Mirantis OpenStack for Kubernetes Documentation¶
This documentation provides information on how to deploy and operate a Mirantis OpenStack for Kubernetes (MOSK) environment. The documentation is intended to help operators to understand the core concepts of the product. The documentation provides sufficient information to deploy and operate the solution.
The information provided in this documentation set is being constantly improved and amended based on the feedback and kind requests from the consumers of MOS.
The following table lists the guides included in the documentation set you are reading:
Guide |
Purpose |
|---|---|
Learn the fundamentals of MOSK reference architecture to appropriately plan your deployment |
|
Deploy a MOSK environment of a preferred configuration using supported deployment profiles tailored to the demands of specific business cases |
|
Operate your MOSK environment |
|
Learn about new features and bug fixes in the current MOSK version |
Intended audience¶
This documentation is intended for engineers who have the basic knowledge of Linux, virtualization and containerization technologies, Kubernetes API and CLI, Helm and Helm charts, Mirantis Kubernetes Engine (MKE), and OpenStack.
Documentation history¶
The following table contains the released revision of the documentation set you are reading.
Release date |
Release name |
|---|---|
August, 2023 |
MOSK 23.2 series |
Conventions¶
This documentation set uses the following conventions in the HTML format:
Convention |
Description |
|---|---|
boldface font |
Inline CLI tools and commands, titles of the procedures and system response examples, table titles |
|
Files names and paths, Helm charts parameters and their values, names of packages, nodes names and labels, and so on |
italic font |
Information that distinguishes some concept or term |
External links and cross-references, footnotes |
|
Main menu > menu item |
GUI elements that include any part of interactive user interface and menu navigation |
Superscript |
Some extra, brief information |
Note The Note block |
Messages of a generic meaning that may be useful for the user |
Caution The Caution block |
Information that prevents a user from mistakes and undesirable consequences when following the procedures |
Warning The Warning block |
Messages that include details that can be easily missed, but should not be ignored by the user and are valuable before proceeding |
See also The See also block |
List of references that may be helpful for understanding of some related tools, concepts, and so on |
Learn more The Learn more block |
Used in the Release Notes to wrap a list of internal references to the reference architecture, deployment and operation procedures specific to a newly implemented product feature |
Product Overview¶
Mirantis OpenStack for Kubernetes (MOSK) combines the power of Mirantis Container Cloud for delivering and managing Kubernetes clusters, with the industry standard OpenStack APIs, enabling you to build your own cloud infrastructure.
The advantages of running all of the OpenStack components as a Kubernetes application are multi-fold and include the following:
Zero downtime, non-disruptive updates
Fully automated Day-2 operations
Full-stack management from bare metal through the operating system and all the necessary components
The list of the most common use cases includes:
- Software-defined data center
The traditional data center requires multiple requests and interactions to deploy new services, by abstracting the data center functionality behind a standardized set of APIs service can be deployed faster and more efficiently. MOSK enables you to define all your data center resources behind the industry standard OpenStack APIs allowing you to automate the deployment of applications or simply request resources through the UI to quickly and efficiently provision virtual machines, storage, networking, and other resources.
- Virtual Network Functions (VNFs)
VNFs require high performance systems that can be accessed on demand in a standardized way, with assurances that they will have access to the necessary resources and performance guarantees when needed. MOSK provides extensive support for VNF workload enabling easy access to functionality such as Intel EPA (NUMA, CPU pinning, Huge Pages) as well as the consumption of specialized networking interfaces cards to support SR-IOV and DPDK. The centralized management model of MOSK and Mirantis Container Cloud also enables the easy management of multiple MOSK deployments with full lifecycle management.
- Legacy workload migration
With the industry moving toward cloud-native technologies many older or legacy applications are not able to be moved easily and often it does not make financial sense to transform the applications to cloud-native applications. MOSK provides a stable cloud platform that can cost-effectively host legacy applications whilst still providing the expected levels of control, customization, and uptime.
Reference Architecture¶
Mirantis OpenStack for Kubernetes (MOSK) is a virtualization platform that provides an infrastructure for cloud-ready applications, in combination with reliability and full control over the data.
MOSK combines OpenStack, an open-source cloud infrastructure software, with application management techniques used in the Kubernetes ecosystem that include container isolation, state enforcement, declarative definition of deployments, and others.
MOSK integrates with Mirantis Container Cloud to rely on its capabilities for bare-metal infrastructure provisioning, Kubernetes cluster management, and continuous delivery of the stack components.
MOSK simplifies the work of a cloud operator by automating all major cloud life cycle management routines including cluster updates and upgrades.
Deployment profiles¶
A Mirantis OpenStack for Kubernetes (MOSK) deployment profile is a thoroughly tested and officially supported reference architecture that is guaranteed to work at a specific scale and is tailored to the demands of a specific business case, such as generic IaaS cloud, Network Function Virtualisation infrastructure, Edge Computing, and others.
A deployment profile is defined as a combination of:
Services and features the cloud offers to its users.
Non-functional characteristics that users and operators should expect when running the profile on top of a reference hardware configuration. Including, but not limited to:
Performance characteristics, such as an average network throughput between VMs in the same virtual network.
Reliability characteristics, such as the cloud API error response rate when recovering a failed controller node.
Scalability characteristics, such as the total amount of virtual routers tenants can run simultaneously.
Hardware requirements - the specification of physical servers, and networking equipment required to run the profile in production.
Deployment parameters that an operator for the cloud can tweak within a certain range without being afraid of breaking the cloud or losing support.
In addition, the following items may be included in a definition:
Compliance-driven technical requirements, such as TLS encryption of all external API endpoints.
Foundation-level software components, such as Tungsten Fabric or Open vSwitch as a back end for the networking service.
Note
Mirantis reserves the right to revise the technical implementation of any profile at will while preserving its definition - the functional and non-functional characteristics that operators and users are known to rely on.
MOSK supports a huge list of different deployment profiles to address a wide variety of business tasks. The table below includes the profiles for the most common use cases.
Note
Some components of a MOSK cluster are mandatory and are being installed during the managed cluster deployment by Container Cloud regardless of the deployment profile in use. StackLight is one of the cluster components that are enabled by default. See Container Cloud Operations Guide for details.
Profile |
OpenStackDeployment CR Preset |
Description |
|---|---|---|
Cloud Provider Infrastructure (CPI) |
|
Provides the core set of the services an IaaS vendor would need including some extra functionality. The profile is designed to support up 50-70 compute nodes and a reasonable number of storage nodes. 0 The core set of services provided by the profile includes:
|
CPI with Tungsten Fabric |
|
A variation of the CPI profile 1 with Tugsten Fabric as a back end for networking. |
- 0
The supported node count is approximate and may vary depending on the hardware, cloud configuration, and planned workload.
- 1(1,2)
Ironic is an optional component for the CPI profile. See Bare Metal service for details.
- 2
Ironic is not supported for the CPI with Tungsten Fabric profile. See Tungsten Fabric known limitations for details.
- 3
Telemetry services are optional components with the Technology preview status and should be enabled together through the list of services to be deployed in the
OpenStackDeploymentCR as described in Deploy an OpenStack cluster.
Components overview¶
Mirantis OpenStack for Kubernetes (MOSK) includes the following key design elements.
HelmBundle Operator¶
The HelmBundle Operator is the realization of the Kubernetes Operator
pattern that provides a Kubernetes custom resource of the HelmBundle
kind and code running inside a pod in Kubernetes. This code handles changes,
such as creation, update, and deletion, in the Kubernetes resources of this
kind by deploying, updating, and deleting groups of Helm releases from
specified Helm charts with specified values.
OpenStack¶
The OpenStack platform manages virtual infrastructure resources, including virtual servers, storage devices, networks, and networking services, such as load balancers, as well as provides management functions to the tenant users.
Various OpenStack services are running as pods in Kubernetes and are
represented as appropriate native Kubernetes resources, such as
Deployments, StatefulSets, and DaemonSets.
For a simple, resilient, and flexible deployment of OpenStack and related services on top of a Kubernetes cluster, MOSK uses OpenStack-Helm that provides a required collection of the Helm charts.
Also, MOSK uses OpenStack Operator as the realization
of the Kubernetes Operator pattern. The OpenStack Operator provides a custom
Kubernetes resource of the OpenStackDeployment kind and code running
inside a pod in Kubernetes. This code handles changes such as creation,
update, and deletion in the Kubernetes resources of this kind by
deploying, updating, and deleting groups of the Helm releases.
Ceph¶
Ceph is a distributed storage platform that provides storage resources, such as objects and virtual block devices, to virtual and physical infrastructure.
MOSK uses Rook as the implementation of the
Kubernetes Operator pattern that manages resources of the CephCluster
kind to deploy and
manage Ceph services as pods on top of Kubernetes to provide Ceph-based
storage to the consumers, which include OpenStack services, such as Volume
and Image services, and underlying Kubernetes through Ceph CSI (Container
Storage Interface).
The Ceph Controller is the implementation of the Kubernetes Operator
pattern, that manages resources of the MiraCeph kind to simplify
management of the Rook-based Ceph clusters.
StackLight Logging, Monitoring, and Alerting¶
The StackLight component is responsible for collection, analysis, and visualization of critical monitoring data from physical and virtual infrastructure, as well as alerting and error notifications through a configured communication system, such as email. StackLight includes the following key sub-components:
Prometheus
OpenSearch
OpenSearch Dashboards
Fluentd
Requirements¶
MOSK cluster hardware requirements¶
This section provides hardware requirements for the Mirantis Container Cloud management cluster with a managed Mirantis OpenStack for Kubernetes (MOSK) cluster.
For installing MOSK, the Mirantis Container Cloud management cluster and managed cluster must be deployed with baremetal provider.
Important
A MOSK cluster is to be used for a deployment of an OpenStack cluster and its components. Deployment of third-party workloads on a MOSK cluster is neither allowed nor supported.
Note
One of the industry best practices is to verify every new update or configuration change in a non-customer-facing environment before applying it to production. Therefore, Mirantis recommends having a staging cloud, deployed and maintained along with the production clouds. The recommendation is especially applicable to the environments that:
Receive updates often and use continuous delivery. For example, any non-isolated deployment of Mirantis Container Cloud.
Have significant deviations from the reference architecture or third party extensions installed.
Are managed under the Mirantis OpsCare program.
Run business-critical workloads where even the slightest application downtime is unacceptable.
A typical staging cloud is a complete copy of the production environment including the hardware and software configurations, but with a bare minimum of compute and storage capacity.
The table below describes the node types the MOSK reference architecture includes.
Node type |
Description |
|---|---|
Mirantis Container Cloud management cluster nodes |
The Container Cloud management cluster architecture on bare metal requires three physical servers for manager nodes. On these hosts, we deploy a Kubernetes cluster with services that provide Container Cloud control plane functions. |
OpenStack control plane node and StackLight node |
Host OpenStack control plane services such as database, messaging, API, schedulers conductors, and L3 and L2 agents, as well as the StackLight components. Note MOSK enables the cloud operator to collocate the OpenStack control plane with the managed cluster master nodes on the OpenStack deployments of a small size. This capability is available as technical preview. Use such configuration for testing and evaluation purposes only. |
Tenant gateway node |
Optional. Hosts OpenStack gateway services including L2, L3, and DHCP agents. The tenant gateway nodes are combined with OpenStack control plane nodes. The strict requirement is a dedicated physical network (bond) for tenant network traffic. |
Tungsten Fabric control plane node |
Required only if Tungsten Fabric is enabled as a back end for the OpenStack networking. These nodes host the TF control plane services such as Cassandra database, messaging, API, control, and configuration services. |
Tungsten Fabric analytics node |
Required only if Tungsten Fabric is enabled as a back end for the OpenStack networking. These nodes host the TF analytics services such as Cassandra, ZooKeeper, and collector. |
Compute node |
Hosts the OpenStack Compute services such as QEMU, L2 agents, and others. |
Infrastructure nodes |
Runs underlying Kubernetes cluster management services. The MOSK reference configuration requires minimum three infrastructure nodes. |
The table below specifies the hardware resources the MOSK reference architecture recommends for each node type.
Node type |
# of servers |
CPU cores # per server |
RAM per server, GB |
Disk space per server, GB |
NICs # per server |
|---|---|---|---|---|---|
Mirantis Container Cloud management cluster node |
3 0 |
16 |
128 |
1 SSD x 960
1 SSD x 1900 1
|
3 2 |
OpenStack control plane, gateway 3, and StackLight nodes |
3 or more |
32 |
128 |
1 SSD x 500
2 SSD x 1000 6
|
5 |
Tenant gateway (optional) |
0-3 |
32 |
128 |
1 SSD x 500 |
5 |
Tungsten Fabric control plane nodes 4 |
3 |
16 |
64 |
1 SSD x 500 |
1 |
Tungsten Fabric analytics nodes 4 |
3 |
32 |
64 |
1 SSD x 1000 |
1 |
Compute node |
3 (varies) |
16 |
64 |
1 SSD x 500 7 |
5 |
Infrastructure node (Kubernetes cluster management) |
3 8 |
16 |
64 |
1 SSD x 500 |
5 |
Infrastructure node (Ceph) 5 |
3 |
16 |
64 |
1 SSD x 500
2 HDDs x 2000
|
5 |
Note
The exact hardware specifications and number of the control plane and gateway nodes depend on a cloud configuration and scaling needs. For example, for the clouds with more than 12,000 Neutron ports, Mirantis recommends increasing the number of gateway nodes.
- 0
Adding more than 3 nodes to a management cluster is not supported.
- 1
In total, at least 2 disks are required:
disk0- system storage, minimum 60 GB.disk1- Container Cloud services storage, not less than 110 GB. The exact capacity requirements depend on StackLight data retention period.
See Management cluster storage for details.
- 2
OOB management (IPMI) port is not included.
- 3
OpenStack gateway services can optionally be moved to separate nodes.
- 4(1,2)
TF control plane and analytics nodes can be combined with a respective addition of RAM, CPU, and disk space to the hardware hosts. Though, Mirantis does not recommend such configuration for production environments as the risk of the cluster downtime if one of the nodes unexpectedly fails increases.
- 5
A Ceph cluster with 3 Ceph nodes does not provide hardware fault tolerance and is not eligible for recovery operations, such as a disk or an entire node replacement.
A Ceph cluster uses the replication factor that equals 3. If the number of Ceph OSDs is less than 3, a Ceph cluster moves to the degraded state with the write operations restriction until the number of alive Ceph OSDs equals the replication factor again.
- 6
1 SSD x 500 for operating system
1 SSD x 1000 for OpenStack LVP
1 SSD x 1000 for StackLight LVP
- 7
When Nova is used with local folders, additional capacity is required depending on the VM images size.
- 8
For nodes hardware requirements, refer to Container Cloud Reference Architecture: Managed cluster hardware configuration.
Note
If you would like to evaluate the MOSK capabilities and do not have much hardware at your disposal, you can deploy it in a virtual environment. For example, on top of another OpenStack cloud using the sample Heat templates.
Please mind, the tooling is provided for reference only and is not a part of the product itself. Mirantis does not guarantee its interoperability with any MOSK version.
Management cluster storage¶
The management cluster requires minimum two storage devices per node. Each device is used for different type of storage:
One storage device for boot partitions and root file system. SSD is recommended. A RAID device is not supported.
One storage device per server is reserved for local persistent volumes. These volumes are served by the Local Storage Static Provisioner, that is
local-volume-provisioner, and used by many services of Mirantis Container Cloud.
You can configure host storage devices using BareMetalHostProfile
resources. For details, see Create a custom bare metal host profile.
System requirements for the seed node¶
The seed node is only necessary to deploy the management cluster. When the bootstrap is complete, the bootstrap node can be discarded and added back to the MOSK cluster as a node of any type.
The minimum reference system requirements for a baremetal-based bootstrap seed node are as follow:
Basic Ubuntu 18.04 server with the following configuration:
Kernel of version 4.15.0-76.86 or later
8 GB of RAM
4 CPU
10 GB of free disk space for the bootstrap cluster cache
No DHCP or TFTP servers on any NIC networks
Routable access IPMI network for the hardware servers.
Internet access for downloading of all required artifacts
If you use a firewall or proxy, make sure that the bootstrap and management clusters have access to the following IP ranges and domain names:
IP ranges:
Microsoft Azure (only IP addresses for
MicrosoftContainerRegistry)Amazon AWS (only IP addresses for
"service": "CLOUDFRONT")
Domain names:
mirror.mirantis.com and repos.mirantis.com for packages
binary.mirantis.com for binaries and Helm charts
mirantis.azurecr.io and *.blob.core.windows.net for Docker images
mcc-metrics-prod-ns.servicebus.windows.net:9093 for Telemetry (port 443 if proxy is enabled)
mirantis.my.salesforce.com and login.salesforce.com for Salesforce alerts
Note
Access to Salesforce is required from any Container Cloud cluster type.
If any additional Alertmanager notification receiver is enabled, for example, Slack, its endpoint must also be accessible from the cluster.
Components collocation¶
MOSK uses Kubernetes labels to place components onto hosts. For the default locations of components, see MOSK cluster hardware requirements. Additionally, MOSK supports component collocation. This is mostly useful for OpenStack compute and Ceph nodes. For component collocation, consider the following recommendations:
When calculating hardware requirements for nodes, consider the requirements for all collocated components.
When performing maintenance on a node with collocated components, execute the maintenance plan for all of them.
When combining other services with the OpenStack compute host, verify that
reserved_host_*has increased accordingly to the needs of collocated components by using node-specific overrides for thecomputeservice.
Infrastructure requirements¶
This section lists the infrastructure requirements for the Mirantis OpenStack for Kubernetes (MOSK) reference architecture.
Service |
Description |
|---|---|
MetalLB |
MetalLB exposes external IP addresses of cluster services to access applications in a Kubernetes cluster. |
DNS |
The Kubernetes Ingress NGINX controller is used to expose OpenStack services outside of a Kubernetes deployment. Access to the Ingress services is allowed only by its FQDN. Therefore, DNS is a mandatory infrastructure service for an OpenStack on Kubernetes deployment. |
See also
Automatic upgrade of a host operating system¶
To keep operating system on a bare metal host up to date with the latest security updates, the operating system requires periodic software packages upgrade that may or may not require the host reboot.
Mirantis Container Cloud uses life cycle management tools to update the operating system packages on the bare metal hosts.
In a management cluster, software package upgrade and host restart are applied automatically when a new Container Cloud version with available kernel or software packages upgrade is released.
In a managed cluster, package upgrade and host restart are applied as part of usual cluster update, when applicable. To start planning the maintenance window and proceed with the managed cluster update, see Update a MOSK cluster to a major release version.
Operating system upgrade and host restart are applied to cluster nodes one by one. If Ceph is installed in the cluster, the Container Cloud orchestration securely pauses the Ceph OSDs on the node before restart. This allows avoiding degradation of the storage service.
Cloud services¶
Each section below is dedicated to a particular service provided by MOSK. They contain configuration details and usage samples of supported capabilities provided through the custom resources.
Note
The list of the services and their supported features included in this section is not full and is being constantly amended based on the complexity of the architecture and use of a particular service.
Core cloud services
Compute service¶
Mirantis OpenStack for Kubernetes (MOSK) provides instances management capability through the Compute service (OpenStack Nova). The Compute service interacts with other OpenStack components of an OpenStack environment to provide life-cycle management of the virtual machine instances.
Resource oversubscription¶
The Compute service (OpenStack Nova) enables you to spawn instances that can collectively consume more resources than what is physically available on a compute node through resource oversubscription, also known as overcommit or allocation ratio.
Resources available for oversubscription on a compute node include the number of CPUs, amount of RAM, and amount of available disk space. When making a scheduling decision, the scheduler of the Compute service takes into account the actual amount of resources multiplied by the allocation ratio. Thereby, the service allocates resources based on the assumption that not all instances will be using their full allocation of resources at the same time.
Oversubscription enables you to increase the density of workloads and compute resource utilization and, thus, achieve better Return on Investment (ROI) on compute hardware. In addition, oversubscription can also help avoid the need to create too many fine-grained flavors, which is commonly known as flavor explosion.
Available since MOSK 23.1
There are two ways to control the oversubscription values for compute nodes:
The legacy approach entails utilizing the
{cpu,disk,ram}_allocation_ratioconfiguration options offered by the Compute service. A drawback of this method is that restarting the Compute service is mandatory to apply the new configuration. This introduces the risk of possible interruptions of cloud user operations, for example, instance build failures.The modern and recommended approach, adopted in MOSK 23.1, involves using the
initial_{cpu,disk,ram}_allocation_ratioconfiguration options, which are employed exclusively during the initial provisioning of a compute node. This may occur during the initial deployment of the cluster or when new compute nodes are added subsequently. Any further alterations can be performed dynamically using the OpenStack Placement service API without necessitating the restart of the service.
There is no definitive method for selecting optimal oversubscription values. As a cloud operator, you should continuously monitor your workloads, ideally have a comprehensive understanding of their nature, and experimentally determine the maximum values that do not impact performance. This approach ensures maximum workload density and cloud resource utilization.
To configure the initial compute resource oversubscription in
MOSK, specify the spec:features:nova:allocation_ratios
parameter in the OpenStackDeployment custom resource as explained in the
table below.
Parameter |
|
|---|---|
Configuration |
Configure initial oversubscription of CPU, disk space, and RAM resources on compute nodes. By default, the following values are applied:
Note In MOSK 22.5 and earlier, the effective
default value of RAM allocation ratio is Warning Mirantis strongly advises against oversubscribing RAM, by any amount. See Preventing resource overconsumption for details. Changing the resource oversubscription configuration through the
|
Usage |
Configuration example: kind: OpenStackDeployment
spec:
features:
nova:
allocation_ratios:
cpu: 8
disk: 1.6
ram: 1.0
Configuration example of setting different oversubscription values for specific nodes: spec:
nodes:
compute-type::hi-perf:
features:
nova:
allocation_ratios:
cpu: 2.0
disk: 1.0
In the example configuration above, the compute nodes labeled with
|
When using oversubscription, it is important to conduct thorough cloud management and monitoring to avoid system overloading and performance degradation. If many or all instances on a compute node start using all allocated resources at once and, thereby, overconsume physical resources, failure scenarios depend on the resource being exhausted.
Affected resource |
Symptoms |
|---|---|
CPU |
Workloads are getting slower as they actively compete for physical CPU usage. A useful indicator is the steal time as reported inside the workload, which is a percentage of time the operating system in the workload is waiting for actual physical CPU core availability to run instructions. To verify the steal time in the Linux-based workload, use the top command: top -bn1 | head | grep st$ | awk -F ',' '{print $NF}'
Generally, steal times of >10 for 20-30 minutes are considered alarming. |
RAM |
Operating system on the compute node starts to aggressively use physical swap space, which significantly slows the workloads down. Sometimes, when the swap is also exhausted, the operating system of a compute node can outright OOM kill most offending processes, which can cause major disruptions to workloads or a compute node itself. Warning While it may seem like a good idea to make the most of available resources, oversubscribing RAM can lead to various issues and is generally not recommended due to potential performance degradation, reduced stability, and security risks for the workloads. Mirantis strongly advises against oversubscribing RAM, by any amount. |
Disk space |
Depends on the physical layout of storage. Virtual root and ephemeral storage devices that are hosted on a compute node itself are put in the read-only mode negatively affecting workloads. Additionally, the file system used by the operating system on a compute node may become read-only too blocking the compute node operability. See also |
There are workload types that are not suitable for running in an oversubscribed environment, especially those with high performance, latency-sensitive, or real-time requirements. Such workloads are better suited for compute nodes with dedicated CPUs, ensuring that only processes of a single instance run on each CPU core.
Virtual CPU¶
MOSK provides the capability to configure virtual CPU types
for OpenStack instances through the OpenStackDeployment custom resource.
This feature enables cloud user to tailor performance and resource allocation
within their OpenStack environment to meet specific workload demands
effectively.
Parameter |
|
|---|---|
Usage |
Configures the type of virtual CPU that Nova will use when creating instances. The list of supported CPU models include |
The host-model CPU model (default) mimics the host CPU and provides for
decent performance, good security, and moderate compatibility with live
migrations.
With this mode, libvirt finds an available predefined CPU model that best matches the host CPU, and then explicitly adds the missing CPU feature flags to closely match the host CPU features. To mitigate known security flaws, libvirt automatically adds critical CPU flags, supported by installed libvirt, QEMU, kernel, and CPU microcode versions.
This is a safe choice if your OpenStack compute node CPUs are of the same generation. If your OpenStack compute node CPUs are sufficiently different, for example, span multiple CPU generations, Mirantis strongly recommends setting explicit CPU models supported by all of your OpenStack compute node CPUs or organizing your OpenStack compute nodes into host aggregates and availability zones that have largely identical CPUs.
Note
The host-model model does not guarantee two-way live migrations
between nodes.
When migrating instances, the libvirt domain XML is first copied as is to the destination OpenStack compute node. Once the instance is hard rebooted or shut down and started again, the domain XML will be re-generated. If versions of libvirt, kernel, CPU microcode, or BIOS firmware differ from what they were on the source compute node the instance was started before, libvirt may pick up additional CPU feature flags, making it impossible to live-migrate back to the original compute node.
The host-passthrough CPU model provides maximum performance, especially
when nested virtualization is required or if live migration support is not
a concern for workloads. Live migration requires exactly the same CPU
on all OpenStack compute nodes, including the CPU microcode and kernel
versions. Therefore, for live migrations support, organize your compute
nodes into host aggregates and availability zones. For workload migration
between non-identical OpenStack compute nodes, contact Mirantis support.
For example, to set the host-passthrough CPU model for all OpenStack
compute nodes:
spec:
features:
nova:
vcpu_type: host-passthrough
MOSK enables you to specify a comma-separated list of exact QEMU CPU models to create and emulate. Specify the common and less advanced CPU models first. All explicit CPU models provided must be compatible with the OpenStack compute node CPUs.
To specify an exact CPU model, review the available CPU models and their
features. List and inspect the /usr/share/libvirt/cpu_map/*.xml files in
the libvirt containers of pods of the libvirt DeamonSet or multiple
DaemonSets if you are using node-specific settings.
To review the available CPU models
Identify the available libvirt DaemonSets:
kubectl -n openstack get ds -l application=libvirt --show-labels
Example of system response:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE LABELS libvirt-libvirt-default 2 2 2 2 2 openstack-compute-node=enabled 34d app.kubernetes.io/managed-by=Helm,application=libvirt,component=libvirt,release_group=openstack-libvirt
Identify the pods of libvirt DaemonSets:
kubectl -n openstack get po -l application=libvirt,release_group=openstack-libvirt
Example of system response:
NAME READY STATUS RESTARTS AGE libvirt-libvirt-default-5zs8m 2/2 Running 0 8d libvirt-libvirt-default-vt8wd 2/2 Running 0 3d14h
List and review the available CPU model definition files. For example:
kubectl -n openstack exec -ti libvirt-libvirt-default-5zs8m -c libvirt -- ls /usr/share/libvirt/cpu_map/*.xml
List and review the content of all CPU model definition files. For example:
kubectl -n openstack exec -ti libvirt-libvirt-default-5zs8m -c libvirt -- bash -c 'for f in `ls /usr/share/libvirt/cpu_map/*.xml`; do echo $f; cat $f; done'
For example, for nodes that are labeled with processor=amd-epyc, set
a custom EPYC CPU model:
spec:
nodes:
processor::amd-epyc
features:
nova:
vcpu_type: EPYC
Live migration¶
Parameter |
Usage |
|---|---|
|
Specifies the name of the NIC device on the actual host that will be used by Nova for the live migration of instances. Mirantis recommends setting up your Kubernetes hosts in such a way that networking is configured identically on all of them, and names of the interfaces serving the same purpose or plugged into the same network are consistent across all physical nodes. Also, set the option to
|
|
Available since MOSK 23.2.
If set to spec:
features:
nova:
libvirt:
tls:
enabled: true
See also Encryption of live migration data. |
Image storage back end¶
Parameter |
|
|---|---|
Usage |
Defines the type of storage for Nova to use on the compute hosts for the images that back up the instances. The list of supported options include:
|
Remote console access to virtual machines¶
MOSK provides a number of different methods to interact
with OpenStack virtual machines including VNC (default) and SPICE remote
consoles. This section outlines how you can configure these different
console services through the OpenStackDeployment custom resource.
The noVNC client provides remote control or remote desktop access to guest virtual machines through the Virtual Network Computing (VNC) system. The MOSK Compute service users can access their instances using the noVNC clients through the noVNC proxy server.
The VNC remote console is enabled by default in MOSK.
To disable VNC remote console through the OpenStackDeployment custom
resource, set spec:features:nova:console:novnc to false:
spec:
features:
nova:
console:
novnc:
enabled: false
Available since MOSK 23.1
MOSK uses TLS to secure public-facing VNC access on networks between a noVNC client and noVNC proxy server.
The features:nova:console:novnc:tls:enabled ensures that the data
transferred between the instance and the noVNC proxy server is encrypted.
Both servers use the VeNCrypt authentication scheme for the data
encryption.
To enable the encrypted data transfer for noVNC, use the following
structure in the OpenStackDeployment custom resource:
kind: OpenStackDeployment
spec:
features:
nova:
console:
novnc:
tls:
enabled: true
TechPreview Available since MOSK 24.1
The VNC protocol has its limitations, such as the lack of support for multiple monitors, bi-directional audio, reliable cut-and-paste, video streaming, and others. The SPICE protocol aims to overcome these limitations and deliver a robust remote desktop support.
The SPICE remote console is disabled by default in MOSK.
To enable SPICE remote console through the OpenStackDeployment custom
resource, set spec:features:nova:console:spice:enabled to true:
spec:
features:
nova:
console:
spice:
enabled: true
GPU virtualization¶
Available since MOSK 24.1 TechPreview
MOSK provides GPU virtualization capabilities to its users through the NVIDIA vGPU and Multi-Instance GPU (MIG) technologies.
GPU virtualization is a capability offered by modern datacenter-grade GPUs, enabling the partitioning of a single physical GPU into smaller virtual devices, that can then be attached to individual virtual machines.
In contrast to the Peripheral Component Interconnect (PCI) passthrough feature, leveraging the GPU virtualization enables concurrent utilization of the same physical GPU device by multiple virtual machines. This enhances hardware utilization and fosters a more elastic consumption of expensive hardware resources.
When using GPU virtualization, the physical device and its drivers manage computing resource partitioning and isolation.
The use case for GPU virtualization aligns with any application necessitating or benefiting from accelerated parallel floating-point calculations, such as graphic-intensive desktop workloads, for example, 3D modeling and rendering, as well as computationally intensive tasks, for example, artifial intelligence, specifically, machine learning training and classification.
At its core, GPU virtualization operates on base of the single-root input/output virtualization framework (SR-IOV), which is already widely used by datacenter-grade network adapters and mediated devices Linux kernel framework.
Typically, using GPU virtualization requires the installation of specific physical GPU drivers on the host system. For detailed instructions on obtaining and installing the required drivers, refer to official documentation from the vendor of your GPU.
For the latest family of NVIDIA GPUs under NVIDIA AI Enterprise, start with NVIDIA AI Enterprise documentation.
You can automate the configuration of drivers by adding a custom post-install
script to the BareMetalHostProfile object of your
MOSK cluster. See Configure GPU virtualization for details.
Certain NVIDIA GPUs, for example, Ampere GPU architecture and later, support GPU virtualization in two modes: time sliced (vGPU) or Multi-Instance GPU (MIG). Older architectures support only the time-sliced mode.
The distinction between these modes lies in resource isolation, dedicated performance levels, and partitioning flexibility.
Typically, there is no fixed rule dictating which mode should be used, as it depends on the intended workloads for the virtual GPUs and the level of experience and assurances the cloud operator aims to offer users. Below, there is a brief overview of the differences between these two modes.
In time-sliced vGPU mode, each virtual GPU is allocated dedicated slices of the physical GPU memory while sharing the physical GPU engines. Only one vGPU operates at a time, with full access to all physical GPU engines. The resource scheduler within the physical GPU regulates the timing of each vGPU execution, ensuring fair allocation of resources.
Therefore, this setup may encounter issues with noisy neighbors, where the performance of one vGPU is affected by resource contention from others. However, when not all available vGPU slots are occupied, the active ones can fully utilize the power of its physical GPU.
Advantages:
Potential ability to fully utilize the compute power of physical GPU, even if not all possible vGPUs have yet been created on that physical GPU.
Easier configuration.
Disadvantages:
Only a single vGPU type (size of the vGPU) can be created on any given physical GPU. The cloud operator must decide beforehand what type of vGPU each physical GPU will be providing.
Less strict resource isolation. Noisy neighbors and unpredictable level of performance for every single guest vGPU.
In Multi-Instance GPUs (MIG) mode, each virtual GPU is allocated dedicated physical GPU engines, exclusively utilized by that specific virtual GPU. Virtual GPUs run in parallel, each on its own engines according to their type.
Advantages:
Ability to partition a single physical GPU into various types of virtual GPUs. This approach provides cloud operators with enhanced flexibility in determining the available vGPU types for cloud users. However, the cloud operator has to decide beforehand what types of virtual GPU each physical GPU will be providing and partition each GPU accordingly.
Better resource isolation and guaranteed resource access with predictable performance levels for every virtual GPU.
Disadvantages:
Under-utilization of physical GPU when not all possible virtual GPU slots are occupied.
Comparatively complicated configuration, especially in heterogeneous hardware environments.
Note
Some of these restrictions may be lifted in future releases of MOSK.
Cloud users will face the following limitations when working with GPU virtualization in MOSK:
Inability to create several instances with virtual GPUs in one request if there is no physical GPU available that can fit all of them at once. For NVIDIA MIG, this effectively means that you cannot create several instances with virtual GPUs in one request.
Inability to create an instance with several virtual GPUs.
Inability to attach virtual GPU to or detach virtual GPU from a running instance.
Inability to live-migrate instances with virtual GPU attached.
Cloud operator will face the following limitations when configuring GPU virtualization in MOSK:
Partition of physical GPUs to virtual GPUs is static and not on-demand. You need to decide beforehand what types of virtual GPUs each physical GPU will get partinioned into. Changing of the partitioning requires removing all instances using virtual GPUs from the compute node before initiating the repartitioning process.
Repartitioning may require additional manual steps to eliminate orphan resource providers in the placement service, and thus, avoid resource over-reporting and instance scheduling problems.
Configuration of multiple virtual GPU types per node may be very verbose since configuration depends on particular PCI addresses of physical GPUs on each node.
See also
Learn more
Networking service¶
Mirantis OpenStack for Kubernetes (MOSK) Networking service (OpenStack Neutron) provides cloud applications with Connectivity-as-a-Service enabling instances to communicate with each other and the outside world.
The API provided by the service abstracts all the nuances of implementing a virtual network infrastructure on top of your own physical network infrastructure. The service allows cloud users to create advanced virtual network topologies that may include load balancing, virtual private networking, traffic filtering, and other services.
MOSK Networking service supports Open vSwitch and Tungsten Fabric SDN technologies as back ends.
General configuration¶
MOSK offers the Networking service as a part of its
core setup. You can configure the service through the
spec:features:neutron section of the OpenStackDeployment custom
resource.
Parameter |
|
|---|---|
Usage |
Defines the name of the NIC device on the actual host that will be used for Neutron. Mirantis recommends setting up your Kubernetes hosts in such a way that networking is configured identically on all of them, and names of the interfaces serving the same purpose or plugged into the same network are consistent across all physical nodes. |
Parameter |
|
|---|---|
Usage |
Defines the list of IPs of DNS servers that are accessible from virtual networks. Used as default DNS servers for VMs. |
Parameter |
|
|---|---|
Usage |
Contains the data structure that defines external (provider) networks on top of which the Neutron networking will be created. |
Parameter |
|
|---|---|
Usage |
If enabled, must contain the data structure defining the floating IP network that will be created for Neutron to provide external access to your Nova instances. |
BGP dynamic routing¶
Available since MOSK 23.2 TechPreview
The BGP dynamic routing extension to the Networking service (OpenStack Neutron) is particularly useful for the MOSK clouds where private networks managed by cloud users need to be transparently integrated into the networking of the data center.
For example, the BGP dynamic routing is a common requirement for IPv6-enabled environments, where clients need to seamlessly access cloud workloads using dedicated IP addresses with no address translation involved in between the cloud and the external network.
BGP dynamic routing changes the way self-service (private) network prefixes are communicated to BGP-compatible physical network devices, such as routers, present in the data center. It eliminates the traditional reliance on static routes or ICMP-based advertising by enabling the direct passing of private network prefix information to router devices.
Note
To effectively use the BGP dynamic routing feature, Mirantis recommends acquiring good understanding of OpenStack address scopes and how they work.
The components of the OpenStack BGP dynamic routing are:
- Service plugin
An extension to the Networking service (OpenStack Neutron) that implements the logic for BGP-related entities orhestration and provides the cloud user-facing API. A cloud administrator creates and configures a BGP speaker using the CLI or API and manually schedules it to one or more hosts running the agent.
- Agent
Manages BGP peering sessions. In MOSK, the BGP agent runs on nodes labeled with
openstack-gateway=enabled.
Prefix advertisement depends on the binding of external networks to a BGP speaker and the address scope of external and internal IP address ranges or subnets.
BGP dynamic routing advertises prefixes for self-service networks and host routes for floating IP addresses.
To successfully advertise a self-service network, you need to fulfill the following conditions:
External and self-service networks reside in the same address scope.
The router contains an interface on the self-service subnet and a gateway on the external network.
The BGP speaker associates with the external network that provides a gateway on the router.
The BGP speaker has the
advertise_tenant_networksattribute set toTrue.
To successfully advertise a floating IP address, you need to fulfill the following conditions:
The router with the floating IP address binding contains a gateway on an external network with the BGP speaker association.
The BGP speaker has the
advertise_floating_ip_host_routesattribute set totrue.
The diagram below is an example of the BGP dynamic routing in the non-DVR mode with self-service networks and the following advertisements:
B>* 192.168.0.0/25 [200/0]through10.11.12.1B>* 192.168.0.128/25 [200/0]through10.11.12.2B>* 10.11.12.234/32 [200/0]through10.11.12.1
For both floating IP and IPv4 fixed IP addresses, the BGP speaker advertises the gateway of the floating IP agent on the corresponding compute node as the next-hop IP address. When using IPv6 fixed IP addresses, the BGP speaker advertises the DVR SNAT node as the next-hop IP address.
The diagram below is an example of the BGP dynamic routing in the DVR mode with self-service networks and the following advertisements:
B>* 192.168.0.0/25 [200/0]through10.11.12.1B>* 192.168.0.128/25 [200/0]through10.11.12.2B>* 10.11.12.234/32 [200/0]through10.11.12.12
DVR incompatibility with ARP announcements and VRRP¶
Due to the known issue #1774459 in the upstream implementation, Mirantis does not recommend using Distributed Virtual Routing (DVR) routers in the same networks as load balancers or other applications that utilize the Virtual Router Redundancy Protocol (VRRP) such as Keepalived. The issue prevents the DVR functionality from working correctly with network protocols that rely on the Address Resolution Protocol (ARP) announcements such as VRRP.
The issue occurs when updating permanent ARP entries for
allowed_address_pair IP addresses in DVR routers because DVR performs
the ARP table update through the control plane and does not allow any
ARP entry to leave the node to prevent the router IP/MAC from
contaminating the network.
This results in various network failover mechanisms not functioning in virtual networks that have a distributed virtual router plugged in. For instance, the default back end for MOSK Load Balancing service, represented by OpenStack Octavia with the OpenStack Amphora back end when deployed in the HA mode in a DVR-connected network, is not able to redirect the traffic from a failed active service instance to a standby one without interruption.
Block Storage service¶
Mirantis OpenStack for Kubernetes (MOSK) provides volume management capability through the Block Storage service (OpenStack Cinder).
Backup configuration¶
MOSK provides support for the following back ends for the Block Storage service (OpenStack Cinder):
Back end |
Support status |
|---|---|
Ceph |
Full support, default |
NFS |
|
S3 |
|
In MOSK, Cinder backup is enabled and uses the Ceph back
end for Cinder by default. The backup configuration is stored
in the spec:features:cinder:backup structure in the
OpenStackDeployment custom resource. If necessary, you can disable
the backup feature in Cinder as follows:
kind: OpenStackDeployment
spec:
features:
cinder:
backup:
enabled: false
Using this structure, you can also configure another backup driver supported by MOSK for Cinder as described below. At any given time, only one back end can be enabled.
Available since MOSK 23.2 TechPreview
MOSK supports NFS Unix authentication exclusively.
To use an NFS driver with MOSK, ensure you have
a preconfigured NFS server with an NFS share accessible to a Unix
Cinder user. This user must be the owner of the exported NFS folder,
and the folder must have the permission value set to 775.
All Cinder services run with the same user by default. To obtain the Unix user ID:
kubectl -n openstack get pod -l application=cinder,component=api -o jsonpath='{.items[0].spec.securityContext.runAsUser}'
Note
The NFS server must be accessible through the network from all OpenStack control plane nodes of the cluster.
To enable the NFS storage for Cinder backup, configure the following
structure in the OpenStackDeployment object:
spec:
features:
cinder:
backup:
drivers:
<BACKEND_NAME>:
type: nfs
enabled: true
backup_share: <URL_TO_NFS_SHARE>
You can specify the backup_share parameter in following formats:
hostname:path, ipv4addr:path, or [ipv6addr]:path.
For example: 1.2.3.4:/cinder_backup.
Available since MOSK 23.2 TechPreview
To use an S3 driver with MOSK, ensure you have a preconfigured S3 storage with a user account created for access.
Note
The S3 storage must be accessible through the network from all OpenStack control plane nodes of the cluster.
To enable the S3 storage for Cinder backup:
Create a dedicated secret in Kuberbetes to securely store the credentials required for accessing the S3 storage:
--- apiVersion: v1 kind: Secret metadata: labels: openstack.lcm.mirantis.com/osdpl_secret: "true" name: cinder-backup-s3-hidden namespace: openstack type: Opaque data: access_key: <ACCESS_KEY_FOR_S3_ACCOUNT> secret_key: <ACCESS_KEY_FOR_S3_ACCOUNT>
Configure the following structure in the
OpenStackDeploymentobject:spec: features: cinder: backup: drivers: <BACKEND_NAME>: type: s3 enabled: true endpoint_url: <URL_TO_S3_STORAGE> store_bucket: <S3_BUCKET_NAME> store_access_key: value_from: secret_key_ref: key: access_key name: cinder-backup-s3-hidden store_secret_key: value_from: secret_key_ref: key: secret_key name: cinder-backup-s3-hidden
Volume encryption¶
TechPreview
The Block Storage service (OpenStack Cinder) supports volume encryption using a key stored in the Key Manager service (OpenStack Barbican). Such configuration uses Linux Unified Key Setup (LUKS) to create an encrypted volume type and attach it to the Compute service (OpenStack Nova) instances. Nova retrieves the asymmetric key from Barbican and stores it on the OpenStack compute node as a libvirt key to encrypt the volume locally or on the back end and only after that transfers it to Cinder.
Note
To create an encrypted volume under a non-admin user, the
creatorrole must be assigned to the user.When planning your cloud, consider that encryption may impact CPU.
Identity service¶
Mirantis OpenStack for Kubernetes (MOSK) provides authentication, service discovery, and distributed multi-tenant authorization through the OpenStack Identity service, aka Keystone.
Integration with Mirantis Container Cloud IAM¶
MOSK integrates with Mirantis Container Cloud Identity and Access Management (IAM) subsystem to allow centralized management of users and their permissions across multiple clouds.
The core component of Container Cloud IAM is Keycloak, the open-source identity and access management software. Its primary function is to perform secure authentication of cloud users against its built-in or various external identity databases, such as LDAP directories, OpenID Connect or SAML compatible identity providers.
By default, every MOSK cluster is integrated with the
Keycloak running in the Container Cloud management cluster. The integration
automatically provisions the necessary configuration on the
MOSK and Container Cloud IAM sides, such as the os
client object in Keycloak. However, for the federated users to get proper
permissions after logging in, the cloud operator needs to define the role
mapping rules specific to each MOSK environment.
See also
Parameter |
|
|---|---|
Usage |
Defines parameters to connect to the Keycloak identity provider |
Regions¶
A region in MOSK represents a complete OpenStack cluster that has a dedicated control plane and set of API endpoints. It is not uncommon for operators of large clouds to offer their users several OpenStack regions, which differ by their geographical location or purpose. In order to easily navigate in a multi-region environment, cloud users need a way to distinguish clusters by their names.
The region_name parameter of an OpenStackDeployment custom resource
specifies the name of the region that will be configured in all the OpenStack
services comprising the MOSK cluster upon the initial
deployment.
Important
Once the cluster is up and running, the cloud operator cannot set or change the name of the region. Therefore, Mirantis recommends selecting a meaningful name for the new region before the deployment starts. For example, the region name can be based on the name of the data center the cluster is located in.
Usage sample:
apiVersion: lcm.mirantis.com/v1alpha1
kind: OpenStackDeployment
metadata:
name: openstack-cluster
namespace: openstack
spec:
region_name: <your-region-name>
Application credentials¶
Application credentials is a mechanism in the MOSK Identity service that enables application automation tools, such as shell scripts, Terraform modules, Python programs, and others, to securely perform various actions in the cloud API in order to deploy and manage application components.
Application credentials is a modern alternative to the legacy approach where every application owner had to request several technical user accounts to ensure their tools could authenticate in the cloud.
For the details on how to create and authenticate with application credentials, refer to Manage application credentials.
By default, cloud users logging in to the cloud through the Mirantis Container Cloud IAM or any external identity provider cannot use the application credentials mechanism.
An application credential is heavily tied to the account of the cloud user owning it. An application automation tool that is a consumer of the credential acts on behalf of the human user who created the credential. Each action that the application automation tool performs gets authorized against the permissions, including roles and groups, the user currently has.
The source of truth about a federated user permissions is the identity provider. This information gets temporary transferred to the cloud’s Identity service inside a token once the user authenticates. By default, if such a user creates an application credential and passes it to the automation tool, there is no data to validate the tool’s action on the user’s behalf.
However, a cloud operator can configure the authorization_ttl parameter
for an identity provider object to enable caching of its users authorization
data. The parameter defines for how long in minutes the information about
user permissions is preserved in the database after the user successfully
logs in to the cloud.
Warning
Authorization data caching has security implications. In case a federated user account is revoked or his permissions change in the identity provider, the cloud Identity service will still allow performing actions on the user behalf until the cached data expires or the user re-authenticates in the cloud.
To set authorization_ttl to, for example, 60 minutes for the keycloak
identity provider in Keystone:
Log in to the
keystone-clientPod:kubectl -n openstack exec $(kubectl -n openstack get po -l application=keystone,component=client -oname) -ti -c keystone-client -- bash
Inside the Pod, run the following command:
openstack identity provider set keycloak --authorization-ttl 60
Domain-specific configuration¶
Parameter |
|
|---|---|
Usage |
Defines the domain-specific configuration and is useful for integration
with LDAP. An example of OsDpl with LDAP integration, which will create
a separate spec:
features:
keystone:
domain_specific_configuration:
enabled: true
domains:
domain.with.ldap:
enabled: true
config:
assignment:
driver: keystone.assignment.backends.sql.Assignment
identity:
driver: ldap
ldap:
chase_referrals: false
group_desc_attribute: description
group_id_attribute: cn
group_member_attribute: member
group_name_attribute: ou
group_objectclass: groupOfNames
page_size: 0
password: XXXXXXXXX
query_scope: sub
suffix: dc=mydomain,dc=com
url: ldap://ldap01.mydomain.com,ldap://ldap02.mydomain.com
user: uid=openstack,ou=people,o=mydomain,dc=com
user_enabled_attribute: enabled
user_enabled_default: false
user_enabled_invert: true
user_enabled_mask: 0
user_id_attribute: uid
user_mail_attribute: mail
user_name_attribute: uid
user_objectclass: inetOrgPerson
|
Image service¶
Mirantis OpenStack for Kubernetes (MOSK) provides the image management capability through the OpenStack Image service, aka Glance.
The Image service enables you to discover, register, and retrieve virtual machine images. Using the Glance API, you can query virtual machine image metadata and retrieve actual images.
MOSK deployment profiles include the Image service in the
core set of services. You can configure the Image service through the
spec:features definition in the OpenStackDeployment custom resource.
Image signature verification¶
TechPreview
MOSK can automatically verify the cryptographic signatures
associated with images to ensure the integrity of their data. A signed image
has a few additional properties set in its metadata that include
img_signature, img_signature_hash_method, img_signature_key_type,
and img_signature_certificate_uuid. You can find more information about
these properties and their values in the upstream OpenStack documentation.
MOSK performs image signature verification during the following operations:
A cloud user or a service creates an image in the store and starts to upload its data. If the signature metadata properties are set on the image, its content gets verified against the signature. The Image service accepts non-signed image uploads.
A cloud user spawns a new instance from an image. The Compute service ensures that the data it downloads from the image storage matches the image signature. If the signature is missing or does not match the data, the operation fails. Limitations apply, see Known limitations.
A cloud user boots an instance from a volume, or creates a new volume from an image. If the image is signed, the Block Storage service compares the downloaded image data against the signature. If there is a mismatch, the operation fails. The service will accept a non-signed image as a source for a volume. Limitations apply, see Known limitations.
spec:
features:
glance:
signature:
enabled: true
Every MOSK cloud is pre-provisioned with a baseline set of images containing most popular operating systems, such as Ubuntu, Fedora, CirrOS.
In addition, a few services in MOSK rely on the creation of service instances to provide their functions, namely the Load Balancer service and the Bare Metal service, and require corresponding images to exist in the image store.
When image signature verification is enabled during the cloud deployment, all these images get automatically signed with a pre-generated self-signed certificate. Enabling the feature in an already existing cloud requires manual signing of all of the images stored in it. Consult the OpenStack documentation for an example of the image signing procedure.
The image signature verification is supported for LVM and local back ends for ephemeral storage.
The functionality is not compatible with Ceph-backed ephemeral storage combined with RAW formatted images. The Ceph copy-on-write mechanism enables the user to create instance virtual disks without downloading the image to a compute node, the data is handled completely on the side of a Ceph cluster. This enables you to spin up instances almost momentarily but makes it impossible to verify the image data before creating an instance from it.
The Image service does not enforce the presence of a signature in the metadata when the user creates a new image. The service will accept the non-signed image uploads.
The Image service does not verify the correctness of an image signature upon update of the image metadata.
MOSK does not validate if the certificate used to sign an image is trusted, it only ensures the correctness of the signature itself. Cloud users are allowed to use self-signed certificates.
The Compute service does not verify image signature for Ceph back end when the RAW image format is used as described in Supported storage back ends.
The Compute service does not verify image signature if the image is already cached on the target compute node.
The Instance HA service may experience issues when auto-evacuating instances created from signed images if it does have access to the corresponding secrets in the Key manager service.
The Block Storage service does not perform image signature verification when a Ceph back end is used and the images are in the RAW format.
The Block Storage service does not enforce the presence of a signature on the images.
Object Storage service¶
Ceph Object Gateway provides Object Storage (Swift) API for end users in MOSK deployments. For the API compatibility, refer to Ceph Documentation: Ceph Object Gateway Swift API.
Object storage enablement¶
Parameter |
|
|---|---|
Usage |
Enables the object storage and provides a RADOS Gateway Swift API that is compatible with the OpenStack Swift API. To enable the service, add spec:
features:
services:
- object-storage
To create the RADOS Gateway pool in Ceph, see Container Cloud Operations Guide: Enable Ceph RGW Object Storage. |
Object storage server-side encryption¶
TechPreview
Ceph Object Gateway also provides Amazon S3 compatible API. For details, see Ceph Documentation: Ceph Object Gateway S3 API. Using integration with the OpenStack Key Manager service (Barbican), the objects uploaded through S3 API can be encrypted by Ceph Object Gateway according to the AWS Documentation: Protecting data using server-side encryption with customer-provided encryption keys (SSE-C) specification.
Instead of Swift, such configuration uses an S3 client to upload server-side encrypted objects. Using server-side encryption, the data is sent over a secure HTTPS connection in an unencrypted form and the Ceph Object Gateway stores that data in the Ceph cluster in an encrypted form.
Dashboard¶
MOSK Dashboard (OpenStack Horizon) provides a web-based interface for users to access the functions of the cloud services.
Custom theme¶
Parameter |
|
|---|---|
Usage |
Defines the list of custom OpenStack Dashboard themes. Content of the archive file with a theme depends on the level of customization and can include static files, Django templates, and other artifacts. For the details, refer to OpenStack official documentation: Customizing Horizon Themes. spec:
features:
horizon:
themes:
- name: theme_name
description: The brand new theme
url: https://<path to .tgz file with the contents of custom theme>
sha256summ: <SHA256 checksum of the archive above>
|
Auxiliary cloud services
Telemetry services¶
TechPreview
The Telemetry services are part of OpenStack services available in Mirantis OpenStack for Kubernetes (MOSK). The Telemetry services monitor OpenStack components, collect and store the telemetry data from them, and perform responsive actions upon this data. See OpenStack cluster for details about OpenStack services in MOSK.
OpenStack Ceilometer is a service that collects data from various OpenStack
components. The service can also collect and process notifications from
different OpenStack services. Ceilometer stores the data in the Gnocchi
database. The service is specified as metering in the
OpenStackDeployment custom resource (CR).
Gnocchi is an open-source time series database. One of the advantages of this
database is the ability to pre-aggregate the telemetry data while storing it.
Gnocchi is specified as metric in the OpenStackDeployment CR.
OpenStack Aodh is part of the Telemetry project. Aodh provides a service that
creates alarms based on various metric values or specific events and triggers
response actions. The service uses data collected and stored by Ceilometer
and Gnocchi. Aodh is specified as alarming in the OpenStackDeployment
CR.
Enabling Telemetry services¶
The Telemetry feature in MOSK has a single mode.
The autoscaling mode provides settings for telemetry data collection and
storing. The OpenStackDeployment CR should have this mode specified for the
correct work of the OpenStack Telemetry services. The autoscaling mode has
the following notable configurations:
Gnocchi stores cache and data using the Redis storage driver.
Metric stores data for one hour with a resolution of 1 minute.
The Telemetry services are disabled by default in MOSK.
You have to enable them
in the openstackdeployment.yaml file (the OpenStackDeployment CR).
The following code block provides an example of deploying the Telemetry
services as part of MOSK:
kind: OpenStackDeployment
spec:
features:
services:
- alarming
- metering
- metric
telemetry:
mode: autoscaling
Gnocchi is not an OpenStack service, so the settings related to its
functioning should be included in the spec:common:infra section of the
OpenStackDeployment CR.
The Ceilometer configuration files contain many list structures. Overriding
list elements in YAML files is context-dependent and error-prone. Therefore,
to override these configuration files, define the spec:services
structure in the OpenStackDeployment CR.
The spec:services structure provides the ability to use a complete file as
text and not as YAML data structure.
Overriding through the spec:services structure is possible for the
following files:
pipeline.yamlpolling.yamlmeters.yamlgnocchi_resources.yamlevent_pipeline.yamlevent_definitions.yaml
An example of overriding through the OpenStackDeployment CR
By default, the autoscaling mode collects the data related to CPU, disk, and memory every minute. The autoscaling mode collects the rest of the available metrics every hour.
The following example shows the overriding of the polling.yaml
configuration file through the spec:services structure of the
OpenStackDeployment CR.
Get the current configuration file:
kubectl -n openstack get secret ceilometer-etc -ojsonpath="{.data['polling\.yaml']}" | base64 -d sources: - interval: 60 meters: - cpu - disk* - memory* name: ascale_pollsters - interval: 3600 meters: - '*' name: all_pollsters
Add the
networkparameter to the file.Copy and paste the edited
polling.yamlfile content to thespec:services:meteringsection of theOpenStackDeploymentCR:spec: services: metering: ceilometer: conf: polling: | # Obligatory. The "|" indicator denotes the literal style. See https://yaml.org/spec/1.2-old/spec.html#id2795688 for details. sources: - interval: 60 meters: - cpu - disk* - memory* - network* name: ascale_pollsters - interval: 3600 meters: - '*' name: all_pollsters
Bare Metal service¶
The Bare Metal service (Ironic) is an extra OpenStack service that can be
deployed by the OpenStack Operator. This section provides the
baremetal-specific configuration options of the OpenStackDeployment
resource.
Enabling the Bare Metal service¶
The Bare Metal service is not included into the core set of services and needs
to be explicitly enabled in the OpenStackDeployment custom resource.
To install bare metal services, add the baremetal keyword to the
spec:features:services list:
spec:
features:
services:
- baremetal
Note
All bare metal services are scheduled to the nodes with the
openstack-control-plane: enabled label.
Ironic agent deployment images¶
To provision a user image onto a bare metal server, Ironic boots a node with
a ramdisk image. Depending on the node’s deploy interface and hardware, the
ramdisk may require different drivers (agents). MOSK
provides tinyIPA-based ramdisk images and uses the direct deploy interface
with the ipmitool power interface.
Example of agent_images configuration:
spec:
features:
ironic:
agent_images:
base_url: https://binary.mirantis.com/openstack/bin/ironic/tinyipa
initramfs: tinyipa-stable-ussuri-20200617101427.gz
kernel: tinyipa-stable-ussuri-20200617101427.vmlinuz
Since the bare metal nodes hardware may require additional drivers, you may need to build a deploy ramdisk for particular hardware. For more information, see Ironic Python Agent Builder. Be sure to create a ramdisk image with the version of Ironic Python Agent appropriate for your OpenStack release.
Bare metal networking¶
Ironic supports the flat and multitenancy networking modes.
The flat networking mode assumes that all bare metal nodes are
pre-connected to a single network that cannot be changed during the
virtual machine provisioning. This network with bridged interfaces
for Ironic should be spread across all nodes including compute nodes
to allow plug-in regular virtual machines to connect to Ironic network.
In its turn, the interface defined as provisioning_interface should
be spread across gateway nodes. The cloud operator can perform
all these underlying configuration through the L2 templates.
Example of the OsDpl resource illustrating the configuration for the flat
network mode:
spec:
features:
services:
- baremetal
neutron:
external_networks:
- bridge: ironic-pxe
interface: <baremetal-interface>
network_types:
- flat
physnet: ironic
vlan_ranges: null
ironic:
# The name of neutron network used for provisioning/cleaning.
baremetal_network_name: ironic-provisioning
networks:
# Neutron baremetal network definition.
baremetal:
physnet: ironic
name: ironic-provisioning
network_type: flat
external: true
shared: true
subnets:
- name: baremetal-subnet
range: 10.13.0.0/24
pool_start: 10.13.0.100
pool_end: 10.13.0.254
gateway: 10.13.0.11
# The name of interface where provision services like tftp and ironic-conductor
# are bound.
provisioning_interface: br-baremetal
The multitenancy network mode uses the neutron Ironic network
interface to share physical connection information with Neutron. This
information is handled by Neutron ML2 drivers when plugging a Neutron port
to a specific network. MOSK supports the
networking-generic-switch Neutron ML2 driver out of the box.
Example of the OsDpl resource illustrating the configuration for the
multitenancy network mode:
spec:
features:
services:
- baremetal
neutron:
tunnel_interface: ens3
external_networks:
- physnet: physnet1
interface: <physnet1-interface>
bridge: br-ex
network_types:
- flat
vlan_ranges: null
mtu: null
- physnet: ironic
interface: <physnet-ironic-interface>
bridge: ironic-pxe
network_types:
- vlan
vlan_ranges: 1000:1099
ironic:
# The name of interface where provision services like tftp and ironic-conductor
# are bound.
provisioning_interface: <baremetal-interface>
baremetal_network_name: ironic-provisioning
networks:
baremetal:
physnet: ironic
name: ironic-provisioning
network_type: vlan
segmentation_id: 1000
external: true
shared: false
subnets:
- name: baremetal-subnet
range: 10.13.0.0/24
pool_start: 10.13.0.100
pool_end: 10.13.0.254
gateway: 10.13.0.11
DNS service¶
Mirantis OpenStack for Kubernetes (MOSK) provides DNS records managing capability through the DNS service (OpenStack Designate).
LoadBalancer type for PowerDNS¶
The supported back end for Designate is PowerDNS. If required, you can specify whether to use an external IP address or UDP, TCP, or TCP + UDP kind of Kubernetes for the PowerDNS service.
To configure LoadBalancer for PowerDNS, use the spec:features:designate
definition in the OpenStackDeployment custom resource.
The list of supported options includes:
external_ip- Optional. An IP address for the LoadBalancer service. If not defined, LoadBalancer allocates the IP address.protocol- A protocol for the Designate back end in Kubernetes. Can only beudp,tcp, ortcp+udp.type- The type of the back end for Designate. Can only bepowerdns.
For example:
spec:
features:
designate:
backend:
external_ip: 10.172.1.101
protocol: udp
type: powerdns
DNS service known limitations¶
Due to an issue in the dnspython library, Asynchronous Transfer Full Range
(AXFR) requests do not work and cause inability to set up a secondary DNS zone.
The issue affects OpenStack Victoria and will be fixed in the Yoga release.
Key Manager service¶
MOSK Key Manager service (OpenStack Barbican) provides secure storage, provisioning, and management of cloud application secret data, such as Symmetric Keys, Asymmetric Keys, Certificates, and raw binary data.
Configuring the Vault back end¶
Parameter |
|
|---|---|
Usage |
Specifies the object containing the Vault parameters to connect to Barbican. The list of supported options includes:
If the Vault back end is used, configure it properly using the following parameters: spec:
features:
barbican:
backends:
vault:
enabled: true
approle_role_id: <APPROLE_ROLE_ID>
approle_secret_id: <APPROLE_SECRET_ID>
vault_url: <VAULT_SERVER_URL>
use_ssl: false
Mirantis recommeds hiding the Note Since MOSK does not currently support the
Vault SSL encryption, set the |
Instance High Availability service¶
TechPreview
Instance High Availability service (OpenStack Masakari) enables cloud users to ensure that their instances get automatically evacuated from a failed hypervisor.
Architecture of the Instance HA service¶
The service consists of the following components:
API recieves requests from users and events from monitors, and sends them to engine
Engine executes recovery workflow
Monitors detect failures and notifies API. MOSK uses monitors of the following types:
Instance monitor performs liveness of instance processes
Host monitor performs liveness of a compute host, runs as part of the Node controller from the OpenStack Controller
Note
The Processes monitor is not present in MOSK as far as HA for the compute processes is handled by Kubernetes.
Enabling the Instance HA service¶
The Instance HA service is not included into the core set of services and needs
to be explicitly enabled in the OpenStackDeployment custom resource.
Parameter |
|
|---|---|
Usage |
Enables Masakari, the OpenStack service that ensures high availability
of instances running on a host. To enable the service, add
spec:
features:
services:
- instance-ha
|
OpenStack¶
OpenStack cluster¶
OpenStack and auxiliary services are running as containers in the kind: Pod
Kubernetes resources. All long-running services are governed by one of
the ReplicationController-enabled Kubernetes resources, which include
either kind: Deployment, kind: StatefulSet, or kind: DaemonSet.
The placement of the services is mostly governed by the Kubernetes node labels. The labels affecting the OpenStack services include:
openstack-control-plane=enabled- the node hosting most of the OpenStack control plane services.openstack-compute-node=enabled- the node serving as a hypervisor for Nova. The virtual machines with tenants workloads are created there.openvswitch=enabled- the node hosting Neutron L2 agents and OpenvSwitch pods that manage L2 connection of the OpenStack networks.openstack-gateway=enabled- the node hosting Neutron L3, Metadata and DHCP agents, Octavia Health Manager, Worker and Housekeeping components.
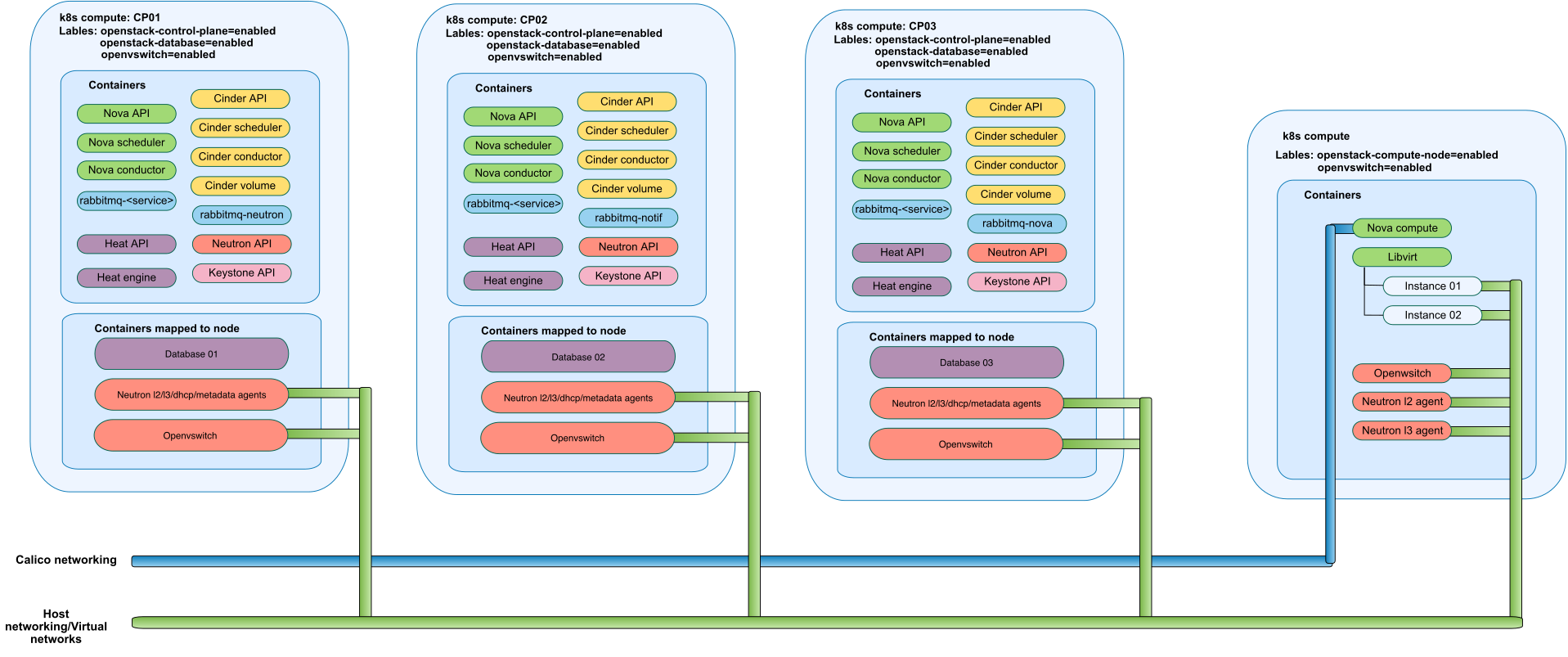
Note
OpenStack is an infrastructure management platform. Mirantis OpenStack for Kubernetes (MOSK) uses Kubernetes mostly for orchestration and dependency isolation. As a result, multiple OpenStack services are running as privileged containers with host PIDs and Host Networking enabled. You must ensure that at least the user with the credentials used by Helm/Tiller (administrator) is capable of creating such Pods.
Infrastructure services¶
Service |
Description |
|---|---|
Storage |
While the underlying Kubernetes cluster is configured to use Ceph CSI for providing persistent storage for container workloads, for some types of workloads such networked storage is suboptimal due to latency. This is why the separate |
Database |
A single WSREP (Galera) cluster of MariaDB is deployed as the SQL
database to be used by all OpenStack services. It uses the storage class
provided by Local Volume Provisioner to store the actual database files.
The service is deployed as |
Messaging |
RabbitMQ is used as a messaging bus between the components of the OpenStack services. A separate instance of RabbitMQ is deployed for each OpenStack service that needs a messaging bus for intercommunication between its components. An additional, separate RabbitMQ instance is deployed to serve as a notification messages bus for OpenStack services to post their own and listen to notifications from other services. StackLight also uses this message bus to collect notifications for monitoring purposes. Each RabbitMQ instance is a single node and is deployed as
|
Caching |
A single multi-instance of the Memcached service is deployed to be used by all OpenStack services that need caching, which are mostly HTTP API services. |
Coordination |
A separate instance of etcd is deployed to be used by Cinder, which require Distributed Lock Management for coordination between its components. |
Ingress |
Is deployed as |
Image pre-caching |
A special This is especially useful for containers used in |
OpenStack services¶
Service |
Description |
|---|---|
Identity (Keystone) |
Uses MySQL back end by default.
|
Image (Glance) |
Supported back end is RBD (Ceph is required). |
Volume (Cinder) |
Supported back end is RBD (Ceph is required). |
Network (Neutron) |
Supported back ends are Open vSwitch and Tungsten Fabric. |
Placement |
|
Compute (Nova) |
Supported hypervisor is Qemu/KVM through libvirt library. |
Dashboard (Horizon) |
|
DNS (Designate) |
Supported back end is PowerDNS. |
Load Balancer (Octavia) |
|
Ceph Object Gateway (SWIFT) |
Provides the object storage and a Ceph Object Gateway Swift API that is
compatible with the OpenStack Swift API. You can manually enable the
service in the |
Instance HA (Masakari) |
An OpenStack service that ensures high availability of instances running
on a host. You can manually enable Masakari in the
|
Orchestration (Heat) |
|
Key Manager (Barbican) |
The supported back ends include:
|
Tempest |
Runs tests against a deployed OpenStack cloud. You can manually enable
Tempest in the |
Telemetry |
Telemetry services include alarming (aodh), metering (Ceilometer),
and metric (Gnocchi). All services should be enabled together through
the list of services to be deployed in the |
OpenStack database architecture¶
A complete setup of a MariaDB Galera cluster for OpenStack is illustrated in the following image:
MariaDB server pods are running a Galera multi-master cluster. Clients
requests are forwarded by the Kubernetes mariadb service to the
mariadb-server pod that has the primary label. Other pods from
the mariadb-server StatefulSet have the backup label. Labels are
managed by the mariadb-controller pod.
The MariaDB Controller periodically checks the readiness of the
mariadb-server pods and sets the primary label to it if the following
requirements are met:
The
primarylabel has not already been set on the pod.The pod is in the ready state.
The pod is not being terminated.
The pod name has the lowest integer suffix among other ready pods in the StatefulSet. For example, between
mariadb-server-1andmariadb-server-2, the pod with themariadb-server-1name is preferred.
Otherwise, the MariaDB Controller sets the backup label. This means that
all SQL requests are passed only to one node while other two nodes are in
the backup state and replicate the state from the primary node.
The MariaDB clients are connecting to the mariadb service.
OpenStack lifecycle management¶
The OpenStack Operator component is a combination of the following entities:
OpenStack Controller¶
The OpenStack Controller runs in a set of containers in a pod in Kubernetes. The OpenStack Controller is deployed as a Deployment with 1 replica only. The failover is provided by Kubernetes that automatically restarts the failed containers in a pod.
However, given the recommendation to use a separate Kubernetes cluster for each OpenStack deployment, the controller in envisioned mode for operation and deployment will only manage a single OpenStackDeployment resource, making the proper HA much less of an issue.
The OpenStack Controller is written in Python using Kopf, as a Python framework to build Kubernetes operators, and Pykube, as a Kubernetes API client.
Using Kubernetes API, the controller subscribes to changes to resources of
kind: OpenStackDeployment, and then reacts to these changes by creating,
updating, or deleting appropriate resources in Kubernetes.
The basic child resources managed by the controller are Helm releases.
They are rendered from templates taking into account
an appropriate values set from the main and features fields in the
OpenStackDeployment resource.
Then, the common fields are merged to resulting data structures. Lastly, the services fields are merged providing the final and precise override for any value in any Helm release to be deployed or upgraded.
The constructed values are then used by the OpenStack Controller during a
Helm release installation.
Container |
Description |
|---|---|
|
The core container that handles changes in the |
|
The container that watches the |
|
The container that watches all Kubernetes native
resources, such as |
|
The container that provides data exchange between different components such as Ceph. |
|
The container that handles the node events. |
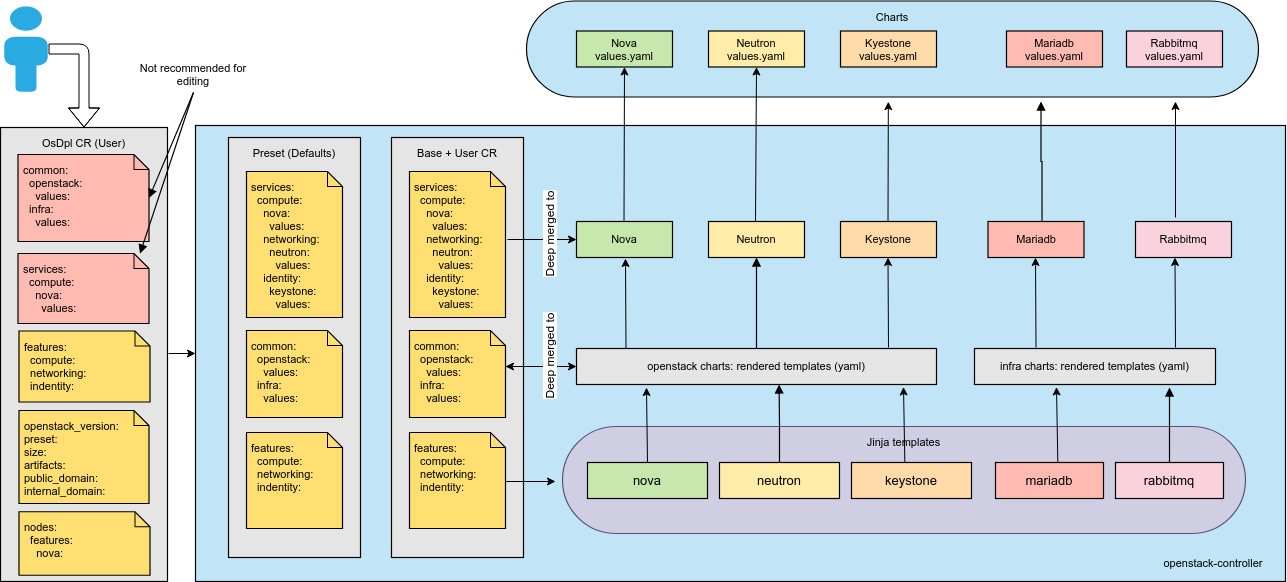
OpenStackDeployment Admission Controller¶
The CustomResourceDefinition resource in Kubernetes uses the
OpenAPI Specification version 2 to specify the schema of the resource
defined. The Kubernetes API outright rejects the resources that do not
pass this schema validation.
The language of the schema, however, is not expressive enough to define a specific validation logic that may be needed for a given resource. For this purpose, Kubernetes enables the extension of its API with Dynamic Admission Control.
For the OpenStackDeployment (OsDpl) CR the ValidatingAdmissionWebhook
is a natural choice. It is deployed as part of OpenStack Controller
by default and performs specific extended validations when an OsDpl CR is
created or updated.
The inexhaustive list of additional validations includes:
Deny the OpenStack version downgrade
Deny the OpenStack version skip-level upgrade
Deny the OpenStack master version deployment
Deny upgrade to the OpenStack master version
Deny upgrade if any part of an OsDpl CR specification changes along with the OpenStack version
Under specific circumstances, it may be viable to disable the Admission Controller, for example, when you attempt to deploy or upgrade to the master version of OpenStack.
Warning
Mirantis does not support MOSK deployments performed without the OpenStackDeployment Admission Controller enabled. Disabling of the OpenStackDeployment Admission Controller is only allowed in staging non-production environments.
To disable the Admission Controller, ensure that the following structures and
values are present in the openstack-controller HelmBundle resource:
apiVersion: lcm.mirantis.com/v1alpha1
kind: HelmBundle
metadata:
name: openstack-operator
namespace: osh-system
spec:
releases:
- name: openstack-operator
values:
admission:
enabled: false
At that point, all safeguards except for those expressed by the CR definition are disabled.
OpenStack configuration¶
MOSK provides the configurational capabilities through a number of custom resources. This section is intended to provide detailed overview of these custom resources and their possible configuration.
OpenStackDeployment custom resource¶
The detailed information about schema of an OpenStackDeployment
custom resource can be obtained by running:
kubectl get crd openstackdeployments.lcm.mirantis.com -o yaml
The definition of a particular OpenStack deployment can be obtained by running:
kubectl -n openstack get osdpl -o yaml
apiVersion: lcm.mirantis.com/v1alpha1
kind: OpenStackDeployment
metadata:
name: openstack-cluster
namespace: openstack
spec:
openstack_version: victoria
preset: compute
size: tiny
internal_domain_name: cluster.local
public_domain_name: it.just.works
features:
neutron:
tunnel_interface: ens3
external_networks:
- physnet: physnet1
interface: veth-phy
bridge: br-ex
network_types:
- flat
vlan_ranges: null
mtu: null
floating_network:
enabled: False
nova:
live_migration_interface: ens3
images:
backend: local
Available since MOSK 23.1
The OpenStackDeployment custom resource enables you to securely store
sensitive fields in Kubernetes secrets. To do that, verify that the
reference secret is present in the same namespace as the
OpenStackDeployment object and the
openstack.lcm.mirantis.com/osdpl_secret label is set to true.
The list of fields that can be hidden from OpenStackDeployment is limited
and defined by the OpenStackDeployment schema.
For example, to hide spec:features:ssl:public_endpoints:api_cert, use the
following structure:
spec:
features:
ssl:
public_endpoints:
api_cert:
value_from:
secret_key_ref:
key: api_cert
name: osh-dev-hidden
Note
The fields that used to store confidential settings
in OpenStackDeploymentSecret and OpenStackDeployment
before MOSK 23.1 include:
spec:
features:
ssl:
public_endpoints:
- ca_cert
- api_cert
- api_key
barbican:
backends:
vault:
- approle_role_id
- approle_secret_id
- ssl_ca_crt_file
baremetal:
ngs:
hardware:
*:
- username
- password
- ssh_private_key
- secret
Element |
Sub-element |
Description |
|---|---|---|
|
n/a |
Specifies the version of the Kubernetes API that is used to create this object |
|
n/a |
Specifies the kind of the object |
|
|
Specifies the name of metadata. Should be set in compliance with the Kubernetes resource naming limitations |
|
Specifies the metadata namespace. While technically it is possible to
deploy OpenStack on top of Kubernetes in other than Warning Both OpenStack and Kubernetes platforms provide resources to applications. When OpenStack is running on top of Kubernetes, Kubernetes is completely unaware of OpenStack-native workloads, such as virtual machines, for example. For better results and stability, Mirantis recommends using a dedicated Kubernetes cluster for OpenStack, so that OpenStack and auxiliary services, Ceph, and StackLight are the only Kubernetes applications running in the cluster. |
|
|
|
Specifies the OpenStack release to deploy |
|
String that specifies the name of the
Every supported deployment profile incorporates an OpenStack preset. Refer to Deployment profiles for the list of possible values. |
|
|
String that specifies the size category for the OpenStack cluster. The size category defines the internal configuration of the cluster such as the number of replicas for service workers and timeouts, etc. The list of supported sizes include:
|
|
|
Specifies the public DNS name for OpenStack services. This is a base DNS name that must be accessible and resolvable by API clients of your OpenStack cloud. It will be present in the OpenStack endpoints as presented by the OpenStack Identity service catalog. The TLS certificates used by the OpenStack services (see below) must also be issued to this DNS name. |
|
|
Specifies the Kubernetes storage class name used for services to create
persistent volumes. For example, backups of MariaDB. If not specified,
the storage class marked as |
|
|
Contains the top-level collections of settings for the OpenStack deployment that potentially target several OpenStack services. The section where the customizations should take place. The |
region_name¶TechPreview
The name of the region used for deployment, defaults to RegionOne.
features:policies¶Defines the list of custom policies for OpenStack services.
Configuration structure:
spec:
features:
policies:
nova:
custom_policy: custom_value
The list of services available for configuration includes: Cinder, Nova, Designate, Keystone, Glance, Neutron, Heat, Octavia, Barbican, Placement, Ironic, aodh, Gnocchi, and Masakari.
Caution
Mirantis is not responsible for cloud operability in case of default policies modifications but provides API to pass the required configuration to the core OpenStack services.
features:policies:strict_admin¶TechPreview
Enables a tested set of policies that limits the global admin role to
only the user with admin role in the admin project or user with the
service role. The latter should be used only for service users utilizied
for communication between OpenStack services.
Configuration structure:
spec:
features:
policies:
strict_admin:
enabled: true
services:
identity:
keystone:
values:
conf:
keystone:
resource:
admin_project_name: admin
admin_project_domain_name: Default
Note
The spec.services part of the above section will become
redundant in one of the following releases.
artifacts¶A low-level section that defines the base URI prefixes for images and binary artifacts.
common¶A low-level section that defines values that will be passed to all
OpenStack (spec:common:openstack) or auxiliary
(spec:common:infra) services Helm charts.
Configuration structure:
spec:
artifacts:
common:
openstack:
values:
infra:
values:
services¶A section of the lowest level, enables the definition of specific values to pass to specific Helm charts on a one-by-one basis:
Warning
Mirantis does not recommend changing the default settings for
spec:artifacts, spec:common, and spec:services elements.
Customizations can compromise the OpenStack deployment update and upgrade
processes.
However, you may need to edit the spec:services section to limit
hardware resources in case of a hyperconverged architecture as described in
Limit HW resources for hyperconverged OpenStack compute nodes.
Parameter |
|
|---|---|
Usage |
Specifies the standard logging levels for OpenStack services that
include the following, at increasing severity: Configuration example: spec:
features:
logging:
nova:
level: DEBUG
|
Depending on the use case, you may need to configure the same application components differently on different hosts. MOSK enables you to easily perform the required configuration through node-specific overrides at the OpenStack Controller side.
The limitation of using the node-specific overrides is that they override only the configuration settings while other components, such as startup scripts and others, should be reconfigured as well.
Caution
The overrides have been implemented in a similar way to the OpenStack node and node label specific DaemonSet configurations. Though, the OpenStack Controller node-specific settings conflict with the upstream OpenStack node and node label specific DaemonSet configurations. Therefore, we do not recommend configuring node and node label overrides.
The list of allowed node labels is located in the Cluster object status
providerStatus.releaseRef.current.allowedNodeLabels field.
If the value field is not defined in allowedNodeLabels, a label can
have any value.
Before or after a machine deployment, add the required label from the allowed
node labels list with the corresponding value to
spec.providerSpec.value.nodeLabels in machine.yaml. For example:
nodeLabels:
- key: <NODE-LABEL>
value: <NODE-LABEL-VALUE>
The addition of a node label that is not available in the list of allowed node labels is restricted.
The node-specific settings are activated through the spec:nodes
section of the OsDpl CR. The spec:nodes section contains the following
subsections:
features- implements overrides for a limited subset of fields and is constructed similarly tospec::featuresservices- similarly tospec::services, enables you to override settings in general for the components running as DaemonSets.
Example configuration:
spec:
nodes:
<NODE-LABEL>::<NODE-LABEL-VALUE>:
features:
# Detailed information about features might be found at
# openstack_controller/admission/validators/nodes/schema.yaml
services:
<service>:
<chart>:
<chart_daemonset_name>:
values:
# Any value from specific helm chart
Parameter |
|
|---|---|
Usage |
Enables tests against a deployed OpenStack cloud: spec:
features:
services:
- tempest
|
See also
OpenStackDeploymentSecret custom resource¶
The resource of kind OpenStackDeploymentSecret (OsDplSecret) is a custom
resource that is intended to aggregate cloud’s confidential settings such
as SSL/TLS certificates, external systems access credentials, and other
secrets.
To obtain detailed information about the schema of an OsDplSecret custom resource, run:
kubectl get crd openstackdeploymentsecret.lcm.mirantis.com -o yaml
The resource has similar structure as the OpenStackDeployment custom
resource and enables the user to set a limited subset of fields that
contain sensitive data.
Important
If you are migrating the related fields from the
OpenStackDeployment custom resource, refer to
Migrating secrets from OpenStackDeployment to OpenStackDeploymentSecret CR.
Example of an OpenStackDeploymentSecret custom resource of minimum
configuration:
1apiVersion: lcm.mirantis.com/v1alpha1
2kind: OpenStackDeploymentSecret
3metadata:
4 name: osh-dev
5 namespace: openstack
6spec:
7 features:
8 ssl:
9 public_endpoints:
10 ca_cert: |-
11 -----BEGIN CERTIFICATE-----
12 ...
13 -----END CERTIFICATE-----
14 api_cert: |-
15 -----BEGIN CERTIFICATE-----
16 ...
17 -----END CERTIFICATE-----
18 api_key: |-
19 -----BEGIN RSA PRIVATE KEY-----
20 ...
21 -----END RSA PRIVATE KEY-----
22 barbican:
23 backends:
24 vault:
25 approle_role_id: f6f0f775-...-cc00a1b7d0c3
26 approle_secret_id: 2b5c4b87-...-9bfc6d796f8c
features:ssl¶Contains the content of SSL/TLS certificates (server, key, and CA bundle) used to enable secure communication to public OpenStack API services.
These certificates must be issued to the DNS domain specified in the
public_domain_name field.
features:barbican:backends:vault¶Specifies the object containing parameters used to connect to a Hashicorp Vault instance. The list of supported configurations includes:
approle_role_id– Vault app role IDapprole_secret_id– Secret ID created for the app role
OpenStackDeploymentStatus custom resource¶
The resource of kind OpenStackDeploymentStatus (OsDplSt) is a custom
resource that describes the status of an OpenStack deployment.
To obtain detailed information about the schema of an
OpenStackDeploymentStatus (OsDplSt) custom resource, run:
kubectl get crd openstackdeploymentstatus.lcm.mirantis.com -o yaml
To obtain the status definition for a particular OpenStack deployment, run:
kubectl -n openstack get osdplst -o yaml
Example of an OpenStackDeploymentStatus custom resource
configuration
1 kind: OpenStackDeploymentStatus
2 metadata:
3 name: osh-dev
4 namespace: openstack
5 spec: {}
6 status:
7 handle:
8 lastStatus: update
9 health:
10 barbican:
11 api:
12 generation: 2
13 status: Ready
14 cinder:
15 api:
16 generation: 2
17 status: Ready
18 backup:
19 generation: 1
20 status: Ready
21 scheduler:
22 generation: 1
23 status: Ready
24 volume:
25 generation: 1
26 status: Ready
27 osdpl:
28 cause: update
29 changes: '((''add'', (''status'',), None, {''watched'': {''ceph'': {''secret'':
30 {''hash'': ''0fc01c5e2593bc6569562b451b28e300517ec670809f72016ff29b8cbaf3e729''}}}}),)'
31 controller_version: 0.5.3.dev12
32 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
33 openstack_version: ussuri
34 state: APPLIED
35 timestamp: "2021-09-08 17:01:45.633143"
36 services:
37 baremetal:
38 controller_version: 0.5.3.dev12
39 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
40 openstack_version: ussuri
41 state: APPLIED
42 timestamp: "2021-09-08 17:00:54.081353"
43 block-storage:
44 controller_version: 0.5.3.dev12
45 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
46 openstack_version: ussuri
47 state: APPLIED
48 timestamp: "2021-09-08 17:00:57.306669"
49 compute:
50 controller_version: 0.5.3.dev12
51 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
52 openstack_version: ussuri
53 state: APPLIED
54 timestamp: "2021-09-08 17:01:18.853068"
55 coordination:
56 controller_version: 0.5.3.dev12
57 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
58 openstack_version: ussuri
59 state: APPLIED
60 timestamp: "2021-09-08 17:01:00.593719"
61 dashboard:
62 controller_version: 0.5.3.dev12
63 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
64 openstack_version: ussuri
65 state: APPLIED
66 timestamp: "2021-09-08 17:00:57.652145"
67 database:
68 controller_version: 0.5.3.dev12
69 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
70 openstack_version: ussuri
71 state: APPLIED
72 timestamp: "2021-09-08 17:01:00.233777"
73 dns:
74 controller_version: 0.5.3.dev12
75 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
76 openstack_version: ussuri
77 state: APPLIED
78 timestamp: "2021-09-08 17:00:56.540886"
79 identity:
80 controller_version: 0.5.3.dev12
81 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
82 openstack_version: ussuri
83 state: APPLIED
84 timestamp: "2021-09-08 17:01:00.961175"
85 image:
86 controller_version: 0.5.3.dev12
87 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
88 openstack_version: ussuri
89 state: APPLIED
90 timestamp: "2021-09-08 17:00:58.976976"
91 ingress:
92 controller_version: 0.5.3.dev12
93 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
94 openstack_version: ussuri
95 state: APPLIED
96 timestamp: "2021-09-08 17:01:01.440757"
97 key-manager:
98 controller_version: 0.5.3.dev12
99 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
100 openstack_version: ussuri
101 state: APPLIED
102 timestamp: "2021-09-08 17:00:51.822997"
103 load-balancer:
104 controller_version: 0.5.3.dev12
105 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
106 openstack_version: ussuri
107 state: APPLIED
108 timestamp: "2021-09-08 17:01:02.462824"
109 memcached:
110 controller_version: 0.5.3.dev12
111 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
112 openstack_version: ussuri
113 state: APPLIED
114 timestamp: "2021-09-08 17:01:03.165045"
115 messaging:
116 controller_version: 0.5.3.dev12
117 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
118 openstack_version: ussuri
119 state: APPLIED
120 timestamp: "2021-09-08 17:00:58.637506"
121 networking:
122 controller_version: 0.5.3.dev12
123 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
124 openstack_version: ussuri
125 state: APPLIED
126 timestamp: "2021-09-08 17:01:35.553483"
127 object-storage:
128 controller_version: 0.5.3.dev12
129 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
130 openstack_version: ussuri
131 state: APPLIED
132 timestamp: "2021-09-08 17:01:01.828834"
133 orchestration:
134 controller_version: 0.5.3.dev12
135 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
136 openstack_version: ussuri
137 state: APPLIED
138 timestamp: "2021-09-08 17:01:02.846671"
139 placement:
140 controller_version: 0.5.3.dev12
141 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
142 openstack_version: ussuri
143 state: APPLIED
144 timestamp: "2021-09-08 17:00:58.039210"
145 redis:
146 controller_version: 0.5.3.dev12
147 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec
148 openstack_version: ussuri
149 state: APPLIED
150 timestamp: "2021-09-08 17:00:36.562673"
The health subsection provides a brief output on services health.
The osdpl subsection describes the overall status of the OpenStack
deployment.
Element |
Description |
|---|---|
|
The cause that triggered the LCM action: |
|
A string representation of changes in the |
|
The version of |
|
The SHA sum of the |
|
The current OpenStack version specified in the |
|
The current state of the LCM action. Possible values include:
|
|
The timestamp of the |
The services subsection provides detailed information of LCM performed with
a specific service. This is a dictionary where keys are service names, for
example, baremetal or compute and values are dictionaries with the
following items.
Element |
Description |
|---|---|
|
The version of the |
|
The SHA sum of the |
|
The OpenStack version specified in the |
|
The current state of the LCM action performed on a service. Possible values include:
|
|
The timestamp of the |
OpenStack Controller configuration¶
Available since MOSK 23.2
The OpenStack Controller enables you to modify its configuration at runtime
without restarting. MOSK stores the controller configuration
in the openstack-controller-config ConfigMap in the osh-system
namespace of your cluster.
To retrieve the OpenStack Controller configuration ConfigMap, run:
kubectl get configmaps openstack-controller-config -o yaml
Example of an OpenStack Controller configuration ConfigMap
apiVersion: v1
data:
extra_conf.ini: |
[maintenance]
respect_nova_az = false
kind: ConfigMap
metadata:
annotations:
openstackdeployments.lcm.mirantis.com/skip_update: "true"
name: openstack-controller-config
namespace: osh-system
Section |
Parameter |
Default value |
Description |
|---|---|---|---|
|
|
|
The number of seconds to wait for all application components to become ready. |
|
|
The number of seconds before going to the sleep mode between attempts to verify if the application is ready. |
|
|
|
The amount of time to wait for the flapping node. |
|
|
|
|
The number of seconds to wait until the values set in the manifest are propagated to the dependent objects. |
|
|
The number of seconds between attempts to verify if the values were applied. |
|
|
|
The number of seconds to wait until the values are removed from the manifest and propagated to the child objects. |
|
|
|
The number of seconds between attempts to verify if the values were removed from the release. |
|
|
|
The number of seconds to wait until the Kubernetes object is removed. |
|
|
|
The number of seconds between attempts to verify if the Kubernetes object is removed. |
|
|
|
The number of seconds to pause for the Helm bundle changes. |
|
|
|
|
The number of instances to migrate concurrently. |
|
|
The maximum number of compute nodes allowed for a parallel update. |
|
|
|
The maximum number of gateway nodes allowed for a parallel update. |
|
|
|
Respect Nova availability zone (AZ). The |
|
|
|
The flag to skip the instance verification on a host before proceeding
with the node removal. The |
|
|
|
The flag to skip the volume verification on a host before proceeding
with the node removal. The |
OpenStack database¶
MOSK relies on the MariaDB Galera cluster to provide its OpenStack components with a reliable storage of persistent data.
For successful long-term operations of a MOSK cloud, it is crucial to ensure the healthy state of the OpenStack database as well as the safety of the data stored in it. To help you with that, MOSK provides built-in automated procedures for OpenStack database maintenance, backup, and restoration. The hereby chapter describes the internal mechanisms and configuration details for the provided tools.
Overview of the OpenStack database backup and restoration¶
MOSK relies on the MariaDB Galera cluster to provide its OpenStack components with a reliable storage for persistent data. Mirantis recommends backing up your OpenStack databases daily to ensure the safety of your cloud data. Also, you should always create an instant backup before updating your cloud or performing any kind of potentially disruptive experiment.
MOSK has a built-in automated backup routine that can be triggered manually or by schedule. For detailed information about the process of MariaDB Galera cluster backup, refer to Workflows of the OpenStack database backup and restoration.
Backup and restoration can only be performed against the OpenStack database as a whole. Granular per-service or per-table procedures are not supported by MOSK.
By default, periodic backups are turned off. Though, a cloud operator can
easily enable this capability by adding the following structure to the
OpenStackDeployment custom resource:
spec:
features:
database:
backup:
enabled: true
For the configuration details, refer to Periodic OpenStack database backups.
Along with the automated backup routine, MOSK provides the Mariabackup tool for the OpenStack database restoration. For the database restoration procedure, refer to Restore OpenStack databases from a backup. For more information about the restoration process, consult Workflows of the OpenStack database backup and restoration.
By default, MOSK backup routine stores the OpenStack database data into the Mirantis Ceph cluster, which is a part of the same cloud. This is sufficient for the vast majority of clouds. However, you may want to have the backup data stored off the cloud to comply with specific enterprise practices for infrastructure recovery and data safety.
To achieve that, MOSK enables you to point the backup routine to an external data volume. For details, refer to Remote storage for OpenStack database backups.
The size of a backup storage volume depends directly on the size of the
MOSK cluster, which can be determined through the
size parameter in the OpenStackDeployment CR.
The list of the recommended sizes for a minimal backup volume includes:
20 GB for the
tinycluster size40 GB for the
smallcluster size80 GB for the
mediumcluster size
If required, you can change the default size of a database backup volume. However, make sure that you configure the volume size before OpenStack deployment is complete. This is because there is no automatic way to resize the backup volume once the cloud is deployed. Also, only the local backup storage (Ceph) supports the configuration of the volume size.
To change the default size of the backup volume, use the following structure
in the OpenStackDeployment CR:
spec:
services:
database:
mariadb:
values:
volume:
phy_backup:
size: "200Gi"
To store the backup data to a local Mirantis Ceph, the MOSK underlying Kubernetes cluster needs to have a preconfigured storage class for Kubernetes persistent volumes with the Ceph cluster as a storage back end.
When restoring the OpenStack database from a local Ceph storage, the cron job restores the state on each MariaDB node sequentially. It is not possible to perform parallel restoration because Ceph Kubernetes volumes do not support concurrent mounting from multiple places.
MOSK provides you with a capability to store the OpenStack database data outside of the cloud, on an external storage device that supports common data access protocols, such as third-party NAS appliances.
Refer to Remote storage for OpenStack database backups for the configuration details.
Workflows of the OpenStack database backup and restoration¶
This section provides technical details about the internal implementation of automated backup and restoration routines built into MOSK. The below information would be helpful for troubleshooting of any issues related to the process or understanding the impact these procedures impose on a running cloud.
The OpenStack database backup workflow consists of the following phases.
The mariadb-phy-backup job launches the
mariadb-phy-backup-<TIMESTAMP> pod. This pod contains the main backup
script, which is responsible for:
Basic sanity checks and choosing right node for backup
Verifying the wsrep status and changing the
wsrep_desyncparameter settingsManaging the
mariadb-phy-backup-runnerpod
During the first backup phase, the following actions take place:
Sanity check: verification of the Kubernetes status and wsrep status of each MariaDB pod. If some pods have wrong statuses, the backup job fails unless the
--allow-unsafe-backupparameter is passed to the main script in the Kubernetes backup job.Note
Since MOSK 22.4, the
--allow-unsafe-backupfunctionality is removed from the product for security and backup procedure simplification purposes.Mirantis does not recommend setting the
--allow-unsafe-backupparameter unless it is absolutely required. To ensure the consistency of a backup, verify that the MariaDB Galera cluster is in a working state before you proceed with the backup.
Select the replica to back up. The system selects the replica with the highest number in its name as a target replica. For example, if the MariaDB server pods have the
mariadb-server-0,mariadb-server-1, andmariadb-server-2names, themariadb-server-2replica will be backed up.Desynchronize the replica from the Galera cluster. The script connects the target replica and sets the
wsrep_desyncvariable toON. Then, the replica stops receiving write-sets and receives the wsrep statusDonor/Desynced. The Kubernetes health check of thatmariadb-serverpod fails and the Kubernetes status of that pod becomesNot ready. If the pod has theprimarylabel, the MariaDB Controller sets thebackuplabel to it and the pod is removed from the endpoints list of the MariaDB service.
The main script in the
mariadb-phy-backuppod launches the Kubernetes podmariadb-phy-backup-runner-<TIMESTAMP>on the same node where the targetmariadb-serverreplica is running, which is nodeXin the example.The
mariadb-phy-backup-runnerpod has bothmysqldata directory andbackupdirectory mounted. The pod performs the following actions:Verifies that there is enough space in the
/var/backupfolder to perform the backup. The amount of available space in the folder should be greater than<DB-SIZE> * <MARIADB-BACKUP-REQUIRED-SPACE-RATIOin KB.Performs the actual backup using the mariabackup tool.
If the number of current backups is greater than the value of the
MARIADB_BACKUPS_TO_KEEPjob parameter, the script removes all old backups exceeding the allowed number of backups.Exits with
0code.
The script waits untill the
mariadb-phy-backup-runnerpod is completed and collects its logs.The script puts the backed up replica back to sync with the Galera cluster by setting
wsrep_desynctoOFFand waits for the replica to becomeReadyin Kubernetes.
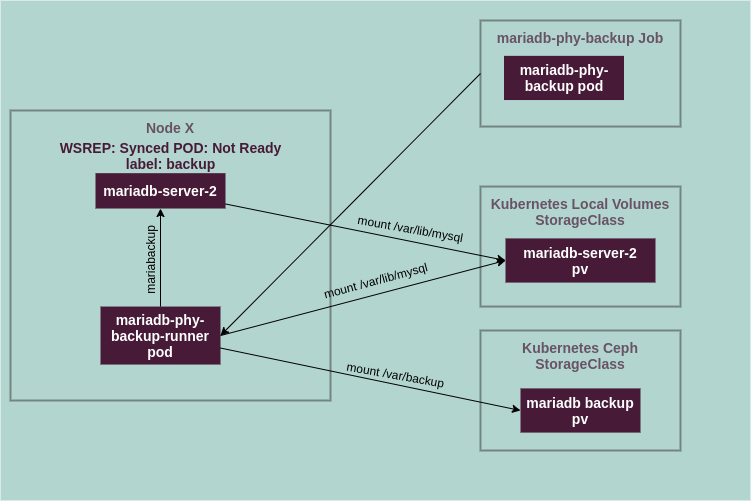
The OpenStack database restoration workflow consists of the following phases.
The mariadb-phy-restore job launches the mariadb-phy-restore pod.
This pod contains the main restore script, which is responsible for:
Scaling of the
mariadb-serverStatefulSetVerifying of the
mariadb-serverpods statusesManaging of the
openstack-mariadb-phy-restore-runnerpods
Caution
During the restoration, the database is not available for OpenStack services that means a complete outage of all OpenStack services.
During the first phase, the following actions are performed:
Save the list of
mariadb-serverpersistent volume claims (PVC).Scale the
mariadbserver StatefulSet to0replicas. At this point, the database becomes unavailable for OpenStack services.
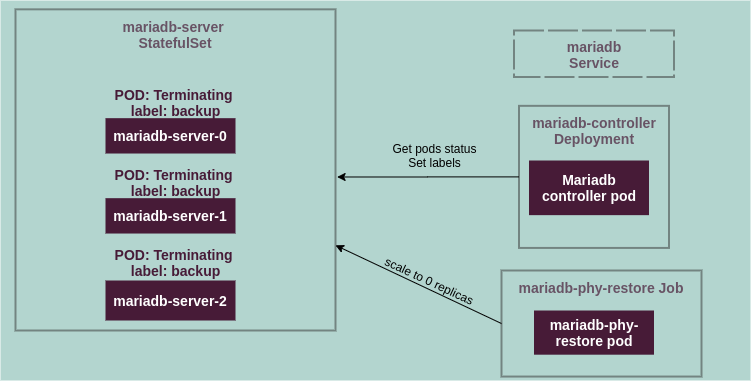
The
mariadb-phy-restorepod launchesopenstack-mariadb-phy-restore-runnerwith the firstmariadb-serverreplica PVC mounted to the/var/lib/mysqlfolder and the backup PVC mounted to/var/backup. Theopenstack-mariadb-phy-restore-runnerpod performs the following actions:Unarchives the database backup files to a temporary directory within
/var/backup.Executes
mariabackup --prepareon the unarchived data.Creates the
.preparedfile in the temporary directory in/var/backup.Restores the backup to
/var/lib/mysql.Exits with 0.
The script in the
mariadb-phy-restorepod collects the logs from theopenstack-mariadb-phy-restore-runnerpod and removes the pod. Then, the script launches the nextopenstack-mariadb-phy-restore-runnerpod for the nextmariadb-serverreplica PVC. Theopenstack-mariadb-phy-restore-runnerpod restores the backup to/var/lib/mysqland exits with0.Step 2 is repeated for every
mariadb-serverreplica PVC sequentially.When the last replica’s data is restored, the last
openstack-mariadb-phy-restore-runnerpod removes the.preparedfile and the temporary folder with unachieved data from/var/backup.
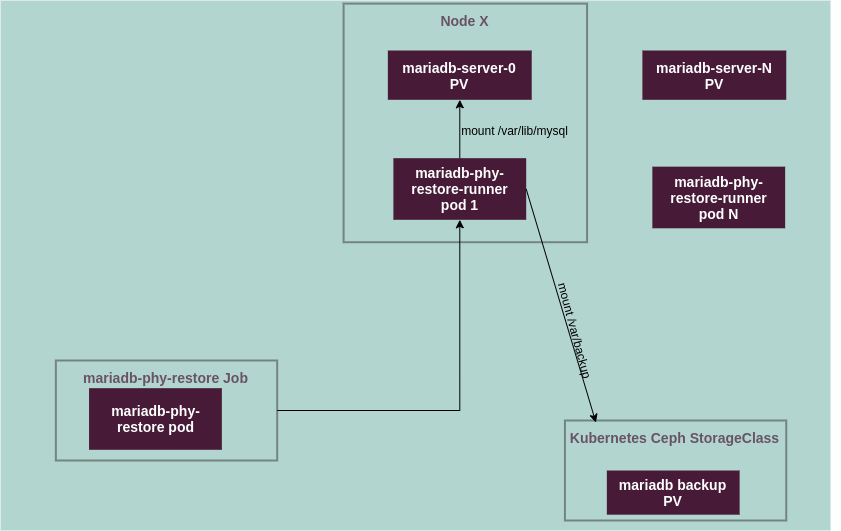
The
mariadb-phy-restorepod scales themariadb-serverStatefulSet back to the configured number of replicas.The
mariadb-phy-restorepod waits until allmariadb-serverreplicas are ready.
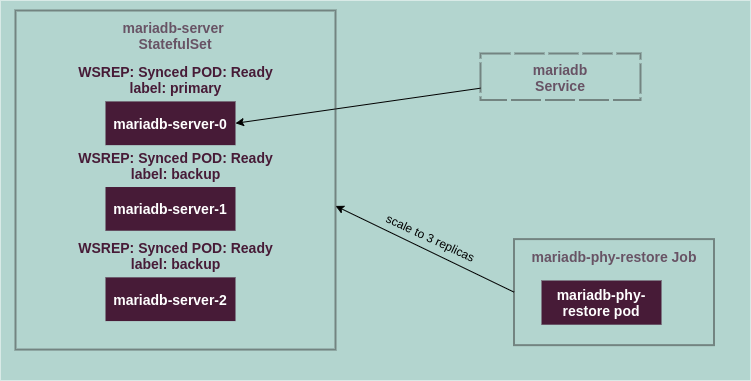
OpenStack database auto-cleanup¶
By design, when deleting a cloud resource, for example, an instance, volume, or router, an OpenStack service does not immediately delete its data but marks it as removed so that it can later be picked up by the garbage collector.
Given that an OpenStack resource is often represented by more than one record in the database, deletion of all of them right away could affect the overall responsiveness of the cloud API. On the other hand, an OpenStack database being severely clogged with stale data is one of the most typical reasons for the cloud slowness.
To keep the OpenStack database small and performance fast, MOSK is pre-configured to automatically clean up the removed database records older than 30 days. By default, the clean up is performed for the following MOSK services every Monday according to the schedule:
Service |
Service identifier |
Clean up time |
|---|---|---|
Block Storage (OpenStack Cinder) |
|
12:01 a.m. |
Compute (OpenStack Nova) |
|
01:01 a.m. |
Image (OpenStack Glance) |
|
02:01 a.m. |
Instance HA (OpenStack Masakari) |
|
03:01 a.m. |
Key Manager (OpenStack Barbican) |
|
04:01 a.m. |
Orchestration (OpenStack Heat) |
|
05:01 a.m. |
If required, you can adjust the cleanup schedule for the OpenStack database by
adding the features:database:cleanup setting to the OpenStackDeployment
CR following the example below. The schedule parameter must contain a
valid cron expression. The age parameter specifies the number of days after
which a stale record gets cleaned up.
spec:
features:
database:
cleanup:
<os-service-identifier>:
enabled: true
schedule: "1 0 * * 1"
age: 30
batch: 1000
Periodic OpenStack database backups¶
MOSK uses the Mariabackup utility to back up the MariaDB Galera cluster data where the OpenStack data is stored. The Mariabackup gets launched on a periodic basis as a part of the Kubernetes CronJob included in any MOSK deployment and is suspended by default.
Note
If you are using the default back end to store the backup data, which is Ceph, you can increase the default size of a backup volume. However, make sure to configure the volume size before you deploy OpenStack.
For the default sizes and configuration details, refer to Size of a backup storage.
MOSK enables you to configure the periodic backup of the
OpenStack database through the OpenStackDeployment object. To enable the
backup, use the following structure:
spec:
features:
database:
backup:
enabled: true
By default, the backup job:
Runs backup on a daily basis at 01:00 AM
Creates incremental backups daily and full backups weekly
Keeps 10 latest full backups
Stores backups in the
mariadb-phy-backup-dataPVCHas the backup timeout of
3600secondsHas the
incrementalbackup type
To verify the configuration of the mariadb-phy-backup CronJob
object, run:
kubectl -n openstack get cronjob mariadb-phy-backup
Example of a mariadb-phy-backup CronJob object
apiVersion: batch/v1beta1
kind: CronJob
metadata:
annotations:
openstackhelm.openstack.org/release_uuid: ""
creationTimestamp: "2020-09-08T14:13:48Z"
managedFields:
<<<skipped>>>>
name: mariadb-phy-backup
namespace: openstack
resourceVersion: "726449"
selfLink: /apis/batch/v1beta1/namespaces/openstack/cronjobs/mariadb-phy-backup
uid: 88c9be21-a160-4de1-afcf-0853697dd1a1
spec:
concurrencyPolicy: Forbid
failedJobsHistoryLimit: 1
jobTemplate:
metadata:
creationTimestamp: null
labels:
application: mariadb-phy-backup
component: backup
release_group: openstack-mariadb
spec:
activeDeadlineSeconds: 4200
backoffLimit: 0
completions: 1
parallelism: 1
template:
metadata:
creationTimestamp: null
labels:
application: mariadb-phy-backup
component: backup
release_group: openstack-mariadb
spec:
containers:
- command:
- /tmp/mariadb_resque.py
- backup
- --backup-timeout
- "3600"
- --backup-type
- incremental
env:
- name: MARIADB_BACKUPS_TO_KEEP
value: "10"
- name: MARIADB_BACKUP_PVC_NAME
value: mariadb-phy-backup-data
- name: MARIADB_FULL_BACKUP_CYCLE
value: "604800"
- name: MARIADB_REPLICAS
value: "3"
- name: MARIADB_BACKUP_REQUIRED_SPACE_RATIO
value: "1.2"
- name: MARIADB_RESQUE_RUNNER_IMAGE
value: docker-dev-kaas-local.docker.mirantis.net/general/mariadb:10.4.14-bionic-20200812025059
- name: MARIADB_RESQUE_RUNNER_SERVICE_ACCOUNT
value: mariadb-phy-backup-runner
- name: MARIADB_RESQUE_RUNNER_POD_NAME_PREFIX
value: openstack-mariadb
- name: MARIADB_POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
image: docker-dev-kaas-local.docker.mirantis.net/general/mariadb:10.4.14-bionic-20200812025059
imagePullPolicy: IfNotPresent
name: phy-backup
resources: {}
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /tmp
name: pod-tmp
- mountPath: /tmp/mariadb_resque.py
name: mariadb-bin
readOnly: true
subPath: mariadb_resque.py
- mountPath: /tmp/resque_runner.yaml.j2
name: mariadb-bin
readOnly: true
subPath: resque_runner.yaml.j2
- mountPath: /etc/mysql/admin_user.cnf
name: mariadb-secrets
readOnly: true
subPath: admin_user.cnf
dnsPolicy: ClusterFirst
initContainers:
- command:
- kubernetes-entrypoint
env:
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: INTERFACE_NAME
value: eth0
- name: PATH
value: /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/
- name: DEPENDENCY_SERVICE
- name: DEPENDENCY_DAEMONSET
- name: DEPENDENCY_CONTAINER
- name: DEPENDENCY_POD_JSON
- name: DEPENDENCY_CUSTOM_RESOURCE
image: docker-dev-kaas-local.docker.mirantis.net/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233
imagePullPolicy: IfNotPresent
name: init
resources: {}
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsUser: 65534
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
nodeSelector:
openstack-control-plane: enabled
restartPolicy: Never
schedulerName: default-scheduler
securityContext:
runAsUser: 999
serviceAccount: mariadb-phy-backup
serviceAccountName: mariadb-phy-backup
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: pod-tmp
- name: mariadb-secrets
secret:
defaultMode: 292
secretName: mariadb-secrets
- configMap:
defaultMode: 365
name: mariadb-bin
name: mariadb-bin
schedule: 0 1 * * *
successfulJobsHistoryLimit: 3
suspend: false
To override the default configuration, set the parameters and environment variables that are passed to the CronJob as described in the tables below.
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
String |
|
Type of a backup. The list of possible values include:
Usage example: spec:
features:
database:
backup:
backup_type: incremental
|
|
Integer |
|
Timeout in seconds for the system to wait for the backup operation to succeed. Usage example: spec:
services:
database:
mariadb:
values:
conf:
phy_backup:
backup_timeout: 30000
|
|
Boolean |
|
Not recommended, removed since MOSK 22.4. If set to
Usage example: spec:
services:
database:
mariadb:
values:
conf:
phy_backup:
allow_unsafe_backup: true
|
Variable |
Type |
Default |
Description |
|---|---|---|---|
|
Integer |
|
Number of full backups to keep. Usage example: spec:
features:
database:
backup:
backups_to_keep: 3
|
|
String |
|
Persistent volume claim used to store backups. Usage example: spec:
services:
database:
mariadb:
values:
conf:
phy_backup:
backup_pvc_name: mariadb-phy-backup-data
|
|
Integer |
|
Number of seconds that defines a period between 2 full backups.
During this period, incremental backups are performed. The parameter
is taken into account only if Usage example: spec:
features:
database:
backup:
full_backup_cycle: 70000
|
|
Floating |
|
Multiplier for the database size to predict the space required to create a backup, either full or incremental, and perform a restoration keeping the uncompressed backup files on the same file system as the compressed ones. To estimate the size of The Usage example: spec:
services:
database:
mariadb:
values:
conf:
phy_backup:
backup_required_space_ratio: 1.4
|
For example, to perform full backups monthly and incremental backups
daily at 02:30 AM and keep the backups for the last six months,
configure the database backup in your OpenStackDeployment object
as follows:
spec:
features:
database:
backup:
enabled: true
backups_to_keep: 6
schedule_time: '30 2 * * *'
full_backup_cycle: 2628000
Remote storage for OpenStack database backups¶
By default, MOSK stores the OpenStack database backups locally in the Mirantis Ceph cluster, which is a part of the same cloud.
Alternatively, MOSK provides you with a capability to create remote backups using an external storage. This section contains configuration details for a remote back end to be used for the OpenStack data backup.
In general, the built-in automated backup routine saves the data to the
mariadb-phy-backup-data PersistentVolumeClaim (PVC), which is provisioned
from StorageClass specified in the spec.persistent_volume_storage_class
parameter of the OpenstackDeployment custom resource (CR).
TechPreview
A preconfigured NFS server with NFS share that a Unix backup and restore user has access to. By default, it is the same user that runs MySQL server in a MariaDB image.
To get the Unix user ID, run:
kubectl -n openstack get cronjob mariadb-phy-backup -o jsonpath='{.spec.jobTemplate.spec.template.spec.securityContext.runAsUser}'
Note
Verify that the NFS server is accessible through the network from all of the OpenStack control plane nodes of the cluster.
The
nfs-commonpackage installed on all OpenStack control plane nodes.
Only NFS Unix authentication is supported.
Removal of the NFS persistent volume does not automatically remove the data.
No validation of mount options. If mount options are specified incorrectly in the
OpenStackDeploymentCR, the mount command fails upon the creation of a backup runner pod.
To enable the NFS back end, configure the following structure in the
OpenStackDeployment object:
spec:
features:
database:
backup:
enabled: true
backend: pv_nfs
pv_nfs:
server: <ip-address/dns-name-of-the-server>
path: <path-to-the-share-folder-on-the-server>
Optionally, MOSK enables you to set the required mount options for the NFS mount command. You can set as many options of mount as you need. For example:
spec:
services:
database:
mariadb:
values:
volume:
phy_backup:
nfs:
mountOptions:
- "nfsvers=4"
- "hard"
OpenStack message bus¶
The internal components of Mirantis OpenStack for Kubernetes (MOSK) coordinate their operations and exchange status information using the cluster’s message bus (RabbitMQ).
Exposable OpenStack notifications¶
Available since MOSK 22.5
MOSK enables you to configure OpenStack services to emit
notification messages to the MOSK cluster messaging bus
(RabbitMQ) every time an OpenStack resource, for example, an instance, image,
and so on, changes its state due to a cloud user action or through its
lifecycle. For example, MOSK Compute service (OpenStack
Nova) can publish the instance.create.end notification once a newly created
instance is up and running.
Note
In certain cases, RabbitMQ notifications may prove unreliable, such as when the RabbitMQ server undergoes a restart or when communication between the server and the client reading the notifications breaks down. To optimize reliability, Mirantis suggests using multiple channels to store notification events, encompassing:
StackLight notifications
Storing audit as part of the OpenStack logs
Sample of an instance.create.end notification
{
"event_type": "instance.create.end",
"payload": {
"nova_object.data": {
"action_initiator_project": "6f70656e737461636b20342065766572",
"action_initiator_user": "fake",
"architecture": "x86_64",
"auto_disk_config": "MANUAL",
"availability_zone": "nova",
"block_devices": [],
"created_at": "2012-10-29T13:42:11Z",
"deleted_at": null,
"display_description": "some-server",
"display_name": "some-server",
"fault": null,
"flavor": {
"nova_object.data": {
"description": null,
"disabled": false,
"ephemeral_gb": 0,
"extra_specs": {
"hw:watchdog_action": "disabled"
},
"flavorid": "a22d5517-147c-4147-a0d1-e698df5cd4e3",
"is_public": true,
"memory_mb": 512,
"name": "test_flavor",
"projects": null,
"root_gb": 1,
"rxtx_factor": 1.0,
"swap": 0,
"vcpu_weight": 0,
"vcpus": 1
},
"nova_object.name": "FlavorPayload",
"nova_object.namespace": "nova",
"nova_object.version": "1.4"
},
"host": "compute",
"host_name": "some-server",
"image_uuid": "155d900f-4e14-4e4c-a73d-069cbf4541e6",
"instance_name": "instance-00000001",
"ip_addresses": [
{
"nova_object.data": {
"address": "192.168.1.3",
"device_name": "tapce531f90-19",
"label": "private",
"mac": "fa:16:3e:4c:2c:30",
"meta": {},
"port_uuid": "ce531f90-199f-48c0-816c-13e38010b442",
"version": 4
},
"nova_object.name": "IpPayload",
"nova_object.namespace": "nova",
"nova_object.version": "1.0"
}
],
"kernel_id": "",
"key_name": "my-key",
"keypairs": [
{
"nova_object.data": {
"fingerprint": "1e:2c:9b:56:79:4b:45:77:f9:ca:7a:98:2c:b0:d5:3c",
"name": "my-key",
"public_key": "ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAAAgQDx8nkQv/zgGgB4rMYmIf+6A4l6Rr+o/6lHBQdW5aYd44bd8JttDCE/F/pNRr0lRE+PiqSPO8nDPHw0010JeMH9gYgnnFlyY3/OcJ02RhIPyyxYpv9FhY+2YiUkpwFOcLImyrxEsYXpD/0d3ac30bNH6Sw9JD9UZHYcpSxsIbECHw== Generated-by-Nova",
"type": "ssh",
"user_id": "fake"
},
"nova_object.name": "KeypairPayload",
"nova_object.namespace": "nova",
"nova_object.version": "1.0"
}
],
"launched_at": "2012-10-29T13:42:11Z",
"locked": false,
"locked_reason": null,
"metadata": {},
"node": "fake-mini",
"os_type": null,
"power_state": "running",
"progress": 0,
"ramdisk_id": "",
"request_id": "req-5b6c791d-5709-4f36-8fbe-c3e02869e35d",
"reservation_id": "r-npxv0e40",
"state": "active",
"tags": [
"tag"
],
"task_state": null,
"tenant_id": "6f70656e737461636b20342065766572",
"terminated_at": null,
"trusted_image_certificates": [
"cert-id-1",
"cert-id-2"
],
"updated_at": "2012-10-29T13:42:11Z",
"user_id": "fake",
"uuid": "178b0921-8f85-4257-88b6-2e743b5a975c"
},
"nova_object.name": "InstanceCreatePayload",
"nova_object.namespace": "nova",
"nova_object.version": "1.12"
},
"priority": "INFO",
"publisher_id": "nova-compute:compute"
}
OpenStack notification messages can be consumed and processed by various corporate systems to integrate MOSK clouds into the company infrastructure and business processes.
The list of the most common use cases includes:
Using notification history for retrospective security audit
Using the real-time aggregation of notification messages to gather statistics on cloud resource consumption for further capacity planning
Cloud billing considerations
Notifications alone should not be considered as a source of data for any kind of financial reporting. The delivery of the messages can not be guaranteed due to various technical reasons. For example, messages can be lost if an external consumer is not fetching them from the queue fast enough.
Mirantis strongly recommends that your cloud billing solutions rely on the combination of the following data sources:
Periodic polling of the OpenStack API as a reliable source of information about allocated resources
Subscription to notifications to receive timely updates about the resource status change
If you are looking for a ready-to-use billing solution for your cloud, contact Mirantis or one of our partners.
A cloud administrator can securely expose part of a MOSK cluster message bus to the outside world. This enables an external consumer to subscribe to the notification messages emitted by the cluster services.
Important
The latest OpenStack release available in MOSK supports notifications from the following services:
Block storage (OpenStack Cinder)
DNS (OpenStack Designate)
Image (OpenStack Glance)
Orchestration (OpenStack Heat)
Bare Metal (OpenStack Ironic)
Identity (OpenStack Keystone)
Shared Filesystems (OpenStack Manila)
Instance High Avalability (OpenStack Masakari)
Networking (OpenStack Neutron)
Compute (OpenStack Nova)
To enable the external notification endpoint, add the following structure
to the OpenStackDeployment custom resource. For example:
spec:
features:
messaging:
notifications:
external:
enabled: true
topics:
- external-consumer-A
- external-consumer-2
For each topic name specified in the topics field, MOSK
creates a topic exchange in its RabbitMQ cluster together with a set of queues
bound to this topic. All enabled MOSK services will
publish their notification messages to all configured topics so that
multiple consumers can receive the same messages in parallel.
A topic name must follow Kubernetes standard format for object names and IDs
that is only lowercase alphanumeric characters, -, or . The topic
name notifications is reserved for the internal use.
MOSK supports the connection to message bus (RabbitMQ) through an encrypted or non-encrypted endpoint. Once connected, it supports authentication through either a plain text user name and password or mutual TLS authentication using encrypted X.509 client certificates.
Each topic exchange is protected by automatically generated authentication
credentials and certificates for secure connection that are stored as a secret
in the openstack-external namespace of a MOSK underlying
Kubernetes cluster. A secret is identified by the name of the topic. The list
of attributes for the secret object includes:
hostsThe IP addresses which an external notification endpoint is available on
port_amqp,port_amqp-tlsThe TCP ports which external notification endpoint is available on
vhostThe name of the RabbitMQ virtual host which the topic queues are created on
username,passwordAuthentication data
ca_certThe client CA certificate
client_certThe client certificate
client_keyThe client private key
For the configuration example above, the following objects will be created:
kubectl -n openstack-external get secret
NAME TYPE DATA AGE
openstack-external-consumer-A-notifications Opaque 4 4m51s
openstack-external-consumer-2-notifications Opaque 4 4m51s
Tungsten Fabric¶
Tungsten Fabric provides basic L2/L3 networking to an OpenStack environment running on the MKE cluster and includes the IP address management, security groups, floating IP addresses, and routing policies functionality. Tungsten Fabric is based on overlay networking, where all virtual machines are connected to a virtual network with encapsulation (MPLSoGRE, MPLSoUDP, VXLAN). This enables you to separate the underlay Kubernetes management network. A workload requires an external gateway, such as a hardware EdgeRouter or a simple gateway to route the outgoing traffic.
The Tungsten Fabric vRouter uses different gateways for the control and data planes.
Tungsten Fabric cluster¶
All services of Tungsten Fabric are delivered as separate containers, which are deployed by the Tungsten Fabric Operator (TFO). Each container has an INI-based configuration file that is available on the host system. The configuration file is generated automatically upon the container start and is based on environment variables provided by the TFO through Kubernetes ConfigMaps.
The main Tungsten Fabric containers run with the host network as
DeploymentSet, without using the Kubernetes networking layer. The services
listen directly on the host network interface.
The following diagram describes the minimum production installation of Tungsten Fabric with a Mirantis OpenStack for Kubernetes (MOSK) deployment.
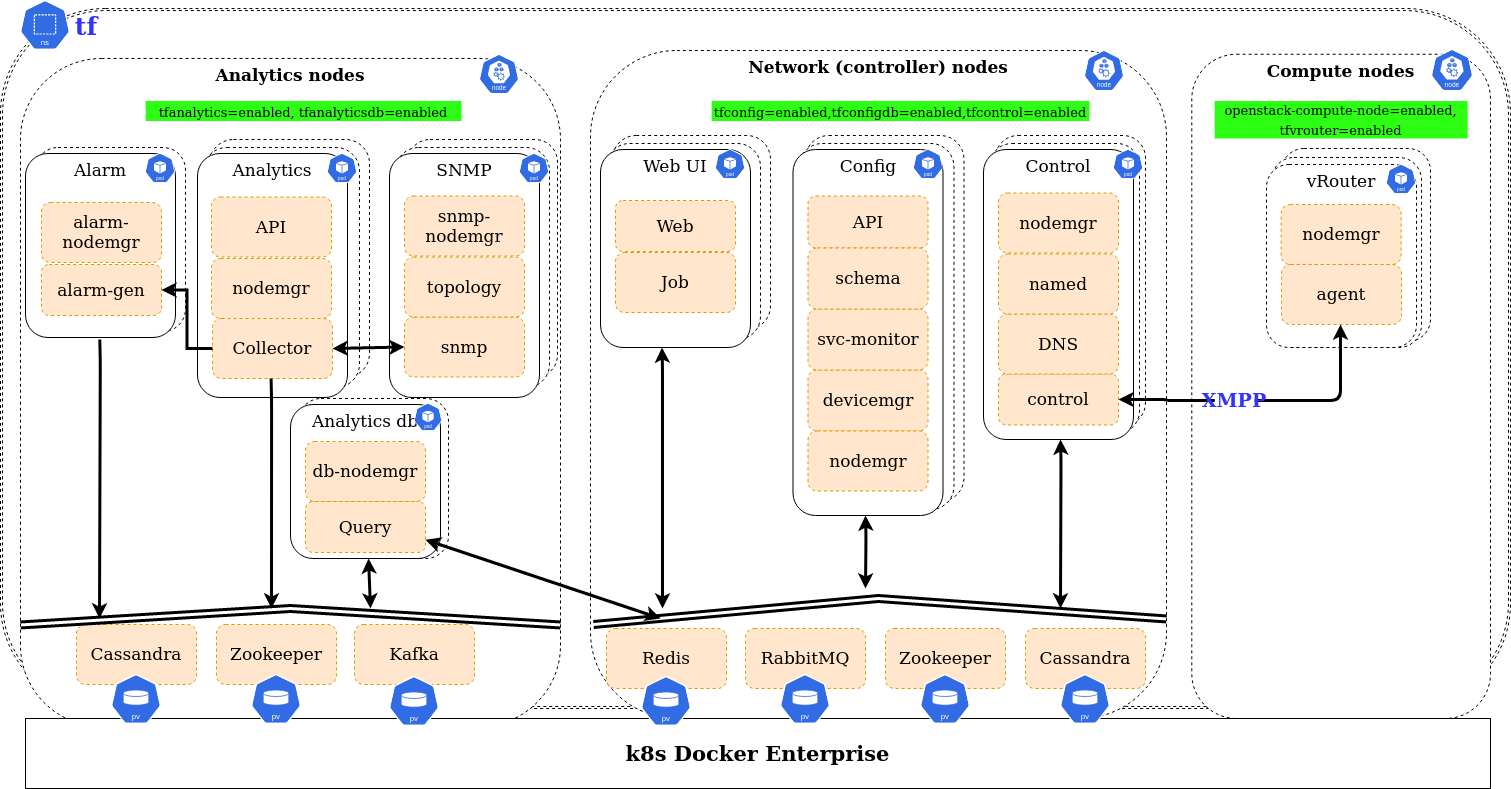
For the details about the Tungsten Fabric services included in MOSK deployments and the types of traffic and traffic flow directions, see the subsections below.
Tungsten Fabric cluster components¶
This section describes the Tungsten Fabric services and their distribution across the Mirantis OpenStack for Kubernetes (MOSK) deployment.
The Tungsten Fabric services run mostly as DaemonSets in separate containers for each service. The deployment and update processes are managed by the Tungsten Fabric Operator. However, Kubernetes manages the probe checks and restart of broken containers.
All configuration and control services run on the Tungsten Fabric Controller nodes.
Service name |
Service description |
|---|---|
|
Exposes a REST-based interface for the Tungsten Fabric API. |
|
Collects data of the Tungsten Fabric configuration processes and sends
it to the Tungsten Fabric |
|
Communicates with the cluster gateways using BGP and with the vRouter agents using XMPP, as well as redistributes appropriate networking information. |
|
Collects the Tungsten Fabric Controller process data and sends
this information to the Tungsten Fabric |
|
Manages physical networking devices using |
|
Using the |
|
The customized Berkeley Internet Name Domain (BIND) daemon of
Tungsten Fabric that manages DNS zones for the |
|
Listens to configuration changes performed by a user and generates corresponding system configuration objects. In multi-node deployments, it works in the active-backup mode. |
|
Listens to configuration changes of |
|
Consists of the |
All analytics services run on Tungsten Fabric analytics nodes.
Service name |
Service description |
|---|---|
|
Evaluates and manages the alarms rules. |
|
Provides a REST API to interact with the Cassandra analytics database. |
|
Collects all Tungsten Fabric analytics process data and sends
this information to the Tungsten Fabric |
|
Provisions the init model if needed. Collects data of the |
|
Collects and analyzes data from all Tungsten Fabric services. |
|
Handles the queries to access data from the Cassandra database. |
|
Receives the authorization and configuration of the physical routers
from the |
|
Reads the SNMP information from the physical router user-visible entities (UVEs), creates a neighbor list, and writes the neighbor information to the physical router UVEs. The Tungsten Fabric web UI uses the neighbor list to display the physical topology. |
The Tungsten Fabric vRouter provides data forwarding to an OpenStack tenant instance and reports statistics to the Tungsten Fabric analytics service. The Tungsten Fabric vRouter is installed on all OpenStack compute nodes. Mirantis OpenStack for Kubernetes (MOSK) supports the kernel-based deployment of the Tungsten Fabric vRouter.
Service name |
Service description |
|---|---|
|
Connects to the Tungsten Fabric Controller container and the Tungsten Fabric DNS system using the Extensible Messaging and Presence Protocol (XMPP). The vRouter Agent acts as a local control plane. Each Tungsten Fabric vRouter Agent is connected to at least two Tungsten Fabric controllers in an active-active redundancy mode. The Tungsten Fabric vRouter Agent is responsible for all networking-related functions including routing instances, routes, and others. The Tungsten Fabric vRouter uses different gateways for the control and data planes. For example, the Linux system gateway is located on the management network, and the Tungsten Fabric gateway is located on the data plane network. |
|
Collects the supervisor |
The following diagram illustrates the Tungsten Fabric kernel vRouter set up by the TF operator:
On the diagram above, the following types of networks interfaces are used:
eth0- for the management (PXE) network (eth1andeth2are the slave interfaces ofBond0)Bond0.x- for the MKE control plane networkBond0.y- for the MKE data plane network
Service name |
Service description |
|---|---|
|
|
|
The Kubernetes operator that enables the Cassandra clusters creation and management. |
|
Handles the messaging bus and generates alarms across the Tungsten Fabric analytics containers. |
|
The Kubernetes operator that enables Kafka clusters creation and management. |
|
Stores the physical router UVE storage and serves as a messaging bus for event notifications. |
|
The Kubernetes operator that enables Redis clusters creation and management. |
|
Holds the active-backup status for the |
|
The Kubernetes operator that enables ZooKeeper clusters creation and management. |
|
Exchanges messages between API servers and original request senders. |
|
The Kubernetes operator that enables RabbitMQ clusters creation and management. |
All Tungsten Fabric plugin services are installed on the OpenStack controller nodes.
Service name |
Service description |
|---|---|
|
The Neutron server that includes the Tungsten Fabric plugin. |
|
The Octavia API that includes the Tungsten Fabric Octavia driver. |
|
The Heat API that includes the Tungsten Fabric Heat resources and templates. |
Along with the Tungsten Fabric services, MOSK deploys and
updates special image precaching DaemonSets when the kind TFOperator
resource is created or image references in it get updated.
These DaemonSets precache container images on Kubernetes nodes minimizing
possible downtime when updating container images. Cloud operator can
disable image precaching through the TFOperator resource.
See also
Tungsten Fabric traffic flow¶
This section describes the types of traffic and traffic flow directions in a Mirantis OpenStack for Kubernetes (MOSK) cluster.
The following diagram illustrates all types of UI and API traffic in a Mirantis OpenStack for Kubernetes cluster, including the monitoring and OpenStack API traffic. The OpenStack Dashboard pod hosts Horizon and acts as a proxy for all other types of traffic. TLS termination is also performed for this type of traffic.
SDN or Tungsten Fabric traffic goes through the overlay Data network and processes east-west and north-south traffic for applications that run in a MOSK cluster. This network segment typically contains tenant networks as separate MPLS-over-GRE and MPLS-over-UDP tunnels. The traffic load depends on the workload.
The control traffic between the Tungsten Fabric controllers, edge routers, and vRouters uses the XMPP with TLS and iBGP protocols. Both protocols produce low traffic that does not affect MPLS over GRE and MPLS over UDP traffic. However, this traffic is critical and must be reliably delivered. Mirantis recommends configuring higher QoS for this type of traffic.
The following diagram displays both MPLS over GRE/MPLS over UDP and iBGP and XMPP traffic examples in a MOSK cluster:
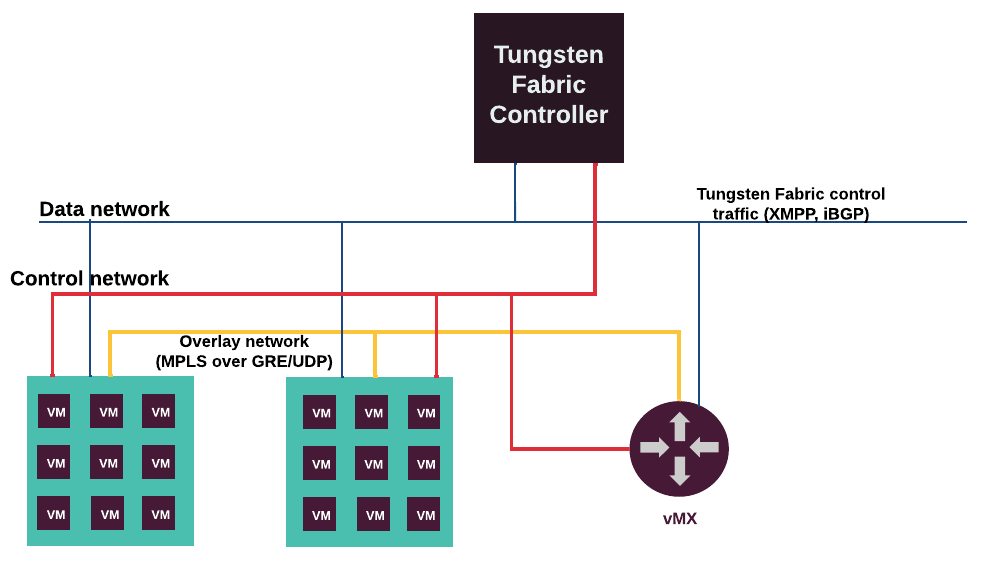
Tungsten Fabric lifecycle management¶
Mirantis OpenStack for Kubernetes (MOSK) provides the Tungsten Fabric lifecycle management including pre-deployment custom configurations, updates, data backup and restoration, as well as handling partial failure scenarios, by means of the Tungsten Fabric operator.
This section is intended for the cloud operators who want to gain insight into the capabilities provided by the Tungsten Fabric operator along with the understanding of how its architecture allows for easy management while addressing the concerns of users of Tungsten Fabric-based MOSK clusters.
Tungsten Fabric Operator¶
The Tungsten Fabric Operator (TFO) is based on the Kubernetes operator SDK project. The Kubernetes operator SDK is a framework that uses the controller-runtime library to make writing operators easier by providing the following:
High-level APIs and abstractions to write the operational logic more intuitively.
Tools for scaffolding and code generation to bootstrap a new project fast.
Extensions to cover common operator use cases.
The TFO deploys the following sub-operators. Each sub-operator handles a separate part of a TF deployment:
Network |
Description |
|---|---|
TFControl |
Deploys the Tungsten Fabric control services, such as:
|
TFConfig |
Deploys the Tungsten Fabric configuration services, such as:
|
TFAnalytics |
Deploys the Tungsten Fabric analytics services, such as:
|
TFVrouter |
Deploys a vRouter on each compute node with the following services:
|
TFWebUI |
Deploys the following web UI services:
|
TFTool |
Deploys the following tools for debug purposes:
|
TFTest |
An operator to run Tempest tests. |
Besides the sub-operators that deploy TF services, TFO uses operators to deploy and maintain third-party services, such as different types of storage, cache, message system, and so on. The following table describes all third-party operators:
Network |
Description |
|---|---|
casandra-operator |
An upstream operator that automates the Cassandra HA storage operations for the configuration and analytics data. |
zookeeper-operator |
An upstream operator for deployment and automation of a ZooKeeper cluster. |
kafka-operator |
An operator for the Kafka cluster used by analytics services. |
redis-operator |
An upstream operator that automates the Redis cluster deployment and keeps it healthy. |
rabbitmq-operator |
An operator for the messaging system based on RabbitMQ. |
The following diagram illustrates a simplified TFO workflow:
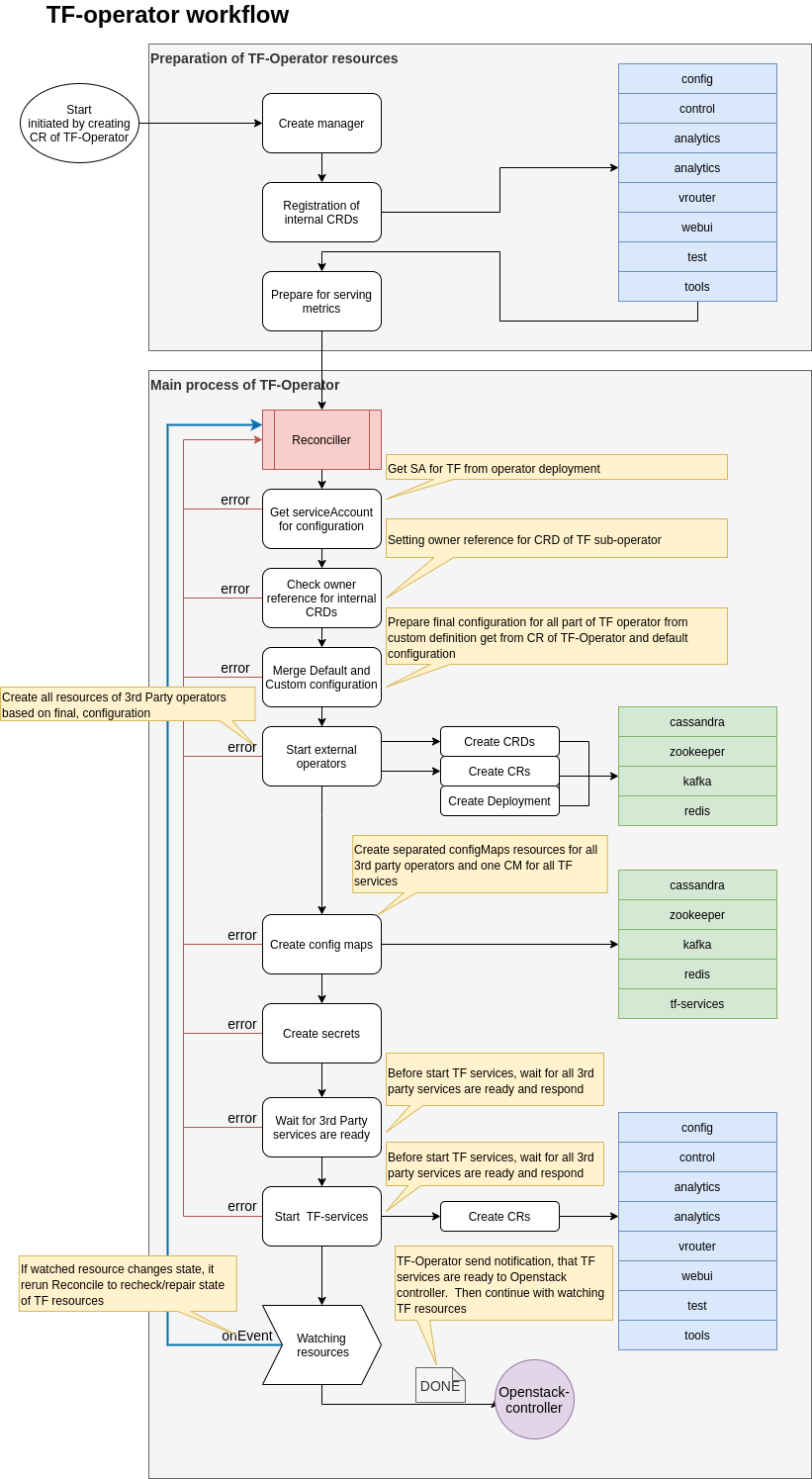
TFOperator custom resource¶
The resource of kind TFOperator (TFO) is a custom resource (CR) defined by
a resource of kind CustomResourceDefinition.
The CustomResourceDefinition resource in Kubernetes uses the OpenAPI
Specification (OAS) version 2 to specify the schema of the defined resource.
The Kubernetes API outright rejects the resources that do not pass this schema
validation. Along with schema validation, TFOperator uses
ValidatingAdmissionWebhook for extended validations when a CR is created
or updated.
For the list of configuration options available to a cloud operator, refer to Tungsten Fabric configuration. Also, check out the Tungsten Fabric API Reference document of the MOSK version that your cluster has been deployed with.
Tungsten Fabric Operator uses ValidatingAdmissionWebhook to validate
environment variables set to Tungsten Fabric components upon the TFOperator
object creation or update. The following validations are performed:
Environment variables passed to TF components containers
Mapping between
tfVersionandtfImageTag, if definedSchedule and data capacity format for
tf-dbBackup
If required, you can disable ValidatingAdmissionWebhook through the
TFOperator HelmBundle resource:
apiVersion: lcm.mirantis.com/v1alpha1
kind: HelmBundle
metadata:
name: tungstenfabric-operator
namespace: tf
spec:
releases:
- name: tungstenfabric-operator
values:
admission:
enabled: false
Environment variables |
TF components and containers |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
See also
Tungsten Fabric configuration¶
Mirantis OpenStack for Kubernetes (MOSK) allows you to easily adapt
your Tungsten Fabric deployment to the needs of your environment through the
TFOperator custom resource.
This section includes custom configuration details available to you.
Important
Since 24.1, MOSK introduces the technical preview support for the API v2 for the Tungsten Fabric Operator. This version of the Tungsten Fabric Operator API aligns with the OpenStack Controller API and provides better interface for advanced configurations. In MOSK 24.1, the API v2 is available only for the new product deployments with Tungsten Fabric.
Cassandra configuration¶
This section describes the Cassandra configuration through the Tungsten Fabric Operator custom resource.
By default, Tungsten Fabric Operator sets up the following resource limits for Cassandra analytics and configuration StatefulSets:
Limits:
cpu: 8
memory: 32Gi
Requests:
cpu: 1
memory: 16Gi
This is a verified configuration suitable for most cases. However, if nodes
are under a heavy load, the KubeContainerCPUThrottlingHigh StackLight alert
may raise for Tungsten Fabric Pods of the tf-cassandra-analytics and
tf-cassandra-config StatefulSets. If such alerts appear constantly, you can
increase the limits through the TFOperator custom resource. For example:
spec:
controllers:
cassandra:
deployments:
- name: tf-cassandra-config
resources:
limits:
cpu: "12"
memory: 32Gi
requests:
cpu: "2"
memory: 16Gi
- name: tf-cassandra-analytics
resources:
limits:
cpu: "12"
memory: 32Gi
requests:
cpu: "2"
memory: 16Gi
spec:
services:
analytics:
enabled: true
cassandra:
resources:
limits:
cpu: "12"
memory: 32Gi
requests:
cpu: "2"
memory: 16Gi
config:
cassandra:
resources:
limits:
cpu: "12"
memory: 32Gi
requests:
cpu: "2"
memory: 16Gi
To specify custom configurations for Cassandra clusters, use the
configOptions settings in the TFOperator custom resource.
For example, you may need to increase the file cache size in case
of a heavy load on the nodes labeled with tfanalyticsdb=enabled
or tfconfigdb=enabled:
spec:
controllers:
cassandra:
deployments:
- name: tf-cassandra-analytics
configOptions:
file_cache_size_in_mb: 1024
spec:
services:
analytics:
enabled: true
cassandra:
configOptions:
file_cache_size_in_mb: 1024
Custom vRouter settings¶
TechPreview
Depending on the Tungsten Fabric Operator API version in use, proceed with one of the following options:
To specify custom settings for the Tungsten Fabric vRouter nodes, for
example, to change the name of the tunnel network interface or enable
debug level logging on some subset of nodes, use the customSpecs
settings in the TFOperator custom resource.
For example, to enable debug level logging on a specific node or multiple nodes:
spec:
controllers:
tf-vrouter:
agent:
customSpecs:
- name: <CUSTOMSPEC-NAME>
label:
name: <NODE-LABEL>
value: <NODE-LABEL-VALUE>
containers:
- name: agent
env:
- name: LOG_LEVEL
value: SYS_DEBUG
Caution
The customspecs:name value must follow the RFC 1123
international format. Verify that the name of a DaemonSet object
is a valid DNS subdomain name.
The customSpecs parameter inherits all settings for the tf-vrouter
containers that are set on the spec:controllers:agent level and
overrides or adds additional parameters. The example configuration above
overrides the logging level from SYS_INFO, which is the default logging
level, to SYS_DEBUG.
For clusters with a multi-rack architecture, you may need to redefine the
gateway IP for the Tungsten Fabric vRouter nodes using the
VROUTER_GATEWAY parameter. For details, see Multi-rack architecture.
To specify custom settings for the Tungsten Fabric vRouter nodes, for
example, to change the name of the tunnel network interface or enable
debug level logging on some subset of nodes, use the nodes settings in
the TFOperator custom resource.
For example, to enable debug level logging on a specific node or multiple nodes:
spec:
nodes:
<CUSTOMSPEC-NAME>:
labels:
name: <NODE-LABEL>
value: <NODE-LABEL-VALUE>
nodeVRouter:
enabled: true
envSettings:
agent:
env:
- name: LOG_LEVEL
value: SYS_DEBUG
Control plane traffic interface¶
By default, the TF control service uses the management interface for
the BGP and XMPP traffic. You can change the control service interface
using the controlInterface parameter in the TFOperator custom resource,
for example, to combine the BGP and XMPP traffic with the data (tenant)
traffic:
spec:
settings:
controlInterface: <tunnel-interface>
spec:
features:
control:
controlInterface: <tunnel-interface>
Traffic encapsulation¶
Tungsten Fabric implements cloud tenants’ virtual networks as Layer 3 overlays. Tenant traffic gets encapsulated into one of the supported protocols and is carried over the infrastructure network between 2 compute nodes or a compute node and an edge router device.
In addition, Tungsten Fabric is capable of exchanging encapsulated traffic with external systems in order to build advanced virtual networking topologies, for example, BGP VPN connectivity between 2 MOSK clouds or a MOSK cloud and a cloud tenant premises.
MOSK supports the following encapsulation protocols:
- MPLS over Generic Routing Encapsulation (GRE)
A traditional encapsulation method supported by several router vendors, including Cisco and Juniper. The feature is applicable when other encapsulation methods are not available. For example, an SDN gateway runs software that does not support MPLS over UDP.
- MPLS over User Datagram Protocol (UDP)
A variation of the MPLS over GRE mechanism. It is the default and the most frequently used option in MOSK. MPLS over UDP replaces headers in UDP packets. In this case, a UDP port stores a hash of the packet payload (entropy). It provides a significant benefit for equal-cost multi-path (ECMP) routing load balancing. MPLS over UDP and MPLS over GRE transfer Layer 3 traffic only.
- Virtual Extensible LAN (VXLAN) TechPrev
The combination of VXLAN and EVPN technologies is often used for creating advanced cloud networking topologies. For example, it can provide transparent Layer 2 interconnections between Virtual Network Functions running on top of the cloud and physical traffic generator appliances hosted somewhere else.
The ENCAP_PRIORIY parameter defines the priority in which the
encapsulation protocols are attempted to be used when setting the BGP VPN
connectivity between the cloud and external systems.
By default, the encapsulation order is set to MPLSoUDP,MPLSoGRE,VXLAN.
The cloud operator can change it depending their needs in the TFOperator
custom resource as it is illustrated in Configuring encapsulation.
The list of supported encapsulated methods along with their order is shared between BGP peers as part of the capabilities information exchange when establishing a BGP session. Both parties must support the same encapsulation methods to build a tunnel for the network traffic.
For example, if the cloud operator wants to set up a Layer 2 VPN between the cloud and their network infrastructure, they configure the cloud’s virtual networks with VXLAN identifiers (VNIs) and do the same on the other side, for example, on a network switch. Also, VXLAN must be set in the first position in encapsulation priority order. Otherwise, VXLAN tunnels will not get established between endpoints, even though both endpoints may support the VXLAN protocol.
However, setting VXLAN first in the encapsulation priority order will not enforce VXLAN encapsulation between compute nodes or between compute nodes and gateway routers that use Layer 3 VPNs for communication.
The TFOperator custom resource allows you to define encapsulation settings
for your Tungsten Fabric cluster.
Important
The TFOperator custom resource must be the only place to
configure the cluster encapsulation. Performing these configurations through
the Tungsten Fabric web UI, CLI, or API does not provide the configuration
persistency, and the settings defined this way may get reset to defaults
during the cluster services restart or update.
Note
Defining the default values for encapsulation parameters in
the TFOperator custom resource is unnecessary.
Depending on the Tungsten Fabric operator API version in use, proceed with one of the following options:
Parameter |
Default value |
Description |
|---|---|---|
|
|
Defines the encapsulation priority order. |
|
|
Defines the Virtual Network ID type. The list of possible values includes:
Typically, for a Layer 2 VPN use case, the |
Example configuration:
controllers:
tf-config:
provisioner:
containers:
- env:
- name: VXLAN_VN_ID_MODE
value: automatic
- name: ENCAP_PRIORITY
value: VXLAN,MPLSoUDP,MPLSoGRE
name: provisioner
Parameter |
Default value |
Description |
|---|---|---|
|
|
Defines the encapsulation priority order. |
|
|
Defines the Virtual Network ID type. The list of possible values includes:
|
Example configuration:
features:
config:
vxlanVnIdMode: automatic
encapPriority: VXLAN,MPLSoUDP,MPLSoGRE
Autonomous System Number (ASN)¶
In the routing fabric of a data centre, a MOSK cluster with Tungsten Fabric enabled can be represented either by a separate Autonomous System (AS) or as part of a bigger autonomous system. In either case, Tungsten Fabric needs to participate in the BGP peering, exchanging routes with external devices and within the cloud.
The Tungsten Fabric Controller acts as an internal (iBGP) route reflector for
the cloud AS by populating /32 routes pointing to VMs across all compute
nodes as well as the cloud’s edge gateway devices in case they belong to the
same AS. Apart from being an iBGP router reflector for the cloud AS, the
Tungsten Fabric Controller can act as a BGP peer for autonomous systems
external to the cloud, for example, for the AS configured across the
leaf-spine fabric of the data center.
The Autonomous System Number (ASN) setting contains the unique identifier of the autonomous system that the MOSK cluster with Tungsten Fabric belongs to. The ASN number does not affect the internal iBGP communication between vRouters running on the compute nodes. Such communication will work regardless of the ASN number settings. However, any network appliance that is not managed by the Tungsten Fabric control plane will have BGP configured manually. Therefore, the ASN settings should be configured accordingly on both sides. Otherwise, it would result in the inability to establish BPG sessions, regardless of whether the external device peers with Tungsten Fabric over iBGP or eBGP.
The TFOperator custom resource enables you to define ASN settings for
your Tungsten Fabric cluster.
Important
The TFOperator CR must be the only place to configure
the cluster ASN. Performing these configurations through the Tungsten
Fabric web UI, CLI, or API does not provide the configuration persistency,
and the settings defined this way may get reset to defaults during
the cluster services restart or update.
Note
Defining the default values for ASN parameters in the Tungsten Fabric Operator custom resource is unnecessary.
Depending on the Tungsten Fabric Operator API version in use, proceed with one of the following options:
Parameter |
Default value |
Description |
|---|---|---|
|
|
Defines ASN of the control node. |
|
|
Enables the 4-byte ASN format. |
Example configuration:
controllers:
tf-config:
provisioner:
containers:
- env:
- name: BGP_ASN
value: "64515"
- name: ENABLE_4BYTE_AS
value: "true"
name: provisioner
tf-control:
provisioner:
containers:
- env:
- name: BGP_ASN
value: "64515"
name: provisioner
Parameter |
Default value |
Description |
|---|---|---|
|
|
Defines ASN of the control node. |
|
|
Enables the 4-byte ASN format. |
Example configuration:
features:
config:
BgpAsn: 64515
Enable4byteAS: true
Access to external DNS¶
By default, the Tungsten Fabric tf-control-dns-external service is created
to expose the Tungsten Fabric control dns. You can disable creation of this
service through the enableDNSExternal parameter in the TFOperator
custom resource. For example:
spec:
controllers:
tf-control:
dns:
enableDNSExternal: false
spec:
features:
control:
enableDNSExternal: false
Gateway for vRouter data plane network¶
If an edge router is accessible from the data plane through a gateway, define
the vRouter gateway in the TFOperator custom resource. Otherwise,
the default system gateway is used.
Depending on the Tungsten Fabric Operator API version in use, proceed with one of the following configurations:
Define the VROUTER_GATEWAY parameter in the TFOperator custom
resource:
spec:
controllers:
tf-vrouter:
agent:
containers:
- name: agent
env:
- name: VROUTER_GATEWAY
value: <data-plane-network-gateway>
You can also configure the parameter for Tungsten Fabric vRouter in the DPDK mode:
spec:
controllers:
tf-vrouter:
agent-dpdk:
enabled: true
containers:
- name: agent
env:
- name: VROUTER_GATEWAY
value: <data-plane-network-gateway>
Define the vRouterGateway parameter in the features section of
the TFOperator custom resource:
spec:
features:
vRouter:
vRouterGateway: <data-plane-network-gateway>
You can also configure the parameter for Tungsten Fabric vRouter in the DPDK mode:
spec:
services:
vRouter:
agentDPDK:
enabled: true
envSettings:
agent:
env:
- name: VROUTER_GATEWAY
value: <data-plane-network-gateway>
Tungsten Fabric image precaching¶
By default, MOSK deploys image precaching DaemonSets
to minimize possible downtime when updating container images. You can disable
creation of these DaemonSets by setting the imagePreCaching parameter in
the TFOperator custom resource to false:
spec:
settings:
imagePreCaching: false
spec:
features:
imagePreCaching: false
Graceful restart and long-lived graceful restart¶
Available since MOSK 23.2 for Tungsten Fabric 21.4 only TechPreview
Graceful restart and long-lived graceful restart are vital mechanisms within BGP (Border Gateway Protocol) routing, designed to optimize the routing tables convergence in scenarios where a BGP router restarts or a networking failure is experienced, leading to interruptions of router peering.
During a graceful restart, a router can signal its BGP peers about its impending restart, requesting them to retain the routes it had previously advertised as active. This allows for seamless network operation and minimal disruption to data forwarding during the router downtime.
The long-lived aspect of the long-lived graceful restart extends the graceful restart effectiveness beyond the usual restart duration. This extension provides an additional layer of resilience and stability to BGP routing updates, bolstering the network ability to manage unforeseen disruptions.
Caution
Mirantis does not generally recommend using the graceful restart and long-lived graceful restart features with the Tungsten Fabric XMPP helper, unless the configuration is done by proficient operators with at-scale expertise in networking domain and exclusively to address specific corner cases.
