io/general/dnsmasq:focal-20210617094827 |
|
httpd |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20210719060025 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20210719060025 |
|
ironic-operator Updated |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20210908110402 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20210608113804 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20210819150000 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210617085111 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-bionic-20210617094817 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.25.6.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.25.6.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.25.6.tgz |
agent-controller New |
https://binary.mirantis.com/core/helm/agent-controller-1.25.6.tgz |
|
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.25.6.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.25.6.tgz |
|
azure-credentials-controller Updated |
https://binary.mirantis.com/core/helm/azure-credentials-controller-1.25.6.tgz |
|
azure-provider Updated |
https://binary.mirantis.com/core/helm/azure-provider-1.25.6.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.25.6.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.25.6.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.25.6.tgz |
|
equinix-credentials-controller |
https://binary.mirantis.com/core/helm/equinix-credentials-controller-1.25.6.tgz |
|
equinix-provider |
https://binary.mirantis.com/core/helm/equinix-provider-1.25.6.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.25.6.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.25.6.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.25.6.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.25.6.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.25.6.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.25.6.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.25.6.tgz |
|
rbac-controller New |
https://binary.mirantis.com/core/helm/rbac-controller-1.25.7.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.25.6.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.25.6.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.25.6.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.25.6.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.25.6.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.25.6 |
agent-controller New |
mirantis.azurecr.io/core/agent-controller:1.25.6 |
|
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.25.6 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.25.6 |
|
azure-cluster-api-controller Updated |
mirantis.azurecr.io/core/azure-cluster-api-controller:1.25.6 |
|
azure-credentials-controller Updated |
mirantis.azurecr.io/core/azure-credentials-controller:1.25.6 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.25.6 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.25.6 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.25.6 |
|
cluster-api-provider-equinix Updated |
mirantis.azurecr.io/core/cluster-api-provider-equinix:1.25.6 |
|
equinix-credentials-controller Updated |
mirantis.azurecr.io/core/equinix-credentials-controller:1.25.6 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.25.8 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.25.6 |
|
kproxy Updated |
mirantis.azurecr.io/lcm/kproxy:1.25.6 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:v0.3.0-41-g6ecc1974 |
|
nginx |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.25.6 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.25.6 |
|
rbac-controller New |
mirantis.azurecr.io/core/rbac-controller:1.25.7 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.25.6 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.25.6 |
|
squid-proxy Updated |
mirantis.azurecr.io/core/squid-proxy:0.0.1-5 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-api-controller:1.25.6 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.25.6 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux Updated |
||
iamctl-darwin Updated |
||
iamctl-windows Updated |
||
Helm charts Updated |
iam |
|
iam-proxy |
||
keycloak_proxy |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.26.1.tgz |
|
Docker images |
api Updated |
mirantis.azurecr.io/iam/api:0.5.3 |
auxiliary Updated |
mirantis.azurecr.io/iam/auxiliary:0.5.3 |
|
kubernetes-entrypoint Updated |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak Updated |
mirantis.azurecr.io/iam/keycloak:0.5.3 |
|
keycloak-gatekeeper Updated |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-2 |
The Mirantis Container Cloud GA release 2.11.0:
Introduces support for the Cluster release 7.1.0 that is based on Mirantis Container Runtime 20.10.5 and Mirantis Kubernetes Engine 3.4.0 with Kubernetes 1.20.
Introduces support for the Cluster release 5.18.0 that is based on Mirantis Kubernetes Engine 3.3.6 with Kubernetes 1.18 and Mirantis Container Runtime 20.10.5.
Introduces support for the Cluster release 6.18.0 that is based on the Cluster release 5.18.0 and represents Mirantis OpenStack for Kubernetes (MOS) 21.4.
Continues supporting the Cluster release 6.16.0 that is based on the Cluster release 5.16.0 and represents Mirantis OpenStack for Kubernetes (MOS) 21.3.
Supports deprecated Cluster releases 5.17.0, 6.16.0, and 7.0.0 that will become unsupported in the following Container Cloud releases.
Supports the Cluster release 5.11.0 only for attachment of existing MKE 3.3.4 clusters. For the deployment of new or attachment of existing MKE 3.3.6 clusters, the latest available Cluster release is used.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
Caution
Before upgrading an existing managed cluster with StackLight deployed in HA mode to the latest Cluster release, add the StackLight node label to at least 3 worker machines as described in Upgrade managed clusters with StackLight deployed in HA mode. Otherwise, the cluster upgrade will fail.
This section outlines release notes for the Container Cloud release 2.11.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.11.0. For the list of enhancements in the Cluster releases 7.1.0, 6.18.0, and 5.18.0 that are supported by the Container Cloud release 2.11.0, see the Cluster releases (managed).
TECHNOLOGY PREVIEW
Introduced the Technology Preview support for the Microsoft Azure cloud provider, including support for creating and operating of management, regional, and managed clusters.
Note
For the Technology Preview feature definition, refer to Technology Preview features.
Implemented the capability to bootstrap the vSphere provider clusters on the bootstrap node that is based on RHEL 7.9.
Implemented validation labels for the vSphere-based VM templates in the Container Cloud web UI. If a VM template was initially created using the built-in Packer mechanism, the Container Cloud version has a green label on the right side of the drop-down list with VM templates. Otherwise, a template is marked with the Unknown label.
Mirantis recommends using only green-labeled templates for production deployments.
Implemented automatic migration of Docker data located at /var/lib/docker
and local provisioner volumes from existing EBS to local NVMe SSDs during
the AWS-based management and managed clusters upgrade. On new clusters,
the /var/lib/docker Docker data is now located on local NVMe SSDs
by default.
The migration allows moving heavy workloads such as etcd and MariaDB to local NVMe SSDs that significantly improves cluster performance.
Upgraded all core Helm releases in the ClusterRelease and KaasRelease
objects from v2 to v3. Switching of the remaining Helm releases to v3 will
be implemented in one of the following Container Cloud releases.
Added the possibility to configure L2 templates for the baremetal-based management cluster to set up a bond network interface to the PXE/Management network.
Apply this configuration to the bootstrap templates before you run the bootstrap script to deploy the management cluster.
Caution
Using this configuration requires that every host in your management cluster has at least two physical interfaces.
Connect at least two interfaces per host to an Ethernet switch that supports Link Aggregation Control Protocol (LACP) port groups and LACP fallback.
Configure an LACP group on the ports connected to the NICs of a host.
Configure the LACP fallback on the port group to ensure that the host can boot over the PXE network before the bond interface is set up on the host operating system.
Configure server BIOS for both NICs of a bond to be PXE-enabled.
If the server does not support booting from multiple NICs, configure the port of the LACP group that is connected to the PXE-enabled NIC of a server to be primary port. With this setting, the port becomes active in the fallback mode.
Learn more
Implemented the following amendments for bare metal advanced configuration in the Container Cloud web UI:
On the Cluster page, added the Subnets section with a list of available subnets.
Added the Add new subnet wizard.
Renamed the BareMetal tab to BM Hosts.
Added the BM Host Profiles tab that contains a list of custom bare metal host profiles, if any.
Added the BM Host Profile drop-down list to the Create new machine wizard.
Implemented the verification mechanism for the actual capacity of the Equinix Metal facilities before machines deployment. Now, you can see the following labels in the Equinix Metal Create a machine wizard of the Container Cloud web UI:
Normal - the facility has a lot of available machines. Prioritize this machine type over others.
Limited - the facility has a limited number of machines. Do not request many machines of this type.
Unknown - Container Cloud cannot fetch information about the capacity level since the feature is disabled.
On top of continuous improvements delivered to the existing Container Cloud guides, added a procedure on how to update the Keycloak IP address on bare metal clusters.
The following issues have been addressed in the Mirantis Container Cloud release 2.11.0 along with the Cluster releases 7.1.0, 6.18.0, and 5.18.0.
For more issues addressed for the Cluster release 6.18.0, see also addressed issues 2.10.0.
[15698][vSphere] Fixed the issue with a load balancer virtual IP address (VIP) being assigned to each manager node on any type of the vSphere-based cluster.
[7573][Ceph] To avoid the Rook community issue with updating Rook to version 1.6, added the
rgw_data_log_backingconfiguration option set toomapby default.[10050][Ceph] Fixed the issue with Ceph OSD pod being stuck in the
CrashLoopBackOffstate due to the Ceph OSD authorization key failing to be created properly after disk replacement if a customBareMetalHostProfilewas used.[16233][Ceph][Upgrade] Fixed the issue with
ironicanddnsmasqpods failing during a baremetal-based management cluster upgrade due to Ceph not unmounting RBD volumes.[7655][BM] Fixed the issue with a bare metal cluster to be deployed successfully but with the runtime errors in the
IpamHostobject if an L2 template was configured incorrectly.[15348][StackLight] Fixed the issue with some panels of the Alertmanager and Prometheus Grafana dashboards not displaying data due to an invalid query.
[15834][StackLight] Removed the CPU resource limit from the
elasticsearch-curatorcontainer to avoid issues with theCPUThrottlingHighalert false-positively firing for Elasticsearch Curator.[16141][StackLight] Fixed the issue with the Alertmanager pod getting stuck in
CrashLoopBackOffduring upgrade of a management, regional, or managed cluster and thus causing upgrade failure with the Loading configuration file failed error message in logs.[15766][StackLight][Upgrade] Fixed the issue with management or regional cluster upgrade failure from version 2.9.0 to 2.10.0 and managed cluster from 5.16.0 to 5.17.0 with the Cannot evict pod error for the
patroni-12-0,patroni-12-1, orpatroni-12-2pod.[16398][StackLight] Fixed the issue with inability to set
require_tlstofalsefor Alertmanager email notifications.[13303] [LCM] Fixed the issue with managed clusters update from the Cluster release 6.12.0 to 6.14.0 failing with worker nodes being stuck in the
Deploystate with theNetwork is unreachableerror.[13845] [LCM] Fixed the issue with the LCM Agent upgrade failing with x509 error during managed clusters update from the Cluster release 6.12.0 to 6.14.0.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.11.0 including the Cluster releases 7.1.0, 6.18.0, and 5.18.0.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Fixed in the Cluster release 7.0.0
Note
The issue below affects only the Kubernetes 1.18 deployments. Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
On a management cluster with multiple AWS-based managed
clusters, some clusters fail to complete the deployments that require
persistent volumes (PVs), for example, Elasticsearch.
Some of the affected pods get stuck in the Pending state
with the pod has unbound immediate PersistentVolumeClaims and
node(s) had volume node affinity conflict errors.
Warning
The workaround below applies to HA deployments where data can be rebuilt from replicas. If you have a non-HA deployment, back up any existing data before proceeding, since all data will be lost while applying the workaround.
Workaround:
Obtain the persistent volume claims related to the storage mounts of the affected pods:
kubectl get pod/<pod_name1> pod/<pod_name2> \ -o jsonpath='{.spec.volumes[?(@.persistentVolumeClaim)].persistentVolumeClaim.claimName}'
Note
In the command above and in the subsequent steps, substitute the parameters enclosed in angle brackets with the corresponding values.
Delete the affected
PodsandPersistentVolumeClaimsto reschedule them: For example, for StackLight:kubectl -n stacklight delete \ pod/<pod_name1> pod/<pod_name2> ... pvc/<pvc_name2> pvc/<pvc_name2> ...
Fixed in 2.12.0
If an Equinix Metal based cluster is being deployed in an Equinix Metal project with no SSH keys, the Equinix Metal provider fails to create machines with the following error:
Failed to create machine "kaas-mgmt-controlplane-0"...
failed to create device: POST https://api.equinix.com/metal/v1/projects/...
<deviceID> must have at least one SSH key or explicitly send no_ssh_keys option
Workaround:
Create a new SSH key.
Log in to the Equinix Metal console.
In Project Settings, click Project SSH Keys.
Click Add New Key and add details of the newly created SSH key.
Click Add.
Restart the cluster deployment.
Fixed in 2.12.0
Adding a new machine to a baremetal-based
managed cluster may fail after the baremetal-based management cluster upgrade.
The issue occurs because the PXE boot is not working for the new node.
In this case, file /volume/tftpboot/ipxe.efi not found logs appear on
dnsmasq-tftp.
Workaround:
Log in to a local machine where your management cluster
kubeconfigis located and where kubectl is installed.Scale the Ironic deployment down to
0replicas.kubectl -n kaas scale deployments/ironic --replicas=0
Scale the Ironic deployment up to
1replica:kubectl -n kaas scale deployments/ironic --replicas=1
Fixed in 2.12.0
An OpenStack-based regional cluster being deployed using proxy fails with the Not ready objects: not ready: statefulSets: kaas/mcc-cache got 0/1 replicas error message due to the issue with the proxy secret creation.
Workaround:
Run the following command:
kubectl get secret -n kube-system mke-proxy-secret -o yaml | sed '/namespace.*/d' | kubectl create -n kaas -f -
Rerun the bootstrap script:
./bootstrap.sh deploy_regional
An OpenStack-based regional cluster cleanup fails with the timeout error.
Workaround:
Wait for the
Clusterobject to be deleted in the bootstrap cluster:kubectl --kubeconfig <(./bin/kind get kubeconfig --name clusterapi) get cluster
The system output must be empty.
Remove the bootstrap cluster manually:
./bin/kind delete cluster --name clusterapi
Fixed in 2.9.0 for new clusters
Newly created pods may fail to run and have the CrashLoopBackOff status
on long-living Container Cloud clusters deployed on RHEL 7.8 using the VMware
vSphere provider. The following is an example output of the
kubectl describe pod <pod-name> -n <projectName> command:
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: ContainerCannotRun
Message: OCI runtime create failed: container_linux.go:349:
starting container process caused "process_linux.go:297:
applying cgroup configuration for process caused
"mkdir /sys/fs/cgroup/memory/kubepods/burstable/<pod-id>/<container-id>>:
cannot allocate memory": unknown
The issue occurs due to the Kubernetes and Docker community issues.
According to the RedHat solution,
the workaround is to disable the kernel memory accounting feature
by appending cgroup.memory=nokmem to the kernel command line.
Note
The workaround below applies to the existing clusters only. The issue is resolved for new Container Cloud 2.9.0 deployments since the workaround below automatically applies to the VM template built during the vSphere-based management cluster bootstrap.
Apply the following workaround on each machine of the affected cluster.
Workaround
SSH to any machine of the affected cluster using
mcc-userand the SSH key provided during the cluster creation to proceed as therootuser.In
/etc/default/grub, setcgroup.memory=nokmemforGRUB_CMDLINE_LINUX.Update kernel:
yum install kernel kernel-headers kernel-tools kernel-tools-libs kexec-tools
Update the grub configuration:
grub2-mkconfig -o /boot/grub2/grub.cfg
Reboot the machine.
Wait for the machine to become available.
Wait for 5 minutes for Docker and Kubernetes services to start.
Verify that the machine is
Ready:docker node ls kubectl get nodes
Repeat the steps above on the remaining machines of the affected cluster.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
A vSphere-based management cluster bootstrap fails due to a node leaving the cluster after an accidental IP address change.
The issue may affect a vSphere-based cluster only when IPAM is not enabled and IP addresses assignment to the vSphere virtual machines is done by a DHCP server present in the vSphere network.
By default, a DHCP server keeps lease of the IP address for 30 minutes.
Usually, a VM dhclient prolongs such lease by frequent DHCP requests
to the server before the lease period ends.
The DHCP prolongation request period is always less than the default lease time
on the DHCP server, so prolongation usually works.
But in case of network issues, for example, when dhclient from the
VM cannot reach the DHCP server, or the VM is being slowly powered on
for more than the lease time, such VM may lose its assigned IP address.
As a result, it obtains a new IP address.
Container Cloud does not support network reconfiguration after the IP of the VM has been changed. Therefore, such issue may lead to a VM leaving the cluster.
Symptoms:
One of the nodes is in the
NodeNotReadyordownstate:kubectl get nodes -o wide docker node ls
The UCP Swarm manager logs on the healthy manager node contain the following example error:
docker logs -f ucp-swarm-manager level=debug msg="Engine refresh failed" id="<docker node ID>|<node IP>: 12376"
If the affected node is manager:
The output of the docker info command contains the following example error:
Error: rpc error: code = Unknown desc = The swarm does not have a leader. \ It's possible that too few managers are online. \ Make sure more than half of the managers are online.
The UCP controller logs contain the following example error:
docker logs -f ucp-controller "warning","msg":"Node State Active check error: \ Swarm Mode Manager health check error: \ info: Cannot connect to the Docker daemon at tcp://<node IP>:12376. \ Is the docker daemon running?
On the affected node, the IP address on the first interface
eth0does not match the IP address configured in Docker. Verify theNode Addressfield in the output of the docker info command.The following lines are present in
/var/log/messages:dhclient[<pid>]: bound to <node IP> -- renewal in 1530 seconds
If there are several lines where the IP is different, the node is affected.
Workaround:
Select from the following options:
Bind IP addresses for all machines to their MAC addresses on the DHCP server for the dedicated vSphere network. In this case, VMs receive only specified IP addresses that never change.
Remove the Container Cloud node IPs from the IP range on the DHCP server for the dedicated vSphere network and configure the first interface
eth0on VMs with a static IP address.If a managed cluster is affected, redeploy it with IPAM enabled for new machines to be created and IPs to be assigned properly.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
Occasionally, kubelet may get stuck on the Cluster release 5.x.x series
with different errors in the ucp-kubelet containers leading to the nodes
failures. The following error occurs every time when accessing
the Kubernetes API server:
an error on the server ("") has prevented the request from succeeding
As a workaround, restart ucp-kubelet on the failed node:
ctr -n com.docker.ucp snapshot rm ucp-kubelet
docker rm -f ucp-kubelet
Fixed in 2.12.0
Adding of a new manager node to a managed cluster may hang due to
issues with joining etcd from a new node to the existing etcd cluster.
The new manager node hangs in the Deploy stage.
Symptoms:
The Ansible run tries executing the
Wait for Docker UCP to be accessiblestep and fails with the following error message:Status code was -1 and not [200]: Request failed: <urlopen error [Errno 111] Connection refused>
The etcd logs on the leader etcd node contain the following example error message occurring every 1-2 minutes:
2021-06-10 03:21:53.196677 W | etcdserver: not healthy for reconfigure, rejecting member add {ID:22bb1d4275f1c5b0 RaftAttributes:{PeerURLs:[https://<new manager IP>:12380] IsLearner:false} Attributes:{Name: ClientURLs:[]}}
To determine the etcd leader, run on any manager node:
docker exec -it ucp-kv sh # From the inside of the container: ETCDCTL_API=3 etcdctl -w table --endpoints=https://<1st manager IP>:12379,https://<2nd manager IP>:12379,https://<3rd manager IP>:12379 endpoint status
To verify logs on the leader node:
docker logs ucp-kv
Root cause:
In case of an unlucky network partition, the leader may lose quorum and members are not able to perform the election. For more details, see Official etcd documentation: Learning, figure 5.
Workaround:
Restart etcd on the leader node:
docker rm -f ucp-kv
Wait several minutes until the etcd cluster starts and reconciles.
The deployment of the new manager node will proceed and it will join the etcd cluster. After that, other MKE components will be configured and the node deployment will be finished successfully.
Note
The issue affects only Helm v2 releases and is addressed for Helm v3. Starting from Container Cloud 2.19.0, all Helm releases are switched to v3.
During a management, regional, or managed cluster deployment,
Helm releases may get stuck in the FAILED or UNKNOWN state
although the corresponding machines statuses are Ready
in the Container Cloud web UI. For example, if the StackLight Helm release
fails, the links to its endpoints are grayed out in the web UI.
In the cluster status, providerStatus.helm.ready and
providerStatus.helm.releaseStatuses.<releaseName>.success are false.
HelmBundle cannot recover from such states and requires manual actions.
The workaround below describes the recovery steps for the stacklight
release that got stuck during a cluster deployment.
Use this procedure as an example for other Helm releases as required.
Workaround:
Verify the failed release has the
UNKNOWNorFAILEDstatus in the HelmBundle object:kubectl --kubeconfig <regionalClusterKubeconfigPath> get helmbundle <clusterName> -n <clusterProjectName> -o=jsonpath={.status.releaseStatuses.stacklight} In the command above and in the steps below, replace the parameters enclosed in angle brackets with the corresponding values of your cluster.
Example of system response:
stacklight: attempt: 2 chart: "" finishedAt: "2021-02-05T09:41:05Z" hash: e314df5061bd238ac5f060effdb55e5b47948a99460c02c2211ba7cb9aadd623 message: '[{"occurrence":1,"lastOccurrenceDate":"2021-02-05 09:41:05","content":"error updating the release: rpc error: code = Unknown desc = customresourcedefinitions.apiextensions.k8s.io \"helmbundles.lcm.mirantis.com\" already exists"}]' notes: "" status: UNKNOWN success: false version: 0.1.2-mcp-398
Log in to the
helm-controllerpod console:kubectl --kubeconfig <affectedClusterKubeconfigPath> exec -n kube-system -it helm-controller-0 sh -c tiller
Download the Helm v3 binary. For details, see official Helm documentation.
Remove the failed release:
helm delete <failed-release-name>
For example:
helm delete stacklight
Once done, the release triggers for redeployment.
Fixed in 2.12.0
The MariaDB pods fail to start after MariaDB blocks itself during the State Snapshot Transfers sync.
Workaround:
Verify the failed pod readiness:
kubectl describe pod -n kaas <failedMariadbPodName>
If the readiness probe failed with the WSREP not synced message, proceed to the next step. Otherwise, assess the MariaDB pod logs to identify the failure root cause.
Obtain the MariaDB admin password:
kubectl get secret -n kaas mariadb-dbadmin-password -o jsonpath='{.data.MYSQL_DBADMIN_PASSWORD}' | base64 -d ; echo
Verify that
wsrep_local_state_commentisDonororDesynced:kubectl exec -it -n kaas <failedMariadbPodName> -- mysql -uroot -p<mariadbAdminPassword> -e "SHOW status LIKE \"wsrep_local_state_comment\";"
Restart the failed pod:
kubectl delete pod -n kaas <failedMariadbPodName>
Fixed in 2.12.0
It may be impossible to override the default route matchers for Salesforce notifier.
Note
After applying the workaround, you may notice the following warning message. It is expected and does not affect configuration rendering:
Warning: Merging destination map for chart 'stacklight'. Overwriting table
item 'match', with non table value: []
Workaround:
Open the StackLight configuration manifest as described in StackLight configuration procedure.
In
alertmanagerSimpleConfig.salesForce, specify the following configuration:alertmanagerSimpleConfig: salesForce: route: match: [] match_re: your_matcher_key1: your_matcher_value1 your_matcher_key2: your_matcher_value2 ...
Fixed in 2.13.0
The Watchdog alert is not routed to Salesforce by default.
Note
After applying the workaround, you may notice the following warning message. It is expected and does not affect configuration rendering:
Warning: Merging destination map for chart 'stacklight'. Overwriting table
item 'match', with non table value: []
Workaround:
Open the StackLight configuration manifest as described in StackLight configuration procedure.
In
alertmanagerSimpleConfig.salesForce, specify the following configuration:alertmanagerSimpleConfig: salesForce: route: match: [] match_re: severity: "informational|critical" matchers: - severity=~"informational|critical"
Affects only Container Cloud 2.11,0, 2.12,0, 2.13.0, and 2.13.1
Ceph LCM automatic operations such as Ceph OSD or Ceph node removal are
unstable for the new Rook 1.6.8 and Ceph 15.2.13 (Ceph Octopus) versions and
may cause data corruption. Therefore, manageOsds is disabled until further
notice.
As a workaround, to safely remove a Ceph OSD or node from a Ceph cluster, perform the steps described in Remove Ceph OSD manually.
Fixed in 2.12.0
If the latest Ubuntu 18.04 image, for example, with kernel 4.15.0-153-generic, is installed on the bootstrap node, a management cluster bootstrap fails during the setup of the Kubernetes cluster by kind.
The issue occurs since the kind version 0.9.0 delivered with the bootstrap script is not compatible with the latest Ubuntu 18.04 image that requires kind version 0.11.1.
To verify that the bootstrap node is affected by the issue:
In the bootstrap script stdout, verify the connection to Tiller.
Example of system response extract on an affected bootstrap node:
clusterdeployer.go:164] Initialize Tiller in bootstrap cluster. bootstrap_create.go:64] unable to initialize Tiller in bootstrap cluster: \ failed to establish connection with tiller
In the bootstrap script stdout, identify the step after which the bootstrap process fails.
Example of system response extract on an affected bootstrap node:
clusterdeployer.go:128] Connecting to bootstrap cluster
In the kind cluster, verify the
kube-proxyservice readiness:./bin/kind get kubeconfig --name clusterapi > /tmp/kind_kubeconfig.yaml ./bin/kubectl --kubeconfig /tmp/kind_kubeconfig.yaml get po -n kube-system | grep kube-proxy ./bin/kubectl --kubeconfig /tmp/kind_kubeconfig.yaml-n kube-system logs kube-proxy-<podPostfixID>
Example of the
kube-proxyservice stdout extract on an affected bootstrap node:I0831 11:56:16.139300 1 conntrack.go:100] Set sysctl 'net/netfilter/nf_conntrack_max' to 131072 F0831 11:56:16.139313 1 server.go:497] open /proc/sys/net/netfilter/nf_conntrack_max: permission denied
If the verification steps below are positive, proceed with the workaround below.
Workaround:
Clean up the bootstrap cluster:
./bin/kind delete cluster --name clusterapi
Upgrade the kind binary to version 0.11.1:
curl -L https://github.com/kubernetes-sigs/kind/releases/download/v0.11.1/kind-linux-amd64 -o bin/kind chmod a+x bin/kind
Restart the bootstrap script:
./bootstrap.sh all
Fixed in 2.12.0
The deployment of new managed clusters using the Cluster release 6.18.0 with StackLight enabled in the HA mode on control plane nodes does not have StackLight deployed. The update of existing clusters with such StackLight configuration that were created using the Cluster release 6.16.0 is blocked with the following error message:
cluster release version upgrade is forbidden: \
Minimum number of worker machines with StackLight label is 3
Workaround:
On the affected managed cluster:
Create a key-value pair that will be used as a unique label on the cluster nodes. In our example, it is
forcedRole: stacklight.To verify the labels names that already exist on the cluster nodes:
kubectl get nodes --show-labels
Add the new label to the target nodes for StackLight. For example, to the Kubernetes master nodes:
kubectl label nodes --selector=node-role.kubernetes.io/master forcedRole=stacklight
Verify that the new label is added:
kubectl get nodes --show-labels
On the related management cluster:
Configure
nodeSelectorfor the StackLight components by modifying the affectedClusterobject:kubectl edit cluster <affectedManagedClusterName> -n <affectedManagedClusterProjectName>
For example:
spec: ... providerSpec: ... value: ... helmReleases: ... - name: stacklight values: ... nodeSelector: default: forcedRole: stacklight
Select from the following options:
If you faced the issue during a managed cluster deployment, skip this step.
If you faced the issue during a managed cluster update, wait until all StackLight components resources are recreated on the target nodes with updated node selectors.
To monitor the cluster status:
kubectl get cluster <affectedManagedClusterName> -n <affectedManagedClusterProjectName> -o jsonpath='{.status.providerStatus.conditions[?(@.type=="StackLight")]}' | jq
In the cluster status, verify that the
elasticsearch-masterandprometheus-serverresources are ready. The process can take up to 30 minutes.Example of a negative system response:
{ "message": "not ready: statefulSets: stacklight/elasticsearch-master got 2/3 replicas", "ready": false, "type": "StackLight" }
In the Container Cloud web UI, add a fake StackLight label to any 3 worker nodes to satisfy the deployment requirement as described in Create a machine using web UI. Eventually, StackLight will be still placed on the target nodes with the
forcedRole: stacklightlabel.Once done, the StackLight deployment or update proceeds.
An upgrade of a bare metal or Equinix metal based management cluster originally deployed using the Container Cloud release earlier than 2.8.0 fails with the following error message:
Upgrade "kaas-public-api" failed: \
cannot patch "kaascephclusters.kaas.mirantis.com" with kind \
CustomResourceDefinition: CustomResourceDefinition.apiextensions.k8s.io \
kaascephclusters.kaas.mirantis.com" is invalid: \
spec.preserveUnknownFields: Invalid value: true: \
must be false in order to use defaults in the schema
Workaround:
Change the
preserveUnknownFieldsvalue for theKaaSCephClusterCRD tofalse:kubectl patch crd kaascephclusters.kaas.mirantis.com -p '{"spec":{"preserveUnknownFields":false}}'
Upgrade
kaas-public-api:helm -n kaas upgrade kaas-public-api https://binary.mirantis.com/core/helm/kaas-public-api-1.24.6.tgz --reuse-values
Fixed in 2.12.0
An upgrade of a bare metal or Equinix Metal based management or managed cluster fails with the following exemplary error messages:
- message: 'Failed to configure Ceph cluster: ceph cluster verification is failed:
[PG_AVAILABILITY: Reduced data availability: 33 pgs inactive, OSD_DOWN: 3 osds
down, OSD_HOST_DOWN: 3 hosts (3 osds) down, OSD_ROOT_DOWN: 1 root (3 osds) down,
Not all Osds are up]'
- message: 'not ready: deployments: kaas/dnsmasq got 0/1 replicas, kaas/ironic got
0/1 replicas, rook-ceph/rook-ceph-osd-0 got 0/1 replicas, rook-ceph/rook-ceph-osd-1
got 0/1 replicas, rook-ceph/rook-ceph-osd-2 got 0/1 replicas; statefulSets: kaas/httpd
got 0/1 replicas, kaas/mariadb got 0/1 replicas'
ready: false
type: Kubernetes
The cluster is affected by the issue if it has different Ceph versions installed:
kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l app=rook-ceph-tools -o name) -- ceph versions
Example of system response:
"mon": {
"ceph version 15.2.13 (c44bc49e7a57a87d84dfff2a077a2058aa2172e2) octopus (stable)": 3
},
"mgr": {
"ceph version 15.2.13 (c44bc49e7a57a87d84dfff2a077a2058aa2172e2) octopus (stable)": 1
},
"osd": {
"ceph version 14.2.19 (bb796b9b5bab9463106022eef406373182465d11) nautilus (stable)": 3
},
"mds": {},
"overall": {
"ceph version 15.2.13 (c44bc49e7a57a87d84dfff2a077a2058aa2172e2) octopus (stable)": 4
"ceph version 14.2.19 (bb796b9b5bab9463106022eef406373182465d11) nautilus (stable)": 3
}
Additionally, the output may display no Ceph OSDs:
"mon": {
"ceph version 15.2.13 (c44bc49e7a57a87d84dfff2a077a2058aa2172e2) octopus (stable)": 3
},
"mgr": {
"ceph version 15.2.13 (c44bc49e7a57a87d84dfff2a077a2058aa2172e2) octopus (stable)": 1
},
"osd": {},
"mds": {},
"overall": {
"ceph version 15.2.13 (c44bc49e7a57a87d84dfff2a077a2058aa2172e2) octopus (stable)": 4
}
Workaround:
Manually update the image of each
rook-ceph-osddeployment tohttp://mirantis.azurecr.io/ceph/ceph:v15.2.13:kubectl -n rook-ceph edit deploy rook-ceph-osd-<i>
In the system output, grep
14.2.19and replace with15.2.13.Verify that all OSDs for all
rook-ceph-osddeployments have the 15.2.13 image version:kubectl -n rook-ceph get pod -l app=rook-ceph-osd -o jsonpath='{range .items[*]}{@.metadata.name}{" "}{@.spec.containers[0].image}{"\n"}{end}'
Restart the
rook-ceph-operatorpod:kubectl -n rook-ceph delete pod -l app=rook-ceph-operator
Fixed in 2.12.0
During a management cluster upgrade of any supported cloud provider except
vSphere, you may notice the following false-positive messages for the
squid-proxy Helm release that is disabled in Container Cloud 2.11.0:
Helm charts not installed yet: squid-proxy
Error: release: "squid-proxy" not found
Ignore these errors for any cloud provider except vSphere that continues
using squid-proxy in Container Cloud 2.11.0.
Fixed in 2.12.0
Management cluster upgrade may get stuck and then fail with the following error message: ClusterWorkloadLocks in cluster default/kaas-mgmt are still active - ceph-clusterworkloadlock.
To verify that the cluster is affected:
Enter the
ceph-toolspod.Verify that some Ceph daemons were not upgraded to Octopus:
ceph versionsRun ceph -s and verify that the output contains the following health warning:
mons are allowing insecure global_id reclaim clients are allowing insecure global_id reclaim
If the upgrade is stuck, some Ceph daemons are stuck on upgrade to Octopus, and the health warning above is present, perform the following steps.
Workaround:
Run the following commands:
ceph config set global mon_warn_on_insecure_global_id_reclaim false ceph config set global mon_warn_on_insecure_global_id_reclaim_allowed false
Exit the
ceph-toolspod.Restart the
rook-ceph-operatorpod:kubectl -n rook-ceph delete app=rook-ceph-operator
Fixed in 2.12.0
An update of the Container Cloud management, regional, or managed cluster of any cloud provider type from the Cluster release 7.0.0 to 7.1.0 fails due to the failed Patroni pod.
As a workaround, increase the default resource requests and limits
for PostgreSQL as follows:
resources:
postgresql:
requests:
cpu: "256m"
memory: "1Gi"
limits:
cpu: "512m"
memory: "2Gi"
For details, see Resource limits.
An Equinix-based management or managed cluster fails to update with the
FailedAttachVolume and FailedMount warnings.
Workaround:
Verify that the description of the pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
<affectedProjectName>is the Container Cloud project name where the pods failed to run<affectedPodName>is a pod name that failed to run in this project
In the pod description, identify the node name where the pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain the rbd volume mount failed: <csi-vol-uuid> is being used error. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the pod that fails to init to0replicas.On every
csi-rbdpluginpod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state isRunning.
Helm releases may get stuck in the PENDING_UPGRADE status
during a management or managed cluster upgrade. The HelmBundle Controller
cannot recover from this state and requires manual actions. The workaround
below describes the recovery process for the openstack-operator release
that stuck during a managed cluster update. Use it as an example for other
Helm releases as required.
Workaround:
Log in to the
helm-controllerpod console:kubectl exec -n kube-system -it helm-controller-0 sh -c tiller
Identify the release that stuck in the
PENDING_UPGRADEstatus. For example:./helm --host=localhost:44134 history openstack-operator
Example of system response:
REVISION UPDATED STATUS CHART DESCRIPTION 1 Tue Dec 15 12:30:41 2020 SUPERSEDED openstack-operator-0.3.9 Install complete 2 Tue Dec 15 12:32:05 2020 SUPERSEDED openstack-operator-0.3.9 Upgrade complete 3 Tue Dec 15 16:24:47 2020 PENDING_UPGRADE openstack-operator-0.3.18 Preparing upgrade
Roll back the failed release to the previous revision:
Download the Helm v3 binary. For details, see official Helm documentation.
Roll back the failed release:
helm rollback <failed-release-name>
For example:
helm rollback openstack-operator 2
Once done, the release will be reconciled.
Fixed in 2.13.0
On a managed cluster with logging disabled, changing NodeSelector can cause StackLight update failure with the following message in the StackLight Helm Controller logs:
Upgrade "stacklight" failed: Job.batch "stacklight-delete-logging-pvcs-*" is invalid: spec.template: Invalid value: ...
As a workaround, disable the stacklight-delete-logging-pvcs-* job.
Workaround:
Open the affected
Clusterobject for editing:kubectl edit cluster <affectedManagedClusterName> -n <affectedManagedClusterProjectName>
Set
deleteVolumestofalse:spec: ... providerSpec: ... value: ... helmReleases: ... - name: stacklight values: ... logging: deleteVolumes: false ...
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.11.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.24.6 |
aws-credentials-controller |
1.24.6 |
|
Azure New |
azure-provider |
1.24.6 |
azure-credentials-controller |
1.24.6 |
|
Bare metal |
baremetal-operator Updated |
5.1.0 |
baremetal-public-api Updated |
5.1.0 |
|
baremetal-provider Updated |
1.24.6 |
|
httpd |
1.18.0 |
|
ironic Updated |
victoria-bionic-20210719060025 |
|
ironic-operator Updated |
base-bionic-20210726193746 |
|
kaas-ipam Updated |
base-bionic-20210729185610 |
|
local-volume-provisioner |
1.0.6-mcp |
|
mariadb |
10.4.17-bionic-20210617085111 |
|
IAM |
iam |
2.4.2 |
iam-controller Updated |
1.24.6 |
|
keycloak |
12.0.0 |
|
Container Cloud |
admission-controller Updated |
1.24.8 |
byo-credentials-controller Updated |
1.24.6 |
|
byo-provider Updated |
1.24.6 |
|
kaas-public-api Updated |
1.24.6 |
|
kaas-exporter Updated |
1.24.6 |
|
kaas-ui Updated |
1.24.7 |
|
lcm-controller Updated |
0.2.0-404-g7f77e62c |
|
mcc-cache Updated |
1.24.6 |
|
proxy-controller Updated |
1.24.6 |
|
release-controller Updated |
1.24.6 |
|
rhellicense-controller Updated |
1.24.6 |
|
squid-proxy |
0.0.1-5 |
|
Equinix Metal Updated |
equinix-provider |
1.24.6 |
equinix-credentials-controller |
1.24.6 |
|
OpenStack Updated |
openstack-provider |
1.24.6 |
os-credentials-controller |
1.24.6 |
|
VMware vSphere Updated |
vsphere-provider |
1.24.6 |
vsphere-credentials-controller |
1.24.6 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.11.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-5.1.0.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-5.1.0.tgz |
|
ironic-python-agent-bionic.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-victoria-bionic-debug-20210622161844 |
|
ironic-python-agent-bionic.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-victoria-bionic-debug-20210622161844 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-1.0.6-mcp.tgz |
|
provisioning_ansible Updated |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-74-8ab0bf0.tgz |
|
target ubuntu system |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-20210622161844 |
|
Docker images |
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20210623143347 |
dnsmasq |
mirantis.azurecr.io/general/dnsmasq:focal-20210617094827 |
|
httpd |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20210719060025 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20210719060025 |
|
ironic-operator Updated |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20210726193746 |
|
ironic-prometheus-exporter |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20210608113804 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20210729185610 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210617085111 |
|
syslog-ng |
mirantis.azurecr.io/bm/syslog-ng:base-bionic-20210617094817 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.24.6.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.24.6.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.24.6.tgz |
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.24.6.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.24.6.tgz |
|
azure-credentials-controller New |
https://binary.mirantis.com/core/helm/azure-credentials-controller-1.24.6.tgz |
|
azure-provider New |
https://binary.mirantis.com/core/helm/azure-provider-1.24.6.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.24.6.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.24.6.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.24.6.tgz |
|
equinix-credentials-controller |
https://binary.mirantis.com/core/helm/equinix-credentials-controller-1.24.6.tgz |
|
equinix-provider |
https://binary.mirantis.com/core/helm/equinix-provider-1.24.6.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.24.6.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.24.6.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.24.6.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.24.6.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.24.6.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.24.6.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.24.6.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.24.6.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.24.6.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.24.6.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.24.6.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.24.6.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.24.8 |
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.24.6 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.24.6 |
|
azure-cluster-api-controller New |
mirantis.azurecr.io/core/azure-cluster-api-controller:1.24.6 |
|
azure-credentials-controller New |
mirantis.azurecr.io/core/azure-credentials-controller:1.24.6 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.24.6 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.24.6 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.24.6 |
|
cluster-api-provider-equinix Updated |
mirantis.azurecr.io/core/cluster-api-provider-equinix:1.24.6 |
|
equinix-credentials-controller Updated |
mirantis.azurecr.io/core/equinix-credentials-controller:1.24.6 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.24.7 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.24.6 |
|
kproxy Updated |
mirantis.azurecr.io/lcm/kproxy:1.24.6 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:v0.2.0-404-g7f77e62c |
|
nginx |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.24.6 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.24.6 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.24.6 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.24.6 |
|
squid-proxy Updated |
mirantis.azurecr.io/core/squid-proxy:0.0.1-5 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-api-controller:1.24.6 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.24.6 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux Updated |
||
iamctl-darwin Updated |
||
iamctl-windows Updated |
||
Helm charts |
iam Updated |
|
iam-proxy Updated |
||
keycloak_proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.25.0.tgz |
|
Docker images |
api |
mirantis.azurecr.io/iam/api:0.5.2 |
auxiliary |
mirantis.azurecr.io/iam/auxiliary:0.5.2 |
|
kubernetes-entrypoint Updated |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v0.3.1 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak Updated |
mirantis.azurecr.io/iam/keycloak:0.5.2 |
|
keycloak-gatekeeper Updated |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3 |
Starting from Container Cloud 2.11.0, the StackLight node label is required for managed clusters deployed in HA mode. The StackLight node label allows running StackLight components on specific worker nodes with corresponding resources.
Before upgrading an existing managed cluster with StackLight deployed in HA mode to the latest Cluster release, add the StackLight node label to at least 3 worker machines. Otherwise, the cluster upgrade will fail.
To add the StackLight node label to a worker machine:
Log in to the Container Cloud web UI.
On the Machines page, click the More action icon in the last column of the required machine field and select Configure machine.
In the window that opens, select the StackLight node label.
Caution
If your managed cluster contains more than 3 worker nodes, select from the following options:
If you have a small cluster, add the StackLight label to all worker nodes.
If you have a large cluster, identify the exact nodes that run StackLight and add the label to these specific nodes only.
Otherwise, some of the StackLight components may become inaccessible after the cluster update.
To identify the worker machines where StackLight is deployed:
Log in to the Container Cloud web UI.
Download the required cluster
kubeconfig:On the Clusters page, click the More action icon in the last column of the required cluster and select Download Kubeconfig.
Not recommended. Select Offline Token to generate an offline IAM token. Otherwise, for security reasons, the
kubeconfigtoken expires every 30 minutes of the Container Cloud API idle time and you have to downloadkubeconfigagain with a newly generated token.Click Download.
Export the
kubeconfigparameters to your local machine with access to kubectl. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Obtain the list of machines with the StackLight local volumes attached.
Note
In the command below, substitute
<mgmtKubeconfig>with the path to your management clusterkubeconfigandprojectNamewith the project name where your cluster is located.kubectl get persistentvolumes -o=json | \ jq '.items[]|select(.spec.claimRef.namespace=="stacklight")|.spec.nodeAffinity.required.nodeSelectorTerms[].matchExpressions[].values[]| sub("^kaas-node-"; "")' | \ sort -u | xargs -I {} kubectl --kubeconfig <mgmtKubeconfig> -n <projectName> get machines -o=jsonpath='{.items[?(@.metadata.annotations.kaas\.mirantis\.com/uid=="{}")].metadata.name}{"\n"}'
In the Container Cloud web UI, add the StackLight node label to every machine from the list obtained in the previous step.
The Mirantis Container Cloud GA release 2.10.0:
Introduces support for the Cluster release 7.0.0 that is based on the updated versions of Mirantis Container Runtime 20.10.5, and Mirantis Kubernetes Engine 3.4.0 with Kubernetes 1.20.
Introduces support for the Cluster release 5.17.0 that is based on Mirantis Kubernetes Engine 3.3.6 with Kubernetes 1.18 and the updated version of Mirantis Container Runtime 20.10.5.
Continues supporting the Cluster release 6.16.0 that is based on the Cluster release 5.16.0 and represents Mirantis OpenStack for Kubernetes (MOS) 21.3.
Supports deprecated Cluster releases 5.16.0 and 6.14.0 that will become unsupported in one of the following Container Cloud releases.
Supports the Cluster release 5.11.0 only for attachment of existing MKE 3.3.4 clusters. For the deployment of new or attachment of existing MKE 3.3.6 clusters, the latest available Cluster release is used.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.10.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.10.0. For the list of enhancements in the Cluster releases 7.0.0, 5.17.0, and 6.16.0 that are supported by the Container Cloud release 2.10.0, see the Cluster releases (managed).
7.x Cluster release series with updated versions of MCR, MKE, and Kubernetes
Removal of IAM and Keycloak IPs configuration for the vSphere provider
Support of MKE 3.3.x series and 3.4.0 for cluster attachment
Implemented the 7.x Cluster release series that contains updated versions of:
Mirantis Container Runtime (MCR) 20.10.5
Mirantis Kubernetes Engine (MKE) 3.4.0
Kubernetes 1.20.1
Learn more
Added support of several Mirantis Kubernetes Engine (MKE) versions of the 3.3.x series and 3.4.0 for attaching or detaching of existing MKE 3.3.3 - 3.3.6 and 3.4.0 clusters as well as updating them to the latest supported version.
This feature allows for visualization of all your MKE clusters details on one management cluster including clusters health, capacity, and usage.
Learn more
Technology Preview
Introduced the initial Technology Preview support of the CentOS 7.9 operating system for the vSphere-based management, regional, and managed clusters.
Note
Deployment of a Container Cloud cluster that is based on both RHEL and CentOS operating systems is not supported.
To deploy a vSphere-based managed cluster on CentOS with custom or additional mirrors configured in the VM template, the
squid-proxyconfiguration on the management or regional cluster is required. It is done automatically if you use the Container Cloud script for the VM template creation.
Added support of RHEL 7.9 for the vSphere provider. This operating system is now installed by default on any type of the vSphere-based Container Cloud clusters.
RHEL 7.8 deployment is still possible with allowed access to the
rhel-7-server-rpms repository provided by the Red Hat Enterprise
Linux Server 7 x86_64.
Verify that your RHEL license or activation key meets this requirement.
Implemented the guided tour in the Container Cloud web UI to help you get oriented with the multi-cluster multi-cloud Container Cloud platform. This brief guided tour will step you through the key features of Container Cloud that can be performed using the Container Cloud web UI.
Removed the following Keycloak and IAM services variables that were used during a vSphere-based management cluster bootstrap for the MetalLB configuration:
KEYCLOAK_FLOATING_IPIAM_FLOATING_IP
Now, these IPs are automatically generated in the MetalLB range for certificates creation.
Learn more
Implemented the container-cloud bootstrap user add command that allows creating Keycloak users with specific permissions to access the Container Cloud web UI and manage the Container Cloud clusters.
For security reasons, removed the default password password for Keycloak
that was generated during a management cluster bootstrap to access
the Container Cloud web UI.
On top of continuous improvements delivered to the existing Container Cloud guides, added documentation about the Container Cloud user roles management through the Keycloak Admin Console. The section outlines the IAM roles and scopes structure in Container Cloud as well as role assignment to users using the Keycloak Admin Console.
The following issues have been addressed in the Mirantis Container Cloud release 2.10.0 along with the Cluster releases 7.0.0 and 5.17.0.
For more issues addressed for the Cluster release 6.16.0, see also addressed issues 2.8.0 and 2.9.0.
[8013][AWS] Fixed the issue with managed clusters deployment, that requires persistent volumes (PVs), failing with pods being stuck in the
Pendingstate and having thepod has unbound immediate PersistentVolumeClaimsandnode(s) had volume node affinity conflicterrors.Note
The issue affects only the MKE deployments with Kubernetes 1.18 and is fixed for MKE 3.4.x with Kubernetes 1.20 that is available since the Cluster release 7.0.0.
[14981] [Equinix Metal] Fixed the issue with a manager machine deployment failing if the cluster contained at least one manager machine that was stuck in the
Provisioningstate due to the capacity limits in the selected Equinix Metal data center.[13402] [LCM] Fixed the issue with the existing clusters failing with the no space left on device error due to an excessive amount of core dumps produced by applications that fail frequently.
[14125] [LCM] Fixed the issue with managed clusters deployed or updated on a regional cluster of another provider type displaying inaccurate Nodes readiness live status in the Container Cloud web UI.
[14040][StackLight] Fixed the issue with the Tiller container of the
stacklight-helm-controllerpods switching toCrashLoopBackOffand then being OOMKilled. Limited the releases number in history to3to prevent RAM overconsumption by Tiller.[14152] [Upgrade] Fixed the issue with managed cluster release upgrade failing and the DNS names of the Kubernetes services on the affected pod not being resolved due to DNS issues on pods with host networking.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.10.0 including the Cluster releases 7.0.0, 6.16.0, and 5.16.0.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Fixed in the Cluster release 7.0.0
Note
The issue below affects only the Kubernetes 1.18 deployments. Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
On a management cluster with multiple AWS-based managed
clusters, some clusters fail to complete the deployments that require
persistent volumes (PVs), for example, Elasticsearch.
Some of the affected pods get stuck in the Pending state
with the pod has unbound immediate PersistentVolumeClaims and
node(s) had volume node affinity conflict errors.
Warning
The workaround below applies to HA deployments where data can be rebuilt from replicas. If you have a non-HA deployment, back up any existing data before proceeding, since all data will be lost while applying the workaround.
Workaround:
Obtain the persistent volume claims related to the storage mounts of the affected pods:
kubectl get pod/<pod_name1> pod/<pod_name2> \ -o jsonpath='{.spec.volumes[?(@.persistentVolumeClaim)].persistentVolumeClaim.claimName}'
Note
In the command above and in the subsequent steps, substitute the parameters enclosed in angle brackets with the corresponding values.
Delete the affected
PodsandPersistentVolumeClaimsto reschedule them: For example, for StackLight:kubectl -n stacklight delete \ pod/<pod_name1> pod/<pod_name2> ... pvc/<pvc_name2> pvc/<pvc_name2> ...
Fixed in 2.12.0
If an Equinix Metal based cluster is being deployed in an Equinix Metal project with no SSH keys, the Equinix Metal provider fails to create machines with the following error:
Failed to create machine "kaas-mgmt-controlplane-0"...
failed to create device: POST https://api.equinix.com/metal/v1/projects/...
<deviceID> must have at least one SSH key or explicitly send no_ssh_keys option
Workaround:
Create a new SSH key.
Log in to the Equinix Metal console.
In Project Settings, click Project SSH Keys.
Click Add New Key and add details of the newly created SSH key.
Click Add.
Restart the cluster deployment.
Fixed in 2.12.0
Adding a new machine to a baremetal-based
managed cluster may fail after the baremetal-based management cluster upgrade.
The issue occurs because the PXE boot is not working for the new node.
In this case, file /volume/tftpboot/ipxe.efi not found logs appear on
dnsmasq-tftp.
Workaround:
Log in to a local machine where your management cluster
kubeconfigis located and where kubectl is installed.Scale the Ironic deployment down to
0replicas.kubectl -n kaas scale deployments/ironic --replicas=0
Scale the Ironic deployment up to
1replica:kubectl -n kaas scale deployments/ironic --replicas=1
Fixed in 2.11.0
If an L2 template is configured incorrectly, a bare metal cluster is deployed
successfully but with the runtime errors in the IpamHost object.
Workaround:
If you suspect that the machine is not working properly because
of incorrect network configuration, verify the status of the corresponding
IpamHost object. Inspect the l2RenderResult and ipAllocationResult
object fields for error messages.
An OpenStack-based regional cluster cleanup fails with the timeout error.
Workaround:
Wait for the
Clusterobject to be deleted in the bootstrap cluster:kubectl --kubeconfig <(./bin/kind get kubeconfig --name clusterapi) get cluster
The system output must be empty.
Remove the bootstrap cluster manually:
./bin/kind delete cluster --name clusterapi
Fixed in 2.11.0
A load balancer virtual IP address (VIP) is assigned to each manager
node on any type of the vSphere-based cluster. The issue occurs because
the Keepalived instances cannot set up a cluster due to the blocked
vrrp protocol traffic in the firewall configuration on the Container Cloud
nodes.
Note
Before applying the workaround below, verify that the dedicated
vSphere network does not have any other virtual machines with the
keepalived instance running with the same vrouter_id.
You can verify the vrouter_id value of the cluster
in /etc/keepalived/keepalived.conf on the manager nodes.
Workaround
Update the firewalld configuration on each manager node of the affected
cluster to allow the vrrp protocol traffic between the nodes:
SSH to any manager node using
mcc-user.Apply the
firewalldconfiguration:firewall-cmd --add-rich-rule='rule protocol value="vrrp" accept' --permanent firewall-cmd --reload
Apply the procedure to the remaining manager nodes of the cluster.
Fixed in 2.9.0 for new clusters
Newly created pods may fail to run and have the CrashLoopBackOff status
on long-living Container Cloud clusters deployed on RHEL 7.8 using the VMware
vSphere provider. The following is an example output of the
kubectl describe pod <pod-name> -n <projectName> command:
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: ContainerCannotRun
Message: OCI runtime create failed: container_linux.go:349:
starting container process caused "process_linux.go:297:
applying cgroup configuration for process caused
"mkdir /sys/fs/cgroup/memory/kubepods/burstable/<pod-id>/<container-id>>:
cannot allocate memory": unknown
The issue occurs due to the Kubernetes and Docker community issues.
According to the RedHat solution,
the workaround is to disable the kernel memory accounting feature
by appending cgroup.memory=nokmem to the kernel command line.
Note
The workaround below applies to the existing clusters only. The issue is resolved for new Container Cloud 2.9.0 deployments since the workaround below automatically applies to the VM template built during the vSphere-based management cluster bootstrap.
Apply the following workaround on each machine of the affected cluster.
Workaround
SSH to any machine of the affected cluster using
mcc-userand the SSH key provided during the cluster creation to proceed as therootuser.In
/etc/default/grub, setcgroup.memory=nokmemforGRUB_CMDLINE_LINUX.Update kernel:
yum install kernel kernel-headers kernel-tools kernel-tools-libs kexec-tools
Update the grub configuration:
grub2-mkconfig -o /boot/grub2/grub.cfg
Reboot the machine.
Wait for the machine to become available.
Wait for 5 minutes for Docker and Kubernetes services to start.
Verify that the machine is
Ready:docker node ls kubectl get nodes
Repeat the steps above on the remaining machines of the affected cluster.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
A vSphere-based management cluster bootstrap fails due to a node leaving the cluster after an accidental IP address change.
The issue may affect a vSphere-based cluster only when IPAM is not enabled and IP addresses assignment to the vSphere virtual machines is done by a DHCP server present in the vSphere network.
By default, a DHCP server keeps lease of the IP address for 30 minutes.
Usually, a VM dhclient prolongs such lease by frequent DHCP requests
to the server before the lease period ends.
The DHCP prolongation request period is always less than the default lease time
on the DHCP server, so prolongation usually works.
But in case of network issues, for example, when dhclient from the
VM cannot reach the DHCP server, or the VM is being slowly powered on
for more than the lease time, such VM may lose its assigned IP address.
As a result, it obtains a new IP address.
Container Cloud does not support network reconfiguration after the IP of the VM has been changed. Therefore, such issue may lead to a VM leaving the cluster.
Symptoms:
One of the nodes is in the
NodeNotReadyordownstate:kubectl get nodes -o wide docker node ls
The UCP Swarm manager logs on the healthy manager node contain the following example error:
docker logs -f ucp-swarm-manager level=debug msg="Engine refresh failed" id="<docker node ID>|<node IP>: 12376"
If the affected node is manager:
The output of the docker info command contains the following example error:
Error: rpc error: code = Unknown desc = The swarm does not have a leader. \ It's possible that too few managers are online. \ Make sure more than half of the managers are online.
The UCP controller logs contain the following example error:
docker logs -f ucp-controller "warning","msg":"Node State Active check error: \ Swarm Mode Manager health check error: \ info: Cannot connect to the Docker daemon at tcp://<node IP>:12376. \ Is the docker daemon running?
On the affected node, the IP address on the first interface
eth0does not match the IP address configured in Docker. Verify theNode Addressfield in the output of the docker info command.The following lines are present in
/var/log/messages:dhclient[<pid>]: bound to <node IP> -- renewal in 1530 seconds
If there are several lines where the IP is different, the node is affected.
Workaround:
Select from the following options:
Bind IP addresses for all machines to their MAC addresses on the DHCP server for the dedicated vSphere network. In this case, VMs receive only specified IP addresses that never change.
Remove the Container Cloud node IPs from the IP range on the DHCP server for the dedicated vSphere network and configure the first interface
eth0on VMs with a static IP address.If a managed cluster is affected, redeploy it with IPAM enabled for new machines to be created and IPs to be assigned properly.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
Occasionally, kubelet may get stuck on the Cluster release 5.x.x series
with different errors in the ucp-kubelet containers leading to the nodes
failures. The following error occurs every time when accessing
the Kubernetes API server:
an error on the server ("") has prevented the request from succeeding
As a workaround, restart ucp-kubelet on the failed node:
ctr -n com.docker.ucp snapshot rm ucp-kubelet
docker rm -f ucp-kubelet
Fixed in 2.12.0
Adding of a new manager node to a managed cluster may hang due to
issues with joining etcd from a new node to the existing etcd cluster.
The new manager node hangs in the Deploy stage.
Symptoms:
The Ansible run tries executing the
Wait for Docker UCP to be accessiblestep and fails with the following error message:Status code was -1 and not [200]: Request failed: <urlopen error [Errno 111] Connection refused>
The etcd logs on the leader etcd node contain the following example error message occurring every 1-2 minutes:
2021-06-10 03:21:53.196677 W | etcdserver: not healthy for reconfigure, rejecting member add {ID:22bb1d4275f1c5b0 RaftAttributes:{PeerURLs:[https://<new manager IP>:12380] IsLearner:false} Attributes:{Name: ClientURLs:[]}}
To determine the etcd leader, run on any manager node:
docker exec -it ucp-kv sh # From the inside of the container: ETCDCTL_API=3 etcdctl -w table --endpoints=https://<1st manager IP>:12379,https://<2nd manager IP>:12379,https://<3rd manager IP>:12379 endpoint status
To verify logs on the leader node:
docker logs ucp-kv
Root cause:
In case of an unlucky network partition, the leader may lose quorum and members are not able to perform the election. For more details, see Official etcd documentation: Learning, figure 5.
Workaround:
Restart etcd on the leader node:
docker rm -f ucp-kv
Wait several minutes until the etcd cluster starts and reconciles.
The deployment of the new manager node will proceed and it will join the etcd cluster. After that, other MKE components will be configured and the node deployment will be finished successfully.
Fixed in 2.11
A managed cluster update from the Cluster release 6.12.0 to
6.14.0 fails with worker nodes being stuck in the Deploy state with
the Network is unreachable error.
Workaround:
Verify the state of the loopback network interface:
ip l show lo
If the interface is not in the
UNKNOWNorUPstate, enable it manually:ip l set lo up
If the interface is in the
UNKNOWNorUPstate, assess the cluster logs to identify the failure root cause.Repeat the cluster update procedure.
Fixed in 2.11.0
During update of a managed cluster from the Cluster releases 6.12.0 to 6.14.0, the LCM Agent upgrade fails with the following error in logs:
lcmAgentUpgradeStatus:
error: 'failed to download agent binary: Get https://<mcc-cache-address>/bin/lcm/bin/lcm-agent/v0.2.0-289-gd7e9fa9c/lcm-agent:
x509: certificate signed by unknown authority'
Only clusters initially deployed using Container Cloud 2.4.0 or earlier are affected.
As a workaround, restart lcm-agent using the
service lcm-agent-* restart command on the affected nodes.
Note
The issue affects only Helm v2 releases and is addressed for Helm v3. Starting from Container Cloud 2.19.0, all Helm releases are switched to v3.
During a management, regional, or managed cluster deployment,
Helm releases may get stuck in the FAILED or UNKNOWN state
although the corresponding machines statuses are Ready
in the Container Cloud web UI. For example, if the StackLight Helm release
fails, the links to its endpoints are grayed out in the web UI.
In the cluster status, providerStatus.helm.ready and
providerStatus.helm.releaseStatuses.<releaseName>.success are false.
HelmBundle cannot recover from such states and requires manual actions.
The workaround below describes the recovery steps for the stacklight
release that got stuck during a cluster deployment.
Use this procedure as an example for other Helm releases as required.
Workaround:
Verify the failed release has the
UNKNOWNorFAILEDstatus in the HelmBundle object:kubectl --kubeconfig <regionalClusterKubeconfigPath> get helmbundle <clusterName> -n <clusterProjectName> -o=jsonpath={.status.releaseStatuses.stacklight} In the command above and in the steps below, replace the parameters enclosed in angle brackets with the corresponding values of your cluster.
Example of system response:
stacklight: attempt: 2 chart: "" finishedAt: "2021-02-05T09:41:05Z" hash: e314df5061bd238ac5f060effdb55e5b47948a99460c02c2211ba7cb9aadd623 message: '[{"occurrence":1,"lastOccurrenceDate":"2021-02-05 09:41:05","content":"error updating the release: rpc error: code = Unknown desc = customresourcedefinitions.apiextensions.k8s.io \"helmbundles.lcm.mirantis.com\" already exists"}]' notes: "" status: UNKNOWN success: false version: 0.1.2-mcp-398
Log in to the
helm-controllerpod console:kubectl --kubeconfig <affectedClusterKubeconfigPath> exec -n kube-system -it helm-controller-0 sh -c tiller
Download the Helm v3 binary. For details, see official Helm documentation.
Remove the failed release:
helm delete <failed-release-name>
For example:
helm delete stacklight
Once done, the release triggers for redeployment.
Fixed in 2.12.0
The MariaDB pods fail to start after MariaDB blocks itself during the State Snapshot Transfers sync.
Workaround:
Verify the failed pod readiness:
kubectl describe pod -n kaas <failedMariadbPodName>
If the readiness probe failed with the WSREP not synced message, proceed to the next step. Otherwise, assess the MariaDB pod logs to identify the failure root cause.
Obtain the MariaDB admin password:
kubectl get secret -n kaas mariadb-dbadmin-password -o jsonpath='{.data.MYSQL_DBADMIN_PASSWORD}' | base64 -d ; echo
Verify that
wsrep_local_state_commentisDonororDesynced:kubectl exec -it -n kaas <failedMariadbPodName> -- mysql -uroot -p<mariadbAdminPassword> -e "SHOW status LIKE \"wsrep_local_state_comment\";"
Restart the failed pod:
kubectl delete pod -n kaas <failedMariadbPodName>
Fixed in 2.12.0
It may be impossible to override the default route matchers for Salesforce notifier.
Note
After applying the workaround, you may notice the following warning message. It is expected and does not affect configuration rendering:
Warning: Merging destination map for chart 'stacklight'. Overwriting table
item 'match', with non table value: []
Workaround:
Open the StackLight configuration manifest as described in StackLight configuration procedure.
In
alertmanagerSimpleConfig.salesForce, specify the following configuration:alertmanagerSimpleConfig: salesForce: route: match: [] match_re: your_matcher_key1: your_matcher_value1 your_matcher_key2: your_matcher_value2 ...
Fixed in 2.13.0
The Watchdog alert is not routed to Salesforce by default.
Note
After applying the workaround, you may notice the following warning message. It is expected and does not affect configuration rendering:
Warning: Merging destination map for chart 'stacklight'. Overwriting table
item 'match', with non table value: []
Workaround:
Open the StackLight configuration manifest as described in StackLight configuration procedure.
In
alertmanagerSimpleConfig.salesForce, specify the following configuration:alertmanagerSimpleConfig: salesForce: route: match: [] match_re: severity: "informational|critical" matchers: - severity=~"informational|critical"
Fixed in 2.11.0
If you use a custom BareMetalHostProfile, after disk replacement
on a Ceph OSD, the Ceph OSD pod switches to the CrashLoopBackOff state
due to the Ceph OSD authorization key failing to be created properly.
Workaround:
Export
kubeconfigof your managed cluster. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
Delete the authorization key for the failed Ceph OSD:
ceph auth del osd.<ID>
SSH to the node on which the Ceph OSD cannot be created.
Clean up the disk that will be a base for the failed Ceph OSD. For details, see official Rook documentation.
Note
Ignore failures of the sgdisk --zap-all $DISK and blkdiscard $DISK commands if any.
On the managed cluster, restart Rook Operator:
kubectl -n rook-ceph delete pod -l app=rook-ceph-operator
Fixed in 2.12.0
If the latest Ubuntu 18.04 image, for example, with kernel 4.15.0-153-generic, is installed on the bootstrap node, a management cluster bootstrap fails during the setup of the Kubernetes cluster by kind.
The issue occurs since the kind version 0.9.0 delivered with the bootstrap script is not compatible with the latest Ubuntu 18.04 image that requires kind version 0.11.1.
To verify that the bootstrap node is affected by the issue:
In the bootstrap script stdout, verify the connection to Tiller.
Example of system response extract on an affected bootstrap node:
clusterdeployer.go:164] Initialize Tiller in bootstrap cluster. bootstrap_create.go:64] unable to initialize Tiller in bootstrap cluster: \ failed to establish connection with tiller
In the bootstrap script stdout, identify the step after which the bootstrap process fails.
Example of system response extract on an affected bootstrap node:
clusterdeployer.go:128] Connecting to bootstrap cluster
In the kind cluster, verify the
kube-proxyservice readiness:./bin/kind get kubeconfig --name clusterapi > /tmp/kind_kubeconfig.yaml ./bin/kubectl --kubeconfig /tmp/kind_kubeconfig.yaml get po -n kube-system | grep kube-proxy ./bin/kubectl --kubeconfig /tmp/kind_kubeconfig.yaml-n kube-system logs kube-proxy-<podPostfixID>
Example of the
kube-proxyservice stdout extract on an affected bootstrap node:I0831 11:56:16.139300 1 conntrack.go:100] Set sysctl 'net/netfilter/nf_conntrack_max' to 131072 F0831 11:56:16.139313 1 server.go:497] open /proc/sys/net/netfilter/nf_conntrack_max: permission denied
If the verification steps below are positive, proceed with the workaround below.
Workaround:
Clean up the bootstrap cluster:
./bin/kind delete cluster --name clusterapi
Upgrade the kind binary to version 0.11.1:
curl -L https://github.com/kubernetes-sigs/kind/releases/download/v0.11.1/kind-linux-amd64 -o bin/kind chmod a+x bin/kind
Restart the bootstrap script:
./bootstrap.sh all
Fixed in 2.11.0
A baremetal-based management cluster upgrade can fail with stuck ironic
and dnsmasq pods. The issue may occur due to the Ceph pre-upgraded
persistent volumes being unmapped incorrectly. As a result, the RBD volumes
mounts on nodes are without any real RBD volumes.
Symptoms:
The
ironicanddnsmasqdeployments fail:kubectl -n kaas get deploy
Example of system response:
NAME READY UP-TO-DATE AVAILABLE AGE ironic 0/1 0 0 6d10h dnsmasq 0/1 0 0 6d10h
The bare metal
mariadbandhttpdstatefulSetsfail:kubectl -n kaas get statefulset
Example output:
NAME READY AGE httpd 0/1 6d10h mariadb 0/1 6d10h
On the failed deployments pods, the ll /volume command hangs or outputs the
input/output error:Enter any pod of the failed deployment:
kubectl -n kaas exec -it <podName> -- bash
Replace
<podName>with the affected pod name. For example,httpd-0.Obtain the list of files in the
/volumedirectory:ll /volumeExample of system response:
ls: reading directory '.': Input/output error
If the above command gets stuck or outputs the
Input/output errorerror, the issue relates to theceph-csiunmounted RBD devices.
Workaround:
Identify the names of nodes with the affected pods:
kubectl -n kaas get pod <podName> -o jsonpath='{.spec.nodeName}'
Replace
<podName>with the affected pod name.Identify which
csi-rbdpluginpod is assigned to which node:kubectl -n rook-ceph get pod -l app=csi-rbdplugin -o jsonpath='{range .items[*]}{.metadata.name}{" "}{.spec.nodeName}{"\n"}'
Enter any affected
csi-rbdpluginpod.kubectl -n rook-ceph exec -it <csiPodName> -c csi-rbdplugin -- bash
Identify the mapped device classes on this pod:
rbd device list
Identify which devices are mounted on this pod:
mount | grep rbd
Unmount all devices that are not included into the rbd device list command output:
umount <rbdDeviceName>Replace
<rbdDeviceName>with a mounted RBD device name that is not included into the rbd device list output. For example,/dev/rbd0.Exit the
csi-rbdpluginpod:exitRepeat the steps above for the remaining affected
csi-rbdpluginpods on every affected node.Once all nonexistent mounts are unmounted on all nodes, restart the stuck deployments:
kubectl -n kaas get deploy kubectl -n kaas scale deploy <deploymentName> --replicas 0 kubectl -n kaas scale deploy <deploymentName> --replicas <replicasNumber>
<deploymentName>is a stuck bare metal deployment name, for example,ironic<replicasNumber>is the original number of replicas for the deployment that you can obtain using the get deploy command
Restart the failed bare metal
statefulSets:kubectl -n kaas get statefulset kubectl -n kaas scale statefulset <statefulSetName> --replicas 0 kubectl -n kaas scale statefulset <statefulSetName> --replicas <replicasNumber>
<statefulSetName>is a failed bare metalstatefulSetname, for example,mariadb<replicasNumber>is the original number of replicas for thestatefulSetthat you can obtain using the get statefulset command
An Equinix-based management or managed cluster fails to update with the
FailedAttachVolume and FailedMount warnings.
Workaround:
Verify that the description of the pods that failed to run contain the
FailedMountevents:kubectl -n <affectedProjectName> describe pod <affectedPodName>
<affectedProjectName>is the Container Cloud project name where the pods failed to run<affectedPodName>is a pod name that failed to run in this project
In the pod description, identify the node name where the pod failed to run.
Verify that the
csi-rbdpluginlogs of the affected node contain the rbd volume mount failed: <csi-vol-uuid> is being used error. The<csi-vol-uuid>is a unique RBD volume name.Identify
csiPodNameof the correspondingcsi-rbdplugin:kubectl -n rook-ceph get pod -l app=csi-rbdplugin \ -o jsonpath='{.items[?(@.spec.nodeName == "<nodeName>")].metadata.name}'
Output the affected
csiPodNamelogs:kubectl -n rook-ceph logs <csiPodName> -c csi-rbdplugin
Scale down the affected
StatefulSetorDeploymentof the pod that fails to init to0replicas.On every
csi-rbdpluginpod, search for stuckcsi-vol:for pod in `kubectl -n rook-ceph get pods|grep rbdplugin|grep -v provisioner|awk '{print $1}'`; do echo $pod kubectl exec -it -n rook-ceph $pod -c csi-rbdplugin -- rbd device list | grep <csi-vol-uuid> done
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
The
/dev/rbd<i>value is a mapped RBD volume that usescsi-vol.Delete
volumeattachmentof the affected pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale up the affected
StatefulSetorDeploymentback to the original number of replicas and wait until its state isRunning.
Helm releases may get stuck in the PENDING_UPGRADE status
during a management or managed cluster upgrade. The HelmBundle Controller
cannot recover from this state and requires manual actions. The workaround
below describes the recovery process for the openstack-operator release
that stuck during a managed cluster update. Use it as an example for other
Helm releases as required.
Workaround:
Log in to the
helm-controllerpod console:kubectl exec -n kube-system -it helm-controller-0 sh -c tiller
Identify the release that stuck in the
PENDING_UPGRADEstatus. For example:./helm --host=localhost:44134 history openstack-operator
Example of system response:
REVISION UPDATED STATUS CHART DESCRIPTION 1 Tue Dec 15 12:30:41 2020 SUPERSEDED openstack-operator-0.3.9 Install complete 2 Tue Dec 15 12:32:05 2020 SUPERSEDED openstack-operator-0.3.9 Upgrade complete 3 Tue Dec 15 16:24:47 2020 PENDING_UPGRADE openstack-operator-0.3.18 Preparing upgrade
Roll back the failed release to the previous revision:
Download the Helm v3 binary. For details, see official Helm documentation.
Roll back the failed release:
helm rollback <failed-release-name>
For example:
helm rollback openstack-operator 2
Once done, the release will be reconciled.
Fixed in 2.11.0
Upgrade of a Container Cloud management or regional cluster from version 2.9.0
to 2.10.0 and managed cluster from 5.16.0 to 5.17.0 may fail with the following
error message for the patroni-12-0, patroni-12-1 or patroni-12-2
pod.
error when evicting pods/"patroni-12-2" -n "stacklight" (will retry after 5s):
Cannot evict pod as it would violate the pod's disruption budget.
As a workaround, reinitialize the Patroni pod that got stuck:
kubectl -n stacklight exec -ti -c patroni $(kubectl -n stacklight \
get ep/patroni-12 -o jsonpath='{.metadata.annotations.leader}') -- \
patronictl reinit patroni-12 <POD_NAME> --force --wait
Substitute <POD_NAME> with the name of the Patroni pod from the error
message. For example:
kubectl -n stacklight exec -ti -c patroni $(kubectl -n stacklight \
get ep/patroni-12 -o jsonpath='{.metadata.annotations.leader}') -- \
patronictl reinit patroni-12 patroni-12-2
If the command above fails, reinitialize the affected pod with a new volume by
deleting the pod itself and the associated PersistentVolumeClaim (PVC):
Obtain the PVC of the affected pod:
kubectl -n stacklight get "pod/<POD_NAME>" -o jsonpath='{.spec.volumes[?(@.name=="storage-volume")].persistentVolumeClaim.claimName}'
Delete the affected pod and its PVC:
kubectl -n stacklight delete "pod/<POD_NAME>" "pvc/<POD_PVC>" sleep 3 # wait for StatefulSet to reschedule the pod, but miss dependent PVC creation kubectl -n stacklight delete "pod/<POD_NAME>"
Fixed in 2.11.0
An Alertmanager pod may get stuck in the CrashLoopBackOff state during
upgrade of a management, regional, or managed cluster and thus cause upgrade
failure with the Loading configuration file failed error message in logs.
Workaround:
Delete the Alertmanager pod that is stuck in the
CrashLoopBackOffstate. For example:kubectl delete pod/prometheus-alertmanager-1 -n stacklight
Wait for several minutes and verify that Alertmanager and its pods are up and running:
kubectl get all -n stacklight -l app=prometheus,component=alertmanager
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.10.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.23.2 |
aws-credentials-controller |
1.23.2 |
|
Bare metal |
baremetal-operator Updated |
5.0.5 |
baremetal-public-api Updated |
5.0.4 |
|
baremetal-provider Updated |
1.23.2 |
|
httpd |
1.18.0 |
|
ironic Updated |
victoria-bionic-20210615143607 |
|
ironic-operator Updated |
base-bionic-20210622124940 |
|
kaas-ipam Updated |
base-bionic-20210617150226 |
|
local-volume-provisioner |
1.0.6-mcp |
|
mariadb Updated |
10.4.17-bionic-20210617085111 |
|
IAM |
iam Updated |
2.4.2 |
iam-controller Updated |
1.23.2 |
|
keycloak |
12.0.0 |
|
Container Cloud Updated |
admission-controller |
1.23.3 |
byo-credentials-controller |
1.23.2 |
|
byo-provider |
1.23.2 |
|
kaas-public-api |
1.23.2 |
|
kaas-exporter |
1.23.2 |
|
kaas-ui |
1.23.4 |
|
lcm-controller |
0.2.0-372-g7e042f4d |
|
mcc-cache |
1.23.2 |
|
proxy-controller |
1.23.2 |
|
release-controller |
1.23.2 |
|
rhellicense-controller |
1.23.2 |
|
squid-proxy |
0.0.1-5 |
|
Equinix Metal Updated |
equinix-provider |
1.23.2 |
equinix-credentials-controller |
1.23.2 |
|
OpenStack Updated |
openstack-provider |
1.23.2 |
os-credentials-controller |
1.23.2 |
|
VMware vSphere Updated |
vsphere-provider |
1.23.2 |
vsphere-credentials-controller |
1.23.2 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.10.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-5.0.5.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-5.0.4.tgz |
|
ironic-python-agent-bionic.kernel Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-victoria-bionic-debug-20210622161844 |
|
ironic-python-agent-bionic.initramfs Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-victoria-bionic-debug-20210622161844 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-1.0.6-mcp.tgz |
|
provisioning_ansible Updated |
https://binary.mirantis.com/bm/bin/ansible/provisioning_ansible-0.1.1-72-3120eae.tgz |
|
target ubuntu system Updated |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-20210622161844 |
|
Docker images |
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20210623143347 |
dnsmasq Updated |
mirantis.azurecr.io/general/dnsmasq:focal-20210617094827 |
|
httpd |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20210615143607 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20210615143607 |
|
ironic-operator Updated |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20210622124940 |
|
ironic-prometheus-exporter Updated |
mirantis.azurecr.io/stacklight/ironic-prometheus-exporter:0.1-20210608113804 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20210617150226 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210617085111 |
|
syslog-ng Updated |
mirantis.azurecr.io/bm/syslog-ng:base-bionic-20210617094817 |
Artifact |
Component |
Paths |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.23.2.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.23.2.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.23.2.tgz |
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.23.2.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.23.2.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.23.2.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.23.2.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.23.2.tgz |
|
equinix-credentials-controller |
https://binary.mirantis.com/core/helm/equinix-credentials-controller-1.23.2.tgz |
|
equinix-provider |
https://binary.mirantis.com/core/helm/equinix-provider-1.23.2.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.23.2.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.23.2.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.23.2.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.23.2.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.23.2.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.23.2.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.23.2.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.23.2.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.23.2.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.23.2.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.23.2.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.23.2.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.23.3 |
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.23.2 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.23.2 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.23.2 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.23.2 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.23.2 |
|
cluster-api-provider-equinix Updated |
mirantis.azurecr.io/core/cluster-api-provider-equinix:1.23.2 |
|
equinix-credentials-controller Updated |
mirantis.azurecr.io/core/equinix-credentials-controller:1.23.2 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.23.4 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.23.2 |
|
kproxy Updated |
mirantis.azurecr.io/lcm/kproxy:1.23.2 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:v0.2.0-372-g7e042f4d |
|
nginx |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.23.2 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.23.2 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.23.2 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.23.2 |
|
squid-proxy Updated |
mirantis.azurecr.io/core/squid-proxy:0.0.1-5 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-api-controller:1.23.2 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.23.2 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux Updated |
||
iamctl-darwin Updated |
||
iamctl-windows Updated |
||
Helm charts |
iam Updated |
|
iam-proxy |
||
keycloak-proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.23.2.tgz |
|
Docker images |
api Updated |
mirantis.azurecr.io/iam/api:0.5.2 |
auxiliary Updated |
mirantis.azurecr.io/iam/auxiliary:0.5.2 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.4.0 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:6.0.1 |
The Mirantis Container Cloud GA release 2.9.0:
Introduces support for the Cluster release 5.16.0 that is based on Kubernetes 1.18, Mirantis Container Runtime 19.03.14, and Mirantis Kubernetes Engine 3.3.6.
Introduces support for the Cluster release 6.16.0 that is based on the Cluster release 5.16.0 and represents Mirantis OpenStack for Kubernetes (MOS) 21.3.
Supports deprecated Cluster releases 5.15.0 and 6.14.0 that will become unsupported in one of the following Container Cloud releases.
Supports the Cluster release 5.11.0 only for attachment of existing MKE 3.3.4 clusters. For the deployment of new or attachment of existing MKE 3.3.6 clusters, the latest available Cluster release is used.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.9.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.9.0. For the list of enhancements in the Cluster release 5.16.0 and Cluster release 6.16.0 that are supported by the Container Cloud release 2.9.0, see the 5.16.0 and 6.16.0 sections.
Introduced support for the Equinix Metal cloud provider. Equinix Metal integrates a fully automated bare metal infrastructure at software speed.
Now, you can deploy managed clusters that are based on the Equinix Metal management or regional clusters or on top of the AWS-based management cluster.
Using the Equinix Metal management cluster, you can also deploy additional regional clusters that are based the OpenStack, AWS, vSphere, or Equinix Metal cloud providers to deploy and operate managed clusters of different provider types or configurations from a single Container Cloud management plane.
The Equinix Metal based managed clusters also include a Ceph cluster that can be configured either automatically or manually before or after the cluster deployment.
Learn more
Implemented the Container Cloud integration to Lens. Using the Container Cloud web UI and the Lens extension, you can now add any type of Container Cloud clusters to Lens for further inspection and monitoring.
The following options are now available in the More action icon menu of each deployed cluster:
Add cluster to Lens
Open cluster in Lens
Added the possibility to use a new bootstrap node for deployment of additional regional clusters. You can now deploy regional clusters not only on the bootstrap node where you originally deployed the related management cluster, but also on a new node.
Implemented the possibility to configure TLS certificates for Keycloak and Container Cloud web UI on new management clusters.
Caution
Adding of TLS certificates for Keycloak is not supported on existing clusters deployed using the Container Cloud release earlier than 2.9.0.
Implemented management of SSH keys only for the universal mcc-user that is
now applicable to any Container Cloud provider and node type,
including Bastion. All existing SSH user names, such as ubuntu,
cloud-user for the vSphere-based clusters, are replaced with the universal
mcc-user user name.
Learn more
Implemented the vsphereResources controller to represent the vSphere
resources as Kubernetes objects and manage them using the Container Cloud
web UI.
You can now use the drop-down list fields to filter results by a short resource name during a cluster and machine creation. The drop-down lists for the following vSphere resources paths are added to the Container Cloud web UI:
|
|
Updated the L2 templates format for baremetal-based deployments.
In the new format, l2template:status:npTemplate is used
directly during provisioning. Therefore, a hardware node obtains and applies
a complete network configuration during the first system boot.
Before the Container Cloud 2.9.0, you were able to configure any network
interface except the default provisioning NIC for the PXE and LCM
managed to manager connection.
Since Container Cloud 2.9.0, you can configure any interface if required.
Caution
Deploy any new node using the L2 template of the new format.
Replace all deprecated L2 templates created before Container Cloud 2.9.0 with the L2 templates of new format.
Learn more
The following issues have been addressed in the Mirantis Container Cloud release 2.9.0 along with the Cluster releases 6.16.0 and 5.16.0.
For more issues addressed for the Cluster release 6.16.0, see also 2.8.0 addressed issues.
[14682][StackLight] Reduced the amount of
KubePodNotReadyandKubePodCrashLoopingalerts. Reworked these alerts and renamed toKubePodsNotReadyandKubePodsCrashLooping.[14663][StackLight] Removed the inefficient Kubernetes API and etcd latency alerts.
[14458][vSphere] Fixed the issue with newly created pods failing to run and having the
CrashLoopBackOffstatus on long-living vSphere-based clusters.The issue is fixed for new clusters deployed using Container Cloud 2.9.0. For existing clusters, apply the workaround described in vSphere known issues.
[14051][Ceph] Fixed the issue with the
CephClustercreation failure ifmanageOsdswas enabled before deploy.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.9.0 including the Cluster release 5.16.0 and 6.16.0.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Fixed in the Cluster release 7.0.0
Note
The issue below affects only the Kubernetes 1.18 deployments. Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
On a management cluster with multiple AWS-based managed
clusters, some clusters fail to complete the deployments that require
persistent volumes (PVs), for example, Elasticsearch.
Some of the affected pods get stuck in the Pending state
with the pod has unbound immediate PersistentVolumeClaims and
node(s) had volume node affinity conflict errors.
Warning
The workaround below applies to HA deployments where data can be rebuilt from replicas. If you have a non-HA deployment, back up any existing data before proceeding, since all data will be lost while applying the workaround.
Workaround:
Obtain the persistent volume claims related to the storage mounts of the affected pods:
kubectl get pod/<pod_name1> pod/<pod_name2> \ -o jsonpath='{.spec.volumes[?(@.persistentVolumeClaim)].persistentVolumeClaim.claimName}'
Note
In the command above and in the subsequent steps, substitute the parameters enclosed in angle brackets with the corresponding values.
Delete the affected
PodsandPersistentVolumeClaimsto reschedule them: For example, for StackLight:kubectl -n stacklight delete \ pod/<pod_name1> pod/<pod_name2> ... pvc/<pvc_name2> pvc/<pvc_name2> ...
Fixed in 2.11.0
A load balancer virtual IP address (VIP) is assigned to each manager
node on any type of the vSphere-based cluster. The issue occurs because
the Keepalived instances cannot set up a cluster due to the blocked
vrrp protocol traffic in the firewall configuration on the Container Cloud
nodes.
Note
Before applying the workaround below, verify that the dedicated
vSphere network does not have any other virtual machines with the
keepalived instance running with the same vrouter_id.
You can verify the vrouter_id value of the cluster
in /etc/keepalived/keepalived.conf on the manager nodes.
Workaround
Update the firewalld configuration on each manager node of the affected
cluster to allow the vrrp protocol traffic between the nodes:
SSH to any manager node using
mcc-user.Apply the
firewalldconfiguration:firewall-cmd --add-rich-rule='rule protocol value="vrrp" accept' --permanent firewall-cmd --reload
Apply the procedure to the remaining manager nodes of the cluster.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
A vSphere-based management cluster bootstrap fails due to a node leaving the cluster after an accidental IP address change.
The issue may affect a vSphere-based cluster only when IPAM is not enabled and IP addresses assignment to the vSphere virtual machines is done by a DHCP server present in the vSphere network.
By default, a DHCP server keeps lease of the IP address for 30 minutes.
Usually, a VM dhclient prolongs such lease by frequent DHCP requests
to the server before the lease period ends.
The DHCP prolongation request period is always less than the default lease time
on the DHCP server, so prolongation usually works.
But in case of network issues, for example, when dhclient from the
VM cannot reach the DHCP server, or the VM is being slowly powered on
for more than the lease time, such VM may lose its assigned IP address.
As a result, it obtains a new IP address.
Container Cloud does not support network reconfiguration after the IP of the VM has been changed. Therefore, such issue may lead to a VM leaving the cluster.
Symptoms:
One of the nodes is in the
NodeNotReadyordownstate:kubectl get nodes -o wide docker node ls
The UCP Swarm manager logs on the healthy manager node contain the following example error:
docker logs -f ucp-swarm-manager level=debug msg="Engine refresh failed" id="<docker node ID>|<node IP>: 12376"
If the affected node is manager:
The output of the docker info command contains the following example error:
Error: rpc error: code = Unknown desc = The swarm does not have a leader. \ It's possible that too few managers are online. \ Make sure more than half of the managers are online.
The UCP controller logs contain the following example error:
docker logs -f ucp-controller "warning","msg":"Node State Active check error: \ Swarm Mode Manager health check error: \ info: Cannot connect to the Docker daemon at tcp://<node IP>:12376. \ Is the docker daemon running?
On the affected node, the IP address on the first interface
eth0does not match the IP address configured in Docker. Verify theNode Addressfield in the output of the docker info command.The following lines are present in
/var/log/messages:dhclient[<pid>]: bound to <node IP> -- renewal in 1530 seconds
If there are several lines where the IP is different, the node is affected.
Workaround:
Select from the following options:
Bind IP addresses for all machines to their MAC addresses on the DHCP server for the dedicated vSphere network. In this case, VMs receive only specified IP addresses that never change.
Remove the Container Cloud node IPs from the IP range on the DHCP server for the dedicated vSphere network and configure the first interface
eth0on VMs with a static IP address.If a managed cluster is affected, redeploy it with IPAM enabled for new machines to be created and IPs to be assigned properly.
Fixed in 2.9.0 for new clusters
Newly created pods may fail to run and have the CrashLoopBackOff status
on long-living Container Cloud clusters deployed on RHEL 7.8 using the VMware
vSphere provider. The following is an example output of the
kubectl describe pod <pod-name> -n <projectName> command:
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: ContainerCannotRun
Message: OCI runtime create failed: container_linux.go:349:
starting container process caused "process_linux.go:297:
applying cgroup configuration for process caused
"mkdir /sys/fs/cgroup/memory/kubepods/burstable/<pod-id>/<container-id>>:
cannot allocate memory": unknown
The issue occurs due to the Kubernetes and Docker community issues.
According to the RedHat solution,
the workaround is to disable the kernel memory accounting feature
by appending cgroup.memory=nokmem to the kernel command line.
Note
The workaround below applies to the existing clusters only. The issue is resolved for new Container Cloud 2.9.0 deployments since the workaround below automatically applies to the VM template built during the vSphere-based management cluster bootstrap.
Apply the following workaround on each machine of the affected cluster.
Workaround
SSH to any machine of the affected cluster using
mcc-userand the SSH key provided during the cluster creation to proceed as therootuser.In
/etc/default/grub, setcgroup.memory=nokmemforGRUB_CMDLINE_LINUX.Update kernel:
yum install kernel kernel-headers kernel-tools kernel-tools-libs kexec-tools
Update the grub configuration:
grub2-mkconfig -o /boot/grub2/grub.cfg
Reboot the machine.
Wait for the machine to become available.
Wait for 5 minutes for Docker and Kubernetes services to start.
Verify that the machine is
Ready:docker node ls kubectl get nodes
Repeat the steps above on the remaining machines of the affected cluster.
An OpenStack-based regional cluster cleanup fails with the timeout error.
Workaround:
Wait for the
Clusterobject to be deleted in the bootstrap cluster:kubectl --kubeconfig <(./bin/kind get kubeconfig --name clusterapi) get cluster
The system output must be empty.
Remove the bootstrap cluster manually:
./bin/kind delete cluster --name clusterapi
Fixed in 2.10.0
An Equinix Metal manager machine deployment may fail if the cluster contains
at least one manager machine that is stuck in the Provisioning state
due to the capacity limits in the selected Equinix Metal data center.
In this case, other machines that were successfully created in Equinix Metal
may also fail to finalize the deployment and get stuck on the Deploy stage.
If this is the case, remove all manager machines that are stuck in the
Provisioning state.
Workaround:
Export the
kubeconfigof the management cluster. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-mgmt.yml
Add the
kaas.mirantis.com/validate: "false"annotation to all machines that are stuck in theProvisioningstate.Note
In the commands below, replace
$MACHINE_PROJECT_NAMEand$MACHINE_NAMEwith the cluster project name and name of the affected machine respectively:kubectl -n $MACHINE_PROJECT_NAME annotate machine $MACHINE_NAME kaas.mirantis.com/validate="false"
Remove the machine that is stuck in the
Provisioningstate using the Container Cloud web UI or using the following command:kubectl -n $MACHINE_PROJECT_NAME delete machine $MACHINE_NAME
After all machines that are stuck in the Provisioning state are removed,
the deployment of the manager machine that is stuck on the Deploy stage
restores.
On the baremetal-based management clusters with the Cluster version 2.9.0 or earlier, the storage volume used by Ironic can run out of free space. As a result, an automatic upgrade of the management cluster fails with the no space left on device error in the Ironic logs.
Symptoms:
The
httpdDeploymentand theironicanddnsmasqstatefulSetsare not in theOKstatus:kubectl -n kaas get deployments kubectl -n kaas get statefulsets
One or more of the
httpd,ironic, anddnsmasqpods fail to start:kubectl get pods -n kaas -o wide | grep httpd-0
If the number of ready containers for the pod is 0/1, the management cluster can be affected by the issue.
kubectl get pods -n kaas -o wide | grep ironic
If the number of ready containers for the pod is not 6/6, the management cluster can be affected by the issue.
Logs of the affected pods contain the no space left on device error:
kubectl -n kaas logs httpd-0 | grep -i 'no space left on device'
As a workaround, truncate the Ironic log files on the storage volume:
kubectl -n kaas exec -ti sts/httpd -- /bin/bash -c 'truncate -s 0 /volume/log/ironic/ironic-api.log'
kubectl -n kaas exec -ti sts/httpd -- /bin/bash -c 'truncate -s 0 /volume/log/ironic/ironic-conductor.log'
kubectl -n kaas exec -ti sts/httpd -- /bin/bash -c 'truncate -s 0 /volume/log/ironic/ansible-playbook.log'
kubectl -n kaas exec -ti sts/httpd -- /bin/bash -c 'truncate -s 0 /volume/log/ironic-inspector/ironic-inspector.log'
kubectl -n kaas exec -ti sts/httpd -- /bin/bash -c 'truncate -s 0 /volume/log/dnsmasq/dnsmasq-dhcpd.log'
Fixed in 2.11.0
If an L2 template is configured incorrectly, a bare metal cluster is deployed
successfully but with the runtime errors in the IpamHost object.
Workaround:
If you suspect that the machine is not working properly because
of incorrect network configuration, verify the status of the corresponding
IpamHost object. Inspect the l2RenderResult and ipAllocationResult
object fields for error messages.
Fixed in 2.11.0
If you use a custom BareMetalHostProfile, after disk replacement
on a Ceph OSD, the Ceph OSD pod switches to the CrashLoopBackOff state
due to the Ceph OSD authorization key failing to be created properly.
Workaround:
Export
kubeconfigof your managed cluster. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
Delete the authorization key for the failed Ceph OSD:
ceph auth del osd.<ID>
SSH to the node on which the Ceph OSD cannot be created.
Clean up the disk that will be a base for the failed Ceph OSD. For details, see official Rook documentation.
Note
Ignore failures of the sgdisk --zap-all $DISK and blkdiscard $DISK commands if any.
On the managed cluster, restart Rook Operator:
kubectl -n rook-ceph delete pod -l app=rook-ceph-operator
Fixed in 2.12.0
The MariaDB pods fail to start after MariaDB blocks itself during the State Snapshot Transfers sync.
Workaround:
Verify the failed pod readiness:
kubectl describe pod -n kaas <failedMariadbPodName>
If the readiness probe failed with the WSREP not synced message, proceed to the next step. Otherwise, assess the MariaDB pod logs to identify the failure root cause.
Obtain the MariaDB admin password:
kubectl get secret -n kaas mariadb-dbadmin-password -o jsonpath='{.data.MYSQL_DBADMIN_PASSWORD}' | base64 -d ; echo
Verify that
wsrep_local_state_commentisDonororDesynced:kubectl exec -it -n kaas <failedMariadbPodName> -- mysql -uroot -p<mariadbAdminPassword> -e "SHOW status LIKE \"wsrep_local_state_comment\";"
Restart the failed pod:
kubectl delete pod -n kaas <failedMariadbPodName>
Fixed in 2.8.0 for new clusters and in 2.10.0 for existing clusters
If an application running on a Container Cloud management or managed cluster fails frequently, for example, PostgreSQL, it may produce an excessive amount of core dumps. This leads to the no space left on device error on the cluster nodes and, as a result, to the broken Docker Swarm and the entire cluster.
Core dumps are disabled by default on the operating system of the Container Cloud nodes. But since Docker does not inherit the operating system settings, disable core dumps in Docker using the workaround below.
Warning
The workaround below does not apply to the baremetal-based clusters, including MOS deployments, since Docker restart may destroy the Ceph cluster.
Workaround:
SSH to any machine of the affected cluster using
mcc-userand the SSH key provided during the cluster creation.In
/etc/docker/daemon.json, add the following parameters:{ ... "default-ulimits": { "core": { "Hard": 0, "Name": "core", "Soft": 0 } } }
Restart the Docker daemon:
systemctl restart docker
Repeat the steps above on each machine of the affected cluster one by one.
Fixed in 2.12.0
Adding of a new manager node to a managed cluster may hang due to
issues with joining etcd from a new node to the existing etcd cluster.
The new manager node hangs in the Deploy stage.
Symptoms:
The Ansible run tries executing the
Wait for Docker UCP to be accessiblestep and fails with the following error message:Status code was -1 and not [200]: Request failed: <urlopen error [Errno 111] Connection refused>
The etcd logs on the leader etcd node contain the following example error message occurring every 1-2 minutes:
2021-06-10 03:21:53.196677 W | etcdserver: not healthy for reconfigure, rejecting member add {ID:22bb1d4275f1c5b0 RaftAttributes:{PeerURLs:[https://<new manager IP>:12380] IsLearner:false} Attributes:{Name: ClientURLs:[]}}
To determine the etcd leader, run on any manager node:
docker exec -it ucp-kv sh # From the inside of the container: ETCDCTL_API=3 etcdctl -w table --endpoints=https://<1st manager IP>:12379,https://<2nd manager IP>:12379,https://<3rd manager IP>:12379 endpoint status
To verify logs on the leader node:
docker logs ucp-kv
Root cause:
In case of an unlucky network partition, the leader may lose quorum and members are not able to perform the election. For more details, see Official etcd documentation: Learning, figure 5.
Workaround:
Restart etcd on the leader node:
docker rm -f ucp-kv
Wait several minutes until the etcd cluster starts and reconciles.
The deployment of the new manager node will proceed and it will join the etcd cluster. After that, other MKE components will be configured and the node deployment will be finished successfully.
Fixed in 2.11
A managed cluster update from the Cluster release 6.12.0 to
6.14.0 fails with worker nodes being stuck in the Deploy state with
the Network is unreachable error.
Workaround:
Verify the state of the loopback network interface:
ip l show lo
If the interface is not in the
UNKNOWNorUPstate, enable it manually:ip l set lo up
If the interface is in the
UNKNOWNorUPstate, assess the cluster logs to identify the failure root cause.Repeat the cluster update procedure.
Fixed in 2.11.0
During update of a managed cluster from the Cluster releases 6.12.0 to 6.14.0, the LCM Agent upgrade fails with the following error in logs:
lcmAgentUpgradeStatus:
error: 'failed to download agent binary: Get https://<mcc-cache-address>/bin/lcm/bin/lcm-agent/v0.2.0-289-gd7e9fa9c/lcm-agent:
x509: certificate signed by unknown authority'
Only clusters initially deployed using Container Cloud 2.4.0 or earlier are affected.
As a workaround, restart lcm-agent using the
service lcm-agent-* restart command on the affected nodes.
Note
The issue affects only Helm v2 releases and is addressed for Helm v3. Starting from Container Cloud 2.19.0, all Helm releases are switched to v3.
During a management, regional, or managed cluster deployment,
Helm releases may get stuck in the FAILED or UNKNOWN state
although the corresponding machines statuses are Ready
in the Container Cloud web UI. For example, if the StackLight Helm release
fails, the links to its endpoints are grayed out in the web UI.
In the cluster status, providerStatus.helm.ready and
providerStatus.helm.releaseStatuses.<releaseName>.success are false.
HelmBundle cannot recover from such states and requires manual actions.
The workaround below describes the recovery steps for the stacklight
release that got stuck during a cluster deployment.
Use this procedure as an example for other Helm releases as required.
Workaround:
Verify the failed release has the
UNKNOWNorFAILEDstatus in the HelmBundle object:kubectl --kubeconfig <regionalClusterKubeconfigPath> get helmbundle <clusterName> -n <clusterProjectName> -o=jsonpath={.status.releaseStatuses.stacklight} In the command above and in the steps below, replace the parameters enclosed in angle brackets with the corresponding values of your cluster.
Example of system response:
stacklight: attempt: 2 chart: "" finishedAt: "2021-02-05T09:41:05Z" hash: e314df5061bd238ac5f060effdb55e5b47948a99460c02c2211ba7cb9aadd623 message: '[{"occurrence":1,"lastOccurrenceDate":"2021-02-05 09:41:05","content":"error updating the release: rpc error: code = Unknown desc = customresourcedefinitions.apiextensions.k8s.io \"helmbundles.lcm.mirantis.com\" already exists"}]' notes: "" status: UNKNOWN success: false version: 0.1.2-mcp-398
Log in to the
helm-controllerpod console:kubectl --kubeconfig <affectedClusterKubeconfigPath> exec -n kube-system -it helm-controller-0 sh -c tiller
Download the Helm v3 binary. For details, see official Helm documentation.
Remove the failed release:
helm delete <failed-release-name>
For example:
helm delete stacklight
Once done, the release triggers for redeployment.
Fixed in 2.10.0
A managed cluster deployed or updated on a regional cluster of another provider type may display inaccurate Nodes readiness live status in the Container Cloud web UI. While all nodes are ready, the Nodes status indicates that some nodes are still not ready.
The issue occurs due to the cordon-drain desynchronization between
the LCMClusterState objects and the actual state of the cluster.
Note
The workaround below must be applied only by users with
the writer or cluster-admin access role
assigned by the Infrastructure Operator.
To verify that the cluster is affected:
Export the regional cluster
kubeconfigcreated during the regional cluster deployment:export KUBECONFIG=<PathToRegionalClusterKubeconfig>
Verify that all Kubernetes nodes of the affected managed cluster are in the
readystate:kubectl --kubeconfig <managedClusterKubeconfigPath> get nodes
Verify that all Swarm nodes of the managed cluster are in the
readystate:ssh -i <sshPrivateKey> root@<controlPlaneNodeIP> docker node ls
Replace the parameters enclosed in angle brackets with the SSH key that was used for the managed cluster deployment and the private IP address of any control plane node of the cluster.
If the status of the Kubernetes and Swarm nodes is
ready, proceed with the next steps. Otherwise, assess the cluster logs to identify the issue with not ready nodes.Obtain the
LCMClusterStateitems related to theswarm-drainandcordon-draintype:kubectl get lcmlusterstates -n <managedClusterProjectName>
The command above outputs the list of all
LCMClusterStateitems. Verify only theLCMClusterStateitems names that start with theswarm-drain-andcordon-drain-prefix.Verify the status of each
LCMClusterStateitem of theswarm-drainandcordon-draintype:kubectl -n <clusterProjectName> get lcmlusterstates <lcmlusterstatesItemNameOfSwarmDrainOrCordonDrainType> -o=yaml
Example of system response extract for the
LCMClusterStateitems of thecordon-draintype:spec: arg: kaas-node-4c026e7a-8acd-48b2-bf5c-cdeaf99d812f clusterName: test-child-namespace type: cordon-drain value: "false" status: attempt: 0 value: "false"
Example of system response extract for the
LCMClusterStateitems of theswarm-draintype:spec: arg: kaas-node-4c026e7a-8acd-48b2-bf5c-cdeaf99d812f clusterName: test-child-namespace type: swarm-drain value: "true" status: attempt: 334 message: 'Error: waiting for kubernetes node kaas-node-4c026e7a-8acd-48b2-bf5c-cdeaf99d812f to be drained first'
The cluster is affected if:
For
cordon-drain,spec.valueandstatus.valueare"false"For
swarm-drain,spec.valueis"true"and thestatus.messagecontains an error related to waiting for the Kubernetes cordon-drain to finish
Workaround:
For each LCMClusterState item of the swarm-drain type with
spec.value == "true" and the status.message described above,
replace "true" with "false" in spec.value:
kubectl -n <clusterProjectName> edit lcmclusterstate <lcmlusterstatesItemNameOfSwarmDrainType>
The iam-api pods are in the Not Ready state on the management cluster
after the Container Cloud upgrade to 2.9.0 since they cannot reach Keycloak
due to the CA certificate issue.
The issue affects only the clusters originally deployed using the Container Cloud release earlier than 2.6.0.
Workaround:
Replace the
tls.crtandtls.keyfields in themcc-ca-certsecret in thekaasnamespace with the certificate and key generated during the management cluster bootstrap. These credentials are stored in thekaas-bootstrap/tlsdirectory.kubectl -n kaas delete secret mcc-ca-cert && kubectl create secret generic mcc-ca-cert -n kaas --dry-run=client --from-file=tls.key=./kaas-bootstrap/tls/ca-key.pem --from-file=tls.crt=./kaas-bootstrap/tls/ca.pem -o yaml | kubectl apply -f -
Wait for the
oidc-ca-certsecret in thekaasnamespace to be updated with the certificate from themcc-ca-certsecret in thekaasnamespace.Restart the
iam-apipods:kubectl -n kaas rollout restart deployment iam-api
Helm releases may get stuck in the PENDING_UPGRADE status
during a management or managed cluster upgrade. The HelmBundle Controller
cannot recover from this state and requires manual actions. The workaround
below describes the recovery process for the openstack-operator release
that stuck during a managed cluster update. Use it as an example for other
Helm releases as required.
Workaround:
Log in to the
helm-controllerpod console:kubectl exec -n kube-system -it helm-controller-0 sh -c tiller
Identify the release that stuck in the
PENDING_UPGRADEstatus. For example:./helm --host=localhost:44134 history openstack-operator
Example of system response:
REVISION UPDATED STATUS CHART DESCRIPTION 1 Tue Dec 15 12:30:41 2020 SUPERSEDED openstack-operator-0.3.9 Install complete 2 Tue Dec 15 12:32:05 2020 SUPERSEDED openstack-operator-0.3.9 Upgrade complete 3 Tue Dec 15 16:24:47 2020 PENDING_UPGRADE openstack-operator-0.3.18 Preparing upgrade
Roll back the failed release to the previous revision:
Download the Helm v3 binary. For details, see official Helm documentation.
Roll back the failed release:
helm rollback <failed-release-name>
For example:
helm rollback openstack-operator 2
Once done, the release will be reconciled.
Fixed in 2.10.0
A managed cluster release upgrade may fail due to DNS issues on pods with host networking. If this is the case, the DNS names of the Kubernetes services on the affected pod cannot be resolved.
Workaround:
Export kubeconfig of the affected managed cluster. For example:
export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Identify any existing pod with host networking. For example,
tf-config-xxxxxx:kubectl get pods -n tf -l app=tf-config
Verify the DNS names resolution of the Kubernetes services from this pod. For example:
kubectl -n tf exec -it tf-config-vl4mh -c svc-monitor -- curl -k https://kubernetes.default.svc
The system output must not contain DNS errors.
If the DNS name cannot be resolved, restart all
calico-nodepods:kubectl delete pods -l k8s-app=calico-node -n kube-system
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.9.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.22.4 |
aws-credentials-controller |
1.22.4 |
|
Bare metal |
baremetal-operator Updated |
5.0.2 |
baremetal-public-api Updated |
5.0.2 |
|
baremetal-provider Updated |
1.22.4 |
|
httpd |
1.18.0 |
|
ironic |
victoria-bionic-20210408180013 |
|
ironic-operator Updated |
base-bionic-20210513142132 |
|
kaas-ipam |
base-bionic-20210427213631 |
|
local-volume-provisioner Updated |
1.0.6-mcp |
|
mariadb |
10.4.17-bionic-20210203155435 |
|
IAM |
iam Updated |
2.4.0 |
iam-controller Updated |
1.22.4 |
|
keycloak |
12.0.0 |
|
Container Cloud |
admission-controller Updated |
1.22.4 |
byo-credentials-controller Updated |
1.22.4 |
|
byo-provider Updated |
1.22.4 |
|
kaas-public-api Updated |
1.22.4 |
|
kaas-exporter Updated |
1.22.4 |
|
kaas-ui Updated |
1.22.4 |
|
lcm-controller Updated |
0.2.0-351-g3151d0cd |
|
mcc-cache Updated |
1.22.4 |
|
proxy-controller Updated |
1.22.4 |
|
release-controller Updated |
1.22.4 |
|
rhellicense-controller Updated |
1.22.4 |
|
squid-proxy |
0.0.1-3 |
|
Equinix Metal New |
equinix-provider |
1.22.5 |
equinix-credentials-controller |
1.22.4 |
|
OpenStack Updated |
openstack-provider |
1.22.4 |
os-credentials-controller |
1.22.4 |
|
VMware vSphere Updated |
vsphere-provider |
1.22.4 |
vsphere-credentials-controller |
1.22.4 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.9.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-5.0.2.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-5.0.2.tgz |
|
ironic-python-agent-bionic.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-victoria-bionic-debug-20210226182519 |
|
ironic-python-agent-bionic.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-victoria-bionic-debug-20210226182519 |
|
kaas-ipam Updated |
||
local-volume-provisioner Updated |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-1.0.6-mcp.tgz |
|
Docker images |
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20210513173947 |
httpd |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20210408180013 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20210408180013 |
|
ironic-operator Updated |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20210513142132 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20210427213631 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210203155435 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.22.4.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.22.4.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.22.4.tgz |
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.22.4.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.22.4.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.22.4.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.22.4.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.22.4.tgz |
|
equinix-credentials-controller New |
https://binary.mirantis.com/core/helm/equinix-credentials-controller-1.22.4.tgz |
|
equinix-provider New |
https://binary.mirantis.com/core/helm/equinix-provider-1.22.5.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.22.4.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.22.4.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.22.4.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.22.4.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.22.4.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.22.4.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.22.4.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.22.4.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.22.4.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.22.4.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.22.4.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.22.4.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.22.4 |
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.22.4 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.22.4 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.22.4 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.22.4 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.22.4 |
|
cluster-api-provider-equinix New |
mirantis.azurecr.io/core/cluster-api-provider-equinix:1.22.5 |
|
equinix-credentials-controller New |
mirantis.azurecr.io/core/equinix-credentials-controller:1.22.4 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.22.4 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.22.4 |
|
kproxy Updated |
mirantis.azurecr.io/lcm/kproxy:1.22.4 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:v0.2.0-351-g3151d0cd |
|
nginx |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.22.4 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.22.4 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.22.4 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.22.4 |
|
squid-proxy |
mirantis.azurecr.io/core/squid-proxy:0.0.1-3 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-api-controller:1.22.4 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.22.4 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux |
||
iamctl-darwin |
||
iamctl-windows |
||
Helm charts |
iam Updated |
|
iam-proxy |
||
keycloak-proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.22.4.tgz |
|
Docker images |
api |
mirantis.azurecr.io/iam/api:0.5.1 |
auxiliary |
mirantis.azurecr.io/iam/auxiliary:0.5.1 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.4.0 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:6.0.1 |
Before the Container Cloud 2.9.0, you were able to configure any network
interface except the default provisioning NIC for the PXE and LCM
managed to manager connection.
Since Container Cloud 2.9.0, you can configure any interface if required.
Caution
Deploy any new node using the updated L2 template format.
All L2 templates created before Container Cloud 2.9.0 are now deprecated and must not be used.
In the old L2 templates format, ipamhost spawns 2 structures after
processing l2template for machines:
l2template:status:osMetadataNetworkthat renders automatically using thedefaultsubnet from the management cluster and is used during thecloud-initdeployment phase after provisioning is donel2template:status:npTemplatethat is used during thelcm-agentdeployment phase and applied afterlcmmachinestarts deployment
In the new L2 templates format, l2template:status:npTemplate is used
directly during provisioning. Therefore, a hardware node obtains and applies
a complete network configuration during the first system boot.
To switch to the new L2 template format:
If you do not have a subnet for connection to the
managementLCM cluster network (lcm-nw), manually create one. For details, see Operations Guide: Create subnets.Manually create a new L2 template that is based on your existing one. For details, see Operations Guide: Create L2 templates.
In the
npTemplatesection, add the{{ nic 0}}parameters for thelcm-nwnetwork.Configuration example:
apiVersion: ipam.mirantis.com/v1alpha1 kind: L2Template metadata: labels: bm-1490-template-controls-netplan: anymagicstring cluster.sigs.k8s.io/cluster-name: child-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: bm-1490-template-controls-netplan namespace: child-ns spec: l3Layout: - subnetName: lcm-nw scope: namespace ifMapping: - enp9s0f0 - enp9s0f1 - eno1 - ens3f1 npTemplate: |- version: 2 ethernets: {{nic 0}}: dhcp4: false dhcp6: false match: macaddress: {{mac 0}} mtu: 1500 nameservers: addresses: [ 172.18.176.6 ] # Name if mandatory set-name: "k8s-lcm" gateway4: {{ gateway_from_subnet "lcm-nw" }} addresses: - {{ ip "0:lcm-nw" }} {{nic 1}}: dhcp4: false dhcp6: false match: macaddress: {{mac 1}} set-name: {{nic 1}} mtu: 1500 .... ....
Note
In the previous L2 template format,
{{ nic 0}}for the PXE interface was not defined.
After switching to the new l2template format, the following info
message appears in the ipamhost status and indicates that bmh
successfully migrated to the new format of L2 templates:
KUBECONFIG=kubeconfig kubectl -n managed-ns get ipamhosts
NAME STATUS AGE REGION
cz7700-bmh L2Template + L3Layout used, osMetadataNetwork is unacceptable in this mode 49m region-one
The Mirantis Container Cloud GA release 2.8.0:
Introduces support for the Cluster release 5.15.0 that is based on Kubernetes 1.18, Mirantis Container Runtime 19.03.14, and Mirantis Kubernetes Engine 3.3.6.
Supports the Cluster release 6.14.0 that is based on the Cluster release 5.14.0 and represents Mirantis OpenStack for Kubernetes (MOS) 21.2.
Supports deprecated Cluster releases 5.14.0 and 6.12.0 that will become unsupported in one of the following Container Cloud releases.
Supports the Cluster release 5.11.0 only for attachment of existing MKE 3.3.4 clusters. For the deployment of new or attachment of existing MKE 3.3.6 clusters, the latest available Cluster release is used.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.8.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.8.0. For the list of enhancements in the Cluster release 5.15.0 and Cluster release 6.14.0 that are supported by the Container Cloud release 2.8.0, see the 5.15.0 and 6.14.0 sections.
Updated notification about outdated cluster version in web UI
LoadBalancer and ProviderInstance monitoring for cluster and machine statuses
Updated the Keycloak major version from 9.0 to 12.0. For the list of highlights and enhancements, see Official Keycloak documentation.
TECHNOLOGY PREVIEW
Implemented the possibility to collect logs of the syslog container that runs in the Ironic pod on the bare metal bootstrap, management, and managed clusters.
You can collect Ironic pod logs using the standard Container Cloud
container-cloud collect logs command. The output is located in
/objects/namespaced/<namespaceName>/core/pods/<ironicPodId>/syslog.log.
To simplify operations with logs, the syslog container generates output
in the JSON format.
Note
Logs collected by the syslog container during the bootstrap phase
are not transferred to the management cluster during pivoting.
These logs are located in
/volume/log/ironic/ansible_conductor.log inside the Ironic pod.
Improved monitoring of the cluster and machine live statuses in the Container Cloud web UI:
Added the
LoadBalancerandProviderInstancefields.Added the
providerInstanceStatefield for an AWS machine status that includes the AWS VM ID, state, and readiness. The analogous fieldsinstanceStateandinstanceIDare deprecated as of Container Cloud 2.8.0 and will be removed in one of the following releases. For details, see Deprecation notes.
Updated the notification about outdated cluster version in the Container Cloud web UI. Now, you will be notified about any outdated managed cluster that must be updated to unblock the upgrade of the management cluster and Container Cloud to the latest version.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
Learn more
The following issues have been addressed in the Mirantis Container Cloud release 2.8.0 along with the Cluster release 5.15.0:
[12723] [Ceph] Fixed the issue with the
ceph_role_monandceph_role_mgrlabels remaining after deletion of a node fromKaaSCephCluster.[13381] [LCM] Fixed the issue with requests to
apiserverfailing after bootstrap on the management and regional clusters with enabled proxy.[13402] [LCM] Fixed the issue with the cluster failing with the no space left on device error due to an excessive amount of core dumps produced by applications that fail frequently.
Note
The issue is addressed only for new clusters created using Container Cloud 2.8.0. To workaround the issue on existing clusters created using the Container Cloud version below 2.8.0, see LCM known issues: 13402.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.8.0 including the Cluster release 5.15.0 and 6.14.0.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Fixed in the Cluster release 7.0.0
Note
The issue below affects only the Kubernetes 1.18 deployments. Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
On a management cluster with multiple AWS-based managed
clusters, some clusters fail to complete the deployments that require
persistent volumes (PVs), for example, Elasticsearch.
Some of the affected pods get stuck in the Pending state
with the pod has unbound immediate PersistentVolumeClaims and
node(s) had volume node affinity conflict errors.
Warning
The workaround below applies to HA deployments where data can be rebuilt from replicas. If you have a non-HA deployment, back up any existing data before proceeding, since all data will be lost while applying the workaround.
Workaround:
Obtain the persistent volume claims related to the storage mounts of the affected pods:
kubectl get pod/<pod_name1> pod/<pod_name2> \ -o jsonpath='{.spec.volumes[?(@.persistentVolumeClaim)].persistentVolumeClaim.claimName}'
Note
In the command above and in the subsequent steps, substitute the parameters enclosed in angle brackets with the corresponding values.
Delete the affected
PodsandPersistentVolumeClaimsto reschedule them: For example, for StackLight:kubectl -n stacklight delete \ pod/<pod_name1> pod/<pod_name2> ... pvc/<pvc_name2> pvc/<pvc_name2> ...
Fixed in 2.11.0
A load balancer virtual IP address (VIP) is assigned to each manager
node on any type of the vSphere-based cluster. The issue occurs because
the Keepalived instances cannot set up a cluster due to the blocked
vrrp protocol traffic in the firewall configuration on the Container Cloud
nodes.
Note
Before applying the workaround below, verify that the dedicated
vSphere network does not have any other virtual machines with the
keepalived instance running with the same vrouter_id.
You can verify the vrouter_id value of the cluster
in /etc/keepalived/keepalived.conf on the manager nodes.
Workaround
Update the firewalld configuration on each manager node of the affected
cluster to allow the vrrp protocol traffic between the nodes:
SSH to any manager node using
mcc-user.Apply the
firewalldconfiguration:firewall-cmd --add-rich-rule='rule protocol value="vrrp" accept' --permanent firewall-cmd --reload
Apply the procedure to the remaining manager nodes of the cluster.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
A vSphere-based management cluster bootstrap fails due to a node leaving the cluster after an accidental IP address change.
The issue may affect a vSphere-based cluster only when IPAM is not enabled and IP addresses assignment to the vSphere virtual machines is done by a DHCP server present in the vSphere network.
By default, a DHCP server keeps lease of the IP address for 30 minutes.
Usually, a VM dhclient prolongs such lease by frequent DHCP requests
to the server before the lease period ends.
The DHCP prolongation request period is always less than the default lease time
on the DHCP server, so prolongation usually works.
But in case of network issues, for example, when dhclient from the
VM cannot reach the DHCP server, or the VM is being slowly powered on
for more than the lease time, such VM may lose its assigned IP address.
As a result, it obtains a new IP address.
Container Cloud does not support network reconfiguration after the IP of the VM has been changed. Therefore, such issue may lead to a VM leaving the cluster.
Symptoms:
One of the nodes is in the
NodeNotReadyordownstate:kubectl get nodes -o wide docker node ls
The UCP Swarm manager logs on the healthy manager node contain the following example error:
docker logs -f ucp-swarm-manager level=debug msg="Engine refresh failed" id="<docker node ID>|<node IP>: 12376"
If the affected node is manager:
The output of the docker info command contains the following example error:
Error: rpc error: code = Unknown desc = The swarm does not have a leader. \ It's possible that too few managers are online. \ Make sure more than half of the managers are online.
The UCP controller logs contain the following example error:
docker logs -f ucp-controller "warning","msg":"Node State Active check error: \ Swarm Mode Manager health check error: \ info: Cannot connect to the Docker daemon at tcp://<node IP>:12376. \ Is the docker daemon running?
On the affected node, the IP address on the first interface
eth0does not match the IP address configured in Docker. Verify theNode Addressfield in the output of the docker info command.The following lines are present in
/var/log/messages:dhclient[<pid>]: bound to <node IP> -- renewal in 1530 seconds
If there are several lines where the IP is different, the node is affected.
Workaround:
Select from the following options:
Bind IP addresses for all machines to their MAC addresses on the DHCP server for the dedicated vSphere network. In this case, VMs receive only specified IP addresses that never change.
Remove the Container Cloud node IPs from the IP range on the DHCP server for the dedicated vSphere network and configure the first interface
eth0on VMs with a static IP address.If a managed cluster is affected, redeploy it with IPAM enabled for new machines to be created and IPs to be assigned properly.
Fixed in 2.9.0 for new clusters
Newly created pods may fail to run and have the CrashLoopBackOff status
on long-living Container Cloud clusters deployed on RHEL 7.8 using the VMware
vSphere provider. The following is an example output of the
kubectl describe pod <pod-name> -n <projectName> command:
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: ContainerCannotRun
Message: OCI runtime create failed: container_linux.go:349:
starting container process caused "process_linux.go:297:
applying cgroup configuration for process caused
"mkdir /sys/fs/cgroup/memory/kubepods/burstable/<pod-id>/<container-id>>:
cannot allocate memory": unknown
The issue occurs due to the Kubernetes and Docker community issues.
According to the RedHat solution,
the workaround is to disable the kernel memory accounting feature
by appending cgroup.memory=nokmem to the kernel command line.
Note
The workaround below applies to the existing clusters only. The issue is resolved for new Container Cloud 2.9.0 deployments since the workaround below automatically applies to the VM template built during the vSphere-based management cluster bootstrap.
Apply the following workaround on each machine of the affected cluster.
Workaround
SSH to any machine of the affected cluster using
mcc-userand the SSH key provided during the cluster creation to proceed as therootuser.In
/etc/default/grub, setcgroup.memory=nokmemforGRUB_CMDLINE_LINUX.Update kernel:
yum install kernel kernel-headers kernel-tools kernel-tools-libs kexec-tools
Update the grub configuration:
grub2-mkconfig -o /boot/grub2/grub.cfg
Reboot the machine.
Wait for the machine to become available.
Wait for 5 minutes for Docker and Kubernetes services to start.
Verify that the machine is
Ready:docker node ls kubectl get nodes
Repeat the steps above on the remaining machines of the affected cluster.
An OpenStack-based regional cluster cleanup fails with the timeout error.
Workaround:
Wait for the
Clusterobject to be deleted in the bootstrap cluster:kubectl --kubeconfig <(./bin/kind get kubeconfig --name clusterapi) get cluster
The system output must be empty.
Remove the bootstrap cluster manually:
./bin/kind delete cluster --name clusterapi
Fixed in 2.11.0
If an L2 template is configured incorrectly, a bare metal cluster is deployed
successfully but with the runtime errors in the IpamHost object.
Workaround:
If you suspect that the machine is not working properly because
of incorrect network configuration, verify the status of the corresponding
IpamHost object. Inspect the l2RenderResult and ipAllocationResult
object fields for error messages.
Fixed in 2.9.0
If manageOsds is enabled in the pre-deployment KaaSCephCluster
template, the bare metal management or managed cluster fails to deploy
due to the CephCluster creation failure.
As a workaround, disable manageOsds in the KaaSCephCluster
template before the cluster deployment.
You can enable this parameter after deployment as described in
Ceph advanced configuration.
Fixed in 2.11.0
If you use a custom BareMetalHostProfile, after disk replacement
on a Ceph OSD, the Ceph OSD pod switches to the CrashLoopBackOff state
due to the Ceph OSD authorization key failing to be created properly.
Workaround:
Export
kubeconfigof your managed cluster. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
Delete the authorization key for the failed Ceph OSD:
ceph auth del osd.<ID>
SSH to the node on which the Ceph OSD cannot be created.
Clean up the disk that will be a base for the failed Ceph OSD. For details, see official Rook documentation.
Note
Ignore failures of the sgdisk --zap-all $DISK and blkdiscard $DISK commands if any.
On the managed cluster, restart Rook Operator:
kubectl -n rook-ceph delete pod -l app=rook-ceph-operator
Fixed in 2.12.0
The MariaDB pods fail to start after MariaDB blocks itself during the State Snapshot Transfers sync.
Workaround:
Verify the failed pod readiness:
kubectl describe pod -n kaas <failedMariadbPodName>
If the readiness probe failed with the WSREP not synced message, proceed to the next step. Otherwise, assess the MariaDB pod logs to identify the failure root cause.
Obtain the MariaDB admin password:
kubectl get secret -n kaas mariadb-dbadmin-password -o jsonpath='{.data.MYSQL_DBADMIN_PASSWORD}' | base64 -d ; echo
Verify that
wsrep_local_state_commentisDonororDesynced:kubectl exec -it -n kaas <failedMariadbPodName> -- mysql -uroot -p<mariadbAdminPassword> -e "SHOW status LIKE \"wsrep_local_state_comment\";"
Restart the failed pod:
kubectl delete pod -n kaas <failedMariadbPodName>
Fixed in 2.8.0 for new clusters and in 2.10.0 for existing clusters
If an application running on a Container Cloud management or managed cluster fails frequently, for example, PostgreSQL, it may produce an excessive amount of core dumps. This leads to the no space left on device error on the cluster nodes and, as a result, to the broken Docker Swarm and the entire cluster.
Core dumps are disabled by default on the operating system of the Container Cloud nodes. But since Docker does not inherit the operating system settings, disable core dumps in Docker using the workaround below.
Warning
The workaround below does not apply to the baremetal-based clusters, including MOS deployments, since Docker restart may destroy the Ceph cluster.
Workaround:
SSH to any machine of the affected cluster using
mcc-userand the SSH key provided during the cluster creation.In
/etc/docker/daemon.json, add the following parameters:{ ... "default-ulimits": { "core": { "Hard": 0, "Name": "core", "Soft": 0 } } }
Restart the Docker daemon:
systemctl restart docker
Repeat the steps above on each machine of the affected cluster one by one.
Fixed in 2.11.0
During update of a managed cluster from the Cluster releases 6.12.0 to 6.14.0, the LCM Agent upgrade fails with the following error in logs:
lcmAgentUpgradeStatus:
error: 'failed to download agent binary: Get https://<mcc-cache-address>/bin/lcm/bin/lcm-agent/v0.2.0-289-gd7e9fa9c/lcm-agent:
x509: certificate signed by unknown authority'
Only clusters initially deployed using Container Cloud 2.4.0 or earlier are affected.
As a workaround, restart lcm-agent using the
service lcm-agent-* restart command on the affected nodes.
Note
The issue affects only Helm v2 releases and is addressed for Helm v3. Starting from Container Cloud 2.19.0, all Helm releases are switched to v3.
During a management, regional, or managed cluster deployment,
Helm releases may get stuck in the FAILED or UNKNOWN state
although the corresponding machines statuses are Ready
in the Container Cloud web UI. For example, if the StackLight Helm release
fails, the links to its endpoints are grayed out in the web UI.
In the cluster status, providerStatus.helm.ready and
providerStatus.helm.releaseStatuses.<releaseName>.success are false.
HelmBundle cannot recover from such states and requires manual actions.
The workaround below describes the recovery steps for the stacklight
release that got stuck during a cluster deployment.
Use this procedure as an example for other Helm releases as required.
Workaround:
Verify the failed release has the
UNKNOWNorFAILEDstatus in the HelmBundle object:kubectl --kubeconfig <regionalClusterKubeconfigPath> get helmbundle <clusterName> -n <clusterProjectName> -o=jsonpath={.status.releaseStatuses.stacklight} In the command above and in the steps below, replace the parameters enclosed in angle brackets with the corresponding values of your cluster.
Example of system response:
stacklight: attempt: 2 chart: "" finishedAt: "2021-02-05T09:41:05Z" hash: e314df5061bd238ac5f060effdb55e5b47948a99460c02c2211ba7cb9aadd623 message: '[{"occurrence":1,"lastOccurrenceDate":"2021-02-05 09:41:05","content":"error updating the release: rpc error: code = Unknown desc = customresourcedefinitions.apiextensions.k8s.io \"helmbundles.lcm.mirantis.com\" already exists"}]' notes: "" status: UNKNOWN success: false version: 0.1.2-mcp-398
Log in to the
helm-controllerpod console:kubectl --kubeconfig <affectedClusterKubeconfigPath> exec -n kube-system -it helm-controller-0 sh -c tiller
Download the Helm v3 binary. For details, see official Helm documentation.
Remove the failed release:
helm delete <failed-release-name>
For example:
helm delete stacklight
Once done, the release triggers for redeployment.
Fixed in 2.10.0
A managed cluster deployed or updated on a regional cluster of another provider type may display inaccurate Nodes readiness live status in the Container Cloud web UI. While all nodes are ready, the Nodes status indicates that some nodes are still not ready.
The issue occurs due to the cordon-drain desynchronization between
the LCMClusterState objects and the actual state of the cluster.
Note
The workaround below must be applied only by users with
the writer or cluster-admin access role
assigned by the Infrastructure Operator.
To verify that the cluster is affected:
Export the regional cluster
kubeconfigcreated during the regional cluster deployment:export KUBECONFIG=<PathToRegionalClusterKubeconfig>
Verify that all Kubernetes nodes of the affected managed cluster are in the
readystate:kubectl --kubeconfig <managedClusterKubeconfigPath> get nodes
Verify that all Swarm nodes of the managed cluster are in the
readystate:ssh -i <sshPrivateKey> root@<controlPlaneNodeIP> docker node ls
Replace the parameters enclosed in angle brackets with the SSH key that was used for the managed cluster deployment and the private IP address of any control plane node of the cluster.
If the status of the Kubernetes and Swarm nodes is
ready, proceed with the next steps. Otherwise, assess the cluster logs to identify the issue with not ready nodes.Obtain the
LCMClusterStateitems related to theswarm-drainandcordon-draintype:kubectl get lcmlusterstates -n <managedClusterProjectName>
The command above outputs the list of all
LCMClusterStateitems. Verify only theLCMClusterStateitems names that start with theswarm-drain-andcordon-drain-prefix.Verify the status of each
LCMClusterStateitem of theswarm-drainandcordon-draintype:kubectl -n <clusterProjectName> get lcmlusterstates <lcmlusterstatesItemNameOfSwarmDrainOrCordonDrainType> -o=yaml
Example of system response extract for the
LCMClusterStateitems of thecordon-draintype:spec: arg: kaas-node-4c026e7a-8acd-48b2-bf5c-cdeaf99d812f clusterName: test-child-namespace type: cordon-drain value: "false" status: attempt: 0 value: "false"
Example of system response extract for the
LCMClusterStateitems of theswarm-draintype:spec: arg: kaas-node-4c026e7a-8acd-48b2-bf5c-cdeaf99d812f clusterName: test-child-namespace type: swarm-drain value: "true" status: attempt: 334 message: 'Error: waiting for kubernetes node kaas-node-4c026e7a-8acd-48b2-bf5c-cdeaf99d812f to be drained first'
The cluster is affected if:
For
cordon-drain,spec.valueandstatus.valueare"false"For
swarm-drain,spec.valueis"true"and thestatus.messagecontains an error related to waiting for the Kubernetes cordon-drain to finish
Workaround:
For each LCMClusterState item of the swarm-drain type with
spec.value == "true" and the status.message described above,
replace "true" with "false" in spec.value:
kubectl -n <clusterProjectName> edit lcmclusterstate <lcmlusterstatesItemNameOfSwarmDrainType>
After upgrade of Container Cloud from 2.6.0 to 2.7.0, the local
volume provisioner pod in the default project is stuck in the
Terminating status, even after upgrade to 2.8.0.
This issue does not affect functioning of the management, regional, or managed clusters. The issue does not prevent the successful upgrade of the cluster.
Workaround:
Verify that the cluster is affected:
kubectl get pods -n default | grep local-volume-provisioner
If the output contains a pod with the
Terminatingstatus, the cluster is affected.Capture the affected pod name, if any.
Delete the affected pod:
kuebctl -n default delete pod <LVPPodName> --force
Helm releases may get stuck in the PENDING_UPGRADE status
during a management or managed cluster upgrade. The HelmBundle Controller
cannot recover from this state and requires manual actions. The workaround
below describes the recovery process for the openstack-operator release
that stuck during a managed cluster update. Use it as an example for other
Helm releases as required.
Workaround:
Log in to the
helm-controllerpod console:kubectl exec -n kube-system -it helm-controller-0 sh -c tiller
Identify the release that stuck in the
PENDING_UPGRADEstatus. For example:./helm --host=localhost:44134 history openstack-operator
Example of system response:
REVISION UPDATED STATUS CHART DESCRIPTION 1 Tue Dec 15 12:30:41 2020 SUPERSEDED openstack-operator-0.3.9 Install complete 2 Tue Dec 15 12:32:05 2020 SUPERSEDED openstack-operator-0.3.9 Upgrade complete 3 Tue Dec 15 16:24:47 2020 PENDING_UPGRADE openstack-operator-0.3.18 Preparing upgrade
Roll back the failed release to the previous revision:
Download the Helm v3 binary. For details, see official Helm documentation.
Roll back the failed release:
helm rollback <failed-release-name>
For example:
helm rollback openstack-operator 2
Once done, the release will be reconciled.
Fixed in 2.10.0
A managed cluster release upgrade may fail due to DNS issues on pods with host networking. If this is the case, the DNS names of the Kubernetes services on the affected pod cannot be resolved.
Workaround:
Export kubeconfig of the affected managed cluster. For example:
export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Identify any existing pod with host networking. For example,
tf-config-xxxxxx:kubectl get pods -n tf -l app=tf-config
Verify the DNS names resolution of the Kubernetes services from this pod. For example:
kubectl -n tf exec -it tf-config-vl4mh -c svc-monitor -- curl -k https://kubernetes.default.svc
The system output must not contain DNS errors.
If the DNS name cannot be resolved, restart all
calico-nodepods:kubectl delete pods -l k8s-app=calico-node -n kube-system
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.8.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.20.2 |
aws-credentials-controller |
1.20.2 |
|
Bare metal |
baremetal-operator Updated |
4.1.3 |
baremetal-public-api Updated |
4.1.3 |
|
baremetal-provider Updated |
1.20.2 |
|
httpd |
1.18.0 |
|
ironic Updated |
victoria-bionic-20210408180013 |
|
ironic-operator Updated |
base-bionic-20210409133604 |
|
kaas-ipam Updated |
base-bionic-20210427213631 |
|
local-volume-provisioner |
1.0.5-mcp |
|
mariadb |
10.4.17-bionic-20210203155435 |
|
IAM |
iam Updated |
2.3.2 |
iam-controller Updated |
1.20.2 |
|
keycloak |
12.0.0 |
|
Container Cloud Updated |
admission-controller |
1.20.2 |
byo-credentials-controller |
1.20.2 |
|
byo-provider |
1.20.2 |
|
kaas-public-api |
1.20.2 |
|
kaas-exporter |
1.20.2 |
|
kaas-ui |
1.20.2 |
|
lcm-controller |
0.2.0-327-g5676f4e3 |
|
mcc-cache |
1.20.2 |
|
proxy-controller |
1.20.2 |
|
release-controller |
1.20.2 |
|
rhellicense-controller |
1.20.2 |
|
squid-proxy |
0.0.1-3 |
|
OpenStack Updated |
openstack-provider |
1.20.2 |
os-credentials-controller |
1.20.2 |
|
VMware vSphere Updated |
vsphere-provider |
1.20.2 |
vsphere-credentials-controller |
1.20.2 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.8.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-4.1.3.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-4.1.3.tgz |
|
ironic-python-agent-bionic.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-victoria-bionic-debug-20210226182519 |
|
ironic-python-agent-bionic.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-victoria-bionic-debug-20210226182519 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-1.0.5-mcp.tgz |
|
Docker images |
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20210317164614 |
httpd |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20210408180013 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20210408180013 |
|
ironic-operator Updated |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20210409133604 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20210427213631 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210203155435 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.20.2.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.20.2.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.20.2.tgz |
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.20.2.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.20.2.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.20.2.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.20.2.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.20.2.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.20.2.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.20.2.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.20.2.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.20.2.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.20.2.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.20.2.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.20.2.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.20.2.tgz |
|
rhellicense-controller |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.20.2.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.20.2.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.20.2.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.20.2.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.20.2 |
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.20.2 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.20.2 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.20.2 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.20.2 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.20.2 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.20.2 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.20.2 |
|
kproxy Updated |
mirantis.azurecr.io/lcm/kproxy:1.20.2 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:v0.2.0-327-g5676f4e3 |
|
nginx |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.20.2 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.20.2 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.20.2 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.20.2 |
|
squid-proxy Updated |
mirantis.azurecr.io/core/squid-proxy:0.0.1-3 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-api-controller:1.20.2 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.20.2 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux Updated |
||
iamctl-darwin Updated |
||
iamctl-windows Updated |
||
Helm charts Updated |
iam |
|
iam-proxy |
||
keycloak-proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.20.2.tgz |
|
Docker images |
api Updated |
mirantis.azurecr.io/iam/api:0.5.1 |
auxiliary Updated |
mirantis.azurecr.io/iam/auxiliary:0.5.1 |
|
kubernetes-entrypoint Updated |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.4.0 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:6.0.1 |
The Mirantis Container Cloud GA release 2.7.0:
Introduces support for the Cluster release 5.14.0 that is based on Kubernetes 1.18, Mirantis Container Runtime 19.03.14, and Mirantis Kubernetes Engine 3.3.6.
Supports the Cluster release 6.14.0 that is based on the Cluster release 5.14.0 and represents Mirantis OpenStack for Kubernetes (MOS) 21.2.
Supports deprecated Cluster releases 5.13.0 and 6.12.0 that will become unsupported in one of the following Container Cloud releases.
Supports the Cluster release 5.11.0 only for attachment of existing MKE 3.3.4 clusters. For the deployment of new or attachment of existing MKE 3.3.6 clusters, the latest available Cluster release is used.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.7.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.7.0. For the list of enhancements in the Cluster release 5.14.0 and Cluster release 6.14.0 that are supported by the Container Cloud release 2.7.0, see the 5.14.0 and 6.14.0 sections.
Introduced general availability support for the VMware vSphere provider after completing full integration of the vSphere provider on RHEL with Container Cloud.
During the Container Cloud 2.6.0 - 2.7.0 release cycle, added the following improvements:
Removed the StackLight limitations
Completed the integration of proxy support for the vSphere-based managed clusters
Completed the integration of the non-DHCP support for regional clusters
Addressed a number of critical and major issues
Implemented a universal SSH user mcc-user to replace the existing
default SSH user names. The mcc-user user name is applicable
to any Container Cloud provider and node type, including Bastion.
The existing SSH user names are deprecated as of Container Cloud 2.7.0.
SSH keys will be managed only for mcc-user as of one of the following
Container Cloud releases.
Implemented the possibility to configure SSH keys on existing clusters using the Container Cloud web UI. You can now add or remove SSH keys on running managed clusters using the Configure cluster web UI menu.
After the update of your Cluster release to the latest version supported by 2.7.0 for the OpenStack and AWS-based managed clusters, a one-time redeployment of the Bastion node is required to apply the first configuration change of SSH keys. For this purpose, the Allow Bastion Redeploy one-time check box is added to the Configure Cluster wizard in the Container Cloud web UI.
Note
After the Bastion node redeploys on the AWS-based clusters, its public IP address changes.
Implemented the possibility to monitor live status of a cluster and machine deployment or update using the Container Cloud web UI. You can now follow the deployment readiness and health of essential cluster components, such as Helm, Kubernetes, kubelet, Swarm, OIDC, StackLight, and others. For machines, you can monitor nodes readiness reported by kubelet and nodes health reported by Swarm.
Extended the Container Cloud web UI with the parameters that enable proxy access on managed clusters for the remaining cloud providers: vSphere, AWS, and bare metal.
Created a separate QuickStart guides section in the Container Cloud documentation with a set of QuickStart guides that contain only essential lightweight instructions with no additional options to quickly get started with Container Cloud on the AWS, OpenStack, or vSphere providers.
The following issues have been addressed in the Mirantis Container Cloud release 2.7.0 along with the Cluster releases 5.14.0 and 6.14.0:
[13176] [vSphere] Fixed the issue with the cluster network settings related to IPAM disappearing from the cluster provider spec and leading to invalid metadata provided to virtual machines.
[12683] [vSphere] Fixed the issue with the
kaas-ipampods being installed and continuously restarted even if IPAM was disabled on the vSphere-based regional cluster deployed on top of an AWS-based management cluster.
[12305] [Ceph] Fixed the issue with inability to define the CRUSH map rules through the
KaaSCephClustercustom resource. For details, see Operations Guide: Ceph advanced configuration.[10060] [Ceph] Fixed the issue with a Ceph OSD node removal not being triggered properly and failing after updating the
KaasCephClustercustom resource (CR).
[13078] [StackLight] Fixed the issue with Elasticsearch not receiving data from Fluentd due to the limit of open index shards per node.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.7.0 including the Cluster release 5.14.0 and 6.14.0.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Fixed in the Cluster release 7.0.0
Note
The issue below affects only the Kubernetes 1.18 deployments. Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
On a management cluster with multiple AWS-based managed
clusters, some clusters fail to complete the deployments that require
persistent volumes (PVs), for example, Elasticsearch.
Some of the affected pods get stuck in the Pending state
with the pod has unbound immediate PersistentVolumeClaims and
node(s) had volume node affinity conflict errors.
Warning
The workaround below applies to HA deployments where data can be rebuilt from replicas. If you have a non-HA deployment, back up any existing data before proceeding, since all data will be lost while applying the workaround.
Workaround:
Obtain the persistent volume claims related to the storage mounts of the affected pods:
kubectl get pod/<pod_name1> pod/<pod_name2> \ -o jsonpath='{.spec.volumes[?(@.persistentVolumeClaim)].persistentVolumeClaim.claimName}'
Note
In the command above and in the subsequent steps, substitute the parameters enclosed in angle brackets with the corresponding values.
Delete the affected
PodsandPersistentVolumeClaimsto reschedule them: For example, for StackLight:kubectl -n stacklight delete \ pod/<pod_name1> pod/<pod_name2> ... pvc/<pvc_name2> pvc/<pvc_name2> ...
Fixed in 2.9.0 for new clusters
Newly created pods may fail to run and have the CrashLoopBackOff status
on long-living Container Cloud clusters deployed on RHEL 7.8 using the VMware
vSphere provider. The following is an example output of the
kubectl describe pod <pod-name> -n <projectName> command:
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: ContainerCannotRun
Message: OCI runtime create failed: container_linux.go:349:
starting container process caused "process_linux.go:297:
applying cgroup configuration for process caused
"mkdir /sys/fs/cgroup/memory/kubepods/burstable/<pod-id>/<container-id>>:
cannot allocate memory": unknown
The issue occurs due to the Kubernetes and Docker community issues.
According to the RedHat solution,
the workaround is to disable the kernel memory accounting feature
by appending cgroup.memory=nokmem to the kernel command line.
Note
The workaround below applies to the existing clusters only. The issue is resolved for new Container Cloud 2.9.0 deployments since the workaround below automatically applies to the VM template built during the vSphere-based management cluster bootstrap.
Apply the following workaround on each machine of the affected cluster.
Workaround
SSH to any machine of the affected cluster using
mcc-userand the SSH key provided during the cluster creation to proceed as therootuser.In
/etc/default/grub, setcgroup.memory=nokmemforGRUB_CMDLINE_LINUX.Update kernel:
yum install kernel kernel-headers kernel-tools kernel-tools-libs kexec-tools
Update the grub configuration:
grub2-mkconfig -o /boot/grub2/grub.cfg
Reboot the machine.
Wait for the machine to become available.
Wait for 5 minutes for Docker and Kubernetes services to start.
Verify that the machine is
Ready:docker node ls kubectl get nodes
Repeat the steps above on the remaining machines of the affected cluster.
An OpenStack-based regional cluster cleanup fails with the timeout error.
Workaround:
Wait for the
Clusterobject to be deleted in the bootstrap cluster:kubectl --kubeconfig <(./bin/kind get kubeconfig --name clusterapi) get cluster
The system output must be empty.
Remove the bootstrap cluster manually:
./bin/kind delete cluster --name clusterapi
Fixed in 2.11.0
If an L2 template is configured incorrectly, a bare metal cluster is deployed
successfully but with the runtime errors in the IpamHost object.
Workaround:
If you suspect that the machine is not working properly because
of incorrect network configuration, verify the status of the corresponding
IpamHost object. Inspect the l2RenderResult and ipAllocationResult
object fields for error messages.
When removing a worker node, it is not possible to automatically remove a Ceph node. The workaround is to manually remove the Ceph node from the Ceph cluster as described in Operations Guide: Add, remove, or reconfigure Ceph nodes before removing the worker node from your deployment.
Fixed in 2.11.0
If you use a custom BareMetalHostProfile, after disk replacement
on a Ceph OSD, the Ceph OSD pod switches to the CrashLoopBackOff state
due to the Ceph OSD authorization key failing to be created properly.
Workaround:
Export
kubeconfigof your managed cluster. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
Delete the authorization key for the failed Ceph OSD:
ceph auth del osd.<ID>
SSH to the node on which the Ceph OSD cannot be created.
Clean up the disk that will be a base for the failed Ceph OSD. For details, see official Rook documentation.
Note
Ignore failures of the sgdisk --zap-all $DISK and blkdiscard $DISK commands if any.
On the managed cluster, restart Rook Operator:
kubectl -n rook-ceph delete pod -l app=rook-ceph-operator
Fixed in 2.8.0
The ceph_role_mon and ceph_role_mgr labels that Ceph Controller
assigns to a node during a Ceph cluster creation are not automatically
removed after deleting a node from KaaSCephCluster.
As a workaround, manually remove the labels using the following commands:
kubectl unlabel node <nodeName> ceph_role_mon
kubectl unlabel node <nodeName> ceph_role_mgr
Fixed in 2.12.0
The MariaDB pods fail to start after MariaDB blocks itself during the State Snapshot Transfers sync.
Workaround:
Verify the failed pod readiness:
kubectl describe pod -n kaas <failedMariadbPodName>
If the readiness probe failed with the WSREP not synced message, proceed to the next step. Otherwise, assess the MariaDB pod logs to identify the failure root cause.
Obtain the MariaDB admin password:
kubectl get secret -n kaas mariadb-dbadmin-password -o jsonpath='{.data.MYSQL_DBADMIN_PASSWORD}' | base64 -d ; echo
Verify that
wsrep_local_state_commentisDonororDesynced:kubectl exec -it -n kaas <failedMariadbPodName> -- mysql -uroot -p<mariadbAdminPassword> -e "SHOW status LIKE \"wsrep_local_state_comment\";"
Restart the failed pod:
kubectl delete pod -n kaas <failedMariadbPodName>
Fixed in 2.11.0
During update of a managed cluster from the Cluster releases 6.12.0 to 6.14.0, the LCM Agent upgrade fails with the following error in logs:
lcmAgentUpgradeStatus:
error: 'failed to download agent binary: Get https://<mcc-cache-address>/bin/lcm/bin/lcm-agent/v0.2.0-289-gd7e9fa9c/lcm-agent:
x509: certificate signed by unknown authority'
Only clusters initially deployed using Container Cloud 2.4.0 or earlier are affected.
As a workaround, restart lcm-agent using the
service lcm-agent-* restart command on the affected nodes.
Fixed in 2.8.0
After bootstrap, requests to apiserver fail
on the management and regional clusters with enabled proxy.
As a workaround, before running bootstrap.sh,
add the entire range of IP addresses that will be used for floating IPs
to the NO_PROXY environment variable.
Fixed in 2.8.0 for new clusters and in 2.10.0 for existing clusters
If an application running on a Container Cloud management or managed cluster fails frequently, for example, PostgreSQL, it may produce an excessive amount of core dumps. This leads to the no space left on device error on the cluster nodes and, as a result, to the broken Docker Swarm and the entire cluster.
Core dumps are disabled by default on the operating system of the Container Cloud nodes. But since Docker does not inherit the operating system settings, disable core dumps in Docker using the workaround below.
Warning
The workaround below does not apply to the baremetal-based clusters, including MOS deployments, since Docker restart may destroy the Ceph cluster.
Workaround:
SSH to any machine of the affected cluster using
mcc-userand the SSH key provided during the cluster creation.In
/etc/docker/daemon.json, add the following parameters:{ ... "default-ulimits": { "core": { "Hard": 0, "Name": "core", "Soft": 0 } } }
Restart the Docker daemon:
systemctl restart docker
Repeat the steps above on each machine of the affected cluster one by one.
On long-running Container Cloud clusters, one or more nodes may occasionally
become Not Ready with different errors in the ucp-kubelet containers
of failed nodes.
As a workaround, restart ucp-kubelet on the failed node:
ctr -n com.docker.ucp snapshot rm ucp-kubelet
docker rm -f ucp-kubelet
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
Note
The issue affects only Helm v2 releases and is addressed for Helm v3. Starting from Container Cloud 2.19.0, all Helm releases are switched to v3.
During a management, regional, or managed cluster deployment,
Helm releases may get stuck in the FAILED or UNKNOWN state
although the corresponding machines statuses are Ready
in the Container Cloud web UI. For example, if the StackLight Helm release
fails, the links to its endpoints are grayed out in the web UI.
In the cluster status, providerStatus.helm.ready and
providerStatus.helm.releaseStatuses.<releaseName>.success are false.
HelmBundle cannot recover from such states and requires manual actions.
The workaround below describes the recovery steps for the stacklight
release that got stuck during a cluster deployment.
Use this procedure as an example for other Helm releases as required.
Workaround:
Verify the failed release has the
UNKNOWNorFAILEDstatus in the HelmBundle object:kubectl --kubeconfig <regionalClusterKubeconfigPath> get helmbundle <clusterName> -n <clusterProjectName> -o=jsonpath={.status.releaseStatuses.stacklight} In the command above and in the steps below, replace the parameters enclosed in angle brackets with the corresponding values of your cluster.
Example of system response:
stacklight: attempt: 2 chart: "" finishedAt: "2021-02-05T09:41:05Z" hash: e314df5061bd238ac5f060effdb55e5b47948a99460c02c2211ba7cb9aadd623 message: '[{"occurrence":1,"lastOccurrenceDate":"2021-02-05 09:41:05","content":"error updating the release: rpc error: code = Unknown desc = customresourcedefinitions.apiextensions.k8s.io \"helmbundles.lcm.mirantis.com\" already exists"}]' notes: "" status: UNKNOWN success: false version: 0.1.2-mcp-398
Log in to the
helm-controllerpod console:kubectl --kubeconfig <affectedClusterKubeconfigPath> exec -n kube-system -it helm-controller-0 sh -c tiller
Download the Helm v3 binary. For details, see official Helm documentation.
Remove the failed release:
helm delete <failed-release-name>
For example:
helm delete stacklight
Once done, the release triggers for redeployment.
After upgrade of Container Cloud from 2.6.0 to 2.7.0, the local
volume provisioner pod in the default project is stuck in the
Terminating status, even after upgrade to 2.8.0.
This issue does not affect functioning of the management, regional, or managed clusters. The issue does not prevent the successful upgrade of the cluster.
Workaround:
Verify that the cluster is affected:
kubectl get pods -n default | grep local-volume-provisioner
If the output contains a pod with the
Terminatingstatus, the cluster is affected.Capture the affected pod name, if any.
Delete the affected pod:
kuebctl -n default delete pod <LVPPodName> --force
Helm releases may get stuck in the PENDING_UPGRADE status
during a management or managed cluster upgrade. The HelmBundle Controller
cannot recover from this state and requires manual actions. The workaround
below describes the recovery process for the openstack-operator release
that stuck during a managed cluster update. Use it as an example for other
Helm releases as required.
Workaround:
Log in to the
helm-controllerpod console:kubectl exec -n kube-system -it helm-controller-0 sh -c tiller
Identify the release that stuck in the
PENDING_UPGRADEstatus. For example:./helm --host=localhost:44134 history openstack-operator
Example of system response:
REVISION UPDATED STATUS CHART DESCRIPTION 1 Tue Dec 15 12:30:41 2020 SUPERSEDED openstack-operator-0.3.9 Install complete 2 Tue Dec 15 12:32:05 2020 SUPERSEDED openstack-operator-0.3.9 Upgrade complete 3 Tue Dec 15 16:24:47 2020 PENDING_UPGRADE openstack-operator-0.3.18 Preparing upgrade
Roll back the failed release to the previous revision:
Download the Helm v3 binary. For details, see official Helm documentation.
Roll back the failed release:
helm rollback <failed-release-name>
For example:
helm rollback openstack-operator 2
Once done, the release will be reconciled.
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.7.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.19.10 |
aws-credentials-controller |
1.19.10 |
|
Bare metal |
baremetal-operator Updated |
4.0.7 |
baremetal-public-api Updated |
4.0.7 |
|
baremetal-provider Updated |
1.19.10 |
|
httpd |
1.18.0 |
|
ironic |
victoria-bionic-20210302180018 |
|
ironic-operator Updated |
base-bionic-20210326130922 |
|
kaas-ipam Updated |
base-bionic-20210329201651 |
|
local-volume-provisioner Updated |
1.0.5-mcp |
|
mariadb |
10.4.17-bionic-20210203155435 |
|
IAM |
iam Updated |
2.2.0 |
iam-controller Updated |
1.19.10 |
|
keycloak |
9.0.0 |
|
Container Cloud |
admission-controller Updated |
1.19.10 |
byo-credentials-controller Updated |
1.19.10 |
|
byo-provider Updated |
1.19.10 |
|
kaas-public-api Updated |
1.19.10 |
|
kaas-exporter Updated |
1.19.10 |
|
kaas-ui Updated |
1.19.10 |
|
lcm-controller Updated |
0.2.0-299-g32c0398a |
|
mcc-cache Updated |
1.19.10 |
|
proxy-controller Updated |
1.19.10 |
|
release-controller Updated |
1.19.10 |
|
rhellicense-controller Updated |
1.19.10 |
|
squid-proxy |
0.0.1-1 |
|
OpenStack Updated |
openstack-provider |
1.19.10 |
os-credentials-controller |
1.19.10 |
|
VMware vSphere Updated |
vsphere-provider |
1.19.10 |
vsphere-credentials-controller |
1.19.10 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.7.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-4.0.7.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-4.0.7.tgz |
|
ironic-python-agent-bionic.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-victoria-bionic-debug-20210226182519 |
|
ironic-python-agent-bionic.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-victoria-bionic-debug-20210226182519 |
|
kaas-ipam Updated |
||
local-volume-provisioner Updated |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-1.0.5-mcp.tgz |
|
Docker images |
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20210317164614 |
httpd |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20210302180018 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20210302180018 |
|
ironic-operator |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20210301104323 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20210329201651 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210203155435 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.19.10.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.19.10.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.19.10.tgz |
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.19.10.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.19.10.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.19.10.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.19.10.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.19.10.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.19.10.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.19.10.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.19.10.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.19.10.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.19.10.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.19.10.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.19.10.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.19.10.tgz |
|
rhellicense-controller Updated |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.19.10.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.19.10.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.19.10.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.19.10.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.19.10 |
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.19.10 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.19.10 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.19.10 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.19.10 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.19.10 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.19.10 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.19.10 |
|
kproxy Updated |
mirantis.azurecr.io/lcm/kproxy:1.19.10 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:v0.2.0-299-g32c0398a |
|
nginx |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.19.10 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.19.10 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.19.10 |
|
rhellicense-controller Updated |
mirantis.azurecr.io/core/rhellicense-controller:1.19.10 |
|
squid-proxy |
mirantis.azurecr.io/core/squid-proxy:0.0.1-1 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-api-controller:1.19.10 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.19.10 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux |
||
iamctl-darwin |
||
iamctl-windows |
||
Helm charts Updated |
iam |
|
iam-proxy |
||
keycloak-proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.19.10.tgz |
|
Docker images |
api |
mirantis.azurecr.io/iam/api:0.4.0 |
auxiliary |
mirantis.azurecr.io/iam/auxiliary:0.4.0 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.4.0 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:6.0.1 |
The Mirantis Container Cloud GA release 2.6.0:
Introduces support for the Cluster release 5.13.0 that is based on Kubernetes 1.18, Mirantis Container Runtime 19.03.14, and Mirantis Kubernetes Engine 3.3.6.
Supports the Cluster release 6.12.0 that is based on the Cluster release 5.12.0 and represents Mirantis OpenStack for Kubernetes (MOS) 21.1.
Still supports deprecated Cluster releases 5.12.0 and 6.10.0 that will become unsupported in one of the following Container Cloud releases.
Supports the Cluster release 5.11.0 only for attachment of existing MKE 3.3.4 clusters. For the deployment of new or attachment of existing MKE 3.3.6 clusters, the latest available Cluster release is used.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.6.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.6.0. For the list of enhancements in the Cluster release 5.13.0 and Cluster release 6.12.0 that are supported by the Container Cloud release 2.6.0, see the 5.13.0 and 6.12.0 sections.
Technology Preview
In the scope of Technology Preview support for the VMware vSphere cloud provider on RHEL, added an additional RHEL license activation method that uses the activation key through RedHat Customer Portal or RedHat Satellite server.
The Satellite configuration on the hosts is done by installing a specific pre-generated RPM package from the Satellite package URL provided by the user through API. The activation key is provided by the user through API.
Along with the new activation method, you can still use the existing method that is adding of your RHEL subscription with the user name and password of your RedHat Customer Portal account associated with your RHEL license for Virtual Datacenters.
Technology Preview
In the scope of Technology Preview support for the VMware vSphere cloud
provider on RHEL, added support for VMware vSphere Distributed Switch (VDS)
to provide networking to the vSphere virtual machines.
This is an alternative to the vSphere Standard Switch with network on top of
it. A VM is attached to a VDS port group. You can specify the path
to the port group using the NetworkPath parameter in
VsphereClusterProviderSpec.
Technology Preview
In the scope of Technology Preview support for the VMware vSphere cloud provider on RHEL, enabled the vSphere provider to use IPAM controller to assign IP addresses to VMs automatically, without an external DHCP server. If the IPAM controller is not enabled in the bootstrap template, the vSphere provider must rely on external provisioning of the IP addresses by a DHCP server of the user infrastructure.
Extended proxy support by enabling the feature for the remaining supported AWS and bare metal cloud providers. If you require all Internet access to go through a proxy server for security and audit purposes, you can now bootstrap management and regional clusters of any cloud provider type using proxy.
You can also enable a separate proxy access on the OpenStack-based managed clusters using the Container Cloud web UI. This proxy is intended for the end user needs and is not used for a managed cluster deployment or for access to the Mirantis resources.
Caution
Enabling of proxy access using the Container Cloud web UI for the vSphere, AWS, and baremetal-based managed clusters is on the final development stage and will become available in the next release.
Expanded and restructured the bare metal networking documentation that now contains the following subsections with a detailed description of every bare metal network type:
IPAM network
Management network
Cluster network
Host network
The following issues have been addressed in the Mirantis Container Cloud release 2.6.0 and the Cluster release 5.13.0:
[11302] [LCM] Fixed the issue with inability to delete a Container Cloud project with attached MKE clusters that failed to be cleaned up properly.
[11967] [LCM] Added
vrrp_script chk_myscriptto the Keepalived configuration to prevent issues with VIP (Virtual IP) pointing to a node with broken Kubernetes API.[10491] [LCM] Fixed the issue with
kubeletbeing randomly stuck, for example, after a management cluster upgrade. The fix enables automatic restart ofkubeletin case of failures.[7782] [bootstrap] Renamed the SSH key used during bootstrap for every cloud provider from
openstack_tmpto an accurate and clearssh_key.[11927] [StackLight] Fixed the issue with StackLight failing to integrate with an external proxy with authentication handled by a proxy server and ignoring the HTTP
Authorizationheader for basic authentication passed by Prometheus Alertmanager.[11001] [StackLight] Fixed the issue with Patroni pod failing to start and remaining in the
CrashLoopBackOffstatus after the management cluster update.[10829] [IAM] Fixed the issue with the Keycloak pods failing to start during a management cluster bootstrap with the Failed to update database exception in logs.
[11468] [BM] Fixed the issue with the persistent volumes (PVs) that are created using local volume provisioner (LVP) not being mounted on the dedicated disk labeled as
local-volumeand using the root volume instead.[9875] [BM] Fixed the issue with the bootstrap.sh preflight script failing with a timeout waiting for
BareMetalHostifKAAS_BM_FULL_PREFLIGHTwas enabled.[11633] [vSphere] Fixed the issue with the vSphere-based managed cluster projects failing to be cleaned up because of stale secret(s) related to the RHEL license object(s).
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.6.0 including the Cluster release 5.13.0 and 6.12.0.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Fixed in the Cluster release 7.0.0
Note
The issue below affects only the Kubernetes 1.18 deployments. Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
On a management cluster with multiple AWS-based managed
clusters, some clusters fail to complete the deployments that require
persistent volumes (PVs), for example, Elasticsearch.
Some of the affected pods get stuck in the Pending state
with the pod has unbound immediate PersistentVolumeClaims and
node(s) had volume node affinity conflict errors.
Warning
The workaround below applies to HA deployments where data can be rebuilt from replicas. If you have a non-HA deployment, back up any existing data before proceeding, since all data will be lost while applying the workaround.
Workaround:
Obtain the persistent volume claims related to the storage mounts of the affected pods:
kubectl get pod/<pod_name1> pod/<pod_name2> \ -o jsonpath='{.spec.volumes[?(@.persistentVolumeClaim)].persistentVolumeClaim.claimName}'
Note
In the command above and in the subsequent steps, substitute the parameters enclosed in angle brackets with the corresponding values.
Delete the affected
PodsandPersistentVolumeClaimsto reschedule them: For example, for StackLight:kubectl -n stacklight delete \ pod/<pod_name1> pod/<pod_name2> ... pvc/<pvc_name2> pvc/<pvc_name2> ...
Fixed in Container Cloud 2.7.0
Even though IPAM is disabled on the vSphere-based regional cluster deployed
on top of an AWS-based management cluster, the regional cluster still has
the kaas-ipam pods installed and continuously restarts them.
In this case, the pods logs contain the following exemplary errors:
Waiting for CRDs. [baremetalhosts.metal3.io clusters.cluster.k8s.io machines.cluster.k8s.io
ipamhosts.ipam.mirantis.com ipaddrs.ipam.mirantis.com subnets.ipam.mirantis.com subnetpools.ipam.mirantis.com \
l2templates.ipam.mirantis.com] not found yet
E0318 11:58:21.067502 1 main.go:240] Fetch CRD list failed: \
Object 'Kind' is missing in 'unstructured object has no kind'
As a result, the KubePodCrashLooping StackLight alerts are firing
in Alertmanager for kaas-ipam. Disregard these alerts.
Fixed in Container Cloud 2.7.0
A vSphere-based cluster with IPAM enabled may lose cluster network settings related to IPAM leading to invalid metadata provided to virtual machines. As a result, virtual machines can not obtain assigned IP addresses. The issue occurs during a management cluster bootstrap or a managed cluster creation.
Workaround:
If the management cluster with IPAM enabled is not deployed yet, follow the steps below before launching the
bootstrap.shscript:Open
kaas-bootstrap/releases/kaas/2.6.0.yamlfor editing.Change the
release-controllerversion from 1.18.1 to 1.18.3:- name: release-controller version: 1.18.3 chart: kaas-release/release-controller namespace: kaas values: image: tag: 1.18.3
Now, proceed with the management cluster bootstrap.
If the management cluster is already deployed, and you want to create a vSphere-based managed cluster with IPAM enabled:
Log in to a local machine where your management or regional cluster
kubeconfigis located and export it:export KUBECONFIG=kaas-bootstrap/kubeconfig
Edit the
kaasreleaseobject by updating therelease-controllerchart and image version from 1.18.1 to 1.18.3:kubectl edit kaasrelease kaas-2-6-0
- chart: kaas-release/release-controller name: release-controller namespace: kaas values: image: tag: 1.18.3 version: 1.18.3
Verify that the
release-controllerdeployment is ready with3/3replicas:kubectl get deployment release-controller-release-controller -n kaas -o=jsonpath='{.status.readyReplicas}/{.status.replicas}'
Now, you can deploy managed clusters with IPAM enabled. For details, see Operations Guide: Create a vSphere-based managed cluster.
Fixed in 2.11.0
If an L2 template is configured incorrectly, a bare metal cluster is deployed
successfully but with the runtime errors in the IpamHost object.
Workaround:
If you suspect that the machine is not working properly because
of incorrect network configuration, verify the status of the corresponding
IpamHost object. Inspect the l2RenderResult and ipAllocationResult
object fields for error messages.
Fixed in Container Cloud 2.7.0
Elasticsearch may stop receiving new data from Fluentd. In such case, error
messages similar to the following will be present in
fluentd-elasticsearch logs:
ElasticsearchError error="400 - Rejected by Elasticsearch [error type]:
illegal_argument_exception [reason]: 'Validation Failed: 1: this action would
add [15] total shards, but this cluster currently has [2989]/[3000] maximum
shards open;'" location=nil tag="ucp-kubelet"
The workaround is to manually increase the limit of open index shards per node:
kubectl -n stacklight exec -ti elasticsearch-master-0 -- \
curl -XPUT -H "content-type: application/json" \
-d '{"persistent":{"cluster.max_shards_per_node": 20000}}' \
http://127.0.0.1:9200/_cluster/settings
Fixed in Container Cloud 2.7.0
A Ceph node removal is not being triggered properly after updating
the KaasCephCluster custom resource (CR). Both management and managed
clusters are affected.
Workaround:
Remove the parameters for a Ceph OSD from the
KaasCephClusterCR as described in Operations Guide: Add, remove, or reconfigure Ceph nodes.Obtain the IDs of the
osdandmonservices that are located on the old node:Obtain the UID of the affected machine:
kubectl get machine <CephOSDNodeName> -n <ManagedClusterProjectName> -o jsonpath='{.metadata.annotations.kaas\.mirantis\.com\/uid}'
Export
kubeconfigof your managed cluster. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Identify the pods IDs that run the
osdandmonservices:kubectl get pods -o wide -n rook-ceph | grep <affectedMachineUID> | grep -E "mon|osd"
Example of the system response extract:
rook-ceph-mon-c-7bbc5d757d-5bpws 1/1 Running 1 6h1m rook-ceph-osd-2-58775d5568-5lklw 1/1 Running 4 44h rook-ceph-osd-prepare-705ae6c647cfdac928c63b63e2e2e647-qn4m9 0/1 Completed 0 94s
The pods IDs include the
osdormonservices IDs. In the example system response above, theosdID is2and themonID isc.
Delete the deployments of the
osdandmonservices obtained in the previous step:kubectl delete deployment rook-ceph-osd(mon)-<ID> -n rook-ceph
For example:
kubectl delete deployment rook-ceph-mon-c -n rook-ceph kubectl delete deployment rook-ceph-osd-2 -n rook-ceph
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
Rebalance the Ceph OSDs:
ceph osd out osd(s).ID
Wait for the rebalance to complete.
Rebalance the Ceph data:
ceph osd purge osd(s).ID
Wait for the Ceph data to rebalance.
Remove the old node from the Ceph OSD tree:
ceph osd crush rm <NodeName>
If the removed node contained
monservices, remove them:ceph mon rm <monID>
When removing a worker node, it is not possible to automatically remove a Ceph node. The workaround is to manually remove the Ceph node from the Ceph cluster as described in Operations Guide: Add, remove, or reconfigure Ceph nodes before removing the worker node from your deployment.
Fixed in 2.11.0
If you use a custom BareMetalHostProfile, after disk replacement
on a Ceph OSD, the Ceph OSD pod switches to the CrashLoopBackOff state
due to the Ceph OSD authorization key failing to be created properly.
Workaround:
Export
kubeconfigof your managed cluster. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
Delete the authorization key for the failed Ceph OSD:
ceph auth del osd.<ID>
SSH to the node on which the Ceph OSD cannot be created.
Clean up the disk that will be a base for the failed Ceph OSD. For details, see official Rook documentation.
Note
Ignore failures of the sgdisk --zap-all $DISK and blkdiscard $DISK commands if any.
On the managed cluster, restart Rook Operator:
kubectl -n rook-ceph delete pod -l app=rook-ceph-operator
Fixed in 2.8.0
The ceph_role_mon and ceph_role_mgr labels that Ceph Controller
assigns to a node during a Ceph cluster creation are not automatically
removed after deleting a node from KaaSCephCluster.
As a workaround, manually remove the labels using the following commands:
kubectl unlabel node <nodeName> ceph_role_mon
kubectl unlabel node <nodeName> ceph_role_mgr
Fixed in 2.8.0 for new clusters and in 2.10.0 for existing clusters
If an application running on a Container Cloud management or managed cluster fails frequently, for example, PostgreSQL, it may produce an excessive amount of core dumps. This leads to the no space left on device error on the cluster nodes and, as a result, to the broken Docker Swarm and the entire cluster.
Core dumps are disabled by default on the operating system of the Container Cloud nodes. But since Docker does not inherit the operating system settings, disable core dumps in Docker using the workaround below.
Warning
The workaround below does not apply to the baremetal-based clusters, including MOS deployments, since Docker restart may destroy the Ceph cluster.
Workaround:
SSH to any machine of the affected cluster using
mcc-userand the SSH key provided during the cluster creation.In
/etc/docker/daemon.json, add the following parameters:{ ... "default-ulimits": { "core": { "Hard": 0, "Name": "core", "Soft": 0 } } }
Restart the Docker daemon:
systemctl restart docker
Repeat the steps above on each machine of the affected cluster one by one.
Note
The issue affects only Helm v2 releases and is addressed for Helm v3. Starting from Container Cloud 2.19.0, all Helm releases are switched to v3.
During a management, regional, or managed cluster deployment,
Helm releases may get stuck in the FAILED or UNKNOWN state
although the corresponding machines statuses are Ready
in the Container Cloud web UI. For example, if the StackLight Helm release
fails, the links to its endpoints are grayed out in the web UI.
In the cluster status, providerStatus.helm.ready and
providerStatus.helm.releaseStatuses.<releaseName>.success are false.
HelmBundle cannot recover from such states and requires manual actions.
The workaround below describes the recovery steps for the stacklight
release that got stuck during a cluster deployment.
Use this procedure as an example for other Helm releases as required.
Workaround:
Verify the failed release has the
UNKNOWNorFAILEDstatus in the HelmBundle object:kubectl --kubeconfig <regionalClusterKubeconfigPath> get helmbundle <clusterName> -n <clusterProjectName> -o=jsonpath={.status.releaseStatuses.stacklight} In the command above and in the steps below, replace the parameters enclosed in angle brackets with the corresponding values of your cluster.
Example of system response:
stacklight: attempt: 2 chart: "" finishedAt: "2021-02-05T09:41:05Z" hash: e314df5061bd238ac5f060effdb55e5b47948a99460c02c2211ba7cb9aadd623 message: '[{"occurrence":1,"lastOccurrenceDate":"2021-02-05 09:41:05","content":"error updating the release: rpc error: code = Unknown desc = customresourcedefinitions.apiextensions.k8s.io \"helmbundles.lcm.mirantis.com\" already exists"}]' notes: "" status: UNKNOWN success: false version: 0.1.2-mcp-398
Log in to the
helm-controllerpod console:kubectl --kubeconfig <affectedClusterKubeconfigPath> exec -n kube-system -it helm-controller-0 sh -c tiller
Download the Helm v3 binary. For details, see official Helm documentation.