Tungsten Fabric Operator allows for easy enablement and configuration
of the graceful restart and long-lived graceful restart features through
the TFOperator custom resource:
spec:
settings:
settings:
gracefulRestart:
enabled: <BOOLEAN>
bgpHelperEnabled: <BOOLEAN>
xmppHelperEnabled: <BOOLEAN>
restartTime: <TIME_IN_SECONDS>
llgrRestartTime: <TIME_IN_SECONDS>
endOfRibTimeout: <TIME_IN_SECONDS>
spec:
features:
control:
gracefulRestart:
enabled: <BOOLEAN>
bgpHelperEnabled: <BOOLEAN>
xmppHelperEnabled: <BOOLEAN>
restartTime: <TIME_IN_SECONDS>
llgrRestartTime: <TIME_IN_SECONDS>
endOfRibTimeout: <TIME_IN_SECONDS>
Parameter |
Default value |
Description |
|---|---|---|
|
|
Enables or disables graceful restart and long-lived graceful restart features. |
|
|
Specifies the time interval, when the Tungsten Fabric control services act as a graceful restart helper to the edge router or any other BGP peer by retaining the routes learned from this peer and advertising them to the rest of the network as applicable. Note BGP peer should support and be configured with graceful restart for all of the address families used. |
|
|
Specifies the time interval, when the datapath agent should retain the last route path from the Tungsten Fabric Controller when an XMPP-based connection is lost. |
|
|
Configures a non-zero restart time in seconds to advertise for graceful restart capability from peers. |
|
|
Specifies the amount of time in seconds the vRouter datapath should keep advertised routes from the Tungsten Fabric control services, when an XMPP connection between the control and vRouter agent services is lost. Note When graceful restart and long-lived graceful restart are both configured, the duration of the long-lived graceful restart timer is the sum of both timers. |
|
|
Specifies the amount of time in seconds a control node waits to remove stale routes from a vRouter agent Routing Information Base (RIB). |
Enabling CQL to connect with Cassandra clusters¶
Available since MOSK 24.1 TechPreview
To streamline and improve the efficiency of communication between clients and the database, Cassandra is transitioning away from the Thrift protocol in favor of the Cassandra Query Language (CQL) protocol. CQL provides a more user-friendly and SQL-like interface for interacting with the database.
With the move towards CQL, the Thrift-based client drivers are no longer actively supported encouraging the users to migrate to CQL-based client drivers to take advantage of new features and improvements in Cassandra.
By default, MOSK uses the Thrift protocol to connect with Cassandra clusters. To enable the CQL protocol, proceed with one of the following options depending on the Tungsten Fabric Operator API version in use.
Define the CONFIGDB_CASSANDRA_DRIVER variable for the tf-analytics,
tf-config, and tf-control controllers in the TFOperator custom
resource:
spec:
controllers:
tf-analytics:
alarm-gen:
containers:
- env:
- name: CONFIGDB_CASSANDRA_DRIVER
value: cql
name: alarm-gen
api:
containers:
- env:
- name: CONFIGDB_CASSANDRA_DRIVER
value: cql
name: api
collector:
containers:
- env:
- name: CONFIGDB_CASSANDRA_DRIVER
value: cql
name: collector
snmp:
containers:
- env:
- name: CONFIGDB_CASSANDRA_DRIVER
value: cql
name: snmp
topology:
containers:
- env:
- name: CONFIGDB_CASSANDRA_DRIVER
value: cql
name: topology
tf-config:
api:
containers:
- env:
- name: CONFIGDB_CASSANDRA_DRIVER
value: cql
name: api
devicemgr:
containers:
- env:
- name: CONFIGDB_CASSANDRA_DRIVER
value: cql
name: devicemgr
schema:
containers:
- env:
- name: CONFIGDB_CASSANDRA_DRIVER
value: cql
name: schema
svc-monitor:
containers:
- env:
- name: CONFIGDB_CASSANDRA_DRIVER
value: cql
name: svc-monitor
tf-control:
control:
containers:
- env:
- name: CONFIGDB_CASSANDRA_DRIVER
value: cql
name: control
dns:
containers:
- env:
- name: CONFIGDB_CASSANDRA_DRIVER
value: cql
name: dns
Define the cassandraDriver parameter in the devOptions section of
the TFOperator custom resource:
spec:
devOptions:
cassandraDriver: cql
Tungsten Fabric database¶
Tungsten Fabric (TF) uses Cassandra and ZooKeeper to store its data. Cassandra is a fault-tolerant and horizontally scalable database that provides persistent storage of configuration and analytics data. ZooKeeper is used by TF for allocation of unique object identifiers and transactions implementation.
To prevent data loss, Mirantis recommends that you simultaneously back up the ZooKeeper database dedicated to configuration services and the Cassandra database.
The backup of database must be consistent across all systems because the state of the Tungsten Fabric databases is associated with other system databases, such as OpenStack databases.
Periodic Tungsten Fabric database backups¶
MOSK enables you to perform the automatic TF
data backup in the JSON format using the tf-dbbackup-job cron job.
By default, it is disabled. To back up the TF databases, enable
tf-dbBackup in the TF Operator custom resource:
spec:
controllers:
tf-dbBackup:
enabled: true
By default, the tf-dbbackup-job job is scheduled for weekly execution,
allocating PVC of 5 Gi size for storing backups and keeping 5 previous
backups. To configure the backup parameters according to the needs of your
cluster, use the following structure:
spec:
controllers:
tf-dbBackup:
enabled: true
dataCapacity: 30Gi
schedule: "0 0 13 * 5"
storedBackups: 10
To temporarily disable tf-dbbackup-job, suspend the job:
spec:
controllers:
tf-dbBackup:
enabled: true
suspend: true
To delete the tf-dbbackup-job job, disable tf-dbBackup in
the TF Operator custom resource:
spec:
controllers:
tf-dbBackup:
enabled: false
Remote storage for Tungsten Fabric database backups¶
Available since MOSK 23.2 TechPreview
MOSK supports configuring a remote NFS storage for TF data backups through the TF Operator custom resource:
spec:
controllers:
tf-dbBackup:
enabled: true
backupType: "pv_nfs"
nfsOptions:
path: <PATH_TO_SHARE_FOLDER_ON_SERVER>
server: <IP_ADDRESS/DNS_NAME_OF_SERVER>
If PVC backups were used previously, the old PVC will not be utilized. You can delete it with the following command:
kubectl -n tf delete pvc <TF_DB_BACKUP_PVC>
Tungsten Fabric services¶
The section explains specifics of the Tungsten Fabric services provided by Mirantis OpenStack for Kubernetes (MOSK). The list of the services and their supported features included in this section is not full and is being constantly amended based on the complexity of the architecture and use of a particular service.
Tungsten Fabric load balancing (HAProxy)¶
Note
Since 23.1, MOSK provides technology preview for Octavia Amphora load balancing. To start experimenting with the new load balancing solution, refer to Octavia Amphora load balancing.
MOSK ensures Octavia with Tungsten Fabric integration by OpenStack Octavia Driver with Tungsten Fabric HAProxy as a back end.
The Tungsten Fabric-based MOSK deployment supports creation, update, and deletion operations with the following standard load balancing API entities:
Load balancers
Note
For a load balancer creation operation, the driver supports only the
vip-subnet-idargument, thevip-network-idargument is not supported.Listeners
Pools
Health monitors
The Tungsten Fabric-based MOSK deployment does not support the following load balancing capabilities:
L7 load balancing capabilities, such as L7 policies, L7 rules, and others
Setting specific availability zones for load balancers and their resources
Using of the UDP protocol
Operations with Octavia quotas
Operations with Octavia flavors
Warning
The Tungsten Fabric-based MOSK deployment enables you to manage the load balancer resources by means of the OpenStack CLI or OpenStack Horizon. Do not perform any manipulations with the load balancer resources through the Tungsten Fabric web UI because in this case the changes will not be reflected on the OpenStack API side.
Octavia Amphora load balancing¶
Available since MOSK 23.1 TechPreview
Octavia Amphora (Amphora v2) load balancing provides a scalable and flexible solution for load balancing in cloud environments. MOSK deploys Amphora load balancer on each node of the OpenStack environment ensuring that load balancing services are easily accessible, highly scalable, and highly reliable.
Compared to the Octavia Tungsten Fabric driver for LBaaS v2 solution, Amphora offers several advanced features including:
Full compatibility with the Octavia API, which provides a standardized interface for load balancing in MOSK OpenStack environments. This makes it easier to manage and integrate with other OpenStack services.
Layer 7 policies and rules, which allow for more granular control over traffic routing and load balancing decisions. This enables users to optimize their application performance and improve the user experience.
Support for the UDP protocol, which is commonly used for real-time communications and other high-performance applications. This enables users to deploy a wider range of applications with the same load balancing infrastructure.
By default, MOSK uses the Octavia Tungsten Fabric load balancing. Once Octavia Amphora load balancing is enabled, the existing Octavia Tungsten Fabric driver load balancers will continue to function normally. However, you cannot migrate your load balancer workloads from the old LBaaS v2 solution to Amphora.
Note
As long as MOSK provides Octavia Amphora load balancing as a technology preview feature, Mirantis cannot guarantee the stability of this solution and does not provide a migration path from Tungsten Fabric load balancing (HAProxy), which is used by default.
To enable Octavia Amphora load balancing:
Assign
openstack-gateway: enabledlabels to the compute nodes in either order.Caution
Assigning the
openstack-gateway: enabledlabels on compute nodes is crucial for the effective operation of Octavia Amphora load balancing within an OpenStack environment. Double-check the labels assignment to guarantee proper configuration.To make Amphora the default provider, specify it in the
OpenStackDeploymentcustom resource:spec: features: octavia: default_provider: amphorav2
Verify that the OpenStack Controller has scheduled new Octavia pods that include health manager, worker, and housekeeping pods.
kubectl get pods -n openstack -l 'application=octavia,component in (worker, health_manager, housekeeping)'
Example of output for an environment with two compute nodes:
NAME READY STATUS RESTARTS AGE octavia-health-manager-default-48znl 1/1 Running 0 4h32m octavia-health-manager-default-jk82v 1/1 Running 0 4h34m octavia-housekeeping-7bdf9cbd6c-24vc4 1/1 Running 0 4h34m octavia-housekeeping-7bdf9cbd6c-h9ccv 1/1 Running 0 4h34m octavia-housekeeping-7bdf9cbd6c-rptvv 1/1 Running 0 4h34m octavia-worker-665f84fc7-8kdqd 1/1 Running 0 4h34m octavia-worker-665f84fc7-j6jn9 1/1 Running 0 4h31m octavia-worker-665f84fc7-kqf9t 1/1 Running 0 4h33m
The workflow for creating new load balancers with Amphora is identical to the workflow for creating load balancers with Octavia Tungsten Fabric driver for LBaaS v2. You can do it either through the OpenStack Horizon UI or OpenStack CLI.
If you have not defined amphorav2 as default provider in the
OpenStackDeployment custom resource, you can specify it explicitly
when creating a load balancer using the provider argument:
openstack loadbalancer create --provider amphorav2
Tungsten Fabric known limitations¶
This section contains a summary of the Tungsten Fabric upstream features and use cases not supported in MOSK, features and use cases offered as Technology Preview in the current product release if any, and known limitations of Tungsten Fabric in integration with other product components.
Feature or use case |
Status |
Description |
|---|---|---|
Tungsten Fabric web UI |
Provided as is |
MOSK provides the TF web UI as is and does not include this service in the support Service Level Agreement |
Automatic generation of network port records in DNSaaS (Designate) |
Not supported |
As a workaround, you can use the Tungsten Fabric built-in DNS service that enables virtual machines to resolve each other names |
Secret management (Barbican) |
Not supported |
It is not possible to use the certificates stored in Barbican to terminate HTTPs on a load balancer in a Tungsten Fabric deployment |
Role Based Access Control (RBAC) for Neutron objects |
Not supported |
|
Advanced Tungsten Fabric features |
Provided as is |
MOSK provides the following advanced Tungsten Fabric features as is and does not include them in the support Service Level Agreement:
|
Technical Preview |
DPDK |
|
Monitoring of |
Not supported |
Due to a known issue, |
Tungsten Fabric integration with OpenStack¶
The levels of integration between OpenStack and Tungsten Fabric (TF) include controllers and services integration levels.
Controllers integration¶
The integration between the OpenStack and TF controllers is
implemented through the shared Kubernetes openstack-tf-shared namespace.
Both controllers have access to this namespace to read and write the Kubernetes
kind: Secret objects.
The OpenStack Controller posts the data into the openstack-tf-shared
namespace required by the TF services. The TF controller watches this
namespace. Once an appropriate secret is created, the TF controller obtains it
into the internal data structures for further processing.
The OpenStack Controller includes the following data for the TF Controller:
tunnel_intefaceName of the network interface for the TF data plane. This interface is used by TF for the encapsulated traffic for overlay networks.
- Keystone authorization information
Keystone Administrator credentials and an up-and-running IAM service are required for the TF Controller to initiate the deployment process.
- Nova metadata information
Required for the TF vRrouter agent service.
Also, the OpenStack Controller watches the openstack-tf-shared namespace
for the vrouter_port parameter that defines the vRouter port number and
passes it to the nova-compute pod.
Services integration¶
The list of the OpenStack services that are integrated with TF through their API include:
neutron-server- integration is provided by thecontrail-neutron-plugincomponent that is used by theneutron-serverservice for transformation of the API calls to the TF API compatible requests.nova-compute- integration is provided by thecontrail-nova-vif-driverandcontrail-vrouter-apipackages used by thenova-computeservice for interaction with the TF vRouter to the network ports.octavia-api- integration is provided by the Octavia TF Driver that enables you to use OpenStack CLI and Horizon for operations with load balancers. See Tungsten Fabric load balancing (HAProxy) for details.
Warning
TF is not integrated with the following OpenStack services:
DNS service (Designate)
Key management (Barbican)
Networking¶
Depending on the size of an OpenStack environment and the components that you use, you may want to have a single or multiple network interfaces, as well as run different types of traffic on a single or multiple VLANs.
This section provides the recommendations for planning the network configuration and optimizing the cloud performance.
Networking overview¶
Mirantis OpenStack for Kubernetes (MOSK) cluster networking is complex and defined by the security requirements and performance considerations. It is based on the Kubernetes cluster networking provided by Mirantis Container Cloud and expanded to facilitate the demands of the OpenStack virtualization platform.
A Container Cloud Kubernetes cluster provides a platform for MOSK and is considered a part of its control plane. All networks that serve Kubernetes and related traffic are considered control plane networks. The Kubernetes cluster networking is typically focused on connecting pods of different nodes as well as exposing the Kubernetes API and services running in pods into an external network.
The OpenStack networking connects virtual machines to each other and the outside world. Most of the OpenStack-related networks are considered a part of the data plane in an OpenStack cluster. Ceph networks are considered data plane networks for the purpose of this reference architecture.
When planning your OpenStack environment, consider the types of traffic that your workloads generate and design your network accordingly. If you anticipate that certain types of traffic, such as storage replication, will likely consume a significant amount of network bandwidth, you may want to move that traffic to a dedicated network interface to avoid performance degradation.
The following diagram provides a simplified overview of the underlay networking in a MOSK environment:
Management cluster networking¶
This page summarizes the recommended networking architecture of a Mirantis Container Cloud management cluster for a Mirantis OpenStack for Kubernetes (MOSK) cluster.
We recommend deploying the management cluster with a dedicated interface for the provisioning (PXE) network. The separation of the provisioning network from the management network ensures additional security and resilience of the solution.
MOSK end users typically should have access to the Keycloak service in the management cluster for authentication to the Horizon web UI. Therefore, we recommend that you connect the management network of the management cluster to an external network through an IP router. The default route on the management cluster nodes must be configured with the default gateway in the management network.
If you deploy the multi-rack configuration, ensure that the provisioning network of the management cluster is connected to an IP router that connects it to the provisioning networks of all racks.
MOSK cluster networking¶
Mirantis OpenStack for Kubernetes (MOSK) clusters managed by Mirantis Container Cloud use the following networks to serve different types of traffic:
Network role |
Description |
|---|---|
Provisioning (PXE) network |
Facilitates the iPXE boot of all bare metal machines in a MOSK cluster and provisioning of the operating system to machines. This network is only used during provisioning of the host. It must not be configured on an operational MOSK node. |
Life-cycle management (LCM) network |
Connects LCM Agents running on the hosts to the Container Cloud LCM API.
The LCM API is provided by the management cluster.
The LCM network is also used for communication between The LCM subnet(s) provides IP addresses that are statically allocated by the IPAM service to bare metal hosts. This network must be connected to the Kubernetes API endpoint of the management cluster through an IP router. LCM Agents running on MOSK clusters will connect to the management cluster API through this router. LCM subnets may be different per MOSK cluster as long as this connection requirement is satisfied. You can use more than one LCM network segment in a MOSK cluster. In this case, separated L2 segments and interconnected L3 subnets are still used to serve LCM and API traffic. All IP subnets in the LCM networks must be connected to each other by IP routes. These routes must be configured on the hosts through L2 templates. All IP subnets in the LCM network must be connected to the Kubernetes API endpoints of the management cluster through an IP router. You can manually select the load balancer IP address for external
access to the cluster API and specify it in the Note When using the ARP announcement of the IP address for the cluster API load balancer, the following limitations apply:
When using the BGP announcement of the IP address for the cluster API load balancer, which is available as Technology Preview since MOSK 23.2.2, no segment stretching is required between Kubernetes master nodes. Also, in this scenario, the load balancer IP address is not required to match the LCM subnet CIDR address. |
Kubernetes workloads network |
Serves as an underlay network for traffic between pods in the MOSK cluster. Do not share this network between clusters. There might be more than one Kubernetes pods network segment in the cluster. In this case, they must be connected through an IP router. Kubernetes workloads network does not need an external access. The Kubernetes workloads subnet(s) provides IP addresses that are statically allocated by the IPAM service to all nodes and that are used by Calico for cross-node communication inside a cluster. By default, VXLAN overlay is used for Calico cross-node communication. |
Kubernetes external network |
Serves for an access to the OpenStack endpoints in a MOSK cluster. When using the ARP announcement of the external endpoints of load-balanced services, the network must contain a VLAN segment extended to all MOSK nodes connected to this network. When using the BGP announcement of the external endpoints of load-balanced services, which is available as Technology Preview since MOSK 23.2.2, there is no requirement of having a single VLAN segment extended to all MOSK nodes connected to this network. A typical MOSK cluster only has one external network. The external network must include at least two IP address ranges
defined by separate
|
Storage access network |
Serves for the storage access traffic from and to Ceph OSD services. A MOSK cluster may have more than one VLAN segment and IP subnet in the storage access network. All IP subnets of this network in a single cluster must be connected by an IP router. The storage access network does not require external access unless you want to directly expose Ceph to the clients outside of a MOSK cluster. Note A direct access to Ceph by the clients outside of a MOSK cluster is technically possible but not supported by Mirantis. Use at your own risk. The IP addresses from subnets in this network are statically allocated by the IPAM service to Ceph nodes. The Ceph OSD services bind to these addresses on their respective nodes. This is a public network in Ceph terms. 1 |
Storage replication network |
Serves for the storage replication traffic between Ceph OSD services. A MOSK cluster may have more than one VLAN segment and IP subnet in this network as long as the subnets are connected by an IP router. This network does not require external access. The IP addresses from subnets in this network are statically allocated by the IPAM service to Ceph nodes. The Ceph OSD services bind to these addresses on their respective nodes. This is a cluster network in Ceph terms. 1 |
Out-of-Band (OOB) network |
Connects Baseboard Management Controllers (BMCs) of the bare metal hosts. Must not be accessible from a MOSK cluster. |
- 1(1,2)
For more details about Ceph networks, see Ceph Network Configuration Reference.
The following diagram illustrates the networking schema of the Container Cloud deployment on bare metal with a MOSK cluster using ARP announcements:
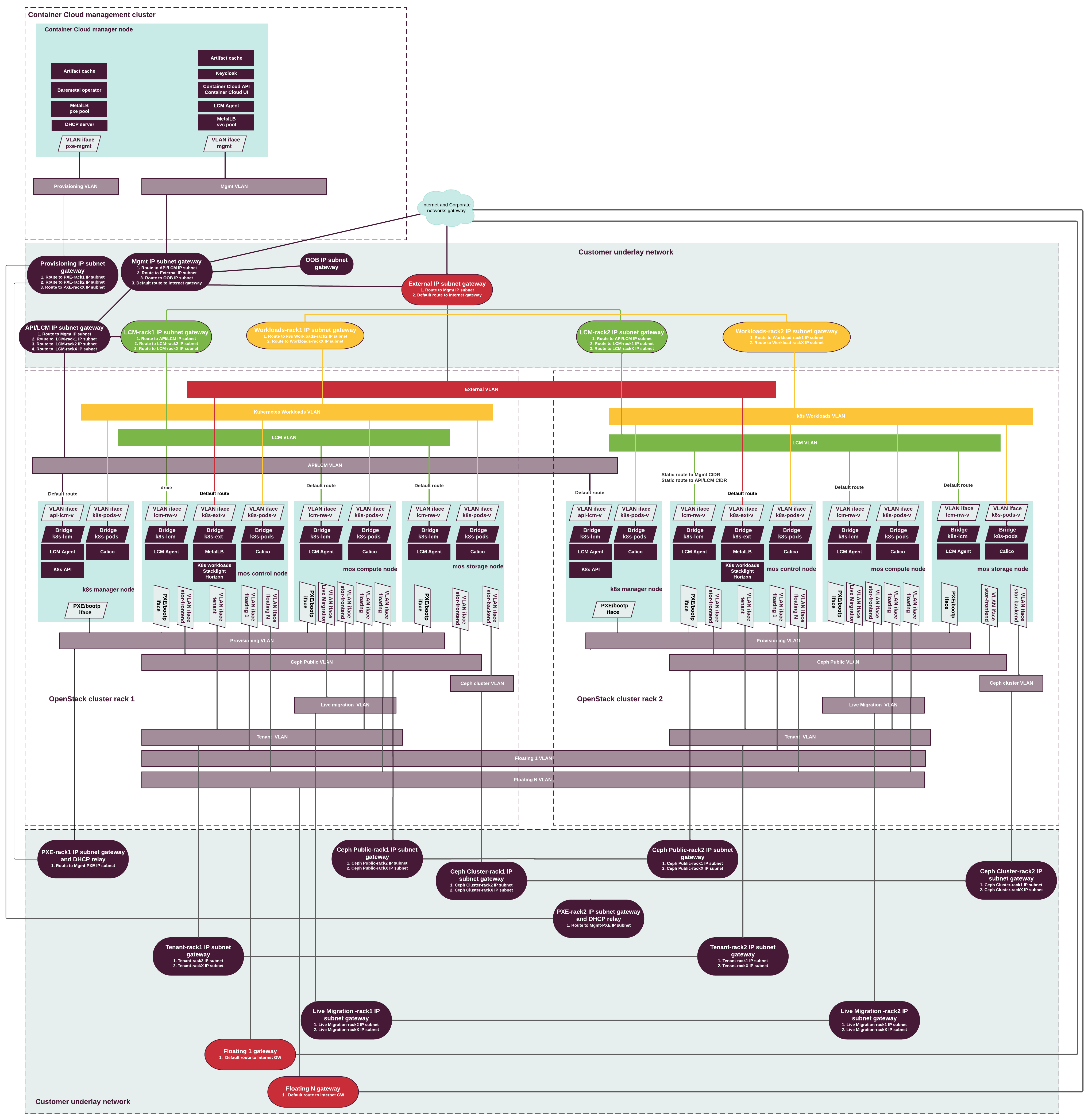
Since 23.2.2, MOSK supports full L3 networking topology in the Technology Preview scope. The following diagram illustrates the networking schema of the Container Cloud deployment on bare metal with a MOSK cluster using BGP announcements:
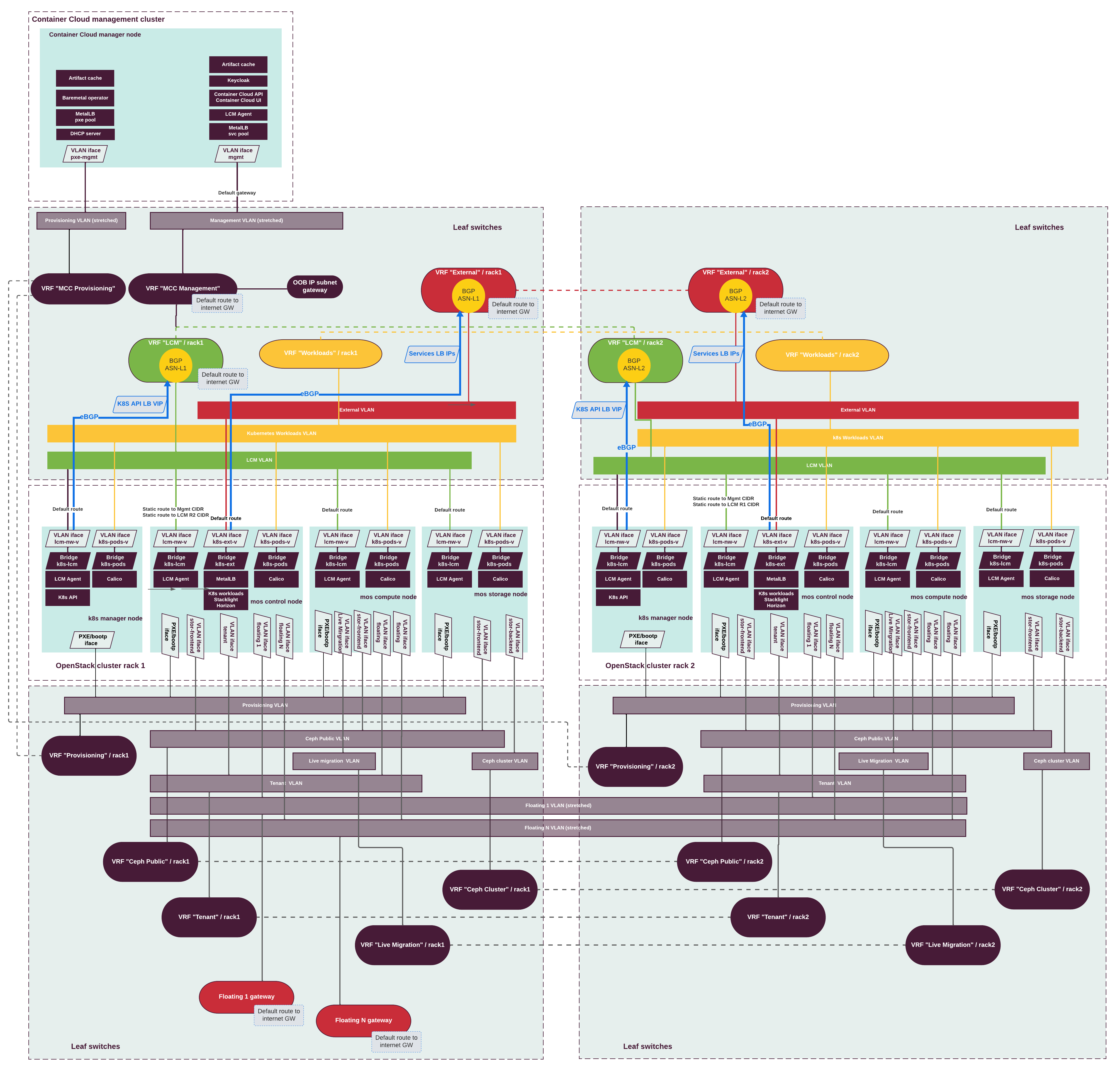
Network types¶
This section describes network types for Layer 3 networks used for Kubernetes and Mirantis OpenStack for Kubernetes (MOSK) clusters along with requirements for each network type.
Note
Only IPv4 is currently supported by Container Cloud and IPAM for infrastructure networks. IPv6 is not supported and not used in Container Cloud and MOSK underlay infrastructure networks.
The following diagram provides an overview of the underlay networks in a MOSK environment:
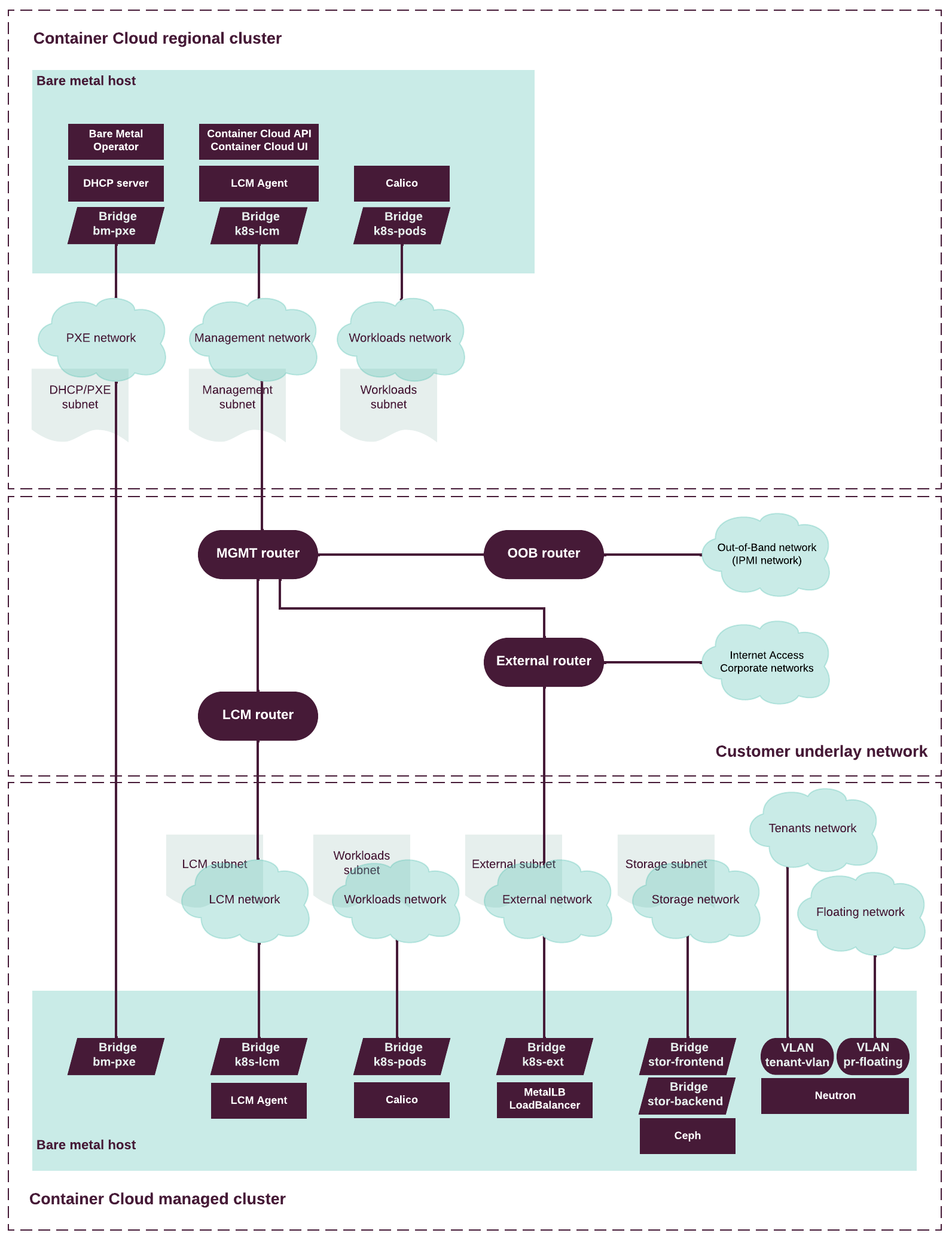
L3 networks for Kubernetes¶
A MOSK deployment typically requires the following types of networks:
- Provisioning network
Used for provisioning of bare metal servers.
- Management network
Used for management of the Container Cloud infrastructure and for communication between containers in Kubernetes.
- LCM/API network
Since 23.2.2, MOSK supports full L3 networking topology in the Technology Preview scope. This enables deployment of specific cluster segments in dedicated racks without the need for L2 layer extension between them. For configuration procedure, see Configure BGP announcement for cluster API LB address and Configure BGP announcement of external addresses of Kubernetes load-balanced services in Deployment Guide.
If BGP announcement is configured for the MOSK cluster API LB address, the API/LCM network is not required. Announcement of the cluster API LB address is done using the LCM network.
If you configure ARP announcement of the load-balancer IP address for the MOSK cluster API, the API/LCM network must be configured on the Kubernetes manager nodes of the cluster. This network contains the Kubernetes API endpoint with the VRRP virtual IP address.
- LCM network
Enables communication between the MKE cluster nodes. Multiple VLAN segments and IP subnets can be created for a multi-rack architecture. Each server must be connected to one of the LCM segments and have an IP from the corresponding subnet.
- External network
Used to expose the OpenStack, StackLight, and other services of the MOSK cluster.
- Kubernetes workloads network
Used for communication between containers in Kubernetes.
- Storage access network (Ceph)
Used for accessing the Ceph storage. In Ceph terms, this is a public network 0. We recommended that it is placed on a dedicated hardware interface.
- Storage replication network (Ceph)
Used for Ceph storage replication. In Ceph terms, this is a cluster network 0. To ensure low latency and fast access, place the network on a dedicated hardware interface.
- 0(1,2)
For details about Ceph networks, see Ceph Network Configuration Reference.
L3 networks for MOSK¶
The MOSK deployment additionally requires the following networks.
Service name |
Network |
Description |
VLAN name |
|---|---|---|---|
Networking |
Provider networks |
Typically, a routable network used to provide the external access to OpenStack instances (a floating network). Can be used by the OpenStack services such as Ironic, Manila, and others, to connect their management resources. |
|
Networking |
Overlay networks (virtual networks) |
The network used to provide denied, secure tenant networks with the help of the tunneling mechanism (VLAN/GRE/VXLAN). If the VXLAN and GRE encapsulation takes place, the IP address assignment is required on interfaces at the node level. |
|
Compute |
Live migration network |
The network used by the OpenStack compute service (Nova) to transfer data during live migration. Depending on the cloud needs, it can be placed on a dedicated physical network not to affect other networks during live migration. The IP address assignment is required on interfaces at the node level. |
|
The way of mapping of the logical networks described above to physical networks and interfaces on nodes depends on the cloud size and configuration. We recommend placing OpenStack networks on a dedicated physical interface (bond) that is not shared with storage and Kubernetes management network to minimize the influence on each other.
L3 networks requirements¶
The following tables describe networking requirements for a MOSK cluster, Container Cloud management and Ceph clusters.
Network type |
Provisioning |
Management |
|---|---|---|
Suggested interface name |
N/A |
|
Minimum number of VLANs |
1 |
1 |
Minimum number of IP subnets |
3 |
2 |
Minimum recommended IP subnet size |
|
|
External routing |
Not required |
Required, may use proxy server |
Multiple segments/stretch segment |
Stretch segment for management cluster due to MetalLB Layer 2 limitations 1 |
Stretch segment due to VRRP, MetalLB Layer 2 limitations |
Internal routing |
Routing to separate DHCP segments, if in use |
|
- 1
Multiple VLAN segments with IP subnets can be added to the cluster configuration for separate DHCP domains.
Since 23.2.2, MOSK supports full L3 networking topology in the Technology Preview scope. This enables deployment of specific cluster segments in dedicated racks without the need for L2 layer extension between them. For configuration procedure, see Configure BGP announcement for cluster API LB address and Configure BGP announcement of external addresses of Kubernetes load-balanced services in Deployment Guide.
If you configure BGP announcement of the load-balancer IP address for a MOSK cluster API and for load-balanced services of the cluster:
Network type |
Provisioning |
LCM |
External |
Kubernetes workloads |
|---|---|---|---|---|
Minimum number of VLANs |
1 (optional) |
1 |
1 |
1 |
Suggested interface name |
N/A |
|
|
|
Minimum number of IP subnets |
1 (optional) |
1 |
2 |
1 |
Minimum recommended IP subnet size |
16 IPs (DHCP range) |
|
|
1 IP per cluster node |
Stretch or multiple segments |
Multiple |
Multiple |
Multiple For details, see Configure the MetalLB speaker node selector. |
Multiple |
External routing |
Not required |
Not required |
Required, default route |
Not required |
Internal routing |
Routing to the provisioning network of the management cluster |
|
Routing to the IP subnet of the Container Cloud Management API |
Routing to all IP subnets of Kubernetes workloads |
If you configure ARP announcement of the load-balancer IP address for a MOSK cluster API and for load-balanced services of the cluster:
Network type |
Provisioning |
LCM/API |
LCM |
External |
Kubernetes workloads |
|---|---|---|---|---|---|
Minimum number of VLANs |
1 (optional) |
1 |
1 (optional) |
1 |
1 |
Suggested interface name |
N/A |
|
|
|
|
Minimum number of IP subnets |
1 (optional) |
1 |
1 (optional) |
2 |
1 |
Minimum recommended IP subnet size |
16 IPs (DHCP range) |
|
1 IP per MOSK node (Kubernetes worker) |
|
1 IP per cluster node |
Stretch or multiple segments |
Multiple |
Stretch due to VRRP limitations |
Multiple |
Stretch connected to all MOSK controller nodes. For details, see Configure the MetalLB speaker node selector. |
Multiple |
External routing |
Not required |
Not required |
Not required |
Required, default route |
Not required |
Internal routing |
Routing to the provisioning network of the management cluster |
|
|
Routing to the IP subnet of the Container Cloud Management API |
Routing to all IP subnets of Kubernetes workloads |
- 2(1,2)
The bridge interface with this name is mandatory if you need to separate Kubernetes workloads traffic. You can configure this bridge over the VLAN or directly over the bonded or single interface.
Network type |
Storage access |
Storage replication |
|---|---|---|
Minimum number of VLANs |
1 |
1 |
Suggested interface name |
|
|
Minimum number of IP subnets |
1 |
1 |
Minimum recommended IP subnet size |
1 IP per cluster node |
1 IP per cluster node |
Stretch or multiple segments |
Multiple |
Multiple |
External routing |
Not required |
Not required |
Internal routing |
Routing to all IP subnets of the Storage access network |
Routing to all IP subnets of the Storage replication network |
Note
When selecting externally routable subnets, ensure that the subnet ranges do not overlap with the internal subnets ranges. Otherwise, internal resources of users will not be available from the MOSK cluster.
- 3(1,2)
For details about Ceph networks, see Ceph Network Configuration Reference.
Multi-rack architecture¶
TechPreview
Mirantis OpenStack for Kubernetes (MOSK) enables you to deploy a cluster with a multi-rack architecture, where every data center cabinet (a rack) incorporates its own Layer 2 network infrastructure that does not extend beyond its top-of-rack switch. The architecture allows a MOSK cloud to integrate natively with the Layer 3-centric networking topologies such as Spine-Leaf that are commonly seen in modern data centers.
The architecture eliminates the need to stretch and manage VLANs across parts of a single data center, or to build VPN tunnels between the segments of a geographically distributed cloud.
The set of networks present in each rack depends on the back end used by the OpenStack networking service.
Bare metal provisioning network¶
In the Mirantis Container Cloud and MOSK multi-rack reference architecture, every rack has its own L2 segment (VLAN) to bootstrap and install servers.
Segmentation of the provisioning network requires additional configuration of the underlay networking infrastructure and certain Container Cloud API objects. You need to configure a DHCP Relay agent on the border of each VLAN in the provisioning network. The agent handles broadcast DHCP requests coming from the bare metal servers in the rack and forwards them as unicast packets across L3 fabric of the data center to a Container Cloud management cluster.
From the standpoint of Container Cloud API, you need to configure per-rack DHCP
ranges by adding Subnet resources in Container Cloud as described in
Container Cloud documentation: Configure multiple DHCP ranges using Subnet
resources.
The DHCP server of Container Cloud automatically leases a temporary IP address from the DHCP range to the requester host depending on the address of the DHCP agent that relays the request.
Multi-rack MOSK cluster¶
To deploy a MOSK cluster with multi-rack reference architecture, you need to create a dedicated set of subnets and L2 templates for every rack in your cluster.
Every specific host type in the rack, which is defined by the role in the MOSK cluster and network-related hardware configuration, may require a specific L2 template.
Note
Since 23.2.2, MOSK supports full L3 networking topology in the Technology Preview scope. This enables deployment of specific cluster segments in dedicated racks without the need for L2 layer extension between them. For configuration procedure, see Configure BGP announcement for cluster API LB address and Configure BGP announcement of external addresses of Kubernetes load-balanced services in Deployment Guide.
For MOSK 23.1 and older versions, due to the Container Cloud limitations, you need to configure the following networks to have L2 segments (VLANs) stretch across racks to all hosts of certain types in a multi-rack environment:
- LCM/API network
Must be configured on the Kubernetes manager nodes of the MOSK cluster. Contains a Kubernetes API endpoint with a VRRP virtual IP address. Enables MKE cluster nodes to communicate with each other.
- External network
Exposes OpenStack, StackLight, and other services of the MOSK cluster to external clients.
For details, see Underlay networking: routing configuration.
When planning space allocation for IP addresses in your cluster, pick large IP ranges for each type of network. Then you will split these ranges into per-rack subnets.
For example, if you allocate a /20 address block for LCM network,
then you can create up to 16 Subnet objects with the /24 address block
each for up to 16 racks. This way you can simplify routing on your hosts using
the large /20 IP subnet as an aggregated route destination. For details,
see Underlay networking: routing configuration.
Multi-rack MOSK cluster with Tungsten Fabric¶
A typical medium and more sized MOSK cloud consists of three or more racks that can generally be divided into the following major categories:
Compute/Storage racks that contain the hypervisors and instances running on top of them. Additionally, they contain nodes that store cloud applications’ block, ephemeral, and object data as part of the Ceph cluster.
Control plane racks that incorporate all the components needed by the cloud operator to manage its life cycle. Also, they include the services through which the cloud users interact with the cloud to deploy their applications, such as cloud APIs and web UI.
A control plane rack may also contain additional compute and storage nodes.
The diagram below will help you to plan the networking layout of a multi-rack MOSK cloud with Tungsten Fabric.
Note
Since 23.2.2, MOSK supports full L3 networking topology in the Technology Preview scope. This enables deployment of specific cluster segments in dedicated racks without the need for L2 layer extension between them. For configuration procedure, see Configure BGP announcement for cluster API LB address and Configure BGP announcement of external addresses of Kubernetes load-balanced services in Deployment Guide.
For MOSK 23.1 and older versions, Kubernetes masters (3 nodes) either need to be placed into a single rack or, if distributed across multiple racks for better availability, require stretching of the L2 segment of the management network across these racks. This requirement is caused by the Mirantis Kubernetes Engine underlay for MOSK relying on the Layer 2 VRRP protocol to ensure high availability of the Kubernetes API endpoint.
The table below provides a mapping between the racks and the network types participating in a multi-rack MOSK cluster with the Tungsten Fabric back end.
Network |
VLAN name |
Control Plane rack |
Compute/Storage rack |
|---|---|---|---|
Common/PXE |
|
Yes |
Yes |
Management |
|
Yes |
Yes |
External (MetalLB) |
|
Yes |
No |
Kubernetes workloads |
|
Yes |
Yes |
Storage access (Ceph) |
|
Yes |
Yes |
Storage replication (Ceph) |
|
Yes |
Yes |
Overlay |
|
Yes |
Yes |
Live migration |
|
Yes |
Yes |
Physical networks layout¶
This section summarizes the requirements for the physical layout of underlay network and VLANs configuration for the multi-rack architecture of Mirantis OpenStack for Kubernetes (MOSK).
Physical networking of a Container Cloud management cluster¶
Due to limitations of virtual IP address for Kubernetes API and of MetalLB load balancing in Container Cloud, the management cluster nodes must share VLAN segments in the provisioning and management networks.
In the multi-rack architecture, the management cluster nodes may be placed to a single rack or spread across three racks. In either case, provisioning and management network VLANs must be stretched across ToR switches of the racks.
The following diagram illustrates physical and L2 connections of the Container Cloud management cluster.
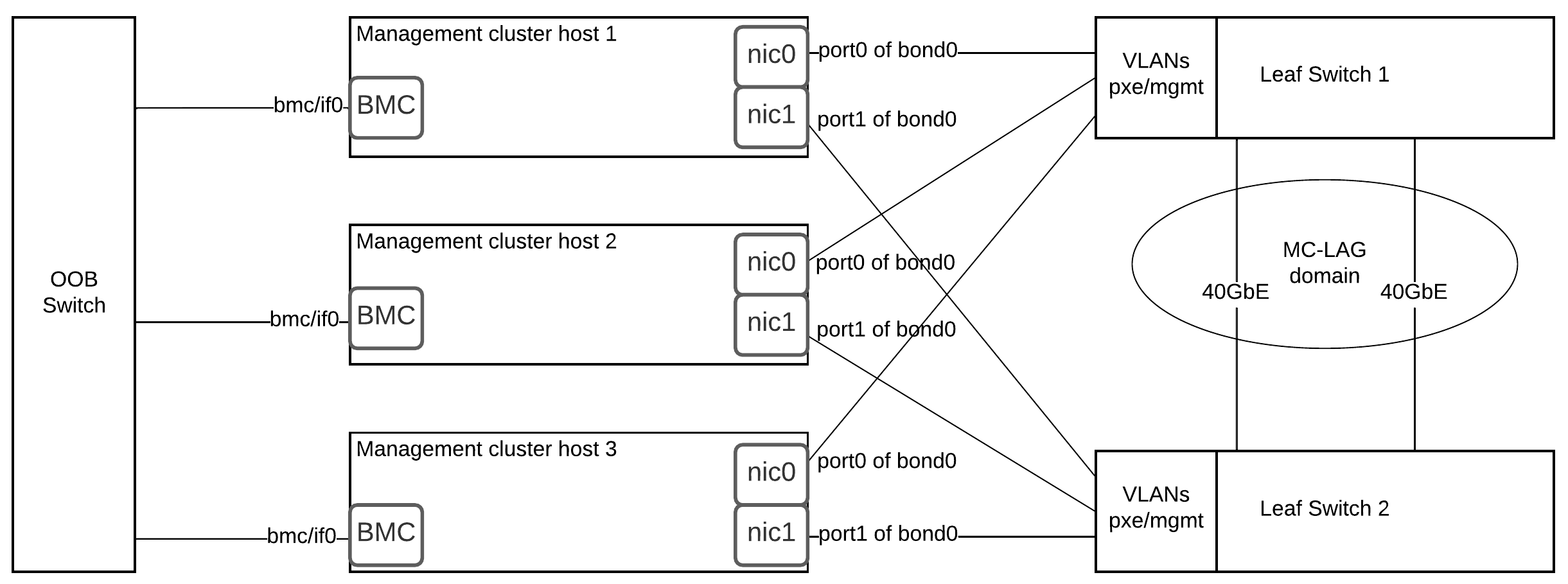
Physical networking of a MOSK cluster¶
Since 23.2.2, MOSK supports full L3 networking topology in the Technology Preview scope. This enables deployment of specific cluster segments in dedicated racks without the need for L2 layer extension between them. For configuration procedure, see Configure BGP announcement for cluster API LB address and Configure BGP announcement of external addresses of Kubernetes load-balanced services in Deployment Guide.
If you configure BGP announcement for IP addresses of load-balanced services of a MOSK cluster, the external network can consist of multiple VLAN segments connected to all nodes of a MOSK cluster where MetalLB speaker components are configured to announce IP addresses for Kubernetes load-balanced services. Mirantis recommends that you use OpenStack controller nodes for this purpose.
If you configure ARP announcement for IP addresses of load-balanced services of a MOSK cluster, the external network must consist of a single VLAN stretched to the ToR switches of all the racks where MOSK nodes connected to the external network are located. Those are the nodes where MetalLB speaker components are configured to announce IP addresses for Kubernetes load-balanced services. Mirantis recommends that you use OpenStack controller nodes for this purpose.
Note
Since 23.2.2, MOSK supports full L3 networking topology in the Technology Preview scope. This enables deployment of specific cluster segments in dedicated racks without the need for L2 layer extension between them. For configuration procedure, see Configure BGP announcement for cluster API LB address and Configure BGP announcement of external addresses of Kubernetes load-balanced services in Deployment Guide.
If BGP announcement is configured for MOSK cluster API LB address, Kubernetes manager nodes have no requirement to share the single stretched VLAN segment in the API/LCM network. All VLANs may be configured per rack.
If ARP announcement is configured for MOSK cluster API LB address, Kubernetes manager nodes must share the VLAN segment in the API/LCM network. In the multi-rack architecture, Kubernetes manager nodes may be spread across three racks. The API/LCM network VLAN must be stretched to the ToR switches of the racks. All other VLANs may be configured per rack. This requirement is caused by the Mirantis Kubernetes Engine underlay for MOSK relying on the Layer 2 VRRP protocol to ensure high availability of the Kubernetes API endpoint.
The following diagram illustrates physical and L2 network connections of the Kubernetes manager nodes in a MOSK cluster.
Caution
Such configuration does not apply to a compact control plane MOSK installation. See Create a MOSK cluster.
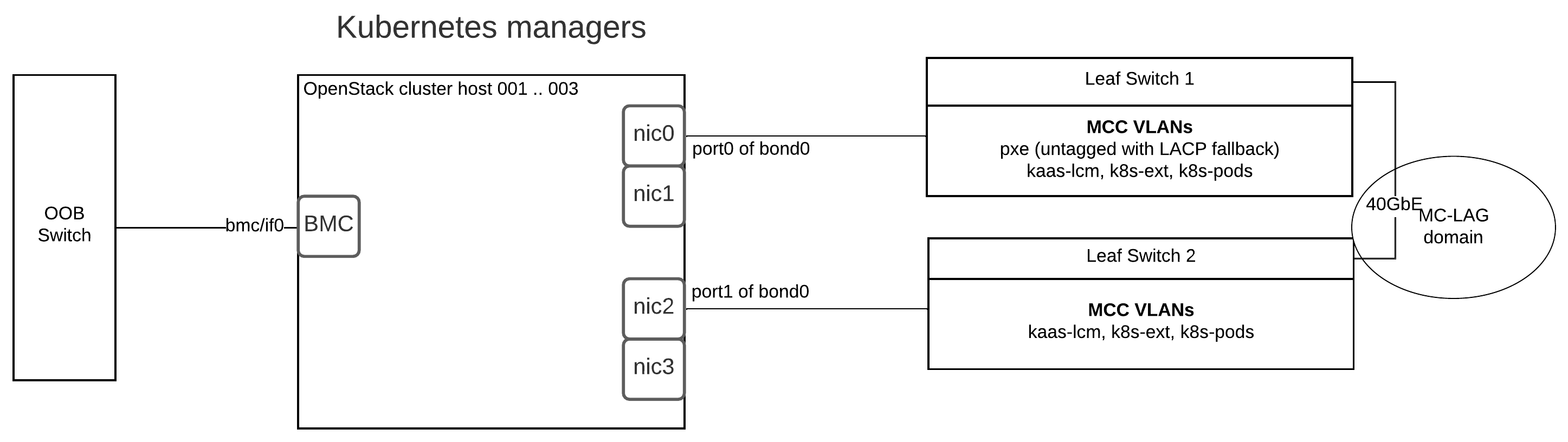
The following diagram illustrates physical and L2 network connections of the control plane nodes in a MOSK cluster.
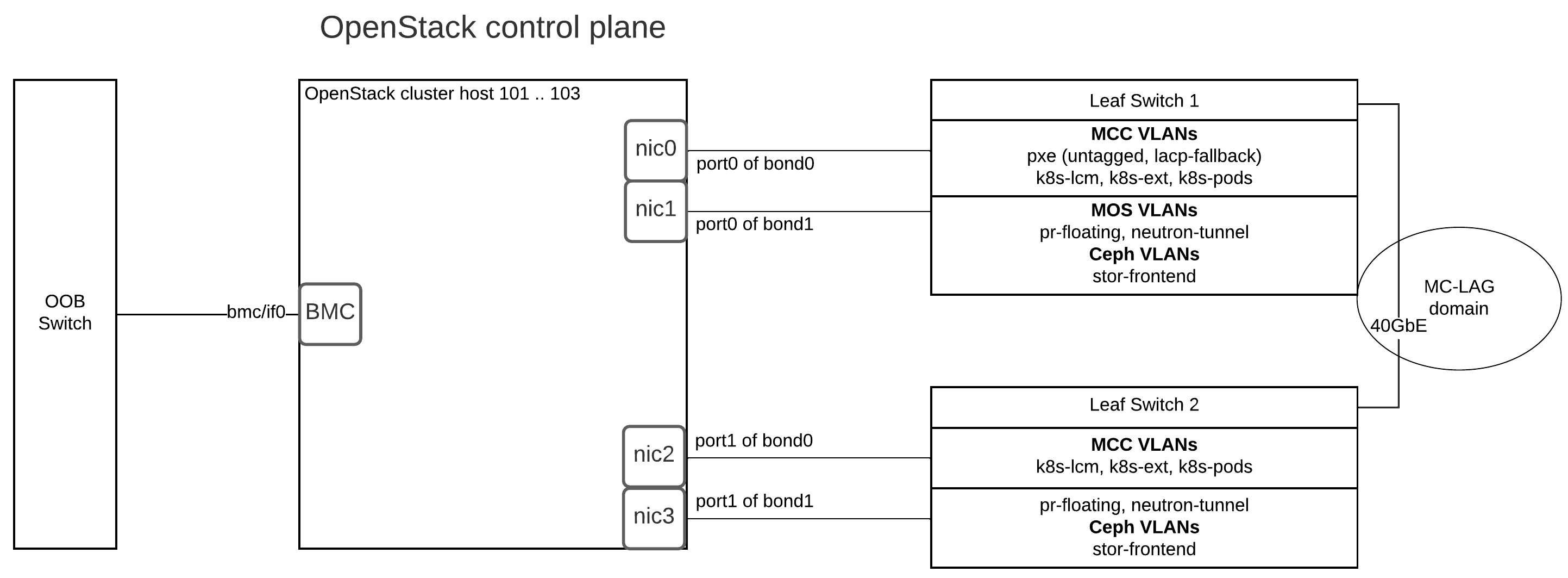
All VLANs for OpenStack compute nodes may be configured per rack. No VLAN should be stretched across multiple racks.
The following diagram illustrates physical and L2 network connections of the compute nodes in a MOSK cluster.
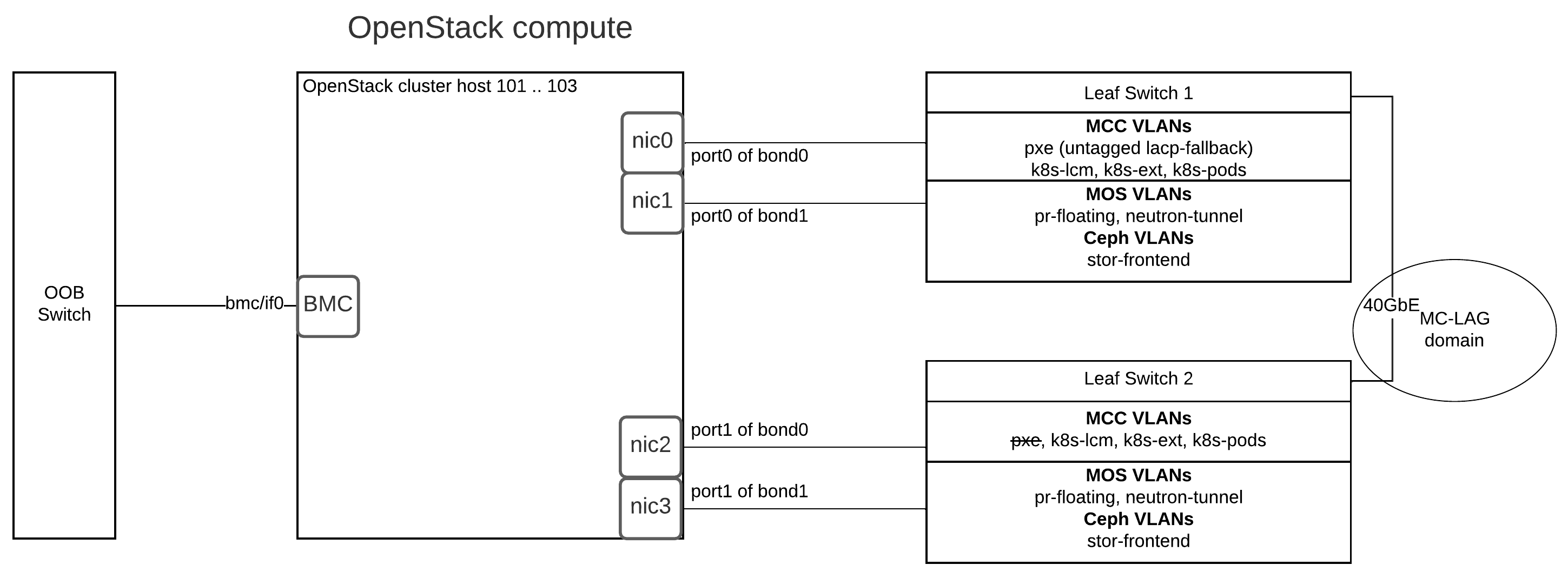
All VLANs for OpenStack storage nodes may be configured per rack. No VLAN should be stretched across multiple racks.
The following diagram illustrates physical and L2 network connections of the storage nodes in a MOSK cluster.
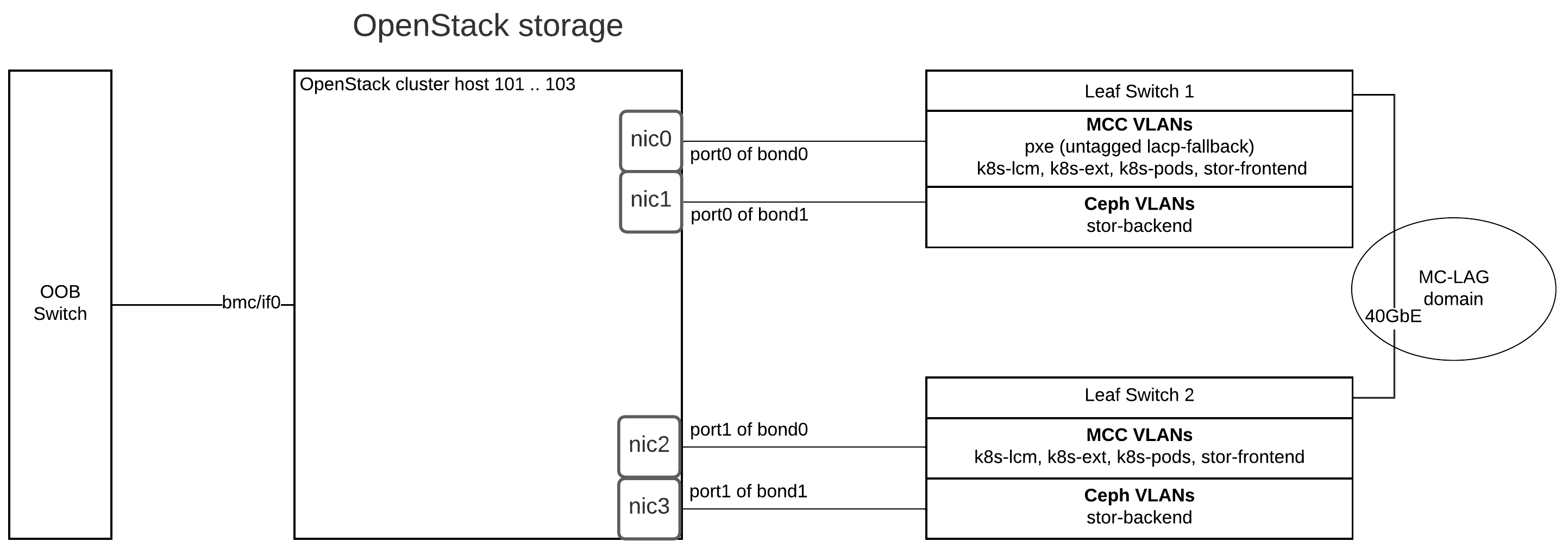
Underlay networking: routing configuration¶
This section describes requirements for the configuration of the underlay network for an MOSK cluster in a multi-rack reference configuration. The infrastructure operator must configure the underlay network according to these guidelines. Mirantis Container Cloud will not configure routing on the network devices.
Provisioning network¶
In the multi-rack reference architecture, every server rack has its own layer-2 segment (VLAN) for network bootstrap and installation of physical servers.
You need to configure top-of-rack (ToR) switches in each rack with the default gateway for the provisioning network VLAN. This gateway must also serve as a DHCP Relay Agent on the border of the VLAN. The agent handles broadcast DHCP requests coming from the bare metal servers in the rack and forwards them as unicast packets across the data center L3 fabric to the provisioning network of a Container Cloud management cluster.
Therefore, each ToR gateway must have an IP route to the IP subnet of the provisioning network of the management cluster. The provisioning network gateway, in turn, must have routes to all IP subnets of all racks.
The hosts of the management cluster must have routes to all IP subnets in the provisioning network through the gateway in the provisioning network of the management cluster.
All hosts in the management cluster must have IP addresses from the same IP subnet of the provisioning network. Even if the hosts of the management cluster are mounted to different racks, they must share a single provisioning VLAN segment.
Management network¶
All hosts of a management cluster must have IP addresses from the same subnet of the management network. Even if hosts of a management cluster are mounted to different racks, they must share a single management VLAN segment.
The gateway in this network is used as the default route on the nodes in a Container Cloud management cluster. This gateway must connect to external Internet networks directly or through a proxy server. If the Internet is accessible through a proxy server, you must configure Container Cloud bootstrap to use it as well. For details, see Container Cloud Deployment Guide: Deploy a management cluster using CLI.
This network connects a Container Cloud management cluster to Kubernetes API endpoints of MOSK clusters. It also connects LCM agents of MOSK nodes to the Kubernetes API endpoint of the management cluster.
The network gateway must have routes to all API/LCM subnets of all MOSK clusters.
LCM network¶
This network may include multiple VLANs, typically, one VLAN per rack. Each VLAN may have one or more IP subnets with gateways configured on ToR switches.
Each ToR gateway must provide routes to all other IP subnets in all other VLANs in the LCM network to enable communication between nodes in the cluster.
Note
Since 23.2.2, MOSK supports full L3 networking topology in the Technology Preview scope. This enables deployment of specific cluster segments in dedicated racks without the need for L2 layer extension between them. For configuration procedure, see Configure BGP announcement for cluster API LB address and Configure BGP announcement of external addresses of Kubernetes load-balanced services in Deployment Guide.
If you configure BGP announcement of the load-balancer IP address for a MOSK cluster API:
All nodes of a MOSK cluster must be connected to the LCM network. Each host connected to this network must have routes to all IP subnets in the LCM network and to the management subnet of the management cluster, through the ToR gateway for the rack of this host.
It is not required to configure a separate API/LCM network. Announcement of the IP address of the load balancer is done using the LCM network.
If you configure ARP announcement of the load-balancer IP address for a MOSK cluster API:
All nodes of a MOSK cluster excluding manager nodes must be connected to the LCM network. Each host connected to this network must have routes to all IP subnets in the LCM network, including the API/LCM network of this MOSK cluster and to the Management subnet of the management cluster, through the ToR gateway for the rack of this host.
It is required to configure a separate API/LCM network. All manager nodes of a MOSK cluster must be connected to the API/LCM network. IP address announcement for load balancing is done using the API/LCM network.
API/LCM network¶
Note
Since 23.2.2, MOSK supports full L3 networking topology in the Technology Preview scope. This enables deployment of specific cluster segments in dedicated racks without the need for L2 layer extension between them. For configuration procedure, see Configure BGP announcement for cluster API LB address and Configure BGP announcement of external addresses of Kubernetes load-balanced services in Deployment Guide.
If BGP announcement is configured for the MOSK cluster API LB address, the API/LCM network is not required. Announcement of the cluster API LB address is done using the LCM network.
If you configure ARP announcement of the load-balancer IP address for the MOSK cluster API, the API/LCM network must be configured on the Kubernetes manager nodes of the cluster. This network contains the Kubernetes API endpoint with the VRRP virtual IP address.
This network consists of a single VLAN shared between all MOSK manager nodes in a MOSK cluster, even if the nodes are spread across multiple racks. All manager nodes of a MOSK cluster must be connected to this network and have IP addresses from the same subnet in this network.
The gateway in the API/LCM network for a MOSK cluster must have a route to the Management subnet of the management cluster. This is required to ensure symmetric traffic flow between the management and MOSK clusters.
The gateway in this network must also have routes to all IP subnets in the LCM network of this MOSK cluster.
The load-balancer IP address for cluster API must be allocated from the same CIDR address that the API/LCM subnet uses.
External network¶
Note
Since 23.2.2, MOSK supports full L3 networking topology in the Technology Preview scope. This enables deployment of specific cluster segments in dedicated racks without the need for L2 layer extension between them. For configuration procedure, see Configure BGP announcement for cluster API LB address and Configure BGP announcement of external addresses of Kubernetes load-balanced services in Deployment Guide.
If you configure BGP announcement for IP addresses of load-balanced services of a MOSK cluster, the external network can consist of multiple VLAN segments connected to all nodes of a MOSK cluster where MetalLB speaker components are configured to announce IP addresses for Kubernetes load-balanced services. Mirantis recommends that you use OpenStack controller nodes for this purpose.
If you configure ARP announcement for IP addresses of load-balanced services of a MOSK cluster, the external network must consist of a single VLAN stretched to the ToR switches of all the racks where MOSK nodes connected to the external network are located. Those are the nodes where MetalLB speaker components are configured to announce IP addresses for Kubernetes load-balanced services. Mirantis recommends that you use OpenStack controller nodes for this purpose.
The IP gateway in this network is used as the default route on all nodes in the MOSK cluster, which are connected to this network. This allows external users to connect to the OpenStack endpoints exposed as Kubernetes load-balanced services.
Dedicated IP ranges from this network must be configured as address pools for the MetalLB service. MetalLB allocates addresses from these address pools to Kubernetes load-balanced services.
Ceph public network¶
This network may include multiple VLANs and IP subnets, typically, one VLAN and IP subnet per rack. All IP subnets in this network must be connected by IP routes on the ToR switches.
Typically, every node in a MOSK cluster is connected to this network and have routes to all IP subnets from this network through its rack IP gateway.
This network is not connected to the external networks.
Ceph cluster network¶
This network may include multiple VLANs and IP subnets, typically, one VLAN and IP subnet per rack. All IP subnets in this network must be connected by IP routes on the ToR switches.
Every Ceph OSD node in a MOSK cluster must be connected to this network and have routes to all IP subnets from this network through its rack IP gateway.
This network is not connected to the external networks.
Kubernetes workloads network¶
This network may include multiple VLANs and IP subnets, typically, one VLAN and IP subnet per rack. All IP subnets in this network must be connected by IP routes on the ToR switches.
All nodes in a MOSK cluster must be connected to this network and have routes to all IP subnets from this network through its rack IP gateway.
This network is not connected to the external networks.
Performance optimization¶
The following recommendations apply to all types of nodes in the Mirantis OpenStack for Kubernetes (MOSK) clusters.
Jumbo frames¶
To improve the goodput, we recommend that you enable jumbo frames where possible. The jumbo frames have to be enabled on the whole path of the packets traverse. If one of the network components cannot handle jumbo frames, the network path uses the smallest MTU.
Bonding¶
To provide fault tolerance of a single NIC, we recommend using the link aggregation, such as bonding. The link aggregation is useful for linear scaling of bandwidth, load balancing, and fault protection. Depending on the hardware equipment, different types of bonds might be supported. Use the multi-chassis link aggregation as it provides fault tolerance at the device level. For example, MLAG on Arista equipment or vPC on Cisco equipment.
The Linux kernel supports the following bonding modes:
active-backupbalance-xor802.3ad(LACP)balance-tlbbalance-alb
Since LACP is the IEEE standard 802.3ad supported by the majority of
network platforms, we recommend using this bonding mode.
Use the Link Aggregation Control Protocol (LACP) bonding mode
with MC-LAG domains configured on ToR switches. This corresponds to
the 802.3ad bond mode on hosts.
Additionally, follow these recommendations in regards to bond interfaces:
Use ports from different multi-port NICs when creating bonds. This makes network connections redundant if failure of a single NIC occurs.
Configure the ports that connect servers to the PXE network with PXE VLAN as native or untagged. On these ports, configure LACP fallback to ensure that the servers can reach DHCP server and boot over network.
Spanning tree portfast mode¶
Configure Spanning Tree Protocol (STP) settings on the network switch ports to ensure that the ports start forwarding packets as soon as the link comes up. It helps avoid iPXE timeout issues and ensures reliable boot over network.
Storage¶
A MOSK cluster uses Ceph as a distributed storage system for file, block, and object storage. This section provides an overview of a Ceph cluster deployed by Container Cloud.
Ceph overview¶
Mirantis Container Cloud deploys Ceph on MOSK using Helm charts with the following components:
- Rook Ceph Operator
A storage orchestrator that deploys Ceph on top of a Kubernetes cluster. Also known as
RookorRook Operator. Rook operations include:Deploying and managing a Ceph cluster based on provided Rook CRs such as
CephCluster,CephBlockPool,CephObjectStore, and so on.Orchestrating the state of the Ceph cluster and all its daemons.
KaaSCephClustercustom resource (CR)Represents the customization of a Kubernetes installation and allows you to define the required Ceph configuration through the Container Cloud web UI before deployment. For example, you can define the failure domain, Ceph pools, Ceph node roles, number of Ceph components such as Ceph OSDs, and so on. The
ceph-kcc-controllercontroller on the Container Cloud management cluster manages theKaaSCephClusterCR.- Ceph Controller
A Kubernetes controller that obtains the parameters from Container Cloud through a CR, creates CRs for Rook and updates its CR status based on the Ceph cluster deployment progress. It creates users, pools, and keys for OpenStack and Kubernetes and provides Ceph configurations and keys to access them. Also, Ceph Controller eventually obtains the data from the OpenStack Controller for the Keystone integration and updates the Ceph Object Gateway services configurations to use Kubernetes for user authentication. Ceph Controller operations include:
Transforming user parameters from the Container Cloud Ceph CR into Rook CRs and deploying a Ceph cluster using Rook.
Providing integration of the Ceph cluster with Kubernetes.
Providing data for OpenStack to integrate with the deployed Ceph cluster.
- Ceph Status Controller
A Kubernetes controller that collects all valuable parameters from the current Ceph cluster, its daemons, and entities and exposes them into the
KaaSCephClusterstatus. Ceph Status Controller operations include:Collecting all statuses from a Ceph cluster and corresponding Rook CRs.
Collecting additional information on the health of Ceph daemons.
Provides information to the
statussection of theKaaSCephClusterCR.
- Ceph Request Controller
A Kubernetes controller that obtains the parameters from Container Cloud through a CR and manages Ceph OSD lifecycle management (LCM) operations. It allows for a safe Ceph OSD removal from the Ceph cluster. Ceph Request Controller operations include:
Providing an ability to perform Ceph OSD LCM operations.
Obtaining specific CRs to remove Ceph OSDs and executing them.
Pausing the regular Ceph Controller reconciliation until all requests are completed.
A typical Ceph cluster consists of the following components:
Ceph Monitors - three or, in rare cases, five Ceph Monitors.
Ceph Managers - one Ceph Manager in a regular cluster.
Ceph Object Gateway (
radosgw) - Mirantis recommends having three or moreradosgwinstances for HA.Ceph OSDs - the number of Ceph OSDs may vary according to the deployment needs.
Warning
A Ceph cluster with 3 Ceph nodes does not provide hardware fault tolerance and is not eligible for recovery operations, such as a disk or an entire Ceph node replacement.
A Ceph cluster uses the replication factor that equals 3. If the number of Ceph OSDs is less than 3, a Ceph cluster moves to the degraded state with the write operations restriction until the number of alive Ceph OSDs equals the replication factor again.
The placement of Ceph Monitors and Ceph Managers is defined in the
KaaSCephCluster CR.
The following diagram illustrates the way a Ceph cluster is deployed in Container Cloud:
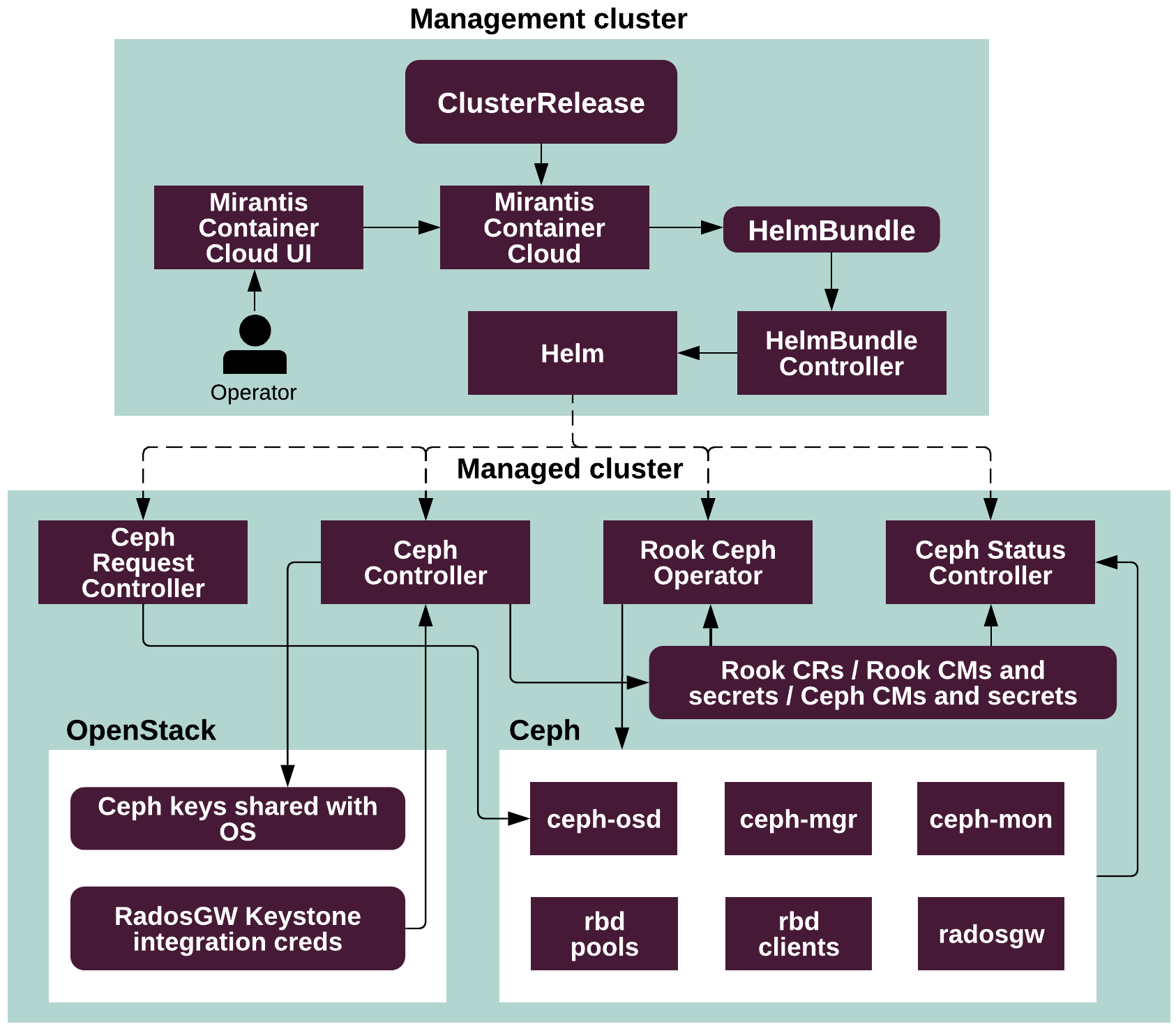
The following diagram illustrates the processes within a deployed Ceph cluster:
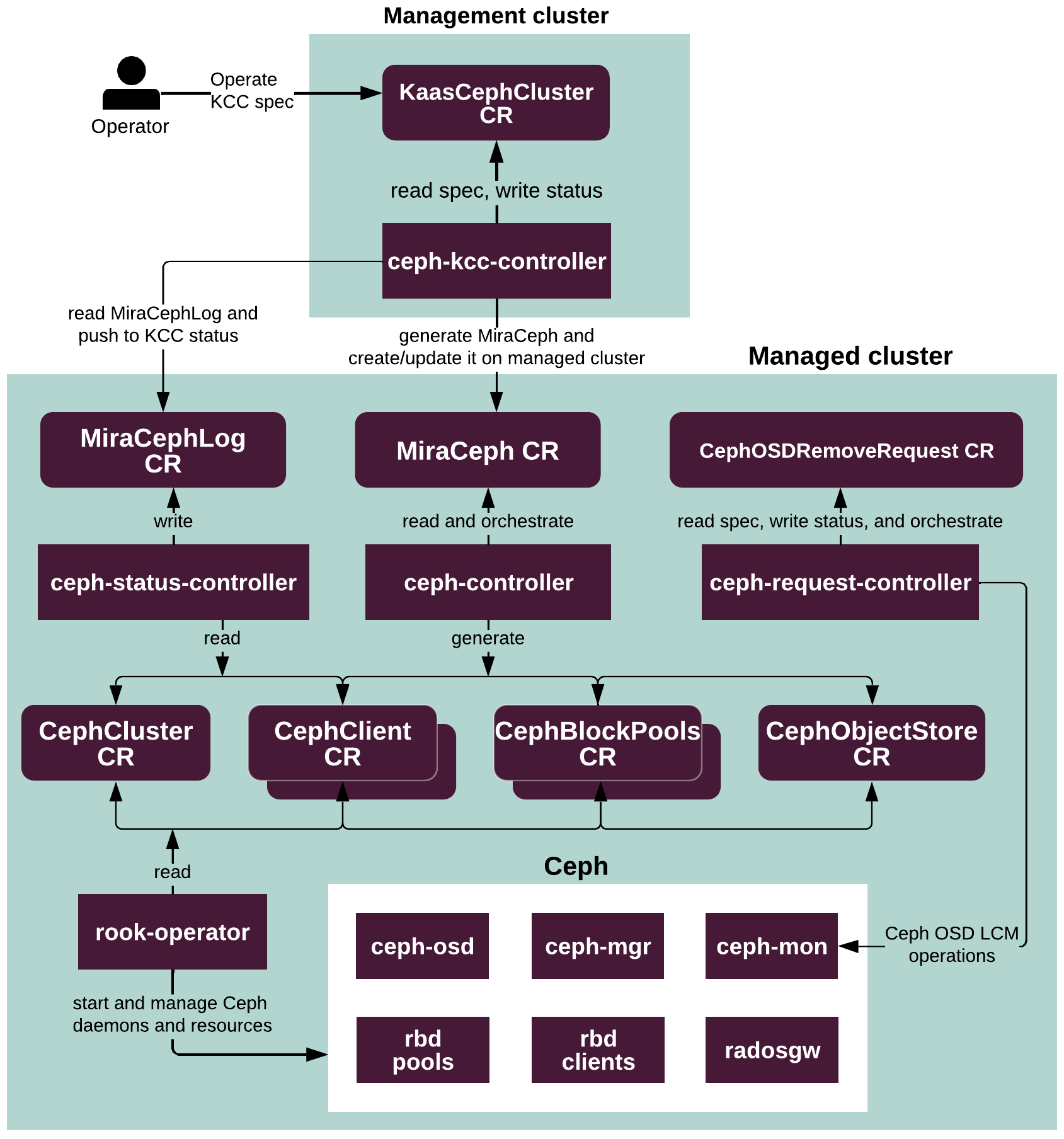
See also
Ceph limitations¶
A Ceph cluster configuration in MOSK includes but is not limited to the following limitations:
Only one Ceph Controller per MOSK cluster and only one Ceph cluster per Ceph Controller are supported.
The replication size for any Ceph pool must be set to more than 1.
Only one CRUSH tree per cluster. The separation of devices per Ceph pool is supported through device classes with only one pool of each type for a device class.
All CRUSH rules must have the same
failure_domain.Only the following types of CRUSH buckets are supported:
topology.kubernetes.io/regiontopology.kubernetes.io/zonetopology.rook.io/datacentertopology.rook.io/roomtopology.rook.io/podtopology.rook.io/pdutopology.rook.io/rowtopology.rook.io/racktopology.rook.io/chassis
RBD mirroring is not supported.
Consuming an existing Ceph cluster is not supported.
CephFS is not supported.
Only IPv4 is supported.
If two or more Ceph OSDs are located on the same device, there must be no dedicated WAL or DB for this class.
Only a full collocation or dedicated WAL and DB configurations are supported.
The minimum size of any defined Ceph OSD device is 5 GB.
Reducing the number of Ceph Monitors is not supported and causes the Ceph Monitor daemons removal from random nodes.
Ceph cluster does not support removable devices (with hotplug enabled) for deploying Ceph OSDs.
When adding a Ceph node with the Ceph Monitor role, if any issues occur with the Ceph Monitor,
rook-cephremoves it and adds a new Ceph Monitor instead, named using the next alphabetic character in order. Therefore, the Ceph Monitor names may not follow the alphabetical order. For example,a,b,d, instead ofa,b,c.
Ceph integration with OpenStack¶
The integration between Ceph and OpenStack controllers is implemented
through the shared Kubernetes openstack-ceph-shared namespace.
Both controllers have access to this namespace to read and write
the Kubernetes kind: Secret objects.
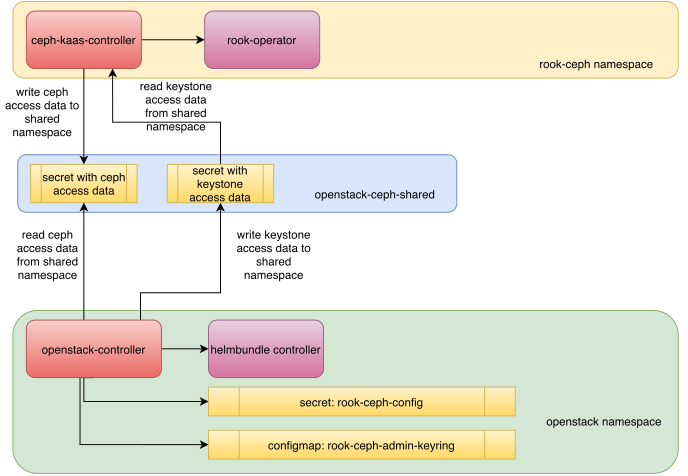
As Ceph is required and only supported back end for several OpenStack
services, all necessary Ceph pools must be specified in the configuration
of the kind: MiraCeph custom resource as part of the deployment.
Once the Ceph cluster is deployed, the Ceph Controller posts the
information required by the OpenStack services to be properly configured
as a kind: Secret object into the openstack-ceph-shared namespace.
The OpenStack Controller watches this namespace. Once the corresponding
secret is created, the OpenStack Controller transforms this secret to the
data structures expected by the OpenStack-Helm charts. Even if an OpenStack
installation is triggered at the same time as a Ceph cluster deployment, the
OpenStack Controller halts the deployment of the OpenStack services that
depend on Ceph availability until the secret in the shared namespace is
created by the Ceph Controller.
For the configuration of Ceph Object Gateway as an OpenStack Object
Storage, the reverse process takes place. The OpenStack Controller waits
for the OpenStack-Helm to create a secret with OpenStack Identity
(Keystone) credentials that Ceph Object Gateway must use to validate the
OpenStack Identity tokens, and posts it back to the same
openstack-ceph-shared namespace in the format suitable for
consumption by the Ceph Controller. The Ceph Controller then reads this
secret and reconfigures Ceph Object Gateway accordingly.
Mirantis StackLight¶
StackLight is the logging, monitoring, and alerting solution that provides a single pane of glass for cloud maintenance and day-to-day operations as well as offers critical insights into cloud health including operational information about the components deployed with Mirantis OpenStack for Kubernetes (MOSK). StackLight is based on Prometheus, an open-source monitoring solution and a time series database, and OpenSearch, the logs and notifications storage.
Deployment architecture¶
Mirantis OpenStack for Kubernetes (MOSK) deploys the StackLight stack as a release of a Helm chart that contains the helm-controller and HelmBundle custom resources. The StackLight HelmBundle consists of a set of Helm charts describing the StackLight components. Apart from the OpenStack-specific components below, StackLight also includes the components described in Mirantis Container Cloud Reference Architecture: Deployment architecture. By default, StackLight logging stack is disabled.
During the StackLight configuration when deploying a MOSK cluster, you can define the HA or non-HA StackLight architecture type. For details, see Mirantis Container Cloud Reference Architecture: StackLight database modes.
StackLight component |
Description |
|---|---|
Prometheus native exporters and endpoints |
Export the existing metrics as Prometheus metrics and include:
|
Telegraf OpenStack plugin |
Collects and processes the OpenStack metrics. |
Monitored components¶
StackLight measures, analyzes, and reports in a timely manner about failures that may occur in the following Mirantis OpenStack for Kubernetes (MOSK) components and their sub-components. Apart from the components below, StackLight also monitors the components listed in Mirantis Container Cloud Reference Architecture: Monitored components.
Libvirt
Memcached
MariaDB
NTP
OpenStack (Barbican, Cinder, Designate, Glance, Heat, Horizon, Ironic, Keystone, Neutron, Nova, Octavia)
OpenStack SSL certificates
Tungsten Fabric (Casandra, Kafka, Redis, ZooKeeper)
RabbitMQ
Note
Due to a known issue,
tf-rabbitmqis not monitored on new MOSK 22.5 clusters. The existing clusters updated to MOSK 22.5 are not affected.
OpenSearch and Prometheus storage sizing¶
Caution
Calculations in this document are based on numbers from a real-scale test cluster with 34 nodes. The exact space required for metrics and logs must be calculated depending on the ongoing cluster operations. Some operations force the generation of additional metrics and logs. The values below are approximate. Use them only as recommendations.
During the deployment of a new cluster, you must specify the OpenSearch retention time and Persistent Volume Claim (PVC) size, Prometheus PVC, retention time, and retention size. When configuring an existing cluster, you can only set OpenSearch retention time, Prometheus retention time, and retention size.
The following table describes the recommendations for both OpenSearch
and Prometheus retention size and PVC size for a cluster with 34 nodes.
Retention time depends on the space allocated for the data. To calculate
the required retention time, use the
{retention time} = {retention size} / {amount of data per day} formula.
Service |
Required space per day |
Description |
|---|---|---|
OpenSearch |
|
When setting Persistent Volume Claim Size for OpenSearch during the cluster creation, take into account that it defines the PVC size for a single instance of the OpenSearch cluster. StackLight in HA mode has 3 OpenSearch instances. Therefore, for a total OpenSearch capacity, multiply the PVC size by 3. |
Prometheus |
|
Every Prometheus instance stores the entire database. Multiple replicas store multiple copies of the same data. Therefore, treat the Prometheus PVC size as the capacity of Prometheus in the cluster. Do not sum them up. Prometheus has built-in retention mechanisms based on the database size and time series duration stored in the database. Therefore, if you miscalculate the PVC size, retention size set to ~1 GB less than the PVC size will prevent disk overfilling. |
StackLight integration with OpenStack¶
StackLight integration with OpenStack includes automatic discovery of RabbitMQ
credentials for notifications and OpenStack credentials for OpenStack API
metrics. For details, see the
openstack.rabbitmq.credentialsConfig and
openstack.telegraf.credentialsConfig parameters description in
StackLight configuration parameters.
Workload monitoring¶
Available since MOSK 23.2 TechPreview
LCM operations may require measuring the downtime of cloud end user instances to assess if SLA commitments regarding workload downtime are being met. Additionally, continuous monitoring of network connectivity is essential for early problem detection.
To address these needs, MOSK provides the OpenStack workload monitoring feature through the Cloudprober exporter. Presently, MOSK supports monitoring of floating IP addresses exclusively through the Internet Control Message Protocol (ICMP).
To be able to monitor instance availability, your cluster should meet the following requirements:
IP connectivity between the network used to assign floating IP addresses and all OpenStack control plane nodes
ICMP ingress and egress traffic allowed in operating systems on the monitored virtual machines
ICMP ingress and egress traffic allowed in the OpenStack project by configuring security groups
To enable the workload monitoring service, use the following
OpenStackDeployment definition:
spec:
features:
services:
- cloudprober
For the detailed configuration procedure of the instance availability monitoring, refer to Configure monitoring of instance availability.
Blueprints¶
This section contains a collection of Mirantis OpenStack for Kubernetes (MOSK) architecture blueprints that include common cluster topology and configuration patterns that can be referred to when building a MOSK cloud. Every blueprint is validated by Mirantis and is known to work. You can use these blueprints alone or in combination, although the interoperability of all possible combinations can not be guaranteed.
The section provides information on the target use cases, pros and cons of every blueprint and outlines the extents of its applicability. However, do not hesitate to reach out to Mirantis if you have any questions or doubts on whether a specific blueprint can be applied when designing your cloud.
Remote compute nodes¶
Introduction to edge computing¶
Although a classic cloud approach allows resources to be distributed across multiple regions, it still needs powerful data centers to host control planes and compute clusters. Such regional centralization poses challenges when the number of data consumers grows. It becomes hard to access the resources hosted in the cloud even though the resources are located in the same geographic region. The solution would be to bring the data closer to the consumer. And this is exactly what edge computing provides.
Edge computing is a paradigm that brings computation and data storage closer to the sources of data or the consumer. It is designed to improve response time and save bandwidth.
A few examples of use cases for edge computing include:
Hosting a video stream processing application on premises of a large stadium during the Super Bowl match
Placing the inventory or augmented reality services directly in the industrial facilities, such as storage, powerplant, shipyard, and so on
A small computation node deployed in a far-distanced village supermarket to host an application for store automatization and accounting
These and many other use cases could be solved by deploying multiple edge clusters managed from a single central place. The idea of centralized management plays a significant role for the business efficiency of the edge cloud environment:
Cloud operators obtain a single management console for the cloud that simplifies the Day-1 provisioning of new edge sites and Day-2 operations across multiple geographically distributed points of presence
Cloud users get ability to transparently connect their edge applications with central databases or business logic components hosted in data centers or public clouds
Depending on the size, location, and target use case, the points of presence comprising an edge cloud environment can be divided into five major categories. Mirantis OpenStack powered by Mirantis Container Cloud offers reference architectures to address the centralized management in core and regional data centers as well as edge sites.
Overview of the remote compute nodes approach¶
Remote compute nodes is one of the approaches to the implementation of the edge computing concept offered by MOSK. The topology consists of a MOSK cluster residing in a data center, which is extended with multiple small groups of compute nodes deployed in geographically distanced remote sites. Remote compute nodes are integrated into the MOSK cluster just like the nodes in the central site with their configuration and life cycle managed through the same means.
Along with compute nodes, remote sites need to incorporate network gateway components that allow application users to consume edge services directly without looping the traffic through the central site.
Design considerations for a remote site¶
Deployment of an edge cluster managed from a single central place starts with a proper planning. This section provides recommendations on how to approach the deployment design.
Mirantis recommends organizing nodes in each remote site into separate Availability Zones in the MOSK Compute (OpenStack Nova), Networking (OpenStack Neutron), and Block Storage (OpenStack Cinder) services. This enables the cloud users to be aware of the failure domain represented by a remote site and distribute the parts of their applications accordingly.
Typically, high latency in between the central control plane and remote sites makes it not feasible to rely on Ceph as a storage for the instance root/ephemeral and block data.
Mirantis recommends that you configure the remote sites to use the following back ends:
Local storage (LVM or QCOW2) as a storage back end for the MOSK Compute service. See images-storage-back-end for the configuration details.
LVM on iSCSI back end for the MOSK Block Storage service. See Enable LVM block storage for the enablement procedure.
To maintain the small size of a remote site, the compute nodes need to be hyper-converged and combine the compute and block storage functions.
There is no limitation on the number of the remote sites and their size.
However, when planning the cluster, ensure consistency between the total number
of nodes managed by a single control plane and the value of the size
parameter set in the OpenStackDeployment custom resource. For the list of
supported sizes, refer to Main elements.
Additionally, the sizing of the remote site needs to take into account the characteristics of the networking channel with the main site.
Typically, an edge site consists of 3-7 compute nodes installed in a single, usually rented, rack.
Mirantis recommends keeping the network latency between the main and remote sites as low as possible. For stable interoperability of cluster components, the latency needs to be around 30-70 milliseconds. Though, depending on the cluster configuration and dynamism of the workloads running in the remote site, the stability of the cluster can be preserved with the latency of up to 190 milliseconds.
The bandwidth of the communication channel between the main and remote sites needs to be sufficient to run the following traffic:
The control plane and management traffic, such as OpenStack messaging, database access, MOSK underlay Kubernetes cluster control plane, and so on. A single remote compute node in the idle state requires at minimum 1.5 Mbit/s of bandwidth to perform the non-data plane communications.
The data plane traffic, such as OpenStack image operations, instances VNC console traffic, and so on, that heavily depend on the profile of the workloads and other aspects of the cloud usage.
In general, Mirantis recommends having a minimum of 100 MBit/s bandwidth between the main and remote sites.
MOSK remote compute nodes architecture is designed to tolerate a temporary loss of connectivity between the main cluster and the remote sites. In case of a disconnection, the instances running on remote compute nodes will keep running normally preserving their ability to read and write ephemeral and block storage data presuming it is located in the same site, as well as connectivity to their neighbours and edge application users. However, the instances will not have access to any cloud services or applications located outside of their remote site.
Since the MOSK control plane communicates with remote compute nodes through the same network channel, cloud users will not be able to perform any manipulations, for example, instance creation, deletion, snapshotting, and so on, over their edge applications until the connectivity gets restored. MOSK services providing high availability to cloud applications, such as the Instance HA service and Network service, need to be connected to the remote compute nodes to perform a failover of application components running in the remote site.
Once the connectivity between the main and the remote site restores, all functions become available again. The period during which an edge application can sustain normal function after a connectivity loss is determined by multiple factors including the selected networking back end for the MOSK cluster. Mirantis recommends that a cloud operator performs a set of test manipulations over the cloud resources hosted in the remote site to ensure that it has been fully restored.
When configured in Tungsten Fabric-powered clouds, the Graceful restart and long-lived graceful restart feature significantly improves the MOSK ability to sustain the connectivity of workloads running at remote sites in situations when a site experiences a loss of connection to the central hosting location of the control plane.
Extensive testing has demonstrated that remote sites can effectively withstand a 72-hour control plane disconnection with zero impact on the running applications.
Given that a remote site communicates with its main MOSK cluster across a wide area network (WAN), it becomes important to protect sensitive data from being intercepted and viewed by a third party. Specifically, you should ensure the protection of the data belonging to the following cloud components:
- Mirantis Container Cloud life-cycle management plane
Bare metal servers provisioning and control, Kubernetes cluster deployment and management, Mirantis StackLight telemetry
- MOSK control plane
Communication between the components of OpenStack, Tungsten Fabric, and Mirantis Ceph
- MOSK data plane
Cloud application traffic
The most reliable way to protect the data is to configure the network equipment in the data center and the remote site to encapsulate all the bypassing remote-to-main communications into an encrypted VPN tunnel. Alternatively, Mirantis Container Cloud and MOSK can be configured to force encryption of specific types of network traffic, such as:
Kubernetes networking for MOSK underlying Kubernetes cluster that handles the vast majority of in-MOSK communications
OpenStack tenant networking that carries all the cloud application traffic
The ability to enforce traffic encryption depends on the specific version of the Mirantis Container Cloud and MOSK in use, as well as the selected SDN back end for OpenStack.
Remote compute nodes with Tungsten Fabric¶
TechPreview
In MOSK, the main cloud that controls remote computes can be the regional site that locates the regional cluster and the MOSK control plane. Additionally, it can contain a local storage and compute nodes.
The remote computes implementation in MOSK considers Tungsten Fabric as an SDN solution.
Remote computes bare metal servers are configured as Kubernetes workers hosting the deployments for:
Tungsten Fabric vRouter-gateway service
Nova-compute
Local storage (LVM with iSCSI block storage)
Large clusters¶
This section describes a validated MOSK cluster architecture that is capable of handling 10,000 instances under a single control plane.
Hardware characteristics¶
Role |
Nodes count |
Server specification |
|---|---|---|
Management cluster Kubernetes nodes |
3 |
|
MOSK cluster Kubernetes master nodes |
3 |
|
OpenStack controller nodes |
5 |
|
OpenStack compute and storage nodes |
Up to 500 total |
|
StackLight nodes |
3 |
|
Cluster architecture¶
Configuration |
Value |
|---|---|
Dedicated StackLight nodes |
Yes |
Dedicated Ceph storage nodes |
Yes |
Dedicated control plane Kubernetes nodes |
Yes |
Dedicated OpenStack gateway nodes |
No, collocated with OpenStack controller nodes |
OpenStack networking backend |
Open vSwitch, no Distributed Virtual Router |
Cluster size in the |
|
Cluster validation¶
The architecture validation is perfomed by means of simultanious creation of multiple OpenStack resources of various types and execution of functional tests against each resource. The amount of resources hosted in the cluster at the moment when a certain threshold of non-operational resources starts being observed, is described below as cluster capacity limit.
Note
A successfully created resource has the Active status in the API
and passes the functional tests, for example, its floating IP address is
accessible. The MOSK cluster is considered to be able to
handle the created resources if it successfully performs the LCM operations
including the OpenStack services restart, both on the control and data
plane.
Note
The key limiting factor for creating more OpenStack objects in this illustrative setup is hardware resources (vCPU and RAM) available on the compute nodes.
OpenStack resource |
Limit |
|---|---|
Instances |
11101 |
Network ports - instances |
37337 |
Network ports - service (avg. per gateway node) |
3517 |
Volumes |
2784 |
Routers |
2448 |
Networks |
3383 |
Orchestration stacks |
2419 |
Node role |
Load average |
vCPU |
RAM in GB |
|---|---|---|---|
OpenStack controller + gateway |
10 |
10 |
100 |
OpenStack compute |
30 |
25 |
160 |
Ceph storage |
2 |
2 |
15 |
StackLight |
10 |
8 |
102 |
Kubernetes master |
10 |
6 |
13 |
Cephless cloud¶
Persistent storage is a key component of any MOSK deployment. Out of the box, MOSK includes an open-source software-defined storage solution (Ceph), which hosts various kinds of cloud application data, such as root and ephemeral disks for virtual machines, virtual machine images, attachable virtual block storage, and object data. In addition, a Ceph cluster usually acts as a storage for the internal MOSK components, such as Kubernetes, OpenStack, StackLight, and so on.
Being distributed and redundant by design, Ceph requires a certain minimum amount of servers, also known as OSD or storage nodes, to work. A production-grade Ceph cluster typically consists of at least nine storage nodes, while a development and test environment may include four to six servers. For details, refer to MOSK cluster hardware requirements.
It is possible to reduce the overall footprint of a MOSK cluster by collocating the Ceph components with hypervisors on the same physical servers; this is also known as hyper-converged design. However, this architecture still may not satisfy the requirements of certain use cases for the cloud.
Standalone telco-edge MOSK clouds typically consist of three to seven servers hosted in a single rack, where every piece of CPU, memory and disk resources is strictly accounted and better be dedicated to the cloud workloads, rather than control plane. For such clouds, where the cluster footprint is more important than the resiliency of the application data storage, it makes sense either not to have a Ceph cluster at all or to replace it with some primitive non-redundant solution.
Enterprise virtualization infrastructure with third-party storage is not a rare strategy among large companies that rely on proprietary storage appliances, provided by NetApp, Dell, HPE, Pure Storage, and other major players in the data storage sector. These industry leaders offer a variety of storage solutions meticulously designed to suit various enterprise demands. Many companies, having already invested substantially in proprietary storage infrastructure, prefer integrating MOSK with their existing storage systems. This approach allows them to leverage this investment rather than incurring new costs and logistical complexities associated with migrating to Ceph.
Architecture¶
Kind of data |
MOSK component |
Data storage in Cephless architecture |
Configuration |
|---|---|---|---|
Root and ephemeral disks of instances |
Compute service (OpenStack Nova) |
|
|
Volumes |
Block Storage service (OpenStack Cinder) |
|
|
Volumes backups |
Block Storage service (OpenStack Cinder) |
Alternatively, you can disable the volume backup functionality. |
|
Tungsten Fabric database backups |
Tungsten Fabric (Cassandra, ZooKeeper) |
External NFS share TechPreview Alternatively, you can disable the Tungsten Fabric database backups functionality. |
|
OpenStack database backups |
OpenStack (MariaDB) |
Alternatively, you can disable the database backup functionality. |
|
Results of functional testing |
OpenStack Tempest |
Local file system of MOSK controller nodes. The |
|
Instance images and snapshots |
Image service (OpenStack Glance) |
You can configure the Block Storage service (OpenStack Cinder) to be used as a storage back end for images and snapshots. In this case, each image is represented as a volume. Important Representing volumes as images implies a hard requirement for the selected block storage back end to support multi-attach capability that is concurrent reads and writes to and from a single volume. |
|
Application object data |
Object storage service (Ceph RADOS Gateway) |
External S3, Swift, or any other third-party storage solutions compatible with object access protocols. Note An external object storage solution will not be integrated into the MOSK identity service (OpenStack Keystone), the cloud applications will need to take care of managing access to their object data themselves. If no Ceph is deployed as part of a cluster, the MOSK built-in Object Storage service API endpoints are disabled automatically. |
|
Logs, metrics, alerts |
Mirantis StackLight (Prometeus, Alertmanager, Patroni, OpenSearch) |
Local file system of MOSK controller nodes. StackLight must be deployed in the HA mode, when all its data gets stored on the local file system of the nodes running StackLight services. In this mode, StackLight components get configured to handle the data replication themselves. |
Limitations¶
The determination of whether a MOSK cloud will include Ceph or not should take place during its planning and design phase. Once the deployment is complete, reconfiguring the cloud to switch between Ceph and non-Ceph architectures becomes impossible.
Mirantis recommends avoiding substitution of Ceph-backed persistent volumes in the MOSK underlying Kubernetes cluster with local volumes (local volume provisioner) for production environments. MOSK does not support such configuration unless the components that rely on these volumes can replicate their data themselves, for example, StackLight. Volumes provided by the local volume provisioner are not redundant, as they are bound to just a single node and can only be mounted from the Kubernetes pods running on the same nodes.
Node maintenance API¶
This section describes internal implementation of the node maintenance API and how OpenStack and Tungsten Fabric controllers communicate with LCM and each other during a managed cluster update.
Node maintenance API objects¶
The node maintenance API consists of the following objects:
Cluster level:
ClusterWorkloadLockClusterMaintenanceRequest
Node level:
NodeWorkloadLockNodeMaintenanceRequest
WorkloadLock objects¶
The WorkloadLock objects are created by each Application Controller.
These objects prevent LCM from performing any changes on the cluster or node
level while the lock is in the active state. The inactive state of the lock
means that the Application Controller has finished its work and the LCM can
proceed with the node or cluster maintenance.
apiVersion: lcm.mirantis.com/v1alpha1
kind: ClusterWorkloadLock
metadata:
name: cluster-1-openstack
spec:
controllerName: openstack
status:
state: active # inactive;active;failed (default: active)
errorMessage: ""
release: "6.16.0+21.3"
apiVersion: lcm.mirantis.com/v1alpha1
kind: NodeWorkloadLock
metadata:
name: node-1-openstack
spec:
nodeName: node-1
controllerName: openstack
status:
state: active # inactive;active;failed (default: active)
errorMessage: ""
release: "6.16.0+21.3"
MaintenanceRequest objects¶
The MaintenanceRequest objects are created by LCM. These objects notify
Application Controllers about the upcoming maintenance of a cluster or
a specific node.
apiVersion: lcm.mirantis.com/v1alpha1
kind: ClusterMaintenanceRequest
metadata:
name: cluster-1
spec:
scope: drain # drain;os
apiVersion: lcm.mirantis.com/v1alpha1
kind: NodeMaintenanceRequest
metadata:
name: node-1
spec:
nodeName: node-1
scope: drain # drain;os
The scope parameter in the object specification defines the impact on
the managed cluster or node. The list of the available options include:
drainA regular managed cluster update. Each node in the cluster goes over a drain procedure. No node reboot takes place, a maximum impact includes restart of services on the node including Docker, which causes the restart of all containers present in the cluster.
osA node might be rebooted during the update. Triggers the workload evacuation by the OpenStack Controller.
When the MaintenanceRequest object is created, an Application Controller
executes a handler to prepare workloads for maintenance and put appropriate
WorkloadLock objects into the inactive state.
When maintenance is over, LCM removes MaintenanceRequest objects,
and the Application Controllers move their WorkloadLocks objects into
the active state.
OpenStack Controller maintenance API¶
When LCM creates the ClusterMaintenanceRequest object, the OpenStack
Controller ensures that all OpenStack components are in the Healthy
state, which means that the pods are up and running, and the readiness
probes are passing.
The ClusterMaintenanceRequest object creation flow:
When LCM creates the NodeMaintenanceRequest, the OpenStack Controller:
Prepares components on the node for maintenance by removing
nova-computefrom scheduling.If the reboot of a node is possible, the instance migration workflow is triggered. The Operator can configure the instance migration flow through the Kubernetes node annotation and should define the required option before the managed cluster update.
To mitigate the potential impact on the cloud workloads, you can define the instance migration flow for the compute nodes running the most valuable instances.
The list of available options for the instance migration configuration includes:
The
openstack.lcm.mirantis.com/instance_migration_modeannotation:liveDefault. The OpenStack controller live migrates instances automatically. The update mechanism tries to move the memory and local storage of all instances on the node to another node without interrupting before applying any changes to the node. By default, the update mechanism makes three attempts to migrate each instance before falling back to the
manualmode.Note
Success of live migration depends on many factors including the selected vCPU type and model, the amount of data that needs to be transferred, the intensity of the disk IO and memory writes, the type of the local storage, and others. Instances using the following product features are known to have issues with live migration:
LVM-based ephemeral storage with and without encryption
Encrypted block storage volumes
CPU and NUMA node pinning
manualThe OpenStack Controller waits for the Operator to migrate instances from the compute node. When it is time to update the compute node, the update mechanism asks you to manually migrate the instances and proceeds only once you confirm the node is safe to update.
skipThe OpenStack Controller skips the instance check on the node and reboots it.
Note
For the clouds relying on the converged LVM with iSCSI block storage that offer persistent volumes in a remote edge sub-region, it is important to keep in mind that applying a major change to a compute node may impact not only the instances running on this node but also the instances attached to the LVM devices hosted there. We recommend that in such environments you perform the update procedure in the
manualmode with mitigation measures taken by the Operator for each compute node. Otherwise, all the instances that have LVM with iSCSI volumes attached would need reboot to restore the connectivity.
- The
openstack.lcm.mirantis.com/instance_migration_attemptsannotation Defines the number of times the OpenStack Controller attempts to migrate a single instance before giving up. Defaults to
3.
- The
Note
You can also use annotations to control the update of non-compute nodes if they represent critical points of a specific cloud architecture. For example, setting the
instance_migration_modetomanualon a controller node with a collocated gateway (Open vSwitch) will allow the Operator to gracefully shut down all the virtual routers hosted on this node.If the OpenStack Controller cannot migrate instances due to errors, it is suspended unless all instances are migrated manually or the
openstack.lcm.mirantis.com/instance_migration_modeannotation is set toskip.
The NodeMaintenanceRequest object creation flow:
When the node maintenance is over, LCM removes the NodeMaintenanceRequest
object and the OpenStack Controller:
Verifies that the Kubernetes Node becomes
Ready.Verifies that all OpenStack components on a given node are
Healthy, which means that the pods are up and running, and the readiness probes are passing.Ensures that the OpenStack components are connected to RabbitMQ. For example, the Neutron Agents become alive on the node, and compute instances are in the
UPstate.
Note
The OpenStack Controller enables you to have only one
nodeworkloadlock object at a time in the inactive state. Therefore,
the update process for nodes is sequential.
The NodeMaintenanceRequest object removal flow:
When the cluster maintenance is over, the OpenStack Controller sets the
ClusterWorkloadLock object to back active and the update completes.
The CLusterMaintenanceRequest object removal flow:
Tungsten Fabric Controller maintenance API¶
The Tungsten Fabric (TF) Controller creates and uses both types of
workloadlocks that include ClusterWorkloadLock and NodeWorkloadLock.
When the ClusterMaintenanceRequest object is created, the TF Controller
verifies the TF cluster health status and proceeds as follows:
If the cluster is
Ready, the TF Controller moves theClusterWorkloadLockobject to the inactive state.Otherwise, the TF Controller keeps the
ClusterWorkloadLockobject in the active state.
When the NodeMaintenanceRequest object is created, the TF Controller
verifies the vRouter pod state on the corresponding node and proceeds as
follows:
If all containers are
Ready, the TF Controller moves theNodeWorkloadLockobject to the inactive state.Otherwise, the TF Controller keeps the
NodeWorkloadLockin the active state.
Note
If there is a NodeWorkloadLock object in the inactive state
present in the cluster, the TF Controller does not process the
NodeMaintenanceRequest object for other nodes until this inactive
NodeWorkloadLock object becomes active.
When the cluster LCM removes the MaintenanceRequest object, the TF
Controller waits for the vRouter pods to become ready and proceeds as follows:
If all containers are in the
Readystate, the TF Controller moves theNodeWorkloadLockobject to the active state.Otherwise, the TF Controller keeps the
NodeWorkloadLockobject in the inactive state.
Cluster update flow¶
This section describes the MOSK cluster update flow to the product releases that contain major updates and require node reboot such as support for new Linux kernel, and similar.
The diagram below illustrates the sequence of operations controlled by
LCM and taking place during the update under the hood. We assume that the
ClusterWorkloadLock and NodeWrokloadLock objects present in the cluster
are in the active state before the cloud operator triggers the update.
See also
For details about the Application Controllers flow during different maintenance stages, refer to:
Phase 1: The Operator triggers the update¶
The Operator sets appropriate annotations on nodes and selects suitable migration mode for workloads.
The Operator triggers the managed cluster update through the Mirantis Container Cloud web UI as described in Step 2. Initiate MOSK cluster update.
LCM creates the
ClusterMaintenanceobject and notifies the application controllers about planned maintenance.
Phase 2: LCM triggers the OpenStack and Ceph update¶
The OpenStack update starts.
Ceph is waiting for the OpenStack
ClusterWorkloadLockobject to become inactive.When the OpenStack update is finalized, the OpenStack Controller marks
ClusterWorkloadLockas inactive.The Ceph Controller triggers an update of the Ceph cluster.
When the Ceph update is finalized, Ceph marks the
ClusterWorkloadLockobject as inactive.
Phase 3: LCM initiates the Kubernetes master nodes update¶
If a master node has collocated roles, LCM creates
NodeMainteananceRequestfor the node.All Application Controllers mark their
NodeWorkloadLockobjects for this node as inactive.LCM starts draining the node by gracefully moving out all pods from the node. The DaemonSet pods are not evacuated and left running.
LCM downloads the new version of the LCM Agent and runs its states.
Note
While running Ansible states, the services on the node may be restarted.
The above flow is applied to all Kubernetes master nodes one by one.
LCM removes
NodeMainteananceRequest.
Phase 4: LCM initiates the Kubernetes worker nodes update¶
LCM creates
NodeMaintenanceRequestfor the node with specifying scope.Application Controllers start preparing the node according to the scope.
LCM waits until all Application Controllers mark their
NodeWorkloadLockobjects for this node as inactive.All pods are evacuated from the node by draining it. This does not apply to the DaemonSet pods, which cannot be removed.
LCM downloads the new version of the LCM Agent and runs its states.
Note
While running Ansible states, the services on the node may be restarted.
The above flow is applied to all Kubernetes worker nodes one by one.
LCM removes
NodeMainteananceRequest.
Phase 5: Finalization¶
LCM triggers the update for all other applications present in the cluster, such as StackLight, Tungsten Fabric, and others.
LCM removes
ClusterMaintenanceRequest.
After a while the cluster update completes and becomes fully operable again.
Parallelizing node update operations¶
Available since MOSK 23.2 TechPreview
MOSK enables you to parallelize node update operations, significantly improving the efficiency of your deployment. This capability applies to any operation that utilizes the Node Maintenance API, such as cluster updates or graceful node reboots.
The core implementation of parallel updates is handled by the LCM Controller
ensuring seamless execution of parallel operations. LCM starts performing an
operation on the node only when all NodeWorkloadLock objects for the node
are marked as inactive. By default, the LCM Controller creates one
NodeMaintenanceRequest at a time.
Each application controller, including Ceph, OpenStack, and Tungsten Fabric
Controllers, manages parallel NodeMaintenanceRequest objects independently.
The controllers determine how to handle and execute parallel node maintenance
requests based on specific requirements of their respective applications.
To understand the workflow of the Node Maintenance API, refer to
WorkloadLock objects.
Enhancing parallelism during node updates¶
- Set the nodes update order.
You can optimize parallel updates by setting the order in which nodes are updated. You can accomplish this by configuring
upgradeIndexof theMachineobject. For the procedure, refer to Mirantis Container Cloud: Change upgrade order for machines.
- Increase parallelism.
Boost parallelism by adjusting the maximum number of worker node updates that are allowed during LCM operations using the
spec.providerSpec.value.maxWorkerUpgradeCountconfiguration parameter, which is set to1by default.For configuration details, refer to Mirantis Container Cloud: Configure the parallel update of worker nodes.
- Execute LCM operations.
Run LCM operations, such as cluster updates, taking advantage of the increased parallelism.
OpenStack nodes update¶
By default, the OpenStack Controller handles the NodeMaintenanceRequest
objects as follows:
Updates the OpenStack controller nodes sequentially (one by one).
Updates the gateway nodes sequentially. Technically, you can increase the number of gateway nodes upgrades allowed in parallel using the
nwl_parallel_max_gatewayparameter but Mirantis does not recommend to do so.Updates the compute nodes in parallel. The default number of allowed parallel updates is
30. You can adjust this value through thenwl_parallel_max_computeparameter.Parallelism considerations for compute nodes
When considering parallelism for compute nodes, take into account that during certain pod restarts, for example, the
openvswitch-vswitchdpods, a brief instance downtime may occur. Select a suitable level of parallelism to minimize the impact on workloads and prevent excessive load on the control plane nodes.If your cloud environment is distributed across failure domains, which are represented by Nova availability zones, you can limit the parallel updates of nodes to only those within the same availability zone. This behavior is controlled by the
respect_nova_azoption in the OpenStack Controller.
The OpenStack Controller configuration is stored in the
openstack-controller-config configMap of the osh-system namespace.
The options are picked up automatically after update. To learn more about
the OpenStack Controller configuration parameters,
refer to OpenStack Controller configuration.
Ceph nodes update¶
By default, the Ceph Controller handles the NodeMaintenanceRequest
objects as follows:
Updates the non-storage nodes sequentially. Non-storage nodes include all nodes that have
mon,mgr,rgw, ormdsroles.Updates storage nodes in parallel. The default number of allowed parallel updates is calculated automatically based on the minimal failure domain in a Ceph cluster.
Parallelism calculations for storage nodes
The Ceph Controller automatically calculates the parallelism number in the following way:
Finds the minimal failure domain for a Ceph cluster. For example, the minimal failure domain is
rack.Filters all currently requested nodes by minimal failure domain. For example, parallelism equals to 5, and LCM requests 3 nodes from the
rack1rack and 2 nodes from therack2rack.Handles each filtered node group one by one. For example, the controller handles in parallel all nodes from
rack1before processing nodes fromrack2.
The Ceph Controller handles non-storage nodes before the storage ones. If there are node requests for both node types, the Ceph Controller handles sequentially the non-storage nodes first. Therefore, Mirantis recommends setting the upgrade index of a higher priority for the non-storage nodes to decrease the total upgrade time.
If the minimal failure domain is host, the Ceph Controller updates only
one storage node per failure domain unit. This results in updating all Ceph
nodes sequentially, despite the potential for increased parallelism.
Tungsten Fabric nodes update¶
By default, the Tungsten Fabric Controller handles the
NodeMaintenanceRequest objects as follows:
Updates the Tungsten Fabric Controller and gateway nodes sequentially.
Updates the vRouter nodes in parallel. The Tungsten Fabric Controller allows updating up to 30 vRouter nodes in parallel.
Maximum amount of vRouter nodes in maintenance
While the Tungsten Fabric Controller has the capability to process up to 30
NodeMaintenanceRequestobjects targeted to vRouter nodes, the actual amount may be lower. This is due to a check that ensures OpenStack readiness to unlock the relevant nodes for maintenance. If OpenStack allows for maintenance, the Tungsten Fabric Controller verifies the vRouter pods. Upon successful verification, theNodeWorkloadLockobject is switched to the maintenance mode.
Deployment Guide¶
Mirantis OpenStack for Kubernetes (MOSK) enables the operator to create, scale, update, and upgrade OpenStack deployments on Kubernetes through a declarative API.
The Kubernetes built-in features, such as flexibility, scalability, and declarative resource definition make MOSK a robust solution.
Plan the deployment¶
The detailed plan of any Mirantis OpenStack for Kubernetes (MOSK) deployment is determined on a per-cloud basis. For the MOSK reference architecture and design overview, see Reference Architecture.
Also, read through Mirantis Container Cloud Reference Architecture: Container Cloud bare metal as a MOSK cluster is deployed on top of a bare metal cluster managed by Mirantis Container Cloud.
Note
One of the industry best practices is to verify every new update or configuration change in a non-customer-facing environment before applying it to production. Therefore, Mirantis recommends having a staging cloud, deployed and maintained along with the production clouds. The recommendation is especially applicable to the environments that:
Receive updates often and use continuous delivery. For example, any non-isolated deployment of Mirantis Container Cloud.
Have significant deviations from the reference architecture or third party extensions installed.
Are managed under the Mirantis OpsCare program.
Run business-critical workloads where even the slightest application downtime is unacceptable.
A typical staging cloud is a complete copy of the production environment including the hardware and software configurations, but with a bare minimum of compute and storage capacity.
Provision a Container Cloud bare metal management cluster¶
The bare metal management system enables the Infrastructure Operator to deploy Container Cloud on a set of bare metal servers. It also enables Container Cloud to deploy MOSK clusters on bare metal servers without a pre-provisioned operating system.
To provision your bare metal management cluster, refer to Mirantis Container Cloud Deployment Guide: Deploy a Container Cloud management cluster.
Create a managed cluster¶
After bootstrapping your baremetal-based Mirantis Container Cloud management cluster, you can create a baremetal-based managed cluster to deploy Mirantis OpenStack for Kubernetes using the Container Cloud API.
Add a bare metal host¶
Before creating a bare metal managed cluster, add the required number of bare metal hosts using CLI and YAML files for configuration. This section describes how to add bare metal hosts using the Container Cloud CLI during a managed cluster creation.
To add a bare metal host:
Verify that you configured each bare metal host as follows:
Enable the boot NIC support for UEFI load. Usually, at least the built-in network interfaces support it.
Enable the UEFI-LAN-OPROM support in BIOS -> Advanced -> PCIPCIe.
Enable the IPv4-PXE stack.
Set the following boot order:
UEFI-DISK
UEFI-PXE
If your PXE network is not configured to use the first network interface, fix the UEFI-PXE boot order to speed up node discovering by selecting only one required network interface.
Power off all bare metal hosts.
Warning
Only one Ethernet port on a host must be connected to the Common/PXE network at any given time. The physical address (MAC) of this interface must be noted and used to configure the
BareMetalHostobject describing the host.Log in to the host where your management cluster
kubeconfigis located and where kubectl is installed.Describe the unique credentials of the new bare metal host:
Create a YAML file that describes the unique credentials of the new bare metal host as a
BareMetalHostCredentialobject.apiVersion: kaas.mirantis.com/v1alpha1 kind: BareMetalHostCredential metadata: labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: <bare-metal-host-credential-unique-name> namespace: <managed-cluster-project-name> spec: username: <ipmi-user-name> password: value: <ipmi-user-password>
In the
metadatasection, add a unique credentialsnameand the name of the non-defaultproject (namespace) dedicated for the managed cluster being created.In the
specsection, add the IPMI user name and password in plain text to access the Baseboard Management Controller (BMC). The password will not be stored in theBareMetalHostCredentialobject but will be erased and saved in an underlyingSecretobject.
Caution
Each bare metal host must have a unique
BareMetalHostCredential. For details about theBareMetalHostCredentialobject, refer to Mirantis Container Cloud API Reference: BareMetalHostCredential.Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
Create a secret YAML file that describes the unique credentials of the new bare metal host. Example of the bare metal host secret:
apiVersion: v1 data: password: <credentials-password> username: <credentials-user-name> kind: Secret metadata: labels: kaas.mirantis.com/credentials: "true" kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: <credentials-name> namespace: <managed-cluster-project-name> type: Opaque
In the
datasection, add the IPMI user name and password in the base64 encoding to access the BMC. To obtain the base64-encoded credentials, you can use the following command in your Linux console:echo -n <username|password> | base64
Caution
Each bare metal host must have a unique
Secret.In the
metadatasection, add the uniquenameof credentials and the name of the non-defaultproject (namespace) dedicated for the managed cluster being created. To create a project, refer to Mirantis Container Cloud Operations Guide: Create a project for managed clusters.
Apply this secret YAML file to your deployment:
kubectl apply -f ${<bmh-cred-file-name>}.yaml
Create a YAML file that contains a description of the new bare metal host:
apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: annotations: kaas.mirantis.com/baremetalhost-credentials-name: <bare-metal-host-credential-unique-name> labels: kaas.mirantis.com/baremetalhost-id: <unique-bare-metal-host-hardware-node-id> hostlabel.bm.kaas.mirantis.com/worker: "true" kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: <bare-metal-host-unique-name> namespace: <managed-cluster-project-name> spec: bmc: address: <ip-address-for-bmc-access> credentialsName: <credentials-name> bootMACAddress: <bare-metal-host-boot-mac-address> online: true
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: labels: kaas.mirantis.com/baremetalhost-id: <unique-bare-metal-host-hardware-node-id> hostlabel.bm.kaas.mirantis.com/worker: "true" kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: <bare-metal-host-unique-name> namespace: <managed-cluster-project-name> spec: bmc: address: <ip-address-for-bmc-access> credentialsName: <credentials-name> bootMACAddress: <bare-metal-host-boot-mac-address> online: true
For a detailed fields description, see Mirantis Container Cloud API Reference: BareMetalHost.
Apply this configuration YAML file to your deployment:
kubectl create -f ${<bare-metal-host-config-file-name>}.yaml
Verify the new
BareMetalHostobject status:kubectl get -n <managed-cluster-project-name> bmh -o wide <bare-metal-host-unique-name>
Example of system response:
NAMESPACE NAME STATUS STATE CONSUMER BMC BOOTMODE ONLINE ERROR REGION my-project bmh1 OK preparing ip-address-for-bmc-access legacy true region-one
During provisioning, the status changes as follows:
registeringinspectingpreparing
After
BareMetalHostswitches to thepreparingstage, theinspectingphase finishes and you can verify that hardware information is available in the object status and matches the MOSK cluster hardware requirements.For example:
Verify the status of hardware NICs:
kubectl -n <managed-cluster-project-name> get bmh -o yaml <bare-metal-host-unique-name> -o json | jq -r '[.status.hardware.nics]'
Example of system response:
[ [ { "ip": "172.18.171.32", "mac": "ac:1f:6b:02:81:1a", "model": "0x8086 0x1521", "name": "eno1", "pxe": true }, { "ip": "fe80::225:90ff:fe33:d5ac%ens1f0", "mac": "00:25:90:33:d5:ac", "model": "0x8086 0x10fb", "name": "ens1f0" }, ...
Verify the status of RAM:
kubectl -n <managed-cluster-project-name> get bmh -o yaml <bare-metal-host-unique-name> -o json | jq -r '[.status.hardware.ramMebibytes]'
Example of system response:
[ 98304 ]
Now, proceed with Create a custom bare metal host profile.
Create a custom bare metal host profile¶
The bare metal host profile is a Kubernetes custom resource. It enables the Operator to define how the storage devices and the operating system are provisioned and configured.
This section describes the bare metal host profile default settings and configuration of custom profiles for managed clusters using Mirantis Container Cloud API.
Default configuration of the host system storage¶
The default host profile requires three storage devices in the following strict order:
- Boot device and operating system storage
This device contains boot data and operating system data. It is partitioned using the GUID Partition Table (GPT) labels. The root file system is an
ext4file system created on top of an LVM logical volume. For a detailed layout, refer to the table below.
- Local volumes device
This device contains an
ext4file system with directories mounted as persistent volumes to Kubernetes. These volumes are used by the Mirantis Container Cloud services to store its data, including monitoring and identity databases.
- Ceph storage device
This device is used as a Ceph datastore or Ceph OSD on managed clusters.
The following table summarizes the default configuration of the host system storage set up by the Container Cloud bare metal management.
Device/partition |
Name/Mount point |
Recommended size, GB |
Description |
|---|---|---|---|
|
|
4 MiB |
The mandatory GRUB boot partition required for non-UEFI systems. |
|
|
0.2 GiB |
The boot partition required for the UEFI boot mode. |
|
|
64 MiB |
The mandatory partition for the |
|
|
100% of the remaining free space in the LVM volume group |
The main LVM physical volume that is used to create the root file system. |
|
|
100% of the remaining free space in the LVM volume group |
The LVM physical volume that is used to create the file system
for |
|
|
100% of the remaining free space in the LVM volume group |
Clean raw disk that will be used for the Ceph storage back end on managed clusters. |
Now, proceed to Create MOSK host profiles.
Create MOSK host profiles¶
Different types of MOSK nodes require differently configured host storage. This section describes how to create custom host profiles for different types of MOSK nodes.
You can create custom profiles for managed clusters using Container Cloud API.
You can use flexible size units throughout bare metal host profiles.
For example, you can now use either sizeGiB: 0.1 or size: 100Mi
when specifying a device size.
Mirantis recommends using only one parameter name type and units throughout
the configuration files. If both sizeGiB and size are used,
sizeGiB is ignored during deployment and the suffix is adjusted
accordingly. For example, 1.5Gi will be serialized as 1536Mi. The size
without units is counted in bytes. For example, size: 120 means 120 bytes.
Warning
All data will be wiped during cluster deployment on devices
defined directly or indirectly in the fileSystems list of
BareMetalHostProfile. For example:
A raw device partition with a file system on it
A device partition in a volume group with a logical volume that has a file system on it
An mdadm RAID device with a file system on it
An LVM RAID device with a file system on it
The wipe field is always considered true for these devices.
The false value is ignored.
Therefore, to prevent data loss, move the necessary data from these file systems to another server beforehand, if required.
To create MOSK bare metal host profiles:
Log in to the local machine where you management cluster
kubeconfigis located and wherekubectlis installed.Note
The management cluster
kubeconfigis created automatically during the last stage of the management cluster bootstrap.Create a new bare metal host profile for MOSK compute nodes in a YAML file under the
templates/bm/directory.Edit the host profile using the example template below to meet your hardware configuration requirements:
apiVersion: metal3.io/v1alpha1 kind: BareMetalHostProfile metadata: name: <PROFILE_NAME> namespace: <PROJECT_NAME> spec: devices: # From the HW node, obtain the first device, which size is at least 60Gib - device: workBy: "by_id,by_wwn,by_path,by_name" minSize: 60Gi type: ssd wipe: true partitions: - name: bios_grub partflags: - bios_grub size: 4Mi wipe: true - name: uefi partflags: - esp size: 200Mi wipe: true - name: config-2 size: 64Mi wipe: true # This partition is only required on compute nodes if you plan to # use LVM ephemeral storage. - name: lvm_nova_part wipe: true size: 100Gi - name: lvm_root_part size: 0 wipe: true # From the HW node, obtain the second device, which size is at least 60Gib # If a device exists but does not fit the size, # the BareMetalHostProfile will not be applied to the node - device: workBy: "by_id,by_wwn,by_path,by_name" minSize: 60Gi type: ssd wipe: true # From the HW node, obtain the disk device with the exact name - device: workBy: "by_id,by_wwn,by_path,by_name" minSize: 60Gi wipe: true partitions: - name: lvm_lvp_part size: 0 wipe: true # Example of wiping a device w\o partitioning it. # Mandatory for the case when a disk is supposed to be used for Ceph back end # later - device: workBy: "by_id,by_wwn,by_path,by_name" wipe: true fileSystems: - fileSystem: vfat partition: config-2 - fileSystem: vfat mountPoint: /boot/efi partition: uefi - fileSystem: ext4 logicalVolume: root mountPoint: / - fileSystem: ext4 logicalVolume: lvp mountPoint: /mnt/local-volumes/ logicalVolumes: - name: root size: 0 vg: lvm_root - name: lvp size: 0 vg: lvm_lvp postDeployScript: | #!/bin/bash -ex echo $(date) 'post_deploy_script done' >> /root/post_deploy_done preDeployScript: | #!/bin/bash -ex echo $(date) 'pre_deploy_script done' >> /root/pre_deploy_done volumeGroups: - devices: - partition: lvm_root_part name: lvm_root - devices: - partition: lvm_lvp_part name: lvm_lvp grubConfig: defaultGrubOptions: - GRUB_DISABLE_RECOVERY="true" - GRUB_PRELOAD_MODULES=lvm - GRUB_TIMEOUT=20 kernelParameters: sysctl: # For the list of options prohibited to change, refer to # https://docs.mirantis.com/mke/3.7/install/predeployment/set-up-kernel-default-protections.html kernel.dmesg_restrict: "1" kernel.core_uses_pid: "1" fs.file-max: "9223372036854775807" fs.aio-max-nr: "1048576" fs.inotify.max_user_instances: "4096" vm.max_map_count: "262144"
Add or edit the mandatory parameters in the new
BareMetalHostProfileobject. For the parameters description, see Container Cloud API: BareMetalHostProfile spec.Note
If asymmetric traffic is expected on some of the MOSK cluster nodes, enable the loose mode for the corresponding interfaces on those nodes by setting the
net.ipv4.conf.<interface-name>.rp_filterparameter to"2"in thekernelParameters.sysctlsection. For example:kernelParameters: sysctl: net.ipv4.conf.k8s-lcm.rp_filter: "2"
Add the bare metal host profile to your management cluster:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <projectName> apply -f <pathToBareMetalHostProfileFile>
If required, further modify the host profile:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <projectName> edit baremetalhostprofile <hostProfileName>
Repeat the steps above to create host profiles for other OpenStack node roles such as control plane nodes and storage nodes.
Now, proceed to Enable huge pages in a host profile.
Enable huge pages in a host profile¶
The BareMetalHostProfile API allows configuring a host to use the
huge pages feature of the Linux kernel on managed clusters.
Note
Huge pages is a mode of operation of the Linux kernel. With huge pages enabled, the kernel allocates the RAM in bigger chunks, or pages. This allows a KVM (kernel-based virtual machine) and VMs running on it to use the host RAM more efficiently and improves the performance of VMs.
To enable huge pages in a custom bare metal host profile for a managed cluster:
Log in to the local machine where you management cluster
kubeconfigis located and wherekubectlis installed.Note
The management cluster
kubeconfigis created automatically during the last stage of the management cluster bootstrap.Open for editing or create a new bare metal host profile under the
templates/bm/directory.Edit the
grubConfigsection of the host profilespecusing the example below to configure the kernel boot parameters and enable huge pages:spec: grubConfig: defaultGrubOptions: - GRUB_DISABLE_RECOVERY="true" - GRUB_PRELOAD_MODULES=lvm - GRUB_TIMEOUT=20 - GRUB_CMDLINE_LINUX_DEFAULT="hugepagesz=1G hugepages=N"
The example configuration above will allocate
Nhuge pages of 1 GB each on the server boot. The lasthugepageszparameter value is default unlessdefault_hugepageszis defined. For details about possible values, see official Linux kernel documentation.Add the bare metal host profile to your management cluster:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <projectName> apply -f <pathToBareMetalHostProfileFile>
If required, further modify the host profile:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <projectName> edit baremetalhostprofile <hostProfileName>
Proceed to Create a MOSK cluster.
Configure RAID support¶
TechPreview
You can configure the support of the software-based Redundant Array of
Independent Disks (RAID) using BareMetalHosProfile to set up an LVM-based
RAID level 1 (raid1) or an mdadm-based RAID level 0, 1, or 10 (raid0,
raid1, or raid10).
If required, you can further configure RAID in the same profile, for example, to install a cluster operating system onto a RAID device.
Caution
RAID configuration on already provisioned bare metal machines or on an existing cluster is not supported.
To start using any kind of RAIDs, reprovisioning of machines with a new
BaremetalHostProfileis required.Mirantis supports the
raid1type of RAID devices both for LVM and mdadm.Mirantis supports the
raid0type for the mdadm RAID to be on par with the LVMlineartype.Mirantis recommends having at least two physical disks for
raid0andraid1devices to prevent unnecessary complexity.Mirantis supports the
raid10type for mdadm RAID. At least four physical disks are required for this type of RAID.Only an even number of disks can be used for a
raid1orraid10device.
TechPreview
Warning
The EFI system partition partflags: ['esp'] must be
a physical partition in the main partition table of the disk, not under
LVM or mdadm software RAID.
During configuration of your custom bare metal host profile,
you can create an LVM-based software RAID device raid1 by adding
type: raid1 to the logicalVolume spec in BaremetalHostProfile.
For the LVM RAID parameters description, refer to Container Cloud API: BareMetalHostProfile spec.
For a bare metal host profile configuration, refer to Create a custom bare metal host profile.
Caution
The logicalVolume spec of the raid1 type requires
at least two devices (partitions) in volumeGroup where you
build a logical volume. For an LVM of the linear type,
one device is enough.
You can use flexible size units throughout bare metal host profiles.
For example, you can now use either sizeGiB: 0.1 or size: 100Mi
when specifying a device size.
Mirantis recommends using only one parameter name type and units throughout
the configuration files. If both sizeGiB and size are used,
sizeGiB is ignored during deployment and the suffix is adjusted
accordingly. For example, 1.5Gi will be serialized as 1536Mi. The size
without units is counted in bytes. For example, size: 120 means 120 bytes.
Note
The LVM raid1 requires additional space to store the raid1
metadata on a volume group, roughly 4 MB for each partition.
Therefore, you cannot create a logical volume of exactly the same
size as the partitions it works on.
For example, if you have two partitions of 10 GiB, the corresponding
raid1 logical volume size will be less than 10 GiB. For that
reason, you can either set size: 0 to use all available
space on the volume group, or set a smaller size than the partition
size. For example, use size: 9.9Gi instead of
size: 10Gi for the logical volume.
The following example illustrates an extract of BaremetalHostProfile
with / on the LVM raid1.
...
devices:
- device:
workBy: "by_id,by_wwn,by_path,by_name"
minSize: 200Gi
type: hdd
wipe: true
partitions:
- name: root_part1
size: 120Gi
partitions:
- name: rest_sda
size: 0
- device:
workBy: "by_id,by_wwn,by_path,by_name"
minSize: 200Gi
type: hdd
wipe: true
partitions:
- name: root_part2
size: 120Gi
partitions:
- name: rest_sdb
size: 0
volumeGroups:
- name: vg-root
devices:
- partition: root_part1
- partition: root_part2
- name: vg-data
devices:
- partition: rest_sda
- partition: rest_sdb
logicalVolumes:
- name: root
type: raid1 ## <-- LVM raid1
vg: vg-root
size: 119.9Gi
- name: data
type: linear
vg: vg-data
size: 0
fileSystems:
- fileSystem: ext4
logicalVolume: root
mountPoint: /
mountOpts: "noatime,nodiratime"
- fileSystem: ext4
logicalVolume: data
mountPoint: /mnt/data
Warning
All data will be wiped during cluster deployment on devices
defined directly or indirectly in the fileSystems list of
BareMetalHostProfile. For example:
A raw device partition with a file system on it
A device partition in a volume group with a logical volume that has a file system on it
An mdadm RAID device with a file system on it
An LVM RAID device with a file system on it
The wipe field is always considered true for these devices.
The false value is ignored.
Therefore, to prevent data loss, move the necessary data from these file systems to another server beforehand, if required.
TechPreview
Warning
The EFI system partition partflags: ['esp'] must be
a physical partition in the main partition table of the disk, not under
LVM or mdadm software RAID.
During configuration of your custom bare metal host profile as described in
Create a custom bare metal host profile, you can create an mdadm-based software RAID
device raid0 and raid1 by describing the mdadm devices under the
softRaidDevices field in BaremetalHostProfile. For example:
...
softRaidDevices:
- name: /dev/md0
devices:
- partition: sda1
- partition: sdb1
- name: raid-name
devices:
- partition: sda2
- partition: sdb2
...
You can also use the raid10 type for the mdadm-based software RAID devices.
This type requires at least four and in total an even number of storage devices
available on your servers. For example:
softRaidDevices:
- name: /dev/md0
level: raid10
devices:
- partition: sda1
- partition: sdb1
- partition: sdd1
The following fields in softRaidDevices describe RAID devices:
nameName of the RAID device to refer to throughout the
baremetalhostprofile.
levelType or level of RAID used to create a device, defaults to
raid1. Set toraid0orraid10to create a device of the corresponding type.
devicesList of physical devices or partitions used to build a software RAID device. It must include at least two partitions or devices to build a
raid0andraid1devices and at least four forraid10.
For the rest of the mdadm RAID parameters, see Container Cloud API: BareMetalHostProfile spec.
Caution
The mdadm RAID devices cannot be created on top of LVM devices.
You can use flexible size units throughout bare metal host profiles.
For example, you can now use either sizeGiB: 0.1 or size: 100Mi
when specifying a device size.
Mirantis recommends using only one parameter name type and units throughout
the configuration files. If both sizeGiB and size are used,
sizeGiB is ignored during deployment and the suffix is adjusted
accordingly. For example, 1.5Gi will be serialized as 1536Mi. The size
without units is counted in bytes. For example, size: 120 means 120 bytes.
Warning
All data will be wiped during cluster deployment on devices
defined directly or indirectly in the fileSystems list of
BareMetalHostProfile. For example:
A raw device partition with a file system on it
A device partition in a volume group with a logical volume that has a file system on it
An mdadm RAID device with a file system on it
An LVM RAID device with a file system on it
The wipe field is always considered true for these devices.
The false value is ignored.
Therefore, to prevent data loss, move the necessary data from these file systems to another server beforehand, if required.
The following example illustrates an extract of BaremetalHostProfile
with / on the mdadm raid1 and some data storage on raid0:
Example with / on the mdadm raid1 and data storage on raid0
...
devices:
- device:
workBy: "by_id,by_wwn,by_path,by_name"
type: nvme
wipe: true
partitions:
- name: root_part1
size: 120Gi
partitions:
- name: rest_sda
size: 0
- device:
workBy: "by_id,by_wwn,by_path,by_name"
type: nvme
wipe: true
partitions:
- name: root_part2
size: 120Gi
partitions:
- name: rest_sdb
size: 0
softRaidDevices:
- name: root
level: raid1 ## <-- mdadm raid1
devices:
- partition: root_part1
- partition: root_part2
- name: raid-name
level: raid0 ## <-- mdadm raid0
devices:
- partition: rest_sda
- partition: rest_sdb
fileSystems:
- fileSystem: ext4
softRaidDevice: root
mountPoint: /
mountOpts: "noatime,nodiratime"
- fileSystem: ext4
softRaidDevice: data
mountPoint: /mnt/data
...
The following example illustrates an extract of BaremetalHostProfile
with data storage on a raid10 device:
Example with data storage on the mdadm raid10
...
devices:
- device:
workBy: "by_id,by_wwn,by_path,by_name"
minSize: 60Gi
type: ssd
wipe: true
partitions:
- name: bios_grub1
partflags:
- bios_grub
size: 4Mi
wipe: true
- name: uefi
partflags:
- esp
size: 200Mi
wipe: true
- name: config-2
size: 64Mi
wipe: true
- name: lvm_root
size: 0
wipe: true
- device:
workBy: "by_id,by_wwn,by_path,by_name"
minSize: 60Gi
type: nvme
wipe: true
partitions:
- name: md_part1
partflags:
- raid
size: 40Gi
wipe: true
- device:
workBy: "by_id,by_wwn,by_path,by_name"
minSize: 60Gi
type: nvme
wipe: true
partitions:
- name: md_part2
partflags:
- raid
size: 40Gi
wipe: true
- device:
workBy: "by_id,by_wwn,by_path,by_name"
minSize: 60Gi
type: nvme
wipe: true
partitions:
- name: md_part3
partflags:
- raid
size: 40Gi
wipe: true
- device:
workBy: "by_id,by_wwn,by_path,by_name"
minSize: 60Gi
type: nvme
wipe: true
partitions:
- name: md_part4
partflags:
- raid
size: 40Gi
wipe: true
fileSystems:
- fileSystem: vfat
partition: config-2
- fileSystem: vfat
mountPoint: /boot/efi
partition: uefi
- fileSystem: ext4
mountOpts: rw,noatime,nodiratime,lazytime,nobarrier,commit=240,data=ordered
mountPoint: /
partition: root
- filesystem: ext4
mountPoint: /var
softRaidDevice: /dev/md0
softRaidDevices:
- devices:
- partition: md_root_part1
- partition: md_root_part2
- partition: md_root_part3
- partition: md_root_part4
level: raid10
metadata: "1.2"
name: /dev/md0
...
Create LVM volume groups on top of RAID devices¶
TechPreview
You can configure an LVM volume group on top of mdadm-based RAID devices as
physical volumes using the BareMetalHostProfile resource. List the
required RAID devices in a separate field of the volumeGroups definition
within the storage configuration of BareMetalHostProfile.
You can use flexible size units throughout bare metal host profiles.
For example, you can now use either sizeGiB: 0.1 or size: 100Mi
when specifying a device size.
Mirantis recommends using only one parameter name type and units throughout
the configuration files. If both sizeGiB and size are used,
sizeGiB is ignored during deployment and the suffix is adjusted
accordingly. For example, 1.5Gi will be serialized as 1536Mi. The size
without units is counted in bytes. For example, size: 120 means 120 bytes.
Warning
All data will be wiped during cluster deployment on devices
defined directly or indirectly in the fileSystems list of
BareMetalHostProfile. For example:
A raw device partition with a file system on it
A device partition in a volume group with a logical volume that has a file system on it
An mdadm RAID device with a file system on it
An LVM RAID device with a file system on it
The wipe field is always considered true for these devices.
The false value is ignored.
Therefore, to prevent data loss, move the necessary data from these file systems to another server beforehand, if required.
The following example illustrates an extract of BaremetalHostProfile with
a volume group named lvm_nova to be created on top of an mdadm-based
RAID device raid1:
...
devices:
- device:
workBy: "by_id,by_wwn,by_path,by_name"
minSize: 60Gi
type: ssd
wipe: true
partitions:
- name: bios_grub
partflags:
- bios_grub
size: 4Mi
- name: uefi
partflags:
- esp
size: 200Mi
- name: config-2
size: 64Mi
- device:
workBy: "by_id,by_wwn,by_path,by_name"
minSize: 30Gi
type: ssd
wipe: true
partitions:
- name: md0_part1
- device:
workBy: "by_id,by_wwn,by_path,by_name"
minSize: 30Gi
type: ssd
wipe: true
partitions:
- name: md0_part2
softRaidDevices:
- devices:
- partition: md0_part1
- partition: md0_part2
level: raid1
metadata: "1.0"
name: /dev/md0
volumeGroups:
- devices:
- softRaidDevice: /dev/md0
name: lvm_nova
...
Create a MOSK cluster¶
With L2 networking templates, you can create MOSK clusters with advanced host networking configurations. For example, you can create bond interfaces on top of physical interfaces on the host or use multiple subnets to separate different types of network traffic.
You can use several host-specific L2 templates per one cluster to support different hardware configurations. For example, you can create L2 templates with a different number and layout of NICs to be applied to specific machines of one cluster.
You can also use multiple L2 templates to support different roles for nodes in a MOSK installation. You can create L2 templates with different logical interfaces and assign them to individual machines based on their roles in a MOSK cluster.
When you create a baremetal-based project in the Container Cloud web UI, the
exemplary templates with the ipam/PreInstalledL2Template label are copied
to this project. These templates are preinstalled during the management
cluster bootstrap.
Using the L2 Templates section of the Clusters tab in the Container Cloud web UI, you can view a list of preinstalled templates and the ones that you manually create before a cluster deployment.
Note
Mirantis does not recommend modifying L2 templates in use to prevent accidental cluster failures due to unsafe changes.
The list of risks posed by modifying L2 templates includes:
Services running on hosts cannot reconfigure automatically to switch to the new IP addresses and/or interfaces.
Connections between services are interrupted unexpectedly, which can cause data loss.
Incorrect configurations on hosts can lead to irrevocable loss of connectivity between services and unexpected cluster partition or disassembly.
Since MOSK 23.2.2, in the Technology Preview scope, you can create a MOSK cluster with the multi-rack topology, where cluster nodes including Kubernetes masters are distributed across multiple racks without L2 layer extension between them, and use BGP for announcement of the cluster API load balancer address and external addresses of Kubernetes load-balanced services.
Implementation of the multi-rack topology implies the use of Rack and
MultiRackCluster objects that support configuration of BGP announcement
of the cluster API load balancer address. For the configuration procedure,
refer to Configure BGP announcement for cluster API LB address. For configuring the BGP announcement of
external addresses of Kubernetes load-balanced services, refer to
Configure MetalLB.
Follow the procedures described in the below subsections to configure initial settings and advanced network objects for your managed clusters.
Create a managed bare metal cluster¶
This section instructs you on how to configure and deploy a managed cluster that is based on the baremetal-based management cluster through the Mirantis Container Cloud web UI.
To create a managed cluster on bare metal:
Log in to the Container Cloud web UI with the
writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
Caution
Do not create a new managed cluster for MOSK in the
defaultproject (Kubernetes namespace). If no projects are defined, create a newmoskproject first.In the SSH keys tab, click Add SSH Key to upload the public SSH key that will be used for the SSH access to VMs.
Optional. In the Proxies tab, enable proxy access to the managed cluster:
Click Add Proxy.
In the Add New Proxy wizard, fill out the form with the following parameters:
Proxy configuration¶ Parameter
Description
Proxy Name
Name of the proxy server to use during a managed cluster creation.
Region Removed in MOSK 24.1
From the drop-down list, select the required region.
HTTP Proxy
Add the HTTP proxy server domain name in the following format:
http://proxy.example.com:port- for anonymous accesshttp://user:password@proxy.example.com:port- for restricted access
HTTPS Proxy
Add the HTTPS proxy server domain name in the same format as for HTTP Proxy.
No Proxy
Comma-separated list of IP addresses or domain names.
For the list of Mirantis resources and IP addresses to be accessible from the Container Cloud clusters, see Reference Architecture: Requirements.
In the Clusters tab, click Create Cluster.
Configure the new cluster in the Create New Cluster wizard that opens:
Define general and Kubernetes parameters:
Create new cluster: General, Provider, and Kubernetes¶ Section
Parameter name
Description
General settings
Cluster name
The cluster name.
Provider
Select Baremetal.
Region Removed since MOSK 24.1
From the drop-down list, select Baremetal.
Release version
Select a Container Cloud version with the OpenStack label tag. Otherwise, you will not be able to deploy MOSK on this managed cluster.
Proxy
Optional. From the drop-down list, select the proxy server name that you have previously created.
SSH keys
From the drop-down list, select the SSH key name that you have previously added for SSH access to the bare metal hosts.
Provider
LB host IP
The IP address of the load balancer endpoint that will be used to access the Kubernetes API of the new cluster. This IP address must be in the LCM network if a separate LCM network is in use and if L2 (ARP) announcement of cluster API load balancer IP is in use.
LB address range
The range of IP addresses that can be assigned to load balancers for Kubernetes Services by MetalLB. For a more flexible MetalLB configuration, refer to Configure MetalLB.
Kubernetes
Services CIDR blocks
The Kubernetes Services CIDR blocks. For example,
10.233.0.0/18.Pods CIDR blocks
The Kubernetes pods CIDR blocks. For example,
10.233.64.0/18.Configure StackLight:
StackLight configuration¶ Section
Parameter name
Description
StackLight
Enable Monitoring
Selected by default. Deselect to skip StackLight deployment.
Note
You can also enable, disable, or configure StackLight parameters after deploying a managed cluster. For details, see Mirantis Container Cloud Operations Guide:
Enable Logging
Select to deploy the StackLight logging stack. For details about the logging components, see Deployment architecture.
Note
The logging mechanism performance depends on the cluster log load. In case of a high load, you may need to increase the default resource requests and limits for
fluentdLogs. For details, see Mirantis Container Cloud Operations Guide: StackLight resource limits.HA Mode
Select to enable StackLight monitoring in the HA mode. For the differences between HA and non-HA modes, see Deployment architecture.
StackLight Default Logs Severity Level
Log severity (verbosity) level for all StackLight components. The default value for this parameter is Default component log level that respects original defaults of each StackLight component. For details about severity levels, see Mirantis Container Cloud Operations Guide: StackLight log verbosity.
StackLight Component Logs Severity Level
The severity level of logs for a specific StackLight component that overrides the value of the StackLight Default Logs Severity Level parameter. For details about severity levels, see Mirantis Container Cloud Operations Guide: StackLight log verbosity.
Expand the drop-down menu for a specific component to display its list of available log levels.
OpenSearch
Logstash Retention Time Removed in {{ product_name_abbr }} 24.1
Available if you select Enable Logging. Specifies the
logstash-*index retention time.Events Retention Time
Available if you select Enable Logging. Specifies the
kubernetes_events-*index retention time.Notifications Retention Time
Available if you select Enable Logging. Specifies the
notification-*index retention time.Persistent Volume Claim Size
Available if you select Enable Logging. The OpenSearch persistent volume claim size.
Collected Logs Severity Level
Available if you select Enable Logging. The minimum severity of all Container Cloud components logs collected in OpenSearch. For details about severity levels, see Mirantis Container Cloud Operations Guide: StackLight logging.
Prometheus
Retention Time
The Prometheus database retention period.
Retention Size
The Prometheus database retention size.
Persistent Volume Claim Size
The Prometheus persistent volume claim size.
Enable Watchdog Alert
Select to enable the Watchdog alert that fires as long as the entire alerting pipeline is functional.
Custom Alerts
Specify alerting rules for new custom alerts or upload a YAML file in the following exemplary format:
- alert: HighErrorRate expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5 for: 10m labels: severity: page annotations: summary: High request latency
For details, see Official Prometheus documentation: Alerting rules. For the list of the predefined StackLight alerts, see Operations Guide: StackLight alerts.
StackLight Email Alerts
Enable Email Alerts
Select to enable the StackLight email alerts.
Send Resolved
Select to enable notifications about resolved StackLight alerts.
Require TLS
Select to enable transmitting emails through TLS.
Email alerts configuration for StackLight
Fill out the following email alerts parameters as required:
To - the email address to send notifications to.
From - the sender address.
SmartHost - the SMTP host through which the emails are sent.
Authentication username - the SMTP user name.
Authentication password - the SMTP password.
Authentication identity - the SMTP identity.
Authentication secret - the SMTP secret.
StackLight Slack Alerts
Enable Slack alerts
Select to enable the StackLight Slack alerts.
Send Resolved
Select to enable notifications about resolved StackLight alerts.
Slack alerts configuration for StackLight
Fill out the following Slack alerts parameters as required:
API URL - The Slack webhook URL.
Channel - The channel to send notifications to, for example, #channel-for-alerts.
Click Create.
To monitor the cluster readiness, hover over the status icon of a specific cluster in the Status column of the Clusters page.
Once the orange blinking status icon is green and Ready, the cluster deployment or update is complete.
You can monitor live deployment status of the following cluster components:
Component
Description
Helm
Installation or upgrade status of all Helm releases
Kubelet
Readiness of the node in a Kubernetes cluster, as reported by kubelet
Kubernetes
Readiness of all requested Kubernetes objects
Nodes
Equality of the requested nodes number in the cluster to the number of nodes having the
ReadyLCM statusOIDC
Readiness of the cluster OIDC configuration
StackLight
Health of all StackLight-related objects in a Kubernetes cluster
Swarm
Readiness of all nodes in a Docker Swarm cluster
LoadBalancer
Readiness of the Kubernetes API load balancer
ProviderInstance
Readiness of all machines in the underlying infrastructure (virtual or bare metal, depending on the provider type)
Optional. Colocate the OpenStack control plane with the managed cluster Kubernetes manager nodes by adding the following field to the
Clusterobject spec:spec: providerSpec: value: dedicatedControlPlane: false
Note
This feature is available as technical preview. Use such configuration for testing and evaluation purposes only.
Optional. Customize MetalLB speakers that are deployed on all Kubernetes nodes except master nodes by default. For details, see Configure the MetalLB speaker node selector.
Once you have created a MOSK cluster, some StackLight alerts may raise as false-positive until you deploy the Mirantis OpenStack environment.
Proceed to Workflow of network interface naming.
Workflow of network interface naming¶
To simplify operations with L2 templates, before you start creating them, inspect the general workflow of a network interface name gathering and processing.
Network interface naming workflow:
The Operator creates a
baremetalHostobject.The
baremetalHostobject executes theintrospectionstage and becomesready.The Operator collects information about NIC count, naming, and so on for further changes in the mapping logic.
At this stage, the NICs order in the object may randomly change during each introspection, but the NICs names are always the same. For more details, see Predictable Network Interface Names.
For example:
# Example commands: # kubectl -n managed-ns get bmh baremetalhost1 -o custom-columns='NAME:.metadata.name,STATUS:.status.provisioning.state' # NAME STATE # baremetalhost1 ready # kubectl -n managed-ns get bmh baremetalhost1 -o yaml # Example output: apiVersion: metal3.io/v1alpha1 kind: BareMetalHost ... status: ... nics: - ip: fe80::ec4:7aff:fe6a:fb1f%eno2 mac: 0c:c4:7a:6a:fb:1f model: 0x8086 0x1521 name: eno2 pxe: false - ip: fe80::ec4:7aff:fe1e:a2fc%ens1f0 mac: 0c:c4:7a:1e:a2:fc model: 0x8086 0x10fb name: ens1f0 pxe: false - ip: fe80::ec4:7aff:fe1e:a2fd%ens1f1 mac: 0c:c4:7a:1e:a2:fd model: 0x8086 0x10fb name: ens1f1 pxe: false - ip: 192.168.1.151 # Temp. PXE network adress mac: 0c:c4:7a:6a:fb:1e model: 0x8086 0x1521 name: eno1 pxe: true ...
The Operator selects from the following options:
Create an
l2templateobject with theifMappingconfiguration. For details, see Create L2 templates.Create a
Machineobject, with thel2TemplateIfMappingOverrideconfiguration. For details, see Override network interfaces naming and order.
The Operator creates a
MachineorSubnetobject.The
baremetal-providerservice links theMachineobject to thebaremetalHostobject.The
kaas-ipamandbaremetal-providerservices collect hardware information from thebaremetalHostobject and use it to configure host networking and services.The
kaas-ipamservice:Spawns the
IpamHostobject.Renders the
l2templateobject.Spawns the
ipaddrobject.Updates the
IpamHostobject status with all rendered and linked information.
The
baremetal-providerservice collects the rendered networking information from theIpamHostobjectThe
baremetal-providerservice proceeds with theIpamHostobject provisioning.
Now proceed to Create subnets.
Service labels and their life cycle¶
Any Subnet object may contain ipam/SVC-<serviceName> labels.
All IP addresses allocated from the Subnet object that has service labels
defined inherit those labels.
When a particular IpamHost uses IP addresses allocated from such labeled
Subnet objects, the ServiceMap field in IpamHost.Status
contains information about which IPs and interfaces correspond to which service
labels (that have been set in the Subnet objects). Using ServiceMap,
you can understand what IPs and interfaces of a particular host are used
for network traffic of a given service.
Container Cloud uses the following service labels that allow using of the specific subnets for particular Container Cloud services:
ipam/SVC-k8s-lcmipam/SVC-ceph-clusteripam/SVC-ceph-publicipam/SVC-dhcp-rangeipam/SVC-MetalLBipam/SVC-LBhost
Caution
The use of the ipam/SVC-k8s-lcm label is mandatory
for every cluster.
You can also add own service labels to the Subnet objects the same way you
add Container Cloud service labels. The mapping of IPs and interfaces to the
defined services is displayed in IpamHost.Status.ServiceMap.
You can assign multiple service labels to one network. You can also assign the
ceph-*, dhcp-range, and MetalLB services to multiple networks.
In the latter case, the system sorts the IP addresses in the ascending order:
serviceMap:
ipam/SVC-ceph-cluster:
- ifName: ceph-br2
ipAddress: 10.0.10.11
- ifName: ceph-br1
ipAddress: 10.0.12.22
ipam/SVC-ceph-public:
- ifName: ceph-public
ipAddress: 10.1.1.15
ipam/SVC-k8s-lcm:
- ifName: k8s-lcm
ipAddress: 10.0.1.52
You can add service labels during creation of subnets as described in Create subnets.
Create subnets¶
Before creating an L2 template, ensure that you have the required subnets
that can be used in the L2 template to allocate IP addresses for the
MOSK cluster nodes.
Where required, create a number of subnets for a particular project
using the Subnet CR. A subnet has three logical scopes:
global - CR uses the
defaultnamespace. A subnet can be used for any cluster located in any project.namespaced - CR uses the namespace that corresponds to a particular project where MOSK clusters are located. A subnet can be used for any cluster located in the same project.
cluster - CR uses the namespace where the referenced cluster is located. A subnet is only accessible to the cluster that
L2Template.metadata.labels:cluster.sigs.k8s.io/cluster-name(mandatory since MOSK 23.3) orL2Template.spec.clusterRef(deprecated since MOSK 23.3) refers to. TheSubnetobjects with theclusterscope will be created for every new cluster.