Remove the failed release:
helm delete <failed-release-name>
For example:
helm delete stacklight
Once done, the release triggers for redeployment.
Helm releases may get stuck in the PENDING_UPGRADE status
during a management or managed cluster upgrade. The HelmBundle Controller
cannot recover from this state and requires manual actions. The workaround
below describes the recovery process for the openstack-operator release
that stuck during a managed cluster update. Use it as an example for other
Helm releases as required.
Workaround:
Log in to the
helm-controllerpod console:kubectl exec -n kube-system -it helm-controller-0 sh -c tiller
Identify the release that stuck in the
PENDING_UPGRADEstatus. For example:./helm --host=localhost:44134 history openstack-operator
Example of system response:
REVISION UPDATED STATUS CHART DESCRIPTION 1 Tue Dec 15 12:30:41 2020 SUPERSEDED openstack-operator-0.3.9 Install complete 2 Tue Dec 15 12:32:05 2020 SUPERSEDED openstack-operator-0.3.9 Upgrade complete 3 Tue Dec 15 16:24:47 2020 PENDING_UPGRADE openstack-operator-0.3.18 Preparing upgrade
Roll back the failed release to the previous revision:
Download the Helm v3 binary. For details, see official Helm documentation.
Roll back the failed release:
helm rollback <failed-release-name>
For example:
helm rollback openstack-operator 2
Once done, the release will be reconciled.
An OpenStack-based regional cluster cleanup fails with the timeout error.
Workaround:
Wait for the
Clusterobject to be deleted in the bootstrap cluster:kubectl --kubeconfig <(./bin/kind get kubeconfig --name clusterapi) get cluster
The system output must be empty.
Remove the bootstrap cluster manually:
./bin/kind delete cluster --name clusterapi
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.6.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.18.4 |
aws-credentials-controller |
1.18.1 |
|
Bare metal |
baremetal-operator Updated |
4.0.4 |
baremetal-public-api Updated |
4.0.4 |
|
baremetal-provider Updated |
1.18.6 |
|
httpd |
1.18.0 |
|
ironic Updated |
victoria-bionic-20210302180018 |
|
ironic-operator Updated |
base-bionic-20210301104323 |
|
kaas-ipam Updated |
base-bionic-20210304134548 |
|
local-volume-provisioner |
1.0.4-mcp |
|
mariadb |
10.4.17-bionic-20210203155435 |
|
IAM |
iam Updated |
2.0.0 |
iam-controller Updated |
1.18.1 |
|
keycloak |
9.0.0 |
|
Container Cloud |
admission-controller Updated |
1.18.1 |
byo-credentials-controller Updated |
1.18.1 |
|
byo-provider Updated |
1.18.4 |
|
kaas-public-api Updated |
1.18.1 |
|
kaas-exporter Updated |
1.18.1 |
|
kaas-ui Updated |
1.18.3 |
|
lcm-controller Updated |
0.2.0-289-gd7e9fa9c |
|
mcc-cache Updated |
1.18.1 |
|
proxy-controller Updated |
1.18.1 |
|
release-controller Updated |
1.18.1 |
|
rhellicense-controller New |
1.18.1 |
|
squid-proxy |
0.0.1-1 |
|
OpenStack Updated |
openstack-provider |
1.18.4 |
os-credentials-controller |
1.18.1 |
|
VMware vSphere Updated |
vsphere-provider |
1.18.7 |
vsphere-credentials-controller |
1.18.1 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.6.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-4.0.4.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-4.0.4.tgz |
|
ironic-python-agent-bionic.kernel Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-victoria-bionic-debug-20210226182519 |
|
ironic-python-agent-bionic.initramfs Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-victoria-bionic-debug-20210226182519 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-1.0.4-mcp.tgz |
|
Docker images |
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20210216135743 |
httpd |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20210302180018 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20210302180018 |
|
ironic-operator Updated |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20210301104323 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20210304134548 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210203155435 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.18.6.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.18.6.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.18.1.tgz |
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.18.1.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.18.4.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.18.6.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.18.1.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.18.4.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.18.1.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.18.1.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.18.1.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.18.1.tgz |
|
mcc-cache |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.18.4.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.18.1.tgz |
|
proxy-controller |
https://binary.mirantis.com/core/helm/proxy-controller-1.18.1.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.18.1.tgz |
|
rhellicense-controller New |
https://binary.mirantis.com/core/helm/rhellicense-controller-1.18.1.tgz |
|
squid-proxy |
https://binary.mirantis.com/core/helm/squid-proxy-1.18.1.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.18.1.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.18.7.tgz |
|
Docker images |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.18.1 |
aws-cluster-api-controller Updated |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.18.4 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.18.1 |
|
byo-cluster-api-controller Updated |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.18.4 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.18.1 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.18.6 |
|
frontend Updated |
mirantis.azurecr.io/core/frontend:1.18.3 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.18.1 |
|
kproxy Updated |
mirantis.azurecr.io/lcm/kproxy:1.18.1 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:v0.2.0-289-gd7e9fa9c |
|
nginx |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
openstack-cluster-api-controller Updated |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.18.4 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.18.1 |
|
registry |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.18.1 |
|
rhellicense-controller New |
mirantis.azurecr.io/core/rhellicense-controller:1.18.1 |
|
squid-proxy |
mirantis.azurecr.io/core/squid-proxy:0.0.1-1 |
|
vsphere-cluster-api-controller Updated |
mirantis.azurecr.io/core/vsphere-api-controller:1.18.7 |
|
vsphere-credentials-controller Updated |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.18.1 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux Updated |
||
iamctl-darwin Updated |
||
iamctl-windows Updated |
||
Helm charts Updated |
iam |
|
iam-proxy |
||
keycloak-proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.18.7.tgz |
|
Docker images |
api |
mirantis.azurecr.io/iam/api:0.4.0 |
auxiliary |
mirantis.azurecr.io/iam/auxiliary:0.4.0 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.4.0 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:6.0.1 |
The Mirantis Container Cloud GA release 2.5.0:
Introduces support for the Cluster release 5.12.0 that is based on Kubernetes 1.18, Mirantis Container Runtime 19.03.14, and the updated version of Mirantis Kubernetes Engine 3.3.6.
Introduces support for the Cluster release 6.12.0 that is based on the Cluster release 5.12.0 and supports Mirantis OpenStack for Kubernetes (MOS) 21.1.
Still supports previous Cluster releases 5.11.0 and 6.10.0 that are now deprecated and will become unsupported in one of the following Container Cloud releases.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.5.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.5.0. For the list of enhancements in the Cluster release 5.12.0 and Cluster release 6.12.0 that are supported by the Container Cloud release 2.5.0, see the 5.12.0 and 6.12.0 sections.
Updated the Mirantis Kubernetes Engine (MKE) version to 3.3.6 for the Container Cloud management and managed clusters.
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
Implemented proxy support for OpenStack-based and vSphere-based Technology Preview clusters. If you require all Internet access to go through a proxy server for security and audit purposes, you can now bootstrap management and regional clusters using proxy.
You can also enable a separate proxy access on an OpenStack-based managed cluster using the Container Cloud web UI. This proxy is intended for the end user needs and is not used for a managed cluster deployment or for access to the Mirantis resources.
Note
The proxy support for:
The OpenStack provider is generally available.
The VMware vSphere provider is available as Technology Preview. For the Technology Preview feature definition, refer to Technology Preview features.
The AWS and bare metal providers is in the development stage and will become available in the future Container Cloud releases.
Introduced artifacts caching support for all Container Cloud providers to enable deployment of managed clusters without direct Internet access. The Mirantis artifacts used during managed clusters deployment are downloaded through a cache running on a regional cluster.
The feature is enabled by default on new managed clusters based on the Cluster releases 5.12.0 and 6.12.0 and will be automatically enabled on existing clusters during upgrade to the latest version.
Implemented the possibility to configure regional NTP server parameters to be applied to all machines of regional and managed clusters in the specified region. The feature is applicable to all supported cloud providers. The NTP server parameters can be added before or after management and regional clusters deployment.
Optimized the ClusterRelease upgrade process by enabling the Container Cloud provider to upgrade the LCMCluster components, such as MKE, before the HelmBundle components, such as StackLight or Ceph.
Technology Preview
Implemented the k8s-ext bridge in L2 templates that allows you to use
a dedicated network for external connection to the Kubernetes services
exposed by the cluster. When using such bridge, the MetalLB ranges and the
IP addresses provided by the subnet that is associated with the bridge
must fit in the same CIDR.
If enabled, MetalLB will listen and respond on the dedicated virtual bridge. Also, you can create additional subnets to configure additional address ranges for MetalLB.
Caution
Use of a dedicated network for Kubernetes pods traffic, for external connection to the Kubernetes services exposed by the cluster, and for the Ceph cluster access and replication traffic is available as Technology Preview. Use such configurations for testing and evaluation purposes only. For the Technology Preview feature definition, refer to Technology Preview features.
The following issues have been addressed in the Mirantis Container Cloud release 2.5.0 and the Cluster releases 5.12.0 and 6.12.0:
[10453] [LCM] Fixed the issue with time synchronization on nodes that could cause networking issues.
[9748] [LCM] Fixed the issue with the false-positive
helmReleasesuccess status inHelmBundleduring Helm upgrade operations.[9748] [LCM] Fixed the issue with the false-positive
helmReleasesuccess status inHelmBundleduring Helm upgrade operations.[8464] Fixed the issue with Helm controller and OIDC integration failing to be deleted during detach of an MKE cluster.
[9928] [Ceph] Fixed the issue with Ceph rebalance leading to data loss during a managed cluster update by implementing the
maintenancelabel to be set before and unset after the cluster update.[9892] [Ceph] Fixed the issue with Ceph being locked during a managed cluster update by adding the
PodDisruptionBudgetobject that enables minimum 2 Ceph OSD nodes running without rescheduling during update.
[6988] [BM] Fixed the issue with LVM failing to deploy on a new disk if an old volume group with the same name already existed on the target hardware node but on the different disk.
[8560] [BM] Fixed the issue with manual deletion of
BareMetalHostfrom a managed cluster leading to its silent removal without a power-off and deprovision. The fix adds the admission controller webhook to validate the oldBareMetalHostwhen the deletion is requested.[11102] [BM] Fixed the issue with Keepalived not detecting and restoring a VIP of a managed cluster node after running the netplan apply command.
[9905] [9906] [9909] [9914] [9921] [BM] Fixed the following Ubuntu CVEs in the bare metal Docker images:
CVE-2019-20477 and CVE-2020-1747 for PyYAML in
vbmc:latest-20201029CVE-2020-1971 for OpenSSL in the following images:
dnsmasq:bionic-20201105044831rabbitmq-management:3.7.15-bionic-20200812044813kaas-ipam:base-bionic-20201208153852ironic-operator:base-bionic-20201106182102
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.5.0 including the Cluster release 5.12.0 and 6.12.0.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Fixed in the Cluster release 7.0.0
Note
The issue below affects only the Kubernetes 1.18 deployments. Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
On a management cluster with multiple AWS-based managed
clusters, some clusters fail to complete the deployments that require
persistent volumes (PVs), for example, Elasticsearch.
Some of the affected pods get stuck in the Pending state
with the pod has unbound immediate PersistentVolumeClaims and
node(s) had volume node affinity conflict errors.
Warning
The workaround below applies to HA deployments where data can be rebuilt from replicas. If you have a non-HA deployment, back up any existing data before proceeding, since all data will be lost while applying the workaround.
Workaround:
Obtain the persistent volume claims related to the storage mounts of the affected pods:
kubectl get pod/<pod_name1> pod/<pod_name2> \ -o jsonpath='{.spec.volumes[?(@.persistentVolumeClaim)].persistentVolumeClaim.claimName}'
Note
In the command above and in the subsequent steps, substitute the parameters enclosed in angle brackets with the corresponding values.
Delete the affected
PodsandPersistentVolumeClaimsto reschedule them: For example, for StackLight:kubectl -n stacklight delete \ pod/<pod_name1> pod/<pod_name2> ... pvc/<pvc_name2> pvc/<pvc_name2> ...
Fixed in Container Cloud 2.6.0
A vSphere-based managed cluster project can fail to be cleaned up because of stale secret(s) related to the RHEL license object(s). Before you can successfully clean up such project, manually delete the secret using the steps below.
Workaround:
Log in to a local machine where your management cluster
kubeconfigis located and where kubectl is installed.Obtain the list of stale secrets:
kubectl --kubeconfig <kubeconfigPath> get secrets -n <projectName>
Open each secret for editing:
kubectl --kubeconfig <kubeconfigPath> edit secret <secret name> -n <projectName>
Remove the following lines:
finalizers: - kaas.mirantis.com/credentials-secretRemove stale secrets:
kubectl --kubeconfig <kubeconfigPath> delete secret <secretName> -n <projectName>
Fixed in 2.11.0
If an L2 template is configured incorrectly, a bare metal cluster is deployed
successfully but with the runtime errors in the IpamHost object.
Workaround:
If you suspect that the machine is not working properly because
of incorrect network configuration, verify the status of the corresponding
IpamHost object. Inspect the l2RenderResult and ipAllocationResult
object fields for error messages.
Fixed in Container Cloud 2.6.0
If you run bootstrap.sh preflight with
KAAS_BM_FULL_PREFLIGHT=true, the script fails with the following message:
failed to create BareMetal objects: failed to wait for objects of kinds BareMetalHost
to become available: timed out waiting for the condition
As a workaround, unset full preflight using unset KAAS_BM_FULL_PREFLIGHT
to run fast preflight instead.
Fixed in Container Cloud 2.6.0
The persistent volumes (PVs) that are created using local volume provisioner
(LVP), are not mounted on the dedicated disk labeled as local-volume
and use the root volume instead. In the workaround below, we use StackLight
volumes as an example.
Workaround:
Identify whether your cluster is affected:
Log in to any control plane node on the management cluster.
Run the following command:
findmnt /mnt/local-volumes/stacklight/elasticsearch-data/vol00In the output, inspect the
SOURCEcolumn. If the path starts with/dev/mapper/lvm_root-root, the host is affected by the issue.Example of system response:
TARGET SOURCE FSTYPE OPTIONS /mnt/local-volumes/stacklight/elasticsearch-data/vol00 /dev/mapper/lvm_root-root[/var/lib/local-volumes/stacklight/elasticsearch-data/vol00] ext4 rw,relatime,errors=remount-ro,data=ordered
Verify other StackLight directories by replacing
elasticsearch-datain the command above with the corresponding folders names.If your cluster is affected, follow the steps below to manually move all data for volumes that must be on the dedicated disk to the mounted device.
Identify all nodes that run the
elasticsearch-masterpod:kubectl -n stacklight get pods -o wide | grep elasticsearch-master
Apply the steps below to all nodes provided in the output.
Identify the mount point for the dedicated device
/dev/mapper/lvm_lvp-lvp. Typically, this device is mounted as/mnt/local-volumes.findmnt /mnt/local-volumesVerify that
SOURCEfor the/mnt/local-volumes mounttarget is/dev/mapper/lvm_lvp-lvpon all the nodes.Create new source directories for the volumes on the dedicated device
/dev/mapper/lvm_lvp-lvp:mkdir -p /mnt/local-volumes/src/stacklight/elasticsearch-data/vol00
Stop the pods that use the volumes to ensure that the data is not corrupted during the switch. Set the number of replicas in
StatefulSetto0:kubectl -n stacklight edit statefulset elasticsearch-master
Wait until all
elasticsearch-masterpods are stopped.Move the Elasticsearch data from the current location to the new directory:
cp -pR /var/lib/local-volumes/stacklight/elasticsearch-data/vol00/** /mnt/local-volumes/src/stacklight/elasticsearch-data/vol00/
Unmount the old source directory from the volume mount point:
umount /mnt/local-volumes/stacklight/elasticsearch-data/vol00Apply this step and the next one to every node with the
/mnt/local-volumes/stacklight/elasticsearch-data/vol00volume.Remount the new source directory to the volume mount point:
mount --bind /mnt/local-volumes/src/stacklight/elasticsearch-data/vol00 /mnt/local-volumes/stacklight/elasticsearch-data/vol00
Edit the
Clusterobject by adding the highlighted parameters below for the StackLight Helm chart:kubectl --kubeconfig <mgmtClusterKubeconfig> edit -n <projectName> cluster <managedClusterName>
spec: helmReleases: - name: stacklight values: ... elasticsearch: clusterHealthCheckParams: wait_for_status=red&timeout=1s
Start the Elasticsearch pods by setting the number of replicas in
StatefulSetto3:kubectl -n stacklight edit statefulset elasticsearch-master
Wait until all
elasticsearch-masterpods are up and running.Remove the previously added
clusterHealthCheckParamsparameters from theClusterobject.In
/etc/fstabon every node that has the volume/mnt/local-volumes/stacklight/elasticsearch-data/vol00, edit the following entry:/var/lib/local-volumes/stacklight/elasticsearch-data/vol00 /mnt/local-volumes/stacklight/elasticsearch-data/vol00 none bind 0 0
In this entry, replace the old directory
/var/lib/local-volumes/stacklight/elasticsearch-data/vol00with the new one:/mnt/local-volumes/src/stacklight/elasticsearch-data/vol00.
Fixed in Container Cloud 2.7.0
A Ceph node removal is not being triggered properly after updating
the KaasCephCluster custom resource (CR). Both management and managed
clusters are affected.
Workaround:
Remove the parameters for a Ceph OSD from the
KaasCephClusterCR as described in Operations Guide: Add, remove, or reconfigure Ceph nodes.Obtain the IDs of the
osdandmonservices that are located on the old node:Obtain the UID of the affected machine:
kubectl get machine <CephOSDNodeName> -n <ManagedClusterProjectName> -o jsonpath='{.metadata.annotations.kaas\.mirantis\.com\/uid}'
Export
kubeconfigof your managed cluster. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Identify the pods IDs that run the
osdandmonservices:kubectl get pods -o wide -n rook-ceph | grep <affectedMachineUID> | grep -E "mon|osd"
Example of the system response extract:
rook-ceph-mon-c-7bbc5d757d-5bpws 1/1 Running 1 6h1m rook-ceph-osd-2-58775d5568-5lklw 1/1 Running 4 44h rook-ceph-osd-prepare-705ae6c647cfdac928c63b63e2e2e647-qn4m9 0/1 Completed 0 94s
The pods IDs include the
osdormonservices IDs. In the example system response above, theosdID is2and themonID isc.
Delete the deployments of the
osdandmonservices obtained in the previous step:kubectl delete deployment rook-ceph-osd(mon)-<ID> -n rook-ceph
For example:
kubectl delete deployment rook-ceph-mon-c -n rook-ceph kubectl delete deployment rook-ceph-osd-2 -n rook-ceph
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
Rebalance the Ceph OSDs:
ceph osd out osd(s).ID
Wait for the rebalance to complete.
Rebalance the Ceph data:
ceph osd purge osd(s).ID
Wait for the Ceph data to rebalance.
Remove the old node from the Ceph OSD tree:
ceph osd crush rm <NodeName>
If the removed node contained
monservices, remove them:ceph mon rm <monID>
When removing a worker node, it is not possible to automatically remove a Ceph node. The workaround is to manually remove the Ceph node from the Ceph cluster as described in Operations Guide: Add, remove, or reconfigure Ceph nodes before removing the worker node from your deployment.
Fixed in 2.11.0
If you use a custom BareMetalHostProfile, after disk replacement
on a Ceph OSD, the Ceph OSD pod switches to the CrashLoopBackOff state
due to the Ceph OSD authorization key failing to be created properly.
Workaround:
Export
kubeconfigof your managed cluster. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
Delete the authorization key for the failed Ceph OSD:
ceph auth del osd.<ID>
SSH to the node on which the Ceph OSD cannot be created.
Clean up the disk that will be a base for the failed Ceph OSD. For details, see official Rook documentation.
Note
Ignore failures of the sgdisk --zap-all $DISK and blkdiscard $DISK commands if any.
On the managed cluster, restart Rook Operator:
kubectl -n rook-ceph delete pod -l app=rook-ceph-operator
Fixed in Container Cloud 2.6.0
The Keycloak pods may fail to start during a management cluster bootstrap with the Failed to update database exception in logs.
Caution
The following workaround is applicable only to deployments
where mariadb-server has started successfully. Otherwise,
fix the issues with MariaDB first.
Workaround:
Verify that
mariadb-serverhas started:kubectl get po -n kaas | grep mariadb-server
Scale down the Keycloak instances:
kubectl scale sts iam-keycloak --replicas=0 -n kaas
Open the
iam-keycloak-shconfigmap for editing:kubectl edit cm -n kaas iam-keycloak-sh
On the last line of the configmap, before the
$MIGRATION_ARGSvariable, add the following parameter:-Djboss.as.management.blocking.timeout=<RequiredValue>The recommended timeout value is minimum 15 minutes set in seconds. For example,
-Djboss.as.management.blocking.timeout=900.Open the
iam-keycloak-startupconfigmap for editing:kubectl edit cm -n kaas iam-keycloak-startup
In the
iam-keycloak-startupconfigmap, add the following line:/subsystem=transactions/:write-attribute(name=default-timeout,value=<RequiredValue>)
The recommended timeout value is minimum 15 minutes set in seconds.
In the Keycloak
StatefulSet, adjust liveness probe timeouts:kubectl edit sts -n kaas iam-keycloak
Scale up the Keycloak instances:
kubectl scale sts iam-keycloak --replicas=3 -n kaas
Note
The issue affects only Helm v2 releases and is addressed for Helm v3. Starting from Container Cloud 2.19.0, all Helm releases are switched to v3.
During a management, regional, or managed cluster deployment,
Helm releases may get stuck in the FAILED or UNKNOWN state
although the corresponding machines statuses are Ready
in the Container Cloud web UI. For example, if the StackLight Helm release
fails, the links to its endpoints are grayed out in the web UI.
In the cluster status, providerStatus.helm.ready and
providerStatus.helm.releaseStatuses.<releaseName>.success are false.
HelmBundle cannot recover from such states and requires manual actions.
The workaround below describes the recovery steps for the stacklight
release that got stuck during a cluster deployment.
Use this procedure as an example for other Helm releases as required.
Workaround:
Verify the failed release has the
UNKNOWNorFAILEDstatus in the HelmBundle object:kubectl --kubeconfig <regionalClusterKubeconfigPath> get helmbundle <clusterName> -n <clusterProjectName> -o=jsonpath={.status.releaseStatuses.stacklight} In the command above and in the steps below, replace the parameters enclosed in angle brackets with the corresponding values of your cluster.
Example of system response:
stacklight: attempt: 2 chart: "" finishedAt: "2021-02-05T09:41:05Z" hash: e314df5061bd238ac5f060effdb55e5b47948a99460c02c2211ba7cb9aadd623 message: '[{"occurrence":1,"lastOccurrenceDate":"2021-02-05 09:41:05","content":"error updating the release: rpc error: code = Unknown desc = customresourcedefinitions.apiextensions.k8s.io \"helmbundles.lcm.mirantis.com\" already exists"}]' notes: "" status: UNKNOWN success: false version: 0.1.2-mcp-398
Log in to the
helm-controllerpod console:kubectl --kubeconfig <affectedClusterKubeconfigPath> exec -n kube-system -it helm-controller-0 sh -c tiller
Download the Helm v3 binary. For details, see official Helm documentation.
Remove the failed release:
helm delete <failed-release-name>
For example:
helm delete stacklight
Once done, the release triggers for redeployment.
Fixed in Container Cloud 2.6.0
After the management cluster update, a Patroni pod may fail to start and remain
in the CrashLoopBackOff status. Messages similar to the following ones may
be present in Patroni logs:
Local timeline=4 lsn=0/A000000
master_timeline=6
master: history=1 0/1ADEB48 no recovery target specified
2 0/8044500 no recovery target specified
3 0/A0000A0 no recovery target specified
4 0/A1B6CB0 no recovery target specified
5 0/A2C0C80 no recovery target specified
As a workaround, reinitialize the affected pod with a new volume by deleting
the pod itself and the associated PersistentVolumeClaim (PVC).
Workaround:
Obtain the PVC of the affected pod:
kubectl -n stacklight get "pod/${POD_NAME}" -o jsonpath='{.spec.volumes[?(@.name=="storage-volume")].persistentVolumeClaim.claimName}'
Delete the affected pod and its PVC:
kubectl -n stacklight delete "pod/${POD_NAME}" "pvc/${POD_PVC}" sleep 3 # wait for StatefulSet to reschedule the pod, but miss dependent PVC creation kubectl -n stacklight delete "pod/${POD_NAME}"
Helm releases may get stuck in the PENDING_UPGRADE status
during a management or managed cluster upgrade. The HelmBundle Controller
cannot recover from this state and requires manual actions. The workaround
below describes the recovery process for the openstack-operator release
that stuck during a managed cluster update. Use it as an example for other
Helm releases as required.
Workaround:
Log in to the
helm-controllerpod console:kubectl exec -n kube-system -it helm-controller-0 sh -c tiller
Identify the release that stuck in the
PENDING_UPGRADEstatus. For example:./helm --host=localhost:44134 history openstack-operator
Example of system response:
REVISION UPDATED STATUS CHART DESCRIPTION 1 Tue Dec 15 12:30:41 2020 SUPERSEDED openstack-operator-0.3.9 Install complete 2 Tue Dec 15 12:32:05 2020 SUPERSEDED openstack-operator-0.3.9 Upgrade complete 3 Tue Dec 15 16:24:47 2020 PENDING_UPGRADE openstack-operator-0.3.18 Preparing upgrade
Roll back the failed release to the previous revision:
Download the Helm v3 binary. For details, see official Helm documentation.
Roll back the failed release:
helm rollback <failed-release-name>
For example:
helm rollback openstack-operator 2
Once done, the release will be reconciled.
An OpenStack-based regional cluster cleanup fails with the timeout error.
Workaround:
Wait for the
Clusterobject to be deleted in the bootstrap cluster:kubectl --kubeconfig <(./bin/kind get kubeconfig --name clusterapi) get cluster
The system output must be empty.
Remove the bootstrap cluster manually:
./bin/kind delete cluster --name clusterapi
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.5.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.17.4 |
aws-credentials-controller |
1.17.4 |
|
Bare metal |
baremetal-operator Updated |
3.2.1 |
baremetal-public-api Updated |
3.2.1 |
|
baremetal-provider Updated |
1.17.6 |
|
httpd Updated |
1.18.0 |
|
ironic Updated |
ussuri-bionic-20210202180025 |
|
ironic-operator |
base-bionic-20210106163336 |
|
kaas-ipam Updated |
base-bionic-20210218141033 |
|
local-volume-provisioner |
1.0.4-mcp |
|
mariadb Updated |
10.4.17-bionic-20210203155435 |
|
IAM |
iam Updated |
1.3.0 |
iam-controller Updated |
1.17.4 |
|
keycloak |
9.0.0 |
|
Container Cloud Updated |
admission-controller |
1.17.5 |
byo-credentials-controller |
1.17.4 |
|
byo-provider |
1.17.4 |
|
kaas-public-api |
1.17.4 |
|
kaas-exporter |
1.17.4 |
|
kaas-ui |
1.17.4 |
|
lcm-controller |
0.2.0-259-g71792430 |
|
mcc-cache New |
1.17.4 |
|
proxy-controller New |
1.17.4 |
|
release-controller |
1.17.4 |
|
squid-proxy New |
0.0.1-1 |
|
OpenStack Updated |
openstack-provider |
1.17.4 |
os-credentials-controller |
1.17.4 |
|
VMware vSphere Updated |
vsphere-provider |
1.17.6 |
vsphere-credentials-controller |
1.17.4 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.5.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-3.2.1.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-3.2.1.tgz |
|
ironic-python-agent-bionic.kernel Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-ussuri-bionic-debug-20210204084827 |
|
ironic-python-agent-bionic.initramfs Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-ussuri-bionic-debug-20210204084827 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-1.0.4-mcp.tgz |
|
Docker images |
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20201113171304 |
httpd Updated |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20210202180025 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:ussuri-bionic-20210202180025 |
|
ironic-operator |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20210106163336 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20210218141033 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210203155435 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.17.5.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.17.5.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.17.4.tgz |
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.17.4.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.17.4.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.17.4.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.17.4.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.17.4.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.17.4.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.17.4.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.17.4.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.17.4.tgz |
|
mcc-cache New |
||
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.17.4.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.17.4.tgz |
|
proxy-controller New |
https://binary.mirantis.com/core/helm/proxy-controller-1.17.4.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.17.4.tgz |
|
squid-proxy New |
https://binary.mirantis.com/core/helm/squid-proxy-1.17.4.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.17.4.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.17.4.tgz |
|
Docker images Updated |
admission-controller |
mirantis.azurecr.io/core/admission-controller:1.17.5 |
aws-cluster-api-controller |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.17.4 |
|
aws-credentials-controller |
mirantis.azurecr.io/core/aws-credentials-controller:1.17.4 |
|
byo-cluster-api-controller |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.17.4 |
|
byo-credentials-controller |
mirantis.azurecr.io/core/byo-credentials-controller:1.17.4 |
|
cluster-api-provider-baremetal |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.17.6 |
|
frontend |
mirantis.azurecr.io/core/frontend:1.17.4 |
|
iam-controller |
mirantis.azurecr.io/core/iam-controller:1.17.4 |
|
kproxy New |
mirantis.azurecr.io/lcm/kproxy:1.17.4 |
|
lcm-controller |
mirantis.azurecr.io/core/lcm-controller:v0.2.0-259-g71792430 |
|
nginx New |
mirantis.azurecr.io/lcm/nginx:1.18.0 |
|
openstack-cluster-api-controller |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.17.4 |
|
os-credentials-controller |
mirantis.azurecr.io/core/os-credentials-controller:1.17.4 |
|
registry New |
mirantis.azurecr.io/lcm/registry:2.7.1 |
|
release-controller |
mirantis.azurecr.io/core/release-controller:1.17.4 |
|
squid-proxy New |
mirantis.azurecr.io/core/squid-proxy:0.0.1-1 |
|
vsphere-cluster-api-controller |
mirantis.azurecr.io/core/vsphere-api-controller:1.17.6 |
|
vsphere-credentials-controller |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.17.6 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux |
||
iamctl-darwin |
||
iamctl-windows |
||
Helm charts Updated |
iam |
|
iam-proxy |
||
keycloak-proxy |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.17.4.tgz |
|
Docker images |
api Updated |
mirantis.azurecr.io/iam/api:0.4.0 |
auxiliary Updated |
mirantis.azurecr.io/iam/auxiliary:0.4.0 |
|
kubernetes-entrypoint Updated |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak Updated |
mirantis.azurecr.io/iam/keycloak:0.4.0 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:6.0.1 |
The Mirantis Container Cloud GA release 2.4.0:
Introduces support for the Cluster release 5.11.0 that is based on Kubernetes 1.18, Mirantis Kubernetes Engine 3.3.4, and the updated version of Mirantis Container Runtime 19.03.14.
Supports the Cluster release 6.10.0 that is based on the Cluster release 5.10.0 and supports Mirantis OpenStack for Kubernetes (MOSK) Ussuri.
Still supports previous Cluster releases 5.10.0 and 6.8.1 that are now deprecated and will become unsupported in one of the following Container Cloud releases.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.4.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.4.0. For the list of enhancements in the Cluster release 5.11.0 and Cluster release 6.10.0 that are supported by the Container Cloud release 2.4.0, see the 5.11.0 and 6.10.0 sections.
Support for the updated version of Mirantis Container Runtime
Dedicated network for Kubernetes pods traffic on bare metal clusters
Updated the Mirantis Container Runtime (MCR) version to 19.03.14 for all types of Container Cloud clusters.
For the MCR release highlights, see MCR documentation: MCR release notes.
Caution
Due to the development limitations, the MCR upgrade to version 19.03.13 or 19.03.14 on existing Container Cloud clusters is not supported.
Technology Preview
Implemented the k8s-pods bridge in L2 templates that allows you to use
a dedicated network for Kubernetes pods traffic.
When the k8s-pods bridge is defined in an L2 template,
Calico CNI uses that network for routing the pods traffic between nodes.
Caution
Using of a dedicated network for Kubernetes pods traffic described above is available as Technology Preview. Use such configuration for testing and evaluation purposes only. For the Technology Preview feature definition, refer to Technology Preview features.
The following features are still under development and will be announced in one of the following Container Cloud releases:
Switching Kubernetes API to listen to the specified IP address on the node
Enable MetalLB to listen and respond on the dedicated virtual bridge.
Learn more
Extended the functionality of the feedback form for the Container Cloud web UI. Using the Feedback button, you can now provide 5-star product rating and feedback about Container Cloud. If you have an idea or found a bug in Container Cloud, you can create a ticket for the Mirantis support team to help us improve the product.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.4.0 including the Cluster release 5.11.0 and 6.10.0.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Fixed in the Cluster release 7.0.0
Note
The issue below affects only the Kubernetes 1.18 deployments. Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
On a management cluster with multiple AWS-based managed
clusters, some clusters fail to complete the deployments that require
persistent volumes (PVs), for example, Elasticsearch.
Some of the affected pods get stuck in the Pending state
with the pod has unbound immediate PersistentVolumeClaims and
node(s) had volume node affinity conflict errors.
Warning
The workaround below applies to HA deployments where data can be rebuilt from replicas. If you have a non-HA deployment, back up any existing data before proceeding, since all data will be lost while applying the workaround.
Workaround:
Obtain the persistent volume claims related to the storage mounts of the affected pods:
kubectl get pod/<pod_name1> pod/<pod_name2> \ -o jsonpath='{.spec.volumes[?(@.persistentVolumeClaim)].persistentVolumeClaim.claimName}'
Note
In the command above and in the subsequent steps, substitute the parameters enclosed in angle brackets with the corresponding values.
Delete the affected
PodsandPersistentVolumeClaimsto reschedule them: For example, for StackLight:kubectl -n stacklight delete \ pod/<pod_name1> pod/<pod_name2> ... pvc/<pvc_name2> pvc/<pvc_name2> ...
Fixed in Container Cloud 2.6.0
If you run bootstrap.sh preflight with
KAAS_BM_FULL_PREFLIGHT=true, the script fails with the following message:
failed to create BareMetal objects: failed to wait for objects of kinds BareMetalHost
to become available: timed out waiting for the condition
As a workaround, unset full preflight using unset KAAS_BM_FULL_PREFLIGHT
to run fast preflight instead.
Fixed in Container Cloud 2.5.0
This issue may occur on the baremetal-based managed clusters that are created using L2 templates when network configuration is changed by the user or when Container Cloud is updated from version 2.3.0 to 2.4.0.
Due to the community issue, Keepalived 1.3.9 does not detect and restore a VIP of a managed cluster node after running the netplan apply command. The command is used to apply network configuration changes.
As a result, the Kubernetes API on the affected managed clusters becomes inaccessible.
As a workaround, log in to all nodes of the affected managed clusters and restart Keepalived using systemctl restart keepalived.
Fixed in Container Cloud 2.5.0
During a management or managed cluster deployment, LVM cannot be deployed on a new disk if an old volume group with the same name already exists on the target hardware node but on the different disk.
Workaround:
In the bare metal host profile specific to your hardware configuration,
add the wipe: true parameter to the device that fails to be deployed.
For the procedure details,
see Operations Guide: Create a custom host profile.
Fixed in 2.11.0
If an L2 template is configured incorrectly, a bare metal cluster is deployed
successfully but with the runtime errors in the IpamHost object.
Workaround:
If you suspect that the machine is not working properly because
of incorrect network configuration, verify the status of the corresponding
IpamHost object. Inspect the l2RenderResult and ipAllocationResult
object fields for error messages.
Fixed in Container Cloud 2.5.0
If BareMetalHost is manually removed from a managed cluster, it is
silently removed without a power-off and deprovision that leads to a managed
cluster failures.
Workaround:
Do not manually delete a BareMetalHost that has the Provisioned status.
Fixed in Container Cloud 2.7.0
A Ceph node removal is not being triggered properly after updating
the KaasCephCluster custom resource (CR). Both management and managed
clusters are affected.
Workaround:
Remove the parameters for a Ceph OSD from the
KaasCephClusterCR as described in Operations Guide: Add, remove, or reconfigure Ceph nodes.Obtain the IDs of the
osdandmonservices that are located on the old node:Obtain the UID of the affected machine:
kubectl get machine <CephOSDNodeName> -n <ManagedClusterProjectName> -o jsonpath='{.metadata.annotations.kaas\.mirantis\.com\/uid}'
Export
kubeconfigof your managed cluster. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Identify the pods IDs that run the
osdandmonservices:kubectl get pods -o wide -n rook-ceph | grep <affectedMachineUID> | grep -E "mon|osd"
Example of the system response extract:
rook-ceph-mon-c-7bbc5d757d-5bpws 1/1 Running 1 6h1m rook-ceph-osd-2-58775d5568-5lklw 1/1 Running 4 44h rook-ceph-osd-prepare-705ae6c647cfdac928c63b63e2e2e647-qn4m9 0/1 Completed 0 94s
The pods IDs include the
osdormonservices IDs. In the example system response above, theosdID is2and themonID isc.
Delete the deployments of the
osdandmonservices obtained in the previous step:kubectl delete deployment rook-ceph-osd(mon)-<ID> -n rook-ceph
For example:
kubectl delete deployment rook-ceph-mon-c -n rook-ceph kubectl delete deployment rook-ceph-osd-2 -n rook-ceph
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
Rebalance the Ceph OSDs:
ceph osd out osd(s).ID
Wait for the rebalance to complete.
Rebalance the Ceph data:
ceph osd purge osd(s).ID
Wait for the Ceph data to rebalance.
Remove the old node from the Ceph OSD tree:
ceph osd crush rm <NodeName>
If the removed node contained
monservices, remove them:ceph mon rm <monID>
Fixed in Container Cloud 2.5.0
During a managed cluster update, Ceph rebalance leading to data loss may occur.
Workaround:
Before updating a managed cluster:
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it <ceph-tools-pod-name> bash
Set the
nooutflag:ceph osd set noout
After updating a managed cluster:
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it <ceph-tools-pod-name> bash
Unset the
nooutflag:ceph osd unset noout
When removing a worker node, it is not possible to automatically remove a Ceph node. The workaround is to manually remove the Ceph node from the Ceph cluster as described in Operations Guide: Add, remove, or reconfigure Ceph nodes before removing the worker node from your deployment.
Fixed in 2.11.0
If you use a custom BareMetalHostProfile, after disk replacement
on a Ceph OSD, the Ceph OSD pod switches to the CrashLoopBackOff state
due to the Ceph OSD authorization key failing to be created properly.
Workaround:
Export
kubeconfigof your managed cluster. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
Delete the authorization key for the failed Ceph OSD:
ceph auth del osd.<ID>
SSH to the node on which the Ceph OSD cannot be created.
Clean up the disk that will be a base for the failed Ceph OSD. For details, see official Rook documentation.
Note
Ignore failures of the sgdisk --zap-all $DISK and blkdiscard $DISK commands if any.
On the managed cluster, restart Rook Operator:
kubectl -n rook-ceph delete pod -l app=rook-ceph-operator
Note
The issue affects only Helm v2 releases and is addressed for Helm v3. Starting from Container Cloud 2.19.0, all Helm releases are switched to v3.
During a management, regional, or managed cluster deployment,
Helm releases may get stuck in the FAILED or UNKNOWN state
although the corresponding machines statuses are Ready
in the Container Cloud web UI. For example, if the StackLight Helm release
fails, the links to its endpoints are grayed out in the web UI.
In the cluster status, providerStatus.helm.ready and
providerStatus.helm.releaseStatuses.<releaseName>.success are false.
HelmBundle cannot recover from such states and requires manual actions.
The workaround below describes the recovery steps for the stacklight
release that got stuck during a cluster deployment.
Use this procedure as an example for other Helm releases as required.
Workaround:
Verify the failed release has the
UNKNOWNorFAILEDstatus in the HelmBundle object:kubectl --kubeconfig <regionalClusterKubeconfigPath> get helmbundle <clusterName> -n <clusterProjectName> -o=jsonpath={.status.releaseStatuses.stacklight} In the command above and in the steps below, replace the parameters enclosed in angle brackets with the corresponding values of your cluster.
Example of system response:
stacklight: attempt: 2 chart: "" finishedAt: "2021-02-05T09:41:05Z" hash: e314df5061bd238ac5f060effdb55e5b47948a99460c02c2211ba7cb9aadd623 message: '[{"occurrence":1,"lastOccurrenceDate":"2021-02-05 09:41:05","content":"error updating the release: rpc error: code = Unknown desc = customresourcedefinitions.apiextensions.k8s.io \"helmbundles.lcm.mirantis.com\" already exists"}]' notes: "" status: UNKNOWN success: false version: 0.1.2-mcp-398
Log in to the
helm-controllerpod console:kubectl --kubeconfig <affectedClusterKubeconfigPath> exec -n kube-system -it helm-controller-0 sh -c tiller
Download the Helm v3 binary. For details, see official Helm documentation.
Remove the failed release:
helm delete <failed-release-name>
For example:
helm delete stacklight
Once done, the release triggers for redeployment.
Fixed in Container Cloud 2.6.0
After the management cluster update, a Patroni pod may fail to start and remain
in the CrashLoopBackOff status. Messages similar to the following ones may
be present in Patroni logs:
Local timeline=4 lsn=0/A000000
master_timeline=6
master: history=1 0/1ADEB48 no recovery target specified
2 0/8044500 no recovery target specified
3 0/A0000A0 no recovery target specified
4 0/A1B6CB0 no recovery target specified
5 0/A2C0C80 no recovery target specified
As a workaround, reinitialize the affected pod with a new volume by deleting
the pod itself and the associated PersistentVolumeClaim (PVC).
Workaround:
Obtain the PVC of the affected pod:
kubectl -n stacklight get "pod/${POD_NAME}" -o jsonpath='{.spec.volumes[?(@.name=="storage-volume")].persistentVolumeClaim.claimName}'
Delete the affected pod and its PVC:
kubectl -n stacklight delete "pod/${POD_NAME}" "pvc/${POD_PVC}" sleep 3 # wait for StatefulSet to reschedule the pod, but miss dependent PVC creation kubectl -n stacklight delete "pod/${POD_NAME}"
Helm releases may get stuck in the PENDING_UPGRADE status
during a management or managed cluster upgrade. The HelmBundle Controller
cannot recover from this state and requires manual actions. The workaround
below describes the recovery process for the openstack-operator release
that stuck during a managed cluster update. Use it as an example for other
Helm releases as required.
Workaround:
Log in to the
helm-controllerpod console:kubectl exec -n kube-system -it helm-controller-0 sh -c tiller
Identify the release that stuck in the
PENDING_UPGRADEstatus. For example:./helm --host=localhost:44134 history openstack-operator
Example of system response:
REVISION UPDATED STATUS CHART DESCRIPTION 1 Tue Dec 15 12:30:41 2020 SUPERSEDED openstack-operator-0.3.9 Install complete 2 Tue Dec 15 12:32:05 2020 SUPERSEDED openstack-operator-0.3.9 Upgrade complete 3 Tue Dec 15 16:24:47 2020 PENDING_UPGRADE openstack-operator-0.3.18 Preparing upgrade
Roll back the failed release to the previous revision:
Download the Helm v3 binary. For details, see official Helm documentation.
Roll back the failed release:
helm rollback <failed-release-name>
For example:
helm rollback openstack-operator 2
Once done, the release will be reconciled.
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following issues have been addressed in the Mirantis Container Cloud release 2.4.0 and the Cluster releases 5.11.0 and 6.10.0:
[10351] [BM] [IPAM] Fixed the issue with the automatically allocated subnet having the ability to requeue allocation from a
SubnetPoolin theerrorstate.[10104] [BM] [Ceph] Fixed the issue with OpenStack services failing to access
rook-ceph-mon-*pods due to the changed metadata for connection after pods restart if Ceph was deployed withouthostNetwork: true.
[2757] [IAM] Fixed the issue with IAM failing to start with the IAM pods being in the
CrashLoopBackOffstate during a management cluster deployment.[7562] [IAM] Disabled the
httpport in Keycloak to prevent security vulnerabilities.
[10108] [LCM] Fixed the issue with accidental upgrade of the
docker-ee,docker-ee-cli, andcontainerd.iopackages that must be pinned during the host OS upgrade.[10094] [LCM] Fixed the issue with error handling in the
manage-taintsAnsible script.[9676] [LCM] Fixed the issue with Keepalived and NGINX being installed on worker nodes instead of being installed on control plane nodes only.
[10323] [UI] Fixed the issue with offline tokens being expired over time if fetched using the Container Cloud web UI. The issue occurred if the Log in with Keycloak option was used.
[8966] [UI] Fixed the issue with the “invalid_grant”,”error_description”: “Session doesn’t have required client” error occurring over time after logging in to the Container Cloud web UI through Log in with Keycloak.
[10180] [UI] Fixed the issue with the SSH Keys dialog becoming blank after the token expiration.
[7781] [UI] Fixed the issue with the previously selected Ceph cluster machines disappearing from the drop-down menu of the Create New Ceph Cluster dialog.
[7843] [UI] Fixed the issue with Provider Credentials being stuck in the
Processingstate if created using the Add new credential option of the Create New Cluster dialog.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.4.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.16.1 |
aws-credentials-controller |
1.16.1 |
|
Bare metal |
baremetal-operator Updated |
3.1.7 |
baremetal-public-api Updated |
3.1.7 |
|
baremetal-provider Updated |
1.16.4 |
|
httpd |
2.4.46-20201001171500 |
|
ironic Updated |
ussuri-bionic-20210113180016 |
|
ironic-operator Updated |
base-bionic-20210106163336 |
|
kaas-ipam Updated |
base-bionic-20210106163449 |
|
local-volume-provisioner |
1.0.4-mcp |
|
mariadb Updated |
10.4.17-bionic-20210106145941 |
|
IAM |
iam Updated |
1.2.1 |
iam-controller Updated |
1.16.1 |
|
keycloak |
9.0.0 |
|
Container Cloud |
admission-controller Updated |
1.16.1 |
byo-credentials-controller Updated |
1.16.1 |
|
byo-provider Updated |
1.16.1 |
|
kaas-public-api Updated |
1.16.1 |
|
kaas-exporter Updated |
1.16.1 |
|
kaas-ui Updated |
1.16.2 |
|
lcm-controller |
0.2.0-224-g5c413d37 |
|
release-controller Updated |
1.16.1 |
|
OpenStack Updated |
openstack-provider |
1.16.1 |
os-credentials-controller |
1.16.1 |
|
VMware vSphere Updated |
vsphere-provider |
1.16.1 |
vsphere-credentials-controller |
1.16.4 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.4.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-3.1.7.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-3.1.7.tgz |
|
ironic-python-agent-bionic.kernel Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-ussuri-bionic-debug-20210108095808 |
|
ironic-python-agent-bionic.initramfs Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-ussuri-bionic-debug-20210108095808 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-1.0.4-mcp.tgz |
|
Docker images |
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20201113171304 |
httpd |
mirantis.azurecr.io/bm/external/httpd:2.4.46-20201001171500 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20210113180016 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:ussuri-bionic-20210113180016 |
|
ironic-operator Updated |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20210106163336 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20210106163449 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210106145941 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.16.1.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.16.1.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.16.1.tgz |
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.16.1.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.16.1.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.16.1.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.16.1.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.16.1.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.16.1.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.16.1.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.16.1.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.16.1.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.16.1.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.16.1.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.16.1.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.16.1.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.16.1.tgz |
|
Docker images Updated |
admission-controller |
mirantis.azurecr.io/core/admission-controller:1.16.1 |
aws-cluster-api-controller |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.16.1 |
|
aws-credentials-controller |
mirantis.azurecr.io/core/aws-credentials-controller:1.16.1 |
|
byo-cluster-api-controller |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.16.1 |
|
byo-credentials-controller |
mirantis.azurecr.io/core/byo-credentials-controller:1.16.1 |
|
cluster-api-provider-baremetal |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.16.1 |
|
frontend |
mirantis.azurecr.io/core/frontend:1.16.1 |
|
iam-controller |
mirantis.azurecr.io/core/iam-controller:1.16.1 |
|
lcm-controller |
mirantis.azurecr.io/core/lcm-controller:v0.2.0-224-g5c413d37 |
|
openstack-cluster-api-controller |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.16.1 |
|
os-credentials-controller |
mirantis.azurecr.io/core/os-credentials-controller:1.16.1 |
|
release-controller |
mirantis.azurecr.io/core/release-controller:1.16.1 |
|
vsphere-cluster-api-controller |
mirantis.azurecr.io/core/vsphere-api-controller:1.16.1 |
|
vsphere-credentials-controller |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.16.4 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux Updated |
||
iamctl-darwin Updated |
||
iamctl-windows Updated |
||
Helm charts |
iam Updated |
|
iam-proxy |
||
keycloak-proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.16.3.tgz |
|
Docker images |
api |
mirantis.azurecr.io/iam/api:0.3.18 |
auxiliary |
mirantis.azurecr.io/iam/auxiliary:0.3.18 |
|
kubernetes-entrypoint Updated |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.3.19 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:6.0.1 |
The Mirantis Container Cloud GA release 2.3.0:
Introduces support for the Cluster release 5.10.0 that is based on Kubernetes 1.18 and the updated versions of Mirantis Kubernetes Engine 3.3.4 and Mirantis Container Runtime 19.03.13.
Introduces support for the Cluster release 6.10.0 that is based on the Cluster release 5.10.0 and supports Mirantis OpenStack for Kubernetes (MOSK) Ussuri.
Still supports previous Cluster releases 5.9.0 and 6.8.1 that are now deprecated and will become unsupported in one of the following Container Cloud releases.
Caution
Make sure to update the Cluster release version of your managed cluster before the current Cluster release version becomes unsupported by a new Container Cloud release version. Otherwise, Container Cloud stops auto-upgrade and eventually Container Cloud itself becomes unsupported.
This section outlines release notes for the Container Cloud release 2.3.0.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.3.0. For the list of enhancements in the Cluster release 5.10.0 and Cluster release 6.10.0 introduced by the Container Cloud release 2.3.0, see the 5.10.0 and 6.10.0 sections.
Updated versions of Mirantis Kubernetes Engine and Container Runtime
Automated setup of a VM template for the VMware vSphere provider
Support of multiple host-specific L2 templates per a bare metal cluster
Updated the Mirantis Kubernetes Engine (MKE) version to 3.3.4 and the Mirantis Container Runtime (MCR) version to 19.03.13 for the Container Cloud management and managed clusters.
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
For the MCR release highlights, see MCR documentation: MCR release notes.
Caution
Due to the development limitations, the MCR upgrade to version 19.03.13 or 19.03.14 on existing Container Cloud clusters is not supported.
Technical Preview
In scope of Technology Preview support for the VMware vSphere provider, added the capability to deploy an additional regional vSphere-based cluster on top of the vSphere management cluster to create managed clusters with different configurations if required.
Technical Preview
Automated the process of a VM template setup for the vSphere-based
management and managed clusters deployments.
The VM template is now set up by Packer using the vsphere_template flag
that is integrated into bootstrap.sh.
Learn more
Technical Preview
Added the capability to deploy StackLight on management clusters. However, such deployment has the following limitations:
The Kubernetes Nodes and Kubernetes Cluster Grafana dashboards may have empty panels.
The
DockerNetworkUnhealthyandetcdGRPCRequestsSlowalerts may fail to raise.The
CPUThrottlingHigh,CalicoDatapaneIfaceMsgBatchSizeHigh,KubeCPUOvercommitPods,KubeMemOvercommitPodsalerts, and theTargetDownalert for theprometheus-node-exporterandcalico-nodepods may be constantly firing.
Added support of multiple host-specific L2 templates to be applied to different nodes of the same bare metal cluster. Now, you can use several independent host-specific L2 templates on a cluster to support different hardware configurations. For example, you can create L2 templates with a different number and layout of NICs to be applied to the specific machines of a cluster.
Learn more
Improved user experience with the Container Cloud resources logs collection by implementing collecting of logs on the Mirantis Kubernetes Engine cluster and on all Kubernetes pods, including the ones that were previously removed or failed.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.3.0 including the Cluster release 5.10.0.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Fixed in the Cluster release 7.0.0
Note
The issue below affects only the Kubernetes 1.18 deployments. Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
On a management cluster with multiple AWS-based managed
clusters, some clusters fail to complete the deployments that require
persistent volumes (PVs), for example, Elasticsearch.
Some of the affected pods get stuck in the Pending state
with the pod has unbound immediate PersistentVolumeClaims and
node(s) had volume node affinity conflict errors.
Warning
The workaround below applies to HA deployments where data can be rebuilt from replicas. If you have a non-HA deployment, back up any existing data before proceeding, since all data will be lost while applying the workaround.
Workaround:
Obtain the persistent volume claims related to the storage mounts of the affected pods:
kubectl get pod/<pod_name1> pod/<pod_name2> \ -o jsonpath='{.spec.volumes[?(@.persistentVolumeClaim)].persistentVolumeClaim.claimName}'
Note
In the command above and in the subsequent steps, substitute the parameters enclosed in angle brackets with the corresponding values.
Delete the affected
PodsandPersistentVolumeClaimsto reschedule them: For example, for StackLight:kubectl -n stacklight delete \ pod/<pod_name1> pod/<pod_name2> ... pvc/<pvc_name2> pvc/<pvc_name2> ...
Fixed in Container Cloud 2.5.0
During a management or managed cluster deployment, LVM cannot be deployed on a new disk if an old volume group with the same name already exists on the target hardware node but on the different disk.
Workaround:
In the bare metal host profile specific to your hardware configuration,
add the wipe: true parameter to the device that fails to be deployed.
For the procedure details,
see Operations Guide: Create a custom host profile.
Fixed in 2.11.0
If an L2 template is configured incorrectly, a bare metal cluster is deployed
successfully but with the runtime errors in the IpamHost object.
Workaround:
If you suspect that the machine is not working properly because
of incorrect network configuration, verify the status of the corresponding
IpamHost object. Inspect the l2RenderResult and ipAllocationResult
object fields for error messages.
Fixed in Container Cloud 2.5.0
If BareMetalHost is manually removed from a managed cluster, it is
silently removed without a power-off and deprovision that leads to a managed
cluster failures.
Workaround:
Do not manually delete a BareMetalHost that has the Provisioned status.
Fixed in Container Cloud 2.6.0
If you run bootstrap.sh preflight with
KAAS_BM_FULL_PREFLIGHT=true, the script fails with the following message:
failed to create BareMetal objects: failed to wait for objects of kinds BareMetalHost
to become available: timed out waiting for the condition
As a workaround, unset full preflight using unset KAAS_BM_FULL_PREFLIGHT
to run fast preflight instead.
Fixed in Container Cloud 2.4.0
During a management cluster deployment, IAM fails to start with the IAM
pods being in the CrashLoopBackOff status.
Workaround:
Log in to the bootstrap node.
Remove the
iam-mariadb-stateconfigmap:kubectl delete cm -n kaas iam-mariadb-state
Manually delete the
mariadbpods:kubectl delete po -n kaas mariadb-server-{0,1,2}
Wait for the pods to start. If the
mariadbpod does not start with the connection to peer timed out exception, repeat the step 2.Obtain the MariaDB database admin password:
kubectl get secrets -n kaas mariadb-dbadmin-password \ -o jsonpath='{.data.MYSQL_DBADMIN_PASSWORD}' | base64 -d ; echo
Log in to MariaDB:
kubectl exec -it -n kaas mariadb-server-0 -- bash -c 'mysql -uroot -p<mysqlDbadminPassword>'
Substitute
<mysqlDbadminPassword>with the corresponding value obtained in the previous step.Run the following command:
DROP DATABASE IF EXISTS keycloak;
Manually delete the Keycloak pods:
kubectl delete po -n kaas iam-keycloak-{0,1,2}
Helm releases may get stuck in the PENDING_UPGRADE status
during a management or managed cluster upgrade. The HelmBundle Controller
cannot recover from this state and requires manual actions. The workaround
below describes the recovery process for the openstack-operator release
that stuck during a managed cluster update. Use it as an example for other
Helm releases as required.
Workaround:
Log in to the
helm-controllerpod console:kubectl exec -n kube-system -it helm-controller-0 sh -c tiller
Identify the release that stuck in the
PENDING_UPGRADEstatus. For example:./helm --host=localhost:44134 history openstack-operator
Example of system response:
REVISION UPDATED STATUS CHART DESCRIPTION 1 Tue Dec 15 12:30:41 2020 SUPERSEDED openstack-operator-0.3.9 Install complete 2 Tue Dec 15 12:32:05 2020 SUPERSEDED openstack-operator-0.3.9 Upgrade complete 3 Tue Dec 15 16:24:47 2020 PENDING_UPGRADE openstack-operator-0.3.18 Preparing upgrade
Roll back the failed release to the previous revision:
Download the Helm v3 binary. For details, see official Helm documentation.
Roll back the failed release:
helm rollback <failed-release-name>
For example:
helm rollback openstack-operator 2
Once done, the release will be reconciled.
Fixed in Container Cloud 2.7.0
A Ceph node removal is not being triggered properly after updating
the KaasCephCluster custom resource (CR). Both management and managed
clusters are affected.
Workaround:
Remove the parameters for a Ceph OSD from the
KaasCephClusterCR as described in Operations Guide: Add, remove, or reconfigure Ceph nodes.Obtain the IDs of the
osdandmonservices that are located on the old node:Obtain the UID of the affected machine:
kubectl get machine <CephOSDNodeName> -n <ManagedClusterProjectName> -o jsonpath='{.metadata.annotations.kaas\.mirantis\.com\/uid}'
Export
kubeconfigof your managed cluster. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Identify the pods IDs that run the
osdandmonservices:kubectl get pods -o wide -n rook-ceph | grep <affectedMachineUID> | grep -E "mon|osd"
Example of the system response extract:
rook-ceph-mon-c-7bbc5d757d-5bpws 1/1 Running 1 6h1m rook-ceph-osd-2-58775d5568-5lklw 1/1 Running 4 44h rook-ceph-osd-prepare-705ae6c647cfdac928c63b63e2e2e647-qn4m9 0/1 Completed 0 94s
The pods IDs include the
osdormonservices IDs. In the example system response above, theosdID is2and themonID isc.
Delete the deployments of the
osdandmonservices obtained in the previous step:kubectl delete deployment rook-ceph-osd(mon)-<ID> -n rook-ceph
For example:
kubectl delete deployment rook-ceph-mon-c -n rook-ceph kubectl delete deployment rook-ceph-osd-2 -n rook-ceph
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
Rebalance the Ceph OSDs:
ceph osd out osd(s).ID
Wait for the rebalance to complete.
Rebalance the Ceph data:
ceph osd purge osd(s).ID
Wait for the Ceph data to rebalance.
Remove the old node from the Ceph OSD tree:
ceph osd crush rm <NodeName>
If the removed node contained
monservices, remove them:ceph mon rm <monID>
Fixed in Container Cloud 2.5.0
During a managed cluster update, Ceph rebalance leading to data loss may occur.
Workaround:
Before updating a managed cluster:
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it <ceph-tools-pod-name> bash
Set the
nooutflag:ceph osd set noout
After updating a managed cluster:
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it <ceph-tools-pod-name> bash
Unset the
nooutflag:ceph osd unset noout
When removing a worker node, it is not possible to automatically remove a Ceph node. The workaround is to manually remove the Ceph node from the Ceph cluster as described in Operations Guide: Add, remove, or reconfigure Ceph nodes before removing the worker node from your deployment.
Fixed in 2.11.0
If you use a custom BareMetalHostProfile, after disk replacement
on a Ceph OSD, the Ceph OSD pod switches to the CrashLoopBackOff state
due to the Ceph OSD authorization key failing to be created properly.
Workaround:
Export
kubeconfigof your managed cluster. For example:export KUBECONFIG=~/Downloads/kubeconfig-test-cluster.yml
Log in to the
ceph-toolspod:kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
Delete the authorization key for the failed Ceph OSD:
ceph auth del osd.<ID>
SSH to the node on which the Ceph OSD cannot be created.
Clean up the disk that will be a base for the failed Ceph OSD. For details, see official Rook documentation.
Note
Ignore failures of the sgdisk --zap-all $DISK and blkdiscard $DISK commands if any.
On the managed cluster, restart Rook Operator:
kubectl -n rook-ceph delete pod -l app=rook-ceph-operator
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following issues have been addressed in the Mirantis Container Cloud release 2.3.0 and the Cluster releases 5.10.0 and 6.10.0:
[8869] Upgraded
kindfrom version 0.3.0 to 0.9.0 and thekindest/nodeimage version from 1.14.2 to 1.18.8 to enhance the Container Cloud performance and prevent compatibility issues.[8220] Fixed the issue with failure to switch the
defaultlabel from oneBareMetalHostProfileto another.[7255] Fixed the issue with slow creation of the OpenStack clients and pools by redesigning as well as increasing efficiency and speed of
ceph-controller.[8618] Fixed the issue with missing pools during a Ceph cluster deployment.
[8111] Fixed the issue with a Ceph cluster being available after deleting it using the Container Cloud web UI or deleting the
KaaSCephClusterobject from the Kubernetes namespace using CLI.[8409, 3836] Refactored and stabilized the upgrade procedure to prevent locks during the upgrade operations.
[8925] Fixed improper handling of errors in
lcm-controllerthat may lead to its panic.[8361] Fixed the issue with
admission-controllerallowing addition of duplicated node labels per machine.[8402] Fixed the issue with the AWS provider failing during node labeling with the Observed a panic: “invalid memory address or nil pointer dereference” error if
privateIPis not set for a machine.[7673] Moved logs collection of the bootstrap cluster to the
/bootstrapsubdirectory to prevent unintentional erasure of the management and regional cluster logs.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.3.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.15.4 |
aws-credentials-controller |
1.15.4 |
|
Bare metal |
baremetal-operator Updated |
3.1.6 |
baremetal-public-api Updated |
3.1.6 |
|
baremetal-provider Updated |
1.15.4 |
|
httpd |
2.4.46-20201001171500 |
|
ironic Updated |
ussuri-bionic-20201111180110 |
|
ironic-operator Updated |
base-bionic-20201106182102 |
|
kaas-ipam Updated |
20201210175212 |
|
local-volume-provisioner |
1.0.4-mcp |
|
mariadb |
10.4.14-bionic-20200812025059 |
|
IAM |
iam |
1.1.22 |
iam-controller Updated |
1.15.4 |
|
keycloak |
9.0.0 |
|
Container Cloud Updated |
admission-controller |
1.15.4 |
byo-credentials-controller |
1.15.4 |
|
byo-provider |
1.15.4 |
|
kaas-public-api |
1.15.4 |
|
kaas-exporter |
1.15.4 |
|
kaas-ui |
1.15.4 |
|
lcm-controller |
0.2.0-224-g5c413d37 |
|
release-controller |
1.15.4 |
|
OpenStack Updated |
openstack-provider |
1.15.4 |
os-credentials-controller |
1.15.4 |
|
VMware vSphere Updated |
vsphere-provider |
1.15.4 |
vsphere-credentials-controller |
1.15.4 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.3.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-3.1.6.tgz |
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-3.1.6.tgz |
|
ironic-python-agent.kernel Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-ussuri-bionic-debug-20201119132200 |
|
ironic-python-agent.initramfs Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-ussuri-bionic-debug-20201119132200 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-1.0.4-mcp.tgz |
|
Docker images |
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20201113171304 |
httpd |
mirantis.azurecr.io/bm/external/httpd:2.4.46-20201001171500 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20201111180110 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:ussuri-bionic-20201111180110 |
|
ironic-operator Updated |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20201106182102 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20201210175212 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.14-bionic-20200812025059 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.15.4.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.15.4.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.15.4.tgz |
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.15.4.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.15.4.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.15.4.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.15.4.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.15.4.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.15.4.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.15.4.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.15.4.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.15.4.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.15.4.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.15.4.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.15.4.tgz |
|
vsphere-credentials-controller |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.15.4.tgz |
|
vsphere-provider |
https://binary.mirantis.com/core/helm/vsphere-provider-1.15.4.tgz |
|
Docker images Updated |
admission-controller |
mirantis.azurecr.io/core/admission-controller:1.15.4 |
aws-cluster-api-controller |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.15.4 |
|
aws-credentials-controller |
mirantis.azurecr.io/core/aws-credentials-controller:1.15.4 |
|
byo-cluster-api-controller |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.15.4 |
|
byo-credentials-controller |
mirantis.azurecr.io/core/byo-credentials-controller:1.15.4 |
|
cluster-api-provider-baremetal |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.15.4 |
|
frontend |
mirantis.azurecr.io/core/frontend:1.15.4 |
|
iam-controller |
mirantis.azurecr.io/core/iam-controller:1.15.4 |
|
lcm-controller |
mirantis.azurecr.io/core/lcm-controller:v0.2.0-224-g5c413d37 |
|
openstack-cluster-api-controller |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.15.4 |
|
os-credentials-controller |
mirantis.azurecr.io/core/os-credentials-controller:1.15.4 |
|
release-controller |
mirantis.azurecr.io/core/release-controller:1.15.4 |
|
vsphere-cluster-api-controller |
mirantis.azurecr.io/core/vsphere-api-controller:1.15.4 |
|
vsphere-credentials-controller |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.15.4 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux |
||
iamctl-darwin |
||
iamctl-windows |
||
Helm charts |
iam Updated |
|
iam-proxy |
||
keycloak-proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.14.3.tgz |
|
Docker images |
api |
mirantis.azurecr.io/iam/api:0.3.18 |
auxiliary |
mirantis.azurecr.io/iam/auxiliary:0.3.18 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
|
mariadb |
mirantis.azurecr.io/iam/external/mariadb:10.2.18 |
|
keycloak Updated |
mirantis.azurecr.io/iam/keycloak:0.3.19 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:6.0.1 |
This section outlines release notes for the Mirantis Container Cloud GA release 2.2.0. This release introduces support for the Cluster release 5.9.0 that is based on Mirantis Kubernetes Engine 3.3.3, Mirantis Container Runtime 19.03.12, and Kubernetes 1.18. This release also introduces support for the Cluster release 6.8.1 that introduces the support of the Mirantis OpenStack for Kubernetes (MOSK) product.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.2.0. For the list of enhancements in the Cluster release 5.9.0 and Cluster release 6.8.1 introduced by the Container Cloud release 2.2.0, see 5.9.0 and 6.8.1.
TECHNICAL PREVIEW
Introduced the Technology Preview support for the VMware vSphere cloud provider on RHEL, including support for creation and operating of managed clusters using the Container Cloud web UI.
Deployment of an additional regional vSphere-based cluster or attaching an existing Mirantis Kubernetes Engine (MKE) cluster to a vSphere-based management cluster is on the development stage and will be announced in one of the following Container Cloud releases.
Note
For the Technology Preview feature definition, refer to Technology Preview features.
Implemented the API for managing kernel parameters typically managed by
sysctl for bare metal hosts through the BareMetalHost and
BareMetalHostProfile objects fields.
Implemented support of multiple subnets per a Container Cloud cluster with
an ability to specify a different network type for each subnet.
Introduced the SubnetPool object that allows for automatic creation of the
Subnet objects. Also, added the L3Layout section to
L2Template.spec. The L3Layout configuration allows defining the
subnets scopes to be used and to enable auto-creation of subnets
from a subnet pool.
Optimized user experience with the Container Cloud resources logs collection:
Added a separate file with a human-readable table that contains information about cluster events
Implemented collecting of system logs from cluster nodes
On top of continuous improvements delivered to the existing Container Cloud guides, added the Mirantis Container Cloud API section to the Operations Guide. This section is intended only for advanced Infrastructure Operators who are familiar with Kubernetes Cluster API.
Currently, this section contains descriptions and examples of the Container Cloud API resources for the bare metal cloud provider. The API documentation for the OpenStack, AWS, and VMware vSphere API resources will be added in the upcoming Container Cloud releases.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.2.0 including the Cluster release 5.9.0.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Fixed in the Cluster release 7.0.0
Note
The issue below affects only the Kubernetes 1.18 deployments. Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
On a management cluster with multiple AWS-based managed
clusters, some clusters fail to complete the deployments that require
persistent volumes (PVs), for example, Elasticsearch.
Some of the affected pods get stuck in the Pending state
with the pod has unbound immediate PersistentVolumeClaims and
node(s) had volume node affinity conflict errors.
Warning
The workaround below applies to HA deployments where data can be rebuilt from replicas. If you have a non-HA deployment, back up any existing data before proceeding, since all data will be lost while applying the workaround.
Workaround:
Obtain the persistent volume claims related to the storage mounts of the affected pods:
kubectl get pod/<pod_name1> pod/<pod_name2> \ -o jsonpath='{.spec.volumes[?(@.persistentVolumeClaim)].persistentVolumeClaim.claimName}'
Note
In the command above and in the subsequent steps, substitute the parameters enclosed in angle brackets with the corresponding values.
Delete the affected
PodsandPersistentVolumeClaimsto reschedule them: For example, for StackLight:kubectl -n stacklight delete \ pod/<pod_name1> pod/<pod_name2> ... pvc/<pvc_name2> pvc/<pvc_name2> ...
Fixed in Container Cloud 2.5.0
During a management or managed cluster deployment, LVM cannot be deployed on a new disk if an old volume group with the same name already exists on the target hardware node but on the different disk.
Workaround:
In the bare metal host profile specific to your hardware configuration,
add the wipe: true parameter to the device that fails to be deployed.
For the procedure details,
see Operations Guide: Create a custom host profile.
Fixed in 2.11.0
If an L2 template is configured incorrectly, a bare metal cluster is deployed
successfully but with the runtime errors in the IpamHost object.
Workaround:
If you suspect that the machine is not working properly because
of incorrect network configuration, verify the status of the corresponding
IpamHost object. Inspect the l2RenderResult and ipAllocationResult
object fields for error messages.
Fixed in Container Cloud 2.5.0
If BareMetalHost is manually removed from a managed cluster, it is
silently removed without a power-off and deprovision that leads to a managed
cluster failures.
Workaround:
Do not manually delete a BareMetalHost that has the Provisioned status.
Fixed in Container Cloud 2.4.0
During a management cluster deployment, IAM fails to start with the IAM
pods being in the CrashLoopBackOff status.
Workaround:
Log in to the bootstrap node.
Remove the
iam-mariadb-stateconfigmap:kubectl delete cm -n kaas iam-mariadb-state
Manually delete the
mariadbpods:kubectl delete po -n kaas mariadb-server-{0,1,2}
Wait for the pods to start. If the
mariadbpod does not start with the connection to peer timed out exception, repeat the step 2.Obtain the MariaDB database admin password:
kubectl get secrets -n kaas mariadb-dbadmin-password \ -o jsonpath='{.data.MYSQL_DBADMIN_PASSWORD}' | base64 -d ; echo
Log in to MariaDB:
kubectl exec -it -n kaas mariadb-server-0 -- bash -c 'mysql -uroot -p<mysqlDbadminPassword>'
Substitute
<mysqlDbadminPassword>with the corresponding value obtained in the previous step.Run the following command:
DROP DATABASE IF EXISTS keycloak;
Manually delete the Keycloak pods:
kubectl delete po -n kaas iam-keycloak-{0,1,2}
When removing a worker node, it is not possible to automatically remove a Ceph node. The workaround is to manually remove the Ceph node from the Ceph cluster as described in Operations Guide: Add, remove, or reconfigure Ceph nodes before removing the worker node from your deployment.
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following issues have been addressed in the Mirantis Container Cloud release 2.2.0 including the Cluster release 5.9.0:
[8012] Fixed the issue with
helm-controllerpod being stuck in theCrashLoopBackOffstate after reattaching of a Mirantis Kubernetes Engine (MKE) cluster.[7131] Fixed the issue with the deployment of a managed cluster failing during the Ceph Monitor or Manager deployment.
[6164] Fixed the issue with the number of placement groups (PGs) per Ceph OSD being too small and the Ceph cluster having the
HEALTH_WARNstatus.[8302] Fixed the issue with deletion of a regional cluster leading to the deletion of the related management cluster.
[7722] Fixed the issue with the Internal Server Error or similar errors appearing in the
HelmBundlecontroller logs after bootstrapping the management cluster.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.2.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.14.0 |
aws-credentials-controller |
1.14.0 |
|
Bare metal |
baremetal-operator Updated |
3.1.3 |
baremetal-public-api Updated |
3.1.3 |
|
baremetal-provider Updated |
1.14.0 |
|
httpd |
2.4.46-20201001171500 |
|
ironic Updated |
ussuri-bionic-20201021180016 |
|
ironic-operator Updated |
base-bionic-20201023172943 |
|
kaas-ipam Updated |
20201026094912 |
|
local-volume-provisioner |
1.0.4-mcp |
|
mariadb |
10.4.14-bionic-20200812025059 |
|
IAM |
iam Updated |
1.1.22 |
iam-controller Updated |
1.14.0 |
|
keycloak |
9.0.0 |
|
Container Cloud Updated |
admission-controller |
1.14.0 |
byo-credentials-controller |
1.14.0 |
|
byo-provider |
1.14.3 |
|
kaas-public-api |
1.14.0 |
|
kaas-exporter |
1.14.0 |
|
kaas-ui |
1.14.2 |
|
lcm-controller |
0.2.0-178-g8cc488f8 |
|
release-controller |
1.14.0 |
|
OpenStack Updated |
openstack-provider |
1.14.0 |
os-credentials-controller |
1.14.0 |
|
VMware vSphere New |
vsphere-provider |
1.14.1 |
vsphere-credentials-controller |
1.14.1 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.2.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
Target system image (ubuntu-bionic) |
https://binary.mirantis.com/bm/bin/efi/ubuntu/qcow2-bionic-debug-20200730084816 |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-3.1.3.tgz |
|
baremetal-public-api Updated |
https://binary.mirantis.com/bm/helm/baremetal-public-api-3.1.3.tgz |
|
ironic-python-agent.kernel Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-ussuri-bionic-debug-20201022084817 |
|
ironic-python-agent.initramfs Updated |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-ussuri-bionic-debug-20201022084817 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-1.0.4-mcp.tgz |
|
Docker images |
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20201028131325 |
httpd |
mirantis.azurecr.io/bm/external/httpd:2.4.46-20201001171500 |
|
ironic Updated |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20201021180016 |
|
ironic-inspector Updated |
mirantis.azurecr.io/openstack/ironic-inspector:ussuri-bionic-20201021180016 |
|
ironic-operator Updated |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20201023172943 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20201026094912 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.14-bionic-20200812025059 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.14.0.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.14.0.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.14.0.tgz |
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.14.0.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.14.0.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.14.0.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.14.0.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.14.3.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.14.0.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.14.0.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.14.0.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.14.0.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.14.0.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.14.0.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.14.0.tgz |
|
vsphere-credentials-controller New |
https://binary.mirantis.com/core/helm/vsphere-credentials-controller-1.14.1.tgz |
|
vsphere-provider New |
https://binary.mirantis.com/core/helm/vsphere-provider-1.14.1.tgz |
|
Docker images for Container Cloud deployment |
admission-controller Updated |
mirantis.azurecr.io/core/admission-controller:1.14.0 |
aws-cluster-api-controller |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.14.0 |
|
aws-credentials-controller Updated |
mirantis.azurecr.io/core/aws-credentials-controller:1.14.0 |
|
byo-cluster-api-controller |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.14.3 |
|
byo-credentials-controller Updated |
mirantis.azurecr.io/core/byo-credentials-controller:1.14.0 |
|
cluster-api-provider-baremetal Updated |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.14.0 |
|
frontend |
mirantis.azurecr.io/core/frontend:1.14.2 |
|
iam-controller Updated |
mirantis.azurecr.io/core/iam-controller:1.14.0 |
|
lcm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:v0.2.0-178-g8cc488f8 |
|
openstack-cluster-api-controller |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.14.0 |
|
os-credentials-controller Updated |
mirantis.azurecr.io/core/os-credentials-controller:1.14.0 |
|
release-controller Updated |
mirantis.azurecr.io/core/release-controller:1.14.0 |
|
vsphere-cluster-api-controller New |
mirantis.azurecr.io/core/vsphere-api-controller:1.14.1 |
|
vsphere-credentials-controller New |
mirantis.azurecr.io/core/vsphere-credentials-controller:1.14.1 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-268-3cf7f17-darwin |
|
iamctl-linux |
||
iamctl-darwin |
||
iamctl-windows |
||
Helm charts |
iam Updated |
|
iam-proxy |
||
keycloak-proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.14.3.tgz |
|
Docker images |
api |
mirantis.azurecr.io/iam/api:0.3.18 |
auxiliary |
mirantis.azurecr.io/iam/auxiliary:0.3.18 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
|
mariadb |
mirantis.azurecr.io/iam/external/mariadb:10.2.18 |
|
keycloak Updated |
mirantis.azurecr.io/iam/keycloak:0.3.19 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:6.0.1 |
This section outlines release notes for the Mirantis Container Cloud GA release 2.1.0. This release introduces support for the Cluster release 5.8.0 that is based on Mirantis Kubernetes Engine 3.3.3, Mirantis Container Runtime 19.03.12, and Kubernetes 1.18.
This section outlines new features and enhancements introduced in the Mirantis Container Cloud release 2.1.0. For the list of enhancements in the Cluster release 5.8.0 introduced by the KaaS release 2.1.0, see 5.8.0.
Implemented the possibility to assign labels to specific machines with
dedicated system and hardware resources through the Container Cloud web UI.
For example, you can label the StackLight nodes that run Elasticsearch and
require more resources than a standard node to run the StackLight components
services on the dedicated nodes.
You can label a machine before or after it is deployed.
The list of available labels is taken from the current Cluster release.
Node labeling greatly improves cluster performance and prevents pods from being quickly exhausted.
Improved the user experience during a managed cluster creation using the Container Cloud web UI by implementing drop-down menus with available supported values for the following AWS resources:
AWS region
AWS AMI ID
AWS instance type
To apply the feature to existing deployments, update the IAM policies for AWS as described in Apply updates to the AWS-based management clusters.
Implemented the following statuses for the OpenStack-based and AWS-based credentials in the Container Cloud web UI:
- Ready
Credentials are valid and ready to be used for a managed cluster creation.
- In Use
Credentials are being used by a managed cluster.
- Error
Credentials are invalid. You can hover over the Error status to determine the reason of the issue.
Learn more
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.1.0.
Note
This section also outlines still valid known issues from previous Container Cloud releases.
Fixed in the Cluster release 7.0.0
Note
The issue below affects only the Kubernetes 1.18 deployments. Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
On a management cluster with multiple AWS-based managed
clusters, some clusters fail to complete the deployments that require
persistent volumes (PVs), for example, Elasticsearch.
Some of the affected pods get stuck in the Pending state
with the pod has unbound immediate PersistentVolumeClaims and
node(s) had volume node affinity conflict errors.
Warning
The workaround below applies to HA deployments where data can be rebuilt from replicas. If you have a non-HA deployment, back up any existing data before proceeding, since all data will be lost while applying the workaround.
Workaround:
Obtain the persistent volume claims related to the storage mounts of the affected pods:
kubectl get pod/<pod_name1> pod/<pod_name2> \ -o jsonpath='{.spec.volumes[?(@.persistentVolumeClaim)].persistentVolumeClaim.claimName}'
Note
In the command above and in the subsequent steps, substitute the parameters enclosed in angle brackets with the corresponding values.
Delete the affected
PodsandPersistentVolumeClaimsto reschedule them: For example, for StackLight:kubectl -n stacklight delete \ pod/<pod_name1> pod/<pod_name2> ... pvc/<pvc_name2> pvc/<pvc_name2> ...
Fixed in Container Cloud 2.5.0
During a management or managed cluster deployment, LVM cannot be deployed on a new disk if an old volume group with the same name already exists on the target hardware node but on the different disk.
Workaround:
In the bare metal host profile specific to your hardware configuration,
add the wipe: true parameter to the device that fails to be deployed.
For the procedure details,
see Operations Guide: Create a custom host profile.
Fixed in Container Cloud 2.4.0
During a management cluster deployment, IAM fails to start with the IAM
pods being in the CrashLoopBackOff status.
Workaround:
Log in to the bootstrap node.
Remove the
iam-mariadb-stateconfigmap:kubectl delete cm -n kaas iam-mariadb-state
Manually delete the
mariadbpods:kubectl delete po -n kaas mariadb-server-{0,1,2}
Wait for the pods to start. If the
mariadbpod does not start with the connection to peer timed out exception, repeat the step 2.Obtain the MariaDB database admin password:
kubectl get secrets -n kaas mariadb-dbadmin-password \ -o jsonpath='{.data.MYSQL_DBADMIN_PASSWORD}' | base64 -d ; echo
Log in to MariaDB:
kubectl exec -it -n kaas mariadb-server-0 -- bash -c 'mysql -uroot -p<mysqlDbadminPassword>'
Substitute
<mysqlDbadminPassword>with the corresponding value obtained in the previous step.Run the following command:
DROP DATABASE IF EXISTS keycloak;
Manually delete the Keycloak pods:
kubectl delete po -n kaas iam-keycloak-{0,1,2}
Fixed in 2.2.0
After deploying a managed cluster with Ceph, the number of placement groups
(PGs) per Ceph OSD may be too small and the Ceph cluster may have the
HEALTH_WARN status:
health: HEALTH_WARN
too few PGs per OSD (3 < min 30)
The workaround is to enable the PG balancer to properly manage the number of PGs:
kexec -it $(k get pod -l "app=rook-ceph-tools" --all-namespaces -o jsonpath='{.items[0].metadata.name}') -n rook-ceph bash
ceph mgr module enable pg_autoscaler
Fixed in 2.2.0
Occasionally, the deployment of a managed cluster may fail during the Ceph Monitor or Manager deployment. In this case, the Ceph cluster may be down and and a stack trace similar to the following one may be present in Ceph Manager logs:
kubectl -n rook-ceph logs rook-ceph-mgr-a-c5dc846f8-k68rs
/home/jenkins-build/build/workspace/ceph-build/ARCH/x86_64/AVAILABLE_ARCH/x86_64/AVAILABLE_DIST/centos7/DIST/centos7/MACHINE_SIZE/gigantic/release/14.2.9/rpm/el7/BUILD/ceph-14.2.9/src/mon/MonMap.h: In function 'void MonMap::add(const mon_info_t&)' thread 7fd3d3744b80 time 2020-09-03 10:16:46.586388
/home/jenkins-build/build/workspace/ceph-build/ARCH/x86_64/AVAILABLE_ARCH/x86_64/AVAILABLE_DIST/centos7/DIST/centos7/MACHINE_SIZE/gigantic/release/14.2.9/rpm/el7/BUILD/ceph-14.2.9/src/mon/MonMap.h: 195: FAILED ceph_assert(addr_mons.count(a) == 0)
ceph version 14.2.9 (581f22da52345dba46ee232b73b990f06029a2a0) nautilus (stable)
1: (ceph::__ceph_assert_fail(char const*, char const*, int, char const*)+0x14a) [0x7fd3ca9b2875]
2: (()+0x253a3d) [0x7fd3ca9b2a3d]
3: (MonMap::add(mon_info_t const&)+0x80) [0x7fd3cad49190]
4: (MonMap::add(std::string const&, entity_addrvec_t const&, int)+0x110) [0x7fd3cad493a0]
5: (MonMap::init_with_ips(std::string const&, bool, std::string const&)+0xc9) [0x7fd3cad43849]
6: (MonMap::build_initial(CephContext*, bool, std::ostream&)+0x314) [0x7fd3cad45af4]
7: (MonClient::build_initial_monmap()+0x130) [0x7fd3cad2e140]
8: (MonClient::get_monmap_and_config()+0x5f) [0x7fd3cad365af]
9: (global_pre_init(std::map<std::string, std::string, std::less<std::string>, std::allocator<std::pair<std::string const, std::string> > > const*, std::vector<char const*, std::allocator<char const*> >&, unsigned int, code_environment_t, int)+0x524) [0x55ce86711444]
10: (global_init(std::map<std::string, std::string, std::less<std::string>, std::allocator<std::pair<std::string const, std::string> > > const*, std::vector<char const*, std::allocator<char const*> >&, unsigned int, code_environment_t, int, char const*, bool)+0x76) [0x55ce86711b56]
11: (main()+0x136) [0x55ce864ff9a6]
12: (__libc_start_main()+0xf5) [0x7fd3c6e73555]
13: (()+0xfc010) [0x55ce86505010]
The workaround is to start the managed cluster deployment from scratch.
When removing a worker node, it is not possible to automatically remove a Ceph node. The workaround is to manually remove the Ceph node from the Ceph cluster as described in Operations Guide: Add, remove, or reconfigure Ceph nodes before removing the worker node from your deployment.
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
In the Mirantis Container Cloud release 2.1.0, the following issues have been addressed:
[7281] Fixed the issue with a management cluster bootstrap script failing if there was a space in the
PATHenvironment variable.[7205] Fixed the issue with some cluster objects being stuck during deletion of an AWS-based managed cluster due to unresolved VPC dependencies.
[7304] Fixed the issue with failure to reattach a Mirantis Kubernetes Engine (MKE) cluster with the same name.
[7101] Fixed the issue with the monitoring of Ceph and Ironic being enabled when Ceph and Ironic are disabled on the baremetal-based clusters.
[7324] Fixed the issue with the monitoring of Ceph being disabled on the baremetal-based managed clusters due to the missing
provider: BareMetalparameter.[7180] Fixed the issue with
lcm-controllerperiodically failing with the invalid memory address or nil pointer dereference runtime error.[7251] Fixed the issue with setting up the OIDC integration on the MKE side.
[7326] Fixed the issue with the missing entry for the host itself in
etc/hostscausing failure of services that require node FQDN.[6989] Fixed the issue with
baremetal-operatorignoring theclean failedprovisioning state if a node fails to deploy on a baremetal-based managed cluster.[7231] Fixed the issue with the
baremetal-providerpod not restarting after theConfigMapchanges and causing thetelemeter-clientpod to fail during deployment.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.1.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
AWS Updated |
aws-provider |
1.12.2 |
aws-credentials-controller |
1.12.2 |
|
Bare metal |
baremetal-operator Updated |
3.1.0 |
baremetal-public-api New |
3.1.0 |
|
baremetal-provider Updated |
1.12.2 |
|
httpd Updated |
2.4.46-20201001171500 |
|
ironic |
train-bionic-20200803180020 |
|
ironic-operator |
base-bionic-20200805144858 |
|
kaas-ipam Updated |
20201007180518 |
|
local-volume-provisioner |
1.0.4-mcp |
|
mariadb Updated |
10.4.14-bionic-20200812025059 |
|
IAM |
iam Updated |
1.1.18 |
iam-controller Updated |
1.12.2 |
|
keycloak |
9.0.0 |
|
Container Cloud Updated |
admission-controller |
1.12.3 |
byo-credentials-controller |
1.12.2 |
|
byo-provider |
1.12.2 |
|
kaas-public-api |
1.12.2 |
|
kaas-exporter |
1.12.2 |
|
kaas-ui |
1.12.2 |
|
lcm-controller |
0.2.0-169-g5668304d |
|
release-controller |
1.12.2 |
|
OpenStack Updated |
openstack-provider |
1.12.2 |
os-credentials-controller |
1.12.2 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.1.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
Target system image (ubuntu-bionic) |
https://binary.mirantis.com/bm/bin/efi/ubuntu/qcow2-bionic-debug-20200730084816 |
baremetal-operator Updated |
https://binary.mirantis.com/bm/helm/baremetal-operator-3.1.0.tgz |
|
baremetal-public-api New |
https://binary.mirantis.com/bm/helm/baremetal-public-api-3.1.0.tgz |
|
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-train-bionic-debug-20200730084816 |
|
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-train-bionic-debug-20200730084816 |
|
kaas-ipam Updated |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-1.0.4-mcp.tgz |
|
Docker images |
baremetal-operator Updated |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20201005150946 |
httpd Updated |
mirantis.azurecr.io/bm/external/httpd:2.4.46-20201001171500 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:train-bionic-20200803180020 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:train-bionic-20200803180020 |
|
ironic-operator |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20200805144858 |
|
kaas-ipam Updated |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20201007180518 |
|
mariadb Updated |
mirantis.azurecr.io/general/mariadb:10.4.14-bionic-20200812025059 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball Updated |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.12.2.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.12.2.tar.gz |
|
Helm charts Updated |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.12.3.tgz |
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.12.2.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.12.2.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.12.2.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.12.2.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.12.2.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.12.2.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.12.2.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.12.2.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.12.2.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.12.2.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.12.2.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.12.2.tgz |
|
Docker images for Container Cloud deployment Updated |
admission-controller |
mirantis.azurecr.io/core/admission-controller:1.12.3 |
aws-cluster-api-controller |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.12.2 |
|
byo-cluster-api-controller |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.12.2 |
|
aws-credentials-controller |
mirantis.azurecr.io/core/aws-credentials-controller:1.12.2 |
|
byo-credentials-controller |
mirantis.azurecr.io/core/byo-credentials-controller:1.12.2 |
|
cluster-api-provider-baremetal |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.12.2 |
|
frontend |
mirantis.azurecr.io/core/frontend:1.12.2 |
|
iam-controller |
mirantis.azurecr.io/core/iam-controller:1.12.2 |
|
lcm-controller |
mirantis.azurecr.io/core/lcm-controller:v0.2.0-169-g5668304d |
|
openstack-cluster-api-controller |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.12.2 |
|
os-credentials-controller |
mirantis.azurecr.io/core/os-credentials-controller:1.12.2 |
|
release-controller |
mirantis.azurecr.io/core/release-controller:1.12.2 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-236-9cea809-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-236-9cea809-darwin |
|
iamctl-linux |
||
iamctl-darwin |
||
iamctl-windows |
||
Helm charts |
iam Updated |
|
iam-proxy |
||
keycloak-proxy Updated |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.12.2.tgz |
|
Docker images |
api |
mirantis.azurecr.io/iam/api:0.3.18 |
auxiliary |
mirantis.azurecr.io/iam/auxiliary:0.3.18 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
|
mariadb |
mirantis.azurecr.io/iam/external/mariadb:10.2.18 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.3.18 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:6.0.1 |
To complete the AWS-based management cluster upgrade to version 2.1.0, manually update the IAM policies for AWS before updating your AWS-based managed clusters.
To update the IAM policies for AWS:
Choose from the following options:
Update the IAM policies using
get_container_cloud.sh:On any local machine, download and run the latest version of the Container Cloud bootstrap script:
wget https://binary.mirantis.com/releases/get_container_cloud.sh chmod 0755 get_container_cloud.sh ./get_container_cloud.sh
Change the directory to the
kaas-bootstrapfolder created by theget_container_cloud.shscript.Export the following parameters by adding the corresponding values for the AWS
admincredentials:export AWS_SECRET_ACCESS_KEY=XXXXXXX export AWS_ACCESS_KEY_ID=XXXXXXX export AWS_DEFAULT_REGION=us-east-2
Update the AWS
CloudFormationtemplate for IAM policy:./container-cloud bootstrap aws policy
Update the IAM policies using the AWS Management Console:
Log in to your AWS Management Console.
Verify that the
controllers.cluster-api-provider-aws.kaas.mirantis.comrole or another AWS role that you use for Container Cloud users contains the following permissions:"ec2:DescribeRegions", "ec2:DescribeInstanceTypes"
Otherwise, add these permissions manually.
Proceed to updating your AWS-based managed clusters as described in Operations Guide: Update a managed cluster.
This section outlines release notes for the initial Mirantis Container Cloud GA release 2.0.0. This release introduces support for the Cluster release 5.7.0 that is based on Mirantis Kubernetes Engine 3.3.3, Mirantis Container Runtime 19.03.12, and Kubernetes 1.18.
This section lists known issues with workarounds for the Mirantis Container Cloud release 2.0.0.
Fixed in the Cluster release 7.0.0
Note
The issue below affects only the Kubernetes 1.18 deployments. Moving forward, the workaround for this issue will be moved from Release Notes to Operations Guide: Troubleshooting.
On a management cluster with multiple AWS-based managed
clusters, some clusters fail to complete the deployments that require
persistent volumes (PVs), for example, Elasticsearch.
Some of the affected pods get stuck in the Pending state
with the pod has unbound immediate PersistentVolumeClaims and
node(s) had volume node affinity conflict errors.
Warning
The workaround below applies to HA deployments where data can be rebuilt from replicas. If you have a non-HA deployment, back up any existing data before proceeding, since all data will be lost while applying the workaround.
Workaround:
Obtain the persistent volume claims related to the storage mounts of the affected pods:
kubectl get pod/<pod_name1> pod/<pod_name2> \ -o jsonpath='{.spec.volumes[?(@.persistentVolumeClaim)].persistentVolumeClaim.claimName}'
Note
In the command above and in the subsequent steps, substitute the parameters enclosed in angle brackets with the corresponding values.
Delete the affected
PodsandPersistentVolumeClaimsto reschedule them: For example, for StackLight:kubectl -n stacklight delete \ pod/<pod_name1> pod/<pod_name2> ... pvc/<pvc_name2> pvc/<pvc_name2> ...
Fixed in Container Cloud 2.5.0
During a management or managed cluster deployment, LVM cannot be deployed on a new disk if an old volume group with the same name already exists on the target hardware node but on the different disk.
Workaround:
In the bare metal host profile specific to your hardware configuration,
add the wipe: true parameter to the device that fails to be deployed.
For the procedure details,
see Operations Guide: Create a custom host profile.
Fixed in Container Cloud 2.4.0
During a management cluster deployment, IAM fails to start with the IAM
pods being in the CrashLoopBackOff status.
Workaround:
Log in to the bootstrap node.
Remove the
iam-mariadb-stateconfigmap:kubectl delete cm -n kaas iam-mariadb-state
Manually delete the
mariadbpods:kubectl delete po -n kaas mariadb-server-{0,1,2}
Wait for the pods to start. If the
mariadbpod does not start with the connection to peer timed out exception, repeat the step 2.Obtain the MariaDB database admin password:
kubectl get secrets -n kaas mariadb-dbadmin-password \ -o jsonpath='{.data.MYSQL_DBADMIN_PASSWORD}' | base64 -d ; echo
Log in to MariaDB:
kubectl exec -it -n kaas mariadb-server-0 -- bash -c 'mysql -uroot -p<mysqlDbadminPassword>'
Substitute
<mysqlDbadminPassword>with the corresponding value obtained in the previous step.Run the following command:
DROP DATABASE IF EXISTS keycloak;
Manually delete the Keycloak pods:
kubectl delete po -n kaas iam-keycloak-{0,1,2}
Fixed in 2.1.0
On the baremetal-based clusters, the monitoring of Ceph and Ironic is enabled when Ceph and Ironic are disabled. The issue with Ceph relates to both management or managed clusters, the issue with Ironic relates to managed clusters only.
Workaround:
Open the StackLight configuration manifest as described in Operations Guide: Configure StackLight.
Add the following parameter to the StackLight
helmReleasesvalues of the Cluster object to explicitly disable the required component monitoring:For Ceph:
helmReleases: - name: stacklight values: ... ceph: disabledOnBareMetal: true ...
For Ironic:
helmReleases: - name: stacklight values: ... ironic: disabledOnBareMetal: true ...
Fixed in 2.1.0
Ceph monitoring may be disabled on the baremetal-based managed clusters due
to a missing provider: BareMetal parameter.
Workaround:
Open the StackLight configuration manifest as described in Operations Guide: Configure StackLight.
Add the
provider: BareMetalparameter to the StackLighthelmReleasesvalues of the Cluster object:spec: providerSpec: value: helmReleases: - name: stacklight values: ... provider: BareMetal ...
Fixed in 2.2.0
After deploying a managed cluster with Ceph, the number of placement groups
(PGs) per Ceph OSD may be too small and the Ceph cluster may have the
HEALTH_WARN status:
health: HEALTH_WARN
too few PGs per OSD (3 < min 30)
The workaround is to enable the PG balancer to properly manage the number of PGs:
kexec -it $(k get pod -l "app=rook-ceph-tools" --all-namespaces -o jsonpath='{.items[0].metadata.name}') -n rook-ceph bash
ceph mgr module enable pg_autoscaler
Fixed in 2.2.0
Occasionally, the deployment of a managed cluster may fail during the Ceph Monitor or Manager deployment. In this case, the Ceph cluster may be down and and a stack trace similar to the following one may be present in Ceph Manager logs:
kubectl -n rook-ceph logs rook-ceph-mgr-a-c5dc846f8-k68rs
/home/jenkins-build/build/workspace/ceph-build/ARCH/x86_64/AVAILABLE_ARCH/x86_64/AVAILABLE_DIST/centos7/DIST/centos7/MACHINE_SIZE/gigantic/release/14.2.9/rpm/el7/BUILD/ceph-14.2.9/src/mon/MonMap.h: In function 'void MonMap::add(const mon_info_t&)' thread 7fd3d3744b80 time 2020-09-03 10:16:46.586388
/home/jenkins-build/build/workspace/ceph-build/ARCH/x86_64/AVAILABLE_ARCH/x86_64/AVAILABLE_DIST/centos7/DIST/centos7/MACHINE_SIZE/gigantic/release/14.2.9/rpm/el7/BUILD/ceph-14.2.9/src/mon/MonMap.h: 195: FAILED ceph_assert(addr_mons.count(a) == 0)
ceph version 14.2.9 (581f22da52345dba46ee232b73b990f06029a2a0) nautilus (stable)
1: (ceph::__ceph_assert_fail(char const*, char const*, int, char const*)+0x14a) [0x7fd3ca9b2875]
2: (()+0x253a3d) [0x7fd3ca9b2a3d]
3: (MonMap::add(mon_info_t const&)+0x80) [0x7fd3cad49190]
4: (MonMap::add(std::string const&, entity_addrvec_t const&, int)+0x110) [0x7fd3cad493a0]
5: (MonMap::init_with_ips(std::string const&, bool, std::string const&)+0xc9) [0x7fd3cad43849]
6: (MonMap::build_initial(CephContext*, bool, std::ostream&)+0x314) [0x7fd3cad45af4]
7: (MonClient::build_initial_monmap()+0x130) [0x7fd3cad2e140]
8: (MonClient::get_monmap_and_config()+0x5f) [0x7fd3cad365af]
9: (global_pre_init(std::map<std::string, std::string, std::less<std::string>, std::allocator<std::pair<std::string const, std::string> > > const*, std::vector<char const*, std::allocator<char const*> >&, unsigned int, code_environment_t, int)+0x524) [0x55ce86711444]
10: (global_init(std::map<std::string, std::string, std::less<std::string>, std::allocator<std::pair<std::string const, std::string> > > const*, std::vector<char const*, std::allocator<char const*> >&, unsigned int, code_environment_t, int, char const*, bool)+0x76) [0x55ce86711b56]
11: (main()+0x136) [0x55ce864ff9a6]
12: (__libc_start_main()+0xf5) [0x7fd3c6e73555]
13: (()+0xfc010) [0x55ce86505010]
The workaround is to start the managed cluster deployment from scratch.
When removing a worker node, it is not possible to automatically remove a Ceph node. The workaround is to manually remove the Ceph node from the Ceph cluster as described in Operations Guide: Add, remove, or reconfigure Ceph nodes before removing the worker node from your deployment.
Fixed in 2.1.0
A management cluster bootstrap script fails if there is a space
in the PATH environment variable. As a workaround, before running the
bootstrap.sh script, verify that there are no spaces in the PATH
environment variable.
Affects only Container Cloud 2.18.0 and earlier
A project that is newly created in the Container Cloud web UI does not display in the Projects list even after refreshing the page. The issue occurs due to the token missing the necessary role for the new project. As a workaround, relogin to the Container Cloud web UI.
The following table lists the major components and their versions of the Mirantis Container Cloud release 2.0.0.
Component |
Application/Service |
Version |
|---|---|---|
AWS |
aws-provider |
1.10.12 |
aws-credentials-controller |
1.10.12 |
|
Bare metal |
baremetal-operator |
3.0.7 |
baremetal-provider |
1.10.12 |
|
httpd |
2.4.43-20200710111500 |
|
ironic |
train-bionic-20200803180020 |
|
ironic-operator |
base-bionic-20200805144858 |
|
kaas-ipam |
20200807130953 |
|
local-volume-provisioner |
1.0.4-mcp |
|
mariadb |
10.4.12-bionic-20200803130834 |
|
IAM |
iam |
1.1.16 |
iam-controller |
1.10.12 |
|
keycloak |
9.0.0 |
|
Container Cloud |
admission-controller |
1.10.12 |
byo-credentials-controller |
1.10.12 |
|
byo-provider |
1.10.12 |
|
kaas-public-api |
1.10.12 |
|
kaas-exporter |
1.10.12 |
|
kaas-ui |
1.10.12 |
|
lcm-controller |
0.2.0-149-g412c5a05 |
|
release-controller |
1.10.12 |
|
OpenStack |
openstack-provider |
1.10.12 |
os-credentials-controller |
1.10.12 |
This section lists the components artifacts of the Mirantis Container Cloud release 2.0.0.
Artifact |
Component |
Path |
|---|---|---|
Binaries |
Target system image (ubuntu-bionic) |
https://binary.mirantis.com/bm/bin/efi/ubuntu/qcow2-bionic-debug-20200730084816 |
baremetal-operator |
https://binary.mirantis.com/bm/helm/baremetal-operator-3.0.7.tgz |
|
ironic-python-agent.kernel |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/kernel-train-bionic-debug-20200730084816 |
|
ironic-python-agent.initramfs |
https://binary.mirantis.com/bm/bin/ironic/ipa/ubuntu/initramfs-train-bionic-debug-20200730084816 |
|
kaas-ipam |
||
local-volume-provisioner |
https://binary.mirantis.com/bm/helm/local-volume-provisioner-1.0.4-mcp.tgz |
|
Docker images |
baremetal-operator |
mirantis.azurecr.io/bm/baremetal-operator:base-bionic-20200812172956 |
httpd |
mirantis.azurecr.io/bm/external/httpd:2.4.43-20200710111500 |
|
ironic |
mirantis.azurecr.io/openstack/ironic:train-bionic-20200803180020 |
|
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:train-bionic-20200803180020 |
|
ironic-operator |
mirantis.azurecr.io/bm/ironic-operator:base-bionic-20200805144858 |
|
kaas-ipam |
mirantis.azurecr.io/bm/kaas-ipam:base-bionic-20200807130953 |
|
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.12-bionic-20200803130834 |
Artifact |
Component |
Path |
|---|---|---|
Bootstrap tarball |
bootstrap-linux |
https://binary.mirantis.com/core/bin/bootstrap-linux-1.10.12.tar.gz |
bootstrap-darwin |
https://binary.mirantis.com/core/bin/bootstrap-darwin-1.10.12.tar.gz |
|
Helm charts |
admission-controller |
https://binary.mirantis.com/core/helm/admission-controller-1.10.12.tgz |
aws-credentials-controller |
https://binary.mirantis.com/core/helm/aws-credentials-controller-1.10.12.tgz |
|
aws-provider |
https://binary.mirantis.com/core/helm/aws-provider-1.10.12.tgz |
|
baremetal-provider |
https://binary.mirantis.com/core/helm/baremetal-provider-1.10.12.tgz |
|
byo-credentials-controller |
https://binary.mirantis.com/core/helm/byo-credentials-controller-1.10.12.tgz |
|
byo-provider |
https://binary.mirantis.com/core/helm/byo-provider-1.10.12.tgz |
|
iam-controller |
https://binary.mirantis.com/core/helm/iam-controller-1.10.12.tgz |
|
kaas-exporter |
https://binary.mirantis.com/core/helm/kaas-exporter-1.10.12.tgz |
|
kaas-public-api |
https://binary.mirantis.com/core/helm/kaas-public-api-1.10.12.tgz |
|
kaas-ui |
||
lcm-controller |
https://binary.mirantis.com/core/helm/lcm-controller-1.10.12.tgz |
|
openstack-provider |
https://binary.mirantis.com/core/helm/openstack-provider-1.10.12.tgz |
|
os-credentials-controller |
https://binary.mirantis.com/core/helm/os-credentials-controller-1.10.12.tgz |
|
release-controller |
https://binary.mirantis.com/core/helm/release-controller-1.10.12.tgz |
|
Docker images for Container Cloud deployment |
aws-cluster-api-controller |
mirantis.azurecr.io/core/aws-cluster-api-controller:1.10.12 |
aws-credentials-controller |
mirantis.azurecr.io/core/aws-credentials-controller:1.10.12 |
|
byo-cluster-api-controller |
mirantis.azurecr.io/core/byo-cluster-api-controller:1.10.12 |
|
byo-credentials-controller |
mirantis.azurecr.io/core/byo-credentials-controller:1.10.12 |
|
cluster-api-provider-baremetal |
mirantis.azurecr.io/core/cluster-api-provider-baremetal:1.10.12 |
|
frontend |
mirantis.azurecr.io/core/frontend:1.10.12 |
|
iam-controller |
mirantis.azurecr.io/core/iam-controller:1.10.12 |
|
lcm-controller |
mirantis.azurecr.io/core/lcm-controller:v0.2.0-149-g412c5a05 |
|
openstack-cluster-api-controller |
mirantis.azurecr.io/core/openstack-cluster-api-controller:1.10.12 |
|
os-credentials-controller |
mirantis.azurecr.io/core/os-credentials-controller:1.10.12 |
|
release-controller |
mirantis.azurecr.io/core/release-controller:1.10.12 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
hash-generate-linux |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-236-9cea809-linux |
hash-generate-darwin |
http://binary.mirantis.com/iam/bin/hash-generate-0.0.1-236-9cea809-darwin |
|
iamctl-linux |
||
iamctl-darwin |
||
iamctl-windows |
||
Helm charts |
iam |
|
iam-proxy |
||
keycloak-proxy |
http://binary.mirantis.com/core/helm/keycloak_proxy-1.10.12.tgz |
|
Docker images |
api |
mirantis.azurecr.io/iam/api:0.3.18 |
auxiliary |
mirantis.azurecr.io/iam/auxiliary:0.3.18 |
|
kubernetes-entrypoint |
mirantis.azurecr.io/iam/external/kubernetes-entrypoint:v0.3.1 |
|
mariadb |
mirantis.azurecr.io/iam/external/mariadb:10.2.18 |
|
keycloak |
mirantis.azurecr.io/iam/keycloak:0.3.18 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:6.0.1 |
Cluster releases (managed)¶
This section outlines the release notes for major and patch Cluster releases that are supported by specific Container Cloud releases. For details about the Container Cloud releases, see: Container Cloud releases.
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on your deployment needs, you can either update only between major Cluster releases or apply patch updates between major releases. Choosing the latter option ensures you receive security fixes as soon as they become available. Though, be prepared to update your cluster frequently, approximately once every three weeks. Otherwise, you can update only between major Cluster releases as each subsequent major Cluster release includes patch Cluster release updates of the previous major Cluster release.
17.x series (current)¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on your deployment needs, you can either update only between major Cluster releases or apply patch updates between major releases. Choosing the latter option ensures you receive security fixes as soon as they become available. Though, be prepared to update your cluster frequently, approximately once every three weeks. Otherwise, you can update only between major Cluster releases as each subsequent major Cluster release includes patch Cluster release updates of the previous major Cluster release.
This section outlines release notes for supported major and patch Cluster releases of the 17.x series dedicated for Mirantis OpenStack for Kubernetes (MOSK).
17.2.x series¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on your deployment needs, you can either update only between major Cluster releases or apply patch updates between major releases. Choosing the latter option ensures you receive security fixes as soon as they become available. Though, be prepared to update your cluster frequently, approximately once every three weeks. Otherwise, you can update only between major Cluster releases as each subsequent major Cluster release includes patch Cluster release updates of the previous major Cluster release.
This section outlines release notes for supported major and patch Cluster releases of the 17.2.x series dedicated for Mirantis OpenStack for Kubernetes (MOSK).
This section outlines release notes for the major Cluster release 17.2.0 that is introduced in the Container Cloud release 2.27.0. This Cluster release is based on the Cluster release 16.2.0. The Cluster release 17.2.0 supports:
Mirantis OpenStack for Kubernetes (MOSK) 24.2. For details, see MOSK Release Notes.
Mirantis Kubernetes Engine (MKE) 3.7.8. For details, see MKE Release Notes.
Mirantis Container Runtime (MCR) 23.0.11. For details, see MCR Release Notes.
Kubernetes 1.27.
For the list of known and addressed issues, refer to the Container Cloud release 2.27.0 section.
This section outlines new features implemented in the Cluster release 17.2.0 that is introduced in the Container Cloud release 2.27.0.
Introduced support for Mirantis Kubernetes Engine (MKE) 3.7.8 that supports Kubernetes 1.27. On existing clusters, MKE is updated to the latest supported version when you update your managed cluster to the Cluster release 17.2.0.
Note
This enhancement applies to users who follow the update train using major releases. Users who install patch releases, have already obtained MKE 3.7.8 in Container Cloud 2.26.4 (Cluster release 17.1.4).
Learn more
Analyzed and fixed the majority of failed compliance checks in the MKE benchmark compliance for Container Cloud core components and StackLight. The following controls were analyzed:
Control ID |
Component |
Control description |
Analyzed item |
|---|---|---|---|
5.1.2 |
client-certificate-controller
helm-controller
local-volume-provisioner
|
Minimize access to secrets |
|
5.1.4 |
local-volume-provisioner |
Minimize access to create pods |
|
5.2.5 |
client-certificate-controller
helm-controller
policy-controller
stacklight
|
Minimize the admission of containers with |
Containers with |
Upgraded Ceph major version from Quincy 17.2.7 (17.2.7-12.cve in the patch release train) to Reef 18.2.3 with an automatic upgrade of Ceph components on existing managed clusters during the Cluster version update.
Ceph Reef delivers new version of RocksDB which provides better IO performance. Also, this version supports RGW multisite re-sharding and contains overall security improvements.
Added support for Rook v1.13 that contains the Ceph CSI plugin 3.10.x as the default supported version. For a complete list of features and breaking changes, refer to official Rook documentation.
Learn more
Implemented the section option for the rookConfig parameter that
enables you to specify the section where a Rook parameter must be placed.
The use of this option enables restart of only specific daemons related to the
corresponding section instead of restarting all Ceph daemons except Ceph OSD.
Implemented monitoring of disk along with I/O errors in kernel logs to detect
hardware and software issues. The implementation includes the dedicated
KernelIOErrorsDetected alert, the kernel_io_errors_total metric that
is collected on the Fluentd side using the I/O error patterns, and general
refactoring of metrics created in Fluentd.
Added documentation describing usage examples of alert rules based on S.M.A.R.T. metrics to monitor disk information on bare metal clusters.
The StackLight telegraf-ds-smart exporter uses the
S.M.A.R.T. plugin to
obtain detailed disk information and export it as metrics. S.M.A.R.T. is a
commonly used system across vendors with performance data provided as
attributes.
Improved performance and UX visibility of the OpenSearch and OpenSearch Indices Grafana dashboards as well as added the capability to minimize the number of indices to be displayed on dashboards.
Learn more
As part of StackLight refactoring, removed grafana-image-renderer from the
Grafana installation in Container Cloud. StackLight uses this component only
for image generation in the Grafana web UI, which can be easily replaced with
standard screenshots.
The improvement optimizes resources usage and prevents potential CVEs that frequently affect this component.
The following table lists the components versions of the Cluster release 17.2.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.7.8 0 |
Container runtime Updated |
Mirantis Container Runtime |
23.0.11 1 |
Distributed storage |
Ceph |
18.2.3-1.release (Reef) |
Rook |
1.13.5-15 |
|
LCM Updated |
helm-controller |
1.40.11 |
lcm-ansible |
0.25.0-37-gc15c97d |
|
lcm-agent |
1.40.11 |
|
StackLight |
Alerta |
9.0.1 |
Alertmanager |
0.25.0 |
|
Alertmanager Webhook ServiceNow |
0.1 |
|
Blackbox Exporter |
0.24.0 |
|
cAdvisor |
0.47.2 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.5.0 |
|
Fluentd |
1.15.3 |
|
Grafana |
10.3.1 |
|
Grafana Image Renderer Removed |
n/a |
|
kube-state-metrics |
2.10.1 |
|
Metric Collector |
0.1 |
|
Metricbeat |
7.12.1 |
|
Node Exporter |
1.7.0 |
|
OAuth2 Proxy |
7.1.3 |
|
OpenSearch |
2.12.0 |
|
OpenSearch Dashboards |
2.12.0 |
|
Prometheus |
2.48.0 |
|
Prometheus ES Exporter |
0.14.0 |
|
Prometheus MS Teams |
1.5.2 |
|
Prometheus Patroni Exporter |
0.0.1 |
|
Prometheus Postgres Exporter |
0.15.0 |
|
Prometheus Relay |
0.4 |
|
sf-notifier |
0.4 |
|
sf-reporter |
0.1 |
|
Spilo |
13-2.1p9 |
|
Telegraf |
1.9.1 |
|
1.30.2 |
||
Telemeter |
4.4 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the artifacts of components included in the Cluster release 17.2.0.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.27.0-7.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/mirantis/ceph:v18.2.3-1.release |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.27.0-6 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-12.release |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-4.release |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-4.release |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-4.release |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-4.release |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-4.release |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.13.5-15 |
|
snapshot-controller New |
mirantis.azurecr.io/mirantis/snapshot-controller:v6.3.2-4.release |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.25.0-37-gc15c97d/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.40.11.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.40.11.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.40.11 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-238.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-300.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-87.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.15.3.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-42.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-42.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web |
mirantis.azurecr.io/stacklight/alerta-web:9-20240515023009 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240515023012 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240318145925 |
|
alpine-utils |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240515023017 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20240408080237 |
|
cadvisor |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240515023012 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240611084259 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer Removed |
n/a |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240515023018 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240515023015 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240515023016 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240515023009 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-8 |
|
opensearch |
mirantis.azurecr.io/stacklight/opensearch:2-20240515023012 |
|
opensearch-dashboards |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240515023010 |
|
pgbouncer |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240515023018 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240515023016 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20240408080322 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240515023017 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240515023017 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240515023012 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240318145903 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240515023010 |
|
stacklight-toolkit |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240515023016 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240515023008 |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240426131156 |
||
telemeter |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240515023015 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240515023012 |
|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.25.0-37-gc15c97d/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.40.11.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.40.11.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.40.11 |
Artifact |
Component |
Path |
|---|---|---|
Configuration management Updated |
Ansible |
|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-05-17-013445.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240517090228 |
See also
17.1.6¶
This section includes release notes for the patch Cluster release 17.1.6 that is introduced in the Container Cloud patch release 2.27.1 and is based on the previous Cluster releases of the 17.1.x series series.
This patch Cluster release introduces MOSK 24.1.6 that is
based on Mirantis Kubernetes Engine 3.7.10 with Kubernetes 1.27 and Mirantis
Container Runtime 23.0.9, in which docker-ee-cli was updated to version
23.0.13 to fix several CVEs.
For details on MOSK 24.1.6, see MOSK documentation: Release Notes
For the list of CVE fixes delivered with this patch Cluster release, see 2.27.1
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 17.1.6.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.27.1-6.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/mirantis/ceph:v17.2.7-15.cve |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.27.1-5 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-15.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-3.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-3.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-3.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-3.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-3.cve |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.12.10-21 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts Updated |
cinder-csi-plugin |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.39.29.tgz |
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.39.29.tgz |
|
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.39.29.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.39.29.tgz |
|
openstack-cloud-controller-manager |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.39.29.tgz |
|
policy-controller |
https://binary.mirantis.com/core/helm/policy-controller-1.39.29.tgz |
|
vsphere-cloud-controller-manager |
https://binary.mirantis.com/core/helm/vsphere-cloud-controller-manager-1.39.29.tgz |
|
vsphere-csi-plugin |
https://binary.mirantis.com/core/helm/vsphere-csi-plugin-1.39.29.tgz |
|
Docker images |
cinder-csi-plugin |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-16 |
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.39.29 |
|
csi-attacher |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-5 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-5 |
|
csi-provisioner |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-5 |
|
csi-resizer |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-5 |
|
csi-snapshotter |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-4 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-7 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-16 |
|
policy-controller Updated |
mirantis.azurecr.io/core/policy-controller:1.39.29 |
|
vsphere-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/vsphere-cloud-controller-manager:v1.27.0-6 |
|
vsphere-csi-driver |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-driver:v3.0.2-1 |
|
vsphere-csi-syncer |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-syncer:v3.0.2-1 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.24.0-52-gd8adaba/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.39.29.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.39.29.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.39.29 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-223.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-290.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-88.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.14.14.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-42.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-42.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240701140358 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240701140403 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240318145925 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240701140404 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20240408080237 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240701140359 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240701140357 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20240318142141 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240701140403 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240701140401 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240701140400 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240626023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-8 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240701140359 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240701140352 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240701140404 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240701140403 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20240408080322 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240701140402 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240701140404 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240701140403 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240318145903 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240701140359 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240701140402 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240605023010 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240426131156 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240701140401 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240701140402 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-06-27-014654/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-06-27-014654.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240627095142 Updated |
See also
16.x series (current)¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on your deployment needs, you can either update only between major Cluster releases or apply patch updates between major releases. Choosing the latter option ensures you receive security fixes as soon as they become available. Though, be prepared to update your cluster frequently, approximately once every three weeks. Otherwise, you can update only between major Cluster releases as each subsequent major Cluster release includes patch Cluster release updates of the previous major Cluster release.
This section outlines release notes for supported major and patch Cluster releases of the 16.x series.
16.2.x series¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on your deployment needs, you can either update only between major Cluster releases or apply patch updates between major releases. Choosing the latter option ensures you receive security fixes as soon as they become available. Though, be prepared to update your cluster frequently, approximately once every three weeks. Otherwise, you can update only between major Cluster releases as each subsequent major Cluster release includes patch Cluster release updates of the previous major Cluster release.
This section outlines release notes for supported major and patch Cluster releases of the 16.2.x series.
This section includes release notes for the patch Cluster release 16.2.1 that is introduced in the Container Cloud patch release 2.27.1 and is based on the Cluster release 16.2.0.
This Cluster release supports Mirantis Kubernetes Engine 3.7.10
with Kubernetes 1.27 and Mirantis Container Runtime 23.0.11, in which
docker-ee-cli was updated to version 23.0.13 to fix several CVEs.
For the list of CVE fixes delivered with this patch Cluster release, see 2.27.1
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 16.2.1.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.27.0-13.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/mirantis/ceph:v18.2.3-2.cve |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.27.0-12 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-14.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-4.release |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-4.release |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-4.release |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-4.release |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-4.release |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.13.5-16 |
|
snapshot-controller |
mirantis.azurecr.io/mirantis/snapshot-controller:v6.3.2-4.release |
Artifact |
Component |
Path |
|---|---|---|
Helm charts Updated |
cinder-csi-plugin |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.40.15.tgz |
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.40.15.tgz |
|
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.40.15.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.40.15.tgz |
|
openstack-cloud-controller-manager |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.40.15.tgz |
|
policy-controller |
https://binary.mirantis.com/core/helm/policy-controller-1.40.15.tgz |
|
vsphere-cloud-controller-manager |
https://binary.mirantis.com/core/helm/vsphere-cloud-controller-manager-1.40.15.tgz |
|
vsphere-csi-plugin |
https://binary.mirantis.com/core/helm/vsphere-csi-plugin-1.40.15.tgz |
|
Docker images |
cinder-csi-plugin |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-16 |
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.40.15 |
|
csi-attacher |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-5 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-5 |
|
csi-provisioner |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-5 |
|
csi-resizer |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-5 |
|
csi-snapshotter |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-4 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-7 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-16 |
|
policy-controller Updated |
mirantis.azurecr.io/core/policy-controller:1.40.15 |
|
vsphere-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/vsphere-cloud-controller-manager:v1.27.0-6 |
|
vsphere-csi-driver |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-driver:v3.0.2-1 |
|
vsphere-csi-syncer |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-syncer:v3.0.2-1 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.25.0-40-g890ffca/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.40.15.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.40.15.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.40.15 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-238.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-300.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-88.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-16.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.15.5.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-42.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-42.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240701140358 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240701140403 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240318145925 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240701140404 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20240408080237 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240701140359 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240701140357 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240701140403 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240701140401 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240701140400 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240626023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-8 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240701140359 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240701140352 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.7 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240701140404 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240701140403 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20240408080322 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240701140402 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240701140404 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240701140403 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240318145903 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240701140359 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240701140402 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240605023010 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240426131156 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240701140401 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240701140402 |
Artifact |
Component |
Path |
|---|---|---|
Configuration management |
Ansible |
|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-06-27-014654/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-06-27-014654.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/jammy/pool/stable-23.0/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-jammy-20240627095125 Updated |
This section outlines release notes for the major Cluster release 16.2.0 that is introduced in the Container Cloud release 2.27.0. The Cluster release 16.2.0 supports:
Mirantis Kubernetes Engine (MKE) 3.7.8. For details, see MKE Release Notes.
Mirantis Container Runtime (MCR) 23.0.11. For details, see MCR Release Notes.
Kubernetes 1.27.
For the list of known and addressed issues, refer to the Container Cloud release 2.27.0 section.
This section outlines new features implemented in the Cluster release 16.2.0 that is introduced in the Container Cloud release 2.27.0.
Introduced support for Mirantis Kubernetes Engine (MKE) 3.7.8 that supports Kubernetes 1.27 for the Container Cloud management and managed clusters.
On existing managed clusters, MKE is updated to the latest supported version when you update your managed cluster to the Cluster release 16.2.0.
Note
This enhancement applies to users who follow the update train using major releases. Users who install patch releases, have already obtained MKE 3.7.8 in Container Cloud 2.26.4 (Cluster release 16.1.4).
Learn more
Analyzed and fixed the majority of failed compliance checks in the MKE benchmark compliance for Container Cloud core components and StackLight. The following controls were analyzed:
Control ID |
Component |
Control description |
Analyzed item |
|---|---|---|---|
5.1.2 |
client-certificate-controller
helm-controller
local-volume-provisioner
|
Minimize access to secrets |
|
5.1.4 |
local-volume-provisioner |
Minimize access to create pods |
|
5.2.5 |
client-certificate-controller
helm-controller
policy-controller
stacklight
|
Minimize the admission of containers with |
Containers with |
Upgraded Ceph major version from Quincy 17.2.7 (17.2.7-12.cve in the patch release train) to Reef 18.2.3 with an automatic upgrade of Ceph components on existing managed clusters during the Cluster version update.
Ceph Reef delivers new version of RocksDB which provides better IO performance. Also, this version supports RGW multisite re-sharding and contains overall security improvements.
Added support for Rook v1.13 that contains the Ceph CSI plugin 3.10.x as the default supported version. For a complete list of features and breaking changes, refer to official Rook documentation.
Learn more
Implemented the section option for the rookConfig parameter that
enables you to specify the section where a Rook parameter must be placed.
The use of this option enables restart of only specific daemons related to the
corresponding section instead of restarting all Ceph daemons except Ceph OSD.
Implemented monitoring of disk along with I/O errors in kernel logs to detect
hardware and software issues. The implementation includes the dedicated
KernelIOErrorsDetected alert, the kernel_io_errors_total metric that
is collected on the Fluentd side using the I/O error patterns, and general
refactoring of metrics created in Fluentd.
Added documentation describing usage examples of alert rules based on S.M.A.R.T. metrics to monitor disk information on bare metal clusters.
The StackLight telegraf-ds-smart exporter uses the
S.M.A.R.T. plugin to
obtain detailed disk information and export it as metrics. S.M.A.R.T. is a
commonly used system across vendors with performance data provided as
attributes.
Improved performance and UX visibility of the OpenSearch and OpenSearch Indices Grafana dashboards as well as added the capability to minimize the number of indices to be displayed on dashboards.
Learn more
As part of StackLight refactoring, removed grafana-image-renderer from the
Grafana installation in Container Cloud. StackLight uses this component only
for image generation in the Grafana web UI, which can be easily replaced with
standard screenshots.
The improvement optimizes resources usage and prevents potential CVEs that frequently affect this component.
The following table lists the components versions of the Cluster release 16.2.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.7.8 0 |
Container runtime Updated |
Mirantis Container Runtime |
23.0.11 1 |
Distributed storage |
Ceph |
18.2.3-1.release (Reef) |
Rook |
1.13.5-15 |
|
LCM Updated |
helm-controller |
1.40.11 |
lcm-ansible |
0.25.0-37-gc15c97d |
|
lcm-agent |
1.40.11 |
|
StackLight |
Alerta |
9.0.1 |
Alertmanager |
0.25.0 |
|
Alertmanager Webhook ServiceNow |
0.1 |
|
Blackbox Exporter |
0.24.0 |
|
cAdvisor |
0.47.2 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.5.0 |
|
Fluentd |
1.15.3 |
|
Grafana |
10.3.1 |
|
Grafana Image Renderer Removed |
n/a |
|
kube-state-metrics |
2.10.1 |
|
Metric Collector |
0.1 |
|
Metricbeat |
7.12.1 |
|
Node Exporter |
1.7.0 |
|
OAuth2 Proxy |
7.1.3 |
|
OpenSearch |
2.12.0 |
|
OpenSearch Dashboards |
2.12.0 |
|
Prometheus |
2.48.0 |
|
Prometheus ES Exporter |
0.14.0 |
|
Prometheus MS Teams |
1.5.2 |
|
Prometheus Patroni Exporter |
0.0.1 |
|
Prometheus Postgres Exporter |
0.15.0 |
|
Prometheus Relay |
0.4 |
|
sf-notifier |
0.4 |
|
sf-reporter |
0.1 |
|
Spilo |
13-2.1p9 |
|
Telegraf |
1.9.1 |
|
1.30.2 |
||
Telemeter |
4.4 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the artifacts of components included in the Cluster release 16.2.0.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.27.0-7.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/mirantis/ceph:v18.2.3-1.release |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.27.0-6 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-12.release |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-4.release |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-4.release |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-4.release |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-4.release |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-4.release |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.13.5-15 |
|
snapshot-controller New |
mirantis.azurecr.io/mirantis/snapshot-controller:v6.3.2-4.release |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.25.0-37-gc15c97d/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.40.11.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.40.11.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.40.11 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-238.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-300.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-87.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-16.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.15.3.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-42.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-42.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web |
mirantis.azurecr.io/stacklight/alerta-web:9-20240515023009 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240515023012 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240318145925 |
|
alpine-utils |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240515023017 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20240408080237 |
|
cadvisor |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240515023012 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240611084259 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer Removed |
n/a |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240515023018 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240515023015 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240515023016 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240515023009 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-8 |
|
opensearch |
mirantis.azurecr.io/stacklight/opensearch:2-20240515023012 |
|
opensearch-dashboards |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240515023010 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.7 |
|
pgbouncer |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240515023018 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240515023016 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20240408080322 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240515023017 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240515023017 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240515023012 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240318145903 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240515023010 |
|
stacklight-toolkit |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240515023016 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240515023008 |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240426131156 |
||
telemeter |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240515023015 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240515023012 |
Artifact |
Component |
Path |
|---|---|---|
Configuration management Updated |
Ansible |
|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-05-17-013445.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/jammy/pool/stable-23.0/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-jammy-20240517090139 |
See also
16.1.6¶
This section includes release notes for the patch Cluster release 16.1.6 that is introduced in the Container Cloud patch release 2.27.1 and is based on the previous Cluster releases of the 16.1.x series series.
This Cluster release supports Mirantis Kubernetes Engine 3.7.10
with Kubernetes 1.27 and Mirantis Container Runtime 23.0.9, in which
docker-ee-cli was updated to version 23.0.13 to fix several CVEs.
For the list of CVE fixes delivered with this patch Cluster release, see 2.27.1
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 16.1.6.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.27.1-6.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/mirantis/ceph:v17.2.7-15.cve |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.27.1-5 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-15.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-3.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-3.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-3.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-3.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-3.cve |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.12.10-21 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts Updated |
cinder-csi-plugin |
https://binary.mirantis.com/core/helm/cinder-csi-plugin-1.39.29.tgz |
client-certificate-controller |
https://binary.mirantis.com/core/helm/client-certificate-controller-1.39.29.tgz |
|
local-volume-provisioner |
https://binary.mirantis.com/core/helm/local-volume-provisioner-1.39.29.tgz |
|
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.39.29.tgz |
|
openstack-cloud-controller-manager |
https://binary.mirantis.com/core/helm/openstack-cloud-controller-manager-1.39.29.tgz |
|
policy-controller |
https://binary.mirantis.com/core/helm/policy-controller-1.39.29.tgz |
|
vsphere-cloud-controller-manager |
https://binary.mirantis.com/core/helm/vsphere-cloud-controller-manager-1.39.29.tgz |
|
vsphere-csi-plugin |
https://binary.mirantis.com/core/helm/vsphere-csi-plugin-1.39.29.tgz |
|
Docker images |
cinder-csi-plugin |
mirantis.azurecr.io/lcm/kubernetes/cinder-csi-plugin:v1.27.2-16 |
client-certificate-controller Updated |
mirantis.azurecr.io/core/client-certificate-controller:1.39.29 |
|
csi-attacher |
mirantis.azurecr.io/lcm/k8scsi/csi-attacher:v4.2.0-5 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/lcm/k8scsi/csi-node-driver-registrar:v2.7.0-5 |
|
csi-provisioner |
mirantis.azurecr.io/lcm/k8scsi/csi-provisioner:v3.4.1-5 |
|
csi-resizer |
mirantis.azurecr.io/lcm/k8scsi/csi-resizer:v1.7.0-5 |
|
csi-snapshotter |
mirantis.azurecr.io/lcm/k8scsi/csi-snapshotter:v6.2.1-mcc-4 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.6.3-7 |
|
openstack-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/openstack-cloud-controller-manager:v1.27.2-16 |
|
policy-controller Updated |
mirantis.azurecr.io/core/policy-controller:1.39.29 |
|
vsphere-cloud-controller-manager |
mirantis.azurecr.io/lcm/kubernetes/vsphere-cloud-controller-manager:v1.27.0-6 |
|
vsphere-csi-driver |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-driver:v3.0.2-1 |
|
vsphere-csi-syncer |
mirantis.azurecr.io/lcm/kubernetes/vsphere-csi-syncer:v3.0.2-1 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.24.0-52-gd8adaba/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.39.29.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.39.29.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.39.29 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-223.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-290.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-88.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-16.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.14.14.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-42.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-42.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240701140358 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240701140403 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240318145925 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240701140404 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20240408080237 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240701140359 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240701140357 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20240318142141 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240701140403 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240701140401 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240701140400 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240626023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-8 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240701140359 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240701140352 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.7 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240701140404 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240701140403 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20240408080322 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240701140402 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240701140404 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240701140403 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240318145903 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240701140359 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240701140402 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240605023010 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240426131156 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240701140401 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240701140402 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-06-27-014654/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-06-27-014654.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240627095142 Updated |
- 1
Only for bare metal clusters
See also
Deprecated Cluster releases¶
This section describes the release notes for the deprecated major Cluster releases that will become unsupported in one of the following Container Cloud releases. Make sure to update your managed clusters to the latest supported version as described in Update a managed cluster.
17.1.x series¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on your deployment needs, you can either update only between major Cluster releases or apply patch updates between major releases. Choosing the latter option ensures you receive security fixes as soon as they become available. Though, be prepared to update your cluster frequently, approximately once every three weeks. Otherwise, you can update only between major Cluster releases as each subsequent major Cluster release includes patch Cluster release updates of the previous major Cluster release.
This section outlines release notes for deprecated major and patch Cluster releases of the 17.1.x series dedicated for Mirantis OpenStack for Kubernetes (MOSK).
This section includes release notes for the patch Cluster release 17.1.5 that is introduced in the Container Cloud patch release 2.26.5 and is based on the previous Cluster releases of the 17.1.x series series.
This patch Cluster release introduces MOSK 24.1.5 that is based on Mirantis Kubernetes Engine 3.7.8 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.9.
For details on MOSK 24.1.5, see MOSK documentation: Release Notes
For the list of CVE fixes delivered with this patch Cluster release, see 2.26.5
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 17.1.5.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.26.5-1.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/mirantis/ceph:v17.2.7-13.cve |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.26.5-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-10.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-3.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-3.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-3.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-3.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-3.cve |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.12.10-19 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.24.0-47-gf77368e/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.39.28.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.39.28.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.39.28 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-223.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-290.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-86.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.14.11.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-42.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-42.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240515023009 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240515023012 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240318145925 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240515023017 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20240408080237 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240515023012 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240515023009 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20240318142141 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240515023018 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240515023015 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240515023016 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240515023009 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-8 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240515023012 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240515023010 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240515023018 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240515023016 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20240408080322 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240515023017 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240515023017 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240515023012 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240318145903 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240515023010 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240515023016 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240515023008 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240426131156 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240515023015 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240515023012 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-05-17-013445/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-05-17-013445.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240517090228 Updated |
This section includes release notes for the patch Cluster release 17.1.4 that is introduced in the Container Cloud patch release 2.26.4 and is based on the previous Cluster releases of the 17.1.x series series.
This patch Cluster release introduces MOSK 24.1.4 that is based on Mirantis Kubernetes Engine 3.7.8 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.9.
For details on MOSK 24.1.4, see MOSK documentation: Release Notes
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.26.4
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 17.1.4.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.26.4-1.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/mirantis/ceph:v17.2.7-12.cve |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.26.4-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-9.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-3.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-3.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-3.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-3.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-3.cve |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.12.10-18 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.24.0-47-gf77368e/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.39.26.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.39.26.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.39.26 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-223.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-290.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-86.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.14.10.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-42.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-42.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240424023010 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240424023016 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240318145925 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240424023018 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20240408080237 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240424023015 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240424023010 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20240318142141 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240424023020 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240424023017 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240424023015 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240424023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-8 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240424023015 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240424023010 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240424023020 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240424023018 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20240408080322 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240424023018 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240424023017 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240424023015 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240318145903 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240424023015 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240424023017 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240424023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240426131156 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240424023014 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240424023015 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-05-02-014050/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-05-02-014050.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240502102020 Updated |
This section includes release notes for the patch Cluster release 17.1.3 that is introduced in the Container Cloud patch release 2.26.3 and is based on the previous Cluster releases of the 17.1.x series series.
This patch Cluster release introduces MOSK 24.1.3 that is based on Mirantis Kubernetes Engine 3.7.7 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.9.
For details on MOSK 24.1.3, see MOSK documentation: Release Notes
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.26.3
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 17.1.3.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.26.3-1.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.7-11.cve |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.26.3-0 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-8.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-3.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-3.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-3.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-3.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-3.cve |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.12.10-17 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.24.0-47-gf77368e/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.39.23.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.39.23.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.39.23 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-223.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-290.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-86.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.14.9.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-42.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-42.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240403023008 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240408080051 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240318145925 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240403023017 |
|
blackbox-exporter Updated |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20240408080237 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240408140050 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240403023009 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20240318142141 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240403023017 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240403023014 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240408155718 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240408135717 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy Updated |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-8 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240403023014 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240403023009 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240403023017 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240403023016 |
|
prometheus-msteams Updated |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20240408080322 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240403023017 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240408135804 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240403023015 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240318145903 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240403023013 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240403023016 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240403023008 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240306130859 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240408155750 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240408155738 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-04-11-013237/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-04-11-013237.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240411171541 Updated |
This section includes release notes for the patch Cluster release 17.1.2 that is introduced in the Container Cloud patch release 2.26.2 and is based on the Cluster releases 17.1.1 and 17.1.0.
This patch Cluster release introduces MOSK 24.1.2 that is
based on Mirantis Kubernetes Engine 3.7.6 with Kubernetes 1.27 and Mirantis
Container Runtime 23.0.9, in which docker-ee-cli was updated to version
23.0.10 to fix several CVEs.
For details on MOSK 24.1.2, see MOSK documentation: Release Notes
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.26.2
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 17.1.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.26.2-4.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.7-10.release |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.26.2-3 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-7.release |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-2.release |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-2.release |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-2.release |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-2.release |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-2.release |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.12.10-16 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.24.0-47-gf77368e/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.39.19.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.39.19.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.39.19 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-223.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-290.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-86.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.14.8.tgz |
|
telegraf-ds Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-42.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-42.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240318062240 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240318062244 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240318145925 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240318062249 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20231204053401 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240318062245 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240318062244 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20240318142141 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240318062249 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240318062246 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240318062249 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240318062240 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-7 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240318062244 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240318062241 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240318062240 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240318062248 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20231204064415 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240318062250 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240318062249 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240318062246 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240318145903 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240318062245 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240318062247 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240318062240 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240306130859 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240318062245 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240318062247 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-03-24-012650/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-03-24-012650.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240324172903 Updated |
This section includes release notes for the patch Cluster release 17.1.1 that is introduced in the Container Cloud patch release 2.26.1 and is based on the Cluster release 17.1.0.
This patch Cluster release introduces MOSK 24.1.1 that is based on Mirantis Kubernetes Engine 3.7.5 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.9.
For details on MOSK 24.1.1, see MOSK documentation: Release Notes
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.26.1
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 17.1.1.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.26.1-1.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/mirantis/ceph:v17.2.7-9.release |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.26.1-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-5.release |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-1.release |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-1.release |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-1.release |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-1.release |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-1.release |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.12.10-14 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.24.0-47-gf77368e/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.39.15.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.39.15.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.39.15 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-223.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-285.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-86.tgz |
|
opensearch-dashboards Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.14.7.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-40.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-41.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240228023009 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240228023011 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240226135626 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240228023020 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20231204053401 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240228023015 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240228023011 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20240228060359 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240228023018 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240228023017 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240228023015 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240228023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-7 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240228023015 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240228023009 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240228023020 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240228023015 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20231204064415 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240228023020 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240228023015 |
|
psql-client Updated |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240228023016 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240226135743 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240228023016 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240228023017 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240228023008 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240219105842 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240228023013 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240228023014 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-03-02-014158/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-03-02-014158.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240302175618 Updated |
This section outlines release notes for the major Cluster release 17.1.0 that is introduced in the Container Cloud release 2.26.0. This Cluster release is based on the Cluster release 16.1.0. The Cluster release 17.1.0 supports:
Mirantis OpenStack for Kubernetes (MOSK) 24.1. For details, see MOSK Release Notes.
Mirantis Kubernetes Engine (MKE) 3.7.5. For details, see MKE Release Notes.
Mirantis Container Runtime (MCR) 23.0.9. For details, see MCR Release Notes.
Kubernetes 1.27.
For the list of known and addressed issues, refer to the Container Cloud release 2.26.0 section.
This section outlines new features implemented in the Cluster release 17.1.0 that is introduced in the Container Cloud release 2.26.0.
Introduced support for Mirantis Container Runtime (MCR) 23.0.9 and Mirantis Kubernetes Engine (MKE) 3.7.5 that supports Kubernetes 1.27.
On existing MOSK clusters, MKE and MCR are updated to the latest supported version when you update your cluster to the Cluster release 17.1.0.
Added support for Rook v1.12 that contains the Ceph CSI plugin 3.9.x and introduces automated recovery of RBD (RWO) volumes from a failed node onto a new one, ensuring uninterrupted operations.
For a complete list of features introduced in the new Rook version, refer to official Rook documentation.
Learn more
TechPreview
Implemented the customDeviceClasses parameter that enables you to specify
the custom names different from the default ones, which include ssd,
hdd, and nvme, and use them in nodes and pools definitions.
Using this parameter, you can, for example, separate storage of large snapshots without touching the rest of Ceph cluster storage.
To enhance network security, added NetworkPolicy objects for all types of
Ceph daemons. These policies allow only specified ports to be used by the
corresponding Ceph daemon pods.
Completely reorganized and significantly improved the StackLight logging pipeline by implementing the following changes:
Switched to the storage-based log retention strategy that optimizes storage utilization and ensures effective data retention. This approach ensures that storage resources are efficiently allocated based on the importance and volume of different data types. The logging index management implies the following advantages:
Storage-based rollover mechanism
Consistent shard allocation
Minimal size of cluster state
Storage compression
No filter by logging level (filtering by tag is still available)
Control over disk space to be taken by indices types:
Logs
OpenStack notifications
Kubernetes events
Introduced new system and audit indices that are managed by OpenSearch data streams. It is a convenient way to manage insert-only pipelines such as log message collection.
Introduced the
OpenSearchStorageUsageCriticalandOpenSearchStorageUsageMajoralerts to monitor OpenSearch used and free space from the file system perspective.Introduced the following parameters:
persistentVolumeUsableStorageSizeGBto define exclusive OpenSearch node usageoutput_kindto define the type of logs to be forwarded to external outputs
Important
Changes in the StackLight logging pipeline require the following actions before and after the manged cluster update:
Added the alertsCommonLabels parameter for Prometheus server that defines
the list of custom labels to be injected to firing alerts while they are sent
to Alertmanager.
Caution
When new labels are injected, Prometheus sends alert updates with a new set of labels, which can potentially cause Alertmanager to have duplicated alerts for a short period of time if the cluster currently has firing alerts.
The following table lists the components versions of the Cluster release 17.1.0.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration Updated |
Mirantis Kubernetes Engine |
3.7.5 0 |
Container runtime Updated |
Mirantis Container Runtime |
23.0.9 1 |
Distributed storage Updated |
Ceph |
17.2.7 (Quincy) |
Rook |
1.12.10 |
|
StackLight |
Alerta Updated |
9.0.1 |
Alertmanager |
0.25.0 |
|
Alertmanager Webhook ServiceNow |
0.1 |
|
Blackbox Exporter |
0.24.0 |
|
cAdvisor |
0.47.2 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.5.0 |
|
Fluentd |
1.15.3 |
|
Grafana Updated |
10.3.1 |
|
Grafana Image Renderer Updated |
3.8.4 |
|
kube-state-metrics Updated |
2.10.1 |
|
Metric Collector |
0.1 |
|
Metricbeat |
7.12.1 |
|
Node Exporter Updated |
1.7.0 |
|
OAuth2 Proxy |
7.1.3 |
|
OpenSearch Updated |
2.11.0 |
|
OpenSearch Dashboards Updated |
2.11.1 |
|
Prometheus Updated |
2.48.0 |
|
Prometheus ES Exporter |
0.14.0 |
|
Prometheus MS Teams |
1.5.2 |
|
Prometheus Patroni Exporter |
0.0.1 |
|
Prometheus Postgres Exporter Updated |
0.15.0 |
|
Prometheus Relay |
0.4 |
|
sf-notifier |
0.4 |
|
sf-reporter |
0.1 |
|
Spilo |
13-2.1p9 |
|
Telegraf |
1.9.1 |
|
1.28.5 Updated |
||
Telemeter |
4.4 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the artifacts of components included in the Cluster release 17.1.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.26.0-16.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.7-8.release |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.26.0-15 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-4.release |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-1.release |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-1.release |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-1.release |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-1.release |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-1.release |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.12.10-13 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.24.0-46-gdaf7dbc/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.39.13.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.39.13.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.39.13 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow Updated |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor Updated |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-219.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-278.tgz |
|
iam-proxy Updated |
||
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat Updated |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-80.tgz |
|
opensearch-dashboards Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-53.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
refapp Updated |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-16.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.14.2.tgz |
|
telegraf-ds Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-40.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-41.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240201074016 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240201074016 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240119023014 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240201074025 |
|
blackbox-exporter Updated |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20231204053401 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240201074020 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq Removed |
n/a |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20231215023011 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20231124023009 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240201074025 |
|
kube-state-metrics Updated |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240201074022 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240201074019 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240201074016 |
|
node-exporter Updated |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy Updated |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-7 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240201074019 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240201074016 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240201074024 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240201074023 |
|
prometheus-msteams Updated |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20231204064415 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240201074021 |
|
prometheus-postgres-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240201074019 |
|
psql-client Updated |
mirantis.azurecr.io/scale/psql-client:v13-20240117093252 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240201074022 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240119124536 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240201074020 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240201074021 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240201074016 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240201074023 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240201074019 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240201074020 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
https://mirror.mirantis.com/kaas/kubernetes-extra-0.0.9/ Updated |
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-02-01-020317/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-02-01-020317.target.txt Updated |
||
MCR repositories |
MCR Updated |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system |
Ubuntu Updated |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240201171126 |
See also
16.1.x series¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on your deployment needs, you can either update only between major Cluster releases or apply patch updates between major releases. Choosing the latter option ensures you receive security fixes as soon as they become available. Though, be prepared to update your cluster frequently, approximately once every three weeks. Otherwise, you can update only between major Cluster releases as each subsequent major Cluster release includes patch Cluster release updates of the previous major Cluster release.
This section outlines release notes for deprecated major and patch Cluster releases of the 16.1.x series.
This section includes release notes for the patch Cluster release 16.1.5 that is introduced in the Container Cloud patch release 2.26.5 and is based on the previous Cluster releases of the 16.1.x series series.
This Cluster release supports Mirantis Kubernetes Engine 3.7.8 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.9.
For the list of CVE fixes delivered with this patch Cluster release, see 2.26.5
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 16.1.5.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.26.5-1.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/mirantis/ceph:v17.2.7-13.cve |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.26.5-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-10.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-3.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-3.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-3.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-3.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-3.cve |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.12.10-19 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.24.0-47-gf77368e/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.39.28.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.39.28.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.39.28 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-223.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-290.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-86.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-16.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.14.11.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-42.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-42.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240515023009 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240515023012 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240318145925 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240515023017 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20240408080237 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240515023012 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240515023009 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20240318142141 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240515023018 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240515023015 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240515023016 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240515023009 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-8 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240515023012 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240515023010 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.7 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240515023018 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240515023016 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20240408080322 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240515023017 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240515023017 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240515023012 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240318145903 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240515023010 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240515023016 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240515023008 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240426131156 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240515023015 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240515023012 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-05-17-013445/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-05-17-013445.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240517090228 Updated |
- 1
Only for bare metal clusters
This section includes release notes for the patch Cluster release 16.1.4 that is introduced in the Container Cloud patch release 2.26.4 and is based on the previous Cluster releases of the 16.1.x series series.
This Cluster release supports Mirantis Kubernetes Engine 3.7.8 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.9.
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.26.4
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 16.1.4.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.26.4-1.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/mirantis/ceph:v17.2.7-12.cve |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.26.4-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-9.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-3.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-3.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-3.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-3.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-3.cve |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.12.10-18 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.24.0-47-gf77368e/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.39.26.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.39.26.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.39.26 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-223.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-290.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-86.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-16.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.14.10.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-42.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-42.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240424023010 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240424023016 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240318145925 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240424023018 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20240408080237 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240424023015 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240424023010 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20240318142141 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240424023020 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240424023017 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240424023015 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240424023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-8 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240424023015 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240424023010 |
|
openstack-refapp Updated |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.7 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240424023020 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240424023018 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20240408080322 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240424023018 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240424023017 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240424023015 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240318145903 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240424023015 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240424023017 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240424023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240426131156 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240424023014 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240424023015 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-05-02-014050/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-05-02-014050.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240502102020 Updated |
- 1
Only for bare metal clusters
This section includes release notes for the patch Cluster release 16.1.3 that is introduced in the Container Cloud patch release 2.26.3 and is based on the previous Cluster releases of the 16.1.x series series.
This Cluster release supports Mirantis Kubernetes Engine 3.7.7 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.9.
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.26.3
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 16.1.3.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.26.3-1.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.7-11.cve |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.26.3-0 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-8.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-3.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-3.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-3.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-3.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-3.cve |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.12.10-17 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.24.0-47-gf77368e/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.39.23.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.39.23.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.39.23 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-223.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-290.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-86.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-16.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.14.9.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-42.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-42.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240403023008 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240408080051 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240318145925 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240403023017 |
|
blackbox-exporter Updated |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20240408080237 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240408140050 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240403023009 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20240318142141 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240403023017 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240403023014 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240408155718 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240408135717 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy Updated |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-8 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240403023014 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240403023009 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.6 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240403023017 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240403023016 |
|
prometheus-msteams Updated |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20240408080322 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240403023017 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240408135804 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240403023015 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240318145903 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240403023013 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240403023016 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240403023008 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240306130859 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240408155750 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240408155738 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-04-11-013237/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-04-11-013237.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240411171541 Updated |
- 1
Only for bare metal clusters
This section includes release notes for the patch Cluster release 16.1.2 that is introduced in the Container Cloud patch release 2.26.2 and is based on the Cluster releases 16.1.1 and 16.1.0.
This Cluster release supports Mirantis Kubernetes Engine 3.7.6
with Kubernetes 1.27 and Mirantis Container Runtime 23.0.9, in which
docker-ee-cli was updated to version 23.0.10 to fix several CVEs.
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.26.2
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 16.1.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.26.2-4.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.7-10.release |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.26.2-3 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-7.release |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-2.release |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-2.release |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-2.release |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-2.release |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-2.release |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.12.10-16 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.24.0-47-gf77368e/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.39.19.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.39.19.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.39.19 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-223.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-290.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-86.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-16.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.14.8.tgz |
|
telegraf-ds Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-42.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-42.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240318062240 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240318062244 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240318145925 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240318062249 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20231204053401 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240318062245 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240318062244 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20240318142141 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240318062249 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240318062246 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240318062249 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240318062240 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-7 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240318062244 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240318062241 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.6 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240318062240 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240318062248 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20231204064415 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240318062250 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240318062249 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240318062246 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240318145903 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240318062245 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240318062247 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240318062240 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240306130859 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240318062245 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240318062247 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-03-24-012650/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-03-24-012650.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240324172903 Updated |
- 1
Only for bare metal clusters
This section includes release notes for the patch Cluster release 16.1.1 that is introduced in the Container Cloud patch release 2.26.1 and is based on the Cluster release 16.1.0.
This Cluster release supports Mirantis Kubernetes Engine 3.7.5 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.9.
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.26.1
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 16.1.1.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.26.1-1.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/mirantis/ceph:v17.2.7-9.release |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.26.1-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-5.release |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-1.release |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-1.release |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-1.release |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-1.release |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-1.release |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.12.10-14 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.24.0-47-gf77368e/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.39.15.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.39.15.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.39.15 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-223.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-285.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-86.tgz |
|
opensearch-dashboards Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-54.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-16.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.14.7.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-40.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-41.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240228023009 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240228023011 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240226135626 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240228023020 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20231204053401 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240228023015 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20240228023011 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20240228060359 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240228023018 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240228023017 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240228023015 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240228023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-7 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240228023015 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240228023009 |
|
openstack-refapp Updated |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.6 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240228023020 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240228023015 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20231204064415 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240228023020 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240228023015 |
|
psql-client Updated |
mirantis.azurecr.io/scale/psql-client:v13-20240222083402 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240228023016 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240226135743 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240228023016 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240228023017 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240228023008 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240219105842 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240228023013 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240228023014 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-03-02-014158/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-03-02-014158.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240302175618 Updated |
- 1
Only for bare metal clusters
This section outlines release notes for the major Cluster release 16.1.0 that is introduced in the Container Cloud release 2.26.0. The Cluster release 16.1.0 supports:
Mirantis Kubernetes Engine (MKE) 3.7.5. For details, see MKE Release Notes.
Mirantis Container Runtime (MCR) 23.0.9. For details, see MCR Release Notes.
Kubernetes 1.27.
For the list of known and addressed issues, refer to the Container Cloud release 2.26.0 section.
This section outlines new features implemented in the Cluster release 16.1.0 that is introduced in the Container Cloud release 2.26.0.
Introduced support for Mirantis Container Runtime (MCR) 23.0.9 and Mirantis Kubernetes Engine (MKE) 3.7.5 that supports Kubernetes 1.27 for the Container Cloud management and managed clusters.
On existing managed clusters, MKE and MCR are updated to the latest supported version when you update your managed cluster to the Cluster release 16.1.0.
Added support for Rook v1.12 that contains the Ceph CSI plugin 3.9.x and introduces automated recovery of RBD (RWO) volumes from a failed node onto a new one, ensuring uninterrupted operations.
For a complete list of features introduced in the new Rook version, refer to official Rook documentation.
Learn more
TechPreview
Implemented the customDeviceClasses parameter that enables you to specify
the custom names different from the default ones, which include ssd,
hdd, and nvme, and use them in nodes and pools definitions.
Using this parameter, you can, for example, separate storage of large snapshots without touching the rest of Ceph cluster storage.
To enhance network security, added NetworkPolicy objects for all types of
Ceph daemons. These policies allow only specified ports to be used by the
corresponding Ceph daemon pods.
Completely reorganized and significantly improved the StackLight logging pipeline by implementing the following changes:
Switched to the storage-based log retention strategy that optimizes storage utilization and ensures effective data retention. This approach ensures that storage resources are efficiently allocated based on the importance and volume of different data types. The logging index management implies the following advantages:
Storage-based rollover mechanism
Consistent shard allocation
Minimal size of cluster state
Storage compression
No filter by logging level (filtering by tag is still available)
Control over disk space to be taken by indices types:
Logs
OpenStack notifications
Kubernetes events
Introduced new system and audit indices that are managed by OpenSearch data streams. It is a convenient way to manage insert-only pipelines such as log message collection.
Introduced the
OpenSearchStorageUsageCriticalandOpenSearchStorageUsageMajoralerts to monitor OpenSearch used and free space from the file system perspective.Introduced the following parameters:
persistentVolumeUsableStorageSizeGBto define exclusive OpenSearch node usageoutput_kindto define the type of logs to be forwarded to external outputs
Important
Changes in the StackLight logging pipeline require the following actions before and after the manged cluster update:
Added the alertsCommonLabels parameter for Prometheus server that defines
the list of custom labels to be injected to firing alerts while they are sent
to Alertmanager.
Caution
When new labels are injected, Prometheus sends alert updates with a new set of labels, which can potentially cause Alertmanager to have duplicated alerts for a short period of time if the cluster currently has firing alerts.
The following table lists the components versions of the Cluster release 16.1.0.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration Updated |
Mirantis Kubernetes Engine |
3.7.5 0 |
Container runtime Updated |
Mirantis Container Runtime |
23.0.9 1 |
Distributed storage Updated |
Ceph |
17.2.7 (Quincy) |
Rook |
1.12.10 |
|
StackLight |
Alerta Updated |
9.0.1 |
Alertmanager |
0.25.0 |
|
Alertmanager Webhook ServiceNow |
0.1 |
|
Blackbox Exporter |
0.24.0 |
|
cAdvisor |
0.47.2 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.5.0 |
|
Fluentd |
1.15.3 |
|
Grafana Updated |
10.3.1 |
|
Grafana Image Renderer Updated |
3.8.4 |
|
kube-state-metrics Updated |
2.10.1 |
|
Metric Collector |
0.1 |
|
Metricbeat |
7.12.1 |
|
Node Exporter Updated |
1.7.0 |
|
OAuth2 Proxy |
7.1.3 |
|
OpenSearch Updated |
2.11.0 |
|
OpenSearch Dashboards Updated |
2.11.1 |
|
Prometheus Updated |
2.48.0 |
|
Prometheus ES Exporter |
0.14.0 |
|
Prometheus MS Teams |
1.5.2 |
|
Prometheus Patroni Exporter |
0.0.1 |
|
Prometheus Postgres Exporter Updated |
0.15.0 |
|
Prometheus Relay |
0.4 |
|
sf-notifier |
0.4 |
|
sf-reporter |
0.1 |
|
Spilo |
13-2.1p9 |
|
Telegraf |
1.9.1 |
|
1.28.5 Updated |
||
Telemeter |
4.4 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the artifacts of components included in the Cluster release 16.1.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.26.0-16.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.7-8.release |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.26.0-15 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.9.0-4.release |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.9.2-1.release |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.6.2-1.release |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.3.2-1.release |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.4.2-1.release |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.9.2-1.release |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.12.10-13 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.24.0-46-gdaf7dbc/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.39.13.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.39.13.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.39.13 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow Updated |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor Updated |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-7.tgz |
|
elasticsearch-curator Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-219.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-278.tgz |
|
iam-proxy Updated |
||
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat Updated |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-80.tgz |
|
opensearch-dashboards Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-53.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-258.tgz |
|
prometheus-blackbox-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
refapp Updated |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-16.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.14.2.tgz |
|
telegraf-ds Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-40.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-41.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20240201074016 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20240201074016 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20240119023014 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20240201074025 |
|
blackbox-exporter Updated |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20231204053401 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20240201074020 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq Removed |
n/a |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20231215023011 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:10.3.1 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20231124023009 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20240201074025 |
|
kube-state-metrics Updated |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20240201074022 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20240201074019 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20240201074016 |
|
node-exporter Updated |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy Updated |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-7 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20240201074019 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20240201074016 |
|
openstack-refapp Updated |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.5 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20240201074024 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20240201074023 |
|
prometheus-msteams Updated |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20231204064415 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20240201074021 |
|
prometheus-postgres-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20240201074019 |
|
psql-client Updated |
mirantis.azurecr.io/scale/psql-client:v13-20240117093252 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20240201074022 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20240119124536 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20240201074020 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20240201074021 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20240201074016 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20240201074023 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20240201074019 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20240201074020 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
https://mirror.mirantis.com/kaas/kubernetes-extra-0.0.9/ Updated |
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-02-01-020317/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2024-02-01-020317.target.txt Updated |
||
MCR repositories |
MCR Updated |
https://repos.mirantis.com/ubuntu/dists/focal/pool/stable-23.0/ |
Target ubuntu system 1 |
Ubuntu Updated |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20240201171126 |
- 1
Only for bare metal clusters
See also
Unsupported Cluster releases¶
This section describes the release notes for the unsupported Cluster releases. For details about supported Cluster releases, see Cluster releases (managed).
17.0.x series¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on your deployment needs, you can either update only between major Cluster releases or apply patch updates between major releases. Choosing the latter option ensures you receive security fixes as soon as they become available. Though, be prepared to update your cluster frequently, approximately once every three weeks. Otherwise, you can update only between major Cluster releases as each subsequent major Cluster release includes patch Cluster release updates of the previous major Cluster release.
This section outlines release notes for unsupported major and patch Cluster 17.0.x series dedicated for Mirantis OpenStack for Kubernetes (MOSK).
This section includes release notes for the patch Cluster release 17.0.4 that is introduced in the Container Cloud patch release 2.25.4 and is based on Cluster releases 17.0.0, 17.0.1, 17.0.2, and 17.0.3.
This patch Cluster release introduces MOSK 23.3.4 that is based on Mirantis Kubernetes Engine 3.7.3 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.7.
For details on MOSK 23.3.4, see MOSK documentation: Release Notes
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.25.4
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 17.0.4.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.25.4-1 |
Docker images |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-8.cve |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.25.4-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.1-9.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-2.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-2.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-2.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-2.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-2.cve |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.11.11-22 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.23.0-88-g35be0fc/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.38.33.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.38.33.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.38.33 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-6.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-196.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-254.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-63.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-49.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-257.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.13.12.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-40.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-40.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20231215023009 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20231215023011 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20231211141923 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20231215023021 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20231204053401 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20231215023012 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq |
mirantis.azurecr.io/scale/curl-jq:alpine-20231127081128 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20231215023011 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.2.2 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20231124023009 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20231215023018 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20231226150248 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20231215023013 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20231215023009 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-6 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20231215023014 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20231215023009 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20231215023019 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20231215023018 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20231204064415 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20231215023018 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20231215023011 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20231116082249 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20231215023014 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20231211141939 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20231215023013 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20231215023015 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20231215023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20231204142011 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20231215023013 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20231215023013 |
Unchanged as compared to 17.0.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-10-11-015021.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-23.10/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20231011091340 |
This section includes release notes for the patch Cluster release 17.0.3 that is introduced in the Container Cloud patch release 2.25.3 and is based on Cluster releases 17.0.0, 17.0.1, and 17.0.2.
This patch Cluster release introduces MOSK 23.3.3 that is based on Mirantis Kubernetes Engine 3.7.3 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.7.
For details on MOSK 23.3.3, see MOSK documentation: Release Notes
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.25.3
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 17.0.3.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.25.3-3 |
Docker images |
ceph Updated |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-8.cve |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.25.3-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.1-8.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-2.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-2.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-2.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-2.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-2.cve |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.11.11-21 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.23.0-87-gc9d7d3b/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.38.31.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.38.31.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.38.31 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-6.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-196.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-254.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-63.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-49.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-257.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.13.10.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-40.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-40.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20231201023009 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20231201023012 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20231114075954 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20231201023019 |
|
blackbox-exporter Updated |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20231204053401 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20231201023011 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq Updated |
mirantis.azurecr.io/scale/curl-jq:alpine-20231127081128 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20231204142422 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:10.2.2 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20231124023009 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20231201023018 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20231201023019 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20231201023014 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20231201023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-6 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20231201023011 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20231201023009 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20231201023014 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20231201023015 |
|
prometheus-msteams Updated |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20231204064415 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20231201023016 |
|
prometheus-postgres-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20231201023016 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20231116082249 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20231201023011 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20231110023016 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20231207134103 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20231201023015 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20231207133615 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20231204142011 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20231201023015 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20231201023012 |
Unchanged as compared to 17.0.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-10-11-015021.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-23.10/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20231011091340 |
This section includes release notes for the patch Cluster release 17.0.2 that is introduced in the Container Cloud patch release 2.25.2 and is based on Cluster releases 17.0.0 and 17.0.1.
This patch Cluster release introduces MOSK 23.3.2 that is based on Mirantis Kubernetes Engine 3.7.2 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.7.
For details on MOSK 23.3.2, see MOSK documentation: Release Notes
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.25.2
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 17.0.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.25.2-3 |
Docker images |
ceph Updated |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-5.cve |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.25.2-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.1-6.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-2.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-2.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-2.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-2.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-2.cve |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.11.11-17 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.23.0-84-g8d74d7c/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.38.29.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.38.29.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.38.29 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-6.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-196.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-254.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-63.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-49.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-57.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-257.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.13.8.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-40.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-40.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20231117023008 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20231121101237 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20231114075954 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20231117023019 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20231121100850 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq |
mirantis.azurecr.io/scale/curl-jq:alpine-20231019061751 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20231117023010 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.5.13 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20231030112043 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20231117023017 |
|
kube-state-metrics Updated |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20231117023017 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20231117023011 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20231117023008 |
|
node-exporter Updated |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy Updated |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-6 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20231121103248 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20231121104249 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20231117023020 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20231117023017 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20231117023018 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20231117023012 |
|
psql-client Updated |
mirantis.azurecr.io/scale/psql-client:v13-20231116082249 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20231117023016 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20231110023016 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20231117023015 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20231117023017 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20231110023008 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20231030132045 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20231117023011 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20231117023011 |
Unchanged as compared to 17.0.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-10-11-015021.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-23.10/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20231011091340 |
This section includes release notes for the patch Cluster release 17.0.1 that is introduced in the Container Cloud patch release 2.25.1 and is based on the Cluster release 17.0.0.
This patch Cluster release introduces MOSK 23.3.1 that is based on Mirantis Kubernetes Engine 3.7.2 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.7.
For details on MOSK 23.3.1, see MOSK documentation: Release Notes
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.25.1
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 17.0.1.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.25.1-9 |
Docker images Updated |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-2.cve |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.25.1-8 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.1-4.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-2.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-2.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-2.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-2.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-2.cve |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.11.11-15 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.23.0-84-g8d74d7c/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.38.22.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.38.22.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.38.22 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts Updated |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-6.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-196.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-254.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-63.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-49.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-57.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-257.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight |
https://binary.mirantis.com/stacklight/helm/stacklight-0.13.7.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-40.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-40.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20231103023010 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20231103023014 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20231027101957 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20231027023014 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20231027023014 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq Updated |
mirantis.azurecr.io/scale/curl-jq:alpine-20231019061751 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20231027023015 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:9.5.13 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20231030112043 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20231030141315 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20231103023015 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20231103023010 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20231027023009 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.6.0 |
|
oauth2-proxy Updated |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-5 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20231103023014 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20231103023010 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20231103023015 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20231103023015 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20231103023015 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20231103023010 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20230817113822 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20231027023020 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230911151029 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20231103023014 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20231103023015 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20231103023010 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20231030132045 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20231027023011 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20231103023014 |
Unchanged as compared to 17.0.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-10-11-015021.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-23.10/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20231011091340 |
This section outlines release notes for the major Cluster release 17.0.0 that is introduced in the Container Cloud release 2.25.0. This Cluster release is based on the Cluster release 16.0.0. The Cluster release 17.0.0 supports:
Mirantis OpenStack for Kubernetes (MOSK) 23.3. For details, see MOSK Release Notes.
Mirantis Kubernetes Engine (MKE) 3.7.1. For details, see MKE Release Notes.
Mirantis Container Runtime (MCR) 23.0.7. For details, see MCR Release Notes.
Kubernetes 1.27.
For the list of known and addressed issues, refer to the Container Cloud release 2.25.0 section.
This section outlines new features implemented in the Cluster release 17.0.0 that is introduced in the Container Cloud release 2.25.0.
Introduced support for Mirantis Container Runtime (MCR) 23.0.7 and Mirantis Kubernetes Engine (MKE) 3.7.1 that supports Kubernetes 1.27 for the Container Cloud management and managed clusters. On existing clusters, MKE and MCR are updated to the latest supported version when you update your managed cluster to the Cluster release 17.0.0.
Caution
Support for MKE 3.6.x is dropped. Therefore, new deployments on MKE 3.6.x are not supported.
Implemented the Ceph Cluster details page in the Container Cloud web UI containing the Machines and OSDs tabs with a detailed descriptions and statuses of Ceph machines and Ceph OSDs comprising a Ceph cluster deployment.
Implemented the capability to address Ceph storage devices using the by-id
identifiers.
The by-id identifier is the only persistent device identifier for a Ceph
cluster that remains stable after the cluster upgrade or any other maintenance.
Therefore, Mirantis recommends using device by-id symlinks rather than
device names or by-path symlinks.
Added the kaasCephState field in the KaaSCephCluster.status
specification to display the current state of KaasCephCluster and
any errors during object reconciliation, including specification
generation, object creation on a managed cluster, and status retrieval.
TechPreview
Added initial Technology Preview support for forwarding of Container Cloud services logs, which are sent to OpenSearch by default, to Splunk using the syslog external output configuration.
Implemented the following monitoring improvements for Ceph:
Optimized the following Ceph dashboards in Grafana: Ceph Cluster, Ceph Pools, Ceph OSDs.
Removed the redundant Ceph Nodes Grafana dashboard. You can view its content using the following dashboards:
Ceph stats through the Ceph Cluster dashboard.
Resource utilization through the System dashboard, which now includes filtering by Ceph node labels, such as
ceph_role_osd,ceph_role_mon, andceph_role_mgr.
Removed the
rook_clusteralert label.Removed the redundant
CephOSDDownalert.Renamed the
CephNodeDownalert toCephOSDNodeDown.
Optimized StackLight NodeDown alerts for a better notification handling
after cluster recovery from an accident:
Reworked the
NodeDown-related alert inhibition rulesReworked the logic of all
NodeDown-related alerts for all supported groups of nodes, which includes renaming of the<alertName>TargetsOutagealerts to<alertNameTargetDown>Added the
TungstenFabricOperatorTargetDownalert for Tungsten Fabric deployments of MOSK clustersRemoved redundant
KubeDNSTargetsOutageandKubePodsNotReadyalerts
Optimized OpenSearch configuration and StackLight datamodel to provide better resources utilization and faster query response. Added the following enhancements:
Limited the default namespaces for log collection with the ability to add custom namespaces to the monitoring list using the following parameters:
logging.namespaceFiltering.logs- limits the number of namespaces for Pods log collection. Enabled by default.logging.namespaceFiltering.events- limits the number of namespaces for Kubernetes events collection. Disabled by default.logging.namespaceFiltering.events/logs.extraNamespaces- adds extra namespaces, which are not in the default list, to collect specific Kubernetes Pod logs or Kubernetes events. Empty by default.
Added the
logging.enforceOopsCompressionparameter that enforces 32 GB of heap size, unless the defined memory limit allows using 50 GB of heap. Enabled by default.Added the
NO_SEVERITYseverity label that is automatically added to a log with no severity label in the message. This allows having more control over which logs are actually being processed by Fluentd and which are skipped by mistake.Added documentation on how to tune OpenSearch performance using hardware and software settings for baremetal-based Container Cloud clusters.
On top of continuous improvements delivered to the existing Container Cloud guides, added the documentation on how to export data from the Table panels of Grafana dashboards to CSV.