You can have subnets with the same name in different projects. In this case, the subnet that has the same project as the cluster will be used. One L2 template may often reference several subnets, those subnets may have different scopes in this case.
The IP address objects (IPaddr CR) that are allocated from subnets
always have the same project as their corresponding IpamHost objects,
regardless of the subnet scope.
To create subnets for a cluster:
Log in to a local machine where your management cluster
kubeconfigis located and wherekubectlis installed.Note
The management cluster
kubeconfigis created during the last stage of the management cluster bootstrap.Create the
subnet.yamlfile with a number of global or namespaced subnets depending on the configuration of your cluster:kubectl --kubeconfig <pathToManagementClusterKubeconfig> apply -f <SubnetFileName.yaml>
Note
In the command above and in the steps below, substitute the parameters enclosed in angle brackets with the corresponding values.
Example of a
subnet.yamlfile:apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: name: demo namespace: demo-namespace labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: cidr: 10.11.0.0/24 gateway: 10.11.0.9 includeRanges: - 10.11.0.5-10.11.0.70 nameservers: - 172.18.176.6
Note
/./common/region-label-rm.rst
Specification fields of the Subnet object¶ Parameter
Description
cidr(singular)A valid IPv4 CIDR, for example, 10.11.0.0/24.
includeRanges(list)A list of IP address ranges within the given CIDR that should be used in the allocation of IPs for nodes. If the
includeRangesparameter is not set, the entire address range within the given CIDR is used in the allocation of IPs for nodes. The gateway, network, broadcast, and DNS addresses will be excluded (protected) automatically if they intersect with one IP in the range. The IPs outside the given ranges will not be used in the allocation. Each element of the list can be either an interval10.11.0.5-10.11.0.70or a single address10.11.0.77. In the example above, the addresses10.11.0.5-10.11.0.70(excluding the gateway address 10.11.0.9) will be allocated for nodes. TheincludeRangesparameter is mutually exclusive withexcludeRanges.excludeRanges(list)A list of IP address ranges within the given CIDR that should not be used in the allocation of IPs for nodes. The IPs within the given CIDR but outside the given ranges will be used in the allocation. The gateway, network, broadcast, and DNS addresses will be excluded (protected) automatically if they are included in the CIDR. Each element of the list can be either an interval
10.11.0.5-10.11.0.70or a single address10.11.0.77. TheexcludeRangesparameter is mutually exclusive withincludeRanges.useWholeCidr(boolean)If set to
true, the subnet address (10.11.0.0 in the example above) and the broadcast address (10.11.0.255 in the example above) are included into the address allocation for nodes. Otherwise, (falseby default), the subnet address and broadcast address are excluded from the address allocation.gateway(singular)A valid gateway address, for example, 10.11.0.9.
nameservers(list)A list of the IP addresses of name servers. Each element of the list is a single address, for example, 172.18.176.6.
Note
You may use different subnets to allocate IP addresses to different Container Cloud components in your cluster. Add a label with the
ipam/SVC-prefix to each subnet that is used to configure a Container Cloud service. For details, see Service labels and their life cycle and the optional steps below.Caution
Use of a dedicated network for Kubernetes pods traffic, for external connection to the Kubernetes services exposed by the cluster, and for the Ceph cluster access and replication traffic is available as Technology Preview. Use such configurations for testing and evaluation purposes only. For the Technology Preview feature definition, refer to Technology Preview features.
Add one or more subnets for the LCM network:
Set the
ipam/SVC-k8s-lcmlabel with the value"1"to create a subnet that will be used to assign IP addresses in the LCM network.Optional. Set the
cluster.sigs.k8s.io/cluster-namelabel to the name of the target cluster during the subnet creation.Use this subnet in the L2 template for all cluster nodes.
Assign this subnet to the interface connected to your LCM network.
Precautions for the LCM network usage
Each cluster must use at least one subnet for its LCM network. Every node must have the address allocated in the LCM network using such subnet(s).
Each node of every cluster must have one and only IP address in the LCM network that is allocated from one of the
Subnetobjects having theipam/SVC-k8s-lcmlabel defined. Therefore, allSubnetobjects used for LCM networks must have theipam/SVC-k8s-lcmlabel defined.You can use any interface name for the LCM network traffic. The
Subnetobjects for the LCM network must have theipam/SVC-k8s-lcmlabel. For details, see Service labels and their life cycle.
Optional. Deprecated since MOSK 24.2 (Cluster release 17.2.0). Add subnets to configure address pools for the MetalLB service. Refer to Configure MetalLB for MetalLB configuration guidelines.
Optional. Technology Preview. Add a subnet for the externally accessible API endpoint of the MOSK cluster.
Make sure that
loadBalancerHostis set to""(empty string) in theClusterspec.spec: providerSpec: value: apiVersion: baremetal.k8s.io/v1alpha1 kind: BaremetalClusterProviderSpec ... loadBalancerHost: ""
Create a subnet with the
ipam/SVC-LBhostlabel having the"1"value to make thebaremetal-provideruse this subnet for allocation of addresses for cluster API endpoints.
One IP address will be allocated for each cluster to serve its Kubernetes/MKE API endpoint.
Caution
Make sure that master nodes have host local-link addresses in the same subnet as the cluster API endpoint address. These host IP addresses will be used for VRRP traffic. The cluster API endpoint address will be assigned to the same interface on one of the master nodes where these host IPs are assigned.
Note
We highly recommend that you assign the cluster API endpoint address from the LCM network. For details on cluster networks types, refer to MOSK cluster networking. See also the Single MOSK cluster use case example in the following table.
You can use several options of addresses allocation scope of API endpoints using subnets:
Use case
Example configuration
Several MOSK clusters with one management cluster
Create a subnet in the
defaultnamespace with no reference to any cluster.apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: name: lbhost-per-mgmt-cluster namespace: default labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one ipam/SVC-LBhost: "1" spec: cidr: 191.11.0.0/24 includeRanges: - 191.11.0.6-191.11.0.20
Warning
Combining the
ipam/SVC-LBhostlabel with any other service labels on a single subnet is not supported. Use a dedicated subnet for addresses allocation for cluster API endpoints.Several MOSK clusters in a project
Create a subnet in a namespace corresponding to your project with no reference to any cluster. Such subnet has priority over the one described above.
apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: name: lbhost-per-cluster namespace: my-project labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one ipam/SVC-LBhost: "1" spec: cidr: 191.11.0.0/24 includeRanges: - 191.11.0.6-191.11.0.20
Warning
Combining the
ipam/SVC-LBhostlabel with any other service labels on a single subnet is not supported. Use a dedicated subnet for addresses allocation for cluster API endpoints.Single MOSK cluster
Create a subnet in a namespace corresponding to your project with a reference to the target cluster using the
cluster.sigs.k8s.io/cluster-namelabel. Such subnet has priority over the ones described above. In this case, it is not obligatory to use a dedicated subnet for addresses allocation of API endpoints. You can add theipam/SVC-LBhostlabel to the LCM subnet, and one of the addresses from this subnet will be allocated for an API endpoint:apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: name: lbhost-per-namespace namespace: my-project labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one ipam/SVC-LBhost: "1" ipam/SVC-k8s-lcm: "1" cluster.sigs.k8s.io/cluster-name: my-cluster spec: cidr: 10.11.0.0/24 includeRanges: - 10.11.0.6-10.11.0.50
Warning
You can combine the
ipam/SVC-LBhostlabel only with the following service labels on a single subnet:ipam/SVC-k8s-lcmipam/SVC-ceph-clusteripam/SVC-ceph-public
Otherwise, use a dedicated subnet for address allocation for the cluster API endpoint. Other combinations are not supported and can lead to unexpected results.
Note
/./common/region-label-rm.rst
The above options can be used in conjunction. For example, you can define a subnet for all managed clusters within one management cluster, a number of subnets within this management cluster defined for particular namespaces, and a number of subnets within the same management cluster and namespaces defined for particular clusters.
Optional. Add a subnet(s) for the storage access network.
Set the
ipam/SVC-ceph-publiclabel with the value"1"to create a subnet that will be used to configure the Ceph public network.Set the
cluster.sigs.k8s.io/cluster-namelabel to the name of the target cluster during the subnet creation.Use this subnet in the L2 template for all cluster nodes except Kubernetes manager nodes.
Assign this subnet to the interface connected to your Storage access network.
Ceph will automatically use this subnet for its external connections.
A Ceph OSD will look for and bind to an address from this subnet when it is started on a machine.
Optional. Add a subnet(s) for the storage replication network.
Set the
ipam/SVC-ceph-clusterlabel with the value"1"to create a subnet that will be used to configure the Ceph cluster network.Set the
cluster.sigs.k8s.io/cluster-namelabel to the name of the target cluster during the subnet creation.Use this subnet in the L2 template for storage nodes.
Assign this subnet to the interface connected to your storage replication network.
Ceph will automatically use this subnet for its internal replication traffic.
Optional. Add a subnet for the Kubernetes Pods traffic.
Use this subnet in the L2 template for all nodes in the cluster.
Assign this subnet to the interface connected to your Kubernetes workloads network.
Use the
npTemplate.bridges.k8s-podsbridge name in the L2 template. This bridge name is reserved for the Kubernetes workloads network. When thek8s-podsbridge is defined in an L2 template, Calico CNI uses that network for routing the Pods traffic between nodes.
Optional. Add a subnet for the MOSK overlay network:
Use this subnet in the L2 template for the compute and gateway (controller) nodes in the MOSK cluster.
Assign this subnet to the interface connected to your MOSK overlay network.
This network is used to provide denied and secure tenant networks with the help of the tunneling mechanism (VLAN/GRE/VXLAN). If the VXLAN and GRE encapsulation takes place, the IP address assignment is required on interfaces at the node level. On the Tungsten Fabric deployments, this network is used for MPLS over UDP+GRE traffic.
Optional. Add a subnet for the MOSK live migration network:
Use this subnet in the L2 template for compute nodes in the MOSK cluster.
Assign this subnet to the interface connected to your MOSK overlay network.
This subnet is used by the Compute service (OpenStack Nova) to transfer data during live migration. Depending on the cloud needs, you can place it on a dedicated physical network not to affect other networks during live migration. The IP address assignment is required on interfaces at the node level.
Verify that the subnet is successfully created:
kubectl get subnet kaas-mgmt -oyaml
In the system output, verify the
statusfields of thesubnet.yamlfile using the table below.Status fields of the Subnet object¶ Parameter
Description
stateSince 23.1Contains a short state description and a more detailed one if applicable. The short status values are as follows:
OK- object is operational.ERR- object is non-operational. This status has a detailed description in themessageslist.TERM- object was deleted and is terminating.
messagesSince 23.1Contains error or warning messages if the object state is
ERR. For example,ERR: Wrong includeRange for CIDR….statusMessageDeprecated since MOSK 23.1 and will be removed in one of the following releases in favor of
stateandmessages. Since MOSK 23.2, this field is not set for the objects of newly created clusters.cidrReflects the actual CIDR, has the same meaning as
spec.cidr.gatewayReflects the actual gateway, has the same meaning as
spec.gateway.nameserversReflects the actual name servers, has same meaning as
spec.nameservers.rangesSpecifies the address ranges that are calculated using the fields from
spec: cidr, includeRanges, excludeRanges, gateway, useWholeCidr. These ranges are directly used for nodes IP allocation.allocatableIncludes the number of currently available IP addresses that can be allocated for nodes from the subnet.
allocatedIPsSpecifies the list of IPv4 addresses with the corresponding
IPaddrobject IDs that were already allocated from the subnet.capacityContains the total number of IP addresses being held by ranges that equals to a sum of the
allocatableandallocatedIPsparameters values.objCreatedDate, time, and IPAM version of the
SubnetCR creation.objStatusUpdatedDate, time, and IPAM version of the last update of the
statusfield in theSubnetCR.objUpdatedDate, time, and IPAM version of the last
SubnetCR update bykaas-ipam.Example of a successfully created subnet:
apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: labels: ipam/UID: 6039758f-23ee-40ba-8c0f-61c01b0ac863 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one ipam/SVC-k8s-lcm: "1" name: kaas-mgmt namespace: default spec: cidr: 10.0.0.0/24 excludeRanges: - 10.0.0.100 - 10.0.0.101-10.0.0.120 gateway: 10.0.0.1 includeRanges: - 10.0.0.50-10.0.0.90 nameservers: - 172.18.176.6 status: allocatable: 38 allocatedIPs: - 10.0.0.50:0b50774f-ffed-11ea-84c7-0242c0a85b02 - 10.0.0.51:1422e651-ffed-11ea-84c7-0242c0a85b02 - 10.0.0.52:1d19912c-ffed-11ea-84c7-0242c0a85b02 capacity: 41 cidr: 10.0.0.0/24 gateway: 10.0.0.1 objCreated: 2021-10-21T19:09:32Z by v5.1.0-20210930-121522-f5b2af8 objStatusUpdated: 2021-10-21T19:14:18.748114886Z by v5.1.0-20210930-121522-f5b2af8 objUpdated: 2021-10-21T19:09:32.606968024Z by v5.1.0-20210930-121522-f5b2af8 nameservers: - 172.18.176.6 ranges: - 10.0.0.50-10.0.0.90
Note
/./common/region-label-rm.rst
Create other subnets for your MOSK cluster:
If you plan to create a multi-rack MOSK cluster, proceed to Create subnets for a multi-rack Mirantis OpenStack for Kubernetes cluster.
If you plan to create a single-rack MOSK cluster, proceed to Create subnets for a MOSK cluster.
Create subnets for a multi-rack Mirantis OpenStack for Kubernetes cluster¶
When planning your installation in advance, you need to prepare a set of subnets and L2 templates for every rack in your cluster. For details, see Multi-rack architecture.
Ensure that the underlay network in your cluster satisfies the requirements listed in Networking.
Configure all required VLANs on the network switches as described in Network types.
Configure gateway IP addresses on the ToR switches. Set up static routes as described in Underlay networking: routing configuration.
Note
In this section, the exemplary cluster name is mosk-cluster-name.
Adjust it to fit your deployment.
Log in to a local machine where your management cluster
kubeconfigis located and wherekubectlis installed.Note
The management cluster
kubeconfigis created during the last stage of the management cluster bootstrap.Create the
subnet.yamlfile with a number of subnets depending on the configuration of your MOSK cluster:kubectl --kubeconfig <pathToManagementClusterKubeconfig> apply -f <SubnetFileName.yaml>
Using the
Subnetobject examples for a multi-rack cluster that are described in the following sections, create subnets for the target cluster.
Note
Subnet labels such as rack-x-lcm, rack-api-lcm, and so on are
optional. You can use them in L2 templates to select Subnet objects by
label.
Note
Before the Cluster release 16.1.0, the Subnet object contains
the kaas.mirantis.com/region label that specifies the region
where the Subnet object will be applied.
Configure DHCP relay agents on the edges of the broadcast domains in the provisioning network, as needed.
Make sure to assign the IP address ranges you want to allocate
to the hosts using DHCP for discovery and inspection. Create subnets
using these IP parameters. Specify the IP address of your DHCP relay
as the default gateway in the corresponding Subnet object.
Caution
Support of multiple DHCP ranges has the following limitations:
Using of custom DNS server addresses for servers that boot over PXE is not supported.
The
Subnetobjects for DHCP ranges cannot be associated with any specific cluster, as the DHCP server configuration is only applicable to the management cluster where the DHCP server is running. Thecluster.sigs.k8s.io/cluster-namelabel will be ignored.
Example mos-racks-dhcp-subnets.yaml
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-1-dhcp
namespace: default
labels:
ipam/SVC-dhcp-range: "1"
kaas.mirantis.com/provider: baremetal
spec:
cidr: 10.20.101.0/24
gateway: 10.20.101.1
includeRanges:
- 10.20.101.16-10.20.101.127
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-2-dhcp
namespace: default
labels:
ipam/SVC-dhcp-range: "1"
kaas.mirantis.com/provider: baremetal
spec:
cidr: 10.20.102.0/24
gateway: 10.20.102.1
includeRanges:
- 10.20.102.16-10.20.102.127
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-3-dhcp
namespace: default
labels:
ipam/SVC-dhcp-range: "1"
kaas.mirantis.com/provider: baremetal
spec:
cidr: 10.20.103.0/24
gateway: 10.20.103.1
includeRanges:
- 10.20.103.16-10.20.103.127
---
# Add more Subnet object templates as required using the above example
# (one subnet per rack)
This is the IP address space that Container Cloud uses to ensure communication between the LCM agents and the management API. These addresses are also used by Kubernetes nodes for communication. The addresses from the subnets are assigned to all MOSK cluster nodes.
Example mosk-racks-lcm-subnets.yaml
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-1-lcm
namespace: mosk-namespace-name
labels:
ipam/SVC-k8s-lcm: "1"
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-1-lcm: "true"
spec:
cidr: 10.20.111.0/24
gateway: 10.20.111.1
includeRanges:
- 10.20.111.16-10.20.111.255
nameservers:
- 8.8.8.8
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-2-lcm
namespace: mosk-namespace-name
labels:
ipam/SVC-k8s-lcm: "1"
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-2-lcm: "true"
spec:
cidr: 10.20.112.0/24
gateway: 10.20.112.1
includeRanges:
- 10.20.112.16-10.20.112.255
nameservers:
- 8.8.8.8
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-3-lcm
namespace: mosk-namespace-name
labels:
ipam/SVC-k8s-lcm: "1"
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-3-lcm: "true"
spec:
cidr: 10.20.113.0/24
gateway: 10.20.113.1
includeRanges:
- 10.20.113.16-10.20.113.255
nameservers:
- 8.8.8.8
---
# Add more subnet object templates as required using the above example
# (one subnet per rack)
Note
Since 23.2.2, MOSK supports full L3 networking topology in the Technology Preview scope. This enables deployment of specific cluster segments in dedicated racks without the need for L2 layer extension between them. For configuration procedure, see Configure BGP announcement for cluster API LB address and Configure BGP announcement of external addresses of Kubernetes load-balanced services in Deployment Guide.
If BGP announcement is configured for the MOSK cluster API LB address, the API/LCM network is not required. Announcement of the cluster API LB address is done using the LCM network.
If you configure ARP announcement of the load-balancer IP address for the MOSK cluster API, the API/LCM network must be configured on the Kubernetes manager nodes of the cluster. This network contains the Kubernetes API endpoint with the VRRP virtual IP address.
This network contains Kubernetes API endpoint with the VRRP virtual IP address. This is the IP address space that Container Cloud uses to ensure communication between the LCM agents and the management API. These addresses are also used by Kubernetes nodes for communication. The addresses from the subnet are assigned to all Kubernetes manager nodes of the MOSK cluster.
Example mosk-racks-api-lcm-subnet.yaml
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-api-lcm
namespace: mosk-namespace-name
labels:
ipam/SVC-k8s-lcm: "1"
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-api-lcm: "true"
spec:
cidr: 10.20.110.0/24
gateway: 10.20.110.1
includeRanges:
- 10.20.110.16-10.20.110.25
nameservers:
- 8.8.8.8
The network is used to expose the OpenStack, StackLight, and other services of the MOSK cluster.
Note
Since 23.2.2, MOSK supports full L3 networking topology in the Technology Preview scope. This enables deployment of specific cluster segments in dedicated racks without the need for L2 layer extension between them. For configuration procedure, see Configure BGP announcement for cluster API LB address and Configure BGP announcement of external addresses of Kubernetes load-balanced services in Deployment Guide.
If you configure BGP announcement for IP addresses of load-balanced services of a MOSK cluster, the external network can consist of multiple VLAN segments connected to all nodes of a MOSK cluster where MetalLB speaker components are configured to announce IP addresses for Kubernetes load-balanced services. Mirantis recommends that you use OpenStack controller nodes for this purpose.
If you configure ARP announcement for IP addresses of load-balanced services of a MOSK cluster, the external network must consist of a single VLAN stretched to the ToR switches of all the racks where MOSK nodes connected to the external network are located. Those are the nodes where MetalLB speaker components are configured to announce IP addresses for Kubernetes load-balanced services. Mirantis recommends that you use OpenStack controller nodes for this purpose.
The subnets are used to assign addresses to the external interfaces of the MOSK controller nodes and will be used to assign the default gateway to these hosts. The default gateway for other hosts of the MOSK cluster is assigned using the LCM and optionally API/LCM subnets.
Example mosk-racks-external-subnets.yaml
Example of a subnet where a single VLAN segment is stretched to all MOSK controller nodes:
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: k8s-external
namespace: mosk-namespace-name
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
k8s-external: true
spec:
cidr: 10.20.120.0/24
gateway: 10.20.120.1 # This will be the default gateway on hosts
includeRanges:
- 10.20.120.16-10.20.120.20
nameservers:
- 8.8.8.8
Example of subnets where separate VLAN segments per rack are used:
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-1-k8s-ext
namespace: mosk-namespace-name
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-1-k8s-ext: true
spec:
cidr: 10.20.121.0/24
gateway: 10.20.121.1 # This will be the default gateway on hosts
includeRanges:
- 10.20.121.16-10.20.121.20
nameservers:
- 8.8.8.8
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-2-k8s-ext
namespace: mosk-namespace-name
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-2-k8s-ext: true
spec:
cidr: 10.20.122.0/24
gateway: 10.20.122.1 # This will be the default gateway on hosts
includeRanges:
- 10.20.122.16-10.20.122.20
nameservers:
- 8.8.8.8
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-3-k8s-ext
namespace: mosk-namespace-name
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-3-k8s-ext: true
spec:
cidr: 10.20.123.0/24
gateway: 10.20.123.1 # This will be the default gateway on hosts
includeRanges:
- 10.20.123.16-10.20.123.20
nameservers:
- 8.8.8.8
See also
This network may have per-rack VLANs and IP subnets. The addresses from the subnets are assigned to all MOSK cluster nodes besides Kubernetes manager nodes.
Example mosk-racks-ceph-public-subnets.yaml
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-1-ceph-public
namespace: mosk-namespace-name
labels:
ipam/SVC-ceph-public: "1"
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-1-ceph-public: true
spec:
cidr: 10.20.131.0/24
gateway: 10.20.131.1
includeRanges:
- 10.20.131.16-10.20.131.255
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-2-ceph-public
namespace: mosk-namespace-name
labels:
ipam/SVC-ceph-public: "1"
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-2-ceph-public: true
spec:
cidr: 10.20.132.0/24
gateway: 10.20.132.1
includeRanges:
- 10.20.132.16-10.20.132.255
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-3-ceph-public
namespace: mosk-namespace-name
labels:
ipam/SVC-ceph-public: "1"
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-3-ceph-public: true
spec:
cidr: 10.20.133.0/24
gateway: 10.20.133.1
includeRanges:
- 10.20.133.16-10.20.133.255
---
# Add more Subnet object templates as required using the above example
# (one subnet per rack)
This network may have per-rack VLANs and IP subnets. The addresses from the subnets are assigned to storage nodes in the MOSK cluster.
Example mosk-racks-ceph-cluster-subnets.yaml
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-1-ceph-cluster
namespace: mosk-namespace-name
labels:
ipam/SVC-ceph-cluster: "1"
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-1-ceph-cluster: true
spec:
cidr: 10.20.141.0/24
gateway: 10.20.141.1
includeRanges:
- 10.20.141.16-10.20.141.255
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-2-ceph-cluster
namespace: mosk-namespace-name
labels:
ipam/SVC-ceph-cluster: "1"
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-2-ceph-cluster: true
spec:
cidr: 10.20.142.0/24
gateway: 10.20.142.1
includeRanges:
- 10.20.142.16-10.20.142.255
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-3-ceph-cluster
namespace: mosk-namespace-name
labels:
ipam/SVC-ceph-cluster: "1"
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-3-ceph-cluster: true
spec:
cidr: 10.20.143.0/24
gateway: 10.20.143.1
includeRanges:
- 10.20.143.16-10.20.143.255
---
# Add more Subnet object templates as required using the above example
# (one subnet per rack)
This network may include multiple per-rack VLANs and IP subnets. The addresses from the subnets are assigned to all MOSK cluster nodes. For details, see Network types.
Example mosk-racks-k8s-pods.yaml
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-1-k8s-pods
namespace: mosk-namespace-name
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-1-k8s-pods: true
spec:
cidr: 10.20.151.0/24
gateway: 10.20.151.1
includeRanges:
- 10.20.151.16-10.20.151.255
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-2-k8s-pods
namespace: mosk-namespace-name
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-2-k8s-pods: true
spec:
cidr: 10.20.152.0/24
gateway: 10.20.152.1
includeRanges:
- 10.20.152.16-10.20.152.255
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-3-k8s-pods
namespace: mosk-namespace-name
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-3-k8s-pods: true
spec:
cidr: 10.20.153.0/24
gateway: 10.20.153.1
includeRanges:
- 10.20.153.16-10.20.153.255
---
# Add more Subnet object templates as required using the above example
# (one subnet per rack)
The underlay network for VXLAN tunnels for the MOSK tenants traffic. If deployed with Tungsten Fabric, it is used for MPLS over UDP+GRE traffic.
Example mosk-racks-tenant-tunnel.yaml
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-1-tenant-tunnel
namespace: mosk-namespace-name
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-1-tenant-tunnel: true
spec:
cidr: 10.20.161.0/24
gateway: 10.20.161.1
includeRanges:
- 10.20.161.16-10.20.161.255
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-2-tenant-tunnel
namespace: mosk-namespace-name
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-2-tenant-tunnel: true
spec:
cidr: 10.20.162.0/24
gateway: 10.20.162.1
includeRanges:
- 10.20.162.16-10.20.162.255
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-3-tenant-tunnel
namespace: mosk-namespace-name
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-3-tenant-tunnel: true
spec:
cidr: 10.20.163.0/24
gateway: 10.20.163.1
includeRanges:
- 10.20.163.16-10.20.163.255
---
# Add more Subnet object templates as required using the above example
# (one subnet per rack)
The network is used by the Compute service (OpenStack Nova) to transfer data during live migration. Depending on the cloud needs, it can be placed on a dedicated physical network not to affect other networks during live migration.
Example mosk-racks-live-migration.yaml
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-1-live-migration
namespace: mosk-namespace-name
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-1-live-migration: true
spec:
cidr: 10.20.171.0/24
gateway: 10.20.171.1
includeRanges:
- 10.20.171.16-10.20.171.255
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-2-live-migration
namespace: mosk-namespace-name
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-2-live-migration: true
spec:
cidr: 10.20.172.0/24
gateway: 10.20.172.1
includeRanges:
- 10.20.172.16-10.20.172.255
---
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
name: rack-3-live-migration
namespace: mosk-namespace-name
labels:
kaas.mirantis.com/provider: baremetal
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
rack-3-live-migration: true
spec:
cidr: 10.20.173.0/24
gateway: 10.20.173.1
includeRanges:
- 10.20.173.16-10.20.173.255
---
# Add more Subnet object templates as required using the above example
# (one subnet per rack)
Create subnets for a MOSK cluster¶
According to the MOSK reference architecture, you should create the following subnets.
Note
/./common/region-label-rm.rst
lcm-nw¶The LCM network of the MOSK cluster. Example of lcm-nw
subnet:
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
ipam/SVC-k8s-lcm: "1"
name: lcm-nw
namespace: <MOSKClusterNamespace>
spec:
cidr: 172.16.43.0/24
gateway: 172.16.43.1
includeRanges:
- 172.16.43.10-172.16.43.100
nameservers:
- 8.8.8.8
k8s-ext-subnet¶The addresses from this subnet are assigned to nodes interfaces connected to the external network.
Example of k8s-ext-subnet:
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
name: k8s-ext-subnet
namespace: <MOSKClusterNamespace>
spec:
cidr: 172.16.45.0/24
gateway: 172.16.45.1
includeRanges:
- 172.16.45.10-172.16.45.100
nameservers:
- 8.8.8.8
mosk-metallb-subnet¶The addresses from this subnet are not allocated to interfaces, but used as a MetalLB address pool to expose MOSK API endpoints as Kubernetes cluster services.
Example of mosk-metallb-subnet:
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
ipam/SVC-metallb: true
cluster.sigs.k8s.io/cluster-name: <MOSKClusterName>
name: mosk-metallb-subnet
namespace: <MOSKClusterNamespace>
spec:
cidr: 172.16.45.0/24
includeRanges:
- 172.16.45.101-172.16.45.200
k8s-pods-subnet¶The addresses from this subnet are assigned to interfaces connected to the Kubernetes workloads network and used by Calico CNI as underlay for traffic between the pods in the Kubernetes cluster.
Example of k8s-pods-subnet:
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
name: k8s-pods-subnet
namespace: <MOSKClusterNamespace>
spec:
cidr: 10.12.3.0/24
includeRanges:
- 10.12.3.10-10.12.3.100
neutron-tunnel-subnet¶The underlay network for VXLAN tunnels for the MOSK tenants traffic. If deployed with Tungsten Fabric, it is used for MPLS over UDP+GRE traffic.
Example of neutron-tunnel-subnet:
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
name: neutron-tunnel-subnet
namespace: <MOSKClusterNamespace>
spec:
cidr: 10.12.2.0/24
includeRanges:
- 10.12.2.10-10.12.2.100
live-migration-subnet¶The network is used by the Compute service (OpenStack Nova) to transfer data during live migration. Depending on the cloud needs, you can place it on a dedicated physical network not to affect other networks during live migration.
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
name: live-migration-subnet
namespace: <MOSKClusterNamespace>
spec:
cidr: 10.12.7.0/24
includeRanges:
- 10.12.7.10-10.12.7.100
ceph-public-subnet¶Ceph uses this network for its external connections. Example of a subnet for the storage access network:
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
ipam/SVC-ceph-public: true
cluster.sigs.k8s.io/cluster-name: <MOSKClusterName>
name: ceph-public-subnet
namespace: <MOSKClusterNamespace>
spec:
cidr: 10.12.0.0/24
ceph-cluster-subnet¶Ceph uses this network for its internal replication traffic. Example of a subnet for the storage replication network:
apiVersion: ipam.mirantis.com/v1alpha1
kind: Subnet
metadata:
labels:
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
ipam/SVC-ceph-cluster: true
cluster.sigs.k8s.io/cluster-name: <MOSKClusterName>
name: ceph-cluster-subnet
namespace: <MOSKClusterNamespace>
spec:
cidr: 10.12.1.0/24
Now, proceed with creating L2 templates for the MOSK cluster as described in Create L2 templates.
Configure MetalLB¶
This section describes how to set up and verify MetalLB parameters during configuration of subnets for a MOSK cluster creation.
Caution
The use of the MetalLBConfig object is mandatory after your
management cluster upgrade to the Cluster release 17.0.0.
The following rules and requirements apply to configuration of the
MetalLBConfig and MetalLBConfigTemplate objects:
Define one
MetalLBConfigandMetalLBConfigTemplateobject per cluster.Define the following mandatory labels:
cluster.sigs.k8s.io/cluster-nameSpecifies the cluster name where the MetalLB address pool is used.
kaas.mirantis.com/regionSpecifies the region name of the cluster where the MetalLB address pool is used.
kaas.mirantis.com/providerSpecifies the provider of the cluster where the MetalLB address pool is used.
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
You can use
MetalLBConfigwithoutMetalLBConfigTemplatebut not the opposite way.You can use the
MetalLBConfigandMetalLBConfigTemplateobjects to optimize address announcement for load-balanced services using theinterfacesselector for thel2Advertisementsobject. This selector allows for announcing addresses only on selected host interfaces. For details, see Container Cloud API Reference: MetalLBConfigTemplate spec.Mirantis recommends this configuration if nodes use separate host networks for different types of traffic. The advantages of such configuration include reduced congestion on other interfaces and networks, as well as limited exposure of addresses of load-balanced services to irrelevant interfaces and networks.
When using
MetalLBConfigTemplate:MetalLBConfigmust referenceMetalLBConfigTemplateby name:spec: templateName: <managed-metallb-template>
You can use
Subnetobjects for defining MetalLB address pools. Refer to MetalLB configuration guidelines for subnets for guidelines on configuring MetalLB address pools usingSubnetobjects.
The use of
MetalLBConfigTemplateobject gives more flexibility when describing MetalLB configuration as it allows using variables, functions, and the Go template expressions inside object templates.Intersection of IP address ranges within any single MetalLB address pool is not allowed.
At least one MetalLB address pool must have the auto-assign policy enabled so that unannotated services can have load balancer IPs allocated for them.
When configuring multiple address pools with the auto-assign policy enabled, keep in mind that it is not determined in advance which pool of those multiple address pools is used to allocate an IP for a particular unannotated service.
Optional. Configure parameters related to MetalLB components life cycle such as deployment and update using the
metallbHelm chart values in theClusterspecsection. For example:Increase Pod resource limits for MetalLB as described in Container Cloud documentation: Increase memory limits for cluster components.
Configure Pod node selectors or affinity for MetalLB speakers as described in Configure the MetalLB speaker node selector.
Configure the MetalLB parameters related to IP address allocation and announcement for load-balanced cluster services:
Select from the following options:
Mandatory after a management cluster upgrade to the Cluster release 17.0.0. Recommended and default since MOSK 23.2 in the Technology Preview scope. Create
MetalLBConfigandMetalLBConfigTemplateobjects. This method allows using theSubnetobject to define MetalLB address pools.For configuration rules and requirements, see Configuration rules for ‘MetalLBConfig’ and ‘MetalLBConfigTemplate’ objects.
For objects description, see Container Cloud API documentation: MetalLBConfig resource and MetalLBConfigTemplate resource.
For configuration examples that use
MetalLBConfigandMetalLBConfigTemplate, see the following sections in Container Cloud documentation:Example of a complete L2 templates configuration for cluster creation (the MetalLB configuration objects step)
Since MOSK 23.2.2, in the Technology Preview scope, you can use BGP for announcement of external addresses of Kubernetes load-balanced services for a MOSK cluster. To configure the BGP announcement mode for MetalLB, use
MetalLBConfigandMetalLBConfigTemplateobjects.The use of BGP is required to announce IP addresses for load-balanced services when using MetalLB on nodes that are distributed across multiple racks. In this case, setting of
rack-idlabels on nodes is required, they are used in node selectors forBGPPeer,BGPAdvertisement, or both MetalLB objects to properly configure BGP connections from each node.Configuration example of the
Machineobject for the BGP announcement modeapiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: name: test-cluster-compute-1 namespace: mosk-ns labels: cluster.sigs.k8s.io/cluster-name: test-cluster ipam/RackRef: rack-1 # reference to the "rack-1" Rack kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: providerSpec: value: ... nodeLabels: - key: rack-id # node label can be used in "nodeSelectors" inside value: rack-1 # "BGPPeer" and/or "BGPAdvertisement" MetalLB objects ...
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
Configuration example of the
MetalLBConfigTemplateobject for the BGP announcement modeapiVersion: ipam.mirantis.com/v1alpha1 kind: MetalLBConfigTemplate metadata: name: test-cluster-metallb-config-template namespace: mosk-ns labels: cluster.sigs.k8s.io/cluster-name: test-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: templates: ... bgpPeers: | - name: svc-peer-1 spec: peerAddress: 10.77.42.1 peerASN: 65100 myASN: 65101 nodeSelectors: - matchLabels: rack-id: rack-1 # references the nodes having # the "rack-id=rack-1" label bgpAdvertisements: | - name: services spec: ipAddressPools: - services peers: - svc-peer-1 ...
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
The
bgpPeersandbgpAdvertisementsfields are used to configure BGP announcement instead ofl2Advertisements.The use of BGP for announcement also allows for better balancing of service traffic between cluster nodes as well as gives more configuration control and flexibility for infrastructure administrators. For configuration examples, refer to Examples of MetalLBConfigTemplate. For configuration procedure, refer to Configure BGP announcement for cluster API LB address.
Not recommended. Configure the
configInlinevalue in the MetalLB chart of theClusterobject.Warning
This option is deprecated since MOSK 23.2 and is removed during the management cluster upgrade to the Cluster release 17.0.0, which is introduced in Container Cloud 2.25.0.
Therefore, this option becomes unavailable on MOSK 23.2 clusters after the parent management cluster upgrade to 2.25.0.
Not recommended. Configure the
Subnetobjects withoutMetalLBConfigTemplate.Warning
This option is deprecated since MOSK 23.2 and is removed during the management cluster upgrade to the Cluster release 17.0.0, which is introduced in Container Cloud 2.25.0.
Therefore, this option becomes unavailable on MOSK 23.2 clusters after the parent management cluster upgrade to 2.25.0.
Caution
If the
MetalLBConfigobject is not used for MetalLB configuration related to address allocation and announcement for load-balanced services, then automated migration applies during cluster creation or update to MOSK 23.2.During automated migration, the
MetalLBConfigandMetalLBConfigTemplateobjects are created and contents of the MetalLB chartconfigInlinevalue is converted to the parameters of theMetalLBConfigTemplateobject.Any change to the
configInlinevalue made on a MOSK 23.2 cluster will be reflected in theMetalLBConfigTemplateobject.This automated migration is removed during your management cluster upgrade to the Cluster release 17.0.0, which is introduced in Container Cloud 2.25.0, together with the possibility to use the
configInlinevalue of the MetalLB chart. After that, any changes in MetalLB configuration related to address allocation and announcement for load-balanced services are applied using theMetalLBConfig,MetalLBConfigTemplate, andSubnetobjects only.Select from the following options:
Configure
Subnetobjects. For details, see MetalLB configuration guidelines for subnets.Configure the
configInlinevalue for the MetalLB chart in theClusterobject.Configure both the
configInlinevalue for the MetalLB chart andSubnetobjects.The resulting MetalLB address pools configuration will contain address ranges from both cluster specification and
Subnetobjects. All address ranges for L2 address pools will be aggregated into a single L2 address pool and sorted as strings.
Changes to be applied since MOSK 23.2
The configuration options above become deprecated since 23.2, and automated migration of MetalLB parameters applies during cluster creation or update to MOSK 23.2.
During automated migration, the
MetalLBConfigandMetalLBConfigTemplateobjects are created and contents of the MetalLB chartconfigInlinevalue is converted to the parameters of theMetalLBConfigTemplateobject.Any change to the
configInlinevalue made on a MOSK 23.2 cluster will be reflected in theMetalLBConfigTemplateobject.This automated migration is removed during your management cluster upgrade to Container Cloud 2.25.0 together with the possibility to use the
configInlinevalue of the MetalLB chart. After that, any changes in MetalLB configuration related to address allocation and announcement for load-balanced services will be applied using theMetalLBConfigTemplateandSubnetobjects only.Verify the current MetalLB configuration:
Verify the MetalLB configuration that is stored in
MetalLBobjects:kubectl -n metallb-system get ipaddresspools,l2advertisements
The example system output:
NAME AGE ipaddresspool.metallb.io/default 129m ipaddresspool.metallb.io/services-pxe 129m NAME AGE l2advertisement.metallb.io/default 129m l2advertisement.metallb.io/services-pxe 129m
Verify one of the listed above
MetalLBobjects:kubectl -n metallb-system get <object> -o json | jq '.spec'
The example system output for
ipaddresspoolobjects:$ kubectl -n metallb-system get ipaddresspool.metallb.io/default -o json | jq '.spec' { "addresses": [ "10.0.11.61-10.0.11.80" ], "autoAssign": true, "avoidBuggyIPs": false } $ kubectl -n metallb-system get ipaddresspool.metallb.io/services-pxe -o json | jq '.spec' { "addresses": [ "10.0.0.61-10.0.0.70" ], "autoAssign": false, "avoidBuggyIPs": false }
Verify the MetalLB configuration that is stored in the
ConfigMapobject:kubectl -n metallb-system get cm metallb -o jsonpath={.data.config}
An example of a successful output:
address-pools: - name: default protocol: layer2 addresses: - 10.0.11.61-10.0.11.80 - name: services-pxe protocol: layer2 auto-assign: false addresses: - 10.0.0.61-10.0.0.70
The
auto-assignparameter will be set tofalsefor all address pools except thedefaultone. So, a particular service will get an address from such an address pool only if theServiceobject has a specialmetallb.universe.tf/address-poolannotation that points to the specific address pool name.
MetalLB configuration guidelines for subnets¶
Each Subnet object can define either a MetalLB address range or MetalLB
address pool. A MetalLB address pool may contain one or several address
ranges. The following rules apply to creation of address ranges or pools:
To designate a subnet as a MetalLB address pool or range, use the
ipam/SVC-MetalLBlabel key. Set the label value to"1".The object must contain the
cluster.sigs.k8s.io/<cluster-name>label to reference the name of the target cluster where the MetalLB address pool is used.You may create multiple subnets with the
ipam/SVC-MetalLBlabel to define multiple IP address ranges or multiple address pools for MetalLB in the cluster.The IP addresses of the MetalLB address pool are not assigned to the interfaces on hosts. This subnet is virtual. Do not include such subnets to the L2 template definitions for your cluster.
If a
Subnetobject defines a MetalLB address range, no additional object properties are required.You can use any number of
Subnetobjects that define a single MetalLB address range. In this case, all address ranges are aggregated into a single MetalLB L2 address pool namedserviceshaving the auto-assign policy enabled.Intersection of IP address ranges within any single MetalLB address pool is not allowed.
The bare metal provider verifies intersection of IP address ranges. If it detects intersection, the MetalLB configuration is blocked and the provider logs contain corresponding error messages.
Use the following labels to identify the Subnet object as a MetalLB
address pool and configure the name and protocol for that address pool.
All labels below are mandatory for the Subnet object that configures
a MetalLB address pool.
Label |
Description |
|---|---|
Labels to link |
Note The Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label. |
|
Defines that the |
|
Every address pool must have a distinct name. The |
|
Configures the auto-assign policy of an address pool. Boolean. Caution For the address pools defined using the MetalLB Helm chart
values in the For any service that does not have a specific MetalLB annotation
configured, MetalLB allocates external IPs from arbitrary address
pools that have the auto-assign policy set to Only for the service that has a specific MetalLB annotation with
the address pool name, MetalLB allocates external IPs from the address
pool having the auto-assign policy set to |
|
Sets the address pool protocol.
The only supported value is |
Caution
Do not set the same address pool name for two or more
Subnet objects. Otherwise, the corresponding MetalLB address pool
configuration fails with a warning message in the bare metal provider log.
Caution
For the auto-assign policy, the following configuration rules apply:
At least one MetalLB address pool must have the auto-assign policy enabled so that unannotated services can have load balancer IPs allocated for them. To satisfy this requirement, either configure one of address pools using the
Subnetobject withmetallb/address-pool-auto-assign: "true"or configure address range(s) using theSubnetobject(s) withoutmetallb/address-pool-*labels.When configuring multiple address pools with the auto-assign policy enabled, keep in mind that it is not determined in advance which pool of those multiple address pools is used to allocate an IP for a particular unannotated service.
Configure the MetalLB speaker node selector¶
By default, MetalLB speakers are deployed on all Kubernetes nodes except master nodes. You can configure MetalLB to run its speakers on a particular set of nodes. This decreases the number of nodes that should be connected to external network. In this scenario, only a few nodes are exposed for ingress traffic from the outside world.
To customize the MetalLB speaker node selector:
Using
kubeconfigof the Container Cloud management cluster, open the MOSKClusterobject for editing:kubectl --kubeconfig <pathToManagementClusterKubeconfig> -n <OSClusterNamespace> edit cluster <OSClusterName>
In the
spec:providerSpec:value:helmReleasessection, add thespeaker.nodeSelectorfield formetallb:spec: ... providerSpec: value: ... helmReleases: - name: metallb values: ... speaker: nodeSelector: metallbSpeakerEnabled: "true"
The
metallbSpeakerEnabled: "true"parameter in this example is the label on Kubernetes nodes where MetalLB speakers will be deployed. It can be an already existing node label or a new one.Note
The issue [24435] MetalLB speaker fails to announce the LB IP for the Ingress service, which is related to collocation of MetalLB speakers and the OpenStack Ingress service pods is addressed in MOSK 22.5. For details, see Release Notes: Set externalTrafficPolicy=Local for the OpenStack Ingress service.
You can add user-defined labels to nodes using the
nodeLabelsfield.This field contains the list of node labels to be attached to a node for the user to run certain components on separate cluster nodes. The list of allowed node labels is located in the
Clusterobject statusproviderStatus.releaseRef.current.allowedNodeLabelsfield.If the
valuefield is not defined inallowedNodeLabels, a label can have any value. For example:allowedNodeLabels: - displayName: Stacklight key: stacklight
Before or after a machine deployment, add the required label from the allowed node labels list with the corresponding value to
spec.providerSpec.value.nodeLabelsinmachine.yaml. For example:nodeLabels: - key: stacklight value: enabled
Adding of a node label that is not available in the list of allowed node labels is restricted.
Configure BGP announcement for cluster API LB address¶
TechPreview Available since 23.2.2
When you create a MOSK cluster with the multi-rack topology, where Kubernetes masters are distributed across multiple racks without an L2 layer extension between them, you must configure BGP announcement of the cluster API load balancer address.
For clusters where Kubernetes masters are in the same rack or with an L2 layer extension between masters, you can configure either BGP or L2 (ARP) announcement of the cluster API load balancer address. The L2 (ARP) announcement is used by default and its configuration is covered in Create a managed bare metal cluster.
Caution
Create Rack and MultiRackCluster objects, which are
described in the below procedure, before initiating the provisioning
of master nodes to ensure that both BGP and netplan configurations
are applied simultaneously during the provisioning process.
To enable the use of BGP announcement for the cluster API LB address:
In the
Clusterobject, set theuseBGPAnnouncementparameter totrue:spec: providerSpec: value: useBGPAnnouncement: true
Create the
MultiRackClusterobject that is mandatory when configuring BGP announcement for the cluster API LB address. This object enables you to set cluster-wide parameters for configuration of BGP announcement.In this scenario, the
MultiRackClusterobject must be bound to the correspondingClusterobject using thecluster.sigs.k8s.io/cluster-namelabel.Container Cloud uses the
birdBGP daemon for announcement of the cluster API LB address. For this reason, set the correspondingbgpdConfigFileNameandbgpdConfigFilePathparameters in theMultiRackClusterobject, so thatbirdcan locate the configuration file. For details, see the configuration example below.The
bgpdConfigTemplateobject contains the default configuration file template for thebirdBGP daemon, which you can override inRackobjects.The
defaultPeerparameter contains default parameters of the BGP connection from master nodes to infrastructure BGP peers, which you can override inRackobjects.Configuration example for
MultiRackClusterapiVersion: ipam.mirantis.com/v1alpha1 kind: MultiRackCluster metadata: name: multirack-test-cluster namespace: mosk-ns labels: cluster.sigs.k8s.io/cluster-name: test-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: bgpdConfigFileName: bird.conf bgpdConfigFilePath: /etc/bird bgpdConfigTemplate: | ... defaultPeer: localASN: 65101 neighborASN: 65100 neighborIP: "" password: deadbeef
Note
/./common/region-label-rm.rst
For the object description, see Container Cloud API documentation: MultiRackCluster resource.
Create the
Rackobject(s). This object is mandatory when configuring BGP announcement for the cluster API LB address and it allows you to configure BGP announcement parameters for each rack.In this scenario,
Rackobjects must be bound toMachineobjects corresponding to master nodes of the cluster. EachRackobject describes the configuration for thebirdBGP daemon used to announce the cluster API LB address from a particular master node or from several master nodes in the same rack.The
Machineobject can optionally define therack-idnode label that is not used for BGP announcement of the cluster API LB IP but can be used for MetalLB. This label is required for MetalLB node selectors when MetalLB is used to announce LB IP addresses on nodes that are distributed across multiple racks. In this scenario, the L2 (ARP) announcement mode cannot be used for MetalLB because master nodes are in different L2 segments. So, the BGP announcement mode must be used for MetalLB, and node selectors are required to properly configure BGP connections from each node. See Configure MetalLB for details.The
L2Templateobject includes thelointerface configuration to set the IP address for thebirdBGP daemon that will be advertised as the cluster API LB address. The{{ cluster_api_lb_ip }}function is used innpTemplateto obtain the cluster API LB address value.Configuration example for
RackapiVersion: ipam.mirantis.com/v1alpha1 kind: Rack metadata: name: rack-master-1 namespace: mosk-ns labels: cluster.sigs.k8s.io/cluster-name: test-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: bgpdConfigTemplate: | # optional ... peeringMap: lcm-rack-control-1: peers: - neighborIP: 10.77.31.2 # "localASN" & "neighborASN" are taken from - neighborIP: 10.77.31.3 # "MultiRackCluster.spec.defaultPeer" if # not set here
Note
/./common/region-label-rm.rst
Configuration example for
MachineapiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: name: test-cluster-master-1 namespace: mosk-ns annotations: metal3.io/BareMetalHost: mosk-ns/test-cluster-master-1 labels: cluster.sigs.k8s.io/cluster-name: test-cluster cluster.sigs.k8s.io/control-plane: controlplane hostlabel.bm.kaas.mirantis.com/controlplane: controlplane ipam/RackRef: rack-master-1 # reference to the "rack-master-1" Rack kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one spec: providerSpec: value: kind: BareMetalMachineProviderSpec apiVersion: baremetal.k8s.io/v1alpha1 hostSelector: matchLabels: kaas.mirantis.com/baremetalhost-id: test-cluster-master-1 l2TemplateSelector: name: test-cluster-master-1 nodeLabels: # optional. it is not used for BGP announcement - key: rack-id # of the cluster API LB IP but it can be used value: rack-master-1 # for MetalLB if "nodeSelectors" are required ...
Note
/./common/region-label-rm.rst
Configuration example for
L2TemplateapiVersion: ipam.mirantis.com/v1alpha1 kind: L2Template metadata: labels: cluster.sigs.k8s.io/cluster-name: test-cluster kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: test-cluster-master-1 namespace: mosk-ns spec: ... l3Layout: - subnetName: lcm-rack-control-1 # this network is referenced scope: namespace # in the "rack-master-1" Rack - subnetName: ext-rack-control-1 # optional. this network is used scope: namespace # for k8s services traffic and # MetalLB BGP connections ... npTemplate: | ... ethernets: lo: addresses: - {{ cluster_api_lb_ip }} # function for cluster API LB IP dhcp4: false dhcp6: false ...
Note
/./common/region-label-rm.rst
The
Rackobject fields are described in Container Cloud API documentation: Rack resource.The configuration example for the scenario where Kubernetes masters are in the same rack or with an L2 layer extension between masters is described in Container Cloud API documentation: Single rack configuration example.
The configuration example for the scenario where Kubernetes masters are distributed across multiple racks without L2 layer extension between them is described in Container Cloud API documentation: Multiple rack configuration example.
See also
Create L2 templates¶
After you create subnets for the MOSK cluster as described in Create subnets, follow the procedure below to create L2 templates for different types of OpenStack nodes in the cluster.
See the following subsections for templates that implement the MOSK Reference Architecture: Networking. You may adjust the templates according to the requirements of your architecture using the last two subsections of this section. They explain mandatory parameters of the templates and supported configuration options.
For a multi-rack MOSK cluster, you need to create one L2 template for each type of server in each rack. This may result in a large number of L2 templates in your configuration.
For example, if you have a three-rack deployment of MOSK with 4 types of nodes evenly distributed across three racks, you have to create at least the following L2 templates:
rack-1-k8s-manager,rack-2-k8s-manager,rack-3-k8s-managerfor Kubernetes control plane nodes, unless you use the compact control plane option.rack-1-mosk-control,rack-2-mosk-control,rack-3-mosk-controlfor OpenStack controller nodes in each rack.rack-1-mosk-compute,rack-2-mosk-compute,rack-3-mosk-computefor OpenStack compute nodes in each rack.rack-1-mosk-storage,rack-2-mosk-storage,rack-3-mosk-storagefor OpenStack storage nodes in each rack.
In total, twelve L2 templates are required for this relatively simple cluster. In the following sections, the examples cover only one rack, but can be easily expanded to more racks.
Note
Three servers are required for Kubernetes control plane and for the OpenStack control plane. So, you might not need more L2 templates for these roles when expanding beyond three racks.
Now, proceed to creating L2 templates for your cluster, starting from Create an L2 template for a Kubernetes manager node.
Note
Mirantis does not recommend modifying L2 templates in use to prevent accidental cluster failures due to unsafe changes.
The list of risks posed by modifying L2 templates includes:
Services running on hosts cannot reconfigure automatically to switch to the new IP addresses and/or interfaces.
Connections between services are interrupted unexpectedly, which can cause data loss.
Incorrect configurations on hosts can lead to irrevocable loss of connectivity between services and unexpected cluster partition or disassembly.
According to the reference architecture, the Kubernetes manager nodes in the MOSK cluster must be connected to the following networks:
PXE network
API/LCM network (if you configure ARP announcement of the load-balancer IP address for the MOSK cluster API)
LCM network (if you configure BGP announcement of the load-balancer IP address for the MOSK cluster API)
Kubernetes workloads network
Caution
If you plan to deploy MOSK cluster with the compact control plane option, skip this section entirely and proceed with Create an L2 template for a MOSK controller node.
To create L2 templates for Kubernetes manager nodes:
Create or open the
mosk-l2templates.ymlfile that contains the L2 templates you are preparing.Add L2 templates using the following example. Adjust the values of specific parameters according to the specifications of your environment, specifically the name of your project (namespace) and cluster, IP address ranges and networks, subnet names.
L2 template example for Kubernetes manager node¶apiVersion: ipam.mirantis.com/v1alpha1 kind: L2Template metadata: labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one cluster.sigs.k8s.io/cluster-name: mosk-cluster-name rack1-mosk-manager: "true" name: rack1-mosk-manager namespace: mosk-namespace-name spec: autoIfMappingPrio: - provision - eno - ens - enp l3Layout: - subnetName: api-lcm scope: namespace - subnetName: rack1-k8s-pods scope: namespace npTemplate: |- version: 2 ethernets: {{nic 0}}: dhcp4: false dhcp6: false match: macaddress: {{mac 0}} set-name: {{nic 0}} mtu: 9000 {{nic 1}}: dhcp4: false dhcp6: false match: macaddress: {{mac 1}} set-name: {{nic 1}} mtu: 9000 {{nic 2}} dhcp4: false dhcp6: false match: macaddress: {{mac 2}} set-name: {{nic 2}} mtu: 9000 {{nic 3}}: dhcp4: false dhcp6: false match: macaddress: {{mac 3}} set-name: {{nic 3}} mtu: 9000 bonds: bond0: mtu: 9000 parameters: mode: 802.3ad mii-monitor-interval: 100 interfaces: - {{nic 0}} - {{nic 1}} vlans: k8s-lcm-v: id: 403 link: bond0 mtu: 9000 k8s-pods-v: id: 408 link: bond0 mtu: 9000 bridges: k8s-lcm: interfaces: [k8s-lcm-v] addresses: - {{ ip "k8s-lcm:api-lcm" }} nameservers: addresses: {{nameservers_from_subnet "api-lcm"}} gateway4: {{ gateway_from_subnet "api-lcm" }} k8s-pods: interfaces: [k8s-pods-v] addresses: - {{ip "k8s-pods:rack1-k8s-pods"}} mtu: 9000 routes: - to: 10.199.0.0/22 # aggregated address space for Kubernetes workloads via: {{gateway_from_subnet "rack1-k8s-pods"}}
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
Note
Before MOSK 23.3, an L2 template requires
clusterRef: <clusterName>in thespecsection. Since MOSK 23.3, this parameter is deprecated and automatically migrated to thecluster.sigs.k8s.io/cluster-name: <clusterName>label.To create L2 templates for other racks, change the rack identifier in the names and labels above.
Proceed with Create an L2 template for a MOSK controller node. The resulting L2 templates will be used to render the netplan configuration for the managed cluster machines.
Note
Mirantis does not recommend modifying L2 templates in use to prevent accidental cluster failures due to unsafe changes.
The list of risks posed by modifying L2 templates includes:
Services running on hosts cannot reconfigure automatically to switch to the new IP addresses and/or interfaces.
Connections between services are interrupted unexpectedly, which can cause data loss.
Incorrect configurations on hosts can lead to irrevocable loss of connectivity between services and unexpected cluster partition or disassembly.
According to the reference architecture, MOSK controller nodes must be connected to the following networks:
PXE network
LCM network
Kubernetes workloads network
Storage access network (if deploying with Ceph as a back end for ephemeral storage)
Floating IP and provider networks. Not required for deployment with Tungsten Fabric.
Tenant underlay networks. If deploying with VXLAN networking or with Tungsten Fabric. In the latter case, the BGP service is configured over this network.
To create L2 templates for MOSK controller nodes:
Create or open the
mosk-l2template.ymlfile that contains the L2 templates.Add L2 templates using the following example. Adjust the values of specific parameters according to the specification of your environment.
Example of an L2 template for a MOSK controller node¶apiVersion: ipam.mirantis.com/v1alpha1 kind: L2Template metadata: labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one cluster.sigs.k8s.io/cluster-name: mosk-cluster-name rack1-mosk-controller: "true" name: rack1-mosk-controller namespace: mosk-namespace-name spec: autoIfMappingPrio: - provision - eno - ens - enp l3Layout: - subnetName: mgmt-lcm scope: global - subnetName: rack1-k8s-lcm scope: namespace - subnetName: k8s-external scope: namespace - subnetName: rack1-k8s-pods scope: namespace - subnetName: rack1-ceph-public scope: namespace - subnetName: rack1-tenant-tunnel scope: namespace npTemplate: |- version: 2 ethernets: {{nic 0}}: dhcp4: false dhcp6: false match: macaddress: {{mac 0}} set-name: {{nic 0}} mtu: 9000 {{nic 1}}: dhcp4: false dhcp6: false match: macaddress: {{mac 1}} set-name: {{nic 1}} mtu: 9000 {{nic 2}} dhcp4: false dhcp6: false match: macaddress: {{mac 2}} set-name: {{nic 2}} mtu: 9000 {{nic 3}}: dhcp4: false dhcp6: false match: macaddress: {{mac 3}} set-name: {{nic 3}} mtu: 9000 bonds: bond0: mtu: 9000 parameters: mode: 802.3ad mii-monitor-interval: 100 interfaces: - {{nic 0}} - {{nic 1}} bond1: mtu: 9000 parameters: mode: 802.3ad mii-monitor-interval: 100 interfaces: - {{nic 2}} - {{nic 3}} vlans: k8s-lcm-v: id: 403 link: bond0 mtu: 9000 k8s-ext-v: id: 409 link: bond0 mtu: 9000 k8s-pods-v: id: 408 link: bond0 mtu: 9000 pr-floating: id: 407 link: bond1 mtu: 9000 stor-frontend: id: 404 link: bond0 addresses: - {{ip "stor-frontend:rack1-ceph-public"}} mtu: 9000 routes: - to: 10.199.16.0/22 # aggregated address space for Ceph public network via: {{ gateway_from_subnet "rack1-ceph-public" }} tenant-tunnel: id: 406 link: bond1 addresses: - {{ip "tenant-tunnel:rack1-tenant-tunnel"}} mtu: 9000 routes: - to: 10.195.0.0/22 # aggregated address space for tenant networks via: {{ gateway_from_subnet "rack1-tenant-tunnel" }} bridges: k8s-lcm: interfaces: [k8s-lcm-v] addresses: - {{ ip "k8s-lcm:rack1-k8s-lcm" }} nameservers: addresses: {{nameservers_from_subnet "rack1-k8s-lcm"}} routes: - to: 10.197.0.0/21 # aggregated address space for LCM and API/LCM networks via: {{ gateway_from_subnet "rack1-k8s-lcm" }} - to: {{ cidr_from_subnet "mgmt-lcm" }} via: {{ gateway_from_subnet "rack1-k8s-lcm" }} k8s-ext: interfaces: [k8s-ext-v] addresses: - {{ip "k8s-ext:k8s-external"}} nameservers: addresses: {{nameservers_from_subnet "k8s-external"}} gateway4: {{ gateway_from_subnet "k8s-external" }} mtu: 9000 k8s-pods: interfaces: [k8s-pods-v] addresses: - {{ip "k8s-pods:rack1-k8s-pods"}} mtu: 9000 routes: - to: 10.199.0.0/22 # aggregated address space for Kubernetes workloads via: {{ gateway_from_subnet "rack1-k8s-pods" }}
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
Note
Before MOSK 23.3, an L2 template requires
clusterRef: <clusterName>in thespecsection. Since MOSK 23.3, this parameter is deprecated and automatically migrated to thecluster.sigs.k8s.io/cluster-name: <clusterName>label.
Caution
If you plan to deploy a MOSK cluster with
the compact control plane option and configure ARP announcement of the
load-balancer IP address for the MOSK cluster API, the
API/LCM network will be used for MOSK controller nodes.
Therefore, change the rack1-k8s-lcm subnet to the api-lcm one in
the corresponding L2Template object:
spec:
...
l3Layout:
...
- subnetName: api-lcm
scope: namespace
...
npTemplate: |-
...
bridges:
k8s-lcm:
interfaces: [k8s-lcm-v]
addresses:
- {{ ip "k8s-lcm:api-lcm" }}
nameservers:
addresses: {{nameservers_from_subnet "api-lcm"}}
routes:
- to: 10.197.0.0/21 # aggregated address space for LCM and API/LCM networks
via: {{ gateway_from_subnet "api-lcm" }}
- to: {{ cidr_from_subnet "mgmt-lcm" }}
via: {{ gateway_from_subnet "api-lcm" }}
...
Proceed with Create an L2 template for a MOSK compute node.
Note
Mirantis does not recommend modifying L2 templates in use to prevent accidental cluster failures due to unsafe changes.
The list of risks posed by modifying L2 templates includes:
Services running on hosts cannot reconfigure automatically to switch to the new IP addresses and/or interfaces.
Connections between services are interrupted unexpectedly, which can cause data loss.
Incorrect configurations on hosts can lead to irrevocable loss of connectivity between services and unexpected cluster partition or disassembly.
According to the reference architecture, MOSK compute nodes must be connected to the following networks:
PXE network
LCM network
Kubernetes workloads network
Storage access network (if deploying with Ceph as a back end for ephemeral storage)
Floating IP and provider networks (if deploying OpenStack with DVR)
Tenant underlay networks
To create L2 templates for MOSK compute nodes:
Add L2 templates to the
mosk-l2templates.ymlfile using the following example. Adjust the values of parameters according to the specification of your environment.Example of an L2 template for a MOSK compute node¶apiVersion: ipam.mirantis.com/v1alpha1 kind: L2Template metadata: labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one cluster.sigs.k8s.io/cluster-name: mosk-cluster-name rack1-mosk-compute: "true" name: rack1-mosk-compute namespace: mosk-namespace-name spec: autoIfMappingPrio: - provision - eno - ens - enp l3Layout: - subnetName: rack1-k8s-lcm scope: namespace - subnetName: rack1-k8s-pods scope: namespace - subnetName: rack1-ceph-public scope: namespace - subnetName: rack1-tenant-tunnel scope: namespace npTemplate: |- version: 2 ethernets: {{nic 0}}: dhcp4: false dhcp6: false match: macaddress: {{mac 0}} set-name: {{nic 0}} mtu: 9000 {{nic 1}}: dhcp4: false dhcp6: false match: macaddress: {{mac 1}} set-name: {{nic 1}} mtu: 9000 {{nic 2}} dhcp4: false dhcp6: false match: macaddress: {{mac 2}} set-name: {{nic 2}} mtu: 9000 {{nic 3}}: dhcp4: false dhcp6: false match: macaddress: {{mac 3}} set-name: {{nic 3}} mtu: 9000 bonds: bond0: mtu: 9000 parameters: mode: 802.3ad mii-monitor-interval: 100 interfaces: - {{nic 0}} - {{nic 1}} bond1: mtu: 9000 parameters: mode: 802.3ad mii-monitor-interval: 100 interfaces: - {{nic 2}} - {{nic 3}} vlans: k8s-lcm-v: id: 403 link: bond0 mtu: 9000 k8s-pods-v: id: 408 link: bond0 mtu: 9000 pr-floating: id: 407 link: bond1 mtu: 9000 stor-frontend: id: 404 link: bond0 addresses: - {{ip "stor-frontend:rack1-ceph-public"}} mtu: 9000 routes: - to: 10.199.16.0/22 # aggregated address space for Ceph public network via: {{ gateway_from_subnet "rack1-ceph-public" }} tenant-tunnel: id: 406 link: bond1 addresses: - {{ip "tenant-tunnel:rack1-tenant-tunnel"}} mtu: 9000 routes: - to: 10.195.0.0/22 # aggregated address space for tenant networks via: {{ gateway_from_subnet "rack1-tenant-tunnel" }} bridges: k8s-lcm: interfaces: [k8s-lcm-v] addresses: - {{ ip "k8s-lcm:rack1-k8s-lcm" }} nameservers: addresses: {{nameservers_from_subnet "rack1-k8s-lcm"}} gateway4: {{ gateway_from_subnet "rack1-k8s-lcm" }} k8s-pods: interfaces: [k8s-pods-v] addresses: - {{ip "k8s-pods:k8s-pods-subnet"}} mtu: 9000 routes: - to: 10.199.0.0/22 # aggregated address space for Kubernetes workloads via: {{gateway_from_subnet "rack1-k8s-pods"}}
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
Note
Before MOSK 23.3, an L2 template requires
clusterRef: <clusterName>in thespecsection. Since MOSK 23.3, this parameter is deprecated and automatically migrated to thecluster.sigs.k8s.io/cluster-name: <clusterName>label.Proceed with Create an L2 template for a MOSK storage node.
Note
Mirantis does not recommend modifying L2 templates in use to prevent accidental cluster failures due to unsafe changes.
The list of risks posed by modifying L2 templates includes:
Services running on hosts cannot reconfigure automatically to switch to the new IP addresses and/or interfaces.
Connections between services are interrupted unexpectedly, which can cause data loss.
Incorrect configurations on hosts can lead to irrevocable loss of connectivity between services and unexpected cluster partition or disassembly.
According to the reference architecture, MOSK storage nodes in the MOSK cluster must be connected to the following networks:
PXE network
LCM network
Kubernetes workloads network
Storage access network
Storage replication network
To create L2 templates for MOSK storage nodes:
Add L2 templates to the
mosk-l2templates.ymlfile using the following example. Adjust the values of parameters according to the specification of your environment.Example of an L2 template for a MOSK storage node¶apiVersion: ipam.mirantis.com/v1alpha1 kind: L2Template metadata: labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one cluster.sigs.k8s.io/cluster-name: mosk-cluster-name rack1-mosk-storage: "true" name: rack1-mosk-storage namespace: mosk-namespace-name spec: autoIfMappingPrio: - provision - eno - ens - enp l3Layout: - subnetName: rack1-k8s-lcm scope: namespace - subnetName: rack1-k8s-pods scope: namespace - subnetName: rack1-ceph-public scope: namespace - subnetName: rack1-ceph-cluster scope: namespace npTemplate: |- version: 2 ethernets: {{nic 0}}: dhcp4: false dhcp6: false match: macaddress: {{mac 0}} set-name: {{nic 0}} mtu: 9000 {{nic 1}}: dhcp4: false dhcp6: false match: macaddress: {{mac 1}} set-name: {{nic 1}} mtu: 9000 {{nic 2}} dhcp4: false dhcp6: false match: macaddress: {{mac 2}} set-name: {{nic 2}} mtu: 9000 {{nic 3}}: dhcp4: false dhcp6: false match: macaddress: {{mac 3}} set-name: {{nic 3}} mtu: 9000 bonds: bond0: mtu: 9000 parameters: mode: 802.3ad mii-monitor-interval: 100 interfaces: - {{nic 0}} - {{nic 1}} bond1: mtu: 9000 parameters: mode: 802.3ad mii-monitor-interval: 100 interfaces: - {{nic 2}} - {{nic 3}} vlans: k8s-lcm-v: id: 403 link: bond0 mtu: 9000 k8s-pods-v: id: 408 link: bond0 mtu: 9000 stor-frontend: id: 404 link: bond0 addresses: - {{ip "stor-frontend:rack1-ceph-public"}} mtu: 9000 routes: - to: 10.199.16.0/22 # aggregated address space for Ceph public network via: {{ gateway_from_subnet "rack1-ceph-public" }} stor-backend: id: 405 link: bond1 addresses: - {{ip "stor-backend:rack1-ceph-cluster"}} mtu: 9000 routes: - to: 10.199.32.0/22 # aggregated address space for Ceph cluster network via: {{ gateway_from_subnet "rack1-ceph-cluster" }} bridges: k8s-lcm: interfaces: [k8s-lcm-v] addresses: - {{ ip "k8s-lcm:rack1-k8s-lcm" }} nameservers: addresses: {{nameservers_from_subnet "rack1-k8s-lcm"}} gateway4: {{ gateway_from_subnet "rack1-k8s-lcm" }} k8s-pods: interfaces: [k8s-pods-v] addresses: - {{ip "k8s-pods:k8s-pods-subnet"}} mtu: 9000 routes: - to: 10.199.0.0/22 # aggregated address space for Kubernetes workloads via: {{gateway_from_subnet "rack1-k8s-pods"}}
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
Note
Before MOSK 23.3, an L2 template requires
clusterRef: <clusterName>in thespecsection. Since MOSK 23.3, this parameter is deprecated and automatically migrated to thecluster.sigs.k8s.io/cluster-name: <clusterName>label.Proceed with Edit and apply L2 templates.
To add L2 templates to a MOSK cluster:
Log in to a local machine where your management cluster
kubeconfigis located and wherekubectlis installed.Note
The management cluster
kubeconfigis created during the last stage of the management cluster bootstrap.Add the L2 template to your management cluster:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> apply -f <pathToL2TemplateYamlFile>
Inspect the existing L2 templates to see if any one fits your deployment:
kubectl --kubeconfig <pathToManagementClusterKubeconfig> \ get l2template -n <ProjectNameForNewManagedCluster>
Optional. Further modify the template, if required or in case of mistake in configuration. See Mandatory parameters of L2 templates and Netplan template macros for details.
kubectl --kubeconfig <pathToManagementClusterKubeconfig> \ -n <ProjectNameForNewManagedCluster> edit l2template <L2templateName>
Note
Mirantis does not recommend modifying L2 templates in use to prevent accidental cluster failures due to unsafe changes.
The list of risks posed by modifying L2 templates includes:
Services running on hosts cannot reconfigure automatically to switch to the new IP addresses and/or interfaces.
Connections between services are interrupted unexpectedly, which can cause data loss.
Incorrect configurations on hosts can lead to irrevocable loss of connectivity between services and unexpected cluster partition or disassembly.
Think of an L2 template as a template for networking configuration for your hosts. You may adjust the parameters according to the actual requirements and hardware setup of your hosts.
Parameter |
Description |
|---|---|
|
Mandatory since MOSK 23.3. References the L2 template requirements
|
|
Deprecated since MOSK 23.3. References the Note Before MOSK 23.3, an L2 template requires
|
|
|
|
Subnets to be used in the
Caution The Caution Using the If Mirantis recommends using a unique label prefix such as
|
|
A netplan-compatible configuration with special lookup functions
that defines the networking settings for the cluster hosts,
where physical NIC names and details are parameterized.
This configuration will be processed using Go templates.
Instead of specifying IP and MAC addresses, interface names,
and other network details specific to a particular host,
the template supports use of special lookup functions.
These lookup functions, such as Caution All rules and restrictions of the netplan configuration also apply to L2 templates. For details, see the official netplan documentation. Caution We strongly recommend following the below conventions on network interface naming:
We recommend setting interfaces names that do not exceed 13 symbols for both physical and virtual interfaces to avoid corner cases and issues in netplan rendering. |
Parameter |
Description |
|---|---|
|
Name of the reference to the subnet that will be used in the
|
|
A dictionary of the labels and values that are used to filter out
and find the |
|
Optional. Default: none. Name of the parent |
|
Logical scope of the
|
The following table describes the main lookup functions, or macros,
that can be used in the npTemplate field of an L2 template.
Lookup function |
Description |
|---|---|
|
Name of a NIC number N. NIC numbers correspond to the interface
mapping list. This macro can be used as a key for the elements
of |
|
MAC address of a NIC number N registered during a host hardware inspection. |
|
IP address and mask for a NIC number N. If the address does not exist yet, it will be automatically allocated from the given subnet. The interface is identified by its MAC address. |
|
IP address and mask for a virtual interface, |
|
IPv4 CIDR address from the given subnet. |
|
IPv4 default gateway address from the given subnet. |
|
List of the IP addresses of name servers from the given subnet. |
|
Technology Preview since MOSK 23.2.2. IP address for a cluster API load balancer. |
This section contains an exemplary L2 template that demonstrates how to set up bonds and bridges on hosts for your managed clusters.
Caution
Use of a dedicated network for Kubernetes pods traffic, for external connection to the Kubernetes services exposed by the cluster, and for the Ceph cluster access and replication traffic is available as Technology Preview. Use such configurations for testing and evaluation purposes only. For the Technology Preview feature definition, refer to Technology Preview features.
The Kubernetes LCM network connects LCM Agents running on nodes to the LCM API
of the management cluster. It is also used for communication between
kubelet and Kubernetes API server inside a Kubernetes cluster.
The MKE components use this network for communication inside a swarm
cluster.
Each node of every cluster must have one and only IP address in the LCM network that is allocated from one of the
Subnetobjects having theipam/SVC-k8s-lcmlabel defined. Therefore, allSubnetobjects used for LCM networks must have theipam/SVC-k8s-lcmlabel defined.You can use any interface name for the LCM network traffic. The
Subnetobjects for the LCM network must have theipam/SVC-k8s-lcmlabel. For details, see Service labels and their life cycle.
If you want to use a dedicated network for Kubernetes pods traffic,
configure each node with an IPv4
address that will be used to route the pods traffic between nodes.
To accomplish that, use the npTemplate.bridges.k8s-pods bridge
in the L2 template, as demonstrated in the example below.
As defined in Container Cloud Reference Architecture: Host networking,
this bridge name is reserved for the Kubernetes pods network. When the
k8s-pods bridge is defined in an L2 template, Calico CNI uses that network
for routing the pods traffic between nodes.
You can use a dedicated network for external connection to the Kubernetes
services exposed by the cluster.
If enabled, MetalLB will listen and respond on the dedicated virtual bridge.
To accomplish that, configure each node where metallb-speaker is deployed
with an IPv4 address. The default route on the MOSK nodes
that are connected to the external network must be configured with the
default gateway in the external network.
Use the npTemplate.bridges.k8s-ext bridge in the L2 template,
as demonstrated in the example below.
The Subnet object that corresponds to the k8s-ext bridge must have
explicitly excluded IP address ranges that are in use by MetalLB.
Starting from Container Cloud 2.7.0, you can configure dedicated networks
for the Ceph cluster access and replication traffic. Set labels on the
Subnet CRs for the corresponding networks, as described in
Create subnets.
Container Cloud automatically configures Ceph to use the addresses from these
subnets. Ensure that the addresses are assigned to the storage nodes.
The Subnet objects used to assign IP addresses to these networks
must have corresponding labels ipam/SVC-ceph-public for the
Ceph public (storage access) network and ipam/SVC-ceph-cluster for the
Ceph cluster (storage replication) network.
apiVersion: ipam.mirantis.com/v1alpha1
kind: L2Template
metadata:
name: test-managed
namespace: managed-ns
cluster.sigs.k8s.io/cluster-name: mosk-cluster-name
spec:
autoIfMappingPrio:
- provision
- eno
- ens
- enp
l3Layout:
- subnetName: mgmt-lcm
scope: global
- subnetName: demo-lcm
scope: namespace
- subnetName: demo-ext
scope: namespace
- subnetName: demo-pods
scope: namespace
- subnetName: demo-ceph-cluster
scope: namespace
- subnetName: demo-ceph-public
scope: namespace
npTemplate: |
version: 2
ethernets:
ten10gbe0s0:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 2}}
set-name: {{nic 2}}
ten10gbe0s1:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 3}}
set-name: {{nic 3}}
bonds:
bond0:
interfaces:
- ten10gbe0s0
- ten10gbe0s1
mtu: 9000
parameters:
mode: 802.3ad
mii-monitor-interval: 100
vlans:
k8s-lcm-vlan:
id: 1009
link: bond0
k8s-ext-vlan:
id: 1001
link: bond0
k8s-pods-vlan:
id: 1002
link: bond0
stor-frontend:
id: 1003
link: bond0
stor-backend:
id: 1004
link: bond0
bridges:
k8s-lcm:
interfaces: [k8s-lcm-vlan]
addresses:
- {{ip "k8s-lcm:demo-lcm"}}
routes:
- to: {{ cidr_from_subnet "mgmt-lcm" }}
via: {{ gateway_from_subnet "demo-lcm" }}
k8s-ext:
interfaces: [k8s-ext-vlan]
addresses:
- {{ip "k8s-ext:demo-ext"}}
nameservers:
addresses: {{nameservers_from_subnet "demo-ext"}}
gateway4: {{ gateway_from_subnet "demo-ext" }}
k8s-pods:
interfaces: [k8s-pods-vlan]
addresses:
- {{ip "k8s-pods:demo-pods"}}
ceph-cluster:
interfaces: [stor-backend]
addresses:
- {{ip "ceph-cluster:demo-ceph-cluster"}}
ceph-public:
interfaces: [stor-frontend]
addresses:
- {{ip "ceph-public:demo-ceph-public"}}
Note
Before MOSK 23.3, an L2 template requires
clusterRef: <clusterName> in the spec section. Since MOSK 23.3,
this parameter is deprecated and automatically migrated to the
cluster.sigs.k8s.io/cluster-name: <clusterName> label.
Add a machine¶
This section describes how to add a machine to a managed MOSK cluster using CLI for advanced configuration.
Create a machine using CLI¶
This section describes adding machines to a new MOSK cluster using Mirantis Container Cloud CLI.
If you need to add more machines to an existing MOSK cluster, see Add a controller node and Add a compute node.
To add machine to the MOSK cluster:
Log in to the host where your management cluster
kubeconfigis located and where kubectl is installed.Create a new text file
mosk-cluster-machines.yamland create the YAML definitons of theMachineresources. Use this as an example, and see the descriptions of the fields below:apiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: name: mosk-node-role-name namespace: mosk-project labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one cluster.sigs.k8s.io/cluster-name: mosk-cluster spec: providerSpec: value: apiVersion: baremetal.k8s.io/v1alpha1 kind: BareMetalMachineProviderSpec bareMetalHostProfile: name: mosk-k8s-mgr namespace: mosk-project l2TemplateSelector: name: mosk-k8s-mgr hostSelector: {} l2TemplateMappingOverride: []
Note
/./common/region-label-rm.rst
Add the top level fields:
apiVersionAPI version of the object that is
cluster.k8s.io/v1alpha1.
kindObject type that is
Machine.
metadataThis section will contain the metadata of the object.
specThis section will contain the configuration of the object.
Add mandatory fields to the
metadatasection of theMachineobject definition.nameThe name of the
Machineobject.
namespaceThe name of the Project where the
Machinewill be created.
labelsThis section contains additional metadata of the machine. Set the following mandatory labels for the
Machineobject.kaas.mirantis.com/providerSet to
"baremetal".
kaas.mirantis.com/regionRegion name that matches the region name in the
Clusterobject.
cluster.sigs.k8s.io/cluster-nameThe name of the cluster to add the machine to.
Note
/./common/region-label-rm.rst
Configure the mandatory parameters of the
Machineobject inspecfield. AddproviderSpecfield that contains parameters for deployment on bare metal in a form of Kubernetes subresource.In the
providerSpecsection, add the following mandatory configuration parameters:apiVersionAPI version of the subresource that is
baremetal.k8s.io/v1alpha1.
kindObject type that is
BareMetalMachineProviderSpec.
bareMetalHostProfileReference to a configuration profile of a bare metal host. It helps to pick bare metal host with suitable configuration for the machine. This section includes two parameters:
nameName of a bare metal host profile
namespaceProject in which the bare metal host profile is created.
l2TemplateSelectorIf specified, contains the
name(first priority) orlabelof the L2 template that will be applied during a machine creation. Note that changing this field afterMachineobject is created will not affect the host network configuration of the machine.You should assign one of the templates you defined in Create L2 templates to the machine. If there is no suitable templates, you should create one per Create L2 templates.
hostSelectorThis parameter defines matching criteria for picking a bare metal host for the machine by label.
Any custom label that is assigned to one or more bare metal hosts using API can be used as a host selector. If the
BareMetalHostobjects with the specified label are missing, theMachineobject will not be deployed until at least one bare metal host with the specified label is available.See Deploy a machine to a specific bare metal host for details.
l2TemplateIfMappingOverrideThis parameter contains a list of names of network interfaces of the host. It allows to override the default naming and ordering of network interfaces defined in L2 template referenced by the
l2TemplateSelector. This ordering informs the L2 templates how to generate the host network configuration.See Override network interfaces naming and order for details.
Depending on the role of the machine in the MOSK cluster, add labels to the
nodeLabelsfield.This field contains the list of node labels to be attached to a node for the user to run certain components on separate cluster nodes. The list of allowed node labels is located in the
Clusterobject statusproviderStatus.releaseRef.current.allowedNodeLabelsfield.If the
valuefield is not defined inallowedNodeLabels, a label can have any value. For example:allowedNodeLabels: - displayName: Stacklight key: stacklight
Before or after a machine deployment, add the required label from the allowed node labels list with the corresponding value to
spec.providerSpec.value.nodeLabelsinmachine.yaml. For example:nodeLabels: - key: stacklight value: enabled
Adding of a node label that is not available in the list of allowed node labels is restricted.
If you are NOT deploying MOSK with the compact control plane, add 3 dedicated Kubernetes manager nodes.
Add 3
Machineobjects for Kubernetes manager nodes using the following label:metadata: labels: cluster.sigs.k8s.io/control-plane: "true"
Note
The value of the label might be any non-empty string. On a worker node, this label must be omitted entirely.
Add 3
Machineobjects for MOSK controller nodes using the following labels:spec: providerSpec: value: nodeLabels: openstack-control-plane: enabled openstack-gateway: enabled
If you are deploying MOSK with compact control plane, add
Machineobjects for 3 combined control plane nodes using the following labels and parameters to thenodeLabelsfield:metadata: labels: cluster.sigs.k8s.io/control-plane: true spec: providerSpec: value: nodeLabels: openstack-control-plane: enabled openstack-gateway: enabled openvswitch: enabled
Add
Machineobjects for as many compute nodes as you want to install using the following labels:spec: providerSpec: value: nodeLabels: openstack-compute-node: enabled openvswitch: enabled
Save the text file and repeat the process to create configuration for all machines in your MOSK cluster.
Create machines in the cluster using command:
kubectl create -f mosk-cluster-machines.yaml
Proceed to Add a Ceph cluster.
See also
Assign L2 templates to machines¶
To install MOSK on bare metal with Container Cloud, you must create L2 templates for each node type in the MOSK cluster. Additionally, you may have to create separate templates for nodes of the same type when they have different configuration.
To assign specific L2 templates to machines in a cluster:
Select from the following options to assign the templates to the cluster:
Since MOSK 23.3, use the
cluster.sigs.k8s.io/cluster-namelabel in thelabelssection.Before MOSK 23.3, use the
clusterRefparameter in thespecsection.
Add a unique identifier label to every L2 template. Typically, that would be the name of the MOSK node role, for example
l2template-compute, orl2template-compute-5nics.Assign an L2 template to a machine. Set the
l2TemplateSelectorfield in the machine spec to the name of the label added in the previous step. IPAM Controller uses this field to use a specific L2 template for the corresponding machine.Alternatively, you may set the
l2TemplateSelectorfield to the name of the L2 template.
Consider the following examples of an L2 template assignment to a machine.
apiVersion: ipam.mirantis.com/v1alpha1
kind: L2Template
metadata:
name: example-node-netconfig
namespace: my-project
labels:
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
l2template-example-node-netconfig: "1"
cluster.sigs.k8s.io/cluster-name: my-cluster
...
Note
/./common/region-label-rm.rst
Note
Before MOSK 23.3, an L2 template requires
clusterRef: <clusterName> in the spec section. Since MOSK 23.3,
this parameter is deprecated and automatically migrated to the
cluster.sigs.k8s.io/cluster-name: <clusterName> label.
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
name: machine1
namespace: my-project
labels:
cluster.sigs.k8s.io/cluster-name: my-cluster
...
...
spec:
providerSpec:
value:
l2TemplateSelector:
label: l2template-example-node-netconfig
...
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
name: machine1
namespace: my-project
labels:
cluster.sigs.k8s.io/cluster-name: my-cluster
...
...
spec:
providerSpec:
value:
l2TemplateSelector:
name: example-node-netconfig
...
Now, proceed to Deploy a machine to a specific bare metal host.
Deploy a machine to a specific bare metal host¶
Machine in a MOSK cluster requires dedicated bare metal
host for deployment. The bare metal hosts are represented by the
BareMetalHost objects in MCC management API. All BareMetalHost
objects must be labeled upon creation with a label that will allow to
identify the host and assign it to a machine.
The labels may be unique, or applied to a group of hosts, based on similarities in their capacity, capabilities and hardware configuration, on their location, suitable role, or a combination of thereof.
In some cases, you may need to deploy a machine to a specific bare metal host. This is especially useful when some of your bare metal hosts have different hardware configuration than the rest.
To deploy a machine to a specific bare metal host:
Log in to the host where your management cluster
kubeconfigis located and where kubectl is installed.Identify the bare metal host that you want to associate with the specific machine. For example, host
host-1.kubectl get baremetalhost host-1 -o yaml
Add a label that will uniquely identify this host, for example, by the name of the host and machine that you want to deploy on it.
Caution
Do not remove any existing labels from the
BareMetalHostresource.kubectl edit baremetalhost host-1
Configuration example:
kind: BareMetalHost metadata: name: host-1 namespace: myProjectName labels: kaas.mirantis.com/baremetalhost-id: host-1-worker-HW11-cad5 ...
Open the text file with the YAML definition of the
Machineobject, created in Create a machine using CLI.Add a host selector that matches the label you have added to the
BareMetalHostobject in the previous step.Example:
kind: Machine metadata: name: worker-HW11-cad5 namespace: myProjectName spec: ... providerSpec: value: apiVersion: baremetal.k8s.io/v1alpha1 kind: BareMetalMachineProviderSpec ... hostSelector: matchLabels: kaas.mirantis.com/baremetalhost-id: host-1-worker-HW11-cad5 ...
Once created, this machine will be associated with the specified bare metal host, and you can return to Create a machine using CLI.
Override network interfaces naming and order¶
An L2 template contains the ifMapping field that allows you to
identify Ethernet interfaces for the template. The Machine object
API enables the Operator to override the mapping from the L2 template
by enforcing a specific order of names of the interfaces when applied
to the template.
The field l2TemplateIfMappingOverride in the spec of the Machine
object contains a list of interfaces names. The order of the interfaces
names in the list is important because the L2Template object will
be rendered with NICs ordered as per this list.
Note
Changes in the l2TemplateIfMappingOverride field will apply
only once when the Machine and corresponding IpamHost objects
are created. Further changes to l2TemplateIfMappingOverride
will not reset the interfaces assignment and configuration.
Caution
The l2TemplateIfMappingOverride field must contain the names of
all interfaces of the bare metal host.
The following example illustrates how to include the override field to the
Machine object. In this example, we configure the interface eno1,
which is the second on-board interface of the server, to precede the first
on-board interface eno0.
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
finalizers:
- foregroundDeletion
- machine.cluster.sigs.k8s.io
labels:
cluster.sigs.k8s.io/cluster-name: kaas-mgmt
cluster.sigs.k8s.io/control-plane: "true"
kaas.mirantis.com/provider: baremetal
kaas.mirantis.com/region: region-one
spec:
providerSpec:
value:
apiVersion: baremetal.k8s.io/v1alpha1
hostSelector:
matchLabels:
baremetal: hw-master-0
image: {}
kind: BareMetalMachineProviderSpec
l2TemplateIfMappingOverride:
- eno1
- eno0
- enp0s1
- enp0s2
Note
/./common/region-label-rm.rst
As a result of the configuration above, when used with the example
L2 template for bonds and bridges described in Create L2 templates,
the enp0s1 and enp0s2 interfaces will be in predictable
ordered state. This state will be used to create subinterfaces for
Kubernetes networks (k8s-pods) and for Kubernetes external
network (k8s-ext).
Add a Ceph cluster¶
After you add machines to your new bare metal managed cluster as described in Add a machine, create a Ceph cluster on top of this managed cluster using the Mirantis Container Cloud web UI.
For an advanced configuration through the KaaSCephCluster CR, see
Mirantis Container Cloud Operations Guide: Ceph advanced configuration.
To configure Ceph Controller through Kubernetes templates to manage Ceph nodes
resources, see
Mirantis Container Cloud Operations Guide: Enable Ceph tolerations and
resources management.
The procedure below enables you to create a Ceph cluster with minimum three Ceph nodes that provides persistent volumes to the Kubernetes workloads in the managed cluster.
To create a Ceph cluster in the managed cluster:
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the required cluster name. The Cluster page with the Machines and Ceph clusters lists opens.
In the Ceph Clusters block, click Create Cluster.
Configure the Ceph cluster in the Create New Ceph Cluster wizard that opens:
Create new Ceph cluster¶ Section
Parameter name
Description
General settings
Name
The Ceph cluster name.
Cluster Network
Replication network for Ceph OSDs. Must contain the CIDR definition and match the corresponding values of the cluster
L2Templateobject or the environment network values.Public Network
Public network for Ceph data. Must contain the CIDR definition and match the corresponding values of the cluster
L2Templateobject or the environment network values.Enable OSDs LCM
Select to enable LCM for Ceph OSDs.
Machines / Machine #1-3
Select machine
Select the name of the Kubernetes machine that will host the corresponding Ceph node in the Ceph cluster.
Manager, Monitor
Select the required Ceph services to install on the Ceph node.
Devices
Select the disk that Ceph will use.
Warning
Do not select the device for system services, for example,
sda.Warning
A Ceph cluster does not support removable devices that are hosts with hotplug functionality enabled. To use devices as Ceph OSD data devices, make them non-removable or disable the hotplug functionality in the BIOS settings for disks that are configured to be used as Ceph OSD data devices.
Enable Object Storage
Select to enable the single-instance RGW Object Storage.
To add more Ceph nodes to the new Ceph cluster, click + next to any Ceph Machine title in the Machines tab. Configure a Ceph node as required.
Warning
Do not add more than 3
Managerand/orMonitorservices to the Ceph cluster.After you add and configure all nodes in your Ceph cluster, click Create.
Open the
KaaSCephClusterCR for editing as described in Mirantis Container Cloud Operations Guide: Ceph advanced configuration.Verify that the following snippet is present in the
KaaSCephClusterconfiguration:network: clusterNet: 10.10.10.0/24 publicNet: 10.10.11.0/24
Configure the pools for Image, Block Storage, and Compute services.
Note
Ceph validates the specified pools. Therefore, do not omit any of the following pools.
spec: pools: - default: true deviceClass: hdd name: kubernetes replicated: size: 3 role: kubernetes - default: false deviceClass: hdd name: volumes replicated: size: 3 role: volumes - default: false deviceClass: hdd name: vms replicated: size: 3 role: vms - default: false deviceClass: hdd name: backup replicated: size: 3 role: backup - default: false deviceClass: hdd name: images replicated: size: 3 role: images
Each Ceph pool, depending on its role, has a default
targetSizeRatiovalue that defines the expected consumption of the total Ceph cluster capacity. The default ratio values for MOSK pools are as follows:20.0% for a Ceph pool with role
volumes40.0% for a Ceph pool with role
vms10.0% for a Ceph pool with role
images10.0% for a Ceph pool with role
backup
Once all pools are created, verify that an appropriate secret required for a successful deployment of the OpenStack services that rely on Ceph is created in the
openstack-ceph-sharednamespace:kubectl -n openstack-ceph-shared get secrets openstack-ceph-keys
Example of a positive system response:
NAME TYPE DATA AGE openstack-ceph-keys Opaque 7 36m
Verify your Ceph cluster as described in Mirantis Container Cloud Operations Guide: Verify Ceph.
Delete a managed cluster¶
Due to a development limitation in baremetal operator,
deletion of a managed cluster requires preliminary deletion
of the worker machines running on the cluster.
Using the Container Cloud web UI, first delete worker machines one by one until you hit the minimum of 2 workers for an operational cluster. After that, you can delete the cluster with the remaining workers and managers.
To delete a baremetal-based managed cluster:
Log in to the Mirantis Container Cloud web UI with the
writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, click the required cluster name to open the list of machines running on it.
Click the More action icon in the last column of the worker machine you want to delete and select Delete. Confirm the deletion.
Repeat the step above until you have 2 workers left.
In the Clusters tab, click the More action icon in the last column of the required cluster and select Delete.
Verify the list of machines to be removed. Confirm the deletion.
Optional. If you do not plan to reuse the credentials of the deleted cluster, delete them:
In the Credentials tab, click the Delete credential action icon next to the name of the credentials to be deleted.
Confirm the deletion.
Warning
You can delete credentials only after deleting the managed cluster they relate to.
Deleting a cluster automatically frees up the resources allocated for this cluster, for example, instances, load balancers, networks, floating IPs, and so on.
Deploy OpenStack¶
This section instructs you on how to deploy OpenStack on top of Kubernetes as well as how to troubleshoot the deployment and access your OpenStack environment after deployment.
Deploy an OpenStack cluster¶
This section instructs you on how to deploy OpenStack on top of Kubernetes
using the OpenStack Controller and openstackdeployments.lcm.mirantis.com
(OsDpl) CR.
To deploy an OpenStack cluster:
Verify that you have pre-configured the networking according to Networking.
Verify that the TLS certificates that will be required for the OpenStack cluster deployment have been pre-generated.
Note
The Transport Layer Security (TLS) protocol is mandatory on public endpoints.
Caution
To avoid certificates renewal with subsequent OpenStack updates during which additional services with new public endpoints may appear, we recommend using wildcard SSL certificates for public endpoints. For example,
*.it.just.works, whereit.just.worksis a cluster public domain.The sample code block below illustrates how to generate a self-signed certificate for the
it.just.worksdomain. The procedure presumes the cfssl and cfssljson tools are installed on the machine.mkdir cert && cd cert tee ca-config.json << EOF { "signing": { "default": { "expiry": "8760h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "8760h" } } } } EOF tee ca-csr.json << EOF { "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names":[{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] } EOF cfssl gencert -initca ca-csr.json | cfssljson -bare ca tee server-csr.json << EOF { "CN": "*.it.just.works", "hosts": [ "*.it.just.works" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "US", "L": "CA", "ST": "San Francisco" }] } EOF cfssl gencert -ca=ca.pem -ca-key=ca-key.pem --config=ca-config.json -profile=kubernetes server-csr.json | cfssljson -bare server
Create the
openstackdeployment.yamlfile that will include the OpenStack cluster deployment configuration. For the configuration details, refer to OpenStack configuration and API Reference.Note
The resource of kind
OpenStackDeployment(OsDpl) is a custom resource defined by a resource of kindCustomResourceDefinition. The resource is validated with the help of the OpenAPI v3 schema.Configure the OsDpl resource depending on the needs of your deployment. For the configuration details, refer to OpenStack configuration.
Note
If you plan to deploy the Telemetry service, you have to specify the Telemetry mode through
features:telemetry:modeas described in OpenStack configuration. Otherwise, Telemetry will fail to deploy.Example of an OpenStackDeployment CR of minimum configuration¶apiVersion: lcm.mirantis.com/v1alpha1 kind: OpenStackDeployment metadata: name: openstack-cluster namespace: openstack spec: openstack_version: victoria preset: compute size: tiny internal_domain_name: cluster.local public_domain_name: it.just.works features: neutron: tunnel_interface: ens3 external_networks: - physnet: physnet1 interface: veth-phy bridge: br-ex network_types: - flat vlan_ranges: null mtu: null floating_network: enabled: False nova: live_migration_interface: ens3 images: backend: local
If required, enable DPDK, huge pages, and other supported Telco features as described in Advanced OpenStack configuration (optional).
To the
openstackdeploymentobject, add information about the TLS certificates:ssl:public_endpoints:ca_cert- CA certificate content (ca.pem)ssl:public_endpoints:api_cert- server certificate content (server.pem)ssl:public_endpoints:api_key- server private key (server-key.pem)
Verify that the Load Balancer network does not overlap your corporate or internal Kubernetes networks, for example, Calico IP pools. Also, verify that the pool of Load Balancer network is big enough to provide IP addresses for all Amphora VMs (
loadbalancers).If required, reconfigure the Octavia network settings using the following sample structure:
spec: services: load-balancer: octavia: values: octavia: settings: lbmgmt_cidr: "10.255.0.0/16" lbmgmt_subnet_start: "10.255.1.0" lbmgmt_subnet_end: "10.255.255.254"
If you are using the default back end to store OpenStack database backups, which is Ceph, you may want to increase the default size of the allocated storage since there is no automatic way to resize the backup volume once the cloud is deployed.
For the default sizes and configuration details, refer to Size of a backup storage.
Trigger the OpenStack deployment:
kubectl apply -f openstackdeployment.yaml
Monitor the status of your OpenStack deployment:
kubectl -n openstack get pods kubectl -n openstack describe osdpl osh-dev
Assess the current status of the OpenStack deployment using the
statussection output in the OsDpl resource:Get the OsDpl YAML file:
kubectl -n openstack get osdpl osh-dev -o yaml
Analyze the
statusoutput using the detailed description in OpenStack configuration.
Verify that the OpenStack cluster has been deployed:
clinet_pod_name=$(kubectl -n openstack get pods -l application=keystone,component=client | grep keystone-client | head -1 | awk '{print $1}') kubectl -n openstack exec -it $clinet_pod_name -- openstack service list
Example of a positive system response:
+----------------------------------+---------------+----------------+ | ID | Name | Type | +----------------------------------+---------------+----------------+ | 159f5c7e59784179b589f933bf9fc6b0 | cinderv3 | volumev3 | | 6ad762f04eb64a31a9567c1c3e5a53b4 | keystone | identity | | 7e265e0f37e34971959ce2dd9eafb5dc | heat | orchestration | | 8bc263babe9944cdb51e3b5981a0096b | nova | compute | | 9571a49d1fdd4a9f9e33972751125f3f | placement | placement | | a3f9b25b7447436b85158946ca1c15e2 | neutron | network | | af20129d67a14cadbe8d33ebe4b147a8 | heat-cfn | cloudformation | | b00b5ad18c324ac9b1c83d7eb58c76f5 | radosgw-swift | object-store | | b28217da1116498fa70e5b8d1b1457e5 | cinderv2 | volumev2 | | e601c0749ce5425c8efb789278656dd4 | glance | image | +----------------------------------+---------------+----------------+
Register a record on the customer DNS:
Caution
The DNS component is mandatory to access OpenStack public endpoints.
Obtain the full list of endpoints:
kubectl -n openstack get ingress -ocustom-columns=NAME:.metadata.name,HOSTS:spec.rules[*].host | awk '/namespace-fqdn/ {print $2}'
Example of system response:
barbican.<spec:public_domain_name> cinder.<spec:public_domain_name> cloudformation.<spec:public_domain_name> designate.<spec:public_domain_name> glance.<spec:public_domain_name> heat.<spec:public_domain_name> horizon.<spec:public_domain_name> keystone.<spec:public_domain_name> metadata.<spec:public_domain_name> neutron.<spec:public_domain_name> nova.<spec:public_domain_name> novncproxy.<spec:public_domain_name> octavia.<spec:public_domain_name> placement.<spec:public_domain_name>
Obtain the public endpoint IP:
kubectl -n openstack get services ingress
In the system response, capture
EXTERNAL-IP.Example of system response:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ingress LoadBalancer 10.96.32.97 10.172.1.101 80:34234/TCP,443:34927/TCP,10246:33658/TCP 4h56m
Ask the customer to create records for public endpoints, obtained earlier in this procedure, to
EXTERNAL-IPfrom the Ingress service.
See also
Advanced OpenStack configuration (optional)¶
This section includes configuration information for available advanced Mirantis OpenStack for Kubernetes features that include DPDK with the Neutron OVS back end, huge pages, CPU pinning, and other Enhanced Platform Awareness (EPA) capabilities.
Enable LVM ephemeral storage¶
TechPreview
Note
Consider this section as part of Deploy an OpenStack cluster.
This section instructs you on how to configure LVM as back end for the VM disks and ephemeral storage.
You can use flexible size units throughout bare metal host profiles.
For example, you can now use either sizeGiB: 0.1 or size: 100Mi
when specifying a device size.
Mirantis recommends using only one parameter name type and units throughout
the configuration files. If both sizeGiB and size are used,
sizeGiB is ignored during deployment and the suffix is adjusted
accordingly. For example, 1.5Gi will be serialized as 1536Mi. The size
without units is counted in bytes. For example, size: 120 means 120 bytes.
Warning
All data will be wiped during cluster deployment on devices
defined directly or indirectly in the fileSystems list of
BareMetalHostProfile. For example:
A raw device partition with a file system on it
A device partition in a volume group with a logical volume that has a file system on it
An mdadm RAID device with a file system on it
An LVM RAID device with a file system on it
The wipe field is always considered true for these devices.
The false value is ignored.
Therefore, to prevent data loss, move the necessary data from these file systems to another server beforehand, if required.
Warning
Usage of more than one nonvolatile memory express (NVMe) drive per node may cause update issues and is therefore not supported.
To enable LVM ephemeral storage:
In
BareMetalHostProfilein thespec:volumeGroupssection, add the following configuration for the OpenStack compute nodes:spec: devices: - device: byName: /dev/nvme0n1 minSize: 30Gi wipe: true partitions: - name: lvm_nova_vol size: 0 wipe: true volumeGroups: - devices: - partition: lvm_nova_vol name: nova-vol logicalVolumes: - name: nova-fake vg: nova-vol size: 100Mi fileSystems: - fileSystem: ext4 logicalVolume: nova-fake mountPoint: /nova-fake
Note
Due to a limitation, it is not possible to create volume groups without logical volumes and formatted partitions. Therefore, set the
logicalVolumes:name,fileSystems:logicalVolume, andfileSystems:mountPointparameters tonova-fake.For details about
BareMetalHostProfile, see Mirantis Container Cloud Operations Guide: Create a custom bare metal host profile.Configure the
OpenStackDeploymentCR to deploy OpenStack with LVM ephemeral storage. For example:spec: features: nova: images: backend: lvm lvm: volume_group: "nova-vol"
Optional. Enable encryption for the LVM ephemeral storage by adding the following metadata in the
OpenStackDeploymentCR:spec: features: nova: images: encryption: enabled: true cipher: "aes-xts-plain64" key_size: 256
Caution
Both live and cold migrations are not supported for such instances.
Enable LVM block storage¶
TechPreview
Note
Consider this section as part of Deploy an OpenStack cluster.
This section instructs you on how to configure LVM as a back end for the OpenStack Block Storage service.
You can use flexible size units throughout bare metal host profiles.
For example, you can now use either sizeGiB: 0.1 or size: 100Mi
when specifying a device size.
Mirantis recommends using only one parameter name type and units throughout
the configuration files. If both sizeGiB and size are used,
sizeGiB is ignored during deployment and the suffix is adjusted
accordingly. For example, 1.5Gi will be serialized as 1536Mi. The size
without units is counted in bytes. For example, size: 120 means 120 bytes.
Warning
All data will be wiped during cluster deployment on devices
defined directly or indirectly in the fileSystems list of
BareMetalHostProfile. For example:
A raw device partition with a file system on it
A device partition in a volume group with a logical volume that has a file system on it
An mdadm RAID device with a file system on it
An LVM RAID device with a file system on it
The wipe field is always considered true for these devices.
The false value is ignored.
Therefore, to prevent data loss, move the necessary data from these file systems to another server beforehand, if required.
To enable LVM block storage:
Open
BareMetalHostProfilefor editing.In the
spec:volumeGroupssection, specify the following data for the OpenStack compute nodes. In the following example, we deploy a Cinder volume with LVM on compute nodes. However, you can use dedicated nodes for this purpose.spec: devices: - device: byName: /dev/nvme0n1 minSize: 30Gi wipe: true partitions: - name: lvm_cinder_vol size: 0 wipe: true volumeGroups: - devices: - partition: lvm_cinder_vol name: cinder-vol
Important
Since MOSK 23.1, the
open-iscsipackage does not install by default on bare metal hosts. Install it manually during cluster deployment inBareMetalHostProfilein thespec:postDeployScriptsection:spec: postDeployScript: | #!/bin/bash -ex apt-get update apt-get install --no-install-recommends -y open-iscsi echo $(date) 'post_deploy_script done' >> /root/post_deploy_done
For details about
BareMetalHostProfile, see Mirantis Container Cloud Operations Guide: Create a custom bare metal host profile.Configure the
OpenStackDeploymentCR to deploy OpenStack with LVM block storage. For example:spec: nodes: openstack-compute-node::enabled: features: cinder: volume: backends: lvm: lvm: volume_group: "cinder-vol"
Enable DPDK with OVS¶
TechPreview
Note
Consider this section as part of Deploy an OpenStack cluster.
This section instructs you on how to enable DPDK with the Neutron OVS back end.
To enable DPDK with OVS:
Verify that your deployment meets the following requirements:
The required drivers have been installed on the host operating system.
Different Poll Mode Driver (PMD) types may require different kernel drivers to properly work with NIC. For more information about the DPDK drivers, read DPDK official documentation: Linux Drivers and Overview of Networking Drivers.
The DPDK NICs are not used on the host operating system.
The huge pages feature is enabled on the host. See Enable huge pages for OpenStack for details.
Enable DPDK in the OsDpl custom resource through the
node specific overridessettings. For example:spec: nodes: <NODE-LABEL>::<NODE-LABEL-VALUE>: features: neutron: dpdk: bridges: - ip_address: 10.12.2.80/24 name: br-phy driver: igb_uio enabled: true nics: - bridge: br-phy name: nic01 pci_id: "0000:05:00.0" tunnel_interface: br-phy
Enable SR-IOV with OVS¶
Note
Consider this section as part of Deploy an OpenStack cluster.
This section instructs you on how to enable SR-IOV with the Neutron OVS back end.
To enable SR-IOV with OVS:
Verify that your deployment meets the following requirements:
NICs with the SR-IOV support are installed
SR-IOV and VT-d are enabled in BIOS
Enable IOMMU in the kernel by configuring
intel_iommu=onin the GRUB configuration file. Specify the parameter for compute nodes inBareMetalHostProfilein thegrubConfigsection:spec: grubConfig: defaultGrubOptions: - 'GRUB_CMDLINE_LINUX="$GRUB_CMDLINE_LINUX intel_iommu=on"'
Configure the
OpenStackDeploymentCR to deploy OpenStack with the VLAN tenant network encapsulation.Caution
To ensure correct appliance of the configuration changes, configure VLAN segmentation during the initial OpenStack deployment.
Configuration example:
spec: features: neutron: external_networks: - bridge: br-ex interface: pr-floating mtu: null network_types: - flat physnet: physnet1 vlan_ranges: null - bridge: br-tenant interface: bond0 network_types: - vlan physnet: tenant vlan_ranges: 490:499,1420:1459 tenant_network_types: - vlan
Enable SR-IOV in the
OpenStackDeploymentCR through the node-specific overrides settings. For example:spec: nodes: <NODE-LABEL>::<NODE-LABEL-VALUE>: features: neutron: sriov: enabled: true nics: - device: enp10s0f1 num_vfs: 7 physnet: tenant
Enable BGP VPN¶
TechPreview
Note
Consider this section as part of Deploy an OpenStack cluster.
The BGP VPN service is an extra OpenStack Neutron plugin that enables connection of OpenStack Virtual Private Networks with external VPN sites through either BGP/MPLS IP VPNs or E-VPN.
To enable the BGP VPN service:
Enable BGP VPN in the OsDpl custom resource through the
node specific overrides settings. For example:
spec:
features:
neutron:
bgpvpn:
enabled: true
route_reflector:
# Enable deploygin FRR route reflector
enabled: true
# Local AS number
as_number: 64512
# List of subnets we allow to connect to
# router reflector BGP
neighbor_subnets:
- 10.0.0.0/8
- 172.16.0.0/16
nodes:
openstack-compute-node::enabled:
features:
neutron:
bgpvpn:
enabled: true
When the service is enabled, a route reflector is scheduled on nodes with
the openstack-frrouting: enabled label. Mirantis recommends collocating
the route reflector nodes with the OpenStack controller nodes. By default, two
replicas are deployed.
Encrypt the east-west traffic¶
TechPreview
Note
Consider this section as part of Deploy an OpenStack cluster.
MOSK allows configuring Internet Protocol Security (IPSec) encryption for the east-west tenant traffic between the OpenStack compute nodes and gateways. The feature uses the strongSwan open source IPSec solution. Authentication is accomplished through a pre-shared key (PSK). However, other authentication methods are upcoming.
To encrypt the east-west tenant traffic, enable ipsec in the
spec:features:neutron settings of the OpenStackDeployment CR:
spec:
features:
neutron:
ipsec:
enabled: true
Caution
Enabling IPSec adds extra headers to the tenant traffic. The header size varies depending on IPSec configuration.
Therefore, Mirantis recommends decreasing network MTU for virtual networks and reserve 73 bytes overhead for the worst-case scenario as described in Cisco documentation: Configuring IPSec VPN Fragmentation and MTU.
Enable Cinder back end for Glance¶
TechPreview
Note
Consider this section as part of Deploy an OpenStack cluster.
This section instructs you on how to configure Cinder back end for the for images through the OpenStackDeployment CR.
Note
This feature depends heavily on Cinder multi-attach, which enables you to simultaneously attach volumes to multiple instances. Therefore, only the block storage back ends that support multi-attach can be used.
To configure a Cinder back end for Glance, define the back end identity in the OpenStackDeployment CR. This identity will be used as a name for the back end section in the Glance configuration file.
When defining the back end:
Configure one of the back ends as default.
Configure each back end to use specific Cinder volume type.
Note
You can use the
volume_typeparameter instead ofbackend_name. If so, you have to create this volume type beforehand and take into account that the bootstrap script does not manage such volume types.
The blockstore identity definition example:
spec:
features:
glance:
backends:
cinder:
blockstore:
default: true
backend_name: <volume_type:volume_name>
# e.g. backend_name: lvm:lvm_store
spec:
features:
glance:
backends:
cinder:
blockstore:
default: true
volume_type: netapp
Enable Cinder volume encryption¶
TechPreview
Note
Consider this section as part of Deploy an OpenStack cluster.
This section instructs you on how to enable Cinder volume encryption
through the OpenStackDeployment CR using Linux Unified Key Setup (LUKS)
and store the encryption keys in Barbican. For details, see
Volume encryption.
To enable Cinder volume encryption:
In the
OpenStackDeploymentCR, specify the LUKS volume type and configure the required encryption parameters for the storage system to encrypt or decrypt the volume.The
volume_typesdefinition example:spec: services: block-storage: cinder: values: bootstrap: volume_types: volumes-hdd-luks: arguments: encryption-cipher: aes-xts-plain64 encryption-control-location: front-end encryption-key-size: 256 encryption-provider: luks volume_backend_name: volumes-hdd
To create an encrypted volume as a non-admin user and store keys in the Barbican storage, assign the
creatorrole to the user since the default Barbican policy allows only theadminorcreatorrole:openstack role add --project <PROJECT-ID> --user <USER-ID> --creator <CREATOR-ID> creator
Optional. To define an encrypted volume as a default one, specify
volumes-hdd-luksindefault_volume_typein the Cinder configuration:spec: services: block-storage: cinder: values: conf: cinder: DEFAULT: default_volume_type: volumes-hdd-luks
Advanced configuration for OpenStack compute nodes¶
Note
Consider this section as part of Deploy an OpenStack cluster.
The section describes how to perform advanced configuration for the OpenStack compute nodes. Such configuration can be required in some specific use cases, such as DPDK, SR-IOV, or huge pages features usage.
This section contains recommendations for configuration of an
OpenStackDeployment custom resource for the compute nodes
of the following types:
Compute nodes with the default configuration, without local NVMe storage and SR-IOV network interface cards (NICs)
Compute nodes with the NVMe local storage
Compute nodes with the SR-IOV NICs
Compute nodes with both the NVMe local storage and SR-IOV NICs
Note
If the local NVMe storage is enabled, Mirantis recommends using it and enable SR-IOV if possible.
Caution
Before using the NVMe local storage and mount point, define them
in BareMetalHostProfile. For example:
apiVersion: metal3.io/v1alpha1
kind: BareMetalHostProfile
...
spec:
devices:
...
- device:
byName: /dev/nvme0n1
minSizeGiB: 30
wipe: true
partitions:
- name: local-volumes-partition
sizeGiB: 0
wipe: true
...
fileSystems:
...
- fileSystem: ext4
partition: local-volumes-partition
# mountpoint for Nova images
mountPoint: /var/lib/nova
Caution
To control the storage type (local NVMe or Ceph) for virtual machines, place a node into the OpenStack aggregate. For details, see OpenStack documentation: Host aggregates.
As defined in Node-specific configuration, each node with a non-default configuration
must be configured separately. Each Machine object must have a
configuration-specific label. For example, for a compute node with the local
NVMe storage:
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
...
spec:
providerSpec:
value:
nodeLabels:
- key: node-type
value: compute-nvme
Caution
The <NODE-LABEL> value must match one of the allowed labels
defined in the nodeLabels section of the Cluster object:
nodeLabels:
- key: <NODE-LABEL>
value: <NODE-LABEL-VALUE>
Mirantis recommends using node-type as the <NODE-LABEL> key. To view
the full list of allowed node labels:
kubectl \
-n <NAMESPACE> \
get <CLUSTER-NAME> \
-o json \
| jq .status.providerStatus.releaseRefs.current.allowedNodeLabels
The list of node labels is read-only and cannot be modified.
For compute nodes with the SR-IOV NIC, use compute-sriov as the
node-type value of nodeLabels:
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
...
spec:
providerSpec:
value:
nodeLabels:
- key: node-type
value: compute-sriov
For compute nodes with the local NVMe storage and SR-IOV NICs, use the
compute-nvme-sriov as the node-type value of nodeLabels:
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
...
spec:
providerSpec:
value:
nodeLabels:
- key: node-type
value: compute-nvme-sriov
In the examples above, compute-sriov, compute-nvme-sriov, and
compute-nvme are human-readable string identifiers. You can use any unique
string value for each type of compute node.
In the OpenStackDeployment object of each node group, define its own
section that starts with <NODE-LABEL>::<NODE-LABEL-VALUE>::
apiVersion: lcm.mirantis.com/v1alpha1
kind: OpenStackDeployment
...
spec:
...
nodes:
node-type::compute-nvme:
features:
nova:
images:
backend: local
node-type::compute-sriov:
features:
neutron:
sriov:
enabled: true
nics:
- device: enp10s0f1
num_vfs: 7
physnet: tenant
node-type::compute-nvme-sriov:
features:
nova:
images:
backend: local
neutron:
sriov:
enabled: true
nics:
- device: enp10s0f1
num_vfs: 7
physnet: tenant
Note
Consider this section as part of Deploy an OpenStack cluster.
Mirantis OpenStack for Kubernetes (MOSK) enables you to configure the
vCPU model for all instances managed by the OpenStack Compute service (Nova)
using the following osdpl definition:
spec:
features:
nova:
vcpu_type: host-model
For the supported values and configuration examples, see Virtual CPU.
Note
Consider this section as part of Deploy an OpenStack cluster.
Note
The instruction provided in this section applies to both OpenStack with OVS and OpenStack with Tungsten Fabric topologies.
The huge pages OpenStack feature provides essential performance improvements
for applications that are highly memory IO-bound. Huge pages should be enabled
on a per compute node basis. By default, NUMATopologyFilter is enabled.
To activate the feature, you need to enable huge pages on the dedicated bare metal host as described in Enable huge pages in a host profile during the predeployment bare metal configuration.
Note
The multi-size huge pages are not fully supported by Kubernetes versions before 1.19. Therefore, define only one size in kernel parameters.
TechPreview
Note
Consider this section as part of Deploy an OpenStack cluster.
CPU isolation is a way to force the system scheduler to use only some logical
CPU cores for processes. For compute hosts, you should typically isolate system
processes and virtual guests on different cores through the cpusets
mechanism in Linux kernel.
The Linux kernel and cpuset provide a mechanism to run tasks by limiting the
resources defined by a cpuset. The tasks can be moved from one cpuset to
another to use the resources defined in other cpusets. The cset Python tool
is a command-line interface to work with cpusets.
To configure CPU isolation using cpusets:
Configure core isolation:
Note
You can also automate this step during deployment by using the
postDeployscript as described in Create MOSK host profiles.cat <<-"EOF" > /usr/bin/setup-cgroups.sh #!/bin/bash set -x UNSHIELDED_CPUS=${UNSHIELDED_CPUS:-"0-3"} SHIELD_CPUS=${SHIELD_CPUS:-"4-15"} SHIELD_MODE=${SHIELD_MODE:-"cpuset"} # One of isolcpu or cpuset DOCKER_CPUS=${DOCKER_CPUS:-$UNSHIELDED_CPUS} KUBERNETES_CPUS=${KUBERNETES_CPUS:-$UNSHIELDED_CPUS} CSET_CMD=${CSET_CMD:-"python2 /usr/bin/cset"} if [[ ${SHIELD_MODE} == "cpuset" ]]; then ${CSET_CMD} set -c ${UNSHIELDED_CPUS} -s system ${CSET_CMD} proc -m -f root -t system ${CSET_CMD} proc -k -f root -t system fi ${CSET_CMD} set --cpu=${DOCKER_CPUS} --set=docker ${CSET_CMD} set --cpu=${KUBERNETES_CPUS} --set=kubepods ${CSET_CMD} set --cpu=${DOCKER_CPUS} --set=com.docker.ucp EOF chmod +x /usr/bin/setup-cgroups.sh cat <<-"EOF" > /etc/systemd/system/shield-cpus.service [Unit] Description=Shield CPUs DefaultDependencies=no After=systemd-udev-settle.service Before=lvm2-activation-early.service Wants=systemd-udev-settle.service [Service] ExecStart=/usr/bin/setup-cgroups.sh RemainAfterExit=true Type=oneshot Restart=on-failure #Service should restart on failure RestartSec=5s #Restart each five seconds until success [Install] WantedBy=basic.target EOF systemctl enable shield-cpus reboot
As root user, verify that isolation has been applied:
cset set -l
Example of system response:
cset: Name CPUs-X MEMs-X Tasks Subs Path ------------ ---------- - ------- - ----- ---- ---------- root 0-15 y 0 y 165 4 / kubepods 0-3 n 0 n 0 2 /kubepods docker 0-3 n 0 n 0 0 /docker system 0-3 n 0 n 65 0 /system com.docker.ucp 0-3 n 0 n 0 0 /com.docker.ucp
Run the
cpustresscontainer:docker run -it --name cpustress --rm containerstack/cpustress --cpu 4 --timeout 30s --metrics-brief
Verify that isolated cores are not affected:
htop
Example of system response highlighting the load created on all available Docker cores:

Note
Consider this section as part of Deploy an OpenStack cluster.
The majority of CPU topologies features are activated by NUMATopologyFilter
that is enabled by default. Such features do not require any further service
configuration and can be used directly on a vanilla MOSK
deployment. The list of the CPU topologies features includes, for example:
NUMA placement policies
CPU pinning policies
CPU thread pinning policies
CPU topologies
To enable libvirt CPU pinning through the node-specific overrides in the
OpenStackDeployment custom resource, use the following sample
configuration structure:
spec:
nodes:
<NODE-LABEL>::<NODE-LABEL-VALUE>:
services:
compute:
nova:
nova_compute:
values:
conf:
nova:
compute:
cpu_dedicated_set: 2-17
cpu_shared_set: 18-47
Note
Consider this section as part of Deploy an OpenStack cluster.
The Peripheral Component Interconnect (PCI) passthrough feature in OpenStack allows full access and direct control over physical PCI devices in guests. The mechanism applies to any kind of PCI devices including a Network Interface Card (NIC), Graphics Processing Unit (GPU), and any other device that can be attached to a PCI bus. The only requirement for the guest to properly use the device is to correctly install the driver.
To enable PCI passthrough in a MOSK deployment:
For Linux X86 compute nodes, verify that the following features are enabled on the host:
VT-d in BIOS
IOMMU on the host operating system as described in Enable SR-IOV with OVS.
Configure the
nova-apiservice that is scheduled on OpenStack controllers nodes. To generate the alias for PCI innova.conf, add the alias configuration through theOpenStackDeploymentCR.Note
When configuring PCI with SR-IOV on the same host, the values specified in
aliastake precedence. Therefore, add the SR-IOV devices topassthrough_whitelistexplicitly.For example:
spec: services: compute: nova: values: conf: nova: pci: alias: '{ "vendor_id":"8086", "product_id":"154d", "device_type":"type-PF", "name":"a1" }'
Configure the
nova-computeservice that is scheduled on OpenStack compute nodes. To enable Nova to pass PCI devices to virtual machines, configure thepassthrough_whitelistsection innova.confthrough the node-specific overrides in theOpenStackDeploymentCR. For example:spec: nodes: <NODE-LABEL>::<NODE-LABEL-VALUE>: services: compute: nova: nova_compute: values: conf: nova: pci: alias: '{ "vendor_id":"8086", "product_id":"154d", "device_type":"type-PF", "name":"a1" }' passthrough_whitelist: | [{"devname":"enp216s0f0","physical_network":"sriovnet0"}, { "vendor_id": "8086", "product_id": "154d" }]
Available since MOSK 23.1
MOSK enables you to configure initial oversubscription
through the OpenStackDeployment custom resource. For configuration details
and oversubscription considerations, refer to
Configuring initial resource oversubscription.
By default, the following values are applied:
8.0for the number of CPUs1.6for the disk space1.0for the amount of RAMNote
In MOSK 22.5 and earlier, the effective default value of RAM allocation ratio is
1.1.
Changing oversubscription configuration after deployment will only affect the newly added compute nodes and will not change oversubscription for already existing compute nodes. You can change oversubscription for existing compute nodes through the placement API as described in Change oversubscription settings for existing compute nodes.
Note
Consider this section as part of Deploy an OpenStack cluster.
Hyperconverged architecture combines OpenStack compute nodes along with Ceph nodes. To avoid nodes overloading, which can cause Ceph performance degradation and outage, limit the hardware resources consumption by the OpenStack compute services.
You can reserve hardware resources for non-workload related consumption using
the following nova-compute parameters. For details, see
OpenStack documentation: Overcommitting CPU and RAM
and OpenStack documentation: Configuration Options.
cpu_allocation_ratio- in case of a hyperconverged architecture, the value depends on the number of vCPU used for non-workload related operations, total number of vCPUs of a hyperconverged node, and on workload vCPU consumption:cpu_allocation_ratio = (${vCPU_count_on_a_hyperconverged_node} - ${vCPU_used_for_non_OpenStack_related_tasks}) / ${vCPU_count_on_a_hyperconverged_node} / ${workload_vCPU_utilization}To define the vCPU count used for non-OpenStack related tasks, use the following formula, considering the storage data plane performance tests:
vCPU_used_for_non-OpenStack_related_tasks = 2 * SSDs_per_hyperconverged_node + 1 * Ceph_OSDs_per_hyperconverged_node + 0.8 * Ceph_OSDs_per_hyperconverged_node
Consider the following example with 5 SSD disks for Ceph OSDs per hyperconverged node and 2 Ceph OSDs per disk:
vCPU_used_for_non-OpenStack_related_tasks = 2 * 5 + 1 * 10 + 0.8 * 10 = 28
In this case, if there are 40 vCPUs per hyperconverged node, 28 vCPUs are required for non-workload related calculations, and a workload consumes 50% of the allocated CPU time:
cpu_allocation_ratio = (40-28) / 40 / 0.5 = 0.6.
reserved_host_memory_mb- a dedicated variable in the OpenStack Nova configuration, to reserve memory for non-OpenStack related VM activities:reserved_host_memory_mb = 13 GB * Ceph_OSDs_per_hyperconverged_node
For example for 10 Ceph OSDs per hyperconverged node:
reserved_host_memory_mb = 13 GB * 10 = 130 GB = 133120
ram_allocation_ratio- the allocation ratio of virtual RAM to physical RAM. To completely exclude the possibility of memory overcommitting, set to1.
To limit HW resources for hyperconverged OpenStack compute nodes:
In the OpenStackDeployment CR, specify the cpu_allocation_ratio,
ram_allocation_ratio, and reserved_host_memory_mb parameters as
required using the calculations described above.
For example:
apiVersion: lcm.mirantis.com/v1alpha1
kind: OpenStackDeployment
spec:
services:
compute:
nova:
values:
conf:
nova:
DEFAULT:
cpu_allocation_ratio: 0.6
ram_allocation_ratio: 1
reserved_host_memory_mb: 133120
Note
For an existing OpenStack deployment:
Obtain the name of your
OpenStackDeploymentCR:kubectl -n openstack get osdpl
Open the
OpenStackDeploymentCR for editing and specify the parameters as required.kubectl -n openstack edit osdpl <osdpl name>
Available since MOSK 24.1 TechPreview
This section delves into virtual GPU configuration. It is specifically tailored for NVIDIA physical GPUs, with a focus on the A100 40GB GPU and NVIDIA AIE 4.1 drivers.
While setup procedures may vary among different cards and vendors, MOSK can generally ensure compatibility between the MOSK Compute service (Nova) and vGPU functionality, as long as the drivers for the physical GPU expose an VFIO mdev-compatible interface to the Linux host.
For configuration specifics of other physical GPUs, refer to the official documentation provided by the vendor.
Visit NVIDIA AI Enterprise documentation for comprehensive guidance on how to download the required drivers.
Also, if you have access to the NVIDIA NGC Catalog, search for the latest Infra Release that provides NVIDIA vGPU Host Driver there.
NVIDIA licensing
To fully utilize the capabilities of NVIDIA GPU virtualization, you may need to set up and configure the NVIDIA licensing server.
To install the acquired drivers within your cluster, add a custom
postDeployScript script to the custom BareMetalHostProfile object
used for the compute nodes with GPUs.
Note
For the instruction on how to create a custom host profile, refer to Mirantis Container Cloud: Create a custom host profile.
This script must solve the following tasks:
Download and install the drivers, if needed
Configure physical GPU according to your cluster requirements
Configure a startup task to reconfigure the physical GPU after node reboots.
Example postDeployScript script:
#!/bin/bash -ex
# Create a one time script that will initialize physical GPU right now and self-destruct
cat << EOF > /root/test_postdeploy_job.sh
#!/bin/bash -ex
systemctl enable initialize-vgpu
systemctl start --no-block initialize-vgpu
crontab -l | grep -v test_postdeploy_job.sh | crontab -
rm /root/test_postdeploy_job.sh
EOF
mkdir -p /var/spool/cron/crontabs/ && echo "*/1 * * * * sudo /root/test_postdeploy_job.sh >> /var/log/test_postdeploy_job.log 2>&1" >> /var/spool/cron/crontabs/root
chmod +x /root/test_postdeploy_job.sh
# Create a systemd unit that will re-initialize physical GPU on restart
cat << EOF > /etc/systemd/system/initialize-vgpu.service
[Unit]
Description=Configure VGPU
After=systemd-modules-load.service
[Service]
Type=oneshot
ExecStart=/root/initialize_vgpu.sh
RemainAfterExit=true
StandardOutput=journal
[Install]
RequiredBy=multi-user.target
EOF
cat << EOF > /root/initialize_vgpu.sh
#!/bin/bash
set -ex
while ! docker inspect ucp-kubelet;
do echo "Waiting lcm-agent is finished.";
sleep 1;
done
# Download and install the driver, dependencies and tools
if [[ ! -f /root/nvidia-vgpu-ubuntu-aie-535_535.129.03_amd64.deb ]]; then
apt update
apt install -y dkms unzip gcc libc-dev make linux-headers-$(uname -r) pciutils lshw mdevctl
wget https://my.intra.net//root/gpu-driver-x-y-z.deb -O /root/gpu-driver-x-y-z.deb
apt install /root/gpu-driver-x-y-z.deb
systemctl enable initialize-vgpu
fi
systemctl restart nvidia-vgpud.service
# Enable SR-IOV mode for the pGPU
/usr/lib/nvidia/sriov-manage -e <PCI-ADDRESS-OF-NVIDIA-CARD>
# Enable MIG mode for pGPU
nvidia-smi -i 0 -mig 1
systemctl enable nvidia-vgpu-mgr.service
systemctl start nvidia-vgpu-mgr.service
EOF
chmod +x /root/initialize_vgpu.sh
Virtual GPU types are similar to compute flavors as they determine the resources allocated to each virtual GPU. This allows for efficient allocation and optimization of GPU resources in virtualized environments.
Each physical GPU has a maximum number of virtual GPUs of a specific type that can be created on it, with no possibility for overallocation. In the time-sliced vGPU configuration, each particular physical GPU can only instantiate vGPUs of the same selected type. In the Multi-Instance GPU (MIG), a single physical GPU may be partitioned into several differently sized virtual GPUs.
Either way, prior to accepting workloads, Mirantis recommends determining the virtual GPU types that each of your physical GPU will provide. Altering these settings afterward necessitates terminating every virtual machine currently running on the physical GPU intended for reconfiguration or repurposing for another virtual GPU type.
This section outlines the process for partitioning physical GPUs into Multi-Instance GPUs (MIG) using the nvidia-smi tool provided by the NVIDIA Host GPU driver.
To list available virtual GPU instance profiles:
nvidia-smi mig -lgip
Example system response:
+-----------------------------------------------------------------------------+
| GPU instance profiles: |
| GPU Name ID Instances Memory P2P SM DEC ENC |
| Free/Total GiB CE JPEG OFA |
|=============================================================================|
| 0 MIG 1g.5gb 19 7/7 4.75 No 14 0 0 |
| 1 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 1g.5gb+me 20 1/1 4.75 No 14 1 0 |
| 1 1 1 |
+-----------------------------------------------------------------------------+
| 0 MIG 1g.10gb 15 4/4 9.75 No 14 1 0 |
| 1 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 2g.10gb 14 3/3 9.75 No 28 1 0 |
| 2 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 3g.20gb 9 2/2 19.62 No 42 2 0 |
| 3 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 4g.20gb 5 1/1 19.62 No 56 2 0 |
| 4 0 0 |
+-----------------------------------------------------------------------------+
| 0 MIG 7g.40gb 0 1/1 39.50 No 98 5 0 |
| 7 1 1 |
+-----------------------------------------------------------------------------+
To create seven, which is a maximum possible amount of instances according to the system response above, MIG vGPUs of the smallest size:
nvidia-smi mig -cgi 19,19,19,19,19,19,19
To create three differently sized vGPUs of 4g.20gb, 2g.10gb, and
1g.5gb sizes:
nvidia-smi mig -cgi 5,14,19
Caution
Keep in mind that not all combinations of differently sized vGPU instances are supported. Additionally, the order in which you create vGPUs is important.
For example configurations, see NVIDIA documentation.
To correctly configure the MOSK Compute service, you need to correlate the following naming schemes related to virtual GPU types:
The GPU instance profile as reported by nvidia-smi mig. For example,
MIG 1g.5gb.The vGPU type as reported by the driver. For example,
GRID A100-1-5C.The mdev class that corresponds to the vGPU type. For example,
nvidia-474.
For the compatibility between GPU instance profiles and virtual GPU types, refer to NVIDIA documentation: Virtual GPU Types for Supported GPUs.
To determine the mdev class supported by a specific virtual GPU type listed by a PCI device address, verify the output of the mdevctl types command executed on the compute node that has a physical GPU available on it:
mdevctl types
Example system response for MIGs:
0000:42:00.4
nvidia-1053
Available instances: 0
Device API: vfio-pci
Name: GRID A100-1-10C
Description: num_heads=1, frl_config=60, framebuffer=10240M, max_resolution=4096x2400, max_instance=4
...
nvidia-474
Available instances: 1
Device API: vfio-pci
Name: GRID A100-1-5C
Description: num_heads=1, frl_config=60, framebuffer=5120M, max_resolution=4096x2400, max_instance=7
...
The Name field from the example system output above corresponds to the
supported virtual GPU type, linking the GPU instance profile with the mdev class
supported by your physical GPU.
In the example above, the MIG 1g.5gb GPU instance profile corresponds
to the GRID A100-1-5C vGPU type as per NVIDIA documentation, and according
to the mdevctl types` output, it corresponds to the nvidia-474
mdev class.
Note
Notice that Available instances is zero for vGPU types that are
not actually supported by this given card and configuration. For MIGs,
the Available instances will be non-zero only for the virtual GPU types
for which the MIG virtual GPU instances have already been created. See
Partition to Multi-Instance GPUs.
The parameters you need to define for the nova-compute service on each
compute node with physical GPUs you want to expose as virtual GPUs include:
[devices]enabled_mdev_typesRequired. List of the mdev classes, see the previous step for details.
[devices]cleanup_mdev_devicesOptional. By default, the Compute service does not delete created mdev devices but reuses them instead. While this speeds up processes, it may pose challenges when reconfiguring the
enabled_mdev_typesparameter. Setcleanup_mdev_devicestoTruefor the Compute service to auto-delete created mdev devices upon instance deletion.
If you plan to use only time-sliced vGPUs and provide a single virtal GPU type
across the entire cloud, you only need to configure the options mentioned
above once globally for all compute nodes through the spec.services section
of the OpenStackDeployment custom resource.
With the configuration below, the Compute service will auto-detect all PCI
devices that provide this mdev type and automatically create required resource
providers in the placement service with the resource class VGPU.
Example configuration for the nvidia-474 mdev type:
kind: OpenStackDeployment
spec:
services:
compute:
nova:
values:
conf:
nova:
devices:
enabled_mdev_types: nvidia-474
cleanup_mdev_devices: true
If you plan to provide multiple time-sliced vGPU types, simplify the
configuration by grouping the nodes based on a node label (not necessarily
aggregates). Ensure that each group exposes only one mdev type using the
Node-specific configuration settings. Additionally, use custom resource classes to
facilitate flavor creation, ensuring consistent use of the CUSTOM_ prefix
for custom mdev_class.
For example, if you want to provide the nvidia-474 and nvidia-475 mdev
types, label your nodes with the vgpu-type=nvidia-474 and
vgpu-type=nvidia-475 labels and use the following node-specific settings:
kind: OpenStackDeployment
spec:
nodes:
vgpu-type::nvidia-474:
services:
compute:
nova:
nova_compute:
values:
conf:
nova:
devices:
enabled_mdev_types: nvidia-474
cleanup_mdev_devices: true
mdev_nvidia-474:
mdev_class: CUSTOM_VGPU_A100_1_5C
vgpu-type::nvidia-475:
services:
compute:
nova:
nova_compute:
values:
conf:
nova:
devices:
enabled_mdev_types: nvidia-475
cleanup_mdev_devices: true
mdev_nvidia-475:
mdev_class: CUSTOM_VGPU_A100_2_10C
The configuration above creates corresponding resource providers in the
placement service that provide CUSTOM_VGPU_A100_1_5C or
CUSTOM_VGPU_A100_2_10C resources.
You can use these resources during the definition of flavors for instances
with corresponding vGPU types.
In some cases, you may need to provide different vGPU types from a single compute node, for example, if the compute node has 2 physical GPUs and you want to create two different types of vGPU on them. For such scenarios, you should provide explicit PCI device addresses of these physical GPUs in the settings. This makes such configuration verbose in heterogeneous hardware environments where physical GPUs have different PCI addresses on each node. For example, when targeting node-specific settings by node name:
kind: OpenStackDeployment
spec:
nodes:
kubernetes.io/hostname::kaas-node-7af9aab1-596d-4ba3-a717-846653aa441a:
services:
compute:
nova:
nova_compute:
values:
conf:
nova:
devices:
enabled_mdev_types: nvidia-474,nvidia-475
cleanup_mdev_devices: true
mdev_nvidia-474:
device_addresses: 0000:42:00.0
mdev_class: CUSTOM_VGPU_A100_1_5C
mdev_nvidia-475:
device_addresses: 0000:43:00.0
mdev_class: CUSTOM_VGPU_A100_2_10C
In the SR-IOV mode, the driver typically creates more virtual functions than the maximum capacity of the physical GPU, even for the smallest virtual GPU type. Each virtual function can hold only one single virtual GPU. This leads to resource over-reporting to the placement service.
Therefore, to ensure efficient resource allocation and utilization within a homogeneous hardware environment, assuming that each compute node in it has the same PCI address for the physical GPU and the physical GPU has been partitioned to the MIG GPU instances identically:
Identify the number of instances created of each MIG profile.
Select random but not overlapping sets of PCI addresses from the list of virtual functions of the physical GPU. The amount of addresses in each set must correspond to the number of instances created of each MIG profile.
Assign the mdev type to the selected devices.
For example, for the environment with the following configuration:
3 MIG instances of
MIG 1.5gband 2 MIG instances ofMIG 2.10gb16 virtual functions created for the physical GPU with the PCI address range from
0000:42:00.0to0000:42:01.7
Pick 3 and 2 random PCI addresses from that pool and assign them to
CUSTOM_VGPU_A100_1_5C and CUSTOM_VGPU_A100_2_10C mdev classes
respectively:
spec:
services:
compute:
nova:
values:
conf:
nova:
devices:
enabled_mdev_types: nvidia-474,nvidia-475
cleanup_mdev_devices: true
mdev_nvidia-474:
device_addresses: 0000:42:00.0,0000:42:00.1,0000:42:00.2
mdev_class: CUSTOM_VGPU_A100_1_5C
mdev_nvidia-475:
device_addresses: 0000:42:01.0,0000:42:01.1
mdev_class: CUSTOM_VGPU_A100_2_10C
In a heterogeneous hardware environment, use node-specific settings to group nodes with the same PCI addresses and intended vGPU configuration, or use explicit setting for each node targeting node-specific settings to every node, sequentially if needed.
This section provides guidelines for verifying that virtual GPUs are correctly accounted for in the OpenStack Placement service, ensuring proper scheduling of instances that utilize virtual GPUs.
Firstly, verify that resource providers have been created with accurate
inventories. For each PCI device associated with a virtual GPU, including
virtual instances in the case of MIG/SR-IOV, there should be a nested resource
provider under the resource provider of the corresponding compute node.
The name of this nested resource provider should follow the format
<node-name>_pci_<pci-address-with-underscores>:
openstack resource provider list --resource CUSTOM_VGPU_A100_1_5C=1 -f yaml
Example system response:
- generation: 1
name: kaas-node-9d18b7c8-7ea8-4b13-abe9-0e76ee8db596.kaas-kubernetes-294cbb1cbf084789b931ebc54d3f9b05_pci_0000_42_00_4
parent_provider_uuid: c922488b-69eb-42a8-afad-dc7d3d56b8fd
root_provider_uuid: c922488b-69eb-42a8-afad-dc7d3d56b8fd
uuid: 963bb3ce-3ed1-421f-a186-a808c3460c48
...
Also, examine the inventory of each resource provider. It should exclusively
consist of the VGPU resource or any custom resource name configured in
the Compute service settings. The total capacity of the resource should match
the capacity reported by the mdevctl types output, reflecting the
capabilities of the PCI device for the specified mdev class. In the case
of MIG, this total capacity will always be 1.
openstack resource provider inventory list 963bb3ce-3ed1-421f-a186-a808c3460c48 -f yaml
Example system response:
- allocation_ratio: 1.0
max_unit: 1
min_unit: 1
reserved: 0
resource_class: CUSTOM_VGPU_A100_1_5C
step_size: 1
total: 1
used: 0
This section provides instructions for creating a flavor that requests a specific virtual GPU resource, using the mdev classes configured in the Compute service and registered in the placement service.
To create the flavor, use the openstack flavor create command.
Ensure that the flavor properties match the configured mdev classes in the
Compute service. For example, to request one vGPU of type nvidia-474 using
the resource class from the previous examples:
openstack flavor create --ram 1024 --vcpus 2 --disk 5 --property resources:CUSTOM_VGPU_A100_1_5C=1
Replace the --property resources:CUSTOM_VGPU_A100_1_5C=1 parameter with the
appropriate property matching the desired virtual GPU type and quantity.
Once the flavor is created, you can start launching instances using the created flavor as usual.
Enable image signature verification¶
TechPreview
Note
Consider this section as part of Deploy an OpenStack cluster.
Mirantis OpenStack for Kubernetes (MOSK) enables you to perform image signature verification when booting an OpenStack instance, uploading a Glance image with signature metadata fields set, and creating a volume from an image.
To enable signature verification, use the following osdpl definition:
spec:
features:
glance:
signature:
enabled: true
When enabled during initial deployment, all internal images such as Amphora, Ironic, and test (CirrOS, Fedora, Ubuntu) images, will be signed by a self-signed certificate.
Enable Telemetry services¶
TechPreview
The Telemetry services monitor OpenStack components, collect and store the telemetry data from them, and perform responsive actions upon this data.
To enable the Telemetry service:
Specify the following definition in the OpenStackDeployment
custom resource (CR):
kind: OpenStackDeployment
spec:
features:
services:
- alarming
- metering
- metric
telemetry:
mode: autoscaling
See also
Configure LoadBalancer for PowerDNS¶
Note
Consider this section as part of Deploy an OpenStack cluster.
Mirantis OpenStack for Kubernetes (MOSK) allows configuring
LoadBalancer for the Designate PowerDNS back end. For example, you can expose a
TCP port for zone transferring using the following exemplary osdpl
definition:
spec:
designate:
backend:
external_ip: 10.172.1.101
protocol: udp
type: powerdns
For the supported values, see LoadBalancer type for PowerDNS.
Access OpenStack after deployment¶
This section contains the guidelines on how to access your MOSK OpenStack environment.
Configure DNS to access OpenStack¶
DNS is a mandatory component for MOSK deployment, all records must be created on the customer DNS server. The OpenStack services are exposed through the Ingress NGINX controller.
Warning
This document describes how to temporarily configure DNS. The workflow contains non-permanent changes that will be rolled back during a managed cluster update or reconciliation loop. Therefore, proceed at your own risk.
To configure DNS to access your OpenStack environment:
Obtain the external IP address of the Ingress service:
kubectl -n openstack get services ingress
Example of system response:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ingress LoadBalancer 10.96.32.97 10.172.1.101 80:34234/TCP,443:34927/TCP,10246:33658/TCP 4h56m
Select from the following options:
If you have a corporate DNS server, update your corporate DNS service and create appropriate DNS records for all OpenStack public endpoints.
To obtain the full list of public endpoints:
kubectl -n openstack get ingress -ocustom-columns=NAME:.metadata.name,HOSTS:spec.rules[*].host | awk '/namespace-fqdn/ {print $2}'
Example of system response:
barbican.it.just.works cinder.it.just.works cloudformation.it.just.works designate.it.just.works glance.it.just.works heat.it.just.works horizon.it.just.works keystone.it.just.works neutron.it.just.works nova.it.just.works novncproxy.it.just.works octavia.it.just.works placement.it.just.works
If you do not have a corporate DNS server, perform one of the following steps:
Add the appropriate records to
/etc/hostslocally. For example:10.172.1.101 barbican.it.just.works 10.172.1.101 cinder.it.just.works 10.172.1.101 cloudformation.it.just.works 10.172.1.101 designate.it.just.works 10.172.1.101 glance.it.just.works 10.172.1.101 heat.it.just.works 10.172.1.101 horizon.it.just.works 10.172.1.101 keystone.it.just.works 10.172.1.101 neutron.it.just.works 10.172.1.101 nova.it.just.works 10.172.1.101 novncproxy.it.just.works 10.172.1.101 octavia.it.just.works 10.172.1.101 placement.it.just.works
Deploy your DNS server on top of Kubernetes:
Deploy a standalone CoreDNS server by including the following configuration into
coredns.yaml:apiVersion: lcm.mirantis.com/v1alpha1 kind: HelmBundle metadata: name: coredns namespace: osh-system spec: repositories: - name: hub_stable url: https://charts.helm.sh/stable releases: - name: coredns chart: hub_stable/coredns version: 1.8.1 namespace: coredns values: image: repository: mirantis.azurecr.io/openstack/extra/coredns tag: "1.6.9" isClusterService: false servers: - zones: - zone: . scheme: dns:// use_tcp: false port: 53 plugins: - name: cache parameters: 30 - name: errors # Serves a /health endpoint on :8080, required for livenessProbe - name: health # Serves a /ready endpoint on :8181, required for readinessProbe - name: ready # Required to query kubernetes API for data - name: kubernetes parameters: cluster.local - name: loadbalance parameters: round_robin # Serves a /metrics endpoint on :9153, required for serviceMonitor - name: prometheus parameters: 0.0.0.0:9153 - name: forward parameters: . /etc/resolv.conf - name: file parameters: /etc/coredns/it.just.works.db it.just.works serviceType: LoadBalancer zoneFiles: - filename: it.just.works.db domain: it.just.works contents: | it.just.works. IN SOA sns.dns.icann.org. noc.dns.icann.org. 2015082541 7200 3600 1209600 3600 it.just.works. IN NS b.iana-servers.net. it.just.works. IN NS a.iana-servers.net. it.just.works. IN A 1.2.3.4 *.it.just.works. IN A 1.2.3.4
Update the public IP address of the Ingress service:
sed -i 's/1.2.3.4/10.172.1.101/' coredns.yaml kubectl apply -f coredns.yaml
Verify that the DNS resolution works properly:
Assign an external IP to the service:
kubectl -n coredns patch service coredns-coredns --type='json' -p='[{"op": "replace", "path": "/spec/ports", "value": [{"name": "udp-53", "port": 53, "protocol": "UDP", "targetPort": 53}]}]' kubectl -n coredns patch service coredns-coredns --type='json' -p='[{"op": "replace", "path": "/spec/type", "value":"LoadBalancer"}]'
Obtain the external IP address of CoreDNS:
kubectl -n coredns get service coredns-coredns
Example of system response:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE coredns-coredns ClusterIP 10.96.178.21 10.172.1.102 53/UDP,53/TCP 25h
Point your machine to use the correct DNS. It is
10.172.1.102in the example system response above.If you plan to launch Tempest tests or use the OpenStack client from a
keystone-client-XXXpod, verify that the Kubernetes built-in DNS service is configured to resolve your public FQDN records by adding your public domain toCorefile. For example, to add theit.just.worksdomain:kubectl -n kube-system get configmap coredns -oyaml
Example of system response:
apiVersion: v1 data: Corefile: | .:53 { errors health ready kubernetes cluster.local in-addr.arpa ip6.arpa { pods insecure fallthrough in-addr.arpa ip6.arpa } prometheus :9153 forward . /etc/resolv.conf cache 30 loop reload loadbalance } it.just.works:53 { errors cache 30 forward . 10.96.178.21 }
Access your OpenStack environment¶
This section explains how to access your OpenStack environment as admin user.
Before you proceed, make sure that you can access the Kubernetes API and have
privileges to read secrets from the openstack-external namespace in
Kubernetes or you are able to exec to the pods in the openstack
namespace.
You can use the built-in admin CLI client and execute the openstack
commands from a dedicated pod deployed in the openstack namespace:
kubectl -n openstack exec \
$(kubectl -n openstack get pod -l application=keystone,component=client -ojsonpath='{.items[*].metadata.name}') \
-ti -- bash
This pod has python-openstackclient and all required plugins already
installed. The python-openstackclient command-line client is configured
to use the admin user credentials. You can view the detailed configuration
for the openstack command in /etc/openstack/clouds.yaml file in
the pod.
Configure the external DNS resolution for OpenStack services as described in Configure DNS to access OpenStack.
Obtain the admin user credentials from the
openstack-identity-credentialssecret in theopenstack-externalnamespace:kubectl -n openstack-external get secrets openstack-identity-credentials -o jsonpath='{.data.clouds\.yaml}' | base64 -d
Example of a system response:
clouds: admin: auth: auth_url: https://keystone.it.just.works/ password: <ADMIN_PWD> project_domain_name: <ADMIN_PROJECT_DOMAIN> project_name: <ADMIN_PROJECT> user_domain_name: <ADMIN_USER_DOMAIN> username: <ADMIN_USER_NAME> endpoint_type: public identity_api_version: 3 interface: public region_name: CustomRegion admin-system: auth: auth_url: https://keystone.it.just.works/ password: <ADMIN_PWD> system_scope: all user_domain_name: <ADMIN_USER_DOMAIN> username: <ADMIN_USER_NAME> endpoint_type: public identity_api_version: 3 interface: public region_name: CustomRegion
Access Horizon through your browser using its public service. For example,
https://horizon.it.just.works.To log in, specify the user name and domain name obtained in previous step from the
<ADMIN_USER_NAME>and<ADMIN_USER_DOMAIN>values.If the OpenStack Identity service has been deployed with the OpenID Connect integration:
From the Authenticate using drop-down menu, select OpenID Connect.
Click Connect. You will be redirected to your identity provider to proceed with the authentication.
Note
If OpenStack has been deployed with self-signed TLS certificates for public endpoints, you may get a warning about an untrusted certificate. To proceed, allow the connection.
To be able to access your OpenStack environment through the CLI,
you need to configure the openstack client environment
using either an openstackrc environment file or clouds.yaml file.
Log in to Horizon as described in Access an OpenStack environment through Horizon.
Download the
openstackrcfile from the web UI.On any shell from which you want to run OpenStack commands, source the environment file for the respective project.
Obtain
clouds.yaml:mkdir -p ~/.config/openstack kubectl -n openstack-external get secrets openstack-identity-credentials -o jsonpath='{.data.clouds\.yaml}' | base64 -d > ~/.config/openstack/clouds.yaml
The OpenStack client looks for
clouds.yamlin the following locations: current directory,~/.config/openstack, and/etc/openstack.Export the
OS_CLOUDenvironment variable:export OS_CLOUD=admin
Now, you can use the openstack CLI as usual. For example:
openstack user list
Example of an expected system response:
+----------------------------------+-----------------+
| ID | Name |
+----------------------------------+-----------------+
| dc23d2d5ee3a4b8fae322e1299f7b3e6 | internal_cinder |
| 8d11133d6ef54349bd014681e2b56c7b | admin |
+----------------------------------+-----------------+
Note
If OpenStack was deployed with self-signed TLS certificates for public endpoints, you may need to use the openstack command-line client with certificate validation disabled. For example:
openstack --insecure user list
Troubleshoot an OpenStack deployment¶
This section provides the general debugging instructions for your OpenStack on Kubernetes deployment. Start your troubleshooting with the determination of the failing component that can include the OpenStack Operator, Helm, a particular pod or service.
Note
For Kubernetes cluster debugging and troubleshooting, refer to Kubernetes official documentation: Troubleshoot clusters and Docker Enterprise v3.0 documentation: Monitor and troubleshoot.
Debugging the Helm releases¶
Note
MOSK uses direct communication with Helm 3.
Log in to the
openstack-controllerpod, where the Helm v3 client is installed, or download the Helm v3 binary locally:kubectl -n osh-system get pods |grep openstack-controller
Example of a system response:
openstack-controller-5c6947c996-vlrmv 5/5 Running 0 10m openstack-controller-admission-f946dc8d6-6bgn2 1/1 Running 0 4h3m
Verify the Helm releases statuses:
helm3 --namespace openstack list --all
Example of a system response:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION etcd openstack 4 2021-07-09 11:06:25.377538008 +0000 UTC deployed etcd-0.1.0-mcp-2735 ingress-openstack openstack 4 2021-07-09 11:06:24.892822083 +0000 UTC deployed ingress-0.1.0-mcp-2735 openstack-barbican openstack 4 2021-07-09 11:06:25.733684392 +0000 UTC deployed barbican-0.1.0-mcp-3890 openstack-ceph-rgw openstack 4 2021-07-09 11:06:25.045759981 +0000 UTC deployed ceph-rgw-0.1.0-mcp-2735 openstack-cinder openstack 4 2021-07-09 11:06:42.702963544 +0000 UTC deployed cinder-0.1.0-mcp-3890 openstack-designate openstack 4 2021-07-09 11:06:24.400555027 +0000 UTC deployed designate-0.1.0-mcp-3890 openstack-glance openstack 4 2021-07-09 11:06:25.5916904 +0000 UTC deployed glance-0.1.0-mcp-3890 openstack-heat openstack 4 2021-07-09 11:06:25.3998706 +0000 UTC deployed heat-0.1.0-mcp-3890 openstack-horizon openstack 4 2021-07-09 11:06:23.27538297 +0000 UTC deployed horizon-0.1.0-mcp-3890 openstack-iscsi openstack 4 2021-07-09 11:06:37.891858343 +0000 UTC deployed iscsi-0.1.0-mcp-2735 v1.0.0 openstack-keystone openstack 4 2021-07-09 11:06:24.878052272 +0000 UTC deployed keystone-0.1.0-mcp-3890 openstack-libvirt openstack 4 2021-07-09 11:06:38.185312907 +0000 UTC deployed libvirt-0.1.0-mcp-2735 openstack-mariadb openstack 4 2021-07-09 11:06:24.912817378 +0000 UTC deployed mariadb-0.1.0-mcp-2735 openstack-memcached openstack 4 2021-07-09 11:06:24.852840635 +0000 UTC deployed memcached-0.1.0-mcp-2735 openstack-neutron openstack 4 2021-07-09 11:06:58.96398517 +0000 UTC deployed neutron-0.1.0-mcp-3890 openstack-neutron-rabbitmq openstack 4 2021-07-09 11:06:51.454918432 +0000 UTC deployed rabbitmq-0.1.0-mcp-2735 openstack-nova openstack 4 2021-07-09 11:06:44.277976646 +0000 UTC deployed nova-0.1.0-mcp-3890 openstack-octavia openstack 4 2021-07-09 11:06:24.775069513 +0000 UTC deployed octavia-0.1.0-mcp-3890 openstack-openvswitch openstack 4 2021-07-09 11:06:55.271711021 +0000 UTC deployed openvswitch-0.1.0-mcp-2735 openstack-placement openstack 4 2021-07-09 11:06:21.954550107 +0000 UTC deployed placement-0.1.0-mcp-3890 openstack-rabbitmq openstack 4 2021-07-09 11:06:25.431404853 +0000 UTC deployed rabbitmq-0.1.0-mcp-2735 openstack-tempest openstack 2 2021-07-09 11:06:21.330801212 +0000 UTC deployed tempest-0.1.0-mcp-3890
If a Helm release is not in the
DEPLOYEDstate, obtain the details from the output of the following command:helm3 --namespace openstack history <release-name>
To verify the status of a Helm release:
helm3 --namespace openstack status <release-name>
Example of a system response:
NAME: openstack-memcached
LAST DEPLOYED: Fri Jul 9 11:06:24 2021
NAMESPACE: openstack
STATUS: deployed
REVISION: 4
TEST SUITE: None
Debugging the OpenStack Controller¶
The OpenStack Controller is running in several containers in the
openstack-controller-xxxx pod in the osh-system namespace.
For the full list of containers and their roles, refer to
OpenStack Controller.
To verify the status of the OpenStack Controller, run:
kubectl -n osh-system get pods
Example of a system response:
NAME READY STATUS RESTARTS AGE
openstack-controller-5c6947c996-vlrmv 5/5 Running 0 17m
openstack-controller-admission-f946dc8d6-6bgn2 1/1 Running 0 4h9m
openstack-operator-ensure-resources-5ls8k 0/1 Completed 0 4h12m
To verify the logs for the osdpl container, run:
kubectl -n osh-system logs -f <openstack-controller-xxxx> -c osdpl
Debugging the OsDpl CR¶
This section includes the ways to mitigate the most common issues with the OsDpl CR. We assume that you have already debugged the Helm releases and OpenStack Controllers to rule out possible failures with these components as described in Debugging the Helm releases and Debugging the OpenStack Controller.
osdpl has DEPLOYED=false¶Possible root cause: One or more Helm releases have not been deployed successfully.
To determine if you are affected:
Verify the status of the osdpl object:
kubectl -n openstack get osdpl osh-dev
Example of a system response:
NAME AGE DEPLOYED DRAFT
osh-dev 22h false false
To debug the issue:
Identify the failed release by assessing the
status:childrensection in the OsDpl resource:Get the OsDpl YAML file:
kubectl -n openstack get osdpl osh-dev -o yaml
Analyze the
statusoutput using the detailed description in OpenStackDeploymentStatus custom resource.
For further debugging, refer to Debugging the Helm releases.
Init¶Possible root cause: MOSK uses the Kubernetes entrypoint
init container to resolve dependencies between objects. If the pod is stuck
in Init:0/X, this pod may be waiting for its dependencies.
To debug the issue:
Verify the missing dependencies:
kubectl -n openstack logs -f placement-api-84669d79b5-49drw -c init
Example of a system response:
Entrypoint WARNING: 2020/04/21 11:52:50 entrypoint.go:72: Resolving dependency Job placement-ks-user in namespace openstack failed: Job Job placement-ks-user in namespace openstack is not completed yet .