The following table lists the components versions of the Cluster release 17.0.0.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.7.1 0 |
Container runtime |
Mirantis Container Runtime |
23.0.7 1 |
Distributed storage |
Ceph |
17.2.6 (Quincy) |
Rook |
1.11.11-13 |
|
LCM |
helm-controller |
1.38.17 |
lcm-ansible |
0.23.0-73-g01aa9b3 |
|
lcm-agent |
1.38.17 |
|
StackLight |
Alerta |
9.0.0 |
Alertmanager |
0.25.0 |
|
Alertmanager Webhook ServiceNow |
0.1 |
|
Blackbox Exporter |
0.24.0 |
|
cAdvisor |
0.47.2 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.5.0 |
|
Fluentd |
1.15.3 |
|
Grafana |
9.5.7 |
|
Grafana Image Renderer |
3.7.1 |
|
kube-state-metrics |
2.8.2 |
|
Metric Collector |
0.1 |
|
Metricbeat |
7.12.1 |
|
Node Exporter |
1.6.0 |
|
OAuth2 Proxy |
7.1.3 |
|
OpenSearch |
2.8.0 |
|
OpenSearch Dashboards |
2.7.0 |
|
Prometheus |
2.44.0 |
|
Prometheus ES Exporter |
0.14.0 |
|
Prometheus MS Teams |
1.5.2 |
|
Prometheus Patroni Exporter |
0.0.1 |
|
Prometheus Postgres Exporter |
0.12.0 |
|
Prometheus Relay |
0.4 |
|
sf-notifier |
0.4 |
|
sf-reporter |
0.1 |
|
Spilo |
13-2.1p9 |
|
Telegraf |
1.9.1 |
|
1.27.3 |
||
Telemeter |
4.4 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the artifacts of components included in the Cluster release 17.0.0.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.25.0-1.tgz |
Docker images |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-rel-5 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.25.0-0 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.1-rel-1 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-cve-1 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-cve-1 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-1 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-cve-1 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-cve-1 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.11.11-13 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.23.0-73-g01aa9b3/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.38.17.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.38.17.tgz |
|
Docker images |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.38.17 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-3.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-12.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-7.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-193.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-250.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-60.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-47.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-54.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-245.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-15.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-7.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-7.tgz |
|
stacklight |
https://binary.mirantis.com/stacklight/helm/stacklight-0.13.3.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-37.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-37.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web |
mirantis.azurecr.io/stacklight/alerta-web:9-20230929023008 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0-20230929023012 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230912073324 |
|
alpine-utils |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230929023018 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230929023009 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq |
mirantis.azurecr.io/scale/curl-jq:alpine-20230925094109 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230929023011 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.5.7 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230929023011 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230929023017 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230929023018 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230929023015 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230929023009 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.6.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-4 |
|
opensearch |
mirantis.azurecr.io/stacklight/opensearch:2-20230929023012 |
|
opensearch-dashboards |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20230929023008 |
|
pgbouncer |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230929023018 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230929023017 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230929023018 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230929023016 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20230817113822 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20230929023013 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230911151029 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230929023012 |
|
stacklight-toolkit |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20231004090138 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230915023009 |
|
mirantis.azurecr.io/stacklight/telegraf:1.27-20230809094327 |
||
telemeter |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230929023011 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230929023012 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-10-11-015021.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-23.10/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20231011091340 |
16.0.x series¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on your deployment needs, you can either update only between major Cluster releases or apply patch updates between major releases. Choosing the latter option ensures you receive security fixes as soon as they become available. Though, be prepared to update your cluster frequently, approximately once every three weeks. Otherwise, you can update only between major Cluster releases as each subsequent major Cluster release includes patch Cluster release updates of the previous major Cluster release.
This section outlines release notes for unsupported major and patch Cluster releases of the 16.0.x series.
This section outlines release notes for the patch Cluster release 16.0.4 that is introduced in the Container Cloud release 2.25.4. and is based on Cluster releases 16.0.0, 16.0.1, 16.0.2, and 16.0.3.
This Cluster release supports Mirantis Kubernetes Engine 3.7.3 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.7.
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.25.4
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 16.0.4.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.25.4-1 |
Docker images |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-8.cve |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.25.4-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.1-9.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-2.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-2.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-2.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-2.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-2.cve |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.11.11-22 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.23.0-88-g35be0fc/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.38.33.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.38.33.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.38.33 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-6.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-196.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-254.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-63.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-49.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-257.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-13.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.13.12.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-40.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-40.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20231215023009 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20231215023011 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20231211141923 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20231215023021 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20231204053401 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20231215023012 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq |
mirantis.azurecr.io/scale/curl-jq:alpine-20231127081128 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20231215023011 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:10.2.2 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20231124023009 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20231215023018 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20231226150248 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20231215023013 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20231215023009 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-6 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20231215023014 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20231215023009 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.4 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20231215023019 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20231215023018 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20231204064415 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20231215023018 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20231215023011 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20231116082249 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20231215023014 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20231211141939 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20231215023013 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20231215023015 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20231215023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20231204142011 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20231215023013 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20231215023013 |
Unchanged as compared to 16.0.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-10-11-015021.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-23.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20231011091340 |
- 1
Only for bare metal clusters
This section outlines release notes for the patch Cluster release 16.0.3 that is introduced in the Container Cloud release 2.25.3. and is based on Cluster releases 16.0.0, 16.0.1, and 16.0.2.
This Cluster release supports Mirantis Kubernetes Engine 3.7.3 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.7.
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.25.3
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 16.0.3.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.25.3-3 |
Docker images |
ceph Updated |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-8.cve |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.25.3-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.1-8.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-2.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-2.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-2.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-2.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-2.cve |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.11.11-21 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.23.0-87-gc9d7d3b/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.38.31.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.38.31.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.38.31 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-6.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-196.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-254.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-63.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-49.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-59.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-257.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-13.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.13.10.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-40.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-40.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20231201023009 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20231201023012 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20231114075954 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20231201023019 |
|
blackbox-exporter Updated |
mirantis.azurecr.io/stacklight/blackbox-exporter:0-20231204053401 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20231201023011 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq Updated |
mirantis.azurecr.io/scale/curl-jq:alpine-20231127081128 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20231204142422 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:10.2.2 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20231124023009 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20231201023018 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20231201023019 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20231201023014 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20231201023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-6 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20231201023011 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20231201023009 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.4 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20231201023014 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.48.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20231201023015 |
|
prometheus-msteams Updated |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5-20231204064415 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20231201023016 |
|
prometheus-postgres-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.15.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20231201023016 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20231116082249 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20231201023011 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20231110023016 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20231207134103 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20231201023015 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20231207133615 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20231204142011 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20231201023015 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20231201023012 |
Unchanged as compared to 16.0.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-10-11-015021.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-23.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20231011091340 |
- 1
Only for bare metal clusters
This section outlines release notes for the patch Cluster release 16.0.2 that is introduced in the Container Cloud release 2.25.2. and is based on Cluster releases 16.0.0 and 16.0.1.
This Cluster release supports Mirantis Kubernetes Engine 3.7.2 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.7.
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.25.2
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 16.0.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.25.2-3 |
Docker images |
ceph Updated |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-5.cve |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.25.2-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.1-6.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-2.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-2.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-2.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-2.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-2.cve |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.11.11-17 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.23.0-84-g8d74d7c/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.38.29.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.38.29.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.38.29 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-6.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-196.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-254.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-63.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-49.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-57.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-257.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-13.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.13.8.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-40.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-40.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20231117023008 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20231121101237 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20231114075954 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20231117023019 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20231121100850 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq |
mirantis.azurecr.io/scale/curl-jq:alpine-20231019061751 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20231117023010 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.5.13 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20231030112043 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20231117023017 |
|
kube-state-metrics Updated |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.10.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20231117023017 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20231117023011 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20231117023008 |
|
node-exporter Updated |
mirantis.azurecr.io/stacklight/node-exporter:v1.7.0 |
|
oauth2-proxy Updated |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-6 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20231121103248 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20231121104249 |
|
openstack-refapp Updated |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.4 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20231117023020 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20231117023017 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20231117023018 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20231117023012 |
|
psql-client Updated |
mirantis.azurecr.io/scale/psql-client:v13-20231116082249 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20231117023016 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20231110023016 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20231117023015 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20231117023017 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20231110023008 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20231030132045 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20231117023011 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20231117023011 |
Unchanged as compared to 16.0.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-10-11-015021.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-23.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20231011091340 |
- 1
Only for bare metal clusters
This section outlines release notes for the patch Cluster release 16.0.1 that is introduced in the Container Cloud release 2.25.1. and is based on the Cluster release 16.0.0.
This Cluster release supports Mirantis Kubernetes Engine 3.7.2 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.7.
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.25.1
For details on patch release delivery, see Patch releases
This section lists the artifacts of components included in the Cluster release 16.0.1.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.25.1-9 |
Docker images Updated |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-2.cve |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.25.1-8 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.1-4.cve |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-2.cve |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-2.cve |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-2.cve |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-2.cve |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-2.cve |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.11.11-15 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.23.0-84-g8d74d7c/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.38.22.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.38.22.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.38.22 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-33.tgz |
alertmanager-webhook-servicenow Updated |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-8.tgz |
|
cadvisor Updated |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-6.tgz |
|
elasticsearch-curator Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-15.tgz |
|
elasticsearch-exporter Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-10.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-196.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-254.tgz |
|
iam-proxy Updated |
||
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-17.tgz |
|
metricbeat Updated |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-25.tgz |
|
opensearch Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-63.tgz |
|
opensearch-dashboards Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-49.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-57.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-257.tgz |
|
prometheus-blackbox-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-19.tgz |
|
prometheus-es-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-18.tgz |
|
prometheus-msteams Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-12.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-13.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-10.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.13.7.tgz |
|
telegraf-ds Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-40.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-40.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-14.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-14.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20231103023010 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20231103023014 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20231027101957 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20231027023014 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20231027023014 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq Updated |
mirantis.azurecr.io/scale/curl-jq:alpine-20231019061751 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20231027023015 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:9.5.13 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20231030112043 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1-20231030141315 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20231103023015 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20231103023010 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20231027023009 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.6.0 |
|
oauth2-proxy Updated |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-5 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20231103023014 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20231103023010 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.3 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20231103023015 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20231103023015 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20231103023015 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20231103023010 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20230817113822 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20231027023020 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230911151029 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20231103023014 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20231103023015 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20231103023010 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1-20231030132045 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20231027023011 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20231103023014 |
Unchanged as compared to 16.0.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-10-11-015021.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-23.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20231011091340 |
- 1
Only for bare metal clusters
This section outlines release notes for the Cluster release 16.0.0 that is introduced in the Container Cloud release 2.25.0.
This Cluster release supports Mirantis Kubernetes Engine 3.7.1 with Kubernetes 1.27 and Mirantis Container Runtime 23.0.7.
For the list of known and addressed issues, refer to the Container Cloud release 2.25.0 section.
This section outlines new features implemented in the Cluster release 16.0.0 that is introduced in the Container Cloud release 2.25.0.
Introduced support for Mirantis Container Runtime (MCR) 23.0.7 and Mirantis Kubernetes Engine (MKE) 3.7.1 that supports Kubernetes 1.27 for the Container Cloud management and managed clusters. On existing clusters, MKE and MCR are updated to the latest supported version when you update your managed cluster to the Cluster release 16.0.0.
Caution
Support for MKE 3.6.x is dropped. Therefore, new deployments on MKE 3.6.x are not supported.
Implemented the Ceph Cluster details page in the Container Cloud web UI containing the Machines and OSDs tabs with a detailed descriptions and statuses of Ceph machines and Ceph OSDs comprising a Ceph cluster deployment.
Implemented the capability to address Ceph storage devices using the by-id
identifiers.
The by-id identifier is the only persistent device identifier for a Ceph
cluster that remains stable after the cluster upgrade or any other maintenance.
Therefore, Mirantis recommends using device by-id symlinks rather than
device names or by-path symlinks.
Added the kaasCephState field in the KaaSCephCluster.status
specification to display the current state of KaasCephCluster and
any errors during object reconciliation, including specification
generation, object creation on a managed cluster, and status retrieval.
TechPreview
Added initial Technology Preview support for forwarding of Container Cloud services logs, which are sent to OpenSearch by default, to Splunk using the syslog external output configuration.
Implemented the following monitoring improvements for Ceph:
Optimized the following Ceph dashboards in Grafana: Ceph Cluster, Ceph Pools, Ceph OSDs.
Removed the redundant Ceph Nodes Grafana dashboard. You can view its content using the following dashboards:
Ceph stats through the Ceph Cluster dashboard.
Resource utilization through the System dashboard, which now includes filtering by Ceph node labels, such as
ceph_role_osd,ceph_role_mon, andceph_role_mgr.
Removed the
rook_clusteralert label.Removed the redundant
CephOSDDownalert.Renamed the
CephNodeDownalert toCephOSDNodeDown.
Optimized StackLight NodeDown alerts for a better notification handling
after cluster recovery from an accident:
Reworked the
NodeDown-related alert inhibition rulesReworked the logic of all
NodeDown-related alerts for all supported groups of nodes, which includes renaming of the<alertName>TargetsOutagealerts to<alertNameTargetDown>Added the
TungstenFabricOperatorTargetDownalert for Tungsten Fabric deployments of MOSK clustersRemoved redundant
KubeDNSTargetsOutageandKubePodsNotReadyalerts
Optimized OpenSearch configuration and StackLight datamodel to provide better resources utilization and faster query response. Added the following enhancements:
Limited the default namespaces for log collection with the ability to add custom namespaces to the monitoring list using the following parameters:
logging.namespaceFiltering.logs- limits the number of namespaces for Pods log collection. Enabled by default.logging.namespaceFiltering.events- limits the number of namespaces for Kubernetes events collection. Disabled by default.logging.namespaceFiltering.events/logs.extraNamespaces- adds extra namespaces, which are not in the default list, to collect specific Kubernetes Pod logs or Kubernetes events. Empty by default.
Added the
logging.enforceOopsCompressionparameter that enforces 32 GB of heap size, unless the defined memory limit allows using 50 GB of heap. Enabled by default.Added the
NO_SEVERITYseverity label that is automatically added to a log with no severity label in the message. This allows having more control over which logs are actually being processed by Fluentd and which are skipped by mistake.Added documentation on how to tune OpenSearch performance using hardware and software settings for baremetal-based Container Cloud clusters.
On top of continuous improvements delivered to the existing Container Cloud guides, added the documentation on how to export data from the Table panels of Grafana dashboards to CSV.
The following table lists the components versions of the Cluster release 16.0.0.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.7.1 0 |
Container runtime |
Mirantis Container Runtime |
23.0.7 1 |
Distributed storage |
Ceph |
17.2.6 (Quincy) |
Rook |
1.11.11-13 |
|
LCM |
helm-controller |
1.38.17 |
lcm-ansible |
0.23.0-73-g01aa9b3 |
|
lcm-agent |
1.38.17 |
|
StackLight |
Alerta |
9.0.0 |
Alertmanager |
0.25.0 |
|
Alertmanager Webhook ServiceNow |
0.1 |
|
Blackbox Exporter |
0.24.0 |
|
cAdvisor |
0.47.2 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.5.0 |
|
Fluentd |
1.15.3 |
|
Grafana |
9.5.7 |
|
Grafana Image Renderer |
3.7.1 |
|
kube-state-metrics |
2.8.2 |
|
Metric Collector |
0.1 |
|
Metricbeat |
7.12.1 |
|
Node Exporter |
1.6.0 |
|
OAuth2 Proxy |
7.1.3 |
|
OpenSearch |
2.8.0 |
|
OpenSearch Dashboards |
2.7.0 |
|
Prometheus |
2.44.0 |
|
Prometheus ES Exporter |
0.14.0 |
|
Prometheus MS Teams |
1.5.2 |
|
Prometheus Patroni Exporter |
0.0.1 |
|
Prometheus Postgres Exporter |
0.12.0 |
|
Prometheus Relay |
0.4 |
|
sf-notifier |
0.4 |
|
sf-reporter |
0.1 |
|
Spilo |
13-2.1p9 |
|
Telegraf |
1.9.1 |
|
1.27.3 |
||
Telemeter |
4.4 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the artifacts of components included in the Cluster release 16.0.0.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.25.0-1.tgz |
Docker images |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-rel-5 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.25.0-0 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.1-rel-1 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-cve-1 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-cve-1 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-1 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-cve-1 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-cve-1 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.11.11-13 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.23.0-73-g01aa9b3/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.38.17.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.38.17.tgz |
|
Docker images |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.38.17 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-3.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-12.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-7.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-193.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-250.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-60.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-47.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-54.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-245.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-15.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-13.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-7.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-7.tgz |
|
stacklight |
https://binary.mirantis.com/stacklight/helm/stacklight-0.13.3.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-37.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-37.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web |
mirantis.azurecr.io/stacklight/alerta-web:9-20230929023008 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0-20230929023012 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230912073324 |
|
alpine-utils |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230929023018 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230929023009 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq |
mirantis.azurecr.io/scale/curl-jq:alpine-20230925094109 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230929023011 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.5.7 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230929023011 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230929023017 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230929023018 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230929023015 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230929023009 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.6.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-4 |
|
opensearch |
mirantis.azurecr.io/stacklight/opensearch:2-20230929023012 |
|
opensearch-dashboards |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20230929023008 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.3 |
|
pgbouncer |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230929023018 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230929023017 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230929023018 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230929023016 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20230817113822 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20230929023013 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230911151029 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230929023012 |
|
stacklight-toolkit |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20231004090138 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230915023009 |
|
mirantis.azurecr.io/stacklight/telegraf:1.27-20230809094327 |
||
telemeter |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230929023011 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230929023012 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-10-11-015021.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-23.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20231011091340 |
- 1
Only for bare metal clusters
15.x series¶
This section outlines release notes for unsupported Cluster releases of the 15.x series.
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on your deployment needs, you can either update only between major Cluster releases or apply patch updates between major releases. Choosing the latter option ensures you receive security fixes as soon as they become available. Though, be prepared to update your cluster frequently, approximately once every three weeks. Otherwise, you can update only between major Cluster releases as each subsequent major Cluster release includes patch Cluster release updates of the previous major Cluster release.
This section includes release notes for the patch Cluster release 15.0.3 that is introduced in the Container Cloud patch release 2.24.5 and is based on Cluster releases 15.0.1, 15.0.2, and 15.0.3.
This patch Cluster release introduces MOSK 23.2.3 that is based on Mirantis Kubernetes Engine 3.6.6 with Kubernetes 1.24 and Mirantis Container Runtime 20.10.17.
For details on MOSK 23.2.3, see MOSK documentation: Release Notes
For the list of CVE fixes delivered with this patch Cluster release, see Container Cloud 2.24.5
For details on patch release delivery, see Patch releases
This section lists the components artifacts of the Cluster release 15.0.4.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.24.4-8.tgz |
Docker images |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-cve-1 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.24.4-7 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.0-cve-2 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-cve-1 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-cve-1 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-1 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-cve-1 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-cve-1 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.11.4-12 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.22.0-75-g08569a8/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.37.25.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.37.25.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.37.25 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-7.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-176.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-231.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-58.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-47.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-52.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-240.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-7.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.12.13.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-37.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-37.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20230915023010 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20230915023015 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230912073324 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230915023025 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230915023013 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq Updated |
mirantis.azurecr.io/scale/curl-jq:alpine-20230821070620 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230915023013 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.5.7 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230915023013 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230915023025 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230915023021 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230915023017 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230915023011 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.6.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-4 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20230915023015 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20230915023009 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.3 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230915023025 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230915023021 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230915023025 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230915023021 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20230817113822 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230915023010 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230911151029 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230915023014 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230915023021 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230915023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.27-20230809094327 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230915023020 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230915023020 |
Unchanged as compared to 15.0.1
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-06-01-014502.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230606111629 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230606111551 1 |
- 1
Only for existing clusters
This section includes release notes for the patch Cluster release 15.0.3 that is introduced in the Container Cloud patch release 2.24.4 and is based on Cluster releases 15.0.1 and 15.0.2.
This patch Cluster release introduces MOSK 23.2.2 that is based on Mirantis Kubernetes Engine 3.6.6 with Kubernetes 1.24 and Mirantis Container Runtime 20.10.17.
For details on MOSK 23.2.2, see MOSK documentation: Release Notes
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.24.4
For details on patch release delivery, see Patch releases
This section lists the components artifacts of the Cluster release 15.0.3.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.24.4-8.tgz |
Docker images |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-cve-1 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.24.4-7 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.0-cve-2 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-cve-1 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-cve-1 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-1 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-cve-1 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-cve-1 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.11.4-12 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.22.0-66-ga855169/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.37.24.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.37.24.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.37.24 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-7.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-176.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-231.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-58.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-47.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-52.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-240.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-7.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.12.10.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-37.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-37.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20230829061227 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20230825023014 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230601043943 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230825023021 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230825023011 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq |
mirantis.azurecr.io/scale/curl-jq:alpine-20230706142802 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230825023012 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.5.7 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230712154008 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230825023020 |
|
keycloak-gatekeeper Removed |
n/a |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230825023019 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230825023018 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230825023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.6.0 |
|
oauth2-proxy New |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-4 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20230825023013 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20230825023009 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.3 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230825023021 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230825023020 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230825023021 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230825023020 |
|
psql-client Updated |
mirantis.azurecr.io/scale/psql-client:v13-20230817113822 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230825023009 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230601044047 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230825023018 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230825023019 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230825023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.27-20230809094327 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230825023014 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230825023013 |
Unchanged as compared to 15.0.1
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-06-01-014502.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230606111629 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230606111551 1 |
- 1
Only for existing clusters
This section includes release notes for the patch Cluster release 15.0.2 that is introduced in the Container Cloud patch release 2.24.3 and is based on the major Cluster release 15.0.1.
This patch Cluster release introduces MOSK 23.2.1 that is
based on Mirantis Kubernetes Engine 3.6.6 with Kubernetes 1.24 and Mirantis
Container Runtime 20.10.17, in which docker-ee-cli was updated to version
20.10.18 to fix the following CVEs:
CVE-2023-28840,
CVE-2023-28642,
CVE-2022-41723.
For details on MOSK 23.2.1, see MOSK documentation: Release Notes
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.24.3
For details on patch release delivery, see Patch releases
This section lists the components artifacts of the Cluster release 15.0.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.24.3-2.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-cve-1 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.24.3-0 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.0-cve-1 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-cve-1 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-cve-1 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-1 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-cve-1 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-cve-1 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.11.4-11 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.22.0-63-g8f4f248/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.37.23.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.37.23.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.37.23 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-7.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-176.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-231.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-58.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-47.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-52.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-240.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-7.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.12.9.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-37.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-37.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web |
mirantis.azurecr.io/stacklight/alerta-web:9-20230714023009 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20230811023012 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230601043943 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230811023020 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230811023011 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq |
mirantis.azurecr.io/scale/curl-jq:alpine-20230706142802 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230811023012 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:9.5.7 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230712154008 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230811023020 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-5 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230811023020 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230811023017 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230811023011 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.6.0 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20230811023016 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20230811023009 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.3 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230811023021 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230811023019 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230811023020 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230811023018 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20230706142757 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230811023011 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230601044047 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230811023016 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230811023013 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230811023008 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.27-20230809094327 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230811023013 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230811023014 |
Unchanged as compared to 15.0.1
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-06-01-014502.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230606111629 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230606111551 1 |
- 1
Only for existing clusters
This section outlines release notes for the major Cluster release 15.0.1 that is introduced in the Container Cloud release 2.24.2. This Cluster release is based on the Cluster release 14.0.1. The Cluster release 15.0.1 supports:
Mirantis OpenStack for Kubernetes (MOSK) 23.2. For details, see MOSK Release Notes.
Mirantis Kubernetes Engine (MKE) 3.6.5. For details, see MKE Release Notes.
Mirantis Container Runtime (MCR) 20.10.17. For details, see MCR Release Notes.
Kubernetes 1.24.
For the list of known and addressed issues, refer to the Container Cloud release 2.24.0 section.
This section outlines new features implemented in the Cluster release 15.0.1 that is introduced in the Container Cloud release 2.24.2.
Added support for Mirantis Container Runtime (MCR) 20.10.17 and Mirantis Kubernetes Engine (MKE) 3.6.5 that supports Kubernetes 1.24.
An update from the Cluster release 12.7.0 or 12.7.4 to 15.0.1 becomes available through the Container Cloud web UI menu once the related management or regional cluster automatically upgrades to Container Cloud 2.24.2.
Caution
Support for MKE 3.5.x is dropped. Therefore, new deployments on MKE 3.5.x are not supported.
Upgraded Ceph major version from Pacific 16.2.11 to Quincy 17.2.6 with an automatic upgrade of Ceph components on existing managed clusters during the Cluster version update.
Introduced healthcheck metrics and the following Ceph alerts to monitor network connectivity between Ceph nodes:
CephDaemonSlowOpsCephMonClockSkewCephOSDFlappingCephOSDSlowClusterNetworkCephOSDSlowPublicNetwork
Learn more
Updated OpenSearch and OpenSearch Dashboards from major version 1.3.7 to 2.7.0. The latest version includes a number of enhancements along with bug and security fixes.
Caution
The version update process can take up to 20 minutes, during
which both OpenSearch and OpenSearch Dashboards may become temporarily
unavailable. Additionally, the KubeStatefulsetUpdateNotRolledOut alert
for the opensearch-master StatefulSet may fire for a short period of time.
Note
The end-of-life support of the major version 1.x ends on December 31, 2023.
The following table lists the components versions of the Cluster release 15.0.1.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.6.5 0 |
Container runtime |
Mirantis Container Runtime |
20.10.17 1 |
Distributed storage |
Ceph |
17.2.6 (Quincy) |
Rook |
1.11.4-10 |
|
LCM |
helm-controller |
1.37.15 |
lcm-ansible |
0.22.0-52-g62235a5 |
|
lcm-agent |
1.37.15 |
|
StackLight |
Alerta |
9.0.0 |
Alertmanager |
0.25.0 |
|
Alertmanager Webhook ServiceNow |
0.1 |
|
Blackbox Exporter |
0.24.0 |
|
cAdvisor |
0.47.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.5.0 |
|
Fluentd |
1.15.3 |
|
Grafana |
9.4.9 |
|
Grafana Image Renderer |
3.7.0 |
|
keycloak-gatekeeper |
7.1.3-5 |
|
kube-state-metrics |
2.8.2 |
|
Metric Collector |
0.1 |
|
Metricbeat |
7.12.1 |
|
Node Exporter |
1.6.0 |
|
OpenSearch |
2.7.0 |
|
OpenSearch Dashboards |
2.7.0 |
|
Prometheus |
2.44.0 |
|
Prometheus ES Exporter |
0.14.0 |
|
Prometheus MS Teams |
1.5.2 |
|
Prometheus Patroni Exporter |
0.0.1 |
|
Prometheus Postgres Exporter |
0.12.0 |
|
Prometheus Relay |
0.4 |
|
sf-notifier |
0.3 |
|
sf-reporter |
0.1 |
|
Spilo |
13-2.1p9 |
|
Telegraf |
1.9.1 |
|
1.26.2 |
||
Telemeter |
4.4 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 15.0.1.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.24.0-10.tgz |
Docker images |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-rel-5 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.24.0-9 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.0-rel-3 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-rel-1 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-rel-1 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-rel-1 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-rel-1 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-rel-1 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.11.4-10 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.22.0-49-g9618f2a/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.37.15.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.37.15.tgz |
|
Docker images |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.37.15 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-7.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-175.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-225.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-58.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-47.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-52.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-240.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight |
https://binary.mirantis.com/stacklight/helm/stacklight-0.12.8.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-37.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-37.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web |
mirantis.azurecr.io/stacklight/alerta-web:9-20230602023009 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.25.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230601043943 |
|
alpine-utils |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230602023019 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230602023019 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq |
mirantis.azurecr.io/scale/curl-jq:alpine-20230120171102 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230602023011 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.4.9 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230418140825 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230602023018 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-5 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230602023016 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230602111822 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230602023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.6.0 |
|
opensearch |
mirantis.azurecr.io/stacklight/opensearch:2-20230602023014 |
|
opensearch-dashboards |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20230602023014 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.0.1.dev33 |
|
pgbouncer |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230602023019 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230602023016 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230602023018 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230602023016 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20230124173121 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230602023012 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230601044047 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230602023015 |
|
stacklight-toolkit |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230602123559 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230602023009 |
|
mirantis.azurecr.io/stacklight/telegraf:1.26-20230602023017 |
||
telemeter |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230602023011 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230602023012 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-06-01-014502.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230606111629 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230606111551 1 |
- 1
Only for existing bare metal clusters
See also
14.x series¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on your deployment needs, you can either update only between major Cluster releases or apply patch updates between major releases. Choosing the latter option ensures you receive security fixes as soon as they become available. Though, be prepared to update your cluster frequently, approximately once every three weeks. Otherwise, you can update only between major Cluster releases as each subsequent major Cluster release includes patch Cluster release updates of the previous major Cluster release.
This section outlines release notes for unsupported Cluster releases of the 14.x series.
This section outlines release notes for the Cluster release 14.1.0 that is introduced in the Container Cloud release 2.25.0. This Cluster release is dedicated for the vSphere provider only. This is the last Cluster release for the vSphere provider based on Mirantis Kubernetes Engine 3.6.6 with Kubernetes 1.24.
Important
The major Cluster release 14.1.0 is the last Cluster release for the vSphere provider based on MCR 20.10 and MKE 3.6.6 with Kubernetes 1.24. Therefore, Mirantis highly recommends updating your existing vSphere-based managed clusters to the Cluster release 16.0.1 that contains newer versions on MCR and MKE with Kubernetes. Otherwise, your management cluster upgrade to Container Cloud 2.25.2 will blocked.
For the update procedure, refer to Operations Guide: Update a patch Cluster release of a managed cluster.
Since Container Cloud 2.25.1, the major Cluster release 14.1.0 is deprecated. Greenfield vSphere-based deployments on this Cluster release are not supported. Use the patch Cluster release 16.0.1 for new deployments instead.
For the list of known and addressed issues delivered in the Cluster release 14.1.0, refer to the Container Cloud release 2.25.0 section.
This section outlines new features implemented in the Cluster release 14.1.0 that is introduced in the Container Cloud release 2.25.0.
Introduced support for Mirantis Container Runtime (MCR) 23.0.7 for the Container Cloud management and managed clusters. On existing clusters, MCR is updated to the latest supported version when you update your managed cluster to the Cluster release 14.1.0.
Learn more
Implemented the capability to address Ceph storage devices using the by-id
identifiers.
The by-id identifier is the only persistent device identifier for a Ceph
cluster that remains stable after the cluster upgrade or any other maintenance.
Therefore, Mirantis recommends using device by-id symlinks rather than
device names or by-path symlinks.
Added the kaasCephState field in the KaaSCephCluster.status
specification to display the current state of KaasCephCluster and
any errors during object reconciliation, including specification
generation, object creation on a managed cluster, and status retrieval.
TechPreview
Added initial Technology Preview support for forwarding of Container Cloud services logs, which are sent to OpenSearch by default, to Splunk using the syslog external output configuration.
Implemented the following monitoring improvements for Ceph:
Optimized the following Ceph dashboards in Grafana: Ceph Cluster, Ceph Pools, Ceph OSDs.
Removed the redundant Ceph Nodes Grafana dashboard. You can view its content using the following dashboards:
Ceph stats through the Ceph Cluster dashboard.
Resource utilization through the System dashboard, which now includes filtering by Ceph node labels, such as
ceph_role_osd,ceph_role_mon, andceph_role_mgr.
Removed the
rook_clusteralert label.Removed the redundant
CephOSDDownalert.Renamed the
CephNodeDownalert toCephOSDNodeDown.
Optimized StackLight NodeDown alerts for a better notification handling
after cluster recovery from an accident:
Reworked the
NodeDown-related alert inhibition rulesReworked the logic of all
NodeDown-related alerts for all supported groups of nodes, which includes renaming of the<alertName>TargetsOutagealerts to<alertNameTargetDown>Added the
TungstenFabricOperatorTargetDownalert for Tungsten Fabric deployments of MOSK clustersRemoved redundant
KubeDNSTargetsOutageandKubePodsNotReadyalerts
Optimized OpenSearch configuration and StackLight datamodel to provide better resources utilization and faster query response. Added the following enhancements:
Limited the default namespaces for log collection with the ability to add custom namespaces to the monitoring list using the following parameters:
logging.namespaceFiltering.logs- limits the number of namespaces for Pods log collection. Enabled by default.logging.namespaceFiltering.events- limits the number of namespaces for Kubernetes events collection. Disabled by default.logging.namespaceFiltering.events/logs.extraNamespaces- adds extra namespaces, which are not in the default list, to collect specific Kubernetes Pod logs or Kubernetes events. Empty by default.
Added the
logging.enforceOopsCompressionparameter that enforces 32 GB of heap size, unless the defined memory limit allows using 50 GB of heap. Enabled by default.Added the
NO_SEVERITYseverity label that is automatically added to a log with no severity label in the message. This allows having more control over which logs are actually being processed by Fluentd and which are skipped by mistake.Added documentation on how to tune OpenSearch performance using hardware and software settings for baremetal-based Container Cloud clusters.
On top of continuous improvements delivered to the existing Container Cloud guides, added the documentation on how to export data from the Table panels of Grafana dashboards to CSV.
The following table lists the components versions of the Cluster release 14.1.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous major Cluster release version, are marked with
a corresponding superscript, for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration Updated |
Mirantis Kubernetes Engine |
3.6.6 0 |
Container runtime Updated |
Mirantis Container Runtime |
23.0.7 1 |
Distributed storage |
Ceph |
17.2.6 (Quincy) |
Rook Updated |
1.11.11-13 |
|
LCM |
helm-controller Updated |
1.38.17 |
lcm-ansible Updated |
0.23.0-73-g01aa9b3 |
|
StackLight |
Alerta |
9.0.0 |
Alertmanager |
0.25.0 |
|
Alertmanager Webhook ServiceNow |
0.1 |
|
Blackbox Exporter |
0.24.0 |
|
cAdvisor Updated |
0.47.2 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.5.0 |
|
Fluentd |
1.15.3 |
|
Grafana Updated |
9.5.7 |
|
Grafana Image Renderer Updated |
3.7.1 |
|
keycloak-gatekeeper Removed |
n/a |
|
kube-state-metrics |
2.8.2 |
|
Metric Collector |
0.1 |
|
Metricbeat |
7.12.1 |
|
Node Exporter |
1.6.0 |
|
OAuth2 Proxy New |
7.1.3 |
|
OpenSearch Updated |
2.8.0 |
|
OpenSearch Dashboards |
2.7.0 |
|
Prometheus |
2.44.0 |
|
Prometheus ES Exporter |
0.14.0 |
|
Prometheus MS Teams |
1.5.2 |
|
Prometheus Patroni Exporter |
0.0.1 |
|
Prometheus Postgres Exporter |
0.12.0 |
|
Prometheus Relay |
0.4 |
|
sf-notifier Updated |
0.4 |
|
sf-reporter |
0.1 |
|
Spilo |
13-2.1p9 |
|
Telegraf |
1.9.1 |
|
1.27.3 Updated |
||
Telemeter |
4.4 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 14.1.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous major Cluster release version, are marked with
a corresponding superscript, for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.25.0-1.tgz |
Docker images |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-rel-5 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.25.0-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.1-rel-1 |
|
cephcsi-registrar Updated |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-cve-1 |
|
cephcsi-provisioner Updated |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-cve-1 |
|
cephcsi-snapshotter Updated |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-1 |
|
cephcsi-attacher Updated |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-cve-1 |
|
cephcsi-resizer Updated |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-cve-1 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.11.11-13 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.23.0-73-g01aa9b3/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.38.17.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.38.17.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.38.17 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor Updated |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-3.tgz |
|
elasticsearch-curator Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-12.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-7.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-193.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-250.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-60.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-47.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-54.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-245.tgz |
|
prometheus-blackbox-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-15.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
refapp Updated |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-13.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-7.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-7.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.13.3.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-37.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-37.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20230929023008 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20230929023012 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230912073324 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230929023018 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230929023009 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq Updated |
mirantis.azurecr.io/scale/curl-jq:alpine-20230925094109 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230929023011 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:9.5.7 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230929023011 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230929023017 |
|
keycloak-gatekeeper Removed |
n/a |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230929023018 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230929023015 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230929023009 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.6.0 |
|
oauth2-proxy New |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-4 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20230929023012 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20230929023008 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.3 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230929023018 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230929023017 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230929023018 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230929023016 |
|
psql-client Updated |
mirantis.azurecr.io/scale/psql-client:v13-20230817113822 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.4-20230929023013 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230911151029 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230929023012 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20231004090138 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230915023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.27-20230809094327 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230929023011 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230929023012 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-10-11-015021/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-10-11-015021.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-23.10/ Updated |
This section includes release notes for the patch Cluster release 14.0.4 that is introduced in the Container Cloud patch release 2.24.5 and is based on Cluster releases 14.0.1, 14.0.2, and 14.0.3.
This patch Cluster release is based on Mirantis Kubernetes Engine 3.6.6 with Kubernetes 1.24 and Mirantis Container Runtime 20.10.17.
For the list of CVE fixes delivered with this patch Cluster release, see Container Cloud 2.24.5
For details on patch release delivery, see Patch releases
This section lists the components artifacts of the Cluster release 14.0.4.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.24.4-8.tgz |
Docker images |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-cve-1 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.24.4-7 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.0-cve-2 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-cve-1 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-cve-1 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-1 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-cve-1 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-cve-1 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.11.4-12 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.22.0-75-g08569a8/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.37.25.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.37.25.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.37.25 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-7.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-176.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-231.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-58.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-47.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-52.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-240.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-11.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-7.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.12.13.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-37.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-37.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20230915023010 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20230915023015 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230912073324 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230915023025 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230915023013 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq Updated |
mirantis.azurecr.io/scale/curl-jq:alpine-20230821070620 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230915023013 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.5.7 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230915023013 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230915023025 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230915023021 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230915023017 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230915023011 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.6.0 |
|
oauth2-proxy |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-4 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20230915023015 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20230915023009 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.3 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230915023025 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230915023021 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230915023025 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230915023021 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20230817113822 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230915023010 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230911151029 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230915023014 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230915023021 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230915023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.27-20230809094327 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230915023020 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230915023020 |
Unchanged as compared to 14.0.1
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-06-01-014502.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230606111629 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230606111551 2 |
This section includes release notes for the patch Cluster release 14.0.3 that is introduced in the Container Cloud patch release 2.24.4 and is based on Cluster releases 14.0.1 and 14.0.2.
This patch Cluster release is based on Mirantis Kubernetes Engine 3.6.6 with Kubernetes 1.24 and Mirantis Container Runtime 20.10.17.
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.24.4
For details on patch release delivery, see Patch releases
This section lists the components artifacts of the Cluster release 14.0.3.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.24.4-8.tgz |
Docker images |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-cve-1 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.24.4-7 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.0-cve-2 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-cve-1 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-cve-1 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-1 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-cve-1 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-cve-1 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.11.4-12 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.22.0-66-ga855169/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.37.24.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.37.24.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.37.24 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-7.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-176.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-231.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-58.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-47.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-52.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-240.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-11.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-7.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.12.10.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-37.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-37.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20230829061227 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20230825023014 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230601043943 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230825023021 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230825023011 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq |
mirantis.azurecr.io/scale/curl-jq:alpine-20230706142802 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230825023012 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.5.7 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230712154008 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230825023020 |
|
keycloak-gatekeeper Removed |
n/a |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230825023019 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230825023018 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230825023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.6.0 |
|
oauth2-proxy New |
mirantis.azurecr.io/iam/oauth2-proxy:v7.1.3-4 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20230825023013 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20230825023009 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.3 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230825023021 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230825023020 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230825023021 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230825023020 |
|
psql-client Updated |
mirantis.azurecr.io/scale/psql-client:v13-20230817113822 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230825023009 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230601044047 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230825023018 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230825023019 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230825023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.27-20230809094327 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230825023014 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230825023013 |
Unchanged as compared to 14.0.1
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-06-01-014502.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230606111629 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230606111551 2 |
This section includes release notes for the patch Cluster release 14.0.2 that is introduced in the Container Cloud patch release 2.24.3 and is based on the Cluster release 14.0.1.
This patch Cluster release is based on Mirantis Kubernetes Engine 3.6.6
with Kubernetes 1.24 and Mirantis Container Runtime 20.10.17, in which
docker-ee-cli was updated to version 20.10.18 to fix the following CVEs:
CVE-2023-28840,
CVE-2023-28642,
CVE-2022-41723.
For the list of enhancements and CVE fixes delivered with this patch Cluster release, see 2.24.3
For details on patch release delivery, see Patch releases
This section lists the components artifacts of the Cluster release 14.0.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart Updated |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.24.3-2.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-cve-1 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.24.3-0 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.0-cve-1 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-cve-1 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-cve-1 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-1 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-cve-1 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-cve-1 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.11.4-11 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.22.0-63-g8f4f248/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.37.23.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.37.23.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.37.23 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-7.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-176.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-231.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-58.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-47.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-52.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-240.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-11.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-7.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.12.9.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-37.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-37.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web |
mirantis.azurecr.io/stacklight/alerta-web:9-20230714023009 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20230811023012 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230601043943 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230811023020 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230811023011 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq |
mirantis.azurecr.io/scale/curl-jq:alpine-20230706142802 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230811023012 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:9.5.7 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230712154008 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230811023020 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-5 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230811023020 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230811023017 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230811023011 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.6.0 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20230811023016 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20230811023009 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.3 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230811023021 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230811023019 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230811023020 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230811023018 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20230706142757 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230811023011 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230601044047 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230811023016 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230811023013 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230811023008 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.27-20230809094327 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230811023013 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230811023014 |
Unchanged as compared to 14.0.1
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-06-01-014502.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230606111629 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230606111551 2 |
This section outlines release notes for the major Cluster release 14.0.1 that is introduced in the Container Cloud release 2.24.2.
This Cluster release supports Mirantis Kubernetes Engine 3.6.5 with Kubernetes 1.24 and Mirantis Container Runtime 20.10.17.
The Cluster release 14.0.1 is based on 14.0.0 introduced in Container Cloud 2.24.0. The only difference between these two 14.x releases is that 14.0.1 contains the following updated LCM and StackLight artifacts to address critical CVEs:
StackLight chart -
stacklight/helm/stacklight-0.12.8.tgzLCM Ansible image -
lcm-ansible-v0.22.0-52-g62235a5
For For the list of enhancements, refer to the Cluster release 14.0.0. For For the list of known and addressed issues, refer to the Container Cloud release 2.24.0 section.
The following table lists the components versions of the Cluster release 14.0.1.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.6.5 0 |
Container runtime |
Mirantis Container Runtime |
20.10.17 1 |
Distributed storage |
Ceph |
17.2.6 (Quincy) |
Rook |
1.11.4-10 |
|
LCM |
helm-controller |
1.37.15 |
lcm-ansible Updated |
0.22.0-52-g62235a5 |
|
lcm-agent |
1.37.15 |
|
StackLight |
Alerta |
9.0.0 |
Alertmanager |
0.25.0 |
|
Alertmanager Webhook ServiceNow |
0.1 |
|
Blackbox Exporter |
0.24.0 |
|
cAdvisor |
0.47.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.5.0 |
|
Fluentd |
1.15.3 |
|
Grafana Updated |
9.5.5 |
|
Grafana Image Renderer Updated |
3.7.1 |
|
keycloak-gatekeeper |
7.1.3-5 |
|
kube-state-metrics |
2.8.2 |
|
Metric Collector |
0.1 |
|
Metricbeat |
7.12.1 |
|
Prometheus Node Exporter |
1.6.0 |
|
OpenSearch Updated |
2.8.0 |
|
OpenSearch Dashboards |
2.7.0 |
|
Prometheus |
2.44.0 |
|
Prometheus ES Exporter |
0.14.0 |
|
Prometheus MS Teams |
1.5.2 |
|
Prometheus Patroni Exporter |
0.0.1 |
|
Prometheus Postgres Exporter |
0.12.0 |
|
Prometheus Relay |
0.4 |
|
sf-notifier |
0.3 |
|
sf-reporter |
0.1 |
|
Spilo |
13-2.1p9 |
|
Telegraf |
1.9.1 |
|
1.26.2 |
||
Telemeter |
4.4 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 14.0.1.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.24.0-10.tgz |
Docker images |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-rel-5 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.24.0-9 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.0-rel-3 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-rel-1 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-rel-1 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-rel-1 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-rel-1 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-rel-1 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.11.4-10 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible Updated |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.22.0-52-g62235a5/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.37.15.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.37.15.tgz |
|
Docker images |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.37.15 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-7.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-176.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-231.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-58.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-47.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-52.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-240.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-11.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-7.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.12.8.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-37.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-37.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20230714023009 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0-20230717144436 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230601043943 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230714023021 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230714023020 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq Updated |
mirantis.azurecr.io/scale/curl-jq:alpine-20230706142802 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230714023011 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:9.5.5 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230712154008 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230714023021 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-5 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230714023020 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230714023015 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230714023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.6.0 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:2-20230707023015 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20230719110228 |
|
openstack-refapp Updated |
mirantis.azurecr.io/openstack/openstack-refapp:0.1.3 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230714023021 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230714023018 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230714023020 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230714023016 |
|
psql-client Updated |
mirantis.azurecr.io/scale/psql-client:v13-20230706142757 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230714113914 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230601044047 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230717125456 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230714023018 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230714023010 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.26-20230602023017 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230714023014 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230714023016 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-06-01-014502.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230606111629 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230606111551 2 |
This section outlines release notes for the Cluster release 14.0.0 that is introduced in the Container Cloud release 2.24.0.
This Cluster release supports Mirantis Kubernetes Engine 3.6.5 with Kubernetes 1.24 and Mirantis Container Runtime 20.10.17.
For the list of known and addressed issues, refer to the Container Cloud release 2.24.0 section.
This section outlines new features implemented in the Cluster release 14.0.0 that is introduced in the Container Cloud release 2.24.0.
Dropping of redundant Ceph components from management and regional clusters
Major version update of OpenSearch and OpenSearch Dashboards
Introduced support for Mirantis Container Runtime (MCR) 20.10.17 and Mirantis Kubernetes Engine (MKE) 3.6.5 that supports Kubernetes 1.24 for the Container Cloud management, regional, and managed clusters. On existing clusters, MKE and MCR are updated to the latest supported version when you update your managed cluster to the Cluster release 14.0.0.
Caution
Support for MKE 3.5.x is dropped. Therefore, new deployments on MKE 3.5.x are not supported.
Note
For MOSK-based deployments, the feature support is available since MOSK 23.2.
Upgraded Ceph major version from Pacific 16.2.11 to Quincy 17.2.6 with an automatic upgrade of Ceph components on existing managed clusters during the Cluster version update.
Note
For MOSK-based deployments, the feature support is available since MOSK 23.2.
As the final part of Ceph removal from Container Cloud management clusters, which reduces resource consumption, removed the following Ceph components that were present on clusters for backward compatibility:
Helm chart of the Ceph Controller (
ceph-operator)Ceph deployments
Ceph namespaces
ceph-lcm-mirantisandrook-ceph
Learn more
Introduced healthcheck metrics and the following Ceph alerts to monitor network connectivity between Ceph nodes:
CephDaemonSlowOpsCephMonClockSkewCephOSDFlappingCephOSDSlowClusterNetworkCephOSDSlowPublicNetwork
Note
For MOSK-based deployments, the feature support is available since MOSK 23.2.
Learn more
Implemented the following improvements to StackLight alerting:
Changed severity for multiple alerts to increase visibility of potentially workload-impacting alerts and decrease noise of non-workload-impacting alerts
Renamed
MCCLicenseExpirationCriticaltoMCCLicenseExpirationHigh,MCCLicenseExpirationMajortoMCCLicenseExpirationMediumFor Ironic:
Removed
IronicBmMetricsMissingin favor ofIronicBmApiOutageRemoved inhibition rules for
IronicBmTargetDownandIronicBmApiOutageImproved expression for
IronicBmApiOutage
For Kubernetes applications:
Reworked troubleshooting steps for
KubeStatefulSetUpdateNotRolledOut,KubeDeploymentOutage,KubeDeploymentReplicasMismatchUpdated descriptions for
KubeStatefulSetOutageandKubeDeploymentOutageChanged expressions for
KubeDeploymentOutage,KubeDeploymentReplicasMismatch,CephOSDDiskNotResponding, andCephOSDDown
Learn more
Updated OpenSearch and OpenSearch Dashboards from major version 1.3.7 to 2.7.0. The latest version includes a number of enhancements along with bug and security fixes.
Note
For MOSK-based deployments, the feature support is available since MOSK 23.2.
Caution
The version update process can take up to 20 minutes, during
which both OpenSearch and OpenSearch Dashboards may become temporarily
unavailable. Additionally, the KubeStatefulsetUpdateNotRolledOut alert
for the opensearch-master StatefulSet may fire for a short period of time.
Note
The end-of-life support of the major version 1.x ends on December 31, 2023.
Tuned the performance of Grafana dashboards for faster loading and a better UX by refactoring and optimizing different Grafana dashboards.
This enhancement includes extraction of the OpenSearch Indices dashboard out of the OpenSearch dashboard to provide detailed information about the state of indices, including their size, the size of document values and segments.
Learn more
To improve Prometheus performance and provide better resource utilization with faster query response, dropped metrics that are unused by StackLight. Also created the default white list of metrics that you can expand.
The feature is enabled by default using the
prometheusServer.metricsFiltering.enabled:true parameter. Thus, if you
have created custom alerts, recording rules, dashboards, or if you were
actively using some metrics for different purposes, some of those metrics can
be dropped. Therefore, verify the white list of Prometheus scrape jobs to ensure that the required metrics are not dropped.
If a job name that relates to the required metric is not present in this list,
its target metrics are not dropped and are collected by Prometheus by default.
If the required metric is not present in this list, you can whitelist it
using the prometheusServer.metricsFiltering.extraMetricsInclude parameter.
The following table lists the components versions of the Cluster release 14.0.0.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.6.5 0 |
Container runtime |
Mirantis Container Runtime |
20.10.17 1 |
Distributed storage |
Ceph |
17.2.6 (Quincy) |
Rook |
1.11.4-10 |
|
LCM |
helm-controller |
1.37.15 |
lcm-ansible |
0.22.0-49-g9618f2a |
|
lcm-agent |
1.37.15 |
|
StackLight |
Alerta |
9.0.0 |
Alertmanager |
0.25.0 |
|
Alertmanager Webhook ServiceNow |
0.1 |
|
Blackbox Exporter |
0.24.0 |
|
cAdvisor |
0.47.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.5.0 |
|
Fluentd |
1.15.3 |
|
Grafana |
9.4.9 |
|
Grafana Image Renderer |
3.7.0 |
|
keycloak-gatekeeper |
7.1.3-5 |
|
kube-state-metrics |
2.8.2 |
|
Metric Collector |
0.1 |
|
Metricbeat |
7.12.1 |
|
Node Exporter |
1.6.0 |
|
OpenSearch |
2.7.0 |
|
OpenSearch Dashboards |
2.7.0 |
|
Prometheus |
2.44.0 |
|
Prometheus ES Exporter |
0.14.0 |
|
Prometheus MS Teams |
1.5.2 |
|
Prometheus Patroni Exporter |
0.0.1 |
|
Prometheus Postgres Exporter |
0.12.0 |
|
Prometheus Relay |
0.4 |
|
sf-notifier |
0.3 |
|
sf-reporter |
0.1 |
|
Spilo |
13-2.1p9 |
|
Telegraf |
1.9.1 |
|
1.26.2 |
||
Telemeter |
4.4 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 14.0.0.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.24.0-10.tgz |
Docker images |
ceph |
mirantis.azurecr.io/mirantis/ceph:v17.2.6-rel-5 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.24.0-9 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.8.0-rel-3 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.8.0-rel-1 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.5.0-rel-1 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-rel-1 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.3.0-rel-1 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.8.0-rel-1 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.11.4-10 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.22.0-49-g9618f2a/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.37.15.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.37.15.tgz |
|
Docker images |
helm-controller |
mirantis.azurecr.io/core/lcm-controller:1.37.15 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-7.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-175.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-225.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-58.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-47.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-52.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-240.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-11.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight |
https://binary.mirantis.com/stacklight/helm/stacklight-0.12.6.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-37.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-37.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web |
mirantis.azurecr.io/stacklight/alerta-web:9-20230602023009 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.25.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230601043943 |
|
alpine-utils |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230602023019 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.24.0 |
|
cadvisor |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230602023019 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
curl-jq |
mirantis.azurecr.io/scale/curl-jq:alpine-20230120171102 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch-exporter:v1.5.0 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230602023011 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.4.9 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230418140825 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230602023018 |
|
keycloak-gatekeeper |
mirantis.azurecr.io/iam/keycloak-gatekeeper:7.1.3-5 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230602023016 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230602111822 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230602023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.6.0 |
|
opensearch |
mirantis.azurecr.io/stacklight/opensearch:2-20230602023014 |
|
opensearch-dashboards |
mirantis.azurecr.io/stacklight/opensearch-dashboards:2-20230602023014 |
|
openstack-refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.0.1.dev33 |
|
pgbouncer |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230602023019 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.44.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230602023016 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230602023018 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230602023016 |
|
psql-client |
mirantis.azurecr.io/scale/psql-client:v13-20230124173121 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230602023012 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230601044047 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230602023015 |
|
stacklight-toolkit |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230602123559 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230602023009 |
|
mirantis.azurecr.io/stacklight/telegraf:1.26-20230602023017 |
||
telemeter |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230602023011 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230602023012 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.8/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-06-01-014502.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230606111629 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230606111551 2 |
See also
12.x series¶
This section outlines release notes for the unsupported Cluster releases of the 12.x series. Cluster releases ending with a zero, for example, 12.x.0, are major releases. Cluster releases ending with with a non-zero, for example, 12.x.1, are patch releases of a major release 12.x.0.
This section outlines release notes for unsupported Cluster releases of the 12.7.x series.
This section includes release notes for the patch Cluster release 12.7.4 that is introduced in the Container Cloud patch release 2.23.5 and is based on the Cluster release 12.7.0. This patch Cluster release supports MOSK 23.1.4.
For details on MOSK 23.1.4, see MOSK documentation: Release Notes
For CVE fixes delivered with this patch Cluster release, see security notes for 2.23.5
For CVE fixes delivered with the previous patch Cluster releases, see security notes for 2.23.4, 2.23.3, and 2.23.2
For details on patch release delivery, see Patch releases
This section lists the components artifacts of the Cluster release 12.7.4.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.23.5-1.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v16.2.11-cve-4 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.23.5-0 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.7.2-cve-4 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.2.0-cve-2 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.4.0-cve-2 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.7.0-cve-2 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.7.0-cve-2 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-2 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.10.10-10 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.21.0-39-g5b167de/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.36.27.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.36.27.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/helm-controller:1.36.27 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-170.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-200.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-44.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-48.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-229.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.11.9.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20230523144245 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.25.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230519023013 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230519023021 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.23.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230519023020 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:v0.9-20230505023015 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch_exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230519023011 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.4.9 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230418140825 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230519023019 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230519023019 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230330133800 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230519023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.5.0 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20230523124159 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20230519023015 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230519023020 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.40.7 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230519023018 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230519023019 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230519023015 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230523144230 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230403174259 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230519023017 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230519023016 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230519023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.26-20230523091335 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230519023012 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230519023015 |
|
yq |
mirantis.azurecr.io/stacklight/yq:4.33.2 |
Unchanged as compared to 12.7.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.7/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-01-26-014412.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230126185755 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230126183021 |
This section includes release notes for the patch Cluster release 12.7.3 that is introduced in the Container Cloud patch release 2.23.4 and is based on the Cluster release 12.7.0. This patch Cluster release supports MOSK 23.1.3.
For details on MOSK 23.1.3, see MOSK documentation: Release Notes
For CVE fixes delivered with this patch Cluster release, see security notes for 2.23.4
For CVE fixes delivered with the previous patch Cluster releases, see security notes for 2.23.3 and 2.23.2
For details on patch release delivery, see Patch releases
This section lists the components artifacts of the Cluster release 12.7.3.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.23.4-4.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v16.2.11-cve-4 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.23.4-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.7.2-cve-4 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.2.0-cve-2 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.4.0-cve-2 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.7.0-cve-2 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.7.0-cve-2 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-2 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.10.10-10 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.21.0-39-g5b167de/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.36.26.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.36.26.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/helm-controller:1.36.26 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-170.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-200.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-44.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-48.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-229.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.11.7.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20230505023008 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.25.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230505023012 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230505023019 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.23.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230505023018 |
|
cerebro Updated |
mirantis.azurecr.io/stacklight/cerebro:v0.9-20230505023015 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch_exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230428063240 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:9.4.9 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230418140825 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230505023018 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230505023017 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230330133800 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230505023009 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.5.0 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20230505023014 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20230505023013 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230505023019 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.40.7 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230505023016 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230505023017 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230505023012 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230505023013 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230403174259 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230404125347 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230505023015 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230505023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.26.1-20230505023017 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230505023010 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230505023010 |
|
yq |
mirantis.azurecr.io/stacklight/yq:4.33.2 |
Unchanged as compared to 12.7.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.7/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-01-26-014412.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230126185755 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230126183021 |
This section includes release notes for the patch Cluster release 12.7.2 that is introduced in the Container Cloud patch release 2.23.3 and is based on the Cluster release 12.7.0. This patch Cluster release supports MOSK 23.1.2.
For details on MOSK 23.1.2, see MOSK documentation: Release Notes
For CVE fixes delivered with this patch Cluster release, see security notes for 2.23.3
For CVE fixes delivered with the previous patch Cluster release, see security notes for 2.23.2
For details on patch release delivery, see Patch releases
This section lists the components artifacts of the Cluster release 12.7.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.23.3-2.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/ceph/ceph:v16.2.11-cve-4 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.23.3-0 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.7.2-cve-3 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.2.0-cve-2 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.4.0-cve-2 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.7.0-cve-2 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.7.0-cve-2 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-2 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.10.10-10 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.21.0-39-g5b167de/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.36.23.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.36.23.tgz |
|
Docker images |
helm-controller Updated |
mirantis.azurecr.io/core/helm-controller:1.36.23 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-170.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-200.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-44.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-48.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-229.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.11.6.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20230414023009 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.25.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230414023012 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230414023019 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.23.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230414023019 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:v0.9-20230316081755 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch_exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230414023011 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.4.7 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230418140825 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230414023019 |
|
kube-state-metrics Updated |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230414023019 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230330133800 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230417102535 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.5.0 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20230414023016 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20230414023010 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230414023019 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.40.7 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230414023017 |
|
prometheus-msteams Updated |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230414023019 |
|
prometheus-postgres-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230414023019 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230414023014 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230403174259 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230404125347 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230414023017 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230414023010 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.26.1-20230414023019 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230414023013 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230414023013 |
|
yq Updated |
mirantis.azurecr.io/stacklight/yq:4.33.2 |
Unchanged as compared to 12.7.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.7/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-01-26-014412.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230126185755 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230126183021 |
This section outlines release notes for the patch Cluster release 12.7.1 that is introduced in the Container Cloud patch release 2.23.2 and is based on the Cluster release 12.7.0. This patch Cluster release supports MOSK 23.1.1.
For details on MOSK 23.1.1, see MOSK documentation: Release Notes
For the list of CVE fixes, see 2.23.2
For details on patch release delivery, see Patch releases
This section lists the components artifacts of the Cluster release 12.7.1. For artifacts of the Container Cloud release, see Container Cloud release 2.23.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.23.2-7.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/ceph/ceph:v16.2.11-cve-2 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.23.2-6 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.7.2-cve-1 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.2.0-cve-1 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.4.0-cve-1 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.7.0-cve-1 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.7.0-cve-1 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-1 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.10.10-9 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.21.0-39-g5b167de/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.36.14.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.36.14.tgz |
|
Docker images |
helm-controller Updated |
mirantis.azurecr.io/core/helm-controller:1.36.14 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-170.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-194.tgz |
|
iam-proxy Updated |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-44.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-48.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-229.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.11.5.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:8-20230331023009 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.25.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230331023013 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230331023020 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.23.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230331023021 |
|
cerebro Updated |
mirantis.azurecr.io/stacklight/cerebro:v0.9-20230316081755 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator Updated |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch_exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230331023012 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:9.4.7 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230310145607 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230331023020 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.7.0 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230331023019 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230330133800 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230331123540 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.5.0 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20230403060750 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20230403060759 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230331023020 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.40.7 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230331023015 |
|
prometheus-msteams Updated |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.1 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230331023020 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230331023018 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230331023014 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230403174259 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230404125347 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230331023016 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230331023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.23.4-20230317023017 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230331023013 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230331023015 |
|
yq Updated |
mirantis.azurecr.io/stacklight/yq:4.32.2 |
Unchanged as compared to 12.7.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.7/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-01-26-014412.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230126185755 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230126183021 |
This section outlines release notes for the Cluster release 12.7.0 that is introduced in the Container Cloud release 2.23.1. This Cluster release is based on the Cluster release 11.7.0.
The Cluster release 12.7.0 supports:
Mirantis OpenStack for Kubernetes (MOSK) 23.1. For details, see MOSK Release Notes.
Mirantis Kubernetes Engine (MKE) 3.5.7. For details, see MKE Release Notes.
Mirantis Container Runtime (MCR) 20.10.13. For details, see MCR Release Notes.
Kubernetes 1.21.
For the list of known and resolved issues, refer to the Container Cloud release 2.23.0 section.
This section outlines new features implemented in the Cluster release 12.7.0 that is introduced in the Container Cloud release 2.23.1.
Calculation of storage retention time using OpenSearch and Prometheus panels
‘MCC Applications Performance’ Grafana dashboard for StackLight
Updated the Mirantis Kubernetes Engine (MKE) patch release from 3.5.5 to 3.5.7. The MKE update occurs automatically when you update your managed cluster.
Upgraded Ceph major version from Octopus 15.2.17 to Pacific 16.2.11 with an automatic upgrade of Ceph components on existing managed clusters during the Cluster version update.
Caution
Since Ceph Pacific, while mounting an RBD or CephFS volume, CSI
drivers do not propagate the 777 permission on the mount path.
Learn more
Increased the default number of Ceph Managers deployed on a Ceph cluster to two, active and stand-by, to improve fault tolerance and HA.
On existing clusters, the second Ceph Manager deploys automatically after a managed cluster update.
Note
Mirantis recommends labeling at least 3 Ceph nodes with the mgr
role that equals the default number of Ceph nodes for the mon role.
In such configuration, one back-up Ceph node will be available to redeploy
a failed Ceph Manager in case of a server outage.
Implemented monitoring of bond interfaces for clusters based on bare metal. The number of active and configured slaves per bond is now monitored with the following alerts raising in case of issues:
BondInterfaceDownBondInterfaceSlaveDownBondInterfaceOneSlaveLeftBondInterfaceOneSlaveConfigured
Learn more
Implemented the following panels in the Grafana dashboards for OpenSearch and Prometheus that provide details on the storage usage and allow calculating the possible retention time based on provisioned storage and average usage:
OpenSearch dashboard:
Cluster > Estimated Retention
Resources > Disk
Resources > File System Used Space by Percentage
Resources > Stored Indices Disk Usage
Resources > Age of Logs
Prometheus dashboard:
Cluster > Estimated Retention
Resources > Storage
Resources > Strage by Percentage
Implemented deployment of two iam-proxy instances for the StackLight HA
setup that ensures access to HA components if one iam-proxy instance
fails. The second iam-proxy instance is automatically deployed during
cluster update on existing StackLight HA deployments.
Added the capability to forward logs to external Elasticsearch and OpenSearch
servers as the fluentd-logs output. This enhancement also expands existing
configuration options for log forwarding to syslog.
Introduced logging.externalOutputs that deprecates logging.syslog and
enables you to configure any number of outputs with more configuration
flexibility.
Implemented the MCC Applications Performance Grafana dashboard that provides information on the Container Cloud internals work based on Golang, controller runtime, and some custom metrics. You can use it to verify performance of applications and for troubleshooting purposes.
Learn more
The following table lists the components versions of the Cluster release 12.7.0. For major components and versions of the Container Cloud release, see Container Cloud release 2.23.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.5.7 0 |
Container runtime |
Mirantis Container Runtime |
20.10.13 1 |
Distributed storage Updated |
Ceph |
16.2.11 (Pacific) |
Rook |
1.0.0-20230120144247 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
1.36.3 |
|
lcm-ansible Updated |
0.21.0-39-g5b167de |
|
lcm-agent Updated |
1.36.3 |
|
StackLight |
Alerta Updated |
8.5.0 |
Alertmanager Updated |
0.25.0 |
|
Alertmanager Webhook ServiceNow Updated |
0.1 |
|
Blackbox Exporter Updated |
0.23.0 |
|
cAdvisor New |
0.46.0 |
|
Cerebro Updated |
0.9.4 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd Updated |
1.15.3 |
|
Grafana Updated |
9.1.8 |
|
Grafana Image Renderer Updated |
3.6.1 |
|
kube-state-metrics New |
2.7.0 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector Updated |
0.1 |
|
Metricbeat Updated |
7.10.2 |
|
Node Exporter Updated |
1.5.0 |
|
OpenSearch Updated |
1.3.7 |
|
OpenSearch Dashboards Updated |
1.3.7 |
|
Prometheus Updated |
2.40.7 |
|
Prometheus ES Exporter Updated |
0.14.0 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Patroni Exporter Updated |
0.0.1 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay Updated |
0.4 |
|
sf-notifier Updated |
0.3 |
|
sf-reporter Updated |
0.1 |
|
Spilo Updated |
13-2.1p9 |
|
Telegraf |
1.9.1 Updated |
|
1.23.4 Updated |
||
Telemeter Updated |
4.4 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 12.7.0. For artifacts of the Container Cloud release, see Container Cloud release 2.23.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.23-12.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/ceph/ceph:v16.2.11 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.23-11 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.7.2 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.5.1 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v3.3.0 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v6.1.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v4.0.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.6.0 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.0.0-20230120144247 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.21.0-39-g5b167de/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.36.3.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.36.3.tgz |
|
Docker images |
helm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.36.3 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor New |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-170.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-194.tgz |
|
iam-proxy Updated |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat Updated |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-44.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-48.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-229.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.11.3.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20230206172055 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0.25.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230206145038 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230203125601 |
|
blackbox-exporter Updated |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.23.0 |
|
cadvisor New |
mirantis.azurecr.io/stacklight/cadvisor:v0.46.0 |
|
cerebro Updated |
mirantis.azurecr.io/stacklight/cerebro:v0.9-20230203125548 |
|
configmap-reload Updated |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator Updated |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230206171950 |
|
elasticsearch_exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230203125530 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.1.8 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.6.1-20221103105602 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.21.0-20230206130934 |
|
kube-state-metrics Updated |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.7.0 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22.13 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20221227141656 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20230203125534 |
|
node-exporter Updated |
mirantis.azurecr.io/stacklight/node-exporter:v1.5.0 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20230203125541 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20230203125528 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230203125558 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.40.7 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230206130434 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230203125555 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230203125553 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230206130301 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230206133637 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230203124803 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230203125546 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230203125527 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.23.4-20220915114529 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230203125536 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230203125540 |
|
yq Updated |
mirantis.azurecr.io/stacklight/yq:4.30.6 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages Updated |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.7/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-01-26-014412.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system |
Ubuntu Updated |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230126185755 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230126183021 |
See also
See also
This section outlines release notes for the Cluster release 12.5.0 that is introduced in the Container Cloud release 2.21.1. This Cluster release is based on the Cluster release 11.5.0.
The Cluster release 12.5.0 supports:
Mirantis OpenStack for Kubernetes (MOSK) 22.5. For details, see MOSK Release Notes.
Mirantis Kubernetes Engine (MKE) 3.5.5. For details, see MKE Release Notes.
Mirantis Container Runtime (MCR) 20.10.13. For details, see MCR Release Notes.
Kubernetes 1.21.
For the list of known and resolved issues, refer to the Container Cloud release 2.21.0 section.
This section outlines new features implemented in the Cluster release 12.5.0 that is introduced in the Container Cloud release 2.21.1.
Added support for the Mirantis Kubernetes Engine (MKE) 3.5.5 with Kubernetes 2.21 and the Mirantis Container Runtime (MCR) version 20.10.13.
An update from the Cluster release 8.10.0 to 12.5.0 becomes available through the Container Cloud web UI menu once the related management or regional cluster automatically upgrades to Container Cloud 2.21.1.
Updated the MetalLB version from 0.12.1 to 0.13.4 to apply the latest
enhancements. The MetalLB configuration is now stored in dedicated MetalLB
objects instead of the ConfigMap object.
Improved etcd monitoring by implementing the Etcd dashboard and
etcdDbSizeCritical and etcdDbSizeMajor alerts that inform about the
size of the etcd database.
Learn more
The following table lists the components versions of the Cluster release 12.5.0. For major components and versions of the Container Cloud release, see Container Cloud release 2.21.0.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.5.5 0 |
Container runtime |
Mirantis Container Runtime |
20.10.13 1 |
Distributed storage |
Ceph |
15.2.17 (Octopus) |
Rook |
1.0.0-20220809220209 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller |
0.3.0-327-gbc30b11b |
|
lcm-ansible |
0.19.0-12-g6cad672 |
|
lcm-agent |
0.3.0-327-gbc30b11b |
|
StackLight |
Alerta |
8.5.0-20220923121625 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow |
0.1-20220706035316 |
|
Cerebro |
0.9-20220923122026 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.14-20220922214003 |
|
Grafana |
9.0.2 |
|
Grafana Image Renderer |
3.5.0 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector |
0.1-20220711134630 |
|
Metricbeat |
7.10.2-20220909091002 |
|
OpenSearch |
1-20220517112057 |
|
OpenSearch Dashboards |
1-20220517112107 |
|
Prometheus |
2.35.0 |
|
Prometheus Blackbox Exporter |
0.19.0 |
|
Prometheus ES Exporter |
0.14.0-20220517111946 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20220624102731 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier |
0.3-20220706035002 |
|
sf-reporter |
0.1-20220916113234 |
|
Spilo |
13-2.1p1-20220921105803 |
|
Telegraf |
1.9.1-20221107155248 |
|
1.23.4-20220915114529 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 12.5.0. For artifacts of the Container Cloud release, see Container Cloud release 2.21.0.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-964.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.17 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20221024145202 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.0.0-20220809220209 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.19.0-12-g6cad672/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-327-gbc30b11b/lcm-agent |
|
Helm charts |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.34.16.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.34.16.tgz |
|
Docker images |
helm-controller |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-327-gbc30b11b |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-37.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-142.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-173.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-40.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-42.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-229.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-5.tgz |
|
stacklight |
https://binary.mirantis.com/stacklight/helm/stacklight-0.9.3.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20220923121625 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20220706035316 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:v0.9-20220923122026 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch_exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220922214003 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.0.2 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.5.0 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.15.9 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22.13 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220711134630 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220909091002 |
|
nginx-prometheus-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch |
mirantis.azurecr.io/stacklight/opensearch:1-20220517112057 |
|
opensearch-dashboards |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20220517112107 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.35.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220517111946 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20220624102731 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20220706035002 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20220916113234 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220921105803 |
|
stacklight-toolkit |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20220729121446 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20221107155248 |
|
mirantis.azurecr.io/stacklight/telegraf:1.23.4-20220915114529 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:4.25.2 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2022-07-13-020010.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20220915105522 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20220915105637 0 |
- 0
Only for existing bare metal clusters
11.x series¶
This section outlines release notes for the unsupported Cluster releases of the 11.x series. Cluster releases ending with a zero, for example, 11.x.0, are major releases. Cluster releases ending with with a non-zero, for example, 11.x.1, are patch releases of a major release 11.x.0.
This section outlines release notes for unsupported Cluster releases of the 11.7.x series.
This section includes release notes for the patch Cluster release 11.7.4 that is introduced in the Container Cloud patch release 2.23.5 and is based on the Cluster release 11.7.0.
For CVE fixes delivered with this patch Cluster release, see security notes for 2.23.5
For CVE fixes delivered with the previous patch Cluster releases, see security notes for 2.23.4, 2.23.3, and 2.23.2
For details on patch release delivery, see Patch releases
This section lists the components artifacts of the Cluster release 11.7.4.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.23.5-1.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v16.2.11-cve-4 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.23.5-0 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.7.2-cve-4 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.2.0-cve-2 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.4.0-cve-2 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.7.0-cve-2 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.7.0-cve-2 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-2 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.10.10-10 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.21.0-39-g5b167de/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.36.27.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.36.27.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/helm-controller:1.36.27 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-170.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-200.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-44.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-48.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-229.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.11.9.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20230523144245 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.25.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230519023013 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230519023021 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.23.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230519023020 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:v0.9-20230505023015 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch_exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230519023011 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.4.9 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230418140825 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230519023019 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230519023019 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230330133800 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230519023010 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.5.0 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20230523124159 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20230519023015 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230519023020 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.40.7 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230519023018 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230519023019 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230519023015 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230523144230 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230403174259 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230519023017 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230519023016 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230519023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.26-20230523091335 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230519023012 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230519023015 |
|
yq |
mirantis.azurecr.io/stacklight/yq:4.33.2 |
Unchanged as compared to 11.7.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.7/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-01-26-014412.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230126185755 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230126183021 2 |
This section includes release notes for the patch Cluster release 11.7.3 that is introduced in the Container Cloud patch release 2.23.4 and is based on the Cluster release 11.7.0.
For CVE fixes delivered with this patch Cluster release, see security notes for 2.23.4
For CVE fixes delivered with the previous patch Cluster releases, see security notes for 2.23.3 and 2.23.2
For details on patch release delivery, see Patch releases
This section lists the components artifacts of the Cluster release 11.7.3.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.23.4-4.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v16.2.11-cve-4 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.23.4-0 |
|
cephcsi Updated |
mirantis.azurecr.io/mirantis/cephcsi:v3.7.2-cve-4 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.2.0-cve-2 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.4.0-cve-2 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.7.0-cve-2 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.7.0-cve-2 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-2 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.10.10-10 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.21.0-39-g5b167de/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.36.26.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.36.26.tgz |
|
Docker images Updated |
helm-controller |
mirantis.azurecr.io/core/helm-controller:1.36.26 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-170.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-200.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-44.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-48.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-229.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.11.7.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20230505023008 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.25.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230505023012 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230505023019 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.23.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230505023018 |
|
cerebro Updated |
mirantis.azurecr.io/stacklight/cerebro:v0.9-20230505023015 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch_exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230428063240 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:9.4.9 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230418140825 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230505023018 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230505023017 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230330133800 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230505023009 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.5.0 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20230505023014 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20230505023013 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230505023019 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.40.7 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230505023016 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230505023017 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230505023012 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230505023013 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230403174259 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230404125347 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230505023015 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230505023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.26.1-20230505023017 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230505023010 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230505023010 |
|
yq |
mirantis.azurecr.io/stacklight/yq:4.33.2 |
Unchanged as compared to 11.7.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.7/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-01-26-014412.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230126185755 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230126183021 2 |
This section includes release notes for the patch Cluster release 11.7.2 that is introduced in the Container Cloud patch release 2.23.3 and is based on the Cluster release 11.7.0.
For CVE fixes delivered with this patch Cluster release, see security notes for 2.23.3
For CVE fixes delivered with the previous patch Cluster release, see security notes for 2.23.2
For details on patch release delivery, see Patch releases
This section lists the components artifacts of the Cluster release 11.7.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.23.3-2.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/ceph/ceph:v16.2.11-cve-4 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.23.3-0 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.7.2-cve-3 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.2.0-cve-2 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.4.0-cve-2 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.7.0-cve-2 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.7.0-cve-2 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-2 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.10.10-10 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.21.0-39-g5b167de/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.36.14.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.36.14.tgz |
|
Docker images |
helm-controller Updated |
mirantis.azurecr.io/core/helm-controller:1.36.23 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-170.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-200.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-44.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-48.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-229.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.11.6.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:9-20230414023009 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.25.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230414023012 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230414023019 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.23.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230414023019 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:v0.9-20230316081755 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch_exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230414023011 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.4.7 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230418140825 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230414023019 |
|
kube-state-metrics Updated |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.8.2 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230414023019 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230330133800 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230417102535 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.5.0 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20230414023016 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20230414023010 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230414023019 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.40.7 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230414023017 |
|
prometheus-msteams Updated |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230414023019 |
|
prometheus-postgres-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.12.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230414023019 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230414023014 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230403174259 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230404125347 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230414023017 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230414023010 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.26.1-20230414023019 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230414023013 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230414023013 |
|
yq Updated |
mirantis.azurecr.io/stacklight/yq:4.33.2 |
Unchanged as compared to 11.7.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.7/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-01-26-014412.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230126185755 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230126183021 2 |
This section outlines release notes for the patch Cluster release 11.7.1 that is introduced in the Container Cloud patch release 2.23.2 and is based on the Cluster release 11.7.0. For the list of CVE fixes delivered with this patch Cluster release, see 2.23.2. For details on patch release delivery, see Patch releases.
This section lists the components artifacts of the Cluster release 11.7.1. For artifacts of the Container Cloud release, see Container Cloud release 2.23.2.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.23.2-7.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/ceph/ceph:v16.2.11-cve-2 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.23.2-6 |
|
cephcsi |
mirantis.azurecr.io/mirantis/cephcsi:v3.7.2-cve-1 |
|
cephcsi-attacher |
mirantis.azurecr.io/mirantis/cephcsi-attacher:v4.2.0-cve-1 |
|
cephcsi-provisioner |
mirantis.azurecr.io/mirantis/cephcsi-provisioner:v3.4.0-cve-1 |
|
cephcsi-registrar |
mirantis.azurecr.io/mirantis/cephcsi-registrar:v2.7.0-cve-1 |
|
cephcsi-resizer |
mirantis.azurecr.io/mirantis/cephcsi-resizer:v1.7.0-cve-1 |
|
cephcsi-snapshotter |
mirantis.azurecr.io/mirantis/cephcsi-snapshotter:v6.2.1-cve-1 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.10.10-9 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.21.0-39-g5b167de/lcm-ansible.tar.gz |
lcm-agent Updated |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.36.14.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.36.14.tgz |
|
Docker images |
helm-controller Updated |
mirantis.azurecr.io/core/helm-controller:1.36.14 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-170.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-194.tgz |
|
iam-proxy Updated |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-44.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-48.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-229.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
refapp |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.11.5.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:8-20230331023009 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.25.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230331023013 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230331023020 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.23.0 |
|
cadvisor Updated |
mirantis.azurecr.io/stacklight/cadvisor:v0.47-20230331023021 |
|
cerebro Updated |
mirantis.azurecr.io/stacklight/cerebro:v0.9-20230316081755 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator Updated |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230404082402 |
|
elasticsearch_exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230331023012 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:9.4.7 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3-20230310145607 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.22-20230331023020 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.7.0 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22-20230331023019 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20230330133800 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.12.1-20230331123540 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.5.0 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20230403060750 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20230403060759 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230331023020 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.40.7 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230331023015 |
|
prometheus-msteams Updated |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.5.1 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230331023020 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230331023018 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230331023014 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230403174259 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230404125347 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230331023016 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230331023009 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.23.4-20230317023017 Updated |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230331023013 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230331023015 |
|
yq Updated |
mirantis.azurecr.io/stacklight/yq:4.32.2 |
Unchanged as compared to 11.7.0
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.7/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-01-26-014412.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230126185755 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230126183021 2 |
This section outlines release notes for the Cluster release 11.7.0 that is introduced in the Mirantis Container Cloud release 2.23.0.
This Cluster release supports Mirantis Kubernetes Engine 3.5.7 with Kubernetes 1.21 and Mirantis Container Runtime 20.10.13.
This section outlines new features implemented in the Cluster release 11.7.0 that is introduced in the Container Cloud release 2.23.0.
Updated the Mirantis Kubernetes Engine (MKE) version from 3.5.5 to 3.5.7 for the Container Cloud management, regional, and managed clusters on all supported cloud providers, as well as for non Container Cloud based MKE cluster attachment.
Note
For MOSK-based deployments, the feature support is available since MOSK 23.1.
Learn more
Upgraded Ceph major version from Octopus 15.2.17 to Pacific 16.2.11 with an automatic upgrade of Ceph components on existing managed clusters during the Cluster version update.
Caution
Since Ceph Pacific, while mounting an RBD or CephFS volume, CSI
drivers do not propagate the 777 permission on the mount path.
Note
For MOSK-based deployments, the feature support is available since MOSK 23.1.
Learn more
Implemented deployment of two iam-proxy instances for the StackLight HA
setup that ensures access to HA components if one iam-proxy instance
fails. The second iam-proxy instance is automatically deployed during
cluster update on existing StackLight HA deployments.
Note
For MOSK-based deployments, the feature support is available since MOSK 23.1.
Added the capability to forward logs to external Elasticsearch and OpenSearch
servers as the fluentd-logs output. This enhancement also expands existing
configuration options for log forwarding to syslog.
Introduced logging.externalOutputs that deprecates logging.syslog and
enables you to configure any number of outputs with more configuration
flexibility.
Note
For MOSK-based deployments, the feature support is available since MOSK 23.1.
Implemented the MCC Applications Performance Grafana dashboard that provides information on the Container Cloud internals work based on Golang, controller runtime, and some custom metrics. You can use it to verify performance of applications and for troubleshooting purposes.
Note
For MOSK-based deployments, the feature support is available since MOSK 23.1.
Learn more
Implemented the following options that enable configuration of persistent volumes for Reference Application :
refapp.workload.persistentVolumeEnabledrefapp.workload.persistentVolumeSize
Note
The refapp.workload.persistentVolumeEnabled option is enabled by
default and is recommended for production clusters.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature is not supported yet.
The following table lists the components versions of the Cluster release 11.7.0. For major components and versions of the Container Cloud release, see Container Cloud release 2.23.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.5.7 0 |
Container runtime |
Mirantis Container Runtime |
20.10.13 1 |
Distributed storage Updated |
Ceph |
16.2.11 (Pacific) |
Rook |
1.0.0-20230120144247 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
1.36.3 |
|
lcm-ansible Updated |
0.21.0-39-g5b167de |
|
lcm-agent Updated |
1.36.3 |
|
StackLight |
Alerta Updated |
8.5.0 |
Alertmanager Updated |
0.25.0 |
|
Alertmanager Webhook ServiceNow Updated |
0.1 |
|
Blackbox Exporter Updated |
0.23.0 |
|
cAdvisor |
0.46.0 |
|
Cerebro |
0.9.4 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.15.3 |
|
Grafana |
9.1.8 |
|
Grafana Image Renderer Updated |
3.6.1 |
|
kube-state-metrics Updated |
2.7.0 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector Updated |
0.1 |
|
Metricbeat |
7.10.2 |
|
Node Exporter Updated |
1.5.0 |
|
OpenSearch Updated |
1.3.7 |
|
OpenSearch Dashboards Updated |
1.3.7 |
|
Prometheus Updated |
2.40.7 |
|
Prometheus ES Exporter Updated |
0.14.0 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Patroni Exporter |
0.0.1 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay Updated |
0.4 |
|
sf-notifier Updated |
0.3 |
|
sf-reporter Updated |
0.1 |
|
Spilo Updated |
13-2.1p9 |
|
Telegraf |
1.9.1 Updated |
|
1.23.4 Updated |
||
Telemeter |
4.4 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 11.7.0. For artifacts of the Container Cloud release, see Container Cloud release 2.23.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.23-12.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/ceph/ceph:v16.2.11 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:2.23-11 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.7.2 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.5.1 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v3.3.0 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v6.1.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v4.0.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.6.0 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.0.0-20230120144247 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.21.0-39-g5b167de/lcm-ansible.tar.gz |
lcm-agent |
||
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.36.3.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.36.3.tgz |
|
Docker images |
helm-controller Updated |
mirantis.azurecr.io/core/lcm-controller:1.36.3 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-29.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-170.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-194.tgz |
|
iam-proxy Updated |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-44.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-48.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-229.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
refapp Updated |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-9.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.11.3.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20230206172055 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0.25.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20230206145038 |
|
alpine-utils Updated |
mirantis.azurecr.io/stacklight/alpine-utils:1-20230203125601 |
|
blackbox-exporter Updated |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.23.0 |
|
cadvisor |
mirantis.azurecr.io/stacklight/cadvisor:v0.46.0 |
|
cerebro Updated |
mirantis.azurecr.io/stacklight/cerebro:v0.9-20230203125548 |
|
configmap-reload Updated |
mirantis.azurecr.io/stacklight/configmap-reload:v0.8.0 |
|
curator Updated |
mirantis.azurecr.io/stacklight/curator:5.7.6-20230206171950 |
|
elasticsearch_exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20230203125530 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.1.8 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.6.1-20221103105602 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.21.0-20230206130934 |
|
kube-state-metrics Updated |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.7.0 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22.13 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20221227141656 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20230203125534 |
|
node-exporter Updated |
mirantis.azurecr.io/stacklight/node-exporter:v1.5.0 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20230203125541 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20230203125528 |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20230203125558 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.40.7 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20230206130434 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-20230203125555 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.4-20230203125553 |
|
refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.0.1.dev29 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20230206130301 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20230206133637 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p9-20230203124803 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20230203125546 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20230203125527 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.23.4-20220915114529 |
||
telemeter Updated |
mirantis.azurecr.io/stacklight/telemeter:4.4-20230203125536 |
|
telemeter-token-auth Updated |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20230203125540 |
|
yq Updated |
mirantis.azurecr.io/stacklight/yq:4.30.6 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.7/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2023-01-26-014412.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system 1 |
Ubuntu Updated |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20230126185755 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20230126183021 2 |
For the list of known and addressed issues, refer to the Container Cloud release 2.23.0 section.