Entrypoint WARNING: 2020/04/21 11:52:52 entrypoint.go:72: Resolving dependency Job placement-ks-endpoints in namespace openstack failed: Job Job placement-ks-endpoints in namespace openstack is not completed yet .
Possible root cause: some OpenStack services depend on Ceph. These services
include OpenStack Image, OpenStack Compute, and OpenStack Block Storage.
If the Helm releases for these services are not present, the
openstack-ceph-keys secret may be missing in the openstack-ceph-shared
namespace.
To debug the issue:
Verify that the Ceph Controller has created the openstack-ceph-keys
secret in the openstack-ceph-shared namespace:
kubectl -n openstack-ceph-shared get secrets openstack-ceph-keys
Example of a positive system response:
NAME TYPE DATA AGE
openstack-ceph-keys Opaque 7 23h
If the secret is not present, create one manually.
Support dump¶
TechPreview
Support dump described in this section specifically targets OpenStack components, providing valuable insights for troubleshooting OpenStack-related problems.
To generate a support dump for your MOSK environment,
use the osctl sos report tool present within
the openstack-controller image.
This section focuses only on the essential capabilities of the tool. For all available parameters, consult osctl sos report --help.
The support dump is modular. Each module is responsible for specific
functionality. To enable or disable specific modules during support
dump creation, use the --collector option. If not specified,
all collectors are used.
Collector |
Description |
|---|---|
|
Collects logs from StackLight by connecting to the OpenSearch API. |
|
Collects data about objects from Kubernetes. |
|
Collects metadata associated with the Compute service (OpenStack Nova) from the OpenStack nodes. This encompasses a wide range of data, including instance details, general libvirt information, and so on. |
|
Collects metadata associated with the Networking service (OpenStack Neutron) from the OpenStack nodes. This encompasses a wide range of data, including Open vSwitch statistics, list of namespaces, IP address statistics in namespaces, Open vSwitch flows, and so on. |
Given the substantial amount of information, you can manage the components
included in a support dump using the mutually exclusive --component
or --all-components options. Within the elastic collector component,
you can specify which loggers to gather logs for. For example,
the --component nova option restricts log collection to pods related
to Nova, which names start with nova-* and libvirt-*.
Another filtering criterion involves specifying the host for which you intend
to collect support information. This can be accomplished through the use of
mutually exclusive --host or --all-hosts options. This feature is
particularly valuable for limiting the volume of data included in
the support dump.
Support dump works in the following modes:
reportGeneric report is created, no specific information such as resource UUID is included. The tool collects as much information as possible.
traceProvides more sophisticated filtering criteria rather than the
reportmode. For example, you can search for specific message patterns in OpenSearch.
Since MOSK 23.2, you can execute the osctl sos
commands directly in the openstack-controller pod. For example:
kubectl -n osh-system exec -it deployment/openstack-controller bash
osctl sos --since 1d \
--all-hosts \
--component neutron \
--collector elastic \
--workspace /tmp/ report
To get trace for a specific resource UUID in Neutron for a specific host, use the following command as an example:
kubectl -n osh-system exec -it deployment/openstack-controller bash
osctl sos --since 1d \
--host kaas-node-fe0734de-20e8-4493-9f7d-52c4f8a8a98c \
--component neutron \
--workspace /workspace/ \
--collector elastic trace --message ".4a055675-89b0-45c2-a3b3-a10dffa07f31."
For older MOSK versions, to start generating support dumps, execute the osctl sos commands from a manually started Docker container on any node of your cluster. For example, to create a generic report for the Neutron component:
docker run -v /home/ubuntu/sosreport/:/workspace -v /root/.kube/config:/root/.kube/config -it mirantis.azurecr.io/openstack/openstack-controller:0.13.11 bash
osctl sos --since 1d \
--elastic-url http://172.16.37.11:9200 \
--all-hosts \
--component neutron \
--collector elastic \
--workspace /workspace/ report
Note
172.16.37.11 is the IP address of the opensearch-master
StackLight service. To obtain it, run:
kubectl -n stacklight get svc opensearch-master -o jsonpath='{.spec.clusterIP}')
Deploy Tungsten Fabric¶
This section describes how to deploy Tungsten Fabric as a back end for networking for your MOSK environment.
Caution
Before you proceed with the Tungsten Fabric deployment, read through Tungsten Fabric known limitations.
Tungsten Fabric deployment prerequisites¶
Before you proceed with the actual Tungsten Fabric (TF) deployment, verify that your deployment meets the following prerequisites:
Your MOSK OpenStack cluster is deployed as described in Deploy an OpenStack cluster with the Tungsten Fabric back end enabled for Neutron using the following structure:
spec: features: neutron: backend: tungstenfabric
Your MOSK OpenStack cluster uses the correct value of
features:neutron:tunnel_interfacein theopenstackdeploymentobject. The TF Operator will consume this value through the shared secret and use it as a network interface from the underlay network to create encapsulated tunnels with the tenant networks.Considerations for
tunnel_interfacePlan this interface as a dedicated physical interface for TF overlay networks. TF uses
features:neutron:tunnel_interfaceto create thevhost0virtual interface and transfers the IP configuration from thetunnel_interfaceto the virtual one.Do not use
bridgesfrom L2 templates astunnel_interface. Such usage might lead to networking performance degradation and data plane downtime.
The Kubernetes nodes are labeled according to the TF node roles:
Tungsten Fabric (TF) node roles¶ Node role
Description
Kubernetes labels
Minimal count
TF control plane
Hosts the TF control plane services such as
database,messaging,api,svc,config.tfconfig=enabledtfcontrol=enabledtfwebui=enabledtfconfigdb=enabled3
TF analytics
Hosts the TF analytics services.
tfanalytics=enabledtfanalyticsdb=enabled3
TF vRouter
Hosts the TF vRouter module and vRouter Agent.
tfvrouter=enabledVaries
TF vRouter DPDK Technical Preview
Hosts the TF vRouter Agent in DPDK mode.
tfvrouter-dpdk=enabledVaries
Note
TF supports only Kubernetes OpenStack workloads. Therefore, you should label OpenStack compute nodes with the
tfvrouter=enabledlabel.Note
Do not specify the
openstack-gateway=enabledandopenvswitch=enabledlabels for the OpenStack deployments with TF as a networking back end.
Deploy Tungsten Fabric¶
Deployment of Tungsten Fabric (TF) is managed by the
tungstenfabric-operator Helm resource in a respective MOS
ClusterRelease.
To deploy TF:
Optional. Configure the ASN and encapsulation settings if you need custom values for these parameters. For configuration details, see Autonomous System Number (ASN).
Verify that you have completed all prerequisite steps as described in Tungsten Fabric deployment prerequisites.
Create the
tungstenfabric.yamlfile with the TF resource configuration. For example:apiVersion: operator.tf.mirantis.com/v1alpha1 kind: TFOperator metadata: name: openstack-tf namespace: tf spec: settings: orchestrator: openstack
If you do not specify
tfVersion, MOSK deploys TF 2011.Note
The TF 21.4 version is available for deployment as technical preview only.
Configure the
TFOperatorcustom resource according to the needs of your deployment. For the configuration details, refer to TFOperator custom resource and API Reference.Trigger the TF deployment:
kubectl apply -f tungstenfabric.yaml
Verify that TF has been successfully deployed:
kubectl get pods -n tf
The successfully deployed TF services should appear in the
Runningstatus in the system response.If you have enabled StackLight, enable Tungsten Fabric monitoring by setting
tungstenFabricMonitoring.enabledtotrueas described in StackLight configuration procedure.Since MOSK 23.1,
tungstenFabricMonitoring.enabledis enabled by default during the TF deployment. Therefore, skip this step.
Advanced Tungsten Fabric configuration (optional)¶
This section includes configuration information for available advanced Mirantis OpenStack for Kubernetes features that include SR-IOV and DPDK with the Neutron Tungsten Fabric back end.
Enable huge pages for OpenStack with Tungsten Fabric¶
Note
The instruction provided in this section applies to both OpenStack with OVS and OpenStack with Tungsten Fabric topologies.
The huge pages OpenStack feature provides essential performance improvements
for applications that are highly memory IO-bound. Huge pages should be enabled
on a per compute node basis. By default, NUMATopologyFilter is enabled.
To activate the feature, you need to enable huge pages on the dedicated bare metal host as described in Enable huge pages in a host profile during the predeployment bare metal configuration.
Note
The multi-size huge pages are not fully supported by Kubernetes versions before 1.19. Therefore, define only one size in kernel parameters.
Enable DPDK for Tungsten Fabric¶
TechPreview
This section describes how to enable DPDK mode for the Tungsten Fabric (TF) vRouter.
To enable DPDK for TF, follow one of the procedures below depending on the API version used:
Install the
vfio-pci(recommended) oruio_pci_genericdriver on the host operating system. For more information about drivers, see Linux Drivers.An example of the
DPDK_UIO_DRIVERconfiguration:spec: tf-vrouter: agent-dpdk: enabled: true containers: - name: dpdk env: - name: DPDK_UIO_DRIVER value: vfio-pci
Verify that DPDK NICs are not used on the host operating system.
Note
For use in the Linux user space, DPDK NICs will be bound to specific Linux drivers, required by PMDs. In such a way, bounded NICs are not available for usage by standard Linux network utilities. Therefore, allocate a dedicated NIC(s) for the vRouter deployment in DPDK mode.
Enable huge pages on the host as described in Enable huge pages in a host profile.
Mark the hosts for deployment with DPDK with the
tfvrouter-dpdk=enabledlabel.Open the TF Operator custom resource for editing:
kubectl -n tf edit tfoperators.operator.tf.mirantis.com openstack-tf
Enable DPDK:
spec: controllers: tf-vrouter: agent-dpdk: enabled: true
Install the
vfio-pci(recommended) oruio_pci_genericdriver on the host operating system. For more information about drivers, see Linux Drivers.An example of the
DPDK_UIO_DRIVERconfiguration:spec: services: vRouter: agentDPDK: enabled: true envSettings: dpdk: - name: DPDK_UIO_DRIVER value: vfio-pci
Open the TF Operator custom resource for editing:
kubectl -n tf edit tfoperators.tf.mirantis.com openstack-tf
Enable DPDK:
spec: services: vRouter: agentDPDK: enabled: true
Enable SR-IOV for Tungsten Fabric¶
This section instructs you on how to enable SR-IOV with the Neutron Tungsten Fabric (TF) back end.
To enable SR-IOV for TF:
Verify that your deployment meets the following requirements:
NICs with the SR-IOV support are installed
SR-IOV and VT-d are enabled in BIOS
Enable IOMMU in the kernel by configuring
intel_iommu=onin the GRUB configuration file. Specify the parameter for compute nodes inBareMetalHostProfilein thegrubConfigsection:spec: grubConfig: defaultGrubOptions: - 'GRUB_CMDLINE_LINUX="$GRUB_CMDLINE_LINUX intel_iommu=on"'
Enable SR-IOV in the
OpenStackDeploymentCR through the node-specific overrides settings. For example:spec: nodes: <NODE-LABEL>::<NODE-LABEL-VALUE>: features: neutron: sriov: enabled: true nics: - device: enp10s0f1 num_vfs: 7 physnet: tenant
Warning
After the
OpenStackDeploymentCR modification, the TF Operator generates a separate vRouter DaemonSet with specified settings. Thetf-vrouter-agent-<XXXXX>pods will be automatically restarted on the affected nodes causing the network services interruption on virtual machines running on these hosts.Optional. To modify a vRouter DaemonSet according to the SR-IOV definition in the
OpenStackDevelopmentCR, add vRouter custom specs to the TF Operator CR with the node label specified in theOpenStackDeploymentCR. For example:spec: controllers: tf-vrouter: agent: customSpecs: - name: sriov label: name: <NODE-LABEL> value: <NODE-LABEL-VALUE> containers: - name: agent env: - name: <VROUTER-GATEWAY> value: <VROUTER-GATEWAY-IP>
spec: nodes: sriov: labels: name: <NODE-LABEL> value: <NODE-LABEL-VALUE> nodeVRouter: enabled: true envSettings: agent: - name: VROUTER_GATEWAY value: <VROUTER-GATEWAY-IP>
Configure multiple Contrail API workers¶
TechPreview
Tungsten Fabric MOSK deployments use six workers of the
contrail-api service by default. This section instructs you on how to
change the default configuration if needed.
To configure the number of Contrail API workers on a TF deployment:
Specify the required number of workers in the
TFOperatorcustom resource:spec: controllers: tf-config: api: containers: - env: - name: CONFIG_API_WORKER_COUNT value: "7" name: api
spec: features: config: configApiWorkerCount: 7
Wait until all
tf-config-*pods are restarted.Verify the number of workers inside the running API container:
kubectl -n tf exec -ti tf-config-rclzq -c api -- ps aux --width 500 kubectl -n tf exec -ti tf-config-rclzq -c api -- ls /etc/contrail/
Verify that the ps output lists one API process with PID
"1"and the number of workers set in theTFOperatorcustom resource.In
/etc/contrail/, verify that the number of configuration filescontrail-api-X.confmatches the number of workers set in theTFOperatorcustom resource.
Disable Tungsten Fabric analytics services¶
Available since MOSK 23.3 TechPreview
By default, analytics services are part of basic setups for Tungsten Fabric deployments. To obtain a more lightweight setup, you can disable these services through the custom resource of the Tungsten Fabric Operator.
Warning
Disabling of the Tungsten Fabric analytics services requires
restart of the data plane services for existing environments and must be
planned in advance. While calculating the maintenance window for this
operation, take into account the deletion of the analytics DaemonSets
and automatic restart of the tf-config, tf-control, and
tf-webui pods.
To disable Tungsten Fabric analytics services:
Open the
TFOperatorcustom resource for editing:kubectl -n tf edit tfoperators.operator.tf.mirantis.com openstack-tf
kubectl -n tf edit tfoperators.tf.mirantis.com openstack-tf
Disable Tungsten Fabric analytics services in the
TFOperatorcustom resource:spec: settings: disableTFAnalytics: true
spec: services: analytics: enabled: false
Clean up the Kubernetes resources. To free up the space that has been used by Cassandra, ZooKeeper, and Kafka analytics storage, manually delete the related PVC:
kubectl -n tf delete pvc -l app=cassandracluster,cassandracluster=tf-cassandra-analytics kubectl -n tf delete pvc -l app=tf-zookeeper-nal kubectl -n tf delete pvc -l app=tf-kafka
Remove the
tfanalytics=enabledandtfanalyticsdb=enabledlabels from nodes, as they are not required by the Tungsten Fabric Operator anymore.Manually restart the vRouter pods:
Note
To avoid network disruption, restart the vRouter pods in chunks.
kubectl -n tf get pod -l app=tf-vrouter-agent kubectl -n tf delete pod <POD_NAME>
Delete terminated nodes from the Tungsten Fabric configuration through the Tungsten Fabric web UI:
Caution
With disabled Tungsten Fabric analytics, the Tungsten Fabric web UI may not work properly.
Log in to the Tungsten Fabric web UI.
On Configure > Infrastructure > Nodes > Analytics Nodes, delete all terminated analytics nodes.
On Configure > Infrastructure > Nodes > Database Analytics Nodes, delete all terminated database analytics nodes.
Since MOSK 24.1, disable monitoring of the Tungsten Fabric analytics services in StackLight by setting the following parameter in StackLight values of the
Clusterobject tofalse:tungstenFabricMonitoring: analyticsEnabled: false
When done, the monitoring of the Tungsten Fabric analytics components will become disabled and Kafka alerts along with the Kafka dashboard will disappear from StackLight.
Now, with the Tungsten Fabric analytics services successfully disabled, you have optimized resource utilization and system performance. While these services are deactivated, related alerts may still be present in StackLight. However, do not consider such alerts as indicative of the actual status of the analytics services.
Access the Tungsten Fabric web UI¶
The Tungsten Fabric (TF) web UI allows for easy and fast TF resources
configuration, monitoring, and debugging. You can access
the TF web UI through either the Ingress service or the Kubernetes Service
directly. TLS termination for the https protocol is performed through the
Ingress service.
Note
Mirantis OpenStack for Kubernetes provides the TF web UI as is and does not include this service in the support Service Level Agreement.
To access the TF web UI through Ingress:
Log in to a local machine where kubectl is installed.
Obtain and export
kubeconfigof your managed cluster as described in Mirantis Container Cloud Operations Guide: Connect to a Container Cloud managed cluster.Obtain the password of the Admin user:
kubectl -n openstack get secret keystone-keystone-admin -ojsonpath='{.data.OS_PASSWORD}' | base64 -d
Obtain the external IP address of the Ingress service:
kubectl -n openstack get services ingress
Example of system response:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ingress LoadBalancer 10.96.32.97 10.172.1.101 80:34234/TCP,443:34927/TCP,10246:33658/TCP 4h56m
Note
Do not use the
EXTERNAL-IPvalue to directly access the TF web UI. Instead, use the FQDN from the list below.Obtain the FQDN of
tf-webui:Note
The command below outputs all host names assigned to the TF web UI service. Use one of them.
kubectl -n tf get ingress tf-webui -o custom-columns=HOSTS:.spec.rules[*].host
Configure DNS to access the TF web UI host as described in Configure DNS to access OpenStack.
Use your favorite browser to access the TF web UI at
https://<FQDN-WEBUI>.
Troubleshoot the Tungsten Fabric deployment¶
This section provides the general debugging instructions for your Tungsten Fabric (TF) on Kubernetes deployment.
Enable debug logs for the Tungsten Fabric services¶
To enable debug logging for the Tungsten Fabric (TF) services:
Open the TF custom resource for modification:
kubectl -n tf edit tfoperators.operator.tf.mirantis.com openstack-tf
Specify the
LOG_LEVELvariable with theSYS_DEBUGvalue for the required TF service. For example, for theconfig-apiservice:spec: controllers: tf-config: api: containers: - name: api env: - name: LOG_LEVEL value: SYS_DEBUG
Warning
After the TF custom resource modification, the pods
related to the affected services will be restarted. This rule does not
apply to the tf-vrouter-agent-<XXXXX> pods as their update strategy
differs. Therefore, if you enable the debug logging for the services in
a tf-vrouter-agent-<XXXXX> pod, restart this pod manually after you
modify the custom resource.
Troubleshoot access to the Tungsten Fabric web UI¶
If you cannot access the Tungsten Fabric (TF) web UI service, verify that the FQDN of the TF web UI is resolvable on your PC by running one of the following commands:
host tf-webui.it.just.works
# or
ping tf-webui.it.just.works
# or
dig host tf-webui.it.just.works
All commands above should resolve the web UI domain name to the IP address
that should match the EXTERNAL-IPs subnet dedicated to Kubernetes.
If the TF web UI domain name has not been resolved to the IP address, your PC
is using a different DNS or the DNS does not contain the record for the TF web
UI service. To resolve the issue, define the IP address of the Ingress service
from the openstack namespace of Kubernetes in the hosts file of your
machine. To obtain the Ingress IP address:
kubectl -n openstack get svc ingress -o custom-columns=HOSTS:.status.loadBalancer.ingress[*].ip
If the web UI domain name is resolvable but you still cannot access the service, verify the connectivity to the cluster.
Disable TX offloading on NICs used by vRouter¶
In the following cases, a TCP-based service may not work on VMs:
If the setup has nested VMs.
If VMs are running in the ESXi hypervisor.
If the Network Interface Cards (NICs) do not support the IP checksum calculation and generate an incorrect checksum. For example, the Broadcom Corporation NetXtreme BCM5719 Gigabit Ethernet PCIe NIC cards.
To resolve the issue, disable the transmit (TX) offloading on all OpenStack compute nodes for the affected NIC used by the vRouter as described below.
To identify the issue:
Verify whether ping is working between VMs on different hypervisor hosts and the TCP services are working.
Run the following command for the vRouter Agent and verify whether the output includes the number of
Checksum errors:kubectl -n tf exec tf-vrouter-agent-XXXXX -c agent -- dropstats
Run the following command and verify if the output includes the
cksum incorrectentries:kubectl -n tf exec tf-vrouter-agent-XXXXX -c agent -- tcpdump -i <tunnel interface> -v -nn | grep -i incorrect
Example of system response:
tcpdump: listening on <tunnel interface>, link-type EN10MB (Ethernet), capture size 262144 bytes <src ip.port> > <dst ip.port>: Flags [S.], cksum 0x43bf (incorrect -> 0xb8dc), \ seq 1901889431, ack 1081063811, win 28960, options [mss 1420,sackOK,\ TS val 456361578 ecr 41455995,nop,wscale 7], length 0 <src ip.port> > <dst ip.port>: Flags [S.], cksum 0x43bf (incorrect -> 0xb8dc), \ seq 1901889183, ack 1081063811, win 28960, options [mss 1420,sackOK,\ TS val 456361826 ecr 41455995,nop,wscale 7], length 0 <src ip.port> > <dst ip.port>: Flags [S.], cksum 0x43bf (incorrect -> 0xb8dc), \ seq 1901888933, ack 1081063811, win 28960, options [mss 1420,sackOK,\ TS val 456362076 ecr 41455995,nop,wscale 7], length 0
Run the following command for the vRouter Agent container and verify whether the output includes the information about a drop for an unknown reason:
kubectl -n tf exec tf-vrouter-agent-XXXXX -c agent -- flow -l
To disable the TX offloading on NICs used by vRouter:
Open the
TFOperatorcustom resource (CR) for editing:kubectl -n tf edit tfoperators.operator.tf.mirantis.com openstack-tf
Specify the
DISABLE_TX_OFFLOADvariable with the"YES"value for the vRouter Agent container:spec: controllers: tf-vrouter: agent: containers: - name: agent env: - name: DISABLE_TX_OFFLOAD value: "YES"
Warning
Once you modify the
TFOperatorCR, thetf-vrouter-agent-<XXXXX>pods will not restart automatically because they use the OnDelete update strategy. Restart such pods manually, considering that the vRouter pods restart causes network services interruption for the VMs hosted on the affected nodes.To disable TX offloading on a specific subset of nodes, use custom vRouter settings. For details, see Custom vRouter settings.
Warning
Once you add a new
CustomSpec, a new daemon set will be generated and thetf-vrouter-agent-<XXXXX>pods will be automatically restarted. The vRouter pods restart causes network services interruption for VMs hosted on the affected node. Therefore, plan this procedure accordingly.
Operations Guide¶
This guide outlines the post-deployment Day-2 operations for a Mirantis OpenStack for Kubernetes environment. It describes how to configure and manage the MOSK components, perform different types of cloud verification, and enable additional features depending on your cloud needs. The guide also contains day-to-day maintenance procedures such as how to back up and restore, update and upgrade, or troubleshoot your MOSK cluster.
Update a MOSK cluster to a major release version¶
This section describes the workflow you as a cloud operator need to follow to correctly update your Mirantis OpenStack for Kubernetes (MOSK) cluster to a major release version.
The provided guidelines are generic and apply to any MOSK cluster regardless of its configuration specifics. However, every target major release may have its own update peculiarities. Therefore, to accurately plan and successfully perform a specific update, in addition to the procedure below, read the update-related section in the Release Notes of the target MOSK version.
Depending on the payload of a target release, the update mechanism can perform the changes on different levels of the stack, from the configuration of the host operating system to the code of OpenStack itself. The update mechanism is designed to avoid the impact on the workloads and cloud users as much as possible. The life-cycle management logic minimizes the downtime for the cloud API by means of smart management of the cluster components under the hood and only requests your involvement when a human decision is required to proceed.
Though the update mechanism may change the internal components of the cluster, it will always preserve the major versions of OpenStack, that is, the APIs that cloud users and workloads deal with. After the cluster is successfully updated, you can initiate a dedicated upgrade procedure to obtain the latest supported versions of OpenStack.
See also
Before you begin¶
Before updating, we recommend that you closely peruse the Release Compatibility Matrix document and Release notes of the target release, as well as thoroughly plan a maintenance window for each update phase depending on the configurational specifics of your cluster.
Read the release notes¶
Read carefully Release Compatibility Matrix and Release Notes of the target MOSK version paying particular attention to the following:
Current Mirantis Container Cloud software version and the need to first update to the latest cluster release version
Update notes provided in the Release notes for the target MOSK version
New product features that will get enabled in your cloud by default
New product features that may have already been configured in your cloud as customizations and now need to be properly re-enabled to be eligible for further support
Any changes in the behavior of the product features enabled in your cloud
List of the addressed and known issues in the target MOSK version
Warning
If your cloud configuration is known to have any custom configuration that was not explicitly approved by Mirantis, make sure to bring this up with your dedicated Mirantis representative before proceeding with the update. Mirantis cannot guarantee the safe updating of a customized cloud.
Plan the cluster update¶
Depending on the payload brought by a particular target release, a generic cluster update includes from three to six major phases.
The first three phases are present in any update. They focus on the containerized components of the software stack and have minimal impact on the cloud users and workloads.
The remaining phases are only present if any changes need to be made to the foundation layers: the underlay Kubernetes cluster and host operating system. For the changes to take effect, you may need to reboot the cluster nodes. This procedure imposes a severe impact on cloud workloads and, therefore, needs to be thoroughly planned across several sequential maintenance windows.
Important
To effectively plan a cluster update, keep in mind the architecture of your specific cloud. Depending on the selected design, the components of a MOSK cluster may have different distribution across the nodes (physical servers) comprising the underlay bare metal Kubernetes cluster. The more components are collocated on a single node, the harder is the impact on the functions of the cloud when the changes are applied.
The tables below will help you to plan your cluster update and include the following information for each mandatory and additional update phase:
- What happens during the phase
Includes the phase milestones. This content is important for understanding the impact.
- Impact
Describes any possible impact on cloud users and workloads.
The impact estimate represents the worst-case scenario in the architectures that imply a combination of several cluster roles on the same physical nodes, such as hyper-converged compute nodes and clusters with the compact control plane. Also, the impact estimation presumes that your cluster uses one of the standard architectures provided by the product and follows Mirantis design guidelines.
Several update phases will occur simultaneously, resulting in a greater cumulative impact, but a shorter completion time.
- Time to complete
Provides a rough estimation of the time required to complete the phase.
The estimates for a phase timeline presume that your cluster uses one of the standard architectures provided by the product and follows Mirantis design guidelines.
Warning
During the update, prevent users from performing write operations on the cloud resources. Any intensive manipulations may lead to workload corruption.
Phase 1: Life-cycle management modules update
Important
This phase is mandatory. It is always present in the update flow regardless of the contents of the target release.
What happens during the phase |
New versions of OpenStack, Tungsten Fabric, and Ceph controllers downloaded and installed. OpenStack and Tungsten Fabric images precached. |
|---|---|
Impact |
None |
Time to complete |
Depending on the quality of the Internet connectivity, up to 45 minutes. |
Phase 2: OpenStack and Tungsten Fabric components update
Important
This phase is mandatory. It is always present in the update flow regardless of the contents of the target release.
What happens during the phase |
New versions of OpenStack and Tungsten Fabric container images downloaded, services restarted sequentially. |
|---|---|
Impact |
|
Time to complete |
|
Phase 3: Ceph cluster update and upgrade
Important
This phase is mandatory. It is always present in the update flow regardless of the contents of the target release.
What happens during the phase |
New versions of Ceph components downloaded, services restarted. If applicable, Ceph switched to the latest major version. |
|---|---|
Impact |
None |
Time to complete |
The update of a Ceph cluster with 30 storage nodes can take up to 35 minutes. Additionally, 15 minutes are required for the major Ceph version upgrade, if any. |
Phase 4a: Host operating system update on Kubernetes master nodes
Important
This phase is optional. The presense of this phase in the update flow depends on the contents of the target release.
What happens during the phase |
New system packages downloaded and installed on the host operating system, other major changes get applied. |
|---|---|
Impact |
None |
Time to complete |
The nodes are updated sequentially. Up to 15 minutes per node. |
Phase 4b: Kubernetes components update on Kubernetes master nodes
Important
This phase is optional. The presense of this phase in the update flow depends on the contents of the target release.
What happens during the phase |
New versions of Kubernetes control plane components downloaded and installed. |
|---|---|
Impact |
For the compact control plane, approximately 8% of the running cloud operations may fail over the course of the phase due to minor unavailability of the cloud API. For the compact control plane with collocated gateway nodes (Open vSwitch), minor loss of the North-South connectivity:
|
Time to complete |
Up to 40 minutes total |
Phases 5a and 5b: Host operating system and Kubernetes cluster
update on Kubernetes worker nodes
Important
This phase is optional. The presense of this phase in the update flow depends on the contents of the target release.
Important
Both phases, 5a and 5b, are applied together, either node by node (default) or to several nodes in parallel. The parallel updating is available since 23.1.
Take this into consideration when estimating the impact and planning the maintenance window.
What happens during the phase |
During the host operating system update:
During the Kubernetes cluster update:
|
|---|---|
Impact |
|
Time to complete |
By default, the nodes are updated sequentially as follows:
For MOSK 23.1 to 23.2 and newer updates, you can reduce update time by enabling parallel node update. The procedure is described further in the Enable parallel update of Kubernetes worker nodes subsection. |
Phase 6: Cluster nodes reboot
Important
This phase is optional. The presense of this phase in the update flow depends on the contents of the target release.
Important
An update to a newer MOSK version may require reboot of the cluster nodes for changes to take effect. Although, you can decide when to restart each particular node, an update process can not be considered complete until all of the nodes get handled.
To determine whether the reboot is required, consult the Step 4. Reboot the nodes with optional instance migration section.
What happens during the phase |
|
|---|---|
Impact |
|
Time to complete |
|
Step 1. Verify that the Container Cloud management cluster is up-to-date¶
MOSK relies on Mirantis Container Cloud to manage the underlying software stack for a cluster, as well as to deliver updates for all the components.
Since every MOSK release is tightly coupled with a Container Cloud release, a MOSK cluster update becomes possible once the management cluster is known to run the latest Container Cloud version. The management cluster periodically verifies public Mirantis repositories and updates itself automatically when a newer version becomes available. Having any of the managed clusters, including MOSK, running outdated Container Cloud version will prevent the management cluster from automatic self-update.
To identify the current version of the Container Cloud software your management cluster is running, refer to the Container Cloud web UI.
Step 2. Initiate MOSK cluster update¶
Silence alerts¶
During an update of a MOSK cluster, numerous alerts may be seen in StackLight. This is expected behavior. Therefore, ignore or temporarily mute the alerts as described in Container Cloud Operations Guide: Silence alerts.
Verify Ceph configuration¶
If you update MOSK to 23.1, verify that the
KaaSCephCluster custom resource does not contain the following entries.
If they exist, remove them.
In the
spec.cephClusterSpecsection, theexternalsection.In the
spec.cephClusterSpec.rookConfigsection, thems_crc_dataorms crc dataconfiguration key. After you remove the key, wait forrook-ceph-monpods to restart on the MOSK cluster.
Enable parallel update of Kubernetes worker nodes¶
Optional. Starting from MOSK 23.1 to 23.2 update, you can enable and configure parallel node update to reduce update time and minimize downtime:
To enable parallel update of Kubernetes worker nodes, set the
spec.providerSpec.value.maxWorkerUpgradeCountconfiguration parameter in the Mirantis Container Cloud management cluster as described in Container Cloud Operations Guide: Configure the parallel update of worker nodes.Consider the specifics of handling of parallel node updates by OpenStack, Ceph, and Tungsten Fabric Controllers to properly plan the maintenance window. For handling details and possible configuration, refer to Parallelizing node update operations.
Trigger the update¶
Log in to the Container Cloud web UI with the
m:kaas:namespace@operatororm:kaas:namespace@writerpermissions.Switch to the required project using the Switch Project action icon located on top of the main left-side navigation panel.
In the Clusters tab, find the managed MOSK cluster.
Click the More action icon to see whether a new release is available. If that is the case, click Update cluster.
In the Release Update window, select the required Cluster release to update your managed cluster to.
The Description section contains the list of components versions to be installed with a new Cluster release.
Click Update.
Before the cluster update starts, Container Cloud performs a backup of MKE and Docker Swarm. The backup directory is located under:
/srv/backup/swarmon every Container Cloud node for Docker Swarm/srv/backup/ucpon one of the controller nodes for MKE
To view the update status, verify the cluster status on the Clusters page. Once the orange blinking dot near the cluster name disappears, the update is complete.
Step 3. Watch the cluster update¶
Watch the update process through the web UI¶
To view the update status through the Container Cloud web UI, navigate to the Clusters page. Once the orange blinking dot next to the cluster name disappears, the cluster update is complete.
Also, you can see the general status of each node during the update on the Container Cloud cluster view page.
Follow the update process through logs¶
The whole update process is controlled by lcm-controller, which runs in
the kaas namespace of the Container Cloud management cluster. Follow
its logs to watch the progress of the update, discover, and debug any issues.
Watch the state of the cluster and nodes update through the CLI¶
The lcmclusterstate and lcmmachines objects in the mos namespace
of the Container Cloud management cluster provide detailed information about
the current phase of the update process in the context of the managed cluster
overall as well as specific nodes.
The lcmmachine object being in the Ready state indicates that a node
has been successfully updated.
To display the detailed view of the cluster update state, run:
kubectl -n child-ns get lcmclusterstates -o wide
Example system response:
NAME CLUSTERNAME TYPE ARG VALUE ACTUALVALUE ATTEMPT MESSAGE
cd-cz7506-child-cl-storage-worker-noefi-rgxhk child-cl cordon-drain cz7506-child-cl-storage-worker-noefi-rgxhk true 0 Error: following NodeWorkloadLocks are still active - ceph: UpdatingController,openstack: InProgress
sd-cz7506-child-cl-storage-worker-noefi-rgxhk child-cl swarm-drain cz7506-child-cl-storage-worker-noefi-rgxhk true 0 Error: waiting for kubernetes node kaas-node-5222a92f-5523-457c-8c69-b7aa0ffc235c to be drained first
To display the detailed view of the nodes update state, run:
kubectl -n child-ns get lcmmachines
Example system response:
NAME CLUSTERNAME TYPE STATE
cz5018-child-cl-storage-worker-noefi-dzttw child-cl worker Prepare
cz5019-child-cl-storage-worker-noefi-vxcm9 child-cl worker Prepare
cz7500-child-cl-control-storage-worker-noefi-nkk9t child-cl control Ready
cz7501-child-cl-control-storage-worker-noefi-7pcft child-cl control Ready
cz7502-child-cl-control-storage-worker-noefi-c7k6f child-cl control Ready
cz7503-child-cl-storage-worker-noefi-5lvd7 child-cl worker Prepare
cz7505-child-cl-storage-worker-noefi-jh4mc child-cl worker Prepare
cz7506-child-cl-storage-worker-noefi-rgxhk child-cl worker Prepare
Step 4. Reboot the nodes with optional instance migration¶
Depending on the target release content, you may need to reboot the cluster nodes for the changes to take effect. Running a MOSK cluster in a semi-updated state for an extended period may result in unpredictable behavior of the cloud and impact users and workloads. Therefore, when it is required, you need to reboot the cluster nodes as soon as possible to avoid potential risks.
Determine if the node needs to be rebooted¶
Verify the YAML definitions of the LCMMachine and Machine objects.
The node must be rebooted if the rebootRequired flag is set to true.
In addition, objects explicitly specify the reason for rebooting. For example:
The
LCMMachineobject of the node that requires rebooting:... status: hostInfo: rebootRequired: true rebootReason: "linux-image-5.13.0-51-generic"
The
Machineobject of the node that does not require rebooting:... status: ... providerStatus: ... reboot: reason: "" required: false status: Ready
Since MOSK 23.1, you can also use the Mirantis Container Cloud web UI to identify the nodes requiring reboot:
In the Clusters tab, click the required cluster name. The page with Machines opens.
Hover over the status of every machine. A machine to reboot contains the Reboot > The machine requires a reboot notification in the Status tooltip.
Configure instance migration policy for cluster nodes¶
Restarting the cluster causes downtime of the cloud services running on the nodes. While the MOSK control plane is built for high availability and can tolerate temporary loss of at least 1/3 of services without a significant impact on user experience, rebooting nodes that host the elements of cloud data plane, such as network gateway nodes and compute nodes, has a detrimental effect on the cloud workloads, if not performed gracefully.
To mitigate the potential impact on the cloud workloads, you can define the instance migration flow for the compute nodes running the most valuable instances.
The list of available options for the instance migration configuration includes:
The
openstack.lcm.mirantis.com/instance_migration_modeannotation:liveDefault. The OpenStack controller live migrates instances automatically. The update mechanism tries to move the memory and local storage of all instances on the node to another node without interrupting before applying any changes to the node. By default, the update mechanism makes three attempts to migrate each instance before falling back to the
manualmode.Note
Success of live migration depends on many factors including the selected vCPU type and model, the amount of data that needs to be transferred, the intensity of the disk IO and memory writes, the type of the local storage, and others. Instances using the following product features are known to have issues with live migration:
LVM-based ephemeral storage with and without encryption
Encrypted block storage volumes
CPU and NUMA node pinning
manualThe OpenStack Controller waits for the Operator to migrate instances from the compute node. When it is time to update the compute node, the update mechanism asks you to manually migrate the instances and proceeds only once you confirm the node is safe to update.
skipThe OpenStack Controller skips the instance check on the node and reboots it.
Note
For the clouds relying on the converged LVM with iSCSI block storage that offer persistent volumes in a remote edge sub-region, it is important to keep in mind that applying a major change to a compute node may impact not only the instances running on this node but also the instances attached to the LVM devices hosted there. We recommend that in such environments you perform the update procedure in the
manualmode with mitigation measures taken by the Operator for each compute node. Otherwise, all the instances that have LVM with iSCSI volumes attached would need reboot to restore the connectivity.
- The
openstack.lcm.mirantis.com/instance_migration_attemptsannotation Defines the number of times the OpenStack Controller attempts to migrate a single instance before giving up. Defaults to
3.
- The
Note
You can also use annotations to control the update of
non-compute nodes if they represent critical points of a specific
cloud architecture. For example, setting the instance_migration_mode
to manual on a controller node with a collocated gateway (Open vSwitch)
will allow the Operator to gracefully shut down all the virtual routers
hosted on this node.
To configure the instance migration policy:
Edit the target compute node resource. For example:
kubectl edit node kaas-node-03ab613d-cf79-4830-ac70-ed735453481a
Set the migration mode and the number of attempts the OpenStack Controller should make to migrate a single instance. For example:
apiVersion: v1 kind: Node metadata: name: kaas-node-03ab613d-cf79-4830-ac70-ed735453481a selfLink: /api/v1/nodes/kaas-node-03ab613d-cf79-4830-ac70-ed735453481a uid: 54be5139-aba7-47e7-92bf-5575773a12a6 resourceVersion: '299734609' creationTimestamp: '2021-03-24T16:03:11Z' labels: ... openstack-compute-node: enabled openvswitch: enabled annotations: openstack.lcm.mirantis.com/instance_migration_mode: "live" openstack.lcm.mirantis.com/instance_migration_attempts: "5" ...
Reboot MOSK cluster¶
Since MOSK 23.1, you can reboot several cluster nodes in one go by using the Graceful reboot mechanism provided by Mirantis Container Cloud. The mechanism restarts the selected nodes one by one, honoring the instance migration policies.
For older versions of MOSK, you need to reboot each node manually as follows:
For each node in the cluster:
If
manualinstance migration policy is configured for the node, perform manual migration once the node is ready to reboot (see below).
Perform manual actions before node reboot¶
When a node that has a manual instance migration policy is ready to be
restarted, the life-cycle management mechanism notifies you about that by
creating a NodeMaintenanceRequest object for the node and setting the
active status attribute for the corresponding NodeWorkloadLock object.
Note
Verify the status:errorMessage attribute before proceeding.
To view the NodeWorkloadLock objects details for a specific node, run:
kubectl get nodeworkloadlocks <NODE-NAME> -o yaml
Example system response:
apiVersion: lcm.mirantis.com/v1alpha1
kind: NodeWorkloadLock
metadata:
annotations:
inner_state: active
creationTimestamp: "2022-02-04T13:24:48Z"
generation: 1
name: openstack-kaas-node-b2a55089-5b03-4698-9879-8756e2e81df5
resourceVersion: "173934"
uid: 0cb4428f-dd0d-401d-9d5e-e9e97e077422
spec:
controllerName: openstack
nodeName: kaas-node-b2a55089-5b03-4698-9879-8756e2e81df5
status:
errorMessage: 2022-02-04 14:43:52.674125 Some servers ['0ab4dd8f-ef0d-401d-9d5e-e9e97e077422'] are still present on host kaas-node-b2a55089-5b03-4698-9879-8756e2e81df5.
Waiting unless all of them are migrated manually or instance_migration_mode is set to 'skip'
release: 8.5.0-rc+22.1
state: active
Note
For MOSK compute nodes, you need to manually shut down all instances running on it, or perform cold or live migration of the instances.
After the update¶
Once your MOSK cluster update is complete, proceed with the following:
Perform the post-update steps recommended in the update notes of the target release if any.
Use the standard configuration mechanisms to re-enable the new product features that could previously exist in your cloud as a custom configuration.
To ensure the cluster operability, execute a set of smoke tests as described in Run Tempest tests.
Optional. Proceed with the upgrade of OpenStack.
If necessary, expire alert silences in StackLight as described in Container Cloud Operations Guide: Silence alerts.
What to do if the update hangs or fails¶
If an update phase takes significantly longer than expected according to the tables included in Plan the cluster update, you should consider the update process hung.
If you observe errors that are not described explicitly in the documentation, immediately contact Mirantis support.
Troubleshoot issues¶
To see any issues that might have occurred during the update, verify the logs
of the lcm-controller pods in the kaas namespace of the Container Cloud
management cluster.
To troubleshoot the update that involves the operating system upgrade with host reboot, refer to Container Cloud documentation.
Roll back the changes¶
Container Cloud and MOSK life-cycle management mechanism does not provide a way to perform a cluster-wide rollback of an update.
Update a MOSK cluster to a patch release version¶
Patch releases aim to significantly shorten the cycle of CVE fixes delivery onto your MOSK deployments to help you avoid cyber threats and data breaches.
Your management bare-metal cluster obtains patch releases automatically the same way as major releases. A new patch MOSK release version becomes available through the Container Cloud web UI after the automatic upgrade of the management cluster.
It is not possible to update between the patch releases that belong to different release series in one go. For example, you can update from MOSK 23.1.1 to 23.1.2, but you cannot immediately update from MOSK 23.1.x to 23.2.x because you need to update to the major MOSK 23.2 release first.
For the update procedure, refer to Mirantis Container Cloud Operations Guide: Update a patch Cluster release of a managed cluster.
Pre-update actions¶
Determine if cluster nodes need to be rebooted¶
The application of the patch releases may not require the cluster nodes reboot. Though, your cluster can contain nodes that require reboot after the last update to a major release, and this requirement will remain after update to any of the following patch releases. Therefore, Mirantis strongly recommends that you determine if there are such nodes in your cluster before you update to the next patch release and reboot them if any, as described in Step 4. Reboot the nodes with optional instance migration.
Consider pinning the Open vSwitch and Kubernetes entrypoint images¶
When applying a new patch release, Open vSwitch pods handling instance data plane may be restarted. Depending on the exact workload configuration, such as the number of virtual machines, security group configuration, and so on, the downtime may differ and take up to 5 minutes per compute host.
If you do not want the Open vSwitch pods to restart, pin the following images:
Open vSwitch
Kubernetes entrypoint
To pin the images:
Depending on the proxy configuration, the image base URL differs. To obtain the list of currently used images on the cluster, run:
kubectl -n openstack get ds openvswitch-openvswitch-vswitchd-default -o yaml |grep "image:" | sort -u
Example of system response:
image: mirantis.azurecr.io/general/openvswitch:2.13-focal-20230211095312 image: mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-48d1e8a-20220919122849
Add the
openvswitchandkubernetes-entrypointimages used on your cluster to theopenstackdeploymentobject:spec: services: networking: openvswitch: values: images: tags: dep_check: <kubernetes-entrypoint-image-URL> openvswitch_db_server: <openvswitch-image-URL> openvswitch_vswitchd: <openvswitch-image-URL>
For example:
spec: services: networking: openvswitch: values: images: tags: dep_check: mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-48d1e8a-20220919122849 openvswitch_db_server: mirantis.azurecr.io/general/openvswitch:2.13-focal-20230211095312 openvswitch_vswitchd: mirantis.azurecr.io/general/openvswitch:2.13-focal-20230211095312
Calculate a maintenance window duration for update¶
This section provides an online calculator for quick calculation of the approximate time required to update your MOSK cluster that uses Open vSwitch as a networking back end.
Additionally, for a more accurate calculation, consider any cluster-specific factors that can have a large impact on the update time in some edge cases, such as number of routers, frequency of CPU, and so on.
OpenStack operations¶
The section covers the management aspects of an OpenStack cluster deployed on Kubernetes.
Update OpenStack¶
The update of the OpenStack components is performed during the MOSK cluster release update.
Upgrade OpenStack¶
This section provides instructions on how to upgrade the OpenStack version on a MOSK cluster.
Prerequisites¶
Verify that your OpenStack cloud is running on the latest MOSK release. See Release Compatibility Matrix for the release matrix and supported upgrade paths.
Just before the upgrade, back up your OpenStack databases. See the following documentation for details:
Verify that OpenStack is healthy and operational. All OpenStack components in the
healthgroup in theOpenStackDeploymentStatusCR should be in theReadystate. See OpenStackDeploymentStatus custom resource for details.Verify the workability of your OpenStack deployment by running Tempest against the OpenStack cluster as described in Run Tempest tests. Verification of the testing pass rate before upgrading will help you measure your cloud quality before and after upgrade.
Read carefully through the Release Notes of your MOSK version paying attention to the Known issues section and the OpenStack upstream release notes for the target OpenStack version.
Calculate the maintenance window using services-update-details and notify users.
When upgrading to OpenStack Yoga, remove the Panko service from the cloud by removing the
evententry from thespec:features:servicesstructure in theOpenStackDeploymentresource as described in Remove an OpenStack service.Note
The OpenStack Panko service has been removed from the product. See Deprecation Notes: The OpenStack Panko service for details.
Perform the upgrade¶
To start the OpenStack upgrade, change the value of the
spec:openstack_version parameter in the OpenStackDeployment object
to the target OpenStack release.
After you change the value of the spec:openstack_version parameter,
the OpenStack Controller initializes the upgrade process.
To verify the upgrade status, use:
Logs from the
osdplcontainer in the OpenStack Controller pod.The
OpenStackDeploymentStatusobject.When upgrade starts, the
OPENSTACK VERSIONfield content changes to the target OpenStack version, andSTATEdisplaysAPPLYING:kubectl -n openstack get osdplst
Example of system output:
NAME OPENSTACK VERSION CONTROLLER VERSION STATE osh-dev antelope 0.15.6 APPLYING
When upgrade finishes, the
STATEfield should displayAPPLIED:kubectl -n openstack get osdplst
Example of system output:
NAME OPENSTACK VERSION CONTROLLER VERSION STATE osh-dev antelope 0.15.6 APPLIED
The maintenance window for the OpenStack upgrade usually takes from two to four hours, depending on the cloud size.
Verify the upgrade¶
Verify that OpenStack is healthy and operational. All OpenStack components in the
healthgroup in theOpenStackDeploymentStatusCR should be in theReadystate. See OpenStackDeploymentStatus custom resource for details.Verify the workability of your OpenStack deployment by running Tempest against the OpenStack cluster as described in Run Tempest tests.
Upgrade from Yoga to Antelope¶
MOSK enables you to upgrade directly from Yoga to Antelope without the need to upgrade to the intermediate Zed release.
Before upgrading, verify that you have completed the Prerequisites.
To upgrade the cloud, complete the upgrade steps
instruction changing the value of the spec:openstack_version parameter
in the OpenStackDeployment object from yoga to antelope.
Upgrade from Victoria to Yoga¶
Caution
If your cluster is running on top of the MOSK 23.1.2 patch version, the OpenStack upgrade to Yoga may fail due to the delay in the Cinder start. For the workaround, see 23.1.2 known issues: OpenStack upgrade failure.
Before upgrading, verify that you have completed the Prerequisites.
If your cloud runs on top of the OpenStack Victoria release, you must first upgrade to the technical OpenStack releases Wallaby and Xena before upgrading to Yoga.
Caution
The Wallaby and Xena releases are not recommended for a long-run production usage. These versions are transitional, so-called technical releases with limited testing scopes. For the OpenStack versions support cycle, refer to OpenStack support cycle.
To upgrade the cloud, complete the upgrade steps for each release version in line in the following strict order:
Upgrade the cloud from
victoriatowallabyUpgrade the cloud from
wallabytoxenaUpgrade the cloud from
xenatoyoga
Backup and restore OpenStack databases¶
Mirantis OpenStack for Kubernetes (MOSK) relies on the MariaDB Galera cluster to provide its OpenStack components with reliable storage of persistent data. Mirantis recommends backing up your OpenStack databases daily to ensure the safety of your cloud data. Also, you should always create an instant backup before updating your cloud or performing any kind of potentially disruptive experiment.
MOSK has a built-in automated backup routine that can be
triggered manually or by schedule. Periodic backups are suspended by default
but you can easily enable them through the OpenStackDeployment custom
resource. For the details about enablement and configuration of the periodic
backups, refer to Periodic OpenStack database backups in the Reference Architecture.
This section includes more intricate procedures that involve additional steps
beyond editing the OpenStackDeployment custom resource, such as restoring
the OpenStack database from a backup or configuring a remote storage for
backups.
Enable OpenStack database remote backups¶
TechPreview
By default, MOSK stores the OpenStack database backups locally in the Mirantis Ceph cluster, which is a part of the same cloud.
Alternatively, MOSK enables you to save the backup data to an external storage. This section contains the details on how you, as a cloud operator, can configure a remote storage back end for OpenStack database backups.
In general, the built-in automated backup mechanism saves the data to the
mariadb-phy-backup-data PersistentVolumeClaim (PVC), which is provisioned
from StorageClass specified in the spec.persistent_volume_storage_class
parameter of the OpenstackDeployment custom resource (CR).
If your MOSK cluster was originally deployed with the default backup storage, proceed with this step. Otherwise, skip it.
Copy the already existing backup data to a storage different from the
mariadb-phy-backup-dataPVC.Remove the
mariadb-phy-backup-dataPVC manually:kubectl -n openstack delete pvc mariadb-phy-backup-data
Enable the NFS back end in the
OpenStackDeploymentobject by editing the backup section of theOpenStackDeploymentCR as follows:spec: features: database: backup: enabled: true backend: pv_nfs pv_nfs: server: <ip-address/dns-name-of-the-server> path: <path-to-the-share-folder-on-the-server>
Optional. Set the required mount options for the NFS mount command. You can set as many options of mount as you need. For example:
spec: services: database: mariadb: values: volume: phy_backup: nfs: mountOptions: - "nfsvers=4" - "hard"
Verify the
mariadb-phy-backup-dataPVC and NFS persistent volume (PV):kubectl -n openstack get pvc mariadb-phy-backup-data -o wide
kubectl -n openstack get pv mariadb-phy-backup-data-nfs-pv -o yaml
An example of a positive system response:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE mariadb-phy-backup-data Bound mariadb-phy-backup-data-nfs-pv 20Gi RWO 5m40s Filesystem
apiVersion: v1 kind: PersistentVolume metadata: annotations: meta.helm.sh/release-name: openstack-mariadb meta.helm.sh/release-namespace: openstack <<<skipped>>>> name: mariadb-phy-backup-data-nfs-pv resourceVersion: "2279204" uid: 60db9f89-afc4-417b-bf44-8acab844f17e spec: accessModes: - ReadWriteOnce capacity: storage: 20Gi claimRef: apiVersion: v1 kind: PersistentVolumeClaim name: mariadb-phy-backup-data namespace: openstack resourceVersion: "2279201" uid: e0e08d73-e56f-425a-ad4e-e5393aa3cdc1 mountOptions: - nfsvers=4 - hard nfs: path: / server: 10.10.0.116 persistentVolumeReclaimPolicy: Retain volumeMode: Filesystem status: phase: Bound
Remove NFS PVC and PV:
kubectl -n openstack delete pvc mariadb-phy-backup-data
kubectl -n openstack delete pv mariadb-phy-backup-data-nfs-pv
Re-enable the local backup in the
OpenStackDeploymentCR:spec: features: database: backup: enabled: true backend: pvc
Verify that the
mariadb-phy-backup-dataPVC uses the default PV:kubectl -n openstack get pvc mariadb-phy-backup-data
An example of a positive system response:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE mariadb-phy-backup-data Bound pvc-a4f6e24b-c05b-4a76-bca2-bb6a5c8ef5b5 20Gi RWO mirablock-k8s-block-hdd 80m
Restore OpenStack databases from a backup¶
During the OpenStack database restoration, the MariaDB cluster is unavailable due to the MariaDB StatefulSet being scaled down to 0 replicas. Therefore, to safely restore the state of the OpenStack database, plan the maintenance window thoroughly and in accordance with the database size.
The duration of the maintenance window may depend on the following:
Network throughput
Performance of the storage where backups are kept, which is Mirantis Ceph by default
Local disks performance of the nodes where MariaDB data resides
To restore OpenStack databases:
Obtain an image of the MariaDB container:
kubectl -n openstack get pods mariadb-server-0 -o jsonpath='{.spec.containers[0].image}'
Create the
check_pod.yamlfile to create the helper pod required to view the backup volume content:--- apiVersion: v1 kind: ServiceAccount metadata: name: check-backup-helper namespace: openstack --- apiVersion: v1 kind: Pod metadata: name: check-backup-helper namespace: openstack labels: application: check-backup-helper spec: nodeSelector: openstack-control-plane: enabled containers: - name: helper securityContext: allowPrivilegeEscalation: false runAsUser: 0 readOnlyRootFilesystem: true command: - sleep - infinity image: << image of mariadb container >> imagePullPolicy: IfNotPresent volumeMounts: - name: pod-tmp mountPath: /tmp - mountPath: /var/backup name: mysql-backup restartPolicy: Never serviceAccount: check-backup-helper serviceAccountName: check-backup-helper volumes: - name: pod-tmp emptyDir: {} - name: mariadb-secrets secret: secretName: mariadb-secrets defaultMode: 0444 - name: mariadb-bin configMap: name: mariadb-bin defaultMode: 0555 - name: mysql-backup persistentVolumeClaim: claimName: mariadb-phy-backup-data
Create the helper pod:
kubectl -n openstack apply -f check_pod.yaml
Obtain the name of the backup to restore:
kubectl -n openstack exec -t check-backup-helper -- tree /var/backup
Example of system response:
/var/backup |-- base | `-- 2020-09-09_11-35-48 | |-- backup.stream.gz | |-- backup.successful | |-- grastate.dat | |-- xtrabackup_checkpoints | `-- xtrabackup_info |-- incr | `-- 2020-09-09_11-35-48 | |-- 2020-09-10_01-02-36 | |-- 2020-09-11_01-02-02 | |-- 2020-09-12_01-01-54 | |-- 2020-09-13_01-01-55 | `-- 2020-09-14_01-01-55 `-- lost+found 10 directories, 5 files
If you want to restore the full backup, the name from the example above is
2020-09-09_11-35-48. To restore a specific incremental backup, the name from the example above is2020-09-09_11-35-48/2020-09-12_01-01-54.In the example above, the backups will be restored in the following strict order:
2020-09-09_11-35-48- full backup, path/var/backup/base/2020-09-09_11-35-482020-09-10_01-02-36- incremental backup, path/var/backup/incr/2020-09-09_11-35-48/2020-09-10_01-02-362020-09-11_01-02-02- incremental backup, path/var/backup/incr/2020-09-09_11-35-48/2020-09-11_01-02-022020-09-12_01-01-54- incremental backup, path/var/backup/incr/2020-09-09_11-35-48/2020-09-12_01-01-54
Delete the helper pod:
kubectl -n openstack delete -f check_pod.yaml
Pass the following parameters to the
mariadb_resque.pyscript from the OsDpl object:Parameter
Type
Default
Description
--backup-nameString
Name of a folder with backup in
<BASE_BACKUP>or<BASE_BACKUP>/<INCREMENTAL_BACKUP>.--replica-restore-timeoutInteger
3600Timeout in seconds for 1 replica data to be restored to the
mysqldata directory. Also, includes time for spawning a rescue runner pod in Kubernetes and extracting data from a backup archive.Edit the
OpenStackDeploymentobject as follows:spec: services: database: mariadb: values: manifests: job_mariadb_phy_restore: true conf: phy_restore: backup_name: "2020-09-09_11-35-48/2020-09-12_01-01-54" replica_restore_timeout: 7200
Wait until the
mariadb-phy-restorejob suceeds:kubectl -n openstack get jobs mariadb-phy-restore -o jsonpath='{.status}'The
mariadb-phy-restorejob is an immutable object. Therefore, remove the job after each successful execution. To correctly remove the job, clean up all the settings from theOpenStackDeploymentobject that you have configured during step 7 of this procedure. This will remove all related pods as well.
Important
If mariadb-phy-restore fails, the MariaDB Pods do not start automatically.
For example, the failure may occur due to discrepancy between the current
and backup versions of MariaDB, broken backup archive, and so on.
Assess the mariadb-phy-restore job log to identify the issue:
kubectl -n openstack logs --tail=10000 -l application=mariadb-phy-restore,job-name=mariadb-phy-restore
If the restoration process does not start due to the MariaDB versions discrepancy:
Use other backup file with the corresponding MariaDB version for restoration, if any.
Start MariaDB Pods without restoration:
kubectl scale --replicas=3 sts/mariadb-server -n openstack
The command above restores the previous cluster state.
Verify the periodic backup jobs for the OpenStack database¶
Verify pods in the
openstacknamespace. After the backup jobs have succeeded, the pods stay in theCompletedstate:kubectl -n openstack get pods -l application=mariadb-phy-backup
Example of a posistive system response:
NAME READY STATUS RESTARTS AGE mariadb-phy-backup-1599613200-n7jqv 0/1 Completed 0 43h mariadb-phy-backup-1599699600-d79nc 0/1 Completed 0 30h mariadb-phy-backup-1599786000-d5kc7 0/1 Completed 0 6h17m
Note
By default, the system keeps three latest successful and one latest failed pods.
Obtain an image of the MariaDB container:
kubectl -n openstack get pods mariadb-server-0 -o jsonpath='{.spec.containers[0].image}'
Create the
check_pod.yamlfile to create the helper pod required to view the backup volume content.Configuration example:
apiVersion: v1 kind: ServiceAccount metadata: name: check-backup-helper namespace: openstack --- apiVersion: v1 kind: Pod metadata: name: check-backup-helper namespace: openstack labels: application: check-backup-helper spec: nodeSelector: openstack-control-plane: enabled containers: - name: helper securityContext: allowPrivilegeEscalation: false runAsUser: 0 readOnlyRootFilesystem: true command: - sleep - infinity image: << image of mariadb container >> imagePullPolicy: IfNotPresent volumeMounts: - name: pod-tmp mountPath: /tmp - mountPath: /var/backup name: mysql-backup restartPolicy: Never serviceAccount: check-backup-helper serviceAccountName: check-backup-helper volumes: - name: pod-tmp emptyDir: {} - name: mariadb-secrets secret: secretName: mariadb-secrets defaultMode: 0444 - name: mariadb-bin configMap: name: mariadb-bin defaultMode: 0555 - name: mysql-backup persistentVolumeClaim: claimName: mariadb-phy-backup-data
Apply the helper service account and pod resources:
kubectl -n openstack apply -f check_pod.yaml kubectl -n openstack get pods -l application=check-backup-helper
Example of a positive system response:
NAME READY STATUS RESTARTS AGE check-backup-helper 1/1 Running 0 27s
Verify the directories structure within the
/var/backupdirectory of the spawned pod:kubectl -n openstack exec -t check-backup-helper -- tree /var/backup
Example of a system response:
/var/backup |-- base | `-- 2020-09-09_11-35-48 | |-- backup.stream.gz | |-- backup.successful | |-- grastate.dat | |-- xtrabackup_checkpoints | `-- xtrabackup_info |-- incr | `-- 2020-09-09_11-35-48 | |-- 2020-09-10_01-02-36 | | |-- backup.stream.gz | | |-- backup.successful | | |-- grastate.dat | | |-- xtrabackup_checkpoints | | `-- xtrabackup_info | `-- 2020-09-11_01-02-02 | |-- backup.stream.gz | |-- backup.successful | |-- grastate.dat | |-- xtrabackup_checkpoints | `-- xtrabackup_info
The
basedirectory contains full backups. Each directory in theincrfolder contains incremental backups related to a certain full backup in thebasefolder. All incremental backups always have the base backup name as parent folder.Delete the helper pod:
kubectl delete -f check_pod.yaml
Add a controller node¶
This section describes how to add a new control plane node to the existing MOSK deployment.
To add an OpenStack controller node:
Add a bare metal host to the managed cluster with MOSK as described in Add a bare metal host.
When adding the bare metal host YAML file, specify the following OpenStack control plane node labels for the OpenStack control plane services such as database, messaging, API, schedulers, conductors, L3 and L2 agents:
openstack-control-plane=enabledopenstack-gateway=enabledopenvswitch=enabled
Create a Kubernetes machine in your cluster as described in Add a machine.
When adding the machine, verify that OpenStack control plane node has the following labels:
openstack-control-plane=enabledopenstack-gateway=enabledopenvswitch=enabled
Note
Depending on the applications that were colocated on the failed controller node, you may need to specify some additional labels, for example,
ceph_role_mgr=trueandceph_role_mon=true. To successfuly replace a failedmonandmgrnode, refer to Mirantis Container Cloud Operations Guide: Manage Ceph.Verify that the node is in the
Readystate through the Kubernetes API:kubectl get node <NODE-NAME> -o wide | grep Ready
Verify that the node has all required labels described in the previous steps:
kubectl get nodes --show-labels
Configure new Octavia health manager resources:
Rerun the
octavia-create-resourcesjob:kubectl -n osh-system exec -t <OS-CONTROLLER-POD> -c osdpl osctl-job-rerun octavia-create-resources openstack
Wait until the Octavia health manager pod on the newly added control plane node appears in the
Runningstate:kubectl -n openstack get pods -o wide | grep <NODE_ID> | grep octavia-health-manager
Note
If the pod is in the
crashloopbackoffstate, remove it:kubectl -n openstack delete pod <OCTAVIA-HEALTH-MANAGER-POD-NAME>
Verify that an OpenStack port for the node has been created and the node is in the
Activestate:kubectl -n openstack exec -t <KEYSTONE-CLIENT-POD-NAME> openstack port show octavia-health-manager-listen-port-<NODE-NAME>
Replace a failed controller node¶
This section describes how to replace a failed control plane node in your
MOSK deployment. The procedure applies to the control plane
nodes that are, for example, permanently failed due to a hardware failure and
appear in the NotReady state:
kubectl get nodes <CONTAINER-CLOUD-NODE-NAME>
Example of system response:
NAME STATUS ROLES AGE VERSION
<CONTAINER-CLOUD-NODE-NAME> NotReady <none> 10d v1.18.8-mirantis-1
To replace a failed controller node:
Remove the Kubernetes labels from the failed node by editing the
.metadata.labelsnode object:kubectl edit node <CONTAINER-CLOUD-NODE-NAME>
If your cluster is deployed with a compact control plane, inspect Mirantis Container Cloud Operations Guide: Precautions for a cluster machine deletion.
Add the control plane node to your deployment as described in Add a controller node.
Identify all stateful applications present on the failed node:
node=<CONTAINER-CLOUD-NODE-NAME> claims=$(kubectl -n openstack get pv -o jsonpath="{.items[?(@.spec.nodeAffinity.required.nodeSelectorTerms[0].matchExpressions[0].values[0] == '${node}')].spec.claimRef.name}") for i in $claims; do echo $i; done
Example of system response:
mysql-data-mariadb-server-2 openstack-operator-bind-mounts-rfr-openstack-redis-1 etcd-data-etcd-etcd-0
For MOSK 23.3 series or earlier, reschedule stateful applications pods to healthy controller nodes as described in Reschedule stateful applications. For the newer versions, MOSK performs the rescheduling of stateful applications automatically.
If the failed controller node had the
StackLightlabel, fix the StackLight volume node affinity conflict as described in Mirantis Container Cloud Operations Guide: Delete a cluster machine.Remove the OpenStack port related to the Octavia health manager pod of the failed node:
kubectl -n openstack exec -t <KEYSTONE-CLIENT-POD-NAME> openstack port delete octavia-health-manager-listen-port-<NODE-NAME>
Add a compute node¶
This section describes how to add a new compute node to your existing Mirantis OpenStack for Kubernetes deployment.
To add a compute node:
Add a bare metal host to the managed cluster with MOSK as described in Add a bare metal host.
Create a Kubernetes machine in your cluster as described in Add a machine.
When adding the machine, specify the node labels as required for an OpenStack compute node:
OpenStack node roles¶ Node role
Description
Kubernetes labels
Minimal count
OpenStack control plane
Hosts the OpenStack control plane services such as database, messaging, API, schedulers, conductors, L3 and L2 agents.
openstack-control-plane=enabledopenstack-gateway=enabledopenvswitch=enabled3
OpenStack compute
Hosts the OpenStack compute services such as libvirt and L2 agents.
openstack-compute-node=enabledopenvswitch=enabled(for a deployment with Open vSwitch as a back end for networking)Varies
If required, configure the compute host to enable DPDK, huge pages, SR-IOV, and other advanced features in your MOSK deployment. See Advanced OpenStack configuration (optional) for details.
Once the node is available in Kubernetes and when the
nova-computeandneutronpods are running on the node, verify that the compute service and Neutron Agents are healthy in OpenStack API.In the
keystone-clientpod, run:openstack network agent list --host <cmp_host_name> openstack compute service list --host <cmp_host_name>
Verify that the compute service is mapped to cell.
The OpenStack Controller triggers the
nova-cell-setupjob once it detects a new compute pod in theReadystate. This job sets mapping for new compute services to cells.In the
nova-api-osapipod, run:nova-manage cell_v2 list_hosts | grep <cmp_host_name>
Change oversubscription settings for existing compute nodes¶
Available since MOSK 23.1
MOSK enables you to control the oversubscription of compute node resources through the placement service API.
To manage the oversubscription through the placement API:
Obtain the host name of the hypervisor in question:
openstack hypervisor list -f yaml
Example of system response:
- Host IP: 10.10.0.78 Hypervisor Hostname: ps-ps-obnqilm4xxlu-0-gdy3x46euaeu-server-ftp6p7j6pyjl.cluster.local Hypervisor Type: QEMU ID: 1 State: up - Host IP: 10.10.0.118 Hypervisor Hostname: ps-ps-obnqilm4xxlu-1-n36gax6zqgef-server-xtby2leuercd.cluster.local Hypervisor Type: QEMU ID: 7 State: up
Determine the resource provider that corresponds to the hypervisor:
openstack resource provider list -f yaml --name <hypervisor_hostname>
Example of system response:
- generation: 4 name: ps-ps-obnqilm4xxlu-1-n36gax6zqgef-server-xtby2leuercd.cluster.local parent_provider_uuid: null root_provider_uuid: b16e9094-3f0e-4b8e-a138-e0b1f0a980db uuid: b16e9094-3f0e-4b8e-a138-e0b1f0a980db
Verify the current values in the resource provider by its UUID:
openstack resource provider inventory list <provider_uuid> -f yaml
Example of system response:
- allocation_ratio: 8.0 max_unit: 8 min_unit: 1 reserved: 0 resource_class: VCPU step_size: 1 total: 8 used: 0 - allocation_ratio: 1.0 max_unit: 7956 min_unit: 1 reserved: 512 resource_class: MEMORY_MB step_size: 1 total: 7956 used: 0 - allocation_ratio: 1.6 max_unit: 145 min_unit: 1 reserved: 0 resource_class: DISK_GB step_size: 1 total: 145 used: 0
Update the allocation ratio for the required resource class in the resource provider and inspect the system response to verify that the change has been applied:
openstack resource provider inventory set <provider_uuid> --amend --resource VCPU:allocation_ratio=10
Caution
To ensure accurate resource updates, it is crucial to specify the
--amendargument when making requests. Failure to do so will require the inclusion of values for all fields associated with the resource provider.Example of system response:
- allocation_ratio: 10.0 max_unit: 8 min_unit: 1 reserved: 0 resource_class: VCPU step_size: 1 total: 8 used: 0 - allocation_ratio: 1.0 max_unit: 7956 min_unit: 1 reserved: 512 resource_class: MEMORY_MB step_size: 1 total: 7956 used: 0 - allocation_ratio: 1.6 max_unit: 145 min_unit: 1 reserved: 0 resource_class: DISK_GB step_size: 1 total: 145 used: 0
Delete a compute node¶
Since MOSK 23.2, the OpenStack-related metadata is automatically removed during the graceful machine deletion through the Mirantis Container Cloud web UI. For the procedure, refer to Mirantis Container Cloud Operations Guide: Delete a cluster machine.
During the graceful machine deletion, the OpenStack Controller performs the following operations:
Disables the OpenStack Compute and Block Storage services on the node to prevent further scheduling of workloads to it.
Verifies if any resources are present on the node, for example, instances and volumes. By default, the OpenStack Controller blocks the removal process until the resources are removed by the user. To adjust this behavior to the needs of your cluster, refer to OpenStack Controller configuration.
Removes OpenStack services metadata including compute services, Neutron agents, and volume services.
Caution
You cannot collocate the OpenStack compute node with other cluster components, such as Ceph. If done so, refer to the removal steps of the collocated components when planning the maintenance window.
If your cluster runs MOSK 23.1 or older version, perfrom the following steps before you remove the node from the cluster through the web UI to correctly remove the OpenStack-related metadata from it:
Disable the compute service to prevent spawning of new instances. In the
keystone-clientpod, run:openstack compute service set --disable <cmp_host_name> nova-compute --disable-reason "Compute is going to be removed."
Migrate all workloads from the node. For more information, follow Nova official documentation: Migrate instances.
Ensure that there are no pods running on the node to delete by draining the node as instructed in the Kubernetes official documentation: Safely drain node.
Delete the compute service using the OpenStack API. In the
keystone-clientpod, run:openstack compute service delete <service_id>
Note
To obtain
<service_id>, run:openstack compute service list --host <cmp_host_name>
Depending on the networking back end in use, proceed with one of the following:
Obtain the network agent ID:
openstack network agent list --host <cmp_host_name>
Delete the Neutron Agent service running the following command in the
keystone-clientpod:openstack network agent delete <agent_id>
Log in to the Tungsten Fabric web UI.
Navigate to Configure > Infrastructure > Virtual Routers.
Select the target compute node.
Click Delete.
Reschedule stateful applications¶
Note
The procedure applies to the MOSK clusters running MOSK 23.3 series or earlier versions. Starting from 24.1, MOSK performs the rescheduling of stateful applications automatically.
The rescheduling of stateful applications may be required when replacing a permanently failed node, decommissioning a node, migrating applications to nodes with a more suitable set of hardware, and in several other use cases.
MOSK deployment profiles include the following stateful applications:
OpenStack database (MariaDB)
OpenStack coordination (etcd)
OpenStack Time Series Database back end (Redis)
Each stateful application from the list above has a persistent volume claim (PVC) based on a local persistent volume per pod. Each of control plane nodes has a set of local volumes available. To migrate an application pod to another node, recreate a PVC with the persistent volume from the target node.
Caution
A stateful application pod can only be migrated to a node that does not contain other pods of this application.
Caution
When a PVC is removed, all data present in the related persistent volume is removed from the node as well.
Reschedule pods to another control plane node¶
This section describes how to reschedule pods for MariaDB, etcd, and Redis to another control plane node.
Important
Perform the pods rescheduling if you have to move a PVC to another node and the current node is still present in the cluster. If the current node has been removed already, MOSK reschedules pods automatically when a node with required labels is present in the cluster.
Recreate PVCs as described in Recreate a PVC on another control plane node.
Remove the pod:
Note
To remove a pod from a node in the
NotReadystate, add--grace-period=0 --forceto the following command.kubectl -n openstack delete pod <STATEFULSET-NAME>-<NUMBER>
Wait until the pod appears in the
Readystate.When the rescheduling is finalized, the
<STATEFULSET-NAME>-<NUMBER>pod rejoins the Galera cluster with a clean MySQL data directory and requests the Galera state transfer from the available nodes.
Important
Perform the pods rescheduling if you have to move a PVC to another node and the current node is still present in the cluster. If the current node has been removed already, MOSK reschedules pods automatically when a node with required labels is present in the cluster.
Recreate PVCs as described in Recreate a PVC on another control plane node.
Remove the pod:
Note
To remove a pod from a node in the
NotReadystate, add--grace-period=0 --forceto the following command.kubectl -n openstack-redis delete pod <STATEFULSET-NAME>-<NUMBER>
Wait until the pod is in the
Readystate.
Warning
During the reschedule procedure of the etcd LCM, a short cluster downtime is expected.
Before MOSK 23.1:
Identify the etcd replica ID that is a numeric suffix in a pod name. For example, the ID of the
etcd-etcd-0pod is0. This ID is required during the reschedule procedure.kubectl -n openstack get pods | grep etcd
Example of a system response:
etcd-etcd-0 0/1 Pending 0 3m52s etcd-etcd-1 1/1 Running 0 39m etcd-etcd-2 1/1 Running 0 39m
If the replica ID is
1or higher:Add the
coordinationsection to thespec.servicessection of the OsDpl object:spec: services: coordination: etcd: values: conf: etcd: ETCD_INITIAL_CLUSTER_STATE: existing
Wait for the etcd
statefulSetto update the new state parameter:kubectl -n openstack get sts etcd-etcd -o jsonpath='{.spec.template.spec.containers[0].env[?(@.name=="ETCD_INITIAL_CLUSTER_STATE")].value}'
Scale down the etcd
StatefulSetto0replicas. Verify that no replicas are running on the failed node.kubectl -n openstack scale sts etcd-etcd --replicas=0
Select from the following options:
If the current node is still present in the cluster and the PVC should be moved to another node, recreate the PVC as described in Recreate a PVC on another control plane node.
If the current node has been removed, remove the PVC related to the etcd replica of the failed node:
kubectl -n <NAMESPACE> delete pvc <PVC-NAME>
The PVC will be recreated automatically after the etcd
StatefulSetis scaled to the initial number of replicas.
Scale the etcd
StatefulSetto the initial number of replicas:kubectl -n openstack scale sts etcd-etcd --replicas=<NUMBER-OF-REPLICAS>
Wait until all etcd pods are in the
Readystate.Verify that the etcd cluster is healthy:
kubectl -n openstack exec -t etcd-etcd-1 -- etcdctl -w table endpoint --cluster status
Before MOSK 23.1, if the replica ID is
1or higher:Remove the
coordinationsection from thespec.servicessection of the OsDpl object.Wait until all etcd pods appear in the
Readystate.Verify that the etcd cluster is healthy:
kubectl -n openstack exec -t etcd-etcd-1 -- etcdctl -w table endpoint --cluster status
Recreate a PVC on another control plane node¶
This section describes how to recreate a PVC of a stateful application on another control plane node.
To recreate a PVC on another control plane node:
Select one of the persistent volumes available on the node:
Caution
A stateful application pod can only be migrated to the node that does not contain other pods of this application.
NODE_NAME=<NODE-NAME> STORAGE_CLASS=$(kubectl -n openstack get osdpl <OSDPL_OBJECT_NAME> -o jsonpath='{.spec.local_volume_storage_class}') kubectl -n openstack get pv -o json | jq --arg NODE_NAME $NODE_NAME --arg STORAGE_CLASS $STORAGE_CLASS -r '.items[] | select(.spec.nodeAffinity.required.nodeSelectorTerms[0].matchExpressions[0].values[0] == $NODE_NAME and .spec.storageClassName == $STORAGE_CLASS and .status.phase == "Available") | .metadata.name'
As the new PVC should contain the same parameters as the deleted one except for
volumeName, save the old PVC configuration in YAML:kubectl -n <NAMESPACE> get pvc <PVC-NAME> -o yaml > <OLD-PVC>.yaml
Note
<NAMESPACE>is a Kubernetes namespace where the PVC is created. For Redis, specifyopenstack-redis, for other applications specifyopenstack.Delete the old PVC:
kubectl -n <NAMESPACE> delete pvc <PVC-NAME>
Note
If a PVC has stuck in the
terminatingstate, runkubectl -n openstack edit pvc <PVC-NAME>and remove thefinalizerssection frommetadataof the PVC.Create a PVC with a new persistent volume:
cat <<EOF | kubectl apply -f - apiVersion: v1 kind: PersistentVolumeClaim metadata: name: <PVC-NAME> namespace: <NAMESPACE> spec: accessModes: - ReadWriteOnce resources: requests: storage: <STORAGE-SIZE> storageClassName: <STORAGE-CLASS> volumeMode: Filesystem volumeName: <PV-NAME> EOF
Caution
<STORAGE-SIZE>,<STORAGE-CLASS>, and<NAMESPACE>should correspond to thestorage,storageClassName, andnamespacevalues from the<OLD-PVC>.yamlfile with the old PVC configuration.
Run Tempest tests¶
The OpenStack Integration Test Suite (Tempest), is a set of integration tests to be run against a live OpenStack environment. This section instructs you on how to verify the workability of your OpenStack deployment using Tempest.
To verify an OpenStack deployment using Tempest:
Configure the Tempest run parameters using the
features:services:tempeststructure in theOpenStackDeploymentcustom resource.Note
To perform the smoke testing of your deployment, no additional configuration is required.
Configuration examples:
To perform the full Tempest testing:
spec: services: tempest: tempest: values: conf: script: | tempest run --config-file /etc/tempest/tempest.conf --concurrency 4 --blacklist-file /etc/tempest/test-blacklist --regex test
To set the image build timeout to
600:spec: services: tempest: tempest: values: conf: tempest: image: build_timeout: 600
Run Tempest. The OpenStack Tempest is deployed like other OpenStack services in a dedicated
openstack-tempestHelm release by addingtempesttospec:features:servicesin theOpenStackDeploymentcustom resource:spec: features: services: - tempest
Wait until Tempest is ready. The Tempest tests are launched by the
openstack-tempest-run-testsjob. To keep track of the tests execution, run:kubectl -n openstack logs -l application=tempest,component=run-tests
Get the Tempest results. The Tempest results can be stored in a
pvc-tempestPersistentVolumeClaim (PVC). To get them from a PVC, use:# Run pod and mount pvc to it cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: tempest-test-results-pod namespace: openstack spec: nodeSelector: openstack-control-plane: enabled volumes: - name: tempest-pvc-storage persistentVolumeClaim: claimName: pvc-tempest containers: - name: tempest-pvc-container image: ubuntu command: ['sh', '-c', 'sleep infinity'] volumeMounts: - mountPath: "/var/lib/tempest/data" name: tempest-pvc-storage EOF
If required, copy the results locally:
kubectl -n openstack cp tempest-test-results-pod:/var/lib/tempest/data/report_file.xml .
Remove the Tempest test results pod:
kubectl -n openstack delete pod tempest-test-results-pod
To rerun Tempest:
Remove Tempest from the list of enabled services.
Wait until Tempest jobs are removed.
Add Tempest back to the list of the enabled services.
Remove an OpenStack cluster¶
This section instructs you on how to remove an OpenStack cluster, deployed on
top of Kubernetes, by deleting the openstackdeployments.lcm.mirantis.com
(OsDpl) CR.
To remove an OpenStack cluster:
Verify that the OsDpl object is present:
kubectl get osdpl -n openstack
Delete the OsDpl object:
kubectl delete osdpl osh-dev -n openstack
The deletion may take a certain amount of time.
Verify that all pods and jobs have been deleted and no objects are present in the command output:
kubectl get pods,jobs -n openstack
Delete Persistent Volume Claims (PVCs) using the following snippet. Deletion of PVCs causes data deletion on Persistent Volumes. The volumes themselves will become available for further operations.
Caution
Before deleting PVCs, save valuable data in a safe place.
#!/bin/bash PVCS=$(kubectl get pvc --all-namespaces |egrep "openstack|openstack-redis" | egrep "redis|etcd|mariadb" | awk '{print $1" "$2" "$4}'| column -t ) echo "$PVCS" | while read line; do PVC_NAMESPACE=$(echo "$line" | awk '{print $1}') PVC_NAME=$(echo "$line" | awk '{print $2}') echo "Deleting PVC ${PVC_NAME}" kubectl delete pvc ${PVC_NAME} -n ${PVC_NAMESPACE} done
Note
Deletion of PVCs may get stuck if a resource that uses the PVC is still running. Once the resource is deleted, the PVC deletion process will proceed.
Delete the MariaDB state ConfigMap:
kubectl delete configmap openstack-mariadb-mariadb-state -n openstack
Delete secrets using the following snippet:
#!/bin/bash SECRETS=$(kubectl get secret -n openstack | awk '{print $1}'| column -t | awk 'NR>1') echo "$SECRETS" | while read line; do echo "Deleting Secret ${line}" kubectl delete secret ${line} -n openstack done
Verify that OpenStack ConfigMaps and secrets have been deleted:
kubectl get configmaps,secrets -n openstack
Remove an OpenStack service¶
This section instructs you on how to remove an OpenStack service deployed on
top of Kubernetes. A service is typically removed by deleting a corresponding
entry in the spec.features.services section of the
openstackdeployments.lcm.mirantis.com (OsDpl) CR.
Caution
You cannot remove the default services built into the preset
section.
Remove a service¶
Verify that the
spec.features.servicessection is present in the OsDpl object:kubectl -n openstack get osdpl osh-dev -o jsonpath='{.spec.features.services}'
Example of system output:
[instance-ha object-storage]
Obtain the user name of the service database that will be required during Clean up OpenStack database leftovers after the service removal to substitute
SERVICE-DB-NAME:Note
For example, the
<SERVICE-NAME>for theinstance-haservice type ismasakari.kubectl -n osh-system exec -t <OPENSTACK-CONTROLLER-POD-NAME> -- helm3 -n openstack get values openstack-<SERVICE-NAME> -o json | jq -r .endpoints.oslo_db.auth.<SERVICE-NAME>.username
Delete the service from the
spec.features.servicessection of the OsDpl CR:kubectl -n openstack edit osdpl osh-dev
The deletion may take a certain amount of time.
Verify that all related objects have been deleted and no objects are present in the output of the following command:
for i in $(kubectl api-resources --namespaced -o name | grep -v event); do kubectl -n openstack get $i 2>/dev/null | grep <SERVICE-NAME>; done
Clean up OpenStack API leftovers after the service removal¶
Log in to the Keystone client pod shell:
kubectl -n openstack exec -it <KEYSTONE-CLIENT-POD-NAME> -- bash
Remove service endpoints from the Keystone catalog:
for i in $(openstack endpoint list --service <SERVICE-NAME> -f value -c ID); do openstack endpoint delete $i; done
Remove the service user from the Keystone catalog:
openstack user list --project service | grep <SERVICE-NAME> openstack user delete <SERVICE-USER-ID>
Remove the service from the catalog:
openstack service list | grep <SERVICE-NAME> openstack service delete <SERVICE-ID>
Clean up OpenStack database leftovers after the service removal¶
Caution
The procedure below will permanently destroy the data of the removed service.
Log in to the
mariadb-serverpod shell:kubectl -n openstack exec -it mariadb-server-0 -- bash
Remove the service database user and its permissions:
Note
Use the user name for the service database obtained during the Remove a service procedure to substitute
SERVICE-DB-NAME:mysql -u root -p${MYSQL_DBADMIN_PASSWORD} -e "REVOKE ALL PRIVILEGES, GRANT OPTION FROM '<SERVICE-DB-USERNAME>'@'%';" mysql -u root -p${MYSQL_DBADMIN_PASSWORD} -e "DROP USER '<SERVICE-DB-USERNAME>'@'%';"
Remove the service database:
mysql -u root -p${MYSQL_DBADMIN_PASSWORD} -e "DROP DATABASE <SERVICE-NAME>;"
Enable uploading of an image through Horizon with untrusted SSL certificates¶
By default, the OpenStack Dashboard (Horizon) is configured to load images directly into Glance. However, if a MOSK cluster is deployed using untrusted certificates for public API endpoints and Horizon, uploading of images to Glance through the Horizon web UI may fail.
When accessing the Horizon web UI of such MOSK deployment
for the first time, a warning informs you that the site is insecure and you
must force trust the certificate of this site. However, when trying to upload
an image directly from a web browser, the certificate of the Glance API is
still not considered by the web browser as a trusted one since host:port
of the site is different. In this case, you must explicitly trust the
certificate of the Glance API.
To enable uploading of an image through Horizon with untrusted SSL certificates:
Navigate to the Horizon web UI.
Configure your web browser to trust the Horizon certificate if you have not done so yet:
In Google Chrome or Chromium, click Advanced > Proceed to <URL> (unsafe).
In Mozilla Firefox, navigate to Advanced > Add Exception, enter the URL in the Location field, and click Confirm Security Exception.
Note
For other web browsers, the steps may vary slightly.
Navigate to Project > API Access.
Copy the Service Endpoint URL of the Image service.
Open this URL in a new window or tab of the same web browser.
Configure your web browser to trust the certificate of this site as described in the step 2.
As a result, the version discovery document should appear with contents that varies depending on the OpenStack version. For example, for OpenStack Victoria:
{"versions": [{"id": "v2.9", "status": "CURRENT", "links": \ [{"rel": "self", "href": "https://glance.ic-eu.ssl.mirantis.net/v2/"}]}, \ {"id": "v2.7", "status": "SUPPORTED", "links": \ [{"rel": "self", "href": "https://glance.ic-eu.ssl.mirantis.net/v2/"}]}, \ {"id": "v2.6", "status": "SUPPORTED", "links": \ [{"rel": "self", "href": "https://glance.ic-eu.ssl.mirantis.net/v2/"}]}, \ {"id": "v2.5", "status": "SUPPORTED", "links": \ [{"rel": "self", "href": "https://glance.ic-eu.ssl.mirantis.net/v2/"}]}, \ {"id": "v2.4", "status": "SUPPORTED", "links": \ [{"rel": "self", "href": "https://glance.ic-eu.ssl.mirantis.net/v2/"}]}, \ {"id": "v2.3", "status": "SUPPORTED", "links": \ [{"rel": "self", "href": "https://glance.ic-eu.ssl.mirantis.net/v2/"}]}, \ {"id": "v2.2", "status": "SUPPORTED", "links": \ [{"rel": "self", "href": "https://glance.ic-eu.ssl.mirantis.net/v2/"}]}, \ {"id": "v2.1", "status": "SUPPORTED", "links": \ [{"rel": "self", "href": "https://glance.ic-eu.ssl.mirantis.net/v2/"}]}, \ {"id": "v2.0", "status": "SUPPORTED", "links": \ [{"rel": "self", "href": "https://glance.ic-eu.ssl.mirantis.net/v2/"}]}]}
Once done, you should be able to upload an image through Horizon with untrusted SSL certificates.
Rotate OpenStack credentials¶
The credential rotation procedure is designed to minimize the impact on service availability and workload downtime. It depends on the credential type and is based on the following principles:
Credentials for OpenStack admin database and messaging are immediately changed during one rotation cycle, without a transition period.
Credentials for OpenStack admin identity are rotated with a transition period of one extra rotation cycle. This means that the credentials become invalid after two rotations. MOSK exposes the latest valid credentials to the
openstack-externalnamespace. For details, refer to Access OpenStack through CLI from your local machine.Credentials for OpenStack service users, including those for messaging, identity, and database, undergo a transition period of one extra rotation cycle during rotation.
Note
If immediate inactivation of credentials is required, initiate the rotation procedure twice.
Impact on workloads availability¶
The restarts of the Networking service may cause workload downtimes. The exact lengths of these downtimes depend on the cloud density and scale.
Impact on APIs availability¶
Rotating both administrator and service credentials can potentially result in certain API operations failing.
Rotation prerequisites¶
Verify that the current
stateof the LCM action inOpenstackDeploymentStatusisAPPLIED:kubectl -n openstack get osdplst -o yaml
Example of an expected system response:
1 kind: OpenStackDeploymentStatus 2 metadata: 3 name: osh-dev 4 namespace: openstack 5 spec: {} 6 status: 7 ... 8 osdpl: 9 cause: update 10 changes: '((''add'', (''status'',), None, {''watched'': {''ceph'': {''secret'': 11 {''hash'': ''0fc01c5e2593bc6569562b451b28e300517ec670809f72016ff29b8cbaf3e729''}}}}),)' 12 controller_version: 0.5.3.dev12 13 fingerprint: a112a4a7d00c0b5b79e69a2c78c3b50b0caca76a15fe7d79a6ad1305b19ee5ec 14 openstack_version: ussuri 15 state: APPLIED 16 timestamp: "2021-09-08 17:01:45.633143"
Verify that there are no other LCM operations running on the OpenStack cluster.
Thoroughly plan the maintenance window taking into account the following considerations:
All OpenStack control plane services, components of the Networking service (OpenStack Neutron) responsible for the data plane and messaging services are restarted during service credentials rotation.
OpenStack database and OpenStack messaging services are restarted during administrator credentials rotation, as well as some of the Openstack control plane services, including the Instance High Availability service (OpenStack Masakari), Dashboard (OpenStack Horizon), and Identity service (OpenStack Keystone).
For approximate maintenance window duration, refer to Calculate a maintenance window duration for update.
Rotate the credentials¶
Log in to the
osdplcontainer in theopenstack-controllerpod:kubectl -n osh-system exec -it <openstack-controller-pod> -c osdpl -- bash
Use the osctl utility to trigger credentials rotation:
osctl credentials rotate --osdpl <osdpl-object-name> --type <credentials-type>
Where the
<credentials-type>value is eitheradminorservice.Note
Mirantis recommends rotating both admin and service credentials simultaneously to decrease the duration of the maintenance window and number of service restarts. You can do this by passing the
--typeargument twice:osctl credentials rotate --osdpl <osdpl-object-name> --type service --type admin
Wait until the
OpenStackDeploymentStatusobject has stateAPPLIEDand all OpenStack components in thehealthgroup in theOpenStackDeploymentStatuscustom resource are in theReadystate.Alternatively, you can launch the rotation command with the
--waitflag.
Now, the latest admin password for your OpenStack environment is available in
the openstack-identity-credentials secret in the openstack-external
namespace.
Customize OpenStack container images¶
This section provides instructions on how to customize the functionality of your MOSK OpenStack services by installing custom system or Python packages into their container images.
The MOSK services are running in Ubuntu-based containers, which can be extended to meet specific requirements or implement specific use cases, for example:
Enabling third-party storage driver for OpenStack Cinder
Implementing a custom scheduler for OpenStack Nova
Adding a custom dashboard to OpenStack Horizon
Building your own image importing workflow for OpenStack Glance
Warning
Mirantis cannot be held responsible for any consequences arising from using customized container images. Mirantis does not provide support for such actions, and any modifications to production systems are made at your own risk.
Note
Custom images are pinned in the OpenStackDeployment custom
resource. These images do not undergo automatic updates or upgrades.
Cloud administrator is responsible for image update during OpenStack
updating and upgrading.
Build a custom container image¶
Create a new directory and switch to it:
mkdir my-custom-image cd my-custom-image
Create a Dockerfile:
touch DockerfileSpecify the location for the base image in the Dockerfile.
A custom image can be derived from any OpenStack image shipped with MOSK. For locations of the images comprising a specific MOSK release, refer to a corresponding release artifacts page in the Release Notes.
ARG FROM=<images-base-url>/openstack/<image-name>:<tag> FROM $FROM
Note
Presuming the custom image will need to get rebuilt for every new MOSK release, Mirantis recommends parametrizing the location of its base by introducing the
$FROMargument to the Dockerfile.Instruct the Dockerfile to install additional system packages:
RUN apt-get update ;\ apt-get install --no-install-recommends -y <package name> ;\ apt-get clean -y
If you need to install packages from a third-party repository:
Make sure that the
add-apt-repositoryutility is installed:RUN apt-get install --no-install-recommends -y software-properties-common
Add the third-party repository:
RUN add-apt-repository <repository_name>
Instruct the Dockerfile to install additional Python packages:
Caution
Rules to comply with when extending MOSK container images with Python packages:
Use only Python wheel packaging standard, the older
*.eggpackage type is not supportedHonor upper constraints that MOSK defines for its OpenStack packages prerequisites
OpenStack components in every MOSK release are shipped together with their requirements packaged as Python wheels and constraints file. Download and extract these artifacts from the corresponding
requirementscontainer image, so that they can be used for building your packages as well. Use therequirementsimage with the same tag as the base image that you plan to customize:docker pull <images-base-url>/openstack/requirements:<tag> docker save -o requirements.tar <images-base-url>/openstack/requirements:<tag> mkdir requirements tar -xf requirements.tar -C requirements tar -xf requirements/<shasum>/layer.tar -C requirements
Build your Python wheel packages using one of the commands below depending on the place where the source code is stored:
Build from source:
pip wheel --no-binary <package> <package> --wheel-dir=custom-wheels -c requirements/dev-upper-constraints.txt
Build from an upstream pip repository:
pip wheel <package> --wheel-dir=custom-wheels -c requirements/dev-upper-constraints.txt
Build from a custom repository:
pip wheel <package> --extra-index-url <Repo-URL> --wheel-dir=custom-wheels -c requirements/dev-upper-constraints.txt
Include the built custom wheel packages and packages for the requirements into the Dockerfile:
COPY custom-wheels /tmp/custom-wheels COPY requirements /tmp/wheels
Install the necessary wheel packages to be stored along with other OpenStack components:
RUN source /var/lib/openstack/bin/activate ;\ pip install <package> --no-cache-dir --only-binary :all: --no-compile --find-links /tmp/wheels --find-links /tmp/custom-wheels -c /tmp/wheels/dev-upper-constraints.txt
Build the container image from your Dockerfile:
docker build --tag <user-name>/<repo-name>:<tag> .
When selecting the name for your image, Mirantis recommends following the common practice across major public Docker repositories, that is Docker Hub. The image name should be
<user-name>/<repo-name>, where<user-name>is a unique identifier of the user who authored it and<repo-name>is the name of the software shipped.Specify the current directory as the build context. Also, use the
--tagoption to assign the tag to your image. Assigning a tag:<tag>enables you to add multiple versions of the same image to the repository. Unless you assign a tag, it defaults tolatest.If you are adding Python packages, you can minimize the size of the custom image by building it with the
--squashflag. It merges all the image layers into one and instructs the system not to store the cache layers of the wheel packages.Verify that the image has been built and is present on your system:
docker image ls
Publish the image to the designated registry by its name and tag:
Note
Before pushing the image, make sure that you have authenticated with the registry using the docker login command.
docker push <user-name>/<repo-name>:<tag>
Attach a private Docker registry to MOSK Kubernetes underlay¶
To ensure that the Kubernetes worker nodes in your MOSK cluster can locate and download the custom image, it should be published to a container image registry that the cluster is configured to use.
To configure the MOSK Kubernetes underlay to use your
private registry, you need to create a ContainerRegistry resource in the
Mirantis Container Cloud API with the registry domain and CA certificate in it,
and specify the resource in the Cluster object that corresponds to
MOSK.
For the details, refer to the Mirantis Container Cloud documentation:
Inject a custom image into MOSK cluster¶
To inject a customized OpenStack container into your MOSK
cluster, you need to use the spec:services section in the
OpenStackDeployment custom resource to override the default location of
the container image with your own:
Open the
OpenStackDeploymentcustom resource for editing:kubectl -n openstack edit osdpl osh-dev
Specify the path to your custom image:
For MOSK Dashboard (OpenStack Horizon):
spec: services: dashboard: horizon: values: images: tags: horizon: <image_path>
For the MOSK Block Storage service (OpenStack Cinder):
spec: services: block-storage: cinder: values: images: tags: <image_name>: <image_path>
HowTo examples¶
To help you better understand the process, this section provides a few examples illustrating how to add various plugins to MOSK services.
Warning
Mirantis cannot be held responsible for any consequences arising from using storage drivers, plugins, or features that are not explicitly tested or documented with MOSK. Mirantis does not provide support for such configurations as a part of standard product subscription.
See also
OpenStack services configuration¶
The section covers OpenStack services post-deployment configuration and is intended for cloud operators who are responsible for providing working cloud infrastructure to the cloud end users.
Configure high availability with Masakari¶
Instances High Availability Service or Masakari is an OpenStack project designed to ensure high availability of instances and compute processes running on hosts.
Before the end user can start enjoying the benefits of Masakari, the cloud operator has to configure the service properly. This section includes instructions on how to create segments and host through the Masakari API as well as provides the list of additional settings that can be useful in certain use cases.
Group compute nodes into segments¶
The segment object is a logical grouping of compute nodes into zones
also known as availability zones. The segment object enables
the cloud operator to list, create, show details for, update,
and delete segments.
To create a segment named allcomputes with service_type = compute,
and recovery_method = auto, run:
openstack segment create allcomputes auto compute
Example of a positive system response:
+-----------------+--------------------------------------+
| Field | Value |
+-----------------+--------------------------------------+
| created_at | 2021-07-06T07:34:23.000000 |
| updated_at | None |
| uuid | b8b0d7ca-1088-49db-a1e2-be004522f3d1 |
| name | allcomputes |
| description | None |
| id | 2 |
| service_type | compute |
| recovery_method | auto |
+-----------------+--------------------------------------+
Create hosts under segments¶
The host object represents compute service hypervisors. A host belongs
to a segment. The host can be any kind of virtual machine that has
compute service running on it. The host object enables the operator
to list, create, show details for, update, and delete hosts.
To create a host under a given segment:
Obtain the hypervisor hostname:
openstack hypervisor list
Example of a positive system response:
+----+-------------------------------------------------------+-----------------+------------+-------+ | ID | Hypervisor Hostname | Hypervisor Type | Host IP | State | +----+-------------------------------------------------------+-----------------+------------+-------+ | 2 | vs-ps-vyvsrkrdpusv-1-w2mtagbeyhel-server-cgpejthzbztt | QEMU | 10.10.0.39 | up | | 5 | vs-ps-vyvsrkrdpusv-0-ukqbpy2pkcuq-server-s4u2thvgxdfi | QEMU | 10.10.0.14 | up | +----+-------------------------------------------------------+-----------------+------------+-------+
Create the host under previously created segment. For example, with
uuid = b8b0d7ca-1088-49db-a1e2-be004522f3d1:Caution
The segment under which you create a host must exist.
openstack segment host create \ vs-ps-vyvsrkrdpusv-1-w2mtagbeyhel-server-cgpejthzbztt \ compute \ SSH \ b8b0d7ca-1088-49db-a1e2-be004522f3d1
Positive system response:
+---------------------+-------------------------------------------------------+ | Field | Value | +---------------------+-------------------------------------------------------+ | created_at | 2021-07-06T07:37:26.000000 | | updated_at | None | | uuid | 6f1bd5aa-0c21-446a-b6dd-c1b4d09759be | | name | vs-ps-vyvsrkrdpusv-1-w2mtagbeyhel-server-cgpejthzbztt | | type | compute | | control_attributes | SSH | | reserved | False | | on_maintenance | False | | failover_segment_id | b8b0d7ca-1088-49db-a1e2-be004522f3d1 | +---------------------+-------------------------------------------------------+
Enable notifications¶
The alerting API is used by Masakari monitors to notify about a failure
of either a host, process, or instance. The notification object enables
the operator to list, create, and show details of notifications.
Useful tunings¶
The list of useful tunings for the Masakari service includes:
[host_failure]\evacuate_all_instancesEnables the operator to decide whether to evacuate all instances or only the instances that have
[host_failure]\ha_enabled_instance_metadata_keyset toTrue. By default, the parameter is set toFalse.[host_failure]\ha_enabled_instance_metadata_keyEnables the operator to decide on the instance metadata key naming that affects the per instance behavior of
[host_failure]\evacuate_all_instances. The default is the same for both failure types, which includehostandinstance, but the value can be overridden to make the metadata key different per failure type.[host_failure]\ignore_instances_in_error_stateEnables the operator to decide whether error instances should be allowed for evacuation from a failed source compute node or not. If set to
True, it will ignore error instances from evacuation from a failed source compute node. Otherwise, it will evacuate error instances along with other instances from a failed source compute node.[instance_failure]\process_all_instancesEnables the operator to decide whether all instances or only the ones that have
[instance_failure]\ha_enabled_instance_metadata_keyset toTrueshould be recovered from instance failure events. If set toTrue, it will execute instance failure recovery actions for an instance irrespective of whether that particular instance has[instance_failure]\ha_enabled_instance_metadata_keyset toTrueor not. Otherwise, it will only execute instance failure recovery actions for an instance which has[instance_failure]\ha_enabled_instance_metadata_keyset toTrue.[instance_failure]\ha_enabled_instance_metadata_keyEnables the operators to decide on the instance metadata key naming that affects the per-instance behavior of
[instance_failure]\process_all_instances. The default is the same for both failure types, which includehostandinstance, but you can override the value to make the metadata key different per failure type.
Configure monitoring of instance availability¶
Available since MOSK 23.2 TechPreview
MOSK provides the OpenStack workload monitoring feature through the Cloudprober exporter. This section explains the monitoring configuration details.
For the feature description and usage requirements, refer to Reference Architecture: Workload monitoring.
Enable OpenStack instances monitoring¶
Enable the Cloudprober service in the
OpenStackDeploymentcustom resource:spec: features: services: - cloudprober
Wait untill the
OpenStackDeploymentstate becomesapplied:kubectl -n openstack get osdplst
Example of a positive system response:
NAME OPENSTACK VERSION CONTROLLER VERSION STATE osh-dev yoga 0.13.1.dev54 APPLIED
Verify that the Cloudprober service has been deployed:
kubectl -n openstack get pods -l application=cloudprober
Example of a positive system response:
NAME READY STATUS RESTARTS AGE openstack-cloudprober-587b4bf7c4-lwmxx 2/2 Running 2 3d1h openstack-cloudprober-587b4bf7c4-v9tt9 2/2 Running 0 3d1h
Verify that the Cloudprober service is operational:
Log in to the StackLight Prometheus web UI.
Navigate to Status - Targets.
Search for the
openstack-cloudprobertarget and verify that it isUP.
Configure security groups for monitoring¶
By default, for outgoing traffic, the IP address for the Cloudprober Pod is translated to the node IP address. In this procedure, we assume no further translation of that node IP address on the path between the node and floating network.
Identify the node IP address used for traffic destined to floating network by selecting the IP address from the floating network and running the following command on each OpenStack control plane node:
ip r get <floating ip> | grep -E -o '(src .*)' | awk '{print $2}'
In the project where monitored virtual machines are running, create a security group:
openstack security group create --project <project_id> instance-monitoring
Create the rule for each IP address you obtain in step 1:
openstack security group rule create --proto icmp --ingress --remote-ip <node ip> instance-monitoring
Add instances to monitoring¶
Log in to the
keystone-clientPod to assign theopenstack.lcm.mirantis.com:probertag to each instance to be added to monitoring:openstack --os-compute-api-version 2.26 server set --tag openstack.lcm.mirantis.com:prober <INSTANCE_ID>
Assign the
instance-monitoringsecurity group to the server:openstack server add security group <SERVER_ID> <SECURITY_GROUP_ID>
Verify that the instances have been added successfully.
Cloudprober uses auto-discovery of instances on periodic basis. Therefore, wait for the discovery interval to pass (defaults to 600 seconds) and execute the following command inside the
keystone-clientPod:curl -s http://cloudprober.openstack.svc.cluster.local:9313/metrics | grep <INSTANCE_ID>
Example of a positive system response:
cloudprober_total{ptype="ping",probe="openstack-instances-icmp-probe",dst="d34a0c6b-91a2-4bd3-95ea-772da49b90c3-10.11.12.122",openstack_hypervisor_hostname="mk-ps-xp4m27lfl56j-1-w74pc7cinu67-server-42kx24m22xop.cluster.local",openstack_instance_id="d34a0c6b-91a2-4bd3-95ea-772da49b90c3",openstack_instance_name="test-vm-proj",openstack_project_id="1eb031db8add42fda2fdb0ef2c2ad8d7"} 266388 1685963215202 cloudprober_success{ptype="ping",probe="openstack-instances-icmp-probe",dst="d34a0c6b-91a2-4bd3-95ea-772da49b90c3-10.11.12.122",openstack_hypervisor_hostname="mk-ps-xp4m27lfl56j-1-w74pc7cinu67-server-42kx24m22xop.cluster.local",openstack_instance_id="d34a0c6b-91a2-4bd3-95ea-772da49b90c3",openstack_instance_name="test-vm-proj",openstack_project_id="1eb031db8add42fda2fdb0ef2c2ad8d7"} 266386 1685963215202 cloudprober_latency{ptype="ping",probe="openstack-instances-icmp-probe",dst="d34a0c6b-91a2-4bd3-95ea-772da49b90c3-10.11.12.122",openstack_hypervisor_hostname="mk-ps-xp4m27lfl56j-1-w74pc7cinu67-server-42kx24m22xop.cluster.local",openstack_instance_id="d34a0c6b-91a2-4bd3-95ea-772da49b90c3",openstack_instance_name="test-vm-proj",openstack_project_id="1eb031db8add42fda2fdb0ef2c2ad8d7"} 315484742.137 1685963215202 cloudprober_validation_failure{ptype="ping",probe="openstack-instances-icmp-probe",dst="d34a0c6b-91a2-4bd3-95ea-772da49b90c3-10.11.12.122",openstack_hypervisor_hostname="mk-ps-xp4m27lfl56j-1-w74pc7cinu67-server-42kx24m22xop.cluster.local",openstack_instance_id="d34a0c6b-91a2-4bd3-95ea-772da49b90c3",openstack_instance_name="test-vm-proj",openstack_project_id="1eb031db8add42fda2fdb0ef2c2ad8d7",validator="data-integrity"} 0 1685963215202
Note
You can adjust the instance auto-discovery interval in the
OpenStackDeploymentobject. However, Mirantis does not recommend setting it to too low values to avoid high load on the OpenStack API:spec: features: cloudprober: discovery: interval: 300
Now, you can start monitoring the availability of instance floating IP addresses per OpenStack compute node and project, as well as viewing the probe statistics for individual instance floating IP addresses through the Openstack Instances Availability dashboard in Grafana.
See also
Ceph operations¶
To manage a running Ceph cluster, for example, to add or remove a Ceph OSD, remove a Ceph node, replace a failed physical disk with a Ceph node, or update your Ceph cluster, refer to Mirantis Container Cloud Operations Guide: Manage Ceph.
Before you proceed with any reading or writing operation, first check the cluster status using the ceph tool as described in Mirantis Container Cloud Operations Guide: Verify the Ceph core services.
This section describes the OpenStack-related Ceph operations.
Configure Ceph Object Gateway TLS¶
Once you enable Ceph Object Gateway (radosgw) as described in
Mirantis Container Cloud: Enable Ceph RGW Object Storage,
you can configure the Transport Layer Security (TLS) protocol for a Ceph Object
Gateway public endpoint using the following options:
Using MOSK TLS, if it is enabled and exposes its certificates and domain for Ceph. In this case, Ceph Object Gateway will automatically create an ingress rule with MOSK certificates and domain to access the Ceph Object Gateway public endpoint. Therefore, you only need to reach the Ceph Object Gateway public and internal endpoints and set the CA certificates for a trusted TLS connection.
Using custom
ingressspecified in theKaaSCephClusterCR. In this case, Ceph Object Gateway public endpoint will use the public domain specified using theingressparameters.
Caution
External Ceph Object Gateway service is not supported and will be deleted during update. If your system already uses endpoints of an external Ceph Object Gateway service, reconfigure them to the ingress endpoints.
Caution
When using a custom or OpenStack ingress, ensure to configure the DNS name for RGW to target an external IP address of that ingress. If there is no OpenStack or custom ingress available, point the DNS to an external load balancer of RGW.
Note
Since MOSK 23.3, if the cluster has
tls-proxy enabled, TLS certificates specified in ingress objects,
including those configured in the KaaSCephCluster specification,
are disregarded. Instead, common certificates are applied to all ingresses
from the OpenStackDeployment object. This implies that tlsCert and
other ingress certificates specified in KaaSCephCluster are ignored,
and the common certificate from the OpenStackDeployment object is used.
This section also describes how to specify a custom public endpoint for the Object Storage service.
To configure Ceph Object Gateway TLS:
Verify whether MOSK TLS is enabled. The
spec.features.ssl.public_endpointssection should be specified in theOpenStackDeploymentCR.To generate an SSL certificate for internal usage, verify that the gateway
securePortparameter is specified in theKaasCephClusterCR. For details, see Mirantis Container Cloud: Enable Ceph RGW Object Storage.Select from the following options:
If MOSK TLS is enabled, obtain the MOSK CA certificate for a trusted connection:
kubectl -n openstack-ceph-shared get secret openstack-rgw-creds -o jsonpath="{.data.ca_cert}" | base64 -d
Configure Ceph Object Gateway TLS using a custom
ingress:Warning
The
rgwsection is deprecated and theingressparameters are moved undercephClusterSpec.ingress. If you continue usingrgw.ingress, it will be automatically translated intocephClusterSpec.ingressduring the MOSK cluster release update.Open the
KaasCephClusterCR for editing.Specify the
ingressparameters:publicDomain- domain name to use for the external service.Caution
Since MOSK 23.3, the default ingress controller does not support
publicDomainvalues different from the OpenStack ingress public domain. Therefore, if you intend to use the default OpenStack ingress controller for your Ceph Object Storage public endpoint, plan to use the same public domain as your OpenStack endpoints.cacert- Certificate Authority (CA) certificate, used for the ingress rule TLS support.tlsCert- TLS certificate, used for the ingress rule TLS support.tlsKey- TLS private key, used for the ingress rule TLS support.customIngressOptional - includes the following custom Ingress Controller parameters:className- the custom Ingress Controller class name. If not specified, theopenstack-ingress-nginxclass name is used by default.annotations- extra annotations for the ingress proxy. For details, see NGINX Ingress Controller: Annotations.By default, the following annotations are set:
nginx.ingress.kubernetes.io/rewrite-targetis set to/nginx.ingress.kubernetes.io/upstream-vhostis set to<rgwName>.rook-ceph.svc.The value for
<rgwName>isspec.cephClusterSpec.objectStorage.rgw.name.
Optional annotations:
nginx.ingress.kubernetes.io/proxy-request-buffering: "off"that disables buffering foringressto prevent the 413 (Request Entity Too Large) error when uploading large files usingradosgw.nginx.ingress.kubernetes.io/proxy-body-size: <size>that increases the default uploading size limit to prevent the 413 (Request Entity Too Large) error when uploading large files usingradosgw. Set the value in MB (m) or KB (k). For example,100m.
For example:
customIngress: className: openstack-ingress-nginx annotations: nginx.ingress.kubernetes.io/rewrite-target: / nginx.ingress.kubernetes.io/upstream-vhost: openstack-store.rook-ceph.svc nginx.ingress.kubernetes.io/proxy-body-size: 100m
Note
An ingress rule is by default created with an internal Ceph Object Gateway service endpoint as a back end. Also,
rgw dns nameis specified in the Ceph configuration and is set to<rgwName>.rook-ceph.svcby default. You can override this option using thespec.cephClusterSpec.rookConfigkey-value parameter. In this case, also change the corresponding ingress annotation.
For example:
spec: cephClusterSpec: objectStorage: rgw: name: rgw-store ingress: publicDomain: public.domain.name cacert: | -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE----- tlsCert: | -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE----- tlsKey: | -----BEGIN RSA PRIVATE KEY----- ... -----END RSA PRIVATE KEY----- customIngress: annotations: "nginx.ingress.kubernetes.io/upstream-vhost": rgw-store.public.domain.name rookConfig: "rgw dns name": rgw-store.public.domain.name
Warning
For clouds with the
publicDomainparameter specified, align theupstream-vhostingress annotation with the name of the Ceph Object Storage and the specified public domain.Ceph Object Storage requires the
upstream-vhostandrgw dns nameparameters to be equal. Therefore, override the defaultrgw dns nameto the corresponding ingress annotation value.
To access internal and public Ceph Object Gateway endpoints:
Select from the following options:
Note
If you are using the HTTP scheme instead of HTTPS, skip obtaining CA certificates and add the following configuration to the
KaaSCephClusterobject on a management cluster:spec: cephClusterSpec: rookConfig: rgw_remote_addr_param: "HTTP_X_FORWARDED_FOR"
To access Ceph Object Gateway with a public endpoint:
Obtain the Ceph Object Gateway public endpoint:
kubectl -n rook-ceph get ingress
Obtain the public endpoint TLS CA certificate:
kubectl -n rook-ceph get secret $(kubectl -n rook-ceph get ingress -o jsonpath='{.items[0].spec.tls[0].secretName}{"\n"}') -o jsonpath='{.data.ca\.crt}' | base64 -d; echo
To access Ceph Object Gateway with an internal endpoint:
Obtain the internal endpoint name for Ceph Object Gateway:
kubectl -n rook-ceph get svc -l app=rook-ceph-rgw
The internal endpoint for Ceph Object Gateway has the
https://<internal-svc-name>.rook-ceph.svc:<rgw-secure-port>/format, where<rgw-secure-port>isspec.rgw.gateway.securePortspecified in theKaaSCephClusterCR.Obtain the internal endpoint TLS CA certificate:
kubectl -n rook-ceph get secret <rgwCacertSecretName> -o jsonpath="{.data.cacert}" | base64 -d
Substitute
<rgwCacertSecretName>withrgw-ssl-certificate.
Update the zonegroup
hostnamesof Ceph Object Gateway:The
hostnameszonegroup of Ceph Object Gateway updates automatically and you can skip this step if one of the following requirements is met:The public hostname matches the public domain name set by the
spec.cephClusterSpec.ingress.publicDomainfieldThe OpenStack configuration has been applied
Otherwise, complete the steps for MOSK 22.4 and earlier product versions.
Enter the
rook-ceph-toolspod:kubectl -n rook-ceph exec -it deployment/rook-ceph-tools -- bash
Obtain Ceph Object Gateway default zonegroup configuration:
radosgw-admin zonegroup get --rgw-zonegroup=<objectStorageName> --rgw-zone=<objectStorageName> | tee zonegroup.json
Substitute
<objectStorageName>with the Ceph Object Storage name fromspec.cephClusterSpec.objectStorage.rgw.name.Inspect
zonegroup.jsonand verify that thehostnameskey is a list that contains two endpoints: an internal endpoint and a custom public endpoint:"hostnames": ["rook-ceph-rgw-<objectStorageName>.rook-ceph.svc", <customPublicEndpoint>]
Substitute
<objectStorageName>with the Ceph Object Storage name and<customPublicEndpoint>with the public endpoint with a custom public domain.If one or both endpoints are omitted in the list, add the missing endpoints to the
hostnameslist in thezonegroup.jsonfile and update Ceph Object Gateway zonegroup configuration:radosgw-admin zonegroup set --rgw-zonegroup=<objectStorageName> --rgw-zone=<objectStorageName> --infile zonegroup.json radosgw-admin period update --commit
Verify that the
hostnameslist contains both the internal and custom public endpoint:radosgw-admin --rgw-zonegroup=<objectStorageName> --rgw-zone=<objectStorageName> zonegroup get | jq -r ".hostnames"
Example of system response:
[ "rook-ceph-rgw-obj-store.rook-ceph.svc", "obj-store.mcc1.cluster1.example.com" ]
Exit the
rook-ceph-toolspod:exit
Once done, Ceph Object Gateway becomes available by the custom public endpoint with an S3 API client, OpenStack Swift CLI, and OpenStack Horizon Containers plugin.
Ceph default configuration options¶
Ceph Controller provides the capability to specify configuration options for
the Ceph cluster through the spec.cephClusterSpec.rookConfig key-value
parameter of the KaaSCephCluster resource as if they were set in a usual
ceph.conf file. For details, see
Mirantis Container Cloud Operations Guide: Ceph advanced configuration.
However, if rookConfig is empty but the
spec.cephClsuterSpec.objectStore.rgw section is defined, Ceph Controller
specifies the following OpenStack-related default configuration options for
each Ceph cluster. For other default options, see Mirantis Container Cloud
Operations Guide: Ceph default configuration options.
Ceph Object Gateway options, which you can override using the
rookConfigparameter:rgw swift account in url = true rgw keystone accepted roles = '_member_, Member, member, swiftoperator' rgw keystone accepted admin roles = admin rgw keystone implicit tenants = true rgw swift versioning enabled = true rgw enforce swift acls = true rgw_max_attr_name_len = 64 rgw_max_attrs_num_in_req = 32 rgw_max_attr_size = 1024 rgw_bucket_quota_ttl = 0 rgw_user_quota_bucket_sync_interval = 0 rgw_user_quota_sync_interval = 0 rgw s3 auth use keystone = true
Additional parameters for the Keystone integration:
Warning
All values with the
keystoneprefix are programmatically specified for each MOSK deployment. Do not modify these parameters manually.rgw keystone api version = 3 rgw keystone url = <keystoneAuthURL> rgw keystone admin user = <keystoneUser> rgw keystone admin password = <keystonePassword> rgw keystone admin domain = <keystoneProjectDomain> rgw keystone admin project = <keystoneProjectName>
Use object storage server-side encryption¶
TechPreview
When you use Ceph Object Gateway server-side encryption (SSE), unencrypted data sent over HTTPS is stored encrypted by the Ceph Object Gateway in the Ceph cluster. The current implementation integrates Barbican as a key management service.
The object storage SSE feature is enabled by default in MOSK deployments with Barbican. To use object storage SSE, the AWS CLI S3 client is used.
To use object storage server-side encryption:
Create Amazon Elastic Compute Cloud (EC2) credentials:
openstack ec2 credentials create
Configure AWS CLI with
accessandsecretcreated in the previous step:aws configureCreate a secret key in Barbican secret key:
openstack secret order create --name <name> --algorithm <algorithm> --mode <mode> --bit-length 256 --payload-content-type=<payload-content-type> key
Substitute the parameters enclosed in angle brackets:
<name>- human-friendly name.<algorithm>- algorithm to use with the requested key. For example,aes.<mode>- algorithm mode to use with the requested key. For example,ctr.<payload-content-type>- type/format of the secret to generate. For example,application/octet-stream.
Verify that the key has been created:
openstack secret order get <order-href>
Substitute
<order-href>with the corresponding value from the output of the previous command.Specify the
ceph-rgwuser in the Barbican secret Access Control List (ACL):Obtain the list of
ceph-rgwusers:openstack user list --domain service | grep ceph-rgw
Example output:
| c63b70134e0845a2b13c3f947880f66a | ceph-rgwZ6ycK3dY |
In the output, capture the first value as the
<user-id>, which isc63b70134e0845a2b13c3f947880f66ain the above example.Specify the
ceph-rgwuser in the Barbican ACL:openstack acl user add --user <user-id> <secret-href>
Substitute
<user-id>with the corresponding value from the output of the previous command and<secret-href>with the corresponding value obtained in step 3.
Create an S3 bucket:
aws --endpoint-url <rgw-endpoint-url> --ca-bundle <ca-bundle> s3api create-bucket --bucket <bucket-name>
Substitute the parameters enclosed in angle brackets:
<rgw-endpoint-url>- Ceph Object Gateway endpoint DNS name<ca-bundle>- CA Certificate Bundle<bucket-name>- human-friendly bucket name
Upload a file using object storage SSE:
aws --endpoint-url <rgw-endpoint-url> --ca-bundle <ca-bundle> s3 cp <path-to-file> "s3://<bucket-name>/<filename>" --sse aws:kms --sse-kms-key-id <key-id>
Substitute the parameters enclosed in angle brackets:
<path-to-file>- path to the file that you want to upload<filename>- name under which the uploaded file will be stored in the bucket<key-id>- Barbican secret key ID
Select from the following options to download the file:
Download the file using a key:
aws --endpoint-url <rgw-endpoint-url> --ca-bundle <ca-bundle> s3 cp "s3://<bucket-name>/<filename>" <path-to-output-file> --sse aws:kms --sse-kms-key-id <key-id>
Substitute
<path-to-output-file>with the path to the file you want to download.Download the file without a key:
aws --endpoint-url <rgw-endpoint-url> --ca-bundle <ca-bundle> s3 cp "s3://<bucket-name>/<filename>" <output-filename>
Set a bucket policy for OpenStack users¶
The following procedure illustrates the process of setting a bucket policy for a bucket between two OpenStack users.
Due to specifics of the Ceph integration with OpenStack projects, you should configure the bucket policy for OpenStack users indirectly through setting permissions for corresponding OpenStack projects.
For illustration purposes, we use the following names in the procedure:
test01for the bucketuser-a,user-tfor the OpenStack usersproject-a,project-tfor the OpenStack projects
To configure an Amazon S3 bucket policy for OpenStack users:
Specify the
rookConfigparameter in thecephClusterSpecsection of theKaaSCephClustercustom resource:spec: cephClusterSpec: rookConfig: rgw keystone implicit tenants: "swift"
Prepare the Ceph Object Storage similarly to the procedure described in Mirantis Container Cloud Operations Guide: Create Ceph Object Storage users.
Create two OpenStack projects:
openstack project create project-a openstack project create project-t
Example of system response:
+-------------+----------------------------------+ | Field | Value | +-------------+----------------------------------+ | description | | | domain_id | default | | enabled | True | | id | faf957b776874a2e80384cb882ebf6ab | | is_domain | False | | name | project-a | | options | {} | | parent_id | default | | tags | [] | +-------------+----------------------------------+
You can also use existing projects. Save the ID of each project for the bucket policy specification.
Note
For details how to access OpenStack CLI, refer Access your OpenStack environment.
Create an OpenStack user for each project:
openstack user create user-a --project project-a openstack user create user-t --project project-t
Example of system response:
+---------------------+----------------------------------+ | Field | Value | +---------------------+----------------------------------+ | default_project_id | faf957b776874a2e80384cb882ebf6ab | | domain_id | default | | enabled | True | | id | cc2607dc383e4494948d68eeb556f03b | | name | user-a | | options | {} | | password_expires_at | None | +---------------------+----------------------------------+
You can also use existing project users.
Assign the
memberrole to the OpenStack users:openstack role add member --user user-a --project project-a openstack role add member --user user-t --project project-t
Verify that the OpenStack users have obtained the
memberroles paying attention to the role IDs:openstack role show member
Example of system response:
+-------------+----------------------------------+ | Field | Value | +-------------+----------------------------------+ | description | None | | domain_id | None | | id | 8f0ce4f6cd61499c809d6169b2b5bd93 | | name | member | | options | {'immutable': True} | +-------------+----------------------------------+
List the role assignments for the
user-aanduser-t:openstack role assignment list --user user-a --project project-a openstack role assignment list --user user-t --project project-t
Example of system response:
+----------------------------------+----------------------------------+-------+----------------------------------+--------+--------+-----------+ | Role | User | Group | Project | Domain | System | Inherited | +----------------------------------+----------------------------------+-------+----------------------------------+--------+--------+-----------+ | 8f0ce4f6cd61499c809d6169b2b5bd93 | cc2607dc383e4494948d68eeb556f03b | | faf957b776874a2e80384cb882ebf6ab | | | False | +----------------------------------+----------------------------------+-------+----------------------------------+--------+--------+-----------+
Create Amazon EC2 credentials for
user-aanduser-t:openstack ec2 credentials create --user user-a --project project-a openstack ec2 credentials create --user user-t --project project-t
Example of system response:
+------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Field | Value | +------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------+ | access | d03971aedc2442dd9a79b3b409c32046 | | links | {'self': 'http://keystone-api.openstack.svc.cluster.local:5000/v3/users/cc2607dc383e4494948d68eeb556f03b/credentials/OS-EC2/d03971aedc2442dd9a79b3b409c32046'} | | project_id | faf957b776874a2e80384cb882ebf6ab | | secret | 0a9fd8d9e0d24aecacd6e75951154d0f | | trust_id | None | | user_id | cc2607dc383e4494948d68eeb556f03b | +------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------+
Obtain the values from the
accessandsecretfields to connect with Ceph Object Storage trough the s3cmd tool.Note
The s3cmd is a free command-line tool for uploading, retrieving, and managing data in Amazon S3 and other cloud storage service providers that use the S3 protocol. You can download the s3cmd tool from Amazon S3 tools: Download s3cmd.
Create bucket users and configure a bucket policy for the
project-tOpenStack project similarly to the procedure described in Mirantis Container Cloud Operations Guide: Set a bucket policy for a Ceph Object Storage user. Ceph integration does not allow providing permissions for OpenStack users directly. Therefore, you need to set permissions for the project that corresponds to the user:{ "Version": "2012-10-17", "Id": "S3Policy1", "Statement": [ { "Sid": "BucketAllow", "Effect": "Allow", "Principal": { "AWS": ["arn:aws:iam::<PROJECT-T_ID>:root"] }, "Action": [ "s3:ListBucket", "s3:PutObject", "s3:GetObject" ], "Resource": [ "arn:aws:s3:::test01", "arn:aws:s3:::test01/*" ] } ] }
Ceph Object Storage bucket policy examples¶
You can configure different bucket policies for various situations. See examples below.
Provide access to a bucket from one OpenStack project to another
{
"Version": "2012-10-17",
"Id": "S3Policy1",
"Statement": [
{
"Sid": "BucketAllow",
"Effect": "Allow",
"Principal": {
"AWS": ["arn:aws:iam::<osProjectId>:root"]
},
"Action": [
"s3:ListBucket",
"s3:PutObject",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::<bucketName>",
"arn:aws:s3:::<bucketName>/*"
]
}
]
}
Substitute the following parameters:
<osProjectId>- the target OpenStack project ID<bucketName>- the target bucket name where the policy will be set
Provide access to a bucket from a Ceph Object Storage user to an OpenStack project
{
"Version": "2012-10-17",
"Id": "S3Policy1",
"Statement": [
{
"Sid": "BucketAllow",
"Effect": "Allow",
"Principal": {
"AWS": ["arn:aws:iam::<osProjectId>:root"]
},
"Action": [
"s3:ListBucket",
"s3:PutObject",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::<bucketName>",
"arn:aws:s3:::<bucketName>/*"
]
}
]
}
Substitute the following parameters:
<osProjectId>- the target OpenStack project ID<bucketName>- the target bucket name where policy will be set
Provide access to a bucket from an OpenStack user to a Ceph Object Storage user
{
"Version": "2012-10-17",
"Id": "S3Policy1",
"Statement": [
{
"Sid": "BucketAllow",
"Effect": "Allow",
"Principal": {
"AWS": ["arn:aws:iam:::user/<userName>"]
},
"Action": [
"s3:ListBucket",
"s3:PutObject",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::<bucketName>",
"arn:aws:s3:::<bucketName>/*"
]
}
]
}
Substitute the following parameters:
<userName>- the target Ceph Object Storage user name<bucketName>- the target bucket name where policy will be set
Provide access to a bucket from one Ceph Object Storage user to another
{
"Version": "2012-10-17",
"Id": "S3Policy1",
"Statement": [
{
"Sid": "BucketAllow",
"Effect": "Allow",
"Principal": {
"AWS": ["arn:aws:iam:::user/<userName>"]
},
"Action": [
"s3:ListBucket",
"s3:PutObject",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::<bucketName>",
"arn:aws:s3:::<bucketName>/*"
]
}
]
}
Substitute the following parameters:
<userName>- the target Ceph Object Storage user name<bucketName>- the target bucket name where policy will be set
Calculate target ratio for Ceph pools¶
Ceph pool target ratio defines for the Placement Group (PG) autoscaler the amount of data the pools are expected to acquire over time in relation to each other. You can set initial PG values for each Ceph pool. Otherwise, the autoscaler starts with the minimum value and scales up, causing a lot of data to move in the background.
You can allocate several pools to use the same device class, which is a solid
block of available capacity in Ceph. For example, if three pools
(kubernetes-hdd, images-hdd, and volumes-hdd) are set to use the
same device class hdd, you can set the target ratio for Ceph pools to
provide 80% of capacity to the volumes-hdd pool and distribute the
remaining capacity evenly between the two other pools. This way, Ceph pool
target ratio instructs Ceph on when to warn that a pool is running out of free
space and, at the same time, instructs Ceph on how many placement groups Ceph
should allocate/autoscale for a pool for better data distribution.
Ceph pool target ratio is not a constant value and you can change it according to new capacity plans. Once you specify target ratio, if the PG number of a pool scales, other pools with specified target ratio will automatically scale accordingly.
For details, see Ceph Documentation: Autoscaling Placement Groups.
To calculate target ratio for each Ceph pool:
Define raw capacity of the entire storage by device class:
kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o name) -- ceph df
For illustration purposes, the procedure below uses raw capacity of 185 TB or 189440 GB.
Design Ceph pools with the considered device class upper bounds of the possible capacity. For example, consider the
hdddevice class that contains the following pools:The
kubernetes-hddpool will contain not more than 2048 GB.The
images-hddpool will contain not more than 2048 GB.The
volumes-hddpool will contain 50 GB per VM. The upper bound of used VMs on the cloud is 204, the pool replicated size is3. Therefore, calculate the upper bounds forvolumes-hdd:50 GB per VM * 204 VMs * 3 replicas = 30600 GB
The
backup-hddpool can be calculated as a relative ofvolumes-hdd. For example, 1volumes-hddstorage unit per 5backup-hddunits.The
vms-hddis a pool for ephemeral storage Copy on Write (CoW). We recommend designing the amount of ephemeral data it should store. For example purposes, we use 500 GB. However, in reality, despite the CoW data reduction, this value is very optimistic.
Note
If
dataPoolis replicated and Ceph Object Store is planned for intensive use, also calculate upper bounds fordataPool.Calculate target ratio for each considered pool. For example:
Example bounds and capacity¶ Pools upper bounds
Pools capacity
kubernetes-hdd= 2048 GBimages-hdd= 2048 GBvolumes-hdd= 30600 GBbackup-hdd= 30600 GB * 5 = 153000 GBvms-hdd= 500 GB
Summary capacity = 188196 GB
Total raw capacity = 189440 GB
Calculate pools fit factor using the (total raw capacity) / (pools summary capacity) formula. For example:
pools fit factor = 189440 / 188196 = 1.0066
Calculate pools upper bounds size using the (pool upper bounds) * (pools fit factor) formula. For example:
kubernetes-hdd = 2048 GB * 1.0066 = 2061.5168 GB images-hdd = 2048 GB * 1.0066 = 2061.5168 GB volumes-hdd = 30600 GB * 1.0066 = 30801.96 GB backup-hdd = 153000 GB * 1.0066 = 154009.8 GB vms-hdd = 500 GB * 1.0066 = 503.3 GB
Calculate pool target ratio using the (pool upper bounds) * 100 / (total raw capacity) formula. For example:
kubernetes-hdd = 2061.5168 GB * 100 / 189440 GB = 1.088 images-hdd = 2061.5168 GB * 100 / 189440 GB = 1.088 volumes-hdd = 30801.96 GB * 100 / 189440 GB = 16.259 backup-hdd = 154009.8 GB * 100 / 189440 GB = 81.297 vms-hdd = 503.3 GB * 100 / 189440 GB = 0.266
If required, calculate the target ratio for erasure-coded pools.
Due to erasure-coded pools splitting each object into
Kdata parts andMcoding parts, the total used storage for each object is less than that in replicated pools. Indeed,Mis equal to the number of OSDs that can be missing from the cluster without the cluster experiencing data loss. This means that planned data is stored with an efficiency of(K+M)/2on the Ceph cluster. For example, if an erasure-coded data pool withK=2, M=2planned capacity is 200 GB, then the total used capacity is200*(2+2)/2, which is 400 GB.Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with the corresponding value.In the
spec.cephClusterSpec.poolssection, specify the calculated relatives astargetSizeRatiofor each considered replicated pool. For example:spec: cephClusterSpec: pools: - name: kubernetes deviceClass: hdd ... replicated: size: 3 targetSizeRatio: 1.088 - name: images deviceClass: hdd ... replicated: size: 3 targetSizeRatio: 1.088 - name: volumes deviceClass: hdd ... replicated: size: 3 targetSizeRatio: 16.259 - name: backup deviceClass: hdd ... replicated: size: 3 targetSizeRatio: 81.297 - name: vms deviceClass: hdd ... replicated: size: 3 targetSizeRatio: 0.266
If Ceph Object Store
dataPoolisreplicatedand a proper value is calculated, also specify it:spec: cephClusterSpec: objectStorage: rgw: name: rgw-store ... dataPool: deviceClass: hdd ... replicated: size: 3 targetSizeRatio: <relative>
In the
spec.cephClusterSpec.poolssection, specify the calculated relatives asparameters.target_size_ratiofor each considered erasure-coded pool. For example:Note
The
parameterssection is a key-value mapping where the value is of the string type and should be quoted.spec: cephClusterSpec: pools: - name: ec-pool deviceClass: hdd ... parameters: target_size_ratio: "<relative>"
If Ceph Object Store
dataPooliserasure-codedand a proper value is calculated, also specify it:spec: cephClusterSpec: objectStorage: rgw: name: rgw-store ... dataPool: deviceClass: hdd ... parameters: target_size_ratio: "<relative>"
Verify that all target ratio has been successfully applied to the Ceph cluster:
kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o name) -- ceph osd pool autoscale-status
Example of system response:
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE device_health_metrics 0 2.0 149.9G 0.0000 1.0 1 on kubernetes-hdd 2068 2.0 149.9G 0.0000 1.088 1.0885 1.0 32 on volumes-hdd 19 2.0 149.9G 0.0000 16.259 16.2591 1.0 256 on vms-hdd 19 2.0 149.9G 0.0000 0.266 0.2661 1.0 128 on backup-hdd 19 2.0 149.9G 0.0000 81.297 81.2972 1.0 256 on images-hdd 888.8M 2.0 149.9G 0.0116 1.088 1.0881 1.0 32 on
Optional. Repeat the steps above for other device classes.
Ceph pools for Cinder multi-backend¶
Available since MOSK 23.2
The KaaSCephCluster object supports multiple Ceph pools with the
volumes role to configure Cinder multiple back ends.
To define Ceph pools for Cinder multiple back ends:
In the
KaaSCephClusterobject, add the desired number of Ceph pools to thepoolssection with thevolumesrole:kubectl -n <MOSKClusterProject> edit kaascephcluster
Substitute
<MOSKClusterProject>with corresponding namespace of the MOSK cluster.Example configuration:
spec: cephClusterSpec: pools: - default: false deviceClass: hdd name: volumes replicated: size: 3 role: volumes - default: false deviceClass: hdd name: volumes-backend-1 replicated: size: 3 role: volumes - default: false deviceClass: hdd name: volumes-backend-2 replicated: size: 3 role: volumes
Verify that Cinder back-end pools are created and ready:
kubectl -n <managedClusterProject> get kaascephcluster -o yaml
Example output:
status: fullClusterStatus: blockStorageStatus: poolsStatus: volumes-hdd: present: true status: observedGeneration: 1 phase: Ready volumes-backend-1-hdd: present: true status: observedGeneration: 1 phase: Ready volumes-backend-2-hdd: present: true status: observedGeneration: 1 phase: Ready
Verify that the added Ceph pools are accessible from the Cinder service. For example:
kubectl -n openstack exec -it cinder-volume-0 -- rbd ls -p volumes-backend-1-hdd -n client.cinder kubectl -n openstack exec -it cinder-volume-0 -- rbd ls -p volumes-backend-2-hdd -n client.cinder
After the Ceph pool becomes available, it is automatically specified as an additional Cinder back end and registered as a new volume type, which you can use to create Cinder volumes.
StackLight operations¶
The section covers the StackLight management aspects.
View Grafana dashboards¶
Using the Grafana web UI, you can view the visual representation of the metric graphs based on the time series databases.
This section describes only the OpenStack-related Grafana dashboards. For other dashboards, including the system, Kubernetes, Ceph, and StackLight dashboards that can contain information about both OpenStack and MOSK clusters, see Mirantis Container Cloud Operations Guide: View Grafana dashboards.
Note
Some Grafana dashboards include a View logs in OpenSearch Dashboards link to immediately view relevant logs in the OpenSearch Dashboards web UI.
Grafana dashboards that present node data have an additional Node identifier drop-down menu. By default, it is set to machine to display short names for Kubernetes nodes. To display Kubernetes node name labels, change this option to node.
To view the Grafana dashboards:
Log in to the Grafana web UI as described in Mirantis Container Cloud Operations Guide: Access StackLight web UIs.
From the drop-down list, select the required dashboard to inspect the status and statistics of the corresponding service deployed in Mirantis OpenStack on Kubernetes:
Dashboard
Description
OpenStack - Overview
Provides general information on OpenStack services resources consumption, API errors, deployed OpenStack compute nodes and block storage usage.
OpenStack Ingress controller
Available since MOSK 23.3. Monitors the number of requests, response times and statuses, as well as the number of Ingress SSL certificates including expiration time and resources usage.
OpenStack Instances Availability
Available since MOSK 23.2. Provides information about the availability of instance floating IPs per OpenStack compute node and project. Also, enables monitoring of probe statistics for individual instance floating IPs.
OpenStack Usage Efficiency
Available since MOSK 23.3. Provides information about requested (allocated) CPU and memory usage efficiency on a per-project and per-flavor basis. Aims to identify flavors that specific projects are not effectively using, with allocations significantly exceeding actual usage. Also, evaluates per-instance underuse for specific projects.
KPI - Provisioning
Provides provisioning statistics for OpenStack compute instances, including graphs on VM creation results by day.
Cinder
Provides graphs on the OpenStack Block Storage service health, HTTP API availability, pool capacity and utilization, number of created volumes and snapshots.
Glance
Provides graphs on the OpenStack Image service health, HTTP API availability, number of created images and snapshots.
Gnocchi
Provides panels and graphs on the Gnocchi health and HTTP API availability.
Heat
Provides graphs on the OpenStack Orchestration service health, HTTP API availability and usage.
Ironic OpenStack
Provides graphs on the OpenStack Bare Metal Provisioning service health, HTTP API availability, provisioned nodes by state and installed ironic-conductor back-end drivers.
Keystone
Provides graphs on the OpenStack Identity service health, HTTP API availability, number of tenants and users by state.
Neutron
Provides graphs on the OpenStack networking service health, HTTP API availability, agents status and usage of Neutron L2 and L3 resources.
NGINX Ingress controller
Not recommended. Deprecated since MOSK 23.3 and is removed in MOSK 24.1. Use OpenStack Ingress controller instead.
Monitors the number of requests, response times and statuses, as well as the number of Ingress SSL certificates including expiration time and resources usage.
Nova - Availability Zones
Provides detailed graphs on the OpenStack availability zones and hypervisor usage.
Nova - Hypervisor Overview
Provides a set of single-stat panels presenting resources usage by host.
Nova - Instances
Provides graphs on libvirt Prometheus exporter health and resources usage. Monitors the number of running instances and tasks and allows sorting the metrics by top instances.
Nova - Overview
Provides graphs on the OpenStack compute services (
nova-scheduler,nova-conductor, andnova-compute) health, as well as HTTP API availability.Nova - Tenants
Provides graphs on CPU, RAM, disk throughput, IOPS, and space usage and allocation and allows sorting the metrics by top tenants.
Nova - Users
Provides graphs on CPU, RAM, disk throughput, IOPS, and space usage and allocation and allows sorting the metrics by top users.
Nova - Utilization
Provides detailed graphs on Nova hypervisor resources capacity and consumption.
Memcached
Memcached Prometheus exporter dashboard. Monitors Kubernetes Memcached pods and displays memory usage, hit rate, evicts and reclaims rate, items in cache, network statistics, and commands rate.
MySQL
MySQL Prometheus exporter dashboard. Monitors Kubernetes MySQL pods, resources usage and provides details on current connections and database performance.
RabbitMQ
RabbitMQ Prometheus exporter dashboard. Monitors Kubernetes RabbitMQ pods, resources usage and provides details on cluster utilization and performance.
Cassandra
Provides graphs on Cassandra clusters’ health, ongoing operations, and resource consumption.
Kafka
Provides graphs on Kafka clusters’ and broker health, as well as broker and topic usage.
Redis
Provides graphs on Redis clusters’ and pods’ health, connections, command calls, and resource consumption.
Tungsten Fabric Controller
Provides graphs on the overall Tungsten Fabric Controller cluster processes and usage.
Tungsten Fabric vRouter
Provides graphs on the overall Tungsten Fabric vRouter cluster processes and usage.
ZooKeeper
Provides graphs on ZooKeeper clusters’ quorum health and resource consumption.
View OpenSearch Dashboards¶
OpenSearch Dashboards is part of the StackLight logging stack. Using the OpenSearch Dashboards web UI, you can view the visual representation of your OpenStack deployment notifications.
The Notifications dashboard provides visualizations on the number of notifications over time per source and severity, host, and breakdowns. The dashboard includes search.
For other dashboards, including the logs and Kubernetes events dashboards, see Mirantis Container Cloud Operations Guide: View OpenSearch Dashboards.
Note
By default, StackLight logging stack, including OpenSearch Dashboards, is disabled. For details, see Mirantis Container Cloud Reference Architecture: Deployment architecture.
To view the OpenSearch Dashboards:
Log in to the OpenSearch Dashboards web UI as described in Mirantis Container Cloud Operations Guide: Access StackLight web UIs.
Click the required dashboard to inspect the visualizations or perform a search.
StackLight alerts¶
This section provides an overview of the available predefined OpenStack-related StackLight alerts. To view the alerts, use the Prometheus web UI. To view the firing alerts, use the Alertmanager or Alerta web UI.
For other alerts, including the node, system, Kubernetes, Ceph, and StackLight alerts that can contain information about both OpenStack and MOSK clusters, see Mirantis Container Cloud Operations Guide: Available StackLight alerts.
Core services¶
This section describes the alerts available for the core services.
This section lists the alerts for the libvirt service.
Severity |
Critical |
|---|---|
Summary |
Failure to gather libvirt metrics. |
Description |
Libvirt Exporter fails to gather metrics on the
|
Severity |
Major |
|---|---|
Summary |
Libvirt Exporter Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the Libvirt Exporter endpoint
on the |
Severity |
Critical |
|---|---|
Summary |
Libvirt Exporter Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from all Libvirt Exporter endpoints. |
This section lists the alerts for the MariaDB service.
Severity |
Critical |
|---|---|
Summary |
MariaDB cluster is down. |
Description |
The MariaDB |
Replaced with MariadbExporterTargetDown in 23.3
Severity |
Critical |
|---|---|
Summary |
MariaDB Exporter cluster Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from 2/3 of the
|
Since 23.3 to replace MariadbExporterClusterTargetsOutage
Severity |
Critical |
|---|---|
Summary |
MariaDB Exporter cluster Prometheus target down. |
Description |
Prometheus fails to scrape metrics from the
|
Severity |
Warning |
|---|---|
Summary |
MariaDB node is falling behind. |
Description |
The |
Severity |
Major |
|---|---|
Summary |
MariaDB cluster node is not ready. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
MariaDB cluster node is out of sync. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
MariaDB InnoDB log writes are stalling. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
MariaDB table lock waits are high. |
Description |
The |
This section lists the alerts for the Memcached service.
Severity |
Critical |
|---|---|
Summary |
Memcached cluster is down. |
Description |
The Memcached |
Severity |
Warning |
|---|---|
Summary |
Memcached has no open connections. |
Description |
The Memcached database cluster |
Severity |
Warning |
|---|---|
Summary |
Memcached has no open connections on all nodes. |
Description |
The Memcached database cluster |
Severity |
Warning |
|---|---|
Summary |
10 Memcached evictions. |
Description |
An average of |
Since 23.3 to replace MemcachedExporterClusterTargetsOutage
Severity |
Critical |
|---|---|
Summary |
Memcached Exporter cluster Prometheus target down. |
Description |
Prometheus fails to scrape metrics from the
|
Replaced with MemcachedExporterTargetDown in 23.3
Severity |
Critical |
|---|---|
Summary |
Memcached Exporter cluster Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from 2/3 of the
|
This section describes the alerts for the OpenStack SSL certificates.
By default, these alerts are disabled. To enable them, set
openstack.externalFQDNs.enabled to true. For details, see
Configuration options for SSL certificates.
Severity |
Critical |
|---|---|
Summary |
SSL certificate for an OpenStack service expires in 10 days. |
Description |
The SSL certificate for the OpenStack
|
Severity |
Major |
|---|---|
Summary |
SSL certificate for an OpenStack service expires in 30 days. |
Description |
The SSL certificate for the OpenStack
|
Severity |
Critical |
|---|---|
Summary |
SSL certificate probes for an OpenStack service are failing. |
Description |
The SSL certificate probes for the OpenStack
|
Severity |
Critical |
|---|---|
Summary |
OpenStack |
Description |
Prometheus fails to probe the OpenStack
|
This section lists the alerts for the RabbitMQ service.
Severity |
Major |
|---|---|
Summary |
RabbitMQ network partitions detected. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
RabbitMQ is down. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
|
Description |
Prometheus fails to scrape metrics from the
|
Severity |
Major |
|---|---|
Summary |
RabbitMQ operator Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the
|
Severity |
Warning |
|---|---|
Summary |
RabbitMQ file descriptors usage is high for the last 10 minutes. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
RabbitMQ disk space usage is high. |
Description |
The |
Severity |
Major |
|---|---|
Summary |
RabbitMQ memory usage is high. |
Description |
The |
OpenStack¶
This section describes the alerts available for the OpenStack services.
This section describes the alerts for the OpenStack services API:
Severity |
Critical |
|---|---|
Summary |
OpenStack ingress controller Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from all OpenStack ingress controller endpoints. |
Severity |
Critical |
|---|---|
Summary |
OpenStack API responds with HTTP 401. |
Description |
The OpenStack API |
Severity |
Critical |
|---|---|
Summary |
OpenStack API responds with HTTP 5xx. |
Description |
The OpenStack API |
Severity |
Critical |
|---|---|
Summary |
OpenStack public API responds with HTTP 401. |
Description |
The OpenStack |
Severity |
Critical |
|---|---|
Summary |
OpenStack Public API responds with HTTP 5xx. |
Description |
The OpenStack |
Severity |
Critical |
|---|---|
Summary |
OpenStack |
Description |
The OpenStack |
Severity |
Critical |
|---|---|
Summary |
OpenStack |
Description |
The OpenStack |
This section lists the alerts for Cinder:
Severity |
Critical |
|---|---|
Summary |
|
Description |
The |
Severity |
Major |
|---|---|
Summary |
|
Description |
The |
Severity |
Critical |
|---|---|
Summary |
|
Description |
The |
This section lists the alerts for Ironic.
Severity |
Major |
|---|---|
Summary |
|
Description |
The |
This section lists the alerts for Neutron:
Severity |
Critical |
|---|---|
Summary |
|
Description |
The |
Severity |
Critical |
|---|---|
Summary |
|
Description |
The |
Severity |
Critical |
|---|---|
Summary |
|
Description |
The |
This section lists the alerts for Nova:
Severity |
Critical |
|---|---|
Summary |
|
Description |
The |
Severity |
Critical |
|---|---|
Summary |
|
Description |
The |
Severity |
Critical |
|---|---|
Summary |
|
Description |
The |
This section lists the alerts for the Cloudprober service:
Since 23.3 to replace OpenstackCloudproberTargetsOutage TechPreview
Severity |
Major |
|---|---|
Summary |
Openstack Cloudprober Prometheus target down. |
Description |
Prometheus fails to scrape metrics from the
|
Replaced with OpenstackCloudproberTargetDown in 23.3 Available since 23.2 TechPreview
Severity |
Major |
|---|---|
Summary |
Openstack Cloudprober Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from all OpenStack Cloudprober endpoints (more than 1/10 failed scrapes). |
Available since MOSK 24.1
This section lists the alerts for OpenStack credential rotation:
Note
You can adjust thresholds for the alerts included in this section. If needed, refer to Mirantis Container Cloud documentation: Alerts configuration.
Severity |
Warning |
|---|---|
Summary |
OpenStack administrator credentials are overdue for rotation. |
Description |
The OpenStack administrator credentials have not been rotated for more than 30 days. |
Severity |
Warning |
|---|---|
Summary |
OpenStack service user credentials are overdue for rotation. |
Description |
The OpenStack service user credentials have not been rotated for more than 30 days. |
OpenStack Controller¶
This section describes the alerts available for the OpenStack Controller.
Severity |
Critical |
|---|---|
Summary |
OpenStackDeployment Exporter Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the OpenStackDeployment Exporter endpoint. |
Severity |
Warning |
|---|---|
Summary |
SSL certificate for an OpenStack service expires in less than 10 days. |
Description |
The SSL certificate |
Severity |
Major |
|---|---|
Summary |
SSL certificate for an OpenStack service expires in less than 30 days. |
Description |
The SSL certificate |
Tungsten Fabric¶
This section describes the alerts available for the Tungsten Fabric services.
This section lists the alerts for Cassandra.
Severity |
Warning |
|---|---|
Summary |
Cassandra authentication failures. |
Description |
The |
Severity |
Major |
|---|---|
Summary |
Cassandra cache hit rate is too low. |
Description |
The average hit rate for the |
Severity |
Major |
|---|---|
Summary |
Cassandra client |
Description |
The |
Available since 23.3 to replace CassandraClusterTargetsOutage
Severity |
Critical |
|---|---|
Summary |
Cassandra cluster target down. |
Description |
Prometheus fails to scrape metrics from the
|
Replaced by CassandraClusterTargetDown in 23.3
Severity |
Critical |
|---|---|
Summary |
Cassandra cluster Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from 2/3 of the
|
Severity |
Warning |
|---|---|
Summary |
Cassandra |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Cassandra compaction executor tasks are blocked. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Cassandra has too many pending compactions. |
Description |
The pending compaction tasks in the
|
Severity |
Critical |
|---|---|
Summary |
Cassandra connection timeouts. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Cassandra flush writer tasks are blocked. |
Description |
The |
Severity |
Major |
|---|---|
Summary |
Cassandra has too many hints. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Cassandra repair tasks are blocked. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Cassandra storage exceptions. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Cassandra scanned 50000 tombstones. |
Description |
The |
Available since MOSK 22.2
Severity |
Critical |
|---|---|
Summary |
Cassandra scanned 50000 tombstones. |
Description |
The |
Severity |
Major |
|---|---|
Summary |
Cassandra scanned 25000 tombstones. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Cassandra scanned 10000 tombstones. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
Cassandra high view/write latency. |
Description |
The |
This section lists the alerts for Kafka.
Since 23.3 to replace KafkaClusterTargetsOutage
Severity |
Critical |
|---|---|
Summary |
Kafka cluster Prometheus target down. |
Description |
Prometheus fails to scrape metrics from the
|
Replaced with KafkaClusterTargetDown in 23.3
Severity |
Critical |
|---|---|
Summary |
Kafka cluster Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from 2/3 of the
|
Severity |
Critical |
|---|---|
Summary |
Kafka cluster has missing brokers. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Kafka cluster controller is missing. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Unavailable partitions in Kafka cluster. |
Description |
Partitions without a primary replica have been detected in the
|
Severity |
Critical |
|---|---|
Summary |
Kafka cluster has too many controllers. |
Description |
The |
Severity |
Major |
|---|---|
Summary |
Unclean Kafka broker was elected as cluster leader. |
Description |
A Kafka broker that has not finished the replication state has been
elected as leader in |
Severity |
Warning |
|---|---|
Summary |
Kafka cluster has underreplicated partitions. |
Description |
The topics in the |
This section lists the alerts for Redis.
Severity |
Major |
|---|---|
Summary |
Redis cluster is flapping. |
Description |
Changes have been detected in the |
Since 23.3 to replace RedisClusterTargetsOutage
Severity |
Major |
|---|---|
Summary |
Redis cluster Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from the
|
Replaced with RedisClusterTargetDown in 23.3
Severity |
Major |
|---|---|
Summary |
Redis cluster Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from 2/3 of the
|
Severity |
Warning |
|---|---|
Summary |
Redis has disconnected replicas. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Redis Pod is down. |
Description |
The |
Severity |
Critical |
|---|---|
Summary |
Redis cluster has no primary node. |
Description |
The |
Severity |
Major |
|---|---|
Summary |
Redis has multiple primaries. |
Description |
The |
Severity |
Major |
|---|---|
Summary |
Redis cluster has rejected connections. |
Description |
Some connections to the |
Severity |
Major |
|---|---|
Summary |
Redis replication is broken. |
Description |
The |
This section lists alerts for the Tungsten Fabric Operator.
Available since 23.3
Severity |
Critical |
|---|---|
Summary |
Tungsten Fabric Operator Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the Tungsten Fabric Operator metrics service. |
This section lists the alerts for Tungsten Fabric.
Severity |
Critical |
|---|---|
Summary |
Tungsten Fabric API responds with HTTP 401. |
Description |
The Tungsten Fabric API responds with HTTP 401 for more than 5% of requests for the last 10 minutes. |
Severity |
Critical |
|---|---|
Summary |
Tungsten Fabric API responds with HTTP 5xx. |
Description |
The Tungsten Fabric API responds with HTTP 5xx for more than 1% of requests for the last 10 minutes. |
Severity |
Warning |
|---|---|
Summary |
Tungsten Fabric BGP sessions are down. |
Description |
|
Severity |
Warning |
|---|---|
Summary |
No active Tungsten Fabric BGP sessions. |
Description |
There are no active Tungsten Fabric BGP sessions on the
|
Severity |
Warning |
|---|---|
Summary |
No established Tungsten Fabric BGP sessions. |
Description |
There are no established Tungsten Fabric BGP sessions on the
|
Severity |
Warning |
|---|---|
Summary |
Tungsten Fabric Controller is down. |
Description |
The Tungsten Fabric Controller on the |
Severity |
Critical |
|---|---|
Summary |
All Tungsten Fabric Controllers are down. |
Description |
All Tungsten Fabric Controllers are down for 2 minutes. |
Severity |
Critical |
|---|---|
Summary |
Tungsten Fabric Controller Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from 2/3 of the Tungsten Fabric Controller exporter endpoints. |
Severity |
Warning |
|---|---|
Summary |
Tungsten Fabric vRouter is down. |
Description |
The Tungsten Fabric vRouter on the |
Severity |
Warning |
|---|---|
Summary |
Tungsten Fabric vRouter LLS sessions changes reached the limit of 5. |
Description |
The Tungsten Fabric vRouter LLS sessions on the |
Severity |
Warning |
|---|---|
Summary |
Tungsten Fabric vRouter LLS sessions reached the limit of 10. |
Description |
|
Severity |
Critical |
|---|---|
Summary |
Tungsten Fabric metadata is unavailable. |
Description |
The Tungsten Fabric metadata on the |
Severity |
Critical |
|---|---|
Summary |
All Tungsten Fabric vRouters are down. |
Description |
All Tungsten Fabric vRouters are down for 2 minutes. |
Severity |
Major |
|---|---|
Summary |
Tungsten Fabric vRouter Prometheus target is down. |
Description |
Prometheus fails to scrape metrics from the Tungsten Fabric vRouter
exporter endpoint on the |
Severity |
Critical |
|---|---|
Summary |
Tungsten Fabric vRouter Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from all Tungsten Fabric vRouter exporter endpoints. |
Severity |
Warning |
|---|---|
Summary |
Tungsten Fabric vRouter XMPP sessions changes reached the limit of 5. |
Description |
The Tungsten Fabric vRouter XMPP sessions on the |
Severity |
Warning |
|---|---|
Summary |
Tungsten Fabric vRouter XMPP sessions reached the limit of 10. |
Description |
|
Severity |
Warning |
|---|---|
Summary |
No Tungsten Fabric vRouter XMPP sessions. |
Description |
There are no Tungsten Fabric vRouter XMPP sessions on the
|
Severity |
Warning |
|---|---|
Summary |
Tungsten Fabric XMPP sessions changes reached the limit of 100. |
Description |
The Tungsten Fabric XMPP sessions on the |
Severity |
Warning |
|---|---|
Summary |
Tungsten Fabric XMPP sessions are down. |
Description |
|
Severity |
Warning |
|---|---|
Summary |
Missing Tungsten Fabric XMPP sessions. |
Description |
|
Severity |
Warning |
|---|---|
Summary |
Missing established Tungsten Fabric XMPP sessions. |
Description |
|
Severity |
Warning |
|---|---|
Summary |
Tungsten Fabric XMPP sessions reached the limit of 500. |
Description |
|
This section lists the alerts for ZooKeeper.
Since 23.3 to replace ZooKeeperClusterTargetsOutage
Severity |
Major |
|---|---|
Summary |
ZooKeeper cluster Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from the
|
Replaced with ZooKeeperClusterTargetDown in 23.3
Severity |
Major |
|---|---|
Summary |
ZooKeeper cluster Prometheus targets outage. |
Description |
Prometheus fails to scrape metrics from 2/3 of the
|
Severity |
Warning |
|---|---|
Summary |
ZooKeeper cluster has missing followers. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
ZooKeeper server request overload. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
ZooKeeper server is running out of file descriptors. |
Description |
The |
Severity |
Warning |
|---|---|
Summary |
ZooKeeper leader synchronization overload. |
Description |
The ZooKeeper leader in the |
Alert dependencies¶
Using alert inhibition rules, Alertmanager decreases alert noise by suppressing dependent alerts notifications to provide a clearer view on the cloud status and simplify troubleshooting. Alert inhibition rules are enabled by default. The following table describes the dependency between the OpenStack-related alerts. For other alerts that can contain information about both OpenStack and MOSK clusters, see Mirantis Container Cloud Operations Guide: Alert dependencies.
Once an alert from the Alert column raises, the alert from the Inhibits and rules column will be suppressed with the Inhibited status in the Alertmanager web UI.
The Inhibits and rules column lists the labels and conditions, if any, for the inhibition to apply.
Alert |
Inhibits and rules |
|---|---|
|
|
|
|
|
|
|
And other alerts described in Mirantis Container Cloud Operations Guide: Alert dependencies. |
|
And other alerts described in Mirantis Container Cloud Operations Guide: Alert dependencies. |
|
And other alerts described in Mirantis Container Cloud Operations Guide: Alert dependencies. |
|
|
|
|
|
|
|
Alerts with the same
Since 23.3:
And other alerts described in Mirantis Container Cloud Operations Guide: Alert dependencies. |
|
|
|
|
|
|
|
|
|
|
|
|
Configure StackLight¶
This section describes how to configure StackLight in your Mirantis OpenStack on Kubernetes deployment and includes the description of OpenStack-related StackLight parameters and their verification. For other available configuration keys and their configuration verification, see Mirantis Container Cloud Operations Guide: Manage StackLight.
StackLight configuration procedure¶
This section describes the StackLight configuration workflow.
To configure StackLight:
Obtain
kubeconfigof the Mirantis Container Cloud management cluster and open the Cluster object manifest of the managed cluster for editing as described in the steps 1-2 in Mirantis Container Cloud Operations Guide: StackLight configuration procedure.In the following section of the opened manifest, configure the StackLight parameters as required:
For the OpenStack-based parameters, see StackLight configuration parameters.
For other parameters, see Mirantis Container Cloud Operations Guide: StackLight configuration parameters.
spec: providerSpec: value: helmReleases: - name: stacklight values:
Verify StackLight configuration depending on the modified parameters:
For OpenStack-related parameters, see Verify StackLight after configuration.
For other parameters, see Mirantis Container Cloud Operations Guide: Verify StackLight after configuration.
StackLight configuration parameters¶
This section describes the OpenStack-related StackLight configuration keys that
you can specify in the values section to change StackLight settings as
required. For other available configuration keys, see
Mirantis Container Cloud Operations Guide: StackLight configuration parameters.
Prior to making any changes to StackLight configuration, perform the steps described in StackLight configuration procedure. After changing StackLight configuration, verify the changes as described in Verify StackLight after configuration.
Key |
Description |
Example values |
|---|---|---|
|
Enables OpenStack monitoring. Set to |
|
|
Defines the namespace within which the OpenStack virtualized control
plane is installed. Set to |
|
Key |
Description |
Example values |
|---|---|---|
|
Enables Gnocchi monitoring. Set to |
|
Key |
Description |
Example values |
|---|---|---|
|
Enables Ironic monitoring. Set to |
|
Key |
Description |
Example values |
|---|---|---|
|
Defines the RabbitMQ credentials to use if credentials discovery is disabled or some required parameters were not found during the discovery. |
credentialsConfig:
username: "stacklight"
password: "stacklight"
host: "rabbitmq.openstack.svc"
queue: "notifications"
vhost: "openstack"
|
|
Enables the credentials discovery to obtain the username and password from the secret object. |
credentialsDiscovery:
enabled: true
namespace: openstack
secretName: os-rabbitmq-user-credentials
|
Key |
Description |
Example values |
|---|---|---|
|
Specifies the OpenStack credentials to use if the credentials discovery is disabled or some required parameters were not found during the discovery. |
credentialsConfig:
identityEndpoint: "" # "http://keystone-api.openstack.svc:5000/v3"
domain: "" # "default"
password: "" # "workshop"
project: "" # "admin"
region: "" # "RegionOne"
username: "" # "admin"
|
|
Enables the credentials discovery to obtain all required parameters from the secret object. |
credentialsDiscovery:
enabled: true
namespace: openstack
secretName: keystone-keystone-admin
|
|
Specifies the interval of metrics gathering from the OpenStack API. Set
to |
|
|
Enables or disables the server certificate chain and host name
verification. Set to |
|
|
Enables or disables HTTP probes for public endpoints from the OpenStack
service catalog. Set to |
|
Key |
Description |
Example values |
|---|---|---|
|
External FQDN used to communicate with OpenStack services for
certificates monitoring. The option is deprecated, use
|
|
|
External FQDN used to communicate with OpenStack services. Used for
certificates monitoring. Set to |
|
|
Defines whether to verify the trust chain of the OpenStack endpoint SSL certificates during monitoring. |
insecure:
internal: true
external: false
|
Key |
Description |
Example values |
|---|---|---|
|
Enables Tungsten Fabric monitoring. Since MOSK 23.1, the parameter is set
to Before MOSK 23.1, the parameter is set to
|
|
|
Available since MOSK 23.3. Defines the timeout of
the |
tungstenFabricMonitoring:
exportersTimeout: "5s"
|
|
Available since MOSK 24.1. Enables or disables
monitoring of Tungsten Fabric analytics services. By default, set to
|
|
Verify StackLight after configuration¶
This section describes how to verify StackLight after configuring its OpenStack-related parameters as described in StackLight configuration procedure and StackLight configuration parameters. Perform the verification procedure for a particular modified StackLight key.
To verify StackLight after configuring other parameters, see Mirantis Container Cloud Operations Guide: Verify StackLight after configuration.
To verify StackLight after configuration:
Key |
Verification procedure |
|---|---|
|
|
|
|
|
|
|
In the OpenSearch Dashboards web UI, click Discover and
verify that the |
|
In the Grafana web UI, verify that the OpenStack dashboards are present and not empty. |
|
|
|
|
Tungsten Fabric operations¶
The section covers the management aspects of a Tungsten Fabric cluster deployed on Kubernetes.
Caution
Before you proceed with the Tungsten Fabric management, read through Tungsten Fabric known limitations.
Update Tungsten Fabric¶
The Tungsten Fabric cluster update is performed during the MOSK cluster release update.
The control plane update is performed automatically. To complete the data plane update, you will need to manually remove the vRouter pods. See Update a MOSK cluster to a major release version for details.
Upgrade Tungsten Fabric to 2011¶
This section describes how to upgrade Tungsten Fabric from version 5.1 to 2011.
Note
Tungsten Fabric 5.1 is considered deprecated and will be declared unsupported in one of the upcoming releases.
The update of the Tungsten Fabric control plane is performed automatically while the data plane requires manual restart of the vRouter pods for the changes to be applied.
Prerequisites¶
Verify that your OpenStack cloud is running on the latest MOSK release. See Release Compatibility Matrix for the release matrix and supported upgrade paths.
Verify that your OpenStack cloud is running OpenStack Victoria. If upgrade is required, proceed with Upgrade OpenStack.
Verify that running vRouter pods are up-to-date with the MOSK release.
Calculate the maintenance window for the Tungsten Fabric upgrade considering the following:
Upgrade requires pulling of new images. The amount of time required for this phase depends on quality of network connection to the Mirantis image registry, amount of workloads, and specification of the cluster nodes.
Upgrade includes the Tungsten Fabric control plane and data plane (vRouters) upgrade:
The control plane pods upgrade usually takes about 20 minutes.
The data plane may require workloads migration before the vRouter upgrade that causes network service interruption on the affected nodes. The pure vRouter upgrade takes 5-7 minutes in average.
Back up the databases as described in Back up TF databases.
Perform the upgrade¶
Open the
TFOperatorcustom resource for editing.Set the
tfVersionparameter to2011:spec: settings: tfVersion: "2011"
Verify that all
tf-analytics-*,tf-config-*, andtf-control-*pods are updated. This may take some time.kubectl -n tf get ds
The
CURRENT,UP-TO-DATE, andAVAILABLEfields must have the same values.
Verify the upgrade¶
Verify the consistency of the cloud after Tungsten Fabric upgrade through sanity tests using the Tempest service as described in Run Tempest tests.
Roll back the upgrade¶
If any failures occur after the upgrade, you can roll back your Tungsten Fabric cluster to version 5.1:
In the
tfVersionparameter of theTFOperatorcustom resource, specify5.1:spec: settings: tfVersion: "5.1"
The Tungsten Fabric control plane services will be rolled back to version 5.1.
Roll back the vRouter pods manually as described in Perform the upgrade. The rollback procedure for the vRouter pods is the same as the upgrade one.
Back up TF databases¶
MOSK enables you to perform the automatic TF
data backup using the tf-dbbackup-job cron job. Also, you can configure
a remote NFS storage for TF data backups. For configuration details,
refer to the Tungsten Fabric database section in Reference Architecture.
This section provides instructions on how to back up the TF data manually if needed.
Manually back up TF data in the JSON format¶
Disable the Neutron server that is used by OpenStack to communicate with the Tungsten Fabric API:
Note
The database changes associated with northbound APIs must be stopped on all systems before performing any backup operations.
Scale the
neutron-serverdeployment to 0 replicas:kubectl -n openstack scale deploy neutron-server --replicas 0
Verify the number of replicas:
kubectl -n openstack get deploy neutron-server
Example of a positive system response:
NAME READY UP-TO-DATE AVAILABLE AGE neutron-server 0/0 0 0 6d22h
Join the Tungsten Fabric API that is part of the
configDaemonSet:Obtain the
tf-configpod:kubectl -n tf get pod -l tungstenfabric=config
Example of a system response:
NAME READY STATUS RESTARTS AGE tf-config-6ppvc 5/5 Running 0 5d4h tf-config-rgqqq 5/5 Running 0 5d4h tf-config-sb4kk 5/5 Running 0 5d4h
Join the Bash shell of one of the
apicontainer from the previous step:kubectl -n tf exec -it tf-config-<hash> -c api -- bash
Example of a system response:
(config-api[hostname])[<USER>@<HOSTNAME> /]$
Inside the
apicontainer, change the directory to the Pythonconfig managementpackages:cd /usr/lib/python2.7/site-packages/cfgm_common
Back up data using
db_json_eximin JSON format:python db_json_exim.py --export-to /tmp/db-dump.json
Verify the created dump:
cat /tmp/db-dump.json | python -m json.tool | less
Copy the backup from the container:
kubectl -n tf cp tf-config-<hash>:/tmp/db-dump.json <DESTINATION-PATH-FOR-BACKUP>
On the same
confignode, copy thecontrail-api.conffile from the container to the host:kubectl -n tf cp tf-config-<hash>:/etc/contrail/contrail-api.conf <DESTINATION-PATH-FOR-CONF>
Enable the Neutron server:
Scale the
neutron-serverdeployment back to the desired number of replicas. Default is 3.kubectl -n openstack scale deploy neutron-server --replicas <DESIRED-NUM-REPLICAS>
Verify the number of replicas:
kubectl -n openstack get deploy neutron-server
Example of a system response:
NAME READY UP-TO-DATE AVAILABLE AGE neutron-server 3/3 3 3 6d23h
See also
Restore TF data¶
This section describes how to restore the Cassandra and ZooKeeper TF databases from the backups created either automatically or manually as described in Back up TF databases.
Caution
The data backup must be consistent across all systems because the state of the Tungsten Fabric databases is associated with other system databases, such as OpenStack databases.
Automatically restore TF data¶
Verify that there is no existing
tfdbrestoreobject in the cluster. If there is still one remaining from the previous restoration, delete it:kubectl -n tf delete tfdbrestores.tf-dbrestore.tf.mirantis.com tf-dbrestore
Edit the TF Operator CR to perform the TF data restoration:
spec: settings: dbRestoreMode: enabled: true
Warning
When restoring the data, MOSK stops the TF services and recreates the database back ends that include Cassandra, Kafka, and ZooKeeper.
Note
The automated restoration process relies on automated database backups configured by the TF Operator. The TF data is restored from the backup type specified in the
tf-dbBackupsection of the TF Operator custom resource, or the defaultpvctype if not specified. For the configuration details, refer to Periodic Tungsten Fabric database backups.Optional. Specify the name of the backup to be used for the
dbDumpNameparameter. By default, the latestdb-dumpis used.spec: settings: dbRestoreMode: enabled: true dbDumpName: db-dump-20220111-110138.json
To verify the restoration status and stage, verify the events recorded for the
tfdbrestoreobject:kubectl -n tf describe tfdbrestores.tf-dbrestore.tf.mirantis.com
Example of a system response:
... Status: Health: Ready Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal TfDaemonSetsDeleted 18m (x4 over 18m) tf-dbrestore TF DaemonSets were deleted Normal zookeeperOperatorScaledDown 18m tf-dbrestore zookeeper operator scaled to 0 Normal zookeeperStsScaledDown 18m tf-dbrestore tf-zookeeper statefulset scaled to 0 Normal cassandraOperatorScaledDown 17m tf-dbrestore cassandra operator scaled to 0 Normal cassandraStsScaledDown 17m tf-dbrestore tf-cassandra-config-dc1-rack1 statefulset scaled to 0 Normal cassandraStsPodsDeleted 16m tf-dbrestore tf-cassandra-config-dc1-rack1 statefulset pods deleted Normal cassandraPVCDeleted 16m tf-dbrestore tf-cassandra-config-dc1-rack1 PVC deleted Normal zookeeperStsPodsDeleted 16m tf-dbrestore tf-zookeeper statefulset pods deleted Normal zookeeperPVCDeleted 16m tf-dbrestore tf-zookeeper PVC deleted Normal kafkaOperatorScaledDown 16m tf-dbrestore kafka operator scaled to 0 Normal kafkaStsScaledDown 16m tf-dbrestore tf-kafka statefulset scaled to 0 Normal kafkaStsPodsDeleted 16m tf-dbrestore tf-kafka statefulset pods deleted Normal AllOperatorsStopped 16m tf-dbrestore All 3rd party operator's stopped Normal CassandraOperatorScaledUP 16m tf-dbrestore CassandraOperator scaled to 1 Normal CassandraStsScaledUP 16m tf-dbrestore Cassandra statefulset scaled to 3 Normal CassandraPodsActive 12m tf-dbrestore Cassandra pods active Normal ZookeeperOperatorScaledUP 12m tf-dbrestore Zookeeper Operator scaled to 1 Normal ZookeeperStsScaledUP 12m tf-dbrestore Zookeeper Operator scaled to 3 Normal ZookeeperPodsActive 12m tf-dbrestore Zookeeper pods active Normal DBRestoreFinished 12m tf-dbrestore TF db restore finished Normal TFRestoreDisabled 12m tf-dbrestore TF Restore disabled
Note
If the restoration was completed several hours ago, events may not be shown with kubectl describe. If so, verify the
Statusfield and get events using the following command:kubectl -n tf get events --field-selector involvedObject.name=tf-dbrestore
After the job completes, it can take around 15 minutes to stabilize
tf-controlservices. If some pods are still in theCrashLoopBackOffstatus, restart these pods manually one by one:List the
tf-controlpods:kubectl -n tf get pods -l app=tf-control
Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only the
tf-controlpod that will be restarted.Restart the
tf-controlpods sequentially:kubectl -n tf delete pod tf-control-<hash>
When the restoration completes, MOSK automatically sets
dbRestoreModetofalsein the TF Operator custom resource.Delete the
tfdbrestoreobject from the cluster to be able to perform the next restoration:kubectl -n tf delete tfdbrestores.tf-dbrestore.tf.mirantis.com tf-dbrestore
Manually restore TF data¶
Obtain the config API image repository and tag.
kubectl -n tf get tfconfig tf-config -o=jsonpath='{.spec.api.containers[?(@.name=="api")].image}'
From the output, copy the entire image link.
Terminate the configuration and analytics services and stop the database changes associated with northbound APIs on all systems.
Note
The TF Operator watches related resources and keeps them updated and healthy. If any resource is deleted or changed, the TF Operator automatically runs reconciling to create a resource or change the configuration back to the desired state. Therefore, the TF Operator must not be running during the data restoration.
Scale the
tungstenfabric-operatordeployment to 0 replicas:kubectl -n tf scale deploy tungstenfabric-operator --replicas 0
Verify the number of replicas:
kubectl -n tf get deploy tungstenfabric-operator
Example of a positive system response:
NAME READY UP-TO-DATE AVAILABLE AGE tungstenfabric-operator 0/0 0 0 10h
Delete the TF configuration and analytics daemonsets:
kubectl -n tf delete daemonset tf-config kubectl -n tf delete daemonset tf-config-db kubectl -n tf delete daemonset tf-analytics kubectl -n tf delete daemonset tf-analytics-snmp
The TF configuration pods should be automatically terminated.
Verify that the TF configuration pods are terminated:
kubectl -n tf get pod -l app=tf-config kubectl -n tf get pod -l tungstenfabric=analytics kubectl -n tf get pod -l tungstenfabric=analytics-snmp
Example of a positive system response:
No resources found.
Stop Kafka:
Scale the
kafka-operatordeployment to 0 replicas:kubectl -n tf scale deploy kafka-operator --replicas 0
Scale the
tf-kafkastatefulSet to 0 replicas:kubectl -n tf scale sts tf-kafka --replicas 0
Verify the number of replicas:
kubectl -n tf get sts tf-kafka
Example of a positive system response:
NAME READY AGE tf-kafka 0/0 10h
Stop and wipe the Cassandra database:
Scale the
cassandra-operatordeployment to 0 replicas:kubectl -n tf scale deploy cassandra-operator --replicas 0
Scale the
tf-cassandra-config-dc1-rack1statefulSet to 0 replicas:kubectl -n tf scale sts tf-cassandra-config-dc1-rack1 --replicas 0
Verify the number of replicas:
kubectl -n tf get sts tf-cassandra-config-dc1-rack1
Example of a positive system response:
NAME READY AGE tf-cassandra-config-dc1-rack1 0/0 10h
Delete Persistent Volume Claims (PVCs) for the Cassandra configuration pods:
kubectl -n tf delete pvc -l app=cassandracluster,cassandracluster=tf-cassandra-config
Once PVCs are deleted, the related Persistent Volumes are automatically released. The release process takes approximately one minute.
Stop and wipe the ZooKeeper database:
Scale the
zookeeper-operatordeployment to 0 replicas:kubectl -n tf scale deploy zookeeper-operator --replicas 0
Scale the
tf-zookeeperstatefulSet to 0 replicas:kubectl -n tf scale sts tf-zookeeper --replicas 0
Verify the number of replicas:
kubectl -n tf get sts tf-zookeeper
Example of a positive system response:
NAME READY AGE tf-zookeeper 0/0 10h
Delete PVCs for the ZooKeeper configuration pods:
kubectl -n tf delete pvc -l app=tf-zookeeper
Once PVCs are deleted, the related Persistent Volumes are automatically released. The release process takes approximately one minute.
Restore the number of replicas to run Cassandra and ZooKeeper and restore the deleted PVCs.
Restore the
cassandra-operatordeployment replicas:kubectl -n tf scale deploy cassandra-operator --replicas 1
Restore the
tf-cassandra-config-dc1-rack1statefulSet replicas:kubectl -n tf scale sts tf-cassandra-config-dc1-rack1 --replicas 3
Verify that Cassandra pods have been created and are running:
kubectl -n tf get pod -l app=cassandracluster,cassandracluster=tf-cassandra-config
Example of a positive system response:
NAME READY STATUS RESTARTS AGE tf-cassandra-config-dc1-rack1-0 1/1 Running 0 4m43s tf-cassandra-config-dc1-rack1-1 1/1 Running 0 3m30s tf-cassandra-config-dc1-rack1-2 1/1 Running 0 2m6s
Restore the
zookeeper-operatordeployment replicas:kubectl -n tf scale deploy zookeeper-operator --replicas 1
Restore the
tf-zookeeperstatefulSet replicas:kubectl -n tf scale sts tf-zookeeper --replicas 3
Verify that ZooKeeper pods have been created and are running:
kubectl -n tf get pod -l app=tf-zookeeper
Example of a positive system response:
NAME READY STATUS RESTARTS AGE tf-zookeeper-0 1/1 Running 0 3m23s tf-zookeeper-1 1/1 Running 0 2m56s tf-zookeeper-2 1/1 Running 0 2m20s
Restore the data from the backup:
Note
Do not use the TF API container used for the backup file creation. In this case, a session with the Cassandra and ZooKeeper databases is created once the TF API service starts but the TF configuration services are stopped. The tools for the data backup and restore are available only in the TF configuration API container. Using the steps below, start a blind container based on the
config-apiimage.Deploy a pod using the configuration API image obtained in the first step:
Note
Since MOSK 24.1, if your deployment uses the
cqlCassandra driver, update the value of theCONFIGDB_CASSANDRA_DRIVERenvironment variable tocql.cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: annotations: kubernetes.io/psp: privileged labels: app: tf-restore-db name: tf-restore-db namespace: tf spec: containers: - name: api image: <PUT_LINK_TO_CONFIG_API_IMAGE_FROM_STEP_ABOVE> command: - sleep - infinity envFrom: - configMapRef: name: tf-rabbitmq-cfgmap - configMapRef: name: tf-zookeeper-cfgmap - configMapRef: name: tf-cassandra-cfgmap - configMapRef: name: tf-services-cfgmap - secretRef: name: tf-os-secret env: - name: CONFIGDB_CASSANDRA_DRIVER value: thrift imagePullPolicy: Always nodeSelector: tfcontrol: enabled dnsPolicy: ClusterFirstWithHostNet enableServiceLinks: true hostNetwork: true priority: 0 restartPolicy: Always serviceAccount: default serviceAccountName: default EOF
If you use the backup that was created automatically, extend the YAML file content above with the following configuration:
... spec: containers: - name: api volumeMounts: - mountPath: </PATH/TO/MOUNT> name: <TF-DBBACKUP-VOL-NAME> volumes: - name: <TF-DBBACKUP-VOL-NAME> persistentVolumeClaim: claimName: <TF-DBBACKUP-PVC-NAME>
Copy the database dump to the container:
Warning
Skip this step if you use the auto-backup and have provided the volume definition as described above.
kubectl cp <PATH_TO_DB_DUMP> tf/tf-restore-db:/tmp/db-dump.json
Copy the
contrail-api.conffile to the container:kubectl cp <PATH-TO-CONFIG> tf/tf-restore-db:/tmp/contrail-api.conf
Join the restarted container:
kubectl -n tf exec -it tf-restore-db -- bash
Restore the Cassandra database from the backup:
(config-api) $ cd /usr/lib/python2.7/site-packages/cfgm_common (config-api) $ python db_json_exim.py --import-from /tmp/db-dump.json --api-conf /tmp/contrail-api.conf
Delete the restore container:
kubectl -n tf delete pod tf-restore-db
Restore the replica number to run Kafka:
Restore the
kafka-operatordeployment replicas:kubectl -n tf scale deploy kafka-operator --replicas 1
Kafka operator should automatically restore the number of replicas of the appropriate StatefulSet.
Verify the number of replicas:
kubectl -n tf get sts tf-kafka
Example of a positive system response:
NAME READY AGE tf-kafka 3/3 10h
Run TF Operator to restore the TF configuration and analytics services:
Restore the TF Operator deployment replica:
kubectl -n tf scale deploy tungstenfabric-operator --replicas 1
Verify that the TF Operator is running properly without any restarts:
kubectl -n tf get pod -l name=tungstenfabric-operator
Verify that the configuration pods have been automatically started:
kubectl -n tf get pod -l app=tf-config kubectl -n tf get pod -l tungstenfabric=analytics kubectl -n tf get pod -l tungstenfabric=analytics-snmp
Restart the
tf-controlservices:Caution
To avoid network downtime, do not restart all pods simultaneously.
List the
tf-controlpodskubectl -n tf get pods -l app=tf-control
Restart the
tf-controlpods one by one.Caution
Before restarting the
tf-controlpods:Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only one
tf-controlpod that will be restarted.
kubectl -n tf delete pod tf-control-<hash>
Replace a failed TF controller node¶
If one of the Tungsten Fabric (TF) controller nodes has failed, follow this procedure to replace it with a new node.
To replace a TF controller node:
Note
Pods that belong to the failed node can stay in the Terminating
state.
If a failed node has
tfconfigdb=enabledortfanalyticsdb=enabled, or both labels assigned to it, get and note down the IP addresses of the Cassandra pods that run on the node to be replaced:kubectl -n tf get pods -owide | grep 'tf-cassandra.*<FAILED-NODE-NAME>'
Delete the failed TF controller node from the Kubernetes cluster:
kubectl delete node <FAILED-TF-CONTROLLER-NODE-NAME>
Note
Once the failed node has been removed from the cluster, all pods that hanged in the
Terminatingstate should be removed.Assign the TF labels for the new control plane node as per the table below using the following command:
kubectl label node <NODE-NAME> <LABEL-KEY=LABEL-VALUE> ...
Tungsten Fabric (TF) node roles¶ Node role
Description
Kubernetes labels
Minimal count
TF control plane
Hosts the TF control plane services such as
database,messaging,api,svc,config.tfconfig=enabledtfcontrol=enabledtfwebui=enabledtfconfigdb=enabled3
TF analytics
Hosts the TF analytics services.
tfanalytics=enabledtfanalyticsdb=enabled3
TF vRouter
Hosts the TF vRouter module and vRouter Agent.
tfvrouter=enabledVaries
TF vRouter DPDK Technical Preview
Hosts the TF vRouter Agent in DPDK mode.
tfvrouter-dpdk=enabledVaries
Note
TF supports only Kubernetes OpenStack workloads. Therefore, you should label OpenStack compute nodes with the
tfvrouter=enabledlabel.Note
Do not specify the
openstack-gateway=enabledandopenvswitch=enabledlabels for the OpenStack deployments with TF as a networking back end.Once you label the new Kubernetes node, new pods start scheduling on the node. Though, pods that use Persistent Volume Claims are stuck in the
Pendingstate as their volume claims stay bounded to the local volumes from the deleted node. To resolve the issue:Delete the PersistentVolumeClaim (PVC) bounded to the local volume from the failed node:
kubectl -n tf delete pvc <PVC-BOUNDED-TO-NON-EXISTING-VOLUME>
Note
Clustered services that use PVC, such as Cassandra, Kafka, and ZooKeeper, start the replication process when new pods move to the
Readystate.Check the PersistenceVolumes (PVs) claimed by the deleted PVCs. If a PV is stuck in the
Releasedstate, delete it manually:kubectl -n tf delete pv <PV>
Delete the pod that is using the removed PVC:
kubectl -n tf delete pod <POD-NAME>
Verify that the pods have successfully started on the replaced controller node and stay in the
Readystate.If the failed controller node had
tfconfigdb=enabledortfanalyticsdb=enabled, or both labels assigned to it, remove old Cassandra hosts from theconfigandanalyticscluster configuration:Get the host ID of the removed Cassandra host using the pod IP addresses saved during Step 1:
kubectl -n tf exec tf-cassandra-<config/analytics>-dc1-rack1-1 -c cassandra -- nodetool status
Verify that the removed Cassandra node has the
DNstatus that indicates that this node is currently offline.Remove the failed Cassandra host:
kubectl -n tf exec tf-cassandra-<config/analytics>-dc1-rack1-1 -c cassandra -- nodetool removenode <HOST-ID>
Delete terminated nodes from the TF configuration through the TF web UI:
Log in to the TF web UI.
Navigate to Configure > BGP Routers.
Delete all terminated control nodes.
Note
You can manage nodes of other types from Configure > Nodes.
Verify the Tungsten Fabric deployment¶
This section explains how to use the tungsten-pytest test set to
verify your Tungsten Fabric (TF) deployment. The tungsten-pytest test
set is part of the TF operator and allows for prompt verification of the
Kubernetes objects related to TF and basic verification of the TF services.
To verify the TF deployment using tungsten-pytest:
Enable the
tf-testcontroller in the TF Operator resource for the Operator to start the pod with the test set:spec: controllers: tf-test: tungsten-pytest: enabled: true
Wait until the
tungsten-pytestpod is ready. To keep track of the tests execution and view the results, run:kubectl -n tf logs -l app=tf-test
Optional. The test results are stored in the
tf-test-tungsten-pytestPVC. To obtain the results:Deploy the pod with the mounted volume:
# Run pod and mount pvc to it cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: tf-test-results-pod namespace: tf spec: volumes: - name: tf-test-data-volume persistentVolumeClaim: claimName: tf-test-tungsten-pytest containers: - name: tempest-pvc-container image: ubuntu command: ['sh', '-c', 'sleep infinity'] volumeMounts: - mountPath: "/tungsten-pytest/data" name: tf-test-data-volume EOF
Copy the results locally:
kubectl -n tf cp tf-test-results-pod:tungsten-pytest/data/results.xml results.xml
Remove the Tempest test results pod:
kubectl -n tf delete pod tf-test-results-pod
Disable the
tf-testcontroller:kubectl -n tf patch tfoperator openstack-tf --type='json' -p='[{"op": "replace", "path": "/spec/controllers/tf-test/tungsten-pytest/enabled", "value": false}]'
Manually remove the pod with tests:
kubectl -n tf delete pod -l app=tf-test
Configure load balancing¶
This section describes a simple load balancing configuration. As an example, we use a topology for balancing the traffic between two HTTP servers listening on port 80. The example topology includes the following parameters:
Back-end servers
10.10.0.4and10.10.0.3in theprivate-subnetsubnet run an HTTP application that listens on the TCP port 80.The
public-subnetsubnet is a shared external subnet created by the cloud operator and accessible from the Internet.The created load balancer is accessible through an IP address from the public subnet that will distribute web requests between the back-end servers.
To configure load balancing:
Log in to a
keystone-clientpod.Create a load balancer:
openstack loadbalancer create --vip-subnet-id=private-subnet --name test-lb
Note
By default, MOSK uses the Octavia Tungsten Fabric load balancing. Since 23.1, you can explicitly specify
amphorav2as a provider when creating a load balancer using theproviderargument:openstack loadbalancer create --provider amphorav2
Octavia Amphora load balancing is available as a Technology Preview feature. For details, refer to Octavia Amphora load balancing.
Create an HTTP listener:
openstack loadbalancer listener create --name test-listener \ --protocol HTTP --protocol-port 80 test-lb
Create a LBaaS pool that will be used by default for
test-listener:openstack loadbalancer pool create --protocol HTTP \ --lb-algorithm ROUND_ROBIN --name test-pool --listener test-listener
Create a health monitor that ensures health of the pool members:
openstack loadbalancer healthmonitor create --delay 5 --name test-hm \ --timeout 3 --max-retries 3 --type HTTP test-pool
Add back-end servers to the pool. The following example adds the
10.10.0.3and10.10.0.4back-end servers:openstack loadbalancer member create --address 10.10.0.3 --protocol-port 80 test-pool openstack loadbalancer member create --address 10.10.0.4 --protocol-port 80 test-pool
Create a floating IP address in a public network and associate it with a port of the load balancer VIP:
vip_port_id=$(openstack loadbalancer show test-lb -c vip_port_id \ -f value) fip_id=$openstack floating ip create public -c floating_ip_address \ -f value) openstack floating ip set --port $vip_port_id $fip_id
Optionally, enable security groups using the Tungsten Fabric web UI:
Navigate to Configure > Networking > Ports.
Find the load balancer ports.
In the Device column, find the VIP port.
Using the gear icon menu of the VIP port, enable Security Groups.
Access the VIP floating IP address and verify that requests are distributed between the two servers. For example:
curl http://10.11.12.103:80 Welcome to addr:10.10.10.4 curl http://10.11.12.103:80 Welcome to addr:10.10.10.3
In the example above, an HTTP application that runs on the back-end servers returns an IP address of the host on which it runs.
Enable contrail-tools¶
Caution
You can enable the Tungsten Fabric (TF) contrail-tools in the TF 2011 deployments only.
Contrail-tools is a container that provides a centralized location for all
available TF tools and CLI commands. The container includes such utilities
as vif, flow, nh and other tools to debug
network issues. MOSK deploys contrail-tools using the TF
operator through the TFOperator CR.
To enable the TF contrail-tools Deployment using the TF operator:
Enable the
toolsDeployment in the TF Operator resource for the Operator to start the Pods with utilities to debug TF on nodes with thetfvrouter:enabledlabel:spec: controllers: tf-tool: tools: enabled: true labels: tfvrouter: enabled
Note
Use the
labelssection to specify target nodes for the contrail-tools Deployment. If thelabelssection is not specified, thetf-tool-ctools-<xxxxx>Pods will be scheduled to all available nodes in current Deployment.Wait until the
tf-tool-ctools-<xxxxx>Pods are ready in thetfnamespace.Note
The
<xxxxx>string in a Pod name consists of random alpha-numeric symbols generated by Kubernetes to differentiate thetf-tool-ctoolsPods.Use interactive shell in the
tf-tool-ctools-<xxxxx>Pod to debug current Deployment or run commands throughkubectl, for example:kubectl -n tf exec tf-tool-ctools-<xxxxx> -- vif --list
Disable the
toolsDeployment:kubectl -n tf patch tfoperator <TFOperator CR name> --type='json' -p='[{"op": "replace", "path": "/spec/controllers/tf-tool/tools/enabled", "value": false}]'
Manually remove the DaemonSet with contrail-tools:
kubectl -n tf delete ds tf-tool-ctools
Enable tf-api-cli¶
The tf-api-cli container provides access to the Tungsten Fabric (TF)
API through a command-line interface (CLI). See the
contrail-api-cli documentation
for details.
Note
The tf-api-cli tool was initially called contrail-api-cli.
To enable the TF API CLI Deployment using the TF Operator custom resource (CR):
Enable the
tf-cliDeployment in the TF Operator CR to start the Pod with utilities to access the TF API CLI:spec: controllers: tf-tool: tf-cli: enabled: true
Wait for the
tf-tool-cliPod to start running in thetfnamespace.
Once the tf-tool-cli Pod is running, use the interactive shell to
access the TF API CLI:
kubectl -n tf exec tf-tool-cli -it -- bash
The following example illustrates the use of the tf-api-cli command inside
a container:
tf-api-cli ls virtual-network
To disable the TF API CLI Deployment:
Update the TF Operator CR and disable the
tf-cliDeployment:kubectl -n tf patch tfoperator <TFOperator CR name> --type='json' -p='[{"op": "replace", "path": "/spec/controllers/tf-tool/tf-cli/enabled", "value": false}]'
Manually remove the Pod with
tf-cli:kubectl -n tf delete pod tf-tool-cli
Container Cloud operations¶
This section covers the management aspects of the bare metal Container Cloud cluster that MOSK is based on.
Replace a failed manager node¶
This section describes how to replace a failed manager node in your
MOSK deployment. The procedure applies to the manager
nodes that are, for example, permanently failed due to a hardware failure and
remain in the NotReady state.
Note
If your cluster is deployed with a compact control plane, follow the Replace a failed controller node procedure.
To replace a failed manager node:
Verify that the affected manager node is in the
NotReadystate:kubectl get nodes <CONTAINER-CLOUD-NODE-NAME>
Example of system response:
NAME STATUS ROLES AGE VERSION <CONTAINER-CLOUD-NODE-NAME> NotReady <none> 10d v1.18.8-mirantis-1
Delete the affected manager node as described in Mirantis Container Cloud Operations Guide: Delete a cluster machine.
Add a manager node as described in Add a machine.
Modify network configuration on an existing machine¶
TechPreview
Note
Mirantis does not recommend modifying L2 templates in use to prevent accidental cluster failures due to unsafe changes.
The list of risks posed by modifying L2 templates includes:
Services running on hosts cannot reconfigure automatically to switch to the new IP addresses and/or interfaces.
Connections between services are interrupted unexpectedly, which can cause data loss.
Incorrect configurations on hosts can lead to irrevocable loss of connectivity between services and unexpected cluster partition or disassembly.
To modify network configuration of an existing machine, you need to create a new L2 template and change the assignment of the template for that particular machine.
Warning
When a new network configuration is being applied on nodes, sequential draining of corresponding nodes and re-running of LCM on them occurs the same way as it is done during cluster update.
Therefore, before proceeding with modifying the network configuration, verify that the Container Cloud management cluster is up-to-date as described in Container Cloud documentation: Verify the Container Cloud status before cluster update.
To modify network configuration on an existing machine:
Select from the following options:
Create a new L2 template using the Create L2 templates procedure.
Duplicate the existing
L2Templateobject associated with the machine to be configured, ensuring that the duplicatedL2Template:Does not contain the
ipam/DefaultForClusterlabelSince MOSK 23.3, refers to the cluster using the
cluster.sigs.k8s.io/cluster-namelabelBefore MOSK 23.3, refers to the cluster using
Spec.clusterRef: <cluster-name>
Assign a new L2 template to an existing machine by editing the
ipamhostobject associated with the required machine. Add the following fields to thespecsection:Note
The
IpamHostobject is automatically created with the same name as the relatedMachineobject and is located in the same namespace.kubectl edit ipamhost <ipamhost-name>
spec: l2TemplateSelector: name: <new-l2-template-name>
Verify the statuses of the
IpamHostobjects that use the objects updated in the previous step:kubectl get IpamHost <ipamHostName> -o=jsonpath-as-json='{.status.netconfigCandidate}{"\n"}{.status.netconfigCandidateState}{"\n"}{.status.netconfigFilesStates}{"\n"}{.status.messages}'
Caution
The following fields of the
ipamHoststatus are renamed since MOSK 23.1 in the scope of theL2TemplateandIpamHostobjects refactoring:netconfigV2tonetconfigCandidatenetconfigV2statetonetconfigCandidateStatenetconfigFilesStatetonetconfigFilesStates(per file)
No user actions are required after renaming.
The format of
netconfigFilesStatechanged after renaming. ThenetconfigFilesStatesfield contains a dictionary of statuses of network configuration files stored innetconfigFiles. The dictionary contains the keys that are file paths and values that have the same meaning for each file thatnetconfigFilesStatehad:For a successfully rendered configuration file:
OK: <timestamp> <sha256-hash-of-rendered-file>, where a timestamp is in the RFC 3339 format.For a failed rendering:
ERR: <error-message>.
If the configuration is valid:
The
netconfigCandidatefield contains the Netplan configuration file candidate rendered using the modified objectsThe
netconfigCandidateStateandnetconfigFilesStatesfields have theOKstatusThe
netconfigFilesStatesfield contains the old date and checksum meaning that the effective Netplan configuration is still based on the previous versions of the modified objectsThe
messagesfield may contain some warnings but no errors
If the L2 template rendering fails, the candidate for Netplan configuration is empty and its
netconfigCandidateStatestatus contains an error message. A broken candidate for Netplan configuration cannot be approved and become the effective Netplan configuration.
Warning
Do not proceed to the next step until you make sure that the
netconfigCandidatefield contains the valid configuration and this configuration meets your expectations.Approve the new network configuration for the related
IpamHostobjects:kubectl patch IpamHost <ipamHostName> --type='merge' -p "{\"spec\":{\"netconfigUpdateAllow\":true}}"
Once applied, the new configuration is copied to the
netconfigFilesfield of the effective Netplan configuration, then copied to the correspondingLCMMachineobjects.Verify the statuses of the updated
IpamHostobjects:kubectl get IpamHost <ipamHostName> -o=jsonpath-as-json='{.status.netconfigCandidate}{"\n"}{.status.netconfigCandidateState}{"\n"}{.status.netconfigFilesStates}{"\n"}{.status.messages}'
Caution
The following fields of the
ipamHoststatus are renamed since MOSK 23.1 in the scope of theL2TemplateandIpamHostobjects refactoring:netconfigV2tonetconfigCandidatenetconfigV2statetonetconfigCandidateStatenetconfigFilesStatetonetconfigFilesStates(per file)
No user actions are required after renaming.
The format of
netconfigFilesStatechanged after renaming. ThenetconfigFilesStatesfield contains a dictionary of statuses of network configuration files stored innetconfigFiles. The dictionary contains the keys that are file paths and values that have the same meaning for each file thatnetconfigFilesStatehad:For a successfully rendered configuration file:
OK: <timestamp> <sha256-hash-of-rendered-file>, where a timestamp is in the RFC 3339 format.For a failed rendering:
ERR: <error-message>.
The new configuration is copied to the effective Netplan configuration and both configurations are valid when:
The
netconfigCandidateStateandnetconfigFilesStatesfields have theOKstatus and the same checksumThe messages list does not contain any errors
Verify the updated
LCMMachineobjects:kubectl get LCMMachine <LCMMachineName> -o=jsonpath-as-json='{.spec.stateItemsOverwrites}'
In the output of the above command, hash sums contained in the
bm_ipam_netconfig_filesvalues must match those in theIpamHost.status.netconfigFilesStatesoutput. If so, the new configuration is copied toLCMMachineobjects.Monitor the update operations that start on nodes. For details, see Container Cloud documentation: Update a managed cluster.
Add more racks to an existing MOSK cluster¶
This section describes exemplary L2 templates to demonstrate how to add more racks to an existing MOSK cluster.
The following exemplary L2 template belongs to a single-rack MOSK cluster. This template has the following characteristics:
Describes all networks that are used for cluster nodes communication
Can be transformed into several L2 templates depending on nodes roles
Uses the IP gateway in the external network as default route on the nodes in the MOSK cluster
Example of an L2 template for a single-rack cluster
l3Layout:
- subnetName: kaas-mgmt
scope: global
labelSelector:
kaas.mirantis.com/provider: baremetal
kaas-mgmt-subnet: ""
- subnetName: k8s-lcm
scope: namespace
- subnetName: k8s-ext-ipam
scope: namespace
- subnetName: tenant
scope: namespace
- subnetName: k8s-pods
scope: namespace
- subnetName: ceph-front
scope: namespace
- subnetName: ceph-back
scope: namespace
npTemplate: |-
version: 2
ethernets:
{{nic 0}}:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 0}}
set-name: {{nic 0}}
mtu: 1500
{{nic 1}}:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 1}}
set-name: {{nic 1}}
mtu: 1500
{{nic 2}}:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 2}}
set-name: {{nic 2}}
mtu: 9050
{{nic 3}}:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 3}}
set-name: {{nic 3}}
mtu: 9050
bonds:
bond0:
interfaces:
- {{nic 0}}
- {{nic 1}}
parameters:
mode: 802.3ad
transmit-hash-policy: layer3+4
mtu: 1500
bond1:
interfaces:
- {{nic 2}}
- {{nic 3}}
parameters:
mode: 802.3ad
transmit-hash-policy: layer3+4
mtu: 9050
vlans:
k8s-lcm-v:
id: 738
link: bond0
k8s-pod-v:
id: 731
link: bond1
mtu: 9000
k8s-ext-v:
id: 736
link: bond1
mtu: 9000
tenant-vlan:
id: 732
link: bond1
addresses:
- {{ip "tenant-vlan:tenant"}}
mtu: 9050
ceph-front-v:
id: 733
link: bond1
addresses:
- {{ip "ceph-front-v:ceph-front"}}
mtu: 9000
ceph-back-v:
id: 734
link: bond1
addresses:
- {{ip "ceph-back-v:ceph-back"}}
mtu: 9000
bridges:
k8s-lcm:
interfaces: [k8s-lcm-v]
addresses:
- {{ip "k8s-lcm:k8s-lcm"}}
routes:
# to management network of MCC cluster
- to: {{cidr_from_subnet "kaas-mgmt"}}
via: {{gateway_from_subnet "k8s-lcm"}}
table: 101
# fips network
- to: 10.159.156.0/22
via: {{gateway_from_subnet "k8s-lcm"}}
table: 101
routing-policy:
- from: {{cidr_from_subnet "k8s-lcm"}}
table: 101
k8s-pods:
interfaces: [k8s-pod-v]
addresses:
- {{ip "k8s-pods:k8s-pods"}}
mtu: 9000
k8s-ext:
interfaces: [k8s-ext-v]
addresses:
- {{ip "k8s-ext:k8s-ext-ipam"}}
gateway4: {{gateway_from_subnet "k8s-ext-ipam"}}
nameservers:
addresses: {{nameservers_from_subnet "k8s-ext-ipam"}}
mtu: 9000
## FIP Bridge
br-fip:
interfaces: [bond1]
mtu: 9050
To add nodes to the new rack of the same cluster:
Create
Subnetobjects for the following networks: LCM, workload, tenant, and Ceph (where applicable).Create a new L2 template that nodes in a new rack will use.
In this template, configure the external network to be either stretched between racks or connected to the first rack only.
Caution
API/LCM network is the first rack LCM network in our example, since a single-rack MOSK cluster was deployed first. Therefore, only the first rack can contain Kubernetes master nodes that provide access to Kubernetes API.
In the L2 template for the first rack, add IP routes pointing to the networks in the new rack.
The following examples contain:
The modified L2 template for the first rack. Routes added to the second rack are highlighted.
The new L2 template for the second rack with external network that is stretched between racks. The IP gateway in the external network is used as the default route on the nodes of the second rack.
Example of a modified L2 template for the first rack with routes
to the second rack
l3Layout:
- subnetName: kaas-mgmt
scope: global
labelSelector:
kaas.mirantis.com/provider: baremetal
kaas-mgmt-subnet: ""
- subnetName: k8s-lcm
scope: namespace
- subnetName: k8s-ext-ipam
scope: namespace
- subnetName: tenant
scope: namespace
- subnetName: k8s-pods
scope: namespace
- subnetName: ceph-front
scope: namespace
- subnetName: ceph-back
scope: namespace
- subnetName: k8s-lcm-rack2
scope: namespace
- subnetName: tenant-rack2
scope: namespace
- subnetName: k8s-pods-rack2
scope: namespace
- subnetName: ceph-front-rack2
scope: namespace
- subnetName: ceph-back-rack2
scope: namespace
npTemplate: |-
version: 2
ethernets:
{{nic 0}}:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 0}}
set-name: {{nic 0}}
mtu: 1500
{{nic 1}}:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 1}}
set-name: {{nic 1}}
mtu: 1500
{{nic 2}}:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 2}}
set-name: {{nic 2}}
mtu: 9050
{{nic 3}}:
dhcp4: false
dhcp6: false
match:
macaddress: {{mac 3}}
set-name: {{nic 3}}
mtu: 9050
bonds:
bond0:
interfaces:
- {{nic 0}}
- {{nic 1}}
parameters:
mode: 802.3ad
transmit-hash-policy: layer3+4
mtu: 1500
bond1:
interfaces:
- {{nic 2}}
- {{nic 3}}
parameters:
mode: 802.3ad
transmit-hash-policy: layer3+4
mtu: 9050
vlans:
k8s-lcm-v:
id: 738
link: bond0
k8s-pod-v:
id: 731
link: bond1
mtu: 9000
k8s-ext-v:
id: 736
link: bond1
mtu: 9000
tenant-vlan:
id: 732
link: bond1
addresses:
- {{ip "tenant-vlan:tenant"}}
routes:
# to 2nd rack of MOSK cluster
- to: {{cidr_from_subnet "tenant-rack2"}}
via: {{gateway_from_subnet "tenant"}}
mtu: 9050
ceph-front-v:
id: 733
link: bond1
addresses:
- {{ip "ceph-front-v:ceph-front"}}
routes:
# to 2nd rack of MOSK cluster
- to: {{cidr_from_subnet "ceph-front-rack2"}}
via: {{gateway_from_subnet "ceph-front"}}
mtu: 9000
ceph-back-v:
id: 734
link: bond1
addresses:
- {{ip "ceph-back-v:ceph-back"}}
routes:
# to 2nd rack of MOSK cluster
- to: {{cidr_from_subnet "ceph-back-rack2"}}
via: {{gateway_from_subnet "ceph-back"}}
mtu: 9000
bridges:
k8s-lcm:
interfaces: [k8s-lcm-v]
addresses:
- {{ip "k8s-lcm:k8s-lcm"}}
nameservers:
addresses: {{nameservers_from_subnet "k8s-lcm"}}
routes:
# to management network of Container Cloud cluster
- to: {{cidr_from_subnet "kaas-mgmt"}}
via: {{gateway_from_subnet "k8s-lcm"}}
table: 101
# fips network
- to: 10.159.156.0/22
via: {{gateway_from_subnet "k8s-lcm"}}
table: 101
# to 2nd rack of MOSK cluster
- to: {{cidr_from_subnet "k8s-lcm-rack2"}}
via: {{gateway_from_subnet "k8s-lcm"}}
table: 101
routing-policy:
- from: {{cidr_from_subnet "k8s-lcm"}}
table: 101
k8s-pods:
interfaces: [k8s-pod-v]
addresses:
- {{ip "k8s-pods:k8s-pods"}}
routes:
# to 2nd rack of MOSK cluster
- to: {{cidr_from_subnet "k8s-pods-rack2"}}
via: {{gateway_from_subnet "k8s-pods"}}
mtu: 9000
k8s-ext:
interfaces: [k8s-ext-v]
addresses:
- {{ip "k8s-ext:k8s-ext-ipam"}}
gateway4: {{gateway_from_subnet "k8s-ext-ipam"}}
nameservers:
addresses: {{nameservers_from_subnet "k8s-ext-ipam"}}
mtu: 9000
## FIP Bridge
br-fip:
interfaces: [bond1]
mtu: 9050
Example of a new L2 template for the second rack with external
network
l3Layout: - subnetName: kaas-mgmt scope: global labelSelector: kaas.mirantis.com/provider: baremetal kaas-mgmt-subnet: "" - subnetName: k8s-lcm scope: namespace - subnetName: k8s-ext-ipam scope: namespace - subnetName: tenant scope: namespace - subnetName: k8s-pods scope: namespace - subnetName: ceph-front scope: namespace - subnetName: ceph-back scope: namespace - subnetName: k8s-lcm-rack2 scope: namespace - subnetName: tenant-rack2 scope: namespace - subnetName: k8s-pods-rack2 scope: namespace - subnetName: ceph-front-rack2 scope: namespace - subnetName: ceph-back-rack2 scope: namespace npTemplate: |- version: 2 ethernets: {{nic 0}}: dhcp4: false dhcp6: false match: macaddress: {{mac 0}} set-name: {{nic 0}} mtu: 1500 {{nic 1}}: dhcp4: false dhcp6: false match: macaddress: {{mac 1}} set-name: {{nic 1}} mtu: 1500 {{nic 2}}: dhcp4: false dhcp6: false match: macaddress: {{mac 2}} set-name: {{nic 2}} mtu: 9050 {{nic 3}}: dhcp4: false dhcp6: false match: macaddress: {{mac 3}} set-name: {{nic 3}} mtu: 9050 bonds: bond0: interfaces: - {{nic 0}} - {{nic 1}} parameters: mode: 802.3ad transmit-hash-policy: layer3+4 mtu: 1500 bond1: interfaces: - {{nic 2}} - {{nic 3}} parameters: mode: 802.3ad transmit-hash-policy: layer3+4 mtu: 9050 vlans: k8s-lcm-v: id: 738 link: bond0 k8s-pod-v: id: 731 link: bond1 mtu: 9000 k8s-ext-v: id: 736 link: bond1 mtu: 9000 tenant-vlan: id: 732 link: bond1 addresses: - {{ip "tenant-vlan:tenant-rack2"}} routes: # to 2nd rack of MOSK cluster - to: {{cidr_from_subnet "tenant"}} via: {{gateway_from_subnet "tenant-rack2"}} mtu: 9050 ceph-front-v: id: 733 link: bond1 addresses: - {{ip "ceph-front-v:ceph-front-rack2"}} routes: # to 1st rack of MOSK cluster - to: {{cidr_from_subnet "ceph-front"}} via: {{gateway_from_subnet "ceph-front-rack2"}} mtu: 9000 ceph-back-v: id: 734 link: bond1 addresses: - {{ip "ceph-back-v:ceph-back-rack2"}} routes: # to 2nd rack of MOSK cluster - to: {{cidr_from_subnet "ceph-back"}} via: {{gateway_from_subnet "ceph-back-rack2"}} mtu: 9000 bridges: k8s-lcm: interfaces: [k8s-lcm-v] addresses: - {{ip "k8s-lcm:k8s-lcm-rack2"}} nameservers: addresses: {{nameservers_from_subnet "k8s-lcm-rack2"}} routes: # to management network of Container Cloud cluster - to: {{cidr_from_subnet "kaas-mgmt"}} via: {{gateway_from_subnet "k8s-lcm-rack2"}} table: 101 # fips network - to: 10.159.156.0/22 via: {{gateway_from_subnet "k8s-lcm-rack2"}} table: 101 # to API/LCM network of MOSK cluster - to: {{cidr_from_subnet "k8s-lcm"}} via: {{gateway_from_subnet "k8s-lcm-rack2"}} table: 101 routing-policy: - from: {{cidr_from_subnet "k8s-lcm-rack2"}} table: 101 k8s-pods: interfaces: [k8s-pod-v] addresses: - {{ip "k8s-pods:k8s-pods-rack2"}} routes: # to 2nd rack of MOSK cluster - to: {{cidr_from_subnet "k8s-pods"}} via: {{gateway_from_subnet "k8s-pods-rack2"}} mtu: 9000 k8s-ext: interfaces: [k8s-ext-v] addresses: - {{ip "k8s-ext:k8s-ext-ipam"}} gateway4: {{gateway_from_subnet "k8s-ext-ipam"}} nameservers: addresses: {{nameservers_from_subnet "k8s-ext-ipam"}} mtu: 9000 ## FIP Bridge br-fip: interfaces: [bond1] mtu: 9050
Expand IP addresses capacity in an existing cluster¶
If the subnet capacity on your existing cluster is not enough to add new
machines, use the l2TemplateSelector feature to expand the IP addresses
capacity:
Create new
Subnetobject(s) to define additional address ranges for new machines.Set up routing between the existing and new subnets.
Create new L2 template(s) with the new subnet(s) being used in
l3Layout.Set up
l2TemplateSelectorin theMachineobjects for new machines.
To expand IP addresses capacity for an existing cluster:
Verify the capacity of the subnet(s) currently associated with the L2 template(s) used for cluster deployment:
If
labelSelectoris not used for the given subnet, use thenamespacevalue of the L2 template and thesubnetNamevalue from thel3Layoutsection:kubectl get subnet -n <namespace> <subnetName>
If
labelSelectoris used for the given subnet, use thenamespacevalue of the L2 template and comma-separated key-value pairs from thelabelSelectorsection for the given subnet in thel3Layoutsection:kubectl get subnet -n <namespace> -l <key1=value1>[<,key2=value2>...]
Example command:
kubectl get subnet -n test-ns -l cluster.sigs.k8s.io/cluster-name=managed123,user-defined/purpose=lcm-base
Example of system response:
NAME AGE CIDR GATEWAY CAPACITY ALLOCATABLE STATUS old-lcm-network 8d 192.168.1.0/24 192.168.1.1 253 0 OK
Existing Subnet example
apiVersion: "ipam.mirantis.com/v1alpha1" kind: Subnet metadata: name: old-lcm-network namespace: test-ns labels: cluster.sigs.k8s.io/cluster-name: managed123 ipam/SVC-k8s-lcm: "1" kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one user-defined/purpose: lcm-base spec: cidr: 192.168.1.0/24 gateway: 192.168.1.1 . . . status: allocatable: 0 allocatedIPs: . . . capacity: 253 cidr: 192.168.1.0/24 gateway: 192.168.1.1 ranges: - 192.168.1.2-192.168.1.254
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
Existing L2 template example
apiVersion: ipam.mirantis.com/v1alpha1 kind: L2Template metadata: name: base-template namespace: test-ns labels: ipam/DefaultForCluster: "1" kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one cluster.sigs.k8s.io/cluster-name: managed123 spec: autoIfMappingPrio: - provision - eno - ens l3Layout: - scope: namespace subnetName: lcm-subnet1 labelSelector: cluster.sigs.k8s.io/cluster-name: managed123 user-defined/purpose: lcm-base npTemplate: | version: 2 renderer: networkd ethernets: {{nic 0}}: match: macaddress: {{mac 0}} set-name: {{nic 0}} bridges: k8s-lcm: interfaces: - {{nic 0}} addresses: - {{ip "k8s-lcm:lcm-subnet1"}} gateway4: {{gateway_from_subnet "lcm-subnet1"}} nameservers: addresses: {{nameservers_from_subnet "lcm-subnet1"}}
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
Note
Before MOSK 23.3, an L2 template requires
clusterRef: <clusterName>in thespecsection. Since MOSK 23.3, this parameter is deprecated and automatically migrated to thecluster.sigs.k8s.io/cluster-name: <clusterName>label.Create new objects:
Subnetwith theuser-defined/purpose: lcm-additionallabel.L2Templatewith thealternative-template: “1”label. The L2 template should reference the newSubnetobject using theuser-defined/purpose: lcm-additionallabel in thelabelSelectorfield.
Note
The label name
user-defined/purposeis used for illustration purposes. Use any custom label name that differs from system names. Use of a unique prefix such asuser-defined/is recommended.New subnet example
apiVersion: "ipam.mirantis.com/v1alpha1" kind: Subnet metadata: name: new-lcm-network namespace: test-ns labels: cluster.sigs.k8s.io/cluster-name: managed123 ipam/SVC-k8s-lcm: "1" kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one user-defined/purpose: lcm-additional spec: cidr: 192.168.200.0/24 gateway: 192.168.200.1 . . . status: allocatable: 253 allocatedIPs: . . . capacity: 253 cidr: 192.168.200.0/24 gateway: 192.168.200.1 ranges: - 192.168.200.2-192.168.200.254
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
Alternative L2 template example
apiVersion: ipam.mirantis.com/v1alpha1 kind: L2Template metadata: name: alternative-template namespace: test-ns labels: kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one cluster.sigs.k8s.io/cluster-name: managed123 alternative-template: “1” spec: autoIfMappingPrio: - provision - eno - ens l3Layout: - scope: namespace subnetName: lcm-subnet2 labelSelector: cluster.sigs.k8s.io/cluster-name: managed123 user-defined/purpose: lcm-additional npTemplate: | version: 2 renderer: networkd ethernets: {{nic 0}}: match: macaddress: {{mac 0}} set-name: {{nic 0}} bridges: k8s-lcm: interfaces: - {{nic 0}} addresses: - {{ip "k8s-lcm:lcm-subnet2"}} gateway4: {{gateway_from_subnet "lcm-subnet2"}} nameservers: addresses: {{nameservers_from_subnet "lcm-subnet2"}}
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
Note
Before MOSK 23.3, an L2 template requires
clusterRef: <clusterName>in thespecsection. Since MOSK 23.3, this parameter is deprecated and automatically migrated to thecluster.sigs.k8s.io/cluster-name: <clusterName>label.You can also reference the new
Subnetobject by using its name in thel3Layoutsection of thealternative-templateL2 template.Snippet example of an alternative L2 template
... spec: ... l3Layout: - scope: namespace subnetName: new-lcm-network ... npTemplate: | ... bridges: k8s-lcm: interfaces: - {{nic 0}} addresses: - {{ip "k8s-lcm:new-lcm-network"}} gateway4: {{gateway_from_subnet "new-lcm-network"}} nameservers: addresses: {{nameservers_from_subnet "new-lcm-network"}}
Set up IP routing between the existing and new subnets using the tools of your cloud network infrastructure.
In the
providerSpecsection of the newMachineobject, define thealternative-templatelabel forl2TemplateSelector:Snippet example of the new Machine object
apiVersion: cluster.k8s.io/v1alpha1 kind: Machine metadata: labels: cluster.sigs.k8s.io/cluster-name: managed123 kaas.mirantis.com/provider: baremetal kaas.mirantis.com/region: region-one name: additional-machine namespace: test-ns spec: ... providerSpec: value: ... l2TemplateSelector: label: alternative-template
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
After creation, the new machine will use the alternative L2 template that uses the
new-lcm-networksubnet linked byL3Layout.Define additional address ranges for MetalLB. For details, see the optional step for the MetalLB service in Create subnets.
You can create one or several
Subnetobjects to extend the MetalLB address pool with additional ranges. When the MetalLB traffic is routed through the default gateway, you can add the MetalLB address ranges that belong to different CIDR subnet addresses.For example:
Snippet example of the MetalLB configuration
apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: labels: cluster.sigs.k8s.io/cluster-name: managed123 ipam/SVC-MetalLB: '1' kaas.mirantis.com/region: region-one kaas.mirantis.com/provider: baremetal user-defined/purpose: metallb-additional1 name: metallb-svc1-for-managed namespace: test-ns spec: cidr: 172.16.168.0/24 includeRanges: - 172.16.168.11-172.16.168.30 - 172.16.168.41-172.16.168.50 apiVersion: ipam.mirantis.com/v1alpha1 kind: Subnet metadata: labels: cluster.sigs.k8s.io/cluster-name: managed123 ipam/SVC-MetalLB: '1' kaas.mirantis.com/region: region-one kaas.mirantis.com/provider: baremetal user-defined/purpose: metallb-additional2 name: metallb-svc2-for-managed namespace: test-ns spec: cidr: 172.16.169.0/24 includeRanges: - 172.16.169.11-172.16.169.20
Note
The
kaas.mirantis.com/regionlabel is removed from all Container Cloud and MOSK objects in 24.1.Therefore, do not add the label starting with these releases. On existing clusters updated to these releases, or if added manually, Container Cloud ignores this label.
Verify the created objects for MetalLB.
For reference, use
managed-ns_Subnet_metallb-public-for-managed.yamlin Container Cloud documentation: Example of a complete L2 templates configuration for cluster creation.
Restart a bare metal host¶
You can use the Container Cloud API to restart a bare metal host in Mirantis OpenStack for Kubernetes clusters. The workflow of the host restart is as follows:
Setting the maintenance mode on the cluster that contains the target node.
Setting the maintenance mode on the target node for OpenStack and Container Cloud to drain it from workloads. No new workloads will be provisioned to a host in the maintenance mode.
Using the
BareMetalHostobject to initiate a hard reboot of the bare metal server that hosts the node.
To restart a bare metal host:
Using
kubeconfigof the Container Cloud management cluster, access the Container Cloud API and open theClusterobject for editing:kubectl -n <project-name> edit cluster <cluster-name>
Add the following field to the
specsection to set the maintenance mode on the cluster:spec: providerSpec: value: maintenance: true
Verify that the
Clusterobject status forMaintenanceisready: true:kubectl -n <project-name> get cluster <cluster-name>
Example of a negative system response:
... status: providerStatus: conditions: ... - message: 'Maintenance state of the cluster is false, expected: # true. Waiting for the cluster to enter the maintenance state' ready: false type: Maintenance ... maintenance: true
Open the required
Machineobject for editing:kubectl -n <project-name> edit machine <machine-name>
In the
spec:providerSpecsection, set the maintenance mode on the node:spec: providerSpec: value: maintenance: true
In the
annotationssection of theMachinedefinition, capture the bare metal host name connected to the machine:metadata: annotations: metal3.io/BareMetalHost: <project-name>/<host-name>
Verify that the
Machinemaintenance status istrue:status: maintenance: true
Important
Proceed with the node maintenance only after the machine switches to the maintenance mode.
Open the required
BareMetalHostobject for editing using the previously captured<host-name>:kubectl -n <project-name> edit baremetalhost <host-name>
In the
specsection, set theonlinefield tofalse:spec: online: false
Wait for the host to shut down.
In the
specsection, set theonlinefield totrue:spec: online: true
Restore the machine from the maintenance mode by deleting the previously set
maintenance: trueline from theMachineobject:kubectl -n <project-name> edit machine <machine-name>Restore the cluster from the maintenance mode by deleting the previously set
maintenance: trueline from theClusterobject.kubectl -n <project-name> edit cluster <cluster-name>
Limitations¶
The section covers the limitations of Mirantis OpenStack for Kubernetes (MOSK).
[3544] Due to a community issue,
Kubernetes pods may occasionally not be rescheduled on the nodes that are in
the NotReady state. As a workaround, manually reschedule the pods from
the node in the NotReady state using the
kubectl drain --ignore-daemonsets --force <node-uuid> command.
API Reference¶
Mirantis OpenStack for Kubernetes (MOSK) provides a cloud operator with a declarative interface to describe the desired configuration of the cloud.
The program modules responsible for life cycle management of MOSK components extend the API of the underlying Kubernetes cluster with Custom Resources (CRs). These data structures define the services the cloud will provide and specifics of its behavior.
CRs used in MOSK contain dozens of tunable parameters, and the number is constantly growing with every new release as new capabilities get added to the product. Also, each parameter value must be in a specific format and within a range of valid values.
The purpose of the reference documents below is to provide cloud operators with an up-to-date and comprehensive definition of the language they need to use to communicate with MOSK:
User Guide¶
This guide provides the usage instructions for a Mirantis OpenStack for Kubernetes (MOSK) environment and is intended for the cloud end user to successfully perform the OpenStack lifecycle management.
Use the Instance HA service¶
The section provides instructions on how to verify whether the Masakari service has been correctly configured by the cloud operator and will recover an instance from the process and compute node failures.
Verify recovery from a VM process failure¶
Create an instance:
openstack server create --image Cirros-5.1 --flavor m1.tiny --network DemoNetwork DemoInstance01
If required, mark it with the
HA_Enabledtag:Note
Depending on the Masakari service configuration, you may need to mark instances with the
HA_Enabledtag. For more information about service configuration, refer to Configure high availability with Masakari.openstack server set --property HA_Enabled=True DemoInstance01
Identify the compute host with the instance:
openstack server show DemoInstance01 |grep host | OS-EXT-SRV-ATTR:host | vs-ps-vyvsrkrdpusv-1-w2mtagbeyhel-server-cgpejthzbztt |
Log in to the compute host and obtain the instance PID:
ps xafu |grep qemu nova 5231 34.3 1.1 5459452 184712 ? Sl 07:39 0:18 | \_ /usr/bin/qemu-system-x86_64 -name guest=instance-00000002....
Simulate the failure by killing the process:
kill -9 5231
Verify notifications:
openstack notification list +--------------------------------------+----------------------------+---------+------+--------------------------------------+-----------------------------------------------------------------------------------------------------------------------+ | notification_uuid | generated_time | status | type | source_host_uuid | payload | +--------------------------------------+----------------------------+---------+------+--------------------------------------+-----------------------------------------------------------------------------------------------------------------------+ | 2fb82a5c-9a8b-4cef-a06e-a737e1b565a0 | 2021-07-06T07:40:40.000000 | running | VM | 6f1bd5aa-0c21-446a-b6dd-c1b4d09759be | {'event': 'LIFECYCLE', 'instance_uuid': '165cdfaf-b9e5-42b2-bbb9-af9283a789ae', 'vir_domain_event': 'STOPPED_FAILED'} | +--------------------------------------+----------------------------+---------+------+--------------------------------------+-----------------------------------------------------------------------------------------------------------------------+ openstack notification list +--------------------------------------+----------------------------+----------+------+--------------------------------------+-----------------------------------------------------------------------------------------------------------------------+ | notification_uuid | generated_time | status | type | source_host_uuid | payload | +--------------------------------------+----------------------------+----------+------+--------------------------------------+-----------------------------------------------------------------------------------------------------------------------+ | 2fb82a5c-9a8b-4cef-a06e-a737e1b565a0 | 2021-07-06T07:40:40.000000 | finished | VM | 6f1bd5aa-0c21-446a-b6dd-c1b4d09759be | {'event': 'LIFECYCLE', 'instance_uuid': '165cdfaf-b9e5-42b2-bbb9-af9283a789ae', 'vir_domain_event': 'STOPPED_FAILED'} | +--------------------------------------+----------------------------+----------+------+--------------------------------------+-----------------------------------------------------------------------------------------------------------------------+
Verify that the instance process has been recovered:
ps xafu |grep qemu root 8800 0.0 0.0 11488 1104 pts/1 S+ 07:41 0:00 | | \_ grep --color=auto qemu nova 8323 104 0.7 1262628 128936 ? Sl 07:40 0:09 | \_ /usr/bin/qemu-system-x86_64 -name guest=instance-00000002
Verify recovery from a node failure¶
Create an instance:
openstack server create --image Cirros-5.1 --flavor m1.tiny --network DemoNetwork DemoInstance01
If required, mark it with the
HA_Enabledtag:Note
Depending on the Masakari service configuration, you may need to mark instances with the
HA_Enabledtag. For more information about service configuration, refer to Configure high availability with Masakari.openstack server set --property HA_Enabled=True DemoInstance01
Identify the compute host with the instance:
openstack server show DemoInstance01 |grep host | OS-EXT-SRV-ATTR:host | vs-ps-vyvsrkrdpusv-1-w2mtagbeyhel-server-cgpejthzbztt |
Log in to the compute host and power it off.
After a while, verify that the instance has been evacuated:
openstack server show DemoInstance01 |grep host | OS-EXT-SRV-ATTR:host | vs-ps-vyvsrkrdpusv-0-ukqbpy2pkcuq-server-s4u2thvgxdfi |
Manage application credentials¶
Application credentials is a mechanism in the MOSK Identity service (Keystone) that enables application automation tools, such as shell scripts, Terraform modules, Python programs, and others, to securely perform various actions in the cloud API in order to deploy and manage application components.
Historically, dedicated technical user accounts were created to be used by application automation tools. The application credentials mechanism has significant advantages over the legacy approach in terms of the following.
Self-service
Cloud users manage application credential objects completely on their own, without having to reach out to cloud operators
Note
Application credentials are owned by the cloud user who created them, not the project, domain, or system that they have access to. Non-admin users only have access to application credentials that they have created themselves.
Security
Cloud users creating application credentials have control over the actions that automation tools will be allowed to perform on their behalf by the following:
Specifying the cloud API endpoints the tool may access
Delegating to the tool just a subset of the owner’s roles
Restricting the tool from creating new application credential objects or trusts
Defining the validity period for a credential
Simplicity
In case a credential is compromised, the automation tools using it can be easily switched to a new object
See also
Usage limitations¶
For security reasons, a cloud user who logs in to the cloud through the Mirantis Container Cloud IAM or an external identity provider cannot use the application credentials mechanism by default. To enable the functionality, contact your cloud operator.
MOSK Object Storage service does not support application credentials authentication to access S3 API. To authenticate in S3 API, use the EC2 credentials mechanism.
MOSK Object Storage service has limited support for application credentials when accessing Swift API. The service does not accept application credentials with restrictions to allowed API endpoints.
Create an application credential using CLI¶
You can create an application credential using OpenStack CLI or Horizon. To create an application credential using CLI, use the openstack application credential create command.
If you do not provide the application credential secret, one will be generated automatically.
Warning
The application credential secret displays only once upon creation. It cannot be recovered from the Identity service. Therefore, capture the secret string from the command output and keep it in a safe place for future usage.
When creating application credentials, you can limit their capabilities depending on the security requirements of your deployment:
Define expiration time.
Limit the roles of an application credential to only a subset of roles that the user creating the credential has.
Pass a list of allowed API paths and actions, aka access rules, that the application credential will have access to. For the comprehensive list of possible options when creating credentials, consult the upstream OpenStack documentation.
Restrict an application credential from creating another application credential or a trust.
Note
This is the default behavior, but depending on what the application credential is used for, you may need to loosen this restriction.
An application credential will be created with access to the scope of your current session. For example, if your current credential is scoped to a specific project, domain, or system, the created application credential will have access to the same scope.
Create an application credential through Horizon¶
In the Identity panel, select Application Credentials.
In this view, you can list, create, and delete application credentials as well as display details of a specific application credential.
Click Create Application Credential.
In the wizard that opens, fill in the required fields and download
clouds.yamlor an RC file to authenticate with the created application credential.
Authenticate with an application credential¶
To authenticate in a MOSK cloud using an application credential, you need to know the ID and secret of the application credential.
When using the human-readable name of an application credential instead of its ID, you also have to supply the user ID or the user name with the user domain ID or name. These details are required for the Identity service (Keystone) to resolve your application credential, since different users may have application credentials with the same name.
The following example illustrates a snippet from an RC file with required environment variables using the application credential name:
export OS_AUTH_URL="https://keystone.it.just.works/v3"
export OS_AUTH_TYPE=v3applicationcredential
export OS_APPLICATION_CREDENTIAL_NAME=myappcreds
export OS_APPLICATION_CREDENTIAL_SECRET=supersecret
export OS_USERNAME=demo
export OS_USER_DOMAIN_NAME=Default
The following example illustrates a snippet of an entry in clouds.yaml
using the application credential ID:
clouds:
my-app:
auth_type: v3applicationcredential
auth:
auth_url: https://keystone.it.just.works/v3
application_credential_id: 21dced0fd20347869b93710d2b98aae0
application_credential_secret: supersecret
Using OpenStack CLI explicit arguments¶
Use the following openstackclient explicit arguments while authenticating
with an application credential:
openstack --os-auth-type v3applicationcredential \
--os-auth-url https://keystone.it.just.works/v3 \
--os-application-credential-name my-appcreds \
--os-application-credential-secret supersecret \
--os-username demo \
--os-user-domain-name Default \
<ANY OSC COMMAND>
Using shell scripting¶
The following example curl command outputs the OpenStack keystone token
using the application_credential authentication method:
curl -X POST https://keystone.it.just.works/v3/auth/tokens \
-i -H "Content-Type: application/json" \
-d '{"auth":{"identity":{"methods":["application_credential"],"application_credential":{"id": "21dced0fd20347869b93710d2b98aae0","secret": "supersecret"}}}}'
The token is located in the x-subject-token header of the response, and
the response body contains information about the user, scope, effective roles,
and the service catalog.
Rotate an application credential¶
In case an application credential becomes invalid due to the expiry or the owner-user leaving the team, or compromised if its secret gets exposed, Mirantis recommends rotating the credential immediately as follows:
Create a new application credential with the same permissions.
Adjust the automation tooling configuration to use the new object.
Delete the old object. This can be performed by the owner-user or cloud operator.
Authenticate in OpenStack API as a federated OIDC user¶
This section offers an example workflow of federated user authentication in OpenStack using an external identity provider and OpenID Connect (OIDC) protocol. The example illustrates a typical HTTP-based interchange of authentication data happening underneath between the client software, identity provider, and MOSK Identity service (OpenStack Keystone) when a cloud user logs in to a cloud using their corporate or social ID, depending on cloud configuration.
The instructions below can be handy for cloud operators who want to delve into how federated authentication operates in OpenStack and troubleshoot any related issues, as well as advanced cloud users keen on crafting their own basic automation tools for cloud interactions.
The instructions are provided for educational purposes. Mirantis encourages
the majority of cloud users to rely on existing mature tools and libraries,
such as openstacksdk, keystoneauth, python-openstackclient,
or gophercloud to communicate with OpenStack APIs in a programmable
manner.
Warning
Mirantis advises cloud users not to rely on federated authentication when managing their cloud resources using command line and cloud automation tool. Instead, consider using OpenStack built-in application credentials mechanism to ensure secure and reliable access to OpenStack APIs of your MOSK cloud. See Manage application credentials for details.
Verify cloud configuration with the cloud administrator¶
For cloud users to be able to log in to an OpenStack cloud using their federated identity, the cloud administrator should configure the cloud to integrate with an external OIDC-compatible identity provider, such as Mirantis Container Cloud IAM (Keycloak) with all the necessary resources pre-created in the OpenStack Keystone API.
To authenticate in OpenStack using your federated identity, an
OIDC-compatible identity provider protocol, and the v3oidcpassword
authentication method, get yourself acquainted with the authentication
parameters listed below. You can extract the required information from the
OpenStack RC file that is available for download from OpenStack Dashboard
(Horizon) once you log in to it with your federated identity, or the
clouds.yaml file.
Parameter |
Description |
|---|---|
|
The URL pointing to the OpenStack Keystone API. |
|
The URL pointing to the OIDC discovery document served by the identity provider,
usually ends with |
|
The identifier of the OIDC client to use. |
|
The secret for the OIDC client. Many OIDC providers require this parameter. Some providers, including Mirantis Container Cloud IAM (Keycloak), allow so-called public clients, where secrets are not used and can be any string. |
|
The scope requested when using OIDC authentication. This is at least
|
|
The name of the corresponding identity provider object as created in the Keystone API. |
|
The name of the protocol object as created in the Keystone API. |
|
Your user name. |
|
Your password in the identity provider, such as Mirantis Container Cloud IAM (Keycloak). |
Note
Additionally, to obtain a scoped token, you need information about
the target scope, such as, OS_PROJECT_DOMAIN_NAME and
OS_PROJECT_NAME.
Below is an example of RC file to set environment variables used in the further code examples for the project scope authentication:
export OS_AUTH_URL=https://keystone.it.just.works
export OS_DISCOVERY_ENDPOINT=https://keycloak.it.just.works/auth/realms/iam/.well-known/openid-configuration
export OS_CLIENT_ID=os
export OS_CLIENT_SECRET=someRandomClientSecretMightBeNull
export OS_USERNAME=writer
export OS_PASSWORD=password
export OS_IDENTITY_PROVIDER=keycloak
export OS_PROTOCOL=mapped
export OS_OPENID_SCOPE=openid
export OS_PROJECT_DOMAIN_NAME=Default
export OS_PROJECT_NAME=admin
Obtain the OIDC access token¶
Obtain the token endpoint of the identity provider by extracting it from the OIDC discovery document:
token_endpoint=$(curl -sk -X GET $OS_DISCOVERY_ENDPOINT | jq -r .token_endpoint)
Obtain the access token from the identity provider by sending the POST request to the token endpoint that will return the access token in exchange to the login credentials:
access_token=$(curl -sk \ -X POST $token_endpoint \ -u $OS_CLIENT_ID:$OS_CLIENT_SECRET \ -d "username=${OS_USERNAME}&password=${OS_PASSWORD}&scope=${OS_OPENID_SCOPE}&grant_type=password" \ -H "Content-Type: application/x-www-form-urlencoded" \ | jq -r .access_token)
Note
As per OIDC RFC, the request to the endpoint must be of the URL-encoded content type.
Now, you can exchange the OIDC access token for an unscoped token from OpenStack Keystone.
Obtain the unscoped token from OpenStack Keystone¶
The Keystone token is included in the response header. However, the response
body in the JSON format often contains additional data that may prove useful
for certain applications. The following example excludes the body by using
the -I flag:
unscoped_token=$(curl -sik \
-I \
-X POST $OS_AUTH_URL/OS-FEDERATION/identity_providers/${OS_IDENTITY_PROVIDER}/protocols/${OS_PROTOCOL}/auth \
-H "Authorization: Bearer $access_token" \
| grep x-subject-token \
| awk '{print $2}' \
| tr -d '\r')
Note
The tr -d '\r' line trims the carriage return characters from
grep and awk outputs so that the extracted data
can be properly inserted into the JSON authentication request later.
Now, you can generate a scoped token from OpenStack Keystone using the unscoped token and specifying the project scope.
Optional. Discover available scopes¶
In case you do not know beforehand the OpenStack authorization scope you want to log in to, use the unscoped token to get a list of the available scopes:
curl -sk $OS_AUTH_URL/auth/projects \
-H "X-Auth-Token: $unscoped_token" | jq .projects
Obtain the scoped token from OpenStack Keystone¶
Create a JSON-formatted authentication request using the following script. For example, for the project scope:
token_request=$(mktemp) cat > $token_request << EOJSON { "auth": { "identity": { "methods": [ "token" ], "token": { "id": "$unscoped_token" } }, "scope": { "project": { "domain": { "name": "$OS_PROJECT_DOMAIN_NAME" }, "name": "$OS_PROJECT_NAME" } } } } EOJSON
Send the authentication request to OpenStack Keystone to obtain a scoped token:
scoped_token=$(curl -sik \ -X POST $OS_AUTH_URL/auth/tokens \ -d "@$token_request" -H "Content-Type: application/json" \ | grep x-subject-token \ | awk '{print $2}' \ | tr -d '\r')
Remove the temporary file used to store the authentication request:
rm $token_request
Use the scoped token to access OpenStack services APIs¶
To verify that you can access the OpenStack services APIs, for example, obtain the list of available images:
curl -sk -H "X-Auth-Token: $scoped_token" \
-X GET https://glance.it.just.works/v2/images
Replace https://glance.it.just.works with the endpoint of the
MOSK Image service (OpenStack Glance) that you can obtain
from the Access & Security dashboard of OpenStack Horizon.
Deploy your first cloud application using automation¶
This section aims to help you build your first cloud application and onboard it to a MOSK cloud. It will guide you through the process of deploying and managing a sample application using automation, and showcase the powerful capabilities of OpenStack.
Sample application¶
The sample application offered by Mirantis is a typical web-based application consisting of a front end that provides a RESTful API situated behind the cloud load balancer (OpenStack Octavia) and a back-end database that stores data in the cloud block storage (OpenStack Cinder volumes).
You can extend the sample application to make use of advanced features offered by MOSK, for example:
An HTTPS-terminating load balancer that stores its certificate in the Key Manager service (OpenStack Barbican)
A public endpoint accessible by the domain name with the help of the DNS service (OpenStack Designate)
Deployment automation tools¶
The sample application intends to showcase how deployment automation can enable the DevOps engineers to streamline the process of installing, updating, and managing their workloads in the cloud providing an efficient and scalable approach to building and running cloud-based applications.
The sample application offers example templates for the most common tools that include:
OpenStack Heat, an OpenStack service used to orchestrate composite cloud applications with a declarative template format through the OpenStack-native REST API
Terraform, an Infrastructure-as-code tool from HashiCorp, designed to build, change, and version cloud and on-prem resources using a declarative configuration language
You can easily customize and extend the templates for similar workloads.
Note
The sample source code and automation templates reside in the OpenStack RefApp GitHub repository.
Environment
The sample cloud application deployment has been verified in the following environment:
OpenStack command-line client v5.8.1
Terraform v1.3.x
OpenStack Yoga
Ubuntu 18.04 LTS (Bionic Beaver) as guest operating system
Obtain the access credentials to the cloud¶
Log in to the cloud web UI (OpenStack Horizon).
Navigate to the project where you want to deploy the application.
Use the top-right user menu to download the
OpenStack RC Fileto your local machine.
Note
As an example, you will be using your own user credential to deploy the sample application. However, in the future, Mirantis strongly recommends creating dedicated application credentials for your workloads.
Deploy sample application with OpenStack Heat¶
Prepare for the Heat stack creation:
Load the previously downloaded
openrcfile into the environment to configure the OpenStack client with the access credentials:source <YOUR_PROJECT>-openrc.sh
Verify that a Heat stack with the target name does not exist:
STACK_NAME=sampleapp openstack stack check $STACK_NAME
Generate an SSH keypair to access front-end and database instances:
cd <OPENSTACK_REFAPP>/heat-templates ssh-keygen -m PEM -N '' -C '' -f .openstack
Verify the default deployment configuration in the
top.yamltemplate. Modify parameters as required. For example, you may want to change the image, flavor, or network parameters.Create the stack using the provided template with the public key generated above:
PUBLIC_KEY=$(<.openstack.pub) openstack stack create -t top.yaml --parameter "cluster_public_key=${PUBLIC_KEY}" $STACK_NAME
Verify that the Heat stack has been created successfully and the application instances are running:
openstack stack event list $STACK_NAME openstack stack resource list $STACK_NAME openstack stack show $STACK_NAME
Obtain the URL of application public endpoint:
openstack stack output show $STACK_NAME app_url
Deploy sample application with Terraform¶
Download and install the Terraform binary on your local machine, for example:
wget -O- https://releases.hashicorp.com/terraform/1.3.9/terraform_1.3.9_linux_amd64.zip | funzip > /usr/bin/terraform chmod +x /usr/bin/terraform
Generate an SSH keypair to be used to log in to the application instances:
cd <OPENSTACK_REFAPP>/terraform/templates ssh-keygen -m PEM -N '' -C '' -f .openstack
Load the previously downloaded
openrcfile into the environment to configure Terraform with the cloud access credentials:source <YOUR_PROJECT>-openrc.sh
Verify that all required Terraform providers are properly installed and configured:
terraform initGenerate a speculative execution plan that outlines the actions required to implement the current configuration and apply the Terraform state:
terraform plan terraform apply -auto-approve
Note
If
HTTPS_PROXYis set, also setNO_PROXYbefore running terraform plan:export NO_PROXY="it.just.works"
Obtain the URL of the application public endpoint:
terraform output app_url
Verify application functioning¶
Run the curl tool against the URL of the application public end point to make sure that all components of the application have been deployed correctly and it is responding to user requests:
$ curl http://<APP_URL>/
{"host": "host name of API instance that replied","app": "openstack-refapp"}
The sample application provides a RESTful API, which you can use for advanced database queries.
See also
Deploy your first cloud application using cloud web UI¶
This section aims to help you build your first cloud application and onboard it to a MOSK cloud. It will guide you through the process of deploying a simple application using the cloud web UI (OpenStack Horizon).
The section will also introduce you into the fundamental OpenStack primitives that are commonly used to create virtual infrastructures for cloud applications.
Sample application¶
The sample application in the context of this tutorial is a typical web-based application consisting of Wordpress, a popular web content management system, and a database that stores Wordpress data in the cloud block storage (OpenStack Cinder volume).
You can extend the sample application to make use of advanced features offered by MOSK, for example:
Add an HTTPS-terminating load balancer that stores its certificate in the Key Manager service (OpenStack Barbican)
Make the public endpoint accessible by the domain name with the help of the DNS service (OpenStack Designate)
Prerequisites¶
You can run the sample application on any OpenStack cloud. It can be a private MOSK cluster of your company, a public OpenStack cloud, or even your own tiny TryMOSK instance spinned up in an AWS tenant as described in the Try Mirantis OpenStack for Kubernetes on AWS article.
To deploy the sample application, you need:
Access to your cloud web UI with the credentails obtained from your cloud administator:
The URL of the cloud web UI (OpenStack Horizon)
The login, password, and, optionally, authentication method that you need to use to log in to the MOSK cloud
The name of the OpenStack project with enough resources available
Connectivity from the MOSK cluster to the Internet to be able to download the components of the sample application. If needed, consult with your cloud administrator.
A local machine with the SSH client installed and connectivity to the cloud public address (floating IP) space.
Environment
The sample cloud application deployment has been verified in the following environment:
OpenStack Yoga
Ubuntu 18.04 LTS (Bionic Beaver) as guest operating system
Deploy sample application using the web UI¶
Log in to the cloud web UI:
Open your favorite web browser and navigate to the URL of the cloud web UI.
Use the access credentials to log in.
Select the appropriate project from the drop-down menu at the top left.
Create a dedicated private network for your application:
Note
Virtual networks in OpenStack are used for isolated communication between instances (virtual machines) within the cloud. Instances get plugged into networks to communicate with any virtual networking entities, such as virtual routers and load balancers as well as the outside world.
Navigate to Network > Networks.
Click Create Network. The Create Network dialog box opens.
In the Network tab, specify a name for the new network. Select the Enable Admin State and Create Subnet check boxes.
In the Subnet tab, specify a name for the subnet and network address, for example,
192.168.1.0/24.In the Subnet Details tab, keep the preset configuration.
Click Create.
Create and connect a network router.
Note
A virtual router, just like its physical counterpart, is used to pass the layer 3 network traffic between two or more networks. Also, a router performs the network address translation (NAT) for instances to be able to communicate with the outside world through the external networks.
To create the network router:
Navigate to Network > Routers.
Click Create Router. The Create Router dialog box opens.
Specify a meaningful name for the new router and select the external network it needs to be plugged in. If you do not know which external network to select, consult your cloud administator.
Now, when the router is up and running, you need to plug it into the application private network, so it can forward the packets between your local machine and the instance, which you will create later.
To connect the network router:
Navigate to Network > Routers.
Find the router you have just created and click on its name.
Open the Interfaces tab and click Add Interface. The Add Interface dialog box opens.
Select the subnetwork that you provided in the first step.
Click Add Interface.
Create an instance:
Note
A virtual machine, or an instance in the OpenStack terminology, is the machine where your application processes will be effectively running.
Navigate to Compute > Instances.
Click Launch Instance. The Launch Instance dialog box opens.
In the Details tab, specify a meaningful name for the new instance, so that you can easily identify it among others later.
In the Source tab, select the Image boot source. MOSK comes with a few prebuilt images, we will be using the one with the Ubuntu Bionic Server image for the sample application.
In the Flavor tab, pick the m1.small size for the instance, which provides just enough resources for the application to run.
In the Networks tab, select the previously created private network to plug the instance into.
In the Security Groups tab, verify that the default security group is selected and it allows the ingress HTTP, HTTPs, and SSH traffic.
In the Key Pair tab, create or import a new key pair to be able to log in to the instance securily through the SSH protocol. Make sure to have a copy of the private key on your local machine to pass to the SSH client.
Now all the needed settings have been made, click Launch Instance.
Wait for the new instance to get shown in the Active state in the Instances dashboard.
Attach a volume to the instance.
Note
Volumes in OpenStack provide persistent storage for applications, allowing the data, which is placed on them, to exist independently from the instances, as opposed to the data written to ephemeral storage, which automatically gets terminated together with its instance.
To create the volume:
Navigate to Volumes > Volumes.
Click Create Volume. The Create Volume dialog box opens.
Specify a meaningful name for the new volume.
Leave all fields with the default values. A 1 GiB volume will be enough for the sample application.
Once the volume is allocated, it shows up in the same Volumes dashboard. Now, you can attach the new volume to your running instance:
In the Volumes dashboard, select the volume to add to the instance.
Click Manage Attachments. The Manage Volume Attachments dialog box opens.
Select the required instance.
Click Attach Volume.
Now, the Attached To column in the Volumes dashboard will display your volume device name as the volume attached to your instance. Also, you can view the status of a volume that can be either Available or In-Use.
Expose the instance outside:
Note
A floating IP address in OpenStack is an abstraction over a publicly routable IP address that allows an instance to be accessed from outside the cloud. Floating IPv4 addresses are typically scarce and expensive resources and, so they need to be explicitly allocated and assigned to selected instances.
Navigate to Compute > Instances.
From the Actions drop-down list next to your instance, select Associate Floating IP. The Manage Floating IP Associations dialog box opens.
Allocate a new floating IP address using the + button.
The Port to be associated should be already filled in with the instance private port.
Click Associate.
The Compute > Instances dashboard will display the instance floating IP address along with the private one. Write down the floating IP address as you will need it in the next step.
Access the instance through SSH.
On your local machine use the SSH client to log in to the instance by its floating IP address. Ensure the
0600permission on the private key file.ssh -i <path-to-your-private-key> ubuntu@<floating-IP>
All operations on the instance listed below must be performed by the superuser, as
root:sudo su -
Initialize persistent storage for the application data.
A newly created volume is always an empty block device that needs to be provisioned before the application can write or read any data.
Use the device name under which the volume got attached to the instance to create a file system on the block device:
mkfs.ext4 <volume-device-name> -q
Create a mount point and mount the newly provisioned block device into the guest operating system:
mkdir /mnt/data && mount <volume-device-name> /mnt/data
Start the application components.
We will run the application components as Docker containers to simplify their provisioning and configuration and isolate them from each other.
The common Ubuntu cloud image does not have Docker engine preinstalled, so you need to install it manually:
sudo apt-get update && sudo apt-get install -y docker.io
Our sample application consists of two Docker containers:
MySQL database server
Wordpress instance
First, we create a new Docker network so that both containers can communicate with each other:
docker network create samplenet
Now, let’s spin up the MySQL database. We will place all its data in a separate directory on the mounted volume. You can find more information about the parameters of MySQL image on its DockerHub page.
mkdir /mnt/data/db docker run -d --name db --network samplenet --volume /mnt/data/db:/var/lib/mysql -e MYSQL_DATABASE=exampledb -e MYSQL_USER=exampleuser -e MYSQL_PASSWORD=examplepass -e MYSQL_RANDOM_ROOT_PASSWORD=1 mysql:5.7
It is time to start the Wordpress Docker container. Its data will be also hosted on the volume.
mkdir /mnt/data/wordpress docker run -d --name wordpress --network samplenet --publish 80:80 --volume /mnt/data/wordpress:/var/www/html -e WORDPRESS_DB_HOST=db -e WORDPRESS_DB_USER=exampleuser -e WORDPRESS_DB_PASSWORD=examplepass -e WORDPRESS_DB_NAME=exampledb wordpress
Now, the sample application is up and running.
Verify application functioning¶
Use the web browser on you local machine to navigate to the application
endpoint http://<instance-floating-IP-address>. If you have followed
all the steps accurately, your browser should now display the Wordpress
Getting Started dialog.
Feel free to provide the necessary parameters and proceed with the initialization. Once it finishes, you proceed with building your own cloud-hosted website and start serving the users. Congratulations!
Use Heat to create and manage Tungsten Fabric objects¶
Utilizing OpenStack Heat templates is a common practice to orchestrate Tungsten Fabric resources. Heat allows for the definition of templates, which can depict the relationships between resources such as networks, and enforce policies accordingly. Through these templates, OpenStack REST APIs are invoked to create the necessary infrastructure in the correct order required to launch applications.
Managing Tungsten Fabric resources through OpenStack Heat represents a structured and automated approach as compared to using of Tungsten Fabric UI or API directly. The Heat templates provide a declarative mechanism to define and manage infrastructure, ensuring repeatability and consistency across deployments. This contrasts with the manual and potentially error-prone process of managing resources through the Tungsten Fabric UI and API.
To orchestrate Tungsten Fabric objects through a Heat template:
Define the template with the Tungsten Fabric objects as required.
Note
You can view the full list of Heat resources available in your environment from either OpenStack Horizon dashboard, the Project > Orchestration > Resource Types page, or the OpenStack CLI:
openstack orchestration resource type list
Also, you can obtain the specification of the Tungsten Fabric configuration API by accessing
http://TF_API_ADDRESS:8082/documentation/contrail_openapi.htmlon your environment.Below is an example template showcasing a Heat topology that illustrates the creation sequence of the following Tungsten Fabric resources: instance, port, network, router, and external network.
Example Heat topology with Tungsten Fabric resources
heat_template_version: 2015-04-30 description: HOT template to create a Instance connected to external network parameters: stack_prefix: type: string description: Prefix name for stack resources. default: "net-logical-router" project: type: string description: project for the Server public_network_id: type: string floating_ip_pool: type: string subnet_ip_prefix: type: string default: '192.168.96.0' subnet_ip_prefix_len: type: string default: '24' server_image: type: string description: Name of image to use for server. default: 'Cirros-6.0' availability_zone: type: string default: 'nova' resources: ipam: type: OS::ContrailV2::NetworkIpam properties: name: { list_join: [ '_', [ get_param: stack_prefix, "ipam" ] ] } project: { get_param: project } private_network: type: OS::ContrailV2::VirtualNetwork properties: name: { list_join: [ '_', [ get_param: stack_prefix, "network" ] ] } project: { get_param: project } network_ipam_refs: [{ get_resource: ipam }] network_ipam_refs_data: [ { network_ipam_refs_data_ipam_subnets: [ { network_ipam_refs_data_ipam_subnets_subnet_name: { list_join: [ '_', [ get_param: stack_prefix, "subnet" ] ] }, network_ipam_refs_data_ipam_subnets_subnet: { network_ipam_refs_data_ipam_subnets_subnet_ip_prefix: '192.168.96.0', network_ipam_refs_data_ipam_subnets_subnet_ip_prefix_len: '24', }, network_ipam_refs_data_ipam_subnets_allocation_pools: [ { network_ipam_refs_data_ipam_subnets_allocation_pools_start: '192.168.96.10', network_ipam_refs_data_ipam_subnets_allocation_pools_end: '192.168.96.100' } ], network_ipam_refs_data_ipam_subnets_default_gateway: '192.168.96.1', network_ipam_refs_data_ipam_subnets_enable_dhcp: 'true', } ] } ] private_network_interface: type: OS::ContrailV2::VirtualMachineInterface properties: name: { list_join: [ '_', [ get_param: stack_prefix, "interface" ] ] } project: { get_param: project } virtual_machine_interface_device_owner: 'network:router_interface' virtual_machine_interface_bindings: { virtual_machine_interface_bindings_key_value_pair: [ { virtual_machine_interface_bindings_key_value_pair_key: 'vnic_type', virtual_machine_interface_bindings_key_value_pair_value: 'normal' } ] } virtual_network_refs: [{ get_resource: private_network }] instance_ip: type: OS::ContrailV2::InstanceIp properties: name: { list_join: [ '_', [ get_param: stack_prefix, "instance_ip" ] ] } fq_name: { list_join: [ '_', [ "fq_name", get_param: stack_prefix ] ] } virtual_network_refs: [{ get_resource: private_network }] virtual_machine_interface_refs: [{ get_resource: private_network_interface }] router: type: OS::ContrailV2::LogicalRouter properties: name: { list_join: [ '_', [ get_param: stack_prefix, "router" ] ] } project: { get_param: project } virtual_machine_interface_refs: [{ get_resource: private_network_interface }] virtual_network_refs: [{ get_param: public_network_id }] virtual_network_refs_data: [ { virtual_network_refs_data_logical_router_virtual_network_type: 'ExternalGateway' }, ] security_group: type: OS::ContrailV2::SecurityGroup properties: # description: SG with allowed ssh/icmp traffic name: { list_join: [ '_', [ get_param: stack_prefix, "sg" ] ] } project: { get_param: project } security_group_entries: { security_group_entries_policy_rule: [ { security_group_entries_policy_rule_direction: '>', security_group_entries_policy_rule_protocol: 'any', security_group_entries_policy_rule_ethertype: 'IPv4', security_group_entries_policy_rule_src_addresses: [ { security_group_entries_policy_rule_src_addresses_security_group: 'local', } ], security_group_entries_policy_rule_dst_addresses: [ { security_group_entries_policy_rule_dst_addresses_subnet: { security_group_entries_policy_rule_dst_addresses_subnet_ip_prefix: '0.0.0.0', security_group_entries_policy_rule_dst_addresses_subnet_ip_prefix_len: '0', }, } ] }, { security_group_entries_policy_rule_direction: '>', security_group_entries_policy_rule_protocol: 'any', security_group_entries_policy_rule_ethertype: 'IPv6', security_group_entries_policy_rule_src_addresses: [ { security_group_entries_policy_rule_src_addresses_security_group: 'local', } ], security_group_entries_policy_rule_dst_addresses: [ { security_group_entries_policy_rule_dst_addresses_subnet: { security_group_entries_policy_rule_dst_addresses_subnet_ip_prefix: '::', security_group_entries_policy_rule_dst_addresses_subnet_ip_prefix_len: '0', }, } ] }, { security_group_entries_policy_rule_direction: '>', security_group_entries_policy_rule_protocol: 'icmp', security_group_entries_policy_rule_ethertype: 'IPv4', security_group_entries_policy_rule_src_addresses: [ { security_group_entries_policy_rule_src_addresses_subnet: { security_group_entries_policy_rule_src_addresses_subnet_ip_prefix: '0.0.0.0', security_group_entries_policy_rule_src_addresses_subnet_ip_prefix_len: '0', }, } ], security_group_entries_policy_rule_dst_addresses: [ { security_group_entries_policy_rule_dst_addresses_security_group: 'local', } ] }, { security_group_entries_policy_rule_direction: '>', security_group_entries_policy_rule_protocol: 'tcp', security_group_entries_policy_rule_ethertype: 'IPv4', security_group_entries_policy_rule_src_addresses: [ { security_group_entries_policy_rule_src_addresses_subnet: { security_group_entries_policy_rule_src_addresses_subnet_ip_prefix: '0.0.0.0', security_group_entries_policy_rule_src_addresses_subnet_ip_prefix_len: '0', } } ], security_group_entries_policy_rule_dst_addresses: [ { security_group_entries_policy_rule_dst_addresses_security_group: 'local', } ], security_group_entries_policy_rule_dst_ports: [ { security_group_entries_policy_rule_dst_ports_start_port: '22', security_group_entries_policy_rule_dst_ports_end_port: '22', } ] } ] } flavor: type: OS::Nova::Flavor properties: disk: 3 name: { list_join: [ '_', [ get_param: stack_prefix, "flavor" ] ] } ram: 1024 vcpus: 2 server_port: type: OS::Neutron::Port properties: network_id: { get_resource: private_network } binding:vnic_type: 'normal' security_groups: [ { get_resource: security_group } ] server: type: OS::Nova::Server properties: name: { list_join: [ '_', [ get_param: stack_prefix, "server" ] ] } image: { get_param: server_image } flavor: { get_resource: flavor } availability_zone: { get_param: availability_zone } networks: - port: { get_resource: server_port } server_fip: type: OS::ContrailV2::FloatingIp properties: floating_ip_pool: { get_param: floating_ip_pool } virtual_machine_interface_refs: [{ get_resource: server_port }] outputs: server_fip: description: Floating IP address of server in public network value: { get_attr: [ server_fip, floating_ip_address ] }
Create an environment file to define values to put in the variables in the template file:
parameters: stack_prefix: <STACK_NAME> project: <PROJECT> public_network_id: <PUBLIC_NETWORK_ID> floating_ip_pool: <FLOATING_IP_POOL_UUID> server_image: <SERVER_IMAGE>
Use the OpenStack CLI or other client libraries to deploy the defined template:
openstack stack create -e <ENV_FILE_NAME> -t <TEMPLATE_FILE_NAME> <STACK_NAME>
As a result of this procedure, you create and configure the Tungsten Fabric resources as specified in the template.
Use S3 API for MOSK Object Storage¶
In this section, discover how to harness the S3 API functionality within the OpenStack Object Storage environment.
Prerequisites¶
Before you start using the S3 API, ensure you have the necessary prerequisites in place. This includes having access to an OpenStack deployment with the Object Storage service enabled and authenticated credentials.
Object Storage service enabled¶
Verify the presence of the object-store service within the OpenStack
Identity service catalog. If the service is present, the following command
returns endpoints related to the object-store service:
openstack catalog show object-store
If the object-store service is not present in the OpenStack Identity
service catalog, consult your cloud operator to confirm that the Object
Store service is enabled in the kind: OpenStackDeployment resource
controlling your OpenStack installation. The following element must be
present in the configuration:
kind: OpenStackDeployment
spec:
features:
services:
- object-storage
Obtaining the S3 endpoint¶
When using the Object Storage service endpoint, exclude the final
/swift/v1/... section.
To obtain the endpoint:
openstack versions show --service object-store --status CURRENT \
--interface public --region <desired region> \
-c Endpoint -f value | sed 's/\/swift\/.*$//'
Example output:
https://openstack-store.it.just.works
S3-specific tools configuration¶
To interact seamlessly with OpenStack Object Storage through the S3 API, familiarize yourself with essential S3-specific tools, such as s3cmd, the AWS Command Line Interface (CLI), and Boto3 SDK for Python.
This section provides concise yet comprehensive configuration examples for utilizing these S3-specific tools allowing users to interact with the Amazon S3 and other cloud storage providers employing the S3 protocol.
s3cmd¶
S3cmd is a free command-line client designed for uploading, retrieving, and managing data across various cloud storage service providers that utilize the S3 protocol, including Amazon S3.
Example of a minimal s3cfg configuration:
[default]
# use 'access' value from "openstack ec2 credentials create"
access_key = a354a74e0fa3434e8039d0425f7a0b59
# use 'secret' value from "openstack ec2 credentials create"
secret_key = d7c2ca9488dd4c8ab3cff2f1aad1c683
# use hostname of the "openstack-store" service, without protocol
host_base = openstack-store.it.just.works
# important, leave empty
host_bucket =
When configured, you can use s3cmd as usual:
s3cmd -c s3cfg ls # list buckets
s3cmd -c s3cfg mb s3://my-bucket # create a bucket
s3cmd -c s3cfg put myfile.txt s3://my-bucket # upload file to bucket
s3cmd -c s3cfg get s3://my-bucket/myfile.txt myfile2.txt # download file
s3cmd -c s3cfg rm s3://my-bucket/myfile.txt # delete file from bucket
s3cmd -c s3cfg rb s3://my-bucket # delete bucket
AWS CLI¶
The AWS CLI stands as the official and powerful command-line interface provided by Amazon Web Services (AWS). It serves as a versatile tool that enables users to interact with AWS services directly from the command line. Offering a wide range of functionalities, the AWS CLI facilitates diverse operations, including but not limited to resource provisioning, configuration management, deployment, and monitoring across various AWS services.
To start using the AWS CLI:
Set the authorization values as shell variables:
# use "access" field from created ec2 credentials export AWS_ACCESS_KEY_ID=a354a74e0fa3434e8039d0425f7a0b59 # use "secret" field from created ec2 credentials export AWS_SECRET_ACCESS_KEY=a354a74e0fa3434e8039d0425f7a0b59
Explicitly provide the
--endpoint-urlset to the endpoint of theopenstack-storeservice to every aws CLI command:export S3_API_URL=https://openstack-store.it.just.works aws --endpoint-url $S3_API_URL s3 mb s3://my-bucket aws --endpoint-url $S3_API_URL s3 cp myfile.txt s3://my-bucket aws --endpoint-url $S3_API_URL s3 ls s3://my-bucket aws --endpoint-url $S3_API_URL s3 rm s3://my-bucket/myfile.txt aws --endpoint-url $S3_API_URL s3 rm s3://my-bucket
boto¶
Boto3 is the official Python3 SDK (Software Development Kit) specifically designed for Amazon Web Services (AWS), providing comprehensive support for various AWS services, including the S3 API for object storage. It offers extensive functionality and tools for developers to interact programmatically with AWS services, facilitating tasks such as managing, accessing, and manipulating data stored in Amazon S3 buckets.
Presuming that you have configured the environment with the same environment variables as in the example for AWS CLI, you can create an S3 client in Python as follows:
import boto3, os
# high level "resource" interface
s3 = boto3.resources("s3", endpoint_url=os.getenv("S3_API_URL"))
for bucket in s3.buckets.all(): # returns rich objects
print(bucket.name)
# low level "client" interface
s3 = boto3.client("s3", endpoint_url=os.getenv("S3_API_URL"))
buckets = s3.list_buckets() # returns raw JSON-like dictionaries
Run Windows guests¶
Available since MOSK 24.1 TechPreview
MOSK enables users to configure and run Windows guests on OpenStack, which allows for optimization of cloud infrastructure for diverse workloads. This section delves into the nuances of achieving seamless integration between the Windows operating system and MOSK clouds.
Supported Windows versions¶
The list of the supported Windows versions includes:
Windows 10 22H2
Windows 11 23H2
Note
While Windows operating system of other versions may function, their compatibility is unverified.
Configuring Windows images or flavors¶
You can configure Windows guests through the image metadata properties
os_distro and os_type or through the flavor extra specs
os:distro and os:type.
Configuration example using image metadata properties:
$ openstack image set $WINDOWS_IMAGE \
--property os_distro=windows \
--property os_type=windows
Also, you have the option to set up Windows guests in a way that supports UEFI Secure Boot and includes an emulated virtual Trusted Platform Module (TPM). This configuration enhances security features for your Windows virtual machines within the OpenStack environment.
Note
Windows 11 imposes a security system requirement, necessitating the activation of UEFI Secure Boot and ensuring that TPM version 2.0 is enabled.
Configuration example for the image with Windows 11:
$ openstack image set $WINDOWS_IMAGE \
--property os_distro=windows \
--property os_type=windows \
--property hw_firmware_type=uefi \
--property hw_machine_type=q35 \
--property os_secure_boot=required \
--property hw_tpm_model=tpm-tis \
--property hw_tpm_version=2.0
Enabling UEFI Secure Boot¶
To confirm support for the UEFI Secure Boot feature, examine the traits associated with the compute node resource provider:
$ COMPUTE_UUID=$(openstack resource provider list --name $HOST -f value -c uuid)
$ openstack resource provider trait list $COMPUTE_UUID | grep COMPUTE_SECURITY_UEFI_SECURE_BOOT
| COMPUTE_SECURITY_UEFI_SECURE_BOOT |
You can configure the UEFI Secure Boot support through flavor extra specs or
image metadata properties. For x86_64 hosts, enabling secure boot also
necessitates configuring the use of the Q35 machine type.
MOSK enables you to configure this on a per-guest basis
using the hw_machine_type image metadata property.
Configuration example for the image that meets both requirements:
$ openstack image set $IMAGE \
--property hw_firmware_type=uefi \
--property hw_machine_type=q35 \
--property os_secure_boot=required
Enabling vTPM¶
Caution
MOSK does not support the live migration operation for instances with virtual Trusted Platform Module (vTPM) enabled.
To confirm support for the vTPM feature, examine the traits associated with the compute node resource provider:
$ COMPUTE_UUID=$(openstack resource provider list --name $HOST -f value -c uuid)
$ openstack resource provider trait list $COMPUTE_UUID | grep SECURITY_TPM
| COMPUTE_SECURITY_TPM_1_2 |
| COMPUTE_SECURITY_TPM_2_0 |
A vTPM can be requested for a server through either flavor extra specs or image metadata properties. There are two supported TPM versions: 1.2 and 2.0, along with two models: TPM Interface Specification (TIS) and Command-Response Buffer (CRB). Notably, the CRB model is only supported with version 2.0.
TPM version |
1.2 |
2.0 |
|---|---|---|
TPM Interface Specification (TIS) model |
||
Command-Response Buffer (CRB) model |
Configuration example for a flavor to use the TPM 2.0 with the TIS model:
$ openstack flavor set $FLAVOR \
--property hw:tpm_version=2.0 \
--property hw:tpm_model=tpm-tis
Security Guide¶
This guide provides recommendations on how to effectively use product capabilities to harden the security of a Mirantis OpenStack for Kubernetes (MOSK) deployment.
Note
The guide is being under development and will be updated with new sections in future releases of the product documentation.
CADF audit notifications in OpenStack services¶
MOSK services can emit notifications in the Cloud Auditing Data Federation (CADF) format, which is a standardized format for event data. The information contained in such notifications describes every action users perform in the cloud and is commonly used by organizations to perform security audits and intrusion detection.
Currently, the following MOSK services support the emission of CADF notifications:
Compute service (OpenStack Nova)
Block Storage service (OpenStack Cinder)
Images service (OpenStack Glance)
Networking service (OpenStack Neutron)
Orchestration service (OpenStack Heat)
DNS service (OpenStack Designate)
Bare Metal service (OpenStack Ironic)
Load Balancing service (OpenStack Octavia)
CADF notifications are enabled in the features:logging:cadf section of
the OpenStackDeployment custom resource. For example:
spec:
features:
logging:
cadf:
enabled: true
The way the notification messages get delivered to the consumers is controlled by the notification driver setting. The following options are supported:
messagingv2- DefaultMessages get posted to the
notifications.infoqueue in the MOSK message bus, which is RabbitMQ
logMessages get posted to a standard log output and then collected by Mirantis StackLight
Configuration example:
spec:
features:
logging:
cadf:
enabled: true
driver: log
Rotation of credentials in OpenStack¶
MOSK generates all credentials used internally, including two types of credentials generated during the OpenStack deployment:
Credentials for admin users provide unlimited access and enable the initial configuration of cloud entities. Three sets of such credentials are generated for accessing the following services:
OpenStack database
OpenStack APIs (OpenStack admin identity account)
OpenStack messaging
Credentials for OpenStack service users are generated for each deployed OpenStack service. To operate successfully, OpenStack services require three sets of credentials for accessing the following services:
OpenStack database
OpenStack APIs (OpenStack service identity account)
OpenStack messaging
To enhance the information security level, Mirantis recommends changing the passwords of internally used credentials periodically. We suggest changing the credentials every month. MOSK includes an automated routine for changing credentials, which must be triggered manually.
Restarting OpenStack services is necessary to apply new credentials. Therefore, it is crucial to have a smooth transition period to minimize the downtime for the OpenStack control plane. To achieve this, perform the credential rotation as described in Rotate OpenStack credentials.
Firewall configuration¶
This section includes the details about ports and protocols used in a MOSK deployment.
Container Cloud¶
Component |
Network |
Protocol |
Port |
Consumers |
|---|---|---|---|---|
Web UI, cache, Kubernetes API, and others |
LCM API/Mgmt |
TCP |
|
External clients |
Squid Proxy |
LCM API/Mgmt |
TCP |
3128 |
All nodes in management and managed clusters |
SSH |
LCM API/Mgmt |
TCP |
22 |
External clients |
Chrony |
LCM_API/Mgmt |
TCP |
323 |
All nodes in management and managed clusters |
NTP |
LCM_API/Mgmt |
UDP |
123 |
All nodes in management and managed clusters |
LDAP |
LCM API/Mgmt |
UDP |
389 |
|
LDAPs |
LCM API/Mgmt |
TCP/UDP |
686 |
Component |
Network |
Protocol |
Port |
|---|---|---|---|
Ironic |
PXE |
TCP |
6385 |
Ironic syslog |
PXE |
TCP |
601, udp_514 |
Ironic image repo |
PXE |
TCP |
80, 69 |
DHCP server |
PXE |
UDP |
67, 68 |
IPMI / ILO |
PXE |
TCP |
udp_623, 663/443, 17990, 1988 |
SSH |
PXE |
TCP |
22 |
DNS |
PXE |
TCP/UDP |
53 |
Mirantis Kubernetes Engine¶
For available Mirantis Kubernetes Engine (MKE) ports, refer to MKE Documentation: Open ports to incoming traffic.
StackLight¶
The tables below contain the details about ports and protocols used by different StackLight components.
Warning
This section does not describe communications within the cluster network.
User interfaces¶
Component |
Network |
Direction |
Port/Protocol |
Consumer |
Comments |
|---|---|---|---|---|---|
Alerta UI |
External network (LB service) |
Inbound |
443/TCP/HTTPS |
Cluster users |
Add the assigned external IP to the |
Alertmanager UI |
External network (LB service) |
Inbound |
443/TCP/HTTPS |
Cluster users |
Add the assigned external IP to the |
Grafana UI |
External network (LB service) |
Inbound |
443/TCP/HTTPS |
Cluster users |
Add the assigned external IP to the |
OpenSearch Dashboards UI |
External network (LB service) |
Inbound |
443/TCP/HTTPS |
Cluster users |
Only when the StackLight logging stack
is enabled. Add the assigned external IP to the |
Prometheus UI |
External network (LB service) |
Inbound |
443/TCP/HTTPS |
Cluster users |
Add the assigned external IP to the |
Alertmanager notifications receivers¶
Component |
Network |
Direction |
Port/Protocol |
Destination |
Comments |
|---|---|---|---|---|---|
Alertmanager Email notifications integration |
Cluster network |
Outbound |
TCP/SMTP |
Depends on the configuration, see the comment. |
Only when email notifications
are enabled. Add an SMTP host URL to the |
Alertmanager Microsoft Teams notifications integration |
Cluster network |
Outbound |
TCP/HTTPS |
Depends on the configuration, see the comment. |
Only when Microsoft Teams notifications
are enabled. Add a webhook URL to the |
Alertmanager Salesforce notifications integration |
Cluster network |
Outbound |
TCP/HTTPS |
For Mirantis support mirantis.my.salesforce.com and login.salesforce.com. Depends on the configuration, see the comment. |
Only when Salesforce notifications
are enabled. Add an SF instance URL and an SF login URL to the |
Alertmanager ServiceNow notifications integration |
Cluster network |
Outbound |
TCP/HTTPS |
Depends on the configuration, see the comment. |
Only when notifications to ServiceNow
are enabled. Add a configured ServiceNow URL to the |
Alertmanager Slack notifications integration |
Cluster network |
Outbound |
TCP/HTTPS |
Depends on the configuration, see the comment. |
Only when notifications to Slack
are enabled. Add a configured Slack URL to the |
Notification integration of Alertmanager generic receivers |
Cluster network |
Outbound |
Customizable, see the comment |
Depends on the configuration, see the comment. |
Only when any custom Alertmanager integration
is enabled. Depending on the integration type, add the corresponding URL to the |
External integrations¶
Component |
Network |
Direction |
Port/Protocol |
Destination |
Comments |
|---|---|---|---|---|---|
Salesforce reporter |
Cluster network |
Outbound |
TCP/HTTPS |
For Mirantis support mirantis.my.salesforce.com and login.salesforce.com. Depends on the configuration, see the comment. |
Only when the
Salesforce reporter
is enabled. Add a SF instance URL and SF login URL to the |
Prometheus Remote Write |
Cluster network |
Outbound |
TCP |
Depends on the configuration, see the comment. |
Only when the
Prometheus Remote Write
feature is enabled. Add a configured remote write destination URL to the |
Prometheus custom scrapes |
Cluster network |
Outbound |
TCP |
Depends on the configuration, see the comment. |
Only when the
Custom Prometheus scrapes
feature is enabled. Add configured scrape targets to the |
Fluentd remote syslog output |
Cluster network |
Outbound |
TCP or UDP (protocol and port are configurable) |
Depends on the configuration, see the comment. |
Only when the
Logging to remote Syslog
feature is enabled. Add a configured remote syslog URL to the |
Metric Collector |
Cluster network |
Outbound |
9093/443/TCP |
Applicable to management clusters only. Add a specific URL from Microsoft Azure to the |
|
External Endpoint monitoring |
Cluster network |
Outbound |
TCP/HTTP(S) |
Depends on the configuration, see the comment. |
Only when the
External endpoint monitoring
feature is enabled. Add configured monitored URLs to the |
SSL certificate monitoring |
Cluster network |
Outbound |
TCP/HTTP(S) |
Depends on the configuration, see the comment. |
Only when SSL certificates monitoring feature is enabled. Add configured monitored URLs to the allowlist. |
Metrics exporters¶
Component |
Network |
Direction |
Port/Protocol |
Consumer |
Comments |
|---|---|---|---|---|---|
Prometheus Node Exporter |
Host network |
Inbound (from cluster network) |
|
Prometheus from the |
Prometheus from Cluster network scrape metrics from all nodes. |
Fluentd (Prometheus metrics endpoint) |
Host network |
Inbound (from cluster network) |
24231/TCP |
Prometheus from the |
Only when the StackLight logging stack is enabled. Prometheus from the cluster network scrapes metrics from all nodes. |
Calico node |
Host network |
Inbound (from cluster network) |
9091/TCP |
Prometheus from the |
Prometheus from cluster network scrape metrics from all nodes. |
Telegraf SMART plugin |
Host network |
Inbound (from cluster network) |
9126/TCP |
Prometheus from the |
Prometheus from cluster network scrapes metrics from all nodes. |
MKE Manager API |
Host network |
Inbound (from cluster network) |
4443/TCP |
Blackbox exporter from the |
Applicable to Master node only. Blackbox exporter from cluster network probes all master nodes. |
MKE Metrics Engine |
Host network |
Inbound (from cluster network) |
12376/TCP |
Prometheus from the |
Prometheus from cluster network scrape metrics from all nodes. |
Kubernetes Master API |
Host network |
Inbound (from cluster network) |
5443/TCP |
Blackbox exporter from the |
Applicable to Master node only. Blackbox exporter from cluster network probes all master nodes. |
Libvirt Exporter |
Host network |
Inbound (from cluster network) |
9177/TCP |
Blackbox exporter from the |
Prometheus from cluster network scrapes metrics from all compute nodes. |
TF Controller Exporter |
Host network |
Inbound (from cluster network) |
9779/TCP |
Blackbox exporter from the |
Applicable to MOSK with Tungsten Fabric deployments only. Prometheus from Cluster network scrapes metrics from all Tungsten Fabric control nodes. |
TF vRouter Exporter |
Host network |
Inbound (from cluster network) |
9779/TCP |
Blackbox exporter from the |
Applicable to MOSK with Tungsten Fabric deployment only. Prometheus from Cluster network scrapes metrics from all compute nodes. |
Container Cloud telemetry¶
Component |
Network |
Direction |
Port/Protocol |
Destination |
Comments |
|---|---|---|---|---|---|
Telemeter client |
Cluster network |
Outbound (to management cluster External LB) |
443/TCP |
Telemeter server on a management cluster ( |
The Telemeter client on the MOSK cluster pushes
metrics to the |
Ceph¶
Ceph monitors use their node host networks to interact with Ceph daemons. Ceph daemons communicate with each other over a specified cluster network and provide endpoints over the public network.
The messenger V2 (msgr2) or earlier V1 (msgr) protocols are used for
communication between Ceph daemons.
Ceph daemon |
Network |
Protocol |
Port |
Description |
Consumers |
|---|---|---|---|---|---|
Manager ( |
Cluster network |
msgr/msgr2 |
6800,
9283
|
Listens on the first available port of the 6800-7300 range.
Uses 9283 port for exporting metrics.
|
csi-rbdplugin,csi-rbdprovisioner,rook-ceph-mon |
Metadata server ( |
Cluster network |
msgr/msgr2 |
6800 |
Listens on the first available port of the 6800-7300 range |
csi-cephfsplugin,csi-cephfsprovisioner |
Monitor ( |
LCM host network |
msgr/msgr2 |
msgr:3300,
msgr2:6789
|
Monitor has separate ports for |
Ceph clients
rook-ceph-osd,rook-ceph-rgw |
Ceph OSD ( |
Cluster network |
msgr/msgr2 |
6800-7300 |
Binds to the first available port from the 6800-7300 range |
rook-ceph-mon,rook-ceph-mgr,rook-ceph-mds |
Ceph network policies¶
Available since MOSK 24.1
Ceph Controller uses the NetworkPolicy objects for each Ceph daemon.
Each NetworkPolicy is applied to a pod with defined labels in the
rook-ceph namespace. It only allows the use of the ports specified in the
NetworkPolicy spec. Any other port is prohibited.
Ceph daemon |
Pod label |
Allowed ports |
|---|---|---|
Manager ( |
|
6800-7300,
9283
|
Monitor ( |
|
3300,
6789
|
Ceph OSD ( |
|
6800-7300 |
Metadata server ( |
|
6800-7300 |
Ceph Object Storage ( |
|
Value from
spec.cephClusterSpec.objectStorage.rgw.gateway.port,Value from
spec.cephClusterSpec.objectStorage.rgw.gateway.securePort |
MOSK¶
Communications between Mirantis OpenStack for Kubernetes (MOSK) components are provided by the Calico networking. All internal communications occur through the Calico tunnel through the VXLAN or WireGuard protocols.
Caution
These ports are only used for in-cluster communications. Open them only to a trusted network and never at a perimeter firewall.
Component |
Protocol |
Port |
Description |
|---|---|---|---|
Calico VXLAN |
UDP |
4792 |
Calico networking with VXLAN enabled |
Calico WireGuard |
UPD |
51820 |
Calico networking with IPv4 Wireguard enabled |
In-cluster communications between MetalLB speaker components are done using the LCM network. MetalLB components also provide metrics to be collected by StackLight.
Caution
These ports are only used for in-cluster communications. Open them only to a trusted network and never at a perimeter firewall.
Component |
Protocol |
Port |
Description |
|---|---|---|---|
MetalLB MemberList |
TCP/UDP |
7947 |
MetalLB speaker communications using MemberList |
MetalLB metrics |
TCP |
7472 |
MetalLB controller & speaker metrics |
OpenStack¶
The table below describes OpenStack internal protocols and ports used outside the Calico networking.
Component |
Network |
Protocol |
Port |
Description |
Consumers |
|---|---|---|---|---|---|
Nova |
Live migration network |
TCP |
8022 |
SSH transport for migration |
|
Libvirt |
Live migration network |
TCP |
16509 |
Libvirt |
|
Libvirt |
Live migration network |
TCP |
5900-6923 |
VNC ports accessed from noVNC Proxy |
nova-novncproxy,nova-spiceproxy |
Neutron |
Tunnel network |
UDP |
4790 |
Neutron tenant networks |
|
Neutron/IPsec |
Tunnel network |
UDP |
500 |
IKE/ISAKMP |
|
Neutron/IPsec |
Tunnel network |
ESP (50) |
|
||
Neutron/IPsec |
Tunnel network |
AH (51) |
|
||
Ironic |
OpenStack bare metal network |
TCP |
8080 |
NGINX HTTP storage |
Bare metal nodes |
Ironic |
OpenStack bare metal network |
UDP |
69 |
TFTP |
Bare metal nodes |
Component |
Network |
Protocol |
Port |
Description |
|---|---|---|---|---|
Ingress |
MetalLB |
TCP |
80, 443 |
Public OpenStack endpoints |
Designate/PowerDNS |
MetalLB |
UDP/UDP |
53 |
PowerDNS back end |
Tungsten Fabric¶
The table below describes Tungsten Fabric internal protocols and ports used outside the Calico networking.
Component |
Network |
Protocol |
Port |
Description |
Consumers |
|---|---|---|---|---|---|
TF vRouter |
MPLSoUDP Tunnel networks |
UDP |
6635, 51234 |
Tenant networks |
TF vRouter |
TF vRouter |
VxLAN Tunnel Networks |
UDP |
4789 |
Tenant networks |
TF vRouter |
Introspect |
Management network |
TCP |
8085, 8083 |
All TF services |
|
BGP peering |
Management or data network |
TCP |
1179 |
TF controller |
|
XMPP peering |
Management or data network |
TCP |
5269 |
Component |
Network |
Protocol |
Port |
Description |
|---|---|---|---|---|
Ingress |
MetalLB |
TCP |
80,443 |
Public TF endpoints including API and web UI |
TF DNS |
MetalLB |
UDP/UDP |
53 |
DNS back end |
OpenStack API access policies¶
OpenStack provides operators with fine-grained control over access to API endpoints and actions through access policies. These policies allow cloud administrators to restrict or grant access based on roles and the current request context, such as the project, domain, or system.
OpenStack services come with a set of default policy rules that are generally sufficient for most users. However, for specific use cases, these policies may need to be modified.
MOSK enables you to define custom policies through
the OpenStackDeployment custom resource. For configuration details,
refer to features:policies.
New and legacy defaults¶
OpenStack Victoria and Yoga have two sets of default policies for each of its services:
- Legacy default policies
With these policies, the role of administrator in any context grants the user global admin access to the given service. Any other role in the project grants the user normal access, enabling the user to create resources as well.
- New default policies
These policies are written based on the possibilities of the updated version of OpenStack Keystone. They take into account the hierarchical default roles, such as reader, member, and admin, and the system scope.
Warning
Mirantis does not recommend using the new default policies at the moment. Our testing results indicate that this set of policies is not consistently reliable across all services. Moreover, as of the OpenStack Yoga release, the new default policies have not undergone extensive testing in the upstream development.
Enforcing or utilizing these new default policies may result in unexpected consequences for the functionality of your MOSK deployment affecting its LCM operations, such as running Tempest tests or automatic live migrating of instances during node maintenance.
Changes to upstream default policies in MOSK¶
MOSK deploys OpenStack with some policies already customized. The list of such policies includes:
- [Barbican] The
global-secret-decoderrole A user with this role can decode any Barbican secret in any project. This role is specifically granted to the service user that performs automatic instance live migrations during node maintenance.
This role enables the service user to live migrate instances that use encrypted volumes. By upstream defaults, only the user who created the secret or the admin of the corresponding project can decode a secret.
- [Barbican] The
Data protection¶
MOSK offers various mechanisms to ensure data integrity and confidentiality. This section provides an overview of the data protection capabilities available in MOSK.
Data encryption capabilities¶
This section provides an overview of the data protection capabilities available in MOSK, focusing primarily on data encryption. You will gain insights into different data encryption features of MOSK, understand the type of data they protect, where encryption occurs concerning cloud boundaries, and whether these mechanisms are available by default or require explicit enablement by the cloud operator or cloud user.
Data protection capability |
Data category |
Data |
Protection type |
Protection boundaries |
Availability |
|---|---|---|---|---|---|
Encryption of MOSK internal communications |
User, system |
Cloud control plane traffic |
In-flight |
Cloud control plane including all the nodes |
Enabled by default. |
User |
Instance VNC console access traffic |
In-flight |
Cloud user - Compute hypervisor |
Disabled by default.
Enabled by the cloud operator.
|
|
Application |
Instance network traffic |
In-flight |
Private network |
Disabled by default.
Enabled by the cloud operator.
|
|
Application |
Volumes |
In-flight and at-rest |
Compute hypervisor - storage cluster |
Disabled by default.
Enabled by the cloud operator.
Activated by the cloud user per each volume.
|
|
Ephemeral storage encryption |
Application |
Instances ephemeral storage |
At-rest |
Compute hypervisor |
Disabled by default.
Enabled by the cloud operator per compute node.
|
Object storage server-side encryption |
Application |
Object data |
In-flight and at-rest |
Cloud API - Storage cluster |
Enabled by default.
Activated by the cloud user per object bucket.
|
Application |
Inside memory and ephemeral storage |
In-flight |
Source hypervisor - Target hypervisor |
Disabled by default.
Enabled by the cloud operator.
|
|
API communications encryption |
User |
User communication with the cloud API |
In-flight |
Cloud user - Cloud API |
Always enabled. |
Application |
Application secrets |
At-rest |
HashiCorp Vault service 0 |
Disabled by default.
Enabled by the cloud operator.
|
|
System |
OpenStack configuration secrets |
At-rest |
MOSK underlay Kubernetes cluster |
Always enabled.
Activated by the cloud operator per configuration secret.
|
- 0
Communication between HashiCort Vault and Key Manager is protected with TLS/SSL
Encryption of live migration data¶
Available since MOSK 23.2
Live migration enables the seamless movement of a running instance to another node within the cluster, ensuring uninterrupted access to the virtual workload.
In MOSK, the native TLS encryption feature is available for QEMU and libvirt, securing all data transports, including disks not on shared storage. Additionally, the libvirt daemon exclusively listens to TLS connections.
To establish a TLS environment, encompassing CA, server, and client certificates, the relevant compute nodes automatically generate these components. By default, these certificates are encrypted with a 2048-bit RSA private key and are valid for 3650 days.
You can easily enable live migration over TLS by configuring the
features:nova:libvirt:tls parameter in the OpenStackDeployment custom
resource. For reference, see Live migration.
Caution
Instances started before enabling secure live migration will not support live migration.
The issue arises due to the SSL certificates for live migration with QEMU native TLS being generated during the service update. Thus, these certificates do not exist in the libvirt container when existing instances were started. Consequently, QEMU processes of those instances lack the required SSL certificate information, leading to migration failures with an internal error:
internal error: unable to execute QEMU command ‘object-add’: Unable to access credentials /etc/pki/qemu/ca-cert.pem: No such file or directory
As a workaround, stop and then start the instances that failed to live migrate. This process will create new QEMU processes within the libvirt container, ensuring the availability of TLS certificate details.
Encryption of cloud control plane communications¶
Available since MOSK 23.2 TechPreview
In a cloud infrastructure, the components comprising the cloud control plane exchange messages that may contain sensitive information, such as cloud configuration details, application and cloud user credentials, and other essential data that an attacker can use to highjack the cloud. Encrypting the control plane traffic is crucial for data confidentiality and overall security of the cloud.
MOSK offers the ability to encrypt its control plane communication by means of encapsulating the in-cluster traffic of the underlying Kubernetes into a WireGuard mesh network built across its nodes.
Benefits of the WireGuard encryption¶
When an attacker is able to intercept the traffic between the nodes of a MOSK cluster but does not have access to the nodes themselves, WireGuard ensures the following:
- Data confidentiality
Any intercepted traffic remains unreadable, especially the traffic of those components of the MOSK control plane that do not enable SSL/TLS encryption on the application level and rather rely on the underlying networking layer.
- Data integrity
Alterations in traffic are detectable, ensuring that no tampering has occurred during transit.
- Authentication
Only machines with valid cryptographic credentials can join the network and exchange data.
Communications protected by WireGuard encryption¶
The following control plane components can have their communications protected with the WireGuard encryption:
OpenStack database (MariaDB)
OpenStack message bus (RabbitMQ)
OpenStack internal API
OpenStack services interacting with auxiliary components, such as memcached, RedisDB, and PowerDNS
Interaction between StackLight internal components, including collection of metrics from OpenStack, Ceph, and other subsystems
Tungsten Fabric auxiliary components that include ZooKeeper, Kafka, Cassandra database, Redis database, and RabbitMQ
Communications not protected by WireGuard encryption¶
All components of the cloud control plane that require explicit firewall rules configuration as per MOSK firewall configuration guide utilize the Kubernetes host network mode for their pods, and, therefore, cannot be protected by WireGuard.
Enabling the WireGuard encryption¶
By default, the WireGuard encryption of the control plane communications is not enabled in MOSK. However, it is possible to enable the encryption upon initial deployment or later.
For the details, refer to Mirantis Container Cloud: Enable Secure Overlay considering a certain downtime for the cloud control plane.
When enabling WireGuard, make sure to configure the Calico MTU size correctly. It must be at least 60 bytes smaller than the interface MTU size of the workload network.
How the WireGuard encryption works¶
Protocols and ports:
WireGuard operates on UDP and uses a single port for all traffic. Usually it is port
51820. Therefore, ensure that this port is open in your firewall.See also
Key generation, distribution, and rotation:
WireGuard uses public-private ECDH key pairs for secure handshake between the nodes of the cluster. Each node obtains its unique pair, with the public key shared across other nodes. A key pair persists indefinitely unless the node is reprovisioned and re-added to the cluster.
The handshake procedure establishes symmetric keys used for traffic encryption and automatically re-occurs every few minutes to ensure data security.
WireGuard encryption characteristics¶
Characteristic |
Details |
|---|---|
Handshake |
WireGuard uses the Noise_IK handshake from Noise framework, building on the work of CurveCP, NaCL, KEA+, SIGMA, FHMQV, and HOMQV |
Cipher |
WireGuard uses the ChaCha20 cipher for symmetric encryption, authenticated with Poly1305 |
Key length |
The symmetric encryption key length is 256 bits |
Impact on cloud performance¶
While WireGuard is designed for efficiency, enabling encryption introduces some overhead.
Caution
The impact can vary depending on the cloud scale and usage profile.
You may experience the following:
A slight increase in CPU utilization on the MOSK cluster nodes.
Less than 30% loss of network throughput, which, given the cluster is designed according to Mirantis recommendations, does not impact control plane communications of an average cloud.
Compliance¶
This section provides insights into the standards and regulatory requirements that MOSK adheres to, ensuring a secure and compliant environment that you can trust.
FIPS compliance¶
Federal Information Processing Standard Publication (FIPS), outlines security requirements for cryptographic modules used by the US government and its contractors to protect sensitive and valuable information. It categorizes the level of security provided by these modules, ranging from level 1 to level 4, with each level having progressively stringent security measures.
The FIPS mode within OpenStack verifies that its cryptographic algorithms and modules strictly conform to approved standards. This is crucial for several reasons:
- Regulatory compliance
Many government agencies and industries dealing with sensitive data, such as finance and healthcare, require FIPS-140 compliance as a regulatory mandate. Ensuring compliance enables organizations to operate within legal boundaries and meet industry standards.
- Data security
FIPS-140 compliance ensures a higher level of security for cryptographic functions, protecting sensitive information from unauthorized access and manipulation. FIPS-compliant environments have a high level of security for data encryption, digital signatures, and the integrity of communication channels.
- Interoperability
FIPS-140 compliance can enhance interoperability by ensuring that systems and cryptographic modules across different platforms or vendors meet a standard set of security requirements. This is essential, especially in multi-cloud or interconnected environments.
OpenStack API¶
Available since MOSK 23.3
MOSK ensures that the user-to-cloud communications are always protected in compliance with FIPS 140-2. The capability is implemented as an SSL/TLS proxy injected into MOSK underlying Kubernetes ingress networking and performs the data encryption using a FIPS-validated cryptographic module.
FAQ¶
This section provides answers to common questions about MOSK, and it is designed to help you quickly find the information you need. We have included answers to the most common questions and uncertainties that our users encounter, along with helpful tips and references to step-by-step instructions where required.
The questions with answers in this section are organized by topic. If you cannot find the information you are looking for in this section, search in the whole documentation set. Also, do not hesitate to contact us through the Feedback button. We are always available to answer your questions and provide you with the assistance you need to use our product effectively.
Major and patch releases: updating your cluster¶
What is the difference between patch and major release versions?¶
Both major and patch release versions incorporate solutions for security vulnerabilities and known product issues. The primary distinction between these two release types lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements.
Patch releases strive to considerably reduce the timeframe for delivering CVE resolutions in images to your deployments, aiding in the mitigation of cyber threats and data breaches.
Content |
Major release |
Patch release |
|---|---|---|
Version update and upgrade of the major product components including but not limited to OpenStack, Tungsten Fabric, Kubernetes, Ceph, and Stacklight 0 |
||
Container runtime changes including Mirantis Container Runtime and containerd updates |
||
Changes in public API |
||
Changes in the Container Cloud and MOSK lifecycle management including but not limited to machines, clusters, Ceph OSDs |
||
Host machine changes including host operating system and kernel updates |
||
Patch version bumps of MKE and Kubernetes |
||
Fixes for Common Vulnerabilities and Exposures (CVE) in images |
||
Fixes for known product issues |
- 0
StackLight subcomponents may be updated during patch releases
Learn more about product releases in MOSK major and patch releases.
What is a product release series?¶
A product release series is a series of consecutive releases that starts with a major release and includes a number of patch releases built on top of the major release.
For example, the 23.1 series includes the 23.1 major release and 23.1.1, 23.1.2, 23.1.3, and 23.1.4 patch releases.
Is updating to patch release versions mandatory?¶
No.
Apply patch updates only if you want to receive security fixes as soon as they become available and you are prepared to update your cluster often, approximately once in three weeks.
Otherwise, you can skip patch releases and update only between major releases. Each subsequent major release includes patch release updates of the previous major release.
When planning the update path for your cluster, take into account the release support status included in Release Compatibility Matrix.
Can I skip patch releases within a single series?¶
Yes.
Moreover, it is technically not possible to update to any intermediate release version if the newer patch version has been released. You can update only to the latest available patch version in the series, which contains the updates from all the preceding versions. For example, if your cluster is running MOSK 23.1 and the latest available patch version is MOSK 23.1.2, you can update to 23.1.2 receiving the product updates from 23.1.1 and 23.1.2 at one go.
Additionally, if between the two major releases you apply at least one patch version belonging to the N series, you have to obtain the last patch release in the series to be able to update to the N+1 major release version.
How do I update to the latest available (current) patch release?¶
You can update to the current patch release as described in Update a MOSK cluster to a patch release version.
How do I update between major release versions?¶
If you skip patch versions and update only between major release versions, follow the Update a MOSK cluster to a major release version procedure.
How do I update to the next major version if I started receiving patches of the previous series?¶
Firstly, if you started receiving patch updates from the previous release series, update your cluster to the latest patch release in that series as described the Update a MOSK cluster to a patch release version procedure.
After, follow the Update a MOSK cluster to a major release version procedure to update from the latest patch release in the series to the next major release. It is technically impossible to receive a major release while on any patch release in the previous series other than the last one.
Release Notes¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on the needs of your deployment, you can either update between only major releases, or update between the major releases receiving the patch updates in between. Choose the second option, which includes patch updates, only if you want to receive security fixes as soon as they become available and you are prepared to update your cluster often, approximately once in three weeks.
You can delve deeper into the product updates by referring to our FAQ section. The list of questions it addresses includes, but is not limited to the following:
MOSK 24.1 17.1.0+24.1 current major
Pre-update inspection of pinned product artifacts in a
ClusterobjectOpenStack Antelope
Technical preview for SPICE remote console
Technical preview for Windows guests
Technical preview for GPU virtualization
Deterministic Open vSwitch restarts
Orchestration of stateful applications rescheduling
Technical preview for CQL to connect with Cassandra clusters
Technical preview for Tungsten Fabric Operator API v2
Tungsten Fabric analytics services unsupported
Monitoring of OpenStack credential rotation dates
Removal of the StackLight
telegraf-openstackpluginRestrictive network policies
MOSK 23.3 17.0.0+23.3
Technical preview for OpenStack Antelope
Technical preview for generation of OpenStack support dump
FIPS-compatible OpenStack API
MKE 3.7 with Kubernetes 1.27
Open vSwitch 2.17
Technical preview for Tungsten Fabric analytics disablement
OpenStack Usage Efficiency Grafana dashboard
Ceph monitoring improvements
Documentation enhancements
MOSK 23.2 15.0.1+23.2
Technical preview for parallel node update
Automatic cleanup of OpenStack metadata during node removal
Technical preview for workload monitoring
Technical preview for BGP dynamic routing
Encryption of exposable OpenStack notification endpoint
Secure live migration of OpenStack instances
Technical preview for Tungsten Fabric graceful restart and long-lived graceful restart
Technical preview for external storage for Tungsten Fabric
Major version updates: MKE 3.6, Keycloak Quarkus, and Ceph Quincy
Technical preview for Cephless cloud architecture
Technical preview for WireGuard support
Technical preview for custom host names for cluster machines configuration
Technical preview for auditd support
Workload onboarding tutorial
MOSK 23.1 12.7.0+23.1
Full support for Tungsten Fabric 21.4 with automatic upgrade from Tungsten Fabric 2011 and hardened web UI
Technical Preview of Octavia Amphora support load balancers with Tungsten Fabric
Dynamic control over resource oversubscription
Sensitive information hidden from
OpenStackDeploymentRestricted privileges for project administrator
Automated password rotation for MOSK superuser and service accounts
Encrypted data transfer between VNC proxy and hypervisor VNC server
Upgraded Ceph to Pacific 16.2.11 and PowerDNS to 4.7
MOSK 22.5 12.5.0+22.5
The fifth and last MOSK release in 2022 introduces the following key features:
OpenStack Yoga full support
Exposure of OpenStack notifications
Technical preview for Shared Filesystems as a service
Technical preview for L3 networking for the MOSK control plane
MKE version update to 3.5.5
Documentation enhancements
MOSK 22.4 8.10.0+22.4
The fourth MOSK release in 2022 introduces the following key features:
Technical preview of OpenStack Yoga
Technical preview of Tungsten Fabric 21.4
Application credentials
CADF audit notifications
Technical preview of the OpenStack region name configuration
Automated restart of the Tungsten Fabric vRouter pods after the update
Technical preview of external OpenStack database backup
MOSK 22.3 8.8.0+22.3
The third MOSK release in 2022 introduces the following key features:
Support for Ubuntu 20.04 on OpenStack with OVS and Tungsten Fabric greenfield deployments
Support for large clusters
Introduction of the OpenStackDeploymentSecret custom resource
Switching to built-in policies for OpenStack services
Tungsten Fabric image precaching
24.1 series¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on the needs of your deployment, you can either update between only major releases, or update between the major releases receiving the patch updates in between. Choose the second option, which includes patch updates, only if you want to receive security fixes as soon as they become available and you are prepared to update your cluster often, approximately once in three weeks.
You can delve deeper into the product updates by referring to our FAQ section. The list of questions it addresses includes, but is not limited to the following:
MOSK 24.1 17.1.0+24.1 current major
Pre-update inspection of pinned product artifacts in a
ClusterobjectOpenStack Antelope
Technical preview for SPICE remote console
Technical preview for Windows guests
Technical preview for GPU virtualization
Deterministic Open vSwitch restarts
Orchestration of stateful applications rescheduling
Technical preview for CQL to connect with Cassandra clusters
Technical preview for Tungsten Fabric Operator API v2
Tungsten Fabric analytics services unsupported
Monitoring of OpenStack credential rotation dates
Removal of the StackLight
telegraf-openstackpluginRestrictive network policies
24.1¶
Release date |
March 04, 2024 |
|---|---|
Name |
MOSK 24.1 |
Cluster release |
17.1.0 |
Highlights |
|
New features¶
Component |
Support scope |
Feature |
|---|---|---|
Update |
Full |
Pre-update inspection of pinned product artifacts in a Cluster object |
OpenStack |
Full |
|
TechPreview |
||
TechPreview |
||
TechPreview |
||
Full |
||
Full |
||
Tungsten Fabric |
TechPreview |
|
Unsupported |
||
TechPreview |
||
StackLight |
Full |
|
Removed |
||
Security |
Full |
To ensure that Container Cloud clusters remain consistently updated with the
latest security fixes and product improvements, the Admission Controller
has been enhanced. Now, it actively prevents the utilization of pinned
custom artifacts for Container Cloud components. Specifically, it blocks
a management or managed cluster release update, or any cluster configuration
update, for example, adding public keys or proxy, if a Cluster object
contains any custom Container Cloud artifacts with global or image-related
values overwritten in the helm-releases section, until these values are
removed.
Normally, the Container Cloud clusters do not contain pinned artifacts,
which eliminates the need for any pre-update actions in most deployments.
However, if the update of your cluster is blocked with the
invalid HelmReleases configuration error, refer to
Update notes: Pre-update actions for details.
Note
In rare cases, if the image-related or global values should be
changed, you can use the ClusterRelease or KaaSRelease objects
instead. But make sure to update these values manually after every major
and patch update.
Note
The pre-update inspection applies only to images delivered by Container Cloud that are overwritten. Any custom images unrelated to the product components are not verified and do not block cluster update.
Learn more
Added full support for OpenStack Antelope with Open vSwitch and Tungsten Fabric 21.4 networking back ends.
Starting from 24.1, MOSK deploys all new clouds with OpenStack Antelope by default. To upgrade an existing cloud from OpenStack Yoga to Antelope, follow the Upgrade OpenStack procedure.
For the OpenStack support cycle in MOSK, refer to OpenStack support cycle.
Highlights from upstream OpenStack supported by MOSK deployed on Antelope
Designate:
Ability to share Designate zones across multiple projects. This not only allows two or more projects to manage recordsets in the zone but also enables “Classless IN-ADDR.ARPA delegation” (RFC 2317) in Designate. “Classless IN-ADDR.ARPA delegation” permits IP address DNS PTR record assignment in smaller blocks without creating a DNS zone for each address.
Manila:
Feature parity between the native client and OSC.
Capability for users to specify metadata when creating their share snapshots. The behavior should be similar to Manila shares, allowing users to query snapshots filtering them by metadata, and update or delete the metadata of the given resources.
Neutron:
Capability for managing network traffic based on packet rate by implementing the QoS (Quality of Service) rule type “packet per second” (pps).
Nova:
Improved behavior for Windows guests by adding new Hyper-V enlightments on all libvirt guests by default.
Ability to unshelve an instance to a specific host (admin only).
With microversion 2.92, the capability to only import a public key and not generate a keypair. Also, the capability to use an extended name pattern.
Octavia:
Support for notifications about major events of the life cycle of a load balancer. Only
loadbalancer.[create|update|delete].endevents are emitted.
TechPreview
Implemented the capability to enable SPICE remote console through the
OpenStackDeployment custom resource as a method to interact with
OpenStack virtual machines through the CLI and desktop client as well
as MOSK Dashboard (OpenStack Horizon).
The usage of the SPICE remote console is an alternative to using the noVNC-based VNC remote console.
Learn more
TechPreview
Implemented the capability to configure and run Windows guests on OpenStack, which allows for optimization of cloud infrastructure for diverse workloads.
Learn more
TechPreview
Introduced support for the Virtual Graphics Processing Unit (vGPU) feature that allows for leveraging the power of virtualized GPU resources to enhance performance and scalability of cloud deployments.
Implemented a new logic for Open vSwitch restart process during a MOSK cluster update that allows for minimized workload downtime.
Implemented automated management and coordination of relocating stateful applications.
TechPreview
Enhanced the connectivity between the Tungsten Fabric services and Cassandra database clusters through the Cassandra Query Language (CQL) protocol.
TechPreview
Introduced the technical preview support for the API v2 for the Tungsten Fabric Operator. This API version aligns with the OpenStack Controller API and provides better interface for advanced configurations.
In MOSK 24.1, the API v2 is available only for the greenfield product deployments with Tungsten Fabric. The Tungsten Fabric configuration documentation provides configuration examples for both API v1alpha1 and API v2.
Removed from support Tungsten Fabric analytics services, primarily designed for collecting various metrics from the Tungsten Fabric services.
Despite its initial implementation, user demand for this feature has been minimal. As a result, Tungsten Fabric analytics services become unsupported in the product.
All greenfield deployments starting from MOSK 24.1 do not include Tungsten Fabric analytics services using StackLight capabilities instead by default. The existing deployments updated to 24.1 and newer versions will include Tungsten Fabric analytics services as well as the ability to disable them.
Implemented alerts to notify the cloud users when their OpenStack administrator and OpenStack service user credentials are overdue for rotation.
Learn more
Removed StackLight telegraf-openstack plugin and replaced it with
osdpl-exporter.
All valuable Telegraf metrics used by StackLight components have been
reimplemented in osdpl-exporter and all dependent StackLight alerts
and dashboards started using new metrics.
Implemented more restrictive network policies for Kubernetes pods running OpenStack services.
As part of the enhancement, added NetworkPolicy objects for all types of
Ceph daemons. These policies allow only specified ports to be used by the
corresponding Ceph daemon pods.
Learn more
Major components versions¶
Mirantis has tested MOSK against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOSK components with the exact versions against which testing has been performed.
Component |
Version |
|---|---|
Cluster release |
17.1.0 (Cluster release notes) |
OpenStack |
Antelope, Yoga |
OpenStack Operator |
0.15.9 |
Tungsten Fabric |
21.4 |
Tungsten Fabric Operator |
0.14.3 |
See also
For the supported versions of operating system, Ceph, and other components, refer to Release Compatibility Matrix.
Known issues¶
This section describes the MOSK known issues with available workarounds. For the known issues in the related version of Mirantis Container Cloud, refer to Mirantis Container Cloud: Release Notes.
This section lists the OpenStack known issues with workarounds for the Mirantis OpenStack for Kubernetes release 24.1.
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
After provisioning the controller node, the etcd pod initiates before the Kubernetes networking is fully operational. As a result, the pod encounters difficulties resolving DNS and establishing connections with other members, ultimately leading to a panic state for the etcd service.
Workaround:
Delete the PVC related to the replaced controller node:
kubectl -n openstack delete pvc <PVC-NAME>
Delete pods related to the crashing etcd service on the replaced controller node:
kubectl -n openstack delete pods <ETCD-POD-NAME>
On large (500+ compute nodes) clusters, openstack-controller-exporter may
fail to initialize within the default timeout.
As a workaround, define OSCTL_EXPORTER_MAX_POLL_TIMEOUT in the cluster
object:
spec:
providerSpec:
value:
helmReleases:
- name: openstack-operator
values:
exporter:
settings:
raw:
OSCTL_EXPORTER_MAX_POLL_TIMEOUT: 900
This section lists the Tungsten Fabric (TF) known issues with workarounds for the Mirantis OpenStack for Kubernetes release 24.1. For TF limitations, see Tungsten Fabric known limitations.
Occasionally, RabbitMQ instances in tf-rabbitmq pods fail to enable
the tracking_records_in_ets during the initialization process.
To work around the problem, restart the affected pods manually.
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete the Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica_num>
This section lists the update known issues with workarounds for the MOSK release 24.1.
During the ClusterRelease update of a MOSK cluster, a
node cannot be removed from the Kubernetes cluster if the related
Machine object is disabled.
As a workaround, remove the finalizer from the affected Node
object.
Release artifacts¶
This section lists the components artifacts of the MOSK 24.1 release that includes binaries, Docker images, and Helm charts.
MOSK 24.1 OpenStack Antelope binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-antelope-20240117112744.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-antelope-18a1377-20230817112356.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-antelope-20231123060809.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:antelope-jammy-20240202140750 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:antelope-jammy-20240202140750 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:antelope-jammy-20240202140750 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:antelope-jammy-20240202140750 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.13.2-20240131075124 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:antelope-jammy-20240202140750 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:antelope-jammy-20240202140750 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:antelope-jammy-20240202140750 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:antelope-jammy-20240202140750 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:antelope-jammy-20240202140750 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:antelope-jammy-20240202140750 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:antelope-jammy-20240202140750 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:antelope-jammy-20240202140750 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:8.0.x-jammy-20231211175451 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.17-jammy-20231018050930 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.17-jammy-20231018050930 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-jammy-20240202140749 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.23-alpine-20240131134844 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.11-alpine-20240131112547 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20240131140954 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.9.6-alpine-20240129151228 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0-20231208095208 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:antelope-jammy-20240202140750 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:antelope-jammy-20240202140750 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:antelope-jammy-20240202140750 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.2.4-alpine3.19-1 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20240131110410 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.12-20240129155309 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20231018050930 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.28.1 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.3-20240131112557 |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:antelope-jammy-20240202140750 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:antelope-jammy-20240124144254 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:antelope-jammy-20240202140750 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:antelope-jammy-20240202140750 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:antelope-jammy-20240202140750 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:antelope-jammy-20240202140750 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:antelope-jammy-20240202140750 |
Apache License 2.0 |
MOSK 24.1 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20240115150429.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-yoga-186584b-20230817112411.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20231004061110.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20231004061110.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-jammy-20240202140749 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-jammy-20240202140749 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-jammy-20240202140749 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-jammy-20240202140749 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.13.2-20240131075124 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-jammy-20240202140749 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-jammy-20240202140749 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-jammy-20240202140749 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-jammy-20240202140749 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-jammy-20240202140749 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-jammy-20240202140749 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20240202140749 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-jammy-20240202140749 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:8.0.x-jammy-20231211175451 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.17-jammy-20231018050930 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.17-jammy-20231018050930 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-jammy-20240202140749 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.23-alpine-20240131134844 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.11-alpine-20240131112547 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20240131140954 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.9.6-alpine-20240129151228 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0-20231208095208 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-jammy-20240202140749 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-jammy-20240202140749 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-jammy-20240202140749 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.2.4-alpine3.19-1 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20240131110410 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.12-20240129155309 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20231018050930 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.28.1 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.3-20240131112557 |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-jammy-20240202140749 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20240104174902 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-jammy-20240202140749 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-jammy-20240202140749 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-jammy-20240202140749 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20240202140749 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-jammy-20240202140749 |
Apache License 2.0 |
MOSK 24.1 OpenStack Helm charts
MOSK 24.1 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.14.3.tgz |
Mirantis Proprietary License |
Docker images |
||
tungstenfabric-operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.14.3 |
Mirantis Proprietary License |
tungsten-pytest |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20240123162016 |
MIT License |
casskop |
mirantis.azurecr.io/tungsten-operator/casskop:v2.2.1 |
Apache License 2.0 |
cassandra-bootstrap |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.13 |
Apache License 2.0 |
cassandra |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230622 |
Apache License 2.0 |
cassandra-config-builder |
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20240122114202 |
Apache License 2.0 |
kafka-k8s-operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.8 |
Mirantis Proprietary License |
cp-kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.5.3 |
Apache License 2.0 |
kafka-jmx-exporter |
mirantis.azurecr.io/stacklight/jmx-exporter:0.20.0-debian-11-r1 |
Apache License 2.0 |
rabbitmq-operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.4.2 |
Mirantis Proprietary License |
rabbitmq |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.16 |
Mozilla Public License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
zookeeper-operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.20-mcp |
Apache License 2.0 |
zookeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.8.3-20231019 |
Apache License 2.0 |
redis-operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.4.2 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/tungsten/redis:7.2.4-alpine |
BSD 3-Clause “New” or “Revised” License |
redis-exporter |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
tf-cli |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20240116162056 |
MIT License |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
tf-nodeinfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20231017142953 |
MIT License |
contrail-analytics-alarm-gen |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:21.4.20240118000000 |
Apache License 2.0 |
contrail-analytics-api |
mirantis.azurecr.io/tungsten/contrail-analytics-api:21.4.20240118000000 |
Apache License 2.0 |
contrail-analytics-collector |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:21.4.20240118000000 |
Apache License 2.0 |
contrail-analytics-query-engine |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:21.4.20240118000000 |
Apache License 2.0 |
contrail-analytics-snmp-collector |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:21.4.20240118000000 |
Apache License 2.0 |
contrail-analytics-snmp-topology |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:21.4.20240118000000 |
Apache License 2.0 |
contrail-controller-config-api |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:21.4.20240118000000 |
Apache License 2.0 |
contrail-controller-config-devicemgr |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:21.4.20240118000000 |
Apache License 2.0 |
contrail-controller-config-dnsmasq |
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:21.4.20240118000000 |
Apache License 2.0 |
contrail-controller-config-schema |
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:21.4.20240118000000 |
Apache License 2.0 |
contrail-controller-config-svcmonitor |
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:21.4.20240118000000 |
Apache License 2.0 |
contrail-controller-control-control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:21.4.20240118000000 |
Apache License 2.0 |
contrail-controller-control-dns |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:21.4.20240118000000 |
Apache License 2.0 |
contrail-controller-control-named |
mirantis.azurecr.io/tungsten/contrail-controller-control-named:21.4.20240118000000 |
Apache License 2.0 |
contrail-controller-webui-job |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:21.4.20240118000000 |
Apache License 2.0 |
contrail-controller-webui-web |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:21.4.20240118000000 |
Apache License 2.0 |
contrail-node-init |
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20240118000000 |
Apache License 2.0 |
contrail-nodemgr |
mirantis.azurecr.io/tungsten/contrail-nodemgr:21.4.20240118000000 |
Apache License 2.0 |
contrail-provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:21.4.20240118000000 |
Apache License 2.0 |
contrail-tools |
mirantis.azurecr.io/tungsten/contrail-tools:21.4.20240118000000 |
Apache License 2.0 |
contrail-vrouter-agent |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20240118000000 |
Apache License 2.0 |
contrail-vrouter-agent-dpdk |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20240118000000 |
Apache License 2.0 |
contrail-vrouter-kernel-build-init |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20240118000000 |
Apache License 2.0 |
MOSK 24.1 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20240201074016 |
Mirantis Proprietary License |
tungstenfabric-prometheus-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20240119124301 |
Mirantis Proprietary License |
Helm charts |
||
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-52.tgz |
Mirantis Proprietary License |
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-7.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-7.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the MOSK 24.1 release:
[OpenStack] [Antelope] [37678] Resolved the issue that prevented instance live-migration due to CPU incompatibility.