See also
This section outlines release notes for the Cluster release 11.6.0 that is introduced in the Mirantis Container Cloud release 2.22.0.
This Cluster release supports Mirantis Kubernetes Engine 3.5.5 with Kubernetes 1.21 and Mirantis Container Runtime 20.10.13.
This section outlines new features implemented in the Cluster release 11.6.0 that is introduced in the Container Cloud release 2.22.0.
Implemented monitoring of bond interfaces for clusters based on bare metal and Equinix Metal with public or private networking. The number of active and configured slaves per bond is now monitored with the following alerts raising in case of issues:
BondInterfaceDownBondInterfaceSlaveDownBondInterfaceOneSlaveLeftBondInterfaceOneSlaveConfigured
Note
For MOSK-based deployments, the feature support is available since MOSK 23.1.
Learn more
Implemented the following panels in the Grafana dashboards for OpenSearch and Prometheus that provide details on the storage usage and allow calculating the possible retention time based on provisioned storage and average usage:
OpenSearch dashboard:
Cluster > Estimated Retention
Resources > Disk
Resources > File System Used Space by Percentage
Resources > Stored Indices Disk Usage
Resources > Age of Logs
Prometheus dashboard:
Cluster > Estimated Retention
Resources > Storage
Resources > Strage by Percentage
Note
For MOSK-based deployments, the feature support is available since MOSK 23.1.
Added cAdvisor to the StackLight deployment on any type of Container Cloud cluster that allows gathering metrics about usage of container resources.
Enhanced support for Reference Application that is designed for workload monitoring on managed clusters adding the Enable Reference Application check box to the StackLight tab of the Create new cluster wizard in the Container Cloud web UI.
You can also enable this option after deployment using the
Configure cluster menu of the Container Cloud web UI or using CLI
by editing the StackLight parameters in the Cluster object.
The Reference Application enhancement also comprises switching from MariaDB to PostgreSQL to improve the application stability and performance.
Note
Reference Application requires the following resources per cluster on top of the main product requirements:
Up to 1 GiB of RAM
Up to 3 GiB of storage
Note
For the feature support on MOSK deployments, refer to MOSK documentation: Deploy RefApp using automation tools.
Increased the default number of Ceph Managers deployed on a Ceph cluster to two, active and stand-by, to improve fault tolerance and HA.
On existing clusters, the second Ceph Manager deploys automatically after a managed cluster update.
Note
Mirantis recommends labeling at least 3 Ceph nodes with the mgr
role that equals the default number of Ceph nodes for the mon role.
In such configuration, one back-up Ceph node will be available to redeploy
a failed Ceph Manager in case of a server outage.
Note
For MOSK-based deployments, the feature support is available since MOSK 23.1.
The following table lists the components versions of the Cluster release 11.6.0. For major components and versions of the Container Cloud release, see Container Cloud release 2.22.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.5.5 0 |
Container runtime |
Mirantis Container Runtime |
20.10.13 1 |
Distributed storage |
Ceph |
15.2.17 (Octopus) |
Rook |
1.0.0-20220809220209 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-352-gf55d6378 |
|
lcm-ansible Updated |
0.20.1-2-g9148ac3 |
|
lcm-agent Updated |
0.3.0-352-gf55d6378 |
|
StackLight |
Alerta Updated |
8.5.0-20221122164956 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow Updated |
0.1-20221124153923 |
|
Blackbox Exporter |
0.19.0 |
|
cAdvisor New |
0.46.0 |
|
Cerebro Updated |
0.9.4 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd Updated |
1.15.3 |
|
Grafana Updated |
9.1.8 |
|
Grafana Image Renderer Updated |
3.6.1-20221103105602 |
|
kube-state-metrics |
2.2.4 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector Updated |
0.1-20221115143126 |
|
Metricbeat Updated |
7.10.2 |
|
Node Exporter |
1.2.2 |
|
OpenSearch Updated |
1-20221129201140 |
|
OpenSearch Dashboards Updated |
1-20221213070555 |
|
Prometheus |
2.35.0 |
|
Prometheus ES Exporter Updated |
0.14.0-20221028070923 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus NGINX Exporter Removed |
n/a |
|
Prometheus Node Exporter Renamed to Node Exporter |
n/a |
|
Prometheus Patroni Exporter Updated |
0.0.1 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier Updated |
0.3-20221103105502 |
|
sf-reporter Updated |
0.1-20221128192801 |
|
Spilo |
13-2.1p1-20220921105803 |
|
Telegraf |
1.9.1-20221107155248 Updated |
|
1.23.4-20220915114529 |
||
Telemeter Updated |
4.4 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 11.6.0. For artifacts of the Container Cloud release, see Container Cloud release 2.22.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcc-2.22-3.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.17 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20221221183423 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.0.0-20220809220209 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.20.1-2-g9148ac3/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-352-gf55d6378/lcm-agent |
|
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.35.11.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.35.11.tgz |
|
Docker images |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-352-gf55d6378 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-27.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cadvisor New |
https://binary.mirantis.com/stacklight/helm/cadvisor-0.1.0-mcp-2.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-44.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-156.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-191.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-40.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-45.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-229.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
prometheus-nginx-exporter Removed |
n/a |
|
refapp Updated |
https://binary.mirantis.com/scale/helm/refapp-0.2.1-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.10.6.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20221122164956 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20221124153923 |
|
alpine-utils New |
mirantis.azurecr.io/stacklight/alpine-utils:1-20221213101955 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
busybox Removed |
n/a |
|
cadvisor New |
mirantis.azurecr.io/stacklight/cadvisor:v0.46.0 |
|
cerebro Updated |
mirantis.azurecr.io/stacklight/cerebro:v0.9-20221028114642 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curator Updated |
mirantis.azurecr.io/stacklight/curator:5.7.6-20221125180652 |
|
curl Removed |
n/a |
|
curl-jq Removed |
n/a |
|
elasticsearch_exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.15-20221205103417 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:9.1.8 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.6.1-20221103105602 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.21.0-20221122115008 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.22.13 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20221115143126 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20221208132713 |
|
nginx-prometheus-exporter Removed |
n/a |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20221129201140 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20221213070555 |
|
origin-telemeter Removed |
n/a |
|
pgbouncer Updated |
mirantis.azurecr.io/stacklight/pgbouncer:1-20221116202249 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.35.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20221028070923 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:0.0.1-2022111wont-fix/8112512 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
refapp |
mirantis.azurecr.io/openstack/openstack-refapp:0.0.1.dev29 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20221103105502 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20221128192801 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220921105803 |
|
stacklight-toolkit Updated |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20221202065207 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20221107155248 Updated |
|
mirantis.azurecr.io/stacklight/telegraf:1.23.4-20220915114529 |
||
telemeter New |
mirantis.azurecr.io/stacklight/telemeter:4.4-20221129100512 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq Updated |
mirantis.azurecr.io/stacklight/yq:4.30.5 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.6/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2022-09-15-014207.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20220915105522 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20220915105637 2 |
For the list of known and addressed issues, refer to the Container Cloud release 2.22.0 section.
See also
This section outlines release notes for the Cluster release 11.5.0 that is introduced in the Mirantis Container Cloud release 2.21.0.
This Cluster release supports Mirantis Kubernetes Engine 3.5.5 with Kubernetes 1.21 and Mirantis Container Runtime 20.10.13.
This section outlines new features implemented in the Cluster release 11.5.0 that is introduced in the Container Cloud release 2.21.0.
Updated the Mirantis Kubernetes Engine (MKE) version from 3.5.4 to 3.5.5 and the Mirantis Container Runtime (MCR) version from 20.10.12 to 20.10.13 for the Container Cloud management, regional, and managed clusters on all supported cloud providers, as well as for non Container Cloud based MKE cluster attachment.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
Updated the MetalLB version from 0.12.1 to 0.13.4 for the Container Cloud management, regional, and managed clusters of all cloud providers that use MetalLB: bare metal, Equinix Metal with public and private networking, vSphere.
The MetalLB configuration is now stored in dedicated MetalLB objects
instead of the ConfigMap object.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
Improved etcd monitoring by implementing the Etcd dashboard and
etcdDbSizeCritical and etcdDbSizeMajor alerts that inform about the
size of the etcd database.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
Learn more
Implemented Reference Application that is a small microservice application that enables workload monitoring on non-MOSK managed clusters. It mimics a classical microservice application and provides metrics that describe the likely behavior of user workloads.
Reference Application contains a set of alerts and a separate Grafana dashboard to provide check statuses of Reference Application and statistics such as response time and content length.
The feature is disabled by default and can be enabled using the StackLight configuration manifest.
Note
For the feature support on MOSK deployments, refer to MOSK documentation: Deploy RefApp using automation tools.
Added the miraCephSecretsInfo specification to KaaSCephCluster.status.
This specification contains current state and details of secrets that are used
in the Ceph cluster, such as keyrings, Ceph clients, RADOS Gateway user
credentials, and so on.
Using miraCephSecretsInfo, you can create, access, and remove Ceph RADOS
Block Device (RBD) or Ceph File System (CephFS) clients and RADOS Gateway
(RGW) users.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature is not supported yet.
Implemented the ability to create and configure Amazon S3 bucket policies between Ceph Object Storage users.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
The following table lists the components versions of the Cluster release 11.5.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration Updated |
Mirantis Kubernetes Engine |
3.5.5 0 |
Container runtime Updated |
Mirantis Container Runtime |
20.10.13 1 |
Distributed storage Updated |
Ceph |
15.2.17 (Octopus) |
Rook |
1.0.0-20220809220209 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-327-gbc30b11b |
|
lcm-ansible Updated |
0.19.0-12-g6cad672 |
|
lcm-agent Updated |
0.3.0-327-gbc30b11b |
|
StackLight |
Alerta Updated |
8.5.0-20220923121625 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow |
0.1-20220706035316 |
|
Cerebro Updated |
0.9-20220923122026 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd Updated |
1.14-20220922214003 |
|
Grafana |
9.0.2 |
|
Grafana Image Renderer Updated |
3.5.0 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector |
0.1-20220711134630 |
|
Metricbeat Updated |
7.10.2-20220909091002 |
|
OpenSearch |
1-20220517112057 |
|
OpenSearch Dashboards |
1-20220517112107 |
|
Prometheus |
2.35.0 |
|
Prometheus Blackbox Exporter |
0.19.0 |
|
Prometheus ES Exporter |
0.14.0-20220517111946 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20220624102731 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Reference Application New |
0.0.1 |
|
sf-notifier |
0.3-20220706035002 |
|
sf-reporter Updated |
0.1-20220916113234 |
|
Spilo Updated |
13-2.1p1-20220921105803 |
|
Telegraf |
1.9.1-20220714080809 |
|
1.23.4-20220915114529 Updated |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 11.5.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-964.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/ceph/ceph:v15.2.17 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20221024145202 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.0.0-20220809220209 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.19.0-12-g6cad672/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-327-gbc30b11b/lcm-agent |
|
Helm charts Updated |
helm-controller |
https://binary.mirantis.com/core/helm/helm-controller-1.34.16.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.34.16.tgz |
|
Docker images |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-327-gbc30b11b |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow Updated |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-37.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-142.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-173.tgz |
|
iam-proxy |
||
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-40.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-42.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-229.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
refapp New |
https://binary.mirantis.com/scale/helm/refapp-0.1.1-mcp-1.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-5.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.9.2.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20220923121625 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20220706035316 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro Updated |
mirantis.azurecr.io/stacklight/cerebro:v0.9-20220923122026 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch_exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220922214003 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.0.2 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.5.0 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.15.9 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22.13 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220711134630 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220909091002 |
|
nginx-prometheus-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch |
mirantis.azurecr.io/stacklight/opensearch:1-20220517112057 |
|
opensearch-dashboards |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20220517112107 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
pgbouncer |
mirantis.azurecr.io/stacklight/pgbouncer:1.12.0 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.35.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220517111946 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20220624102731 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
refapp New |
mirantis.azurecr.io/openstack/openstack-refapp:0.0.1.dev29 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20220706035002 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20220916113234 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220921105803 |
|
stacklight-toolkit New |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20220729121446 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20220714080809 |
|
mirantis.azurecr.io/stacklight/telegraf:1.23.4-20220915114529 Updated |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:4.25.2 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2022-07-13-020010.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20220915105522 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20220915105637 2 |
For the list of known and resolved issues, refer to the Container Cloud release 2.21.0 section.
This section outlines release notes for the Cluster release 11.4.0 that is introduced in the Mirantis Container Cloud release 2.20.0.
This Cluster release supports Mirantis Kubernetes Engine 3.5.4 with Kubernetes 1.21 and Mirantis Container Runtime 20.10.12.
This section outlines new features implemented in the Cluster release 11.4.0 that is introduced in the Container Cloud release 2.20.0.
Updated the Mirantis Kubernetes Engine (MKE) version from 3.5.3 to 3.5.4 and the Mirantis Container Runtime (MCR) version from 20.10.11 to 20.10.12 for the Container Cloud management, regional, and managed clusters on all supported cloud providers, as well as for non Container Cloud based MKE cluster attachment.
To reduce resource consumption, removed Ceph cluster deployment from management and regional clusters based on bare metal and Equinix Metal with private networking. Ceph is automatically removed during the Cluster release update to 11.4.0. Managed clusters continue using Ceph as a distributed storage system.
Implemented the objectUsers RADOS Gateway parameter in the
KaaSCephCluster CR. The new parameter allows for an easy creation of custom
Ceph RADOS Gateway users with permission rules. The users parameter is now
deprecated and, if specified, will be automatically transformed to
objectUsers.
Learn more
Implemented the rbdDeviceMapOptions field in the Ceph pool parameters of
the KaaSCephCluster CR. The new field allows specifying custom RADOS Block
Device (RBD) map options to use with StorageClass of a corresponding Ceph
pool.
Learn more
Implemented the mgr.mgrModules parameter that includes the name and
enabled keys to provide the capability to disable a particular Ceph Manager
module. The mgr.modules parameter is now deprecated and, if specified, will
be automatically transformed to mgr.mgrModules.
Implemented the capability to configure health checks and liveness probe
settings for Ceph daemons through the KaaSCephCluster CR.
The following table lists the components versions of the Cluster release 11.4.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.5.4 0 |
Container runtime |
Mirantis Container Runtime Updated |
20.10.12 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.0.0-20220504194120 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-285-g8498abe0 |
|
lcm-ansible Updated |
0.18.1 |
|
lcm-agent Updated |
0.3.0-288-g405179c2 |
|
metallb-controller Updated |
0.12.1 |
|
metrics-server |
0.5.2 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow Updated |
0.1-20220706035316 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.14-20220111114545 |
|
Grafana Updated |
9.0.2 |
|
Grafana Image Renderer |
3.4.2 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector Updated |
0.1-20220711134630 |
|
Metricbeat |
7.10.2-20220309185937 |
|
OpenSearch |
1-20220517112057 |
|
OpenSearch Dashboards |
1-20220517112107 |
|
Prometheus |
2.35.0 |
|
Prometheus Blackbox Exporter |
0.19.0 |
|
Prometheus ES Exporter |
0.14.0-20220517111946 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter Updated |
0.1-20220624102731 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier Updated |
0.3-20220706035002 |
|
sf-reporter Updated |
0.1-20220622101204 |
|
Spilo |
13-2.1p1-20220225091552 |
|
Telegraf Updated |
1.9.1-20220714080809 |
|
1.20.2-20220204122426 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 11.4.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-908.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220819101016 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.0.0-20220504194120 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.18.1/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-288-g405179c2/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.33.5.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.33.5.tgz |
|
Docker images |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-285-g8498abe0 |
metallb-controller Updated |
mirantis.azurecr.io/bm/external/metallb/controller:v0.12.1 |
|
metallb-speaker Updated |
mirantis.azurecr.io/bm/external/metallb/speaker:v0.12.1 |
|
metrics-server |
mirantis.azurecr.io/core/external/metrics-server:v0.5.2 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-9.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-37.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-131.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-154.tgz |
|
iam-proxy Updated |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-6.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-40.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-42.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-228.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-8.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-2.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-3.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.8.1.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-6.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-6.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20220706035316 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220111114545 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:9.0.2 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.4.2 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.15.9 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220711134630 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220309185937 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch |
mirantis.azurecr.io/stacklight/opensearch:1-20220517112057 |
|
opensearch-dashboards |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20220517112107 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
pgbouncer |
mirantis.azurecr.io/stacklight/pgbouncer:1.12.0 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.35.0 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220517111946 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20220624102731 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20220706035002 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20220622101204 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220225091552 |
|
telegraf Updated |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20220714080809 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.2-20220204122426 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:4.25.2 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2022-07-13-020010.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
For the list of known and resolved issues, refer to the Container Cloud release 2.20.0 section.
This section outlines release notes for the Cluster release 11.3.0 that is introduced in the Mirantis Container Cloud release 2.19.0.
This Cluster release supports Mirantis Kubernetes Engine 3.5.3 with Kubernetes 1.21 and Mirantis Container Runtime 20.10.11.
This section outlines new features implemented in the Cluster release 11.3.0 that is introduced in the Container Cloud release 2.19.0.
Implemented a new Kubernetes Containers Grafana dashboard that provides resources consumption metrics of containers running on Kubernetes nodes.
Learn more
Enhanced the documentation by adding troubleshooting guidelines for the Kubernetes system, Metric Collector, Helm Controller, Release Controller, and MKE alerts.
Learn more
As part of the Elasticsearch switching to OpenSearch, replaced the Elasticsearch parameters with OpenSearch in the Container Cloud web UI.
Implemented the capability to easily view the summary and health status of all Ceph clusters through the Container Cloud web UI.
Implemented the capability to remove or replace Ceph OSDs not only by the
device name or path but also by ID, using the by-id parameter in the
KaaSCephOperationRequest CR.
Learn more
TechPreview
Implemented the capability to create multiple Ceph data pools per a single
CephFS installation using the dataPools parameter in the CephFS
specification. The dataPool parameter is now deprecated.
Learn more
The following table lists the components versions of the Cluster release 11.3.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.5.3 0 |
Container runtime |
Mirantis Container Runtime |
20.10.11 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.0.0-20220504194120 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-257-ga93244da |
|
lcm-ansible Updated |
0.17.1-2-g1e337f8 |
|
lcm-agent Updated |
0.3.0-257-ga93244da |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.5.2 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow |
0.1-20220420161450 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.14-20220111114545 |
|
Grafana |
8.5.0 |
|
Grafana Image Renderer Updated |
3.4.2 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector Updated |
0.1-20220614110617 |
|
Metricbeat |
7.10.2-20220309185937 |
|
OpenSearch Updated |
1-20220517112057 |
|
OpenSearch Dashboards Updated |
1-20220517112107 |
|
Patroni |
13-2.1p1-20220225091552 |
|
Prometheus Updated |
2.35.0 |
|
Prometheus Blackbox Exporter |
0.19.0 |
|
Prometheus ES Exporter Updated |
0.14.0-20220517111946 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier Updated |
0.3-20220514051554 |
|
sf-reporter |
0.1-20220419092138 |
|
Telegraf |
1.9.1-20210225142050 |
|
1.20.2-20220204122426 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 11.3.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-831.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220715144333 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.0.0-20220504194120 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.17.1-2-g1e337f8/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-257-ga93244da/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.32.4.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.32.4.tgz |
|
Docker images |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-257-ga93244da |
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/core/external/metrics-server:v0.5.2 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-9.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-37.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-128.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-150.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-6.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-50.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-40.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-42.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-228.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-8.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-2.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-3.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.7.2.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-5.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-5.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20220420161450 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220111114545 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:8.5.0 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.4.2 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.15.9 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220614110617 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220309185937 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20220517112057 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20220517112107 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.35.0 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220517111946 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20220514051554 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20220419092138 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220225091552 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225142050 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.2-20220204122426 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq Updated |
mirantis.azurecr.io/stacklight/yq:4.25.2 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2022-05-03-013543.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
For the list of known and resolved issues, refer to the Container Cloud release 2.19.0 section.
This section outlines release notes for the Cluster release 11.2.0 that is introduced in the Mirantis Container Cloud release 2.18.0.
This Cluster release supports Mirantis Kubernetes Engine 3.5.3 with Kubernetes 1.21 and Mirantis Container Runtime 20.10.11.
This section outlines new features implemented in the Cluster release 11.2.0 that is introduced in the Container Cloud release 2.18.0.
Updated the Mirantis Kubernetes Engine (MKE) version from 3.5.1 to 3.5.3 and the Mirantis Container Runtime (MCR) version from 20.10.8 to 20.10.11 for the Container Cloud management, regional, and managed clusters on all supported cloud providers, as well as for non Container Cloud based MKE cluster attachment.
As part of the Elasticsearch switching to OpenSearch, removed the Elasticsearch and Kibana services, as well as introduced a set of new parameters that will replace the current ones in future releases. The old parameters are supported and take precedence over the new ones. For details, see Deprecation notes and StackLight configuration parameters.
Note
In the Container Cloud web UI, the Elasticsearch and Kibana naming is still present. However, the services behind them have switched to OpenSearch and OpenSearch Dashboards.
Implemented the following improvements to StackLight alerting:
Added the
MCCClusterUpdatinginformational alert that raises when the Mirantis Container Cloud cluster starts updating.Enhanced StackLight alerting by clarifying alert severity levels. Switched all
Minoralerts toWarning. Now, only alerts of the following severities exist:informational,warning,major, andcritical.Enhanced the documentation by adding troubleshooting guidelines for the Kubernetes applications, resources, and storage alerts.
Implemented the capability to allow sending of metrics from Prometheus, using the Prometheus remote write feature to a custom monitoring endpoint.
Defined the following parameters in the StackLight configuration of the Cluster object for all types of clusters as mandatory. This applies to the clusters with StackLight enabled only. For existing clusters, Cluster object will be updated automatically.
Important
When creating a new cluster, specify these parameters through the Container Cloud web UI or as described in StackLight configuration parameters. Update all cluster templates created before Container Cloud 2.18.0 that do not have values for these parameters specified. Otherwise, the admission controller will reject cluster creation.
Web UI parameter |
API parameter |
|---|---|
Enable Logging |
|
HA Mode |
|
Prometheus Persistent Volume Claim Size |
|
Elasticsearch Persistent Volume Claim Size |
|
Implemented the capability to configure the placement of the
rook-ceph-operator, rook-discover, and csi-rbdplugin Ceph daemons.
Learn more
The following table lists the components versions of the Cluster release 11.2.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.5.3 0 |
Container runtime |
Mirantis Container Runtime Updated |
20.10.11 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.0.0-20220504194120 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-239-gae7218ea |
|
lcm-ansible Updated |
0.16.0-13-gcac49ca |
|
lcm-agent Updated |
0.3.0-239-gae7218ea |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.5.2 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow Updated |
0.1-20220420161450 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.14-20220111114545 |
|
Grafana Updated |
8.5.0 |
|
Grafana Image Renderer |
3.2.1 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector |
0.1-20220209123106 |
|
Metricbeat |
7.10.2-20220309185937 |
|
OpenSearch |
1-20220316161927 |
|
OpenSearch Dashboards |
1-20220316161951 |
|
Patroni |
13-2.1p1-20220225091552 |
|
Prometheus |
2.31.1 |
|
Prometheus Blackbox Exporter |
0.19.0 |
|
Prometheus ES Exporter |
0.14.0-20220111114356 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier |
0.3-20210930112115 |
|
sf-reporter Updated |
0.1-20220419092138 |
|
Telegraf |
1.9.1-20210225142050 |
|
1.20.2-20220204122426 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 11.2.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-792.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220506180707 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.0.0-20220504194120 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.16.0-13-gcac49ca/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-239-gae7218ea/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.31.9.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.31.9.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-239-gae7218ea |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.5.2 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow Updated |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Removed |
n/a |
|
elasticsearch-curator Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-9.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-37.tgz |
|
fluentd-elasticsearch Removed |
n/a |
|
fluentd-logs New |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-128.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-145.tgz |
|
iam-proxy |
||
kibana Removed |
n/a |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-6.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch New |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-50.tgz |
|
opensearch-dashboards New |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-40.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-42.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-225.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-8.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-2.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-3.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.6.1.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-5.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-5.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20220420161450 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220111114545 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:8.5.0 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.2.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.15.9 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220209123106 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220309185937 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch |
mirantis.azurecr.io/stacklight/opensearch:1-20220316161927 |
|
opensearch-dashboards |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20220316161951 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.31.1 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220111114356 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20220419092138 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220225091552 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.2-20220204122426 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2022-05-03-013543.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
For the list of known and resolved issues, refer to the Container Cloud release 2.18.0 section.
This section outlines release notes for the Cluster release 11.1.0 that is introduced in the Mirantis Container Cloud release 2.17.0.
This Cluster release supports Mirantis Kubernetes Engine 3.5.1 with Kubernetes 1.21 and Mirantis Container Runtime 20.10.8.
This section outlines new features implemented in the Cluster release 11.1.0 that is introduced in the Container Cloud release 2.17.0.
Expanded support for the Mirantis Kubernetes Engine (MKE) 3.5.1 that includes Kubernetes 1.21 to be deployed on the Container Cloud management and regional clusters. The MKE 3.5.1 support for managed clusters was introduced in Container Cloud 2.16.0.
Learn more
Implemented the capability to configure the Elasticsearch retention time per logs, events, and notifications indices when creating a managed cluster through Container Cloud web UI.
The Retention Time parameter in the Container Cloud web UI is now replaced with the Logstash Retention Time, Events Retention Time, and Notifications Retention Time parameters.
Learn more
Implemented monitoring and added alerts for the Helm Controller
service and the HelmBundle custom resources.
Learn more
Implemented configurable timeouts for Ceph requests processing. The default is
set to 30 minutes. You can configure the timeout using the
pgRebalanceTimeoutMin parameter in the Ceph Helm chart.
Implemented the capability to configure the replicas count for
cephController, cephStatus, and cephRequest controllers using the
replicas parameter in the Ceph Helm chart. The default is set to 3
replicas.
Implemented a separate ceph-kcc-controller that runs on a management
cluster and manages the KaaSCephCluster custom resource (CR). Previously,
the KaaSCephCluster CR was managed by bm-provider.
Learn more
The following table lists the components versions of the Cluster release 11.1.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.5.1 0 |
Container runtime |
Mirantis Container Runtime |
20.10.8 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook Updated |
1.0.0-20220504194120 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-229-g4774bbbb |
|
lcm-ansible Updated |
0.15.0-24-gf023ea1 |
|
lcm-agent Updated |
0.3.0-229-g4774bbbb |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.5.2 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.14-20220111114545 |
|
Grafana |
8.2.7 |
|
Grafana Image Renderer |
3.2.1 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector |
0.1-20220209123106 |
|
Metricbeat Updated |
7.10.2-20220309185937 |
|
OpenSearch Updated |
1-20220316161927 |
|
OpenSearch Dashboards Updated |
1-20220316161951 |
|
Patroni Updated |
13-2.1p1-20220225091552 |
|
Prometheus |
2.31.1 |
|
Prometheus Blackbox Exporter |
0.19.0 |
|
Prometheus ES Exporter |
0.14.0-20220111114356 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier |
0.3-20210930112115 |
|
sf-reporter |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
Updated |
1.20.2-20220204122426 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 11.1.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-719.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220421152918 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.0.0-20220504194120 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.15.0-24-gf023ea1/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-229-g4774bbbb/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.30.6.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.30.6.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-229-g4774bbbb |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.5.2 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-1.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-45.tgz |
|
elasticsearch-curator Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-8.tgz |
|
elasticsearch-exporter Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-36.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-123.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-130.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-36.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-4.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-42.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-218.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-1.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-1.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.5.3.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-4.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-4.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220111114545 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:8.2.7 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.2.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220209123106 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220309185937 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20220316161927 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20220316161951 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.31.1 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220111114356 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220225091552 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
Updated |
mirantis.azurecr.io/stacklight/telegraf:1.20.2-20220204122426 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2021-11-11-014639.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
For the list of known and resolved issues, refer to the Container Cloud release 2.17.0 section.
This section outlines release notes for the Cluster release 11.0.0 that is introduced in the Mirantis Container Cloud release 2.16.0 and is designed for managed clusters.
This Cluster release supports Mirantis Kubernetes Engine 3.5.1 with Kubernetes 1.21 and Mirantis Container Runtime 20.10.8.
For the list of known and resolved issues, refer to the Container Cloud release 2.16.0 section.
This section outlines new features implemented in the Cluster release 11.0.0 that is introduced in the Container Cloud release 2.16.0.
Introduced support for the Mirantis Kubernetes Engine (MKE) 3.5.1 that includes Kubernetes 1.21 to be deployed on the Container Cloud managed clusters. Also, added support for attachment of existing MKE 3.5.1 clusters.
Learn more
Added the KubePodsRegularLongTermRestarts alert that raises in case of a
long-term periodic restart of containers.
Learn more
Implemented the capability to configure the Elasticsearch retention time per
index using the elasticsearch.retentionTime parameter in the StackLight
Helm chart. Now, you can configure different retention periods for different
indices: logs, events, and notifications.
The elasticsearch.logstashRetentionTime parameter is now deprecated.
Learn more
Implemented the capability to configure Prometheus Blackbox Exporter, including
customModules and timeoutOffset, through the StackLight Helm chart.
Implemented the capability to define custom Prometheus scrape configurations.
Due to licensing changes for Elasticsearch, Mirantis Container Cloud has switched from using Elasticsearch to OpenSearch and Kibana has switched to OpenSearch Dashboards. OpenSearch is a fork of Elasticsearch under the open-source Apache License with development led by Amazon Web Services.
For new deployments with the logging stack enabled, OpenSearch is now deployed by default. For existing deployments, migration to OpenSearch is performed automatically during clusters update. However, the entire Elasticsearch cluster may go down for up to 15 minutes.
Learn more
The following table lists the components versions of the Cluster release 11.0.0.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.5.1 0 |
Container runtime |
Mirantis Container Runtime |
20.10.8 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.7.6 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller |
0.3.0-187-gba894556 |
|
lcm-ansible |
0.14.0-14-geb6a51f |
|
lcm-agent |
0.3.0-187-gba894556 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.5.2 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.14-20220111114545 |
|
Grafana |
8.2.7 |
|
Grafana Image Renderer |
3.2.1 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector |
0.1-20220209123106 |
|
Metricbeat |
7.10.2-20220111114624 |
|
OpenSearch |
1.2-20220114131142 |
|
OpenSearch Dashboards |
1.2-20220114131222 |
|
Patroni |
13-2.1p1-20220131130853 |
|
Prometheus |
2.31.1 |
|
Prometheus Blackbox Exporter |
0.19.0 |
|
Prometheus ES Exporter |
0.14.0-20220111114356 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier |
0.3-20210930112115 |
|
sf-reporter |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
1.20.0-20210927090119 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 11.0.0.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-661.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220203124822 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.7.6 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.14.0-14-geb6a51f/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-187-gba894556/lcm-agent |
|
Helm charts |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.29.6.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.29.6.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-187-gba894556 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.5.2 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-1.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-44.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-36.tgz |
|
fluentd-elasticsearch |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-120.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-125.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-36.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-4.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-38.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-218.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-1.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-1.tgz |
|
stacklight |
https://binary.mirantis.com/stacklight/helm/stacklight-0.4.3.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-4.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-4.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220111114545 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:8.2.7 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.2.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220209123106 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220111114624 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch |
mirantis.azurecr.io/stacklight/opensearch:1.2-20220114131142 |
|
opensearch-dashboards |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1.2-20220114131222 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.31.1 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220111114356 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220131130853 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.0-20210927090119 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2021-11-11-014639.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
8.x series¶
This section outlines release notes for the unsupported Cluster releases of the 8.x series.
The Cluster release 8.10.0 is introduced in the Mirantis Container Cloud release 2.20.1. This Cluster release is based on the Cluster release 7.10.0.
The Cluster release 8.10.0 supports:
Mirantis OpenStack for Kubernetes (MOSK) 22.4. For details, see MOSK Release Notes.
Mirantis Kubernetes Engine (MKE) 3.4.10. For details, see MKE Release Notes.
Mirantis Container Runtime (MCR) 20.10.12. For details, see MCR Release Notes.
Kubernetes 1.20.
For the list of addressed and known issues, refer to the Container Cloud release 2.20.0 section.
This section outlines new features implemented in the Cluster release 8.10.0 that is introduced in the Container Cloud release 2.20.1.
Updated the Mirantis Kubernetes Engine (MKE) version from 3.4.8 to 3.4.10 and the Mirantis Container Runtime (MCR) version from 20.10.11 to 20.10.12.
Implemented the objectUsers RADOS Gateway parameter in the
KaaSCephCluster CR. The new parameter allows for an easy creation of custom
Ceph RADOS Gateway users with permission rules. The users parameter is now
deprecated and, if specified, will be automatically transformed to
objectUsers.
Learn more
Implemented the capability to easily view the summary and health status of all Ceph clusters through the Container Cloud web UI.
Implemented the capability to remove or replace Ceph OSDs not only by the
device name or path but also by ID, using the by-id parameter in the
KaaSCephOperationRequest CR.
Learn more
Implemented a new Kubernetes Containers Grafana dashboard that provides resources consumption metrics of containers running on Kubernetes nodes.
Learn more
The following table lists the components versions of the Cluster release 8.10.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.4.10 0 |
Container runtime |
Mirantis Container Runtime Updated |
20.10.12 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.0.0-20220504194120 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-285-g8498abe0 |
|
lcm-ansible Updated |
0.18.1 |
|
lcm-agent Updated |
0.3.0-288-g405179c2 |
|
metallb-controller Updated |
0.12.1 |
|
metrics-server |
0.5.2 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow Updated |
0.1-20220706035316 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.14-20220111114545 |
|
Grafana Updated |
9.0.2 |
|
Grafana Image Renderer Updated |
3.4.2 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector Updated |
0.1-20220711134630 |
|
Metricbeat |
7.10.2-20220309185937 |
|
OpenSearch Updated |
1-20220517112057 |
|
OpenSearch Dashboards Updated |
1-20220517112107 |
|
Prometheus Updated |
2.35.0 |
|
Prometheus Blackbox Exporter |
0.19.0 |
|
Prometheus ES Exporter Updated |
0.14.0-20220517111946 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter Updated |
0.1-20220624102731 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier Updated |
0.3-20220706035002 |
|
sf-reporter Updated |
0.1-20220622101204 |
|
Spilo |
13-2.1p1-20220225091552 |
|
Telegraf Updated |
1.9.1-20220714080809 |
|
1.20.2-20220204122426 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 8.10.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-908.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220819101016 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.0.0-20220504194120 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.18.1/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-288-g405179c2/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.33.5.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.33.5.tgz |
|
Docker images |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-285-g8498abe0 |
metallb-controller Updated |
mirantis.azurecr.io/bm/external/metallb/controller:v0.12.1 |
|
metallb-speaker Updated |
mirantis.azurecr.io/bm/external/metallb/speaker:v0.12.1 |
|
metrics-server |
mirantis.azurecr.io/core/external/metrics-server:v0.5.2 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-9.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-37.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-131.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-154.tgz |
|
iam-proxy Updated |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-6.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-40.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-42.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-228.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-8.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-2.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-3.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.8.1.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-6.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-6.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20220706035316 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220111114545 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:9.0.2 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.4.2 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.15.9 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220711134630 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220309185937 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20220517112057 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20220517112107 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
pgbouncer |
mirantis.azurecr.io/stacklight/pgbouncer:1.12.0 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.35.0 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220517111946 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20220624102731 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20220706035002 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20220622101204 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220225091552 |
|
telegraf Updated |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20220714080809 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.2-20220204122426 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq Updated |
mirantis.azurecr.io/stacklight/yq:4.25.2 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2022-07-13-020010.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
The Cluster release 8.8.0 is introduced in the Mirantis Container Cloud release 2.18.1. This Cluster release is based on the Cluster release 7.8.0.
The Cluster release 8.8.0 supports:
Mirantis OpenStack for Kubernetes (MOSK) 22.3. For details, see MOSK Release Notes.
Mirantis Kubernetes Engine (MKE) 3.4.8. For details, see MKE Release Notes.
Mirantis Container Runtime (MCR) 20.10.11. For details, see MCR Release Notes.
Kubernetes 1.20.
For the list of addressed and known issues, refer to the Container Cloud release 2.18.0 section.
This section outlines new features implemented in the Cluster release 8.8.0 that is introduced in the Container Cloud release 2.18.1.
Updated the Mirantis Kubernetes Engine (MKE) version from 3.4.7 to 3.4.8 and the Mirantis Container Runtime (MCR) version from 20.10.8 to 20.10.11.
As part of the Elasticsearch switching to OpenSearch, removed the Elasticsearch and Kibana services, as well as introduced a set of new parameters that will replace the current ones in future releases. The old parameters are supported and take precedence over the new ones. For details, see Deprecation notes and StackLight configuration parameters.
Note
In the Container Cloud web UI, the Elasticsearch and Kibana naming is still present. However, the services behind them have switched to OpenSearch and OpenSearch Dashboards.
Implemented the following improvements to StackLight alerting:
Added the
MCCClusterUpdatinginformational alert that raises when the Mirantis Container Cloud cluster starts updating.Enhanced StackLight alerting by clarifying alert severity levels. Switched all
Minoralerts toWarning. Now, only alerts of the following severities exist:informational,warning,major, andcritical.Enhanced the documentation by adding troubleshooting guidelines for the Kubernetes applications, resources, and storage alerts.
Implemented the capability to allow sending of metrics from Prometheus, using the Prometheus remote write feature to a custom monitoring endpoint.
Defined the following parameters in the StackLight configuration of the Cluster object for all types of clusters as mandatory. This applies to the clusters with StackLight enabled only. For existing clusters, Cluster object will be updated automatically.
Important
When creating a new cluster, specify these parameters through the Container Cloud web UI or as described in StackLight configuration parameters. Update all cluster templates created before Container Cloud 2.18.0 that do not have values for these parameters specified. Otherwise, the Admission Controller will reject cluster creation.
Web UI parameter |
API parameter |
|---|---|
Enable Logging |
|
HA Mode |
|
Prometheus Persistent Volume Claim Size |
|
Elasticsearch Persistent Volume Claim Size |
|
Implemented the capability to configure the Elasticsearch retention time per logs, events, and notifications indices when creating a managed cluster through Container Cloud web UI.
The Retention Time parameter in the Container Cloud web UI is now replaced with the Logstash Retention Time, Events Retention Time, and Notifications Retention Time parameters.
Learn more
Implemented monitoring and added alerts for the Helm Controller
service and the HelmBundle custom resources.
Learn more
Implemented the capability to configure the placement of the
rook-ceph-operator, rook-discover, and csi-rbdplugin Ceph daemons.
Learn more
Implemented configurable timeouts for Ceph requests processing. The default is
set to 30 minutes. You can configure the timeout using the
pgRebalanceTimeoutMin parameter in the Ceph Helm chart.
Implemented the capability to configure the replicas count for
cephController, cephStatus, and cephRequest controllers using the
replicas parameter in the Ceph Helm chart. The default is set to 3
replicas.
Implemented a separate ceph-kcc-controller that runs on a management
cluster and manages the KaaSCephCluster custom resource (CR). Previously,
the KaaSCephCluster CR was managed by bm-provider.
Learn more
The following table lists the components versions of the Cluster release 8.8.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.4.8 0 |
Container runtime |
Mirantis Container Runtime Updated |
20.10.11 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook Updated |
1.0.0-20220504194120 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-239-gae7218ea |
|
lcm-ansible Updated |
0.16.0-13-gcac49ca |
|
lcm-agent Updated |
0.3.0-239-gae7218ea |
|
metallb-controller |
0.9.3-1 |
|
metrics-server Updated |
0.5.2 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow Updated |
0.1-20220420161450 |
|
Cerebro |
0.9.3 |
|
Elasticsearch curator |
5.7.6 |
|
Elasticsearch exporter |
1.0.2 |
|
Fluentd |
1.14-20220111114545 |
|
Grafana Updated |
8.5.0 |
|
Grafana Image Renderer |
3.2.1 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector |
0.1-20220209123106 |
|
Metricbeat Updated |
7.10.2-20220309185937 |
|
OpenSearch Updated |
1-20220316161927 |
|
OpenSearch Dashboards Updated |
1-20220316161951 |
|
Patroni Updated |
13-2.1p1-20220225091552 |
|
Prometheus |
2.31.1 |
|
Prometheus Blackbox Exporter |
0.19.0 |
|
Prometheus ES Exporter |
0.14.0-20220111114356 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier |
0.3-20210930112115 |
|
sf-reporter Updated |
0.1-20220419092138 |
|
Telegraf |
1.9.1-20210225142050 |
|
1.20.2-20220204122426 Updated |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 8.8.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-792.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220506180707 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.0.0-20220504194120 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.16.0-13-gcac49ca/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-239-gae7218ea/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.31.9.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.31.9.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-239-gae7218ea |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.5.2 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow Updated |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Removed |
n/a |
|
elasticsearch-curator Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-9.tgz |
|
elasticsearch-exporter Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-37.tgz |
|
fluentd-elasticsearch Removed |
n/a |
|
fluentd-logs New |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-128.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-145.tgz |
|
iam-proxy |
||
kibana Removed |
n/a |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-6.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch New |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-50.tgz |
|
opensearch-dashboards New |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-40.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-42.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-225.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-8.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-2.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-3.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.6.1.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-5.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-5.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20220420161450 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220111114545 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:8.5.0 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.2.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.15.9 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220209123106 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220309185937 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20220316161927 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20220316161951 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
pgbouncer |
mirantis.azurecr.io/stacklight/pgbouncer:1.12.0 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.31.1 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220111114356 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20220419092138 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220225091552 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
Updated |
mirantis.azurecr.io/stacklight/telegraf:1.20.2-20220204122426 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2022-05-03-013543.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
The Cluster release 8.6.0 is introduced in the Mirantis Container Cloud release 2.16.1. This Cluster release is based on the Cluster release 7.6.0.
The Cluster release 8.6.0 supports:
Mirantis OpenStack for Kubernetes (MOSK) 22.2. For details, see MOSK Release Notes.
Mirantis Kubernetes Engine (MKE) 3.4.7. For details, see MKE Release Notes.
Mirantis Container Runtime (MCR) 20.10.8. For details, see MCR Release Notes.
Kubernetes 1.20.
For the list of addressed and known issues, refer to the Container Cloud release 2.16.0 section.
This section outlines new features implemented in the Cluster release 8.6.0 that is introduced in the Container Cloud release 2.16.1.
Updated the Mirantis Kubernetes Engine (MKE) major version from 3.4.6 to 3.4.7 for the Container Cloud management, regional, and managed clusters. Also, added support for attachment of existing MKE 3.4.7 clusters.
Learn more
Added the KubePodsRegularLongTermRestarts alert that raises in case of a
long-term periodic restart of containers.
Learn more
Implemented the capability to configure the Elasticsearch retention time per
index using the elasticsearch.retentionTime parameter in the StackLight
Helm chart. Now, you can configure different retention periods for different
indices: logs, events, and notifications.
The elasticsearch.logstashRetentionTime parameter is now deprecated.
Learn more
Implemented the capability to configure Prometheus Blackbox Exporter, including
customModules and timeoutOffset, through the StackLight Helm chart.
Implemented the capability to define custom Prometheus scrape configurations.
Due to licensing changes for Elasticsearch, Mirantis Container Cloud has switched from using Elasticsearch to OpenSearch and Kibana has switched to OpenSearch Dashboards. OpenSearch is a fork of Elasticsearch under the open-source Apache License with development led by Amazon Web Services.
For new deployments with the logging stack enabled, OpenSearch is now deployed by default. For existing deployments, migration to OpenSearch is performed automatically during clusters update. However, the entire Elasticsearch cluster may go down for up to 15 minutes.
Learn more
The following table lists the components versions of the Cluster release 8.6.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.4.7 0 |
Container runtime |
Mirantis Container Runtime |
20.10.8 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.7.6 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-187-gba894556 |
|
lcm-ansible Updated |
0.14.0-14-geb6a51f |
|
lcm-agent Updated |
0.3.0-187-gba894556 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server Updated |
0.5.2 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Removed |
n/a |
|
Elasticsearch curator |
5.7.6 |
|
Elasticsearch exporter |
1.0.2 |
|
Fluentd Updated |
1.14-20220111114545 |
|
Grafana |
8.2.7 |
|
Grafana Image Renderer |
3.2.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana Removed |
n/a |
|
Metric Collector Updated |
0.1-20220209123106 |
|
Metricbeat Updated |
7.10.2-20220111114624 |
|
OpenSearch New |
1.2-20220114131142 |
|
OpenSearch Dashboards New |
1.2-20220114131222 |
|
Patroni Updated |
13-2.1p1-20220131130853 |
|
Prometheus |
2.31.1 |
|
Prometheus Blackbox Exporter Updated |
0.19.0 |
|
Prometheus ES Exporter Updated |
0.14.0-20220111114356 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier |
0.3-20210930112115 |
|
sf-reporter |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
1.20.0-20210927090119 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 8.6.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-661.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220303130346 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.7.6 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.14.0-14-geb6a51f/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-187-gba894556/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.29.6.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.29.6.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-187-gba894556 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server Updated |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.5.2 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-1.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-44.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-36.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-120.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-125.tgz |
|
iam-proxy Updated |
||
kibana Updated |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-36.tgz |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-4.tgz |
|
metricbeat Updated |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-38.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-218.tgz |
|
prometheus-blackbox-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-1.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-1.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.4.3.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-4.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-4.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch Removed |
n/a |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220111114545 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:8.2.7 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.2.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana Removed |
n/a |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220209123106 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220111114624 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch New |
mirantis.azurecr.io/stacklight/opensearch:1.2-20220114131142 |
|
opensearch-dashboards New |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1.2-20220114131222 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.31.1 |
|
prometheus-blackbox-exporter Updated |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220111114356 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220131130853 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.0-20210927090119 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2021-11-11-014639.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
The Cluster release 8.5.0 is introduced in the Mirantis Container Cloud release 2.15.1. This Cluster release is based on the Cluster release 7.5.0.
The Cluster release 8.5.0 supports:
Mirantis OpenStack for Kubernetes (MOSK) 22.1. For details, see MOSK Release Notes.
Mirantis Kubernetes Engine (MKE) 3.4.6. For details, see MKE Release Notes.
Mirantis Container Runtime (MCR) 20.10.8. For details, see MCR Release Notes.
Kubernetes 1.20.
For the list of addressed and known issues, refer to the Container Cloud release 2.15.0 section.
This section outlines new features implemented in the Cluster release 8.5.0 that is introduced in the Container Cloud release 2.15.1.
Available since 2.16.0 Technology Preview
Implemented the initial Technology Preview support for Mirantis OpenStack for Kubernetes (MOSK) deployment on local software-based Redundant Array of Independent Disks (RAID) devices to withstand failure of one device at a time. The feature becomes available once your Container Cloud cluster is automatically upgraded to 2.16.0.
Using a custom bare metal host profile, you can configure and create
an mdadm-based software RAID device of type raid10 if you have
an even number of devices available on your servers. At least four
storage devices are required for such RAID device.
Introduced support for the Mirantis Kubernetes Engine version 3.4.6 with Kubernetes 1.20 for the Container Cloud management, regional, and managed clusters. Also, added support for attachment of existing MKE 3.4.6 clusters.
Learn more
Updated the Mirantis Container Runtime (MCR) version from 20.10.6 to 20.10.8 for the Container Cloud management, regional, and managed clusters on all supported cloud providers.
Learn more
Limited the number of monitored network interfaces to prevent extended Prometheus RAM consumption in big clusters. By default, Prometheus Node Exporter now only collects information of a basic set of interfaces, both host and container. If required you can edit the list of excluded devices as needed.
Implemented the capability to define custom Prometheus recording rules through
the prometheusServer.customRecordingRules parameter in the StackLight Helm
chart. Overriding of existing recording rules is not supported.
Implemented the capability to configure packet size for the syslog logging
output. If remote logging to syslog is enabled in StackLight, use the
logging.syslog.packetSize parameter in the StackLight Helm chart to
configure the packet size.
Learn more
Implemented the capability to configure the Prometheus Relay client timeout and
response size limit through the prometheusRelay.clientTimeout and
prometheusRelay.responseLimitBytes parameters in the StackLight Helm chart.
Implemented the MCCLicenseExpirationCritical and
MCCLicenseExpirationMajor alerts that notify about Mirantis Container Cloud
license expiration in less than 10 and 30 days.
Learn more
Implemented the following improvements to StackLight alerting:
Enhanced Kubernetes applications alerting:
Reworked the Kubernetes applications alerts to minimize flapping, avoid firing during pod rescheduling, and to detect crash looping for pods that restart less frequently.
Added the
KubeDeploymentOutage,KubeStatefulSetOutage, andKubeDaemonSetOutagealerts.Removed the redundant
KubeJobCompletionalert.Enhanced the alert inhibition rules to reduce alert flooding.
Improved alert descriptions.
Split
TelemeterClientFederationFailedintoTelemeterClientFailedandTelemeterClientHAFailedto separate alerts depending on the HA mode disabled or enabled.Updated the description for
DockerSwarmNodeFlapping.
Disabled unused Node Exporter collectors and implemented the capability to
manually enable needed collectors using the
nodeExporter.extraCollectorsEnabled parameter. Only the following
collectors are now enabled by default in StackLight:
|
|
|
|
To improve debugging and log reading, separated Ceph Controller, Ceph Status Controller, and Ceph Request Controller, which used to run in one pod, into three different deployments.
Learn more
Implemented additional validation of networks specified in
spec.cephClusterSpec.network.publicNet and
spec.cephClusterSpec.network.clusterNet and prohibited the use of the
0.0.0.0/0 CIDR. Now, the bare metal provider automatically translates
the 0.0.0.0/0 network range to the default LCM IPAM subnet if it exists.
You can now also add corresponding labels for the bare metal IPAM subnets when configuring the Ceph cluster during the management cluster deployment.
Learn more
Implemented full support for automated Ceph LCM operations using the
KaaSCephOperationRequest CR, such as addition or removal of Ceph OSDs and
nodes, as well as replacement of failed Ceph OSDs or nodes.
Learn more
Implemented the capability to specify Container Storage Interface (CSI)
provisioner tolerations and node affinity for different Rook resources.
Added support for the all and mds keys in toleration rules.
Extended the fullClusterInfo section of the KaaSCephCluster.status
resource with the following fields:
cephDetails- contains verbose details of a Ceph cluster statecephCSIPluginDaemonsStatus- contains details on all Ceph CSIs
Learn more
The following table lists the components versions of the Cluster release 8.5.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.4.6 0 |
Container runtime |
Mirantis Container Runtime Updated |
20.10.8 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook Updated |
1.7.6 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-132-g83a348fa |
|
lcm-ansible Updated |
0.13.0-27-gcb6022b |
|
lcm-agent Updated |
0.3.0-132-g83a348fa |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta Updated |
8.5.0-20211108051042 |
Alertmanager Updated |
0.23.0 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Updated |
7.10.2-2021110210112 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20210915110132 |
|
Grafana Updated |
8.2.7 |
|
Grafana Image Renderer Updated |
3.2.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana Updated |
7.10.2-20211101074638 |
|
Metric Collector Updated |
0.1-20211109121134 |
|
Metricbeat Updated |
7.10.2-20211103140113 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus Updated |
2.31.1 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.14.0-20210812120726 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter Updated |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier |
0.3-20210930112115 |
|
sf-reporter |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
1.20.0-20210927090119 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 8.5.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-606.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220204145523 |
|
cephcsi Updated |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook/ceph:v1.7.6 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.13.0-27-gcb6022b/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-132-g83a348fa/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.28.7.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.28.7.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-132-g83a348fa |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow Updated |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-1.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-37.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-32.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-115.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-121.tgz |
|
iam-proxy Updated |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-30.tgz |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-3.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-36.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-214.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-1.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-1.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.3.1.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-1.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-1.tgz |
|
Docker images |
alerta Updated |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch Updated |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20211102101126 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210915110132 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:8.2.7 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.2.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana Updated |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20211101074638 |
|
kube-state-metrics Updated |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20211109121134 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20211103140113 |
|
node-exporter Updated |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.31.1 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20210812120726 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.0-20210927090119 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2021-11-11-014639/ Updated |
||
https://mirror.mirantis.com/kaas/ubuntu-2021-11-11-014639.target.txt Updated |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ Updated |
7.x series¶
This section outlines release notes for the unsupported Cluster releases of the 7.x series.
This section outlines release notes for the Cluster release 7.11.0 that is introduced in the Mirantis Container Cloud release 2.21.0 and is the last release in the 7.x series.
This Cluster release supports Mirantis Kubernetes Engine 3.4.11 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.13.
For the list of known and resolved issues, refer to the Container Cloud release 2.21.0 section.
This section outlines new features implemented in the Cluster release 7.11.0 that is introduced in the Container Cloud release 2.21.0.
Updated the Mirantis Kubernetes Engine (MKE) version from 3.4.10 to 3.4.11 and the Mirantis Container Runtime (MCR) version from 20.10.12 to 20.10.13 for the Container Cloud management, regional, and managed clusters on all supported cloud providers, as well as for non Container Cloud based MKE cluster attachment.
Updated the MetalLB version from 0.12.1 to 0.13.4 for the Container Cloud management, regional, and managed clusters of all cloud providers that use MetalLB: bare metal, Equinix Metal with public and private networking, vSphere.
The MetalLB configuration is now stored in dedicated MetalLB objects
instead of the ConfigMap object.
Improved etcd monitoring by implementing the Etcd dashboard and
etcdDbSizeCritical and etcdDbSizeMajor alerts that inform about the
size of the etcd database.
Learn more
Implemented Reference Application that is a small microservice application that enables workload monitoring on non-MOSK managed clusters. It mimics a classical microservice application and provides metrics that describe the likely behavior of user workloads.
Reference Application contains a set of alerts and a separate Grafana dashboard to provide check statuses of Reference Application and statistics such as response time and content length.
The feature is disabled by default and can be enabled using the StackLight configuration manifest.
Added the miraCephSecretsInfo specification to KaaSCephCluster.status.
This specification contains current state and details of secrets that are used
in the Ceph cluster, such as keyrings, Ceph clients, RADOS Gateway user
credentials, and so on.
Using miraCephSecretsInfo, you can create, access, and remove Ceph RADOS
Block Device (RBD) or Ceph File System (CephFS) clients and RADOS Gateway
(RGW) users.
Implemented the ability to create and configure Amazon S3 bucket policies between Ceph Object Storage users.
The following table lists the components versions of the Cluster release 7.11.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration Updated 0 |
Mirantis Kubernetes Engine |
3.4.11 1 |
Container runtime Updated 0 |
Mirantis Container Runtime |
20.10.13 2 |
Distributed storage Updated |
Ceph |
15.2.17 (Octopus) |
Rook |
1.0.0-20220809220209 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-327-gbc30b11b |
|
lcm-ansible Updated |
0.19.0-12-g6cad672 |
|
lcm-agent Updated |
0.3.0-327-gbc30b11b |
|
metallb-controller Updated |
0.13.4 3 |
|
metrics-server |
0.5.2 |
|
StackLight |
Alerta Updated |
8.5.0-20220923121625 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow |
0.1-20220706035316 |
|
Cerebro Updated |
0.9-20220923122026 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd Updated |
1.14-20220922214003 |
|
Grafana |
9.0.2 |
|
Grafana Image Renderer Updated |
3.5.0 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector |
0.1-20220711134630 |
|
Metricbeat Updated |
7.10.2-20220909091002 |
|
OpenSearch |
1-20220517112057 |
|
OpenSearch Dashboards |
1-20220517112107 |
|
Prometheus |
2.35.0 |
|
Prometheus Blackbox Exporter |
0.19.0 |
|
Prometheus ES Exporter |
0.14.0-20220517111946 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20220624102731 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Reference Application New |
0.0.1 |
|
sf-notifier |
0.3-20220706035002 |
|
sf-reporter Updated |
0.1-20220916113234 |
|
Spilo Updated |
13-2.1p1-20220921105803 |
|
Telegraf |
1.9.1-20220714080809 |
|
1.23.4-20220915114529 Updated |
||
Telemeter |
4.4.0-20200424 |
- 0(1,2)
For MOSK-based deployments, MKE will be updated from 3.4.10 to 3.4.11 and MCR will be updated from 20.10.12 to 20.10.13 in one of the following Container Cloud releases.
- 1
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 2
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
- 3
For MOSK-based deployments, the
metallb-controllerversion is updated from 0.12.1 to 0.13.4 in MOSK 22.5.
This section lists the components artifacts of the Cluster release 7.11.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-964.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/ceph/ceph:v15.2.17 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20221024145202 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.0.0-20220809220209 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.19.0-12-g6cad672/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-327-gbc30b11b/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.34.16.tgz |
metallb 0 |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.34.16.tgz |
|
Docker images |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-327-gbc30b11b |
metallb-controller Updated 0 |
mirantis.azurecr.io/bm/external/metallb/controller:v0.13.4 |
|
metallb-speaker Updated 0 |
mirantis.azurecr.io/bm/external/metallb/speaker:v0.13.4 |
|
metrics-server |
mirantis.azurecr.io/core/external/metrics-server:v0.5.2 |
- 0(1,2,3)
For MOSK-based deployments, the
metallbversion is updated from 0.12.1 to 0.13.4 in MOSK 22.5.
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow Updated |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-4.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-10.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-37.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-logs-0.1.0-mcp-142.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-173.tgz |
|
iam-proxy |
||
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-10.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-40.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-42.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-229.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-9.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
refapp New |
https://binary.mirantis.com/scale/helm/refapp-0.1.1-mcp-1.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-4.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-5.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.9.2.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-7.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-7.tgz |
|
Docker images |
alerta-web Updated |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20220923121625 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20220706035316 |
|
blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro Updated |
mirantis.azurecr.io/stacklight/cerebro:v0.9-20220923122026 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch_exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220922214003 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:9.0.2 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.5.0 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.15.9 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.22.13 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220711134630 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220909091002 |
|
nginx-prometheus-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch |
mirantis.azurecr.io/stacklight/opensearch:1-20220517112057 |
|
opensearch-dashboards |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20220517112107 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
pgbouncer |
mirantis.azurecr.io/stacklight/pgbouncer:1.12.0 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.35.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220517111946 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20220624102731 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
refapp New |
mirantis.azurecr.io/openstack/openstack-refapp:0.0.1.dev29 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20220706035002 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20220916113234 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220921105803 |
|
stacklight-toolkit New |
mirantis.azurecr.io/stacklight/stacklight-toolkit:20220729121446 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20220714080809 |
|
mirantis.azurecr.io/stacklight/telegraf:1.23.4-20220915114529 Updated |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:4.25.2 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2022-07-13-020010.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
Target ubuntu system 1 |
Ubuntu |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-focal-20220915105522 |
https://binary.mirantis.com/bm/bin/efi/ubuntu/tgz-bionic-5.4-20220915105637 2 |
This section outlines release notes for the Cluster release 7.10.0 that is introduced in the Mirantis Container Cloud release 2.20.0.
This Cluster release supports Mirantis Kubernetes Engine 3.4.10 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.12.
For the list of known and resolved issues, refer to the Container Cloud release 2.20.0 section.
This section outlines new features implemented in the Cluster release 7.10.0 that is introduced in the Container Cloud release 2.20.0.
Updated the Mirantis Kubernetes Engine (MKE) version from 3.4.9 to 3.4.10 and the Mirantis Container Runtime (MCR) version from 20.10.11 to 20.10.12 for the Container Cloud management, regional, and managed clusters on all supported cloud providers except MOSK-based deployments, as well as for non Container Cloud based MKE cluster attachment.
To reduce resource consumption, removed Ceph cluster deployment from management and regional clusters based on bare metal and Equinix Metal with private networking. Ceph is automatically removed during the Cluster release update to 7.10.0. Managed clusters continue using Ceph as a distributed storage system.
Implemented the objectUsers RADOS Gateway parameter in the
KaaSCephCluster CR. The new parameter allows for an easy creation of custom
Ceph RADOS Gateway users with permission rules. The users parameter is now
deprecated and, if specified, will be automatically transformed to
objectUsers.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
Learn more
Implemented the rbdDeviceMapOptions field in the Ceph pool parameters of
the KaaSCephCluster CR. The new field allows specifying custom RADOS Block
Device (RBD) map options to use with StorageClass of a corresponding Ceph
pool.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
Learn more
Implemented the mgr.mgrModules parameter that includes the name and
enabled keys to provide the capability to disable a particular Ceph Manager
module. The mgr.modules parameter is now deprecated and, if specified, will
be automatically transformed to mgr.mgrModules.
Implemented the capability to configure health checks and liveness probe
settings for Ceph daemons through the KaaSCephCluster CR.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
The following table lists the components versions of the Cluster release 7.10.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.4.10 0 |
Container runtime |
Mirantis Container Runtime Updated |
20.10.12 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.0.0-20220504194120 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-285-g8498abe0 |
|
lcm-ansible Updated |
0.18.1 |
|
lcm-agent Updated |
0.3.0-288-g405179c2 |
|
metallb-controller Updated |
0.12.1 |
|
metrics-server |
0.5.2 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow Updated |
0.1-20220706035316 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.14-20220111114545 |
|
Grafana Updated |
9.0.2 |
|
Grafana Image Renderer |
3.4.2 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector Updated |
0.1-20220711134630 |
|
Metricbeat |
7.10.2-20220309185937 |
|
OpenSearch |
1-20220517112057 |
|
OpenSearch Dashboards |
1-20220517112107 |
|
Prometheus |
2.35.0 |
|
Prometheus Blackbox Exporter |
0.19.0 |
|
Prometheus ES Exporter |
0.14.0-20220517111946 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter Updated |
0.1-20220624102731 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier Updated |
0.3-20220706035002 |
|
sf-reporter Updated |
0.1-20220622101204 |
|
Spilo |
13-2.1p1-20220225091552 |
|
Telegraf Updated |
1.9.1-20220714080809 |
|
1.20.2-20220204122426 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 7.10.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-908.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220819101016 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.0.0-20220504194120 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.18.1/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-288-g405179c2/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.33.5.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.33.5.tgz |
|
Docker images |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-285-g8498abe0 |
metallb-controller Updated |
mirantis.azurecr.io/bm/external/metallb/controller:v0.12.1 |
|
metallb-speaker Updated |
mirantis.azurecr.io/bm/external/metallb/speaker:v0.12.1 |
|
metrics-server |
mirantis.azurecr.io/core/external/metrics-server:v0.5.2 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-9.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-37.tgz |
|
fluentd-logs Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-131.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-154.tgz |
|
iam-proxy Updated |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-6.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch Updated |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-52.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-40.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-42.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-228.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-8.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-2.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-3.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.8.1.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-6.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-6.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20220706035316 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220111114545 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:9.0.2 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.4.2 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.15.9 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220711134630 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220309185937 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch |
mirantis.azurecr.io/stacklight/opensearch:1-20220517112057 |
|
opensearch-dashboards |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20220517112107 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
pgbouncer |
mirantis.azurecr.io/stacklight/pgbouncer:1.12.0 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.35.0 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220517111946 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20220624102731 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20220706035002 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20220622101204 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220225091552 |
|
telegraf Updated |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20220714080809 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.2-20220204122426 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:4.25.2 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2022-07-13-020010.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 7.9.0 that is introduced in the Mirantis Container Cloud release 2.19.0.
This Cluster release supports Mirantis Kubernetes Engine 3.4.9 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.11.
For the list of known and resolved issues, refer to the Container Cloud release 2.19.0 section.
This section outlines new features implemented in the Cluster release 7.9.0 that is introduced in the Container Cloud release 2.19.0.
Updated the Mirantis Kubernetes Engine (MKE) version from 3.4.8 to 3.4.9 for the Container Cloud management, regional, and managed clusters on all supported cloud providers except MOSK-based deployments, as well as for non Container Cloud based MKE cluster attachment.
Learn more
Implemented a new Kubernetes Containers Grafana dashboard that provides resources consumption metrics of containers running on Kubernetes nodes.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
Learn more
Enhanced the documentation by adding troubleshooting guidelines for the Kubernetes system, Metric Collector, Helm Controller, Release Controller, and MKE alerts.
Learn more
As part of the Elasticsearch switching to OpenSearch, replaced the Elasticsearch parameters with OpenSearch in the Container Cloud web UI.
Implemented the capability to easily view the summary and health status of all Ceph clusters through the Container Cloud web UI. The feature is supported for the bare metal provider only.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
Implemented the capability to remove or replace Ceph OSDs not only by the
device name or path but also by ID, using the by-id parameter in the
KaaSCephOperationRequest CR.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature support will become available in one of the following Container Cloud releases.
Learn more
TechPreview
Implemented the capability to create multiple Ceph data pools per a single
CephFS installation using the dataPools parameter in the CephFS
specification. The dataPool parameter is now deprecated.
Caution
For MKE clusters that are part of MOSK infrastructure, the feature is not supported yet.
Learn more
The following table lists the components versions of the Cluster release 7.9.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.4.9 0 |
Container runtime |
Mirantis Container Runtime |
20.10.11 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.0.0-20220504194120 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-257-ga93244da |
|
lcm-ansible Updated |
0.17.1-2-g1e337f8 |
|
lcm-agent Updated |
0.3.0-257-ga93244da |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.5.2 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow |
0.1-20220420161450 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.14-20220111114545 |
|
Grafana |
8.5.0 |
|
Grafana Image Renderer Updated |
3.4.2 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector Updated |
0.1-20220614110617 |
|
Metricbeat |
7.10.2-20220309185937 |
|
OpenSearch Updated |
1-20220517112057 |
|
OpenSearch Dashboards Updated |
1-20220517112107 |
|
Patroni |
13-2.1p1-20220225091552 |
|
Prometheus Updated |
2.35.0 |
|
Prometheus Blackbox Exporter |
0.19.0 |
|
Prometheus ES Exporter Updated |
0.14.0-20220517111946 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier Updated |
0.3-20220514051554 |
|
sf-reporter |
0.1-20220419092138 |
|
Telegraf |
1.9.1-20210225142050 |
|
1.20.2-20220204122426 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 7.9.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-831.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220715144333 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.0.0-20220504194120 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.17.1-2-g1e337f8/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-257-ga93244da/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.32.4.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.32.4.tgz |
|
Docker images |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-257-ga93244da |
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/core/external/metrics-server:v0.5.2 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-9.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-37.tgz |
|
fluentd-logs |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-128.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-150.tgz |
|
iam-proxy |
||
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-6.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-50.tgz |
|
opensearch-dashboards |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-40.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-42.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-228.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-8.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-2.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-3.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.7.2.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-5.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-5.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20220420161450 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220111114545 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:8.5.0 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.4.2 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.15.9 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220614110617 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220309185937 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20220517112057 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20220517112107 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.35.0 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220517111946 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20220514051554 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20220419092138 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220225091552 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225142050 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.2-20220204122426 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq Updated |
mirantis.azurecr.io/stacklight/yq:4.25.2 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2022-05-03-013543.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 7.8.0 that is introduced in the Mirantis Container Cloud release 2.18.0.
This Cluster release supports Mirantis Kubernetes Engine 3.4.8 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.11.
For the list of known and resolved issues, refer to the Container Cloud release 2.18.0 section.
This section outlines new features implemented in the Cluster release 7.8.0 that is introduced in the Container Cloud release 2.18.0.
Updated the Mirantis Kubernetes Engine (MKE) version from 3.4.7 to 3.4.8 and the Mirantis Container Runtime (MCR) version from 20.10.8 to 20.10.11 for the Container Cloud management, regional, and managed clusters on all supported cloud providers, as well as for non Container Cloud based MKE cluster attachment.
As part of the Elasticsearch switching to OpenSearch, removed the Elasticsearch and Kibana services, as well as introduced a set of new parameters that will replace the current ones in future releases. The old parameters are supported and take precedence over the new ones. For details, see Deprecation notes and StackLight configuration parameters.
Note
In the Container Cloud web UI, the Elasticsearch and Kibana naming is still present. However, the services behind them have switched to OpenSearch and OpenSearch Dashboards.
Implemented the following improvements to StackLight alerting:
Added the
MCCClusterUpdatinginformational alert that raises when the Mirantis Container Cloud cluster starts updating.Enhanced StackLight alerting by clarifying alert severity levels. Switched all
Minoralerts toWarning. Now, only alerts of the following severities exist:informational,warning,major, andcritical.Enhanced the documentation by adding troubleshooting guidelines for the Kubernetes applications, resources, and storage alerts.
Implemented the capability to allow sending of metrics from Prometheus, using the Prometheus remote write feature to a custom monitoring endpoint.
Defined the following parameters in the StackLight configuration of the Cluster object for all types of clusters as mandatory. This applies to the clusters with StackLight enabled only. For existing clusters, Cluster object will be updated automatically.
Important
When creating a new cluster, specify these parameters through the Container Cloud web UI or as described in StackLight configuration parameters. Update all cluster templates created before Container Cloud 2.18.0 that do not have values for these parameters specified. Otherwise, the Admission Controller will reject cluster creation.
Web UI parameter |
API parameter |
|---|---|
Enable Logging |
|
HA Mode |
|
Prometheus Persistent Volume Claim Size |
|
Elasticsearch Persistent Volume Claim Size |
|
Implemented the capability to configure the placement of the
rook-ceph-operator, rook-discover, and csi-rbdplugin Ceph daemons.
Learn more
The following table lists the components versions of the Cluster release 7.8.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.4.8 0 |
Container runtime |
Mirantis Container Runtime Updated |
20.10.11 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.0.0-20220504194120 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-239-gae7218ea |
|
lcm-ansible Updated |
0.16.0-13-gcac49ca |
|
lcm-agent Updated |
0.3.0-239-gae7218ea |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.5.2 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow Updated |
0.1-20220420161450 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.14-20220111114545 |
|
Grafana Updated |
8.5.0 |
|
Grafana Image Renderer |
3.2.1 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector |
0.1-20220209123106 |
|
Metricbeat |
7.10.2-20220309185937 |
|
OpenSearch |
1-20220316161927 |
|
OpenSearch Dashboards |
1-20220316161951 |
|
Patroni |
13-2.1p1-20220225091552 |
|
Prometheus |
2.31.1 |
|
Prometheus Blackbox Exporter |
0.19.0 |
|
Prometheus ES Exporter |
0.14.0-20220111114356 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier |
0.3-20210930112115 |
|
sf-reporter Updated |
0.1-20220419092138 |
|
Telegraf |
1.9.1-20210225142050 |
|
1.20.2-20220204122426 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 7.8.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-792.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220506180707 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook:v1.0.0-20220504194120 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.16.0-13-gcac49ca/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-239-gae7218ea/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.31.9.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.31.9.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-239-gae7218ea |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.5.2 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow Updated |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Removed |
n/a |
|
elasticsearch-curator Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-9.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-37.tgz |
|
fluentd-elasticsearch Removed |
n/a |
|
fluentd-logs New |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-128.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-145.tgz |
|
iam-proxy |
||
kibana Removed |
n/a |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-6.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
opensearch New |
https://binary.mirantis.com/stacklight/helm/opensearch-0.1.0-mcp-50.tgz |
|
opensearch-dashboards New |
https://binary.mirantis.com/stacklight/helm/opensearch-dashboards-0.1.0-mcp-40.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-42.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-225.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-8.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-2.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-3.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.6.1.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-5.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-5.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20220420161450 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220111114545 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:8.5.0 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.2.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.15.9 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220209123106 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220309185937 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch |
mirantis.azurecr.io/stacklight/opensearch:1-20220316161927 |
|
opensearch-dashboards |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20220316161951 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.31.1 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220111114356 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20220419092138 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220225091552 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.2-20220204122426 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2022-05-03-013543.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 7.7.0 that is introduced in the Mirantis Container Cloud release 2.17.0.
This Cluster release supports Mirantis Kubernetes Engine 3.4.7 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.8.
For the list of known and resolved issues, refer to the Container Cloud release 2.17.0 section.
This section outlines new features implemented in the Cluster release 7.7.0 that is introduced in the Container Cloud release 2.17.0.
Implemented the capability to configure the Elasticsearch retention time per logs, events, and notifications indices when creating a managed cluster through Container Cloud web UI.
The Retention Time parameter in the Container Cloud web UI is now replaced with the Logstash Retention Time, Events Retention Time, and Notifications Retention Time parameters.
Learn more
Implemented monitoring and added alerts for the Helm Controller
service and the HelmBundle custom resources.
Learn more
Implemented configurable timeouts for Ceph requests processing. The default is
set to 30 minutes. You can configure the timeout using the
pgRebalanceTimeoutMin parameter in the Ceph Helm chart.
Implemented the capability to configure the replicas count for
cephController, cephStatus, and cephRequest controllers using the
replicas parameter in the Ceph Helm chart. The default is set to 3
replicas.
Implemented a separate ceph-kcc-controller that runs on a management
cluster and manages the KaaSCephCluster custom resource (CR). Previously,
the KaaSCephCluster CR was managed by bm-provider.
Learn more
The following table lists the components versions of the Cluster release 7.7.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.4.7 0 |
Container runtime |
Mirantis Container Runtime Updated |
20.10.8 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook Updated |
1.0.0-20220504194120 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-229-g4774bbbb |
|
lcm-ansible Updated |
0.15.0-24-gf023ea1 |
|
lcm-agent Updated |
0.3.0-229-g4774bbbb |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.5.2 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.14-20220111114545 |
|
Grafana |
8.2.7 |
|
Grafana Image Renderer |
3.2.1 |
|
IAM Proxy |
6.0.1 |
|
Metric Collector |
0.1-20220209123106 |
|
Metricbeat Updated |
7.10.2-20220309185937 |
|
OpenSearch Updated |
1-20220316161927 |
|
OpenSearch Dashboards Updated |
1-20220316161951 |
|
Patroni Updated |
13-2.1p1-20220225091552 |
|
Prometheus |
2.31.1 |
|
Prometheus Blackbox Exporter |
0.19.0 |
|
Prometheus ES Exporter |
0.14.0-20220111114356 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier |
0.3-20210930112115 |
|
sf-reporter |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
Updated |
1.20.2-20220204122426 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 7.7.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-719.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220421152918 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook:v1.0.0-20220504194120 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.15.0-24-gf023ea1/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-229-g4774bbbb/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.30.6.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.30.6.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-229-g4774bbbb |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.5.2 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-1.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-45.tgz |
|
elasticsearch-curator Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-8.tgz |
|
elasticsearch-exporter Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-6.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-36.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-123.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-130.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-36.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-4.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-42.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-218.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-1.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-1.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.5.3.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-4.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-4.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220111114545 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:8.2.7 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.2.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220209123106 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220309185937 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch Updated |
mirantis.azurecr.io/stacklight/opensearch:1-20220316161927 |
|
opensearch-dashboards Updated |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1-20220316161951 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.31.1 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220111114356 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220225091552 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
Updated |
mirantis.azurecr.io/stacklight/telegraf:1.20.2-20220204122426 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2021-11-11-014639.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 7.6.0 that is introduced in the Mirantis Container Cloud release 2.16.0.
This Cluster release supports Mirantis Kubernetes Engine 3.4.7 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.8.
For the list of known and resolved issues, refer to the Container Cloud release 2.16.0 section.
This section outlines new features implemented in the Cluster release 7.6.0 that is introduced in the Container Cloud release 2.16.0.
Updated the Mirantis Kubernetes Engine (MKE) major version from 3.4.6 to 3.4.7 for the Container Cloud management, regional, and managed clusters. Also, added support for attachment of existing MKE 3.4.7 clusters.
Learn more
Added the KubePodsRegularLongTermRestarts alert that raises in case of a
long-term periodic restart of containers.
Learn more
Implemented the capability to configure the Elasticsearch retention time per
index using the elasticsearch.retentionTime parameter in the StackLight
Helm chart. Now, you can configure different retention periods for different
indices: logs, events, and notifications.
The elasticsearch.logstashRetentionTime parameter is now deprecated.
Learn more
Implemented the capability to configure Prometheus Blackbox Exporter, including
customModules and timeoutOffset, through the StackLight Helm chart.
Implemented the capability to define custom Prometheus scrape configurations.
Due to licensing changes for Elasticsearch, Mirantis Container Cloud has switched from using Elasticsearch to OpenSearch and Kibana has switched to OpenSearch Dashboards. OpenSearch is a fork of Elasticsearch under the open-source Apache License with development led by Amazon Web Services.
For new deployments with the logging stack enabled, OpenSearch is now deployed by default. For existing deployments, migration to OpenSearch is performed automatically during clusters update. However, the entire Elasticsearch cluster may go down for up to 15 minutes.
Learn more
The following table lists the components versions of the Cluster release 7.6.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.4.7 0 |
Container runtime |
Mirantis Container Runtime Updated |
20.10.8 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.7.6 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-187-gba894556 |
|
lcm-ansible Updated |
0.14.0-14-geb6a51f |
|
lcm-agent Updated |
0.3.0-187-gba894556 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server Updated |
0.5.2 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager |
0.23.0 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Removed |
n/a |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd Updated |
1.14-20220111114545 |
|
Grafana |
8.2.7 |
|
Grafana Image Renderer |
3.2.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana Removed |
n/a |
|
Metric Collector Updated |
0.1-20220209123106 |
|
Metricbeat Updated |
7.10.2-20220111114624 |
|
OpenSearch New |
1.2-20220114131142 |
|
OpenSearch Dashboards New |
1.2-20220114131222 |
|
Patroni Updated |
13-2.1p1-20220131130853 |
|
Prometheus |
2.31.1 |
|
Prometheus Blackbox Exporter Updated |
0.19.0 |
|
Prometheus ES Exporter Updated |
0.14.0-20220111114356 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
sf-notifier |
0.3-20210930112115 |
|
sf-reporter |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
1.20.0-20210927090119 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 7.6.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-661.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220203124822 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.7.6 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.14.0-14-geb6a51f/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-187-gba894556/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.29.6.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.29.6.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-187-gba894556 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server Updated |
mirantis.azurecr.io/lcm/metrics-server-amd64:v0.5.2 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-1.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-44.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-36.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-120.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-125.tgz |
|
iam-proxy Updated |
||
kibana Updated |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-36.tgz |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-4.tgz |
|
metricbeat Updated |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-16.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-38.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-218.tgz |
|
prometheus-blackbox-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-11.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-1.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-1.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.4.3.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-4.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-4.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch Removed |
n/a |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.14-20220111114545 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:8.2.7 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.2.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana Removed |
n/a |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20220209123106 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20220111114624 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
opensearch New |
mirantis.azurecr.io/stacklight/opensearch:1.2-20220114131142 |
|
opensearch-dashboards New |
mirantis.azurecr.io/stacklight/opensearch-dashboards:1.2-20220114131222 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.31.1 |
|
prometheus-blackbox-exporter Updated |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.19.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20220111114356 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.1p1-20220131130853 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.0-20210927090119 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2021-11-11-014639.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 7.5.0 that is introduced in the Mirantis Container Cloud release 2.15.0.
This Cluster release supports Mirantis Kubernetes Engine 3.4.6 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.8.
For the list of known and resolved issues, refer to the Container Cloud release 2.15.0 section.
This section outlines new features implemented in the Cluster release 7.5.0 that is introduced in the Container Cloud release 2.15.0.
Updated the Mirantis Container Runtime (MCR) version from 20.10.6 to 20.10.8 for the Container Cloud management, regional, and managed clusters on all supported cloud providers.
Learn more
Implemented the MCCLicenseExpirationCritical and
MCCLicenseExpirationMajor alerts that notify about Mirantis Container Cloud
license expiration in less than 10 and 30 days.
Learn more
Implemented the following improvements to StackLight alerting:
Enhanced Kubernetes applications alerting:
Reworked the Kubernetes applications alerts to minimize flapping, avoid firing during pod rescheduling, and to detect crash looping for pods that restart less frequently.
Added the
KubeDeploymentOutage,KubeStatefulSetOutage, andKubeDaemonSetOutagealerts.Removed the redundant
KubeJobCompletionalert.Enhanced the alert inhibition rules to reduce alert flooding.
Improved alert descriptions.
Split
TelemeterClientFederationFailedintoTelemeterClientFailedandTelemeterClientHAFailedto separate alerts depending on the HA mode disabled or enabled.Updated the description for
DockerSwarmNodeFlapping.
Disabled unused Node Exporter collectors and implemented the capability to
manually enable needed collectors using the
nodeExporter.extraCollectorsEnabled parameter. Only the following
collectors are now enabled by default in StackLight:
|
|
|
|
Implemented full support for automated Ceph LCM operations using the
KaaSCephOperationRequest CR, such as addition or removal of Ceph OSDs and
nodes, as well as replacement of failed Ceph OSDs or nodes.
Learn more
Implemented the capability to specify Container Storage Interface (CSI)
provisioner tolerations and node affinity for different Rook resources.
Added support for the all and mds keys in toleration rules.
Extended the fullClusterInfo section of the KaaSCephCluster.status
resource with the following fields:
cephDetails- contains verbose details of a Ceph cluster statecephCSIPluginDaemonsStatus- contains details on all Ceph CSIs
Learn more
The following table lists the components versions of the Cluster release 7.5.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.4.6 0 |
Container runtime |
Mirantis Container Runtime Updated |
20.10.8 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.7.6 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-132-g83a348fa |
|
lcm-ansible Updated |
0.13.0-26-gad73ff7 |
|
lcm-agent Updated |
0.3.0-132-g83a348fa |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager Updated |
0.23.0 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.10.2-2021110210112 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20210915110132 |
|
Grafana Updated |
8.2.7 |
|
Grafana Image Renderer |
3.2.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.10.2-20211101074638 |
|
Metric Collector |
0.1-20211109121134 |
|
Metricbeat |
7.10.2-20211103140113 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus Updated |
2.31.1 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.14.0-20210812120726 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter Updated |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway Removed |
n/a |
|
sf-notifier |
0.3-20210930112115 |
|
sf-reporter |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
1.20.0-20210927090119 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 7.5.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-606.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220110132813 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.7.6 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.13.0-26-gad73ff7/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-132-g83a348fa/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.28.7.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.28.7.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-132-g83a348fa |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-1.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-37.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-32.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-115.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-121.tgz |
|
iam-proxy Updated |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-30.tgz |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-3.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-36.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-214.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-1.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-1.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.3.1.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-1.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-1.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20211102101126 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210915110132 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:8.2.7 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.2.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20211101074638 |
|
kube-state-metrics Updated |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20211109121134 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20211103140113 |
|
node-exporter Updated |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.31.1 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20210812120726 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway Removed |
n/a |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.0-20210927090119 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2021-11-11-014639.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 7.4.0 that is introduced in the Mirantis Container Cloud release 2.14.0.
This Cluster release supports Mirantis Kubernetes Engine 3.4.6 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.6.
For the list of known and resolved issues, refer to the Container Cloud release 2.14.0 section.
This section outlines new features implemented in the Cluster release 7.4.0 that is introduced in the Container Cloud release 2.14.0.
Updated the Mirantis Kubernetes Engine version from 3.4.5 to 3.4.6 for the Container Cloud management, regional, and managed clusters. Also, added support for attachment of existing MKE 3.4.6 clusters.
Learn more
Limited the number of monitored network interfaces to prevent extended Prometheus RAM consumption in big clusters. By default, Prometheus Node Exporter now only collects information of a basic set of interfaces, both host and container. If required you can edit the list of excluded devices as needed.
Implemented the capability to define custom Prometheus recording rules through
the prometheusServer.customRecordingRules parameter in the StackLight Helm
chart. Overriding of existing recording rules is not supported.
Implemented the capability to configure packet size for the syslog logging
output. If remote logging to syslog is enabled in StackLight, use the
logging.syslog.packetSize parameter in the StackLight Helm chart to
configure the packet size.
Learn more
Implemented the capability to configure the Prometheus Relay client timeout and
response size limit through the prometheusRelay.clientTimeout and
prometheusRelay.responseLimitBytes parameters in the StackLight Helm chart.
Implemented additional validation of networks specified in
spec.cephClusterSpec.network.publicNet and
spec.cephClusterSpec.network.clusterNet and prohibited the use of the
0.0.0.0/0 CIDR. Now, the bare metal provider automatically translates
the 0.0.0.0/0 network range to the default LCM IPAM subnet if it exists.
You can now also add corresponding labels for the bare metal IPAM subnets when configuring the Ceph cluster during the management cluster deployment.
Learn more
To improve debugging and log reading, separated Ceph Controller, Ceph Status Controller, and Ceph Request Controller, which used to run in one pod, into three different deployments.
Learn more
TechPreview
Implemented the KaaSCephOperationRequest CR that provides LCM operations
for Ceph OSDs and nodes by automatically creating separate
CephOsdRemoveRequest requests. It allows for automated removal of healthy
or non-healthy Ceph OSDs from a Ceph cluster.
Due to the Technology Preview status of the feature, Mirantis recommends following Remove Ceph OSD manually for Ceph OSDs removal.
Learn more
The following table lists the components versions of the Cluster release 7.4.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.4.6 0 |
Container runtime |
Mirantis Container Runtime |
20.10.6 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook Updated |
1.7.6 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-104-gb7f5e8d8 |
|
lcm-ansible Updated |
0.12.0-6-g5329efe |
|
lcm-agent Updated |
0.3.0-104-gb7f5e8d8 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta Updated |
8.5.0-20211108051042 |
Alertmanager |
0.22.2 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Updated |
7.10.2-2021110210112 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20210915110132 |
|
Grafana Updated |
8.2.2 |
|
Grafana Image Renderer Updated |
3.2.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana Updated |
7.10.2-20211101074638 |
|
Metric Collector Updated |
0.1-20211109121134 |
|
Metricbeat Updated |
7.10.2-20211103140113 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.14.0-20210812120726 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20210930112115 |
|
sf-reporter |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
1.20.0-20210927090119 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 7.4.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-526.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20211109132703 |
|
cephcsi Updated |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook/ceph:v1.7.6 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.12.0-6-g5329efe/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-104-gb7f5e8d8/lcm-agent |
|
Helm charts |
managed-lcm-api Updated |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.27.6.tgz |
metallb Updated |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.27.6.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-104-gb7f5e8d8 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-22.tgz |
alertmanager-webhook-servicenow Updated |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-1.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-37.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-32.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-112.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-115.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-30.tgz |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-1.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-36.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-208.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-1.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-1.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.2.5.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-1.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-1.tgz |
|
Docker images |
alerta Updated |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.22.2 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch Updated |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20211102101126 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210915110132 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:8.2.2 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.2.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana Updated |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20211101074638 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20211109121134 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20211103140113 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20210812120726 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.0-20210927090119 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ New |
||
https://mirror.mirantis.com/kaas/ubuntu-2020-07-40-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 7.3.0 that is introduced in the Mirantis Container Cloud release 2.13.0.
This Cluster release supports Mirantis Kubernetes Engine 3.4.5 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.6.
For the list of known and resolved issues, refer to the Container Cloud release 2.13.0 section.
This section outlines new features implemented in the Cluster release 7.3.0 that is introduced in the Container Cloud release 2.13.0.
Implemented the following improvements to StackLight alerting:
Implemented per-service
*TargetDownand*TargetsOutagealerts that raise if one or all Prometheus targets are down.Enhanced the alert inhibition rules to reduce alert flooding.
Removed the following inefficient alerts:
TargetDownTargetFlappingKubeletDownServiceNowWebhookReceiverDownSfNotifierDownPrometheusMsTeamsDown
Learn more
The following table lists the components versions of the Cluster release 7.3.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.4.5 0 |
Container runtime |
Mirantis Container Runtime |
20.10.6 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.6.8 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-67-g25ab9f1a |
|
lcm-ansible Updated |
0.11.0-6-gbfce76e |
|
lcm-agent Updated |
0.3.0-67-g25ab9f1a |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.4.1-20210707092546 |
Alertmanager |
0.22.2 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.10.2-20210601104922 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd Updated |
1.10.2-20210915110132 |
|
Grafana Updated |
8.1.2 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.10.2-20210601104911 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat |
7.10.2 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.14.0-20210812120726 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier Updated |
0.3-20210930112115 |
|
sf-reporter New |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
New 1.20.0-20210927090119 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 7.3.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-427.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20211013104642 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.3.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.6.8 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.11.0-6-gbfce76e/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-67-g25ab9f1a/lcm-agent |
|
Helm charts |
managed-lcm-api Updated |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.26.6.tgz |
metallb Updated |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.24.6.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-67-g25ab9f1a |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-22.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.1.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-37.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-32.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-105.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-110.tgz |
|
iam-proxy Updated |
||
kibana Updated |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-30.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-12.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-34.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-202.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-16.tgz |
|
sf-reporter New |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-13.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-807.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-19.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-19.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210707092546 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.22.2 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20210601104922 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210915110132 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:8.1.2 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20210601104911 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20210812120726 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter New |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
New mirantis.azurecr.io/stacklight/telegraf:1.20.0-20210927090119 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 7.2.0 that is introduced in the Mirantis Container Cloud release 2.12.0.
This Cluster release supports Mirantis Kubernetes Engine 3.4.5 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.6.
For the list of known and resolved issues, refer to the Container Cloud release 2.12.0 section.
This section outlines new features implemented in the Cluster release 7.2.0 that is introduced in the Container Cloud release 2.12.0.
Updated the Mirantis Container Runtime (MCR) version from 20.10.5 to 20.10.6 and Mirantis Kubernetes Engine (MKE) version from 3.4.0 to 3.4.5 for the Container Cloud management, regional, and managed clusters. Also, added support for attachment of existing MKE clusters 3.3.7-3.3.12 and 3.4.1-3.4.5.
For the MCR release highlights and components versions, see MCR documentation: MCR release notes and MKE documentation: MKE release notes.
Integrated the Ceph maintenance to the common upgrade procedure. Now, the
maintenance flag function is set up programmatically and the flag itself is
deprecated.
Technology Preview
Implemented the capability to specify RADOS Gateway tolerations through the
KaaSCephCluster spec using the native Rook way for setting resource
requirements for Ceph daemons.
Enhanced the Grafana dashboards to display user-friendly short names for
Kubernetes nodes, for example, master-0, instead of long name labels
such as kaas-node-f736fc1c-3baa-11eb-8262-0242ac110002.
This feature provides for consistency with Kubernetes nodes naming in the
Container Cloud web UI.
All Grafana dashboards that present node data now have an additional Node identifier drop-down menu. By default, it is set to machine to display short names for Kubernetes nodes. To display Kubernetes node name labels as previously, change this option to node.
Learn more
Implemented the following improvements to StackLight alerting:
Enhanced the alert inhibition rules.
Reworked a number of alerts to improve alerting efficiency and reduce alert flooding.
Removed the inefficient
DockerSwarmLeadElectionLoopandSystemDiskErrorsTooHighalerts.Added the
matcherskey to the routes configuration. Deprecated thematchandmatch_rekeys.
Learn more
Implemented the capability to create custom logs-based metrics that you can use to configure StackLight notifications.
Learn more
The following table lists the components versions of the Cluster release 7.2.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration Updated |
Mirantis Kubernetes Engine |
3.4.5 0 |
Container runtime Updated |
Mirantis Container Runtime |
20.10.6 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.6.8 |
|
LCM |
descheduler Removed |
n/a |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.3.0-32-gee08c2b8 |
|
lcm-ansible Updated |
0.10.0-12-g7cd13b6 |
|
lcm-agent Updated |
0.3.0-32-gee08c2b8 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.4.1-20210707092546 |
Alertmanager |
0.22.2 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.10.2-20210601104922 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20210602174807 |
|
Grafana |
7.5.4 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.10.2-20210601104911 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat |
7.10.2 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter Updated |
0.14.0-20210812120726 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20210702081359 |
|
Telegraf |
1.9.1-20210225142050 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 7.2.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-409.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210921155643 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.3.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner Updated |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.6.8 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.10.0-12-g7cd13b6/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-32-gee08c2b8/lcm-agent |
|
Helm charts |
descheduler Removed |
n/a |
managed-lcm-api Updated |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.25.6.tgz |
|
metallb Updated |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.24.6.tgz |
|
Docker images |
descheduler Removed |
n/a |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-32-gee08c2b8 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-22.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.1.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-36.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-32.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-97.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-110.tgz |
|
iam-proxy Updated |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-29.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-12.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-34.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-201.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-16.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-595.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-19.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-19.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210707092546 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.22.2 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20210601104922 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210602174807 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.5.4 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20210601104911 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20210812120726 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210702081359 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 7.1.0 that is introduced in the Mirantis Container Cloud release 2.11.0.
This Cluster release supports Mirantis Kubernetes Engine 3.4.0 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.5.
For the list of known and resolved issues, refer to the Container Cloud release 2.11.0 section.
This section outlines new features implemented in the Cluster release 7.1.0 that is introduced in the Container Cloud release 2.11.0.
Upgraded Ceph from 14.2.19 (Nautilus) to 15.2.13 (Octopus) and Rook from 1.5.9 to 1.6.8.
Technology Preview
Implemented the capability to define Ceph tolerations and resources management
through the KaaSCephCluster spec using the native Rook way for setting
resource requirements for Ceph daemons.
Improved the MiraCephLog custom resource by adding more information about
all Ceph cluster entities and their statuses. The MiraCeph, MiraCephLog
statuses and MiraCephLog values are now integrated to
KaaSCephCluster.status and can be viewed using the miraCephInfo,
shortClusterInfo, and fullClusterInfo fields.
Implemented the capability to define a list of Ceph Manager modules to enable
on the Ceph cluster using the mgr.modules parameter in KaaSCephCluster.
Implemented the following improvements for the StackLight node labeling during a cluster creation or post-deployment configuration:
Added a verification that a cluster contains minimum 3 worker nodes with the StackLight label for clusters with StackLight deployed in HA mode. This verification applies to cluster deployment and update processes. For details on how to add the StackLight label before upgrade to the latest Cluster releases of Container Cloud 2.11.0, refer to Upgrade managed clusters with StackLight deployed in HA mode.
Added a notification about the minimum number of worker nodes with the StackLight label for HA StackLight deployments to the cluster live status description in the Container Cloud web UI.
Caution
Removal of the StackLight label from worker nodes along with removal of worker nodes with StackLight label can cause the StackLight components to become inaccessible. It is important to keep the worker nodes where the StackLight local volumes were provisioned.
Implemented the capability to set the default log level severity for all StackLight components as well as set a custom log level severity for specific StackLight components in the Container Cloud web UI. You can update this setting either during a managed cluster creation or during a post-deployment configuration.
Implemented the following improvements to StackLight alerting:
Added the following alerts:
KubeContainersCPUThrottlingHighthat raises in case of containers CPU throttling.KubeletDownthat raises if kubelet is down.
Reworked the alert inhibition rules.
Reworked a number of alerts to improve alerting efficiency and reduce alert flooding.
Removed the following inefficient alerts:
FileDescriptorUsageCriticalKubeCPUOvercommitNamespacesKubeMemOvercommitNamespacesKubeQuotaExceededContainerScrapeError
Implemented the capability to enable feed update in Salesforce using
the feed_enabled parameter. By default, this parameter is set to false
to save API calls.
On top of continuous improvements delivered to the existing Container Cloud guides, added a procedure on how to manually remove a Ceph OSD from a Ceph cluster.
Learn more
The following table lists the components versions of the Cluster release 7.1.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.4.0 0 |
Container runtime |
Mirantis Container Runtime |
20.10.5 1 |
Distributed storage Updated |
Ceph |
15.2.13 (Octopus) |
Rook |
1.6.8 |
|
LCM |
descheduler |
0.8.0 |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.2.0-399-g85be100f |
|
lcm-ansible Updated |
0.9.0-17-g28bc9ce |
|
lcm-agent Updated |
0.2.0-399-g85be100f |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta Updated |
8.4.1-20210707092546 |
Alertmanager |
0.22.2 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.10.2-20210601104922 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20210602174807 |
|
Grafana |
7.5.4 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.10.2-20210601104911 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat |
7.10.2 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20210323132924 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter Updated |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier Updated |
0.3-20210702081359 |
|
Telegraf |
1.9.1-20210225142050 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 7.1.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-368.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210807103257 |
|
cephcsi Updated |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.3.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner Updated |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook/ceph:v1.6.8 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.9.0-17-g28bc9ce/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-399-g85be100f/lcm-agent |
|
Helm charts Updated |
descheduler |
https://binary.mirantis.com/core/helm/descheduler-1.24.6.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.24.6.tgz |
|
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.24.6.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-399-g85be100f |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-22.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.1.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-36.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-30.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-96.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-108.tgz |
|
iam-proxy Updated |
||
kibana Updated |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-29.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-12.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-33.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-188.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-10.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-16.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-574.tgz |
|
telegraf-ds Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-29.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-17.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-17.tgz |
|
Docker images |
alerta Updated |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210707092546 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.22.2 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20210601104922 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210602174807 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.5.4 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20210601104911 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20210323132924 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210702081359 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 7.0.0 that is introduced in the Mirantis Container Cloud release 2.10.0.
This Cluster release introduces support for the updated versions of Mirantis Kubernetes Engine 3.4.0 with Kubernetes 1.20 and Mirantis Container Runtime 20.10.5.
For the list of known and resolved issues, refer to the Container Cloud release 2.10.0 section.
This section outlines new features introduced in the Cluster release 7.0.0 that is the initial release of the 7.x Cluster release series.
The 7.0.0 Cluster release introduces support for the updated versions of:
Mirantis Container Runtime (MCR) 20.10.5
Mirantis Kubernetes Engine (MKE) 3.4.0
Kubernetes 1.20.1
All existing management and regional clusters with the Cluster release 5.16.0 are automatically updated to the Cluster release 7.0.0 with the updated versions of MCR, MKE, and Kubernetes.
Once you update your existing managed clusters from the Cluster release 5.16.0 to 5.17.0, an update to the Cluster release 7.0.0 becomes available through the Container Cloud web UI menu.
Implemented a graceful Mirantis Container Runtime (MCR) upgrade from 19.03.14 to 20.10.5 on existing Container Cloud clusters.
Improved the MKE logs gathering by replacing the default DEBUG logs level
with INFO. This change reduces the unnecessary load on the MKE cluster
caused by an excessive amount of logs generated with the DEBUG level
enabled.
Implemented the capability to configure the verbosity level of logs produced by all StackLight components or by each component separately.
Implemented the following improvements to StackLight alerting:
Added the following alerts:
PrometheusMsTeamsDownthat raises ifprometheus-msteamsis down.ServiceNowWebhookReceiverDownthat raises ifalertmanager-webhook-servicenowis down.SfNotifierDownthat raises if thesf-notifieris down.KubeAPICertExpirationMajor,KubeAPICertExpirationWarning,MKEAPICertExpirationMajor,MKEAPICertExpirationWarningthat inform on SSL certificates expiration.
Removed the inefficient
PostgresqlPrimaryDownalert.Reworked a number of alerts to improve alerting efficiency and reduce alert flooding.
Reworked the alert inhibition rules to match the receivers.
Updated Alertmanager to v0.22.2.
Changed the default behavior of the Salesforce alerts integration. Now, by default, only
Criticalalerts will be sent to the Salesforce.
Implemented the capability to add or configure proxy on existing Container Cloud managed clusters using the Container Cloud web UI.
On top of continuous improvements delivered to the existing Container Cloud guides, added a procedure on how to move a Ceph Monitor daemon to another node.
The following table lists the components versions of the Cluster release 7.0.0.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.4.0 0 |
Container runtime |
Mirantis Container Runtime |
20.10.5 1 |
Distributed storage |
Ceph |
14.2.19 (Nautilus) |
Rook |
1.5.9 |
|
LCM |
descheduler |
0.8.0 |
Helm |
2.16.11-40 |
|
helm-controller |
0.2.0-372-g7e042f4d |
|
lcm-ansible |
0.8.0-17-g63ec424 |
|
lcm-agent |
0.2.0-373-gae771bb4 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.4.1-20210312131419 |
Alertmanager |
0.22.2 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.10.2-20210601104922 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20210602174807 |
|
Grafana |
7.5.4 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.10.2-20210601104911 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat |
7.10.2 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20210323132924 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20210617140951 |
|
sf-reporter |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 7.0.0.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-305.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v14.2.19 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210716222903 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.2.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.1 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.5.9 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.8.0-17-g63ec424/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-373-gae771bb4/lcm-agent |
|
Helm charts |
descheduler |
https://binary.mirantis.com/core/helm/descheduler-1.23.2.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.23.2.tgz |
|
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.23.2.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-372-g7e042f4d |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-22.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.1.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-33.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-25.tgz |
|
fluentd-elasticsearch |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-93.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-105.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-27.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-12.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-30.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-158.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-10.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-16.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-13.tgz |
|
stacklight |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-538.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-20.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-20.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-16.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-16.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210312131419 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.22.2 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20210601104922 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210602174807 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.5.4 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.2 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20210601104911 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20210323132924 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210617140951 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
6.x series¶
This section outlines release notes for the unsupported Cluster releases of the 6.x series.
The Cluster release 6.20.0 is introduced in the Mirantis Container Cloud release 2.13.1. This Cluster release is based on the Cluster release 5.20.0.
The Cluster release 6.20.0 supports:
Mirantis OpenStack for Kubernetes (MOS) 21.6. For details, see MOS Release Notes.
Mirantis Kubernetes Engine (MKE) 3.3.12. For details, see MKE Release Notes.
Mirantis Container Runtime (MCR) 20.10.6. For details, see MCR Release Notes.
Kubernetes 1.18.
For the list of addressed and known issues, refer to the Container Cloud release 2.13.0 section.
This section outlines new features and enhancements introduced in the Cluster release 6.20.0.
Implemented the following improvements to StackLight alerting:
Implemented per-service
*TargetDownand*TargetsOutagealerts that raise if one or all Prometheus targets are down.Enhanced the alert inhibition rules to reduce alert flooding.
Removed the following inefficient alerts:
TargetDownTargetFlappingKubeletDownServiceNowWebhookReceiverDownSfNotifierDownPrometheusMsTeamsDown
Learn more
The following table lists the components versions of the Cluster release 6.20.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.3.12 0 |
Container runtime |
Mirantis Container Runtime |
20.10.6 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.6.8 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-67-g25ab9f1a |
|
lcm-ansible Updated |
0.11.0-6-gbfce76e |
|
lcm-agent Updated |
0.3.0-67-g25ab9f1a |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.4.1-20210707092546 |
Alertmanager |
0.22.2 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.10.2-20210601104922 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd Updated |
1.10.2-20210915110132 |
|
Grafana Updated |
8.1.2 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.10.2-20210601104911 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat |
7.10.2 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.14.0-20210812120726 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier Updated |
0.3-20210930112115 |
|
sf-reporter New |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
New 1.20.0-20210927090119 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 6.20.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-427.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20211013104642 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.3.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.6.8 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.11.0-6-gbfce76e/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-67-g25ab9f1a/lcm-agent |
|
Helm charts |
managed-lcm-api Updated |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.26.6.tgz |
metallb Updated |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.24.6.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-67-g25ab9f1a |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-22.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.1.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-37.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-32.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-105.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-110.tgz |
|
iam-proxy Updated |
||
kibana Updated |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-30.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-12.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-34.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-202.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-16.tgz |
|
sf-reporter New |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-13.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-807.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-19.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-19.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210707092546 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.22.2 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20210601104922 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210915110132 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:8.1.2 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20210601104911 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20210812120726 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter New |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
New mirantis.azurecr.io/stacklight/telegraf:1.20.0-20210927090119 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
See also
The Cluster release 6.19.0 is introduced in the Mirantis Container Cloud release 2.12.0. This Cluster release is based on the Cluster release 5.19.0.
The Cluster release 6.19.0 supports:
Mirantis OpenStack for Kubernetes (MOS) 21.5. For details, see MOS Release Notes.
Mirantis Kubernetes Engine (MKE) 3.3.12. For details, see MKE Release Notes.
Mirantis Container Runtime (MCR) 20.10.6. For details, see MCR Release Notes.
Kubernetes 1.18.
For the list of addressed and known issues, refer to the Container Cloud release 2.12.0 section.
This section outlines new features and enhancements introduced in the Cluster release 6.19.0.
Updated the Mirantis Container Runtime (MCR) version from 20.10.5 to 20.10.6 and Mirantis Kubernetes Engine version from 3.3.6 to 3.3.12 for the Container Cloud management, regional, and managed clusters. Also, added support for attachment of existing MKE clusters 3.3.7-3.3.12 and 3.4.1-3.4.5.
For the MCR release highlights and components versions, see MCR documentation: MCR release notes and MKE documentation: MKE release notes.
Integrated the Ceph maintenance to the common upgrade procedure. Now, the
maintenance flag function is set up programmatically and the flag itself is
deprecated.
Technology Preview
Implemented the capability to specify RADOS Gateway tolerations through the
KaaSCephCluster spec using the native Rook way for setting resource
requirements for Ceph daemons.
Enhanced the Grafana dashboards to display user-friendly short names for
Kubernetes nodes, for example, master-0, instead of long name labels
such as kaas-node-f736fc1c-3baa-11eb-8262-0242ac110002.
This feature provides for consistency with Kubernetes nodes naming in the
Container Cloud web UI.
All Grafana dashboards that present node data now have an additional Node identifier drop-down menu. By default, it is set to machine to display short names for Kubernetes nodes. To display Kubernetes node name labels as previously, change this option to node.
Learn more
Implemented the following improvements to StackLight alerting:
Enhanced the alert inhibition rules.
Reworked a number of alerts to improve alerting efficiency and reduce alert flooding.
Removed the inefficient
DockerSwarmLeadElectionLoopandSystemDiskErrorsTooHighalerts.Added the
matcherskey to the routes configuration. Deprecated thematchandmatch_rekeys.
Learn more
Implemented the capability to create custom logs-based metrics that you can use to configure StackLight notifications.
Learn more
The following table lists the components versions of the Cluster release 6.19.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration Updated |
Mirantis Kubernetes Engine |
3.3.12 0 |
Container runtime Updated |
Mirantis Container Runtime |
20.10.6 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.6.8 |
|
LCM |
descheduler Removed |
n/a |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.3.0-32-gee08c2b8 |
|
lcm-ansible Updated |
0.10.0-12-g7cd13b6 |
|
lcm-agent Updated |
0.3.0-32-gee08c2b8 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.4.1-20210707092546 |
Alertmanager |
0.22.2 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.10.2-20210601104922 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20210602174807 |
|
Grafana |
7.5.4 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.10.2-20210601104911 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat |
7.10.2 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter Updated |
0.14.0-20210812120726 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20210702081359 |
|
Telegraf |
1.9.1-20210225142050 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 6.19.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-409.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210921155643 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.3.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner Updated |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.6.8 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.10.0-12-g7cd13b6/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-32-gee08c2b8/lcm-agent |
|
Helm charts |
descheduler Removed |
n/a |
managed-lcm-api Updated |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.25.6.tgz |
|
metallb Updated |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.24.6.tgz |
|
Docker images |
descheduler Removed |
n/a |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-32-gee08c2b8 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-22.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.1.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-36.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-32.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-97.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-110.tgz |
|
iam-proxy Updated |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-29.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-12.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-34.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-201.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-16.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-595.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-19.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-19.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210707092546 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.22.2 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20210601104922 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210602174807 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.5.4 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20210601104911 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20210812120726 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210702081359 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ Updated |
See also
The Cluster release 6.18.0 is introduced in the Mirantis Container Cloud release 2.11.0. This Cluster release is based on the Cluster release 5.18.0.
The Cluster release 6.18.0 supports:
Mirantis OpenStack for Kubernetes (MOS) 21.4. For details, see MOS Release Notes.
Mirantis Kubernetes Engine (MKE) 3.3.6 and the updated version of Mirantis Container Runtime (MCR) 20.10.5. For details, see MKE Release Notes and MCR Release Notes.
Kubernetes 1.18.
For the list of addressed issues, refer to the Container Cloud releases 2.10.0 and 2.11.0 sections. For the list of known issues, refer to the Container Cloud release 2.11.0.
This section outlines new features and enhancements introduced in the Cluster release 6.18.0.
Implemented a graceful Mirantis Container Runtime (MCR) upgrade from 19.03.14 to 20.10.5 on existing Container Cloud clusters.
Improved the MKE logs gathering by replacing the default DEBUG logs level
with INFO. This change reduces the unnecessary load on the MKE cluster
caused by an excessive amount of logs generated with the DEBUG level
enabled.
Implemented the capability to configure the verbosity level of logs produced by all StackLight components or by each component separately.
Implemented the capability to set the default log level severity for all StackLight components as well as set a custom log level severity for specific StackLight components in the Container Cloud web UI. You can update this setting either during a managed cluster creation or during a post-deployment configuration.
Implemented the following improvements to StackLight alerting:
Added the following alerts:
PrometheusMsTeamsDownthat raises ifprometheus-msteamsis down.ServiceNowWebhookReceiverDownthat raises ifalertmanager-webhook-servicenowis down.SfNotifierDownthat raises if thesf-notifieris down.KubeAPICertExpirationMajor,KubeAPICertExpirationWarning,MKEAPICertExpirationMajor,MKEAPICertExpirationWarningthat inform on SSL certificates expiration.KubeContainersCPUThrottlingHighthat raises in case of containers CPU throttling.KubeletDownthat raises if kubelet is down.
Removed the following inefficient alerts:
PostgresqlPrimaryDownFileDescriptorUsageCriticalKubeCPUOvercommitNamespacesKubeMemOvercommitNamespacesKubeQuotaExceededContainerScrapeError
Reworked a number of alerts to improve alerting efficiency and reduce alert flooding.
Reworked the alert inhibition rules to match the receivers.
Updated Alertmanager to v0.22.2.
Changed the default behavior of the Salesforce alerts integration. Now, by default, only
Criticalalerts will be sent to the Salesforce.
Implemented the following improvements for the StackLight node labeling during a cluster creation or post-deployment configuration:
Added a verification that a cluster contains minimum 3 worker nodes with the StackLight label for clusters with StackLight deployed in HA mode. This verification applies to cluster deployment and update processes. For details on how to add the StackLight label before upgrade to the latest Cluster releases of Container Cloud 2.11.0, refer to Upgrade managed clusters with StackLight deployed in HA mode.
Added a notification about the minimum number of worker nodes with the StackLight label for HA StackLight deployments to the cluster live status description in the Container Cloud web UI.
Caution
Removal of the StackLight label from worker nodes along with removal of worker nodes with StackLight label can cause the StackLight components to become inaccessible. It is important to keep the worker nodes where the StackLight local volumes were provisioned.
Implemented the capability to enable feed update in Salesforce using
the feed_enabled parameter. By default, this parameter is set to false
to save API calls.
Implemented the capability to add or configure proxy on existing Container Cloud managed clusters using the Container Cloud web UI.
Learn more
Upgraded Ceph from 14.2.19 (Nautilus) to 15.2.13 (Octopus) and Rook from 1.5.9 to 1.6.8.
On top of continuous improvements delivered to the existing Container Cloud guides, added the following procedures:
Technology Preview
Implemented the capability to define Ceph tolerations and resources management
through the KaaSCephCluster spec using the native Rook way for setting
resource requirements for Ceph daemons.
Improved the MiraCephLog custom resource by adding more information about
all Ceph cluster entities and their statuses. The MiraCeph, MiraCephLog
statuses and MiraCephLog values are now integrated to
KaaSCephCluster.status and can be viewed using the miraCephInfo,
shortClusterInfo, and fullClusterInfo fields.
Implemented the capability to define a list of Ceph Manager modules to enable
on the Ceph cluster using the mgr.modules parameter in KaaSCephCluster.
The following table lists the components versions of the Cluster release 6.18.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.3.6 0 |
Container runtime |
Mirantis Container Runtime Updated |
20.10.5 1 |
Distributed storage Updated |
Ceph |
15.2.13 (Octopus) |
Rook |
1.6.8 |
|
LCM |
descheduler |
0.8.0 |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.2.0-399-g85be100f |
|
lcm-ansible Updated |
0.9.0-17-g28bc9ce |
|
lcm-agent Updated |
0.2.0-399-g85be100f |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta Updated |
8.4.1-20210707092546 |
Alertmanager Updated |
0.22.2 |
|
Alertmanager Webhook ServiceNow Updated |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Updated |
7.10.2-20210601104922 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd Updated |
1.10.2-20210602174807 |
|
Grafana |
7.5.4 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana Updated |
7.10.2-20210601104911 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat |
7.10.2 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20210323132924 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter Updated |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier Updated |
0.3-20210702081359 |
|
Telegraf |
1.9.1-20210225142050 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
Due to the development limitations, the MCR upgrade to version 19.03.14 on existing Container Cloud clusters is not supported.
This section lists the components artifacts of the Cluster release 6.18.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-368.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210807103257 |
|
cephcsi Updated |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.3.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner Updated |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook/ceph:v1.6.8 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.9.0-17-g28bc9ce/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-399-g85be100f/lcm-agent |
|
Helm charts Updated |
descheduler |
https://binary.mirantis.com/core/helm/descheduler-1.24.6.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.24.6.tgz |
|
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.24.6.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-399-g85be100f |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-22.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.1.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-36.tgz |
|
elasticsearch-curator Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-30.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-96.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-108.tgz |
|
iam-proxy Updated |
||
kibana Updated |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-29.tgz |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-12.tgz |
|
metricbeat Updated |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-33.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-188.tgz |
|
prometheus-blackbox-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-10.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-16.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-574.tgz |
|
telegraf-ds Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-29.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-17.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-17.tgz |
|
Docker images |
alerta Updated |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210707092546 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0.22.2 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch Updated |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20210601104922 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210602174807 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.5.4 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana Updated |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20210601104911 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20210323132924 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210702081359 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories Updated |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
See also
The Cluster release 6.16.0 is introduced in the Mirantis Container Cloud release 2.9.0. This Cluster release is based on the Cluster release 5.16.0.
The Cluster release 6.16.0 supports:
Mirantis OpenStack for Kubernetes (MOS) 21.3. For details, see MOS Release Notes.
Mirantis Kubernetes Engine (MKE) 3.3.6 and Mirantis Container Runtime (MCR) 19.03.14. For details, see MKE Release Notes and MCR Release Notes.
Kubernetes 1.18.
For the list of addressed issues, refer to the Container Cloud releases 2.8.0 and 2.9.0 sections. For the list of known issues, refer to the Container Cloud release 2.9.0.
This section outlines new features and enhancements introduced in the Cluster release 6.16.0.
Upgraded PostgreSQL from version 12 to 13
Updated Elasticsearch, Kibana, and Metricbeat from version 7.6.1 to 7.10.2
Implemented the capability to enable Alertmanager to send notifications to a Microsoft Teams channel.
Learn more
Implemented the capability to enable Alertmanager to send notifications to
ServiceNow. Also added the ServiceNowAuthFailure alert that will raise in
case of failure to authenticate to ServiceNow.
Learn more
Improved the log collection mechanism by optimizing the existing and adding new log parsers for multiple Container Cloud components.
Learn more
Enhanced Ceph Controller to automatically specify default configuration options for each Ceph cluster during the Ceph deployment.
Implemented the following Ceph enhancements in the KaaSCephCluster CR:
Added the capability to specify the
rgwrole using therolesparameterAdded the following parameters:
rookConfigto override the Ceph configuration optionsuseAsFullNameto enable the Ceph block pool to use only thenamevalue as a nametargetSizeRatioto specify the expected consumption of the Ceph cluster total capacitySSLCertto use a custom TLS certificate to access the Ceph RGW endpointnodeGroupsto easily define specifications for multiple Ceph nodes using lists, grouped by node lists or node labelsclientsto specify the Ceph clients and their capabilities
Implemented the capability to configure multiple networks for a Ceph cluster.
Learn more
Implemented the capability to configure TLS for a Ceph cluster using a custom ingress rule for Ceph public endpoints.
Learn more
Implemented the capability to enable RADOS Block Device (RBD) mirroring for Ceph pools.
Learn more
The following table lists the components versions of the Cluster release 6.16.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Distributed storage Updated |
Ceph |
14.2.19 (Nautilus) |
Rook |
1.5.9 |
|
Container runtime |
Mirantis Container Runtime |
19.03.14 1 |
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.3.6 0 |
LCM |
descheduler |
0.8.0 |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.2.0-349-g4870b7f5 |
|
lcm-ansible Updated |
0.7.0-9-g30acaae |
|
lcm-agent Updated |
0.2.0-349-g4870b7f5 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.4.1-20210312131419 |
Alertmanager |
0.21.0 |
|
Alertmanager Webhook ServiceNow New |
0.1-20210426114325 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Updated |
7.10.2-20210513065347 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd Updated |
1.10.2-20210518100631 |
|
Grafana Updated |
7.5.4 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana Updated |
7.10.2-20210513065546 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat Updated |
7.10.2 |
|
Netchecker Deprecated |
1.4.1 |
|
Patroni Updated |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20210323132924 |
|
Prometheus MS Teams New |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter Updated |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20210323132354 |
|
sf-reporter |
0.1-20201216142628 |
|
Telegraf |
1.9.1-20210225142050 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
Due to the development limitations, the MCR upgrade to version 19.03.14 on existing Container Cloud clusters is not supported.
This section lists the components artifacts of the Cluster release 6.16.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-271.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/ceph/ceph:v14.2.19 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210521190241 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.2.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner Updated |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.1 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook/ceph:v1.5.9 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible Updated |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.7.0-9-g30acaae/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-349-g4870b7f5/lcm-agent |
|
Helm charts Updated |
descheduler |
https://binary.mirantis.com/core/helm/descheduler-1.22.4.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.22.4.tgz |
|
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.22.4.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-349-g4870b7f5 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-20.tgz |
alertmanager-webhook-servicenow New |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.1.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-31.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-2.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-20.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-83.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-102.tgz |
|
iam-proxy |
||
kibana Updated |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-25.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-8.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-8.tgz |
|
netchecker Deprecated |
||
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-24.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-139.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-4.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-3.tgz |
|
prometheus-msteams New |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-11.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-492.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-20.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-20.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-12.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-12.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210312131419 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.21.0 |
|
alertmanager-webhook-servicenow New |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210426114325 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch Updated |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20210513065347 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210518100631 |
|
gce-proxy |
mirantis.azurecr.io/stacklight/gce-proxy:1.11 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:7.5.4 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.2 |
|
k8s-netchecker-agent Deprecated |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-agent:2019.1 |
|
k8s-netchecker-server Deprecated |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-server:2019.1 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana Updated |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20210513065546 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20210323132924 |
|
prometheus-msteams New |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210323132354 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20201216152628 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-19.03/ |
See also
The Cluster release 6.14.0 is introduced in the Mirantis Container Cloud release 2.7.0. This Cluster release is based on the Cluster release 5.14.0.
The Cluster release 6.14.0 supports:
Mirantis OpenStack for Kubernetes (MOS) 21.2. For details, see MOS Release Notes.
Mirantis Kubernetes Engine (MKE) 3.3.6 and Mirantis Container Runtime (MCR) 19.03.14. For details, see MKE Release Notes and MCR Release Notes.
Kubernetes 1.18.
For the list of resolved issues, refer to the Container Cloud releases 2.6.0 and 2.7.0 sections. For the list of known issues, refer to the Container Cloud releases 2.7.0.
This section outlines new features and enhancements introduced in the Cluster release 6.14.0.
Significantly enhanced the StackLight log collection mechanism to avoid
collecting and keeping an excessive amount of log messages when it is not
essential. Now, during or after deployment of StackLight, you can select one of
the 9 available logging levels depending on the required severity. The default
logging level is INFO.
Learn more
Implemented the capability to configure StackLight to forward all logs to an external syslog server. In this case, StackLight will send logs both to the syslog server and to Elasticsearch, which is the default target.
Learn more
Improved the log collection mechanism by optimizing the existing and adding new log parsers for multiple Container Cloud components.
Learn more
Technology Preview
Implemented the capability to configure Ceph Controller to start pods on the taint nodes and manage the resources of Ceph nodes. Now, when bootstrapping a new management or managed cluster, you can specify requests, limits, or tolerations for Ceph resources. You can also configure resource management for an existing Ceph cluster. However, such approach may cause downtime.
Improved user experience by moving the rgw section of the
KaasCephCluster CR to a common objectStorage section that now includes
all RADOS Gateway configurations of a Ceph cluster. The spec.rgw section is
deprecated. However, if you continue using spec.rgw, it will be
automatically translated into the new objectStorage.rgw section during the
Container Cloud update to 2.6.0.
Learn more
Implemented the capability to enable Ceph maintenance mode using the
maintenance flag not only during a managed cluster update but also when
required. However, Mirantis does not recommend enabling maintenance on
production deployments other than during update.
Learn more
TECHNOLOGY PREVIEW
Added the possibility to configure dedicated networks for the Ceph cluster access and replication traffic using dedicated subnets. Container Cloud automatically configures Ceph to use the addresses from the dedicated subnets after you assign the corresponding addresses to the storage nodes.
Technology Preview
Implemented the capability to enable the Ceph Multisite configuration that allows object storage to replicate its data over multiple Ceph clusters. Using Multisite, such object storage is independent and isolated from another object storage in the cluster.
On top of continuous improvements delivered to the existing Container Cloud guides, added the Troubleshoot Ceph section to the Operations Guide. This section now contains a detailed procedure on a failed or accidentally removed Ceph cluster recovery.
Learn more
The following table lists the components versions of the Cluster release 6.14.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Distributed storage |
Ceph |
14.2.12 (Nautilus) |
Rook |
1.5.5 |
|
Container runtime |
Mirantis Container Runtime |
19.03.14 1 |
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.3.6 0 |
LCM |
descheduler |
0.8.0 |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.2.0-297-g8c87ad67 |
|
lcm-ansible Updated |
0.5.0-10-gdd307e6 |
|
lcm-agent Updated |
0.2.0-300-ga874e0df |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta Updated |
8.4.1-20210312131419 |
Alertmanager |
0.21.0 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.6.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd Updated |
1.10.2-20210301155825 |
|
Grafana Updated |
7.3.7 |
|
Grafana Image Renderer Updated |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.6.1 |
|
Metric Collector Updated |
0.1-20210219112938 |
|
Metricbeat |
7.6.1 |
|
Netchecker |
1.4.1 |
|
Patroni |
12-1.6p3 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter Updated |
0.5.1-20210323132924 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter |
0.8.0-20201006113956 |
|
Prometheus Relay Updated |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier Updated |
0.3-20210323132354 |
|
sf-reporter |
0.1-20201216142628 |
|
Telegraf Updated |
1.9.1-20210225142050 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
Due to the development limitations, the MCR upgrade to version 19.03.14 on existing Container Cloud clusters is not supported.
This section lists the components artifacts of the Cluster release 6.14.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-177.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v14.2.12 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210322210534 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.2.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.0 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.5.5 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible Updated |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.5.0-10-gdd307e6/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-300-ga874e0df/lcm-agent |
|
Helm charts |
descheduler Updated |
https://binary.mirantis.com/core/helm/descheduler-1.19.1.tgz |
managed-lcm-api Updated |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.19.1.tgz |
|
metallb Updated |
||
metrics-server Updated |
https://binary.mirantis.com/core/helm/metrics-server-1.19.1.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-297-g8c87ad67 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-15.tgz |
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-22.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-2.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-17.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-61.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-93.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-20.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-8.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-8.tgz |
|
netchecker |
||
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-20.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-124.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-4.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-3.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-11.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-438.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-20.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-20.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-12.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-12.tgz |
|
Docker images |
alerta Updated |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210312131419 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.21.0 |
|
alpine-python3-requests |
mirantis.azurecr.io/stacklight/alpine-python3-requests:latest-20200618 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.6.1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210301155825 |
|
gce-proxy |
mirantis.azurecr.io/stacklight/gce-proxy:1.11 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:7.3.7 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.2 |
|
k8s-netchecker-agent |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-agent:2019.1 |
|
k8s-netchecker-server |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-server:2019.1 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.6.1 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.6.1 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20210323132924 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.8.0-20201006113956 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210323132354 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20201216142628 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:12-1.6p3 |
|
telegraf Updated |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225142050 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-19.03/ |
See also
The Cluster release 6.12.0 is introduced in the Mirantis Container Cloud release 2.5.0 and is supported by 2.6.0. This Cluster release is based on the Cluster release 5.12.0.
The Cluster release 6.12.0 supports:
Mirantis OpenStack for Kubernetes (MOS) 21.1. For details, see MOS Release Notes.
Updated versions of Mirantis Kubernetes Engine (MKE) 3.3.6 and Mirantis Container Runtime (MCR) 19.03.14. For details, see MKE Release Notes and MCR Release Notes.
Kubernetes 1.18.
For the list of resolved issues, refer to the Container Cloud releases 2.4.0 and 2.5.0 sections. For the list of known issues, refer to the Container Cloud release 2.5.0 section.
This section outlines new features and enhancements introduced in the Cluster release 6.12.0.
Implemented alert inhibition rules to provide a clearer view on the cloud status and simplify troubleshooting. Using alert inhibition rules, Alertmanager decreases alert noise by suppressing dependent alerts notifications. The feature is enabled by default. For details, see Alert dependencies.
Implemented integration between Grafana and Kibana by adding a View logs in Kibana link to the majority of Grafana dashboards, which allows you to immediately view contextually relevant logs through the Kibana web UI.
Learn more
Implemented the TelegrafGatherErrors alert that raises if Telegraf fails to
gather metrics.
Learn more
Added the ironic.insecure parameter for enabling or disabling the host and
chain verification for bare metal Ironic monitoring.
Learn more
Enhanced StackLight to automatically set clusterId that defines an ID of
a Container Cloud cluster. Now, you do not need to set or modify this parameter
manually when configuring the sf-notifier and sf-reporter services.
Learn more
Enhanced StackLight by adding support for Cerebro, a web UI that visualizes health of Elasticsearch clusters and allows for convenient debugging. Cerebro is disabled by default.
Implemented the maintenance label to set for Ceph during a managed
cluster update. This prevents Ceph rebalance leading to data loss
during a managed cluster update.
Learn more
Implemented the Enable Object Storage checkbox in the Container Cloud web UI to allow enabling a single-instance RGW Object Storage when creating a Ceph cluster as described in Add a Ceph cluster.
Enhanced Ceph to support RADOS Gateway (RGW) high availability. Now, you can run multiple instances of Ceph RGW in active/active mode.
Learn more
Added proxy support for Alertmanager, Metric collector, Salesforce notifier and reporter, and Telemeter client. Now, these StackLight components automatically use the same proxy that is configured for Container Cloud clusters.
Note
Proxy handles only the HTTP and HTTPS traffic. Therefore, for clusters with limited or no Internet access, it is not possible to set up Alertmanager email notifications, which use SMTP, when proxy is used.
Note
Due to a limitation, StackLight fails to integrate with an external
proxy with authentication handled by a proxy server. In such cases, the
proxy server ignores the HTTP Authorization header for basic
authentication passed by Prometheus Alertmanager. Therefore, use proxies
without authentication or with authentication handled by a reverse proxy.
Learn more
The following table lists the components versions of the Cluster release 6.12.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Distributed storage |
Ceph |
14.2.12 (Nautilus) |
Rook |
1.5.5 |
|
Container runtime |
Mirantis Container Runtime |
19.03.14 1 |
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.3.6 0 |
LCM |
descheduler |
0.8.0 |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.2.0-258-ga2d72294 |
|
lcm-ansible Updated |
0.3.0-10-g7c2a87e |
|
lcm-agent Updated |
0.2.0-258-ga2d72294 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.0.2-20201014133832 |
Alertmanager |
0.21.0 |
|
Cerebro New |
0.9.3 |
|
Elasticsearch |
7.6.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20200609085335 |
|
Grafana |
7.1.5 |
|
Grafana Image Renderer |
2.0.0 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.6.1 |
|
Metric Collector |
0.1-20201222100033 |
|
Metricbeat |
7.6.1 |
|
Netchecker |
1.4.1 |
|
Patroni |
12-1.6p3 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20201002144823 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter |
0.8.0-20201006113956 |
|
Prometheus Relay |
0.3-20200519054052 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20201216142028 |
|
sf-reporter |
0.1-20201216142628 |
|
Telegraf |
1.9.1-20201222194740 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
Due to the development limitations, the MCR upgrade to version 19.03.14 on existing Container Cloud clusters is not supported.
This section lists the components artifacts of the Cluster release 6.12.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-127.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v14.2.12 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210201202754 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.2.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.0 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.5.5 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible Updated |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.3.0-10-g7c2a87e/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-258-ga2d72294/lcm-agent |
|
Helm charts |
descheduler Updated |
https://binary.mirantis.com/core/helm/descheduler-1.17.4.tgz |
managed-lcm-api Updated |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.17.4.tgz |
|
metallb Updated |
||
metrics-server Updated |
https://binary.mirantis.com/core/helm/metrics-server-1.17.4.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-258-ga2d72294 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-13.tgz |
cerebro New |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-22.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-2.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-15.tgz |
|
fluentd-elasticsearch |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-33.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-89.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-20.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-8.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-8.tgz |
|
netchecker |
||
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-19.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-114.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-4.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-3.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-11.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-401.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-20.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-20.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-12.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-12.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.0.2-20201014133832 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.21.0 |
|
alpine-python3-requests |
mirantis.azurecr.io/stacklight/alpine-python3-requests:latest-20200618 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro New |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.6.1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20200609085335 |
|
gce-proxy |
mirantis.azurecr.io/stacklight/gce-proxy:1.11 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.1.5 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.0 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.2 |
|
k8s-netchecker-agent |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-agent:2019.1 |
|
k8s-netchecker-server |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-server:2019.1 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:0.1.178 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.6.1 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20201222100033 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.6.1 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20201002144823 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.8.0-20201006113956 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20200519054052 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20201216142028 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20201216142628 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:12-1.6p3 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20201222194740 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq New |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
See also
The Cluster release 6.10.0 is introduced in the Mirantis Container Cloud release 2.3.0 and supports:
Mirantis OpenStack for Kubernetes (MOS) Ussuri Update. For details, see MOS Release Notes.
Updated versions of Mirantis Kubernetes Engine 3.3.4 and Mirantis Container Runtime 19.03.13. For details, see MKE Release Notes and MCR Release Notes.
Kubernetes 1.18.
For the list of known and resolved issues, refer to the Container Cloud release 2.3.0 section.
This section outlines new features and enhancements introduced in the Cluster release 6.10.0.
Enhanced Ceph to support RADOS Gateway (RGW) Object Storage.
Learn more
Implemented the capability to obtain detailed information on the Ceph cluster state, including Ceph logs, Ceph OSDs state, and a list of Ceph pools.
Learn more
The following table lists the components versions of the Cluster release 6.10.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Distributed storage |
Ceph |
14.2.11 (Nautilus) |
Rook |
1.4.4 |
|
Container runtime |
Mirantis Container Runtime Updated |
19.03.13 1 |
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.3.4 0 |
LCM |
descheduler |
0.8.0 |
Helm Updated |
2.16.11-40 |
|
helm-controller Updated |
0.2.0-221-g32bd5f56 |
|
lcm-ansible Updated |
0.2.0-381-g720ec96 |
|
lcm-agent Updated |
0.2.0-221-g32bd5f56 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.0.2-20201014133832 |
Alertmanager |
0.21.0 |
|
Elasticsearch |
7.6.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20200609085335 |
|
Grafana |
7.1.5 |
|
Grafana Image Renderer |
2.0.0 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.6.1 |
|
Metric Collector Updated |
0.1-20201120155524 |
|
Metricbeat |
7.6.1 |
|
Netchecker |
1.4.1 |
|
Patroni |
12-1.6p3 |
|
Prometheus Updated |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20201002144823 |
|
Prometheus libvirt Exporter |
0.1-20200610164751 |
|
Prometheus Memcached Exporter |
0.5.0 |
|
Prometheus MySQL Exporter |
0.11.0 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter |
0.8.0-20201006113956 |
|
Prometheus RabbitMQ Exporter Updated |
v1.0.0-RC7.1 |
|
Prometheus Relay |
0.3-20200519054052 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20201001081256 |
|
sf-reporter |
0.1-20200219140217 |
|
Telegraf Updated |
1.9.1-20201120081248 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
Due to the development limitations, the MCR upgrade to version 19.03.14 on existing Container Cloud clusters is not supported.
This section lists the components artifacts of the Cluster release 6.10.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-95.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v14.2.11 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20201215142221 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.1.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v1.2.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v1.6.0 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v2.1.1 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v2.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.4.4 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible Updated |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.2.0-381-g720ec96/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-221-g32bd5f56/lcm-agent |
|
Helm charts |
descheduler Updated |
https://binary.mirantis.com/core/helm/descheduler-1.15.1.tgz |
managed-lcm-api New |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.15.1.tgz |
|
metallb Updated |
||
metrics-server Updated |
https://binary.mirantis.com/core/helm/metrics-server-1.15.1.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm Updated |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-221-g32bd5f56 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-13.tgz |
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-22.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-2.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-15.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-33.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-74.tgz |
|
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-20.tgz |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-5.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-8.tgz |
|
netchecker |
||
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-17.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-102.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-3.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-3.tgz |
|
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/heprometheus-libvirt-exporter-0.1.0-mcp-2.tgz |
|
prometheus-memcached-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-memcached-exporter-0.1.0-mcp-1.tgz |
|
prometheus-mysql-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-mysql-exporter-0.3.2-mcp-1.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
prometheus-rabbitmq-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-rabbitmq-exporter-0.4.1-mcp-1.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-9.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-8.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-354.tgz |
|
telegraf-ds Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-19.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-19.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-11.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-11.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.0.2-20201014133832 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.21.0 |
|
alpine-python3-requests |
mirantis.azurecr.io/stacklight/alpine-python3-requests:latest-20200618 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.6.1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20200609085335 |
|
gce-proxy |
mirantis.azurecr.io/stacklight/gce-proxy:1.11 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.1.5 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.0 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.2 |
|
k8s-netchecker-agent |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-agent:2019.1 |
|
k8s-netchecker-server |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-server:2019.1 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:0.1.178 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.6.1 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20201120155524 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.6.1 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20201002144823 |
|
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/libvirt-exporter:v0.1-20200610164751 |
|
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
|
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.8.0-20201006113956 |
|
prometheus-rabbitmq-exporter Updated |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC7.1 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20200519054052 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20201001081256 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20200219140217 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:12-1.6p3 |
|
telegraf Updated |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20201120081248 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
See also
The Cluster release 6.8.1 is introduced in the Mirantis Container Cloud release 2.2.0. This Cluster release is based on the Cluster release 5.8.0 and the main difference is support of the Mirantis OpenStack for Kubernetes (MOS) product.
For details about MOS, see MOS Release Notes.
For details about the Cluster release 5.8.0, refer to the 5.8.0 section.
5.x series¶
This section outlines release notes for the unsupported Cluster releases of the 5.x series.
This section outlines release notes for the Cluster release 5.22.0 that is introduced in the Mirantis Container Cloud release 2.15.0. This Cluster release supports Mirantis Container Runtime 20.10.8 and Mirantis Kubernetes Engine 3.3.13 with Kubernetes 1.18.
For the list of known and resolved issues, refer to the Container Cloud release 2.15.0 section.
This section outlines new features and enhancements introduced in the Cluster release 5.22.0.
Updated the Mirantis Container Runtime (MCR) version from 20.10.6 to 20.10.8 for the Container Cloud management, regional, and managed clusters on all supported cloud providers.
Learn more
Implemented the MCCLicenseExpirationCritical and
MCCLicenseExpirationMajor alerts that notify about Mirantis Container Cloud
license expiration in less than 10 and 30 days.
Learn more
Implemented the following improvements to StackLight alerting:
Enhanced Kubernetes applications alerting:
Reworked the Kubernetes applications alerts to minimize flapping, avoid firing during pod rescheduling, and to detect crash looping for pods that restart less frequently.
Added the
KubeDeploymentOutage,KubeStatefulSetOutage, andKubeDaemonSetOutagealerts.Removed the redundant
KubeJobCompletionalert.Enhanced the alert inhibition rules to reduce alert flooding.
Improved alert descriptions.
Split
TelemeterClientFederationFailedintoTelemeterClientFailedandTelemeterClientHAFailedto separate alerts depending on the HA mode disabled or enabled.Updated the description for
DockerSwarmNodeFlapping.
Disabled unused Node Exporter collectors and implemented the capability to
manually enable needed collectors using the
nodeExporter.extraCollectorsEnabled parameter. Only the following
collectors are now enabled by default in StackLight:
|
|
|
|
Implemented full support for automated Ceph LCM operations using the
KaaSCephOperationRequest CR, such as addition or removal of Ceph OSDs and
nodes, as well as replacement of failed Ceph OSDs or nodes.
Learn more
Implemented the capability to specify Container Storage Interface (CSI)
provisioner tolerations and node affinity for different Rook resources.
Added support for the all and mds keys in toleration rules.
Extended the fullClusterInfo section of the KaaSCephCluster.status
resource with the following fields:
cephDetails- contains verbose details of a Ceph cluster statecephCSIPluginDaemonsStatus- contains details on all Ceph CSIs
Learn more
The following table lists the components versions of the Cluster release 5.22.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.3.13 0 |
Container runtime |
Mirantis Container Runtime Updated |
20.10.8 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.7.6 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-132-g83a348fa |
|
lcm-ansible Updated |
0.13.0-26-gad73ff7 |
|
lcm-agent Updated |
0.3.0-132-g83a348fa |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.5.0-20211108051042 |
Alertmanager Updated |
0.23.0 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.10.2-2021110210112 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20210915110132 |
|
Grafana Updated |
8.2.7 |
|
Grafana Image Renderer |
3.2.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.10.2-20211101074638 |
|
Metric Collector |
0.1-20211109121134 |
|
Metricbeat |
7.10.2-20211103140113 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus Updated |
2.31.1 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.14.0-20210812120726 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter Updated |
1.2.2 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway Removed |
n/a |
|
sf-notifier |
0.3-20210930112115 |
|
sf-reporter |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
1.20.0-20210927090119 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 5.22.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-606.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20220110132813 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.7.6 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.13.0-26-gad73ff7/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-132-g83a348fa/lcm-agent |
|
Helm charts Updated |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.28.7.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.28.7.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-132-g83a348fa |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-25.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-1.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-37.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-32.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-115.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-121.tgz |
|
iam-proxy Updated |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-30.tgz |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-3.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-36.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-214.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-1.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-1.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.3.1.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-1.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-1.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0.23.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20211102101126 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210915110132 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:8.2.7 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.2.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20211101074638 |
|
kube-state-metrics Updated |
mirantis.azurecr.io/stacklight/kube-state-metrics:v2.2.4 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20211109121134 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20211103140113 |
|
node-exporter Updated |
mirantis.azurecr.io/stacklight/node-exporter:v1.2.2 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.31.1 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20210812120726 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway Removed |
n/a |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.0-20210927090119 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2021-11-11-014639.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 5.21.0 that is introduced in the Mirantis Container Cloud release 2.14.0. This Cluster release supports Mirantis Container Runtime 20.10.6 and Mirantis Kubernetes Engine 3.3.12 with Kubernetes 1.18.
For the list of known and resolved issues, refer to the Container Cloud release 2.14.0 section.
This section outlines new features and enhancements introduced in the Cluster release 5.21.0.
Updated the Mirantis Kubernetes Engine version from 3.3.12 to 3.3.13 for the Container Cloud management, regional, and managed clusters. Also, added support for attachment of existing MKE 3.3.13 clusters.
Learn more
Limited the number of monitored network interfaces to prevent extended Prometheus RAM consumption in big clusters. By default, Prometheus Node Exporter now only collects information of a basic set of interfaces, both host and container. If required you can edit the list of excluded devices as needed.
Implemented the capability to define custom Prometheus recording rules through
the prometheusServer.customRecordingRules parameter in the StackLight Helm
chart. Overriding of existing recording rules is not supported.
Implemented the capability to configure packet size for the syslog logging
output. If remote logging to syslog is enabled in StackLight, use the
logging.syslog.packetSize parameter in the StackLight Helm chart to
configure the packet size.
Learn more
Implemented the capability to configure the Prometheus Relay client timeout and
response size limit through the prometheusRelay.clientTimeout and
prometheusRelay.responseLimitBytes parameters in the StackLight Helm chart.
Implemented additional validation of networks specified in
spec.cephClusterSpec.network.publicNet and
spec.cephClusterSpec.network.clusterNet and prohibited the use of the
0.0.0.0/0 CIDR. Now, the bare metal provider automatically translates
the 0.0.0.0/0 network range to the default LCM IPAM subnet if it exists.
You can now also add corresponding labels for the bare metal IPAM subnets when configuring the Ceph cluster during the management cluster deployment.
Learn more
To improve debugging and log reading, separated Ceph Controller, Ceph Status Controller, and Ceph Request Controller, which used to run in one pod, into three different deployments.
Learn more
TechPreview
Implemented the KaaSCephOperationRequest CR that provides LCM operations
for Ceph OSDs and nodes by automatically creating separate
CephOsdRemoveRequest requests. It allows for automated removal of healthy
or non-healthy Ceph OSDs from a Ceph cluster.
Due to the Technology Preview status of the feature, Mirantis recommends following Remove Ceph OSD manually for Ceph OSDs removal.
Learn more
The following table lists the components versions of the Cluster release 5.21.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.3.13 0 |
Container runtime |
Mirantis Container Runtime |
20.10.6 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook Updated |
1.7.6 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-104-gb7f5e8d8 |
|
lcm-ansible Updated |
0.12.0-6-g5329efe |
|
lcm-agent Updated |
0.3.0-104-gb7f5e8d8 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta Updated |
8.5.0-20211108051042 |
Alertmanager |
0.22.2 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Updated |
7.10.2-2021110210112 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20210915110132 |
|
Grafana Updated |
8.2.2 |
|
Grafana Image Renderer Updated |
3.2.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana Updated |
7.10.2-20211101074638 |
|
Metric Collector Updated |
0.1-20211109121134 |
|
Metricbeat Updated |
7.10.2-20211103140113 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.14.0-20210812120726 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20210930112115 |
|
sf-reporter |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
1.20.0-20210927090119 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 5.21.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-526.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20211109132703 |
|
cephcsi Updated |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.4.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook/ceph:v1.7.6 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.12.0-6-g5329efe/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-104-gb7f5e8d8/lcm-agent |
|
Helm charts |
managed-lcm-api Updated |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.27.6.tgz |
metallb Updated |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.27.6.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-104-gb7f5e8d8 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-22.tgz |
alertmanager-webhook-servicenow Updated |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.2.0-mcp-1.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-37.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-32.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-112.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-115.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-30.tgz |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.3.0-mcp-1.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-36.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-208.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.2.0-mcp-1.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.2.0-mcp-1.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.2.0-mcp-1.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.2.5.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.2.0-mcp-1.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.2.0-mcp-1.tgz |
|
Docker images |
alerta Updated |
mirantis.azurecr.io/stacklight/alerta-web:8.5.0-20211108051042 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.22.2 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch Updated |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20211102101126 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210915110132 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:8.2.2 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:3.2.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana Updated |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20211101074638 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20211109121134 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2-20211103140113 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20210812120726 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
mirantis.azurecr.io/stacklight/telegraf:1.20.0-20210927090119 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
http://mirror.mirantis.com/kaas/kubernetes-extra-rhel7-0.0.5/ |
||
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 5.20.0 that is introduced in the Mirantis Container Cloud release 2.13.0. This Cluster release supports Mirantis Container Runtime 20.10.6 and Mirantis Kubernetes Engine 3.3.12 with Kubernetes 1.18.
For the list of known and resolved issues, refer to the Container Cloud release 2.13.0 section.
This section outlines new features and enhancements introduced in the Cluster release 5.20.0.
Implemented the following improvements to StackLight alerting:
Implemented per-service
*TargetDownand*TargetsOutagealerts that raise if one or all Prometheus targets are down.Enhanced the alert inhibition rules to reduce alert flooding.
Removed the following inefficient alerts:
TargetDownTargetFlappingKubeletDownServiceNowWebhookReceiverDownSfNotifierDownPrometheusMsTeamsDown
Learn more
The following table lists the components versions of the Cluster release 5.20.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.3.12 0 |
Container runtime |
Mirantis Container Runtime |
20.10.6 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.6.8 |
|
LCM |
Helm |
2.16.11-40 |
helm-controller Updated |
0.3.0-67-g25ab9f1a |
|
lcm-ansible Updated |
0.11.0-6-gbfce76e |
|
lcm-agent Updated |
0.3.0-67-g25ab9f1a |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.4.1-20210707092546 |
Alertmanager |
0.22.2 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.10.2-20210601104922 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd Updated |
1.10.2-20210915110132 |
|
Grafana Updated |
8.1.2 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.10.2-20210601104911 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat |
7.10.2 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.14.0-20210812120726 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier Updated |
0.3-20210930112115 |
|
sf-reporter New |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
New 1.20.0-20210927090119 |
||
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 5.20.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-427.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20211013104642 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.3.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.6.8 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.11.0-6-gbfce76e/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-67-g25ab9f1a/lcm-agent |
|
Helm charts |
managed-lcm-api Updated |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.26.6.tgz |
metallb Updated |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.24.6.tgz |
|
Docker images |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-67-g25ab9f1a |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-22.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.1.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-37.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-32.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-105.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-110.tgz |
|
iam-proxy Updated |
||
kibana Updated |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-30.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-12.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-34.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-202.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-16.tgz |
|
sf-reporter New |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-13.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-807.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-19.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-19.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210707092546 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.22.2 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20210601104922 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210915110132 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:8.1.2 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20210601104911 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20210812120726 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210930112115 |
|
sf-reporter New |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
New mirantis.azurecr.io/stacklight/telegraf:1.20.0-20210927090119 |
||
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 5.19.0 that is introduced in the Mirantis Container Cloud release 2.12.0. This Cluster release supports Mirantis Container Runtime 20.10.6 and Mirantis Kubernetes Engine 3.3.12 with Kubernetes 1.18.
For the list of known and resolved issues, refer to the Container Cloud release 2.12.0 section.
This section outlines new features and enhancements introduced in the Cluster release 5.19.0.
Updated the Mirantis Container Runtime (MCR) version from 20.10.5 to 20.10.6 and Mirantis Kubernetes Engine version from 3.3.6 to 3.3.12 for the Container Cloud management, regional, and managed clusters. Also, added support for attachment of existing MKE clusters 3.3.7-3.3.12 and 3.4.1-3.4.5.
For the MCR release highlights and components versions, see MCR documentation: MCR release notes and MKE documentation: MKE release notes.
Integrated the Ceph maintenance to the common upgrade procedure. Now, the
maintenance flag function is set up programmatically and the flag itself is
deprecated.
Technology Preview
Implemented the capability to specify RADOS Gateway tolerations through the
KaaSCephCluster spec using the native Rook way for setting resource
requirements for Ceph daemons.
Enhanced the Grafana dashboards to display user-friendly short names for
Kubernetes nodes, for example, master-0, instead of long name labels
such as kaas-node-f736fc1c-3baa-11eb-8262-0242ac110002.
This feature provides for consistency with Kubernetes nodes naming in the
Container Cloud web UI.
All Grafana dashboards that present node data now have an additional Node identifier drop-down menu. By default, it is set to machine to display short names for Kubernetes nodes. To display Kubernetes node name labels as previously, change this option to node.
Learn more
Implemented the following improvements to StackLight alerting:
Enhanced the alert inhibition rules.
Reworked a number of alerts to improve alerting efficiency and reduce alert flooding.
Removed the inefficient
DockerSwarmLeadElectionLoopandSystemDiskErrorsTooHighalerts.Added the
matcherskey to the routes configuration. Deprecated thematchandmatch_rekeys.
Learn more
Implemented the capability to create custom logs-based metrics that you can use to configure StackLight notifications.
Learn more
The following table lists the components versions of the Cluster release 5.19.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration Updated |
Mirantis Kubernetes Engine |
3.3.12 0 |
Container runtime Updated |
Mirantis Container Runtime |
20.10.6 1 |
Distributed storage |
Ceph |
15.2.13 (Octopus) |
Rook |
1.6.8 |
|
LCM |
descheduler Removed |
n/a |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.3.0-32-gee08c2b8 |
|
lcm-ansible Updated |
0.10.0-12-g7cd13b6 |
|
lcm-agent Updated |
0.3.0-32-gee08c2b8 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.4.1-20210707092546 |
Alertmanager |
0.22.2 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.10.2-20210601104922 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20210602174807 |
|
Grafana |
7.5.4 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.10.2-20210601104911 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat |
7.10.2 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter Updated |
0.14.0-20210812120726 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20210702081359 |
|
Telegraf |
1.9.1-20210225142050 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 5.19.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-409.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210921155643 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.3.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner Updated |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.6.8 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.10.0-12-g7cd13b6/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.3.0-32-gee08c2b8/lcm-agent |
|
Helm charts |
descheduler Removed |
n/a |
managed-lcm-api Updated |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.25.6.tgz |
|
metallb Updated |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.24.6.tgz |
|
Docker images |
descheduler Removed |
n/a |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.3.0-32-gee08c2b8 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-22.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.1.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-36.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-32.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-97.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-110.tgz |
|
iam-proxy Updated |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-29.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-12.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-34.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-201.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-11.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-16.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-595.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-30.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-19.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-19.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210707092546 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.22.2 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20210601104922 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210602174807 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.5.4 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20210601104911 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.14.0-20210812120726 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210702081359 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories Updated |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 5.18.0 that is introduced in the Mirantis Container Cloud release 2.11.0. This Cluster release supports Mirantis Container Runtime 20.10.5 and Mirantis Kubernetes Engine 3.3.6 with Kubernetes 1.18.
For the list of known and resolved issues, refer to the Container Cloud release 2.11.0 section.
This section outlines new features and enhancements introduced in the Cluster release 5.18.0.
Upgraded Ceph from 14.2.19 (Nautilus) to 15.2.13 (Octopus) and Rook from 1.5.9 to 1.6.8.
Technology Preview
Implemented the capability to define Ceph tolerations and resources management
through the KaaSCephCluster spec using the native Rook way for setting
resource requirements for Ceph daemons.
Improved the MiraCephLog custom resource by adding more information about
all Ceph cluster entities and their statuses. The MiraCeph, MiraCephLog
statuses and MiraCephLog values are now integrated to
KaaSCephCluster.status and can be viewed using the miraCephInfo,
shortClusterInfo, and fullClusterInfo fields.
Implemented the capability to define a list of Ceph Manager modules to enable
on the Ceph cluster using the mgr.modules parameter in KaaSCephCluster.
Implemented the following improvements for the StackLight node labeling during a cluster creation or post-deployment configuration:
Added a verification that a cluster contains minimum 3 worker nodes with the StackLight label for clusters with StackLight deployed in HA mode. This verification applies to cluster deployment and update processes. For details on how to add the StackLight label before upgrade to the latest Cluster releases of Container Cloud 2.11.0, refer to Upgrade managed clusters with StackLight deployed in HA mode.
Added a notification about the minimum number of worker nodes with the StackLight label for HA StackLight deployments to the cluster live status description in the Container Cloud web UI.
Caution
Removal of the StackLight label from worker nodes along with removal of worker nodes with StackLight label can cause the StackLight components to become inaccessible. It is important to keep the worker nodes where the StackLight local volumes were provisioned.
Implemented the capability to set the default log level severity for all StackLight components as well as set a custom log level severity for specific StackLight components in the Container Cloud web UI. You can update this setting either during a managed cluster creation or during a post-deployment configuration.
Implemented the following improvements to StackLight alerting:
Added the following alerts:
KubeContainersCPUThrottlingHighthat raises in case of containers CPU throttling.KubeletDownthat raises if kubelet is down.
Reworked a number of alerts to improve alerting efficiency and reduce alert flooding.
Reworked the alert inhibition rules.
Removed the following inefficient alerts:
FileDescriptorUsageCriticalKubeCPUOvercommitNamespacesKubeMemOvercommitNamespacesKubeQuotaExceededContainerScrapeError
Implemented the capability to enable feed update in Salesforce using
the feed_enabled parameter. By default, this parameter is set to false
to save API calls.
On top of continuous improvements delivered to the existing Container Cloud guides, added a procedure on how to manually remove a Ceph OSD from a Ceph cluster.
Learn more
The following table lists the components versions of the Cluster release 5.18.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.3.6 0 |
Container runtime |
Mirantis Container Runtime |
20.10.5 1 |
Distributed storage Updated |
Ceph |
15.2.13 (Octopus) |
Rook |
1.6.8 |
|
LCM |
descheduler |
0.8.0 |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.2.0-399-g85be100f |
|
lcm-ansible Updated |
0.9.0-17-g28bc9ce |
|
lcm-agent Updated |
0.2.0-399-g85be100f |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta Updated |
8.4.1-20210707092546 |
Alertmanager |
0.22.2 |
|
Alertmanager Webhook ServiceNow |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.10.2-20210601104922 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20210602174807 |
|
Grafana |
7.5.4 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.10.2-20210601104911 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat |
7.10.2 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20210323132924 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter Updated |
0.1-20210708141736 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier Updated |
0.3-20210702081359 |
|
Telegraf |
1.9.1-20210225142050 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 5.18.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-368.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/ceph/ceph:v15.2.13 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210807103257 |
|
cephcsi Updated |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.3.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner Updated |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.2 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook/ceph:v1.6.8 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.9.0-17-g28bc9ce/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-399-g85be100f/lcm-agent |
|
Helm charts Updated |
descheduler |
https://binary.mirantis.com/core/helm/descheduler-1.24.6.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.24.6.tgz |
|
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.24.6.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-399-g85be100f |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-22.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.1.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-36.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-30.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-96.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-108.tgz |
|
iam-proxy Updated |
||
kibana Updated |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-29.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-12.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-33.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-188.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-10.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-16.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-574.tgz |
|
telegraf-ds Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-29.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-29.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-17.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-17.tgz |
|
Docker images |
alerta Updated |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210707092546 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.22.2 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20210601104922 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210602174807 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.5.4 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.19.13 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20210601104911 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20210323132924 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20210708141736 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210702081359 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories Updated |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 5.17.0 that is introduced in the Mirantis Container Cloud release 2.10.0. This Cluster release introduces support for the updated version of Mirantis Container Runtime 20.10.5 and supports Mirantis Kubernetes Engine 3.3.6 with Kubernetes 1.18.
For the list of known and resolved issues, refer to the Container Cloud release 2.10.0 section.
This section outlines new features and enhancements introduced in the Cluster release 5.17.0.
Implemented a graceful Mirantis Container Runtime (MCR) upgrade from 19.03.14 to 20.10.5 on existing Container Cloud clusters.
Improved the MKE logs gathering by replacing the default DEBUG logs level
with INFO. This change reduces the unnecessary load on the MKE cluster
caused by an excessive amount of logs generated with the DEBUG level
enabled.
Implemented the capability to configure the verbosity level of logs produced by all StackLight components or by each component separately.
Implemented the following improvements to StackLight alerting:
Added the following alerts:
PrometheusMsTeamsDownthat raises ifprometheus-msteamsis down.ServiceNowWebhookReceiverDownthat raises ifalertmanager-webhook-servicenowis down.SfNotifierDownthat raises if thesf-notifieris down.KubeAPICertExpirationMajor,KubeAPICertExpirationWarning,MKEAPICertExpirationMajor,MKEAPICertExpirationWarningthat inform on SSL certificates expiration.
Removed the inefficient
PostgresqlPrimaryDownalert.Reworked a number of alerts to improve alerting efficiency and reduce alert flooding.
Reworked the alert inhibition rules to match the receivers.
Updated Alertmanager to v0.22.2.
Changed the default behavior of the Salesforce alerts integration. Now, by default, only
Criticalalerts will be sent to the Salesforce.
Implemented the capability to add or configure proxy on existing Container Cloud managed clusters using the Container Cloud web UI.
Learn more
On top of continuous improvements delivered to the existing Container Cloud guides, added a procedure on how to move a Ceph Monitor daemon to another node.
Learn more
The following table lists the components versions of the Cluster release 5.17.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.3.6 0 |
Container runtime |
Mirantis Container Runtime Updated |
20.10.5 1 |
Distributed storage |
Ceph |
14.2.19 (Nautilus) |
Rook |
1.5.9 |
|
LCM |
descheduler |
0.8.0 |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.2.0-372-g7e042f4d |
|
lcm-ansible Updated |
0.8.0-17-g63ec424 |
|
lcm-agent Updated |
0.2.0-373-gae771bb4 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.4.1-20210312131419 |
Alertmanager Updated |
0.22.2 |
|
Alertmanager Webhook ServiceNow Updated |
0.1-20210601141858 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Updated |
7.10.2-20210601104922 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd Updated |
1.10.2-20210602174807 |
|
Grafana |
7.5.4 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana Updated |
7.10.2-20210601104911 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat |
7.10.2 |
|
Patroni |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20210323132924 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier Updated |
0.3-20210617140951 |
|
sf-reporter Updated |
0.1-20210607111404 |
|
Telegraf |
1.9.1-20210225142050 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the Mirantis Kubernetes Engine (MKE) release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the Mirantis Container Runtime (MCR) release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 5.17.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-305.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v14.2.19 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210716222903 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.2.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.1 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.5.9 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.8.0-17-g63ec424/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-373-gae771bb4/lcm-agent |
|
Helm charts Updated |
descheduler |
https://binary.mirantis.com/core/helm/descheduler-1.23.2.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.23.2.tgz |
|
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.23.2.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-372-g7e042f4d |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-22.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.1.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-33.tgz |
|
elasticsearch-curator Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-6.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-25.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-93.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-105.tgz |
|
iam-proxy |
||
kibana Updated |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-27.tgz |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-12.tgz |
|
metricbeat Updated |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-12.tgz |
|
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-30.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-158.tgz |
|
prometheus-blackbox-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-7.tgz |
|
prometheus-es-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-10.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-16.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-13.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-538.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-20.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-20.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-16.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-16.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210312131419 |
alertmanager Updated |
mirantis.azurecr.io/stacklight/alertmanager:v0.22.2 |
|
alertmanager-webhook-servicenow Updated |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210601141858 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch Updated |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20210601104922 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210602174807 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.5.4 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.2 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana Updated |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20210601104911 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20210323132924 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210617140951 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20210607111404 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories Updated |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-20.10/ |
This section outlines release notes for the Cluster release 5.16.0 that is introduced in the Mirantis Container Cloud release 2.9.0. This Cluster release supports Mirantis Kubernetes Engine 3.3.6, Mirantis Container Runtime 19.03.14, and Kubernetes 1.18.
For the list of known and resolved issues, refer to the Container Cloud release 2.9.0 section.
This section outlines new features and enhancements introduced in the Cluster release 5.16.0.
Upgraded PostgreSQL from version 12 to 13
Updated Elasticsearch, Kibana, and Metricbeat from version 7.6.1 to 7.10.2
Implemented the capability to configure multiple networks for a Ceph cluster.
Learn more
Implemented the capability to configure TLS for a Ceph cluster using a custom ingress rule for Ceph public endpoints.
Learn more
Implemented the capability to enable RADOS Block Device (RBD) mirroring for Ceph pools.
Learn more
The following table lists the components versions of the Cluster release 5.16.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.3.6 0 |
Container runtime |
Mirantis Container Runtime |
19.03.14 1 |
Distributed storage |
Ceph |
14.2.19 (Nautilus) |
Rook |
1.5.9 |
|
LCM |
descheduler |
0.8.0 |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.2.0-349-g4870b7f5 |
|
lcm-ansible Updated |
0.7.0-9-g30acaae |
|
lcm-agent Updated |
0.2.0-349-g4870b7f5 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.4.1-20210312131419 |
Alertmanager |
0.21.0 |
|
Alertmanager Webhook ServiceNow |
0.1-20210426114325 |
|
Cerebro |
0.9.3 |
|
Elasticsearch Updated |
7.10.2-20210513065347 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd Updated |
1.10.2-20210518100631 |
|
Grafana |
7.5.4 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana Updated |
7.10.2-20210513065546 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat Updated |
7.10.2 |
|
Netchecker Deprecated |
1.4.1 |
|
Patroni Updated |
13-2.0p6-20210525081943 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20210323132924 |
|
Prometheus MS Teams |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter Updated |
0.9.0 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20210323132354 |
|
sf-reporter |
0.1-20201216142628 |
|
Telegraf |
1.9.1-20210225142050 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
Due to the development limitations, the MCR upgrade to version 19.03.14 on existing Container Cloud clusters is not supported.
This section lists the components artifacts of the Cluster release 5.16.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-271.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v14.2.19 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210521190241 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.2.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.1 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.5.9 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.7.0-9-g30acaae/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-349-g4870b7f5/lcm-agent |
|
Helm charts Updated |
descheduler |
https://binary.mirantis.com/core/helm/descheduler-1.22.4.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.22.4.tgz |
|
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.22.4.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-349-g4870b7f5 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-20.tgz |
alertmanager-webhook-servicenow |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.1.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-31.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-2.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-20.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-83.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-102.tgz |
|
iam-proxy |
||
kibana Updated |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-25.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-8.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-8.tgz |
|
netchecker Deprecated |
||
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-24.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-139.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-4.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-3.tgz |
|
prometheus-msteams |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-11.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-492.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-20.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-20.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-12.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-12.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210312131419 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.21.0 |
|
alertmanager-webhook-servicenow |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210426114325 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch Updated |
mirantis.azurecr.io/stacklight/elasticsearch:7.10.2-20210513065347 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210518100631 |
|
gce-proxy |
mirantis.azurecr.io/stacklight/gce-proxy:1.11 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.5.4 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.2 |
|
k8s-netchecker-agent Deprecated |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-agent:2019.1 |
|
k8s-netchecker-server Deprecated |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-server:2019.1 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana Updated |
mirantis.azurecr.io/stacklight/kibana:7.10.2-20210513065546 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat Updated |
mirantis.azurecr.io/stacklight/metricbeat:7.10.2 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20210323132924 |
|
prometheus-msteams |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.9.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210323132354 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20201216152628 |
|
spilo Updated |
mirantis.azurecr.io/stacklight/spilo:13-2.0p6-20210525081943 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-19.03/ |
This section outlines release notes for the Cluster release 5.15.0 that is introduced in the Mirantis Container Cloud release 2.8.0. This Cluster release supports Mirantis Kubernetes Engine 3.3.6, Mirantis Container Runtime 19.03.14, and Kubernetes 1.18.
For the list of known and resolved issues, refer to the Container Cloud release 2.8.0 section.
This section outlines new features and enhancements introduced in the Cluster release 5.15.0.
Implemented the capability to enable Alertmanager to send notifications to a Microsoft Teams channel.
Learn more
Implemented the capability to enable Alertmanager to send notifications to
ServiceNow. Also added the ServiceNowAuthFailure alert that will raise in
case of failure to authenticate to ServiceNow.
Learn more
Improved the log collection mechanism by optimizing the existing and adding new log parsers for multiple Container Cloud components.
Learn more
Enhanced Ceph Controller to automatically specify default configuration options for each Ceph cluster during the Ceph deployment.
Implemented the following Ceph enhancements in the KaaSCephCluster CR:
Added the capability to specify the
rgwrole using therolesparameterAdded the following parameters:
rookConfigto override the Ceph configuration optionsuseAsFullNameto enable the Ceph block pool to use only thenamevalue as a nametargetSizeRatioto specify the expected consumption of the Ceph cluster total capacitySSLCertto use a custom TLS certificate to access the Ceph RGW endpointnodeGroupsto easily define specifications for multiple Ceph nodes using lists, grouped by node lists or node labelsclientsto specify the Ceph clients and their capabilities
Learn more
On top of continuous improvements delivered to the existing Container Cloud guides, added the following detailed procedures:
Recovery of failed Ceph Monitors of a Ceph cluster.
Silencing of StackLight alerts, for example, for maintenance or before performing an update.
Learn more
The following table lists the components versions of the Cluster release 5.15.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.3.6 0 |
Container runtime |
Mirantis Container Runtime |
19.03.14 1 |
Distributed storage Updated |
Ceph |
14.2.19 (Nautilus) |
Rook |
1.5.9 |
|
LCM |
descheduler |
0.8.0 |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.2.0-327-g5676f4e3 |
|
lcm-ansible Updated |
0.6.0-19-g0004de6 |
|
lcm-agent Updated |
0.2.0-327-g5676f4e3 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.4.1-20210312131419 |
Alertmanager |
0.21.0 |
|
Alertmanager Webhook ServiceNow New |
0.1-20210426114325 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.6.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20210301155825 |
|
Grafana Updated |
7.5.4 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.6.1 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat |
7.6.1 |
|
Netchecker |
1.4.1 |
|
Patroni |
12-1.6p3 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20210323132924 |
|
Prometheus MS Teams New |
1.4.2 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter |
0.8.0-20201006113956 |
|
Prometheus Relay |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20210323132354 |
|
sf-reporter |
0.1-20201216142628 |
|
Telegraf |
1.9.1-20210225142050 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
Due to the development limitations, the MCR upgrade to version 19.03.14 on existing Container Cloud clusters is not supported.
This section lists the components artifacts of the Cluster release 5.15.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-242.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/ceph/ceph:v14.2.19 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210425091701 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.2.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner Updated |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.1 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook/ceph:v1.5.9 |
Artifact |
Component |
Path |
|---|---|---|
Binaries Updated |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.6.0-19-g0004de6/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-327-g5676f4e3/lcm-agent |
|
Helm charts Updated |
descheduler |
https://binary.mirantis.com/core/helm/descheduler-1.20.2.tgz |
managed-lcm-api |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.20.2.tgz |
|
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.20.2.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-327-g5676f4e3 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-20.tgz |
alertmanager-webhook-servicenow New |
https://binary.mirantis.com/stacklight/helm/alertmanager-webhook-servicenow-0.1.0-mcp-3.tgz |
|
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-29.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-2.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-20.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-79.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-98.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-20.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-8.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-8.tgz |
|
netchecker |
||
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-21.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-130.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-4.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-3.tgz |
|
prometheus-msteams New |
https://binary.mirantis.com/stacklight/helm/prometheus-msteams-0.1.0-mcp-2.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-11.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-464.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-20.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-20.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-12.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-12.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210312131419 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.21.0 |
|
alertmanager-webhook-servicenow New |
mirantis.azurecr.io/stacklight/alertmanager-webhook-servicenow:v0.1-20210426114325 |
|
alpine-python3-requests |
mirantis.azurecr.io/stacklight/alpine-python3-requests:latest-20200618 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.6.1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210301155825 |
|
gce-proxy |
mirantis.azurecr.io/stacklight/gce-proxy:1.11 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:7.5.4 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.2 |
|
k8s-netchecker-agent |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-agent:2019.1 |
|
k8s-netchecker-server |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-server:2019.1 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.6.1 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.6.1 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20210323132924 |
|
prometheus-msteams New |
mirantis.azurecr.io/stacklight/prometheus-msteams:v1.4.2 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.8.0-20201006113956 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210323132354 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20201216152628 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:12-1.6p3 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225152050 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-19.03/ |
This section outlines release notes for the Cluster release 5.14.0 that is introduced in the Mirantis Container Cloud release 2.7.0. This Cluster release supports Mirantis Kubernetes Engine 3.3.6, Mirantis Container Runtime 19.03.14, and Kubernetes 1.18.
For the list of known and resolved issues, refer to the Container Cloud release 2.7.0 section.
This section outlines new features and enhancements introduced in the Cluster release 5.14.0.
Improved the log collection mechanism by optimizing the existing and adding new log parsers for multiple Container Cloud components.
Learn more
TECHNOLOGY PREVIEW
Added the possibility to configure dedicated networks for the Ceph cluster access and replication traffic using dedicated subnets. Container Cloud automatically configures Ceph to use the addresses from the dedicated subnets after you assign the corresponding addresses to the storage nodes.
TECHNOLOGY PREVIEW
Implemented the capability to enable the Ceph Multisite configuration that allows object storage to replicate its data over multiple Ceph clusters. Using Multisite, such object storage is independent and isolated from another object storage in the cluster.
On top of continuous improvements delivered to the existing Container Cloud guides, added the Troubleshoot Ceph section to the Operations Guide. This section now contains a detailed procedure to recover a failed or accidentally removed Ceph cluster.
Learn more
The following table lists the components versions of the Cluster release 5.14.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.3.6 0 |
Container runtime |
Mirantis Container Runtime |
19.03.14 1 |
Distributed storage |
Ceph |
14.2.12 (Nautilus) |
Rook |
1.5.5 |
|
LCM |
descheduler |
0.8.0 |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.2.0-297-g8c87ad67 |
|
lcm-ansible Updated |
0.5.0-10-gdd307e6 |
|
lcm-agent Updated |
0.2.0-300-ga874e0df |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta Updated |
8.4.1-20210312131419 |
Alertmanager |
0.21.0 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.6.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20210301155825 |
|
Grafana |
7.3.7 |
|
Grafana Image Renderer |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.6.1 |
|
Metric Collector |
0.1-20210219112938 |
|
Metricbeat |
7.6.1 |
|
Netchecker |
1.4.1 |
|
Patroni |
12-1.6p3 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter Updated |
0.5.1-20210323132924 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter |
0.8.0-20201006113956 |
|
Prometheus Relay Updated |
0.3-20210317133316 |
|
Pushgateway |
1.2.0 |
|
sf-notifier Updated |
0.3-20210323132354 |
|
sf-reporter |
0.1-20201216142628 |
|
Telegraf |
1.9.1-20210225142050 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
Due to the development limitations, the MCR upgrade to version 19.03.14 on existing Container Cloud clusters is not supported.