[OpenStack] [38629] Optimized resource allocation to enable
designate-apito scale up its operation.[OpenStack] [38792] Resolved the issue that prevented MOSK from creating instances and volumes from images stored in Pure Storage.
[OpenStack] [39069] Resolved the issue that caused the logging of false alerts about 401 responses from OpenStack endpoints.
[StackLight] [36211] Resolved the issue that caused the deprecated dashboards NGINX Ingress controller and Ceph Nodes to be displayed in Grafana. These dashboards are now removed. Therefore, Mirantis recommends switching to the following dashboards:
OpenStack Ingress controller instead of NGINX Ingress controller
For Ceph:
Ceph Cluster dashboard for Ceph stats
System dashboard for resource utilization, which includes filtering by Ceph node labels, such as
ceph_role_osd,ceph_role_mon, andceph_role_mgr
Update notes¶
This section describes the specific actions you as a Cloud Operator need to complete to accurately plan and successfully perform your Mirantis OpenStack for Kubernetes (MOSK) cluster update to the version 24.1. Consider this information as a supplement to the generic update procedure published in Operations Guide: Update a MOSK cluster.
The MOSK cluster will obtain the newly implemented capabilities automatically with no significant impact on the update procedure.
See also
The update to MOSK 24.1 does not include any version-specific impact on the cluster.
To properly plan the update maintenance window, use the following documentation:
Before updating the cluster, be sure to review the potential issues that may arise during the process and the recommended solutions to address them, as outlined in Update known issues.
If your are updating to MOSK 24.1 from the 23.2 series, make sure that you apply the workaround for [37545] Cloud public API becomes inaccessible during update.
If any pinned product artifacts are present in the Cluster object of a
management or managed cluster, the update will be blocked by the Admission
Controller with the invalid HelmReleases configuration error until such
artifacts are removed. The update process does not start and any changes in
the Cluster object are blocked by the Admission Controller except the
removal of fields with pinned product artifacts.
Therefore, verify that the following sections of the Cluster objects
do not contain any image-related (tag, name, pullPolicy,
repository) and global values inside Helm releases:
.spec.providerSpec.value.helmReleases.spec.providerSpec.value.kaas.management.helmReleases.spec.providerSpec.value.regionalHelmReleases.spec.providerSpec.value.regional
For example, a cluster configuration that contains the following highlighted lines will be blocked until you remove them:
- name: kaas-ipam
values:
kaas_ipam:
image:
tag: base-focal-20230127092754
exampleKey: exampleValue
- name: kaas-ipam
values:
global:
anyKey: anyValue
kaas_ipam:
image:
tag: base-focal-20230127092754
exampleKey: exampleValue
The custom pinned product artifacts are inspected and blocked by the Admission Controller to ensure that Container Cloud clusters remain consistently updated with the latest security fixes and product improvements
Note
The pre-update inspection applies only to images delivered by Container Cloud that are overwritten. Any custom images unrelated to the product components are not verified and do not block cluster update.
With 24.1, MOSK is rolling out OpenStack Antelope support for both Open vSwitch and Tungsten Fabric-based deployments.
Mirantis encourages you to upgrade to Antelope to start benefitting from the enhanced functionality and new features of this OpenStack release. MOSK allows for direct upgrade from Yoga to Antelope, without the need to upgrade to the intermediate Zed release. To upgrade the cloud, complete the Upgrade OpenStack procedure.
If your cluster runs Tungsten Fabric analytics services and you want to obtain a more lightweight setup, you can disable these services through the custom resource of the Tungsten Fabric Operator. For the details, refer to the Tungsten Fabric analytics services deprecation notice.
Security notes¶
In total, since MOSK 23.3 major release, in 24.1, 327 Common Vulnerabilities and Exposures (CVE) have been fixed: 15 of critical and 312 of high severity.
The table below includes the total number of addressed unique and common CVEs by MOSK-specific component since MOSK 23.3.4. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
OpenStack |
Unique |
2 |
8 |
10 |
Common |
2 |
10 |
12 |
|
Tungsten Fabric |
Unique |
4 |
29 |
33 |
Common |
8 |
44 |
52 |
Mirantis Security Portal
For the detailed list of fixed and present CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
Mirantis Container Cloud CVEs
For the number of fixed CVEs in the Mirantis Container Cloud-related components including kaas core, bare metal, Ceph, and StackLight, refer to Container Cloud 2.26.0: Security notes.
24.1.1 patch¶
The patch release notes contain the description of product enhancements, the list of updated artifacts and Common Vulnerabilities and Exposures (CVE) fixes as well as description of the addressed product issues for the MOSK 24.1.1 patch.
For the list of enhancements and bug fixes that relate to Mirantis Container Cloud, refer to the Mirantis Container Cloud Release notes.
Release date |
March 20, 2024 |
|---|---|
Scope |
Patch |
Cluster release |
17.1.1 |
OpenStack Operator |
0.15.10 |
Tungsten Fabric Operator |
0.14.5 |
Enhancements¶
This section outlines enhancements introduced in the MOSK 24.1.1 patch release.
Introduced the ability to update Ubuntu packages including kernel minor version update, when available in a product release, to address CVE issues on a host operating system.
On management clusters, the update of Ubuntu mirror along with the update of minor kernel version occurs automatically with cordon-drain and reboot of machines.
On MOSK clusters, the update of Ubuntu mirror along with the update of
minor kernel version applies during a manual cluster update without automatic
cordon-drain and reboot of machines. After a managed cluster update, all
cluster machines have the reboot is required notification.
The kernel update is not obligatory on MOSK clusters. Though, if you prefer obtaining the latest CVE fixes for Ubuntu, update the kernel by manually rebooting machines during a convenient maintenance window using GracefulRebootRequest.
In MOSK 24.1.1, the kernel version has been updated to
5.15.0-97-generic.
Release artifacts¶
This section lists the components artifacts of the MOSK 24.1.1 release that includes binaries, Docker images, and Helm charts.
MOSK 24.1.1 OpenStack Antelope binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-antelope-20240117112744.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-antelope-18a1377-20230817112356.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-antelope-20231123060809.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:antelope-jammy-20240223093139 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:antelope-jammy-20240223093139 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:antelope-jammy-20240223093139 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:antelope-jammy-20240223093139 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.13.2-20240131075124 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:antelope-jammy-20240223093139 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:antelope-jammy-20240223093139 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:antelope-jammy-20240223093139 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:antelope-jammy-20240223093139 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:antelope-jammy-20240223093139 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:antelope-jammy-20240223093139 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:antelope-jammy-20240223093139 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:antelope-jammy-20240223093139 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:8.0.x-jammy-20240209162006 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.17-jammy-20231018050930 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.17-jammy-20231018050930 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-jammy-20240223093139 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.23-alpine-20240131134844 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.11-alpine-20240131112547 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20240212154001 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.9.6-alpine-20240129151228 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0-20231208095208 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:antelope-jammy-20240223093139 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:antelope-jammy-20240223093139 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:antelope-jammy-20240223093139 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.2.4-alpine3.19-1 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20240212084423 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.12-20240129155309 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20231018050930 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.29.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.3-20240131112557 |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:antelope-jammy-20240223093139 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:antelope-jammy-20240220093950 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:antelope-jammy-20240223093139 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:antelope-jammy-20240223093139 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:antelope-jammy-20240223093139 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:antelope-jammy-20240223093139 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:antelope-jammy-20240223093139 |
Apache License 2.0 |
MOSK 24.1.1 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20240115150429.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-yoga-186584b-20230817112411.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20231004061110.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20231004061110.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-jammy-20240223093139 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-jammy-20240223093139 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-jammy-20240223093139 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-jammy-20240223093139 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.13.2-20240131075124 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-jammy-20240223093139 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-jammy-20240223093139 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-jammy-20240223093139 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-jammy-20240223093139 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-jammy-20240223093139 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-jammy-20240223093139 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20240223093139 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-jammy-20240223093139 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:8.0.x-jammy-20240209162006 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.17-jammy-20231018050930 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.17-jammy-20231018050930 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-jammy-20240223093139 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.23-alpine-20240131134844 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.11-alpine-20240131112547 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20240212154001 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.9.6-alpine-20240129151228 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0-20231208095208 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-jammy-20240223093139 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-jammy-20240223093139 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-jammy-20240223093139 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.2.4-alpine3.19-1 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20240212084423 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.12-20240129155309 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20231018050930 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.29.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.3-20240131112557 |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-jammy-20240223093139 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20240220093914 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-jammy-20240223093139 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-jammy-20240223093139 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-jammy-20240223093139 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20240223093139 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-jammy-20240223093139 |
Apache License 2.0 |
MOSK 24.1.1 OpenStack Helm charts
MOSK 24.1.1 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.14.5.tgz |
Mirantis Proprietary License |
Docker images |
||
tungstenfabric-operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.14.5 |
Mirantis Proprietary License |
tungsten-pytest |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20240213163655 |
MIT License |
casskop |
mirantis.azurecr.io/tungsten-operator/casskop:v2.2.1 |
Apache License 2.0 |
cassandra-bootstrap |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.13 |
Apache License 2.0 |
cassandra |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230622 |
Apache License 2.0 |
cassandra-config-builder |
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20240122114202 |
Apache License 2.0 |
kafka-k8s-operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.8 |
Mirantis Proprietary License |
cp-kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.5.3 |
Apache License 2.0 |
kafka-jmx-exporter |
mirantis.azurecr.io/stacklight/jmx-exporter:0.20.0-debian-11-r24 |
Apache License 2.0 |
rabbitmq-operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.4.2 |
Mirantis Proprietary License |
rabbitmq |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.16 |
Mozilla Public License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
zookeeper-operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.20-mcp |
Apache License 2.0 |
zookeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.8.3-20231019 |
Apache License 2.0 |
redis-operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.4.2 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/tungsten/redis:7.2.4-alpine3.19 |
BSD 3-Clause “New” or “Revised” License |
redis-exporter |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
tf-cli |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20240116162056 |
MIT License |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
tf-nodeinfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20231017142953 |
MIT License |
contrail-analytics-alarm-gen |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-analytics-api |
mirantis.azurecr.io/tungsten/contrail-analytics-api:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-analytics-collector |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-analytics-query-engine |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-analytics-snmp-collector |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-analytics-snmp-topology |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-controller-config-api |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-controller-config-devicemgr |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-controller-config-dnsmasq |
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-controller-config-schema |
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-controller-config-svcmonitor |
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-controller-control-control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-controller-control-dns |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-controller-control-named |
mirantis.azurecr.io/tungsten/contrail-controller-control-named:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-controller-webui-job |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-controller-webui-web |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-node-init |
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20240118000000 |
Apache License 2.0 |
contrail-nodemgr |
mirantis.azurecr.io/tungsten/contrail-nodemgr:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-tools |
mirantis.azurecr.io/tungsten/contrail-tools:24.1-r21.4.20240227154027 |
Apache License 2.0 |
contrail-vrouter-agent |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20240118000000 |
Apache License 2.0 |
contrail-vrouter-agent-dpdk |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20240118000000 |
Apache License 2.0 |
contrail-vrouter-kernel-build-init |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20240118000000 |
Apache License 2.0 |
MOSK 24.1.1 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20240228023010 |
Mirantis Proprietary License |
tungstenfabric-prometheus-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20230912105027 |
Mirantis Proprietary License |
Helm charts |
||
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-52.tgz |
Mirantis Proprietary License |
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-7.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-7.tgz |
Mirantis Proprietary License |
Security notes¶
In total, since MOSK 24.1 release, in 24.1.1, 223 Common Vulnerabilities and Exposures (CVE) have been fixed: 8 of critical and 215 of high severity.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
OpenStack |
Unique |
0 |
8 |
8 |
Common |
0 |
50 |
50 |
|
Tungsten Fabric |
Unique |
8 |
50 |
58 |
Common |
8 |
165 |
173 |
Mirantis Security Portal
For the detailed list of fixed and present CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
Mirantis Container Cloud CVEs
For the number of fixed CVEs in the Mirantis Container Cloud-related components including kaas core, bare metal, Ceph, and StackLight, refer to Container Cloud 2.26.1: Security notes.
Addressed issues¶
The following issues have been addressed in the MOSK 24.1.1 release:
[40036] Resolved the issue causing nodes to remain in the Kubernetes cluster when the corresponding machine is marked as disabled during cluster update.
Known issues¶
This section lists MOSK known issues with workarounds for the Mirantis OpenStack for Kubernetes release 24.1.1.
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
After provisioning the controller node, the etcd pod initiates before the Kubernetes networking is fully operational. As a result, the pod encounters difficulties resolving DNS and establishing connections with other members, ultimately leading to a panic state for the etcd service.
Workaround:
Delete the PVC related to the replaced controller node:
kubectl -n openstack delete pvc <PVC-NAME>
Delete pods related to the crashing etcd service on the replaced controller node:
kubectl -n openstack delete pods <ETCD-POD-NAME>
On large (500+ compute nodes) clusters, openstack-controller-exporter may
fail to initialize within the default timeout.
As a workaround, define OSCTL_EXPORTER_MAX_POLL_TIMEOUT in the cluster
object:
spec:
providerSpec:
value:
helmReleases:
- name: openstack-operator
values:
exporter:
settings:
raw:
OSCTL_EXPORTER_MAX_POLL_TIMEOUT: 900
Occasionally, RabbitMQ instances in tf-rabbitmq pods fail to enable
the tracking_records_in_ets during the initialization process.
To work around the problem, restart the affected pods manually.
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete the Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica_num>
Learn more about the release cadence
24.1.2 patch¶
The patch release notes contain the description of product enhancements, the list of updated artifacts and Common Vulnerabilities and Exposures (CVE) fixes as well as description of the addressed product issues for the MOSK 24.1.2 patch.
Release date |
April 08, 2024 |
|---|---|
Scope |
Patch |
Cluster release |
17.1.2 |
OpenStack Operator |
0.15.13 |
Tungsten Fabric Operator |
0.14.7 |
The MOSK 24.1.2 patch provides the following updates:
Support for MKE 3.7.6
Update of minor kernel version from
5.15.0-97-genericto5.15.0-101-genericSecurity fixes for CVEs in images
Resolved product issues
Release artifacts¶
This section lists the components artifacts of the MOSK 24.1.2 release that includes binaries, Docker images, and Helm charts.
MOSK 24.1.2 OpenStack Antelope binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-antelope-20240117112744.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-antelope-18a1377-20230817112356.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-antelope-20231123060809.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:antelope-jammy-20240318153252 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:antelope-jammy-20240318153252 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:antelope-jammy-20240318153252 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:antelope-jammy-20240318153252 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.13.2-20240131075124 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:antelope-jammy-20240318153252 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:antelope-jammy-20240318153252 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:antelope-jammy-20240318153252 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:antelope-jammy-20240318153252 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:antelope-jammy-20240318153252 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:antelope-jammy-20240318153252 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:antelope-jammy-20240318153252 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:antelope-jammy-20240318153252 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:8.0.x-jammy-20240316092942 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.17-jammy-20231018050930 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.17-jammy-20231018050930 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-jammy-20240318153251 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.23-alpine-20240131134844 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.11-alpine-20240131112547 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.8-alpine-20240308161357 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.10.0-alpine-20240305082401 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20240311120505 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0-20231208095208 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:antelope-jammy-20240318153252 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:antelope-jammy-20240318153252 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:antelope-jammy-20240318153252 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.2.4-alpine3.19-1 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v9.0.2-20240318063427 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.12-20240129155309 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20231018050930 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.29.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.3-20240131112557 |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:antelope-jammy-20240318153252 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:antelope-jammy-20240315112519 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:antelope-jammy-20240318153252 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:antelope-jammy-20240318153252 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:antelope-jammy-20240318153252 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:antelope-jammy-20240318153252 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:antelope-jammy-20240318153252 |
Apache License 2.0 |
MOSK 24.1.2 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20240115150429.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-yoga-186584b-20230817112411.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20231004061110.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20231004061110.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-jammy-20240318153251 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-jammy-20240318153251 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-jammy-20240318153251 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-jammy-20240318153251 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.13.2-20240131075124 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-jammy-20240318153251 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-jammy-20240318153251 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-jammy-20240318153251 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-jammy-20240318153251 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-jammy-20240318153251 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-jammy-20240318153251 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20240318153251 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-jammy-20240318153251 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:8.0.x-jammy-20240316092942 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.17-jammy-20231018050930 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.17-jammy-20231018050930 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-jammy-20240318153251 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.23-alpine-20240131134844 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.11-alpine-20240131112547 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.8-alpine-20240308161357 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.10.0-alpine-20240305082401 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20240311120505 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0-20231208095208 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-jammy-20240318153251 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-jammy-20240318153251 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-jammy-20240318153251 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.2.4-alpine3.19-1 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v9.0.2-20240318063427 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.12-20240129155309 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20231018050930 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.29.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.3-20240131112557 |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-jammy-20240318153251 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20240313091248 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-jammy-20240318153251 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-jammy-20240318153251 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-jammy-20240318153251 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20240318153251 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-jammy-20240318153251 |
Apache License 2.0 |
MOSK 24.1.2 OpenStack Helm charts
MOSK 24.1.2 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
tungstenfabric-operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.14.7.tgz |
Mirantis Proprietary License |
Docker images |
||
tungstenfabric-operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.14.7 |
Mirantis Proprietary License |
tungsten-pytest |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20240307145514 |
MIT License |
casskop |
mirantis.azurecr.io/tungsten-operator/casskop:v2.2.1 |
Apache License 2.0 |
cassandra-bootstrap |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.14 |
Apache License 2.0 |
cassandra |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230622 |
Apache License 2.0 |
cassandra-config-builder |
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20240122114202 |
Apache License 2.0 |
kafka-k8s-operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.8 |
Mirantis Proprietary License |
cp-kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.5.3 |
Apache License 2.0 |
kafka-jmx-exporter |
mirantis.azurecr.io/stacklight/jmx-exporter:0.20.0-debian-11-r24 |
Apache License 2.0 |
rabbitmq-operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.4.2 |
Mirantis Proprietary License |
rabbitmq |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.16 |
Mozilla Public License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
zookeeper-operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.20-mcp |
Apache License 2.0 |
zookeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.8.3-20231019 |
Apache License 2.0 |
redis-operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.4.2 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/tungsten/redis:7.2.4-alpine3.19 |
BSD 3-Clause “New” or “Revised” License |
redis-exporter |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
tf-cli |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20240116162056 |
MIT License |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
tf-nodeinfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20231017142953 |
MIT License |
contrail-analytics-alarm-gen |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-analytics-api |
mirantis.azurecr.io/tungsten/contrail-analytics-api:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-analytics-collector |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-analytics-query-engine |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-analytics-snmp-collector |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-analytics-snmp-topology |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-controller-config-api |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-controller-config-devicemgr |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-controller-config-dnsmasq |
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-controller-config-schema |
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-controller-config-svcmonitor |
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-controller-control-control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-controller-control-dns |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-controller-control-named |
mirantis.azurecr.io/tungsten/contrail-controller-control-named:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-controller-webui-job |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-controller-webui-web |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-node-init |
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20240118000000 |
Apache License 2.0 |
contrail-nodemgr |
mirantis.azurecr.io/tungsten/contrail-nodemgr:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-tools |
mirantis.azurecr.io/tungsten/contrail-tools:24.1-r21.4.20240322210912 |
Apache License 2.0 |
contrail-vrouter-agent |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20240118000000 |
Apache License 2.0 |
contrail-vrouter-agent-dpdk |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20240118000000 |
Apache License 2.0 |
contrail-vrouter-kernel-build-init |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20240118000000 |
Apache License 2.0 |
MOSK 24.1.2 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20240318062244 |
Mirantis Proprietary License |
tungstenfabric-prometheus-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20240119124301 |
Mirantis Proprietary License |
Helm charts |
||
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-52.tgz |
Mirantis Proprietary License |
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-7.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-7.tgz |
Mirantis Proprietary License |
Security notes¶
The table below includes the total number of addressed unique and common CVEs by MOSK-specific component since MOSK 24.1.1. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
OpenStack |
Unique |
0 |
7 |
7 |
Common |
0 |
7 |
7 |
|
Tungsten Fabric |
Unique |
0 |
3 |
3 |
Common |
0 |
4 |
4 |
Mirantis Security Portal
For the detailed list of fixed and present CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
Mirantis Container Cloud CVEs
For the number of fixed CVEs in the Mirantis Container Cloud-related components including kaas core, bare metal, Ceph, and StackLight, refer to Container Cloud 2.26.2: Security notes.
Addressed issues¶
The following issues have been addressed in the MOSK 24.1.2 release:
[39663] Resolved the issue in OpenStack notifications for the Keystone component where the
"event_type": "identity.user.deleted"field lacked the ID of the request initiator (req_initiator) in the CADF payload.[39768] Resolved the issue that caused the OpenStack controller exporter to fail to initialize within the default timeout on large (500+ compute nodes) clusters.
[40712] Resolved the issue that caused
nova-manageimage_propertyto show traces.[40740] Resolved the issue that caused the OpenStack sos report logs collection failure.
Known issues¶
This section lists MOSK known issues with workarounds for the Mirantis OpenStack for Kubernetes release 24.1.2.
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
After provisioning the controller node, the etcd pod initiates before the Kubernetes networking is fully operational. As a result, the pod encounters difficulties resolving DNS and establishing connections with other members, ultimately leading to a panic state for the etcd service.
Workaround:
Delete the PVC related to the replaced controller node:
kubectl -n openstack delete pvc <PVC-NAME>
Delete pods related to the crashing etcd service on the replaced controller node:
kubectl -n openstack delete pods <ETCD-POD-NAME>
Occasionally, RabbitMQ instances in tf-rabbitmq pods fail to enable
the tracking_records_in_ets during the initialization process.
To work around the problem, restart the affected pods manually.
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete the Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica_num>
For the list of enhancements and bug fixes that relate to Mirantis Container Cloud, refer to the Mirantis Container Cloud Release notes.
Learn more about the release cadence
23.3 series¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on the needs of your deployment, you can either update between only major releases, or update between the major releases receiving the patch updates in between. Choose the second option, which includes patch updates, only if you want to receive security fixes as soon as they become available and you are prepared to update your cluster often, approximately once in three weeks.
You can delve deeper into the product updates by referring to our FAQ section. The list of questions it addresses includes, but is not limited to the following:
MOSK 23.3 17.0.0+23.3
Technical preview for OpenStack Antelope
Technical preview for generation of OpenStack support dump
FIPS-compatible OpenStack API
MKE 3.7 with Kubernetes 1.27
Open vSwitch 2.17
Technical preview for Tungsten Fabric analytics disablement
OpenStack Usage Efficiency Grafana dashboard
Ceph monitoring improvements
Documentation enhancements
23.3¶
Release date |
November 06, 2023 |
|---|---|
Name |
MOSK 23.3 |
Cluster release |
17.0.0 |
Highlights |
|
New features¶
Component |
Support scope |
Feature |
|---|---|---|
OpenStack |
TechPreview |
|
TechPreview |
||
Security |
Full |
|
Full |
|
|
Tungsten Fabric |
TechPreview |
|
StackLight |
Full |
|
Full |
||
n/a |
Operations Guide:
Security Guide:
|
TechPreview
Provided the technical preview support for OpenStack Antelope with Neutron OVS and Tungsten Fabric 21.4 for greenfield deployments.
To start experimenting with the new functionality, set openstack_version to
antelope in the OpenStackDeployment custom resource during the cloud
deployment.
TechPreview
Implemented the capability to automatically collect logs and generate support
dumps that provide valuable insights for troubleshooting OpenStack-related
problems through the osctl sos report tool present within
the openstack-controller image.
Introduced FIPS-compatible encryption into the API of all MOSK cloud services, ensuring data security and regulatory compliance with the FIPS 140-2 standard.
Learn more
Introduced support for Mirantis Kubernetes Engine (MKE) 3.7 with Kubernetes 1.27. MOSK clusters are updated to the latest supported MKE version during the cluster update.
Learn more
Upgraded Open vSwitch to 2.17 for better performance.
TechPreview
Implemented the capability to disable the Tungsten Fabric analytics services to obtain a more lightweight setup.
Implemented the OpenStack Usage Efficiency dashboard for Grafana that provides information about requested (allocated) CPU and memory usage efficiency on a per-project and per-flavor basis.
This dashboard aims to identify flavors that specific projects are not effectively using, with allocations significantly exceeding actual usage. Also, it evaluates per-instance underuse for specific projects.
Implemented the following monitoring improvements for Ceph:
Optimized the following Ceph dashboards in Grafana: Ceph Cluster, Ceph Pools, Ceph OSDs.
Removed the redundant Ceph Nodes Grafana dashboard. You can view its content using the following dashboards:
Ceph stats through the Ceph Cluster dashboard.
Resource utilization through the System dashboard, which now includes filtering by Ceph node labels, such as
ceph_role_osd,ceph_role_mon, andceph_role_mgr.
Removed the
rook_clusteralert label.Removed the redundant
CephOSDDownalert.Renamed the
CephNodeDownalert toCephOSDNodeDown.
Implemented an online calculator for quick calculation of the approximate time required to update your MOSK cluster that uses Open vSwitch as a networking back end.
Published a procedure that instructs on how to orchestrate Tungsten Fabric objects through Heat templates to ensure repeatability and consistency across deployments.
Published an overview of the data protection capabilities available in MOSK, focusing primarily on data encryption.
Learn more
Published a section that explains the principles of encrypting control plane communications in MOSK.
Learn more
Major components versions¶
Mirantis has tested MOSK against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOSK components with the exact versions against which testing has been performed.
Component |
Version |
|---|---|
Cluster release |
17.0.0 (Cluster release notes) |
OpenStack |
Yoga,
Antelope TechPreview
|
OpenStack Operator |
0.14.7 |
Tungsten Fabric |
21.4 |
Tungsten Fabric Operator |
0.13.2 |
See also
For the supported versions of operating system, Ceph, and other components, refer to Release Compatibility Matrix.
Known issues¶
This section describes the MOSK known issues with available workarounds. For the known issues in the related version of Mirantis Container Cloud, refer to Mirantis Container Cloud: Release Notes.
This section lists the OpenStack known issues with workarounds for the Mirantis OpenStack for Kubernetes release 23.3.
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
This section lists the Tungsten Fabric (TF) known issues with workarounds for the Mirantis OpenStack for Kubernetes release 23.3. For TF limitations, see Tungsten Fabric known limitations.
[37684] Cassandra containers are experiencing high resource utilization
[13755] TF pods switch to CrashLoopBackOff after a simultaneous reboot
The Cassandra containers of the tf-cassandra-analytics service are
experiencing high CPU and memory utilization. This is happening because
Cassandra Analytics is running out of memory, causing restarts of both
Cassandra and the Tungsten Fabric control plane services.
To work around the issue, use the custom images from the Mirantis public repository:
Specify the image for
config-apiin theTFOperatorcustom resource:controllers: tf-config: api: containers: - image: mirantis.azurecr.io/tungsten/contrail-controller-config-api:23.2-r21.4.20231208123354 name: api
Wait for the
tf-configpods to restart.Monitor the Cassandra Analytics resources continuously. If the Out Of Memory (OOM) error is not present, the applied workaround is sufficient.
Otherwise, modify the TF vRouters configuration as well:
controllers: tf-vrouter: agent: containers: - env: - name: VROUTER_GATEWAY value: 10.32.6.1 - name: DISABLE_TX_OFFLOAD value: "YES" name: agent image: mirantis.azurecr.io/tungsten/contrail-vrouter-agent:23.2-r21.4.20231208123354
To apply the changes, restart the vRouters manually.
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete the Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica_num>
This section lists the StackLight known issues with workarounds for the Mirantis OpenStack for Kubernetes MOSK release 23.3.
The deprecated dashboards NGINX Ingress controller and Ceph Nodes, which may expose inaccurate information, are displayed in Grafana.
These dashboards will be removed in the following MOSK release. Therefore, Mirantis recommends switching to the following dashboards in this release:
OpenStack Ingress controller instead of NGINX Ingress controller
For Ceph:
Ceph Cluster dashboard for Ceph stats
System dashboard for resource utilization, which includes filtering by Ceph node labels, such as
ceph_role_osd,ceph_role_mon, andceph_role_mgr
This section lists the update known issues with workarounds for the MOSK release 23.3.
While updating your cluster, the Instance High Availability service (OpenStack Masakari) may not work as expected.
As a workaround, temporarily disable the service by removing
instance-ha from the service list in the OpenStackDeployment
custom resource.
During update, the ingress pods that have not been updated yet adopt the configuration meant for the updated pods, causing disruptions. This occurs as ingress pods are sequentially updated, leading to potential inaccessibility to the cloud public API for unpredictable durations until all ingress pods are updated.
To mitigate this issue, Mirantis recommends updating ingress pods in larger batches, preferably half of all pods at a time. This approach minimizes downtime for the public API.
Workaround:
Before you start updating to MOSK 23.3:
Increase
maxUnavailablefor the ingress DaemonSet to 50% of replicas by patching directly the DaemonSet:kubectl -n openstack patch ds ingress -p '{"spec":{"updateStrategy":{"rollingUpdate":{"maxUnavailable":"50%"}}}}'
In certain scenarios, the change may trigger an immediate restart of half of the ingress pods. Therefore, after patching the ingress, wait until all ingress pods become ready, taking into account that there might be occasional failures in public API calls.
To verify that the patch has been applied successfully:
kubectl -n openstack get ds ingress -o jsonpath={.spec.updateStrategy.rollingUpdate.maxUnavailable}
Disable FIPS
tls_proxyexplicitly in MOSK 23.2 by adding the following configuration into theOpenStackDeploymentcustom resource:spec: features: ssl: tls_proxy: enabled: false
Update to MOSK 23.3.
Update to MOSK 24.1.
Re-enable FIPS
tls_proxyby removing the configuration added to theOpenStackDeploymentcustom resource above.
Release artifacts¶
This section lists the components artifacts of the MOSK 23.3 release that includes binaries, Docker images, and Helm charts.
MOSK 23.3 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20230928140935.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-yoga-186584b-20230817112411.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-jammy-20231013125630 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-jammy-20231013125630 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-jammy-20231013125630 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-jammy-20231013125630 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.12.9 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-jammy-20231013125630 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-jammy-20231013125630 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-jammy-20231013125630 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-jammy-20231013125630 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-jammy-20231013125630 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-jammy-20231013125630 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20231013125630 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-jammy-20231013125630 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:8.0.x-jammy-20231006073052 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.17-jammy-20231006073052 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.17-jammy-20231006073052 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-jammy-20231013125630 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.21-alpine-20230913050002 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.9-alpine-20230912131525 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230817061604 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.8.2-alpine-20230928053836 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230920121405 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-jammy-20231013125630 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-jammy-20231013125630 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-jammy-20231013125630 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/tungsten/redis:7.2.1-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20230619084330 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20230928073518 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230920121951 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.1-alpine-slim |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-jammy-20231013125630 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20231007133456 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-jammy-20231013125630 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-jammy-20231013125630 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-jammy-20231013125630 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20231013125630 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-jammy-20231013125630 |
Apache License 2.0 |
MOSK 23.3 OpenStack Antelope binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-antelope-20230927122744.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-antelope-18a1377-20230817112356.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-antelope-20230831060811.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:antelope-jammy-20231013125630 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:antelope-jammy-20231013125630 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:antelope-jammy-20231013125630 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:antelope-jammy-20231013125630 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.12.9 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:antelope-jammy-20231013125630 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:antelope-jammy-20231013125630 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:antelope-jammy-20231013125630 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:antelope-jammy-20231013125630 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:antelope-jammy-20231013125630 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:antelope-jammy-20231013125630 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:antelope-jammy-20231013125630 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:antelope-jammy-20231013125630 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:8.0.x-jammy-20231006073052 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.17-jammy-20231006073052 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.17-jammy-20231006073052 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-jammy-20231013125630 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.21-alpine-20230913050002 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.9-alpine-20230912131525 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230817061604 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.8.2-alpine-20230928053836 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230920121405 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:antelope-jammy-20231013125630 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:antelope-jammy-20231013125630 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:antelope-jammy-20231013125630 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/tungsten/redis:7.2.1-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20230619084330 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20230928073518 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230920121951 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.1-alpine-slim |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:antelope-jammy-20231013125630 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:antelope-jammy-20231006073052 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:antelope-jammy-20231013125630 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:antelope-jammy-20231013125630 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:antelope-jammy-20231013125630 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:antelope-jammy-20231013125630 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:antelope-jammy-20231013125630 |
Apache License 2.0 |
MOSK 23.3 OpenStack Helm charts
MOSK 23.3 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.13.2.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.13.2 |
Mirantis Proprietary License |
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:21.4.20230929000000 |
Apache License 2.0 |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:21.4.20230929000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:21.4.20230929000000 |
Apache License 2.0 |
|
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:21.4.20230929000000 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:21.4.20230929000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:21.4.20230929000000 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:21.4.20230929000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:21.4.20230929000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:21.4.20230929000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:21.4.20230929000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:21.4.20230929000000 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:21.4.20230929000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:21.4.20230929000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:21.4.20230929000000 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:21.4.20230929000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:21.4.20230929000000 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:21.4.20230929000000 |
Apache License 2.0 |
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20230929000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20230929000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20230929000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20230929000000 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:2.1.19 |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.12 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230622 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20230328121138 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20230830113546 |
Apache License 2.0 |
|
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.5.0 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/jmx-exporter:0.18.0-debian-11-r32 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.7 |
Mirantis Proprietary License |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.4.1 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.16 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.19-mcp |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.8.1-20230425 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.4.1 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:7.2.1-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
|
TF Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:21.4.20230929000000 |
Apache License 2.0 |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20230921141620 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20230927135644 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20230328120524 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:21.4.20230929000000 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
MOSK 23.3 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20230929023009 |
Mirantis Proprietary License |
tungstenfabric-prometheus-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20230912105027 |
Mirantis Proprietary License |
Helm charts |
||
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-49.tgz |
Mirantis Proprietary License |
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the MOSK 23.3 release:
[OpenStack] [34897] Resolved the issue that caused the unavailability of machines from the nodes with DPDK after update of OpenStack from Victoria to Wallaby.
[OpenStack] [34411] Resolved the issue with an incorrect port value for RabbitMQ after update.
[OpenStack] [25124] Improved performance while sending data between instances affected by the Multiprotocol Label Switching over Generic Routing Encapsulation (MPLSoGRE) throughput limitation.
[TF] [30738] Fixed the issue that caused the
tf-vrouter-agentreadiness probe failure (No Configuration for self).[Update] [35111] Resolved the issue that caused the openstack-operator-ensure-resources job getting stuck in
CrashLoopBackOff.[WireGuard] [35147] Resolved the issue that prevented the WireGuard interface from having the IPv4 address assigned.
[Bare metal] [34342] Resolved the issue that caused a failure of the etcd pods due to the simultaneous deployment of several pods on a single node. To ensure that etcd pods are always placed on different nodes, MOSK now deploys etcd with the
requiredDuringSchedulingIgnoredDuringExecutionpolicy.[StackLight] [35738] Resolved the issue with
ucp-node-exporter. It was unable to bind port 9100, causing theucp-node-exporterstart failure. This issue was due to a conflict with the StackLightnode-exporter, which was also binding the same port.The resolution of the issue involves an automatic change of the port for the StackLight
node-exporterfrom 9100 to 19100. No manual port update is required.If your cluster uses a firewall, add an additional firewall rule that grants the same permissions to port 19100 as those currently assigned to port 9100 on all cluster nodes.
Update notes¶
This section describes the specific actions you as a Cloud Operator need to complete to accurately plan and successfully perform your Mirantis OpenStack for Kubernetes (MOSK) cluster update to the version 23.3. Consider this information as a supplement to the generic update procedure published in Operations Guide: Update a MOSK cluster.
The MOSK cluster will obtain the newly implemented capabilities automatically with no significant impact on the update procedure.
As part of the update to MOSK 23.3, the following automatic updates of major component versions will take place:
MKE 3.6 with Kubernetes 1.24 to MKE 3.7 with Kubernetes 1.27
Open vSwitch 2.13 to 2.17
See also
The update to MOSK 23.3 does not include any version-specific impact on the cluster.
To properly plan the update maintenance window, use the following documentation:
Before updating the cluster, be sure to review the potential issues that may arise during the process and the recommended solutions to address them, as outlined in Update known issues.
Specifically, apply the workaround for the [37545] Cloud public API becomes inaccessible during update known issue.
In the 23.3 release series, MOSK stops supporting Ubuntu 18.04. Therefore, upgrade the operating system on your cluster machines to Ubuntu 20.04 before you update to MOSK 23.3. Otherwise, the Cluster release update for the cluster running on Ubuntu 18.04 becomes impossible.
It is not mandatory to upgrade all machines at once. You can upgrade them one by one or in small batches, for example, if the maintenance window is limited in time.
For details on distribution upgrade, see Mirantis Container Cloud documentation: Upgrade an operating system distribution.
Warning
Make sure to manually reboot machines after the distribution upgrade before updating MOSK to 23.3.
MOSK supports the OpenStack Victoria version until September, 2023. MOSK 23.2 was the last release version where OpenStack Victoria packages were updated.
If you have not already upgraded your OpenStack version to Yoga, perform the upgrade before cluster update.
See also
While updating your cluster, the Instance High Availability service
(OpenStack Masakari) may not work as expected. Therefore, temporarily
disable the service by removing instance-ha from the service list
in the OpenStackDeployment custom resource.
During the update, you may encounter the issue that causes a failure of the etcd pods due to the simultaneous deployment of several pods on a single node.
Therefore, before starting the update, ensure that each OpenStack controller node runs only one etcd pod.
No specific actions are needed to finalize the cluster update.
Security notes¶
In total, since MOSK 23.2 major release, in 23.3, 466 Common Vulnerabilities and Exposures (CVE) have been fixed: 24 of critical and 442 of high severity.
The table below includes the total numbers of addressed unique and common CVEs by MOSK-specific component since MOSK 23.2.3. The common CVEs are issues addressed across several images.
MOSK component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
OpenStack |
Unique |
0 |
19 |
19 |
Common |
0 |
45 |
45 |
|
Tungsten Fabric |
Unique |
2 |
19 |
21 |
Common |
2 |
57 |
59 |
Mirantis Security Portal
For the detailed list of fixed and present CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
Mirantis Container Cloud CVEs
For the number of fixed CVEs in the Mirantis Container Cloud-related components including kaas core, bare metal, Ceph, and StackLight, refer to Container Cloud 2.25.0: Security notes.
23.3.1 patch¶
The patch release notes contain the list of updated artifacts and Common Vulnerabilities and Exposures (CVE) fixes in images as well as description of the addressed product issues for the MOSK 23.3.1 patch.
For the list of enhancements and bug fixes that relate to Mirantis Container Cloud, refer to the Mirantis Container Cloud Release notes.
Release date |
November 27, 2023 |
|---|---|
Scope |
Patch |
Cluster release |
17.0.1 |
OpenStack Operator |
0.14.12 |
Tungsten Fabric Operator |
0.13.4 |
Release artifacts¶
This section lists the components artifacts of the MOSK 23.3.1 release that includes binaries, Docker images, and Helm charts.
MOSK 23.3.1 OpenStack Antelope binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
Mirantis Proprietary License |
|
mirantis |
Mirantis Proprietary License |
|
kernel |
GPL-2.0 |
|
initramfs |
GPL-2.0 |
|
service-image |
Mirantis Proprietary License |
|
Docker images |
||
keystone |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/keystone:antelope-jammy-20231110182826 |
Apache License 2.0 |
heat |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/heat:antelope-jammy-20231110182826 |
Apache License 2.0 |
glance |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/glance:antelope-jammy-20231110182826 |
Apache License 2.0 |
cinder |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/cinder:antelope-jammy-20231110182826 |
Apache License 2.0 |
cloudprober |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/cloudprober:main-rc1 |
Apache License 2.0 |
neutron |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/neutron:antelope-jammy-20231110182826 |
Apache License 2.0 |
nova |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/nova:antelope-jammy-20231110182826 |
Apache License 2.0 |
horizon |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/horizon:antelope-jammy-20231110182826 |
Apache License 2.0 |
tempest |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/tempest:antelope-jammy-20231110182826 |
Apache License 2.0 |
octavia |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/octavia:antelope-jammy-20231110182826 |
Apache License 2.0 |
designate |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/designate:antelope-jammy-20231110182826 |
Apache License 2.0 |
ironic |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/ironic:antelope-jammy-20231110182826 |
Apache License 2.0 |
barbican |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/barbican:antelope-jammy-20231110182826 |
Apache License 2.0 |
libvirt |
docker-dev-kaas-virtual.docker.mirantis.net/general/libvirt:8.0.x-jammy-20231018050930 |
LGPL-2.1 License |
pause |
docker-dev-kaas-virtual.docker.mirantis.net/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
docker-dev-kaas-virtual.docker.mirantis.net/general/openvswitch:2.17-jammy-20231018050930 |
Apache License 2.0 |
openvswitch-dpdk |
docker-dev-kaas-virtual.docker.mirantis.net/general/openvswitch-dpdk:2.17-jammy-20231018050930 |
Apache License 2.0 |
openstack-tools |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/openstack-tools:yoga-jammy-20231110182826 |
Apache License 2.0 |
rabbitmq-3.10.x |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
memcached |
docker-dev-kaas-virtual.docker.mirantis.net/general/memcached:v1.6.21-alpine-20230913050002 |
BSD 3-Clause “New” or “Revised” License |
etcd |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/etcd:v3.5.10-alpine-20231031103038 |
Apache License 2.0 |
powerdns |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/powerdns:4.7-alpine-20230817061604 |
GPL-2.0 License |
nginx-ingress-controller |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/nginx-ingress-controller:1.9.3 |
Apache License 2.0 |
tls-proxy |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
docker-dev-kaas-virtual.docker.mirantis.net/general/mariadb:10.6.14-focal-20231024091216 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
docker-dev-kaas-virtual.docker.mirantis.net/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
docker-dev-kaas-virtual.docker.mirantis.net/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
docker-dev-kaas-virtual.docker.mirantis.net/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/aodh:antelope-jammy-20231110182826 |
Apache License 2.0 |
ceilometer |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/ceilometer:antelope-jammy-20231110182826 |
Apache License 2.0 |
gnocchi |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/gnocchi:antelope-jammy-20231110182826 |
Apache License 2.0 |
redis |
docker-dev-kaas-virtual.docker.mirantis.net/tungsten/redis:7.2.1-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
docker-dev-kaas-virtual.docker.mirantis.net/general/external/docker.io/frrouting/frr:v8.5.1-20230619084330 |
GPL-2.0 and LGPL-2.1 |
strongswan |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/strongswan:alpine-5.9.8-20231021164312 |
GPL-2.0 |
rsyslog |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/rsyslog:v8.2001.0-20231018050930 |
GNU General Public License v3 |
descheduler |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/nginx:1.25.1-alpine-slim |
Apache License 2.0 |
requirements |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/requirements:antelope-jammy-20231110182826 |
Apache License 2.0 |
stepler |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/stepler:antelope-jammy-20231109062439 |
Apache License 2.0 |
placement |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/placement:antelope-jammy-20231110182826 |
Apache License 2.0 |
masakari |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/masakari:antelope-jammy-20231110182826 |
Apache License 2.0 |
masakari-monitors |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/masakari-monitors:antelope-jammy-20231110182826 |
Apache License 2.0 |
ironic-inspector |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/ironic-inspector:antelope-jammy-20231110182826 |
Apache License 2.0 |
manila |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/manila:antelope-jammy-20231110182826 |
Apache License 2.0 |
MOSK 23.3.1 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
Mirantis Proprietary License |
|
mirantis |
Mirantis Proprietary License |
|
kernel |
GPL-2.0 |
|
initramfs |
GPL-2.0 |
|
service-image |
Mirantis Proprietary License |
|
Docker images |
||
keystone |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/keystone:yoga-jammy-20231110182826 |
Apache License 2.0 |
heat |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/heat:yoga-jammy-20231110182826 |
Apache License 2.0 |
glance |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/glance:yoga-jammy-20231110182826 |
Apache License 2.0 |
cinder |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/cinder:yoga-jammy-20231110182826 |
Apache License 2.0 |
cloudprober |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/cloudprober:main-rc1 |
Apache License 2.0 |
neutron |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/neutron:yoga-jammy-20231110182826 |
Apache License 2.0 |
nova |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/nova:yoga-jammy-20231110182826 |
Apache License 2.0 |
horizon |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/horizon:yoga-jammy-20231110182826 |
Apache License 2.0 |
tempest |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/tempest:yoga-jammy-20231110182826 |
Apache License 2.0 |
octavia |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/octavia:yoga-jammy-20231110182826 |
Apache License 2.0 |
designate |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/designate:yoga-jammy-20231110182826 |
Apache License 2.0 |
ironic |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/ironic:yoga-jammy-20231110182826 |
Apache License 2.0 |
barbican |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/barbican:yoga-jammy-20231110182826 |
Apache License 2.0 |
libvirt |
docker-dev-kaas-virtual.docker.mirantis.net/general/libvirt:8.0.x-jammy-20231018050930 |
LGPL-2.1 License |
pause |
docker-dev-kaas-virtual.docker.mirantis.net/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
docker-dev-kaas-virtual.docker.mirantis.net/general/openvswitch:2.17-jammy-20231018050930 |
Apache License 2.0 |
openvswitch-dpdk |
docker-dev-kaas-virtual.docker.mirantis.net/general/openvswitch-dpdk:2.17-jammy-20231018050930 |
Apache License 2.0 |
openstack-tools |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/openstack-tools:yoga-jammy-20231110182826 |
Apache License 2.0 |
rabbitmq-3.10.x |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
memcached |
docker-dev-kaas-virtual.docker.mirantis.net/general/memcached:v1.6.21-alpine-20230913050002 |
BSD 3-Clause “New” or “Revised” License |
etcd |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/etcd:v3.5.10-alpine-20231031103038 |
Apache License 2.0 |
powerdns |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/powerdns:4.7-alpine-20230817061604 |
GPL-2.0 License |
nginx-ingress-controller |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/nginx-ingress-controller:1.9.3 |
Apache License 2.0 |
tls-proxy |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
docker-dev-kaas-virtual.docker.mirantis.net/general/mariadb:10.6.14-focal-20231024091216 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
docker-dev-kaas-virtual.docker.mirantis.net/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
docker-dev-kaas-virtual.docker.mirantis.net/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
docker-dev-kaas-virtual.docker.mirantis.net/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/aodh:yoga-jammy-20231110182826 |
Apache License 2.0 |
ceilometer |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/ceilometer:yoga-jammy-20231110182826 |
Apache License 2.0 |
gnocchi |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/gnocchi:yoga-jammy-20231110182826 |
Apache License 2.0 |
redis |
docker-dev-kaas-virtual.docker.mirantis.net/tungsten/redis:7.2.1-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
docker-dev-kaas-virtual.docker.mirantis.net/general/external/docker.io/frrouting/frr:v8.5.1-20230619084330 |
GPL-2.0 and LGPL-2.1 |
strongswan |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/strongswan:alpine-5.9.8-20231021164312 |
GPL-2.0 |
rsyslog |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/rsyslog:v8.2001.0-20231018050930 |
GNU General Public License v3 |
descheduler |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/extra/nginx:1.25.1-alpine-slim |
Apache License 2.0 |
requirements |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/requirements:yoga-jammy-20231110182826 |
Apache License 2.0 |
stepler |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/stepler:yoga-focal-20231108073953 |
Apache License 2.0 |
placement |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/placement:yoga-jammy-20231110182826 |
Apache License 2.0 |
masakari |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/masakari:yoga-jammy-20231110182826 |
Apache License 2.0 |
masakari-monitors |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/masakari-monitors:yoga-jammy-20231110182826 |
Apache License 2.0 |
ironic-inspector |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/ironic-inspector:yoga-jammy-20231110182826 |
Apache License 2.0 |
manila |
docker-dev-kaas-virtual.docker.mirantis.net/openstack/manila:yoga-jammy-20231110182826 |
Apache License 2.0 |
MOSK 23.3.1 OpenStack Helm charts
Component |
Path |
License information for main executable programs |
|---|---|---|
openstack-operator |
Mirantis Proprietary License |
|
aodh |
Apache License 2.0 (no License file in Helm chart) |
|
barbican |
Apache License 2.0 (no License file in Helm chart) |
|
ceilometer |
Apache License 2.0 (no License file in Helm chart) |
|
cinder |
Apache License 2.0 (no License file in Helm chart) |
|
designate |
Apache License 2.0 (no License file in Helm chart) |
|
glance |
Apache License 2.0 (no License file in Helm chart) |
|
heat |
Apache License 2.0 (no License file in Helm chart) |
|
horizon |
Apache License 2.0 (no License file in Helm chart) |
|
ironic |
Apache License 2.0 (no License file in Helm chart) |
|
keystone |
Apache License 2.0 (no License file in Helm chart) |
|
neutron |
Apache License 2.0 (no License file in Helm chart) |
|
nova |
Apache License 2.0 (no License file in Helm chart) |
|
octavia |
Apache License 2.0 (no License file in Helm chart) |
|
panko |
Apache License 2.0 (no License file in Helm chart) |
|
tempest |
Apache License 2.0 (no License file in Helm chart) |
|
stepler |
Apache License 2.0 (no License file in Helm chart) |
|
placement |
Apache License 2.0 (no License file in Helm chart) |
|
masakari |
Apache License 2.0 (no License file in Helm chart) |
|
manila |
Apache License 2.0 (no License file in Helm chart) |
|
ceph-rgw |
Apache License 2.0 (no License file in Helm chart) |
|
cloudprober |
Apache License 2.0 (no License file in Helm chart) |
|
etcd |
Apache License 2.0 (no License file in Helm chart) |
|
gnocchi |
Apache License 2.0 (no License file in Helm chart) |
|
helm-toolkit |
Apache License 2.0 (no License file in Helm chart) |
|
ingress |
Apache License 2.0 (no License file in Helm chart) |
|
libvirt |
Apache License 2.0 (no License file in Helm chart) |
|
mariadb |
Apache License 2.0 (no License file in Helm chart) |
|
memcached |
Apache License 2.0 (no License file in Helm chart) |
|
openvswitch |
Apache License 2.0 (no License file in Helm chart) |
|
powerdns |
Apache License 2.0 (no License file in Helm chart) |
|
rabbitmq |
Apache License 2.0 (no License file in Helm chart) |
|
frr |
Apache License 2.0 (no License file in Helm chart) |
|
iscsi |
Apache License 2.0 (no License file in Helm chart) |
|
strongswan |
Apache License 2.0 (no License file in Helm chart) |
|
descheduler |
Apache License 2.0 (no License file in Helm chart) |
MOSK 23.3.1 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.13.4.tgz |
Mirantis Proprietary License |
Docker images |
||
tungstenfabric-operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.13.4 |
Mirantis Proprietary License |
tungsten-pytest |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20231018094104 |
MIT License |
casskop |
mirantis.azurecr.io/tungsten-operator/casskop:v2.2.0 |
Apache License 2.0 |
cassandra-bootstrap |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.13 |
Apache License 2.0 |
cassandra |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230622 |
Apache License 2.0 |
cassandra-config-builder |
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20231026075239 |
Apache License 2.0 |
cassandra-backrest-sidecar |
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20230328121138 |
Apache License 2.0 |
kafka-k8s-operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.8 |
Mirantis Proprietary License |
cp-kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.5.0 |
Apache License 2.0 |
kafka-jmx-exporter |
mirantis.azurecr.io/stacklight/jmx-exporter:0.18.0-debian-11-r32 |
Apache License 2.0 |
rabbitmq-operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.4.2 |
Mirantis Proprietary License |
rabbitmq |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.16 |
Mozilla Public License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
zookeeper-operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.20-mcp |
Apache License 2.0 |
zookeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.8.3-20231019 |
Apache License 2.0 |
redis-operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.4.2 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/tungsten/redis:7.2.1-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
redis-exporter |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
tf-cli |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20231025094005 |
MIT License |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
tf-nodeinfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20231017142953 |
MIT License |
contrail-analytics-alarm-gen |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-api |
mirantis.azurecr.io/tungsten/contrail-analytics-api:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-collector |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-query-engine |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-snmp-collector |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-snmp-topology |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-api |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-devicemgr |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-dnsmasq |
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-schema |
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-svcmonitor |
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-control-control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-control-dns |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-control-named |
mirantis.azurecr.io/tungsten/contrail-controller-control-named:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-webui-job |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-webui-web |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-node-init |
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20230929000000 |
Apache License 2.0 |
contrail-nodemgr |
mirantis.azurecr.io/tungsten/contrail-nodemgr:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-tools |
mirantis.azurecr.io/tungsten/contrail-tools:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-vrouter-agent |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20230929000000 |
Apache License 2.0 |
contrail-vrouter-agent-dpdk |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20230929000000 |
Apache License 2.0 |
contrail-vrouter-kernel-build-init |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20230929000000 |
Apache License 2.0 |
MOSK 23.3.1 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20231027023009 |
Mirantis Proprietary License |
tungstenfabric-prometheus-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20230912105027 |
Mirantis Proprietary License |
Helm charts |
||
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-52.tgz |
Mirantis Proprietary License |
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-7.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-7.tgz |
Mirantis Proprietary License |
Security notes¶
In total, since MOSK 23.3 release, in 23.3.1, 157 Common Vulnerabilities and Exposures (CVE) have been fixed: 5 of critical and 152 of high severity.
The table below includes the total numbers of addressed unique and common CVEs by MOSK-specific component since MOSK 23.2.3. The common CVEs are issues addressed across several images.
MOSK component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
OpenStack |
Unique |
1 |
16 |
17 |
Common |
3 |
69 |
72 |
|
Tungsten Fabric |
Unique |
1 |
15 |
16 |
Common |
2 |
83 |
85 |
Mirantis Security Portal
For the detailed list of fixed and present CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
Mirantis Container Cloud CVEs
For the number of fixed CVEs in the Mirantis Container Cloud-related components including kaas core, bare metal, Ceph, and StackLight, refer to Container Cloud 2.25.1: Security notes.
Addressed issues¶
The following issues have been addressed in the MOSK 23.3.1 release:
[37012] Resolved the issue that caused the cluster update failure due to instances evacuation when they were not supposed to be evacuated.
[37083] Resolved the issue that caused Cloudprober to produce warnings about large amount of targets.
[37185] Resolved the issue that caused the OpenStack Controller to fail while applying the Manila Helm charts during the attempt to enable Manila through the
OpenStackDeploymentcustom resource.
Learn more about the release cadence
23.3.2 patch¶
The patch release notes contain the list of updated artifacts and Common Vulnerabilities and Exposures (CVE) fixes in images for the MOSK 23.3.2 patch.
For the list of enhancements and bug fixes that relate to Mirantis Container Cloud, refer to the Mirantis Container Cloud Release notes.
Release date |
December 05, 2023 |
|---|---|
Scope |
Patch |
Cluster release |
17.0.2 |
OpenStack Operator |
0.14.14 |
Tungsten Fabric Operator |
0.13.5 |
Release artifacts¶
This section lists the components artifacts of the MOSK 23.3.2 release that includes binaries, Docker images, and Helm charts.
MOSK 23.3.2 OpenStack Antelope binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-antelope-20230927122744.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-antelope-18a1377-20230817112356.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-antelope-20230831060811.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:antelope-jammy-20231110182826 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:antelope-jammy-20231110182826 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:antelope-jammy-20231110182826 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:antelope-jammy-20231110182826 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.13.1-6-geb9d5960-20231120094223 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:antelope-jammy-20231110182826 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:antelope-jammy-20231110182826 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:antelope-jammy-20231110182826 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:antelope-jammy-20231110182826 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:antelope-jammy-20231110182826 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:antelope-jammy-20231110182826 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:antelope-jammy-20231110182826 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:antelope-jammy-20231110182826 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:8.0.x-jammy-20231114112207 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.17-jammy-20231018050930 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.17-jammy-20231018050930 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-jammy-20231110182826 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.22-alpine-20231117094504 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.10-alpine-20231117141230 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20231116135030 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.9.3-alpine-20231120101958 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231024091216 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:antelope-jammy-20231110182826 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:antelope-jammy-20231110182826 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:antelope-jammy-20231110182826 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.2.3-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20231117093402 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20231116165931 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20231018050930 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.3-20231120120521 |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:antelope-jammy-20231110182826 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:antelope-jammy-20231117084119 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:antelope-jammy-20231110182826 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:antelope-jammy-20231110182826 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:antelope-jammy-20231110182826 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:antelope-jammy-20231110182826 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:antelope-jammy-20231110182826 |
Apache License 2.0 |
MOSK 23.3.2 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20230928140935.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-yoga-186584b-20230817112411.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-jammy-20231110182826 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-jammy-20231110182826 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-jammy-20231110182826 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-jammy-20231110182826 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.13.1-6-geb9d5960-20231120094223 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-jammy-20231110182826 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-jammy-20231110182826 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-jammy-20231110182826 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-jammy-20231110182826 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-jammy-20231110182826 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-jammy-20231110182826 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20231110182826 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-jammy-20231110182826 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:8.0.x-jammy-20231114112207 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.17-jammy-20231018050930 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.17-jammy-20231018050930 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-jammy-20231110182826 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.22-alpine-20231117094504 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.10-alpine-20231117141230 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20231116135030 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.9.3-alpine-20231120101958 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231024091216 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-jammy-20231110182826 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-jammy-20231110182826 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-jammy-20231110182826 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.2.3-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20231117093402 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20231116165931 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20231018050930 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.3-20231120120521 |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-jammy-20231110182826 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20231117072125 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-jammy-20231110182826 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-jammy-20231110182826 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-jammy-20231110182826 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20231110182826 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-jammy-20231110182826 |
Apache License 2.0 |
MOSK 23.3.2 OpenStack Helm charts
MOSK 23.3.2 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.13.5.tgz |
Mirantis Proprietary License |
Docker images |
||
tungstenfabric-operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.13.5 |
Mirantis Proprietary License |
tungsten-pytest |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20231018094104 |
MIT License |
casskop |
mirantis.azurecr.io/tungsten-operator/casskop:v2.2.0 |
Apache License 2.0 |
cassandra-bootstrap |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.13 |
Apache License 2.0 |
cassandra |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230622 |
Apache License 2.0 |
cassandra-config-builder |
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20231115112406 |
Apache License 2.0 |
cassandra-backrest-sidecar |
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20230328121138 |
Apache License 2.0 |
kafka-k8s-operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.8 |
Mirantis Proprietary License |
cp-kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.5.2 |
Apache License 2.0 |
kafka-jmx-exporter |
mirantis.azurecr.io/stacklight/jmx-exporter:0.20.0-debian-11-r1 |
Apache License 2.0 |
rabbitmq-operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.4.2 |
Mirantis Proprietary License |
rabbitmq |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.16 |
Mozilla Public License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
zookeeper-operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.20-mcp |
Apache License 2.0 |
zookeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.8.3-20231019 |
Apache License 2.0 |
redis-operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.4.2 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/tungsten/redis:7.2.3-alpine |
BSD 3-Clause “New” or “Revised” License |
redis-exporter |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
tf-cli |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20231120173127 |
MIT License |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
tf-nodeinfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20231017142953 |
MIT License |
contrail-analytics-alarm-gen |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-api |
mirantis.azurecr.io/tungsten/contrail-analytics-api:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-collector |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-query-engine |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-snmp-collector |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-snmp-topology |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-api |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-devicemgr |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-dnsmasq |
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-schema |
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-svcmonitor |
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-control-control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-control-dns |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-control-named |
mirantis.azurecr.io/tungsten/contrail-controller-control-named:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-webui-job |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-webui-web |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-node-init |
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20230929000000 |
Apache License 2.0 |
contrail-nodemgr |
mirantis.azurecr.io/tungsten/contrail-nodemgr:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-tools |
mirantis.azurecr.io/tungsten/contrail-tools:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-vrouter-agent |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20230929000000 |
Apache License 2.0 |
contrail-vrouter-agent-dpdk |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20230929000000 |
Apache License 2.0 |
contrail-vrouter-kernel-build-init |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20230929000000 |
Apache License 2.0 |
MOSK 23.3.2 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20231117023009 |
Mirantis Proprietary License |
tungstenfabric-prometheus-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20230912105027 |
Mirantis Proprietary License |
Helm charts |
||
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-52.tgz |
Mirantis Proprietary License |
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-7.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-7.tgz |
Mirantis Proprietary License |
Security notes¶
The table below includes the total number of addressed unique and common CVEs by MOSK-specific component since MOSK 23.3.1. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
OpenStack |
Unique |
0 |
2 |
2 |
Common |
0 |
19 |
19 |
|
Tungsten Fabric |
Unique |
0 |
18 |
18 |
Common |
0 |
39 |
39 |
Mirantis Security Portal
For the detailed list of fixed and present CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
Mirantis Container Cloud CVEs
For the number of fixed CVEs in the Mirantis Container Cloud-related components including kaas core, bare metal, Ceph, and StackLight, refer to Container Cloud 2.25.2: Security notes.
Learn more about the release cadence
23.3.3 patch¶
The patch release notes contain the lists of updated artifacts and addressed product issues, as well as the details on Common Vulnerabilities and Exposures (CVE) fixes in images for the MOSK 23.3.3 patch.
For the list of enhancements and bug fixes that relate to Mirantis Container Cloud, refer to the Mirantis Container Cloud Release notes.
Release date |
December 18, 2023 |
|---|---|
Scope |
Patch |
Cluster release |
17.0.3 |
OpenStack Operator |
0.14.17 |
Tungsten Fabric Operator |
0.13.5 |
Release artifacts¶
This section lists the components artifacts of the MOSK 23.3.3 release that includes binaries, Docker images, and Helm charts.
MOSK 23.3.3 OpenStack Antelope binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-antelope-20230927122744.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-antelope-18a1377-20230817112356.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-antelope-20230831060811.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:antelope-jammy-20231204144213 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:antelope-jammy-20231204144213 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:antelope-jammy-20231204144213 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:antelope-jammy-20231204144213 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.13.1-6-geb9d5960-20231120094223 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:antelope-jammy-20231204144213 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:antelope-jammy-20231204144213 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:antelope-jammy-20231204144213 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:antelope-jammy-20231204144213 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:antelope-jammy-20231204144213 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:antelope-jammy-20231204144213 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:antelope-jammy-20231204144213 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:antelope-jammy-20231204144213 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:8.0.x-jammy-20231114112207 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.17-jammy-20231018050930 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.17-jammy-20231018050930 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-jammy-20231204144213 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.22-alpine-20231117094504 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.10-alpine-20231117141230 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20231201092632 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.9.3-alpine-20231120101958 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0-20231208095208 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:antelope-jammy-20231204144213 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:antelope-jammy-20231204144213 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:antelope-jammy-20231204144213 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.2.3-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20231117093402 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20231116165931 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20231018050930 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.28.1 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.3-20231120120521 |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:antelope-jammy-20231204144213 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:antelope-jammy-20231205121024 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:antelope-jammy-20231204144213 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:antelope-jammy-20231204144213 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:antelope-jammy-20231204144213 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:antelope-jammy-20231204144213 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:antelope-jammy-20231204144213 |
Apache License 2.0 |
MOSK 23.3.3 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20230928140935.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-yoga-186584b-20230817112411.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-jammy-20231204144213 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-jammy-20231204144213 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-jammy-20231204144213 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-jammy-20231204144213 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.13.1-6-geb9d5960-20231120094223 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-jammy-20231204144213 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-jammy-20231204144213 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-jammy-20231204144213 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-jammy-20231204144213 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-jammy-20231204144213 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-jammy-20231204144213 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20231204144213 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-jammy-20231204144213 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:8.0.x-jammy-20231114112207 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.17-jammy-20231018050930 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.17-jammy-20231018050930 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-jammy-20231204144213 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.22-alpine-20231117094504 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.10-alpine-20231117141230 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20231201092632 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.9.3-alpine-20231120101958 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0-20231208095208 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-jammy-20231204144213 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-jammy-20231204144213 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-jammy-20231204144213 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.2.3-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20231117093402 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20231116165931 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20231018050930 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.28.1 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.3-20231120120521 |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-jammy-20231204144213 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20231205122540 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-jammy-20231204144213 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-jammy-20231204144213 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-jammy-20231204144213 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20231204144213 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-jammy-20231204144213 |
Apache License 2.0 |
MOSK 23.3.3 OpenStack Helm charts
MOSK 23.3.3 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.13.5.tgz |
Mirantis Proprietary License |
Docker images |
||
tungstenfabric-operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.13.5 |
Mirantis Proprietary License |
tungsten-pytest |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20231018094104 |
MIT License |
casskop |
mirantis.azurecr.io/tungsten-operator/casskop:v2.2.0 |
Apache License 2.0 |
cassandra-bootstrap |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.13 |
Apache License 2.0 |
cassandra |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230622 |
Apache License 2.0 |
cassandra-config-builder |
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20231115112406 |
Apache License 2.0 |
cassandra-backrest-sidecar |
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20230328121138 |
Apache License 2.0 |
kafka-k8s-operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.8 |
Mirantis Proprietary License |
cp-kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.5.2 |
Apache License 2.0 |
kafka-jmx-exporter |
mirantis.azurecr.io/stacklight/jmx-exporter:0.20.0-debian-11-r1 |
Apache License 2.0 |
rabbitmq-operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.4.2 |
Mirantis Proprietary License |
rabbitmq |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.16 |
Mozilla Public License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
zookeeper-operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.20-mcp |
Apache License 2.0 |
zookeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.8.3-20231019 |
Apache License 2.0 |
redis-operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.4.2 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/tungsten/redis:7.2.3-alpine |
BSD 3-Clause “New” or “Revised” License |
redis-exporter |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
tf-cli |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20231120173127 |
MIT License |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
tf-nodeinfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20231017142953 |
MIT License |
contrail-analytics-alarm-gen |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-api |
mirantis.azurecr.io/tungsten/contrail-analytics-api:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-collector |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-query-engine |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-snmp-collector |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-analytics-snmp-topology |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-api |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-devicemgr |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-dnsmasq |
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-schema |
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-config-svcmonitor |
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-control-control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-control-dns |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-control-named |
mirantis.azurecr.io/tungsten/contrail-controller-control-named:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-webui-job |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-controller-webui-web |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-node-init |
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20230929000000 |
Apache License 2.0 |
contrail-nodemgr |
mirantis.azurecr.io/tungsten/contrail-nodemgr:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-tools |
mirantis.azurecr.io/tungsten/contrail-tools:23.3-r21.4.20231030213711 |
Apache License 2.0 |
contrail-vrouter-agent |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20230929000000 |
Apache License 2.0 |
contrail-vrouter-agent-dpdk |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20230929000000 |
Apache License 2.0 |
contrail-vrouter-kernel-build-init |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20230929000000 |
Apache License 2.0 |
MOSK 23.3.3 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20231201023010 |
Mirantis Proprietary License |
tungstenfabric-prometheus-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20231204150325 |
Mirantis Proprietary License |
Helm charts |
||
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-52.tgz |
Mirantis Proprietary License |
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-7.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-7.tgz |
Mirantis Proprietary License |
Security notes¶
The table below includes the total number of addressed unique and common CVEs by MOSK-specific component since MOSK 23.3.2. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
OpenStack |
Unique |
0 |
1 |
1 |
Common |
0 |
1 |
1 |
Mirantis Security Portal
For the detailed list of fixed and present CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
Mirantis Container Cloud CVEs
For the number of fixed CVEs in the Mirantis Container Cloud-related components including kaas core, bare metal, Ceph, and StackLight, refer to Container Cloud 2.25.3: Security notes.
Addressed issues¶
The following issues have been addressed in the MOSK 23.3.3 release:
[37545] Resolved the issue that led to potential inaccessibility to the cloud public API for unpredictable durations during a cluster update.
Learn more about the release cadence
23.3.4 patch¶
The patch release notes contain the lists of updated artifacts and addressed product issues, as well as the details on Common Vulnerabilities and Exposures (CVE) fixes in images for the MOSK 23.3.4 patch.
For the list of enhancements and bug fixes that relate to Mirantis Container Cloud, refer to the Mirantis Container Cloud Release notes.
Release date |
January 10, 2023 |
|---|---|
Scope |
Patch |
Cluster release |
17.0.4 |
OpenStack Operator |
0.14.18 |
Tungsten Fabric Operator |
0.13.6 |
Release artifacts¶
This section lists the components artifacts of the MOSK 23.3.4 release that includes binaries, Docker images, and Helm charts.
MOSK 23.3.4 OpenStack Antelope binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-antelope-20230927122744.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-antelope-18a1377-20230817112356.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-antelope-20230831060811.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:antelope-jammy-20231214160210 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:antelope-jammy-20231214160210 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:antelope-jammy-20231214160210 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:antelope-jammy-20231214160210 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.13.1-6-geb9d5960-20231120094223 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:antelope-jammy-20231214160210 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:antelope-jammy-20231214160210 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:antelope-jammy-20231214160210 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:antelope-jammy-20231214160210 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:antelope-jammy-20231214160210 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:antelope-jammy-20231214160210 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:antelope-jammy-20231214160210 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:antelope-jammy-20231214160210 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:8.0.x-jammy-20231211175451 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.17-jammy-20231018050930 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.17-jammy-20231018050930 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-jammy-20231214151928 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.22-alpine-20231117094504 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.11-alpine-20231211203412 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20231201092632 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.9.3-alpine-20231120101958 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0-20231208095208 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:antelope-jammy-20231214160210 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:antelope-jammy-20231214160210 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:antelope-jammy-20231214160210 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.2.3-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20231117093402 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20231116165931 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20231018050930 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.28.1 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.3-20231120120521 |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:antelope-jammy-20231214160210 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:antelope-jammy-20231205121024 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:antelope-jammy-20231214160210 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:antelope-jammy-20231214160210 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:antelope-jammy-20231214160210 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:antelope-jammy-20231214160210 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:antelope-jammy-20231214160210 |
Apache License 2.0 |
MOSK 23.3.4 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20230928140935.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-yoga-186584b-20230817112411.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-jammy-20231214151928 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-jammy-20231214151928 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-jammy-20231214151928 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-jammy-20231214151928 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.13.1-6-geb9d5960-20231120094223 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-jammy-20231214151928 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-jammy-20231214151928 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-jammy-20231214151928 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-jammy-20231214151928 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-jammy-20231214151928 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-jammy-20231214151928 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-jammy-20231214151928 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-jammy-20231214151928 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:8.0.x-jammy-20231211175451 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.17-jammy-20231018050930 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.17-jammy-20231018050930 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-jammy-20231214151928 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-55b02f7-20231019172556 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.22-alpine-20231117094504 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.11-alpine-20231211203412 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20231201092632 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.9.3-alpine-20231120101958 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20231127070342 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0-20231208095208 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-jammy-20231214151928 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-jammy-20231214151928 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-jammy-20231214151928 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.2.3-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20231117093402 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20231116165931 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20231018050930 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.28.1 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.3-20231120120521 |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-jammy-20231214151928 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20231205122540 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-jammy-20231214151928 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-jammy-20231214151928 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-jammy-20231214151928 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-jammy-20231214151928 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-jammy-20231214151928 |
Apache License 2.0 |
MOSK 23.3.4 OpenStack Helm charts
MOSK 23.3.4 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.13.6.tgz |
Mirantis Proprietary License |
Docker images |
||
tungstenfabric-operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.13.6 |
Mirantis Proprietary License |
tungsten-pytest |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20231213155208 |
MIT License |
casskop |
mirantis.azurecr.io/tungsten-operator/casskop:v2.2.1 |
Apache License 2.0 |
cassandra-bootstrap |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.13 |
Apache License 2.0 |
cassandra |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230622 |
Apache License 2.0 |
cassandra-config-builder |
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20231115112406 |
Apache License 2.0 |
cassandra-backrest-sidecar |
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20230328121138 |
Apache License 2.0 |
kafka-k8s-operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.8 |
Mirantis Proprietary License |
cp-kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.5.2 |
Apache License 2.0 |
kafka-jmx-exporter |
mirantis.azurecr.io/stacklight/jmx-exporter:0.20.0-debian-11-r1 |
Apache License 2.0 |
rabbitmq-operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.4.2 |
Mirantis Proprietary License |
rabbitmq |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.16 |
Mozilla Public License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
zookeeper-operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.20-mcp |
Apache License 2.0 |
zookeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.8.3-20231019 |
Apache License 2.0 |
redis-operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.4.2 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/tungsten/redis:7.2.3-alpine |
BSD 3-Clause “New” or “Revised” License |
redis-exporter |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
tf-cli |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20231120173127 |
MIT License |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
tf-nodeinfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20231017142953 |
MIT License |
contrail-analytics-alarm-gen |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-analytics-api |
mirantis.azurecr.io/tungsten/contrail-analytics-api:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-analytics-collector |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-analytics-query-engine |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-analytics-snmp-collector |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-analytics-snmp-topology |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-controller-config-api |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-controller-config-devicemgr |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-controller-config-dnsmasq |
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-controller-config-schema |
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-controller-config-svcmonitor |
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-controller-control-control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-controller-control-dns |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-controller-control-named |
mirantis.azurecr.io/tungsten/contrail-controller-control-named:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-controller-webui-job |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-controller-webui-web |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-node-init |
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20230929000000 |
Apache License 2.0 |
contrail-nodemgr |
mirantis.azurecr.io/tungsten/contrail-nodemgr:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-tools |
mirantis.azurecr.io/tungsten/contrail-tools:23.3-r21.4.20231214142113 |
Apache License 2.0 |
contrail-vrouter-agent |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20230929000000 |
Apache License 2.0 |
contrail-vrouter-agent-dpdk |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20230929000000 |
Apache License 2.0 |
contrail-vrouter-kernel-build-init |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20230929000000 |
Apache License 2.0 |
MOSK 23.3.4 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20231215023010 |
Mirantis Proprietary License |
tungstenfabric-prometheus-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20231204150325 |
Mirantis Proprietary License |
Helm charts |
||
fluentd |
https://binary.mirantis.com/stacklight/helm/fluentd-2.0.3-mcp-52.tgz |
Mirantis Proprietary License |
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-7.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-7.tgz |
Mirantis Proprietary License |
Security notes¶
The table below includes the total number of addressed unique and common CVEs by MOSK-specific component since MOSK 23.3.3. The common CVEs are issues addressed across several images.
Product component |
CVE type |
Critical |
High |
Total |
|---|---|---|---|---|
OpenStack |
Unique |
0 |
1 |
1 |
Common |
0 |
3 |
3 |
|
Tungsten Fabric |
Unique |
2 |
22 |
24 |
Common |
2 |
26 |
28 |
Mirantis Security Portal
For the detailed list of fixed and present CVEs across the Mirantis Container Cloud and MOSK products, refer to Mirantis Security Portal.
Mirantis Container Cloud CVEs
For the number of fixed CVEs in the Mirantis Container Cloud-related components including kaas core, bare metal, Ceph, and StackLight, refer to Container Cloud 2.25.4: Security notes.
Addressed issues¶
The following issue has been addressed in the MOSK 23.3.4 release:
[37684] Resolved the issue that led to high resource utilization by Cassandra containers of the
tf-cassandra-analyticsservice.
Learn more about the release cadence
23.2 series¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on the needs of your deployment, you can either update between only major releases, or update between the major releases receiving the patch updates in between. Choose the second option, which includes patch updates, only if you want to receive security fixes as soon as they become available and you are prepared to update your cluster often, approximately once in three weeks.
You can delve deeper into the product updates by referring to our FAQ section. The list of questions it addresses includes, but is not limited to the following:
MOSK 23.2 15.0.1+23.2
Technical preview for parallel node update
Automatic cleanup of OpenStack metadata during node removal
Technical preview for workload monitoring
Technical preview for BGP dynamic routing
Encryption of exposable OpenStack notification endpoint
Secure live migration of OpenStack instances
Technical preview for Tungsten Fabric graceful restart and long-lived graceful restart
Technical preview for external storage for Tungsten Fabric
Major version updates: MKE 3.6, Keycloak Quarkus, and Ceph Quincy
Technical preview for Cephless cloud architecture
Technical preview for WireGuard support
Technical preview for custom host names for cluster machines configuration
Technical preview for auditd support
Workload onboarding tutorial
23.2¶
Release date |
August 21, 2023 |
|---|---|
Name |
MOSK 23.2 |
Cluster release |
15.0.1 |
Highlights |
|
New features¶
Component |
Support scope |
Feature |
|---|---|---|
OpenStack |
TechPreview |
|
Full |
||
TechPreview |
||
TechPreview |
||
Security |
Full |
|
Full |
||
Tungsten Fabric |
TechPreview |
Tungsten Fabric graceful restart and long-lived graceful restart |
TechPreview |
||
Major version changes |
Full |
|
Full |
||
Full |
||
Other components |
TechPreview |
|
TechPreview |
||
TechPreview |
||
TechPreview |
||
Documentation |
n/a |
TechPreview
Implemented the capability to parallelize OpenStack, Ceph, and Tungsten Fabric node update operations, significantly improving the efficiency of MOSK deployments. The parallel node update feature applies to any operation that utilizes the Node Maintenance API, such as cluster updates or graceful node reboots.
Implemented the automatic removal of OpenStack-related metadata during the graceful machine deletion.
Learn more
TechPreview
Implemented the OpenStack workload monitoring feature through the Cloudprober exporter.
After enablement and proper configuration, the exporter allows for monitoring the availability of instance floating IP addresses per OpenStack compute node and project, as well as viewing the probe statistics for individual instance floating IP addresses through the Openstack Instances Availability dashboard in Grafana.
TechPreview
Introduced the Technology Preview support for the BGP dynamic routing extension to the Networking service (OpenStack Neutron) that will be particularly useful for the MOSK clouds where private networks managed by cloud users need to be transparently integrated into the networking of the data center.
Learn more
Implemented the encryption of the exposed message bus (RabbitMQ) endpoint for secure connection.
Implemented the TLS encryption feature for QEMU and libvirt to secure all data transports during live migration, including disks not on shared storage.
Available since MOSK 23.2 for Tungsten Fabric 21.4 only TechPreview
Added support for graceful restart and long-lived graceful restart allowing for a more efficient and robust routing experience for Tungsten Fabric. These features enhance the speed at which routing tables converge, specifically when dealing with BGP router restarts or failures.
TechPreview
Implemented Technology Preview support for configuring a remote NFS storage for Tungsten Fabric data backup and restoration.
Introduced support for Mirantis Kubernetes Engine (MKE) 3.6 with Kubernetes 1.24. MOSK clusters are updated to the latest supported MKE version during the cluster update.
Learn more
Upgraded Keycloak major version from 18.0.0 to 21.1.1 during the Cluster version update.
Learn more
Upgraded Ceph major version from Pacific to Quincy with an automatic upgrade of Ceph components during the Cluster version update.
Learn more
TechPreview
Implemented the capability to configure a MOSK cluster without Ceph and, for example, rely on external storage appliances to host their data instead.
Learn more
TechPreview
Added initial Technology Preview support for WireGuard that enables traffic encryption on the Kubernetes workloads network.
TechPreview
Added initial Technology Preview support for custom host names of cluster machines. When enabled, any machine host name in a particular region matches the related Machine object name.
TechPreview
Added initial Technology Preview support for the Linux Audit daemon auditd to monitor activity of cluster processes that allow for detection of potential malicious activity.
Added a tutorial to help you build your first cloud application and onboard it to a MOSK cloud. It will guide you through the process of deploying a simple application using the cloud web UI (OpenStack Horizon).
Major components versions¶
Mirantis has tested MOSK against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOSK components with the exact versions against which testing has been performed.
Component |
Version |
|---|---|
Cluster release |
15.0.1 (Cluster release notes) |
OpenStack |
Yoga |
OpenStack Operator |
0.13.8 |
Tungsten Fabric |
21.4 |
Tungsten Fabric Operator |
0.12.4 |
See also
For the supported versions of operating system, Ceph, and other components, refer to Release Compatibility Matrix.
Known issues¶
This section describes the MOSK known issues with available workarounds. For the known issues in the related version of Mirantis Container Cloud, refer to Mirantis Container Cloud: Release Notes.
This section lists the OpenStack known issues with workarounds for the Mirantis OpenStack for Kubernetes release 23.2.
Multiprotocol Label Switching over Generic Routing Encapsulation (MPLSoGRE) provides limited throughput while sending data between VMs up to 38 Mbps, as per Mirantis tests.
As a workaround, switch the encapsulation type to VXLAN in the
OpenStackDeployment custom resource:
spec:
services:
networking:
neutron:
values:
conf:
bagpipe_bgp:
dataplane_driver_ipvpn:
mpls_over_gre: "False"
vxlan_encap: "True"
Due to the upstream MariaDB issue, during MariaDB operations on a management cluster, Pods may get stuck in continuous restarts with the following example error:
[ERROR] WSREP: Corrupt buffer header: \
addr: 0x7faec6f8e518, \
seqno: 3185219421952815104, \
size: 909455917, \
ctx: 0x557094f65038, \
flags: 11577. store: 49, \
type: 49
Workaround:
Create a backup of the
/var/lib/mysqldirectory on themariadb-serverPod.Verify that other replicas are up and ready.
Remove the
galera.cachefile for the affectedmariadb-serverPod.Remove the affected
mariadb-serverPod or wait until it is automatically restarted.
After Kubernetes restarts the Pod, the Pod clones the database in 1-2 minutes and restores the quorum.
After update of OpenStack from Victoria to Wallaby, the machines from nodes with DPDK become unavailable.
Workaround:
Search for the nodes with the OVS ports:
for i in $(kubectl -n openstack get pods |grep openvswitch-vswitchd | awk '{print $1}'); do kubectl -n openstack exec -it -c openvswitch-vswitchd $i -- ovs-vsctl show |grep -q "tag: 4095" && echo $i; done
Restart the
neutron-ovs-agentagent on the affected nodes.
This section lists the Tungsten Fabric (TF) known issues with workarounds for the Mirantis OpenStack for Kubernetes release 23.2. For TF limitations, see Tungsten Fabric known limitations.
[37684] Cassandra containers are experiencing high resource utilization
[30738] ‘tf-vrouter-agent’ readiness probe failed (No Configuration for self)
[13755] TF pods switch to CrashLoopBackOff after a simultaneous reboot
The Cassandra containers of the tf-cassandra-analytics service are
experiencing high CPU and memory utilization. This is happening because
Cassandra Analytics is running out of memory, causing restarts of both
Cassandra and the Tungsten Fabric control plane services.
To work around the issue, use the custom images from the Mirantis public repository:
Specify the image for
config-apiin theTFOperatorcustom resource:controllers: tf-config: api: containers: - image: mirantis.azurecr.io/tungsten/contrail-controller-config-api:23.2-r21.4.20231208123354 name: api
Wait for the
tf-configpods to restart.Monitor the Cassandra Analytics resources continuously. If the Out Of Memory (OOM) error is not present, the applied workaround is sufficient.
Otherwise, modify the TF vRouters configuration as well:
controllers: tf-vrouter: agent: containers: - env: - name: VROUTER_GATEWAY value: 10.32.6.1 - name: DISABLE_TX_OFFLOAD value: "YES" name: agent image: mirantis.azurecr.io/tungsten/contrail-vrouter-agent:23.2-r21.4.20231208123354
To apply the changes, restart the vRouters manually.
Execution of the TF Heat Tempest test test_template_global_vrouter_config
can result in lost vRouter configuration. This causes the tf-vrouter pod
readiness probe to fail with the following error message:
"Readiness probe failed: vRouter is PRESENT contrail-vrouter-agent: initializing (No Configuration for self)"
As a result, vRouters may have an incomplete routing table making some services, such as metadata, become unavailable.
Workaround:
Add the
tf_heat_tempest_plugintests with global configuration to the exclude list in theOpenStackDeploymentcustom resource:spec: tempest: tempest: values: conf: blacklist: - (?:tf_heat_tempest_plugin.tests.functional.test_global.*)
If you ran
test_template_global_vrouter_configandtf-vrouter-agentpods moved to theerrorstate with the above error, re-create these pods through deletion:kubectl -n tf delete pod tf-vrouter-agent-*
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete the Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica_num>
This section lists the Wireguard known issues with workarounds for the Mirantis OpenStack for Kubernetes release 23.2.
Due to the upstream Calico issue, on clusters with Wireguard enabled, the Wireguard interface on a node may not have the IPv4 address assigned. This leads to broken inter-Pod communication between the affected node and other cluster nodes.
The node is affected if the IP address is missing on the Wireguard interface:
ip a show wireguard.cali
Example of system response:
40: wireguard.cali: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000 link/none
The workaround is to manually restart the calico-node Pod to allocate
the IPv4 address on the Wireguard interface:
docker restart $(docker ps -f "label=name=Calico node" -q)
This section lists the cluster update known issues with workarounds for the Mirantis OpenStack for Kubernetes release 23.2.
During MOSK update to either 23.2 major release or
any patch release of the 23.2 release series, the
openstack-operator-ensure-resources job may get stuck in
the CrashLoopBackOff state with the following error:
Traceback (most recent call last):
File "/usr/local/bin/osctl-ensure-shared-resources", line 8, in <module>
sys.exit(main())
File "/usr/local/lib/python3.8/dist-packages/openstack_controller/cli/ensure_shared_resources.py", line 61, in main
obj.update()
File "/usr/local/lib/python3.8/dist-packages/pykube/objects.py", line 165, in update
self.patch(self.obj, subresource=subresource)
File "/usr/local/lib/python3.8/dist-packages/pykube/objects.py", line 157, in patch
self.api.raise_for_status(r)
File "/usr/local/lib/python3.8/dist-packages/pykube/http.py", line 444, in raise_for_status
raise HTTPError(resp.status_code, payload["message"])
pykube.exceptions.HTTPError: CustomResourceDefinition.apiextensions.k8s.io "redisfailovers.databases.spotahome.com" is invalid: spec.preserveUnknownFields: Invalid value: true: must be false in order to use defaults in the schema
As a workaround, delete the redisfailovers.databases.spotahome.com
CRD from your cluster:
kubectl delete crd redisfailovers.databases.spotahome.com
While updating your cluster, the Instance High Availability service (OpenStack Masakari) may not work as expected.
As a workaround, temporarily disable the service by removing
instance-ha from the service list in the OpenStackDeployment
custom resource.
Release artifacts¶
This section lists the components artifacts of the MOSK 23.2 release that includes binaries, Docker images, and Helm charts.
MOSK 23.2 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20230718165730.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-xena-9f691e3-20220110111511.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-focal-20230730141349 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-focal-20230730141349 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-focal-20230730141349 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-focal-20230730141349 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.12.7-20230623070627 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-focal-20230730141349 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-focal-20230730141349 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-focal-20230730141349 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-focal-20230730141349 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-focal-20230730141349 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-focal-20230730141349 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230730141349 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-focal-20230730141349 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230730124813 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230730124813 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230730124813 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20230718163224 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.20-alpine-20230614113432 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.9-alpine-20230610071256 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230610074056 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.8.0-alpine-20230617191825 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230730124341 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-focal-20230730141349 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-focal-20230730141349 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-focal-20230730141349 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.11-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20230619084330 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20230720054838 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230730124813 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.1-alpine-slim |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20230730124813 |
GPL-2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-focal-20230730141349 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20230730124813 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-focal-20230730141349 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-focal-20230730141349 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-focal-20230730141349 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230730141349 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-focal-20230730141349 |
Apache License 2.0 |
MOSK 23.2 OpenStack Victoria binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20230706155916.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-victoria-20230128063511.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-focal-20230730130947 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-focal-20230730130947 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-focal-20230730130947 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-focal-20230730130947 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.12.7-20230623070627 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-focal-20230730130947 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-focal-20230730130947 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-focal-20230730130947 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-focal-20230730130947 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-focal-20230730130947 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-focal-20230730130947 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-focal-20230730130947 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-focal-20230730130947 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230730124813 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230730124813 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230730124813 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20230718163224 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.20-alpine-20230614113432 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.9-alpine-20230610071256 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230610074056 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.8.0-alpine-20230617191825 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230730124341 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-focal-20230730130947 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-focal-20230730130947 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-focal-20230730130947 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.11-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20230619084330 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20230720054838 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230730124813 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.1-alpine-slim |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20230730124813 |
GPL-2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:victoria-focal-20230730130947 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:victoria-focal-20230730130947 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-focal-20230730124813 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-focal-20230730130947 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-focal-20230730130947 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-focal-20230730130947 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-focal-20230730130947 |
Apache License 2.0 |
MOSK 23.2 OpenStack Helm charts
MOSK 23.2 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.12.4.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.12.4 |
Mirantis Proprietary License |
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:23.2_R21.4.20230810083758 |
Apache License 2.0 |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:23.2_R21.4.20230810083758 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:23.2_R21.4.20230810083758 |
Apache License 2.0 |
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:2.1.17 |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.12 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230622 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20230328121138 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20230622161721 |
Apache License 2.0 |
|
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.4.1 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/jmx-exporter:0.18.0-debian-11-r32 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.5 |
Mirantis Proprietary License |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.3.7 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.16 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.17-mcp |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.8.1-20230425 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.3.8 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:7.0.11-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
|
TF Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:23.2_R21.4.20230810083758 |
Apache License 2.0 |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20230713172410 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20230802163214 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20230328120524 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:23.2_R21.4.20230810083758 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
MOSK 23.2 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20230714023011 |
Mirantis Proprietary License |
tungstenfabric-prometheus-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20230531104437 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the MOSK 23.2 release:
[OpenStack] [33006] Fixed the issue that prevented communication between virtual machines on the same network.
[OpenStack] [34208] Prevented the Masakari API pods from constant restart.
[TF] [32723] Fixed the issue that prevented a compiled vRouter
kmodfrom automatic refreshing with the new kernel.[TF] [32326] Fixed the issue that allowed for unathorized access to the Tungsten Fabric API.
[Ceph] [30635] Fixed the issue with irrelevant error message displaying in the
osd-preparePod during the deployment of Ceph OSDs on removable devices on AMD nodes. Now, the error message clearly states that removable devices with hotplug enabled are not supported for deploying Ceph OSDs.[Ceph] [31630] Fixed the issue that caused the Ceph cluster upgrade to Pacific to be stuck with Rook connection failure.
[Ceph] [31555] Fixed the issue with Ceph finding only 1 out of 2
mgrafter update.[Ceph] [23292] Fixed the issue that caused the failure of the Ceph
rook-operatorwith FIPS kernel.[Update] [27797] Fixed the issue that stopped cluster
kubeconfigfrom working during the MKE minor version update.[Update] [32311] Fixed the issue with the
tf-rabbit-exporterReplicaSet blocking the cluster update.[StackLight] [30867] Fixed the Instance Info panel for RabbitMQ in Grafana.
Update notes¶
This section describes the specific actions you as a Cloud Operator need to complete to accurately plan and successfully perform your Mirantis OpenStack for Kubernetes (MOSK) cluster update to the version 23.2. Consider this information as a supplement to the generic update procedure published in Operations Guide: Update a MOSK cluster.
The MOSK cluster will obtain the newly implemented capabilities automatically with no significant impact on the update procedure.
As part of the update to MOSK 23.2, the following automatic updates of major component versions will take place:
MKE 3.5 with Kubernetes 1.21 to 3.6 with Kubernetes 1.24
Ceph Pacific to Quincy
See also
The update to MOSK 23.2 does not include any version-specific impact on the cluster. To start planning a maintenance window, use the Operations Guide: Update a MOSK cluster standard procedure.
Before updating the cluster, be sure to review the potential issues that may arise during the process and the recommended solutions to address them, as outlined in Cluster update known issues.
While updating your cluster, the Instance High Availability service
(OpenStack Masakari) may not work as expected. Therefore, temporarily
disable the service by removing instance-ha from the service list
in the OpenStackDeployment custom resource.
In the next release series, MOSK will stop supporting Ubuntu 18.04. Therefore, Mirantis highly recommends upgrading an operating system on your cluster machines to Ubuntu 20.04 during the course of the MOSK 23.2 series by rebooting cluster nodes.
It is not mandatory to reboot all machines at once. You can reboot them one by one or in small batches, for example, if the maintenance window is limited in time.
Otherwise, the Cluster release update for the cluster running on Ubuntu 18.04 will become impossible.
For details on distribution upgrade, see Mirantis Container Cloud documentation: Upgrade an operating system distribution.
MOSK supports the OpenStack Victoria version until September, 2023. MOSK 23.2 is the last release version where OpenStack Victoria packages are updated.
If you have not already upgraded your OpenStack version to Yoga, Mirantis highly recommends doing this during the course of the MOSK 23.2 series.
After the update, the notifications from OpenStack become unavailable in StackLight. On an attempt to establish a TCP connection to the RabbitMQ server, the connection is refused with the following error:
Could not establish TCP connection to any of the configured hosts
As a workaround, add the following annotation to
the openstack-rabbitmq-users-credentials secret:
kubectl -n openstack patch secrets openstack-rabbitmq-users-credentials --type='json' -p='[{"op": "add", "path": "/metadata/annotations/foo", "value":"bar"}]'
Security notes¶
In total, since MOSK 23.1 major release, in 23.2, 1611 Common Vulnerabilities and Exposures (CVE) have been fixed: 65 of critical and 1546 of high severity.
Among them, 689 CVEs that are listed in Addressed CVEs - detailed have been fixed since 23.1.4 patch release: 29 of critical and 660 of high severity. The fixes for the rest of CVEs were released with the patch releases of the MOSK 23.1 series.
The full list of the CVEs present in the current Mirantis OpenStack for Kubernetes (MOSK) release is available at the Mirantis Security Portal.
The Addressed CVEs - summary table includes the total number of unique CVEs along with the total number of issues fixed across images.
Severity |
Critical |
High |
Total |
|---|---|---|---|
Unique CVEs |
5 |
64 |
69 |
Total issues across images |
29 |
660 |
689 |
Note
Duplicate CVEs for packages in
the Addressed CVEs - detailed table can mean that they were
discovered in container images with the same names but different tags,
for example, openstack/barbican for Openstack Victoria and Yoga
versions.
Image |
Component name |
CVE |
|---|---|---|
ceph/mcp/ceph-controller |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
ceph/rook |
openssl |
CVE-2022-3786 (High) |
CVE-2022-3602 (High) |
||
CVE-2023-0286 (High) |
||
openssl-libs |
CVE-2022-3602 (High) |
|
CVE-2022-3786 (High) |
||
CVE-2023-0286 (High) |
||
cryptography |
CVE-2023-2650 (High) |
|
general/amqproxy |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
general/external/docker.io/frrouting/frr |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
libcap2 |
CVE-2023-2603 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
general/memcached |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
general/openvswitch |
linux-libc-dev |
CVE-2023-3090 (High) |
CVE-2023-32629 (High) |
||
CVE-2023-3390 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-1380 (High) |
||
CVE-2023-30456 (High) |
||
CVE-2023-31436 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2023-35788 (High) |
||
general/openvswitch-dpdk |
linux-libc-dev |
CVE-2023-35788 (High) |
CVE-2023-1380 (High) |
||
CVE-2023-30456 (High) |
||
CVE-2023-31436 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2023-3090 (High) |
||
CVE-2023-32629 (High) |
||
CVE-2023-3390 (High) |
||
CVE-2023-35001 (High) |
||
mirantis/ceph |
openssl |
CVE-2022-3786 (High) |
CVE-2022-3602 (High) |
||
CVE-2023-0286 (High) |
||
openssl-libs |
CVE-2022-3602 (High) |
|
CVE-2022-3786 (High) |
||
CVE-2023-0286 (High) |
||
python3 |
CVE-2023-24329 (High) |
|
python3-devel |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
mirantis/cephcsi |
openssl |
CVE-2022-3786 (High) |
CVE-2022-3602 (High) |
||
CVE-2023-0286 (High) |
||
openssl-libs |
CVE-2022-3602 (High) |
|
CVE-2022-3786 (High) |
||
CVE-2023-0286 (High) |
||
cryptography |
CVE-2023-2650 (High) |
|
mirantis/fio |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
openstack/aodh |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/barbican |
linux-libc-dev |
CVE-2023-1380 (High) |
CVE-2023-30456 (High) |
||
CVE-2023-31436 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2023-35788 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3567 (High) |
||
CVE-2023-3090 (High) |
||
CVE-2023-32629 (High) |
||
CVE-2023-3390 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-1380 (High) |
||
CVE-2023-30456 (High) |
||
CVE-2023-31436 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2023-3090 (High) |
||
CVE-2023-32629 (High) |
||
CVE-2023-3390 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-35788 (High) |
||
cryptography |
CVE-2023-2650 (High) |
|
sqlparse |
CVE-2023-30608 (High) |
|
openstack/ceilometer |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/cinder |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/designate |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/extra/etcd |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
openstack/extra/kubernetes-entrypoint |
github.com/emicklei/go-restful |
CVE-2022-1996 (Critical) |
golang.org/x/net |
CVE-2022-27664 (High) |
|
CVE-2022-41721 (High) |
||
golang.org/x/text |
CVE-2022-32149 (High) |
|
openstack/extra/nginx |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
openstack/extra/nginx-ingress-controller |
golang.org/x/net |
CVE-2022-41721 (High) |
CVE-2022-27664 (High) |
||
curl |
CVE-2023-28319 (High) |
|
libcurl |
CVE-2023-28319 (High) |
|
libcrypto1.1 |
CVE-2023-2650 (High) |
|
libssl1.1 |
CVE-2023-2650 (High) |
|
openssl |
CVE-2023-2650 (High) |
|
github.com/opencontainers/runc |
CVE-2023-28642 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
nghttp2-libs |
CVE-2023-35945 (High) |
|
openstack/extra/powerdns |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
openstack/extra/redis |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
openstack/extra/strongswan |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
openssl |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
nghttp2-libs |
CVE-2023-35945 (High) |
|
openstack/glance |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/gnocchi |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/heat |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/horizon |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
Django |
CVE-2023-36053 (High) |
|
openstack/ironic |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/ironic-inspector |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/keystone |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/manila |
cryptography |
CVE-2023-2650 (High) |
openstack/masakari |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/masakari-monitors |
cryptography |
CVE-2023-2650 (High) |
openstack/neutron |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/nova |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/octavia |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/openstack-controller |
cryptography |
CVE-2023-2650 (High) |
aiohttp |
CVE-2023-37276 (High) |
|
openstack/openstack-tools |
cryptography |
CVE-2023-2650 (High) |
openstack/panko |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/placement |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
openstack/stepler |
linux-libc-dev |
CVE-2023-1380 (High) |
CVE-2023-30456 (High) |
||
CVE-2023-31436 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3567 (High) |
||
CVE-2023-3090 (High) |
||
CVE-2023-32629 (High) |
||
CVE-2023-3390 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-35788 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-35788 (High) |
||
CVE-2023-3090 (High) |
||
CVE-2023-32629 (High) |
||
CVE-2023-3390 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-1380 (High) |
||
CVE-2023-30456 (High) |
||
CVE-2023-31436 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2023-3567 (High) |
||
cryptography |
CVE-2023-2650 (High) |
|
openstack/tempest |
cryptography |
CVE-2023-2650 (High) |
sqlparse |
CVE-2023-30608 (High) |
|
stacklight/alerta-web |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/alertmanager |
golang.org/x/net |
CVE-2022-41723 (High) |
stacklight/alertmanager-webhook-servicenow |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
openssl-dev |
CVE-2023-2650 (High) |
|
Flask |
CVE-2023-30861 (High) |
|
stacklight/alpine-utils |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/blackbox-exporter |
golang.org/x/net |
CVE-2022-41723 (High) |
stacklight/cadvisor |
libcrypto1.1 |
CVE-2023-2650 (High) |
libssl1.1 |
CVE-2023-2650 (High) |
|
stacklight/cerebro |
org.xerial:sqlite-jdbc |
CVE-2023-32697 (Critical) |
com.fasterxml.jackson.core:jackson-databind |
CVE-2021-46877 (High) |
|
CVE-2022-42003 (High) |
||
CVE-2022-42004 (High) |
||
CVE-2020-36518 (High) |
||
libssl1.1 |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
openssl |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
stacklight/fluentd |
libssl-dev |
CVE-2023-0464 (High) |
CVE-2023-2650 (High) |
||
libssl1.1 |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
openssl |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
stacklight/grafana |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/grafana-image-renderer |
tough-cookie |
CVE-2023-26136 (Critical) |
stacklight/jmx-exporter |
libssl1.1 |
CVE-2023-0464 (High) |
CVE-2023-2650 (High) |
||
libncurses6 |
CVE-2022-29458 (High) |
|
libncursesw6 |
CVE-2022-29458 (High) |
|
libtinfo6 |
CVE-2022-29458 (High) |
|
ncurses-base |
CVE-2022-29458 (High) |
|
stacklight/k8s-sidecar |
libcrypto1.1 |
CVE-2023-2650 (High) |
libssl1.1 |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/kubectl |
libssl1.1 |
CVE-2023-0464 (High) |
CVE-2023-2650 (High) |
||
openssl |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
stacklight/metric-collector |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/metricbeat |
python |
CVE-2023-24329 (High) |
python-libs |
CVE-2023-24329 (High) |
|
stacklight/node-exporter |
golang.org/x/net |
CVE-2022-41723 (High) |
stacklight/opensearch |
org.codelibs.elasticsearch.module:ingest-common |
CVE-2015-5377 (Critical) |
CVE-2019-7611 (High) |
||
org.xerial:sqlite-jdbc |
CVE-2023-32697 (Critical) |
|
org.springframework:spring-core |
CVE-2023-20860 (High) |
|
ncurses |
CVE-2023-29491 (High) |
|
ncurses-base |
CVE-2023-29491 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
stacklight/opensearch-dashboards |
tough-cookie |
CVE-2023-26136 (Critical) |
debug |
CVE-2015-8315 (High) |
|
decode-uri-component |
CVE-2022-38900 (High) |
|
glob-parent |
CVE-2021-35065 (High) |
|
ncurses |
CVE-2023-29491 (High) |
|
ncurses-base |
CVE-2023-29491 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
stacklight/prometheus |
github.com/docker/docker |
CVE-2023-28840 (High) |
golang.org/x/net |
CVE-2022-41723 (High) |
|
stacklight/prometheus-es-exporter |
libcrypto1.1 |
CVE-2023-2650 (High) |
libssl1.1 |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/prometheus-libvirt-exporter |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/prometheus-patroni-exporter |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/prometheus-relay |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/sf-notifier |
libcrypto1.1 |
CVE-2023-2650 (High) |
libssl1.1 |
CVE-2023-2650 (High) |
|
openssl-dev |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/sf-reporter |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/spilo |
PyJWT |
CVE-2022-29217 (High) |
golang.org/x/net |
CVE-2022-27664 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
gopkg.in/yaml.v3 |
CVE-2022-28948 (High) |
|
stacklight/stacklight-toolkit |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
ncurses-libs |
CVE-2023-29491 (High) |
|
ncurses-terminfo-base |
CVE-2023-29491 (High) |
|
stacklight/telegraf |
libssl1.1 |
CVE-2023-0464 (High) |
CVE-2023-2650 (High) |
||
openssl |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
stacklight/telemeter |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/tungstenfabric-prometheus-exporter |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
stacklight/yq |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
tungsten-operator/casskop |
libssl1.1 |
CVE-2023-0464 (High) |
CVE-2023-2650 (High) |
||
openssl |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
tungsten/cass-config-builder |
python-unversioned-command |
CVE-2023-24329 (High) |
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
java-1.8.0-openjdk-headless |
CVE-2023-21930 (High) |
|
tungsten/cassandra |
libssl1.1 |
CVE-2023-0286 (High) |
openssl |
CVE-2023-0286 (High) |
|
tungsten/cassandra-bootstrap |
libssl1.1 |
CVE-2023-0464 (High) |
CVE-2023-2650 (High) |
||
openssl |
CVE-2023-0464 (High) |
|
CVE-2023-2650 (High) |
||
libtinfo6 |
CVE-2022-29458 (High) |
|
ncurses-base |
CVE-2022-29458 (High) |
|
tungsten/contrail-analytics-alarm-gen |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-analytics-api |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-analytics-collector |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-analytics-query-engine |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-analytics-snmp-collector |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-analytics-snmp-topology |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-controller-config-api |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
openssh |
CVE-2023-38408 (High) |
|
openssh-clients |
CVE-2023-38408 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-controller-config-devicemgr |
bottle |
CVE-2022-31799 (Critical) |
git |
CVE-2023-25652 (High) |
|
CVE-2023-29007 (High) |
||
CVE-2022-41903 (High) |
||
CVE-2022-23521 (High) |
||
perl-Git |
CVE-2022-23521 (High) |
|
CVE-2022-41903 (High) |
||
CVE-2023-29007 (High) |
||
CVE-2023-25652 (High) |
||
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
openssh |
CVE-2023-38408 (High) |
|
openssh-clients |
CVE-2023-38408 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-controller-config-dnsmasq |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-controller-config-schema |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
openssh |
CVE-2023-38408 (High) |
|
openssh-clients |
CVE-2023-38408 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-controller-config-svcmonitor |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
openssh |
CVE-2023-38408 (High) |
|
openssh-clients |
CVE-2023-38408 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-controller-control-control |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-controller-control-dns |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-controller-control-named |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-controller-webui-job |
tough-cookie |
CVE-2023-26136 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
ansi-regex |
CVE-2021-3807 (High) |
|
decode-uri-component |
CVE-2022-38900 (High) |
|
minimatch |
CVE-2022-3517 (High) |
|
qs |
CVE-2022-24999 (High) |
|
CVE-2017-1000048 (High) |
||
redis |
CVE-2021-29469 (High) |
|
trim-newlines |
CVE-2021-33623 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-controller-webui-web |
tough-cookie |
CVE-2023-26136 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
ansi-regex |
CVE-2021-3807 (High) |
|
decode-uri-component |
CVE-2022-38900 (High) |
|
minimatch |
CVE-2022-3517 (High) |
|
qs |
CVE-2022-24999 (High) |
|
CVE-2017-1000048 (High) |
||
redis |
CVE-2021-29469 (High) |
|
trim-newlines |
CVE-2021-33623 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-node-init |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-nodemgr |
bottle |
CVE-2022-31799 (Critical) |
github.com/emicklei/go-restful |
CVE-2022-1996 (Critical) |
|
golang.org/x/net |
CVE-2022-27664 (High) |
|
CVE-2021-33194 (High) |
||
CVE-2022-27664 (High) |
||
CVE-2022-41721 (High) |
||
CVE-2022-27664 (High) |
||
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
github.com/opencontainers/runc |
CVE-2023-28642 (High) |
|
pip |
CVE-2018-20225 (High) |
|
golang.org/x/text |
CVE-2022-32149 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-provisioner |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-tools |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
sudo |
CVE-2023-22809 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
openssh |
CVE-2023-38408 (High) |
|
openssh-clients |
CVE-2023-38408 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-vrouter-agent |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
sudo |
CVE-2023-22809 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-export-libs |
CVE-2023-2828 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-vrouter-agent-dpdk |
bottle |
CVE-2022-31799 (Critical) |
python |
CVE-2023-24329 (High) |
|
python-devel |
CVE-2023-24329 (High) |
|
python-libs |
CVE-2023-24329 (High) |
|
python3 |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
openssl |
CVE-2023-0286 (High) |
|
openssl-libs |
CVE-2023-0286 (High) |
|
sudo |
CVE-2023-22809 (High) |
|
c-ares |
CVE-2023-32067 (High) |
|
nss |
CVE-2023-0767 (High) |
|
nss-sysinit |
CVE-2023-0767 (High) |
|
nss-tools |
CVE-2023-0767 (High) |
|
bind-export-libs |
CVE-2023-2828 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
pip |
CVE-2018-20225 (High) |
|
wheel |
CVE-2022-40898 (High) |
|
tungsten/contrail-vrouter-kernel-build-init |
kernel-headers |
CVE-2023-0461 (High) |
CVE-2022-3564 (High) |
||
tungsten/cp-kafka |
python39 |
CVE-2023-24329 (High) |
python39-libs |
CVE-2023-24329 (High) |
|
platform-python |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
tungsten/redis |
libcrypto3 |
CVE-2023-2650 (High) |
libssl3 |
CVE-2023-2650 (High) |
|
tungsten/tf-cli |
kernel-headers |
CVE-2023-0461 (High) |
CVE-2022-3564 (High) |
||
python39 |
CVE-2023-24329 (High) |
|
python39-devel |
CVE-2023-24329 (High) |
|
python39-libs |
CVE-2023-24329 (High) |
|
platform-python |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
bind-libs |
CVE-2023-2828 (High) |
|
bind-libs-lite |
CVE-2023-2828 (High) |
|
bind-license |
CVE-2023-2828 (High) |
|
bind-utils |
CVE-2023-2828 (High) |
|
python3-bind |
CVE-2023-2828 (High) |
|
tungsten/tungsten-pytest |
python39 |
CVE-2023-24329 (High) |
python39-libs |
CVE-2023-24329 (High) |
|
platform-python |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
cryptography |
CVE-2023-2650 (High) |
23.2.1 patch¶
The patch release notes contain the list of artifacts and Common Vulnerabilities and Exposures (CVE) fixes for the MOSK 23.2.1 patch released on August 29, 2023.
For the list of enhancements and bug fixes that relate to Mirantis Container Cloud, refer to the Mirantis Container Cloud Release notes.
Release date |
August 29, 2023 |
|---|---|
Scope |
Patch |
Cluster release |
15.0.2 |
OpenStack Operator |
0.13.10 |
Tungsten Fabric Operator |
0.12.4 |
Release artifacts¶
This section lists the components artifacts of the MOSK 23.2.1 release that includes binaries, Docker images, and Helm charts.
MOSK 23.2.1 OpenStack Victoria binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20230706155916.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-victoria-20230128063511.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-focal-20230821170130 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-focal-20230821170130 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-focal-20230821170130 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-focal-20230821170130 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.12.7-20230623070627 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-focal-20230821170130 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-focal-20230821170130 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-focal-20230821170130 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-focal-20230821170130 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-focal-20230821170130 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-focal-20230821170130 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-focal-20230821170130 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-focal-20230821170130 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230730124813 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230730124813 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230730124813 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20230821170130 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.20-alpine-20230614113432 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.9-alpine-20230610071256 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230817061604 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.8.0-alpine-20230617191825 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230730124341 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-focal-20230821170130 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-focal-20230821170130 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-focal-20230821170130 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.11-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20230619084330 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20230720054838 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230730124813 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.1-alpine-slim |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:victoria-focal-20230821170130 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:victoria-focal-20230821170130 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-focal-20230730124813 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-focal-20230821170130 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-focal-20230821170130 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-focal-20230821170130 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-focal-20230821170130 |
Apache License 2.0 |
MOSK 23.2.1 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20230718165730.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-xena-9f691e3-20220110111511.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-focal-20230821170130 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-focal-20230821170130 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-focal-20230821170130 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-focal-20230821170130 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.12.7-20230623070627 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-focal-20230821170130 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-focal-20230821170130 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-focal-20230821170130 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-focal-20230821170130 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-focal-20230821170130 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-focal-20230821170130 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230821170130 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-focal-20230821170130 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230730124813 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230730124813 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230730124813 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20230821170130 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.20-alpine-20230614113432 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.9-alpine-20230610071256 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230817061604 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.8.0-alpine-20230617191825 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230730124341 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-focal-20230821170130 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-focal-20230821170130 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-focal-20230821170130 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.11-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20230619084330 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20230720054838 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230730124813 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.1-alpine-slim |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-focal-20230821170130 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20230730124813 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-focal-20230821170130 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-focal-20230821170130 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-focal-20230821170130 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230821170130 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-focal-20230821170130 |
Apache License 2.0 |
MOSK 23.2.1 OpenStack Helm charts
MOSK 23.2.1 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.12.4.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.12.4 |
Mirantis Proprietary License |
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:23.2_R21.4.20230810083758 |
Apache License 2.0 |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:23.2_R21.4.20230810083758 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:23.2_R21.4.20230810083758 |
Apache License 2.0 |
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:2.1.17 |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.12 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230622 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20230328121138 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20230622161721 |
Apache License 2.0 |
|
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.4.1 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/jmx-exporter:0.18.0-debian-11-r32 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.5 |
Mirantis Proprietary License |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.3.7 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.16 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.17-mcp |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.8.1-20230425 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.3.8 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:7.0.11-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
|
TF Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:23.2_R21.4.20230810083758 |
Apache License 2.0 |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20230713172410 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20230802163214 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20230328120524 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:23.2_R21.4.20230810083758 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
MOSK 23.2.1 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20230811023010 |
Mirantis Proprietary License |
tungstenfabric-prometheus-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20230531104437 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Security notes¶
In total, in the MOSK 23.2.1 release, 43 Common Vulnerabilities and Exposures (CVE) with high severity have been fixed.
The full list of the CVEs present in the current MOSK release is available at the Mirantis Security Portal.
Severity |
Critical |
High |
Total |
|---|---|---|---|
Unique CVEs |
0 |
10 |
10 |
Total issues across images |
0 |
43 |
43 |
Image |
Component name |
CVE |
|---|---|---|
ceph/rook |
python3 |
CVE-2023-24329 (High) |
python3-devel |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
cryptography |
CVE-2023-38325 (High) |
|
mirantis/ceph |
cryptography |
CVE-2023-2650 (High) |
mirantis/cephcsi |
python3 |
CVE-2023-24329 (High) |
python3-devel |
CVE-2023-24329 (High) |
|
python3-libs |
CVE-2023-24329 (High) |
|
cryptography |
CVE-2023-38325 (High) |
|
openstack/aodh |
cryptography |
CVE-2023-38325 (High) |
openstack/barbican |
cryptography |
CVE-2023-38325 (High) |
openstack/ceilometer |
cryptography |
CVE-2023-38325 (High) |
openstack/cinder |
cryptography |
CVE-2023-38325 (High) |
openstack/designate |
cryptography |
CVE-2023-38325 (High) |
openstack/extra/powerdns |
libpq |
CVE-2023-39417 (High) |
openstack/glance |
cryptography |
CVE-2023-38325 (High) |
openstack/gnocchi |
cryptography |
CVE-2023-38325 (High) |
openstack/heat |
cryptography |
CVE-2023-38325 (High) |
openstack/horizon |
cryptography |
CVE-2023-38325 (High) |
openstack/ironic |
cryptography |
CVE-2023-38325 (High) |
openstack/ironic-inspector |
cryptography |
CVE-2023-38325 (High) |
openstack/keystone |
cryptography |
CVE-2023-38325 (High) |
openstack/manila |
cryptography |
CVE-2023-38325 (High) |
openstack/masakari |
cryptography |
CVE-2023-38325 (High) |
openstack/masakari-monitors |
cryptography |
CVE-2023-38325 (High) |
openstack/neutron |
cryptography |
CVE-2023-38325 (High) |
openstack/nova |
cryptography |
CVE-2023-38325 (High) |
openstack/octavia |
cryptography |
CVE-2023-38325 (High) |
openstack/openstack-tools |
cryptography |
CVE-2023-38325 (High) |
openstack/panko |
cryptography |
CVE-2023-38325 (High) |
openstack/placement |
cryptography |
CVE-2023-38325 (High) |
openstack/tempest |
cryptography |
CVE-2023-38325 (High) |
stacklight/alpine-utils |
nghttp2-libs |
CVE-2023-35945 (High) |
stacklight/cadvisor |
github.com/docker/docker |
CVE-2023-28840 (High) |
github.com/opencontainers/runc |
CVE-2023-28642 (High) |
|
golang.org/x/net |
CVE-2022-41723 (High) |
|
stacklight/grafana |
nghttp2-libs |
CVE-2023-35945 (High) |
stacklight/metricbeat |
bind-license |
CVE-2023-2828 (High) |
stacklight/opensearch |
libnghttp2 |
CVE-2023-35945 (High) |
stacklight/opensearch-dashboards |
libnghttp2 |
CVE-2023-35945 (High) |
stacklight/prometheus-libvirt-exporter |
nghttp2-libs |
CVE-2023-35945 (High) |
stacklight/stacklight-toolkit |
nghttp2-libs |
CVE-2023-35945 (High) |
stacklight/telegraf |
github.com/snowflakedb/gosnowflake |
CVE-2023-34231 (High) |
Addressed issues¶
The following issues have been addressed in the MOSK 23.2.1 release:
[TF] [30738] Fixed the issue that caused the
tf-vrouter-agentreadiness probe failure (No Configuration for self).
Cluster update known issues¶
This section lists the cluster update known issues with workarounds for the Mirantis OpenStack for Kubernetes release 23.2.1.
During MOSK update to either 23.2 major release or
any patch release of the 23.2 release series, the
openstack-operator-ensure-resources job may get stuck in
the CrashLoopBackOff state with the following error:
Traceback (most recent call last):
File "/usr/local/bin/osctl-ensure-shared-resources", line 8, in <module>
sys.exit(main())
File "/usr/local/lib/python3.8/dist-packages/openstack_controller/cli/ensure_shared_resources.py", line 61, in main
obj.update()
File "/usr/local/lib/python3.8/dist-packages/pykube/objects.py", line 165, in update
self.patch(self.obj, subresource=subresource)
File "/usr/local/lib/python3.8/dist-packages/pykube/objects.py", line 157, in patch
self.api.raise_for_status(r)
File "/usr/local/lib/python3.8/dist-packages/pykube/http.py", line 444, in raise_for_status
raise HTTPError(resp.status_code, payload["message"])
pykube.exceptions.HTTPError: CustomResourceDefinition.apiextensions.k8s.io "redisfailovers.databases.spotahome.com" is invalid: spec.preserveUnknownFields: Invalid value: true: must be false in order to use defaults in the schema
As a workaround, delete the redisfailovers.databases.spotahome.com
CRD from your cluster:
kubectl delete crd redisfailovers.databases.spotahome.com
While updating your cluster, the Instance High Availability service (OpenStack Masakari) may not work as expected.
As a workaround, temporarily disable the service by removing
instance-ha from the service list in the OpenStackDeployment
custom resource.
Learn more about the release cadence
23.2.2 patch¶
The patch release notes contain the list of artifacts and Common Vulnerabilities and Exposures (CVE) fixes for the MOSK 23.2.2 patch released on September 14, 2023.
For the list of enhancements and bug fixes that relate to Mirantis Container Cloud, refer to the Mirantis Container Cloud Release notes.
Release date |
September 14, 2023 |
|---|---|
Scope |
Patch |
Cluster release |
15.0.3 |
OpenStack Operator |
0.13.11 |
Tungsten Fabric Operator |
0.12.5 |
Addressed issues¶
The following issues have been addressed in the MOSK 23.2.2 release:
[34342] Resolved the issue that caused a failure of the etcd pods due to the simultaneous deployment of several pods on a single node. To ensure that etcd pods are always placed on different nodes, MOSK now deploys etcd with the
requiredDuringSchedulingIgnoredDuringExecutionpolicy.[34276] Resolved the issue that caused the presence of stale namespaces if the agent responsible for hosting the network was modified while the agent was offline.
Release artifacts¶
This section lists the components artifacts of the MOSK 23.2.2 release that includes binaries, Docker images, and Helm charts.
MOSK 23.2.2 OpenStack Victoria binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20230706155916.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-victoria-20230128063511.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-focal-20230830092445 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-focal-20230830092445 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-focal-20230830092445 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-focal-20230830092445 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.12.7-20230623070627 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-focal-20230830092445 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-focal-20230830092445 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-focal-20230830092445 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-focal-20230830092445 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-focal-20230830092445 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-focal-20230830092445 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-focal-20230830092445 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-focal-20230830092445 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230730124813 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230830072226 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230830072225 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20230830092445 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.20-alpine-20230614113432 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.9-alpine-20230610071256 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230817061604 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.8.0-alpine-20230617191825 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230730124341 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-focal-20230830092445 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-focal-20230830092445 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-focal-20230830092445 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.11-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20230619084330 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20230720054838 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230730124813 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.1-alpine-slim |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:victoria-focal-20230830092445 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:victoria-focal-20230830092445 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-focal-20230830072225 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-focal-20230830092445 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-focal-20230830092445 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-focal-20230830092445 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-focal-20230830092445 |
Apache License 2.0 |
MOSK 23.2.2 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20230718165730.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-xena-9f691e3-20220110111511.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-focal-20230830092445 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-focal-20230830092445 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-focal-20230830092445 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-focal-20230830092445 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.12.7-20230623070627 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-focal-20230830092445 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-focal-20230830092445 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-focal-20230830092445 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-focal-20230830092445 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-focal-20230830092445 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-focal-20230830092445 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230830092445 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-focal-20230830092445 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230730124813 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230830072226 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230830072225 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20230830092445 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.20-alpine-20230614113432 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.9-alpine-20230610071256 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230817061604 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.8.0-alpine-20230617191825 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230730124341 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-focal-20230830092445 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-focal-20230830092445 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-focal-20230830092445 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.11-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20230619084330 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20230720054838 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230730124813 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.1-alpine-slim |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-focal-20230830092445 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20230830072225 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-focal-20230830092445 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-focal-20230830092445 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-focal-20230830092445 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230830092445 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-focal-20230830092445 |
Apache License 2.0 |
MOSK 23.2.2 OpenStack Helm charts
MOSK 23.2.2 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.12.5.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.12.5 |
Mirantis Proprietary License |
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:23.2_R21.4.20230810083758 |
Apache License 2.0 |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:23.2_R21.4.20230810083758 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:23.2_R21.4.20230810083758 |
Apache License 2.0 |
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:2.1.17 |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.12 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230622 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20230328121138 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20230830113546 |
Apache License 2.0 |
|
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.4.1 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/jmx-exporter:0.18.0-debian-11-r32 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.5 |
Mirantis Proprietary License |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.3.7 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.16 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.17-mcp |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.8.1-20230425 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.3.8 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:7.0.11-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
|
TF Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:23.2_R21.4.20230810083758 |
Apache License 2.0 |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20230713172410 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20230828085831 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20230328120524 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:23.2_R21.4.20230810083758 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
MOSK 23.2.2 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20230825023009 |
Mirantis Proprietary License |
tungstenfabric-prometheus-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20230531104437 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Security notes¶
In total, in the MOSK 23.2.2 release, 72 Common Vulnerabilities and Exposures (CVE) have been fixed: 8 of critical and 64 of high severity.
The full list of the CVEs present in the current MOSK release is available at the Mirantis Security Portal.
Severity |
Critical |
High |
Total |
|---|---|---|---|
Unique CVEs |
2 |
19 |
21 |
Total issues across images |
8 |
64 |
72 |
Image |
Component name |
CVE |
|---|---|---|
general/openvswitch |
linux-libc-dev |
CVE-2023-20593 (High) |
CVE-2023-3609 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-3776 (High) |
||
general/openvswitch-dpdk |
linux-libc-dev |
CVE-2023-20593 (High) |
CVE-2023-3609 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-3776 (High) |
||
iam/keycloak-gatekeeper |
golang.org/x/crypto |
CVE-2021-43565 (High) |
CVE-2020-29652 (High) |
||
CVE-2022-27191 (High) |
||
golang.org/x/net |
CVE-2021-33194 (High) |
|
CVE-2022-27664 (High) |
||
golang.org/x/text |
CVE-2021-38561 (High) |
|
CVE-2022-32149 (High) |
||
github.com/prometheus/client_golang |
CVE-2022-21698 (High) |
|
openstack/aodh |
grpcio |
CVE-2023-33953 (High) |
CVE-2023-33953 (High) |
||
openstack/barbican |
linux-libc-dev |
CVE-2023-20593 (High) |
CVE-2023-3609 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2023-20593 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-3776 (High) |
||
openstack/ceilometer |
grpcio |
CVE-2023-33953 (High) |
CVE-2023-33953 (High) |
||
openstack/designate |
Werkzeug |
CVE-2022-29361 (Critical) |
CVE-2023-25577 (High) |
||
Flask |
CVE-2023-30861 (High) |
|
openstack/gnocchi |
Werkzeug |
CVE-2022-29361 (Critical) |
CVE-2023-25577 (High) |
||
grpcio |
CVE-2023-33953 (High) |
|
CVE-2023-33953 (High) |
||
openstack/ironic-inspector |
Werkzeug |
CVE-2022-29361 (Critical) |
CVE-2023-25577 (High) |
||
Flask |
CVE-2023-30861 (High) |
|
openstack/keystone |
Werkzeug |
CVE-2022-29361 (Critical) |
CVE-2023-25577 (High) |
||
Flask |
CVE-2023-30861 (High) |
|
openstack/octavia |
Werkzeug |
CVE-2022-29361 (Critical) |
CVE-2023-25577 (High) |
||
Flask |
CVE-2023-30861 (High) |
|
openstack/panko |
grpcio |
CVE-2023-33953 (High) |
openstack/stepler |
linux-libc-dev |
CVE-2023-20593 (High) |
CVE-2023-3609 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2023-20593 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-3776 (High) |
||
cryptography |
CVE-2023-38325 (High) |
|
CVE-2023-38325 (High) |
||
scale/psql-client |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
libpq |
CVE-2023-39417 (High) |
|
postgresql13-client |
CVE-2023-39417 (High) |
|
stacklight/alerta-web |
grpcio |
CVE-2023-33953 (High) |
libpq |
CVE-2023-39417 (High) |
|
postgresql15-client |
CVE-2023-39417 (High) |
|
stacklight/pgbouncer |
libpq |
CVE-2023-39417 (High) |
postgresql-client |
CVE-2023-39417 (High) |
|
tungsten/cass-config-builder |
cups-libs |
CVE-2023-32360 (High) |
tungsten/tf-cli |
dnf-plugin-subscription-manager |
CVE-2023-3899 (High) |
python3-cloud-what |
CVE-2023-3899 (High) |
|
python3-subscription-manager-rhsm |
CVE-2023-3899 (High) |
|
python3-syspurpose |
CVE-2023-3899 (High) |
|
subscription-manager |
CVE-2023-3899 (High) |
|
subscription-manager-rhsm-certificates |
CVE-2023-3899 (High) |
Cluster update known issues¶
This section lists the cluster update known issues with workarounds for the Mirantis OpenStack for Kubernetes release 23.2.2.
During the update, you may encounter the issue that causes a failure of the etcd pods due to the simultaneous deployment of several pods on a single node.
The workaround is to remove the PVC for one etcd pod.
During MOSK update to either 23.2 major release or
any patch release of the 23.2 release series, the
openstack-operator-ensure-resources job may get stuck in
the CrashLoopBackOff state with the following error:
Traceback (most recent call last):
File "/usr/local/bin/osctl-ensure-shared-resources", line 8, in <module>
sys.exit(main())
File "/usr/local/lib/python3.8/dist-packages/openstack_controller/cli/ensure_shared_resources.py", line 61, in main
obj.update()
File "/usr/local/lib/python3.8/dist-packages/pykube/objects.py", line 165, in update
self.patch(self.obj, subresource=subresource)
File "/usr/local/lib/python3.8/dist-packages/pykube/objects.py", line 157, in patch
self.api.raise_for_status(r)
File "/usr/local/lib/python3.8/dist-packages/pykube/http.py", line 444, in raise_for_status
raise HTTPError(resp.status_code, payload["message"])
pykube.exceptions.HTTPError: CustomResourceDefinition.apiextensions.k8s.io "redisfailovers.databases.spotahome.com" is invalid: spec.preserveUnknownFields: Invalid value: true: must be false in order to use defaults in the schema
As a workaround, delete the redisfailovers.databases.spotahome.com
CRD from your cluster:
kubectl delete crd redisfailovers.databases.spotahome.com
While updating your cluster, the Instance High Availability service (OpenStack Masakari) may not work as expected.
As a workaround, temporarily disable the service by removing
instance-ha from the service list in the OpenStackDeployment
custom resource.
Learn more about the release cadence
23.2.3 patch¶
The patch release notes contain the list of artifacts and Common Vulnerabilities and Exposures (CVE) fixes as well as description of the fixed product issues for the MOSK 23.2.3 patch released on September 26, 2023.
For the list of enhancements and bug fixes that relate to Mirantis Container Cloud, refer to the Mirantis Container Cloud Release notes.
Release date |
September 26, 2023 |
|---|---|
Scope |
Patch |
Cluster release |
15.0.4 |
OpenStack Operator |
0.13.12 |
Tungsten Fabric Operator |
0.12.6 |
Addressed issues¶
The following issues have been addressed in the MOSK 23.2.3 release:
[31155] Resolved the issue that caused the OpenStack Redis operator CPU throttling in StackLight.
[34978] Resolved the issue that caused the Tungsten Fabric Redis operator to crash due to the upcoming MKE version update.
Release artifacts¶
This section lists the components artifacts of the MOSK 23.2.3 release that includes binaries, Docker images, and Helm charts.
MOSK 23.2.3 OpenStack Victoria binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20230706155916.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-victoria-20230128063511.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-focal-20230912131036 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-focal-20230912131036 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-focal-20230912131036 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-focal-20230912131036 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.12.9 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-focal-20230912131036 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-focal-20230912131036 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-focal-20230912131036 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-focal-20230912131036 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-focal-20230912131036 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-focal-20230912131036 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-focal-20230912131036 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-focal-20230912131036 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230730124813 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230912122504 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230912122503 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20230913143832 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.21-alpine-20230913050002 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.9-alpine-20230912131525 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230817061604 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.8.2-alpine-20230912142938 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230912121635 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-focal-20230912131036 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-focal-20230912131036 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-focal-20230912131036 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/tungsten/redis:7.2.1-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20230619084330 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20230720054838 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230912122503 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.1-alpine-slim |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:victoria-focal-20230912131036 |
n/a |
placement |
mirantis.azurecr.io/openstack/placement:victoria-focal-20230912131036 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-focal-20230912122503 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-focal-20230912131036 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-focal-20230912131036 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-focal-20230912131036 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-focal-20230912131036 |
Apache License 2.0 |
MOSK 23.2.3 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20230718165730.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-xena-9f691e3-20220110111511.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-focal-20230913143832 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-focal-20230913143832 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-focal-20230913143832 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-focal-20230913143832 |
Apache License 2.0 |
cloudprober |
mirantis.azurecr.io/openstack/extra/cloudprober:v0.12.9 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-focal-20230913143832 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-focal-20230913143832 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-focal-20230913143832 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-focal-20230913143832 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-focal-20230913143832 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-focal-20230913143832 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230913143832 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-focal-20230913143832 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230730124813 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230912122504 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230912122503 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20230913143832 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-5359171-20230810125608 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:v1.6.21-alpine-20230913050002 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.9-alpine-20230912131525 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230817061604 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.8.2-alpine-20230912142938 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-fipster-20230725114156 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.14-focal-20230912121635 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-focal-20230913143832 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-focal-20230913143832 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-focal-20230913143832 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/tungsten/redis:7.2.1-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1-20230619084330 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20230720054838 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230912122503 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.25.1-alpine-slim |
Apache License 2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-focal-20230913143832 |
n/a |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20230913183155 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-focal-20230913143832 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-focal-20230913143832 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-focal-20230913143832 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230913143832 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-focal-20230913143832 |
Apache License 2.0 |
MOSK 23.2.3 OpenStack Helm charts
MOSK 23.2.3 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.12.6.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.12.6 |
Mirantis Proprietary License |
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:23.2-r21.4.20230913134453 |
Apache License 2.0 |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:23.2-r21.4.20230913134453 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:23.2-r21.4.20230913134453 |
Apache License 2.0 |
|
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:23.2-r21.4.20230913134453 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:23.2-r21.4.20230913134453 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:23.2-r21.4.20230913134453 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:23.2-r21.4.20230913134453 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:23.2-r21.4.20230913134453 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:23.2-r21.4.20230913134453 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:23.2-r21.4.20230913134453 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:23.2-r21.4.20230913134453 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:23.2-r21.4.20230913134453 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:23.2-r21.4.20230913134453 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:23.2-r21.4.20230913134453 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:23.2-r21.4.20230913134453 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:23.2-r21.4.20230913134453 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:23.2-r21.4.20230913134453 |
Apache License 2.0 |
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:23.2_R21.4.20230810083758 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:23.2_R21.4.20230810083758 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:2.1.17 |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.12 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230622 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20230328121138 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20230830113546 |
Apache License 2.0 |
|
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.4.1 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/jmx-exporter:0.18.0-debian-11-r32 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.5 |
Mirantis Proprietary License |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.3.8 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.16 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.17-mcp |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.8.1-20230425 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.3.9 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:7.2.1-alpine3.18 |
BSD 3-Clause “New” or “Revised” License |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
|
TF Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:23.2-r21.4.20230913134453 |
Apache License 2.0 |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20230915094303 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20230828085831 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20230328120524 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:23.2-r21.4.20230913134453 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
MOSK 23.2.3 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20230915023013 |
Mirantis Proprietary License |
tungstenfabric-prometheus-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20230912105027 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Security notes¶
In total, in the MOSK 23.2.3 release, 331 Common Vulnerabilities and Exposures (CVE) have been fixed: 39 of critical and 292 of high severity.
The full list of the CVEs present in the current MOSK release is available at the Mirantis Security Portal.
Severity |
Critical |
High |
Total |
|---|---|---|---|
Unique CVEs |
1 |
18 |
19 |
Total issues across images |
39 |
292 |
331 |
Image |
Component name |
CVE |
|---|---|---|
core/external/nginx |
libwebp |
CVE-2023-4863 (High) |
core/frontend |
libwebp |
CVE-2023-4863 (High) |
general/memcached |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
lcm/kubernetes/openstack-cloud-controller-manager-amd64 |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
lcm/registry |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
openstack/extra/cloudprober |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
openstack/extra/etcd |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
openstack/extra/nginx-ingress-controller |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
openstack/extra/redis |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
openstack/horizon |
Django |
CVE-2023-41164 (High) |
scale/curl-jq |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
stacklight/alertmanager-webhook-servicenow |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
stacklight/grafana-image-renderer |
libwebp |
CVE-2023-4863 (High) |
stacklight/ironic-prometheus-exporter |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
stacklight/sf-reporter |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
stacklight/tungstenfabric-prometheus-exporter |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
|
tungsten/contrail-analytics-alarm-gen |
kernel-headers |
CVE-2022-1012 (High) |
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
CVE-2023-35788 (High) |
||
tungsten/contrail-analytics-api |
kernel-headers |
CVE-2022-1012 (High) |
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
CVE-2023-35788 (High) |
||
tungsten/contrail-analytics-collector |
kernel-headers |
CVE-2023-35788 (High) |
CVE-2022-1012 (High) |
||
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
tungsten/contrail-analytics-query-engine |
kernel-headers |
CVE-2023-35788 (High) |
CVE-2022-1012 (High) |
||
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
tungsten/contrail-analytics-snmp-collector |
kernel-headers |
CVE-2022-1012 (High) |
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
CVE-2023-35788 (High) |
||
tungsten/contrail-analytics-snmp-topology |
kernel-headers |
CVE-2022-1012 (High) |
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
CVE-2023-35788 (High) |
||
tungsten/contrail-controller-config-api |
kernel-headers |
CVE-2022-1012 (High) |
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
CVE-2023-35788 (High) |
||
tungsten/contrail-controller-config-devicemgr |
kernel-headers |
CVE-2022-1012 (High) |
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
CVE-2023-35788 (High) |
||
tungsten/contrail-controller-config-schema |
kernel-headers |
CVE-2023-35788 (High) |
CVE-2022-1012 (High) |
||
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
tungsten/contrail-controller-config-svcmonitor |
kernel-headers |
CVE-2023-35788 (High) |
CVE-2022-1012 (High) |
||
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
tungsten/contrail-controller-control-control |
kernel-headers |
CVE-2022-1012 (High) |
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
CVE-2023-35788 (High) |
||
tungsten/contrail-controller-control-dns |
kernel-headers |
CVE-2023-35788 (High) |
CVE-2022-1012 (High) |
||
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
tungsten/contrail-controller-control-named |
kernel-headers |
CVE-2023-35788 (High) |
CVE-2022-1012 (High) |
||
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
tungsten/contrail-controller-webui-job |
kernel-headers |
CVE-2023-35788 (High) |
CVE-2022-1012 (High) |
||
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
tungsten/contrail-controller-webui-web |
kernel-headers |
CVE-2022-1012 (High) |
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
CVE-2023-35788 (High) |
||
tungsten/contrail-nodemgr |
kernel-headers |
CVE-2023-35788 (High) |
CVE-2022-1012 (High) |
||
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
tungsten/contrail-provisioner |
kernel-headers |
CVE-2022-1012 (High) |
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
CVE-2023-35788 (High) |
||
tungsten/contrail-tools |
kernel-headers |
CVE-2023-35788 (High) |
CVE-2022-1012 (High) |
||
CVE-2023-2163 (High) |
||
CVE-2022-42896 (High) |
||
CVE-2023-3611 (High) |
||
CVE-2023-35001 (High) |
||
CVE-2023-3609 (High) |
||
CVE-2020-8834 (High) |
||
CVE-2021-3715 (High) |
||
CVE-2023-4128 (High) |
||
CVE-2023-32233 (High) |
||
CVE-2022-2639 (High) |
||
CVE-2023-1829 (High) |
||
CVE-2023-3776 (High) |
||
CVE-2018-20976 (High) |
||
CVE-2023-1281 (High) |
||
tungsten/redis |
busybox |
CVE-2022-48174 (Critical) |
busybox-binsh |
CVE-2022-48174 (Critical) |
|
ssl_client |
CVE-2022-48174 (Critical) |
Cluster update known issues¶
This section lists the cluster update known issues with workarounds for the Mirantis OpenStack for Kubernetes release 23.2.3.
During the update, you may encounter the issue that causes a failure of the etcd pods due to the simultaneous deployment of several pods on a single node.
The workaround is to remove the PVC for one etcd pod.
During MOSK update to either 23.2 major release or
any patch release of the 23.2 release series, the
openstack-operator-ensure-resources job may get stuck in
the CrashLoopBackOff state with the following error:
Traceback (most recent call last):
File "/usr/local/bin/osctl-ensure-shared-resources", line 8, in <module>
sys.exit(main())
File "/usr/local/lib/python3.8/dist-packages/openstack_controller/cli/ensure_shared_resources.py", line 61, in main
obj.update()
File "/usr/local/lib/python3.8/dist-packages/pykube/objects.py", line 165, in update
self.patch(self.obj, subresource=subresource)
File "/usr/local/lib/python3.8/dist-packages/pykube/objects.py", line 157, in patch
self.api.raise_for_status(r)
File "/usr/local/lib/python3.8/dist-packages/pykube/http.py", line 444, in raise_for_status
raise HTTPError(resp.status_code, payload["message"])
pykube.exceptions.HTTPError: CustomResourceDefinition.apiextensions.k8s.io "redisfailovers.databases.spotahome.com" is invalid: spec.preserveUnknownFields: Invalid value: true: must be false in order to use defaults in the schema
As a workaround, delete the redisfailovers.databases.spotahome.com
CRD from your cluster:
kubectl delete crd redisfailovers.databases.spotahome.com
While updating your cluster, the Instance High Availability service (OpenStack Masakari) may not work as expected.
As a workaround, temporarily disable the service by removing
instance-ha from the service list in the OpenStackDeployment
custom resource.
Learn more about the release cadence
23.1 series¶
Major and patch versions update path
The primary distinction between major and patch product versions lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements, mostly CVE resolutions for your clusters.
Depending on the needs of your deployment, you can either update between only major releases, or update between the major releases receiving the patch updates in between. Choose the second option, which includes patch updates, only if you want to receive security fixes as soon as they become available and you are prepared to update your cluster often, approximately once in three weeks.
You can delve deeper into the product updates by referring to our FAQ section. The list of questions it addresses includes, but is not limited to the following:
MOSK 23.1 12.7.0+23.1
Full support for Tungsten Fabric 21.4 with automatic upgrade from Tungsten Fabric 2011 and hardened web UI
Technical Preview of Octavia Amphora support load balancers with Tungsten Fabric
Dynamic control over resource oversubscription
Sensitive information hidden from
OpenStackDeploymentRestricted privileges for project administrator
Automated password rotation for MOSK superuser and service accounts
Encrypted data transfer between VNC proxy and hypervisor VNC server
Upgraded Ceph to Pacific 16.2.11 and PowerDNS to 4.7
23.1¶
Release date |
April 4, 2023 |
|---|---|
Name |
MOSK 23.1 |
Cluster release |
12.7.0 |
Highlights |
|
New features¶
Component |
Support scope |
Feature |
|---|---|---|
OpenStack |
Full |
|
Tungsten Fabric |
Full |
|
TechPreview |
||
Full |
|
|
Full |
|
|
TechPreview |
|
|
Full |
|
|
Full |
|
|
n/a |
Introduced a new default way to configure the resource oversubscription in the cloud that enables the cloud operator to dynamically control the oversubscription through the Compute service (OpenStack Nova) placement API.
The initial configuration is performed through the OpenStackDeployment
custom resource. By default, the following values are applied:
cpu: 8.0disk: 1.6ram: 1.0
Starting from 23.1, MOSK deploys all new clouds using Tungsten Fabric 21.4 by default. The existing OpenStack deployments using Tungsten Fabric as a networking back end will obtain this new version automatically during the cluster update to MOSK 23.1.
One of the key highlights of the Tungsten Fabric 21.4 release is the support for configuring Maximum Transmission Unit for virtual networks. This capability enables you to set the maximum packet size for your virtual networks, ensuring that your network traffic is optimized for performance and efficiency.
TechPreview
Enhanced load balancing as a service for Tungsten Fabric -enabled MOSK clouds by adding support for Amphora instances on top of the Tungsten Fabric networks.
Compared to the old implementation, which relied on the Tungsten Fabric-controlled HAproxy, the new approach offers:
Full compatibility with the OpenStack Octavia API
Layer 7 load balancing policies and rules
Support for HTTPs/TLS terminating load balancers
Support for the UDP protocol
Implemented the following list of alerts for the OpenStack controller:
OsDplExporterTargetDownOsDplSSLCertExpirationHighOsDplSSLCertExpirationMedium
Implemented the new panels in the Grafana dashboards for OpenSearch and Prometheus that provide details on the storage usage and allow calculating the possible retention time based on provisioned storage and average usage.
Implemented monitoring of bond interfaces.
Added the capability to forward logs to external Elasticsearch and OpenSearch servers as the
fluentd-logsoutput. This enhancement also expands existing configuration options for log forwarding to syslog.Implemented the ability to set up custom TLS certificates for the following StackLight
iam-proxyendpoints:iam-proxy-alertaiam-proxy-alertmanageriam-proxy-grafanaiam-proxy-kibanaiam-proxy-prometheus
Implemented the capability to hide sensitive fields from the
OpenStackDeploymentobject by adding reference to a secret to this object using thevalue_fromstructure.Implemented the functionality that enables cloud operators to periodically rotate credentials of OpenStack admin and service users with minimized impact on service availability and workload downtime.
Ensured better security for the noVNC client by allowing encryption of data transfer between the instances and the noVNC proxy server using VeNCrypt authentication scheme. You can enable this feature by defining
features:nova:console:novnc:tls:enabledin theOpenStackDeploymentcustom resource.Technology Preview. Reworked the default MOSK access policies to restrict the permissions of a project administrator role exclusively to the scope of their project.
Implemented the capability to reboot several cluster nodes in one go by using the Graceful reboot mechanism provided by Mirantis Container Cloud. The mechanism restarts the selected nodes one by one, honoring the instance migration policies.
Implemented the capability to identify the nodes requiring reboot through both the Mirantis Container Cloud API and web UI:
API:
reboot.required.trueinstatus:providerStatusof aMachineobjectWeb UI: the One or more machines require a reboot notification on the Clusters and Machines pages
Learn more
Upgraded Ceph to Pacific 16.2.11 from Octopus 15.2.17
Upgraded PowerDNS to 4.7 from 4.2
Published the tutorial to help you build your first cloud application and onboard it to a MOSK cloud. The dedicated section in the User Guide will guide you through the process of deploying and managing a sample application using automation, and showcase the powerful capabilities of OpenStack.
Published the instructions on how you can customize the functionality of MOSK OpenStack services by installing custom system or Python packages into their container images.
Major components versions¶
Mirantis has tested MOSK against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOSK components with the exact versions against which testing has been performed.
Component |
Version |
|---|---|
Cluster release |
12.7.0 (Cluster release notes) |
OpenStack |
Yoga |
OpenStack Operator |
0.12.4 |
Tungsten Fabric |
21.4 |
Tungsten Fabric Operator |
0.11.7 |
See also
For the supported versions of operating system, Ceph, and other components, refer to Release Compatibility Matrix.
Known issues¶
This section describes the MOSK known issues with available workarounds. For the known issues in the related version of Mirantis Container Cloud, refer to Mirantis Container Cloud: Release Notes.
This section lists the OpenStack known issues with workarounds for the Mirantis OpenStack for Kubernetes release 23.1.
Multiprotocol Label Switching over Generic Routing Encapsulation (MPLSoGRE) provides limited throughput while sending data between VMs up to 38 Mbps, as per Mirantis tests.
As a workaround, switch the encapsulation type to VXLAN in the
OpenStackDeployment custom resource:
spec:
services:
networking:
neutron:
values:
conf:
bagpipe_bgp:
dataplane_driver_ipvpn:
mpls_over_gre: "False"
vxlan_encap: "True"
This section lists the Tungsten Fabric (TF) known issues with workarounds for the Mirantis OpenStack for Kubernetes release 23.1. For TF limitations, see Tungsten Fabric known limitations.
[30738] ‘tf-vrouter-agent’ readiness probe failed (No Configuration for self)
[13755] TF pods switch to CrashLoopBackOff after a simultaneous reboot
[32723] Compiled vRouter kernel module does not refresh with the new kernel
Execution of the TF Heat Tempest test test_template_global_vrouter_config
can result in lost vRouter configuration. This causes the tf-vrouter pod
readiness probe to fail with the following error message:
"Readiness probe failed: vRouter is PRESENT contrail-vrouter-agent: initializing (No Configuration for self)"
As a result, vRouters may have an incomplete routing table making some services, such as metadata, become unavailable.
Workaround:
Add the
tf_heat_tempest_plugintests with global configuration to the exclude list in theOpenStackDeploymentcustom resource:spec: tempest: tempest: values: conf: blacklist: - (?:tf_heat_tempest_plugin.tests.functional.test_global.*)
If you ran
test_template_global_vrouter_configandtf-vrouter-agentpods moved to theerrorstate with the above error, re-create these pods through deletion:kubectl -n tf delete pod tf-vrouter-agent-*
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete the Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica_num>
The vRouter kernel module remains at
/usr/src/vrouter-<TF-VROUTER-IMAGE-VERSION>, even
if it was initially compiled for an older kernel version. This leads
to the reuse of compiled artifacts without recompilation. Consequently,
after upgrading to Mirantis OpenStack for Kubernetes 23.1, an outdated module gets
loaded onto the new kernel. This mismatch results in a failure that
triggers the CrashLoop state for the vRouter on the affected node.
Workaround:
On the affected node, move the old vRouter kernel module to another directory. For example:
mkdir /root/old_vrouter_kmods mv /lib/modules/`uname -r`/updates/dkms/vrouter* /root/old_vrouter_kmods mv /usr/src/vrouter-21.4.20230306000000 /root/old_vrouter_kmods
On the cluster, remove the
tf-vrouter-agentpod:kubectl delete -n tf pod tf-vrouter-agent-<POD_ID>
This section lists the Ceph known issues with workarounds for the Mirantis OpenStack for Kubernetes release 23.1.
[30857] Irrelevant error during Ceph OSD deployment on removable devices
[31630] Ceph cluster upgrade to Pacific is stuck with Rook connection failure
[31555] Ceph can find only 1 out of 2 ‘mgr’ after update to MOSK 23.1
The deployment of Ceph OSDs fails with the following messages in the status
section of the KaaSCephCluster custom resource:
shortClusterInfo:
messages:
- Not all osds are deployed
- Not all osds are in
- Not all osds are up
To find out if your cluster is affected, verify if the devices on
the AMD hosts you use for the Ceph OSDs deployment are removable.
For example, if the sdb device name is specified in
spec.cephClusterSpec.nodes.storageDevices of the KaaSCephCluster
custom resource for the affected host, run:
# cat /sys/block/sdb/removable
1
The system output shows that the reason of the above messages in status
is the enabled hotplug functionality on the AMD nodes, which marks all drives
as removable. And the hotplug functionality is not supported by Ceph in
MOSK.
As a workaround, disable the hotplug functionality in the BIOS settings for disks that are configured to be used as Ceph OSD data devices.
During update to MOSK 23.1, the Ceph cluster gets stuck during upgrade to Ceph Pacific.
To verify whether your cluster is affected:
The cluster is affected if the following conditions are true:
The
ceph-status-controllerpod on the MOSK cluster contains the following log lines:kubectl -n ceph-lcm-mirantis logs <ceph-status-controller-podname> ... E0405 08:07:15.603247 1 cluster.go:222] Cluster health: "HEALTH_ERR" W0405 08:07:15.603266 1 cluster.go:230] found issue error: {Urgent failed to get status. . timed out: exit status 1}
The
KaaSCephClustercustom resource contains the following configuration option in therookConfigsection:spec: cephClusterSpec: rookConfig: ms_crc_data: "false" # or 'ms crc data: "false"'
As a workaround, remove ms_crc_data (or ms crc data) configuration
key from the KaaSCephCluster custom resource and wait for the
rook-ceph-mon pods to restart on the MOSK cluster:
kubectl -n rook-ceph get pod -l app=rook-ceph-mon -w
Fixed in 23.2
After update to MOSK 23.1, the status section of the KaaSCephCluster
custom resource can contain the following message:
shortClusterInfo:
messages:
- Not all mgrs are running: 1/2
To verify whether the cluster is affected:
If the KaaSCephCluster spec contains the external section, the cluster
is affected:
spec:
cephClusterSpec:
external:
enable: false
Workaround::
In
spec.cephClusterSpecof theKaaSCephClustercustom resource, remove theexternalsection.Wait for the Not all mgrs are running: 1/2 message to disappear from the
KaaSCephClusterstatus.Verify that the
novaCeph client that is integrated to MOSK has the same keyring as in the Ceph cluster.Keyring verification for the Ceph
novaclientCompare the keyring used in the
nova-computeandlibvirtpods with the one from the Ceph cluster:kubectl -n openstack get pod | grep nova-compute kubectl -n openstack exec -it <nova-compute-pod-name> -- cat /etc/ceph/ceph.client.nova.keyring kubectl -n openstack get pod | grep libvirt kubectl -n openstack exec -it <libvirt-pod-name> -- cat /etc/ceph/ceph.client.nova.keyring kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph auth get client.nova
If the keyring differs, change the one stored in Ceph cluster with the key from the OpenStack pods:
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash ceph auth get client.nova -o /tmp/nova.key vi /tmp/nova.key # in the editor, change "key" value to the key obtained from the OpenStack pods # then save and exit editing ceph auth import -i /tmp/nova.key
Verify that the
client.novakeyring of the Ceph cluster matches the one obtained from the OpenStack pods:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph auth get client.nova
Verify that
nova-computeandlibvirtpods have access to the Ceph cluster:kubectl -n openstack get pod | grep nova-compute kubectl -n openstack exec -it <nova-compute-pod-name> -- ceph -s -n client.nova kubectl -n openstack get pod | grep libvirt kubectl -n openstack exec -it <libvirt-pod-name> -- ceph -s -n client.nova
Verify that the
cinderCeph client integrated to MOSK has the same keyring as in the Ceph cluster:Keyring verification for the Ceph
cinderclientCompare the keyring used in the
cinder-volumepods with the one from the Ceph cluster.kubectl -n openstack get pod | grep cinder-volume kubectl -n openstack exec -it <cinder-volume-pod-name> -- cat /etc/ceph/ceph.client.cinder.keyring kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph auth get client.cinder
If the keyring differs, change the one stored in Ceph cluster with the key from the OpenStack pods:
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash ceph auth get client.cinder -o /tmp/cinder.key vi /tmp/cinder.key # in the editor, change "key" value to the key obtained from the OpenStack pods # then save and exit editing ceph auth import -i /tmp/cinder.key
Verify that the
client.cinderkeyring of the Ceph cluster matches the one obtained from the OpenStack pods:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph auth get client.cinder
Verify that the
cinder-volumepods have access to the Ceph cluster:kubectl -n openstack get pod | grep cinder-volume kubectl -n openstack exec -it <cinder-volume-pod-name> -- ceph -s -n client.cinder
Verify that the
glanceCeph client integrated to MOSK has the same keyring as in the Ceph cluster.Keyring verification for the Ceph
glanceclientCompare the keyring used in the
glance-apipods with the one from the Ceph cluster:kubectl -n openstack get pod | grep glance-api kubectl -n openstack exec -it <glance-api-pod-name> -- cat /etc/ceph/ceph.client.glance.keyring kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph auth get client.glance
If the keyring differs, change the one stored in Ceph cluster with the key from the OpenStack pods:
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash ceph auth get client.glance -o /tmp/glance.key vi /tmp/glance.key # in the editor, change "key" value to the key obtained from the OpenStack pods # then save and exit editing ceph auth import -i /tmp/glance.key
Verify that the
client.glancekeyring of the Ceph cluster matches the one obtained from the OpenStack pods:kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- ceph auth get client.glance
Verify that the
glance-apipods have access to the Ceph cluster:kubectl -n openstack get pod | grep glance-api kubectl -n openstack exec -it <glance-api-pod-name> -- ceph -s -n client.glance
This section lists the StackLight known issues with workarounds for the Mirantis OpenStack for Kubernetes release 23.1.
Due to the table widget failure, the Instance Info panel in the RabbitMQ Grafana dashboard is empty.
Workaround:
Download the packaged chart with the fixed RabbitMQ dashboard.
Unpack the archive, open
grafana-3.3.10-mcp-199/grafana/dashboards/rabbitmq.json, and copy the file content to the clipboard.In the Grafana web UI, navigate to Dashboards > Import.
In the Import dashboard wizard that opens, paste the imported RabbitMQ dashboard into the Import via panel json box. Click Load.
Specify the dashboard name, for example,
RabbitMQ_fixto avoid colliding with the current dashboard.Click Import to save the dashboard.
Now, the Instance Info panel in the imported RabbitMQ dashboard should be displayed correctly.
This section lists the cluster update known issues with workarounds for the Mirantis OpenStack for Kubernetes release 23.1.
During update of a Container Cloud management cluster, if the MKE minor
version is updated from 3.4.x to 3.5.x, access to the cluster using the
existing kubeconfig fails with the You must be logged in to the server
(Unauthorized) error due to OIDC settings being reconfigured.
As a workaround, during the Container Cloud cluster update, use the
admin kubeconfig instead of the existing one. Once the update
completes, you can use the existing cluster kubeconfig again.
To obtain the admin kubeconfig:
kubectl --kubeconfig <pathToMgmtKubeconfig> get secret -n <affectedClusterNamespace> \
-o yaml <affectedClusterName>-kubeconfig | awk '/admin.conf/ {print $2}' | \
head -1 | base64 -d > clusterKubeconfig.yaml
On a cluster with Tungsten Fabric enabled, the cluster update is stuck with
the tf-rabbit-exporter deployment having a number of pods in the
Terminating state.
To verify whether your cluster is affected:
kubectl -n tf get pods | grep tf-rabbit-exporter
Example of system response on the affected cluster:
tf-rabbit-exporter-6cd5bcd677-dz4bw 1/1 Running 0 9m13s
tf-rabbit-exporter-8665b5886f-4n66m 0/1 Terminating 0 5s
tf-rabbit-exporter-8665b5886f-58q4z 0/1 Terminating 0 0s
tf-rabbit-exporter-8665b5886f-7t5bp 0/1 Terminating 0 7s
tf-rabbit-exporter-8665b5886f-b2vp9 0/1 Terminating 0 3s
tf-rabbit-exporter-8665b5886f-k4gn2 0/1 Terminating 0 6s
tf-rabbit-exporter-8665b5886f-lscb2 0/1 Terminating 0 5s
tf-rabbit-exporter-8665b5886f-pdp78 0/1 Terminating 0 1s
tf-rabbit-exporter-8665b5886f-qgpcl 0/1 Terminating 0 1s
tf-rabbit-exporter-8665b5886f-vpfrg 0/1 Terminating 0 8s
tf-rabbit-exporter-8665b5886f-vsqqk 0/1 Terminating 0 13s
tf-rabbit-exporter-8665b5886f-xfjgf 0/1 Terminating 0 2s
Workaround:
Drop an extra custom resource of RabbitMQ:
kubectl -n tf get rabbitmq
Example of system response on the affected cluster:
NAME AGE tf-rabbit-exporter 545d tf-rabbitmq 545d
Delete the
tf-rabbit-exportercustom resource:kubectl -n tf delete rabbitmq tf-rabbit-exporter
Release artifacts¶
This section lists the components artifacts of the MOSK 23.1 release that includes binaries, Docker images, and Helm charts.