This section lists the components artifacts of the Cluster release 5.14.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-177.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v14.2.12 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210322210534 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.2.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.0 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.5.5 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible Updated |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.5.0-10-gdd307e6/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-300-ga874e0df/lcm-agent |
|
Helm charts |
descheduler Updated |
https://binary.mirantis.com/core/helm/descheduler-1.19.1.tgz |
managed-lcm-api Updated |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.19.1.tgz |
|
metallb Updated |
||
metrics-server Updated |
https://binary.mirantis.com/core/helm/metrics-server-1.19.1.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-297-g8c87ad67 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-15.tgz |
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-22.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-2.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-17.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-61.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-93.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-20.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-8.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-8.tgz |
|
netchecker |
||
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-20.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-124.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-4.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-3.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-11.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-438.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-20.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-20.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-12.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-12.tgz |
|
Docker images |
alerta Updated |
mirantis.azurecr.io/stacklight/alerta-web:8.4.1-20210312131419 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.21.0 |
|
alpine-python3-requests |
mirantis.azurecr.io/stacklight/alpine-python3-requests:latest-20200618 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.6.1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210301155825 |
|
gce-proxy |
mirantis.azurecr.io/stacklight/gce-proxy:1.11 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.3.7 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.2 |
|
k8s-netchecker-agent |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-agent:2019.1 |
|
k8s-netchecker-server |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-server:2019.1 |
|
k8s-sidecar Updated |
mirantis.azurecr.io/stacklight/k8s-sidecar:1.10.8 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.6.1 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.6.1 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20210323132924 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.8.0-20201006113956 |
|
prometheus-relay Updated |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20210317133316 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20210323132354 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20201216142628 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:12-1.6p3 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225142050 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-19.03/ |
This section outlines release notes for the Cluster release 5.13.0 that is introduced in the Mirantis Container Cloud release 2.6.0. This Cluster release supports Mirantis Kubernetes Engine 3.3.6, Mirantis Container Runtime 19.03.14, and Kubernetes 1.18.
For the list of known and resolved issues, refer to the Container Cloud release 2.6.0 section.
This section outlines new features and enhancements introduced in the Cluster release 5.13.0.
Significantly enhanced the StackLight log collection mechanism to avoid
collecting and keeping an excessive amount of log messages when it is not
essential. Now, during or after deployment of StackLight, you can select one of
the 9 available logging levels depending on the required severity. The default
logging level is INFO.
Learn more
Implemented the capability to configure StackLight to forward all logs to an external syslog server. In this case, StackLight will send logs both to the syslog server and to Elasticsearch, which is the default target.
Learn more
Technology Preview
Implemented the capability to configure Ceph Controller to start pods on the taint nodes and manage the resources of Ceph nodes. Now, when bootstrapping a new management or managed cluster, you can specify requests, limits, or tolerations for Ceph resources. You can also configure resource management for an existing Ceph cluster. However, such approach may cause downtime.
Improved user experience by moving the rgw section of the
KaasCephCluster CR to a common objectStorage section that now includes
all RADOS Gateway configurations of a Ceph cluster. The spec.rgw section is
deprecated. However, if you continue using spec.rgw, it will be
automatically translated into the new objectStorage.rgw section during the
Container Cloud update to 2.6.0.
Learn more
Implemented the capability to enable Ceph maintenance mode using the
maintenance flag not only during a managed cluster update but also when
required. However, Mirantis does not recommend enabling maintenance on
production deployments other than during update.
Learn more
The following table lists the components versions of the Cluster release 5.13.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.3.6 0 |
Container runtime |
Mirantis Container Runtime |
19.03.14 1 |
Distributed storage |
Ceph |
14.2.12 (Nautilus) |
Rook |
1.5.5 |
|
LCM |
descheduler |
0.8.0 |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.2.0-289-gd7e9fa9c |
|
lcm-ansible Updated |
0.4.0-4-ga2bb104 |
|
lcm-agent Updated |
0.2.0-289-gd7e9fa9c |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.0.2-20201014133832 |
Alertmanager |
0.21.0 |
|
Cerebro |
0.9.3 |
|
Elasticsearch |
7.6.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd Updated |
1.10.2-20210301155825 |
|
Grafana Updated |
7.3.7 |
|
Grafana Image Renderer Updated |
2.0.1 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.6.1 |
|
Metric Collector Updated |
0.1-20210219112938 |
|
Metricbeat |
7.6.1 |
|
Netchecker |
1.4.1 |
|
Patroni |
12-1.6p3 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20201002144823 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter |
0.8.0-20201006113956 |
|
Prometheus Relay |
0.3-20200519054052 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20201216142028 |
|
sf-reporter |
0.1-20201216142628 |
|
Telegraf Updated |
1.9.1-20210225142050 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
Due to the development limitations, the MCR upgrade to version 19.03.14 on existing Container Cloud clusters is not supported.
This section lists the components artifacts of the Cluster release 5.13.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-165.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v14.2.12 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210309160354 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.2.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.0 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.5.5 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible Updated |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.4.0-4-ga2bb104/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-289-gd7e9fa9c/lcm-agent |
|
Helm charts |
descheduler Updated |
https://binary.mirantis.com/core/helm/descheduler-1.18.1.tgz |
managed-lcm-api Updated |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.18.1.tgz |
|
metallb Updated |
||
metrics-server Updated |
https://binary.mirantis.com/core/helm/metrics-server-1.18.1.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-289-gd7e9fa9c |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-15.tgz |
cerebro |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-22.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-2.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-16.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-44.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-93.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-20.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-8.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-8.tgz |
|
netchecker |
||
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-20.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-121.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-4.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-3.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-11.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-426.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-20.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-20.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-12.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-12.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.0.2-20201014133832 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.21.0 |
|
alpine-python3-requests |
mirantis.azurecr.io/stacklight/alpine-python3-requests:latest-20200618 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.6.1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd Updated |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20210301155825 |
|
gce-proxy |
mirantis.azurecr.io/stacklight/gce-proxy:1.11 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:7.3.7 |
|
grafana-image-renderer Updated |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.1 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.2 |
|
k8s-netchecker-agent |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-agent:2019.1 |
|
k8s-netchecker-server |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-server:2019.1 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:0.1.178 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.6.1 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20210219112938 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.6.1 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20201002144823 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.8.0-20201006113956 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20200519054052 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20201216142028 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20201216142628 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:12-1.6p3 |
|
telegraf Updated |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20210225142050 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
This section outlines release notes for the Cluster release 5.12.0 that is introduced in the Mirantis Container Cloud release 2.5.0. This Cluster release supports Kubernetes 1.18 and Mirantis Container Runtime 19.03.14 as well as introduces support for the updated version of Mirantis Kubernetes Engine 3.3.6.
For the list of known and resolved issues, refer to the Container Cloud release 2.5.0 section.
This section outlines new features and enhancements introduced in the Cluster release 5.12.0.
Implemented the maintenance label to set for Ceph during a managed
cluster update. This prevents Ceph rebalance leading to data loss
during a managed cluster update.
Learn more
Implemented the Enable Object Storage checkbox in the Container Cloud web UI to allow enabling a single-instance RGW Object Storage when creating a Ceph cluster as described in Add a Ceph cluster.
Enhanced Ceph to support RADOS Gateway (RGW) high availability. Now, you can run multiple instances of Ceph RGW in active/active mode.
Learn more
Enhanced StackLight by adding support for Cerebro, a web UI that visualizes health of Elasticsearch clusters and allows for convenient debugging. Cerebro is disabled by default.
Added proxy support for Alertmanager, Metric collector, Salesforce notifier and reporter, and Telemeter client. Now, these StackLight components automatically use the same proxy that is configured for Container Cloud clusters.
Note
Proxy handles only the HTTP and HTTPS traffic. Therefore, for clusters with limited or no Internet access, it is not possible to set up Alertmanager email notifications, which use SMTP, when proxy is used.
Note
Due to a limitation, StackLight fails to integrate with an external
proxy with authentication handled by a proxy server. In such cases, the
proxy server ignores the HTTP Authorization header for basic
authentication passed by Prometheus Alertmanager. Therefore, use proxies
without authentication or with authentication handled by a reverse proxy.
Learn more
The following table lists the components versions of the Cluster release 5.12.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.3.6 0 |
Container runtime |
Mirantis Container Runtime |
19.03.14 1 |
Distributed storage |
Ceph |
14.2.12 (Nautilus) |
Rook |
1.5.5 |
|
LCM |
descheduler |
0.8.0 |
Helm |
2.16.11-40 |
|
helm-controller Updated |
0.2.0-258-ga2d72294 |
|
lcm-ansible Updated |
0.3.0-10-g7c2a87e |
|
lcm-agent Updated |
0.2.0-258-ga2d72294 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.0.2-20201014133832 |
Alertmanager |
0.21.0 |
|
Cerebro New |
0.9.3 |
|
Elasticsearch |
7.6.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20200609085335 |
|
Grafana |
7.1.5 |
|
Grafana Image Renderer |
2.0.0 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.6.1 |
|
Metric Collector |
0.1-20201222100033 |
|
Metricbeat |
7.6.1 |
|
Netchecker |
1.4.1 |
|
Patroni |
12-1.6p3 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20201002144823 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter |
0.8.0-20201006113956 |
|
Prometheus Relay |
0.3-20200519054052 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20201216142028 |
|
sf-reporter |
0.1-20201216142628 |
|
Telegraf |
1.9.1-20201222194740 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
Due to the development limitations, the MCR upgrade to version 19.03.14 on existing Container Cloud clusters is not supported.
This section lists the components artifacts of the Cluster release 5.12.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-127.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v14.2.12 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210201202754 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.2.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.0 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.5.5 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible Updated |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.3.0-10-g7c2a87e/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-258-ga2d72294/lcm-agent |
|
Helm charts |
descheduler Updated |
https://binary.mirantis.com/core/helm/descheduler-1.17.4.tgz |
managed-lcm-api Updated |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.17.4.tgz |
|
metallb Updated |
||
metrics-server Updated |
https://binary.mirantis.com/core/helm/metrics-server-1.17.4.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-258-ga2d72294 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-13.tgz |
cerebro New |
https://binary.mirantis.com/stacklight/helm/cerebro-0.1.0-mcp-2.tgz |
|
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-22.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-2.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-15.tgz |
|
fluentd-elasticsearch |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-33.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-89.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-20.tgz |
|
metric-collector |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-8.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-8.tgz |
|
netchecker |
||
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-19.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-119.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-4.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-3.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-11.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-413.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-20.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-20.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-12.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-12.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.0.2-20201014133832 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.21.0 |
|
alpine-python3-requests |
mirantis.azurecr.io/stacklight/alpine-python3-requests:latest-20200618 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
cerebro New |
mirantis.azurecr.io/stacklight/cerebro:0.9.3 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.6.1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20200609085335 |
|
gce-proxy |
mirantis.azurecr.io/stacklight/gce-proxy:1.11 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.1.5 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.0 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.2 |
|
k8s-netchecker-agent |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-agent:2019.1 |
|
k8s-netchecker-server |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-server:2019.1 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:0.1.178 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.6.1 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20201222100033 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.6.1 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20201002144823 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.8.0-20201006113956 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20200519054052 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20201216142028 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20201216142628 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:12-1.6p3 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20201222194740 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
This section outlines release notes for the Cluster release 5.11.0 that is introduced in the Mirantis Container Cloud release 2.4.0. This Cluster release supports Kubernetes 1.18 and Mirantis Kubernetes Engine 3.3.4 as well as introduces support for the updated version of Mirantis Container Runtime 19.03.14.
Note
The Cluster release 5.11.0 supports only attachment of existing MKE 3.3.4 clusters.
For the deployment of new or attachment of existing clusters based on other supported MKE versions, the latest available Cluster releases are used.
For the list of known and resolved issues, refer to the Container Cloud release 2.4.0 section.
This section outlines new features and enhancements introduced in the Cluster release 5.11.0.
Implemented alert inhibition rules to provide a clearer view on the cloud status and simplify troubleshooting. Using alert inhibition rules, Alertmanager decreases alert noise by suppressing dependent alerts notifications. The feature is enabled by default. For details, see Alert dependencies.
Implemented integration between Grafana and Kibana by adding a View logs in Kibana link to the majority of Grafana dashboards, which allows you to immediately view contextually relevant logs through the Kibana web UI.
Learn more
Implemented the TelegrafGatherErrors alert that raises if Telegraf fails to
gather metrics.
Learn more
Added the ironic.insecure parameter for enabling or disabling the host and
chain verification for bare metal Ironic monitoring.
Learn more
Enhanced StackLight to automatically set clusterId that defines an ID of
a Container Cloud cluster. Now, you do not need to set or modify this parameter
manually when configuring the sf-notifier and sf-reporter services.
Learn more
The following table lists the components versions of the Cluster release 5.11.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.3.4 0 |
Container runtime |
Mirantis Container Runtime Updated |
19.03.14 1 |
Distributed storage Updated |
Ceph |
14.2.12 (Nautilus) |
Rook |
1.5.5 |
|
LCM |
descheduler |
0.8.0 |
Helm |
2.16.11-40 |
|
helm-controller |
0.2.0-221-g32bd5f56 |
|
lcm-ansible Updated |
0.2.0-394-g599b2a1 |
|
lcm-agent |
0.2.0-221-g32bd5f56 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.0.2-20201014133832 |
Alertmanager |
0.21.0 |
|
Elasticsearch |
7.6.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20200609085335 |
|
Grafana |
7.1.5 |
|
Grafana Image Renderer |
2.0.0 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.6.1 |
|
Metric Collector Updated |
0.1-20201222100033 |
|
Metricbeat |
7.6.1 |
|
Netchecker |
1.4.1 |
|
Patroni |
12-1.6p3 |
|
Prometheus |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20201002144823 |
|
Prometheus libvirt Exporter |
0.1-20200610164751 |
|
Prometheus Memcached Exporter |
0.5.0 |
|
Prometheus MySQL Exporter |
0.11.0 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter |
0.8.0-20201006113956 |
|
Prometheus RabbitMQ Exporter |
1.0.0-RC7.1 |
|
Prometheus Relay |
0.3-20200519054052 |
|
Pushgateway |
1.2.0 |
|
sf-notifier Updated |
0.3-20201216142028 |
|
sf-reporter Updated |
0.1-20201216142628 |
|
Telegraf Updated |
1.9.1-20201222194740 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
Due to the development limitations, the MCR upgrade to version 19.03.14 on existing Container Cloud clusters is not supported.
This section lists the components artifacts of the Cluster release 5.11.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-111.tgz |
Docker images Updated |
ceph |
mirantis.azurecr.io/ceph/ceph:v14.2.12 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20210120004212 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.2.1 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v2.1.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v2.1.0 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v4.0.0 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v3.1.0 |
|
csi-resizer New |
mirantis.azurecr.io/ceph/k8scsi/csi-resizer:v1.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.5.5 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible Updated |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.2.0-394-g599b2a1/lcm-ansible.tar.gz |
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-221-g32bd5f56/lcm-agent |
|
Helm charts |
descheduler Updated |
https://binary.mirantis.com/core/helm/descheduler-1.16.0.tgz |
managed-lcm-api Updated |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.16.0.tgz |
|
metallb Updated |
||
metrics-server Updated |
https://binary.mirantis.com/core/helm/metrics-server-1.16.0.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-221-g32bd5f56 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-13.tgz |
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-22.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-2.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-15.tgz |
|
fluentd-elasticsearch |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-33.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-81.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-20.tgz |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-8.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-8.tgz |
|
netchecker |
||
patroni Updated |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-19.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-114.tgz |
|
prometheus-blackbox-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-4.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-3.tgz |
|
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/heprometheus-libvirt-exporter-0.1.0-mcp-2.tgz |
|
prometheus-memcached-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-memcached-exporter-0.1.0-mcp-1.tgz |
|
prometheus-mysql-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-mysql-exporter-0.3.2-mcp-1.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
prometheus-rabbitmq-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-rabbitmq-exporter-0.4.1-mcp-1.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-11.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-10.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-398.tgz |
|
telegraf-ds Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-20.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-20.tgz |
|
telemeter-server Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-12.tgz |
|
telemeter-client Updated |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-12.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.0.2-20201014133832 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.21.0 |
|
alpine-python3-requests |
mirantis.azurecr.io/stacklight/alpine-python3-requests:latest-20200618 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.6.1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20200609085335 |
|
gce-proxy |
mirantis.azurecr.io/stacklight/gce-proxy:1.11 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.1.5 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.0 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.2 |
|
k8s-netchecker-agent |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-agent:2019.1 |
|
k8s-netchecker-server |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-server:2019.1 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:0.1.178 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.6.1 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20201222100033 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.6.1 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20201002144823 |
|
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/libvirt-exporter:v0.1-20200610164751 |
|
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
|
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.8.0-20201006113956 |
|
prometheus-rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC7.1 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20200519054052 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20201216142028 |
|
sf-reporter Updated |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20201216142628 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:12-1.6p3 |
|
telegraf Updated |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20201222194740 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
|
yq New |
mirantis.azurecr.io/stacklight/yq:v4.2.0 |
Artifact |
Component |
Path |
|---|---|---|
Debian repositories |
System packages |
|
https://mirror.mirantis.com/kaas/ubuntu-2020-07-30-013349.target.txt |
||
MCR repositories |
MCR |
https://repos.mirantis.com/ubuntu/dists/bionic/pool/stable-19.03/ |
This section outlines release notes for the Cluster release 5.10.0 that is introduced in the Mirantis Container Cloud release 2.3.0. This Cluster release supports Kubernetes 1.18 and introduces support for the latest versions of Mirantis Kubernetes Engine 3.3.4 and Mirantis Container Runtime 19.03.13.
For the list of known and resolved issues, refer to the Container Cloud release 2.3.0 section.
This section outlines new features and enhancements introduced in the Cluster release 5.10.0.
Enhanced Ceph to support RADOS Gateway (RGW) Object Storage.
Learn more
Implemented the capability to obtain detailed information on the Ceph cluster state, including Ceph logs, Ceph OSDs state, and a list of Ceph pools.
Learn more
The following table lists the components versions of the Cluster release 5.10.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine Updated |
3.3.4 0 |
Container runtime |
Mirantis Container Runtime Updated |
19.03.13 1 |
Distributed storage |
Ceph |
14.2.11 (Nautilus) |
Rook |
1.4.4 |
|
LCM |
descheduler |
0.8.0 |
Helm Updated |
2.16.11-40 |
|
helm-controller Updated |
0.2.0-221-g32bd5f56 |
|
lcm-ansible Updated |
0.2.0-381-g720ec96 |
|
lcm-agent Updated |
0.2.0-221-g32bd5f56 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
8.0.2-20201014133832 |
Alertmanager |
0.21.0 |
|
Elasticsearch |
7.6.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20200609085335 |
|
Grafana |
7.1.5 |
|
Grafana Image Renderer |
2.0.0 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.6.1 |
|
Metric Collector Updated |
0.1-20201120155524 |
|
Metricbeat |
7.6.1 |
|
Netchecker |
1.4.1 |
|
Patroni |
12-1.6p3 |
|
Prometheus Updated |
2.22.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20201002144823 |
|
Prometheus libvirt Exporter |
0.1-20200610164751 |
|
Prometheus Memcached Exporter |
0.5.0 |
|
Prometheus MySQL Exporter |
0.11.0 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter |
0.8.0-20201006113956 |
|
Prometheus RabbitMQ Exporter Updated |
v1.0.0-RC7.1 |
|
Prometheus Relay |
0.3-20200519054052 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20201001081256 |
|
sf-reporter |
0.1-20200219140217 |
|
Telegraf Updated |
1.9.1-20201120081248 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
Due to the development limitations, the MCR upgrade to version 19.03.14 on existing Container Cloud clusters is not supported.
This section lists the components artifacts of the Cluster release 5.10.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-95.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v14.2.11 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20201215142221 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.1.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v1.2.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v1.6.0 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v2.1.1 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v2.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.4.4 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
lcm-ansible Updated |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.2.0-381-g720ec96/lcm-ansible.tar.gz |
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-221-g32bd5f56/lcm-agent |
|
Helm charts |
descheduler Updated |
https://binary.mirantis.com/core/helm/descheduler-1.15.1.tgz |
managed-lcm-api New |
https://binary.mirantis.com/core/helm/managed-lcm-api-1.15.1.tgz |
|
metallb Updated |
||
metrics-server Updated |
https://binary.mirantis.com/core/helm/metrics-server-1.15.1.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm Updated |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.11-40 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-221-g32bd5f56 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-13.tgz |
elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-22.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-2.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-15.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-33.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-74.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-20.tgz |
|
metric-collector Updated |
https://binary.mirantis.com/stacklight/helm/metric-collector-0.2.0-mcp-5.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-8.tgz |
|
netchecker |
||
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-17.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-102.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-3.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-3.tgz |
|
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/heprometheus-libvirt-exporter-0.1.0-mcp-2.tgz |
|
prometheus-memcached-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-memcached-exporter-0.1.0-mcp-1.tgz |
|
prometheus-mysql-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-mysql-exporter-0.3.2-mcp-1.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
prometheus-rabbitmq-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-rabbitmq-exporter-0.4.1-mcp-1.tgz |
|
sf-notifier Updated |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-9.tgz |
|
sf-reporter Updated |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-8.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-354.tgz |
|
telegraf-ds Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-19.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-19.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-11.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-11.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:8.0.2-20201014133832 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.21.0 |
|
alpine-python3-requests |
mirantis.azurecr.io/stacklight/alpine-python3-requests:latest-20200618 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.6.1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20200609085335 |
|
gce-proxy |
mirantis.azurecr.io/stacklight/gce-proxy:1.11 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.1.5 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.0 |
|
kubectl |
mirantis.azurecr.io/stacklight/kubectl:1.19.2 |
|
k8s-netchecker-agent |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-agent:2019.1 |
|
k8s-netchecker-server |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-server:2019.1 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:0.1.178 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.6.1 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
metric-collector Updated |
mirantis.azurecr.io/stacklight/metric-collector:v0.1-20201120155524 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.6.1 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.22.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20201002144823 |
|
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/libvirt-exporter:v0.1-20200610164751 |
|
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
|
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.8.0-20201006113956 |
|
prometheus-rabbitmq-exporter Updated |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC7.1 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20200519054052 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20201001081256 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20200219140217 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:12-1.6p3 |
|
telegraf Updated |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20201120081248 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
This section outlines release notes for the Cluster release 5.9.0 that is introduced in the Mirantis Container Cloud release 2.2.0 and supports Mirantis Kubernetes Engine 3.3.3, Mirantis Container Runtime 19.03.12, and Kubernetes 1.18.
For the list of known and resolved issues, refer to the Container Cloud release 2.2.0 section.
This section outlines new features and enhancements introduced in the Cluster release 5.9.0.
Upgraded Alerta from version 7.4.4 to 8.0.2.
Enhanced StackLight to monitor the number of file descriptors on nodes and
raise FileDescriptorUsage* alerts when a node uses 80%, 90%, or 95% of
file descriptors.
Learn more
Added the
SSLProbesFailingalert that raises in case of an SSL certificate probes failure.Improved alerts descriptions and raise conditions.
The following table lists the components versions of the Cluster release 5.9.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.3.3 0 |
Container runtime |
Mirantis Container Runtime |
19.03.12 1 |
Distributed storage |
Ceph Updated |
14.2.11 (Nautilus) |
Rook Updated |
1.4.4 |
|
LCM |
ansible-docker Updated |
0.3.5-147-g18f3b44 |
descheduler |
0.8.0 |
|
Helm |
2.16.9-39 |
|
helm-controller Updated |
0.2.0-178-g8cc488f8 |
|
lcm-ansible Updated |
0.2.0-132-g49f7591 |
|
lcm-agent Updated |
0.2.0-178-g8cc488f8 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta Updated |
8.0.2-20201014133832 |
Alertmanager |
0.21.0 |
|
Elasticsearch |
7.6.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20200609085335 |
|
Grafana |
7.1.5 |
|
Grafana Image Renderer |
2.0.0 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.6.1 |
|
MCC Metric Collector |
0.1-20201005141816 |
|
Metricbeat |
7.6.1 |
|
Netchecker |
1.4.1 |
|
Patroni |
12-1.6p3 |
|
Prometheus Updated |
2.19.3 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20201002144823 |
|
Prometheus libvirt Exporter |
0.1-20200610164751 |
|
Prometheus Memcached Exporter |
0.5.0 |
|
Prometheus MySQL Exporter |
0.11.0 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter |
0.8.0-20201006113956 |
|
Prometheus RabbitMQ Exporter |
0.29.0 |
|
Prometheus Relay |
0.3-20200519054052 |
|
Pushgateway |
1.2.0 |
|
sf-notifier Updated |
0.3-20201001081256 |
|
sf-reporter |
0.1-20200219140217 |
|
telegraf-ds |
1.9.1-20200901112858 |
|
telegraf-s |
1.9.1-20200901112858 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 5.9.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-33.tgz |
Docker images |
ceph Updated |
mirantis.azurecr.io/ceph/ceph:v14.2.11 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20201022081323 |
|
cephcsi Updated |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v3.1.0 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v1.2.0 |
|
csi-provisioner Updated |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v1.6.0 |
|
csi-snapshotter Updated |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v2.1.1 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v2.1.0 |
|
rook Updated |
mirantis.azurecr.io/ceph/rook/ceph:v1.4.4 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
ansible-docker Updated |
https://binary.mirantis.com/lcm/bin/ansible-docker/v0.3.5-147-g18f3b44/ansible-docker.tar.gz |
lcm-ansible Updated |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.2.0-132-g49f7591-1/lcm-ansible.tar.gz |
|
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-178-g8cc488f8/lcm-agent |
|
Helm charts |
descheduler Updated |
https://binary.mirantis.com/core/helm/descheduler-1.14.0.tgz |
metallb Updated |
||
metrics-server Updated |
https://binary.mirantis.com/core/helm/metrics-server-1.14.0.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.9-39 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-178-g8cc488f8 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta Updated |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-13.tgz |
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-20.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-2.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-15.tgz |
|
fluentd-elasticsearch Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-28.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-66.tgz |
|
iam-proxy |
||
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-20.tgz |
|
mcc-metric-collector |
https://binary.mirantis.com/stacklight/helm/mcc-metric-collector-0.1.0-mcp-22.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-8.tgz |
|
netchecker |
||
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-17.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-83.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-3.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-3.tgz |
|
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/heprometheus-libvirt-exporter-0.1.0-mcp-2.tgz |
|
prometheus-memcached-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-memcached-exporter-0.1.0-mcp-1.tgz |
|
prometheus-mysql-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-mysql-exporter-0.3.2-mcp-1.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
prometheus-rabbitmq-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-rabbitmq-exporter-0.4.1-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-5.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-325.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-16.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-16.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-11.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-11.tgz |
|
Docker images |
alerta Updated |
mirantis.azurecr.io/stacklight/alerta-web:8.0.2-20201014133832 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.21.0 |
|
alpine-python3-requests Updated |
mirantis.azurecr.io/stacklight/alpine-python3-requests:latest-20200618 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.6.1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20200609085335 |
|
gce-proxy |
mirantis.azurecr.io/stacklight/gce-proxy:1.11 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:7.1.5 |
|
grafana-image-renderer |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.0 |
|
kubectl Updated |
mirantis.azurecr.io/stacklight/kubectl:1.19.2 |
|
k8s-netchecker-agent |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-agent:2019.1 |
|
k8s-netchecker-server |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-server:2019.1 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:0.1.178 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.6.1 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
mcc-metric-collector |
mirantis.azurecr.io/stacklight/mcc-metric-collector:v0.1-20201005141816 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.6.1 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus Updated |
mirantis.azurecr.io/stacklight/prometheus:v2.19.3 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20201002144823 |
|
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/libvirt-exporter:v0.1-20200610164751 |
|
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
|
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.8.0-20201006113956 |
|
prometheus-rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v0.29.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20200519054052 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20201001081256 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20200219140217 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:12-1.6p3 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20200901112858 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
This section outlines release notes for the Cluster release 5.8.0 that is introduced in the Mirantis Container Cloud release 2.1.0 and supports Mirantis Kubernetes Engine 3.3.3, Mirantis Container Runtime 19.03.12, and Kubernetes 1.18.
For the list of known issues, refer to the Container Cloud release 2.1.0 Known issues.
This section outlines new features and enhancements introduced in the Cluster release 5.8.0.
Upgraded Grafana from version 6.6.2 to 7.1.5.
Introduced Grafana Image Renderer, a separate Grafana container in a pod to offload rendering of images from charts. Grafana Image Renderer is enabled by default.
Configured a home dashboard to replace the Installation/configuration panel that opens when you access Grafana. By default, Kubernetes Cluster is set as a home dashboard. However, you can set any of the available Grafana dashboards.
Split the regional and management cluster function in StackLight telemetry. Now, the metrics from managed clusters are aggregated on regional clusters, then both regional and managed clusters metrics are sent from regional clusters to the management cluster.
Added the capability to filter panels by regions in the Clusters Overview and Telemeter Server Grafana dashboards.
Learn more
Improved alerts descriptions and raise conditions.
Changed severity in some alerts to improve operability.
Improved raise conditions of some alerts by adding the
forclause and unifying the existingforclauses.
Learn more
The following table lists the components versions of the Cluster release 5.8.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.3.3 0 |
Container runtime |
Mirantis Container Runtime |
19.03.12 1 |
Distributed storage |
Ceph |
14.2.9 (Nautilus) |
Rook |
1.3.8 |
|
LCM |
ansible-docker Updated |
0.3.5-141-g1007cc9 |
descheduler |
0.8.0 |
|
Helm Updated |
2.16.9-39 |
|
helm-controller Updated |
0.2.0-169-g5668304d |
|
lcm-ansible Updated |
0.2.0-119-g8f05f58-1 |
|
lcm-agent |
0.2.0-149-g412c5a05 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
7.4.4-20200615123606 |
Alertmanager |
0.21.0 |
|
Elasticsearch |
7.6.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20200609085335 |
|
Grafana Updated |
7.1.5 |
|
Grafana Image Renderer New |
2.0.0 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.6.1 |
|
MCC Metric Collector Updated |
0.1-20201005141816 |
|
Metricbeat |
7.6.1 |
|
Netchecker |
1.4.1 |
|
Patroni |
12-1.6p3 |
|
Prometheus |
2.19.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter Updated |
0.5.1-20201002144823 |
|
Prometheus libvirt Exporter |
0.1-20200610164751 |
|
Prometheus Memcached Exporter |
0.5.0 |
|
Prometheus MySQL Exporter |
0.11.0 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter Updated |
0.8.0-20201006113956 |
|
Prometheus RabbitMQ Exporter |
0.29.0 |
|
Prometheus Relay |
0.3-20200519054052 |
|
Pushgateway |
1.2.0 |
|
sf-notifier Updated |
0.3-20200813125431 |
|
sf-reporter |
0.1-20200219140217 |
|
telegraf-ds Updated |
1.9.1-20200901112858 |
|
telegraf-s Updated |
1.9.1-20200901112858 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
This section lists the components artifacts of the Cluster release 5.8.0.
Note
The components that are newly added, updated, deprecated, or removed
as compared to the previous release version, are marked
with a corresponding superscript,
for example, lcm-ansible Updated.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller Updated |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-18.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v14.2.9 |
ceph-controller Updated |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20200903151423 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v2.1.2 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v1.2.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v1.4.0 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v1.2.2 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v2.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.3.8 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
ansible-docker Updated |
https://binary.mirantis.com/lcm/bin/ansible-docker/v0.3.5-141-g1007cc9/ansible-docker.tar.gz |
lcm-ansible Updated |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.2.0-119-g8f05f58-1/lcm-ansible.tar.gz |
|
lcm-agent Updated |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-169-g5668304d/lcm-agent |
|
Helm charts |
descheduler Updated |
https://binary.mirantis.com/core/helm/descheduler-1.12.2.tgz |
metallb Updated |
||
metrics-server Updated |
https://binary.mirantis.com/core/helm/metrics-server-1.12.2.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm Updated |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.9-39 |
|
helm-controller Updated |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-169-g5668304d |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-12.tgz |
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-20.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-2.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd Updated |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-15.tgz |
|
fluentd-elasticsearch |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-25.tgz |
|
grafana Updated |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-64.tgz |
|
iam-proxy |
||
kibana Updated |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-20.tgz |
|
mcc-metric-collector |
https://binary.mirantis.com/stacklight/helm/mcc-metric-collector-0.1.0-mcp-22.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-8.tgz |
|
netchecker |
||
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-17.tgz |
|
prometheus Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-80.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-3.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-3.tgz |
|
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/heprometheus-libvirt-exporter-0.1.0-mcp-2.tgz |
|
prometheus-memcached-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-memcached-exporter-0.1.0-mcp-1.tgz |
|
prometheus-mysql-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-mysql-exporter-0.3.2-mcp-1.tgz |
|
prometheus-nginx-exporter Updated |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-4.tgz |
|
prometheus-rabbitmq-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-rabbitmq-exporter-0.4.1-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-5.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-6.tgz |
|
stacklight Updated |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-312.tgz |
|
telegraf-ds Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-16.tgz |
|
telegraf-s Updated |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-16.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-11.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-11.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:7.4.4-20200615123606 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.21.0 |
|
alpine-python3-requests |
mirantis.azurecr.io/stacklight/alpine-python3-requests:latest-20200320 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.6.1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20200609085335 |
|
gce-proxy |
mirantis.azurecr.io/stacklight/gce-proxy:1.11 |
|
grafana Updated |
mirantis.azurecr.io/stacklight/grafana:7.1.5 |
|
grafana-image-renderer New |
mirantis.azurecr.io/stacklight/grafana-image-renderer:2.0.0 |
|
kubectl New |
mirantis.azurecr.io/stacklight/kubectl:1.15.3 |
|
k8s-netchecker-agent |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-agent:2019.1 |
|
k8s-netchecker-server |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-server:2019.1 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:0.1.178 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.6.1 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
mcc-metric-collector Updated |
mirantis.azurecr.io/stacklight/mcc-metric-collector:v0.1-20201005141816 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.6.1 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.19.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20201002144823 |
|
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/libvirt-exporter:v0.1-20200610164751 |
|
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
|
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter Updated |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.8.0-20201006113956 |
|
prometheus-rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v0.29.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20200519054052 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier Updated |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20200813125431 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20200219140217 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:12-1.6p3 |
|
telegraf Updated |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20200901112858 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
See also
This section outlines release notes for the Cluster release 5.7.0 that is introduced in the Mirantis Container Cloud release 2.0.0 and supports Mirantis Kubernetes Engine 3.3.3, Mirantis Container Runtime 19.03.12, and Kubernetes 1.18.
For the list of known issues, refer to the Container Cloud release 2.0.0 Known issues.
The following table lists the components versions of the Cluster release 5.7.0.
Component |
Application/Service |
Version |
|---|---|---|
Cluster orchestration |
Mirantis Kubernetes Engine |
3.3.3 0 |
Container runtime |
Mirantis Container Runtime |
19.03.12 1 |
Distributed storage |
Ceph |
14.2.9 (Nautilus) |
Rook |
1.3.8 |
|
LCM |
ansible-docker |
0.3.5-136-g38653c7 |
descheduler |
0.8.0 |
|
Helm |
2.16.7-38 |
|
helm-controller |
0.2.0-149-g412c5a05 |
|
lcm-ansible |
0.2.0-110-g63cf88b |
|
lcm-agent |
0.2.0-149-g412c5a05 |
|
metallb-controller |
0.9.3-1 |
|
metrics-server |
0.3.6-1 |
|
StackLight |
Alerta |
7.4.4-20200615123606 |
Alertmanager |
0.21.0 |
|
Elasticsearch |
7.6.1 |
|
Elasticsearch Curator |
5.7.6 |
|
Elasticsearch Exporter |
1.0.2 |
|
Fluentd |
1.10.2-20200609085335 |
|
Grafana |
6.6.2 |
|
IAM Proxy |
6.0.1 |
|
Kibana |
7.6.1 |
|
MCC Metric Collector |
0.1-20200806113043 |
|
Metricbeat |
7.6.1 |
|
Netchecker |
1.4.1 |
|
Patroni |
12-1.6p3 |
|
Prometheus |
2.19.2 |
|
Prometheus Blackbox Exporter |
0.14.0 |
|
Prometheus ES Exporter |
0.5.1-20200313132957 |
|
Prometheus libvirt Exporter |
0.1-20200610164751 |
|
Prometheus Memcached Exporter |
0.5.0 |
|
Prometheus MySQL Exporter |
0.11.0 |
|
Prometheus Node Exporter |
1.0.1 |
|
Prometheus NGINX Exporter |
0.6.0 |
|
Prometheus Patroni Exporter |
0.1-20200428121305 |
|
Prometheus Postgres Exporter |
0.8.0-20200715102834 |
|
Prometheus RabbitMQ Exporter |
0.29.0 |
|
Prometheus Relay |
0.3-20200519054052 |
|
Pushgateway |
1.2.0 |
|
sf-notifier |
0.3-20200430122138 |
|
sf-reporter |
0.1-20200219140217 |
|
telegraf-ds |
1.9.1-20200806073506 |
|
telegraf-s |
1.9.1-20200806073506 |
|
Telemeter |
4.4.0-20200424 |
- 0
For the MKE release highlights and components versions, see MKE documentation: MKE release notes.
- 1
For the MCR release highlights, see MCR documentation: MCR release notes.
Due to the development limitations, the MCR upgrade to version 19.03.14 on existing Container Cloud clusters is not supported.
This section lists the components artifacts of the Cluster release 5.7.0.
Artifact |
Component |
Path |
|---|---|---|
Helm chart |
ceph-controller |
https://binary.mirantis.com/ceph/helm/ceph-operator-1.0.0-mcp-16.tgz |
Docker images |
ceph |
mirantis.azurecr.io/ceph/ceph:v14.2.9 |
ceph-controller |
mirantis.azurecr.io/ceph/mcp/ceph-controller:v1.0.0-20200805103414 |
|
cephcsi |
mirantis.azurecr.io/ceph/cephcsi/cephcsi:v2.1.2 |
|
csi-node-driver-registrar |
mirantis.azurecr.io/ceph/k8scsi/csi-node-driver-registrar:v1.2.0 |
|
csi-provisioner |
mirantis.azurecr.io/ceph/k8scsi/csi-provisioner:v1.4.0 |
|
csi-snapshotter |
mirantis.azurecr.io/ceph/k8scsi/csi-snapshotter:v1.2.2 |
|
csi-attacher |
mirantis.azurecr.io/ceph/k8scsi/csi-attacher:v2.1.0 |
|
rook |
mirantis.azurecr.io/ceph/rook/ceph:v1.3.8 |
Artifact |
Component |
Path |
|---|---|---|
Binaries |
ansible-docker |
https://binary.mirantis.com/lcm/bin/ansible-docker/v0.3.5-136-g38653c7/ansible-docker.tar.gz |
lcm-ansible |
https://binary.mirantis.com/lcm/bin/lcm-ansible/v0.2.0-110-g63cf88b/lcm-ansible.tar.gz |
|
lcm-agent |
https://binary.mirantis.com/lcm/bin/lcm-agent/v0.2.0-149-g412c5a05/lcm-agent |
|
Helm charts |
descheduler |
https://binary.mirantis.com/core/helm/descheduler-1.10.12.tgz |
metallb |
||
metrics-server |
https://binary.mirantis.com/core/helm/metrics-server-1.10.12.tgz |
|
Docker images |
descheduler |
mirantis.azurecr.io/lcm/descheduler/v0.8.0 |
helm |
mirantis.azurecr.io/lcm/helm/tiller:v2.16.9-39 |
|
helm-controller |
mirantis.azurecr.io/lcm/lcm-controller:v0.2.0-149-g412c5a05 |
|
metallb-controller |
mirantis.azurecr.io/lcm/metallb/controller:v0.9.3-1 |
|
metallb-speaker |
mirantis.azurecr.io/lcm/metallb/speaker:v0.9.3-1 |
|
metrics-server |
mirantis.azurecr.io/lcm/metrics-server-amd64/v0.3.6-1 |
Artifact |
Component |
Path |
|---|---|---|
Helm charts |
alerta |
https://binary.mirantis.com/stacklight/helm/alerta-0.1.0-mcp-12.tgz |
elasticsearch |
https://binary.mirantis.com/stacklight/helm/elasticsearch-7.1.1-mcp-20.tgz |
|
elasticsearch-curator |
https://binary.mirantis.com/stacklight/helm/elasticsearch-curator-1.5.0-mcp-2.tgz |
|
elasticsearch-exporter |
https://binary.mirantis.com/stacklight/helm/elasticsearch-exporter-1.2.0-mcp-2.tgz |
|
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-15.tgz |
|
fluentd-elasticsearch |
https://binary.mirantis.com/stacklight/helm/fluentd-elasticsearch-3.0.0-mcp-24.tgz |
|
grafana |
https://binary.mirantis.com/stacklight/helm/grafana-3.3.10-mcp-59.tgz |
|
kibana |
https://binary.mirantis.com/stacklight/helm/kibana-3.2.1-mcp-19.tgz |
|
mcc-metric-collector |
https://binary.mirantis.com/stacklight/helm/mcc-metric-collector-0.1.0-mcp-22.tgz |
|
metricbeat |
https://binary.mirantis.com/stacklight/helm/metricbeat-1.7.1-mcp-8.tgz |
|
netchecker |
||
patroni |
https://binary.mirantis.com/stacklight/helm/patroni-0.15.1-mcp-17.tgz |
|
prometheus |
https://binary.mirantis.com/stacklight/helm/prometheus-8.11.4-mcp-73.tgz |
|
prometheus-blackbox-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-blackbox-exporter-0.3.0-mcp-3.tgz |
|
prometheus-es-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-es-exporter-1.0.0-mcp-3.tgz |
|
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/heprometheus-libvirt-exporter-0.1.0-mcp-2.tgz |
|
prometheus-memcached-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-memcached-exporter-0.1.0-mcp-1.tgz |
|
prometheus-mysql-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-mysql-exporter-0.3.2-mcp-1.tgz |
|
prometheus-nginx-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-nginx-exporter-0.1.0-mcp-2.tgz |
|
prometheus-rabbitmq-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-rabbitmq-exporter-0.4.1-mcp-1.tgz |
|
sf-notifier |
https://binary.mirantis.com/stacklight/helm/sf-notifier-0.1.0-mcp-5.tgz |
|
sf-reporter |
https://binary.mirantis.com/stacklight/helm/sf-reporter-0.1.0-mcp-6.tgz |
|
stacklight |
https://binary.mirantis.com/stacklight/helm/stacklight-0.1.2-mcp-285.tgz |
|
telegraf-ds |
https://binary.mirantis.com/stacklight/helm/telegraf-ds-1.1.5-mcp-14.tgz |
|
telegraf-s |
https://binary.mirantis.com/stacklight/helm/telegraf-s-1.1.5-mcp-14.tgz |
|
telemeter-server |
https://binary.mirantis.com/stacklight/helm/telemeter-server-0.1.0-mcp-11.tgz |
|
telemeter-client |
https://binary.mirantis.com/stacklight/helm/telemeter-client-0.1.0-mcp-11.tgz |
|
Docker images |
alerta |
mirantis.azurecr.io/stacklight/alerta-web:7.4.4-20200615123606 |
alertmanager |
mirantis.azurecr.io/stacklight/alertmanager:v0.21.0 |
|
alpine-python3-requests |
mirantis.azurecr.io/stacklight/alpine-python3-requests:latest-20200320 |
|
busybox |
mirantis.azurecr.io/stacklight/busybox:1.30 |
|
configmap-reload |
mirantis.azurecr.io/stacklight/configmap-reload:v0.3.0 |
|
curl |
mirantis.azurecr.io/stacklight/curl:7.69.0 |
|
curl-jq |
mirantis.azurecr.io/stacklight/curl-jq:1.5-1 |
|
elasticsearch |
mirantis.azurecr.io/stacklight/elasticsearch:7.6.1 |
|
elasticsearch-curator |
mirantis.azurecr.io/stacklight/curator:5.7.6 |
|
elasticsearch-exporter |
mirantis.azurecr.io/stacklight/elasticsearch_exporter:1.0.2 |
|
fluentd |
mirantis.azurecr.io/stacklight/fluentd:1.10.2-20200609085335 |
|
gce-proxy |
mirantis.azurecr.io/stacklight/gce-proxy:1.11 |
|
grafana |
mirantis.azurecr.io/stacklight/grafana:6.6.2 |
|
k8s-netchecker-agent |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-agent:2019.1 |
|
k8s-netchecker-server |
mirantis.azurecr.io/lcm/kubernetes/k8s-netchecker-server:2019.1 |
|
k8s-sidecar |
mirantis.azurecr.io/stacklight/k8s-sidecar:0.1.178 |
|
kibana |
mirantis.azurecr.io/stacklight/kibana:7.6.1 |
|
kube-state-metrics |
mirantis.azurecr.io/stacklight/kube-state-metrics:v1.9.2 |
|
mcc-metric-collector |
mirantis.azurecr.io/stacklight/mcc-metric-collector:v0.1-20200806113043 |
|
metricbeat |
mirantis.azurecr.io/stacklight/metricbeat:7.6.1 |
|
node-exporter |
mirantis.azurecr.io/stacklight/node-exporter:v1.0.1 |
|
origin-telemeter |
mirantis.azurecr.io/stacklight/origin-telemeter:4.4.0-20200424 |
|
prometheus |
mirantis.azurecr.io/stacklight/prometheus:v2.19.2 |
|
prometheus-blackbox-exporter |
mirantis.azurecr.io/stacklight/blackbox-exporter:v0.14.0 |
|
prometheus-es-exporter |
mirantis.azurecr.io/stacklight/prometheus-es-exporter:v0.5.1-20200313132957 |
|
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/libvirt-exporter:v0.1-20200610164751 |
|
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
|
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
|
prometheus-nginx-exporter |
mirantis.azurecr.io/stacklight/nginx-prometheus-exporter:0.6.0 |
|
prometheus-patroni-exporter |
mirantis.azurecr.io/stacklight/prometheus-patroni-exporter:v0.1-20200428121305 |
|
prometheus-postgres-exporter |
mirantis.azurecr.io/stacklight/prometheus-postgres-exporter:v0.8.0-20200715102834 |
|
prometheus-rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v0.29.0 |
|
prometheus-relay |
mirantis.azurecr.io/stacklight/prometheus-relay:v0.3-20200519054052 |
|
pushgateway |
mirantis.azurecr.io/stacklight/pushgateway:v1.2.0 |
|
sf-notifier |
mirantis.azurecr.io/stacklight/sf-notifier:v0.3-20200430122138 |
|
sf-reporter |
mirantis.azurecr.io/stacklight/sf-reporter:v0.1-20200219140217 |
|
spilo |
mirantis.azurecr.io/stacklight/spilo:12-1.6p3 |
|
telegraf |
mirantis.azurecr.io/stacklight/telegraf:v1.9.1-20200806073506 |
|
telemeter-token-auth |
mirantis.azurecr.io/stacklight/telemeter-token-auth:v0.1-20200406175600 |
See also
See also
Patch releases¶
Since Container Cloud 2.23.2, the release train comprises several patch releases that Mirantis delivers on top of a major release mainly to incorporate security updates as soon as they become available without waiting for the next major release. By significantly reducing the time to provide fixes for Common Vulnerabilities and Exposures (CVE), patch releases protect your clusters from cyber threats and potential data breaches.
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on your deployment needs, you can either update only between major Cluster releases or apply patch updates between major releases. Choosing the latter option ensures you receive security fixes as soon as they become available. Though, be prepared to update your cluster frequently, approximately once every three weeks. Otherwise, you can update only between major Cluster releases as each subsequent major Cluster release includes patch Cluster release updates of the previous major Cluster release.
Content delivery in major and patch releases¶
As compared to a major Cluster release update, a patch release update does not involve any public API or LCM changes, major version bumps of MKE or other major components, workloads evacuation. A patch cluster update only may require restart of containers running the Container Cloud controllers, MKE, Ceph, and StackLight services to update base images with related libraries and apply CVE fixes to images. The data plane is not affected.
The following table lists differences between content delivery in major releases as compared to patch releases:
Content |
Major release |
Patch release |
|---|---|---|
Major version upgrade of the major product components including but not limited to Ceph and StackLight 0 |
||
Patch version bumps of MKE and Kubernetes 1 |
||
Container runtime changes including Mirantis Container Runtime and containerd updates |
||
Changes in public API |
||
Changes in the Container Cloud lifecycle management |
||
Host machine changes including host operating system updates and upgrades, kernel updates, and so on |
||
CVE fixes for images |
||
Fixes for known product issues |
Update paths for major vs patch releases¶
Management clusters obtain patch releases automatically the same way as major releases. Managed clusters use the same update delivery method as for the major Cluster release updates. New patch Cluster releases become available through the Container Cloud web UI after automatic upgrade of a management cluster to the latest patch Cluster release.
You may decide to use only major Cluster releases without updating to patch Cluster releases. In this case, you will perform updates from an N to N+1 major release.
Major Cluster releases include all patch updates of the previous major Cluster release. However, Mirantis recommends applying security fixes using patch releases as soon as they become available to avoid security threats and potentially achieve legal compliance.
If you delay the Container Cloud upgrade and schedule it at a later time as described in Schedule Mirantis Container Cloud upgrades, make sure to schedule a longer maintenance window as the upgrade queue can include several patch releases along with the major release upgrade.
For the update procedure, refer to Operations Guide: Update a patch Cluster release of a managed cluster.
Patch update schemes before and since 2.26.5¶
Starting from Container Cloud 2.26.5 (Cluster releases 16.1.5 and 17.1.5), Mirantis introduces a new update scheme for managed clusters allowing for the update path flexibility.
Since Container Cloud 2.26.5 |
Before Container Cloud 2.26.5 |
|---|---|
The user can update a managed cluster to any patch version in the series even if a newer patch version has been released already. Note In Container Cloud patch releases 2.27.1 and 2.27.2, only the 16.2.x patch Cluster releases will be delivered with an automatic update of management clusters and the possibility to update non-MOSK managed clusters. In parallel, 2.27.1 and 2.27.2 will include new 16.1.x and 17.1.x patches for MOSK 24.1.x. And the first 17.2.x patch Cluster release for MOSK 24.2.x will be delivered in 2.27.3. For details, see MOSK documentation: Update path for 24.1 and 24.2 series. |
The user cannot update a managed cluster to the intermediate patch version in the series if a newer patch version has been released. For example, when the patch Cluster release 17.0.4 becomes available, you can update from 17.0.1 to 17.0.4 at once, but not from 17.0.1 to 17.0.2. |
The user can always update to the newer major version from the latest patch version of the previous series. Additionally, there will be another possibility of major update during the course of the patch series from the patch version released immediately before the target major version. |
If the cluster starts receiving patch releases, the user must apply the latest patch version in the series to be able to update to the following major release. For example, to obtain the major Cluster release 17.1.0 while using the patch Cluster release 17.0.2, you must update your cluster to the latest patch Cluster release 17.0.4 first. |
Latest supported patch releases¶
The following table lists the Container Cloud 2.26.x patch release and its supported Cluster releases that are being delivered on top of the Container Cloud major release 2.26.0. Click the required patch release link to learn more about its deliverables.
Patch release |
Container Cloud |
||||||||
|---|---|---|---|---|---|---|---|---|---|
Release history |
Patch release date |
July 16, 2024 |
July 02, 2024 |
June 18, 2024 |
May 20, 2024 |
Apr 29, 2024 |
Apr 08, 2024 |
Mar 20, 2024 |
Mar 04, 2024 |
Patch Cluster releases (managed) |
17.1.x +
MOSK 24.1.x
|
17.1.5 + 24.1.5
17.1.4 + 24.1.4
|
|||||||
16.2.x |
|||||||||
16.1.x |
Legend
- Cluster release is deprecated and will become unsupported in one of the following Container Cloud releases.
Deprecation notes¶
Taking into account continuous reorganization and enhancement of Mirantis Container Cloud, certain components are deprecated and eventually removed from the product. This section provides the following details about the deprecated and removed functionality that may potentially impact the existing Container Cloud deployments:
The Container Cloud release version in which deprecation is initially announced
The final Container Cloud release version in which a deprecated component is present
The target Container Cloud release version in which a deprecated component is removed
Component |
Deprecated in |
Finally available in |
Removed in |
Comments |
|---|---|---|---|---|
Ceph metrics |
2.27.0 |
2.27.0 |
2.28.0 |
Deprecated the performance metric exporter that is integrated into the Ceph Manager daemon for the sake of the dedicated Ceph Exporter daemon. Names of metrics will not be changed, no metrics will be removed. All Ceph metrics to be collected by the Ceph Exporter daemon will change
their labels
Therefore, if Ceph metrics to be collected by the Ceph Exporter daemon are used in any customizations, for example, custom alerts, Grafana dashboards, or queries in custom tools, update your customizations to use new labels since Container Cloud 2.28.0 (Cluster releases 16.3.0 and 17.3.0).
List of affected Ceph RGW metrics
List of all metrics to be collected by Ceph Exporter instead of
Ceph Manager
|
|
2.27.0 |
2.27.0 |
2.28.0 |
Deprecated the Existing configurations that use the If you still require this feature, contact Mirantis support for further information. |
|
2.27.0 |
2.27.0 |
2.28.0 |
Deprecated the Existing |
|
2.27.0 |
Deprecated the |
||
|
2.26.0 |
2.26.0 |
2.27.0 |
Deprecated the |
|
2.26.0 |
Deprecated the Instead of floats that define sizes in GiB for All newly created profiles are automatically migrated to the |
||
The |
2.26.0 |
Deprecated the For backward compatibility, any existing wipeDevice:
eraseMetadata:
enabled: True
For new machines, use the |
||
Several StackLight logging parameters |
2.25.0 |
2.25.0 |
2.26.0 |
Removed the following logging-related StackLight parameters in the light of the logging pipeline refactoring:
|
Regional clusters |
2.25.0 |
2.25.0 |
2.26.0 |
Suspended support for regional clusters of the same or different cloud provider type on a single management cluster. Additionally, suspended support for several regions on a single management cluster. Simultaneously, ceased performing functional integration testing of the feature and removed the related code in Container Cloud 2.26.0. If you still require this feature, contact Mirantis support for further information. |
CentOS and RHEL 7.9 support for the vSphere provider |
2.25.0 |
2.25.0 |
2.26.0 |
Suspended support for CentOS and ended support for the deprecated RHEL 7.9 operating system by the vSphere provider. Instead, use RHEL 8.7 or Ubuntu 20.04. Note EOL for RHEL 7.9 is planned for June-July 2024. For details, see Official RedHat documentation: Maintenance Support 2 Phase (RHEL 7). |
Bootstrap v1 |
2.25.0 |
2.25.0 |
2.26.0 |
Deprecated the bootstrap procedure using Bootstrap v1 in the sake of Bootstrap v2. For details, see Deploy Container Cloud using Bootstrap v2. |
Default L2Template for a namespace |
2.25.0 |
Disabled creation of the default L2 template for a namespace. On existing clusters, |
||
L2Template |
2.25.0 |
Deprecated the On existing clusters, this parameter is automatically migrated to the
|
||
L2Template without |
2.9.0 |
2.23.5 |
2.24.0 |
Deprecated the use of the On existing clusters, the Caution Partial definition of subnets is prohibited. |
Bare metal |
2.21.0 |
2.23.0 |
2.24.0 |
Deprecated the Since 2.24.0, |
MetalLB |
2.24.0 |
2.24.0 |
2.25.0 |
Deprecated the
|
|
2.24.0 |
2.24.0 |
2.24.0 |
Removed |
Attachment of MKE clusters |
2.24.0 |
2.24.0 |
2.24.0 |
Suspended support for attachment of existing Mirantis Kubernetes Engine (MKE) clusters that were originally not deployed by Container Cloud. Also suspended support for all related features, such as sharing a Ceph cluster with an attached MKE cluster. Note The feature support is renewed since Container Cloud 2.25.2 for vSphere-based clusters. |
Public cloud providers |
2.23.0 |
2.23.0 |
2.23.0 |
Removed the following cloud providers from the list of supported Container Cloud providers: AWS, Azure, Equinix Metal with private or public networking. |
|
2.23.0 |
Deprecated |
||
|
2.23.0 |
2.24.0 |
2.25.0 |
|
|
2.23.0 |
2.24.0 |
2.25.0 |
|
|
2.23.0 |
2.24.0 |
2.25.0 |
|
|
2.21.0 |
2.21.0 |
2.22.0 |
The following fields of the
The format of
|
Ceph |
2.20.0 |
Deprecated the |
||
Ceph RADOS Gateway |
2.20.0 |
Deprecated the Ceph RADOS Gateway |
||
Ceph on management and regional clusters |
2.19.0 |
2.19.0 |
2.20.0 |
Removed Ceph cluster deployment from the management and regional clusters based on bare metal and Equinix Metal with private networking to reduce resource consumption. Ceph is automatically removed during the Cluster release update to 11.4.0 or 7.10.0. |
Ceph |
2.19.0 |
Deprecated the |
||
|
2.19.0 |
Deprecated the |
||
Public networking mode on the Equinix Metal based deployments |
2.18.0 |
Deprecated the public networking mode on the Equinix Metal based deployments for the sake of the private network mode. |
||
Services and parameters related to OpenSearch and Kibana |
2.18.0 |
Deprecated
|
||
Elasticsearch and Kibana |
2.16.0 |
2.16.0 |
2.18.0 |
Elasticsearch is replaced with OpenSearch, Kibana is replaced with OpenSearch Dashboards. For details, see Elasticsearch switch to OpenSearch. |
Retention Time StackLight parameter in the Container Cloud web UI |
2.17.0 |
2.17.0 |
2.17.0 |
Replaced with the Logstash Retention Time, Events Retention Time, and Notifications Retention Time parameters. |
|
2.16.0 |
2.25.0 |
2.26.0 |
Deprecated the |
|
2.15.0 |
2.17.0 |
2.18.0 |
Deprecated the |
|
2.14.0 |
2.16.0 |
2.17.0 |
Deprecated |
|
2.14.0 |
2.14.0 |
2.15.0 |
Removed |
|
2.14.0 |
Deprecated the |
||
|
2.13.0 |
2.14.0 |
2.14.0 |
Removed the |
|
2.12.0 |
2.21.0 |
2.22.0 |
|
|
2.12.0 |
2.13.0 |
2.14.0 |
Deprecated the Ceph |
|
2.12.0 |
2.13.0 |
2.14.0 |
Replaced with the |
IPAM API resources:
|
2.11.0 |
2.11.0 |
2.12.0 |
These resources will be eventually replaced with:
|
|
2.9.0 |
2.9.0 |
2.10.0 |
These IPs are now automatically generated in the MetalLB range for certificates creation in the VMware vSphere cloud provider. |
Netchecker |
2.9.0 |
2.10.0 |
2.11.0 |
Deprecated the Netchecker service. |
|
2.8.0 |
2.8.0 |
2.9.0 |
The
|
SSH-enabled user names |
2.7.0 |
2.8.0 |
2.9.0 |
All existing SSH user names, such as |
|
2.8.0 |
Replaced with |
QuickStart guides overview¶
This section contains easy and lightweight instructions to get started with Container Cloud.
Select the required cloud provider and use one of QuickStart tutorials listed below to deploy a Mirantis Container Cloud management cluster containing 3 control plane nodes. This cluster will run the public API and the web UI. Using the Container Cloud web UI, you can deploy managed clusters that run Mirantis Kubernetes Engine.
Note
If your deployment requires a complex configuration, refer to complete procedures with a full set of possible options for each supported provider that are described in Deployment Guide.
QuickStart: Container Cloud on OpenStack¶
Caution
This Bootstrap v1 procedure is deprecated since Container Cloud 2.25.0 for the sake of Bootstrap v2. For details, see Deployment Guide: Deploy Container Cloud using Boostrap v2.
We are currently updating this QuickStart guide to align with the Bootstrap v2 procedure and plan to release the revised version in one of the following Container Cloud releases.
Using this QuickStart tutorial, you can deploy a Mirantis Container Cloud OpenStack-based management cluster containing 3 control plane nodes. This cluster will run the public API and the web UI. Using the Container Cloud web UI, you can deploy managed clusters that run Mirantis Kubernetes Engine.
The following diagram illustrates the deployment overview of a Container Cloud OpenStack-based management cluster:
Before you begin¶
Before you start the cluster deployment, verify that your system meets the following minimum hardware and software requirements for an OpenStack-based management cluster.
Note
For the bootstrap node, you can use any local machine running Ubuntu 20.04 with the following resources:
2 vCPUs
4 GB of RAM
5 GB of available storage
Resource |
Requirement |
|---|---|
# of nodes |
4 (3 for HA + 1 for Bastion) |
# of vCPUs |
25 (8 per node + 1 for Bastion) |
RAM in GB |
73 (24 per node + 1 for Bastion) |
Storage in GB |
360 (120 per node) |
OpenStack version |
Queens, Victoria, Yoga 0 |
Obligatory OpenStack components |
|
# of Cinder volumes |
7 (total 110 GB) |
# of load balancers |
10 |
# of floating IPs |
11 |
Prepare the bootstrap node¶
Log in to any personal computer or VM running Ubuntu 20.04 that you will be using as the bootstrap node.
If you use a newly created VM, run:
sudo apt-get update
Install the current Docker version available for Ubuntu 20.04:
sudo apt install docker.io
Grant your
USERaccess to the Docker daemon:sudo usermod -aG docker $USER
Log off and log in again to the bootstrap node to apply the changes.
Verify that Docker is configured correctly and has access to Container Cloud CDN. For example:
docker run --rm alpine sh -c "apk add --no-cache curl; \ curl https://binary.mirantis.com"
The system output must contain no error records. In case of issues, follow the steps provided in Troubleshooting.
Download the bootstrap script¶
On the bootstrap node:
Download and run the Container Cloud bootstrap script:
sudo apt-get update sudo apt-get install wget wget https://binary.mirantis.com/releases/get_container_cloud.sh chmod 0755 get_container_cloud.sh ./get_container_cloud.sh
Change the directory to the
kaas-bootstrapfolder created by the script.
Obtain the Mirantis license¶
Select from the following options:
Open the email from support@mirantis.com with the subject Mirantis Container Cloud License File or Mirantis OpenStack License File
In the Mirantis CloudCare Portal, open the Account or Cloud page
Download the License File and save it as
mirantis.licunder thekaas-bootstrapdirectory on the bootstrap node.Verify that
mirantis.liccontains the previously downloaded Container Cloud license by decoding the license JWT token, for example, using jwt.io.Example of a valid decoded Container Cloud license data with the mandatory
licensefield:{ "exp": 1652304773, "iat": 1636669973, "sub": "demo", "license": { "dev": false, "limits": { "clusters": 10, "workers_per_cluster": 10 }, "openstack": null } }
Warning
The MKE license does not apply to
mirantis.lic. For details about MKE license, see MKE documentation.
Prepare the OpenStack configuration¶
Log in to the OpenStack Horizon.
In the Project section, select API Access.
In the right-side drop-down menu Download OpenStack RC File, select OpenStack clouds.yaml File.
Save the downloaded
clouds.yamlfile in thekaas-bootstrapfolder created by theget_container_cloud.shscript.In
clouds.yaml, add thepasswordfield with your OpenStack password under theclouds/openstack/authsection.Example:
clouds: openstack: auth: auth_url: https://auth.openstack.example.com/v3 username: your_username password: your_secret_password project_id: your_project_id user_domain_name: your_user_domain_name region_name: RegionOne interface: public identity_api_version: 3
If you deploy Container Cloud on top of MOSK Victoria with Tungsten Fabric and use the default security group for newly created load balancers, add the following rules for the Kubernetes API server endpoint, Container Cloud application endpoint, and for the MKE web UI and API using the OpenStack CLI:
direction='ingress'ethertype='IPv4'protocol='tcp'remote_ip_prefix='0.0.0.0/0'port_range_maxandport_range_min:'443'for Kubernetes API and Container Cloud application endpoints'6443'for MKE web UI and API
Verify access to the target cloud endpoint from Docker. For example:
docker run --rm alpine sh -c "apk add --no-cache curl; \ curl https://auth.openstack.example.com/v3"
The system output must contain no error records.
Configure the cluster and machines metadata¶
Adjust the
templates/cluster.yaml.templateparameters to suit your deployment:In the
spec::providerSpec::valuesection, add the mandatoryExternalNetworkIDparameter that is the ID of an external OpenStack network. It is required to have public Internet access to virtual machines.In the
spec::clusterNetwork::servicessection, add the corresponding values forcidrBlocks.Configure other parameters as required.
In
templates/machines.yaml.template, modify thespec:providerSpec:valuesection for 3 control plane nodes marked with thecluster.sigs.k8s.io/control-planelabel by substituting theflavorandimageparameters with the corresponding values of the control plane nodes in the related OpenStack cluster. For example:spec: &cp_spec providerSpec: value: apiVersion: "openstackproviderconfig.k8s.io/v1alpha1" kind: "OpenstackMachineProviderSpec" flavor: kaas.minimal image: bionic-server-cloudimg-amd64-20190612
Note
The
flavorparameter value provided in the example above is cloud-specific and must meet the Container Cloud requirements.Optional. Available as TechPreview. To boot cluster machines from a block storage volume, define the following parameter in the
spec:providerSpecsection oftemplates/machines.yaml.template:bootFromVolume: enabled: true volumeSize: 120
Note
The minimal storage requirement is 120 GB per node. For details, see Requirements for an OpenStack-based cluster.
To boot the Bastion node from a volume, add the same parameter to
templates/cluster.yaml.templatein thespec:providerSpecsection for Bastion. The default amount of storage80is enough.
Also, modify other parameters as required.
Finalize the bootstrap¶
Run the bootstrap script:
./bootstrap.sh allIn case of deployment issues, refer to Troubleshooting and inspect logs.
If the script fails for an unknown reason:
Run the cleanup script:
./bootstrap.sh cleanupRerun the bootstrap script.
When the bootstrap is complete, collect and save the following management cluster details in a secure location:
The
kubeconfigfile located in the same directory as the bootstrap script. This file contains the admin credentials for the management cluster.The private
ssh_keyfor access to the management cluster nodes that is located in the same directory as the bootstrap script.Note
If the initial version of your Container Cloud management cluster was earlier than 2.6.0,
ssh_keyis namedopenstack_tmpand is located at~/.ssh/.The URL for the Container Cloud web UI.
To create users with permissions required for accessing the Container Cloud web UI, see Create initial users after a management cluster bootstrap.
The StackLight endpoints. For details, see Access StackLight web UIs.
The Keycloak URL that the system outputs when the bootstrap completes. The admin password for Keycloak is located in
kaas-bootstrap/passwords.ymlalong with other IAM passwords.
Note
The Container Cloud web UI and StackLight endpoints are available through Transport Layer Security (TLS) and communicate with Keycloak to authenticate users. Keycloak is exposed using HTTPS and self-signed TLS certificates that are not trusted by web browsers.
To use your own TLS certificates for Keycloak, refer to Configure TLS certificates for cluster applications.
Note
When the bootstrap is complete, the bootstrap cluster resources are freed up.
Verify that network addresses used on your clusters do not overlap with the following default MKE network addresses for Swarm and MCR:
10.0.0.0/16is used for Swarm networks. IP addresses from this network are virtual.10.99.0.0/16is used for MCR networks. IP addresses from this network are allocated on hosts.
Verification of Swarm and MCR network addresses
To verify Swarm and MCR network addresses, run on any master node:
docker infoExample of system response:
Server: ... Swarm: ... Default Address Pool: 10.0.0.0/16 SubnetSize: 24 ... Default Address Pools: Base: 10.99.0.0/16, Size: 20 ...
Not all of Swarm and MCR addresses are usually in use. One Swarm Ingress network is created by default and occupies the
10.0.0.0/24address block. Also, three MCR networks are created by default and occupy three address blocks:10.99.0.0/20,10.99.16.0/20,10.99.32.0/20.To verify the actual networks state and addresses in use, run:
docker network ls docker network inspect <networkName>
What’s next¶
Using your newly deployed management cluster, you can:
Create and operate an OpenStack-based managed cluster. Before that, verify that your planned cluster meets the requirements for managed clusters.
Extend your cluster with more options, for example, Configure external identity provider for IAM.
QuickStart: Container Cloud on VMware vSphere¶
Caution
This Bootstrap v1 procedure is deprecated since Container Cloud 2.25.0 for the sake of Bootstrap v2. For details, see Deployment Guide: Deploy Container Cloud using Boostrap v2.
We are currently updating this QuickStart guide to align with the Bootstrap v2 procedure and plan to release the revised version in one of the following Container Cloud releases.
Using this QuickStart tutorial, you can deploy a Mirantis Container Cloud VMware vSphere-based management cluster containing 3 control plane nodes. This cluster will run the public API and the web UI. Using the Container Cloud web UI, you can deploy managed clusters that run Mirantis Kubernetes Engine.
The following diagram illustrates the deployment overview of a Container Cloud vSphere-based management cluster:
Note
Container Cloud does not support mixed operating systems, RHEL combined with Ubuntu, in one cluster.
Before you begin¶
Before you start the cluster deployment, verify that your system meets the following minimum hardware and software requirements for a vSphere-based management cluster:
Note
For the bootstrap node, you can use any local machine running Ubuntu 20.04 with the following resources:
2 vCPUs
4 GB of RAM
5 GB of available storage
Resource |
Requirement |
|---|---|
# of hypervisors |
1 |
# of nodes |
3 (HA) |
# of vCPUs |
24 (8 vCPUs per node) |
RAM in GB |
72 (24 per node) |
Storage in GB |
360 (120 per node) that must be shared to the hypervisor |
RHEL license (for RHEL deployments only) |
1 RHEL license for Virtual Datacenters per hypervisor |
Obligatory vSphere capabilities |
DRS,
Shared datastore
|
IP subnet size |
Minimum 20 IPs:
Also, consider the supported VMware vSphere network objects and IPAM recommendations. |
Software |
Version |
|---|---|
Operating system distribution |
For the bootstrap node: Ubuntu 20.04 or RHEL 8.7
For the Container Cloud clusters:
|
VMware vSphere |
7.0 or 6.7 |
cloud-init version 2 |
20.3 for RHEL 8.7 1 |
VMware Tools version 2 |
11.0.5 |
- 1(1,2)
RHEL 8.7 is generally available since Cluster releases 16.0.0 and 14.1.0. Before these Cluster releases, it is supported within the Technology Preview features scope.
Container Cloud does not support mixed operating systems, RHEL combined with Ubuntu, in one cluster.
- 2(1,2)
The minimal
open-vm-toolsandcloud-initpackages versions built for the VM template.
Prepare the bootstrap node¶
Note
If you require a RHEL-based bootstrap node, refer to the first step of the Set up a bootstrap cluster procedure.
Log in to any personal computer or VM running Ubuntu 20.04 that you will be using as the bootstrap node.
If you use a newly created VM, run:
sudo apt-get update
Install the current Docker version available for Ubuntu 20.04:
sudo apt install docker.io
Grant your
USERaccess to the Docker daemon:sudo usermod -aG docker $USER
Log off and log in again to the bootstrap node to apply the changes.
Verify that Docker is configured correctly and has access to Container Cloud CDN. For example:
docker run --rm alpine sh -c "apk add --no-cache curl; \ curl https://binary.mirantis.com"
The system output must contain no error records. In case of issues, follow the steps provided in Troubleshooting.
Download the bootstrap script¶
On the bootstrap node:
Download and run the Container Cloud bootstrap script:
sudo apt-get update sudo apt-get install wget wget https://binary.mirantis.com/releases/get_container_cloud.sh chmod 0755 get_container_cloud.sh ./get_container_cloud.sh
Change the directory to the
kaas-bootstrapfolder created by the script.
Obtain the Mirantis license¶
Select from the following options:
Open the email from support@mirantis.com with the subject Mirantis Container Cloud License File or Mirantis OpenStack License File
In the Mirantis CloudCare Portal, open the Account or Cloud page
Download the License File and save it as
mirantis.licunder thekaas-bootstrapdirectory on the bootstrap node.Verify that
mirantis.liccontains the previously downloaded Container Cloud license by decoding the license JWT token, for example, using jwt.io.Example of a valid decoded Container Cloud license data with the mandatory
licensefield:{ "exp": 1652304773, "iat": 1636669973, "sub": "demo", "license": { "dev": false, "limits": { "clusters": 10, "workers_per_cluster": 10 }, "openstack": null } }
Warning
The MKE license does not apply to
mirantis.lic. For details about MKE license, see MKE documentation.
Prepare the deployment user setup and permissions¶
Contact your vSphere administrator to set up the required users and permissions following the steps below:
Log in to the vCenter Server Web Console.
Create the
cluster-apiandstorageusers with the following sets of privileges:Privileges set for the cluster-api user¶ General privileges
Virtual machine privileges
Content library
Change configuration
Datastore
Interaction
Distributed switch
Inventory
Folder
Provisioning
Global
Snapshot management
Host local operations
vSphere replication
Network
Resource
Scheduled task
Sessions
Storage views
Tasks
Privileges set for the storage user¶ General privileges
Virtual machine privileges
Cloud Native Storage
Change configuration
Content library
Inventory
Datastore
Folder
Host configuration
Host local operations
Host profile
Profile-driven storage
Resource
Scheduled task
Storage views
For RHEL deployments, if you do not have a RHEL machine with the
virt-whoservice configured to report the vSphere environment configuration and hypervisors information to RedHat Customer Portal or RedHat Satellite server, set up thevirt-whoservice inside the Container Cloud machines for a proper RHEL license activation.Create a
virt-whouser with at least read-only access to all objects in the vCenter Data Center.The
virt-whoservice on RHEL machines will be provided with thevirt-whouser credentials to properly manage RHEL subscriptions.For details on how to create the
virt-whouser, refer to the official RedHat Customer Portal documentation.
Configure the cluster and vSphere credentials¶
Change the directory to the
kaas-bootstrapfolder created by theget_container_cloud.shscript.Configure vSphere credentials by modifying
templates/vsphere/vsphere-config.yaml.template:Note
Contact your vSphere administrator to provide you with the values for the below parameters.
vSphere configuration data¶ Parameter
Description
SET_VSPHERE_SERVERIP address or FQDN of the vCenter Server.
SET_VSPHERE_SERVER_PORTPort of the vCenter Server. For example,
port: "8443". Leave empty to use"443"by default.SET_VSPHERE_DATACENTERvSphere data center name.
SET_VSPHERE_SERVER_INSECUREFlag that controls validation of the vSphere Server certificate. Must be
trueorfalse.SET_VSPHERE_CAPI_PROVIDER_USERNAMEvSphere Cluster API provider user name that you added when preparing the deployment user setup and permissions.
SET_VSPHERE_CAPI_PROVIDER_PASSWORDvSphere Cluster API provider user password.
SET_VSPHERE_CLOUD_PROVIDER_USERNAMEvSphere Cloud Provider deployment user name that you added when preparing the deployment user setup and permissions.
SET_VSPHERE_CLOUD_PROVIDER_PASSWORDvSphere Cloud Provider deployment user password.
Prepare other deployment templates:
Configure MetalLB parameters:
Open the required configuration file for editing:
Open
templates/vsphere/metallbconfig.yaml.template. For a detailedMetalLBConfigobject description, see API Reference: MetalLBConfig resource.Open
templates/vsphere/cluster.yaml.template.Add
SET_VSPHERE_METALLB_RANGEthat is the MetalLB range of IP addresses to assign to load balancers for Kubernetes Services.Note
To obtain the
VSPHERE_METALLB_RANGEparameter for the selected vSphere network, contact your vSphere administrator who provides you with the IP ranges dedicated to your environment.
Modify
templates/vsphere/cluster.yaml.template:vSphere cluster network parameters
Modify the following required network parameters:
Required parameters¶ Parameter
Description
SET_LB_HOSTIP address from the provided vSphere network for Kubernetes API load balancer (Keepalived VIP).
SET_VSPHERE_DATASTOREName of the vSphere datastore. You can use different datastores for vSphere Cluster API and vSphere Cloud Provider.
SET_VSPHERE_MACHINES_FOLDERPath to a folder where the cluster machines metadata will be stored.
SET_VSPHERE_NETWORK_PATHPath to a network for cluster machines.
SET_VSPHERE_RESOURCE_POOL_PATHPath to a resource pool in which VMs will be created.
Note
To obtain the
LB_HOSTparameter for the selected vSphere network, contact your vSphere administrator who provides you with the IP ranges dedicated to your environment.Modify other parameters if required. For example, add the corresponding values for
cidrBlocksin thespec::clusterNetwork::servicessection.For either DHCP or non-DHCP vSphere network:
Determine the vSphere network parameters as described in VMware vSphere network objects and IPAM recommendations.
Provide the following additional parameters for a proper network setup on machines using embedded IP address management (IPAM) in
templates/vsphere/cluster.yaml.template:Note
To obtain IPAM parameters for the selected vSphere network, contact your vSphere administrator who provides you with IP ranges dedicated to your environment only.
vSphere configuration data¶ Parameter
Description
ipamEnabledEnables IPAM. Recommended value is
truefor either DHCP or non-DHCP networks.SET_VSPHERE_NETWORK_CIDRCIDR of the provided vSphere network. For example,
10.20.0.0/16.SET_VSPHERE_NETWORK_GATEWAYGateway of the provided vSphere network.
SET_VSPHERE_CIDR_INCLUDE_RANGESIP range for the cluster machines. Specify the range of the provided CIDR. For example,
10.20.0.100-10.20.0.200. If the DHCP network is used, this range must not intersect with the DHCP range of the network.SET_VSPHERE_CIDR_EXCLUDE_RANGESOptional. IP ranges to be excluded from being assigned to the cluster machines. The MetalLB range and
SET_LB_HOSTshould not intersect with the addresses for IPAM. For example,10.20.0.150-10.20.0.170.SET_VSPHERE_NETWORK_NAMESERVERSList of nameservers for the provided vSphere network.
For RHEL deployments, fill out
templates/vsphere/rhellicenses.yaml.template.RHEL license configuration
Use one of the following set of parameters for RHEL machines subscription:
The user name and password of your RedHat Customer Portal account associated with your RHEL license for Virtual Datacenters.
Optionally, provide the subscription allocation pools to use for the RHEL subscription activation. If not needed, remove the
poolIDsfield forsubscription-managerto automatically select the licenses for machines.For example:
spec: username: <username> password: value: <password> poolIDs: - <pool1> - <pool2>
The activation key and organization ID associated with your RedHat account with RHEL license for Virtual Datacenters. The activation key can be created by the organization administrator on the RedHat Customer Portal.
If you use the RedHat Satellite server for management of your RHEL infrastructure, you can provide a pre-generated activation key from that server. In this case:
Provide the URL to the RedHat Satellite RPM for installation of the CA certificate that belongs to that server.
Configure
squid-proxyon the management cluster to allow access to your Satellite server. For details, see Configure squid-proxy.
For example:
spec: activationKey: value: <activation key> orgID: "<organization ID>" rpmUrl: <rpm url>
Caution
For RHEL, verify mirrors configuration for your activation key. For more details, see RHEL 8 mirrors configuration.
Warning
Provide only one set of parameters. Mixing the parameters from different activation methods will cause deployment failure.
Warning
The kubectl apply command automatically saves the applied data as plain text into the
kubectl.kubernetes.io/last-applied-configurationannotation of the corresponding object. This may result in revealing sensitive data in this annotation when creating or modifying the object.Therefore, do not use kubectl apply on this object. Use kubectl create, kubectl patch, or kubectl edit instead.
If you used kubectl apply on this object, you can remove the
kubectl.kubernetes.io/last-applied-configurationannotation from the object using kubectl edit.
In
bootstrap.env, add theKAAS_VSPHERE_ENABLED=trueenvironment variable that enables the vSphere provider deployment in Container Cloud.
Prepare the virtual machine template¶
Change the directory to the
kaas-bootstrapfolder.Download the ISO image of the required operating system (OS):
Ubuntu 20.04 Server Install Image from Ubuntu images
RHEL 8.7 DVD ISO from the RedHat Customer Portal
Support status for RHEL
RHEL 8.7 is generally available since Cluster releases 16.0.0 and 14.1.0. Before these Cluster releases, it is supported as Technology Preview.
Export the following variables:
The path to the downloaded ISO file.
The vSphere cluster name.
The OS name:
rhelorubuntu.The OS version:
8.7for RHEL,``20.04`` for Ubuntu.Optional. The
virt-whouser name and password for RHEL deployments.
For example, for RHEL:
export KAAS_VSPHERE_ENABLED=true export VSPHERE_RO_USER=virt-who-user export VSPHERE_RO_PASSWORD=virt-who-user-password export VSPHERE_PACKER_ISO_FILE=$(pwd)/iso-file.dvd.iso export VSPHERE_CLUSTER_NAME=vsphere-cluster-name export VSPHERE_PACKER_IMAGE_OS_NAME=rhel export VSPHERE_PACKER_IMAGE_OS_VERSION=8.7
Prepare the virtual machine template:
./bootstrap.sh vsphere_templateIn
templates/vsphere/machines.yaml.template, define the following parameters:rhelLicenseRHEL license name defined in
rhellicenses.yaml.template, defaults tokaas-mgmt-rhel-license. Remove or comment out this parameter for Ubuntu deployments.
diskGiBDisk size in GiB for machines that must match the disk size of the VM template. You can leave this parameter commented to use the disk size of the VM template. The minimum requirement is 120 GiB.
templatePath to the VM template prepared in the previous step.
Sample template:
spec: providerSpec: value: apiVersion: vsphere.cluster.k8s.io/v1alpha1 kind: VsphereMachineProviderSpec rhelLicense: <rhelLicenseName> numCPUs: 8 memoryMiB: 32768 # diskGiB: 120 template: <vSphereVMTemplatePath>
Also, modify other parameters if required.
Finalize the bootstrap¶
Run the bootstrap script:
./bootstrap.sh allIn case of deployment issues, refer to Troubleshooting and inspect logs.
If the script fails for an unknown reason:
Run the cleanup script:
./bootstrap.sh cleanupRerun the bootstrap script.
When the bootstrap is complete, collect and save the following management cluster details in a secure location:
The
kubeconfigfile located in the same directory as the bootstrap script. This file contains the admin credentials for the management cluster.The private
ssh_keyfor access to the management cluster nodes that is located in the same directory as the bootstrap script.Note
If the initial version of your Container Cloud management cluster was earlier than 2.6.0,
ssh_keyis namedopenstack_tmpand is located at~/.ssh/.The URL for the Container Cloud web UI.
To create users with permissions required for accessing the Container Cloud web UI, see Create initial users after a management cluster bootstrap.
The StackLight endpoints. For details, see Access StackLight web UIs.
The Keycloak URL that the system outputs when the bootstrap completes. The admin password for Keycloak is located in
kaas-bootstrap/passwords.ymlalong with other IAM passwords.
Note
The Container Cloud web UI and StackLight endpoints are available through Transport Layer Security (TLS) and communicate with Keycloak to authenticate users. Keycloak is exposed using HTTPS and self-signed TLS certificates that are not trusted by web browsers.
To use your own TLS certificates for Keycloak, refer to Configure TLS certificates for cluster applications.
Note
When the bootstrap is complete, the bootstrap cluster resources are freed up.
Verify that network addresses used on your clusters do not overlap with the following default MKE network addresses for Swarm and MCR:
10.0.0.0/16is used for Swarm networks. IP addresses from this network are virtual.10.99.0.0/16is used for MCR networks. IP addresses from this network are allocated on hosts.
Verification of Swarm and MCR network addresses
To verify Swarm and MCR network addresses, run on any master node:
docker infoExample of system response:
Server: ... Swarm: ... Default Address Pool: 10.0.0.0/16 SubnetSize: 24 ... Default Address Pools: Base: 10.99.0.0/16, Size: 20 ...
Not all of Swarm and MCR addresses are usually in use. One Swarm Ingress network is created by default and occupies the
10.0.0.0/24address block. Also, three MCR networks are created by default and occupy three address blocks:10.99.0.0/20,10.99.16.0/20,10.99.32.0/20.To verify the actual networks state and addresses in use, run:
docker network ls docker network inspect <networkName>
What’s next¶
Using your newly deployed management cluster, you can:
Extend your cluster with more options, for example, Configure external identity provider for IAM.
Create and operate a VMware vSphere-based managed cluster. Before that, verify that your planned cluster meets the requirements for managed clusters.
Attach an existing MKE cluster to a vSphere-based management cluster.