MOSK 23.1 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20230227101732.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-xena-9f691e3-20220110111511.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-focal-20230227093206 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-focal-20230227093206 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-focal-20230227093206 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-focal-20230227093206 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-focal-20230227093206 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-focal-20230227093206 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-focal-20230227093206 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-focal-20230227093206 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-focal-20230227093206 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-focal-20230227093206 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230227093206 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-focal-20230227093206 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230227123148 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230227123148 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230227123149 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20230227093206 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
amqproxy-0.8.x |
mirantis.azurecr.io/general/amqproxy:v0.8.3 |
MIT license |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-48d1e8a-20220919122849 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.17-alpine3.16 |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:pacific-focal-20230227123148 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.4-alpine-20221116085516 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230113154410 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.3.1 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20220804082840 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230227122722 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.1 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.2.0-20230228212732 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-focal-20230227093206 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-focal-20230227093206 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-focal-20230227093206 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.5-alpine3.16 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.3.1 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.5-20221028090933 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230227123149 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.25.0-amd64-20220922181123 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.23.3-alpine-slim |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20230227123149 |
GPL-2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20230223144137 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-focal-20230227093206 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-focal-20230227093206 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-focal-20230227093206 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230227093206 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-focal-20230227093206 |
Apache License 2.0 |
MOSK 23.1 OpenStack Victoria binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20230223191854.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-victoria-20230128063511.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-focal-20230223184118 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-focal-20230223184118 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-focal-20230223184118 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-focal-20230223184118 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-focal-20230223184118 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-focal-20230223184118 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-focal-20230223184118 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-focal-20230223184118 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-focal-20230223184118 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-focal-20230223184118 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-focal-20230223184118 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-focal-20230223184118 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230227123148 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230227123148 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230227123149 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20230227093206 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
amqproxy-0.8.x |
mirantis.azurecr.io/general/amqproxy:v0.8.3 |
MIT license |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-48d1e8a-20220919122849 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.17-alpine3.16 |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:pacific-focal-20230227123148 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.4-alpine-20221116085516 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230113154410 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.3.1 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20220804082840 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230227122722 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.1 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.2.0-20230228212732 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-focal-20230223184118 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-focal-20230223184118 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-focal-20230223184118 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.5-alpine3.16 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.3.1 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.5-20221028090933 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230227123149 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.25.0-amd64-20220922181123 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.23.3-alpine-slim |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20230227123149 |
GPL-2.0 |
placement |
mirantis.azurecr.io/openstack/placement:victoria-focal-20230223184118 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-focal-20230227123149 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-focal-20230223184118 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-focal-20230223184118 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-focal-20230223184118 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-focal-20230223184118 |
Apache License 2.0 |
MOSK 23.1 OpenStack Helm charts
MOSK 23.1 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.11.7.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.11.7 |
Mirantis Proprietary License |
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:21.4.20230306000000 |
Apache License 2.0 |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:21.4.20230306000000 |
Apache License 2.0 |
|
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:21.4.20230306000000 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:21.4.20230306000000 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:21.4.20230306000000 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:21.4.20230306000000 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:21.4.20230306000000 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:21.4.20230306000000 |
Apache License 2.0 |
TF Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:21.4.20230306000000 |
Apache License 2.0 |
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20230306000000 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:2.1.14 |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.11 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230126 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20220919122317 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20220919114133 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.1 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.3.1 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/jmx-exporter:0.17.2-debian-11-r47 |
Apache License 2.0 |
|
Pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Google Cloud Platform |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.3.1 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.11.2 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.14 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.7.1-20220914 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.3.6 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:7.0.5-alpine3.16 |
BSD 3-Clause “New” or “Revised” License |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
|
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20230306110548 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20230223110354 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20221109111149 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:21.4.20230306000000 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-48d1e8a-20220919122849 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
MOSK 23.1 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20230203125533 |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20221226123816 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-1.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the MOSK 23.1 release:
[OpenStack] [30450] Fixed the issue causing high CPU load of MariaDB.
[OpenStack] [29501] Fixed the issue when Cinder periodic database cleanup resets the state of volumes.
[OpenStack] [27168] Fixed the issue that made
openvswitch-openvswitch-vswitchd-defaultandneutron-ovs-agent-defaultpods stuck in theNotReadystatus after restart.[OpenStack] [29539] Fixed the issue with missing network traffic for a trunked port in OpenStack Yoga.
[TF] [10096] Fixed the issue that prevented
tf-controlfrom refreshing IP addresses of Cassandra pods.[TF] [28728] Fixed the issue when
tungstenFabricMonitoring.enabledwas not enabled by default during Tungsten Fabric deployment.[TF] [30449] Fixed the issue that resulted in losing connectivity after the primary TF Controller node reboot.
[Ceph] [28142] Added the ability to specify node affinity for
rook-discoverpods through theceph-operatorHelm release.[Ceph] [26820] Fixed the issue when the
statussection in theKaaSCephCluster.statuscustom resource did not reflect issues during the process of a Ceph cluster deletion.[StackLight] [28372] Fixed the issue causing false-positive liveness probe failures for
fluentd-notifications.[StackLight] [29330] Fixed the issue that prevented
tf-rabbitmqfrom being monitored.[Updates] [29438] Fixed the issue that caused the cluster update being stuck during the Tungsten Fabric Operator update.
Update notes¶
This section describes the specific actions you as a Cloud Operator need to complete to accurately plan and successfully perform your Mirantis OpenStack for Kubernetes (MOSK) cluster update to the version 23.1. Consider this information as a supplement to the generic update procedure published in Operations Guide: Update a MOSK cluster.
The MOSK cluster will obtain the newly implemented capabilities automatically with no significant impact on the update procedure.
As part of the update to MOSK 23.1, Tungsten Fabric will automatically get updated from version 2011 to version 21.4.
Note
For the compatibility matrix of the most recent MOSK releases and their major components in conjunction with Container Cloud and Cluster releases, refer to Release Compatibility Matrix.
The update to MOSK 23.1 does not include any version-specific impact on the cluster. To start planning a maintenance window, use the Operations Guide: Update a MOSK cluster standard procedure.
Before updating the cluster, be sure to review the potential issues that may arise during the process and the recommended solutions to address them, as outlined in Cluster update known issues.
If your Container Cloud management cluster has updated to 2.24.1, to avoid
the issue with waiting for the lcm-agent to update
the currentDistribution field during the cluster update to
MOSK 23.1, replace the baremetal-provider image
1.37.15 tag with 1.37.18:
Open the
kaasreleaseobject for editing:kubectl edit kaasrelease kaas-2-24-1
Replace the
1.37.15tag with1.37.18for thebaremetal-providerimage:- chartURL: core/helm/baremetal-provider-1.37.15.tgz helmV3: true name: baremetal-provider namespace: kaas values: cluster_api_provider_baremetal: image: tag: 1.37.18
MOSK 23.1 introduces a new default value for the
OIDCClaimDelimiter parameter, which defines the delimiter to use when
setting multi-valued claims in the HTTP headers. See the MOSK 23.1 OpenStack
API Reference
for details.
Previously, the value of the OIDCClaimDelimiter parameter defaulted to
",". This value misaligned with the behavior expected by Keystone.
As a result, when creating federation mappings for Keystone, the cloud operator
was forced to write more complex rules. Therefore, in MOSK
22.4, Mirantis announced the change of the default value for the
OIDCClaimDelimiter parameter.
If your deployment is affected and you have not explicitly defined the
OIDCClaimDelimiter parameter, as Mirantis advised, after update to
MOSK 22.4 or 22.5, now would be a good time to do it.
Otherwise, you may encounter unforeseen consequences after the update to
MOSK 23.1.
Affected deployments
Proceed with the instruction below only if the following conditions are true:
Keystone is set to use federation through the OpenID Connect protocol, with Mirantis Container Cloud Keycloak in particular. The following configuration is present in your
OpenStackDeploymentcustom resource:kind: OpenStackDeployment spec: features: keystone: keycloak: enabled: true
No value has already been specified for the
OIDCClaimDelimiterparameter in yourOpenStackDeploymentcustom resource.
To facilitate smooth transition of the existing deployments to the new default
value, explicitly define the OIDCClaimDelimiter parameter as follows:
kind: OpenStackDeployment
spec:
features:
keystone:
keycloak:
oidc:
OIDCClaimDelimiter: ","
Note
The new default value for the OIDCClaimDelimiter parameter
is ";". To find out whether your Keystone mappings will need
adjustment after changing the default value, set the parameter to
";" on your staging environment and verify the rules.
Verify that the KaaSCephCluster custom resource does not contain the
following entries. If they exist, remove them.
In the
spec.cephClusterSpecsection, theexternalsection.Caution
If the
externalsection exists in theKaaSCephClusterspec during upgrade to MOSK 23.1, it will cause Ceph outage that leads to corruption of the Cinder volumes file system and requires a lot of routine work to fix sectors with Cinder volumes one-by-one after fixing Ceph outage.Therefore, make sure that the
externalsection is removed from theKaaSCephClusterspec right before starting cluster upgrade.In the
spec.cephClusterSpec.rookConfigsection, thems_crc_dataorms crc dataconfiguration key. After you remove the key, wait forrook-ceph-monpods to restart on the MOSK cluster.Caution
If the
ms_crc_datakey exists in therookConfigsection ofKaaSCephClusterduring upgrade to MOSK 23.1, it causes missing connection between Rook Operator and Ceph Monitors during Ceph version upgrade leading to a stuck upgrade and requires that you manually disable thems_crc_datakey for all Ceph Monitors.Therefore, make sure that the
ms_crc_datakey is removed from theKaaSCephClusterspec right before starting cluster upgrade.
To prevent issues during graceful reboot of the OpenStack controller nodes,
temporarily remove Tempest from the OpenStackDeployment object:
spec:
features:
services:
- tempest
The OpenStackDeploymentSecret custom resource has been deprecated in
MOSK 23.1. The fields that store confidential settings
in OpenStackDeploymentSecret and OpenStackDeployment custom resources
need to be migrated to the Kubernetes secrets.
Note
For the functionality deprecation and deletion schedule, refer to OpenStackDeploymentSecret custom resource.
The full list of the affected fields include:
spec:
features:
ssl:
public_endpoints:
- ca_cert
- api_cert
- api_key
barbican:
backends:
vault:
- approle_role_id
- approle_secret_id
- ssl_ca_crt_file
baremetal:
ngs:
hardware:
*:
- username
- password
- ssh_private_key
- secret
keystone:
domain_specific_configuration:
...
ks_domains:
*:
config:
...
ldap:
...
password: <password>
user: <user-name>
After the update, migrate the fields mentioned above from
OpenStackDeployment and OpenStackDeploymentSecret custom resources:
Create a Kubernetes secret
<osdpl-name>-hiddenin theopenstacknamespace either using the helper script or manually:Use the
osctl-move-sensitive-datahelper script from theopenstack-controllerpod:osctl-move-sensitive-data osh-dev --secret-name osh-dev-hidden
Create the Kubernetes secret and add content of required fields to the
OpenStackDeploymentcustom resource. For example:apiVersion: v1 kind: Secret metadata: name: osh-dev-hidden namespace: openstack labels: openstack.lcm.mirantis.com/osdpl_secret: 'true' type: Opaque data: ca_cert: ... api_cert: ... api_key: ...
Add a reference from appropriate fields in the
OpenStackDeploymentobject. For example:spec: features: ssl: public_endpoints: api_cert: value_from: secret_key_ref: key: api_cert name: osh-dev-hidden api_key: value_from: secret_key_ref: key: api_key name: osh-dev-hidden ca_cert: value_from: secret_key_ref: key: ca_cert name: osh-dev-hidden
If you used to store your sensitive information in the
OpenStackDeploymentSecretobject, remove it from your cluster configuration.
To ensure stability for production workloads, MOSK 23.1
changes the default value of RAM oversubscription on compute nodes to 1.0,
which is no oversubscription. In MOSK 22.5 and earlier,
the effective default value of RAM allocation ratio is 1.1.
This change will be applied only to the compute nodes added to the cloud after update to MOSK 23.1. The effective RAM oversubscription value for existing compute nodes will not automatically change after updating to MOSK 23.1.
Therefore, Mirantis strongly recommends adjusting the oversubscription values to new defaults for existing compute nodes as well. For the procedure, refer to Change oversubscription settings for existing compute nodes.
Since MOSK 23.1, the Compute service (OpenStack Nova) enables you to control the resource oversubscription dynamically through the placement API.
However, if your cloud already makes use of custom allocation ratios, the new
functionality will not become immediately available after update. Any compute
node configured with explicit values for the cpu_allocation_ratio,
disk_allocation_ratio, and ram_allocation_ratio configuration options
will continue to enforce those values in the placement service. Therefore, any
changes made through the placement API will be overridden by the values set in
those configuration options in the Compute service. To modify oversubscription,
you should adjust the values of these configuration options in the
OpenStackDeployment custom resource. This procedure should be performed
with caution as modifying these values may result in compute service restarts
and potential disruptions in the instance builds.
To enable the use of the new functionality, Mirantis recommends removing
explicit values for the cpu_allocation_ratio, disk_allocation_ratio,
and ram_allocation_ratio options from the OpenStackDeployment custom
resource. Instead, use the new configuration options as described in
Configuring initial resource oversubscription. Also, keep in mind that
the changes will only impact newly added compute nodes and will not be applied
to the existing ones.
Security notes¶
The table below contains the number of vendor-specific addressed CVEs with Critical or High severity.
In total, in the MOSK 23.1 release, 432 CVEs have been fixed and 85 artifacts (images) updated.
Fixed CVE ID |
# of updated artifacts |
|---|---|
ALAS2-2022-1877 |
2 |
ALAS2-2022-1885 |
2 |
ALAS2-2022-1902 |
4 |
ALAS2-2023-1904 |
1 |
ALAS2-2023-1908 |
2 |
ALAS2-2023-1911 |
2 |
ALAS2-2023-1915 |
2 |
ALAS2-2023-1958 |
2 |
CVE-2014-10064 |
4 |
CVE-2015-8315 |
2 |
CVE-2015-8851 |
2 |
CVE-2016-10539 |
2 |
CVE-2016-10540 |
8 |
CVE-2016-1252 |
1 |
CVE-2016-2515 |
2 |
CVE-2016-2537 |
4 |
CVE-2016-6313 |
2 |
CVE-2017-15010 |
4 |
CVE-2017-16042 |
2 |
CVE-2017-16119 |
2 |
CVE-2017-16138 |
8 |
CVE-2017-18077 |
4 |
CVE-2017-20165 |
8 |
CVE-2017-9445 |
1 |
CVE-2018-1000001 |
1 |
CVE-2018-1000620 |
4 |
CVE-2018-16492 |
4 |
CVE-2018-16864 |
1 |
CVE-2018-16865 |
1 |
CVE-2018-20834 |
2 |
CVE-2018-3728 |
4 |
CVE-2018-3737 |
4 |
CVE-2018-7408 |
2 |
CVE-2019-10744 |
4 |
CVE-2019-13173 |
4 |
CVE-2019-16776 |
2 |
CVE-2019-19919 |
2 |
CVE-2019-20920 |
2 |
CVE-2019-20922 |
2 |
CVE-2019-25013 |
9 |
CVE-2019-3462 |
1 |
CVE-2020-10684 |
1 |
CVE-2020-1737 |
1 |
CVE-2020-1971 |
1 |
CVE-2020-26301 |
2 |
CVE-2020-7754 |
2 |
CVE-2020-7774 |
2 |
CVE-2020-7788 |
2 |
CVE-2020-8203 |
6 |
CVE-2021-23337 |
6 |
CVE-2021-23358 |
4 |
CVE-2021-23369 |
4 |
CVE-2021-23383 |
4 |
CVE-2021-23807 |
4 |
CVE-2021-33574 |
69 |
CVE-2021-3711 |
2 |
CVE-2021-3918 |
4 |
CVE-2021-44906 |
7 |
CVE-2022-0144 |
3 |
CVE-2022-0686 |
1 |
CVE-2022-0691 |
1 |
CVE-2022-0778 |
5 |
CVE-2022-1292 |
5 |
CVE-2022-1664 |
6 |
CVE-2022-1941 |
8 |
CVE-2022-2068 |
6 |
CVE-2022-23218 |
6 |
CVE-2022-23219 |
6 |
CVE-2022-24407 |
3 |
CVE-2022-24785 |
2 |
CVE-2022-27404 |
2 |
CVE-2022-29155 |
5 |
CVE-2022-29167 |
4 |
CVE-2022-29217 |
2 |
CVE-2022-31129 |
3 |
CVE-2022-3515 |
2 |
CVE-2022-37599 |
1 |
CVE-2022-37601 |
1 |
CVE-2022-37603 |
1 |
CVE-2022-39379 |
1 |
CVE-2022-40023 |
19 |
CVE-2022-40899 |
10 |
RHSA-2019:0997 |
2 |
RHSA-2019:1145 |
1 |
RHSA-2019:1619 |
1 |
RHSA-2019:1714 |
1 |
RHSA-2019:2692 |
1 |
RHSA-2019:4114 |
5 |
RHSA-2020:0271 |
1 |
RHSA-2020:0273 |
1 |
RHSA-2020:0575 |
4 |
RHSA-2020:0902 |
1 |
RHSA-2020:2338 |
1 |
RHSA-2020:2344 |
3 |
RHSA-2020:2637 |
1 |
RHSA-2020:2755 |
1 |
RHSA-2020:2894 |
2 |
RHSA-2020:3014 |
5 |
RHSA-2020:3658 |
1 |
RHSA-2020:5476 |
1 |
RHSA-2020:5566 |
1 |
RHSA-2021:0670 |
1 |
RHSA-2021:0671 |
3 |
RHSA-2021:1024 |
1 |
RHSA-2021:1206 |
2 |
RHSA-2021:1469 |
3 |
RHSA-2021:1989 |
1 |
RHSA-2021:2147 |
1 |
RHSA-2021:2170 |
1 |
RHSA-2021:2359 |
3 |
RHSA-2021:2717 |
8 |
RHSA-2021:4903 |
5 |
RHSA-2021:4904 |
3 |
RHSA-2021:5082 |
8 |
RHSA-2022:0332 |
8 |
RHSA-2022:0666 |
1 |
RHSA-2022:1066 |
1 |
RHSA-2022:1069 |
1 |
RHSA-2022:2191 |
1 |
RHSA-2022:2213 |
1 |
RHSA-2022:4799 |
2 |
RHSA-2022:5052 |
2 |
RHSA-2022:5056 |
2 |
RHSA-2022:6160 |
2 |
RHSA-2022:6170 |
1 |
RHSA-2022:6765 |
3 |
RHSA-2022:6778 |
3 |
RHSA-2022:6834 |
2 |
RHSA-2022:7186 |
24 |
RHSA-2022:8492 |
5 |
RHSA-2022:8640 |
32 |
RHSA-2023:0101 |
1 |
RHSA-2023:0284 |
2 |
RHSA-2023:0379 |
2 |
RHSA-2023:0610 |
4 |
RHSA-2023:0838 |
8 |
RHSA-2023:1252 |
5 |
The full list of the CVEs present in the current MOSK release is available at the Mirantis Security Portal.
23.1.1 patch¶
The patch release notes contain the list of artifacts and Common Vulnerabilities and Exposures (CVE) fixes for the MOSK 23.1.1 patch released on April 20, 2023.
Release artifacts¶
This section lists the components artifacts of the MOSK 23.1.1 patch release that includes binaries, Docker images, and Helm charts.
MOSK 23.1.1 OpenStack Victoria binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20230223191854.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-victoria-20230128063511.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-focal-20230403060017 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-focal-20230403060017 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-focal-20230403060017 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-focal-20230403060017 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-focal-20230403060017 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-focal-20230403060017 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-focal-20230403060017 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-focal-20230403060017 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-focal-20230403060017 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-focal-20230403060017 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-focal-20230403060017 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-focal-20230403060017 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230323105551 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230227123148 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230227123149 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20230403060017 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
amqproxy-0.8.x |
mirantis.azurecr.io/general/amqproxy:v0.8.3 |
MIT license |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-de7c287-20230321181457 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.19-alpine3.17.3 |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:pacific-focal-20230323105551 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.7-alpine-20230331115754 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230324153219 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.3.1-alpine-20230331115133 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20220804082840 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230331112513 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.1 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.2.0-20230328221837 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-focal-20230403060017 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-focal-20230403060017 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-focal-20230403060017 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.10-alpine3.17 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.0 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.5-20230331105620 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230323105551 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.26.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.23.4-alpine-slim |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20230323105551 |
GPL-2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:victoria-focal-20230403060017 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:victoria-focal-20230403060017 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-focal-20230324131216 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-focal-20230403060017 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-focal-20230403060017 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-focal-20230403060017 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-focal-20230403060017 |
Apache License 2.0 |
MOSK 23.1.1 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20230227101732.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-xena-9f691e3-20220110111511.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-focal-20230403060017 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-focal-20230403060017 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-focal-20230403060017 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-focal-20230403060017 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-focal-20230403060017 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-focal-20230403060017 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-focal-20230403060017 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-focal-20230403060017 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-focal-20230403060017 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-focal-20230403060017 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230403060017 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-focal-20230403060017 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230323105551 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230227123148 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230227123149 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20230403060017 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
amqproxy-0.8.x |
mirantis.azurecr.io/general/amqproxy:v0.8.3 |
MIT license |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-de7c287-20230321181457 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.19-alpine3.17.3 |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:pacific-focal-20230323105551 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.7-alpine-20230331115754 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230324153219 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.3.1-alpine-20230331115133 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20220804082840 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230331112513 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.1 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.2.0-20230328221837 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-focal-20230403060017 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-focal-20230403060017 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-focal-20230403060017 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.10-alpine3.17 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.0 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.5-20230331105620 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230323105551 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.26.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.23.4-alpine-slim |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20230323105551 |
GPL-2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-focal-20230403060017 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20230329122808 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-focal-20230403060017 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-focal-20230403060017 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-focal-20230403060017 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230403060017 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-focal-20230403060017 |
Apache License 2.0 |
MOSK 23.1.1 OpenStack Helm charts
MOSK 23.1.1 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.11.8.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.11.8 |
Mirantis Proprietary License |
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:21.4.20230306000000 |
Apache License 2.0 |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:21.4.20230306000000 |
Apache License 2.0 |
|
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:21.4.20230306000000 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:21.4.20230306000000 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:21.4.20230306000000 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:21.4.20230306000000 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:21.4.20230306000000 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:21.4.20230306000000 |
Apache License 2.0 |
TF Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:21.4.20230306000000 |
Apache License 2.0 |
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20230306000000 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:2.1.15 |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.11 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230126 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20230328121138 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20230328121021 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.2 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.3.1 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/jmx-exporter:0.17.2-debian-11-r54 |
Apache License 2.0 |
|
Pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Google Cloud Platform |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.3.2 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.11.2 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC19 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.15-17-de1dffc4 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.7.1-20230323 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.3.7 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:7.0.9-alpine3.17 |
BSD 3-Clause “New” or “Revised” License |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
|
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20230321053606 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20230223110354 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20230328120524 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:21.4.20230306000000 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-48d1e8a-20220919122849 |
Apache License 2.0 |
MOSK 23.1.1 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20230331023012 |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20230330133839 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-1.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Security notes¶
In total, in the MOSK 23.1.1 release, 418 Common Vulnerabilities and Exposures (CVE) have been fixed: 22 of critical and 396 of high severity.
The full list of the CVEs present in the current MOSK release is available at the Mirantis Security Portal.
Learn more about new release cadence
23.1.2 patch¶
Release date |
May 4, 2023 |
|---|---|
Scope |
Patch |
Cluster release |
12.7.2 |
OpenStack Operator |
0.12.6 |
Tungsten Fabric Operator |
0.11.10 |
Release artifacts¶
This section lists the components artifacts of the MOSK 23.1.2 patch release that includes binaries, Docker images, and Helm charts.
MOSK 23.1.2 OpenStack Victoria binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20230223191854.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-victoria-20230128063511.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-focal-20230403060017 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-focal-20230403060017 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-focal-20230403060017 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-focal-20230403060017 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-focal-20230403060017 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-focal-20230403060017 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-focal-20230403060017 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-focal-20230403060017 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-focal-20230403060017 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-focal-20230403060017 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-focal-20230403060017 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-focal-20230423104356 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230323105551 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230227123148 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230227123149 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
amqproxy-0.8.x |
mirantis.azurecr.io/general/amqproxy:0.8.6-alpine3.17.3-20230422135216 |
MIT license |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.19-alpine3.17.3 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.8-alpine-20230422141943 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230324153219 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.3.1-alpine-20230422140933 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20220804082840 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230331112513 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.1 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.2.0-20230328221837 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-focal-20230403060017 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-focal-20230403060017 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-focal-20230403060017 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.11-alpine3.17 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.0 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.5-20230422141212 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230323105551 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.26.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.23.4-alpine-slim |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20230323105551 |
GPL-2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:victoria-focal-20230403060017 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:victoria-focal-20230403060017 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-focal-20230324131216 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-focal-20230403060017 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-focal-20230403060017 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-focal-20230403060017 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-focal-20230403060017 |
Apache License 2.0 |
MOSK 23.1.2 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20230227101732.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-xena-9f691e3-20220110111511.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-focal-20230403060017 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-focal-20230403060017 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-focal-20230403060017 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-focal-20230403060017 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-focal-20230403060017 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-focal-20230403060017 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-focal-20230403060017 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-focal-20230403060017 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-focal-20230403060017 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-focal-20230403060017 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230403060017 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-focal-20230423104356 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230323105551 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230227123148 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230227123149 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
amqproxy-0.8.x |
mirantis.azurecr.io/general/amqproxy:0.8.6-alpine3.17.3-20230422135216 |
MIT license |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.19-alpine3.17.3 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.8-alpine-20230422141943 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230324153219 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.3.1-alpine-20230422140933 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20220804082840 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230331112513 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.1 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.2.0-20230328221837 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-focal-20230403060017 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-focal-20230403060017 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-focal-20230403060017 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.11-alpine3.17 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.0 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.5-20230422141212 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230323105551 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.26.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.23.4-alpine-slim |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20230323105551 |
GPL-2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-focal-20230403060017 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20230329122808 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-focal-20230403060017 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-focal-20230403060017 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-focal-20230403060017 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230403060017 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-focal-20230403060017 |
Apache License 2.0 |
MOSK 23.1.2 OpenStack Helm charts
MOSK 23.1.2 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.11.10.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.11.10 |
Mirantis Proprietary License |
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:21.4.20230306000000 |
Apache License 2.0 |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:21.4.20230306000000 |
Apache License 2.0 |
|
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:21.4.20230306000000 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:21.4.20230306000000 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:21.4.20230306000000 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:21.4.20230306000000 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:21.4.20230306000000 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:21.4.20230306000000 |
Apache License 2.0 |
TF Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:21.4.20230306000000 |
Apache License 2.0 |
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20230306000000 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:2.1.15 |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.11 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230126 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20230328121138 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20230424135332 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.2 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.3.3 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/jmx-exporter:0.18.0-debian-11-r9 |
Apache License 2.0 |
|
Pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Google Cloud Platform |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.3.2 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.2 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.15-17-de1dffc4 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.7.1-20230323 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.3.7 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:7.0.11-alpine3.17 |
BSD 3-Clause “New” or “Revised” License |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
|
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20230420090701 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20230424100414 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20230328120524 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:21.4.20230306000000 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-48d1e8a-20220919122849 |
Apache License 2.0 |
MOSK 23.1.2 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20230414023012 |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20230330133839 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-1.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Security notes¶
In total, in the MOSK 23.1.2 release, 40 Common Vulnerabilities and Exposures (CVE) have been fixed: 4 of critical and 36 of high severity.
The full list of the CVEs present in the current MOSK release is available at the Mirantis Security Portal.
Known issues¶
This section describes the patch-related known issues with available workarounds.
Fixed in MOSK 23.1.3
The OpenStack upgrade to Yoga fails due to the delay in the Cinder start.
Workaround:
Follow the
openstack-controllerlogs from theOpenStackDeploymentcontainer. When the controller is stuck on checking health for any OpenStack component, verify the Helm releases statuses:helm3 --namespace openstack list
Example of a system response:
NAME NAMESPACE REVISION UPDATED STATUS CHART openstack-cinder openstack 111 2023-04-30 20:49:08.969450386 +0000 UTC failed cinder-0.1.0-mcp-4241
If there is a release in the failed state, roll it back:
helm3 --namespace openstack rollback openstack-cinder
See also
Learn more about new release cadence
23.1.3 patch¶
Release date |
May 22, 2023 |
|---|---|
Scope |
Patch |
Cluster release |
12.7.3 |
OpenStack Operator |
0.12.8 |
Tungsten Fabric Operator |
0.11.11 |
Release artifacts¶
This section lists the components artifacts of the MOSK 23.1.3 release that includes binaries, Docker images, and Helm charts.
MOSK 23.1.3 OpenStack Victoria binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20230223191854.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-victoria-20230128063511.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-focal-20230423104356 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-focal-20230423104356 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-focal-20230423104356 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-focal-20230423104356 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-focal-20230423104356 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-focal-20230423104356 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-focal-20230423104356 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-focal-20230423104356 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-focal-20230423104356 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-focal-20230423104356 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-focal-20230423104356 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-focal-20230423104356 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230427072424 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230427182440 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230427182440 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
amqproxy-0.8.x |
mirantis.azurecr.io/general/amqproxy:0.8.6-alpine3.17.3-20230422135216 |
MIT license |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.19-alpine3.17.3 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.8-alpine-20230422141943 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230324153219 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.3.1-alpine-20230422140933 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20220804082840 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230423170220 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-focal-20230423104356 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-focal-20230423104356 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-focal-20230423104356 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.11-alpine3.17 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.5-20230422141212 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230423172355 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.26.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.23.4-alpine-slim |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20230423172355 |
GPL-2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:victoria-focal-20230423104356 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:victoria-focal-20230423104356 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-focal-20230423172355 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-focal-20230423104356 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-focal-20230423104356 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-focal-20230423104356 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-focal-20230423104356 |
Apache License 2.0 |
MOSK 23.1.3 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20230227101732.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-xena-9f691e3-20220110111511.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-focal-20230423104356 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-focal-20230423104356 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-focal-20230423104356 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-focal-20230423104356 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-focal-20230423104356 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-focal-20230423104356 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-focal-20230423104356 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-focal-20230423104356 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-focal-20230423104356 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-focal-20230423104356 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230423104356 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-focal-20230423104356 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230427072424 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230427182440 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230427182440 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
amqproxy-0.8.x |
mirantis.azurecr.io/general/amqproxy:0.8.6-alpine3.17.3-20230422135216 |
MIT license |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.19-alpine3.17.3 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.8-alpine-20230422141943 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230324153219 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.3.1-alpine-20230422140933 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20220804082840 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230423170220 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-focal-20230423104356 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-focal-20230423104356 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-focal-20230423104356 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.11-alpine3.17 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.5-20230422141212 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230423172355 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.26.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.23.4-alpine-slim |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20230423172355 |
GPL-2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-focal-20230423104356 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20230423172355 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-focal-20230423104356 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-focal-20230423104356 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-focal-20230423104356 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230423104356 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-focal-20230423104356 |
Apache License 2.0 |
MOSK 23.1.3 OpenStack Helm charts
MOSK 23.1.3 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.11.11.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.11.11 |
Mirantis Proprietary License |
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:21.4.20230306000000 |
Apache License 2.0 |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:21.4.20230306000000 |
Apache License 2.0 |
|
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:21.4.20230306000000 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:21.4.20230306000000 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:21.4.20230306000000 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:21.4.20230306000000 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:21.4.20230306000000 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:21.4.20230306000000 |
Apache License 2.0 |
TF Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:21.4.20230306000000 |
Apache License 2.0 |
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20230306000000 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:2.1.16 |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.11 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230126 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20230328121138 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20230424135332 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.2 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.4.0 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/jmx-exporter:0.18.0-debian-11-r9 |
Apache License 2.0 |
|
Pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Google Cloud Platform |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.3.2 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.2 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.15-17-de1dffc4 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.8.1-20230425 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.3.7 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:7.0.11-alpine3.17 |
BSD 3-Clause “New” or “Revised” License |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
|
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20230420090701 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20230424100414 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20230328120524 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:21.4.20230306000000 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-48d1e8a-20220919122849 |
Apache License 2.0 |
MOSK 23.1.3 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20230505023010 |
Mirantis Proprietary License |
tungstenfabric-prometheus-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20230330133839 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-1.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Security notes¶
In total, in the MOSK 23.1.3 release, 7 Common Vulnerabilities and Exposures (CVE) have been fixed: 2 of critical and 5 of high severity.
The full list of the CVEs present in the current MOSK release is available at the Mirantis Security Portal.
Learn more about new release cadence
23.1.4 patch¶
Release date |
June 05, 2023 |
|---|---|
Scope |
Patch |
Cluster release |
12.7.4 |
OpenStack Operator |
0.12.11 |
Tungsten Fabric Operator |
0.11.11 |
Release artifacts¶
This section lists the components artifacts of the MOSK 23.1.4 release that includes binaries, Docker images, and Helm charts.
MOSK 23.1.4 OpenStack Victoria binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20230223191854.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
kernel |
GPL-2.0 |
|
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-victoria-20230128063511.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-focal-20230423104356 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-focal-20230423104356 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-focal-20230423104356 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-focal-20230423104356 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-focal-20230423104356 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-focal-20230423104356 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-focal-20230423104356 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-focal-20230423104356 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-focal-20230423104356 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-focal-20230423104356 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-focal-20230423104356 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-focal-20230423104356 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230427072424 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230524130506 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230524130506 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20230524115243 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
amqproxy-0.8.x |
mirantis.azurecr.io/general/amqproxy:0.8.6-alpine3.17.3-20230422135216 |
MIT license |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.19-alpine3.17.3 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.8-alpine-20230422141943 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230523174753 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.3.1-alpine-20230422140933 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20220804082840 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230423170220 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-focal-20230423104356 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-focal-20230423104356 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-focal-20230423104356 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.11-alpine3.17 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20230522060448 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230423172355 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.23.4-alpine-slim |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20230423172355 |
GPL-2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:victoria-focal-20230423104356 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:victoria-focal-20230423104356 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-focal-20230423172355 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-focal-20230423104356 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-focal-20230423104356 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-focal-20230423104356 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-focal-20230423104356 |
Apache License 2.0 |
MOSK 23.1.4 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20230227101732.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-xena-9f691e3-20220110111511.tar.gz |
Mirantis Proprietary License |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.vmlinuz |
GPL-2.0 |
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20230128061113.gz |
GPL-2.0 |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-20221228132450.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-focal-20230524115243 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-focal-20230524115243 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-focal-20230524115243 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-focal-20230524115243 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-focal-20230524115243 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-focal-20230524115243 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-focal-20230524115243 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-focal-20230524115243 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-focal-20230524115243 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-focal-20230524115243 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20230524115243 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-focal-20230524115243 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20230427072424 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20230524130506 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20230524130506 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20230524115243 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.18-focal-20230222154055 |
Mozilla Public License 2.0 |
amqproxy-0.8.x |
mirantis.azurecr.io/general/amqproxy:0.8.6-alpine3.17.3-20230422135216 |
MIT license |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-27d64fb-20230421151539 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.19-alpine3.17.3 |
BSD 3-Clause “New” or “Revised” License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.8-alpine-20230422141943 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.7-alpine-20230523174753 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.3.1-alpine-20230422140933 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20220804082840 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.12-focal-20230423170220 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.11.3 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-focal-20230524115243 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-focal-20230524115243 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-focal-20230524115243 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:7.0.11-alpine3.17 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.5.1 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.8-20230522060448 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20230423172355 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.27.0 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.23.4-alpine-slim |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20230423172355 |
GPL-2.0 |
requirements |
mirantis.azurecr.io/openstack/requirements:yoga-focal-20230524115243 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20230423172355 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-focal-20230524115243 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-focal-20230524115243 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-focal-20230524115243 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20230524115243 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-focal-20230524115243 |
Apache License 2.0 |
MOSK 23.1.4 OpenStack Helm charts
MOSK 23.1.4 Tungsten Fabric 21.4 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.11.11.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.11.11 |
Mirantis Proprietary License |
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:21.4.20230306000000 |
Apache License 2.0 |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:21.4.20230306000000 |
Apache License 2.0 |
|
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:21.4.20230306000000 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:21.4.20230306000000 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:21.4.20230306000000 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:21.4.20230306000000 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:21.4.20230306000000 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:21.4.20230306000000 |
Apache License 2.0 |
TF Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:21.4.20230306000000 |
Apache License 2.0 |
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20230306000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20230306000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20230306000000 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:2.1.16 |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.11 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10-20230126 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20230328121138 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20230424135332 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.3.2 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.4.0 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/jmx-exporter:0.18.0-debian-11-r9 |
Apache License 2.0 |
|
Pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Google Cloud Platform |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.3.2 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.2 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:1.0.0-RC19 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.15-17-de1dffc4 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.8.1-20230425 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.3.7 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:7.0.11-alpine3.17 |
BSD 3-Clause “New” or “Revised” License |
mirantis.azurecr.io/stacklight/redis_exporter:v1.45.0 |
BSD 3-Clause “New” or “Revised” License |
|
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20230420090701 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20230424100414 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20230328120524 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:21.4.20230306000000 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-48d1e8a-20220919122849 |
Apache License 2.0 |
MOSK 23.1.4 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.2-20230519023010 |
Mirantis Proprietary License |
tungstenfabric-prometheus-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20230330133839 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-1.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Security notes¶
In total, in the MOSK 23.1.4 release, 8 Common Vulnerabilities and Exposures (CVE) have been fixed: 1 of critical and 7 of high severity.
The full list of the CVEs present in the current MOSK release is available at the Mirantis Security Portal.
Image |
Component name |
CVE |
|---|---|---|
openstack/extra/descheduler |
golang.org/x/net |
CVE-2022-41723 (High) |
openstack/extra/powerdns |
libpq |
CVE-2023-2454 (High) |
openstack/extra/strongswan |
libcurl |
CVE-2023-28319 (High) |
CVE-2023-28321 (High) |
||
CVE-2023-28322 (High) |
||
libcap |
CVE-2023-2603 (High) |
|
openstack/horizon |
django |
CVE-2023-31047 (Critical) |
openstack/manila |
sqlparse |
CVE-2023-30608 (High) |
Addressed issues¶
The following issues have been addressed in the MOSK 23.1.4 release:
[27031] Fixed the removal of objects marked as
Deletedfrom the Barbican database during the database cleanup.[30224] Decreased the default weight for
build_failure_weight_multiplierto2to normalize instance spreading across compute nodes.[30673] Fixed the issue with duplicate tasks responses from the
ironic-pythonagent on theironic-conductorside.[30888] Adjusted the caching time for PowerDNS to fit Designate timeouts.
[31021] Fixed the race in
openstack-controllerthat could lead to setting the default user names and passwords in configuration files during initial deployment.[31358] Configured the warning message about the world readable directory with fernet keys to be logged only once during the startup.
[31711] Started to pass the autogenerated
memcache_secret_keyto avoid its regeneration every time the Manila Helm chart gets updated.
Known issues¶
This section describes the patch-related known issues with available workarounds.
During the initial deployment of Mirantis Container Cloud, some nodes may get stuck in the cleaning state. The workaround is to wipe disks manually before initializing the Mirantis Container Cloud bootstrap.
Learn more about new release cadence
22.5¶
Release date |
December 19, 2022 |
|---|---|
Name |
MOSK 22.5 |
Cluster release |
12.5.0 |
Highlights |
The fifth and last MOSK release in 2022 introduces the following key features:
|
New features¶
Component |
Support scope |
Feature |
|---|---|---|
OpenStack |
Full |
|
Full |
||
TechPreview |
||
TechPreview |
||
Mirantis Kubernetes Engine |
Full |
|
Ceph |
Full |
Automated configuration of public FQDN for the Object Storage endpoint |
StackLight |
Full |
|
Container Cloud |
Full |
|
Documentation |
n/a |
OpenStack Yoga¶
Added full support for OpenStack Yoga with Open vSwitch and Tungsten Fabric 2011 networking back ends.
Starting from 22.5, MOSK deploys all new clouds using OpenStack Yoga by default. To upgrade an existing cloud from OpenStack Victoria to Yoga, follow the Upgrade OpenStack procedure.
For the OpenStack support cycle in MOSK, refer to OpenStack support cycle.
Highlights from upstream supported by Mirantis OpenStack deployed on Yoga
[Cinder] Removed the deprecated Block Storage API version 2.0. Instead, use the Block Storage API version 3.0 that is fully compatible with the previous version.
[Cinder] Removed the requirement for the request URLs to contain a project ID in the Block Storage API making it more consistent with other OpenStack APIs. For backward compatibility, legacy URLs containing a project ID continue to be recognized.
[Designate] Added support for the
CERTresource record type enabling new use cases such as secure email and publication of certificate revocation list through DNS.[Horizon] Added support for the Network QoS Policy creation.
[Glance] Implemented
/v2/images/<image-id>/tasksto get tasks associated with an image.[Ironic] Changed the default deployment boot mode from legacy BIOS to UEFI.
[Masakari] Added support for disabling and enabling failover segments. Now, cloud operators can put whole segments into the maintenance mode.
[Neutron] Implemented the
address-groupsresource that can be used to add groups of IP addresses to security group rules.[Nova] Added support for the API microversion 2.90. It enables the users to configure the host name exposed through the Nova metadata service during instances creating or rebuilding.
[Octavia] Increased the performance and scalability of load balancers that use the amphora provider when using amphora images built with version 2.x of the HAProxy load balancing engine.
[Octavia] Improved the observability of load balancers by adding the
PROMETHEUSlisteners that expose a Prometheus exporter endpoint. The Octavia amphora provider exposes over 150 unique metrics.
Exposable OpenStack notifications¶
Implemented the capability to securely expose part of a MOSK cluster message bus (RabbitMQ) to the outside world. This enables external consumers to subscribe to notification messages emitted by the cluster services and can be helpful in several use cases:
Analysis of notification history for retrospective security audit
Real-time aggregation of notification messages to collect statistics of cloud resource consumption for capacity planning or charge-back
The external notification endpoint can be easily enabled and configured through
the OpenStackDeployment custom resource.
L3 networking for MOSK control plane¶
TechPreview
Implemented the ability to enable the BGP load-balancing mode for MOSK underlying Kubernetes to allow distribution of services providing OpenStack APIs across multiple independent racks that have no L2 segments in common.
MKE minor version update to 3.5.5¶
Based MOSK 22.5 on the Cluster release 12.5.0 that supports Mirantis Kubernetes Engine (MKE) 3.5.5.
Learn more
Automated configuration of public FQDN for the Object Storage endpoint¶
The fully qualified domain name (FQDN) for the Object Storage service
(Ceph Object gateway) public endpoint is now configurable through just
a single parameter in the KaaSCephCluster custom resource, which is
spec.cephClusterSpec.ingress.publicDomain. Previously, you had to perform
a set of manual steps to define a custom name. If the parameter is not set,
the FQDN settings from the OpenStackDeployment custom resource apply
by default.
The new parameter simplifies configuration of Transport Layer Security of user-facing endpoints of the Object Storage service.
Enhancements for etcd monitoring¶
Implemented the following enhancements for etcd monitoring:
Introduced etcd monitoring for OpenStack by implementing the Etcd Grafana dashboard and by adding OpenStack to the set of existing alerts for etcd that were used for MKE clusters only in previous releases.
Improved etcd monitoring for MKE on MOSK clusters by implementing the Etcd dashboard and
etcdDbSizeCriticalandetcdDbSizeMajoralerts that inform about the size of the etcd database.
Setting of a custom value for a node label using web UI¶
Implemented the ability to set a custom value for a predefined node label using
the Container Cloud web UI. The list of available node labels is
obtained from allowedNodeLabels of your current Cluster release.
If the value field is not defined in allowedNodeLabels, select the
check box of the required label and define an appropriate custom value for
this label to be set to the node.
Documentation enhancements¶
Published concept documentation about implementing edge computing in MOSK using the remote computes design
Learn more
Restructured the content about the maintenance of OpenStack databases
Major components versions¶
Mirantis has tested MOSK against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOSK components with the exact versions against which testing has been performed.
Component |
Version |
|---|---|
Cluster release |
12.5.0 (Cluster release notes) |
OpenStack |
Yoga |
OpenStack Operator |
0.11.7 |
Tungsten Fabric |
|
Tungsten Fabric Operator |
0.10.5 |
See also
For the supported versions of operating system, Ceph, and other components, refer to Release Compatibility Matrix.
Known issues¶
This section describes the MOSK known issues with available workarounds. For the known issues in the related version of Mirantis Container Cloud, refer to Mirantis Container Cloud: Release Notes.
OpenStack known issues¶
This section lists the OpenStack known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.5.
[29501] Cinder periodic database cleanup resets the state of volumes
[25594] Security groups shared through RBAC cannot be used to create instances
One of the most common symptoms of the high CPU load of MariaDB is slow API responses. To troubleshoot the issue, verify the CPU consumption of MariaDB using the General > Kubernetes Pods Grafana dashboard or through the CLI as follows:
Obtain the resource consumption details for the MariaDB server:
kubectl -n openstack exec -it mariadb-server-0 -- bash mysql@mariadb-server-0:/$ top
Example of system response:
top - 19:16:29 up 278 days, 20:56, 0 users, load average: 16.62, 16.54, 16.39 Tasks: 8 total, 1 running, 7 sleeping, 0 stopped, 0 zombie %Cpu(s): 6.3 us, 2.8 sy, 0.0 ni, 89.6 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st MiB Mem : 515709.3 total, 375731.7 free, 111383.8 used, 28593.7 buff/cache MiB Swap: 0.0 total, 0.0 free, 0.0 used. 399307.2 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 275 mysql 20 0 76.3g 18.8g 1.0g S 786.4 3.7 22656,15 mysqld
Determine which exact query is progressing. This is usually the one in the
Sending datastate:mysql@mariadb-server-0:/$ mysql -u root -p$MYSQL_DBADMIN_PASSWORD -e "show processlist;" | grep -v Sleep
Example of system response:
Id User Host db Command Time State Info Progress 60067757 placementgF9D11u29 10.233.195.246:40746 placement Query 10 Sending data SELECT a.id, a.resource_class_id, a.used, a.updated_at, a.created_at, c.id AS consumer_id, c.generat 0.000
Obtain more information about the query and the used tables:
mysql@mariadb-server-0:/$ mysql -u root -p$MYSQL_DBADMIN_PASSWORD -e " ANALYZE FORMAT=JSON SELECT <QUERY_ID>;"
Example of system response:
"table": { "table_name": "c", "access_type": "eq_ref", "possible_keys": [ "uniq_consumers0uuid", "consumers_project_id_user_id_uuid_idx", "consumers_project_id_uuid_idx" ], "key": "uniq_consumers0uuid", "key_length": "110", "used_key_parts": ["uuid"], "ref": ["placement.a.consumer_id"], "r_loops": 838200, "rows": 1, "r_rows": 1, "r_table_time_ms": 62602.5453, "r_other_time_ms": 369.5835268, "filtered": 100, "r_filtered": 0.005249344, "attached_condition": "c.user_id = u.`id` and c.project_id = p.`id`" }
If you are observing a huge difference between the
filteredandr_filteredcolumns for the query, as in the example of system response above, analyze the performance of tables by running the ANALYZE TABLE <TABLE_NAME>; and ANALYZE TABLE <TABLE_NAME> PERSISTENT FOR ALL; commands:mysql@mariadb-server-0:/$ mysql -u root -p$MYSQL_DBADMIN_PASSWORD MariaDB > ANALYZE TABLE placement.allocations; MariaDB > ANALYZE TABLE placement.allocations PERSISTENT FOR ALL; MariaDB > ANALYZE TABLE placement.consumers; MariaDB > ANALYZE TABLE placement.consumers PERSISTENT FOR ALL; MariaDB > ANALYZE TABLE placement.users; MariaDB > ANALYZE TABLE placement.users PERSISTENT FOR ALL; MariaDB > ANALYZE TABLE placement.projects; MariaDB > ANALYZE TABLE placement.projects PERSISTENT FOR ALL;
Due to an issue in the database auto-cleanup job for the Block Storage service
(OpenStack Cinder), the state of volumes that are attached to instances gets
reset every time the job runs. The instances can still write and read block
storage data, however, volume objects appear in the OpenStack API as
not attached causing confusion.
The workaround is to temporarily disable the job until the issue is fixed and execute the script below to restore the affected instances.
To disable the job, update the OpenStackDeployment custom resource as
follows:
kind: OpenStackDeployment
spec:
features:
database:
cleanup:
cinder:
enabled: false
To restore the affected instances:
Obtain one of the Nova API pods:
nova_api_pod=$(kubectl -n openstack get pod -l application=nova,component=os-api --no-headers | head -n1 | awk '{print $1}')
Download the
restore_volume_attachments.pyscript to your local environment.Note
The provided script does not fix the Cinder database clean-up job and is only intended to restore the functionality of the affected instances. Therefore, leave the job disabled.
Copy the script to the Nova API pod:
kubectl -n openstack cp restore_volume_attachments.py $nova_api_pod:tmp/
Run the script in the dry-run mode to only list affected instances and volumes:
kubectl -n openstack exec -ti $nova_api_pod -- python /tmp/restore_volume_attachments.py --dry-run
Run the script to restore the volume attachments:
kubectl -n openstack exec -ti $nova_api_pod -- python /tmp/restore_volume_attachments.py
Multiprotocol Label Switching over Generic Routing Encapsulation (MPLSoGRE) provides limited throughput while sending data between VMs up to 38 Mbps, as per Mirantis tests.
As a workaround, switch the encapsulation type to VXLAN in the
OpenStackDeployment custom resource:
spec:
services:
networking:
neutron:
values:
conf:
bagpipe_bgp:
dataplane_driver_ipvpn:
mpls_over_gre: "False"
vxlan_encap: "True"
Tungsten Fabric known issues¶
This section lists the Tungsten Fabric known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.5. For Tungsten Fabric limitations, see Tungsten Fabric known limitations.
[13755] TF pods switch to CrashLoopBackOff after a simultaneous reboot
[10096] tf-control does not refresh IP addresses of Cassandra pods
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete a Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica number>
The tf-control service resolves the DNS names of Cassandra pods at startup
and does not update them if Cassandra pods got new IP addresses, for example,
in case of a restart. As a workaround, to refresh the IP addresses of
Cassandra pods, restart the tf-control pods one by one:
kubectl -n tf delete pod tf-control-<hash>
Caution
Before restarting the tf-control pods:
Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only one
tf-controlpod that will be restarted.
Cluster update known issues¶
This section lists the cluster update known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.5.
[29438] Cluster update gets stuck during the Tungsten Fabric operator update
[27797] Cluster ‘kubeconfig’ stops working during MKE minor version update
If the tungstenfabric-operator-metrics service was present on the cluster
in MOSK 22.4, the update to 22.5 can stuck due to absence
of correct labels for this service. As a workaround, delete the service
manually:
kubectl -n tf delete svc tungstenfabric-operator-metrics
During update of a Container Cloud management cluster, if the MKE minor
version is updated from 3.4.x to 3.5.x, access to the cluster using the
existing kubeconfig fails with the You must be logged in to the server
(Unauthorized) error due to OIDC settings being reconfigured.
As a workaround, during the Container Cloud cluster update, use the
admin kubeconfig instead of the existing one. Once the update
completes, you can use the existing cluster kubeconfig again.
To obtain the admin kubeconfig:
kubectl --kubeconfig <pathToMgmtKubeconfig> get secret -n <affectedClusterNamespace> \
-o yaml <affectedClusterName>-kubeconfig | awk '/admin.conf/ {print $2}' | \
head -1 | base64 -d > clusterKubeconfig.yaml
Ceph known issues¶
This section lists the Ceph known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.5.
The status section in the KaaSCephCluster.status CR does not reflect
issues during the process of a Ceph cluster deletion.
As a workaround, inspect Ceph Controller logs on the managed cluster:
kubectl --kubeconfig <managedClusterKubeconfig> -n ceph-lcm-mirantis logs <ceph-controller-pod-name>
StackLight known issues¶
This section lists the StackLight known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.5.
If a cluster does not currently have any ongoing operations that comprise
OpenStack notifications, the fluentd containers in the
fluentd-notifications Pods are frequently restarted due to false-positive
failures of liveness probe and trigger alerts.
Ignore such failures and alerts if the Pods are in the Running state.
To verify the fluentd-notifications Pods:
kubectl get po -n stacklight -l app=fluentd
Example of system response:
fluentd-notifications-64fdc5f5cd-pgmjp 1/1 Running 9 4h51m
fluentd-notifications-64fdc5f5cd-xjfrs 1/1 Running 9 4h51m
Release artifacts¶
This section lists the components artifacts of the MOSK 22.5 release that includes binaries, Docker images, and Helm charts.
MOSK 22.5 OpenStack Yoga binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20221117061110.gz |
GPL-2.0 |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20221117061110.vmlinuz |
GPL-2.0 |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-xena-9f691e3-20220110111511.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20221118095950.qcow2 |
Mirantis Proprietary License |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-1.3.0-77.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-focal-20221118093824 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-focal-20221118093824 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-focal-20221118093824 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-focal-20221118093824 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-focal-20221118093824 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-focal-20221118093824 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-focal-20221118093824 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-focal-20221118093824 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-focal-20221118093824 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-focal-20221118093824 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20221118093824 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-focal-20221118093824 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20221028120749 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20221028120749 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20221028120749 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20221118093824 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.7-focal-20220810183358 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.7-focal-20220810183358 |
Mozilla Public License 2.0 |
amqproxy-0.7.x |
mirantis.azurecr.io/general/amqproxy:v0.7.0 |
MIT license |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-48d1e8a-20220919122849 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.17-alpine3.16 |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:pacific-focal-20221027123328 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.4-alpine-20221116085516 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.3.0 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20220804082840 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.7-focal-20221028120155 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0.9.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.2.0-20221108015104 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-focal-20221118093824 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-focal-20221118093824 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-focal-20221118093824 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:6.2.6-alpine3.15 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.3.1 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.5-20221028090933 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20221028120749 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.25.0-amd64-20220922181123 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.23.2-alpine |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20221028120749 |
GPL-2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20221028141101 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-focal-20221118093824 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-focal-20221118093824 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-focal-20221118093824 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20221118093824 |
Apache License 2.0 |
manila |
mirantis.azurecr.io/openstack/manila:yoga-focal-20221118093824 |
Apache License 2.0 |
MOSK 22.5 OpenStack Victoria binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-victoria-20221021063512.gz |
GPL-2.0 |
kernel |
GPL-2.0 |
|
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20221028084954.qcow2 |
Mirantis Proprietary License |
service-image |
https://binary.mirantis.com/openstack/bin/manila/manila-service-image-1.3.0-77.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-focal-20221028080549 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-focal-20221028080549 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-focal-20221028080549 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-focal-20221028080549 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-focal-20221028080549 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-focal-20221028080549 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-focal-20221028080549 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-focal-20221028080549 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-focal-20221028080549 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-focal-20221028080549 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-focal-20221028080549 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-focal-20221028080549 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20221028120749 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20221028120749 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20221028120749 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:yoga-focal-20221028080549 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.7-focal-20220810183358 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.7-focal-20220810183358 |
Mozilla Public License 2.0 |
amqproxy-0.7.x |
mirantis.azurecr.io/general/amqproxy:v0.7.0 |
MIT license |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-48d1e8a-20220919122849 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.17-alpine3.16 |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:pacific-focal-20221027123328 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.4-alpine-20221116085516 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.3.0 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20220804082840 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.7-focal-20221028120155 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0.9.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.2.0-20221003215949 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-focal-20221028080549 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-focal-20221028080549 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-focal-20221028080549 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:6.2.6-alpine3.15 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.3.1 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.5-20221028090933 |
GPL License |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20221028120749 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.25.0-amd64-20220922181123 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.23.2-alpine |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20221028120749 |
GPL-2.0 |
placement |
mirantis.azurecr.io/openstack/placement:victoria-focal-20221028080549 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-focal-20221028141116 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-focal-20221028080549 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-focal-20221028080549 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-focal-20221028080549 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-focal-20221028080549 |
Apache License 2.0 |
MOSK 22.5 OpenStack Helm charts
MOSK 22.5 Tungsten Fabric 2011 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.10.5.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.10.5 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:2011.20221123000911 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:2011.20221123000911 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:2011.20221123000911 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:2011.20221123000911 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:2011.20221123000911 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:2011.20221123000911 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:2011.20221123000911 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:2011.20221123000911 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:2011.20221123000911 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:2011.20221123000911 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:2011.20221123000911 |
Apache License 2.0 |
|
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:2011.20221123000911 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:2011.20221123000911 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:2011.20221123000911 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:2011.20221123000911 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:2011.20221123000911 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:2011.20221123000911 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:2011.20221123000911 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:2011.20221123000911 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:2011.20221123000911 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:2011.20221123000911 |
Apache License 2.0 |
Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:2011.20221123000911 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:2.1.14 |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.10 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20220919122317 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20220919114133 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.2.2 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.2.2 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/prometheus-jmx-exporter:0.17.2-debian-11-r6 |
Apache License 2.0 |
|
Pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Google Cloud Platform |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.2.3 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.2 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.14 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.7.1-20220914 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.3.4 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:7.0.5-alpine3.16 |
BSD 3-Clause “New” or “Revised” License |
mirantis.azurecr.io/openstack/extra/redis_exporter:v1.43.0-alpine |
BSD 3-Clause “New” or “Revised” License |
|
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20221205131707 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20221030153940 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20221109111149 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:2011.20221123000911 |
Apache License 2.0 |
MOSK 22.5 Tungsten Fabric 21.4 artifacts
Important
Tungsten Fabric 21.4 is available as technical preview. For details, see Tungsten Fabric 21.4 support.
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.10.5.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.10.5 |
Mirantis Proprietary License |
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:21.4.20221205000000 |
Apache License 2.0 |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:21.4.20221205000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:21.4.20221205000000 |
Apache License 2.0 |
|
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:21.4.20221205000000 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:21.4.20221205000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:21.4.20221205000000 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:21.4.20221205000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:21.4.20221205000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:21.4.20221205000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:21.4.20221205000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:21.4.20221205000000 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:21.4.20221205000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:21.4.20221205000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:21.4.20221205000000 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:21.4.20221205000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:21.4.20221205000000 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:21.4.20221205000000 |
Apache License 2.0 |
TF Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:21.4.20221205000000 |
Apache License 2.0 |
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20221205000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20221205000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20221205000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20221205000000 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:2.1.14 |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.10 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20220919122317 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20220919114133 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.2.2 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.2.2 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/prometheus-jmx-exporter:0.17.2-debian-11-r6 |
Apache License 2.0 |
|
Pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Google Cloud Platform |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.2.3 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/tungsten/rabbitmq:3.11.2 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.14 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.7.1-20220914 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.3.4 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:7.0.5-alpine3.16 |
BSD 3-Clause “New” or “Revised” License |
mirantis.azurecr.io/openstack/extra/redis_exporter:v1.43.0-alpine |
BSD 3-Clause “New” or “Revised” License |
|
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20221205131707 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20221030153940 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20221109111149 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:21.4.20221205000000 |
Apache License 2.0 |
MOSK 22.5 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.1-20200610164751 |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20210115152338 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-1.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the MOSK 22.5 release:
[26773] Fixed the issue with VM autoscaling failure when using the CPU-related metrics in Telemetry.
[26534] Fixed the issue with the
ironic-conductorPod getting stuck in theCrashLoopBackOffstate after the Container Cloud management cluster upgrade from 2.19.0 to 2.20.0. The issue occurred due to the race condition between theironic-conductorandironic-conductor-httpcontainers of theironic-conductorPod that tried to useca-bundle.pemsimultaneously but from different users.[25594][Yoga] Fixed the issue with security groups shared through RBAC not being filtered and used by Nova to create instances due to the OpenStack known issue #1942615.
Note
The bug still affects OpenStack Victoria and is fixed for OpenStack Yoga.
[24435] Fixed the issue with MetalLB speaker failing to announce the LB IP for the Ingress service after the MOSK cluster update.
For existing clusters, you can set
externalTrafficPolicyback fromClustertoLocalafter updating to 22.5. For details, see Post-upgrade actions.
Update notes¶
This section describes the specific actions you as a Cloud Operator need to complete to accurately plan and successfully perform your Mirantis OpenStack for Kubernetes (MOSK) cluster update to the version 22.5. Consider this information as a supplement to the generic update procedure published in Operations Guide: Update a MOSK cluster.
Additionally, read through the Cluster update known issues for the problems that are known to occur during update with recommended workarounds.
Features¶
The MOSK cluster will obtain the newly implemented capabilities automatically with no significant impact on the update procedure.
Update impact and maintenance windows planning¶
The update to MOSK 22.5 does not include any version-specific impact on the cluster. To start planning a maintenance window, use the Operations Guide: Update a MOSK cluster standard procedure.
Pre-update actions¶
Before you proceed with updating the cluster, make sure that you perform the following pre-update actions if applicable:
Due to the [29438] Cluster update gets stuck during the Tungsten Fabric operator update known issue, the MOSK cluster update from 22.4 to 22.5 can get stuck. Your cluster is affected if it has been updated from MOSK 22.3 to 22.4, regardless of the SDN back end in use (Open vSwitch or Tungsten Fabric). The newly deployed MOSK 22.4 clusters are not affected.
To avoid the issue, manually delete the
tungstenfabric-operator-metricsservice from the cluster before update:kubectl -n tf delete svc tungstenfabric-operator-metrics
Due to the known issue in the database auto-cleanup job for the Block Storage service (OpenStack Cinder), the state of volumes that are attached to instances gets reset every time the job runs. The workaround is to temporarily disable the job until the issue is fixed. For details, refer to [29501] Cinder periodic database cleanup resets the state of volumes.
Post-update actions¶
The OIDCClaimDelimiter parameter defines the delimiter to use when setting
multi-valued claims in the HTTP headers. See the MOSK 22.5 OpenStack API
Reference
for details.
The current default value of the OIDCClaimDelimiter parameter is ",".
This value misaligns with the behavior expected by Keystone. As a result, when
creating federation mappings for Keystone, the cloud operator may be forced
to write more complex rules. Therefore, in early 2023, Mirantis will change
the default value for the OIDCClaimDelimiter parameter.
Affected deployments
Proceed with the instruction below only if the following conditions are true:
Keystone is set to use federation through the OpenID Connect protocol, with Mirantis Container Cloud Keycloak in particular. The following configuration is present in your
OpenStackDeploymentcustom resource:kind: OpenStackDeployment spec: features: keystone: keycloak: enabled: true
No value has already been specified for the
OIDCClaimDelimiterparameter in yourOpenStackDeploymentcustom resource.
To facilitate smooth transition of the existing deployments to the new default
value, explicitly define the OIDCClaimDelimiter parameter as follows:
kind: OpenStackDeployment
spec:
features:
keystone:
keycloak:
oidc:
OIDCClaimDelimiter: ","
Note
The new default value for the OIDCClaimDelimiter parameter
will be ";". To find out whether your Keystone mappings will need
adjustment after changing the default value, set the parameter to
";" on your staging environment and verify the rules.
In MOSK 22.4 and older versions, the OpenStack Ingress
service was not accessible through its LB IP address on the environments
having the external network restricted to a few nodes in the
MOSK cluster. For such use cases, Mirantis recommended
setting the externalTrafficPolicy parameter to Cluster as a workaround.
The issue #24435 has been fixed in
MOSK 22.5. Therefore, if the monitoring of source IPs of
the requests to OpenStack services is required, you can set the
externalTrafficPolicy parameter back to Local.
Affected deployments
You are affected if your deployment configuration matches the following conditions:
The external network is restricted to a few nodes in the MOSK cluster. In this case, only a limited set of nodes have IPs in the external network where MetalLB announces LB IPs.
The workaround was applied by setting
externalTrafficPolicy=Clusterfor the Ingress service.
To set externalTrafficPolicy back from Cluster to Local:
On the MOSK cluster, add the node selector to the
L2AdvertisementMetalLB object so that it matches the nodes in the MOSK cluster having IPs in the external network, or a subset of those nodes.Example command to edit
L2Advertisement:kubectl -n metallb-system edit l2advertisements
Example of
L2Advertisement.spec:spec: ipAddressPools: - services nodeSelectors: - matchLabels: openstack-control-plane: enabled
The
openstack-control-plane: enabledlabel selector defines nodes in the MOSK cluster having IPs in the external network.In the MOSK
Clusterobject located on the management cluster, remove or edit node selectors and affinity for MetalLB speaker in the MetalLB chart values, if required.Example of the
helmReleasessection inCluster.specafter editing thenodeSelectorparameter:helmReleases: - name: metallb values: configInline: address-pools: [] speaker: nodeSelector: kubernetes.io/os: linux resources: limits: cpu: 100m memory: 500Mi
The MetalLB speaker DaemonSet must have the same node selector as the OpenStack Ingress service DaemonSet.
Note
By default, the OpenStack Ingress service Pods run on all Linux cluster nodes.
Change
externalTrafficPolicytoLocalfor the OpenStack Ingress service.Example command to alter the
Ingressobject:kubectl -n openstack patch svc ingress -p '{"spec":{"externalTrafficPolicy":"Local"}}'
Verify that OpenStack services are accessible through the load balancer IP of the OpenStack Ingress service.
The OpenStack Panko service has been removed from the product since MOSK 22.2 in OpenStack Victoria without the user being involved. See Deprecation Notes: The OpenStack Panko service for details.
Though, in MOSK 22.5, before upgrading to OpenStack Yoga,
verify that you remove the Panko service from the cloud by removing the
event entry from the spec:features:services structure in the
OpenStackDeployment resource as described in Operations Guide:
Remove an OpenStack service.
Security notes¶
The table below contains the number of vendor-specific addressed CVEs with Critical or High severity.
In total, in the MOSK 22.5 release, 108 CVEs have been fixed and 77 artifacts (images) updated.
Fixed CVE ID |
# of updated artifacts |
|---|---|
CVE-2022-29187 |
1 |
CVE-2022-29155 |
1 |
CVE-2022-24765 |
1 |
CVE-2022-23219 |
1 |
CVE-2022-23218 |
1 |
CVE-2022-2068 |
2 |
CVE-2022-1679 |
1 |
CVE-2022-1664 |
2 |
CVE-2022-1292 |
2 |
CVE-2021-39686 |
1 |
CVE-2021-3847 |
1 |
CVE-2021-3737 |
1 |
CVE-2021-3520 |
1 |
CVE-2021-33574 |
1 |
CVE-2021-30475 |
1 |
CVE-2021-30474 |
1 |
CVE-2021-30473 |
1 |
CVE-2021-29921 |
1 |
CVE-2021-20312 |
1 |
CVE-2021-20309 |
1 |
CVE-2021-20246 |
1 |
CVE-2021-20245 |
1 |
CVE-2021-20244 |
1 |
CVE-2019-9169 |
1 |
CVE-2019-25013 |
1 |
CVE-2019-19814 |
1 |
CVE-2019-15794 |
1 |
CVE-2019-12900 |
1 |
CVE-2018-6551 |
1 |
CVE-2018-6485 |
1 |
CVE-2018-1000001 |
1 |
CVE-2016-2779 |
1 |
CVE-2015-20107 |
1 |
CVE-2013-7445 |
1 |
ELSA-2022-9564 |
1 |
RHSA-2022:7110 |
1 |
RHSA-2022:6834 |
24 |
RHSA-2022:6778 |
5 |
RHSA-2022:6765 |
26 |
RHSA-2022:6206 |
7 |
RHSA-2022:6180 |
1 |
RHSA-2022:5696 |
1 |
RHSA-2022:5056 |
1 |
RHSA-2022:4991 |
2 |
RHSA-2022:1642 |
1 |
RHSA-2022:1537 |
1 |
The full list of the CVEs present in the current MOSK release is available at the Mirantis Security Portal.
22.4¶
Release date |
September 29, 2022 |
|---|---|
Name |
MOSK 22.4 |
Cluster release |
8.10.0 |
Highlights |
The fourth MOSK release in 2022 introduces the following key features:
|
New features¶
Component |
Support scope |
Feature |
|---|---|---|
OpenStack |
TechPreview |
|
Full |
||
Full |
||
TechPreview |
||
TechPreview |
||
Tungsten Fabric |
TechPreview |
|
Full |
||
Ceph |
Full |
OpenStack Yoga support¶
TechPreview
Provided the technical preview support for OpenStack Yoga with Neutron OVS and Tungsten Fabric 21.4.
To start experimenting with the new functionality, set openstack_version to
yoga in the OpenStackDeployment custom resource during the cloud
deployment.
Tungsten Fabric 21.4 support¶
TechPreview
Provided the technical preview support for Tungsten Fabric 21.4. The new version of the Tungsten Fabric networking enables support for the EVPN type 2 routes for graceful restart and long-lived graceful restart features in MOSK.
Note
Implementation of the Red Hat Universal Base Image 8 (UBI 8) support for the Tungsten Fabric container images is being under development and will be released in one of the upcoming product versions.
To start experimenting with the new functionality, set tfVersion to
21.4 in the TFOperator custom resource during the cloud deployment.
Learn more
Application credentials¶
Enabled the application credentials mechanism in the Identity service for application automation tools to securely authenticate against the cloud’s API.
CADF audit notifications¶
Enabled the capability of the OpenStack services to emit notifications in
the Cloud Auditing Data Federation (CADF) format. The CADF notifications
configuration is available through the features:logging:cadf section of
the OpenStackDeployment custom resource.
Configurable OpenStack region name¶
TechPreview
Added the capability to configure the name of the OpenStack region used for
the deployment. By default, the name is RegionOne.
Learn more
External OpenStack database backups¶
TechPreview
Implemented the capability to store the OpenStack database backup data
externally. Instead of the default Ceph volume, the cloud operator can
now easily configure the NFS storage back end through the
OpenStackDeployment CR.
Learn more
Post-update restart of the TF vRouter pods¶
Implemented the post-update restart of the TF vRouter pods. Previously, the cloud operator had to manually restart the vRouter pods after updating the deployment to a newer MOSK version. The update procedure has been amended accordingly.
Learn more
Ceph cluster summary in the Container Cloud web UI¶
Implemented the capability to easily view the summary and health status of all Ceph clusters through the Container Cloud web UI.
Major components versions¶
Mirantis has tested MOSK against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOSK components with the exact versions against which testing has been performed.
Component |
Version |
|---|---|
Cluster release |
8.10.0 (Cluster release notes) |
OpenStack |
|
OpenStack Operator |
0.10.5 |
Tungsten Fabric |
|
Tungsten Fabric Operator |
0.9.4 |
See also
Known issues¶
This section describes the MOSK known issues with available workarounds. For the known issues in the related version of Mirantis Container Cloud, refer to Mirantis Container Cloud: Release Notes.
OpenStack known issues¶
This section lists the OpenStack known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.4.
One of the most common symptoms of the high CPU load of MariaDB is slow API responses. To troubleshoot the issue, verify the CPU consumption of MariaDB using the General > Kubernetes Pods Grafana dashboard or through the CLI as follows:
Obtain the resource consumption details for the MariaDB server:
kubectl -n openstack exec -it mariadb-server-0 -- bash mysql@mariadb-server-0:/$ top
Example of system response:
top - 19:16:29 up 278 days, 20:56, 0 users, load average: 16.62, 16.54, 16.39 Tasks: 8 total, 1 running, 7 sleeping, 0 stopped, 0 zombie %Cpu(s): 6.3 us, 2.8 sy, 0.0 ni, 89.6 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st MiB Mem : 515709.3 total, 375731.7 free, 111383.8 used, 28593.7 buff/cache MiB Swap: 0.0 total, 0.0 free, 0.0 used. 399307.2 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 275 mysql 20 0 76.3g 18.8g 1.0g S 786.4 3.7 22656,15 mysqld
Determine which exact query is progressing. This is usually the one in the
Sending datastate:mysql@mariadb-server-0:/$ mysql -u root -p$MYSQL_DBADMIN_PASSWORD -e "show processlist;" | grep -v Sleep
Example of system response:
Id User Host db Command Time State Info Progress 60067757 placementgF9D11u29 10.233.195.246:40746 placement Query 10 Sending data SELECT a.id, a.resource_class_id, a.used, a.updated_at, a.created_at, c.id AS consumer_id, c.generat 0.000
Obtain more information about the query and the used tables:
mysql@mariadb-server-0:/$ mysql -u root -p$MYSQL_DBADMIN_PASSWORD -e " ANALYZE FORMAT=JSON SELECT <QUERY_ID>;"
Example of system response:
"table": { "table_name": "c", "access_type": "eq_ref", "possible_keys": [ "uniq_consumers0uuid", "consumers_project_id_user_id_uuid_idx", "consumers_project_id_uuid_idx" ], "key": "uniq_consumers0uuid", "key_length": "110", "used_key_parts": ["uuid"], "ref": ["placement.a.consumer_id"], "r_loops": 838200, "rows": 1, "r_rows": 1, "r_table_time_ms": 62602.5453, "r_other_time_ms": 369.5835268, "filtered": 100, "r_filtered": 0.005249344, "attached_condition": "c.user_id = u.`id` and c.project_id = p.`id`" }
If you are observing a huge difference between the
filteredandr_filteredcolumns for the query, as in the example of system response above, analyze the performance of tables by running the ANALYZE TABLE <TABLE_NAME>; and ANALYZE TABLE <TABLE_NAME> PERSISTENT FOR ALL; commands:mysql@mariadb-server-0:/$ mysql -u root -p$MYSQL_DBADMIN_PASSWORD MariaDB > ANALYZE TABLE placement.allocations; MariaDB > ANALYZE TABLE placement.allocations PERSISTENT FOR ALL; MariaDB > ANALYZE TABLE placement.consumers; MariaDB > ANALYZE TABLE placement.consumers PERSISTENT FOR ALL; MariaDB > ANALYZE TABLE placement.users; MariaDB > ANALYZE TABLE placement.users PERSISTENT FOR ALL; MariaDB > ANALYZE TABLE placement.projects; MariaDB > ANALYZE TABLE placement.projects PERSISTENT FOR ALL;
Multiprotocol Label Switching over Generic Routing Encapsulation (MPLSoGRE) provides limited throughput while sending data between VMs up to 38 Mbps, as per Mirantis tests.
As a workaround, switch the encapsulation type to VXLAN in the
OpenStackDeployment custom resource:
spec:
services:
networking:
neutron:
values:
conf:
bagpipe_bgp:
dataplane_driver_ipvpn:
mpls_over_gre: "False"
vxlan_encap: "True"
Tungsten Fabric known issues¶
This section lists the Tungsten Fabric known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.4. For Tungsten Fabric limitations, see Tungsten Fabric known limitations.
[13755] TF pods switch to CrashLoopBackOff after a simultaneous reboot
[10096] tf-control does not refresh IP addresses of Cassandra pods
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete a Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica number>
The tf-control service resolves the DNS names of Cassandra pods at startup
and does not update them if Cassandra pods got new IP addresses, for example,
in case of a restart. As a workaround, to refresh the IP addresses of
Cassandra pods, restart the tf-control pods one by one:
kubectl -n tf delete pod tf-control-<hash>
Caution
Before restarting the tf-control pods:
Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only one
tf-controlpod that will be restarted.
Cluster update known issues¶
This section lists the cluster update known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.4.
[26534] The ‘ironic-conductor’ Pod fails after the management cluster upgrade
[24435] MetalLB speaker fails to announce the LB IP for the Ingress service
After the Container Cloud management cluster upgrade from 2.19.0 to 2.20.0,
the ironic-conductor Pod gets stuck in the CrashLoopBackOff state. The
issue occurs due to the race condition between the ironic-conductor and
ironic-conductor-http containers of the ironic-conductor Pod that try
to use ca-bundle.pem simultaneously but from different users.
As a workaround, run the following command:
kubectl -n openstack exec -t <failedPodName> -c ironic-conductor-http -- chown 42424:42424 /certs/ca-bundle.pem
After updating the MOSK cluster, MetalLB speaker may fail to announce the Load Balancer (LB) IP address for the OpenStack Ingress service. As a result, the OpenStack Ingress service is not accessible using its LB IP address.
The issue may occur if the MetalLB speaker nodeSelector selects not all
the nodes selected by nodeSelector of the OpenStack Ingress service.
The issue may arise and disappear when a new MetalLB speaker is being selected by the MetalLB Controller to announce the LB IP address.
The issue occurs since MOSK 22.2 after
externalTrafficPolicy was set to local for the OpenStack Ingress
service.
Workaround:
Select from the following options:
Set
externalTrafficPolicytoclusterfor the OpenStack Ingress service.This option is preferable in the following cases:
If not all cluster nodes have connection to the external network
If the connection to the external network cannot be established
If network configuration changes are not desired
If network configuration is allowed and if you require the
externalTrafficPolicy: localoption:Wire the external network to all cluster nodes where the OpenStack Ingress service Pods are running.
Configure IP addresses in the external network on the nodes and change the default routes on the nodes.
Change
nodeSelectorof MetalLB speaker to matchnodeSelectorof the OpenStack Ingress service.
Ceph known issues¶
This section lists the Ceph known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.4.
The status section in the KaaSCephCluster.status CR does not reflect
issues during the process of a Ceph cluster deletion.
As a workaround, inspect Ceph Controller logs on the managed cluster:
kubectl --kubeconfig <managedClusterKubeconfig> -n ceph-lcm-mirantis logs <ceph-controller-pod-name>
StackLight known issues¶
This section lists the StackLight known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.4.
If a cluster does not currently have any ongoing operations that comprise
OpenStack notifications, the fluentd containers in the
fluentd-notifications Pods are frequently restarted due to false-positive
failures of liveness probe and trigger alerts.
Ignore such failures and alerts if the Pods are in the Running state.
To verify the fluentd-notifications Pods:
kubectl get po -n stacklight -l app=fluentd
Example of system response:
fluentd-notifications-64fdc5f5cd-pgmjp 1/1 Running 9 4h51m
fluentd-notifications-64fdc5f5cd-xjfrs 1/1 Running 9 4h51m
Release artifacts¶
This section lists the components artifacts of the MOSK 22.4 release that includes binaries, Docker images, and Helm charts.
MOSK 22.4 OpenStack Victoria binaries and Docker images
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-victoria-20220210133249.gz |
GPL-2.0 |
kernel |
GPL-2.0 |
|
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20220823190806.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-focal-20220823183431 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-focal-20220823183431 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-focal-20220823183431 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-focal-20220823183431 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-focal-20220823183431 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-focal-20220823183431 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-focal-20220823183431 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-focal-20220823183431 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-focal-20220823183431 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-focal-20220823183431 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-focal-20220823183431 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-focal-20220823183431 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20220811132755 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20220811132755 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20220811132755 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:victoria-focal-20220823183431 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.7-focal-20220810183358 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.7-focal-20220810183358 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-44bd8b3-20220812062625 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.16-alpine3.16 |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:pacific-focal-20220705100042 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.4-alpine-20220808224108 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.3.0 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20220804082840 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.7-focal-20220811085105 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0.9.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.2.0-20220711181928 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-focal-20220823183431 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-focal-20220823183431 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-focal-20220823183431 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:6.2.6-alpine3.15 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.3.0 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.5-20220809060458 |
GPL License |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20210901090922 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.24.1-amd64-20220822204951 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.23.1-alpine |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20220811132755 |
GPL-2.0 |
placement |
mirantis.azurecr.io/openstack/placement:victoria-focal-20220823183431 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-focal-20220811132755 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-focal-20220823183431 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-focal-20220823183431 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-focal-20220823183431 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-focal-20220823183431 |
Apache License 2.0 |
MOSK 22.4 OpenStack Yoga binaries and Docker images
Important
OpenStack Yoga is available as technical preview. For details, see OpenStack Yoga support.
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
initramfs |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20220714061116.gz |
GPL-2.0 |
kernel |
https://binary.mirantis.com/openstack/bin/ironic/tinyipa/tinyipa-stable-yoga-20220714061116.vmlinuz |
GPL-2.0 |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-xena-9f691e3-20220110111511.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-yoga-20220905111550.qcow2 |
Mirantis Proprietary License |
Docker images |
||
keystone |
mirantis.azurecr.io/openstack/keystone:yoga-focal-20220905101550 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:yoga-focal-20220905101550 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:yoga-focal-20220905101550 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:yoga-focal-20220905101550 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:yoga-focal-20220905101550 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:yoga-focal-20220905101550 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:yoga-focal-20220905101550 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:yoga-focal-20220905101550 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:yoga-focal-20220905101550 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:yoga-focal-20220905101550 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:yoga-focal-20220905101550 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:yoga-focal-20220905101550 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20220811132755 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20220811132755 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20220811132755 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:victoria-focal-20220823183431 |
Apache License 2.0 |
rabbitmq-3.10.x |
mirantis.azurecr.io/openstack/extra/rabbitmq:3.10.7-focal-20220810183358 |
Mozilla Public License 2.0 |
rabbitmq-3.10.x-management |
mirantis.azurecr.io/openstack/extra/rabbitmq-management:3.10.7-focal-20220810183358 |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.1-44bd8b3-20220812062625 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.16-alpine3.16 |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:pacific-focal-20220705100042”Apache License 2.0 |
LGPL-2.1 or LGPL-3” |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:v3.5.4-alpine-20220808224108 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:1.3.0 |
Apache License 2.0 |
tls-proxy |
mirantis.azurecr.io/openstack/tls-proxy:focal-20220804082840 |
Mirantis Proprietary License |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:v1.19.2-77af1ef-20220823043839 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.7-focal-20220811085105 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0.9.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.2.0-20220711181928 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:yoga-focal-20220905101550 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:yoga-focal-20220905101550 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:yoga-focal-20220905101550 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:6.2.6-alpine3.15 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.3.0 |
GPL-2.0 and LGPL-2.1 |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.5-20220809060458 |
GPL-2.0 |
rsyslog |
mirantis.azurecr.io/openstack/extra/rsyslog:v8.2001.0-20210901090922 |
GNU General Public License v3 |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.24.1-amd64-20220822204951 |
Apache License 2.0 |
nginx |
mirantis.azurecr.io/openstack/extra/nginx:1.23.1-alpine |
Apache License 2.0 |
tgt |
mirantis.azurecr.io/general/tgt:1.0.x-focal-20220811132755 |
GPL-2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:yoga-focal-20220811132755 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:yoga-focal-20220905101550 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:yoga-focal-20220905101550 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:yoga-focal-20220905101550 |
Apache License 2.0 |
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:yoga-focal-20220905101550 |
Apache License 2.0 |
MOSK 22.4 OpenStack Helm charts
MOSK 22.4 Tungsten Fabric 2011 artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.9.4.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.9.4 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:2011.20220907032746 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:2011.20220907032746 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:2011.20220907032746 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:2011.20220907032746 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:2011.20220907032746 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:2011.20220907032746 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:2011.20220907032746 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:2011.20220907032746 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:2011.20220907032746 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:2011.20220907032746 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:2011.20220907032746 |
Apache License 2.0 |
|
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:2011.20220907032746 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:2011.20220907032746 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:2011.20220907032746 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:2011.20220907032746 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:2011.20220907032746 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:2011.20220907032746 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:2011.20220907032746 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:2011.20220907032746 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:2011.20220907032746 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:2011.20220907032746 |
Apache License 2.0 |
Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:2011.20220907032746 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:2.1.4 |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.9 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20220705125748 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:v2-20220616143636 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.2.0 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:7.1.1 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/prometheus-jmx-exporter:0.17.0-debian-11-r29 |
Apache License 2.0 |
|
Pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Google Cloud Platform |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.2.0 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.9.8 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.14 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.7.0-0.2.14 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.3.2 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:7.0.2-alpine3.16 |
BSD 3-Clause “New” or “Revised” License |
mirantis.azurecr.io/openstack/extra/redis_exporter:v1.43.0-alpine |
BSD 3-Clause “New” or “Revised” License |
|
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20220905045430 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20220819122303 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:2011.20220907032746 |
Apache License 2.0 |
ToR agent |
mirantis.azurecr.io/tungsten/contrail-tor-agent:2011.20220907032746 |
Apache License 2.0 |
TF status |
mirantis.azurecr.io/tungsten/contrail-status:2011.20220907032746 |
Apache License 2.0 |
MOSK 22.4 Tungsten Fabric 21.4 artifacts
Important
Tungsten Fabric 21.4 is available as technical preview. For details, see Tungsten Fabric 21.4 support.
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.9.4.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.9.4 |
Mirantis Proprietary License |
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:21.4.20220801000000 |
Apache License 2.0 |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:21.4.20220801000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:21.4.20220801000000 |
Apache License 2.0 |
|
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:21.4.20220801000000 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:21.4.20220801000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:21.4.20220801000000 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:21.4.20220801000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:21.4.20220801000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-dnsmasq:21.4.20220801000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:21.4.20220801000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:21.4.20220801000000 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:21.4.20220801000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:21.4.20220801000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:21.4.20220801000000 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:21.4.20220801000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:21.4.20220801000000 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:21.4.20220801000000 |
Apache License 2.0 |
TF Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:21.4.20220801000000 |
Apache License 2.0 |
TF status |
mirantis.azurecr.io/tungsten/contrail-status:21.4.20220801000000 |
Apache License 2.0 |
TF tools |
mirantis.azurecr.io/tungsten/contrail-tools:21.4.20220801000000 |
Apache License 2.0 |
ToR agent |
mirantis.azurecr.io/tungsten/contrail-tor-agent:21.4.20220801000000 |
Apache License 2.0 |
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:21.4.20220801000000 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent-dpdk:21.4.20220801000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:21.4.20220801000000 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:21.4.20220801000000 |
Apache License 2.0 |
MOSK 22.4 StackLight artifacts
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.1-20200610164751 |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20210115152338 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-1.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the MOSK 22.4 release:
[25349][Update] Fixed the issue causing MOSK cluster update failure after an OpenStack controller node replacement.
[26278][OpenStack] Fixed the issue with
l3-agentbeing stuck in theNot readystate and routers not being initialized properly during Neutron restart.[25447][OpenStack] Fixed the issue that caused a Masakari instance evacuation to fail if an encrypted volume was attached to a node.
[25448][OpenStack] Fixed the issue that caused some Masakari instances to get stuck in the
RebuildorErrorstate when being migrated to a new OpenStack compute node during host evacuation. The issue occurred on OpenStack compute nodes with a large number of instances.[22930][OpenStack] Fixed the issue wherein Octavia load balancers provisioning, and, occasionally, the listeners or pools associated with these load balancers got stuck in the
ERROR,PENDING_UPDATE,PENDING_CREATE, orPENDING_DELETEstate.[25450][OpenStack] Implemented the capability to enable
trustedmode for SR-IOV ports.[25316][StackLight] Introduced projects filtering by a domain name for the
defaultdomain to fix the issue wherein a wrong project was chosen by name in case of multiple projects with the same names.[24376][Ceph] Implemented the capability to parametrize the RADOS Block Device (RBD) device map to avoid Ceph volumes being unresponsive due to a disabled cyclic redundancy check (CRC) mode. Now you can use the
rbdDeviceMapOptionsfield in the Ceph pool parameters of theKaaSCephClusterCR to specify custom RBD map options to use withStorageClassof a corresponding Ceph pool. For details, see Container Cloud documentation: Ceph pool parameters.[28783] [Ceph] Fixed the issue causing Ceph conditon stuck in absence of the Ceph cluster secrets information. If you applied the workaround to your MOSK 22.3 cluster before the update, remove the
versionparameter definition fromKaaSCephClusterafter the managed cluster update because the Ceph cluster version in MOSK 22.4 updates to 15.2.17.
Update notes¶
This section describes the specific actions you as a Cloud Operator need to complete to accurately plan and successfully perform your Mirantis OpenStack for Kubernetes (MOSK) cluster to the version 22.4. Consider this information as a supplement to the generic update procedure published in Operations Guide: Update a MOSK cluster.
Additionally, read through the Cluster update known issues for the problems that are known to occur during update with recommended workarounds.
Features¶
The MOSK cluster will obtain the newly implemented capabilities automatically with no significant impact on the update procedure.
Update impact and maintenance windows planning¶
When updating to MOSK 22.4, the Cloud Operator can easily
determine if a node needs to be rebooted by checking for the
restartRequired flag in the machine status. For details,
see Determine if the node needs to be rebooted.
Post-upgrade actions¶
The OIDCClaimDelimiter parameter defines the delimiter to use when setting
multi-valued claims in the HTTP headers. See the MOSK 22.4 OpenStack API
Reference
for details.
The current default value of the OIDCClaimDelimiter parameter is ",".
This value misaligns with the behavior expected by Keystone. As a result, when
creating federation mappings for Keystone, the cloud operator may be forced
to write more complex rules. Therefore, in early 2023, Mirantis will change
the default value for the OIDCClaimDelimiter parameter.
Affected deployments
Proceed with the instruction below only if the following conditions are true:
Keystone is set to use federation through the OpenID Connect protocol, with Mirantis Container Cloud Keycloak in particular. The following configuration is present in your
OpenStackDeploymentcustom resource:kind: OpenStackDeployment spec: features: keystone: keycloak: enabled: true
No value has already been specified for the
OIDCClaimDelimiterparameter in yourOpenStackDeploymentcustom resource.
To facilitate smooth transition of the existing deployments to the new default
value, explicitly define the OIDCClaimDelimiter parameter as follows:
kind: OpenStackDeployment
spec:
features:
keystone:
keycloak:
oidc:
OIDCClaimDelimiter: ","
Note
The new default value for the OIDCClaimDelimiter parameter
will be ";". To find out whether your Keystone mappings will need
adjustment after changing the default value, set the parameter to
";" on your staging environment and verify the rules.
Security notes¶
The table below contains the number of vendor-specific addressed CVEs with Critical or High severity.
In total, in the MOSK 22.4 release, 124 CVEs have been fixed and 26 artifacts (images) updated.
Fixed CVE ID |
# of updated artifacts |
|---|---|
CVE-2022-27404 |
3 |
CVE-2022-29217 |
2 |
CVE-2022-1652 |
1 |
CVE-2022-22822 |
1 |
CVE-2022-22823 |
1 |
CVE-2022-22824 |
1 |
CVE-2022-23852 |
1 |
CVE-2022-23990 |
1 |
CVE-2022-25315 |
1 |
CVE-2022-32207 |
1 |
CVE-2022-32250 |
1 |
CVE-2021-20231 |
1 |
CVE-2021-20232 |
1 |
CVE-2021-3156 |
1 |
CVE-2021-3177 |
1 |
CVE-2021-41945 |
1 |
CVE-2021-45960 |
1 |
CVE-2020-10878 |
1 |
RHSA-2022:5052 |
48 |
RHSA-2022:6160 |
54 |
RHSA-2022:6170 |
1 |
The full list of the CVEs present in the current MOSK release is available at the Mirantis Security Portal.
Release notes for older product versions¶
MOSK 22.3 8.8.0+22.3
The second MOSK release in 2022 introduces the following key features:
MariaDB minor version update to 10.6
End-user IP addresses captured in cloud’s logs
Compliance with OpenStack security checklist
Technical Preview of CPU isolation using cpusets
Technical Preview of MOSK on local mdadm RAID devices of level 10
MOSK 22.2 8.6.0+22.2
The second MOSK release in 2022 introduces the following key features:
MariaDB minor version update to 10.6
End-user IP addresses captured in cloud’s logs
Compliance with OpenStack security checklist
Technical Preview of CPU isolation using cpusets
Technical Preview of MOSK on local mdadm RAID devices of level 10
MOS 22.1 8.5.0+22.1
Update for the MOS GA release introducing the following key features:
Virtual CPU mode configuration
Automatic backup and restoration of Tungsten Fabric databases (Cassandra and ZooKeeper)
Tungsten Fabric settings persistency: VxLAN Identifier Mode, Encapsulation Priority Order, BGP Autonomous System
Technical preview of object storage encryption
MOS 21.6 6.20.0+21.6
Update for the MOS GA release introducing the following key features:
Tungsten Fabric 2011 as default
Periodic automatic cleanup of OpenStack databases
Validation of the TF Operator custom resource
Technical preview of image signature verification capability
Technical preview of the multi-rack architecture with Tungsten Fabric
Improvements to StackLight alerting
Technical preview of Vault connectivity configuration
MOS 21.5 6.19.0+21.5
Update for the MOS GA release introducing the following key features:
Tungsten Fabric 2011 LTS
Upgrade path for Tungsten Fabric from 5.1 to 2011
Machine-readable status for OpenStack
Technical preview of Tungsten Fabric multiple workers of Contrail API
Technical preview of Cinder volume encryption
MOS 21.4 6.18.0+21.4
Update for the MOS GA release introducing the following key features:
Full support for OpenStack Victoria with OVS or Tungsten Fabric 5.1 with the verified Ussuri to Victoria upgrade path
Technical preview of SR-IOV and DPDK for Tungsten Fabric 2011
Technical preview of Masakari instance evacuation
MOS 21.3 6.16.0+21.3
Update for the MOS GA release introducing support for Hyperconverged OpenStack compute nodes, SR-IOV and control interface specification for Tungsten Fabric, and the following Technology Preview features:
LVM block storage
East-west traffic encryption
Tungsten Fabric 2011
MOS 21.2 6.14.0+21.2
Update for the MOS GA release introducing proxy support and the following Technology Preview features:
Instances High Availability service
LVM ephemeral storage and encryption
SR-IOV for Tungsten Fabric vRouter
Custom Tungsten Fabric vRouter settings
MOS 21.1 6.12.0+21.1
Update for the MOS GA release introducing support for the PCI passthrough feature and Tungsten Fabric monitoring, as well as the following Technology Preview features:
OpenStack Victoria support with OVS and Tungsten Fabric 5.1
SR-IOV for OpenStack
Components collocation (OpenStack compute and Ceph nodes)
MOS Ussuri Update 6.10.0
The first update to MOS Ussuri release introducing support for object storage and a Telco deployment profile, which includes implementation of baseline Enhanced Platform Awareness (NUMA awareness, huge pages, CPU pinning) capabilities, and Technology Preview of packet processing acceleration (Data Plane Development Kit-enabled Tungsten Fabric).
MOS Ussuri 6.8.1
General availability of the product with OpenStack Ussuri and choice of Neutron/OVS or Tungsten Fabric 5.1 for networking. Runs on top of a bare metal Kubernetes cluster managed by Container Cloud.
22.3¶
Release date |
June 30, 2022 |
|---|---|
Name |
MOSK 22.3 |
Cluster release |
8.8.0 |
Highlights |
The third MOSK release in 2022 introduces the following key features:
|
New features¶
Component |
Support scope |
Feature |
|---|---|---|
OpenStack |
Full |
Ubuntu 20.04 on OpenStack with OVS and Tungsten Fabric greenfield deployments |
Full |
||
Full |
||
Full |
||
Tungsten Fabric |
Full |
|
Container Cloud |
Full |
Implemented full support for Ubuntu 20.04 LTS (Focal Fossa) as the default host operating system on OpenStack with OVS and OpenStack with Tungsten Fabric greenfield deployments.
MOSK is now confirmed to be able to run up to 10,000 virtual machines under a single control plane.
Depending on the cloud workload profile and the number of OpenStack objects in use, the control plane needs to be extended with additional hardware. Specifically, for the MOSK clouds that use Open vSwitch as a back end for the Networking service (OpenStack Neutron) and run more than 12,000 network ports, Mirantis recommends deploying extra tenant gateways.
The maximum size of a MOSK cluster is limited to 500 nodes in total, regardless of their roles.
Introduced the OpenStackDeploymentSecret custom resource to aggregate
the cloud’s confidential settings such as SSL/TLS certificates, access
credentials for external systems, and other secrets. Previously, the secrets
were stored together with the rest of configuration in the
OpenStackDeployment custom resource.
The following fields have been moved out of the OpenStackDeployment
custom resource:
features:sslfeatures:barbican:backends:vault:approle_role_idfeatures:barbican:backends:vault:approle_secret_id
Switched all OpenStack services to use the built-in policies, aka in-code
policies, to control user access to cloud functions. MOSK
keeps the built-in policies up-to-date with the OpenStack development ensuring
safe by default behavior as well as allowing you to override only those access
rules that you actually need through the features:policies structure in
the OpenStackDeployment custom resource.
Sticking to the default policy set as much as possible simplifies the future enablement of advanced authentication and access control functionality, such as scoped tokens and scoped access policies.
Learn more
OpenStack official documentation: Policy in code specification
Added capability to precache containers’ images on Kubernetes nodes
to minimize possible downtime on the components update. The feature is
enabled by default and can be disabled through the TFOperator custom
resource if required.
Implemented support for custom Docker registries configuration. Using the
ContainerRegistry custom resource, you can configure CA certificates on
machines to access private Docker registries.
Learn more
Major components versions¶
Mirantis has tested MOSK against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOSK components with the exact versions against which testing has been performed.
Component |
Version |
|---|---|
Cluster release |
|
OpenStack |
|
openstack-operator |
0.9.7 |
Tungsten Fabric |
|
tungstenfabric-operator |
0.8.5 |
See also
Known issues¶
This section describes the MOSK known issues with available workarounds. For the known issues in the related version of Mirantis Container Cloud, refer to Mirantis Container Cloud: Release Notes.
This section lists the OpenStack known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.3.
During l3-agent restart, routers may not be initialized properly due to
erroneous logic in Neutron code causing l3-agent to get stuck in the
Not ready state. The readiness probe states that one of routers is not
ready with the keepalived process not started.
Example output of the kubectl -n openstack describe pod <neutron-l3 agent pod name> command:
Warning Unhealthy 109s (x476 over 120m) kubelet, ti-rs-nhmrmiuyqzxl-2-2obcnor6vt24-server-tmtr5ajqjflf \
Readiness probe failed: /tmp/health-probe.py:259: \
ERROR:/tmp/health-probe.py:The router: 66a885b7-0c7c-463a-a574-bdb19733baf3 is not initialized.
Workaround:
Remove the router from
l3-agent:neutron l3-agent-router-remove <router-name> <l3-agent-name>
Wait up to one minute.
Add the router back to
l3-agent:neutron l3-agent-router-add <router-name> <l3-agent-name>
Octavia load balancers provisioning_status may get stuck in the
ERROR, PENDING_UPDATE, PENDING_CREATE, or PENDING_DELETE state.
Occasionally, the listeners or pools associated with these load balancers may
also get stuck in the same state.
Workaround:
For administrative users that have access to the keystone-client pod:
Log in to a
keystone-clientpod.Delete the affected load balancer:
openstack loadbalancer delete <load_balancer_id> --force
For non-administrative users, access the Octavia API directly and delete the affected load balancer using the
"force": trueargument in the delete request:Access the Octavia API.
Obtain the token:
TOKEN=$(openstack token issue -f value -c id)
Obtain the endpoint:
ENDPOINT=$(openstack version show --service load-balancer --interface public --status CURRENT -f value -c Endpoint)
Delete the affected load balancers:
curl -H "X-Auth-Token: $TOKEN" -d '{"force": true}' -X DELETE $ENDPOINT/loadbalancers/<load_balancer_id>
This section lists the Tungsten Fabric known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.3. For Tungsten Fabric limitations, see Tungsten Fabric known limitations.
[13755] TF pods switch to CrashLoopBackOff after a simultaneous reboot
[10096] tf-control does not refresh IP addresses of Cassandra pods
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete a Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica number>
The tf-control service resolves the DNS names of Cassandra pods at startup
and does not update them if Cassandra pods got new IP addresses, for example,
in case of a restart. As a workaround, to refresh the IP addresses of
Cassandra pods, restart the tf-control pods one by one:
kubectl -n tf delete pod tf-control-<hash>
Caution
Before restarting the tf-control pods:
Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only one
tf-controlpod that will be restarted.
This section lists the Ceph known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.3.
Ceph conditon gets stuck in absence of the Ceph cluster secrets information. The observed behaviour can be found on the MOSK clusters that have automatically updated their management cluster to Container Cloud 2.21 but are still running the MOSK 22.3 version.
The list of the symptoms includes:
The
Clusterobject contains the following condition:Failed to configure Ceph cluster: ceph cluster status info is not \ updated at least for 5 minutes, ceph cluster secrets info is not available yet
The
ceph-kcc-controllerlogs from thekaasnamespace contain the following loglines:2022-11-30 19:39:17.393595 E | ceph-spec: failed to update cluster condition to \ {Type:Ready Status:True Reason:ClusterCreated Message:Cluster created successfully \ LastHeartbeatTime:2022-11-30 19:39:17.378401993 +0000 UTC m=+2617.717554955 \ LastTransitionTime:2022-05-16 16:14:37 +0000 UTC}. failed to update object \ "rook-ceph/rook-ceph" status: Operation cannot be fulfilled on \ cephclusters.ceph.rook.io "rook-ceph": the object has been modified; please \ apply your changes to the latest version and try again
Workaround:
Edit
KaaSCephClusterof the affected managed cluster:kubectl -n <managedClusterProject> edit kaascephcluster
Substitute
<managedClusterProject>with the corresponding managed cluster namespace.Define the
versionparameter in theKaaSCephClusterspec:spec: cephClusterSpec: version: 15.2.13
Note
Starting from MOSK 22.4, the Ceph cluster version updates to 15.2.17. Therefore, remove the
versionparameter definition fromKaaSCephClusterafter the managed cluster update.Save the updated
KaaSCephClusterspec.Find the
MiraCephCustom Resource on a managed cluster and copy all annotations starting withmeta.helm.sh:kubectl --kubeconfig <managedClusterKubeconfig> get crd miracephs.lcm.mirantis.com -o yaml
Substitute
<managedClusterKubeconfig>with a corresponding managed clusterkubeconfig.Example of a system output:
apiVersion: apiextensions.k8s.io/v1 kind: CustomResourceDefinition metadata: annotations: controller-gen.kubebuilder.io/version: v0.6.0 # save all annotations with "meta.helm.sh" somewhere meta.helm.sh/release-name: ceph-controller meta.helm.sh/release-namespace: ceph ...
Create the
miracephsecretscrd.yamlfile and fill it with the following template:apiVersion: apiextensions.k8s.io/v1 kind: CustomResourceDefinition metadata: annotations: controller-gen.kubebuilder.io/version: v0.6.0 <insert all "meta.helm.sh" annotations here> labels: app.kubernetes.io/managed-by: Helm name: miracephsecrets.lcm.mirantis.com spec: conversion: strategy: None group: lcm.mirantis.com names: kind: MiraCephSecret listKind: MiraCephSecretList plural: miracephsecrets singular: miracephsecret scope: Namespaced versions: - name: v1alpha1 schema: openAPIV3Schema: description: MiraCephSecret aggregates secrets created by Ceph properties: apiVersion: type: string kind: type: string metadata: type: object status: properties: lastSecretCheck: type: string lastSecretUpdate: type: string messages: items: type: string type: array state: type: string type: object type: object served: true storage: true
Insert the copied
meta.helm.shannotations to themetadata.annotationssection of the template.Apply
miracephsecretscrd.yamlon the managed cluster:kubectl --kubeconfig <managedClusterKubeconfig> apply -f miracephsecretscrd.yaml
Substitute
<managedClusterKubeconfig>with a corresponding managed clusterkubeconfig.Obtain the
MiraCephname from the managed cluster:kubectl --kubeconfig <managedClusterKubeconfig> -n ceph-lcm-mirantis get miraceph -o name
Substitute
<managedClusterKubeconfig>with the corresponding managed clusterkubeconfig.Example of a system output:
miraceph.lcm.mirantis.com/rook-ceph
Copy the
MiraCephname after slash, therook-cephpart from the example above.Create the
mcs.yamlfile and fill it with the following template:apiVersion: lcm.mirantis.com/v1alpha1 kind: MiraCephSecret metadata: name: <miracephName> namespace: ceph-lcm-mirantis status: {}
Substitute
<miracephName>with theMiraCephname from the previous step.Apply
mcs.yamlon the managed cluster:kubectl --kubeconfig <managedClusterKubeconfig> apply -f mcs.yaml
Substitute
<managedClusterKubeconfig>with a corresponding managed clusterkubeconfig.
After some delay, the cluster condition will be updated to the health
state.
This section lists the cluster update known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.3.
[26534] The ‘ironic-conductor’ Pod fails after the management cluster upgrade
[25349] Cluster update failure after OpenStack controller node replacement
[24435] MetalLB speaker fails to announce the LB IP for the Ingress service
[23154] Ceph health is in ‘HEALTH_WARN’ state after managed cluster update
After the Container Cloud management cluster upgrade from 2.19.0 to 2.20.0,
the ironic-conductor Pod gets stuck in the CrashLoopBackOff state. The
issue occurs due to the race condition between the ironic-conductor and
ironic-conductor-http containers of the ironic-conductor Pod that try
to use ca-bundle.pem simultaneously but from different users.
As a workaround, run the following command:
kubectl -n openstack exec -t <failedPodName> -c ironic-conductor-http -- chown 42424:42424 /certs/ca-bundle.pem
After an OpenStack controller node replacement, the
octavia-create-resources job does not restart and the Octavia Health
Manager Pod on the new node cannot find its port in the Kubernetes secret. As a
result, MOSK cluster update may fail.
Workaround:
After adding the new OpenStack controller node but before the update process
starts, manually restart the octavia-create-resources job:
kubectl -n osh-system exec <OSCTL_POD> -- osctl-job-rerun octavia-create-resources openstack
After updating the MOSK cluster, MetalLB speaker may fail to announce the Load Balancer (LB) IP address for the OpenStack Ingress service. As a result, the OpenStack Ingress service is not accessible using its LB IP address.
The issue may occur if the MetalLB speaker nodeSelector selects not all
the nodes selected by nodeSelector of the OpenStack Ingress service.
The issue may arise and disappear when a new MetalLB speaker is being selected by the MetalLB Controller to announce the LB IP address.
The issue occurs since MOSK 22.2 after
externalTrafficPolicy was set to local for the OpenStack Ingress
service.
Workaround:
Select from the following options:
Set
externalTrafficPolicytoclusterfor the OpenStack Ingress service.This option is preferable in the following cases:
If not all cluster nodes have connection to the external network
If the connection to the external network cannot be established
If network configuration changes are not desired
If network configuration is allowed and if you require the
externalTrafficPolicy: localoption:Wire the external network to all cluster nodes where the OpenStack Ingress service Pods are running.
Configure IP addresses in the external network on the nodes and change the default routes on the nodes.
Change
nodeSelectorof MetalLB speaker to matchnodeSelectorof the OpenStack Ingress service.
After updating the MOSK cluster, Ceph health is in
the HEALTH_WARN state with the SLOW_OPS health message.
The workaround is to restart the affected Ceph Monitors.
Release artifacts¶
This section lists the components artifacts of the MOSK 22.3 release.
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20220528060551.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-focal-20220528051016 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-focal-20220528051016 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-focal-20220528051016 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:victoria-focal-20220528051016 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-focal-20220528051016 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-focal-20220528051016 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-focal-20220528051016 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-focal-20220528051016 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-focal-20220528051016 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-focal-20220528051016 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-focal-20220528051016 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-focal-20220528051016 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-focal-20220528051016 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-focal-20220528051016 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-focal-20220528051016 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-focal-20220528051016 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20220503164811 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.13-focal-20220505142933 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.13-focal-20220505142933 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:victoria-focal-20220528051016 |
Apache License 2.0 |
rabbitmq-3.9 |
mirantis.azurecr.io/general/rabbitmq:3.9.8 |
Mozilla Public License 2.0 |
rabbitmq-3.9-management |
mirantis.azurecr.io/general/rabbitmq:3.9.8-management |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:octopus-focal-20220516093942 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.5.2 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.49.3 |
Apache License 2.0 |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.7-focal-20220503161631 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0.9.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.2.0-20220217210744 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-focal-20220528051016 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-focal-20220528051016 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-focal-20220528051016 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-focal-20220528051016 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:6.2.6-alpine3.15 |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.2.2 |
GPL-2.0 License |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.1-20211018180158 |
GPL License |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.21.0 |
Apache License 2.0 |
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-ussuri-48f346e-20210119132403.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-ussuri-20220513090507.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:ussuri-bionic-20220513073430 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:ussuri-bionic-20220513073430 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:ussuri-bionic-20220513073430 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:ussuri-bionic-20220513073430 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:6.2.6-alpine3.15 |
BSD 3-Clause “New” or “Revised” License |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:ussuri-bionic-20220513073430 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:ussuri-bionic-20220513073430 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:ussuri-bionic-20220513073430 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:ussuri-bionic-20220513073430 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.2.0-20220217210744 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:0.9.0 |
Apache License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.7-focal-20220503161631 |
GPLv2, LGPLv2.1 (client libraries) |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.49.3 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:octopus-focal-20220516093942 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
rabbitmq-3.9-management |
mirantis.azurecr.io/general/rabbitmq:3.9.8-management |
Mozilla Public License 2.0 |
rabbitmq-3.9 |
mirantis.azurecr.io/general/rabbitmq:3.9.8 |
Mozilla Public License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:victoria-focal-20220516060019 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20220421094914 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20220421094914 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-focal-20220503164811 |
LGPL-2.1 License |
barbican |
mirantis.azurecr.io/openstack/barbican:ussuri-bionic-20220513073430 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20220513073430 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:ussuri-bionic-20220513073430 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:ussuri-bionic-20220513073430 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:ussuri-bionic-20220513073430 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:ussuri-bionic-20220513073430 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:ussuri-bionic-20220513073430 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:ussuri-bionic-20220513073430 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:ussuri-bionic-20220513073430 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:ussuri-bionic-20220513073430 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:ussuri-bionic-20220513073430 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:ussuri-bionic-20220513073430 |
Apache License 2.0 |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v8.2.2 |
GPL-2.0 License |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.1-20211018180158 |
GPL License |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.21.0 |
Apache License 2.0 |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.8.5.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.8.5 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:5.1.20220127155145 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:5.1.20220127155145 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:5.1.20220127155145 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:5.1.20220127155145 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:5.1.20220127155145 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:5.1.20220127155145 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:5.1.20220127155145 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:5.1.20220127155145 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:5.1.20220127155145 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:5.1.20220127155145 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:5.1.20220127155145 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:5.1.20220127155145 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v2.0.2-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.9 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:1.0.4 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:1.1.0 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.1.4 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.7 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/prometheus-jmx-exporter:0.16.1-debian-10-r208 |
Apache License 2.0 |
|
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.9 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.9.8 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.12 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.3-0.2.13 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.2.2-1-8cba7b0 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:6.2.7-alpine3.16 |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20220601115218 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20220406152321 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.8.5.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.8.5 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:2011.20220601111608 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:2011.20220601111608 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:2011.20220601111608 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:2011.20220601111608 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:2011.20220601111608 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:2011.20220601111608 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:2011.20220601111608 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:2011.20220601111608 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:2011.20220601111608 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:2011.20220601111608 |
Apache License 2.0 |
|
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
|
Control |
contrail-controller-control-control:2011.20220601111608 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:2011.20220601111608 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:2011.20220601111608 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:2011.20220601111608 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:2011.20220601111608 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:2011.20220601111608 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:2011.20220601111608 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:2011.20220601111608 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:2011.20220601111608 |
Apache License 2.0 |
Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:2011.20220601111608 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v2.0.2-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.9 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:1.0.4 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:v2-20220601125122 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.1.4 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.7 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/prometheus-jmx-exporter:0.16.1-debian-10-r208 |
Apache License 2.0 |
|
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.9 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.9.8 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.12 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.3-0.2.13 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.2.2-1-8cba7b0 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:6.2.7-alpine3.16 |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20220601115218 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20220406152321 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:2011.20220601111608 |
Apache License 2.0 |
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.1-20200610164751 |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20210115152338 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-1.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the MOSK 22.3 release:
[23771][Update] Fixed the issue that caused connectivity loss due to a wrong update order of Neutron services.
[23131][Update] Fixed the issue that caused live migration to fail during an update of a cluster with encrypted storage. Now, you can perform live migrations using the following command:
openstack --os-cloud osctl server migrate --live-migration <INSTANCE_ID>
[21790][Update] Fixed the issue wherein the Ceph cluster failed to update on a managed cluster with the Daemonset csi-rbdplugin is not found error message.
[23985][OpenStack] Fixed the issue that caused the federated authorization failure on the Keycloak URL update.
[23484][OpenStack] To prevent from
ovsdbsession disconnection causing port processing operations being blocked, configured the default timeouts forovsdb.[23297][OpenStack] Fixed the issue that caused VMs to be unaccessible through floating IP due to missing IPtables rules for floating IPs on the OpenStack compute DVR router.
[23043][OpenStack] Updated Neutron Open vSwitch to version 2.13 to fix the issue that caused broken communication between VMs in the same network.
[19065][OpenStack] Fixed the issue that caused Octavia load balancers to lose Amphora VMs after failover.
[23338][Tungsten Fabric] Fixed the issue wherein the Tungsten Fabric (TF) tools from the
contrail-toolscontainer did not work on DPDK nodes.[22273][Tungsten Fabric] To avoid issues with
CassandraCacheHitRateTooLowStackLight alerts raising for thetf-cassandra-analyticsPods, implemented the capability to configurefile_cache_size_in_mbfor thetf-cassandra-analyticsortf-cassandra-configCassandra deployment. By default, this parameter is set to512. For details, see Cassandra configuration.
Update notes¶
This section describes the specific actions you as a cloud operator need to complete to accurately plan and successfully perform your Mirantis OpenStack for Kubernetes (MOSK) cluster to the version 22.3. Consider this information as a supplement to the generic update procedure published in Operations Guide: Update a MOSK cluster.
Additionally, read through the Cluster update known issues for the problems that are known to occur during update with recommended workarounds.
The OpenStackDeploymentSecret custom resource replaced the fields in
OpenStackDeployment customer resource that used to keep the cloud’s
confidential settings. These include:
features:sslfeatures:barbican:backends:vault:approle_role_idfeatures:barbican:backends:vault:approle_secret_id
After the update, migrate the fields mentioned above from OpenStackDeployment to OpenStackDeploymentSecret custom resource as follows:
Create an
OpenStackDeploymentSecretobject with the same name as theOpenStackDeploymentobject.Set the fields in the
OpenStackDeploymentSecretcustom resource as required. See OpenStackDeploymentSecret custom resource for details.Remove the related fields from the
OpenStackDeploymentcustom resource.
Switched all OpenStack components to built-in policies by default. If you have
any custom policies defined through the features:policies structure in
the OpenStackDeployment custom resource, some API calls may not work as
usual. Therefore, after completing the update, revalidate all the custom
access rules configured for your cloud.
Revalidate all the custom OpenStack access rules configured through the
features:policies structure in the OpenStackDeployment custom
resource.
To complete the update of a cluster with Tungsten Fabric as a back end for networking, manually restart Tungsten Fabric vRouter agent Pods on all compute nodes.
Restart of a vRouter agent on a compute node will cause up to 30-60 seconds of networking downtime per instance hosted there. If downtime is unacceptable for some workloads, we recommend that you migrate them before restarting the vRouter Pods.
Warning
Under certain rare circumstances, the reload of the vRouter kernel
module triggered by the restart of a vRouter agent can hang due to
the inability to complete the drop_caches operation. Watch the status
and logs of the vRouter agent being restarted and trigger the reboot of
the node, if necessary.
To restart the vRouter Pods:
Remove the vRouter pods one by one manually.
Note
Manual removal is required because vRouter pods use the
OnDeleteupdate strategy. vRouter pod restart causes networking downtime for workloads on the affected node. If it is not applicable for some workloads, migrate them before restarting the vRouter pods.kubectl -n tf delete pod <VROUTER-POD-NAME>
Verify that all
tf-vrouter-*pods have been updated:kubectl -n tf get ds | grep tf-vrouter
The
UP-TO-DATEandCURRENTfields must have the same values.
Switch to the new format of domain_specific_configuration in the
OpenStackDeployment object. For details, see Reference Architecture:
Standard configuration.
Reboot the cluster nodes to complete the update as described in Update a MOSK cluster to a major release version.
Security notes¶
The table below contains the number of vendor-specific addressed CVEs with Critical or High severity.
In total, in the MOSK 22.3 release, 88 CVEs have been fixed and 196 artifacts updated.
Fixed CVE ID |
# of updated artifacts |
|---|---|
CVE-2022-28347 |
3 |
CVE-2022-28346 |
3 |
CVE-2022-1048 |
2 |
CVE-2022-0435 |
1 |
CVE-2021-43527 |
2 |
CVE-2021-42008 |
1 |
CVE-2021-4197 |
2 |
CVE-2021-4157 |
1 |
CVE-2021-41495 |
1 |
CVE-2021-4083 |
1 |
CVE-2021-4034 |
1 |
CVE-2021-39713 |
1 |
CVE-2021-39698 |
1 |
CVE-2021-39685 |
1 |
CVE-2021-39634 |
1 |
CVE-2021-38300 |
1 |
CVE-2021-38160 |
1 |
CVE-2021-37576 |
1 |
CVE-2021-3752 |
1 |
CVE-2021-3715 |
1 |
CVE-2021-3640 |
1 |
CVE-2021-3612 |
1 |
CVE-2021-3609 |
1 |
CVE-2021-3573 |
1 |
CVE-2021-35550 |
1 |
CVE-2021-3517 |
1 |
CVE-2021-33909 |
1 |
CVE-2021-3347 |
1 |
CVE-2021-31535 |
2 |
CVE-2021-29154 |
1 |
CVE-2021-28972 |
1 |
CVE-2021-28660 |
1 |
CVE-2021-27928 |
1 |
CVE-2021-2389 |
1 |
CVE-2021-23133 |
1 |
CVE-2021-20302 |
1 |
CVE-2021-20300 |
1 |
CVE-2021-20292 |
1 |
CVE-2021-1048 |
1 |
CVE-2021-0941 |
1 |
CVE-2021-0920 |
1 |
CVE-2020-36329 |
1 |
CVE-2020-36328 |
1 |
CVE-2020-36158 |
1 |
CVE-2020-29661 |
1 |
CVE-2020-29569 |
1 |
CVE-2020-29368 |
1 |
CVE-2020-27843 |
1 |
CVE-2020-27786 |
1 |
CVE-2020-27777 |
1 |
CVE-2020-25696 |
1 |
CVE-2020-25671 |
1 |
CVE-2020-25670 |
1 |
CVE-2020-25669 |
1 |
CVE-2020-25668 |
1 |
CVE-2020-25643 |
1 |
CVE-2020-1747 |
1 |
CVE-2020-15780 |
1 |
CVE-2020-15436 |
1 |
CVE-2020-14386 |
1 |
CVE-2020-14356 |
1 |
CVE-2020-13974 |
1 |
CVE-2020-12464 |
1 |
CVE-2020-10757 |
1 |
CVE-2020-0466 |
1 |
CVE-2020-0465 |
1 |
CVE-2020-0452 |
1 |
CVE-2020-0444 |
1 |
CVE-2019-20908 |
1 |
CVE-2019-19816 |
1 |
CVE-2019-19813 |
1 |
CVE-2019-19074 |
1 |
CVE-2019-11324 |
1 |
CVE-2019-10906 |
1 |
CVE-2019-1010142 |
1 |
CVE-2019-0145 |
1 |
CVE-2018-7750 |
1 |
CVE-2018-25014 |
1 |
CVE-2018-25011 |
1 |
CVE-2018-20060 |
1 |
CVE-2018-18074 |
1 |
CVE-2018-1000805 |
1 |
CVE-2017-18342 |
1 |
CVE-2017-12852 |
1 |
RHSA-2022:2213 |
27 |
RHSA-2022:2191 |
23 |
RHSA-2022:1069 |
23 |
RHSA-2022:1066 |
31 |
The full list of the CVEs present in the current MOSK release is available at the Mirantis Security Portal.
MOSK 22.2 release¶
Release date |
April 14, 2022 |
|---|---|
Name |
MOSK 22.2 |
Cluster release |
8.6.0+22.2 |
Highlights |
The second MOSK release in 2022 introduces the following key features:
|
New features¶
Component |
Support scope |
Feature |
|---|---|---|
OpenStack |
Full |
|
Full |
||
TechPreview |
||
n/a |
||
Full |
||
Tungsten Fabric |
Full |
|
Bare metal |
TechPreview |
Updated the minor version of MariaDB from 10.4 to 10.6. The update applies automatically during the MOSK cluster update procedure.
Exposed the IP addresses of the cloud users that consume API of a cloud to all user-facing cloud services, such as OpenStack, Ceph, and others. Now, the IP addresses get recoded in the corresponding logs allowing for easy troubleshooting and security auditing of the cloud.
TechPreview
Implemented the capability to configure CPU isolation using the cpusets
mechanism in Linux kernel. Configuring CPU isolation using the isolcpus
configuration parameter for Linux kernel is considered deprecated.
Validated MOSK against the upstream OpenStack Security Checklist. The default configuration of MOSK services that include Identity, Dashboard, Compute, Block Storage, and Networking services is compliant with the security recommendations from the OpenStack community.
Encryption of all the internal communications for MOSK services will become available in one of the nearest product releases.
Implemented the capability to configure the LoadBalancer type for PowerDNS
through the spec:features:designate definition in the
OpenStackDeployment CR, for example, to expose the TCP protocol instead of
the default UDP, or both.
Added the tf-control-dns-external service to the list of the Tungsten
Fabric configuration options. The service is created by default to expose TF
control dns. You can disable creation of this service using the
enableDNSExternal parameter in the TFOperator CR.
TechPreview
Implemented the initial Technology Preview support for MOSK
deployment on local software-based mdadm Redundant Array of Independent Disks
(RAID) devices of level 10 (raid10) to withstand failure of one device
at a time.
The raid10 RAID type requires at least four and in total an even number
of storage devices available on your servers.
To create and configure RAID, use the softRaidDevices field in
BaremetalHostProfile.
Also, added the capability to create LVM volume groups on top of mdadm-based RAID devices.
Major components versions¶
Mirantis has tested MOSK against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOSK components with the exact versions against which testing has been performed.
Component |
Version |
|---|---|
Cluster release |
|
OpenStack |
|
openstack-operator |
0.8.4 |
Tungsten Fabric |
|
tungstenfabric-operator |
0.7.2 |
See also
Known issues¶
This section describes the MOSK known issues with available workarounds. For the known issues in the related version of Mirantis Container Cloud, refer to Mirantis Container Cloud: Release Notes.
This section lists the Tungsten Fabric known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.2. For Tungsten Fabric limitations, see Tungsten Fabric known limitations.
[13755] TF pods switch to CrashLoopBackOff after a simultaneous reboot
[10096] tf-control does not refresh IP addresses of Cassandra pods
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete a Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica number>
The tf-control service resolves the DNS names of Cassandra pods at startup
and does not update them if Cassandra pods got new IP addresses, for example,
in case of a restart. As a workaround, to refresh the IP addresses of
Cassandra pods, restart the tf-control pods one by one:
kubectl -n tf delete pod tf-control-<hash>
Caution
Before restarting the tf-control pods:
Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only one
tf-controlpod that will be restarted.
This section lists the OpenStack known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.2.
[25594] Security groups shared through RBAC cannot be used to create instances
[23985] Federated authorization fails after updating Keycloak URL
[19065] Octavia load balancers lose Amphora VMs after failover
[6912] Octavia load balancers may not work properly with DVR
During l3-agent restart, routers may not be initialized properly due to
erroneous logic in Neutron code causing l3-agent to get stuck in the
Not ready state. The readiness probe states that one of routers is not
ready with the keepalived process not started.
Example output of the kubectl -n openstack describe pod <neutron-l3 agent pod name> command:
Warning Unhealthy 109s (x476 over 120m) kubelet, ti-rs-nhmrmiuyqzxl-2-2obcnor6vt24-server-tmtr5ajqjflf \
Readiness probe failed: /tmp/health-probe.py:259: \
ERROR:/tmp/health-probe.py:The router: 66a885b7-0c7c-463a-a574-bdb19733baf3 is not initialized.
Workaround:
Remove the router from
l3-agent:neutron l3-agent-router-remove <router-name> <l3-agent-name>
Wait up to one minute.
Add the router back to
l3-agent:neutron l3-agent-router-add <router-name> <l3-agent-name>
Octavia load balancers provisioning_status may get stuck in the
ERROR, PENDING_UPDATE, PENDING_CREATE, or PENDING_DELETE state.
Occasionally, the listeners or pools associated with these load balancers may
also get stuck in the same state.
Workaround:
For administrative users that have access to the keystone-client pod:
Log in to a
keystone-clientpod.Delete the affected load balancer:
openstack loadbalancer delete <load_balancer_id> --force
For non-administrative users, access the Octavia API directly and delete the affected load balancer using the
"force": trueargument in the delete request:Access the Octavia API.
Obtain the token:
TOKEN=$(openstack token issue -f value -c id)
Obtain the endpoint:
ENDPOINT=$(openstack version show --service load-balancer --interface public --status CURRENT -f value -c Endpoint)
Delete the affected load balancers:
curl -H "X-Auth-Token: $TOKEN" -d '{"force": true}' -X DELETE $ENDPOINT/loadbalancers/<load_balancer_id>
If an Amphora VM does not respond or responds too long to heartbeat requests, the Octavia load balancer automatically initiates a failover process after 60 seconds of unsuccessful attempts. Long responses of an Amphora VM may be caused by various events, such as a high load on the OpenStack compute node that hosts the Amphora VM, network issues, system service updates, and so on. After a failover, the Amphora VMs may be missing in the completed Octavia load balancer.
Workaround:
If your deployment is already affected, manually restore the work of the load balancer by recreating the Amphora VM:
Define the load balancer ID:
openstack loadbalancer amphora list --column loadbalancer_id --format value --status ERROR
Start the load balancer failover:
openstack loadbalancer failover <Load balancer ID>
To avoid an automatic failover start that may cause the issue, set the
heartbeat_timeoutparameter in theOpenStackDeploymentCR to a large value in seconds. The default is 60 seconds. For example:spec: services: load-balancer: octavia: values: conf: octavia: health_manager: heartbeat_timeout: 31536000
Limitation
When Neutron is deployed in the DVR mode, Octavia load balancers may not work correctly. The symptoms include both failure to properly balance traffic and failure to perform an amphora failover. For details, see DVR incompatibility with ARP announcements and VRRP.
This section lists the cluster update known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.2.
[22777] Admission Controller exception for deployments with Tungsten Fabric
[21790] Ceph cluster fails to update due to ‘csi-rbdplugin’ not found
[23154] Ceph health is in ‘HEALTH_WARN’ state after managed cluster update
[23771] Connectivity loss due to wrong update order of Neutron services
[24435] MetalLB speaker fails to announce the LB IP for the Ingress service
Affects only MOSK 22.2
After updating the MOSK cluster, Admission
Controller prohibits the OsDpl update with the following error message:
TungstenFabric as network backend and setting of floating network
physnet name without network type and segmentation id are not compatible.
As a workaround, after the update remove the orphaned physnet parameter
from the OsDpl CR:
features:
neutron:
backend: tungstenfabric
floating_network:
enabled: true
physnet: physnet1
A Ceph cluster fails to update on a managed cluster with the following message:
Failed to configure Ceph cluster: ceph cluster verification is failed:
[Daemonset csi-rbdplugin is not found]
As a workaround, restart the rook-ceph-operator pod:
kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 0
kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 1
After updating the MOSK cluster, Ceph health is in
the HEALTH_WARN state with the SLOW_OPS health message.
The workaround is to restart the affected Ceph Monitors.
After updating the cluster, simultaneous unordered restart of Neutron L2
and L3, DHCP, and Metadata services leads to the state when ports on
br-int are tagged with valid VLAN tags but with trunks: [4095].
Example of affected ports in Open vSwitch:
Port "tapdb11212e-15"
tag: 1
trunks: [4095]
Workaround:
Search for the nodes with the OVS ports:
for i in $(kubectl -n openstack get pods |grep openvswitch-vswitchd | awk '{print $1}'); do echo $i; kubectl -n openstack exec -it -c openvswitch-vswitchd $i -- ovs-vsctl show |grep trunks|head -1; done
Exec into the
openvswitch-vswitchdpod with affected ports obtained in the previous step and run:for i in $(ovs-vsctl show |grep trunks -B 3 |grep Port | awk '{print $2}' | tr -d '"'); do ovs-vsctl set port $i tag=4095; done
Restart the
neutron-ovsagent on the affected nodes.
After updating the MOSK cluster, MetalLB speaker may fail to announce the Load Balancer (LB) IP address for the OpenStack Ingress service. As a result, the OpenStack Ingress service is not accessible using its LB IP address.
The issue may occur if the MetalLB speaker nodeSelector selects not all
the nodes selected by nodeSelector of the OpenStack Ingress service.
The issue may arise and disappear when a new MetalLB speaker is being selected by the MetalLB Controller to announce the LB IP address.
The issue occurs since MOSK 22.2 after
externalTrafficPolicy was set to local for the OpenStack Ingress
service.
Workaround:
Select from the following options:
Set
externalTrafficPolicytoclusterfor the OpenStack Ingress service.This option is preferable in the following cases:
If not all cluster nodes have connection to the external network
If the connection to the external network cannot be established
If network configuration changes are not desired
If network configuration is allowed and if you require the
externalTrafficPolicy: localoption:Wire the external network to all cluster nodes where the OpenStack Ingress service Pods are running.
Configure IP addresses in the external network on the nodes and change the default routes on the nodes.
Change
nodeSelectorof MetalLB speaker to matchnodeSelectorof the OpenStack Ingress service.
Release artifacts¶
This section lists the components artifacts of the MOSK 22.2 release.
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20220324132511.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20220324125700 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-bionic-20220324125700 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-bionic-20220324125700 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:victoria-bionic-20220324125700 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-bionic-20220324125700 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-bionic-20220324125700 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-bionic-20220324125700 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-bionic-20220324125700 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-bionic-20220324125700 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-bionic-20220324125700 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-bionic-20220324125700 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-bionic-20220324125700 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-bionic-20220324125700 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-bionic-20220324125700 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20220324125700 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-bionic-20220324125700 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20220217094810 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20220217094810 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20220217094810 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20220113100346 |
Apache License 2.0 |
rabbitmq-3.9 |
mirantis.azurecr.io/general/rabbitmq:3.9.8 |
Mozilla Public License 2.0 |
rabbitmq-3.9-management |
mirantis.azurecr.io/general/rabbitmq:3.9.8-management |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6.2.6-alpine3.15 |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20211025114106 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.49.3 |
Apache License 2.0 |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.7-bionic-20220303173211 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.9.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.2.0-20220217210744 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-bionic-20220324125700 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-bionic-20220324125700 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-bionic-20220324125700 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-bionic-20220324125700 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v7.5.0 |
GPL-2.0 License |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.1-20211018180158 |
GPL License |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.21.0 |
Apache License 2.0 |
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-ussuri-48f346e-20210119132403.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-ussuri-20220316010058.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:ussuri-bionic-20220113100346 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:ussuri-bionic-20220113100346 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:ussuri-bionic-20220113100346 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:ussuri-bionic-20220113100346 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:ussuri-bionic-20220113100346 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:ussuri-bionic-20220113100346 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:ussuri-bionic-20220113100346 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:ussuri-bionic-20220113100346 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.2.0-20220217210744 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.9.0 |
Apache License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
mariadb |
mirantis.azurecr.io/general/mariadb:10.6.7-bionic-20220303173211 |
GPLv2, LGPLv2.1 (client libraries) |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.49.3 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20211025114106 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6.2.6-alpine3.15 |
BSD 3-Clause “New” or “Revised” License |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
rabbitmq-3.9-management |
mirantis.azurecr.io/general/rabbitmq:3.9.8-management |
Mozilla Public License 2.0 |
rabbitmq-3.9 |
mirantis.azurecr.io/general/rabbitmq:3.9.8 |
Mozilla Public License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20220113100346 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20220217094810 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20220217094810 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20220217094810 |
LGPL-2.1 License |
barbican |
mirantis.azurecr.io/openstack/barbican:ussuri-bionic-20220113100346 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20220113100346 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:ussuri-bionic-20220113100346 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:ussuri-bionic-20220113100346 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:ussuri-bionic-20220113100346 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:ussuri-bionic-20220113100346 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:ussuri-bionic-20220113100346 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:ussuri-bionic-20220113100346 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:ussuri-bionic-20220113100346 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:ussuri-bionic-20220113100346 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:ussuri-bionic-20220113100346 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:ussuri-bionic-20220113100346 |
Apache License 2.0 |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v7.5.0 |
GPL-2.0 License |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.1-20211018180158 |
GPL License |
descheduler |
mirantis.azurecr.io/openstack/extra/descheduler:v0.21.0 |
Apache License 2.0 |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.7.2.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.7.2 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:5.1.20220127155145 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:5.1.20220127155145 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:5.1.20220127155145 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:5.1.20220127155145 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:5.1.20220127155145 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:5.1.20220127155145 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:5.1.20220127155145 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:5.1.20220127155145 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:5.1.20220127155145 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:5.1.20220127155145 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:5.1.20220127155145 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:5.1.20220127155145 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v2.0.2-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.9 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:1.0.4 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:1.1.0 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.1.2 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.7 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/prometheus-jmx-exporter:0.16.1-debian-10-r208 |
Apache License 2.0 |
|
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.8 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.23 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.12 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.3-0.2.13 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.2.2-1-8cba7b0 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:6.2.6-alpine3.15 |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20220321092905 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20210214191656 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.7.2.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.7.2 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:2011.20220322143737 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:2011.20220322143737 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:2011.20220322143737 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:2011.20220322143737 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:2011.20220322143737 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:2011.20220322143737 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:2011.20220322143737 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:2011.20220322143737 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:2011.20220322143737 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:2011.20220322143737 |
Apache License 2.0 |
|
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
|
Control |
contrail-controller-control-control:2011.20220322143737 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:2011.20220322143737 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:2011.20220322143737 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:2011.20220322143737 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:2011.20220322143737 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:2011.20220322143737 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:2011.20220322143737 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-node-init:2011.20220322143737 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:2011.20220322143737 |
Apache License 2.0 |
Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:2011.20220322143737 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v2.0.2-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.9 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:1.0.4 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:1.1.0 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.1.2 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.7 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/prometheus-jmx-exporter:0.16.1-debian-10-r208 |
Apache License 2.0 |
|
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.8 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.23 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.12 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.3-0.2.13 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.2.2-1-8cba7b0 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:6.2.6-alpine3.15 |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20220321092905 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20210214191656 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:2011.20220322143737 |
Apache License 2.0 |
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.1-20200610164751 |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20210115152338 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-1.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the MOSK 22.2 release:
[22725][Update] Fixed the issue raising upon managed cluster update and causing live migration to fail for instances with deleted images.
[18871][Update] Fixed the issue causing MySQL to crash during a managed cluster update or instances live migration.
[16987][Update] Fixed the issue that caused update of a MOSK cluster to fail with the ceph csi-driver is not evacuated yet, waiting… error during the Ceph CSI pod eviction.
[22321][OpenStack] Fixed the issue wherein the Neutron back-end option in
OsDplinadvertently changed fromml2totungstenfabricupon managed cluster update.[21998][OpenStack] Fixed the issue wherein the OpenStack Controller got stuck during the managed cluster update.
[21838][OpenStack] Fixed the issue wherein the Designate API failed to log requests.
[21376][OpenStack] Fixed the issue that caused inability to create non-encrypted volumes from a large image.
[15354][OpenStack] Implemented coordination between instances of the Masakari API service to prevent creation of multiple evacuation flows for instances.
[1659][OpenStack] Fixed the issue wherein the Neutron Open vSwitch agent did not clean tunnels upon changes of the
tunnel_ipoption.[20192][StackLight] To avoid issues causing false-positive
CassandraTombstonesTooManyMajorStackLight alerts, adjusted the thresholds for theCassandraTombstonesTooManyMajorandCassandraTombstonesTooManyWarningalerts and added a newCassandraTombstonesTooManyCriticalalert.[21064][Ceph] Fixed the issue causing the MOSK managed cluster to fail with the Error updating release ceph/ceph-controller error and enabled Helm v3 for Ceph Controller.
Update notes¶
This section describes the specific actions you as a cloud operator need to complete to accurately plan and successfully perform your Mirantis OpenStack for Kubernetes (MOSK) cluster to the version 22.2. Consider this information as a supplement to the generic update procedure published in Operations Guide: Update a MOSK cluster.
Additionally, read through the Cluster update known issues for the problems that are known to occur during update with recommended workarounds.
Your MOSK cluster will obtain the newly implemented capabilities automatically with no significant impact on the update procedure.
During the Kubernetes master nodes update, there is a downtime on Kubernetes cluster’s internal DNS service. Thus, Tungsten Fabric vRouter pods lose connection with the control plane resulting in up to 1 minute of downtime for the Tungsten Fabric data plane nodes and impact on the tenant networking.
To complete the update of the cluster with Tungsten Fabric, manually restart Tungsten Fabric vRouter Agent pods on all compute nodes. The restart of a vRouter Agent on a compute node will cause up to 30-60 seconds of networking downtime per instance hosted there. If downtime is unacceptable for some workloads, we recommend that you migrate them before restarting the vRouter pods.
Warning
Under certain rare circumstances, the reload of the vRouter kernel
module triggered by the restart of a vRouter Agent can hang due to
the inability to complete the drop_caches operation. Watch the status
and logs of the vRouter Agent being restarted and trigger the reboot of
the node, if necessary.
Security notes¶
The table below contains the number of vendor-specific addressed CVEs with Critical or High severity.
CVE ID |
Fixed artifacts |
|---|---|
CVE-2022-23833 |
3 |
CVE-2022-26485 |
1 |
CVE-2022-26486 |
1 |
RHSA-2021:4904 |
6 |
RHSA-2022:0666 |
37 |
The full list of the CVEs present in the current MOSK release is available at the Mirantis Security Portal.
MOSK 22.1 release¶
Release date |
February 23, 2022 |
|---|---|
Name |
MOSK 22.1 |
Cluster release |
8.5.0+22.1 |
Highlights |
The first MOSK release in 2022 introduces the following key features:
The list of the major changes in the component versions includes:
|
New features¶
Component |
Support scope |
Feature |
|---|---|---|
OpenStack |
Full |
|
Full |
||
Tungsten Fabric |
Full |
|
Full |
||
TechPreview |
||
Documentation |
n/a |
The list of the major changes in the component versions includes:
Host OS kernel v5.4
RabbitMQ 3.9
Mirantis Kubernetes Engine (MKE) 3.4.6 with Kubernetes 1.20
All the relevant changes are applied to the MOSK cluster automatically during the cluster update procedure. The host machine’s kernel update implies node reboot. See the links below for details.
Implemented the capability to configure the CPU model through the
spec:features:nova:vcpu_type definition of the OpenStackDeployment CR.
The default CPU model is now host-model, which replaces the previous
default kvm64 CPU model.
For deployments with CPU model customized through spec:services, remove
this customization after upgrading your managed cluster.
Learn more
Implemented the capability to automatically back up and restore the Tungsten Fabric data stored in Cassandra and ZooKeeper.
The user can perform the automatic data backup by enabling the
tf-dbBackup controller through the Tungsten Fabric Operator CR.
By default, the job is scheduled for weekly execution, allocating PVC
with 5Gi size for storing backups, and keeping 5 previous backups.
Also, MOSK allows for automatic data restoration with the ability to restore from the exact backup if required.
Implemented the Border Gateway Protocol (BGP) and encapsulation settings in the Tungsten Fabric Operator custom resource. This feature provides persistency of the BGP and encapsulation parameters.
Also, added technical preview of the VxLAN encapsulation feature.
TechPreview
Implemented object storage encryption integrated with the OpenStack Key Manager service (Barbican). The feature is enabled by default in MOSK deployments with Barbican.
Published the procedure on how to calculate target ratio for Ceph pools.
Learn more
Major components versions¶
Mirantis has tested MOSK against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOSK components with the exact versions against which testing has been performed.
Component |
Version |
|---|---|
Cluster release |
|
OpenStack |
|
openstack-operator |
0.7.14 |
Tungsten Fabric |
|
tungstenfabric-operator |
0.6.11 |
See also
Known issues¶
This section describes the MOSK known issues with available workarounds. For the known issues in the related version of Mirantis Container Cloud, refer to Mirantis Container Cloud: Release Notes.
This section lists the Tungsten Fabric known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.1.
[10096] tf-control does not refresh IP addresses of Cassandra pods
[13755] TF pods switch to CrashLoopBackOff after a simultaneous reboot
[15684] Pods fail when rolling Tungsten Fabric 2011 back to 5.1
Tungsten Fabric does not provide the following functionality:
Automatic generation of network port records in DNSaaS (Designate) as Neutron with Tungsten Fabric as a back end is not integrated with DNSaaS. As a workaround, you can use the Tungsten Fabric built-in DNS service that enables virtual machines to resolve each other names.
Secret management (Barbican). You cannot use the certificates stored in Barbican to terminate HTTPs in a load balancer.
Role Based Access Control (RBAC) for Neutron objects.
The tf-control service resolves the DNS names of Cassandra pods at startup
and does not update them if Cassandra pods got new IP addresses, for example,
in case of a restart. As a workaround, to refresh the IP addresses of
Cassandra pods, restart the tf-control pods one by one:
kubectl -n tf delete pod tf-control-<hash>
Caution
Before restarting the tf-control pods:
Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only one
tf-controlpod that will be restarted.
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete a Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica number>
Some tf-control and tf-analytics pods may fail during the Tungsten
Fabric rollback from version 2011 to 5.1. In this case, the control
container from the tf-control pod and/or the collector container from
the tf-analytics pod contain SYS_WARN messages such as
… AMQP_QUEUE_DELETE_METHOD caused: PRECONDITION_FAILED - queue
‘<contrail-control/contrail-collector>.<nodename>’ in vhost ‘/’ not empty
….
The workaround is to manually delete the queue that fails to be deleted by
AMQP_QUEUE_DELETE_METHOD:
kubectl -n tf exec -it tf-rabbitmq-<num of replica> -- rabbitmqctl delete_queue <queue name>
This section lists the OpenStack known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.1.
[25594] Security groups shared through RBAC cannot be used to create instances
[23985] Federated authorization fails after updating Keycloak URL
[6912] Octavia load balancers may not work properly with DVR
[19065] Octavia load balancers lose Amphora VMs after failover
Limitation
When Neutron is deployed in the DVR mode, Octavia load balancers may not work correctly. The symptoms include both failure to properly balance traffic and failure to perform an amphora failover. For details, see DVR incompatibility with ARP announcements and VRRP.
If an Amphora VM does not respond or responds too long to heartbeat requests, the Octavia load balancer automatically initiates a failover process after 60 seconds of unsuccessful attempts. Long responses of an Amphora VM may be caused by various events, such as a high load on the OpenStack compute node that hosts the Amphora VM, network issues, system service updates, and so on. After a failover, the Amphora VMs may be missing in the completed Octavia load balancer.
Workaround:
If your deployment is already affected, manually restore the work of the load balancer by recreating the Amphora VM:
Define the load balancer ID:
openstack loadbalancer amphora list --column loadbalancer_id --format value --status ERROR
Start the load balancer failover:
openstack loadbalancer failover <Load balancer ID>
To avoid an automatic failover start that may cause the issue, set the
heartbeat_timeoutparameter in theOpenStackDeploymentCR to a large value in seconds. The default is 60 seconds. For example:spec: services: load-balancer: octavia: values: conf: octavia: health_manager: heartbeat_timeout: 31536000
This section lists the cluster update known issues with workarounds for the Mirantis OpenStack for Kubernetes release 22.1.
[21790] Ceph cluster fails to update due to ‘csi-rbdplugin’ not found
[22725] Live migration may fail for instances with deleted images
[18871] MySQL crashes during managed cluster update or instances live migration
[21998] OpenStack Controller may get stuck during the managed cluster update
A Ceph cluster fails to update on a managed cluster with the following message:
Failed to configure Ceph cluster: ceph cluster verification is failed:
[Daemonset csi-rbdplugin is not found]
As a workaround, restart the rook-ceph-operator pod:
kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 0
kubectl -n rook-ceph scale deploy rook-ceph-operator --replicas 1
During the update of a MOSK cluster to 22.1, live
migration may fail for instances if their images were previously deleted. In
this case, the nova-compute pod contains an error message similar to the
following one:
2022-03-22 23:55:24.468 11816 ERROR nova.compute.manager [instance: 128cf508-f7f7-4a40-b742-392c8c80fc7d] Command: scp -C -r kaas-node-03ab613d-cf79-4830-ac70-ed735453481a:/var/l
ib/nova/instances/_base/e2b6c1622d45071ec8a88a41d07ef785e4dfdfe8 /var/lib/nova/instances/_base/e2b6c1622d45071ec8a88a41d07ef785e4dfdfe8
2022-03-22 23:55:24.468 11816 ERROR nova.compute.manager [instance: 128cf508-f7f7-4a40-b742-392c8c80fc7d] Exit code: 1
2022-03-22 23:55:24.468 11816 ERROR nova.compute.manager [instance: 128cf508-f7f7-4a40-b742-392c8c80fc7d] Stdout: ''
2022-03-22 23:55:24.468 11816 ERROR nova.compute.manager [instance: 128cf508-f7f7-4a40-b742-392c8c80fc7d] Stderr: 'ssh: Could not resolve hostname kaas-node-03ab613d-cf79-4830-ac
70-ed735453481a: Name or service not known\r\n'
Workaround:
If you have not yet started the managed cluster update, change the
nova-computeimage by setting the following metadata in theOpenStackDeploymentCR:spec: services: compute: nova: values: images: tags: nova_compute: mirantis.azurecr.io/openstack/nova:victoria-bionic-20220324125700
If you have already started the managed cluster update, manually update the
nova-computecontainer image in thenova-computeDaemonSet tomirantis.azurecr.io/openstack/nova:victoria-bionic-20220324125700.
An update of a MOSK cluster may fail with the ceph csi-driver is not evacuated yet, waiting… error during the Ceph CSI pod eviction.
Workaround:
Scale the affected
StatefulSetof the pod that fails to init down to0replicas. If it is theDaemonSetsuch asnova-compute, it must not be scheduled on the affected node.On every
csi-rbdpluginpod, search for stuckcsi-vol:rbd device list | grep <csi-vol-uuid>
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
Delete
volumeattachmentof the affected pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale the affected
StatefulSetback to the original number of replicas or until its state isRunning. If it is aDaemonSet, run the pod on the affected node again.
MySQL may crash when performing instances live migration or during a managed
cluster update. After the crash, MariaDB cannot connect to the cluster and gets
stuck in the CrashLoopBackOff state.
Workaround:
Verify that other MariaDB replicas are up and running and have joined the cluster:
Verify that at least 2 pods are running and operational (
2/2andRunning):kubectl -n openstack get pods |grep maria
Example of system response where the pods
mariadb-server-0andmariadb-server-2are operational:mariadb-controller-77b5ff47d5-ndj68 1/1 Running 0 39m mariadb-server-0 2/2 Running 0 39m mariadb-server-1 0/2 Running 0 39m mariadb-server-2 2/2 Running 0 39m
Log in to each operational pod and verify that the node is
Primaryand the cluster size is at least2. For example:mysql -u root -p$MYSQL_DBADMIN_PASSWORD -e "show status;" |grep -e \ wsrep_cluster_size -e "wsrep_cluster_status" -e "wsrep_local_state_comment"
Example of system response:
wsrep_cluster_size 2 wsrep_cluster_status Primary wsrep_local_state_comment Synced
Remove the content of the
/var/lib/mysql/*directory:kubectl -n openstack exec -it mariadb-server-1 – rm -rf /var/lib/mysql/*
Restart the MariaDB container:
kubectl -n openstack delete pod mariadb-server-1
During the MOSK cluster update, the OpenStack Controller may get stuck with the following symptoms:
Multiple
nodemaintenancerequestsexist:kubectl get nodemaintenancerequests NAME AGE kaas-node-50a51d95-1e4b-487e-a973-199de400b97d 17m kaas-node-e41a610a-ceaf-4d80-90ee-4ea7b4dee161 85s
One
nodemaintenancerequesthas aDeletedAttime stamp and an activeopenstack-controllerfinalizer:finalizers: - lcm.mirantis.com/openstack-controller.nodemaintenancerequest-finalizerIn the
openstack-controllerlogs, retries are exhausted:2022-02-17 18:41:43,317 [ERROR] kopf._core.engines.peering: Request attempt #8 failed; will retry: PATCH https://10.232.0.1:443/apis/zalando.org/v1/namespaces/openstack/kopfpeerings/openstack-controller.nodemaintenancerequest -> APIServerError('Internal error occurred: unable to unmarshal response in forceLegacy: json: cannot unmarshal number into Go value of type bool', {'kind': 'Status', 'apiVersion': 'v1', 'metadata': {}, 'status': 'Failure', 'message': 'Internal error occurred: unable to unmarshal response in forceLegacy: json: cannot unmarshal number into Go value of type bool', 'reason': 'InternalError', 'details': {'causes': [{'message': 'unable to unmarshal response in forceLegacy: json: cannot unmarshal number into Go value of type bool'}]}, 'code': 500}) 2022-02-17 18:42:50,834 [INFO] kopf.objects: Timer 'heartbeat' succeeded. 2022-02-17 18:47:50,848 [INFO] kopf.objects: Timer 'heartbeat' succeeded. 2022-02-17 18:52:50,853 [INFO] kopf.objects: Timer 'heartbeat' succeeded. 2022-02-17 18:57:50,858 [INFO] kopf.objects: Timer 'heartbeat' succeeded. 2022-02-17 19:02:50,862 [INFO] kopf.objects: Timer 'heartbeat' succeeded.
Notification about a successful finish does not exist:
kopf.objects: Handler 'node_maintenance_request_delete_handler' succeeded.
As a workaround, delete the OpenStack Controller pod:
kubectl -n osh-system delete pod -l app.kubernetes.io/name=openstack-operator
An update of the MOSK cluster with Tungsten Fabric may hang due to the changed Neutron back end with the following symptoms:
The
libvirtandnova-computepods fail to start:Entrypoint WARNING: 2022/03/03 08:49:45 entrypoint.go:72: Resolving dependency Pod on same host with labels map[application:neutron component:neutron-ovs-agent] in namespace openstack failed: Found no pods matching labels: map[application:neutron component:neutron-ovs-agent] .
In the
OSDPLnetwork section, theml2back end is specified instead oftungstenfabric:spec: features: neutron: backend: ml2
As a workaround, change the back end option from ml2 to
tungstenfabric:
spec:
features:
neutron:
backend: tungstenfabric
Release artifacts¶
This section lists the components artifacts of the MOSK 22.1 release.
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20220119130236.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20220119123458 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-bionic-20220119123458 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-bionic-20220119123458 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:victoria-bionic-20220119123458 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-bionic-20220119123458 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-bionic-20220119123458 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-bionic-20220119123458 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-bionic-20220119123458 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-bionic-20220119123458 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-bionic-20220119123458 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-bionic-20220119123458 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-bionic-20220119123458 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-bionic-20220119123458 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-bionic-20220119123458 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20220119123458 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-bionic-20220119123458 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20220106104815 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20220106104815 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20220106104815 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20220113100346 |
Apache License 2.0 |
rabbitmq-3.9 |
mirantis.azurecr.io/general/rabbitmq:3.9.8 |
Mozilla Public License 2.0 |
rabbitmq-3.9-management |
mirantis.azurecr.io/general/rabbitmq:3.9.8-management |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20211025114106 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.49.3 |
Apache License 2.0 |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20220106095058 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.9.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0-20211116035447 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-bionic-20220119123458 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-bionic-20220119123458 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-bionic-20220119123458 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-bionic-20220119123458 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v7.5.0 |
GPL-2.0 License |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.1-20211018180158 |
GPL License |
descheduler NEW |
mirantis.azurecr.io/openstack/extra/descheduler:v0.21.0 |
Apache License 2.0 |
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-ussuri-48f346e-20210119132403.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-ussuri-20220113104335.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:ussuri-bionic-20220113100346 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:ussuri-bionic-20220113100346 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:ussuri-bionic-20220113100346 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:ussuri-bionic-20220113100346 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:ussuri-bionic-20220113100346 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:ussuri-bionic-20220113100346 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:ussuri-bionic-20220113100346 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:ussuri-bionic-20220113100346 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0-20211116035447 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.9.0 |
Apache License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20220106095058 |
GPLv2, LGPLv2.1 (client libraries) |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.49.3 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20211025114106 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
rabbitmq-3.9-management |
mirantis.azurecr.io/general/rabbitmq:3.9.8-management |
Mozilla Public License 2.0 |
rabbitmq-3.9 |
mirantis.azurecr.io/general/rabbitmq:3.9.8 |
Mozilla Public License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20220113100346 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20220106104815 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20220106104815 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20220106104815 |
LGPL-2.1 License |
barbican |
mirantis.azurecr.io/openstack/barbican:ussuri-bionic-20220113100346 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20220113100346 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:ussuri-bionic-20220113100346 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:ussuri-bionic-20220113100346 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:ussuri-bionic-20220113100346 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:ussuri-bionic-20220113100346 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:ussuri-bionic-20220113100346 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:ussuri-bionic-20220113100346 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:ussuri-bionic-20220113100346 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:ussuri-bionic-20220113100346 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:ussuri-bionic-20220113100346 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:ussuri-bionic-20220113100346 |
Apache License 2.0 |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v7.5.0 |
GPL-2.0 License |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.1-20211018180158 |
GPL License |
descheduler NEW |
mirantis.azurecr.io/openstack/extra/descheduler:v0.21.0 |
Apache License 2.0 |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.6.11.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.6.11 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:5.1.20220127155145 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:5.1.20220127155145 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:5.1.20220127155145 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:5.1.20220127155145 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:5.1.20220127155145 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:5.1.20220127155145 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:5.1.20220127155145 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:5.1.20220127155145 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:5.1.20220127155145 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:5.1.20220127155145 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:5.1.20220127155145 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:5.1.20220127155145 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:5.1.20220127155145 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v2.0.2-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.9 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:1.0.4 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:1.1.0 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.1.0 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.7 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/prometheus-jmx-exporter:0.14.0-r50 |
Apache License 2.0 |
|
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.5 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.23 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.12 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.3-0.2.13 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.2.2-1-8cba7b0 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:6-alpine |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20220120132145 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20210214191656 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.6.11.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.6.11 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:2011.20220202093934 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:2011.20220202093934 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:2011.20220202093934 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:2011.20220202093934 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:2011.20220202093934 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:2011.20220202093934 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:2011.20220202093934 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:2011.20220202093934 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:2011.20220202093934 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:2011.20220202093934 |
Apache License 2.0 |
|
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
|
Control |
contrail-controller-control-control:2011.20220202093934 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:2011.20220202093934 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:2011.20220202093934 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:2011.20220202093934 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:2011.20220202093934 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:2011.20220202093934 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:2011.20220202093934 |
Apache License 2.0 |
|
NEW mirantis.azurecr.io/tungsten/contrail-node-init:2011.20220202093934 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:2011.20220202093934 |
Apache License 2.0 |
Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:2011.20220202093934 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v2.0.2-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.9 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.10 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/cass-config-builder:1.0.4 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/instaclustr-icarus:1.1.0 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.1.0 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.7 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/prometheus-jmx-exporter:0.14.0-r50 |
Apache License 2.0 |
|
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.5 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.23 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.12 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.3-0.2.13 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.2.2-1-8cba7b0 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:6-alpine |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20220120132145 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20210214191656 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:2011.20220202093934 |
Apache License 2.0 |
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/prometheus-libvirt-exporter:v0.1-20200610164751 |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20210115152338 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.2.0-mcp-1.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.2.0-mcp-3.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the MOSK 22.1 release:
[16495][OpenStack] Fixed the issue with Kubernetes not rescheduling OpenStack deployment pods after a node recovery.
[18713][OpenStack] Fixed the issue causing inability to remove a Glance image after an unsuccessful instance spawn attempt when image signature verification was enabled but the signature on the image was incorrect.
[19274][OpenStack] Fixed the issue causing inability to create a Heat stack by specifying the Heat template as a URL link due to Horizon container missing proxy variables.
[19791][OpenStack] Fixed the issue with the
DEFAULTvolume type being automatically created, as well as listed as a volume type in Horizon, for database migration even ifdefault_volume_typewas set incinder.conf.[18829][StackLight] Fixed the issue causing the Prometheus exporter for the Tungsten Fabric Controller pod to fail to start upon the StackLight log level change.
[18879][Ceph] Fixed the issue with the RADOS Gateway (RGW) pod overriding the global CA bundle located at
/etc/pki/tls/certswith an incorrect self-signed CA bundle during deployment of a Ceph cluster.[19195][Tungsten Fabric] Fixed the issue causing the managed cluster status to flap between the
Ready/Not Readystates in the Container Cloud web UI.
Update notes¶
This section describes the specific actions you as a cloud operator need to complete to accurately plan and successfully perform your Mirantis OpenStack for Kubernetes (MOSK) cluster to the version 22.1. Consider this information as a supplement to the generic update procedure published in Operations Guide: Update a MOSK cluster.
Additionally, read through the Cluster update known issues for the problems that are known to occur during update with recommended workarounds.
Starting from MOSK 22.1, the virtual CPU mode is set to
host-model by default, which replaces the previous default kvm64
CPU model.
The new default option provides performance and workload portability, namely reliable live and cold migration of instances between hosts, and ability to run modern guest operating systems, such as Windows Server.
For the deployments the virtual CPU mode settings customized through
spec:services, remove this customization in favor of the defaults
after the update.
MOSK 22.1 includes the updated version of the host machine’s kernel that is v5.4. All nodes in the cluster will get restarted to apply the relevant changes.
Node group |
Sequential restart |
Impact on end users and workloads |
|---|---|---|
Kubernetes master nodes |
Yes |
No |
Control plane nodes |
Yes |
No |
Storage nodes |
Yes |
No |
Compute nodes |
Yes |
15-20 minutes of downtime for workloads hosted on a compute node depending on the hardware specifications of the node |
During the Kubernetes master nodes update, there is a downtime on Kubernetes cluster’s internal DNS service. Thus, Tungsten Fabric vRouter pods lose connection with the control plane resulting in up to 1 minute of downtime for the Tungsten Fabric data plane nodes and impact on the tenant networking.
To complete the update of the cluster with Tungsten Fabric, manually restart Tungsten Fabric vRouter Agent pods on all compute nodes. The restart of a vRouter Agent on a compute node will cause up to 30-60 seconds of networking downtime per instance hosted there. If downtime is unacceptable for some workloads, we recommend that you migrate them before restarting the vRouter pods.
Warning
Under certain rare circumstances, the reload of the vRouter kernel
module triggered by the restart of a vRouter Agent is known to hang due to
the inability to complete the drop_caches operation. Watch the status
and logs of the vRouter Agent being restarted and trigger the reboot of
the node if necessary.
MOS 21.6 release¶
Release date |
Name |
Cluster release |
Highlights |
|---|---|---|---|
November 11, 2021 |
MOS 21.6 |
6.20.0+21.6 |
|
New features¶
Component |
Support scope |
Feature |
|---|---|---|
OpenStack |
Full |
|
TechPreview |
||
TechPreview |
||
Tungsten Fabric |
Full |
|
TechPreview |
||
Tungsten Fabric |
Full |
|
StackLight |
Full |
Implemented an automatic cleanup of deleted entries from the databases of OpenStack services. By default, the deleted rows older than 30 days are sanely and safely purged from the Barbican, Cinder, Glance, Heat, Masakari, and Nova databases for all relevant tables.
TechPreview
Implemented the capability to perform image signature verification when booting an OpenStack instance, uploading a Glance image with signature metadata fields set, and creating a volume from an image.
TechPreview
Implemented the ability to set the kv_mountpoint and namespace
in spec:features:barbican to specify the mountpoint of a Key-Value
store and the Vault namespace to be used for all requests to Vault
respectively.
Implemented the capability for the Tungsten Fabric Operator to use
ValidatingAdmissionWebhook to validate environment variables set to
Tungsten Fabric components upon the TFOperator object creation or update.
Tungsten Fabric 2011 is now set as the default version for deployment.
Tungsten Fabric 5.1 is considered deprecated and will be declared unsupported in one of the upcoming releases. Therefore, Mirantis highly recommends upgrading from Tungsten Fabric 5.1 to 2011.
TechPreview
Implemented the capability to deploy a MOS with Tungsten Fabric cluster with a multi-rack architecture to allow for native integration with the Layer 3-centric networking topologies.
Implemented the following improvements to StackLight alerting:
Implemented per-service
*TargetDownand*TargetsOutagealerts that raise if one or all Prometheus targets are down.Enhanced the alert inhibition rules to reduce alert flooding.
Learn more
Major components versions¶
Mirantis has tested MOS against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOS components with the exact versions against which testing has been performed.
Component |
Version |
|---|---|
Cluster release |
|
OpenStack |
|
openstack-operator |
0.6.3 |
Tungsten Fabric |
|
tungstenfabric-operator |
0.5.3 |
See also
Known issues¶
This section describes the MOS known issues with available workarounds. For the known issues in the related version of Mirantis Container Cloud, refer to Mirantis Container Cloud: Release Notes.
This section lists the Tungsten Fabric known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.6.
[10096] tf-control does not refresh IP addresses of Cassandra pods
[13755] TF pods switch to CrashLoopBackOff after a simultaneous reboot
[15684] Pods fail when rolling Tungsten Fabric 2011 back to 5.1
[18148] TF resets BGP_ASN, ENCAP_PRIORITY, and VXLAN_VN_ID_MODE to defaults
[19195] Managed cluster status is flapping between the Ready/Not Ready states
Tungsten Fabric does not provide the following functionality:
Automatic generation of network port records in DNSaaS (Designate) as Neutron with Tungsten Fabric as a back end is not integrated with DNSaaS. As a workaround, you can use the Tungsten Fabric built-in DNS service that enables virtual machines to resolve each other names.
Secret management (Barbican). You cannot use the certificates stored in Barbican to terminate HTTPs in a load balancer.
Role Based Access Control (RBAC) for Neutron objects.
Modification of custom vRouter DaemonSets based on the SR-IOV definition in the
OsDplCR.
The tf-control service resolves the DNS names of Cassandra pods at startup
and does not update them if Cassandra pods got new IP addresses, for example,
in case of a restart. As a workaround, to refresh the IP addresses of
Cassandra pods, restart the tf-control pods one by one:
Caution
Before restarting the tf-control pods:
Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only one
tf-controlpod that will be restarted.
kubectl -n tf delete pod tf-control-<hash>
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete a Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica number>
Some tf-control and tf-analytics pods may fail during the Tungsten
Fabric rollback from version 2011 to 5.1. In this case, the control
container from the tf-control pod and/or the collector container from
the tf-analytics pod contain SYS_WARN messages such as
… AMQP_QUEUE_DELETE_METHOD caused: PRECONDITION_FAILED - queue
‘<contrail-control/contrail-collector>.<nodename>’ in vhost ‘/’ not empty
….
The workaround is to manually delete the queue that fails to be deleted by
AMQP_QUEUE_DELETE_METHOD:
kubectl -n tf exec -it tf-rabbitmq-<num of replica> -- rabbitmqctl delete_queue <queue name>
During LCM operations such as Tungsten Fabric update or upgrade, the following
parameters defined by the cluster administrator are reset to the following
defaults upon the tf-config pod restart:
BGP_ASNto64512ENCAP_PRIORITYtoMPLSoUDP,MPLSoGRE,VXLANVXLAN_VN_ID_MODEtoautomatic
As a workaround, manually set up values for the required parameters if they differ from the defaults:
controllers:
tf-config:
provisioner:
containers:
- env:
- name: BGP_ASN
value: <USER_BGP_ASN_VALUE>
- name: ENCAP_PRIORITY
value: <USER_ENCAP_PRIORITY_VALUE>
name: provisioner
The status of a managed cluster may be flapping between the Ready and
Not Ready states in the Container Cloud web UI. In this case, if the
cluster Status field includes a message about not ready
tf/tf-tool-status-aggregator and/or tf-tool-status-party deployments
with 1/1 replicas, the status flapping may be caused by frequent updates of
these deployments by the Tungsten Fabric Operator.
Workaround:
Verify whether the
tf/tf-tool-status-aggregatorandtf-tool-status-partydeployments are up and running:kubectl -n tf get deployments
Safely disable the
tf/tf-tool-status-aggregatorandtf-tool-status-partydeployments through theTFOperatorCR:spec: controllers: tf-tool: status: enabled: false statusAggregator: enabled: false statusThirdParty: enabled: false
This section lists the OpenStack known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.6.
[25594] Security groups shared through RBAC cannot be used to create instances
[23985] Federated authorization fails after updating Keycloak URL
[6912] Octavia load balancers may not work properly with DVR
[16495] Failure to reschedule OpenStack deployment pods after a node recovery
[18713] Inability to remove a Glance image after an unsuccessful instance spawn
[19065] Octavia load balancers lose Amphora VMs after failover
Limitation
When Neutron is deployed in the DVR mode, Octavia load balancers may not work correctly. The symptoms include both failure to properly balance traffic and failure to perform an amphora failover. For details, see DVR incompatibility with ARP announcements and VRRP.
Kubernetes does not reschedule OpenStack deployment pods after a node recovery.
As a workaround, delete all pods of the deployment:
for i in $(kubectl -n openstack get deployments |grep -v NAME | awk '{print $1}');
do
kubectl -n openstack rollout restart deployment/$i;
done
Once done, the pods will respawn automatically.
When image signature verification is enabled and the signature is incorrect on the image, it is impossible to remove a Glance image right after an unsuccessful instance spawn attempt. As a workaround, wait for at least one minute before trying to remove the image.
Horizon container is missing proxy variables. As a result, it is not possible to create a Heat stack by specifying the Heat template as a URL link. As a workaround, use a different upload method and specify the file from a local folder.
If an Amphora VM does not respond or responds too long to heartbeat requests, the Octavia load balancer automatically initiates a failover process after 60 seconds of unsuccessful attempts. Long responses of an Amphora VM may be caused by various events, such as a high load on the OpenStack compute node that hosts the Amphora VM, network issues, system service updates, and so on. After a failover, the Amphora VMs may be missing in the completed Octavia load balancer.
Workaround:
If your deployment is already affected, manually restore the work of the load balancer by recreating the Amphora VM:
Define the load balancer ID:
openstack loadbalancer amphora list --column loadbalancer_id --format value --status ERROR
Start the load balancer failover:
openstack loadbalancer failover <Load balancer ID>
To avoid an automatic failover start that may cause the issue, set the
heartbeat_timeoutparameter in theOpenStackDeploymentCR to a large value in seconds. The default is 60 seconds. For example:spec: services: load-balancer: octavia: values: conf: octavia: health_manager: heartbeat_timeout: 31536000
This section lists the cluster update known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.6.
Note
Moving forward, the workaround for this issue will be moved from Release Notes to Mirantis Container Cloud documentation: MOS clusters update fails with stuck kubelet.
A MOS cluster may fail to update to the latest Cluster release with kubelet being stuck and reporting authorization errors.
The cluster is affected by the issue if you see the Failed to make webhook authorizer request: context canceled error in the kubelet logs:
docker logs ucp-kubelet --since 5m 2>&1 | grep 'Failed to make webhook authorizer request: context canceled'
As a workaround, restart the ucp-kubelet container on the affected
node(s):
ctr -n com.docker.ucp snapshot rm ucp-kubelet
docker rm -f ucp-kubelet
Note
Ignore failures in the output of the first command, if any.
An update of a MOS cluster may fail with the ceph csi-driver is not evacuated yet, waiting… error during the Ceph CSI pod eviction.
Workaround:
Scale the affected
StatefulSetof the pod that fails to init down to0replicas. If it is theDaemonSetsuch asnova-compute, it must not be scheduled on the affected node.On every
csi-rbdpluginpod, search for stuckcsi-vol:rbd device list | grep <csi-vol-uuid>
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
Delete
volumeattachmentof the affected pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale the affected
StatefulSetback to the original number of replicas or until its state isRunning. If it is aDaemonSet, run the pod on the affected node again.
MySQL may crash when performing instances live migration or during an update of
a managed cluster running MOS from version 6.19.0 to 6.20.0. After the crash,
MariaDB cannot connect to the cluster and gets stuck in the
CrashLoopBackOff state.
Workaround:
Verify that other MariaDB replicas are up and running and have joined the cluster:
Verify that at least 2 pods are running and operational (
2/2andRunning):kubectl -n openstack get pods |grep maria
Example of system response where the pods
mariadb-server-0andmariadb-server-2are operational:mariadb-controller-77b5ff47d5-ndj68 1/1 Running 0 39m mariadb-server-0 2/2 Running 0 39m mariadb-server-1 0/2 Running 0 39m mariadb-server-2 2/2 Running 0 39m
Log in to each operational pod and verify that the node is
Primaryand the cluster size is at least2. For example:mysql -u root -p$MYSQL_DBADMIN_PASSWORD -e "show status;" |grep -e \ wsrep_cluster_size -e "wsrep_cluster_status" -e "wsrep_local_state_comment"
Example of system response:
wsrep_cluster_size 2 wsrep_cluster_status Primary wsrep_local_state_comment Synced
Remove the content of the
/var/lib/mysql/*directory:kubectl -n openstack exec -it mariadb-server-1 – rm -rf /var/lib/mysql/*
Restart the MariaDB container:
kubectl -n openstack delete pod mariadb-server-1
This section lists Ceph known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.6.
During deployment of a Ceph cluster, the RADOS Gateway (RGW) pod overrides
the global CA bundle located at /etc/pki/tls/certs with an incorrect
self-signed CA bundle. The issue affects only clusters with public
certificates.
Workaround:
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with a corresponding value.Note
If the public CA certificates also apply to the
OsDplCR, edit this resource as well.Select from the following options:
If you are using the GoDaddy certificates, in the
cephClusterSpec.objectStorage.rgwsection, replace thecacertparameters with your public CA certificate that already contains both the root CA certificate and intermediate CA certificate:cephClusterSpec: objectStorage: rgw: SSLCert: cacert: | -----BEGIN CERTIFICATE----- ca-certificate here -----END CERTIFICATE----- tlsCert: | -----BEGIN CERTIFICATE----- private TLS certificate here -----END CERTIFICATE----- tlsKey: | -----BEGIN RSA PRIVATE KEY----- private TLS key here -----END RSA PRIVATE KEY-----
If you are using the DigiCert certificates:
Download the
<root_CA>from DigiCert.In the
cephClusterSpec.objectStorage.rgwsection, replace thecacertparameters with your public intermediate CA certificate along with the root one:cephClusterSpec: objectStorage: rgw: SSLCert: cacert: | -----BEGIN CERTIFICATE----- <root CA here> <intermediate CA here> -----END CERTIFICATE----- tlsCert: | -----BEGIN CERTIFICATE----- private TLS certificate here -----END CERTIFICATE----- tlsKey: | -----BEGIN RSA PRIVATE KEY----- private TLS key here -----END RSA PRIVATE KEY-----
Release artifacts¶
This section lists the components artifacts of the MOS 21.6 release:
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20211025092055.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20211025085835 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-bionic-20211025085835 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-bionic-20211025085835 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:victoria-bionic-20211025085835 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-bionic-20211025085835 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-bionic-20211025085835 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-bionic-20211025085835 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-bionic-20211025085835 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-bionic-20211025085835 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-bionic-20211025085835 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-bionic-20211025085835 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-bionic-20211025085835 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-bionic-20211025085835 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-bionic-20211025085835 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20211025085835 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-bionic-20211025085835 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20211007094813 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20211007094813 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20211007094813 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20211025060022 |
Apache License 2.0 |
rabbitmq-3.8 |
mirantis.azurecr.io/general/rabbitmq:3.8.14 |
Mozilla Public License 2.0 |
rabbitmq-3.8-management |
mirantis.azurecr.io/general/rabbitmq:3.8.14-management |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20210804080905 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.49.3 |
Apache License 2.0 |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20211007085158 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.9.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0-20211007200025 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-bionic-20211025085835 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-bionic-20211025085835 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-bionic-20211025085835 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-bionic-20211025085835 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v7.5.0 |
GPL-2.0 License |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.1-20211018180158 |
GPL License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-ussuri-48f346e-20210119132403.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-ussuri-20211025093130.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:ussuri-bionic-20211025085835 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:ussuri-bionic-20211025085835 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:ussuri-bionic-20211025085835 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:ussuri-bionic-20211025085835 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:ussuri-bionic-20211025085835 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:ussuri-bionic-20211025085835 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:ussuri-bionic-20211025085835 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:ussuri-bionic-20211025085835 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0-20211007200025 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.9.0 |
Apache License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20211007085158 |
GPLv2, LGPLv2.1 (client libraries) |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.49.3 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20210804080905 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
rabbitmq-3.8-management |
mirantis.azurecr.io/general/rabbitmq:3.8.14-management |
Mozilla Public License 2.0 |
rabbitmq-3.8 |
mirantis.azurecr.io/general/rabbitmq:3.8.14 |
Mozilla Public License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20211025085835 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20211007094813 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20211007094813 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20211007094813 |
LGPL-2.1 License |
barbican |
mirantis.azurecr.io/openstack/barbican:ussuri-bionic-20211025085835 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20211025085835 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:ussuri-bionic-20211025085835 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:ussuri-bionic-20211025085835 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:ussuri-bionic-20211025085835 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:ussuri-bionic-20211025085835 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:ussuri-bionic-20211025085835 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:ussuri-bionic-20211025085835 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:ussuri-bionic-20211025085835 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:ussuri-bionic-20211025085835 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:ussuri-bionic-20211025085835 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:ussuri-bionic-20211025085835 |
Apache License 2.0 |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v7.5.0 |
GPL-2.0 License |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.1-20211018180158 |
GPL License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.5.3.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.5.3 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:5.1.20211021075650 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:5.1.20211021075650 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:5.1.20211021075650 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:5.1.20211021075650 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:5.1.20211021075650 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:5.1.20211021075650 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:5.1.20211021075650 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:5.1.20211021075650 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:5.1.20211021075650 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:5.1.20211021075650 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:5.1.20211021075650 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:5.1.20211021075650 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:5.1.20211021075650 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:5.1.20211021075650 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:5.1.20211021075650 |
Apache License 2.0 |
|
Status |
mirantis.azurecr.io/tungsten/contrail-status:5.1.20211021075650 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-tf-status:5.1.20211021075650 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-aggregator:5.1.20211021075650 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-party:5.1.20211021075650 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:5.1.20211021075650 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:5.1.20211021075650 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:5.1.20211021075650 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v2.0.2-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.4 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.6 |
Apache License 2.0 |
|
NEW mirantis.azurecr.io/tungsten/cass-config-builder:1.0.4 |
Apache License 2.0 |
|
NEW mirantis.azurecr.io/tungsten/instaclustr-icarus:1.1.0 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.1.0 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.4 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/prometheus-jmx-exporter:0.14.0-r50 |
Apache License 2.0 |
|
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.5 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.23 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.12 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.3-0.2.13 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.2.2-1-8cba7b0 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:6-alpine |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20211019145848 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20210214191656 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.4.2.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.4.2 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:2011.20211019042938 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:2011.20211019042938 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:2011.20211019042938 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:2011.20211019042938 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:2011.20211019042938 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:2011.20211019042938 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:2011.20211019042938 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:2011.20211019042938 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:2011.20211019042938 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:2011.20211019042938 |
Apache License 2.0 |
|
Control |
contrail-controller-control-control:2011.20211019042938 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:2011.20211019042938 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:2011.20211019042938 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:2011.20211019042938 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:2011.20211019042938 |
Apache License 2.0 |
|
Status |
mirantis.azurecr.io/tungsten/contrail-status:2011.20211019042938 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-tf-status:2011.20211019042938 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-aggregator:2011.20211019042938 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-party:2011.20211019042938 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:2011.20211019042938 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:2011.20211019042938 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:2011.20211019042938 |
Apache License 2.0 |
Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:2011.20211019042938 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v2.0.2-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.4 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.6 |
Apache License 2.0 |
|
NEW mirantis.azurecr.io/tungsten/cass-config-builder:1.0.4 |
Apache License 2.0 |
|
NEW mirantis.azurecr.io/tungsten/instaclustr-icarus:1.1.0 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.1.0 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.4 |
Apache License 2.0 |
mirantis.azurecr.io/stacklight/prometheus-jmx-exporter:0.14.0-r50 |
Apache License 2.0 |
|
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.5 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.23 |
Mozilla Public License 2.0 |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
|
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.12 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.3-0.2.13 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.2.2-1-8cba7b0 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:6-alpine |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20211019145848 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20210214191656 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:2011.20211019042938 |
Apache License 2.0 |
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/libvirt-exporter:v0.1-20200610164751 |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20210115152338 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.1.0-mcp-2.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.1.0-mcp-1.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the Mirantis OpenStack for Kubernetes 21.6 release:
[16452][OpenStack] Fixed the issue causing failure to update the Octavia policy after policies removal from the OsDpl CR. The issue affected OpenStack Victoria.
[16103][OpenStack] Fixed the issue causing Glance client to return the
HTTPInternalServerErrorwhile operating with volume when Glance was configured with the Cinder back end TechPreview.[17321][OpenStack] Fixed the issue causing RPC errors in the logs of the
designate-centralpods during liveness probes.[17927][OpenStack] Fixed the issue causing inability to delete volume backups created from encrypted volumes.
[18029][OpenStack] Fixed the issue with live migration of instances with SR-IOV
macvtapports occasionally requiring the same virtual functions (VF) number to be free on the destination compute nodes.[18744][OpenStack] Fixed the issue with the
application_credentialauthentication method being disabled in Keystone in case of an enabled Keycloak integration.[17246][StackLight] Deprecated the redundant
openstack.externalFQDN(string) parameter and added the newexternalFQDNs.enabled(bool) parameter.
MOS 21.5 release¶
Release date |
Name |
Cluster release |
Highlights |
|---|---|---|---|
October 05, 2021 |
MOS 21.5 |
6.19.0+21.5 |
Update for the MOS GA release introducing the following key features:
|
New features¶
Component |
Support scope |
Feature |
|---|---|---|
OpenStack |
Full |
|
TechPreview |
||
Tungsten Fabric |
Full |
|
TechPreview |
||
StackLight |
Full |
|
Full |
||
Documentation |
n/a |
|
n/a |
Implemented a machine-readable status for OpenStack deployments. Now, you can
use the OpenStackDeploymentStatus (OsDplSt) custom resource as a single
data structure that describes the OpenStackDeployment (OsDpl) status at a
particular moment.
Learn more
TechPreview
Implemented the capability to enable Cinder volume encryption through the
OpenStackDeployment CR using Barbican that will store the encryption keys
and Linux Unified Key Setup (LUKS) that will create encrypted Cinder volumes
including bootable ones. If an encrypted volume is bootable, Nova will get a
symmetric encryption key from Barbican.
Learn more
Implemented full support for Tungsten Fabric 2011. Though, Tungsten Fabric 5.1
is deployed by default in MOS 21.5, you can use the
tfVersion parameter to define the 2011 version for deployment.
TechPreview
Implemented support for multiple workers of the contrail-api in Tungsten
Fabric. Starting from the MOS 21.5 release, six workers
of the contrail-api
service are used by default. In the previous MOS releases,
only one worker of this service was used.
Learn more
Enhanced the Grafana dashboards to display user-friendly short names for
Kubernetes nodes, for example, master-0, instead of long name labels
such as kaas-node-f736fc1c-3baa-11eb-8262-0242ac110002.
This feature provides for consistency with Kubernetes nodes naming in the
Mirantis Container Cloud web UI.
All Grafana dashboards that present node data now have an additional Node identifier drop-down menu. By default, it is set to machine to display short names for Kubernetes nodes. To display Kubernetes node name labels as previously, change this option to node.
Learn more
Implemented the following improvements to StackLight alerting:
Added the
OpenstackServiceInternalApiOutageandOpenstackServicePublicApiOutagealerts that raise in case of an OpenStack service internal or public API outage.Enhanced the alert inhibition rules.
Reworked a number of alerts to improve alerting efficiency and reduce alert flooding.
Removed the inefficient
OpenstackServiceApiDownandOpenstackServiceApiOutagealerts.
Learn more
Published MOS Release Compatibility Matrix that describes the cloud configurations that have been supported by the product over the course of its lifetime and the path a MOS cloud can take to move from an older configuration to a newer one.
Learn more
Published the OpenStack Ussuri to Victoria upgrade procedure and Tungsten Fabric 5.1 to 2011 upgrade procedure that instruct cloud operators on how to prepare for the upgrade, use the MOS life cycle management API to perform the upgrade, and verify the cloud operability after the upgrade.
Learn more
Major components versions¶
Mirantis has tested MOS against a very specific configuration and can guarantee a predictable behavior of the product onlyin the exact same environments. The table below includes the major MOS components with the exact versions against which testing has been performed.
Known issues¶
This section describes the MOS known issues with available workarounds. For the known issues in the related version of Mirantis Container Cloud, refer to Mirantis Container Cloud: Release Notes.
This section lists the Tungsten Fabric known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.5.
[10096] tf-control does not refresh IP addresses of Cassandra pods
[13755] TF pods switch to CrashLoopBackOff after a simultaneous reboot
[15684] Pods fail when rolling Tungsten Fabric 2011 back to 5.1
[18148] TF resets BGP_ASN, ENCAP_PRIORITY, and VXLAN_VN_ID_MODE to defaults
Tungsten Fabric does not provide the following functionality:
Automatic generation of network port records in DNSaaS (Designate) as Neutron with Tungsten Fabric as a back end is not integrated with DNSaaS. As a workaround, you can use the Tungsten Fabric built-in DNS service that enables virtual machines to resolve each other names.
Secret management (Barbican). You cannot use the certificates stored in Barbican to terminate HTTPs in a load balancer.
Role Based Access Control (RBAC) for Neutron objects.
Modification of custom vRouter DaemonSets based on the SR-IOV definition in the
OsDplCR.
The tf-control service resolves the DNS names of Cassandra pods at startup
and does not update them if Cassandra pods got new IP addresses, for example,
in case of a restart. As a workaround, to refresh the IP addresses of
Cassandra pods, restart the tf-control pods one by one:
Caution
Before restarting the tf-control pods:
Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only one
tf-controlpod that will be restarted.
kubectl -n tf delete pod tf-control-<hash>
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete a Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica number>
Some tf-control and tf-analytics pods may fail during the Tungsten
Fabric rollback from version 2011 to 5.1. In this case, the control
container from the tf-control pod and/or the collector container from
the tf-analytics pod contain SYS_WARN messages such as
… AMQP_QUEUE_DELETE_METHOD caused: PRECONDITION_FAILED - queue
‘<contrail-control/contrail-collector>.<nodename>’ in vhost ‘/’ not empty ….
The workaround is to manually delete the queue that fails to be deleted by
AMQP_QUEUE_DELETE_METHOD:
kubectl -n tf exec -it tf-rabbitmq-<num of replica> -- rabbitmqctl delete_queue <queue name>
During LCM operations such as Tungsten Fabric update or upgrade, the following
parameters defined by the cluster administrator are reset to the following
defaults upon the tf-config pod restart:
BGP_ASNto64512ENCAP_PRIORITYtoMPLSoUDP,MPLSoGRE,VXLANVXLAN_VN_ID_MODEtoautomatic
As a workaround, manually set up values for the required parameters if they differ from the defaults:
controllers:
tf-config:
provisioner:
containers:
- env:
- name: BGP_ASN
value: <USER_BGP_ASN_VALUE>
- name: ENCAP_PRIORITY
value: <USER_ENCAP_PRIORITY_VALUE>
name: provisioner
This section lists the OpenStack known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.5.
[6912] Octavia load balancers may not work properly with DVR
[16495] Failure to reschedule OpenStack deployment pods after a node recovery
[16452] Failure to update the Octavia policy after policies removal
[19065] Octavia load balancers lose Amphora VMs after failover
Limitation
When Neutron is deployed in the DVR mode, Octavia load balancers may not work correctly. The symptoms include both failure to properly balance traffic and failure to perform an amphora failover. For details, see DVR incompatibility with ARP announcements and VRRP.
Kubernetes does not reschedule OpenStack deployment pods after a node recovery.
As a workaround, delete all pods of the deployment:
for i in $(kubectl -n openstack get deployments |grep -v NAME | awk '{print $1}');
do
kubectl -n openstack rollout restart deployment/$i;
done
Once done, the pods will respawn automatically.
The Octavia policy fails to be updated after policies removal from the OsDpl CR. The issue affects OpenStack Victoria.
As a workaround, restart the Octavia API pods:
kubectl -n openstack delete pod -l application=octavia,component=api
When Glance is configured with the Cinder back end TechPreview, the
Glance client may return the HTTPInternalServerError error while operating
with volume. In this case, repeat the action again until it succeeds.
If an Amphora VM does not respond or responds too long to heartbeat requests, the Octavia load balancer automatically initiates a failover process after 60 seconds of unsuccessful attempts. Long responses of an Amphora VM may be caused by various events, such as a high load on the OpenStack compute node that hosts the Amphora VM, network issues, system service updates, and so on. After a failover, the Amphora VMs may be missing in the completed Octavia load balancer.
Workaround:
If your deployment is already affected, manually restore the work of the load balancer by recreating the Amphora VM:
Define the load balancer ID:
openstack loadbalancer amphora list --column loadbalancer_id --format value --status ERROR
Start the load balancer failover:
openstack loadbalancer failover <Load balancer ID>
To avoid an automatic failover start that may cause the issue, set the
heartbeat_timeoutparameter in theOpenStackDeploymentCR to a large value in seconds. The default is 60 seconds. For example:spec: services: load-balancer: octavia: values: conf: octavia: health_manager: heartbeat_timeout: 31536000
This section lists the cluster update known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.5.
A MOS cluster may fail to update to the latest Cluster release with kubelet being stuck and reporting authorization errors.
The cluster is affected by the issue if you see the Failed to make webhook authorizer request: context canceled error in the kubelet logs:
docker logs ucp-kubelet --since 5m 2>&1 | grep 'Failed to make webhook authorizer request: context canceled'
As a workaround, restart the ucp-kubelet container on the affected
node(s):
ctr -n com.docker.ucp snapshot rm ucp-kubelet
docker rm -f ucp-kubelet
Note
Ignore failures in the output of the first command, if any.
An update of a MOS cluster may fail with the ceph csi-driver is not evacuated yet, waiting… error during the Ceph CSI pod eviction.
Workaround:
Scale the affected
StatefulSetof the pod that fails to init down to0replicas. If it is theDaemonSetsuch asnova-compute, it must not be scheduled on the affected node.On every
csi-rbdpluginpod, search for stuckcsi-vol:rbd device list | grep <csi-vol-uuid>
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
Delete
volumeattachmentof the affected pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale the affected
StatefulSetback to the original number of replicas or until its state isRunning. If it is aDaemonSet, run the pod on the affected node again.
This section lists Ceph known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.5.
During deployment of a Ceph cluster, the RADOS Gateway (RGW) pod overrides
the global CA bundle located at /etc/pki/tls/certs with an incorrect
self-signed CA bundle. The issue affects only clusters with public
certificates.
Workaround:
Open the
KaasCephClusterCR of a managed cluster for editing:kubectl edit kaascephcluster -n <managedClusterProjectName>
Substitute
<managedClusterProjectName>with a corresponding value.Note
If the public CA certificates also apply to the
OsDplCR, edit this resource as well.Select from the following options:
If you are using the GoDaddy certificates, in the
cephClusterSpec.objectStorage.rgwsection, replace thecacertparameters with your public CA certificate that already contains both the root CA certificate and intermediate CA certificate:cephClusterSpec: objectStorage: rgw: SSLCert: cacert: | -----BEGIN CERTIFICATE----- ca-certificate here -----END CERTIFICATE----- tlsCert: | -----BEGIN CERTIFICATE----- private TLS certificate here -----END CERTIFICATE----- tlsKey: | -----BEGIN RSA PRIVATE KEY----- private TLS key here -----END RSA PRIVATE KEY-----
If you are using the DigiCert certificates:
Download the
<root_CA>from DigiCert.In the
cephClusterSpec.objectStorage.rgwsection, replace thecacertparameters with your public intermediate CA certificate along with the root one:cephClusterSpec: objectStorage: rgw: SSLCert: cacert: | -----BEGIN CERTIFICATE----- <root CA here> <intermediate CA here> -----END CERTIFICATE----- tlsCert: | -----BEGIN CERTIFICATE----- private TLS certificate here -----END CERTIFICATE----- tlsKey: | -----BEGIN RSA PRIVATE KEY----- private TLS key here -----END RSA PRIVATE KEY-----
Release artifacts¶
This section lists the components artifacts of the MOS 21.5 release:
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20210819064238.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20210913060022 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-bionic-20210913060022 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-bionic-20210913060022 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-bionic-20210909120529 |
Mirantis Proprietary License |
placement |
mirantis.azurecr.io/openstack/placement:victoria-bionic-20210913060022 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-bionic-20210913060022 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-bionic-20210913060022 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-bionic-20210913060022 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-bionic-20210913060022 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-bionic-20210913060022 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-bionic-20210913060022 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-bionic-20210913060022 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-bionic-20210913060022 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-bionic-20210913060022 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-bionic-20210913060022 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20210913060022 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-bionic-20210913060022 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20210617094817 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20210617094817 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20210617094817 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20210913060022 |
Apache License 2.0 |
rabbitmq-3.8 |
mirantis.azurecr.io/general/rabbitmq:3.8.14 |
Mozilla Public License 2.0 |
rabbitmq-3.8-management |
mirantis.azurecr.io/general/rabbitmq:3.8.14-management |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20210804080905 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.49.0 |
Apache License 2.0 |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210617085111 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0-20210830173823 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-bionic-20210913060022 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-bionic-20210913060022 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-bionic-20210913060022 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-bionic-20210913060022 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v7.5.0 |
GPL-2.0 License |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.1-20210511072313 |
GPL License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-ussuri-48f346e-20210119132403.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-ussuri-20210121085750.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:ussuri-bionic-20210910182329 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:ussuri-bionic-20210910182329 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:ussuri-bionic-20210910182329 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:ussuri-bionic-20210909094910 |
Mirantis Proprietary License |
placement |
mirantis.azurecr.io/openstack/placement:ussuri-bionic-20210910182329 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:ussuri-bionic-20210910182329 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:ussuri-bionic-20210910182329 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:ussuri-bionic-20210910182329 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:ussuri-bionic-20210910182329 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0-20210830173823 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
Apache License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210617085111 |
GPLv2, LGPLv2.1 (client libraries) |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.49.0 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20210804080905 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
rabbitmq-3.8-management |
mirantis.azurecr.io/general/rabbitmq:3.8.14-management |
Mozilla Public License 2.0 |
rabbitmq-3.8 |
mirantis.azurecr.io/general/rabbitmq:3.8.14 |
Mozilla Public License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20210910182329 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20210617094817 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20210617094817 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20210617094817 |
LGPL-2.1 License |
barbican |
mirantis.azurecr.io/openstack/barbican:ussuri-bionic-20210910182329 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20210910182329 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:ussuri-bionic-20210910182329 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:ussuri-bionic-20210910182329 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:ussuri-bionic-20210910182329 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:ussuri-bionic-20210910182329 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:ussuri-bionic-20210910182329 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:ussuri-bionic-20210910182329 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:ussuri-bionic-20210910182329 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:ussuri-bionic-20210910182329 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:ussuri-bionic-20210910182329 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:ussuri-bionic-20210910182329 |
Apache License 2.0 |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v7.5.0 |
GPL-2.0 License |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.1-20210511072313 |
GPL License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.4.2.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.4.2 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:5.1.20210826171459 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:5.1.20210826171459 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:5.1.20210826171459 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:5.1.20210826171459 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:5.1.20210826171459 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:5.1.20210826171459 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:5.1.20210826171459 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:5.1.20210826171459 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:5.1.20210826171459 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:5.1.20210826171459 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:5.1.20210826171459 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:5.1.20210826171459 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:5.1.20210826171459 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:5.1.20210826171459 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:5.1.20210826171459 |
Apache License 2.0 |
|
Status |
mirantis.azurecr.io/tungsten/contrail-status:5.1.20210826171459 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-tf-status:5.1.20210826171459 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-aggregator:5.1.20210826171459 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-party:5.1.20210826171459 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:5.1.20210826171459 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:5.1.20210826171459 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:5.1.20210826171459 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v0.5.3-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.4 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.6 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.0.9 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.4 |
Apache License 2.0 |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.4 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.14 |
Mozilla Public License 2.0 |
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.10 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.1-0.2.9 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.1.5-1-ccd6a63 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:5-alpine |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20210428100236 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20210214191656 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.4.2.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.4.2 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:2011.20210906142040 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:2011.20210906142040 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:2011.20210906142040 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:2011.20210906142040 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:2011.20210906142040 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:2011.20210906142040 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:2011.20210906142040 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:2011.20210906142040 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:2011.20210906142040 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:2011.20210906142040 |
Apache License 2.0 |
|
Control |
contrail-controller-control-control:2011.20210906142040 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:2011.20210906142040 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:2011.20210906142040 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:2011.20210906142040 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:2011.20210906142040 |
Apache License 2.0 |
|
Status |
mirantis.azurecr.io/tungsten/contrail-status:2011.20210906142040 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-tf-status:2011.20210906142040 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-aggregator:2011.20210906142040 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-party:2011.20210906142040 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:2011.20210906142040 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:2011.20210906142040 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:2011.20210906142040 |
Apache License 2.0 |
Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:2011.20210906142040 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v0.5.3-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.4 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.6 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.0.9 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.4 |
Apache License 2.0 |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.4 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.14 |
Mozilla Public License 2.0 |
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.10 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.1-0.2.9 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.1.5-1-ccd6a63 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:5-alpine |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20210428100236 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20210214191656 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
TF Tools |
mirantis.azurecr.io/tungsten/contrail-tools:2011.20210906142040 |
Apache License 2.0 |
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/libvirt-exporter:v0.1-20200610164751 |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20210115152338 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.1.0-mcp-2.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.1.0-mcp-1.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the Mirantis OpenStack for Kubernetes 21.5 release:
[17115][Update] Fixed the issue with the
status.providerStatus.releaseRefs.previous.namefield in the Cluster object for Ceph not changing during the MOS cluster update. If you have previously applied the workaround as described in [17115] Cluster update does not change releaseRefs in Cluster object for Ceph, manually add thesubresourcessection back to theclusterworkloadlockCRD:kubectl edit crd clusterworkloadlocks.lcm.mirantis.com # add here 'subresources' section: spec: versions: - name: v1alpha1 subresources: status: {}
[17477][Update] Fixed the issue with StackLight in HA mode placed on controller nodes being not deployed or cluster update being blocked. Once you update your MOS cluster from the Cluster release 6.18.0 to 6.19.0, roll back the workaround applied as described in [17477] StackLight in HA mode is not deployed or cluster update is blocked:
Remove
stacklightlabels from worker nodes. Wait for the labels to be removed.Remove the custom
nodeSelectorsection from the cluster spec.
[16103][OpenStack] Fixed the issue with the Glance client returning the
HTTPInternalServerErrorerror while operating with a volume if Glance was configured with the Cinder back end TechPreview.[14678][OpenStack] Fixed the issue with instance being inaccessible through floating IP upon floating IP quick reuse when using a small floating network.
[16963][OpenStack] Fixed the issue with Ironic failing to provide nodes on deployments with OpenStack Victoria.
[16241][Tungsten Fabric] Fixed the issue causing failure to update a port, or security group assigned to the port, through the Horizon web UI.
[17045][StackLight] Fixed the issue causing the
fluentd-notificationspod failing to track the RabbitMQ credentials updates in the Secret object.[17573][StackLight] Fixed the issue with OpenStack notifications missing in Elasticsearch and the Kibana
notification-*index being empty.
MOS 21.4 release¶
Release date |
Name |
Container Cloud Cluster release |
Highlights |
|---|---|---|---|
September 01, 2021 |
MOS 21.4 |
6.18.0+21.4 |
Update for the MOS GA release introducing the following key features:
|
New features¶
Component |
Support scope |
Feature |
|---|---|---|
OpenStack |
Full |
|
Full |
||
TechPreview |
||
Full |
||
TechPreview |
||
TechPreview |
||
Full |
||
Full |
||
TechPreview |
||
n/a |
||
Tungsten Fabric |
TechPreview |
|
StackLight |
Full |
|
Full |
Implemented full support for OpenStack Victoria with OVS or Tungsten Fabric 5.1. However, for new OpenStack Victoria with Tungsten Fabric deployments, Mirantis recommends that you install Tungsten Fabric 2011, which is shipped as TechPreview in this release.
Verified the upgrade path from Ussuri with OVS or Tungsten Fabric 5.1 to Victoria with OVS or Tungsten Fabric 5.1.
OpenStack Ussuri is considered deprecated and will be declared unsupported in one of the upcoming releases. Therefore, start planning your Ussuri to Victoria cloud upgrade.
Implemented the mechanism to define additional policy rules for the core
OpenStack services through the OpenStackDeployment Custom Resource.
TechPreview
Implemented support for Masakari instance evacuation. Now, Masakari host monitor is deployed by default with Instances High Availability Service for OpenStack to provide automatic instance evacuation from failed instances.
Implemented the usage of direct Helm 3 communication by the OpenStack operator. The usage of HelmBundles is dropped and automatic transition from Helm 2 to Helm 3 is performed during the MOS 21.3 to MOS 21.4 release update.
TechPreview
Implemented the capability to configure Cinder back end for images through
the OpenStackDeployment Custom Resource. The usage of Cinder back end
for Glance enables the OpenStack clouds relying on third-party appliances
for block storage to have images in one place.
TechPreview
Added the capability to collocate the OpenStack control plane with the managed
cluster master nodes through the OpenStackDeployment Custom Resource.
Note
If the StackLight cluster is configured to run in the HA mode on the same nodes with the control plane services, additional manual steps are required for an upgrade to MOS 21.4 or for a greenfield deployment. For details, see known issue 17477.
Implemented full support for the SR-IOV with the Neutron OVS back end topology.
Learn more
Added support for large-scale deployments that number up to 200 nodes out of the box. The use case has been verified for core OpenStack services with OVS and non-DVR Neutron configuration on a dedicated hardware scale lab.
For a successful deployment, we recommend sticking to the optimal limit for the number of ports on gateway nodes that is 1500 ports per gateway node. This recommendation was confirmed during the testing and should be taken into account when planning large environments.
TechPreview
Implemented the capability to enable the BGP VPN service to allow for connection of OpenStack Virtual Private Networks with external VPN sites through either BGP/MPLS IP VPNs or E-VPN.
Learn more
Published MOS API Reference to provide cloud operators with an up-to-date and comprehensive definition of the language they need to use to communicate with MOS OpenStack and Tungsten Fabric.
Learn more
TechPreview
Implemented support for SR-IOV and DPDK with Tungsten Fabric 2011.
Implemented the following improvements to StackLight alerting:
Added the following alerts:
CinderServiceDisabledthat raises when a Cinder service is disabled on all hosts.NeutronAgentDisabledthat raises when a Neutron Agent is disabled on all hosts.NeutronAgentOutagethat raises when a Neutron Agent is down on all hosts where it is enabled.NovaServiceDisabledthat raises when a Nova service is disabled on all hosts.TungstenFabricAPI401Criticalthat raises when Tungsten Fabric API responds with HTTP 401.TungstenFabricAPI5xxCriticalthat raises when Tungsten Fabric API responds with HTTP 5xx.
Reworked the alert inhibition rules.
Reworked a number of alerts to improve alerting efficiency and reduce alert flooding.
Removed the inefficient
*ServicesDownMajor,*ServicesDownMinor,*AgentsDownMajor,*AgentsDownMinoralerts.
Learn more
Enhanced StackLight to send all OpenStack notifications to the notification
index. Now, to view the previously called audit notifications, see the
cadf Logger in the Kibana Notifications
dashboard.
Major components versions¶
Mirantis has tested MOS against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOS components with the exact versions against which testing has been performed.
Known issues¶
This section describes the MOS known issues with available workarounds. For the known issues in the related version of Mirantis Container Cloud, refer to Mirantis Container Cloud: Release Notes.
This section lists the Tungsten Fabric known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.4.
[10096] tf-control does not refresh IP addresses of Cassandra pods
[13755] TF pods switch to CrashLoopBackOff after a simultaneous reboot
Tungsten Fabric does not provide the following functionality:
Automatic generation of network port records in DNSaaS (Designate) as Neutron with Tungsten Fabric as a back end is not integrated with DNSaaS. As a workaround, you can use the Tungsten Fabric built-in DNS service that enables virtual machines to resolve each other names.
Secret management (Barbican). You cannot use the certificates stored in Barbican to terminate HTTPs in a load balancer.
Role Based Access Control (RBAC) for Neutron objects.
Modification of custom vRouter DaemonSets based on the SR-IOV definition in the
OsDplCR.
The tf-control service resolves the DNS names of Cassandra pods at startup
and does not update them if Cassandra pods got new IP addresses, for example,
in case of a restart. As a workaround, to refresh the IP addresses of
Cassandra pods, restart the tf-control pods one by one:
Caution
Before restarting the tf-control pods:
Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only one
tf-controlpod that will be restarted.
kubectl -n tf delete pod tf-control-<hash>
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete a Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica number>
Fixed in MOS 21.5
Updating a port or security group assigned to the port through the Horizon web UI fails with an error.
Workaround:
Update the port through the Tungsten Fabric web UI:
Log in to the Tungsten Fabric web UI.
Navigate to Configure > Networking > Ports.
Click the gear icon next to the required port and click Edit.
Change the parameters as required and click Save.
Update the port through CLI:
Log in to the
keystone-clientpod.Run the openstack port set with the required parameters. For example:
openstack port set 48f7dfce-9111-4951-a2d3-95a63c94b64e --name port-name-changed
This section lists the OpenStack known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.4.
[6912] Octavia load balancers may not work properly with DVR
[14678] Instance inaccessible through floating IP upon floating IP quick reuse
[16495] Failure to reschedule OpenStack deployment pods after a node recovery
[16452] Failure to update the Octavia policy after policies removal
Limitation
When Neutron is deployed in the DVR mode, Octavia load balancers may not work correctly. The symptoms include both failure to properly balance traffic and failure to perform an amphora failover. For details, see DVR incompatibility with ARP announcements and VRRP.
Fixed in MOS 21.5
When using a small floating network and the floating IP that was previously allocated to an instance and re-associated with another instance in a short period of time, the instance may be inaccessible. The Address Resolution Protocol (ARP) cache timeout on the infrastructure layer is typically set to 5 minutes.
As a workaround, set a shorter ARP cache timeout on the infrastructure side.
Fixed in MOS 21.5
On deployments with OpenStack Victoria, Ironic may fail to provide nodes.
Workaround:
In the OsDpl CR, set
valid_interfacestopublic,internal:spec: services: baremetal: ironic: values: conf: ironic: service_catalog: valid_interfaces: public,internal
Trigger the OpenStack deployment to restart Ironic:
kubectl apply -f openstackdeployment.yaml
To monitor the status:
kubectl -n openstack get pods kubectl -n openstack describe osdpl osh-dev
Kubernetes does not reschedule OpenStack deployment pods after a node recovery.
As a workaround, delete all pods of the deployment:
for i in $(kubectl -n openstack get deployments |grep -v NAME | awk '{print $1}');
do
kubectl -n openstack rollout restart deployment/$i;
done
Once done, the pods will respawn automatically.
The Octavia policy fails to be updated after policies removal from the OsDpl CR. The issue affects OpenStack Victoria.
As a workaround, restart the Octavia API pods:
kubectl -n openstack delete pod -l application=octavia,component=api
When Glance is configured with the Cinder back end TechPreview, the
Glance client may return the HTTPInternalServerError error while operating
with volume. In this case, repeat the action again until it succeeds.
This section lists the StackLight known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.4.
[17045] fluentd-notifications does not track RabbitMQ credentials updates
[17573] OpenStack notifications missing in Elasticsearch and Kibana
Fixed in MOS 21.5
The fluentd-notifications pod fails to track the RabbitMQ credentials
updates in the Secret object. In this case, the fluentd-notifications pods
in the StackLight namespace are being restarted too often with the following
error message present in logs:
Authentication with RabbitMQ failed. Please check your connection settings.
Workaround:
Delete the affected fluentd-notifications pod. For example:
kubectl delete pod fluentd-notifications-cfcf77f9-h2wd7 -n stacklight
Once done, a new pod will be created automatically and will read the valid credentials from the Secret object.
If the issue still persists, apply the workaround described in [17573] OpenStack notifications missing in Elasticsearch and Kibana.
Fixed in MOS 21.5
OpenStack notifications may be missing in Elasticsearch and the Kibana
notification-* index may be empty. In this case, error messages
similar to the following one may be present in the
fluentd-notifications logs:
kubectl logs -l release=fluentd-notifications -n stacklight
2021-09-08 11:02:49 +0000 [error]: #0 unexpected error error_class=Bunny::
# AuthenticationFailureError error="Authentication with RabbitMQ failed.
# Please check your connection settings. Username: stacklight5BwVEEwd4s,
# vhost: openstack, password length: 10"
Workaround:
Apply the workaround described in [17045] fluentd-notifications does not track RabbitMQ credentials updates. If the issue still persists, perform the following steps:
On the affected managed cluster, obtain the proper user name and password from the
rabbitmq-credsSecret in theopenstack-lma-sharednamespace (stripb'prefix and'suffix):kubectl get secret -n openstack-lma-shared rabbitmq-creds -o jsonpath="{.data.password}" | base64 -d b'81g4B0wvEJ0rB2LWdAQcMBANf3E2DaEa' kubectl get secret -n openstack-lma-shared rabbitmq-creds -o jsonpath="{.data.username}" | base64 -d b'stacklightN7MAuk4LVd'
On the related management cluster, modify the affected Cluster object by specifying the obtained user name and password.
kubectl edit cluster <affectedManagedClusterName> -n <affectedManagedClusterProjectName>
For example:
spec: ... providerSpec: ... value: ... helmReleases: ... - name: stacklight values: ... openstack: rabbitmq: credentialsDiscovery: enabled: false credentialsConfig: username: stacklightN7MAuk4LVd password: 81g4B0wvEJ0rB2LWdAQcMBANf3E2DaEa
This section lists the cluster update known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.4.
[17477] StackLight in HA mode is not deployed or cluster update is blocked
[17305] Cluster update fails with the ‘Not ready releases: descheduler’ error
[17115] Cluster update does not change releaseRefs in Cluster object for Ceph
Fixed in MOS 21.5
The deployment of new managed clusters using the Cluster release 6.18.0 with StackLight enabled in the HA mode on control plane nodes does not have StackLight deployed. The update of existing clusters with such StackLight configuration that were created using the Cluster release 6.16.0 is blocked with the following error message:
cluster release version upgrade is forbidden: \
Minimum number of worker machines with StackLight label is 3
Workaround:
On the affected managed cluster:
Create a key-value pair that will be used as a unique label on the cluster nodes. In our example, it is
forcedRole: stacklight.To verify the labels names that already exist on the cluster nodes:
kubectl get nodes --show-labels
Add the new label to the target nodes for StackLight. For example, to the Kubernetes master nodes:
kubectl label nodes --selector=node-role.kubernetes.io/master forcedRole=stacklight
Verify that the new label is added:
kubectl get nodes --show-labels
On the related management cluster:
Configure
nodeSelectorfor the StackLight components by modifying the affectedClusterobject:kubectl edit cluster <affectedManagedClusterName> -n <affectedManagedClusterProjectName>
For example:
spec: ... providerSpec: ... value: ... helmReleases: ... - name: stacklight values: ... nodeSelector: default: forcedRole: stacklight
Select from the following options:
If you faced the issue during a managed cluster deployment, skip this step.
If you faced the issue during a managed cluster update, wait until all StackLight components resources are recreated on the target nodes with updated node selectors.
To monitor the cluster status:
kubectl get cluster <affectedManagedClusterName> -n <affectedManagedClusterProjectName> -o jsonpath='{.status.providerStatus.conditions[?(@.type=="StackLight")]}' | jq
In the cluster status, verify that the
elasticsearch-masterandprometheus-serverresources are ready. The process can take up to 30 minutes.Example of a negative system response:
{ "message": "not ready: statefulSets: stacklight/elasticsearch-master got 2/3 replicas", "ready": false, "type": "StackLight" }
In the Container Cloud web UI, add a fake StackLight label to any 3 worker nodes to satisfy the deployment requirement as described in Mirantis Container Cloud Operations Guide: Create a machine using web UI. Eventually, StackLight will be still placed on the target nodes with the
forcedRole: stacklightlabel.Once done, the StackLight deployment or update proceeds
Affects only MOS 21.4
An update of a MOS cluster from the Cluster release 6.16.0 to 6.18.0 may fail with the following exemplary error message:
Cluster data status: conditions:
- message: 'Helm charts are not installed(upgraded) yet. Not ready releases: descheduler.'
ready: false
type: Helm
The issue may affect the descheduler and metrics-server Helm releases.
As a workaround, run helm uninstall descheduler or helm uninstall metrics-server and wait for Helm Controller to recreate the affected release.
Fixed in MOS 22.2
An update of a MOS cluster may fail with the ceph csi-driver is not evacuated yet, waiting… error during the Ceph CSI pod eviction.
Workaround:
Scale the affected
StatefulSetof the pod that fails to init down to0replicas. If it is theDaemonSetsuch asnova-compute, it must not be scheduled on the affected node.On every
csi-rbdpluginpod, search for stuckcsi-vol:rbd device list | grep <csi-vol-uuid>
Unmap the affected
csi-vol:rbd unmap -o force /dev/rbd<i>
Delete
volumeattachmentof the affected pod:kubectl get volumeattachments | grep <csi-vol-uuid> kubectl delete volumeattacmhent <id>
Scale the affected
StatefulSetback to the original number of replicas or until its state isRunning. If it is aDaemonSet, run the pod on the affected node again.
Fixed in MOS 21.5
During an update of a MOS cluster from the Cluster release 6.16.0 to 6.18.0,
the status.providerStatus.releaseRefs.previous.name field in the Cluster
object does not change.
Workaround:
In the
clusterworkloadlockCRD, remove thesubresourcessection:kubectl edit crd clusterworkloadlocks.lcm.mirantis.com # remove here 'subresources' section: spec: versions: - name: v1alpha1 subresources: status: {}
Obtain
clusterReleasefrom theceph-controllersettings ConfigMap:kubectl -n ceph-lcm-mirantis get cm ccsettings -o jsonpath='{.data.clusterRelease}'
Create a
ceph-cwl.yamlfile with CephClusterWorkloadLock:apiVersion: lcm.mirantis.com/v1alpha1 kind: ClusterWorkloadLock metadata: name: ceph-clusterworkloadlock spec: controllerName: ceph status: state: inactive release: <clusterRelease> # from the previous step
Substitute
<clusterRelease>withclusterReleaseobtained in the previous step.Apply the resource:
kubectl apply -f ceph-cwl.yaml
Verify that the lock has been created:
kubectl get clusterworkloadlock ceph-clusterworkloadlock -o yaml
Affects only MOS 21.4
A MOS cluster update from the Cluster version
6.16.0 to 6.18.0 may fail with the Timeout waiting for pods statuses
timeout error. The error means that pods containers will be not ready
and will often restart with OOMKilled as a restart reason. For example:
kubectl describe pod prometheus-server-0 -n stacklight
...
Containers:
...
prometheus-server:
...
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Mon, 16 Aug 2021 12:47:57 +0400
Finished: Mon, 16 Aug 2021 12:58:02 +0400
...
Workaround:
In the cluster object, set
clusterSizetomediumas described in Mirantis Container Cloud Operations Guide: StackLight configuration parameters.Wait until the updated resource limits propagate to the
prometheus-serverStatefulSetobject.Delete the affected
prometheus-serverpods. For example:kubectl delete pods prometheus-server-0 prometheus-server-1 -n stacklight
Once done, new pods with updated resource limits will be created automatically.
Release artifacts¶
This section lists the components artifacts of the MOS 21.4 release:
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20210813064403.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20210816060025 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-bionic-20210816060025 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-bionic-20210816060025 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-bionic-20210812104817 |
Mirantis Proprietary License |
placement |
mirantis.azurecr.io/openstack/placement:victoria-bionic-20210816060025 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-bionic-20210816060025 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-bionic-20210816060025 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-bionic-20210816060025 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-bionic-20210816060025 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-bionic-20210816060025 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-bionic-20210816060025 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-bionic-20210816060025 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-bionic-20210816060025 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-bionic-20210816060025 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-bionic-20210816060025 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20210816060025 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-bionic-20210816060025 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20210617094817 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20210617094817 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20210617094817 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20210809060028 |
Apache License 2.0 |
rabbitmq-3.8 |
mirantis.azurecr.io/general/rabbitmq:3.8.14 |
Mozilla Public License 2.0 |
rabbitmq-3.8-management |
mirantis.azurecr.io/general/rabbitmq:3.8.14-management |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20210804080905 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.47.0 |
Apache License 2.0 |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210617085111 |
GPLv2, LGPLv2.1 (client libraries) |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0-20210729214058 |
Apache License 2.0 |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-bionic-20210816060025 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-bionic-20210816060025 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-bionic-20210816060025 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-bionic-20210816060025 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v7.5.0 |
GPL-2.0 License |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.1-20210511072313 |
GPL License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-ussuri-48f346e-20210119132403.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-ussuri-20210121085750.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:ussuri-bionic-20210805152625 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:ussuri-bionic-20210805152625 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:ussuri-bionic-20210805152625 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:ussuri-bionic-20210805094820 |
Mirantis Proprietary License |
placement |
mirantis.azurecr.io/openstack/placement:ussuri-bionic-20210805152625 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:ussuri-bionic-20210805152625 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:ussuri-bionic-20210805152625 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:ussuri-bionic-20210805152625 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:ussuri-bionic-20210805152625 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0-20210729214058 |
Apache License 2.0 |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210617085111 |
GPLv2, LGPLv2.1 (client libraries) |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.47.0 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20210804080905 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
rabbitmq-3.8-management |
mirantis.azurecr.io/general/rabbitmq:3.8.14-management |
Mozilla Public License 2.0 |
rabbitmq-3.8 |
mirantis.azurecr.io/general/rabbitmq:3.8.14 |
Mozilla Public License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20210805152625 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20210617094817 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20210617094817 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20210617094817 |
LGPL-2.1 License |
barbican |
mirantis.azurecr.io/openstack/barbican:ussuri-bionic-20210805152625 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20210805152625 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:ussuri-bionic-20210805152625 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:ussuri-bionic-20210805152625 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:ussuri-bionic-20210805152625 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:ussuri-bionic-20210805152625 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:ussuri-bionic-20210805152625 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:ussuri-bionic-20210805152625 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:ussuri-bionic-20210805152625 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:ussuri-bionic-20210805152625 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:ussuri-bionic-20210805152625 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:ussuri-bionic-20210805152625 |
Apache License 2.0 |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v7.5.0 |
GPL-2.0 License |
strongswan |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.1-20210511072313 |
GPL License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.3.9.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.3.9 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:5.1.20210723093724 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:5.1.20210723093724 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:5.1.20210723093724 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:5.1.20210723093724 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:5.1.20210723093724 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:5.1.20210723093724 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:5.1.20210723093724 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:5.1.20210723093724 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:5.1.20210723093724 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:5.1.20210723093724 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:5.1.20210723093724 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:5.1.20210723093724 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:5.1.20210723093724 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:5.1.20210723093724 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:5.1.20210723093724 |
Apache License 2.0 |
|
Status |
mirantis.azurecr.io/tungsten/contrail-status:5.1.20210723093724 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-tf-status:5.1.20210723093724 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-aggregator:5.1.20210723093724 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-party:5.1.20210723093724 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:5.1.20210723093724 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:5.1.20210723093724 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:5.1.20210723093724 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v0.5.3-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.4 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.6 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.0.9 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.4 |
Apache License 2.0 |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.4 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.14 |
Mozilla Public License 2.0 |
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.10 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.1-0.2.9 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.1.5-1-ccd6a63 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:5-alpine |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20210428100236 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20210214191656 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.3.9.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.3.9 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:2011.20210728070330 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:2011.20210728070330 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:2011.20210728070330 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:2011.20210728070330 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:2011.20210728070330 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:2011.20210728070330 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:2011.20210728070330 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:2011.20210728070330 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:2011.20210728070330 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:2011.20210728070330 |
Apache License 2.0 |
|
Control |
contrail-controller-control-control:2011.20210728070330 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:2011.20210728070330 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:2011.20210728070330 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:2011.20210728070330 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:2011.20210728070330 |
Apache License 2.0 |
|
Status |
mirantis.azurecr.io/tungsten/contrail-status:2011.20210728070330 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-tf-status:2011.20210728070330 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-aggregator:2011.20210728070330 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-party:2011.20210728070330 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:2011.20210728070330 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:2011.20210728070330 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:2011.20210728070330 |
Apache License 2.0 |
Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:2011.20210728070330 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v0.5.3-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.4 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.6 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.0.9 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.4 |
Apache License 2.0 |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.4 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.14 |
Mozilla Public License 2.0 |
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.10 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.1-0.2.9 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.1.5-1-ccd6a63 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:5-alpine |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20210428100236 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20210214191656 |
MIT License |
TF NodeInfo |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
TF Tools New |
mirantis.azurecr.io/tungsten/contrail-tools:2011.20210728070330 |
Apache License 2.0 |
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/libvirt-exporter:v0.1-20200610164751 |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20210115152338 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.1.0-mcp-2.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.1.0-mcp-1.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the Mirantis OpenStack for Kubernetes 21.4 release:
[13273][OpenStack] Fixed the issue with Octavia amphora getting stuck after the MOS cluster update.
[16849][OpenStack] Fixed the issue causing inability to delete a load balancer with a number higher than the maximum limit in API.
[16180][Tungsten Fabric] Fixed the issue with inability to schedule vRouter DPDK on a node with DPDK and 1 GB huge pages enabled. Enhanced Tungsten Fabric Operator to support 1 GB huge pages for a DPDK-based vRouter.
[16033][Ceph] Fixed the issue with inability to access RADOS Gateway through using S3 authentication. Added
rgw s3 auth use keystone = trueto the default RADOS Gateway options.[16604][StackLight] To avoid issues with
defunctprocesses on the OpenStack controller nodes, temporarily disabled instances downtime monitoring and removed the KPI - Downtime Grafana dashboard.
MOS 21.3 release¶
Release date |
Name |
Container Cloud Cluster release |
Highlights |
|---|---|---|---|
June 15, 2021 |
MOS 21.3 |
6.16.0+21.3 |
Update for the MOS GA release introducing support for Hyperconverged OpenStack compute nodes, SR-IOV and control interface specification for Tungsten Fabric, and the following Technology Preview features:
|
New features¶
Implemented full support for colocation of a cluster services on the same host, for example, Ceph OSD and OpenStack compute. To avoid nodes overloading, limit the hardware resources consumption by the OpenStack compute services as described in Deployment Guide: Limit HW resources for hyperconverged OpenStack compute nodes.
TechPreview
Implemented the capability to configure LVM as a back end for the OpenStack Block Storage service.
TechPreview
Implemented the capability to encrypt the east-west tenant traffic between the OpenStack compute nodes and gateways using strongSwan Internet Protocol Security (IPsec) solution.
Implemented the capability to specify the TF control service interface for
the BGP and XMPP traffic, for example, to combine it with the data traffic.
TechPreview
Implemented support for Tungsten Fabric 2011.
Implemented full support for SR-IOV in Tungsten Fabric.
After the OpenStackDeployment CR modification, the TF Operator
now generates a separate vRouter DaemonSet with specified settings.
After the SR-IOV enablement, the tf-vrouter-agent pods
are automatically restarted on the corresponding nodes causing
the network services interruption on virtual machines running on these hosts.
Therefore, plan this procedure accordingly.
Enhanced Ceph Controller to automatically specify default configuration options for each Ceph cluster during the Ceph deployment.
Implemented the capability to disable the transmit (TX) offloading using the
DISABLE_TX_OFFLOAD parameter in the TFOperator CR.
Implemented the targetSizeRatio parameter for the replicated
MOS Ceph pools. The targetSizeRatio value specifies
the default ratio for each Ceph pool type to define the expected consumption
of the Ceph cluster capacity.
Added the customIngress parameter to implement the capability to specify
a custom Ingress Controller when configuring the Ceph RGW TLS.
Caution
Starting from MOS 21.3, external Ceph RGW service is not supported and will be deleted during update. If your system already uses endpoints of an external RGW service, reconfigure them to the ingress endpoints.
Learn more
Implemented the following OpenStack service-level alerts on public/ingress endpoints:
OpenstackAPI401CriticalOpenstackAPI5xxCriticalOpenstackPublicAPI401CriticalOpenstackPublicAPI5xxCritical
Learn more
Major components versions¶
Mirantis has tested MOS against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOS components with the exact versions against which testing has been performed.
Known issues¶
This section contains the description of the known issues with available workarounds.
This section lists the Tungsten Fabric known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.3.
[10096] tf-control does not refresh IP addresses of Cassandra pods
[13755] TF pods switch to CrashLoopBackOff after a simultaneous reboot
Tungsten Fabric does not provide the following functionality:
Automatic generation of network port records in DNSaaS (Designate) as Neutron with Tungsten Fabric as a back end is not integrated with DNSaaS. As a workaround, you can use the Tungsten Fabric built-in DNS service that enables virtual machines to resolve each other names.
Secret management (Barbican). You cannot use the certificates stored in Barbican to terminate HTTPs in a load balancer.
Role Based Access Control (RBAC) for Neutron objects.
Modification of custom vRouter DaemonSets based on the SR-IOV definition in the
OsDplCR.
The tf-control service resolves the DNS names of Cassandra pods at startup
and does not update them if Cassandra pods got new IP addresses, for example,
in case of a restart. As a workaround, to refresh the IP addresses of
Cassandra pods, restart the tf-control pods one by one:
Caution
Before restarting the tf-control pods:
Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only one
tf-controlpod that will be restarted.
kubectl -n tf delete pod tf-control-<hash>
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes, maintenance, or other circumstances that cause the Cassandra pods to start simultaneously may cause a broken Cassandra TFConfig and/or TFAnalytics cluster. In this case, Cassandra nodes do not join the ring and do not update the IPs of the neighbor nodes. As a result, the TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete a Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica number>
This section lists the OpenStack known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.3.
[15525] HelmBundle Controller gets stuck during cluster update
[6912] Octavia load balancers may not work properly with DVR
Affects only MOS 21.3
The HelmBundle Controller that handles OpenStack releases gets stuck during
cluster update and does not apply HelmBundle changes. The issue is caused
by an unlimited releases history that increases the amount of RAM consumed by
Tiller. The workaround is to manually limit the releases number history to 3.
Workaround:
Remove the old releases:
Clean up releases in the
stacklightnamespace:function cleanup_release_history { pattern=$1 left_items=${2:-3} for i in $(kubectl -n stacklight get cm |grep "$pattern" | awk '{print $1}' | sort -V | head -n -${left_items}) do kubectl -n stacklight delete cm $i done }
For example:
kubectl -n stacklight get cm |grep "openstack-cinder.v" | awk '{print $1}' openstack-cinder.v1 ... openstack-cinder.v50 openstack-cinder.v51 cleanup_release_history openstack-cinder.v
Fix the releases in the
FAILEDstate:Connect to one of StackLight Helm Controller pods and list the releases in the
FAILEDstate:kubectl -n stacklight exec -it stacklight-helm-controller-699cc6949-dtfgr -- sh ./helm --host localhost:44134 list
Example of system response:
# openstack-heat 2313 Wed Jun 23 06:50:55 2021 FAILED heat-0.1.0-mcp-3860 openstack # openstack-keystone 76 Sun Jun 20 22:47:50 2021 FAILED keystone-0.1.0-mcp-3860 openstack # openstack-neutron 147 Wed Jun 23 07:00:37 2021 FAILED neutron-0.1.0-mcp-3860 openstack # openstack-nova 1 Wed Jun 23 07:09:43 2021 FAILED nova-0.1.0-mcp-3860 openstack # openstack-nova-rabbitmq 15 Wed Jun 23 07:04:38 2021 FAILED rabbitmq-0.1.0-mcp-2728 openstack
Determine the reason for a release failure. Typically, this is due to changes in the immutable objects (jobs). For example:
./helm --host localhost:44134 history openstack-mariadb
Example of system response:
REVISION UPDATED STATUS CHART APP VERSION DESCRIPTION 173 Thu Jun 17 20:26:14 2021 DEPLOYED mariadb-0.1.0-mcp-2710 Upgrade complete 212 Wed Jun 23 07:07:58 2021 FAILED mariadb-0.1.0-mcp-2728 Upgrade "openstack-mariadb" failed: Job.batch "openstack-... 213 Wed Jun 23 07:55:22 2021 FAILED mariadb-0.1.0-mcp-2728 Upgrade "openstack-mariadb" failed: Job.batch "exporter-c...
Remove the
FAILEDjob and roll back the release. For example:kubectl -n openstack delete job -l application=mariadb ./helm --host localhost:44134 rollback openstack-mariadb 213
Verify that the release is in the
DEPLOYEDstate. For example:./helm --host localhost:44134 history openstack-mariadb
Perform the steps above for all releases in the
FAILEDstate one by one.
Set
TILLER_HISTORY_MAXin the StackLight Controller to3:kubectl -n stacklight edit deployment stacklight-helm-controller
Fixed in MOS 21.4
After the MOS cluster update, Octavia amphora may get stuck with the WARNING octavia.amphorae.drivers.haproxy.rest_api_driver [-] Could not connect to instance. Retrying. error message present in the Octavia worker logs. The workaround is to manually switch the Octavia amphorae driver from V2 to V1.
Workaround:
In the OsDpl CR, specify the following configuration:
spec: services: load-balancer: octavia: values: conf: octavia: api_settings: default_provider_driver: amphora
Trigger the OpenStack deployment to restart Octavia:
kubectl apply -f openstackdeployment.yaml
To monitor the status:
kubectl -n openstack get pods kubectl -n openstack describe osdpl osh-dev
Limitation
When Neutron is deployed in the DVR mode, Octavia load balancers may not work correctly. The symptoms include both failure to properly balance traffic and failure to perform an amphora failover. For details, see DVR incompatibility with ARP announcements and VRRP.
This section lists the Ceph known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.3.
During the MOS cluster update to Cluster release 6.16.0, the Ceph Controller may fail with the following traceback:
panic: runtime error: invalid memory address on nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x28 pc=0x15d2c58]
goroutine 352 [running]:
github.com/Mirantis/ceph-controller/pkg/controller/miraceph.VerifyCertificateExpireDate(0x0, 0x0, 0x0, 0x6, 0x28a7bc0)
ceph-controller/pkg/controller/miraceph/util.go:250 +0x48
Workaround:
Obtain the
certbase64-encoded value of therook-ceph/rgw-ssl-certificatesecret:kubectl -n rook-ceph get secret rgw-ssl-certificate -o jsonpath='{.data.cert}' | base64 -d
Example of system response:
-----BEGIN RSA PRIVATE KEY----- ... -----END RSA PRIVATE KEY----- -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE-----
Copy last certificate in the chain and save it to the temp file, for example,
tmp-cacert.crt.Encode the certificate from
tmp-cacert.crtwith base64 encoding in one line:cat tmp-cacert.crt | base64 -w 0
Create a new
cacertkey in therook-ceph/rgw-ssl-certificatesecret and copy the base64-encodedcacertto its value. The following is an example of the resulting secret data:data: cert: <base64 string> cacert: <copied base64 cacert string>
Restart the
ceph-lcm-mirantis/ceph-controllerpod:kubectl -n ceph-lcm-mirantis delete pod -l app=ceph-controller
This section lists the StackLight known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.3.
OpenStack API availability data is shown in a 0 - 1 scale instead of an expected 0 - 100 scale.
As a workaround, manually set the extraQueries for OpenStack services
API to * 100 in the StackLight Helm chart values of the Cluster release
resource:
sfReporter:
extraQueries:
nova_api:
title: 'Nova API'
expr: 'avg(avg_over_time(openstack_api_check_status{service_name="nova"}[24h])) * 100'
cinder_api:
title: 'Cinder API'
expr: 'avg(avg_over_time(openstack_api_check_status{service_name="cinderv2"}[24h])) * 100'
glance_api:
title: 'Glance API'
expr: 'avg(avg_over_time(openstack_api_check_status{service_name="glance"}[24h])) * 100'
keystone_api:
title: 'Keystone API'
expr: 'avg(avg_over_time(openstack_api_check_status{service_name="keystone"}[24h])) * 100'
neutron_api:
title: 'Neutron API'
expr: 'avg(avg_over_time(openstack_api_check_status{service_name="neutron"}[24h])) * 100'
Release artifacts¶
This section lists the components artifacts of the MOS 21.3 release:
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20210518064309.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20210521110756 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-bionic-20210521110756 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:victoria-bionic-20210521110756 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-bionic-20210520105038 |
Mirantis Proprietary License |
placement |
mirantis.azurecr.io/openstack/placement:victoria-bionic-20210521110756 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-bionic-20210521110756 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-bionic-20210521110756 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-bionic-20210521110756 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-bionic-20210521110756 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-bionic-20210521110756 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-bionic-20210521110756 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-bionic-20210521110756 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-bionic-20210521110756 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-bionic-20210521110756 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-bionic-20210521110756 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20210521110756 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-bionic-20210521110756 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20210509034813 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20210509034813 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20210509034813 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20210517170337 |
Apache License 2.0 |
rabbitmq-3.8 |
mirantis.azurecr.io/general/rabbitmq:3.8.14 |
Mozilla Public License 2.0 |
rabbitmq-3.8-management |
mirantis.azurecr.io/general/rabbitmq:3.8.14-management |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20210519111601 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.42.0 |
Apache License 2.0 |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210509025121 |
GPLv2, LGPLv2.1 (client libraries) |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0-20210408062007 |
Apache License 2.0 |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-bionic-20210521110756 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-bionic-20210521110756 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-bionic-20210521110756 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-bionic-20210521110756 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v7.5.0 |
GPL-2.0 License |
strongswan New |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.1-20210511072313 |
GPL License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-ussuri-48f346e-20210119132403.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-ussuri-20210121085750.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector |
mirantis.azurecr.io/openstack/ironic-inspector:ussuri-bionic-20210517170337 |
Apache License 2.0 |
masakari-monitors |
mirantis.azurecr.io/openstack/masakari-monitors:ussuri-bionic-20210517170337 |
Apache License 2.0 |
masakari |
mirantis.azurecr.io/openstack/masakari:ussuri-bionic-20210517170337 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:ussuri-bionic-20210512124012 |
Mirantis Proprietary License |
placement |
mirantis.azurecr.io/openstack/placement:ussuri-bionic-20210517170337 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:ussuri-bionic-20210517170337 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:ussuri-bionic-20210517170337 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:ussuri-bionic-20210517170337 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:ussuri-bionic-20210517170337 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0-20210408062007 |
Apache License 2.0 |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC8 |
MIT License |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210509025121 |
GPLv2, LGPLv2.1 (client libraries) |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.42.0 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20210519111601 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
rabbitmq-3.8-management |
mirantis.azurecr.io/general/rabbitmq:3.8.14-management |
Mozilla Public License 2.0 |
rabbitmq-3.8 |
mirantis.azurecr.io/general/rabbitmq:3.8.14 |
Mozilla Public License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20210517170337 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20210509034813 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20210509034813 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20210509034813 |
LGPL-2.1 License |
barbican |
mirantis.azurecr.io/openstack/barbican:ussuri-bionic-20210517170337 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20210517170337 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:ussuri-bionic-20210517170337 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:ussuri-bionic-20210517170337 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:ussuri-bionic-20210517170337 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:ussuri-bionic-20210517170337 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:ussuri-bionic-20210517170337 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:ussuri-bionic-20210517170337 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:ussuri-bionic-20210517170337 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:ussuri-bionic-20210517170337 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:ussuri-bionic-20210517170337 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:ussuri-bionic-20210517170337 |
Apache License 2.0 |
frr |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v7.5.0 |
GPL-2.0 License |
strongswan New |
mirantis.azurecr.io/openstack/extra/strongswan:alpine-5.9.1-20210511072313 |
GPL License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.3.1.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.3.1 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:5.1.20210518083050 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:5.1.20210518083050 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:5.1.20210518083050 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:5.1.20210518083050 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:5.1.20210518083050 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:5.1.20210518083050 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:5.1.20210518083050 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:5.1.20210518083050 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:5.1.20210518083050 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:5.1.20210518083050 |
Apache License 2.0 |
|
Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:5.1.20210518083050 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:5.1.20210518083050 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:5.1.20210518083050 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:5.1.20210518083050 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:5.1.20210518083050 |
Apache License 2.0 |
|
Status |
mirantis.azurecr.io/tungsten/contrail-status:5.1.20210518083050 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-tf-status:5.1.20210518083050 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-aggregator:5.1.20210518083050 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-party:5.1.20210518083050 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:5.1.20210518083050 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:5.1.20210518083050 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:5.1.20210518083050 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v0.5.3-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.4 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.6 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.0.8 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.4 |
Apache License 2.0 |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.3 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.14 |
Mozilla Public License 2.0 |
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.10 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.1-0.2.9 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.1.5-1-ccd6a63 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:5-alpine |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20210428100236 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20210214191656 |
MIT License |
TF NodeInfo New |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.3.1.tgz |
Mirantis Proprietary License |
Docker images |
||
Tungsten Fabric Operator |
mirantis.azurecr.io/tungsten-operator/tungstenfabric-operator:0.3.1 |
Mirantis Proprietary License |
Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:mos-R2011-20210520121530 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:mos-R2011-20210520121530 |
Apache License 2.0 |
|
Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:mos-R2011-20210520121530 |
Apache License 2.0 |
Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:mos-R2011-20210520121530 |
Apache License 2.0 |
Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:mos-R2011-20210520121530 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:mos-R2011-20210520121530 |
Apache License 2.0 |
|
Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:mos-R2011-20210520121530 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:mos-R2011-20210520121530 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:mos-R2011-20210520121530 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:mos-R2011-20210520121530 |
Apache License 2.0 |
|
Control |
contrail-controller-control-control:mos-R2011-20210520121530 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:mos-R2011-20210520121530 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:mos-R2011-20210520121530 |
Apache License 2.0 |
|
Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:mos-R2011-20210520121530 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:mos-R2011-20210520121530 |
Apache License 2.0 |
|
Status |
mirantis.azurecr.io/tungsten/contrail-status:mos-R2011-20210520121530 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-tf-status:mos-R2011-20210520121530 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-aggregator:mos-R2011-20210520121530 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-party:mos-R2011-20210520121530 |
Apache License 2.0 |
|
vRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:mos-R2011-20210520121530 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:mos-R2011-20210520121530 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:mos-R2011-20210520121530 |
Apache License 2.0 |
Provisioner |
mirantis.azurecr.io/tungsten/contrail-provisioner:mos-R2011-20210520121530 |
Apache License 2.0 |
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v0.5.3-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.4 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.6 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.0.8 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.4 |
Apache License 2.0 |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.3 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.14 |
Mozilla Public License 2.0 |
ZooKeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.10 |
Apache License 2.0 |
ZooKeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.1-0.2.9 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.1.5-1-ccd6a63 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:5-alpine |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20210428100236 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20210214191656 |
MIT License |
TF NodeInfo New |
mirantis.azurecr.io/tungsten/tf-nodeinfo:0.1-20210430090010 |
MIT License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/libvirt-exporter:v0.1-20200610164751 |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20210115152338 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.1.0-mcp-2.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.1.0-mcp-1.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the Mirantis OpenStack for Kubernetes 21.3 release:
[13422][OpenStack] Fixed the issue with some Redis pods remaining in
Pendingstate and causing failure to update the Cluster release.[12511][OpenStack] Fixed the issue with Kubernetes nodes getting stuck in the
Preparestate during the MOS cluster update.[13233][StackLight] Fixed the issue with low memory limits for StackLight Helm Controller causing update failure.
[12917][StackLight] Fixed the issue with
prometheus-tf-vrouter-exporterpods failing to start on Tungsten Fabric nodes with DPDK. To remove thenodeSelectordefinition specified when applying the workaround:Remove the
nodeSelector.component.tfVrouterExporterdefinition from thestackLighthelmRelease(.spec.providerSpec.value.helmReleases) values of the Cluster resource.Remove the label using the following command. Do not remove the last dash sign.
kubectl label node <node_name> tfvrouter-fix-
[11961][Tungsten Fabric] Fixed the issue with members failing to join the RabbitMQ cluster after the
tf-controlnodes reboot.
MOS 21.2 release¶
Release date |
Name |
Container Cloud Cluster release |
Highlights |
|---|---|---|---|
April 22, 2021 |
MOS 21.2 |
6.14.0+21.2 |
Update for the MOS GA release introducing proxy support and the following Technology Preview features:
|
New features¶
Implemented the cache and proxy support for MOS managed clusters. By default, during a MOS cluster deployment and update the Mirantis artifacts are downloaded through a cache running on a management or regional cluster. If you have an external application that requires Internet access, you can now use proxy with required parameters specified for that application.
TechPreview
Implemented the capability to enable Masakari, the OpenStack service that ensures high availability of instances running on a host. The feature is disabled by default.
TechPreview
Implemented the capability to configure LVM as a back end for the VM disks and ephemeral storage and configure ephemeral disk encryption.
TechPreview
Implemented the capability to enable SR-IOV for the Tungsten Fabric vRouter.
TechPreview
Implemented the capability to specify custom settings for the Tungsten Fabric
vRouter nodes using the customSpecs parameter, such as to change the name
of the tunnel network interface or enable debug level logging.
Improved user experience by moving the rgw.ingress parameters of the
KaasCephCluster CR to a common cephClusterSpec.ingress section. The
rgw section is deprecated. However, if you continue using rgw.ingress,
it will be automatically translated into cephClusterSpec.ingress during
the MOS cluster release update.
Learn more
Major components versions¶
Mirantis has tested MOS against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOS components with the exact versions against which testing has been performed.
Known issues¶
This section contains the description of the known issues with available workarounds.
This section lists the Tungsten Fabric known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.2.
[10096] tf-control does not refresh IP addresses of Cassandra pods
[13755] TF pods switch to CrashLoopBackOff after a simultaneous reboot
Tungsten Fabric does not provide the following functionality:
Automatic generation of network port records in DNSaaS (Designate) as Neutron with Tungsten Fabric as a back end is not integrated with DNSaaS. As a workaround, you can use the Tungsten Fabric built-in DNS service that enables virtual machines to resolve each other names.
Secret management (Barbican). You cannot use the certificates stored in Barbican to terminate HTTPs in a load balancer.
Role Based Access Control (RBAC) for Neutron objects.
Modification of custom vRouter DaemonSets based on the SR-IOV definition in the
OsDplCR.
The tf-control service resolves the DNS names of Cassandra pods at startup
and does not update them if Cassandra pods got new IP addresses, for example,
in case of a restart. As a workaround, to refresh the IP addresses of
Cassandra pods, restart the tf-control pods one by one:
Caution
Before restarting the tf-control pods:
Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only one
tf-controlpod that will be restarted.
kubectl -n tf delete pod tf-control-<hash>
Rebooting all Cassandra cluster TFConfig or TFAnalytics nodes,
maintenance, or other circumstances that cause the Cassandra pods to
start simultaneously may cause a broken Cassandra TFConfig and/or
TFAnalytics cluster. In this case, Cassandra nodes do not join the
ring and do not update the IPs of the neighbor nodes. As a result, the
TF services cannot operate Cassandra cluster(s).
To verify that a Cassandra cluster is affected:
Run the nodetool status command specifying the config or
analytics cluster and the replica number:
kubectl -n tf exec -it tf-cassandra-<config/analytics>-dc1-rack1-<replica number> -c cassandra -- nodetool status
Example of system response with outdated IP addresses:
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN <outdated ip> ? 256 64.9% a58343d0-1e3f-4d54-bcdf-9b9b949ca873 r1
DN <outdated ip> ? 256 69.8% 67f1d07c-8b13-4482-a2f1-77fa34e90d48 r1
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN <actual ip> 3.84 GiB 256 65.2% 7324ebc4-577a-425f-b3de-96faac95a331 rack1
Workaround:
Manually delete a Cassandra pod from the failed config or analytics
cluster to re-initiate the bootstrap process for one of the Cassandra nodes:
kubectl -n tf delete pod tf-cassandra-<config/analytics>-dc1-rack1-<replica number>
This section lists the OpenStack known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.2.
[13422] Redis pods remain in Pending state and cause update failure
[6912] Octavia load balancers may not work properly with DVR
During the MOS cluster update to Cluster release
6.14.0, some Redis pods may remain in the Pending state and cause update
failure.
Workaround:
Scale the Redis deployment to
0replicas:kubectl -n openstack-redis scale deployment rfs-openstack-redis --replicas=0
Wait for the pods removal.
Scale the Redis deployment back to
3replicas:kubectl -n openstack-redis scale deployment rfs-openstack-redis --replicas=3
Obtain the list of replicas:
kubectl -n openstack-redis get replicaset
Example of system response:
NAME DESIRED CURRENT READY AGE os-redis-operator-redisoperator-6bd8455f8c 1 1 1 26h rfs-openstack-redis-568b8f6fcb 0 0 0 26h rfs-openstack-redis-798655cf9b 3 3 3 24h
Remove the ReplicaSet with
0replicas:kubectl -n openstack-redis delete replicaset rfs-openstack-redis-568b8f6fcb
During the MOS cluster update to Cluster release
6.14.0, Kubernetes nodes may get stuck in the Prepare state. At the same
time, the LCM Controller logs may contain the following errors:
evicting pod "horizon-57f7ccff74-d469c"
error when evicting pod "horizon-57f7ccff74-d469c" (will retry after
5s): Cannot evict pod as it would violate the pod's disruption budget.
The workaround is to decrease the Pod Disruption Budget (PDB) limit for Horizon by executing the following command on the managed cluster:
kubectl -n openstack patch pdb horizon -p='{"spec": {"minAvailable": 1}}'
After the MOS cluster update, Octavia amphora may get stuck with the WARNING octavia.amphorae.drivers.haproxy.rest_api_driver [-] Could not connect to instance. Retrying. error message present in the Octavia worker logs. The workaround is to manually switch the Octavia amphorae driver from V2 to V1.
Workaround:
In the OsDpl CR, specify the following configuration:
spec: services: load-balancer: octavia: values: conf: octavia: api_settings: default_provider_driver: amphora
Trigger the OpenStack deployment to restart Octavia:
kubectl apply -f openstackdeployment.yaml
To monitor the status:
kubectl -n openstack get pods kubectl -n openstack describe osdpl osh-dev
Limitation
When Neutron is deployed in the DVR mode, Octavia load balancers may not work correctly. The symptoms include both failure to properly balance traffic and failure to perform an amphora failover. For details, see DVR incompatibility with ARP announcements and VRRP.
This section lists the StackLight known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.2.
[13233] Low memory limits for StackLight Helm Controller cause update failure
[12917] prometheus-tf-vrouter-exporter pods fail to start on TF nodes with DPDK
During the MOS cluster update to Cluster release
6.14.0, StackLight Helm Controller containers (controller and/or
tiller) may get OOMKilled and cause failure to update.
As a workaround, manually increase the default resource requests and limits
for stacklightHelmControllerController and
stacklightHelmControllerTiller in the StackLight Helm chart values of the
Cluster release resource:
resources:
stacklightHelmControllerController:
requests:
cpu: "250m"
memory: "128Mi"
limits:
cpu: "1000m"
memory: "512Mi"
stacklightHelmControllerTiller:
requests:
cpu: "250m"
memory: "128Mi"
limits:
cpu: "1000m"
memory: "2048Mi"
For details about resource limits, see Mirantis Container Cloud Operations Guide: Resource limits.
StackLight deploys the prometheus-tf-vrouter-exporter exporter based on the
node selector matching the tfvrouter: enabled node label. The Tungsten
Fabric nodes with DPDK have the tfvrouter-dpdk: enabled label set instead.
Therefore, the prometheus-tf-vrouter-exporter exporter fails to start on
these nodes.
Workaround:
Add the
tfvrouter-fix: enabledlabel to every node that contains either thetfvrouter: enabledor thetfvrouter-dpdk: enablednode label.kubectl label node <node_name> tfvrouter-fix=enabled
In the Cluster release resource, specify the following
nodeSelectordefinition in the StackLight Helm chart values:nodeSelector: component: tfVrouterExporter: tfvrouter-fix: enabled
Once done, prometheus-tf-vrouter-exporter will be deployed to every node
with the tfvrouter-fix: enabled label.
Release artifacts¶
This section lists the components artifacts of the MOS 21.2 release:
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20210318064459.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector New |
mirantis.azurecr.io/openstack/ironic-inspector:victoria-bionic-20210326055904 |
Apache License 2.0 |
masakari-monitors New |
mirantis.azurecr.io/openstack/masakari-monitors:victoria-bionic-20210326055904 |
Apache License 2.0 |
masakari New |
mirantis.azurecr.io/openstack/masakari:victoria-bionic-20210326055904 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-bionic-20210325154004 |
Mirantis Proprietary License |
placement |
mirantis.azurecr.io/openstack/placement:victoria-bionic-20210326055904 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-bionic-20210326055904 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-bionic-20210326055904 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-bionic-20210326055904 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-bionic-20210326055904 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-bionic-20210326055904 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-bionic-20210326055904 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-bionic-20210326055904 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-bionic-20210326055904 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-bionic-20210326055904 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-bionic-20210326055904 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20210326055904 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-bionic-20210326055904 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20210325145045 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20210325145045 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20210325145045 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20210323180013 |
Apache License 2.0 |
rabbitmq-3.8 |
mirantis.azurecr.io/general/rabbitmq:3.8.9 |
Mozilla Public License 2.0 |
rabbitmq-3.8-management |
mirantis.azurecr.io/general/rabbitmq:3.8.9-management |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20210202133935 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.42.0 |
Apache License 2.0 |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210203155435 |
GPLv2, LGPLv2.1 (client libraries) |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0-20210212172540 |
Apache License 2.0 |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC7.1 |
MIT License |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-bionic-20210326055904 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-bionic-20210326055904 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-bionic-20210326055904 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-bionic-20210326055904 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
frr New |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v7.5.0 |
GPL-2.0 License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-ussuri-48f346e-20210119132403.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-ussuri-20210121085750.qcow2 |
Mirantis Proprietary License |
Docker images |
||
ironic-inspector New |
mirantis.azurecr.io/openstack/ironic-inspector:ussuri-bionic-20210326055904 |
Apache License 2.0 |
masakari-monitors New |
mirantis.azurecr.io/openstack/masakari-monitors:ussuri-bionic-20210326055904 |
Apache License 2.0 |
masakari New |
mirantis.azurecr.io/openstack/masakari:ussuri-bionic-20210326055904 |
Apache License 2.0 |
stepler |
mirantis.azurecr.io/openstack/stepler:ussuri-bionic-20210325151618 |
Mirantis Proprietary License |
placement |
mirantis.azurecr.io/openstack/placement:ussuri-bionic-20210326055904 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:ussuri-bionic-20210326055904 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:ussuri-bionic-20210326055904 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:ussuri-bionic-20210326055904 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:ussuri-bionic-20210326055904 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0-20210212172540 |
Apache License 2.0 |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC7.1 |
MIT License |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210203155435 |
GPLv2, LGPLv2.1 (client libraries) |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.42.0 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20210202133935 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
rabbitmq-3.8-management |
mirantis.azurecr.io/general/rabbitmq:3.8.9-management |
Mozilla Public License 2.0 |
rabbitmq-3.8 |
mirantis.azurecr.io/general/rabbitmq:3.8.9 |
Mozilla Public License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20210326055904 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20210325145045 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20210325145045 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20210325145045 |
LGPL-2.1 License |
barbican |
mirantis.azurecr.io/openstack/barbican:ussuri-bionic-20210326055904 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20210326055904 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:ussuri-bionic-20210326055904 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:ussuri-bionic-20210326055904 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:ussuri-bionic-20210326055904 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:ussuri-bionic-20210326055904 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:ussuri-bionic-20210326055904 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:ussuri-bionic-20210326055904 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:ussuri-bionic-20210326055904 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:ussuri-bionic-20210326055904 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:ussuri-bionic-20210326055904 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:ussuri-bionic-20210326055904 |
Apache License 2.0 |
frr New |
mirantis.azurecr.io/general/external/docker.io/frrouting/frr:v7.5.0 |
GPL-2.0 License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.2.6.tgz |
Mirantis Proprietary License |
Docker images |
||
TF Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:5.1.20210312153639 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:5.1.20210312153639 |
Apache License 2.0 |
|
TF Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:20210312153639 |
Apache License 2.0 |
TF Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:5.1.20210312153639 |
Apache License 2.0 |
TF Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:5.1.20210312153639 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:5.1.20210312153639 |
Apache License 2.0 |
|
TF Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:5.1.20210312153639 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:5.1.20210312153639 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:5.1.20210312153639 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:5.1.20210312153639 |
Apache License 2.0 |
|
TF Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:5.1.20210312153639 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:5.1.20210312153639 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:5.1.20210312153639 |
Apache License 2.0 |
|
TF Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:5.1.20210312153639 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:5.1.20210312153639 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:5.1.20210312153639 |
Apache License 2.0 |
TF Status |
mirantis.azurecr.io/tungsten/contrail-status:5.1.20210312153639 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-tf-status:5.1.20210312153639 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-aggregator:5.1.20210312153639 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-party:5.1.20210312153639 |
Apache License 2.0 |
|
TF VRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:5.1.20210312153639 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:5.1.20210312153639 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v0.5.3-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.4 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.6 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.0.7 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.2 |
Apache License 2.0 |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.1 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.9 |
Mozilla Public License 2.0 |
Zookeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.9 |
Apache License 2.0 |
Zookeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.1-0.2.9 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.1.5-1-ccd6a63 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:5-alpine |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20210211114307 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20210214191656 |
MIT License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/libvirt-exporter:v0.1-20200610164751 |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20210115152338 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.1.0-mcp-2.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.1.0-mcp-1.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the Mirantis OpenStack for Kubernetes 21.2 release:
[7725][Tungsten Fabric] Fixed the issue with the Neturon service failing to create a network through Horizon and OpenStack CLI throwing the
An unknown exception occurrederror.
MOS 21.1 release¶
Release date |
Name |
Container Cloud Cluster release |
Highlights |
|---|---|---|---|
March 01, 2021 |
MOS 21.1 |
6.12.0+21.1 |
Update for the MOS GA release introducing support for the PCI passthrough feature and Tungsten Fabric monitoring, as well as the following Technology Preview features:
|
New features¶
Added support for the Peripheral Component Interconnect (PCI) passthrough feature in OpenStack to use, mainly, as a part of the SR-IOV network traffic acceleration technique. Now, MOS enables the user to configure Nova on a per-node basis to allow PCI devices to be passed through from hosts to virtual machines.
TechPreview
Implemented support for OpenStack Victoria with Neutron OVS and Tungsten Fabric 5.1.
TechPreview
Implemented support for the SR-IOV with the Neutron OVS back end topology.
Learn more
TechPreview
Implemented the capability to colocate components on the same host, for example, Ceph OSD and OpenStack compute.
Enhanced StackLight to monitor Tungsten Fabric and its components, including Casandra, Kafka, Redis, and ZooKeeper. Implemented the Tungsten Fabric alerts and Grafana dashboards. The feature is disabled by default. You can enable it manually during or after the Tungsten Fabric deployment.
Implemented alert inhibition rules to provide a clearer view on the cloud status and simplify troubleshooting. Using alert inhibition rules, Alertmanager decreases alert noise by suppressing dependent alerts notifications. The feature is enabled by default. For details, see Operations Guide: Alert dependencies.
Implemented integration between Grafana and Kibana by adding a View logs in Kibana link to most Grafana dashboards, which allows you to immediately view contextually relevant logs through the Kibana web UI.
Learn more
Added the capability to configure the Transport Layer Security (TLS) protocol
for a Ceph RGW public endpoint using MOS TLS if enabled,
or using a custom ingress specified in the KaaSCephCluster custom
resource.
Learn more
Major components versions¶
Mirantis has tested MOS against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOS components with the exact versions against which testing has been performed.
Known issues¶
This section contains the description of the known issues with available workarounds.
This section lists the OpenStack known issues for the Mirantis OpenStack for Kubernetes release 21.1.
Limitation
When Neutron is deployed in the DVR mode, Octavia load balancers may not work correctly. The symptoms include both failure to properly balance traffic and failure to perform an amphora failover. For details, see DVR incompatibility with ARP announcements and VRRP.
This section lists the Tungsten Fabric known issues with workarounds for the Mirantis OpenStack for Kubernetes release 21.1.
Tungsten Fabric does not provide the following functionality:
Automatic generation of network port records in DNSaaS (Designate) as Neutron with Tungsten Fabric as a back end is not integrated with DNSaaS. As a workaround, you can use the Tungsten Fabric built-in DNS service that enables virtual machines to resolve each other names.
Secret management (Barbican). You cannot use the certificates stored in Barbican to terminate HTTPs in a load balancer.
Role Based Access Control (RBAC) for Neutron objects.
Fixed in MOS 21.2
The Neturon service fails to create a network through Horizon and
OpenStack CLI throwing the An unknown exception occurred error.
The workaround is to restart the tf-config pods:
Obtain the list of the
tf-configpods:kubectl -n tf get pod -l app=tf-config
Delete the
tf-config-*pods. For example:kubectl -n tf delete pod tf-config-2whbb
Verify that the pods have been recreated:
kubectl -n tf get pod -l app=tf-config
The tf-control service resolves the DNS names of Cassandra pods at startup
and does not update them if Cassandra pods got new IP addresses, for example,
in case of a restart. As a workaround, to refresh the IP addresses of
Cassandra pods, restart the tf-control pods one by one:
Caution
Before restarting the tf-control pods:
Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only one
tf-controlpod that will be restarted.
kubectl -n tf delete pod tf-control-<hash>
Release artifacts¶
This section lists the components artifacts of the MOS 21.1 release:
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-victoria-8f71802-20210119120707.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-victoria-20210119144419.qcow2 |
Mirantis Proprietary License |
Docker images |
||
stepler |
mirantis.azurecr.io/openstack/stepler:victoria-bionic-20210118135111 |
Mirantis Proprietary License |
placement |
mirantis.azurecr.io/openstack/placement:victoria-bionic-20210129120815 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:victoria-bionic-20210129120815 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:victoria-bionic-20210129120815 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:victoria-bionic-20210129120815 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:victoria-bionic-20210129120815 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:victoria-bionic-20210129120815 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:victoria-bionic-20210129120815 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:victoria-bionic-20210129120815 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:victoria-bionic-20210129120815 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:victoria-bionic-20210129120815 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:victoria-bionic-20210129120815 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:victoria-bionic-20210129120815 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:victoria-bionic-20210129120815 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20210106163230 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20210106163231 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20210106163230 |
Apache License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20210127180024 |
Apache License 2.0 |
rabbitmq-3.8 |
mirantis.azurecr.io/general/rabbitmq:3.8.9 |
Mozilla Public License 2.0 |
rabbitmq-3.8-management |
mirantis.azurecr.io/general/rabbitmq:3.8.9-management |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra:ceph-config-helper:nautilus-bionic-20210112174540 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.42.0 |
Apache License 2.0 |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210106145941 |
GPLv2, LGPLv2.1 (client libraries) |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0-20210115084431 |
Apache License 2.0 |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC7.1 |
MIT License |
aodh |
mirantis.azurecr.io/openstack/aodh:victoria-bionic-20210129120815 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:victoria-bionic-20210129120815 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:victoria-bionic-20210129120815 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:victoria-bionic-20210129120815 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-ussuri-48f346e-20210119132403.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-ussuri-20210121085750.qcow2 |
Mirantis Proprietary License |
Docker images |
||
stepler |
mirantis.azurecr.io/openstack/stepler:ussuri-bionic-20210121144938 |
Mirantis Proprietary License |
placement |
mirantis.azurecr.io/openstack/placement:ussuri-bionic-20210127180024 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:ussuri-bionic-20210127180024 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:ussuri-bionic-20210127180024 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:ussuri-bionic-20210127180024 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:ussuri-bionic-20210127180024 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0-20210115084431 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.17-bionic-20210106145941 |
GPLv2, LGPLv2.1 (client libraries) |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.42.0 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20210112174540 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
rabbitmq-3.8-management |
mirantis.azurecr.io/general/rabbitmq:3.8.9-management |
Mozilla Public License 2.0 |
rabbitmq-3.8 |
mirantis.azurecr.io/general/rabbitmq:3.8.9 |
Mozilla Public License 2.0 |
openstack-tools |
mirantis.azurecr.io/openstack/openstack-tools:ussuri-bionic-20210127180024 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20210106163230 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20210106163231 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC7.1 |
MIT License |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20210106163230 |
LGPL-2.1 License |
barbican |
mirantis.azurecr.io/openstack/barbican:ussuri-bionic-20210127180024 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20210127180024 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:ussuri-bionic-20210127180024 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:ussuri-bionic-20210127180024 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:ussuri-bionic-20210127180024 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:ussuri-bionic-20210127180024 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:ussuri-bionic-20210127180024 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:ussuri-bionic-20210127180024 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:ussuri-bionic-20210127180024 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:ussuri-bionic-20210127180024 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:ussuri-bionic-20210127180024 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:ussuri-bionic-20210127180024 |
Apache License 2.0 |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary.mirantis.com/tungsten/helm/tungstenfabric-operator-0.2.3.tgz |
Mirantis Proprietary License |
Docker images |
||
TF Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:5.1.20210129092117 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:5.1.20210129092117 |
Apache License 2.0 |
|
TF Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:5.1.20210129092117 |
Apache License 2.0 |
TF Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:5.1.20210129092117 |
Apache License 2.0 |
TF Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:5.1.20210129092117 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:5.1.20210129092117 |
Apache License 2.0 |
|
TF Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:5.1.20210129092117 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:5.1.20210129092117 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:5.1.20210129092117 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:5.1.20210129092117 |
Apache License 2.0 |
|
TF Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:5.1.20210129092117 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:5.1.20210129092117 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:5.1.20210129092117 |
Apache License 2.0 |
|
TF Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:5.1.20210129092117 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:5.1.20210129092117 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:5.1.20210129092117 |
Apache License 2.0 |
TF Status |
mirantis.azurecr.io/tungsten/contrail-status:5.1.20210129092117 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-tf-status:5.1.20210129092117 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-aggregator:5.1.20210129092117 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-party:5.1.20210129092117 |
Apache License 2.0 |
|
TF VRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:5.1.20210129092117 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:5.1.20210129092117 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v0.5.3-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.4 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.6 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.0.7 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.2 |
Apache License 2.0 |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.1.1 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.9 |
Mozilla Public License 2.0 |
Zookeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.9 |
Apache License 2.0 |
Zookeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.1-0.2.9 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.1.5-1-ccd6a63 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:5-alpine |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20210202061227 |
MIT License |
TF CLI |
mirantis.azurecr.io/tungsten/tf-cli:0.1-20210202130729 |
MIT License |
Component |
Path |
License information for main executable programs |
|---|---|---|
Docker images |
||
prometheus-libvirt-exporter |
mirantis.azurecr.io/stacklight/libvirt-exporter:v0.1-20200610164751 |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter New |
mirantis.azurecr.io/stacklight/tungstenfabric-prometheus-exporter:0.1-20210115152338 |
Mirantis Proprietary License |
Helm charts |
||
prometheus-libvirt-exporter |
https://binary.mirantis.com/stacklight/helm/prometheus-libvirt-exporter-0.1.0-mcp-2.tgz |
Mirantis Proprietary License |
prometheus-tungstenfabric-exporter New |
https://binary.mirantis.com/stacklight/helm/prometheus-tungstenfabric-exporter-0.1.0-mcp-1.tgz |
Mirantis Proprietary License |
Addressed issues¶
The following issues have been addressed in the Mirantis OpenStack for Kubernetes 21.1 release:
[9809] [Kubernetes] Fixed the issue with the pods getting stuck in the
Pendingstate during update of a MOSK cluster by increasing the defaultkubelet_max_podssetting to150.[9589][StackLight] Fixed the issue with the Patroni pod crashing when scheduled to an OpenStack compute node with huge pages.
[8573] [OpenStack] Fixed the issue with the external authentication to Horizon failing to log in a different user.
MOS Ussuri GA Update release¶
Release date |
Name |
Container Cloud Cluster release |
Highlights |
|---|---|---|---|
December 23, 2020 |
MOS Ussuri Update |
6.10.0 |
The first update to MOS Ussuri release introducing support for object storage and a Telco deployment profile, which includes implementation of baseline Enhanced Platform Awareness (NUMA awareness, huge pages, CPU pinning) capabilities, and a technical preview of packet processing acceleration (Data Plane Development Kit-enabled Tungsten Fabric). |
New features¶
Implemented the capability to easily perform the node-specific configuration through the OpenStack Controller. More specifically, the node-specific overrides allow you to:
Enable DPDK with OVS Technical Preview
Enable libvirt CPU pinning
Implemented the capability to customize the look and feel of Horizon through
the OpenStackDeployment custom resource. Cloud operator is now able
to specify the origin of the theme bundle to be applied to OpenStack Horizon
in features:horizon:themes.
TechPreview
Implemented the capability to enable the DPDK mode for OVS.
Implemented the capability to enable huge pages and configure CPU isolation and CPU pinning in your MOS deployment.
Added support for RADOS Gateway Object Storage (SWIFT).
Implemented the capability to disable HTTP probes for public endpoints from the OpenStack service catalog. In this case, Telegraf performs HTTP checks only for the admin and internal OpenStack endpoints. By default, Telegraf verifies all endpoints from the OpenStack service catalog.
TechPreview
Implemented the capability to enable DPDK mode for the Tungsten Fabric vRouter.
Implemented the capability to verify the status of Tungsten Fabric services,
including the third-party services such as Cassandra, ZooKeeper, Kafka, Redis,
and RabbitMQ using the Tungsten Fabric Operator tf-status tool.
Major components versions¶
Mirantis has tested MOS against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOS components with the exact versions against which testing has been performed.
Known issues¶
This section contains the description of the known issues with available workarounds.
[9809] The default max_pods setting does not allow upgrading a cluster
[6912] Octavia load balancers may not work properly with DVR
[8573] External authentication to Horizon fails to log in a different user
Due to limitations in the Octavia and MOS integration, the clusters where Neutron is deployed in the Distributed Virtual Router (DVR) mode are not stable. Therefore, Mirantis does not recommend such configuration for production deployments.
Fixed in MOS 21.1
During update of a MOS cluster, the pods may get
stuck in the Pending state with the following example warning:
Warning FailedScheduling <unknown> default-scheduler 0/9 nodes are available:
1 node(s) were unschedulable, 2 Too many pods, 6 node(s) didn't match node selector.
Workaround
Before you update the managed cluster:
Set
kubelet_max_podsto250:UCP_HOST=$(kubectl -n <child name space> get clusters <child name> -o jsonpath='{.status.providerStatus.ucpDashboard}') AUTHTOKEN=$(curl --silent --insecure --data '{"username":"admin","password":"<PASWORD>"}' $UCP_HOST/auth/login | jq --raw-output .auth_token) curl --insecure -X GET "$UCP_HOST/api/ucp/config-toml" -H "accept: application/toml" -H "Authorization: Bearer $AUTHTOKEN" > ucp-config.toml sed -i 's/kubelet_max_pods = 110/kubelet_max_pods = 250/g' ucp-config.toml curl --insecure -X PUT -H "accept: application/toml" -H "Authorization: Bearer $AUTHTOKEN" --upload-file 'ucp-config.toml' -H "X-Ucp-Allow-Restricted-Api: i-solemnly-swear-i-am-up-to-no-good" $UCP_HOST/api/ucp/config-toml curl -k -X PUT "$UCP_HOST/api/ucp/config/tuning" -H "X-Ucp-Allow-Restricted-Api: i-solemnly-swear-i-am-up-to-no-good" -H "Authorization: Bearer $AUTHTOKEN" --data '{"kaasManagedCluster":true}'
Verify that the changes have been applied:
kubectl get nodes -o jsonpath='{.items[*].status.capacity.pods}'Example of a positive system response:
250 250 250 250 250 250 250 250 250
After you update the managed cluster, set
kubelet_max_podsto the default110value:UCP_HOST=$(kubectl -n <child name space> get clusters <child name> -o jsonpath='{.status.providerStatus.ucpDashboard}') AUTHTOKEN=$(curl --silent --insecure --data '{"username":"admin","password":"<PASWORD>"}' $UCP_HOST/auth/login | jq --raw-output .auth_token) curl --insecure -X GET "$UCP_HOST/api/ucp/config-toml" -H "accept: application/toml" -H "Authorization: Bearer $AUTHTOKEN" > ucp-config.toml sed -i 's/kubelet_max_pods = 250/kubelet_max_pods = 110/g' ucp-config.toml curl --insecure -X PUT -H "accept: application/toml" -H "Authorization: Bearer $AUTHTOKEN" --upload-file 'ucp-config.toml' -H "X-Ucp-Allow-Restricted-Api: i-solemnly-swear-i-am-up-to-no-good" $UCP_HOST/api/ucp/config-toml curl -k -X PUT "$UCP_HOST/api/ucp/config/tuning" -H "X-Ucp-Allow-Restricted-Api: i-solemnly-swear-i-am-up-to-no-good" -H "Authorization: Bearer $AUTHTOKEN" --data '{"kaasManagedCluster":true}'
Limitation
When Neutron is deployed in the DVR mode, Octavia load balancers may not work correctly. The symptoms include both failure to properly balance traffic and failure to perform an amphora failover. For details, see DVR incompatibility with ARP announcements and VRRP.
Fixed in MOS 21.1
Horizon retains the user’s credentials following their initial login using External Authentication Service, and does not allow to log in with another user credentials.
Workaround:
Clear cookies in your browser.
Select External Authentication Service on the Horizon login page.
Click Sign In. The Keycloak login page opens.
If the following error occurs, refresh the page and try again:
CSRF token missing or incorrect. Cookies may be turned off. Make sure cookies are enabled and try again.
Tungsten Fabric is not monitored by StackLight
Tungsten Fabric does not provide the following functionality:
Automatic generation of network port records in DNSaaS (Designate) as Neutron with Tungsten Fabric as a back end is not integrated with DNSaaS. As a workaround, you can use the Tungsten Fabric built-in DNS service that enables virtual machines to resolve each other names.
Secret management (Barbican). You cannot use the certificates stored in Barbican to terminate HTTPs in a load balancer.
Role Based Access Control (RBAC) for Neutron objects.
The tf-control service resolves the DNS names of Cassandra pods at startup
and does not update them if Cassandra pods got new IP addresses, for example,
in case of a restart. As a workaround, to refresh the IP addresses of
Cassandra pods, restart the tf-control pods one by one:
Caution
Before restarting the tf-control pods:
Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only one
tf-controlpod that will be restarted.
kubectl -n tf delete pod tf-control-<hash>
Release artifacts¶
This section lists the components artifacts of the MOS Ussuri Update release:
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-ussuri-43c3886-20201121205800.tar.gz |
Mirantis Proprietary License |
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-ussuri-20201120005752.qcow2 |
Mirantis Proprietary License |
Docker images |
||
aodh |
mirantis.azurecr.io/openstack/aodh:ussuri-bionic-20201121180111 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:ussuri-bionic-20201121180111 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:ussuri-bionic-20201121180111 |
Apache License 2.0 |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20200810084204 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
cinder |
mirantis.azurecr.io/openstack/cinder:ussuri-bionic-20201121180111 |
Apache License 2.0 |
dashboard-selenium |
mirantis.azurecr.io/openstack/dashboard-selenium:ussuri-bionic-20201123130303 |
Apache License 2.0 |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:ussuri-bionic-20201121180111 |
Apache License 2.0 |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:ussuri-bionic-20201121180111 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:ussuri-bionic-20201121180111 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:ussuri-bionic-20201121180111 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:ussuri-bionic-20201121180111 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20201121180111 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:ussuri-bionic-20201121180111 |
Apache License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20201105044831 |
LGPL-2.1 License |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.16-bionic-20201105025052 |
GPLv2, LGPLv2.1 (client libraries) |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
neutron |
mirantis.azurecr.io/openstack/neutron:ussuri-bionic-20201121180111 |
Apache License 2.0 |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.32.0 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:ussuri-bionic-20201121180111 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:ussuri-bionic-20201121180111 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20201109141859 |
Apache License 2.0 |
openvswitch-dpdk |
mirantis.azurecr.io/general/openvswitch-dpdk:2.11-bionic-20201109141858 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:ussuri-bionic-20201121180111 |
Apache License 2.0 |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
placement |
mirantis.azurecr.io/openstack/placement:ussuri-bionic-20201121180111 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
rabbitmq-3.8 |
mirantis.azurecr.io/general/rabbitmq:3.8.7 |
Mozilla Public License 2.0 |
rabbitmq-3.8-management |
mirantis.azurecr.io/general/rabbitmq:3.8.7-management |
Mozilla Public License 2.0 |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v1.0.0-RC7.1 |
MIT License |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
tempest |
mirantis.azurecr.io/openstack/tempest:ussuri-bionic-20201121180111 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:2.1.0 |
Apache License 2.0 |
Helm charts |
||
openstack-operator |
https://binary.mirantis.com/openstack/helm/openstack-controller/openstack-operator-0.3.18.tgz |
Mirantis Proprietary License |
aodh |
https://binary.mirantis.com/openstack/helm/openstack-helm/aodh-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
barbican |
https://binary.mirantis.com/openstack/helm/openstack-helm/barbican-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
ceilometer |
https://binary.mirantis.com/openstack/helm/openstack-helm/ceilometer-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
cinder |
https://binary.mirantis.com/openstack/helm/openstack-helm/cinder-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
designate |
https://binary.mirantis.com/openstack/helm/openstack-helm/designate-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
glance |
https://binary.mirantis.com/openstack/helm/openstack-helm/glance-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
heat |
https://binary.mirantis.com/openstack/helm/openstack-helm/heat-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
horizon |
https://binary.mirantis.com/openstack/helm/openstack-helm/horizon-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
ironic |
https://binary.mirantis.com/openstack/helm/openstack-helm/ironic-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
keystone |
https://binary.mirantis.com/openstack/helm/openstack-helm/keystone-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
magnum |
https://binary.mirantis.com/openstack/helm/openstack-helm/magnum-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
mistral |
https://binary.mirantis.com/openstack/helm/openstack-helm/mistral-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
neutron |
https://binary.mirantis.com/openstack/helm/openstack-helm/neutron-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
nova |
https://binary.mirantis.com/openstack/helm/openstack-helm/nova-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
octavia |
https://binary.mirantis.com/openstack/helm/openstack-helm/octavia-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
panko |
https://binary.mirantis.com/openstack/helm/openstack-helm/panko-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
rally |
https://binary.mirantis.com/openstack/helm/openstack-helm/rally-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
senlin |
https://binary.mirantis.com/openstack/helm/openstack-helm/senlin-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
tempest |
https://binary.mirantis.com/openstack/helm/openstack-helm/tempest-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
dashboard-selenium |
https://binary.mirantis.com/openstack/helm/openstack-helm/dashboard-selenium-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
placement |
https://binary.mirantis.com/openstack/helm/openstack-helm/placement-0.1.0-mcp-3760.tgz |
Apache License 2.0 (no License file in Helm chart) |
calico |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/calico-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
ceph-client |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/ceph-client-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
ceph-mon |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/ceph-mon-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
ceph-osd |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/ceph-osd-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
ceph-provisioners |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/ceph-provisioners-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
ceph-rgw |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/ceph-rgw-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
dnsmasq |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/dnsmasq-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
elastic-apm-server |
Apache License 2.0 (no License file in Helm chart) |
|
elastic-filebeat |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/elastic-filebeat-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
elastic-metricbeat |
Apache License 2.0 (no License file in Helm chart) |
|
elastic-packetbeat |
Apache License 2.0 (no License file in Helm chart) |
|
etcd |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/etcd-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
falco |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/falco-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
flannel |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/flannel-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
fluentbit |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/fluentbit-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
fluentd |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/fluentd-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
gnocchi |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/gnocchi-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
grafana |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/grafana-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
helm-toolkit |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/helm-toolkit-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
ingress |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/ingress-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
kube-dns |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/kube-dns-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
kubernetes-keystone-webhook |
Apache License 2.0 (no License file in Helm chart) |
|
ldap |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/ldap-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
libvirt |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/libvirt-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
lockdown |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/lockdown-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
mariadb |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/mariadb-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
memcached |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/memcached-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
mongodb |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/mongodb-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
nagios |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/nagios-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
nfs-provisioner |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/nfs-provisioner-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
openvswitch |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/openvswitch-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
podsecuritypolicy |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/podsecuritypolicy-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
postgresql |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/postgresql-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
powerdns |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/powerdns-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
prometheus |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/prometheus-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
prometheus-alertmanager |
Apache License 2.0 (no License file in Helm chart) |
|
prometheus-kube-state-metrics |
Apache License 2.0 (no License file in Helm chart) |
|
prometheus-node-exporter |
Apache License 2.0 (no License file in Helm chart) |
|
prometheus-openstack-exporter |
Apache License 2.0 (no License file in Helm chart) |
|
prometheus-process-exporter |
Apache License 2.0 (no License file in Helm chart) |
|
rabbitmq |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/rabbitmq-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
redis |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/redis-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
registry |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/registry-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
tiller |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/tiller-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
zookeeper |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/zookeeper-0.1.0-mcp-2672.tgz |
Apache License 2.0 (no License file in Helm chart) |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary-mirantis-com/tungsten/helm/tungstenfabric-operator-0.2.1.tgz |
Mirantis Proprietary License |
Docker images |
||
TF Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:5.1.20201127135523 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:5.1.20201127135523 |
Apache License 2.0 |
|
TF Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:5.1.20201127135523 |
Apache License 2.0 |
TF Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:5.1.20201127135523 |
Apache License 2.0 |
TF Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:5.1.20201127135523 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:5.1.20201127135523 |
Apache License 2.0 |
|
TF Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:5.1.20201127135523 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:5.1.20201127135523 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:5.1.20201127135523 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:5.1.20201127135523 |
Apache License 2.0 |
|
TF Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:5.1.20201127135523 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:5.1.20201127135523 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:5.1.20201127135523 |
Apache License 2.0 |
|
TF Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:5.1.20201127135523 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:5.1.20201127135523 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:5.1.20201127135523 |
Apache License 2.0 |
TF Status |
mirantis.azurecr.io/tungsten/contrail-status:5.1.20201127135523 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-tf-status:5.1.20201127135523 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-aggregator:5.1.20201127135523 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-party:5.1.20201127135523 |
Apache License 2.0 |
|
TF VRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:5.1.20201127135523 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:5.1.20201127135523 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v0.5.3-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.4 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.6 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.0.6 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.2 |
Apache License 2.0 |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.0.7 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.7 |
Mozilla Public License 2.0 |
Zookeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.9 |
Apache License 2.0 |
Zookeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.1-0.2.9 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.1.5-1-ccd6a63 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:5-alpine |
BSD 3-Clause “New” or “Revised” License |
TF Test |
mirantis.azurecr.io/tungsten/tungsten-pytest:0.1-20201127103849 |
MIT License |
Addressed issues¶
The following issues have been addressed in the Mirantis OpenStack for Kubernetes Ussuri Update release:
[9681] [OS] Fixed the issue that caused the
openstack-mariadb-cluster-waitjob reaching the backoff limit during the MOS cluster update.[9883] [OS] Improved the logic of the MOS cluster update to prevent the occurrence of deadlock.
[8293] [TF] Fixed the configuration error that caused the logging of error messages on attempts to use loggers in
contrail-lbaas-haproxy-stdout.log.
MOS Ussuri GA release¶
Release date |
Name |
Container Cloud Cluster release |
Highlights |
|---|---|---|---|
November 05, 2020 |
MOS Ussuri |
6.8.1 |
General availability of the product with OpenStack Ussuri and choice of Neutron/OVS or Tungsten Fabric 5.1 for networking. Runs on top of a bare metal Kubernetes cluster managed by Container Cloud. |
Product highlights¶
Mirantis OpenStack for Kubernetes (MOS) represents a frictionless cloud infrastructure on-premise. MOS Ussuri is integrated with Container Cloud bare metal with Ceph and StackLight onboard and, optionally, supports Tugsten Fabric 5.1 as a back end for the OpenStack networking. In terms of updates, MOS Ussuri fully relies on the Container Cloud update delivery mechanism.
MOS provides support for OpenStack Ussuri and the following OpenStack components of this release, in particular:
Identity service (Keystone)
Compute service (Nova)
Image service (Glance)
Block Storage service (Cinder)
Orchestration (Heat)
Networking (Neutron)
Load Balancer (Octavia)
DNS service (Designate)
Dashboard (Horizon)
Key management (Barbican)
Tempest
MOS provides support for Tungsten Fabric 5.1 as an SDN back end for OpenStack.
The list of the key highlights include:
Integration with OpenStack Ussuri
Implementation of the Octavia Tungsten Fabric driver for OpenStack LBaaS
LCM operations for supported Tungsten Fabric services as well as third-party services such as Cassandra, ZooKeeper, Kafka, Redis, and RabbitMQ.
Major components versions¶
Mirantis has tested MOS against a very specific configuration and can guarantee a predictable behavior of the product only in the exact same environments. The table below includes the major MOS components with the exact versions against which testing has been performed.
Known issues¶
This section contains the description of the known issues with available workarounds.
[6912] Octavia load balancers may not work properly with DVR
[8573] External authentication to Horizon fails to log in a different user
Due to limitations in the Octavia and MOS integration, the clusters where Neutron is deployed in the Distributed Virtual Router (DVR) mode are not stable. Therefore, Mirantis does not recommend such configuration for production deployments.
Limitation
When Neutron is deployed in the DVR mode, Octavia load balancers may not work correctly. The symptoms include both failure to properly balance traffic and failure to perform an amphora failover. For details, see DVR incompatibility with ARP announcements and VRRP.
Target fix version: next MOS update
Horizon retains the user’s credentials following their initial login using External Authentication Service, and does not allow to log in with another user credentials.
Workaround:
Clear cookies in your browser.
Select External Authentication Service on the Horizon login page.
Click Sign In. The Keycloak login page opens.
If the following error occurs, refresh the page and try again:
CSRF token missing or incorrect. Cookies may be turned off. Make sure cookies are enabled and try again.
Tungsten Fabric is not monitored by StackLight
Tungsten Fabric does not provide the following functionality:
Automatic generation of network port records in DNSaaS (Designate) as Neutron with Tungsten Fabric as a back end is not integrated with DNSaaS. As a workaround, you can use the Tungsten Fabric built-in DNS service that enables virtual machines to resolve each other names.
Secret management (Barbican). You cannot use the certificates stored in Barbican to terminate HTTPs in a load balancer.
Role Based Access Control (RBAC) for Neutron objects.
Fixed in MOS Ussuri Update
The HAProxy service, which is used as a back end for load balancers in
Tungsten Fabric, uses non-existing socket files from the log collection
service. This error in the configuration causes the logging of error
messages on attempts to use loggers in contrail-lbaas-haproxy-stdout.log.
The issue does not affect the service operability.
The tf-control service resolves the DNS names of Cassandra pods at startup
and does not update them if Cassandra pods got new IP addresses, for example,
in case of a restart. As a workaround, to refresh the IP addresses of
Cassandra pods, restart the tf-control pods one by one:
Caution
Before restarting the tf-control pods:
Verify that the new pods are successfully spawned.
Verify that no vRouters are connected to only one
tf-controlpod that will be restarted.
kubectl -n tf delete pod tf-control-<hash>
Release artifacts¶
This section lists the components artifacts of the MOS Ussuri release:
Component |
Path |
License information for main executable programs |
|---|---|---|
Binaries |
||
octavia-amphora |
https://binary.mirantis.com/openstack/bin/octavia/amphora-x64-haproxy-ussuri-20200926005743.qcow2 |
Mirantis Proprietary License |
mirantis |
https://binary.mirantis.com/openstack/bin/horizon/mirantis-ussuri-26b0ff5.tar.gz |
Mirantis Proprietary License |
Docker images |
||
placement |
mirantis.azurecr.io/openstack/placement:ussuri-bionic-20201019180023 |
Apache License 2.0 |
keystone |
mirantis.azurecr.io/openstack/keystone:ussuri-bionic-20201019180023 |
Apache License 2.0 |
heat |
mirantis.azurecr.io/openstack/heat:ussuri-bionic-20201019180023 |
Apache License 2.0 |
glance |
mirantis.azurecr.io/openstack/glance:ussuri-bionic-20201019180023 |
Apache License 2.0 |
cinder |
mirantis.azurecr.io/openstack/cinder:ussuri-bionic-20201019180023 |
Apache License 2.0 |
neutron |
mirantis.azurecr.io/openstack/neutron:ussuri-bionic-20201019180023 |
Apache License 2.0 |
nova |
mirantis.azurecr.io/openstack/nova:ussuri-bionic-20201019180023 |
Apache License 2.0 |
horizon |
mirantis.azurecr.io/openstack/horizon:ussuri-bionic-20201019180023 |
Apache License 2.0 |
tempest |
mirantis.azurecr.io/openstack/tempest:ussuri-bionic-20201019180023 |
Apache License 2.0 |
dashboard-selenium |
mirantis.azurecr.io/openstack/dashboard-selenium:ussuri-bionic-20201006074752 |
Apache License 2.0 |
octavia |
mirantis.azurecr.io/openstack/octavia:ussuri-bionic-20201019180023 |
Apache License 2.0 |
designate |
mirantis.azurecr.io/openstack/designate:ussuri-bionic-20201019180023 |
Apache License 2.0 |
ironic |
mirantis.azurecr.io/openstack/ironic:ussuri-bionic-20201019180023 |
Apache License 2.0 |
barbican |
mirantis.azurecr.io/openstack/barbican:ussuri-bionic-20201019180023 |
Apache License 2.0 |
libvirt |
mirantis.azurecr.io/general/libvirt:6.0.0-bionic-20201007084753 |
LGPL-2.1 License |
pause |
mirantis.azurecr.io/general/external/pause:3.1 |
Apache License 2.0 |
openvswitch |
mirantis.azurecr.io/general/openvswitch:2.11-bionic-20200812034813 |
Apache License 2.0 |
rabbitmq-3.8 |
mirantis.azurecr.io/general/rabbitmq:3.8.7 |
Mozilla Public License 2.0 |
rabbitmq-3.8-management |
mirantis.azurecr.io/general/rabbitmq:3.8.7-management |
Mozilla Public License 2.0 |
kubernetes-entrypoint |
mirantis.azurecr.io/openstack/extra/kubernetes-entrypoint:v1.0.0-20200311160233 |
Apache License 2.0 |
docker |
mirantis.azurecr.io/openstack/extra/docker:17.07.0 |
Apache License 2.0 |
memcached |
mirantis.azurecr.io/general/memcached:1.6.6-alpine |
BSD 3-Clause “New” or “Revised” License |
ceph-config-helper |
mirantis.azurecr.io/openstack/extra/ceph-config-helper:nautilus-bionic-20200810084204 |
Apache License 2.0, LGPL-2.1 or LGPL-3 |
etcd |
mirantis.azurecr.io/openstack/extra/etcd:3.2.26 |
Apache License 2.0 |
powerdns |
mirantis.azurecr.io/openstack/extra/powerdns:4.2-alpine-20200117133238 |
GPL-2.0 License |
nginx-ingress-controller |
mirantis.azurecr.io/openstack/extra/nginx-ingress-controller:0.32.0 |
Apache License 2.0 |
defaultbackend |
mirantis.azurecr.io/openstack/extra/defaultbackend:1.0 |
Apache License 2.0 |
mariadb |
mirantis.azurecr.io/general/mariadb:10.4.14-bionic-20200812025059 |
GPLv2, LGPLv2.1 (client libraries) |
rabbitmq-exporter |
mirantis.azurecr.io/stacklight/rabbitmq-exporter:v0.29.0 |
MIT License |
prometheus-memcached-exporter |
mirantis.azurecr.io/stacklight/memcached-exporter:v0.5.0 |
Apache License 2.0 |
prometheus-mysql-exporter |
mirantis.azurecr.io/stacklight/mysqld-exporter:v0.11.0 |
Apache License 2.0 |
xrally-openstack |
mirantis.azurecr.io/openstack/extra/xrally-openstack:1.5.0 |
Apache License 2.0 |
aodh |
mirantis.azurecr.io/openstack/aodh:ussuri-bionic-20201019180023 |
Apache License 2.0 |
panko |
mirantis.azurecr.io/openstack/panko:ussuri-bionic-20201019180023 |
Apache License 2.0 |
ceilometer |
mirantis.azurecr.io/openstack/ceilometer:ussuri-bionic-20201019180023 |
Apache License 2.0 |
gnocchi |
mirantis.azurecr.io/openstack/gnocchi:ussuri-bionic-20201019180023 |
Apache License 2.0 |
redis |
mirantis.azurecr.io/openstack/extra/redis:5.0-alpine |
BSD 3-Clause “New” or “Revised” License |
Helm charts |
||
openstack-operator |
https://binary.mirantis.com/openstack/helm/openstack-controller/openstack-operator-0.3.9.tgz |
Mirantis Proprietary License |
aodh |
https://binary.mirantis.com/openstack/helm/openstack-helm/aodh-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
barbican |
https://binary.mirantis.com/openstack/helm/openstack-helm/barbican-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
ceilometer |
https://binary.mirantis.com/openstack/helm/openstack-helm/ceilometer-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
cinder |
https://binary.mirantis.com/openstack/helm/openstack-helm/cinder-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
designate |
https://binary.mirantis.com/openstack/helm/openstack-helm/designate-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
glance |
https://binary.mirantis.com/openstack/helm/openstack-helm/glance-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
heat |
https://binary.mirantis.com/openstack/helm/openstack-helm/heat-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
horizon |
https://binary.mirantis.com/openstack/helm/openstack-helm/horizon-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
ironic |
https://binary.mirantis.com/openstack/helm/openstack-helm/ironic-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
keystone |
https://binary.mirantis.com/openstack/helm/openstack-helm/keystone-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
magnum |
https://binary.mirantis.com/openstack/helm/openstack-helm/magnum-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
mistral |
https://binary.mirantis.com/openstack/helm/openstack-helm/mistral-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
neutron |
https://binary.mirantis.com/openstack/helm/openstack-helm/neutron-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
nova |
https://binary.mirantis.com/openstack/helm/openstack-helm/nova-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
octavia |
https://binary.mirantis.com/openstack/helm/openstack-helm/octavia-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
panko |
https://binary.mirantis.com/openstack/helm/openstack-helm/panko-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
rally |
https://binary.mirantis.com/openstack/helm/openstack-helm/rally-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
senlin |
https://binary.mirantis.com/openstack/helm/openstack-helm/senlin-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
tempest |
https://binary.mirantis.com/openstack/helm/openstack-helm/tempest-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
dashboard-selenium |
https://binary.mirantis.com/openstack/helm/openstack-helm/dashboard-selenium-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
placement |
https://binary.mirantis.com/openstack/helm/openstack-helm/placement-0.1.0-mcp-3742.tgz |
Apache License 2.0 (no License file in Helm chart) |
calico |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/calico-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
ceph-client |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/ceph-client-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
ceph-mon |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/ceph-mon-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
ceph-osd |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/ceph-osd-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
ceph-provisioners |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/ceph-provisioners-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
ceph-rgw |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/ceph-rgw-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
dnsmasq |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/dnsmasq-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
elastic-apm-server |
Apache License 2.0 (no License file in Helm chart) |
|
elastic-filebeat |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/elastic-filebeat-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
elastic-metricbeat |
Apache License 2.0 (no License file in Helm chart) |
|
elastic-packetbeat |
Apache License 2.0 (no License file in Helm chart) |
|
etcd |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/etcd-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
falco |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/falco-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
flannel |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/flannel-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
fluentbit |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/fluentbit-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
fluentd |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/fluentd-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
gnocchi |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/gnocchi-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
grafana |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/grafana-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
helm-toolkit |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/helm-toolkit-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
ingress |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/ingress-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
kube-dns |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/kube-dns-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
kubernetes-keystone-webhook |
Apache License 2.0 (no License file in Helm chart) |
|
ldap |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/ldap-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
libvirt |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/libvirt-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
lockdown |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/lockdown-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
mariadb |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/mariadb-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
memcached |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/memcached-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
mongodb |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/mongodb-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
nagios |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/nagios-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
nfs-provisioner |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/nfs-provisioner-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
openvswitch |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/openvswitch-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
podsecuritypolicy |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/podsecuritypolicy-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
postgresql |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/postgresql-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
powerdns |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/powerdns-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
prometheus |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/prometheus-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
prometheus-alertmanager |
Apache License 2.0 (no License file in Helm chart) |
|
prometheus-kube-state-metrics |
Apache License 2.0 (no License file in Helm chart) |
|
prometheus-node-exporter |
Apache License 2.0 (no License file in Helm chart) |
|
prometheus-openstack-exporter |
Apache License 2.0 (no License file in Helm chart) |
|
prometheus-process-exporter |
Apache License 2.0 (no License file in Helm chart) |
|
rabbitmq |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/rabbitmq-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
redis |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/redis-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
registry |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/registry-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
tiller |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/tiller-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
zookeeper |
https://binary.mirantis.com/openstack/helm/openstack-helm-infra/zookeeper-0.1.0-mcp-2650.tgz |
Apache License 2.0 (no License file in Helm chart) |
Component |
Path |
License information for main executable programs |
|---|---|---|
Helm charts |
||
Tungsten Fabric Operator |
https://binary-mirantis-com/tungsten/helm/tungstenfabric-operator-0.1.3.tgz |
Mirantis Proprietary License |
Docker images |
||
TF Analytics |
mirantis.azurecr.io/tungsten/contrail-analytics-api:5.1.20201022210010 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-collector:5.1.20201022210010 |
Apache License 2.0 |
|
TF Analytics Alarm |
mirantis.azurecr.io/tungsten/contrail-analytics-alarm-gen:5.1.20201022210010 |
Apache License 2.0 |
TF Analytics DB |
mirantis.azurecr.io/tungsten/contrail-analytics-query-engine:5.1.20201022210010 |
Apache License 2.0 |
TF Analytics SNMP |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-collector:5.1.20201022210010 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-analytics-snmp-topology:5.1.20201022210010 |
Apache License 2.0 |
|
TF Config |
mirantis.azurecr.io/tungsten/contrail-controller-config-api:5.1.20201022210010 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-config-devicemgr:5.1.20201022210010 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-schema:5.1.20201022210010 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-config-svcmonitor:5.1.20201022210010 |
Apache License 2.0 |
|
TF Control |
mirantis.azurecr.io/tungsten/contrail-controller-control-control:5.1.20201022210010 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-control-dns:5.1.20201022210010 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-controller-control-named:5.1.20201022210010 |
Apache License 2.0 |
|
TF Web UI |
mirantis.azurecr.io/tungsten/contrail-controller-webui-job:5.1.20201022210010 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-controller-webui-web:5.1.20201022210010 |
Apache License 2.0 |
|
Nodemanager |
mirantis.azurecr.io/tungsten/contrail-nodemgr:5.1.20201022210010 |
Apache License 2.0 |
TF Status |
mirantis.azurecr.io/tungsten/contrail-status:5.1.20201022210010 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-tf-status:5.1.20201022210010 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-aggregator:5.1.20201022210010 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tf-status-party:5.1.20201022210010 |
Apache License 2.0 |
|
mirantis.azurecr.io/tungsten/contrail-tungsten-pytest:5.1.20201022210010 |
MIT License |
|
TF VRouter |
mirantis.azurecr.io/tungsten/contrail-vrouter-agent:5.1.20201022210010 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/contrail-vrouter-kernel-build-init:5.1.20201022210010 |
Apache License 2.0 |
|
Cassandra operator |
mirantis.azurecr.io/tungsten-operator/casskop:v0.5.3-release |
Apache License 2.0 |
Cassandra |
mirantis.azurecr.io/tungsten/cassandra-bootstrap:0.1.4 |
Apache License 2.0 |
mirantis.azurecr.io/tungsten/cassandra:3.11.6 |
Apache License 2.0 |
|
Kafka operator |
mirantis.azurecr.io/tungsten-operator/kafka-k8s-operator:0.0.6 |
Mirantis Proprietary License |
Kafka |
mirantis.azurecr.io/tungsten/cp-kafka:5.5.2 |
Apache License 2.0 |
RabbitMQ operator |
mirantis.azurecr.io/tungsten-operator/rabbitmq-operator:0.0.7 |
Mirantis Proprietary License |
RabbitMQ |
mirantis.azurecr.io/general/rabbitmq:3.8.7 |
Mozilla Public License 2.0 |
Zookeeper operator |
mirantis.azurecr.io/tungsten-operator/zookeeper-operator:0.2.9 |
Apache License 2.0 |
Zookeeper |
mirantis.azurecr.io/tungsten/zookeeper:3.6.1-0.2.9 |
Apache License 2.0 |
Redis operator |
mirantis.azurecr.io/tungsten-operator/redis-operator:0.1.5-1-ccd6a63 |
Apache License 2.0 |
Redis |
mirantis.azurecr.io/tungsten/redis:5-alpine |
BSD 3-Clause “New” or “Revised” License |
Deprecation Notes¶
Considering continuous reorganization and enhancement of Mirantis OpenStack for Kubernetes (MOSK), certain components are deprecated and eventually removed from the product. This section provides the following details about the deprecated and removed functionality that may potentially impact existing MOSK deployments:
The MOSK release version in which deprecation is announced
The final MOSK release version in which a deprecated component is present
The MOSK release version in which a deprecated component is removed
Tungsten Fabric analytics services¶
Deprecated |
MOSK 24.1 |
|---|---|
Unsupported |
MOSK 24.2 |
Details |
Tungsten Fabric analytics services, primarily designed for collecting various metrics from the Tungsten Fabric services, is being deprecated. Despite its initial implementation, user demand for this feature has been minimal. As a result, Tungsten Fabric analytics services will become unsupported in the product. All greenfield deployments starting from MOSK 24.1 do not include Tungsten Fabric analytics services. The existing deployments updated to 24.1 and newer versions will include Tungsten Fabric analytics services as well as the ability to disable them as described in Disable Tungsten Fabric analytics services. |
StackLight telegraf-openstack plugin¶
Deprecated |
MOSK 23.3 |
|---|---|
Final release |
MOSK 23.3.4 |
Removed |
MOSK 24.1 |
Details |
The StackLight Therefore, if you use any To obtain the list of metrics that are removed and replaced with new ones, contact Mirantis support. |
Default L2Template for a namespace¶
Deprecated |
MOSK 23.2 |
|---|---|
Unsupported |
MOSK 23.3 |
Details |
Disabled creation of the default L2 template for a namespace. On existing clusters, |
The clusterRef parameter in L2Template¶
Deprecated |
MOSK 23.3 |
|---|---|
Unsupported |
To be decided |
Details |
Deprecated the On existing clusters, this parameter is automatically migrated to the
|
OpenStackDeploymentSecret custom resource¶
Deprecated |
MOSK 23.1 |
|---|---|
Final release |
MOSK 23.2 |
Removed |
MOSK 23.2 |
Details |
The |
The allow-unsafe-backup parameter for MariaDB¶
Deprecated |
MOSK 22.3 |
|---|---|
Final release |
MOSK 22.3 |
Removed |
MOSK 22.4 |
Details |
Removed the unsafe |
OpenStackDeployment CR fields containing cloud secret parameters¶
Deprecated |
MOSK 22.3 |
|---|---|
Final release |
MOSK 22.4 |
Removed |
MOSK 22.5 |
Details |
A number of fields intended to store confidential settings in the
The list of deprecated parameters includes To migrate to the new schema, refer to Migrating secrets from OpenStackDeployment to OpenStackDeploymentSecret CR. |
The OpenStack Panko service¶
Deprecated |
MOSK 22.1 |
|---|---|
Final release |
MOSK 22.1 |
Removed |
MOSK 22.2 |
Details |
The OpenStack Panko service is no longer maintained in the upstream OpenStack. See the project repository page for details. |
The tf-status service¶
Deprecated |
MOSK 21.5 |
|---|---|
Final release |
MOSK 21.5 |
Removed |
MOSK 21.6 |
Details |
The Additionally, MOSK 21.5 introduces an overall
health status in the Tungsten Fabric Operator CR status with health
status for every module of Tungsten Fabric. To get the overall cluster
status, verify the output of
|
The status element in the OsDpl CR¶
Deprecated |
MOSK 21.5 |
|---|---|
Final release |
MOSK 21.6 |
Removed |
MOSK 22.1 |
Details |
The |
CPU isolation using isolcpus¶
Deprecated |
MOSK 22.2 |
|---|---|
Final release |
To be decided |
Removed |
To be decided |
Details |
Configuring CPU isolation through the |
The OpenStack Panko service¶
Deprecated |
MOSK 22.1 |
|---|---|
Final release |
MOSK 22.1 |
Removed |
MOSK 22.2 |
Details |
The OpenStack Panko service is no longer maintained in the upstream OpenStack. See the project repository page for details. |
Release cadence and support cycle¶
Mirantis aims to release Mirantis OpenStack for Kubernetes (MOSK) software regularly and often.
MOSK software includes OpenStack, Tungsten Fabric, life-cycle management tooling, other supporting software, and dependencies. Mirantis’s goal is to ensure that such updates are easy to install in zero-touch and zero-downtime fashion.
MOSK major and patch releases¶
MOSK release cadence consists of major, for example, MOSK 24.1, and patch, for example, MOSK 24.1.1 or 24.1.2, releases. The major release with the patch releases based on it are called a release series, for example, MOSK 24.1 series.
Both major and patch release versions incorporate solutions for security vulnerabilities and known product issues. The primary distinction between these two release types lies in the fact that major release versions introduce new functionalities, whereas patch release versions predominantly offer minor product enhancements.
Patch releases strive to considerably reduce the timeframe for delivering CVE resolutions in images to your deployments, aiding in the mitigation of cyber threats and data breaches.
Content |
Major release |
Patch release |
|---|---|---|
Version update and upgrade of the major product components including but not limited to OpenStack, Tungsten Fabric, Kubernetes, Ceph, and Stacklight 0 |
||
Container runtime changes including Mirantis Container Runtime and containerd updates |
||
Changes in public API |
||
Changes in the Container Cloud and MOSK lifecycle management including but not limited to machines, clusters, Ceph OSDs |
||
Host machine changes including host operating system and kernel updates |
||
Patch version bumps of MKE and Kubernetes |
||
Fixes for Common Vulnerabilities and Exposures (CVE) in images |
||
Fixes for known product issues |
- 0
StackLight subcomponents may be updated during patch releases
Most patch release versions involve minor changes that only require restarting containers on the cluster during updates. However, the product can also deliver CVE fixes on Ubuntu, which includes updating the minor version of the Ubuntu kernel. This kernel update is not mandatory, but if you prioritize getting the latest CVE fixes for Ubuntu, you can manually reboot machines during a convenient maintenance window to update the kernel.
Each subsequent major release includes patch release updates of the previous major release.
You may decide to update between only major releases without updating to patch releases. In this case, you will perform updates from an N to N+1 major release. However, Mirantis recommends applying security fixes using patch releases as soon as they become available.
You can skip a number of patch releases and update to the latest one. Though, if between the two major releases you apply at least one patch release belonging to the N series, you should obtain the last patch release in the series to be able to update to the N+1 major release version.
OpenStack support cycle¶
Mirantis provides Long Term Support (LTS) for specific versions of OpenStack. LTS includes scheduled updates with new functionality, bug and security fixes. Mirantis intends to introduce support for new OpenStack version once a year. The LTS duration of an OpenStack version is two years.
The diagram below illustrates the current LTS support cycle for OpenStack. The upstream versions not mentioned in the diagram are not supported in the product as well as the upgrade paths from or to such versions.
Important
MOSK supports the OpenStack Victoria version until September, 2023. MOSK 23.2 is the last release version where OpenStack Victoria packages are updated.
If you have not already upgraded your OpenStack version to Yoga, Mirantis highly recommends doing this during the course of the MOSK 23.2 series.
Versions of Tungsten Fabric, underlying Kubernetes, Ceph, StackLight, and other supporting software and dependencies may change at Mirantis discretion. Follow Release Compatibility Matrix and product Release Notes for any changes in product component versions.
See also
Technology Preview features¶
A Technology Preview feature provides early access to upcoming product innovations, allowing customers to experiment with the functionality and provide feedback.
Technology Preview features may be privately or publicly available but neither are intended for production use. While Mirantis will provide assistance with such features through official channels, normal Service Level Agreements do not apply.
As Mirantis considers making future iterations of Technology Preview features generally available, we will do our best to resolve any issues that customers experience when using these features.
During the development of a Technology Preview feature, additional components may become available to the public for evaluation. Mirantis cannot guarantee the stability of such features. As a result, if you are using Technology Preview features, you may not be able to seamlessly update to subsequent product releases, as well as upgrade or migrate to the functionality that has not been announced as full support yet.
Mirantis makes no guarantees that Technology Preview features will graduate to generally available features.
Release Compatibility Matrix¶
The Release Compatibility Matrix describes the cloud configurations that have been supported by the product over the course of its lifetime and the path a MOSK cloud can take to move from an older configuration to a newer one.
For each MOSK release, the document outlines the versions of the product major components, the valid combinations of these versions, and the way every component must be updated or upgraded.
For a more comprehensive list of the product subcomponents and their respective versions included in each MOSK release, refer to Release Notes, or use the Releases section in the Container Cloud UI or API.
Compatibility matrix¶
The following table outlines the compatibility matrix of the most recent MOSK releases and their major components in conjunction with Container Cloud and Cluster releases.
MOSK |
24.1.2 |
24.1.1 |
24.1 |
|---|---|---|---|
Release date |
Apr 08, 2024 |
Mar 20, 2024 |
Mar 04, 2024 |
Container Cloud |
2.26.2 |
2.26.1 |
2.26.0 |
Release support status 0 |
Supported |
Deprecated |
Supported |
Deprecated major MOSK 1 |
23.3 |
23.3 |
23.3 |
MOSK cluster |
17.1.2 |
17.1.1 |
17.1.0 |
MKE |
3.7.6 with K8s 1.27 |
3.7.5 with K8s 1.27 |
3.7.5 with K8s 1.27 |
OpenStack 2 |
Antelope, Yoga |
Antelope, Yoga |
Antelope, Yoga |
Tungsten Fabric |
21.4 |
21.4 |
21.4 |
Ceph |
Quincy 17.2.7-10.release |
Quincy 17.2.7-9.release |
Quincy 17.2.7-8.release |
Operating system |
Ubuntu 20.04 |
Ubuntu 20.04 |
Ubuntu 20.04 |
Linux kernel 3 |
5.15.0-101-generic |
5.15.0-97-generic |
5.15.0-92-generic |
23.3 series compatibility matrix
MOSK |
23.3.4 patch |
23.3.3 patch |
23.3.2 patch |
23.3.1 patch |
23.3 |
|---|---|---|---|---|---|
Release date |
Jan 10, 2024 |
Dec 18, 2023 |
Dec 05, 2023 |
Nov 27, 2023 |
Nov 06, 2023 |
Container Cloud |
2.25.4 - Jan 10, 2024 |
2.25.3 - Dec 18, 2023 |
2.25.2 - Dec 05, 2023 |
2.25.1 - Nov 27, 2023 |
2.25 - Nov 06, 2023 |
Release support status 0 |
Deprecated |
Unsupported |
Unsupported |
Unsupported |
Deprecated |
Deprecated major MOSK 1 |
23.2 |
23.2 |
23.2 |
23.2 |
23.2 |
MOSK cluster |
17.0.4 |
17.0.3 |
17.0.2 |
17.0.1 |
17.0.0 |
MKE |
3.7.3 with K8s 1.27 |
3.7.3 with K8s 1.27 |
3.7.2 with K8s 1.27 |
3.7.2 with K8s 1.27 |
3.7.1 with K8s 1.27 |
OpenStack 2 |
Yoga,
Antelope TechPreview
|
Yoga,
Antelope TechPreview
|
Yoga,
Antelope TechPreview
|
Yoga,
Antelope TechPreview
|
Yoga,
Antelope TechPreview
|
Tungsten Fabric |
21.4 |
21.4 |
21.4 |
21.4 |
21.4 |
Ceph |
Quincy 17.2.6-8.cve |
Quincy 17.2.6-8.cve |
Quincy 17.2.6-5.cve |
Quincy 17.2.6-2.cve |
Quincy 17.2.6-cve-1 |
Operating system |
Ubuntu 20.04 |
Ubuntu 20.04 |
Ubuntu 20.04 |
Ubuntu 20.04 |
Ubuntu 20.04 |
Linux kernel 3 |
5.15.0-86-generic |
5.15.0-86-generic |
5.15.0-86-generic |
5.15.0-86-generic |
5.15.0-86-generic |
23.2 series compatibility matrix
MOSK |
23.2.3 patch |
23.2.2 patch |
23.2.1 patch |
23.2 |
|---|---|---|---|---|
Release date |
Sept 26, 2023 |
Sept 14, 2023 |
Aug 29, 2023 |
Aug 21, 2023 |
Container Cloud |
2.24.5 - Sept 26, 2023 |
2.24.4 - Sept 14, 2023 |
2.24.3 - Aug 28, 2023 |
2.24.2 - Aug 21, 2023
2.24.3 - Aug 28, 2023
|
Release support status 0 |
Unsupported |
Unsupported |
Unsupported |
Unsupported |
Deprecated major MOSK 1 |
23.1 |
23.1 |
23.1 |
23.1 |
MOSK cluster |
15.0.4 |
15.0.3 |
15.0.2 |
15.0.1 |
MKE |
3.6.6 with K8s 1.24 |
3.6.6 with K8s 1.24 |
3.6.6 with K8s 1.24 |
3.6.5 with K8s 1.24 |
OpenStack 2 |
Yoga,
Victoria Deprecated
|
Yoga,
Victoria Deprecated
|
Yoga,
Victoria Deprecated
|
Yoga,
Victoria Deprecated
|
Tungsten Fabric |
21.4 |
21.4 |
21.4 |
21.4 |
Ceph |
Quincy 17.2.6-cve-1 |
Quincy 17.2.6-cve-1 |
Quincy 17.2.6-cve-1 |
Quincy 17.2.6-rel-5 |
Operating system |
Ubuntu 20.04,
Ubuntu 18.04 Deprecated
|
Ubuntu 20.04,
Ubuntu 18.04 Deprecated
|
Ubuntu 20.04,
Ubuntu 18.04 Deprecated
|
Ubuntu 20.04,
Ubuntu 18.04 Deprecated
|
Linux kernel 3 |
5.4.0-150-generic |
5.4.0-150-generic |
5.4.0-150-generic |
5.4.0-150-generic |
23.1 series compatibility matrix
MOSK version |
23.1.4 patch |
23.1.3 patch |
23.1.2 patch |
23.1.1 patch |
23.1 |
|---|---|---|---|---|---|
Release date |
Jun 05, 2023 |
May 22, 2023 |
May 04, 2023 |
Apr 20, 2023 |
Apr 04, 2023 |
Container Cloud |
2.24.1 - Jul 27, 2023
2.24.0 - Jul 20, 2023
2.23.5 - Jun 05, 2023
|
2.23.4 - May 22, 2023 |
2.23.3 - May 04, 2023 |
2.23.2 - Apr 20, 2023 |
2.23.3 - May 04, 2023
2.23.2 - Apr 20, 2023
2.23.1 - Apr 04, 2023
|
Release support status 0 |
Unsupported |
Unsupported |
Unsupported |
Unsupported |
Unsupported |
Deprecated major MOSK 1 |
22.5 |
22.5 |
22.5 |
22.5 |
22.5 |
MOSK cluster |
12.7.4 |
12.7.3 |
12.7.2 |
12.7.1 |
12.7.0 |
MKE |
3.5.7 with K8s 1.21 |
3.5.7 with K8s 1.21 |
3.5.7 with K8s 1.21 |
3.5.7 with K8s 1.21 |
3.5.7 with K8s 1.21 |
OpenStack 2 |
Yoga,
Victoria
|
Yoga,
Victoria
|
Yoga,
Victoria
|
Yoga,
Victoria
|
Yoga,
Victoria
|
Tungsten Fabric |
21.4 |
21.4 |
21.4 |
21.4 |
21.4 |
Ceph |
Pacific 16.2.11-cve-4 |
Pacific 16.2.11-cve-4 |
Pacific 16.2.11-cve-4 |
Pacific 16.2.11-cve-2 |
Pacific 16.2.11 |
Operating system |
Ubuntu 20.04 Greenfield,
Ubuntu 18.04
|
Ubuntu 20.04 Greenfield,
Ubuntu 18.04
|
Ubuntu 20.04 Greenfield,
Ubuntu 18.04
|
Ubuntu 20.04 Greenfield,
Ubuntu 18.04
|
Ubuntu 20.04 Greenfield,
Ubuntu 18.04
|
Linux kernel 3 |
5.4.0-137-generic |
5.4.0-137-generic |
5.4.0-137-generic |
5.4.0-137-generic |
5.4.0-137-generic |
22.5 compatibility matrix
MOSK |
22.5 |
|---|---|
Release date |
Dec 19, 2022 |
Container Cloud |
2.23.0 - Mar 7, 2023,
2.22.0 - Jan 31, 2023,
2.21.1 - Dec 19, 2022
|
Release support status 0 |
Unupported |
Deprecated major MOSK 1 |
22.4 |
MOSK cluster |
12.5.0 |
MKE |
3.5.5 with K8s 1.21 |
OpenStack 2 |
Yoga, Victoria |
Tungsten Fabric |
2011,
21.4 TechPreview
|
Ceph |
Octopus 15.2.17 |
Operating system |
Ubuntu 20.04 Greenfield,
Ubuntu 18.04
|
Linux kernel 3 |
5.4.0-125-generic |
- 0(1,2,3,4,5)
The product support status reflects the freshness of a MOSK cluster and should be considered when planning the cluster update path:
- Supported
Latest supported product release version to use for a greenfield cluster deployment and to update to.
- Deprecated
Product release version that you should update to the latest supported product release. You cannot update between two deprecated release versions.
The deprecated product release version becomes unsupported when newer product versions are released. Therefore, when planning the update path for the cluster, consider the dates of the upcoming product releases.
Greenfield deployments based on a deprecated product release are not supported. Use the latest supported release version for initial deployments instead.
- Unsupported
Product release that blocks automatic upgrade of a management cluster and must be updated immediately to resume receiving newest product features and enhancements.
- 1(1,2,3,4,5)
Mirantis Container Cloud will update itself automatically as long as the release of each managed cluster has either supported or deprecated status in the new version of Container Cloud.
A deprecated cluster release becomes unsupported in one of the following Container Cloud releases. Therefore, we strongly recommend that you update your deprecated MOSK clusters to the latest supported version as described in Upgrade paths.
- 2(1,2,3,4,5)
The LTS duration of an OpenStack version is two years. For support timeline for different OpenStack versions, refer to OpenStack support cycle.
- 3(1,2,3,4,5)
The kernel version of the host operating system validated by Mirantis and confirmed to be working for the supported use cases. Usage of custom kernel versions or third-party vendor-provided kernels, such as FIPS-enabled, assume full responsibility for validating the compatibility of components in such environments.
Upgrade paths¶
Component |
From |
To |
Procedure |
|---|---|---|---|
Container Cloud |
N version |
N+1 version |
Mirantis Container Cloud will update itself automatically as long as the release of each managed cluster has either supported or deprecated status in the new version of Container Cloud. In case, any of the clusters managed by Container Cloud is about to get an unsupported status as a result of an update, the Container Cloud updates will get blocked till the cluster gets to a later release. For the cluster release statuses, see Container Cloud documentation: Cluster releases (managed). |
MOSK major cluster release |
N major version |
N+1 major version |
A cloud operator initiates an update of a MOSK cluster using the Container Cloud UI. The update procedure is automated and covers all the life cycle management modules of the cluster that include OpenStack, Tungsten Fabric, Ceph, and StackLight. See Update a MOSK cluster to a major release version for details. If between the major releases you apply at least one patch release belonging to the N series, you should obtain the last patch release in the series to be able to update to the N+1 major release version. |
MOSK patch cluster release |
N patch version |
M patch version |
A cloud operator initiates an update of a MOSK cluster using the Container Cloud UI. The update procedure is automated and covers all the life cycle management modules of the cluster that include OpenStack, Tungsten Fabric, Ceph, and StackLight. See Update a MOSK cluster to a patch release version for details. You can skip a number of patch releases and update to the latest one. Though, if you start receiving the patch releases, you should always apply the latest patch release in the series to be able to update to the following major release. |
OpenStack |
Yoga |
Antelope |
A cloud operator uses the MOSK life-cycle management API to upgrade OpenStack. See Upgrade OpenStack for details |
Ceph |
N |
N+1 |
Ceph cluster is updated and upgraded automatically as a part of the MOSK cluster update. |